Массивы в ассемблере примеры
| Введение | ||
| Теоретическая часть | ||
| 1 | Архитектура компьютера | |
| Лабораторный практикум | ||
| 1 | Создание программы на языке ассемблера | |
| 2 | Применение функций DOS и BIOS | |
| 3 | Линейные алгоритмы | |
| 4 | Десятичная арифметика | |
| 5 | Команды передачи управления | |
| 6 | Циклы с условием | |
| 7 | Циклы со счетчиком | |
| 8 | Работа с массивами | |
| 9 | Цепочечные команды | |
| Приложения | ||
| 1 | Таблица кодов символов ASCII | |
| 2 | Функции DOS и BIOS | |
Лабораторная работа №8
Работа с массивами
Вопросы для повторения:
- Для каких данных целесообразно использовать массивы?
- Как организуется работа с массивами в языках высокого уровня?
- Какие алгоритмы существуют для сортировки массивов и поиска элементов в них?
В языке ассемблера не существует специальных средств для организации работы с массивами. Массивы описываются в виде последовательности элементов нужной размерности; работа с ними ведется с использованием методов косвенной адресации.
Массивы описываются в виде последовательности элементов нужной размерности; работа с ними ведется с использованием методов косвенной адресации.
Пример: Задан массив. Вывести на экран сумму его элементов.
При обработке не байтовых массивов следует учитывать размер элементов. Так в приведенном выше примере в строке 3 вычисляется размер массива в байтах, и в строке 13 он берётся за количество элементов. Для массива слов это значение придется поделить на 2. В строке 16 для перехода к следующему элементу используется простой инкремент адреса, для массива слов эта строка может выглядеть так: add bx, 2 .
Так в приведенном выше примере в строке 3 вычисляется размер массива в байтах, и в строке 13 он берётся за количество элементов. Для массива слов это значение придется поделить на 2. В строке 16 для перехода к следующему элементу используется простой инкремент адреса, для массива слов эта строка может выглядеть так: add bx, 2 .
Методические указания к выполнению лабораторной работы
1) разобрать приведенные примеры;
2) внести изменения в предложенные исходные тексты:
— в примере 1 дописать необходимые команды,
— в примере 2 изменить программу так, чтобы ввод элементов массива осуществлялся с клавиатуры;
— в примере 3 изменить программу так, чтобы количество элементов массива и их значения вводились с клавиатуры;
3) в среде TASM создать исполняемые файлы и выполнить программы, реализующие примеры;
4) проверить правильность работы программ на тестах;
5) выполнить самостоятельное задание, предложенное преподавателем;
6) разработать систему тестов для верификации программы и провести тестирование.
Для самопроверки рекомендуется выполнить рассмотренные примеры, внеся необходимые изменения в тексты программ, а также одно из предложенных заданий.
Для контроля преподавателем необходимо выполнить рассмотренные примеры с необходимыми изменениями и выполнить задание преподавателя.
Следует продемонстрировать преподавателю работу приложения на разработанной системе тестов.
Необходимо подсчитать сумму элементов массива, состоящего из 10 однобайтовых элементов.
mas db size dup (?)
start : . . . ; ввод элементов массива
xor ax , ax ; в ax будем накапливать сумму
begin : add ax,[bx]
inc bx ;переход к следующему элементу (размер элемента=1 байту)
Необходимо подсчитать количество нулевых элементов массива.
Элементы массива являются однобайтовыми числами и заданы в сегменте данных.
len equ 10 ;количество элементов в mas
mas db 1,0,9,8,0,7,8,0,2,0
mov cx,len ; количество элементов в массиве в cx
xor si,si ; регистр si — индекс i , нумерация с 0
jcxz exit ;проверка cx на 0, если 0 (все элементы просмотрели), то на выход
cycl: cmp mas[si],0 ;сравнить очередной элемент mas с 0
jne m1 ; если не равно, то на m1
inc al ;если =0, то al +1, al — c четчик нулевых элементов
m1: i nc si ;перейти к следующему элементу i := i +1
exit : mov ax,4c00h
int 21h ;возврат управления операционной системе
Необходимо проверить, есть ли в массиве нулевые элементы
Элементы массива являются однобайтовыми числами и заданы в сегменте данных.
len equ 10 ;количество элементов в mas
mas db 1,0,9,8,0,7,8,0,2,0
message db 0 dh ,0 ah ,’В поле mas нет элементов, равных нулю ,$’
mov cx,len ; количество элементов массива=число повторений цикла
xor si,si ; индекс i , нумерация с нуля
jcxz exit ;проверка cx на 0, если 0, то на выход
mov si,-1 ;готовим si к адресации элементов поля mas
cmp mas[si],0 ;сравнить очередной элемент mas с 0
jz yes ;почему вышли из цикла?
mov ah,09 h ; вывод сообщения, если нет нулевых элементов
yes : ; есть нулевые элементы
int 21h ;возврат управления операционной системе
Задания
1. Задан одномерный массив двухбайтовых знаковых чисел.
Необходимо разработать программу для п роверки, существуют ли в заданном массиве отрицательные элементы.
2. Задан одномерный массив двухбайтовых знаковых чисел.
Необходимо разработать программу для подсчета суммы положительных элементов массива.
3. Задан одномерный массив однобайтовых чисел без знака.
Необходимо разработать программу для п оиска минимального (максимального) элемента массива.
4. Задан одномерный массив однобайтовых чисел без знака. Необходимо в ычислить среднее арифметическое ненулевых элементов массива. (Замечание. Нулевой элемент не должен суммироваться.)
Изучение с «нуля»
О комментариях
Поиск
Архив блога
- ▼2009 (47)
- ►апреля (1)
- ►мая (31)
- ▼июня (15)
- О книгах по ассемблеру
- И снова о данных
- Синтаксис ассемблера
- Операнды
- Операторы
- Данные сложного типа. Массивы.
- Данные сложного типа. Стуктуры.
- Данные сложного типа. Объединения.
- Данные сложного типа. Записи.
- Способы адресации
- Регистровая адресация
- Непосредственная адресация
- Прямая адресация
- Косвенная адресация
- Косвенная адресация со смещением
Линки
Ярлыки
- антиотладка (1)
- архитектура эвм (1)
- данные сложного типа (4)
- двоичная система (1)
- директива ASSUME (1)
- директива END (1)
- директива >(1)
- директива LABEL (1)
- директива MODEL (2)
- директива PROC (1)
- директива RECORD (1)
- директива REPT (1)
- директива SEGMENT (5)
- директива STRUC (1)
- директива UNION (1)
- директивы описания данных (6)
- книги по ассемблеру (1)
- косвенная адресация (1)
- косвенная адресация со смещением (1)
- метки (1)
- непосредственная адресация (1)
- оператор mask (1)
- оператор w >(1)
- подпрограммы (2)
- практика ассемблирования (3)
- практика отладки (4)
- практика программирования (9)
- прямая адресация (1)
- реальный режим (1)
- регистровая адресация (1)
- регистры процессора 8086 (1)
- режимом реального адреса (1)
- сегментная адресация (1)
- синтаксис ассемблера (11)
- системы счисления (1)
- способы адресации (6)
- точка входа (1)
- установка (1)
- шестнадцатеричная система (1)
- assemblers (1)
- BCD (2)
- binary-coded decimal (2)
- debug.

- masm 6.15 (2)
- Program Segment Prefix (1)
- PSP (1)
- R-режим (1)
- Real Address Mode (1)
- stack (4)
- tasm 5.0 (2)
- Turbo Debagger 5.0 (2)
Данные сложного типа. Массивы.
Массив — структурированный тип данных, состоящий из некоторого числа элементов одного типа.
Для того чтобы разобраться в возможностях и особенностях обработки массивов в программах на ассемблере, нужно ответить на следующие вопросы:
- Как описать массив в программе?
- Как инициализировать массив, то есть как задать начальные значения его элементов?
- Как организовать доступ к элементам массива?
- Как организовать массивы с размерностью более одной?
- Как организовать выполнение типовых операций с массивами?
Описание и инициализация массива в программе
Специальных средств описания массивов в программах ассемблера, конечно, нет. При необходимости использовать массив в программе его нужно моделировать одним из следующих способов:
1) Перечислением элементов массива в поле операндов одной из директив описания данных. При перечислении элементы разделяются запятыми. К примеру:
При перечислении элементы разделяются запятыми. К примеру:
;массив из 5 элементов.Размер каждого
элемента 4 байта:
mas dd 1,2,3,4,5
2) Используя оператор повторения dup. К примеру:
;массив из 5 нулевых элементов.
;Размер каждого элемента 2 байта:
mas dw 5 dup (0)
Такой способ определения используется для резервирования памяти с целью размещения и инициализации элементов массива.
3) Используя директивы label и rept . Пара этих директив может облегчить описание больших массивов в памяти и повысить наглядность такого описания. Директива rept относится к макросредствам языка ассемблера и вызывает повторение указанное число раз строк, заключенных между директивой и строкой endm . К примеру, определим массив байт в области памяти, обозначенной идентификатором mas_b. В данном случае директива label определяет символическое имя mas_b, аналогично тому, как это делают директивы резервирования и инициализации памяти. Достоинство директивы label в том, что она не резервирует память, а лишь определяет характеристики объекта.
.
n=0
.
mas_b label byte
mas_w label word
rept 4
dw 0f1f0h
endm
В результате в памяти будет создана последовательность из четырех слов f1f0. Эту последовательность можно трактовать как массив байт или слов в зависимости от того, какое имя области мы будем использовать в программе — mas_b или mas_w.
4) Использование цикла для инициализации значениями области памяти, которую можно будет впоследствии трактовать как массив.
Посмотрим на примере, каким образом это делается.
;prg_12_1.asm
MASM
MODEL small
STACK 256
.data
mes db 0ah,0dh,’Массив- ‘,’$’
mas db 10 dup (?) ;исходный массив
i db 0
.code
main:
mov ax,@data
mov ds,ax
xor ax,ax ;обнуление ax
mov cx,10 ;значение счетчика цикла в cx
mov si,0 ;индекс начального элемента в cx
go: ;цикл инициализации
mov bh,i ;i в bh
mov mas[si],bh ;запись в массив i
inc i ;инкремент i
inc si ;продвижение к следующему
;элементу массива
loop go ;повторить цикл
;вывод на экран получившегося массива
mov cx,10
mov si,0
mov ah,09h
lea dx,mes
int 21h
show:
mov ah,02h ;функция вывода значения
;из al на экран
mov dl,mas[si]
add dl,30h ;преобразование числа в символ
int 21h
inc si
loop show
exit:
mov ax,4c00h ;стандартный выход
int 21h
end main ;конец программы
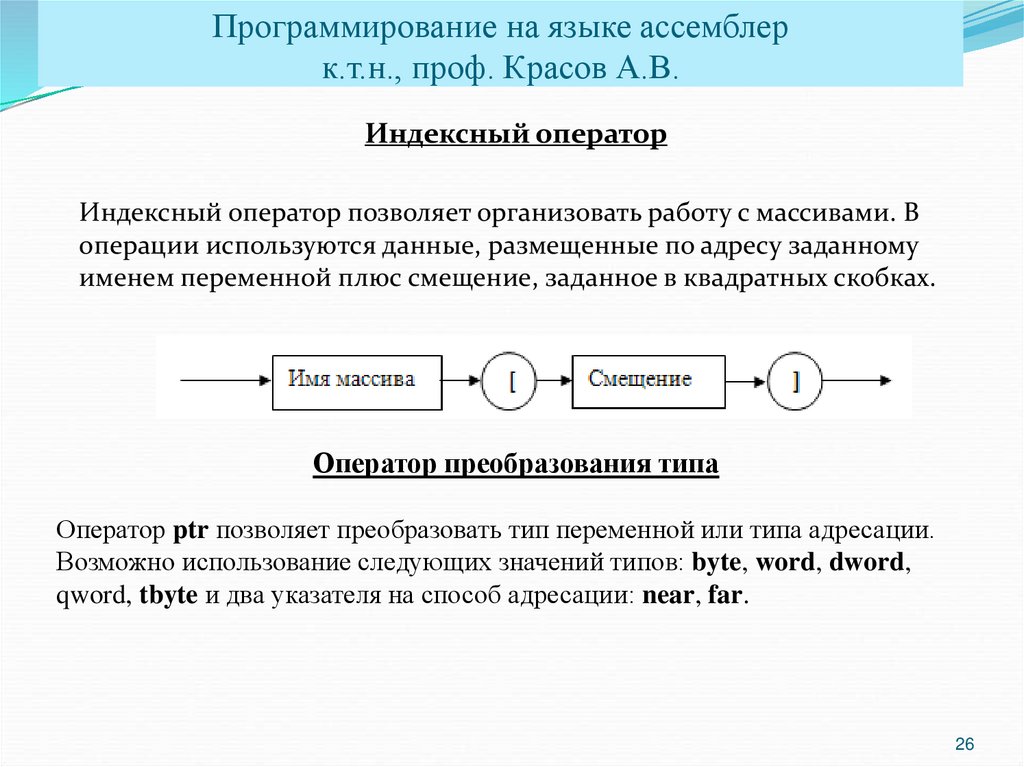
Доступ к элементам массива
При работе с массивами необходимо четко представлять себе, что все элементы массива располагаются в памяти компьютера последовательно.
Само по себе такое расположение ничего не говорит о назначении и порядке использования этих элементов. И только лишь программист с помощью составленного им алгоритма обработки определяет, как нужно трактовать эту последовательность байт, составляющих массив. Так, одну и ту же область памяти можно трактовать как одномерный массив, и одновременно те же самые данные могут трактоваться как двухмерный массив. Все зависит только от алгоритма обработки этих данных в конкретной программе. Сами по себе данные не несут никакой информации о своем “смысловом”, или логическом, типе. Помните об этом принципиальном моменте.
Эти же соображения можно распространить и на индексы элементов массива. Ассемблер не подозревает об их существовании и ему абсолютно все равно, каковы их численные смысловые значения.
Для того чтобы локализовать определенный элемент массива, к его имени нужно добавить индекс. Так как мы моделируем массив, то должны позаботиться и о моделировании индекса. В языке ассемблера индексы массивов — это обычные адреса, но с ними работают особым образом. Другими словами, когда при программировании на ассемблере мы говорим об индексе, то скорее подразумеваем под этим не номер элемента в массиве, а некоторый адрес.
Другими словами, когда при программировании на ассемблере мы говорим об индексе, то скорее подразумеваем под этим не номер элемента в массиве, а некоторый адрес.
Давайте еще раз обратимся к описанию массива. К примеру, в программе статически определена последовательность данных:
dim dw 0011h,2233h,4455h,6677h,8899h
Пусть эта последовательность чисел трактуется как одномерный массив. Размерность каждого элемента определяется директивой dw , то есть она равна 2 байта . Чтобы получить доступ к числу 6677h, нужно к адресу массива прибавить 6. Нумерация элементов массива в ассемблере начинается с нуля.
В общем случае для получения адреса элемента в массиве необходимо начальный (базовый) адрес массива сложить с произведением индекса этого элемента на размер элемента массива:
база + (индекс*размер элемента)
Архитектура микропроцессора предоставляет достаточно удобные программно-аппаратные средства для работы с массивами. К ним относятся базовые и индексные регистры, позволяющие реализовать несколько режимов адресации данных. Используя данные режимы адресации, можно организовать эффективную работу с массивами в памяти.
Используя данные режимы адресации, можно организовать эффективную работу с массивами в памяти.
Для более глубокого понимания можно помедитировать на эту програмку:
Эта программа ни чего не выводит на экран. Предназначена просто для медитации на нее под отладчиком. Внимание. При отладке, чтобы увидеть работу цикла, на команде loop go, нужно нажимать клавишу F7.
Зарисовка из медитации на эту прогу:
Двухмерные массивы
С представлением одномерных массивов в программе на ассемблере и организацией их обработки все достаточно просто. А как быть если программа должна обрабатывать двухмерный массив? Все проблемы возникают по-прежнему из-за того, что специальных средств для описания такого типа данных в ассемблере нет. Двухмерный массив нужно моделировать. На описании самих данных это почти никак не отражается — память под массив выделяется с помощью директив резервирования и инициализации памяти.
Непосредственно моделирование обработки массива производится в сегменте кода, где программист, описывая алгоритм обработки ассемблеру, определяет, что некоторую область памяти необходимо трактовать как двухмерный массив.
При этом вы вольны в выборе того, как понимать расположение элементов двухмерного массива в памяти: по строкам или по столбцам.
Если последовательность однотипных элементов в памяти трактуется как двухмерный массив, расположенный по строкам, то адрес элемента (i, j) вычисляется по формуле
(база + количество_элементов_в_строке * размер_элемента * i+j)
Здесь i = 0. n–1 указывает номер строки, а j = 0. m–1 указывает номер столбца.
Например, пусть имеется массив чисел (размером в 1 байт) mas(i, j) с размерностью 4 на 4
(i= 0. 3, j = 0. 3):
23 04 05 67
05 06 07 99
67 08 09 23
87 09 00 08
В памяти элементы этого массива будут расположены в следующей последовательности:
23 04 05 67 05 06 07 99 67 08 09 23 87 09 00 08
Если мы хотим трактовать эту последовательность как двухмерный массив, приведенный выше, и извлечь, например, элемент
mas(2, 3) = 23, то проведя нехитрый подсчет, убедимся в правильности наших рассуждений:
Эффективный адрес mas(2, 3) = mas + 4 * 1 * 2 + 3 = mas + 11
Посмотрите на представление массива в памяти и убедитесь, что по этому смещению действительно находится нужный элемент массива. Прога для медитации:
Прога для медитации:
Эта программа, тоже ни чего не выводит, так как предназначена для выполнения ее под отладчиком, для пущего научения.
3 коммент.:
Сколько по русскому было?
(база + количество_элементов_в_строке * размер_элемента * i+j)
Мне кажется, правильно должно быть
(база + размер_элемента * (количество_элементов_в_строке * i+j))
Массивы и структуры в MASM
1. ЭВМ и Периферийные устройства лекция 7
2. MOVZX. Расширение без знака.
MOVZX приемник, источникMOV with zero extend
Перенос в приемник источника с заполнением старших битов
нулями всегда. Команду имеет смысл применять для беззнаковых
чисел. Для чисел со знаком вы рискуете потерять знак.
3. MOVSX. Расширение со знаком.
MOVSX приемник, источникMOV with sign extend
Перенос в приемник источника с заполнением старших битов с
учётом знака. Команда применяется для знаковых чисел, поскольку
так вы не потеряете знак.
4.
 LEA.LEA (Load Effective Address) – команда помещения адреса.
LEA.LEA (Load Effective Address) – команда помещения адреса.LEA приемник, источник
Команда похожа на mov. Однако она используется исключительно
для помещения адреса в указанный регистр.
Приемник – регистр, куда помещается адрес. Именно регистр.
Источник – источник адреса (то есть у чего берем адрес). Под
источником подразумевается память.
LEA dx, arr; поместить в dx адрес переменной arr
Можно ещё и так:
MOV dx, offset arr; поместить в dx адрес переменной arr
5. OFFSET.
OFFSET– команда помещения адреса.MOV dx, offset arr; поместить в dx адрес переменной arr
6. LEA и OFSSET
LEA и OFFSET делают одно и тоже – получают адрес чего-либо.Однако LEA, будучи отдельной командой даёт больше
возможностей.
Пусть дан однобайтовый массив arr. Также пусть в bx хранится
какой-то номер элемента массива arr. Мы хотим, чтобы в dx
оказался адрес номера элемента, хранящегося в bx.
С помощью OFFSET:
mov dx, offset arr
add dx, bx
C помощью LEA:
lea dx, [arr + bx]
7.
 МассивыМассив – куча однотипных чисел в памяти, идущих по порядку.
МассивыМассив – куча однотипных чисел в памяти, идущих по порядку.В Ассемблере специального типа «массив» не существует.
8. Массивы. Объявление.
1. Перечислением элементов массива в поле операндов одной издиректив описания данных. При перечислении элементы
разделяются запятыми.
;массив из 5 элементов.Размер каждого элемента 4 байта:
mas dd 1,2,3,4,5
;массив из 15 элементов. Или массив 3×5. Это как вы решите
table
db 10h, 20h, 30h, 40h, 50h
db 60h, 70h, 80h, 90h, 0A0h
db 0B0H, 0C0h, 0D0h, 0E0h, 0F0h
2. Используя оператор повторения dup.
;массив из 5 нулевых элементов.
;Размер каждого элемента 2 байта:
mas dw 5 dup (0)
;массив из 32 необъявленных элементов, каждый из которых размером 2
; байта.
;Ну или массив 4×8 . Чем его считать — ваше дело
TwoD
dw 4 dup (8 dup (?))
9. Массивы. Объявление.
3. Используя директивы label и rept. Директива rept относится кмакросредствам языка ассемблера и вызывает повторение
указанное число раз строк, заключенных между директивой и
строкой endm.
К примеру, определим массив байт в области памяти,обозначенной идентификатором mas_b. В данном случае директива
label определяет символическое имя mas_b, аналогично тому, как
это делают директивы резервирования и инициализации памяти.
