Как думать на SQL? / Хабр
Надо “SELECT * WHERE a=b FROM c” или “SELECT WHERE a=b FROM c ON *” ?
Если вы похожи на меня, то согласитесь: SQL — это одна из тех штук, которые на первый взгляд кажутся легкими (читается как будто по-английски!), но почему-то приходится гуглить каждый простой запрос, чтобы найти правильный синтаксис.
А потом начинаются джойны, агрегирование, подзапросы, и получается совсем белиберда. Вроде такой:
SELECT members.firstname || ' ' || members.lastname
AS "Full Name"
FROM borrowings
INNER JOIN members
ON members.memberid=borrowings.memberid
INNER JOIN books
ON books.bookid=borrowings.bookid
WHERE borrowings.bookid IN (SELECT bookid
FROM books
WHERE stock>(SELECT avg(stock)
FROM books))
GROUP BY members.firstname, members.lastname;Буэ! Такое спугнет любого новичка, или даже разработчика среднего уровня, если он видит SQL впервые. Но не все так плохо.
Легко запомнить то, что интуитивно понятно, и с помощью этого руководства я надеюсь снизить порог входа в SQL для новичков, а уже опытным предложить по-новому взглянуть на SQL.
Не смотря на то, что синтаксис SQL почти не отличается в разных базах данных, в этой статье для запросов используется PostgreSQL. Некоторые примеры будут работать в MySQL и других базах.
В SQL много ключевых слов, но SELECT, FROM и WHERE присутствуют практически в каждом запросе. Чуть позже вы поймете, что эти три слова представляют собой самые фундаментальные аспекты построения запросов к базе, а другие, более сложные запросы, являются всего лишь надстройками над ними.
Давайте взглянем на базу данных, которую мы будем использовать в качестве примера в этой статье:
(ссылка на таблицу)
У нас есть книжная библиотека и люди. Также есть специальная таблица для учета выданных книг.
- В таблице «books» хранится информация о заголовке, авторе, дате публикации и наличии книги. Все просто.
- В таблице “members” — имена и фамилии всех записавшихся в библиотеку людей.

- В таблице “borrowings” хранится информация о взятых из библиотеки книгах. Колонка
bookidотносится к идентификатору взятой книги в таблице “books”, а колонкаmemberidотносится к соответствующему человеку из таблицы “members”. У нас также есть дата выдачи и дата, когда книгу нужно вернуть.
Давайте начнем с простого запроса: нам нужны имена и идентификаторы (id) всех книг, написанных автором “Dan Brown”
Запрос будет таким:
SELECT bookid AS "id", title
FROM books
WHERE author='Dan Brown';А результат таким:
| id | title |
|---|---|
| 2 | The Lost Symbol |
| 4 | Inferno |
Довольно просто. Давайте разберем запрос чтобы понять, что происходит.
3.1 FROM — откуда берем данные
Сейчас это может показаться очевидным, но FROM будет очень важен позже, когда мы перейдем к соединениям и подзапросам.
FROM указывает на таблицу, по которой нужно делать запрос. Это может быть уже существующая таблица (как в примере выше), или таблица, создаваемая на лету через соединения или подзапросы.
3.2 WHERE — какие данные показываем
WHERE просто-напросто ведет себя как фильтр строк, которые мы хотим вывести. В нашем случае мы хотим видеть только те строки, где значение в колонке author — это “Dan Brown”.
3.3 SELECT — как показываем данные
Теперь, когда у нас есть все нужные нам колонки из нужной нам таблицы, нужно решить, как именно показывать эти данные. В нашем случае нужны только названия и идентификаторы книг, так что именно это мы и выберем с помощью SELECT. Заодно можно переименовать колонку используя AS.
Весь запрос можно визуализировать с помощью простой диаграммы:
4. Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
SELECT books. title AS "Title", borrowings.returndate AS "Return Date"
FROM borrowings JOIN books ON borrowings.bookid=books.bookid
WHERE books.author='Dan Brown';
title AS "Title", borrowings.returndate AS "Return Date"
FROM borrowings JOIN books ON borrowings.bookid=books.bookid
WHERE books.author='Dan Brown';Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции FROM. Это означает, что мы запрашиваем данные из другой таблицы. Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице, которая создалась соединением этих двух таблиц.
borrowings JOIN books ON borrowings.bookid=books.bookid — это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц «books» и «borrowings», в которых значения bookid совпадают. Результатом такого слияния будет:
Результатом такого слияния будет:
А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 — откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
borrowings
JOIN books ON borrowings.bookid=books.bookid
JOIN members ON members.memberid=borrowings.memberidРезультат соединения можно увидеть по ссылке.
Шаг 2 — какие данные показываем? Нас интересуют только те данные, где автор книги — “Dan Brown”
WHERE books. author='Dan Brown'
author='Dan Brown'Шаг 3 — как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
SELECT
members.firstname AS "First Name",
members.lastname AS "Last Name"Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
SELECT
members.firstname AS "First Name",
members.lastname AS "Last Name"
FROM borrowings
JOIN books ON borrowings.bookid=books.bookid
JOIN members ON members.memberid=borrowings.memberid
WHERE books.author='Dan Brown';Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
SELECT
members.firstname AS "First Name",
members.lastname AS "Last Name",
count(*) AS "Number of books borrowed"
FROM borrowings
JOIN books ON borrowings.bookid=books.bookid
JOIN members ON members.memberid=borrowings.memberid
WHERE books.author='Dan Brown'
GROUP BY members.firstname, members.lastname;Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением GROUP BY. Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в
Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в GROUP BY. В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с count, которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.
Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в GROUP BY, или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их
В примере выше функция count обрабатывала все строки (так как мы считали количество строк). Другие функции вроде
Другие функции вроде sum или max обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
SELECT author, sum(stock)
FROM books
GROUP BY author;Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция sum обрабатывает только колонку stock и считает сумму всех значений в каждой группе.
Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
6.1 Двумерная таблица
Есть запросы, которые возвраща
Что такое SQL
Что такое SQL. Давайте попробуем разобраться в этом вопросе.
Рано или поздно, при разработке программ, не важно на каком языке программирования вы работаете, вам придется столкнуться с работой с базой данных.
Когда пишется какая-то программа, она, как правило, работает с какими-то данными и эти данные нужно где-то хранить. Хранить их в памяти, не лучшая идея. Данных может быть много (они просто не поместятся в оперативную память) и к этим данным нужно обращаться через какое-то время и после отключения компьютера.
Нужно где-то хранить данные, которые обрабатывает программа. Эти данные хранятся в базе данных.
Не важно, какая это база данных. У нас есть программа и эта программа обрабатывает какие-то данные, которые хранятся в базе данных.
Как же мы можем «общаться» с данными, которые хранятся в базе данных?
Как их можно прочитать, добавить, удалить и обновить?
Для решения этой проблемы, в большинстве случаев, для общения программы с базой данных используется специальный язык программирования, который называется SQL.
Это структурированный язык запросов, которые мы можем делать к базе данных и каким-то образом взаимодействовать с теми данными, которые там находятся.
Это будет в большинстве случаев. В зависимости от той базы данных, с которой вы работаете могут быть исключения, но как правило, общаться с базами данных можно с помощью языка SQL.
SQL — это стандарт, который используется для многих баз данных. Производители баз данных используют для взаимодействия с данными, которые в этих базах данных хранятся, язык SQL.
Это достаточно сложный язык, в нем можно выполнять сложные логические операции, поэтому его еще называют языком программирования.
Но, по сути, это не совсем язык программирования. Это структурированный язык запросов, с помощью которого мы общаемся с базами данных.
Не все базы данных могут понимать язык SQL, те, которые не понимают его, они называются noSQL базы данных. Есть даже такой термин noSQL.
SQL — это такой общий стандарт.
