PostgreSQL : Документация: 9.6: Команды SQL : Компания Postgres Professional
RU
EN
RU EN
Эта часть документации содержит справочную информацию по командам SQL, поддерживаемым PostgreSQL. Под «SQL» здесь понимается язык вообще; сведения о соответствии стандартам и совместимости всех команд приведены на соответствующих страниц справочника.
Содержание
- ABORT — прервать текущую транзакцию
- ALTER AGGREGATE — изменить определение агрегатной функции
- ALTER COLLATION — изменить определение правила сортировки
- ALTER CONVERSION — изменить определение перекодировки
- ALTER DATABASE — изменить атрибуты базы данных
- ALTER DEFAULT PRIVILEGES — определить права доступа по умолчанию
- ALTER DOMAIN — изменить определение домена
- ALTER EVENT TRIGGER — изменить определение событийного триггера
- ALTER EXTENSION — изменить определение расширения
- ALTER FOREIGN DATA WRAPPER — изменить определение обёртки сторонних данных
- ALTER FOREIGN TABLE — изменить определение сторонней таблицы
- ALTER GROUP — изменить имя роли или членство
- ALTER INDEX — изменить определение индекса
- ALTER LANGUAGE — изменить определение процедурного языка
- ALTER LARGE OBJECT — изменить определение большого объекта
- ALTER MATERIALIZED VIEW — изменить определение материализованного представления
- ALTER OPERATOR — изменить определение оператора
- ALTER OPERATOR CLASS — изменить определение класса операторов
- ALTER OPERATOR FAMILY — изменить определение семейства операторов
- ALTER POLICY — изменить определение политики защиты на уровне строк
- ALTER ROLE — изменить роль в базе данных
- ALTER RULE — изменить определение правила
- ALTER SCHEMA — изменить определение схемы
- ALTER SEQUENCE — изменить определение генератора последовательности
- ALTER SERVER — изменить определение стороннего сервера
- ALTER SYSTEM — изменить параметр конфигурации сервера
- ALTER TABLE — изменить определение таблицы
- ALTER TABLESPACE — изменить определение табличного пространства
- ALTER TEXT SEARCH CONFIGURATION — изменить определение конфигурации текстового поиска
- ALTER TEXT SEARCH DICTIONARY — изменить определение словаря текстового поиска
- ALTER TEXT SEARCH PARSER — изменить определение анализатора текстового поиска
- ALTER TEXT SEARCH TEMPLATE — изменить определение шаблона текстового поиска
- ALTER TRIGGER — изменить определение триггера
- ALTER TYPE — изменить определение типа
- ALTER USER — изменить роль в базе данных
- ALTER USER MAPPING — изменить определение сопоставления пользователей
- ALTER VIEW — изменить определение представления
- ANALYZE — собрать статистику по базе данных
- BEGIN — начать блок транзакции
- CHECKPOINT — записать контрольную точку в журнал транзакций
- CLOSE — закрыть курсор
- CLUSTER — кластеризовать таблицу согласно индексу
- COMMENT — задать или изменить комментарий объекта
- COMMIT — зафиксировать текущую транзакцию
- COMMIT PREPARED — зафиксировать транзакцию, которая ранее была подготовлена для двухфазной фиксации
- CREATE ACCESS METHOD — создать новый метод доступа
- CREATE AGGREGATE — создать агрегатную функцию
- CREATE CAST — создать приведение
- CREATE COLLATION — создать правило сортировки
- CREATE CONVERSION — создать перекодировку
- CREATE DATABASE — создать базу данных
- CREATE DOMAIN — создать домен
- CREATE EVENT TRIGGER — создать событийный триггер
- CREATE EXTENSION — установить расширение
- CREATE FOREIGN DATA WRAPPER — создать новую обёртку сторонних данных
- CREATE FOREIGN TABLE — создать стороннюю таблицу
- CREATE FUNCTION — создать функцию
- CREATE GROUP — создать роль в базе данных
- CREATE INDEX — создать индекс
- CREATE LANGUAGE — создать процедурный язык
- CREATE MATERIALIZED VIEW — создать материализованное представление
- CREATE OPERATOR — создать оператор
- CREATE OPERATOR CLASS — создать класс операторов
- CREATE OPERATOR FAMILY — создать семейство операторов
- CREATE POLICY — создать новую политику защиты на уровне строк для таблицы
- CREATE ROLE — создать роль в базе данных
- CREATE RULE — создать правило перезаписи
- CREATE SCHEMA — создать схему
- CREATE SEQUENCE — создать генератор последовательности
- CREATE SERVER — создать сторонний сервер
- CREATE TABLE — создать таблицу
- CREATE TABLE AS — создать таблицу из результатов запроса
- CREATE TABLESPACE — создать табличное пространство
- CREATE TEXT SEARCH CONFIGURATION — создать конфигурацию текстового поиска
- CREATE TEXT SEARCH DICTIONARY — создать словарь текстового поиска
- CREATE TEXT SEARCH PARSER — создать анализатор текстового поиска
- CREATE TEXT SEARCH TEMPLATE — создать шаблон текстового поиска
- CREATE TRANSFORM — создать трансформацию
- CREATE TRIGGER — создать триггер
- CREATE TYPE — создать новый тип данных
- CREATE USER — создать роль в базе данных
- CREATE USER MAPPING — создать сопоставление пользователя для стороннего сервера
- DEALLOCATE — освободить подготовленный оператор
- DECLARE — определить курсор
- DELETE — удалить записи таблицы
- DISCARD — очистить состояние сеанса
- DO — выполнить анонимный блок кода
- DROP ACCESS METHOD — удалить метод доступа
- DROP AGGREGATE — удалить агрегатную функцию
- DROP CAST — удалить приведение типа
- DROP COLLATION — удалить правило сортировки
- DROP CONVERSION — удалить преобразование
- DROP DATABASE — удалить базу данных
- DROP DOMAIN — удалить домен
- DROP EVENT TRIGGER — удалить событийный триггер
- DROP EXTENSION — удалить расширение
- DROP FOREIGN DATA WRAPPER — удалить обёртку сторонних данных
- DROP FOREIGN TABLE — удалить стороннюю таблицу
- DROP FUNCTION — удалить функцию
- DROP GROUP — удалить роль в базе данных
- DROP INDEX — удалить индекс
- DROP LANGUAGE — удалить процедурный язык
- DROP MATERIALIZED VIEW — удалить материализованное представление
- DROP OPERATOR — удалить оператор
- DROP OPERATOR CLASS — удалить класс операторов
- DROP OPERATOR FAMILY — удалить семейство операторов
- DROP OWNED — удалить объекты базы данных, принадлежащие роли
- DROP POLICY — удалить политику защиты на уровне строк для таблицы
- DROP ROLE — удалить роль в базе данных
- DROP RULE — удалить правило перезаписи
- DROP SCHEMA — удалить схему
- DROP SEQUENCE — удалить последовательность
- DROP SERVER — удалить описание стороннего сервера
- DROP TABLE — удалить таблицу
- DROP TABLESPACE — удалить табличное пространство
- DROP TEXT SEARCH CONFIGURATION — удалить конфигурацию текстового поиска
- DROP TEXT SEARCH DICTIONARY — удалить словарь текстового поиска
- DROP TEXT SEARCH PARSER — удалить анализатор текстового поиска
- DROP TEXT SEARCH TEMPLATE — удалить шаблон текстового поиска
- DROP TRANSFORM — удалить трансформацию
- DROP TRIGGER — удалить триггер
- DROP TYPE — удалить тип данных
- DROP USER — удалить роль в базе данных
- DROP USER MAPPING — удалить сопоставление пользователя для стороннего сервера
- END — зафиксировать текущую транзакцию
- EXECUTE — выполнить подготовленный оператор
- EXPLAIN — показать план выполнения оператора
- FETCH — получить результат запроса через курсор
- GRANT — определить права доступа
- IMPORT FOREIGN SCHEMA — импортировать определения таблиц со стороннего сервера
- INSERT — добавить строки в таблицу
- LISTEN — ожидать уведомления
- LOAD — загрузить файл разделяемой библиотеки
- LOCK — заблокировать таблицу
- MOVE — переместить курсор
- NOTIFY — сгенерировать уведомление
- PREPARE — подготовить оператор к выполнению
- PREPARE TRANSACTION — подготовить текущую транзакцию для двухфазной фиксации
- REASSIGN OWNED — сменить владельца объектов базы данных, принадлежащих заданной роли
- REFRESH MATERIALIZED VIEW — заменить содержимое материализованного представления
- REINDEX — перестроить индексы
- RELEASE SAVEPOINT — высвободить ранее определённую точку сохранения
- RESET — восстановить значение по умолчанию заданного параметра времени выполнения
- REVOKE — отозвать права доступа
- ROLLBACK — прервать текущую транзакцию
- ROLLBACK PREPARED — отменить транзакцию, которая ранее была подготовлена для двухфазной фиксации
- ROLLBACK TO SAVEPOINT — откатиться к точке сохранения
- SAVEPOINT — определить новую точку сохранения в текущей транзакции
- SECURITY LABEL — определить или изменить метку безопасности, применённую к объекту
- SELECT — получить строки из таблицы или представления
- SELECT INTO — создать таблицу из результатов запроса
- SET — изменить параметр времени выполнения
- SET CONSTRAINTS — установить время проверки ограничений для текущей транзакции
- SET ROLE — установить идентификатор текущего пользователя в рамках сеанса
- SET SESSION AUTHORIZATION — установить идентификатор пользователя сеанса и идентификатор текущего пользователя в рамках сеанса
- SET TRANSACTION — установить характеристики текущей транзакции
- SHOW — показать значение параметра времени выполнения
- TRUNCATE — опустошить таблицу или набор таблиц
- UNLISTEN — прекратить ожидание уведомления
- UPDATE — изменить строки таблицы
- VACUUM — провести сборку мусора и, возможно, проанализировать базу данных
- VALUES — вычислить набор строк
- ALTER AGGREGATE — изменить определение агрегатной функции
Использование мета-команды psql — Русские Блоги
Мета-команда в psql относится к команде, начинающейся с обратной косой черты. Например, \ db используется для просмотра табличного пространства. \ dt tablename — это размер таблицы просмотра.
Например, \ db используется для просмотра табличного пространства. \ dt tablename — это размер таблицы просмотра.
При использовании psql для подключения к базе данных параметр -E может получить код SQL метакоманды, например:
[email protected]:~$ psql -E
psql (10.2)
Type "help" for help.
postgres=# \db
********* QUERY **********
SELECT spcname AS "Name",
pg_catalog.pg_get_userbyid(spcowner) AS "Owner",
pg_catalog.pg_tablespace_location(oid) AS "Location"
FROM pg_catalog.pg_tablespace
ORDER BY 1;
**************************
List of tablespaces
Name | Owner | Location
------------+----------+----------
pg_default | postgres |
pg_global | postgres |
(2 rows)Используйте \?, Чтобы перечислить все мета-команды, а также описание и синтаксис этих мета-команд. Например:
postgres=# \? General \copyright show PostgreSQL usage and distribution terms \crosstabview [COLUMNS] execute query and display results in crosstab \errverbose show most recent error message at maximum verbosity \g [FILE] or ; execute query (and send results to file or |pipe) \gexec execute query, then execute each value in its result \gset [PREFIX] execute query and store results in psql variables \gx [FILE] as \g, but forces expanded output mode \q quit psql \watch [SEC] execute query every SEC seconds ... ... ...
В psql используйте -A, чтобы установить режим вывода без выравнивания. Например:
[email protected]:~$ psql -A psql (10.2) Type "help" for help. postgres=# select * from test; id|passstring|pass1|pass2|pass3 1|abcdefghijklmnopqrstu|:nDNL76IgtKSYo|:dmlF6XruXN2IA|:bgxgYjIs/NhT. 2|hoge|:Bra44iY.vmPzA|:003uyQxlYQEgE|:A0zs16Dq9cdcI (2 rows)
Используйте -t для отображения только данных записи (не отображать имя поля и количество строк в возвращаемом наборе результатов). Например:
[email protected]:~$ psql -t psql (10.2) Type "help" for help. postgres=# select * from test; 1 | abcdefghijklmnopqrstu | :nDNL76IgtKSYo | :dmlF6XruXN2IA | :bgxgYjIs/NhT. 2 | hoge | :Bra44iY.vmPzA | :003uyQxlYQEgE | :A0zs16Dq9cdcI
Параметр -t обычно используется вместе с параметром -A, и в это время возвращаются только сами данные. Например:
[email protected]:~$ psql -At psql (10.2) Type "help" for help. postgres=# select * from test; 1|abcdefghijklmnopqrstu|:nDNL76IgtKSYo|:dmlF6XruXN2IA|:bgxgYjIs/NhT.2|hoge|:Bra44iY.vmPzA|:003uyQxlYQEgE|:A0zs16Dq9cdcI
By Kalath
Интеллектуальная рекомендация
Синхронизированное ключевое слово многопоточности Java
Синхронизированная функция Метод синхронизации поддерживает простую стратегию предотвращения пересечения потоков и ошибок согласованности содержимого. Если объект виден для нескольких потоков, все чте…
Проблема: [шаблон] LCA ближайшего общего предка
Проблема: [шаблон] LCA ближайшего общего предка Time Limit: 3 Sec Memory Limit: 128 MB Description Дает N, Q означает, что дерево имеет N точек, а корень дерева равен 1. Q означает, что есть Q запросо…
Круд реализации на основе гибернации
цель: понятьHibernateИспользование основного интерфейса; Оставьте основной метод проектирования интерфейса настойчивости; ЗнакомствоHibernateСпособ использования производительности; содер…
Интернет-протокол (2) — сверху вниз
Продолжить с предыдущего поста: блог Ruan Yifeng каталог Семь, резюме Восемь, интернет-настройки пользователя 8. 1 Статический IP-адрес 8.2 Динамический IP-адрес 8.3 Протокол DHCP 8.4 Настройки Интерне…
1 Статический IP-адрес 8.2 Динамический IP-адрес 8.3 Протокол DHCP 8.4 Настройки Интерне…
Путь обучения Python
Эта часть представляет собой ссылку на блоги, которые вы читали в лабораторном здании, и вы обычно читаете ее, потому что вы можете избежать создания среды в лабораторном здании, и вы можете начать пр…
Вам также может понравиться
Почему MySQL использует, почему влияет на производительность
1、 2、 3, MySQL версия 5.7 Идентификатор является самоинтенсивным первичным ключом, Val — неиспользуемый индекс. Инфузия многих данных, всего 5 миллионов: Мы знаем, что когда смещение в ограниченных ст…
Программирование Java использует массив вывода Tang Poetry
Описание проблемы: Использование программирования Java для использования массива для вывода поэзии Tang. Исходный код программы: …
oracle 11g r2 OEM конфигурация
Используйте среду:win8+oracle 11g r2 Предисловие:Я не знаю, в чем причина (несколько причин), установленный Oracle не имеет EM, поэтому вам нужно настроить PS:В процессе настройки возникли различные п. ..
..
В Java реализована фильтрация чувствительных слов — инструмент сегментации китайских слов IKAnalyzer
IKAnalyzer — это легкий набор инструментов для сегментации китайских слов с открытым исходным кодом, разработанный на основе языка java. Официальный веб-сайт:https://code.google.com/archive/p/ik-analy…
Объектно-ориентированный
1.1SinStance и IssubClass ISinstance (OBJ, CLS) Проверьте объект (OBJ), является ли это классом (объект класса) ISBClass (sub, super) Проверьте класс класса (sub) — это производный класс супер -класса…
Краткое руководство. Подключение к гибкому серверу Базы данных Azure PostgreSQL с помощью Azure CLI
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 3 мин
Область применения: гибкий сервер Базы данных Azure для PostgreSQL
В этом кратком руководстве объясняется, как подключиться к гибкому серверу Базы данных Azure PostgreSQL с помощью команды az postgres flexible-server connect Azure CLI и выполнить одиночный запрос или файл sql с помощью команды az postgres flexible-server execute.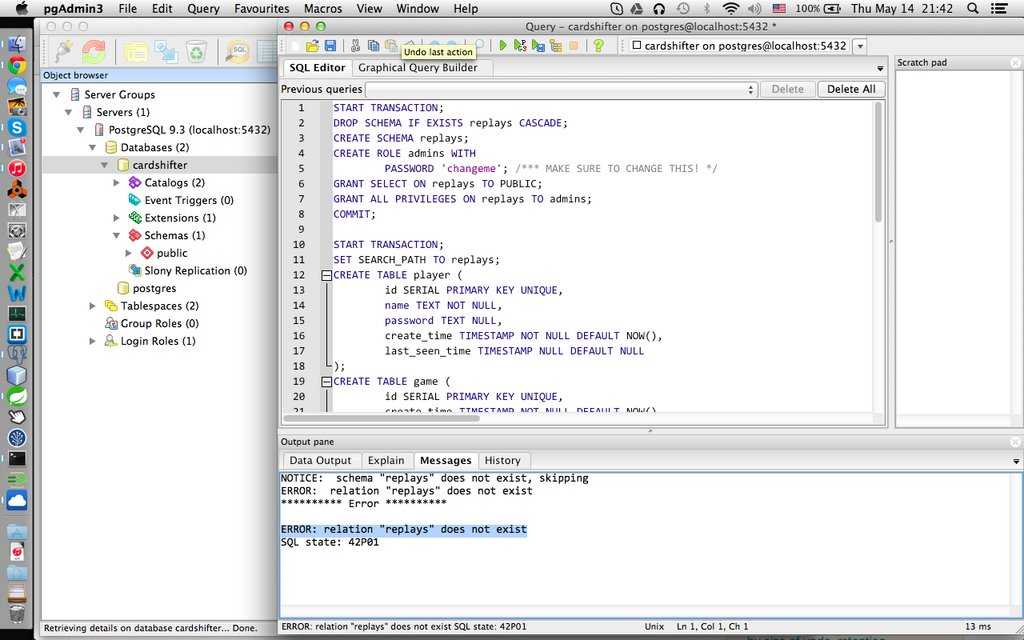 С помощью этой команды можно проверить подключение к серверу базы данных и выполнить запросы. Вы также можете выполнить несколько запросов в интерактивном режиме.
