INSERT INTO | Документация ClickHouse
- Справка по SQL
- Выражения
INSERT
Добавление данных.
Базовый формат запроса:
INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
Вы можете указать список столбцов для вставки, используя синтаксис (c1, c2, c3). Также можно использовать выражение cо звездочкой и/или модификаторами, такими как APPLY, EXCEPT, REPLACE.
В качестве примера рассмотрим таблицу:
SHOW CREATE insert_select_testtable
┌─statement────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ CREATE TABLE insert_select_testtable
(
`a` Int8,
`b` String,
`c` Int8
)
ENGINE = MergeTree()
ORDER BY a │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
INSERT INTO insert_select_testtable (*) VALUES (1, 'a', 1)
Если вы хотите вставить данные во все столбцы, кроме ‘b’, вам нужно передать столько значений, сколько столбцов вы указали в скобках:
INSERT INTO insert_select_testtable (* EXCEPT(b)) Values (2, 2)
SELECT * FROM insert_select_testtable
┌─a─┬─b─┬─c─┐
│ 2 │ │ 2 │
└───┴───┴───┘
┌─a─┬─b─┬─c─┐
│ 1 │ a │ 1 │
└───┴───┴───┘
В этом примере мы видим, что вторая строка содержит столбцы a и c, заполненные переданными значениями и b, заполненный значением по умолчанию.
Если список столбцов не включает все существующие столбцы, то все остальные столбцы заполняются следующим образом:
- Значения, вычисляемые из
DEFAULTвыражений, указанных в определении таблицы. - Нули и пустые строки, если
DEFAULTне определены.
В INSERT можно передавать данные любого формата, который поддерживает ClickHouse. Для этого формат необходимо указать в запросе в явном виде:
INSERT INTO [db.]table [(c1, c2, c3)] FORMAT format_name data_set
Например, следующий формат запроса идентичен базовому варианту INSERT … VALUES:
INSERT INTO [db.]table [(c1, c2, c3)] FORMAT Values (v11, v12, v13), (v21, v22, v23), ...
ClickHouse отсекает все пробелы и один перенос строки (если он есть) перед данными. Рекомендуем при формировании запроса переносить данные на новую строку после операторов запроса (это важно, если данные начинаются с пробелов).
Пример:
INSERT INTO t FORMAT TabSeparated
11 Hello, world!
22 Qwerty
С помощью консольного клиента или HTTP интерфейса можно вставлять данные отдельно от запроса. Как это сделать, читайте в разделе «Интерфейсы».
Как это сделать, читайте в разделе «Интерфейсы».
Ограничения (constraints)
Если в таблице объявлены ограничения, то их выполнимость будет проверена для каждой вставляемой строки. Если для хотя бы одной строки ограничения не будут выполнены, запрос будет остановлен.
Вставка результатов
SELECTINSERT INTO [db.]table [(c1, c2, c3)] SELECT ...
Соответствие столбцов определяется их позицией в секции SELECT. При этом, их имена в выражении SELECT и в таблице для INSERT, могут отличаться. При необходимости выполняется приведение типов данных, эквивалентное соответствующему оператору CAST.
Все форматы данных кроме Values не позволяют использовать в качестве значений выражения, такие как now(), 1 + 2 и подобные. Формат Values позволяет ограниченно использовать выражения, но это не рекомендуется, так как в этом случае для их выполнения используется неэффективный вариант кода.
Не поддерживаются другие запросы на модификацию части данных: UPDATE, DELETE, REPLACE, MERGE, UPSERT, INSERT UPDATE.
Вы можете удалять старые данные с помощью запроса
ALTER TABLE ... DROP PARTITION.Для табличной функции input() после секции SELECT должна следовать
секция FORMAT.
Замечания о производительности
INSERT сортирует входящие данные по первичному ключу и разбивает их на партиции по ключу партиционирования. Если вы вставляете данные в несколько партиций одновременно, то это может значительно снизить производительность запроса INSERT. Чтобы избежать этого:
- Добавляйте данные достаточно большими пачками. Например, по 100 000 строк.
- Группируйте данные по ключу партиционирования самостоятельно перед загрузкой в ClickHouse.
Снижения производительности не будет, если:
- Данные поступают в режиме реального времени.
- Вы загружаете данные, которые как правило отсортированы по времени.
Postgresql insert into values
Название
Синтаксис
Описание
INSERT добавляет строки в таблицу. Эта команда может добавить одну или несколько строк, сформированных выражениями значений, либо ноль или более строк, выданных дополнительным запросом.
Эта команда может добавить одну или несколько строк, сформированных выражениями значений, либо ноль или более строк, выданных дополнительным запросом.
Имена целевых колонок могут перечисляться в любом порядке. Если список с именами колонок отсутствует, по умолчанию целевыми колонками становятся все колонки заданной таблицы; либо первые N из них, если только N колонок поступает от предложения VALUES или запроса. Значения, получаемые от предложения VALUES или запроса, связываются с явно или неявно определённым списком колонок слева направо.
Все колонки, не представленные в явном или неявном списке колонок, получат значения по умолчанию, если для них заданы эти значения, либо NULL в противном случае.
Если выражение для любой колонки выдаёт другой тип данных, система попытается автоматически привести его к нужному.
С необязательным предложением RETURNING команда INSERT вычислит и возвратит значения для каждой фактически добавленной строки.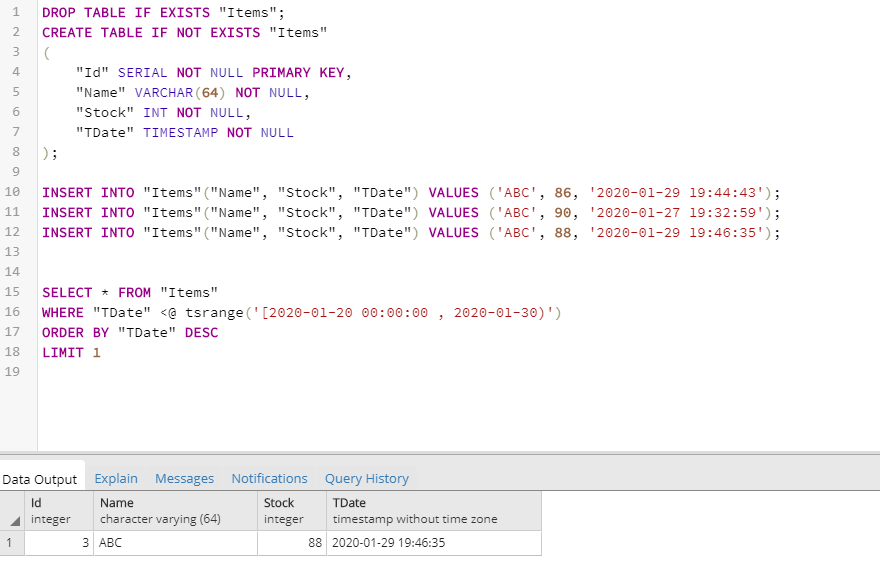 В основном это полезно для получения значений, присвоенных по умолчанию, например, последовательного номера записи. Однако в этом предложении можно задать любое выражение с колонками таблицы. Список RETURNING имеет тот же синтаксис, что и список результатов SELECT.
В основном это полезно для получения значений, присвоенных по умолчанию, например, последовательного номера записи. Однако в этом предложении можно задать любое выражение с колонками таблицы. Список RETURNING имеет тот же синтаксис, что и список результатов SELECT.
Чтобы вставить строки в таблицу, необходимо иметь право INSERT для этой таблицы. Если указывается список колонок, достаточно иметь право INSERT для перечисленных колонок. Для применения предложения RETURNING требуется право SELECT для всех колонок, перечисленных в RETURNING. Если для добавления строк применяется запрос, для всех таблиц или колонок, задействованных в этом запросе, разумеется, необходимо иметь право SELECT.
Параметры
Предложение WITH позволяет задать один или несколько подзапросов, на которые затем можно ссылаться по имени в запросе INSERT. Подробнее об этом см. Раздел 7.8 и SELECT.
Заданный запрос (оператор SELECT) также может содержать предложение WITH. В этом случае в запросе можно обращаться к обоим запросам_WITH, но второй будет иметь приоритет, так как он вложен ближе. table_name
table_name
Имя (возможно, дополненное схемой) существующей таблицы. имя_колонки
Имя колонки в таблице имя_таблицы. Имя колонки может быть дополнено именем вложенного поля или индексом массива, если требуется. (При заполнении только некоторых полей составной колонки остальные поля получают значения NULL.) DEFAULT VALUES
Все колонки получат значения по умолчанию. выражение
Выражение или значение, которое будет присвоено соответствующей колонке. DEFAULT
Соответствующая колонка получит значение по умолчанию. запрос
Запрос (оператор SELECT), который выдаст строки для добавления в таблицу. Его синтаксис описан в справке оператора SELECT. выражение_результата
Выражение, которое будет вычисляться и возвращаться командой INSERT после добавления каждой строки. В этом выражении можно использовать имена любых колонок таблицы имя_таблицы. Чтобы получить все колонки, достаточно написать *. имя_результата
Имя, назначаемое возвращаемой колонке.
Выводимая информация
В случае успешного завершения, INSERT возвращает метку команды в виде
Здесь число представляет количество добавленных строк. Если число равняется одному, а целевая таблица содержит o > oid выводится OID , назначенный добавленной строке. В противном случае вместо oid выводится ноль.
Если команда INSERT содержит предложение RETURNING, её результат будет похож на результат оператора SELECT (с теми же колонками и значениями, что содержатся в списке RETURNING), полученный для строк, добавленных этой командой.
Примеры
Добавление одной строки в таблицу films:
В этом примере колонка len опускается и, таким образом, получает значение по умолчанию:
В этом примере для колонки с датой задаётся указание DEFAULT, а не явное значение:
Добавление строки, полностью состоящей из значений по умолчанию:
Добавление нескольких строк с использованием многострочного синтаксиса VALUES:
В этом примере в таблицу films вставляются некоторые строки из таблицы tmp_films, имеющей ту же структуру колонок, что и films:
Этот пример демонстрирует добавление данных в колонки с типом массива:
Увеличение счётчика продаж для продавца, занимающегося компанией Acme Corporation, и сохранение всей изменённой строки вместе с текущим временем в таблице журнала:
Совместимость
INSERT соответствует стандарту SQL, но предложение RETURNING относится к расширениям PostgreSQL , как и возможность применять WITH с INSERT. Кроме того, ситуация, когда список колонок опущен, но не все колонки получают значения из предложения VALUES или запроса, стандартом не допускается.
Возможные ограничения предложения запрос описаны в справке SELECT.
Synopsis
Description
INSERT inserts new rows into a table. One can insert one or more rows specified by value expressions, or zero or more rows resulting from a query.
The target column names can be listed in any order. If no list of column names is given at all, the default is all the columns of the table in their declared order; or the first N column names, if there are only N columns supplied by the VALUES clause or query. The values supplied by the VALUES clause or query are associated with the explicit or implicit column list left-to-right.
Each column not present in the explicit or implicit column list will be filled with a default value, either its declared default value or null if there is none.
If the expression for any column is not of the correct data type, automatic type conversion will be attempted.
The optional RETURNING clause causes INSERT to compute and return value(s) based on each row actually inserted. This is primarily useful for obtaining values that were supplied by defaults, such as a serial sequence number. However, any expression using the table’s columns is allowed. The syntax of the RETURNING list is >SELECT.
You must have INSERT privilege on a table in order to insert into it. If a column list is specified, you only need INSERT privilege on the listed columns. Use of the RETURNING clause requires SELECT privilege on all columns mentioned in RETURNING. If you use the query clause to insert rows from a query, you of course need to have SELECT privilege on any table or column used in the query.
Parameters
The WITH clause allows you to specify one or more subqueries that can be referenced by name in the INSERT query. See Section 7.8 and SELECT for details.
It is possible for the query ( SELECT statement) to also contain a WITH clause. In such a case both sets of with_query can be referenced within the query, but the second one takes precedence since it is more closely nested.
In such a case both sets of with_query can be referenced within the query, but the second one takes precedence since it is more closely nested.
The name (optionally schema-qualified) of an existing table.
The name of a column in the table named by table_name. The column name can be qualified with a subfield name or array subscript, if needed. (Inserting into only some fields of a composite column leaves the other fields null.)
All columns will be filled with their default values.
An expression or value to assign to the corresponding column.
The corresponding column will be filled with its default value.
A query ( SELECT statement) that supplies the rows to be inserted. Refer to the SELECT statement for a description of the syntax.
An expression to be computed and returned by the INSERT command after each row is inserted. The expression can use any column names of the table named by table_name. Write * to return all columns of the inserted row(s).
A name to use for a returned column.
Outputs
On successful completion, an INSERT command returns a command tag of the form
The count is the number of rows inserted. If count is exactly one, and the target table has O >oid is the OID assigned to the inserted row. Otherwise oid is zero.
If the INSERT command contains a RETURNING clause, the result will be similar to that of a SELECT statement containing the columns and values defined in the RETURNING list, computed over the row(s) inserted by the command.
Examples
Insert a single row into table films:
In this example, the len column is omitted and therefore it will have the default value:
This example uses the DEFAULT clause for the date columns rather than specifying a value:
To insert a row consisting entirely of default values:
To insert multiple rows using the multirow VALUES syntax:
This example inserts some rows into table films from a table tmp_films with the same column layout as films:
This example inserts into array columns:
Insert a single row into table distributors, returning the sequence number generated by the DEFAULT clause:
Increment the sales count of the salesperson who manages the account for Acme Corporation, and record the whole updated row along with current time in a log table:
Compatibility
INSERT conforms to the SQL standard, except that the RETURNING clause is a PostgreSQL extension, as is the ability to use WITH with INSERT. Also, the case in which a column name list is omitted, but not all the columns are filled from the VALUES clause or query, is disallowed by the standard.
Also, the case in which a column name list is omitted, but not all the columns are filled from the VALUES clause or query, is disallowed by the standard.
Possible limitations of the query clause are documented under SELECT.