…
n=0
…
mas_b label byte
mas_w label word
rept
4
dw 0f1f0h
endm
В результате в памяти будет создана последовательность из
четырех слов f1f0. Эту последовательность можно трактовать как
массив байт или слов в зависимости от того, какое имя области мы
будем использовать в программе — mas_b или mas_w.
10. Массивы. Объявление.
4. Массив можно задать программно..data
mas db 10 dup (?) ;исходный массив
i db 0 ;переменная I со значением 0
…
mov ecx,10
go:
;цикл инициализации
mov bh,i
;i в bh
mov mas[si],bh ;запись в массив i
inc i
;инкремент i
inc si
;продвижение к следующему ;элементу массива
loop go ;повторить цикл
11.
 Массивы. Базово-индексный режим адресации.Итоговый адрес при базово индексном режиме адресации складывается из
Массивы. Базово-индексный режим адресации.Итоговый адрес при базово индексном режиме адресации складывается иззначения двух регистров, один из которых называется базовым, другойиндексным. Для организации подобного режима адресации может быть
использована пара любых 32-разрядных регистров общего назначения.
.data
array dw 1000h,2000h.3000h
…
.code
…
mov ebx, OFFSET array
mov esi,2
mov ax,[ebx+esi]
;AX = 2000h
mov edi, OFFSET array
mov ecx,4
mov ax,[edi+ecx]
;AX = 3000h
mov ebp, OFFSET array
mov esi,0
mov ax, [ebp+esi]
;AX = 1000h
12. Массивы. Базово-индексный режим адресации со смещением.
При использовании данного режима адресации для вычисления адреса ксодержимому базового и индексного регистров прибавляется
дополнительное смещение. Есть 2 варианта записи подобного способа
адресации
[смещение + база + индекс]
смещение [база + индекс]
Вместо смещения обычно указывается либо имя переменной, либо
константное выражение.
 В качестве базового и индексного регистров может
В качестве базового и индексного регистров можетиспользоваться любой 32-разрядных регистр общего назначения.
13. Массивы. Базово-индексный режим адресации со смещением.
Возьмём пример с двухмерным массивом table. Пусть смещение table равно150:
.data
table
db 10h, 20h, 30h, 40h, 50h
db 60h, 70h, 80h, 90h, 0A0h
db 0B0H, 0C0h, 0D0h, 0E0h, 0F0h
NumCols=5
..
.code
…
mov ebx, NumCols
;Смещение строки
mov esi,2
; Номер столбца
mov al, table[ebx+esi]
;[150+5+2]=[157]
;AL=80h
14. Массивы. Масштабирование индексной адресации.
Микропроцессор позволяет масштабировать индекс. Это означает, чтоесли указать после имени индексного регистра знак умножения “*” с
последующей цифрой 2, 4 или 8, то содержимое индексного регистра будет
умножаться на 2, 4 или 8, то есть масштабироваться.
Применение масштабирования облегчает работу с массивами, которые
имеют размер элементов, равный 2, 4 или 8 байт, так как микропроцессор
сам производит коррекцию индекса для получения адреса очередного
элемента массива.

.386
…
mas dw 0,1,2,3,4,5
…
mov esi,3 ;поместить 3-й элемент массива mas в регистр ax
mov ax,mas[esi*2]
15. Массивы. Одномерный массив.
Доступ к элементу массива можно получить, зная адрес памяти.В общем случае для получения адреса элемента в одномерном массиве
необходимо начальный (базовый) адрес массива сложить с произведением
индекса (i) (номер элемента минус единица) этого элемента на размер
элемента массива. Для одномерного массива это можно сделать так:
база + i*размер_элемента_в_байтах
mas dw 0,1,2,3,4,5
…
mov esi, offset mas
mov ax,[esi+2*2] ;поместить 2-й элемент (да, 2-й) массива mas в регистр ax
mov ax, mas[2*2] ; можно и так
Размер элементов массива вы должны учитывать самостоятельно. В [ ]
вы указываете смещение в байтах.
16. Массивы. Двухмерный массив
Элементы двухмерного массива располагаются в памяти такжепоследовательно.
Например, пусть имеется массив чисел (размером в 1 байт) mas(i, j) с
размерностью 4 на 4
(i= 0.
 ..3, j = 0…3):
..3, j = 0…3):В нашем представлении это выглядит так:
23
05
67
87
04
06
08
09
05
07
09
00
67
99
23
08
В памяти это выглядит так:
23 04 05 67 05 06 07 99 67 08 09 23 87 09 00 08
17. Массивы. Двухмерный массив.
А что если у нас двухмерный массив? Пусть i = 0…n–1 указывает номерстроки, а j = 0…m–1 указывает номер столбца. n – количество строк в
массиве, m – количество столбцов.
Адрес нужного элемента можно вычислить по формуле:
база + (количество_элементов_в_строке *i + j) * размер_элемента
Доступ к двумерному массиву удобно организовывать как к одномерному, но
с хитро вычисленным адресом с использованием масштабирования
.data
TwoD
i
j
dw 4 dup (8 dup (?))
integer ?
integer ?
.code
; Мы хотим TwoD[i,j] := 5
mov
eax, 8
; 8 столбцов в строке
mul I
; номер строки
add ax, j ; номер столбца
mov TwoD[eax*2], 5 ; «*2» масштабирование на 2 байта (слово)
18.
 Получение элемента массиваДвухмерный массив:
Получение элемента массиваДвухмерный массив:Element_Address = Base_Address + (rowindex * col_size + colindex) * Element_Size
Трехмерный массив
Element_Address = Base + ((rowindex*col_size+colindex) * depth_size + depthindex) *
Element_Size
Четерыхмерный массив:
Element_Address = Base + (((rowindex * col_size + colindex)*depth_size+depthindex) *
Left_size + Leftindex) * Element_Size
.data
TwoD
i
j
dw 4 dup (8 dup (?))
integer ?
integer ?
.code
; Мы хотим TwoD[i,j] := 5; :
mov
eax, 8
; 8 столбцов в строке
mul I
; номер строки
add ax, j ; ; номер столбца
mov TwoD[eax*2], 5 ; «*2» масштабирование на 2 байта (слово)
19. Структуры
Структура это набор переменных (данных). Структура задаётся с помощьюдирективы struct и ends. Перед использованием структуры её нужно описать:
SOMESTRUCTURE STRUCT
dword1 dd ?
dword2 dd ?
some_word dw ?
abyte db ?
anotherbyte db ?
SOMESTRUCTURE ENDS
Уже после можно объявлять её конкретные экземпляры.
20. Структуры
Структуры можно объявлять как в секции .data, так и в секцииMYSTRUCT struc
dword1 dd ?
dword2 dd ?
some_word dw ?
abyte db ?
anotherbyte db ?
MYSTRUCT ends
.data
msg1 MYSTRUCT <?>
.data
msg2 MYSTRUCT <?>
21. Структуры
MYSTRUCT strucdword1 dd ?
dword2 dd ?
some_word dw ?
abyte db ?
anotherbyte db ?
MYSTRUCT ends
Для того чтобы получить доступ к записи надо указать метку переменной,
которой она обозначена и через точку указать имя поля.
mov [msg.dword1], 45h
xor eax,eax
mov eax, [msg.dword1] ; eax = 45
при этом запись msg.dword1 считается обычной меткой данных: берётся
смещение метки msg плюс смещение поля dword1 в структуре,
размер данных по умолчанию равен размеру директивы указанной
после метки поля. Также можно пользоваться обращением к полю
при обращении к записи через регистр:
mov [msg.dword2], 45h
xor eax,eax
lea ebx, msg
mov eax, [ebx].
 dword2 ; eax = 45
dword2 ; eax = 4522. Структуры
MYSTRUCT strucdword1 dd ?
dword2 dd ?
some_word dw ?
abyte db ?
anotherbyte db ?
MYSTRUCT ends
Если имя поля не гарантирует уникальности то лучше использовать такой
тип использования записи:
mov [msg.dword2], 45h
xor eax,eax
lea ebx, msg
mov eax, [ebx].MYSTRUCT.dword2 ; eax = 45
Указанная запись гарантирует, что мы получаем доступ к нужному нам
полю, нужной нам структуры.
23. Структуры
MYSTRUCT strucdword1 dd ?
dword2 dd ?
some_word dw ?
abyte db ?
anotherbyte db ?
MYSTRUCT ends
Как и всё остальное, структуры- это всего-лишь данные в памяти. Поэтому
вместо обращения по конкретным именам, можно использовать смещение в
памяти
mov [msg.abyte], 45h
xor eax,eax
lea ebx, msg
mov al, [ebx+10d] ; al = 45
к ebx прибавлено10d, потому что смещение поля abyte в структуре равно
10d.
Массивы
Массивы Массив — структурированный тип данных, состоящий из некоторого числа элементов одного типа.
В Ассемблере массивом можно назвать несколько подряд идущих в памяти байт, слов или двойных слов, но все элементы массива должны быть либо байтами, либо словами, либо двойными словами, т.е. иметь одинаковую длину. В качестве имени массива используется символическое имя адреса (смещения) первого байта первого элемента массива.
Для понимания расположения элементов массива в памяти и обращения к ним необходимо вспомнить основные типы данных микропроцессора и расположение байтов в них (рис 1).
Рис 1.Основные типы данных микропроцессора
Пример описания и определения массива:
— из 5 элементов, размер каждого элемента 4 байта:
mas1 dd 1,2,3,4,5 ;mas –имя массива, dd-тип элементов массива двойное слово
— используя оператор повторения dup:
;массив из 5 нулевых элементов, размер каждого элемента 2 байта: mas2 dw 5 dup (0)
При работе с массивами необходимо четко представлять себе, что все элементы массива располагаются в памяти компьютера последовательно. Только программист с помощью составленного им алгоритма обработки определяет, как нужно трактовать эту последовательность байт, составляющих массив. Так, одну и ту же область памяти можно трактовать как одномерный массив, и одновременно те же самые данные могут трактоваться как двухмерный массив. Все зависит только от алгоритма обработки этих данных в конкретной программе. Сами по себе данные не несут никакой информации о своем “смысловом”, или логическом, типе. Помните об этом принципиальном моменте.
Только программист с помощью составленного им алгоритма обработки определяет, как нужно трактовать эту последовательность байт, составляющих массив. Так, одну и ту же область памяти можно трактовать как одномерный массив, и одновременно те же самые данные могут трактоваться как двухмерный массив. Все зависит только от алгоритма обработки этих данных в конкретной программе. Сами по себе данные не несут никакой информации о своем “смысловом”, или логическом, типе. Помните об этом принципиальном моменте.
Эти же соображения можно распространить и на индексы элементов массива. Ассемблер не подозревает об их существовании и ему абсолютно все равно, каковы их численные смысловые значения.
Для того чтобы обратиться к элементу массива, к его имени нужно добавить индекс. В языке ассемблера индексы массивов — это обычные
адреса.
Чтобы получить доступ к третьему элементу, нужно к адресу массива mas3 прибавить 6. Нумерация элементов массива в ассемблере начинается с нуля. То есть в нашем случае речь, фактически, идет о 4-м элементе массива — 7, но об этом знает только программист; микропроцессору в данном случае все равно — ему нужен только адрес.
Архитектура микропроцессора предоставляет достаточно удобные программно-аппаратные средства для работы с массивами. К ним относятся базовые и индексные регистры, позволяющие реализовать несколько режимов адресации данных. Используя данные режимы адресации, можно организовать эффективную работу с массивами в памяти. Вспомним эти режимы: индексная адресация со смещением — режим адресации, при котором эффективный адрес (т.е. смещение данных относительно начала сегмента данных) формируется из двух компонентов:
o постоянного (базового) — указанием прямого адреса массива в виде имени идентификатора, обозначающего начало массива; o переменного (индексного) — указанием имени индексного регистра.
Пример обращения к элементам массива:
mas3 | dw | 0,5,6,7,8,9 ;определили одномерный массив с размерностью элементов в слово (2 байта) |
… |
|
|
mov | si,4 | ;поместить в регистр SI индекс 4 для обращения к третьему элементу массива |
;поместить 3-й элемент массива mas в регистр АХ: | ||
mov | ax,mas[si] | |
В общем случае для получения адреса элемента в массиве необходимо начальный (базовый) адрес массива сложить с произведением индекса (номер элемента минус единица) этого элемента на размер элемента массива:
база + (индекс*размер элемента).
Микропроцессор позволяет масштабировать индекс. Это означает, что если указать после имени индексного регистра знак умножения “*” с последующей цифрой 2, 4 или 8, то содержимое индексного регистра будет умножаться на 2, 4 или 8, то есть масштабироваться. Применение масштабирования облегчает работу с массивами, которые имеют размер элементов, равный 2, 4 или 8 байт, так как микропроцессор сам производит коррекцию индекса для получения адреса очередного элемента массива. Нам нужно лишь загрузить в индексный регистр значение требуемого индекса (считая от 0).
Возможность масштабирования появилась в микропроцессорах Intel, начиная с модели i486. По этой причине в программах необходимо писать директиву
.486.
Пример использования масштабирования: |
| ||
;просмотр элементов массива |
| ||
mas | dw | 2,7,0,0,1,9,3,6,0,8 | ;исходный массив |
… |
|
|
|
mov | cx,10 | ;значение счетчика цикла в cx | |
mov | esi,0 | ;индекс в esi |
|
see: |
|
|
|
mov | dx,mas[esi*2];первый элемент массива в dx | ||
inc | esi | ;на следующий элемент | |
loop see |
|
|
|
Упражнение 1. |
|
|
|
| Упражнение 2. |
|
|
|
|
| ||
Использование цикла для инициализации значениями области памяти, | Просмотр массива, состоящего из слов, и сравнение его элементов с | |||||||||||
которую можно будет впоследствии трактовать как массив. | нулем. Выводится соответствующее сообщение. | |||||||||||
TITLE Инициализация массива из 10 элементов внутри программы числами | .686 |
|
|
|
|
|
| |||||
option casemap:none |
|
|
| |||||||||
;0 1 2 3 4 5 6 7 8 9 |
|
|
|
|
|
|
|
|
| |||
. |
|
|
|
|
| include \masm32\include\masm32rt.inc |
|
| ||||
option casemap:none |
|
|
| .data |
|
|
|
|
|
| ||
|
|
|
|
|
|
|
|
|
|
|
| |
include \masm32\include\masm32rt.inc |
| ConsoleTitle db ‘Concole input-output ‘,0 | ;наименования консоли | |||||||||
|
|
|
|
|
| msg_1 | db | ‘ not equality 0!’, 0ah, 0dh,0 |
| ;сообщение если элемент | ||
. |
|
|
|
|
|
|
|
|
|
|
| ;массива «не равен нулю» |
ConsoleTitle db ‘Concole input-output ‘,0 | ;определение строки для | msg_2 | db |
| ‘ equality 0!’, 0ah, 0dh,0 | ;сообщение если елемент | ||||||
|
|
|
|
| ;наименования консоли |
|
|
|
|
|
| ;массива «равен нулю» |
msg db ‘Result massive :’,0ah, 0dh, 0 ; комментарий к выводимому массиву | msg_3 | db |
| 0ah, 0dh, ‘Element ‘,0 |
| ;сообщение: «Элемент» | ||||||
mas db 10 dup (?) |
|
| ;исходный массив (неинициализированный) | mas | dw |
| 2,7,0,0,1,9,3,6,0,8 |
| ;исходный массив | |||
i db 0 |
|
| ;переменная для инициализации массива | format db ‘%d’,0 ;формат выводимых целых чисел (для invoke crt_printf) | ||||||||
format db ‘%d’,0 | ;формат выводимых целых чисел (для invoke crt_printf) |
|
|
|
|
|
|
| ||||
format_c db ‘%c’,0 |
| ;формат для вывода символов (для invoke crt_printf) | . |
|
|
|
|
|
| |||
|
|
|
|
|
| main: |
|
|
|
|
|
|
.code |
|
|
|
|
| invoke SetConsoleTitle, addr ConsoleTitle |
| ;вывод имени консоли | ||||
main: |
|
|
|
|
| xor eax,eax |
|
|
|
|
| |
invoke SetConsoleTitle, addr ConsoleTitle | ;вывод имени консоли |
| ;обнуление eax |
|
| |||||||
|
|
|
|
|
| prepare: |
|
|
|
|
| |
| xor eax,eax |
| ;обнуление eax |
| mov |
| ecx,10 | ;значение счетчика цикла в ecx | ||||
| mov ecx,10 |
| ;значение счетчика цикла в ecx |
| mov |
| esi,0 | ;индекс в esi | ||||
| mov esi,0 |
|
| ;индекс начального элемента в esi | compare: |
|
|
|
|
| ||
go: |
|
| ;цикл инициализации |
| mov |
| dx,mas[esi*2] ;первый элемент массива в dx | |||||
| mov bh,i |
| ;i в bh |
|
|
| cmp |
| dx,0 | ;сравнение dx c 0 | ||
| mov mas[esi],bh | ;запись в массив значения i |
| je |
| equal | ;переход, если равно 0 | |||||
| inc i |
|
| ;инкремент i (i=i+1) | not_equal: |
|
| ;не равно 0 |
|
| ||
| inc esi | ;продвижение к следующему элементу массива |
| push ecx |
| ;сохранить значение ECX в стеке | ||||||
| loop go | ;повторить цикл |
| invoke crt_printf, addr msg_3 | ;вывод сообщения msg_3 | |||||||
|
|
|
|
|
| invoke | crt_printf, addr format, esi ;вывод номера элемента массива на экран | |||||
;вывод на экран получившегося массива |
| invoke crt_printf, addr msg_1 | ;вывод сообщения msg_1 | |||||||||
invoke crt_printf, addr msg | ;Сообщение о выводе массива |
| pop ecx |
| ;восстановление из стека значения ECX | |||||||
mov | ecx,10 |
|
| ;значение счетчика цикла в ECX |
| inc |
| esi | ;на следующий элемент | |||
mov | esi,0 |
|
| ;присвоение индексному регистру значения 0 |
| dec |
| ecx | ;условие для выхода из цикла | |||
show: |
|
| ;цикл вывода на экран получившегося массива |
| jecxz | exit_ | ;ecx=0? Если да — на выход | |||||
xor edx,edx |
|
|
|
|
| jmp |
| compare ;нет — повторить цикл | ||||
mov dl,mas[esi] |
|
| ;значение элемента массива | equal: |
|
|
| ;равно 0 |
|
| ||
push ecx |
| ;сохранение значения регистра ECX в стеке | push ecx |
|
|
|
|
| ||||
invoke crt_printf, addr format, edx ;вывод очередного элемента массива | invoke crt_printf, addr msg_3 | ;вывод сообщения msg_3 | ||||||||||
invoke | crt_printf, addr format_c,’ ‘ ;вывод пробела между выводимыми | invoke | crt_printf, addr format, esi ;вывод номера элемента массива на экран | |||||||||
pop ecx |
|
|
| ;элем. | invoke crt_printf, addr msg_2 | ;вывод сообщения msg_2 | ||||||
;возвращение сохраненного значения регистра ECX из стека |
| pop ecx |
|
|
|
| ||||||
inc esi |
|
|
|
|
|
| inc |
| esi | ;на следующий элемент | ||
loop show |
| ;повторить цикл |
| dec |
| ecx | ;все элементы обработаны? | |||||
invoke Sleep, INFINITE ;задержка закрытия консоли для просмотра результатов |
| jecxz | exit_ |
|
|
| ||||||
| jmp |
| compare |
|
|
| ||||||
invoke ExitProcess,0 |
| ;передача управления Windows | exit_: |
|
|
|
|
|
| |||
end main |
|
| ;конец программы | invoke Sleep, INFINITE ;задержка закрытия консоли для просмотра результатов | ||||||||
Результат работы программы: |
| invoke ExitProcess,0 |
| ;передача управления Windows | ||||||||
| end main |
|
| ;конец программы | ||||||||
Result massive : |
|
|
|
| Ррезультат работы программы: |
|
| |||||
0 1 2 3 4 5 6 7 8 9 |
|
|
|
| Element 0 not equality 0! |
|
|
| ||||
Задание 1. | Element 1 not equality 0! |
|
|
| ||||||||
Element 2 not equality 0! |
|
|
| |||||||||
|
|
|
|
|
| Element 3 equality 0! |
|
|
|
| ||
|
|
|
|
|
| Element 4 equality 0! |
|
|
|
| ||
|
|
|
|
|
| Element 5 equality 0! |
|
|
|
| ||
|
|
|
|
|
| Element 6 equality 0! |
|
|
|
| ||
|
|
|
|
|
| Element 7 not equality 0! |
|
|
| |||
|
|
|
|
|
| Element 8 not equality 0! |
|
|
| |||
|
|
|
|
|
| Element 9 not equality 0! |
|
|
| |||
|
|
|
|
|
| Задание 2. | ||||||
|
|
|
|
|
| программы, чтобы она выдавала корректный результат. | ||||||
Масштабирование эффективно лишь тогда, когда размерность элементов | Упражнение 4. | Ввод и вывод элементов массива в консоли | ||||||||||
массива равна 2, 4 или 8 байт. Если же размерность элементов другая, то | TITLE Ввод размерности массива |
|
| |||||||||
организовывать обращение к элементам массива нужно обычным способом, | TITLE Ввод элементов массива через пробел | |||||||||||
как описано ранее. |
|
|
|
| TITLE Удвоение элементов массива |
|
| |||||
