Изменение изображений SVG в Майкрософт 365
Майкрософт Word, PowerPoint, Outlook и Excel для Microsoft 365 в Windows, Mac, Android и Windows Mobile поддерживают вставку и редактирование масштабируемой векторной графики (. SVG) файлы в документах, презентациях, сообщениях электронной почты и книгах.
В iOS вы можете редактировать изображения SVG, которые вы уже вставили на другую платформу.
|
Эта функция доступна только подписчикам Microsoft 365 для классических клиентов Windows. |
Совет: SVG — это открытый стандарт, который был создан в 1999 году.
Вставка образа SVG
SvG-файл вставляется так же, как и другие типы файлов изображений:
Выберите Вставить > рисунки > это устройство.
Перейдите к SVG-файлу, который нужно вставить, а затем выберите его и нажмите кнопку Вставка.
Вставка значка
Библиотека значков в приложениях Office состоит из образов SVG, которые можно вставить в документ Office, а затем настроить:
-
На вкладке Вставка нажмите кнопку Значки
.
-
Обзор изображения или поиск по ключевым словам. Затем выберите его и нажмите кнопку Вставить.
Дополнительные сведения о том, как добавить изображение SVG в файл, см. в статье Вставка значков в Майкрософт Office.
Настройка образа SVG
После размещения изображения SVG в документе можно настроить его внешний вид:
-
Изменение размера изображения без потери качества изображения
-
Изменение цвета заливки
 org/ListItem»>
org/ListItem»>
Добавление или изменение структуры
-
Применение предустановленного стиля, который включает как цвет заливки, так и контур
-
Применение специальных эффектов, таких как тень, отражение или свечение
Все перечисленные выше параметры доступны на вкладке Формат графики ленты, когда изображение выбрано на холсте:
Дополнительные настройки образа
Как и любая фигура в документе Office, ее можно повернуть и использовать параметры выравнивания для более точного размещения. Параметры Размер на вкладке Формат графики на ленте позволяют обрезать изображение или указать точные размеры для него:
Параметры Размер на вкладке Формат графики на ленте позволяют обрезать изображение или указать точные размеры для него:
Преобразование изображения SVG в фигуру Office
Многие SVG-файлы (включая значки Office) являются одноцветными изображениями. Но вы можете разобрать SVG-файл и настроить отдельные его части с помощью параметра
-
На холсте документа щелкните изображение правой кнопкой мыши.
-
Выберите отдельный фрагмент изображения, а затем используйте параметры на вкладке Формат фигуры на ленте, чтобы изменить его по желанию.

-
Повторите шаг 2 для каждого фрагмента изображения, который требуется изменить.
-
( толькоPowerPoint и Excel ) Когда вы закончите настройку элементов, нажмите клавиши CTRL+ щелчок, чтобы выбрать все из них. Затем на вкладке Формат фигуры на ленте выберите Группировать > Группировать. Это действие снова объединяет фрагменты вместе как один объект на случай, если впоследствии потребуется переместить или изменить размер изображения в целом.
Вот короткий видеоролик, в котором Дуг показывает, как это сделать.
Чтобы вставить SVG-файл в Office для Mac просто используйте команду Вставка >

Существует несколько действий, которые можно сделать, чтобы настроить внешний вид изображения SVG в документе. Чтобы получить доступ к этим средствам, щелкните изображение SVG, и на ленте должна появиться контекстная вкладка Формат рисунка . Давайте рассмотрим некоторые из более полезных параметров, доступных на вкладке Графический формат .
-
Заменить рисунок: позволяет выбрать другое изображение.
-
Стили графики . Коллекция содержит коллекцию предварительно определенных стилей для преобразования изображения в рисунок линии или изменения цвета заливки. В приведенном ниже примере я вставил черный рисунок велосипеда. В коллекции стилей я выбрал предустановку, которая имеет светло-синюю заливку в соответствии с моей темой компании.

-
Если вы хотите изменить цвет изображения и ни один из стилей в коллекции вам не подходит, воспользуйтесь командой Заливка рисунка. Выбранный цвет будет применен ко всему изображению.
-
Хотите сделать изображения SVG более интересными? С помощью меню Эффекты рисунка
-
Чтобы изменить (или удалить) линию вокруг изображения SVG, нажмите кнопку Контур рисунка.
 Это позволит задать цвет границы вокруг изображения. Здесь также можно использовать пипетку.
Это позволит задать цвет границы вокруг изображения. Здесь также можно использовать пипетку. -
Чтобы управлять тем, как текст перемещается вокруг изображения SVG, используйте инструмент «Обтекать текстом ».
