Hello World на Ассемблере
Главная / Ассемблер / Для чайников / Введение в Ассемблер /
После примеров простых программ на Паскале и С++ вы, наверно, не ожидали что я сразу перепрыгну на Ассемблер. Но вот перепрыгнул. И сегодня мы поприветствуем мир на языке ассемблера.
Итак, вот сразу пример, а потом его рассмотрим:
.model tiny
.code
ORG 100h
begin:
MOV AH, 9 ; Функция вывода строки на экран
MOV DX, OFFSET Msg ; Адрес строки
INT 21h ; Выполнить функцию
RET ; Вернуться в операционную систему
Msg DB 'Hello, World!!!$' ; Строка для вывода
END begin
Как видите, программа на ассемблере, даже такая простая, содержит исходный текст значительно большего размера по сравнению с аналогичной программой на С++, а уж тем более на Паскале.
С другой стороны, это не так уж и страшно, как иногда думают те, кто никогда не программировал на Ассемблере.
Во всех подробностях разбирать этот код не будем — подробности в другой раз. Рассмотрим только основные инструкции.
Программа начинается с метки begin. В отличие, например, от Паскаля, это слово может быть каким угодно,
например, start. Это всего лишь метка, которая обозначает начало какого-то участка кода.
К конце программы мы видим END begin. Инструкция END говорит ассемблеру,
что следующее за ней слово означает конец блока кода, обозначенного этим словом. В нашем примере это означает,
что здесь кончается блок кода, начинающийся со слова begin.
Далее уже начинается программа. Сначала в регистр АН мы записываем номер функции, которую собираемся потом выполнить. Номер 9 — это функция BIOS, которая выполняет вывод на устройство вывода.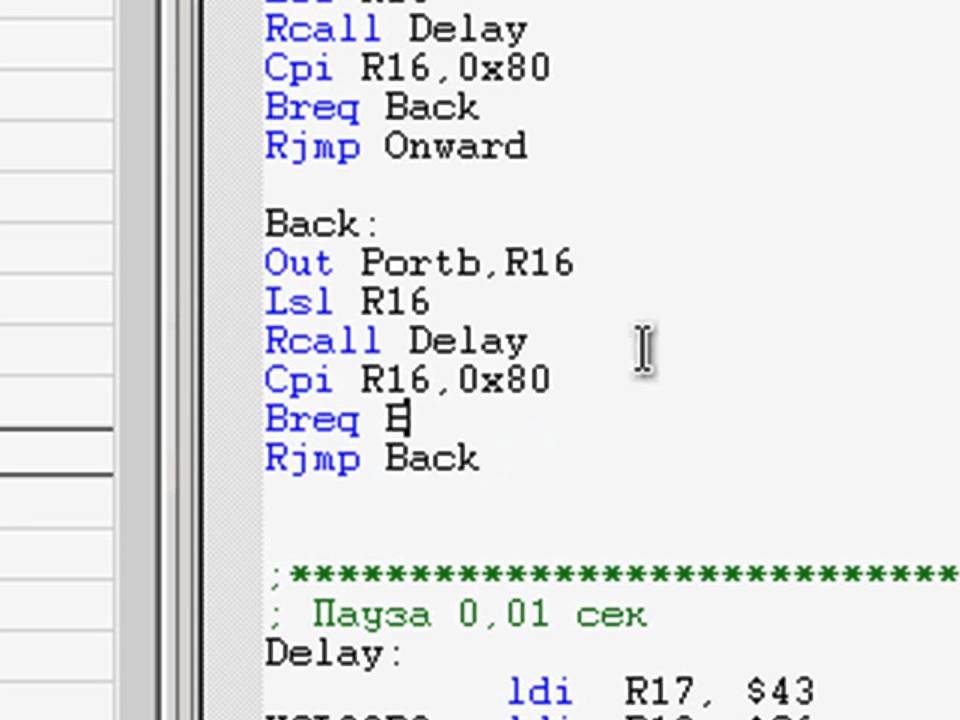
Затем в регистр DX мы записываем адрес строки. Адрес вычисляется с помощью оператора OFFSET. Например:
OFFSET Msg
Здесь мы получаем адрес первого байта блока данных, обозначенного идентификатором Msg.
