Примитивы синхронизации в Go. Изучаем Mutex, WaitGroup и Once с… | by Андрей Шагин | NOP::Nuances of Programming
В данной статье кратко рассмотрим некоторые конструкции низкоуровневой синхронизации, которые наряду с горутинами и каналами предлагает нам один из самых популярных стандартных библиотечных пакетов Go, а именно пакет sync. Таких конструкций очень много, а мы изучим лишь три из них, зато с примерами: WaitGroup, Mutex и Once.
Примеры кода можно найти на GitHub. Поехали!
WaitGroup используется для координации в случае, когда программе приходится ждать окончания работы нескольких горутин. Эта конструкция похожа на CountDownLatch в Java. Обратимся к примеру.
Предположим, нам нужно вывести список всех файлов нашего домашнего каталога одновременно. Используем WaitGroup для указания числа задач/горутин, завершения которых нам надо дождаться.
В данном случае оно совпадает с числом файлов/каталогов домашнего каталога. Используем
Используем Wait() для блокировки, пока счётчик WaitGroup не дойдёт до нуля.
...
func main() {
homeDir, err := os.UserHomeDir()
if err != nil {
panic(err)
}
filesInHomeDir, err := ioutil.ReadDir(homeDir)
if err != nil {
panic(err)
}
var wg sync.WaitGroup
wg.Add(len(filesInHomeDir))
for _, file := range filesInHomeDir {
go func(f os.FileInfo) {
defer wg.Done()
}(file)
}
wg.Wait()
}
...
Для выполнения этой программы понадобится:
curl https://raw.githubusercontent.com/abhirockzz/just-enough-go/master/sync/wait-group-example.go -o wait-group-example.go
go run wait-group-example.go
Под каждую os.FileInfo, которую мы находим в домашнем каталоге пользователя, создаётся горутина и при выводе её названия счётчик даёт отрицательное приращение с помощью этого Done. Выполнение завершается после того, как программа пробежится по всему содержимому домашнего каталога.
Общий мьютекс — это блокировка с общим доступом, которая даёт возможность получать эксклюзивный доступ к тем или иным участкам кода. Далее в простом примере в функции incr мы используем общую/глобальную переменную accessCount.
func incr() {
mu.Lock()
defer mu.Unlock()
accessCount = accessCount + 1
}Обратите внимание, что функция incr защищена мьютексом, поэтому только одна горутина может иметь к ней доступ. Мы бросаем на неё несколько горутин.
loop := 500
for i := 1; i <= loop; i++ {
go func(c int) {
wg.Add(1)
defer wg.Done()
incr()
}(i)
}
При выполнении результат здесь всегда будет один и тот же, т.е. Final = 500 (так как выполняются 500 итераций цикла for). Для выполнения программы понадобится:
curl https://raw.githubusercontent.com/abhirockzz/just-enough-go/master/sync/mutex-example.go -o mutex-example.go
go run mutex-example.go
Добавьте комментарий к следующим двум строчкам в функции incr (или удалите эти строчки):
mu.Lock()
defer mu.Unlock()
Запустите программу на локальном компьютере и снова выполните программу. Результат будет иной. Например, Final = 474.
Настоятельно рекомендую почитать о RWMutex. Это особая разновидность захвата, предполагающая параллельное чтение (несколько читателей: когда к одним и тем же данным имеют доступ несколько читающих потоков или горутин, как в нашем случае) и синхронизированные записи (один писатель: когда к данным имеет доступ только записывающий поток или горутина).
Позволяет определить задачу для однократного выполнения за всё время работы программы. Содержит одну-единственную функцию Do, позволяющую передавать другую функцию для однократного применения. Вот вам пример:
Допустим, вы создаёте REST API с помощью пакета Go net/http и хотите, чтобы участок кода выполнялся только после вызова обработчика HTTP-данных (например, для соединения с базой данных).
Используем в коде once.Do: теперь можете быть уверены, что он выполнится только при первом вызове обработчика.
Вот как выглядит функция для однократного выполнения:
func oneTimeOp() {
fmt.Println("one time op start")
time.Sleep(3 * time.Second)
fmt.Println("one time op started")
}Видите этот once.Do(oneTimeOp)? Вот что мы делаем внутри нашего HTTP-обработчика!
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Println("http handler start")
once.Do(oneTimeOp)
fmt.Println("http handler end")
w.Write([]byte("done!"))
})
log.Fatal(http.ListenAndServe(":8080", nil))
}Запускаем код и получаем доступ к конечной точке REST.
curl https://raw.githubusercontent.com/abhirockzz/just-enough-go/master/sync/once-example.go -o once-example.go
go run once-example.go
И с другого терминала:
curl localhost:8080
//результат - готово!
При первом доступе возврат функции будет немного медленным, и вы увидите следующие логи сервера:
http handler start
one time op start
one time op end
http handler end
При повторных запусках (сколько бы вы ни пытались) функция oneTimeOp не выполнится. Для подтверждения проверьте логи.
Для подтверждения проверьте логи.
На этом пока всё.
Читайте также:
- Ловушка для горутины
- Что такого в языке Go?
- Интерфейсы в Go для повышения тестируемости кода
Читайте нас в телеграмме, vk и Яндекс.Дзен
Перевод статьи Abhishek Gupta: Using Synchronization Primitives in Go
Примитивы синхронизации в Go
Изучаем Mutex, WaitGroup и Once с примерами
В данной статье кратко рассмотрим некоторые конструкции низкоуровневой синхронизации, которые наряду с горутинами и каналами предлагает нам один из самых популярных стандартных библиотечных пакетов Go, а именно пакет sync. Таких конструкций очень много, а мы изучим лишь три из них, зато с примерами: WaitGroup, Mutex и Once.
Примеры кода можно найти на GitHub. Поехали!
WaitGroup
WaitGroup используется для координации в случае, когда программе приходится ждать окончания работы нескольких горутин. Эта конструкция похожа на
Эта конструкция похожа на CountDownLatch в Java. Обратимся к примеру.
Предположим, нам нужно вывести список всех файлов нашего домашнего каталога одновременно. Используем WaitGroup для указания числа задач/горутин, завершения которых нам надо дождаться.
В данном случае оно совпадает с числом файлов/каталогов домашнего каталога. Используем Wait() для блокировки, пока счётчик WaitGroup не дойдёт до нуля.
...
func main() {
homeDir, err := os.UserHomeDir()
if err != nil {
panic(err)
}
filesInHomeDir, err := ioutil.ReadDir(homeDir)
if err != nil {
panic(err)
}
var wg sync.WaitGroup
wg.Add(len(filesInHomeDir))
for _, file := range filesInHomeDir {
go func(f os.FileInfo) {
defer wg.Done()
}(file)
}
wg.Wait()
}
...Для выполнения этой программы понадобится:
curl https://raw.githubusercontent.com/abhirockzz/just-enough-go/master/sync/wait-group-example.go -o wait-group-example.go go run wait-group-example.go
Под каждую os.FileInfo, которую мы находим в домашнем каталоге пользователя, создаётся горутина и при выводе её названия счётчик даёт отрицательное приращение с помощью этого Done. Выполнение завершается после того, как программа пробежится по всему содержимому домашнего каталога.
Мьютекс
Общий мьютекс — это блокировка с общим доступом, которая даёт возможность получать эксклюзивный доступ к тем или иным участкам кода. Далее в простом примере в функции incr мы используем общую/глобальную переменную accessCount.
func incr() {
mu.Lock()
defer mu.Unlock()
accessCount = accessCount + 1
}Обратите внимание, что функция incr защищена мьютексом, поэтому только одна горутина может иметь к ней доступ. Мы бросаем на неё несколько горутин.
loop := 500
for i := 1; i <= loop; i++ {
go func(c int) {
wg. Add(1)
defer wg.Done()
incr()
}(i)
}
Add(1)
defer wg.Done()
incr()
}(i)
}При выполнении результат здесь всегда будет один и тот же, т.е. Final = 500 (так как выполняются 500 итераций цикла for). Для выполнения программы понадобится:
curl https://raw.githubusercontent.com/abhirockzz/just-enough-go/master/sync/mutex-example.go -o mutex-example.go go run mutex-example.go
Добавьте комментарий к следующим двум строчкам в функции incr
mu.Lock() defer mu.Unlock()
Запустите программу на локальном компьютере и снова выполните программу. Результат будет иной. Например, Final = 474.
Настоятельно рекомендую почитать о RWMutex. Это особая разновидность захвата, предполагающая параллельное чтение (несколько читателей: когда к одним и тем же данным имеют доступ несколько читающих потоков или горутин, как в нашем случае) и синхронизированные записи (один писатель: когда к данным имеет доступ только записывающий поток или горутина).
Once
Позволяет определить задачу для однократного выполнения за всё время работы программы. Содержит одну-единственную функцию Do, позволяющую передавать другую функцию для однократного применения. Вот вам пример:
Допустим, вы создаёте REST API с помощью пакета Go net/http и хотите, чтобы участок кода выполнялся только после вызова обработчика HTTP-данных (например, для соединения с базой данных).
Используем в коде once.Do: теперь можете быть уверены, что он выполнится только при первом вызове обработчика.
Вот как выглядит функция для однократного выполнения:
func oneTimeOp() {
fmt.Println("one time op start")
time.Sleep(3 * time.Second)
fmt.Println("one time op started")
}Видите этот once.Do(oneTimeOp)? Вот что мы делаем внутри нашего HTTP-обработчика!
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Println("http handler start")
once. Do(oneTimeOp)
fmt.Println("http handler end")
w.Write([]byte("done!"))
})
log.Fatal(http.ListenAndServe(":8080", nil))
}
Do(oneTimeOp)
fmt.Println("http handler end")
w.Write([]byte("done!"))
})
log.Fatal(http.ListenAndServe(":8080", nil))
}Запускаем код и получаем доступ к конечной точке REST.
curl https://raw.githubusercontent.com/abhirockzz/just-enough-go/master/sync/once-example.go -o once-example.go go run once-example.go
И с другого терминала:
curl localhost:8080 //результат - готово!
При первом доступе возврат функции будет немного медленным, и вы увидите следующие логи сервера:
http handler start one time op start one time op end http handler end
При повторных запусках (сколько бы вы ни пытались) функция oneTimeOp не выполнится. Для подтверждения проверьте логи.
На этом пока всё.
Читайте также:
- Ловушка для горутины
- Что такого в языке Go?
- Интерфейсы в Go для повышения тестируемости кода
Перевод статьи Abhishek Gupta: Using Synchronization Primitives in Go
Читайте также
Примитивы синхронизации задач в asyncio в Python.
Примитивы Lock, Event, Condition и Semaphore в asyncio.
Примитивы синхронизации модуля asyncio очень похожи на примитивы синхронизации модуля threading с двумя важными оговорками:
- примитивы синхронизации
asyncioне являются потокобезопасными, поэтому их не следует использовать для синхронизации потоков ОС; - методы этих примитивов синхронизации не принимают аргумент таймаута. Для выполнения операций с таймаутами используйте функцию
asyncio.wait_for().
Базовые примитивы синхронизации
asyncio:asyncio.Lock— монопольный доступ к общему ресурсу,asyncio.Event— доступ к ресурсу по событию,asyncio.Condition— сочетает в себеLockиEvent,asyncio.Semaphore— управляет внутренним счетчиком,asyncio.BoundedSemaphore— ограниченный объектSemaphore.
Изменено в Python 3.9: было удалено получение блокировки с помощью await lock или with (yield from lock). Вместо этого используйте async lock.
asyncio.Lock(*, loop=None):Класс asyncio.Lock() реализует блокировку взаимное исполнения критических участков кода для задач asyncio. Не потокобезопасный.
Блокировка asyncio может использоваться, чтобы гарантировать монопольный доступ к общему ресурсу.
С версии Python 3.8 не рекомендуется использовать аргумент loop, будет удален в Python 3.10
Предпочтительный способ использования asyncio.Lock() — это асинхронный оператор async with:
# получаем объект блокировки
lock = asyncio.Lock()
async with lock:
# доступ к общему состоянию
# Что эквивалентно:
await lock.acquire()
try:
# доступ к общему состоянию
finally:
lock.release()
Методы объекта
Lock:Lock. acquire()
acquire():Метод Lock.acquire() получает блокировку. Для других — устанавливает блокировку в состояние locked и возвращает True.
Метод представляет собой сопрограмму.
Если более чем одна сопрограмма блокируется методом Lock.acquire, то продолжать работу будет только одна сопрограмма, которая получила блокировку, в то время как другие сопрограммы будут ждать, пока блокировка не будет снята.
Получение блокировки справедливо: выполняющаяся сопрограмма будет первой сопрограммой, которая начала ожидать блокировки.
Lock.release():Метод Lock.release() сбрасывает полученную блокировку в состояние unlocked и возвращает результат.
Если блокировка уже разблокирована, то возникает исключение RuntimeError.
Lock.locked():Метод Lock.locked() возвращает True, если блокировка установлена.
asyncio.Event(*, loop=None):Класс asyncio.Event() представляет собой объект события. Не потокобезопасный.
Объект события asyncio можно использовать для уведомления нескольких задач asyncio о том, что произошло какое-то событие.
Объект Event управляет внутренним флагом, которому можно присвоить значение True
Event.set() и сбросить значение в False с помощью метода Event.clear().Метод Event.wait() блокируется, пока флаг не будет установлен в значение True. Первоначально флаг установлен в значение False.
С версии Python 3.8 не рекомендуется использовать аргумент loop, будет удален в Python 3.10
async def waiter(event):
print('waiting for it ...')
await event.wait()
print('... got it!')
async def main():
# Create an Event object. event = asyncio.Event()
# Spawn a Task to wait until 'event' is set.
waiter_task = asyncio.create_task(waiter(event))
# Sleep for 1 second and set the event.
await asyncio.sleep(1)
event.set()
# Wait until the waiter task is finished.
await waiter_task
asyncio.run(main())
event = asyncio.Event()
# Spawn a Task to wait until 'event' is set.
waiter_task = asyncio.create_task(waiter(event))
# Sleep for 1 second and set the event.
await asyncio.sleep(1)
event.set()
# Wait until the waiter task is finished.
await waiter_task
asyncio.run(main())
Методы объекта
Event:Event.wait():Метод Event.wait() ждет, пока объект события будет установлено в True. Метод представляет собой сопрограмму.
