Базы данных и Kubernetes (обзор и видео доклада) / Хабр
8 ноября в главном зале конференции HighLoad++ 2018, в рамках секции «DevOps и эксплуатация», прозвучал доклад «Базы данных и Kubernetes». В нём рассказывается о высокой доступности баз данных и подходах к отказоустойчивости до Kubernetes и вместе с ним, а также практических вариантах размещения СУБД в кластерах Kubernetes и существующие для этого решения (включая Stolon для PostgreSQL).
По традиции рады представить видео с докладом (около часа, гораздо информативнее статьи) и основную выжимку в текстовом виде. Поехали!
Теория
Этот доклад появился как ответ на один из самых популярных вопросов, что все последние годы нам неустанно задают в разных местах: комментариях на хабре или YouTube, социальных сетях и т.п. Звучит он просто: «Можно ли запустить базу в Kubernetes?», — и если мы обычно отвечали на него «в целом да, но…», то пояснений к этим «в целом» и «но» явно не хватало, а уместить их в короткое сообщение никак не удавалось.
Однако для начала обобщу вопрос от «базы [данных]» до stateful в целом. СУБД — это лишь частный случай stateful-решений, более полный список которых можно представить так:
Перед тем, как смотреть конкретные случаи, расскажу о трёх важных особенностях работы/использования Kubernetes.
1. Философия высокой доступности в Kubernetes
Все знают аналогию «питомцы против стада» (pets vs cattle) и понимают, что если Kubernetes — история из мира стада, то классические СУБД — это именно питомцы.
И как выглядела архитектура «питомцев» в «традиционном» варианте? Классический пример инсталляции MySQL — репликация на двух железных серверах с резервированным питанием, диском, сетью… и всем остальным (включая инженера и различные вспомогательные средства), что поможет нам быть уверенными, что процесс MySQL не упадёт, а если случится проблема с любым из критичных для него компонентов, отказоустойчивость будет соблюдена:
Как то же самое будет выглядеть в Kubernetes? Здесь обычно гораздо больше железных серверов, они проще и у них нет резервированного питания и сети (в том смысле, что выпадание одной машины ни на что не влияет) — всё это объединено в кластер.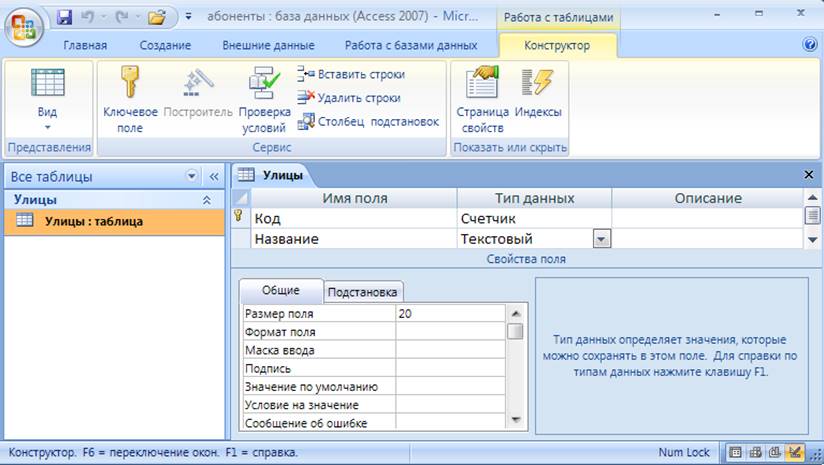 Его отказоустойчивость обеспечивается софтом: если что-то происходит с узлом, Kubernetes это обнаруживает и запускает нужные экземпляры на другом узле.
Его отказоустойчивость обеспечивается софтом: если что-то происходит с узлом, Kubernetes это обнаруживает и запускает нужные экземпляры на другом узле.
Какие есть механизмы для высокой доступности в K8s?
- Контроллеры. Их много, но основных два:
Deployment(для stateless-приложений) иStatefulSet(для stateful-приложений). В них хранится вся логика действий, предпринимаемых в случае падения узла (недоступности pod’а). -
PodAntiAffinity— возможность указывать определённым pod’ам, чтобы они не находились на одном и том же узле. -
PodDisruptionBudgets— лимит на количество экземпляров pod’ов, которые можно одновременно выключить в случае плановых работ.
2. Гарантии согласованности в Kubernetes
Как работает привычная схема отказоустойчивости с одним мастером? Два сервера (master и standby), к одному из которых постоянно обращается приложение, которым в свою очередь пользуются через балансировщик нагрузки. Что происходит в случае сетевой проблемы?
Что происходит в случае сетевой проблемы?
Классический split-brain: приложение начинает обращаться к обоим экземплярам СУБД, каждый из которых считает себя главным. Чтобы избежать этого, keepalived заменялся на corosync уже с тремя его экземплярами для достижения кворума при голосовании за мастера. Однако даже в таком случае есть проблемы: если отвалившийся экземпляр СУБД всячески пытается «самоубиться» (убрать IP-адрес, перевести БД в read-only…), то другая часть кластера не знает, что произошло с мастером — ведь может случиться и так, что тот узел в действительности всё ещё работает и к нему попадают запросы, а значит, что переключать мастера мы ещё не можем.
Чтобы решить такую ситуацию, существует механизм изоляции узла с целью защиты всего кластера от некорректной работы, — этот процесс называют fencing. Практическая суть сводится к тому, что мы пытаемся какими-либо внешними способами «убить» отвалившуюся машину. Подходы могут быть разные: от выключения машины по IPMI и блокирования порта на свитче до обращения к API облачного провайдера и т.
Как добиться такого же в Kubernetes? Для этого есть уже упомянутые контроллеры, поведение которых в случае недоступности узла различается:
-
Deployment: «Мне сказали, что должно быть 3 pod’а, а теперь их всего 2 — я создам новый»; -
StatefulSet: «Pod’а не стало? Подожду: либо этот узел вернётся, либо нам скажут его убить», — т.е. контейнеры сами (без действий оператора) не пересоздаются. Именно так достигается та же самая гарантия at-most-once.
