Postgres Pro Standard : Документация: 9.5: 17.2. Создание кластера баз данных : Компания Postgres Professional
17.2. Создание кластера баз данных
Прежде чем вы сможете работать с базами данных, вы должны проинициализировать область хранения баз данных на диске. Мы называем это хранилище кластером баз данных. (В SQL применяется термин «кластер каталога».) Кластер баз данных представляет собой набор баз, управляемых одним экземпляром работающего сервера. После инициализации кластер будет содержать базу данных с именем postgres, предназначенную для использования по умолчанию утилитами, пользователями и сторонними приложениями. Сам сервер баз данных не требует наличия базы postgres, но многие внешние вспомогательные программы рассчитывают на её существование. При инициализации в каждом кластере создаётся ещё одна база, с именем template1. Как можно понять из имени, она применяется впоследствии в качестве шаблона создаваемых баз данных; использовать её в качестве рабочей не следует.
С точки зрения файловой системы, кластер баз данных представляет собой один каталог, в котором будут храниться все данные. Мы называем его каталогом данных или областью данных. Где именно хранить данные, вы абсолютно свободно можете выбирать сами. Какого-либо стандартного пути не существует, но часто данные размещаются в /usr/local/pgsql/data или в /var/lib/pgsql/data. Для инициализации кластера баз данных применяется команда initdb, которая устанавливается в составе Postgres Pro. Расположение кластера базы данных в файловой системе задаётся параметром -D, например:
$initdb -D /usr/local/pgsql/data
Заметьте, что эту команду нужно выполнять от имени учётной записи Postgres Pro, о которой говорится в предыдущем разделе.
Подсказка
В качестве альтернативы параметра -D можно установить переменную окружения PGDATA.
Также можно запустить команду initdb, воспользовавшись программой pg_ctl , примерно так:
$pg_ctl -D /usr/local/pgsql/data initdb
Этот вариант может быть удобнее, если вы используете pg_ctl для запуска и остановки сервера (см. Раздел 17.3), так как pg_ctl будет единственной командой, с помощью которой вы будете управлять экземпляром сервера баз данных.
Команда initdb попытается создать указанный вами каталог, если он не существует. Конечно, она не сможет это сделать, если initdb не будет разрешено записывать в родительский каталог. Вообще рекомендуется, чтобы пользователь Postgres Pro был владельцем не только каталога данных, но и родительского каталога, так что такой проблемы быть не должно. Если же и нужный родительский каталог не существует, вам нужно будет сначала создать его, используя права root, если вышестоящий каталог защищён от записи. Таким образом, процедура может быть такой:
root#mkdir /usr/local/pgsqlroot#chown postgres /usr/local/pgsqlroot#su postgrespostgres$initdb -D /usr/local/pgsql/data
Команда initdb не будет работать, если указанный каталог данных уже существует и содержит файлы; это мера предохранения от случайной перезаписи существующей инсталляции.
Так как каталог данных содержит все данные базы, очень важно защитить его от неавторизованного доступа. Для этого initdb лишает прав доступа к нему всех пользователей, кроме пользователя Postgres Pro.
Однако, даже когда содержимое каталога защищено, если проверка подлинности клиентов настроена по умолчанию, любой локальный пользователь может подключиться к базе данных и даже стать суперпользователем. Если вы не доверяете другим локальным пользователям, мы рекомендуем использовать один из параметров команды initdb: -W, --pwprompt или --pwfile и назначить пароль суперпользователя баз данных. Кроме того, воспользуйтесь параметром -A md5 или -A password и отключите разрешённый по умолчанию режим аутентификации trust; либо измените сгенерированный файл pg_hba.conf после выполнения initdb, но перед тем, как запустить сервер в первый раз. (Возможны и другие разумные подходы — применить режим проверки подлинности peer или ограничить подключения на уровне файловой системы. За дополнительными сведениями обратитесь к Главе 19.)
За дополнительными сведениями обратитесь к Главе 19.)
Команда initdb также устанавливает для кластера баз данных локаль по умолчанию. Обычно она просто берёт параметры локали из текущего окружения и применяет их к инициализируемой базе данных. Однако можно выбрать и другую локаль для базы данных; за дополнительной информацией обратитесь к Разделу 22.1. Команда initdb задаёт порядок сортировки по умолчанию для применения в определённом кластере баз данных, и хотя новые базы данных могут создаваться с иным порядком сортировки, порядок в базах-шаблонах, создаваемых initdb, можно изменить, только если удалить и пересоздать их. Также учтите, что при использовании локалей, отличных от C и POSIX, возможно снижение производительности. Поэтому важно правильно выбрать локаль с самого начала.
Команда initdb также задаёт кодировку символов по умолчанию для кластера баз данных. Обычно она должна соответствовать кодировке локали.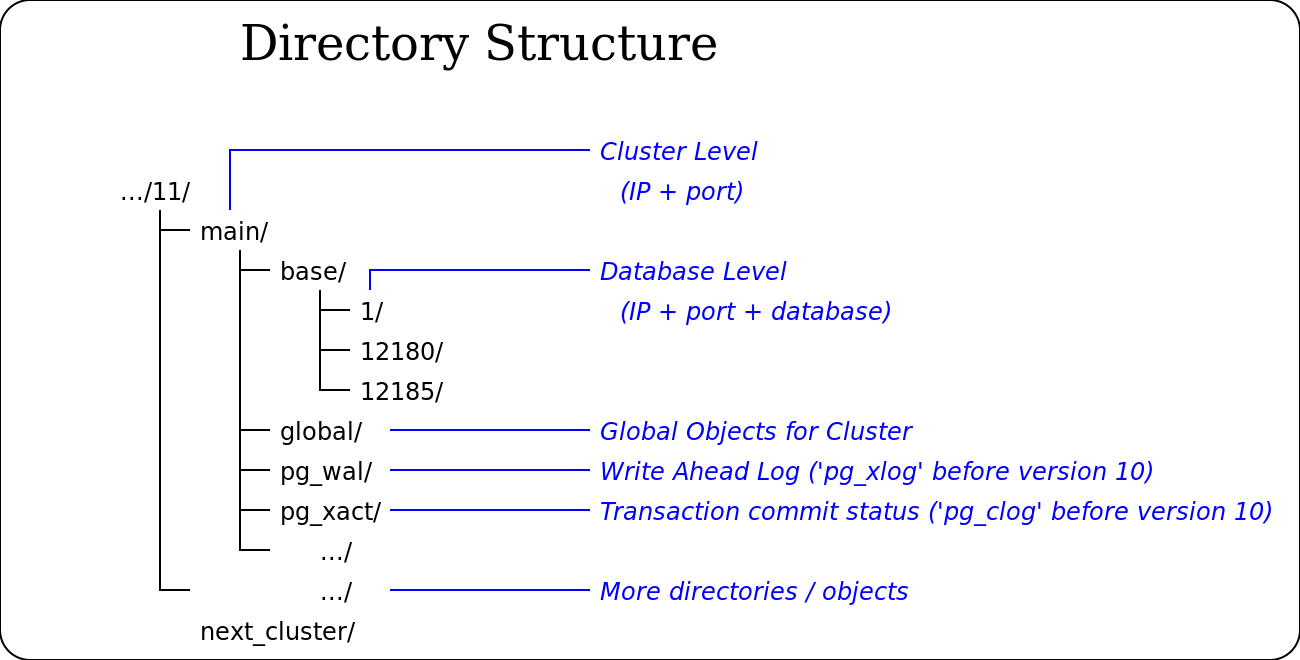
Для локалей, отличных от C и POSIX, порядок сортировки символов зависит от системной библиотеки локализации, а он, в свою очередь, влияет на порядок ключей в индексах. Поэтому кластер нельзя перевести на несовместимую версию библиотеки ни путём восстановления снимка, ни через двоичную репликацию, ни перейдя на другую операционную систему или обновив её версию.
17.2.1. Использование дополнительных файловых систем
Во многих инсталляциях кластеры баз данных создаются не в «корневом» томе, а в отдельных файловых системах (томах). Если вы решите сделать так же, то не следует выбирать в качестве каталога данных самый верхний каталог дополнительного тома (точку монтирования). Лучше всего создать внутри каталога точки монтирования каталог, принадлежащий пользователю Postgres Pro, а затем создать внутри него каталог данных. Это исключит проблемы с разрешениями, особенно для таких операций, как pg_upgrade, и при этом гарантирует чистое поведение в случае, если дополнительный том окажется отключён.
17.2.2. Использование сетевых файловых систем
Во многих инсталляциях кластеры баз данных создаются в сетевых файловых ресурсах. Иногда это реализуется с прим
PostgreSQL : Документация: 10: 18.2. Создание кластера баз данных : Компания Postgres Professional
18.2. Создание кластера баз данных
Прежде чем вы сможете работать с базами данных, вы должны проинициализировать область хранения баз данных на диске. Мы называем это хранилище кластером баз данных. (В SQL применяется термин «кластер каталога».) Кластер баз данных представляет собой набор баз, управляемых одним экземпляром работающего сервера. После инициализации кластер будет содержать базу данных с именем postgres, предназначенную для использования по умолчанию утилитами, пользователями и сторонними приложениями. Сам сервер баз данных не требует наличия базы template1. Как можно понять из имени, она применяется впоследствии в качестве шаблона создаваемых баз данных; использовать её в качестве рабочей не следует. (За информацией о создании новых баз данных в кластере обратитесь к Главе 22.)
Как можно понять из имени, она применяется впоследствии в качестве шаблона создаваемых баз данных; использовать её в качестве рабочей не следует. (За информацией о создании новых баз данных в кластере обратитесь к Главе 22.)
С точки зрения файловой системы, кластер баз данных представляет собой один каталог, в котором будут храниться все данные. Мы называем его каталогом данных или областью данных. Где именно хранить данные, вы абсолютно свободно можете выбирать сами. Какого-либо стандартного пути не существует, но часто данные размещаются в /usr/local/pgsql/data или в /var/lib/pgsql/data
-D, например:$initdb -D /usr/local/pgsql/data
Заметьте, что эту команду нужно выполнять от имени учётной записи PostgreSQL, о которой говорится в предыдущем разделе.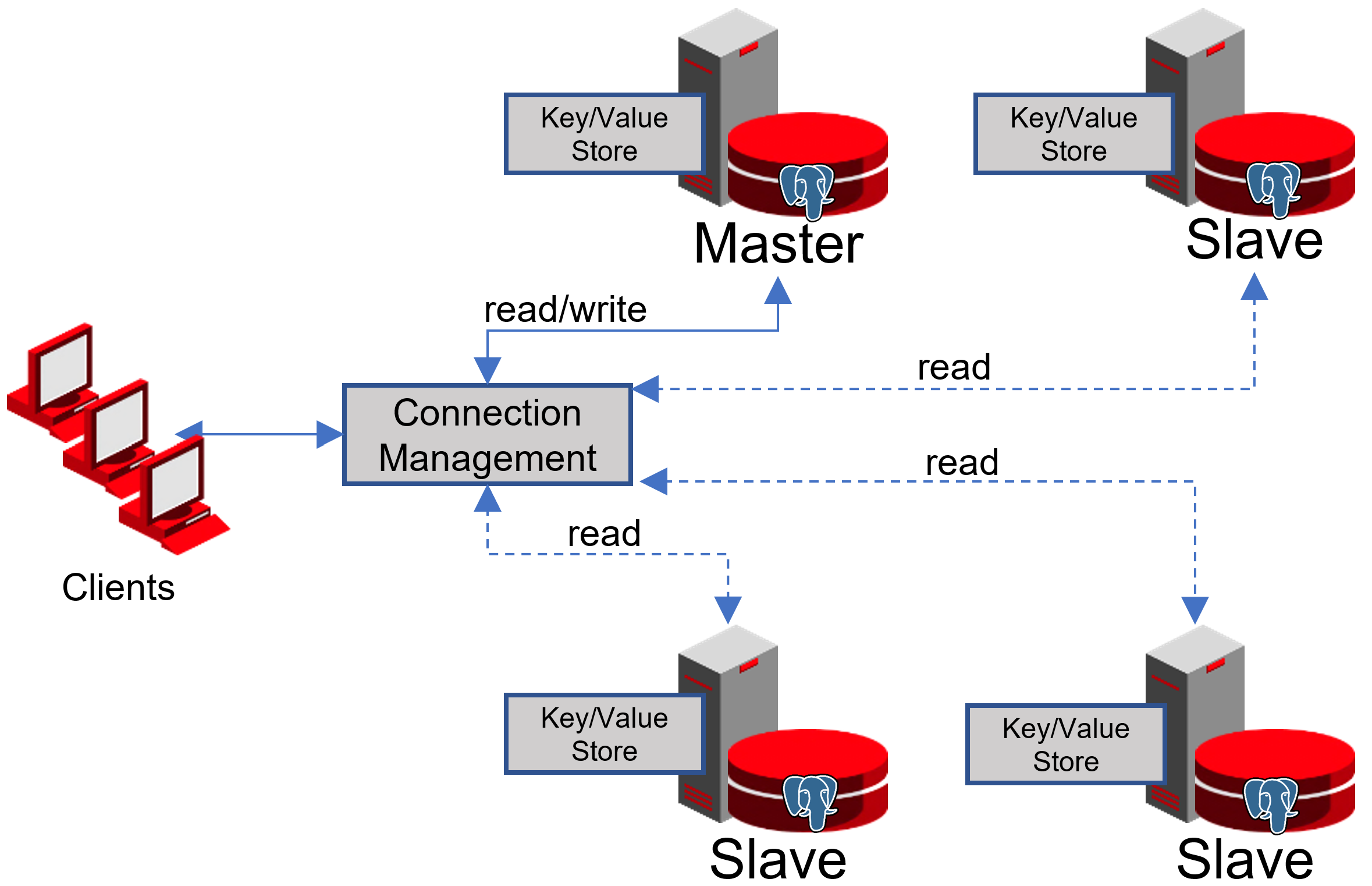
Подсказка
В качестве альтернативы параметра -D можно установить переменную окружения PGDATA.