Рассмотрим пример работы с массивом из пяти трехбайтовых элементов. | TITLE Вывод элементов массива |
|
| |||||||||
Младший байт в каждом из этих элементов представляет собой некий | .686 |
|
|
|
|
|
| |||||
счетчик, а старшие два байта — что-то еще, для нас не имеющее никакого | option casemap:none |
|
|
| ||||||||
значения. Необходимо последовательно обработать элементы данного |
|
|
|
|
|
|
| |||||
массива, увеличив значения счетчиков на единицу. | include \masm32\include\masm32rt.inc |
|
| |||||||||
Упражнение 3. | .data |
|
|
|
|
|
| |||||
.686 |
|
|
|
|
| ConsoleTitle db ‘Concole input-output ‘,0 | ;наименования консоли | |||||
option casemap:none |
|
|
| msg_1 db ‘Input elements array: ‘,0 ;сообщение о вводе элементов массива | ||||||||
|
|
|
|
|
| msg_2 db ‘Input number elements array n=: ‘,0 ;сообщение о вводе кол-ва | ||||||
include \masm32\include\masm32rt.inc |
| msg_3 db ‘Result array: ‘,0 |
|
| ;элем. | |||||||
|
|
|
|
|
| ;сообщение о результативном массиве | ||||||
.data |
|
|
|
|
| msg_4 db ‘ ‘,0 ;переменная содержащая ASCII код пробела | ||||||

 686
686 data
data code
code массива
массива Инициализируйте область памяти числами 9,8,7,6,5,4,3,2,1,0
Инициализируйте область памяти числами 9,8,7,6,5,4,3,2,1,0 Программа выводит неверный результат. Исправьте код
Программа выводит неверный результат. Исправьте код
 Обработка массива элементов с нечетной длиной
Обработка массива элементов с нечетной длиной массива
массиваConsoleTitle db ‘Concole input-output ‘,0 ;наименования консоли
N=5 | ;количество элементов массива |
mas db 5 dup (3 dup (0)) | ;исходный массив из 5-и элем. по 3 байта в |
| ;каждом и во всех 15 байтов записано число 0 |
msg db ‘ ‘,0
msg_1 db ‘Byte counter: ‘,0 ;сообщение: Байт-счетчик
format db ‘%d’,0 | ;формат выводимых целых чисел (для invoke crt_printf) | ||||
. |
|
|
|
|
|
main: |
|
|
|
|
|
invoke SetConsoleTitle, addr ConsoleTitle | ;вывод имени консоли | ||||
xor eax,eax |
| ;обнуление eax |
| ||
| mov |
| esi,0 |
| ;0 в esi |
| mov |
| ecx,N | ;N в ecx | |
go: |
|
|
|
|
|
xor edx,edx |
| ;обнуление edx |
| ||
mov | dl,mas[esi] | ;первый байт поля в dl | |||
inc | dl | ;увеличение dl на 1 (по условию) | |||
mov | mas[esi],dl | ;заслать обратно в массив | |||
add | esi,3 |
| ;сдвиг на следующий элемент массива | ||
loop | go |
| ;повтор цикла |
| |
invoke crt_printf, addr msg_1 |
|
| |||
mov | esi,0 ;подготовка к выводу на экран элементов массива | ||||
|
| ;содержащие байт-счетчик | |||
mov | ecx,N |
|
|
| |
show: | ;вывод на экран содержимого первых байт полей | ||||
xor edx,edx |
|
|
|
| |
mov dl,mas[esi] | ;1-й байт для вывода, затем 3, 6, 9 и 12 | ||||
push ecx |
|
|
|
| |
invoke | crt_printf, addr format, edx |
|
| ||
 code
codeinvoke crt_printf, addr msg ; вывод пробела между выводимыми элементами add esi,3
pop ecx loop show
exit_:
invoke Sleep, INFINITE invoke ExitProcess,0 end main
Результат работы программы:
Byte counter: 1 1 1 1 1
mas dd 128 dup (?) ;исходный массив с неопределенными элементами
x_mas dd ? | ;переменная для хранения одного введенного элемента | |||
массива |
|
|
|
|
n dd ? | ;кол-во элементов массива |
| ||
formats db ‘%d’,0 | ;формат вводимых и выводимых целых чисел | |||
. |
|
|
|
|
main: |
|
|
|
|
invoke SetConsoleTitle, addr ConsoleTitle | ;вывод имени консоли | |||
invoke crt_printf, addr msg_2 |
| ;вывод сообщения о вводе n | ||
invoke crt_scanf, ADDR formats, ADDR n | ;ввод n | |||
invoke crt_printf, addr msg_1 | ;вывод сообщения о вводе элем. массива | |||
 code
codemov esi,0 mov ecx,n m1:
push ecx
invoke crt_scanf,ADDR formats,ADDR x_mas ;ввод x_mas как символьной
;строки и преобр. ее в число, с помещ. в яч. x_mas mov eax,x_mas ;1-й, 2-й и т.д. введенный элемент поместить в EAX
mov mas[esi*4],eax ;1-й, 2-й и т.д. введенные элем. в mas[0], mas[1], и т д. inc esi ;продвижение к вводу следующего элемента массива
inc esi ;продвижение к вводу следующего элемента массива
pop ecx
loop m1 ;повторить цикл ввода элементов массива
;вывод на экран получившегося массива
invoke crt_printf, addr msg_3 | ;сообщение о выводе массива | ||
mov | ecx,n |
| ;значение счетчика цикла в ECX |
mov | esi,0 |
| ;присвоение индексному регистру значения 0 |
show: |
| ;цикл вывода на экран получившегося массива | |
xor edx,edx
imul eax,mas[esi*4],2 ;удвоение элементов массива командой
mov edx,eax | ;целочисленного умножения со знаком |
;значение элемента массива в EDX | |
push ecx | ;сохранение значения регистра ECX в стеке |
invoke crt_printf, addr formats, edx ;вывод очередного элемента массива invoke crt_printf, addr msg_4 ;вывод пробела между выводимыми элем. массива
массива
pop ecx | ;возвращение сохраненного значения регистра ECX из стека |
inc esi |
|
loop show | ;повторить цикл |
invoke Sleep, INFINITE ;задержка закрытия консоли invoke ExitProcess,0
end main
Результат работы программы:
Input number elements array n=: 5 Input elements array: 0 -23 5 7 -4 Result array: 0 -46 10 14 -8
Задача 1. Сложить соответствующие элементы двух массивов, результат вывести на экран.
masx | dw | 2,1,2,1,2,1,2,1,2,1 |
masy | dw | 1,2,1,2,1,2,1,2,1,2 |
Работа с массивами в ассемблере
Работа добавлена на сайт samzan.net: 2016-06-20
Если у вас возникли сложности с курсовой, контрольной, дипломной, рефератом, отчетом по практике, научно-исследовательской и любой другой работой — мы готовы помочь.
Имя
Выберите тип работы:
Курсовая работаДипломная работаКонтрольная работаРефератОтчет по практикеЭссеДокладРешение задачНаучно-исследовательская работаМонографияАспирантский рефератМагистерская работаНаучная статьяПубликация статьи в ВАКПубликация статьи в ScopusДипломная работа MBAБизнес-планТест/экзамен onlineЧертежРецензияПринимаю Политику конфиденциальности
Скидка 25% при заказе до 22.9.2022
;font-family:’Arial CYR'» xml:lang=»ru-RU» lang=»ru-RU»>Лабораторная работа №;font-family:’Arial CYR'» xml:lang=»en-US» lang=»en-US»>3
;font-family:’Arial CYR'» xml:lang=»ru-RU» lang=»ru-RU»>Работа с массивами в ассемблере
;font-family:’Arial CYR’;text-decoration:underline» xml:lang=»ru-RU» lang=»ru-RU»>Теоретическая часть
Массивы представляют собой упорядоченные наборы однотипных элементов. Массив характеризуется типом элементов, числом элементов и способом их нумерации. Число элементов называется размером, или длиной, массива; способ нумерации описывается одномерным целочисленным массивом, называемым формой массива.
Массив характеризуется типом элементов, числом элементов и способом их нумерации. Число элементов называется размером, или длиной, массива; способ нумерации описывается одномерным целочисленным массивом, называемым формой массива.
Число измерений называется рангом массива; число элементов в измерении называется экстентом массива в данном измерении. Целочисленный массив, длина которого равна рангу заданного массива, а каждый его элемент равен экстенту массива в данном измерении, называется формой массива. Массивы, имеющие одинаковую форму называются совместимыми.
Массив это последовательность элементов, доступ к которым осуществляется при помощи целочисленного индекса. Индексы всегда следуют по порядку, и поэтому очевидным является использование “циклов” для работы с массивами.
Можно обращаться не только к массиву целиком, но и к группе его элементов, которые называются сечениями массива. Сечения массива очень эффективное средство, которое позволяет устранить многие циклы и повысить читаемость программы.
Массивы, доступ к элементам которых осуществляется при помощи одного индекса, называются одномерными массивами или векторами.
При работе с массивами необходимо четко представлять себе, что все элементы массива располагаются в памяти компьютера последовательно. Само по себе такое расположение ничего не говорит о назначении и порядке использования этих элементов. И только лишь программист с, помощью составленного им алгоритма обработки определяет, как нужно трактовать последовательность байтов, составляющих массив. Так, одну и ту же область памяти можно трактовать одновременно и как одномерный, и как двухмерный массив. Все зависит только от алгоритма обработки этих данных в конкретной программе. Сами по себе данные не несут никакой информации о своем «смысловом», или логическом, типе.
Те же соображения можно распространить и на индексы элементов массива. Ассемблер не подозревает ни об их существовании, ни об их численных смысловых значениях. Для того чтобы локализовать определенный элемент массива, к его имени нужно добавить индекс. Так как мы моделируем массив, то должны позаботиться и о моделировании индекса. В языке ассемблера индексы массивов это обычные адреса, но с ними работают особым образом. Другими словами, когда при программировании на ассемблере мы говорим об индексе, то, скорее, подразумеваем под этим не номер элемента в массиве, а некоторый адрес. Нумерация элементов массива в ассемблере начинается с нуля.
Для того чтобы локализовать определенный элемент массива, к его имени нужно добавить индекс. Так как мы моделируем массив, то должны позаботиться и о моделировании индекса. В языке ассемблера индексы массивов это обычные адреса, но с ними работают особым образом. Другими словами, когда при программировании на ассемблере мы говорим об индексе, то, скорее, подразумеваем под этим не номер элемента в массиве, а некоторый адрес. Нумерация элементов массива в ассемблере начинается с нуля.
В общем случае для получения адреса элемента в массиве необходимо начальный (базовый) адрес массива сложить с произведением индекса (номер элемента минус единица) этого элемента на размер элемента массива:
база + (индекс • размер элемента).
Архитектура процессора предоставляет довольно удобные программно-аппаратные средства для работы с массивами. К ним относятся базовые и индексные регистры, позволяющие реализовать несколько режимов адресации данных. Используя данные режимы адресации, можно организовать эффективную работу с массивами в памяти. (см. лабораторную работу №1.)
(см. лабораторную работу №1.)
Работу с массивами в ассемблере рассмотрим на примерах.
;font-family:’Arial CYR’;text-decoration:underline» xml:lang=»ru-RU» lang=»ru-RU»>Практическая часть.
Пример №1. Найти сумму квадратов элементов массива.
Решение:
Результат работы программы:
Пример №2. Расположить элементы массива по возрастанию.
Решение:
Результат работы программы:
;font-family:’Arial CYR'» xml:lang=»ru-RU» lang=»ru-RU»>Задания для самостоятельной работы
Ознакомьтесь с теоретическим материалом.
Разберите все примеры из практической части лабораторной работы, т.е. наберите и просмотрите их работу.
Выполните индивидуальные задания.
;font-family:’Arial CYR'» xml:lang=»ru-RU» lang=»ru-RU»>Индивидуальные варианты
1. Составить программу для анализа элементов массива
1. 1.1. Дан массив целых чисел, состоящий из 10 элементов.
1.1. Дан массив целых чисел, состоящий из 10 элементов.
найти сумму четных элементов, имеющих нечетные индексы;
найти номер последнего положительного элемента.
1.1.2. Дан массив целых чисел, состоящий из 15 элементов.
найти среднее арифметическое отрицательных элементов;
вывести индексы нулевых элементов.
1.2.1. Дан массив целых чисел, состоящий из 15 элементов.
найти среднее арифметическое положительных элементов;
вывести количество отрицательных элементов.
1.2.2. Дан массив целых чисел, состоящий из 10 элементов.
найти произведение нечетных элементов;
найти номер первого нулевого элемента.
1.3.1. Дан массив целых чисел, состоящий из 15 элементов. Заполнить его с клавиатуры.
найти сумму элементов, кратных 3;
вывести количество тех элементов, значения которых меньше значения предыдущего элемента (начиная со второго).
1.3.2. Дан массив целых чисел, состоящий из 10 элементов.
найти произведение четных элементов;
определить, есть ли в данном массиве нулевые элементы.
1.4.1. Дан массив целых чисел, состоящий из 15 элементов.
найти сумму отрицательных элементов, значения которых больше заданного числа A;
количество тех элементов, значения которых положительны и не превосходят заданного числа B.
1.4.2. Дан массив целых чисел, состоящий из 10 элементов.
найти сумму отрицательных элементов, модуль которых не превосходит 5;
номер последней пары соседних элементов с разными знаками.
1.5.1. Дан массив целых чисел, состоящий из 15 элементов.
найти сумму элементов, имеющих четное значение;
вывести количество тех элементов, значения которых больше заданного числа А.
1.5.2. Дан массив целых чисел, состоящий из 10 элементов.
найти сумму элементов, имеющих нечетное значение;
определить, есть ли в данном массиве положительные элементы, кратные k (k вводится с клавиатуры).
1.6.1. Дан массив целых чисел, состоящий из 15 элементов.
найти сумму элементов, имеющих нечетные индексы;
подсчитать количество элементов массива, значения которых больше заданного числа А.
1.6.2. Дан массив целых чисел, состоящий из 10 элементов.
найти сумму элементов, имеющих четные индексы;
найти номер первого отрицательного элемента.
1.7.1. Дан массив целых чисел, состоящий из 15 элементов.
найти сумму положительных элементов, значения которых меньше 10;
вывести количество тех элементов, значения которых кратны 3.
1.7.2. Дан массив целых чисел, состоящий из 10 элементов.
найти сумму элементов, значения которых больше заданного числа A;
определить, есть ли пара соседних элементов с суммой, равной заданному числу B.
1.8.1. Дан массив целых чисел, состоящий из 15 элементов.
найти удвоенную сумму положительных элементов;
вывести количество тех элементов, значения которых больше значения предыдущего элемента (начиная со второго).
1.8.2. Дан массив целых чисел, состоящий из 10 элементов.
найти удвоенную сумму отрицательных элементов;
определить количество пар соседних элементов с одинаковыми знаками.
2. Составить программу для обработки элементов массива
2.1.1. Дан массив из четного числа элементов. Отсортировать первую половину этого массива по возрастанию, а вторую по убыванию.
2.1.2. Перенести в конец массива все отрицательные элементы.
2.2.1. Заменить нулями все элементы массива, равные максимальному.
2.2.2. Перенести в начало массива все положительные элементы.
2.3.1. Заменить максимальные элементы массива на минимальные.
2.3.2. Заменить последний положительный элемент массива на первый элемент массива.
2.4.1. Заменить нулями элементы массива между минимальными и максимальными, кроме их самих.
2.4.2. Перенести в начало массива максимальный элемент
2.5.1. Заменить минимальный положительный элемент массива нулем.
2.5.2. Заменить элементы массива с k1-го по k2-й на те же элементы в обратном порядке.
2.6.1. Заменить первый отрицательный элемент массива на последний элемент массива.
2.6.2. Найти максимальный элемент среди отрицательных элементов и поменять его местами с минимальным положительным.
2.7.1. Заменить первые k элементов массива на максимальный элемент.
2.7.2. Перенести в конец массива минимальный элемент.
2.8.1. Заменить минимальный по модулю отрицательный элемент массива нулем.
2.8.2. Отсортировать массив по убыванию начиная с минимального элемента.
1. Замещаемая должность ~курсант очного обучения далее ~курсант
2. Литература — Хирургия (ГАСТРОДУОДЕНАЛЬНОЕ КРОВОТЕЧЕНИЕ)
3. Роль и функции эмоций Эмоциями называются такие психические процессы в которых человек переживает свое
4. Введение5
5. дипломатия кононерка
6. Похвала глупости Роттердамский Эразм
7. Норманское завоевание Англии 1066 года
8. The mass media in the Great Britai
9. По теме- Тенденции развития капиталистических отношений в России XVII века
10. Аудит реализованной продукции
11. Пересветов Иван Семенович русский писатель-публицист
12. Студент Харківського медичного університету громадянин Лівії познайомився зі студенткою яка
13. первых с постоянно меняющейся политической конфигурацией появлением уже в ходе избирательной кампании нов
14. Разработка дизайна веб-продукта
15. О некоторых мерах по обеспечению проведения на территории Ставропольского края Эстафеты Олимпийского огня
16. на тему- ДРАМАТИЗАЦІЯ КАЗКИ НАТАЛІ ЗАБІЛИ ldquo;ПРО ПІВНИКА ТА КУРОЧКУ І ПРО ХИТРУ ЛИСИЧКУrdquo;
на тему- ДРАМАТИЗАЦІЯ КАЗКИ НАТАЛІ ЗАБІЛИ ldquo;ПРО ПІВНИКА ТА КУРОЧКУ І ПРО ХИТРУ ЛИСИЧКУrdquo;
17. МЕТОДИЧЕСКИЕ РЕКОМЕНДАЦИИ ОРГАНАМ МЕСТНОГО САМОУПРАВЛЕНИЯ ПО РЕАЛИЗАЦИИ ФЕДЕРАЛЬНОГО ЗАКОНА ОТ 6 ОКТЯБР
18. дама такие нарушения называются параротацизмами
19. Фронтовой бомбардировщик Су-2
20. Рабство в Римской Испании
Материалы собраны группой SamZan и находятся в свободном доступе
Ассемблер под Windows для чайников. Часть 12
Сегодня мы поговорим о массивах данных. Работая за компьютером, с массивами данных мы сталкиваемся практически повсеместно: сортировка файлов, индексированный поиск, электронные таблицы, списки и многое, многое другое. Теперь, когда мы изучили столько важных команд ассемблера, можем всерьез заняться изучением алгоритмов работы с массивами. Тема эта весьма сложная, но без умения управляться с массивами данных нельзя далеко продвинуться в программировании. Так что собирайтесь с силами, и приступим к изучению массивов.
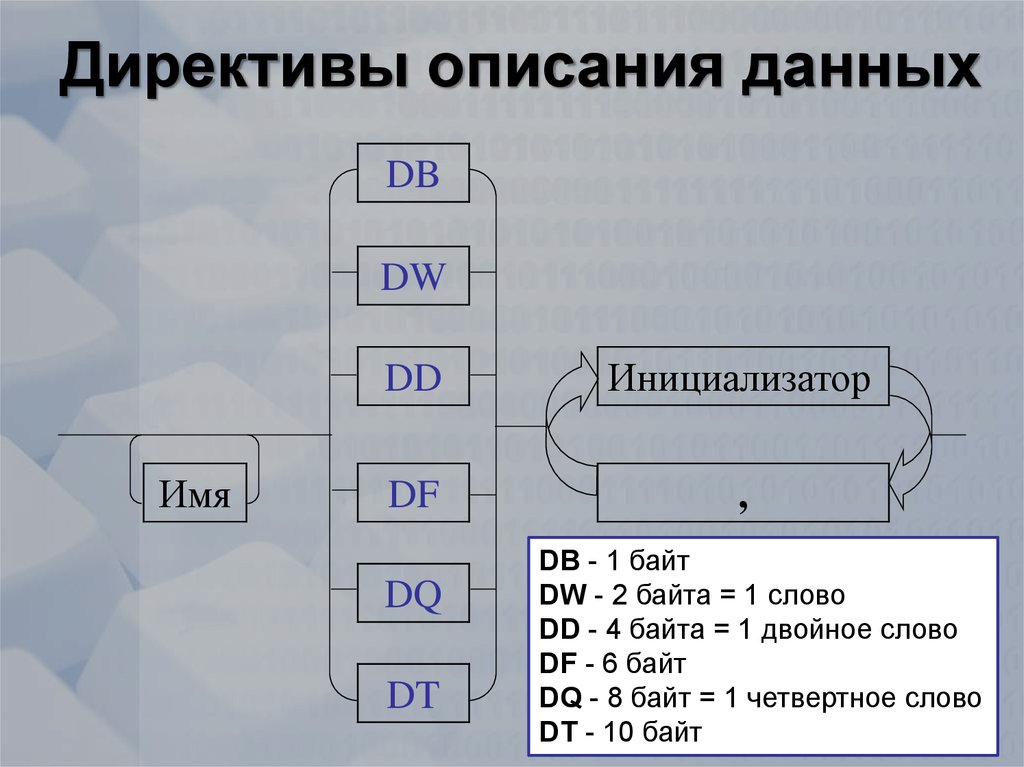
Массив — это структурированный тип данных, состоящий из нескольких элементов одного типа. В высокоуровневых языках существуют специальные средства для описания массивов. В ассемблере такие средства отсутствуют, а потому массив обычно обозначается просто как линейная область данных. Например, чтобы обозначить одномерный массив однобайтовых элементов и выделить под него память, обычно достаточно директивы RB (Reserve Bytes — Зарезервировать Байты), за которой следует число резервируемых байт. Если элемент массива должен иметь размер в два байта, будем использовать директиву RW (Reserve Words) и число резервируемых слов. Для четырехбайтовых элементов — соответственно RD и количество двойных слов и так далее. Если мы хотим не только выделить память, но и сразу внести в массив значения элементов, можно описать элементы при помощи стандартных директив описания данных — таких, как DB, DW, DD и т.д. За директивой определения данных должно следовать одно или несколько числовых выражений, разделенных запятыми. Эти выражения определяют значение элементов массива. Если вместо значения указан символ вопроса, то значение считается неопределенным, то есть таким же, как если бы мы использовали директиву резервирования данных. Размер элемента зависит от того, какая директива используется.