В видео вы можете видеть несколько команд на этом языке. Вот такой вот смысл понятия SQL.
SQL — операторы | ИТ Блог. Администрирование серверов на основе Linux (Ubuntu, Debian, CentOS, openSUSE)
Что такое оператор в SQL?
Оператор – это зарезервированное слово или символ, используемый в основном в WHERE и давал инструкцию SQL для выполнения операции (ий), например, сравнения и арифметических операций.Операторы используются для определения условий в SQL и служат в качестве соединений для нескольких условий в заявлении.
- Арифметические операторы
- Операторы сравнения
- Логические операторы
- Операторы, используемые для отрицания условия
Арифметические операторы в SQL:
Предположим, переменная а равна 10, а переменная b равна 20, тогда:
Показать примеры
| оператор | Описание | пример |
|---|---|---|
| + | Добавление – Добавление значения по обе стороны от оператора | a + b = 30 |
| – | Вычитание – Вычитание правого операнда из левого операнда | а – b = -10 |
| * | Умножение – Умножение значения по обе стороны от оператора | а * б = 200 |
| / | Деление – Делит левый операнд на правый операнда | b / a = 2 |
| % | Модуль – Делит левый операнд на правый операнд и возвращает остаток | b % а = 0 |
Операторы сравнения в SQL:
Предположим, переменная а равно 10, а переменная b равна 20, тогда:
Показать примеры
| оператор | Описание | пример |
|---|---|---|
| = | Проверяет, является ли значения двух операндов равны или нет, если да, то условие становится истинным. | (a = b) не соответствует действительности. |
| != | Проверяет, является ли значения двух операндов равны или нет, если значения не равны, то условие становится истинным. | (a != b) истинно. |
| <> | Проверяет, является ли значения двух операндов равны или нет, если значения не равны, то условие становится истинным. | (a <> b) истинно. |
| > | Проверяет, является ли значение левого операнда больше значения правого операнда, если да, то условие становится истинным. | (a > b) не соответствует действительности. |
| < | Проверяет, является ли значение левого операнда меньше значения правого операнда, если да, то условие становится истинным. | (a < b) истинно. |
| > = | Проверяет, является ли значение левого операнда больше или равно значению правого операнда, если да, то условие становится истинным. | (a >= b) неверно. |
| <= | Проверяет, является ли значение левого операнда меньше или равно значению правого операнда, если да, то условие становится истинным. | (a <= b) истинно. |
| <! | Проверяет, является ли значение левого операнда не меньше, чем значение правого операнда, если да, то условие становится истинным. | (a! < b) неверно. |
| !> | Проверяет, является ли значение левого операнда не больше, чем значение правого операнда, если да, то условие становится истинным. | (a! > b) верно. |
Логические операторы в SQL:
Вот список всех логических операторов, доступных в SQL.
Показать примеры
| оператор | Описание |
|---|---|
| ALL | Оператор ALL используется для сравнения значения для всех значений в другом наборе значений. |
| AND | Оператор AND допускает существование нескольких условий в SQL-инструкции WHERE. |
| ANY | Оператор ANY используется для сравнения любого применимого значения в списке в соответствии с условиями. |
| BETWEEN | Оператор BETWEEN используется для поиска значений, которые находятся в пределах набора значений, учитывая минимальное значение и максимальное значение. |
| EXIST | Оператор EXISTS используется для поиска наличия строки в указанной таблице, которая соответствуют определенным критериям. |
| IN | Оператор IN используется для сравнения значения в списке буквенных значений, которые были определены. |
| LIKE | Оператор LIKE используется для сравнения аналогичных значений с использованием подстановочных операторов. |
| NOT | Оператор NOT изменяет значение логического оператора, с которым она используется. Например: NOT EXISTS, NOT BETWEEN, NOT IN и т.д. Это оператор отрицает. |
| OR | Оператор OR используется для объединения нескольких условий в SQL-инструкции WHERE. |
| IS NULL | Оператор NULL, используется для сравнения значения со значением NULL. |
| UNIQUE | Единственный оператор выполняет поиск каждой строки из указанной таблицы для уникальности (без дубликатов). |
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Полезные оконные функции SQL — Разработка на vc.ru
{«id»:130856,»url»:»https:\/\/vc.ru\/dev\/130856-poleznye-okonnye-funkcii-sql»,»title»:»\u041f\u043e\u043b\u0435\u0437\u043d\u044b\u0435 \u043e\u043a\u043e\u043d\u043d\u044b\u0435 \u0444\u0443\u043d\u043a\u0446\u0438\u0438 SQL»,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/dev\/130856-poleznye-okonnye-funkcii-sql»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/dev\/130856-poleznye-okonnye-funkcii-sql&title=\u041f\u043e\u043b\u0435\u0437\u043d\u044b\u0435 \u043e\u043a\u043e\u043d\u043d\u044b\u0435 \u0444\u0443\u043d\u043a\u0446\u0438\u0438 SQL»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter. com\/intent\/tweet?url=https:\/\/vc.ru\/dev\/130856-poleznye-okonnye-funkcii-sql&text=\u041f\u043e\u043b\u0435\u0437\u043d\u044b\u0435 \u043e\u043a\u043e\u043d\u043d\u044b\u0435 \u0444\u0443\u043d\u043a\u0446\u0438\u0438 SQL»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/dev\/130856-poleznye-okonnye-funkcii-sql&text=\u041f\u043e\u043b\u0435\u0437\u043d\u044b\u0435 \u043e\u043a\u043e\u043d\u043d\u044b\u0435 \u0444\u0443\u043d\u043a\u0446\u0438\u0438 SQL»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/dev\/130856-poleznye-okonnye-funkcii-sql»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u041f\u043e\u043b\u0435\u0437\u043d\u044b\u0435 \u043e\u043a\u043e\u043d\u043d\u044b\u0435 \u0444\u0443\u043d\u043a\u0446\u0438\u0438 SQL&body=https:\/\/vc.
com\/intent\/tweet?url=https:\/\/vc.ru\/dev\/130856-poleznye-okonnye-funkcii-sql&text=\u041f\u043e\u043b\u0435\u0437\u043d\u044b\u0435 \u043e\u043a\u043e\u043d\u043d\u044b\u0435 \u0444\u0443\u043d\u043a\u0446\u0438\u0438 SQL»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/dev\/130856-poleznye-okonnye-funkcii-sql&text=\u041f\u043e\u043b\u0435\u0437\u043d\u044b\u0435 \u043e\u043a\u043e\u043d\u043d\u044b\u0435 \u0444\u0443\u043d\u043a\u0446\u0438\u0438 SQL»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.shareUrl=https:\/\/vc.ru\/dev\/130856-poleznye-okonnye-funkcii-sql»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=\u041f\u043e\u043b\u0435\u0437\u043d\u044b\u0435 \u043e\u043a\u043e\u043d\u043d\u044b\u0435 \u0444\u0443\u043d\u043a\u0446\u0438\u0438 SQL&body=https:\/\/vc. ru\/dev\/130856-poleznye-okonnye-funkcii-sql»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorit
ru\/dev\/130856-poleznye-okonnye-funkcii-sql»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorit
Почему растет LOG в MS SQL ?
Почему растет LOG в MS SQL ?
Друзья, почти ежедневно сталкиваюсь с тем, что на курсе: Администратор 1С, при опросе студентов, на предмет «Как Вы организовали бэкап в MS SQL?». Очень редко кто пишет: «Да, помимо «полного» я делаю и бэкап журналов транзакций».
К сожалению, редко кто делает бэкап ЖТР (
И тем самым открывает прямой путь к таким проблемам как:
«Распух лог в MS SQL», «Сильно увеличился LDF», «Разрастается log, что делать?», «Журнал занял все свободное место на диске», и многое, многое другое.
