PostgreSQL : Документация: 9.6: 13.4. Проверки целостности данных на уровне приложения : Компания Postgres Professional
RU
EN
RU EN
- 13.4.1. Обеспечение согласованности в сериализуемых транзакциях
- 13.4.2. Применение явных блокировок для обеспечения согласованности
Используя транзакции Read Committed, очень сложно обеспечить целостность данных с точки зрения бизнес-логики, так как представление данных смещается с каждым оператором и даже один оператор может не ограничиваться своим снимком состояния в случае конфликта записи.
Хотя транзакция Repeatable Read получает стабильное представление данных в процессе выполнения, с использованием снимков MVCC для проверки целостности данных всё же связаны тонкие моменты, включая так называемые конфликты чтения/записи. Если одна транзакция записывает данные, а другая в это же время пытается их прочитать (до или после записи), она не может увидеть результат работы первой. В таком случае создаётся впечатление, что читающая транзакция выполняется первой вне зависимости от того, какая из них была начата или зафиксирована раньше. Если этим всё и ограничивается, нет никаких проблем, но если читающая транзакция также пишет данные, которые читает параллельная транзакция, получается, что теперь эта транзакция будет исполняться, как будто она запущена перед другими вышеупомянутыми. Если же транзакция, которая должна исполняться как последняя, на самом деле зафиксирована первой, в графе упорядоченных транзакций легко может возникнуть цикл. И когда он возникает, проверки целостности не будут работать правильно без дополнительных мер.
В таком случае создаётся впечатление, что читающая транзакция выполняется первой вне зависимости от того, какая из них была начата или зафиксирована раньше. Если этим всё и ограничивается, нет никаких проблем, но если читающая транзакция также пишет данные, которые читает параллельная транзакция, получается, что теперь эта транзакция будет исполняться, как будто она запущена перед другими вышеупомянутыми. Если же транзакция, которая должна исполняться как последняя, на самом деле зафиксирована первой, в графе упорядоченных транзакций легко может возникнуть цикл. И когда он возникает, проверки целостности не будут работать правильно без дополнительных мер.
Как было сказано в Подразделе 13.2.3, сериализуемые транзакции представляют собой те же транзакции Repeatable Read, но дополненные неблокирующим механизмом отслеживания опасных условий конфликтов чтения/записи. Когда выявляется условие, приводящее к циклу в порядке транзакций, одна из этих транзакций откатывается и этот цикл таким образом разрывается.
13.4.1. Обеспечение согласованности в сериализуемых транзакциях
Если для всех операций чтения и записи, нуждающихся в согласованном представлении данных, используются транзакции уровня изоляции Serializable, это обеспечивает необходимую согласованность без дополнительных усилий. Приложения из других окружений, применяющие сериализуемые транзакции для обеспечения целостности, в PostgreSQL в этом смысле будут «просто работать».
Применение этого подхода избавляет программистов приложений от лишних сложностей, если приложение использует инфраструктуру, которая автоматически повторяет транзакции в случае отката из-за сбоев сериализации. Возможно, serializable стоит даже установить в качестве уровня изоляции по умолчанию (default_transaction_isolation). Также имеет смысл принять меры для предотвращения использования других уровней изоляции, непреднамеренного или с целью обойти проверки целостности, например проверять уровень изоляции в триггерах.
Рекомендации по увеличению быстродействия приведены в Подразделе 13.2.3.
Предупреждение
Защита целостности с применением сериализуемых транзакций пока ещё не поддерживается в режиме горячего резерва (Раздел 26.5). Поэтому там, где применяется горячий резерв, следует использовать уровень Repeatable Read и явные блокировки на главном сервере.
13.4.2. Применение явных блокировок для обеспечения согласованности
Когда возможны несериализуемые операции записи, для обеспечения целостности строк и защиты от одновременных изменений, следует использовать SELECT FOR UPDATE, SELECT FOR SHARE или соответствующий оператор LOCK TABLE. (SELECT FOR UPDATE и SELECT FOR SHARE защищают от параллельных изменений только возвращаемые строки, тогда как LOCK TABLE блокирует всю таблицу.) Это следует учитывать, перенося в PostgreSQL приложения из других СУБД.
Мигрируя в PostgreSQL из других СУБД также следует учитывать, что команда SELECT FOR UPDATE сама по себе не гарантирует, что параллельная транзакция не изменит или не удалит выбранную строку.