С помощью этой команды можно проверить подключение к серверу базы данных и выполнить запросы. Вы также можете выполнить несколько запросов в интерактивном режиме.
Предварительные требования
- Учетная запись Azure. Если у вас ее нет, получите бесплатную пробную версию.
- Установите последнюю версию Azure CLI (2.20.0 или более позднюю).
- Войдите с помощью Azure CLI, выполнив команду
az login. - Включите функцию сохраняемости параметров, выполнив команду
az config param-persist on. Функция сохраняемости параметров позволит использовать локальный контекст без необходимости повторения большого количества аргументов, таких как группа ресурсов или расположение.
Создание гибкого сервера PostgreSQL
Прежде всего мы создадим управляемый сервер PostgreSQL. В Azure Cloud Shell выполните следующий скрипт и запишите имя сервера, имя пользователя и пароль, созданные с помощью этой команды.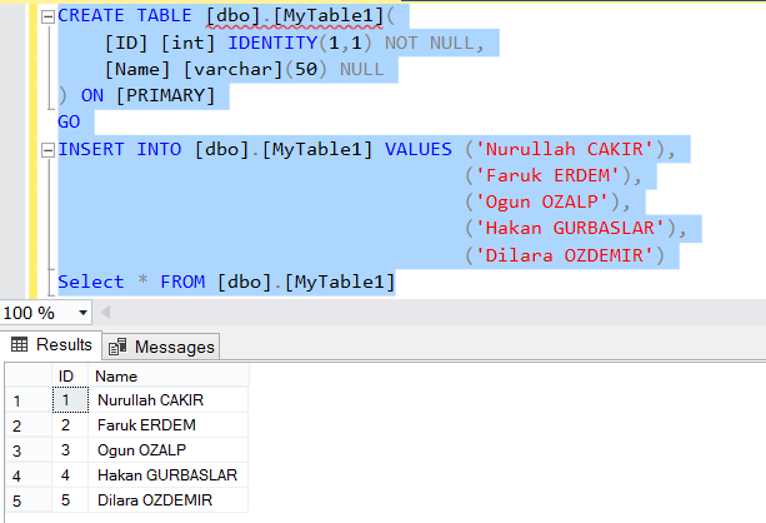
az postgres flexible-server create --public-access <your-ip-address>
Чтобы настроить эту команду, вы можете указать дополнительные аргументы. Ознакомьтесь со всеми аргументами для команды az postgres flexible-server create.
Просмотр всех аргументов
Вы можете просмотреть все аргументы для этой команды с помощью аргумента --help.
az postgres flexible-server connect --help
Проверка подключения к серверу базы данных
Вы можете протестировать и проверить подключение к базе данных из окружения разработки, выполнив следующую команду:
az postgres flexible-server connect -n <servername> -u <username> -p "<password>" -d <databasename>
Пример.
az postgres flexible-server connect -n postgresdemoserver -u dbuser -p "dbpassword" -d postgres
Если подключение установлено успешно, отобразятся выходные данные.
Command group 'postgres flexible-server' is in preview and under development.Reference and support levels: https://aka.ms/CLI_refstatus Successfully connected to postgresdemoserver. Local context is turned on. Its information is saved in working directory C:\mydir. You can run `az local-context off` to turn it off. Your preference of are now saved to local context. To learn more, type in `az local-context --help`
Если установить подключение не удалось, воспользуйтесь приведенными ниже решениями:
- Проверьте, открыт ли порт 5432 на клиентском компьютере.
- Проверьте, правильно ли указаны имя пользователя и пароль администратора сервера.
- Проверьте, настроено ли правило брандмауэра для клиентского компьютера.
- Если вы настроили сервер с закрытым доступом в виртуальной сети, убедитесь, что клиентский компьютер находится в той же виртуальной сети.
Выполнение нескольких запросов в интерактивном режиме
Вы можете выполнить несколько запросов в интерактивном режиме. Чтобы включить интерактивный режим, выполните следующую команду:
az postgres flexible-server connect -n <servername> -u <username> -p "<password>" -d <databasename>
Пример.
az postgres flexible-server connect -n postgresdemoserver -u dbuser -p "dbpassword" -d flexibleserverdb --interactive
Отобразится приведенная ниже оболочка PSQL:
Command group 'postgres flexible-server' is in preview and under development. Reference and support levels: https://aka.ms/CLI_refstatus Password for earthyTurtle7: Server: PostgreSQL 12.5 Version: 3.0.0 Chat: https://gitter.im/dbcli/pgcli Home: http://pgcli.com postgres> create database pollsdb; CREATE DATABASE Time: 0.308s postgres> exit Goodbye! Local context is turned on. Its information is saved in working directory C:\sunitha. You can run `az local-context off` to turn it off. Your preference of are now saved to local context. To learn more, type in `az local-context --help`
Пример.
az postgres flexible-server execute -n postgresdemoserver -u dbuser -p "dbpassword" -d flexibleserverdb -q "select * from table1;" --output table
Результат выполнения команды будет таким:
Command group 'postgres flexible-server' is in preview and under development.Reference and support levels: https://aka.ms/CLI_refstatus Successfully connected to postgresdemoserver. Ran Database Query: 'select * from table1;' Retrieving first 30 rows of query output, if applicable. Closed the connection postgresdemoserver. Local context is turned on. Its information is saved in working directory C:\mydir. You can run `az local-context off` to turn it off. Your preference of are now saved to local context. To learn more, type in `az local-context --help` Txt Val ----- ----- test 200 test 200 test 200 test 200 test 200 test 200 test 200
Выполнение файла SQL
Чтобы выполнить файл SQL, используйте следующую команду с аргументом --file-path, -f.
az postgres flexible-server execute -n <server-name> -u <username> -p "<password>" -d <database-name> --file-path "<file-path>"
Пример.
az postgres flexible-server execute -n postgresdemoserver -u dbuser -p "dbpassword" -d flexibleserverdb -f "./test.sql"
Результат выполнения команды будет таким:
Command group 'postgres flexible-server' is in preview and under development. Reference and support levels: https://aka.ms/CLI_refstatus Running sql file '.\test.sql'... Successfully executed the file. Closed the connection to postgresdemoserver.
Next Steps
Управление сервером
Базы данных списков PostgreSQL
Ранее мы использовали встроенные команды и функции для создания или удаления таблиц, таких как «СОЗДАТЬ ТАБЛИЦУ», «УДАЛИТЬ ТАБЛИЦЫ» для перечисления таблиц или баз данных; в PostgreSQL нет специальных встроенных команд. PostgreSQL не поддерживает такие команды, как «список базы данных» или «Показать базу данных» для вывода списка баз данных на сервере. Чтобы перечислить все базы данных, которые в настоящее время работают на сервере, пользователи могут использовать PostgreSQL по-разному. PostgreSQL имеет собственный инструмент командной строки psql, который можно использовать для вывода списка баз данных с помощью метакоманд и SQL-запросов, или вы можете просто использовать pgAdmin4 для вывода списка всех баз данных, имеющихся на сервере. В этой статье мы поговорим об эффективных способах создания базы данных листингов в PostgreSQL.
В этой статье мы поговорим об эффективных способах создания базы данных листингов в PostgreSQL.
Содержание
- Различные способы отображения базы данных в PostgreSQL
- 1. Список баз данных с помощью pgAdmin4 в PostgreSQL
- Что такое мета-команды?
- 2. Список баз данных с помощью psql с мета-командами в PostgreSQL
- 3. Вывести список базы данных с помощью psql с оператором SELECT
- Заключение
Различные способы отображения базы данных в PostgreSQL
Вам нужно найти и составить список базы данных на вашем сервере, и вы не знаете, как это сделать; Тогда это руководство — то место, где вы можете найти ответы на свои вопросы. Это не только предоставит вам один метод, но и три с объясненными примерами для составления списка баз данных, находящихся на вашем сервере:
- Используя pgAdmin4.
- Использование psql с метакомандами.
- Использование psql с оператором SELECT.
1. Список баз данных с помощью pgAdmin4 в PostgreSQL
При установке PostgreSQL вам был предоставлен сервер, для которого вы установили пароль. Когда вы входите на сервер, вы видите базу данных; там вы можете создавать свои собственные базы данных, щелкнув по ней правой кнопкой мыши, как вы можете видеть ниже:
Когда вы входите на сервер, вы видите базу данных; там вы можете создавать свои собственные базы данных, щелкнув по ней правой кнопкой мыши, как вы можете видеть ниже:
Как только вы нажмете на базу данных, появится этот экран:
В текстовом поле «База данных» введите желаемое имя базы данных и сохраните изменения. Будет создана новая база данных, которую вы сможете просмотреть позже, используя оператор «Выбрать» в инструменте запросов.
Вы также можете проверить, сколько баз данных присутствует на вашем сервере. В левом меню навигации pgAdmin4 вы можете увидеть ярлык «База данных»; при нажатии на нее появится выпадающий список: все базы данных на вашем сервере. Для получения дополнительной информации вы можете щелкнуть вкладку свойств.
Выше вы можете увидеть все перечисленные базы данных на вашем сервере, включая ту, которую мы создали в приведенном выше примере.
Что такое мета-команды?
Psql поддерживает мета-команды, которые также называются обратной косой чертой или косой чертой (\). Вы также можете запускать SQL-запросы к инструменту командной строки PostgreSQL, но мета-команды делают psql удобным для сценариев, которые они обрабатывают сами. Некоторые примеры мета-команд упомянуты далее в этой статье в psql.
Вы также можете запускать SQL-запросы к инструменту командной строки PostgreSQL, но мета-команды делают psql удобным для сценариев, которые они обрабатывают сами. Некоторые примеры мета-команд упомянуты далее в этой статье в psql.
2. Список баз данных с помощью psql с мета-командами в PostgreSQL
Теперь мы перейдем к тому, как составить список базы данных на вашем сервере. После того, как вы открыли инструмент psql, выберите базу данных по умолчанию и не вводите какую-либо конкретную базу данных, это не будет перечислять базы данных, присутствующие на вашем сервере, потому что вы будете в самой базе данных; изображение ниже показывает это:
Теперь вы вошли в базу данных по умолчанию «postgres», созданную самим PostgreSQL. Теперь выполните следующую метакоманду, чтобы вывести список баз данных, существующих на сервере:
Команда «\ l» вернет список баз данных на вашем сервере и отобразит их как:
В приведенной выше таблице отображается информация о базах данных, включая их имя, владельца, кодировку, сопоставление, ctype и права доступа.
Если вам нужна дополнительная информация о базах данных, выполните следующую команду:
Приведенная выше команда «\ l +» вернет расширенную информацию о базах данных, включая размер, табличное пространство и описание. Команда «\ l +» отображает следующие результаты:
Обратите внимание: вы также можете использовать команду «\ list» вместо «\ l» и команду «\ list +» вместо «\ l +».
3. Вывести список базы данных с помощью psql с оператором SELECT
Мы видели, как составлять список баз данных с помощью мета-команд, теперь мы научимся составлять список баз данных с помощью оператора «SELECT» или запроса SQL с помощью инструмента psql. Мы будем использовать «pg_database» в нашем операторе «SELECT», потому что «pg_database» хранит всю информацию о базах данных на текущем сервере. Выполните следующий запрос для вывода списка баз данных с помощью оператора «SELECT»:
# SELECT datname FROM pg_database;
Оператор «SELECT» выберет столбец «имя данных» из «pg_database» и отобразит только этот столбец в результатах, как показано ниже:
Все базы данных теперь перечислены на изображении выше, которое присутствует на сервере.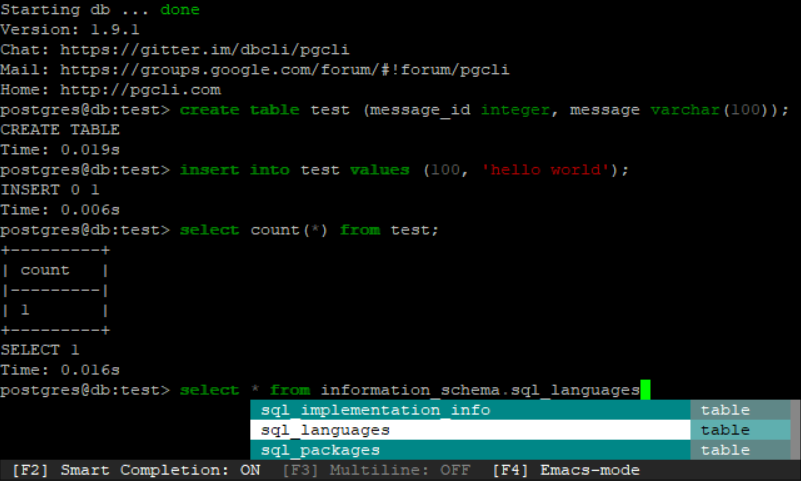 Вы также можете проверить базы данных, просмотрев приведенные выше примеры, которые мы выполнили.
Вы также можете проверить базы данных, просмотрев приведенные выше примеры, которые мы выполнили.
Если вам нужна вся информация о базах данных, выполните следующий запрос:
# SELECT * FROM pg_database;
Этот запрос отобразит результаты баз данных со всей информацией в них. Вы можете выбрать любой конкретный столбец для отображения в результатах в соответствии с вашими требованиями. В приведенном ниже примере я выбрал два столбца для отображения «имени данных» и «oid» базы данных:
SELECT oid, datname FROM pg_database;
Если выбрать два столбца, «oid» и «имя данных», запрос отобразит в результатах только эти столбцы.
Обратите внимание: если вы хотите упомянуть условие в своем запросе, используйте предложение «WHERE» в операторе для отображения записей необходимых вам баз данных. Ниже я продемонстрировал один пример с условием «ГДЕ»:
SELECT oid, datname FROM pg_database WHERE datistemplate= FALSE;
В условии «WHERE» я отобразил только те записи, в которых значение столбца «datistemplate» равно false, и завершил другие значения, кроме этого, что показывает следующий результат:
Заключение
Эта статья была основана на том, как составить список баз данных, находящихся на сервере. В этой статье мы получили знания о листинге баз данных разными способами. Мы использовали pgAdmin4, мета-команды psql и операторы psql «SELECT» для вывода списка базы данных в PostgreSQL. Все методы оказались успешными для вывода списка баз данных в PostgreSQL; каждый из методов зависит от того, как вы хотите отображать информацию в своих базах данных. Первый метод отображает меньшую информацию. Но второй и третий методы отображают подробную информацию о базе данных. Пользователи сами решают, какой метод из трех для листинговых баз данных они предпочитают больше всего.
В этой статье мы получили знания о листинге баз данных разными способами. Мы использовали pgAdmin4, мета-команды psql и операторы psql «SELECT» для вывода списка базы данных в PostgreSQL. Все методы оказались успешными для вывода списка баз данных в PostgreSQL; каждый из методов зависит от того, как вы хотите отображать информацию в своих базах данных. Первый метод отображает меньшую информацию. Но второй и третий методы отображают подробную информацию о базе данных. Пользователи сами решают, какой метод из трех для листинговых баз данных они предпочитают больше всего.
как создать и удалить базу данных, настроить бэкап, добавить пользователя
PostgreSQL – опенсорсная реляционная СУБД. Отличается гибкостью и надежностью, поддерживает большое количество полезных возможностей. Часто используется в проектах, где требуется работа со сложными структурами данных, с которыми не справляются простые СУБД.
В этой статье мы разберемся, как работать с PostgreSQL. В качестве примера я буду использовать Ubuntu 18.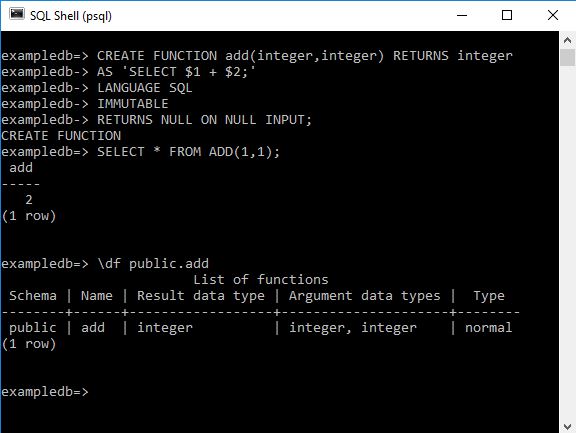 04.
04.