В этой статье я не буду рассыпать терминами и сложными понятиями гуру специалиста DBA, нет!
Так как вижу реальную картину, реальную проблематику вопроса, на более чем 5000 тыс студентов (Что проходили у нас курс: Администратор 1С). И реальность она несколько в другом!
И реальность она несколько в другом!
Большинство не делает бэкапов журналов транзакций, так как не понимает зависимостей (связей), между их созданием и размерами самого журнала (*ldf).
Собственно цель данной статьи, максимально понятно, на простом языке, объяснить и закрыть раз и навсегда проблему растущего лога в MS SQL!
Приступим…
Кратко пройдемся по основам, чтоб даже новички быстро смогли уловить суть и не потеряться в терминах.
Файл *LDF он же и есть наш журнал транзакций!
Что там хранится?
Каждая база данных SQL Server имеет журнал транзакций, в котором фиксируются все транзакции и производимые ими в базе изменения.
Журнал транзакций — это важная составляющая базы данных. Если система даст сбой, этот журнал поможет вам вернуть базу данных в согласованное состояние.
Если говорить еще проще, благодаря бэкапу ЖТР есть возможность восстановить базу фактически на любой момент времени (вплоть до нужной секунды)!
При этом следует понимать, что никаких по факту данных из 1С в прямом смысле этого слова в журнале нет!
Все данные пишутся в файл *mdf, а вот фиксация этих действий пишется в *ldf, по каждому действию (транзакции), что происходит у Вас в 1С. Все что делают пользователи в 1С, фиксируется в журнале транзакций, только сам факт (фиксация) произошедших событий в базе, а не сами данные.
Все что делают пользователи в 1С, фиксируется в журнале транзакций, только сам факт (фиксация) произошедших событий в базе, а не сами данные.
Собственно отсюда и название «Журнал транзакций». Конечно на практике все сложнее, но в упрощенном для понимания виде все именно так.
Почему растет лог файл в MS SQL (*ldf) ?
Конечно, если учитывать что каждое действие сделанное пользователем в 1С фиксируется в журнале транзакций, то он просто не может не расти! И здесь также стоит отметить, что не только действие пользователя влияет на рост журнала, но и различные регламентные задачи (фоновые различные процессы), особенно сильно заметен рост, когда происходит в базе 1С реструктуризация. Собственно при обновлении конфигурации также можем замечать “взрывной” рост журнала транзакций.
К слову мы только что ответили на частый вопрос: «Вот у меня лог не разрастался» в базе «А», а в базе «Б» растет очень быстро».
Конечно если с базой «Б» пользователи работают интенсивно или различные фоновые, регламентные задачи (их много), безусловно, он будет расти быстрее, такова физика работы «MS SQL»!
MS SQL всегда (в “полной” модели восстановления) будет пытаться зафиксировать, фактически все действия в базе. И журнал будет расти до тех пор, пока мы не сделаем его бэкап, этим мы и «усекаем» его!
И журнал будет расти до тех пор, пока мы не сделаем его бэкап, этим мы и «усекаем» его!
«Простая» и «полная» модель восстановления
Да, «полная» модель восстановления подразумевает, что в журнал будем писать «По максимуму» все возможное. Все что сможет записать MS SQL, он туда запишет. Исключения конечно есть. К примеру, когда свободное место закончилось на диске или есть ограничения на сам лог (если установили). Есть и другие причины, но мы сейчас не об этом.
Нам важно понимать одно: «Полная» модель = «Полный» лог! А значит, есть возможность не терять данные, при необходимости восстановится на любой момент времени (фактически до секунды), а выполнив бэкап еще и «заключительного фрагмента журнала» и вообще ничего не потерять!
На сайте Microsoft можно найти информацию о том, что единственная «рабочая» модель, предназначенная для реальной работы, есть только «Полная» модель восстановления! Так как в работе недопустимо терять данные, а это гарантированно произойдет в «Простой» модели восстановления, если случится “сбой”.
«Простая» модель восстановления может использоваться для тестирования, разработки, для временного переключения (Обязательно! С предварительным бэкапом базы и лога). К примеру, только на время реструктуризации ее можно включить, а потом обратно вернуть в «Полную» модель. Есть и другие случаи, когда мы только временно переключаем режим с «Полной в Простой» Но работаем всегда в “полной” модели восстановления!
В “простой” модели мы никак не можем восстановиться (в случаи чего) на интересующий нас момент времени. Только на тот момент, когда сделан либо «полный» бэкап, либо «полный» + «разностный»!
Вывод:
Только в «полной» модели мы должны работать! Она не зря «по умолчанию» в MS SQL!
«Активная» и «Неактивная» часть журнала
Сперва дадим ответ на вопрос: «Что происходит в момент создания бэкапа ЖТР ?»
Чтоб разобраться в этом вопросе, нам нужно понимать, что журнал транзакций может быть «условно разделен» на две части: «Активная» и «Неактивная» часть журнала.
«Активная» – содержит изменения, которые были сделаны в базе, но еще не зафиксированы на диске.
«Неактивная» – изменения уже зафиксированы на диске, следовательно, можно усекать неактивную часть журнала (делать бэкап), вплоть до его активной части!
Неактивная часть журнала транзакций содержит информацию о завершенных транзакциях и не используется сервером SQL Server в процессе восстановления данных. Вместо увеличения размера файла журнала транзакций SQL Server будет повторно использовать освободившееся пространство.
И вот в момент, когда мы создаем бэкап журналов транзакций, мы тем самым «усекаем» его «неактивную» часть (точнее это делает сам MS SQL), вплоть до начала его активной части!
При этом вначале всегда происходит его бэкап, а только после уже «усечение», как на рисунке выше.
Бэкап журналов нужно делать довольно часто (раз на 30-60 мин), особенно если с базой активно работают пользователи, он может вырасти довольно быстро, и конечно без автоматизации этого процесса не обойтись!