SELECT FOR UPDATE временно блокирует другие транзакции, не давая им получить ту же блокировку или выполнить команды UPDATE или DELETE, которые бы повлияли на заблокированную строку, но как только транзакция, владеющая этой блокировкой, фиксируется или откатывается, заблокированная транзакция сможет выполнить конфликтующую операцию, если только для данной строки действительно не был выполнен UPDATE, пока транзакция владела блокировкой.Реализация глобальной целостности с использованием несериализуемых транзакций MVCC требует более вдумчивого подхода. Например, банковскому приложению может потребоваться проверить, равняется ли сумма всех расходов в одной таблице сумме приходов в другой, при том, что обе таблицы активно изменяются. Просто сравнивать результаты двух успешных последовательных команд SELECT sum(. в режиме Read Committed нельзя, так как вторая команда может захватить результаты транзакций, пропущенных первой. Подсчитывая суммы в одной транзакции Repeatable Read, можно получить точную картину только для транзакций, которые были зафиксированы до начала данной, но при этом может возникнуть законный вопрос — будет ли этот результат актуален тогда, когда он будет выдан. Если транзакция Repeatable Read сама вносит какие-то изменения, прежде чем проверять равенство сумм, полезность этой проверки становится ещё более сомнительной, так как при проверке будут учитываться некоторые, но не все изменения, произошедшие после начала транзакции. В таких случаях предусмотрительный разработчик может заблокировать все таблицы, задействованные в проверке, чтобы получить картину действительности, не вызывающую сомнений. Для этого применяется блокировка 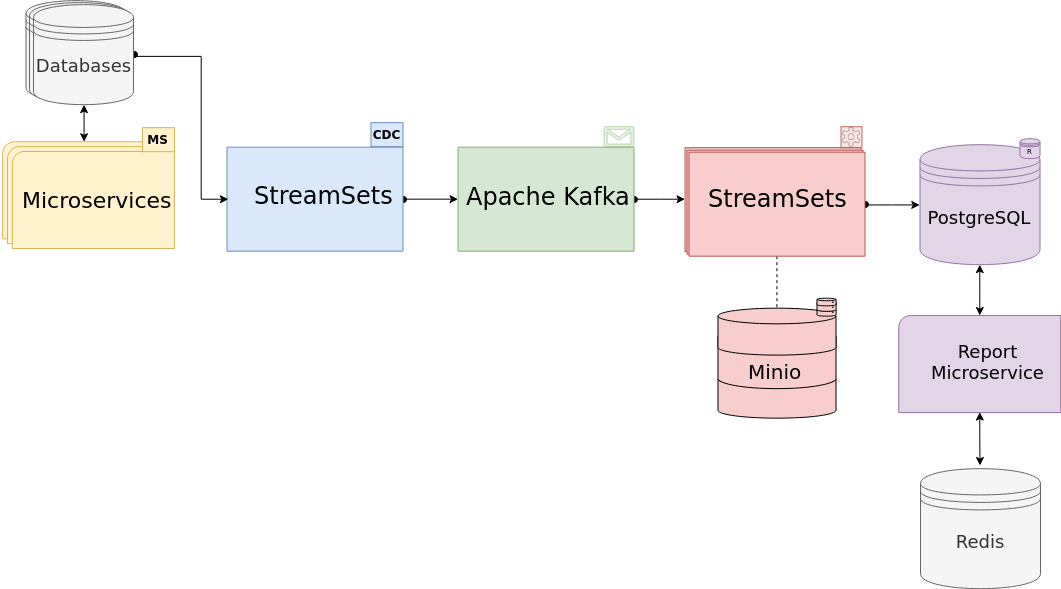 ..)
..)
Также заметьте, что, применяя явные блокировки для предотвращения параллельных операций записи, следует использовать либо режим Read Committed, либо в режиме Repeatable Read обязательно получать блокировки прежде, чем выполнять запросы. Блокировка, получаемая транзакцией Repeatable Read, гарантирует, что никакая другая транзакция, изменяющая таблицу, не выполняется, но если снимок состояния, полученный транзакцией, предшествует блокировке, он может не включать на данный момент уже зафиксированные изменения. Снимок состояния в транзакции Repeatable Read создаётся фактически на момент начала первой команды выборки или изменения данных ( SELECT, INSERT, UPDATE или DELETE), так что получить явные блокировки можно до того, как он будет сформирован.
PostgreSQL : Документация: 14: F.2. amcheck : Компания Postgres Professional
RU
EN
RU EN
- F.2.1. Функции
- F.2.2.
 Дополнительная проверка
Дополнительная проверка heapallindexed- F.2.3. Эффективное использование
amcheck- F.2.4. Исправление повреждений
- F.2.2.
Модуль amcheck предоставляет функции, позволяющие проверять логическую целостность структуры отношений.
Функции проверки B-дерева контролируют различные инварианты в структуре представления определённых отношений. Правильность работы функций методов доступа, стоящих за сканированием индекса и другими важными операциями, зависит от всегда соблюдаемых инвариантов. Например, определённые функции проверяют, помимо остальных вещей, что все страницы B-дерева содержат элементы в «логическом» порядке (например, индекс-B-дерево, построенный по столбцу  Если нарушения структуры не обнаруживаются, эти функции отрабатывают без ошибок.
Если нарушения структуры не обнаруживаются, эти функции отрабатывают без ошибок.
Проверка выполняется теми же процедурами, что используются при сканировании индекса, и это может быть код пользовательского класса операторов. Например, проверка индекса-B-дерева задействует сравнения, выполняемые одной или несколькими опорными функциями B-дерева под номером 1. Подробнее опорные функции класса операторов описываются в Подразделе 38.16.3.