Также можно запустить команду initdb, воспользовавшись программой pg_ctl , примерно так:
$pg_ctl -D /usr/local/pgsql/data initdb
Этот вариант может быть удобнее, если вы используете pg_ctl будет единственной командой, с помощью которой вы будете управлять экземпляром сервера баз данных.
Команда initdb попытается создать указанный вами каталог, если он не существует. Конечно, она не сможет это сделать, если initdb не будет разрешено записывать в родительский каталог. Вообще рекомендуется, чтобы пользователь PostgreSQL был владельцем не только каталога данных, но и родительского каталога, так что такой проблемы быть не должно. Если же и нужный родительский каталог не существует, вам нужно будет сначала создать его, используя права root, если вышестоящий каталог защищён от записи. Таким образом, процедура может быть такой:
Таким образом, процедура может быть такой:
root#mkdir /usr/local/pgsqlroot#chown postgres /usr/local/pgsqlroot#su postgrespostgres$initdb -D /usr/local/pgsql/data
Команда initdb не будет работать, если указанный каталог данных уже существует и содержит файлы; это мера предохранения от случайной перезаписи существующей инсталляции.
Так как каталог данных содержит все данные базы, очень важно защитить его от неавторизованного доступа. Для этого initdb лишает прав доступа к нему всех пользователей, кроме пользователя PostgreSQL.
Однако, даже когда содержимое каталога защищено, если проверка подлинности клиентов настроена по умолчанию, любой локальный пользователь может подключиться к базе данных и даже стать суперпользователем. Если вы не доверяете другим локальным пользователям, мы рекомендуем использовать один из параметров команды initdb: -W, --pwprompt или --pwfile и назначить пароль суперпользователя баз данных.
-A md5 или -A password и отключите разрешённый по умолчанию режим аутентификации trust; либо измените сгенерированный файл pg_hba.conf после выполнения initdb, но перед тем, как запустить сервер в первый раз. (Возможны и другие разумные подходы — применить режим проверки подлинности peer или ограничить подключения на уровне файловой системы. За дополнительными сведениями обратитесь к Главе 20.)Команда initdb также устанавливает для кластера баз данных локаль по умолчанию. Обычно она просто берёт параметры локали из текущего окружения и применяет их к инициализируемой базе данных. Однако можно выбрать и другую локаль для базы данных; за дополнительной информацией обратитесь к Разделу 23.1. Команда initdb задаёт порядок сортировки по умолчанию для применения в определённом кластере баз данных, и хотя новые базы данных могут создаваться с иным порядком сортировки, порядок в базах-шаблонах, создаваемых initdb, можно изменить, только если удалить и пересоздать их. Также учтите, что при использовании локалей, отличных от
Также учтите, что при использовании локалей, отличных от C и POSIX, возможно снижение производительности. Поэтому важно правильно выбрать локаль с самого начала.
Команда initdb также задаёт кодировку символов по умолчанию для кластера баз данных. Обычно она должна соответствовать кодировке локали. За подробностями обратитесь к Разделу 23.3.
Для локалей, отличных от C и POSIX, порядок сортировки символов зависит от системной библиотеки локализации, а он, в свою очередь, влияет на порядок ключей в индексах. Поэтому кластер нельзя перевести на несовместимую версию библиотеки ни путём восстановления снимка, ни через двоичную репликацию, ни перейдя на другую операционную систему или обновив её версию.
18.2.1. Использование дополнительных файловых систем
Во многих инсталляциях кластеры баз данных создаются не в «корневом» томе, а в отдельных файловых системах (томах). Если вы решите сделать так же, то не следует выбирать в качестве каталога данных самый верхний каталог дополнительного тома (точку монтирования).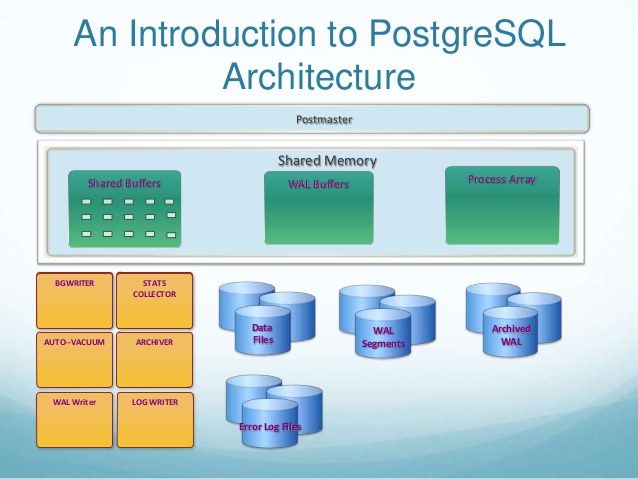 Лучше всего создать внутри каталога точки монтирования каталог, принадлежащий пользователю PostgreSQL, а затем создать внутри него каталог данных. Это исключит проблемы с разрешениями, особенно для таких операций, как pg_upgrade, и при этом гарантирует чистое поведение в случае, если дополнительный том окажется отключён.
Лучше всего создать внутри каталога точки монтирования каталог, принадлежащий пользователю PostgreSQL, а затем создать внутри него каталог данных. Это исключит проблемы с разрешениями, особенно для таких операций, как pg_upgrade, и при этом гарантирует чистое поведение в случае, если дополнительный том окажется отключён.
18.2.2. Использование сетевых файловых систем
Во многих инсталляциях кластеры баз данных создаются в сетевых файловых ресурсах. Иногда это реализуется
Отказоустойчивый кластер PostgreSQL + Patroni. Опыт внедрения / Блог компании Miro / Хабр
В статье я расскажу, как мы подошли к вопросу отказоустойчивости PostgreSQL, почему это стало для нас важно и что в итоге получилось.У нас высоконагруженный сервис: 2,5 млн пользователей по всему миру, 50К+ активных пользователей каждый день. Сервера находятся в Amazone в одном регионе Ирландии: в работе постоянно 100+ различных серверов, из них почти 50 — с базами данных.
Весь backend — большое монолитное stateful-приложение на Java, которое держит постоянное websocket соединение с клиентом. При одновременной работе нескольких пользователей на одной доске все они видят изменения в режиме реального времени, потому что каждое изменение мы записываем в базу. У нас примерно 10К запросов в секунду к нашим базам. В пиковой нагрузке в Redis мы пишем по 80-100К запросов в секунду.
При одновременной работе нескольких пользователей на одной доске все они видят изменения в режиме реального времени, потому что каждое изменение мы записываем в базу. У нас примерно 10К запросов в секунду к нашим базам. В пиковой нагрузке в Redis мы пишем по 80-100К запросов в секунду.
Почему мы перешли с Redis на PostgreSQL
Изначально наш сервис работал с Redis, key-value хранилищем, которое хранит все данные в оперативной памяти сервера.
Плюсы Redis:
- Высокая скорость ответа, т.к. всё хранится в памяти;
- Удобство бэкапа и репликации.
Минусы Redis для нас:
- Нет настоящих транзакций. Мы пытались имитировать их на уровне нашего приложения. К сожалению, это не всегда хорошо работало и требовало написания очень сложного кода.
- Объём данных ограничен количеством памяти. При увеличении количества данных память будет расти, и, в конце концов, мы упрёмся в характеристики выбранного инстанса, что в AWS требует остановки нашего сервиса для изменения типа инстанса.
- Необходимо постоянно поддерживать уровень низкого latency, т.к. у нас очень большое количество запросов. Оптимальный для нас уровень задержки — 17-20 ms. При уровне 30-40 ms мы получаем долгие ответы на запросы нашего приложения и деградацию сервиса. К сожалению, у нас это случилось в сентябре 2018 года, когда один из инстансов с Redis почему-то получил latency в 2 раза больше обычного. Для решения проблемы мы остановили сервис в середине рабочего дня для внепланового maintenance и заменили проблемный инстанс Redis.
- Легко получить неконсинстентность данных даже при незначительных ошибках в коде и потом потратить много времени на написание кода для исправления этих данных.
Мы учли минусы и поняли, что нам необходимо переехать на что-то более удобное, с нормальными транзакциями и меньшей зависимостью от latency. Провели исследование, проанализировали множество вариантов и выбрали PostgreSQL.
На новую БД мы переезжаем уже 1,5 года и перевезли только небольшую часть данных, поэтому сейчас работаем одновременно с Redis и PostgreSQL. Подробнее об этапах переезда и переключении данных между БД написано в статье моего коллеги.
Подробнее об этапах переезда и переключении данных между БД написано в статье моего коллеги.
Когда мы только начинали переезжать, наше приложение работало напрямую с БД и обращалось к мастеру Redis и PostgreSQL. Кластер PostgreSQL состоял из мастера и реплики с асинхронной репликацией. Так выглядела схема работы с базами:
Внедрение PgBouncer
Пока мы переезжали, продукт тоже развивался: увеличивалось количество пользователей и количество серверов, которые работали с PostgreSQL, и нам стало не хватать соединений. PostgreSQL на каждое соединение создаёт отдельный процесс и потребляет ресурсы. Увеличивать число коннектов можно до определённого момента, иначе есть шанс получить неоптимальную работу БД. Идеальным вариантом в такой ситуации будет выбор менеджера коннектов, который встанет перед базой.
У нас было два варианта для менеджера соединений: Pgpool и PgBouncer. Но первый не поддерживает транзакционный режим работы с базой, поэтому мы выбрали PgBouncer.
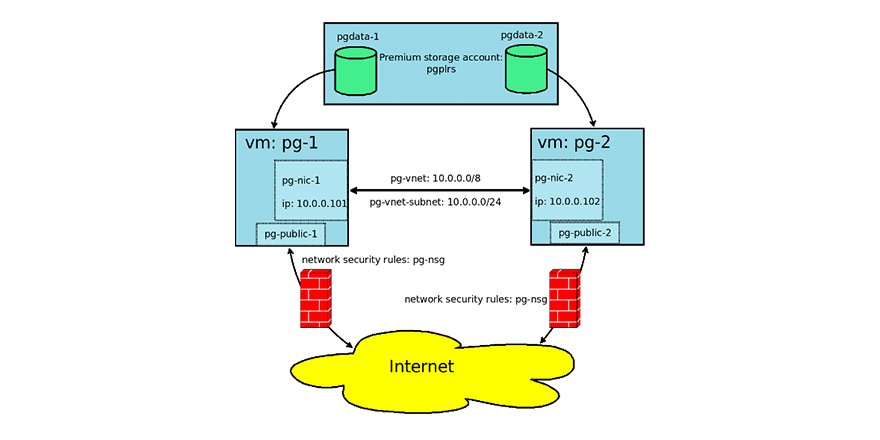
Мы настроили следующую схему работы: наше приложение обращается к одному PgBouncer, за которым находятся masters PostgreSQL, а за каждым мастером — одна реплика с асинхронной репликацией.