Однако и здесь, в последнем случае, требуется fencing: нужен механизм, который подтвердит, что этого узла точно больше нет. Сделать его автоматическим, во-первых, очень сложно (требуется множество реализаций), а во-вторых, что ещё хуже, он обычно убивает узлы медленно (обращение к IPMI может занять секунды или десятки секунд, а то и минуты).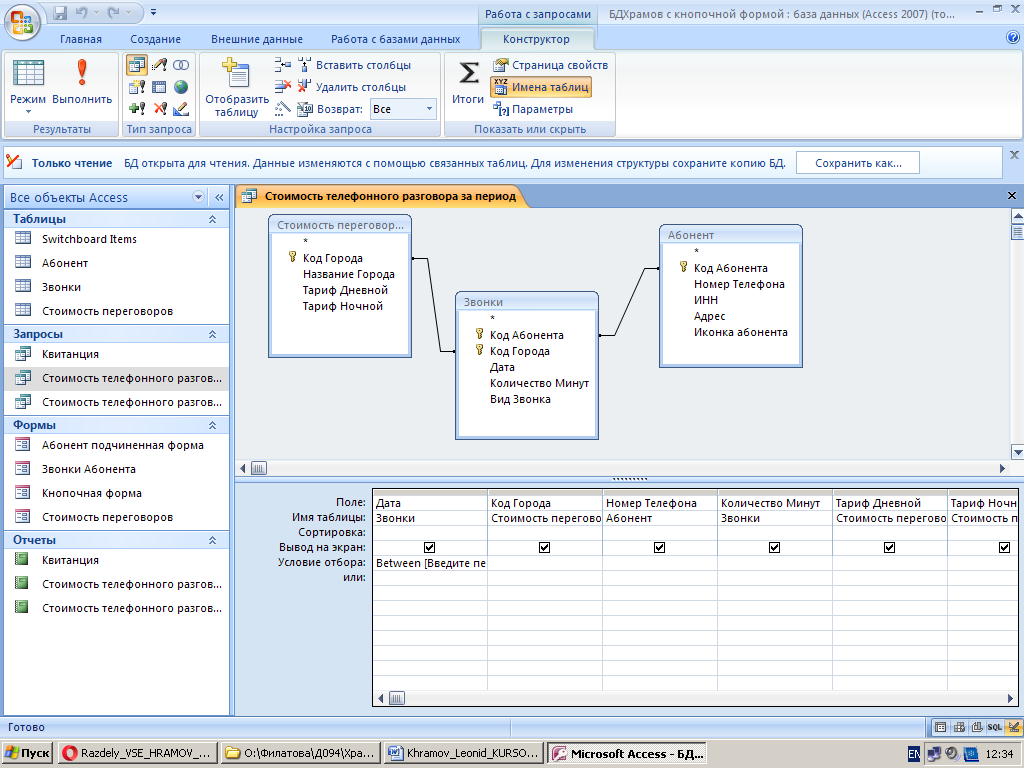
Начну его описание вне Kubernetes. В нём используется особый балансировщик нагрузки (load balancer), через который бэкенды обращаются к СУБД. Его специфика заключается в том, что он обладает свойством согласованности, т.е. защитой от сетевых сбоев и split-brain, поскольку позволяет убрать все подключения к текущему мастеру, дождаться синхронизации (реплики) на другом узле и переключиться на него. Я не нашёл устоявшегося термина для этого подхода и назвал его Consistent Switchover
.Главный вопрос с ним заключается в том, как сделать его универсальным, обеспечив поддержку и облачных провайдеров, и частных инсталляций. Для этого к приложениям добавляются прокси-серверы. Каждый из них будет принимать запросы от своего приложения (и пересылать их в СУБД), а из всех вместе будет собран кворум. Как только происходит отказ какой-то части кластера, те прокси, что потеряли кворум, сразу убирают свои подключения к СУБД.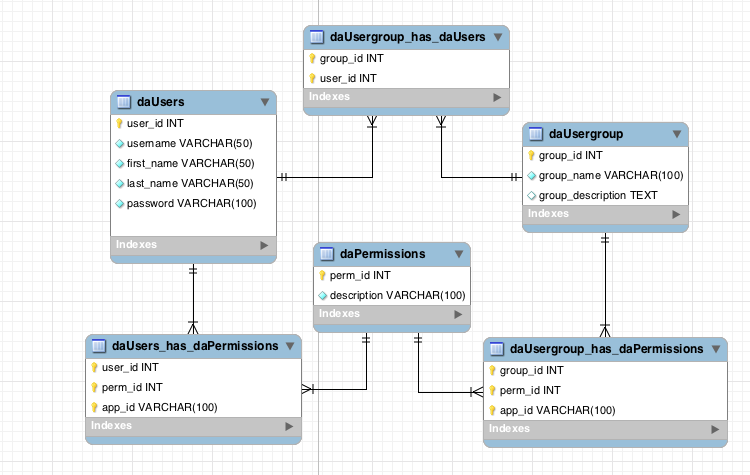
3. Хранение данных и Kubernetes
Основной механизм — это сетевой диск Network Block Device (он же SAN) в разных реализациях для нужных вариантов облака или bare metal. Однако поместить нагруженную базу данных (например, MySQL, от которой требуется 50 тысяч IOPS) в облако (AWS EBS) из-за имеющейся задержки (latency) не получится.
В Kubernetes для таких случаев есть возможность подключения локального жёсткого диска —
Оба варианта (Network Block Device и Local Storage) относятся к категории ReadWriteOnce: хранилище невозможно примонтировать в два места (pod’а) — для такого масштабирования потребуется создать новый диск и подключить его к новому pod’у (для этого есть встроенный механизм K8s), а затем наполнить нужными данными (делается уже нашими силами).
Если нам нужен режим ReadWriteMany, то доступны реализации Network File System (или NAS): для публичного облака это AzureFile и AWSElasticFileSystem, а для своих инсталляций — CephFS и Glusterfs для любителей распределённых систем, а также NFS.
Практика
1. Standalone
Этот вариант про случай, когда ничто не мешает запустить СУБД в режиме отдельного сервера с локальным хранилищем. Тут не идёт речь о высокой доступности… хотя и она может быть в некоторой мере (т.е. достаточно для данного применения) реализована на уровне железа. Есть множество случаев для такого применения. В первую очередь это всевозможные staging- и dev-окружения, но не только: сюда же попадают и вторичные сервисы, отключение которых на 15 минут не является критичным. В Kubernetes это реализуется StatefulSet‘ом с одним pod’ом:
В целом это жизнеспособный вариант, у которого, с моей точки зрения, нет минусов по сравнению с установкой СУБД на отдельной виртуалке.
2. Реплицированная пара с ручным переключением
StatefulSet, но общая схема выглядит уже следующим образом:Если произошёл сбой у одного из узлов (mysql-a-0), чуда не происходит, но у нас есть реплика (mysql-b-0), на которую мы можем переключить трафик. При этом — ещё до переключения трафика — важно не забыть не только убрать запросы к СУБД от сервиса mysql, но и зайти на СУБД вручную и убедиться, что все соединения завершены (убить их), а также зайти на второй узел с СУБД и перенастроить реплику в обратную сторону.
Если вы сейчас используете классический вариант с двумя серверами (master + standby) без автоматического переключения (failover), то это решение — эквивалент в Kubernetes. Подходит для MySQL, PostgreSQL, Redis и других продуктов.
3. Масштабирование нагрузки на чтение
По сути этот случай не является stateful, потому речь идёт только про чтение.
4. Умный клиент
Если сделать StatefulSet из трёх memcached, в Kubernetes доступен специальный сервис, который будет не балансировать запросы, а создаст каждому pod’у по своему домену. С ними сможет работать клиент в том случае, если он сам умеет шардинг и репликацию.
За примером далеко ходить не надо: так «из коробки» работает хранение сессий в PHP. На каждый запрос сессии делаются запросы одновременно на все серверы, после чего из них отбирается самый актуальный ответ (аналогично и на запись).
5. Cloud Native-решения
Есть множество решений, изначально ориентированных на выход из строя узлов, т.е. они сами умеют делать отказоустойчивость (failover) и восстановление узлов (recovery), предоставляют гарантии согласованности (consistency). Это не полный их список, а лишь часть популярных примеров:
Все они попросту ставятся в StatefulSet, после чего узлы находят друг друга и образуют кластер. Сами же продукты отличаются тем, как в них реализованы три вещи:
- Как узлы узнают друг о друге? Для этого есть такие способы, как Kubernetes API, DNS-записи, статическая конфигурация, специализированные узлы (seed), сторонний service discovery…
- Как подключается клиент? Через балансировщик нагрузки, распределяющий по хостам, или же клиенту нужно знать обо всех хостах, а он сам решит, как действовать дальше.
- Как делается горизонтальное масштабирование? Никак, полноценно или сложно/с ограничениями.