Если событие установлено, то немедленно возвращает True. В противном случае блокирует, пока другая задача не вызовет метод Event.set().
Event.set():Метод Event.set() устанавливает событие.
Все задачи, ожидающие установки события, будут немедленно разбужены.
Event.clear():Метод Event.clear() очищает/сбрасывает событие.
Задачи, ожидающие методом Event. будут блокироваться до тех пор, пока метод `Event.set() снова не установит объект события. wait()
wait()
Event.is_set():Метод Event.is_set() возвращает True, если событие установлено.
asyncio.Condition(lock=None, *, loop=None):Класс asyncio.Condition() представляет собой объект какого-то условного события. Не потокобезопасный.
Примитив синхронизации по условию Condition модуля asyncio может использоваться задачей для ожидания некоторого события и затем получения монопольного доступа к общему ресурсу.
По сути, объект Condition сочетает в себе функции события Event и блокировки Lock. Можно иметь несколько объектов Condition, совместно использующих одну Lock, что позволяет координировать монопольный доступ к общему ресурсу между различными задачами, заинтересованными в определенных состояниях этого общего ресурса.
Необязательный аргумент lock должен быть объектом asyncio.Lock или None. В последнем случае автоматически создается новый объект
С версии Python 3.8 не рекомендуется использовать аргумент loop, будет удален в Python 3.10
Предпочтительный способ использования asyncio.Condition() — это асинхронный оператор async with:
# получаем объект условия
cond = asyncio.Condition()
async with cond:
await cond.wait()
# Что эквивалентно:
await cond.acquire()
try:
await cond.wait()
finally:
cond.release()
Методы объекта
Condition:Condition.acquire():Метод Condition.acquire() получает базовую блокировку. Для других — устанавливает состояние блокировки и возвращает True.
Представляет собой сопрограмму. Метод будет ждать, пока базовая блокировка не будет снята.
Condition. notify(n=1)
notify(n=1):Метод Condition.notify() будит не более n задач (по умолчанию 1), ожидающих этого условия. Метод не работает, если нет ожидающих задач.
Блокировка должна быть получена до вызова этого метода и снимается только после ее получения. Если базовая блокировка не получена, то при вызове этого метода возникает ошибка RuntimeError.
Condition.locked():Метод Condition.is_set() возвращает True, если основная блокировка получена.
Condition.notify_all():Метод Condition.notify_all() будит все задачи, ожидающие этого условия.
Этот метод действует как Condition.notify(), но пробуждает все ожидающие задачи.
Блокировка должна быть получена до вызова этого метода и снимается только после ее получения. Если базовая блокировка не получена, то при вызове этого метода возникает ошибка RuntimeError.
Condition.release():Метод Condition.release() снимает базовую блокировку.
Если базовая блокировка не получена, то при вызове этого метода возникает ошибка RuntimeError.
Condition.wait():Метод Condition.wait() будет ждать уведомления. Представляет собой сопрограмму.
Если вызывающая задача не получила блокировку при вызове этого метода, возникает ошибка RuntimeError.
Этот метод снимает базовую блокировку, а затем блокирует, пока не будет разбужен вызовом Condition.notify() или Condition.notify_all(). После пробуждения объект Condition повторно получает свою блокировку, а этот метод возвращает True.
Condition.wait_for(predicate):Метод Condition.wait_for() будет ждать, пока аргумент predicate станет истинным. Представляет собой сопрограмму.
Предикат predicate должен быть вызываемым объектом, результат которого будет интерпретироваться как логическое значение. Конечное значение — это возвращаемое значение.
Конечное значение — это возвращаемое значение.
asyncio.Semaphore(value=1, *, loop=None):Класс asyncio.Semaphore() представляет собой объект семафора. Не потокобезопасный.
Семафор управляет внутренним счетчиком, который уменьшается при каждом вызове метода Semaphore.acquire() и увеличивается при каждом вызове Semaphore.release(). Счетчик никогда не может опуститься ниже нуля; когда Semaphore.acquire() обнаруживает, что он равен нулю, то блокируется, ожидая, пока какая-либо задача не вызовет Semaphore.release()
Необязательный аргумент value (по умолчанию 1) задает начальное значение для внутреннего счетчика. Если заданное значение меньше 0,то возникает ошибка ValueError.
С версии Python 3.8 не рекомендуется использовать аргумент loop, будет удален в Python 3.10
Предпочтительный способ использования asyncio. — это асинхронный оператор  Semaphore()
Semaphore()async with:
# получаем объект семафора
sem = asyncio.Semaphore(10)
async with sem:
# работа с общим ресурсом
# что эквивалентно:
await sem.acquire()
try:
# работа с общим ресурсом
finally:
sem.release()
Semaphore.acquire():Метод Semaphore.acquire() приобретает семафор. Представляет собой сопрограмму.
Если внутренний счетчик больше нуля, то уменьшает его на единицу и немедленно возвращает True. Если счетчик равен нулю, то ждет вызова Semaphore.release() и возвращает True.
Semaphore.locked():Метод Semaphore.locked() возвращает True, если семафор не может быть получен немедленно.
Semaphore.release():Метод Semaphore.release() освобождает семафор, увеличив внутренний счетчик на единицу. Может разбудить задачу, ожидающую получения семафора.
В отличие от BoundedSemaphore, объект Semaphore позволяет делать больше вызовов Semaphore.release(), чем Semaphore.acquire().
asyncio.BoundedSemaphore(value=1, *, loop=None):Класс asyncio.BoundedSemaphore() представляет собой ограниченный объект семафора, рассмотренного выше. Не потокобезопасный.
Класс asyncio.BoundedSemaphore() — это версия asyncio.Semaphore, которая вызывает исключение ValueError в при вызове метода Semaphore.release(), если увеличивает внутренний счетчик выше начального значения value.
С версии Python 3.8 не рекомендуется использовать аргумент loop, будет удален в Python 3.10
Примитивы синхронизации — pythobyte.com
Автор оригинала: Doug Hellmann.
Хотя приложения asyncio обычно выполняются как однопоточный процесс, они по-прежнему создаются как параллельные приложения. Каждая сопрограмма или задача могут выполняться в непредсказуемом порядке, основанном на задержках и прерываниях от ввода-вывода и других внешних событий. Для поддержки безопасного параллелизма
Каждая сопрограмма или задача могут выполняться в непредсказуемом порядке, основанном на задержках и прерываниях от ввода-вывода и других внешних событий. Для поддержки безопасного параллелизма asyncio включает в себя реализации некоторых из тех же низкоуровневых примитивов, что и в модулях потоковой и многопроцессорной обработки.
Замки
Lock можно использовать для защиты доступа к общему ресурсу. Ресурс может использовать только владелец замка. Множественные попытки получить блокировку будут заблокированы, так что одновременно будет только один держатель.
asyncio_lock.py
import asyncio
import functools
def unlock(lock):
print('callback releasing lock')
lock. release()
async def coro1(lock):
print('coro1 waiting for the lock')
async with lock:
print('coro1 acquired lock')
print('coro1 released lock')
async def coro2(lock):
print('coro2 waiting for the lock')
await lock.acquire()
try:
print('coro2 acquired lock')
finally:
print('coro2 released lock')
lock.release()
async def main(loop):
# Create and acquire a shared lock.
lock asyncio.Lock()
print('acquiring the lock before starting coroutines')
await lock.acquire()
print('lock acquired: {}'.format(lock.locked()))
# Schedule a callback to unlock the lock.
loop.call_later(0.1, functools.partial(unlock, lock))
# Run the coroutines that want to use the lock.
print('waiting for coroutines')
await asyncio.wait([coro1(lock), coro2(lock)]),
event_loop asyncio.get_event_loop()
try:
event_loop.run_until_complete(main(event_loop))
finally:
event_loop.close()
release()
async def coro1(lock):
print('coro1 waiting for the lock')
async with lock:
print('coro1 acquired lock')
print('coro1 released lock')
async def coro2(lock):
print('coro2 waiting for the lock')
await lock.acquire()
try:
print('coro2 acquired lock')
finally:
print('coro2 released lock')
lock.release()
async def main(loop):
# Create and acquire a shared lock.
lock asyncio.Lock()
print('acquiring the lock before starting coroutines')
await lock.acquire()
print('lock acquired: {}'.format(lock.locked()))
# Schedule a callback to unlock the lock.
loop.call_later(0.1, functools.partial(unlock, lock))
# Run the coroutines that want to use the lock.
print('waiting for coroutines')
await asyncio.wait([coro1(lock), coro2(lock)]),
event_loop asyncio.get_event_loop()
try:
event_loop.run_until_complete(main(event_loop))
finally:
event_loop.close()Метод блокировки Acquire () может быть вызван напрямую, используя await и вызывая метод release () , когда это выполняется, как в coro2 () в этом примере. Их также можно использовать в качестве асинхронных менеджеров контекста с ключевыми словами
Их также можно использовать в качестве асинхронных менеджеров контекста с ключевыми словами with await , как в coro1 () .
$ python3 asyncio_lock.py acquiring the lock before starting coroutines lock acquired: True waiting for coroutines coro2 waiting for the lock coro1 waiting for the lock callback releasing lock coro2 acquired lock coro2 released lock coro1 acquired lock coro1 released lock
События
asyncio.Event основан на threading.Event и используется, чтобы позволить нескольким потребителям ждать, пока что-то произойдет, не ища конкретное значение, связанное с уведомлением.
asyncio_event.py
import asyncio
import functools
def set_event(event):
print('setting event in callback')
event.set()
async def coro1(event):
print('coro1 waiting for event')
await event.wait()
print('coro1 triggered')
async def coro2(event):
print('coro2 waiting for event')
await event.wait()
print('coro2 triggered')
async def main(loop):
# Create a shared event
event asyncio.Event()
print('event start state: {}'.format(event.is_set()))
loop.call_later(
0.1, functools.partial(set_event, event)
)
await asyncio.wait([coro1(event), coro2(event)])
print('event end state: {}'.format(event. is_set()))
event_loop asyncio.get_event_loop()
try:
event_loop.run_until_complete(main(event_loop))
finally:
event_loop.close()
is_set()))
event_loop asyncio.get_event_loop()
try:
event_loop.run_until_complete(main(event_loop))
finally:
event_loop.close()Как и в случае с Lock , оба coro1 () и coro2 () ждут, пока событие не будет установлено. Разница в том, что оба они могут запускаться, как только состояние события изменится, и им не нужно приобретать уникальную фиксацию объекта события.
$ python3 asyncio_event.py event start state: False coro2 waiting for event coro1 waiting for event setting event in callback coro2 triggered coro1 triggered event end state: True
Условия
Condition работает аналогично Event , за исключением того, что вместо уведомления всех ожидающих сопрограмм количество пробужденных официантов контролируется аргументом для notify () .
asyncio_condition.py
import asyncio
async def consumer(condition, n):
async with condition:
print('consumer {} is waiting'.format(n))
await condition.wait()
print('consumer {} triggered'.format(n))
print('ending consumer {}'.format(n))
async def manipulate_condition(condition):
print('starting manipulate_condition')
# pause to let consumers start
await asyncio.sleep(0.1)
for i in range(1, 3):
async with condition:
print('notifying {} consumers'.format(i))
condition.notify(ni)
await asyncio.sleep(0.1)
async with condition:
print('notifying remaining consumers')
condition. notify_all()
print('ending manipulate_condition')
async def main(loop):
# Create a condition
condition asyncio.Condition()
# Set up tasks watching the condition
consumers [
consumer(condition, i)
for i in range(5)
]
# Schedule a task to manipulate the condition variable
loop.create_task(manipulate_condition(condition))
# Wait for the consumers to be done
await asyncio.wait(consumers)
event_loop asyncio.get_event_loop()
try:
result event_loop.run_until_complete(main(event_loop))
finally:
event_loop.close()
notify_all()
print('ending manipulate_condition')
async def main(loop):
# Create a condition
condition asyncio.Condition()
# Set up tasks watching the condition
consumers [
consumer(condition, i)
for i in range(5)
]
# Schedule a task to manipulate the condition variable
loop.create_task(manipulate_condition(condition))
# Wait for the consumers to be done
await asyncio.wait(consumers)
event_loop asyncio.get_event_loop()
try:
result event_loop.run_until_complete(main(event_loop))
finally:
event_loop.close()В этом примере запускаются пять потребителей Condition . Каждый из них использует метод wait () для ожидания уведомления о том, что они могут продолжить. manage_condition () уведомляет одного потребителя, затем двух потребителей, а затем всех остальных потребителей.
