Java найти подстроку в строке — Playsguide.ru
Содержание
Описание проблемы
Как найти последнюю позицию подстроки в строке?
Решение
В этом примере показано, как определить последнюю позицию подстроки внутри строки с помощью метода lastIndexOf(String).
Результат
Получим следующий результат:
Пример
В этом примере показано, как определить последнюю позицию подстроки в строке с помощью метода lastIndexOf(String).
Строка — это упорядоченная последовательность символов. В Java строка является основным носителем текстовой информации. Для работы со строками здесь используются следующие классы: String, StringBuilder, StringBuffer. В этом уроке речь пойдет о классе String, его на первых порах будет вполне достаточно.
В данном уроке рассматривается:
В уроке 6 уже упоминалась работа со строками, а именно, как создавать строку. Также частично со строками мы встречались в предыдущих уроках.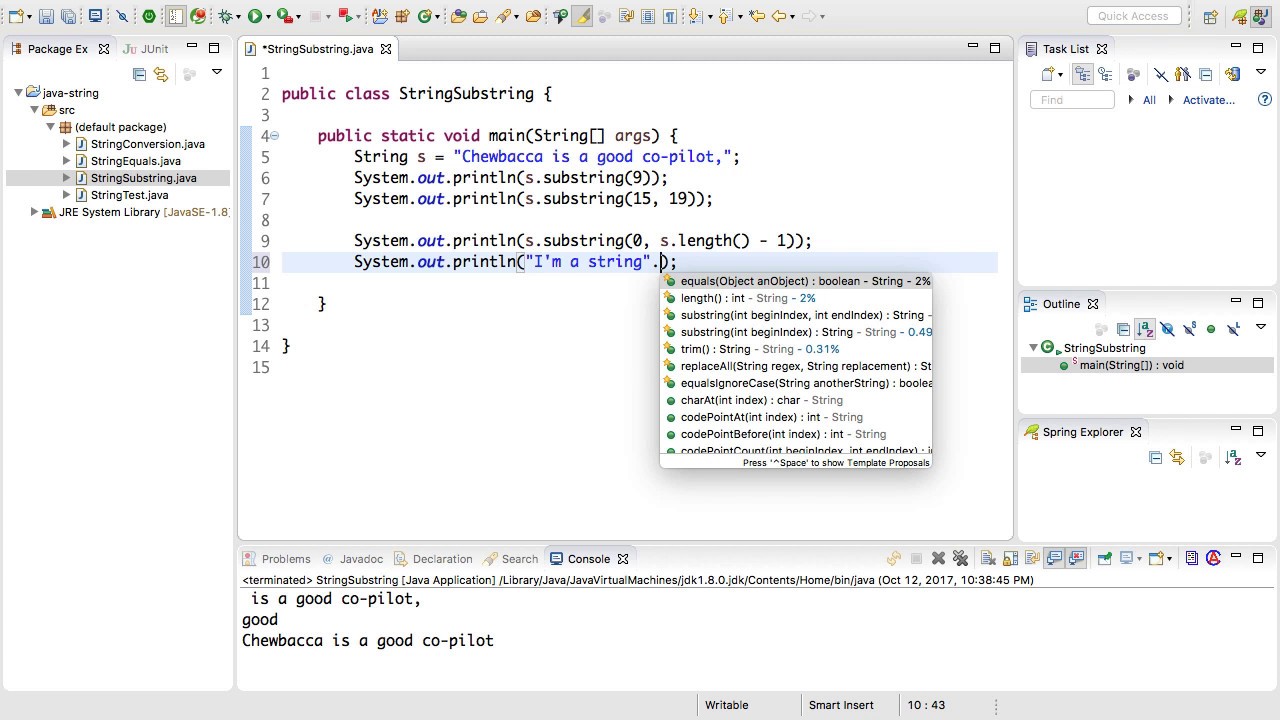
Но начнем с самого начала.
Создание строк
Строка в Java является объектом, поэтому ее можно создать, как и любой другой объект, при помощи оператора new.
Также строку можно создать при помощи литерала (фразы заключенной в кавычки) следующим образом.
Обе строки, независимо от способа создания являются объектами — экземплярами класса String.
Важный момент: создание объектов при помощи литерала возможно только в классе String. Объекты любого другого класса при помощи литерала создать нельзя.
Можно также создать массив строк. Например, так:
Подробнее о массивах и их создании написано в уроке 10 .
Конкатенация или слияние строк в Java
Для того, чтобы объединить несколько разных строк в одну, в Java можно использовать перегруженные (специально для объектов String) операторы «+» и «=+».
Еще один важный момент : операторы «+» и «=+», перегруженные для String, являются единственными перегруженными операторами в Java. Программист здесь не имеет возможности самостоятельно перегружать какие-либо операторы (как, например, в С++ и некоторых других языках).
Пример 1:
На консоль будет выведено «Мама мыла раму»
Пример 2:
Пример 3:
Наиболее употребительные методы класса String
При использовании IDE можно легко увидеть, какие методы есть у класса и получить подсказку по их использованию. На примере IDE Eclipse
 После этого появится окно, как на рисунке 14.1, где будут перечислены все доступные методы класса.
