Insert into postgresql пример
Добавление данных. Команда Insert
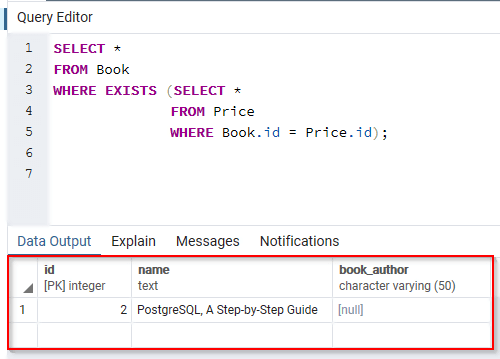
Для добавления данных применяется команда INSERT , которая имеет следующий формальный синтаксис:
После INSERT INTO идет имя таблицы, затем в скобках указываются все столбцы через запятую, в которые надо добавлять данные. И в конце после слова VALUES в скобках перечисляются добавляемые значения.
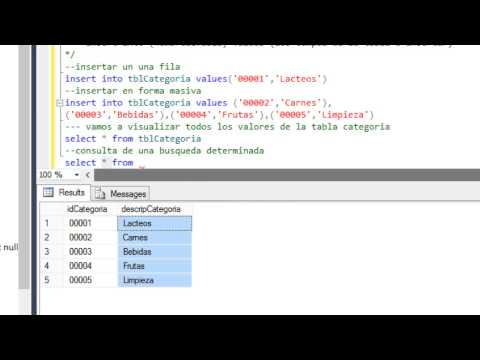
Допустим, у нас в базе данных есть следующая талица:
Добавим в нее одну строку с помощью команды INSERT:
После удачного выполнения в pgAdmin в поле сообщений должно появиться сообщение «INSERT 0 1»:
Стоит учитывать, что значения для столбцов в скобках после ключевого слова VALUES передаются по порядку их объявления. Например, в выражении CREATE TABLE выше можно увидеть, что первым столбцом идет Id, поэтому этому столбцу передаетсячисло 1. Второй столбец называется ProductName, поэтому второе значение – строка «Galaxy S9» будет передано именно этому столбцу и так далее. То есть значения передаются столбцам следующим образом:
ProductName: ‘Galaxy S9’
Также при вводе значений можно указать непосредственные столбцы, в которые будут добавляться значения:
Здесь значение указывается только для трех столбцов. Причем теперь значения передаются в порядке следования столбцов:
Причем теперь значения передаются в порядке следования столбцов:
ProductName: ‘iPhone X’
Для столбца Id значение будет генерироваться автоматически базой данных, так как он представляет тип Serial. То есть к значению из последней строки будет добавляться единица.
Для остальных столбцов будет добавляться значение по умолчанию, если задан атрибут DEFAULT (например, для столбца ProductCount), значение NULL. При этом неуказанные столбцы (за исключением тех, которые имеют тип Serial) должны допускать значение NULL или иметь атрибут DEFAULT.
Если конкретные столбцы не указываются, как в первом примере, тогда мы должны передать значения для всех столбцов в таблице.
Также мы можем добавить сразу несколько строк:
В данном случае в таблицу будут добавлены три строки.
Возвращение значений
Если мы добавляем значения только для части столбцов, то мы можем не знать, какие значения будут у других столбцов. Например, какое значени получит столбец >RETURNING мы можем получить это значение:
Название
Синтаксис
Описание
INSERT добавляет строки в таблицу. Эта команда может добавить одну или несколько строк, сформированных выражениями значений, либо ноль или более строк, выданных дополнительным запросом.
Эта команда может добавить одну или несколько строк, сформированных выражениями значений, либо ноль или более строк, выданных дополнительным запросом.
Имена целевых колонок могут перечисляться в любом порядке. Если список с именами колонок отсутствует, по умолчанию целевыми колонками становятся все колонки заданной таблицы; либо первые N из них, если только N колонок поступает от предложения VALUES или запроса. Значения, получаемые от предложения VALUES или запроса, связываются с явно или неявно определённым списком колонок слева направо.
Все колонки, не представленные в явном или неявном списке колонок, получат значения по умолчанию, если для них заданы эти значения, либо NULL в противном случае.
Если выражение для любой колонки выдаёт другой тип данных, система попытается автоматически привести его к нужному.
С необязательным предложением RETURNING команда INSERT вычислит и возвратит значения для каждой фактически добавленной строки. В основном это полезно для получения значений, присвоенных по умолчанию, например, последовательного номера записи. Однако в этом предложении можно задать любое выражение с колонками таблицы. Список RETURNING имеет тот же синтаксис, что и список результатов SELECT.
В основном это полезно для получения значений, присвоенных по умолчанию, например, последовательного номера записи. Однако в этом предложении можно задать любое выражение с колонками таблицы. Список RETURNING имеет тот же синтаксис, что и список результатов SELECT.
Чтобы вставить строки в таблицу, необходимо иметь право INSERT для этой таблицы. Если указывается список колонок, достаточно иметь право INSERT для перечисленных колонок. Для применения предложения RETURNING требуется право SELECT для всех колонок, перечисленных в RETURNING. Если для добавления строк применяется запрос, для всех таблиц или колонок, задействованных в этом запросе, разумеется, необходимо иметь право SELECT.
Параметры
Предложение WITH позволяет задать один или несколько подзапросов, на которые затем можно ссылаться по имени в запросе INSERT. Подробнее об этом см. Раздел 7.8 и SELECT.
Заданный запрос (оператор SELECT) также может содержать предложение WITH. В этом случае в запросе можно обращаться к обоим запросам_WITH, но второй будет иметь приоритет, так как он вложен ближе. table_name
table_name
Имя (возможно, дополненное схемой) существующей таблицы. имя_колонки
Имя колонки в таблице имя_таблицы. Имя колонки может быть дополнено именем вложенного поля или индексом массива, если требуется. (При заполнении только некоторых полей составной колонки остальные поля получают значения NULL.) DEFAULT VALUES
Все колонки получат значения по умолчанию. выражение
Выражение или значение, которое будет присвоено соответствующей колонке. DEFAULT
Соответствующая колонка получит значение по умолчанию. запрос
Запрос (оператор SELECT), который выдаст строки для добавления в таблицу. Его синтаксис описан в справке оператора SELECT. выражение_результата
Выражение, которое будет вычисляться и возвращаться командой INSERT после добавления каждой строки. В этом выражении можно использовать имена любых колонок таблицы имя_таблицы. Чтобы получить все колонки, достаточно написать *. имя_результата
Имя, назначаемое возвращаемой колонке.
Выводимая информация
В случае успешного завершения, INSERT возвращает метку команды в виде
Здесь число представляет количество добавленных строк. Если число равняется одному, а целевая таблица содержит o >oid выводится OID , назначенный добавленной строке. В противном случае вместо oid выводится ноль.
Если команда INSERT содержит предложение RETURNING, её результат будет похож на результат оператора SELECT (с теми же колонками и значениями, что содержатся в списке RETURNING), полученный для строк, добавленных этой командой.
Примеры
Добавление одной строки в таблицу films:
В этом примере колонка len опускается и, таким образом, получает значение по умолчанию:
В этом примере для колонки с датой задаётся указание DEFAULT, а не явное значение:
Добавление строки, полностью состоящей из значений по умолчанию:
Добавление нескольких строк с использованием многострочного синтаксиса VALUES:
В этом примере в таблицу films вставляются некоторые строки из таблицы tmp_films, имеющей ту же структуру колонок, что и films:
Этот пример демонстрирует добавление данных в колонки с типом массива:
Добавление одной строки в таблицу distributors и получение последовательного номера, сгенерированного благодаря указанию DEFAULT:
Увеличение счётчика продаж для продавца, занимающегося компанией Acme Corporation, и сохранение всей изменённой строки вместе с текущим временем в таблице журнала:
Совместимость
INSERT соответствует стандарту SQL, но предложение RETURNING относится к расширениям PostgreSQL , как и возможность применять WITH с INSERT. Кроме того, ситуация, когда список колонок опущен, но не все колонки получают значения из предложения VALUES или запроса, стандартом не допускается.
Кроме того, ситуация, когда список колонок опущен, но не все колонки получают значения из предложения VALUES или запроса, стандартом не допускается.
Возможные ограничения предложения запрос описаны в справке SELECT.
I’m not sure if its standard SQL:
What I’m looking for is: what if tblA and tblB are in different DB Servers.
Does PostgreSql gives any utility or has any functionality that will help to use INSERT query with PGresult struct
I mean SELECT id, time FROM tblB . will return a PGresult* on using PQexec . Is it possible to use this struct in another PQexec to execute an INSERT command.
EDIT:
If not possible then I would go for extracting the values from PQresult* and create a multiple INSERT statement syntax like:
Is it possible to create a prepared statement out of this!! 🙁
6 Answers 6
As Henrik wrote you can use dblink to connect remote database and fetch result. For example:
PostgreSQL has record pseudo-type (only for function’s argument or result type), which allows you query data from another (unknown) table.
You can make it as prepared statement if you want and it works as well:
Edit (yeah, another):
I just saw your revised question (closed as duplicate, or just very similar to this).
If my understanding is correct (postgres has tbla and dbtest has tblb and you want remote insert with local select, not remote select with local insert as above):
I don’t like that nested dblink, but AFAIK I can’t reference to tblB in dblink_exec body. Use LIMIT to specify top 20 rows, but I think you need to sort them using ORDER BY clause first.
insert into postgresql пример — ComputerMaker.info
Автор admin На чтение 7 мин. Просмотров 157 Опубликовано
Содержание
- Добавление данных. Команда Insert
- Возвращение значений
- Название
- Синтаксис
- Описание
- Параметры
- Выводимая информация
- Примеры
- Совместимость
- 6 Answers 6
Добавление данных.
 Команда Insert
Команда InsertДля добавления данных применяется команда INSERT , которая имеет следующий формальный синтаксис:
После INSERT INTO идет имя таблицы, затем в скобках указываются все столбцы через запятую, в которые надо добавлять данные. И в конце после слова VALUES в скобках перечисляются добавляемые значения.
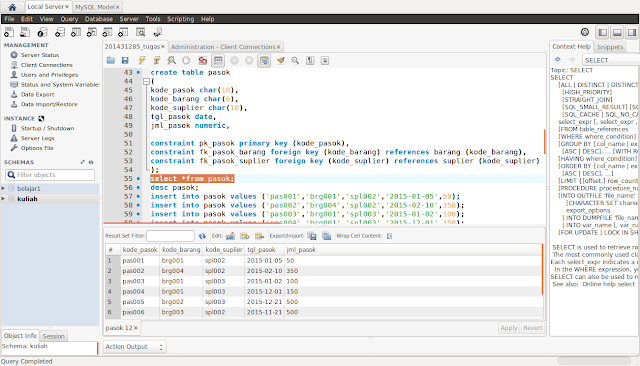
Допустим, у нас в базе данных есть следующая талица:
Добавим в нее одну строку с помощью команды INSERT:
После удачного выполнения в pgAdmin в поле сообщений должно появиться сообщение «INSERT 0 1»:
Стоит учитывать, что значения для столбцов в скобках после ключевого слова VALUES передаются по порядку их объявления. Например, в выражении CREATE TABLE выше можно увидеть, что первым столбцом идет Id, поэтому этому столбцу передаетсячисло 1. Второй столбец называется ProductName, поэтому второе значение — строка «Galaxy S9» будет передано именно этому столбцу и так далее. То есть значения передаются столбцам следующим образом:
ProductName: ‘Galaxy S9’
Также при вводе значений можно указать непосредственные столбцы, в которые будут добавляться значения:
Здесь значение указывается только для трех столбцов. Причем теперь значения передаются в порядке следования столбцов:
Причем теперь значения передаются в порядке следования столбцов:
ProductName: ‘iPhone X’
Для столбца Id значение будет генерироваться автоматически базой данных, так как он представляет тип Serial. То есть к значению из последней строки будет добавляться единица.
Для остальных столбцов будет добавляться значение по умолчанию, если задан атрибут DEFAULT (например, для столбца ProductCount), значение NULL. При этом неуказанные столбцы (за исключением тех, которые имеют тип Serial) должны допускать значение NULL или иметь атрибут DEFAULT.
Если конкретные столбцы не указываются, как в первом примере, тогда мы должны передать значения для всех столбцов в таблице.
Также мы можем добавить сразу несколько строк:
В данном случае в таблицу будут добавлены три строки.
Возвращение значений
Если мы добавляем значения только для части столбцов, то мы можем не знать, какие значения будут у других столбцов. Например, какое значени получит столбец >RETURNING мы можем получить это значение:
Название
Синтаксис
Описание
INSERT добавляет строки в таблицу. Эта команда может добавить одну или несколько строк, сформированных выражениями значений, либо ноль или более строк, выданных дополнительным запросом.
