Полезные оконные функции SQL — Разработка на vc.ru
Можно бесконечно долго «воротить нос» от использования SQL для Data Preparation, отдавая лавры змеиному языку, но нельзя не признавать факт, что чаще мы используем и еще долго будем использовать SQL для работы с данными, в том числе и очень объемными.
29 900 просмотров
Более того, считаем, что на текущий момент SQL окажется под рукой сотрудника с большей вероятностью, чем Python, и поможет быстро решить аналитическую задачку с приоритетом «-1».
Предложение OVER помогает «открыть окно», т.е. определить строки, с которым будет работать та или иная функция.
Предложение partion BY не является обязательным, но дополняет OVER и показывает, как именно мы разделяем строки, к которым будет применена функция.
ORDER BY определит порядок обработки строк.
В одном select может быть больше одного OVER, эта прекрасная особенность упростит выполнение аналитической задачи в дальнейшем.
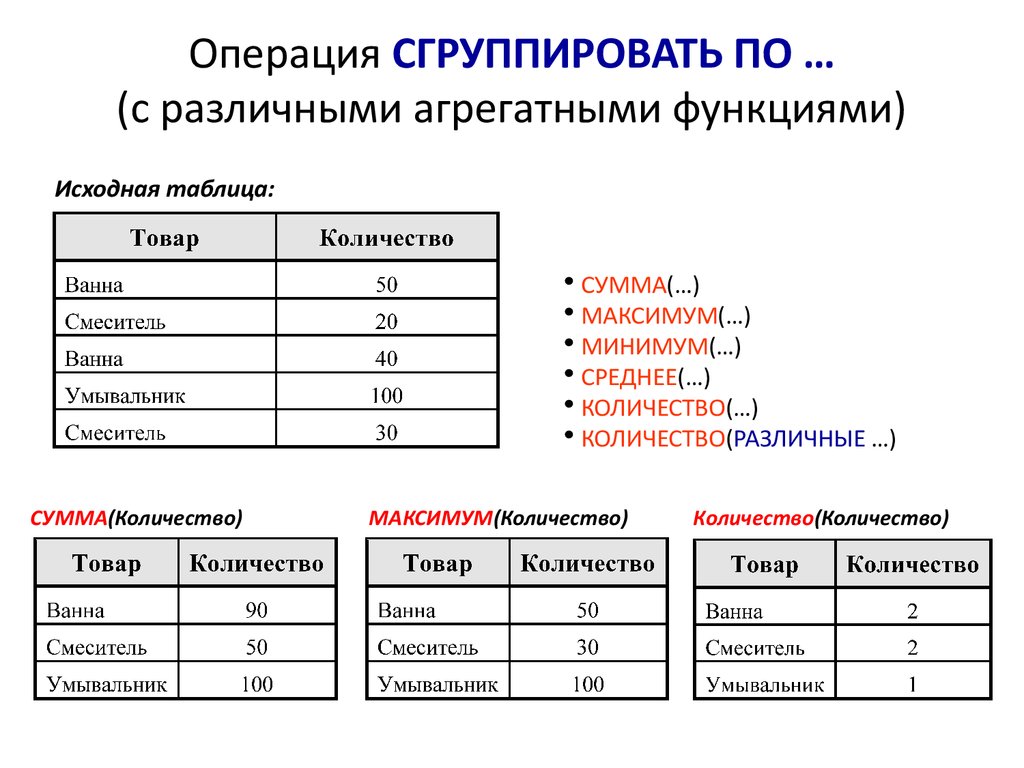
Итак, оконные функции делятся на:
- Агрегатные функции
- Ранжирующие функции
- Функции смещения
- Аналитические функции
Собственно, те же, что и обычные, только встроенные в конструкцию с OVER
SUM/ AVG / COUNT/ MIN/ MAX
Для наглядности работы данных функций воспользуемся базовым набором данных (T)
Задача:
Найти максимальную задолженность в каждом банке.
