PostgreSQL : Документация: 9.4: Язык SQL : Компания Postgres Professional
RU
EN
RU EN
В этой части книги описывается использование языка SQL в PostgreSQL. Мы начнём с описания общего синтаксиса SQL, затем расскажем, как создавать структуры для хранения данных, как наполнять базу данных и как выполнять запросы к ней. В продолжении будут перечислены существующие типы данных и функции, применяемые с командами SQL. И наконец, закончится эта часть рассмотрением важных аспектов настройки базы данных для оптимальной производительности.
Материал этой части упорядочен так, чтобы новичок мог прочитать её от начала до конца и полностью понять все темы, не забегая вперёд. При этом главы сделаны самодостаточными, так что опытные пользователи могут читать главы по отдельности. Информация в этой части книги представлена в повествовательном стиле и разделена по темам. Если же вас интересует формальное и полное описание определённой команды, см. Часть VI.
Часть VI.
Читатели этой части книги должны уже знать, как подключаться к базе данных PostgreSQL и выполнять команды SQL. Если вы ещё не знаете этого, рекомендуется сначала прочитать Часть I. Команды SQL обычно вводятся в psql — интерактивном терминальном приложении PostgreSQL, но можно воспользоваться и другими программами с подобными функциями.
- Содержание
- 4. Синтаксис SQL
- 4.1. Лексическая структура
- 4.2. Выражения значения
- 4.3. Вызов функций
- 4.2. Выражения значения
- 4.1. Лексическая структура
- 5. Определение данных
- 5.1. Основы таблиц
- 5.2. Значения по умолчанию
- 5.3. Ограничения
- 5.4. Системные колонки
- 5.5. Изменение таблиц
- 5.6. Права
- 5.7. Схемы
- 5.8. Наследование
- 5.9. Секционирование
- 5.10. Сторонние данные
- 5.11. Другие объекты баз данных
- 5.12. Отслеживание зависимостей
- 5.2. Значения по умолчанию
- 5.1. Основы таблиц
- 6. Модификация данных
- 6.1. Добавление данных
- 6.2. Изменение данных
- 6.
 3. Удаление данных
3. Удаление данных - 6.2. Изменение данных
- 6.1. Добавление данных
- 7. Запросы
- 7.1. Обзор
- 7.2. Табличные выражения
- 7.3. Списки выборки
- 7.4. Сочетание запросов
- 7.5. Сортировка строк
- 7.6. LIMIT и OFFSET
- 7.7. Списки VALUES
- 7.8. Запросы WITH (Общие табличные выражения)
- 7.2. Табличные выражения
- 7.1. Обзор
- 8. Типы данных
- 8.1. Числовые типы
- 8.2. Денежные типы
- 8.3. Символьные типы
- 8.4. Двоичные типы данных
- 8.5. Типы даты/времени
- 8.6. Логический тип
- 8.7. Типы перечислений
- 8.8. Геометрические типы
- 8.9. Типы, описывающие сетевые адреса
- 8.10. Битовые строки
- 8.11. Типы, предназначенные для текстового поиска
- 8.12. Тип UUID
- 8.13. Тип XML
- 8.14. Типы JSON
- 8.15. Массивы
- 8.16. Составные типы
- 8.17. Диапазонные типы
- 8.18. Идентификаторы объектов
- 8.19. Тип pg_lsn
- 8.20. Псевдотипы
- 8.2. Денежные типы
- 8.1. Числовые типы
- 9. Функции и операторы
- 9.
 1. Логические операторы
1. Логические операторы- 9.2. Операторы сравнения
- 9.3. Математические функции и операторы
- 9.4. Строковые функции и операторы
- 9.5. Функции и операторы двоичных строк
- 9.6. Функции и операторы для работы с битовыми строками
- 9.7. Поиск по шаблону
- 9.8. Функции форматирования данных
- 9.9. Операторы и функции даты/времени
- 9.10. Функции для перечислений
- 9.11. Геометрические функции и операторы
- 9.12. Функции и операторы для работы с сетевыми адресами
- 9.13. Функции и операторы текстового поиска
- 9.14. XML-функции
- 9.15. Функции и операторы JSON
- 9.16. Функции для работы с последовательностями
- 9.17. Условные выражения
- 9.18. Функции и операторы для работы с массивами
- 9.19. Диапазонные функции и операторы
- 9.20. Агрегатные функции
- 9.21. Оконные функции
- 9.22. Выражения подзапросов
- 9.23. Сравнение табличных строк и массивов
- 9.24. Функции, возвращающие множества
- 9.25. Системные информационные функции
- 9.26. Функции для системного администрирования
- 9.
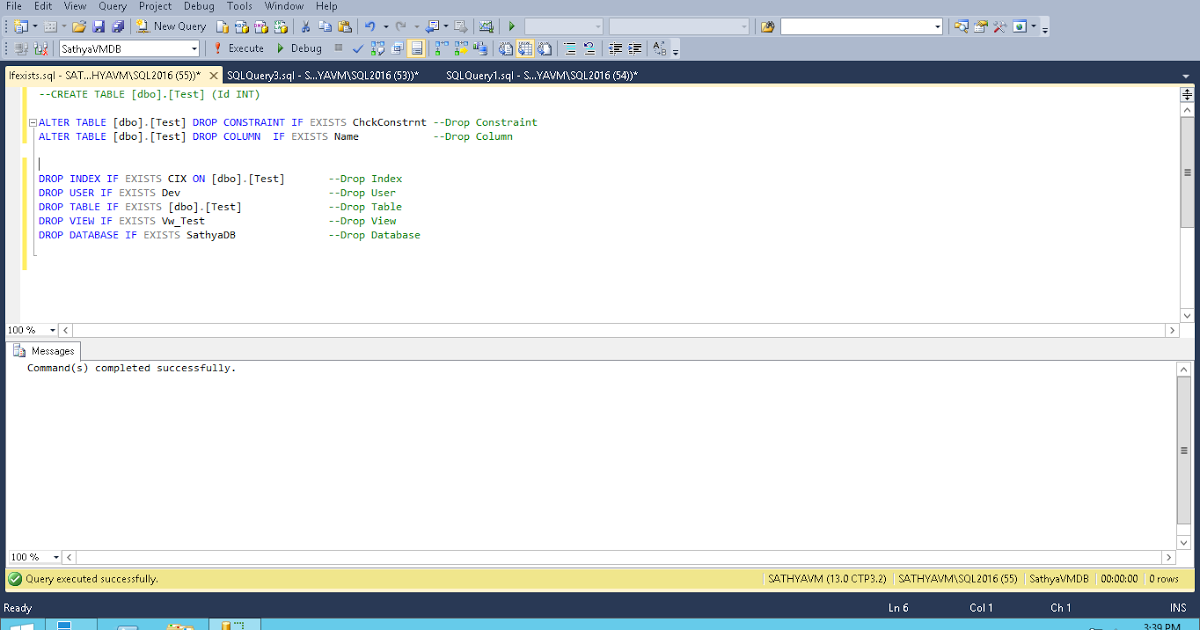 27. Триггерные функции
27. Триггерные функции- 9.28. Функции событийных триггеров
- 9.2. Операторы сравнения
- 9.
- 10. Преобразование типов
- 10.1. Обзор
- 10.2. Операторы
- 10.3. Функции
- 10.4. Хранимое значение
- 10.5. UNION, CASE и связанные конструкции
- 10.2. Операторы
- 10.1. Обзор
- 11. Индексы
- 11.1. Введение
- 11.2. Типы индексов
- 11.3. Составные индексы
- 11.4. Индексы и предложения ORDER BY
- 11.5. Объединение нескольких индексов
- 11.6. Уникальные индексы
- 11.8. Частичные индексы
- 11.9. Семейства и классы операторов
- 11.10. Индексы и правила сортировки
- 11.11. Контроль использования индексов
- 11.2. Типы индексов
- 11.1. Введение
- 12. Полнотекстовый поиск
- 12.1. Введение
- 12.2. Таблицы и индексы
- 12.3. Управление текстовым поиском
- 12.4. Дополнительные возможности
- 12.
 5. Анализаторы
5. Анализаторы- 12.6. Словари
- 12.7. Пример конфигурации
- 12.8. Тестирование и отладка текстового поиска
- 12.9. Типы индексов GiST и GIN
- 12.10. Поддержка psql
- 12.11. Ограничения
- 12.12. Миграция с реализации текстового поиска в версиях до 8.3
- 12.2. Таблицы и индексы
- 12.1. Введение
- 13. Управление конкурентным доступом
- 13.1. Введение
- 13.2. Изоляция транзакций
- 13.3. Явные блокировки
- 13.4. Проверки целостности данных на уровне приложения
- 13.5. Блокировки и индексы
- 13.2. Изоляция транзакций
- 13.1. Введение
- 14. Оптимизация производительности
- 14.1. Использование EXPLAIN
- 14.2. Статистика, используемая планировщиком
- 14.3. Управление планировщиком с помощью явных предложений JOIN
- 14.4. Наполнение базы данных
- 14.5. Оптимизация, угрожающая стабильности
- 14.2. Статистика, используемая планировщиком
- 14.1. Использование EXPLAIN
Иллюстрированный самоучитель по PostgreSQL › Команды PostgreSQL [страница — 308] | Самоучители по программированию
В данной главе приведена сводная информация по всем основным командам SQL, поддерживаемым в PostgreSQL. В этот справочник включены как стандартные команды SQL (например, INSERT и SELECT), так и специфические команды PostgreSQL (такие, как CREATE OPERATOR и CREATE TYPE).
В этот справочник включены как стандартные команды SQL (например, INSERT и SELECT), так и специфические команды PostgreSQL (такие, как CREATE OPERATOR и CREATE TYPE).
Модификация структуры группы пользователей. | Синтаксис: | ALTER GROUP имя ADD USER | пользователь [….] ALTER GROUP имя DROP USER | пользователь [….] | Параметры: | имя. Имя группы, в которую вносятся изменения. | пользователь. Имена пользователей, включаемых в группу или удаляемых из нее.
Модификация таблиц и атрибутов полей.
Модификация атрибутов и прав пользователя. | Синтаксис: | ALTER USER пользователь | [ WITH PASSWORD ‘пароль’ ] | [ CREATEDB I NOCREATEDB ] [ CREATEUSER | NOCREATEUSER ] | [ VALID UNTIL ‘время’ ] | Параметры: | пользователь. Имя пользователя PostgreSQL, данные которого изменяются командой ALTER USER. | пароль.