Затем мы вызываем прерывание 21h. Это прерывание выполняет функцию, номер которой записан в регистре АН. Поскольку у нас там записана функция 9, то прерывание выведет на экран строку.
Команда RET выполняет выход из процедуры или из программы. В нашем случае из программы. Таким образом программа завершается и мы возвращаемся в операционную систему.
Ещё несколько слов об объявлении строки:
Msg DB 'Hello, World!!!$'
Вначале мы записываем идентификатор (в нашем случае Msg, но может быть и любой дугой),
чтобы было проще работать со строкой. Затем пишем DB — Define Byte — Определить Байт. В нашем случае это будет массив байтов, в котором каждый элемент имеет размер один байт.
Затем пишем DB — Define Byte — Определить Байт. В нашем случае это будет массив байтов, в котором каждый элемент имеет размер один байт.
Потом пишем саму строку. Каждый символ занимает один байт, поэтому мы и объявили массив байтов. Знак доллара означает конец строки. Так функция вывода понимает, где она должна завершить вывод. Если этот знак не поставить, то будет выведено множество символов — сначала наша строка, а потом разный мусор, содержащийся в ячейках памяти, следующих за нашей строкой. А в эмуляторах это вообще может считаться ошибкой и вывода не будет.
Ну вот мы и написали свою первую программу на языке ассемблера. Если что-то пропустили, то посмотрите видео:
Ассемблер Введение
Главная / Ассемблер / Для чайников /
Для начала разберёмся с терминологией.
Машинный код – система команд конкретной вычислительной машины (процессора), которая интерпретируется непосредственно процессором. Команда, как правило, представляет собой целое число, которое записывается в регистр процессора. Процессор читает это число и выполняет операцию, которая соответствует этой команде. Популярно это описано в книге Как стать программистом.
Язык программирования низкого уровня (низкоуровневый язык программирования) –
это язык программирования, максимально приближённый к программированию в машинных кодах.
В отличие от машинных кодов, в языке низкого уровня каждой команде соответствует не число,
а сокращённое название команды (мнемоника). Например, команда ADD – это сокращение от слова
ADDITION (сложение). Поэтому использование языка низкого уровня существенно упрощает написание
и чтение программ (по сравнению с программированием в машинных кодах). Язык низкого уровня
привязан к конкретному процессору. Например, если вы написали программу на языке низкого
уровня для процессора PIC, то можете быть уверены, что она не будет работать с процессором AVR.
Язык низкого уровня
привязан к конкретному процессору. Например, если вы написали программу на языке низкого
уровня для процессора PIC, то можете быть уверены, что она не будет работать с процессором AVR.
Язык программирования высокого уровня
– это язык программирования, максимально приближённый к человеческому языку (обычно к английскому, но есть языки программирования на национальных языках, например, язык 1С основан на русском языке). Язык высокого уровня практически не привязан ни к конкретному процессору, ни к операционной системе (если не используются специфические директивы).Язык ассемблера – это низкоуровневый язык программирования, на котором вы пишите свои программы. Для каждого процессора существует свой язык ассемблера.
Ассемблер – это специальная программа, которая преобразует (компилирует)
исходные тексты вашей программы, написанной на языке ассемблера, в исполняемый файл (файл
с расширением EXE или COM). Если быть точным, то для создания исполняемого файла требуются
дополнительные программы, а не только ассемблер. Но об этом позже…
Если быть точным, то для создания исполняемого файла требуются
дополнительные программы, а не только ассемблер. Но об этом позже…
В большинстве случаев говорят «ассемблер», а подразумевают «язык ассемблера». Теперь вы знаете, что это разные вещи и так говорить не совсем правильно. Хотя все программисты вас поймут.
ВАЖНО!