Установка PostgreSQL
PostgreSQL есть в репозитории Ubuntu, поэтому установка выполняется одной командой. Но сначала нужно проверить обновления самой системы:
sudo apt-get update
Для выполнения команды нужны права суперпользователя. Так что придется вспомнить пароль.
После установки апдейтов инсталлируем PostgreSQL:
sudo apt-get install postgresql postgresql-contrib
PostgreSQL установится вместе с пакетом contrib, в котором содержится дополнительная функциональность, а также утилиты для работы СУБД.
Чтобы убедиться, что все работает, проверим версию:
postgres --version
При установке автоматически создается роль и пользователь postgres.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Настройка PostgreSQL
Работать с PostgreSQL мы будем через терминал с помощью встроенной утилиты psql. Запускаем ее следующей командой:
psql postgres
Можно установить сторонние инструменты для администрирования PostgreSQL, но в этом мало смысла — psql справляется со всеми основными задачами.
Чтобы получить поддержку, вводим в терминале команду:
\help
Если нужна справка по конкретной команде, пишем:
\help [имя команды]
Выйти из psql можно командой \q.
Управление пользователями
В PostgreSQL используется концепция ролей. Одну роль можно рассматривать как отдельного пользователя или как группу пользователей. Роли могут владеть объектами БД и выдавать разрешения другим ролям.
По умолчанию была создана роль postgres. Давайте создадим еще одну роль. Для этого из консоли системы выполняем команду:
createuser -P --interactive
Система запросит имя для новой роли, пароль, а также позволит настроить привилегии — например, нужно ли давать права суперпользователя или разрешать создавать другие роли и базы данных.
Если вы уже зашли в psql, то создать новую роль можно командой:
CREATE ROLE имя_новой_роли WITH LOGIN CREATEDB CREATEROLE; // В конце обязательно ставим ;
Затем задаем пароль:
\password имя_роли
Вывести список всех ролей можно командой /du.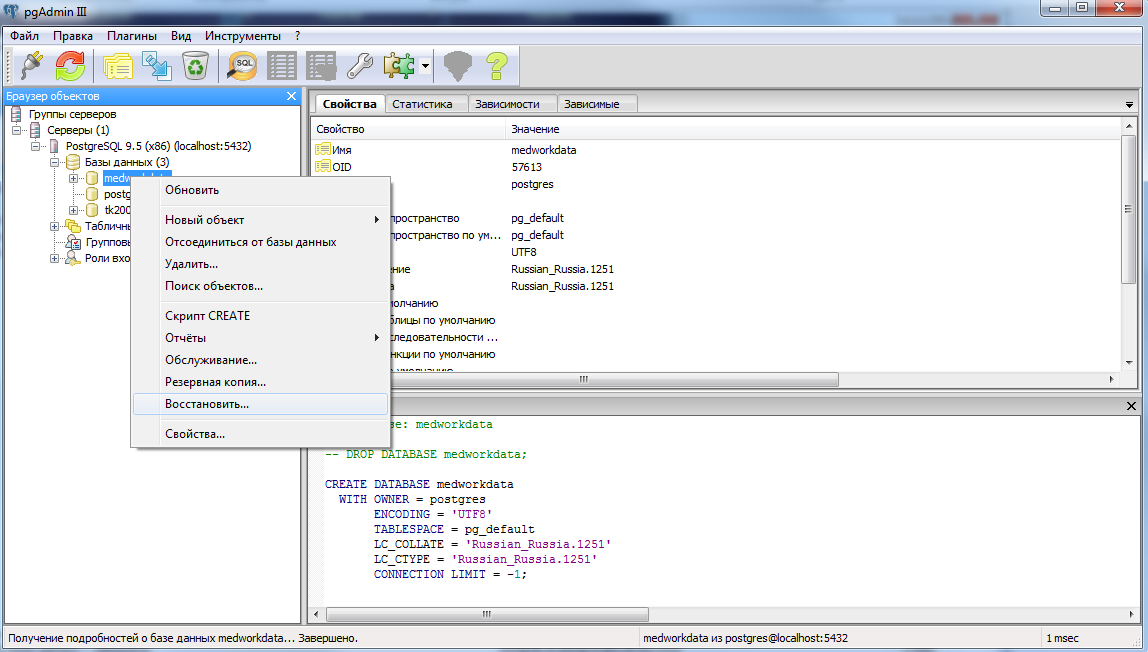 Кроме имен отобразятся привилегии каждого роли.
Кроме имен отобразятся привилегии каждого роли.
Чтобы закрыть список ролей, выполняем команду q.
Для удаления пользователя выполняем команду:
DROP ROLE имя_роли;
Это можно также сделать из консоли системы с помощью команды:
drop user имя_роли
Чтоб сменить пароль пользователя, подключаемся к psql с правами суперпользователя. Затем выполняем следующую команду:
ALTER USER имя_роли WITH PASSWORD 'новый_пароль';
Эта операция сохраняется в файле .psql_history вместе с паролем, который не будет зашифрован. В качестве дополнительной меры безопасности эту запись рекомендуется удалить. Файл обычно находится в директории /var/lib/postgresql.
Работа с базами данных в PostgreSQL
Создать базу данных из консоли можно следующей командой:
createdb имя_БД
Если вы используете терминальный клиент psql, то команда будет немного отличаться:
CREATE DATABASE имя_БД;
Чтобы посмотреть список всех БД, выполняем команду \l.
Для удаления базы данных используется та же команда, что и для удаления роли — drop. В терминале системы синтаксис будет таким:
drop database имя_БД
В клиенте psql синтаксис похожий:
DROP DATABASE имя_БД;
Подключение к базе данных
По умолчанию psql подключается от имени текущего пользователя Linux к БД с таким же названием. Если эти данные совпадают, достаточно выполнить запуск самого терминального клиента:
Чтобы вывести информацию о текущем соединении, выполняем команду:
\conninfo
Если имя базы данных отличается от имени пользователя, нужно указать его явно:
psql -d имя_БД
Если имя роли не совпадает с именем пользователя в Linux, прописываем дополнительные параметры.
Имя роли и название БД совпадают:
psql -U имя_роли -h localhost -W
Название базы данных отличается от имени роли:
psql -U имя_роли -d имя_базы -h localhost -W // Разница в том, что явно указано название БД
Чтобы переключиться на другую базу данных внутри psql используем команду:
\c имя_БД
Создание резервной копии и восстановление из бэкапа
Для создания резервной копии базы данных используется сложная команда:
pg_dump -h хост -U имя_роли -F формат_дампа -f путь_к_дампу имя_БД
Чтобы было проще разобраться, рассмотрим каждый параметр:
- хост – сервер, на котором располагается БД.
 Например, можно указать localhost, домен, IP-адрес.
Например, можно указать localhost, домен, IP-адрес. - имя_роли – имя пользователя PostgreSQL, под которым мы работаем с базой данных.
- формат_дампа – формат, в котором дамп сохранится на сервере. Доступны следующие форматы: c (custom) – архив .tar.gz, t (tar) – архив .tar, p (plain) – текст без сжатия, обычно .sql.
- путь_к_дампу – путь, по которому будет сохранена резервная копия.
- имя_БД – название БД, для которой будет создана резервная копия.
Выглядит это примерно так:
pg_dump -h localhost -U mybase -F c -f /home/user/backups/dump.tar.gz mybase
Для выполнения этой команды нужно ввести пароль, который используется при входе в psql от имени указанной роли (mybase в приведенном примере).
Восстановление из резервной копии выполняется аналогичным образом:
pg_restore -h хост -U имя_роли -F формат_дампа -d имя_базы путь_к_дампу
Параметры похожие, отличия минимальные. Важно знать хост, помнить формат и путь к бэкапу.
Мы разобрались с основными действиями и настройками PostgreSQL. На этом все!
Шпаргалка по PostgreSQL
Сделал для себя небольшую шпаргалку по Postrgess. Пока это очень короткая версия не окончательная, буду добавлять и обновлять. Я использую Ubuntu, для других систем некоторые моменты могут отличаться.
Посмотрите заметку об установке PostgreSQL на WSL. Кроме установки там есть информация как создать пользователя и базу данных.
Утилита psql
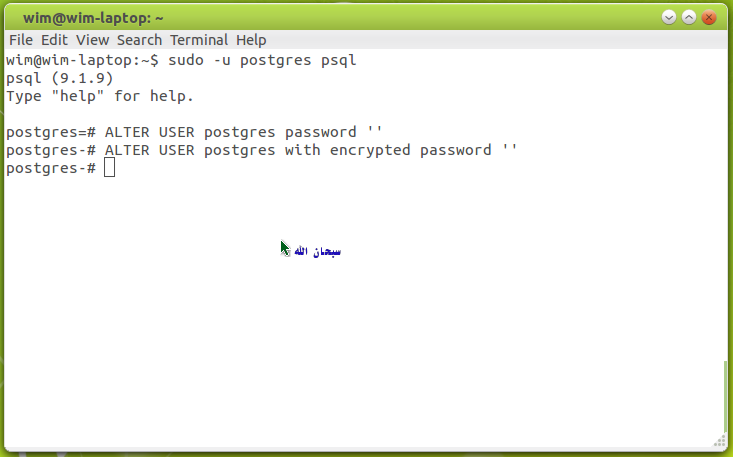
sudo -u postgres psql — войти в утилиту
Обратите внимание, команды самой утилиты psql начинаются с «\»
| \l | Список баз данных |
| \с db_name | Подключение к определенной базе данных |
| \dt | Список таблиц в текущей БД |
| \d table_name | Получение информации о конкретной таблице |
| \dn | Список всех схем в текущей БД |
| \df | Список всех хранимых процедур и функций в текущей БД |
| \dv | Список всех представлений в текущей БД |
| \q | Выход из консоли postgres (psql) |
| \h | Помощь по командам SQL |
| \? | Помощь по командам psql |
Создание резервных копий
Для создание резервных копий PostgreSQL я использую утилиту pg_dump.
Например, нужно создать дамп бд blog от пользователя django (в этой заметке я создал такую БД с таким пользователем), для этого в консоли выполняем команду:
sudo pg_dump -U django -h localhost -Fc blog > blog.dump
В папке откуда мы выполнили команду, должен появится файл blog.dump
Ниже перечислены опции утилиты pg_dump:
-d <имя_бд>, —dbname=имя_бд — база данных, к которой выполняется подключение.
-h <сервер>, —host=сервер — имя сервера.
-p <порт>, —port=порт — порт для подключения.
-U <пользователь>, —username=пользователь) — учетная запись, используемое для подключения.
-w, —no-password — деактивация требования ввода пароля.
-W, —password — активация требования ввода пароля.
—role=имя роли — роль, от имени которой генерируется резервная копия.
-a, —data-only — вывод только данных, вместо схемы объектов (DDL).
-b, —blobs — параметр добавляет в выгрузку большие объекты.
-c, —clean — добавление команд DROP перед командами CREATE в файл резервной копии.
-C, —create — генерация реквизитов для подключения к базе данных в файле резервной копии.
-E <кодировка>, —encoding=кодировка — определение кодировки резервной копии.
-f <файл>, —file=файл — задает имя файла, в который будет сохраняться вывод утилиты.
-F <формат>, —format=формат — параметр определяет формат резервной копии. Доступные форматы:
- p, plain) — формирует текстовый SQL-скрипт;
- c, custom) — формирует резервную копию в архивном формате;
- d, directory) — формирует копию в directory-формате;
- t, tar) — формирует копию в формате tar.

-j <число_заданий>, —jobs=число_заданий — параметр активирует параллельную выгрузку для одновременной обработки нескольких таблиц (равной числу заданий). Работает только при выгрузке копии в формате directory.
-n <схема>, —schema=схема — выгрузка в файл копии только определенной схемы.
-N <схема>, —exclude-schema=схема — исключение из выгрузки определенных схем.
-o, —oids — добавляет в выгрузку идентификаторы объектов (OIDs) вместе с данными таблиц.
-O, —no-owner — деактивация создания команд, определяющих владельцев объектов в базе данных.
-s, —schema-only —добавление в выгрузку только схемы данных, без самих данных.
-S <пользователь>, —superuser=пользователь — учетная запись привилегированного пользователя, которая должна использоваться для отключения триггеров.
-t <таблица>, —table=таблица — активация выгрузки определенной таблицы.
-T <таблица>, —exclude-table=таблица —исключение из выгрузки определенной таблицы.
-v, —verbose — режим подробного логирования.
-V, —version — вывод версии pg_dump.
-Z 0..9, —compress=0..9 — установка уровня сжатия данных. 0 — сжатие выключено.
Восстановление из резервной копии
Для восстановлении базы данных PostgreSQL из резервной копии, я использую утилиту pg_restore.
Восстановим дамп базы из файла blog.dump созданный на предыдущем шаге, для этого введем команду:
sudo pg_restore -v --clean --no-owner --host=localhost --port=5432 --username=django --dbname=blog blog.dump
Ниже перечислены опции утилиты pg_restore:
-h <сервер>, —host=сервер — имя сервера, на котором работает база данных.
-p <порт>, —port=порт — TCP-порт, через база данных принимает подключения.
-U <пользователь>, —username=пользователь — имя пользователя для подключения..
-w, —no-password — деактивация требования ввода пароля.
-W, —password — активация требования ввода пароля.
—role=имя роли — роль, от имени которой выполняется восстановление резервная копия.
<имя_файла> — расположение восстанавливаемых данных.
-a, —data-only — восстановление данных без схемы.
-c, —clean — добавление операторов DROP перед операторами CREATE.
-C, —create — создание базы данных перед запуском процесса восстановления.
-d <имя_бд>, —dbname=имя_бд — имя целевой базы данных.
-e, —exit-on-error — завершение работы в случае возникновения ошибки при выполнении SQL-команд.
-f <имя_файла>, —file=имя_файла — файл для вывода сгенерированного скрипта.
-F <формат>, —format=формат — формат резервной копии. Допустимые форматы:
- p, plain — формирует текстовый SQL-скрипт;
- c, custom — формирует резервную копию в архивном формате;
- d, directory — формирует копию в directory-формате;
- t, tar — формирует копию в формате tar.
-I <индекс>, —index=индекс — восстановление только заданного индекса.
-j <число-заданий>, —jobs=число-заданий — запуск самых длительных операций в нескольких параллельных потоках.
-l, —list) — активация вывода содержимого архива.
-L <файл-список>, —use-list=файл-список — восстановление из архива элементов, перечисленных в файле-списке в соответствующем порядке.
-n <пространство_имен>, —schema=схема — восстановление объектов в указанной схеме.
-O, —no-owner — деактивация генерации команд, устанавливающих владение объектами по образцу исходной базы данных.
-P <имя-функции(тип-аргумента[, …])>, —function=имя-функции(тип-аргумента[, …]) — восстановление только указанной функции.
-s, —schema-only — восстановление только схемы без самих данных.
-S <пользователь>, —superuser=пользователь — учетная запись привилегированного пользователя, используемая для отключения триггеров.
-t <таблица>, —table=таблица — восстановление определенной таблицы.
-T <триггер>, —trigger=триггер — восстановление конкретного триггера.
-v, —verbose — режим подробного логирования.
-V, —version — вывод версии утилиты pg_restore.
Шпаргалка PostgreSQL
PostgreSQL: Документация: 14: Команды SQL
PostgreSQL: Документация: 14: Команды SQL8 сентября 2022 г.: Выпущена бета-версия 4 PostgreSQL 15!
Документация → PostgreSQL 14
Поддерживаемые версии: Текущий (14) / 13 / 12 / 11 / 10
Разрабатываемые версии: 15 / devel
Неподдерживаемые версии:
9,6
/
9,5
/
9. 4
/
9.3
/
9.2
/
9.1
/
9,0
/
8.4
/
8.3
/
8.2
/
8.1
/
8,0
/
7.4
/
7.3
/
7.2
/
7.1
4
/
9.3
/
9.2
/
9.1
/
9,0
/
8.4
/
8.3
/
8.2
/
8.1
/
8,0
/
7.4
/
7.3
/
7.2
/
7.1
Эта часть содержит справочную информацию о командах SQL, поддерживаемых PostgreSQL.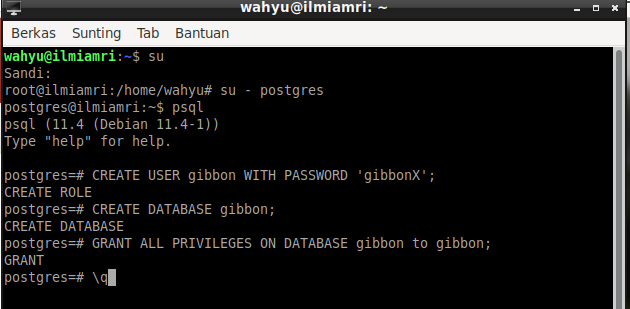 Под «SQL» подразумевается язык в целом; информацию о соответствии стандартам и совместимости каждой команды можно найти на соответствующей справочной странице.
Под «SQL» подразумевается язык в целом; информацию о соответствии стандартам и совместимости каждой команды можно найти на соответствующей справочной странице.
