Кодовые таблицы символов
4.7
Средняя оценка: 4.7
Всего получено оценок: 196.
4.7
Средняя оценка: 4.7
Всего получено оценок: 196.
Для представления букв в вычислительной технике используют кодовые таблицы. Кратко о видах таблиц символов и их использовании рассказано в данной статье.
Что такое кодовая таблица
Известно, что числа в ЭВМ представляются в двоичной форме, в виде набора нулей и единиц. Для этого разработаны специальные приемы перевода числовых значений в двоичную последовательность. А как же компьютером обрабатываются текстовая информация – предложение, слова и буквы? Точно также как и числа – в виде последовательности нулей и единиц.
Для представления буквы в компьютере ее заменяют числовым эквивалентом, а затем переводят в двоичный код. Каждой букве соответствует своя цифра. Все буквы с их числовыми эквивалентами сведены в кодовую таблицу символов, которая может называться ASCII, Unicode, КОИ-7, КОИ-8, Windows-1251.
Таблица ASCII
Самой первой системой кодирования текстовой информации была ASCII (американский стандартный код для обмена информацией).
Таблица ASCII была разработана в США в шестидесятые годы прошлого столетия. Появление такой единой унифицированной системы кодировки символов было продиктовано необходимостью реализации компьютерного взаимодействия и обмена информацией. В то время каждый производитель вычислительной техники самостоятельно представлял буквы, цифры и управляющие коды. Только специалистами корпорации IBM применялись девять различных наборов кодировки символов.
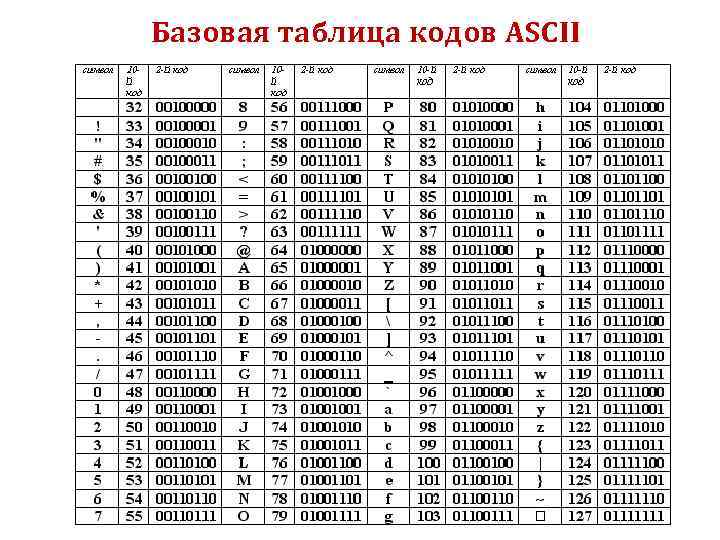
Рис. 1. Символы таблицы ASCII.Идея создания единой стандартизированной системы кодирования символов в виде числовых эквивалентов принадлежит американскому специалисту в области информационных технологий Роберту Уильяму Бемеру. Это он придумал экранирующий символ «Esc», обозначающий то, что следующий после него символ, имеет некоторое другое значение, не такое как ему назначено в таблице ASCII.
Первоначально таблица использовалась для кодировки только 128 знаков, затем была расширена до 256 символов. Первые тридцать два символа в таблице ASCI не имеют печатных эквивалентов и используются для управления. Числа в диапазоне 32 –127 предназначены для кодирования прописных и строчных латинских букв, цифр и знаков препинания.
Знак пробела имеет код 32 и также является печатным символом. Проверить соответствие символа печатному коду легко. Для этого можно воспользоваться простейшим текстовым редактором Блокнот в группе программ Стандартные операционной системы Windows. Нажав одновременно функциональную клавишу Alt и введя код символа – десятичное число, в окне редактора на месте расположения курсора будет напечатан соответствующий символ.
Национальные версии таблицы ASCII
Таблица ASCII в интервале символов от 0 до 127 остается неизменной для любых программ. Диапазон кодовых значений от 128 до 255 может варьироваться в зависимости от языковых и национальных особенностей.