После этого появится окно, как на рисунке 14.1, где будут перечислены все доступные методы класса.При выборе метода из этого списка, справа (или слева) появится желтое окно с подсказкой по его использованию. При помощи нажатия Enter или двойного клика мыши метод можно вставить в ваш код, не прибегая к ручному набору.
Также после имени переменной и точки можно начать набирать вручную имя метода и после введения нескольких первых букв нажать CTRL + Space (пробел). При этом, если метод, начинающийся на эти буквы один, то он автоматически подставится в код, если методов несколько, то откроется окно, как на рисунке 14.1, где будут перечислены только те методы, которые начинаются с этих введенных вами букв.
 В дальнейшем описании, первое слово, которое стоит перед названием метода — тип значения, которое возникнет в результате работы метода (значение, которое метод возвращает).
В дальнейшем описании, первое слово, которое стоит перед названием метода — тип значения, которое возникнет в результате работы метода (значение, которое метод возвращает).Еще раз конкатенация
String concat(String str) — производит ту же конкатенацию, что была описана выше, но использование этого метода из класса String положительно влияет на производительность и скорость программы. На небольших примерах это незаметно и не существенно, но в более серьезных приложениях стоит использовать этот метод. Результатом работы метода будет строка. Параметр, который нужно передавать в метод для конкатенации — тоже строка, о чем нам говорит значение в скобках (String str).
Перепишем пример 2, при помощи concat():
Определение количества символов в строке
Для того чтобы определить количество символов в строке, используется метод length.
int length() — возвращает длину строки. Длина равна количеству символов Unicode в строке.
Длина равна количеству символов Unicode в строке.
Пример 4:
Извлечение символов из строки
Если нам требуется узнать, какой символ находиться в строке на конкретной позиции, можем использовать метод charAt.
char charAt(int index) — возвращает символ, находящийся по указанному индексу в строке. Результатом работы метода будет символ типа char. Параметр, который передается в метод — целое число. Первый символ в строке, подобно массивам, имеет индекс 0.
Пример 5: определить последний символ в строке.
Если мы хотим работать со строкой, как с массивом символов, можем конвертировать строку в массив при помощи метода toCharArray.
char[] toCharArray() — преобразует строку в новый массив символов.
Пример 6: поменять в строке символы пробела на точки при помощи преобразования в массив символов (для этой задачи есть более простое решение, нежели преобразование в массив, но об этом чуть позже).
Примечание: в данном случае мы не сможем использовать метод charAt. При помощи этого метода мы бы смогли только найти пробелы в строке, но не поменять их.
Извлечение подстроки из строки
String substring(int beginIndex, int endIndex) или
Пример 7.
Разбиение строк
Для разбиения строк на части используется метод String[] split(String regex), который разбивает строку на основании заданного регулярного выражения. О регулярных выражениях поговорим в одном из следующих уроков. Здесь покажем пример простого разбиения строки заданного одним символом.
Здесь покажем пример простого разбиения строки заданного одним символом.
Пример 8.
Поиск в строке
boolean contains(CharSequence s) — проверяет, содержит ли строка заданную последовательность символов и возвращает true или false.
Пример 9.
boolean endsWith(String suffix) — проверяет завершается ли строка определенными символами и возвращает true или false.
Пример 10.
boolean startsWith(String prefix) или startsWith(String prefix, int toffset) — проверяет, начинается ли строка с определенных символов. Во втором случае можно указать позицию с которой необходимо начать поиск префикса.
Пример 11.
int indexOf(int ch), indexOf(int ch, int fromIndex), indexOf(String str), indexOf(String str, int fromIndex) — метод indexOf применяется для поиска первого вхождения указанного символа в строке или первого вхождения указанной подстроки.
Пример 12
int lastIndexOf(int ch), lastIndexOf(int ch, int fromIndex), lastIndexOf(String str), lastIndexOf(String str, int fromIndex) — аналогично предыдущему случаю, только ищется последнее вхождение символа или подстроки в строке.
Модификация строк
Модификация строк не является модификацией как таковой. Дело в том, что объекты класса String после создания уже нельзя изменять. Но можно создать копию строки с изменениями. Именно это и делают следующие методы.
toLowerCase () — преобразовать строку в нижний регистр;
toUpperCase() — преобразовать строку в верхний регистр;
trim() — отсечь на концах строки пустые символы;
String replace(char oldChar, char newChar), replace(CharSequence target, CharSequence replacement) — замена в строке одного символа или подстроки на другой символ или подстроку.
Вспомним пример 6, где нужно было поменять в строке символы пробела на точки и перепишем его с использованием replace:
Сравнение строк
boolean equals(Object anObject) — проверяет идентичность строк. Возвращает true только в том случае, если в строках представлена одинаковая последовательность символов одной величены.
Пример 14
- нулевое значение, если строки равны,
- целое отрицательное число, если первая строка предшествует второй
- целое положительное число, если первая строка следует за второй
Данный метод предназначен для упорядочивания строк. Он позволяет сравнить строки между собой и определить предшествующую строку. Для того, чтобы реализовать такое сравнение метод сравнивает числовые значения букв.
