Язык запросов SQL для начинающих
Пол Уилтон, Джон Колби Beginning SQL Кол-во страниц: 496 Оглавление | Дополнительные материалы | | Купить книгу: Книга в типографии |
Читайте отдельное сообщение в блоге Виктора Штонда о новой книге по SQL:2011 — «SQL для чайников» (8-е издание)
Язык запросов SQL используется для добавления и извлечения данных, являясь международным стандартом в области баз данных. В книге «Язык запросов SQL для начинающих» обсуждаются все основные вопросы указанной области — от основ SQL и вопросов проектирования баз данных до создания собственных баз данных и применения SQL в самых разных приложениях.
Расскажи про книгу своим друзьям и коллегам:
Твитнуть
Нравится
| ISBN | 5-8459-0971-6 |
| ISBN ENG | 0-7645-7732-8 |
| Кол-во страниц | 496 |
| Год выпуска | 2006 |
| Формат | 70×100/16 |
| Тип переплета | мягкий переплет |
| Тип бумаги | газетная |
| Серия | . ..для начинающих (от Wrox) ..для начинающих (от Wrox) |
| Автор | Пол Уилтон, Джон Колби |
| Название ориг. | Beginning SQL |
| Автор ориг. | Paul Wilton, John Colby |
Вас, возможно, заинтересуют следующие книги
|
Оглавление к книге Язык запросов SQL для начинающих
ОглавлениеВведение 14
Глава 1. Введение в SQL 19
Глава 2. Ввод информации 55
Глава 3. Извлечение информации 67
Глава 4. Проектирование баз данных 129
Глава 5. Обработка данных 167
Глава 6. Группировка данных и вычисление итогов 199
Группировка данных и вычисление итогов 199
Глава 7. Извлечение данных из нескольких таблиц 217
Глава 8. Запросы внутри других запросов 243
Глава 9. Сложные запросы 271
Глава 10. Представления 295
Глава 11. Транзакции 309
Глава 12. Безопасность SQL 339
Приложение А. Решения упражнений 381
Приложение Б. Установка и использование систем баз данных 403
Приложение В. Установка начальных данных 463
Предметный указатель 483
Материалы к книге Язык запросов SQL для начинающих
Полное содержаниеОб авторах
Введение
Transact-SQL Введение — Transact-SQL В подлиннике : Персональный сайт Михаила Флёнова
Уже долгое время язык запросов SQL (Structured Query Language, структурированный язык запросов) является стандартом доступа к базам данных. Не имеет значения, какой язык программирования вы используете, я больше чем уверен, что доступ к данным на сервере баз данных происходит с помощью запросов SQL. Исключением могут быть только локальные таблицы типа DBF или Paradox. В них доступ к данным может происходить благодаря драйверу через прямой доступ. Но и в этом случае, драйвер может поддерживать запросы, с помощью которых возможности по работе с данными увеличиваются в разы.
Исключением могут быть только локальные таблицы типа DBF или Paradox. В них доступ к данным может происходить благодаря драйверу через прямой доступ. Но и в этом случае, драйвер может поддерживать запросы, с помощью которых возможности по работе с данными увеличиваются в разы.
При работе с клиент-серверными или n-уровневыми системами, доступ обязательно происходит именно через SQL запросы. Более удобного и мощного средства пока не придумали. Даже там, где вы думаете, что доступ идет напрямую, используется SQL, просто среда разработки прячет от нас запросы.
Если вы работаете с базами данных, то хорошее знание и умение создавать эффективные запросы позволит вам создавать действительно быстрые и эффективные приложения. Помимо этого, можно быстро решать одноразовые задачи. Программистам очень часто приходиться выполнять какое-либо одноразовое задание, и SQL позволяет сделать все быстро и качественно.
Язык запросов стандартизирован еще в 1992-м году. За это время его возможности немного устарели, но не потеряли своей актуальности. В конце 90-х годов предпринимались попытки принять обновленный стандарт, но война между различными производителями баз данных не позволили найти компромисса. В связи с этим SQL получил два вида расширений Transact-SQL или T-SQL (поддерживается Microsoft) и PL\SQL (яркий представитель — Oracle). Каждый из этих производителей максимально придерживается стандарта SQL 92-го года, и все запросы на этом языке будут выполняться корректно. Но для предоставления пользователю новых возможностей добавлены новые команды, которые объединены под именами Transact-SQL и PL\SQL и поддерживаются на разных базах данных.