Существуют различные национальные варианты системы кодирования. Для кодирования букв русского алфавита используются:
- IBM cp866
- Win-1251
- KOI8
Unicode
Unicode представляет собой промышленный стандарт для кодирования символов всех письменных языков мира. Он был предложен в 1991 году некоммерческой организацией Unicode Consortium.
Рис. 3. Логотип Unicode Consortium.Кодовое пространство Unicode разделено на несколько областей. Диапазон кодовых значений от 0 до 127 полностью дублирует кодовую систему ASCII. Затем располагаются области знаков разных языков, пунктуационные знаки и некоторые технические символы.
Unicode имеет несколько форм представления: UTF-8, UTF-16 и UTF-32.
Что мы узнали?
Для представления символьных значений в ЭВМ используются таблицы кодирования символов. Каждому символу в такой таблице соответствует числовое значение. Использование стандартизированных кодовых таблиц позволило обеспечить взаимодействие и информационный обмен между средствами вычислительной техники.
Тест по теме
Доска почёта
Чтобы попасть сюда — пройдите тест.
Никита Червоненко
5/5
Михаил Соколов
5/5
Алексей Беляев
5/5
Олег Сильченко
5/5
Оценка статьи
4.7
Средняя оценка: 4.7
Всего получено оценок: 196.
А какая ваша оценка?
3.3. Кодовая таблица
Кодовая таблица – это внутреннее (закодированное) представление в машине букв, цифр, символов и управляющих сигналов. Так, латинская буква А в кодовой таблице представлена десятичным числом 65D (внутри ЭВМ это число будет представлено двоичным числом 01000001В), латинская буква С – числом 67D, латинская буква М – 77D и т. д. Таким образом, слово «САМАРА», написанное заглавными латинскими буквами будет циркулировать внутри ЭВМ в виде цифр:
Если говорить точнее, то внутри ЭВМ данное слово циркулирует в виде двоичных чисел:
01000011В-01000001В-01001101В-01000001В-01010000В-01000001В.
Аналогично кодируются цифры (например, 1 – 49D, 2 – 59D) и символы (например, ! – 33D, + – 43D).
Наряду с алфавитно-цифровыми символами в кодовой таблице закодированы управляющие сигналы. Например, код 13D заставляет печатающую головку принтера вернуться к началу текущей строки, а код 10D перемещает бумагу, заправленную в принтер, на одну строку вперед.
Кодовая таблица может быть представлена не только с помощью десятичной СС, но и при помощи шестнадцатеричной СС. Еще раз обращаем внимание на тот факт, что внутри ЭВМ циркулируют сигналы, представленные в двоичной системе счисления, а в кодовой таблице для большего удобства чтения пользователем – в десятичной или шестнадцатеричной СС.
Каждая буква,
цифра, знак препинания или управляющий
сигнал кодируются восьмиразрядным
двоичным числом. С помощью восьмиразрядного
числа (однобайтового числа) можно
представить (закодировать) 256 произвольных
символов – букв, цифр и вообще графических
образов.
Во всем мире в качестве стандарта принята кодовая таблица ASCII (American Standard Code for Information Interchange – Американский стандарт кодов для обмена информацией). Таблица ASCII регламентирует (строго определяет) ровно половину возможных символов (латинские буквы, арабские цифры, знаки препинания, управляющие сигналы). Для их кодировки используются коды от OD до 127D.
Вторая
половина кодовой таблицы ASCII
(с кодами от 128 до 255) не определена
американским стандартом и предназначена
для размещения символов национальных
алфавитов других стран (в частности, кириллицы – русских
букв), псевдографических символов,
некоторых математических знаков. В
разных странах, на различных моделях
ЭВМ, в разных операционных системах
могут использоваться и разные варианты
второй половины кодовой таблицы (их
называют расширениями ASCII).
Например, таблица, которая используется
в операционной системе MS-DOS,
называется СР-866. Используя эту таблицу
для кодировки слова «САМАРА», записанного
русскими буквами, получим такие коды:
Используя эту таблицу
для кодировки слова «САМАРА», записанного
русскими буквами, получим такие коды:
При работе в операционной системе Windows используется таблица кодов СР-1251, в которой кодировка латинских букв совпадает с кодировкой таблиц СР-866 и ASCII, a вторая половина таблицы имеет собственную раскладку (кодировку) символов. Поэтому слово «САМАРА», написанное заглавными русскими буквами, будет иметь внутри ЭВМ другое представление:
Таким образом,
внешне одинаковое слово (например,
«САМАРА») внутри ЭВМ может быть
представлено различным образом.
