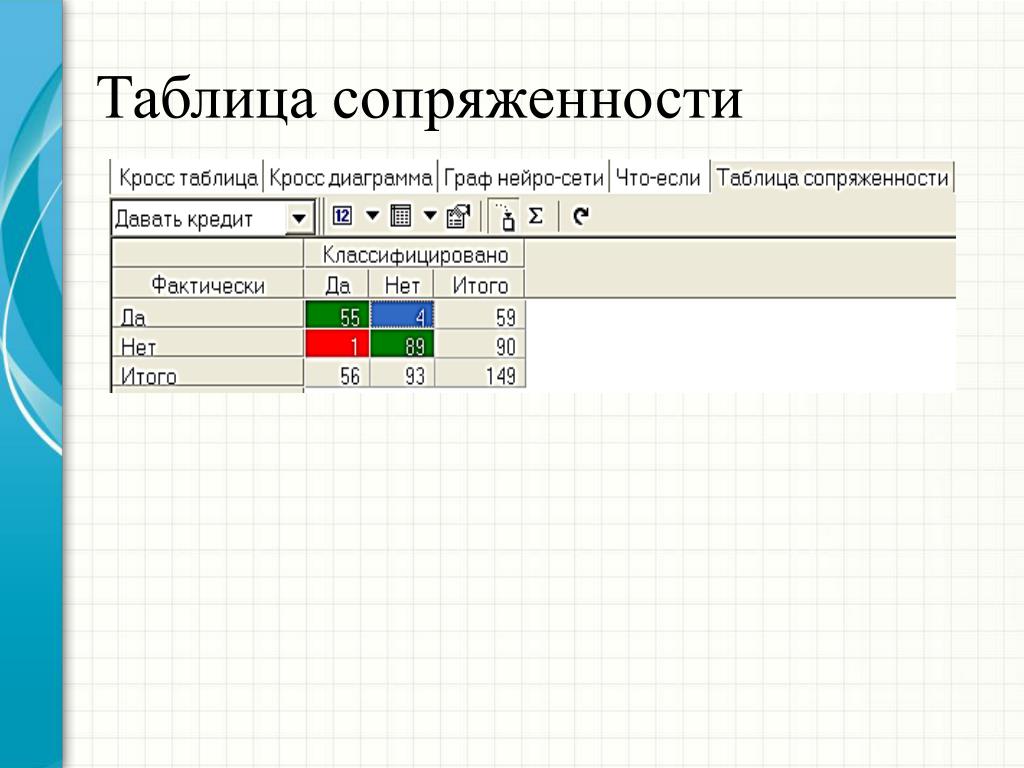
влияние прививки на холерную инфекцию
В таблице ниже приведены сведения о числе людей, заболевших или не заболевших холерой, с указанием, была ли им сделана противохолерная прививка.
Фрагмент таблицы с исходными данными
Файл содержит данные по 2663 пациентам.
В первой переменной указано была ли сделана пациенту прививка, а во второй – был ли зафиксирован факт заболевания холерой после прививки.
Задача: Требуется выяснить, эффективна прививка или нет.
Мы критикуем прививку и выдвигаем гипотезу: связи между заболеваемостью и прививкой нет.
Наблюдаемые частоты: Для решения задачи построим таблицу сопряженности, т.е. сопряжем признаки:
Таблица с наблюдаемыми частотами
Четыре элемента таблицы, а именно 1022, 11, 1625, 5 — это частоты; мы имеем, таким образом, таблицу в виде квадрата вместо привычного ряда столбцов.
По ней строится критерий согласия хи-квадрат с некоторой выдвинутой гипотезой:
Нулевая гипотеза:
Переформулируем нашу задачу.
Значимо ли воздействие прививки на вероятность заболевания?
Попробуем принять в качестве нулевой гипотезы, что прививка не оказывает воздействия на заболевание и что видимый эффект от прививки есть результат случайных флуктуаций.
Мы должны, следовательно, сравнить элементы в таблице с соответствующими ожидаемыми элементами в предположении справедливости гипотезы.
Ожидаемые частоты. Из гипотезы следует, что для 2663 человек, находящихся в группе риска, ожидаемая доля заболевших после прививки будет той же, что и ожидаемая доля заболевших среди тех, кому прививку не делали; общее значение этих долей совпадает с долей заболевших во всей выборке, а именно p = 16/2663 (~0,006). Эти ожидаемые доли представлены в таблице ниже:
Подставляя, полученное значение p:
Таблица с ожидаемыми частотами
При нулевой гипотезе ожидаемая частота в любой ячейке может быть найдена умножением доли (p или 1-p) на маргинальное общее число соответствующей строки (1630 — для категории привитых, 1033 — для остальных).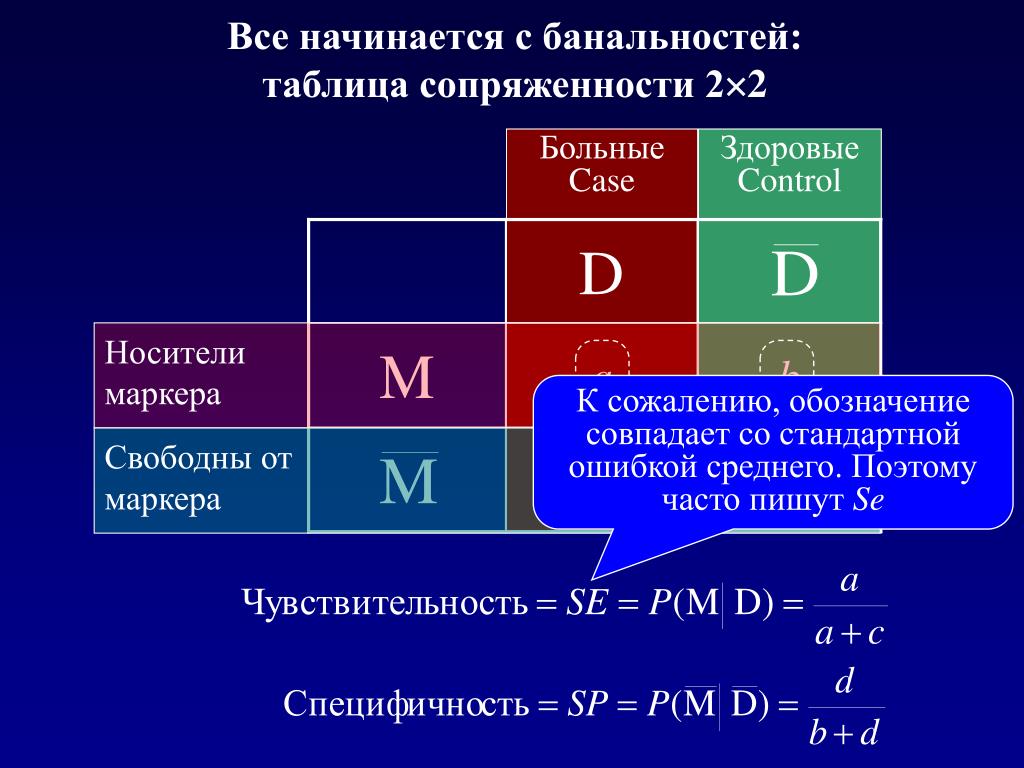
В принципе, только один элемент следует вычислять умножением маргинально частоты на ожидаемую долю; остальные элементы находятся вычитанием.