Добавление данных. Команда Insert
Для добавления данных применяется команда INSERT , которая имеет следующий формальный синтаксис:
После INSERT INTO идет имя таблицы, затем в скобках указываются все столбцы через запятую, в которые надо добавлять данные. И в конце после слова VALUES в скобках перечисляются добавляемые значения.
Допустим, у нас в базе данных есть следующая талица:
Добавим в нее одну строку с помощью команды INSERT:
После удачного выполнения в pgAdmin в поле сообщений должно появиться сообщение «INSERT 0 1»:
Стоит учитывать, что значения для столбцов в скобках после ключевого слова VALUES передаются по порядку их объявления. Например, в выражении CREATE TABLE выше можно увидеть, что первым столбцом идет Id, поэтому этому столбцу передаетсячисло 1.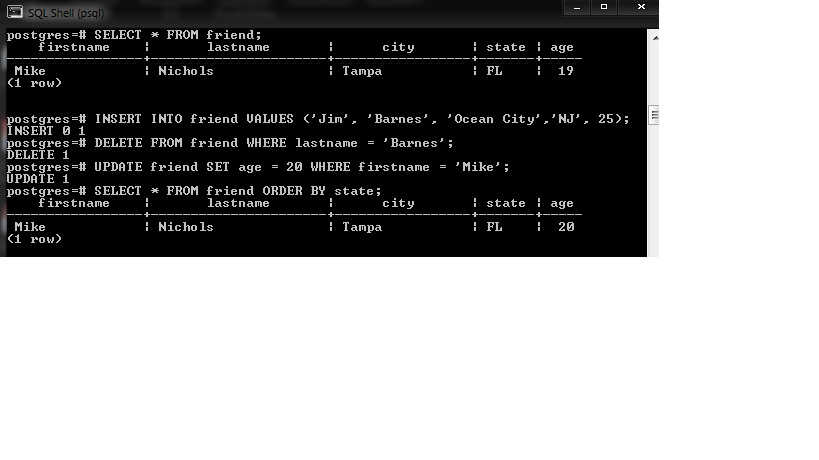 Второй столбец называется ProductName, поэтому второе значение – строка «Galaxy S9» будет передано именно этому столбцу и так далее. То есть значения передаются столбцам следующим образом:
Второй столбец называется ProductName, поэтому второе значение – строка «Galaxy S9» будет передано именно этому столбцу и так далее. То есть значения передаются столбцам следующим образом:
ProductName: ‘Galaxy S9’
Также при вводе значений можно указать непосредственные столбцы, в которые будут добавляться значения:
Здесь значение указывается только для трех столбцов. Причем теперь значения передаются в порядке следования столбцов:
ProductName: ‘iPhone X’
Для столбца Id значение будет генерироваться автоматически базой данных, так как он представляет тип Serial. То есть к значению из последней строки будет добавляться единица.
Для остальных столбцов будет добавляться значение по умолчанию, если задан атрибут DEFAULT (например, для столбца ProductCount), значение NULL. При этом неуказанные столбцы (за исключением тех, которые имеют тип Serial) должны допускать значение NULL или иметь атрибут DEFAULT.
Если конкретные столбцы не указываются, как в первом примере, тогда мы должны передать значения для всех столбцов в таблице.
Также мы можем добавить сразу несколько строк:
В данном случае в таблицу будут добавлены три строки.
Возвращение значений
Если мы добавляем значения только для части столбцов, то мы можем не знать, какие значения будут у других столбцов. Например, какое значени получит столбец >RETURNING мы можем получить это значение:
Операции Insert, Update и Delete в базе данных PostgreSQL на Python
В этом руководстве рассмотрим, как выполнять операции Insert, Update и Delete в базе данных PostgreSQL из Python-скриптов. Их еще называют DML-операциями. Также научимся передавать параметры в SQL-запросы.
В итоге разберем, как использовать cursor.executemany() для выполнения вставки, обновления или удаления нескольких строк в один запрос.
Операция Insert
В этом разделе рассмотрим, как выполнять команду Insert для вставки одной или нескольких записей в таблицу PostgreSQL из Python с помощью Psycopg2.
Для выполнения запроса нужно сделать следующее:
- Установить psycopg2 с помощью pip.

- Установить соединение с базой данных из Python.
- Создать запрос Insert. Для этого требуется знать название таблицы и ее колонок.
- Выполнить запрос с помощью
cursor.execute(). В ответ вы получите количество затронутых строк. - После выполнения запроса нужно закоммитить изменения в базу данных.
- Закрыть объект
cursorи соединение с базой данных. - Также важно перехватить любые исключения, которые могут возникнуть в процессе.
- Наконец, можно проверить результаты, запросив данные из таблицы.
Теперь посмотрим реальный пример.
import psycopg2
from psycopg2 import Error
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection. cursor()
postgres_insert_query = """ INSERT INTO mobile (ID, MODEL, PRICE)
VALUES (%s,%s,%s)"""
record_to_insert = (5, 'One Plus 6', 950)
cursor.execute(postgres_insert_query, record_to_insert)
connection.commit()
count = cursor.rowcount
print (count, "Запись успешно добавлена в таблицу mobile")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
cursor()
postgres_insert_query = """ INSERT INTO mobile (ID, MODEL, PRICE)
VALUES (%s,%s,%s)"""
record_to_insert = (5, 'One Plus 6', 950)
cursor.execute(postgres_insert_query, record_to_insert)
connection.commit()
count = cursor.rowcount
print (count, "Запись успешно добавлена в таблицу mobile")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
Вывод:
1 Запись успешно добавлена в таблицу mobile
Соединение с PostgreSQL закрыто- В этом примере использовался запрос с параметрами для передачи значений во время работы программы. А в конце изменения сохранились с помощью
cursor.commit. - С помощью запроса с параметрами можно передавать переменные python в качестве параметров на месте
%s.
Операция Update
В этом разделе вы узнаете, как обновлять значение в одной или нескольких колонках для одной или нескольких строк таблицы. Для этого нужно изменить запрос к базе данных.
# Задать новое значение price в строке с id для таблицы mobile
Update mobile set price = %s where id = %sПосмотрим на примере обновления одной строки таблицы:
import psycopg2
from psycopg2 import Error
def update_table(mobile_id, price):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.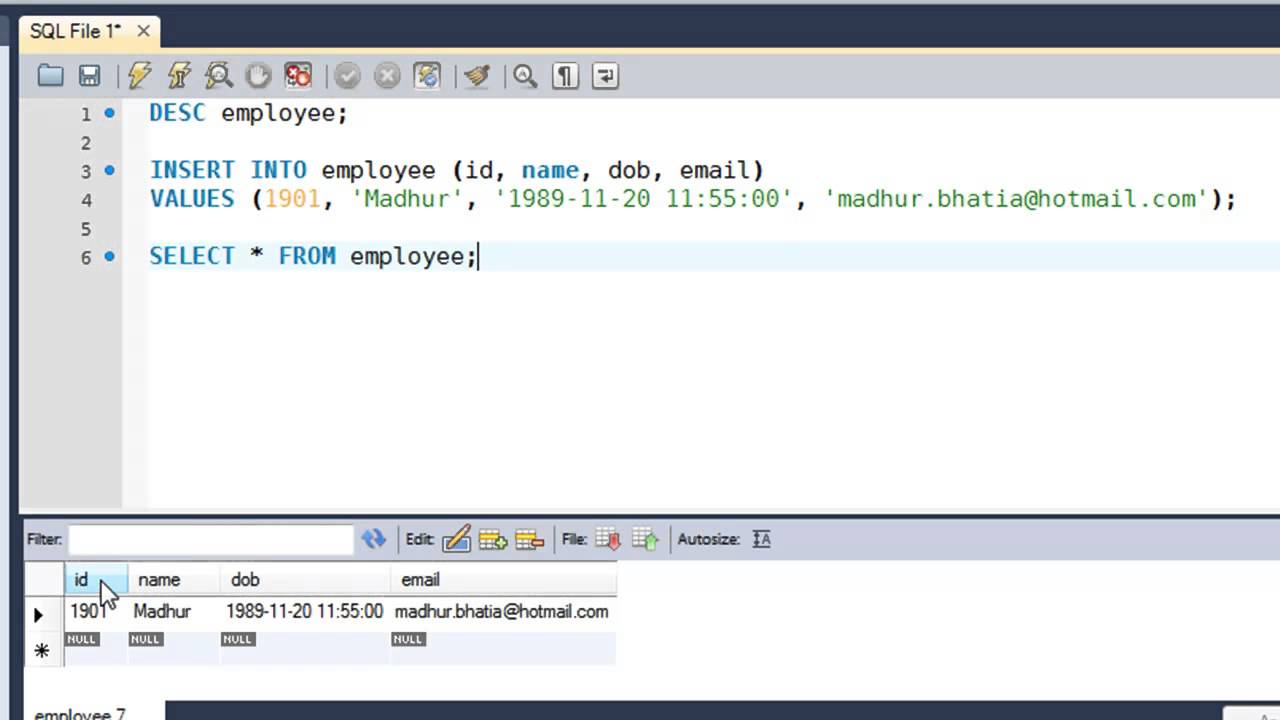 cursor()
print("Таблица до обновления записи")
sql_select_query = """select * from mobile where id = %s"""
cursor.execute(sql_select_query, (mobile_id,))
record = cursor.fetchone()
print(record)
# Обновление отдельной записи
sql_update_query = """Update mobile set price = %s where id = %s"""
cursor.execute(sql_update_query, (price, mobile_id))
connection.commit()
count = cursor.rowcount
print(count, "Запись успешно обновлена")
print("Таблица после обновления записи")
sql_select_query = """select * from mobile where id = %s"""
cursor.execute(sql_select_query, (mobile_id,))
record = cursor.fetchone()
print(record)
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
update_table(3, 970)
cursor()
print("Таблица до обновления записи")
sql_select_query = """select * from mobile where id = %s"""
cursor.execute(sql_select_query, (mobile_id,))
record = cursor.fetchone()
print(record)
# Обновление отдельной записи
sql_update_query = """Update mobile set price = %s where id = %s"""
cursor.execute(sql_update_query, (price, mobile_id))
connection.commit()
count = cursor.rowcount
print(count, "Запись успешно обновлена")
print("Таблица после обновления записи")
sql_select_query = """select * from mobile where id = %s"""
cursor.execute(sql_select_query, (mobile_id,))
record = cursor.fetchone()
print(record)
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
update_table(3, 970)
Убедимся, что обновление сработало. Вывод:
Вывод:
Таблица до обновления записи
(3, 'Samsung Galaxy S21', 900.0)
1 Запись успешно обновлена
Таблица после обновления записи
(3, 'Samsung Galaxy S21', 970.0)
Соединение с PostgreSQL закрытоУдаление строк и колонок
В этом разделе рассмотрим, как выполнять операцию удаления данных из таблицы с помощью программы на Python и Psycopg2.
# Удалить из таблицы ... в строке с id ...
Delete from mobile where id = %sМожно сразу перейти к примеру. Он выглядит следующим образом:
import psycopg2
from psycopg2 import Error
def delete_data(mobile_id):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127. 0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# Удаление записи
sql_delete_query = """Delete from mobile where id = %s"""
cursor.execute(sql_delete_query, (mobile_id,))
connection.commit()
count = cursor.rowcount
print(count, "Запись успешно удалена")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
delete_data(4)
delete_data(5)
0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# Удаление записи
sql_delete_query = """Delete from mobile where id = %s"""
cursor.execute(sql_delete_query, (mobile_id,))
connection.commit()
count = cursor.rowcount
print(count, "Запись успешно удалена")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
delete_data(4)
delete_data(5)
Убедимся, что запись исчезла из таблицы.
1 Запись успешно удалена
Соединение с PostgreSQL закрыто
1 Запись успешно удалена
Соединение с PostgreSQL закрытоCursor.executemany() запросов нескольких строк
Метод cursor.executemany() делает запрос в базу данных со всеми параметрами.
Очень часто нужно выполнить один и тот же запрос с разными данными. Например, обновить информацию о посещаемости студентов. Скорее всего, данные будут разные, но SQL останется неизменным.
Используйте cursor.executemany() для вставки, обновления и удаления нескольких строк в один запрос.
Синтаксис executemany():
executemany(query, vars_list)- В этом случае запросом может быть любая DML-операция (вставка, обновление, удаление).
vars_list— это всего лишь список кортежей, которые передаются в запрос.- Каждый кортеж содержит одну строку для вставки или удаления.
Теперь посмотрим, как использовать этот метод.
Вставка нескольких строк в таблицу PostgreSQL
Можно выполнить вставку нескольких строк с помощью SQL-запроса. Для этого используется запрос с параметрами и метод executemany().
import psycopg2
from psycopg2 import Error
def bulk_insert(records):
try:
# Подключиться к существующей базе данных
connection = psycopg2. connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
sql_insert_query = """ INSERT INTO mobile (id, model, price)
VALUES (%s,%s,%s) """
# executemany() для вставки нескольких строк
result = cursor.executemany(sql_insert_query, records)
connection.commit()
print(cursor.rowcount, "Запись(и) успешно вставлена(ы) в таблицу mobile")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
records_to_insert = [ (4,'LG', 800) , (5,'One Plus 6', 950)]
bulk_insert(records_to_insert)
connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
sql_insert_query = """ INSERT INTO mobile (id, model, price)
VALUES (%s,%s,%s) """
# executemany() для вставки нескольких строк
result = cursor.executemany(sql_insert_query, records)
connection.commit()
print(cursor.rowcount, "Запись(и) успешно вставлена(ы) в таблицу mobile")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
records_to_insert = [ (4,'LG', 800) , (5,'One Plus 6', 950)]
bulk_insert(records_to_insert)
Проверим результат, вернув данные из таблицы.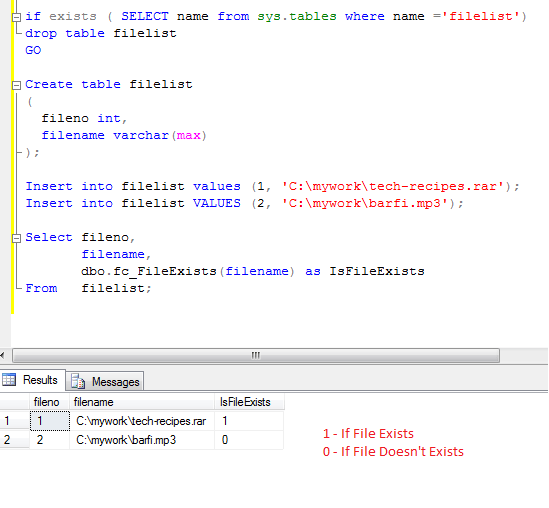
2 Запись(и) успешно вставлена(ы) в таблицу mobile
Соединение с PostgreSQL закрытоПримечание: для этого запроса был создан список записей, включающий два кортежа. Также использовались заменители. Они позволяют передать значения в запрос уже во время работы программы.