Эти выражения определяют значение элементов массива. Если вместо значения указан символ вопроса, то значение считается неопределенным, то есть таким же, как если бы мы использовали директиву резервирования данных. Размер элемента зависит от того, какая директива используется.
Табл. 1. Директивы определения и резервирования данных
| Размер элемента в байтах | Директивы определения данных | Директивы резервирования данных |
| 1 | db file | rb |
| 2 | dw du | rw |
| 4 | dd | |
| 6 | dp df | rprf |
| 8 | dq | rq |
| 10 | dt | rt |
Для инициализации элементов массива одним и тем же значением или повторяющейся цепочкой значений можно использовать специальный оператор DUP. Количество дубликатов указывается перед DUP, а дублируемое значение или цепочка значений, разделенных запятыми, указывается после оператора DUP и заключается в скобки. Например, db 5 dup (1,2) означает, что необходимо создать 5 копий указанной последовательности из двух байт. Массивы бывают статические и динамические. Динамические массивы отложим на потом, а пока попробуем разобраться хотя бы со статическими. Размер статического массива не меняется на протяжении времени работы программы. Поэтому с ними работать несколько проще. Достаточно выделить область памяти под статический массив лишь один раз, и потом остается лишь работать с содержимым массива — его элементами.
Например, db 5 dup (1,2) означает, что необходимо создать 5 копий указанной последовательности из двух байт. Массивы бывают статические и динамические. Динамические массивы отложим на потом, а пока попробуем разобраться хотя бы со статическими. Размер статического массива не меняется на протяжении времени работы программы. Поэтому с ними работать несколько проще. Достаточно выделить область памяти под статический массив лишь один раз, и потом остается лишь работать с содержимым массива — его элементами.
Перечислим основные операции, которые мы можем производить над массивами:
— ввод данных в массив;
— вывод данных из массива;
— поиск значения в массиве;
— сортировка элементов.
Начнем мы, пожалуй, с операции вывода, чтобы позже у нас было на чем проверить правильность наших операций ввода, поиска и сортировки. Создадим массив из пяти элементов размером в один байт и выведем значение каждого элемента в отдельном поле окна:
format PE GUI 4.0
entry start
include ‘win32a.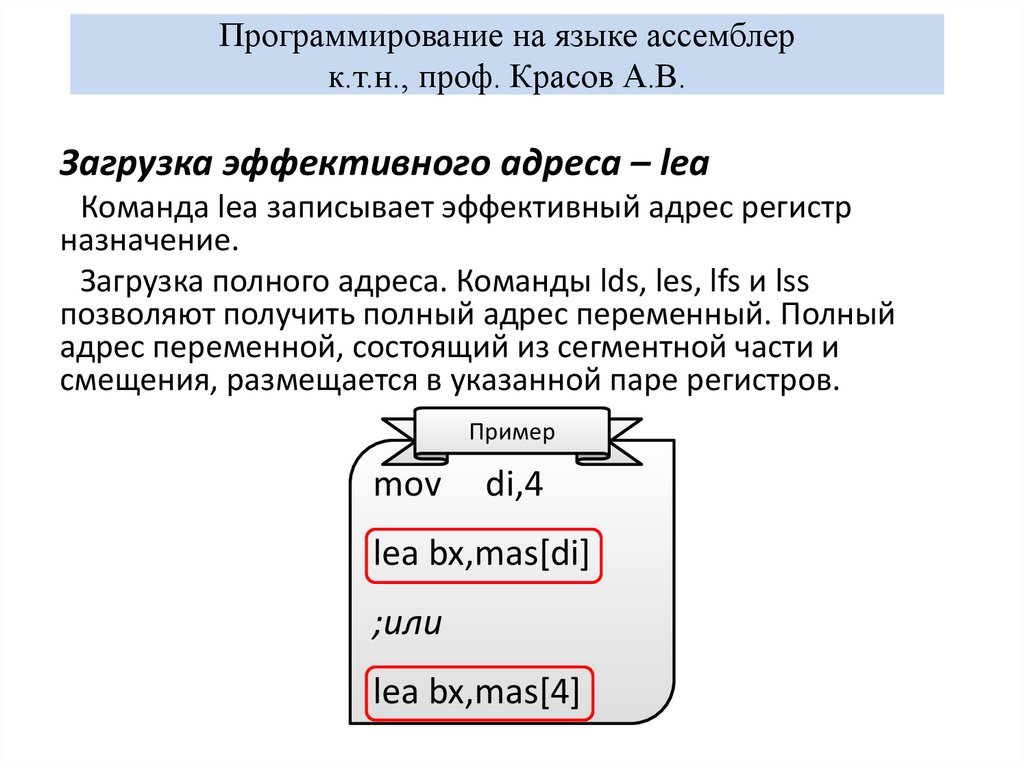 inc’
inc’
;константы
MASSIZE=5 ;количество элементов массива
BUFSIZE=3 ;макс.кол-во знаков в элементе
;(для буфера вывода десятичных значений)
section ‘.data’ data readable writeable
_class db ‘FASMWIN32’,0
_cedit db ‘EDIT’,0
_title db ‘Работа с массивами’,0
_error db ‘Ошибка запуска.’,0
buf rb BUFSIZE+1 ;+1 для нуль-терминатора
mas db 123,23,3,4,5
hmas dd MASSIZE dup (?)
wc WNDCLASS 0,WindowProc,0,0,NULL,NULL,NULL,COLOR_BTNFACE+1,NULL,_class
msg MSG
section ‘.code’ code readable executable
start:
invoke GetModuleHandle,0
mov [wc.hInstance],eax
invoke LoadIcon,0,IDI_APPLICATION
mov [wc.hIcon],eax
invoke LoadCursor,0,IDC_ARROW
mov [wc.hCursor],eax
invoke RegisterClass,wc
test eax,eax
jz error
invoke CreateWindowEx,0,_class,_title,WS_VISIBLE+WS_DLGFRAME+ WS_SYSMENU,128,128,256,192,NULL,NULL,[wc.hInstance],NULL
test eax,eax
jz error
msg_loop:
invoke GetMessage,msg,NULL,0,0
cmp eax,1
jb end_loop
jne msg_loop
invoke TranslateMessage,msg
invoke DispatchMessage,msg
jmp msg_loop
error:
invoke MessageBox,NULL,_error,NULL,MB_ICONERROR+MB_OK
end_loop:
invoke ExitProcess,[msg. wParam]
wParam]
proc WindowProc hwnd,wmsg,wparam,lparam
push ebx esi edi
cmp [wmsg],WM_CREATE
je .wmcreate
cmp [wmsg],WM_DESTROY
je .wmdestroy
.defwndproc:
invoke DefWindowProc,[hwnd],[wmsg],[wparam],[lparam]
jmp .finish
.wmcreate:
;создаем поле под каждый элемент массива mas
;и помещаем дескриптор каждого поля в массив hmas
mov esi,5
mov edi,5
xor ebx,ebx
.create_cycl:
invoke CreateWindowEx,0,_cedit,0,WS_VISIBLE+WS_CHILD+WS_BORDER+ ES_READONLY+ES_RIGHT,esi,edi,40,20,[hwnd],ebx,[wc.hInstance],0
test eax,eax
jz error
mov [hmas+ebx*4],eax
add esi,50
inc ebx
cmp ebx,MASSIZE
jne .create_cycl
.out_mas:
;заполняем поля значениями элементов массива
xor ebx,ebx
.masout_cycl:
mov ah,[mas+ebx]
lea edi,[buf+BUFSIZE]
.dec:
movzx ax,ah
aam
or al,30h
dec edi
mov byte [edi],al
test ah,ah
jnz .dec
invoke SendMessage,[hmas+ebx*4],WM_SETTEXT,0,edi
inc ebx
cmp ebx,MASSIZE
jne . masout_cycl
masout_cycl
jmp .finish
.wmdestroy:
invoke PostQuitMessage,0
xor eax,eax
.finish:
pop edi esi ebx
ret
endp
section ‘.idata’ import data readable writeable
library kernel32,’KERNEL32.DLL’,\
user32,’USER32.DLL’
include ‘api\kernel32.inc’
include ‘api\user32.inc’
Для верного отображения значений элементов они должны находиться в диапазоне от 0 до 255 включительно, то есть являться однобайтовыми беззнаковыми целыми. Позже, научимся отображать и числа со знаком, но сейчас нам это только осложнит задачу и отвлечет от понимания принципов работы с массивами. Раз самое длинное число у нас состоит из трех знаков, то и буфер для его вывода (buf) будет иметь размер 3+1 байта. Четвертый байт выделяется специально под нолик, обозначающий конец строки. Значения всех пяти элементов массива (mas) мы на данном этапе определим сразу в секции данных, поскольку функция ввода значений массива пока что отсутствует в нашей программе. Массив hmas (h означает handles — дескрипторы), состоящий из пяти двойных слов (MASSIZE=5), будет содержать дескрипторы полей для вывода значений элементов массива. Так нам на первых порах будет проще: берем значение первого элемента mas, преобразовываем его к символьному виду и выводим в поле, дескриптор которого хранится в первом элементе hmas. Потом выводим значение второго элемента mas в поле, дескриптор которого берем соответственно из второго элемента hmas. Аналогично поступаем с третьим элементом, четвертым, пятым… да хоть миллионным, лишь бы все поля уместились на экране, а массивы значений и дескрипторов — в памяти компьютера. Разумеется, весь этот вывод нам выгоднее оформить в повторяющемся цикле. Этот цикл и будет скелетом функции вывода.
Так нам на первых порах будет проще: берем значение первого элемента mas, преобразовываем его к символьному виду и выводим в поле, дескриптор которого хранится в первом элементе hmas. Потом выводим значение второго элемента mas в поле, дескриптор которого берем соответственно из второго элемента hmas. Аналогично поступаем с третьим элементом, четвертым, пятым… да хоть миллионным, лишь бы все поля уместились на экране, а массивы значений и дескрипторов — в памяти компьютера. Разумеется, весь этот вывод нам выгоднее оформить в повторяющемся цикле. Этот цикл и будет скелетом функции вывода.
Не будем останавливаться на участках подготовки и создания окна, так как это было подробно описано еще в первых частях данного курса. Обратим внимание сразу на обработчик сообщения WM_CREATE. Здесь мы создаем поле под каждый элемент массива mas и помещаем дескриптор каждого созданного поля в соответствующий элемент hmas. Это еще не сам вывод, но создание полей для вывода значений. Перед циклом мы помещаем в esi и edi соответственно X- и Y-координаты расположения первого поля относительно левого верхнего угла клиентской области нашего основного окна. На каждом шаге цикла мы будем увеличивать esi (координата X) на 50, исходя из того, что ширина самого поля равна 40, а 10 — зазор между соседними полями. Ввиду того, что пять полей прекрасно умещаются в одну строку, содержимое edi мы сейчас изменять не станем. Его на данном этапе можно было бы и не использовать вообще, но это — так сказать, задел на будущее. Подробно разберем, что происходит в цикле «.create_cycl:». Первым делом мы создаем окно стандартного класса «EDIT» с указанными параметрами. Содержимое EBX выступает в качестве идентификатора каждого нового окна, поэтому поля будут иметь идентификаторы 0, 1, 2 и т.д. Это, конечно, не самый красивый вариант, но в данном примере мы не будем обращаться к окнам по их идентификаторам, а потому имеем полное право указать даже один и тот же идентификатор для всех создаваемых полей. Но я решил их все же сделать отличными друг от друга без каких-либо дополнительных действий. Впрочем, это мелочи. Главное назначение регистра EBX в этом цикле — счетчик.
На каждом шаге цикла мы будем увеличивать esi (координата X) на 50, исходя из того, что ширина самого поля равна 40, а 10 — зазор между соседними полями. Ввиду того, что пять полей прекрасно умещаются в одну строку, содержимое edi мы сейчас изменять не станем. Его на данном этапе можно было бы и не использовать вообще, но это — так сказать, задел на будущее. Подробно разберем, что происходит в цикле «.create_cycl:». Первым делом мы создаем окно стандартного класса «EDIT» с указанными параметрами. Содержимое EBX выступает в качестве идентификатора каждого нового окна, поэтому поля будут иметь идентификаторы 0, 1, 2 и т.д. Это, конечно, не самый красивый вариант, но в данном примере мы не будем обращаться к окнам по их идентификаторам, а потому имеем полное право указать даже один и тот же идентификатор для всех создаваемых полей. Но я решил их все же сделать отличными друг от друга без каких-либо дополнительных действий. Впрочем, это мелочи. Главное назначение регистра EBX в этом цикле — счетчик. Сразу после создания окна мы убеждаемся в отсутствии ошибки и помещаем содержимое EAX (дескриптор созданного окна) в очередной элемент массива hmas. Вам понятно, как это происходит? Элементы считаются в программировании с нулевого (а не с первого) именно потому, что первый элемент никуда не смещен относительно начала строки или массива. Он первый, он находится по адресу начала массива, и его смещение — нулевое. А вот второй элемент уже имеет смещение на размер одного (первого) элемента, третий — на размер двух элементов, четвертый — трех и т.д. Размер дескриптора, как и большинства других элементов в 32-битной системе, равняется 32 битам или 4 байтам. Поэтому мы умножаем 4 на EBX, чтобы получить смещение очередного элемента от начала массива. А затем прибавляем к нему еще смещение самого hmas относительно начала сегмента. Таким образом, для первого элемента смещение получится равным hmas+0, для второго — hmas+4, для третьего — hmas+8 и т.д. Обычно в качестве счетчика используют регистр ECX, который изначально и задуман для этих целей.
Сразу после создания окна мы убеждаемся в отсутствии ошибки и помещаем содержимое EAX (дескриптор созданного окна) в очередной элемент массива hmas. Вам понятно, как это происходит? Элементы считаются в программировании с нулевого (а не с первого) именно потому, что первый элемент никуда не смещен относительно начала строки или массива. Он первый, он находится по адресу начала массива, и его смещение — нулевое. А вот второй элемент уже имеет смещение на размер одного (первого) элемента, третий — на размер двух элементов, четвертый — трех и т.д. Размер дескриптора, как и большинства других элементов в 32-битной системе, равняется 32 битам или 4 байтам. Поэтому мы умножаем 4 на EBX, чтобы получить смещение очередного элемента от начала массива. А затем прибавляем к нему еще смещение самого hmas относительно начала сегмента. Таким образом, для первого элемента смещение получится равным hmas+0, для второго — hmas+4, для третьего — hmas+8 и т.д. Обычно в качестве счетчика используют регистр ECX, который изначально и задуман для этих целей. Однако API-функции (в нашем случае функция CreateWindowEx) используют некоторые регистры в своих целях и могут изменить содержимое этих регистров за время своего исполнения. Гарантированно сохраняется лишь содержимое регистров EBX, EBP, ESP, ESI, EDI. Поэтому содержимое остальных регистров по необходимости следует сохранить командой PUSH, а потом восстановить командой POP. В нашем случае такой необходимости нет, так как в данном цикле мы вполне можем обойтись регистрами EBX, ESI, EDI. Итак, мы сохраняем дескриптор очередного созданного поля EDIT в массив hmas. Увеличиваем ESI на 50, чтобы следующее поле было создано на 50 точек правее. Увеличиваем EBX на единицу. И повторяем цикл при условии, что EBX еще не равен количеству элементов массива. Если EBX=MASSIZE — значит, мы создали поля для всех элементов массива и можем переходить к выводу значений в эти поля. Тут же прописана метка «.out_mas:» для того, чтобы можно было впоследствии осуществлять повторный вывод текущих значений без повторного создания полей.
Однако API-функции (в нашем случае функция CreateWindowEx) используют некоторые регистры в своих целях и могут изменить содержимое этих регистров за время своего исполнения. Гарантированно сохраняется лишь содержимое регистров EBX, EBP, ESP, ESI, EDI. Поэтому содержимое остальных регистров по необходимости следует сохранить командой PUSH, а потом восстановить командой POP. В нашем случае такой необходимости нет, так как в данном цикле мы вполне можем обойтись регистрами EBX, ESI, EDI. Итак, мы сохраняем дескриптор очередного созданного поля EDIT в массив hmas. Увеличиваем ESI на 50, чтобы следующее поле было создано на 50 точек правее. Увеличиваем EBX на единицу. И повторяем цикл при условии, что EBX еще не равен количеству элементов массива. Если EBX=MASSIZE — значит, мы создали поля для всех элементов массива и можем переходить к выводу значений в эти поля. Тут же прописана метка «.out_mas:» для того, чтобы можно было впоследствии осуществлять повторный вывод текущих значений без повторного создания полей. Перед циклом вывода обнуляем наш счетчик EBX. Задвигаем в AH значение текущего элемента (mas+счетчик*размер_элемента). Так как размер элемента у нас 1 байт, то есть единица, пишем просто mas+EBX. Загружаем в EDI эффективный адрес последнего символа буфера — нуль-терминатора. В данном примере буфер у нас состоит из трех символов + нуль-терминатор, потому что константа BUFSIZE у нас равна трем. Адрес первого символа буфера — buf, адрес второго — buf+1, …, адрес нуль-терминатора — buf+3 или buf+BUFSIZE. Адрес нуль-терминатора нам, конечно, не нужен. Но для корректного перевода числа из машинного представления в символьное нам необходимо записывать символы, начиная с конца. Поэтому мы сразу поместим в EDI адрес последнего символа, а потом будем уменьшать EDI на единицу перед записью каждого следующего символа. Таким образом мы запишем сначала число единиц, затем — число десятков, затем — сотен. Для приведения числа к символьному виду можно было бы воспользоваться и API-функцией ОС — например, wsprintf.
Перед циклом вывода обнуляем наш счетчик EBX. Задвигаем в AH значение текущего элемента (mas+счетчик*размер_элемента). Так как размер элемента у нас 1 байт, то есть единица, пишем просто mas+EBX. Загружаем в EDI эффективный адрес последнего символа буфера — нуль-терминатора. В данном примере буфер у нас состоит из трех символов + нуль-терминатор, потому что константа BUFSIZE у нас равна трем. Адрес первого символа буфера — buf, адрес второго — buf+1, …, адрес нуль-терминатора — buf+3 или buf+BUFSIZE. Адрес нуль-терминатора нам, конечно, не нужен. Но для корректного перевода числа из машинного представления в символьное нам необходимо записывать символы, начиная с конца. Поэтому мы сразу поместим в EDI адрес последнего символа, а потом будем уменьшать EDI на единицу перед записью каждого следующего символа. Таким образом мы запишем сначала число единиц, затем — число десятков, затем — сотен. Для приведения числа к символьному виду можно было бы воспользоваться и API-функцией ОС — например, wsprintf. Но давайте на всякий случай научимся делать такие вещи вручную. Это может сильно помочь вам в понимании низкоуровневых алгоритмов преобразования типов.
Но давайте на всякий случай научимся делать такие вещи вручную. Это может сильно помочь вам в понимании низкоуровневых алгоритмов преобразования типов.
Табл. 2. Размещение разрядов в буфере
| Смещение | buf+0 | buf+1 | buf+2 | buf+3 |
| Назначение | сотни | десятки | единицы | нуль-терминатор |
Цикл «.masout_cycl:» повторяется для каждого элемента массива, а цикл «.dec:» — для каждого десятичного разряда выводимого элемента. На первом шаге цикла «.dec:» в AH находится значение текущего элемента массива. Чтобы выделить из него число единиц, мы копируем его в AL. Команда AAM, как вы уже знаете, делит содержимое AL на 10 и помещает частное в AH, а остаток — в AL. Остаток от деления числа на 10 и будет числом единиц в нем. Частное на следующем шаге цикла можно будет снова поделить на 10 и получить в остатке уже число десятков, а потом — и сотен. Но сейчас, чтобы привести число единиц в AL к символьному виду, мы выполняем команду or al,30h.