Рассмотрим пример с именами «Маша» и «Миша». При сравнении этих двух имен (пример 15), метод compareTo укажет, что имя «Маша» предшествует имени «Миша» (выдав отрицательное число) или наоборот, «Миша» следует за «Маша» (выдав положительное число). При упорядочивании имен по алфавиту мы бы упорядочили эти имена именно так. Метод в данном случае определяет, что числовое значение буквы «а» в «Маша» меньше, чем числовое значение «и» в Миша.
Пример 15
Однако, в случае, если мы напишем «маша» с маленькой буквы и попробуем сравнить с «Миша», то получим положительное число.
То есть в данном случае имя «Миша» предшествует имени «маша». Это происходит потому, что в таблице символов Юникода буквы верхнего регистра предшествуют нижнему.
Для сравнения строк без учета регистра символов используется функция int compareToIgnoreCase(String str)
Как мы видим, при сравнивании «маша» с «Миша» мы снова получаем отрицательное значение, то есть «маша» предшествует имени «Миша».
Для соединения строк можно использовать операцию сложения («+»):
При этом если в операции сложения строк используется нестроковый объект, например, число, то этот объект преобразуется к строке:
Фактически же при сложении строк с нестроковыми объектами будет вызываться метод valueOf() класса String. Данный метод имеет множество перегрузок и преобразует практически все типы данных к строке. Для преобразования объектов различных классов метод valueOf вызывает метод toString() этих классов.
Другой способ объединения строк представляет метод concat() :
Метод concat() принимает строку, с которой надо объединить вызывающую строку, и возвращает соединенную строку.
Еще один метод объединения — метод join() позволяет объединить строки с учетом разделителя. Например, выше две строки сливались в одно слово «HelloJava», но в идеале мы бы хотели, чтобы две подстроки были разделены пробелом. И для этого используем метод join() :
Метод join является статическим. Первым параметром идет разделитель, которым будут разделяться подстроки в общей строке, а все последующие параметры передают через запятую произвольный набор объединяемых подстрок — в данном случае две строки, хотя их может быть и больше
Первым параметром идет разделитель, которым будут разделяться подстроки в общей строке, а все последующие параметры передают через запятую произвольный набор объединяемых подстрок — в данном случае две строки, хотя их может быть и больше
Извлечение символов и подстрок
Для извлечения символов по индексу в классе String определен метод char charAt(int index) . Он принимает индекс, по которому надо получить символов, и возвращает извлеченный символ:
Как и в массивах индексация начинается с нуля.
Если надо извлечь сразу группу символов или подстроку, то можно использовать метод getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin) . Он принимает следующие параметры:
srcBegin : индекс в строке, с которого начинается извлечение символов
srcEnd : индекс в строке, до которого идет извлечение символов
dst : массив символов, в который будут извлекаться символы
dstBegin : индекс в массиве dst, с которого надо добавлять извлеченные из строки символы
Сравнение строк
Для сравнения строк используются методы equals() (с учетом регистра) и equalsIgnoreCase() (без учета регистра). Оба метода в качестве параметра принимают строку, с которой надо сравнить:
Оба метода в качестве параметра принимают строку, с которой надо сравнить:
В отличие от сравнения числовых и других данных примитивных типов для строк не применяется знак равенства ==. Вместо него надо использовать метод equals() .
Еще один специальный метод regionMatches() сравнивает отдельные подстроки в рамках двух строк. Он имеет следующие формы:
Метод принимает следующие параметры:
ignoreCase : надо ли игнорировать регистр символов при сравнении. Если значение true , регистр игнорируется
toffset : начальный индекс в вызывающей строке, с которого начнется сравнение
other : строка, с которой сравнивается вызывающая
oofset : начальный индекс в сравниваемой строке, с которого начнется сравнение
len : количество сравниваемых символов в обеих строках
В данном случае метод сравнивает 3 символа с 6-го индекса первой строки («wor») и 3 символа со 2-го индекса второй строки («wor»). Так как эти подстроки одинаковы, то возвращается true .
И еще одна пара методов int compareTo(String str) и int compareToIgnoreCase(String str) также позволяют сравнить две строки, но при этом они также позволяют узнать больше ли одна строка, чем другая или нет. Если возвращаемое значение больше 0, то первая строка больше второй, если меньше нуля, то, наоборот, вторая больше первой. Если строки равны, то возвращается 0.
Для определения больше или меньше одна строка, чем другая, используется лексикографический порядок. То есть, например, строка «A» меньше, чем строка «B», так как символ ‘A’ в алфавите стоит перед символом ‘B’. Если первые символы строк равны, то в расчет берутся следующие символы. Например:
Поиск в строке
Метод indexOf() находит индекс первого вхождения подстроки в строку, а метод lastIndexOf() — индекс последнего вхождения. Если подстрока не будет найдена, то оба метода возвращают -1:
Метод startsWith() позволяют определить начинается ли строка с определенной подстроки, а метод endsWith() позволяет определить заканчивается строка на определенную подстроку:
Замена в строке
Метод replace() позволяет заменить в строке одну последовательность символов на другую:
Обрезка строки
Метод trim() позволяет удалить начальные и конечные пробелы:
Метод substring() возвращает подстроку, начиная с определенного индекса до конца или до определенного индекса:
Изменение регистра
Метод toLowerCase() переводит все символы строки в нижний регистр, а метод toUpperCase() — в верхний:
Split
Метод split() позволяет разбить строку на подстроки по определенному разделителю. Разделитель — какой-нибудь символ или набор символов передается в качестве параметра в метод. Например, разобьем текст на отдельные слова:
Разделитель — какой-нибудь символ или набор символов передается в качестве параметра в метод. Например, разобьем текст на отдельные слова:
В данном случае строка будет разделяться по пробелу. Консольный вывод:
Строки. Часть 6 – методы класса String.