Вне зависимости от выбранных путей решения этих вопросов, все такие продукты хорошо работают с Kubernetes, потому что изначально были созданы как «стадо» (cattle).
6. Stolon PostgreSQL
Stolon фактически позволяет превратить СУБД PostgreSQL, созданную как pet, в cattle. За счёт чего это достигается?
- Во-первых, нужен service discovery, в роли которого может быть etcd (доступны и другие варианты) — кластер из них помещается в
StatefulSet. - Другая часть инфраструктуры —
StatefulSetс экземплярами PostgreSQL. Кроме собственно СУБД рядом с каждой инсталляцией также помещается компонент под названием keeper, который осуществляет настройку СУБД. - Другой компонент — sentinel — разворачивается как
Deploymentи следит за конфигурацией кластера. Именно он решает, кто будет master и standby, записывает эту информацию в etcd.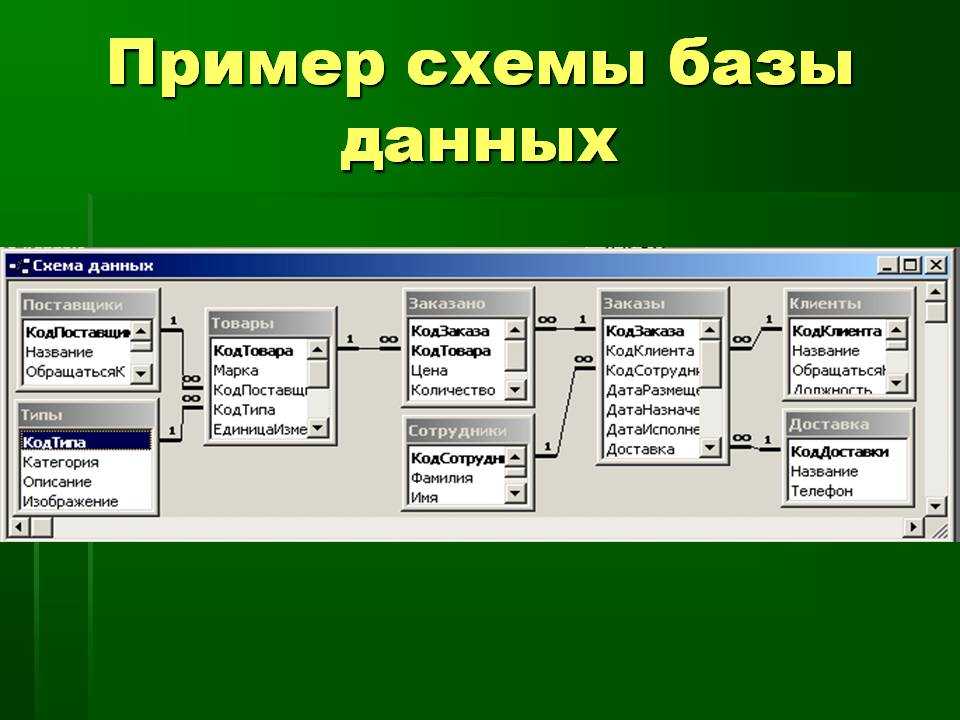 А keeper читает данные из etcd и выполняет соответствующие актуальному статусу действия с экземпляром PostgreSQL.
А keeper читает данные из etcd и выполняет соответствующие актуальному статусу действия с экземпляром PostgreSQL. - Ещё один компонент, разворачиваемый в
Deploymentи стоящий перед экземплярами PostgreSQL, — proxy — является реализацией уже упомянутого паттерна Consistent Switchover. Эти компоненты подключаются к etcd, а если эта связь теряется, то proxy сразу убивает исходящие соединения, потому что с этого момента он не знает роль своего сервера (сейчас это master или standby?). - Наконец, перед экземплярами proxy стоит обычный
LoadBalancerиз Kubernetes.
Выводы
Так можно ли базу в Kubernetes? Да, конечно, можно, в некоторых случаях… И если это целесообразно, то делается вот так (см. схему работы Stolon)…
Все знают, что технологии развиваются волнами. Изначально любое новое устройство бывает очень сложным в использовании, но со временем всё меняется: технология становится доступной. К чему идём? Да, оно останется вот таким внутри, но как оно будет работать, мы уже не будем знать. В Kubernetes активно развиваются операторы. Пока их не так много и они не так хороши, но есть движение в этом направлении.
К чему идём? Да, оно останется вот таким внутри, но как оно будет работать, мы уже не будем знать. В Kubernetes активно развиваются операторы. Пока их не так много и они не так хороши, но есть движение в этом направлении.
Видео и слайды
Видео с выступления (около часа):
Презентация доклада:
P.S. Мы также нашли в сети очень(!) краткую текстовую выжимку с этого доклада — спасибо за неё Николаю Волынкину.
P.P.S.
Другие доклады в нашем блоге:
- «Мониторинг и Kubernetes»; (Дмитрий Столяров; 28 мая 2018 на RootConf);
- «Лучшие практики CI/CD с Kubernetes и GitLab»; (Дмитрий Столяров; 7 ноября 2017 на HighLoad++);
- «Наш опыт с Kubernetes в небольших проектах»; (Дмитрий Столяров; 6 июня 2017 на RootConf);
- «Собираем Docker-образы для CI/CD быстро и удобно вместе с dapp» (Дмитрий Столяров; 8 ноября 2016 на HighLoad++);
- «Практики Continuous Delivery с Docker» (Дмитрий Столяров; 31 мая 2016 на RootConf).

Возможно, вас также заинтересуют следующие публикации:
- «Kubernetes tips & tricks: ускоряем bootstrap больших баз данных»;
- «Оркестровка СУБД CockroachDB в Kubernetes».