Табл. 3. Символьное представление чисел в ASCII
| Символ | Шестнадцатеричное значение (ASCII-код) | Двоичное значение (ASCII-код) |
| 0 | 30h | 00110000b |
| 1 | 31h | 00110001b |
| 2 | 32h | 00110010b |
| 3 | 33h | 00110011b |
| … | … | … |
| 9 | 39h | 00111001b |
Как видно из третьей таблицы, шестнадцатеричное значение символа отличается от машинного представления числа ровно на 30h. То есть, чтобы число от нуля до девяти преобразовать в значение соответствующего ему символа, достаточно прибавить к числу 30h. Двоичные значения я тоже привел неслучайно. Из них понятно, что 30h — это, по сути, два установленных бита — пятый и шестой. То есть, если мы к двоичному значению числа от 0 до 9 (от 0b до 1001b) применим команду OR со вторым операндом 30h (00110000b), то получим соответствующий этому числу ASCII-код символа. Стало быть, в таких случаях можно на равных правах использовать как команду ADD, так и команду OR. Привели число единиц к символьному виду, уменьшаем EDI (а то он у нас еще на нуль-терминатор указывает, а нам уже единицы в буфер вписать требуется). Копируем байт из AL по адресу, содержащемуся в EDI. Тестируем AH на предмет нулевого содержимого. Если в AH (ведь это частное нашего последнего деления) содержится ноль — значит, десятков в данном элементе нет (или нет сотен на втором шаге цикла), и мы не станем повторять цикл «.dec:», а перейдем к выводу полного значения данного элемента в соответствующее поле. Если же AH нулю не равен — значит, еще остались старшие разряды, которые необходимо обработать аналогичным способом. Функцией SendMessage выводим значение элемента в текущее поле. Дескриптор берем по адресу hmas+ebx*4. Выводимый текст — по адресу, хранящемуся в EDI. Обратите внимание, что не по адресу buf, а именно по адресу в EDI! Буфер целиком у нас содержит неопределенное значение.
Стало быть, в таких случаях можно на равных правах использовать как команду ADD, так и команду OR. Привели число единиц к символьному виду, уменьшаем EDI (а то он у нас еще на нуль-терминатор указывает, а нам уже единицы в буфер вписать требуется). Копируем байт из AL по адресу, содержащемуся в EDI. Тестируем AH на предмет нулевого содержимого. Если в AH (ведь это частное нашего последнего деления) содержится ноль — значит, десятков в данном элементе нет (или нет сотен на втором шаге цикла), и мы не станем повторять цикл «.dec:», а перейдем к выводу полного значения данного элемента в соответствующее поле. Если же AH нулю не равен — значит, еще остались старшие разряды, которые необходимо обработать аналогичным способом. Функцией SendMessage выводим значение элемента в текущее поле. Дескриптор берем по адресу hmas+ebx*4. Выводимый текст — по адресу, хранящемуся в EDI. Обратите внимание, что не по адресу buf, а именно по адресу в EDI! Буфер целиком у нас содержит неопределенное значение. Если, к примеру, первый элемент состоял из трех десятичных знаков, а второй — из двух, то на момент вывода второго элемента в окно буфер будет содержать в первом байте сотни, оставшиеся от первого элемента, и только со второго байта пойдут десятки текущего элемента. Поэтому верное значение текущего элемента у нас будет только с адреса в EDI. Именно по данному адресу в буфер был прописан последний старший разряд текущего элемента. Увеличиваем EBX на единицу, и, если он еще не равен MASSIZE, переходим в начало цикла «.masout_cycl:» для вывода следующего элемента в следующее поле. Иначе прыгаем на финиш ввиду того, что все элементы выведены на экран, то есть в окно на экране. Ну, а теперь тем, кому «деление на десять» показалось слишком сложным циклом, покажу упрощенный вариант с использованием функции wsprintf. Преобразование значения в символьный вид выполнит за нас эта функция, поэтому мы сможем избавиться от цикла «.dec:». Мы обсудили возможности данной функции еще в четвертой части курса.
Если, к примеру, первый элемент состоял из трех десятичных знаков, а второй — из двух, то на момент вывода второго элемента в окно буфер будет содержать в первом байте сотни, оставшиеся от первого элемента, и только со второго байта пойдут десятки текущего элемента. Поэтому верное значение текущего элемента у нас будет только с адреса в EDI. Именно по данному адресу в буфер был прописан последний старший разряд текущего элемента. Увеличиваем EBX на единицу, и, если он еще не равен MASSIZE, переходим в начало цикла «.masout_cycl:» для вывода следующего элемента в следующее поле. Иначе прыгаем на финиш ввиду того, что все элементы выведены на экран, то есть в окно на экране. Ну, а теперь тем, кому «деление на десять» показалось слишком сложным циклом, покажу упрощенный вариант с использованием функции wsprintf. Преобразование значения в символьный вид выполнит за нас эта функция, поэтому мы сможем избавиться от цикла «.dec:». Мы обсудили возможности данной функции еще в четвертой части курса. В первом параметре указывается буфер для результата, во втором — задается формат, а в остальных указываются данные, которые необходимо преобразовать. Так что нам остается лишь добавить в секцию данных строку с образцом формата:
В первом параметре указывается буфер для результата, во втором — задается формат, а в остальных указываются данные, которые необходимо преобразовать. Так что нам остается лишь добавить в секцию данных строку с образцом формата:
form db ‘%u’,0
Управляющий символ ‘%u’ означает тип «unsigned integer» — беззнаковое целое. И теперь мы можем цикл вывода упростить до следующего вида:
.out_mas:
xor ebx,ebx
.masout_cycl:
movzx eax,[mas+ebx]
invoke wsprintf,buf,form,eax
invoke SendMessage,[hmas+ebx*4],WM_SETTEXT,0,buf
inc ebx
cmp ebx,MASSIZE
jne .masout_cycl
jmp .finish
Функции 32-битных ОС обычно нуждаются в том, чтобы параметры были 32-битными. Поэтому командой movzx мы расширяем 8-битное значение из ячейки [mas+ebx] до 32-битного в регистре eax. Вызываем wsprintf и получаем в буфере искомое значение в символьном виде. Далее все так же, как и в первом варианте программы, но… Помните, друзья мои, что бесплатный сыр бывает только в мышеловке! Используя для такого простого преобразования всю мощь универсальной функции wsprintf, мы совершаем кучу лишних действий и слегка теряем в скорости исполнения. Конечно, на такой простенькой программе вы этого не заметите. На современных мощных компьютерах вы также можете не увидеть разницу невооруженным глазом даже в более прожорливой программе. Но вы же планируете в дальнейшем писать намного более серьезные вещи, не так ли? А значит, всегда следуйте хакерским путем: сперва используйте наиболее простой для понимания метод, а затем оптимизируйте его, преобразуя в более простой для исполнения процессором. Сейчас часто можно услышать, что экономия в несколько тактов или пару байт памяти ничего не дает. Даже и не пытайтесь с этим спорить. Но для себя не забывайте, что вычислительные мощности с каждым днем растут, а большинство программ почему-то становятся все более тормознутыми. Весьма странная закономерность! Да не будем обращать внимание на ошибки окружающих, а вместо этого давайте все же не лениться экономить такты и байты. На сегодня все. В следующий раз продолжим о массивах.
Конечно, на такой простенькой программе вы этого не заметите. На современных мощных компьютерах вы также можете не увидеть разницу невооруженным глазом даже в более прожорливой программе. Но вы же планируете в дальнейшем писать намного более серьезные вещи, не так ли? А значит, всегда следуйте хакерским путем: сперва используйте наиболее простой для понимания метод, а затем оптимизируйте его, преобразуя в более простой для исполнения процессором. Сейчас часто можно услышать, что экономия в несколько тактов или пару байт памяти ничего не дает. Даже и не пытайтесь с этим спорить. Но для себя не забывайте, что вычислительные мощности с каждым днем растут, а большинство программ почему-то становятся все более тормознутыми. Весьма странная закономерность! Да не будем обращать внимание на ошибки окружающих, а вместо этого давайте все же не лениться экономить такты и байты. На сегодня все. В следующий раз продолжим о массивах.
Все приводимые примеры были протестированы на правильность работы под Windows XP и, скорее всего, будут работать под другими версиями Windows, однако я не даю никаких гарантий их правильной работы на вашем компьютере. Исходные тексты программ вы можете найти на форуме: сайт
Исходные тексты программ вы можете найти на форуме: сайт
BarMentaLisk, [email protected]
Компьютерная газета. Статья была опубликована в номере 34 за 2008 год в рубрике программирование
Иллюстрированный самоучитель по задачам и примерам Assembler › Содержание | Самоучители по программированию
| Введение | 2 |
| Программирование целочисленных арифметических операций | 4 |
| Арифметические операции | 5 |
| Двоичные числа. Сложение двоичных чисел. | 6 |
| Вычитание двоичных чисел | 9 |
| Умножение двоичных чисел | 11 |
| Деление двоичных чисел | 15 |
| Двоично-десятичные числа (BCD-числа). Неупакованные BCD-числа. | 20 |
| Упакованные BCD-числа | 24 |
| Генерация последовательности случайных чисел | 25 |
| Сложные структуры данных | 30 |
| Основные понятия | 31 |
| Множество | 35 |
Массив. Описание массивов. Описание массивов. | 36 |
| Работа с массивами. Сортировка массивов. | 38 |
| Улучшение классических методов сортировки | 41 |
| Поиск в массивах | 45 |
| Действия с матрицами | 48 |
| Структура. Вложенные структуры. | 49 |
| Массивы структур – таблицы | 51 |
| Выбор способа перевода ключевых слов в числовую форму | 57 |
| Список | 60 |
| Сеть | 68 |
| Дерево | 71 |
| Элементы компиляции программ | 76 |
| Процедуры в программах ассемблера | 84 |
| Реализация рекурсивных процедур | 85 |
| Реализация вложенных процедур | 88 |
| Разработка динамических (DLL) библиотек. Разработка текста DLL-библиотеки. | 90 |
Трансляция и компоновка исходного текста DLL-библиотеки. Создание lib-файла. Создание lib-файла. | 92 |
| Сборка приложения с использованием DLL-библиотеки. Проверка работоспособности приложения с использованием DLL-библиотеки. | 93 |
| Обработка цепочек элементов | 94 |
| Работа с консолью в программах на ассемблере | 99 |
| Функции BIOS для работы с консолью | 100 |
| Функции BIOS для работы с экраном | 103 |
| Функции MS DOS для работы с консолью | 107 |
| Функции MS DOS для вывода данных на экран | 110 |
| Работа с консолью в среде Windows. Организация ввода-вывода в консольном приложении Windows. | 111 |
| Организация высокоуровневого консольного ввода-вывода | 113 |
| Организация низкоуровнего консольного ввода-вывода | 117 |
| Окно консоли и экранный буфер | 119 |
| Преобразование чисел | 122 |
| Проблемы ввода-вывода числовой информации | 123 |
Ввод чисел с консоли. Преобразование целых десятичных чисел. Преобразование целых десятичных чисел. | 124 |
| Ввод вещественных чисел | 127 |
| Вывод чисел на консоль. Вывод шестнадцатеричных чисел. | 128 |
| Вывод целых десятичных чисел | 129 |
| Вывод вещественных чисел | 131 |
| Работа с файлами в программах на ассемблере | 132 |
| Программа на ассемблере | 133 |
| Работа с файлами в MS DOS (имена 8.3). Создание, открытие, закрытие и удаление файла. | 134 |
| Чтение, запись, позиционирование в файле | 136 |
| Получение и изменение атрибутов файла | 140 |
| Работа с дисками, каталогами и организация поиска файлов | 142 |
| Работа с файлами в MS DOS (длинные имена) | 145 |
| Создание, открытие, закрытие и удаление файла. Атрибуты файла. | 148 |
| Работа с дисками, каталогами и организация поиска файлов | 151 |
| Файловый ввод-вывод в Win32 | 157 |
| Создание, открытие, закрытие и удаление файла | 158 |
| Чтение, запись, позиционирование в файле | 161 |
| Получение и изменение атрибутов файла | 162 |
| Работа с дисками, каталогами и организация поиска файлов | 164 |
| Профайлер | 170 |
| Расширение традиционной архитектуры Intel | 171 |
| Команды RDMSR и WRMSR | 172 |
| Команда CPUID – получение информации о текущем процессоре | 173 |
| Использование счетчика меток реального времени TSC | 175 |
| Вычисление CRC | 177 |
| Идентификация исходной битовой последовательности | 178 |
| CRC-арифметика | 180 |
| Прямой алгоритм вычисления CRC | 184 |
| Табличные алгоритмы вычисления CRC | 186 |
| Прямой табличный алгоритм CRC32 | 189 |
| «Зеркальный» табличный алгоритм CRC32 | 192 |
| Программирование ХММ-расширения | 194 |
| Программирование ХММ-расширения | 195 |
| Описание упакованных и скалярных данных | 197 |
| Примеры использования команд ХММ-расширения | 198 |
| Препроцессор команд ХММ-расширения | 200 |
| Язык описания команд ассемблера | 203 |
| Выделение классов лексем | 204 |
| Заключение | 206 |
SamoYchiteli. ru
ru
Иллюстрированные самоучители
9.2: Определение и создание массива в сборке
- Последнее обновление
- Сохранить как PDF
- Идентификатор страницы
- 27149
- Чарльз В. Канн III
- Геттисбергский колледж
Большинство читателей этого текста знакомы с концепцией массивов и их использованием в HLL.
Таким образом, в этой главе речь пойдет не об их использовании, а о том, как реализуются массивы и к элементам массива обращаются в ассемблере. Большинство HLL прилагают большие усилия, чтобы скрыть эти детали от программиста, и на то есть веские причины. Когда программисты на самом деле имеют дело с деталями, они часто делают ошибки, которые имеют серьезные последствия для правильности их программ: ошибки, которые приводят к серьезным проблемам корректности их программ, и ошибки, которые часто могут привести к тому, что их очень трудно найти и исправить.
Но даже несмотря на то, что детали массивов скрыты в большинстве языков HLL, эти детали влияют на то, как HLL реализует абстракции массивов, а правильное понимание массивов может помочь предотвратить разработку программистами неуместных метафор, которые приводят к проблемам с программами. Неправильное использование нарезки объектов в C++ или выделение и попытка использования массивов нулевых объектов в Java — это проблемы, которые могут возникнуть, если программист не понимает истинной природы массива.
В этой главе будет использоваться следующее определение массива. Массив — это многозначная переменная, хранящаяся в непрерывной области памяти, которая содержит элементы одинакового размера . Некоторые программисты обнаружат, что это определение не соответствует определению массивов на языке HLL, который они используют. Это результат того, что HLL добавляет уровни абстракции, такие как ассоциативный массив Perl (который на самом деле является хэш-таблицей) или массивы объектов Java или ArrayList. Эти массивы HLL всегда скрывают некоторую абстракцию, и знание того, что такое массив на самом деле, может помочь понять, как HLL манипулирует массивом.
Эти массивы HLL всегда скрывают некоторую абстракцию, и знание того, что такое массив на самом деле, может помочь понять, как HLL манипулирует массивом.
Определение массива становится очевидным, когда объясняется механизм доступа к элементам массива. Минимальные данные, необходимые для определения массива, состоят из переменной, которая содержит адрес начала массива, размер каждого элемента и место для хранения элементов. Например, массив, основанный на адресе 0x10010044 и содержащий 5 32-битных целых чисел, показан на рис. 9-2.
Рисунок 9-2: Реализация массиваЧтобы получить доступ к любому элементу в массиве, адрес элемента вычисляется по следующей формуле, и элемент со значением загружается с этого адреса.
elemAddress = basePtr + индекс * размер
где
-
elemAddress— это адрес (или указатель) используемого элемента. -
basePtr— адрес переменной массива -
индекс— это индекс элемента (с использованием массивов на основе 0) -
размерразмер каждого элемента
Таким образом, чтобы загрузить элемент с индексом 0, elemAddress просто (0x10010044 + (0 * 4)) = 0x10010044 или basePtr для массива 25 . Аналогично, чтобы загрузить элемент с индексом 2, elemAddress равен (0x10010044 + (2 * 4)) = 0x1001004C.
Аналогично, чтобы загрузить элемент с индексом 2, elemAddress равен (0x10010044 + (2 * 4)) = 0x1001004C.
Далее следуют два примера массива. Первый создает массив с именемgrades, в котором будут храниться 10 элементов размером 4 байта каждый, выровненных по границам слов. Второй создает массив с именем id из 10 байт. Обратите внимание, что выравнивание не указано, поэтому байты могут пересекать границы слов.
.данные. .выровнять 2 оценки: .space 40 идентификатор: .space 10
Чтобы получить доступ к элементу класса в массиве классов, уровень 0 будет иметь значение basePtr, уровень 1 — значение basePtr+4, уровень 2 — значение basePtr + 8 и т. д. В следующем фрагменте кода показано, как можно получить доступ к уровню 2. в коде сборки MIPS:
addi $t0, 2 # установить номер элемента 2 sll $t0, $t0, 2 # умножьте $t0 на 4 (размер), чтобы получить смещение la $t1, basePtr # $t1 — основание массива добавить $t0, $t0, $t1 # basePtr + (индекс * размер) lw $t2, 0($t0) # загрузить элемент 2 в $t2
Адресация массивов не сложна, но требует, чтобы программист помнил, что представляет собой адрес, а не значение, и умел вычислять смещение массива.
В некоторых языках, таких как Java, массивы могут размещаться только в куче. Другие, такие как C/C++ или C#, позволяют размещать массивы некоторых типов в любом месте памяти. В сборке MIPS массивы могут размещаться в любой части памяти. Однако помните, что массивы, размещенные в области статических данных или в куче, должны иметь фиксированный размер, причем размер фиксируется во время сборки. Только массивы, выделенные в куче, могут иметь свой размер, установленный во время выполнения.
Для размещения массива в статических данных определяется метка, содержащая базовый адрес массива, и выделяется достаточно места для элементов массива. Также обратите внимание, что массив должен учитывать любые соображения выравнивания (например, слова должны находиться на границах слов). Следующий фрагмент кода выделяет массив из 10 целых слов в сегменте данных.
.данные
.выровнять 2
массив: .space 40
Чтобы выделить массив в стеке, $sp корректируется так, чтобы в стеке оставалось место для массива. В случае стека нет эквивалента директиве ассемблера .align 2, поэтому программист несет ответственность за то, чтобы любая память стека была правильно выровнена. Следующий фрагмент кода размещает массив из 10 целочисленных слов в стеке после регистра $raregister.
В случае стека нет эквивалента директиве ассемблера .align 2, поэтому программист несет ответственность за то, чтобы любая память стека была правильно выровнена. Следующий фрагмент кода размещает массив из 10 целочисленных слов в стеке после регистра $raregister.
добавить $sp, $sp, -44 sw $ra, 0(sp) # массив начинается с 4($sp)
( basePtr + 0 ), поэтому количество элементов больше связано с тем, как реализованы массивы, чем с семантическими соображениями о том, что означают номера элементов.
Наконец, чтобы выделить массив в куче, количество выделяемых элементов умножается на размер каждого элемента, чтобы получить объем выделяемой памяти. Подпрограмма для этого, называемая AllocateArray, показана ниже.
Программа 9-2: Подпрограмма AllocateArray
# Подпрограмма: AllocateArray
# Цель: Выделить массив из $a0 элементов, каждый из которых имеет размер $a1.
# Автор: Чарльз Канн
# Ввод: $a0 - количество элементов в массиве
# $a1 - размер каждого элемента
# Вывод: $v0 - Адрес выделенного массива
Распределить массив:
добавить $sp, $sp, -4
sw $ra, 0($sp)
мул $a0, $a0, $a1
ли $v0, 9
системный вызов
лв $ра, 0($сп)
добавить $sp, $sp, 4
младший $ ра
25 Это вычисление адреса массива сделает очевидным для многих читателей, почему массивы во многих языках основаны на нуле (первый элемент равен 0), а не более интуитивная концепция массивов, основанных на 1 (первый элемент это 1). С точки зрения адресации массива первый элемент массива имеет базовый адрес массива
С точки зрения адресации массива первый элемент массива имеет базовый адрес массива
- Наверх
- Была ли эта статья полезной?
