PostgreSQL оператор DISTINCT — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
В этом учебном пособии вы узнаете, как использовать PostgreSQL оператор DISTINCT с синтаксисом и примерами.
Описание
PostgreSQL оператор DISTINCT используется для удаления дубликатов из набора результатов. DISTINCT может использоваться только с операторами SELECT.
Синтаксис
Синтаксис для оператора DISTINCT в PostgreSQL:
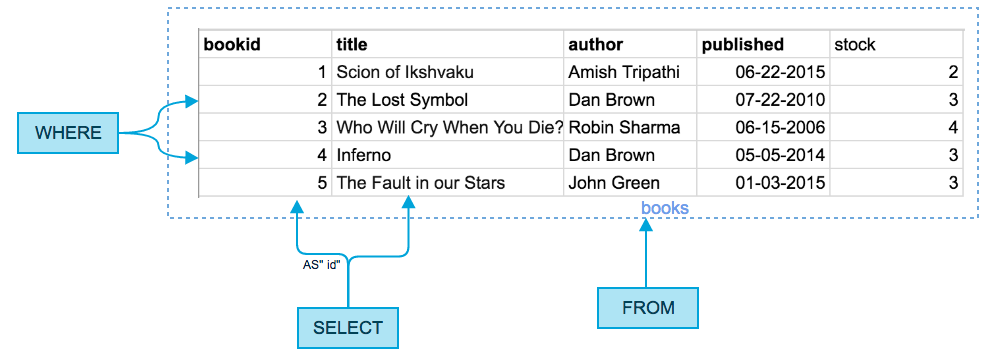
SELECT DISTINCT | DISTINCT ON (distinct_expressions)
expressions
FROM tables
[WHERE conditions];
Параметры или аргументы
- distinct_expressions
- Выражения, используемые для удаления дубликатов.
- expressions
- Столбцы или вычисления, которые вы хотите получить.
- tables
- Таблицы, из которых вы хотите получить записи. В операторе FROM должна быть указана хотя бы одна таблица.
- WHERE conditions
- Необязательный. Условия, которые должны быть выполнены для записей, которые будут выбраны.

Примечание
- Если в DISTINCT указано только одно выражение, запрос возвратит уникальные значения для этого выражения.
- Если в DISTINCT указано несколько выражений, запрос извлекает уникальные комбинации для перечисленных выражений.
- Если заданы ключевые слова DISTINCT ON, запрос возвратит уникальные значения для Different_expressions и вернет другие поля для выбранных записей на основе предложения ORDER BY (limit 1).
- В PostgreSQL DISTINCT не игнорирует значения NULL. Поэтому при использовании DISTINCT в вашем операторе SQL ваш результирующий набор будет содержать значение NULL как отдельное значение.
Пример — с одним выражением
Рассмотрим на простейший пример DISTINCT в PostgreSQL. Мы можем использовать оператор DISTINCT, чтобы вернуть одно поле, которое удаляет дубликаты из набора результатов.
Например:
SELECT DISTINCT last_name FROM contacts ORDER BY last_name;
SELECT DISTINCT last_name FROM contacts ORDER BY last_name; |
В этом PostgreSQL примере DISTINCT будут возвращены все уникальные значения last_name из таблицы contacts.
Пример — с несколькими выражениями
Давайте посмотрим, как вы можете использовать оператор PostgreSQL DISTINCT для удаления дубликатов из более чем одного поля в вашем операторе SELECT.
Например:
SELECT DISTINCT last_name, city, state FROM contacts ORDER BY last_name, city, state;
SELECT DISTINCT last_name, city, state FROM contacts ORDER BY last_name, city, state; |
Этот пример будет возвращать каждую уникальную комбинацию last_name, city и state из таблицы contacts. В этом случае DISTINCT применяется к каждому полю, указанному после ключевого слова DISTINCT, и, следовательно, возвращает различные комбинации.
Пример — DISTINCT ON
Одна вещь, которая уникальна в PostgreSQL, по сравнению с другими базами данных, заключается в том, что у вас есть еще одна опция при использовании оператора DISTINCT, которая называется DISTINCT ON.
DISTINCT ON вернет только первую строку для DISTINCT ON (diver_expressions) на основе оператора ORDER BY, предоставленного в запросе. Любые другие поля, перечисленные в операторе SELECT, будут возвращены для этой первой строки. Это похоже на выполнение LIMIT в 1 для каждой комбинации DISTINCT ON (Different_expressions).
Любые другие поля, перечисленные в операторе SELECT, будут возвращены для этой первой строки. Это похоже на выполнение LIMIT в 1 для каждой комбинации DISTINCT ON (Different_expressions).
Давайте подробнее рассмотрим, как использовать DISTINCT ON в операторе DISTINCT и что он возвращает.
SELECT DISTINCT ON (last_name) last_name, city, state FROM contacts ORDER BY last_name, city, state;
SELECT DISTINCT ON (last_name) last_name, city, state FROM contacts ORDER BY last_name, city, state; |
Этот пример DISTINCT, в котором используются ключевые слова DISTINCT ON, вернет все уникальные значения last_name. Но в этом случае для каждого уникального значения last_name он будет возвращать только первую уникальную запись last_name, с которой он сталкивается, на основе оператора ORDER BY вместе с city и state значениями из этой записи.