$ python3 asyncio_condition.py starting manipulate_condition consumer 3 is waiting consumer 0 is waiting consumer 4 is waiting consumer 1 is waiting consumer 2 is waiting notifying 1 consumers consumer 3 triggered ending consumer 3 notifying 2 consumers consumer 0 triggered ending consumer 0 consumer 4 triggered ending consumer 4 notifying remaining consumers ending manipulate_condition consumer 1 triggered ending consumer 1 consumer 2 triggered ending consumer 2
Очереди
asyncio.Queue предоставляет структуру данных «первым пришел – первым вышел» для сопрограмм, как queue.Queue для потоков или multiprocessing.Queue делает для процессов.
asyncio_queue.py
import asyncio
async def consumer(n, q):
print('consumer {}: starting'. format(n))
while True:
print('consumer {}: waiting for item'.format(n))
item await q.get()
print('consumer {}: has item {}'.format(n, item))
if item is None:
# None is the signal to stop.
q.task_done()
break
else:
await asyncio.sleep(0.01 * item)
q.task_done()
print('consumer {}: ending'.format(n))
async def producer(q, num_workers):
print('producer: starting')
# Add some numbers to the queue to simulate jobs
for i in range(num_workers * 3):
await q.put(i)
print('producer: added task {} to the queue'.format(i))
# Add None entries in the queue
# to signal the consumers to exit
print('producer: adding stop signals to the queue')
for i in range(num_workers):
await q.put(None)
print('producer: waiting for queue to empty')
await q.join()
print('producer: ending')
async def main(loop, num_consumers):
# Create the queue with a fixed size so the producer
# will block until the consumers pull some items out.
format(n))
while True:
print('consumer {}: waiting for item'.format(n))
item await q.get()
print('consumer {}: has item {}'.format(n, item))
if item is None:
# None is the signal to stop.
q.task_done()
break
else:
await asyncio.sleep(0.01 * item)
q.task_done()
print('consumer {}: ending'.format(n))
async def producer(q, num_workers):
print('producer: starting')
# Add some numbers to the queue to simulate jobs
for i in range(num_workers * 3):
await q.put(i)
print('producer: added task {} to the queue'.format(i))
# Add None entries in the queue
# to signal the consumers to exit
print('producer: adding stop signals to the queue')
for i in range(num_workers):
await q.put(None)
print('producer: waiting for queue to empty')
await q.join()
print('producer: ending')
async def main(loop, num_consumers):
# Create the queue with a fixed size so the producer
# will block until the consumers pull some items out. q asyncio.Queue(maxsizenum_consumers)
# Scheduled the consumer tasks.
consumers [
loop.create_task(consumer(i, q))
for i in range(num_consumers)
]
# Schedule the producer task.
prod loop.create_task(producer(q, num_consumers))
# Wait for all of the coroutines to finish.
await asyncio.wait(consumers + [prod])
event_loop asyncio.get_event_loop()
try:
event_loop.run_until_complete(main(event_loop, 2))
finally:
event_loop.close()
q asyncio.Queue(maxsizenum_consumers)
# Scheduled the consumer tasks.
consumers [
loop.create_task(consumer(i, q))
for i in range(num_consumers)
]
# Schedule the producer task.
prod loop.create_task(producer(q, num_consumers))
# Wait for all of the coroutines to finish.
await asyncio.wait(consumers + [prod])
event_loop asyncio.get_event_loop()
try:
event_loop.run_until_complete(main(event_loop, 2))
finally:
event_loop.close()Добавление элементов с помощью put () или удаление элементов с помощью get () являются асинхронными операциями, поскольку размер очереди может быть фиксированным (блокирование добавления) или очередь может быть пустой (блокирование вызова для получения элемента).
$ python3 asyncio_queue.py consumer 0: starting consumer 0: waiting for item consumer 1: starting consumer 1: waiting for item producer: starting producer: added task 0 to the queue producer: added task 1 to the queue consumer 0: has item 0 consumer 1: has item 1 producer: added task 2 to the queue producer: added task 3 to the queue consumer 0: waiting for item consumer 0: has item 2 producer: added task 4 to the queue consumer 1: waiting for item consumer 1: has item 3 producer: added task 5 to the queue producer: adding stop signals to the queue consumer 0: waiting for item consumer 0: has item 4 consumer 1: waiting for item consumer 1: has item 5 producer: waiting for queue to empty consumer 0: waiting for item consumer 0: has item None consumer 0: ending consumer 1: waiting for item consumer 1: has item None consumer 1: ending producer: ending
АНАЛИЗ МЕХАНИЗМОВ СИНХРОНИЗАЦИИ ПОТОКОВ ДЛЯ СИСТЕМ-НА-КРИСТАЛЛЕ С БОЛЬШИМ ЧИСЛОМ ВЫЧИСЛИТЕЛЬНЫХ ЯДЕР Текст научной статьи по специальности «Компьютерные и информационные науки»
СХЕМОТЕХНИКА И ПРОЕКТИРОВАНИЕ
УДК 004. 272.3
272.3
Анализ механизмов синхронизации потоков для систем-на-кристалле с большим числом вычислительных ядер
Ф.М.Путря, И.А.Медведев ГУП НПЦ «ЭЛВИС» (г. Москва)
Рассмотрен способ синхронизации потоков на основе небольшого объема общей памяти с аппаратной поддержкой примитивов синхронизации для систем-на-кристалле, реализованный в многоядерном DSP-кластере. Предложено решение проблемы масштабируемости, заключающееся в применении распределенного буфера синхронизации, и рассмотрен метод повышения эффективности аппаратной синхронизации, основанный на использовании очередей типа FIFO.
Ключевые слова: многоядерные процессоры, синхронизация, очереди типа FIFO, масштабируемость, система-на-кристалле.
Возможность размещать на кристалле все большее число транзисторов на протяжении долгого времени использовалась разработчиками для повышения производительности одного вычислительного ядра процессора. Как правило, это достигалось за счет увеличения тактовой частоты ядра и числа инструкций, исполняемых ядром за такт. и синхронизация [3]. Под программируемостью понимается наложение распараллеливаемых приложений на многоядерную архитектуру, под синхронизацией — обеспечение корректности параллельного выполнения потоков за счет исполнения зависимостей между командами. Задача распараллеливания достаточно нетривиальна и для ряда алгоритмов практически неразрешима. На сегодня уже имеется большой опыт создания многопоточных приложений для суперкомпьютеров и многопроцессорных вычислительных комплексов, который с учетом специфики однокристальных систем применим и к многоядерным процессорам. Однако потокам, на которые распараллелено некоторое приложение, необходимо взаимодействовать друг с другом, и при отсутствии механизмов синхронизации между такими потоками корректная работа приложения невозможна.
и синхронизация [3]. Под программируемостью понимается наложение распараллеливаемых приложений на многоядерную архитектуру, под синхронизацией — обеспечение корректности параллельного выполнения потоков за счет исполнения зависимостей между командами. Задача распараллеливания достаточно нетривиальна и для ряда алгоритмов практически неразрешима. На сегодня уже имеется большой опыт создания многопоточных приложений для суперкомпьютеров и многопроцессорных вычислительных комплексов, который с учетом специфики однокристальных систем применим и к многоядерным процессорам. Однако потокам, на которые распараллелено некоторое приложение, необходимо взаимодействовать друг с другом, и при отсутствии механизмов синхронизации между такими потоками корректная работа приложения невозможна.
© Ф.М.Путря, И.А.Медведев, 2011
Методы синхронизации потоков в многоядерных системах. Под синхронизацией потоков понимается процесс приведения двух или нескольких потоков к такому их протеканию, когда определенные стадии разных потоков совершаются в определенном порядке либо одновременно. С увеличением числа ядер в процессоре для более эффективного использования системы необходимо большее число параллельно исполняемых потоков и, соответственно, более частый вызов процедур синхронизации. В результате накладные расходы на процедуры синхронизации могут привести к тому, что эффективность исполнения приложения с ростом числа ядер не будет увеличиваться, а в ряде случаев может даже и уменьшаться.
С увеличением числа ядер в процессоре для более эффективного использования системы необходимо большее число параллельно исполняемых потоков и, соответственно, более частый вызов процедур синхронизации. В результате накладные расходы на процедуры синхронизации могут привести к тому, что эффективность исполнения приложения с ростом числа ядер не будет увеличиваться, а в ряде случаев может даже и уменьшаться.
Аппаратная поддержка стандартных механизмов синхронизации потоков — необходимый элемент в современных многоядерных системах. Поэтому от эффективности работы механизма синхронизации зависит и производительность всего программно-аппаратного комплекса, реализующего определенную функцию на многоядерном процессоре. Одним из способов синхронизации является организация небольшого объема общей для всех ядер памяти с аппаратной поддержкой примитивов синхронизации. Преимущество такого способа — скорость, достигаемая за счет быстрого доступа к общему участку памяти и синхронизации между потоками, выполняемой всего одной инструкцией обращения к памяти. Данный способ использован в многоядерных ББР-процессорах серии «МУЛЬТИКОР» [4]. Синхронизацию между потоками можно разделить на сильную и слабую. В случае сильной синхронизации аппаратурой гарантируется определенная последовательность выполнения команд различных потоков. При слабой синхронизации не отслеживается последовательность обращения разных потоков к разделяемому ресурсу. В этом случае программист должен быть уверен в том, что последовательность таких обращений не критична, либо дополнительно использовать программные примитивы синхронизации.
Данный способ использован в многоядерных ББР-процессорах серии «МУЛЬТИКОР» [4]. Синхронизацию между потоками можно разделить на сильную и слабую. В случае сильной синхронизации аппаратурой гарантируется определенная последовательность выполнения команд различных потоков. При слабой синхронизации не отслеживается последовательность обращения разных потоков к разделяемому ресурсу. В этом случае программист должен быть уверен в том, что последовательность таких обращений не критична, либо дополнительно использовать программные примитивы синхронизации.
Централизованный буфер синхронизации. Проблема масштабируемости. Общая архитектура многоядерных DSP-процессоров серии «МУЛЬТИКОР» представляет собой гетерогенную систему-на-кристалле, состоящую из одного управляющего ядра и многоядерного DSP-кластера. Дальнейший анализ проводится для кластера, содержащего четыре ядра. В таком кластере с точки зрения топологии ядра располагаются в виде двумерной решетки, возможности масштабируемости которой позволяют обобщать результаты исследований на случаи реализации DSP-кластера с большим числом ядер.
В кластере используется метод аппаратной поддержки синхронизации, основанный на использовании небольшого объема доступной всем ядрам памяти. Буфер синхронизации, входящий в состав кластера, представляет собой многопортовый регистровый файл, каждая ячейка которого снабжена дополнительным битом состояния для сохранения информации о типе последней операции. Запись и чтение в регистровый файл производится согласно управляющей модели, которая в зависимости от режима работы буфера синхронизации обеспечивает сильную или слабую зависимость последовательности выполнения операций. При сильной зависимости запись в ячейку буфера возможна только после чтения, и наоборот, чтение из ячейки возможно только после записи. Невозможная операция (например, «чтение после чтения») приводит к блокировке ядра, которое отправило запрос, до тех пор, пока действиями другого ядра данный конфликт не разрешится. При слабой зависимости ограничений на последовательность выполнения операций нет. Оба режима работы буфера позволяют реализовать синхронизацию ядер, но при этом режим слабой зависимости требует более детального анализа программы со стороны программиста.
Буфер синхронизации топологически расположен в центре DSP-кластера, и все ядра имеют к нему равноправный доступ. Однако с ростом числа ядер в DSP-кластере существенно усложняется коммутационная логика в централизованном буфере, усложняются пути линий связи на топологии кристалла и увеличиваются задержки на них, что ограничивает масштабируемость всей системы. Таким образом, реализация буфера синхронизации, обращения к которому могут выполняться всеми ядрами без потери рабочих тактов, сильно усложняется даже для случая четырех ядер.
Распределенный буфер синхронизации. Для решения проблемы масштабируемости разработан распределенный буфер синхронизации, который разделен на равные части (почтовые ящики Xmail), каждая из которых помещена рядом с соответствующим ядром и является для него ближней, остальные части — дальними. Можно выделить три основных варианта коммутации между ядрами: коммутация типа «каждый с каждым», однонаправленное кольцо, двунаправленное кольцо (рис.1). Первые два варианта реализованы в виде RTL-модели и для них проведен анализ производительности.
Рис.1. Распределенный буфер синхронизации: а — «каждый с каждым»; б — однонаправленное кольцо; в — двунаправленное кольцо
Реализация буфера синхронизации с коммутацией типа «каждый с каждым» не решает проблему масштабируемости системы из-за сложности организации межсоединений и используется в работе для анализа производительности, так как из всех распределенных систем она обладает минимальными расстояниями между элементами с точки
Для буфера синхронизации с коммутацией однонаправленного кольца разработана схема маршрутизации (рис.2). Ее несложно модифицировать и для двунаправленного кольца путем дублирования ресурсов и внедрения протокола маршрутизации, который будет отвечать за распределение запросов по разным направлениям кольца. Также следует отметить, что для эффективного использования таких вариантов коммутации необходимо, чтобы при блокировке определенного запроса не блокировались все порты на пути, который он проходит. В этом случае заблоки-
зрения времени доступа.
Рис. 2. Схема маршрутизации однонаправленного кольца
рованный запрос должен сохраняться в том ядре, в котором он был заблокирован. Для этого в коммутационной логике введены специальные буферные элементы, содержащие регистры flip-flop (на рисунке обозначены буквами «ff»).
Анализ производительности. Для анализа производительности использовались RTL-модели для следующих проектов: централизованный буфер синхронизации, распределенный буфер с коммутацией «каждый с каждым», распределенный буфер с коммутацией в виде однонаправленного кольца. Набор тестов состоит из алгоритма быстрого преобразования Фурье (БПФ) и тестов на передачу управления. Результаты выполнения тестов получены путем моделирования RTL-моделей средствами САПР. Тест БПФ представляет собой вариант распараллеливания путем разбиения на параллельные потоки, тесты на передачу управления — вариант программной конвейеризации.
Исходный тест БПФ показал логичное падение производительности для распределенных вариантов буфера синхронизации, вызванное простоями ядер при обращениях к дальним частям буфера. Поэтому код теста был оптимизирован. Оптимизация проводилась под однонаправленную кольцевую архитектуру распределенного буфера синхронизации таким образом, чтобы большая часть обращений к регистрам буфера синхронизации приходилась на регистры ближней для данного ядра части буфера и в результате минимизировалось время простоя ядра при обращениях к дальним регистрам буфера. Результаты представлены для двух вариантов теста: неоптимизированного и оптимизированного. Время выполнения теста БПФ при кольцевой архитектуре X-буфера существенно сокращается после оптимизации теста (рис.3).