Значение Xи-квадрат используется для оценки меры рассогласованности наблюдаемого и ожидаемого результата. Если, согласно нулевой гипотезе, ожидаемый результат будет сильно отличаться от наблюдаемых значений, значит стоит поставить под сомнение справедливость гипотезы.
Перед тем, рассчитывать значение хи-квадрат, рассмотрим некоторые особенности таблиц 2х2, которые заслуживают специального упоминания.
В некоторых случаях необходимо делать «поправку на непрерывность» (так называемая «поправка Йетса»). Такие расхождения могут возникать, когда в таблице встречаются малые частоты (меньше 10).
Математически, «поправка на непрерывность» уменьшает погрешность, возникающую при аппроксимации непрерывным распределением хи-квадрат точного выборочного распределения, которое является дискретным.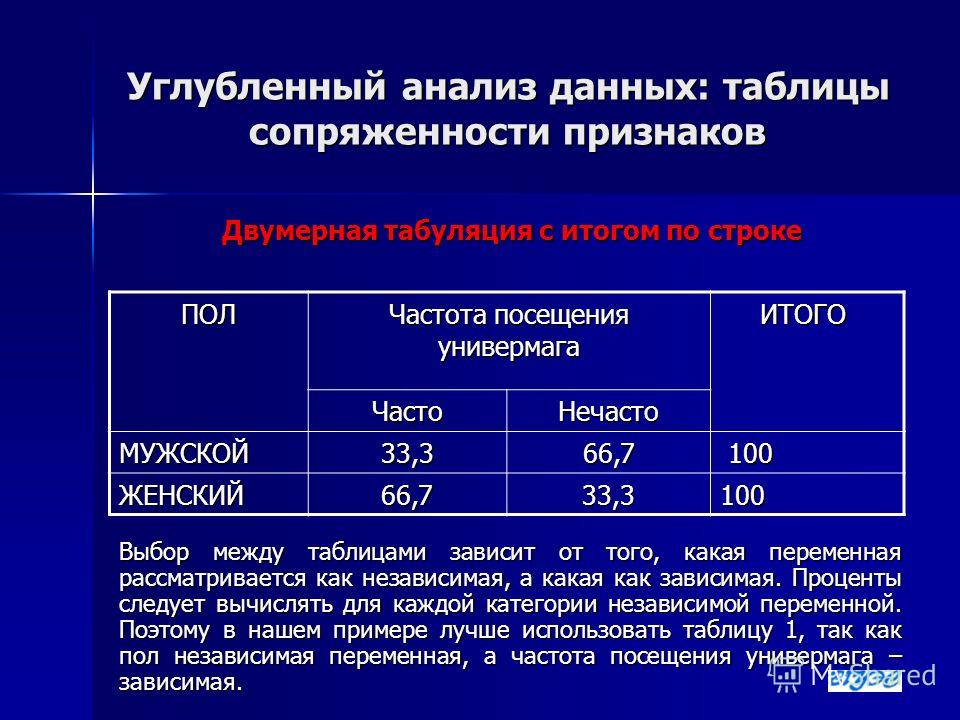
Вычислим значение хи-квадрат без поправки Йетса. Значение представляет собой сумму квадратов разностей наблюдаемой и ожидаемой частоты, деленную на соответствующую ожидаемую частоту:
(Смотрите значения в таблицах с наблюдаемыми и ожидаемыми частотами выше.)
Отметим, что в нашем случае, для более точного вычисления статистики хи-квадрат необходимо использовать поправку Йетса (пять пациентов заболели, несмотря на сделанную противохолерную прививку).
Поправка Йетса немного изменит таблицу наблюдаемых частот:
Модифицированная таблица с наблюдаемыми частотами
В модифицированной таблице частота «5» заменена на «5,5», а все остальные элементы изменены так, чтобы общие суммарные (маргинальные) частоты сохранились.
Отметим, что при такой модификации ожидаемые частоты остаются без изменения.