В отличие от функций проверки B-дерева, которые сообщают о повреждениях, выдавая ошибки, функция проверки кучи verify_heapam проверяет таблицу и пытается вернуть набор строк: по одной строке на каждое обнаруженное повреждение. Тем не менее, если будут повреждены средства, которые использует функция verify_heapam, она не сможет продолжить работу и выдаст ошибку.
Права на выполнение функций amcheck можно выдать и не суперпользователю, но перед этим следует тщательно учесть аспекты безопасности и конфиденциальности данных. Хотя эти функции прежде всего выдают информацию о структуре данных и характере найденных повреждений, а не выводят собственно повреждённые данные, если злоумышленник сможет выполнять эти функции, а особенно если ему также удастся вызвать повреждение данных, он сможет узнать что-то о самих данных из полученной информации.
Хотя эти функции прежде всего выдают информацию о структуре данных и характере найденных повреждений, а не выводят собственно повреждённые данные, если злоумышленник сможет выполнять эти функции, а особенно если ему также удастся вызвать повреждение данных, он сможет узнать что-то о самих данных из полученной информации.
F.2.1. Функции
-
bt_index_check(index regclass, heapallindexed boolean) returns void bt_index_checkпроверяет, соблюдаются ли в целевом индексе-B-дереве различные инварианты. Пример использования:test=# SELECT bt_index_check(index => c.oid, heapallindexed => i.indisunique), c.relname, c.relpages FROM pg_index i JOIN pg_opclass op ON i.indclass[0] = op.oid JOIN pg_am am ON op.opcmethod = am.oid JOIN pg_class c ON i.indexrelid = c.oid JOIN pg_namespace n ON c.relnamespace = n.oid WHERE am.amname = 'btree' AND n.nspname = 'pg_catalog' -- Не проверять временные таблицы (они могут относиться к другим сеансам): AND c. relpersistence != 't'
-- Функция может выдать ошибку без этих условий:
AND c.relkind = 'i' AND i.indisready AND i.indisvalid
ORDER BY c.relpages DESC LIMIT 10;
bt_index_check | relname | relpages
----------------+---------------------------------+----------
| pg_depend_reference_index | 43
| pg_depend_depender_index | 40
| pg_proc_proname_args_nsp_index | 31
| pg_description_o_c_o_index | 21
| pg_attribute_relid_attnam_index | 14
| pg_proc_oid_index | 10
| pg_attribute_relid_attnum_index | 9
| pg_amproc_fam_proc_index | 5
| pg_amop_opr_fam_index | 5
| pg_amop_fam_strat_index | 5
(10 rows)
relpersistence != 't'
-- Функция может выдать ошибку без этих условий:
AND c.relkind = 'i' AND i.indisready AND i.indisvalid
ORDER BY c.relpages DESC LIMIT 10;
bt_index_check | relname | relpages
----------------+---------------------------------+----------
| pg_depend_reference_index | 43
| pg_depend_depender_index | 40
| pg_proc_proname_args_nsp_index | 31
| pg_description_o_c_o_index | 21
| pg_attribute_relid_attnam_index | 14
| pg_proc_oid_index | 10
| pg_attribute_relid_attnum_index | 9
| pg_amproc_fam_proc_index | 5
| pg_amop_opr_fam_index | 5
| pg_amop_fam_strat_index | 5
(10 rows)
Этот пример демонстрирует сеанс проверки 10 самых больших индексов системных каталогов в базе данных «test».

bt_index_checkвызывалась для всех индексов в базе, которые поддерживают эту проверку.Функция
bt_index_checkзапрашивает блокировкуAccessShareLockдля целевого индекса и отношения, которому он принадлежит. Это тот же режим блокировки, что запрашивается для отношений обычными операторамиSELECT.bt_index_checkне проверяет инварианты, существующие в иерархии потомок/родитель, но проверяет представление всех кортежей кучи в индексе в виде индексных кортежей, когда параметрheapallindexedравенtrue. Когда в работающей производственной среде требуется регулярная лёгкая проверка на наличие нарушений, использованиеbt_index_checkчасто будет подходящим компромиссом между полнотой проверки и минимизацией влияния на производительность и доступность приложения.