Поэтому код теста был оптимизирован. Оптимизация проводилась под однонаправленную кольцевую архитектуру распределенного буфера синхронизации таким образом, чтобы большая часть обращений к регистрам буфера синхронизации приходилась на регистры ближней для данного ядра части буфера и в результате минимизировалось время простоя ядра при обращениях к дальним регистрам буфера. Результаты представлены для двух вариантов теста: неоптимизированного и оптимизированного. Время выполнения теста БПФ при кольцевой архитектуре X-буфера существенно сокращается после оптимизации теста (рис.3).
В
■ II I I II I
DSPl DSP2 а
и и ■ I
Рис.3. Время выполнения основной части теста БПФ: а — неоптимизи-рованная программа; б — оптимизированная (■ — централизованный; ■ — «каждый с каждым»; ■ — однонапрвленное кольцо)
В распределенном варианте реализации буфера синхронизации доступ к дальним регистрам осуществляется дольше, чем к ближним. Поэтому для буфера с распределенной архитектурой следует говорить о двух типах блокировок: блокировки ядра при передаче запроса к дальним регистрам и стандартные блокировки ядер для режима сильной зависимости. Причем здесь следует учитывать их взаимосвязь и влияние друг на друга. Соотношение блокировок двух типов (рис.4), возникающих при синхронизации в распределенной системе для оптимизированного и неоптимизированного варианта теста БПФ, говорит о неэффективном использовании коммутационного механизма без оптимизации тестов под распределенную архитектуру.
Причем здесь следует учитывать их взаимосвязь и влияние друг на друга. Соотношение блокировок двух типов (рис.4), возникающих при синхронизации в распределенной системе для оптимизированного и неоптимизированного варианта теста БПФ, говорит о неэффективном использовании коммутационного механизма без оптимизации тестов под распределенную архитектуру.
Общий принцип тестов на передачу управления заключается в конвейеризации: каждое ядро, выполнив свой этап обработки данных, передает управление и данные следующему ядру. При анализе производительности следует менять число операций Т, требующихся каждому ядру на выполнение очередного этапа перед передачей управления следующему ядру.
70
DSPO DSPI DSP2 DSP3 DSPO DSP1 DSP2 DSP3 а б
Рис.4. Соотношение блокировок, возникающих при выполнении основной части теста БПФ при коммутации буфера синхронизации в виде однонаправленного кольца: а — неоптимизированная программа; б — оптимизированная (■ — стандартные блокировки режима сильной зависимости; ■ — блокировки при обращении к дальним регистрам)
Рассмотрим два варианта данного теста (для определенности обозначим их соответственно A и Б). DSP3. В этом случае, если ядра DSP0 и DSP3 выполняют Т операций перед передачей управления, то ядра DSP1 и DSP2 выполняют один и тот же этап, но на него необходимо в два раза больше операций — 2Т. Для каждого теста конвейерный алгоритм выполняется для большого числа входных блоков данных.
DSP3. В этом случае, если ядра DSP0 и DSP3 выполняют Т операций перед передачей управления, то ядра DSP1 и DSP2 выполняют один и тот же этап, но на него необходимо в два раза больше операций — 2Т. Для каждого теста конвейерный алгоритм выполняется для большого числа входных блоков данных.
Из отношения производительностей тестов при распределенной архитектуре буфера синхронизации к производительности тестов при централизованной архитектуре (рис.5) можно сделать вывод, что падение производительности при распределенной архитектуре буфера синхронизации ощутимо сказывается на приложениях, которые достаточно часто используют механизм синхронизации. В случае редкого использования механизма синхронизации и оптимизации приложений под распределенную архитектуру буфера синхронизации падение производительности значительно меньше.
Для повышения эффективности механизма синхронизации предлагается новый режим работы распределенного буфера, который реализует еще один механизм синхронизации с сильной зависимостью. Основная идея такой реализации заключается в том, чтобы использовать каждую часть распределенного буфера, принадлежащую конкретному ядру, как очередь типа FIFO. В этом случае сообщение будет адресовано не определенному регистру буфера синхронизации, а определенному почтовому ящику. При этом путем введения ограничения на чтение только из ближнего почтового ящика и применения механизма отложенной записи в почтовые ящики можно практически устранить блокировки ядер, обусловленные обращениями к дальним почтовым ящикам.
Основная идея такой реализации заключается в том, чтобы использовать каждую часть распределенного буфера, принадлежащую конкретному ядру, как очередь типа FIFO. В этом случае сообщение будет адресовано не определенному регистру буфера синхронизации, а определенному почтовому ящику. При этом путем введения ограничения на чтение только из ближнего почтового ящика и применения механизма отложенной записи в почтовые ящики можно практически устранить блокировки ядер, обусловленные обращениями к дальним почтовым ящикам.
В этом случае можно добиться существенного сокращения простоя ядер при синхронизации по сравнению с обычной распределенной реализацией буфера синхронизации, поскольку при такой организации буфера ядра будут блокироваться только при попытках чтения из пустой очереди либо при записи в полную очередь. Применение почтовых ящиков на основе очереди предоставляет возможность для создания более гибких и более эффективных примитивов синхронизации.
Итак, с ростом числа вычислительных ядер реализация аппаратной поддержки синхронизации на основе централизованных решений становится все менее эффективной.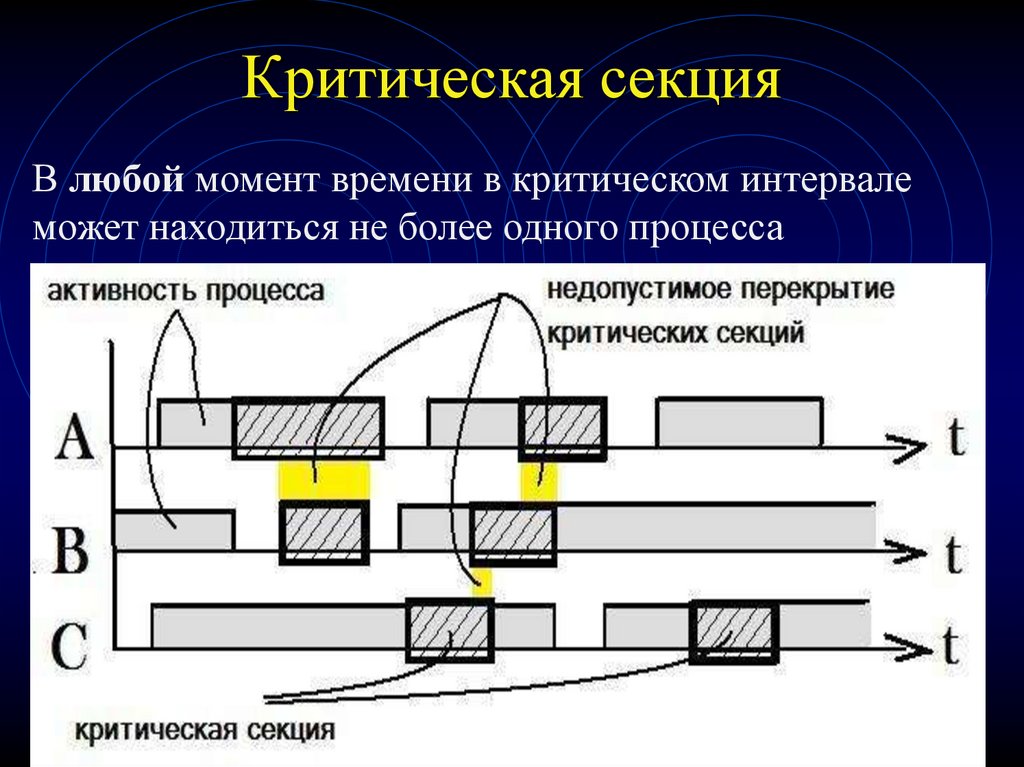 Применение распределенных решений, когда регистровый файл с аппаратной поддержкой синхронизации распределяется между ядрами, дает возможность создавать быстродействующие программы, использующие стандартные примитивы синхронизации, для которых производительность системы будет сопоставима с идеальным централизованным вариантом. Однако при программировании такой распределенной системы необходима оптимизация программы с учетом особенностей архитектуры. Более того, при частом использовании примитивов синхронизации наблюдается падение эффективности, вызванное простоями ядер, при обращениях к дальним регистрам буфера синхронизации. Предложенный метод повышения эффективности аппаратной синхронизации на основе очередей типа FIFO дает возможность решить данную проблему.
Применение распределенных решений, когда регистровый файл с аппаратной поддержкой синхронизации распределяется между ядрами, дает возможность создавать быстродействующие программы, использующие стандартные примитивы синхронизации, для которых производительность системы будет сопоставима с идеальным централизованным вариантом. Однако при программировании такой распределенной системы необходима оптимизация программы с учетом особенностей архитектуры. Более того, при частом использовании примитивов синхронизации наблюдается падение эффективности, вызванное простоями ядер, при обращениях к дальним регистрам буфера синхронизации. Предложенный метод повышения эффективности аппаратной синхронизации на основе очередей типа FIFO дает возможность решить данную проблему.
Литература
1. Путря Ф.М. Архитектурные особенности процессоров с большим числом вычислительных ядер // Информационные технологии. — 2009. — № 4. — С. 2-7.
2. Held J., Bautista J., Koehl S. From a few cores to many: A tera-scale computing research overview // Intel White Paper. — 2006. — URL: ftp://download.intel.com/research/platform/terascale/terascale_ove.
— 2006. — URL: ftp://download.intel.com/research/platform/terascale/terascale_ove.
3. Shaoshan L., Gaudiot J.-L. Synchronization Mechanisms on Modern Multi-core Architectures // Advances in Computer Systems Architecture / Computer Systems Architecture Conference. — 2007. -P. 290-303.
4. http://www.multicore.ru (дата обращения 21.01.10)
Статья поступила 24 ноября 2010 г.
Путря Фёдор Михайлович — кандидат технических наук, старший научный сотрудник ГУП НПЦ «ЭЛВИС» (г. Москва). Область научных интересов: организация подсистемы памяти в многоядерных процессорах, аппаратные механизмы синхронизации вычислительных ядер в многоядерных системах, механизмы обмена данными между ядрами/процессами; методы тестирования систем-на-кристалле и многоядерных процессоров.
Медведев Илья Александрович — инженер ГУП НПЦ «ЭЛВИС» (г. Москва). Область научных интересов: аппаратные механизмы синхронизации вычислительных ядер в многоядерных системах, сихронизация потоков в многопоточных приложениях; масштабируемость многоядерных систем. E-mail: [email protected]
E-mail: [email protected]
Рис.5. Сравнительный анализ производительности тестами на передачу управления (♦ — централизованный; ■ — «каждый с каждым»; ▲ — однонаправленное кольцо)
Примитивы Синхронизации в Go | Ubik Lab
Продолжаем серию статей о проблемах многопоточности, параллелизме, concurrency и других интересных штуках.
- Race condition и Data Race
- Deadlocks, Livelocks и Starvation
- Примитивы синхронизации в Go
- Безопасная работа с каналами в Go
- Goroutine Leaks
Пакет sync содержит примитивы, которые наиболее полезны для низкоуровневой синхронизации доступа к памяти.
WaitGroup — это отличный способ дождаться завершения набора одновременных операций.
Запустим несколько goroutine и дождемся завершения их работы:
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println("1st goroutine sleeping. ..")
time.Sleep(100 * time.Millisecond)
}()
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println("2nd goroutine sleeping...")
time.Sleep(200 * time.Millisecond)
}()
wg.Wait()
fmt.Println("All goroutines complete.")
..")
time.Sleep(100 * time.Millisecond)
}()
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println("2nd goroutine sleeping...")
time.Sleep(200 * time.Millisecond)
}()
wg.Wait()
fmt.Println("All goroutines complete.")
У нас нет гарантий когда будут запущены наши goroutine. Возможна ситуация когда при вызове Wait еще не будет ни одной запущенной goroutine. По этому важно вызвать Add за пределами процедур, которые они помогают отслеживать.
Пример неопределенного поведения:
var wg sync.WaitGroup
go func() {
wg.Add(1)
defer wg.Done()
fmt.Println("1st goroutine sleeping...")
time.Sleep(1)
}()
wg.Wait()
fmt.Println("All goroutines complete.")
О WaitGroup можно думать как о concurrent-safe счетчике.
Вызовы Add увеличивает счетчик на переданное число, а вызовы Done уменьшают счетчик на единицу. Wait блокируется пока счетчик не станет равным нулю.
Обычно Add вызывают как можно ближе к goroutine. Но иногда удобно используют Add для отслеживания группы goroutine одновременно.
Например в таких циклах:
hello := func(wg *sync.WaitGroup, id int) {
defer wg.Done()
fmt.Printf("Hello from %v!\n", id)
}
const numGreeters = 5
var wg sync.WaitGroup
wg.Add(numGreeters)
for i := 0; i < numGreeters; i++ {
go hello(&wg, i+1)
}
wg.Wait()
go-patterns
Mutex означает mutual exclusion(взаимное исключение) и является способом защиты critical section(критическая секция) вашей программы.
Критическая секция — это область вашей программы, которая требует эксклюзивного доступа к общему ресурсу. При нахождении в критической секции двух (или более) потоков возникает состояние race(гонки). Так же возможны проблемы взаимной блокировки(deadlock).

Mutex обеспечивает безопасный доступ к общим ресурсам.