Естественно, это вызывает определенные
неудобства. При работе в Интернет
национальный текст порой становится
нечитаемым. Наиболее вероятной причиной
в этом случае является несовпадение
кодировок второй половины кодовых
таблиц. Заметим, что если для составления
писем, отправляемых по электронной
почте, используется первая половина
кодовой таблицы (латиница), то проблемы
с кодировкой не возникают.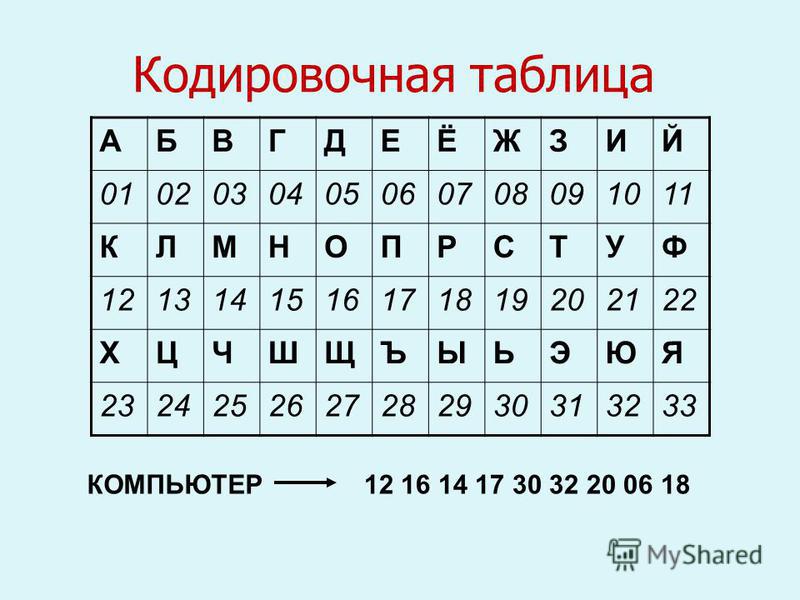
Общим недостатком всех однобайтовых кодовых таблиц (в них для кодировки используются восьмиразрядные двоичные числа) является отсутствие в коде символа какой-либо информации, которая подсказывает машине, какая в данном случае используется кодовая таблица.
Сообществом фирм Unicode предложена в качестве стандарта другая система кодировки символов. В этой системе для представления (кодирования) одного символа используются два байта (16 битов), и это позволяет включить в код символа информацию о том, какому языку принадлежит символ и как его нужно воспроизводить на экране монитора или на принтере. Два байта позволяют закодировать 65 536 символов. Правда, объем информации, занимаемой одним и тем же текстом, увеличится вдвое. Зато тексты всегда будут «читаемыми» независимо от использованного национального языка и операционной системы.
Таблица ASCII | Информатика
Редактировать меня
Эта страница была адаптирована отсюда.
ASCII означает американский стандартный код для обмена информацией. Ниже приведена таблица символов ASCII, включая описания первых 32 символов. ASCII изначально был разработан для использования с телетайпами, поэтому описания несколько неясны, и их использование часто не соответствует назначению.
Java на самом деле использует Unicode, который включает ASCII и другие символы из языков по всему миру.
В C/C++ тип данных char используется для хранения символов ASCII. Если мы напишем char c = ‘5’, то c сохранит значение 53. Если мы напишем ‘5’-‘0’, будет получено значение 53-48 или int 5. Если мы напишем char c = ‘B’+32 ; затем c сохраняет «b».