Для чего тут оконные функции? Можно же просто написать:
SELECT TB, max(OSZ) OSZ FROM T group by TB
В данном контексте, действительно, применение оконных функций нецелесообразно, но, когда речь заходит о задаче:
Собрать дэшборд, в котором содержится информация о максимальной задолженности в каждом банке, а также средний размер процентной ставки в каждом банке в зависимости от сегмента, плюс еще количество договоров всего всем банкам (в голове рисуются множественные джойны из подзапросов и как-то сразу тяжело на душе).
SELECT TB, ID_CLIENT, ID_DOG, OSZ, PROCENT_RATE, RATING, SEGMENT , MAX(OSZ) OVER (PARTITION BY TB) ‘Максимальная задолженность в разбивке по банкам’ , AVG(PROCENT_RATE) OVER (PARTITION BY TB, SEGMENT) ‘Средняя процентная ставка в разрезе банка и сегмента’ , COUNT(ID_DOG) OVER () ‘Всего договоров во всех банках’ FROM T
На примере AVG(procent_RATE) OVER (partition BY TB, segment) подробнее:
- Мы применяем AVG – агрегатную функцию по подсчету среднего значения к столбцу procent_RATE.
- Затем предложением OVER определяем, что будем работать с некоторым набором строк. По умолчанию, если указать OVER() с пустыми строками, то этот набор строк равен всей таблице.
- Предложением partition BY выделяем разделы в наборе строк по заданному условию, в нашем случае, в разбивке на Территориальные банки и Сегмент.

- В итоге, к каждой строке базовой таблицы применится функция по подсчету среднего из набора строк, разбитых на разделы (по Территориальным Банкам и Сегменту).
Другой тип оконных функций, надо признать, мой любимый и был использован для решения многих задач. Функции ранжирования для каждой строки в разделе возвращают значение рангов или рейтингов. Все ведь любят рейтинги, правда…?
Базовый набор данных: банки, отделы и количество ревизий.
Сами ранжирующие функции:
ROW_number – нумерует строки в результирующем наборе.
RANK -присваивает ранг для каждой строки, если найдутся одинаковые значения, то следующий ранг присваивается с пропуском.
DENSE_RANK -присваивает ранг для каждой строки, если найдутся одинаковые значения, то следующий ранг присваивается без пропуска.
NTILE – помогает разделить результирующий набор на группы.
Для понимания написанного, проранжируем таблицу по убыванию количества ревизий:
SELECT * , ROW_NUMBER() OVER(ORDER BY count_revisions desc) , Rank() OVER(ORDER BY count_revisions desc) , DENSE_RANK() OVER(ORDER BY count_revisions desc) , NTILE(3) OVER(ORDER BY count_revisions desc) FROM Table_Rev