-
Для наложения изображения на страницу можно использовать инструменты «Вперед» или «Отправить назад «. Это удобно, если вы хотите разместить другие объекты перед (или позади) изображения.
-
Область выделения упрощает выбор элементов на сложной странице.
-
С помощью выравнивания можно расположить изображение по левому краю, по центру или в других местах на странице.
-
Если у вас есть несколько изображений, которые вы хотите рассматривать как один объект, выберите первый объект, удерживая нажатой клавишу CTRL, и выберите каждый из остальных объектов, а затем нажмите кнопку Группировать. Чтобы разгруппировать их, выберите любой объект в группе, а затем щелкните Группировать > Разгруппировать.
-
С помощью команды Повернуть можно повернуть изображение и отразить его по вертикали или горизонтали.

-
Инструменты в группе Размер предназначены для обрезки и изменения размера изображения. Дополнительные сведения об инструменте обрезки см. в статье Обрезка рисунка. Чтобы настроить размер, просто укажите нужную высоту и ширину.
-
Область форматирования открывает панель, которая предоставляет удобный доступ к инструментам для изменения этого изображения.
Вы не можете вставить изображение SVG в iOS, но у вас есть некоторые средства редактирования, доступные в Office для образов SVG, которые уже есть в ваших файлах. Чтобы приступить к работе, коснитесь изображения SVG, которое вы хотите изменить, и на ленте должна появиться вкладка Графика .
-
Стили графики . Это набор стандартных стилей, которые можно добавить, чтобы быстро изменить внешний вид SVG-файла.
-
Если вы хотите изменить цвет изображения и ни один из стилей в коллекции вам не подходит, воспользуйтесь командой Заливка рисунка. Выбранный цвет будет применен ко всему изображению.
Примечание: Если вы хотите применить к отдельным частям изображения SVG заливку разного цвета, сначала его необходимо преобразовать в фигуру. Сейчас для этого необходимо открыть документ в Office для Microsoft 365 в Windows.
 org/ListItem»>
org/ListItem»>
Чтобы изменить (или удалить) линию вокруг изображения SVG, нажмите кнопку Контур рисунка. Это позволит задать цвет границы вокруг изображения.
-
Перенос текста позволяет управлять тем, как текст будет перемещаться вокруг изображения в документе.
-
Если вы хотите разместить несколько объектов поверх друг друга , функция Упорядочить позволяет перемещать выбранное изображение вверх или вниз (вперед или назад) в стеке.
-
Используйте инструмент Обрезка , если требуется только часть образа SVG.
 Выбрав изображение, коснитесь элемента Обрезка , а затем перетащите поле, чтобы обрамить изображение в нужном виде. Когда все будет готово, коснитесь элемента Обрезка
Выбрав изображение, коснитесь элемента Обрезка , а затем перетащите поле, чтобы обрамить изображение в нужном виде. Когда все будет готово, коснитесь элемента ОбрезкаСовет: Если вы хотите отменить обрезку, коснитесь изображения, снова выберите Обрезка , а затем в появившемся контекстном меню нажмите кнопку Сброс .
-
Используйте инструмент «Замещающий текст» , чтобы присвоить изображению текстовое описание для пользователей, которые используют средства чтения с экрана для чтения документа.
Чтобы изменить изображение SVG в Office для Android, коснитесь, чтобы выбрать SVG, который нужно изменить, и на ленте должна появиться вкладка Графика.
Примечание: Если вы не видите ленту, коснитесь значка правки .
-
Стили . Это набор стандартных стилей, которые можно добавить, чтобы быстро изменить внешний вид SVG-файла.
-
Если вы хотите изменить цвет изображения и ни один из стилей в коллекции не является тем, что вам нужно, заливка позволяет выбрать один из сотен цветов. Выбранный цвет будет применен ко всему изображению.
Примечание: Если вы хотите применить к отдельным частям изображения SVG заливку разного цвета, сначала его необходимо преобразовать в фигуру. Сейчас для этого необходимо открыть документ в Office для Microsoft 365 в Windows.
 org/ListItem»>
org/ListItem»>
Чтобы изменить (или удалить) линию вокруг изображения SVG, нажмите кнопку Структура. Это позволит задать цвет границы вокруг изображения.
-
Перенос текста позволяет управлять тем, как текст будет перемещаться вокруг изображения в документе.
-
Если вы хотите разместить несколько объектов поверх друг друга , функция Упорядочить позволяет перемещать выбранное изображение вверх или вниз (вперед или назад) в стеке.