В отличие от языков высокого уровня, таких, как
Паскаль,
Бейсик и т.п., для
КАЖДОГО АССЕМБЛЕРА существует СВОЙ ЯЗЫК АССЕМБЛЕРА. Это правило в корне отличает язык
ассемблера от языков высокого уровня. Исходные тексты программы (или просто «исходники»),
написанной на языке высокого уровня, вы в большинстве случаев можете откомпилировать
разными компиляторами для разных процессоров и разных операционных систем.
С ассемблерными исходниками это сделать будет намного сложнее. Конечно, эта разница
почти не ощутима для разных ассемблеров, которые предназначены для одинаковых процессоров.
В этой книге мы будем говорить только о программировании для компьютеров с процессорами Intel (или совместимыми). Для того чтобы на практике проверить приведённые в книге примеры, вам потребуются следующие программы (или хотя бы некоторые из них):
- Emu8086. Хорошая программа, особенно для новичков. Включает в себя редактор исходного кода и некоторые другие полезные вещи. Работает в Windows, хотя программы пишутся под DOS. К сожалению, программа стоит денег (но оно того стоит))). Подробности см. на сайте http://www.emu8086.com.
- TASM – Турбо Ассемблер от фирмы Borland.
 Можно создавать программы как для DOS так и для
Windows. Тоже стоит денег и в данный момент уже не поддерживается (да и фирмы Borland уже
не существует). А вообще вещь хорошая.
Можно создавать программы как для DOS так и для
Windows. Тоже стоит денег и в данный момент уже не поддерживается (да и фирмы Borland уже
не существует). А вообще вещь хорошая. - MASM – Ассемблер от компании Microsoft (расшифровывается как МАКРО ассемблер, а не Microsoft Assembler, как думают многие непосвящённые). Пожалуй, самый популярный ассемблер для процессоров Intel. Поддерживается до сих пор. Условно бесплатная программа. То есть, если вы будете покупать её отдельно, то она будет стоить денег. Но она доступна бесплатно подписчикам MSDN и входит в пакет программ Visual Studio от Microsoft.
- WASM – ассемблер от компании Watcom. Как и все другие, обладает преимуществами и недостатками.
- Debug — обладает скромными возможностями, но имеет большой плюс — входит в стандартный
набор Windows. Поищите ее в папке WINDOWS\COMMAND или WINDOWS\SYSTEM32. Если не найдете,
тогда в других папках каталога WINDOWS.

- Желательно также иметь какой-нибудь шестнадцатеричный редактор. Не помешает и досовский файловый менеджер, например Волков Коммандер (VC) или Нортон Коммандер (NC). С их помощью можно также посмотреть шестнадцатеричные коды файла, но редактировать нельзя. Бесплатных шестнадцатеричных редакторов в Интернете довольно много. Вот один из них: McAfee FileInsight v2.1. Этот же редактор можно использовать для работы с исходными текстами программ. Однако мне больше нравится делать это с помощью следующего редактора:
- Текстовый редактор. Необходим для написания исходных текстов ваших программ. Могу порекомендовать бесплатный редактор PSPad, который поддерживает множество языков программирования, в том числе и язык Ассемблера.
Все представленные в этой книге программы (и примеры программ) проверены на работоспособность.
И именно эти программы используются для реализации примеров программ, приведённых в данной
книге.
И еще – исходный код, написанный, например для Emu8086, будет немного отличаться от кода, написанного, например, для TASM. Эти отличия будут оговорены.
Большая часть программ, приведённых в книге, написана для MASM. Во-первых, потому что этот ассемблер наиболее популярен и до сих пор поддерживается. Во-вторых, потому что он поставляется с MSDN и с пакетом программ Visual Studio от Microsoft. Ну и в третьих, потому что я являюсь счастливым обладателем лицензионной копии MASM.
Если же у вас уже есть какой-либо ассемблер, не вошедший в перечисленный выше список, то вам придётся самостоятельно разобраться с его синтаксисом и почитать руководство пользователя, чтобы научиться правильно с ним работать. Но общие рекомендации, приведённые в данной книге, будут справедливы для любых (ну или почти для любых) ассемблеров.