ROW_number – пронумеровал столбцы в порядке убывания количества ревизий.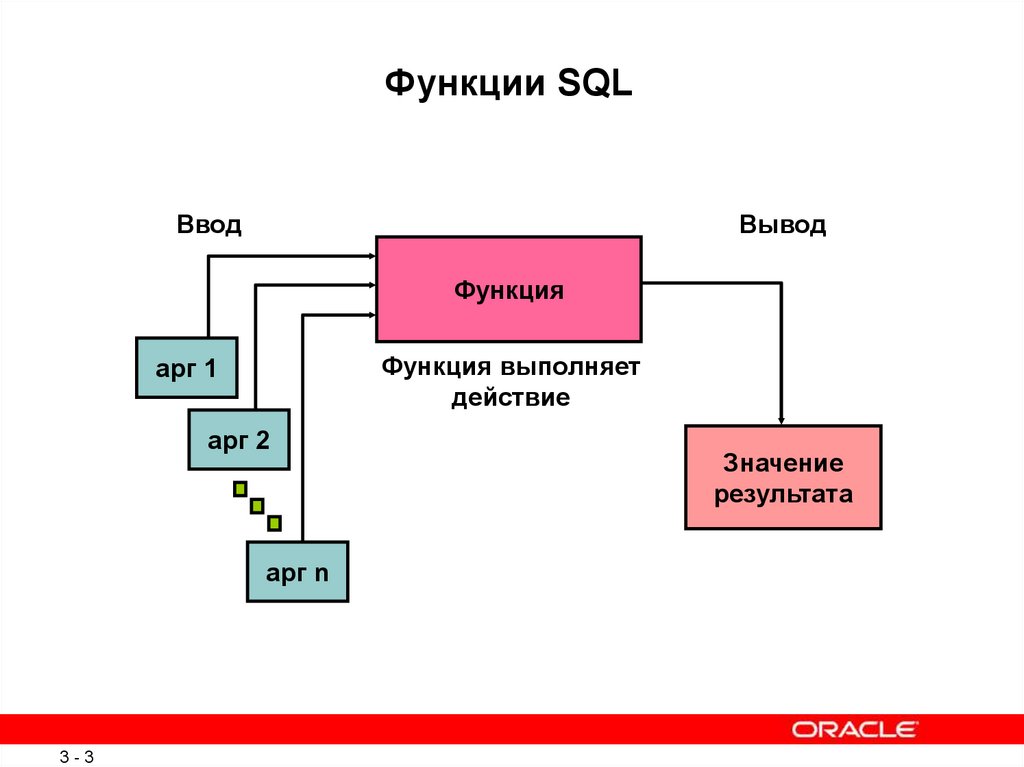
RANK – проранжировал отделы во всех банках в порядке убывания количества ревизий, но как только встретились одинаковые значения (количество ревизий 95), функция присвоила им ранг 4, а следующее значение получило ранг 6.
DENSE_RANK – аналогично RANK, но как только встретились одинаковые значения, следующее значение получило ранг 5.
NTILE – функция помогла разбить таблицу на 3 группы (указал в аргументе). Так как в таблице 18 значений, в каждую группу попало по 6.
Задача:
Найти второй отдел во всех банках по количеству ревизий.
Можно, конечно, воспользоваться чем-то вроде:
SELECT MAX(count_revisions) ms FROM Table_Rev WHERE count_revisions!=(SELECT MAX(count_revisions) FROM Table_Rev)
Но если речь идет не про второй отдел, а про трети? .. уже сложнее. Действительно, никто не списывает со счетов offset, но в этой статье говорится об оконных функциях, так почему бы не написать так:
With T_R as ( SELECT * , DENSE_RANK() OVER(ORDER BY count_revisions desc) ds FROM Table_Rev ) SELECT * FROM T_R WHERE ds=3
Как и во всех других типах функций, здесь можно выделять разделы с помощью partitionby.
With T_R as ( SELECT * , DENSE_RANK() OVER(PARTITION BY tb ORDER BY count_revisions) ds FROM Table_Rev ) SELECT tb,dep,count_revisions FROM T_R WHERE ds=1
Получаем:
Оконные функции смещения помогут нам, когда необходимо обратиться к строке в наборе данных из окна, относительно текущей строки с некоторым смещением. Проще говоря, узнать, какое значение (событие/ дата) идет после/до текущей строки. Похоже на отличную штуку в предобработке лога данных.
LAG — смещение назад.
LEAD — смещение вперед.
FIRST_VALUE — найти первое значение набора данных.
LAST_VALUE — найти последнее значение набора данных.
LAG и LEAD имеют следующие аргументы:
- Столбец, значение которого необходимо вернуть
- На сколько строк выполнить смешение (дефолт =1)
- Что вставить, если вернулся NULL
Как обычно, на практике проще:
Базовый набор данных, содержит id задачи, события внутри нее и их дату:
Применяя конструкцию:
SELECT * , LEAD (Event, 1, ‘end’) OVER (PARTITION BY ID_Task ORDER BY Date_Event) as Next_Event , LEAD (Date_Event, 1, ‘2099-01-01’) OVER(PARTITION BY ID_Task ORDER BY Date_Event) as Next_Date FROM Table_Task
Получаем набор данных, который хоть сейчас в graphviz (нет).