Устранение неполадок подключений к базам данных в Dreamweaver
Руководство пользователя Отмена
Поиск
- Руководство пользователя Dreamweaver
- Введение
- Основы гибкого веб-дизайна
- Новые возможности Dreamweaver
- Веб-разработка с помощью Dreamweaver: обзор
- Dreamweaver / распространенные вопросы
- Сочетания клавиш
- Системные требования Dreamweaver
- Обзор новых возможностей
- Dreamweaver и Creative Cloud
- Синхронизация настроек Dreamweaver с Creative Cloud
- Библиотеки Creative Cloud Libraries в Dreamweaver
- Использование файлов Photoshop в Dreamweaver
- Работа с Adobe Animate и Dreamweaver
- Извлечение файлов SVG, оптимизированных для Интернета, из библиотек
- Рабочие среды и представления Dreamweaver
- Рабочая среда Dreamweaver
- Оптимизация рабочей среды Dreamweaver для визуальной разработки
- Поиск файлов по имени или содержимому | Mac OS
- Настройка сайтов
- О сайтах Dreamweaver
- Настройка локальной версии сайта
- Подключение к серверу публикации
- Настройка тестового сервера
- Импорт и экспорт параметров сайта Dreamweaver
- Перенос существующих веб-сайтов с удаленного сервера в корневой каталог локального сайта
- Специальные возможности в Dreamweaver
- Дополнительные настройки
- Настройка установок сайта для передачи файлов
- Задание параметров прокси-сервера в Dreamweaver
- Синхронизация настроек Dreamweaver с Creative Cloud
- Использование Git в Dreamweaver
- Управление файлами
- Создание и открытие файлов
- Управление файлами и папками
- Получение файлов с сервера и размещение их на нем
- Возврат и извлечение файлов
- Синхронизация файлов
- Сравнение файлов
- Скрытие файлов и папок на сайте Dreamweaver
- Включение заметок разработчика для сайтов Dreamweaver
- Предотвращение использования уязвимости Gatekeeper
- Макет и оформление
- Использование средств визуализации для создания макета
- Об использовании CSS для создания макета страницы
- Создание динамичных веб-сайтов с помощью Bootstrap
- Создание и использование медиазапросов в Dreamweaver
- Представление содержимого в таблицах
- Цвета
- Гибкий дизайн с использованием «резиновых» макетов
- Extract в Dreamweaver
- CSS
- Общие сведения о каскадных таблицах стилей
- Создание макетов страниц с помощью конструктора CSS
- Использование препроцессоров CSS в Dreamweaver
- Установка настроек стиля CSS в Dreamweaver
- Перемещение правил CSS в Dreamweaver
- Преобразование встроенного CSS в правило CSS в Dreamweaver
- Работа с тегами div
- Применение градиентов к фону
- Создание и редактирование эффектов перехода CSS3 в Dreamweaver
- Форматирование кода
- Содержимое страницы и ресурсы
- Задание свойств страницы
- Задание свойств заголовка CSS и свойств ссылки CSS
- Работа с текстом
- Поиск и замена текста, тегов и атрибутов
- Панель DOM
- Редактирование в режиме интерактивного просмотра
- Кодировка документов в Dreamweaver
- Выбор и просмотр элементов в окне документа
- Задание свойств текста в инспекторе свойств
- Проверка орфографии на веб-странице
- Использование горизонтальных линеек в Dreamweaver
- Добавление и изменение сочетаний шрифтов в Adobe Dreamweaver
- Работа с ресурсами
- Вставка и обновление даты в Dreamweaver
- Создание и управление избранными ресурсами в Dreamweaver
- Вставка и редактирование изображений в Dreamweaver
- Добавление мультимедийных объектов
- Добавление видео Dreamweaver
- Добавление видео HTML5
- Вставка файлов SWF
- Добавление звуковых эффектов
- Добавление аудио HTML5 в Dreamweaver
- Работа с элементами библиотеки
- Использование текста на арабском языке и иврите в Dreamweaver
- Создание ссылок и навигация
- О создании ссылок и навигации
- Создание ссылок
- Карты ссылок
- Устранение неполадок со ссылками
- Графические элементы и эффекты jQuery
- Использование пользовательского интерфейса и графических элементов jQuery для мобильных устройств в Dreamweaver
- Использование эффектов jQuery в Dreamweaver
- Написание кода веб-сайтов
- О программировании в Dreamweaver
- Среда написания кода в Dreamweaver
- Настройка параметров написания кода
- Настройка цветового оформления кода
- Написание и редактирование кода
- Подсказки по коду и автозавершение кода
- Свертывание и развертывание кода
- Повторное использование фрагментов кода
- Анализ Linting для проверки кода
- Оптимизация кода
- Редактирование кода в представлении «Дизайн»
- Работа с содержимым заголовков для страниц
- Вставка серверных включений в Dreamweaver
- Использование библиотек тегов в Dreamweaver
- Импорт пользовательских тегов в Dreamweaver
- Использование вариантов поведения JavaScript (общие инструкции)
- Применение встроенных вариантов поведения JavaScript
- Сведения об XML и XSLT
- Выполнение XSL-преобразования на стороне сервера в Dreamweaver
- Выполнение XSL-преобразования на стороне клиента в Dreamweaver
- Добавление символьных сущностей для XSLT в Dreamweaver
- Форматирование кода
- Процессы взаимодействия продуктов
- Установка и использование расширений в Dreamweaver
- Обновления в Dreamweaver, устанавливаемые через приложение
- Вставить документы Microsoft Office в Dreamweaver (только для Windows)
- Работа с Fireworks и Dreamweaver
- Редактирование содержимого на сайтах Dreamweaver с помощью Contribute
- Интеграция Dreamweaver с Business Catalyst
- Создание персонализированных кампаний почтовой рассылки
- Шаблоны
- О шаблонах Dreamweaver
- Распознавание шаблонов и документов на их основе
- Создание шаблона Dreamweaver
- Создание редактируемых областей в шаблонах
- Создание повторяющихся областей и таблиц в Dreamweaver
- Использование дополнительных областей в шаблонах
- Определение редактируемых атрибутов тега в Dreamweaver
- Создание вложенных шаблонов в Dreamweaver
- Редактирование, обновление и удаление шаблонов
- Экспорт и импорт XML-содержимого в Dreamweaver
- Применение или удаление шаблона из существующего документа
- Редактирование содержимого в шаблонах Dreamweaver
- Правила синтаксиса для тегов шаблона в Dreamweaver
- Настройка предпочтений выделения для областей шаблона
- Преимущества использования шаблонов в Dreamweaver
- Мобильные и многоэкранные устройства
- Создание медиазапросов
- Изменение ориентации страницы для мобильных устройств
- Создание веб-приложений для мобильных устройств с помощью Dreamweaver
- Динамические сайты, страницы и веб-формы
- Общие сведения о веб-приложениях
- Настройка компьютера для разработки приложений
- Устранение неполадок подключений к базам данных
- Удаление сценариев подключения в Dreamweaver
- Дизайн динамических страниц
- Обзор динамических источников содержимого
- Определение источников динамического содержимого
- Добавление динамического содержимого на страницы
- Изменение динамического содержимого в Dreamweaver
- Отображение записей баз данных
- Введение интерактивных данных и устранение неполадок с ними в Dreamweaver
- Добавление заказных вариантов поведения сервера в Dreamweaver
- Создание форм с помощью Dreamweaver
- Использование форм для сбора информации от пользователей
- Создание и включение форм ColdFusion в Dreamweaver
- Создание веб-форм
- Расширенная поддержка HTML5 для компонентов формы
- Разработка формы с помощью Dreamweaver
- Визуальное построение приложений
- Создание главной страницы и страницы сведений в Dreamweaver
- Создание страниц поиска и результатов поиска
- Создание страницы для вставки записи
- Создание страницы обновления записи в Dreamweaver
- Создание страниц удаления записей в Dreamweaver
- Применение ASP-команд для изменения базы данных в Dreamweaver
- Создание страницы регистрации
- Создание страницы входа
- Создание страницы с доступом только для авторизованных пользователей
- Защита папок в ColdFusion с помощью Dreamweaver
- Использование компонентов ColdFusion в Dreamweaver
- Тестирование, просмотр и публикация веб-сайтов
- Предварительный просмотр страниц
- Предварительный просмотр веб-страниц Dreamweaver на нескольких устройствах
- Тестирование сайта Dreamweaver
Устранение проблем с разрешениями, сообщения об ошибках в продуктах Майкрософт и MySQL в Dreamweaver.
Пользовательский интерфейс в Dreamweaver и более поздних версиях стал проще. В результате этого некоторые функции, описанные в этой статье, могут отсутствовать в Dreamweaver и более поздних версиях. Дополнительные сведения см. в этой статье.
Одной из наиболее частых проблем являются недостаточные разрешения для папок или файлов. Если база данных расположена на компьютере под управлением Windows 2000 или Windows XP и при попытке просмотра динамической страницы в веб-браузере или интерактивном представлении появляется сообщение об ошибке, то возможной причиной может быть проблема с разрешениями.