Эта команда может добавить одну или несколько строк, сформированных выражениями значений, либо ноль или более строк, выданных дополнительным запросом.
Имена целевых колонок могут перечисляться в любом порядке. Если список с именами колонок отсутствует, по умолчанию целевыми колонками становятся все колонки заданной таблицы; либо первые N из них, если только N колонок поступает от предложения VALUES или запроса. Значения, получаемые от предложения VALUES или запроса, связываются с явно или неявно определённым списком колонок слева направо.
Все колонки, не представленные в явном или неявном списке колонок, получат значения по умолчанию, если для них заданы эти значения, либо NULL в противном случае.
Если выражение для любой колонки выдаёт другой тип данных, система попытается автоматически привести его к нужному.
С необязательным предложением RETURNING команда INSERT вычислит и возвратит значения для каждой фактически добавленной строки. В основном это полезно для получения значений, присвоенных по умолчанию, например, последовательного номера записи. Однако в этом предложении можно задать любое выражение с колонками таблицы. Список RETURNING имеет тот же синтаксис, что и список результатов SELECT.
В основном это полезно для получения значений, присвоенных по умолчанию, например, последовательного номера записи. Однако в этом предложении можно задать любое выражение с колонками таблицы. Список RETURNING имеет тот же синтаксис, что и список результатов SELECT.
Чтобы вставить строки в таблицу, необходимо иметь право INSERT для этой таблицы. Если указывается список колонок, достаточно иметь право INSERT для перечисленных колонок. Для применения предложения RETURNING требуется право SELECT для всех колонок, перечисленных в RETURNING. Если для добавления строк применяется запрос, для всех таблиц или колонок, задействованных в этом запросе, разумеется, необходимо иметь право SELECT.
Параметры
Предложение WITH позволяет задать один или несколько подзапросов, на которые затем можно ссылаться по имени в запросе INSERT. Подробнее об этом см. Раздел 7.8 и SELECT.
Заданный запрос (оператор SELECT) также может содержать предложение WITH. В этом случае в запросе можно обращаться к обоим запросам_WITH, но второй будет иметь приоритет, так как он вложен ближе. table_name
table_name
Имя (возможно, дополненное схемой) существующей таблицы. имя_колонки
Имя колонки в таблице имя_таблицы. Имя колонки может быть дополнено именем вложенного поля или индексом массива, если требуется. (При заполнении только некоторых полей составной колонки остальные поля получают значения NULL.) DEFAULT VALUES
Все колонки получат значения по умолчанию. выражение
Выражение или значение, которое будет присвоено соответствующей колонке. DEFAULT
Соответствующая колонка получит значение по умолчанию. запрос
Запрос (оператор SELECT), который выдаст строки для добавления в таблицу. Его синтаксис описан в справке оператора SELECT. выражение_результата
Выражение, которое будет вычисляться и возвращаться командой INSERT после добавления каждой строки. В этом выражении можно использовать имена любых колонок таблицы имя_таблицы. Чтобы получить все колонки, достаточно написать *. имя_результата
Имя, назначаемое возвращаемой колонке.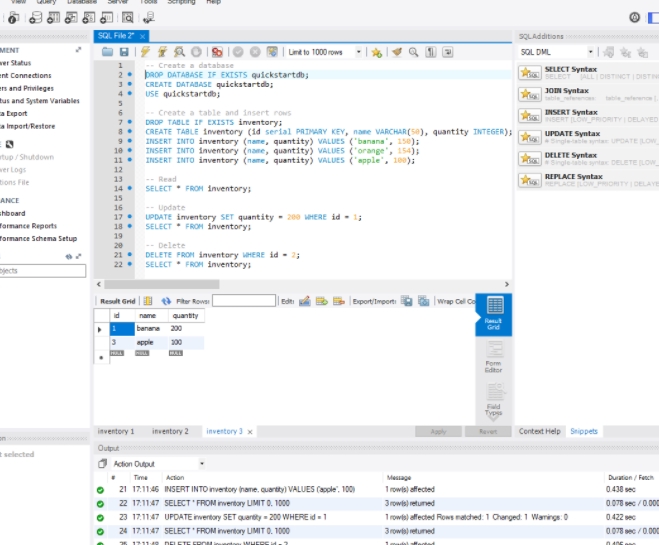
В случае успешного завершения, INSERT возвращает метку команды в виде
Здесь число представляет количество добавленных строк. Если число равняется одному, а целевая таблица содержит o >oid выводится OID , назначенный добавленной строке. В противном случае вместо oid выводится ноль.
Если команда INSERT содержит предложение RETURNING, её результат будет похож на результат оператора SELECT (с теми же колонками и значениями, что содержатся в списке RETURNING), полученный для строк, добавленных этой командой.
Примеры
Добавление одной строки в таблицу films:
В этом примере колонка len опускается и, таким образом, получает значение по умолчанию:
В этом примере для колонки с датой задаётся указание DEFAULT, а не явное значение:
Добавление строки, полностью состоящей из значений по умолчанию:
Добавление нескольких строк с использованием многострочного синтаксиса VALUES:
В этом примере в таблицу films вставляются некоторые строки из таблицы tmp_films, имеющей ту же структуру колонок, что и films:
Этот пример демонстрирует добавление данных в колонки с типом массива:
Добавление одной строки в таблицу distributors и получение последовательного номера, сгенерированного благодаря указанию DEFAULT:
Увеличение счётчика продаж для продавца, занимающегося компанией Acme Corporation, и сохранение всей изменённой строки вместе с текущим временем в таблице журнала:
Совместимость
INSERT соответствует стандарту SQL, но предложение RETURNING относится к расширениям PostgreSQL , как и возможность применять WITH с INSERT. Кроме того, ситуация, когда список колонок опущен, но не все колонки получают значения из предложения VALUES или запроса, стандартом не допускается.
Кроме того, ситуация, когда список колонок опущен, но не все колонки получают значения из предложения VALUES или запроса, стандартом не допускается.
Возможные ограничения предложения запрос описаны в справке SELECT.
I’m not sure if its standard SQL:
What I’m looking for is: what if tblA and tblB are in different DB Servers.
Does PostgreSql gives any utility or has any functionality that will help to use INSERT query with PGresult struct
I mean SELECT id, time FROM tblB . will return a PGresult* on using PQexec . Is it possible to use this struct in another PQexec to execute an INSERT command.
EDIT:
If not possible then I would go for extracting the values from PQresult* and create a multiple INSERT statement syntax like:
Is it possible to create a prepared statement out of this!! 🙁
6 Answers 6
As Henrik wrote you can use dblink to connect remote database and fetch result. For example:
PostgreSQL has record pseudo-type (only for function’s argument or result type), which allows you query data from another (unknown) table.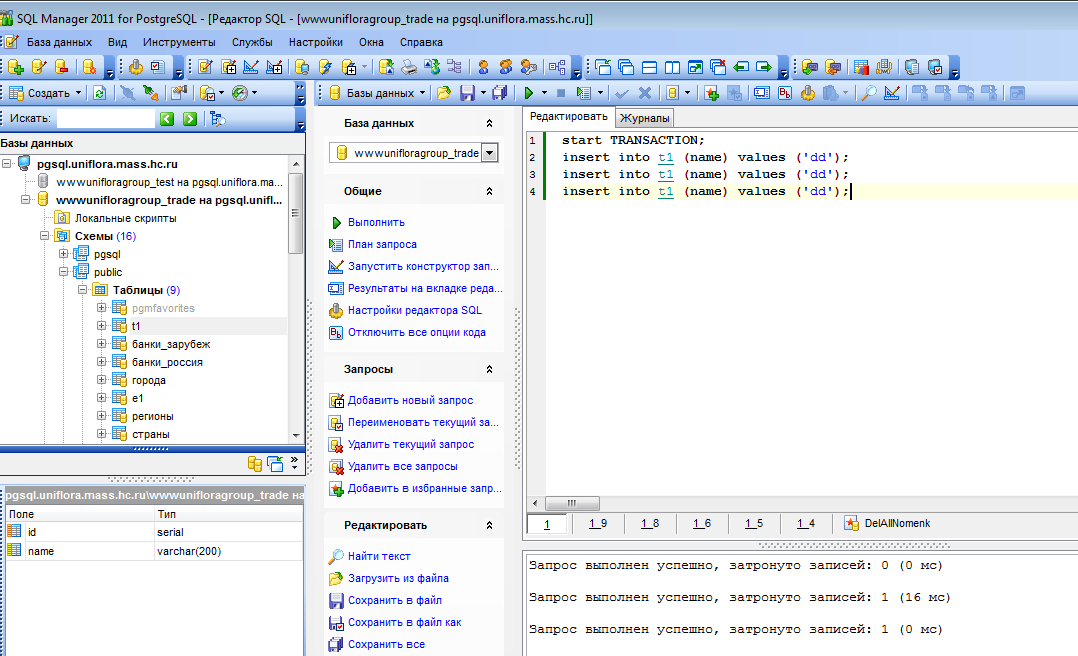
You can make it as prepared statement if you want and it works as well:
Edit (yeah, another):
I just saw your revised question (closed as duplicate, or just very similar to this).
If my understanding is correct (postgres has tbla and dbtest has tblb and you want remote insert with local select, not remote select with local insert as above):
I don’t like that nested dblink, but AFAIK I can’t reference to tblB in dblink_exec body. Use LIMIT to specify top 20 rows, but I think you need to sort them using ORDER BY clause first.
insert into postgresql пример — Все о Windows 10
Содержание
- Добавление данных. Команда Insert
- Возвращение значений
- Название
- Синтаксис
- Описание
- Параметры
- Выводимая информация
- Примеры
- Совместимость
- 6 Answers 6
Добавление данных. Команда Insert
Для добавления данных применяется команда INSERT , которая имеет следующий формальный синтаксис:
После INSERT INTO идет имя таблицы, затем в скобках указываются все столбцы через запятую, в которые надо добавлять данные. И в конце после слова VALUES в скобках перечисляются добавляемые значения.
И в конце после слова VALUES в скобках перечисляются добавляемые значения.
Допустим, у нас в базе данных есть следующая талица:
Добавим в нее одну строку с помощью команды INSERT:
После удачного выполнения в pgAdmin в поле сообщений должно появиться сообщение «INSERT 0 1»:
Стоит учитывать, что значения для столбцов в скобках после ключевого слова VALUES передаются по порядку их объявления. Например, в выражении CREATE TABLE выше можно увидеть, что первым столбцом идет Id, поэтому этому столбцу передаетсячисло 1. Второй столбец называется ProductName, поэтому второе значение — строка «Galaxy S9» будет передано именно этому столбцу и так далее. То есть значения передаются столбцам следующим образом:
ProductName: ‘Galaxy S9’
Также при вводе значений можно указать непосредственные столбцы, в которые будут добавляться значения:
Здесь значение указывается только для трех столбцов. Причем теперь значения передаются в порядке следования столбцов:
ProductName: ‘iPhone X’
Для столбца Id значение будет генерироваться автоматически базой данных, так как он представляет тип Serial.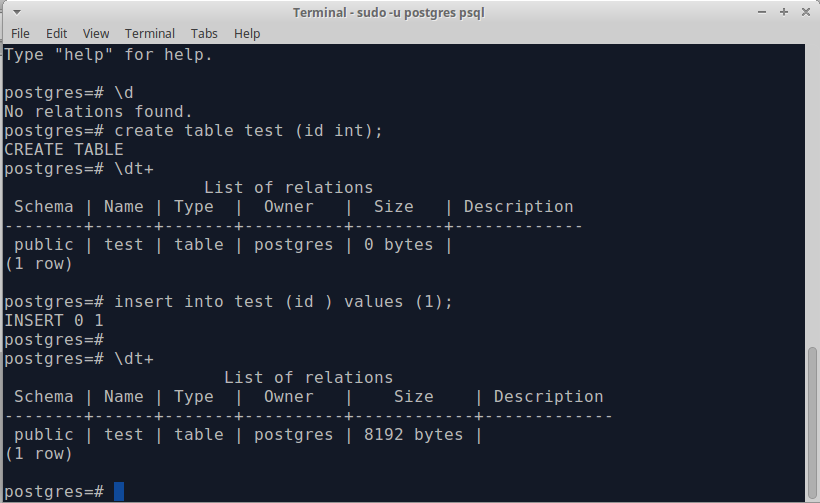 То есть к значению из последней строки будет добавляться единица.
То есть к значению из последней строки будет добавляться единица.