- Тип изделия
- Раздел или Страница
- Автор
- Чарльз В. Канн III
- Лицензия
- СС BY
- Версия лицензии
- 4,0
- Показать оглавление
- нет
- Теги

Как объявить массив на ассемблере emu8086
Как объявить массив на ассемблере emu8086
Что такое массив? Мы уже знаем ответ. Массив — это собирательное название, данное группе подобных величин. Как и в других языках программирования, в ассемблере есть несколько методов для объявления массива. Общими вещами будут имя массива, его тип данных, его длина и его начальное значение. Обычно в языке ассемблера мы используем два типа данных: «DB» для байта данных и «DW» для слова данных. Чтобы узнать больше об объявлении переменных на языке ассемблера, вы можете прочитать статью «Регистрация и объявление переменных». Теперь давайте посмотрим на массив.
Как я уже говорил, существует несколько способов объявления массива на ассемблере. Очень распространенный метод объявления массива в emu 8086 —
Очень распространенный метод объявления массива в emu 8086 —
Array_Name Data_Type Значения
Например:
My_Array БД 10,20,30,40,50
My_Array DW 10,20,30,40,50
Здесь My_Array — имя массива и DB (байт данных), DW (данные Word) являются его типом. Это зависит от вас, какой тип данных вы хотите сохранить в своем массиве. Последнее, что нужно сделать, это присвоить значение в массиве или начальное значение массива. Это предварительно объявленный массив. Здесь мы присваиваем значение во время объявления.
Я также могу разработать для вас простую игру на питоне
Теперь, если мы хотим объявить массив без какого-либо начального значения, тогда это будет
Array_Name Data_Type Number_Of_Index DUP(?)
Пример:
My_Array DB 100 DUP(?)
Здесь «My_Array» — это имя массива и DB (байт данных), DW (данные
Word) — это тип, а 100 означает номер индекса или длины, а «DUP(?)» означает
значение всех индексов изначально равно нулю.
Код простой сборки приведен ниже
.МОДЕЛЬ МАЛЕНЬКАЯ .СТЕК 100ч .ДАННЫЕ ARR DB 1,2,3,4,5 ;объявление массива .КОД ОСНОВНОЙ ПРОЦЕСС MOV AX,@ДАННЫЕ ДВИГАТЕЛЬ ДС, AX ДВИГАТЕЛЬ СХ,5 МОВ СИ,0 МОВ АХ,2 ВЫХОД: MOV DL, ARR[SI] ADD DL, 30H ;преобразовать в запрос ИНТ 21Ч ИНК СИ КОНТУРНЫЙ ВЫХОД ГЛАВНЫЙ КОНЕЦ КОНЕЦ ОСНОВНОЙ
Здесь мы записываем пользовательский ввод в массив с помощью цикла.
Принимать пользовательский ввод в виде массива и отображать вывод на языке ассемблера
Популярные посты из этого блога
Как напечатать новую строку на языке ассемблера emu8086
Существует несколько способов печати новой строки на ассемблере. Мы обсудим наиболее часто используемый. Прежде всего, нам нужно объявить переменную, которая содержит значение символа новой строки. Затем нам нужно сохранить это значение в регистре DX и вызвать прерывание. Взгляните на код. Здесь мы сначала печатаем символ A, затем новую строку и печатаем символ B. Мы знаем, что мы должны сначала поместить наше значение в регистр DL, если мы хотим напечатать один символ. И тогда мы должны вызвать прерывание. Это то, что мы делаем здесь. Но чтобы напечатать новую строку, мы должны сохранить значение символа новой строки в нашем регистре DX. Для перемещения значений в регистре DX мы использовали здесь команду LEA, что означает наименее эффективный адрес. После этого мы вызываем прерывание, которое печатает новую строку. Вот и все, теперь посмотрите на полный код, надеюсь, вы его поймете. .MODEL SMALL .STACK 100h .DATA n_line DB 0AH,0DH,»$» ;для новой строки .CODE MAIN PROC MOV A
Мы обсудим наиболее часто используемый. Прежде всего, нам нужно объявить переменную, которая содержит значение символа новой строки. Затем нам нужно сохранить это значение в регистре DX и вызвать прерывание. Взгляните на код. Здесь мы сначала печатаем символ A, затем новую строку и печатаем символ B. Мы знаем, что мы должны сначала поместить наше значение в регистр DL, если мы хотим напечатать один символ. И тогда мы должны вызвать прерывание. Это то, что мы делаем здесь. Но чтобы напечатать новую строку, мы должны сохранить значение символа новой строки в нашем регистре DX. Для перемещения значений в регистре DX мы использовали здесь команду LEA, что означает наименее эффективный адрес. После этого мы вызываем прерывание, которое печатает новую строку. Вот и все, теперь посмотрите на полный код, надеюсь, вы его поймете. .MODEL SMALL .STACK 100h .DATA n_line DB 0AH,0DH,»$» ;для новой строки .CODE MAIN PROC MOV A
Читать далее
Принимать пользовательский ввод в виде массива и отображать вывод на ассемблере emu8086
Массив — это набор похожих элементов. Эти похожие элементы могут быть все int, или все float, или все char и т. д. Обычно массив символов называется «строкой», тогда как массив int или float называется просто массивом. Но на ассемблере типы данных должны быть DB (байт данных) или DW (слово данных). Итак, мы должны объявить массив, используя типы данных DB или DW. Как и в других языках, мы должны инициализировать массив либо его значением null, либо чем-то еще. Чтобы узнать больше об объявлении массива в ассемблере, я попрошу вас сначала прочитать Array_Declare_in_Assembly_Language эту статью. Здесь мы узнаем о том, как принимать пользовательский ввод в массиве на языке ассемблера и печатать его в качестве вывода. Пожалуйста, взгляните на код, и я объясню его построчно. INCLUDE ‘EMU8086.INC’ ;включить библиотеку сборки .MODEL SMALL .STACK 100h .DATA ARR DB 50 DUP(?) ; сначала объявить массив с нулевым значением .CODE MAIN PROC MOV AX,@DATA MOV DS,AX
Эти похожие элементы могут быть все int, или все float, или все char и т. д. Обычно массив символов называется «строкой», тогда как массив int или float называется просто массивом. Но на ассемблере типы данных должны быть DB (байт данных) или DW (слово данных). Итак, мы должны объявить массив, используя типы данных DB или DW. Как и в других языках, мы должны инициализировать массив либо его значением null, либо чем-то еще. Чтобы узнать больше об объявлении массива в ассемблере, я попрошу вас сначала прочитать Array_Declare_in_Assembly_Language эту статью. Здесь мы узнаем о том, как принимать пользовательский ввод в массиве на языке ассемблера и печатать его в качестве вывода. Пожалуйста, взгляните на код, и я объясню его построчно. INCLUDE ‘EMU8086.INC’ ;включить библиотеку сборки .MODEL SMALL .STACK 100h .DATA ARR DB 50 DUP(?) ; сначала объявить массив с нулевым значением .CODE MAIN PROC MOV AX,@DATA MOV DS,AX
Читать далее
Простой ввод и вывод на языке ассемблера EMU8086
Это код для ввода и вывода одного символа. В ассемблере невозможно взять число, содержащее более одной цифры за раз, или невозможно показать число, содержащее более одной цифры одновременно. Мы должны принимать пользовательский ввод по одному символу, а также печатать по одному. Так что это немного сложно. Давайте посмотрим на программу, которая примет простой пользовательский ввод и распечатает вывод. Мы должны присвоить значение в регистре «AH», а затем вызвать прерывание, чтобы принять пользовательский ввод или показать вывод в ассемблере. Для односимвольного ввода мы должны поставить «1» в AH. Для односимвольного вывода мы должны поставить «2» в AH. Для строкового вывода поставить «9».’ в AH Затем вызовите прерывание, чтобы это произошло. Обычно для ввода и вывода используйте INT 21H. Я выполню ваши задания по программированию на C, C++, Java, Python, MySql в течение нескольких часов? Теперь давайте посмотрим на законченную программу для приема пользовательского ввода и печати вывода. Прежде чем идти на код
В ассемблере невозможно взять число, содержащее более одной цифры за раз, или невозможно показать число, содержащее более одной цифры одновременно. Мы должны принимать пользовательский ввод по одному символу, а также печатать по одному. Так что это немного сложно. Давайте посмотрим на программу, которая примет простой пользовательский ввод и распечатает вывод. Мы должны присвоить значение в регистре «AH», а затем вызвать прерывание, чтобы принять пользовательский ввод или показать вывод в ассемблере. Для односимвольного ввода мы должны поставить «1» в AH. Для односимвольного вывода мы должны поставить «2» в AH. Для строкового вывода поставить «9».’ в AH Затем вызовите прерывание, чтобы это произошло. Обычно для ввода и вывода используйте INT 21H. Я выполню ваши задания по программированию на C, C++, Java, Python, MySql в течение нескольких часов? Теперь давайте посмотрим на законченную программу для приема пользовательского ввода и печати вывода. Прежде чем идти на код
Читать далее
Ассемблер ARMв Raspberry Pi — Глава 8
В предыдущей главе мы видели, что второй операнд большинства арифметических инструкций может использовать оператор сдвига , который позволяет нам сдвигать и вращать биты. В этой главе мы продолжим изучение доступных режимы индексации инструкций ARM. На этот раз мы сосредоточимся на инструкциях загрузки и сохранения.
В этой главе мы продолжим изучение доступных режимы индексации инструкций ARM. На этот раз мы сосредоточимся на инструкциях загрузки и сохранения.
Массивы и структуры
До сих пор мы могли переместить 32 бита из памяти в регистры (загрузить) и обратно в память (сохранить). Но работа с отдельными 32-битными элементами (обычно называемыми скалярами) немного ограничивает. Вскоре мы обнаружим, что работаем с массивами и структурами, даже не зная об этом.
Массив — это последовательность элементов одного типа в памяти. Массивы являются базовой структурой данных почти во всех языках низкого уровня. Каждый массив имеет базовый адрес, обычно обозначаемый именем массива, и содержит N элементов. С каждым из этих элементов связан растущий индекс в диапазоне от 0 до N-1 или от 1 до N. Используя базовый адрес и индекс, мы можем получить доступ к элементу массива. В главе 3 мы упоминали, что память можно рассматривать как массив байтов. Массив в памяти такой же, но элемент может занимать более одного байта.
Структура (или запись, или кортеж) — это последовательность элементов, возможно, различного вида. Каждый элемент структуры обычно называют полем. Поля не имеют ассоциированного индекса, но имеют смещение относительно начала структуры. Структуры располагаются в памяти, чтобы обеспечить правильное выравнивание в каждом поле. Базовый адрес структуры — это адрес ее первого поля. Если базовый адрес выровнен, структура должна располагаться таким образом, чтобы все поля также были правильно выровнены.
Какое отношение массивы и структура имеют к режимам индексации загрузки и хранения? Что ж, эти режимы индексации предназначены для облегчения доступа к массивам и структурам.
Определение массивов и структур
Чтобы проиллюстрировать, как работать с массивами и ссылками, мы будем использовать следующие объявления C и реализовывать их на ассемблере.
инт [100];
структура моя_структура
{
символ f0;
интервал f1;
} б; Давайте сначала определим в нашем ассемблере массив ‘a’. Это всего лишь 100 целых чисел. Целое число в ARM имеет ширину 32 бита, поэтому в нашем коде на ассемблере нам нужно освободить место для 400 байт (4 * 100).
Это всего лишь 100 целых чисел. Целое число в ARM имеет ширину 32 бита, поэтому в нашем коде на ассемблере нам нужно освободить место для 400 байт (4 * 100).
1 2 3 4 5 | /* -- array01.s */ .данные .balign 4 а: .пропустить 400 |
В строке 5 мы определяем символ и , а затем освобождаем место для 400 байт. Директива .skip говорит ассемблеру продвигаться вперед на заданное количество байтов, прежде чем выдать следующее значение. Здесь мы пропускаем 400 байтов, потому что наш массив целых чисел занимает 400 байтов (по 4 байта на каждое из 100 целых чисел). Объявление структуры не сильно отличается.
7 8 | .balign 4 б: .пропустить 8 |
Прямо сейчас вы должны задаться вопросом, почему мы пропустили 8 байтов, когда сама структура занимает всего 5 байтов. Ну, для хранения полезной информации требуется 5 байт. Первое поле
Ну, для хранения полезной информации требуется 5 байт. Первое поле f0 представляет собой символа . Символ занимает 1 байт памяти. Следующее поле f1 является целым числом. Целое число занимает 4 байта, и оно также должно быть выровнено по 4 байтам, поэтому мы должны оставить 3 неиспользуемых байта между полем 9.0052 f0 и поле f1 . Это неиспользуемое хранилище, предназначенное только для выполнения выравнивания, называется padding . Заполнение никогда не должно использоваться вашей программой.
Простой подход без режимов индексации
Хорошо, давайте напишем код для инициализации каждого элемента массива a[i] . Мы сделаем что-то эквивалентное следующему коду C.
для (i = 0; i < 100; i++) а [я] = я;
10 11 12 13 14 15 16 17 18 1920 21 22 23 24 25 | .текст . |
 глобальный основной
главный:
ldr r1, addr_of_a /* r1 ← &a */
mov r2, #0 /* r2 ← 0 */
петля:
cmp r2, #100 /* Мы уже достигли 100? */
beq end /* Если да, выходим из цикла, иначе продолжаем */
добавить r3, r1, r2, LSL #2 /* r3 ← r1 + (r2*4) */
str r2, [r3] /* *r3 ← r2 */
добавить r2, r2, #1 /* r2 ← r2 + 1 */
b loop /* Перейти к началу цикла */
конец:
бх л
addr_of_a: .слово а
глобальный основной
главный:
ldr r1, addr_of_a /* r1 ← &a */
mov r2, #0 /* r2 ← 0 */
петля:
cmp r2, #100 /* Мы уже достигли 100? */
beq end /* Если да, выходим из цикла, иначе продолжаем */
добавить r3, r1, r2, LSL #2 /* r3 ← r1 + (r2*4) */
str r2, [r3] /* *r3 ← r2 */
добавить r2, r2, #1 /* r2 ← r2 + 1 */
b loop /* Перейти к началу цикла */
конец:
бх л
addr_of_a: .слово а
Вау! Мы используем множество вещей, которые узнали из предыдущих глав. В строке 14 мы загружаем базовый адрес массива в r1 . Адрес массива не изменится, поэтому мы загружаем его один раз. В регистре r2 мы сохраним индекс, который будет находиться в диапазоне от 0 до 99. В строке 17 мы сравниваем его со 100, чтобы увидеть, достигли ли мы конца цикла.
Строка 19 является важной. Здесь мы вычисляем адрес элемента. У нас в r1 базовый адрес, и мы знаем, что каждый элемент имеет ширину 4 байта. Мы также знаем, что r2 хранит индекс цикла, который мы будем использовать для доступа к элементу массива. Для элемента с индексом
Для элемента с индексом i его адрес должен быть &a + 4*i , так как между каждым элементом этого массива 4 байта. Итак, r3 имеет адрес текущего элемента на этом шаге цикла. В строке 20 храним r2 , это i , в память на которую указывает r3 , i -й элемент массива, это a[i] .
Затем продолжаем увеличивать r2 и прыгаем назад на следующий шаг цикла.
Как видите, доступ к массиву включает в себя вычисление адреса элемента, к которому осуществляется доступ. Предоставляет ли набор инструкций ARM более компактный способ сделать это? Ответ положительный. На самом деле он обеспечивает несколько режимов индексации .
Режимы индексирования
В предыдущей главе понятие режим индексации немного сбился, потому что мы ничего не индексировали. Теперь это имеет гораздо больше смысла, поскольку мы индексируем элемент массива. ARM предоставляет девять таких режимов индексации. Я различаю два типа режимов индексирования: без обновления и с обновлением в зависимости от того, имеют ли они побочный эффект, который мы обсудим позже, когда будем иметь дело с режимами индексирования с обновлением.
ARM предоставляет девять таких режимов индексации. Я различаю два типа режимов индексирования: без обновления и с обновлением в зависимости от того, имеют ли они побочный эффект, который мы обсудим позже, когда будем иметь дело с режимами индексирования с обновлением.
Режимы индексирования без обновления
-
[Rsource1, +#immediate]или
[Rsource1, -#немедленно]Он просто добавляет (или вычитает) непосредственное значение для формирования адреса. Это очень полезно для элементов массива, индекс которых является константой в коде или полях структуры, поскольку их смещение всегда постоянно. В
Rsource1мы помещаем базовый адрес, а внепосредственныйжелаемое смещение в байтах. Непосредственное значение не может быть больше 12 бит (0..4096). Когда непосредственное значение равно#0, это как обычно, мы использовали[Rsource1].Например, таким образом мы можем установить
a[3]равным 3 (мы предполагаем, что r1 уже содержит базовый адрес a). Обратите внимание, что смещение указано в байтах, поэтому нам нужно смещение 12 (4 байта * 3 пропущенных элемента).
Обратите внимание, что смещение указано в байтах, поэтому нам нужно смещение 12 (4 байта * 3 пропущенных элемента).mov r2, #3 /* r2 ← 3 */ str r2, [r1, #+12] /* *(r1 + 12) ← r2 */
-
[Rsource1, +Rsource2]или
[Rsource1, -Rsource2]Это похоже на предыдущее, но добавляемое (или вычитаемое) смещение представляет собой значение в регистре. Это полезно, когда смещение слишком велико для немедленного. Обратите внимание, что для
+Rsource2два регистра можно поменять местами (поскольку это не повлияет на вычисляемый адрес).Пример. То же, что и выше, но на этот раз с использованием регистра.
mov r2, #3 /* r2 ← 3 */ мов r3, #12 /* r3 ← 12 */ str r2, [r1,+r3] /* *(r1 + r3) ← r2 */
-
[Rsource1, +Rsource2, shift_operation #немедленно]или
[Rsource1, -Rsource2, shift_operation #немедленно]Это похоже на обычную операцию сдвига, которую мы можем выполнять с другими инструкциями.
 Операция сдвига (помните:
Операция сдвига (помните: LSL,LSR,ASRилиROR) применяется кRsource2,Rsource1затем прибавляется (или вычитается) к результату операции сдвига, примененной к- R5source2 90. Это полезно, когда нам нужно умножить адрес на некоторую фиксированную сумму. При доступе к элементам целочисленного массива
инам приходилось умножать результат на 4, чтобы получить осмысленный адрес.Для этого примера давайте сначала вспомним, как мы вычисляли выше адрес в массиве элемента в позиции
р2.19 20
добавить r3, r1, r2, LSL #2 /* r3 ← r1 + r2*4 */ str r2, [r3] /* *r3 ← r2 */
Мы можем выразить это гораздо более компактно (без регистра
r3).str r2, [r1, +r2, LSL #2] /* *(r1 + r2*4) ← r2 */
Обновление режимов индексации
В этих режимах индексации Rsource1 9Регистр 0053 обновляется адресом, синтезированным командой загрузки или сохранения.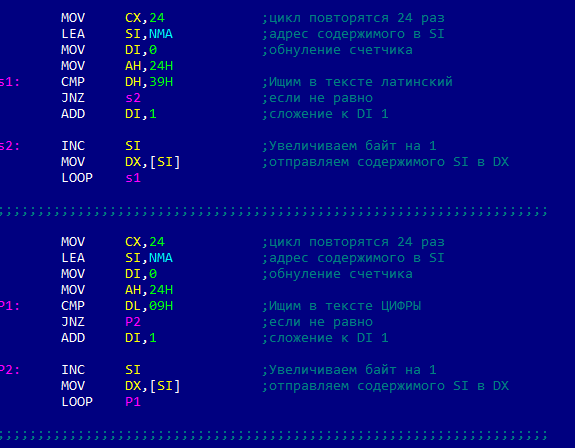 Вы можете быть удивлены, почему кто-то хотел бы сделать это. Сначала небольшой обход. Перепроверьте код загрузки массива. Почему мы должны сохранять базовый адрес массива, если мы всегда эффективно отодвигаем его на 4 байта? Не будет ли гораздо разумнее сохранить адрес текущего объекта? Итак, вместо
Вы можете быть удивлены, почему кто-то хотел бы сделать это. Сначала небольшой обход. Перепроверьте код загрузки массива. Почему мы должны сохранять базовый адрес массива, если мы всегда эффективно отодвигаем его на 4 байта? Не будет ли гораздо разумнее сохранить адрес текущего объекта? Итак, вместо
19 20 | добавить r3, r1, r2, LSL #2 /* r3 ← r1 + r2*4 */ str r2, [r3] /* *r3 ← r2 */ |
мы можем захотеть сделать что-то вроде
строка r2, [r1] /* *r1 ← r2 */ добавить r1, r1, #4 /* r1 ← r1 + 4 */
потому что нет необходимости каждый раз с начала вычислять адрес следующего элемента (поскольку мы обращаемся к ним последовательно). Даже если это выглядит немного лучше, его все же можно немного улучшить. Что, если бы наша инструкция смогла обновить r1 для нас? Что-то вроде этого (очевидно, точный синтаксис не такой, как показано)
/* Неправильный синтаксис */ str r2, [r1] "а затем" добавить r1, r1, #4
Такие режимы индексации существуют. Существует два вида обновления режимов индексации в зависимости от того, когда обновляется
Существует два вида обновления режимов индексации в зависимости от того, когда обновляется Rsource1 . Если Rsource1 обновляется после самой загрузки или сохранения (это означает, что адрес для загрузки или сохранения является начальным значением Rsource1 ), это режим доступа после индексации . Если Rsource1 обновляется до фактической загрузки или сохранения (это означает, что адрес для загрузки или сохранения является окончательным значением Rsource1 ) это режим доступа с предварительным индексированием . Во всех случаях в конце инструкции Rsource1 будет иметь значение вычисления режима индексации. Теперь это звучит немного запутанно, просто посмотрите на пример выше: сначала мы загружаем, используя r1 , а затем делаем r1 ← r1 + 4 . Это постиндексация: сначала мы используем значение r1 в качестве адреса, где мы храним значение r2 . Затем
Затем r1 обновляется с р1 + 4 . Теперь рассмотрим другой гипотетический синтаксис.