Часть методов класса String мы уже рассмотрели в предыдущих постах. Некоторые методы класса String такие же как и у классов StringBuilder и StringBuffer, поэтому здесь их рассматривать уже не будем. Сейчас кратко рассмотрим некоторые оставшиеся на примере простой программы:
Данная программа генерирует следующий вывод:
Метод isEmpty() проверяет является ли строка пустой, то есть не содержащей ни одного символа. Не стоит это путать если переменная типа String содержит null ссылку, то есть не ссылается ни на какой объект.
Выбрать символ с индексом ind можно методом charAt(int ind).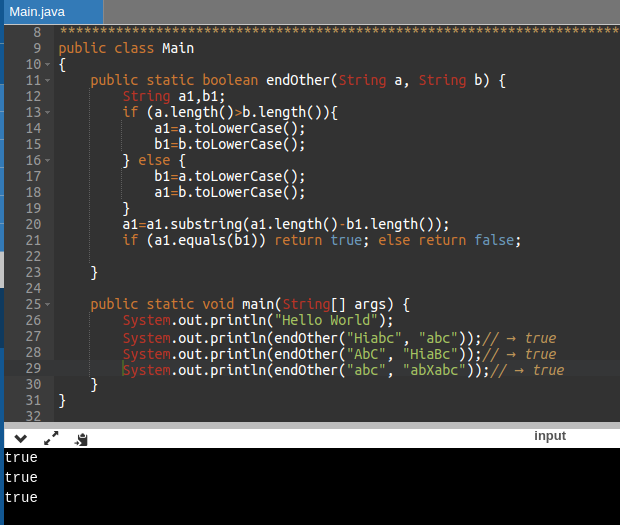 Если индекс ind отрицателен или больше, чем длина строки, возникает исключительная ситуация.
Если индекс ind отрицателен или больше, чем длина строки, возникает исключительная ситуация.
Все символы строки в виде массива символов можно получить методом toCharArray(), но с ним мы уже не раз сталкивались поэтому его нет в этом примере.
Если же надо включить в массив символов dst, начиная с индекса ind массива, подстроку от индекса begin включительно до индекса end исключительно, то используйте метод типа void:
getChars(int begin, int end, char[] dst, int ind)
В массив будет записано end-begin символов, которые займут элементы массива, начиная с индекса ind до индекса ind+(end-begin)-1.
Этот метод создает исключительную ситуацию в следующих случаях:
- ссылка dst == null;
- индекс begin отрицателен;
- индекс begin больше индекса end;
- индекс end больше длины строки;
- индекс ind отрицателен;
- ind+(end—begin) больше dst.
 length.
length.
Если надо получить массив байтов, содержащий все символы строки в байтовой кодировке ASCII, то используйте метод getBytes(). Этот метод при переводе символов из Unicode в ASCII использует локальную кодовую таблицу. Если же надо получить массив байтов не в локальной кодировке, а в какой-то другой, применяйте метод getBytes(String encoding) или метод getBytes(Charset encoding).
Кода мы преобразовали строку str5 в массив byte, то получили отрицательные значения потому что коды латиницы лежат за пределами максимального положительного значения для byte, но если посмотреть на hex код этих отрицательных значений для byte, то к примеру –48 это шестнадцатеричное D0, что соответствует большой русской букве Р в кодировке CP1251.
Метод regionMatches() сравнивает указанную часть строки с другой частью строки. Существует также перегруженная форма, которая игнорирует регистр символов при сравнении. Оба метода возвращают результат boolean. Вот общая форма этих двух методов:
Существует также перегруженная форма, которая игнорирует регистр символов при сравнении. Оба метода возвращают результат boolean. Вот общая форма этих двух методов:
regionMatches(int startIndex, String str2, int str2StartIndex, int numChars)
regionMatches(boolean ignoreCase, int startIndex, String str2, int str2StartIndex, int numChars)
В обеих версиях startIndex задает индекс начала диапазона строки вызывающего объекта String. Строка, подлежащая сравнению, передается в str2. Индекс символа, начиная с которого нужно выполнять сравнение в str2, передается в str2StartIndex, а длина сравниваемой подстроки — в numChars. Во второй версии, если ignoreCase равно true, регистр символов игнорируется. В противном случае регистр учитывается.
В противном случае регистр учитывается.
В классе String определены два метода, представляющие собой более или менее специализированные формы regionMatches(). Метод startWith() определяет, начинается ли заданный объект String с указанной строки. В дополнение endsWith() определяет, завершается ли объект String заданным фрагментом. Эти методы возвращают результат типа boolean. Так как методы достаточно просты, то я думаю достаточно примера в коде, чтобы понять как они работают.