При этом мы не могли хранить весь объём данных в PostgreSQL и для нас была важна скорость работы с базой, поэтому мы начали шардировать PostgreSQL на прикладном уровне. Описанная выше схема является для этого относительно удобной: при добавлении нового шарда PostgreSQL достаточно обновить конфигурацию PgBouncer и приложение может сразу работать с новым шардом.
Отказоустойчивость PgBouncer
Эта схема проработала до момента, пока единственный инстанс PgBouncer не умер. Мы находимся в AWS, где все инстансы запущены на железе, которое периодически умирает. В таких случаях инстанс просто переезжает на новое железо и снова работает. Так произошло и с PgBouncer, однако он стал недоступен. Результатом этого падения стала недоступность нашего сервиса в течение 25 минут. AWS для таких ситуаций рекомендует использовать избыточность на стороне пользователя, что не было реализовано у нас на тот момент.
После этого мы всерьёз задумались об отказоустойчивости PgBouncer и кластеров PostgreSQL, потому что подобная ситуация могла повториться с любым инстансом в нашем AWS аккаунте.
Схему отказоустойчивости PgBouncer мы построили следующим образом: все сервера приложения обращаются к Network Load Balancer, за которым стоят два PgBouncer. Каждый из PgBouncer смотрит на одни и те же master PostgreSQL каждого шарда. В случае повторения ситуации с падением инстанса AWS, весь трафик перенавравляется через другой PgBouncer. Отказоустойчивость Network Load Balancer обеспечивает AWS.
Такая схема позволяет без проблем добавлять новые сервера PgBouncer.
Создание отказоустойчивого кластера PostgreSQL
При решении этой задачи мы рассматривали разные варианты: самописный failover, repmgr, AWS RDS, Patroni.
Самописные скрипты
Могут мониторить работу мастера и, в случае его падения, продвигать реплику до мастера и обновлять конфигурацию PgBouncer.
Плюсы такого подхода в максимальной простоте, потому что вы сами пишите скрипты и точно понимаете, как они работают.
Минусы:
- Мастер мог не умереть, вместо этого мог произойти сетевой сбой.
 Failover, не зная об этом, продвинет реплику до мастера, а старый мастер будет продолжать работать. В результате мы получим два сервера в роли master и не будем знать, на каком из них последние актуальные данные. Такую ситуацию называют ещё split-brain;
Failover, не зная об этом, продвинет реплику до мастера, а старый мастер будет продолжать работать. В результате мы получим два сервера в роли master и не будем знать, на каком из них последние актуальные данные. Такую ситуацию называют ещё split-brain; - Мы остались без реплики. В нашей конфигурации мастер и одна реплика, после переключения реплика продвигается до мастера и у нас больше нет реплик, поэтому приходится в ручном режиме добавлять новую реплику;
- Нужен дополнительный мониторинг работы failover, при этом у нас 12 шардов PostgreSQL, а значит мы должны мониторить 12 кластеров. При увеличении количества шардов надо ещё не забыть обновить failover.
Самописный failover выглядит очень сложно и требует нетривиальной поддержки. При одном PostgreSQL кластере это будет самым простым вариантом, но он не масштабируется, поэтому не подходит для нас.
Repmgr
Replication Manager for PostgreSQL clusters, который умеет управлять работой кластера PostgreSQL.
 При этом в нём нет автоматического failover “из коробки”, поэтому для работы потребуется писать свою “обёртку” поверх готового решения. Так что всё может получится даже сложнее, чем с самописными скриптами, поэтому Repmgr мы даже не стали пробовать.
При этом в нём нет автоматического failover “из коробки”, поэтому для работы потребуется писать свою “обёртку” поверх готового решения. Так что всё может получится даже сложнее, чем с самописными скриптами, поэтому Repmgr мы даже не стали пробовать.AWS RDS
Поддерживает всё необходимое для нас, умеет делать бэкапы и поддерживает пул коннектов. Имеет автоматическое переключение: при смерти мастера реплика становится новым мастером, а AWS меняет dns запись на нового мастера, при этом реплики могут находится в разных AZ.
К минусам можно отнести отсутствие тонких настроек. Как пример тонких настроек: на наших инстансах стоят ограничения для tcp коннектов, чего, к сожалению, нельзя сделать в RDS:
net.ipv4.tcp_keepalive_time=10
net.ipv4.tcp_keepalive_intvl=1
net.ipv4.tcp_keepalive_probes=5
net.ipv4.tcp_retries2=3
Кроме того у AWS RDS цена почти в два раза дороже обычной цены instance, что и послужило главной причиной отказа от этого решения.
Patroni
Это шаблон на python для управления PostgreSQL с хорошей документацией, автоматическим failover и исходным кодом на github.

Плюсы Patroni:
- Расписан каждый параметр конфигурации, понятно как что работает;
- Автоматический failover работает из коробки;
- Написан на python, а так как мы сами много пишем на python, то нам будет проще разбираться с проблемами и, возможно, даже помочь развитию проекта;
- Полностью управляет PostgreSQL, позволяет менять конфигурацию сразу на всех нодах кластера, а если для применения новой конфигурации требуется перезапуск кластера, то это можно сделать опять же с помощью Patroni.
Минусы:
- Из документации непонятно, как правильно работать с PgBouncer. Хотя минусом это назвать сложно, потому что задача Patroni — управлять PostgreSQL, а как будут ходить подключения к Patroni — уже наша проблема;
- Мало примеров внедрения Patroni на больших объёмах, при этом много примеров внедрения с нуля.
В итоге для создания отказоустойчивого кластера мы выбрали именно Patroni.
Процесс внедрения Patroni
До Patroni у нас было 12 шардов PostgreSQL в конфигурации один мастер и одна реплика с асинхронной репликацией.
 Сервера приложения обращались к базам данных через Network Load Balancer, за которым стояли два instance с PgBouncer, а за ними находились все PostgreSQL сервера.
Сервера приложения обращались к базам данных через Network Load Balancer, за которым стояли два instance с PgBouncer, а за ними находились все PostgreSQL сервера.Для внедрения Patroni нам нужно было выбрать распределенное хранилище конфигурации кластера. Patroni работает с распределёнными системами хранения конфигураций, такими как etcd, Zookeeper, Сonsul. У нас как раз на проде есть полноценный кластер Consul, который работает в связке с Vault и больше мы его никак не используем. Отличный повод начать использовать Consul по назначению.
Как работает Patroni с Consul
У нас есть кластер Сonsul, который состоит из трёх нод и кластер Patroni, который состоит из лидера и реплики (в Patroni мастер называется лидером кластера, а слейвы — репликами). Каждый инстанс кластера Patroni постоянно посылает в Consul информацию о состоянии кластера. Поэтому из Сonsul всегда можно узнать текущую конфигурацию кластера Patroni и того, кто является лидером в данный момент.
Для подключения Patroni к Сonsul достаточно изучить официальную документацию, в которой написано, что необходимо указать хост в формате http или https в зависимости от того, как мы работаем с Сonsul, и схему подключения, опционально:
host: the host:port for the Consul endpoint, in format: http(s)://host:port
scheme: (optional) http or https, defaults to httpВыглядит просто, но тут начинаются подводные камни.
 С Сonsul мы работаем по защищённому соединению через https и наш конфиг подключения будет выглядеть следующим образом:
С Сonsul мы работаем по защищённому соединению через https и наш конфиг подключения будет выглядеть следующим образом:consul:
host: https://server.production.consul:8080
verify: true
cacert: {{ consul_cacert }}
cert: {{ consul_cert }}
key: {{ consul_key }}Но так не работает. При старте Patroni не может подключиться к Сonsul, потому что пытается всё равно идти по http.
Разобраться с проблемой помог исходный код Patroni. Хорошо, что он написан на python. Оказывается параметр host никак не парсится, а протокол необходимо указать в scheme. Вот так выглядит работающий блок конфигурации для работы с Сonsul у нас:
consul:
host: server.production.consul:8080
scheme: https
verify: true
cacert: {{ consul_cacert }}
cert: {{ consul_cert }}
key: {{ consul_key }}Consul-template
Итак, хранилище для конфигурации мы выбрали. Теперь нужно понять, как PgBouncer будет переключать свою конфигурацию при смене лидера в кластере Patroni.
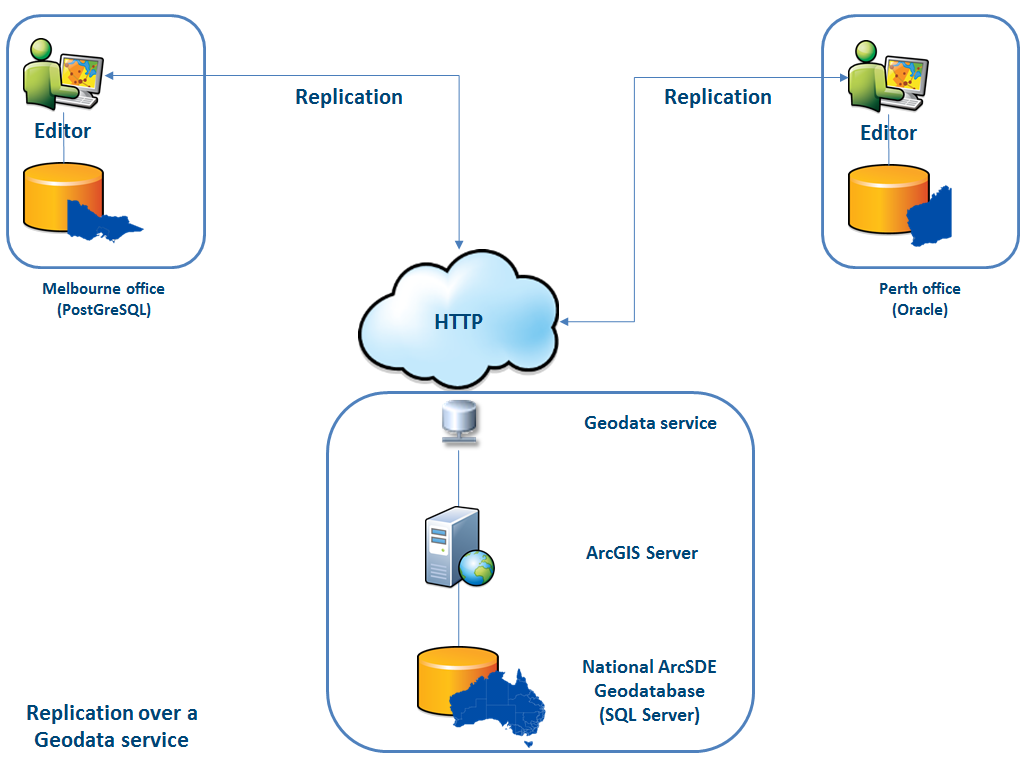 В документации на этот вопрос ответа нет, т.к. там в принципе не описана работа с PgBouncer.
В документации на этот вопрос ответа нет, т.к. там в принципе не описана работа с PgBouncer.В поисках решения мы нашли статью (название, к сожалению, не помню), где было написано, что Сonsul-template очень помог в связке PgBouncer и Patroni. Это подтолкнуло нас на исследование работы Consul-template.
Оказалось, что Сonsul-template постоянно мониторит конфигурацию кластера PostgreSQL в Сonsul. При смене лидера он обновляет конфигурацию PgBouncer и отправляет команду на её перезагрузку.
Большой плюс template в том, что он хранится в виде кода, поэтому при добавлении нового шарда достаточно сделать новый коммит и обновить template в автоматическом режиме, поддерживая принцип Infrastructure as code.
Новая архитектура с Patroni
В результате мы получили такую схему работы:
Все сервера приложения обращаются к балансировщику → за ним стоят два instance PgBouncer → на каждом instance запущен Сonsul-template, который мониторит состояние каждого кластера Patroni и следит за актуальностью конфига PgBouncer, который направляет запросы на текущего лидера каждого кластера.