Теперь вычислим значение хи-квадрат с поправкой Йетса, пользуясь той же формулой, но в качестве наблюдаемых частот берем значения из модифицированной таблицы:
Чтобы оценить какова вероятность получить такое или большее значение хи-квадрат, при условии истинности нулевой гипотезы, необходимо вычислить уровень значимости (p-уровень).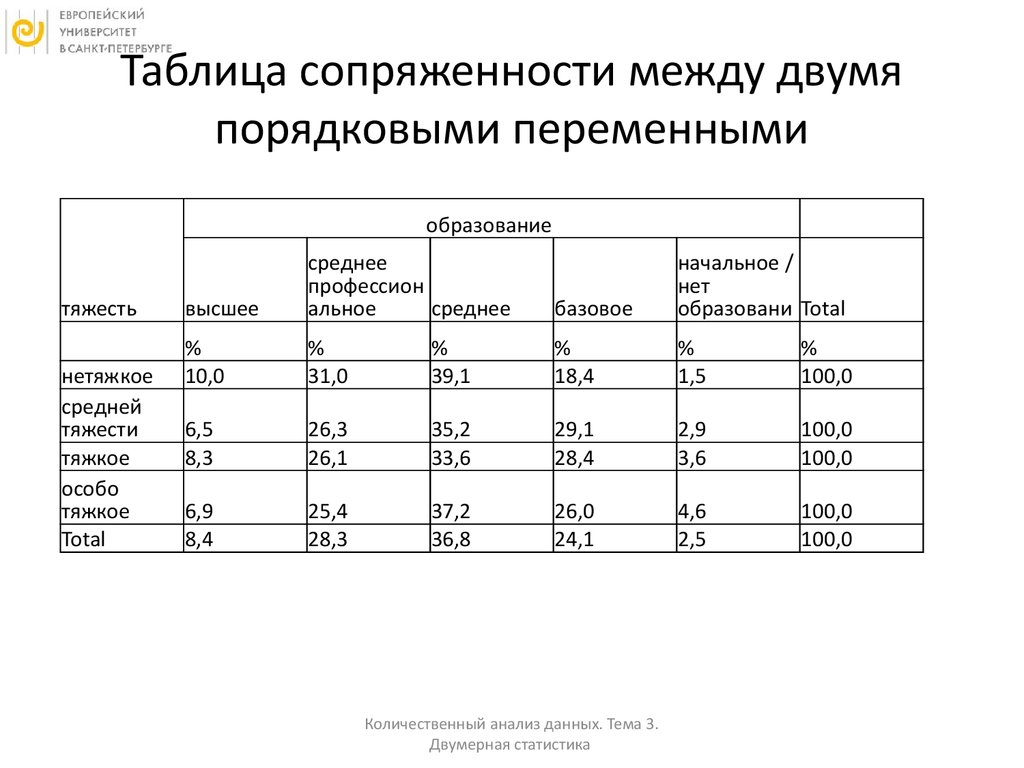
Если он окажется маленьким (обычно берется меньше 0,05), то нулевую гипотезу следует отклонить.
Использование калькулятора таблиц сопряженности 2 на 2.Заполняем таблицу в интерактивном калькуляторе таблиц сопряженности 2х2
Согласно таблице наблюдаемых частот (номера групп и вариантов заменяем на удобные для нас обозначения).
- Устанавливаем галочку напротив поправки Йетса (поправка для случая малых частот).
- Нажимаем кнопку «Вычислить».
Полученные результаты (p-уровень значимости ~ 0.014 < 0.05) говорят о том, что нулевую гипотезу о независимости следует отвергнуть: прививка в действительности имеет некоторый предупредительный эффект.
В нашем случае, значение величины «Отношение шансов» говорит о том, что шанс заболеть у группы непривитых больше, чем у группы привитых. Этот факт подтверждается проведенным выше анализом.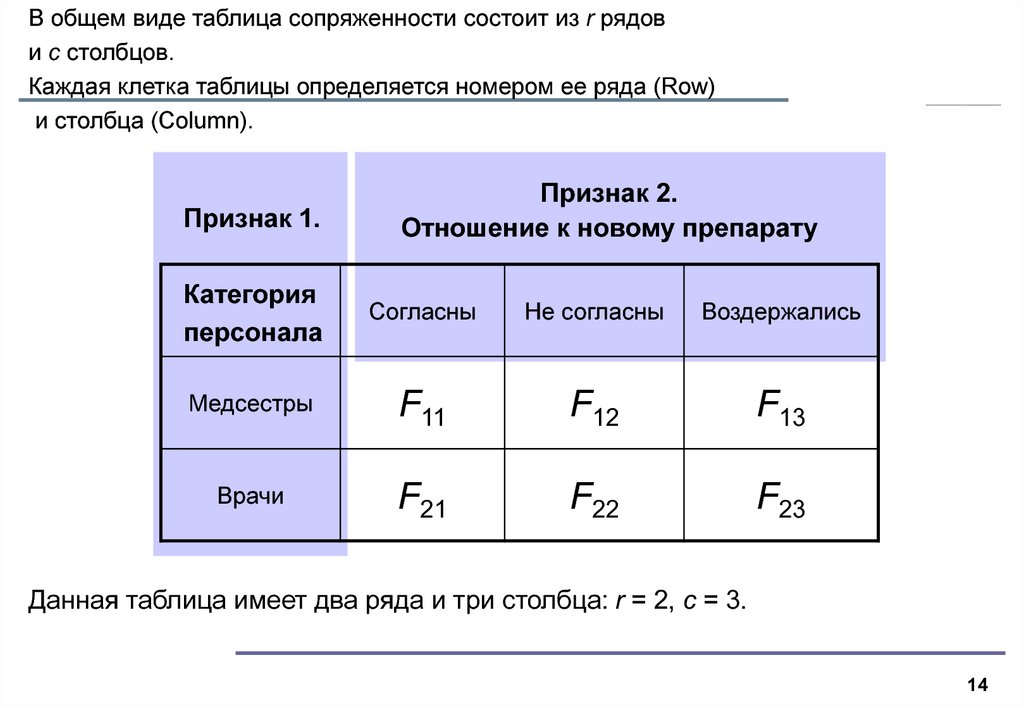
Таким же образом могут быть проверены гипотезы о прививках против гриппа, эффективности диспансеризации и т.д.
В начало
Содержание портала
Таблицы сопряженности презентация, доклад
Таблицы сопряженности
Cтат. методы в психологии
(Радчикова Н.П.)
Цели
Вспомнить, что такое таблицы сопряженности
Вспомнить, какую статистику можно для них считать
ТАБЛИЦЫ СОПРЯЖЕННОСТИ
Таблицы сопряженности − это совместное распределение двух переменных.
Строки таблицы образуются значениями одной переменной.
Столбцы таблицы образуются значениями второй переменной.