Аналитические оконные функции подходят под специфичные задачи и описывать их здесь я, пожалуй, не буду. Но, возможно, вы решите ознакомиться с ними самостоятельно, а значит будете более подготовлены к решению хитро закрученных задач.
Тем, кто слышит про данные функции впервые, надеюсь, статья окажется полезной, а, кто уже со всем этим знаком, простите, потраченное время никто не вернет.
2.2. Агрегатные функции
Все функции,
рассмотренные до этого, предназначены
для обработки данных строка за строкой.
В Oracle также есть агрегатные,
или групповые,
функции (group functions), позволяющие анализировать
группы записей. Под группой записей
понимается любой набор записей, имеющих
что-то общее — например, относящихся к
одному товару, одному отделу или одному
временному интервалу. Для заданных
групп агрегатные функции дают итоговую
сумму, количество записей, а также
среднее, наименьшее и наибольшее,
значения для каждой группы. Эти функции
очень удобны для статистического
анализа.
Группы создаются предложением GROUP BY в операторе SELECT, а предложение HAVING фильтрует группы на основе групповых значений. В отличие от конструкции WHERE, фильтрующей записи до группирования, конструкция HAVING фильтрует уже сформированные группы.
При отсутствии предложений GROUP BY и HAVING в операторе SELECT возвращаемые агрегатными функциями значения будут относиться ко всему множеству записей таблицы.
SUM
Функция SUM суммирует значения и возвращает итог:
SELECT SUM(quantity) FROM purchase;
COUNT
Функция COUNT подсчитывает записи в таблице или значения в столбце. Например, чтобы определить, содержит ли таблица какие-нибудь записи, проще всего ввести такую команду:
SELECT COUNT(*) FROM purchase;
Однако ее не
рекомендуется использовать, поскольку
указание «*» вместо имени столбца
неявно заставляете Oracle считывать всю
таблицу. Это не принципиально для
маленьких учебных таблиц, но представляет
собой серьезную проблему в системах с
сотнями тысяч, а тем более с миллиардами
записей.
SELECT COUNT(product_name) FROM purchase;
Как правило, предпочтение отдается первому столбцу таблицы — по причинам, которые будут объяснены в следующей теме. Можно поступить еще проще, указав в качестве аргумента функции COUNT не имя столбца, а литеральное значение:
SELECT COUNT(1) FROM purchase;
Строго говоря, это заставляет Oracle возвращать значение «1» для каждой записи в таблице. С тем же успехом можно подставить в функцию фразу «Считай!»; какое именно литеральное значение будет использовано — неважно, поскольку само это значение функция игнорирует. Она лишь подсчитывает записи и сообщает, сколько их было найдено.
Функция COUNT имеет
одно интересное свойство: если указать
столбец таблицы, записи которой
подсчитываются, будут учтены только
записи, содержащие в этом столбце
какое-либо значение. Этим можно
воспользоваться для определения процента
записей, имеющих null-значение в определенном
столбце. После ввода показанного ниже
кода первая команда выведет общее
количество записей в таблице; вторая
команда выдаст тот же результат, поскольку
ни в одной из записей название товара
не является пустым; третья команда
сообщит, сколько записей содержит
заполненный столбец LAST_STOCK_DATE; последняя
команда даст процент записей, в которых
этот столбец заполнен. Информация такого
рода может пригодиться, когда необходимо
определить полезность какого-либо
столбца.
Этим можно
воспользоваться для определения процента
записей, имеющих null-значение в определенном
столбце. После ввода показанного ниже
кода первая команда выведет общее
количество записей в таблице; вторая
команда выдаст тот же результат, поскольку
ни в одной из записей название товара
не является пустым; третья команда
сообщит, сколько записей содержит
заполненный столбец LAST_STOCK_DATE; последняя
команда даст процент записей, в которых
этот столбец заполнен. Информация такого
рода может пригодиться, когда необходимо
определить полезность какого-либо
столбца.