| Шестигранник | декабрь | |
|---|---|---|
| 00 | 0 | НУЛ (нулевой) |
| 01 | 1 | SOH (начало заголовка) |
| 02 | 2 | STX (начало текста) |
| 03 | 3 | ETX (конец текста) |
| 04 | 4 | EOT (конец передачи) |
| 05 | 5 | ENQ (запрос) |
| 06 | 6 | ACK (подтверждение) |
| 07 | 7 | БЕЛ (звонок) |
| 08 | 8 | БС (возврат) |
| 09 | 9 | Вкладка (горизонтальная вкладка) |
| 0а | 10 | LF (перевод строки NL, новая строка) |
| 0б | 11 | VT (вертикальная вкладка) |
| 0с | 12 | FF (подача страницы NP, новая страница) |
| 0д | 13 | CR (возврат каретки) |
| 0e | 14 | SO (переключение) |
| 0f | 15 | СИ (сменный) |
| 10 | 16 | DLE (выход канала передачи данных) |
| 11 | 17 | DC1 (управление устройством 1) |
| 12 | 18 | DC2 (управление устройством 2) |
| 13 | 19 | DC3 (управление устройством 3) |
| 14 | 20 | DC4 (управление устройством 4) |
| 15 | 21 | NAK (отрицательное подтверждение) |
| 16 | 22 | SYN (синхронный холостой ход) |
| 17 | 23 | ETB (конец передаточного блока) |
| 18 | 24 | CAN (отмена) |
| 19 | 25 | EM (конец среды) |
| 1а | 26 | SUB (заменитель) |
| 1б | 27 | ESC (выход) |
| 1с | 28 | ФС (разделитель файлов) |
| 1д | 29 | GS (разделитель групп) |
| 1e | 30 | RS (разделитель записей) |
| 1ф | 31 | США (разделитель единиц измерения) |
| Шестигранник | декабрь | Символ |
|---|---|---|
| 20 | 32 | ПРОБЕЛ |
| 21 | 33 | ! |
| 22 | 34 | ” |
| 23 | 35 | # |
| 24 | 36 | $ |
| 25 | 37 | % |
| 26 | 38 | и |
| 27 | 39 | ’ |
| 28 | 40 | ( |
| 29 | 41 | ) |
| 2а | 42 | * |
| 2б | 43 | + |
| 2с | 44 | , |
| 2д | 45 | — |
| 2е | 46 | . |
| 2f | 47 | / |
| 30 | 48 | 0 |
| 31 | 49 | 1 |
| 32 | 50 | 2 |
| 33 | 51 | 3 |
| 34 | 52 | 4 |
| 35 | 53 | 5 |
| 36 | 54 | 6 |
| 37 | 55 | 7 |
| 38 | 56 | 8 |
| 39 | 57 | 9 |
| 3а | 58 | : |
| 3б | 59 | ; |
| 3с | 60 | < |
| 3д | 61 | = |
| 3е | 62 | > |
| 3f | 63 | ? |
| Шестигранник | декабрь | Символ |
|---|---|---|
| 40 | 64 | @ |
| 41 | 65 | А |
| 42 | 66 | Б |
| 43 | 67 | С |
| 44 | 68 | Д |
| 45 | 69 | Е |
| 46 | 70 | Ф |
| 47 | 71 | Г |
| 48 | 72 | Х |
| 49 | 73 | я |
| 4а | 74 | Дж |
| 4б | 75 | К |
| 4с | 76 | л |
| 4д | 77 | М |
| 4е | 78 | Н |
| 4f | 79 | О |
| 50 | 80 | Р |
| 51 | 81 | В |
| 52 | 82 | Р |
| 53 | 83 | С |
| 54 | 84 | Т |
| 55 | 85 | У |
| 56 | 86 | В |
| 57 | 87 | Вт |
| 58 | 88 | х |
| 59 | 89 | Д |
| 5а | 90 | З | 9
| 5f | 95 | _ |
| Шестигранник | декабрь | Символ | |
|---|---|---|---|
| 60 | 96 | ` | |
| 61 | 97 | и | |
| 62 | 98 | б | |
| 63 | 99 | в | |
| 64 | 100 | д | |
| 65 | 101 | и | |
| 66 | 102 | ф | |
| 67 | 103 | г | |
| 68 | 104 | ч | |
| 69 | 105 | и | |
| 6а | 106 | и | |
| 6б | 107 | к | |
| 6с | 108 | л | |
| 6д | 109 | м | |
| 6e | 110 | п | |
| 6f | 111 | или | |
| 70 | 112 | р | |
| 71 | 113 | д | |
| 72 | 114 | р | |
| 73 | 115 | с | |
| 74 | 116 | т | |
| 75 | 117 | и | |
| 76 | 118 | против | |
| 77 | 119 | с | |
| 78 | 120 | х | |
| 79 | 121 | г | |
| 7а | 122 | г | |
| 7б | 123 | { | |
| 7с | 124 | ||
| 7д | 125 | } | |
| 7e | 126 | ~ | |
| 7ф | 127 | ДЕЛ |
Таблица языков программирования
Выпуск 8. 2, март 1996 г.