ТАБЛИЦЫ СОПРЯЖЕННОСТИ
В клетке таблицы (на пересечении строки и столбца) указывается частота совместного появления соответствующих значений.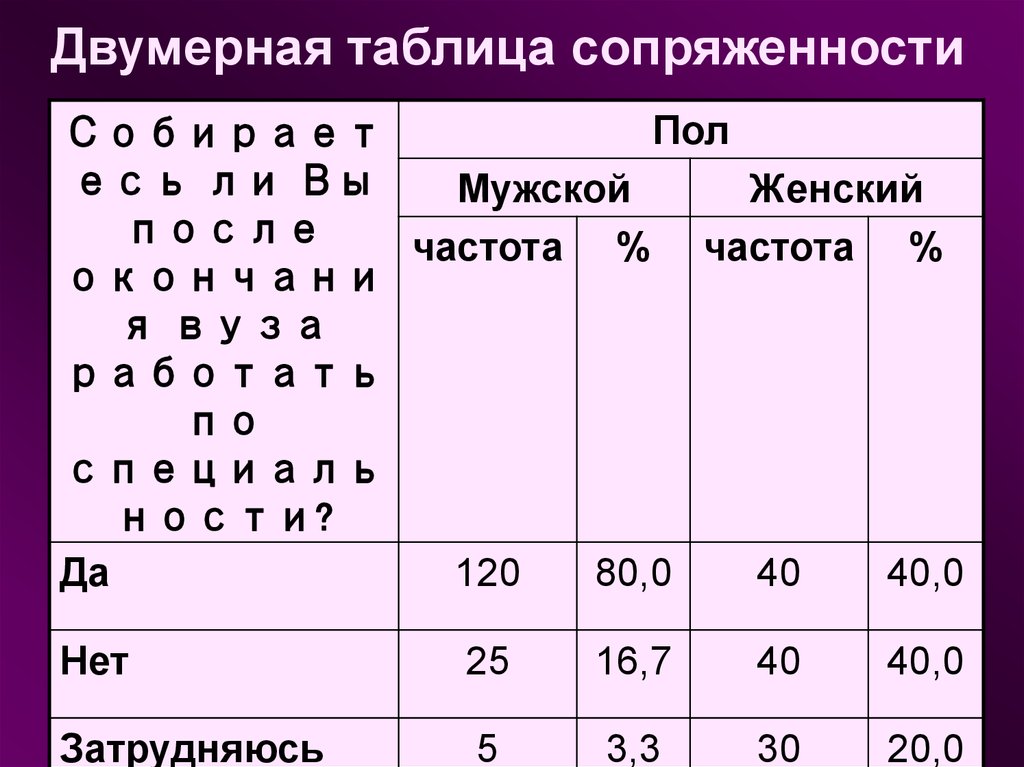
Суммы частот по строке или по столбцу называются маргинальными частотами.
Распределения маргинальных частот представляют собой одномерное распределение переменных.
Таким образом представленные данные
не дают нам много информации.
Проводим исследование:
X – семейное положение – НП
Y – занятость — ЗП
Собранные данные выглядят примерно так:
Можно их сгруппировать в виде таблиц:
по занятости:
и по семейному положению:
А можно и по двум переменным сразу:
Эта замечательная таблица и называется
таблицей сопряженности
По столбцам обычно приводится независимая переменная
По строкам обычно идет зависимая переменная
Проценты в таблице сопряженности можно считать тремя способами:
по столбцам, т. е. по независимой переменной
е. по независимой переменной
по строкам, т.е. по зависимой переменной
по всей таблице сразу:
ТАБЛИЦЫ СОПРЯЖЕННОСТИ
для шкал наименований
для шкал порядка
ТАБЛИЦЫ СОПРЯЖЕННОСТИ
для шкал наименований
для шкал порядка
χ2 Пирсона,
коэффициент сопряженности С,
V Крамера,
Ф
критерий Фишера для таблиц 2х2
критерий Ятса (Yates)
…
+
τ Кендалла,
Гамма (G),
ρ Спирмена,
d Соммера
ТАБЛИЦЫ СОПРЯЖЕННОСТИ
для шкал наименований
для шкал порядка
СТАТИСТИЧЕСКИЕ КРИТЕРИИ
ДЛЯ ТАБЛИЦ СОПРЯЖЕННОСТИ
Проверяют, есть ли зависимость в распределении одной переменной от распределения по другой переменной.
χ2 Пирсона
Пример: мы хотим проверить, правда ли,
что мужчины больше любят собак,
а женщины — кошек
Было опрошено 550 человек. Результаты опроса
представлены в таблице:
Мы можем проверить, зависит ли предпочтение домашнего животного (распределение по переменной Y) от пола
Подсчет критерия χ2
(Пирсона)
— эмпирическая частота,
— теоретическая частота,
k=r*c,
r- число строк в таблице,
c –число столбцов в таблице,
df=(r-1)(c-1).
Как определить теоретическую частоту?
Для выделенной ячейки:
Вероятность оказаться мужчиной равна 200/550.
Вероятность предпочитать собак равна 350/550.
Следовательно, вероятность быть мужчиной и предпочитать собак равна
(200/550 )*(350/550).
Умножив все это на количество испытуемых (550), получим теоретическую частоту для выделенной клетки:
Подсчитав таким образом теоретические частоты для всех клеток, находим
χ2=0,18; р=0,67
Следовательно, предпочтение домашнего животного не зависит от пола: мужчины и женщины одинаково любят собак.
Ограничения критерия χ2
✵ Наблюдения должны быть
независимы. Поэтому нельзя
использовать одного и того
же испытуемого несколько
раз.
✵ χ2 пропорционален размеру
выборки. Если увеличить
размер выборки в 2 раза, то и
значение χ2 возрастет в 2 раза.
Поэтому не рекомендуется
применять χ2 для больших
выборок.