SELECT COUNT(1) FROM product;
SELECT COUNT(product_name) FROM product;
SELECT COUNT(last_stock_date) FROM product;
SELECT COUNT(last_stock_date) / COUNT(product_name) «% заполненных записей»
FROM product;
AVG
Функция AVG
возвращает среднее значение по указанному
столбцу. Поскольку для этого функция
должна выполнить фактическое считывание
всего столбца, нет смысла указывать»
\» или какой-либо другой литерал в
качестве аргумента; необходимо указать
имя столбца. Например, чтобы узнать
среднюю цену товаров из таблицы PRODUCT,
нужно ввести следующий оператор:
Например, чтобы узнать
среднюю цену товаров из таблицы PRODUCT,
нужно ввести следующий оператор:
SELECT AVG(product_price) FROM product;
MIN
Функция MIN возвращает наименьшее из значений, содержащихся в указанном столбце. Например, чтобы узнать, сколько стоит самый дешевый товар из таблицы PRODUCT, можно ввести такую команду:
SELECT MIN(product_price) FROM product;
MAX
Как вы наверняка догадались, функция МАХ возвращает наибольшее из значений указанного столбца. Например, чтобы узнать максимальную цену товара в таблице PRODUCT, можно воспользоваться следующей командой:
SELECT MAX(product_price) FROM product;
Функция MAX применяется в целом ряде случаев. Например, может встать вопрос о сокращении длины текстового столбца существующей таблицы. Чтобы узнать, какая часть столбца действительно используется, нужно определить максимальную длину текста в этом столбце. Это легко сделать, указав в качестве аргумента функции МАХ длину столбца, как показано во второй из следующих команд:
DESC purchase;
SELECT MAX(LENGTH(product_name)) FROM purchase;
Подведение итогов по группам данных
Добавление предложения GROUP BY в оператор SELECT указывает на необходимость применить агрегатную функцию к каждой сформированной группе записей:
SELECT product_name, SUM(quantity) FROM purchase
GROUP BY product_name;
В предложении
GROUP BY указывается столбец, по значениям
которого будет выполняться группирование.
В оператор SELECT можно включать несколько различных агрегатных функций. Например, один и тот же оператор может выдавать суммарное, среднее, наименьшее и наибольшее значения по каждой группе, а также подсчитывать число записей в группах. Приведенный ниже код показывает, как это делается. Чтобы результаты поместились на экране, столбец PRODUCT_NAME сужен с помощью функции SUBSTR.
SELECT SUBSTR(product_name, 1, 15) «Product»,
SUM(quantity) «Total Sold», AVG(quantity) «Average», COUNT(quantity) «Transactions»,
MIN(quantity) «Fewest», MAX(quantity) «Most» FROM purchase
GROUP BY product_name;
При группировании записей предложение WHERE по-прежнему фильтрует отдельные записи, тем самым исключая их из вычислений, выполняемых агрегатными функциями.
Однако после
создания групп возникает новая задача:
фильтрация самих групп на основе
групповой информации. Предположим, что
предприятию не хватает складских
площадей и оно намерено сократить запас
товаров на складе. Для реализации этого
мероприятия требуется составить список
плохо продающихся товаров — например,
тех, для которых общий объем продаж
составляет менее пяти штук. Здесь и
пригодится предложение HAVING, которое
фильтрует группы на основе групповых
значений. В отличие от предложения
WHERE, фильтрующей записи до группирования,
предложение HAVING фильтрует уже
сформированные группы:
Для реализации этого
мероприятия требуется составить список
плохо продающихся товаров — например,
тех, для которых общий объем продаж
составляет менее пяти штук. Здесь и
пригодится предложение HAVING, которое
фильтрует группы на основе групповых
значений. В отличие от предложения
WHERE, фильтрующей записи до группирования,
предложение HAVING фильтрует уже
сформированные группы:
SELECT SUBSTR(product_name, 1, 15) «Product»,
SUM(quantity) «Total Sold», AVG(quantity) «Average», COUNT(quantity) «Transactions»,
MIN(quantity) «Fewest», MAX (quantity) «Most» FROM purchase
GROUP BY product_name
HAVING SUM(quantity) < 5;
Оператор SELECT включит в выходные данные только плохо продающиеся товары. Если нужно решить обратную задачу — составить список хорошо продающихся товаров, достаточно изменить условие в предложение HAVING, как показано ниже:
SELECT SUBSTR(product_name, 1, 15) «Product»,
SUM(quantity) «Total Sold», AVG(quantity) «Average», COUNT(quantity) «Transactions»,
MIN(quantity) «Fewest», MAX (quantity) «Most» FROM purchase
GROUP BY product_name
HAVING SUM(quantity) >= 5;
Обзор агрегатных функций Oracle
Резюме : в этом руководстве вы узнаете, как работают агрегатные функции Oracle и как их применять для вычисления агрегатов.