Также мы можем сделать и бэкап «заключительного фрагмента журнала транзакций», если нужно восстановить базу на самый последний момент времени.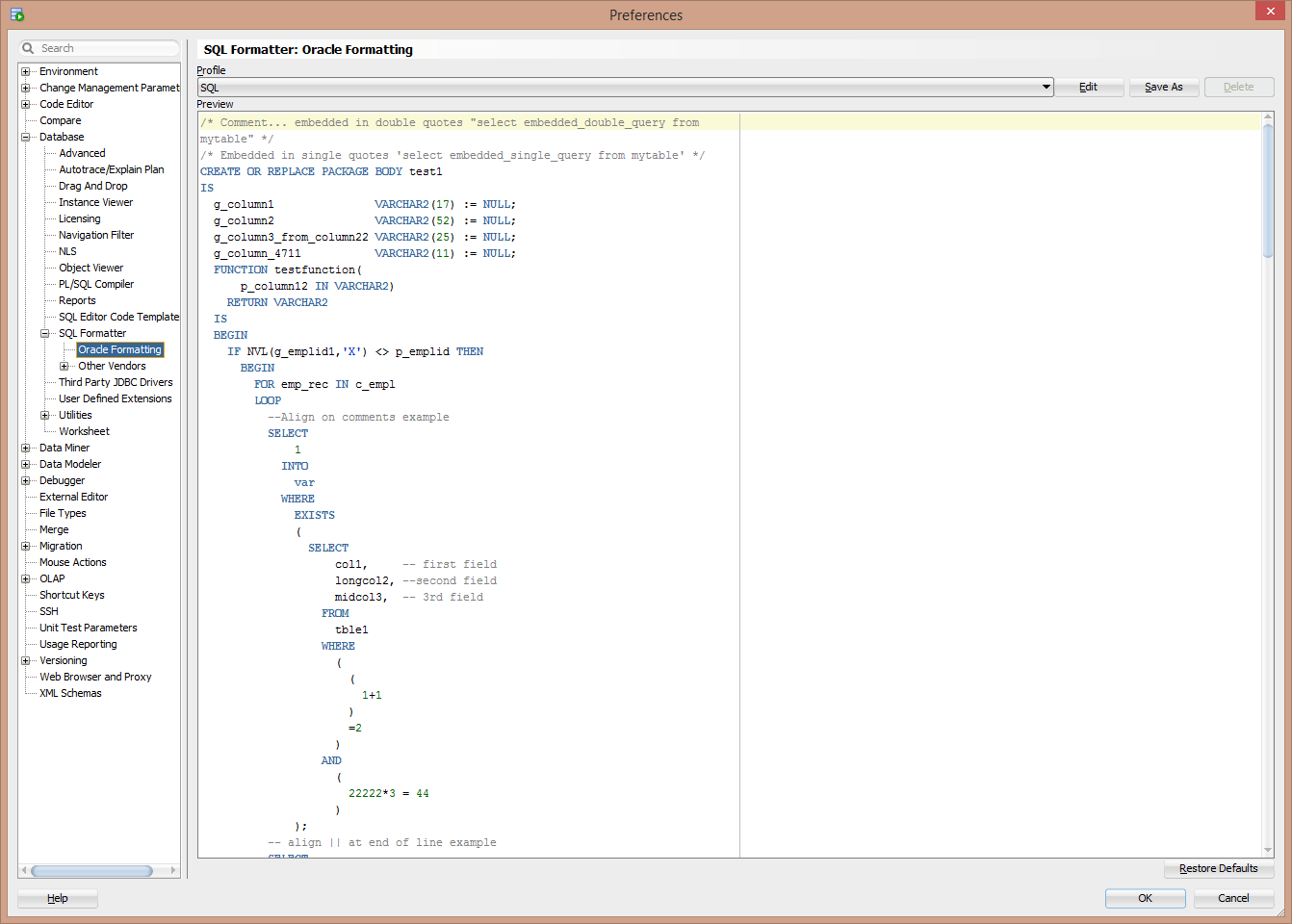 В таком случаи мы также усекаем журнал (ту часть, что есть на момент создания самого заключительного фрагмента журнала).
В таком случаи мы также усекаем журнал (ту часть, что есть на момент создания самого заключительного фрагмента журнала).
Вывод:
В «полной» модели восстановления бэкап журналов транзакций НЕОБХОДИМ! Если Вы не хотите в один прекрасный день обнаружить, что свободное место на диске, где он находится, уже закончилось!
Если ЛОГ уже вырос ?
Конечно, если Вы раньше не делали бэкапов журналов, лог соответственно вырос, то здесь одним бэкапом журналов транзакций не обойтись!
И вот почему:
Если Вы хотите больше узнать о технической стороне 1С, тогда регистрируйтесь на первый бесплатный модуль курса: Администратор 1С >>>
Успехов Вам, Коллега!
С уважением, Богдан.
Что такое SQL
SQL означает S Tructured Q uery L anguage
SQL — стандартный язык для доступа к базам данных
SQL является международным стандартом (ISO) с 1987 г.
Операторы SQL
Для доступа к базе данных вы используете операторы SQL.
Следующий оператор SQL выбирает все записи в таблице базы данных под названием «Клиенты»:
Таблицы базы данных
База данных чаще всего содержит одну или несколько таблиц.
Каждая таблица обозначается таким именем, как «Клиенты» или «Заказы».
Ниже представлен выбор из таблицы «Клиенты»:
| ID | Имя клиента | ContactName | Адрес | Город | Почтовый индекс | Страна |
|---|---|---|---|---|---|---|
| 1 | Альфредс Футтеркисте | Мария Андерс | Обере, ул.57 | Берлин | 12209 | Германия |
| 2 | Ana Trujillo Emparedados y helados | Ана Трухильо | Avda. de la Constitución 2222 | México D. F. F. | 05021 | Мексика |
| 3 | Антонио Морено Такерия | Антонио Морено | Матадерос 2312 | Мексика Д.F. | 05023 | Мексика |
| 4 | Вокруг Рога | Томас Харди | 120 Ганновер пл. | Лондон | WA1 1DP | Великобритания |
| 5 | Berglunds snabbköp | Кристина Берглунд | Berguvsvägen 8 | Лулео | С-958 22 | Швеция |
Таблица выше содержит пять записей (по одной для каждого клиента) и семь столбцов:
- CustomerID (ID)
- CustomerName
- ContactName
- Адрес
- Город
- Почтовый индекс
- Страна
Самые важные операторы SQL:
- SELECT — извлекает данные из базы данных
- UPDATE — обновляет данные в базе данных
- DELETE — удаляет данные из базы данных
- INSERT INTO — вставляет новые данные в базу данных
- CREATE DATABASE — создает новую базу данных
- ALTER DATABASE — изменяет базу данных
- CREATE TABLE — создает новую таблицу
- ALTER TABLE — изменяет таблицу
- DROP TABLE — удаляет таблицу
- CREATE INDEX — создает индекс (ключ поиска)
- DROP INDEX — удаляет индекс
Ключевые слова SQL НЕ чувствительны к регистру: select совпадает с SELECT
Полное руководство по SQL
Это было краткое введение в SQL.
Для получения полного руководства по SQL перейдите к W3Schools SQL Tutorial.
Что такое SQL? Изучение основ SQL, полная форма SQL и способы использования
- Домашняя страница
Тестирование
- Назад
- Гибкое тестирование
- BugZilla
- Cucumber
- Тестирование базы данных
JM- Тестирование ETL
- Назад
- JUnit
- LoadRunner
- Ручное тестирование
- Мобильное тестирование
- Mantis
- Почтальон
- QTP
- Назад
- Центр контроля качества SAP ALM
- Центр контроля качества
- SoapUI
- Управление тестированием
- TestLink
SAP
- Назад
- ABAP 90 133
- APO
- Начинающий
- Basis
- BODS
- BI
- BPC
- CO
- Назад
- CRM
- Crystal Reports 9013 9013 9013 9013 HAN321 901 901 HR1 901 HR1 Расчет заработной платы
- Назад
- PI / PO
- PP
- SD
- SAPUI5
- Безопасность
- Менеджер решений
- Successfactors
- SAP Tutorials
- Назад
- Java
- JSP
- Kotlin MY
- Linux 90D133
- Kotlin MY
- Linux 90D js
- Perl
- Назад
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala 903
- SQL 901 901 901 SQL Server 901 901 SQL 901
- UML
- VB.Net
- VBScript
- Веб-службы
- WPF
Обязательно изучите!
- Назад
- Бухгалтерский учет
- Алгоритмы
- Android
- Блокчейн
- Бизнес-аналитик
- Создание веб-сайта
- Облачные вычисления
- COBOL
Учебные пособия по Excel Программирование на Go IoT ITIL Jenkins MIS Сеть Операционная система - Назад
- Обзоры 903 903 903 903
- Prep
903- Управление проектами Salesforce
- SEO
- Разработка программного обеспечения
- VBA
901 33 Big Data
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Data Warehousing
- DevOps Back
903 901 9019 HBase 901 901 HBase 901- MongoDB
- NiFi
Что такое база данных? Определение, значение, типы, пример
- Домашняя страница
Тестирование
- Назад
- Гибкое тестирование
- BugZilla
- Cucumber
- Тестирование базы данных
Jmeter
- 901 901 Jmeter Тестирование базы данных
- ETL 901
- JUnit
- LoadRunner
- Ручное тестирование
- Мобильное тестирование
- Mantis
- Почтальон
- QTP
- Назад
- Центр качества SAPU (ALM)
9013- RPA
- Центр контроля качества SAPU3
- RPA Управление тестированием
- TestLink
SAP
- Назад
- ABAP
901 32 APO
- Начинающий
- Basis
- BODS
- BI
- BPC
- CO
- Назад
- CRM
- Crystal Reports
- FICO
9013 9013 903 9013 903 903 903 9013 903 903 903 903 903 903 9013 903 903 903 903 903 9013 903 9013 903 9013 903 903 9013 903 901
- Назад
- PI / PO
- PP
- SD
- SAPUI5
- Безопасность
- Менеджер решений
- Successfactors
- SAP Tutorials
2 901 УгловойJS ASP. Сеть
Сеть C C # C ++ CodeIgniter СУБД JavaScript - Назад
- Java
- JSP
- Kotlin
MY- Linux 90D133
- Kotlin
MY- Linux 90D js
- Perl
- Назад
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala
903- SQL
901 901 901 SQL Server 901 901 SQL 901- UML
- VB.Net
- VBScript
- Веб-службы
- WPF
Обязательно изучите!