Ручное тестирование
Эту схему перед выводом на прод мы запустили на небольшой тестовой среде и проверили работу автоматического переключения. Открывали доску, передвигали стикер и в этот момент “убивали” лидера кластера. В AWS для этого достаточно выключить инстанс через консоль.
Стикер в течение 10-20 секунд возвращался назад, а потом вновь начинал нормально перемещаться. Значит, кластер Patroni сработал верно: сменил лидера, отправил информацию в Сonsul, а Сonsul-template сразу подхватил эту информацию, заменил конфигурацию PgBouncer и отправил команду на reload.
Как выжить под высокой нагрузкой и сохранить минимальный даунтайм?
Всё работает отлично! Но появляются новые вопросы: Как это сработает под высокой нагрузкой? Как быстро и безопасно раскатать всё на production?
Ответить на первый вопрос нам помогает тестовая среда, на которой мы проводим нагрузочное тестирование. Она полностью идентична production по архитектуре и имеет сгенерированные тестовые данные, которые по объёму примерно равны production. Мы решаем просто “убить” один из мастеров PostgreSQL во время теста и посмотреть, что будет. Но перед этим важно проверить автоматическую раскатку, ведь на этой среде у нас есть несколько шардов PostgreSQL, так что мы получим отличное тестирование конфигурационных скриптов перед продом.
Обе задачи выглядят амбициозно, но у нас PostgreSQL 9.6. Может мы сразу на 11.2 обновимся?
Мы решаем сделать это в 2 этапа: сначала обновить версию до 11.2, потом запустить Patroni.
Обновление PostgreSQL
Для быстрого обновления версии PostgreSQL необходимо использовать опцию -k, в которой создаются hard link на диске и нет необходимости в копировании ваших данных. На базах в 300-400 ГБ обновление занимает 1 секунду.
У нас много шардов, поэтому обновление нужно сделать в автоматическом режиме. Для этого мы написали Ansible playbook, который выполняет весь процесс обновления за нас:
/usr/lib/postgresql/11/bin/pg_upgrade \
<b>--link \</b>
--old-datadir='' --new-datadir='' \
--old-bindir='' --new-bindir='' \
--old-options=' -c config_file=' \
--new-options=' -c config_file='Здесь важно отметить, что перед запуском апгрейда необходимо выполнить его с параметром —check, чтобы быть уверенным в возможности апгрейда. Так же наш сценарий делает подмену конфигов на время апгрейда. Сценарий у нас выполнился за 30 секунд, это отличный результат.
Запуск Patroni
Для решения второй проблемы достаточно взглянуть на конфигурацию Patroni. В официальном репозитории есть пример конфигурации с initdb, который отвечает за инициализацию новой базы при первом запуске Patroni. Но так как у нас есть уже готовая база, то мы просто удалили этот раздел из конфигурации.
Когда мы начали ставить Patroni уже на готовый кластер PostgreSQL и запускать его, то столкнулись с новой проблемой: оба сервера запускались как leader. Patroni ничего не знает о раннем состоянии кластера и пытается запустить оба сервера как два отдельных кластера с одинаковым именем. Для решения этой проблемы необходимо удалить директорию с данными на slave:
rm -rf /var/lib/postgresql/Это необходимо сделать только на slave!
При подключении чистой реплики Patroni делает basebackup leader и восстанавливает его на реплику, а затем догоняет актуальное состояние по wal-логам.
Ещё одна сложность, с которой мы столкнулись, — все кластеры PostgreSQL по умолчанию называются main. Когда каждый кластер ничего не знает про другой — это нормально. Но когда вы хотите использовать Patroni, то все кластера должны иметь уникальное имя. Решение — поменять имя кластера в конфигурации PostgreSQL.
Нагрузочный тест
Мы запустили тест, который имитирует работу пользователей на досках. Когда нагрузка достигла нашего среднего дневного значения, мы повторили точно такой же тест, мы выключили один instance с leader PostgreSQL. Автоматический failover сработал так, как мы ожидали: Patroni сменил лидера, Сonsul-template обновил конфигурацию PgBouncer и отправил команду на reload. По нашим графиками в Grafana было видно, что есть задержки на 20-30 секунд и небольшой объём ошибок с серверов, связанных с соединением к базе. Это нормальная ситуация, такие значения допустимы для нашего failover и точно лучше, чем даунтайм сервиса.
Вывод Patroni на production
В итоге у нас получился следующий план:
- Деплой Сonsul-template на сервера PgBouncer и запуск;
- Обновления PostgreSQL до версии 11.2;
- Смена имени кластера;
- Запуск кластера Patroni.
При этом наша схема позволяет сделать первый пункт практически в любое время, мы можем по очереди убрать каждый PgBouncer из работы и выполнить на него деплой и запуск consul-template. Так мы и сделали.
Для быстрой раскатки мы использовали Ansible, так как все playbook мы уже проверили на тестовой среде, а время выполнения полного сценария было от 1,5 до 2 минут для каждого шарда. Мы могли всё выкатить поочередно на каждый шард без остановки нашего сервиса, но нам пришлось бы на несколько минут выключать каждый PostgreSQL. В этом случае пользователи, чьи данные есть на этом шарде, не могли бы полноценно работать в это время, а это для нас неприемлемо.
Выходом из этой ситуации стал плановый maintenance, который проходит у нас каждые 3 месяца. Это окно для плановых работ, когда мы полностью выключаем наш сервис и обновляем инстансы баз данных. До очередного окна оставалась одна неделя, и мы решили просто подождать и дополнительно подготовиться. За время ожидания мы дополнительно подстраховались: для каждого шарда PostgreSQL подняли по запасной реплике на случай неудачи, чтобы сохранить самые последние данные, и добавили по новому инстансу для каждого шарда, который должен стать новой репликой в кластере Patroni, чтоб не выполнять команду для удаления данных. Всё это помогло максимально снизить риск ошибки.
Мы перезапустили наш сервис, все заработало как надо, пользователи продолжили работать, но на графиках мы заметили аномально высокую нагрузку на Сonsul-сервера.
Почему мы не увидели это на тестовой среде? Эта проблема очень хорошо иллюстрирует, что необходимо следовать принципу Infrastructure as code и дорабатывать всю инфраструктуру, начиная с тестовых сред и заканчивая production. Иначе очень легко получить такую проблему, которую получили мы. Что произошло? Сonsul сначала появился на production, а потом на тестовых средах, в итоге на тестовых средах версия Consul была выше, чем на production. Как раз в одном из релизов была решена утечка CPU при работе с consul-template. Поэтому мы просто обновили Consul, решив таким образом проблему.
Restart Patroni cluster
Однако мы получили новую проблему, о которой даже не подозревали. При обновлении Consul мы просто удаляем ноду Consul из кластера с помощью команды consul leave → Patroni подключается к другому Consul серверу → всё работает. Но когда мы дошли до последнего инстанса кластера Consul и отправили ему команду consul leave, все кластеры Patroni просто перезапустились, а в логах мы увидели следующую ошибку:
ERROR: get_cluster
Traceback (most recent call last):
...
RetryFailedError: 'Exceeded retry deadline'
ERROR: Error communicating with DCS
<b>LOG: database system is shut down</b>Кластер Patroni не смог получить информацию о своём кластере и перезапустился.
Для поиска решения мы обратились к авторам Patroni через issue на github. Они предложили улучшения наших конфигурационных файлов:
consul:
consul.checks: []
bootstrap:
dcs:
retry_timeout: 8Мы смогли повторить проблему на тестовой среде и протестировали там эти параметры, но, к сожалению, они не сработали.
Проблема до сих пор остаётся нерешённой. Мы планируем попробовать следующие варианты решения:
- Использовать Сonsul-agent на каждом инстансе кластера Patroni;
- Исправить проблему в коде.
Нам понятно место возникновения ошибки: вероятно, проблема в использовании default timeout, который не переопределяется через файл конфигурации. При удалении последнего сервера Сonsul из кластера происходит зависание всего Сonsul-кластера, которое длится дольше секунды, из-за этого Patroni не может получить состояние кластера и полностью перезапускает весь кластер.
К счастью, больше никаких ошибок мы не встретили.
Итоги использования Patroni
После успешного запуска Patroni мы добавили по дополнительной реплике в каждом кластере. Теперь в каждом кластере есть подобие кворума: один лидер и две реплики, — для подстраховки на случай split-brain при переключении.
На production Patroni работает более трёх месяцев. За это время он уже успел нас выручить. Недавно в AWS умер лидер одного из кластеров, автоматический failover сработал и пользователи продолжили работать. Patroni выполнил свою главную задачу.
Небольшой итог использования Patroni:
- Удобство изменения конфигурации. Достаточно изменить конфигурацию на одном инстансе и она подтянется на весь кластер. Если требуется перезагрузка для применения новой конфигурации, то Patroni об этом сообщит. Patroni может перезапустить весь кластер с помощью одной команды, что тоже очень удобно.
- Автоматический failover работает и уже успел нас выручить.
- Обновление PostgreSQL без даунтайма приложения. Необходимо сначала обновить реплики на новую версию, затем сменить лидера в кластере Patroni и обновить старого лидера. При этом происходит необходимое тестирование автоматического failover.
Что такое «кластер» PostgreSQL и как его создать?
база данных PostgreSQL «кластер» — это postmaster и группа субсидиарных процессов, которые управляют общим каталогом данных, содержащим одну или несколько баз данных.
термин «кластер» в PostgreSQL есть историческая причуда*, и совершенно отличается от общего значения «вычислительный кластер», который нормально относится к группам компьютеров, которые работают вместе для достижения более высокой производительности и/или доступности. Также не связано с командой PostgreSQL CLUSTER, который касается организации таблиц.
если Вы читаете это, вы можете на самом деле искать информацию о высокой доступности, репликации или объединении, в этом случае вы должны прочитать репликация, кластеризация и высокая доступность wiki статья и высокая доступность раздел руководства PostgreSQL, затем просмотрите такие инструменты, как repmgr.
A кластер обычно создается для вас при установке PostgreSQL; установка обычно будет initdb новый кластер для вас. Это довольно необычно для базового или промежуточного пользователя, когда-либо нужно создавать кластеры или управлять несколькими кластерами, поэтому это поможет, если вы объясните почему вы хотите сделать это, и что основная проблема, которую вы пытаетесь решить, это. The руководство пользователя возможно, это лучше объяснить, так как предполагается, что вы установка PostgreSQL из исходного кода и относительно немногие люди действительно делают это.
каталог данных каждого кластера создается с помощью initdb и управляется с почтмейстером, который запускается через системную службу (служба Windows,launchd, init, upstart, systemd, etc в зависимости от операционной системы и версии) или сразу через pg_ctl.
кластер имеет встроенные базы данных template0, template1 и postgres; другие базы данных создаются пользователь.
почтмейстер для кластера принимает входящие соединения на прослушивание TCP-порта, и руки их на работника. Только один почтмейстер может работать на данном порту, поэтому каждый кластер должен иметь другой порт.
я написал больше о структуре PostgreSQL в этот предыдущий ответ. См. подзаголовок » отношения? Схема? А?».
как «создать» кластеры в Pg полностью зависит от того, как вы его запускаете. Так как вы спрашивая, Я подозреваю, что вы находитесь в системе Ubuntu, которая использует pg_wrapper в этом случае вы должны использовать pg_wrapper команды типа pg_createcluster.
* путаница между » кластером «в терминологии PostgreSQL и общим использованием термина» кластер » является запутанной и прискорбной исторической странностью, особенно при обсуждении кластеризации экземпляров PostgreSQL. Вы можете иметь кластер кластеров PostgreSQL, который просто болезненный.
Построение кластера PostgreSQL высокой доступности с использованием Patroni, etcd, HAProxy
Так уж вышло, что на момент постановки задачи я не обладал достаточной степенью опытности, чтобы разработать и запустить это решение в одиночку. И тогда я начал гуглить.
Не знаю, в чем загвоздка, но уже в который раз я сталкиваюсь с тем, что даже если делать все пошагово как в туториале, подготовить такой же enviroment как у автора, то все равно никогда ничего не работает. Понятия не имею, в чем тут дело, но когда я столкнулся с этим в очередной раз, я решил — а напишу-ка я свой туториал, когда все получится. Тот, который точно будет работать.