Он не возвращает уникальные комбинации last_name, city и state.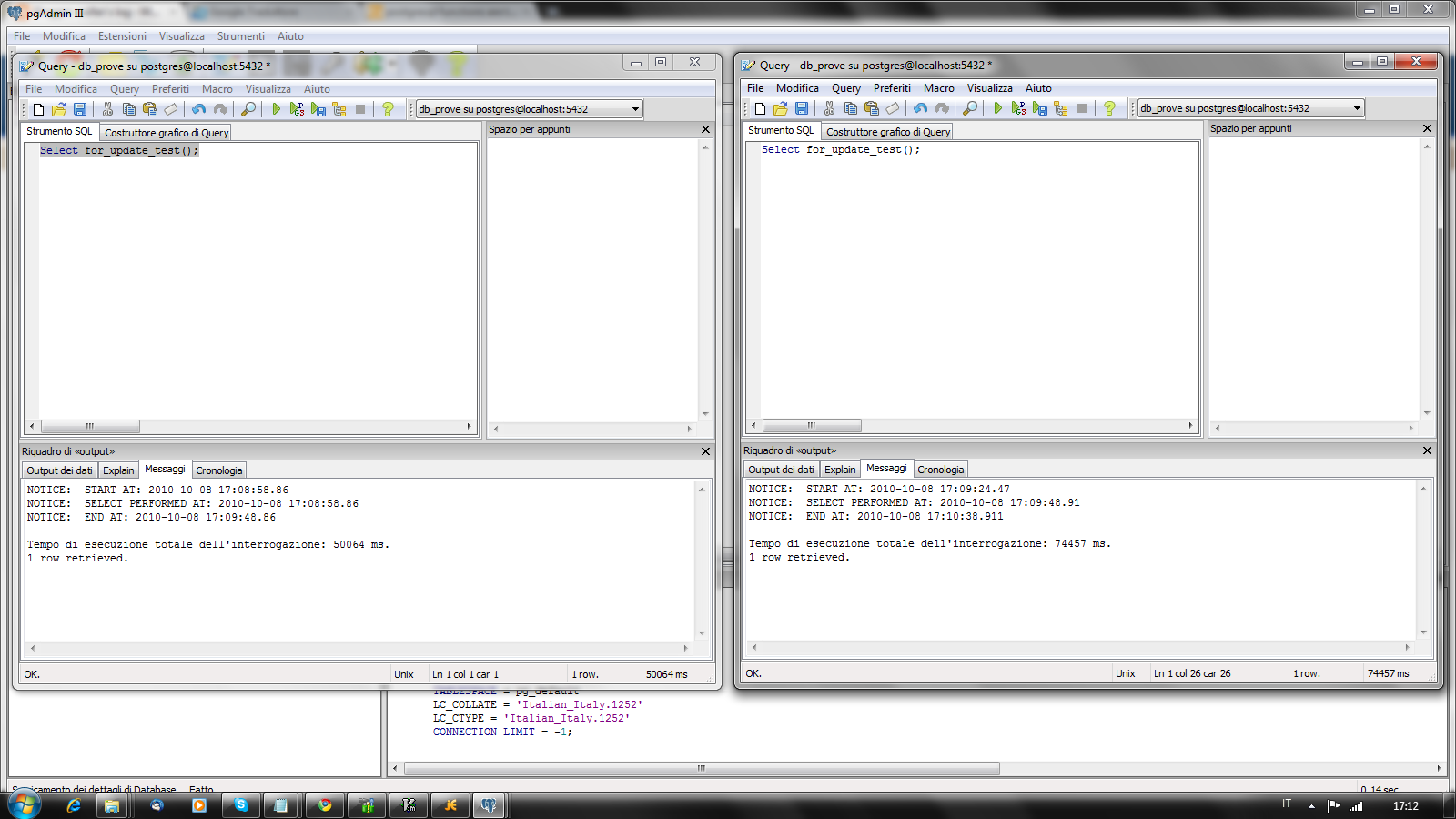 По сути, он выполняет LIMIT, равный 1, для каждого DISTINCT ON (last_name) и возвращает соответствующие значения city и state после того, как он выбрал возвращеные записи.
По сути, он выполняет LIMIT, равный 1, для каждого DISTINCT ON (last_name) и возвращает соответствующие значения city и state после того, как он выбрал возвращеные записи.
PostgreSQL инструкция SELECT — SQL программирование
Платформа PostgreSQL поддерживает простую реализацию инструкции SELECT. Поддерживаются предложения JOIN и подзапросы. В PostgreSQL также можно создавать новые временные или постоянные таблицы с использованием синтаксиса SELECT INTO.
[ALL ‘ DISTINCT [ON (отбираемый_элемент [, …])]]
Поддерживаются ключевые слова ALL и DISTINCT стандарта ANSI SQL, где ALL (задано по умолчанию) возвращает все строки (включая дублирующиеся), a DISTINCT удаляет дублирующиеся строки. Кроме того, предложение DISTINCT ON удаляет дубликаты только в одном из указанных отбираемых элементов, а не во всех отбираемых элементах запроса.
отбираемый_элемент
Включает все стандартные элементы списка отбираемых элементов, принятого стандартом ANSI SQL.
[AS псевдоним [(список псевдонимов)]
Создается псевдоним или список псевдопимов для одного или нескольких столбцов (или таблиц в предложении FROM). Предложение AS является необходимым для создания псевдонимов отбираемых элементов, но не для псевдонимов в предложении FROM. (Некоторые другие платформы считают предложения AS необязательными.)
INTO [[TEMP]ORARY] [TABLE] имя_новой_таблицы
Из результирующего набора запроса создается новая таблица. Для создания временных таблиц, которые автоматически удаляются по окончании сеанса, допустимым является синтаксис TEMP или TEMPORARY. В противном случае команда создает постоянную таблицу. Постоянные таблицы, созданные при помощи этой инструкции, должны иметь новые, уникальные имена, а временные таблицы могут иметь те же имена, что и уже существующие таблицы.
FROM [ONLY] таблица! […]
Указывается одна или несколько таблиц-источников, в которых находятся данные. (Обязательно укажите условие соединения или условие WHERE для тета-соедине-ния, чтобы не получить полный координатный продукт для всех записей во всех таблицах.) PostgreSQL позволяет использовать в таблицах-потомках наследование из родительских таблиц. Ключевое слово ONLY используется для того, чтобы данные не извлекались из таблиц-потомков исходной таблицы. (Вы можете отключить такое наследование на глобальном уровне командой SET SQL Inheritance ТО OFF) Платформа PostgreSQL также поддерживает вложенные табличные подзапросы. Предложение FROM не является необходимым при использовании вычислений.
SELECT 8 * 40;
Платформа PostgreSQL также может включать в инструкции SELECT неявные предложения FROM при использовании столбцов с указанием схемы. Например, следующий столбец является допустимым (хотя так делать и не рекомендуется).
SELECT sales.stor_id WHERE sales.stor_id='6380' GROUP ВY выражение_для group_by
Позволяет указать выражение для группировки, которое может представлять собой имя столбца или его порядковый номер (указывающий на его положение в списке отбираемых элементов). Пример, иллюстрирующий данную концепцию, приводится чуть ниже, в разделе, посвященном предложению ORDER BY.
ORDER BY выражение_для_сортировки
Позволяет указать выражение для сортировки, которое может представлять собой имя столбца, его псевдоним или порядковый номер столбца (указывающий на его положение в списке отбираемых элементов). Например, следующие два запроса функционально идентичны.