- Назад
- Бухгалтерский учет
- Алгоритмы
- Android
- Блокчейн
- Бизнес-аналитик
- Создание веб-сайта
- Облачные вычисления
- COBOL
COBOL Компилятор Дизайн Учебные пособия по Excel Программирование на Go IoT ITIL Jenkins MIS Сеть Операционная система - Назад
- Обзоры 903 903 903 903
- Prep
903- Управление проектами Salesforce
- SEO
- Разработка программного обеспечения
- VBA
901 33 Big Data
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Data Warehousing
- DevOps Back
903 901 9019 HBase 901 901 HBase 901- MongoDB
Что такое SQL | Ключевая концепция
Что такое SQL?
Язык, специфичный для предметной области, разработанный для управления данными и хранящийся в системе управления реляционными базами данных, называется SQL. SQL — это аббревиатура от языка структурированных запросов, разработанная ISO / IEC, и дисциплина типизации стала более строгой. Операторы используются для выполнения многих операций с базой данных, таких как извлечение данных, обновление данных, удаление и переименование данных и удаление данных. Oracle, SyBase, Microsoft SQL Server — это некоторые из баз данных, использующих язык SQL. Мы не можем назвать SQL языком программирования, но у него есть некоторые стандарты для создания процедурных расширений, так что функциональные возможности могут быть расширены для формирования языка программирования.
SQL — это аббревиатура от языка структурированных запросов, разработанная ISO / IEC, и дисциплина типизации стала более строгой. Операторы используются для выполнения многих операций с базой данных, таких как извлечение данных, обновление данных, удаление и переименование данных и удаление данных. Oracle, SyBase, Microsoft SQL Server — это некоторые из баз данных, использующих язык SQL. Мы не можем назвать SQL языком программирования, но у него есть некоторые стандарты для создания процедурных расширений, так что функциональные возможности могут быть расширены для формирования языка программирования.
РСУБД
Прежде чем понимать SQL, нам нужно сначала понять СУБД. СУБД или система управления реляционными базами данных — это просто база данных, в которой хранятся структурированные данные, и между ними существует связь. Он хранит данные в табличном формате. В нем есть столбец и строки, содержащие связанные записи данных. Столбцы — это вертикальный элемент таблицы. Он содержит атрибут записей, а строки представляют собой горизонтальный объект, который содержит записи / данные. На пересечении строк и столбцов содержится информация записи относительно этого атрибута.Ниже приведен пример таблицы.
На пересечении строк и столбцов содержится информация записи относительно этого атрибута.Ниже приведен пример таблицы.
ЗаказчикДетейл:
ID
Имя Возраст
1
Мэтью 35 2
Иоанна
46
3
Линда
25
4
Кен
20
5
Лилия
18
6 Тайсон 21
Понимание SQL
Это язык, используемый для запросов к табличным данным.В отличие от других языков, SQL является декларативным языком, нужно просто указать результат, который они хотят видеть, и отправить запрос в СУБД. РСУБД выполняет код на бэкэнде и дает желаемый результат. В то время как на процедурном языке мы должны указывать компьютеру каждый шаг, который нужно выполнить, чтобы получить результат. Поэтому, если вы хотите выбрать данные из приведенной выше таблицы, вам просто нужно написать запрос ниже и выполнить его.
РСУБД выполняет код на бэкэнде и дает желаемый результат. В то время как на процедурном языке мы должны указывать компьютеру каждый шаг, который нужно выполнить, чтобы получить результат. Поэтому, если вы хотите выбрать данные из приведенной выше таблицы, вам просто нужно написать запрос ниже и выполнить его.
ВЫБРАТЬ * ИЗ CustomerDetail;
Путаница с SQL — это синтаксис SQL-запроса.Элементы не выполняются в том порядке, в котором они используются в запросе. Рассмотрите возможность выбора данных из приведенной выше таблицы CustomerDetail.
ВЫБЕРИТЕ ID, имя, возраст FROM CustomerDetail
WHERE Age> 20
Упорядочить по ID DESC;
Приведенный выше запрос выберет все записи, возраст которых превышает 20, и отобразит результат в порядке идентификатора. Последовательность выполнения элементов следующая:
- FROM: В запросе сначала выполняется предложение FROM.Он выбирает таблицы и объединяет таблицы для получения базовых данных.
- WHERE: Этот пункт фильтрует базовые данные. Чтобы в дальнейшей обработке было меньше записей.
- GROUP BY: Предложение Group By объединяет строки в группы для выполнения агрегирования.
- HAVING: Этот пункт используется для фильтрации
Что такое SQL Server — DatabaseJournal.com
Введение
В этой статье представлен SQL Server, что это такое и почему
использовать это.Мы также рассмотрим, когда использовать базу данных, а когда нет. В
Кроме того, мы познакомим вас с некоторыми ключевыми терминами, используемыми в SQL Server.
Что такое SQL Server?
SQL Server — это продукт Microsoft, используемый для управления и хранения
Информация. Технически SQL Server — это «система управления реляционными базами данных.
система »(RDMS). Разбитый на части, этот термин означает две вещи. Во-первых, эти данные
хранящиеся внутри SQL Server, будут размещены в «реляционной базе данных», а во-вторых,
что SQL Server — это целая «система управления», а не только база данных.SQL
сам по себе означает язык структурированных запросов. Это язык, на котором
управлять и администрировать сервер базы данных.
Реляционная база данных
Итак, теперь, когда SQL Server разбит на два термина,
«Реляционная база данных» и «система управления», давайте рассмотрим первую.
Существует очень техническое определение того, что является или не является реляционным
база данных. Для получения подробной информации об этом определении поищите в Интернете термины
«Эдгар Кодд» (который первым предложил реляционную модель) или термины «реляционная модель».
кортежи базы данных ».Хотя есть базы данных, которые не являются реляционными, большинство
продукты, представленные на рынке сегодня (SQL Server, Oracle, MySQL и MS Access to
назовите несколько) являются продуктами реляционных баз данных. Это означает, что данные хранятся
внутри структуры, называемой «Таблица», в которой используются строки и столбцы (например,
таблица). Однако, в отличие от электронной таблицы, строки данных, хранящиеся внутри таблицы
не в каком-то определенном порядке. Чтобы объяснить это последнее утверждение, подумайте о типичном
столбец электронной таблицы, если мы хотим отсортировать данные в первом столбце
таблицы в алфавитном порядке, мы просто щелкаем первый столбец, а затем
нажмет кнопку «Сортировка».Строки данных изменят свой порядок, чтобы они
теперь были отсортированы так, как мы хотели, как показано на изображениях до и после
ниже:
Раньше:
После:
Обратите внимание, что данные действительно переместились. Имя «Дэйв» переместилось
с третьего ряда в первый. В таблице базы данных этого никогда не происходит. В
данные не будут переставлены. Если бы нам нужен такой отсортированный список, мы бы
попросите базу данных предоставить нам отображаемую копию данных, отсортированных таким образом
мы хотели.Этот запрос на просмотр данных называется запросом. Итак, когда мы запускаем
Запрос, мы видим нашу персональную копию отображения данных, фактические данные
элементы не переставляются.