Содержание
- ABORT — прервать текущую транзакцию
- ALTER AGGREGATE — изменить определение агрегатной функции
- ALTER COLLATION — изменить определение сопоставления
- ALTER CONVERSION — изменить определение преобразования
- ALTER DATABASE — изменить базу данных
- ALTER DEFAULT PRIVILEGES — определить права доступа по умолчанию
- ALTER DOMAIN — изменить определение домена
- ALTER EVENT TRIGGER — изменить определение триггера события
- ALTER EXTENSION — изменить определение расширения
- ALTER FOREIGN DATA WRAPPER — изменить определение оболочки сторонних данных
- ALTER FOREIGN TABLE — изменить определение внешней таблицы
- ALTER FUNCTION — изменить определение функции
- ALTER GROUP — изменить имя роли или членство
- ALTER INDEX — изменить определение индекса
- ALTER LANGUAGE — изменить определение процедурного языка
- ALTER LARGE OBJECT — изменить определение большого объекта
- ALTER MATERIALIZED VIEW — изменить определение материализованного представления
- ALTER OPERATOR — изменить определение оператора
- ALTER OPERATOR CLASS — изменить определение класса операторов
- ALTER OPERATOR FAMILY — изменить определение семейства операторов
- ALTER POLICY — изменить определение политики безопасности на уровне строки
- ALTER PROCEDURE — изменить определение процедуры
- ALTER PUBLICATION — изменить определение публикации
- ALTER ROLE — изменить роль базы данных
- ALTER ROUTINE — изменить определение процедуры
- ALTER RULE — изменить определение правила
- ALTER SCHEMA — изменить определение схемы
- ALTER SEQUENCE — изменить определение генератора последовательности
- ALTER SERVER — изменить определение стороннего сервера
- ALTER STATISTICS — изменить определение объекта расширенной статистики
- ALTER SUBSCRIPTION — изменить определение подписки
- ALTER SYSTEM — изменить параметр конфигурации сервера
- ALTER TABLE — изменить определение таблицы
- ALTER TABLESPACE — изменить определение табличного пространства
- ALTER TEXT SEARCH CONFIGURATION — изменить определение конфигурации текстового поиска
- ALTER TEXT SEARCH DICTIONARY — изменить определение словаря текстового поиска
- ALTER TEXT SEARCH PARSER — изменить определение анализатора текстового поиска
- ALTER TEXT SEARCH TEMPLATE — изменить определение шаблона текстового поиска
- ALTER TRIGGER — изменить определение триггера
- ALTER TYPE — изменить определение типа
- ALTER USER — изменить роль базы данных
- ALTER USER MAPPING — изменить определение сопоставления пользователей
- ALTER VIEW — изменить определение вида
- ANALYZE — собрать статистику по базе данных
- BEGIN — начать блок транзакций
- CALL — вызвать процедуру
- CHECKPOINT — установить контрольную точку журнала с упреждающей записью
- CLOSE — закрыть курсор
- CLUSTER — кластеризовать таблицу по индексу
- КОММЕНТАРИЙ — определить или изменить комментарий объекта
- COMMIT — зафиксировать текущую транзакцию
- COMMIT PREPARED — зафиксировать транзакцию, которая ранее была подготовлена для двухэтапной фиксации
- COPY — копирование данных между файлом и таблицей
- CREATE ACCESS METHOD — определить новый метод доступа
- CREATE AGGREGATE — определить новую агрегатную функцию
- CREATE CAST — определить новый слепок
- CREATE COLLATION — определить новую подборку
- CREATE CONVERSION — определить новое преобразование кодировки
- CREATE DATABASE — создать новую базу данных
- CREATE DOMAIN — определить новый домен
- СОЗДАТЬ ТРИГГЕР СОБЫТИЯ — определить новый триггер события
- CREATE EXTENSION — установить расширение
- CREATE FOREIGN DATA WRAPPER — определение новой оболочки внешних данных
- CREATE FOREIGN TABLE — определить новую внешнюю таблицу
- СОЗДАТЬ ФУНКЦИЮ — определить новую функцию
- CREATE GROUP — определить новую роль базы данных
- CREATE INDEX — определить новый индекс
- CREATE LANGUAGE — определить новый процедурный язык
- CREATE MATERIALIZED VIEW — определить новое материализованное представление
- CREATE OPERATOR — определить нового оператора
- СОЗДАТЬ КЛАСС ОПЕРАТОРА — определить новый класс оператора
- СОЗДАТЬ СЕМЕЙСТВО ОПЕРАТОРОВ — определить новое семейство операторов
- CREATE POLICY — определить новую политику безопасности на уровне строк для таблицы
- СОЗДАТЬ ПРОЦЕДУРУ — определить новую процедуру
- СОЗДАТЬ ПУБЛИКАЦИЯ — определить новую публикацию
- CREATE ROLE — определить новую роль базы данных
- CREATE RULE — определить новое правило перезаписи
- СОЗДАТЬ СХЕМУ — определить новую схему
- СОЗДАТЬ ПОСЛЕДОВАТЕЛЬНОСТЬ — определить новый генератор последовательности
- CREATE SERVER — определить новый внешний сервер
- CREATE STATISTICS — определить расширенную статистику
- СОЗДАТЬ ПОДПИСКУ — определить новую подписку
- CREATE TABLE — определить новую таблицу
- CREATE TABLE AS — определить новую таблицу по результатам запроса
- CREATE TABLESPACE — определить новое табличное пространство
- CREATE TEXT SEARCH CONFIGURATION — определение новой конфигурации текстового поиска
- CREATE TEXT SEARCH DICTIONARY — определение нового словаря текстового поиска
- CREATE TEXT SEARCH PARSER — определение нового анализатора текстового поиска
- CREATE TEXT SEARCH TEMPLATE — определение нового шаблона текстового поиска
- CREATE TRANSFORM — определить новое преобразование
- CREATE TRIGGER — определить новый триггер
- CREATE TYPE — определить новый тип данных
- CREATE USER — определить новую роль базы данных
- CREATE USER MAPPING — определить новое сопоставление пользователя с внешним сервером
- CREATE VIEW — определить новый вид
- DEALLOCATE — освободить подготовленный запрос
- DECLARE — определить курсор
- DELETE — удалить строки таблицы
- DISCARD — отменить состояние сеанса
- DO — выполнить блок анонимного кода
- DROP ACCESS METHOD — удалить метод доступа
- DROP AGGREGATE — удалить агрегатную функцию
- DROP CAST — снять гипс
- DROP COLLATION — удалить подборку
- DROP CONVERSION — удалить конвертацию
- DROP DATABASE — удалить базу данных
- DROP DOMAIN — удалить домен
- DROP EVENT TRIGGER — удалить триггер события
- DROP EXTENSION — удалить расширение
- DROP FOREIGN DATA WRAPPER — удалить оболочку сторонних данных
- DROP FOREIGN TABLE — удалить стороннюю таблицу
- DROP FUNCTION — удалить функцию
- DROP GROUP — удалить роль базы данных
- DROP INDEX — удалить индекс
- DROP LANGUAGE — удалить процедурный язык
- DROP MATERIALIZED VIEW — удалить материализованное представление
- DROP OPERATOR — удалить оператора
- DROP OPERATOR CLASS — удалить класс оператора
- DROP OPERATOR FAMILY — удалить семейство операторов
- DROP OWNED — удалить объекты базы данных, принадлежащие роли базы данных
- DROP POLICY — удалить политику безопасности на уровне строк из таблицы
- DROP PROCEDURE — удалить процедуру
- DROP PUBLICATION — удалить публикацию
- DROP ROLE — удалить роль базы данных
- DROP ROUTINE — удалить процедуру
- DROP RULE — удалить правило перезаписи
- DROP SCHEMA — удалить схему
- DROP SEQUENCE — удалить последовательность
- DROP SERVER — удалить дескриптор стороннего сервера
- DROP STATISTICS — удалить расширенную статистику
- DROP SUBSCRIPTION — удалить подписку
- DROP TABLE — удалить таблицу
- DROP TABLESPACE — удалить табличное пространство
- DROP TEXT SEARCH CONFIGURATION — удалить конфигурацию текстового поиска
- DROP TEXT SEARCH DICTIONARY — удалить словарь текстового поиска
- DROP TEXT SEARCH PARSER — удалить анализатор текстового поиска
- DROP TEXT SEARCH TEMPLATE — удалить шаблон текстового поиска
- DROP TRANSFORM — удалить преобразование
- DROP TRIGGER — удалить триггер
- DROP TYPE — удалить тип данных
- DROP USER — удалить роль базы данных
- DROP USER MAPPING — удалить сопоставление пользователя для внешнего сервера
- DROP VIEW — удалить вид
- END — зафиксировать текущую транзакцию
- EXECUTE — выполнить подготовленный оператор
- EXPLAIN — показать план выполнения инструкции
- FETCH — извлекать строки из запроса с помощью курсора
- GRANT — определить права доступа
- IMPORT FOREIGN SCHEMA — импорт определений таблиц с внешнего сервера
- INSERT — создать новые строки в таблице
- LISTEN — прослушать уведомление
- LOAD — загрузить файл общей библиотеки
- LOCK — блокировка стола
- MOVE — позиционировать курсор
- NOTIFY — создать уведомление
- ПОДГОТОВКА — подготовить оператор к выполнению
- ПОДГОТОВИТЬ ТРАНЗАКЦИЮ — подготовить текущую транзакцию к двухэтапной фиксации
- REASSIGN OWNED — изменить владельца объектов базы данных, принадлежащих роли базы данных
- REFRESH MATERIALIZED VIEW — заменить содержимое материализованного представления
- REINDEX — перестроить индексы
- RELEASE SAVEPOINT — удалить ранее определенную точку сохранения
- RESET — восстановить значение параметра времени выполнения до значения по умолчанию
- REVOKE — удалить привилегии доступа
- ROLLBACK — прервать текущую транзакцию
- ROLLBACK PREPARED — отменить транзакцию, ранее подготовленную для двухфазной фиксации
- ROLLBACK TO SAVEPOINT — откат к точке сохранения
- SAVEPOINT — определить новую точку сохранения в текущей транзакции
- МЕТКА ЗАЩИТЫ — определение или изменение метки безопасности, применяемой к объекту
- SELECT — получить строки из таблицы или представления
- SELECT INTO — определить новую таблицу по результатам запроса
- SET — изменить динамический параметр
- SET CONSTRAINTS — установить время проверки ограничений для текущей транзакции
- SET ROLE — установить текущий идентификатор пользователя текущей сессии
- SET SESSION AUTHORIZATION — установить идентификатор пользователя сессии и текущий идентификатор пользователя текущей сессии
- SET TRANSACTION — установить характеристики текущей транзакции
- SHOW — показать значение динамического параметра
- START TRANSACTION — запустить блок транзакций
- TRUNCATE — очистить таблицу или набор таблиц
- UNLISTEN — перестать слушать уведомление
- UPDATE — обновить строки таблицы
- VACUUM — сборка мусора и опциональный анализ базы данных
- VALUES — вычислить набор строк
10 основных команд PSQL для инженеров данных | от AnBento
Узнайте, как взаимодействовать с базами данных PostgreSQL через командную строку с помощью PSQL.
 Фото Энгина Акьюрта с Pexels
Фото Энгина Акьюрта с PexelsРекомендуемые курсы по запросу:
Многие из вас связались со мной с просьбой предоставить ценные ресурсы , чтобы пройти интервью по Data Engineering на основе Python . Ниже я делюсь 3 курсами по запросу, которые я настоятельно рекомендую:
- Python Data Engineering Nanodegree → Курс высокого качества!
- LeetCode In Python: 50 вопросов по кодированию на собеседовании по алгоритмам
- Расширенные проблемы кодирования Python (StrataScratch) → Лучшая платформа, которую я нашел для подготовки интервью по кодированию Python и SQL! Лучше и дешевле, чем LeetCode.
Надеюсь, они вам тоже пригодятся! А теперь наслаждайтесь статьей: D
На пути к тому, чтобы стать инженером данных, в какой-то момент вы, должно быть, наткнулись на командную строку (, также известную как терминал ).
Возможно, это был коллега, показывающий вам, как создавать переменные окружения? …или научили вас лучшим практикам локального контроля версий?…или вы втайне восхищались тем, как они взаимодействуют с базами данных, казалось бы, без усилий или необходимости в современной СУБД?
Какой бы ни была ваша первая встреча с командной строкой, вы, вероятно, подумали «Я хочу такие же сверхспособности… Мне нужно научиться это делать!».
Какой бы ни была ваша первая встреча с командной строкой, вы, вероятно, подумали «Я хочу такие же сверхспособности… Мне нужно научиться это делать!».
Чтобы помочь вам овладеть одним из самых фундаментальных навыков работы с данными, в этой статье я познакомлю вас с psql и с тем, как использовать его для взаимодействия с базами данных PostgreSQL через терминал. Я также покажу вам 10 групп команд, которые я снова и снова использую на рабочем месте.
Прежде всего, что такое psql? …и, что более важно, какие у него плюсы и минусы?
На официальном сайте PostgreSQL psql определяется как интерактивный терминал PostgreSQL.
Это означает, что если вы ежедневно работаете с PostgreSQL, вы можете использовать psql для подключения к предпочитаемой базе данных, ввода запросов и просмотра результатов запросов через командную строку. Но чем хорош и чем плох psql ?
Плюсы Psql
- Позволяет быстро взаимодействовать с базой данных, оставаясь в той же среде ( терминал ), без необходимости настройки в отличие от стандартной СУБД. Это, в свою очередь, ускоряет вашу работу.
- Позволяет выполнять как короткие, так и более сложные запросы, используя ваш любимый редактор или выполняя запросы из файла.
- Позволяет отслеживать изменения в таблицах, выполняя команды через указанные промежутки времени.
- По сравнению со стандартной СУБД, она позволяет почти без усилий извлекать метаданные и статистику о базах данных, схемах, таблицах и пользователях.
Psql Cons
- Это не лучший инструмент, когда вам нужно отобразить и проанализировать большое количество столбцов или интерактивно изменить порядок столбцов в выводе.

psqlдовольно хорош, когда запрос возвращает небольшое количество столбцов, которые выглядят аккуратно на терминале. - Это не лучший инструмент, если вы хотите сохранить вывод вашего запроса в файл в определенном формате. Несмотря на это можно сделать
psql( как я покажу чуть позже ), современные СУБД предлагают гораздо более широкий и удобный набор опций.
Теперь, когда я объяснил немного больше , когда psql должен быть вашим предпочтительным вариантом, позвольте мне также поделиться , как его использовать!
Mac
Чтобы получить psql на ноутбуке Mac, вам просто нужно загрузить homebrew , а затем выполнить следующие две команды:
$ brew install postgresql
$ brew services start postgresql
Затем, когда служба запущена, проверьте, запущена ли она, с помощью следующей команды:
$ brew services Имя Статус Пользователь Plist postgresql запущен anbento /Users/anbento.Windows..
Чтобы установить psql на компьютер с Windows вместе с другими клиентскими приложениями, следуйте этому превосходному руководству.
Как и другие клиентские приложения терминала, psql предлагает широкий набор команд для взаимодействия с базами данных PostgreSQL. Однако ниже я попытался представить 10 команд, которые я использую чаще всего каждый день.
# 1 Подключение к базе данных PostgreSQL
Первым шагом для взаимодействия с базой данных PG является подключение к ней.
Имейте в виду, что если вы обычно подключаетесь с использованием туннеля SSH или любого другого типа шифрования, вам необходимо разобраться с этим перед выполнением следующей команды.
На рабочем месте, скорее всего, вам придется установить соединение с базой данных, которая находится на определенном хосте. В этом случае следует использовать:
$ psql -h host -d database -U user -W
. = anbento
= anbento
Вот как должны выглядеть команда и вывод:
$ psql -h localhost -p 5000 -d fin_db -U anbento -W Пароль для пользователя anbento:psql (14.0, server 12.5 (Ubuntu 12.5–1.pgdg18.04+1))SSL-соединение (протокол: TLSv1.3, шифр: TLS_AES_256...., биты: 256, сжатие: выключено)Введите «help» для help.fin_db=>
После запуска вам будет предложено ввести пароль пользователя. Если соединение установлено успешно, вы увидите курсор, которому предшествует имя базы данных, появившееся на экране.
Теперь вы можете запускать к нему запросы!
# 2 Схемы списка | Столы | Просмотры | Функции | Пользователи
Как специалист по работе с данными, иногда вам может понадобиться список схем, доступных в базе данных, к которой вы в данный момент подключены.
Этого можно добиться с помощью \dn команда:
fin_db->\dn Список схем
Имя | Владелец
------------------+------------------------------------
аудит | owner_1
fin_data | owner_2
fin_config | owner_3
fin_control | owner_4
fin_internal | owner_5
финансы_аналитика | owner_6
найтиb | owner_7
pdl | owner_8
pdl_map | owner_9
pdl_ob | владелец_10
пд | владелец_11
... | ...(20 rows)
Как видите, база данных fin_db включает 20 схем, привязанных к конкретным владельцам. Однако что, если вам нужна определенная группа схем (скажем, все, начинающиеся с fin_ )? В этом случае вы должны запустить:
db_findb-> \dn fin_* Список схем
Имя | Владелец
— — — — — — — + — — — — — — — — -
fin_adata | владелец_2
fin_config | owner_3
fin_control | owner_4
fin_internal | owner_5(4 rows)
Теперь команда просто отображает 4 схемы, соответствующие предоставленному регулярному выражению.