Класс String предлагает два метода, которые позволяют вам выполнять поиск в строке определенного символа или подстроки.
indexOf() — ищет первое вхождение символа или подстроки.
lastIndexOf() — ищет последнее вхождение символа или подстроки.
Эти два метода перегружены несколькими разными способами. Во всех случаях эти методы возвращают позицию в строке (индекс), где символ или подстрока была найдена, либо -1 в случае неудачи. Поскольку вариантов перегрузки этих методов достаточно много, то описывать их все тут достаточно долго и нудно, поэтому, опять же, предлагаю посмотреть на примере приведенном выше как они работают.
Поскольку вариантов перегрузки этих методов достаточно много, то описывать их все тут достаточно долго и нудно, поэтому, опять же, предлагаю посмотреть на примере приведенном выше как они работают.
Метод replace() имеет две формы. Первая заменяет в исходной строке все вхождения одного символа другим. Вторая форма replace() заменяет одну последовательность символов на другую.
Метод contains() проверяет содержит ли проверяемая строка, строку переданную как аргумент метода и если содержит возвращает true, если нет – false.
Метод join() объединяет строки переданные как параметры и разделяет их разделителем, переданным в качестве первого параметра. В общем смотрите пример.
Метод toLowerCase() преобразует все символы строки из верхнего регистра в нижний. Метод toUpperCase() преобразует все символы строки из нижнего регистра в верхний. Небуквенные символы, такие как десятичные цифры, остаются неизменными.
Метод trim() возвращает новую строку, в которой удалены начальные и конечные символы с кодами, не превышающими ‘ \u0020’.
У класса String существует еще несколько методов для работы с регулярными выражениями, которые мы рассмотрим чуть позже.
Так же хочу отметить, что в примере приведенном выше рассмотрены не все ипостаси методов которые есть у класса String, поэтому, опять же, рекомендую смотреть исходники класса String в JDK, дабы обрести просветление по данной теме.
Строки в языке C++ (класс string)
Строки в языке C++ (класс string)В языке C++ для удобной работы со строками есть класс string, для использования которого необходимо подключить заголовочный файл string.
Строки можно объявлять и одновременно присваивать им значения:
Строка S1 будет пустой, строка S2 будет состоять из 5 символов.
К отдельным символам строки можно обращаться по индексу, как к элементам массива или C-строк. Например S[0] — это первый символ строки.
Например S[0] — это первый символ строки.
Для того, чтобы узнать длину строки можно использовать метод size() строки. Например, последний символ строки S это S[S.size() — 1].
Строки в языке C++ могут
Конструкторы строк
Строки можно создавать с использованием следующих конструкторов:string() — конструктор по умолчанию (без параметров) создает пустую строку.string(string & S) — копия строки Sstring(size_t n, char c)c заданное число n раз.string(size_t c) — строка из одного символа c.string(string & S, size_t start, size_t len)len символов данной строки S, начиная с символа номер start.
Конструкторы можно вызывать явно, например, так:
В этом примере явно вызывается конструктор string для создания строки, состоящей из 10 символов 'z'.
Неявно конструктор вызывается при объявлении строки с указанием дополнительных параметров. Например, так:
Подробней о конструкторах для строк читайте здесь.
Ввод-вывод строк
Строка выводится точно так же, как и числовые значения:
Для считывания строки можно использовать операцию «>>» для объекта cin:
В этом случае считывается строка из непробельных символов, пропуская пробелы и концы строк. Это удобно для того, чтобы разбивать текст на слова, или чтобы читать данные до конца файла при помощи while (cin >> S).
Можно считывать строки до появления символа конца строки при помощи функции getline. Сам символ конца строки считывается из входного потока, но к строке не добавляется:
Арифметические операторы
Со строками можно выполнять следующие арифметические операции:= — присваивание значения.+= — добавление в конец строки другой строки или символа.+ — конкатенация двух строк, конкатенация строки и символа.
==, != — посимвольное сравнение.<, >, <=, >= — лексикографическое сравнение.
То есть можно скопировать содержимое одной строки в другую при помощи операции S1 = S2, сравнить две строки на равенство при помощи S1 == S2, сравнить строки в лексикографическом порядке при помощи S1 < S2, или сделать сложение (конкатенацию) двух строк в виде S = S1 + S2.
Подробней об операторах для строк читайте здесь.
Методы строк
У строк есть разные методы, многие из них можно использовать несколькими разными способами (с разным набором параметров).
Рассмотрим эти методы подробней.
size
Метод size() возращает длину длину строки. Возвращаемое значение является беззнаковым типом (как и во всех случаях, когда функция возращает значение, равное длине строке или индексу элемента — эти значения беззнаковые). Поэтому нужно аккуратно выполнять операцию вычитания из значения, которое возвращает size(). Например, ошибочным будет запись цикла, перебирающего все символы строки, кроме последнего, в виде for (int i = 0; i < S.size() — 1; ++i).
Например, ошибочным будет запись цикла, перебирающего все символы строки, кроме последнего, в виде for (int i = 0; i < S.size() — 1; ++i).
Кроме того, у строк есть метод length(), который также возвращает длину строки.
Подробней о методе size.
resize
S.resize(n) — Изменяет длину строки, новая длина строки становится равна n. При этом строка может как уменьшится, так и увеличиться. Если вызвать в виде S.resize(n, c), где c — символ, то при увеличении длины строки добавляемые символы будут равны c.