✵ Если теоретическая частота
клеток маленькая, то
вычисления могут быть не
точны.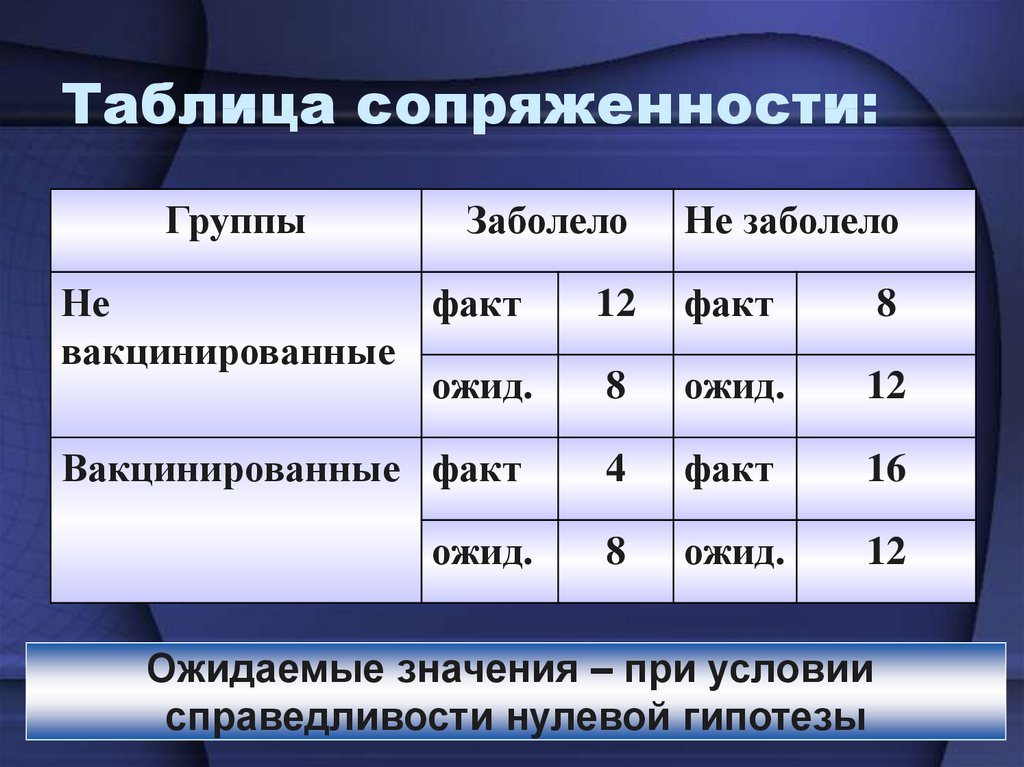
является правило, что когда
df>1 теоретическая частота
должна быть равна или больше
5 по крайней мере в 80%
клеток.
χ2 МакНемара (McNemar)
Увы! Только для таблиц 2*2.
Тот критерий применяется, чтобы определить, произошли ли изменения после какого-либо условия. Данные обычно представляются в виде таблицы:
Получается, что A+D – это число изменений
Подсчет критерия χ2
(МакНемара)
Ограничения:
A+D должно быть не меньше 10!
Пример: в телестудии проводятся дебаты, нужна ли смертная казнь. Зрители, сидящие в зале, опрашиваются до начала дебатов и в конце передачи.
χ2=1,25; p=0,26. Следовательно, можно сделать вывод, что приглашенные ораторы были одинаково успешны в отстаивании своих точек зрения: мнения зрителей существенно не изменились
Что делать, если таблица большей размерности, а схема – интраиндивидуальная?
Для случая, когда условий больше (до дебатов, после дебатов, через год после дебатов…), можно использовать
Q-критерий Кочрена (Кохрена),
но только если данные представлены как дихотомические переменные
(да/нет, за/против,…)
Что делать, если таблица большей размерности, схема – интраиндивидуальная, а данные не дихотомические?
Не проводить такие исследования!
МЕРЫ ЗАВИСИМОСТИ ДЛЯ ТАБЛИЦ СОПРЯЖЕННОСТИ
Меры зависимости
для шкал наименований
Все эти меры не имеют знака и не показывают направление отношений.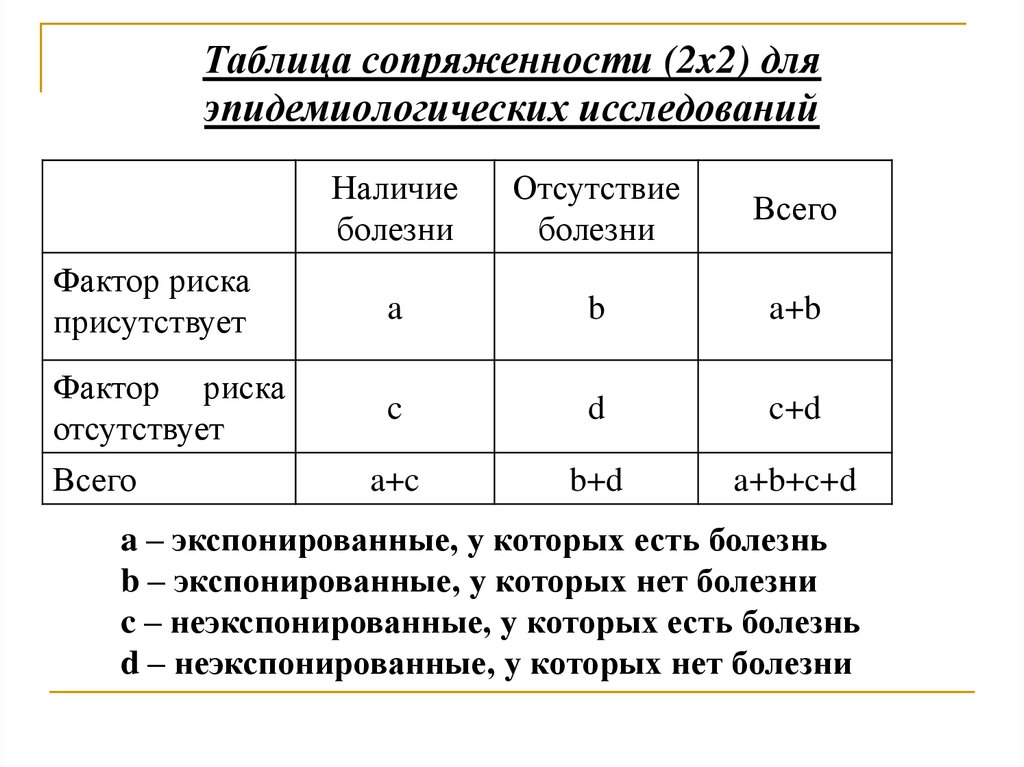
В программе STATISTICA можно посчитать три таких меры
Коэффициент φ
✵ употребляется в основном с
таблицами 2х2
✵ меняется от 0 (когда переменные
независимы) до 1 (когда они
абсолютно зависимы)
Коэффициент сопряженности С (или Ф)
✵ разработан для использования с квадратными
таблицами размера больше, чем 2х2
✵ меняется от 0 (когда переменные независимы)
до , где k — число строк (столбцов)
V Крамера
✵ можно употреблять для любых таблиц —
квадратных и прямоугольных
✵ меняется от 0 (когда переменные
независимы) до 1 (когда они абсолютно
зависимы)
где c – число строк,
r – число столбцов таблицы.