-
bt_index_parent_check(index regclass, heapallindexed boolean, rootdescend boolean) returns void Функция
bt_index_parent_checkпроверяет, соблюдаются ли в целевом объекте, индексе-B-дереве, различные инварианты. Кроме того, если аргументheapallindexedравенtrue, эта функция проверяет наличие в индексе всех кортежей из кучи, которые должны в него попасть. Когда необязательный параметрrootdescendравенtrue, при проверке для каждого кортежа на уровне листьев производится ещё один поиск, начиная с корневой страницы. Проверки, которые может производитьbt_index_parent_check, включают в себя все проверки, выполняемые функциейbt_index_check. Функциюbt_index_parent_checkможно считать более полноценным вариантомbt_index_check: в отличие отbt_index_check,bt_index_parent_checkпроверяет ещё и инварианты, существующие в иерархии родитель/потомок, в том числе отсутствие потерянных связей в структуре индекса.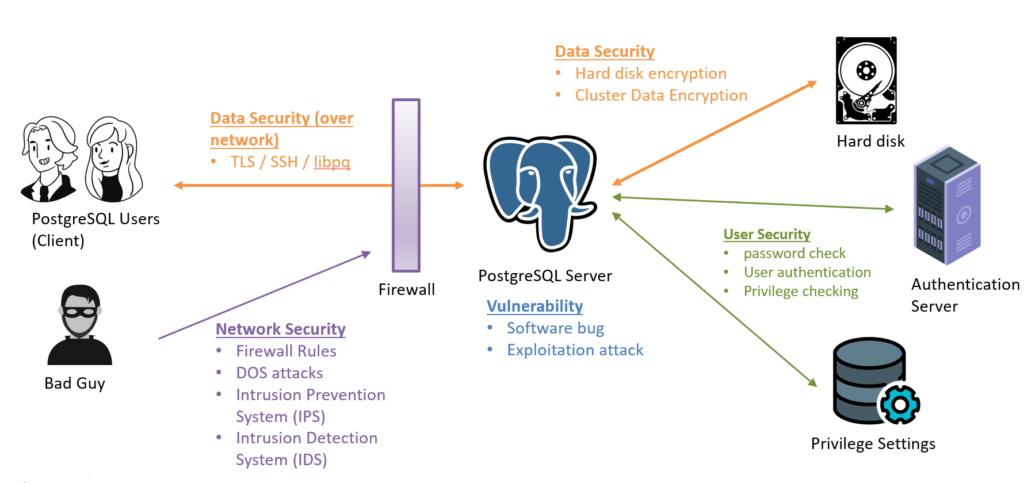
bt_index_parent_checkследует общему соглашению и выдаёт ошибку в случае обнаружения логической несогласованности или другой проблемы.Функция
bt_index_parent_checkзапрашивает в целевом индексе блокировкуShareLock(такжеShareLockзапрашивается и в основном отношении). Эти блокировки предотвращают одновременное изменение данных командамиINSERT,UPDATEиDELETE. Эти блокировки также препятствуют одновременной обработке нижележащего отношения командойVACUUMи другими вспомогательными командами. Заметьте, что эта функция удерживает блокировки только во время выполнения, а не на протяжении всей транзакции.Дополнительные проверки, проводимые функцией
bt_index_parent_check, более ориентированы на выявление различных патологических случаев. В том числе это может быть неправильно реализованный класс операторов B-дерева, используемый проверяемым индексом, или, гипотетически, неизвестные ошибки в нижележащем коде метода доступа индекса-B-дерева. Заметьте, что функцию
Заметьте, что функцию bt_index_parent_checkнельзя применять, когда включён режим горячего резерва (то есть на физических репликах в режиме «только чтение»), в отличие отbt_index_check.
Подсказка
Функции bt_index_check и bt_index_parent_check выводят отладочные сообщения о процессе проверки на уровнях важности DEBUG1 и DEBUG2. Эти сообщения содержат подробные сведения о проверке, которые могут представлять интерес для разработчиков PostgreSQL. Они могут быть полезны и для опытных пользователей в качестве дополнительного контекста в случае обнаружения несогласованности. Чтобы получать сообщения о процессе проверки с подходящим уровнем детализации, выполните до запуска проверяющего запроса в интерактивном psql:
SET client_min_messages = DEBUG1;
-
verify_heapam(relation regclass, on_error_stop boolean, check_toast boolean, skip text, startblock bigint, endblock bigint, blkno OUT bigint, offnum OUT integer, attnum OUT integer, msg OUT text) returns setof record Проверяет таблицу на наличие структурных повреждений (когда страницы отношения содержат данные в неправильном формате) и логических повреждений (когда структура страниц не повреждена, но и не соответствует остальной части кластера).

В качестве необязательных аргументов принимаются:
on_error_stopЕсли true, проверка на наличие повреждений останавливается в конце первого блока, в котором обнаружены какие-либо повреждения.
По умолчанию false.
check_toastЕсли true, поля TOAST проверяются по TOAST-таблице целевого отношения.
Эта проверка может быть длительной. Кроме того, если TOAST-таблица или её индекс повреждены, проверка TOAST-полей потенциально может привести к сбою в работе сервера, хотя во многих случаях это просто вызовет ошибку.
По умолчанию false.
skipЕсли указано значение, отличное от
none, проверка на наличие повреждений пропускает блоки, которые помечены как полностью видимые или полностью замороженные, в зависимости от указанного значения. Допустимые варианты:all-visible,all-frozenиnone.По умолчанию
none.
startblockЕсли этот параметр задан, проверка на наличие повреждений начинается с указанного блока и пропускает все предыдущие блоки. Если в
startblockуказано значение вне диапазона блоков целевой таблицы, выдаётся ошибка.По умолчанию проверка начинается с первого блока.
endblockЕсли этот параметр задан, проверка на наличие повреждений заканчивается на указанном блоке и пропускает все оставшиеся блоки. Если в
endblockуказано значение вне диапазона блоков целевой таблицы, выдаётся ошибка.По умолчанию проверяются все блоки.