Обновление нескольких строк в одном запросе
Чаще всего требуется выполнить один и тот же запрос, но с разными данными. Например, обновить зарплату сотрудников. Сумма будет отличаться, но не запрос.
Обновить несколько колонок таблицы можно с помощью cursor.executemany() и запроса с параметрами (%). Посмотрим на примере.
import psycopg2
from psycopg2 import Error
def update_in_bulk(records):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127. 0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# Обновить несколько записей
sql_update_query = """Update mobile set price = %s where id = %s"""
cursor.executemany(sql_update_query, records)
connection.commit()
row_count = cursor.rowcount
print(row_count, "Записи обновлены")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
update_in_bulk([(750, 4), (950, 5)])
0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
# Обновить несколько записей
sql_update_query = """Update mobile set price = %s where id = %s"""
cursor.executemany(sql_update_query, records)
connection.commit()
row_count = cursor.rowcount
print(row_count, "Записи обновлены")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
update_in_bulk([(750, 4), (950, 5)])
Вывод:
2 Записи обновлены
Соединение с PostgreSQL закрытоПроверим результат.
Используйте cursor.rowcount, чтобы получить общее количество строк, измененных методом executemany().
Удаление нескольких строк из таблицы
В этом примере используем запрос Delete с заменителями, которые подставляют ID записей для удаления. Также есть список записей для удаления. В списке есть кортежи для каждой строки. В примере их два, что значит, что удалены будут две строки.
import psycopg2
from psycopg2 import Error
def delete_in_bulk(records):
try:
# Подключиться к существующей базе данных
connection = psycopg2.connect(user="postgres",
# пароль, который указали при установке PostgreSQL
password="1111",
host="127.0.0.1",
port="5432",
database="postgres_db")
cursor = connection.cursor()
delete_query = """Delete from mobile where id = %s"""
cursor.executemany(delete_query, records)
connection. commit()
row_count = cursor.rowcount
print(row_count, "Записи удалены")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
delete_in_bulk([(5,), (4,), (3,)])
commit()
row_count = cursor.rowcount
print(row_count, "Записи удалены")
except (Exception, Error) as error:
print("Ошибка при работе с PostgreSQL", error)
finally:
if connection:
cursor.close()
connection.close()
print("Соединение с PostgreSQL закрыто")
delete_in_bulk([(5,), (4,), (3,)])
Убедимся, что запрос был выполнен успешно.
3 Записи удалены
Соединение с PostgreSQL закрытоPostgreSQL | ObjectRocket
Введение
Если вы используете PostgreSQL для хранения данных, вам нужно знать, как вставлять данные в таблицы. К счастью, синтаксис оператора PostgreSQL INSERT прост в освоении, что позволяет вставлять либо одну запись, либо несколько записей одновременно. В этой статье мы более подробно рассмотрим оператор PostgreSQL INSERT и рассмотрим некоторые примеры его использования.
Предварительные требования
Перед тем, как приступить к этому руководству, убедитесь, что выполнены следующие предварительные условия:
У вас должны быть базовые знания о командах SQL и управлении базами данных.

На вашем компьютере должен быть установлен и запущен PostgreSQL. Если вы используете дистрибутив Linux, в котором используется
systemd, вы можете проверить, установлен ли и правильно ли работает PostgreSQL, с помощью командыsystemctl status postgresql. Вы также можете проверить версиюpsql, интерактивного терминала для PostgreSQL, с помощью командыpsql -VЕсли вы используете macOS, вы можете установить Postgres с помощью Homebrew.Во-первых, вам нужно будет обновить и проверить работоспособность вашей установки Homebrew, выполнив следующие действия:
brew doctor && brew update. После выполнения этих команд используйте командуbrew install postgresдля установки PostgreSQL. После завершения установки используйте командуpostgres -D / usr / local / var / postgres, чтобы запустить процесс как фоновый демон; в качестве альтернативы вы можете использоватьpg_ctl -D / usr / local / var / postgres startдля запуска сервера на переднем плане окна терминала.
Оператор INSERT PostgreSQL
Теперь, когда мы рассмотрели предварительные условия, давайте обратимся к psql , чтобы мы могли создать образец базы данных и протестировать несколько операторов SQL INSERT INTO .
Используйте psql для подключения к базе данных
Прежде чем мы сможем попробовать несколько примеров операторов INSERT , нам необходимо подключиться к PostgreSQL с помощью интерактивного терминала psql . Мы будем использовать этот интерфейс командной строки для создания базы данных и построения любых необходимых таблиц, а также для выполнения любых команд SQL.
Для доступа к консоли psql нам потребуются привилегии суперпользователя postgres :
После ввода пароля для postgres используйте следующую команду:
Оператор Postgres «CREATE DATABASE»
Затем давайте создадим образец базы данных и таблицу, которые мы будем использовать в наших примерах. Базовый синтаксис для создания базы данных:
Базовый синтаксис для создания базы данных:
Примечание: Для подключения к этой базе данных можно использовать команду \ c , за которой следует имя базы данных test .В отличие от операторов SQL, команды, которые начинаются с обратной косой черты ( \ ) в psql, не должны заканчиваться точкой с запятой.
Оператор Postgres «CREATE TABLE»
После подключения к базе данных мы можем создать таблицу.
Вот команда, которую мы будем использовать для создания таблицы в PostgreSQL:
1 | СОЗДАТЬ ТАБЛИЦУ demo_tbl ( |
Имейте в виду, что включенные нами ограничения являются необязательными — вы можете настроить свою таблицу, как вам удобнее.
Когда вы создаете таблицу в PostgreSQL, вам необходимо указать тип данных для каждого столбца. В показанном выше примере мы использовали три разных типа данных:
В показанном выше примере мы использовали три разных типа данных: INT , TEXT и VARCHAR .
Оператор Postgres «INSERT INTO»
Оператор PostgreSQL INSERT используется для вставки новой отдельной записи или нескольких записей в указанную таблицу. В этом разделе мы заполним нашу вновь созданную таблицу некоторыми записями с помощью оператора INSERT .
Основной синтаксис оператора INSERT :
1 | INSERT INTO demo_tbl (column1, column2) VALUES (value1, value2); |
В этом примере мы используем оператор INSERT , чтобы добавить одну запись в таблицу demo_tbl :
1 | INSERT INTO demo_tbl (id, string, message) |
Чтобы убедиться, что наш оператор INSERT выполнен правильно, мы можем использовать SELECT :
Приведенный выше запрос должен вернуть следующие результаты:
1 | id | строка | сообщение |
Использование SQL и INSERT INTO для нескольких строк
Если вам нужно вставить несколько записей в таблицу PostgreSQL, вы можете использовать тот же SQL-оператор INSERT INTO с немного другим синтаксисом.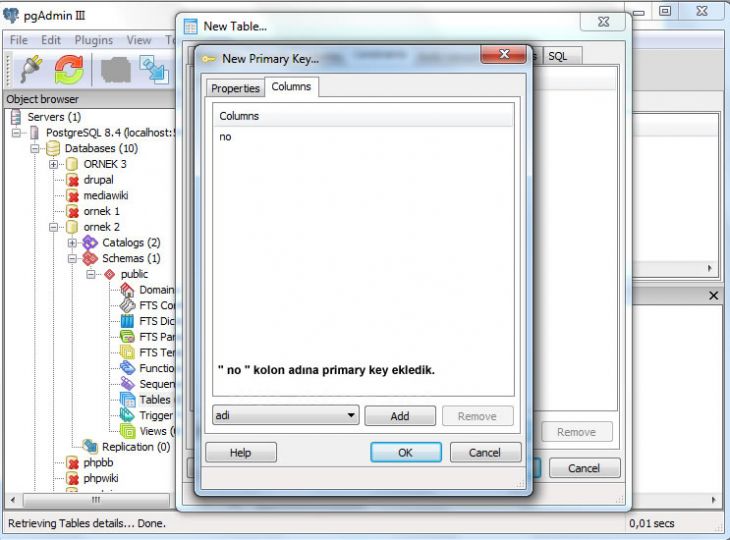
В следующем примере показано, как вставить несколько записей в таблицу demo_tbl :
1 | INSERT INTO demo_tbl (id, string, message) |
Обратите внимание, что каждая запись заключена в круглые скобки, а каждое значение столбца в записи разделено запятыми.
Результат приведенного выше оператора INSERT должен вернуть ответ INSERT 0 2 .
Теперь давайте воспользуемся SELECT * FROM demo_tbl; , чтобы psql возвращал результаты, подобные показанным ниже. Это позволит нам увидеть, сколько записей было вставлено в таблицу demo_tbl :
1 | test = # SELECT * FROM demo_tbl; |
Когда вы закончите, просто используйте команду \ q для выхода из клиентского интерфейса psql для PostgreSQL.
Заключение
Если вы только начинаете работать с PostgreSQL, важно научиться правильно вставлять записи. В этой статье мы показали вам, как использовать оператор PostgreSQL INSERT для вставки как одной записи, так и нескольких записей. С нашими примерами, которые помогут вам, вы будете готовы вставлять записи в свои собственные таблицы PostgreSQL.
13 советов по повышению производительности вставки базы данных PostgreSQL
Некоторые из них могут вас удивить, но все 13 способов помогут вам улучшить производительность приема (INSERT) с помощью PostgreSQL и TimescaleDB — и увидеть скорости приема, аналогичные тем, что в наших сообщениях, сравнивающих производительность TimescaleDB иInfluxDB или MongoDB.
Производительность Ingest критически важна для многих распространенных сценариев использования PostgreSQL, включая мониторинг приложений, аналитику приложений, мониторинг Интернета вещей и многое другое. Хотя базы данных давно имеют временные поля, существует ключевое различие в типах данных, которые собирают эти варианты использования: в отличие от стандартных реляционных «бизнес-данных» изменения обрабатываются как , вставляет , а не перезаписывает (другими словами, каждое новое значение становится новая строка в базе данных, вместо замены предыдущего значения строки последним).
Если вы работаете в сценарии, в котором вам необходимо сохранить все данные v. Перезаписывать прошлые значения, оптимизация скорости, с которой ваша база данных может принимать новые данные, становится важной.
У нас есть большой опыт оптимизации производительности для себя и членов нашего сообщества, и мы разделили наши основные советы на две категории. Во-первых, мы изложили несколько полезных советов для улучшения PostgreSQL в целом. После этого мы выделили несколько, относящихся к TimescaleDB.
Повысьте производительность PostgreSQL
Вот несколько рекомендаций по повышению производительности захвата в обычном PostgreSQL:
1. Используйте индексы в модерации
Наличие правильных индексов может ускорить выполнение ваших запросов, но это не серебряная пуля. Постепенное поддержание индексов с каждой новой строкой требует дополнительной работы. Проверьте количество индексов, которые вы определили для своей таблицы (используйте команду psql \ d имя_таблицы ), и определите, перевешивают ли их потенциальные преимущества запросов на хранение и накладные расходы на вставку. Поскольку все системы индивидуальны, нет никаких жестких правил или «магического числа» индексов — просто будьте разумны.
Поскольку все системы индивидуальны, нет никаких жестких правил или «магического числа» индексов — просто будьте разумны.
2. Пересмотреть ограничения внешнего ключа
Иногда необходимо построить внешние ключи (FK) из одной таблицы в другие реляционные таблицы. Когда у вас есть ограничение FK, каждый INSERT обычно должен будет читать из вашей ссылочной таблицы, что может снизить производительность. Подумайте, можете ли вы денормализовать свои данные — иногда мы видим довольно крайнее использование ограничений FK, сделанное из чувства «элегантности», а не из инженерных компромиссов.
3. Избегайте ненужных ключей UNIQUE
Разработчиков часто обучают указывать первичные ключи в таблицах базы данных, и многие ORM любят их. Тем не менее, во многих случаях использования, включая обычные приложения для мониторинга или создания временных рядов, они не требуются, поскольку каждое событие или показание датчика можно просто зарегистрировать как отдельное событие, вставив его в конец текущего фрагмента гипертаблицы во время записи.
Если ограничение UNIQUE определено иначе, эта вставка может потребовать поиска в индексе, чтобы определить, существует ли уже строка, что отрицательно повлияет на скорость вашего INSERT.
4. Используйте отдельные диски для WAL и данных
Хотя это более продвинутая оптимизация, которая не всегда требуется, если ваш диск становится узким местом, вы можете дополнительно увеличить пропускную способность, используя отдельный диск (табличное пространство) для базы данных. журнал предзаписи (WAL) и данные.
5. Используйте высокопроизводительные диски
Иногда разработчики развертывают свои базы данных в средах с более медленными дисками, будь то из-за некачественных жестких дисков, удаленных сетей SAN или других типов конфигураций.А поскольку при вставке строк данные надежно сохраняются в журнале упреждающей записи (WAL) до завершения транзакции, медленные диски могут повлиять на производительность вставки. Единственное, что нужно сделать, это проверить количество операций ввода-вывода в секунду на вашем диске с помощью команды ioping .
Тест чтения:
$ ioping -q -c 10 -s 8k.