Начало отложенного транзакционного блока. | Синтаксис: | BEGIN [ WORK | TRANSACTION ] | Параметры: | Необязательные ключевые слова, делающие команду SQL более наглядной.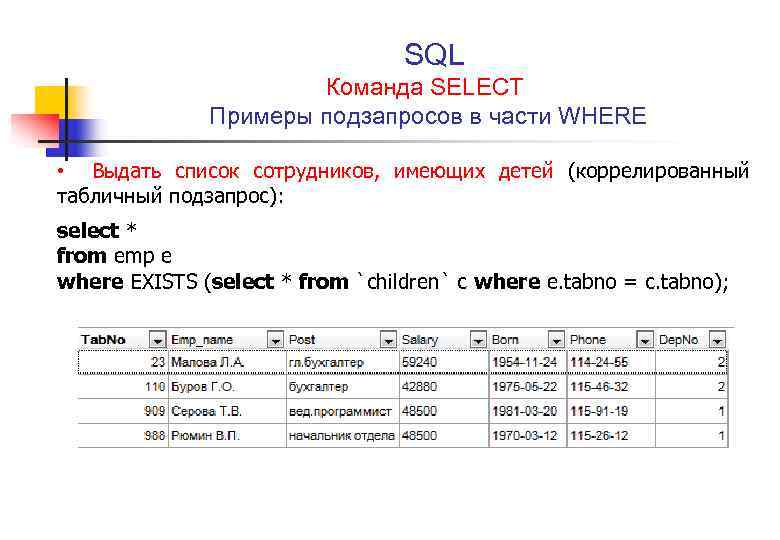 | Результаты: | BEGIN. Сообщение выдается в начале транзакции. | NOTICE: BEGIN: already transaction in progress.
| Результаты: | BEGIN. Сообщение выдается в начале транзакции. | NOTICE: BEGIN: already transaction in progress.
Закрытие объекта курсора. | Синтаксис: | CLOSE курсор | Параметры: | Имя открытого курсора. | Результаты: | CLOSE. Сообщение выдается при успешном закрытии курсора. | NOTICE: PerformPortalClose: portal «курсор» not found. Сообщение выдается в том случае, если заданный курсор не был объявлен или открыт.
Кластеризация таблицы по заданному индексу. | Синтаксис: | CLUSTER индекс ON таблица | Параметры: | индекс. Имя индекса, используемого при кластеризации. | таблица. Имя таблицы, для которой производится кластеризация. | Результаты: | CLUSTER. Сообщение выдается при успешной кластеризации таблицы.
Определение комментария для объекта базы данных. | Синтаксис: | COMMENT ON | [ | [ DATABASE | INDEX | RULE | SEQUENCE | TABLE | TYPE | VIEW ] объект | COLUMN таблица.поле| | FUNCTION функция (аргумент [….]) | | AGGREGATE агрвгатная_функция агрегатный_тип | | OPERATOR оператор (левый_тип, правый_тип) | | TRIGGER триггер ON таблица | ] IS ‘текст’ | Параметры: | DATABASE INDEX | RULE | SEQUENCE | TABLE | TYPE VIEW.
Завершение транзакционного блока и фиксация изменений в базе данных. | Синтаксис: | COMMIT [ WORK | TRANSACTION ] | Параметры: | Необязательные ключевые слова, делающие команду SQL более наглядной. | Результаты: | COMMIT. Сообщение выдается при успешной фиксации изменений в базе данных.
Копирование данных между файлами и таблицами. | Синтаксис: | COPY [ BINARY ] таблица [ WITH OIDS ] | FROM { ‘файл’ | stdin } | [ [ USING ] DELIMITERS ‘разделитель’ ] | [ WITH NULL AS ‘ строка _null’ ] COPY [BINARY ] table [ WITH OIDS ] | TO { ‘файл’ | stdout } | [ [ USING ] DELIMITERS ‘разделитель’ ] | [ WITH NULL AS ‘строка_null’ ] | Параметры: | BINARY.
Определение новой агрегатной функции в базе данных. | Синтаксис: | CREATE AGGREGATE имя (BASETYPE = входной_тип | [, SFUNC = функция. STYPE = переходный_тип ] | [, FINALFUNC = завершающая_функция ] | [, INITCOND = начальное_состояние ]) | Параметры: | имя. Имя создаваемой агрегатной функции. | входной_тип.
Создание новой базы данных в PostgreSQL. | Синтаксис: | CREATE DATABASE база_данных | [ WITH [ LOCATION = { ‘каталог’ | DEFAULT } ] | [ TEMPLATE = шаблон DEFAULT ] | [ ENCODING = имя_нодировки | номер_кодировки | DEFAULT ] ] | Параметры: | база_данных. Имя создаваемой базы данных. | каталог.
Определение новой функции в базе данных. | Синтаксис: | CREATE FUNCTION имя ([ тип_аргумента [….] ]) | RETURNS тип_возвращаемого_значения | AS ‘определение’ | LANGUAGE ‘язык’ | [ WITH (атрибут [….]) ] | CREATE FUNCTION имя ([ тип_аргумента [….] ]) | RETURNS тип_возвращаемого_значения | AS ‘объектный_файл’ [, ‘имя_в_объектном_файле’ ] | LANGUAGE ‘язык’ | [ WITH (атрибут […;]) ] | Параметры: | имя.
Создание новой группы PostgreSQL в базе данных. | Синтаксис: | CREATE GROUP группа | [ WITH [ SYSID идентификатор_группы ] | [ USER пользователь [….]]] | Параметры: | группа. Имя создаваемой группы. | идентификатор_группы. Системный идентификатор, присваиваемый новой группе.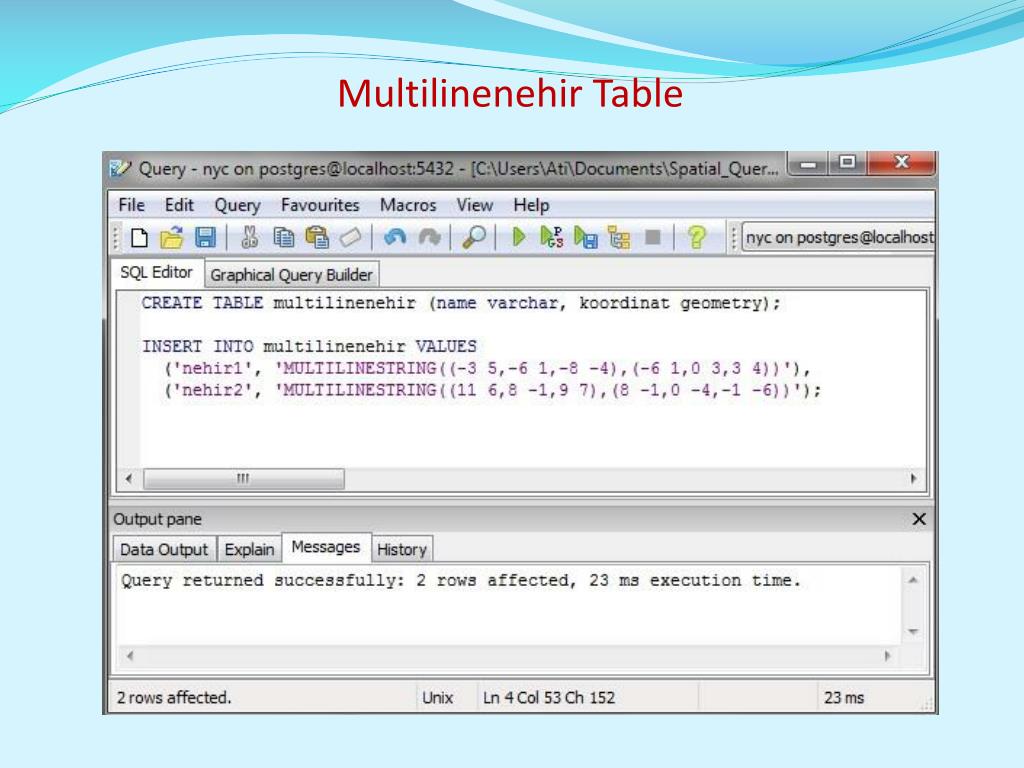
Создает индекс для таблицы. | Синтаксис: | CREATE [ UNIQUE ] INDEX индекс ON таблица | [ USING тип ] (поле [ класс ] [,…]) | CREATE [ UNIQUE ] INDEX индекс ON таблица | [ USING тип ] (функция (поле [….])[ класс ]) | Параметры: | UNIQUE. Необязательное ключевое слово UNIQUE.
Определение нового языка, используемого при создании функций. | Синтаксис: | CREATE [ TRUSTED ] [ PROCEDURAL ] LANGUAGE ‘язык’ | HANDLER обработчик | LANCOMPILER ‘комментарий’ | Параметры: | TRUSTED. Ключевое слово TRUSTED означает, что PostgreSQL разрешает непривилегированным пользователям обходить ограничения, связанные с наличием прав доступа к языку’.
Определение нового оператора в базе данных. | Синтаксис: | CREATE OPERATOR оператор (PROCEDURE = функция | [, LEFTARG = тип1 ] | [, RIGHTARG = тип2 ] | [, COMMUTATOR = коммутатор ] | [, NEGATOR = инвертор ] | [, RESTRICT = функция_ограничения ] | [, JOIN = функция_объединения ] | [, HASHES ] | [, SORT1 = левая_сортировка ] | [.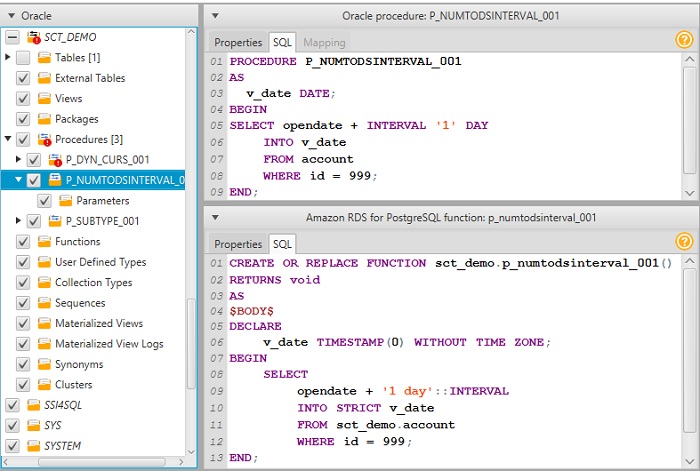 SORT2 = правая_сортировка ]) | Параметры: | оператор.
SORT2 = правая_сортировка ]) | Параметры: | оператор.
Определение нового правила в таблице. | Синтаксис: | CREATE RULE правило AS ON событие ТО объект | [ WHERE условие ] DO [ INSTEAD ] операция | операция:: = NOTHING | query | (query [;…]) | [ query [:…] ] | Параметры: | правило. Имя создаваемого правила. | событие.
Создание нового генератора числовой последовательности. | Синтаксис: | CREATE SEQUENCE последовательность [ INCREMENT приращение ] | [ MINVALUE минимум ] [ MAXVALUE максимум ] | [ START начало ] [ CACHE кэш ][ CYCLE ] | Параметры: | последовательность. Имя создаваемой последовательности. | приращение.
Создание новой таблицы. | Синтаксис: | CREATE [ TEMPORARY | TEMP ] TABLE таблица ( | { поле тип [ограничение_поля [… ] ] | ограничение_таблицы } | [….
Создание новой таблицы по результатам выборки. | Синтаксис: | CREATE TABLE таблица [ (поле [….]) ] | AS выборка | Параметры: | таблица. Имя создаваемой таблицы. умолчанию» ] | [, ELEMENT = элемент ] [.
умолчанию» ] | [, ELEMENT = элемент ] [.
Создание нового пользователя базы данных PostgreSQL. | Синтаксис: | CREATE USER пользователь | [ WITH [ SYSID uid ] | [ PASSWORD ‘пароль’ ] ] | [ CREATEDB | NOCREATEDB ] | [ CREATEUSER | NOCREATEUSER ] | [ IN GROUP группа [….] ] | [ VALID UNTIL ‘срок’ ] | Параметры: | пользователь. Имя создаваемого пользователя.