-
Используйте инструмент «Обрезка графики «, если требуется только часть изображения SVG.
 Выбрав изображение, коснитесь элемента Обрезка , а затем перетащите поле, чтобы обрамить изображение в нужном виде. Когда все будет готово, коснитесь элемента Обрезка
Выбрав изображение, коснитесь элемента Обрезка , а затем перетащите поле, чтобы обрамить изображение в нужном виде. Когда все будет готово, коснитесь элемента Обрезка -
Размер и положение позволяют указать размер изображения SVG на странице.
-
Используйте инструмент «Замещающий текст» , чтобы присвоить изображению текстовое описание для пользователей, которые используют средства чтения с экрана для чтения документа.
У вас есть вопросы, замечания или предложения о Microsoft Office?
См. статью Как оставить отзыв по Microsoft Office?
Обратная связь
В последний раз эта статья была обновлена 30 октября 2022 г. в результате ваших комментариев. Если вы нашли это полезным, и особенно если вы этого не сделали, используйте приведенные ниже элементы управления обратной связи, чтобы сообщить нам, как мы можем сделать это лучше.
в результате ваших комментариев. Если вы нашли это полезным, и особенно если вы этого не сделали, используйте приведенные ниже элементы управления обратной связи, чтобы сообщить нам, как мы можем сделать это лучше.
См. также
Вставка рисунков
Вставка значков
Анимация рисунков, картинок, текста и других объектов
NLP — Преобразование текста: Word2Vec / Хабр
Статья, которая поможет вам разобраться в принципе работы и идее, стоящей за Word2Vec.
В предыдущей статье я рассказывал об основах NLP (Natural Language Processing — обработка естественного языка), и сегодня мы продолжим изучение этой темы.
Если вы еще не читали мою предыдущую статью, то советую вам сделать это: NLP — Text Encoding: A Beginner’s Guide
Перед тем, как мы начнем, обратите внимание на несколько моментов, касаемых статьи:
Я использую в статье как полное название Word2Vec, так и сокращенное w2v.

Здесь мы не будем вдаваться в подробности математических формул или объяснений того, как создавался w2v. Вы можете найти подробное руководство в научно-исследовательской статье по ссылке.
Я не буду слишком углубляться в аспекты глубокого обучения w2v, потому как хотел бы, чтобы эта статья была кратким обзором процесса, его интуитивным объяснением.
Хорошо, теперь, когда мы обозначили все моменты, давайте начнем.
Word2Vec — буквально переводится как “слово, представленное в виде числового вектора”. В этом и заключается вся суть. Главный вопрос КАК это происходит? Что ж, в этом и кроется подвох. Без паники, позвольте мне разложить все вопросы по полочкам — мы во всем с вами разберемся.
Вопрос 1: Что такое w2v?
Word2Vec — это малослойная (shallow) искусственная нейронная сеть (ANN), состоящая из двух слоев, которая обрабатывает текст, преобразуя его в числовые “векторизованные” слова. Входные данные w2v — это громадный текстовый корпус, из которого на выходе мы получаем пространство векторов (линейное пространство), размерность которого обычно достигает сотен, где каждое уникальное слово в корпусе представлено вектором из сгенерированного пространства. Она используется для преобразования лингвистического контекста в числа. Векторы слов расположены в пространстве векторов таким образом, что слова с общим контекстом, располагаются в этом многомерном пространстве в непосредственной близости друг от друга. Проще говоря, слова, близкие по значению, будут помещены рядом. Эта модель фиксирует синтаксическое и семантическое сходство между словами.
Она используется для преобразования лингвистического контекста в числа. Векторы слов расположены в пространстве векторов таким образом, что слова с общим контекстом, располагаются в этом многомерном пространстве в непосредственной близости друг от друга. Проще говоря, слова, близкие по значению, будут помещены рядом. Эта модель фиксирует синтаксическое и семантическое сходство между словами.
Вопрос 2: Каким образом модель фиксирует семантическое и синтаксическое сходство в векторах слов?
Здесь нужно объяснить многое, но я постараюсь не усложнять.
Сначала давайте разберемся, как мы можем понять семантическое сходство между двумя словами? Как объяснить то, что при преобразовании слов в числа расстояние расположения слов по отношению друг к другу зависит от сходства значения? Это несколько очевидных вопросов, ответить на которые мы сможем, когда поймем, что из себя представляют выходные данные модели, и как измерить близость. Затем мы узнаем, как создаются эти векторы.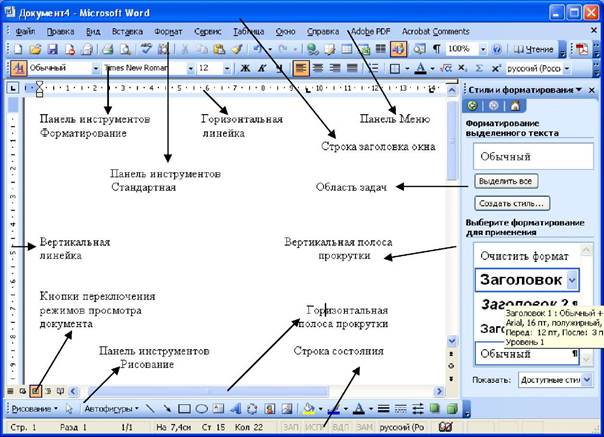
Давайте разберем следующий пример:
возьмем 4 слова: King (король), Queen (королева), Man (мужчина), Woman (женщина).
Если бы я группировал похожие слова вместе, очевидно я бы сделал это следующим образом: (King, Man) и (Queen, Woman). А если, я бы группировал противоположные слова вместе, я бы сделал это так (King, Queen) и (Man, Woman).
Вы могли обратить внимание, что слово King схоже по значению с Man и противоположно Queen, а слово Queen схоже с Woman и противоположно King.
Теперь главный вопрос: как векторное представление сможет уловить эту суть?
Возможно ли это вообще? Да, это возможно.
Давайте разберемся. Для начала, чтобы разобраться в фиксировании синонимов и антонимов, мы должны понять, как сравниваются два вектора и сделать вывод об их математическом сходстве. Нам необходимо сравнить метрики двух векторов.
Чаще всего метрики сходства делятся на две разные группы:
Метрики сходства:
Корреляция Пирсона
Корреляция Спирмена
Коэффициент корреляции Кендэлла
Коэффициент Охаи
Коэффициента Жаккарда
2. Метрики расстояния:
Метрики расстояния:
Евклидово расстояние
Манхэттенское расстояние
Сейчас мы не будем подробно останавливаться на том, как рассчитывать метрики. Но объяснить это можно следующим образом: чем ближе два вектора, тем выше у них коэффициент сходства и меньше расстояние между ними. Чем дальше два вектора, тем меньше их коэффициент сходства и больше расстояние между ними соответственно.
Вы можете представить это как:
1 — Расстояние = Сходство или
1 — Сходство = Расстояние.
Сходство и Расстояние обратно пропорциональны друг другу.
Итак, теперь мы понимаем принцип сравнения двух векторов по их сходству. Вернемся к нашему примеру с набором слов King, Queen, Man и Woman, наше общее понимание будет следующим:
Вектор слова King должен иметь высокий коэффициент сходства и меньшее расстояние с вектором слова Man, а вектор слова Queen должен иметь высокий коэффициент сходства и меньшее расстояние с вектором слова Woman и наоборот.
Для того, чтобы лучше понять это, взгляните на график:
Векторы слов в многомерном пространствеТеперь мы знаем, как можно измерять синонимы и антонимы слов математическим способом.
Возникает главный вопрос: как получить наши целевые векторы?
Вопрос 3: Как w2v преобразует слова в числовые векторы, сохраняя семантическое значение?
Это можно сделать двумя способами, а именно:
CBOW: попытаться предсказать целевое слово, используя слова из контекста.
2. Skip-Gram: попытаться предсказать слова контекста, используя целевое слово.
Давайте об этом поподробнее:
Но прежде чем мы начнем, давайте обозначим ключевые слова и их значение:
Целевое слово (Target Word): слово, которое предсказывается.
Контекстное слово (Context Word): каждое слово в предложении, кроме целевого слова.
Размерность вложения (Embedding Dimension): количество измерений пространства векторов, в которые мы хотим преобразовать слова.
Разберемся на примере:
Предложение: “The quick brown fox jumps over the lazy dog”(Перевод: “Шустрая бурая лиса прыгает через ленивого пса.”).
Допустим, мы пытаемся предсказать слово “fox”, тогда “fox” будет нашим целевым словом.
Остальные слова будут контекстными.
CBOW, Continuous Bag of Words, — это процесс, в котором мы пытаемся предсказать целевое слово с помощью контекста. Мы обучим нашу модель запомнить слово “fox” в контексте, который мы используем в качестве входных данных. CBOW обычно хорошо работает на небольших наборах данных.
Skip-Gram — это процесс, в котором мы пытаемся предсказать контекстные слова с помощью целевого слова, что в точности противоположно CBOW. Skip-gram лучше работает на больших наборах данных.
Источник: GoogleВходное слово унитарно кодируется (One-Hot) и отправляется в модель одно за другим. Скрытый слой пытается предсказать наиболее вероятное слово, основываясь на весах, собранных в слое.
Мы избрали размерность нашего вектора равной 300, поэтому каждое наше слово будет преобразовано в 300-мерный вектор.
Последний слой нашей модели w2v — это классификатор Softmax, который определяет наиболее вероятное выходное слово.
Входными данными сети является one-hot вектор, представляющий входное слово, и метка, которая также является one-hot вектором, представляющим целевое слово, однако выходные данные сети представляют собой вероятностное распределение целевых слов, но не обязательно one-hot вектор, как метки.
Строки матрицы весов скрытого слоя на самом деле являются векторами слов (встраивание слов)!
Скрытый слой работает как справочная таблица. Выходные данные скрытого слоя — это «вектор слов» для входного слова.
Количество нейронов на скрытом слое должно равняться размерности вложений, которую мы задаем.
Допустим, в нашем корпусе 5 слов:
Предложение 1: Have a Good Day
Предложение 2: Have a Great Day
Сколько уникальных слов в этих примерах? “have”, “a”, “good”, “great”, “day” = 5
Теперь предположим, что наше целевое слово для предложения 1 — “good”.
Когда я скармливаю остальную часть контекстных слов своей модели, она должна понять, что “good” — это именно то слово, которое она должна предсказать для предложения 1.
Предположим, что для предложения 2 наше целевое слово — “great”.
Когда я скармливаю своей модели остальную часть контекстных слов, она должна понять, что для предложения 2 корректное слово для предсказания — “great”.
Если вы внимательно посмотрите, то увидите, что когда мы уберем целевые слова, останутся одинаковые для двух предложений контекстные слова. Так каким образом модель точно предскажет, какое из них подойдет? На самом деле это не имеет значения, потому что она предсказывает наиболее вероятное слово, и в нашем случае нет неправильного варианта — подойдут оба “good” и “great”. Таким образом, возвращаясь к фиксации синонимов, тут оба слова “good” и “great” будут по сути означать одно и тоже и являться очень вероятным выходным словом для этих конкретных контекстных слов. Именно так наша модель изучает семантическое значение слов. Говоря простыми словами, если я могу использовать слова взаимозаменяемо, тогда изменяется только мое целевое слово, а не контекстные слова, т.е. любые два похожих слова, имеющих один синоним, будут весьма вероятным результатом для контекстных слов, скормленных модели — они будут иметь почти одинаковые числовые значения. Если у них почти одинаковые числовые значения, их векторы должны располагаться близко согласно их метрикам сходства. Таким образом мы фиксируем семантические значения.
Таким образом мы фиксируем семантические значения.
Вопрос 4: Как работает модель?
Мы разберемся с архитектурой модели за четыре шага.
Подготовка данных
Входные данные
Скрытый слой
Выходные данные
Собственно из этих структур и состоит модель.
Подготовка данных:
Для начала давайте разберемся, как происходит подготовка и передача данных в нашу модель.
Рассмотрим предыдущий пример еще раз — ‘have a good day’. Модель преобразует это предложение в пары слов вида (контекстное слово, целевое слово). Пользователем устанавливается размер окна для контекстного слова и если оно равно двум, то пары слов будут выглядеть следующим образом: ([have, good], a), ([a, day], good). С помощью этих пар слов модель пытается предсказать целевое слово с учетом контекстных слов.
Входные данные:
Входными данными этих моделей является не что иное, как большой one-hot encoded вектор.
Давайте разберем на примерах:
Предположим, что в нашем текстовом корпусе 10000 уникальных слов, и мы хотим, чтобы наша размерность вложения соответствовала 300-мерному вектору.
Таким образом, входными данными будет вектор с размерностью 10000 с 0 для всех других слов, в то время как контекстное слово будет 1. Размерность нашего входного вектора составляет 1 x 10000.
Скрытый слой:
Скрытый слой — это та самая матрица весов со всеми словами, которые в начале случайным образом преобразованы в по 300 измерениям. Затем мы обучаем нашу модель подбирать значения этих весов, чтобы на каждом этапе обучения модель лучше справлялась с предсказанием.
Теперь нейроны в скрытом слое точно равны размерности вложений, которую мы выбираем, т.е. 300.
Таким образом, размерность нашей матрицы весов составляет 10000 x 300.
Выходной слой:
Выходной слой — это не что иное, как слой softmax, который использует значения вероятности для прогнозирования результатов среди 10000 векторов, которые у нас есть. Размер нашего выходного вектора равен 1 x 300.
Размер нашего выходного вектора равен 1 x 300.
Теперь давайте попробуем понять базовую математику, которая за этим стоит
Входные данные: 1 x 10000
Скрытый слой: 10000 x 300
Выходные данные = Softmax (Входные данные x Скрытый слой) (матричное умножение) = 1 x n * n x dim = 1 x dim = 1 x 300
Выше я объяснил архитектуру CBOW, а чтобы понять Skip-gram, нам просто нужно изменить порядок ввода и вместо контекстного слова и определения целевых слов, вводить целевые слова и пытаться определить контекстные слова. CBOW — это несколько способов ввода и только один вывод, Skip-gram — это один ввод и несколько выводов.
В Skip-gram мы можем определять количество контекстных слов, которое по нашему желанию бы предсказывалось, и, соответственно, мы можем создать пары входных-выходных значений.
Например: ‘have a good day’
Если мы установим размер окна равным 2, то обучающие пары будут следующими:
Целевое слово: good
Контекстные слова: have, a, day
(good, have)
(good, a)
(good, day)
Таким образом, модель учится и пытается предсказать слова, близкие к целевому слову.
Вопрос 5: Какова цель преобразования слов в векторы?
Сейчас синтаксическое и семантическое значения хорошо отражены в векторах слов, поэтому они могут идеально использоваться в качестве входных данных для любых других сложных программ NLP, где может появиться необходимость в понимании сложных разговоров людей или контекста языков.
W2V сама по себе является нейронной сетью, но она представляет из себя скорее вспомогательную функцию, которая облегчает работу другим NLP приложениям.
Реализация:
Мы не будем создавать модель w2v с нуля, поскольку у нас уже есть библиотека Gensim, которая может нам помочь, если у нас есть собственный конкретный доменно-ориентированный корпус данных.
Или, если вы работаете с общими текстовыми данными на английском языке, я бы порекомендовал вам попробовать GloveVectors, которая была создана Стэнфордским Университетом с использованием миллиардов текстов из Wikipedia, Twitter и Common Crawl.
Заключение:
Мы разобрались в концепциях Word2Vec и теперь лучше понимаем, что такое вложения (embedding) слов. Теперь мы понимаем разницу между Skip-Gram и CBOW. Мы также интуитивно понимаем, как создаются вложения слов, и что скрытый слой представляет собой гигантскую таблицу поиска вложений слов. Также у нас появилось понимание того, как фиксируются семантические и синтаксические значения. Вложения слов могут быть очень полезными, а для многих задач NLP даже фундаментальными, не только для традиционного текста, но и для генов, языков программирования и других типов языков.
В следующий раз мы рассмотрим BeRT преобразование текста, а пока желаю вам успехов в обучении!
Материал подготовлен в рамках курса «Deep Learning. Basic».
Как создавать векторы в Word
Вектор — это математический объект, характеризующийся величиной и направлением. Чтобы определить вектор, используйте черту вверху (), стрелку вверху (), полужирный шрифт или готический шрифт ().
Word предлагает различные способы создания вектора в документе:
| Используя уравнение — , мы настоятельно рекомендуем этот способ! | |
| Использование Автозамены по математике | |
| Использование диалогового окна Symbol |
I. Использование уравнения:
Этот способ идеален, если вам не нужно заботиться о формате и совместимости с предыдущими версиями Microsoft Office (рекомендуемый подход для физических наук и математики, требующих большого количества математических текст с одинаковыми шрифтами для всех уравнений и символов):
1. В абзаце, куда вы хотите вставить вектор , нажмите Alt+= , чтобы вставить блок экватора:
2. В блоке вождения введите модуль вектора и выберите его. Это может быть одна буква, несколько букв или даже выражение.
В блоке вождения введите модуль вектора и выберите его. Это может быть одна буква, несколько букв или даже выражение.
Например: .
3. На вкладке Equation в 9Группа 0003 Структуры , нажмите кнопку Акцент :
В списке Акцент выберите Бар или Стрелка вправо Над :
или
Примечание : Если вы хотите продолжить работу с этим уравнением, дважды щелкните стрелку вправо, чтобы выйти из поля под вектором: → → . Итак, чтобы продолжить работу с уравнением, в нем не должно быть выделенных данных.
II. Использование автозамены для математики:
Когда вы работаете со многими документами и часто нужно вставить один специальный символ, вам не нужно каждый раз вставлять уравнение. Microsoft Word предлагает полезную функцию под названием AutoCorrect . Параметры AutoCorrect в Microsoft Word предлагают два разных способа быстрого добавления любого специального символа или даже
большие куски текста:
Параметры AutoCorrect в Microsoft Word предлагают два разных способа быстрого добавления любого специального символа или даже
большие куски текста:
- Использование в Заменить текст при вводе функция Автозамена вариантов.
- Использование параметров Math AutoCorrect :
Используя этот метод, вы можете воспользоваться параметрами Math AutoCorrect без вставки уравнения. Чтобы включить или выключить AutoCorrect символов Math , выполните следующие действия:
1. В файле 9Вкладка 0004, нажмите Параметры :
2. В диалоговом окне Параметры Word на Вкладка Правописание нажмите кнопку Параметры автозамены… :
3. В диалоговом окне AutoCorrect на вкладке Math AutoCorrect выберите параметр Использовать правила Math AutoCorrect за пределами математических областей :
В диалоговом окне AutoCorrect на вкладке Math AutoCorrect выберите параметр Использовать правила Math AutoCorrect за пределами математических областей :
После нажатия OK , вы можете использовать любое из перечисленных Имен символов , и Microsoft Word заменит их соответствующими символами:
Примечание : Если вам не нужна последняя замена , щелкните Ctrl+Z , чтобы отменить его.
III. Использование диалогового окна «Символ»:
Microsoft Word предлагает очень удобную возможность комбинировать два символа (см. Наложение символов). Чтобы добавить какой-либо элемент к символу, например, bar , апостроф и т. д., введите символ и сразу вставьте векторный знак из подмножества Комбинирование диакритических знаков для символов любого шрифта (если он существует).
Чтобы объединить элемент с введенным символом, откройте диалоговое окно Символ :
На вкладке Вставка в группе Символы выберите кнопку Символ , а затем нажмите Дополнительные символы. . :
. :
В диалоговом окне Symbol :
- В списке Font выберите шрифт Segoe IU Symbol ,
- При необходимости, чтобы быстрее находить символы, в списке Подмножество выберите подмножество Комбинирование диакритических знаков для символов ,
- Выберите символ:
- Нажмите кнопку Вставить , чтобы вставить символ,
- Нажмите кнопку OK , чтобы закрыть диалоговое окно Symbol .
Встраивание слов: основы. Создать вектор из слова | by Hariom Gautam
Создание вектора из слова
Методы встраивания слов:
- Встраивание на основе частоты:
a. Количество векторов
b. TF-IDF
в. Матрица совпадений - Встраивание на основе предсказания (word2vec)
a. CBOW
б. Скип-грамм - gloVe(Global Vector)
Зачем вставлять слова:
* Компьютер понимает только числа.
* Вложения слов — это тексты, преобразованные в числа.
* Он способен фиксировать контекст слова в документе, семантическое и синтаксическое сходство, связь с другими словами и т. д.
* Встраивание слов — это изученное представление текста, в котором слова, имеющие одинаковое значение, имеют аналогичное представление.
Вектор подсчета основан на частоте каждого слова
Как сделать векторы подсчета:
Давайте разберемся на примере:
Предположим, что в нашем корпусе есть 2 документа:
Document1 = ‘Он ленивый мальчик. Она также ленива».
Document2 = «Нирадж — ленивый человек».
Создать словарь корпуса (уникальное слово в корпусе): ‘Neeraj’,’person’]
Здесь количество уникальных слов (длина корпуса) равно 6.
Создайте счетную матрицу:
Теперь столбец можно понимать как вектор слов для соответствующего слова.
Пример: «Он» имеет вектор счета [1,0]
слово «ленивый» имеет вектор счета [2,1]
слово «человек» имеет вектор счета [0,1]
Изменение вектора счета:
- вы можете поставить счет 1, когда количество любого слова> 1, т.
 е. это показывает, что это конкретное слово присутствует или нет.
е. это показывает, что это конкретное слово присутствует или нет. - Для очень большого корпуса трудно построить такую матрицу терминов документов, поэтому берем то слово, количество которого больше некоторого порога.
- Частота стоп-слов будет больше, и это не повлияет на документ, поэтому удалите стоп-слова перед созданием вектора счета.
* Ограничение вектора подсчета заключается в том, что общие слова появляются часто, а частота важных слов очень мала.
* термин частотно-обратная частота документа (tf-idf) дает вес тому слову, которое встречается очень редко. т. е. фиксирует уникальность.
* встречаемость слова в одном документе, но во всем корпусе.
* этот метод будет наказывать такие высокочастотные слова.
Формула tf-idf:
как именно работает TF-IDF:
Возьмем 2 документа как:
- Частота термина (TF) слова «это» в Документе 1 равна 1/8
- потому что, TF = (Количество терминов t в документе)/(Количество терминов в документе)
- TF слова «Это в документе 2 равно 1/5»
Обозначает вклад слова в документ то есть слова, относящиеся к документу, должны быть частыми.
Например: документ о Месси должен содержать слово «Месси» в большом количестве.
- IDF = log(N/n), где N — общее количество документов, а n — количество документов, в которых появился термин t.
- IDF(This) = log(2/2) = 0,
Если слово встречается в каждом документе данного корпуса, то IDF этого слова = 0
* IDF(Месси) = log(2/1) = 0,301.
Объединение TF и IDF вместе:
TF-IDF(Этот,Документ1) = (1/8) * (0) = 0
TF-IDF(Этот, Документ2) = (1/5) * (0) = 0
TF-IDF(Месси, Документ1) = (4/8)*0,301 = 0,15
Вариант TF-IDF:
- tf-idf — это произведение tf и idf, если значение tf очень велико, то значение tf-idf будет больше.
- Чтобы избежать этого, мы используем логарифмический метод под названием BM25.
* Похожие слова имеют тенденцию встречаться вместе и, например, будут иметь схожий контекст. Яблоко — это фрукт. Манго — это фрукт.
* Яблоко и манго, как правило, имеют схожий контекст, то есть фрукты.
*есть две концепции, которые необходимо прояснить – совместное возникновение и контекстное окно.
1) Совместное появление — Для данного корпуса, совместное появление пары слов, скажем, w1 и w2 — это количество раз, когда они появляются вместе в контекстном окне.
2) Контекстное окно — Контекстное окно определяется номером и направлением.

- Статистика совпадения слов вычисляется просто путем подсчета того, как два или более слова встречаются вместе в данном корпусе.
Например, рассмотрим корпус, состоящий из следующих документов:
умный пенни и глупый фунт.
сэкономленная копейка — это заработанная копейка.
Пусть count(w(next)|w(current)) представляет, сколько раз слово w(next) следует за словом w(current) , мы можем обобщить статистику совпадений для слов « a» и «penny» как:
В приведенной выше таблице показано, что за «a» дважды следует «penny», а слова «заработанный», «сэкономленный» и «мудрый» следуют за «penny» по одному разу в нашем корпусе. Таким образом, «заработанный» в одном из трех случаев может появиться после «копейки».
Таким образом, «заработанный» в одном из трех случаев может появиться после «копейки».
- Матрица совпадений разлагается с использованием таких методов, как PCA, SVD и т. д., на факторы, и комбинация этих факторов формирует векторное представление слов.
Вы выполняете РСА на приведенной выше матрице размера NXN. Вы получите основные компоненты V. Вы можете выбрать k компонентов из этих V компонентов. Таким образом, новая матрица будет иметь вид N X k.
И одно слово вместо того, чтобы быть представленным в N измерениях, будет представлено в k измерениях, сохраняя почти такое же семантическое значение. k обычно порядка сотен.
Преимущества матрицы совпадений:
- Она сохраняет семантическую связь между словами. то есть мужчина и женщина, как правило, ближе, чем мужчина и яблоко.
- В своей основе он использует SVD, который обеспечивает более точное представление вектора слов, чем существующие методы.
- Он использует факторизацию, которая является четко определенной задачей и может быть эффективно решена.

- Он должен быть вычислен один раз и может быть использован в любое время после вычисления. В этом смысле он быстрее по сравнению с другими.
Недостатки матрицы совпадений:
- Для хранения матрицы совпадений требуется огромная память.
Но эту проблему можно обойти, разложив матрицу вне системы, например, в кластерах Hadoop и т. д., и сохранить.
Модель, основанная на частоте:
До сих пор мы видели детерминированные методы определения векторов слов. Но эти методы оказались ограниченными в своих представлениях слов, пока Митолов и др. Эл не представили word2vec сообществу НЛП.
Модель на основе предсказания:
Эти методы были основаны на предсказании в том смысле, что они давали вероятности словам и оказались современными для таких задач, как аналогия слов и сходство слов. Они также смогли выполнить такие задачи, как Король — мужчина + женщина = Королева, что считалось почти волшебным результатом.