Подробней о методе resize.
clear
S.clear() — очищает строчку, строка становится пустой.
Подробней о методе clear.
empty
S.empty() — возвращает true, если строка пуста, false — если непуста.
Подробней о методе empty.
push_back
S.push_back(c) — добавляет в конец строки символ c, вызывается с одним параметром типа char.
Подробней о методе push_back.
append
Добавляет в конец строки несколько символов, другую строку или фрагмент другой строки. Имеет много способов вызова.
Имеет много способов вызова.
S.append(n, c) — добавляет в конец строки n одинаковых символов, равных с. n имеет целочисленный тип, c — char.
S.append(T) — добавляет в конец строки S содержимое строки T. T может быть объектом класса string или C-строкой.
S.append(T, pos, count) — добавляет в конец строки S символы строки T начиная с символа с индексом pos количеством count.
Подробней о методе append.
erase
S.erase(pos) — удаляет из строки S с символа с индексом pos и до конца строки.
S.erase(pos, count) — удаляет из строки S с символа с индексом pos количеством count или до конца строки, если pos + count > S.size().
Подробней о методе erase.
insert
Вставляет в середину строки несколько символов, другую строку или фрагмент другой строки. Способы вызова аналогичны способам вызова метода append, только первым параметром является значение i — позиция, в которую вставляются символы. Первый вставленный символ будет иметь индекс i, а все символы, которые ранее имели индекс i и более сдвигаются вправо.
S.insert(i, n, c) — вставить n одинаковых символов, равных с. n имеет целочисленный тип, c — char.
S.insert(i, T) — вставить содержимое строки T. T может быть объектом класса string или C-строкой.
S.insert(i, T, pos, count) — вставить символы строки T начиная с символа с индексом pos количеством count.
Подробней о методе insert.
substr
S.substr(pos) — возвращает подстроку данной строки начиная с символа с индексом pos и до конца строки.
S.substr(pos, count) — возвращает подстроку данной строки начиная с символа с индексом pos количеством count или до конца строки, если pos + count > S.size().
Подробней о методе substr.
replace
Заменяет фрагмент строки на несколько равных символов, другую строку или фрагмент другой строки. Способы вызова аналогичны способам вызова метода append, только первыми двумя параметрами являются два числа: pos и count. Из данной строки удаляется count символов, начиная с символа pos, и на их место вставляются новые символы.

S.replace(pos, count, n, c) — вставить n одинаковых символов, равных с. n имеет целочисленный тип, c — char.
S.replace(pos, count, T) — вставить содержимое строки T. T может быть объектом класса string или C-строкой.
S.replace(pos, count, T, pos2, count2) — вставить символы строки T начиная с символа с индексом pos количеством count.
Подробней о методе replace.
find
Ищет в данной строке первое вхождение другой строки str. Возвращается номер первого символа, начиная с которого далее идет подстрока, равная строке str. Если эта строка не найдена, то возвращается константа string::npos (которая равна -1, но при этом является беззнаковой, то есть на самом деле является большим безннаковым положительным числом).
Если задано значение pos, то поиск начинается с позиции pos, то есть возращаемое значение будет не меньше, чем pos. Если значение pos не указано, то считается, что оно равно 0 — поиск осуществляется с начала строки.
S.find(str, pos = 0) — искать первое входение строки str начиная с позиции pos. Если pos не задано — то начиная с начала строки S.
Если pos не задано — то начиная с начала строки S.
S.find(str, pos, n) — искать в данной строке подстроку, равную первым n символам строки str. Значение pos должно быть задано.
Подробней о методе find.
rfind
Ищет последнее вхождение подстроки («правый» поиск). Способы вызова аналогичны способам вызова метода find.
Подробней о методе rfind.
find_first_of
Ищет в данной строке первое появление любого из символов данной строки str. Возвращается номер этого символа или значение string::npos.
Если задано значение pos, то поиск начинается с позиции pos, то есть возращаемое значение будет не меньше, чем pos. Если значение pos не указано, то считается, что оно равно 0 — поиск осуществляется с начала строки.
S.find_first_of(str, pos = 0) — искать первое входение любого символа строки str начиная с позиции pos. Если pos не задано — то начиная с начала строки S.
Подробней о методе find_first_of.
find_last_of
Ищет в данной строке последнее появление любого из символов данной строки str. Способы вызова и возвращаемое значение аналогичны методу find_first_of.
Способы вызова и возвращаемое значение аналогичны методу find_first_of.
Подробней о методе find_last_of.
find_first_not_of
Ищет в данной строке первое появление символа, отличного от символов строки str. Способы вызова и возвращаемое значение аналогичны методу find_first_of.
Подробней о методе find_first_not_of.
find_last_not_of
Ищет в данной строке последнее появление символа, отличного от символов строки str. Способы вызова и возвращаемое значение аналогичны методу find_first_of.
Подробней о методе find_last_not_of.
c_str
Возвращает указать на область памяти, в которой хранятся символы строки, возвращает значение типа char*. Возвращаемое значение можно рассматривать как C-строку и использовать в функциях, которые должны получать на вход C-строку.