В конце 90-х годов предпринимались попытки принять обновленный стандарт, но война между различными производителями баз данных не позволили найти компромисса. В связи с этим SQL получил два вида расширений Transact-SQL или T-SQL (поддерживается Microsoft) и PL\SQL (яркий представитель — Oracle). Каждый из этих производителей максимально придерживается стандарта SQL 92-го года, и все запросы на этом языке будут выполняться корректно. Но для предоставления пользователю новых возможностей добавлены новые команды, которые объединены под именами Transact-SQL и PL\SQL и поддерживаются на разных базах данных.
Рассмотреть абсолютно все команды и возможности всех этих стандартов невозможно. Поэтому мы ограничимся стандартом 92-го года и расширением Transact-SQL, потому что сервера от MS получили в нашей стране достаточно широкое распространение и продолжают завоевывать сердца разработчиков. Рассматривать всю спецификацию SQL также не имеет смысла, потому что большая ее часть относиться к разработчикам серверов баз данных (какие должны быть поля, их типы, размерность и т. д.). Мы же будем рассматривать стандарт с точки зрения программистов конечных приложений, которые уже использую SQL, а не реализуют его в своих программах.
д.). Мы же будем рассматривать стандарт с точки зрения программистов конечных приложений, которые уже использую SQL, а не реализуют его в своих программах.
Если у вас возникли вопросы или пожелания по книге или SQL, жду ваших писем и отзывов по адресу – [email protected]. Все мои последние работы основываются на вопросах и предложениях читателей, с которыми я регулярно общаюсь на форуме сайта www.vr-online.ru. Если у вас появятся какие-то вопросы, то милости прошу на этот форум. Я постараюсь помочь по мере возможности и жду любых комментариев по поводу этой книги. Ваши замечания помогут мне сделать эту и последующие работы лучше.
Благодарности
Работа над книгой – это достаточно тяжелый труд, который отнимает очень много сил. Каждую свою работу я стремлюсь сделать лучше предыдущей, а это уже затраты не только сил, но и времени. Если бы не моя семья, то выход этой книги задержался бы наверно на месяц. Лето 2005-го, когда писалась эта книга, выдалось для меня достаточно тяжелым, потому что за три месяца к нам по очереди приезжали гости и родственники из разных городов. В это время дом превращался в сумасшедший, и работать приходилось по ночам. Если бы не помощь семьи с детьми и домашними обязанностями, то книга точно была бы задержана.
В это время дом превращался в сумасшедший, и работать приходилось по ночам. Если бы не помощь семьи с детьми и домашними обязанностями, то книга точно была бы задержана.
Перед сдачей книги из-за отсутствия времени я иногда срывался на своих родных (жену, родителей). Сейчас, оглядываясь на прошлое, хочется попросить прощения за мои срывы.
Пять лет назад я знакомился с MS SQL Server в МГТУ им. Баумана в г. Москве, где курс читал Гилев Алексей Вячеславович. Хочется поблагодарить этого специалиста за то, что дал мне основные знания программирования на языке Transact-SQL. До этого момента я работал только с классическим ANSI SQL, а этот курс помог мне расширить знания.
Хочется поблагодарить Олега (не помню фамилию), который обучает программистов в МВ «Офисная Техника». Этот человек помог мне постигнуть еще одно расширение языка SQL – PL/SQL, который отличается от рассматриваемого в данной книге Transact-SQL, но его знания, помогло мне понять некоторые тонкости классического ANSI SQL.
Отдельное спасибо редакции БХВ-Петербург за то, что помогают в издании моих работ. Редакторам и корректорам за то, что выискивают мои багги и делают мой технический русский немного более литературным и читаемым.
Всех друзей по моему блогу www.flenov.info. C каждым годом количество друзей растет и чтобы поблагодарить всех понадобиться целая книга, а ведь каждый помогает мне своими знаниями, поддержкой и просто советом. Поэтому, если я кого-то упустил, то хочу попросить прощения.
Для кого эта книга
Вполне логичный вопрос – кому будет полезна эта книга? Конечно же, это администраторы и программисты. С программистами все ясно, они должны знать язык, с помощью которого можно получать данные от сервера. Но зачем это нужно администратору.
Начинающие администраторы для управления сервером SQL очень часто используют специальную утилиту Enterprise Manager, которая предоставляет визуальный интерфейс и удобство в администрировании сервером. Визуальность – это хорошо, но сценарии лучше. Я сам в этом убедился, когда нужно было тиражировать схожие настройки базы данных на несколько серверов. Сначала я копировал базу с помощью резервного копирования и восстановления на новый сервер, а затем чистил новую базу данных от ненужных данных. Это долгий и не очень удобный процесс.