ТАБЛИЦЫ СОПРЯЖЕННОСТИ
для шкал наименований
для шкал порядка
✵ В таблице сопряженности можно
представлять и порядковые данные.
✵ Обычно они перечисляются слева направо
(от меньшего к большему) и сверху вниз (от
большего к меньшему):
Согласованная пара — это пара, где оба члена ранжированы в одном порядке по двум направлениям.
B
D
Несогласованная пара — это пара, где оба члена ранжированы в противо-положном порядке по двум направлениям.
B
А
Связанная пара — это пара, где оба члена ранжированы одинаково по крайней мере по одному направлению.
C
D
Если в таблице преобладают несогласованные пары, то зависимость между переменными отрицательная.
10
20
30
Если в таблице преобладают согласованные пары, то зависимость между переменными положительная.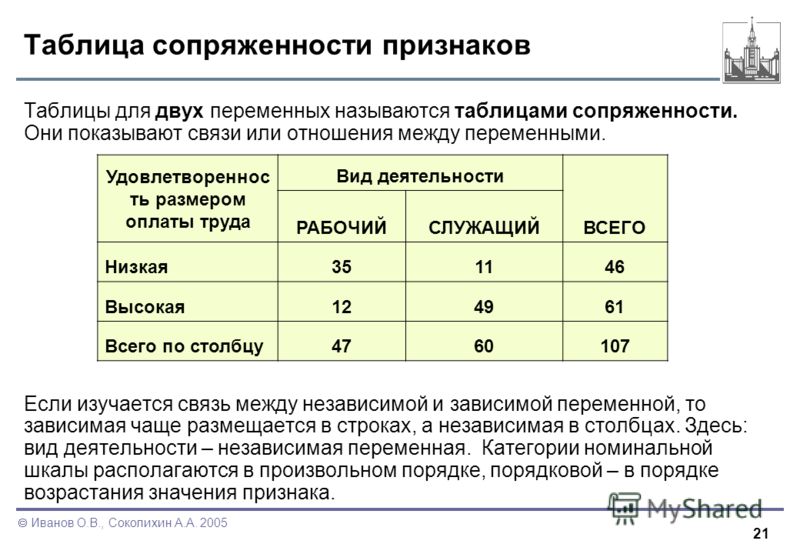
10
20
30
Меры зависимости
С- число согласованных пар,
D — число несогласованных пар,
Tx — число пар, связанных по Х
Ty = число пар, связанных по У
✵ Меры зависимости
для шкал порядка имеют знак
✵ τ Кендалла всегда меньше 1, если таблица не квадратная
☝
STATISTICA не знает, какая шкала была использована: определить подходящий критерий или меру зависимости — полностью ваша проблема
(и ответственность)
Представление данных
Посчитать статистику для таблиц сопряженности можно в модуле
Basic Statistics/ Tables and Banners
Представление данных
Исходные данные:
Представление данных
Представление данных
Представление данных
Для таблиц размером 2×2 есть еще модуль в
Nonparametrics/Distrib.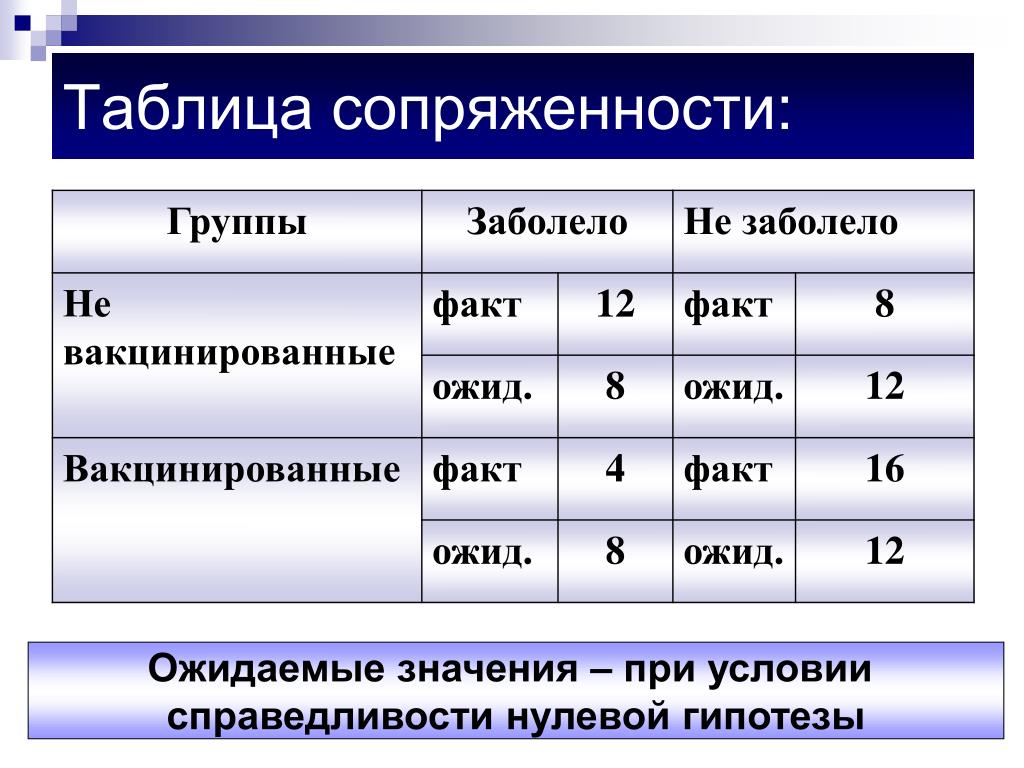
Представление данных
Остается только ввести цифры…
Представление данных
И получаем всю статистику!