SELECT stor_id, ord_date, qty AS quantity FROM sales ORDER BY stor_id, ord_date DESC, qty ASC; SELECT stor_id, ord_date, qty FROM sales ORDER 3Y 1, 2 DESC, quantity;
В инструкциях SELECT, обращающихся к одной таблице, вы можете проводить сортировку по столбцам, не входящим в список отбираемых элементов. Например:
Например:
SELECT * FROM sales ORDER BY stor_id, qty;
Предложения ASC и DESC соответствуют стандарту ANSI. По умолчанию принимается предложение ASC. Платформа PostgreSQL считает, что пустые значения больше всех остальных, поэтому они располагаются в конце при сортировке по возрастанию (ASC) и в начале — при сортировке по убыванию (DESC). FOR UPDATE OF столбец [, …] LIMIT {число ALL)] [OFFSET [количество_записей]] Число строк, возвращаемых запросом, ограничивается максимумом, указанным в целочисленном параметре число. Дополнительное ключевое слово OFFSET заставляет PostgreSQL пропустить указанное количество записей, прежде чем начать извлекать строки. При использовании предложения LIMIT должно обязательно присутствовать предложение ORDER BY, в противном случае результирующий набор будет неопределенным. (PostgreSQL версии 7.0 и выше рассматривают предложение LIMIT/OFFSET как подсказку оптимизатору и используют его для создания оптимальных, но, возможно, очень различных планов обработки запроса.
PostgreSQL поддерживает удобный вариант предложения DISTINCT — DISTINCT ON (отбираемый_элеме///я [, …]). Этот вариант позволяет выбрать, в каких столбцах будет использоваться удаление дубликатов. Платформа PostgreSQL выбирает результирующий набор во многом так же, как для предложения ORDER BY. Вам следует указать предложение ORDER BY, чтобы не было непредсказуемости при выборе записей. Например:
SELECT DISTINCT ON (stor_id), ord_date, qty FROM sales ORDER BY stor_id, ord_date DESC;
Приведенный выше запрос извлекает самый последний отчет о продажах для каждого магазина (storid) на основе даты самого последнего заказа (ord_date). Однако без предложения ORDER BY невозможно будет предсказать, какая запись будет извлечена.
Платформа PostgreSQL поддерживает только следующие типы синтаксиса предложения JOIN (за подробной информацией обращайтесь к разделу «Предложение JOIN»).
Тюнинг производительности запросов в PostgreSQL
Настройка производительности базы данных — разработчики обычно либо любят это, либо ненавидят. Я получаю удовольствие от этого и хочу поделиться некоторыми методами, которые я использовал в последнее время для настройки плохо выполняющихся запросов в PostgreSQL. Мои методы не является исчерпывающими, скорее учебником для тех, кто просто тащится от тюнинга.
Я получаю удовольствие от этого и хочу поделиться некоторыми методами, которые я использовал в последнее время для настройки плохо выполняющихся запросов в PostgreSQL. Мои методы не является исчерпывающими, скорее учебником для тех, кто просто тащится от тюнинга.Поиск медленных запросов
Первый очевидный способ начать тюнинг — это найти конкретные операторы, которые работают плохо.
pg_stats_statements
Модуль pg_stats_statements — отличное место для начала. Он просто отслеживает статистику выполнения операторов SQL и может быть простым способом поиска неэффективных запросов. Как только вы установили этот модуль, системное представление с именем pg_stat_statements будет доступно со всеми своими свойствами. Как только у него будет возможность собрать достаточный объем данных, ищите запросы, которые имеют относительно высокое значение total_time. Сначала сфокусируйтесь на этих операторах.
SELECT *
FROM
pg_stat_statements
ORDER BY
total_time DESC;auto_explain
Модуль auto_explain также полезен для поиска медленных запросов, но имеет 2 явных преимущества: он регистрирует фактический план выполнения и поддерживает запись вложенных операторов с помощью опции log_nested_statements.
 Вложенные операторы — это те операторы, которые выполняются внутри функции. Если ваше приложение использует много функций, auto_explain неоценим для получения подробных планов выполнения.
Вложенные операторы — это те операторы, которые выполняются внутри функции. Если ваше приложение использует много функций, auto_explain неоценим для получения подробных планов выполнения.Тюнинг индексов
Другой важной стратегией настройки является обеспечение правильного использования индексов. В качестве предварительного условия нам нужно включить Cборщик Cтатистики (Statistics Collector).
Postgres Statistics Collector — это подсистема первого класса, которая собирает все виды полезной статистики производительности.
Включив этот сборщик, вы получите тонны представлений pg_stat_…, которые содержат все свойства. В частности, я обнаружил, что это особенно полезно для поиска отсутствующих и неиспользуемых индексов.
Отсутствующие индексы
Отсутствующие индексы может быть одним из самых простых решений для повышения производительности запросов. Однако они не являются серебряной пулей и должны использоваться правильно (подробнее об этом позже). Если у вас включен сборщик статистики, вы можете выполнить следующий запрос (источник).
SELECT
relname,
seq_scan - idx_scan AS too_much_seq,
CASE
WHEN
seq_scan - coalesce(idx_scan, 0) > 0
THEN
'Missing Index?'
ELSE
'OK'
END,
pg_relation_size(relname::regclass) AS rel_size, seq_scan, idx_scan
FROM
pg_stat_all_tables
WHERE
schemaname = 'public'
AND pg_relation_size(relname::regclass) > 80000
ORDER BY
too_much_seq DESC;Запрос находит таблицы, в которых было больше последовательных сканирований (Sequential Scans), чем индексных сканирований (Index Scans) — явный признак того, что индекс поможет. Это не скажет вам, по каким столбцам создать индекс, так что потребуется немного больше работы.
 Однако, знание, какие таблицы нуждаются в них, это хороший первый шаг.
Однако, знание, какие таблицы нуждаются в них, это хороший первый шаг.Неиспользуемые индексы
Индексируйте все сущности, правильно? Знаете ли вы, что неиспользуемые индексы могут негативно повлиять на производительность записи? Причина в том, что при создании индекса Postgres обременен задачей обновления этого индекса после операций записи (INSERT / UPDATE / DELETE). Таким образом, добавление индекса является уравновешивающим действием, поскольку оно может ускорить чтение данных (если оно создано правильно), но замедлит операции записи. Чтобы найти неиспользуемые индексы, вы можете выполнить следующий запрос.
SELECT
indexrelid::regclass as index,
relid::regclass as table,
'DROP INDEX ' || indexrelid::regclass || ';' as drop_statement
FROM
pg_stat_user_indexes
JOIN
pg_index USING (indexrelid)
WHERE
idx_scan = 0
AND indisunique is false;Примечание о статистике сред разработки
Полагаться на статистику, полученную из локальной базы данных разработки, может быть проблематично.