Очень похожие команды можно использовать для вывода списка таблиц, представлений, функций и пользователей базы данных, к которой вы подключены:
# Показать список таблиц
\dt или \dt + regex # Показать список просмотров
\dv или \dv + регулярное выражение # Отображение списка функций
\df или \df + regex # Отображение списка пользователей
\du или \du + regex
# 3 Описание таблицы
900 узнать больше о конкретной таблице, перечислив ее столбцы, типы данных, а также понять, какие поля могут быть пустыми, вы должны использовать команду \d имя_таблицы .
Например, для описания таблицы с именем findb.transactions (где findb — это имя схемы) вы должны запустить:
db_findb-> \d findb.transactions Разделенная таблица «findb.transactions» Column | Тип | сортировка | Обнуляемый | По умолчанию
---------------+--------------+-----------+------ ----+---------
trx_id | большой | | не нуль |
код_источника | большой | | |
ops_type_id | большой | | не нуль |
ручной_статус | целое число | | не нуль |
количество_источника | числовой | | не нуль |
... | ... |... | ... |
# 4 Выполнить предыдущую команду
Чтобы запросить базу данных с помощью psql , вам просто нужно ввести код SQL, за которым следует точка с запятой ; . Если вы опустите точку с запятой, клиентское приложение не сможет понять, готов ли код к выполнению, и будет держать вас в режиме редактирования.
Например, если вы хотите подсчитать общее количество транзакций за findb. created on  transactions
transactions 2021-10-01 вы должны запустить:
db_findb=> select count(trx_id)
from findb.transactions =1–02_at where created;
count
-------
512323(1 строка)
Запрос сообщает нам, что 512 323 было создано в эту дату. Что делать, если вы хотите снова запустить тот же запрос? Вы можете просто ввести \g :
db_findb=> \g count
-------
512323(1 строка)
Это работает со всеми командами и эквивалентно стрелка вверх + введите .
# 5 Выполнение команд из файлов
Иногда сценарии SQL становятся более длинными и сложными, поэтому вы можете сначала создать их, сохранить в файл, а затем выполнить запрос, включенный в файл, с помощью psql . Это возможно, используя \i имя файла .
В приведенном ниже примере я сохранил эквивалент этого запроса:
выберите
TRX_ID
, POSTING_DATE
, SOURCE_AMOUNT
, OPS_TYPE_ID
из FINDB.TRANSACTIONS
, где POSTING_DATE = current_date
ограничение 5;
в файл Sublime Text с именем query_trxs . Файл находится на моем рабочем столе, поэтому для его запуска я запускаю:
db_findb=> \i /Users/Anbento/Desktop/query_trxs trx_id | posting_date | исходное_количество | ops_type_id
-----------+---------------+---------------+----- -------+
5122579747 | 2021-10-24 | 386,00 | 18 |
5115148908 | 2021-10-24 | 0,0 | 252 |
5115148971 | 2021-10-24 | 0,6100 | 70 |
5122580187 | 2021-10-24 | 15000,00 | 62 |
5122580337 | 2021-10-24 | 0,38 | 69 |(5 rows)
# 6 Команды записи в редакторе
Излишне говорить, что терминал — не лучший инструмент для выполнения длинных SQL-запросов. Чтобы помочь с этим, psql позволяет не только выполнять команды из файлов, но и получать доступ к редактору по умолчанию через \e команда.
Например, на моем Mac команда откроет редактор vim , так как это редактор по умолчанию, найденный psql .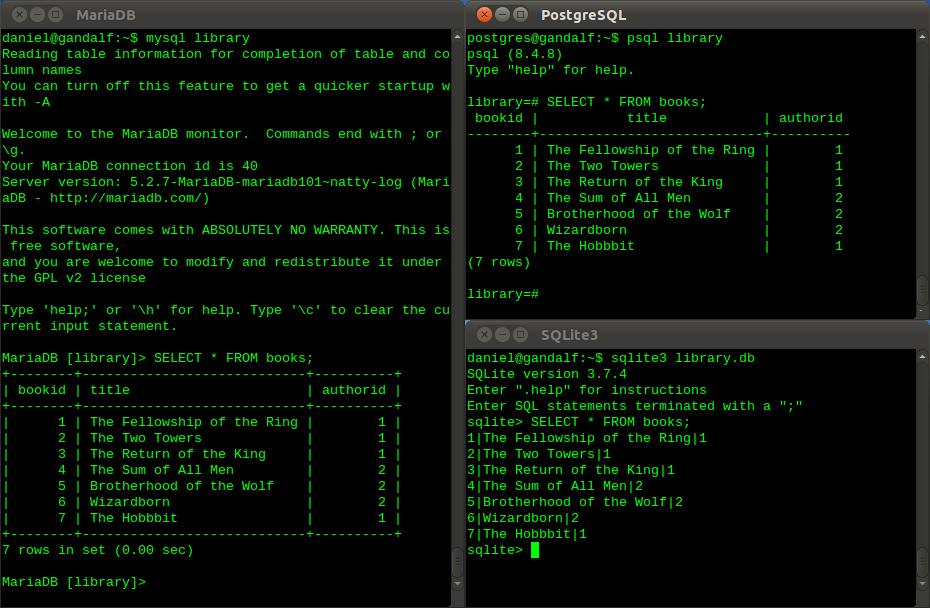 Если это и ваш случай, сделайте две вещи:
Если это и ваш случай, сделайте две вещи:
- введите
iдля доступа к режимуINSERT. Теперь вы сможете ввести свой запрос. В этом случае я пытаюсь найтиmax(trx_id)вfindb.transactions:
- Когда вы довольны своим запросом, введите
escс последующим:x!. Это сохранит ваш контент и автоматически выполнит SQL-скрипт:
db_findb=> \e max_id
— — — — — —
5124302389(1 row)
Однако вы можете переключиться на свой любимый редактор ( например nano ), добавив следующие строки в файл ~/.zshrc , если ваша оболочка по умолчанию zsh , или ~/.bash_profile , если ваша оболочка по умолчанию bash :
export EDITOR=nano
export VISUAL="$EDITOR"
Затем выполните приведенную ниже команду, чтобы обновить конфигурацию:
source ~/.zshrc
#или
source ~/.bash_profile
Если вы выйдете psql и снова подключитесь к базе данных, когда вы запустите \e , вы должны увидеть, как запускается редактор nano :
Данные инженеры часто заняты тестированием производительности определенных сценариев SQL. В этом случае очень полезно знать, сколько времени требуется для выполнения запроса.
Чтобы отобразить время выполнения на psql , вы можете ввести \timing на . Например, запуск того же файла, что и раньше:
db_findb=> \timing on
Время on.db_findb=> \i /Users/Anbento/Desktop/query_trxs trx_id | posting_date | исходное_количество | ops_type_id
-----------+---------------+---------------+----- -------+
5122579747 | 2021-10-24 | 386,00 | 18 |
5115148908 | 2021-10-24 | 0,0 | 252 |
5115148971 | 2021-10-24 | 0,6100 | 70 |
5122580187 | 2021-10-24 | 15000,00 | 62 |
5122580337 | 2021-10-24 | 0,38 | 69 |(5 строк)Время: 2673,033 мс (00:02,673)
Теперь вы знаете, что для выполнения запроса потребовалось 2,67 с .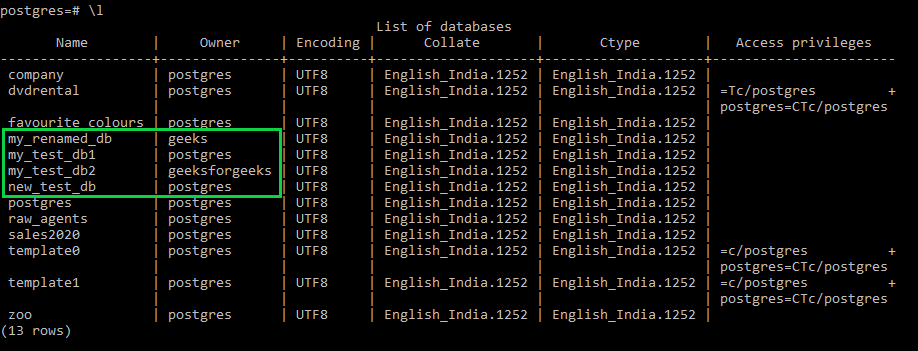
Чтобы отключить синхронизацию, вы можете вместо этого ввести \timing off .
Вам когда-нибудь приходилось запускать один и тот же сценарий SQL несколько раз? Например, чтобы проверить, работает ли конвейер ETL должным образом, загружая данные в определенную таблицу?
Если вы ответили «да», вам повезло, так как с psql вы можете автоматически запускать скрипт столько раз, сколько пожелаете, и с заданными интервалами, используя команду \watch + interval (в секундах) . Например:
db_findb=> выберите
max(TRX_ID) как max_id
из FINDB.TRANSACTIONS; max_id
— — — — — —
5124378773(1 row)db_findb=> \watch 5
Вс 24 октября 18:55:13 2021 (каждые 5 с)max_id
— — — — — —
5124378799(1 строка)Вс 24 октября 18:55:18 2021 (каждые 5 с)max_id
— — — — — —
5124378808(1 строка)
Как видите, я запускаю SQL-запрос, который хочу выполнить в сначала определенные интервалы, затем я набираю \watch 5 , чтобы запрос начинал выполняться каждые 5 секунд .
trx_id продолжает расти по мере добавления новых записей в таблицу.
Тот же запрос продолжает выполняться до тех пор, пока вы не завершите его с помощью ctrl + c .
9Команда 0457 \watch чрезвычайно полезна и определенно является моей любимой из 10, описанных в этой статье 😀
# 9 Экспорт данных в формате CSV
Угадайте, что? Как я упоминал в начале статьи, psql позволяет экспортировать данные в формате CSV. Вы можете выполнить это с помощью команды \copy , используя следующий синтаксис:
\copy (запрос SQL) TO 'путь\имя_файла.csv' С ЗАГОЛОВКОМ CSV
Имейте в виду, что в этом случае запрос SQL не нужна точка с запятой ; в конце (или psql выдаст ошибку). Кроме того, если вы хотите сохранить имена столбцов в файле CSV, не забудьте добавить HEADER в конце.
Например, предположим, что вы хотите экспортировать результат этого запроса в CSV-файл на рабочем столе:
выберите
TRX_ID
,POSTING_DATE
,SOURCE_AMOUNT
,OPS_TYPE_ID
из FINDB current1 TRANSACTIONS
ATE
Затем введите:
DB_FINDB => \ COPY (
SELECT
TRX_ID
, proping_date
, Source_amount
, OPS_TYPE_ID
от Findb.TransCranse
, где posting_date = current_date
333333333333333333333333333333333333333333333333333333333 гг. CSV HEADERCOPY 10
Когда вы запустите эту команду, она создаст CSV-файл с именем query_trxs_v2 , который выглядит следующим образом:
# 10 Выйти из psql
Когда вы закончите использовать psql , вы можете выйти из клиентского приложения, используя \q + введите . В качестве альтернативы вы можете использовать ctrl + z . Это закроет клиентское приложение, и вы не сможете продолжить работу на терминале.
В этой статье я поделился с вами 10 командами psql , которые вы должны освоить, чтобы стать инженером данных со сверхспособностями. Это также команды, которые я непропорционально часто использую в повседневной жизни, поэтому я надеюсь, что вы начнете с них в соответствии с правилом 80/20.
Однако имейте в виду, что psql предлагает очень широкий набор команд, и вам еще многое предстоит изучить, чтобы освоить этот инструмент.
Продолжай учиться!
Как использовать командную строку PostgreSQL для управления базами данных?
Командная строка PostgreSQL , в общем, является программой. И мы выполняем командную строку в интерфейсе командной строки (CLI) для прямого взаимодействия с данными в базе данных. Хотя Графический пользовательский интерфейс (GUI) обеспечивает гораздо лучший пользовательский интерфейс, командная строка PostgreSQL играет жизненно важную роль при управлении приложениями или операционными системами с большим контролем, надежностью и условностью.
PostgreSQL — это СУБД (система управления реляционными базами данных), позволяющая легко и безопасно собирать данные. Сегодня PostgreSQL используется в качестве основного репозитория хранения данных (как хранилище данных) для многих веб-сайтов, мобильных и аналитических приложений. И вы могли заметить (когда устанавливали сервер базы данных PostgreSQL) некоторые инструменты, которые предлагают специалистам по данным с хорошим пониманием SQL простой способ управления базами данных в PostgreSQL с помощью командной строки.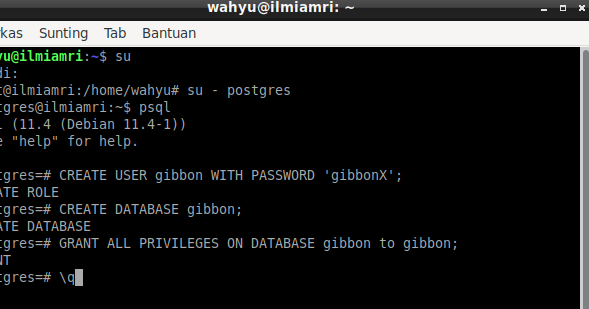
Эти инструменты известны как интерактивная терминальная программа — psql и pgAdmin.
- psql: клиентский интерфейс на основе терминала для сервера базы данных PostgreSQL.
- pgAdmin: веб-интерфейс к серверу базы данных PostgreSQL.
Мы можем использовать psql (терминал или командную строку) и инструмент подключения pgAdmin для подключения нашей базы данных PostgreSQL и управления ею.
В этой учебной статье объясняется, как использовать интерактивные терминальные программы для подключения и управления базой данных PostgreSQL в интерфейсе командной строки. И чтобы получить четкое представление о предмете, мы также кратко обсудим PostgreSQL и его возможности.
Содержание
- Что такое PostgreSQL?
- Подключиться с помощью psql в командной строке PostgreSQL
- Доступ к psql напрямую с помощью sudo в командной строке PostgreSQL
- Подключиться с помощью pgAdmin в командной строке PostgreSQL
- Заключение
Что такое PostgreSQL?
PostgreSQL — это система управления реляционными базами данных (RDBMS) с открытым исходным кодом.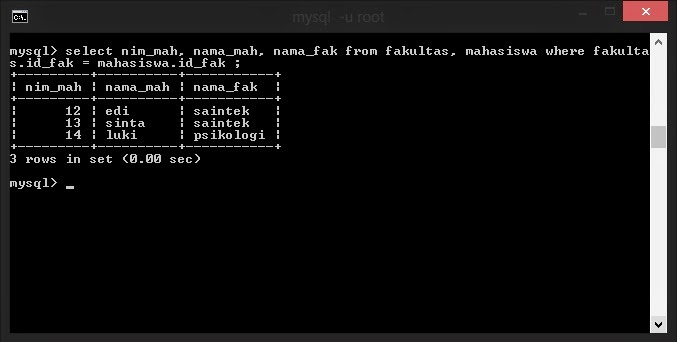 PostgreSQL с его первоклассной оптимизацией производительности и расширенными функциями работы с типами данных сделал себе имя в сообществе данных. Благодаря богатому набору функций, надежной и надежной работе PostgreSQL стал предпочтительным выбором, заняв 4-е место среди самых популярных систем управления базами данных в мире.
PostgreSQL с его первоклассной оптимизацией производительности и расширенными функциями работы с типами данных сделал себе имя в сообществе данных. Благодаря богатому набору функций, надежной и надежной работе PostgreSQL стал предпочтительным выбором, заняв 4-е место среди самых популярных систем управления базами данных в мире.
PostgreSQL безупречно работает со всеми основными операционными системами, такими как Linux, Windows и Mac OS. Благодаря тому, что PostgreSQL предлагает совместимость с несколькими приложениями, платформа предоставляет своим пользователям преимущество в управлении своими базами данных с высокой степенью контроля и гибкости.
Вот некоторые ключевые особенности PostgreSQL:
- Исходный код с открытым исходным кодом, следовательно, бесплатный : PostgreSQL — это реляционная СУБД с открытым исходным кодом, что делает ее подходящей для молодой команды разработчиков. Кроме того, его легко загрузить, и он совместим со всеми основными операционными системами.

- Он известен своей разнообразной пользовательской базой: Apple, Cisco, Etsy, Facebook, Instagram, Red Hat, Skype, Spotify и Yahoo имеют одну общую черту: все они используют PostgreSQL для своих повседневных потребностей в базах данных.
- Очень надежная и совместимая с несколькими типами данных : Ведение журнала PostgreSQL с упреждающей записью делает базу данных очень отказоустойчивой. Более того, высокая совместимость с несколькими типами данных делает его варианты использования синонимом болевых точек современных специалистов по данным, что делает его решением де-факто.
- И это также безопасно : PostgreSQL предлагает надежную систему контроля доступа и соответствует всем основным требованиям безопасности. Чтобы включить несколько, PostgreSQL является жалобой на LDAP, GSSAPI, SSPI и т. д. Учить больше.
Hevo предлагает более быстрый способ перемещения данных из баз данных или приложений SaaS , таких как PostgreSQL , в ваше хранилище данных для визуализации в инструменте бизнес-аналитики. Hevo полностью автоматизирован и, следовательно, не требует написания кода.
Hevo полностью автоматизирован и, следовательно, не требует написания кода.