Я сам в этом убедился, когда нужно было тиражировать схожие настройки базы данных на несколько серверов. Сначала я копировал базу с помощью резервного копирования и восстановления на новый сервер, а затем чистил новую базу данных от ненужных данных. Это долгий и не очень удобный процесс.
Чтобы ускорить тиражирование, я написал один сценарий, который последовательно выполнял все необходимые действия – создание базы данных, процедур, функций и индексов. Этот сценарий выполнялся намного быстрее, потому что не надо было копировать избыточные данные и чистить таблицы. После этого, я сохраняю на диске все сценарии создания базы данных и изменения ее настроек. Это позволяет быстро создать новую базу данных.
Язык SQL необходимо знать и для тестирования производительности сервера. Оптимизация работы сервера входит в обязанности администратора, а значит, он должен уметь выполнять запросы, анализировать их скорость работы и уметь повысить их работу. Конечно же, оптимизацию кода сценария должен делать программист, но скорость можно повысить и с помощью оптимизации базы данных и это должен делать администратор. Например, если администратор увидит с помощью программы мониторинга сервера, что какой-то запрос выполняется достаточно часто, то он должен проанализировать его текст и выяснить, какие поля чаще всего используются для сравнения и если необходимо, добавить соответствующие индексы. Это может в несколько раз поднять производительность.
Например, если администратор увидит с помощью программы мониторинга сервера, что какой-то запрос выполняется достаточно часто, то он должен проанализировать его текст и выяснить, какие поля чаще всего используются для сравнения и если необходимо, добавить соответствующие индексы. Это может в несколько раз поднять производительность.
Введение в SQL
Сначала я хотел выделить отдельный раздел, чтобы описать вводную информацию о языке запросов, но потом решил сократить вводную информацию до минимума, а максимум информации отдать практической стороне книги. Давайте сделаем небольшое введение в стандарт SQL, а остальное увидим на практике, и во время практике.
С помощью SQL-запросов можно создавать и работать с реляционными базами данных. Этот язык стал стандартом, поэтому если вы хотите работать с базами данных, то должны знать этот язык как каждую морщину на своем лице.
Язык SQL определяется Американским Национальным Институтом Стандартов и Международной Организацией по стандартизации (ISO).
Что такое реляционная база данных? Это таблица, в которой в качестве столбцов выступают поля данных (поля определяют класс значений в соответствующей колонке таблицы), а каждая строка хранит данные. Строки очень часто в литературе называют записью. Если честно, то тут действует эффект разных языков. В английском языке строку таблицы принято называть словом record (запись), потому что строкой им называть сложно, ведь слово Line (строка) имеет немного другой, более узкий смысл.
Давайте рассмотрим реляционную базу данных на примере таблицы 1. Заголовок таблицы – это имена полей (колонок). Каждая строка – запись с данными. Реляционная база данных состоит из вот таких вот простых таблиц. На первый взгляд, это слишком просто, но эта простота позволяет решить практически любую задачу. Я, по крайней мере еще не встречался с такой задачей, которую нельзя было бы решить с помощью реляционной базы.
На первый взгляд, это слишком просто, но эта простота позволяет решить практически любую задачу. Я, по крайней мере еще не встречался с такой задачей, которую нельзя было бы решить с помощью реляционной базы.
Таблица 1. Пример таблицы реляционной базы данных
| Фамилия | Имя | Отчество | Пол |
| Иванов | Иван | Иванович | M |
| Петрова | Мария | Анатольевна | Ж |
| Сидоров | Сергей | Петрович | |
| … | … | … | … |
В каждой таблице должно быть одно уникальное поле, которое однозначно будет идентифицировать строку. Это поле называется ключевым. Эти поля очень часто используются для связывания таблиц. Но даже если у вас таблица не связана, ключевое поле все равно обязательно. Допустим, что вам необходимо изменить имя у записи, где в поле «Фамилия» находиться значение Иванов. Для этого нужно написать запрос, который будет иметь следующую логику: «Изменить поле Имя на значение ХХХХ, где поле «Фамилия» содержит значение Иванов». Именно такую логику будет использовать база данных. Но что, если у нас в таблице две записи, в которых поле «Фамилия» содержит одно и то же значение. В этом случае, будут обновлены все строки, в которых в поле «Фамилия» содержится Иванов.
Допустим, что вам необходимо изменить имя у записи, где в поле «Фамилия» находиться значение Иванов. Для этого нужно написать запрос, который будет иметь следующую логику: «Изменить поле Имя на значение ХХХХ, где поле «Фамилия» содержит значение Иванов». Именно такую логику будет использовать база данных. Но что, если у нас в таблице две записи, в которых поле «Фамилия» содержит одно и то же значение. В этом случае, будут обновлены все строки, в которых в поле «Фамилия» содержится Иванов.