Простой пример счетчика:
type counter struct{
count int
}
func (c *counter) Increment() {
c.count++
}
func (c *counter) Decrement() {
c.count--
}
Напишем тест, который будет в разных goroutine увеличивать или уменьшать общее значение:
c := new(counter)
var wg sync.WaitGroup
numLoop := 1000
wg.Add(numLoop)
for i := 0; i < numLoop; i++ {
go func() {
defer wg.Done()
c.Increment()
}()
}
wg.Add(numLoop)
for i := 0; i < numLoop; i++ {
go func() {
defer wg.Done()
c.Decrement()
}()
}
wg.Wait()
expected := 0
assert.Equal(t, expected, c.count)
Результат:
expected: 0 actual: 52
Используем Mutex для синхронизации доступа:
type counter struct{
sync.Mutex
count int
}
func (c *counter) Increment() {
c.Lock()
defer c. Unlock()
c.count++
}
func (c *counter) Decrement() {
c.Lock()
defer c.Unlock()
c.count--
}
Unlock()
c.count++
}
func (c *counter) Decrement() {
c.Lock()
defer c.Unlock()
c.count--
}
Мы вызываем Unlock в defer. Это очень распространенная идиома при использовании Mutex, чтобы гарантировать, что вызов всегда происходит, даже при панике. Несоблюдение этого требования может привести к deadlock вашей программы. Хотя defer и несет небольшие затраты.
Критическая секция названа так, потому что она отражает узкое место в вашей программе. Вход в критическую секцию и выход из нее обходится довольно дорого, поэтому обычно люди пытаются минимизировать время, проведенное в критических секциях.
Возможно не все процессы будут читать и записывать в общую память. В этом случае вы можете воспользоваться мьютексом другого типа.
RWMutex
RWMutex концептуально то же самое, что и Mutex: он защищает доступ к памяти. Тем не менее, RWMutex дает вам немного больше контроля над памятью.
Вы можете запросить блокировку для чтения, и в этом случае вам будет предоставлен доступ, если блокировка не удерживается для записи.
Это означает, что произвольное число читателей может удерживать блокировку читателя, пока ничто другое не удерживает блокировку писателя.
Посмотрим как это работает:
func (c *counter) CountV1() int {
c.Lock()
defer c.Unlock()
return c.count
}
func (c *counter) CountV2() int {
c.RLock()
defer c.RUnlock()
return c.count
}
CountV2 не блокирует count если не было блокировок на запись.
Немного бенчмарков:
func BenchmarkCountV1(b *testing.B) {
c := new(counter)
var wg sync.WaitGroup
for i := 0; i < b.N; i++ {
for j := 0; j < 1000; j++ {
wg.Add(1)
go func() {
defer wg.Done()
c.CountV1()
}()
}
wg.Wait()
}
}
func BenchmarkCountV2(b *testing. B) {
c := new(counter)
var wg sync.WaitGroup
for i := 0; i < b.N; i++ {
for j := 0; j < 1000; j++ {
wg.Add(1)
go func() {
defer wg.Done()
c.CountV2()
}()
}
wg.Wait()
}
}
B) {
c := new(counter)
var wg sync.WaitGroup
for i := 0; i < b.N; i++ {
for j := 0; j < 1000; j++ {
wg.Add(1)
go func() {
defer wg.Done()
c.CountV2()
}()
}
wg.Wait()
}
}
BenchmarkCountV1-8 2132 501896 ns/op BenchmarkCountV2-8 3358 306254 ns/op
go-patterns
Условная переменная(condition variable) — примитив синхронизации, обеспечивающий блокирование одного или нескольких потоков до момента поступления сигнала от другого потока о выполнении некоторого условия или до истечения максимального промежутка времени ожидания.
Сигнал не несет никакой информации, кроме факта, что произошло какое-то событие. Очень часто мы хотим подождать один из этих сигналов, прежде чем продолжить выполнение. Один из наивных подходов состоит в использовании бесконечного цикла:
for conditionTrue() == false {
time. Sleep(1 * time.Millisecond)
}
Sleep(1 * time.Millisecond)
}
Но это довольно неэффективно, и вам нужно выяснить, как долго спать: слишком долго, и вы искусственно снижаете производительность; слишком мало, и вы отнимаете слишком много процессорного времени. Было бы лучше, если бы у процесса был какой-то способ эффективно спать, пока ему не будет дан сигнал проснуться и проверить его состояние.
Такие задачи могут решать каналы или вариации паттерна PubSub(Publisher-Subscriber).
Но если у вас низкоуровневая библиотека, где необходим более производительный код, тогда можно использовать тип sync.Cond.
Пример
Предположим у нас есть некоторый общий ресурс в системе. Одна группа процессов может изменять его состояния, а другая группа должна реагировать на эти изменения.
type message struct {
cond *sync.Cond
msg string
}
func main() {
msg := message{
cond: sync.NewCond(&sync.Mutex{}),
}
// 1
for i := 1; i <= 3; i++ {
go func(num int) {
for {
msg. cond.L.Lock()
msg.cond.Wait()
fmt.Printf("hello, i am worker%d. text:%s\n", num, msg.msg)
msg.cond.L.Unlock()
}
}(i)
}
// 2
scanner := bufio.NewScanner(os.Stdin)
fmt.Print("Enter text: ")
for scanner.Scan() {
msg.cond.L.Lock()
msg.msg = scanner.Text()
msg.cond.L.Unlock()
msg.cond.Broadcast()
}
}
cond.L.Lock()
msg.cond.Wait()
fmt.Printf("hello, i am worker%d. text:%s\n", num, msg.msg)
msg.cond.L.Unlock()
}
}(i)
}
// 2
scanner := bufio.NewScanner(os.Stdin)
fmt.Print("Enter text: ")
for scanner.Scan() {
msg.cond.L.Lock()
msg.msg = scanner.Text()
msg.cond.L.Unlock()
msg.cond.Broadcast()
}
}
Мы запустили 3 goroutine которые ждут сигнала. Обратите внимание, что вызов Wait не просто блокирует, он приостанавливает текущую процедуру, позволяя другим процедурам запускаться.
При входе Wait вызывается Unlock в Locker переменной Cond, а при выходе из Wait вызывается Lock в Locker переменной Cond. К этому нужно немного привыкнуть.
Во второй части мы читаем ввод из консоли и отправляем сигнал об изменении состояния.
Broadcast отправляет сигнал всем ожидающим goroutine. А метод Signal находит goroutine, которая ждала дольше всего и будет ее.
proposal: Go 2: sync: remove the Cond type — дискуссия о необходимости Cond в sync.
concurrency/examples/sync/cond
Дополнительная информация
- Concurrency in Go. by Katherine Cox-Buday
- https://golang.org/pkg/sync
примитивов синхронизации
примитивов синхронизацииДалее: Рекомендации Up: Блокировка многопоточности Предыдущий: Основные инструменты
Подразделы
- Мьютексы
- Переменные условия
- Общие/эксклюзивные замки
- Семафоры
Для облегчения работы было введено несколько примитивов синхронизации.
многопоточность ядра. Эти примитивы реализованы атомарным
операций и использовать соответствующие барьеры памяти, чтобы пользователи этих
примитивам не нужно беспокоиться о том, чтобы сделать это самостоятельно.
примитивы очень похожи на используемые в других операционных системах
включая мьютексы, условные переменные, разделяемые/эксклюзивные блокировки и
семафоры.
Примитив мьютекса обеспечивает взаимное исключение для одного или нескольких данных. объекты. Предоставляются две версии примитива мьютекса: spin мьютексы и мьютексы сна.
Спиновые мьютексы — это простая спиновая блокировка. Если замок держит другой
поток, когда поток пытается получить его, второй поток будет вращаться
ожидание снятия блокировки. Благодаря этому вращательному характеру
переключение контекста не может быть выполнено, удерживая вращающийся мьютекс, чтобы избежать
взаимоблокировка в случае, если поток, владеющий спин-блокировкой, не
выполняется на ЦП, а все остальные ЦП вращаются на этой блокировке. Ан
исключением является блокировка планировщика, которую необходимо удерживать в течение
переключение контекста. Как частный случай, владение планировщиком
блокировка передается от отключаемого потока к потоку, который
включен, чтобы удовлетворить это требование, сохраняя при этом защиту
структуры данных планировщика. Поскольку нижняя половина кода, которая планирует
многопоточные прерывания и запускает обработчики непоточных прерываний, которые также используют
вращающиеся мьютексы, вращающиеся мьютексы должны отключать прерывания, пока они удерживаются
для предотвращения взаимоблокировки нижнего полукода с верхним полукодом
это прерывание на текущем процессоре. Отключение прерываний во время
удержание спин-блокировки имеет неприятный побочный эффект увеличения
задержка прерывания.
Отключение прерываний во время
удержание спин-блокировки имеет неприятный побочный эффект увеличения
задержка прерывания.
Чтобы обойти это, предоставляется второй примитив мьютекса, который выполняет переключение контекста, когда поток блокируется мьютексом. Этот Второй тип мьютекса называется спящим мьютексом. Поскольку нить, которая конкурсы на блоках мьютекса сна вместо вращения, это не восприимчивы к первому типу взаимоблокировок со спин-блокировками. Спать мьютексы нельзя использовать в коде нижней половины, поэтому их не нужно отключите прерывания, пока они удерживаются, чтобы избежать второго типа тупик со спин-блокировками.
Как и в Solaris, когда поток блокирует мьютекс сна, он
его приоритет перед владельцем замка. Таким образом, если поток блокируется на
мьютекс сна и его приоритет выше, чем у потока, который в данный момент
владеет мьютексом сна, текущий владелец унаследует приоритет
первая нить. Если владелец мьютекса сна заблокирован
еще один мьютекс, тогда будет пройдена вся цепочка потоков
повышение приоритета любых потоков, если это необходимо, до запускаемого потока
найден. Это для решения проблемы инверсии приоритетов
где поток с более низким приоритетом блокирует поток с более высоким приоритетом. По
повышение приоритета потока с более низким приоритетом, пока он не освободится
замок, на который заблокирован поток с более высоким приоритетом, ядро
гарантирует, что поток с более высоким приоритетом будет запущен, как только
его приоритет позволяет.
Это для решения проблемы инверсии приоритетов
где поток с более низким приоритетом блокирует поток с более высоким приоритетом. По
повышение приоритета потока с более низким приоритетом, пока он не освободится
замок, на который заблокирован поток с более высоким приоритетом, ядро
гарантирует, что поток с более высоким приоритетом будет запущен, как только
его приоритет позволяет.
Эти два типа мьютексов аналогичны мьютексам Solaris. адаптивные мьютексы. Одно отличие от Solaris API заключается в том, что получение и освобождение спинового мьютекса использует другие функции, чем получение и освобождение мьютекса сна. Отличие от Соляриса реализация заключается в том, что спящие мьютексы не являются адаптивными. Подробная информация о API и реализацию мьютекса Solaris можно найти в разделе 3.5 [Мауро01].
Переменные условия обеспечивают логическую абстракцию для блокировки
поток в ожидании условия. Условные переменные не
содержат фактическое условие для проверки, вместо этого блокируется
соответствующий мьютекс, проверяет условие, а затем блокирует
условная переменная, если условие не истинно. Чтобы не потерять
пробуждения, мьютекс передается как блокировка при ожидании
условие.
Чтобы не потерять
пробуждения, мьютекс передается как блокировка при ожидании
условие.
Переменные условия FreeBSD используют API, очень похожий на предоставляется в Солярисе. Отличия заключаются только в отсутствии cv_wait_sig_swap и добавление cv_init и конструкторы и деструкторы cv_destroy. Реализация также отличается от Solaris тем, что очередь ожидания встроена в сама условная переменная вместо того, чтобы исходить из хэшированного пула очередь сна используется для сна и пробуждения.
Общие/эксклюзивные блокировки, также известные как sx-блокировки, обеспечивают простой блокировки чтения/записи. Как следует из названия, несколько потоков могут содержать общую блокировку одновременно, но только один поток может удерживать эксклюзивный замок. Кроме того, если один поток содержит монопольную блокировку, потоки могут удерживать общую блокировку.
Блокировки sx во FreeBSD имеют некоторые ограничения, отсутствующие в других
реализации блокировки чтения/записи. Во-первых, поток не может
рекурсивно получить эксклюзивную блокировку. Во-вторых, секс-замки не
реализовать любой вид распространения приоритета. Наконец, хотя
реализованы апгрейды и даунгрейды блокировок, они могут не блокировать.
Вместо этого, если обновление не может быть успешным, оно возвращает сообщение об ошибке, и
программист должен явно сбросить свою общую блокировку и получить
эксклюзивный замок. Этот дизайн был преднамерен, чтобы помешать программистам
от создания ложных предположений о блокирующей функции обновления.
В частности, блокирующее обновление должно потенциально освобождать общий доступ.
замок. Кроме того, другой поток может получить монопольную блокировку до того, как
поток, пытающийся выполнить обновление. Например, если два потока
одновременное обновление замка.
Во-первых, поток не может
рекурсивно получить эксклюзивную блокировку. Во-вторых, секс-замки не
реализовать любой вид распространения приоритета. Наконец, хотя
реализованы апгрейды и даунгрейды блокировок, они могут не блокировать.
Вместо этого, если обновление не может быть успешным, оно возвращает сообщение об ошибке, и
программист должен явно сбросить свою общую блокировку и получить
эксклюзивный замок. Этот дизайн был преднамерен, чтобы помешать программистам
от создания ложных предположений о блокирующей функции обновления.
В частности, блокирующее обновление должно потенциально освобождать общий доступ.
замок. Кроме того, другой поток может получить монопольную блокировку до того, как
поток, пытающийся выполнить обновление. Например, если два потока
одновременное обновление замка.
Семафоры FreeBSD — это простые счетные семафоры, использующие API.
аналогично семафорам POSIX.4 [Gallmeister95]. С
sema_wait и sema_timedwait потенциально могут
block, мьютексы не должны удерживаться при вызове этих функций.
Далее: Рекомендации Up: Блокировка многопоточности Предыдущий: Основные инструменты
7.1. Примитивы синхронизации — Основы компьютерных систем
«Это не идея, пока ты ее не запишешь».
Возрождение интереса к многопоточности в конце 1990-х гг. синхронизация с ним в качестве основной темы. Когда несколько потоков используют один и тот же адрес пространство, они должны убедиться, что их доступ к памяти не конфликтует. Эдсгер ОС Дейкстры представила семафоры как программную конструкцию в 1968 году. стандарт POSIX.1c-1995 определил для них интерфейс. Кроме того, примитивы более высокого уровня сделали синхронизацию более управляемой как ключ компонент инфраструктуры для параллельного программного обеспечения.