/* Неправильный синтаксис */ стр r2, [добавить r1, r1, #4]
Это предварительная индексация: сначала мы вычисляем r1 + 4 и используем его как адрес, где мы сохраняем значение r2 . В конце инструкции r1 тоже фактически обновился, но обновленное значение уже использовалось в качестве адреса загрузки или сохранения.
Режимы постиндексации
-
[Rsource1], #+немедленныйили
[Rsource1], #-немедленноЗначение
Rsource1используется в качестве адреса для загрузки или сохранения. ЗатемRsource1обновляется значениемнемедленногопосле прибавления (или вычитания) его кRsource1. Используя этот режим индексации, мы можем переписать цикл нашего первого примера следующим образом:16 17 18 19 20 21 22
петля: cmp r2, #100 /* Мы уже достигли 100? */ beq end /* Если да, выходим из цикла, иначе продолжаем */ str r2, [r1], #4 /* *r1 ← r2, затем r1 ← r1 + 4 */ добавить r2, r2, #1 /* r2 ← r2 + 1 */ b loop /* Перейти к началу цикла */ конец: -
[Rsource1], +Rsource2или
[Rsource1], -Rsource2Аналогичен предыдущему, но вместо непосредственного используется значение
Rsource2. Как обычно, это можно использовать в качестве обходного пути, когда смещение слишком велико для непосредственного значения.
Как обычно, это можно использовать в качестве обходного пути, когда смещение слишком велико для непосредственного значения. -
[Rsource1], +Rsource2, shift_operation #immediateили
[Rsource1], -Rsource2, shift_operation #immediateЗначение
Rsource1используется как адрес для загрузки или сохранения. ЗатемRsource2применяется операция сдвига (LSL,LSR,ASRилиROL). Результирующее значение этого сдвига прибавляется (или вычитается) кRsource1.Rsource1, наконец, обновлен последним значением.
Режимы предварительной индексации
Поначалу режимы предварительной индексации могут показаться немного странными, но они полезны, когда вычисленный адрес скоро будет использоваться повторно. Вместо того, чтобы пересчитывать его, мы можем повторно использовать обновленный Rsource1 . Обратите внимание на
Обратите внимание на ! в этих режимах индексации, что отличает их от режимов индексации без обновления.
-
[Rsource1, #+немедленно]!или
[Rsource1, #-немедленно]!Он ведет себя как аналогичный режим индексации без обновления, но
Rsource1обновляется вычисленным адресом. Представьте, что мы хотим вычислитьa[3] = a[3] + a[3]. Мы могли бы это сделать (мы предполагаем, чтоr1уже имеет базовый адрес массива).ldr r2, [r1, #+12]! /* r1 ← r1 + 12, затем r2 ← *r1 */ добавить r2, r2, r2 /* r2 ← r2 + r2 */ str r2, [r1] /* *r1 ← r2 */
-
[Rsource1, +Rsource2]!или
[Rsource1, +Rsource2]!Аналогичен предыдущему, но с использованием регистра
Rsource2вместо непосредственного. -
[Rsource1, +Rsource2, shift_operation #немедленно]!или
[Rsource1, -Rsource2, shift_operation #immediate]!Аналогично неиндексирующему эквиваленту, но Rsource1 будет обновлен адресом, используемым для инструкции загрузки или сохранения.

Назад к конструкциям
Во всех примерах в этой главе использовался массив. Структуры немного проще: смещение полей всегда постоянное: как только у нас есть базовый адрес структуры (адрес первого поля), доступ к полю — это просто режим индексации со смещением (обычно немедленным). Наша текущая структура намеренно включает char в качестве первого поля f0 . В настоящее время мы не можем работать со скалярами в памяти другого размера, чем 4 байта. Поэтому мы отложим работу над этим первым полем для следующей главы.
Например, представьте, что мы хотели увеличить поле f1 вот так.
б.ф1 = б.ф1 + 7;
Если r1 содержит базовый адрес нашей структуры, доступ к полю f1 теперь довольно прост, поскольку мы знаем все доступные режимы индексации.
1 2 3 | ldr r2, [r1, #+4]! /* r1 ← r1 + 4, затем r2 ← *r1 */ добавить r2, r2, #7 /* r2 ← r2 + 7 */ строка r2, [r1] /* *r1 ← r2 */ |
Обратите внимание, что мы используем режим предварительной индексации, чтобы сохранить в r1 адрес поля f1 . Таким образом, второму хранилищу не нужно снова вычислять этот адрес.
Таким образом, второму хранилищу не нужно снова вычислять этот адрес.
Это все на сегодня.
О языке ассемблера — сканирование массива
В моей последней статье я описал, как создаются детали переменных, перечисленных после команды CALL. доступный в «блоке дескриптора», на который указывает R9, в начале вашей программы машинного кода. R10 содержит общее количество переданных переменных — 0, если их не было — и это позволяет программу, чтобы определить, были ли заданы правильные параметры или нет.
Блок в R9 содержит запись из двух слов для каждого параметра в порядке, обратном порядку, в котором они были перечислены после CALL. Для каждой записи первое слово является адресом, либо указывающим на содержимое самой переменной или в дополнительный блок дескриптора в случае строк и массивы.
Второе слово — это код типа, указывающий, с каким типом переменной мы имеем дело.
В статье прошлого месяца я привел таблицу кодов этих типов. Наиболее важные из них: &004
(целочисленная переменная), &080 (строковая переменная), &081 (строка, заканчивающаяся CR), &104
(целочисленный массив) и &180 (строковый массив).
Наиболее важные из них: &004
(целочисленная переменная), &080 (строковая переменная), &081 (строка, заканчивающаяся CR), &104
(целочисленный массив) и &180 (строковый массив).
Самый простой способ продемонстрировать, как получить доступ к переменным Basic из машинного кода, — дать рабочий пример. Я опишу процедуру, которая использует значения, на которые указывает R9.к искать весь массив для заданного значения, либо строки, либо целого числа в зависимости от типа множество. В отличие от процедур Basic, где вы должны определить тип ожидаемого параметра, подпрограммы машинного кода могут иметь «динамические параметры»; вы можете передать строку, когда вы вызываете свой из одной части вашей программы и значение с плавающей запятой в другом контексте (хотя трудно представить, какую операцию могла бы с пользой выполнять такая подпрограмма!). Вы можете даже передавать разное количество параметров в разных обстоятельствах, проверяя значение в R10 чтобы узнать, сколько ожидать.
В моем примере я буду использовать процедуру с двумя параметрами: ссылка на весь массив,
randomstringarray$() или int%(), а также строковый или целочисленный оператор косвенной адресации, $search или
!search3, указывающее значение для поиска.
Чтобы вызвать его, мы использовали бы, например:
DIM поиск 20, поиск3 20 $search="корзина":!search3=-12 CALL ourcode%,randomstringarray$() ,$search ВЫЗВАТЬ наш код%, int%(),! search3
где randomstringarray$() и int%() — массивы, размер которых уже определен и заполнен.
Прежде чем перейти к ассемблеру, я назову три регистра ARM, R5, R3 и R8, как entry%, ptr% и type%:
записи%=5:ptr%=3:тип%=8 Псевдонимы регистров REM
Для двух параметров блок дескриптора будет состоять из четырех слов.
| Смещение | Значение | Представляет |
| блок!0 | адрес | указатель на последнее значение в списке параметров |
| блок!4 | &004/&081 | тип последнего значения в списке параметров |
| блок!8 | адрес | указатель на первое значение в списке параметров |
| блок!12 | &104/&180 | тип первого значения в списке параметров |
Чтение параметров
LDR type%,[R9,#12] ;получить значение в
;заблокировать!12
;(тип параметра)
ЛДР R0,[R9,#8] ;получить значение в
;блокировать!8 (адрес
;этого параметра)
LDR ptr%,[R0] ;параметр
;указатель для начала
;блока массива
Регистр ptr% теперь содержит адрес начала блока дескриптора массива и тип%
содержит либо значение &180, либо &104, в зависимости от того, какой тип массива мы использовали.
Блоки дескрипторов массива
Для параметра типа целого массива указатель, который вы получаете, указывает не на фактическое начало данных массива, а в блок дескриптора массива, размер которого зависит от количества измерений в ваш массив. Стоит помнить, что базовые индексы массива начинаются с элемента 0; в других слов, DIM a$(7) на самом деле создает восемь элементов, от a$(0) до a$(7) и DIM a$(7,2) создает двадцать четыре - не только от $(0,1) до $(7,1) и от $(0,2) до $(7,2), но и целая дополнительная строка, состоящая из $(0,0) до $(7,0)!Начало блока дескриптора массива состоит из списка слов, задающего количество элементов в каждом измерении массива, за которым следует слово, установленное на ноль, чтобы отметить конец список, за которым следует другое слово, указывающее общее количество элементов во всем массиве. Для двухмерном примере, приведенном выше, блок дескриптора выглядит так (вспоминая, что 8×3 =&18 в шестнадцатеричном формате!):
Для целей нашего примера программы мы собираемся предположить, что наш входной массив
одномерный, так как все элементы массива в любом случае хранятся в памяти последовательно
после окончания блока дескриптора и просто просканируйте всю партию.
Нахождение начала массива данных
Мы собираемся использовать регистровые записи% в качестве счетчика цикла, чтобы сообщить нам, когда мы достигли конца. массива - и, если мы найдем совпадение, мы будем использовать разницу между значением записей% в этой точке и его начальное значение для вычисления нижнего индекса массива элемент, который совпал (конечно, при условии одномерного массива).
.повторение
LDR R0,[ptr%],#4 ;пропустить все
;ограничения подписки
;(первые слова в
;блок массива)
CMP R0,#0 ;пока не дойдем до нулевого слова
BNE повторить
Записи LDR%,[ptr%],#4 ;это следующее
;слово содержит итог
;Число входов
MOV R11,entries% ;сохранить начальное значение в R11 для
;позже косметическое использование
Это «умный» бит. Нам нужно перейти к другой процедуре сравнения в зависимости от
ожидаем ли мы иметь дело с числами или строками.
Тип CMP%,#&180 ;проверьте этот тип
;is &180 (целый массив строк)
Строка печати BEQ
Тип CMP%,#&104 ;или &104 (целое
; целочисленный массив)
BEQ номер печати
Мы также предоставляем ловушку для случая, когда нам был передан неправильный тип параметра. вообще - возможно, int%(5) вместо int%().
FNmessage("Ошибка параметра - необходимо передать имя_массива()")
MOV R15, R14 ;программа выхода
Сканирование целочисленного массива
Как только мы нашли начало фактических данных массива (это следующее слово после 'total количество слов, и поэтому регистр ptr% уже указывает на него), сканируя Целочисленный массив относительно прост. Мы просто смотрим на каждое слово по очереди и сравниваем его с целочисленное значение !search3, которое было вторым параметром, переданным подпрограмме и, следовательно, в начало блока, на которое указывает R9.
.printnum ;для целых чисел (простой)
LDR R7,[R9,#0] ;загрузить R7 из
;block!0 (указатель
;к !искать3)
LDR R8,[R7] ;загрузить R8 из R7
Собственно говоря, я полагаю, что мы должны сначала проверить значение кода типа в [R9,#4], чтобы сделать
уверен, что это действительно одно целое значение.
Мы просто загружаем следующее слово из ptr% (используя постиндексную адресацию, так что ptr% автоматически увеличивается), сравнить два значения и перейти к соответствующей точке, если совпадение найдено.
LDR R0,[ptr%],#4 ;загрузить следующее слово
;(что является значением
;элемента массива!)
FNprintnumber ;печатать номер в
;R0 как строка
ЦМП R8,R0
BEQ abortwhenfound ;проверить совпадение
;с !поиском
Если счетчик не достиг нуля, мы возвращаемся к началу цикла (пропуская инициализация осуществляется первыми двумя инструкциями) и повторяется для последующих слов.
Записи SUBS%,записи%,#1
;уменьшить счетчик
BNE printnum+8 ;возврат к началу
;loop (нам не нужно
;сбросить R7 и я
;лень создавать
;новый лейбл!)
Если счетчик достигает нуля (и мы до сих пор не перешли к . abortwhenfound), то мы знаем,
что поиск не удался. Мы жалуемся и выходим.
abortwhenfound), то мы знаем,
что поиск не удался. Мы жалуемся и выходим.
FNmessage("Ничего не найдено")
MOV R15, R14 ;программа выхода
Успешный результат
.abortwhenfound ;печатать результаты
;затем выход
FNmessage("В элементе массива найдено совпадение")
SUB R0,R11,входов%
Мы сохранили исходное значение % в R11, помните?
FNprintnumber ;печатать номер в R0
;как строка
MOV R15, R14 ;программа выхода
;===================================
;буфер для использования FNprintnumber
.буфер
СРАВНИТЬ СТРОКУ$(8," ")
Вывод целочисленных значений на экран
FNprintnumber — удобная процедура для отображения содержимого R0. Различные OS_Write подпрограммы могут печатать только строки, поэтому мы должны сначала вызвать OS_ConvertInteger.
DEF FNprintnumber
REM напечатать номер в R0
REM портит R1, R2
[OPT проходит%
ADR R1, буфер
MOV R2,#8 ;установлен для
;OS_ConvertInteger
;(нанизывать)
SWI "OS_ConvertInteger3"; R0 сохраняется
;значение, буфер R1,
;размер буфера R2
;R0 теперь указывает на буфер
SWI "OS_Write0" ;печать преобразована
;запись как строка
SWI "OS_NewLine"
]
=0
Сканирование массива строк
Теперь нам нужно мысленно вернуться к тому моменту, когда мы проверили значение type%, чтобы увидеть, что вид массива был передан нашей процедуре. Предположим, это был массив строк? В таком случае,
жизнь становится намного сложнее. Целочисленный массив состоит из простого набора
значения, выровненные по слову; строковый массив состоит из набора 5-байтовых блоков, каждый из которых
содержит (не выровненное по слову) 32-битное значение, указывающее на фактическую ячейку памяти
символов в строке, за которыми следует один байт, указывающий длину (незавершенного)
нить. Прежде чем мы сможем даже начать сравнивать значение элемента массива с поиском
строка, нам нужно каким-то образом получить ее 32-битный адрес в регистр.
Предположим, это был массив строк? В таком случае,
жизнь становится намного сложнее. Целочисленный массив состоит из простого набора
значения, выровненные по слову; строковый массив состоит из набора 5-байтовых блоков, каждый из которых
содержит (не выровненное по слову) 32-битное значение, указывающее на фактическую ячейку памяти
символов в строке, за которыми следует один байт, указывающий длину (незавершенного)
нить. Прежде чем мы сможем даже начать сравнивать значение элемента массива с поиском
строка, нам нужно каким-то образом получить ее 32-битный адрес в регистр.Загрузка с адреса, не выровненного по слову
.printstring ;для строк
;(сложный)
LDRB R0,[ptr%],#1 ;Загрузить R0 с
;байт по адресу ptr%!0
LDRB R2,[ptr%],#1 ;Загрузить R2 с
;байт в точке%!1
ORR R0,R0,R2,LSL#8 ;объединить
;два регистра (R0
;младший байт, старший R2)
LDRB R2,[ptr%],#1 ;Загрузить R2 с
;байт в точке%!2
ORR R0,R0,R2,LSL#16 ;сдвинуть вверх
;к третьему шестнадцатеричному байту
;и объединить
LDRB R2,[ptr%],#1 ;Загрузить R2 с
;байт в точке%!3
ORR R0,R0,R2,LSL#24 ;объединить как
;старший байт, т.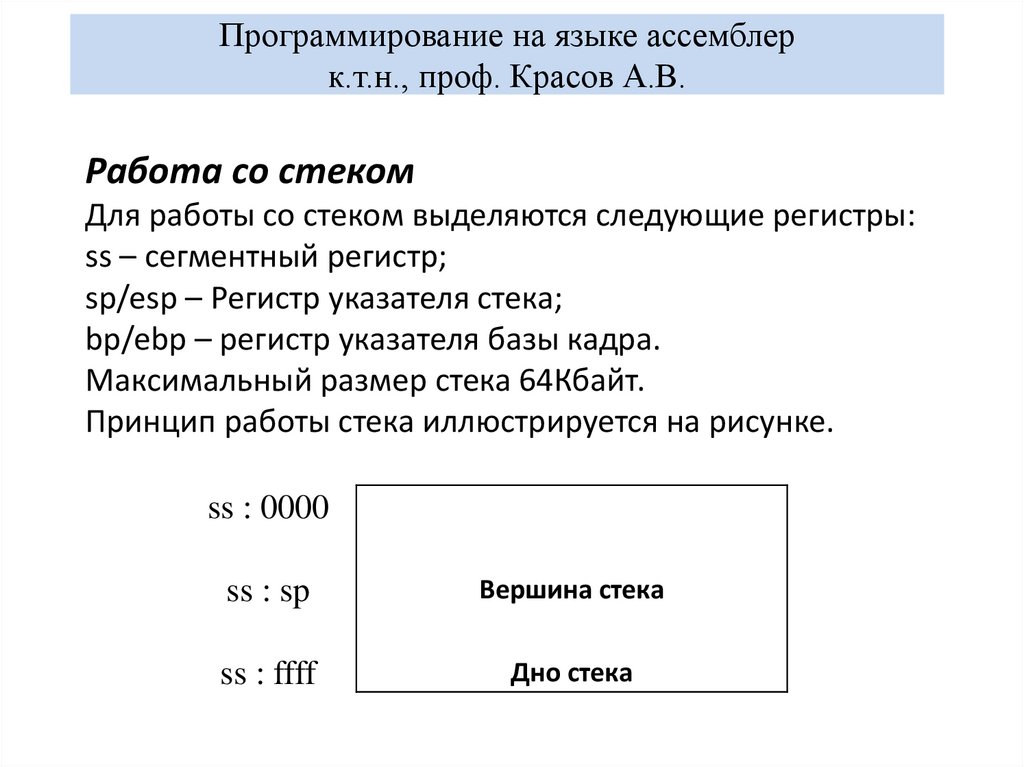 е. загрузить
;слово из не-слова-
;выровненный адрес.
;Загрузить R0 с указателем на
;строка (первые 4 байта в
;5-байтовый блок) и ptr%
;теперь указывает на последний байт
е. загрузить
;слово из не-слова-
;выровненный адрес.
;Загрузить R0 с указателем на
;строка (первые 4 байта в
;5-байтовый блок) и ptr%
;теперь указывает на последний байт
Что мы сделали, так это загрузили его по одному байту за раз, сдвигая каждый байт вверх на соответствующее число. двоичных цифр и объединить его со значением, накопленным до сих пор, используя логическое ИЛИ. (Этот работает, потому что LDRB гарантированно устанавливает старшие, неиспользуемые 24 бита регистра в ноль.) Если кто-нибудь разработал более короткий/более элегантный способ сделать это, пожалуйста, дайте мне знать!
Строковые переменные не заканчиваются нулем, поэтому мы не можем использовать OS_Write0 для отображения содержимого памяти.