Но обновление всех записей не всегда является необходимым. Чтобы однозначно идентифицировать строку лучше использовать ключевые поля. Для ключевого поля база данных сама следит, чтобы данные в поле были уникальными для каждой строки. Для упрощения создания ключевых полей, в большинстве баз данных есть тип данных (например, счетчик), который может автоматически увеличивать значение для каждой новой строки, чем и достигается уникальность. В таблице 2 показана таблица, в которой первое поле – это автоматически увеличиваемое число.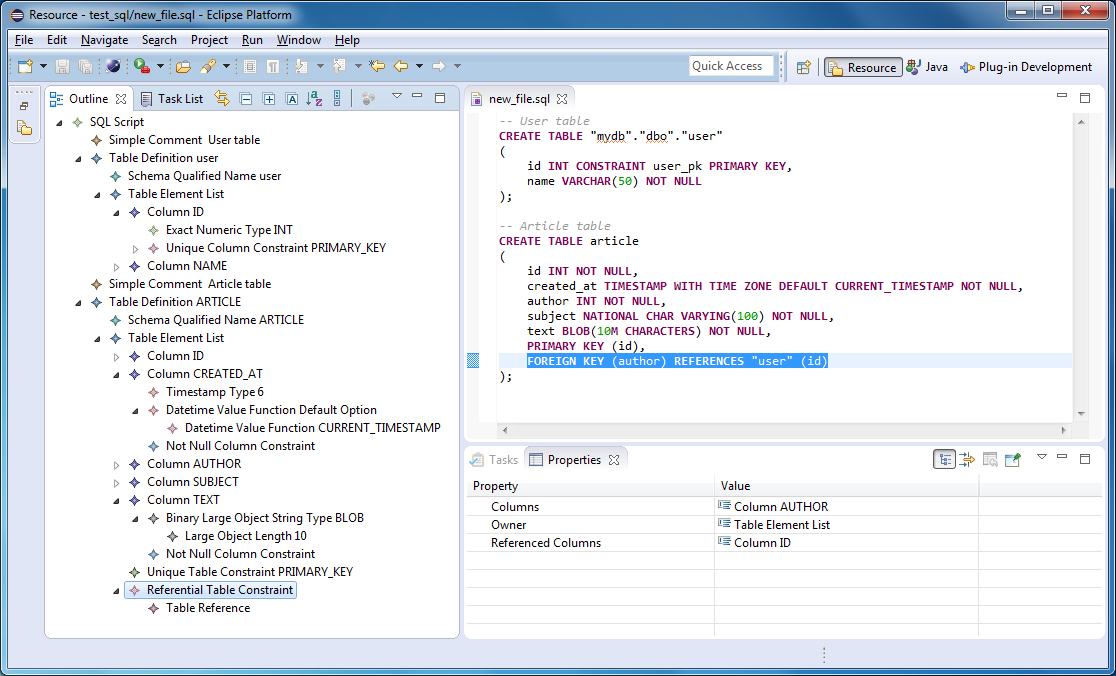
Таблица 2. Пример таблицы реляционной базы данных с ключевым полем
| Ключ | Фамилия | Имя | Отчество | Пол |
| 1 | Иванов | Иван | Иванович | M |
| 2 | Петрова | Мария | Анатольевна | Ж |
| 3 | Сидоров | Сергей | Петрович | M |
| 4 | Иванов | Иван | Иванович | M |
| … | … | … | … |
В таблице 2 я добавил еще одну запись, в которой все поля идентичны строке с номером 1. Это вполне реально, ведь в жизни может быть два человека с одними и теми же фамилией, именем и отчеством, но разной датой рождения. Теперь, чтобы обновить первую запись Иванова необходимо написать запрос со следующей логикой: «Изменить поле Имя на значение ХХХХ, где ключевое поле содержит значение 1». Благодаря уникальному ключевому полю, мы четко определяем запись, которую необходимо обновить.
Теперь, чтобы обновить первую запись Иванова необходимо написать запрос со следующей логикой: «Изменить поле Имя на значение ХХХХ, где ключевое поле содержит значение 1». Благодаря уникальному ключевому полю, мы четко определяем запись, которую необходимо обновить.
Имена полей в базе данных, также должны быть уникальными, но в этом случае не обязательно числовыми. Их можно называть как угодно, лишь бы было уникально внутри одной таблицы и понятно (имя должно отражать содержащиеся данные), а остальное никого не касается.