Учетная запись Windows, с помощью которой пользователь пытается войти в базу данных, не имеет достаточных прав. Эта учетная запись может быть либо анонимной учетной записью Windows (по умолчанию это IUSR_имя_компьютера), либо учетной записью пользователя, если для доступа к странице требуется проверка подлинности.
Чтобы открыть веб-серверу доступ к файлу базы данных, понадобится предоставить учетной записи «IUSR_имя_компьютера» правильные разрешения. Кроме того, чтобы разрешить запись в базу данных, также нужно настроить определенные разрешения для папки, содержащей эту базу данных.
Кроме того, чтобы разрешить запись в базу данных, также нужно настроить определенные разрешения для папки, содержащей эту базу данных.
Если предполагается анонимный доступ к странице, предоставьте учетной записи «IUSR_имя_компьютера» полный доступ к этой папке и файлу базы данных, как описано ниже.
Помимо этого, если путь к базе данных указан в формате UNC (\\Сервер\Папка), убедитесь, что в разрешениях для общего ресурса учетной записи «IUSR_имя_компьютера» предоставлен полный доступ. Этот шаг нужно выполнить даже в том случае, если общий ресурс расположен на локальном веб-сервере.
Если база данных копируется из другого расположения, она может не унаследовать разрешения от папки назначения, поэтому потребуется вручную изменить разрешения для этой базы данных.
Проверка или изменение разрешений для файла базы данных (в Windows XP)
Для изменения разрешений необходимо иметь права администратора на соответствующем компьютере.
Откройте проводник Windows, перейдите к файлу базы данных или папке, содержащей эту базу данных, щелкните правой кнопкой мыши файл или папку и выберите пункт «Свойства».

Перейдите на вкладку «Безопасность».
Этот шаг применим только в том случае, если используется файловая система NTFS. На компьютерах с файловой системой FAT в этом диалоговом окне вкладки «Безопасность» нет.
Если учетной записи «IUSR_имя_компьютера» нет в списке «Группы или пользователи», нажмите кнопку «Добавить» и добавьте ее.
В диалоговом окне «Выбор пользователей или групп» нажмите кнопку «Дополнительно».
В диалоговом окне отобразятся дополнительные параметры.
Щелкните «Размещение» и выберите имя компьютера.
Нажмите кнопку «Поиск», чтобы отобразить список учетных записей, связанных с компьютером.
Выберите учетную запись «IUSR_имя_компьютера» и нажмите кнопку «ОК»; затем нажмите «ОК» еще раз, чтобы очистить это диалоговое окно.
Чтобы предоставить учетной записи IUSR неограниченные права доступа, выберите «Полный доступ» и нажмите кнопку «ОК».
Проверка или изменение разрешений для файла базы данных (в Windows 2000)
Для изменения разрешений необходимо иметь права администратора на соответствующем компьютере.

Откройте проводник Windows, перейдите к файлу базы данных или папке, содержащей эту базу данных, щелкните правой кнопкой мыши файл или папку и выберите пункт «Свойства».
Перейдите на вкладку «Безопасность».
Этот шаг применим только в том случае, если используется файловая система NTFS. На компьютерах с файловой системой FAT в этом диалоговом окне вкладки «Безопасность» нет.
Если учетной записи «IUSR_имя_компьютера» нет в списке учетных записей Windows в диалоговом окне «Разрешения для файлов», нажмите кнопку «Добавить» и добавьте ее.
В диалоговом окне «Выбор пользователей, компьютеров или групп» выберите в меню «Папка» имя компьютера, чтобы отобразить список учетных записей, связанных с компьютером.
Выберите учетную запись «IUSR_имя_компьютера» и нажмите кнопку «Добавить».
Чтобы предоставить учетной записи IUSR все разрешения, в меню «Тип доступа» выберите «Полный доступ» и нажмите кнопку «ОК».

Для дополнительной безопасности можно отключить разрешение на чтение для веб-папки, содержащей базу данных. То есть просмотр содержимого этой папки будет запрещен, но доступ к базе данных для веб-страниц по-прежнему будет открыт.
Дополнительные сведения о разрешениях для учетной записи IUSR и веб-сервера см. в следующих статьях раздела TechNote на веб-сайте центра поддержки Adobe.
Общие сведения об анонимной проверке подлинности и учетной записи IUSR находятся по адресу: www.adobe.com/go/authentication_ru
Подробнее о настройке разрешений веб-сервера IIS см. по адресу: www.adobe.com/go/server_permissions_ru
Подобные сообщения об ошибках могут появляться во время запроса динамической страницы с сервера, если сервер IIS (Internet Information Server) используется с базой данных, разработанной корпорацией Майкрософт, например Access или SQL Server.
Корпорация Adobe не предоставляет техническую поддержку для программных продуктов сторонних разработчиков, например для Microsoft Windows и сервера IIS. Если приведенная в данной главе информация не помогла устранить проблему, обратитесь в службу технической поддержки Майкрософт или посетите веб-сайт технической поддержки Майкрософт по адресу: http://support.microsoft.com/.
Если приведенная в данной главе информация не помогла устранить проблему, обратитесь в службу технической поддержки Майкрософт или посетите веб-сайт технической поддержки Майкрософт по адресу: http://support.microsoft.com/.
Дополнительные сведения об ошибках 80004005 см. в статье «Руководство по устранению неполадок в случае появления ошибки 80004005 при работе со страницами ASP и компонентами Microsoft для доступа к данным (Q306518)» на веб-сайте корпорации Майкрософт по адресу: http://support.microsoft.com/default.aspx?scid=kb;ru-ru;Q306518.
[[Ссылка]80004005 — Источник данных не найден и не указан драйвер, используемый по умолчанию]
Эта ошибка возникает при попытке просмотра динамической страницы в веб-браузере или интерактивном представлении. Текст сообщения может отличаться в зависимости от используемой базы данных и веб-сервера. К вариантам этого сообщения об ошибке относятся следующие.
80004005 — Ошибка SQLSetConnectAttr драйвера
80004005 — Общий сбой.
 Не удается открыть раздел реестра «DriverId»
Не удается открыть раздел реестра «DriverId»Далее перечислены возможные причины и способы решения.
Странице не удается найти имя DSN. Убедитесь, что DSN было создано и на веб-сервере, и на локальном компьютере.
Возможно, имя DSN задано как DSN пользователя, а не DSN системы. Удалите DSN пользователя и создайте вместо него DSN системы.
Если этого не сделать, дублирующиеся имена DSN вызовут новую ошибку ODBC.
Если используется приложение Microsoft Access, файл базы данных (MDB-файл) может быть заблокирован. Причина блокирования может заключаться в том, что DSN с другим именем уже использует базу данных. Откройте проводник Windows, в папке, в которой расположен файл базы данных (MDB-файл), найдите файл блокировки (LDB-файл) и удалите его. Если другое имя DSN указывает на один и тот же файл базы данных, удалите это имя, чтобы избежать ошибок в дальнейшем. Перезагрузите компьютер после внесения изменений.
[[Ссылка]80004005 — Не удается использовать «(нет данных)»; файл уже используется]
Эта ошибка возникает при использовании базы данных Microsoft Access и попытке просмотра динамической страницы в веб-браузере или интерактивном представлении. Еще один вариант текста этого сообщения об ошибке: «80004005 — Обработчик баз данных Microsoft Jet не может открыть файл (нет данных)».
Еще один вариант текста этого сообщения об ошибке: «80004005 — Обработчик баз данных Microsoft Jet не может открыть файл (нет данных)».