Для каждого обнаруженного повреждения
verify_heapamвозвращает строку со следующими столбцами:blknoНомер блока, содержащего повреждённую страницу.
offnumНомер смещения повреждённого кортежа.
attnumНомер атрибута повреждённого столбца в кортеже, если повреждён именно столбец, а не весь кортеж.

msgСообщение с описанием выявленной ошибки.
F.2.2. Дополнительная проверка
heapallindexedКогда аргумент heapallindexed функций проверки B-дерева равен true, для таблицы, связанной с отношением целевого индекса, добавляется дополнительная фаза проверки. Она включает «фиктивную» операцию CREATE INDEX, которая проверяет присутствие всех гипотетических новых индексных кортежей по временной сводной структуре в памяти (она создаётся при необходимости на первом этапе проверки). Сводная структура «помечает» каждый кортеж, который находится в целевом индексе. На высоком уровне идея проверки heapallindexed состоит в том, чтобы убедиться, что новый индекс, равнозначный целевому, содержит только те записи, которые можно найти в существующей структуре.
С дополнительным этапом heapallindexed связаны значительные издержки: проверка обычно будет выполняться в несколько раз дольше. Однако никакие новые блокировки уровня отношения при проверке
Однако никакие новые блокировки уровня отношения при проверке heapallindexed не запрашиваются.
Сводная структура ограничивается по объёму значением maintenance_work_mem. Для выявления несогласованности в представленных в индексе кортежах с вероятностью упущений в пределах 2% требуется приблизительно 2 байта памяти на кортеж. По мере уменьшения объёма памяти в пересчёте на кортеж этот процент медленно растёт. Этот подход значительно ограничивает издержки такой проверки, и при этом лишь немного уменьшается вероятность выявления проблемы, особенно в инсталляциях, где эта проверка включена в процедуру регулярного обслуживания. Даже если единичное отсутствие или повреждение кортежа упущено, есть все шансы выявить его при очередной проверке.
F.2.3. Эффективное использование
amcheckМодуль amcheck может быть полезен для выявления различных типов проблем, которые могут остаться незамеченными при включении контрольных сумм страниц данных. В частности это:
В частности это:
Структурные несоответствия, возникающие при некорректной реализации класса операторов.
В том числе это проблемы, возникающие при изменении правил сравнения в операционной системе. Сравнения данных сортируемого типа, например
text, должны быть постоянными (как и все сравнения, применяемые при сканировании индекса-B-дерева), что подразумевает неизменность правил сортировки в операционной системе. Проблемы могут возникать при обновлениях правил в операционной системе, хотя такие случаи редки. Чаще проявляются несоответствия порядка сортировки между ведущим и ведомым сервером, например, из-за различий основных версий используемых операционных систем. Возникающие расхождения обычно наблюдаются только на ведомых серверах, так что и выявить их обычно можно только на них.Когда возникает подобная проблема, она может затрагивать не абсолютно все индексы, построенные с порочным правилом сортировки, просто потому что индексированные значения могут иметь тот же абсолютный порядок, независящий от различий поведения.
 За дополнительными сведениями об использовании в PostgreSQL правил сортировки и локалей операционной системы обратитесь к Разделу 24.1 и Разделу 24.2.
За дополнительными сведениями об использовании в PostgreSQL правил сортировки и локалей операционной системы обратитесь к Разделу 24.1 и Разделу 24.2.Несоответствия структуры между индексами и проиндексированными отношениями в куче (когда выполняется проверка
heapallindexed).Во время обычных операций перекрёстная проверка индексов по отношениям в куче не производится. Симптомы повреждения данных в куче могут быть неочевидными.
Повреждения, вызванные гипотетическими неизвестными ошибками в нижележащем коде методов доступа, коде сортировки и управления транзакциями PostgreSQL.