Цели главы
В этой главе мы рассмотрим следующие цели обучения:
- Мы обосновываем необходимость примитивов синхронизации как решения проблемы гонки.
 Условия и временные ограничения.
Условия и временные ограничения. - Мы будем сравнивать и противопоставлять примитивные механизмы синхронизации и то, что проблемы, которые они решают.
- Мы будем исследовать код, используя синхронизацию библиотеки потоков POSIX. примитивные реализации.
- Мы выявим условия, которые приводят к тупиковой, сложной гонке состояние, которое может возникнуть в синхронизированном программном обеспечении.
Параллельные программы представляют новый класс программных ошибок, называемый гонкой условия. Условия гонки возникают всякий раз, когда время несколько потоков выполнения определяют результат. проблема в том, что планирование потоков находится вне контроля программист, написавший код, и пользователь, запускающий программу.
Расписание определяется ядром операционной системы, специальной программой
который управляет ресурсами системы. В современных компьютерных системах общего назначения
могут быть сотни или тысячи потоков, которые должны по очереди получать
доступ к небольшому количеству вычислительных ядер процессора. Ядро принимает решение
какой поток запускать в зависимости от того, что еще делает машина, как долго каждый
поток уже запущен и многие другие факторы. Программист не может предсказать или
контролировать любой из этих факторов; на самом деле, точное сочетание факторов
может быть уникальным каждый раз, когда программа запускается.
Ядро принимает решение
какой поток запускать в зависимости от того, что еще делает машина, как долго каждый
поток уже запущен и многие другие факторы. Программист не может предсказать или
контролировать любой из этих факторов; на самом деле, точное сочетание факторов
может быть уникальным каждый раз, когда программа запускается.
Во многих случаях недетерминированный характер планирования потоков не является проблема. Если один поток отвечает за разложение 5 182 397 724 980 в произведения простых чисел, пока другой вычисляет миллиардную цифру числа Пи, он вероятно, не имеет значения, какое вычисление завершится первым. Однако если эти два результаты будут каким-то образом объединены, программа должна гарантировать, что оба они завершили перед попыткой этого третьего шага. То есть эти шаги должны быть синхронизированы.
Существует несколько форм синхронизации, которые могут потребоваться различным программам. Некоторые общие примеры включают следующее:
- Несколько потоков могут попытаться изменить общую структуру данных, но каждый из них запишет должны выполняться по одному, чтобы гарантировать правильный окончательный результат.
- Возможно, системе потребуется установить ограничение на количество одновременных обращений к общий ресурс, чтобы избежать задержек. Например, веб-сервер может ограничить количество входящих сетевых запросов, чтобы убедиться, что он не потребляет слишком много памяти.
- Определенные события могут потребоваться выполнять в определенном порядке, например, когда выходные данные, произведенные одним потоком, требуются в качестве входных данных для другого потока.
- Системе может потребоваться убедиться, что выполнено минимальное количество вычислений. было завершено, прежде чем приступить к каким-либо действиям. Например, некоторые программы запускают несколько разных алгоритмов, которые должны давать один и тот же результат; система может потребовать согласования по крайней мере трех алгоритмов, прежде чем уверенность в правильности результата.

Примитивы синхронизации, описанные в
эта глава может достичь всех этих целей. Примитивы синхронизации
типы переменных, которые имеют один критический аспект: операции, которые манипулируют
примитивы гарантированно атомарны. Эта особенность контрастирует с
стандартные переменные, у которых нет этой гарантии. Например, рассмотрим простой
строка кода C
Эта особенность контрастирует с
стандартные переменные, у которых нет этой гарантии. Например, рассмотрим простой
строка кода C x++ , которая увеличивает переменную int . Эта линия требует трех
отдельные инструкции, чтобы загрузить переменную в регистр, увеличить
зарегистрируйтесь, затем сохраните результат обратно в память. Между этими инструкциями
ядро может прервать выполнение и переключиться на другой поток. В
Напротив, примитив синхронизации будет использовать аппаратное обеспечение специального назначения.
методы, чтобы гарантировать, что такого рода многошаговые операции происходят в
один шаг, который не может быть прерван ядром.
Небрежное неправильное использование примитивов синхронизации может вызвать множество проблем.
Во-первых, некоторые примитивы синхронизации снижают производительность
отключение всего параллельного выполнения в системе. Это отключение требует ядер ЦП
временно сохранять копии своих данных и прекращать работу; им также может понадобиться
выполнять отложенные записи обратно на несколько уровней кэша. Еще хуже,
примитивы синхронизации могут привести к взаимоблокировке, состоянию, при котором
два (или более) потока одновременно ожидают друг друга. Наконец, некоторые
алгоритмы синхронизации содержат тонкие недостатки, которые можно легко не заметить.
Еще хуже,
примитивы синхронизации могут привести к взаимоблокировке, состоянию, при котором
два (или более) потока одновременно ожидают друг друга. Наконец, некоторые
алгоритмы синхронизации содержат тонкие недостатки, которые можно легко не заметить.
Целью этой главы является изучение общих примитивов синхронизации. которые широко поддерживаются, особенно в библиотеке потоков POSIX. Фокус вот основная цель каждого примитива и некоторые принципы, чтобы избежать взаимоблокировка и значительные потери производительности. В разделе «Проблемы синхронизации» мы рассмотрим, как комбинировать примитивы для решать более сложные задачи.
Встроенная ОС, поддержка и услуги | ОСРВ, гипервизор
Запускайте критически важные встраиваемые системы быстрее с помощью нашей коммерческой ОСРВ, гипервизора, средств разработки и услуг.
БЕСПЛАТНАЯ 30-ДНЕВНАЯ ПРОБНАЯ ВЕРСИЯ ПОГОВОРИ С НАМИ
Встраиваемые системы, которым доверяют повсюду
Наша операционная система реального времени (RTOS), гипервизор и промежуточное ПО обеспечивают производительность и безопасность, а также упрощают сертификацию безопасности. Мы являемся предпочтительной встроенной ОС для транспортных средств, вентиляторов, систем управления поездами, систем автоматизации производства, медицинских роботов и многого другого.
Мы являемся предпочтительной встроенной ОС для транспортных средств, вентиляторов, систем управления поездами, систем автоматизации производства, медицинских роботов и многого другого.
Нам доверяют OEM-производители и компании уровня 1 по всему миру, и сейчас мы работаем с более чем 215 миллионами автомобилей.
Мы создаем надежное и безопасное встроенное системное программное обеспечение с 1980 года.
ПОСМОТРЕТЬ ПОРТФОЛИО НАШЕЙ ПРОДУКЦИИ
Все, что вам нужно для создания лучших встраиваемых систем
Если вы хотите повысить уровень безопасности или упростить процесс кроссплатформенной разработки, мы можем помочь. Мы можем воплотить ваши планы в жизнь с RTOS и гипервизор , специально созданный для встраиваемых систем, включая предварительно сертифицированные варианты продукта. Наша модульная микроядерная архитектура обеспечивает безопасность и надежность и позволяет избежать дублирования усилий по разработке ОС для нескольких продуктов. Мы предоставляем поддержку на каждом этапе жизненного цикла продукта и предлагаем профессиональные услуги и обучение , чтобы предоставить вам дополнительные знания, которые вам нужны, когда они вам нужны.
- Программного обеспечения
- Поддерживать
- Профессиональные услуги
Программное обеспечение
Встроенные системы как никогда сложны и программно управляемы. Позвольте нам предоставить программную основу и строительные блоки, чтобы помочь вам сосредоточиться на предоставлении дополнительных функций и программного обеспечения, а не на обслуживании ОС.
Мы предлагаем:
- Основа , включая ОСРВ QNX ® Neutrino ® , платформу разработки программного обеспечения (SDP) QNX ® с POSIX-совместимой средой разработки и гипервизор QNX ® .
- Сертифицированы по безопасности Варианты нашей продукции, ускоряющие процесс сертификации
- Решения для обеспечения безопасности , включая безопасные беспроводные обновления и BlackBerry® Jarvis®, наше уникальное решение для анализа двоичных файлов
- Промежуточное ПО для ускорения разработки и ускорения выхода на рынок
Учить больше
Поддержка
Для успеха вам нужно больше, чем программное обеспечение. Вам нужен партнер, который знает, что работа не сделана, пока вы не приступите к работе.
Мы предлагаем:
- Различные пакеты поддержки и технические консультации от разработчиков, инженеров и архитекторов
- Лучший в своем классе продукт Документация, дополненная нашей базой знаний
- Пакеты поддержки плат для широкого спектра процессоров ARM и x86
Варианты поддержки
Профессиональные услуги
Если вам нужно расширить свою команду, запустить проект или сертифицировать свои продукты, вы можете положиться на наших экспертов по встраиваемым системам и ОС, которые предоставят необходимые вам знания и опыт.
Мы предлагаем:
- Услуги по обеспечению безопасности и решения для анализа двоичного кода
- Индивидуальная разработка
- Услуги по обеспечению безопасности , которые помогут вам получить сертификаты IEC 61508, ISO 26262, IEC 62304 и EN 5012X
- Учебные курсы , разработанные и проводимые экспертами в области функциональной безопасности и разработки встроенного программного обеспечения
Учить больше
Программное обеспечение
Программное обеспечение
Встроенные системы являются более программно управляемыми и сложными, чем когда-либо. Позвольте нам предоставить программную основу и строительные блоки, чтобы помочь вам сосредоточиться на предоставлении дополнительных функций и программного обеспечения, а не на обслуживании ОС.
Мы предлагаем:
- продукты Foundation , включая QNX ® Neutrino ® RTOS, среду QNX ® и платформу разработки программного обеспечения (SDP) с поддержкой QNX ® и POSIX.
 0163® Гипервизор
0163® Гипервизор - Сертифицированы по безопасности Варианты нашей продукции, ускоряющие процесс сертификации
- Решения для обеспечения безопасности , включая безопасные беспроводные обновления и BlackBerry® Jarvis®, наше уникальное решение для анализа двоичных файлов
- Промежуточное ПО для ускорения разработки и ускорения выхода на рынок
Учить больше
- продукты Foundation , включая QNX ® Neutrino ® RTOS, среду QNX ® и платформу разработки программного обеспечения (SDP) с поддержкой QNX ® и POSIX.
Поддержка
Поддержка
Для успеха вам нужно больше, чем программное обеспечение. Вам нужен партнер, который знает, что работа не сделана, пока вы не приступите к работе.
Мы предлагаем:
- Различные пакеты поддержки и технические консультации от разработчиков, инженеров и архитекторов
- Лучший в своем классе продукт Документация, дополненная нашей базой знаний
- Пакеты поддержки плат для широкого спектра процессоров ARM и x86
Варианты поддержки
Профессиональные услуги
Профессиональные услуги
Если вам нужно расширить свою команду, запустить проект или сертифицировать свои продукты, вы можете положиться на наших экспертов по встраиваемым системам и ОС, которые предоставят вам необходимые знания и опыт.
Мы предлагаем:
- Услуги по обеспечению безопасности и решения для анализа двоичного кода
- Индивидуальная разработка
- Услуги по обеспечению безопасности , которые помогут вам получить сертификаты IEC 61508, ISO 26262, IEC 62304 и EN 5012X
- Учебные курсы , разработанные и проводимые экспертами в области функциональной безопасности и разработки встроенного программного обеспечения
Учить больше
Почему стоит выбрать BlackBerry QNX Services
Безопасность
Ускорьте вывод на рынок программного обеспечения, предварительно сертифицированного по IEC 61508, ISO 26262 и IEC 62304, обучения QNX® по функциональной безопасности и услуг по обеспечению безопасности.
Безопасность
Благодаря микроядерной архитектуре наша ОСРВ и гипервизор изначально защищены. Положитесь на наших проверенных экспертов по кибербезопасности, которые помогут защитить ваши системы.
Масштабируемость
Наша полностью управляемая ОСРВ с микроядром может использоваться во всех линейках продуктов, поэтому ваши разработчики могут сосредоточиться на дополнительных функциях, а не на обслуживании ОС.
Надежность
Архитектура микроядра QNX защищает ОС и систему от сбоев компонентов и обеспечивает исключительную производительность.
Где мы помогаем
У нас есть экспертные знания в области программного обеспечения и решения, которые отвечают уникальным потребностям OEM-производителей и производителей в этих отраслях.
Подключенные и автономные транспортные средства
Оптимизируйте разработку безопасных автомобильных систем с помощью нашего программного обеспечения, промежуточного программного обеспечения и услуг, в том числе нашей ОС, предварительно сертифицированной по стандарту ISO 26262.
Учить больше
Робототехника и автоматизация
Ускорьте сертификацию безопасности, обеспечьте надежность и сократите время разработки с помощью нашего специально разработанного встроенного программного обеспечения, промежуточного программного обеспечения и услуг.
Учить больше
Операционная система для медицинских устройств
Убедитесь, что ваши медицинские устройства безопасны, защищены и надежны на протяжении всего жизненного цикла продукта.
Учить больше
ОС реального времени для железнодорожных систем
Удовлетворение сложным нормативным требованиям, повышение надежности и сокращение времени разработки ваших критически важных для безопасности железнодорожных систем.
Учить больше
Операционная система для тяжелого машиностроения
Упростите сертификацию безопасности и ускорьте внедрение новых продуктов для вашего тяжелого машиностроения.
Учить больше
ОС реального времени для промышленных систем управления
Решите уникальные проблемы безопасности, защиты и производительности, которые могут возникнуть при разработке систем промышленного Интернета вещей (IIoT).
Учить больше
Встроенная операционная система для аэрокосмической и оборонной промышленности
Упростите разработку и обеспечьте надежность ваших безопасных, функционально безопасных встроенных аэрокосмических и оборонных систем.