2, март 1996 г.
Каперс Джонс, председатель отдела программного обеспечения Исследование производительности, Inc.
Copyright 1997 by Software Productivity Research, Inc. Все права защищены.
Что такое языковой уровень?
Чем выше языковой уровень, тем меньше операторы для кодирования одной функциональной точки требуется. Например, COBOL относится к уровню 3 и требует около 105 операторов на функциональную точку.
Числовые уровни различных языков предоставить удобный ярлык для преобразования размера из одного языка на другой. Например, если приложение требуется 1000 операторов COBOL без комментариев (уровень 3), тогда потребуется всего 500 утверждений на уровне 6 языке (например, NATURAL) и всего 250 утверждений в язык уровня 12 (например, OBJECTIVE C). Как вы видете, среднее количество требуемых заявлений пропорционально уровням разных языков.
Влияют ли языковые уровни Производительность?
Корреляция между уровнем производительность языка и разработки не является линейной. За В большинстве крупных программных проектов кодирование составляет всего около 30 процентов усилий.
Предположим, что программа написана на язык, вдвое превышающий уровень аналогичной программы, например уровень 6 по сравнению с уровнем 3. В этом примере усилия по кодированию могут быть уменьшены на 50 процентов. Но общий проект может быть улучшен только на 15 процентов, так как кодирование составляло только 30 процентов первоначальных усилий. Удвойте уровень языка снова до уровня 12. Это даст только дополнительные 7,5% чистой прибыли. сбережения. Еще раз, кодирование сокращается вдвое. Но кодирование не важный фактор для языков очень высокого уровня.
Более точная экономическая производительность ставки можно получить, изучив среднемесячный Скорость производства функциональных баллов, связанная с различными языковые уровни. В таблице 1 показано, как языковые уровни влияют на продуктивность.
В таблице 1 показано, как языковые уровни влияют на продуктивность.
Таблица 1. Соотношение языковых уровней к производительности
УРОВЕНЬ ЯЗЫКА ПРОИЗВОДИТЕЛЬНОСТЬ СРЕДНЯЯ
В МЕСЯЦ СОТРУДНИКОВ
-------------- -------------------------
1–3 От 5 до 10 функциональных точек
4–8 От 10 до 20 функциональных точек
9- 15 от 16 до 23 функциональных точек
16–23 От 15 до 30 функциональных точек
24–55 30–50 функциональных точек
Выше 55 От 40 до 100 функциональных баллов
Что является основой для языковых уровней?
Языки и уровни в таблице 2 собирались четырьмя способами.
- Подсчет функциональных точек и Исходный код
- Исходный код подсчета
- Проверка исходного кода
- Изучение языков
Подсчет функциональных точек и источника Код
Фактическое количество функциональных точек и операторы исходного кода были выполнены. Образцы подсчет функциональных точек и операторов исходного кода был сделано на Ada, нескольких диалектах BASIC, COBOL, PASCAL и ПЛ/И.
Образцы подсчет функциональных точек и операторов исходного кода был сделано на Ada, нескольких диалектах BASIC, COBOL, PASCAL и ПЛ/И.
Исходный код подсчета
Операторы исходного кода были подсчитаны, затем по сравнению с размером той же программы в языки известных уровней. Сборка, APL, C, ЦЕЛЬ C, FORTH, FORTRAN, LISP, PILOT и PROLOG — это языки которые производят тот же исходный код, что и COBOL. Итак, код размеры сравнивались с известным количеством источника COBOL код.
Проверка исходного кода
Проверка исходного кода для общих приложений было сделано. Тогда объем кода для было выдвинуто предположение о применении на измеряемом языке. ACTOR, CLARION и TRUE BASIC являются примерами языков которые были проверены, и их уровни были выдвинуты гипотезой субъективные средства.