Для остальных столбцов будет добавляться значение по умолчанию, если задан атрибут DEFAULT (например, для столбца ProductCount), значение NULL. При этом неуказанные столбцы (за исключением тех, которые имеют тип Serial) должны допускать значение NULL или иметь атрибут DEFAULT.
Если конкретные столбцы не указываются, как в первом примере, тогда мы должны передать значения для всех столбцов в таблице.
Также мы можем добавить сразу несколько строк:
В данном случае в таблицу будут добавлены три строки.
Возвращение значений
Если мы добавляем значения только для части столбцов, то мы можем не знать, какие значения будут у других столбцов. Например, какое значени получит столбец >RETURNING мы можем получить это значение:
Название
Синтаксис
Описание
INSERT добавляет строки в таблицу. Эта команда может добавить одну или несколько строк, сформированных выражениями значений, либо ноль или более строк, выданных дополнительным запросом.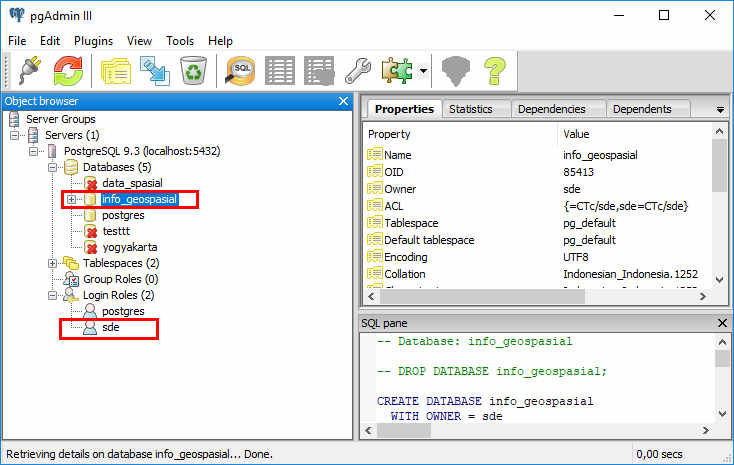
Имена целевых колонок могут перечисляться в любом порядке. Если список с именами колонок отсутствует, по умолчанию целевыми колонками становятся все колонки заданной таблицы; либо первые N из них, если только N колонок поступает от предложения VALUES или запроса. Значения, получаемые от предложения VALUES или запроса, связываются с явно или неявно определённым списком колонок слева направо.
Все колонки, не представленные в явном или неявном списке колонок, получат значения по умолчанию, если для них заданы эти значения, либо NULL в противном случае.
Если выражение для любой колонки выдаёт другой тип данных, система попытается автоматически привести его к нужному.
С необязательным предложением RETURNING команда INSERT вычислит и возвратит значения для каждой фактически добавленной строки. В основном это полезно для получения значений, присвоенных по умолчанию, например, последовательного номера записи. Однако в этом предложении можно задать любое выражение с колонками таблицы. Список RETURNING имеет тот же синтаксис, что и список результатов SELECT.
Список RETURNING имеет тот же синтаксис, что и список результатов SELECT.
Чтобы вставить строки в таблицу, необходимо иметь право INSERT для этой таблицы. Если указывается список колонок, достаточно иметь право INSERT для перечисленных колонок. Для применения предложения RETURNING требуется право SELECT для всех колонок, перечисленных в RETURNING. Если для добавления строк применяется запрос, для всех таблиц или колонок, задействованных в этом запросе, разумеется, необходимо иметь право SELECT.
Параметры
Предложение WITH позволяет задать один или несколько подзапросов, на которые затем можно ссылаться по имени в запросе INSERT. Подробнее об этом см. Раздел 7.8 и SELECT.
Заданный запрос (оператор SELECT) также может содержать предложение WITH. В этом случае в запросе можно обращаться к обоим запросам_WITH, но второй будет иметь приоритет, так как он вложен ближе. table_name
Имя (возможно, дополненное схемой) существующей таблицы. имя_колонки
имя_колонки
Имя колонки в таблице имя_таблицы. Имя колонки может быть дополнено именем вложенного поля или индексом массива, если требуется. (При заполнении только некоторых полей составной колонки остальные поля получают значения NULL.) DEFAULT VALUES
Все колонки получат значения по умолчанию. выражение
Выражение или значение, которое будет присвоено соответствующей колонке. DEFAULT
Соответствующая колонка получит значение по умолчанию. запрос
Запрос (оператор SELECT), который выдаст строки для добавления в таблицу. Его синтаксис описан в справке оператора SELECT. выражение_результата
Выражение, которое будет вычисляться и возвращаться командой INSERT после добавления каждой строки. В этом выражении можно использовать имена любых колонок таблицы имя_таблицы. Чтобы получить все колонки, достаточно написать *. имя_результата
Имя, назначаемое возвращаемой колонке.
В случае успешного завершения, INSERT возвращает метку команды в виде
Здесь число представляет количество добавленных строк.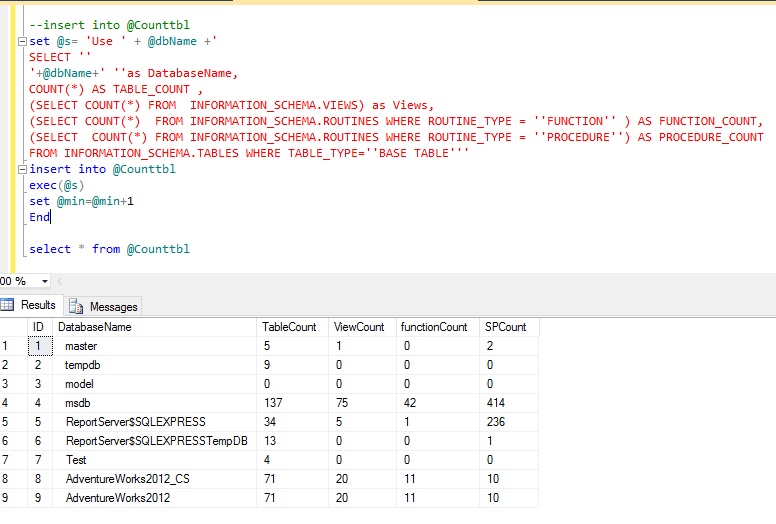 Если число равняется одному, а целевая таблица содержит o >oid выводится OID , назначенный добавленной строке. В противном случае вместо oid выводится ноль.
Если число равняется одному, а целевая таблица содержит o >oid выводится OID , назначенный добавленной строке. В противном случае вместо oid выводится ноль.
Если команда INSERT содержит предложение RETURNING, её результат будет похож на результат оператора SELECT (с теми же колонками и значениями, что содержатся в списке RETURNING), полученный для строк, добавленных этой командой.
Примеры
Добавление одной строки в таблицу films:
В этом примере колонка len опускается и, таким образом, получает значение по умолчанию:
В этом примере для колонки с датой задаётся указание DEFAULT, а не явное значение:
Добавление строки, полностью состоящей из значений по умолчанию:
Добавление нескольких строк с использованием многострочного синтаксиса VALUES:
В этом примере в таблицу films вставляются некоторые строки из таблицы tmp_films, имеющей ту же структуру колонок, что и films:
Этот пример демонстрирует добавление данных в колонки с типом массива:
Добавление одной строки в таблицу distributors и получение последовательного номера, сгенерированного благодаря указанию DEFAULT:
Увеличение счётчика продаж для продавца, занимающегося компанией Acme Corporation, и сохранение всей изменённой строки вместе с текущим временем в таблице журнала:
Совместимость
INSERT соответствует стандарту SQL, но предложение RETURNING относится к расширениям PostgreSQL , как и возможность применять WITH с INSERT.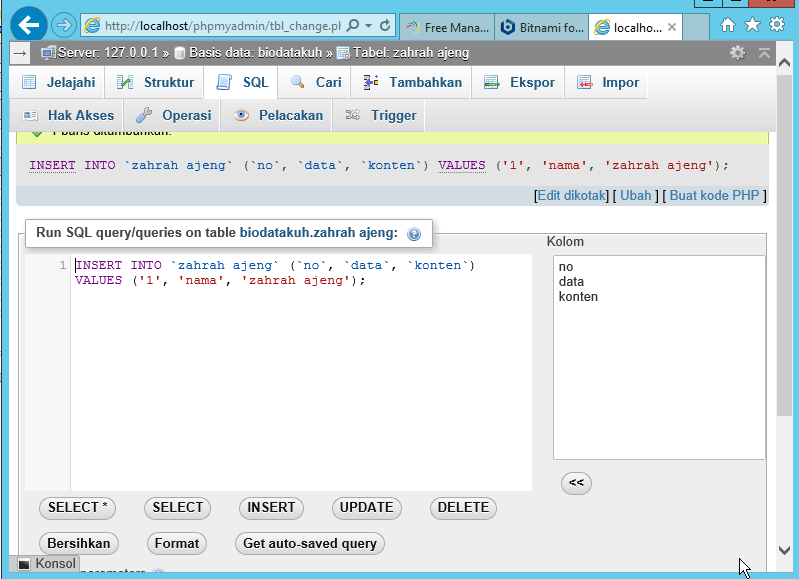 Кроме того, ситуация, когда список колонок опущен, но не все колонки получают значения из предложения VALUES или запроса, стандартом не допускается.
Кроме того, ситуация, когда список колонок опущен, но не все колонки получают значения из предложения VALUES или запроса, стандартом не допускается.
Возможные ограничения предложения запрос описаны в справке SELECT.
I’m not sure if its standard SQL:
What I’m looking for is: what if tblA and tblB are in different DB Servers.
Does PostgreSql gives any utility or has any functionality that will help to use INSERT query with PGresult struct
I mean SELECT id, time FROM tblB . will return a PGresult* on using PQexec . Is it possible to use this struct in another PQexec to execute an INSERT command.
EDIT:
If not possible then I would go for extracting the values from PQresult* and create a multiple INSERT statement syntax like:
Is it possible to create a prepared statement out of this!! 🙁
6 Answers 6
As Henrik wrote you can use dblink to connect remote database and fetch result. For example:
PostgreSQL has record pseudo-type (only for function’s argument or result type), which allows you query data from another (unknown) table.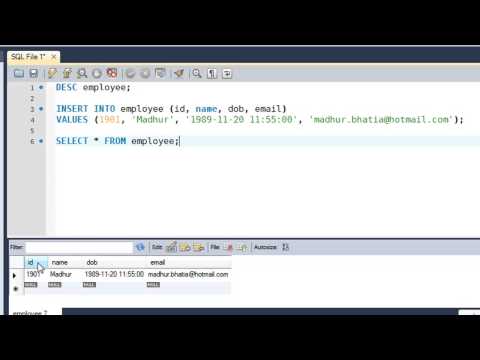
You can make it as prepared statement if you want and it works as well:
Edit (yeah, another):
I just saw your revised question (closed as duplicate, or just very similar to this).
If my understanding is correct (postgres has tbla and dbtest has tblb and you want remote insert with local select, not remote select with local insert as above):
I don’t like that nested dblink, but AFAIK I can’t reference to tblB in dblink_exec body. Use LIMIT to specify top 20 rows, but I think you need to sort them using ORDER BY clause first.
Вставка строк с использованием результатов запроса Select в PostgreSQL.
В этом сообщении блога будет рассмотрено использование результатов запроса оператора SELECT из одной таблицы в качестве значений для INSERT в другой таблице.
Примечание. Все данные, имена или названия, найденные в базе данных, представленной в этом посте, используются исключительно для практики, обучения, обучения и тестирования. Он ни в коем случае не отображает фактические данные, принадлежащие или используемые какой-либо стороной или организацией.
Он ни в коем случае не отображает фактические данные, принадлежащие или используемые какой-либо стороной или организацией.
Для этих упражнений я буду использовать Xubuntu Linux 16.04.2 LTS (Xenial Xerus) и PostgreSQL 9.6.4.
Продолжение работы с базой данных FAB_TRACKING , я заполняю оба PUP_ASSET и Bend_assets Tables с Assisted of Asseted of Assetdested of Assetdestested of Assetdested_ Tables of Asseted.
Цели…
- Проверить общее количество существующих записей в обоих pup_assets и Bend_assets таблицы.
- Проверьте количество каждого значения столбца
типа(BENDилиPIPE_JOINT) записи в таблице staging_assets . -
INSERTзаписей в таблицы pup_assets и Bend_Assets с использованием запросаSELECTиз 6 0_staging0017, в зависимости от значения столбца типатипа.