Самостоятельная работа
К следующему занятию прочитать:
Савина и Ванг. Выбор и принятие решений: риск и социальный контекст// ПЖ, ….
(есть в электронном виде)
Можно передохнуть!
Скачать презентацию
Таблица непредвиденных обстоятельств: для чего она используется?
Определения статистики > Таблица непредвиденных обстоятельств
Таблица непредвиденных обстоятельств: обзор
Таблицы непредвиденных обстоятельств (также называемые перекрестными таблицами или двусторонними таблицами) обобщают отношения между несколькими категориальными переменными.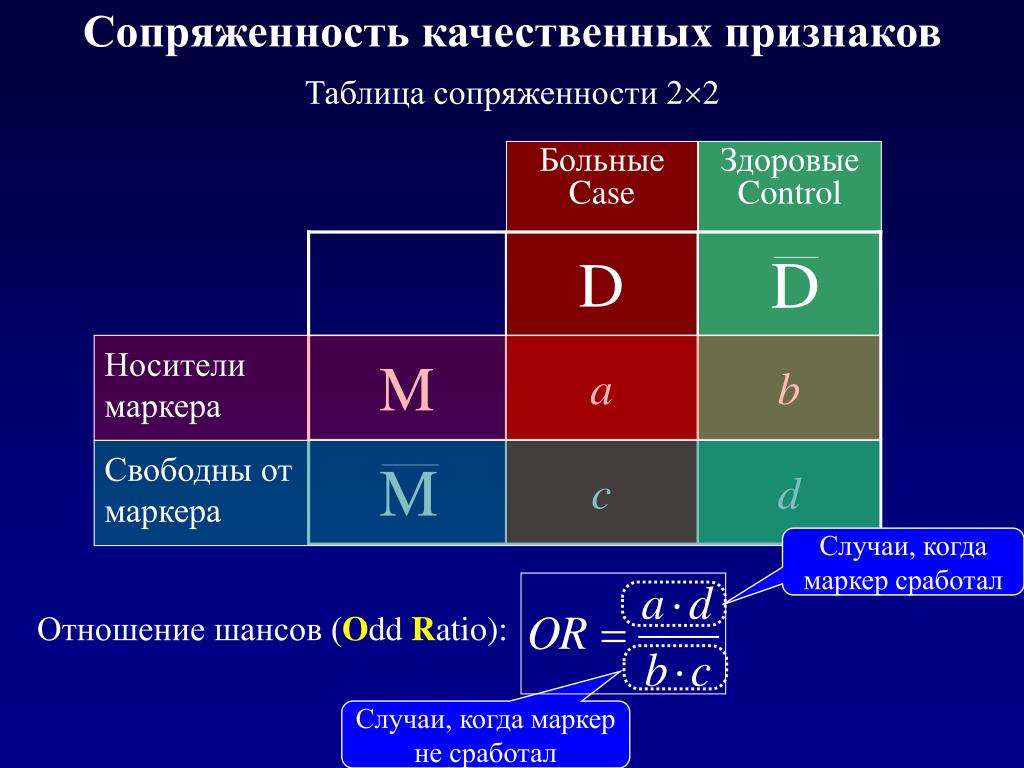 Это особый тип таблицы частотного распределения , в которой одновременно отображаются две переменные.
Это особый тип таблицы частотного распределения , в которой одновременно отображаются две переменные.
Например, исследователь может исследовать взаимосвязь между СПИДом и сексуальными предпочтениями. Двумя переменными будут СПИД и СЕКСУАЛЬНЫЕ ПРЕДПОЧТЕНИЯ. Если вопрос звучит так: «Существует ли значимая связь между СПИДом и сексуальными предпочтениями?», то можно провести тест хи-квадрат для таблицы, чтобы определить, существует ли связь между двумя переменными.
В следующей таблице непредвиденных обстоятельств показано воздействие потенциального источника болезней пищевого происхождения (в данном случае мороженого). Из таблицы видно, что 13 человек в тематическом исследовании ели мороженое; 17 человек не ответили:
Изображение: Департамент сельского хозяйства штата Мичиган
На изображении выше показан расчет отношения шансов.
Тесты хи-квадрат
Хи-тест 2 может быть проведен для таблиц непредвиденных обстоятельств, чтобы проверить, существует ли взаимосвязь между переменными. Эти эффекты определяются как отношения между строками и столбцами. Чи 2 тест:
Эти эффекты определяются как отношения между строками и столбцами. Чи 2 тест:
Где «O» — наблюдаемое значение, «E» — ожидаемое значение, а «i» — «i-я» позиция в таблице. Сигма (Σ) — это символ суммирования. На следующем рисунке показано, как может выглядеть ваша таблица непредвиденных обстоятельств с вашими данными, а также результаты выполнения теста chi 2 для ваших данных. Значение small chi 2 означает, что существует небольшая связь между категориальными переменными. A большой Чи 2 значение означает, что существует определенная корреляция между двумя переменными. Поскольку имеются убедительные доказательства того, что сексуальная ориентация связана с повышенным риском заражения СПИДом, неудивительно, что значение chi 2 высокое:
. ) ожидаемый счет меньше 5». Как правило, если это значение превышает 25%, результат может быть обусловлен только случайностью. Таким образом, результаты этого конкретного теста равны 9.0009 статистически незначимо .
Таким образом, результаты этого конкретного теста равны 9.0009 статистически незначимо .
Таблица непредвиденных обстоятельств в Excel
Таблица непредвиденных обстоятельств в Excel создается в Excel с помощью инструмента сводной таблицы. Посмотрите это видео о том, как создать ее в Excel:
Как создать сводную таблицу в Excel (за 5 минут!)