Подробней о методе c_str.
3 примера, объясняющие функцию подстроки строки
Метод подстроки класса Java String
В главе Java, посвященной классам строк, мы узнали, как создавать строки в Java, а также несколько полезных функций класса String. Один из полезных методов класса String — это substring ().
Один из полезных методов класса String — это substring ().
Что такое метод подстроки?
Подстрока — это часть исходной строки, которую можно получить с помощью метода substring (). В методе подстроки Java вы можете указать начальную и конечную позицию в исходной строке как целые числа.Позиция или индекс строки начинается с 0. Итак, если вы хотите получить подстроку «tutorial» из следующей строки, вот как можно использовать метод substring ():
Исходная строка: «Это учебник по подстроке Java!»
Метод подстроки будет:
Str_substring.substring (23,31)
Где Str_substring — объект исходной строки. Значение 23 указывает, что возвращаемая подстрока должна начинаться с буквы «t» и заканчиваться 31 символом в строке.
Посмотрите на эту демонстрацию в полной программе Java ниже.
Демонстрация использования метода Java подстроки
Щелкните ссылку, чтобы просмотреть код и выходные данные, чтобы получить подстроку «учебник» с помощью метода substring ():
См. Онлайн-демонстрацию и код
Онлайн-демонстрацию и код
Код Java:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 | открытый класс String_demo { public static void main (String [] args) { String Str_substring = «Это учебник по подстрокам Java!»; Систем.out.println («Подстрока:» + Str_substring.substring (23,31)); } } |
Демонстрация использования только начального индекса в Java-методе подстроки
В приведенном выше примере я использовал как начальный, так и конечный индексы для получения подстроки. Однако конечный индекс не требуется. В этом случае возвращаемой подстрокой будут оставшиеся символы, включая символ начала индекса в строке.
FYI, левое значение — для начального индекса, который включает символ в строке.
Правое значение — конечная позиция индекса, которая не включает символ.
См. Этот пример, где я использовал только начальный индекс для той же строки, что и в примере выше. Смотрите код и вывод:
См. Онлайн-демонстрацию и код
Код только с начальным индексом:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 | открытый класс String_demo { public static void main (String [] args) { String Str_substring = «Это учебник по подстрокам Java!»; Систем.out.println («Подстрока:» + Str_substring.substring (8)); } } |
Что делать, если начальный индекс больше длины строки?
Если вы укажете начальный индекс больше, чем длина строки в методе подстроки строки, будет сгенерирована ошибка. Ошибка выглядит примерно так:
Ошибка выглядит примерно так:
Исключение в потоке «main» java.lang.StringIndexOutOfBoundsException: индекс строки вне допустимого диапазона: -1
См. Код этого примера, где длина строки равна 22. Я использовал начальный индекс 23 в методе подстроки и вижу результат:
См. Онлайн-демонстрацию и код
Код:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 18 19 | открытый класс String_demo { public static void main (String [] args) { String Str_substring = «Строки неизменяемы.»; System.out.println (» Длина строки: «+ Str_substring.length ()); System.out.println (» Подстрока: «+ Str_substring. } } |
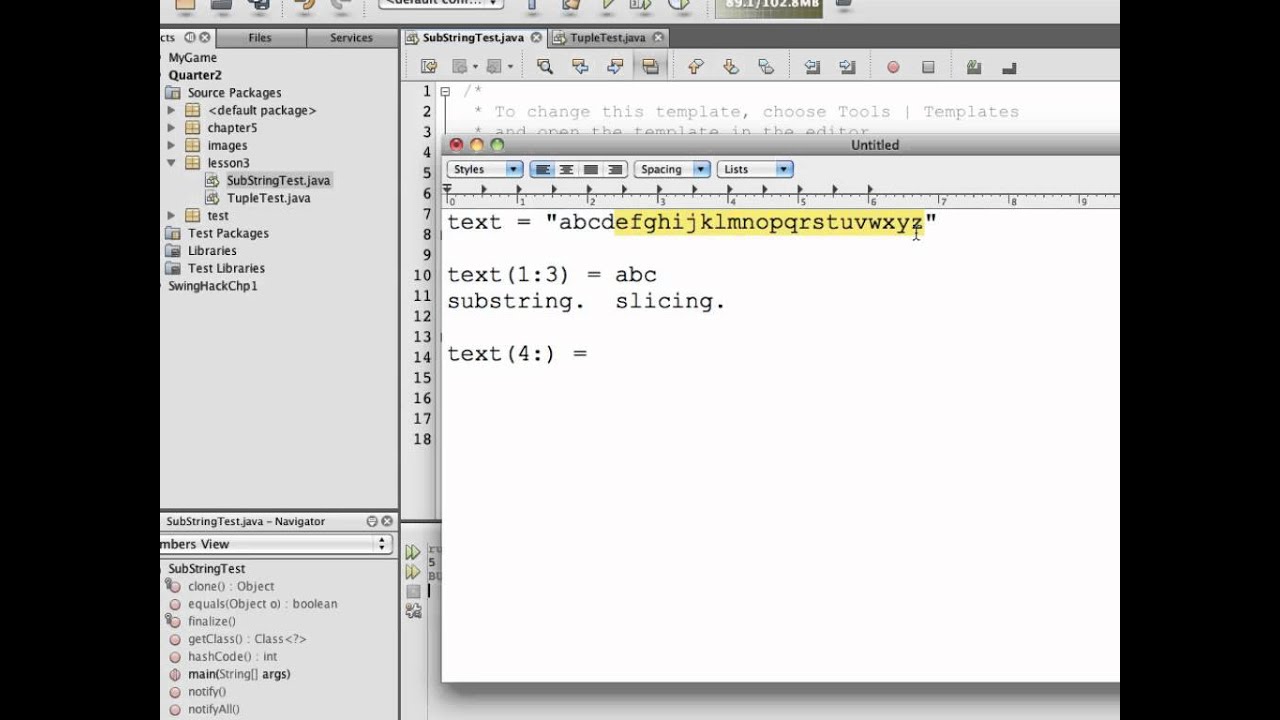 substring (23));
substring (23));Итак, как и при использовании метода substring, остерегайтесь этого исключения.