Автоматическая проверка структурной целостности индексов играет важную роль в общем тестировании новых или предлагаемых возможностей PostgreSQL, с которыми может возникнуть логическая несогласованность. Такую же роль играет проверка структуры таблицы и связанной информации о видимости и состоянии транзакций. И поэтому одна из очевидных стратегий тестирования — регулярно вызывать функции
amcheckпри проведении стандартных регрессионных тестов.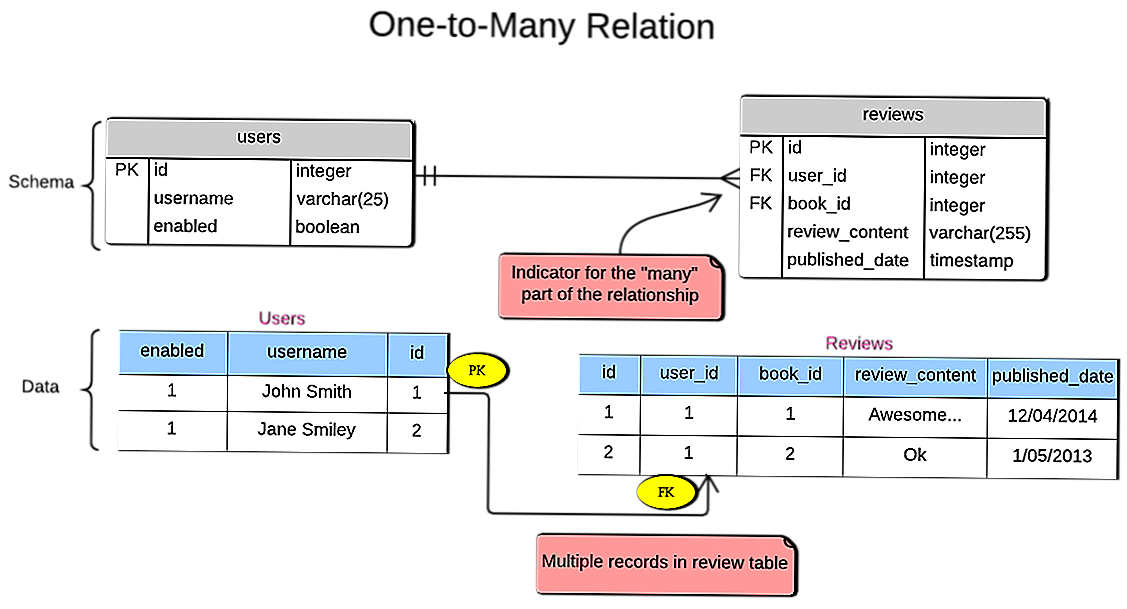 Подробнее о выполнении тестов можно узнать в Разделе 33.1.
Подробнее о выполнении тестов можно узнать в Разделе 33.1.Ошибки в файловой системе или подсистеме хранения, когда просто не включены контрольные суммы.
Заметьте, что
amcheckрассматривает страницу в том виде, как она представлена в некотором буфере разделяемой памяти к моменту проверки, если при обращению к нужному блоку он уже находится в разделяемом буфере. Вследствие этого,amcheckне обязательно видит данные, находящиеся в файловой системе в момент проверки. Заметьте, что когда контрольные суммы включены,amcheckможет выдать ошибку из-за несоответствия контрольных сумм, если в буфер будет считываться испорченный блок.Повреждения, вызванные дефектными чипами ОЗУ или вообще подсистемой памяти.
PostgreSQL не защищает от ошибок памяти; предполагается, что в эксплуатируемом вами сервере установлена память с ECC (Error Correcting Codes, Коды исправления ошибок) или лучшая защита. Однако память ECC обычно защищает только от ошибок в одном бите и не следует считать её абсолютной защитой от сбоев, приводящих к повреждению памяти.

Когда выполняется проверка
heapallindexed, в целом значительно увеличивается шанс выявления ошибок в отдельных битах, так как она тестирует точное двоичное равенство и сверяет проиндексированные атрибуты с кучей.
Причиной повреждения структуры данных может стать неисправность оборудования или же перезапись или изменение файлов отношения сторонним ПО. Этот вид повреждения также можно обнаружить с помощью контрольных сумм страниц данных.
Даже если страницы отношений имеют правильный формат, их внутренняя структура не повреждена и данные соответствуют контрольной сумме, это не гарантирует отсутствие логических повреждений. Повреждения такого типа невозможно обнаружить с помощью контрольных сумм. Примеры: значения TOAST в основной таблице, для которых нет соответствующей записи в таблице TOAST; кортежи в основной таблице с идентификатором транзакции, который старше, чем самый старый действительный идентификатор транзакции в базе данных или кластере.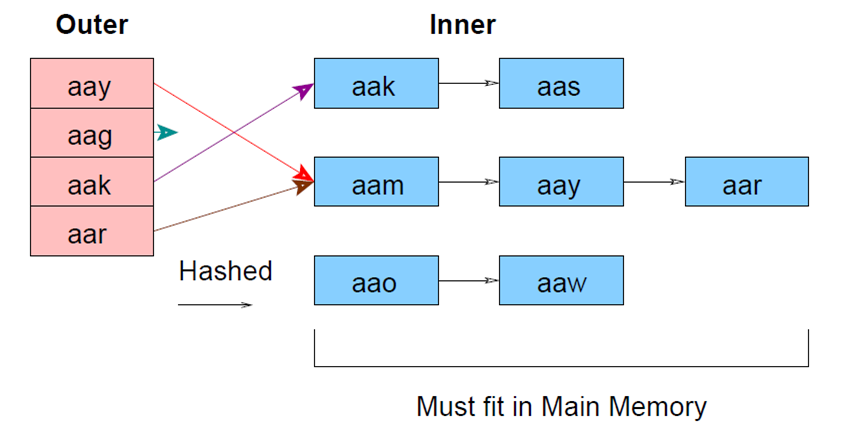
В производственных системах выявляются разнообразные причины логических повреждений: ошибки в серверном ПО PostgreSQL, неисправные и непродуманные инструменты резервного копирования и восстановления, ошибки пользователей.