 В идеале вы можете получить приведенную выше статистику с вашей рабочей машины или сгенерировать ее из восстановленной рабочей резервной копии. Зачем? Факторы окружения могут изменить работу оптимизатора запросов Postgres. Два примера:
В идеале вы можете получить приведенную выше статистику с вашей рабочей машины или сгенерировать ее из восстановленной рабочей резервной копии. Зачем? Факторы окружения могут изменить работу оптимизатора запросов Postgres. Два примера:- когда у машины меньше памяти, PostgreSQL может быть не в состоянии выполнить Hash Join, в противном случае он сможет и сделает это быстрее.
- если в таблице не так много строк (как в базе данных разработки), PostgresSQL может предпочесть выполнять последовательное сканирование таблицы, а не использовать доступный индекс. Когда размеры таблиц невелики, Seq Scan может быть быстрее. (Примечание: вы можете запустить
в сеансе, чтобы оптимизатор предпочел использовать индексы, даже если последовательное сканирование может быть быстрее. Это полезно при работе с базами данных разработки, в которых нет большого количества данных)SET enable_seqscan = OFF
Понимание планов выполнения
Теперь, когда вы нашли несколько медленных запросов, самое время начать веселье.
EXPLAIN
Команда EXPLAIN, безусловно, обязательна при настройке запросов. Он говорит вам, что на самом деле происходит. Чтобы использовать его, просто добавьте к запросу EXPLAIN и запустите его. PostgreSQL покажет вам план выполнения, который он использовал.
При использовании EXPLAIN для настройки, я рекомендую всегда использовать опцию ANALYZE (EXPLAIN ANALYZE), поскольку она дает вам более точные результаты. Опция ANALYZE фактически выполняет оператор (а не просто оценивает его), а затем объясняет его.
Давайте окунемся и начнем понимать вывод EXPLAIN. Вот пример:
Узлы
Первое, что нужно понять, это то, что каждый блок с отступом с предшествующим «->» (вместе с верхней строкой) называется узлом. Узел — это логическая единица работы («шаг», если хотите) со связанной стоимостью и временем выполнения. Стоимость и время, представленные на каждом узле, являются совокупными и сводят все дочерние узлы. Это означает, что самая верхняя строка (узел) показывает совокупную стоимость и фактическое время для всего оператора.
 Это важно, потому что вы можете легко детализировать для определения, какие узлы являются узким местом.
Это важно, потому что вы можете легко детализировать для определения, какие узлы являются узким местом.Стоимость
cost=146.63..148.65Первое число — это начальные затраты (затраты на получение первой записи), а второе число — это затраты на обработку всего узла (общие затраты от начала до конца).
Фактически, это стоимость, которую, по оценкам PostgreSQL, придется выполнить для выполнения оператора. Это число не означает сколько времени потребуется для выполения запроса, хотя обычно существует прямая зависимость, необходимого для выполнения. Стоимость — это комбинация из 5 рабочих компонентов, используемых для оценки требуемой работы: последовательная выборка, непоследовательная (случайная) выборка, обработка строки, оператор (функция) обработки и запись индекса обработки. Стоимость представляет собой операции ввода-вывода и загрузки процессора, и здесь важно знать, что относительно высокая стоимость означает, что PostgresSQL считает, что ему придется выполнять больше работы. Оптимизатор принимает решение о том, какой план выполнения использовать, исходя из стоимости. Оптимизатор предпочитает более низкие затраты.
Оптимизатор принимает решение о том, какой план выполнения использовать, исходя из стоимости. Оптимизатор предпочитает более низкие затраты.
Фактическое время
actual time=55.009..55.012В миллисекундах первое число — это время запуска (время для извлечения первой записи), а второе число — это время, необходимое для обработки всего узла (общее время от начала до конца). Легко понять, верно?
В приведенном выше примере потребовалось 55,009 мс для получения первой записи и 55,012 мс для завершения всего узла.
Узнать больше о планах выполнения
Есть несколько действительно хороших статей для понимания результатов EXPLAIN. Вместо того, чтобы пытаться пересказать их здесь, я рекомендую потратить время на то, чтобы по-настоящему понять их, перейдя к этим 2 замечательным ресурсам:
- http://www.depesz.com/2013/04/16/explaining-the-unexplainable/
- https://wiki.postgresql.org/images/4/45/Explaining_EXPLAIN.pdf
Настройка запросов
Теперь, когда вы знаете, какие операторы работают плохо и можете видеть свои планы выполнения, пришло время приступить к настройке запроса для повышения производительности.
 Здесь вы вносите изменения в запросы и/или добавляете индексы, чтобы попытаться получить лучший план выполнения. Начните с узких мест и посмотрите, есть ли какие-то изменения, которые вы можете сделать, чтобы сократить расходы и/или время выполнения.
Здесь вы вносите изменения в запросы и/или добавляете индексы, чтобы попытаться получить лучший план выполнения. Начните с узких мест и посмотрите, есть ли какие-то изменения, которые вы можете сделать, чтобы сократить расходы и/или время выполнения.Заметка о кеше данных и издержках
При внесении изменений и оценке планов выполнения, чтобы увидеть будут ли улучшения, важно знать, что последующие выполнения могут зависеть от кэширования данных, которые дают представление о лучших результатах. Если вы запустите запрос один раз, сделаете исправление и запустите его второй раз, скорее всего, он будет выполняться намного быстрее, даже если план выполнения не будет более благоприятным. Это связано с тем, что PostgreSQL мог кэшировать данные, используемые при первом запуске, и может использовать их при втором запуске. Поэтому вы должны выполнять запросы как минимум 3 раза и усреднять результаты, чтобы сравнить издержки.
Вещи, которые я узнал, могут помочь улучшить планы выполнения:
- Индексы
- Исключите последовательное сканирование (Seq Scan), добавив индексы (если размер таблицы не мал)
- При использовании многоколоночного индекса убедитесь, что вы обращаете внимание на порядок, в котором вы определяете включенные столбцы — Дополнительная информация
- Попробуйте использовать индексы, которые очень избирательны к часто используемым данным.
 Это сделает их использование более эффективным.
Это сделает их использование более эффективным.
- Условие ГДЕ
- Избегайте LIKE
- Избегайте вызовов функций в условии WHERE
- Избегайте больших условий IN()
- JOINы
- При объединении таблиц попробуйте использовать простое выражение равенства в предложении ON (т.е. a.id = b.person_id). Это позволяет использовать более эффективные методы объединения (т. Е. Hash Join, а не Nested Loop Join)
- Преобразуйте подзапросы в операторы JOIN, когда это возможно, поскольку это обычно позволяет оптимизатору понять цель и, возможно, выбрать лучший план.