Начните работу с Hevo бесплатно
Ознакомьтесь с некоторыми интересными функциями Hevo:
- Полная автоматизация: Платформа Hevo устанавливается всего за несколько минут и требует минимального обслуживания.
- Передача данных в режиме реального времени: Hevo обеспечивает миграцию данных в режиме реального времени, поэтому вы всегда можете иметь готовые к анализу данные.
- 100% полная и точная передача данных: Надежная инфраструктура Hevo обеспечивает надежную передачу данных без потери данных.
- Масштабируемая инфраструктура: Hevo имеет встроенную интеграцию для 100+ источников (включая 30+ бесплатных источников), которые могут помочь вам масштабировать вашу инфраструктуру данных по мере необходимости.
- Круглосуточная поддержка без выходных: Команда Hevo доступна круглосуточно, чтобы оказать вам исключительную поддержку через чат, электронную почту и звонки в службу поддержки.

- Управление схемой: Hevo избавляет от утомительной задачи управления схемой, автоматически определяет схему входящих данных и сопоставляет ее с целевой схемой.
- Мониторинг в реальном времени: Hevo позволяет вам отслеживать поток данных, чтобы вы могли проверить, где находятся ваши данные в определенный момент времени.
Зарегистрируйтесь здесь, чтобы получить 14-дневную бесплатную пробную версию!
Подключиться с помощью psql в командной строке PostgreSQL
Теперь, чтобы начать работу с psql Подключиться к командной строке базы данных, сначала необходимо установить PostgreSQL. После установки PostgreSQL будет создана база данных по умолчанию и учетная запись пользователя с именем «postgres». Теперь, чтобы войти в базу данных, запустите приведенную ниже командную строку в интерфейсе командной строки вашей операционной системы.
sudo -i -u postgres
Приведенная ниже команда является примером из Ubuntu, операционной системы на базе Linux.
Чтобы получить желаемый результат в Centos или Fedora (системы на основе Red Hat), выполните одну из двух следующих команд:
su postgres
или
su -i postgres
Упомянутые выше команды предоставят вам root привилегии для учетной записи пользователя «postgres»
Примечание: эти команды также будут работать и для других пользователей. Например, если пользователя зовут «ThisIsATest», то в командных строках «postgres» по умолчанию будет заменено на «ThisIsATest».
Теперь, чтобы начать использовать psql для подключения к командной строке базы данных, введите команду, представленную ниже:
psql
Последующий экран (показан ниже). Это подтверждает, что теперь вы можете управлять — редактировать и выполнять запросы — базой данных PostgreSQL.
В PostgreSQL легко управлять большим количеством баз данных и пользователей. Вы можете определить текущее соединение или идентифицировать пользователей, просто запустив приведенную ниже командную строку:
conninfo
Следующий экран подтвердит, какой пользователь и база данных в настоящее время не используются.
Доступ к базе данных Непосредственно с помощью «sudo» в командной строке PostgreSQL
Можно получить прямой доступ к базе данных PostgreSQL напрямую, минуя оболочку bash. Используя приведенную ниже командную строку, вы можете легко получить доступ к своей базе данных, но только если вы уверены, что все аспекты вашей базы данных настроены правильно.
sudo -i -u postgres psql
Примечание. В предыдущем методе вы работали с базами данных, выполняя запросы. Но при использовании метода sudo параметр -u (пользователь) заставляет «sudo» запускать некоторые специальные команды от имени пользователя, а не от имени пользователя root.
Подключиться с помощью pgAdmin в командной строке PostgreSQL
Используемый в качестве графического инструмента в PostgreSQL для управления базами данных, pgAdmin представляет собой веб-интерфейс к серверу баз данных PostgreSQL. Чтобы получить доступ к базе данных с помощью pgAdmin, сначала вам необходимо установить и настроить последнюю версию браузера и создать новую учетную запись пользователя pgAdmin. Электронная почта и пароль необходимы для аутентификации доступа.
Электронная почта и пароль необходимы для аутентификации доступа.
python /usr/lib/python2.7/site-packages/pgadmin4-web/setup.py
После завершения процесса аутентификации вы можете получить доступ к интерфейсу phAdmin 4, используя приведенную ниже командную строку:
http://localhost/pgadmin4
или
http://ip-adress/pgadmin4
Теперь используйте адрес электронной почты и пароль, созданные ранее, для аутентификации пользователя. Теперь загрузится пользовательский интерфейс, и теперь вам нужно будет перемещаться, как показано на изображении ниже. (Серверы>Создать>Сервер)
В разделе «Создать — Сервер» вкладки «Общие» и «Подключение» теперь будут использоваться для ввода таких значений, как имя сервера и учетные данные пользователя для базы данных.
Теперь, когда соединение с вашей базой данных установлено, в следующем интерфейсе будет представлен обзор баз данных пользователя. Вы можете выполнять запросы, щелкнув Инструменты > Инструмент запросов или нажав ALT + Shift + Q.
Заключение
Подведем итоги. В этой учебной статье мы предоставили два способа подключения к командной строке базы данных. Во-первых, с помощью метода psql, а во-вторых, с помощью метода pgAdmin. И если вам нужно узнать больше по этому вопросу, любая из этих двух статей может помочь.
- Документация по подключению pgAdmin и psql к командной строке базы данных в PostgreSQL 8.4
- Документация по подключению pgAdmin и psql к командной строке базы данных в PostgreSQL 9.1
В этом отношении извлечение и управление сложными данными из разнообразных источников данных может оказаться непростой задачей, и здесь Hevo может помочь!
Hevo Data предлагает более быстрый способ перемещения данных из баз данных или приложений SaaS в ваше хранилище данных для визуализации в инструменте BI. Hevo полностью автоматизирован и, следовательно, не требует написания кода.
Посетите наш веб-сайт, чтобы ознакомиться с Hevo
Hevo Data автоматизирует процесс передачи данных, что позволит вам сосредоточиться на других аспектах вашего бизнеса, таких как аналитика, управление клиентами и т. д. Эта платформа позволяет передавать данные из более чем 100 различных источников. в облачные хранилища данных, такие как Snowflake, Google BigQuery, Amazon Redshift и т. д. Это обеспечит вам беспроблемную работу и значительно облегчит вашу работу.
д. Эта платформа позволяет передавать данные из более чем 100 различных источников. в облачные хранилища данных, такие как Snowflake, Google BigQuery, Amazon Redshift и т. д. Это обеспечит вам беспроблемную работу и значительно облегчит вашу работу.
Хотите попробовать Hevo? Зарегистрируйтесь , чтобы получить 14-дневную бесплатную пробную версию и опробуйте многофункциональный пакет Hevo из первых рук.
Героку Постгрес | Центр разработки Heroku
Последнее обновление: 29 августа 2022 г.
Содержание
- Понимание планов Heroku Postgres
- Подготовка Heroku Postgres
- Local Setup
- Обозначение первичной базы данных
- Обмен Heroku Postgres между приложениями
- Поддержка версии
- Legacy Infrastructure
- Analytics
- с использованием CLI
- Analytics
- с использованием CLI
- Analytics
- с использованием CLI
- Analytics
- с использованием CLI
- Analytics
- с использованием CLI
- .

- Удаление надстройки
- Поддержка
С 28 ноября 2022 г. бесплатные планы Heroku Dynos, Heroku Postgres и Heroku Data for Redis® больше не будут доступны. Если у вас есть приложения, использующие какой-либо из этих ресурсов, вы должны перейти на платные планы к этой дате, чтобы ваши приложения продолжали работать и сохраняли ваши данные. Для студентов мы объявим новую программу к концу сентября. Смотрите наш блог и часто задаваемые вопросы для получения дополнительной информации.
Heroku Postgres — это управляемая служба базы данных SQL, предоставляемая непосредственно Heroku. Вы можете получить доступ к базе данных Heroku Postgres с любого языка с помощью драйвера PostgreSQL, включая все языки, официально поддерживаемые Heroku.
В дополнение к множеству команд управления, доступных через интерфейс командной строки Heroku, Heroku Postgres предоставляет веб-панель, возможность обмениваться запросами с клипами данных и ряд других полезных функций.
Понимание планов Heroku Postgres
Heroku Postgres предлагает множество планов, распределенных по разным уровням обслуживания: хобби, стандартный, премиальный и корпоративный. Дополнительные сведения о том, что предоставляет каждый план, см. в разделе Выбор правильного плана Heroku Postgres.
Информация о ценах на планы Heroku Postgres доступна на странице надстройки Heroku Postgres.
Если требования вашего приложения со временем превышают ресурсы, предоставляемые первоначальным планом, который вы выбрали, вы можете легко обновить свою базу данных.
Инициализация Heroku Postgres
Перед тем, как подготовить Heroku Postgres, убедитесь, что он не уже подготовлен для вашего приложения. Heroku автоматически подготавливает Postgres для приложений, включающих определенные библиотеки, такие как гем pg Ruby.
Используйте команду heroku addons , чтобы определить, подготовлено ли ваше приложение Heroku Postgres:
$ героику аддоны Стоимость дополнительного плана ─диимобилил ──────── ───────── ───── ─────── heroku-postgresql (postgresql-concave-52656) хобби-разработчик создан бесплатно
Если heroku-postgresql не отображается в списке надстроек вашего приложения, вы можете предоставить его с помощью следующей команды CLI:
$ heroku addons: создать heroku-postgresql:
Например, для предоставления базы данных плана хобби-разработчика:
$ heroku addons:создать heroku-postgresql:hobby-dev Создание heroku-postgresql:hobby-dev на ⬢ суши... бесплатно База данных создана и доступна ! Эта база данных пуста. При обновлении вы можете перенести ! данные из другой базы данных с помощью pg:copy Создан postgresql-concave-52656 как DATABASE_URL.
Вы можете указать версию Postgres, которую хотите предоставить, включив флаг --version в команду подготовки:
$ heroku addons: создать heroku-postgresql:--version=12
Узнайте больше о поддержке версий PostgreSQL.
В зависимости от выбранного вами плана доступ к базе данных может занять до 5 минут. Вы можете отслеживать его статус с помощью команды heroku pg:wait , которая блокируется до тех пор, пока ваша база данных не будет готова к использованию.
В рамках процесса подготовки к конфигурации вашего приложения добавляется переменная конфигурации DATABASE_URL . DATABASE_URL содержит URL-адрес, который ваше приложение использует для доступа к базе данных. Если в вашем приложении уже есть база данных Heroku Postgres и вы подготовили еще одну , имя этой переменной конфигурации вместо этого имеет формат HEROKU_POSTGRESQL_ (например, HEROKU_POSTGRESQL_YELLOW_URL ).
Вы можете подтвердить имена и значения переменных конфигурации вашего приложения с помощью команда heroku config .
Значение переменной конфигурации DATABASE_URL вашего приложения может измениться в любое время.
Не полагайтесь на это значение ни внутри, ни за пределами вашего приложения Heroku.
На данный момент подготовлена пустая база данных PostgreSQL. Чтобы заполнить его данными из существующего источника данных, см. инструкции по импорту или следуйте инструкциям для конкретного языка в этой статье, чтобы подключиться из вашего приложения.
Локальная настройка
- Настройка Mac
- Программа установки Windows
- Настройка Linux
Heroku рекомендует запускать Postgres локально, чтобы обеспечить паритет между средами. Существует несколько предварительно упакованных установщиков для установки PostgreSQL в вашей локальной среде.
После того, как Postgres установлен и вы можете подключиться, вы должны экспортировать переменную среды DATABASE_URL, чтобы ваше приложение могло подключаться к ней при локальном запуске:
-- для Mac и Linux $ export DATABASE_URL=postgres://$(whoami) -- для Windows $ set DATABASE_URL=postgres://$(whoami)
Postgres подключится к локальной базе данных, соответствующей имени вашей учетной записи пользователя (которое настраивается как часть установки).
Настройка Postgres на Mac
Для Postgres.app требуется Mac OS 10.7 или выше.
- Установите Postgres.app и следуйте инструкциям по установке.
- Установите инструменты командной строки postgres.
- Откройте новое окно терминала, чтобы убедиться, что ваши изменения сохранены.
- Убедитесь, что он работает правильно. Версия OS X
psqlдолжен указывать на путь, содержащий каталогPostgres.app.
Если вы используете версию 10, вывод будет выглядеть примерно так:
$ который psql /Applications/Postgres.app/Contents/Versions/latest/bin/psql
Эта команда должна работать правильно:
$ созданоb $ psql -h локальный хост psql (10.14) Введите "помощь" для помощи. =# \q
Также убедитесь, что приложение настроено на автоматический запуск при входе в систему.
PostgreSQL поставляется с несколькими полезными двоичными файлами, включая pg_dump и pg_restore .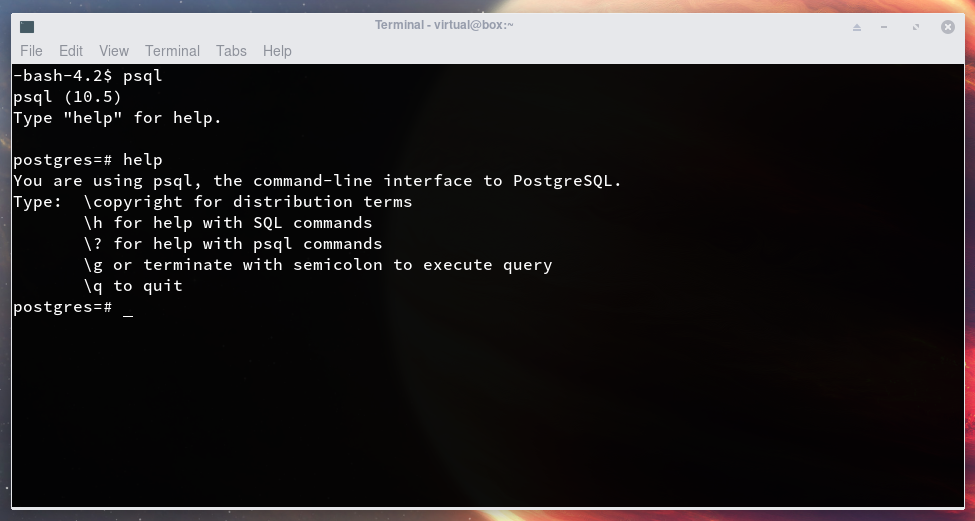 Чтобы сделать их доступными в каждом терминальном сеансе, добавьте каталог
Чтобы сделать их доступными в каждом терминальном сеансе, добавьте каталог /bin , поставляемый с Postgres.app, в PATH (желательно в .profile , .bashrc , .zshrc или аналогичный):
PATH="/Applications/Postgres.app/Contents/Versions/latest/bin:$PATH"
Настройка Postgres в Windows
Установите Postgres в Windows с помощью установщика Windows.
Не забудьте обновить переменную среды PATH, чтобы добавить bin каталог вашей установки Postgres. Каталог похож на: C:\Program Files\PostgreSQL\ . Такие команды, как heroku pg:psql , зависят от ПУТИ и не работают, если ПУТЬ неверен.
Настройка Postgres в Linux
Установите Postgres через менеджер пакетов. Фактическая команда диспетчера пакетов, которую вы используете, зависит от вашего дистрибутива. Следующее работает с Ubuntu, Debian и другими производными от Debian дистрибутивами:
$ sudo apt-get установить postgresql
Если в вашем дистрибутиве нет менеджера пакетов или пакет Postgres недоступен, установите Postgres в Linux с помощью одного из универсальных установщиков.
Клиент psql обычно устанавливается в /usr/bin :
$ который psql /USR/бен/psql
Следующая команда должна работать правильно:
$ psql psql (9.3.5) Введите "помощь" для помощи. мациек# \q
DATABASE_URL config var указывает URL-адрес основной базы данных Heroku Postgres приложения. Для приложений с одной базой данных ее URL-адрес автоматически назначается этой переменной конфигурации.
Для приложений с несколькими базами данных Postgres установите первичную базу данных с помощью heroku pg:promote . Общие варианты использования включают настройки высокой доступности ведущий/ведомый или как часть процесса обновления базы данных.
Совместное использование Heroku Postgres между приложениями
Вы можете совместно использовать одну базу данных Heroku Postgres между несколькими приложениями с помощью аддоны героку: прикрепить команда:
$ heroku addons:attach my-originating-app::DATABASE --app sushi Прикрепление postgresql-addon-name к суши... готово Установка переменных HEROKU_POSTGRESQL_BRONZE и перезапуск суши... готово, v11
URL-адрес прикрепленной базы данных назначается переменной конфигурации с форматом имени HEROKU_POSTGRESQL_[COLOR]_URL . В приведенном выше примере имя переменной конфигурации — HEROKU_POSTGRESQL_BRONZE_URL .
Общая база данных не обязательно является основной базой данных для любого приложения, с которым она используется. Вы продвигаете общую базу данных с помощью той же команды, что и для любой другой базы данных.
Вы можете прекратить совместное использование экземпляра Heroku Postgres с другим приложением с помощью надстроек heroku: команда detach :
$ heroku addons: отсоединить HEROKU_POSTGRESQL_BRONZE --app sushi Отсоединение HEROKU_POSTGRESQL_BRONZE от имени postgresql-addon-name от суши... готово Сброс переменных конфигурации HEROKU_POSTGRESQL_BRONZE и перезапуск суши... готово, v11
Поддержка версии
Проект PostgreSQL ежегодно выпускает новые основные версии. Каждая основная версия поддерживается Heroku Postgres вскоре после ее выпуска.