Возможная причина — неправильно установлены разрешения. Далее перечислены несколько конкретных причин и способов решения.
Возможно, учетная запись, используемая сервером IIS (как правило, это учетная запись IUSR), не имеет нужных разрешений Windows для доступа к файловой базе данных или папке, содержащей эту базу данных. Проверьте разрешения учетной записи IIS (IUSR) в диспетчере пользователей.
Пользователь может не иметь разрешения на создание или удаление временных файлов. Проверьте разрешения для файла и папки. Убедитесь в наличии разрешения на создание или удаление временных файлов. Временные файлы обычно создаются в той же папке, в которой содержится база данных, но они также могут создаваться и в других папках, например «/Winnt».
В Windows 2000 может потребоваться изменить значение времени ожидания для DSN базы данных Access.
 Чтобы изменить это значение, выберите команды «Пуск» > «Настройка» > «Панель управления» > «Администрирование» > «Источники данных» (ODBC). Откройте вкладку «Система», выделите правильное имя DSN и нажмите кнопку «Настройка». Нажмите кнопку «Параметры» и в поле «Время ожидания страницы» введите значение 5000.
Чтобы изменить это значение, выберите команды «Пуск» > «Настройка» > «Панель управления» > «Администрирование» > «Источники данных» (ODBC). Откройте вкладку «Система», выделите правильное имя DSN и нажмите кнопку «Настройка». Нажмите кнопку «Параметры» и в поле «Время ожидания страницы» введите значение 5000.Если проблемы так и не удалось решить, см. следующие статьи базы знаний Майкрософт:
Статья: 80004005 — «Невозможно использовать ‘(неизвестно)’; файл уже используется» по адресу: http://support.microsoft.com/default.aspx?scid=kb;ru-ru;Q174943.
Статья: «Сбой подключения к базам данных Microsoft Access в ASP» по адресу: http://support.microsoft.com/default.aspx?scid=kb;ru-ru;Q253604.
Статья: «Ошибка «не удается открыть неизвестный файл» при использовании Access» по адресу: http://support.microsoft.com/default.aspx?scid=kb;ru-ru;Q166029.
[[Ссылка]80004005 — Сбой при входе в систему()]
Эта ошибка возникает при использовании сервера Microsoft SQL Server и попытке просмотра динамической страницы в веб-браузере или интерактивном представлении.
Эта ошибка создается сервером SQL Server, если он не принимает либо не распознает учетную запись или введенный пароль (если используется стандартная защита), или же если учетная запись Windows не соответствует учетной записи SQL (если используется встроенная система безопасности).
Далее перечислены возможные решения.
Если используется стандартная защита, причиной ошибки может быть неправильные имя учетной записи и пароль. Попробуйте воспользоваться учетной записью и паролем системного администратора (UID= «sa» без пароля), которые должны были быть определены в строке подключения. (Имена DSN не хранят имена и пароли пользователей.)
Если используется встроенная система безопасности, проверьте учетную запись Windows, обращающуюся к странице, и найдите соответствующую ей учетную запись SQL (при наличии).
Сервер SQL Server не допускает использование нижних подчеркиваний в именах учетных записей SQL. Если вручную сопоставить учетную запись Windows «IUSR_имя_компьютера» учетной записи SQL с таким же именем, эта учетная запись не будет принята сервером.
 Учетную запись, в которой использовано нижнее подчеркивание, нужно сопоставлять с именем учетной записи на сервере SQL, в котором нижнее подчеркивание не используется.
Учетную запись, в которой использовано нижнее подчеркивание, нужно сопоставлять с именем учетной записи на сервере SQL, в котором нижнее подчеркивание не используется.
[[Ссылка]80004005 — В операции должен использоваться обновляемый запрос]
Данная ошибка возникает, когда событие обновляет набор записей или вставляет в него данные.
Далее перечислены возможные причины и способы решения.
Разрешения для доступа к папке, содержащей базу данных, слишком ограничены. Учетная запись IUSR должна обладать правами на чтение/запись.
Разрешения для самого файла базы данных не включают действующих полных прав на чтение/запись.
Возможно, база данных не расположена в каталоге Inetpub/wwwroot. Для обновления базы данных требуется, чтобы она располагалась в каталоге wwwroot. В противном случае будут доступны только просмотр и поиск данных, но не их обновление.
Набор записей основан на необновляемом запросе.
 Хорошими примерами необновляемых запросов в базе данных являются соединения. Преобразуйте необновляемые запросы в обновляемые.
Хорошими примерами необновляемых запросов в базе данных являются соединения. Преобразуйте необновляемые запросы в обновляемые.Дополнительные сведения об этой ошибке см. в статье базы знаний Майкрософт «Ошибка ASP «запрос не является обновляемым» при обновлении записи в таблице» по адресу: http://support.microsoft.com/default.aspx?scid=kb;ru-ru;Q174640.
[[Ссылка]80040e07 — Несоответствие типов данных в выражении условия отбора]
Данная ошибка возникает при попытке сервера обработать страницу, содержащую серверное поведение «Вставить запись» или «Обновить запись», которое пытается задать пустую строку («») в качестве значения для столбца «Дата/время» в базе данных Microsoft Access.
Microsoft Access имеет строгую типизацию данных, которая устанавливает четкий набор правил для соответствующих значений столбцов. Пустая строка в запросе SQL не может храниться в столбце «Дата/время» базы данных Access. Единственный известный на текущий момент способ избежать возникновения данной ошибки — это не вставлять и не обновлять столбцы «Дата/время» в Access пустыми строками («») или любыми другими значениями, которые не соответствуют диапазону значений, заданному для этого типа данных.
[[Ссылка] 80040e10 «Слишком мало параметров»]
Данная ошибка возникает в том случае, если столбец, указанный в запросе SQL, отсутствует в таблице базы данных. Проверьте имена столбцов в таблице базы данных на соответствие столбцам, указанным в запросе SQL. Зачастую причиной этой ошибки является опечатка.
[[Ссылка]80040e10 — Неверное поле COUNT]
Данная ошибка возникает при просмотре страницы, содержащей серверное поведение «Вставить запись», в веб-браузере и попытке с ее помощью вставить запись в базу данных Microsoft Access.
Данная ошибка может возникать при попытке вставить запись в поле базы данных, в имени которого содержится вопросительный знак (?). Для некоторых обработчиков баз данных, включая Microsoft Access, вопросительный знак является специальным символом, поэтому его нельзя использовать в именах таблиц баз данных и в именах полей.
Откройте систему базы данных и удалите вопросительный знак (?). из имен полей, а затем обновите на странице варианты поведения сервера, которые ссылаются на это поле.
Данная ошибка возникает при попытке сервера обработать страницу, содержащую серверное поведение «Вставить запись».
Как правило, эта ошибка появляется вследствие одной или нескольких описанных ниже проблем с именами полей, объектов или переменных в базе данных.
В качестве имени использовано зарезервированное слово. Большинство баз данных имеют набор зарезервированных слов. Например, слово «date» является зарезервированным и, следовательно, не может быть использовано в именах столбцов базы данных.
В имени использованы специальные символы. Вот несколько примеров специальных символов:
. / * : ! # & — ?
Имя содержит пробел.
Подобная ошибка также может возникать, если для объекта в базе данных была определена маска ввода, но вставленные данные не соответствуют этой маске.
Чтобы решить проблему, не используйте в именах столбцов базы данных зарезервированные слова, например «date», «name», «select», «select» и «level».