Введение в агрегатные функции Oracle
Агрегатные функции Oracle вычисляют группу строк и возвращают одно значение для каждой группы.
Мы обычно используем агрегатные функции вместе с предложением GROUP BY . Предложение GROUP BY делит строки на группы, а агрегатная функция вычисляет и возвращает один результат для каждой группы.
Если вы используете агрегатные функции без предложения GROUP BY , агрегатные функции применяются ко всем строкам запрашиваемых таблиц или представлений.
Мы также используем агрегатные функции в предложении HAVING для фильтрации групп из выходных данных на основе результатов агрегатных функций.
Агрегированные функции Oracle могут появляться в списках SELECT и предложениях ORDER BY , GROUP BY и HAVING .
DISTINCT vs. ALL
Некоторые агрегатные функции принимают условие DISTINCT или ALL .
- Предложение
DISTINCTпредписывает агрегатной функции учитывать только различные значения аргумента. - Предложение
ALLзаставляет агрегатную функцию учитывать все значения, включая дубликаты.
Например, DISTINCT среднее 2, 2, 2 и 4 равно 3, что является результатом (2 + 4)/2. Однако ALL Среднее значение 2, 2, 2 и 4 равно 2,5, что является результатом (2 + 2 + 2 + 4) / 4.
Oracle использует предложение ALL по умолчанию, если вы не указали явно любая оговорка.
Обработка NULL
Все агрегатные функции игнорируют нулевые значения, кроме COUNT(*) , GROUPING() и GROUPING_ID() .
Если вы хотите заменить значение, например, ноль на нулевое значение, используйте функцию NVL() .
Функции COUNT() и REGR_COUNT() никогда не возвращают null, а либо число, либо ноль (0). Другие агрегатные функции возвращают
Другие агрегатные функции возвращают NULL , если набор входных данных содержит NULL или не содержит строк.
Список агрегатных функций Oracle
В следующей таблице показаны агрегатные функции Oracle:0103
Было ли это руководство полезным?
Агрегированные функции Oracle | Примеры агрегатных функций Oracle
Агрегатная функция Oracle — это тип функции, которая работает с указанным столбцом и возвращает результат в виде одной строки. Эти функции в основном используются в запросе, который содержит предложение GROUP BY в инструкции SELECT, где предложение GROUP BY группирует строки в соответствии с указанным условием, а функция AGGREGATE выполняет агрегирование сгруппированных данных.
- Возвращает результат одной строки на основе условий группы строк.
- В операторе SELECT можно использовать агрегатные функции.
- Агрегированные функции могут использоваться в предложении HAVING в качестве условия.
- Возвращает один результат на группу в качестве вывода.
- Группа строк может представлять собой всю таблицу или строки, разбитые на несколько групп.