Повреждение отношений особенно опасно в работающей производственной среде, то есть в той среде, где высокий риск совсем нежелателен. Поэтому для диагностики повреждения данных без излишнего риска была разработана функция verify_heapam. Она не может обеспечить защиту от всех сбоев сервера, так как даже выполнение вызывающего запроса может быть небезопасным на сильно повреждённой системе. Если сами каталоги повреждены, то вероятны проблемы с доступом к таблицам.
Вообще говоря, amcheck может доказать только наличие повреждений, но не доказать их отсутствие.
F.2.4. Исправление повреждений
Когда amcheck сигнализирует о повреждении данных, ложные срабатывания практически исключены. amcheck считает ошибочными ситуации, которые никогда не должны наблюдаться по определению, поэтому ошибки amcheck, как правило, требуют тщательного анализа.
Общего метода устранения проблем, которые может выявить amcheck, не существует. Начать нужно с поиска корня проблемы, приводящей к нарушению инварианта. Полезную роль в диагностике повреждений, которые выявляет amcheck, может сыграть pageinspect. Одна лишь команда REINDEX может быть неэффективна, когда потребуется исправить повреждения.
mysql — проверка целостности ссылочной полноты в SQL
спросил
Изменено 7 лет, 11 месяцев назад
Просмотрено 586 раз
У меня есть 3 таблицы — пользователей , команд и team_members . Последняя представляет собой карту «многие ко многим» из team(id) to user(id) (внешние ключи для команд и пользователей соответственно). Есть ли какая-либо проверка целостности, которую я могу добавить в свою базу данных, которая может утверждать, что, хотя команды без участников возможны, но пользователи без команд невозможны? Чтобы уточнить, я хочу обеспечить на уровне базы данных, что все пользователи должны принадлежать по крайней мере к 1 команде (хотя нет такого требования, чтобы все команды имели 1 пользователя). Приемлем ответ, который работает в MYSQL или Postgres.
Есть ли какая-либо проверка целостности, которую я могу добавить в свою базу данных, которая может утверждать, что, хотя команды без участников возможны, но пользователи без команд невозможны? Чтобы уточнить, я хочу обеспечить на уровне базы данных, что все пользователи должны принадлежать по крайней мере к 1 команде (хотя нет такого требования, чтобы все команды имели 1 пользователя). Приемлем ответ, который работает в MYSQL или Postgres.
- mysql
- sql
- postgresql
- ограничения
- ссылочная целостность
9
(Ответ предполагает PostgreSQL; подробности о триггерах и блокировках будут отличаться, если вы используете другую СУБД, но большинство СУБД должны поддерживать одни и те же базовые операции.)
Хотя возможно добавить внешний ключ от пользователей до team , для этого требуется дублирование знаний — вы, по сути, создаете дополнительные отношения m: 1 в дополнение к существующим отношениям m: n. Это нежелательно.
Это нежелательно.
Если вам не нужно много параллелизма, лучшим вариантом здесь, вероятно, будет использование отложенных триггеров ограничения и блокировки таблицы. Добавить:
триггер отложенного ограничения
ON INSERT OR UPDATE... ДЛЯ КАЖДОЙ СТРОКИтриггер напользователей, который выполняет с тех пор не удалялся, по крайней мере одна команда использует соединение черезteam_members. Ваше приложение захочетБЛОКИРОВКА пользователей ТАБЛИЦЫ В ЭКСКЛЮЗИВНОМ РЕЖИМЕперед записью в нее, а также для предотвращения взаимоблокировок. Обратите внимание, чтоЭКСКЛЮЗИВНЫЙ РЕЖИМне препятствуетSELECT.триггер отложенного ограничения
ON UPDATE OR DELETE... ДЛЯ КАЖДОЙ СТРОКИнаteam_membersкоторый делает то же самое в обратном порядке, гарантируя, что если вы удалите членство в команде, то пользователь, который был участником, все еще имеет другую команду членство. Он также должен заблокировать обоих пользователей
Он также должен заблокировать обоих пользователей team_members.
Конечно, team_members также нуждается в ограничениях FK для пользователей и команд , но это следует просто предположить для таблицы соединения m:n.
Если вы не возражаете против того, чтобы делать что-то в определенном порядке, т.е. всегда добавляйте новое членство перед удалением старого, вы можете использовать обычный триггер вместо триггера отложенного ограничения. Это даст вам ошибки сразу же после того, как вы сделаете что-то неправильно, а не во время COMMIT, но сделает определенные порядки операторов, которые в противном случае были бы допустимы в условиях ошибки.
Если вам нужен хороший параллелизм, вы, вероятно, переполнены.
5
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
дизайн базы данных — PostgreSQL: ограничение целостности между 2 таблицами
Я подозреваю, что дизайн вашей таблицы не нормализован должным образом. Я не знаю семантики вашей бизнес-задачи, поэтому могу только догадываться.
Я не знаю семантики вашей бизнес-задачи, поэтому могу только догадываться.