Гайды в Интернете
Так уж вышло, что интернет не страдает от недостатка различных гайдов, туториалов, step-by-step и тому подобных вещей. Так уж вышло, что мне была поставлена задача разработать решение для удобной организации и построения отказоустойчивого кластера PostgreSQL, главными требованиями к которому являлись потоковая репликация с Master-сервера на все реплики и автоматический ввод резерва при отказе Master-сервера.
На этом этапе был определен стек используемых технологий:
- PostgreSQL в качестве СУБД
- Patroni в качетсве решения для кластеризации
- etcd в качестве распределенного хранилища для Patroni
- HAproxy для организации единой точки входа для приложений, использующих базу
Установка
Вашему вниманию — построение кластера PostgreSQL высокой доступности с использованием Patroni, etcd, HAProxy.
Все операции выполнялись на виртуальных машинах с установленной ОС Debian 10.
etcd
Не рекомендую устанавливать etcd на тех же машинах, где будет находится patroni и postgresql, так как для etcd очень важна нагрузка на диски. Но в целях обучения, мы поступим именно так.
Установим etcd.
#!/bin/bash
apt-get update
apt-get install etcdДобавьте содержимое в файл /etc/default/etcd
ETCD_NAME=datanode1 # hostname вашей машины
ETCD_DATA_DIR=»/var/lib/etcd/default.etcd»
ETCD_LISTEN_PEER_URLS=»http://192.168.0.143:2380″ # адрес вашей машины
ETCD_LISTEN_CLIENT_URLS=»http://192.168.0.143:2379,http://127.0.0.1:2379″ # адрес вашей машины
ETCD_INITIAL_ADVERTISE_PEER_URLS=»http://192.168.0.143:2380″ # адрес вашей машины
ETCD_INITIAL_CLUSTER=»datanode1=http://192.168.0.143:2380,datanode2=http://192.168.0.144:2380,datanode3=http://192.168.0.145:2380″ # адреса всех машин в кластере etcd
ETCD_INITIAL_CLUSTER_STATE=»new»
ETCD_INITIAL_CLUSTER_TOKEN=»etcd-cluster-1″
ETCD_ADVERTISE_CLIENT_URLS=»http://192.168.0.143:2379″ # адрес вашей машины
Выполните команду
systemctl restart etcdPostgreSQL 9.6 + patroni
Первое, что необходимо сделать, это установить три виртуальные машины для установки на них необходимого ПО. После установки машин, если вы следуете моему туториалу, вы можете запустить этот простой скрипт, который (почти) все сделает за вас. Запускается из-под root.
Обратите внимание, что скрипт использует версию PostgreSQL 9.6, это обусловлено внутренними требованиями нашей компании. Решение не тестировалось на других версиях PostgreSQL.
#!/bin/bash
apt-get install gnupg -y
echo "deb http://apt.postgresql.org/pub/repos/apt/ buster-pgdg main" >> /etc/apt/sources.list
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | apt-key add -
apt-get update
apt-get install postgresql-9.6 python3-pip python3-dev libpq-dev -y
systemctl stop postgresql
pip3 install --upgrade pip
pip install psycopg2
pip install patroni[etcd]
echo "\
[Unit]
Description=Runners to orchestrate a high-availability PostgreSQL
After=syslog.target network.target
[Service]
Type=simple
User=postgres
Group=postgres
ExecStart=/usr/local/bin/patroni /etc/patroni.yml
KillMode=process
TimeoutSec=30
Restart=no
[Install]
WantedBy=multi-user.targ\
" > /etc/systemd/system/patroni.service
mkdir -p /data/patroni
chown postgres:postgres /data/patroni
chmod 700 /data/patroniпо
touch /etc/patroni.ymlДалее, в созданный только что файл /etc/patroni.yml вам необходимо поместить следующее содержимое, конечно же изменив ip-адреса во всех местах, на адреса, которые используете вы.
Обратите внимание на комментарии в данном yaml. Измените адреса на свои, на каждой машине кластера.
/etc/patroni.yml
scope: pgsql # должно быть одинаковым на всех нодах
namespace: /cluster/ # должно быть одинаковым на всех нодах
name: postgres1 # должно быть разным на всех нодах
restapi:
listen: 192.168.0.143:8008 # адрес той ноды, в которой находится этот файл
connect_address: 192.168.0.143:8008 # адрес той ноды, в которой находится этот файл
etcd:
hosts: 192.168.0.143:2379,192.168.0.144:2379,192.168.0.145:2379 # перечислите здесь все ваши ноды, в случае если вы устанавливаете etcd на них же
# this section (bootstrap) will be written into Etcd:/<namespace>/<scope>/config after initializing new cluster
# and all other cluster members will use it as a `global configuration`
bootstrap:
dcs:
ttl: 100
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
wal_level: replica
hot_standby: "on"
wal_keep_segments: 5120
max_wal_senders: 5
max_replication_slots: 5
checkpoint_timeout: 30
initdb:
- encoding: UTF8
- data-checksums
- locale: en_US.UTF8
# init pg_hba.conf должен содержать адреса ВСЕХ машин, используемых в кластере
pg_hba:
- host replication postgres ::1/128 md5
- host replication postgres 127.0.0.1/8 md5
- host replication postgres 192.168.0.143/24 md5
- host replication postgres 192.168.0.144/24 md5
- host replication postgres 192.168.0.145/24 md5
- host all all 0.0.0.0/0 md5
users:
admin:
password: admin
options:
- createrole
- createdb
postgresql:
listen: 192.168.0.143:5432 # адрес той ноды, в которой находится этот файл
connect_address: 192.168.0.143:5432 # адрес той ноды, в которой находится этот файл
data_dir: /data/patroni # эту директорию создаст скрипт, описанный выше и установит нужные права
bin_dir: /usr/lib/postgresql/9.6/bin # укажите путь до вашей директории с postgresql
pgpass: /tmp/pgpass
authentication:
replication:
username: postgres
password: postgres
superuser:
username: postgres
password: postgres
create_replica_methods:
basebackup:
checkpoint: 'fast'
parameters:
unix_socket_directories: '.'
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: falseСкрипт необходимо запустить на выполнение на всех трех машинах кластера, точно так же необходимо поместить приведенную конфигурацию в файл /etc/patroni.yml на всех машинах.
Когда вы проделаете эти операции на всех машинах кластера, выполните следующую команду на любой из них
systemctl start patroni
systemctl start postgresqlПодождите около 30 секунд, затем выполните эту команду на остальных машинах кластера.
HAproxy
Мы используем чудесный HAproxy для предоставления единой точки входа. Master-сервер всегда будет доступен по адресу машины, на которой развернут HAproxy.
Для того, чтобы не сделать машину с HAproxy единой точкой отказа, запустим его в контейнере Docker, в дальнейшем его можно будет запустить в кластер K8’s и сделать наш отказоустойчивый кластер еще более надежным.
Создайте директорию, где вы сможете хранить два файла — Dockerfile и haproxy.cfg. Перейдите в нее.
Dockerfile
FROM ubuntu:latest
RUN apt-get update \
&& apt-get install -y haproxy rsyslog \
&& rm -rf /var/lib/apt/lists/*
RUN mkdir /run/haproxy
COPY haproxy.cfg /etc/haproxy/haproxy.cfg
CMD haproxy -f /etc/haproxy/haproxy.cfg && tail -F /var/log/haproxy.logБудьте внимательны, в трех последних строках файла haproxy.cfg должны быть перечислены адреса ваших машин. HAproxy будет обращаться к Patroni, в HTTP-заголовках master-сервер всегда будет возвращать 200, а replica — 503.
haproxy.cfg
global
maxconn 100
defaults
log global
mode tcp
retries 2
timeout client 30m
timeout connect 4s
timeout server 30m
timeout check 5s
listen stats
mode http
bind *:7000
stats enable
stats uri /
listen postgres
bind *:5000
option httpchk
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server postgresql1 192.168.0.143:5432 maxconn 100 check port 8008
server postgresql2 192.168.0.144:5432 maxconn 100 check port 8008
server postgresql3 192.168.0.145:5432 maxconn 100 check port 8008
Находясь в директории, в которой «лежат» оба наших файла, выполним последовательно команды упаковки контейнера, а также его запуск с пробросом необходимых портов:
docker build -t my-haproxy .
docker run -d -p5000:5000 -p7000:7000 my-haproxy Теперь, открыв в браузере адрес вашей машины с HAproxy и указав порт 7000, вы увидите статистику по вашему кластеру.
В состоянии UP будет находится тот сервер, который является мастером, а реплики в состоянии DOWN. Это нормально, на самом деле они работают, но отображаются в таком виде из-за того, что возвращают 503 на запросы от HAproxy. Это позволяет нам всегда точно знать, какой из трех серверов является мастером на данный момент.
Заключение
Вы восхитительны! Всего лишь за 30 минут вы развернули отличный отказоустойчивый и производительный кластер баз данных с потоковой репликацией и автоматическим вводом резерва. Если вы планируете использовать это решение, ознакомьтесь с официальной документацией Patroni, а особенно с ее частью, касающейся утилиты patronictl, предоставляющей удобный доступ к управлению вашим кластером.
Поздравляю!
Отказоустойчивый PostgreSQL auto-failover кластер с использованием Repmgr и Barman. Часть 1. Введение.
Часть 1. Введение.
Часть 2. Репликация. Repmgr.
Часть 3. Auto-failover. Демоны repmgr.
Часть 4. Высокая доступность. Бэкапирование. Демоны repmgr. Barman.
Часть 5. Тестирование. Ansible. Вместо послесловия.
С места в карьер. Вот то, что вы получите в конце:
- Синхронный резервный сервер с использованием repmgr
- Демоны repmgr, работающие не на серверах БД
- Не нужен witness-сервер с собственным экземпляром PostgreSQL
- Auto-failover устойчивый к split-brain
- Сервер высокой доступности без дополнительных утилит, таких как HAProxy
- Сервер бэкапирования с использованием barman
- Асинхронная потоковая репликация WAL
- Которая становится синхронной, если один из БД серверов упадет. Как минимум два узла кластера работают синхронно в любой момент времени.
- Хранение бэкапов мастера и резервного сервера в одном месте, используя фичу высокой доступности. Экономим дисковое пространство.
- Использование barman как единое место хранения WAL и место восстановления кластера.
- Ansible playbook для автоматического развертывания
Софт
- Debian 9.7
- PostgreSQL 11.2 (Debian 11.2-1.pgdg90+1)
- Repmgr 4.2
- Barman 2.7
- OpenVPN 2.4.0
Топология
Поехали
Для начала, добавим необходимые репозитории и установим PostgreSQL на всех серверах.
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | apt-key add - echo "deb http://apt.postgresql.org/pub/repos/apt/ $(lsb_release -cs)"-pgdg main | tee /etc/apt/sources.list.d/pgdg.list apt update apt install postgresql-11 update-rc.d postgresql enable systemctl restart postgresql
Изменим пароль юзера postgres на серверах db1 и db2. Он понадобится нам в части 3.
passwd postgres
Затем добавим репозитории 2ndQuadrant(разработчик repmgr и barman) на все серверы.
apt install curl apt-transport-https sh -c 'echo "deb https://apt.2ndquadrant.com/ $(lsb_release -cs)-2ndquadrant main" > /etc/apt/sources.list.d/2ndquadrant.list' curl https://apt.2ndquadrant.com/site/keys/9904CD4BD6BAF0C3.asc | apt-key add - apt update
Установите следующие утилиты на все серверы. barman-cli это набор скриптов, позволяющий удаленно и безопасно(в случае разрывов) архивировать и получать WAL.
apt install postgresql-11-repmgr barman-cli sudo
У становите barman на сервер backup.
apt install barman
Измените пароль юзера barman на сервере backup. Он понадобится нам в части 4.
passwd barman
Объединяем серверы в единую сеть(опционально)
Чтобы процесс репликации и бэкапирования был безопасным, мы должны объединить серверы используя безопасное соединение.
Возможно, вам не понадобится выполнять эти шаги, если ваши серверы уже объединены в сеть используя безопасную сеть вашего датацентра. Однако, я не рекомендую вам держать все яйца в одной корзине.
Как бы то ни бьыло, имейте в виду, что вы должны заменить следующие IP на ваши там, где их увидите.
10.8.1.1 10.8.2.1 10.8.3.1
ОК, давайте объединим серверы используя point-to-point соединение OpenVPN.
Для начала, установим OpenVPN и сгенерируем ключ сервера.
apt install openvpn openvpn --genkey --secret /etc/openvpn/server.key
Затем, удаленно скопируем ключи на соответственные серверы-клиенты.
С сервера db1 на db2.
scp /etc/openvpn/server.key root@db2_ip_or_host:/etc/openvpn/client.key
С сервера db2 на backup.
scp /etc/openvpn/server.key root@backup_ip_or_host:/etc/openvpn/client.key
С сервера backup на db1.
scp /etc/openvpn/server.key root@db1_ip_or_host:/etc/openvpn/client.key
Далее создадим конфиги сервера и клиента на всех серверах.
db1/etc/openvpn/server.conf
dev tun ifconfig 10.8.1.1 10.8.2.1 secret server.key cipher AES-256-CBC keepalive 3 9 ping-timer-rem
/etc/openvpn/client.conf
remote backup_ip_or_host dev tun ifconfig 10.8.1.1 10.8.3.1 secret client.key cipher AES-256-CBC keepalive 3 18 nobind
db2/etc/openvpn/server.conf
dev tun ifconfig 10.8.2.1 10.8.3.1 secret server.key cipher AES-256-CBC keepalive 3 9 ping-timer-rem
/etc/openvpn/client.conf
remote db1_ip_or_host dev tun ifconfig 10.8.2.1 10.8.1.1 secret client.key cipher AES-256-CBC keepalive 3 18 nobind
backup/etc/openvpn/server.conf
dev tun ifconfig 10.8.3.1 10.8.1.1 secret server.key cipher AES-256-CBC keepalive 3 9 ping-timer-rem
/etc/openvpn/client.conf
remote db2_ip_or_host dev tun ifconfig 10.8.3.1 10.8.2.1 secret client.key cipher AES-256-CBC keepalive 3 18 nobind
Перегрузим конфиги и рестартанем OpenVPN.
update-rc.d openvpn enable systemctl daemon-reload systemctl restart openvpn
Отлично! Теперь мы готовы к настройке репликации с использованием repmgr.
PostgreSQL: Документация: 9.1: CLUSTER
Эта документация предназначена для неподдерживаемой версии PostgreSQL.Вы можете просмотреть ту же страницу для текущий версия или одна из других поддерживаемых версий, перечисленных выше.
Имя
CLUSTER — кластеризовать таблицу в соответствии с индексСводка
CLUSTER [VERBOSE] имя_таблицы [USING имя_индекса] КЛАСТЕР [ГЛАГОЛ]
Описание
CLUSTER указывает PostgreSQL кластеризовать таблицу, указанную table_name на основе индекса указанный index_name.В index уже должен быть определен для table_name.
Когда таблица кластеризуется, она физически переупорядочивается на основе индексная информация. Кластеризация — разовая операция: когда таблица впоследствии обновляется, изменения не группируются. То есть не предпринимается никаких попыток сохранить новые или обновленные строки. в соответствии с порядком их индекса. (При желании можно периодически производите повторную кластеризацию, подавая команду снова. Также, установка хранилища FILLFACTOR на столе параметр менее 100% может помочь в сохранении кластера упорядочение во время обновлений, поскольку обновленные строки хранятся в одном страницу, если на ней достаточно места.)
Когда таблица кластеризуется, PostgreSQL запоминает, по какому индексу она была сгруппированы по. Форма CLUSTER имя_таблицы повторно кластеризует таблицу, используя тот же индекс, что и раньше. Вы также можете использовать КЛАСТЕР или НАБОР БЕЗ КЛАСТЕРНЫЕ формы ALTER ТАБЛИЦА для установки индекса, который будет использоваться для будущего кластера операций или сбросить любые предыдущие настройки.
КЛАСТЕР без параметров повторно кластеризует все ранее сгруппированные таблицы в текущем база данных, которой владеет вызывающий пользователь, или все такие таблицы, если они вызываются от суперпользователя.Эта форма КЛАСТЕРА не может быть выполнен внутри блока транзакции.
Когда таблица кластеризуется, ACCESS На нем приобретен ИСКЛЮЧИТЕЛЬНЫЙ замок. Это предотвращает любые другие операции с базой данных (как чтение, так и запись) от работы с table, пока КЛАСТЕР не будет закончен.
Параметры
- имя_таблицы
Имя (возможно, дополненное схемой) таблицы.
- имя_индекса
Имя индекса.
- VERBOSE
Печатает отчет о ходе выполнения по мере кластеризации каждой таблицы.
Банкноты
В случаях, когда вы обращаетесь к отдельным строкам случайным образом в table, фактический порядок данных в таблице не имеет значения. Однако, если вы склонны обращаться к одним данным больше, чем другим, и есть индекс, который группирует их вместе, вы выиграете от использования CLUSTER. Если ты запрос диапазона индексированных значений из таблицы или одного индексированное значение, которое имеет несколько совпадающих строк, CLUSTER поможет, потому что как только индекс определяет страницу таблицы для первой совпадающей строки, все другие совпадающие строки, вероятно, уже находятся в той же таблице страницы, и таким образом вы сохраняете доступ к диску и ускоряете запрос.
CLUSTER может пересортировать таблицу, используя либо сканирование индекса по указанному индексу, либо (если индекс b-дерево) последовательное сканирование с последующей сортировкой. Он попытается выбрать способ, который будет быстрее, исходя из стоимости планировщика параметры и доступная статистическая информация.
Когда используется сканирование индекса, временная копия таблицы создан, содержащий данные таблицы в порядке индекса. Также создаются временные копии каждого индекса в таблице.Следовательно, вам необходимо свободное место на диске как минимум равное сумме размера таблицы и размеров индекса.
При использовании последовательного сканирования и сортировки временный файл сортировки также создается, так что пиковая потребность во временном пространстве вдвое больше размера таблицы плюс размеры индекса. Этот часто быстрее, чем метод сканирования индекса, но если требование места на диске недопустимо, вы можете отключить это выбор, временно установив enable_sort на выкл.
Желательно установить maintenance_work_mem на достаточно большое значение (но не более объема оперативной памяти вы можете посвятить КЛАСТЕРУ операция) перед кластеризацией.
Потому что планировщик записывает статистику о заказе table, рекомендуется запустить ANALYZE для новой кластеризованной таблицы. В противном случае планировщик может сделать неправильный выбор запроса. планы.
Потому что КЛАСТЕР запоминает, какой индексы кластеризованы, можно кластеризовать таблицы, которые вы хотите кластеризовать вручную в первый раз, затем настроить периодический сценарий обслуживания, который выполняет CLUSTER без каких-либо параметров, так что желаемые таблицы периодически перегруппировываются.
Примеры
Сгруппируйте сотрудников таблицы на основа его индекса employee_ind:
Сотрудники КЛАСТЕРА ИСПОЛЬЗУЮТ employee_ind;
Кластеризация таблицы сотрудников с помощью тот же индекс, который использовался раньше:
Сотрудники КЛАСТЕРА;
Кластеризация всех таблиц в базе данных, которые ранее были в кластере:
КЛАСТЕР;
Совместимость
Нет оператора CLUSTER в Стандарт SQL.
Синтаксис
CLUSTER имя_индекса ON имя_таблицы
также поддерживается для совместимости с версиями PostgreSQL до 8.3.
PostgreSQL: Документация: 13: CLUSTER
КЛАСТЕР
CLUSTER — кластеризовать таблицу по индексу
Сводка
КЛАСТЕР [VERBOSE]имя_таблицы[ИСПОЛЬЗУЕТСЯимя_индекса] КЛАСТЕР [ГЛАГОЛ]
Описание
CLUSTER указывает PostgreSQL кластеризовать таблицу, указанную в table_name , на основе индекса, указанного в index_name .Индекс должен быть уже определен для имя_таблицы .
Когда таблица кластеризуется, она физически переупорядочивается на основе информации индекса. Кластеризация — это разовая операция: при последующем обновлении таблицы изменения не кластеризуются. То есть не предпринимается никаких попыток сохранить новые или обновленные строки в соответствии с порядком их индекса. (При желании можно периодически выполнять повторную кластеризацию, вводя команду еще раз. Кроме того, установка параметра хранения fillfactor таблицы на менее 100% может помочь в сохранении порядка кластеров во время обновлений, поскольку обновленные строки, если достаточно, сохраняются на той же странице там есть место.)
Когда таблица кластеризуется, PostgreSQL запоминает, по какому индексу она была кластеризована. Форма CLUSTER выполняет повторную кластеризацию таблицы с использованием того же индекса, что и раньше. Вы также можете использовать формы table_name CLUSTER или SET WITHOUT CLUSTER команды ALTER TABLE для установки индекса, который будет использоваться для будущих операций кластера, или для очистки любых предыдущих настроек.
CLUSTER без каких-либо параметров повторно кластеризует все ранее кластеризованные таблицы в текущей базе данных, принадлежащей вызывающему пользователю, или все такие таблицы, если они вызываются суперпользователем.Эта форма CLUSTER не может быть выполнена внутри блока транзакции.
Когда таблица кластеризуется, на нее устанавливается блокировка ACCESS EXCLUSIVE . Это предотвращает выполнение любых других операций с базой данных (как чтения, так и записи) над таблицей до завершения работы CLUSTER .
Параметры
-
имя_таблицы Имя (возможно, дополненное схемой) таблицы.
-
имя_индекса Имя индекса.
-
VERBOSE Печатает отчет о ходе выполнения по мере кластеризации каждой таблицы.
Банкноты
В случаях, когда вы произвольно обращаетесь к отдельным строкам в таблице, фактический порядок данных в таблице не важен. Однако, если вы склонны обращаться к одним данным чаще, чем к другим, и существует индекс, который группирует их вместе, вы выиграете от использования CLUSTER .Если вы запрашиваете диапазон индексированных значений из таблицы или одно индексированное значение, которое имеет несколько совпадающих строк, CLUSTER поможет, потому что, как только индекс идентифицирует страницу таблицы для первой совпадающей строки, все остальные строки, соответствующие вероятно, уже находятся на той же странице таблицы, поэтому вы сохраняете доступ к диску и ускоряете запрос.
CLUSTER может повторно отсортировать таблицу, используя сканирование индекса по указанному индексу или (если индекс представляет собой b-дерево) последовательное сканирование с последующей сортировкой.Он попытается выбрать более быстрый метод на основе параметров затрат планировщика и доступной статистической информации.
При сканировании индекса создается временная копия таблицы, которая содержит данные таблицы в порядке индексации. Также создаются временные копии каждого индекса в таблице. Следовательно, вам необходимо свободное пространство на диске, равное как минимум сумме размера таблицы и размеров индекса.
Когда используются последовательное сканирование и сортировка, также создается временный файл сортировки, так что максимальное временное требование к пространству вдвое превышает размер таблицы плюс размеры индекса.Этот метод часто быстрее, чем метод сканирования индекса, но если потребность в дисковом пространстве недопустима, вы можете отключить этот выбор, временно установив для параметра enable_sort значение с .
Перед кластеризацией рекомендуется установить для maintenance_work_mem достаточно большое значение (но не больше, чем объем RAM, который вы можете выделить для операции CLUSTER ).
Поскольку планировщик записывает статистику о порядке таблиц, рекомендуется выполнить ANALYZE для новой кластеризованной таблицы.В противном случае планировщик может сделать неправильный выбор планов запроса.
Поскольку CLUSTER запоминает, какие индексы кластеризованы, можно кластеризовать таблицы, которые нужно кластеризовать вручную в первый раз, а затем настроить сценарий периодического обслуживания, который выполняет CLUSTER без каких-либо параметров, чтобы желаемые таблицы периодически повторно кластеризовались.
Примеры
Кластеризация таблицы сотрудников на основе индекса employee_ind :
Сотрудники КЛАСТЕРА ИСПОЛЬЗУЮТ employee_ind;
Кластеризация таблицы сотрудников с использованием того же индекса, который использовался раньше:
Сотрудники КЛАСТЕРА;
Кластеризация всех таблиц в базе данных, которые ранее были кластеризованы:
КЛАСТЕР;
Совместимость
В стандарте SQL нет оператора CLUSTER .
Синтаксис
КЛАСТЕРимя_индексаВКЛимя_таблицы
также поддерживается для совместимости с версиями PostgreSQL до 8.3.
кластер PostgreSQL | Примеры реализации кластера PostgreSQL
Введение в кластер PostgreSQL
Основное назначение базы данных — хранить данные, необходимые пользователю, и делать их доступными для использования и манипулирования, когда это необходимо.Несмотря на то, что это утверждение, кажется, легко сказать и выполнить, в действительности очень сложно обеспечить доступность единой базы данных для всех пользователей, присутствующих в огромном количестве. Инженеры баз данных всегда сталкиваются с проблемой обеспечения высокой доступности. Чтобы преодолеть эти несколько методов, используются. Один из важнейших — кластеризация таблиц базы данных. Кластеризация — это операция, которая выполняется один раз и приводит к переупорядочению данных в таблицах на основе определенного указанного индекса, и если какой-либо индекс, присутствующий в этой таблице, не рассматривается для кластеризации.
Синтаксис:
КЛАСТЕР [ГЛАГОЛОВОЙ] nameOfTable [ИСПОЛЬЗОВАНИЕ nameOfIndex]
или
КЛАСТЕР [ГЛАГОЛОМ]
- nameOfTable: Это имя таблицы, которую вы хотите кластеризовать.
- NameOfIndex: Это имя индекса, который уже определен в таблице с именем nameOfTable, по которой вы хотите выполнить кластеризацию. Это необязательный параметр. Если не указано иное, индекс, определенный в таблице, рассматривается для кластеризации.Даже название таблицы необязательно. Если имя таблицы не указано, все таблицы, присутствующие в текущей базе данных, группируются на основе их соответствующих индексов.
- Verbose: Это необязательный параметр, при указании которого информация о процессе кластеризации, выполняемом после запуска запроса CLUSTER, печатается на консоли.
Работа кластера PostgreSQL
Это разовая операция. После этого в таблице все записи переупорядочиваются на основе определенного индекса в таблице.После этого всякий раз, когда с таблицей производятся манипуляции, например, если мы вставляем, обновляем или удаляем записи в ней, порядок во время кластеризации не сохраняется. Для этого вы можете снова периодически выполнять операцию кластеризации, когда и когда это возможно, или можете воспользоваться помощью параметра хранения с именем FILLFACTOR, который может быть установлен для таблицы, которая при значении менее 100% может поддерживать порядок кластеризации при выполнении операции обновления. поскольку значения пытаются сохранить на той же странице, если на этой странице доступно место.
Если кластеризация выполняется внутри блока транзакции, то операция кластера не выполняется. Когда ни один из параметров не указан при запуске команды кластера, тогда в зависимости от того, какой пользователь запускает команду, выполняются шаги команды. Если пользователь является суперпользователем, то все таблицы, присутствующие в этой базе данных, кластеризуются и повторно кластерируются в случае, если они уже были кластеризованы на основе соответствующего индекса. Если команду выдает не суперпользователь, то таблицы, принадлежащие этому пользователю, повторно кластеризуются, предварительно кластеризуются и кластеризуются, если операция выполняется в этой таблице впервые.
Когда мы выполняем кластеризацию для конкретной таблицы, чем в течение этого времени, мы не можем выполнять какие-либо операции чтения или записи для нее, поскольку таблица заблокирована исключительно для доступа и может быть доступна только после завершения операции кластера. Также обратите внимание, что SQL не поддерживает никаких операторов, таких как CLUSTER, в то время как в PostgreSQL работа кластера совместима со всеми последними версиями, а также с версиями, предшествующими PostgreSQL 8.3.
Примеры реализации
Manpage Ubuntu: pg_ctlcluster — запуск / остановка / перезапуск / перезагрузка кластера PostgreSQL
Предоставлено: postgresql-common_154_allНАИМЕНОВАНИЕ
pg_ctlcluster - запустить / остановить / перезапустить / перезагрузить кластер PostgreSQL
ОБЗОР
pg_ctlcluster [ options ] cluster-version cluster-name action - [ pg_ctl options ]
где действие = начало | стоп | перезапуск | перезагрузить | продвижение
ОПИСАНИЕ
Эта программа управляет сервером postmaster для конкретного кластера.Это по сути обертывает
команда pg_ctl (1). Он определяет версию кластера и путь к данным и вызывает правильный
версия pg_ctl с соответствующими параметрами конфигурации и путями.
Вы должны запустить эту программу как пользователь, владеющий кластером базы данных, или как пользователь root.
ДЕЙСТВИЯ
начало
Файл журнала для этого конкретного кластера создается, если он еще не существует (по умолчанию
/ var / log / postgresql / postgresql- cluster-version - имя-кластера .log) и PostreSQL
на нем запускается серверный процесс ( postmaster (1)). Выход с 0 в случае успеха, с 2 в случае успеха
сервер уже запущен, а 1 - в других условиях сбоя.
стоп
Останавливает сервер postmaster (1) данного кластера. По умолчанию "умный" режим выключения
используется, ожидая отключения всех клиентов.
перезапуск
Останавливает сервер, если он запущен, и запускает его (снова). перезагрузить
Вызывает перечитывание файлов конфигурации без полного выключения сервера.
продвижение
Дает команду работающему резервному серверу завершить восстановление и начать операции чтения-записи.
ОПЦИИ
-f | - сила
Для остановить и перезапустить , используется "быстрый" режим, который откатывает все активные
транзакции, немедленно отключает клиентов и, таким образом, завершает работу без ошибок.Если это
не работает, повторная попытка выключения выполняется в «немедленном» режиме, что может оставить
кластер в несогласованном состоянии и, таким образом, приведет к запуску восстановления на следующем
Начало. Если и это не помогает, процесс postmaster завершается. Выход с 0 на
Успех, с 2, если сервер не работает, и с 1 в других условиях сбоя.
Этот режим следует использовать только тогда, когда машина собирается выключить.
-м | - режим [ smart | быстро | немедленно ]
Режим выключения, используемый для действий stop и restart , по умолчанию smart .См. pg_ctl (1)
для документации.
-o | - опции опция
Передайте заданную опцию как параметр командной строки процессу postmaster. Возможно
укажите -o несколько раз. См. postmaster (1) для описания допустимых опций.
pg_ctl опции
Передайте заданные параметры pg_ctl как параметры командной строки в pg_ctl.См. pg_ctl (1) для
описание допустимых вариантов.
ФАЙЛЫ
/ etc / postgresql / версия-кластера / имя-кластера /pg_ctl.conf
Этот файл конфигурации содержит параметры, специфичные для кластера, которые необходимо передать в pg_ctl (1).
/ etc / postgresql / версия-кластера / имя-кластера /start.conf
Этот файл конфигурации управляет поведением запуска / остановки кластера.См. Раздел
«УПРАВЛЕНИЕ ЗАПУСКОМ» в pg_createcluster (8) для подробностей.
СМ. ТАКЖЕ
pg_createcluster (8), pg_ctl (1), pg_wrapper (1), pg_lsclusters (1), postmaster (1)
АВТОР
Мартин Питт
PostgreSQL: КЛАСТЕР — Повышение производительности индекса (нет индекса кластера по умолчанию)
Эта статья наполовину готова, без вашего комментария! *** Пожалуйста, поделитесь своими мыслями в комментариях ***
Я получил несколько писем, связанных с индексом кластера по умолчанию PostgreSQL, и получил от разработчиков Microsoft SQL Server.
Если вы разработчик Microsoft SQL Server, вы знаете, что первичный ключ таблицы работает как индекс кластера и находится на той же странице данных, где данные фактически хранятся.
В PostgreSQL нет такой концепции, как: Первичный ключ таблицы означает индекс кластера по умолчанию для этой таблицы.
В PostgreSQL у нас есть одна команда CLUSTER, аналогичная Cluster Index.
После создания первичного ключа таблицы или любого другого индекса вы можете выполнить команду CLUSTER, указав это имя индекса, чтобы добиться физического порядка данных таблицы.
CLUSTER предписывает PostgreSQL кластеризовать таблицу, заданную параметром table_name, на основе индекса, указанного в index_name. Индекс уже должен быть определен для table_name.
Кластеризация индекса приводит к физическому упорядочиванию данных, и вы можете иметь только один кластеризованный индекс для каждой таблицы, и вам следует тщательно выбирать, какой индекс вы будете использовать для кластеризации.
Когда таблица кластеризуется, она физически переупорядочивается на основе информации индекса.Кластеризация — это разовая операция: при последующем обновлении таблицы изменения не кластеризуются. То есть не предпринимается никаких попыток сохранить новые или обновленные строки в соответствии с порядком их индекса.
При желании вы можете периодически выполнять повторную кластеризацию, снова и снова вводя команду КЛАСТЕР.
Для выполнения команды CLUSTER требуется блокировка ACCESS EXCLUSIVE для таблицы, поскольку она переупорядочивает ваши данные. Вы также можете получить немного свободного места, выполнив CLUSTER, потому что он переупорядочивает данные в определенном порядке.
Когда вы выполняете команду CLUSTER, создается временная копия таблицы, поэтому вам необходимо свободное пространство на диске, по крайней мере, равное исходному размеру таблицы.
При сканировании индекса создается временная копия таблицы, которая содержит данные таблицы в порядке индекса. Также создаются временные копии каждого индекса в таблице. Следовательно, вам необходимо свободное пространство на диске, равное как минимум сумме размера таблицы и размеров индекса.
Перед кластеризацией рекомендуется установить для maintenance_work_mem достаточно большое значение.
После того, как вы закончите работу со своим КЛАСТЕРОМ, вы должны выполнить команду ANALYZE для этой таблицы, потому что планировщик записывает статистику о порядке таблиц.
Синтаксис кластера:
В первый раз вы должны выполнить CLUSTER, используя имя индекса.
CLUSTER имя_таблицы USING имя_индекса; |
Кластеризация таблицы:
После того, как вы выполнили CLUSTER с индексом, в следующий раз вы должны выполнить только CLUSTER TABLE, потому что он знает, какой индекс уже определен как CLUSTER.
Кластеризовать все таблицы базы данных:
Анвеш Патель
Пожалуйста, посетите другие статьи по теме …
Как настроить кластер PostgreSQL с высокой степенью доступности с помощью Patroni в Ubuntu 16.04
В этом руководстве мы будем настраивать кластер PostgreSQL высокой доступности с помощью Patroni в Alibaba Cloud Elastic Compute Service (ECS) с Ubuntu 16.
Присоединяйтесь к нам на онлайн-конференции Alibaba Cloud ACtivate 5-6 марта, чтобы оспорить предположения, обменяться идеями и изучить возможности цифровой трансформации.
Автор: Хитеш Джетва, автор публикации облачных технологий Alibaba. Tech Share — это поощрительная программа Alibaba Cloud, направленная на поощрение обмена техническими знаниями и передовым опытом в облачном сообществе.
Patroni — это инструмент с открытым исходным кодом, который можно использовать для создания и управления вашим собственным настраиваемым кластером высокой доступности для PostgreSQL с Python.Его можно использовать для выполнения таких задач, как репликация, резервное копирование и восстановление. Patroni также предоставляет конфигурацию HAProxy, предоставляя вашему приложению единую конечную точку для подключения к лидеру кластера. Если вы хотите быстро развернуть кластер HA PostgreSQL в центре обработки данных, то вам определенно стоит подумать о Patroni.
В этом руководстве мы будем настраивать кластер PostgreSQL высокой доступности с помощью Patroni на Alibaba Cloud Elastic Compute Service (ECS) с Ubuntu 16.04. Нам понадобится четыре экземпляра ECS; мы будем использовать Instance1 как ведущее устройство и Instance2 как ведомое устройство, настроить репликацию от ведущего устройства к ведомому, а также настроить автоматическое переключение на ведомое устройство, если ведущее устройство выйдет из строя.
Предварительные требования
- Четыре свежих экземпляра облака Alibaba с установленной Ubuntu 16.04.
- Статический IP-адрес настроен для каждого экземпляра.
- Для вашего экземпляра установлен пароль root.
Запуск экземпляра Alibaba Cloud ECS
Сначала войдите в свою консоль Alibaba Cloud ECS.Создайте новый экземпляр ECS, выбрав Ubuntu 16.04 в качестве операционной системы с как минимум 2 ГБ ОЗУ. Подключитесь к своему экземпляру ECS и войдите в систему как пользователь root.
После того, как вы вошли в свой экземпляр Ubuntu 16.04, выполните следующую команду, чтобы обновить базовую систему до последних доступных пакетов.
apt-get update -y Среда настройки
В этом руководстве мы будем использовать следующую настройку:
| Экземпляр | Приложение | IP-адрес |
| Экземпляр 1 | Postgres, Patroni | 192.168.0.105 |
| Экземпляр 2 | Postgres, Patroni | 192.168.0.104 |
| Экземпляр 3 | etcd | 192.168.0.103 |
| Экземпляр 4 | HAProxy | 192.168.0.102 |
Установить PostgreSQL
Во-первых, вам нужно установить PostgreSQL на Instance1 и Instance2. По умолчанию PostgreSQL доступен в Ubuntu 16.04 репозиторий. Вы можете установить его, просто выполнив следующую команду:
apt-get install postgresql -y После завершения установки проверьте состояние PostgreSQL с помощью следующей команды:
статус systemctl postgresql Выход:
● postgresql.service - СУБД PostgreSQL
Загружено: загружено (/lib/systemd/system/postgresql.service; включено; предустановка поставщика: включено)
Активен: активен (покинул) с пт 21.09.2018 20:03:04 IST; 1мин 7с назад
Основной PID: 3994 (код = выход, статус = 0 / УСПЕХ)
CGroup: / system.фрагмент / postgresql.service
21 сен 20:03:04 Node1 systemd [1]: Запуск СУБД PostgreSQL ...
21 сентября 20:03:04 Node1 systemd [1]: запущена СУБД PostgreSQL.
21 сентября 20:03:24 Node1 systemd [1]: запущена СУБД PostgreSQL. Затем остановите службу PostgreSQL, чтобы Patroni мог ею управлять:
systemctl остановить postgresql Затем вам нужно будет создать символические ссылки из /usr/lib/postgresql/9.5/bin. Потому что Patroni использует некоторые инструменты, поставляемые с PostgreSQL. Вы можете создать символическую ссылку с помощью следующей команды:
ln -s / usr / lib / postgresql / 9.5 / bin / * / usr / sbin / Установить Patroni
Вам нужно будет установить Patroni на Instance1 и Instance2.
Перед установкой Patroni вам необходимо установить Python и Python-pip на свой сервер. Вы можете установить их с помощью следующей команды:
apt-get install python3-pip python3-dev libpq-dev
sudo -H pip3 install --upgrade pip Затем установите Patroni с помощью команды pip:
pip install patroni
pip установить python-etcd Установите Etcd и HAProxy
Etcd — это распределенное хранилище значений ключей, которое обеспечивает надежный способ хранения данных в кластере машин.Здесь мы будем использовать Etcd для хранения состояния кластера Postgres. Итак, оба узла Postgres используют etcd для поддержания работоспособности кластера Postgres.
Вы можете установить Etcd на Instance3 с помощью следующей команды:
apt-get install etcd -y HAProxy — это бесплатное программное обеспечение с открытым исходным кодом, которое обеспечивает высокую доступность балансировщика нагрузки и прокси-сервер для приложений на основе TCP и HTTP, которые распределяют запросы между несколькими серверами.
Здесь мы будем использовать HAProxy для перенаправления соединения Master или Slave узла, который в настоящее время является главным и находится в сети.
Вы можете установить HAProxy на Instance4 с помощью следующей команды:
apt-get install haproxy -y Настроить и т.д.
Файл конфигурации по умолчаниюEtcd находится в каталоге / etc / default. Вам нужно будет внести некоторые изменения в файл etcd.
нано / и т.д. / по умолчанию / etcd Добавьте следующие строки:
ETCD_LISTEN_PEER_URLS = "http://192.168.0.103:2380,http://127.0.0.1:7001"
ETCD_LISTEN_CLIENT_URLS = "http: // 127.0.0.1: 2379, http://192.168.0.103:2379 "
ETCD_INITIAL_ADVERTISE_PEER_URLS = "http://192.168.0.103:2380"
ETCD_INITIAL_CLUSTER = "etcd0 = http: //192.168.0.103: 2380,"
ETCD_ADVERTISE_CLIENT_URLS = "http://192.168.0.103:2379"
ETCD_INITIAL_CLUSTER_TOKEN = "кластер1"
ETCD_INITIAL_CLUSTER_STATE = "новый" Сохраните и закройте файл, затем перезапустите службу Etcd с помощью следующей команды:
перезапуск systemctl etcd Теперь вы можете проверить статус Etcd с помощью следующей команды:
systemctl статус etcd Выход:
● etcd.service - etcd - высокодоступное хранилище значений ключей
Загружено: загружено (/lib/systemd/system/etcd.service; включено; предустановка поставщика: включено)
Активен: активен (работает) с Fri 2018-09-21 22:27:47 IST; 5с назад
Документы: https://github.com/coreos/etcd
мужчина: etcd
Основной PID: 4504 (etcd)
CGroup: /system.slice/etcd.service
└─4504 / usr / bin / etcd
21 сентября, 22:27:47 Node2 etcd [4504]: стартовый сервер ... [версия: 2.2.5, версия кластера: to_be_decided]
21 сен, 22:27:47 Node2 systemd [1]: запущено etcd - хранилище значений ключей высокой доступности.21 сентября, 22:27:47 Node2 etcd [4504]: добавлен локальный член ce2a822cea30bfca [http: // localhost: 2380 http: // localhost: 7001] в кластер 7e27652122e8b2ae
21 сентября, 22:27:47 Node2 etcd [4504]: установите начальную версию кластера 2.2.
21 сентября, 22:27:48 Node2 etcd [4504]: ce2a822cea30bfca начинает новые выборы в пятый срок.
21 сентября, 22:27:48 Node2 etcd [4504]: ce2a822cea30bfca стал кандидатом на срок 6
21 сентября, 22:27:48 Node2 etcd [4504]: ce2a822cea30bfca получил голос от ce2a822cea30bfca в шестом семестре
21 сентября, 22:27:48 Node2 etcd [4504]: ce2a822cea30bfca стал лидером в срок 6
21 сен, 22:27:48 Node2 etcd [4504]: плот.узел: ce2a822cea30bfca избранный лидер ce2a822cea30bfca на срок 6
21 сентября, 22:27:48 Node2 etcd [4504]: опубликовано {Имя: hostname ClientURLs: [http://192.168.0.103:2379]} в кластер 7e27652122e8b2ae Настроить Patroni
Patroni использует YAML для хранения своей конфигурации. Итак, вам нужно будет создать файл конфигурации для Patroni на Instance1 и Instance2:
нано /etc/patroni.yml Добавьте следующие строки:
область применения: postgres
пространство имен: / db /
имя: postgresql0
restapi:
Слушайте: 192.168.0.105: 8008
connect_address: 192.168.0.105:8008
etcd:
хост: 192.168.0.103:2379
бутстрап:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: правда
initdb:
- кодировка: UTF8
- контрольные суммы данных
pg_hba:
- репликатор репликации хоста 127.0.0.1/32 md5
- репликатор репликации хоста 192.168.0.105/0 md5
- репликатор репликации хоста 192.168.0.104/0 md5
- хостить все все 0.0.0.0 / 0 мкр5
пользователи:
админ:
пароль: admin
параметры:
- креатероль
- createdb
postgresql:
слушайте: 192.168.0.105:5432
connect_address: 192.168.0.105:5432
каталог_данных: / data / patroni
pgpass: / tmp / pgpass
аутентификация:
репликация:
имя пользователя: репликатор
пароль: пароль
суперпользователь:
имя пользователя: postgres
пароль: пароль
параметры:
unix_socket_directories: '.'
теги:
nofailover: ложь
noloadbalance: false
clonefrom: false
nosync: ложь Сохраните и закройте файл, когда закончите.
Затем создайте каталог данных для Patroni на Instance1 и Instance2:
мкдир -п / данные / патрони Затем измените владельца и разрешения каталога данных:
chown postgres: postgres / data / patroni
chmod 700 / данные / патрони Затем вам нужно будет создать сценарий запуска для Patroni для управления и мониторинга Patroni.Вы можете сделать это с помощью следующей команды:
нано /etc/systemd/system/patroni.service Добавьте следующие строки:
[Единица]
Описание = Бегуны для организации PostgreSQL с высокой доступностью
После = syslog.target network.target
[Обслуживание]
Тип = простой
Пользователь = postgres
Группа = postgres
ExecStart = / usr / local / bin / patroni /etc/patroni.yml
KillMode = процесс
TimeoutSec = 30
Перезагрузка = нет
[Установить]
WantedBy = multi-user.targ Сохраните и закройте файл.Затем запустите службу PostgreSQL и Patroni как на Instance1, так и на Instance2 с помощью следующей команды:
systemctl start patroni
systemctl запустить postgresql Затем проверьте статус Patroni, используя следующую команду:
systemctl status patroni Выход:
● patroni.service - исполнители для организации PostgreSQL с высокой доступностью.
Загружено: загружено (/etc/systemd/system/patroni.service; отключено; предустановка поставщика: включена)
Активен: активен (работает) с Fri 2018-09-21 22:22:22 IST; 3мин 17с назад
Основной PID: 3286 (патроны)
CGroup: / system.slice / patroni.service
├─3286 / usr / bin / python3 / usr / local / bin / patroni /etc/patroni.yml
├─3305 postgres -D / data / patroni --config-file = / data / patroni / postgresql.conf --max_worker_processes = 8 --max_locks_per_transaction = 64
├─3308 postgres: postgres: процесс контрольной точки
├─3309 postgres: postgres: процесс записи
├─3310 postgres: postgres: процесс сборщика статистики
├─3315 постгрес: постгрес: постгрес постгрес 192.168.0.105 (54472) холостой ход
├─3320 postgres: postgres: процесс записи wal
└─3321 postgres: postgres: процесс автоочистки
21 сен 22:24:52 Node1 patroni [3286]: 2018-09-21 22: 24: 52,329 ИНФОРМАЦИЯ: Владелец блокировки: postgresql0; Я postgresql0
21 сен 22:24:52 Node1 patroni [3286]: 2018-09-21 22: 24: 52,391 ИНФОРМАЦИЯ: никаких действий.я лидер с замком Примечание. Повторите все вышеперечисленные шаги как для экземпляра 1, так и для экземпляра 2.
Настроить HAProxy
КластерPostgreSQL теперь запущен и работает. Пришло время настроить HAProxy на пересылку соединения, полученного от клиента PostgreSQL, на главный узел.
Вы можете настроить HAProxy, отредактировав файл /etc/haproxy/haproxy.cfg:
нано /etc/haproxy/haproxy.cfg Добавьте следующие строки:
по всему миру
maxconn 100
значения по умолчанию
журнал глобальный
режим tcp
повторных попыток 2
время ожидания клиента 30 мин.
тайм-аут подключения 4 с
тайм-аут сервера 30 мин.
проверка тайм-аута 5 секунд
слушать статистику
режим http
привязка *: 7000
статистика включить
статистика uri /
послушай постгрес
привязка *: 5000
вариант httpchk
http-check ожидает статус 200
default-server inter 3s падает 3 поднимается 2 on-mark-down shutdown-sessions
сервер postgresql_192.168.0.105_5432 192.0.2.11:5432 maxconn 100 проверить порт 8008
сервер postgresql_192.168.0.104_5432 192.0.2.12:5432 maxconn 100 проверить порт 8008 Сохраните и закройте файл. Затем перезапустите HAProxy с помощью следующей команды:
systemctl перезапуск haproxy Тестовый кластер PostgreSQL
Теперь откройте свой веб-браузер и введите URL-адрес http://192.168.0.102:7000 (IP-адрес HAProxy Instance4). Вы будете перенаправлены на панель инструментов HAProxy, как показано ниже:
На изображении выше postgresql_192.Строка 168.0.105_5432 выделена зеленым цветом. Это означает, что 192.168.0.105 в настоящее время действует как главный.
Если вы выключите основной узел (Экземпляр 1), 192.168.0.104 (Экземпляр 2) должен действовать как главный.
Когда вы перезапустите Instance1, он снова присоединится к кластеру как подчиненный и синхронизируется с главным.
.