 Помимо этого, исключите пробелы и специальные символы.
Помимо этого, исключите пробелы и специальные символы.Списки зарезервированных слов для наиболее распространенных систем баз данных см. на следующих веб-страницах.
Microsoft Access: http://support.microsoft.com/default.aspx?scid=kb;ru-ru;Q209187
MySQL: http://dev.mysql.com/doc/mysql/en/reserved-words.html
[[Ссылка]80040e21 — Ошибка ODBC при вставке или обновлении]
Данная ошибка возникает при попытке сервера обработать страницу, содержащую серверное поведение «Обновить запись» или «Вставить запись». Базе данных не удается обработать операцию обновления или вставки, которую пытается выполнить серверное поведение.
Далее перечислены возможные причины и способы решения.
Серверное поведение пытается обновить поле автонумерации в таблице базы данных или вставить запись в это поле. Так как поля автонумерации заполняются автоматически самой системой базы данных, внешние попытки заполнить эти поля значениями приводят к ошибкам.

Серверное поведение обновляет или вставляет данные неправильного типа в поле базы данных. Например, дата вставляется в логическое поле, требующее значение «да» или «нет», строка вставляется в числовое поле, а неправильно отформатированная строка — в поле «Дата/время».
[[Ссылка]800a0bcd — Функция BOF или EOF возвращает значение True]
Эта ошибка возникает при попытке просмотра динамической страницы в веб-браузере или интерактивном представлении.
Данная проблема возникает при попытке отобразить на странице данные из пустого набора записей. Для решения проблемы к динамическому содержимому, которое будет отображено на странице, нужно применить серверное поведение «Показать область». Вот как это сделать:
Выделите динамическое содержимое на странице.
На панели «Поведение сервера» нажмите кнопку со знаком «Плюс» (+) и выберите пункты «Показать область» > «Показать область, если набор записей не пустой».
Выберите набор записей, из которого берется динамическое содержимое, и нажмите кнопку «ОК».
Повторите шаги 1–3 для каждого элемента динамического содержимого на странице.
Одним из распространенных сообщений об ошибке, которое может появиться во время тестирования подключения базы данных PHP к MySQL 4.1 является «Клиент не поддерживает запрашиваемый протокол аутентификации. Обновите клиент MySQL.»
Может понадобиться вернуться к более ранней версии MySQL или установить PHP 5 и скопировать некоторые динамически связываемые библиотеки (DLL). Подробные инструкции см. в разделе Настройка среды разработки PHP.
Вход в учетную запись
Войти
Управление учетной записью
Создание базы данных с помощью SQLite
Далее
Знакомство с пользовательским интерфейсом браузера баз данных для SQLite
Продолжение в
Создание базы данных с помощью SQLite
Это предварительный просмотр содержимого подписки
Войдите, чтобы проверить доступ
Для просмотра этого видео ваш браузер должен поддерживать JavaScript
Попробуйте перезагрузить эту страницу или проверьте настройки браузера
Вы просматриваете предварительный просмотр содержимого подписки. Войдите, чтобы проверить доступ
- Просмотреть содержание
- Подробности Подробности
- Стенограмма Стенограмма
- Содержание Оглавление
Станьте мастером баз данных, научившись создавать простую базу данных и управлять ее данными. В этом видео эксперт по SQL Аллен Тейлор объясняет, как создать простую базу данных с помощью SQLite, ядра базы данных с открытым исходным кодом. Часть 1 знакомит с SQLite и исследует его основные функции. Во второй части вы создадите свою первую таблицу и начнете вводить некоторые данные. В части 3 объясняются основные запросы и способы использования оператора SELECT, а также предложений FROM и WHERE.
После просмотра Создание базы данных с помощью SQLite вы поймете, как построить базовую базу данных и как запрашивать и извлекать из нее информацию.
Чему вы научитесь
Знакомство с функциями и характеристиками пользовательского интерфейса SQLite
Использование SQLite для добавления или удаления данных в вашей базе данных
Работа с несколькими таблицами в базе данных
Найдите нужную информацию в своей базе данных
Для кого предназначено это видео
Программисты, плохо знакомые с базами данных, а также непрограммисты, которым необходимо извлекать информацию из баз данных.
Об авторе
Аллен Тейлор, ветеран компьютерной индустрии с 30-летним стажем, автор всемирно известных бестселлеров, педагог, консультант и докладчик по технологиям и обществу. Широко известен как эксперт по технологии баз данных, он написал двадцать книг, в том числе SQL для чайников, Разработка баз данных для чайников, Экспресс-курс выходного дня по SQL, и Crystal Reports 9 для чайников . Он преподает электронный курс по разработке баз данных в сети из более чем 1000 местных колледжей и учебных заведений для взрослых, а также преподает цифровые схемы в Портлендском государственном университете.
Об этом видео
- Автор(ы)
- Аллен Тейлор
- ДОИ
- https://doi.org/10.1007/978-1-4842-3899-8
- Онлайн ISBN
- 978-1-4842-3899-8
- Общая продолжительность
- 48 мин
- Издатель
- Апресс
- Информация об авторских правах
- © Аллен Г. Тейлор, 2019 г.
Связанный контент
Видео
- Аллен Тейлор
Начните путь к мастерству в SQL и базах данных: две самые важные темы в ИТ. В этом видео эксперт по SQL Аллен Г. Тейлор рассказывает об основах SQL. Часть 1 объясняет, откуда взялся SQL, почему данные…
Видео
- Аллен Тейлор
Изучите основы создания, обслуживания, защиты и запросов к реляционным базам данных с помощью SQL, стандартного языка, используемого для связи со всеми реляционными базами данных. Опираясь на предыдущие работы автора…
Стенограмма видео
Аллен Тейлор : [Музыка] В настоящее время используется несколько систем управления реляционными базами данных, включая Microsoft SQL Server, Oracle, PostgreSQL и MySQL. Все эти продукты изначально предназначены для работы на больших мощных системах, таких как серверы баз данных, настольные компьютеры и ноутбуки. Смартфоны и планшеты также нуждаются в возможностях базы данных, но в более компактном корпусе. SQLite, как следует из его названия, отвечает всем требованиям высокопроизводительной СУБД, которая нетребовательна к системным ресурсам. Его основное использование — встраивание в операционную систему смартфонов и подобных устройств. Это также полезный инструмент для изучения SQL. Мы встроим его в интуитивно понятный пользовательский интерфейс под названием DB Browser for SQLite, а затем будем использовать его для получения практического опыта и создания операторов SQL.
В этом видео я проведу вас через процесс установки DB Browser для SQLite, а затем расскажу о возможностях среды, которые предоставляют эти два продукта. SQLite и DB Browser для SQLite — это продукты с открытым исходным кодом, которые можно использовать бесплатно. SQLite встроен в DB Browser для SQLite, поэтому при установке DB Browser вы также будете устанавливать SQLite. Вы можете скачать DB Browser для SQLite с сайта SQLitebrowser.org.
Вот что вы увидите, когда доберетесь туда. Для разного оборудования доступны разные исполняемые версии программы установки для него. Как видите, вы можете скачать версию для 32-битной Windows, для 64-битной Windows, для портативной версии, версию для Macintosh, а также исходный файл и tar-файл. Выберите тот, который подходит для вашей системы. В моем случае это 64-битная Windows. Нажмите на соответствующую кнопку для вашего оборудования, и загрузка начнется. Вероятно, это займет несколько секунд. Когда загрузка будет завершена, нажмите на файл .exe, чтобы выполнить установку.