Язык запросов SQL может быть двух типов: интерактивный и вложенный. Интерактивный — это отдельный язык, он сам выполняет запросы и сразу показывает результат работы. Вложенный — это когда SQL язык вложен в другой, как например в С++ или Delphi. Разницы в синтаксисе практически нет, отличие только в том, как использовать запросы. В этой книге мы будем подразумевать, что у нас интерактивный SQL. Интерактивный SQL более близок к стандартному, а во вложенном очень часто встречаются отклонения и дополнения (например, в описании параметров, которые передаются запросу).
В стандартном SQL различаются только два типа данных: строки и числа, но некоторые производители добавляют свои типы и MS SQL Server, который будет рассматриваться в книге не исключение. Базы данных MS SQL Server поддерживает множество различных типов, что упрощает разработку, но нам необходимо научиться правильно отражать эти данные.
Числа в SQL делятся на два типа: целые (INTEGER или INT) и дробные (DECIMAL или DEC). Во многих базах данных числа делятся и по размеру используемого в базе пространства, но стандарт этого уже не требует. Строки в стандарте ограничены размером в 254 символа, но в реальности размер намного больше.
Целочисленные типы указываются, как есть, без каких либо кавычек. Строковые типы, даты, guid оформляются в одинарных кавычках, например;
'Это строка'
Если необходимо указать, что строка должна быть закодирована Unicode символами, то необходимо перед строкой указать букву N, например:
N'Это пример Unicode строки'
Более подробно о типах данных мы постепенно познакомимся в этой и последующих главах, а список поддерживаемых сервером MS SQL типов можно увидеть в приложении 1.
Если исходить из стандарта, то каждый запрос должен заканчиваться символом точки с запятой. Например:
Текст запроса;
Мы же в примерах этот символ будем очень часто опускать, потому что он не является обязательным для MS SQL Server. Я явно буду указывать на те случаи, когда символ просто необходим.
Работа с запросами
Для работы с первыми двумя главами вам понадобиться база данных, которая поддерживает стандарт SQL 1992-го года. На данный момент, это практически все, но не все четко следуют стандарту. Желательно, чтобы база данных поддерживала его максимально полно.
Лучшим вариантом будет MS SQL Server, потому что он максимально полно соответствует стандарту, но можно использовать и MS Access, хотя тут и есть отличия при установке связей между таблицами и поддерживается только SQL, а не Transact-SQL.
Начиная с 3-й главы, мы начнем углубляться в расширение языка SQL под названием Transact-SQL, и вот тут уже MS SQL Server окажется не заменимым, потому что только этот сервер баз данных поддерживает это расширение.
Для вашего удобства, на компакт диске в директориях ChapterX (где X – это номер главы) расположены файлы с текстом запросов и комментариями. Эти файлы позволят вам не набирать коды запросов на клавиатуре, а использовать текст из файлов.
Все возможности языка SQL мы будем рассматривать с одновременным рассмотрением примеров. Сначала я буду приводить общий вид команды, а потом постепенно будем изучать возможности команды на примерах, максимально приближенных к боевым условиям, т.е. такие примеры, которые вы можете встретить в реальных задачах во время решения реальных проблем. Это позволит вам на практике увидеть, как использовать те или иные возможности и иметь готовый багаж запросов для решения наиболее часто встречающихся задач.
Именование
Для того чтобы вам проще было понимать материал книги, вы должны понимать, каким образом я присваиваю имена объектам базы данных. К каждому имени объекта я добавляю префикс, который будет указывать на тип. Это позволит быстро определить по имени тип любого объекта. В приложении 1 показаны типы полей, поддерживаемые в MS SQL Server. Например, если объект имеет тип varchar, то к имени объекта я добавляю префикс vc. После этого идет имя, отображающее суть объекта. Если этот объект предназначен для хранения номера телефона, то полное название поля будет vcTelephon.
В приложении 1 показаны типы полей, поддерживаемые в MS SQL Server. Например, если объект имеет тип varchar, то к имени объекта я добавляю префикс vc. После этого идет имя, отображающее суть объекта. Если этот объект предназначен для хранения номера телефона, то полное название поля будет vcTelephon.
В базах есть определенные поля, которые должны управляться по-другому. Например, для именования ключевого поля можно использовать следующий вид: idИмяТаблицы. Таким образом, по ключу можно понять к какой таблице он относится, а по имени таблицы узнать имя ключа. В некоторых простых примерах для первичного ключа мы будем использовать просто имя id, но при рассмотрении сложных связей я буду следовать правилу именования idИмяТаблицы.
Когда ключ используется для связи с другой таблицей, то после id нужно ставить имя таблицы, с которой происходит связь. Помимо этого, можно отделить идентификатор id знаком подчеркивания, чтобы сразу было видно, что это не основной ключ, а связь. Таким образом, по имени поля можно узнать, для связи с какой таблицей он предназначен.