---. (hfs / dev / disk1 930,7 ГиБ) Статистика операций ---
9 запросов выполнено за 208 мс, 72 КБ чтения, 43,3 тыс. Операций ввода-вывода в секунду, 338,0 МБ / с
сгенерировано 10 запросов за 9,00 с, 80 КБайт, 1 iops, 8,88 КБайт / с
min / avg / max / mdev = 18 мкс / 23.1 мкс / 35 мкс / 6,17 мкс Тест записи:
$ ioping -q -c 10 -s 8k -W.
---. (hfs / dev / disk1 930,7 ГиБ) Статистика операций ---
9 запросов выполнено за 10,8 мс, записано 72 КиБ, 830 операций ввода-вывода в секунду, 6,49 МБ / с
сгенерировано 10 запросов за 9,00 с, 80 КБайт, 1 iops, 8,89 КБайт / с
min / avg / max / mdev = 99 мкс / 1,20 мс / 2,23 мс / 919,3 мс Вы должны увидеть не менее 1000 операций ввода-вывода в секунду при чтении и несколько сотен операций ввода-вывода в секунду при записи. Если вы видите гораздо меньше, на производительность INSERT, вероятно, повлияет ваше дисковое оборудование.Посмотрите, возможны ли альтернативные конфигурации хранилища.![]()
Выберите и настройте TimescaleDB для повышения производительности захвата
TimescaleDB настроен для повышения производительности захвата. Чаще всего TimescaleDB используется для хранения огромных объемов данных для метрик облачной инфраструктуры, аналитики продуктов, веб-аналитики, устройств IoT и многих других сценариев использования временных рядов. Как это типично для данных временных рядов, эти сценарии ориентированы на время, почти полностью предназначены только для добавления (много INSERT) и требуют быстрого приема больших объемов данных в небольших временных окнах.
TimescaleDB упакован как расширение PostgreSQL и специально создан для случаев использования временных рядов. Итак, если для ваших приложений или систем требуется более высокая производительность захвата из PostgreSQL, рассмотрите возможность использования TimescaleDB (доступно с полным управлением через Timescale Cloud — наше предложение базы данных как услуги или самоуправление с помощью нашей бесплатной версии Community Edition) .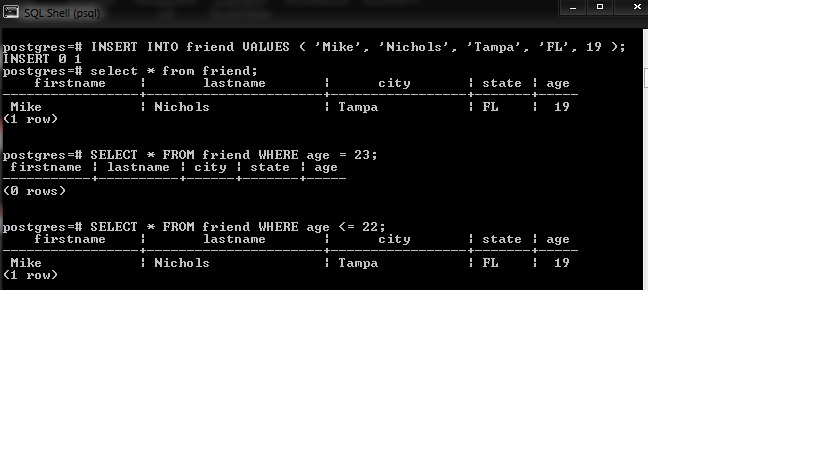
… и вот еще 8 методов повышения производительности захвата с помощью TimescaleDB:
6.Используйте параллельную запись.
Каждая команда INSERT или COPY для TimescaleDB (как в PostgreSQL) выполняется как одна транзакция и, таким образом, выполняется в однопоточном режиме. Чтобы добиться более высокого уровня захвата, вы должны выполнять несколько команд INSERTS или COPY параллельно.
Чтобы получить помощь с параллельной массовой загрузкой больших файлов CSV, ознакомьтесь с командой параллельного копирования TimescaleDB.
⭐ Совет от профессионалов: убедитесь, что на вашей клиентской машине достаточно ядер для выполнения этого параллелизма (запуск 32 клиентских рабочих процессов на машине с 2 виртуальными ЦП не очень помогает — на самом деле рабочие не будут выполняться параллельно).
7. Вставляйте строки группами.
Чтобы добиться более высокой скорости приема, вы должны вставлять данные с большим количеством строк в каждый вызов INSERT (или использовать какую-нибудь команду массовой вставки, например COPY или наш инструмент параллельного копирования).
Не вставляйте данные построчно — вместо этого попробуйте хотя бы сотни (или тысячи) строк на INSERT. Это позволяет базе данных тратить меньше времени на управление соединениями, накладные расходы на транзакции, синтаксический анализ SQL и т. Д. И больше времени на обработку данных.
Обычно мы рекомендуем 25% доступной оперативной памяти. Если вы устанавливаете TimescaleDB с помощью метода, который запускает timescaledb-tune , он должен автоматически настроить shared_buffers на что-то подходящее для ваших аппаратных характеристик.
Примечание: в некоторых случаях, обычно при виртуализации и ограниченном распределении памяти cgroups, эти автоматически настраиваемые параметры могут быть не идеальными. Чтобы проверить, что ваш shared_buffers установлен в пределах диапазона 25%, запустите SHOW shared_buffers из вашего соединения psql .
9.
 Запускаем наши образы Docker на хостах Linux
Запускаем наши образы Docker на хостах LinuxЕсли вы используете Docker-контейнер TimescaleDB (на котором работает Linux) поверх другой операционной системы Linux, вы в отличной форме. Контейнер в основном обеспечивает изоляцию процесса, а накладные расходы крайне минимальны.
Если вы запускаете контейнер на компьютере Mac или Windows, вы увидите некоторое снижение производительности для виртуализации ОС, в том числе для ввода-вывода.
Вместо этого, если вам нужно работать на Mac или Windows, мы рекомендуем установку напрямую вместо использования образа Docker.
10. Записывать данные в произвольном временном порядке
Если размер фрагментов задан соответствующим образом (см. № 11 и № 12), последний фрагмент (-ы) и связанные с ними индексы естественным образом сохраняются в памяти. Новые строки, вставленные с недавними отметками времени, будут записаны в эти блоки и индексы, уже находящиеся в памяти.
Если вставлена строка с достаточно старой меткой времени — т. Е. Это неупорядоченная запись или запись с обратным заполнением — страницы диска, соответствующие старому фрагменту (и его индексам), должны быть прочитаны с диска.Это значительно увеличит задержку записи и снизит пропускную способность вставки.
Е. Это неупорядоченная запись или запись с обратным заполнением — страницы диска, соответствующие старому фрагменту (и его индексам), должны быть прочитаны с диска.Это значительно увеличит задержку записи и снизит пропускную способность вставки.
В частности, когда вы загружаете данные в первый раз, попробуйте загрузить данные в отсортированном порядке с увеличением временных меток.
Будьте осторожны, если вы загружаете данные о множестве различных серверов, устройств и т. Д.:
- Не вставляйте массово данные последовательно по серверу (т. Е. Все данные для сервера A, затем сервера B, затем C и так далее). Это вызовет перегрузку диска, поскольку загрузка каждого сервера будет проходить через все фрагменты перед запуском заново.
- Вместо этого организуйте массовую загрузку таким образом, чтобы данные со всех серверов вставлялись в произвольном порядке меток времени (например, день 1 на всех серверах параллельно, затем день 2 на всех серверах параллельно и т.
 Д.)
Д.)
11. Избегайте » слишком большие »фрагменты
Чтобы поддерживать более высокую скорость приема, вы хотите, чтобы ваш последний фрагмент, а также все связанные с ним индексы оставались в памяти, чтобы записи в фрагмент и обновления индекса просто обновляли память. (Запись по-прежнему продолжительна, поскольку вставки записываются в WAL на диске до обновления страниц базы данных.)
Если ваши фрагменты слишком велики, то запись даже в самый последний фрагмент начнется с перестановки на диск.
Как правило, мы рекомендуем, чтобы последние фрагменты и все их индексы удобно помещались в shared_buffers базы данных. Вы можете проверить размеры блоков с помощью команды SQL chunk_relation_size_pretty .
=> ВЫБРАТЬ chunk_table, table_size, index_size, toast_size, total_sizeFROM chunk_relation_size_pretty ('hypertable_name') ORDER BY range DESC LIMIT 4;
chunk_table | table_size | index_size | toast_size | общий размер
----------------------------------------- + -------- ---- + ------------ + ------------ + ------------
_timescaledb_internal. _hyper_1_96_chunk | 200 МБ | 64 МБ | 8192 байта | 272 МБ
_timescaledb_internal._hyper_1_95_chunk | 388 МБ | 108 МБ | 8192 байта | 500 МБ
_timescaledb_internal._hyper_1_94_chunk | 388 МБ | 108 МБ | 8192 байта | 500 МБ
_timescaledb_internal._hyper_1_93_chunk | 388 МБ | 108 МБ | 8192 байта | 500 МБ
_hyper_1_96_chunk | 200 МБ | 64 МБ | 8192 байта | 272 МБ
_timescaledb_internal._hyper_1_95_chunk | 388 МБ | 108 МБ | 8192 байта | 500 МБ
_timescaledb_internal._hyper_1_94_chunk | 388 МБ | 108 МБ | 8192 байта | 500 МБ
_timescaledb_internal._hyper_1_93_chunk | 388 МБ | 108 МБ | 8192 байта | 500 МБ Если ваши фрагменты слишком велики, вы можете обновить диапазон для будущих фрагментов с помощью команды set_chunk_time_interval . Однако это не изменяет диапазон существующих фрагментов (например,g., переписывая большие куски на несколько маленьких кусков).
Для конфигураций, в которых отдельные фрагменты намного больше, чем ваша доступная память, мы рекомендуем выгружать и перезагружать данные гипертаблицы в фрагменты правильного размера.
Сохранение последнего фрагмента применяется ко всем активным гипертаблицам; если вы активно пишете в две гипертаблицы, последние фрагменты из обеих должны уместиться в shared_buffers .
12.
 Избегайте слишком большого количества или слишком маленьких фрагментов
Избегайте слишком большого количества или слишком маленьких фрагментовЕсли вы не используете многоузловую TimescaleDB, мы в настоящее время не рекомендуем использовать разделение пространства.И если вы это сделаете, помните, что это количество блоков создается для каждого временного интервала.
Итак, если вы создаете 64 раздела пространства и ежедневные порции, у вас будет 24 640 порций в год. Это может привести к большему снижению производительности во время запроса (из-за накладных расходов на планирование) по сравнению со временем вставки, но, тем не менее, это следует учитывать.
Еще одна вещь, которой следует избегать: использование неверного целого числа при указании диапазона временного интервала в create_hypertable .
⭐ Совет от профессионалов:
- Если в столбце времени используется собственный тип метки времени, любое целочисленное значение должно быть выражено в микросекундах (таким образом, один день = 86400000000).
 Мы рекомендуем использовать типы интервалов («1 день»), чтобы избежать путаницы.
Мы рекомендуем использовать типы интервалов («1 день»), чтобы избежать путаницы. - Если ваш столбец времени является целым числом или самим bigint, используйте соответствующий диапазон: если целочисленная метка времени находится в секундах, используйте 86400; если временная метка bigint находится в наносекундах, используйте 86400000000000.
В обоих случаях вы можете использовать
chunk_relation_size_pretty, чтобы убедиться, что размеры ваших блоков или диапазоны разделов кажутся разумными:
=> SELECT chunk_table, range, total_size
ОТ chunk_relation_size_pretty ('имя_гипертаблицы')
ORDER BY диапазоны DESC LIMIT 4;
chunk_table | диапазоны | общий размер
----------------------------------------- + -------- ------------------------------------------------- + ------------
_timescaledb_internal._hyper_1_96_chunk | {"['2020-02-13 23: 00: 00 + 00', '2020-02-14 00: 00: 00 + 00')»} | 272 МБ
_timescaledb_internal._hyper_1_95_chunk | {"['2020-02-13 22: 00: 00 + 00', '2020-02-13 23: 00: 00 + 00')"} | 500 МБ
_timescaledb_internal. _hyper_1_94_chunk | {"['2020-02-13 21: 30: 00 + 00', '2020-02-13 22: 00: 00 + 00')"} | 500 МБ
_timescaledb_internal._hyper_1_93_chunk | {"['2020-02-13 20: 00: 00 + 00', '2020-02-13 21: 00: 00 + 00')"} | 500 МБ
_hyper_1_94_chunk | {"['2020-02-13 21: 30: 00 + 00', '2020-02-13 22: 00: 00 + 00')"} | 500 МБ
_timescaledb_internal._hyper_1_93_chunk | {"['2020-02-13 20: 00: 00 + 00', '2020-02-13 21: 00: 00 + 00')"} | 500 МБ 13. Наблюдайте за шириной строки
Накладные расходы от вставки широкой строки (скажем, 50, 100, 250 столбцов) будут намного выше, чем при вставке более узкой строки (больше сетевого ввода-вывода, больше синтаксического анализа и обработка данных, большие записи в WAL и т. д.). В большинстве опубликованных нами тестов используется TSBS, в котором в каждой строке используется 12 столбцов. Соответственно, вы увидите более низкие скорости вставки, если у вас очень широкие строки.
Если вы рассматриваете очень широкие строки, потому что у вас есть разные типы записей, и каждый тип имеет непересекающийся набор столбцов, вы можете попробовать использовать несколько гипертаблиц (по одной для каждого типа записи) — особенно если вы не часто запрашиваете через эти типы.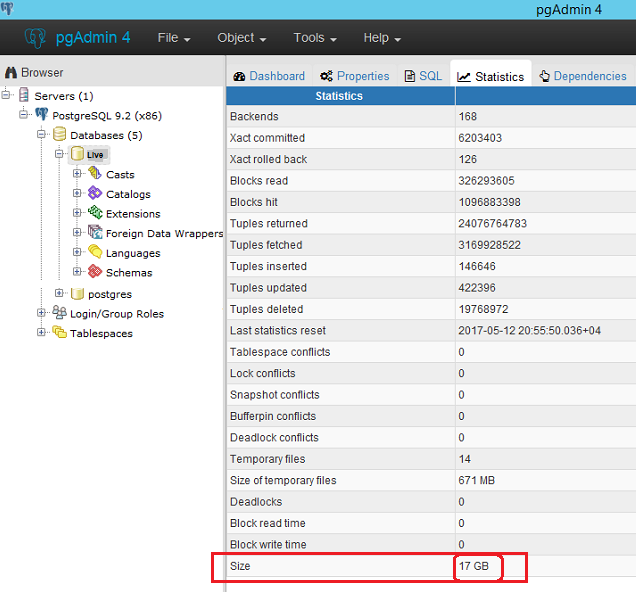
Кроме того, записи JSONB — еще один хороший вариант, если практически все столбцы разрежены.Тем не менее, если вы используете разреженные широкие строки, по возможности используйте NULL для отсутствующих записей, а не значения по умолчанию для максимального увеличения производительности (NULL намного дешевле хранить и запрашивать).
Наконец, стоимость широких строк на самом деле намного меньше, если вы сжимаете строки с помощью собственного сжатия TimescaleDB. Строки преобразуются в более сжатую форму столбцов, разреженные столбцы сжимаются очень хорошо, а сжатые столбцы не считываются с диска для запросов, которые не извлекают отдельные столбцы.
Сводка
Если производительность захвата критична для вашего варианта использования, рассмотрите возможность использования TimescaleDB. Вы можете начать работу с Timescale Cloud бесплатно сегодня или бесплатно загрузить TimescaleDB на свой компьютер или облачный экземпляр.
Наш подход к поддержке заключается в том, чтобы охватить все ваше решение, поэтому мы здесь, чтобы помочь вам достичь желаемых результатов производительности (см.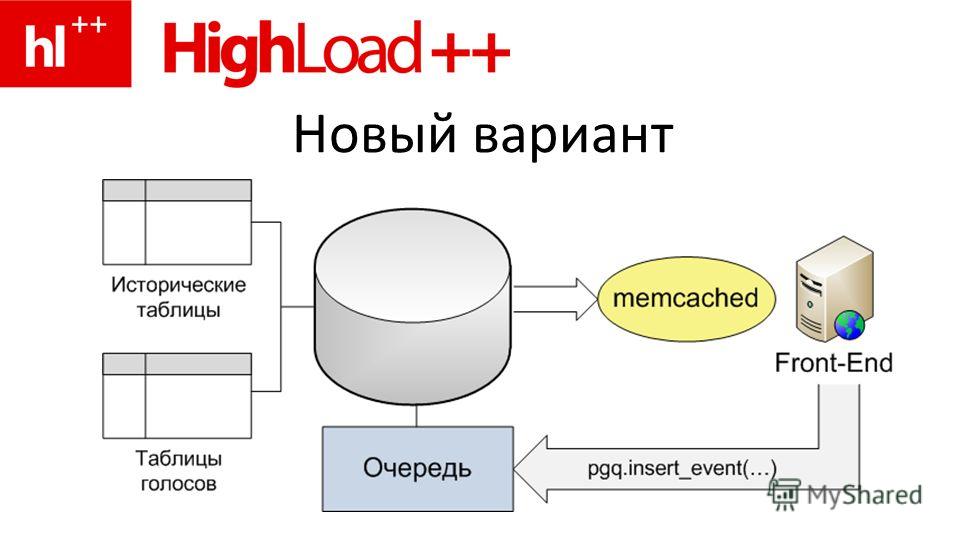 Более подробную информацию о нашей команде обслуживания клиентов и ее идеях).
Более подробную информацию о нашей команде обслуживания клиентов и ее идеях).
Наконец, наше сообщество Slack — отличное место для общения с более чем 4K разработчиками с аналогичными сценариями использования, а также со мной, инженерами Timescale, членами команды разработчиков и адвокатами разработчиков.
Python PostgreSQL CRUD — Вставка, обновление и удаление данных таблицы
В этом руководстве мы узнаем, как выполнять операции PostgreSQL Insert, Update, Delete из Python. Это также известно как операции DML. Кроме того, узнайте, как передавать параметры в запросы SQL , то есть использовать переменные Python в запросе PostgreSQL для вставки, обновления и удаления данных таблицы.
В конце мы увидим использование cursor.executemany () для вставки, обновления и удаления нескольких строк с помощью одного запроса.
Предварительные требования
Перед запуском следующих программ убедитесь, что у вас есть следующие данные
- Имя пользователя и пароль , необходимые для подключения PostgreSQL
- Таблица базы данных PostgreSQL для операций CRUD.
В этой статье я использую «мобильную» таблицу, созданную в моей базе данных PostgreSQL.
Если таблица отсутствует, вы можете обратиться к , чтобы создать таблицу PostgreSQL из Python .
Мобильная таблица PostgreSQLPython PostgreSQL INSERT в таблицу базы данных
В этом разделе мы узнаем, как выполнить запрос INSERT из приложения Python для вставки строк в таблицу PostgreSQL с помощью Psycopg2.
Чтобы выполнить запрос SQL INSERT из Python, вам необходимо выполнить следующие простые шаги: —
- Установите psycopg2 с помощью pip.
- Во-вторых, установите соединение с базой данных PostgreSQL в Python.
- Затем определите запрос вставки.Все, что вам нужно знать, это сведения о столбце таблицы.
- Выполните запрос INSERT, используя
cursor.execute (). Взамен вы получите количество затронутых строк. - После успешного выполнения запроса зафиксируйте изменения в базе данных.

- Закройте курсор и соединение с базой данных PostgreSQL.
- Самое главное, перехватить исключения SQL, если они есть.
- Наконец, проверьте результат, выбрав данные из таблицы PostgreSQL.
импорт psycopg2
пытаться:
соединение = psycopg2.подключиться (пользователь = "системный администратор",
пароль = "pynative @ # 29",
host = "127.0.0.1",
порт = "5432",
база данных = "postgres_db")
курсор = connection.cursor ()
postgres_insert_query = "" "ВСТАВИТЬ В мобильный (ID, МОДЕЛЬ, ЦЕНА) ЗНАЧЕНИЯ (% s,% s,% s)" ""
record_to_insert = (5, 'Один плюс 6', 950)
cursor.execute (postgres_insert_query, record_to_insert)
connection.commit ()
счетчик = курсор.rowcount
print (count, «Запись успешно вставлена в мобильный стол»)
за исключением (Exception, psycopg2.Error) как ошибки:
print («Не удалось вставить запись в мобильную таблицу», ошибка)
наконец-то:
# закрытие соединения с базой данных. если соединение:
cursor.close ()
connection.close ()
print («Соединение с PostgreSQL закрыто»)
если соединение:
cursor.close ()
connection.close ()
print («Соединение с PostgreSQL закрыто»)
Выход :
1 Запись успешно вставлена в мобильный стол Соединение PostgreSQL закрытоТаблица PostgreSQL после операции вставки
Python PostgreSQL Данные таблицы ОБНОВЛЕНИЯ
В этом разделе рассказывается, как обновить данные таблицы PostgreSQL из приложения Python с помощью Psycopg2.
Вы узнаете, как обновить одну и несколько строк, один столбец и несколько столбцов таблицы PostgreSQL.
Чтобы выполнить запрос PostgreSQL UPDATE из Python, вам необходимо выполнить следующие шаги: —
Теперь давайте посмотрим на пример обновления одной строки таблицы базы данных.
импорт psycopg2
def updateTable (mobileId, цена):
пытаться:
connection = psycopg2.connect (user = "sysadmin",
пароль = "pynative @ # 29",
host = "127. 0,0.1 ",
порт = "5432",
база данных = "postgres_db")
курсор = connection.cursor ()
print («Таблица перед обновлением записи»)
sql_select_query = "" "выберите * с мобильного, где id =% s" ""
курсор.execute (sql_select_query, (mobileId,))
запись = cursor.fetchone ()
печать (запись)
# Обновить отдельную запись сейчас
sql_update_query = "" "Обновить цену мобильного набора =% s, где id =% s" ""
курсор.выполнить (sql_update_query, (цена, mobileId))
connection.commit ()
count = cursor.rowcount
print (count, «Запись успешно обновлена»)
print («Таблица после обновления записи»)
sql_select_query = "" "выберите * с мобильного, где id =% s" ""
курсор.execute (sql_select_query, (mobileId,))
запись = cursor.fetchone ()
печать (запись)
за исключением (Exception, psycopg2.Error) как ошибки:
print («Ошибка при обновлении», ошибка)
наконец-то:
# закрытие соединения с базой данных.
0,0.1 ",
порт = "5432",
база данных = "postgres_db")
курсор = connection.cursor ()
print («Таблица перед обновлением записи»)
sql_select_query = "" "выберите * с мобильного, где id =% s" ""
курсор.execute (sql_select_query, (mobileId,))
запись = cursor.fetchone ()
печать (запись)
# Обновить отдельную запись сейчас
sql_update_query = "" "Обновить цену мобильного набора =% s, где id =% s" ""
курсор.выполнить (sql_update_query, (цена, mobileId))
connection.commit ()
count = cursor.rowcount
print (count, «Запись успешно обновлена»)
print («Таблица после обновления записи»)
sql_select_query = "" "выберите * с мобильного, где id =% s" ""
курсор.execute (sql_select_query, (mobileId,))
запись = cursor.fetchone ()
печать (запись)
за исключением (Exception, psycopg2.Error) как ошибки:
print («Ошибка при обновлении», ошибка)
наконец-то:
# закрытие соединения с базой данных. если соединение:
cursor.close ()
connection.close ()
print («Соединение с PostgreSQL закрыто»)
id = 3
цена = 970
updateTable (id, цена)
если соединение:
cursor.close ()
connection.close ()
print («Соединение с PostgreSQL закрыто»)
id = 3
цена = 970
updateTable (id, цена)
Выход :
Таблица Перед обновлением записи (3, 'Google Pixel', 700.0) 1 запись успешно обновлена Таблица После обновления записи (3, 'Google Pixel', 970.0) соединение с PostgreSQL закрытоТаблица PostgreSQL после операции обновления
Проверьте результат вышеуказанной операции обновления, выбрав данные из таблицы PostgreSQL с помощью Python.
Python PostgreSQL Удалить строку и столбцы таблицы
В этом разделе рассказывается, как удалить данные таблицы PostgreSQL из Python с помощью Psycopg2.
Посмотрим на это на примере программы. В этом примере Python мы подготовили запрос на удаление одной строки из таблицы PostgreSQL.
импорт psycopg2
def deleteData (mobileId):
пытаться:
connection = psycopg2. connect (user = "sysadmin",
пароль = "pynative @ # 29",
host = "127.0,0.1 ",
порт = "5432",
база данных = "postgres_db")
курсор = connection.cursor ()
# Обновить отдельную запись сейчас
sql_delete_query = "" "Удалить с мобильного, где id =% s" ""
cursor.execute (sql_delete_query, (mobileId,))
connection.commit ()
count = cursor.rowcount
print (count, «Запись успешно удалена»)
за исключением (Exception, psycopg2.Error) как ошибки:
print («Ошибка при операции удаления», ошибка)
наконец-то:
# закрытие соединения с базой данных.если соединение:
cursor.close ()
connection.close ()
print («Соединение с PostgreSQL закрыто»)
id4 = 4
id5 = 5
deleteData (id4)
deleteData (id5)
connect (user = "sysadmin",
пароль = "pynative @ # 29",
host = "127.0,0.1 ",
порт = "5432",
база данных = "postgres_db")
курсор = connection.cursor ()
# Обновить отдельную запись сейчас
sql_delete_query = "" "Удалить с мобильного, где id =% s" ""
cursor.execute (sql_delete_query, (mobileId,))
connection.commit ()
count = cursor.rowcount
print (count, «Запись успешно удалена»)
за исключением (Exception, psycopg2.Error) как ошибки:
print («Ошибка при операции удаления», ошибка)
наконец-то:
# закрытие соединения с базой данных.если соединение:
cursor.close ()
connection.close ()
print («Соединение с PostgreSQL закрыто»)
id4 = 4
id5 = 5
deleteData (id4)
deleteData (id5)
Выход :
1 Запись успешно удалена Соединение с PostgreSQL закрыто 1 Запись успешно удалена Соединение с PostgreSQL закрытоТаблица PostgreSQL после удаления строки
Проверьте результат вышеуказанной операции удаления, выбрав данные из таблицы PostgreSQL с помощью Python.
Вставка, обновление и удаление нескольких строк из таблицы PostgreSQL с помощью
executemany () Примечание : используйте метод cursor.executemany () для вставки, обновления и удаления нескольких строк таблицы с помощью одного запроса.
Метод cursor.executemany () выполняет запрос к базе данных по всем параметрам.
В большинстве случаев вам необходимо выполнить один и тот же запрос несколько раз, но с разными данными. Как и вставка посещаемости каждого студента, процент посещаемости разный, но запрос SQL тот же.
Синтаксис executemany ()
executemany (запрос, vars_list) - Здесь запрос может быть любым SQL-запросом (вставка, обновление, удаление)
-
vars_list— это не что иное, как список кортежей в качестве входных данных для запроса. - Каждый кортеж в этом списке содержит одну строку данных для вставки или обновления в таблицу.
Теперь давайте посмотрим, как использовать этот метод.
Python Вставить несколько строк в таблицу PostgreSQL
Используйте параметризованный запрос и метод курсора executemany () для добавления нескольких строк в таблицу.Используя заполнители в параметризованном запросе, мы можем передавать значения столбцов во время выполнения.
импорт psycopg2
def bulkInsert (записи):
пытаться:
connection = psycopg2.connect (user = "sysadmin",
пароль = "pynative @ # 29",
host = "127.0.0.1",
порт = "5432",
база данных = "postgres_db")
курсор = connection.cursor ()
sql_insert_query = "" "ВСТАВИТЬ В мобильный (идентификатор, модель, цена)
ЗНАЧЕНИЯ (% s,% s,% s) "" "
# executemany () для вставки нескольких строк
результат = курсор. Executemany (sql_insert_query, записи)
connection.commit ()
print (cursor.rowcount, «Запись успешно вставлена в мобильную таблицу»)
за исключением (Exception, psycopg2.Error) как ошибки:
print ("Не удалось вставить запись в мобильную таблицу {}". формат (ошибка))
наконец-то:
# закрытие соединения с базой данных.
если соединение:
cursor.close ()
connection.close ()
print («Соединение с PostgreSQL закрыто»)
records_to_insert = [(4, 'LG', 800), (5, 'One Plus 6', 950)]
bulkInsert (records_to_insert)
Executemany (sql_insert_query, записи)
connection.commit ()
print (cursor.rowcount, «Запись успешно вставлена в мобильную таблицу»)
за исключением (Exception, psycopg2.Error) как ошибки:
print ("Не удалось вставить запись в мобильную таблицу {}". формат (ошибка))
наконец-то:
# закрытие соединения с базой данных.
если соединение:
cursor.close ()
connection.close ()
print («Соединение с PostgreSQL закрыто»)
records_to_insert = [(4, 'LG', 800), (5, 'One Plus 6', 950)]
bulkInsert (records_to_insert) Выход :
2 Запись успешно вставлена в мобильный стол Соединение с PostgreSQL закрытоТаблица PostgreSQL после вставки нескольких строк
Обновление нескольких строк таблицы PostgreSQL с помощью одного запроса в Python
Например, вы хотите обновить зарплату сотрудников.Теперь зарплата разная для каждого сотрудника, но запрос на обновление остается прежним.
Мы можем обновить несколько строк таблицы, используя курсор cursor.executemany () и параметризованный запрос
импорт psycopg2
def updateInBulk (записи):
пытаться:
ps_connection = psycopg2.connect (user = "sysadmin",
пароль = "pynative @ # 29",
host = "127.0.0.1",
порт = "5432",
база данных = "postgres_db")
курсор = ps_connection.курсор()
# Обновить несколько записей
sql_update_query = "" "Обновить цену мобильного набора =% s, где id =% s" ""
cursor.executemany (sql_update_query, записи)
ps_connection.commit ()
row_count = cursor.rowcount
print (row_count, «Записи обновлены»)
за исключением (Exception, psycopg2.Error) как ошибки:
print («Ошибка при обновлении таблицы PostgreSQL», ошибка)
наконец-то:
# закрытие соединения с базой данных. если ps_connection:
cursor.close ()
ps_connection.Закрыть()
print («Соединение с PostgreSQL закрыто»)
кортежи = [(750, 4), (950, 5)]
updateInBulk (кортежи)
если ps_connection:
cursor.close ()
ps_connection.Закрыть()
print («Соединение с PostgreSQL закрыто»)
кортежи = [(750, 4), (950, 5)]
updateInBulk (кортежи)
Выход :
2 записи обновлены Соединение с PostgreSQL закрытоТаблица PostgreSQL после обновления нескольких строк
Примечание : используйте cursor.rowcount , чтобы получить общее количество строк, затронутых методом executemany () .
Python PostgreSQL Удалить несколько строк из таблицы
В этом примере мы определили запрос SQL Delete с заполнителем, который содержит идентификаторы клиентов для удаления.Также подготовлен список записей для удаления. Этот список содержит кортеж для каждой строки. Здесь мы создали два кортежа, чтобы удалить две строки.
импорт psycopg2
def deleteInBulk (записи):
пытаться:
ps_connection = psycopg2. connect (user = "postgres",
пароль = "вишаль @ # 29",
host = "127.0.0.1",
порт = "5432",
база данных = "postgres_db")
курсор = ps_connection.курсор()
ps_delete_query = "" "Удалить с мобильного, где id =% s" ""
cursor.executemany (ps_delete_query, записи)
ps_connection.commit ()
row_count = cursor.rowcount
print (row_count, «Запись удалена»)
за исключением (Exception, psycopg2.Error) как ошибки:
print («Ошибка при подключении к PostgreSQL», ошибка)
наконец-то:
# закрытие соединения с базой данных.
если ps_connection:
cursor.close ()
ps_connection.close ()
print («Соединение с PostgreSQL закрыто»)
# список кортежей содержит идентификаторы базы данных
кортежи = [(5,), (4,), (3,)]
deleteInBulk (кортежи)
connect (user = "postgres",
пароль = "вишаль @ # 29",
host = "127.0.0.1",
порт = "5432",
база данных = "postgres_db")
курсор = ps_connection.курсор()
ps_delete_query = "" "Удалить с мобильного, где id =% s" ""
cursor.executemany (ps_delete_query, записи)
ps_connection.commit ()
row_count = cursor.rowcount
print (row_count, «Запись удалена»)
за исключением (Exception, psycopg2.Error) как ошибки:
print («Ошибка при подключении к PostgreSQL», ошибка)
наконец-то:
# закрытие соединения с базой данных.
если ps_connection:
cursor.close ()
ps_connection.close ()
print («Соединение с PostgreSQL закрыто»)
# список кортежей содержит идентификаторы базы данных
кортежи = [(5,), (4,), (3,)]
deleteInBulk (кортежи)
Выход :
2 записи удалены Соединение с PostgreSQL закрыто
Следующие шаги:
Чтобы попрактиковаться в том, что вы узнали из этой статьи, решите проект «Упражнение для базы данных Python», чтобы попрактиковаться и освоить операции с базой данных Python.
13 советов по повышению производительности вставки PostgreSQL
Производительность загрузки критически важна для многих распространенных сценариев использования PostgreSQL, включая мониторинг приложений, аналитику приложений, мониторинг Интернета вещей и многое другое. Хотя базы данных давно имеют временные поля, существует ключевое различие в типах данных, которые собирают эти варианты использования: в отличие от стандартных реляционных «бизнес-данных», изменения обрабатываются как , вставляет , а не перезаписывает (другими словами, каждое новое значение становится новая строка в базе данных, вместо замены предыдущего значения строки последним).
Если вы работаете в сценарии, в котором вам необходимо сохранить все данные v. Перезаписать прошлые значения, оптимизация скорости, с которой ваша база данных может принимать новые данные, становится важной.
У нас есть большой опыт оптимизации производительности для себя и членов нашего сообщества, и мы разделили наши главные советы на две категории. Во-первых, мы изложили несколько полезных советов для улучшения PostgreSQL в целом. После этого мы выделили несколько, относящихся к TimescaleDB.
Во-первых, мы изложили несколько полезных советов для улучшения PostgreSQL в целом. После этого мы выделили несколько, относящихся к TimescaleDB.
Повышение производительности PostgreSQL
Вот несколько рекомендаций по повышению производительности захвата в обычном PostgreSQL:
1. Используйте индексы в модерации
Наличие правильных индексов может ускорить выполнение ваших запросов, но это не серебряная пуля. Постепенное поддержание индексов с каждой новой строкой требует дополнительной работы. Проверьте количество индексов, которые вы определили для своей таблицы (используйте команду psql \ d имя_таблицы ), и определите, перевешивают ли их потенциальные преимущества запросов на хранение и накладные расходы на вставку.Поскольку все системы индивидуальны, нет никаких жестких правил или «магического числа» индексов — просто будьте разумны.
2. Пересмотреть ограничения внешнего ключа
Иногда необходимо построить внешние ключи (FK) от одной таблицы к другим реляционным таблицам.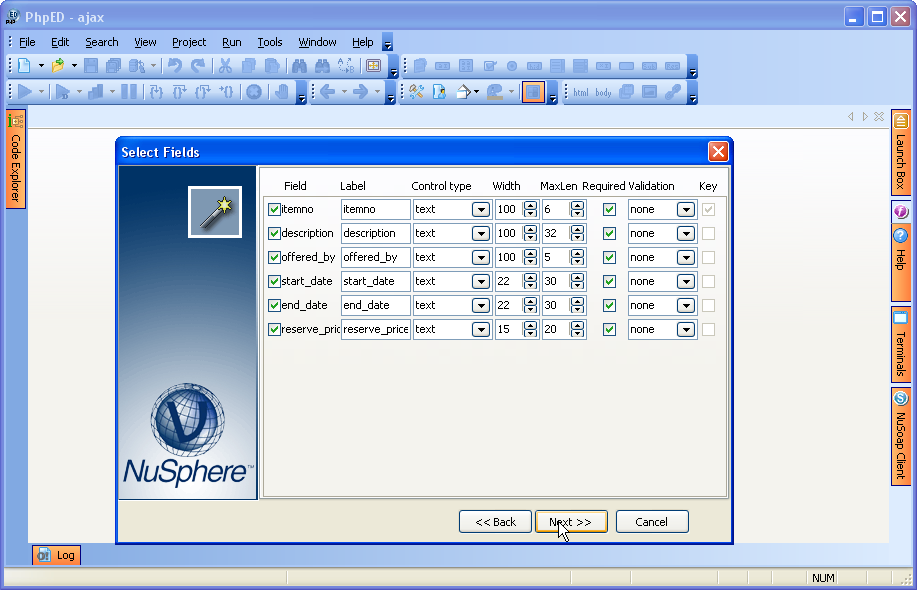 Когда у вас есть ограничение FK, каждый INSERT обычно должен будет читать из вашей ссылочной таблицы, что может снизить производительность. Подумайте, можете ли вы денормализовать свои данные — иногда мы видим довольно крайнее использование ограничений FK, сделанное из чувства «элегантности», а не из инженерных компромиссов.
Когда у вас есть ограничение FK, каждый INSERT обычно должен будет читать из вашей ссылочной таблицы, что может снизить производительность. Подумайте, можете ли вы денормализовать свои данные — иногда мы видим довольно крайнее использование ограничений FK, сделанное из чувства «элегантности», а не из инженерных компромиссов.
3. Избегайте ненужных УНИКАЛЬНЫХ ключей
Разработчиков часто обучают указывать первичные ключи в таблицах базы данных, и многие ORM любят их. Тем не менее, во многих случаях использования, включая обычные приложения для мониторинга или создания временных рядов, они не требуются, поскольку каждое событие или показание датчика можно просто зарегистрировать как отдельное событие, вставив его в конец текущего фрагмента гипертаблицы во время записи.
Если ограничение UNIQUE определено иначе, для этой вставки может потребоваться поиск по индексу, чтобы определить, существует ли уже строка, что отрицательно повлияет на скорость вашего INSERT.
4.
 Используйте отдельные диски для WAL и данных
Используйте отдельные диски для WAL и данныхХотя это более продвинутая оптимизация, которая не всегда требуется, если ваш диск становится узким местом, вы можете дополнительно увеличить пропускную способность, используя отдельный диск (табличное пространство) для журнала упреждающей записи (WAL) и данных базы данных.
5. Используйте рабочие диски
Иногда разработчики развертывают свои базы данных в средах с более медленными дисками, будь то из-за некачественных жестких дисков, удаленных сетей SAN или других типов конфигураций.А поскольку при вставке строк данные надежно сохраняются в журнале упреждающей записи (WAL) до завершения транзакции, медленные диски могут повлиять на производительность вставки. Единственное, что нужно сделать, это проверить количество операций ввода-вывода в секунду на вашем диске с помощью команды ioping .
Тест на чтение:
Тест записи:
Вы должны увидеть не менее 1000 операций ввода-вывода в секунду при чтении и несколько сотен операций ввода-вывода в секунду при записи. Если вы видите гораздо меньше, на производительность INSERT, вероятно, повлияет ваше дисковое оборудование. Посмотрите, возможны ли альтернативные конфигурации хранилища.
Если вы видите гораздо меньше, на производительность INSERT, вероятно, повлияет ваше дисковое оборудование. Посмотрите, возможны ли альтернативные конфигурации хранилища.
Выберите и настройте TimescaleDB для повышения производительности захвата
TimescaleDB настроен для повышения производительности захвата. Чаще всего TimescaleDB используется для хранения огромных объемов данных для метрик облачной инфраструктуры, аналитики продуктов, веб-аналитики, устройств IoT и многих других сценариев использования временных рядов. Как это типично для данных временных рядов, эти сценарии ориентированы на время, почти полностью предназначены только для добавления (много INSERT) и требуют быстрого приема больших объемов данных в небольших временных окнах.
TimescaleDB упакован как расширение PostgreSQL и специально создан для случаев использования временных рядов. Итак, если для ваших приложений или систем требуется более высокая производительность захвата из PostgreSQL, рассмотрите возможность использования TimescaleDB (доступно с полным управлением через Timescale Cloud — наше предложение базы данных как услуги или самоуправление с помощью нашей бесплатной версии Community Edition) .
… и вот еще 8 методов повышения производительности захвата с помощью TimescaleDB:
6.Использовать параллельную запись
Каждая команда INSERT или COPY для TimescaleDB (как в PostgreSQL) выполняется как одна транзакция и, таким образом, выполняется в однопоточном режиме. Чтобы добиться более высокого уровня захвата, вы должны выполнять несколько команд INSERTS или COPY параллельно.
Чтобы получить помощь по параллельной массовой загрузке больших файлов CSV, ознакомьтесь с командой параллельного копирования TimescaleDB.
СоветPro: убедитесь, что на вашей клиентской машине достаточно ядер для выполнения этого параллелизма (запуск 32 клиентских рабочих процессов на машине с двумя виртуальными ЦП не очень помогает — рабочие не будут выполняться параллельно).
7. Вставить строки партиями
Чтобы добиться более высокой скорости приема, вы должны вставлять свои данные с большим количеством строк в каждый вызов INSERT (или использовать какую-нибудь команду массовой вставки, например COPY или наш инструмент параллельного копирования).
Не вставляйте данные построчно — вместо этого попробуйте по крайней мере сотни (или тысячи) строк на INSERT. Это позволяет базе данных тратить меньше времени на управление соединениями, накладные расходы на транзакции, синтаксический анализ SQL и т. Д. И больше времени на обработку данных.
Обычно мы рекомендуем 25% доступной оперативной памяти. Если вы устанавливаете TimescaleDB с помощью метода, который запускает timescaledb-tune , он должен автоматически настроить shared_buffers на что-то подходящее для ваших аппаратных характеристик.
Примечание: в некоторых случаях, обычно при виртуализации и ограниченном распределении памяти контрольных групп, эти автоматически настраиваемые параметры могут быть не идеальными. Чтобы проверить, что ваш shared_buffers установлен в пределах диапазона 25%, запустите SHOW shared_buffers из вашего соединения psql .
9. Запустите наши образы Docker на хостах Linux
Если вы используете Docker-контейнер TimescaleDB (на котором работает Linux) поверх другой операционной системы Linux, вы в отличной форме. Контейнер в основном обеспечивает изоляцию процесса, а накладные расходы крайне минимальны.
Если вы запускаете контейнер на компьютере Mac или Windows, вы увидите некоторое снижение производительности для виртуализации ОС, в том числе для ввода-вывода.
Вместо этого, если вам нужно работать на Mac или Windows, мы рекомендуем установку напрямую вместо использования образа Docker.
10. Запись данных в нерабочее время Порядок
Когда блоки имеют соответствующий размер (см. №11 и №12), последний блок (-ы) и связанные с ними индексы естественным образом сохраняются в памяти. Новые строки, вставленные с недавними отметками времени, будут записаны в эти блоки и индексы, уже находящиеся в памяти.
Если вставлена строка с достаточно старой меткой времени, т.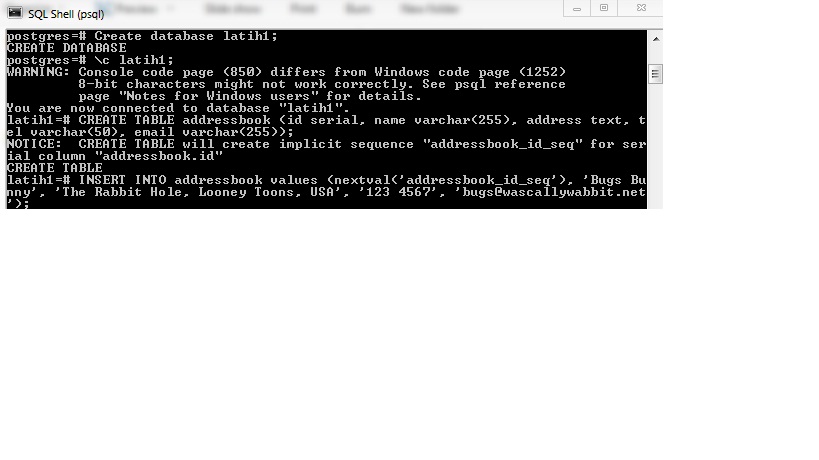 Е. Это неупорядоченная запись или запись с обратным заполнением, страницы диска, соответствующие старому фрагменту (и его индексам), должны быть прочитаны с диска.Это значительно увеличит задержку записи и снизит пропускную способность вставки.
Е. Это неупорядоченная запись или запись с обратным заполнением, страницы диска, соответствующие старому фрагменту (и его индексам), должны быть прочитаны с диска.Это значительно увеличит задержку записи и снизит пропускную способность вставки.
В частности, когда вы загружаете данные в первый раз, попробуйте загрузить данные в отсортированном порядке с увеличением временных меток.
Будьте осторожны при массовой загрузке данных о множестве различных серверов, устройств и т. Д .:
- Не следует массово вставлять данные последовательно сервером (т.е. все данные для сервера A, затем сервера B, затем C и т. Д.). Это вызовет перегрузку диска, поскольку загрузка каждого сервера будет проходить через все фрагменты перед запуском заново.
- Вместо этого организуйте массовую загрузку таким образом, чтобы данные со всех серверов вставлялись в произвольном порядке меток времени (например, день 1 на всех серверах параллельно, затем день 2 на всех серверах параллельно и т.
 Д.).
Д.).
11. Избегайте «слишком больших» кусков
Чтобы поддерживать более высокую скорость приема, вы хотите, чтобы ваш последний фрагмент, а также все связанные с ним индексы оставались в памяти, чтобы записи в фрагмент и обновления индекса просто обновляли память. (Запись по-прежнему продолжительна, поскольку вставки записываются в WAL на диске до обновления страниц базы данных.)
Если ваши фрагменты слишком велики, то запись даже в самый последний фрагмент начнется с перекачки на диск.
Как правило, мы рекомендуем, чтобы последние фрагменты и все их индексы удобно помещались в shared_buffers базы данных. Вы можете проверить размеры блоков с помощью команды SQL chunk_relation_size_pretty .
Если ваши фрагменты слишком велики, вы можете обновить диапазон для будущих фрагментов с помощью команды set_chunk_time_interval .Однако это не изменяет диапазон существующих фрагментов (например, путем переписывания больших фрагментов на несколько небольших фрагментов).
Для конфигураций, в которых отдельные фрагменты намного больше, чем ваша доступная память, мы рекомендуем выгружать и перезагружать данные гипертаблицы в фрагменты правильного размера.
Сохранение последнего фрагмента применяется ко всем активным гипертаблицам; если вы активно пишете в две гипертаблицы, последние фрагменты из обеих должны уместиться в shared_buffers .
12. Избегайте слишком большого количества или слишком маленьких кусков
Если вы не используете многоузловую TimescaleDB, в настоящее время мы не рекомендуем использовать разделение пространства. И если вы это сделаете, помните, что это количество блоков создается для каждого временного интервала.
Итак, если вы создадите 64 раздела пространства и ежедневных порций, у вас будет 24 640 порций в год. Это может привести к большему снижению производительности во время запроса (из-за накладных расходов на планирование) по сравнению со временем вставки, но, тем не менее, это следует учитывать.
Еще одна вещь, которой следует избегать: использование неверного целого числа при указании диапазона временного интервала в create_hypertable .
Совет профессионала:
- Если в столбце времени используется собственный тип метки времени, любое целочисленное значение должно быть выражено в микросекундах (таким образом, один день = 86400000000). Мы рекомендуем использовать типы интервалов («1 день»), чтобы избежать путаницы.
- Если ваш столбец времени является целым числом или самим bigint, используйте соответствующий диапазон: если целочисленная временная метка находится в секундах, используйте 86400; если метка времени bigint указана в наносекундах, используйте 86400000000000.
В обоих случаях вы можете использовать
chunk_relation_size_pretty, чтобы убедиться, что размеры ваших блоков или диапазоны разделов кажутся разумными:
13. Ширина контрольного ряда
Накладные расходы от вставки широкой строки (скажем, 50, 100, 250 столбцов) будут намного выше, чем при вставке более узкой строки (больше сетевых операций ввода-вывода, больше синтаксического анализа и обработки данных, большие записи в WAL и т. Д.) . В большинстве опубликованных нами тестов используется TSBS, в котором в каждой строке используется 12 столбцов.Соответственно, вы увидите более низкие скорости вставки, если у вас очень широкие строки.
Д.) . В большинстве опубликованных нами тестов используется TSBS, в котором в каждой строке используется 12 столбцов.Соответственно, вы увидите более низкие скорости вставки, если у вас очень широкие строки.
Если вы рассматриваете очень широкие строки, потому что у вас есть разные типы записей, и каждый тип имеет непересекающийся набор столбцов, вы можете попробовать использовать несколько гипертаблиц (по одной для каждого типа записи) — особенно если вы не часто запрашиваете по эти типы.
Кроме того, записи JSONB — еще один хороший вариант, если практически все столбцы разрежены. Тем не менее, если вы используете разреженные широкие строки, по возможности используйте NULL для отсутствующих записей, а не значения по умолчанию для максимального увеличения производительности (NULL намного дешевле хранить и запрашивать).
Наконец, стоимость широких строк на самом деле намного меньше, если вы сжимаете строки с помощью собственного сжатия TimescaleDB. Строки преобразуются в более сжатую форму столбцов, разреженные столбцы сжимаются очень хорошо, а сжатые столбцы не считываются с диска для запросов, которые не извлекают отдельные столбцы.
Сводка
Если производительность захвата критична для вашего варианта использования, рассмотрите возможность использования TimescaleDB. Вы можете начать работу с Timescale Cloud бесплатно сегодня или бесплатно загрузить TimescaleDB на свой компьютер или облачный экземпляр.
Наш подход к поддержке заключается в том, чтобы охватить все ваше решение, поэтому мы здесь, чтобы помочь вам достичь желаемых результатов производительности (см. Более подробную информацию о нашей команде по работе с клиентами и ее идеях).
Наконец, наше сообщество Slack — отличное место для общения с 4K + другими разработчиками с аналогичными сценариями использования, а также со мной, инженерами Timescale, членами команды разработчиков и адвокатами разработчиков.
Flask PostgreSQL — вставить данные в таблицу
В этом посте мы объясним, как вставлять данные в таблицу. с приложением Flask postgreSQL.Для этого мы будем использовать оператор Insert SQL.
Установка PostgreSQL
Кому
создать веб-приложение Flask PostgreSQL, необходимое для установки PostgreSQL в
ваша система.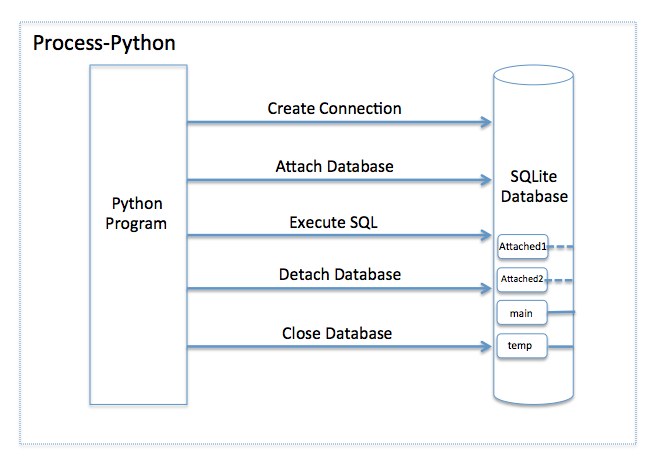 Вы можете нажать здесь и скачать PostgreSQL
и установить. Вам необходимо скачать стабильную версию, совместимую с
Версия FLASK, которую вы используете для разработки приложения. В примере мы использовали
PostgreSQL
(postgresql-10.13-1-windows-x64) с Flask 1.1.2. После установки PostgreSQL
вы должны установить его, задав пароль.Этот пароль требуется, когда
вы подключите сайт Flask к базе данных PostgreSQL.
Вы можете нажать здесь и скачать PostgreSQL
и установить. Вам необходимо скачать стабильную версию, совместимую с
Версия FLASK, которую вы используете для разработки приложения. В примере мы использовали
PostgreSQL
(postgresql-10.13-1-windows-x64) с Flask 1.1.2. После установки PostgreSQL
вы должны установить его, задав пароль.Этот пароль требуется, когда
вы подключите сайт Flask к базе данных PostgreSQL.
Создать локальный веб-сайт
Подготовьте папку вашего веб-сайта, следуя инструкциям в этом посте.
Установка SQLAlchemy
Чтобы установить SQLAlchemy в Windows, используйте команду pip install SQLAlchemy. Открыть командное окно с помощью cmd. Откройте папку проекта с помощью команды CD DOS и запустите команда pip.
Создание таблицы базы данных
После установки PostgreSQL вы можете создавать таблицы двумя способами — из командной строки или через графический интерфейс, запускаемый с помощью pgAdmin, доступного при установке PostgreSQL, как показано на диаграмме ниже.
Если вы использовали Microsoft Access, SQL Server, Oracle или MySQL, вы легко сможете для создания базы данных.
Здесь вы можете создать новую базу данных для вашего приложения. В базах данных щелкните правой кнопкой мыши и выберите «Создать». База данных и укажите имя и другие детали вашей базы данных. Как только вы создадите базу данных, откройте группу схем и создайте там таблицу. Вы можете создавать таблицы двумя способами —
- Щелкните правой кнопкой мыши Таблицы и откройте диалоговое окно создания таблицы, выбрав Создать таблицу
- Создайте ее с помощью инструмента запросов .Щелкните правой кнопкой мыши таблицы и напишите оператор создания таблицы.
СОЗДАТЬ ТАБЛИЦУ public.booklist ( bookid целое НЕ NULL ПО УМОЛЧАНИЮ nextval ('booklist_bookid_seq' :: regclass), символ isbn, изменяющийся COLLATE pg_catalog. "default" NOT NULL, название символа меняется COLLATE pg_catalog. "default" NOT NULL, авторский символ меняется COLLATE pg_catalog. "default" NOT NULL, целое число года NOT NULL )
Создание Application.py
После создания базы данных следующим шагом будет настройка информация о базе данных в приложении Python Flask.py файл, чтобы можно было хранить данные и доступ к данным из таблиц БД.
Включите эти операторы импорта в верхнюю часть этого файла
из sqlalchemy import create_engine из sqlalchemy.orm import scoped_session, sessionmaker
Настройте ядро базы данных в application.py с этими операторами —
engine = create_engine ("postgresql: // postgres: yourpassword @ localhost: 5432 / yourdatabasename")
db = scoped_session (создатель сеанса (привязка = движок)) В первом операторе имя пользователя — postgres.За двоеточием (:) следует пароль, который вы указали при установке PostgreSQL. После @ нужно указать сервер и порт. Поскольку вы создаете веб-приложение на локальном сервере, в большинстве случаев значение, указанное здесь, будет работать. Если это не так, проверьте адресную строку браузера pgAdmin, чтобы получить сведения о сервере базы данных и изменить их в application. py. Наконец, замените yourdatabasename именем созданной вами базы данных.
py. Наконец, замените yourdatabasename именем созданной вами базы данных.
В файле application.py после инструкции app = Flask (__ name__)
ок.secret_key = '12345678' 'этот ключ используется для связи с базой данных. # Настроить сеанс для использования файловой системы app.config ["SESSION_PERMANENT"] = Ложь app.config ["SESSION_TYPE"] = "файловая система"
Создание формы для ввода данных
Форма ввода данных создается с использованием тегов HTML-формы. Мы создали таблицу со следующими полями для хранения деталей таблицы списка книг.
Эта форма создана (addbook.html)
Добавьте маршрут в приложение. py для доступа к этой HTML-форме в браузере
py для доступа к этой HTML-форме в браузере
@ app.route ("/ addbook")
def addbook ():
вернуть render_template ("addbook.html") Добавить маршрут и код для вставки данных в таблицу
Последний шаг — добавить код, сохраняющий данные в таблице списка книг. Оператор INSERT создается с использованием данных, отправленных со страницы надстройки с помощью метода POST.
@ app.route ("/ bookadd", methods = ["POST"]) def bookadd (): isbn = request.form.get ("isbn") название = запрос.form.get ("название") author = request.form.get ("автор") year = request.form.get ("год") db.execute ("ВСТАВИТЬ В список книг (isbn, название, автор, год) VALUES (: isbn,: title,: author,: year)", {"isbn": isbn, "title": title, "author": автор, "year": год}) db.commit () вернуть render_template ("addbook.html")
В следующем посте вы узнаете, как отображать сохраненные данные в табличной форме.
Как преобразовать оператор INSERT ALL из Oracle в PostgreSQL
В Oracle вы можете использовать условные предложения вставки, например, оператор INSERT ALL для добавления нескольких строк с помощью одной команды.Вы можете вставлять строки в одну или даже несколько таблиц, используя всего один оператор SQL в Oracle. Однако PostgreSQL не поддерживает такие операторы, которые пытаются вставить несколько строк.
Итак, когда вы пытаетесь преобразовать исходный код Oracle, который включает оператор INSERT ALL, в PostgreSQL в AWS Schema Conversion Tool, он сгенерирует следующий элемент действия: «9996 — Критическая степень серьезности — Произошла ошибка преобразователя».
Давайте узнаем, как можно решить эту проблему.
Пример исходного кода
Рассмотрим следующий пример кода Oracle, который включает оператор INSERT ALL.
1 | СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ПРОЦЕДУРУ PRC_INSERTALL_MULTIPLER91 BEG 91 ВСТАВИТЬ ВСЕ |
При попытке преобразовать этот код в AWS Schema Conversion Tool вы получите сообщение об ошибке.
Возможные способы устранения
Для решения этой проблемы следует заменить оператор INSERT ALL на ряд обычных операторов вставки.
1 | СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ПРОЦЕДУРУ PRC_INSERTECALL_MULTIPLER91 НАЧАТЬ |
Однако это решение может не работать, если вам нужно вставить большой объем данных.Итак, рассмотрим следующий автоматизированный обходной путь, который использует оператор UNION ALL.
1 | СОЗДАТЬ ИЛИ ПРОЦЕДУРА ЗАМЕНИТЬ PRC_INSERTALL_MULTIPLEREC_MOD2 |
SCT конвертирует этот код без ошибок.Теперь давайте рассмотрим еще один пример исходного кода.
Другой пример
Теперь мы рассмотрим оператор Oracle INSERT ALL, который вставляет данные в несколько таблиц.
1 | СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ПРОЦЕДУРУ PRC_INSERTALL_MULTITAB |
В этом случае вам следует изменить исходный код Oracle следующим образом.
1 | СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ПРОЦЕДУРУ PRC_INSERTALL_MULTITAB_MOD1 |
SCT конвертирует этот код без проблем!
Преобразование оператора INSERT ALL с предложением WHEN
Пожалуйста, проверьте еще один пример, который включает условие в выполненный оператор INSERT ALL.Исходный код Orcale будет выглядеть следующим образом:
1 | СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ПРОЦЕДУРУ PRC_INSERTALL_COND |
В этом случае SCT будет использовать правильный подход преобразования, разделяя исходный оператор на две части.Проблема в том, что SCT не выдает сообщение об ошибке, но сгенерированный код не является логически правильным.
SCT игнорирует условие WHEN и использует точно такие же интервалы дат, как в исходном операторе, для обоих вариантов исходного условия. Итак, вам нужно будет вручную разделить продолжение и создать пару операторов INSERT-SELECT для каждой опции. Если исходный код выглядит следующим образом, SCT правильно конвертирует его в PostgreSQL.
1 | СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ПРОЦЕДУРУ PRC_INSERTALL_CONDTAB_MOD91 ISSETALL_CONDTAB_MOD91 INTO tbl_CompanyEmployees_1 SELECT * FROM tbl_CompanyEmployees WHERE BirthDate BETWEEN TO_DATE (’01 / 01/1980 ‘,’ MM / DD / YYYY ‘) AND TO_DATE (’01 / 01/1985′, ‘MM / DD / YYYY’) ; ВСТАВИТЬ В tbl_CompanyEmployees_2 |
У вас есть другие вопросы или опасения по поводу проблем миграции с AWS SCT или Oracle на PostgreSQL? Обязательно ознакомьтесь с нашим новым предложением AWS Schema Conversion Tool Jumpstart, чтобы быстро приступить к работе над проектами миграции баз данных.
Обязательно проверяйте регулярно обновляемое содержание нашей серии сообщений в блоге о типичных проблемах преобразования AWS SCT.
Источник технической информации: Андрей Оселедко, разработчик DB Best.
Pandas в PostgreSQL с использованием Psycopg2: эталон производительности массовой вставки
Если вы когда-либо пытались вставить относительно большой фрейм данных в таблицу PostgreSQL, вы знаете, что одиночных вставок следует избегать любой ценой из-за того, как долго они выполняются.Есть несколько способов выполнить массовую вставку с помощью Psycopg2 (см., Например, эту страницу переполнения стека и этот пост в блоге). Становится запутанным определить, какой из них наиболее эффективен. В этом посте я, , сравнил следующие 7 методов массовой вставки и провел для вас тесты :
- execute_many ()
- execute_batch ()
- execute_values () — просмотреть сообщение
- mogrify () then execute () — просмотреть сообщение
- copy_from () — это можно сделать двумя способами — см. Пост
- to_sql () через sqlalchemy
Полнофункциональное руководство о том, как это воспроизвести, можно найти в моей записной книжке Jupyter на GitHub.
Шаг 1. Укажите параметры подключения # Здесь вы хотите изменить свою базу данных, имя пользователя и пароль в соответствии с вашими собственными значениями
param_dic = {
"host": "localhost",
"база данных": "глобальные данные",
"пользователь": "myuser",
"пароль": "Passw0rd"
} Шаг 2. Загрузите фрейм данных pandas и подключитесь к базе данных Данные для этого руководства находятся в свободном доступе на https://datahub.io/core/global-temp, но вы также найдете их в каталоге data / моего репозитория GitHub.Что хорошо в этом фрейме данных, так это то, что он содержит столбцы типа string, date и float, поэтому он должен быть хорошим тестовым фреймворком для тестирования массовых вставок.
импортировать панд как pd
csv_file = "../data/global-temp-monthly.csv"
df = pd.read_csv (csv_file)
df = df.rename (columns = {
"Источник": "источник",
"Дата": "дата и время",
"Mean": "mean_temp"
})
def connect (params_dic):
"" "Подключиться к серверу базы данных PostgreSQL" ""
conn = Нет
пытаться:
# подключиться к серверу PostgreSQL
print ('Подключение к базе данных PostgreSQL... ')
conn = psycopg2.connect (** params_dic)
за исключением (Exception, psycopg2.DatabaseError) как ошибки:
печать (ошибка)
sys.exit (1)
print ("Соединение успешно")
return conn
conn = подключить (param_dic)
Шаг 3. Семь различных способов выполнить массовую вставку с помощью Psycopg2 Добро пожаловать.
импорт ОС
импорт psycopg2
импортировать numpy как np
импортировать psycopg2.extras как дополнительные
из io import StringIO
def execute_many (conn, df, table):
"" "
Используя курсор.executemany () для вставки фрейма данных
"" "
# Создаем список кортежей из значений фрейма данных
кортежи = [кортеж (x) для x в df.to_numpy ()]
# Разделенные запятыми столбцы фрейма данных
cols = ','. join (список (df.columns))
# SQL запрос для выполнения
query = "ВСТАВИТЬ В% s (% s) ЗНАЧЕНИЯ (%% s, %% s, %% s)"% (таблица, столбцы)
курсор = conn.cursor ()
пытаться:
cursor.executemany (запрос, кортежи)
conn.commit ()
за исключением (Exception, psycopg2.DatabaseError) как ошибки:
print ("Ошибка:% s"% ошибка)
соед.откат ()
cursor.close ()
возврат 1
print ("execute_many () готово")
cursor.close ()
def execute_batch (conn, df, table, page_size = 100):
"" "
Использование psycopg2.extras.execute_batch () для вставки фрейма данных
"" "
# Создаем список кортежей из значений фрейма данных
кортежи = [кортеж (x) для x в df.to_numpy ()]
# Разделенные запятыми столбцы фрейма данных
cols = ','. join (список (df.columns))
# SQL запрос для выполнения
query = "ВСТАВИТЬ В% s (% s) ЗНАЧЕНИЯ (%% s, %% s, %% s)"% (таблица, столбцы)
курсор = соед.курсор()
пытаться:
extras.execute_batch (курсор, запрос, кортежи, размер_страницы)
conn.commit ()
за исключением (Exception, psycopg2.DatabaseError) как ошибки:
print ("Ошибка:% s"% ошибка)
conn.rollback ()
cursor.close ()
возврат 1
print ("execute_batch () готово")
cursor.close ()
def execute_values (conn, df, table):
"" "
Использование psycopg2.extras.execute_values () для вставки фрейма данных
"" "
# Создаем список кортежей из значений фрейма данных
кортежи = [кортеж (x) для x в df.to_numpy ()]
# Разделенные запятыми столбцы фрейма данных
cols = ','. join (список (df.columns))
# SQL запрос для выполнения
query = "INSERT INTO% s (% s) VALUES %% s"% (таблица, столбцы)
курсор = conn.cursor ()
пытаться:
extras.execute_values (курсор, запрос, кортежи)
conn.commit ()
за исключением (Exception, psycopg2.DatabaseError) как ошибки:
print ("Ошибка:% s"% ошибка)
conn.rollback ()
cursor.close ()
возврат 1
print ("execute_values () выполнено")
cursor.close ()
def execute_mogrify (conn, df, table):
"" "
Используя курсор.mogrify () для создания запроса массовой вставки
затем cursor.execute () для выполнения запроса
"" "
# Создаем список кортежей из значений фрейма данных
кортежи = [кортеж (x) для x в df.to_numpy ()]
# Разделенные запятыми столбцы фрейма данных
cols = ','. join (список (df.columns))
# SQL запрос для выполнения
курсор = conn.cursor ()
values = [cursor.mogrify ("(% s,% s,% s)", tup) .decode ('utf8') для tup в кортежах]
query = "INSERT INTO% s (% s) VALUES"% (table, cols) + ",". join (values)
пытаться:
курсор.выполнить (запрос, кортежи)
conn.commit ()
за исключением (Exception, psycopg2.DatabaseError) как ошибки:
print ("Ошибка:% s"% ошибка)
conn.rollback ()
cursor.close ()
возврат 1
print ("execute_mogrify () готово")
cursor.close ()
def copy_from_file (conn, df, table):
"" "
Здесь мы собираемся сохранить фрейм данных на диск как
файл csv, загрузите файл csv
и используйте copy_from (), чтобы скопировать его в таблицу
"" "
# Сохраняем фрейм данных на диск
tmp_df = "./tmp_dataframe.csv "
df.to_csv (tmp_df, index_label = 'id', header = False)
f = открытый (tmp_df, 'r')
курсор = conn.cursor ()
пытаться:
cursor.copy_from (f, таблица, sep = ",")
conn.commit ()
за исключением (Exception, psycopg2.DatabaseError) как ошибки:
os.remove (tmp_df)
print ("Ошибка:% s"% ошибка)
conn.rollback ()
cursor.close ()
возврат 1
print ("copy_from_file () готово")
cursor.close ()
os.remove (tmp_df)
def copy_from_stringio (conn, df, table):
"" "
Здесь мы собираемся сохранить фрейм данных в памяти.
и используйте copy_from (), чтобы скопировать его в таблицу
"" "
# сохранить фрейм данных в буфер в памяти
буфер = StringIO ()
df.to_csv (буфер, index_label = 'id', header = False)
buffer.seek (0)
курсор = conn.cursor ()
пытаться:
cursor.copy_from (буфер, таблица, sep = ",")
conn.commit ()
за исключением (Exception, psycopg2.DatabaseError) как ошибки:
print ("Ошибка:% s"% ошибка)
conn.rollback ()
cursor.close ()
возврат 1
print ("copy_from_stringio () готово")
cursor.close ()
# ------------------------------------------------- ---------------
Только # SqlAlchemy
# ------------------------------------------------- ---------------
из sqlalchemy import create_engine
connect = "postgresql + psycopg2: //% s:% s @% s: 5432 /% s"% (
param_dic ['пользователь'],
param_dic ['пароль'],
param_dic ['хост'],
param_dic ['база данных']
)
def to_alchemy (df):
"" "
Использование фиктивной таблицы для проверки этой библиотеки вызовов
"" "
двигатель = create_engine (подключиться)
df.to_sql (
'test_table',
con = двигатель,
index = False,
if_exists = 'заменить'
)
print ("to_sql () выполнено (sqlalchemy)")
Шаг 4. Тест производительности Подробнее о том, как проводился сравнительный анализ, см. В разделе «Бенчмаркинг» этой записной книжки.
Итак, execute_values () и execute_mogrify () работают нормально… но самый быстрый способ — использовать copy_from () .Вы можете либо
- сохранить фрейм данных в объект stringio и загрузить его непосредственно в SQL, или
- сохранить фрейм данных на диск и загрузить его в SQL
Не знаю, как вы, но грустно видеть, что старая добрая копия работает лучше, чем execute_values () и execute_mogrify () … Но иногда лучше использовать низкие технологии. Точно так же, как когда вы пытаетесь связаться со своим коллегой через Google Hangouts, Zoom, Skype .