Как проверить, содержит ли строка подстроку в SQL Server
SQL содержит строку — В этом блоге я объясню, как проверить определенное слово или символ в заданном операторе SQL Server с помощью функции CHARINDEX или SQL Server и проверить если строка содержит определенную подстроку с функцией CHARINDEX.
Альтернативой CHARINDEX () является использование предиката LIKE.
Способ 1. Использование функции CHARINDEX ()
CHARINDEX ()
Эта функция используется для поиска определенного слова или подстроки в общей строке и возвращает ее начальную позицию совпадения. Если слово не найдено, возвращается 0 (ноль).
Давайте разберемся в этом на примерах.
Синтаксис
- CHARINDEX (SearchString, WholeString [, startlocation])
- Объявить @mainString nvarchar (100) = ‘Amit Kumar
- ‘ if ‘ , @ mainString)> 0
- начало
- выберите «Найти» в качестве результата
- конец
- иначе
- выберите «Не найти» в качестве результата
Выход
Метод 2 — предикат с использованием LIK
Оператор предиката LIKE может использоваться для поиска подстроки в строке или содержимом. Оператор LIKE в сочетании с% и _ (подчеркивание) используется для поиска еще одного символа и одного символа соответственно. Вы можете использовать оператор%, чтобы найти подстроку.
Оператор LIKE в сочетании с% и _ (подчеркивание) используется для поиска еще одного символа и одного символа соответственно. Вы можете использовать оператор%, чтобы найти подстроку.
В следующем запросе SQL мы будем искать в строке подстроку «Kumar».
- DECLARE @WholeString VARCHAR (50)
- DECLARE @ExpressionToFind VARCHAR (50)
- SET @WholeString = SET @WholeString Amit Kumar Yadav ‘
- SET @ExpressionToFind =’ Kumar ‘
- IF @WholeString LIKE’% ‘+ @ExpressionToFind +’% ‘
- PRINT’ Да, это найти ‘
- ELSE
- PRINT’ ‘t find’
Выход
Этот метод также можно использовать в предложении WHERE операторов SELECT, UPDATE и DELETE.Следующее предложение SELECT выбирает записи из таблицы Employees базы данных Northwind, где Employee’s Title содержит подстроку «Продажи».
SELECT [EmployeeID]
, [LastName]
, [FirstName]
, [Title]
FROM [NORTHWND]. [Dbo]. [Employee]
[Dbo]. [Employee]
WHERE Title LIKE ‘% Sales%’
Вывод вышеуказанного запроса возвращает следующие результаты.
Сводка
В этом блоге мы увидели, как получить данные с подстроками в столбце.
Проверить, содержит ли строка подстроку
В этой статье мы рассмотрим четыре способа использования Python, чтобы проверить, содержит ли строка подстроку. У каждого есть свои варианты использования и плюсы / минусы, некоторые из которых мы кратко рассмотрим здесь:
1) в Оператор
Самый простой способ проверить, содержит ли строка Python подстроку, — использовать оператор in . Оператор in используется для проверки структур данных на принадлежность к Python.Он возвращает логическое значение (либо True , либо False ) и может использоваться следующим образом:
fullstring = "StackAbuse"
substring = "закрепка"
если подстрока в полной строке:
печать "Найдено!"
еще:
печать "Не найдено!"
Этот оператор является сокращением для вызова метода объекта __contains__ , а также хорошо работает для проверки наличия элемента в списке.
2) Метод String.index () Метод
Тип String в Python имеет метод под названием index , который можно использовать для поиска начального индекса первого вхождения подстроки в строку.Если подстрока не найдена, выдается исключение ValueError , которое можно обработать с помощью блока try-except-else:
fullstring = "StackAbuse"
substring = "закрепка"
пытаться:
fullstring.index (подстрока)
кроме ValueError:
печать "Не найдено!"
еще:
печать "Найдено!"
Этот метод полезен, если вам нужно знать позицию подстроки, а не просто ее наличие в полной строке.
3) Метод String.find () Метод
Тип String имеет другой метод, называемый find , который удобнее использовать, чем index , потому что нам не нужно беспокоиться об обработке каких-либо исключений.Если find не находит совпадения, он возвращает -1, в противном случае он возвращает крайний левый индекс подстроки в большей строке.