Каждая основная версия поддерживается Heroku Postgres вскоре после ее выпуска.
Heroku Postgres поддерживает не менее 3 основных версий одновременно. В настоящее время Heroku предлагает Postgres версии 14 по умолчанию. В настоящее время поддерживаются следующие версии:
| Уровень | Версия | Статус | Дата окончания срока службы |
|---|---|---|---|
| хобби | 9,6 | Устарело | 11 ноября 2021 г. |
| хобби | 10 | Устарело | 10 ноября 2022 г. |
| хобби | 11 | В наличии | 9 ноября 2023 г. |
| хобби | 12 | В наличии | 14 ноября 2024 г. |
| хобби | 13 | В наличии | 13 ноября 2025 г. |
| хобби | 14 | Доступно (по умолчанию) | 12 ноября 2026 г. |
| производство | 9,6 | Устарело | 11 ноября 2021 г. |
| производство | 10 | Прекращение поддержки | 10 ноября 2022 г. |
| производство | 11 | В наличии | 9 ноября 2023 г. |
| производство | 12 | В наличии | 14 ноября 2024 г. |
| производство | 13 | В наличии | 13 ноября 2025 г. |
| производство | 14 | Доступно (по умолчанию) | 12 ноября 2026 г. |
Пользователи должны обновляться примерно раз в три года. Однако вы можете в любой момент обновить версию базы данных PostgreSQL, чтобы воспользоваться преимуществами последней версии.
Процесс устаревания версий PostgreSQL в Heroku Postgres начинается за 1 год до даты окончания срока службы. О процессах устаревания сообщается в журнале изменений.
Чтобы создать базу данных в более старой поддерживаемой версии PostgreSQL, используйте флаг –version с командой addons:create .
Миграция устаревших баз данных
Проект PostgreSQL прекращает поддержку основной версии через пять лет после ее первоначального выпуска. Heroku Postgres объявляет эти версии устаревшими, чтобы базы данных не работали на неподдерживаемой основной версии PostgreSQL.
Heroku настоятельно рекомендует выполнить обновление версии до прекращения поддержки, чтобы вы могли протестировать совместимость, спланировать непредвиденные проблемы и перенести базу данных по собственному графику.
Базы данных хобби-уровня
За один (1) год до истечения срока действия версии (EOL) Heroku предотвращает создание новых баз данных Hobby в устаревшей версии.
В это время Heroku начинает миграцию баз данных Hobby, работающих в устаревших версиях, в последнюю доступную версию по умолчанию.
Производственные базы данных
- За один (1) год до окончания срока действия версии (EOL) Heroku уведомляет клиентов по электронной почте о процессе устаревания их уязвимых баз данных.
- За шесть (6) месяцев до EOL Heroku не позволяет создавать новые рабочие базы данных в устаревшей версии. Разрешено создание форков и последователей существующих баз данных.
- За один (1) месяц до EOL Heroku планирует принудительное техническое обслуживание обновления для баз данных, которые все еще работают в устаревшей версии.
Устаревшая инфраструктура
Heroku также иногда отказывается от поддержки старых версий своей инфраструктуры по следующим причинам:
- Операционная система, работающая под управлением базы данных, перестает получать обновления безопасности.
- Поддержка операционной системы больше нецелесообразна из-за ее возраста (необходимые пакеты и исправления больше не доступны или их сложно поддерживать).
- Экземпляры сервера нецелесообразно поддерживать, поскольку они значительно отличаются от текущей инфраструктуры Heroku.
Чтобы узнать, работает ли ваша база данных в устаревшей инфраструктуре, используйте pg:info :
$ геройку пг:информация === DATABASE_URL, HEROKU_POSTGRESQL_IVORY_URL План: Стандартный 0 Статус: Доступен Размер данных: 8,09 МБ Столов: 0 Версия ПГ: 12.5 Соединения: 7/120 Объединение соединений: доступно Учетные данные: 1 Разветвление/следование: Доступно Откат: самое раннее с 24 января 2021 г., 18:59 UTC. Создано: 2020-12-01 02:27 Регион: мы Шифрование данных: используется Непрерывная защита: Вкл. Разветвлено из: HEROKU_POSTGRESQL_SILVER Техническое обслуживание: не требуется Окно технического обслуживания: со среды с 21:30 до четверга с 01:30 UTC. Надстройка: postgresql-cubed-48277
Анализ производительности
Дополнительные сведения об аналитике производительности см. в разделе Аналитика производительности Heroku Postgres.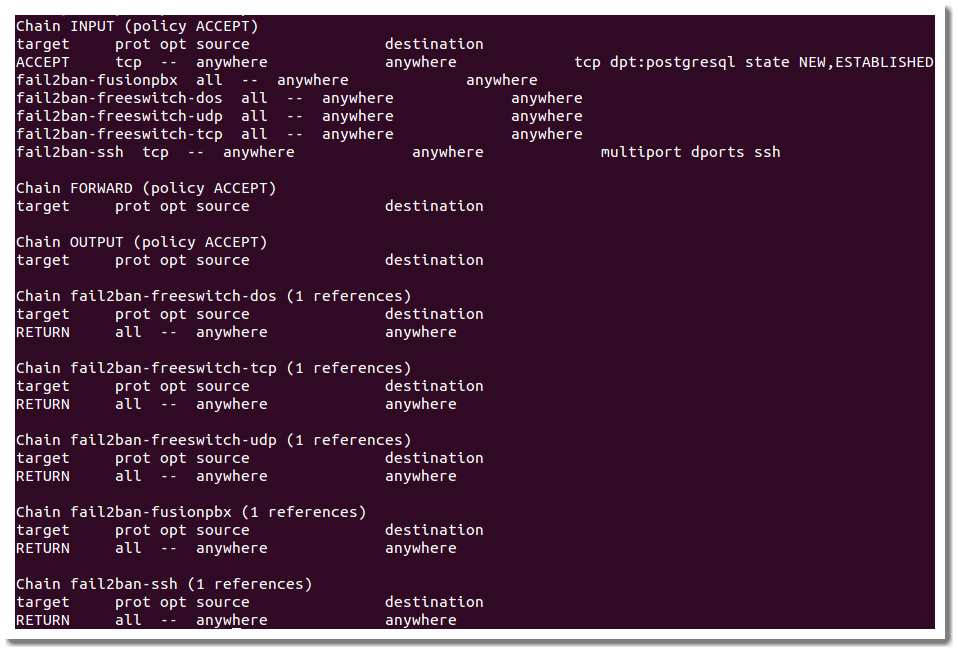
Использование интерфейса командной строки
Дополнительные сведения об управлении Heroku Postgres с помощью CLI см. в разделе Управление Heroku Postgres с помощью CLI.
Подключение к Heroku Postgres
Дополнительные сведения о подключении к Heroku Postgres см. в разделе Подключение к Heroku Postgres.
Миграция между планами
См. это подробное руководство по обновлению и миграции между планами базы данных.
Место жительства данных
При подготовке базы данных данные, связанные с этой базой данных, сохраняются в регионе, в котором она была создана. Однако вспомогательные службы Heroku Postgres и системы, управляющие парком баз данных, могут находиться не в том же регионе, что и подготовленные базы данных:
.- Postgres Continuous Protection для аварийного восстановления хранит базовую резервную копию и журналы упреждающей записи в том же регионе, что и база данных.
- Журналы приложений перенаправляются в Logplex, размещенный в США.
 В дополнение к журналам вашего приложения сюда входят системные журналы и журналы Heroku Postgres из любой базы данных, подключенной к вашему приложению.
В дополнение к журналам вашего приложения сюда входят системные журналы и журналы Heroku Postgres из любой базы данных, подключенной к вашему приложению. - Регистрация запросов и ошибок Heroku Postgres может быть заблокирована с помощью флага
--block-logsпри создании базы данных снадстройками heroku:create heroku-postgres:.... - Моментальные снимки резервной копии PG хранятся в США. Чтобы получить логические резервные копии в другом регионе, см. Логические резервные копии Heroku Postgres.
- Клипы данных хранятся в США.
Журналы блокировки
Во время создания надстройки можно передать флаг, чтобы предотвратить регистрацию запросов, которые выполняются в базе данных. Если этот параметр включен, его нельзя отключить после подготовки базы данных. Если вы должны отключить его после того, как он был включен, потребуется миграция на новую базу данных.
Блокировка запросов в журналах снижает возможности Heroku по отладке приложений и настройке производительности приложений.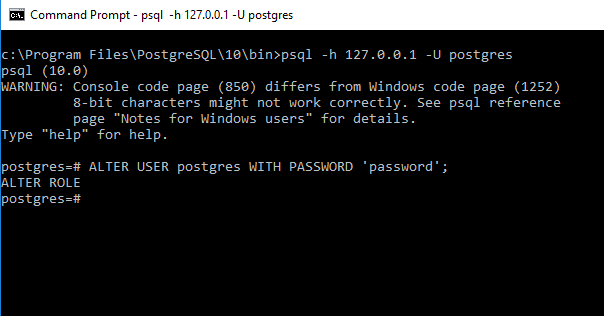
$ heroku addons:создать heroku-postgresql:standard-0 -a sushi --block-logs
Удаление надстройки
Вы должны удалить надстройку, чтобы уничтожить базу данных Heroku Postgres.
$ аддоны heroku:уничтожить heroku-postgresql:hobby-dev
Если у вас есть две базы данных одного типа, вы должны удалить надстройку, используя ее имя переменной конфигурации. Например, чтобы удалить HEROKU_POSTGRESQL_GRAY_URL , вы должны запустить:
аддоны heroku: уничтожить HEROKU_POSTGRESQL_GRAY
Если удаленная база данных была той же, которая использовалась в DATABASE_URL , эта переменная конфигурации DATABASE_URL не устанавливается в приложении.
Базы данных не могут быть восстановлены после уничтожения. Сделайте снимок данных заранее, используя резервные копии PG или экспортировав данные
Поддержка
Все вопросы поддержки и времени выполнения Heroku Postgres должны быть отправлены через один из каналов поддержки Heroku.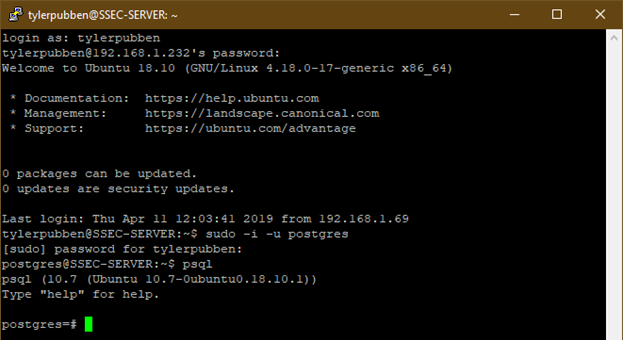
Продолжайте читать
- Основы Postgres
Обратная связь
Войдите, чтобы оставить отзыв.
Использование метакоманд в psql
Последнее изменение: 09 августа 2021 г.
Метакоманды — это функция psql, которая позволяет пользователю выполнять мощные операции без запроса базы данных. Существует множество метакоманд. Вот список некоторых наиболее распространенных мета-команд вместе с очень кратким описанием:
- \c [имя базы данных] — подключиться к указанной базе данных
-
\l— список всех баз -
\d— отображать таблицы, представления и последовательности-
\dt— отображать только таблицы -
\dv— отображать просмотры -
\dm— отображать материализованные представления -
\di— отображать индексы -
\дн— схемы отображения -
\dT— отображать типы данных - и т.
 д.
д.
-
-
\sv[имя представления] — показать определение представлений -
\x— включить расширенное отображение. Полезно для таблиц с большим количеством доступных столбцов.- Можно включить/выключить или установить автоматический режим
-
\set— список всех внутренних переменных-
\set[Имя] [Значение] — установить новую внутреннюю переменную
-
-
\unset[Имя] — удалить внутреннюю переменную -
\cd— изменить каталог, в котором работает psql -
\![Команда] — выполнить команду оболочки- Пр.
\! лсили\! пароль
- Пр.
-
\timing— переключает синхронизацию запросов -
\echo[сообщение] — вывести сообщение в консоль - \copy — копирует в файл
-
\i [имя файла]— выполнять команды из файла - \o [файл] — записывает вывод в файл вместо консоли
-
\q— выход из psql
Расширенные методы метакоманд
Несколько метакоманд
В одной строке можно использовать несколько метакоманд. Например, вы можете использовать
Например, вы можете использовать \dt\di , чтобы вывести список всех таблиц, а затем перечислить все индексы с дополнительной технической информацией об индексах.
Дополнительные детали
Добавление + в конец метакоманды со списком элементов предоставит небольшое количество дополнительной технической информации. Это будет работать на любых \d команды, а также некоторые другие.
Общая ошибка
Метакоманды разделяются новой строкой, а не ; . Это означает, что вы никогда не увидите, чтобы мета-команда выглядела так: \x; Точка с запятой в конце не нужна и вызовет ошибку:
Больше мета-команд
Есть еще довольно много метакоманд, которые не были перечислены, поскольку они были предназначены для относительно узкого применения и не так широко используются. Для полного списка метакоманд используйте \? . Откроется страница справки по метакомандам с полным списком каждой метакоманды и кратким описанием ее функций.
На этом изображении показаны первые команды из \? Всего 102 команды.
Резюме
- Метакоманды — это полезные команды, которые можно запускать из клиента psql.
- Все метакоманды начинаются с
\ - Добавление
+предоставит дополнительную информацию о некоторых метакомандах - Для получения полного списка метакоманд используйте
\?в psql - Не заканчивайте метакоманды
;
Написано:
Мэтью Лейн
Отзыв:
Мэтт Дэвид
Оставьте отзыв о нашем Документе Google Далее – Вывод результатов запроса в файлы с помощью \o
- Дом
- Веб-книги
- Авторы
- Миссия
- Пожертвовать
- Slack-сообщество
Наши веб-книги
- Обмен данными
- Управление облачными данными
- Как спроектировать информационную панель
- Как учить людей SQL
- Изучите SQL
- Избегайте искажения данных
- Оптимизация SQL
- Основы анализа
аз постгрес | Microsoft Learn
- Справочник
Управление базой данных Azure для серверов PostgreSQL.