Посмотрите это видео на YouTube.
Видео не видно? Кликните сюда.
Таблицы непредвиденных обстоятельств, как известно, трудоемки для создания и вычисления ожидаемой частоты для каждой ячейки. Процедура дополнительно усложняется тем фактом, что вам может потребоваться сделать поправку на непрерывность, если ожидаемая частота ячеек ниже 5 (поправка на непрерывность для таблиц 2 x 2 называется поправкой Йейтса). Многие популярные программы имеют возможность создавать таблицы сопряженности, в том числе Microsoft Excel (обратите внимание, что даже в Excel этот процесс довольно сложен, включая создание сводных таблиц).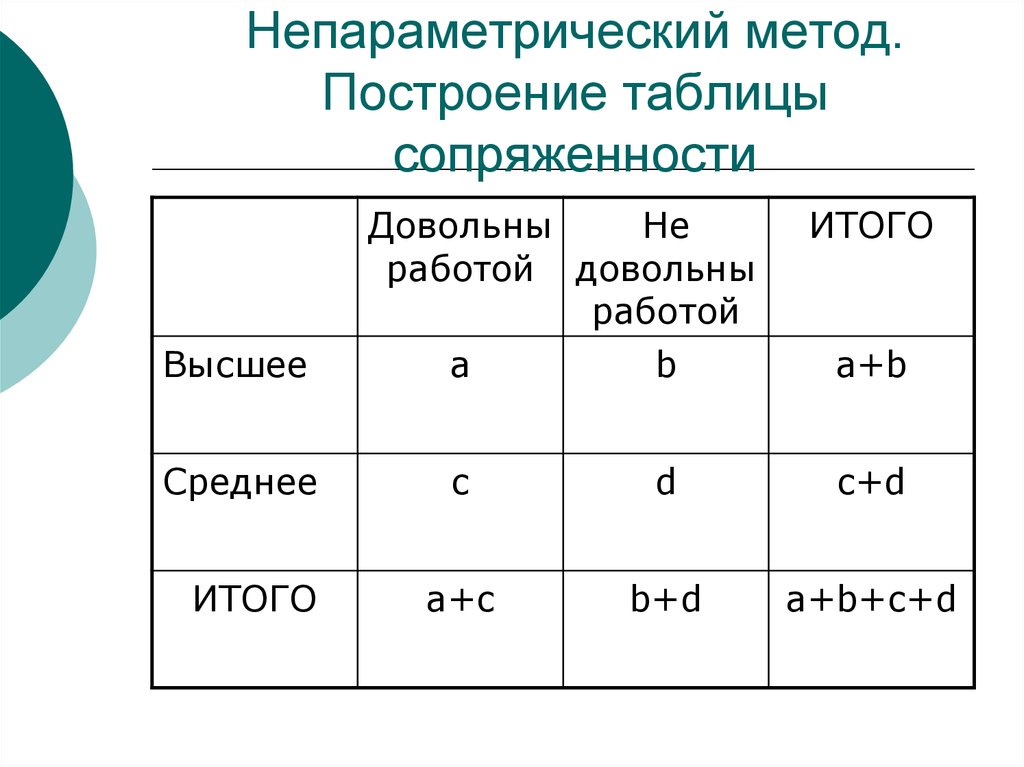
Ссылки
Агрести, А. Введение в анализ категорийных данных (серия Wiley по теории вероятностей и статистике), 3-е издание, 2018 г. «Таблица непредвиденных обстоятельств: для чего она используется?» От StatisticsHowTo.com : элементарная статистика для всех нас! https://www.statisticshowto.com/what-is-a-contingency-table/
————————————————— ————————-
Нужна помощь с домашним заданием или контрольным вопросом? С Chegg Study вы можете получить пошаговые ответы на свои вопросы от эксперта в данной области. Ваши первые 30 минут с репетитором Chegg бесплатны!
Комментарии? Нужно опубликовать исправление? Пожалуйста, Свяжитесь с нами .
Таблица сопряженности > Таблицы сопряженности > Справочное статистическое руководство
- Статистическое справочное руководство
- Таблицы непредвиденных обстоятельств
Таблица непредвиденных обстоятельств, также известная как таблица перекрестной классификации, описывает отношения между двумя или более категориальными переменными.
Таблица перекрестной классификации двух переменных называется двусторонней таблицей непредвиденных обстоятельств и образует прямоугольную таблицу со строками для категорий R переменной X и столбцами для категорий C переменной Y. Каждое пересечение называется ячейкой и представляет возможные результаты. В ячейках содержится частота совместных вхождений исходов X, Y. Таблица непредвиденных обстоятельств, содержащая R строк и C столбцов, называется таблицей R x C.
Переменная, имеющая только две категории, называется двоичной переменной. Когда обе переменные являются двоичными, результирующая таблица непредвиденных обстоятельств представляет собой таблицу 2 x 2. Также широко известна как четырехкратная таблица, потому что в ней четыре ячейки.
| Дым | |||
| Употребление алкоголя | Да | № | Всего |
| Низкий | 10 | 80 | 90 |
| Высокий | 50 | 40 | 90 |
| Итого | 60 | 120 | 180 |
Таблица непредвиденных обстоятельств может суммировать три распределения вероятностей – совместное, маргинальное и
условный.
- Совместное распределение описывает долю субъектов, совместно классифицированных по категории X и категории Y. Ячейки таблицы непредвиденных обстоятельств, разделенные на общее количество, обеспечивают совместное распределение. Сумма совместного распределения равна 1.
- Предельные распределения описывают распределение только переменной X (строка) или Y (столбец). Итоги строк и столбцов таблицы непредвиденных обстоятельств обеспечивают предельное распределение. Сумма предельного распределения равна 1,9.0102
- Условные распределения описывают распределение одной переменной при заданных уровнях другой переменной. Ячейки таблицы непредвиденных обстоятельств, разделенные суммами строк или столбцов, обеспечивают условное распределение. Сумма условного распределения равна 1.
Когда обе переменные являются случайными, вы можете описать данные, используя совместное распределение, условное распределение Y при заданном X или условное распределение X при заданном Y.