postgresql_idx — Создание или удаление индексов из базы данных PostgreSQL — Ansible Documentation
Новое в версии 2.8.
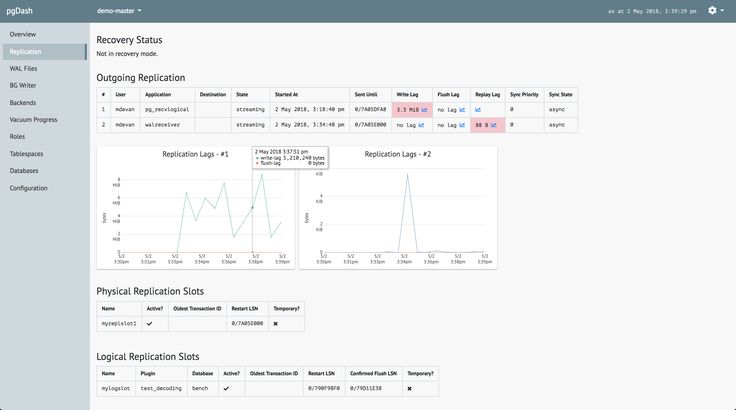
Сводка
Требования
Параметры
Примечания
См. также
Примеры
Возвращаемые значения
Статус
Следующие требования необходимы для хоста, на котором выполняется этот модуль.
psycopg2
| Параметр | Варианты/Значения по умолчанию | Комментарии |
|---|---|---|
| ca_cert строка | Указывает имя файла, содержащего сертификат(ы) центра сертификации (ЦС) SSL. Если файл существует, сертификат сервера будет проверен на предмет его подписи одним из этих органов. | |
| каскад логическое значение |
| Автоматически удалять объекты, зависящие от индекса, и, в свою очередь, все объекты, зависящие от этих объектов. Используется только с state=отсутствует . Взаимоисключающее с |
| столбцов список / элементы=строка | Список столбцов индекса, которые должны быть покрыты индексом. Взаимоисключающее с состояние=отсутствует . | |
| одновременно логическое значение |
|  Обратите внимание, если concurrent=no , таблица будет заблокирована (ЭКСКЛЮЗИВНЫЙ ДОСТУП) в процессе сборки. Для получения дополнительной информации об уровнях блокировки см. https://www.postgresql.org/docs/current/explicit-locking.html. Если процесс построения был прерван по какой-либо причине, когда cuncurrent=yes , индекс становится недействительным. В этом случае его следует удалить и создать заново. Взаимоисключающий с cascade=yes . |
| условие строка | Состояние индекса. Взаимоисключающее с состояние=отсутствует . | |
| дб строка | Имя базы данных для подключения и место, где будет создан/удален индекс. | |
| имя_идентификатора строка / требуется | Имя индекса для создания или удаления. | |
| idxtype строка | Тип индекса (например, btree, gist, gin и т. д.). Взаимоисключающее с состояние=отсутствует . | |
строка | Хост, на котором запущена база данных. | |
| логин_пароль строка | Пароль, используемый для аутентификации. | |
| логин_unix_socket строка | Путь к сокету домена Unix для локальных подключений. | |
| логин_пользователь строка | По умолчанию: «постгрес» | Имя пользователя, используемое для аутентификации. |
| порт целое число | По умолчанию: 5432 | Порт базы данных для подключения. |
| схема строка | Имя схемы базы данных, в которой будет создан индекс. | |
| сессионная_роль строка | Переключиться на session_role после подключения. Проверка разрешений для команд SQL выполняется так, как если бы роль session_role была той, которая входила в систему изначально. | |
| ssl_mode строка |
| Определяет, будет ли и с каким приоритетом согласовываться безопасное соединение SSL TCP/IP с сервером. См. https://www.postgresql.org/docs/current/static/libpq-ssl.html для получения дополнительной информации о режимах. По умолчанию |
| состояние строка |
| Состояние индекса. state=present означает, что индекс будет создан, если он не существует. state=отсутствует означает, что индекс будет удален, если он существует. |
| storage_params список / элементы=строка | Параметры хранения, такие как fillfactor, Vacuum_cleanup_index_scale_factor и т. д. Взаимоисключающее с состояние=отсутствует . | |
| стол строка / требуется | Таблица для создания индекса. Взаимоисключающее с состояние=отсутствует . | |
| табличное пространство строка | Установить табличное пространство для индекса. Взаимоисключающее с состояние=отсутствует . |




 Указанная session_role должна быть ролью, членом которой является текущий login_user.