Сборка
. Часть 1. Изучаем сборку! | Программа инженерного образования (EngEd)
Вначале были перфокарты. В конце концов, кому-то пришла в голову блестящая идея сделать компьютер программируемым. Просто введите шестнадцатеричный код и запустите его. Проблема в том, что очень сложно посмотреть на шестнадцатеричный код и понять, что он делает.
В конце концов, кому-то пришла в голову блестящая идея сделать компьютер программируемым. Просто введите шестнадцатеричный код и запустите его. Проблема в том, что очень сложно посмотреть на шестнадцатеричный код и понять, что он делает.
Войдите в сборку
Сборка по-прежнему очень проста, и каждая деталь того, как компьютер выполняет свою задачу, должна быть указана. Разница в том, что ассемблер делает эти инструкции удобочитаемыми для человека.
Следующим шагом выше будет использование языка программирования, такого как C, Java или Typescript. Это, безусловно, проще, чем использование ассемблера, но и по сей день все еще существуют задачи, которые не могут решить языки системного программирования. Вот некоторые примеры:
- Агрессивная оптимизация (C и Rust уже очень быстры, но не идеальны) Сборка
- упрощает расчет точного времени выполнения программы
- Программы, которые должны работать напрямую с оборудованием, например драйверы
- Загрузка операционной системы
Требования
К сожалению, сборка не одинакова для всех систем. Разным компьютерам для работы нужен разный код. Вот что вам нужно для этого урока:
Разным компьютерам для работы нужен разный код. Вот что вам нужно для этого урока:
- Компьютер x86 (например, он не будет работать на Raspberry Pi)
- 32-битная или 64-битная операционная система (предпочтительно Linux)
- Ассемблер (NASM в Linux или MASM в Windows)
- Опыт низкоуровневого программирования (C, C++, Rust и Go — хорошие языки для изучения)
Разделы
Исполняемые программы можно разделить на три раздела (вы можете использовать больше, но в этом руководстве мы будем придерживаться трех). Вот они:
- текст — Этот раздел содержит фактические инструкции, которые будет выполнять ваш код.
- bss — Здесь хранятся все глобальные переменные. Сюда помещается любая статическая переменная
- data — Этот раздел используется для постоянных глобальных переменных.
Разделы объявляются простым вводом section . . Например, раздел данных будет объявлен с использованием: name
name
section .data
Переменные
Переменные, как мы уже говорили, хранятся в секции bss . Мы не можем просто объявить их значение, как в обычном языке. Вместо этого мы можем точно сказать ассемблеру, сколько байтов нужно зарезервировать.
раздел .bss вар резб 4
Это создает переменную с именем var и резервирует для него четыре байта. Если бы мы хотели зарезервировать два байта, мы бы поставили в конце 2 . Чтобы получить доступ к значению var , мы заключаем его имя в квадратные скобки: [var] .
Операторы
Операторы на ассемблере имеют следующий формат:
Мнемоника [операнды] [;комментарий]
Давайте разберемся.
Мнемоника является фактической для запуска. Некоторые операции принимают один параметр. Некоторые берут несколько. В ассемблере много инструкций, но мы остановимся на следующих.
В ассемблере много инструкций, но мы остановимся на следующих.
| Мнемоника | Операнд 1 | Операнд 2 | Описание |
|---|---|---|---|
| мов | местоположение | значение | Устанавливает операнд 1 в операнд 2 |
| вкл. | местоположение | Добавляет единицу к местоположению | |
| дек | местоположение | Вычитает единицу из местоположения | |
| добавить | местоположение | значение | Добавляет значение в ячейку |
| суб | местоположение | значение | Вычитает значение из местоположения |
| джмп | этикетка | Переход к части программы | |
| смп | значение1 | значение2 | Сравнивает два значения |
| и | этикетка | Переход к части программы, если два значения равны | |
| целое число | прерывание | Создает программное прерывание |
Комментарии в ассемблере — это все, что идет после точки с запятой ( ; ). Вы уже должны быть знакомы с тем, что они делают — они помогают объяснить ваш код другим людям, которые его читают.