При обсуждении SQL Server термин «База данных» может
иногда быть разбросанным, имея в виду разные вещи для разных
люди. Это происходит потому, что база данных является основным, центральным компонентом SQL.
Сервер. Таким образом, этот термин стал сленговым сокращением значения SQL.
Сервер в целом. На самом деле SQL Server — это СУБД (реляционная база данных
Система управления).Его работа — управление базами данных.
«База данных» — это логический контейнерный объект. Он используется для
хранение одинаковых типов информации вместе, чтобы помочь с организацией. Также
База данных может использоваться как простая граница безопасности. Обычно, хотя и не правило,
базы данных отделяют приложения друг от друга. Например, все
Информация о системе учета может содержаться в одной базе данных, при этом все
Маркетинговая информация — в другом. Опять же, это не правило SQL Server; ты
может содержать всю вашу корпоративную информацию в единой базе данных.Это
было бы очень запутанным с точки зрения организации, но SQL Server
разрешить это. И наоборот, вы можете разделить каждую небольшую группу информации на
их собственная база данных, имеющая сотни или даже тысячи баз данных внутри
единый SQL Server. Этот сценарий был бы кошмаром для менеджмента, но там
нет никаких правил SQL Server, препятствующих этому. Обычно применяется правило здравого смысла.
для определения того, что должна содержать база данных. Если данные и объекты
связаны друг с другом, и было бы полезно применить безопасность к группе
в целом, это хороший кандидат на роль собственной базы данных.Единый SQL
Сервер может содержать более 32 000 отдельных баз данных.
При создании новой базы данных создаются два физических файла.
на жестком диске. Один файл содержит все объекты и данные, другой —
журнал всех изменений базы данных. Эти файлы являются собственностью SQL Server.
и не может быть открыт в Word, Excel, Блокноте или любом другом приложении. В
размер файла базы данных может превышать 500 000 терабайт.
Зачем нужна база данных?
Итак, теперь, когда мы знаем, что SQL Server — это приложение для
храня информацию внутри «табличной» структуры, давайте рассмотрим причины, по которым
вы бы использовали базу данных, а не электронную таблицу или какую-либо другую программу для
хранилище данных.
Представьте, что вы создаете приложение для хранения продаж.
транзакции. Начнем с сохранения всего нескольких столбцов информации, например
Проданный товар, количество, цена, дата продажи и покупатель. Один из
первый вариант хранения, который следует рассмотреть, — это сохранение этой информации в большом
текстовый файл. Сохранение текстовых файлов дает такие преимущества, как быстрая запись. В
проблема с текстовыми файлами во время чтения, если текстовый файл большой, он может
потратьте немало времени, чтобы открыть и просканировать содержимое файла в поисках
что мы хотим.Кроме того, если мы хотим увидеть все продажи конкретному покупателю,
весь текстовый файл должен быть прочитан, и каждая строка вхождения
имя клиента нужно будет сохранить в каком-то временном месте, пока они у нас не появятся
все. Если мы сохраним в электронную таблицу, а не в текстовый файл, у нас будет Сортировка
встроенная функция. Таким образом, мы сможем найти все продажи для определенного
покупатель быстрее, но опять же, если файл был большим, электронная таблица открывалась
может занять много времени.
Кроме того, что, если бы мы хотели сохранить адрес клиентов
а также их имя, теперь вместо сохранения пяти частей информации (Item
Продано, Количество, Цена, Дата продажи и Клиент, которому продан), мы сэкономим девять
столбцы с информацией (все предыдущие плюс адрес, город, штат и почтовый индекс).Этот
означает, что размер нашего текстового файла или таблицы увеличится почти вдвое, чтобы
разместить эти дополнительные данные клиента. Однако, если мы использовали базу данных, мы
может сохранять данные о продажах и адресах клиентов в двух разных местах,
чтобы объем данных о продажах не увеличивался. Когда мы хотели отчет
показывая адрес клиентов, мы могли бы «связать» или связать данные адреса с
данные о продажах.
Мало того, что наша информация о продажах была бы меньше в
база данных, но фактические данные адреса также будут меньше.В
электронную таблицу или текстовый файл, каждая строка продаж будет включать полный адрес. В
В базе данных адрес будет записан только один раз. Неважно, если
покупатель совершил 100 или 100 000 покупок. Все записи о продажах будут указывать или «относиться»
в ту же единственную адресную строку.
Это «взаимосвязь» данных, поэтому размеры остаются небольшими — одно из преимуществ
базы данных. Кроме того, чтение и запись в базу данных происходит очень быстро. Плюс,
многие базы данных поддерживают одновременный доступ нескольких пользователей к одним и тем же данным
время.Что-то не работает с текстовыми файлами и таблицами. Также сумма или
объем информации, который может хранить база данных, практически неограничен, в отличие от разброса
лист, где есть фиксированное количество или строк, которые можно сохранить.
Почему бы не использовать базу данных?
Есть некоторые проблемы с использованием базы данных. Первый раз
необходимо принять, чтобы изучить новую систему. База данных не так интуитивно понятна, как
электронная таблица. Кроме того, если имеется небольшой объем данных,
со временем нужно будет изменять, возможно, проще сохранить его в файл.К сожалению, большинство бизнес-проблем непросты и непросты, поэтому
база данных обычно является лучшим инструментом для работы.
Система управления
Второй термин в нашем определении SQL Server — «Управление
Система ». Это означает, что SQL Server — это больше, чем просто приложение для хранения
данные; он также включает инструменты, необходимые для структурирования, манипулирования и управления
эти данные. Кроме того, при установке SQL Server есть варианты для
включая инструменты для написания отчетов, приложения для импорта и экспорта данных, анализ
инструменты и интерфейсы управления.
Заключение
SQL Server — это система управления реляционными базами данных. Данные
хранится — это таблицы, состоящие из столбцов и строк. Таблицы могут быть связаны или «Связаны»,
для другого. Таблицы и предметы, принадлежащие к одному семейству или требующие
аналогичная безопасность коллективно хранится в базе данных.
» Просмотреть все статьи обозревателя Дон Шлихтинг
Что означает SQL? — Определения SQL
Вы ищете значения SQL? На следующем изображении вы можете увидеть основные определения SQL.При желании вы также можете скачать файл изображения для печати или поделиться им с другом через Facebook, Twitter, Pinterest, Google и т. Д. Чтобы увидеть все значения SQL, прокрутите вниз. Полный список определений приведен в таблице ниже в алфавитном порядке.
Основные значения SQL
На следующем изображении представлены наиболее часто используемые значения SQL. Вы можете загрузить файл изображения в формате PNG для использования в автономном режиме или отправить его друзьям по электронной почте. Если вы являетесь веб-мастером некоммерческого веб-сайта, пожалуйста, не стесняйтесь публиковать изображение определений SQL на своем веб-сайте. Все определения SQL
Как упоминалось выше, вы увидите все значения SQL в следующей таблице. Обратите внимание, что все определения перечислены в алфавитном порядке. Вы можете щелкнуть ссылки справа, чтобы просмотреть подробную информацию о каждом определении, включая определения на английском и вашем местном языке. Что означает SQL в тексте
В общем, SQL — это аббревиатура или сокращение, которое определяется простым языком.