Вместо этого мы используем последний байт в 5-байтовом блоке, который содержит длину
строку и использовать OS_WriteN, которая записывает фиксированное количество символов.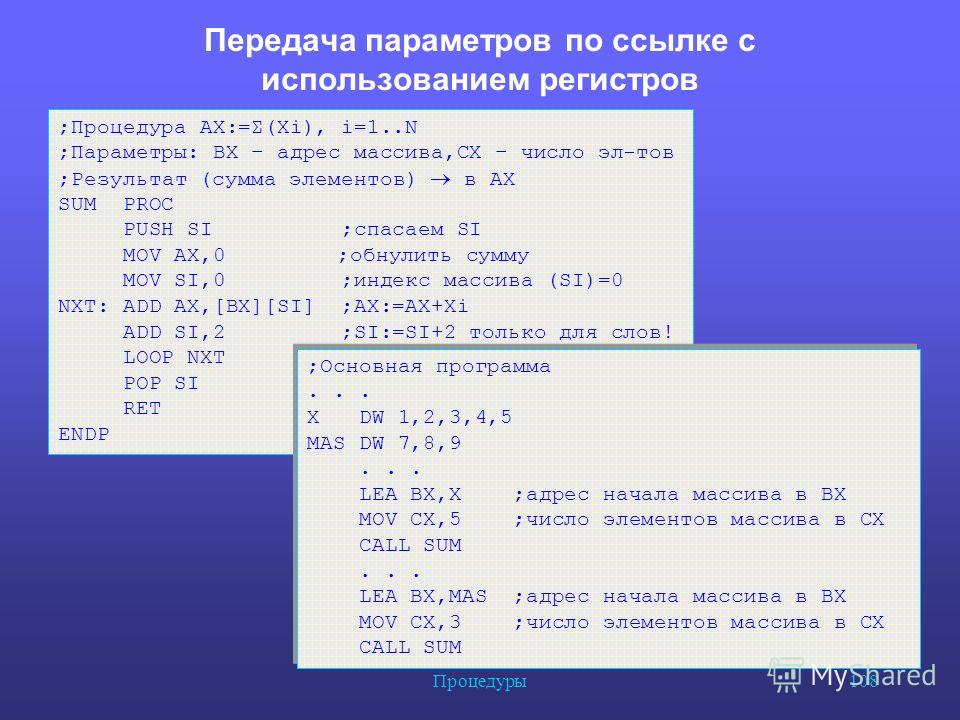
LDRB R1,[ptr%],#1 ;Загрузить R3 с
;длина строки и продвижение
;ptr% 1 байт
SWI "OS_WriteN" ;R0 указывает на
;строка, R1 не содержит
;символов для записи
SWI "OS_NewLine"
Сравнение двух строк
Теперь мы указываем R7 на начало значения, которое мы хотим найти, так же, как мы делали это для .printnum. единственное отличие состоит в том, что в этом случае (строка, заканчивающаяся CR) адрес в R7 не будет обязательно должны быть выровнены по словам, но, поскольку мы все равно собираемся выполнять побайтовое сравнение, это не иметь значение.
LDR R7,[R9,#0] ;наведите R7 на
;начало поиска
.сравнивать
ЛДРБ R2,[R0],#1
ЛДРБ R8,[R7],#1
СМР Р2, Р8
BEQ сравнить
CMP R8,#&0D ;проверить конец
;строка поиска
;т.е. успех
BEQ прерывается при обнаружении
Само сравнение не особенно сложное. Используя R0 (который по-прежнему указывает на
начало строки после OS_WriteN) и R7 в качестве указателей, мы загружаем и сравниваем каждую пару
символы один за другим. Если они отличаются, мы проверяем символ из $search, чтобы увидеть, является ли он
терминатор строки, и, если он есть, мы предполагаем успешное совпадение. Отметим, в частности, что мы
не проверяйте конец элемента массива с двумя последствиями:
Если они отличаются, мы проверяем символ из $search, чтобы увидеть, является ли он
терминатор строки, и, если он есть, мы предполагаем успешное совпадение. Отметим, в частности, что мы
не проверяйте конец элемента массива с двумя последствиями:
а) $search будет соответствовать любому слову, подстрокой которого оно является («car» будет соответствовать «carcase»)
б) если элемент массива является подстрокой $search, может быть получено «ложное срабатывание», если есть случайные данные в памяти после конца элемента массива, который совпадает. Если мы ищет «корзину», и массив содержит трехбуквенную строку «автомобиль», которая оказывается встроенный в память таким образом:
8tYd1cart%joV
этот алгоритм сравнения сообщит об успехе.
Для тех, кто хочет продолжить решение этой проблемы, более сложный «реальный» массив строк
процедуру сканирования можно найти в моем приложении Infozip, в файле !Infozip.Source.codesource. (Infozip был на архивном ежемесячном диске 13. 12 и, следовательно, на
архивный компакт-диск, и я понимаю, что его также можно загрузить с
здесь.
Однако для демонстрационных целей достаточно простого алгоритма.
12 и, следовательно, на
архивный компакт-диск, и я понимаю, что его также можно загрузить с
здесь.
Однако для демонстрационных целей достаточно простого алгоритма.
Записи SUBS%,записи%,#1 ;уменьшение
; возражать против
BNE printstring ;начало цикла
FNmessage("Ничего не найдено")
MOV R15, R14 ;выход из процедуры в
;конец массива
Оставшаяся часть цикла почти идентична той, что используется для сканирования целочисленного массива. Примечание что в этом случае мы должны перезагрузить R7 из [R9, # 0], чтобы переместить указатель обратно в start $search, и мы должны пройти через всю канитель загрузки невыровненного по слову адрес для каждого нового элемента массива. Как и следовало ожидать, сканирование массива строк несколько медленнее, чем сканирование целочисленного массива. Тем не менее, это все же намного быстрее, чем с петля из Basic!
| Источник: | Архивный журнал 14,5 |
| Публикация: | Архивный журнал |
| Автор: | Гарриет Базли |
[сборка x86] Замена элементов массива — блог TermSpar
В этом посте я расскажу, как можно поменять местами элементы массива в ассемблере x86 для Microsoft Visual Studio. В этом проекте будет использоваться библиотека Irvine, которую вы можете скачать с веб-сайта Кипа Ирвина (это первая гиперссылка на странице), и Visual Studio 2017. Итак, как только обе эти вещи правильно настроены, вы можете приступить к выполнению этого руководства!
В этом проекте будет использоваться библиотека Irvine, которую вы можете скачать с веб-сайта Кипа Ирвина (это первая гиперссылка на странице), и Visual Studio 2017. Итак, как только обе эти вещи правильно настроены, вы можете приступить к выполнению этого руководства!
Для начала нам понадобится базовая оболочка для написания нашей программы, и она должна выглядеть так:
ВКЛЮЧИТЬ Irvine32.inc
.данные
.код
основной ПРОЦ
выход
главная ENDP
КОНЕЦ основной
После этого мы можем начать программу, определив несколько переменных в разделе .data. Первое, что нам понадобится, это массив, и вы можете сделать так, чтобы массив содержал все, что вы хотите, но для наших целей здесь я собираюсь придерживаться простого массива целых чисел, хранящихся в виде отдельных байтов. И после того, как мы определим наш массив, мы хотим получить размер массива, вычитая его из текущего адреса в памяти:
numList БАЙТ 1,2,3,4,5,6,7,8,9 Размер массива = ($ - числовой список)
Это позволит нам изменять массив так, как мы хотим, без необходимости изменять код для учета различных длин массивов. Однако нам также нужна еще одна переменная для отслеживания длины массива минус единица:
Однако нам также нужна еще одна переменная для отслеживания длины массива минус единица:
sizeMinus DWORD ?
Как только эти переменные будут созданы, мы можем перейти к разделу .code и начать писать настоящую сборку! Первое, что нам нужно сделать, это сохранить размер массива минус единица в нашей переменной sizeMinus, выполнив следующие действия:0033
; получить размер-1 mov ecx,размер массива дек экх mov sizeMinus,ecx
Причина, по которой мы хотим это сделать, заключается в том, как мы собираемся менять местами значения. Мы собираемся сделать так, чтобы программа брала текущую итерацию массива (в языках более высокого уровня это будет массив [i]), и мы переключаем ее на следующий элемент массива (массив [i+1]) . И поэтому нам нужно только запустить массив до его размера минус один, так как окончательное значение массива будет захвачено окончательным обменом между массивом [i] и массивом [i+1], потому что массив [i] будет индекс предпоследнего элемента, а array[i+1] будет индексом последнего элемента. Если это сбивает с толку, это должно иметь больше смысла, когда мы его реализуем.
Если это сбивает с толку, это должно иметь больше смысла, когда мы его реализуем.
Чтобы начать реализацию, мы будем использовать ecx в качестве регистра-счетчика и начнем с нуля, чтобы представить первый индекс нашего массива:
; установить индекс инициализации на 0: мов экх, 0
Затем мы создадим цикл с именем L1 и начнем его с проверки, равен ли наш регистр счетчика (ecx) размеру массива минус один (sizeMinus), и если да, то мы Перейдем к метке exitL1, которую мы вскоре создадим, чтобы продолжить работу с программой:
L1: ; проверить, если конец цикла: cmp ecx,sizeMinus выход L1
После завершения этой проверки мы начнем процесс подкачки. Мы хотим начать это с получения индекса элемента массива рядом с текущим используемым элементом (получение нашего i+1). Для этого мы просто помещаем текущий индекс (который находится в регистре ecx) в другой регистр (используем для этого регистр ebx), и увеличиваем этот регистр на единицу:
; получить текущий индекс плюс один в ebx: мов ebx,ecx вкл ebx
После этого у нас теперь есть индекс текущего элемента, хранящийся в ecx, и у нас есть индекс элемента рядом с ним, сохраненный в ebx, так что теперь у нас есть все, что нам нужно, чтобы произвести обмен. Чтобы сделать это, мы должны начать с помещения обоих элементов в их собственный регистр. Здесь мы поместим текущий элемент (массив [i]) в регистр dh, а следующий за ним элемент (массив [i+1]) в регистр dl:
Чтобы сделать это, мы должны начать с помещения обоих элементов в их собственный регистр. Здесь мы поместим текущий элемент (массив [i]) в регистр dh, а следующий за ним элемент (массив [i+1]) в регистр dl:
мов дх,[numList+ecx] mov dl,[numList+ebx]
Теперь, когда оба элемента защищены, мы производим обмен, помещая текущий элемент, который теперь хранится в dh, на место элемента, следующего за ним (numList+ebx), и помещая элемент рядом с текущим элементом, хранится в dl вместо текущего элемента (numList+ecx):
mov [numList+ebx],dh mov [numList+ecx],dl
Вот и все, обмен сделан! Осталось просто увеличить счетчик (ecx) и вернуться к началу цикла:
вкл. ecx джмп L1
Однако, если вы похожи на большинство людей и вам трудно читать шестнадцатеричные числа, вы, вероятно, захотите убедиться, что приведенный выше код действительно работает, и именно здесь в игру вступает библиотека Ирвина. Эта библиотека позволяет нам записывать десятичные значения определенных регистров в окно консоли. Чтобы сделать это, первое, что мы должны сделать, убедиться, что L1 зациклен, поэтому мы можем начать с нашей метки exitL1, и мы также хотим очистить регистры, которые мы использовали, чтобы убедиться, что у нас нет любые ненужные оставшиеся данные:
Чтобы сделать это, первое, что мы должны сделать, убедиться, что L1 зациклен, поэтому мы можем начать с нашей метки exitL1, и мы также хотим очистить регистры, которые мы использовали, чтобы убедиться, что у нас нет любые ненужные оставшиеся данные:
выход L1: дв акс,0 мов экх, 0
Отсюда мы хотим начать еще один цикл (L2) с нуля и выполнять его до полной длины массива, после чего мы хотим перейти к другой метке, которую мы собираемся сделать, называемой quit:
L2: ; проверить, если конец цикла: cmp ecx,размер массива я ухожу
Внутри цикла мы собираемся переместить текущий элемент массива (myList+ecx) в регистр al, потому что это нижняя часть регистра eax, из которого функция WriteInt Irvine будет записывать текущий элемент на экран:
; отображать текущую итерацию: mov al,[numList+ecx] вызов WriteInt
И, наконец, последнее, что вам нужно сделать, это убедиться, что регистр ecx увеличивается на протяжении всего цикла, он возвращается к началу и выходит из программы с меткой quit по завершении:
inc ecx джмп л2 покидать: выход
После выполнения всех этих шагов ваша программа должна выглядеть так и полностью функционировать.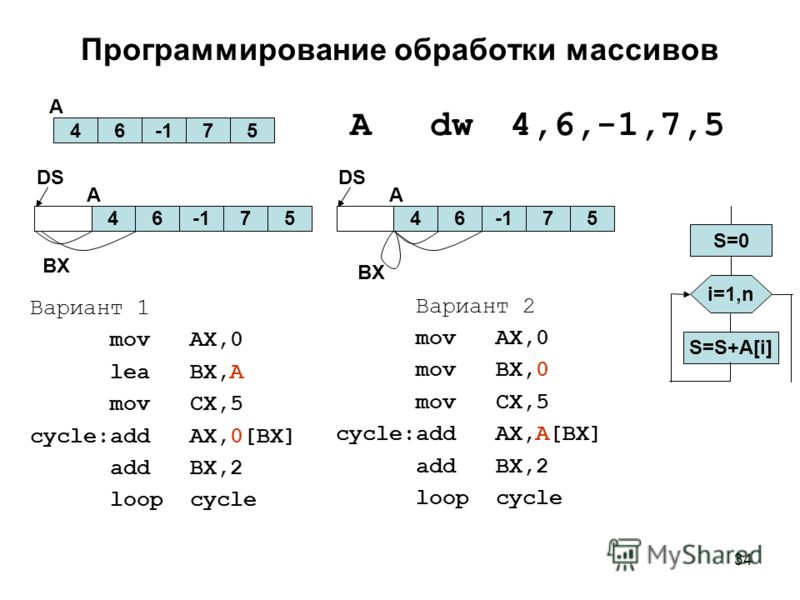 Спасибо за чтение!
Спасибо за чтение!
Вот так:
Нравится Загрузка...
Советы по проектированию массивов печатных плат | PCB Prime
PCB-TIPS
Допустимые форматы файлов
Конструкция массива
Руководство по инструментам CAM
Управляемый диэлектрик или управляемый импеданс?
Зенковка против зенковки
Технические характеристики жесткой печатной платы по умолчанию
Диэлектрические батареи
Сверление и напильник
Чертеж изготовления/Fab Print
Сравнение окончательной отделки
Какой толщины 1 унция меди?
Как избежать инженерной блокировки CAM
Минимизация изгиба и поворота
Паяльная маска
Путем натягивания, заглушки и заполнения
Что такое воровство меди?
Советы по проектированию массивов
Основная причина доставки ваших плат в массиве состоит в том, чтобы сделать автоматическую сборку быстрее и дешевле. Прогон массива досок через машину для захвата и размещения гораздо эффективнее, чем отправка их по одной. Массивы также желательны, потому что они позволяют добавлять направляющие для инструментов, отверстия для инструментов и реперные точки, которые помогают вашему сборщику.
Прогон массива досок через машину для захвата и размещения гораздо эффективнее, чем отправка их по одной. Массивы также желательны, потому что они позволяют добавлять направляющие для инструментов, отверстия для инструментов и реперные точки, которые помогают вашему сборщику.
Инструментальные рельсы являются «рамкой» для массива. Они обеспечивают стабильность и упрощают работу с массивами на протяжении всего процесса сборки. Инструментальные отверстия и реперные точки обычно добавляются к инструментальным рельсам.
Инструментальные отверстия в направляющие добавлены отверстия без покрытия, чтобы массив можно было закрепить штифтами, чтобы предотвратить нежелательное смещение во время сборки. Обычно они имеют диаметр 0,125 дюйма, но могут быть просверлены в соответствии с вашими требованиями.
Реперные знаки
медные пятна на рельсах, которые помогают автоматизированному сборочному оборудованию, обеспечивая единую контрольную точку. Медная реперная метка обычно имеет диаметр 0,04 дюйма и не будет закрыта маской, чтобы ее было лучше видно сборочному оборудованию.
Медная реперная метка обычно имеет диаметр 0,04 дюйма и не будет закрыта маской, чтобы ее было лучше видно сборочному оборудованию.
Многие клиенты компании PCB Prime, Inc. являются контрактными производителями электроники (CEM). большой опыт в настройке массивов для автоматизированной сборки. Мы можем следовать вашим спецификациям массива или мы можем настроить его для вас. Мы будем оценивать, где это возможно, и табулировать маршрут (маршрутизировать и сохранять), где это не так. Многие ассемблеры имеют рекомендации, такие как того, как они предпочитают конструировать массивы. Уточните у своего сборщика, есть ли у него ограничения по размеру или предпочтения в отношении размещения направляющих, отверстий для инструментов или реперных точек. Вот некоторые рекомендации и стандарты, которые подойдут для большинства контрактных сборщиков.
Какой массив вам больше подходит?
Существует три типа массивов: Scored, Tab Routed и их сочетание. Так как же решить, какой из них подходит для вашего дизайна?
Подсчет очков предпочтительнее по двум причинам. Преимущество биговки состоит в том, что края платы получаются более гладкими, и при этом расходуется меньше материала, что может означать экономию средств, особенно при больших количествах или печатных платах с большим количеством слоев, где важен каждый квадратный дюйм.
Преимущество биговки состоит в том, что края платы получаются более гладкими, и при этом расходуется меньше материала, что может означать экономию средств, особенно при больших количествах или печатных платах с большим количеством слоев, где важен каждый квадратный дюйм.
Рассмотрите возможность разводки выступов, если ваша конструкция имеет неправильную форму или если вам нужно пространство между платами, чтобы обеспечить выступающие компоненты.
Комбинация надрезки и фрезерования выступов может использоваться, когда некоторые стороны доски прямые, которые можно надрезать, в то время как неровные стороны должны быть обработаны выступами.
В отсутствие других инструкций,
наша стандартная обработка массива выглядит следующим образом:
Массивы с насечками
Мы поместим 0,25-дюймовые направляющие для инструментов вдоль двух самых длинных сторон, и между досками не будет места. будет производиться по общему контуру доски.Оценка выполняется только параллельно осям X и Y, а не по диагонали.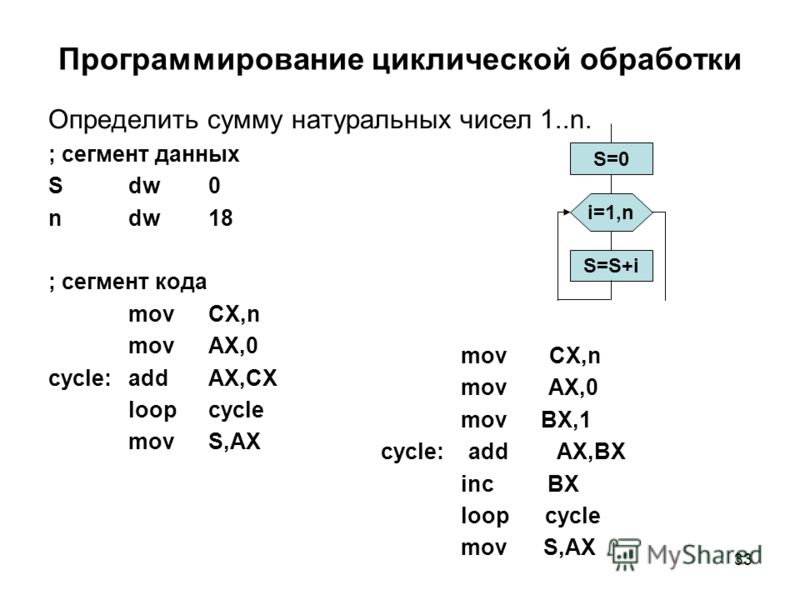 Поскольку оценка проходит по всему массиву по прямой линии, контур доски должен быть прямым для обработанных массивов.
Поскольку оценка проходит по всему массиву по прямой линии, контур доски должен быть прямым для обработанных массивов.
Глубина насечки составляет примерно ⅓ от общей толщины материала. Линии разметки будут сделаны на верхней и нижней сторонах печатной платы. Это оставит оставшуюся полосу материала, равную примерно ⅓ общей толщины доски. Если ваша доска имеет толщину 0,062 дюйма, оставшийся материал будет ~ 0,021 дюйма.
Стандартный материал печатной платы в основном состоит из стекловолокна. Несмотря на то, что ваша доска имеет надрезы, она все равно будет прочной, поэтому будьте осторожны при разделении досок. Ожидайте некоторого количества изгибов, прежде чем линия счета даст. Некоторые нити из стекловолокна часто встречаются вдоль зазубренного края. Быстрая обработка ленточной шлифовальной машиной позаботится о любых шероховатых участках.
Подсчет очков за переход
Можно остановить подсчет очков, чтобы он не продолжался по всему массиву; это называется подсчетом прыжков. Однако это не рекомендуемое решение для массива из-за ограничений и затрат на этот процесс. Мы настоятельно рекомендуем использовать маршрутизацию вкладок, а не подсчет очков.
Однако это не рекомендуемое решение для массива из-за ограничений и затрат на этот процесс. Мы настоятельно рекомендуем использовать маршрутизацию вкладок, а не подсчет очков.
Оценка не может быть остановлена достаточно точно, чтобы закончить линию оценки, как маршрут ЧПУ. Чтобы сделать полный счет, подрезной нож должен пройти конечную точку и остановиться. Мы требуем зазор не менее 0,25 дюйма (6,35 мм) между местом остановки и всем, что не предназначено для нанесения надрезов.
Массивы с маршрутизацией по табуляторам
Если ваш дизайн имеет неправильную форму, может потребоваться маршрутизация по табуляторам. По умолчанию мы добавляем зазор 0,1 дюйма (2,54 мм) между досками, чтобы фреза могла проходить между ними. Небольшие выступы материала останутся, чтобы удерживать доски на месте. Чтобы упростить разделение, мы можем добавить небольшие отверстия на выступах, называемые «мышиными укусами», чтобы перфорировать выступ. Если вы хотите, чтобы края ваших печатных плат были гладкими, эти области необходимо будет отшлифовать после того, как платы будут удалены из массива.