Важные агрегатные функции:
| Функции | Описание |
| СРЕДНИЙ ( ) | Возвращает среднее значение данного выражения. |
| СУММА ( ) | Возвращает значение суммы заданного выражения. |
| МАКС ( ) | Возвращает максимальное значение данного выражения. |
| МИН ( ) | Возвращает минимальное значение данного выражения. |
| СЧЕТ ( ) | Возвращает общее количество строк для данного выражения. |
| СТАНДОТКЛОН ( ) | Возвращает стандартное отклонение столбца. |
| ОТЛИЧИЕ ( ) | Возвращает дисперсию. |
Синтаксис функций агрегирования Oracle
Приведен ниже синтаксис:
Ниже приведены упомянутые примеры: Мы будем использовать приведенную ниже примерную таблицу (Сотрудник) с 14 записями, чтобы увидеть поведение функции Oracle Aggregate. Код: Вывод: AVG (DISTINCT / ALL ColumnName) Функция. Код: Вывод: В приведенном выше примере есть два средних значения столбца зарплаты, и оба они разные, потому что первая функция среднего работает со всеми значениями столбца, а вторая функция среднего работает с уникальными значениями, потому что ключевого слова DISTINCT. Код: Выходные данные: В приведенном выше примере есть среднее значение столбца «Бонус», а столбец «Бонус» содержит значения NULL. Функция AVG игнорирует значения NULL и вычисляет среднее значение ненулевых значений. SUM (DISTINCT / ALL ColumnName) Функция. Код: Вывод: В приведенном выше примере есть два значения суммы столбца зарплаты, и оба они разные, потому что первая функция суммы работает со всеми значениями столбца, а вторая функция суммы работает с уникальными значениями, потому что ключевого слова DISTINCT. Вот почему оба результата разные. Код: Вывод: В приведенном выше примере есть одно значение суммы столбца Bonus, а столбец Bonus содержит значения NULL. Функция SUM игнорирует значения NULL и вычисляет сумму ненулевых значений. MAX (DISTINCT / ALL ColumnName) Функция. Код: Вывод: В приведенном выше примере есть два максимальных значения столбца зарплаты, и оба они одинаковы, но первая максимальная функция работает со всеми значениями столбца, а вторая максимальная функция работает с уникальными значениями, потому что ключевого слова DISTINCT и возвращает соответствующий вывод. Код: Вывод: В приведенном выше примере есть максимальное значение столбца Bonus, а столбец Bonus содержит значения NULL. Функция MAX игнорирует значения NULL и возвращает максимальное значение этого столбца. MIN (DISTINCT / ALL ColumnName) Функция. Код: Вывод: В приведенном выше примере есть два минимальных значения столбца зарплаты, и оба они одинаковы, но первая минимальная функция работает со всеми значениями столбца, а вторая минимальная функция работает с уникальными значениями, потому что ключевого слова DISTINCT и возвращает соответствующий вывод. Код: Выходные данные: В приведенном выше примере есть минимальное значение столбца «Бонус», а столбец «Бонус» содержит значения NULL. СТАНДОТКЛОН (DISTINCT / ALL ColumnName) Функция. Код: Вывод: В приведенном выше примере есть два значения стандартного отклонения столбца зарплаты, и оба они разные, поскольку первая функция стандартного отклонения работает со всеми значениями столбца, а вторая функция стандартного отклонения работает со всеми значениями столбца. уникальные значения из-за ключевого слова DISTINCT. Вот почему оба результата разные. Код: Вывод: В приведенном выше примере есть значение стандартного отклонения столбца бонуса, а столбец бонуса содержит значения NULL. VARIANCE (DISTINCT / ALL ColumnName) Функция. Код: Вывод: В приведенном выше примере есть два значения дисперсии столбца зарплаты, и оба они разные, потому что первая функция дисперсии работает со всеми значениями столбца, а вторая функция дисперсии работает с уникальными значениями, потому что ключевого слова DISTINCT. Вот почему оба результата разные. Код: Выходные данные: В приведенном выше примере есть значение дисперсии столбца «Бонус», а столбец «Бонус» содержит значения NULL. Функция COUNT (*/ DISTINCT / ALL ColumnName). Код: Вывод: В приведенном выше примере функция COUNT возвращает 14, поскольку * учитывает все строки, включая дубликаты и NULL. Код: Выход: В приведенном выше примере возвращает два значения счетчика столбца Обозначение, и оба они различны, поскольку первая функция счетчика работает со всеми значениями столбца, а вторая функция счетчика работает с уникальными значениями из-за ключевого слова DISTINCT и возвращает соответствующий выход. Код: Вывод: В приведенном выше примере есть значение счетчика столбца Bonus, а столбец Bonus содержит значения NULL. Функция COUNT игнорирует значения NULL и считает только не нулевые значения. Предложение GROUP BY с функцией агрегирования. Код: Выходные данные: Приведенный выше пример возвращает ошибку, поскольку функциональный столбец, не являющийся группой, используется с агрегатной функцией MAX. Таким образом, оператор SELECT возвращает все строки для столбца Deptnumber, но агрегатная функция возвращает только одну строку. GroupFunctionNameName (различные / все столбцы. только неповторяющиеся значения. Функция NVL может быть лучшим вариантом для замены значения NULL.