- Правильно используйте СОЕДИНЕНИЯ: используете ли вы GROUP BY или DISTINCT только потому, что получаете дублирующиеся результаты? Это обычно указывает на неправильное использование JOIN и может привести к более высоким затратам
- Если план выполнения использует Hash Join, он может быть очень медленным, если оценки размера таблицы неверны.
 Поэтому убедитесь, что статистика вашей таблицы точна, пересмотрев стратегию очистки (vacuuming strategy )
Поэтому убедитесь, что статистика вашей таблицы точна, пересмотрев стратегию очистки (vacuuming strategy ) - По возможности избегайте коррелированных подзапросов; они могут значительно увеличить стоимость запроса
- Используйте EXISTS при проверке существования строк на основе критерия, поскольку он подобен короткому замыканию (останавливает обработку, когда находит хотя бы одно совпадение)
- Общие рекомендации
Иллюстрированный самоучитель по PostgreSQL › SQL в PostgreSQL › Конструкции CASE [страница — 92] | Самоучители по программированию
Конструкции CASE
Чтобы программа SQL могла принимать простейшие решения, не прибегая к процедурным языкам, в PostgreSQL поддерживаются конструкции CASE, предусмотренные стандартом SQL Ключевые слова SQL CASE, WHEN, THEN и END позволяют выполнять простые условные преобразования записей.
Вся конструкция CASE включается в целевой список команды SELECT. По умолчанию итоговому полю конструкции CASE присваивается имя case, но ему можно назначить синоним, как любому обычному полю. Общий синтаксис конструкции CASE в списке целей команды SELECT выглядит следующим образом:
Общий синтаксис конструкции CASE в списке целей команды SELECT выглядит следующим образом:
CASE WHEN условие! THEN результат! WHEN условие2 THEN результат2 [… ] [ ELSE результат_по_умопчанию END [ AS синоним ]
Конструкция CASE-WHEN-THEN-ELSE отчасти напоминает условные команды if-then-else в традиционных языках программирования (листинг 4.50). Условия секций WHEN должны возвращать логический результат.
Если условие в секции WHEN выполняется, результат соответствующей секции THEN возвращается в поле итогового набора. Если ни одно условие не выполнено, можно задать значение по умолчанию в секции ELSE. Если при отсутствии секции ELSE результат остается неопределенным, возвращается NULL.
Листинг 4.50. Конструкции CASE в командах.
booktown=# SELECT isbn, booktown-# CASE WHEN cost > 20 THEN 'over $20.00 cost' booktown-# WHEN cost = 20 THEN '$20.00 cost1 booktown-# ELSE 'under $20.00 cost' booktown-# END AS cost_range booktown-# FROM stock booktown-# LIMIT 8; Isbn | cost_range 0385121679 | over $20.00 cost 039480001X | over $20.00 cost 044100590X | over $20.00 cost 0451198492 | over $20.00 cost 0394900014 | over $20.00 cost 0441172717 | under $20.00 cost 0451160916 | over $20.00 cost 0679803335 | $20.00 cost (8 rows)
Подзапросы PostgreSQL расширяют возможности конструкций CASE (см. раздел «Подзапросы»). Как показано в листинге 4.51, в качестве результата условного выражения в конструкции может быть задан подзапрос.
Листинг 4.51. Конструкции CASE в подзапросах.
booktown=# SELECT isbn, booktown-# CASE WHEN cost > 20 THEN 'N/A – (Out of price range)' booktown-# ELSE (SELECT title FROM books b JOIN editions e booktown(# ON (b.id = e.book_id) booktown(# WHERE e.isbn = stock.isbn) booktown-# END AS cost_range booktown-# FROM stock booktown-# ORDER BY cost_range ASC booktown-# LIMIT 8; isbn | cost_range 0451457994 | 2001: A Space Odyssey 0394800753 | Bartholomew and the Oobleck 0441172717 | Dune 0760720002 | Little Women 0385121679 | N/A – (Out of price range) 039480001X | N/A – (Out of price range) 044100590X | N/A – (Out of price range) 0451198492 | N/A – (Out of price range) (8 rows)
Для всех книг, цена которых не превышает 20, запрос возвращает название книги (подзапрос к таблице books) и код ISBN (основной запрос к таблице stock).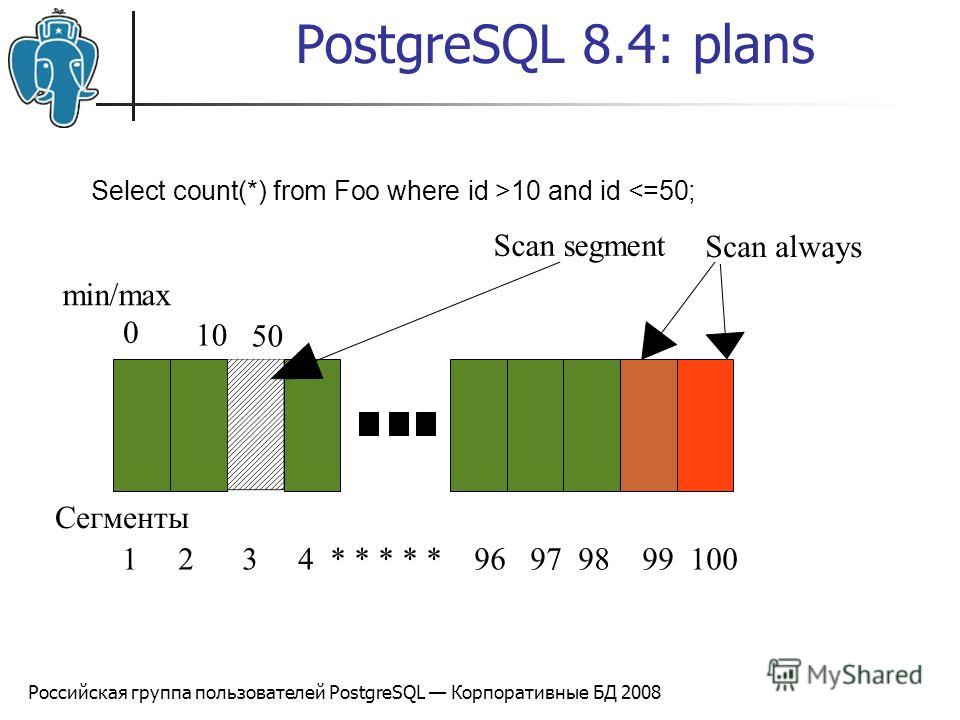
PostgreSQL: инструкция SELECT
В этом руководстве по PostgreSQL объясняется, как использовать оператор PostgreSQL SELECT с синтаксисом и примерами.