Учить больше
Программное обеспечение для коммерческого транспорта
Упростите сертификацию безопасности по ISO 26262, обеспечьте доступность и укрепите безопасность с помощью программных решений, поддерживающих адаптивную платформу AUTOSAR.
Учить больше
Узнать больше
Ресурсы
Доступ к последним официальным документам, веб-семинарам, примерам из практики и руководствам по отраслевым решениям.
Посетите ресурсный центр
Сертификаты
См. список предварительно сертифицированных продуктов и продуктов, подлежащих сертификации безопасности.
Узнать больше
Поддержка
Получите помощь через наш онлайн-портал, личные линии помощи, портал сообщества, базу знаний и многое другое.
Посетите службу поддержки
BSP
Поиск в нашей библиотеке пакетов поддержки плат (BSP) по поставщику микросхем, названию платы или названию BSP.
Найдите свой BSP
Предстоящие События- Предстоящие события
- Технический день NXP в Бостоне — 29 сентября
- Технический день NXP в Детройте — 18–19 октября
- EDGETECH 2022 — 16–18 ноября
- 13-й Аахенский коллоквиум по акустике – 21–23 ноября
|
БЮЛЛЕТЕНЬ НОВОСТЕЙ
Мероприятие, Отрасли встраиваемых системNXP Tech Day Boston — 29 сентября
ЗАРЕГИСТРИРУЙТЕСЬ СЕЙЧАС
Event, AutomotiveNXP Tech Day Detroit — 18–19 октября
ЗАРЕГИСТРИРУЙТЕСЬ СЕЙЧАС
Мероприятие, Медицинское оборудованиеEDGETECH 2022 — 16–18 ноября
ЗАРЕГИСТРИРУЙТЕСЬ СЕЙЧАС
Мероприятие, Автомобильная промышленность13-й Аахенский коллоквиум по акустике – 21–23 ноября
ЗАРЕГИСТРИРУЙТЕСЬ СЕЙЧАС
Введение в синхронизацию потоков — внутренние указатели
Один из самых популярных способов управления параллелизмом в многопоточном приложении.
Как видно из моего предыдущего введения в многопоточность, написание параллельного кода может оказаться сложной задачей. Могут возникнуть две большие проблемы: гонки данных, когда поток записи изменяет память, в то время как поток чтения читает ее, и условия гонки, когда два или более потока выполняют свою работу в непредсказуемом порядке. К счастью для нас, есть несколько способов предотвратить эти ошибки: в этой статье я рассмотрю самый распространенный из них, известный как 9.0010 синхронизация .
Что такое синхронизация
Синхронизация — это набор приемов, позволяющих обеспечить нормальное поведение двух или более потоков. В частности, синхронизация поможет вам реализовать как минимум две важные функции в вашей многопоточной программе:
атомарность — если ваш код содержит инструкции, которые работают с данными, совместно используемыми несколькими потоками, может возникнуть нерегулируемый одновременный доступ к этим данным.
гонка данных. Сегмент кода, содержащий эти инструкции, называется 9.0010 критическая секция . Вы хотите убедиться, что критические секции выполняются атомарно : как было определено в предыдущем эпизоде, атомарная операция не может быть разбита на более мелкие, чтобы во время ее выполнения ни один другой поток не мог проскользнуть;упорядочение — иногда вам нужно, чтобы два или более потоков выполняли свою работу в предсказуемом порядке, или установить ограничение на количество потоков, которые могут получить доступ к определенному ресурсу. Обычно у вас нет контроля над этими вещами, которые могут быть основной причиной состояния гонки. С помощью синхронизации вы можете организовать свои потоки для выполнения в соответствии с планом.
Синхронизация реализуется с помощью специальных объектов, называемых примитивами синхронизации , предоставляемых операционной системой или любым языком программирования, поддерживающим многопоточность. Затем вы используете такие примитивы синхронизации в своем коде, чтобы убедиться, что ваши потоки не запускают гонки данных, условия гонки или и то, и другое.
Синхронизация происходит как в аппаратном, так и в программном обеспечении, а также между потоками и процессами операционной системы. Эта статья посвящена синхронизации программных потоков: физический аналог и синхронизация процессов — увлекательные темы, которые, несомненно, будут рассмотрены в одной из следующих статей.
Общие примитивы синхронизации
Наиболее важными примитивами синхронизации являются мьютексы , семафоры и условные переменные . Для этих терминов нет официальных определений, поэтому разные тексты и реализации связывают с каждым примитивом несколько разные характеристики.
Операционные системы изначально предоставляют эти инструменты. Например, Linux и macOS поддерживают потоков POSIX , также известных как pthreads 9. 0011 — набор функций, позволяющий писать безопасные многопоточные приложения. Windows имеет свои собственные инструменты синхронизации в библиотеках времени выполнения C (CRT): концептуально похожие на функции потоков POSIX, но с другими именами.
Если вы не пишете очень низкоуровневый код, вы обычно хотите использовать примитивы синхронизации, поставляемые с выбранным вами языком программирования. Каждый язык программирования, имеющий дело с многопоточностью, имеет свой собственный набор примитивов синхронизации, а также другие функции для работы с потоками. Например, Java предоставляет java.util.concurrent , современный C++ имеет собственную библиотеку thread , C# поставляет пространство имен System.Threading и так далее. Разумеется, все эти функции и объекты основаны на основных примитивах операционной системы.
Существует множество других инструментов синхронизации. В этой статье я буду придерживаться трех упомянутых выше, поскольку они служат основой, часто используемой для создания более сложных объектов. Давайте посмотрим поближе.
Мьютексы
Мьютекс ( mutex ual ex clusion ) — это примитив синхронизации, который накладывает ограничение на критическую секцию для предотвращения гонки данных. Мьютекс гарантирует атомарность , гарантируя, что только один поток получает доступ к критической секции за раз.
Технически мьютекс — это глобальный объект в вашем приложении, совместно используемый несколькими потоками, который обеспечивает две функции, обычно называемые блокировка и разблокировка . Поток, который собирается войти в критическую секцию, вызывает блокировку , чтобы заблокировать мьютекс; когда это будет сделано, то есть когда критический раздел закончится, тот же поток вызовет unlock , чтобы разблокировать его. Важная особенность мьютекса: только поток, который блокирует мьютекс, может впоследствии разблокировать его.
Если другой поток подключается и пытается заблокировать заблокированный мьютекс, операционная система переводит его в спящий режим до тех пор, пока первый поток не завершит свою задачу и не разблокирует мьютекс. Таким образом, только один поток может получить доступ к критической секции; любой другой поток исключается из него и должен ждать разблокировки. По этой причине мьютекс также известен как запорный механизм .
Вы можете использовать мьютекс для защиты простых действий, таких как одновременное чтение и запись общей переменной, а также более крупных и сложных операций, которые должны выполняться одним потоком за раз, таких как запись в файл журнала или изменение базы данных. В любом случае операции блокировки/разблокировки мьютекса всегда совпадают с границами критической секции.
Рекурсивные мьютексы
В любой обычной реализации мьютекса поток, который дважды блокирует мьютекс, вызывает ошибку. А 9Вместо этого 0010 рекурсивный мьютекс допускает это: поток может блокировать рекурсивный мьютекс несколько раз, не разблокируя его предварительно. Однако никакой другой поток не может заблокировать рекурсивный мьютекс до тех пор, пока все блокировки, удерживаемые первым потоком, не будут сняты. Этот примитив синхронизации также известен как реентерабельный мьютекс , где реентерабельность — это возможность многократного вызова функции (т. е. повторного входа в нее) до завершения предыдущих вызовов.
С рекурсивными мьютексами сложно работать, и они подвержены ошибкам. Вы должны отслеживать, какой поток сколько раз блокировал мьютекс, и следить за тем, чтобы тот же поток полностью его разблокировал. В противном случае останутся заблокированные мьютексы с неприятными последствиями. В большинстве случаев достаточно обычного мьютекса.
Мьютексы чтения/записи
Как мы знаем из предыдущего эпизода, несколько потоков могут одновременно читать из общего ресурса без вреда, если они не изменяют его. Так зачем блокировать мьютекс, если некоторые из ваших потоков работают в режиме «только для чтения»? Например, рассмотрите параллельную базу данных, которая часто читается многими потоками, в то время как другой поток редко записывает обновления. Вам, конечно, нужен мьютекс для защиты доступа на чтение/запись, но большую часть времени вы в конечном итоге заблокируете его только для операций чтения, не давая другим потокам чтения выполнять свою работу.
Мьютекс чтения/записи допускает одновременных операций чтения из нескольких потоков и эксклюзивных операций записи из одного потока в общий ресурс. Его можно заблокировать в режиме чтения или записи . Чтобы изменить ресурс, поток должен сначала получить монопольную блокировку записи. Исключительная блокировка записи не разрешена до тех пор, пока не будут сняты все блокировки чтения.
Семафоры
Семафор — это примитив синхронизации, используемый для управления потоками: какой из них запускается первым, сколько потоков может получить доступ к ресурсу и так далее. Как уличный семафор регулирует трафик, семафор программирования регулирует поток многопоточности: по этой причине семафор также известен как 9-канальный семафор. 0010 сигнальный механизм . Это можно рассматривать как эволюцию мьютекса, потому что он гарантирует как порядок , так и атомарность . Однако через несколько абзацев я покажу вам, почему использование семафоров только для атомарности — не лучшая идея.
Технически семафор — это глобальный объект в вашем приложении, совместно используемый несколькими потоками, который содержит числовой счетчик , управляемый двумя функциями: одна увеличивает счетчик, другая уменьшает его. Исторически называется P и V , в современных реализациях используются более понятные имена для этих функций, например (acquire ) и (release ).
Семафор управляет доступом к общему ресурсу: счетчик определяет максимальное количество потоков, которые могут одновременно получить к нему доступ. В начале вашей программы, когда семафор инициализируется, вы выбираете это число в соответствии с вашими потребностями. Затем поток, который хочет получить доступ к общему ресурсу, вызывает , получает :
- если счетчик больше нуля поток может продолжаться. Счетчик сразу уменьшается на единицу, затем текущий поток начинает выполнять свою работу. По завершении он вызывает
Release, что, в свою очередь, увеличивает значение счетчика на единицу. - если счетчик равен нулю поток не может продолжить работу: другие потоки уже заполнили доступное пространство. Текущий поток приостанавливается операционной системой и пробуждается, когда счетчик семафора снова становится больше нуля (то есть, когда любой другой поток вызывает 9).0100, выпустите после завершения своей работы).
В отличие от мьютекса, любой поток может освободить семафор , а не только тот, который его захватил в первую очередь.
Один семафор используется для ограничения количества потоков, обращающихся к общему ресурсу: например, для ограничения количества многопоточных подключений к базе данных, когда каждый поток запускается кем-то, кто подключается к вашему серверу.
Объединяя несколько семафоров вместе, вы можете решить проблемы упорядочения потоков: например, поток, отображающий веб-страницу в вашем браузере, должен начинаться после потока, загружающего файлы HTML из Интернета. Поток A уведомит поток B, когда это будет сделано, чтобы B мог проснуться и продолжить свою работу: это также известно как знаменитая проблема производитель-потребитель.
Двоичные семафоры
Семафор, счетчик которого ограничен значениями 0 и 1, называется двоичным семафором : только один поток одновременно может получить доступ к общему ресурсу. Подождите: это в основном мьютекс, защищающий критическую секцию! На самом деле вы можете воспроизвести поведение мьютекса с помощью двоичного семафора. Однако следует помнить о двух важных моментах:
- мьютекс может быть разблокирован только тем потоком, который заблокировал его первым, в то время как семафор может быть освобожден любым другим потоком. Это может привести к путанице и тонким ошибкам, если вам нужен просто механизм блокировки; Семафоры
- — это механизмы сигнализации, которые организуют потоки, а мьютексы — это механизмы блокировки, защищающие общие ресурсы. Вы не должны использовать семафоры для защиты общих ресурсов или мьютексы для сигнализации: ваши намерения будут более понятны вам и всем, кто будет читать ваш код.
Переменные условия
Переменные условия — это еще один примитив синхронизации, предназначенный для упорядочения . Они используются для отправки сигнала пробуждения по разным потокам. Переменная условия всегда идет рука об руку с мьютексом; использовать его в одиночку не имеет смысла.
Технически условная переменная — это глобальный объект в вашем приложении, совместно используемый несколькими потоками, который предоставляет три функции, обычно называемые wait , notify_one и notify_all , а также механизм передачи существующего мьютекса для работы с ним. (точный способ зависит от реализации).
Поток, который вызывает ожидание для условной переменной, приостанавливается операционной системой. Затем другой поток, который хочет разбудить его, вызывает notify_one или notify_all . Разница в том, что notify_one размораживает только один поток, а notify_all отправляет вызов пробуждения всем потокам, которые находятся в спящем режиме после вызова wait переменной условия. Мьютекс используется внутри для обеспечения механизма сна/пробуждения.
Переменные условия — это мощный механизм для отправки сигналов между потоками, чего нельзя добиться с помощью одних только мьютексов. Например, вы можете использовать их для решения проблемы «производитель-потребитель» еще раз, когда поток A посылает сигнал, когда это делается, чтобы поток B мог начать свою работу.
Распространенные проблемы синхронизации
Все примитивы синхронизации, описанные в этой статье, имеют нечто общее: они усыпляют потоки. По этой причине их также называют блокирующими механизмами . Механизм блокировки — хороший способ предотвратить одновременный доступ к общему ресурсу, если вы хотите избежать гонок данных или условий гонки: спящий поток не причиняет вреда. Но это может вызвать неприятные побочные эффекты. Давайте быстро взглянем на них.