Отдельного разговора заслуживают триггера. Триггер – это процедура, которая выполняется на определенные действия над данными – вставка, изменение или удаление (операции insert, update или delete). Это как бы обработчики событий, в которых можно повлиять на обработку данных. Вот тут для именования наилучшим способом будет следующий:
ИмяТаблицы_СмыслТриггера_Операции
Порядок может быть любым, лишь бы вам было удобно, но желательно, чтобы все три составляющие присутствовали. Допустим, что у вас должен быть триггер на таблице Person, который при добавлении новых записей или изменении существующих должен проверять существование дублирующих записей. Имя для такого триггера может быть следующим:
Person_CheckDouble_iu
По этому имени можно сразу понять, для какой он таблицы, что делает и когда выполняется. В MS SQL Server триггеры привязаны к базам данных и таблицам, а в Oracle все триггеры хранятся в одном хранилище, в не зависимости от таблиц и здесь вы реально оцените выгоду от такого метода именования.
К именам процедур и функций я не предъявляю особых требований, но рекомендую выделять их из общей массы. Какой способ выберете вы, зависит от личных предпочтений. В данной книге будут использоваться различные способы именования, без жесткой привязки к определенному правилу, чтобы показать вам все способы именования, но определенную закономерность легко проследить.
Язык SQL не чувствителен к регистру, а значит, если написать какой-то оператор в верхнем регистре и в нижнем, результат будет одинаковым. Например, слова SELECT и select для сервера являются идентичными.
Все операторы SQL я пишу в верхнем регистре. Это не является обязательным и можно все писать в нижнем регистре. Большинство интерпретаторов SQL команд не чувствительны к регистру. Благодаря верхнему регистру вы сразу можете выделить из общей массы операторы языка SQL от имен полей, таблиц и т.д.
Научитесь писать базовые SQL-запросы
По сути, язык SQL позволяет нам извлекать и манипулировать данными в таблицах данных. В этой статье мы поймем и научимся писать фундаментальные SQL-запросы. Сначала мы рассмотрим основные понятия, которые нам необходимо знать для написания запросов к базе данных.
В этой статье мы поймем и научимся писать фундаментальные SQL-запросы. Сначала мы рассмотрим основные понятия, которые нам необходимо знать для написания запросов к базе данных.
Что такое T-SQL?
SQL является аббревиатурой слов языка структурированных запросов и используется для запросов к базам данных. Transact-SQL Язык (T-SQL) представляет собой расширенную реализацию SQL для Microsoft SQL Server. В этой статье мы будем использовать в примерах стандарты T-SQL.
Что такое реляционная база данных?
Проще всего мы можем определить реляционную базу данных как логическую структуру, в которой хранятся таблицы данных, которые могут относятся друг к другу.
Что такое таблица данных?
Таблица – это объект базы данных, который позволяет нам хранить данные в столбцах и строках. Можно сказать, что таблицы данных являются основными объектами баз данных, поскольку они содержат данные в реляционных базах данных.
Предположим, у нас есть таблица, в которой хранятся данные о студентах урока истории. Образуется в следующих
столбцы.
Образуется в следующих
столбцы.
Имя: Имя учащегося
Фамилия: Фамилия студента
Урок: Выбранный урок
Возраст: Студенческий возраст
Проходной балл: Проходной балл
Мы будем использовать эту таблицу в наших демонстрациях в этой статье. Имя этой таблицы данных Студент.
Наш первый запрос: инструкция SELECT
Оператор SELECT можно описать как начальную или нулевую точку запросов SQL. Оператор SELECT используется для извлечения данных из таблиц данных. В ВЫБЕРИТЕ синтаксис оператора, сначала мы указываем имена столбцов и разделяем их запятой, если мы используем один столбец, который мы
не используйте запятую в операторах SELECT. На втором шаге пишем ИЗ пункта и как
наконец, мы указываем имя таблицы. Когда мы рассматриваем приведенный ниже пример, он извлекает данные из Name .
и Фамилия , синтаксис оператора SELECT будет следующим:
Когда мы рассматриваем приведенный ниже пример, он извлекает данные из Name .
и Фамилия , синтаксис оператора SELECT будет следующим:
ВЫБЕРИТЕ Имя ,Фамилия ОТ Студент |
Если мы хотим получить данные только из Имя столбца , синтаксис оператора SELECT будет как показано ниже:
ВЫБЕРИТЕ Имя ОТ Учащегося |
Совет: Мы можем легко попробовать все эти примеры в этой статье самостоятельно в SQL Fiddle над этим ссылка на сайт. После перехода к ссылка, нам нужно очистить панель запросов и выполнить примеры запросов.