Для начала я проверю количество в обеих целевых таблицах с помощью следующих операторов SELECT :
fab_tracking=> SELECT COUNT(*) FROM pup_assets;
count
——-
32
fab_tracking=> SELECT COUNT(*) FROM bend_assets;
count
——-
16
(1 строка)
Количество каждого из типов столбцов в staging_assets также показана таблица:
fab_tracking=> SELECT COUNT(*)
FROM staging_assets
WHERE UPPER(kind) = ‘BEND’;
count
——-
15
(1 строка)
fab_tracking=> SELECT COUNT(*)
FROM staging_assets
WHERE UPPER(kind) = ‘PIPE_JOINT’;
count
——-
30
(1 строка)
Поделись…
Теперь, когда мы точно знаем, сколько видов активов хранится в staging_assets таблица, давайте INSERT их в соответствующие таблицы.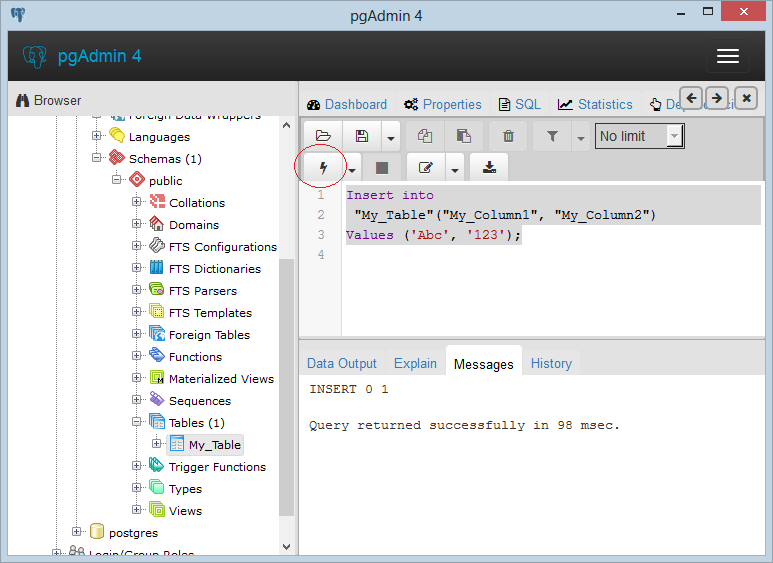
Команда INSERT создает новые строки в таблице базы данных, заполняя столбцы таблицы значениями. Одной из многочисленных доступных опций является возможность использовать результаты запроса SELECT в качестве входных значений для столбцов таблицы.
Во-первых, мы можем ВЫБРАТЬ все активы с типом значением столбца ‘ BEND’ до Вставка в таблицу Bend_assets С Использование Следующей команды:
FAB_TRACKING => Вставка в Bend_ASSET (CUSTEM_ID, BND_PIPE_ID, BND_HEAT,
BND_LENDE, DEGEIER, Wall_THICKS).
степень, pipe_wall_thickness
FROM staging_assets
WHERE UPPER(kind) = ‘BEND’;
ВСТАВИТЬ 0 15
Примечание. Успешный INSERT возвращает командный тег числа вставленных или обновленных строк.
Теперь давайте проверим количество записей в таблице Bend_Assets и подтвердим, что INSERT был успешным:
count
——-
31
(1 строка)
Таблица Bend_Assets теперь содержит в общей сложности 31 запись, что подтверждает это ВСТАВКА прошла успешно.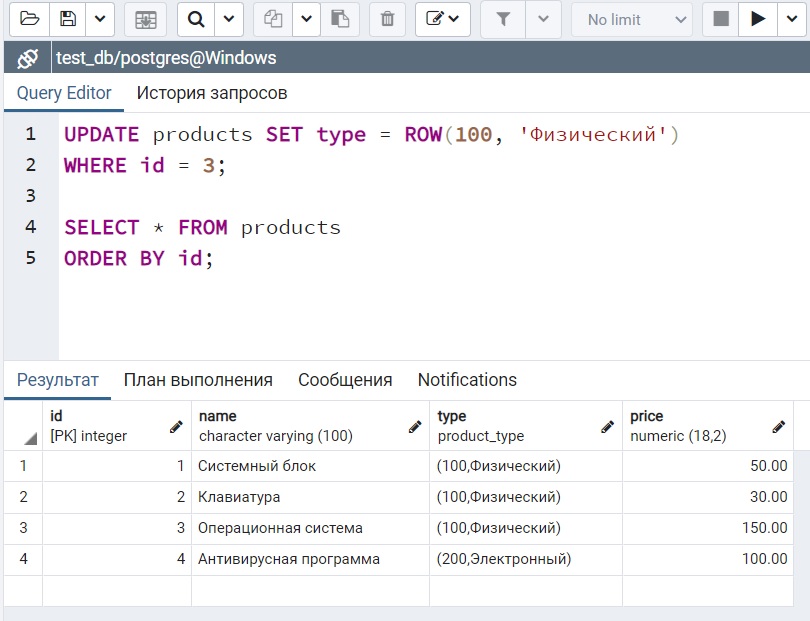
Нам также необходимо SELECT и INSERT все соответствующие записи со значением столбца PIPE_JOINT вида в таблицу pup_assets . Эта команда показана ниже:
fab_tracking=> INSERT INTO pup_assets(custom_pup_id, pup_pipe_id, pup_heat,
pup_length, pup_wall_thickness)0084 pipe_length, pipe_wall_thickness
FROM staging_assets
INSERT 0 30
И проверка количества в таблице pup_assets подтверждает, что операция также прошла успешно:
fab_tracking=> SELECT COUNT(*) FROM pup_assets;
count
——-
62
(1 ряд)
Закрытие.
Использование INSERT в сочетании с результатами командного запроса SELECT позволяет нам в полной мере воспользоваться преимуществами таблицы staging_assets . Сначала поместив наши данные в эту временную таблицу, можно выполнить любые задачи по очистке данных, прежде чем использовать эти строки для вставки в их общую таблицу хранения. Не стесняйтесь просматривать подробную документацию, касающуюся инструкции
Сначала поместив наши данные в эту временную таблицу, можно выполнить любые задачи по очистке данных, прежде чем использовать эти строки для вставки в их общую таблицу хранения. Не стесняйтесь просматривать подробную документацию, касающуюся инструкции INSERT для всех вариантов.
Спасибо, что нашли время прочитать этот пост. Я искренне надеюсь, что вы открыли для себя что-то интересное и поучительное. Пожалуйста, поделитесь своими выводами здесь с кем-то из ваших знакомых, кто также получит от этого такую же пользу.
Чтобы получать по электронной почте уведомления о последнем сообщении от «Digital Owl’s Prose», подпишитесь, нажав кнопку «Нажмите, чтобы подписаться» на боковой панели!
Отказ от ответственности: примеры, представленные в этом посте, являются гипотетическими идеями того, как достичь подобных результатов. Это не самое лучшее решение(я). Большинство, если не все, приведенные примеры выполняются в рабочей среде для персональной разработки/обучения и не должны считаться готовыми к производству. Ваши конкретные цели и потребности могут отличаться. Используйте те методы, которые лучше всего подходят для ваших нужд и целей. Мнения мои собственные.
Ваши конкретные цели и потребности могут отличаться. Используйте те методы, которые лучше всего подходят для ваших нужд и целей. Мнения мои собственные.
Например:
Нравится Загрузка…
Python PostgreSQL CRUD — вставка, обновление и удаление данных таблицы
В этом руководстве мы научимся выполнять операции вставки, обновления и удаления PostgreSQL из Python. Это также известно как операции DML. Кроме того, узнайте, как передавать параметры в SQL-запросы , т. е. использовать переменные Python в запросе PostgreSQL для вставки, обновления и удаления данных таблицы.
В итоге мы увидим использование cursor.executemany() для вставки, обновления и удаления нескольких строк с помощью одного запроса.
Также читайте :
- Решение Python Postgresql Упражнения
- Читать учебник Python Postgresql (Полное руководство)
СОДЕРЖАНИЕ
- .
- Python PostgreSQL Удалить строку и столбцы таблицы
- Вставка, обновление и удаление нескольких строк из таблицы PostgreSQL с помощью executemany()
- Python Вставка нескольких строк в таблицу PostgreSQL
- Обновление нескольких строк таблицы PostgreSQL с помощью одного запроса в Python
- Python PostgreSQL Удаление нескольких строк из таблицы
- следующие программы, убедитесь, что у вас есть следующие данные
- Имя пользователя и пароль , необходимые для подключения к PostgreSQL
- Таблица базы данных PostgreSQL для операций CRUD.

В этой статье я использую «мобильную» таблицу, созданную в моей базе данных PostgreSQL.
Если таблицы нет, вы можете обратиться к создать таблицу PostgreSQL из Python .
Мобильная таблица PostgreSQLPython PostgreSQL INSERT в таблицу базы данных
В этом разделе мы узнаем, как выполнить запрос INSERT Query из приложения Python для вставки строк в таблицу PostgreSQL с помощью Psycopg2.
Чтобы выполнить запрос SQL INSERT из Python, вам необходимо выполнить следующие простые шаги: –
- Установите psycopg2 с помощью pip.
- Во-вторых, установите соединение с базой данных PostgreSQL в Python.
- Далее определите запрос на вставку. Все, что вам нужно знать, это сведения о столбцах таблицы.
- Выполнить запрос INSERT с помощью
cursor.execute(). Взамен вы получите количество затронутых строк. - После успешного выполнения запроса зафиксируйте изменения в базе данных.
- Закройте курсор и соединение с базой данных PostgreSQL.
- Самое главное, поймать исключения SQL, если они есть.
- Наконец, проверьте результат, выбрав данные из таблицы PostgreSQL.
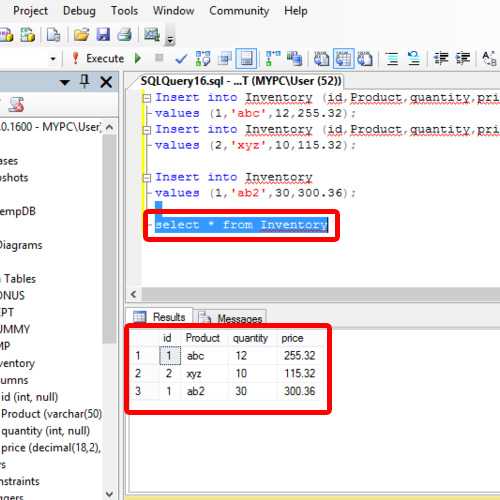
импорт psycopg2 пытаться: соединение = psycopg2.connect (пользователь = "sysadmin", пароль="pynative@#29", хост = "127.0.0.1", порт = "5432", база данных = "postgres_db") курсор = соединение.курсор() postgres_insert_query = """ ВСТАВИТЬ В МОБИЛЬНЫЕ (ИДЕНТИФИКАТОР, МОДЕЛЬ, ЦЕНА) ЗНАЧЕНИЯ (%s,%s,%s)""" record_to_insert = (5, 'One Plus 6', 950) cursor.execute (postgres_insert_query, запись_в_вставку) соединение.коммит() количество = курсор.rowcount print(count, "Запись успешно вставлена в мобильную таблицу") кроме (Exception, psycopg2.Error) как ошибки: print("Не удалось вставить запись в мобильную таблицу", ошибка) в конце концов: # закрытие соединения с базой данных.
Вывод :
1 Запись успешно вставлена в мобильную таблицу Соединение с PostgreSQL закрыто
Таблица PostgreSQL после операции вставкиМы использовали параметризованный запрос для использования переменных Python в качестве значений параметров во время выполнения. В конце концов, мы использовали commit(), чтобы сделать наши изменения постоянными в базе данных.
Python PostgreSQL UPDATE Table Data
В этом разделе рассказывается, как обновить данные таблицы PostgreSQL из приложения Python с помощью Psycopg2.
Вы узнаете, как обновлять одну и несколько строк, один столбец и несколько столбцов таблицы PostgreSQL.
Чтобы выполнить запрос PostgreSQL UPDATE из Python, необходимо выполнить следующие действия: –
- Установить соединение с базой данных PostgreSQL в Python.
- Определите запрос инструкции UPDATE для обновления данных таблицы PostgreSQL.

- Выполните запрос UPDATE с помощью
cursor.execute() - Закройте курсор и соединение с базой данных.
Теперь рассмотрим пример обновления одной строки таблицы базы данных.