Big Data
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Data Warehousing
- DevOps Back 903 901 9019 HBase 901 901 HBase 901
- MongoDB
- NiFi
Тестирование
- Назад
- Гибкое тестирование
- BugZilla
- Cucumber
- Тестирование базы данных Jmeter
- 901 901 Jmeter Тестирование базы данных
- ETL 901
- JUnit
- LoadRunner
- Ручное тестирование
- Мобильное тестирование
- Mantis
- Почтальон
- QTP
- Назад
- Центр качества SAPU (ALM) 9013
- RPA
SAP
- Назад
- ABAP 901 32 APO
- Начинающий
- Basis
- BODS
- BI
- BPC
- CO
- Назад
- CRM
- Crystal Reports
- FICO 9013 9013 903 9013 903 903 903 9013 903 903 903 903 903 903 9013 903 903 903 903 903 9013 903 9013 903 9013 903 903 9013 903 901
Сеть- Назад
- Java
- JSP
- Kotlin MY
- Linux 90D133
- Kotlin MY
- Linux 90D js
- Perl
- Назад
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala 903
- SQL 901 901 901 SQL Server 901 901 SQL 901
- UML
- VB.Net
- VBScript
- Веб-службы
- WPF
Обязательно изучите!
- Назад
- Бухгалтерский учет
- Алгоритмы
- Android
- Блокчейн
- Бизнес-аналитик
- Создание веб-сайта
- Облачные вычисления
- COBOL
Учебные пособия по Excel Программирование на Go IoT ITIL Jenkins MIS Сеть Операционная система - Назад
- Обзоры 903 903 903 903
- Prep
903- Управление проектами Salesforce
- SEO
- Разработка программного обеспечения
- VBA
901 33 Big Data
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Data Warehousing
- DevOps Back
903 901 9019 HBase 901 901 HBase 901- MongoDB
Что такое SQL | Ключевая концепция
Что такое SQL?
Язык, специфичный для предметной области, разработанный для управления данными и хранящийся в системе управления реляционными базами данных, называется SQL. SQL — это аббревиатура от языка структурированных запросов, разработанная ISO / IEC, и дисциплина типизации стала более строгой. Операторы используются для выполнения многих операций с базой данных, таких как извлечение данных, обновление данных, удаление и переименование данных и удаление данных. Oracle, SyBase, Microsoft SQL Server — это некоторые из баз данных, использующих язык SQL. Мы не можем назвать SQL языком программирования, но у него есть некоторые стандарты для создания процедурных расширений, так что функциональные возможности могут быть расширены для формирования языка программирования.
РСУБД
Прежде чем понимать SQL, нам нужно сначала понять СУБД. СУБД или система управления реляционными базами данных — это просто база данных, в которой хранятся структурированные данные, и между ними существует связь. Он хранит данные в табличном формате. В нем есть столбец и строки, содержащие связанные записи данных. Столбцы — это вертикальный элемент таблицы. Он содержит атрибут записей, а строки представляют собой горизонтальный объект, который содержит записи / данные. На пересечении строк и столбцов содержится информация записи относительно этого атрибута.Ниже приведен пример таблицы.
ЗаказчикДетейл:
ID
Имя Возраст
1
Мэтью 35 2
Иоанна
46
3
Линда
25
4
Кен
20
5
Лилия
18
6 Тайсон 21
Понимание SQL
Это язык, используемый для запросов к табличным данным.В отличие от других языков, SQL является декларативным языком, нужно просто указать результат, который они хотят видеть, и отправить запрос в СУБД. РСУБД выполняет код на бэкэнде и дает желаемый результат. В то время как на процедурном языке мы должны указывать компьютеру каждый шаг, который нужно выполнить, чтобы получить результат. Поэтому, если вы хотите выбрать данные из приведенной выше таблицы, вам просто нужно написать запрос ниже и выполнить его.
ВЫБРАТЬ * ИЗ CustomerDetail;
Путаница с SQL — это синтаксис SQL-запроса.Элементы не выполняются в том порядке, в котором они используются в запросе. Рассмотрите возможность выбора данных из приведенной выше таблицы CustomerDetail.
ВЫБЕРИТЕ ID, имя, возраст FROM CustomerDetail
WHERE Age> 20
Упорядочить по ID DESC;
Приведенный выше запрос выберет все записи, возраст которых превышает 20, и отобразит результат в порядке идентификатора. Последовательность выполнения элементов следующая:
- FROM: В запросе сначала выполняется предложение FROM.Он выбирает таблицы и объединяет таблицы для получения базовых данных.
- WHERE: Этот пункт фильтрует базовые данные. Чтобы в дальнейшей обработке было меньше записей.
- GROUP BY: Предложение Group By объединяет строки в группы для выполнения агрегирования.
- HAVING: Этот пункт используется для фильтрации
Что такое SQL Server — DatabaseJournal.com
Введение
В этой статье представлен SQL Server, что это такое и почему
использовать это.Мы также рассмотрим, когда использовать базу данных, а когда нет. В
Кроме того, мы познакомим вас с некоторыми ключевыми терминами, используемыми в SQL Server.
Что такое SQL Server?
SQL Server — это продукт Microsoft, используемый для управления и хранения
Информация. Технически SQL Server — это «система управления реляционными базами данных.
система »(RDMS). Разбитый на части, этот термин означает две вещи. Во-первых, эти данные
хранящиеся внутри SQL Server, будут размещены в «реляционной базе данных», а во-вторых,
что SQL Server — это целая «система управления», а не только база данных.SQL
сам по себе означает язык структурированных запросов. Это язык, на котором
управлять и администрировать сервер базы данных.
Реляционная база данных
Итак, теперь, когда SQL Server разбит на два термина,
«Реляционная база данных» и «система управления», давайте рассмотрим первую.
Существует очень техническое определение того, что является или не является реляционным
база данных. Для получения подробной информации об этом определении поищите в Интернете термины
«Эдгар Кодд» (который первым предложил реляционную модель) или термины «реляционная модель».
кортежи базы данных ».Хотя есть базы данных, которые не являются реляционными, большинство
продукты, представленные на рынке сегодня (SQL Server, Oracle, MySQL и MS Access to
назовите несколько) являются продуктами реляционных баз данных. Это означает, что данные хранятся
внутри структуры, называемой «Таблица», в которой используются строки и столбцы (например,
таблица). Однако, в отличие от электронной таблицы, строки данных, хранящиеся внутри таблицы
не в каком-то определенном порядке. Чтобы объяснить это последнее утверждение, подумайте о типичном
столбец электронной таблицы, если мы хотим отсортировать данные в первом столбце
таблицы в алфавитном порядке, мы просто щелкаем первый столбец, а затем
нажмет кнопку «Сортировка».Строки данных изменят свой порядок, чтобы они
теперь были отсортированы так, как мы хотели, как показано на изображениях до и после
ниже:
Раньше:
После:
Обратите внимание, что данные действительно переместились. Имя «Дэйв» переместилось
с третьего ряда в первый. В таблице базы данных этого никогда не происходит. В
данные не будут переставлены. Если бы нам нужен такой отсортированный список, мы бы
попросите базу данных предоставить нам отображаемую копию данных, отсортированных таким образом
мы хотели.Этот запрос на просмотр данных называется запросом. Итак, когда мы запускаем
Запрос, мы видим нашу персональную копию отображения данных, фактические данные
элементы не переставляются.
При обсуждении SQL Server термин «База данных» может
иногда быть разбросанным, имея в виду разные вещи для разных
люди. Это происходит потому, что база данных является основным, центральным компонентом SQL.
Сервер. Таким образом, этот термин стал сленговым сокращением значения SQL.
Сервер в целом. На самом деле SQL Server — это СУБД (реляционная база данных
Система управления).Его работа — управление базами данных.