Функция NVL может быть лучшим вариантом для замены значения NULL. Примеры агрегатных функций Oracle
ВЫБЕРИТЕ * ОТ Сотрудника; Пример #1
ВЫБЕРИТЕ СРЕДНЕЕ (Зарплата), СРЕДНЕЕ (ОТЛИЧНОЕ ЗП) ОТ Сотрудника;  Вот почему оба результата разные.
Вот почему оба результата разные. ВЫБЕРИТЕ СРЕДНИЙ (Бонус) ОТ Сотрудника; Пример #2
ВЫБЕРИТЕ СУММУ (зарплата), СУММА (ОТЛИЧНАЯ зарплата) ОТ Сотрудника; 
ВЫБЕРИТЕ СУММУ (Бонус) ОТ Сотрудника; Пример #3
ВЫБЕРИТЕ МАКС.(Зарплата), МАКС.(ОТЛИЧНАЯ ЗП) ОТ Сотрудника; ВЫБЕРИТЕ МАКС. (Бонус) ОТ Сотрудника;
(Бонус) ОТ Сотрудника; Пример #4
ВЫБЕРИТЕ МИН (Зарплата), МИН (ОТЛИЧНАЯ зарплата) ОТ Сотрудника; ВЫБЕРИТЕ МИН (ПОНУС) ОТ Сотрудника;  Функция MIN игнорирует значения NULL и возвращает минимальное значение этого столбца.
Функция MIN игнорирует значения NULL и возвращает минимальное значение этого столбца. Пример #5
ВЫБРАТЬ СТАНДОТКЛОН(Зарплата), СТАНДОТКЛОН(ОТЛИЧНАЯ зарплата) ОТ Сотрудника; ВЫБЕРИТЕ СТАНДОТКЛОН(Премия) ОТ Сотрудника;  Функция СТАНДОТКЛОН игнорирует значения NULL и вычисляет стандартное отклонение ненулевых значений.
Функция СТАНДОТКЛОН игнорирует значения NULL и вычисляет стандартное отклонение ненулевых значений. Пример #6
ВЫБЕРИТЕ ОТКЛОНЕНИЕ(ЗАРплата), ОТЛИЧИЕ(ОТЛИЧНАЯ ЗПАР) ОТ Сотрудника; ВЫБЕРИТЕ ОТЛИЧИЕ (БОНУС) ОТ Сотрудника;  Функция VARIANCE игнорирует значения NULL и вычисляет дисперсию ненулевых значений.
Функция VARIANCE игнорирует значения NULL и вычисляет дисперсию ненулевых значений. Пример #7
ВЫБЕРИТЕ СЧЕТ(*) ОТ Сотрудника; ВЫБЕРИТЕ COUNT(Назначение), COUNT(DISTINCT Наименование) FROM Сотрудник; 
ВЫБЕРИТЕ СЧЕТ(Бонус) ОТ Сотрудника; Пример #8
ВЫБЕРИТЕ Номер отдела, МАКС (Зарплата) ОТ Сотрудника; 