импорт psycopg2 def updateTable (мобильный идентификатор, цена): пытаться: соединение = psycopg2.connect (пользователь = "sysadmin", пароль="pynative@#29", хост = "127.0.0.1", порт = "5432", база данных = "postgres_db") курсор = соединение.курсор() print("Таблица перед обновлением записи") sql_select_query = """выберите * с мобильного, где id = %s""" курсор.execute(sql_select_query, (mobileId,)) запись = курсор.fetchone() печать (запись) # Обновить одну запись сейчас sql_update_query = """Цена набора обновлений для мобильных устройств = %s, где id = %s""" курсор. execute(sql_update_query, (цена, mobileId))
соединение.коммит()
количество = курсор.rowcount
print(count, "Запись успешно обновлена")
print("Таблица после обновления записи")
sql_select_query = """выберите * с мобильного, где id = %s"""
курсор.execute(sql_select_query, (mobileId,))
запись = курсор.fetchone()
печать (запись)
кроме (Exception, psycopg2.Error) как ошибка:
print("Ошибка в операции обновления", ошибка)
в конце концов:
# закрытие соединения с базой данных.
если подключение:
курсор.закрыть()
соединение.закрыть()
print("Соединение с PostgreSQL закрыто")
идентификатор = 3
цена = 970
updateTable (идентификатор, цена)
execute(sql_update_query, (цена, mobileId))
соединение.коммит()
количество = курсор.rowcount
print(count, "Запись успешно обновлена")
print("Таблица после обновления записи")
sql_select_query = """выберите * с мобильного, где id = %s"""
курсор.execute(sql_select_query, (mobileId,))
запись = курсор.fetchone()
печать (запись)
кроме (Exception, psycopg2.Error) как ошибка:
print("Ошибка в операции обновления", ошибка)
в конце концов:
# закрытие соединения с базой данных.
если подключение:
курсор.закрыть()
соединение.закрыть()
print("Соединение с PostgreSQL закрыто")
идентификатор = 3
цена = 970
updateTable (идентификатор, цена)
Вывод :
Таблица Перед обновлением записи (3, «Google Pixel», 700.0) 1 Запись успешно обновлена Таблица После обновления записи (3, «Google Pixel», 970.0) Соединение с PostgreSQL закрыто
Таблица PostgreSQL после операции обновленияПроверьте результат описанной выше операции обновления, выбрав данные из таблицы PostgreSQL с помощью Python.
Python PostgreSQL Удалить строку и столбцы таблицы
В этом разделе вы узнаете, как удалить данные таблицы PostgreSQL из Python с помощью Psycopg2.
Давайте рассмотрим это на примере программы. В этом примере Python мы подготовили запрос на удаление одной строки из таблицы PostgreSQL.
импорт psycopg2 деф удалитьДанные (мобильный идентификатор): пытаться: соединение = psycopg2.connect (пользователь = "sysadmin", пароль="pynative@#29", хост = "127.0.0.1", порт = "5432", база данных = "postgres_db") курсор = соединение.курсор() # Обновить одну запись сейчас sql_delete_query = """Удалить с мобильного, где id = %s""" курсор.execute(sql_delete_query, (mobileId,)) соединение.коммит() количество = курсор.rowcount print(count, "Запись успешно удалена") кроме (Exception, psycopg2. Error) как ошибка:
print("Ошибка операции удаления", ошибка)
в конце концов:
# закрытие соединения с базой данных.
если подключение:
курсор.закрыть()
соединение.закрыть()
print("Соединение с PostgreSQL закрыто")
идентификатор4 = 4
идентификатор5 = 5
удалить данные (id4)
удалить данные (id5)
Error) как ошибка:
print("Ошибка операции удаления", ошибка)
в конце концов:
# закрытие соединения с базой данных.
если подключение:
курсор.закрыть()
соединение.закрыть()
print("Соединение с PostgreSQL закрыто")
идентификатор4 = 4
идентификатор5 = 5
удалить данные (id4)
удалить данные (id5)
Вывод :
1 Запись успешно удалена Соединение с PostgreSQL закрыто 1 Запись удалена успешно Соединение с PostgreSQL закрыто
Таблица PostgreSQL после удаления строкиПроверьте результат описанной выше операции удаления, выбрав данные из таблицы PostgreSQL с помощью Python.
Вставка, обновление и удаление нескольких строк из таблицы PostgreSQL с помощью
executemany()Примечание : Используйте
cursor.executemany()для вставки, обновления и удаления нескольких строк таблицы с помощью одного запроса.Метод
cursor.выполняет запрос к базе данных со всеми параметрами. executemany()
executemany() В большинстве случаев вам нужно выполнить один и тот же запрос несколько раз, но с разными данными. Как и вставка посещаемости каждого учащегося, процент посещаемости отличается, но SQL-запрос тот же.
Синтаксис
executemany()executemany(query, vars_list)
- Здесь запрос может быть любым SQL-запросом (вставка, обновление, удаление)
-
vars_listне что иное, как список кортежей в качестве входных данных для запроса. - Каждый кортеж в этом списке содержит одну строку данных для вставки или обновления в таблицу.
Теперь посмотрим, как использовать этот метод.
Python Вставить несколько строк в таблицу PostgreSQL
Использовать параметризованный запрос
executemany()метод для добавления нескольких строк в таблицу. Используя заполнители в параметризованном запросе, мы можем передавать значения столбцов во время выполнения.
импорт psycopg2 def bulkInsert (записи): пытаться: соединение = psycopg2.connect (пользователь = "sysadmin", пароль="pynative@#29", хост = "127.0.0.1", порт = "5432", база данных = "postgres_db") курсор = соединение.курсор() sql_insert_query = """ ВСТАВИТЬ В Мобильный телефон (id, модель, цена) ЗНАЧЕНИЯ (%s,%s,%s) """ # executemany() для вставки нескольких строк результат = cursor.executemany (sql_insert_query, записи) соединение.коммит() print(cursor.rowcount, "Запись успешно вставлена в мобильную таблицу") кроме (Exception, psycopg2.Error) как ошибка: print("Не удалось вставить запись в мобильную таблицу {}".format(ошибка)) в конце концов: # закрытие соединения с базой данных. если подключение: курсор. закрыть()
соединение.закрыть()
print("Соединение с PostgreSQL закрыто")
records_to_insert = [(4, 'LG', 800), (5, 'One Plus 6', 950)]
bulkInsert(records_to_insert)
закрыть()
соединение.закрыть()
print("Соединение с PostgreSQL закрыто")
records_to_insert = [(4, 'LG', 800), (5, 'One Plus 6', 950)]
bulkInsert(records_to_insert) Вывод :
2 Запись успешно вставлена в мобильную таблицу Соединение с PostgreSQL закрыто
Таблица PostgreSQL после вставки нескольких строкОбновите несколько строк таблицы PostgreSQL с помощью одного запроса в Python
Например, вы хотите обновить зарплату сотрудников. Теперь оплата для каждого сотрудника разная, но запрос на обновление остается прежним.
Мы можем обновить несколько строк таблицы, используяimport psycopg2 def updateInBulk (записи): пытаться: ps_connection = psycopg2.connect(user="sysadmin", пароль="pynative@#29", хост = "127.0.0.1", порт = "5432", база данных = "postgres_db") курсор = ps_connection. cursor()
# Обновить несколько записей
sql_update_query = """Цена набора обновлений для мобильных устройств = %s, где id = %s"""
cursor.executemany (sql_update_query, записи)
ps_connection.commit()
row_count = курсор.rowcount
print(row_count, "Записи обновлены")
кроме (Exception, psycopg2.Error) как ошибка:
print("Ошибка при обновлении таблицы PostgreSQL", ошибка)
в конце концов:
# закрытие соединения с базой данных.
если ps_connection:
курсор.закрыть()
ps_connection.close()
print("Соединение с PostgreSQL закрыто")
кортежи = [(750, 4), (950, 5)]
updateInBulk (кортежи)
cursor()
# Обновить несколько записей
sql_update_query = """Цена набора обновлений для мобильных устройств = %s, где id = %s"""
cursor.executemany (sql_update_query, записи)
ps_connection.commit()
row_count = курсор.rowcount
print(row_count, "Записи обновлены")
кроме (Exception, psycopg2.Error) как ошибка:
print("Ошибка при обновлении таблицы PostgreSQL", ошибка)
в конце концов:
# закрытие соединения с базой данных.
если ps_connection:
курсор.закрыть()
ps_connection.close()
print("Соединение с PostgreSQL закрыто")
кортежи = [(750, 4), (950, 5)]
updateInBulk (кортежи)
Вывод :
2 записи обновлены Соединение с PostgreSQL закрыто
Таблица PostgreSQL после обновления нескольких строкПримечание : Используйте
cursor.rowcount, чтобы получить общее количество строк, затронутых методомexecutemany().
Python PostgreSQL Удалить несколько строк из таблицы
В этом примере мы определили запрос SQL Delete с заполнителем, содержащим идентификаторы клиентов для удаления. Также подготовлен список записей, подлежащих удалению. Этот список содержит кортеж для каждой строки. Здесь мы создали два кортежа, чтобы удалить две строки.
импорт psycopg2 def deleteInBulk (записи): пытаться: ps_connection = psycopg2.connect(user="postgres", пароль="вишал@#29", хост = "127.0.0.1", порт = "5432", база данных = "postgres_db") курсор = ps_connection.cursor() ps_delete_query = """Удалить с мобильного, где id = %s""" cursor.executemany (ps_delete_query, записи) ps_connection.commit() row_count = курсор.rowcount print(row_count, "Запись удалена") кроме (Exception, psycopg2. Error) как ошибка:
print("Ошибка при подключении к PostgreSQL", ошибка)
в конце концов:
# закрытие соединения с базой данных.
если ps_connection:
курсор.закрыть()
ps_connection.close()
print("Соединение с PostgreSQL закрыто")
# список кортежей содержит идентификаторы баз данных
кортежи = [(5,), (4,), (3,)]
deleteInBulk (кортежи)
Error) как ошибка:
print("Ошибка при подключении к PostgreSQL", ошибка)
в конце концов:
# закрытие соединения с базой данных.
если ps_connection:
курсор.закрыть()
ps_connection.close()
print("Соединение с PostgreSQL закрыто")
# список кортежей содержит идентификаторы баз данных
кортежи = [(5,), (4,), (3,)]
deleteInBulk (кортежи)
Выход :
2 записи удалены Соединение с PostgreSQL закрыто
Следующие шаги:
Чтобы попрактиковаться в том, что вы узнали из этой статьи, выполните проект «Упражнение с базой данных Python», чтобы попрактиковаться и освоить операции с базой данных Python.
Sql Вставить в выделение | Массовая вставка рядов
Оператор SQL INSERT INTO SELECT копирует данные (все или выбранные пользователем) из одной таблицы базы данных и вставляет их в существующую таблицу базы данных.
По умолчанию оператор SQL INSERT INTO будет копировать только одну запись за раз . Но мы можем использовать оператор SQL INSERT INTO SELECT для копирования одной или нескольких записей одновременно .
Примечание. Таким образом, если вы копируете данные из исходной таблицы, и любые существующие записи в целевой таблице не затрагиваются этим действием.
Вы также можете выполнить поиск по этим темам, используя sql вставка в выбор, вставка в выбор сервера sql, вставка в выбор из, вставка сервера sql в выбор из таблицы, вставка запроса sql в выбор, вставка sql в выбор из той же таблицы, несколько вставка sql, множественная вставка в sql, вставка в синтаксис, вставка в from select, вставка куда, вставка в таблицу, вставка в значения .
Синтаксис SQL INSERT INTO SELECT
Приведенный ниже синтаксис используется для выбора всех столбцов и записей из одной таблицы в другую, существующую таблицу.
ВСТАВИТЬ В table_name2 ВЫБЕРИТЕ * ИЗ имя_таблицы1;
Приведенный ниже синтаксис используется для выбора определенных столбцов из одной таблицы в другую, существующую таблицу.
ВСТАВИТЬ В table_name2 (column_name_list(s)) SELECT имя_столбца_список (я) ОТ имя_таблицы1;
Примечание. Приведенный выше синтаксис является очень простым. Весь оператор sql может содержать Предложения SQL WHERE, SQL ORDER BY и SQL GROUP BY , а также таблица JOINS и псевдонимы .
Образец таблицы базы данных — Book1
БукИд ИмяКниги Описание 101 Полный справочник по Sql Описывает, как записать и выполнить оператор SQL в базе данных. 102 Sql-команды Объясняет список команд SQL. 103 Pl Sql Быстрое программирование Как писать и выполнять программы SQL с помощью pl sql. 
Образец таблицы базы данных — Book2
БукИд Имя автора Имя домена БукПрайс 101 Суреш Бабу База данных 250,5 102 Шива Кумар Программирование 120 Образец таблицы базы данных — Books3
Бид Имя Б BЦена Имя автора BДомен 1 Краткий справочник по MySQL 5.0 140 Суреш Бабу База данных 2 База данных Microsoft SQL Server 100 Харис Картик База данных 3 Руководство по программированию Pl/Sql 50 Шива Кумар Программирование Пример SQL INSERT INTO SELECT
Следующая инструкция SQL SELECT скопирует только несколько столбцов из таблицы «Book1» в таблицу «Book3»
ВСТАВИТЬ В Книгу 3 (BId, BName) SELECT BookID, BookName FROM Book1;
Приведенный выше оператор sql скопирует все данные столбцов «BookID» и «BookName» из таблицы «Book1» и вставит их в столбцы «BID» и «BName» из таблицы «Book2».
После выполнения приведенного выше оператора таблица «Book3» будет выглядеть так:
Бид Имя Б BЦена Имя автора BДомен 1 Краткий справочник по MySQL 5.0 140 Суреш Бабу База данных 2 База данных Microsoft SQL Server 100 Харис Картик База данных 3 Руководство по программированию Pl/Sql 50 Шива Кумар Программирование 101 Полная ссылка на SQL 102 Sql-команды 103 Pl Sql Быстрое программирование Следующая инструкция SQL SELECT скопирует только домен «Программирование» из «Книги 1» в «Книгу 3»
ВСТАВИТЬ В Книгу 3 (BPrice, AuthorName, BDomain) ВЫБЕРИТЕ BookPrice, AuthorName, DomainName FROM Book2 ГДЕ ИмяДомена = 'Программирование';
Приведенный выше оператор sql скопирует все данные столбцов «BookPrice», «AuthorName» и «BDomain» из таблицы «Book2» и вставит их в Столбцы «BPrice», «AuthorName» и «BDomain» из таблицы «Book3».
После выполнения приведенного выше оператора таблица «Book3» будет выглядеть так:
Бид Имя Б BЦена Имя автора BДомен 1 Краткий справочник по MySQL 5.0 140 Суреш Бабу База данных 2 База данных Microsoft SQL Server 100 Харис Картик База данных 3 Руководство по программированию Pl/Sql 50 Шива Кумар Программирование 101 Полная ссылка на SQL 102 Sql-команды 103 Pl Sql Быстрое программирование 120 Шива Кумар Программирование Примечание: В невыбранных столбцах будет значение NULL.

Вы также можете искать эти темы, используя вставить в значения выбрать, sql вставить в таблицу из выбора, sql вставить в пример, sql вставить в значения выбрать, вставить в существующую таблицу, вставить с помощью выбора, вставить в таблицу sql, выбрать из вставить в, вставить выбранные значения, добавить строку в таблицу sql, запрос sql добавить строку, sql добавить данные в таблицу, sql вставить в значения таблицы .
(Реальная) разница между операторами ‘SELECT… INTO’ и ‘INSERT… SELECT’
В этом сообщении блога я исследую разницу между операторами ‘SELECT… INTO’ и ‘INSERT… SELECT’. Недавно я переместил некоторые данные для клиента в совершенно новую таблицу из-за плохого дизайна исходной таблицы. Сначала я создал целевую таблицу, а затем выполнил оператор «INSERT… SELECT». Сначала я запустил это в тестовой среде, где выполнение запроса заняло больше часа, а файл журнала транзакций базы данных увеличился на 50 ГБ, хотя размер таблицы составлял всего 18 ГБ.
 Коллега предложил вместо этого использовать оператор «SELECT … INTO», и это заставило меня задуматься: почему это быстрее или лучше?
Коллега предложил вместо этого использовать оператор «SELECT … INTO», и это заставило меня задуматься: почему это быстрее или лучше?
Сценарий
Наиболее очевидная мысль заключается в том, что первый работает быстрее, потому что он выигрывает от «минимального ведения журнала» и автоматически создает целевую таблицу. Конечно, «SELECT … INTO» создает целевую таблицу «на лету» на основе результата оператора SELECT, однако мне было любопытно, почему это происходит быстрее.В целях тестирования я использовал кластеризованную таблицу FactProductInventory в базе данных AdventureWorksDW2012. В таблице 776 286 строк, общий размер которых составляет 41 МБ. База данных находилась в модели восстановления FULL, и ее файл журнала транзакций был 109.МБ с 98,3% свободного места.
Я включил «STATISTICS TIME» и «STATISTICS IO» для просмотра статистики запроса (время выполнения и ЦП) и дискового ввода-вывода (чтение и запись). Я также отслеживал использование пространства журнала, просматривая представление «DBCC SQLPERF(LOGSPACE)».
SELECT … INTO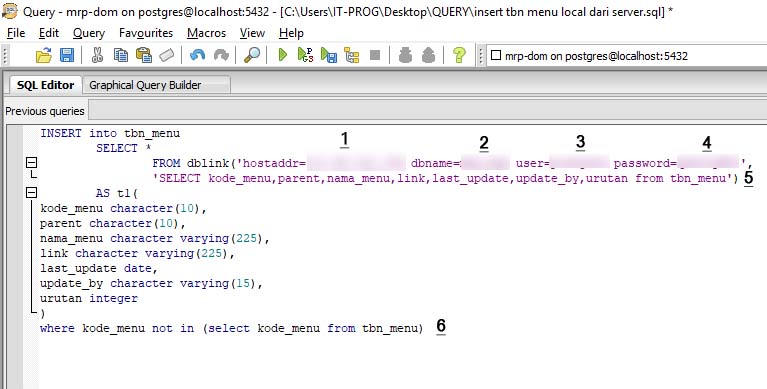 Для тех, кому интересно, функция fn_dblog() предоставляет более подробную информацию, которую я лично считаю более полезной, поскольку вы читаете журнал транзакций и видите построчно, что происходит.
Для тех, кому интересно, функция fn_dblog() предоставляет более подробную информацию, которую я лично считаю более полезной, поскольку вы читаете журнал транзакций и видите построчно, что происходит.Первым тестом, который я провел, был оператор «SELECT … INTO», который выбрал все строки (776 286) из «FactProductInventory» в целевую таблицу «FactProductInventoryNew».
Вот статистика:
Как видно из приведенных выше результатов, SQL Server помещает страницы исходной таблицы в буферный кеш (упреждающее чтение), а затем выполняет 5231 логическое чтение, что именно вы ожидаете увидеть. В таблице 5231 страница (1 IAM, 18 индексных страниц и 5212 страниц данных) и, учитывая, что все было выбрано, SQL-серверу пришлось просмотреть всю таблицу. Продолжительность составляла примерно 1,3 секунды при загрузке ЦП 1 секунду.
Журнал транзакций не увеличился, но на приведенном выше снимке экрана видно, что были использованы дополнительные 37,5% (40,8 МБ) его пространства, что примерно соответствует размеру таблицы.
 Таким образом, все выбранные строки были полностью зарегистрированы в файле журнала транзакций. Имейте в виду, что это не минимально регистрируемая операция, поскольку база данных находится в модели восстановления FULL.
Таким образом, все выбранные строки были полностью зарегистрированы в файле журнала транзакций. Имейте в виду, что это не минимально регистрируемая операция, поскольку база данных находится в модели восстановления FULL.Чтобы воспользоваться преимуществом минимального ведения журнала, база данных должна быть в моделях восстановления BULK_LOGGED или SIMPLE, после чего SQL Server отслеживает только выделение экстентов и изменения метаданных.
INSERT … SELECTПеред началом следующего теста, чтобы убедиться, что у меня есть чистая отправная точка, я восстановил базу данных из резервной копии. Затем я выполнил оператор «INSERT … SELECT», перед которым мне нужно было создать новую таблицу с той же структурой, что и исходная. Ниже приведены результаты: много).
Логические операции чтения исходной таблицы были такими же, однако я заметил кое-что странное. Как видно из выделенной выше статистики, SQL Server выполнил 781 495 операций чтения с целевой таблицей! Мы только вставили данные, так зачем SQL Server читать из целевой таблицы?
Поскольку целевая таблица уже существует, SQL Server должен считывать страницу целевой таблицы для каждой отдельной строки, чтобы установить, куда будет вставлена строка.
 Как вы можете видеть выше, дополнительные 5209чтения были выполнены по сравнению с количеством строк в таблице (776 286). Это количество раз, которое SQL Server должен прочитать страницу PFS. PFS (свободное пространство страницы) отслеживает свободное пространство для значений больших объектов и страниц данных кучи, а 1 страница PFS существует для 8088 страниц базы данных или около 64 МБ.
Как вы можете видеть выше, дополнительные 5209чтения были выполнены по сравнению с количеством строк в таблице (776 286). Это количество раз, которое SQL Server должен прочитать страницу PFS. PFS (свободное пространство страницы) отслеживает свободное пространство для значений больших объектов и страниц данных кучи, а 1 страница PFS существует для 8088 страниц базы данных или около 64 МБ.Кроме того, SQL Server должен заблокировать эту страницу, чтобы предотвратить изменение или вставку строк на той же странице другими транзакциями. Обратите внимание, что эти операции (блокировки, изменения страниц данных, чтение PFS и т. д.) должны отслеживаться в файле журнала транзакций вместе со вставленными строками, поэтому он занимает больше места в файле журнала транзакций. Для тех, кто заинтересован, следующий запрос может быть выполнен для получения вышеуказанной информации (при условии, что ваш оператор вставки — единственный, работающий с вашей базой данных):
INSERT … SELECT WITH(TABLOCK)В этот момент мне было любопытно, что произойдет, если у меня будет эксклюзивная блокировка таблицы.
 Итак, после восстановления базы данных я выполнил следующую инструкцию:
Итак, после восстановления базы данных я выполнил следующую инструкцию:Вот статистика:
Поскольку теперь SQL Server имеет монопольный доступ ко всей таблице, ему больше не нужно беспокоиться о параллелизме и блокировке, и он может просто продолжить и сбросить данные в таблицу. Глядя на статистику, мы видим, что «INSERT SELECT» работает точно так же, как оператор «SELECT INTO», включая использование пространства журнала транзакций.
ВыводыВ модели ПОЛНОГО восстановления нет минимально регистрируемых операций. Поскольку «SELECT… INTO» создает целевую таблицу, он владеет исключительно этой таблицей и работает быстрее по сравнению с «INSERT… SELECT». Поскольку «INSERT … SELECT» вставляет данные в существующую таблицу, это происходит медленнее и требует больше ресурсов из-за большего количества логических операций чтения и большего использования журнала транзакций. Однако, предоставляя подсказку запроса для блокировки всей целевой таблицы, эти два оператора работают одинаково.

Подписаться на обновления по электронной почте
+44 (0)20 3051 3595 | [email protected]
Свяжитесь с нами
Нажав кнопку «Отправить» ниже, вы разрешаете Coeo хранить и обрабатывать личную информацию, предоставленную выше, для предоставления вам запрошенного контента.
Вы можете отказаться от подписки на эти сообщения в любое время. Для получения дополнительной информации о том, как отказаться от подписки, и о нашей приверженности вашей конфиденциальности, пожалуйста, ознакомьтесь с нашими Политика конфиденциальности .
Посмотреть все события
NOW Building, Thames Valley Park Drive, Reading, RG6 1RB
13 советов по улучшению производительности вставки в базу данных PostgreSQL
Некоторые из этих способов могут вас удивить, но все 13 способов помогут вам повысить производительность вставки (INSERT) с помощью PostgreSQL и TimescaleDB — и увидеть показатели вставки, аналогичные тем, которые приведены в наших сообщениях, сравнивающих производительность TimescaleDB и TimescaleDB.
 , InfluxDB или MongoDB.
, InfluxDB или MongoDB.Производительность загрузки имеет решающее значение для многих распространенных случаев использования PostgreSQL, включая мониторинг приложений, аналитику приложений, мониторинг IoT и многое другое. Хотя в базах данных уже давно есть поля времени, есть ключевое различие в типе данных, которые собирают эти варианты использования: в отличие от стандартных реляционных «бизнес» данных, изменения обрабатываются как вставки , а не перезапись (другими словами, каждое новое значение становится новая строка в базе данных вместо замены предыдущего значения строки последним).
Если вы работаете в сценарии, где вам необходимо сохранить все данные v. перезаписать прошлые значения, оптимизация скорости, с которой ваша база данных может принимать новые данные, становится важной задачей.
У нас есть большой опыт оптимизации производительности для себя и членов нашего сообщества, и мы разделили наши главные советы на две категории.
 Во-первых, мы выделили несколько советов, полезных для улучшения PostgreSQL в целом. После этого мы обрисовали в общих чертах несколько, специфичных для TimescaleDB.
Во-первых, мы выделили несколько советов, полезных для улучшения PostgreSQL в целом. После этого мы обрисовали в общих чертах несколько, специфичных для TimescaleDB.Повышение производительности PostgreSQL
Вот несколько рекомендаций по повышению производительности загрузки в vanilla PostgreSQL:
1. Используйте индексы умеренно
Наличие правильных индексов может ускорить ваши запросы, но они не панацея. Инкрементное обслуживание индексов с каждой новой строкой требует дополнительной работы. Проверьте количество индексов, которые вы определили для своей таблицы (используйте команду
psql\d имя_таблицы), и определите, перевешивают ли их потенциальные преимущества запросов затраты на хранение и вставку. Поскольку каждая система уникальна, нет никаких жестких и быстрых правил или «магического числа» индексов — просто будьте разумны.2. Пересмотрите ограничения внешнего ключа
Иногда необходимо построить внешние ключи (FK) из одной таблицы в другие реляционные таблицы.
 Когда у вас есть ограничение FK, каждый INSERT обычно должен читать из вашей таблицы, на которую ссылаются, что может снизить производительность. Подумайте, можете ли вы денормализовать свои данные — иногда мы видим довольно экстремальное использование ограничений FK, сделанное из чувства «элегантности», а не из инженерных компромиссов.
Когда у вас есть ограничение FK, каждый INSERT обычно должен читать из вашей таблицы, на которую ссылаются, что может снизить производительность. Подумайте, можете ли вы денормализовать свои данные — иногда мы видим довольно экстремальное использование ограничений FK, сделанное из чувства «элегантности», а не из инженерных компромиссов.3. Избегайте ненужных УНИКАЛЬНЫХ ключей
Разработчиков часто учат указывать первичные ключи в таблицах базы данных, и многим ORM это нравится. Тем не менее, многие варианты использования, включая обычные приложения для мониторинга или временных рядов, не требуют их, поскольку каждое событие или показание датчика можно просто зарегистрировать как отдельное событие, вставив его в конец текущего фрагмента гипертаблицы во время записи.
Если ограничение UNIQUE определено иным образом, эта вставка может потребовать поиска по индексу, чтобы определить, существует ли уже строка, что отрицательно скажется на скорости вашей INSERT.
4.
 Используйте отдельные диски для WAL и данных
Используйте отдельные диски для WAL и данныхХотя это более продвинутая оптимизация, которая не всегда нужна, если ваш диск становится узким местом, вы можете дополнительно увеличить пропускную способность, используя отдельный диск (табличное пространство) для базы данных. журнал упреждающей записи (WAL) и данные.
5. Используйте высокопроизводительные диски
Иногда разработчики развертывают свои базы данных в средах с более медленными дисками из-за низкой производительности жестких дисков, удаленных SAN или других типов конфигураций. А поскольку при вставке строк данные надежно сохраняются в журнале упреждающей записи (WAL) до завершения транзакции, медленные диски могут повлиять на производительность вставки. Одна вещь, которую нужно сделать, это проверить ваш диск IOPS с помощью
команда ioping.Тест чтения:
$ ioping -q -c 10 -s 8k . --- . (hfs /dev/disk1 930,7 ГиБ) статистика ioping --- 9 запросов выполнено за 208 долларов США, чтение 72 КиБ, 43,3 тыс.
 операций ввода-вывода в секунду, 338,0 МБ/с
сгенерировано 10 запросов за 9,00 с, 80 КиБ, 1 IOPS, 8,88 КиБ/с
min/avg/max/mdev = 18 мкс / 23,1 мкс / 35 мкс / 6,17 мкс
операций ввода-вывода в секунду, 338,0 МБ/с
сгенерировано 10 запросов за 9,00 с, 80 КиБ, 1 IOPS, 8,88 КиБ/с
min/avg/max/mdev = 18 мкс / 23,1 мкс / 35 мкс / 6,17 мкс Тест записи:
$ ioping -q -c 10 -s 8k -W . --- . (hfs /dev/disk1 930,7 ГиБ) статистика ioping --- 9 запросов выполнены за 10,8 мс, записано 72 КиБ, 830 операций ввода-вывода в секунду, 6,49МиБ/с сгенерировано 10 запросов за 9,00 с, 80 КиБ, 1 IOPS, 8,89 КиБ/с min/avg/max/mdev = 99 мкс / 1,20 мс / 2,23 мс / 919,3 мкс
Вы должны увидеть не менее 1000 операций ввода-вывода в секунду при чтении и много сотен операций ввода-вывода в секунду при записи. Если вы видите гораздо меньше, ваша производительность INSERT, вероятно, зависит от вашего дискового оборудования. Посмотрите, возможны ли альтернативные конфигурации хранения.
Выберите и настройте TimescaleDB для повышения производительности приема
TimescaleDB настроен для повышения производительности приема. Чаще всего TimescaleDB используется для хранения огромных объемов данных для показателей облачной инфраструктуры, аналитики продуктов, веб-аналитики, устройств IoT и многих других вариантов использования временных рядов.
 Как это обычно бывает с данными временных рядов, эти сценарии ориентированы на время, почти исключительно только на добавление (множество операций INSERT) и требуют быстрого приема больших объемов данных в короткие временные окна.
Как это обычно бывает с данными временных рядов, эти сценарии ориентированы на время, почти исключительно только на добавление (множество операций INSERT) и требуют быстрого приема больших объемов данных в короткие временные окна.TimescaleDB представляет собой расширение для PostgreSQL и специально разработана для случаев использования временных рядов. Итак, если для ваших приложений или систем требуется более высокая производительность загрузки из PostgreSQL, рассмотрите возможность использования TimescaleDB (доступно полностью управляемое через Timescale Cloud — наше предложение «база данных как услуга» или самоуправляемое через нашу бесплатную версию Community Edition) .
…и еще 8 методов повышения производительности загрузки с помощью TimescaleDB:
6. Используйте параллельную запись.
Каждая команда INSERT или COPY для TimescaleDB (как в PostgreSQL) выполняется как отдельная транзакция и, таким образом, выполняется в однопоточном режиме.
 Чтобы добиться более высокой загрузки, вы должны выполнять несколько команд INSERTS или COPY параллельно.
Чтобы добиться более высокой загрузки, вы должны выполнять несколько команд INSERTS или COPY параллельно.Чтобы получить помощь в параллельной массовой загрузке больших CSV-файлов, ознакомьтесь с командой параллельного копирования TimescaleDB.
⭐ Профессиональный совет: убедитесь, что на вашей клиентской машине достаточно ядер для выполнения этого параллелизма (запуск 32 клиентских воркеров на машине с 2 виртуальными ЦП мало поможет — на самом деле воркеры не будут выполняться параллельно).
7. Вставьте строки пакетами.
Чтобы добиться более высокой скорости загрузки, вы должны вставлять свои данные с большим количеством строк в каждый вызов INSERT (или же использовать какую-либо команду массовой вставки, такую как COPY или наш инструмент параллельного копирования).
Не вставляйте свои данные построчно — вместо этого попробуйте по крайней мере сотни (или тысячи) строк на INSERT. Это позволяет базе данных тратить меньше времени на управление соединениями, накладные расходы на транзакции, синтаксический анализ SQL и т.
 д. и больше времени на обработку данных.
д. и больше времени на обработку данных.Обычно мы рекомендуем 25% доступной оперативной памяти. Если вы устанавливаете TimescaleDB с помощью метода, который запускает
timescaledb-tune, он должен автоматически настроитьshared_buffersна что-то, что хорошо подходит для ваших спецификаций оборудования.Примечание. В некоторых случаях, обычно при виртуализации и ограниченном распределении памяти cgroups, эти автоматически настраиваемые параметры могут быть не идеальными. Чтобы убедиться, что ваши
shared_buffersустановлены в пределах 25 %, запуститеSHOW shared_buffersиз соединенияpsql.9. Запустите наши образы Docker на хостах Linux
Если вы используете контейнер TimescaleDB Docker (который работает под управлением Linux) поверх другой операционной системы Linux, вы в отличной форме. Контейнер в основном обеспечивает изоляцию процесса, а накладные расходы чрезвычайно минимальны.
Если вы запускаете контейнер на компьютере Mac или Windows, вы увидите некоторые скачки производительности при виртуализации ОС, в том числе при вводе-выводе.
Вместо этого, если вам нужно работать на Mac или Windows, мы рекомендуем устанавливать напрямую, а не использовать образ Docker.
10. Запись данных в свободном временном порядке
Когда размеры блоков соответствуют (см. № 11 и № 12), самые последние блоки и связанные с ними индексы естественным образом сохраняются в памяти. Новые строки, вставленные с недавними отметками времени, будут записаны в эти фрагменты и индексы уже в памяти.
Если вставляется строка с достаточно старой временной меткой — т. е. это запись не по порядку или запись с обратной заменой — страницы диска, соответствующие более старому фрагменту (и его индексы), должны быть считаны с диска. Это значительно увеличит задержку записи и снизит пропускную способность вставки.
В частности, когда вы загружаете данные в первый раз, старайтесь загружать данные в отсортированном порядке по возрастанию меток времени.

Будьте осторожны при массовой загрузке данных о множестве разных серверов, устройств и т. д.:
- Не вставляйте данные последовательно по серверам (т. е. все данные для сервера A, затем сервера B, затем C и так далее). Это приведет к перегрузке диска, так как загрузка каждого сервера будет проходить через все фрагменты перед запуском заново.
- Вместо этого организуйте массовую загрузку таким образом, чтобы данные со всех серверов вставлялись в произвольном порядке меток времени (например, день 1 на всех серверах параллельно, затем день 2 на всех серверах параллельно и т. д.)
11. Избегайте «слишком больших» фрагментов
Чтобы поддерживать более высокую скорость загрузки, вы хотите, чтобы ваш последний фрагмент, а также все связанные с ним индексы оставались в памяти, чтобы записи в фрагмент и обновления индекса просто обновляли память. . (Запись по-прежнему устойчива, так как вставки записываются в WAL на диск до обновления страниц базы данных.
 )
)Если ваши фрагменты слишком велики, запись даже в самый последний фрагмент начнет подкачиваться на диск.
Как правило, мы рекомендуем, чтобы последние фрагменты и все их индексы удобно помещались в 9 баз данных.0003 общие_буферы . Вы можете проверить размеры чанков с помощью SQL-команды
chunk_relation_size_pretty.=> ВЫБРАТЬ chunk_table, table_size, index_size, toast_size, total_sizeFROM chunk_relation_size_pretty('hypertable_name')ORDER BY ranges DESC LIMIT 4; чанк_таблица | размер_таблицы | размер_индекса | тост_размер | общий размер --------------------------------------------------------+-------- ----+------------+-------------+------------ _timescaledb_internal._hyper_1_96_chunk | 200 МБ | 64 МБ | 8192 байта | 272 МБ _timescaledb_internal._hyper_1_95_chunk | 388 МБ | 108 МБ | 8192 байта | 500 МБ _timescaledb_internal._hyper_1_94_chunk | 388 МБ | 108 МБ | 8192 байта | 500 МБ _timescaledb_internal._hyper_1_93_chunk | 388 МБ | 108 МБ | 8192 байта | 500 МБЕсли ваши фрагменты слишком велики, вы можете обновить диапазон для будущих фрагментов с помощью команды
set_chunk_time_interval. Однако это не изменяет диапазон существующих фрагментов (например, путем перезаписи больших фрагментов на несколько небольших фрагментов).
Однако это не изменяет диапазон существующих фрагментов (например, путем перезаписи больших фрагментов на несколько небольших фрагментов).Для конфигураций, в которых размер отдельных фрагментов намного превышает объем доступной памяти, рекомендуется выполнять сброс и повторную загрузку данных гипертаблицы в фрагменты надлежащего размера.
Сохранение последнего чанка применяется ко всем активным гипертаблицам; если вы активно пишете в две гипертаблицы, последние фрагменты из обеих должны помещаться в пределах
shared_buffers.12. Избегайте слишком большого количества или слишком маленьких фрагментов
Если вы не используете TimescaleDB с несколькими узлами, в настоящее время мы не рекомендуем использовать разделение пространства. И если вы это сделаете, помните, что это количество чанков создается для каждого временного интервала.
Таким образом, если вы создадите 64 пространственных раздела и ежедневных фрагмента, у вас будет 24 640 фрагментов в год.
 Это может привести к большему падению производительности во время запроса (из-за накладных расходов на планирование) по сравнению со временем вставки, но, тем не менее, это следует учитывать.
Это может привести к большему падению производительности во время запроса (из-за накладных расходов на планирование) по сравнению со временем вставки, но, тем не менее, это следует учитывать.Еще одна вещь, которую следует избегать: использование неправильного целочисленного значения при указании диапазона временных интервалов в
create_hypertable.⭐ Совет:
=> ВЫБЕРИТЕ chunk_table, ranges, total_size ОТ chunk_relation_size_pretty('hypertable_name') ORDER BY диапазоны DESC LIMIT 4; чанк_таблица | диапазоны | общий размер --------------------------------------------------------+-------- --------------------------------------------------+ ------------ _timescaledb_internal._hyper_1_96_чанк | {"['2020-02-13 23:00:00+00','2020-02-14 00:00:00+00')"} | 272 МБ _timescaledb_internal._hyper_1_95_chunk | {"['2020-02-13 22:00:00+00','2020-02-13 23:00:00+00')"} | 500 МБ _timescaledb_internal._hyper_1_94_chunk | {"['2020-02-13 21:30:00+00','2020-02-13 22:00:00+00')"} | 500 МБ _timescaledb_internal.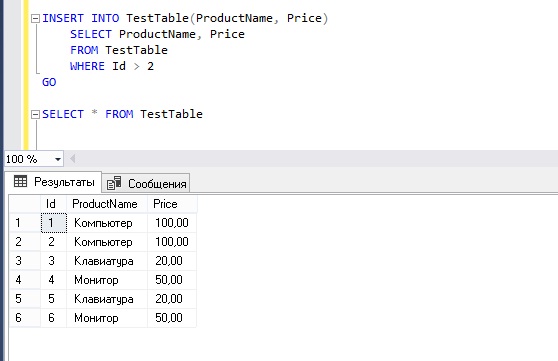 _hyper_1_93_chunk | {"['2020-02-13 20:00:00+00','2020-02-13 21:00:00+00')"} | 500 МБ
_hyper_1_93_chunk | {"['2020-02-13 20:00:00+00','2020-02-13 21:00:00+00')"} | 500 МБ 13. Ширина строки просмотра
Накладные расходы при вставке широкой строки (скажем, 50, 100, 250 столбцов) будут намного выше, чем при вставке более узкой строки (больше сетевых операций ввода-вывода, больше синтаксического анализа и данных). обработка, большие записи в WAL и т. д.). Большинство наших опубликованных тестов используют TSBS, который использует 12 столбцов в строке. Таким образом, вы соответственно увидите более низкую скорость вставки, если у вас очень широкие ряды.
Если вы рассматриваете очень широкие строки, потому что у вас разные типы записей, и каждый тип имеет непересекающийся набор столбцов, вы можете попробовать использовать несколько гипертаблиц (по одной на тип записи), особенно если вы не часто выполняете запросы. по этим типам.
Кроме того, записи JSONB — еще один хороший вариант, если практически все столбцы разрежены. Тем не менее, если вы используете разреженные широкие строки, используйте NULL для отсутствующих записей, когда это возможно, а не значения по умолчанию, для наибольшего повышения производительности (NULL намного дешевле хранить и запрашивать).
Наконец, стоимость широких строк на самом деле намного меньше, если вы сжимаете строки с помощью собственного сжатия TimescaleDB. Строки преобразуются в более сжатую форму столбцов, разреженные столбцы очень хорошо сжимаются, а сжатые столбцы не считываются с диска для запросов, которые не извлекают отдельные столбцы.
Сводка
Если производительность приема критически важна для вашего варианта использования, рассмотрите возможность использования TimescaleDB. Вы можете начать работу с Timescale Cloud бесплатно уже сегодня или бесплатно загрузить TimescaleDB на свой компьютер или в облачный экземпляр.
Наш подход к поддержке заключается в том, чтобы обратиться к вашему решению в целом, поэтому мы здесь, чтобы помочь вам достичь желаемых результатов производительности (см. дополнительные сведения о нашей команде поддержки клиентов и духе).
Наконец, наше сообщество Slack — отличное место для общения с более чем 7 000 других разработчиков с похожими вариантами использования, а также со мной, инженерами Timescale, членами команды разработчиков и защитниками разработчиков.
Реляционная база данных с открытым исходным кодом для временных рядов и аналитики.
Попробуйте Timescale бесплатно
Запросы | node-postgres
API для выполнения запросов поддерживает как обратные вызовы, так и промисы. Я приведу пример для обоих стилей и здесь. Для краткости я использую метод
client.queryвместо методаpool.query— оба метода поддерживают один и тот же API. На самом деле,pool.queryнапрямую делегируетclient.queryвнутренне.Только текст
Если ваш запрос не имеет параметров, вам не нужно включать их в метод запроса:
// обратный вызов
client.query('SELECT NOW() as now', (err, res) => {
if (err) {
console.log(err.stack)
} else {
console.log(res.rows[0])
}
})
// обещание
клиент
.query('ВЫБЕРИТЕ СЕЙЧАС() как сейчас')
.
 then(res => console.log(res.rows[0]))
then(res => console.log(res.rows[0])) .catch(e => console.error(e.stack))
Параметризованный запрос
Если вы передаете параметры своим запросам, вам следует избегать объединения строк параметров напрямую в текст запроса. Это может привести (и часто приводит) к уязвимостям SQL-инъекций. node-postgres поддерживает параметризованные запросы, передавая ваш текст запроса без изменений , а также ваши параметры на сервер PostgreSQL, где параметры безопасно подставляются в запрос с проверенным в бою кодом подстановки параметров на самом сервере.
const text = 'ВСТАВИТЬ В пользователей (имя, адрес электронной почты) VALUES ($1, $2) RETURNING *'
const values = ['brianc', '[email protected]']
// обратный вызов
client.query(text, values, (err, res) => {
if (err) {
console.log(err.stack)
} else {
console.log(res.rows[0 ])
// { имя: 'brianc', электронная почта: 'brian.
 [email protected]' }
[email protected]' } }
})
// обещание
клиент
.query(text, values)
.then(res => {
console.log(res.rows[0])
// { name: 'brianc', email: 'brian.m.carlson@ gmail.com' }
})
.catch(e => console.error(e.stack))
// async/await
try {
const res = await client.query(text, values )
console.log(res.rows[0])
// { name: 'brianc', email: '[email protected]' }
} catch (err) {
console .log(ошибка.стек)
}
PostgreSQL не поддерживает параметры для идентификаторов. Если вам нужно иметь динамическую базу данных, схему, имена таблиц или столбцов (например, в операторах DDL), используйте пакет pg-format для обработки экранирования этих значений, чтобы убедиться, что у вас нет внедрения SQL!
Параметры, переданные в качестве второго аргумента функции
query(), будут преобразованы в необработанные типы данных с использованием следующих правил:null и undefined
При параметризации
nullиundefined, тогда оба будут преобразованы вnull.
Дата
Пользовательское преобразование в строку даты UTC.
Буфер
Экземпляры буфера не изменились.
Массив
Преобразуется в строку, описывающую массив Postgres. Каждый элемент массива рекурсивно преобразуется с использованием описанных здесь правил.
Объект
Если параметризованное значение имеет метод
toPostgres, то он будет вызван, и его возвращаемое значение будет использоваться в запросе. СигнатураtoPostgresследующая:toPostgres (prepareValue: (value) => any): any
Предоставленная функция
prepareValueможет использоваться для преобразования вложенных типов в необработанные типы данных, подходящие для базу данных.В противном случае, если метод
toPostgresне определен, для параметризованного значения вызываетсяJSON.stringify.
Все остальное
Все остальные параметризованные значения будут преобразованы вызовом
value.toStringдля значения.Объект конфигурации запроса
pool.queryиclient.queryподдерживают использование объекта конфигурации в качестве аргумента вместо строки и дополнительного массива параметров. Тот же пример, что и выше, можно выполнить так:const query = {
text: 'ВСТАВИТЬ В ЗНАЧЕНИЯ пользователей (имя, адрес электронной почты) ($1, $2)',
значения: ['brianc', '[email protected]'],
}
// обратный вызов
client.query(query, (err, res) => {
if ( err) {
console.log(err.stack)
} else {
console.log(res.rows[0])
}
})
// обещание
клиент 9000 (запрос)
.then(res => console.log(res.rows[0]))
.catch(e => console.error(e.stack))
Объект конфигурации запроса допускает несколько более сложных сценариев:
Подготовленные операторы
PostgreSQL имеет концепцию подготовленного оператора.
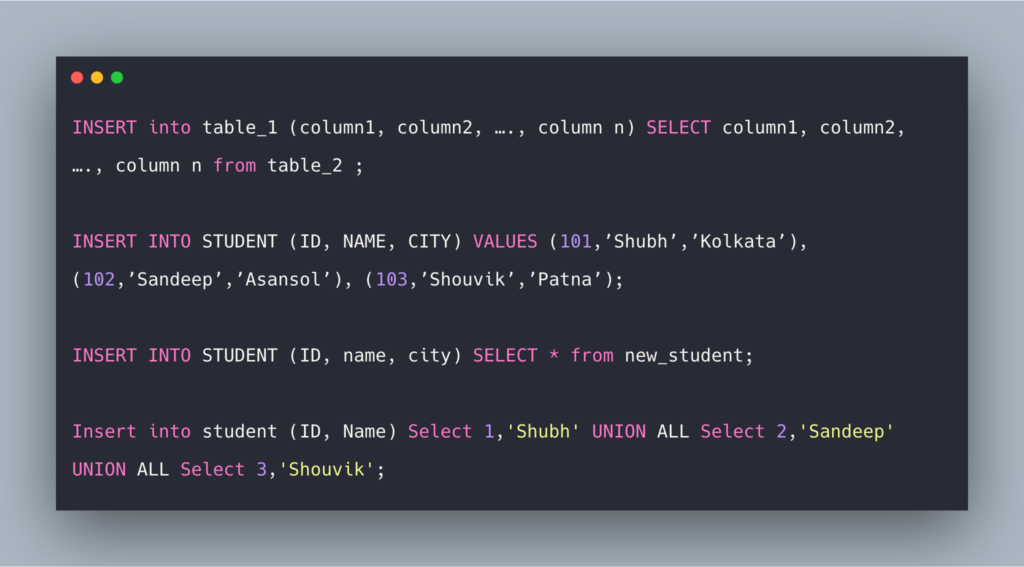 node-postgres поддерживает это, предоставляя параметр
node-postgres поддерживает это, предоставляя параметр nameобъекту конфигурации запроса. Если вы укажете параметрname, план выполнения запроса будет кэшироваться на сервере PostgreSQL из расчета на соединение . Это означает, что если вы используете два разных соединения, каждое из них должно будет анализировать и планировать запрос один раз. node-postgres обрабатывает это прозрачно для вас: клиент запрашивает анализ запроса только в первый раз, когда этот конкретный клиент видит это имя запроса:const query = {
// дать запросу уникальное имя ,
}
// обратный вызов
client.query(query, (err, res) => {
if (err) {
console.log(err.stack)
} else {
2
2 .log(res.rows[0])
}
})
// обещание
клиент
.query(запрос)
.then(res => console.log(res.rows[0]))
.catch(e => console.error(e.stack))
В приведенном выше примере первый раз клиент видит запрос с именем
'fetch-user', он отправит запрос на «анализ» на сервер PostgreSQL и выполнит запрос как обычно. Во второй раз он пропустит запрос «анализ» и отправит имя запроса на сервер PostgreSQL.
Во второй раз он пропустит запрос «анализ» и отправит имя запроса на сервер PostgreSQL.Будьте осторожны, чтобы не попасть в ловушку преждевременной оптимизации. Большинство ваших запросов, скорее всего, не сильно выиграют, если вообще выиграют, от использования подготовленных операторов. Это несколько «опытный пользователь» функции PostgreSQL, которую лучше всего использовать, когда вы знаете, как ее использовать, а именно с очень сложными запросами с большим количеством объединений и расширенными операциями, такими как операторы объединения и переключения. Я редко использую эту функцию в своих собственных приложениях, если только не пишу сложные агрегированные запросы для отчетов, и я знаю, что отчеты будут выполняться очень часто.
Режим строки
По умолчанию node-postgres считывает строки и собирает их в объекты JavaScript с ключами, соответствующими именам столбцов, и значениями, соответствующими соответствующему значению строки для каждого столбца.
 Если вам не нужно или вы не хотите такое поведение, вы можете передать
Если вам не нужно или вы не хотите такое поведение, вы можете передать rowMode: 'array'объекту запроса. Это сообщит синтаксическому анализатору результатов обойти сбор строк в объект JavaScript и вместо этого будет возвращать каждую строку в виде массива значений.константный запрос = {
текст: 'SELECT $1::text as first_name, $2::text as last_name',
значения: ['Brian', 'Carlson'],
rowMode: 'array',
}
// обратный вызов
client.query(запрос, (ошибка, res) => {
if (ошибка) {
console.log(err.stack)
} else {
console.log(res.fields.map (field => field.name)) // ['first_name', 'last_name']
console.log(res.rows[0]) // ['Brian', 'Carlson']
}
})
// обещание
клиент
.query(query)
.then(res => {
console.log(res.fields.map(field => field.name)) // [ 'first_name', 'last_name']
console.log(res.rows[0]) // ['Brian', 'Carlson']
})
.