Вы уже должны быть знакомы с тем, что они делают — они помогают объяснить ваш код другим людям, которые его читают.
Подробнее об этих инструкциях мы поговорим позже. А пока вот несколько примеров:
mov [var], 5 ; переменная = 5 дек [вар] ; вар -- добавить [вар], 3 ; переменная += 3 ; Посмотрим, сможешь ли ты придумать свое!
Метки
Рассмотрим следующий код C
void main() {
интервал переменная = 0;
в то время как (1) {
вар++;
}
}
Этот код использует цикл while для бесконечного повторения. Однако в сборке нет таких простых циклов. В сборке вам нужно сделать что-то более похожее на следующее
void main() {
интервал переменная = 0;
петля:
вар++;
перейти в петлю;
}
Простите, если вы не знаете, что это допустимый код C. (Это довольно плохая практика.) Но в ассемблере это все, что у вас есть. Попробуем перевести это на Ассемблер.
Давайте настроим нашу программу. Нам нужен раздел text для хранения инструкций программы и раздел bss для хранения нашей переменной.
раздел .текст раздел .bss
Мы еще не говорили об этом, но нам нужно сказать программе, с чего начать в нашей программе. Мы создадим метку с именем _start и начнем с нее. Мы можем указать компоновщику, с чего начать, используя global _start .
раздел .текст глобальный _start _Начало:
Теперь нам нужно создать нашу переменную. Мы будем использовать 32-битное целое число, для которого требуется четыре байта.
раздел .bss вар резб 4
Теперь нам нужно инициализировать переменную. Именно для этого и предназначена инструкция mov .
_старт: mov двойное слово [вар], 0 ; Здесь у нас есть «dword», потому что это 32-битная операция.
Теперь нам нужен цикл. Мы создадим метку, назовем ее loop и безоговорочно перейдем к ней.
_старт: mov двойное слово [вар], 0 петля: джмп петля
Наконец, нам нужно увеличить нашу переменную.
раздел .текст глобальный _start _Начало: mov двойное слово [вар], 0 петля: inc двойное слово [var] джмп петля раздел .bss вар резб 4
Вероятно, я должен упомянуть, как вы можете запустить это. Предположим, что файл называется incrementor.asm и вы используете NASM:
nasm -f elf incrementor.asm ld -m elf_i386 -s -o инкрементатор incrementor.o ./инкрементор
Регистры
Знаете ли вы, что ваш процессор имеет встроенную память? 😲 Регистры — это память, встроенная в ЦП. Из-за этого можно молниеносно использовать регистры вместо хранения значений в оперативной памяти.
Так почему бы нам просто не использовать регистры для всего?
Вот в чем проблема. У нас не так много регистров. В этом уроке будут использоваться только четыре. Это станет проблемой позже, но пока нам нужно меньше четырех переменных, это должно работать для нас. Мы будем использовать четыре:
Мы будем использовать четыре: eax , ebx , ecx и edx . Мы будем использовать эти четыре, потому что их очень легко запомнить. Все они имеют формат e_x . Каждый из этих регистров может хранить одно 32-битное число.
Мы можем переписать наш бесконечный цикл, чтобы использовать раздел регистра
.text глобальный _start _Начало: движение акс, 0 петля: вкл. джмп петля
Теперь нам вообще не нужна оперативная память!… кроме как для хранения фактической программы в памяти. Нам также не нужно указывать размер операции. Размер eax всегда равен четырем байтам.
Заключение
На этом основы сборки закончены. Прочтите мою следующую статью о том, как написать настоящую программу с помощью ассемблера.