Взаимная блокировка
Взаимная блокировка возникает, когда поток ожидает общую переменную, которую содержит другой поток, а этот второй поток ожидает общую переменную, которую содержит первый поток. Такие вещи обычно случаются при работе с несколькими мьютексами: два потока вечно ждут в бесконечном круговом цикле: поток A ждет поток B, который ждет поток A, который ждет поток B, который…
Голодание
Поток уходит в голодание , когда ему не хватает любви: он остается на неопределенный срок в спящем состоянии, ожидая доступа к общему ресурсу, который постоянно предоставляется другим потокам. Например, плохо спроектированный алгоритм на основе семафора может забыть разбудить один из множества потоков, стоящих за линией ожидания, отдав приоритет только их подмножеству. Голодный поток будет ждать вечно, не выполняя никакой полезной работы.
Ложные пробуждения
Это неуловимая проблема, возникающая из-за фактической реализации условных переменных в некоторых операционных системах. В ложное пробуждение поток пробуждается, даже если не сигнализируется через переменную условия. Вот почему большинство примитивов синхронизации также включают способ проверки, действительно ли сигнал пробуждения исходит от условной переменной, которую ожидает поток.
Инверсия приоритета
Инверсия приоритета происходит, когда поток, выполняющий задачу с высоким приоритетом, блокируется в ожидании освобождения ресурса, например мьютекса, потоком с более низким приоритетом. Например, когда поток, который выводит звук на звуковую карту (высокий приоритет), блокируется потоком, который отображает интерфейс (низкий приоритет), что приводит к плохому сбою через ваши динамики.
Что дальше
Все эти проблемы синхронизации изучались годами, и существует множество решений, как технических, так и архитектурных. Тщательный дизайн и немного опыта очень помогают в профилактике. Кроме того, учитывая недетерминированную (то есть чрезвычайно сложную) природу многопоточных приложений, люди разработали интересные инструменты для обнаружения ошибок и потенциальных ловушек в параллельном коде. Такие проекты, как Tsan или Helgrind от Google, — лишь некоторые из них.
Однако иногда вы хотите пойти другим путем и избавиться от любого блокирующего механизма в многопоточном приложении. Это означало бы войти в область неблокирующих : очень низкоуровневую территорию, где потоки никогда не усыпляются операционной системой, а параллелизм регулируется с помощью атомарных примитивов и структур данных без блокировок . Это сложная область, не всегда необходимая, которая может повысить скорость вашего программного обеспечения или нанести ему ущерб. Но это история для следующего эпизода…
Источники
Википедия — Синхронизация (информатика)
Википедия — Реентерабельный мьютекс
Википедия — Реентерабельность (вычисления)
Википедия — Семафор (программирование)
Википедия — Ложное пробуждение
Википедия — Инверсия приоритета информатика)
Columbia Engineering — Примитивы синхронизации
StackOverflow — Определение «примитива синхронизации»
StackOverflow — Блокировка, мьютекс, семафор… в чем разница?
StackOverflow — Почему дважды блокируется std::mutex «Неопределенное поведение»?
Операционные системы: три простых элемента — параллелизм
Уголок Джаки — Гонка данных и мьютекс
Спецификации Java 10 API — Семафор классов
Руководство по многопоточному программированию Oracle — Атрибуты блокировки чтения-записи , мьютексы и семафоры: типы объектов синхронизации0002 Cppreference — std::shared_mutex
Cppreference — std::condition_variable
Quora — В чем разница между мьютексом и семафором?
gerald-fahrnholz. eu — Использование условных переменных — безопасный способ
Миланский политехнический университет — Thread Posix: условные переменные
SoftwareEngineering — Ложные объяснения пробуждения звучат как ошибка, которую просто не стоит исправлять, верно?
Проект Android с открытым исходным кодом — предотвращение инверсии приоритетов
thread • многопоточность • параллелизм • мьютекс • семафор • переменная условия
Примитивы синхронизации ОСРВ — мьютексы и семафоры
Узнайте об использовании мьютексов и семафоров во встроенном программировании на C от главного инженера Barr Group Саломона Сингера.
Связанные курсы
Как расставить приоритеты для задач RTOS (и почему это важно)
Учебный курс по встроенному программному обеспечению
Стенограмма
Эндрю Гирсон: Привет. Сегодня я здесь с Саломоном Сингером, главным инженером Barr Group. И мы здесь сегодня, чтобы поговорить о примитивах синхронизации RTOS.
Итак, Саломон, это звучит как полный рот, давайте начнем с разговора о том, что такое примитив синхронизации RTOS и почему они используются?
Саломон Сингер : Верно. Итак, две основные причины, по которым мы собираемся использовать примитив синхронизации.
Первый заключается в передаче информации от одной задачи к другой или от ISR к задаче.
Вторая причина использования одного из этих примитивов синхронизации состоит в том, чтобы избежать состояния гонки. Состоянием гонки является ситуация, когда две или более задачи манипулируют общим ресурсом примерно в одно и то же время.
Эндрю: Хорошо. Таким образом, общий ресурс похож на аппаратный регистр или часть оборудования или что-то в этом роде, где есть только один из них, но в системе может быть несколько задач, которым действительно может потребоваться взаимодействие с ним.
Саломон: Правильно. Таким образом, общий ресурс может быть либо частью оборудования, либо даже глобальной переменной, которая может использоваться в нескольких потоках.
Эндрю: Хорошо. Хорошо. А мьютексы — это хорошо известный тип примитива синхронизации ОСРВ. Что такое мьютекс?
Саломон: Хорошо. Итак, прежде всего, мьютекс означает взаимное исключение.
Эндрю: Хорошо.
Salomon: И в этом конкретном случае это примитив, используемый для предотвращения доступа двух или более задач к одному и тому же общему ресурсу примерно в одно и то же время.
С высоты 25 000 футов мы можем сказать — и это, конечно, чрезмерное упрощение — мы можем сказать, используется или не используется двоичный флаг безопасности от угроз. Хорошо?
Андрей: Хорошо.
Саломон: Хорошо.
Эндрю: И этот флаг становится связанным с глобальной переменной или аппаратным обеспечением —
Саломон: — с чем-то, что мы называем «общим ресурсом».
Андрей: Правильно.
Salomon: Итак, между мьютексом и общим ресурсом существует отношение один к одному. Один мьютекс защищает один общий ресурс. Если у вас есть два общих ресурса, которые необходимо защитить, вам потребуются два мьютекса. Один парный общий ресурс.
Эндрю: Хорошо. Хорошо.
Ну и конечно же семафор. Это еще один тип примитивной синхронизации RTOS. Когда семафор — что такое семафор? Чем он отличается от мьютекса? Когда он используется?
Саломон: Да, это очень хороший вопрос.
Прежде всего, это инструмент синхронизации, позволяющий одной задаче узнать, что произошло событие. О каком событии должны договориться отправитель и получатель.
Как правило, какое-то аппаратное событие. Как что? Например, пользователь нажимает кнопку «А» или, может быть, вы не получите символ, и мы хотим обработать… мы хотим передать информацию вместе с задачей, чтобы она могла обработать пришедший символ, который вы хотите.
Итак, с точки зрения реализации семафор и мьютекс очень и очень похожи.
Андрей: Правильно.
Salomon: Но вы должны забыть, что я так сказал, потому что большинство из нас не всегда реализовывают, мы просто всегда пользователи — мы используем ОС как инструмент. Итак, вы используете мьютексы только для защиты общего ресурса. И вы используете семафоры только для того, чтобы сообщить задаче, что произошло событие — ожидаемое событие.
Эндрю: Итак, в общем, в системах реального времени многозадачность с несколькими общими ресурсами, будь то глобальные переменные, части оборудования или что-то еще, мьютексы или семафоры предоставляют инструменты, позволяющие всем этим вещам работать в единой системе. многозадачная система.
Саломон: Абсолютно. Вы должны быть предельно осторожны, чтобы не использовать семафор, когда мьютекс является инструментом, который необходимо использовать.
Между мьютексом и семафором есть пара существенных различий. Два самых больших отличия заключаются в том, что у мьютекса есть концепция владельца. Если вы запросили мьютекс, и ОС предоставила его вам, теперь вы зарегистрированы как владелец. Таким образом, теперь никто больше не может освободить или опубликовать мьютекс, право собственности на который он ранее не приобрел.
Андрей: Конечно.
Salomon: Эта концепция не применяется к семафорам. Только мьютексы. Второе, что встроено в мьютексы, это какой-то алгоритм — я не хочу сейчас вдаваться в подробности —
Эндрю: Конечно.
Salomon: — для предотвращения инверсии приоритетов.
Эндрю: Хорошо.
Salomon: Если вы реализуете взаимное исключение с помощью семафора, вы не получите алгоритм и можете попасть в ситуации, когда у вас есть инверсия приоритета.
Андрей: Инверсия приоритета, очевидно, отдельная тема.
Саломон: Правильно.
Эндрю: Но в целом, очевидно, если, вы знаете, проблемы синхронизации в реальном времени могут быть одними из самых сложных проблем для отладки во встроенной системе, я думаю, если вы хотите взглянуть на свои мьютексы и ваши семафоры, и то, как вы их используете, если у вас есть проблемы, и убедитесь, что вы используете их правильно, и я полагаю, что вы освещаете это в учебном лагере по встроенному программному обеспечению и на некоторых наших учебных курсах.
Саломон: Да, именно так. Это именно то, куда я собирался прямо сейчас. Во время учебного лагеря мы проводим довольно много времени, рассказывая о различиях между мьютексами и семафорами и обучая студентов тому, какие приложения подходят для каждого из них. Я также провел вебинар около года назад, на котором эта тема была рассмотрена более подробно.
Андрей: Немного подробнее. Верно. И это доступно на нашем сайте.
Саломон: Правильно.
Эндрю: Ладно, отлично. Спасибо, Саломон.
Саломон: Добро пожаловать.
Как использовать примитивы синхронизации в Go: Mutex, WaitGroup, Once
Добро пожаловать в Just Enough Go ! Это второй пост в серии статей о языке программирования Go, в которой я расскажу о некоторых наиболее часто используемых пакетах стандартной библиотеки Go, например. кодировка/json , io , сеть/http , sync и т. д. Я планирую, чтобы они были относительно короткими и приводились в пример.
Давайте рассмотрим некоторые низкоуровневые конструкции синхронизации, которые Go предоставляет в пакете sync в дополнение к go-процедурам и каналам. Их куча, но мы рассмотрим WaitGroup , Mutex и Once на примерах.
Примеры кода доступны на GitHub
группа ожидания
Используйте WaitGroup для координации, если вашей программе нужно дождаться завершения горутин. Он похож на CountDownLatch в Java. Давайте посмотрим пример.
Мы хотим распечатать все файлы в нашем домашнем каталоге параллельно. Используйте WaitGroup , чтобы указать количество задач/горутин для ожидания — в этом случае оно совпадает с количеством файлов/каталогов в вашем домашнем каталоге. Мы используем Wait() для блокировки до Счетчик группы ожидания обнуляется.
...
основная функция () {
homeDir, ошибка := os.UserHomeDir()
если ошибка != ноль {
паника (ошибка)
}
filesInHomeDir, ошибка: = ioutil.ReadDir (homeDir)
если ошибка != ноль {
паника (ошибка)
}
var wg sync.WaitGroup
wg.Add(len(filesInHomeDir))
для _, файл := диапазон filesInHomeDir {
go func(f os.FileInfo) {
отложить wg.Done()
}(файл)
}
wg.Подождите()
}
...
Войти в полноэкранный режимВыйти из полноэкранного режимаЧтобы запустить эту программу:
curl https://raw.Вход в полноэкранный режимВыход из полноэкранного режима
Горутина создается для каждого os.FileInfo , который мы находим в домашнем каталоге пользователя, и как только мы печатаем его имя, счетчик уменьшается с помощью Done . Программа завершает работу после того, как будет закрыто все содержимое домашнего каталога.
Мьютекс
Мьютекс — это общий замок, который вы можете использовать для предоставления эксклюзивного доступа к определенным частям вашего кода. В этом простом примере у нас есть общая/глобальная переменная accessCount , которая используется в функции incr .
функция incr() {
мю.Замок()
отложить mu.Unlock()
кол-во доступа = кол-во доступов + 1
}
Войти в полноэкранный режимВыйти из полноэкранного режима Обратите внимание, что функция incr защищена мьютексом . Таким образом, только одна горутина может получить к нему доступ одновременно. Мы бросаем на него несколько горутин
цикл := 500
для я := 1; я <= петля; я++ {
go func(c int) {
WG.Добавить(1)
отложить wg.Done()
incr()
}(я)
}
Войти в полноэкранный режимВыйти из полноэкранного режима Если вы запустите это, вы всегда будете получать один и тот же результат, т. е. Final = 500 (поскольку цикл for выполняется 500 итераций). Чтобы запустить программу:
curl https://raw.githubusercontent.com/abhirockzz/just-enough-go/master/sync/mutex-example.go -o mutex-example.go запустить mutex-example.goВойти в полноэкранный режимВыйти из полноэкранного режима
Закомментировать (или удалить) следующие строки в функции incr и запустить программу на локальном компьютере с помощью и снова запустить программу
mu.Lock() отложить mu.Unlock()Войти в полноэкранный режимВыйти из полноэкранного режима
Вы заметите переменные результаты, например. Окончательный = 474
Я рекомендую вам прочитать
RWMutex. Это особый вид блокировки, который можно использовать для одновременного чтения и синхронизированной (однократной записи).
Один раз
Позволяет вам определить задачу, которую вы хотите выполнить только один раз за время существования вашей программы. Это очень полезно для поведения, подобного Singleton . Он имеет одну функцию Do , которая позволяет вам передать другую функцию, которую вы намереваетесь выполнить только один раз. Давайте рассмотрим пример
Предположим, вы создаете REST API с использованием пакета Go net/http и хотите, чтобы некоторый фрагмент кода выполнялся только при вызове обработчика HTTP (например, для получения соединения с БД). Вы можете обернуть этот код один раз. Сделайте и будьте уверены, что он будет запущен только при первом вызове обработчика.
Вот функция, которую мы хотим выполнить только один раз
func oneTimeOp() {
fmt.