Указанная session_role должна быть ролью, членом которой является текущий login_user.


Примечание
Процесс построения индекса может повлиять на производительность базы данных.
Чтобы избежать блокировок таблиц в рабочих базах данных, используйте concurrent=yes (поведение по умолчанию).
Аутентификация по умолчанию предполагает, что вы либо входите в систему как, либо используете sudo для
учетной записи postgresна хосте.Чтобы избежать ошибки «Ошибка одноранговой аутентификации для пользователя postgres», используйте пользователя postgres как стать_пользователем .
Этот модуль использует psycopg2, адаптер базы данных Python PostgreSQL. Вы должны убедиться, что psycopg2 установлен на хосте перед использованием этого модуля.
Если удаленный хост является сервером PostgreSQL (что является случаем по умолчанию), то PostgreSQL также должен быть установлен на удаленном хосте.

Для систем на основе Ubuntu перед использованием этого модуля установите пакеты postgresql, libpq-dev и python-psycopg2 на удаленном хосте.
Для параметра ca_cert требуется как минимум Postgres версии 8.4 и psycopg2 версии 2.4.3.
См. также
- postgresql_table — создание, удаление или изменение таблицы PostgreSQL
Официальная документация по модулю postgresql_table .
- postgresql_tablespace — добавление или удаление табличных пространств PostgreSQL с удаленных хостов
Официальная документация по postgresql_tablespace 9Модуль 0533.
- Справочник по индексам PostgreSQL
Общая информация об индексах PostgreSQL.
- Справочник по CREATE INDEX
Полный справочник документации по команде CREATE INDEX.
- Справочник по ALTER INDEX
Полный справочник документации по команде ALTER INDEX.

- Ссылка DROP INDEX
Полный справочник документации по команде DROP INDEX.
- имя: создать индекс btree, если он не существует test_idx, одновременно покрывающий идентификатор столбца и имя табличных продуктов
postgresql_idx:
дБ: акме
Таблица: продукты
столбцы: идентификатор, имя
имя: test_idx
- имя: Создать индекс btree test_idx одновременно с табличным пространством с именем ssd и параметром хранения
postgresql_idx:
дБ: акме
Таблица: продукты
столбцы:
- идентификатор
- имя
имя_идентификатора: test_idx
табличное пространство: ssd
storage_params:
- коэффициент заполнения=90
- имя: Создать gist-индекс test_gist_idx одновременно в столбце geo_data карты таблицы.
postgresql_idx:
дб: какой-то бд
таблица: карта
idxtype: суть
столбцы: гео_данные
имя_идентификатора: test_gist_idx
# Примечание: для приведенного ниже примера расширение pg_trgm должно быть установлено для gin_trgm_ops
- имя: Создать индекс gin gin0_idx не одновременно с комментарием столбца таблицы test
postgresql_idx:
имя_идентификатора: gin0_idx
таблица: тест
столбцы: комментарий gin_trgm_ops
одновременно: нет
idxtype: джин
- имя: Одновременно сбрасывать btree test_idx
postgresql_idx:
БД: МБД
имя_идентификатора: test_idx
состояние: отсутствует
- имя: Отбросить каскад test_idx
postgresql_idx:
БД: МБД
имя_идентификатора: test_idx
состояние: отсутствует
каскад: да
одновременно: нет
- имя: создать индекс btree test_idx одновременно для идентификатора столбца, комментарий, где идентификатор столбца> 1
postgresql_idx:
БД: МБД
таблица: тест
столбцы: идентификатор, комментарий
имя_идентификатора: test_idx
условие: идентификатор> 1
Здесь задокументированы общие возвращаемые значения, следующие поля являются уникальными для этого модуля:
| Ключ | Возвращено | Описание |
|---|---|---|
| имя строка | всегда | Имя индекса. Образец: foo_idx |
| запрос строка | всегда | Запрос, который пытались выполнить. Образец: СОЗДАТЬ ИНДЕКС ОДНОВРЕМЕННО foo_idx НА test_table ИСПОЛЬЗУЯ BTREE (id) |
| схема строка | всегда | Схема, в которой существует индекс. Образец: общественный |
| состояние строка | всегда | Состояние индекса. Образец: подарок |
| storage_params список | всегда | Параметры хранения индекса. Образец: [‘фактор заполнения=90’] |
| табличное пространство строка | всегда | Табличное пространство, в котором существует индекс. Образец: твердотельный накопитель |
| действительный логическое значение | всегда | Действительность индекса. Образец: Правда |

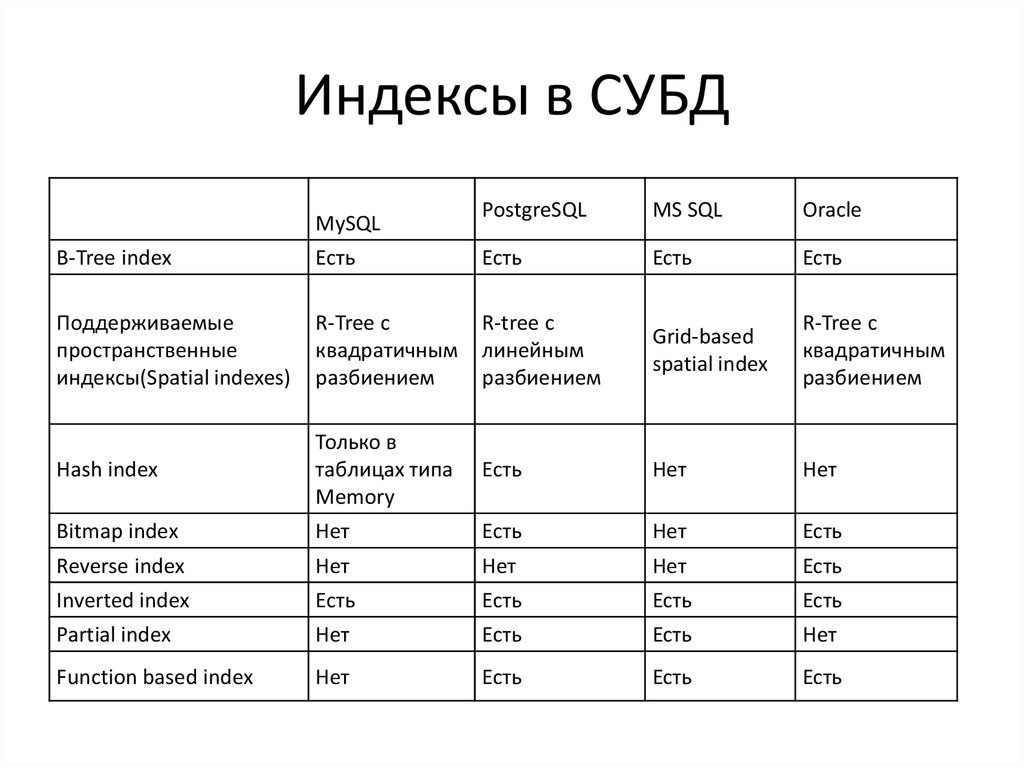
Знакомство с типами индексов Postgres
В Citus мы проводим много времени, работая с клиентами над моделированием данных, оптимизацией запросов и добавлением индексов для ускорения работы. Моя цель — быть настолько доступными для наших клиентов, насколько это необходимо, чтобы сделать вас успешными. Частью этого является поддержание вашего кластера Citus в хорошей настройке и производительности, о чем мы позаботимся за вас. Другая часть поможет вам узнать все, что вам нужно знать о Postgres и Citus. В конце концов, здоровая и производительная база данных означает быстродействующее приложение, а кто бы этого не хотел. Сегодня мы собираемся обобщить часть информации, которой мы поделились с клиентами напрямую об индексах Postgres.
Частью этого является поддержание вашего кластера Citus в хорошей настройке и производительности, о чем мы позаботимся за вас. Другая часть поможет вам узнать все, что вам нужно знать о Postgres и Citus. В конце концов, здоровая и производительная база данных означает быстродействующее приложение, а кто бы этого не хотел. Сегодня мы собираемся обобщить часть информации, которой мы поделились с клиентами напрямую об индексах Postgres.
Postgres имеет несколько типов индексов, и с каждым новым выпуском, похоже, появляется еще один новый тип индекса. Каждый из этих индексов может быть полезен, но какой из них использовать, зависит от 1. типа данных, а иногда 2. базовых данных в таблице и 3. типов выполняемых поисков. Далее мы рассмотрим краткий обзор типов индексов, доступных вам в Postgres, и рассмотрим, когда вы должны использовать каждый из них. Прежде чем мы углубимся, вот краткий обзор индексов, по которым мы вас познакомим:
- B-дерево
- Обобщенный инвертированный индекс (GIN)
- Обобщенное инвертированное дерево поиска (GiST)
- GiST с пространственным разделением (SP-GiST)
- Индексы диапазона блоков (BRIN) 9 Хэш Теперь на indexing
- hStore
- Массивы
- Типы диапазонов
- JSONB
- Типы геометрии
- Текст при работе с полнотекстовым поиском
- 3 цифры для кода города
- 3 цифры для префикса (исторически связанного с переключением оператора телефонной связи)
- 4 цифры для номера линии
В Postgres чаще всего вам нужен индекс B-дерева
Если у вас есть степень в области компьютерных наук, то индекс B-дерева, скорее всего, был первым, о чем вы узнали. Индекс B-дерева создает дерево, которое будет сбалансированным и ровным. Когда он ищет что-то на основе этого индекса, он проходит вниз по дереву, чтобы найти ключ, по которому дерево разбито, а затем возвращает вам данные, которые вы ищете. Использование индекса намного быстрее, чем последовательное сканирование, потому что может потребоваться прочитать всего несколько страниц, а не последовательное сканирование тысяч из них (когда вы возвращаете только несколько записей).
Индекс B-дерева создает дерево, которое будет сбалансированным и ровным. Когда он ищет что-то на основе этого индекса, он проходит вниз по дереву, чтобы найти ключ, по которому дерево разбито, а затем возвращает вам данные, которые вы ищете. Использование индекса намного быстрее, чем последовательное сканирование, потому что может потребоваться прочитать всего несколько страниц, а не последовательное сканирование тысяч из них (когда вы возвращаете только несколько записей).
Если вы запускаете стандартный CREATE INDEX , он создает для вас B-дерево. Индексы сбалансированного дерева полезны для наиболее распространенных типов данных, таких как текст, числа и временные метки. Если вы только начинаете индексировать свою базу данных и не используете слишком много расширенных функций Postgres в своей базе данных, использование стандартных индексов B-Tree, вероятно, является тем путем, который вы хотите выбрать.
Индексы GIN для столбцов с несколькими значениями
Обобщенные инвертированные индексы, обычно называемые GIN, наиболее полезны при наличии типов данных, содержащих несколько значений в одном столбце.
Из документации Postgres: «GIN предназначен для обработки случаев, когда индексируемые элементы являются составными значениями, а запросы, которые должны обрабатываться индексом, должны искать значения элементов, которые появляются в составных элементах. Например, элементы могут быть документами, а запросы могут быть поиском документов, содержащих определенные слова».
Наиболее распространенные типы данных, попадающие в этот сегмент:
Одна из прекрасных особенностей индексов GIN заключается в том, что они осведомлены о данных в составных значениях. Но поскольку GIN-индекс имеет определенные знания о структуре данных, необходимо добавить поддержку каждого отдельного типа, в результате поддерживаются не все типы данных.
GiST-индексы для строк, в которых перекрываются значения
GiST-индексы наиболее полезны, когда у вас есть данные, которые могут каким-то образом перекрываться со значением того же столбца, но из другой строки. Самое лучшее в индексах GiST: если у вас есть тип данных геометрии, и вы хотите увидеть, содержат ли два полигона какую-то точку. В одном случае определенная точка может содержаться внутри прямоугольника, а другая точка существует только в пределах одного многоугольника. Наиболее распространенные типы данных, в которых вы хотите использовать индексы GiST:
Самое лучшее в индексах GiST: если у вас есть тип данных геометрии, и вы хотите увидеть, содержат ли два полигона какую-то точку. В одном случае определенная точка может содержаться внутри прямоугольника, а другая точка существует только в пределах одного многоугольника. Наиболее распространенные типы данных, в которых вы хотите использовать индексы GiST:
Индексы GiST имеют более фиксированные ограничения по размеру, тогда как индексы GIN могут стать довольно большими. В результате индексы GiST имеют потери. Из документов: «Индекс GiST имеет потери, что означает, что индекс может давать ложные совпадения, и необходимо проверить фактическую строку таблицы, чтобы исключить такие ложные совпадения. (PostgreSQL делает это автоматически, когда это необходимо.)» Это не означает, что вы получите неправильные результаты, это просто означает, что Postgres должен проделать небольшую дополнительную работу, чтобы отфильтровать эти ложные срабатывания, прежде чем вернуть вам ваши данные.
Особое примечание. Индексы GIN и GiST часто могут быть полезны для столбцов одного и того же типа. Часто можно похвастаться более высокой производительностью, но большим объемом дискового пространства в случае GIN и, наоборот, в случае GiST. Когда дело доходит до GIN и GiST, не существует идеального решения для всех, но общие правила, приведенные выше, применяются к индексам
SP-GiST для больших данных. некоторые исследования от Purdue. Индексы SP-GiST наиболее полезны, когда ваши данные имеют естественный элемент кластеризации, а также не являются одинаково сбалансированным деревом. Отличным примером этого являются телефонные номера (по крайней мере, американские). Они следуют формату:
второй набор из 3 цифр, тогда числа могут разветвляться в более равномерном распределении. Но с телефонными номерами некоторые коды городов имеют гораздо большую насыщенность, чем другие. В результате дерево может оказаться очень несбалансированным. Из-за изначальной естественной кластеризации и неравномерного распределения данных такие данные, как телефонные номера, могут служить хорошим аргументом в пользу SP-GiST.
Но с телефонными номерами некоторые коды городов имеют гораздо большую насыщенность, чем другие. В результате дерево может оказаться очень несбалансированным. Из-за изначальной естественной кластеризации и неравномерного распределения данных такие данные, как телефонные номера, могут служить хорошим аргументом в пользу SP-GiST.
Индексы BRIN для больших данных
Индексы диапазона блоков могут быть ориентированы на некоторые варианты использования, аналогичные SP-GiST, в том смысле, что они лучше всего подходят для случаев, когда существует некоторый естественный порядок данных, а данные имеют тенденцию быть очень большими. У вас есть таблица с миллиардом записей, особенно если это данные временных рядов? BRIN может помочь. Если вы запрашиваете большой набор данных, которые естественным образом сгруппированы вместе, например данные для нескольких почтовых индексов (которые затем сводятся к какому-то городу), BRIN помогает убедиться, что одинаковые почтовые индексы расположены рядом друг с другом на диске.
При наличии очень больших упорядоченных наборов данных, таких как даты или почтовые индексы, индексы BRIN позволяют очень быстро пропустить или исключить большое количество ненужных данных. BRIN также поддерживаются как меньшие индексы по сравнению с общим размером данных, что делает их большим преимуществом, когда у вас есть большой набор данных.
Хэш-индексы, наконец-то безопасные при сбоях
Хэш-индексы использовались в Postgres в течение многих лет, но до выхода Postgres 10 с гигантским предупреждением о том, что они не регистрируются в WAL. Это означало, что если ваш сервер выйдет из строя и вы переключитесь на резервный сервер или восстановите его из архивов с помощью чего-то вроде wal-g, вы потеряете этот индекс, пока не создадите его заново. В Postgres 10 они теперь регистрируются в WAL, поэтому вы можете начать рассматривать возможность их использования снова, но реальный вопрос заключается в том, стоит ли?
Хэш-индексы иногда обеспечивают более быстрый поиск, чем индексы B-Tree, а также могут похвастаться более быстрым временем создания.