Описание
Оператор SELECT PostgreSQL используется для получения записей из одной или нескольких таблиц в PostgreSQL.
Синтаксис
В простейшей форме синтаксис оператора SELECT в PostgreSQL:
выражения SELECT ИЗ таблиц [ГДЕ условия];
Однако полный синтаксис оператора SELECT PostgreSQL:
ВЫБРАТЬ [ВСЕ | DISTINCT | DISTINCT ON (отдельные_выражения)]
выражения
ИЗ таблиц
[ГДЕ условия]
[GROUP BY выражения]
[ИМЕЕТ состояние]
[ORDER BY выражение [ASC | DESC | USING оператор] [ПЕРВЫЕ НУЛИ | NULLS LAST]]
[LIMIT [number_rows | ВСЕ]
[OFFSET offset_value [ROW | ROWS]]
[ПОИСК {ПЕРВЫЙ | NEXT} [fetch_rows] {ROW | ТОЛЬКО ROWS}]
[ДЛЯ {ОБНОВЛЕНИЯ | ДОЛЯ} В таблице [СЕЙЧАС]]; Параметры или аргументы
- ВСЕ
- Необязательно.
 Возвращает все совпадающие строки.
Возвращает все совпадающие строки. - ОТЛИЧИТЕЛЬНЫЙ
- Необязательно. Удаляет дубликаты из набора результатов. Узнать больше о статье DISTINCT
- ОТЛИЧИТЕЛЬНО НА
- Необязательно. Удаляет дубликаты на основе unique_expressions . Подробнее о предложении DISTINCT ON.
- выражения
- Столбцы или вычисления, которые вы хотите получить. Используйте *, если хотите выбрать все столбцы.
- столов
- Таблицы, из которых вы хотите получить записи.В предложении FROM должна быть хотя бы одна таблица.
- ГДЕ условия
- Необязательно. Условия, которые должны быть выполнены для выбора записей.
- Выражения GROUP BY
- Необязательно. Он собирает данные из нескольких записей и группирует результаты по одному или нескольким столбцам.
- СОСТОЯНИЕ
- Необязательно. Он используется в сочетании с GROUP BY, чтобы ограничить группы возвращаемых строк только теми, для которых условие истинно.

- ORDER BY выражение
- Необязательно. Он используется для сортировки записей в вашем наборе результатов.
- ПРЕДЕЛ
- Необязательно. Если указан LIMIT, он контролирует максимальное количество извлекаемых записей. В наборе результатов будет возвращено самое большее количество записей, указанное в number_rows . Первая строка, возвращаемая LIMIT, будет определяться значением offset_value .
- FETCH
- Необязательно. Если предоставляется FETCH, он контролирует максимальное количество извлекаемых записей.В наборе результатов будет возвращено самое большее количество записей, указанное в fetch_rows . Первая строка, возвращаемая функцией FETCH, будет определяться значением offset_value .
- ДЛЯ ОБНОВЛЕНИЯ
- Необязательно. Записи, затронутые запросом, блокируются от записи до завершения транзакции.
- ДЛЯ АКЦИИ
- Необязательно.
 Записи, затронутые запросом, могут использоваться другими транзакциями, но не могут быть обновлены или удалены этими другими транзакциями
Записи, затронутые запросом, могут использоваться другими транзакциями, но не могут быть обновлены или удалены этими другими транзакциями
Пример — Выбрать все поля из одной таблицы
Давайте посмотрим, как использовать запрос PostgreSQL SELECT для выбора всех полей в таблице.
ВЫБРАТЬ * ИЗ категорий ГДЕ category_id> = 2500 ЗАКАЗАТЬ ПО идентификатору категории ASC;
В этом примере оператора PostgreSQL SELECT мы использовали *, чтобы обозначить, что хотим выбрать все поля из таблицы категорий , где category_id больше или равен 2500. Набор результатов сортируется по category_id в порядке возрастания. заказ.
Пример — выбор отдельных полей из одной таблицы
Вы также можете использовать оператор PostgreSQL SELECT для выбора отдельных полей из таблицы, в отличие от всех полей из таблицы.
Например:
ВЫБЕРИТЕ category_id, category_name, комментарии ИЗ категорий ГДЕ category_name = 'Оборудование' ORDER BY category_name ASC, комментарии DESC;
Этот пример PostgreSQL SELECT вернет только category_id , category_name и поля комментариев из таблицы категорий , где category_name — «Оборудование». Результаты сортируются по category_name в возрастающем порядке, а затем по комментариям в убывающем порядке.
Результаты сортируются по category_name в возрастающем порядке, а затем по комментариям в убывающем порядке.
Пример — выбор полей из нескольких таблиц
Вы также можете использовать оператор PostgreSQL SELECT для извлечения полей из нескольких таблиц.
ВЫБЕРИТЕ продукты.имя_продукта, категории.наименование_категории ИЗ категорий INNER JOIN продукты ВКЛ. Category.category_id = products.category_id ЗАКАЗАТЬ ПО product_name;
Этот пример PostgreSQL SELECT объединяет две таблицы вместе, чтобы получить набор результатов, который отображает поля product_name и category_name , где значение category_id совпадает в таблицах категорий и продуктов .Результаты отсортированы по product_name в возрастающем порядке.
Использование вложенного выбора в Postgres SQL
Введение
В этой статье мы рассмотрим, как использовать вложенное выделение в Postgres SQL. В этом руководстве мы будем использовать следующую структуру:
В этом руководстве мы будем использовать следующую структуру:
- Что? Что делают операторы вложенного выбора и каков их синтаксис?
- Как? Как лучше всего использовать это предложение в наших командах PostgreSQL SQL?
- Почему? Когда мы воспользуемся этим заявлением? Мы будем учиться на реальных примерах использования.Включает использование предложения Postgres «WHERE». Мы также включим изучение «INSERT INTO» и «NOT IN».
Предварительные требования
- Начальный уровень понимания того, как писать SQL для Postgres (или аналогичных реляционных баз данных, таких как MS SQL Server, Oracle и MySQL) с использованием одного из многих доступных инструментов, таких как инструмент администрирования PG, dBeaver или с помощью скриптов или языков программирования, таких как Python, Javascript, Java, PHP, C #, ASP.Net, VB.Net, Ruby, Node.js, B4X, Classic ASP и т. д.), которые обеспечивают соединение с базой данных, а также способ отправки запросов PL / SQL к нашим таблицам базы данных для получения данных или внесения изменений в ваши данные.

- Понимание использования общих операторов PL / SQL, включая операторы
SELECT,,FROMиWHERE,. - Знание того, что такое функция , целое число и строка и как они работают на начальном уровне.
Что такое вложенный оператор выбора?
Вложенные операторы выбора иначе известны как «подзапросы».
Иногда в нашем приложении на основе Postgres нам может потребоваться извлечь данные из подмножества данных, которое мы создаем на лету, обновить таблицу на основе подмножества данных или вставить в таблицу на основе подмножества данных. Позже в этой статье мы разберемся, почему и как это сделать.
Во-первых, давайте изучим синтаксис этого мощного инструмента SQL с нескольких точек зрения:
Синтаксис 1: Подзапросы в WHERE
1 | столбец |

Анализ синтаксиса 1
В приведенном выше примере синтаксиса мы смотрим на два набора данных, которые извлекаются из одной и той же таблицы «tbl_data». Представление высокого уровня состоит в том, что «внутренний» вложенный набор данных, указанный в скобках, выполняется первым, а «внешний» запрос фильтруется на основе результатов возврата этого внутреннего вложенного набора.Модель IN , которую вы видите здесь, очень важна. Он сообщает PostgreSQL: «Извлекать записи из tbl_data только тогда, когда значение в столбце_1 существует в наборе записей, возвращаемом вложенным запросом выбора. Позже мы увидим, как это может быть полезно.
Синтаксис 2: Подзапросы в FROM
1 | SELECT |
Анализ синтаксиса 2
В этом примере синтаксиса мы даем имя нашему «внутреннему» вложенному запросу выбора, «вложенный», чтобы мы могли ссылаться на него в нашем внешнем выборе в верхней части общего SQL. Обратите внимание, что мы снова заключаем вложенный запрос выбора в круглые скобки. Это обязательно.
Обратите внимание, что мы снова заключаем вложенный запрос выбора в круглые скобки. Это обязательно.
Прежде, чем мы рассмотрим реальный пример, давайте посмотрим на синтаксис для использования вложенных операторов выбора с INSERT INTO.
Синтаксис 3: Подзапрос с INSERT INTO
1 | INSERT INTO | столбец INTO |
Анализ синтаксиса 3
В приведенном выше INSERT INTO мы начинаем с того, что говорим Postgres добавить строки в «tbl_data».Затем мы определяем, какие столбцы (column_1 и column_2) мы хотим заполнить двумя соответствующими VALUES, возвращаемыми вложенным оператором SELECT, который следует за ним и заключен в круглые скобки. Наконец, обратите внимание, что вложенный выбор извлекает свои данные из «tbl_other».
Наконец, обратите внимание, что вложенный выбор извлекает свои данные из «tbl_other».
Как и почему мы используем вложенные операторы выбора
Вот реальная ситуация. Если разработчик не знал о вложенных выборках, в некоторых ситуациях он мог бы подумать, что им нужно вытащить данные из таблицы в массив, каким-то образом манипулировать этим массивом (возможно, сортировать), а затем использовать этот массив для добавления строк в свои первая таблица.К счастью, вложенные выборки (подзапросы) предоставляют нам гораздо более эффективный способ выполнения задачи. Мы погрузимся в процесс написания SQL, который будет структурно похож на «Синтаксис 3» выше.
Во-первых, давайте создадим две таблицы с тестовыми данными:
tbl_technologies_used
| t_name_tech | t_category_tech | i_rating |
|---|---|---|
| Javascript | язык | 95 |
| MS SQL Server | База данных SQL | 90 |
| C # | Язык | 92 |
Приведенная выше таблица — это таблица, используемая компанией для отслеживания технологий, используемых компанией. Таблица ниже заполнена потенциальными технологиями. Важно отметить, что в нижней таблице указаны технологии, которые уже указаны в верхней таблице. Поэтому, когда мы создаем наш запрос INSERT INTO с использованием NESTED SELECT, мы хотим убедиться, что дубликаты отсутствуют. Это вариант использования, когда вложенный выбор выделяет excel.
Таблица ниже заполнена потенциальными технологиями. Важно отметить, что в нижней таблице указаны технологии, которые уже указаны в верхней таблице. Поэтому, когда мы создаем наш запрос INSERT INTO с использованием NESTED SELECT, мы хотим убедиться, что дубликаты отсутствуют. Это вариант использования, когда вложенный выбор выделяет excel.
тбл_технологии_предложено
| t_name_tech | t_category_tech | i_rating | ||
|---|---|---|---|---|
| Javascript | Язык | 95 | ||
| PostgreSQL | База данных SQL | 90 | ||
| Python | Язык | 90 | ||
| PHP | Язык | 70 | ||
| Java | Язык | 9024База данных SQL | 90 | |
| C # | Язык | 92 | ||
| C ++ | Язык | 88 | ||
| dBase | Плоская база данных | Writing25 | 2 Запрос PostgreSQL
1 | INSERT INTO |
Анализ
Первое, что вы можете заметить в нашем примере выше, это то, что у нас есть вложенный SELECT в другом вложенном SELECT! Почему мы это сделали? Потому что мы хотим быть уверены, что не добавляем в tbl_technologies_used строку, которая уже есть в этой таблице. Возьмем построчно:
Возьмем построчно:
-
INSERT INTO: Здесь мы устанавливаем, какие столбцы в «tbl_technologies_used» заполняются данными из первого (внешнего) из наших операторов SELECT ниже. -
ЗНАЧЕНИЯ: Это часть функции INSERT. -
ВЫБРАТЬ (ВНЕШНИЙ): Определяет, какие поля (столбцы) извлекаются из «tbl_technologies_proposed». -
WHERE: Эта строка фильтрует результаты нашего подзапроса по двум требованиям.(1) «i_rating» должно быть больше 75. (2) «t_name_tech» уже не должно существовать в «tbl_technologies_used». -
НЕ В ... ВЫБРАТЬ (ВНУТРЕННИЙ): Это часть нашего запроса, которая гарантирует, что мы не копируем повторяющиеся записи из «tbl_technologies_proposed» в «tbl_technologies_used».
После выполнения этого запроса мы получаем следующий результирующий набор данных:
tbl_technologies_used | t_name_tech | t_category_tech | i_rating |
| ————— | —————– | ———: |
| Javascript | Язык | 95 |
| PostgreSQL | База данных SQL | 90 |
| Python | Язык | 90 |
| MS SQL Server | База данных SQL | 90 |
| C # | Язык | 92 |
| C ++ | Язык | 88 |
Интересные факты
- Если вам интересно, почему мы добавили к некоторым из наших полей, переменных и столбцов префикс «i » или «t »? В этой статье мы использовали «i » для обозначения целого числа и «t » для обозначения текста или строки.