Если у вас Windows, как у меня, появится диалоговое окно с вопросом, хотите ли вы разрешить браузеру БД для SQLite вносить изменения в ваш компьютер. Нажмите кнопку Да. Появится диалоговое окно настройки. Нажмите кнопку «Далее». Появится диалоговое окно лицензионного соглашения. Прочтите лицензионное соглашение, чтобы убедиться, что вы не соглашаетесь с чем-то, с чем вы не хотите соглашаться, а затем нажмите кнопку «Я согласен». Появится диалоговое окно «Выбор места установки». Либо принятое местоположение по умолчанию, либо укажите одно из выбранных вами. Я приму значение по умолчанию. После того, как вы либо сохранили его, либо указали другое место, нажмите кнопку «Далее». Следующее диалоговое окно дает вам возможность выбрать папку меню «Пуск». Я приму папку по умолчанию. Нажмите кнопку Установить. Начнется установка. Это займет некоторое время. По завершении установки появится диалоговое окно завершения настройки DB Browser for SQLite с установленным флажком «Запустить DB Browser for SQLite». Нажмите кнопку «Готово», и SQLite запустится. В следующем сегменте мы рассмотрим функции, которые может предложить DB Browser для SQLite.
Создание таблицы — основы SQL
[00:00]
Целью этой серии тем является взаимодействие с данными в нашей базе данных с помощью запроса. Использование этих данных в компонентах в рамках проекта зажигания будет обсуждаться в следующем разделе. Цель этого урока — рассказать, как создать таблицу в базе данных. Мы можем создать таблицу в нашей базе данных, используя определенный тип запроса. Теперь мы можем запустить этот запрос из нашего браузера запросов к базе данных в меню инструментов или мы можем перейти к программному обеспечению для управления базой данных и запустить наш запрос там, но я собираюсь выполнять все запросы в этой серии тем, используя именованный запрос. Я собираюсь создать новый именованный запрос, щелкнув правой кнопкой мыши и выбрав новый запрос, и я назову этот запрос для создания таблицы.
[01:00]
Затем я нажму кнопку «Создать» и перейду на вкладку «Авторство». Первое, что я хочу сделать, это установить соединение с базой данных, которое я собираюсь использовать для этого именованного запроса, поэтому я зайду в раскрывающийся список соединений с базой данных и выберу соединение с базой данных InternalDB. Я хочу отметить, что база данных, которую я здесь использую, — это встроенная база данных SQLite, которую вы можете настроить. Для получения дополнительной информации о настройке соединений с базами данных вы можете посмотреть другие видеоролики Inductive University или перейти к нашему руководству пользователя. Далее мне нужно указать тип запроса, который я хочу запустить. В этом случае я не буду извлекать данные из базы данных, а буду создавать новую таблицу, что аналогично вставке или обновлению базы данных. Поэтому я собираюсь изменить свой тип запроса, чтобы обновить запрос. В данном конкретном случае мне не нужны никакие параметры, поэтому я могу удалить два параметра, которые у меня есть прямо сейчас.
[02:00]
Наконец, я собираюсь вставить свой запрос в область запросов здесь. Чтобы создать таблицу в базе данных, мы начинаем с команды create table, за которой следует имя таблицы, которую мы хотим создать. В этом случае моя таблица будет называться inventory. Затем в скобках мы перечисляем имена столбцов, которые мы хотим создать в нашей таблице, а также их типы данных. Итак, вы можете видеть, что у меня есть три столбца: имя, местоположение и количество, с типами данных текст, текст и целое число соответственно. Я хочу отметить, что этот синтаксис может отличаться в зависимости от того, какой тип базы данных вы используете. Имейте в виду, что мы используем внутреннее соединение с базой данных SQLite. Ваша таблица может иметь любое количество столбцов, а столбцы могут иметь несколько различных типов данных, опять же, имена типов данных различаются в зависимости от того, какой тип базы данных вы используете.
[03:02]
После ввода нашего запроса мы можем запустить его, просто перейдя на вкладку тестирования и нажав кнопку выполнения запроса. Мы не ожидали никаких данных, поэтому я не ожидал увидеть здесь что-либо в этом списке результатов, но если я вернусь на вкладку разработки, мы должны увидеть, что теперь в моем браузере таблиц у меня есть таблица инвентаризации. и если мы развернем его, я увижу три столбца, которые я добавил в эту таблицу: имя, местоположение и количество.
Целью этой серии тем является взаимодействие с данными в нашей базе данных с помощью запроса. Использование этих данных в компонентах в рамках проекта зажигания будет обсуждаться в следующем разделе. Цель этого урока — рассказать, как создать таблицу в базе данных. Мы можем создать таблицу в нашей базе данных, используя определенный тип запроса. Теперь мы можем запустить этот запрос из нашего браузера запросов к базе данных в меню инструментов или мы можем перейти к программному обеспечению для управления базой данных и запустить наш запрос там, но я собираюсь выполнять все запросы в этой серии тем, используя именованный запрос. Я собираюсь создать новый именованный запрос, щелкнув правой кнопкой мыши и выбрав новый запрос, и я назову этот запрос для создания таблицы.
[01:00] Затем я нажму кнопку «Создать» и перейду на вкладку «Авторство». Первое, что я хочу сделать, это установить соединение с базой данных, которое я собираюсь использовать для этого именованного запроса, поэтому я зайду в раскрывающийся список соединений с базой данных и выберу соединение с базой данных InternalDB. Я хочу отметить, что база данных, которую я здесь использую, — это встроенная база данных SQLite, которую вы можете настроить. Для получения дополнительной информации о настройке соединений с базами данных вы можете посмотреть другие видеоролики Inductive University или перейти к нашему руководству пользователя. Далее мне нужно указать тип запроса, который я хочу запустить. В этом случае я не буду извлекать данные из базы данных, а буду создавать новую таблицу, что аналогично вставке или обновлению базы данных. Поэтому я собираюсь изменить свой тип запроса, чтобы обновить запрос. В данном конкретном случае мне не нужны никакие параметры, поэтому я могу удалить два параметра, которые у меня есть прямо сейчас.
[02:00] Наконец, я собираюсь вставить свой запрос в область запросов здесь. Чтобы создать таблицу в базе данных, мы начинаем с команды create table, за которой следует имя таблицы, которую мы хотим создать. В этом случае моя таблица будет называться inventory. Затем в скобках мы перечисляем имена столбцов, которые мы хотим создать в нашей таблице, а также их типы данных. Итак, вы можете видеть, что у меня есть три столбца: имя, местоположение и количество, с типами данных текст, текст и целое число соответственно. Я хочу отметить, что этот синтаксис может отличаться в зависимости от того, какой тип базы данных вы используете. Имейте в виду, что мы используем внутреннее соединение с базой данных SQLite. Ваша таблица может иметь любое количество столбцов, а столбцы могут иметь несколько разных типов данных, опять же, имена типов данных различаются в зависимости от того, какой тип базы данных вы используете.
[03:02] Теперь, когда мы ввели наш запрос, мы можем запустить его, просто перейдя на вкладку «Тестирование» и нажав кнопку «Выполнить запрос». Мы не ожидали никаких данных, поэтому я не ожидал увидеть здесь что-либо в этом списке результатов, но если я вернусь на вкладку разработки, мы должны увидеть, что теперь в моем браузере таблиц у меня есть таблица инвентаризации.