Создание представления для таблицы. | Синтаксис: | CREATE VIEW представление AS запрос | Параметры: | представление. Имя создаваемого представления. | запрос. Запрос SQL, определяющий структуру и содержимое представления. | Результаты: | CREATE. Сообщение, возвращаемое при успешном создании представления.
Получение текущей даты. | Синтаксис: | CURRENT_DATE | Параметры: | Функция вызывается без параметров. | Результаты: | Текущая дата в виде значения типа date. | Описание | Функция CURRENT_DATE возвращает текущую системную дату в виде типа date.
Получение текущих даты и времени. | Синтаксис: | CURRENT_TIMESTAMP | Параметры: | Функция вызывается без параметров. | Результаты: | Текущая дата и текущее время. | Описание | Функция CURRENT_TIME возвращает текущие дату и время в виде значения типа timestamp.
| Синтаксис: | CURRENT_TIMESTAMP | Параметры: | Функция вызывается без параметров. | Результаты: | Текущая дата и текущее время. | Описание | Функция CURRENT_TIME возвращает текущие дату и время в виде значения типа timestamp.
Определение нового курсора. | Синтаксис: | DECLARE курсор | [ BINARY ] [ INSENSITIVE ] [ SCROLL ] | CURSOR FOR запрос | [ FOR { READ ONLY | UPDATE [ OF поле [….]]}] | Параметры: | курсор. Имя нового курсора. | BINARY.
Удаление записей из таблицы. | Синтаксис: | DELETE FROM [ ONLY ] таблица [ WHERE условие ] | Параметры: | таблица. Имя таблицы, из которой удаляются записи. | условие. Критерий отбора удаляемых записей. Структура условия аналогична условию секции WHERE команды SELECT – за дополнительной информацией об условиях обращайтесь к описанию команды SELECT.
Удаление агрегатной функции из базы данных. | Синтаксис: | DROP AGGREGATE функция тип | Параметры: | функция. Имя удаляемой агрегатной функции. | тип. Тип данных, передаваемый агрегатной функции. | Результаты: | DROP. Сообщение выдается при успешном удалении агрегатной функции.
| Результаты: | DROP. Сообщение выдается при успешном удалении агрегатной функции.
Удаление базы данных из системы. | Синтаксис: | DROP DATABASE база_данных | Параметры: | Имя удаляемой базы данных. | Результаты: | DROP DATABASE. Сообщение выдается при успешном удалении базы данных. | ERROR: user ‘пользователь’ is not allowed to create/drop databases.
Удаление пользовательской функции. | Синтаксис: | DROP FUNCTION функция ([ тип [….]]) | Параметры: | функция. Имя существующей функции, удаляемой из базы данных. | тип. Ноль пли более типов аргументов функции. Комбинация имени и типов однозначно определяет функцию. | Результаты: | DROP.
Удаление группы пользователей из базы данных. | Синтаксис: | DROP GROUP группа | Параметры: | Имя удаляемой группы. | Результаты: | DROP GROUP. Это сообщение выдается при успешном удалении группы. | Описание | Команда DROP GROUP удаляет группу из текущей базы данных.
Удаление процедурного языка из базы данных. | Синтаксис: | DROP [ PROCEDURAL ] LANGUAGE ‘язык’ | Параметры: | Имя существующего языка, удаляемого из базы данных. | Результаты: | DROP. Сообщение выдается в том случае, если удаление языка прошло без ошибок. | ERROR: Language «язык» does not exist.
| Синтаксис: | DROP [ PROCEDURAL ] LANGUAGE ‘язык’ | Параметры: | Имя существующего языка, удаляемого из базы данных. | Результаты: | DROP. Сообщение выдается в том случае, если удаление языка прошло без ошибок. | ERROR: Language «язык» does not exist.
Удаление оператора из базы данных. | Синтаксис: | DROP OPERATOR оператор | ({ левый__тип NONE }. | { правый_тип | NONE }) | Параметры: | оператор. Удаляемый оператор. | левый_тип \ NONE. Тип левого операнда (или NONE при его отсутствии). | правый_тип \ NONE. Тип правого операнда (или NONE при его отсутствии).
Удаление правила из базы данных. | Синтаксис: | DROP RULE правило [,…] | Параметры: | Имя удаляемого правила. Одной командой можно удалить сразу несколько правил, имена которых перечисляются через запятую. | Результаты: | DROP. Сообщение возвращается при успешном удалении правила.
Удаление таблицы из базы данных. | Синтаксис: | DROP TABLE таблица [….] | Параметры: | Имя существующей таблицы, удаляемой из базы данных. В одной команде можно удалить сразу несколько таблиц, имена которых перечисляются через запятую. | Результаты: | DROP.
В одной команде можно удалить сразу несколько таблиц, имена которых перечисляются через запятую. | Результаты: | DROP.
Удаление определения триггера из базы данных. | Синтаксис: | DROP TRIGGER триггер ON таблица | Параметры: | триггер. Имя удаляемого триггера. | таблица. Имя таблицы, для которой устанавливался триггер. | Результаты: | DROP. Сообщение возвращается при успешном удалении триггера.
Удаление типа данных из системных каталогов. | Синтаксис: | DROP TYPE тип [,…] | Параметры: | Имя удаляемого типа. В одной команде можно удалить сразу несколько типов, имена которых перечисляются через запятую. | Результаты: | DROP. Сообщение возвращается при успешном удалении типа.
Удаление пользователя PostgreSQL. | Синтаксис: | DROP USER пользователь | Параметры: | Имя удаляемого пользователя PostgreSQL. | Результаты: | DROP USER. Сообщение возвращается при успешном удалении пользователя PostgreSQL. | ERROR: DROP USER: user «пользователь» does not exist.
Удаление существующего представления из базы данных. | Синтаксис: | DROP VIEW представление. [….] | Параметры: | Имя удаляемого представления. | Результаты: | DROP. Сообщение возвращается при успешном удалении представления. | ERROR: view «представление» does not exlst.
Вывод плана выполнения запроса. | Синтаксис: | EXPLAIN [ VERBOSE ] запрос | Параметры: | VERBOSE. При наличии необязательного ключевого слова VERBOSE в плане запроса выводится дополнительная информация. | запрос. Запрос, план выполнения которого вы хотите получить. | Результаты: | NOTICE: QUERY PLAN: plan.
Выборка записей с использованием курсора. | Синтаксис: | FETCH направление | [ количество_записей ] { IN | FROM } курсор | направление:: – { FORWARD | BACKWARD | RELATIVE } | количество_записей:: = { число \ ALL NEXT PRIOR } | Параметры: | направление. Необязательный параметр, определяющий направление выборки.
Предоставление прав доступа пользователю, группе или всем пользователям базы данных. | Синтаксис: | GRANT привилегия [,…] ON объект [….] | ТО { PUBLIC | GROUP группа \ пользователь } | Параметры: | привилегия. Предоставляемая привилегия. Допустимые значения:
| Синтаксис: | GRANT привилегия [,…] ON объект [….] | ТО { PUBLIC | GROUP группа \ пользователь } | Параметры: | привилегия. Предоставляемая привилегия. Допустимые значения:
Вставка новых записей в таблицу. | Синтаксис: | INSERT INTO таблице [ (поле [….]) ] | { DEFAULT VALUES | VALUES (значение [….]) | | запрос } | Параметры: | таблица. Таблица, в которую вставляются новые данные. | поле. Имя поля, для которого задается значение.
Ожидание уведомлений о событиях. | Синтаксис: | LISTEN событие | Параметры: | Имя события, ожидаемого сервером. | Результаты: | LISTEN. Сообщение возвращается при успешном выполнении команды, когда серверный процесс ожидает уведомления. | NOTICE: Async_Listen: We are already listening on событие.
Динамическая загрузка объектных файлов в базу данных. | Синтаксис: | LOAD ‘файл’ | Параметры: | Имя загружаемого объектного файла. | Результаты: | LOAD. Сообщение возвращается при успешной загрузке объектного файла. | ERROR: LOAD: could not open file ‘файл’.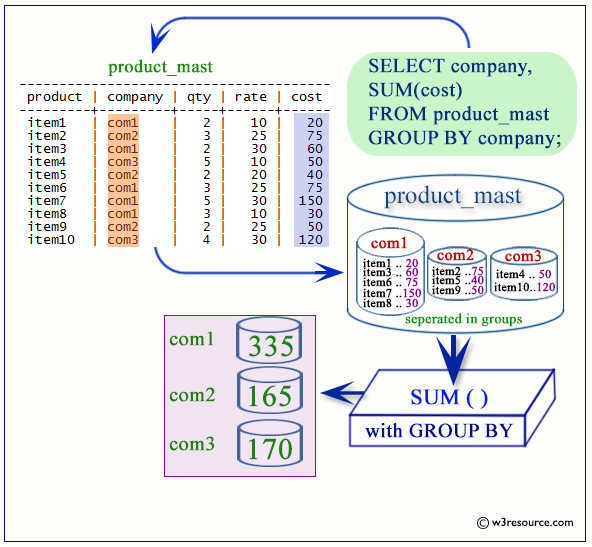 Ошибка – указанный файл не найден.
Ошибка – указанный файл не найден.
Блокировка записей в транзакциях. | Синтаксис: | LOCK [ TABLE ] таблица | LOCK [ TABLE ] таблица IN режим | режим:: = { [ ROW | ACCESS ] { SHARE | EXCLUSIVE } | | SHARE ROW EXCLUSIVE } MODE | Параметры: | таблица. Имя таблицы, для которой устанавливается блокировка. | режим.
Перемещение курсора к другой записи. | Синтаксис: | MOVE [ направление ] [ количество ] | { IN | FROM } курсор | Параметры: | направление. Направление, в котором перемещается указанный курсор. За дополнительной информацией о направлениях обращайтесь к описанию команды FETCH. | количество.
Уведомление всех серверных процессов, ожидающих некоторого события. | Синтаксис: | NOTIFY событие | Параметры: | Событие, о наступлении которого оповещаются процессы. | Результаты: | NOTIFY. Это сообщение выдается в том случае, если рассылка прошла успешно.
Восстановление индексов в таблицах. | Синтаксис: | REINDEX { TABLE | DATABASE | INDEX } объект [ FORCE ] | Параметры: | TABLE | DATABASE | INDEX. Тип индексируемого объекта. | объект. Имя индексируемого объекта. | FORCE. Ключевое слово FORCE восстанавливает индексы для всех перечисленных объектов.
Тип индексируемого объекта. | объект. Имя индексируемого объекта. | FORCE. Ключевое слово FORCE восстанавливает индексы для всех перечисленных объектов.
Восстановление стандартных значений конфигурационных переменных. | Синтаксис: | RESET переменная | Параметры: | Переменная, которой присваивается значение по умолчанию. | Результаты: | RESET VARIABLE. Это сообщение выдается при успешном сбросе переменной.
Отмена привилегий доступа у пользователя, группы или всех пользователей. | Синтаксис: | REVOKE привилегия […. ] | ON объект [….] | FROM { PUBLIC | GROUP группа \ пользователь } | Параметры: | привилегия. Отменяемая привилегия.
Откат текущей транзакции с отменой всех изменений. | Синтаксис: | ROLLBACK [ WORK TRANSACTION ] | Параметры: | Необязательные ключевые слова, делающие команду SQL более наглядной. | Результаты: | ROLLBACK. Сообщение выдается при успешном откате транзакции. | NOTICE: ROLLBACK: no transaction In progress.
Выборка записей из таблицы или представления.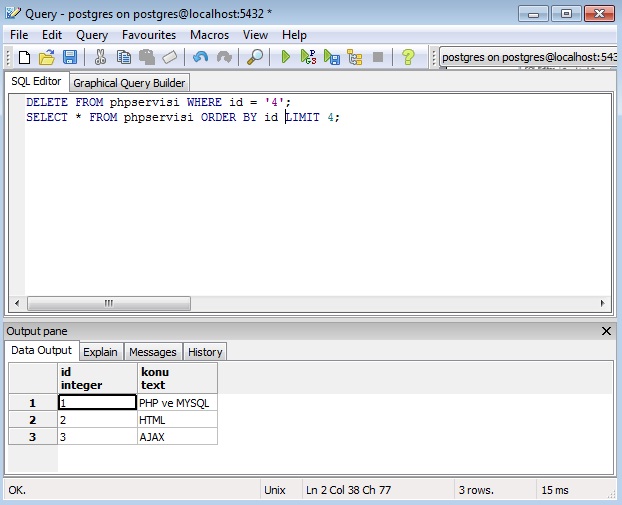 | Синтаксис: | SELECT [ ALL | DISTINCT [ ON (уникальное_выражение [….]) ] ] | цель [ AS выходное_имя ] [….] | [ FROM источник [ {. | CROSS JOIN }…] ] [ WHERE условие_фильтрации ] | [ GROUP BY условие_группировки [….
| Синтаксис: | SELECT [ ALL | DISTINCT [ ON (уникальное_выражение [….]) ] ] | цель [ AS выходное_имя ] [….] | [ FROM источник [ {. | CROSS JOIN }…] ] [ WHERE условие_фильтрации ] | [ GROUP BY условие_группировки [….
Создание новой таблицы по результатам команды SELECT. | Синтаксис: | SELECT [ ALL | DISTINCT [ ON (уникальное_выражение [….]) ] ] | цель [ AS выходное имя ] [,…] [ INTO [ TEMPORARY | TEMP ] [ TABLE ] новая_таблица ] | [ FROM источник [ {.
Присваивание значений конфигурационным переменным. | Синтаксис: | SET переменная {ТО = } { значение \ ‘значение’ DEFAULT } | SET TIME ZONE { ‘часовой_пояс’ \ LOCAL DEFAULT } | Параметры: | переменная. Имя конфигурационной переменной, которой присваивается новое значение. | значение.
Выбор режима проверки ограничений в текущей транзакции. | Синтаксис: | SET CONSTRAINTS { ALL режим […. ] } | { DEFERRED | IMMEDIATE } | Параметры: | ALL. Ключевое слово ALL означает, что указанный режим должен относиться ко всем ограничениям в текущей транзакции. | режим.
| режим.
Выбор уровня изоляции текущей транзакции. | Синтаксис: | SET TRANSACTION ISOLATION LEVEL | { READ COMMITTED | SERIALIZABLE } | SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL | { READ COMMITTED | SERIALIZABLE } | Параметры: | READ COMMITED.
Вывод значений конфигурационных переменных. | Синтаксис: | SHOW переменная | Параметры: | Имя конфигурационной переменной. | Результаты: | SHOW VARIABLE. Сообщение выдается при успешном выполнении команды SHOW. | ERROR: Option ‘переменная’ is not recognized.
Очистка таблицы. | Синтаксис: | TRUNCATE [ TABLE ] таблица | Параметры: | Имя таблицы. В результате очистки из таблицы удаляются все записи. | Результаты: | TRUNCATE. Сообщение выдается при успешной очистке таблицы. | ERROR: Relation ‘таблица’ does not exist.
Серверный процесс выходит из режима ожидания уведомлений. | Синтаксис: | UNLISTEN { событие \ * } | Параметры: | событие. Имя события, ожидаемого сервером. | *. Отмена ожидания всех событий, определенных ранее. | Результаты: | UNLISTEN. Это сообщение выдается при успешном выполнении команды UNLISTEN.
| *. Отмена ожидания всех событий, определенных ранее. | Результаты: | UNLISTEN. Это сообщение выдается при успешном выполнении команды UNLISTEN.
Обновление записей в таблице. | Синтаксис: | UPDATE [ ONLY ] таблица SET | поле = выражение [….] | [ FROM список_источников ] | [ WHERE условие ] | Параметры: | ONLY. Обновление выполняется только в указанной таблице и не распространяется на производные таблицы (если они существуют). | таблица.
Удаление временных данных и анализ базы данных. | Синтаксис: | VACUUM [ VERBOSE ] [ ANALYZE ] [ таблица ] | VACUUM [ VERBOSE ] ANALYZE [ таблица [ (поле [….]) ] ] | Параметры: | VERBOSE. Вывод отчета по каждой обработанной таблице. | ANALYZE.
Создание базы данных для курса Основы SQL
Инструкция по установке PostgreSQL и созданию демонстрационной базы данных для самостоятельного запуска запросов из курса
Если вы хотите не просто смотреть видео курса «Основы SQL», но и самостоятельно экспериментировать с SQL запросами и видеть результаты их выполнения на живой базе данных, то можете установить бесплатную систему управления базами данных PostgreSQL и создать в ней демонстрационную базу с данными, которые показаны в видео.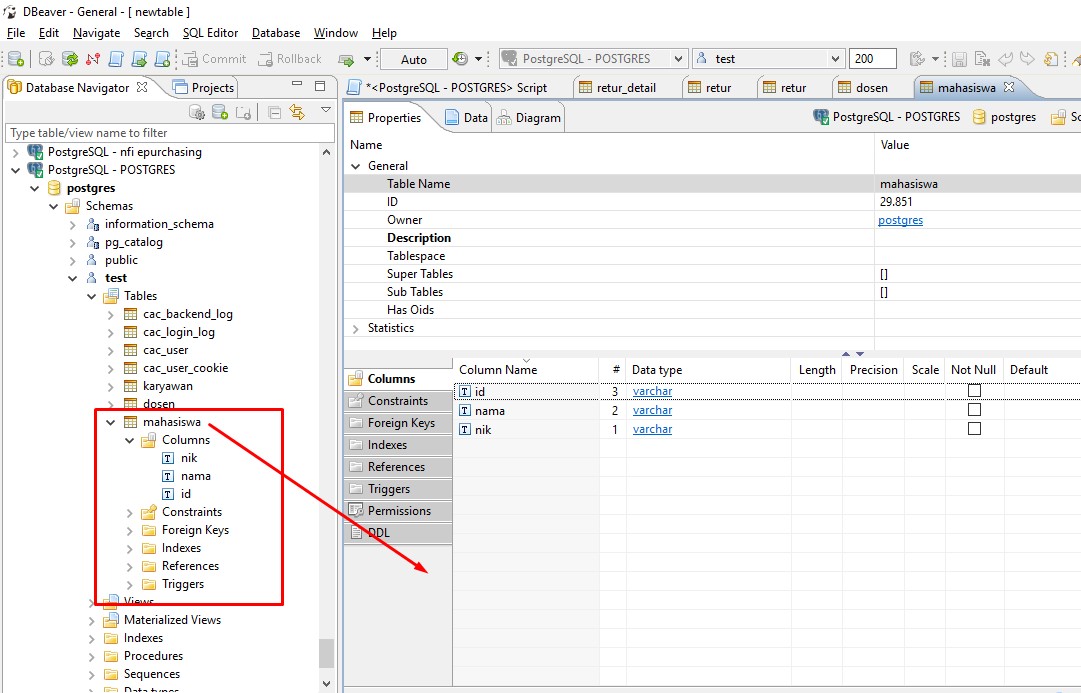 Эта статья содержит подробные инструкции по установке и настройке.
Эта статья содержит подробные инструкции по установке и настройке.
Установка PostgreSQL
В учебном курсе «Основы SQL» для демонстрации работы SQL используется PostgreSQL. Сейчас это самая популярная из бесплатных систем управления базами данных. Все SQL запросы в курсе проверены на работоспособность именно в PostgreSQL. Однако большая часть запросов использует синтаксис стандарта ANSI SQL, поэтому они будут работать и в других системах, включая MySQL, Microsoft SQL Server и Oracle. Вы можете использовать любую систему управления базами данных, которая вам нравится, но я рекомендую PostgreSQL.
1. Загрузите PostgreSQL для вашей операционной системы на странице Downloads официального сайта. Я устанавливал на Windows, если вы используете другую операционную систему, то выбирайте соответствующие ссылки для загрузки. Примеры в курсе проверены на PostgreSQL 13, поэтому рекомендую устанавливать именно эту версию. Однако на предыдущих версиях, начиная с PosgreSQL 10, также все должно работать.
Однако на предыдущих версиях, начиная с PosgreSQL 10, также все должно работать.
Инсталлятор для Windows и Mac OS загружается с сайта компании EDB, которая предоставляет платную поддержку для PostgreSQL. Однако PostgreSQL, которую вы установите с помощью этого инсталлятора от EDB, будет полностью бесплатной.
2. Запустите скачанный инсталлятор PostgreSQL.
Если вы устанавливаете PostgreSQL только для использования в курсе «Основы SQL», то можете оставить почти все настройки по умолчанию, кроме локали, для которой нужно выбрать «Russian, Russia» (русский язык в стране Россия).
Не забудьте запомнить или записать пароль пользователя postgres, он вам понадобится для подключения к базе и выполнения запросов!
После завершения установки инсталлятор предложит вам запустить Stack Builder для установки дополнительных утилит и компонентов. Этого можно не делать, просто снимите галочку в пункте «Stack Builder…» и нажмите кнопку «Finish».
На этом установка PostrgreSQL завершена.
Запуск и настройка pgAdmin
В курсе мы будем работать с PostrgreSQL через Web-интерфейс pgAdmin. Несмотря на Admin в названии, этот инструмент подходит не только администраторам, но и разработчикам.
pgAdmin устанавливается вместе с PostgreSQL. В Windows запустить pgAdmin можно в меню Пуск.
При первом запуске pgAdmin просит задать Master Password. Он будет использоваться для безопасного сохранения паролей к базам данных PosgreSQL, с которыми вы работаете через pgAdmin. Master Password можно выбрать любой, главное, запомните или запишите его.
Для удобства можно переключить интерфейс pgAdmin на русский язык. Для этого выберите меню File->Preferences, в появившемся окне в меню слева выберите Miscellaneous -> User Language, а затем в поле User Language справа «Russian».
Для вступления в силу настроек языка интерфейса нужно нажать кнопку «Save» и перезапустить pgAdmin.
После перезапуска выбирайте в левом меню Servers -> PostgreSQL, после чего pgAdmin запросит пароль пользователя postgres, который вы задали в процессе установки PostgreSQL. Введите этот пароль (можете поставить галочку «Save Password» чтобы pgAdmin запомнил пароль) и вы подключитесь к базе PostgreSQL.
Список существующих на сервере баз данных показывается в левом окне pgAdmin. Нас интересует база данных postgres, схема public и таблицы в ней. pgAdmin показывает много другой информации, не пугайтесь, если вы пока не понимаете, что это такое. Многое мы разберем в курсе, но преимущественно все это нужно только администраторам базы данных.
Пока в нашей базе нет никаких таблиц. Давайте создадим демонстрационные таблицы, которые используются в курсе, и заполним их данными.
Создание демонстрационной базы
1. Скачайте файл с демонстрационной базой данных курса «Основы SQL». Файл называется «sql_foundation» и имеет расширение . sql.
sql.
Файл содержит набор операторов SQL, которые создают используемые в курсе таблицы и заполняют их данными. Если вы пока не понимаете, что именно делают эти операторы, не расстраивайтесь. В курсе мы подробно рассмотрим работу каждого оператора и все будет понятно. На начальном этапе изучения курса необходимо просто запустить этот файл в pgAdmin.
2. Загрузите скачанный файл в pgAdmin. Для этого в меню pgAdmin выберите Инструменты->Запросник (в английском вариант Query Tool). В панели инструментов Запросника выберите кнопку открытия файла и в появившемся окне выберите путь к загруженному sql файлу с демонстрационной базой курса.
3. Запустите загруженный файл в pgAgmin. Для этого нажмите на кнопку запуска в панели инструментов Запросника или на клавишу F5.
4. Проверьте правильность выполнения запроса. В нижней части экрана pgAdmin, на закладке «Сообщения» должны появиться результаты выполнения.
Основное, на что нужно обратить внимание — это сообщение «Запрос завершен успешно». Если такое сообщение появилось, значит все хорошо.
Если такое сообщение появилось, значит все хорошо.
Если вы запускаете файл создания демонстрационной базы курса первый раз, то будет выведено несколько Замечаний, что таблицы не существуют. Их можно игнорировать.
Также в левой части интерфейса pgAdmin появится информация о созданных таблицах.
Итак, демонстрационные таблицы для курса «Основы SQL» созданы и заполнены данными, можно запускать SQL запросы.
Запуск SQL запросов в pgAdmin
В pgAdmin для запуска SQL запросов используется уже знакомый нам инструмент Запросник. Давайте откроем окно Запросника и напишем самый первый SQL запрос из видео про Оператор SELECT.
Запрос пишется в среднем окне, закладка Query Editor. Для запуска запроса нажимаем F5 или кнопку Execute в панели инструментов Запросника.
Полученные в ходе выполнения запроса данные показываются в нижней части окна, на закладке «Результат».
Использование SQL Shell (psql)
Если вы предпочитаете работать в командной строке, а не в громоздких приложениях типа pgAdmin, то можете использовать консольную утилиту для работы с PosgreSQL: SQL Shell (ранее она называлась psql).
SQL Shell, также как и pgAdmin, устанавливается совместно с PostgreSQL. В Windows запустить SQL Shell можно через меню Пуск.
После запуска SQL Shell задаст ряд вопросов о параметрах подключения к PostgreSQL, можно оставить все значения по умолчанию (если вы не меняли настройки при установке). После этого введите пароль пользователя postgres и можете начинать работать с базой данных.
Если вам не повезло, то в Windows SQL Shell запустится с неправильной кодировкой для русского языка, будет выдавать предупреждение и некоторые русские буквы будут выводиться неправильно.
Чтобы решить эту проблему, нужно прописать правильную кодировку в файл для запуска SQL Shell. В моем случае файл называется «C:\Program Files\PostgreSQL\13\scripts\runpsql.bat». В этот файл нужно добавить строку:
chcp 1251
После добавления строки с установкой правильной кодировки файл runpsql. bat стал выглядеть следующим образом.
Сохраняем файл runpsql. bat, перезапускаем SQL Shell, после этого проблем с русской кодировкой быть не должно.
bat, перезапускаем SQL Shell, после этого проблем с русской кодировкой быть не должно.
Для создания демонстрационной базы курса в SQL Shell выполните следующую команду:
\i 'C:/путь/к/файлу/sql_foundation.sql'
\i означает import — загрузка файла sql в базу данных.
Обратите, пожалуйста, внимание:
1. Путь к файлу sql_foundation.sql нужно указывать в одиночных кавычках. Если будете использовать двойные кавычки, то не заработает.
2. В пути используются прямые слеши (/), как в Linux/Unix, несмотря на то, что мы работаем под Windows. Если писать обратные слеши (\), как это принято в Windows, то будет выдаваться ошибка «Permission denied». Не очень информативное поведение SQL Shel.
Запросы в SQL Shell можно писать прямо в командной строке.
Запрос в SQL Shell может занимать несколько строк, как в примере на рисунке. Запрос запускается после ввода ; (точка с запятой) или команды \g.
Результаты выполнения запроса показываются сразу же после него.
Полезная функция SQL Shell — история команд. Если нажимать стрелки вверх или вниз, то можно увидеть, какие команды были запущены ранее и повторить интересующую вас команду.
В этой статье вы узнали, как установить PostgreSQL и как создать в нем демонстрационную базу для курса «Основы SQL». Также вы настроили и научились использовать два инструмента работы с PostgreSQL: pgAdmin и SQL Shell. Не обязательно использовать оба, выбирайте тот, который вам больше нравится: pgAdmin с Web-интерфейсом или командную строку SQL Shell.
В процессе экспериментов с SQL запросами в курсе вы можете случайно повредить созданную базу. В этом нет ничего страшного, базу данных можно легко пересоздать повторно запустив sql файл с операторами по созданию базы. При этом все имеющиеся таблицы будут удалены, заново созданы и заполнены данными. Все изменения, которые вы вносили, будут потеряны.
Полезные ссылки
1. Система управления базами данных PostgreSQL.
Система управления базами данных PostgreSQL.
2. pgAdmin PostgreSQL Tools.
3. Курс «Основы SQL».
4. Файл с демонстрационной базой данных для курса Основы SQL.
Оператор PostgreSQL SELECT {Синтаксис + примеры}
Введение
PostgreSQL — это система управления реляционными базами данных (RDBMS) с открытым исходным кодом. Система баз данных легко справляется с разнообразными рабочими нагрузками и поддерживает большинство операционных систем. Его расширяемость и совместимость с SQL делают PostgreSQL широко популярной СУБД.
Оператор SELECT — это наиболее часто используемая команда языка обработки данных (DML) в PostgreSQL.
В этом руководстве вы научитесь использовать оператор SELECT PostgreSQL с его полным синтаксисом и примерами.
Предварительные требования
- PostgreSQL установлен и настроен.
- База данных для работы (см. как создать базу данных).
Оператор PostgreSQL SELECT
Оператор PostgreSQL SELECT извлекает данные из одной или нескольких таблиц в базе данных и возвращает данные в виде таблица результатов, называемая набором результатов. Используйте оператор
Используйте оператор SELECT , чтобы вернуть одну или несколько строк, соответствующих указанным критериям, из таблиц базы данных.
Примечание: Мы рекомендуем использовать наши серверы Bare Metal Cloud для хранения вашей базы данных. Вы можете хранить базу данных на сервере BMC, а другие части приложения хранить в других облачных средах. Разверните экземпляр Bare Metal Cloud всего за несколько кликов.
Оператор SELECT является наиболее сложным оператором SQL с множеством необязательных ключевых слов и предложений. В следующих разделах подробно объясняется синтаксис SELECT .
PostgreSQL SELECT Syntax
Простейшая форма синтаксиса инструкции SELECT :
SELECT выражения ИЗ столов ГДЕ условия;
- Выражения

- Синтаксис
таблиц— это таблица или таблицы, из которых вы хотите извлечь результаты. - Условия
Пример полного синтаксиса инструкции SELECT :
SELECT [ ALL | ОТЛИЧНЫЙ | DISTINCT ON (различные_выражения) ]
выражения
ИЗ столов
[ГДЕ условия]
[СГРУППИРОВАТЬ ПО выражениям]
[ИМЕЕТ условие]
[ORDER BY выражение [ ASC | DESC | Оператор USING ] [ NULLS FIRST | ПОСЛЕДНИЕ НУЛИ ]]
[LIMIT [ количество_строк | ВСЕ]
[СМЕЩЕНИЕ_значение_сдвига [СТРОКА | РЯДЫ ]]
[ПОЛУЧИТЬ {ПЕРВЫЙ | СЛЕДУЮЩИЙ } [ fetch_rows ] { СТРОКА | РЯДЫ } ТОЛЬКО]
[ДЛЯ {ОБНОВЛЕНИЯ | ДОЛЯ } ИЗ таблицы [ NOWAIT ]];
Мы объясним все параметры в разделе ниже.
Параметры PostgreSQL SELECT
Возможные параметры в операторе SELECT :
-
ALL— необязательный параметр, который возвращает все совпадающие строки.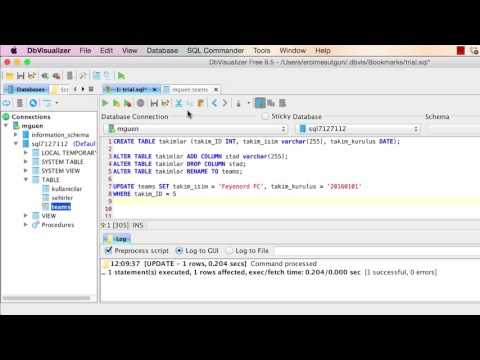
-
DISTINCT— параметр, который удаляет дубликаты из набора результатов. -
DISTINCT ON— необязательный параметр, устраняющий повторяющиеся данные на основеотличные_выраженияключевое слово. -
выражения— Все столбцы и поля, которые вы хотите включить в результат. Указание звездочки (*) выбирает все столбцы. -
таблицы— Укажите таблицы, из которых вы хотите получить записи. ПредложениеFROMдолжно содержать хотя бы одну таблицу. -
Условия WHERE— это предложение является необязательным и содержит условия, которые должны быть выполнены для фильтрации записей в результирующем наборе. -
Выражения GROUP BY— Необязательное предложение, которое собирает данные из нескольких записей, группируя результаты по одному или нескольким столбцам.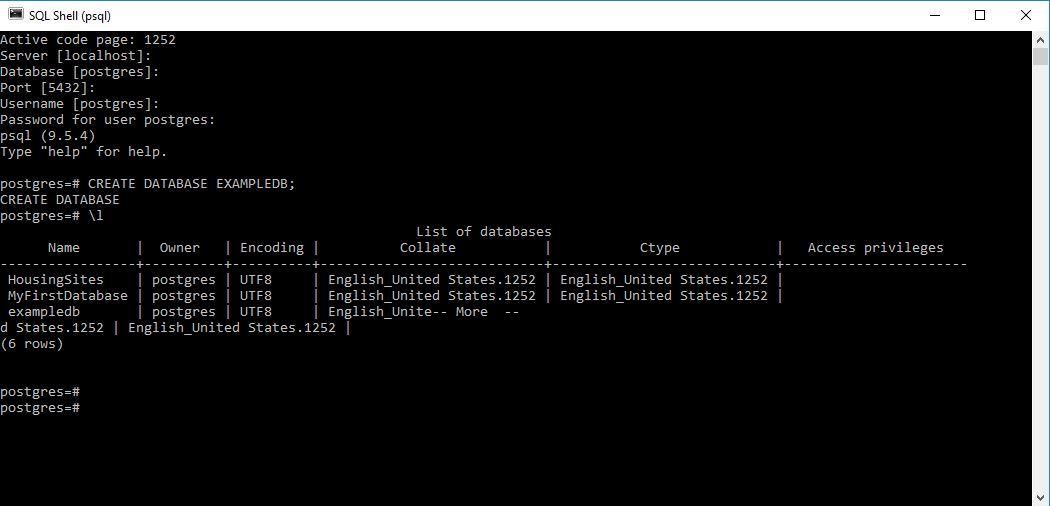
-
ИМЕЮЩИЙ условие— необязательное условие, используемое в сочетании сGROUP BY. Он ограничивает группы возвращаемых строк только теми, которые соответствуют условиюTRUE, тем самым фильтруя их. -
ORDER BY выражение— необязательное предложение, определяющее, какой столбец или столбцы следует использовать для сортировки данных в результирующем наборе. -
LIMIT— необязательное предложение, которое устанавливает максимальное количество записей для извлечения из таблицы, определяемое синтаксисомчисло_строк. Первая строка в результирующем наборе определяетсяoffset_value. -
FETCH— необязательное предложение, которое устанавливает максимальное количество записей в результирующем наборе. Укажите количество записей вместо
Укажите количество записей вместо fetch_rowsсинтаксис.offset_valueопределяет первую строку в результирующем наборе. -
FOR UPDATE— необязательное условие, которое блокирует запись записей, необходимых для выполнения запроса, до завершения транзакции. -
FOR SHARE— необязательное условие, которое позволяет использовать записи другими транзакциями, но предотвращает их обновление или удаление.