«База данных» — это логический контейнерный объект. Он используется для
хранение одинаковых типов информации вместе, чтобы помочь с организацией. Также
База данных может использоваться как простая граница безопасности. Обычно, хотя и не правило,
базы данных отделяют приложения друг от друга. Например, все
Информация о системе учета может содержаться в одной базе данных, при этом все
Маркетинговая информация — в другом. Опять же, это не правило SQL Server; ты
может содержать всю вашу корпоративную информацию в единой базе данных.Это
было бы очень запутанным с точки зрения организации, но SQL Server
разрешить это. И наоборот, вы можете разделить каждую небольшую группу информации на
их собственная база данных, имеющая сотни или даже тысячи баз данных внутри
единый SQL Server. Этот сценарий был бы кошмаром для менеджмента, но там
нет никаких правил SQL Server, препятствующих этому. Обычно применяется правило здравого смысла.
для определения того, что должна содержать база данных. Если данные и объекты
связаны друг с другом, и было бы полезно применить безопасность к группе
в целом, это хороший кандидат на роль собственной базы данных.Единый SQL
Сервер может содержать более 32 000 отдельных баз данных.
При создании новой базы данных создаются два физических файла.
на жестком диске. Один файл содержит все объекты и данные, другой —
журнал всех изменений базы данных. Эти файлы являются собственностью SQL Server.
и не может быть открыт в Word, Excel, Блокноте или любом другом приложении. В
размер файла базы данных может превышать 500 000 терабайт.
Зачем нужна база данных?
Итак, теперь, когда мы знаем, что SQL Server — это приложение для
храня информацию внутри «табличной» структуры, давайте рассмотрим причины, по которым
вы бы использовали базу данных, а не электронную таблицу или какую-либо другую программу для
хранилище данных.
Представьте, что вы создаете приложение для хранения продаж.
транзакции. Начнем с сохранения всего нескольких столбцов информации, например
Проданный товар, количество, цена, дата продажи и покупатель. Один из
первый вариант хранения, который следует рассмотреть, — это сохранение этой информации в большом
текстовый файл. Сохранение текстовых файлов дает такие преимущества, как быстрая запись. В
проблема с текстовыми файлами во время чтения, если текстовый файл большой, он может
потратьте немало времени, чтобы открыть и просканировать содержимое файла в поисках
что мы хотим.Кроме того, если мы хотим увидеть все продажи конкретному покупателю,
весь текстовый файл должен быть прочитан, и каждая строка вхождения
имя клиента нужно будет сохранить в каком-то временном месте, пока они у нас не появятся
все. Если мы сохраним в электронную таблицу, а не в текстовый файл, у нас будет Сортировка
встроенная функция. Таким образом, мы сможем найти все продажи для определенного
покупатель быстрее, но опять же, если файл был большим, электронная таблица открывалась
может занять много времени.
Кроме того, что, если бы мы хотели сохранить адрес клиентов
а также их имя, теперь вместо сохранения пяти частей информации (Item
Продано, Количество, Цена, Дата продажи и Клиент, которому продан), мы сэкономим девять
столбцы с информацией (все предыдущие плюс адрес, город, штат и почтовый индекс).Этот
означает, что размер нашего текстового файла или таблицы увеличится почти вдвое, чтобы
разместить эти дополнительные данные клиента. Однако, если мы использовали базу данных, мы
может сохранять данные о продажах и адресах клиентов в двух разных местах,
чтобы объем данных о продажах не увеличивался. Когда мы хотели отчет
показывая адрес клиентов, мы могли бы «связать» или связать данные адреса с
данные о продажах.
Мало того, что наша информация о продажах была бы меньше в
база данных, но фактические данные адреса также будут меньше.В
электронную таблицу или текстовый файл, каждая строка продаж будет включать полный адрес. В
В базе данных адрес будет записан только один раз. Неважно, если
покупатель совершил 100 или 100 000 покупок. Все записи о продажах будут указывать или «относиться»
в ту же единственную адресную строку.
Это «взаимосвязь» данных, поэтому размеры остаются небольшими — одно из преимуществ
базы данных. Кроме того, чтение и запись в базу данных происходит очень быстро. Плюс,
многие базы данных поддерживают одновременный доступ нескольких пользователей к одним и тем же данным
время.Что-то не работает с текстовыми файлами и таблицами. Также сумма или
объем информации, который может хранить база данных, практически неограничен, в отличие от разброса
лист, где есть фиксированное количество или строк, которые можно сохранить.
Почему бы не использовать базу данных?
Есть некоторые проблемы с использованием базы данных. Первый раз
необходимо принять, чтобы изучить новую систему. База данных не так интуитивно понятна, как
электронная таблица. Кроме того, если имеется небольшой объем данных,
со временем нужно будет изменять, возможно, проще сохранить его в файл.К сожалению, большинство бизнес-проблем непросты и непросты, поэтому
база данных обычно является лучшим инструментом для работы.
Система управления
Второй термин в нашем определении SQL Server — «Управление
Система ». Это означает, что SQL Server — это больше, чем просто приложение для хранения
данные; он также включает инструменты, необходимые для структурирования, манипулирования и управления
эти данные. Кроме того, при установке SQL Server есть варианты для
включая инструменты для написания отчетов, приложения для импорта и экспорта данных, анализ
инструменты и интерфейсы управления.
Заключение
SQL Server — это система управления реляционными базами данных. Данные
хранится — это таблицы, состоящие из столбцов и строк. Таблицы могут быть связаны или «Связаны»,
для другого. Таблицы и предметы, принадлежащие к одному семейству или требующие
аналогичная безопасность коллективно хранится в базе данных.
» Просмотреть все статьи обозревателя Дон Шлихтинг
Что означает SQL? — Определения SQL
Вы ищете значения SQL? На следующем изображении вы можете увидеть основные определения SQL.При желании вы также можете скачать файл изображения для печати или поделиться им с другом через Facebook, Twitter, Pinterest, Google и т. Д. Чтобы увидеть все значения SQL, прокрутите вниз. Полный список определений приведен в таблице ниже в алфавитном порядке.
Основные значения SQL
На следующем изображении представлены наиболее часто используемые значения SQL. Вы можете загрузить файл изображения в формате PNG для использования в автономном режиме или отправить его друзьям по электронной почте. Если вы являетесь веб-мастером некоммерческого веб-сайта, пожалуйста, не стесняйтесь публиковать изображение определений SQL на своем веб-сайте. Все определения SQL
Как упоминалось выше, вы увидите все значения SQL в следующей таблице. Обратите внимание, что все определения перечислены в алфавитном порядке. Вы можете щелкнуть ссылки справа, чтобы просмотреть подробную информацию о каждом определении, включая определения на английском и вашем местном языке. Что означает SQL в тексте
В общем, SQL — это аббревиатура или сокращение, которое определяется простым языком.
Big Data
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Data Warehousing
- DevOps Back 903 901 9019 HBase 901 901 HBase 901
- MongoDB
SQL — это аббревиатура от языка структурированных запросов, разработанная ISO / IEC, и дисциплина типизации стала более строгой. Операторы используются для выполнения многих операций с базой данных, таких как извлечение данных, обновление данных, удаление и переименование данных и удаление данных. Oracle, SyBase, Microsoft SQL Server — это некоторые из баз данных, использующих язык SQL. Мы не можем назвать SQL языком программирования, но у него есть некоторые стандарты для создания процедурных расширений, так что функциональные возможности могут быть расширены для формирования языка программирования. На пересечении строк и столбцов содержится информация записи относительно этого атрибута.Ниже приведен пример таблицы.ID
Возраст
1
2
Иоанна
46
3
Линда
25
4
Кен
20
5
Лилия
18
21
ВЫБРАТЬ * ИЗ CustomerDetail; ВЫБЕРИТЕ ID, имя, возраст FROM CustomerDetail
WHERE Age> 20
Упорядочить по ID DESC; Раньше:
После: