Значение должно быть скаляром или матрицей маткад
Значение должно быть скаляром или матрицей маткад
Автор Alexandr Molskiy задал вопрос в разделе Другие языки и технологии
MathCAD значений должно быть скаляром и получил лучший ответ
Ответ от А[гуру]
Потому что у тебя переменная t — вектор. Нижний индекс означает элементы массива (вектора, матрицы) . Надо писать так t1, t2 — без нижнего индекса.
1.4. Техника безопасности при работе с «болгаркой»
Болгарка — довольно опасный
подробнее.
Предполагается, что стрелок удерживает пистолет в правой руке.
Главное в
подробнее.
Некоторые из операторов Mathcad имеют особые значения в применении к векторам и матрицам. Например, символ умножения означает просто умножение, когда применяется к двум числам, но он же означает скалярное произведение, когда применяется к векторам, и умножение матриц — когда применяется к матрицам.
Таблица описывает векторные и матричные операторы Mathcad. Многие из этих операторов доступны из палитры символов. Обратите внимание, что операторы, которые ожидают в качестве аргумента вектор, всегда ожидают вектор-столбец, а не вектор-строку.
Чтобы заменить вектор-строку на вектор-столбец, используйте оператор транспонирования [Ctrl]1.
Операторы, не перечисленные в этой таблице, не будут работать для векторов и матриц. При попытке использовать такой оператор с вектором или матрицей Mathcad будет отмечать это сообщением об ошибке «неверная операция с массивом», или «нескалярная величина». Можно, однако, использовать оператор векторизации, чтобы выполнить любую скалярную операцию или функцию поэлементно на векторе или матрице. См. раздел «Выполнение параллельных вычислений» ниже в этой главе. Рисунок 9 показывает использование некоторых векторных и матричных операций.
Рисунок 9: Векторные и матричные операции.
В следующей таблице
- A
- u
- M
- и представляют отдельные элементы векторов u и v.
- z представляет скаляр.
- m и n представляют целые числа.
и B представляют массивы (векторы или матрицы).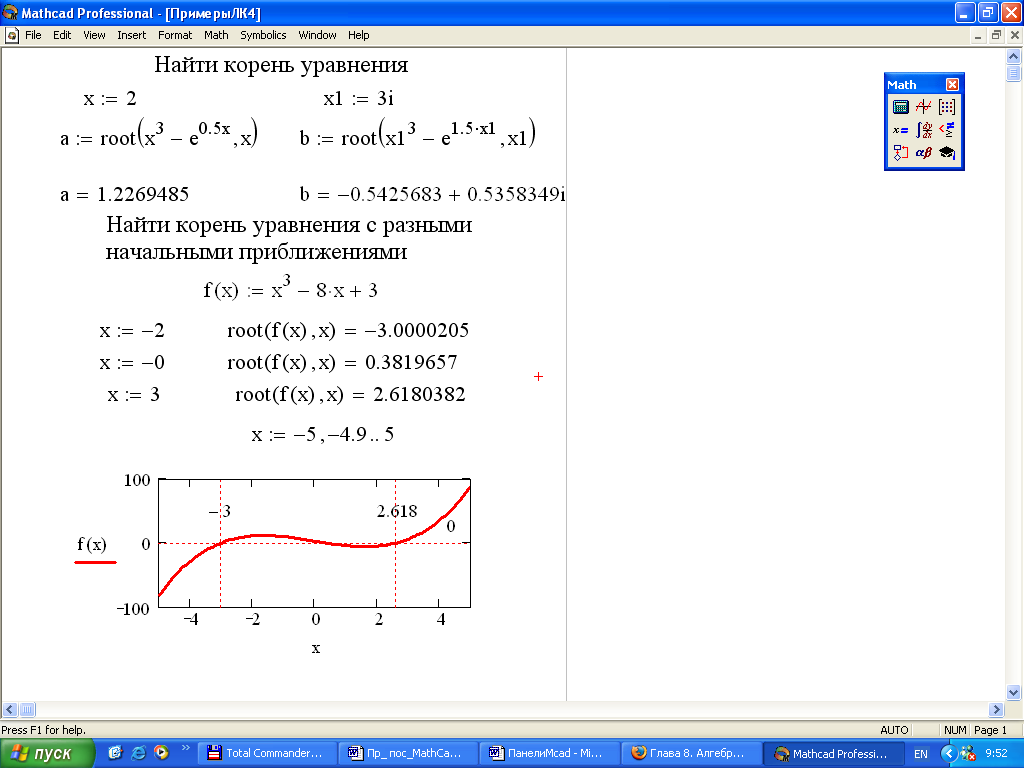
и v представляют векторы.
представляет квадратную матрицу.
| Операция | Обозначение | Клавиши | Описание | |
| Умножение матрицы на скаляр | * | Умножает каждый элемент A на скаляр z. | ||
| Скалярное произведение | * | Возвращает скаляр: . Векторы должны иметь одинаковое число элементов. | ||
| Матричное умножение | * | Возвращает произведение матриц A и B, число столбцов в A должно соответствовать числу строк в B. | ||
| Умножение матрицы на вектор | * | Возвращает произведение матриц A и v, число столбцов в A должно соответствовать числу строк в v. | ||
| Деление | / | Делит каждый элемент массива на скаляр z. | ||
| Сложение векторов и матриц | A + B | + | Складывает соответствующие элементы A и B, массивы A и B должны иметь одинаковое число строк и столбцов. | |
| Скалярная сумма | A + z | + | Добавляет z к каждому элементу A. | |
| Векторное и матричное вычитание | A — B | — | Вычитает соответствующие элементы массива A из элементов массива B, массивы A и B должны иметь одинаковые размеры. | n-ная степень квадратной матрицы M (использует умножение матриц). n должен быть целым числом. M −1 представляет матрицу, обратную к M, другие отрицательные степени — степени обратной матрицы. Возвращает матрицу. |
| Длина вектора | |v| | | | Возвращает , где — вектор, комплексно сопряженный к v. | |
| Детерминант | |M | | | Возвращает детерминант квадратной матрицы M, результат — скаляр. | |
| Транспонирование | A T | [Ctrl]1 | Возвращает матрицу, чьи строки — столбцы А, и чьи столбцы — строки A. А может быть вектором или матрицей. | |
| Векторное произведение | u x v | [Ctrl]8 | Возвращает векторное произведение для векторов с тремя элементами u и v. | |
| Комплексное сопряжение | « | Меняет знак мнимой части каждого элемента A. | ||
| Суммирование элементов | [Ctrl]4 | Суммирует элементы вектора v; возвращает скаляр. | ||
| Векторизация | [Ctrl] — | Предписывает в выражении с A производить операции поэлементно. Полное описание дано в разделе «Выполнение параллельных вычислений» | ||
| Верхний индекс | A | [Ctrl]6 | Извлекает n-ный столбец массива A. Возвращает вектор. | |
| Нижний индекс (вектора) | vn | [ | n-ный элемент вектора. | |
| Нижние индексы матрицы | Am,n | [ | Элемент матрицы, находящийся в m-ном ряду и n-ной строке. |
Исправляем ошибки: Нашли опечатку? Выделите ее мышкой и нажмите Ctrl+Enter
MathCAD — это система, ориентированная на пользователя, который не обязан знать абсолютно ничего о программировании. Создатели MathCAD изначально поставили перед собой такую задачу, чтобы дать возможность профессионалам — математикам, физикам и инженерам самостоятельно проводить сложные расчеты, не обращаясь за помощью к программистам. Несмотря на блестящее воплощение этих замыслов, выяснилось, что совсем без программирования MathCAD серьезно теряет в своей силе, в основном, из-за недовольства пользователей, знакомых с техникой создания программ.
Создатели MathCAD изначально поставили перед собой такую задачу, чтобы дать возможность профессионалам — математикам, физикам и инженерам самостоятельно проводить сложные расчеты, не обращаясь за помощью к программистам. Несмотря на блестящее воплощение этих замыслов, выяснилось, что совсем без программирования MathCAD серьезно теряет в своей силе, в основном, из-за недовольства пользователей, знакомых с техникой создания программ.
В очень ранних версиях MathCAD встроенного языка программирования не было. Чтобы применять привычные операции проверки условий и организовывать циклы, приходилось изобретать причудливую смесь из встроенных функций if и until, а также комбинаций ранжированных переменных. Но надо отметить, что использование ранжированных переменных — мощный аппарат MathCAD, похожий на применение циклов в программировании. В подавляющем большинстве случаев намного удобнее организовать циклы с помощью ранжированных, чем заниматься для этого программированием.
И тем не менее встроенный язык программирования MathCADпозволяет решать самые различные, в том числе и довольно сложные, задачи и является серьезным подспорьем для расчетов. Поэтому последние версии MathCAD имеют не очень мощный, но весьма элегантный собственный язык программирования.
Для вставки программного кода в документы MathCAD имеется специальная панель инструментов . Большинство кнопок этой панели выполнено в виде текстового представления операторов программирования, поэтому их смысл легко понятен. Операторы программирования могут быть введены только с этой панели, но никак не с клавиатуры (можно еще их вводить с помощью сочетаний клавиш, которые приведены в тексте всплывающей подсказки).Создание программного блока начинается с команды
. Нажатие этой клавиши приведет к тому, что в рабочей области документа появится вертикальная черта, а справа от нее — два пустые поля ввода . Вертикальная черта означает, что строки, находящиеся справа от нее, образуют линейную программную последовательность операций.
Для определения функции это будет выглядеть следующим образом:
Внутри программы можно использовать глобальные переменные документа, но изменить их значение внутри программы никак нельзя. Можно создать в программе другие переменные, доступ к которым может осуществляться только из самой программы. Эти переменные называются локальными переменными. Локальные переменные «не видны» извне. Локальная переменная создается с помощью знака локального присвоения
с панели Programming. Для оператора локального присваивания, так же как и для операторов обычного и глобального присваивания, можно изменить внешний вид так, чтобы он выглядел как обычный знак равенства. Для этого достаточно вызвать контекстное меню этого оператора и в нем выбрать команду View Definition As/Equal.
Для оператора локального присваивания, так же как и для операторов обычного и глобального присваивания, можно изменить внешний вид так, чтобы он выглядел как обычный знак равенства. Для этого достаточно вызвать контекстное меню этого оператора и в нем выбрать команду View Definition As/Equal.Последняя строка любой программы не должна содержать никаких управляющих операторов. Эта строка задает значение, возвращаемое программой. В качестве этого значения может быть скаляр (число или переменная), вектор или матрица. Таким образом, последняя строка программы может содержать имя локальной переменной либо некоторое математическое выражение, куда входят как локальные, так и глобальные переменные, либо вектор или матрицу.
Вставить строку программного кода в уже созданную программу можно в любой момент с помощью той же самой кнопки Add Line. Для этого следует поместить на нужное место внутри программы линии ввода.
Если вертикальная линия ввода находится в начале текущей строки, то нажатие кнопки
приведет к появлению новой строки перед текущей строкой, если вертикальная линия ввода находится в конце строки, то нажатие кнопки приведет к появлению новой строки после текущей.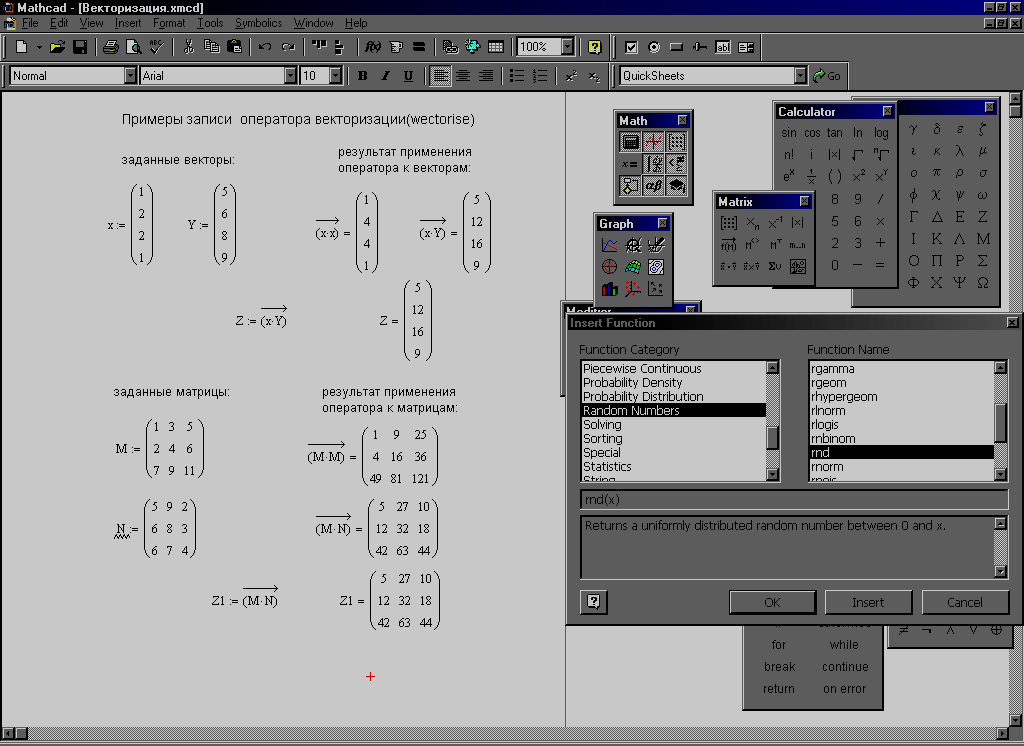 Можно выделить только часть текущей строки, что повлияет на положение новой строки в программе (например, если необходимо для некоторого условия выполнить не одно действие, а несколько). Таким образом, основной принцип создания программных модулей заключается в правильном расположении строк кода. Ориентироваться в их действии довольно легко, т.к. фрагменты кода одного уровня сгруппированы в программе с помощью вертикальных черт.
Можно выделить только часть текущей строки, что повлияет на положение новой строки в программе (например, если необходимо для некоторого условия выполнить не одно действие, а несколько). Таким образом, основной принцип создания программных модулей заключается в правильном расположении строк кода. Ориентироваться в их действии довольно легко, т.к. фрагменты кода одного уровня сгруппированы в программе с помощью вертикальных черт.Проверка условий в программах.
Программы в MathCAD могут быть не только линейными, но и разветвленными. Одним из вариантов ветвления в программах является проверка условия. Условия могут проверять значения как локальных, так и глобальных переменных, а также выражений, содержащих эти переменные.
Для проверки условий в программах MathCAD служит оператор if
. В поле ввода справа нужно ввести условие. Для ввода условий служит панель Boolean. На этой панели есть кнопки, предназначенные для проверки условий , а также кнопки, предназначенные для вставки логических операций (логическое отрицание, операция «и», операция «или», операция «исключающее или»). Вторые позволяют создавать сложные условия. В поле ввода слева нужно ввести строку программы, которая должна выполняться, если введенное условие истинно.
Вторые позволяют создавать сложные условия. В поле ввода слева нужно ввести строку программы, которая должна выполняться, если введенное условие истинно.Если для условия «истинно» необходимо выполнение нескольких строк программы, надо воспользоваться кнопкой
.Если невыполнение условия должно привести к выполнению какого-либо иного программного кода, можно в строке, следующей за оператором if, вставить оператор
. В поле ввода слева от этого оператора необходимо ввести строку программы, которая будет выполняться только в том случае, если не выполнилось условие, заданное в операторе if.Следует помнить, что если в программе введено подряд несколько строк с оператором if
, то выражение слева от оператора otherwise будет выполнено только в том случае, если не выполняются условия, заданные во всех операторах if.Другим очень важным элементом при создании нелинейных программ являются циклы. Циклы позволяют повторять несколько раз выполнение одного и того же программного блока.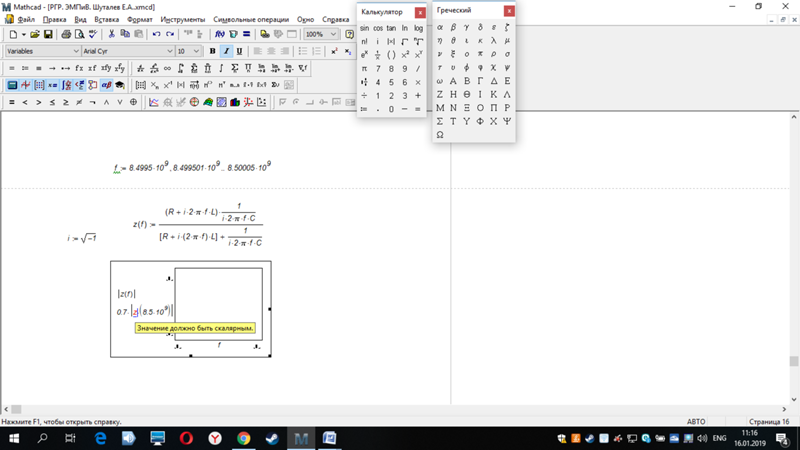 Для создания циклов в MathCAD предусмотрено два оператора for и while.
Для создания циклов в MathCAD предусмотрено два оператора for и while.
Цикл for — цикл со счетчиком.
В таких циклах создается некоторая переменная-счетчик, значение которой изменяется после каждого выполнения тела цикла. Выход из цикла происходит при достижении этой переменной заданного значения. Этот оператор вводится с панели Programming клавишей for
. В поле ввода после слова for следует указать имя переменной — счетчика. Это может быть любое имя, которое не использовалось ранее в программе. Внутри цикла можно использовать эту переменную в любых выражениях, нельзя только присваивать ей никакого значения. В поле ввода после знака следует указать диапазон значений переменной-счетчика. Вводить диапазон в данном случае следует так же, как и при создании ранжированной переменной. Вместо диапазона в данном поле ввода можно указать имя некоторого массива (вектора или матрицы). В этом случае переменная-счетчик будет последовательно принимать значения всех элементов этого массива. Возможность перебора элементов массива не может быть реализована с помощью цикла while, поэтому именно в таких случаях цикл for и является незаменимым. В поле ввода под словом for следует ввести тело цикла.
Возможность перебора элементов массива не может быть реализована с помощью цикла while, поэтому именно в таких случаях цикл for и является незаменимым. В поле ввода под словом for следует ввести тело цикла.Пример: Заполнить вектор числами от xнач до xкон с шагом h. Затем определить сумму элементов этого вектора и найти их среднее арифметическое значение.
Цикл while — цикл, который выполняется до тех пор, пока выполняется определенное условие.
В поле ввода справа от слова while следует ввести условие. Это условие строится по тем же правилам, что и в операторе if. Оно будет проверяться после каждого выполнения тела цикла и в тот момент, когда условие перестанет выполняться, повторение тела цикла прекратится. В поле ввода ниже слова while следует ввести тело цикла (напомним, что для ввода нескольких строк в теле цикла надо воспользоваться кнопкой Add Line).Пример1: Вычислить сумму
с точностью е.
Пример2: Найти первый элемент, превышающий определенный порог.
Использование операторов break и continue.
Иногда возникает необходимость повлиять на выполнение цикла некоторым образом, например, прервать его выполнение по какому-либо условию или выполнять некоторые итерации не так, как другие. Для этого и служат операторы break и continue.
Оператор break, если он расположен внутри цикла, означает немедленное прекращение выполнения текущей итерации и выход из цикла. Если есть необходимость прекратить выполнение цикла по какому-либо условию, то следует использовать конструкцию следующего вида break if (условие).
Пример: Выделить из массива все элементы от начала и до первого вхождения в него заданного числа.
Оператор continue используется для того, чтобы немедленно перейти в начало цикла и начать следующую итерацию. Этот оператор также обычно используется в составе конструкции вида continue if (условие). Оператор continue используется в случаях, когда необходимо чтобы некоторые вычисления производились для одних итераций и не производились для других.
Оператор continue используется в случаях, когда необходимо чтобы некоторые вычисления производились для одних итераций и не производились для других.
Пример: Требуется заполнить элементы квадратной матрицы в шахматном порядке.
Оператор return (возврат значения).
Как мы уже указывали, результат выполнения программного модуля помещается, как правило, в последней его строке. Но можно прервать выполнение программы в любой ее точке (например, с помощью условного оператора) и выдать некоторое значение, применив оператор return. В этом случае при выполнении указанного условия значение, введенное в поле ввода после return, возвращается в качестве результата, и никакой другой код больше не выполняется. Вставляется в программу оператор return с помощью одноименной кнопки панели Programming
. Пример:Система MathCAD предоставляет пользователю некоторый контроль над ошибками, которые могут возникнуть при вычислении выражений или при выполнении программ. Для этой цели служит оператор on error, который можно вставить с помощью одноименной кнопки панели Programming
Для этой цели служит оператор on error, который можно вставить с помощью одноименной кнопки панели Programming
В поле ввода слева может быть введено текстовое выражение, сообщающее об ошибке
Конечно, если программа содержит только простейшие математические операции, то никаких ошибок, кроме деления на нуль или превышения наибольшего допустимого числа в ней возникнуть не может. В таких программах оператор on error используется редко. Но для более сложных программ, которые содержат функции решения дифференциальных уравнений, аппроксимации или другие сложные функции MathCAD, использование on error может избавить от многих трудностей.
В таких программах оператор on error используется редко. Но для более сложных программ, которые содержат функции решения дифференциальных уравнений, аппроксимации или другие сложные функции MathCAD, использование on error может избавить от многих трудностей.
Иногда может возникнуть ситуация обратная той, которая была описана выше, т.е. необходимо, чтобы при определенных условиях результатом выражения было сообщение об ошибке, хотя в действительности при этом не возникает ни одной стандартной ошибки MathCAD. Для таких случаев в MathCAD предусмотрена встроенная функция error. В качестве аргумента этой функции нужно в кавычках указать текст сообщения об ошибке, который должен быть выведен. Таким образом, если необходимо, чтобы программа возвращала ошибку при определенном условии, то следует использовать конструкцию вида: error («текст ошибки») if (условие).
Для того, чтобы иметь возможность нормально вводить текст на русском языке в аргумент функции error (а также во все другие функции со строками), следует изменить шрифт, который используется во встроенном стиле Constant. Для того чтобы этот стиль правильно отображал русские буквы, установите курсор на любом числе или строковом выражении в формульном блоке. При этом в поле на панели инструментов Formatting, отображающем текущий стиль, должно быть написано — Constant. Теперь выберите из раскрывающегося списка шрифтов шрифт, поддерживающий кириллицу.
Для того чтобы этот стиль правильно отображал русские буквы, установите курсор на любом числе или строковом выражении в формульном блоке. При этом в поле на панели инструментов Formatting, отображающем текущий стиль, должно быть написано — Constant. Теперь выберите из раскрывающегося списка шрифтов шрифт, поддерживающий кириллицу.
1. Вычислить функцию sin(x) с точностью е.
2. Даны массивы А(5) и В(5). Получить массив С, в который записаны сначала элементы
массива А в порядке возрастания, а затем элементы массива В порядке убывания
3. По введенным значениям коэффициентов А, В, С определить корни квадратного уравнения
4. Дан массив натуральных чисел В(10). Определить, есть ли в нем 4 последовательных числа (например, 1, 2, 3, 4, и т.п.). Напечатать такие группы чисел.
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: Сдача сессии и защита диплома — страшная бессонница, которая потом кажется страшным сном.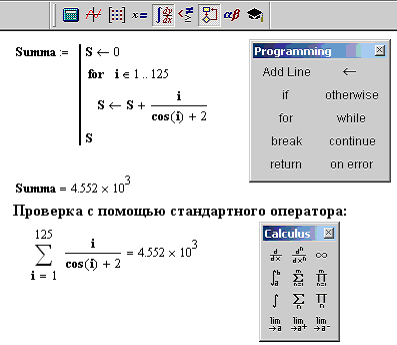 8802 —
8802 —
78.85.5.224 © studopedia.ru Не является автором материалов, которые размещены. Но предоставляет возможность бесплатного использования. Есть нарушение авторского права? Напишите нам | Обратная связь.
Отключите adBlock!
и обновите страницу (F5)
очень нужно
НАШ САЙТ РЕКОМЕНДУЕТ:
МАТЕМАТИКА ДЛЯ НАЧИНАЮЩИХ, 27: гендерного равенства тред
>>12907Общая физика больше о том, чтобы что-то конкратное рассчитать, ответить на вопрос в духе «если мы сделаем вот так и измерим вот это, то что мы увидим в результате». Она оперирует наглядными и интуитивными понятиями, её рассуждения легко визуализировать, нарисовать картинку. Поэтому изучать физику начинают именно с неё — она более «плотская» и осязаемая, позволяет выработать какое-то интуитивное ощущение физической реальности, и в то же время не требует серьёзной математической подготовки и привычки к абстрактному мышлению.
 Кроме того, её изложение больше соответствует тому, как наука развивалась исторически. Она не стесняется апеллировать к эксперименту и каким-то феноменологическим частным законам, вроде закона Ома.
Кроме того, её изложение больше соответствует тому, как наука развивалась исторически. Она не стесняется апеллировать к эксперименту и каким-то феноменологическим частным законам, вроде закона Ома.Теорфиз же от конкретики намеренно дистанцируется — уже уровне используемых понятий и единиц. Чтобы конвертировать его выкладки в конкретные предсказания в конкретном эксперименте, нужно немало попотеть. С точки зрения философии теоретической физики, не так уж важно знать, как далеко полетит снаряд, если выстрелить им из пушки. Гораздо важнее понимать, как природа устроена в целом, на структурном уровне. Наглядность и интуитивность здесь только мешают, и их вытесняют математические выкладки (хоть и не всегда совершенно строгие), а изложение подчинено структуре материала, логическим связям между его частями.
Попробую пояснить эту разницу на примере электродинамики и специальной теории относительности.
Суть кинематики СТО, с точки зрения общей физики: время не является абсолютным, при разгоне оно замедляется, длины сокращаются вдоль направления движения, одновременность относительна, передавать сигналы быстрее скорости света нельзя. Есть преобразования Лоренца, которые связывают разные системы отсчёта.
Есть преобразования Лоренца, которые связывают разные системы отсчёта.
Суть кинематики СТО, с точки зрения теорфиза: время и пространство не существуют по отдельности, а являются разными проявлениями единого объекта — пространства-времени. В нём существует метрика специального вида, и группа преобразований, которая эту метрику сохраняет. Отсюда само собой вытекает требование ковариантности. Все уравнения должны иметь лоренц-ковариантный вид, и все физически реальные сущности должны описываться ковариантными математическими объектами.
Суть электродинамики, с точки зрения общей физики: Существуют электрические и магнитные поля, которые порождаются зарядами и токами, и могут взаимно порождать друг друга, за счёт чего передаются на далёкие расстояния в виде волн, и даже переносят энергию.
Суть электродинамики, с точки зрения теорфиза: Электрическая и магнитная составляющие электромагнитного поля и не могли бы существовать по отдельности, без взаимосвязи друг с другом, поскольку описываются одним и тем же неделимым ковариантным объектом — электромагнитным векторным потенциалом. Магнитное поле можно в первом приближении рассматривать как релятивистскую поправку к электростатике — именно поэтому оно порождается движущимися электрическими зарядами, а не каким-то особым магнитным зарядом.
Магнитное поле можно в первом приближении рассматривать как релятивистскую поправку к электростатике — именно поэтому оно порождается движущимися электрическими зарядами, а не каким-то особым магнитным зарядом.
Взгляд на динамику, с точки зрения общей физики: Существуют уравнения движения (второй закон Ньютона, к примеру, или уравнения Максвелла), которые определяют всю динамику. Свободные тела двигаются равномерно и прямолинейно, а любые отклонения от этого режима определяются действующими силами — силой тяготения, силой реакции опоры, силой трения, и другими — всё, что мы привыкли встречать в обычной жизни. Бывают особые комбинации переменных, которые сохраняются во время движения при определённых условиях — вроде энергии и импульса. Это упрощает расчёты и анализ, и именно поэтому их и ввели. Ещё сохраняется масса, заряды и некоторые другие вещи — так уж нам повезло.
Взгляд на динамику, с точки зрения теорфиза: Вся динамика закодирована в особой величине, называемой лагранжианом, и другой связанной с ним величине — действии.![]() Их вид неслучаен и зачастую может быть выведен из геометрических принципов или каких-то ещё соображений. Ключевое значение имеют симметрии — именно наличием симметрий определяется существование сохраняющихся величин (теорема Нётер). Так, энергия двойственна ко времени и её сохранение связано с однородностью времени, и точно так же импульс двойственен к пространству и его сохранение связано с его однородностью. Таким образом, энергия и импульс гораздо более фундаментальные вещи, чем сила, и, в отличие от неё, сохраняют свой смысл даже в квантовом мире. Единственная сила (читай — взаимодействие), существующая в СТО — это взаимодействие вещества с электромагнитным полем. Единственная сила (читай — взаимодействие), существующая в СТО — это взаимодействие вещества с электромагнитным полем, и оно тоже закодировано в лагранжиане. Другие законы сохранения также имеют соответствующие им симметрии. Таким образом, изучение устройства группы симметрий может многое рассказать о динамике.
Их вид неслучаен и зачастую может быть выведен из геометрических принципов или каких-то ещё соображений. Ключевое значение имеют симметрии — именно наличием симметрий определяется существование сохраняющихся величин (теорема Нётер). Так, энергия двойственна ко времени и её сохранение связано с однородностью времени, и точно так же импульс двойственен к пространству и его сохранение связано с его однородностью. Таким образом, энергия и импульс гораздо более фундаментальные вещи, чем сила, и, в отличие от неё, сохраняют свой смысл даже в квантовом мире. Единственная сила (читай — взаимодействие), существующая в СТО — это взаимодействие вещества с электромагнитным полем. Единственная сила (читай — взаимодействие), существующая в СТО — это взаимодействие вещества с электромагнитным полем, и оно тоже закодировано в лагранжиане. Другие законы сохранения также имеют соответствующие им симметрии. Таким образом, изучение устройства группы симметрий может многое рассказать о динамике.
Как сделать трассировку в маткаде
Трассировка и увеличение графиков. Визуальная среда …
Визуальная среда …
Форматирование плоского графика в MathCAD 14 (11/34) Часть 1
Самоучитель по MathCAD
Трассировка и масштабирование
Трассировка и увеличение графиков. Визуальная среда …
Mathcad \u2014 Википедия
Руководство пользователя Mathcad
Построение графиков в Mathcad Prime
Трассировка и масштабирование
Ответы Mail.ru: MathCAD значение должно быть скалярным
Руководство пользователя Mathcad
MathCAD \u2014 это просто! Часть 3. Уравнения Продолжение
Построение графиков в MathCad | Cl-Box
Tips for Mathcad User
Решение уравнений и систем в Mathcad — PDF
Расчеты в MathCad | Cl-Box
Заметки про …: Отладка сложных документов Mathcad 15
Глава 6
Глава 15. Ввод-вывод данных
Заметки про …: Отладка сложных документов Mathcad 15
Построение графиков в MathCad | Cl-Box
Глава 6
Численные методы на Mathcad
Макаров Е. М15 Инженерные расчеты в Mathcad 15: Учебный курс …
Форматирование трехмерного графика в MathCAD (15/34) Часть 1
Как построить график, заданный несколькими функциями …
Презентация на тему: Математическая система MathCad …
Руководство пользователя Mathcad
Методическое пособие \
Глава 15. Ввод-вывод данных
Самоучитель по MathCAD
Метод золотого сечения | MATHCAD | Mc-Plc.Ru
Ввод-вывод данных
Как построить график функции в \
Лекция №1 — Основы работы в математическом пакете Mathcad
Расчеты с использованием системы MathCAD
Расчеты в MathCad | Cl-Box
Глава 6
MathCAD \u2014 это просто! Часть 3. Уравнения Продолжение
Как заштриховать область под графиком в MathCAD
Вопросы по Mathcad Prime | Mathcad сообщество | ВКонтакте
Построение графиков в Маткаде?
Решение уравнений и систем в Mathcad — PDF
1. Основы работы в системе MathCAD
Моделирование и оптимизация химико-технологических процессов …
Глава 6 Установки форматов объектов системы Mathcad 11
Mathcad 15 F000 (Rus) :: Tapochek.net
Глава 15. Ввод-вывод данных
Ввод-вывод данных
Построение графиков в Маткаде?
Реферат: Построение годографов Михайлова при помощи пакета …
Глава 6 Установки форматов объектов системы Mathcad 11
Заметки про …: Отладка сложных документов Mathcad 15
Экстраполяция данных | MATHCAD | Mc-Plc.Ru
Трассировка и масштабирование
Расчеты с использованием системы MathCAD
Трассировка графика в экселе
Построение графиков в MathCad | Cl-Box
Дифференциальные уравнения
Лекция №1 — Основы работы в математическом пакете Mathcad
Как заштриховать область под графиком в MathCAD
Глава 6 Установки форматов объектов системы MathCAD …
Система Mathcad — Лекция
Презентация на тему: Математическая система MathCad …
Скользящая средняя. Описание индикатора. Секреты использования
Для целостности и последовательности изложения. Сначала естественно определение, что это за функция и как она рассчитывается. Затем для того что бы каждый раз при описании нового индикатора не возвращаться к этому материалу (объяснению академического подхода к анализу). Мне необходимо рассказать про спектр, преобразование Фурье. Дело в вот, что если подходить с научной точки зрения, то любой используемый нами индикатор вносит искажения в исходный сигнал (ряд анализируемых чисел). Это из теории. Нет с большой буквы Теории Цифровой Обработки Сигналов (ЦОС). Нам она очень и очень пригодится. Это важно. Дилетантов с рынка вперед ногами выносит, может и не ногами, но 100% выносит. Постараюсь простым языком объяснить эти сложные вещи, они нам пригодятся при анализе практически любого индикатора SMA, RSI, MACD…
Существует множество названий этого индикатора. Скользящая средняя (МА — moving average). Простое скользящее среднее или арифметическое скользящее среднее (SMA — simple moving average). Оно численно равно среднему арифметическому значений исходного массива чисел за установленный период и вычисляется по формуле:
где SMA — значение простого скользящего среднего; N — количество значений анализируемого массива чисел; A – массив чисел, переданный в функцию для расчета.
Самый известный пример это средний бал
В примере N=5, А – массив чисел [5 3 2 4 5], i – меняется от 0 до N-1. Для тех, кто не программировал, хочу пояснить, компьютер такая дурная железяка что отсчет начинает вести с нуля (программисты это знают). Поэтому i меняется в нашем случае от 0 до 4 (всего 5-ть чисел).
Из-за этого нюанса возникает большая путаница и на многих, очень многих страницах интернета приводится другая, не совсем точная формула расчета (можете для примера википедию посмотреть https://ru.wikipedia.org/wiki/Скользящая_средняя)
В подтверждения моих слов приведу следующий факт. Отсчет баров (свечей) идет справа на лево, и текущий бар у нас всегда нулевой Close[0], предыдущий 1 и т.д. Пришла новая свечка – нумерация сдвигается, новая свечка становится 0, предыдущая 1 и т.д.
Рис.1
В качестве значений массива Ai чаще всего выбирают значения закрытия свечи Close[0], Close[1] …. В продвинутых платформах можно выбирать, что использовать в качестве Ai (Open, High, Low, Median…)
Рис.2
Теперь как происходит «обучение» трейдеров.
Уровень новичок.
Приходит новичок на рынок, ему показывают, рассказывают, учат торговать. Предлагают для принятия торговых решений использовать простую среднюю. Типа смотрите как классно, SMA растет мы покупаем, падает мы продаем, есть и другие варианты, к примеру, цена выше средней покупаем, ниже продаем и т.д. Проходит время трейдер возвращается, через неделю, через месяц, кто то уже никогда не вернется на рынок, т.к. результат такой торговли потеря части депозита или полный слив…
Продвинутый уровень.
Да мы знаем, понимаем, давайте попробуем 2 средних и будем торговать, устанавливая Stop Loss и Take Profit, и снова по кругу, просто количество вариантов увеличивается, комбинаторика начинает действовать. Результат – слив депозита, просветление у новичка — тут что то не так, бесплатные курсы не помогают, наверное нужно заплатить за знания, ведь деньги никуда не деваются, закон то работает, если где то убыло, то значит где то прибыло…
Уровень гуру.
Тут уже на всю катушку — маркетинг, реклама, выпуск книги, платные семинары, мастер классы, СМИ, выступление по телевизору, выездные «эксклюзивные семинары» по стране, по всему миру, по секрету всему свету… Только вот цель этого маркетинга, не научить вас прибыльно торговать, цель всего этого продать очередную торговую систему (семинар, книгу), и автору совершенно фиолетово что счета сливаются. Согласен, что не так быстро, как на первых двух уровнях происходит слив, но итог 100% один и тот же, потеря депозита или его части плюс, разочарование в идее и способности заработать на бирже, форексе, в людях, торговых стратегиях …
Самый известный пример – торговая система «аллигатор»… три простых средних. Вот картинка.
Рис.3
Комбинаторика в действии, добавляем сюда стоплос и тейкпрофит, первая итерация маркетинга – продаем, не работает, добавляем индикатор с громким и красивым название, типа «импульс силы рынка». Вторая волна продаж. Снова не работает… добавляем еще индикатор, добавляем еще правил торговли, количество комбинаций уже такое, что лет на 10 активных продаж хватит…
Уровень фанатов
Веер скользящих средних — супер секретная техника. Отдам индикатор в хорошие руки бесплатно, даром, на халяву… правила торговли придумаете уже сами. Только вот семинары пока не организовывайте, до конца статью дочитайте.
Рис.4
Из опыта трейдинга вы уже знаете, что чем шире сглаживающий интервал (чем больше N), тем более плавным получается график функции, добавляем раскраску и вот такая красота (рис.4). Глазам не вериться, что такая красота может подводить (обманывать)…
Идем дальше, это уже интереснее, это уже «сакральные» знания.
Есть такое преобразование Фурье, его суть в следующем. Есть график к примеру синусоиды рис.5.
Рис.5
Обратите внимание ось Y это амплитуда сигнала для примера выбрана равной 5, ось X – это время. Для задания синусоиды важны еще 2 параметра, частота с которой она колеблется и фаза. В примере частота = 10, фаза равна нулю (для простоты изложения).
Так вот преобразование Фурье связывает время и частоту. По факту это получается просто другое представление того же сигнала, как говорят — вид с боку. На рис.6 представлена та же самая синусоида, что и на рис.5, только выглядит немного непривычно.
Рис.6
Обратите внимание ось Y как была амплитуда, так и осталась, для нашего примера амплитуда = 5 (высота столбика =5), ось Х – это уже частота = 10, т.е. эта та же самая синусоида с амплитудой 5 и частотой 10, только выглядит непривычно.
У кого есть Mathcad может перепроверить вычисления программа (код) полностью виден на рисунке (и на видео, оно прилагается в конце статьи). Идем дальше.
Был такой великий Советский ученый Владимир Александрович Котельников (1908—2005). Так вот его теорема гласит, что любой ограниченный по частоте сигнал, можно представить в виде суммы синусоид (точная формулировка и формулы вот тут https://ru.wikipedia.org/wiki/Теорема_Котельникова). Небольшая ремарка для специалистов ЦОС, пожалуйста, не употребляйте Нейквиста, это плохое, ругательное слово, по крайней мере на этом сайте. Приоритет за Котельниковым, надо чтить наших великих ученых !!!
Теперь самое важное.
Любой индикатор с точки зрения науки это цифровой фильтр !!! Именно для этого я говорил про Фурье. Индикаторы вносят изменения в спектр сигнала, это очень важно….
Фильтр (https://ru.wikipedia.org/wiki/Фильтр) (от лат. filtrum «войлок») — понятия, устройства, механизмы, выделяющие (или удаляющие) из исходного объекта некоторую часть с заданными свойствами.
Согласны, что индикаторы помогают убрать «лишнее» и лучше сосредоточится на необходимом? Теперь посмотрим, что такое цифровой фильтр.
Цифровой фильтр (https://ru.wikipedia.org/wiki/Цифровой_фильтр) — в электронике любой фильтр, обрабатывающий цифровой сигнал с целью выделения и/или подавления определённых частот этого сигнала.
Прежде чем анализировать спектральные искажения (подавление/выделение частот). Посмотрим запаздывает индикатор SMA или нет. Ниже на рисунки приведена синусоида, которую подаем на вход SMA (красный цвет), синим цветом показан выход SMA
Рис.7
Для примера N (величина окна анализа) выбрано равным 10. SMA начинает свой расчёт, когда накопит 10 значений. Из рисунка видно, что индикатор опаздывает и чем больше N — тем больше он запаздывает. Просто представьте (подумайте) если входной массив это часовые свечки, то мы опаздываем на несколько часов !!!
А вот это думаю вас поразит, при определённом N мы попадаем в противофазу.
Рис.8
Посмотрите внимательно, пусть красная линия это цена какого то актива, акции, фьючерсы, валюта (любой) — движется по синусоиде. А мы торгуем по синий линии, по показаниям SMA (можно по вееру средних, сути не меняет), новичков так учат на курсах. SMA растет – покупаем, падает – продаем. Ну как много заработали ? Цена падает, а мы покупаем, цена растет, а мы продаем… класс — «рост» депозита просто сказочный…
Кто ни будь, где ни будь, рассказывал вам про это ?
Пришлите мне ссылку на эти курсы, я обязательно запишусь !
Следующий секрет простого скользящего среднего.
Повторюсь любой индикатор, любое преобразование входного потока ордеров (тиков) вносит искажения, и эти искажения можно увидеть, посмотрев на спектр выходного сигнала его АЧХ (амплитудно-частотную характеристику). Что бы не прибегать к математическим и строгим выкладкам, поступим следующим образом (я на видео все это покажу, будет приложено к статье сможете не только прочесть, но и посмотреть). На вход SMA будем подавать синусоиду, и смотреть выход, если искажений нет, то на выходе будет равномерный спектр (палки с амплитудой 5 по всему спектру см. рис.6). Но если есть искажения, то спектр будет не равномерным.
Рис.9 АЧХ простой скользящей средней N=10
Рис. 10 АЧХ простой скользящей средней N=50
На рисунках 9 и 10 видно, что спектр искажается и АЧХ зависит от выбранного нами N, это фильтр низкой частоты (ФНЧ) у которого очень большие боковые лепестки и плохая полоса пропускания и кривая спада пологая (идеал это прямоугольник – в полосе пропускания искажений нет, а остальные частоты эффективно подавляются).
Есть цифровые фильтры которые превосходят в десятки раз по качеству простую скользящую среднюю и их много, только вот в свободном доступе часто их нет, не встроены по умолчанию в качестве индикаторов в торговые терминалы.
Фильтр Чебышева https://ru.wikipedia.org/wiki/Фильтр_Чебышёва
Фильтр Баттерворта https://ru.wikipedia.org/wiki/Фильтр_Баттерворта
Эллиптический фильтр https://ru.wikipedia.org/wiki/Эллиптический_фильтр
….
Следующий секрет простой средней это её импульсная характеристика
На жаргоне трейдеров это реакция индикатора на ГЭП или шпильку.
Гэп (калька c англ. gap — разрыв) — в техническом анализе потока котировок ситуация существенной разницы между ценой закрытия предыдущей свечки (элемента графика) и ценой открытия следующей.
В ЦОС это стандартное исследование. Это импульсная характеристика фильтра. Хотел вам привести тут её, полез в википедию. И самое интересно это выходит уже действительно «сакральное» знание.
Посмотрите https://ru.wikipedia.org/wiki/Импульсная_переходная_функция
Пусто, нет ничего. Возможно это связано с тем, что знание этого приносит прибыль, может принести. Лично мне уже несколько лет приносит хорошую и устойчивую прибыль. Небольшая ремарка, враки это что ГЭПы закрываются, тот кто это рассказывает не знает что такое импульсная характеристика. Возможно, через 1-2 года и закрывается этот разрыв графика, но прибыль нам нужна здесь и сейчас, а не в далёком будущем. Всё очень просто, если мы умеем зарабатывать здесь и сейчас, то постепенно используя силу сложного процента, мы станем богатыми.
Наоборот не получится, нельзя стать богатым в будущем, если не можешь зарабатывать сейчас !!!
Какие еще недостатки можно отметить у простой средней.
- Полученное значение простой скользящей средней относится к середине выбранного интервала, традиционно его относят к последней точке интервала. Помните запаздывание равно N/2, если вы работаете на часовых свечках и N выбрано к примеру равным 50, то задержка составляет 25 часов. Вы опоздун на сутки…
- Двойная реакция на каждое значение анализируемого ряда чисел, в момент входа в окно вычислений и в момент выхода из него.
- Равенство весового коэффициента при Ai равно 1. Этот недостаток немного поясню, это тема не одной статьи и исследований.
Формулу (1) можно в общем виде записать вот так
Отличие в том, что появились коэффициенты Ci. У простой средней все значения Ci=1. Изменяя их можно менять характеристики цифрового фильтра (индикатора). К примеру экспоненциальная скользящая средняя, все значения Ciубывают по экспоненте. В торговые терминалы обычно встроено экспоненциальное скользящее среднее (англ. exponentially weighted moving average — англ. EWMA, англ. exponential moving average — англ. EMA). Точнее её разновидность — веса никогда не равны нулю, берется вся доступная история от царя гороха.
Продолжение следует…
Надеюсь, у меня хватит сил и времени, написать продолжение. Если вам понравилось, лучший способ выразить благодарность автору – поделится этой статьей с друзьями.
Видео к этой статье.
протестировано: материнские платы X570 могут превзойти Ryzen, но редко
HWinfo утверждает , что материнские платы X570 от различных производителей виновны в занижении мощности процессоров Ryzen, поэтому чипы будут работать быстрее при стандартных настройках, но, возможно, за счет долговечности чипа. Не похоже, что AMD оправдывает неверные данные о мощности, и в ответ AMD заявила, что изучает проблему, но не считает, что чипы пострадают от чрезмерного износа в течение гарантийного периода.Итак, после того, как мы написали статью о претензиях поставщика программного обеспечения и его новой функции (предназначенной для обнаружения проблемы), мы решили определить, был ли новый тест точным и существует ли какая-либо неминуемая опасность для здоровья Процессоры Ryzen от производителей материнских плат готовят книги.
После тестирования трех разных материнских плат X570 с использованием различных настроек, решений для охлаждения и даже прошивки, мы обнаружили, что, хотя HWinfo действительно проливает свет на некоторые проблемы, он может выдавать завышенные значения, которые не отражают фактические неверные данные о мощности.Из трех материнских плат — ASRock X570 Taichi, MSI X570 Godlike и Gigabyte X570 Aorus Master — только Taichi показала огромную разницу между заявленной и фактической мощностью, что привело к повышению производительности. Эти настройки привели к более высоким тактовым частотам, напряжениям и тепловыделению. И эта проблема, которая случилась с BIOS обозревателя, в значительной степени исчезла после того, как мы установили последнюю версию прошивки. Однако оставшиеся относительно небольшие отклонения от 10 до 15 процентов легко объясняются такими факторами, как вариации VRM.Мы даже обнаружили несколько материнских плат, которые неверно сообщают о мощности, что снижает производительность.
HWinfo сообщает, что его новое измерение отклонения мощности, встроенное в бесплатную для загрузки и использования утилиту , дает пользователям возможность определить, не обманывает ли их материнская плата чипы Ryzen. Вам просто нужно загрузить свой процессор под нагрузку с помощью любого обычного многопоточного теста (рекомендуется Cinebench R20), а затем отслеживать значение, чтобы увидеть его отношение к 100%. Значение 100% означает, что материнская плата передает правильные значения процессору Ryzen, поэтому он может регулировать производительность в пределах ожидаемых допусков, в то время как более низкие значения могут указывать на ложные данные телеметрии питания.
Обязательно прочтите ветку форума для более подробного описания рекомендаций фирмы о том, как протестировать собственный процессор с помощью этого инструмента, но до тех пор, пока не будут внесены дальнейшие изменения в программное обеспечение, вы должны воспринимать результаты с некоторой долей вероятности. соль.
Тестирование кодов материнских плат
Услышав сообщение о том, что некоторые материнские платы неверно передают ключевые данные телеметрии питания процессорам Ryzen, я сразу же подумал о материнской плате ASRock X570 Taichi, которую мы оценивали для обзора Ryzen 7 3900X и 3700X.
В то время Taichi была нашей единственной материнской платой X570 в лаборатории, поэтому я попробовал ее, чтобы оценить, подходит ли материнская плата для тестирования ЦП. Я провел несколько дней, тестируя материнскую плату, и столкнулся с несколькими проблемами, такими как крайне неточные показания мощности из приложений для мониторинга программного обеспечения и более низкая производительность с предустановками автоматического разгона PBO, чем я записал при «стандартных» настройках.
Проблемы с прошивкой материнской платы, конечно же, не являются исключением в период действия соглашения о неразглашении информации — фактически, это часто является правилом.Платформы как Intel, так и AMD, как правило, страдают от этих ошибок на ранних этапах процесса проверки, и общение либо с производителем микросхем, либо с поставщиком материнских плат обычно помогает сгладить первоначальные ошибки.
Тем не менее, проблемы, с которыми мы столкнулись с Taichi, остались нерешенными после разговора с ASRock, поэтому мы перешли на материнскую плату MSI X570 Godlike, появившуюся с опозданием, за несколько дней до истечения NDA, увеличив количество тестов, которые вы видите в нашем сегодняшнем обзоре. Это было не весело, но необходимость переключать тестовое оборудование случается чаще, чем вы можете себе представить.
Мы предпочитаем использовать программные инструменты мониторинга, такие как AIDA64 и HWinfo, для наших измерений мощности, поскольку они извлекают измерения энергопотребления непосредственно из контура датчиков, тем самым устраняя неэффективность VRM из значений и показывая нам, сколько энергии потребляет сам процессор. Это позволяет нам получать подробные показатели энергопотребления и эффективности.
Мониторинг программного обеспечения также хорош, потому что мы можем запускать его во время наших тестов по сценариям, что упрощает и ускоряет процесс для наших больших пулов тестирования, которые часто включают 15 различных процессоров / конфигураций.К сожалению, эти измерения могут быть использованы производителями материнских плат, поэтому должная осмотрительность является ключевым моментом, если вы полагаетесь на программный опрос, особенно в свете неверно сообщенной проблемы телеметрии питания с некоторыми материнскими платами AM4.
Перехват питания на разъемах EPS12V (восьмиконтактные разъемы ЦП на материнской плате) — хороший метод измерения энергопотребления. Однако он не измеряет истинное количество энергии, поступающей в процессор, потому что в игру вступает неэффективность VRM, обычно в диапазоне 15% на материнских платах высокого класса.
Современные процессоры также получают питание от отдельных вспомогательных шин на 24-контактном разъеме для различных функций, таких как контроллеры памяти, графика и интерфейсы ввода-вывода. Эти измерения не включены в измерения с разъемов EPS12V. 24-контактный разъем также обеспечивает питание остальной части системы, что делает невозможным разделение количества энергии, выделенной на ЦП. У нас также нет оборудования с программным запуском, которое позволяло бы записывать измерения в наш автоматизированный набор тестов.
Пытаясь получить лучшее от аппаратного и программного обеспечения журналирования, мы используем оборудование Powenetics или тестер питания Passmark In-Line PSU для измерения энергопотребления на разъемах EPS12V (т. Е. Двух разъемах EPS12V, которые питают львиная доля мощности процессора). В рамках нашего обычного процесса оценки новой материнской платы для тестирования ЦП мы проверяем, что показания датчиков, полученные от программного обеспечения для регистрации, такого как AIDA64 или HWinfo, правдоподобно совпадают с показаниями мощности, которые мы перехватываем на разъемах EPS12V.
Это может потребовать некоторой нечеткой математики, поскольку неэффективность VRM может создавать разницы между мощностью, подаваемой на VRM, и мощностью, подаваемой на процессор. Эти дельты различаются в зависимости от компонентов в подсистеме питания каждой материнской платы (обычно от ~ 10% до ~ 15%), но нетрудно заметить огромные неточности, особенно те, которые мы наметили ниже.
Подключение для разгона
Во-первых, нам нужно определить, что будет выделяться как небезопасное поведение.AMD не предоставляет спецификацию «небезопасного напряжения», вместо этого определяя три ключевых ограничения для работы на складе. Приведенный ниже список дословно воспроизведен из руководства AMD для обозревателя процессоров:
Вы можете изменить эти настройки вручную или с помощью автоматического разгона AMD Precision Boost Overdrive. Вы можете получить доступ к этой функции через BIOS или программное обеспечение Ryzen Master. Учитывая утверждения о последствиях для надежности из-за повышенных напряжений при стандартных настройках, мы решили использовать эту функцию аннулирования гарантии в качестве точки сравнения с пороговыми значениями напряжения и мощности, которые являются побочным продуктом ошибочной телеметрии мощности.
К сожалению, PBO обычно не дает большого прироста производительности, если вы придерживаетесь основных предустановок. Производители материнских плат определяют эти профили, и некоторые пользователи считают, что небольшие запасы для автоматического разгона могут быть вызваны неверно сообщенной телеметрией мощности, которая сокращает доступный запас для разгона. Ответ не так прост, но вполне логично, что изменение энергопотребления при стандартных настройках может сказаться на доступном запасе разгона.
При стандартных настройках AMD Precision Boost 2 автоматически обеспечивает максимально возможную производительность с учетом возможностей подсистемы питания материнской платы и кулера.Компоненты премиум-класса обеспечивают большую производительность, но это не квалифицируется как разгон, потому что эти алгоритмы ограничены настройками PPT, TDC и EDC во время стандартной работы.
Включение PBO отменяет стандартные настройки для этих переменных. Базовая предустановка «включен (PBO включен)» включает значительно более высокие пределы PPT / TDC / EDC, но не меняет двух важных настроек: PBO Scalar или Clock.
PBO Scalar переопределяет настройки управления работоспособностью AMD по умолчанию и позволяет повышать напряжение при максимальной частоте повышения и увеличивает продолжительность повышения.Изменение настройки PBO Scalar разблокирует лучшую производительность автоматического разгона, поэтому базовая предустановка может отсутствовать.
Вы также можете использовать профиль «PBO Advanced», который определяет ограничения для каждой материнской платы на основе возможностей подсистемы подачи питания (как определено поставщиком материнской платы). Этот параметр предоставляет самые высокие настройки PPT, TDC и EDC для материнской платы, но также не изменяет настройки PBO Scalar и Clock. Однако этот параметр не позволяет изменять параметры PBO Scalar и Clock вручную, причем первые обычно открывают гораздо более высокий потенциал автоматического разгона.
Для тестирования ниже мы использовали три профиля. Настройки Stock состоят из явного отключения всех функций PBO, в то время как Advanced Motherboard (Adv. Mobo) означает профиль, который устанавливает самые высокие предварительно установленные значения PPT, TDC и EDC для каждой материнской платы, но не меняет PBO Скалярное значение.
Некоторые поставщики материнских плат также включают в BIOS пользовательские предустановки, которые включают скалярные манипуляции, но они доступны не на всех материнских платах. Чтобы обеспечить единообразие, мы также вручную настроили все материнские платы с теми же настройками, которые мы отметили на диаграммах как «Рекомендуемые».’Этот параметр включает в себя вручную определенные параметры Скаляр и AutoOC Clock, как указано в таблице ниже.
В отличие от наших обзоров, мы также сохранили согласованность настроек памяти для различных конфигураций, чтобы исключить это как фактор, способствующий повышению производительности.
| Ryzen 9 3900X | PPT | TDC | EDC | PBO Scalar | AutoOC | Память |
| Stock | 142W | 95A | 140A | Не назначено | Не назначено | DDR4-3200 |
| Расшир.Mobo | 1000W: ASRock, MSI 500W: GB | 540A: ASRock 540A: GB 245A: MSI | 540A: ASRock 600A: GB 280A: MSI | Не назначено | Не назначено | DDR4-3200 |
| Рекомендуемый | 190 Вт | 120A | 160A | 10X | 200 МГц | DDR4-3200 |
История двух «обозревателей BIOS»
Изображение 1 из 3 (Изображение предоставлено: Tom’s Hardware) Изображение 2 из 3 (Изображение предоставлено: Tom’s Hardware) Изображение 3 из 3 (Изображение предоставлено: Tom’s Hardware)Первая диаграмма в этой серии отображает количество энергии, сообщаемое SMU.Это отражает количество общей мощности, которую процессор считает потребляемой, по сравнению с количеством энергии, которое мы зафиксировали на разъемах EPS12V во время пяти последовательных запусков многопоточного теста Cinebench на материнской плате ASRock X570 Taichi.
Мы измерили эти значения при стандартных настройках с прошивкой, предоставленной обозревателям (p1.21), и включенным в комплект стандартным кулером Ryzen для этого первого теста, поскольку AMD указывает процессор для работы с собственным кулером. Измерения от HWinfo, помеченные как «Программное обеспечение», не полностью совпадают с измерениями встроенного тестера блока питания Passmark (помеченного как EPS12V) на оси времени из-за различий в опросе, но это дает нам достаточно хорошее представление разницы между двумя измерениями.
Первая диаграмма показывает, что SMU 3900X сообщает ~ 60 Вт во время рендеринга Cinebench, в то время как наши физические измерения показывают пики около 180 Вт. Под нагрузкой процессор в среднем потреблял ~ 165 Вт. Это огромная разница в ~ 3 раза между мощностью, поступающей на EPS12V, и значениями, контролируемыми программным обеспечением, что точно показывает, почему мы решили не использовать эту плату для нашего обзора.
Второй слайд в альбоме содержит измерения из BIOS рецензента (1015), входящего в комплект MSI X570 Godlike, и измерения программного обеспечения почти полностью совпадают с наблюдаемым потреблением энергии от разъемов EPS12V.Мы ожидаем некоторых потерь из-за неэффективности VRM, так что этот результат почти тоже хороший. Однако, учитывая, что некоторая мощность подается с 24-контактного разъема, который мы не измеряем, результаты гораздо более правдоподобны, чем значения, полученные от материнской платы Taichi.
Мы говорили с MSI о слишком точных измерениях, и компания сообщила нам, что для своего первоначального BIOS использовалось эталонное значение полной шкалы VDD ЦП, полученное из предоставленного AMD тестового комплекта / генератора нагрузки. Это настройка, лежащая в основе всего: процессор использует ее, чтобы определить, сколько энергии он потребляет.
Это эталонное значение привело к тому, что X570 Godlike завышает значение мощности, подаваемой на процессор, что на самом деле может немного снизить производительность. Позже компания проверила этот параметр на реальном процессоре, чтобы точно настроить его для подсистемы питания X570 Godlike, поэтому в более новые версии BIOS были внесены изменения, чтобы отчеты больше соответствовали возможностям материнской платы. Вы увидите влияние этих изменений, когда мы протестируем новый BIOS ниже. Измерение отклонения HWinfo, которое мы не используем для этих тестов, похоже, не принимает во внимание эти рациональные изменения.
На третьем слайде измеряется производительность материнской платы Taichi, но на этот раз мы заменили штатный кулер на 280-мм кулер Corsair h215i AIO. Этот кулер дает процессору больший тепловой запас, и вы увидите результаты инновационных алгоритмов AMD Precision Boost 2 и PBO в следующей серии тестов.
Общий вывод из этого первого взгляда заключается в том, что обозреватель ASRock BIOS для X570 Taichi значительно занижает информацию о мощности процессора, что позволяет ему потреблять больше энергии, чем X570 Godlike, который фактически завышает его энергопотребление.Как вы увидите ниже, это означает большее напряжение, тепло и производительность от ASRock.
Изображение 1 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 2 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 3 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 4 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 5 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 6 из 6 (Изображение предоставлено: Tom’s Hardware)Учитывая, что все ядра могут работать при разных напряжениях одновременно, мы построили максимум значение, записанное по ядрам для каждого измерения, чтобы упростить графики.Мы использовали тот же подход для тактовой частоты и использовали ненулевую ось для большей детализации. Когда процессор находится под нагрузкой, большинство значений напряжения и частоты ядер остаются неизменными.
Первые три диаграммы выше показывают напряжение, подаваемое на Ryzen 9 3900X с прошивкой обозревателя. К счастью, шкала напряжения фиксирована, поэтому эти измерения точны независимо от каких-либо корректировок значения тока полной шкалы, что составляет суть проблемы. Первый слайд показывает, что X570 Taichi при стандартных настройках применяет 1.3В на процессор под нагрузкой, в то время как X570 Godlike подает на чип ~ 1,25В. Это не большая разница, несмотря на разницу в ~ 20 Вт в совокупных измерениях, показанных выше, но, очевидно, существует много различий между тем, как соответствующие материнские платы обрабатывают мощность.
Вы заметите, что предустановленные настройки PBO (PBO Enabled) приводят к более низкому напряжению и тактовой частоте с Taichi. Однако, когда мы регулируем настройку PBO Scalar с нашими изменениями, рекомендованными PBO, напряжения растут вместе с тактовой частотой.Напротив, MSI X570 Godlike работает в соответствии с нашими ожиданиями, с большей производительностью в результате разгона настроек.
Оригинальный BIOS для обозревателя Taichi предлагает аналогичные скорости разгона всех ядер — около 4,125 ГГц при стандартных настройках с кулером h215i, по сравнению с 4,05 ГГц у Godlike. С воздушным охладителем часы Taichi в основном схожи между его стандартными настройками и настройками, рекомендованными PBO, в то время как использование жидкостного охладителя дает больше места для немного более высоких часов.
Изображение 1 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 2 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 3 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 4 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 5 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 6 из 6 (Изображение предоставлено: Tom’s Hardware)Влияние на термические потоки сразу очевидно, поскольку конфигурация, рекомендованная PBO, производит гораздо больше тепла (до 92C) во время теста со штатным охлаждением, превышающим штатные настройки процессоров.Предварительная установка «PBO enabled» фактически выделяет меньше тепла на плате ASRock. Примечательно, что во время этого теста тест со стандартными настройками достигает пиков в диапазоне 87C, но мы опишем более низкие температуры с материнской платой Taichi в серии тестов с последней доступной прошивкой.
Несмотря на более высокую температуру и напряжение в соответствии с рекомендуемыми настройками PBO, материнская плата Taichi обеспечивает меньшую производительность во время тестирования Cinebench при стандартных настройках. Теперь производительность PBO действительно зависит от теплового запаса, доступного для чипа, но это противоречит нашим ожиданиям относительно получения более низкой производительности с разогнанными настройками.
Для Taichi превосходство над 3900X с Corsair h215i устраняет несоответствие и обеспечивает минимальный прирост производительности с настроенными настройками, но имейте в виду, что мы используем ненулевую ось для диаграммы из-за удивительно тонких дельт. . В среднем рост составляет 19 пунктов, или всего 0,24%. Это определенно не стоит повышенного напряжения и термиков.
Изображение 1 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 2 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 3 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 4 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 5 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 6 из 6 (Изображение предоставлено: Tom’s Hardware)В этой серии диаграмм мы построили соответствующие стандартные измерения с помощью BIOS, представленных обозревателем, для обоих MSI X570 Godlike и ASRock X570.Хотя каждый производитель, очевидно, настраивает свою соответствующую материнскую плату, используя множество параметров, ясно, что Taichi имеет преимущество в производительности из-за неверной телеметрии мощности. В результате напряжение, частота, температура и производительность материнской платы Taichi выше. Спорный вопрос, является ли это результатом честной ошибки или просто чрезмерной настройки ради повышения производительности, но искажение данных, похоже, было исправлено в более поздних версиях BIOS, как мы увидим ниже.
Изображение 1 из 10 (Изображение предоставлено: Tom’s Hardware) Изображение 2 из 10 (Изображение предоставлено: Tom’s Hardware) Изображение 3 из 10 (Изображение предоставлено: Tom’s Hardware) Изображение 4 из 10 (Изображение предоставлено: Tom’s Hardware) Изображение 5 из 10 (Изображение предоставлено: Tom’s Hardware) Изображение 6 из 10 (Изображение предоставлено: Tom’s Hardware) Изображение 7 из 10 (Изображение предоставлено: Tom’s Hardware) Изображение 8 из 10 (Изображение кредит: Tom’s Hardware) Изображение 9 из 10 (Изображение предоставлено: Tom’s Hardware) Изображение 10 из 10 (Изображение предоставлено: Tom’s Hardware)Вот серия диаграмм для Taichi с последней прошивкой, доступной на его общедоступном сайте.И снова мы использовали как стандартный кулер, так и моноблок h215i для двух конфигураций.
Разница между потребляемой мощностью, сообщаемой SMU и разъемами EPS12V, значительно уменьшилась. Чип по-прежнему потребляет до 160 Вт под нагрузкой по сравнению с заявленным значением 142 Вт, но мы можем списать это на ожидаемые потери VRM от этой конкретной материнской платы.
Согласно утилите HWinfo, материнская плата Taichi по-прежнему передает неверные данные телеметрии питания на SMU — утилита указывает отклонение на уровне ~ 7%.Однако наши измерения больше соответствуют нашим ожиданиям относительно потерь VRM, поэтому данные HWinfo могут быть неверными. (До сих пор неясно, как именно HWinfo определяет отклонение.)
Сниженная производительность Cinebench с настройками PBO в паре со штатным кулером также сохраняется (два результата PBO перекрывают друг друга в таблице), в то время как верхний предел чипа с h215i дает аналогичные небольшие выигрыши для конфигурации, рекомендованной PBO. Конфигурация с поддержкой PBO во всех случаях остается медленнее.
Важно отметить, что даже с учетом скорректированных данных телеметрии мощности, потребляемая мощность, которую мы измерили на разъеме EPS12V, остается в пределах низкого диапазона 160 Вт, что нормально с учетом ожидаемых потерь VRM.
Gigabyte X570 Aorus Master
Изображение 1 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 2 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 3 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 4 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 5 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 6 из 6 (Изображение предоставлено: Tom’s Hardware)У нас есть еще одна материнская плата X570 в лаборатории, Gigabyte X570 Aorus Master, поэтому мы провели ту же серию тестов, чтобы оценить, насколько он попадает в шкалу точности с последней версией BIOS.Мы также хотели посмотреть, демонстрирует ли он те же тенденции производительности при различных настройках PBO. Aorus Master также обеспечивает около 142 Вт потребляемой мощности, что почти идеально согласуется с измерениями программного обеспечения. Учитывая, что мы не ожидаем идеальных показателей эффективности от подсистемы подачи питания, это означает, что отчеты о мощности не оптимизированы на Aorus Master, создавая ситуацию, очень похожую на то, что мы видели с Godlike X570 — завышение отчетов, которое на самом деле может привести к чтобы немного снизить производительность.Мы связались с Gigabyte по этому поводу.
Однако, даже без явного искажения (возможно, завышения) данных телеметрии мощности, мы все равно сталкиваемся с тем же условием снижения производительности при активации предустановки PBO Enabled. Примечательно, что Aorus Master хорошо реагирует на манипуляции со скалярной переменной и обеспечивает большую производительность. Мы также обрисовали в общих чертах проблемы со стандартным профилем PBO для Gigabyte. Компания воспроизвела это состояние и продолжает расследование.
«Контроль»: MSI X570 Godlike
Изображение 1 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 2 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 3 из 6 (Изображение предоставлено Tom’s Hardware) Изображение 4 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 5 из 6 (Изображение предоставлено: Tom’s Hardware) Изображение 6 из 6 (Изображение предоставлено: Tom’s Hardware)MSI X570 Godlike — единственная материнская плата, которая у нас есть в лаборатории, которая позволяет нам настраивать параметр, отвечающий за изменение данных телеметрии: CPU VDD Full Scale Current.По-видимому, для этого параметра установлено значение по умолчанию 280A на Godlike с последней общедоступной не-бета-версией BIOS (1.8). Помните, компания заявляет, что его значение является точным с учетом точной настройки подсистемы подачи энергии, поэтому мы проверили его, отрегулировав значение 300A (указанное в диаграммах как VDD Adjusted), рекомендованное Стилтом в его сообщении на форуме.
Измерения SMU и EPS12V точно совпадают на первой диаграмме, которая показывает результаты нашей настройки 300A. Вторая диаграмма, измеренная при стандартных настройках без регулировки VDD, четко показывает разницу между нашими зарегистрированными значениями и заявленным энергопотреблением, которое теперь составляет примерно 160 Вт по сравнению с примерно 140 Вт с настроенным значением VDD.Поведение с настройкой по умолчанию «Авто» больше соответствует ожидаемому результату, чем скорректированные значения 300A. Напротив, скорректированное значение 300A почти не показывает потерь из-за неэффективности VRM, что было бы неплохо, если бы это было правдой. Но это не так.
HWinfo не поделился с нами информацией, чтобы прояснить, как он измеряет отклонение, поэтому инструмент представляет собой что-то вроде черного ящика. Инструмент HWinfo сообщает о расхождении в 12% с настройками автоматического VDD, указанными выше, подразумевая, что инструмент принимает свои решения на основе эталонных значений тока полной шкалы, а не оптимизированных поставщиками.
На третьем слайде скорректированная установка VDD на 300 А приводит к более низкому нагреву, а последующие диаграммы охватывают пониженные напряжения, частоты и характеристики, связанные с регулировкой. Мы более склонны полагать, что, исходя из проведенных нами физических измерений и обычного количества ожидаемых потерь эффективности VRM, настройки автоматического VDD от MSI ближе к реальности, чем предполагают показатели отклонения HWinfo.
Изображение 1 из 5 (Изображение предоставлено: Tom’s Hardware) Изображение 2 из 5 (Изображение предоставлено: Tom’s Hardware) Изображение 3 из 5 (Изображение предоставлено: Tom’s Hardware) Изображение 4 из 5 (Изображение предоставлено: Tom’s Hardware) Изображение 5 из 5 (Изображение предоставлено Tom’s Hardware)Мы продолжили и построили нашу теперь стандартную батарею тестов с новой прошивкой Godlike, оставив настройку VDD на Auto.Материнская плата демонстрирует многие из тех же тенденций, которые мы наблюдаем с другими платами с предустановками AMD PBO. Тем не менее, он работает значительно лучше, чем другие платы с профилем с включенным PBO, просто соответствует стандартным настройкам по большинству показателей.
Последние мысли (на данный момент)
Современные микросхемы полагаются на точные данные телеметрии, и новая функция отклонения HWinfo помогает пролить свет на то, как некоторые производители материнских плат нашли способ неверно сообщать телеметрию питания. К сожалению, внутренняя работа инструмента не совсем ясна, и HWinfo не указывает, как он присваивает значение отклонения.Из нашего тестирования кажется, что инструмент не принимает во внимание то, что мы считали бы законными корректировками тока полной шкалы, что приводит к завышенным показаниям отклонения.
Согласно нашим источникам, у AMD есть инструменты генерации нагрузки, которые помогают поставщикам материнских плат определять эталонные значения для отчетов телеметрии питания, но это более общие настройки, которые предполагают накладные расходы ~ 5% для допуска компонентов VRM. На практике допуск может достигать 10%. В результате производители материнских плат могут точно настроить телеметрические отчеты для своих уникальных систем подачи питания, обеспечивая тем самым правильное количество энергии, подаваемой на микросхему.Показатель отклонения HWinfo, по-видимому, не учитывает то, что мы считаем рациональными корректировками в отчетах телеметрии мощности. Кажется, по крайней мере, на первый взгляд, что инструмент HWinfo измеряет, исходя из некоторого понимания эталонных значений, но его метод неясен. Метрика отклонений все еще находится в стадии разработки, но мы заметили довольно небольшие различия в некоторых измерениях, поэтому ваш пробег может отличаться.
Вполне возможно, что преднамеренно измененные отчеты телеметрии мощности могут дать дополнительное преимущество в производительности и остаться незамеченными как обозревателями, так и обычными пользователями, что приведет к публикации ошибочных результатов энергопотребления.Мы видели довольно вопиющий пример неверной отчетности в нашем тестировании с BIOS, предоставленным обозревателям, который также доступен для общественности, поэтому для обозревателей по-прежнему важно использовать измерения физической мощности для проверки результатов, которые они получают от программных утилит. Честно говоря, мы ожидаем более тонких изменений, чем то, что мы наблюдали с BIOS рецензента Taichi, если бы компания пыталась обмануть рецензентов, поэтому остается спорным, были ли изменения в отчетности преднамеренными. Мы даже обнаружили несколько материнских плат, которые неверно сообщают о мощности, что снижает производительность.
Функция автоматического разгона AMD Precision Boost Overdrive (PBO) часто приводит к снижению производительности в некоторых рабочих нагрузках, если вы используете определенные производителем базовые предустановленные значения, но степень серьезности различается от материнской платы к материнской плате. Мы решили использовать значения PBO в качестве справочной информации о том, как выглядят небезопасные настройки (это действительно аннулирует вашу гарантию), но во многих случаях обнаружили, что базовые предустановки PBO приводили к снижению производительности. Им нужно немного поработать, и в настоящее время они не являются хорошей мерой. Даже на материнских платах, которые правильно сообщают о мощности, основные предустановки PBO не принесли ощутимой пользы.
Напротив, ручные изменения (которые мы рассмотрели выше) в настройке Scalar обеспечивают повышение производительности, и это лучшая точка отсчета для небезопасных настроек. BIOS рецензента Taichi пострадал от худших искажений, но это не привело к настройкам мощности, которые соответствуют или превышают настройки, налагаемые нашим профилем PBO с более высокими настройками скалярности.
Неправильные данные могут привести к тому, что ЦП будет работать немного тяжелее (и горячее) во время нормальной работы, но вы не должны слишком беспокоиться о количестве энергии, подаваемой на ваш чип, если ваша плата неверно сообщает данные телеметрии, хотя это приводят к более высокому энергопотреблению, напряжению, нагреву и тактовой частоте.
Лучше оставить оценку влияния на долговечность чипа Ryzen компании AMD или другим специалистам в области полупроводников, которые работают в области надежности, поскольку на эти показатели влияет широкий спектр факторов. Метрики надежности основаны на моделировании и информации, которую мы никогда не увидим, и сложная матрица факторов также учитывается в уравнении. Фактически, нам не известна какая-либо общедоступная информация даже о рабочих нагрузках или рабочих циклах, которые AMD и Intel используют для определения показателей надежности — и мы спросили.
Некоторые факторы увеличивают скорость износа и ускоряют электромиграцию (процесс проскальзывания электронов по электрическим путям), например, более высокий ток и тепловая плотность, но их влияние друг на друга не масштабируется линейно, и это варьируется в зависимости от того, как долго процессор находится в повышенном состоянии.
Микросхема стареет, а транзисторы со временем изнашиваются даже при оптимальных условиях эксплуатации. Тем не менее, хотя повышенное энергопотребление, которое мы наблюдаем из-за ошибочных данных телеметрии, может повлиять на интенсивно используемые процессоры и снизить долговечность, оно сводится к тому, насколько увеличенная мощность и тепловыделение ускоряют процесс старения.
Вероятно, что по крайней мере или могут повлиять на долговечность чипа из-за измененной телеметрии мощности, но первоначальная оценка AMD такова, что это не окажет значимого влияния в течение гарантийного срока. Мы не обнаружили каких-либо явных проблем, которые могли бы вызвать немедленную тревогу, а внутренние механизмы AMD работают хорошо, чтобы защитить пользователей от настроек, которые могут вызвать катастрофические сбои. Инженерные группы компании, очевидно, также в некоторой степени изучили этот вопрос и еще не видели никаких корректировок, которые могли бы привести к значительному ухудшению характеристик в течение гарантийного периода.
Заявление AMD вроде бы подтверждает, что не знала о манипуляциях. Будет интересно посмотреть, прекратят ли производители материнских плат эту практику или AMD обнаружит, что, поскольку изменения существенно не влияют на долговечность, практика может продолжаться. Мы будем следить за новыми выпусками BIOS по мере их появления на предмет каких-либо существенных изменений в отчетах телеметрии питания.
Что делает материнская плата
Вам не нужно проводить весь день с техническими специалистами, чтобы услышать термин «материнская плата».«Этот критически важный компонент современного ПК играет важную роль в поддержании работы вашего компьютера. Но что делает материнская плата? Как убедиться, что она работает правильно? Можно ли заменить ее самостоятельно? Мы отвечаем на все вопросы, связанные с вашей материнской платой. в этом простом руководстве.
Как работает материнская плата
Официальное определение материнской платы состоит в том, что это основная печатная плата в компьютере, что означает, что это основная часть схемы, к которой подключаются все остальные части, чтобы создать единое целое. весь.Материнская плата — это основа, которая связывает компоненты компьютера в одном месте и позволяет им общаться друг с другом. Без него никакие компоненты компьютера, такие как CPU, GPU или жесткий диск, не могли бы взаимодействовать. Для нормальной работы компьютера необходима полная функциональность материнской платы. Если ваша материнская плата не работает, ожидайте больших проблем.
Общие детали материнской платы
Хотя вам не нужно постоянно заглядывать внутрь компьютера, чтобы осматривать материнскую плату, полезно ознакомиться с тонкостями этого важного инструмента.Материнская плата будет выглядеть как кусок плоского картона или пластика с множеством металлических конструкций и проводов на нем и вокруг него.
Части материнской платы включают разъемы питания и данных, конденсаторы, радиаторы и вентиляторы. Вы также можете увидеть отверстия для винтов для добавления новых деталей или для закрепления их в устройстве. Ищите слоты расширения, которые могут присутствовать для добавления других компонентов позже.
Детали, которые подключаются к нему с помощью проводов или напрямую, часто называют компонентами материнской платы.К ним относятся:
- Оптические приводы, такие как DVD и CD-ROM
- Видеокарты и графические процессоры
- Звуковые карты
- Жесткие диски (SSD или HDD)
- Процессоры (CPU)
- Карты памяти (RAM)
Короче говоря, если компьютер использует его для работы, он, вероятно, подключен к материнской плате, чтобы координировать задачи с другими частями компьютера. Без материнской платы ничего не происходит как надо.
Как я могу определить, что моя материнская плата не работает?
Как и все технические вещи, материнские платы рано или поздно умирают или приходят в негодность.Существует множество симптомов неисправности материнской платы, в том числе:
- Периферийные устройства, которые выходят из строя или запускаются долгое время
- Компьютер неожиданно выключается
- Компьютер вообще не включается
- Горит или химический запах, исходящий от вашего компьютера
Совет от профессионала: Плохое соединение или отказ источника питания более распространены, чем отказ материнской платы. Это, безусловно, более доступное решение, поэтому сначала попробуйте их, прежде чем предполагать худшее.
Как заменить материнскую плату
Если вы решили заменить материнскую плату самостоятельно, вам необходимо знать точную модель, а также совместимые модели на замену, прежде чем делать решительный шаг.Материнские платы в ноутбуках может быть чрезвычайно сложно заменить, потому что их нелегко открыть или разобрать. Место также узкое, и одно неверное движение может повредить не только материнскую плату.
Вы также должны быть готовы заменить не только материнскую плату. Большинство людей считают, что процессор, видеокарта и даже источник питания должны быть заменены, когда они получают новую материнскую плату. Это не дешевый ремонт. Убедитесь, что вы исключили другие возможности, а затем составьте бюджет на дорогостоящий ремонт, который можно сделать самостоятельно.
Поиск информации о модели материнской платы
Эту замену, как правило, легче выполнить на настольных компьютерах, но любому, кто не знает точных инструкций по замене для своей конкретной модели, лучше оставить работу профессионалу.
В любом случае, знание того, как найти информацию о модели материнской платы, может быть полезно для вас и вашего профессионального компьютера. Вы можете получить эту информацию, проверив документацию своего компьютера, или, если вы можете войти на свой компьютер, запустите командную строку, чтобы найти ее.
Для этого выполните следующие действия:
- Откройте командную строку в Windows, нажав клавиши Windows + R или используя поле поиска в меню «Пуск», чтобы ввести « cmd »
- Когда команда Появится окно подсказки, введите следующее: « wmic baseboard получить продукт, производитель, версия, серийный номер »
- Запишите информацию или сделайте снимок экрана, который должен включать серийный номер в качестве одного из последних битов информации в новой линейке, которая появляется
Уход за материнской платой
Большинство материнских плат долговечнее остальных компонентов компьютера, если они содержатся в хорошем состоянии. Вам не нужно ничего делать, чтобы активно ухаживать за материнской платой, но знание распространенных убийц материнской платы может быть полезно. Материнская плата может быть преждевременно разрушена:
- Высокая температура, обычно из-за неадекватных систем охлаждения и вентиляторов
- Повреждение от удара, например, падения ноутбука
- Электрическое повреждение, разлив или использование неправильных аксессуаров питания
- Неисправные соединения или типы разъемов
Если вы покупаете компьютер у известного производителя, хорошо относитесь к нему и используете только одобренные аксессуары и устройства питания, вы, скорее всего, не столкнетесь с этими проблемами.
Резюме
Материнская плата — одна из самых сложных частей для диагностики и ремонта, поэтому стоит подумать о дополнительной защите покупателя, чтобы не беспокоиться о поломке. Например, HP Care Pack покроет даже случайное повреждение компьютеров, на которых может быть повреждена материнская плата. Часто лучше заплатить за дополнительное покрытие, чем пытаться решить это дорогостоящее решение самостоятельно.Об авторе
Линси Кнерл — автор статей в HP® Tech Takes.Линси — писатель из Среднего Запада, оратор и член ASJA. Она стремится помочь потребителям и владельцам малого бизнеса более эффективно использовать свои ресурсы с помощью новейших технических решений.Контрольные вопросы для «Суперкомпьютерные вычисления на простом английском» ================================================== ==== Выберите ЛУЧШИЙ ответ на каждый вопрос. ————————————————— ———————- (1) Что из этого * НЕ * вызывает беспокойство в области суперкомпьютеров? (а) Размер (б) объектно-ориентированное программирование (c) Параллельность (d) Скорость ОТВЕТ: (б).Хотя ООП можно использовать в суперкомпьютерах, это не так. необходимо, и многие популярные суперкомпьютерные приложения не используют ООП. ————————————————— ———————- (2) Что из этого * НЕ * является общей категорией использования суперкомпьютеров? а) интеллектуальный анализ данных (б) Графические пользовательские интерфейсы (c) Визуализация (d) Моделирование физических явлений ОТВЕТ: (б). Фактически, многие популярные суперкомпьютерные приложения не имеют GUI, потому что интерактивное использование компьютера не является высокой производительностью.————————————————— ———————- (3) Что такое компилятор? (а) Программа, преобразующая понятный человеку исходный код в машиночитаемый исполняемый код. (б) Программа, которая выполняет другие программы параллельно в кластере. (c) язык программирования. (d) Программа, преобразующая слышимую человеческую речь в видимый текст. ОТВЕТ: (а) ————————————————— ———————- (4) В чем разница между параллелизмом с общей памятью? а распределенный параллелизм? (а) Многие задачи выполняются одновременно.(б) В одной из этих форм параллелизма все данные являются частными, а в другом — некоторые данные могут совместно использоваться процессорами. (c) Необходимо указать количество процессов / потоков. (d) Количество процессов / потоков должно совпадать с количеством доступных процессоров. ОТВЕТ: (б) ————————————————— ———————- (5) Какой из них является правильным порядком скорости, от самой быстрой до самый медленный? (а) CD-ROM, жесткий диск, основная память, кэш-память (b) Основная память, кэш-память, жесткий диск, CD-ROM (c) Жесткий диск, кэш-память, CD-ROM, основная память (d) Кэш-память, основная память, жесткий диск, CD-ROM. ОТВЕТ: (d) ————————————————— ———————- (6) Какой из них является правильным порядком цены, от наивысшей до самый низкий? (а) CD-ROM, жесткий диск, основная память, кэш-память (b) Основная память, кэш-память, жесткий диск, CD-ROM (c) Жесткий диск, кэш-память, CD-ROM, основная память (d) Кэш-память, основная память, жесткий диск, CD-ROM. ОТВЕТ: (d) ————————————————— ———————- (7) Какой из них является правильным порядком размеров, от наибольшего до самый маленький, на обычном компьютере? (а) CD-ROM, жесткий диск, основная память, кэш-память (b) Основная память, кэш-память, жесткий диск, CD-ROM (c) Жесткий диск, кэш-память, CD-ROM, основная память (d) Кэш-память, основная память, жесткий диск, CD-ROM. ОТВЕТ: (а) ————————————————— ———————- (8) Что из этого лучше всего описывает данные, хранящиеся в регистрах? (а) Данные, которые используются прямо сейчас.(b) Данные, которые собираются использовать или только что были использованы. (c) Данные, которые используются программой, которая в настоящее время выполняется. (d) Данные, которые необходимо сохранить, даже когда компьютер выключен. выключенный. ОТВЕТ: (а) ————————————————— ———————- (9) Что из этого лучше всего описывает данные, хранящиеся в кеше? (а) Данные, которые используются прямо сейчас. (б) Данные, которые собираются использовать или только что были использованы. (c) Данные, которые используются программой, которая в настоящее время выполняется.(d) Данные, которые необходимо сохранить, даже когда компьютер выключен. выключенный. ОТВЕТ: (б) ————————————————— ———————- (10) Что из этого лучше всего описывает данные, хранящиеся в ОЗУ? (а) Данные, которые используются прямо сейчас. (б) Данные, которые собираются использовать или только что были использованы. (c) Данные, которые используются программой, которая в настоящее время выполняется. (d) Данные, которые необходимо сохранить, даже когда компьютер выключен. выключенный. ОТВЕТ: (c) ————————————————— ———————- (11) Что из этого лучше всего описывает данные, хранящиеся на жестком диске? (а) Данные, которые используются прямо сейчас.(б) Данные, которые собираются использовать или только что были использованы. (c) Данные, которые используются программой, которая в настоящее время выполняется. (d) Данные, которые необходимо сохранить, даже когда компьютер выключен. выключенный. ОТВЕТ: (d) ————————————————— ———————- (12) Почему у большинства современных компьютеров есть кэш? (а) ЦП может вычислять немного быстрее, чем могут перемещаться данные между процессором и кешем, но намного быстрее, чем данные могут перемещаться между ЦП и ОЗУ.(b) Кэш — это место, где временные результаты сохраняются во время расчета, но эти результаты никогда не переместятся в оперативную память. (c) Кэш — это место, где временные результаты сохраняются во время расчета, и эти результаты в конечном итоге переместятся в ОЗУ. (d) Наиболее важные данные программы хранятся в кеш-памяти, но не в ОЗУ. ОТВЕТ: (а) ————————————————— ———————- (13) Что из этого НЕ является синонимом основной памяти? (а) Оперативная память (RAM) (б) Ядро (c) Постоянное запоминающее устройство (ПЗУ) ОТВЕТ: (c) ————————————————— ———————- (14) Что такое строка кэша? (а) Один байт кеша.(b) Значение с плавающей запятой двойной точности (т. е. 8 байтов). (c) Фиксированное количество байтов, в зависимости от типа ЦП, которое все перемещаться в кэш или из кеша вместе. (d) Все байты в кэше. ОТВЕТ: (c) ————————————————— ———————- (15) В схеме кэша с прямым отображением, сколько разных расположений в кеше мог ли байт ОЗУ войти? (а) 1 (Би 2 (в) 4 (d) Любое место в тайнике ОТВЕТ: (а) ————————————————— ———————- (16) В полностью ассоциативной схеме кэширования сколько разных мест в кеше мог ли байт ОЗУ войти? (а) 1 (Би 2 (в) 4 (d) Любое место в тайнике ОТВЕТ: (d) ————————————————— ———————- (17) В четырехсторонней схеме ассоциативного кеширования, сколько разных расположений в кеше мог ли байт ОЗУ войти? (а) 1 (Би 2 (в) 4 (d) Любое место в тайнике ОТВЕТ: (c) ————————————————— ———————- (18) Что происходит в схеме кэша с прямым отображением в случае конфликт кеша? (a) Данные, находящиеся в данный момент в данной строке кэша, копируются обратно в ОЗУ. при необходимости, а затем новая строка RAM затирает данный строка кэша.(b) Выбрана одна из ограниченного числа возможных строк кэша, данные, находящиеся в данный момент в этой строке кэша, копируются обратно в ОЗУ при необходимости, а затем новая линейка клобберов RAM, которые строка кэша. (c) Выбрана любая из строк кэша, данные, находящиеся в данный момент в этой строке кэша, копируются обратно в ОЗУ, если необходимо, а затем новая линейка клобберов RAM, которые строка кэша. ОТВЕТ: (а) ————————————————— ———————- (19) Популярны ли схемы кэширования с прямым отображением? (а) Да, потому что они недорогие.(b) Нет, поскольку существует неоправданно высокая вероятность затирать строку кэша, которая скоро понадобится. (c) Нет, потому что большое количество соединений между ОЗУ и кешем сделать эту схему слишком дорогой. (d) Нет, потому что множество возможных алгоритмов отображения для этой схемы усложняют проектирование оборудования. ОТВЕТ: (б) ————————————————— ———————- (20) Насколько популярны схемы ассоциативного кэширования? (а) Да, потому что существует достаточно низкая вероятность заткнуть строка кэша, которая понадобится в ближайшее время, в сочетании с разумным низкое количество соединений между ОЗУ и кешем и, следовательно, разумная стоимость.(c) Нет, потому что большое количество соединений между ОЗУ и кешем сделать эту схему слишком дорогой. (d) Нет, потому что множество возможных алгоритмов отображения для этой схемы усложняют проектирование оборудования. ОТВЕТ: (а) ————————————————— ———————- (21) Популярны ли полностью ассоциативные схемы кэширования? (а) Да, потому что существует очень низкая вероятность заткнуть строка кеша, которая скоро понадобится. б) Да, потому что они недорогие. (c) Нет, потому что большое количество соединений между ОЗУ и кешем сделать эту схему слишком дорогой.(d) Нет, потому что множество возможных алгоритмов отображения для этой схемы усложняют проектирование оборудования. ОТВЕТ: (c) ————————————————— ———————- (22) Что из этого * НЕ * является стратегией замены кеша? (а) Наименее недавно использованные (b) Наименее измененные в последнее время (c) Круговая система (d) Первая подгонка ОТВЕТ: (d) ————————————————— ———————- (23) Если переменная находится в кеше, находится ли она также в ОЗУ? (а) Да, потому что кеш содержит подмножество ОЗУ.(б) Нет, потому что кэш и оперативная память не пересекаются. (c) Возможно, потому что программа может использовать кеш, но не использовать оперативную память. (d) Нет, потому что программа не может использовать оба одновременно. ОТВЕТ: (а) ————————————————— ———————- (24) Что значит грязная строка кэша? (a) Все байты в строке кэша были изменены. (b) Любой из байтов в строке кэша был изменен. (c) Ни один из байтов в строке кэша не был изменен. (d) Строка кэша в настоящее время не используется.ОТВЕТ: (б) ————————————————— ———————- (25) Что такое временная локальность данных? (а) Если данные по определенному адресу использовались недавно, то эти данные скоро будут использоваться снова. (b) Если данные по определенному адресу использовались недавно, то данные по близлежащим адресам скоро будут использоваться. (c) Если данные по определенному адресу использовались недавно, то тогда никакие данные на заданном расстоянии от этого адреса не будут используется в течение определенного времени.(d) В любое время данные по всем адресам имеют равную вероятность использовался. ОТВЕТ: (а) ————————————————— ———————- (26) Что такое локальность пространственных данных? (а) Если данные по определенному адресу использовались недавно, то эти данные скоро будут использоваться снова. (b) Если данные по определенному адресу использовались недавно, то данные по близлежащим адресам скоро будут использоваться. (c) Если данные по определенному адресу использовались недавно, то тогда никакие данные на заданном расстоянии от этого адреса не будут используется в течение определенного времени.(d) В любое время данные по всем адресам имеют равную вероятность использовался. ОТВЕТ: (б) ————————————————— ———————- (27) Что такое тайлинг? (а) Разделение проблемной области на части, каждая из которых может уместиться в cache, чтобы увеличить количество попаданий в кеш и, следовательно, представление. (б) разбиение проблемной области на части одинакового размера, для увеличения количества попаданий в кеш и, следовательно, представление. (c) Добавление любого дополнительного кода в программу для улучшения ее представление.ОТВЕТ: (а) ————————————————— ———————- (28) Почему жесткий диск медленнее ОЗУ? (а) Жесткий диск является механическим, а ОЗУ — электронным. (б) Жесткий диск больше ОЗУ. (c) Жесткий диск использует магнетизм, в то время как RAM использует электричество. (г) Жесткий диск дешевле ОЗУ. ОТВЕТ: (а) ————————————————— ———————- (29) Почему для ввода-вывода жесткого диска следует использовать двоичные представления а не текст, читаемый человеком? (a) Двоичные данные обычно занимают меньше места на диске, чем текст.(b) Данные, удобочитаемые человеком, менее безопасны, чем данные, считываемые компьютером. (c) Двоичные данные всегда переносимы между разными типами компьютеры. (d) Двоичные данные не могут быть легко преобразованы в читаемый человеком текст. ОТВЕТ: (а) ————————————————— ———————- (30) Что из этого * НЕ * является причиной использования переносимой библиотеки ввода-вывода? например HDF или NetCDF? (а) Переносимые библиотеки ввода-вывода оптимизированы по скорости. (б) Двоичные данные компактнее текста. (c) Переносимые двоичные данные можно читать на машинах другого типа. чем было написано.(d) Переносимые двоичные данные всегда сохраняют точные побитовые копии данные, которые изначально были в ОЗУ. ОТВЕТ: (d) ————————————————— ———————- (31) Что из перечисленного лучше всего определяет параллелизм? (а) Запуск в кластере. (b) Работает на компьютере с общей памятью. (c) Работает на нескольких процессорах. (d) одновременное выполнение нескольких потоков выполнения. ОТВЕТ: (d) ————————————————— ———————- (32) Что из перечисленного лучше всего определяет параллелизм на уровне инструкций? (а) Набор методов для выполнения нескольких инструкций на в то же время.(b) Набор методов для выполнения нескольких инструкций на в одно и то же время на одном компьютере. (c) Набор методов для выполнения нескольких инструкций на в одно и то же время в одном процессоре. (d) Набор методов для выполнения нескольких инструкций на в то же время на многих процессорах. ОТВЕТ: (c) ————————————————— ———————- (33) Что из этого * НЕ * является формой параллелизма на уровне инструкций? (а) Суперскаляр (б) Трубопровод (c) Вектор (d) OpenMP ОТВЕТ: (d) ————————————————— ———————- (34) Что из этого НЕ является инструкцией? (а) Доступ к памяти (например,г., загрузка, магазин) (б) Арифметические операции (например, сложение, деление) (c) Переход (переход от одной последовательности инструкций к другой) (d) Обратная подстановка (решите систему уравнений, которая была факторизовано разложением LU) ОТВЕТ: (d) ————————————————— ———————- (35) Если процессор имеет частоту 1 ГГц, сколько циклов у него будет? (а) 1 миллиард в секунду (б) 2 миллиарда в секунду (c) 1 миллион в секунду (г) 2 миллиона в секунду ОТВЕТ: (а) ————————————————— ———————- (36) Две инструкции независимы, когда: (а) Неважно, какой из них будет выполнен первым.(b) Имеет значение, кто из них будет выполнен первым. (c) Они работают с разными частями данных. (d) Один использует данные, которые находятся в кеше, а другой использует данные, которые в ОЗУ. ОТВЕТ: (а) ————————————————— ———————- (37) Что из этого * НЕ * является причиной того, почему циклы легко оптимизировать? (а) Их поведение очень предсказуемо. (б) Они очень распространены в программах, которые используют люди. суперкомпьютеры для. (c) У них гарантированно высокая локальность данных.(d) Их можно развернуть. ОТВЕТ: (c) ————————————————— ———————- (38) Какое из них является лучшим определением «редукции»? (а) Выполнение вычисления, которое преобразует множество данных в одно значение. (б) Вычисление суммы или произведения массива. (c) Вычисление скалярного произведения двух массивов. (d) Добавление двух массивов (покомпонентно) для получения нового массива. ОТВЕТ: (а) ————————————————— ———————- (39) Какая из этих арифметических операций обычно занимает меньше всего количество времени на выполнение? (а) Сложение с плавающей запятой (b) Деление с плавающей запятой (c) Квадратный корень с плавающей запятой (d) Возведение числа с плавающей запятой в степень с плавающей запятой ОТВЕТ: (а) ————————————————— ———————- (40) Какая из этих арифметических операций обычно занимает больше всего количество времени на выполнение? (а) Сложение с плавающей запятой (b) Деление с плавающей запятой (c) Квадратный корень с плавающей запятой (d) Возведение числа с плавающей запятой в степень с плавающей запятой ОТВЕТ: (d) ————————————————— ———————- (41) Что из этого * НЕ * предотвратит конвейерную обработку? (а) Выполнение множества операций сложения, вычитания и умножения.(b) Преждевременный выход из цикла. (c) Вызов функции или подпрограммы. (d) Выполнение ввода-вывода внутри цикла. ОТВЕТ: (а) ————————————————— ———————- (42) Что из этого лучше всего описывает векторный регистр? (а) Набор регистров, которые выполняют одну и ту же инструкцию. в то же время. (б) Набор регистров, которые выполняют одну и ту же инструкцию. при этом по разным данным. (c) Один регистр, который может выполнять одну и ту же инструкцию на многих данных очень быстро по очереди.(d) Набор одиночных регистров, которые могут выполнять одну и ту же инструкцию. на многих данных очень быстро по очереди. ОТВЕТ: (б) ————————————————— ———————- (43) Что из этого является примером зависимости управления? (a) ЕСЛИ (a> b) ТО c = d КОНЕЦ ЕСЛИ (b) ЕСЛИ (1> 2) ТО д = г КОНЕЦ ЕСЛИ (c) b = a c = b (г) b = a c = d ОТВЕТ: (а) ————————————————— ———————- (44) Что из этого является примером зависимости ветвления? (a) ЕСЛИ (a> b) ТО c = d КОНЕЦ ЕСЛИ (b) ЕСЛИ (1> 2) ТО д = г КОНЕЦ ЕСЛИ (c) b = a c = b (г) b = a c = d ОТВЕТ: (а) ————————————————— ———————- (45) Что из этого является примером зависимости с переносом цикла? а) DO i = 2, n д (я) = а (я-1) + Ь (я) КОНЕЦ ДЕЛАТЬ (б) DO i = 2, n д (я) = а (я-1) + д (я) КОНЕЦ ДЕЛАТЬ (в) DO i = 2, n д (я) = д (я-1) + Ь (я) КОНЕЦ ДЕЛАТЬ (г) DO i = 2, n д (я) = д (я) + Ь (я) КОНЕЦ ДЕЛАТЬ ОТВЕТ: (c) ————————————————— ———————- (46) Примером какой зависимости является это? DO i = 2, n ЕСЛИ (x (i) / = 0) ТО у (я) = ЖУРНАЛ (х (я)) КОНЕЦ ЕСЛИ КОНЕЦ ДЕЛАТЬ (отделение (б) Данные (c) с петлей (d) Выход ОТВЕТ: (а) ————————————————— ———————- (47) Примером какой зависимости является это? д = х + у г = г + ш q = f — g (отделение (б) Данные (c) с петлей (d) Выход ОТВЕТ: (d) ————————————————— ———————- (48) Что из этого * НЕ * является сокращением? (а) сумма = 0 DO i = 1, n сумма = сумма + а (я) КОНЕЦ ДЕЛАТЬ (б) product = 1 DO i = 1, n product = product * a (i) КОНЕЦ ДЕЛАТЬ (c) максимум = a (1) DO i = 2, n ЕСЛИ (максимум 0) ТО а (я) = а (я) + 1 КОНЕЦ ЕСЛИ КОНЕЦ ДЕЛАТЬ ОТВЕТ: (d) ————————————————— ———————- (49) Какая стратегия оптимизации представлена этим преобразованием кода? а = б с = а + г СТАНОВИТСЯ а = б с = b + d (а) Копирование распространения (б) Постоянное сворачивание (c) Удаление мертвого кода (г) Снижение силы ОТВЕТ: (а) ————————————————— ———————- (50) Какая стратегия оптимизации представлена этим преобразованием кода? а = 2 b = 4 с = а * б СТАНОВИТСЯ с = 6 (а) Копирование распространения (б) Постоянное сворачивание (c) Удаление мертвого кода (г) Снижение силы ОТВЕТ: (б) ————————————————— ———————- (51) Какая стратегия оптимизации представлена этим преобразованием кода? а = б ОСТАНАВЛИВАТЬСЯ c = d СТАНОВИТСЯ а = б ОСТАНАВЛИВАТЬСЯ (а) Копирование распространения (б) Исключение общего подвыражения (c) Удаление мертвого кода (г) Снижение силы ОТВЕТ: (c) ————————————————— ———————- (52) Какая стратегия оптимизации представлена этим преобразованием кода? а = Ь ** 3 СТАНОВИТСЯ а = б * б * б (а) Переименование переменной (б) Постоянное сворачивание (c) Удаление мертвого кода (г) Снижение силы ОТВЕТ: (d) ————————————————— ———————- (53) Какая стратегия оптимизации представлена этим преобразованием кода? а = б + с * г е = е * с * д СТАНОВИТСЯ т = с * д а = Ь + т е = е * т (а) Переименование переменной (б) Исключение общего подвыражения (c) Удаление мертвого кода (г) Снижение силы ОТВЕТ: (б) ————————————————— ———————- (54) Какая стратегия оптимизации представлена этим преобразованием кода? а = б + с * г е = е * с * д а = д + г СТАНОВИТСЯ г = Ь + с * г е = е * с * д а = д + г (а) Переименование переменной (б) Исключение общего подвыражения (c) Удаление мертвого кода (г) Снижение силы ОТВЕТ: (а) ————————————————— ———————- (55) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, n д (я) = г (я) + е * 3 КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ т = е * 3 DO i = 1, n д (я) = г (я) + т КОНЕЦ ДЕЛАТЬ (a) Инвариантный код цикла подъема (b) Отключение (c) Итерационный пилинг (d) Обмен петлей ОТВЕТ: (а) ————————————————— ———————- (56) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, n DO j = 2, n ЕСЛИ (f (i) / = 0) ТО а (я, j) = а (я, j) / f (я) ЕЩЕ а (я, j) = 0 КОНЕЦ ЕСЛИ КОНЕЦ ДЕЛАТЬ КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ DO i = 1, n ЕСЛИ (f (i) / = 0) ТО DO j = 2, n а (я, j) = а (я, j) / f (я) КОНЕЦ ДЕЛАТЬ ЕЩЕ DO j = 2, n а (я, j) = 0 КОНЕЦ ДЕЛАТЬ КОНЕЦ ЕСЛИ КОНЕЦ ДЕЛАТЬ (а) Инвариантный код цикла подъема (b) Отключение (c) Итерационный пилинг (d) Обмен петлей ОТВЕТ: (б) ————————————————— ———————- (57) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, n ЕСЛИ (i == 1) ТО а (я) = 3 * Ь (я) ЕЩЕ а (я) = 3 * Ь (я — 1) КОНЕЦ ЕСЛИ КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ а (1) = 3 * Ь (1) DO i = 2, n а (я) = 3 * Ь (я — 1) КОНЕЦ ДЕЛАТЬ (a) Инвариантный код цикла подъема (b) Отключение (c) Итерационный пилинг (d) Обмен петлей ОТВЕТ: (c) ————————————————— ———————- (58) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, ni DO j = 1, nj q (i, j) = r (i, j) * 2 КОНЕЦ ДЕЛАТЬ КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ DO j = 1, nj DO i = 1, ni q (i, j) = r (i, j) * 2 КОНЕЦ ДЕЛАТЬ КОНЕЦ ДЕЛАТЬ (а) Инвариантный код цикла подъема (b) Отключение (c) Итерационный пилинг (d) Обмен петлей ОТВЕТ: (d) ————————————————— ———————- (59) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, n д (я) = г (я) * 2 ЕСЛИ (i> (n / 2)) ТО s (i) = t (i) / 5 КОНЕЦ ЕСЛИ КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ DO i = 1, n / 2 д (я) = г (я) * 2 КОНЕЦ ДЕЛАТЬ DO i = n / 2 + 1, n д (я) = г (я) * 2 s (i) = t (i) / 5 КОНЕЦ ДЕЛАТЬ (а) Разделение индексного набора (б) Раскрутка (c) Петлевой сплав (d) Петлевое деление ОТВЕТ: (а) ————————————————— ———————- (60) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, n д (я) = г (я) * 2 КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ ДО i = 1, n, 4 д (я) = г (я) * 2 д (я + 1) = г (я + 1) * 2 д (я + 2) = г (я + 2) * 2 д (я + 3) = г (я + 3) * 2 КОНЕЦ ДЕЛАТЬ (а) Разделение индексного набора (б) Раскрутка (c) Петлевой сплав (d) Петлевое деление ОТВЕТ: (б) ————————————————— ———————- (61) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, n д (я) = г (я) * 2 КОНЕЦ ДЕЛАТЬ DO i = 1, n s (i) = r (i) / 2 КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ DO i = 1, n д (я) = г (я) * 2 s (i) = r (i) / 2 КОНЕЦ ДЕЛАТЬ (а) Разделение индексного набора (б) Раскрутка (c) Петлевой сплав (d) Петлевое деление ОТВЕТ: (c) ————————————————— ———————- (62) Какая стратегия оптимизации представлена этим преобразованием кода? DO i = 1, n д (я) = г (я) * 2 s (i) = r (i) / 2 КОНЕЦ ДЕЛАТЬ СТАНОВИТСЯ DO i = 1, n д (я) = г (я) * 2 КОНЕЦ ДЕЛАТЬ DO i = 1, n s (i) = r (i) / 2 КОНЕЦ ДЕЛАТЬ (а) Разделение индексного набора (б) Раскрутка (c) Петлевой сплав (d) Петлевое деление ОТВЕТ: (d) ————————————————— ———————- (63) Что из перечисленного * НЕ * является причиной того, что встраивание может улучшить представление? (а) Это сокращает количество обычных звонков и, следовательно, время потратил на выполнение звонков.(b) Если встроенная процедура находилась внутри цикла, то компилятор может быть возможность оптимизировать цикл, что было бы невозможно внутри рутина, в которой нет цикла. (c) Уменьшает время компиляции. ОТВЕТ: (c) ————————————————— ———————- (64) Что из этого * НЕ * способствует времени выполнения? (а) Время компиляции (б) Количество пользователей в системе, на которой выполняется (c) Операционная система (d) Аппаратное обеспечение ОТВЕТ: (а) ————————————————— ———————- (65) Какого рода информацию дает профилирование подпрограмм? (а) Сколько времени было потрачено на каждое упражнение (б) Сколько времени было потрачено на вычисления (c) Сколько времени было потрачено на ввод-вывод (d) Сколько времени было потрачено на перемещение данных между памятью и ЦП. ОТВЕТ: (а) ————————————————— ———————- (66) Что из этого верно? (а) Потоки используют разделяемую память, а процессы — нет.(b) Процессы используют разделяемую память, а потоки — нет. (c) И потоки, и процессы используют общую память. (d) Ни потоки, ни процессы не используют разделяемую память. ОТВЕТ: (а) ————————————————— ———————- (67) Что из этого * НЕ * связано с потоками? (а) Общая память (б) Процессоры обмениваются данными через память (c) Одни темы расходятся от других. (d) Передача сообщений ОТВЕТ: (d) ————————————————— ———————- (68) Что из этого является свойством Закона Амдала? (а) Ускорение ограничено той частью кода, которая не распараллеливание.(b) Ускорение ограничено частью кода, которая не является ни тем, ни другим. ни последовательный, ни параллельный. (c) Ускорение ограничено той частью кода, которая выполняет ввод-вывод. (d) Ускорение ограничено частью кода, который проходит Сообщения. ОТВЕТ: (а) ————————————————— ———————- (69) Что означает «линейное ускорение»? (а) Ускорение кода равно количеству процессоров. (б) Ускорение кода меньше количества процессоров. (c) Ускорение кода больше, чем количество процессоров.(d) Ускорение кода обратно пропорционально количество процессоров. ОТВЕТ: (а) ————————————————— ———————- (70) Что такое «крупнозернистый» и «мелкозернистый» параллелизм? (а) «Крупнозернистый» — это когда в программе небольшое количество крупных части, которые будут запускаться параллельно; «мелкое зерно» — это когда у него есть большое количество мелких деталей. (б) «Крупнозернистый» — это когда в программе большое количество мелких части, которые будут запускаться параллельно; «мелкое зерно» — это когда у него есть небольшое количество крупных штук.(c) «Крупнозернистый» — это когда программа имеет большое количество крупных части, которые будут запускаться параллельно; «мелкое зерно» — это когда у него есть небольшое количество мелких кусочков. (г) «Крупнозернистый» — это когда в программе есть небольшое количество мелких части, которые будут запускаться параллельно; «мелкое зерно» — это когда у него есть большое количество крупных штук. ОТВЕТ: (а) ————————————————— ———————- (71) Какой из этих факторов НЕ способствует параллельным накладным расходам? (а) Управление потоками / процессами (б) Связь между потоками / процессами (c) Синхронизация (d) Расчеты ОТВЕТ: (d) ————————————————— ———————- (72) Что такое балансировка нагрузки? (а) Обеспечение того, чтобы все переработчики имели примерно одинаковое количество работа, которую нужно сделать (б) Обеспечение того, чтобы у всех переработчиков было много работы (c) Обеспечение того, чтобы у всех переработчиков был разный объем работы. (d) Обеспечение того, чтобы все переработчики завершили свою работу примерно в в то же время ОТВЕТ: (d) ————————————————— ———————- (73) Легко или сложно балансировать нагрузку? (а) Легко (б) сложно (c) Всегда одинаковая сложность независимо от приложения. или алгоритм (d) Сложность зависит от приложения и алгоритма. ОТВЕТ: (d) ————————————————— ———————- (74) Что из этого лучше всего описывает «разветвление»? (а) Поток порождает «дочерний» поток.(б) «Дочерний» поток завершает работу, оставляя только своего родителя. (c) Поток порождает «дочерний» процесс. (d) Все потоки закрываются в конце программы. ОТВЕТ: (а) ————————————————— ———————- (75) Что из этого лучше всего описывает «присоединение»? (а) Поток порождает «дочерний» поток. (б) «Дочерний» поток завершает работу, оставляя только своего родителя. (c) Поток порождает «дочерний» процесс. (d) Все потоки закрываются в конце программы. ОТВЕТ: (б) ————————————————— ———————- (76) Что из этого * НЕ * является частью OpenMP? (а) Директивы компилятора (б) Функции (c) Переменные среды (d) Передача сообщений ОТВЕТ: (d) ————————————————— ———————- (77) Что означает переменная среды OpenMP OMP_NUM_THREADS указывать? (а) Сколько потоков следует использовать в параллельной секции.(б) Сколько процессов должна использовать параллельная секция. (c) Сколько сообщений должна обмениваться параллельная секция. (d) Сколько итераций должен иметь параллельный цикл. ОТВЕТ: (а) ————————————————— ———————- (78) В каком порядке выполняются итерации параллельного цикла. они казнены? (а) От первого к последнему (б) От последнего к первому (c) В заранее заданной случайной последовательности (d) В недетерминированной случайной последовательности ОТВЕТ: (d) ————————————————— ———————- (79) Что из перечисленного лучше всего описывает ключевое различие между частными а общие данные? (a) Частные данные видны только одному потоку, а общие данные доступны для всех потоков.(б) Личные данные видны всем потокам, а общие данные доступны только одному потоку. (c) Личные данные видны только одному потоку за раз, в то время как общие данные доступны для всех потоков. (d) Личные данные видны всем потокам, а общие данные доступны только одному потоку одновременно. ОТВЕТ: (а) ————————————————— ———————- (80) Может ли параллельный цикл иметь только общие данные без личных данных вообще? (а) Да.(b) Нет, потому что индексная переменная цикла (также называемая счетчиком) должно быть приватным. (c) Нет, потому что массив, с которым работает цикл, должен быть частным. (d) Нет, потому что любые скалярные переменные, используемые для промежуточных вычислений должно быть приватным. ОТВЕТ: (б) ————————————————— ———————- (81) Может ли параллельный цикл содержать только частные данные без общих данных вообще? (а) Да. (b) Нет, потому что индексная переменная цикла (также называемая счетчиком) должны быть разделены.(c) Нет, потому что массив, с которым работает цикл, должен быть общим. (d) Нет, потому что любые скалярные переменные, используемые для промежуточных вычислений должны быть разделены. ОТВЕТ: (а) ————————————————— ———————- (82) Какое из этих утверждений о стратегиях планирования НЕВЕРНО? (а) У статики меньше всего накладных расходов. (b) Динамический предназначен для циклов с итерациями, которые сильно изменяются. объем работы, так что циклы трудно сбалансировать. (c) Управляемый — это компромисс между статикой и динамикой.(d) Лучшая стратегия всегда может быть известна до тестирования всех трех. ОТВЕТ: (а) ————————————————— ———————- (83) Что из этого лучше всего описывает синхронизацию? (а) Каждый поток ожидает, пока все другие потоки закончат конкретный параллельный цикл перед переходом к следующему параллельному циклу. (b) Только один поток одновременно может выполнять определенную часть код. (c) Только главный поток может выполнять определенную часть кода. (d) Каждый поток выполняет один и тот же блок кода синхронно, все выполнение одной и той же инструкции в одно и то же время.ОТВЕТ: (а) ————————————————— ———————- (84) Какое из этих утверждений о барьерах является * ЛОЖНЫМ *? (а) Синхронизация сил барьера. (b) Параллельная петля имеет неявный барьер на конце. (c) Заграждение может быть размещено в любом месте на любом параллельном участке. (d) Параллельная петля имеет неявный барьер в начале. ОТВЕТ: (d) ————————————————— ———————- (85) Какой из них лучше всего описывает критические секции? (а) Каждый поток ожидает, пока все другие потоки закончат конкретный параллельный цикл перед переходом к следующему параллельному циклу.(b) Только один поток одновременно может выполнять определенную часть код. (c) Только главный поток может выполнять определенную часть кода. (d) Каждый поток выполняет один и тот же блок кода синхронно, все выполнение одной и той же инструкции в одно и то же время. ОТВЕТ: (б) ————————————————— ———————- (86) Что из этого лучше всего описывает состояние гонки? (а) Значение, помещенное в конкретную переменную, недетерминировано, потому что несколько разных потоков пытаются изменить его на в то же время.(b) Значение, помещенное в конкретную переменную, недетерминировано, потому что каждый поток имеет свою собственную частную копию. (c) Несколько потоков пытаются заполнить разные элементы тот же массив одновременно. (d) Несколько потоков пытаются заполнить разные массивы в в то же время. ОТВЕТ: (а) ————————————————— ———————- (87) Какое из этих утверждений о распределенной обработке верно? (а) Некоторые данные передаются. (b) Процессы обмениваются данными посредством копий из памяти в память.(c) Единственная важная стоимость связи — это полоса пропускания. (d) Все данные являются личными. ОТВЕТ: (d) ————————————————— ———————- (88) Какое из этих определений лучше всего? (а) Задержка — это время, необходимое для подключения, и пропускная способность. время на байт. (б) Пропускная способность — это время, необходимое для подключения и задержка. время на байт. (c) Задержка — это долларовые затраты на подключение, а пропускная способность — это долларовая стоимость за байт.(d) Пропускная способность — это долларовые затраты на подключение, а задержка — это долларовая стоимость за байт. ОТВЕТ: (а) ————————————————— ———————- (89) Что из этого лучше всего описывает, почему так важна балансировка нагрузки? (а) Поскольку несбалансированная нагрузка приводит к простоям некоторых процессоров в некоторых случаях, что увеличивает общее время выполнения по сравнению с сбалансированная нагрузка. (б) Потому что некоторые процессоры будут перегреваться, если им дать слишком много работа, которую нужно сделать. (c) Поскольку балансировка нагрузки — это проблема обычно применимого решение, которое следует использовать в большинстве случаев.(d) Поскольку балансировка нагрузки увеличивает количество процессоров, которые может работать над проблемой. ОТВЕТ: (а) ————————————————— ———————- (90) Какая процедура MPI должна вызываться перед любой другой подпрограммой MPI? (а) MPI_Init (б) MPI_Comm_size (c) MPI_Comm_rank (d) MPI_Finalize ОТВЕТ: (а) ————————————————— ———————- (91) Какая процедура MPI должна вызываться после всех других подпрограмм MPI? (а) MPI_Init (б) MPI_Comm_size (c) MPI_Comm_rank (d) MPI_Finalize ОТВЕТ: (d) ————————————————— ———————- (92) Какая процедура MPI определяет количество используемых процессов. по текущему пробегу? (а) MPI_Init (б) MPI_Comm_size (c) MPI_Comm_rank (d) MPI_Finalize ОТВЕТ: (б) ————————————————— ———————- (93) Какая процедура MPI определяет, какой из процессов является текущий процесс? (а) MPI_Init (б) MPI_Comm_size (c) MPI_Comm_rank (d) MPI_Finalize ОТВЕТ: (c) ————————————————— ———————- (94) Что из этого лучше всего описывает сокрытие общения? (а) Осуществление общения при одновременном выполнении вычисления, чтобы исключить временные затраты на коммуникация.(б) Осуществление общения при одновременном выполнении вычисления, чтобы исключить временные затраты на вычисление. (c) Выполнение связи перед выполнением вычислений, чтобы исключить временные затраты на общение. (c) Выполнение связи перед выполнением вычислений, чтобы исключить временные затраты на вычисления. ОТВЕТ: (а) ————————————————— ———————- (95) Что из этого * НЕ * является хорошим способом решения системы линейных уравнения? (а) Переверните матрицу, затем умножьте.(b) Используйте стандартную переносную библиотеку решателей. (c) Используйте версию стандартной переносимой библиотеки решателей, которая оптимизирован для платформы, на которой вы работаете. (d) Используйте информацию о линейной системе, чтобы выбрать наиболее возможен эффективный алгоритм решателя. ОТВЕТ: (а) ————————————————— ———————- (96) Какие из этих свойств матрицы * НЕ * * помогут вам ускорить решение системы линейных уравнений? (а) Симметрия (б) Трехдиагональность (c) Редкость (d) Асимметрия ОТВЕТ: (d) ————————————————— ———————-
Как правильно выбрать материнскую плату для своего компьютера
Если вы хотите собрать свой собственный ПК или купить готовый ПК, который вы, возможно, захотите расширить или обновить позже, то есть один компонент, который послужит его основой.Этим компонентом является материнская плата, и это невероятно важный элемент компьютерной головоломки. Он определяет многие другие компоненты, которые вы сможете выбрать, и в то же время некоторые другие варианты, такие как процессор, который вы будете использовать в своем новом ПК, определяют, какую материнскую плату вы можете использовать.
Обсуждаемые цены и наличие продуктов были верны на момент публикации, но могут быть изменены.
После выбора ЦП следующим компонентом, который вы выбираете для сборки, обычно будет дополнительная материнская плата.Давайте разберем вашу материнскую плату на несколько (относительно) простых шагов.
Но прежде чем мы начнем, вот вам большой совет. Один из способов облегчить ваше решение — использовать функцию сравнения Newegg. Если вы перейдете на страницу материнских плат Newegg, вы можете выбрать до пяти материнских плат и получить подробный обзор их сравнения по многим темам, обсуждаемым в этом руководстве.
Если вы предпочитаете смотреть, а не читать, вот наше видео, охватывающее информацию из этой статьи:
Что такое материнская плата?
Материнская плата — это печатная плата (PCB), которая создает своего рода магистраль, позволяющую различным компонентам обмениваться данными, и которая предоставляет различные разъемы для таких компонентов, как центральный процессор (CPU), графический процессор (GPU), память. , и хранилище.Большинство компьютеров, производимых сегодня, включая смартфоны, планшеты, ноутбуки и настольные компьютеры, используют материнские платы, чтобы собрать все вместе, но вы обычно покупаете только те, которые предназначены для настольных ПК.
Если посмотреть на материнскую плату сверху вниз, вы увидите набор схем, транзисторов, конденсаторов, слотов, разъемов, радиаторов и прочего, которые объединяются для маршрутизации сигналов и питания по всему ПК и позволяют подключать все необходимые компоненты.Это сложный продукт, и многие технические детали выходят за рамки этого руководства. Однако некоторые из этих деталей важны для вашего решения о покупке, и мы расскажем о них ниже.
Выбирая подходящую материнскую плату, вы должны убедиться, что она соответствует вашим потребностям как сегодня, так и завтра. Если вы знаете, что никогда не захотите модернизировать свой компьютер сверх его исходной конфигурации, тогда вы можете выбрать материнскую плату, которая предоставляет именно то, что вам нужно для начала работы.Но если вы думаете, что позже, возможно, захотите расширить свой компьютер, то убедитесь, что ваша материнская плата будет соответствовать вашим потребностям по мере их роста.
ПлатформаВозможно, первое, что нужно сделать, — это какой процессор вы хотите использовать в качестве мозга своего ПК, что означает выбор между двумя компаниями: Intel и AMD. Оба предлагают процессоры, начиная от вариантов начального уровня, достаточно хороших для просмотра веб-страниц, производительности и игр низкого уровня, до сверхмощных зверей, которые могут выполнять проекты по редактированию видео и запускать самые требовательные современные игры с высокой частотой кадров в секунду ( FPS).
Обе компании постоянно обновляют свои продукты, поэтому эта информация может очень быстро устареть. Однако на момент написания этого руководства Intel работает над процессорами девятого поколения, а AMD недавно представила свою архитектуру Zen 2, ожидается, что Zen 3 ожидается в ближайшее время, и процессоры Ryzen третьего поколения. Какой из них вам подходит, будет зависеть от ваших потребностей, например, если вы больше всего беспокоитесь о приложениях, которые могут использовать несколько процессорных ядер (что может быть в пользу процессоров AMD Ryzen), или вас больше всего беспокоят игры, в которых используется самый быстрый из них. производительность ядра (что может быть в пользу процессоров Intel Core).
После того, как вы определились с выбором процессора, вам нужно будет выбрать материнскую плату, которая использует правильный сокет и правильный набор микросхем . По сути, сокет процессора — это механизм, с помощью которого ЦП прочно прикреплен к материнской плате. Набор микросхем — это программное и аппаратное обеспечение материнской платы, объединяющее в себе все компоненты, обеспечивающие связь.
Разъемы и наборы микросхем, которые необходимо знатьВот самые важные сокеты и чипсеты на сегодняшний день:
| Розетка | Поддерживаемые процессоры | Наборы микросхем |
| LGA 1200 | 10 -е поколение Intel Core | Comet Lake (10 th -gen): Z490 |
| LGA 1151 | Intel Core поколения8 th и 9 th | Coffee Lake (8 th -gen): h410, B360, h470, Q370, Z370 Coffee Lake (9 th -gen): Z390, B365, B360 |
| LGA 2066 | Skylake-X / Kaby-Lake X | X299 |
| sTRX4 | 3 rd — поколение AMD Ryzen Threadripper | TRX40 |
| sTR4 | AMD Ryzen Threadripper | X399 |
| AM4 | AMD Ryzen, 7 th поколения A-Series и Athlon | A300, A320, B350, B450, X370, X470, X570 |
Не так важно понимать все, что нужно для создания набора микросхем, но очень важно понимать, что вам нужно выбрать материнскую плату с правильным набором микросхем — и правильным разъемом — для ЦП, который вы планируете приобрести.Также важно знать, что разные наборы микросхем поддерживают разные комбинации компонентов, таких как ОЗУ, графические процессоры и другие.
По мере того, как вы исследуете и сравниваете материнские платы, вы захотите убедиться, что все, что вы хотите сделать, поддерживается. Если вы воспользуетесь инструментом сравнения Newegg, вы сможете понять, какая материнская плата лучше всего подходит для вашего нового ПК.
Форм-фактор Материнские платыбывают разных размеров, а это означает, что у вас есть некоторая гибкость в создании вашего ПК, который впишется в вашу среду.Если у вас много места, вы можете использовать полноразмерный корпус в корпусе Tower, а если вы собираете ПК с домашним кинотеатром (HTPC), который предназначен для размещения под телевизором в семейной комнате, то вам, вероятно, понадобится гораздо меньший дело.
Вот почему материнские платы бывают разных размеров или форм-факторов, и эти стандарты определяют не только размер материнской платы, но и количество поддерживаемых компонентов. У последнего есть вариации, но, как правило, чем больше физический размер материнской платы, тем больше компонентов она будет поддерживать.Не все корпуса поддерживают все форм-факторы, поэтому вы должны убедиться, что ваша материнская плата и корпус совпадают.
Форм-факторы материнской платы, которые необходимо знатьНиже приведены несколько наиболее популярных форм-факторов и их наиболее распространенные характеристики:
| Mini-ITX | MicroATX | ATX | |
| Размер | 9,0 x 7,5 дюйма | 9,6 x 9,6 дюйма | 12 x 9,6 дюймов |
| Слоты расширения | 1 | 4 | 7 |
| RAM | DIMM | DIMM | DIMM |
| Слоты ОЗУ | 2 | до 4 | До 8 |
| Графические процессоры | До 1 | До 3 | до 4 |
| Порты SATA | До 6 | До 8 | До 12 |
Это общие рекомендации для некоторых наиболее распространенных форм-факторов материнских плат.Их больше, и они различаются по своим возможностям. Самое важное — решить, какой размер ПК вы хотите построить или купить, сколько компонентов вы хотите настроить сейчас и в будущем, а затем выберите форм-фактор материнской платы, который наилучшим образом соответствует вашим потребностям.
Варианты расширения материнской платыМатеринские платы
могут подключать различные компоненты в дополнение к процессору, включая графические карты, звуковые карты, сетевые карты, устройства хранения и соединения, а также множество других.За прошедшие годы появилось много видов портов расширения, но, к счастью, все стало намного проще. Сегодня вы в основном будете иметь дело с портами Peripheral Component Interconnect Express (PCIe), а на некоторых материнских платах также есть слоты PCI для устаревших устройств.
PCIe — самый важный порт, который вы будете использовать сегодня для подключения большинства компонентов. Существует четыре размера слотов PCIe, и последний широко используемый стандарт — это PCIe 3.0, причем PCIe 4.0 доступен на новейших платах, совместимых с Ryzen и Intel Comet Lake.Эти четыре размера определяют как пропускную способность соединения, так и его размер — вам нужно убедиться, что у вас достаточно слотов расширения и что они имеют правильный размер, чтобы удовлетворить все ваши нынешние и будущие потребности.
Четыре размера слотов: x1, x4, x8 и x16, причем x4 и x16 являются наиболее распространенными. Материнские платы сильно различаются по количеству слотов, а также по их размещению. Вы должны быть уверены, что у вас достаточно слотов и вокруг них достаточно места для размещения всех необходимых компонентов.
Поддержка графического процессораВсем ПК нужен способ вывода информации в визуальном формате, который мы, люди, можем использовать. Проще говоря, это означает отображение изображения на мониторе. Компонент, который выполняет эту функцию на типичном ПК, — это видеокарта или графический процессор, и вам необходимо убедиться, что ваша материнская плата может поддерживать тот тип графического процессора, который вам нужен для предполагаемого использования.
Некоторые процессоры Intel Core поставляются со встроенными графическими процессорами, которые предоставляют средства для отображения вывода на монитор, и AMD имеет свою собственную версию того же самого, называемого ускоренным процессором (APU), который объединяет центральный процессор с графическим процессором в одном пакете.Это относительно маломощные графические процессоры, которые отлично подходят для обычных задач производительности, но поддерживают только менее требовательные к графике игры (например, киберспортивные игры).
Если вам нужен более мощный графический процессор для игр или для более требовательных приложений, таких как редактирование видео, которые могут использовать графический процессор для более быстрой обработки, то вам, вероятно, понадобится автономный графический процессор. В этом случае вам нужно помнить, какие типы графических процессоров вы можете подключить к материнской плате и даже сколько графических процессоров может поддерживать ваша материнская плата.
Подключение графических процессоровСегодня большинство графических процессоров подключаются через слоты PCIe, а большинство используют слоты PCIe x16. Кроме того, для большинства современных графических процессоров требуется PCIe 3.0 или новее. Последнее требование — это ширина, доступная для каждого слота PCIe, а для многих графических процессоров требуется ширина в два слота. Это может заблокировать некоторые слоты x1 PCIe и сделать их недоступными, что нормально, если вас это не удивляет. Обратите внимание, что некоторые графические процессоры могут использовать только 75 Вт мощности, обеспечиваемой слотом PCIe, но что большинству графических процессоров требуется больше энергии через шестиконтактные или восьмиконтактные разъемы от достаточно большого блока питания.
Поэтому, выбирая материнскую плату, вы должны убедиться, что она обеспечивает правильный тип слотов PCIe. Это означает тщательную проверку спецификаций графического процессора и сравнение их со спецификациями материнской платы. Если вы хотите подключить два или более графических процессора, называемых «Scalable Link Interface» или SLI от NVIDIA и Crossfire от AMD, вам понадобятся два доступных слота PCIe и совместимая материнская плата.
Мы подчеркнем это еще раз, потому что это очень важно: обязательно сравните требования к графическому процессору с тем, что может обеспечить ваша материнская плата, чтобы убедиться, что все будет правильно соответствовать друг другу.Мы не обсуждаем особенности блока питания в этом руководстве, но вы также должны убедиться, что выбрали блок питания, который может удовлетворить потребности вашего графического процессора при полной нагрузке вместе с остальными вашими компонентами.
RAMВашему процессору требуется место для хранения информации, пока ваш компьютер включен и работает. Это называется «памятью с произвольным доступом» или ОЗУ, и сегодня ПК обычно оснащены как минимум 4 ГБ ОЗУ. Сколько оперативной памяти вам понадобится для вашего собственного ПК, зависит от того, как вы планируете его использовать, и 8 ГБ, как правило, являются безопасной рекомендацией для большинства пользователей с легким весом, а 16 или более ГБ — хороший выбор для более тяжелых пользователей.
Сегодняшняя оперативная память подключается к материнской плате через прямоугольный слот, названный в честь типа оперативной памяти, используемой сегодня: модуль памяти с двойным расположением линий (DIMM). Количество слотов DIMM на материнской плате определяет, сколько оперативной памяти вы можете добавить, и чаще всего варьируется от двух до восьми слотов. Вы можете добавлять по одному модулю ОЗУ за раз, но вы получите максимальную производительность, если установите ОЗУ согласованными парами.
Емкость варьируется от модулей DIMM 1 ГБ до модулей DIMM 128 ГБ, последние из которых чрезвычайно дороги и обычно приобретаются для использования в серверах.Большинство потребительских ПК будут оснащены в общей сложности от 4 ГБ до 64 ГБ, а оперативная память обычно приобретается в виде комплектов из двух или четырех модулей DIMM. Например, если вы хотите оснастить свой компьютер 16 ГБ оперативной памяти, вы обычно покупаете комплект с двумя модулями DIMM по 8 ГБ или четырьмя модулями DIMM по 4 ГБ.
Когда вы выбираете материнскую плату, убедитесь, что на ней достаточно слотов, она может поддерживать всю оперативную память, которую вы когда-либо планируете настраивать, и что она может поддерживать самую быструю оперативную память, которую вы захотите купить. В то же время вам захочется подумать о том, как купить оперативную память.Например, если вы хотите начать с 8 ГБ ОЗУ, а затем увеличить его до 16 ГБ, а на вашей материнской плате есть четыре слота DIMM, тогда вам нужно будет начать с комплекта из двух модулей DIMM по 4 ГБ, а не с набора из четырех модулей DIMM по 2 ГБ, поскольку это позволит вам добавить еще один комплект позже и избежать потери неиспользуемой оперативной памяти.
СкладЧтобы использовать компьютер, вам понадобится место для хранения операционной системы, приложений и данных при выключенном питании. Сегодня это означает выбор между жестким диском (HDD) с вращающимися пластинами, на которых хранятся данные, и твердотельными дисками (SSD), которые хранят данные в гораздо более быстрой флэш-памяти.Жесткие диски, как правило, дешевле и требуют больше места для хранения, в то время как твердотельные накопители дороже, но предлагают дополнительную скорость и отлично подходят для хранения операционной системы и приложений.
Есть несколько основных разъемов для запоминающих устройств, которые следует учитывать при покупке материнской платы. Это включает в себя как типы подключений, так и количество подключений, которые у вас будут для добавления хранилища на свой компьютер. Некоторые из этих соединений являются внутренними, а некоторые — внешними.
Наиболее распространенным сегодня подключением к хранилищу является последовательный ATA или SATA.SATA находится в своей третьей версии, а SATA 3.0 — это соединение, обеспечивающее скорость передачи до шести гигабит в секунду (Гбит / с). Это означает, что скорость чтения и записи для твердотельных накопителей SATA достигает 600 мегабайт в секунду (600 МБ / с), а для жестких дисков обычно значительно меньше 150 МБ / с.
Вы можете купить как жесткие диски, так и SDD, поддерживающие соединения SATA 3.0, а материнские платы могут содержать несколько портов SATA. Существуют варианты SATA 3.X, которые обеспечивают более высокую скорость и немного другие соединения, включая SATA версии 3.2 с форм-фактором M.2.
Все более распространенным типом подключения к хранилищу является NVM Express или NVMe, который подключается через шину PCIe. Это более новый протокол, который предлагает увеличенную пропускную способность, меньшее энергопотребление, меньшую задержку и другие преимущества. Обычные твердотельные накопители NVMe сегодня могут обеспечивать теоретическую скорость более 3 ГБ / с при чтении и 1,5 ГБ / с для записи. Твердотельные накопители NVMe бывают двух форм-факторов: карты, которые подключаются к слотам PCIe, и компактные версии, которые подключаются к разъемам M.2.
Маленький SSD и большой HDDКак и в случае со многими другими компонентами в этом практическом руководстве, выбор подходящего хранилища зависит от многих факторов.Одна из распространенных тактик — покупка относительно небольшого SSD для операционной системы и приложений, что значительно повышает производительность, а затем более крупных жестких дисков для хранения больших объемов данных, таких как фотографии и видео.
Независимо от того, какое хранилище вы выберете, вы должны быть уверены, что ваша материнская плата будет соответствовать вашим потребностям сейчас и в будущем. Для этого необходимо внимательно изучить спецификации материнской платы, чтобы убедиться, что к ней можно подключить все хранилища, которые могут вам когда-нибудь понадобиться. Помните, что при необходимости вы также можете подключить внешние запоминающие устройства, и это требование для данных, которые вам нужно носить с собой.
Возможности подключенияМы рассмотрели несколько различных способов подключения компонентов к материнской плате, включая PCIe, слоты DIMM и подключения к хранилищу. Существует множество других типов подключения, которые материнские платы могут поддерживать сегодня, и вы снова захотите очень внимательно рассмотреть свои потребности при выборе материнской платы.
Кроме того, некоторые разъемы расположены непосредственно на материнской плате и внутри корпуса, а иногда они предназначены для подключения к портам на передней, верхней, боковых сторонах или задней части корпуса.Вы также захотите определить, какие порты поддерживает ваш корпус, и убедитесь, что ваша материнская плата обеспечивает необходимые внутренние соединения. Материнские платы также имеют доступные извне соединения на задней панели ввода / вывода (I / O), которая соответствует стандартному расположению на задней панели корпуса.
Подключения материнской платы, чтобы знатьНекоторые разъемы расположены непосредственно на материнской плате и внутри корпуса, а иногда они предназначены для подключения к портам на передней, верхней, боковой или задней панели корпуса, а также к другим внутренним и внешним компонентам.Вам нужно подумать, какие порты поддерживает ваш корпус, и убедиться, что ваша материнская плата обеспечивает необходимые внутренние соединения, и то же самое касается других дополнений. Эти соединения включают в себя множество встроенных разъемов, которые используются для поддержки таких вещей, как вентиляторы, внешние USB-порты, системы освещения RGB и различные проприетарные продукты от производителя.
Это то, что вы захотите внимательно проверить при выборе компонентов для вашего нового ПК. Например, в вашем корпусе может быть несколько портов USB, для которых требуется несколько внутренних заголовков USB.А для некоторых систем водяного охлаждения требуются специальные разъемы для подключения к программному обеспечению, которое управляет освещением и термодатчиками. Вам нужно будет убедиться, что на материнской плате есть все необходимые заголовки для поддержки всех этих дополнительных компонентов и функций корпуса.
В принципе, подумайте об этом так. Чем сложнее ваш новый компьютер, тем больше вам придется разбираться в выборе материнской платы. Это особенно верно в отношении типов соединений, имеющихся на материнской плате, по сравнению с различными компонентами, которые вам нужно будет добавить.
Ниже приведены некоторые из распространенных подключений на современных материнских платах. Не на всех материнских платах есть все эти разъемы, но вы найдете и другие. Важно убедиться, что выбранная вами материнская плата имеет все необходимые соединения.
| Разъем | Расположение | Назначение | Типовой номер |
| Аудиосистема для задней панели | Внутренний | Позволяет подключаться к заднему внешнему аудиоразъему корпуса (при наличии). | 1 |
| Аудиосистема для передней панели | Внутренний | Позволяет подключаться к переднему внешнему аудиоразъему корпуса (при наличии). | 1 |
| Заголовок цифрового аудио | Внутренний | Позволяет подключаться к цифровому аудиоразъему. | 1 |
| Заголовок передней панели | Внутренний | Предоставляет контакты для подключения к светодиодным индикаторам и кнопкам панели шрифтов, например, для питания и сброса. | 1 |
| 8-контактный разъем питания процессора | Внутренний | Обеспечивает подачу питания от блока питания через материнскую плату к процессору. На современных материнских платах это обычно восьмиконтактный разъем. | 1 |
| 24-контактный разъем основного питания | Позволяет подавать питание от источника питания через материнскую плату к различным подключенным компонентам, таким как компоненты PCIe, RAM и определенные виды хранилищ.На современных материнских платах это обычно восьмиконтактный разъем. | 1 | |
| Разъемы вспомогательного питания | Внутренний | Кроме того, могут быть разъемы питания для вентиляторов и других дополнительных компонентов. | Варьируется |
| USB | Внутренний или внешний | Обеспечивает USB-подключения, включая порты USB-A 2.0, USB-A 3.X и USB-C 3.1. Будут доступны внутренние разъемы для внешних портов корпуса, а также USB-порты для прямого подключения на задней панели ввода-вывода материнской платы. | Варьируется |
| Firewire | Внутренний или внешний | Более старое соединение, оно позволяет подключать устройство Firewire. | Варьируется |
| SATA | Внутренний | Это разъемы для жестких дисков SATA и твердотельных накопителей. | Варьируется |
| Порты дисплея | Внешний | Если вы выбрали ЦП со встроенной графикой, вам нужно будет использовать один из портов дисплея, которые находятся на задней панели ввода-вывода.Они могут включать порты VGA, DVI, DisplayPort и HDMI. | Варьируется |
| Аудиоразъемы | Внешний | Если ваша материнская плата оснащена встроенным звуком, а сегодня большинство из них имеет, то на ней будут аудиоразъемы для подключения динамиков и микрофонов. Количество разъемов и поддерживаемые ими конфигурации динамиков (от стерео до 7.1-канального объемного звука) зависят от аудиосистемы материнской платы. | Варьируется |
| Ethernet | Внешний | Современные материнские платы обычно оснащены гигабитными портами Ethernet для подключения к проводным сетям. | 1 |
| Разъем антенны Wi-Fi | Внешний | Если ваша материнская плата оснащена встроенным сетевым адаптером Wi-Fi, то, как правило, на ней имеется винтовой разъем для подключения внешней антенны. | 1 |
Теперь, когда вы определили, какая материнская плата вам понадобится для сборки вашего конкретного ПК или она должна служить основой для готового ПК, который вы собираетесь купить, вы захотите немного подумать. производителю.Некоторые компании сосредотачиваются на предоставлении материнских плат, предназначенных для геймеров, с огромным пространством для добавления графических процессоров и светодиодными системами освещения, в то время как другие сосредотачиваются на более массовых системах.
Одними из самых известных производителей материнских плат являются ASUS, Gigabyte, MSI и ASRock. Вы можете просмотреть различные варианты от этих и других компаний на странице Материнские платы Newegg.
W-2195, W-2155, W-2123, W-2104 и W-2102 Протестировано
Любой, кто смотрит на высокопроизводительную систему Intel, может выбрать один из трех вариантов: Core i9, Xeon W или более крупный сокет Xeon Scalable.Первые два используют сокет LGA2066 и имеют идентичную конфигурацию ядра / частоты, но фактически представляют собой разные платформы с заблокированными материнскими платами для каждой из них. Преимущества Xeon W и Xeon Scalable заключаются в возможности использования памяти ECC, функций управления vPro, а для некоторых процессоров существуют разные варианты кэш-памяти.
В предыдущем поколении Intel имела аналоги рабочих станций, соответствующие линейке высокопроизводительных настольных компьютеров. Оба продукта использовали один и тот же сокет, что упростило задачу для потребителей, и одна и та же материнская плата с одним сокетом, на которой был установлен Core i7, также могла работать с рядом Xeon: большая серия E7, серия E5-2600, ориентированная на два разъема, и серия E5-1600, ориентированная на рабочие станции.Преимущества этих микросхем для рабочих станций были в первую очередь для памяти ECC, функций управления и поддержки OEM.
Вернемся к сегодняшнему дню, и из-за раздвоения сокетов ни один из процессоров, ориентированных на серверы, не впишется в современную платформу HEDT. В этой связи Intel создала семейство Xeon W, основанное на линейке E5-1600, которая соответствует потребительской линейке, но с обычными надстройками ECC / OEM. Intel также сократила поддержку потребительских наборов микросхем, вытеснив Xeon W из рук потребителей и направив их исключительно на рынок OEM / систем из-за отсутствия материнских плат на базе серверных чипсетов в розничной продаже.Несмотря на обреченность и мрачность, Supermicro недавно представила нам свой серверный чипсет X11SRA и несколько процессоров Xeon W.
Линейка Xeon WОбъявленный еще в январе 2018 года, запуск Xeon W был несколько неожиданным: у нас были основания полагать, что Intel представит компоненты для потребительских высокопроизводительных настольных сокетов с ECC, однако какая форма это примет, была неизвестна, особенно с процессорами до На потребительской стороне выпущено 18 ядер.В конечном итоге Intel придется добиться паритета с линейкой Xeon W, что может вызвать сдвиг на рынке однопроцессорных систем и на стороне серверов.
В итоге Intel выпустила для рынка восемь новых процессоров Xeon W, а также два внедорожных процессора для конкретных OEM-производителей и одну версию для Apple. Конфигурации по существу идентичны потребительской линейке HEDT, с использованием ориентированных на предприятия ядер Skylake-SP с новыми инструкциями AVX512, новым межсоединением ячеистой сети и измененной структурой кэша, ориентированной на данные L2.Мы подробно рассмотрели изменения по сравнению со стандартным ядром Skylake-S в наших первоначальных обзорах Skylake-X и Skylake-SP.
Что Intel сделала с процессорами Xeon W по сравнению с линейкой потребительских HEDT, так это больше сосредоточилась на моделях с меньшим количеством ядер: в полной линейке есть четыре четырехъядерных модели, некоторые с гиперпоточностью, но есть и две шести -сердечные части, одна восьмиядерная часть и десятижильная часть. Это различие SKU можно интерпретировать как то, что Intel не уделяет столько внимания высокопроизводительному сегменту с линейкой Xeon W — где потребительская линейка, как продукты с 18/16/14/12/10 ядрами, Xeon W имеет только 18/14 /. 10/10/8 в качестве пятерки лучших моделей.
| Процессоры Intel Xeon-W (LGA2066) | ||||||||
| Ядра | База Freq. | Турбина 2,0 | L3 (МБ) | L3 / ядро (МБ) | DDR4 ECC | TDP | Цена | |
| Xeon W-2195 | 18/36 | 2.3 ГГц | 4,3 ГГц | 24,75 | 1,375 | 2666 | 140 Вт | $ 2553 |
| Xeon W-2175 | 14/28 | 2,5 ГГц | 4,3 ГГц | 19,25 | 1,375 | 2666 | 140 Вт | $ 1947 |
| Xeon W-2155 | 10/20 | 3.3 ГГц | 4,5 ГГц | 13,75 | 1,375 | 2666 | 140 Вт | $ 1440 |
| Xeon W-2145 | 8/16 | 3,7 ГГц | 4,5 ГГц | 11,00 | 1,375 | 2666 | 140 Вт | $ 1113 |
| Xeon W-2135 | 6/12 | 3.7 ГГц | 4,5 ГГц | 8,25 | 1,375 | 2666 | 140 Вт | $ 835 |
| Xeon W-2133 | 6/12 | 3,6 ГГц | 3,9 ГГц | 8,25 | 1,375 | 2666 | 140 Вт | $ 617 |
| Xeon W-2125 | 4/8 | 4.0 ГГц | 4,5 ГГц | 8,25 | 2,063 | 2666 | 120 Вт | 444 |
| Xeon W-2123 | 4/8 | 3,6 ГГц | 3,9 ГГц | 8,25 | 2,063 | 2666 | 120 Вт | $ 294 |
| Xeon W-2104 * | 4/4 | 3.2 ГГц | – | 8,25 | 2,063 | 2400 | 120 Вт | $ 255 |
| Xeon W-2102 * | 4/4 | 2,9 ГГц | – | 8,25 | 2,063 | 2400 | 120 Вт | $ 202 |
| * Off Roadmap | ||||||||
| Только артикулы Apple | ||||||||
| Xeon W-2191B | 18/36 | 2.3 ГГц | 4,3 ГГц | 24,75 | 1,375 | 2666 | ? | – |
| Xeon W-2170B | 14/28 | 2,5 ГГц | 4,3 ГГц | 19,25 | 1,375 | 2666 | ? | – |
| Xeon W-2150B | 10/20 | 3.0 ГГц | 4,5 ГГц | 13,75 | 1,375 | 2666 | ? | – |
| Xeon W-2140B | 8/16 | 3,2 ГГц | 4,2 ГГц | 11,00 | 1,375 | 2666 | ? | – |
Еще одно изменение касается совместимости с AVX512.В процессорах Xeon Scalable каждое ядро имеет эквивалент двух портов AVX512 FMA на каждом ядре для максимального увеличения пропускной способности, за исключением SKU для внедорожников, у которых он есть. В линейке потребительских товаров также есть два, хотя первоначально Intel заявила, что у некоторых деталей есть только один. Эти части Xeon W также будут иметь по два порта AVX512 FMA каждый, что позволит настроенному вручную коду использовать AVX512 в полной мере. Xeon W также имеет память ECC, что обычно является одной из основных причин покупки процессоров.
Каждый из ЦП может поддерживать до 512 ГБ модулей DDR4-2400 ECC RDIMM в четырехканальной конфигурации, что означает, что каждый модуль может иметь размер 64 ГБ.Это больше, чем поддержка UDIMM 128 ГБ в потребительском пространстве, но ниже, чем поддержка RDIMM 768 ГБ для Xeon Scalable (из-за наличия шести каналов памяти).
Небольшое примечание о «разных» процессорах в стеке. W-2102 и W-2104 — это недорогие четырехъядерные процессоры без гиперпоточности или Turbo, но они классифицируются как «внедорожные». Эти процессоры не продаются всем OEM-производителям, в отличие от других, и обычно производятся для определенных OEM-производителей, которые имеют контракты с конкретными клиентами.В результате в прайс-листах эти детали не отображаются, и, честно говоря, Intel не очень любит говорить о них, поскольку их продвижение не имеет внутренней ценности. Конечно, с нашей точки зрения, нам нравится проверять каждого члена стека, независимо от того, насколько широко он доступен.
Другой набор различных процессоров предназначен только для Apple. Они есть только в модели обновленного iMac Pro конца 2017 года. Возьмем, к примеру, Xeon W-2150B — этот 10-ядерный процессор почти идентичен 10-ядерному Xeon W-2155, но имеет более низкую базовую частоту, равную 3.0 ГГц (по сравнению с 3,5 ГГц). Более низкая базовая частота значительно снизит TDP процессора, однако эти процессоры редко работают на базовой частоте и почти всегда в турбо-состоянии, где TDP не определен, что затрудняет установку этого процессора. Скорее всего, это часть, которая хорошо разделена по напряжению, частоте и мощности. Опять же, это еще одна часть, доступная не всем (но если она у кого-то есть, мы хотели бы ее протестировать).
Для всех этих процессоров потребуется материнская плата с чипсетом C422.Эти наборы микросхем почти идентичны наборам микросхем X299, используемым в потребительской платформе, но микропрограммное обеспечение заблокировано для процессоров Xeon W только с поддержкой ECC. Из-за разделения между потребительскими платформами и платформами рабочих станций на открытом рынке очень мало материнских плат C422 для специализированных сборщиков — большинство OEM-производителей (Dell, Supermicro) создают свои собственные внутренние материнские платы для готовых систем специально для своих клиентов и оптимизированы для их предполагаемый результат (производительность, цена и т. д.).
Турбо-данные на ядро Турбо-данные по ядрам Intel для этих частей рабочих станций разделены на три части из-за имеющихся в них наборов инструкций. В самых «сложных» инструкциях Intel использует специальные значения турбо для AVX-512, так как из-за способа обработки этих инструкций на кристалле выделяется больше тепла. Чип должен сбалансировать частоту и потребляемую мощность, поэтому данные AVX-512 поступают с более низкой частотой, чтобы контролировать турбо.
Первое, на что следует обратить внимание с этими данными, это то, что для большинства процессоров, когда весь процессор использует инструкции AVX-512, частота упадет ниже базовой частоты.Для таких микросхем, как Xeon W-2123 и W-2133, даже при одноядерной загрузке AVX-512 частота будет ниже базовой. Базовая частота Intel выполняет две функции: во-первых, она сообщает вам частоту, на которой применим TDP, а во-вторых, это гарантированная минимальная частота для обычных инструкций, не относящихся к AVX.
За AVX-512 стоит AVX2, который по-прежнему создает некоторую нагрузку на процессор, превышающую обычные инструкции, но не так сильно. Там, где AVX-512 требует выделенной области кристалла для поддержки векторных блоков, AVX2 встроен в базовую часть стандартной конструкции ядра.
Для AVX2 частота W-2133 и W-2123 все еще ниже базовой частоты процессора. Но для больших, таких как W-2195, полная загрузка 18 ядер AVX2 на 500 МГц быстрее, чем AVX-512. Это всего лишь указание на то, что пользователи, которые занимаются тонкой настройкой кода, должны подумать о том, какую часть блока AVX-512 они могут поддерживать — блок AVX-512, несмотря на разницу в 500 МГц, несомненно, будет быстрее, но наполовину -Fed AVX-512 может быть проигнорирован полным AVX2.
Для обычных инструкций турбо выглядит примерно так:
Для ряда пользователей ключевыми показателями здесь являются турбины для всех ядер, а для 18-ядерной части — 3.2 ГГц. Интересно, что W-2155 и W-2145 здесь хорошо подходят: для любого кода, который не может надежно выходить за рамки 12-14 потоков, часть с более высокой частотой, но с меньшим количеством ядер может действительно работать лучше. Мы видели кое-что из этого в нашем обзоре, при этом нагрузка с переменной нагрузкой на W-2155 была несколько лучше, чем на W-2195.
Тогда и сейчас: определение рабочей станцииРазделив поддержку материнской платы на процессоры уровня рабочих станций, Intel (намеренно или нет) изменила определение того, что значит иметь рабочую станцию Intel.В предыдущих поколениях определенный рынок пользователей с удовольствием инвестировал бы в процессор в стиле E5-2640 и поместил его в однопроцессорную потребительскую материнскую плату, воспользовавшись преимуществами потенциально лучше укомплектованного процессора, и на некоторых материнских платах, которые его квалифицировали, память ECC. В зависимости от места и времени, в некоторых случаях этот метод был дешевле, чем использование потребительского процессора аналогичного класса. Благодаря поддержке материнской платы эти системы, безусловно, получили большее распространение по сравнению с сегодняшним днем.Фактически, некоторые пользователи в настоящее время обращаются к eBay и инвестируют в более старые 8-ядерные и 10-ядерные процессоры, потому что они чрезвычайно доступны.
В 2018 году для энтузиастов рабочих станций Intel ситуация сложная и запутанная.
Если пользователь рабочей станции посмотрел на оборудование потребительского уровня, он может получить ядра и материнскую плату, но потерять память ECC и совместимость сопроцессора, непревзойденную с профессиональной системой: некоторое оборудование материнской платы может не соответствовать требованиям Quadro, Tesla, FirePro , Xilinx, Altera и др., потому что эти материнские платы не предназначены для этого рынка.
Если пользователь рабочей станции посмотрел на оборудование профессионального уровня, он столкнулся с трудностями при самостоятельной сборке в зависимости от доступности или полной оплаты OEM-системы, которая могла иметь ужасающую наценку. В прошлом мы говорили с одним OEM-производителем, который сказал, что цены на веб-сайте были почти фиктивными — большая часть их продаж в этой области приходится на крупномасштабные корпоративные контракты, которые предлагают скидки в зависимости от объема.Единственный пользователь рабочей станции для домашнего пивоварения не был их целевым рынком, если только он не хотел платить по высокой цене.
| Сравнение аналогичных артикулов | |||
| Характеристики | Skylake-X (i9-7980XE) | Xeon-W (Xeon W-2195) | Skylake-SP (Xeon 6140 / M) |
| Платформа | X299 | C422 | C620 |
| Розетка | LGA2066 | LGA2066 | LGA3647 |
| Сердечники / резьбы | 18/36 | 18/36 | 18/36 |
| Верхняя база / турбина | 2.6 / 4,2 | 2,3 / 4,3 | 2,3 / 3,7 |
| Графический процессор PCIe 3.0 | 44 | 48 | 48 |
| ОЗУ / DDR4 | 128 ГБ UDIMM Четырехканальный | 512 ГБ RDIMM + LRDIMM Четырехканальный | 768 ГБ / 1536 ГБ RDIMM + LRDIMM Шесть каналов |
| 512-битные FMA | 2 | 2 | 2 |
| Макс розетки | 1 | 1 | 4 |
| Расчетная мощность | 165 Вт | 140 Вт | 140 Вт |
| Цена | $ 1999 | $ 2553 | 2451 долл. США / 5448 долл. США |
В конечном счете, если пользователь делает все возможное для OEM-системы, возможно, стоит обратить внимание на процессоры Xeon Scalable, особенно если требуется несколько сокетов в одной системе.Однако это значительно увеличивает расходы. Преимущества создания потребительской рабочей станции, если память не требуется, также сводятся к тактовой частоте и поддержке AVX-512.
Альтернативой является предложение AMD для рабочих станций, Threadripper, которое дешевле, предлагает аналогичное количество ядер, больше памяти ECC на процессор (в зависимости от поддержки материнской платы) и больше линий PCIe, но не имеет AVX-512 и может пострадать от Неунифицированная архитектура памяти для программного обеспечения, которое требует многоуровневой связи между ядрами и ядрами с памятью.Вариант с несколькими сокетами здесь — EPYC, который получает больше ядер и больше системной памяти, но не увеличивает количество линий PCIe из-за того, как платформа разделяет ресурсы.
| Intel против AMD Сравнение | |||
| Характеристики | Xeon-W Xeon W-2145 | AMD Ryzen TR 1900X | AMD EPYC 7401P |
| Платформа | C422 | X399 | – |
| Розетка | LGA2066 | TR4 | СП3р2 |
| Сердечники / резьбы | 8/16 | 8/16 | 24/48 |
| Базовая / Турбо | 3.7 / 4,5 | 3,8 / 4,0 | 2,0 / 3,0 |
| Графический процессор PCIe 3.0 | 48 | 60 | 124 |
| ОЗУ / DDR4 | 512 ГБ RDIMM + LRDIMM Четыре канала | 128 ГБ UDIMM Четыре канала | 2 ТБ RDIMM + LRDIMM Восемь каналов |
| AVX-512 | 2 FMA | – | – |
| Кэш L3 | 11 МБ | 32 Мб | 64 Мб |
| Расчетная мощность | 140 Вт | 180 Вт | 170 Вт |
| Цена | $ 1113 | $ 549 | $ 1075 |
Многие решения о покупке будут искажены специально из-за рабочего процесса, что является одной из причин, почему у нас так много тестов для наших обзоров — не существует сценария « один тест, который подходит всем », и мы сейчас находятся в ситуации, когда есть несколько вариантов на выбор в зависимости от размера кошелька.
Этот обзорДля нашего сегодняшнего анализа мы смогли защитить пять процессоров Xeon W: топовый 18-ядерный W-2195, средний 10-ядерный W-2155, более бюджетный четырехъядерный W-2153 и два внедорожных процессора в W-2104 и W-2102.
Мы протестировали эти процессоры в нашем пакете тестирования текущего поколения с примененными патчами Spectre и Meltdown. Основными объектами сравнения являются высокопроизводительная настольная платформа Intel Skylake-X, потребительская платформа Intel Skylake-S и платформы AMD Ryzen и Threadripper.
Материнская плата, использованная в нашем обзоре, — это Supermicro X11SRA, одна из наиболее «доступных» материнских плат Xeon W.
Наш обзор платы вы можете прочитать здесь.
Мы также должны поблагодарить Kingston за образец памяти DDR4-2666 C19 RDIMM для этого обзора.
ПроцессорыXeon W поддерживают память RDIMM ECC, а наша материнская плата не поддерживает модули UDIMM, и Kingston любезно предоставила необходимую память.В нашем тестировании модули (KSM26RS8 / 8HAI) показали себя безупречно.
Страниц в этом обзоре
- Обзор Xeon W
- Настройка теста и энергопотребление
- Тестирование ЦП: тесты Office
- Тестирование процессора: системные тесты
- Тестирование процессора: тесты рендеринга
- Тестирование процессора: тесты кодирования
- Тестирование процессора: веб-тесты
- Тестирование ЦП: устаревшие тесты
- Spectre против Meltdown: SYSMark
- Выводы: серьезно ли Intel относится к Xeon W?
% PDF-1.5 % 635 0 объект > эндобдж xref 635 77 0000000017 00000 н. 0000002478 00000 н. 0000002675 00000 н. 0000003284 00000 н. 0000003606 00000 н. 0000003768 00000 н. 0000003961 00000 н. 0000004227 00000 п. 0000004394 00000 п. 0000004995 00000 н. 0000005503 00000 н. 0000005767 00000 н. 0000006259 00000 н. 0000006663 00000 н. 0000006932 00000 н. 0000007034 00000 п. 0000007166 00000 н. 0000007235 00000 н. 0000008706 00000 н. 0000016705 00000 п. 0000031185 00000 п. 0000031393 00000 п. 0000031546 00000 п. 0000031704 00000 п. 0000031913 00000 п. 0000032096 00000 п. 0000032267 00000 п. 0000032419 00000 п. 0000032676 00000 н. 0000032912 00000 п. 0000033069 00000 п. 0000033238 00000 п. 0000033432 00000 п. 0000033605 00000 п. 0000033835 00000 п. 0000034004 00000 п. 0000034172 00000 п. 0000034412 00000 п. 0000034605 00000 п. 0000034796 00000 п. 0000035027 00000 п. 0000035235 00000 п. 0000035484 00000 п. 0000035678 00000 п. 0000035859 00000 п. 0000036054 00000 п. 0000036237 00000 п. 0000036449 00000 н. 0000036612 00000 п. 0000036789 00000 п. 0000037026 00000 п. 0000037202 00000 п. 0000037380 00000 п. 0000037630 00000 п. 0000037821 00000 п. 0000038044 00000 п. 0000038215 00000 п. 0000038385 00000 п. 0000038578 00000 п. 0000038755 00000 п. 0000038938 00000 п. 0000039187 00000 п. 0000039362 00000 п. 0000039554 00000 п., $ | BB6I m n
Различия между материнской платой и процессором | Small Business
Двумя основными компонентами любого компьютера являются материнская плата и центральный процессор.Оба выполняют процессы, жизненно важные для работы операционной системы и программ компьютера — материнская плата служит базой, соединяющей все компоненты компьютера, а ЦП выполняет фактическую обработку данных и вычисления. Если вы хотите обновить компьютер в своем офисе, вы можете заменить процессор с некоторыми ограничениями, но замена материнской платы, по сути, означает перестройку всей машины.
Функции процессора
ЦП выполняет большую часть вычислений и функций, которые позволяют компьютеру запускать свою операционную систему и любые установленные программы.В некоторых компьютерах процессор обрабатывает все данные для системы, в то время как в других карты расширения, такие как видеокарты, разгружают часть работы, чтобы ускорить работу системы. Помимо работы, которая связана с видеокартой, скорость процессора является наиболее важным фактором в определении скорости компьютера.
Функции материнской платы
Материнская плата имеет множество разъемов и разъемов, и она служит основой компьютерной системы. Каждая часть оборудования в компьютере подключается к материнской плате и передает данные между этими компонентами.Многие материнские платы также включают наборы микросхем для обработки аудиоданных, что устраняет необходимость в отдельной звуковой карте. В старых компьютерах материнские платы иногда содержали оборудование для обработки графики, но современные компьютеры используют либо отдельные видеокарты, либо графическую технологию, встроенную в процессор.
Совместимость процессоров
Каждый процессор имеет тип сокета, который должен соответствовать сокету ЦП материнской платы — несовместимые процессоры не поместятся в несовместимую материнскую плату.Это эффективно ограничивает возможность обновления ЦП, поскольку разработчики создают новые сокеты ЦП каждые несколько лет. Если вы хотите обновить компьютер с устаревшим разъемом, вам нужно будет заменить материнскую плату — задача столь же сложная, как создание нового компьютера — или купить процессор старой модели, который подходит к материнской плате.