Примечание: Иногда запросы выполняются долго, если требуется обработать много данных. Посмотрите, какие инструменты вы можете использовать для оптимизации ваших запросов и ускорения их выполнения.
Примеры операторов PostgreSQL SELECT
В разделах ниже показаны несколько вариантов использования оператора SELECT .
Пример 1. Выбрать все поля
Самый простой способ вернуть все поля и просмотреть все содержимое таблицы — использовать оператор PostgreSQL SELECT .
Например:
SELECT * FROM актер;
В приведенном выше примере выходные данные показывают все поля, содержащиеся в таблице субъектов.
Пример 2. Фильтрация результатов по условию
Оператор SELECT позволяет фильтровать результаты, задав условие. В следующем примере мы хотим отображать только названия фильмов, где язык фильма английский ( language_id=1 ):
ВЫБЕРИТЕ название ИЗ фильма ГДЕ language_id=1;
Пример 3. Выбор полей из нескольких таблиц
PostgreSQL позволяет обрабатывать данные из нескольких таблиц в базе данных. Чтобы получить результаты из нескольких таблиц в одном запросе, используйте ПРИСОЕДИНЯЕТСЯ .
Например:
ВЫБРАТЬ клиент.имя, клиент.фамилия, платеж.сумма ОТ клиента ВНУТРЕННЕЕ СОЕДИНЕНИЕ оплата ПО customer.customer_id=payment.customer_id ЗАКАЗАТЬ ПО СУММЕ DESC;
В приведенном выше примере мы объединяем две таблицы, используя INNER JOIN , чтобы получить набор результатов, который отображает столбцы имени и фамилии из одной таблицы и сумму платежа из другой таблицы. Две таблицы объединены идентификатором
Две таблицы объединены идентификатором customer_id 9.Столбец 0009 , одинаковый в обеих таблицах.
Результаты расположены в порядке убывания, заданном условием ORDER BY amount DESC .
Пример 4. Выбор отдельных полей из одной таблицы
Оператор PostgreSQL SELECT позволяет возвращать отдельные поля из таблицы.
Например:
ВЫБЕРИТЕ имя, фамилия ОТ актера ЗАКАЗАТЬ ПО фамилии ASC;
В приведенном выше примере представлены только имена и фамилии актеров, а другие столбцы не указаны. Вывод упорядочивает результаты по фамилии в порядке возрастания.
Пример 5: Объединение столбцов
Если вы хотите, чтобы набор результатов объединял несколько столбцов в один, вы можете использовать оператор объединения || с оператором SELECT . Например:
ВЫБЕРИТЕ имя_имя || ' ' || фамилия ИЗ покупатель;
В этом примере мы объединили столбцы имени и фамилии, чтобы получить полное имя каждого клиента.
Пример 6: Расчеты
Вы также можете использовать SELECT для выполнения некоторых вычислений, но затем вы опускаете предложение FROM . Например:
ВЫБЕРИТЕ 15*3/5;
Вывод является результатом математического выражения, указанного в операторе SELECT .
Заключение
Теперь вы должны знать, как использовать оператор SELECT в PostgreSQL для обработки ваших данных. Если вас интересуют другие СУБД, ознакомьтесь с нашим списком лучших программ для управления базами данных, чтобы выбрать ту, которая лучше всего соответствует вашим потребностям.
PostgreSQL SELECT
Резюме : в этом руководстве вы узнаете, как использовать базовую инструкцию PostgreSQL SELECT для запроса данных из таблицы.
Обратите внимание: если вы не знаете, как выполнить запрос к базе данных PostgreSQL с помощью инструмента командной строки psql или инструмента pgAdmin с графическим интерфейсом, вы можете проверить это в руководстве по подключению к базе данных PostgreSQL.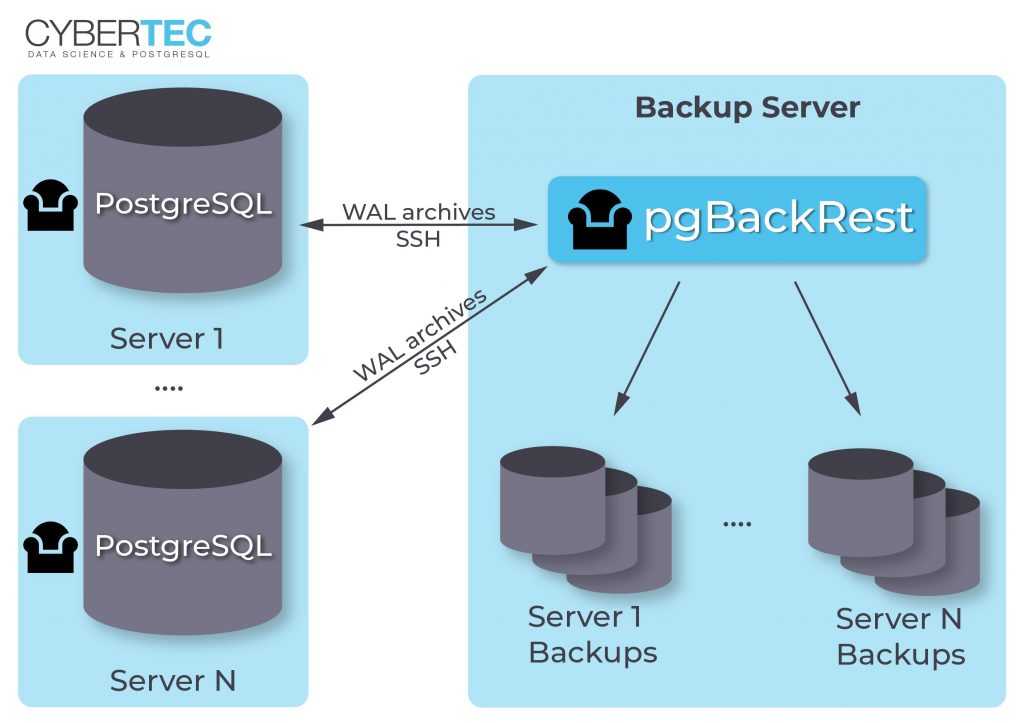
Одной из наиболее распространенных задач при работе с базой данных является запрос данных из таблиц с помощью Оператор SELECT .
Оператор SELECT — один из самых сложных операторов в PostgreSQL. Он имеет множество предложений, которые можно использовать для формирования гибкого запроса.
Из-за его сложности мы разобьем его на множество более коротких и простых для понимания руководств, чтобы вы могли быстрее изучить каждый пункт.
Оператор SELECT содержит следующие пункты:
- Выберите отдельные строки с помощью оператора
DISTINCT. - Сортировка строк с использованием предложения
ORDER BY. - Фильтрация строк с использованием предложения
WHERE. - Выберите подмножество строк из таблицы, используя предложение
LIMITилиFETCH. - Группировать строки в группы с помощью предложения
GROUP BY.
- Фильтрация групп с помощью предложения
HAVING. - Соединение с другими таблицами с использованием соединений, таких как
INNER JOIN,LEFT JOIN,FULL OUTER JOIN,CROSS JOIN 9статьи 0009. - Выполнение операций над множествами с помощью
UNION,INTERSECTиEXCEPT.
В этом руководстве вы сосредоточитесь на предложениях SELECT и FROM .
PostgreSQL
SELECT синтаксис оператора Начнем с базовой формы оператора SELECT , который извлекает данные из одной таблицы.
Ниже показан синтаксис команды SELECT 9.Оператор 0009:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ select_list ИЗ имя_таблицы;
Рассмотрим оператор SELECT более подробно:
- Сначала укажите список выбора, который может быть столбцом или списком столбцов в таблицы, из которой вы хотите получить данные.
 Если вы указываете список столбцов, вам нужно поставить запятую (
Если вы указываете список столбцов, вам нужно поставить запятую ( ,) между двумя столбцами, чтобы разделить их. Если вы хотите выбрать данные из всех столбцов таблицы, вы можете использовать звездочку (*) вместо указания всех имен столбцов. Список выбора может также содержать выражения или литеральные значения. - Во-вторых, укажите имя таблицы, из которой вы хотите запросить данные после ключевого слова
FROM.
Предложение FROM является необязательным. Если вы не запрашиваете данные из какой-либо таблицы, вы можете опустить предложение FROM в операторе SELECT .
PostgreSQL оценивает предложение FROM перед Предложение SELECT в операторе SELECT :
Обратите внимание, что ключевые слова SQL нечувствительны к регистру. Это означает, что SELECT эквивалентно select или Select . По соглашению мы будем использовать все ключевые слова SQL в верхнем регистре, чтобы упростить чтение запросов.
По соглашению мы будем использовать все ключевые слова SQL в верхнем регистре, чтобы упростить чтение запросов.
PostgreSQL
SELECT примеров Давайте рассмотрим несколько примеров использования оператора PostgreSQL SELECT .
Мы будем использовать следующие таблица customer в образце базы данных для демонстрации.
1) Использование оператора PostgreSQL
SELECT для запроса данных из одного столбца пример В этом примере используется оператор SELECT для поиска имен всех клиентов из таблицы Customer :
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT first_name ROM customer_name ;
Вот частичный вывод:
Обратите внимание, что мы добавили точку с запятой ( ; ) в конце инструкции SELECT . Точка с запятой не является частью оператора SQL. Он используется, чтобы сигнализировать PostgreSQL об окончании оператора SQL. Точка с запятой также используется для разделения двух операторов SQL.
Точка с запятой не является частью оператора SQL. Он используется, чтобы сигнализировать PostgreSQL об окончании оператора SQL. Точка с запятой также используется для разделения двух операторов SQL.