Команды
| az postgres db | Управление базами данных PostgreSQL на сервере. |
| az postgres db создать | Создайте базу данных PostgreSQL. |
| az postgres db удалить | Удалить базу данных. |
| список баз данных az postgres | Список баз данных для сервера. |
| az postgres db показать | Показать сведения о базе данных. |
| az postgres не работает | Удалить сервер PostgreSQL и его кешированную информацию. |
| гибкий сервер az postgres | Управление базой данных Azure для гибких серверов PostgreSQL. |
| резервное копирование гибкого сервера az postgres | Управление гибкими резервными копиями сервера. |
| список резервных копий гибкого сервера az postgres | Список всех резервных копий для данного сервера. |
| резервное копирование гибкого сервера az postgres show | Показать сведения о конкретной резервной копии для данного сервера. |
| подключение гибкого сервера az postgres | Подключиться к гибкому серверу. |
| создание гибкого сервера az postgres | Создайте гибкий сервер PostgreSQL. |
| Гибкая серверная база данных az postgres | Управление базами данных PostgreSQL на гибком сервере. |
| az postgres flexible-server db создать | Создайте базу данных PostgreSQL на гибком сервере. |
| az postgres flexible-server db удалить | Удалить базу данных на гибком сервере. |
| список баз данных гибкого сервера az postgres | Список баз данных для гибкого сервера. |
| Гибкий сервер az postgres db показать | Показать сведения о базе данных. |
| Гибкий сервер az postgres удалить | Удалить гибкий сервер. |
| Развертывание гибкого сервера az postgres | Включить и запустить рабочий процесс GitHub Actions для сервера PostgreSQL. |
| запуск развертывания гибкого сервера az postgres | Запустите существующий рабочий процесс в вашем репозитории github. |
| настройка развертывания гибкого сервера az postgres | Создать файл рабочего процесса GitHub Actions для сервера PostgreSQL. |
| выполнение гибкого сервера az postgres | Подключиться к гибкому серверу. |
| Правило брандмауэра гибкого сервера az postgres | Управление правилами брандмауэра для сервера. |
| создать правило брандмауэра гибкого сервера az postgres | Создайте новое правило брандмауэра для гибкого сервера. |
| удалить правило брандмауэра гибкого сервера az postgres | Удалить правило брандмауэра. |
| список правил брандмауэра гибкого сервера az postgres | Список всех правил брандмауэра для гибкого сервера. |
| az postgres flexible-server firewall-rule show | Получить сведения о правиле брандмауэра. |
| обновление правила брандмауэра гибкого сервера az postgres | Обновите правило брандмауэра. |
| список гибких серверов az postgres | Список доступных гибких серверов. |
| az postgres flexible-server list-skus | Список доступных артикулов в данном регионе. |
| Миграция гибкого сервера az postgres | Управление рабочими процессами миграции для гибких серверов PostgreSQL. |
| миграция гибкого сервера az postgres проверка доступности имени | Проверяет, можно ли использовать указанное имя миграции. |
| миграция гибкого сервера az postgres создать | Создайте новый рабочий процесс миграции для гибкого сервера. |
| перенос гибкого сервера az postgres удалить | Удалить конкретную миграцию. |
| список переноса гибкого сервера az postgres | Список миграций гибкого сервера. |
| AZ Postgres Flexible-Server Migration show | Получить сведения о конкретной миграции. |
| Обновление переноса гибкого сервера az postgres | Обновите конкретную миграцию. |
| параметр гибкого сервера az postgres | Команды для управления значениями параметров сервера для гибкого сервера. |
| список параметров гибкого сервера az postgres | Список значений параметров гибкого сервера. |
| набор параметров гибкого сервера az postgres | Обновить параметр гибкого сервера. |
| показать параметр гибкого сервера az postgres | Получить параметр гибкого сервера. |
| перезапуск гибкого сервера az postgres | Перезапустите гибкий сервер. |
| восстановление гибкого сервера az postgres | Восстановить гибкий сервер из резервной копии. |
| Гибкое серверное шоу az postgres | Получите подробную информацию о гибком сервере. |
| az postgres flexible-server show-connection-string | Показать строки подключения для базы данных гибкого сервера PostgreSQL. |
| запуск гибкого сервера az postgres | Запустить гибкий сервер. |
| Гибкая остановка сервера az postgres | Остановить гибкий сервер. |
| обновление гибкого сервера az postgres | Обновите гибкий сервер. |
| Ожидание гибкого сервера az postgres | Подождите, пока гибкий сервер не выполнит определенные условия. |
| az postgres сервер | Управление серверами PostgreSQL. |
| Админ-администратор сервера Postgres AZ | Управление администратором Active Directory сервера postgres. |
| az postgres server ad-admin создать | Создайте администратора Active Directory для сервера PostgreSQL. |
| az postgres server ad-admin удалить | Удалить администратора Active Directory для сервера PostgreSQL. |
| список администраторов объявлений сервера az postgres | Список всех администраторов Active Directory для сервера PostgreSQL. |
| az postgres server ad-admin show | Получить информацию об администраторе Active Directory для сервера PostgreSQL. |
| az postgres server ad-admin ждать | Поместите интерфейс командной строки в состояние ожидания, пока не будет выполнено условие администратора Active Directory сервера PostgreSQL. |
| конфигурация сервера az postgres | Управление значениями конфигурации для сервера. |
| список конфигурации сервера az postgres | Список значений конфигурации для сервера. |
| набор конфигурации сервера az postgres | Обновить конфигурацию сервера. |
| показать конфигурацию сервера az postgres | Получить конфигурацию для сервера.». |
| создание сервера az postgres | Создать сервер. |
| сервер az postgres удалить | Удалить сервер. |
| Правило брандмауэра сервера az postgres | Управление правилами брандмауэра для сервера. |
| создать правило брандмауэра сервера az postgres | Создайте новое правило брандмауэра для сервера. |
| Удалить правило брандмауэра сервера az postgres | Удалить правило брандмауэра. |
| список правил брандмауэра сервера az postgres | Список всех правил брандмауэра для сервера. |
| az postgres server firewall-rule показать | Получить сведения о правиле брандмауэра. |
| обновление правила брандмауэра сервера az postgres | Обновите правило брандмауэра. |
| геовосстановление сервера az postgres | Гео-восстановление сервера из резервной копии. |
| ключ сервера az postgres | Управление ключами сервера PostgreSQL. |
| создать ключ сервера az postgres | Создать ключ сервера. |
| удалить ключ сервера az postgres | Удалить ключ сервера. |
| список ключей сервера az postgres | Получает список ключей сервера. |
| Показать ключ сервера az postgres | Показать ключ сервера. |
| список серверов az postgres | Список доступных серверов. |
| список серверов az postgres-skus | Список доступных артикулов в данном регионе. |
| az postgres server private-endpoint-connection | Управление подключениями к частным конечным точкам сервера PostgreSQL. |
| az postgres server private-endpoint-connection утвердить | Одобрить указанное подключение частной конечной точки, связанное с сервером PostgreSQL. |
| az postgres server private-endpoint-connection удалить | Удалить указанное соединение частной конечной точки, связанное с сервером PostgreSQL. |
| Отказ в подключении к частной конечной точке сервера az postgres | Отклонить указанное соединение с частной конечной точкой, связанное с сервером PostgreSQL. |
| az postgres server private-endpoint-connection показать | Показать сведения о подключении частной конечной точки, связанной с сервером PostgreSQL. |
| az postgres server частная ссылка ресурс | Управление ресурсами частной ссылки сервера PostgreSQL. |
| список ресурсов частной ссылки сервера az postgres | Список ресурсов частных ссылок, поддерживаемых сервером PostgreSQL. |
| реплика сервера az postgres | Управление репликами чтения. |
| создать реплику сервера az postgres | Создать реплику чтения для сервера. |
| список реплик серверов az postgres | Список всех реплик чтения для данного сервера. |
| остановка реплики сервера az postgres | Остановить репликацию на реплику чтения и сделать ее сервером чтения/записи. |
| перезапуск сервера az postgres | Перезапустите сервер. |
| восстановление сервера az postgres | Восстановить сервер из резервной копии. |
| показать сервер az postgres | Получить сведения о сервере. |
| сервер az postgres показать строку подключения | Показать строки подключения к базе данных сервера PostgreSQL. |
| обновление сервера az postgres | Обновить сервер. |
| vnet-правило сервера az postgres | Управление правилами виртуальной сети сервера. |
| az postgres server vnet-rule создать | Создайте правило виртуальной сети, разрешающее доступ к серверу PostgreSQL. |
| az postgres server vnet-rule удалить | Удаляет правило виртуальной сети с заданным именем. |
| список vnet-rule сервера az postgres | Получает список правил виртуальной сети на сервере. |
| az postgres server vnet-rule показать | Получает правило виртуальной сети. |
| обновление vnet-rule сервера az postgres | Обновите правило виртуальной сети. |
| сервер az postgres подождите | Подождите, пока сервер не выполнит определенные условия. |
| серверная дуга az postgres | Управление серверами PostgreSQL с поддержкой Azure Arc. |
| az postgres server-arc создать | Создайте сервер PostgreSQL с поддержкой Azure Arc. |
| az postgres server-arc удалить | Удалите сервер PostgreSQL с поддержкой Azure Arc. |
| конечная точка az postgres server-arc | Управление конечными точками сервера PostgreSQL с поддержкой Azure Arc. |
| список конечных точек az postgres server-arc | Список конечных точек сервера PostgreSQL с поддержкой Azure Arc. |
| az postgres server-arc список | Список серверов PostgreSQL с поддержкой Azure Arc. |
| az postgres server-arc show | Показать сведения о сервере PostgreSQL с поддержкой Azure Arc. |
| обновление дуги сервера az postgres | Обновите конфигурацию сервера PostgreSQL с поддержкой Azure Arc. |
| журналы сервера az postgres | Управление журналами сервера. |
| скачать журналы сервера az postgres | Загрузка файлов журнала. |
| список журналов сервера az postgres | Список файлов журнала для сервера. |
| az postgres показать строку подключения | Показать строки подключения к базе данных сервера PostgreSQL. |
| az postgres вверх | Настройте базу данных Azure для сервера PostgreSQL и конфигураций. |
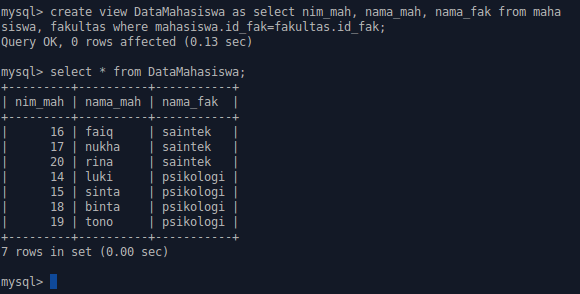

 «.
«.


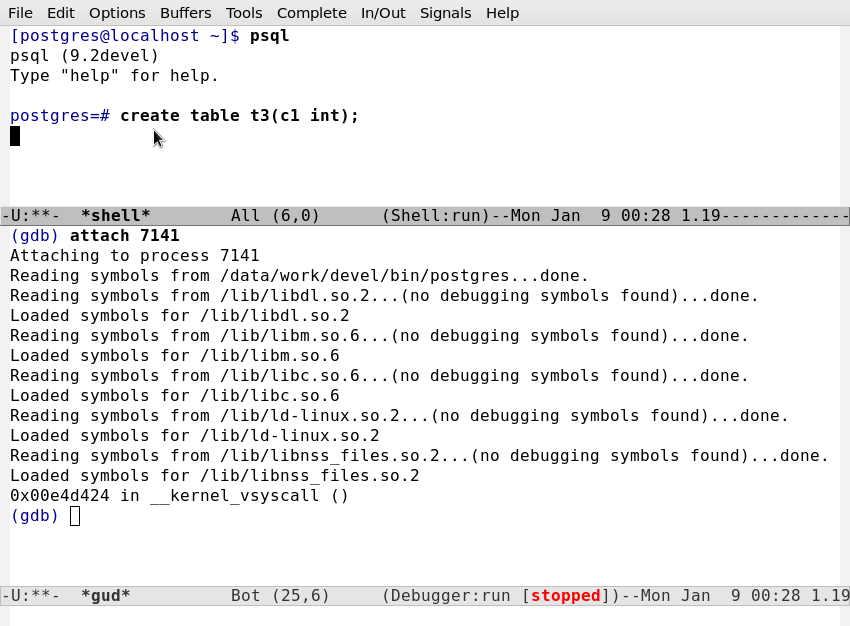
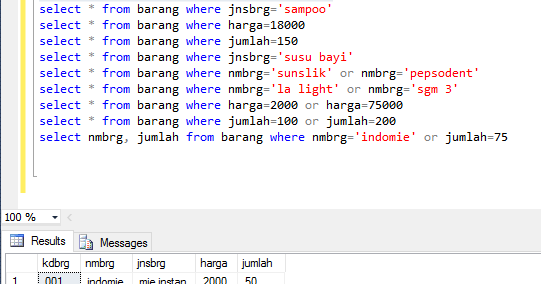

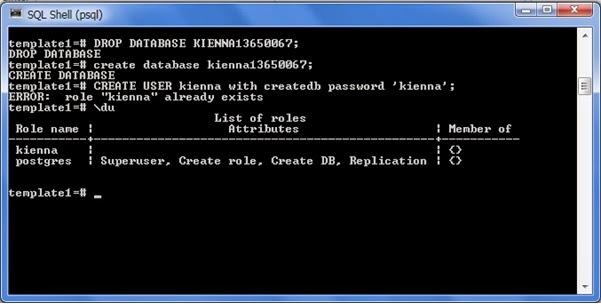

az postgres не работает
Удалите сервер PostgreSQL и его кэшированную информацию.
az postgres не работает [--delete-group]
[--Нет, подождите]
[--ресурс-группа]
[--имя сервера]
[--да] Примеры
Удалите сервер и кэшированные данные, кроме группы ресурсов.
az postgres не работает
Удалите группу ресурсов и полный кэш.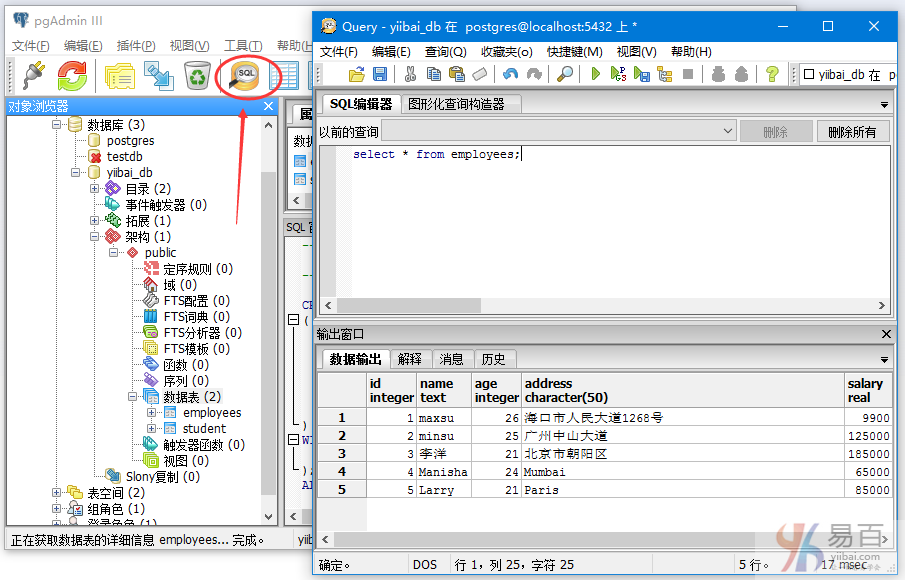
az postgres down --delete-group
Необязательные параметры
—delete-group
Удалить группу ресурсов.
—no-wait
Не ждать завершения длительной операции.
—resource-group -g
Имя группы ресурсов. Вы можете настроить группу по умолчанию, используя az configure --defaults group=<имя> .
—server-name -s
Имя сервера.
—yes -y
Не запрашивать подтверждение.
Глобальные параметры
—debug
Увеличить уровень детализации журнала, чтобы отображались все журналы отладки.
—help -h
Показать это справочное сообщение и выйти.
—only-show-errors
Показывать только ошибки, подавляя предупреждения.
—output -o
Формат вывода.
—query
Строка запроса JMESPath. См. http://jmespath.org/ для получения дополнительной информации и примеров.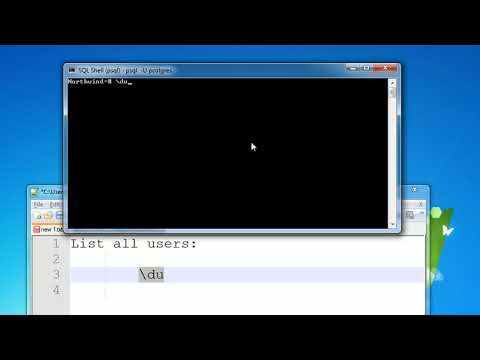
—subscription
Имя или идентификатор подписки. Вы можете настроить подписку по умолчанию, используя набор учетных записей az -s NAME_OR_ID .
—verbose
Увеличить детализацию журнала. Используйте —debug для полных журналов отладки.
az postgres show-connection-string
Показать строки подключения для базы данных сервера PostgreSQL.
az postgres show-connection-string [--admin-password]
[--admin-пользователь]
[--имя-базы-данных]
[--server-name] Дополнительные параметры
—admin-password -p
—admin-user -u
—database-name -d
—server-name -s
Global Параметры
—debug
Увеличить уровень детализации журнала, чтобы отображались все журналы отладки.
—help -h
Показать это справочное сообщение и выйти.
—only-show-errors
Показывать только ошибки, подавляя предупреждения.
—output -o
Формат вывода.
—query
Строка запроса JMESPath. См. http://jmespath.org/ для получения дополнительной информации и примеров.
—subscription
Имя или идентификатор подписки. Вы можете настроить подписку по умолчанию, используя набор учетных записей az -s NAME_OR_ID .
—подробный
Увеличить детализацию журнала. Используйте —debug для полных журналов отладки.
az postgres up
Настройте базу данных Azure для сервера PostgreSQL и конфигураций.
az postgres up [--admin-password]
[--admin-пользователь]
[--резервное копирование]
[--имя-базы-данных]
[--сгенерировать-пароль]
[--geo-redundant-backup {Отключено, Включено}]
[--расположение]
[--ресурс-группа]
[--имя сервера]
[--sku-название]
[--ssl-enforcement {отключено, включено}]
[--размер_хранилища]
[--теги]
[--версия] Примеры
Убедитесь, что сервер базы данных Azure для PostgreSQL запущен, работает и настроен для немедленного использования.
az postgres up
Чтобы переопределить имена по умолчанию, укажите параметры, указывающие желаемые значения/существующие ресурсы.
az postgres up -g MyResourceGroup -s MyServer -d MyDatabase -u MyUsername -p MyPassword
Дополнительные параметры
—admin-password -p
Пароль для входа администратора. Минимум 8 символов и максимум 128 символов. Пароль должен содержать символы трех из следующих категорий: английские прописные буквы, английские строчные буквы, цифры и не буквенно-цифровые символы. Ваш пароль не может содержать все или часть имени для входа. Часть имени для входа определяется как три или более последовательных буквенно-цифровых символа.
—admin-user -u
Логин администратора.
—backup-retention
Количество дней хранения резервной копии.
—database-name -d
Имя инициализируемой базы данных.
—generate-password
Сгенерировать пароль.
—геоизбыточное резервное копирование
—location -l
Местоположение. Значения из: az список местоположений учетных записей . Вы можете настроить местоположение по умолчанию, используя az configure --defaults location= .
—resource-group -g
Имя группы ресурсов. Вы можете настроить группу по умолчанию, используя az configure --defaults group= .
—server-name -s
Имя сервера.
—sku-name
—ssl-enforcement
—storage-size
Максимальный размер хранилища сервера. Единица измерения — мегабайты.
—tags
Теги, разделенные пробелами: ключ[=значение] [ключ[=значение] …]. Используйте «» для очистки существующих тегов.
—version
Глобальные параметры
—debug
Увеличить уровень детализации журнала, чтобы отображались все журналы отладки.
—help -h
Показать это справочное сообщение и выйти.