 Вот краткое руководство по этой теме.
Вот краткое руководство по этой теме.
Заключение
Здесь, в этой статье, мы узнали, как использовать NESTED SELECT для запроса Postgres с помощью SQL, который будет выполнять различные задачи, требующие субсортировки данных. Они также известны как подзапросы. Мы также создали реальный пример, чтобы помочь вам лучше понять, как гнездо выбирает при использовании SQL в базе данных PostgreSQL.
SQL Select Database — MySQL, PostgreSQL, SQL Server
Когда мы работаем с разными базами данных в соответствии с разными требованиями, нам нужно выбрать базу данных перед запуском любой команды SQL.Затем выполняется команда SQL после выбора базы данных. Попробуем разобраться, как выбрать базу данных в разных Базах данных.
- MySQL
- PostgreSQL
- SQL Server
Выбор базы данных MySQL
Для выполнения любой операции с MySQL важно выбрать базу данных. Выбор базы данных из приглашения mysql> выполняется с помощью команды SQL use .
Мы рассмотрим пример, чтобы лучше понять это.
[корень @ хост] # mysql -u root -p
Введите пароль:******
mysql> использовать TESTDB;
База данных изменена
mysql>
В приведенном выше примере мы выбрали TESTDB в качестве базы данных, и последующие операции будут выполняться с той же базой данных.
Мы можем выбрать базу данных (схему) в рабочей среде MySQL, выбрав ее на левой боковой панели.
Выбор базы данных в MySQL workbench
На изображении выше выбрана мировая схема .
PostgreSQL Выбрать базу данных
PostgreSQL позволяет выбирать базу данных разными способами. Если мы используем pgAdmin, мы можем просто дважды щелкнуть по базе данных, и он автоматически выберет базу данных и запросит пароль.
Если мы используем клиент командной строки psql, мы можем использовать следующую команду.
postgres = # \ c testdb;
psql (9.2.4)
Введите "help" для получения справки.
Теперь вы подключены к базе данных "testdb" как пользователь "postgres". testdb = #
testdb = #
В приведенной выше команде мы подключаемся к базе данных testdb .
Для UI-части PostgreSQL мы будем использовать pgAdmin, для выбора любой базы данных в pgAdmin просто дважды щелкните базу данных.
pgAdmin Select Database
SQL Server Select Database
Чтобы выбрать базу данных на сервере SQL, выполните следующие действия.
- Подключиться к базе данных.
- В проводнике объектов слева разверните папку баз данных и дважды щелкните базу данных, которую хотите выбрать.
Выбор базы данных с помощью SQLServer
Вышеупомянутые способы выбора базы данных.Очень важно выбрать базу данных перед выполнением любой операции, иначе это может привести к проблемам из-за неправильного выбора базы данных.
Выбор записей за последние 24 часа в PostgreSQL
Наблюдение за данными за последние 24 часа — отличный способ получить представление о повседневной деятельности вашей компании. Независимо от того, отслеживаете ли вы продажи нового продукта или следите за действиями пользователей на следующий день после рекламной акции, об этом коротком промежутке времени можно многое сказать.В этом руководстве мы рассмотрим различные способы написания запроса для выбора записей за последние 24 часа.
Независимо от того, отслеживаете ли вы продажи нового продукта или следите за действиями пользователей на следующий день после рекламной акции, об этом коротком промежутке времени можно многое сказать.В этом руководстве мы рассмотрим различные способы написания запроса для выбора записей за последние 24 часа.
Выбор последних 24 часов
Например, давайте рассмотрим таблицу с именем «пользователи» с записями, содержащими имя, адрес и другую информацию о новом пользователе. Что еще более важно, таблица содержит атрибут created_date, который содержит время и дату, когда пользователь присоединился. Ниже показано, как мы можем выбрать пользователей, присоединившихся за последние 24 часа, в порядке от самых ранних до самых последних:
ВЫБРАТЬ *
ОТ публики.пользователи КАК "Пользователи"
ГДЕ «Пользователи». «Created_date» МЕЖДУ СЕЙЧАС () - ИНТЕРВАЛ «24 ЧАСА» И СЕЙЧАС ()
ЗАКАЗАТЬ ПО "Пользователи". "Created_date" DESC
Все это делается с помощью предложения WHERE . Мы выбираем записи, дата создания которых находится между текущим временем и за 24 часа до текущего времени. Другой запрос, который выполняет то же самое, может выглядеть примерно так:
Мы выбираем записи, дата создания которых находится между текущим временем и за 24 часа до текущего времени. Другой запрос, который выполняет то же самое, может выглядеть примерно так:
ВЫБРАТЬ *
ОТ public.users КАК "Пользователи"
ГДЕ «Пользователи». «Created_date»> = СЕЙЧАС () - ИНТЕРВАЛ '24 ЧАСА '
ЗАКАЗАТЬ «Пользователи»."created_date" DESC
В этом случае мы выбираем записи с датой создания, которая от 24 часов до текущего времени до текущего времени. В любом случае мы получаем один и тот же результат. Существуют аналогичные функции PostgreSQL, которые могут помочь в решении этой задачи, и вы можете обратиться сюда за дополнительной информацией об этих функциях даты и времени. Отметим, что если мы хотим изменить период времени для поиска, мы должны отредактировать предложение WHERE, чтобы представить желаемый временной интервал для поиска.
Переменные относительной даты
Chartio предлагает встроенные переменные даты, которые могут помочь поддерживать ваши данные в актуальном состоянии при каждом обновлении. Эти переменные можно использовать во всем приложении, где бы вы ни вводили дату. Часть переменных даты включает:
Эти переменные можно использовать во всем приложении, где бы вы ни вводили дату. Часть переменных даты включает:
-
{СЕГОДНЯ} -
{CURRENT_ISO_WEEK.START}и{CURRENT_ISO_WEEK.END} -
{CURRENT_QUARTER.START}и{CURRENT_QUARTER.END}
Использование этих переменных относительной даты гарантирует, что все ваши информационные панели в Chartio будут правильно обновляться. Функции для этих переменных даты также позволяют настроить дату возврата в соответствии с вашими потребностями. Например, мы могли бы написать позавчера (вчера) как:
{TODAY.SUB (1, 'day')}
Мы можем расширить запросы в этом руководстве, чтобы получить более подробное представление в зависимости от того, что мы хотели бы проанализировать, но это дает нам хорошую отправную точку для получения любой информации за предыдущие 24 часа.
.