2) Использование оператора PostgreSQL
SELECT для запроса данных из нескольких столбцов примерПредположим, вы просто хотите узнать имя, фамилию и адрес электронной почты клиентов, вы можете указать эти имена столбцов в 9Предложение 0008 SELECT , как показано в следующем запросе:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT Имя, фамилия, Эл. адрес ИЗ покупатель;
3) Использование оператора PostgreSQL
SELECT для запроса данных из всех столбцов таблицы пример Следующий запрос использует оператор SELECT для выбора данных из всех столбцов таблицы клиента :
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ * ОТ клиента;
В этом примере мы использовали звездочку ( * ) в предложении SELECT , которое является сокращением для всех столбцов.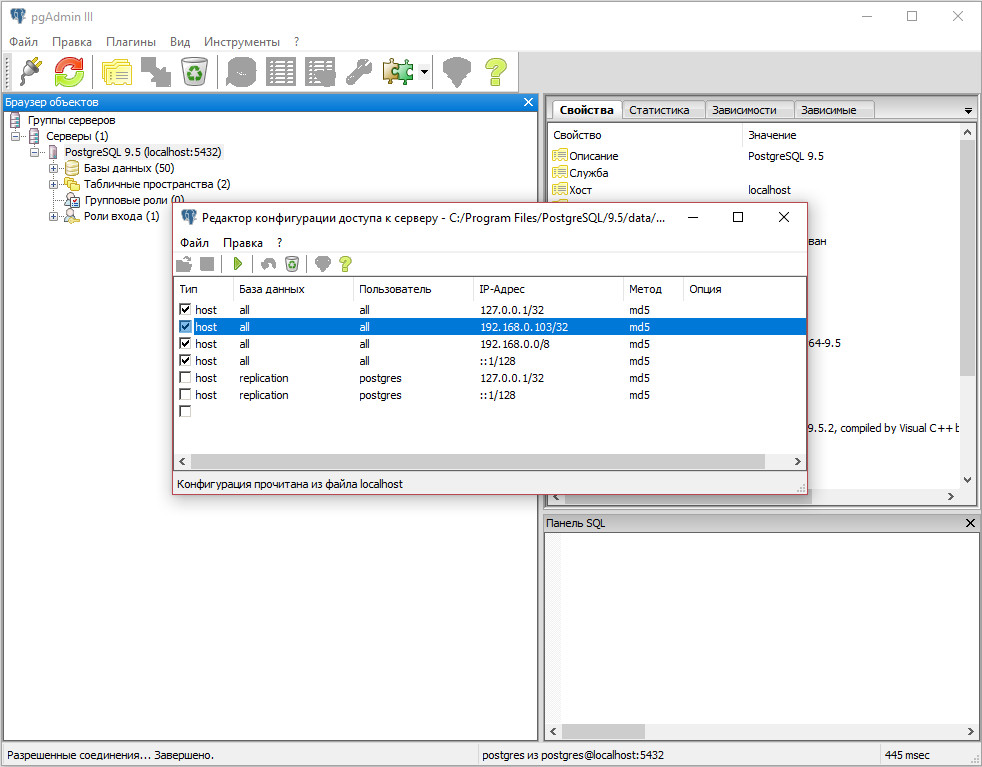 Вместо того, чтобы перечислять все столбцы в предложении
Вместо того, чтобы перечислять все столбцы в предложении SELECT , мы просто использовали звездочку ( * ), чтобы не печатать.
Однако не рекомендуется использовать звездочку ( * ) в операторе SELECT при встраивании операторов SQL в код приложения, такого как Python, Java, Node.js или PHP, по следующим причинам. :
- Производительность базы данных. Предположим, у вас есть таблица с большим количеством столбцов и большим количеством данных. Оператор
SELECTсо звездочкой (*) выберет данные из всех столбцов таблицы, которые могут быть не нужны приложению. - Производительность приложения. Извлечение ненужных данных из базы данных увеличивает трафик между сервером базы данных и сервером приложений. Как следствие, ваши приложения могут работать медленнее и менее масштабируемы.
По этим причинам рекомендуется явно указывать имена столбцов в предложении SELECT , когда это возможно, чтобы получать из базы данных только необходимые данные.
И вы должны использовать звездочку (*) только для специальных запросов, которые проверяют данные из базы данных.
4) Использование инструкции PostgreSQL
SELECT с выражениями example В следующем примере инструкция SELECT используется для возврата полных имен и адресов электронной почты всех клиентов:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ имя_имя || ' ' || фамилия, Эл. адрес ИЗ покупатель;
Вывод:
В этом примере мы использовали оператор конкатенации || , чтобы объединить имя, пробел и фамилию каждого клиента.
В следующем уроке вы узнаете, как использовать псевдонимы столбцов для присвоения выражениям более понятных имен.
5) Использование PostgreSQL
Оператор SELECT с выражениями пример В следующем примере используется оператор SELECT с выражением.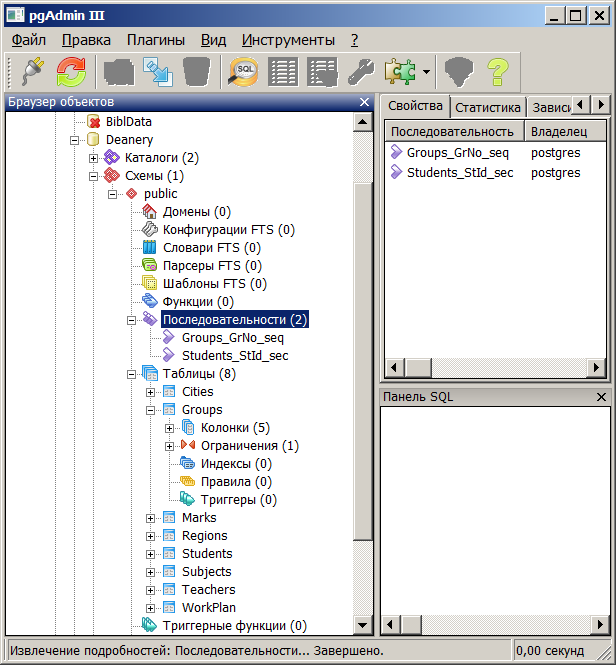 В нем отсутствует предложение
В нем отсутствует предложение FROM :
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT 5 * 3;
Вот результат:
В этом руководстве вы узнали, как использовать базовую форму оператора PostgreSQL SELECT для запроса данных из единый стол.
Было ли это руководство полезным?
В чем разница между ними?
При выборе системы управления базами данных могут возникнуть разные вопросы. Крайне важно найти СУБД, отвечающую вашим потребностям и демонстрирующую максимальную эффективность при решении стоящих перед вами задач. В этой статье мы собираемся обсудить различия между системами управления базами данных PostgreSQL и MySQL.
Будут изучены следующие темы:
- В чем разница между MySQL и PostgreSQL?
- Является ли Postgres быстрее, чем MySQL?
- Должен ли я изучать MySQL или PostgreSQL?
- Когда лучше использовать MySQL или PostgreSQL?
Во-первых, давайте внимательно рассмотрим базы данных Postgres и MySQL.
PostgreSQL (Postgres) — это бесплатная система управления объектно-реляционными базами данных с открытым исходным кодом, которая предоставляет богатый набор функций и легко настраивается. Postgres имеет соответствие свойствам атомарности, согласованности, изоляции, долговечности (ACID). Он удобен в использовании и отлично подходит как для профессионалов, так и для новичков. MySQL — это система управления базами данных с открытым исходным кодом, которая помогает организовывать данные в таблицы. Таблицы могут быть связаны друг с другом и тем самым структурировать данные. MySQL позволяет создать эффективную и безопасную систему хранения данных.
Основные различия между MySQL и PostgreSQLТеперь, когда у нас есть краткие сведения о PostgreSQL и MySQL, давайте обсудим основные различия между этими системами управления базами данных.
СУРБД и ОРСУБД
MySQL — это чисто реляционная система управления базами данных (СУРБД), а PostgreSQL — объектно-реляционная система управления базами данных (ОРСУБД).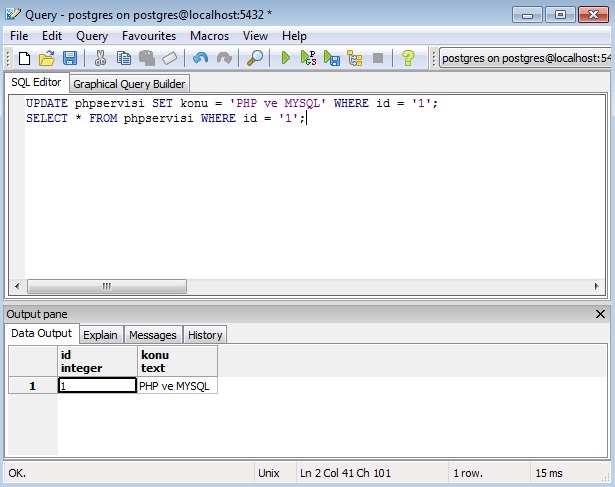 В MySQL и других системах управления реляционными базами данных все таблицы взаимосвязаны. В свою очередь, PostgreSQL сочетает в себе характеристики как СУБД, так и объектно-ориентированной системы управления реляционными базами данных. Такие базы данных содержат не только взаимосвязанные таблицы, но и поддерживают объекты, классы и наследование.
В MySQL и других системах управления реляционными базами данных все таблицы взаимосвязаны. В свою очередь, PostgreSQL сочетает в себе характеристики как СУБД, так и объектно-ориентированной системы управления реляционными базами данных. Такие базы данных содержат не только взаимосвязанные таблицы, но и поддерживают объекты, классы и наследование.
Лицензия
Обе системы основаны на открытом исходном коде, но MySQL поддерживается корпорацией Oracle, а Postgres поддерживается добровольцами.
Репликация
Репликация данных из базы данных на одном компьютере в базу данных на другом выполняется для того, чтобы всем пользователям был доступен одинаковый объем информации. Репликация производится на регулярной основе. Распределенная база данных позволяет одновременно работать нескольким пользователям.
MySQL обеспечивает репликацию Master-Standby, в то время как PostgreSQL не только поддерживает ее, но и имеет улучшенную обработку WAL, что позволяет осуществлять репликацию и резервные возможности практически в реальном времени с минимальным временем простоя резервных серверов.
Производительность
MySQL быстрее для операций чтения, и поэтому его часто выбирают при работе с системами OLAP/OLTP, где быстрое чтение является основной проблемой. PostgreSQL, в свою очередь, отлично подходит для работы с огромными наборами данных и сложными запросами, он отлично подходит для параллельных операций записи. Все это делает PostgreSQL идеальным выбором для задач бизнес-аналитики и обработки данных.
Безопасность
MySQL реализует безопасность управления доступом (ACL) для любых операций, которые пользователь может попытаться выполнить. В PostgreSQL есть РОЛИ и устаревшие роли для установки и обслуживания разрешений. Он также имеет встроенную поддержку SSL-соединений, шифрование сообщений клиент/сервер и безопасность на уровне строк. PostgreSQL имеет расширение SE-PostgreSQL, предоставляющее дополнительные средства управления доступом на основе политики безопасности SELinux.
Поддержка NoSQL
MySQL не предоставлял никакой поддержки NoSQL, но недавно был выпущен с версией 8. 0. В свою очередь, PostgreSQL также предлагает поддержку NoSQL.
0. В свою очередь, PostgreSQL также предлагает поддержку NoSQL.
В этом разделе мы поговорим о других существенных различиях между PostgreSQL и MySQL. Может показаться, что эти две базы данных очень похожи, однако на практике оказывается, что в их использовании есть некоторые особенности. Чтобы помочь вам принять взвешенное решение, мы предлагаем полную сравнительную таблицу PostgreSQL и MySQL.
Хотя две базы данных имеют множество параллелей и совпадений, они также имеют значительные различия. Мы попытались провести честное и честное сравнение между ними, но, в конце концов, вам нужно будет оценить свою личную ситуацию и выбрать СУБД, которая лучше всего соответствует вашим потребностям.
Мы суммировали сходства и различия между наиболее широко используемыми функциями PostgreSQL и MySQL.
Популярность Postgres имеет активное сообщество , основное внимание которого сосредоточено на выпуске самых передовых улучшений безопасности и самых современных функций.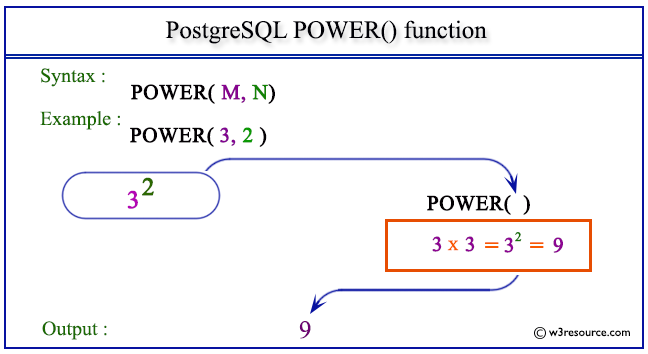 MySQL имеет большое сообщество участников, основной целью которых является обновление существующего набора функций путем добавления новых функций. MySQL является инструментом по умолчанию для создания многих приложений, и с точки зрения MySQL по сравнению с PostgreSQL, он обладает большей долей рынка, чем PostgreSQL, в то время как последний считается более продвинутой базой данных.
MySQL имеет большое сообщество участников, основной целью которых является обновление существующего набора функций путем добавления новых функций. MySQL является инструментом по умолчанию для создания многих приложений, и с точки зрения MySQL по сравнению с PostgreSQL, он обладает большей долей рынка, чем PostgreSQL, в то время как последний считается более продвинутой базой данных.
Что касается синтаксиса, то между PostgresSQL и MySQL почти нет разницы, поскольку оба они основаны на стандарте SQL. Пример оператора SELECT выглядит следующим образом:
MySQL:
SELECT * FROM records;
PostgreSQL:
SELECT * FROM записи;
На самом деле, отсутствие различий между запросами PostgreSQL и MySQL даже позволяет сделать запросы взаимозаменяемыми в обеих СУБД.
Индексы PostgreSQL позволяет создавать индекс выражения на основе функций выражения, а не значений столбца. Также возможно создавать хэш-индексы и индексы B-tree, а также частичные индексы, которые организуют данные из части таблицы.
Также возможно создавать хэш-индексы и индексы B-tree, а также частичные индексы, которые организуют данные из части таблицы.
MySQL поддерживает индексы, хранящиеся в B-деревьях, такие как INDEX, FULLTEXT, PRIMARY KEY и UNIQUE. Он также позволяет создавать индексы, хранящиеся в R-деревьях, а также хэш-индексы и инвертированные списки при использовании вместе с индексом FULLTEXT.
Типы данных в таблицах По сравнению с MySQL Postgres поддерживает более широкий диапазон форматов данных. PostgreSQL может быть предпочтительнее, если ваше приложение работает с любым из предлагаемых им уникальных типов данных, а также с неструктурированными данными в больших таблицах. Обе СУБД будут работать нормально, если вы используете только базовые символьные и числовые типы данных. PostgreSQL поддерживает следующие типы данных: числовые, дата/время, символьные, логические, перечисляемые, геометрические, сетевой адрес, JSON, XML, HSTORE, массивы, диапазоны, составные. MySQL поддерживает типы данных, такие как числовые, дата/время, символьные, пространственные, JSON.
MySQL поддерживает типы данных, такие как числовые, дата/время, символьные, пространственные, JSON.
По умолчанию производительность Postgres выше, поскольку он поддерживает одновременные операции записи без необходимости блокировки чтения/записи. Он также реализует изоляцию транзакций и моментальные снимки и полностью совместим с ACID. MySQL, с другой стороны, стремится достичь параллелизма, используя блокировки записи. В результате количество одновременных действий на процесс уменьшается. Вам нужно будет добавить много ресурсов в MySQL для масштабирования в производственных средах.
Однако есть одна область, в которой MySQL показывает лучшие результаты, — это процессы с интенсивным чтением. Поскольку большинство приложений просто считывают и отображают данные из базы данных, базовая реализация MySQL превосходит реализацию PostgreSQL. Это связано с тем, что когда Postgres разветвляет новый процесс для каждого соединения, он выделяет значительный объем памяти (около 10 МБ). Это приводит к раздуванию использования памяти, что по существу съедает системные ресурсы. В результате скорость приносится в жертву целостности данных и соответствию стандартам.
Это приводит к раздуванию использования памяти, что по существу съедает системные ресурсы. В результате скорость приносится в жертву целостности данных и соответствию стандартам.
Даже когда в рамках одной транзакции выполняется несколько модификаций, соответствие требованиям ACID (атомарность, непротиворечивость, изоляция, надежность) гарантирует, что в случае сбоя данные не будут потеряны или неправильно переданы в системе. MySQL совместим с ACID только через механизмы InnoDB и NDB Cluster Storage. PostgreSQL полностью совместим с ACID.
Кластеризация репликации и масштабируемостьMySQL и PostgreSQL поддерживают репликацию. Репликация в MySQL является односторонней асинхронной. PostgreSQL, с другой стороны, поддерживает синхронную репликацию, а также каскадную и синхронную репликацию.
MySQL предлагает MySQL Cluster, базу данных с несколькими мастерами, в которой приоритет отдается линейному масштабированию. Он использует синхронную репликацию внутри, несмотря на одностороннюю асинхронную репликацию. MySQL избегает любых негативных последствий и сбоев транзакций, удаляя из системы единые точки отказа и гарантируя, что данные записываются на разные узлы.
Он использует синхронную репликацию внутри, несмотря на одностороннюю асинхронную репликацию. MySQL избегает любых негативных последствий и сбоев транзакций, удаляя из системы единые точки отказа и гарантируя, что данные записываются на разные узлы.
Что касается кластеризации, PostgreSQL допускает потоковую или синхронную репликацию, а также Postgres-XL, среду кластеризации баз данных.
J
Поддержка SONMySQL поддерживает JSON, но не поддерживает индексирование для JSON. В свою очередь, PostgreSQL поддерживает как функции JSON, так и индексацию данных JSON для более быстрого доступа.
Поддержка языков программированияMySQL обеспечивает поддержку Delphi, Erlang, Go, Java, Lisp, Perl, PHP, R. В свою очередь, PostgreSQL поддерживает несколько большее количество языков, включая Java, JavaScript, Python, R, Tcl, Lisp, Erlang и другие.
Простота использования для начинающих Если говорить о простоте использования MySQL и PostgreSQL для начинающих, то MySQL более удобен для пользователя, и создание проекта с нуля занимает меньше времени. С другой стороны, новичкам кривая обучения PostgreSQL может показаться чрезмерно жесткой. По сравнению с сообществом баз данных MySQL поддержка PostgreSQL может быть менее существенной и активной.
С другой стороны, новичкам кривая обучения PostgreSQL может показаться чрезмерно жесткой. По сравнению с сообществом баз данных MySQL поддержка PostgreSQL может быть менее существенной и активной.
MySQL легко настроить как отдельный продукт или как часть стека, такого как стек LAMP. Большинство пакетов веб-хостинга теперь содержат базы данных MySQL, к которым вы также можете получить доступ через программное обеспечение для управления базами данных, такое как phpMyAdmin.
С PostgreSQL. более вероятно, что вам нужно будет настроить компьютер для разработки или запустить виртуальный сервер и установить PostgreSQL самостоятельно. С точки зрения доступности для начинающих разработчиков и аналитиков MySQL имеет преимущество. Это не означает, что PostgreSQL не лучший вариант для конкретного приложения, особенно ресурсоемкого, которое может выиграть от повышения безопасности и балансировки нагрузки. Однако, поскольку MySQL более широко используется, он более доступен.
Однако, поскольку MySQL более широко используется, он более доступен.
Помимо самой платформы, вам также нужно подумать о том, какие сторонние приложения и интеграции вам потребуются для вашей инфраструктуры.
Зачем использовать MySQL?Вот несколько веских причин для использования MySQL:
- Поддержка репликации master-slave и масштабирования
- Отчеты о разгрузке и географическое распределение данных
- Низкие накладные расходы механизма хранения MyISAM при использовании для приложений только для чтения
- Поддержка механизма хранения в памяти для часто используемых таблиц
- Кэш запросов для часто используемых операторов
- Множество ресурсов для изучения и устранения неполадок MySQL
При сравнении двух баз данных важно знать основные преимущества PostgreSQL. Некоторые разработчики могут предпочесть его MySQL, потому что он считается лучше и быстрее, а также имеет гораздо более богатую функциональность.
Основные причины выбора PostgreSQL:
- Разделение таблиц, восстановление на определенный момент времени и транзакционные функции DDL
- Возможность использования сторонних хранилищ ключей с полной инфраструктурой PKI
- Поскольку открытый исходный код PostgreSQL распространяется под лицензией BSD, разработчики могут изменять его без необходимости внести свой вклад в улучшения
- Привилегии на уровне объектов могут быть предоставлены пользователям и ролям
- Поддержка AES, 3DES и других методов шифрования данных
- Функции пространственного индексирования
Можно ли перенести базы данных MySQL на PostgreSQL? Предположим, есть пользователь, у которого есть база данных MySQL, и он хочет перенести ее на Postgres. Это легко сделать с помощью полезной среды IDE, которая специально разработана для экономии времени и усилий пользователей. Кроме того, вы можете использовать Studio и драйвер ODBC для переноса данных между двумя СУБД. Чтобы просмотреть подробное руководство по переносу MySQL на PostgreSQL, перейдите по этой ссылке.
Чтобы просмотреть подробное руководство по переносу MySQL на PostgreSQL, перейдите по этой ссылке.
Миграция базы данных из PostgreSQL в MySQL может быть довольно сложной и трудоемкой задачей, которую можно автоматизировать с помощью мощного конвертера — dbForge Studio для PostgreSQL.
Postgres, MySQL и dbForgeЛинейка продуктов dbForge предлагает инструменты разработки и управления базами данных для основных СУБД: SQL, MySQL, PostgreSQL и Oracle. В частности, пользователи высоко ценят dbForge Studios — интегрированную среду разработки «все в одном» для разработки, управления и администрирования баз данных.
dbForge Studio для MySQL dbForge Studio для MySQL предоставляет все необходимое для создания баз данных и управления ими, упрощает рабочий процесс, обеспечивает высокую производительность и снижает затраты. И все это — под красивым и удобным интерфейсом. За прошедшие годы он оказался бесценным для разработчиков баз данных, аналитиков данных, администраторов баз данных и специалистов по данным.
За прошедшие годы он оказался бесценным для разработчиков баз данных, аналитиков данных, администраторов баз данных и специалистов по данным.
Главные причины выбрать dbForge Studio для MySQL
- Расширенное завершение кода и проверка синтаксиса
- Schema and Data Compare tools
- Query Builder
- Data Import and Export
- Backup and Recovery
- Database Projects and Version Control
dbForge Studio for PostgreSQL offers robust database development and administration возможности, охватывающие основные инструменты в одном универсальном решении, которое предназначено для повышения вашей производительности и повышения ценности для ваших клиентов.
главные причины выбора DBForge Studio для Postgresql
- Intellisense-Like Development
- Профильер запросов
- Экспорт данных/Импорт
- Проект
- Pivot Tobles.