Знак звездочки ( * ) определяет все столбцы таблицы. Если мы рассмотрим приведенный ниже пример, то Оператор SELECT возвращает все столбцы таблицы Student .
ВЫБЕРИТЕ * ОТ Студенческого |
- Наконечник:
- Наша главная цель должна состоять в том, чтобы как можно скорее получить результаты запросов SQL с наименьшими ресурсами. потребление и минимальное время выполнения. Насколько это возможно, мы должны избегать использования знака звездочки (*) в SELECT операторов. Этот тип использования приводит к потреблению большего количества операций ввода-вывода, ЦП и сети. Как результат, если нам не нужны все столбцы таблицы в наших запросах, мы можем отказаться от использования знака звездочки и использовать только необходимые столбцы
Фильтрация данных: пункт WHERE
Предложение WHERE используется для фильтрации данных в соответствии с заданными условиями. После WHERE , мы должны определить условие фильтрации. В следующем примере извлекаются учащиеся
чей возраст больше и равен 20.
В следующем примере извлекаются учащиеся
чей возраст больше и равен 20.
ВЫБЕРИТЕ * ОТ Студент ГДЕ Возраст >=20 |
Оператор LIKE — это логический оператор, позволяющий применить специальный шаблон фильтрации к ГДЕ условие в запросах SQL. Знак процента ( % ) является основным подстановочным знаком для использования в качестве соединение с оператором LIKE . С помощью следующего запроса мы получим студентов чьи имена начинаются с J символ.
ВЫБЕРИТЕ * ОТ Студент ГДЕ Имя НРАВИТСЯ ‘J%’ |
Оператор IN позволяет нам применять несколько фильтров значений к предложению WHERE .
Следующий запрос извлекает данные учащихся, которые посещали уроки римской и европейской истории.
ВЫБЕРИТЕ * ОТ Студент ГДЕ Урок В («История Рима», «История Европы») |
Оператор МЕЖДУ фильтрует данные, попадающие в заданное начальное и конечное значения. следующий запрос возвращает данные для учащихся, чьи оценки равны и выше 40 и меньше и равны 60.
ВЫБОР * ОТ Студент ГДЕ PassMark МЕЖДУ 40 И 60 |
Сортировка данных: оператор ORDER BY
Оператор ORDER BY помогает нам сортировать данные в соответствии с указанным столбцом. Результирующий набор
данные могут быть отсортированы по возрастанию или по убыванию. Ключевое слово ASC сортирует данные по возрастанию
порядок, а ключевое слово DESC сортирует данные в порядке убывания. Следующий запрос сортирует
данные учащихся в порядке убывания в соответствии с выражениями столбца PassMark.
ВЫБЕРИТЕ * ОТ Студент ЗАКАЗАТЬ ПО PassMark DESC |
По умолчанию оператор ORDER BY сортирует данные в порядке возрастания. Следующий пример демонстрирует использование по умолчанию оператора ORDER BY .
ВЫБЕРИТЕ * ОТ Студент ЗАКАЗ ПО PassMark |
Устранение повторяющихся данных: пункт DISTINCT
Предложение DISTINCT используется для устранения повторяющихся данных из указанных столбцов, поэтому результат набор заполняется только отдельными (разными) значениями. В следующем примере мы получим Lesson данные столбца, однако при этом мы будем извлекать только отдельные значения с помощью DISTINCT пункт
ВЫБЕРИТЕ * ОТ Учащегося ГДЕ Возраст >= 20 |
Как мы видим, предложение DISTINCT удалило несколько значений, и эти значения были добавлены в
результат установлен только один раз.
Викторина
В этом разделе мы можем проверить наши знания.
Вопрос – 1:
Напишите запрос, который показывает имя и фамилию учащегося в возрасте от 22 до 24 лет.
Ответ :
ВЫБЕРИТЕ Имя, Фамилия ОТ Учащегося ГДЕ Возраст ОТ 22 ДО 24 |
Вопрос – 2:
Напишите запрос, который показывает имена и возраст учащихся в порядке убывания, которые посещают уроки римской и древней истории.
Ответ :
1 2 3 4 5 6 | ВЫБЕРИТЕ Имя, Фамилия, Возраст ОТ Ученик ГДЕ урок В(‘Римская история’, ‘Древняя история’) СОРТИРОВАТЬ ПО Возрасту DESC |
Заключение
В этой статье мы узнали, как писать базовые SQL-запросы, кроме того, мы продемонстрировали использование запросов на простых примерах.
- Автор
- Последние сообщения
Esat Erkec
Esat Erkec — специалист по SQL Server, который начал свою карьеру более 8 лет назад в качестве разработчика программного обеспечения. Он является сертифицированным экспертом по решениям Microsoft для SQL Server.
Большая часть его карьеры была посвящена администрированию и разработке баз данных SQL Server. Его текущие интересы связаны с администрированием баз данных и бизнес-аналитикой. Вы можете найти его в LinkedIn.
Просмотреть все сообщения от Esat Erkec
Последние сообщения Эсата Эркека (посмотреть все)
Введение в язык структурированных запросов (SQL)
Об этом курсе
192 878 недавних просмотров
В этом курсе вы пройдете этапы установки текстового редактора, установка MAMP или XAMPP (или эквивалента) и создание базы данных MySql. Вы узнаете о запросах к одной таблице и базовом синтаксисе языка SQL, а также о структуре базы данных с несколькими таблицами, внешними ключами и операцией JOIN. Наконец, вы научитесь моделировать отношения «многие ко многим», подобные тем, которые необходимы для представления пользователей, ролей и курсов.
Наконец, вы научитесь моделировать отношения «многие ко многим», подобные тем, которые необходимы для представления пользователей, ролей и курсов.
Гибкие сроки
Сброс сроков в соответствии с вашим графиком.
Совместно используемый сертификатСовместно используемый сертификат
Получите сертификат по завершении
100% онлайн100% онлайн
Начните немедленно и учитесь по собственному графику.
СпециализацияКурс 2 из 4 в рамках специализации
Веб-приложения для всех
Средний уровеньСредний уровень
Часов для прохожденияПрибл. 16 часов, чтобы закончить
Доступные языкиАнглийский
Субтитры: арабский, французский, португальский (европейский), сербский, итальянский, вьетнамский, корейский, немецкий, русский, английский, испанский
Гибкие сроки
Сброс сроков в соответствии с вашим графиком.
Общий сертификатОбщий сертификат
Получите сертификат по завершении
100 % онлайн100 % онлайн
Начните сразу и учитесь по собственному графику.
Курс 2 из 4 в рамках специализации
Веб-приложения для всех
Средний уровеньСредний уровень
Часов для прохожденияПрибл. 16 часов
Доступные языкиАнглийский
Субтитры: арабский, французский, португальский (европейский), сербский, итальянский, вьетнамский, корейский, немецкий, русский, английский, испанский
Instructor
Charles Russell Severance
Clinical Professor
School of Information
3,623,180 Learners
48 Courses
Offered by
University of Michigan
The mission of the University of Michigan is служить народу Мичигана и всего мира благодаря превосходству в создании, общении, сохранении и применении знаний, искусства и академических ценностей, а также в развитии лидеров и граждан, которые бросят вызов настоящему и обогатят будущее.
Reviews
4.8
Filled StarFilled StarFilled StarFilled StarFilled Star1086 reviews
5 stars
80.68%
4 stars
16.07%
3 stars
2.01%
2 звезды
0,51%
1 звезда
0,71% Filled0002 от AMS22 сентября 2020 г.
Привет! Я изучаю физику в Мьянме. В моем университете нет курса программирования. Я прохожу этот курс в период COVID-19 и получаю много знаний о языке программирования SQL. Спасибо.
Filled StarFilled StarFilled StarFilled StarFilled Starот RDS 12 сентября 2020 г.
Отличный курс, так многому нужно научиться, но трудно уловить (это было совершенно новым для меня).
Я имею в виду, что несколько дней назад я даже не знал, что такое SQL, а теперь я его понимаю.
Большое спасибо…….
Заполнено StarFilled StarFilled StarFilled StarStarот JW3 июня 2019 г.

Я не могу сказать, слишком ли холодно содержание, прежде чем использовать его в другом месте. Но в целом курс хороший. Стиль преподавания инструктора всеобъемлющий, хотя и слишком многословный.
Заполнено StarFilled StarFilled StarFilled StarStarот USApr 24, 2020
Весь курс был очень хорошим, но последнее задание показывает разные вещи на странице заданий и на странице отправки оценщика, из-за чего трудно отправить этот файл json.
Просмотреть все отзывы
О специализации «Веб-приложения для всех»
Эта специализация представляет собой введение в создание веб-приложений для тех, кто уже имеет базовые знания об адаптивном веб-дизайне с помощью JavaScript, HTML и CSS. Веб-приложения для всех — это введение в разработку веб-приложений. Вы будете разрабатывать веб-приложения и приложения баз данных на PHP, используя SQL для создания базы данных, а также функциональные возможности JavaScript, jQuery и JSON.