Предупреждение: код здесь не проверен; синтаксис может быть неправильным.
Если дочерняя таблица представляет переводы как в локализациях, то все значения, включая оригинал, должны присутствовать в дочерней таблице.
Например, если вы намеревались сохранить английскую формулировку в родительской таблице, в то время как дочерняя таблица содержит французский и арабский языки, не делайте этого. Все три (английский, французский, арабский) должны присутствовать в дочерней таблице.
Кстати, каждой таблице нужен свой уникальный идентификатор. Таким образом, вашей дочерней таблице нужно два поля: одно — это ее собственный идентификатор (первичный ключ), а другой столбец содержит идентификатор ее родителя (внешний ключ).
Обратите внимание на следующий код:
- Удалены столбцы
зоныиязыкаиз первой таблицы. - Добавлен столбец идентификатора в дочернюю таблицу
translation_anomaly.
CREATE TABLE аномалия
(
id BIGINT NOT NULL УНИКАЛЬНЫЙ,
описание ТЕКСТ НЕ ПУСТОЙ,
is_translation_anomaly BOOLEAN NOT NULL,
ПЕРВИЧНЫЙ КЛЮЧ (id)
)
;
СОЗДАТЬ ТАБЛИЦУ translation_anomaly
(
id BIGINT NOT NULL УНИКАЛЬНЫЙ,
anomaly_id BIGINT NOT NULL,
зона VARCHAR(100) НЕ НУЛЕВАЯ,
язык VARCHAR(100) НЕ NULL,
ПЕРВИЧНЫЙ КЛЮЧ (id),
FOREIGN KEY (anomaly_id) REFERENCES аномалия (id)
)
;
- Определите уникальный индекс для комбинации столбцов
anomaly_idплюсзоны спо примените первое правило . - То же самое для
языкаплюсanomaly_id отдо примените ваше второе правило .
См. вопрос В Postgresql принудительно использовать уникальность для комбинации двух столбцов .
Между прочим, нет необходимости объявлять NOT NULL или UNIQUE в столбце, отмеченном цифрой 9.0011 ПЕРВИЧНЫЙ КЛЮЧ ограничение. См. страницу документа Ограничения .
См. страницу документа Ограничения .
Добавление первичного ключа автоматически создаст уникальный индекс B-дерева для столбца или группы столбцов, перечисленных в первичном ключе, и принудительно пометит столбец (столбцы) как NOT NULL.
Обратите внимание на следующий код:
- Добавлена пара ограничений
UNIQUE - Удалено избыточное
NOT NULLиUNIQUEиз объявления столбцов идентификаторов.
CREATE TABLE аномалия
(
идентификатор БОЛЬШОЙ,
описание ТЕКСТ НЕ ПУСТОЙ,
is_translation_anomaly BOOLEAN NOT NULL,
ПЕРВИЧНЫЙ КЛЮЧ (id)
)
;
СОЗДАТЬ ТАБЛИЦУ translation_anomaly
(
идентификатор БОЛЬШОЙ,
anomaly_id BIGINT NOT NULL,
зона VARCHAR(100) НЕ НУЛЕВАЯ,
язык VARCHAR(100) НЕ NULL,
ПЕРВИЧНЫЙ КЛЮЧ (id),
FOREIGN KEY (anomaly_id) REFERENCES аномалия (id),
УНИКАЛЬНЫЙ (зона, аномалия_id),
УНИКАЛЬНЫЙ (язык, аномальный_идентификатор)
)
;
Если ваше истинное правило состоит в том, что в каждой зоне должен быть только один язык для любой одной аномалии, то создайте тройной столбец UNIQUE ограничение: UNIQUE ( язык , зона , аномалия_id ) .
CREATE TABLE аномалия
(
идентификатор БОЛЬШОЙ,
описание ТЕКСТ НЕ ПУСТОЙ,
is_translation_anomaly BOOLEAN NOT NULL,
ПЕРВИЧНЫЙ КЛЮЧ (id)
)
;
СОЗДАТЬ ТАБЛИЦУ translation_anomaly
(
идентификатор БОЛЬШОЙ,
anomaly_id BIGINT NOT NULL,
зона VARCHAR(100) НЕ НУЛЕВАЯ,
язык VARCHAR(100) НЕ NULL,
ПЕРВИЧНЫЙ КЛЮЧ (id),
FOREIGN KEY (anomaly_id) REFERENCES аномалия (id),
UNIQUE (зона, язык, аномалия_id)
)
;
Кстати, вы можете захотеть, чтобы база данных обрабатывала последовательность чисел, назначенных в качестве идентификаторов. Современный подход в Postgres 10 и более поздних версиях состоит в том, чтобы сделать идентификаторы столбцами идентификаторов (см. сообщение Eisentraut и сообщение depesz). Но поскольку вы используете 9.4, устаревший подход использует SERIAL в качестве типа псевдоданных. Очевидно, вам нужны 64-битные целые числа, поэтому используйте BIGSERIAL / SERIAL8 .