Факультет компьютерных наук и технологий — Raspberry Pi: Урок 1 OK01
Урок OK01 содержит объяснение того, как начать работу, и учит, как
для включения светодиода ‘OK’ или ‘ACT’ на Raspberry
Плата Pi рядом с портами RCA и USB. Первоначально этот индикатор был помечен как OK, но в новой редакции он был переименован в ACT.
2 платы Raspberry Pi.
Первоначально этот индикатор был помечен как OK, но в новой редакции он был переименован в ACT.
2 платы Raspberry Pi.
Содержимое
|
1 Начало работы
Я предполагаю, что вы уже посетили Страница загрузок и получил необходимый GNU Toolchain. Также в загрузках page представляет собой файл с именем OS Template. Загрузите это и извлеките его содержимое в новый каталог.
2 Начало
Расширение файла ‘.s’ обычно используется для всех форм ассемблерного кода. чтобы мы помнили, что это ARMv6.
Теперь, когда вы извлекли шаблон, создайте новый файл в исходном каталоге. называется «main.s». Этот файл будет содержать код для этой операционной системы. Чтобы быть явным, структура папок должна выглядеть так:
build/
(пусто)
источник/
main. s
ядро.ld
ЛИЦЕНЗИЯ
Makefile
s
ядро.ld
ЛИЦЕНЗИЯ
Makefile Откройте «main.s» в текстовом редакторе, чтобы мы могли начать вводить ассемблерный код. Малиновый Пи использует разнообразный ассемблерный код под названием ARMv6, так что это то, что нам нужно написать дюйм
Скопируйте эти первые команды.
.секция .инит
.globl_start
_start:
Как оказалось, ни один из них на самом деле ничего не делает на Raspberry Pi, это
все инструкции ассемблеру. Ассемблер — это программа, которая переводит
между ассемблерным кодом, который мы понимаем, и двоичным машинным кодом, который Raspberry
Пи понимает. В ассемблерном коде каждая строка — это новая команда. Первая строка здесь
говорит Ассемблер [1] куда поместить наш код. Предоставленный мной шаблон вызывает код в разделе под названием
.init нужно поставить в начале вывода. Этот
важно, так как мы хотим убедиться, что можем контролировать, какой код запускается первым. Если мы
не делайте этого, сначала запустится код в первом имени файла в алфавитном порядке!
Команда . section просто сообщает ассемблеру, какой
раздел для ввода кода, с этого момента до следующего
.section или конец файла.
section просто сообщает ассемблеру, какой
раздел для ввода кода, с этого момента до следующего
.section или конец файла.
В ассемблерном коде вы можете пропускать строки и ставить пробелы до и после команд, чтобы помощь в удобочитаемости.
Следующие две строки предназначены для остановки предупреждающего сообщения и не так уж важны. [2]
3 Первая линия
Теперь мы на самом деле собираемся что-то закодировать. В ассемблере компьютер просто проходит код, выполняя каждую инструкцию по порядку, если не указано иное. Каждый инструкция начинается с новой строки.
Скопируйте следующую инструкцию.
ldr r0,=0x20200000
ldr reg,=val помещает число val в регистр с именем reg.
Это наша первая команда. Он говорит процессору хранить число 0x20200000. в регистр r0. Здесь мне нужно будет ответить на два вопроса: что такое регистр, а как 0x20200000 число?
В одном регистре может храниться любое целое число от 0 до 4,29. 4 967 295 включительно на
Raspberry Pi, который может показаться большим объемом памяти, но это только
32 двоичных бита.
4 967 295 включительно на
Raspberry Pi, который может показаться большим объемом памяти, но это только
32 двоичных бита.
Регистр — это крошечная часть памяти в процессоре, где процессор хранит числа, над которыми он работает прямо сейчас. Их довольно много, многие из которых имеют особое значение, к которому мы придем позже. Главное там 13 (с именами r0,r1,r2,…,r9,r10,r11,r12), которые называются универсальными, и вы можете использовать их для любых вычислений, которые вам нужно сделать. Так как это первое, В этом примере я использовал r0, но вполне мог бы использовать любой другой. Пока вы последовательны, это не имеет значения.
0x20200000 действительно число. Однако он записывается в шестнадцатеричной системе счисления. К узнать больше о шестнадцатеричном формате развернуть поле ниже:
Шестнадцатеричная — это альтернативная система записи чисел. Вы можете быть в курсе только
десятичная система записи чисел, в которой у нас 10 цифр: 0,1,2,3,4,5,6,7,8
и 9. Шестнадцатеричная система с 16 цифрами: 0,1,2,3,4,5,6,7,8,9,a,b,c,d,e и
ф.
Шестнадцатеричная система с 16 цифрами: 0,1,2,3,4,5,6,7,8,9,a,b,c,d,e и
ф.
Возможно, вы помните, как вас учили, как работают десятичные числа с точки зрения разрядности. Мы говорят, что самые правые цифры — это цифры «единиц», следующая слева — «десятки» цифра, следующая цифра «сотни» и так далее. На самом деле это означало, число 100 × значение в разряде сотен, плюс 10 × число значение в разряде десятков плюс 1 × значение в разряде единиц.
С математической точки зрения теперь мы можем определить закономерность и сказать, что самая правая цифра это цифра 10 0 =1s, следующая слева цифра 10 1 =10s, следующая цифра 10 2 =100 и так далее. Мы все согласились с системой, которая 0 — самая младшая цифра, 1 — следующая и так далее. Но что, если мы использовали другой число вместо 10 в этих степенях? Шестнадцатеричная система — это как раз та система, в которой мы вместо этого используйте 16.
Математика справа показывает, что десятичное число 567 эквивалентно
до числа 237 в шестнадцатеричном формате. Часто, когда нам нужно уточнить, какая система
мы используем для записи чисел, мы ставим 10 для десятичных и 16 для шестнадцатеричной. Так как в коде на ассемблере сложно писать маленькие числа, мы
вместо этого используйте 0x для представления числа в шестнадцатеричном представлении. Итак, 0x237 означает 237 16 .
Часто, когда нам нужно уточнить, какая система
мы используем для записи чисел, мы ставим 10 для десятичных и 16 для шестнадцатеричной. Так как в коде на ассемблере сложно писать маленькие числа, мы
вместо этого используйте 0x для представления числа в шестнадцатеричном представлении. Итак, 0x237 означает 237 16 .
Итак, при чем тут a, b, c, d, e и f? Ну, для того, чтобы можно было написать каждое число в шестнадцатеричном нам нужны дополнительные цифры. Например 9 16 = 9×16 0 = 9 10 , но 10 16 = 1×16 1 + 1×16 0 = 16 10 . Так что, если бы мы просто использовали 0,1,2,3,4,5,6,7,8 и 9, мы бы не смогли написать 10 10 , 11 10 , 12 10 , 13 10 , 14 10 , 15 10 . Таким образом, мы вводим 6 новых цифр, так что 16 = 10 10 , б 16 = 11 10 , в 16 = 12 10 , г 16 = 13 10 , е 16 = 14 10 , f 16 = 15 10
Итак, у нас теперь другая система записи чисел. Но почему мы беспокоились? Хорошо,
оказывается, поскольку компьютеры всегда работают в двоичном формате, шестнадцатеричная система счисления
очень полезно, потому что каждая шестнадцатеричная цифра состоит ровно из четырех двоичных цифр.
У этого есть приятный побочный эффект, заключающийся в том, что многие компьютерные числа представляют собой круглые числа в
шестнадцатеричные, даже если они не десятичные. Например, в ассемблерном коде
чуть выше я использовал число 20200000 16 . Если бы я решил написать это
в десятичном виде это было бы 538968064 10 , что гораздо менее запоминающееся.
Но почему мы беспокоились? Хорошо,
оказывается, поскольку компьютеры всегда работают в двоичном формате, шестнадцатеричная система счисления
очень полезно, потому что каждая шестнадцатеричная цифра состоит ровно из четырех двоичных цифр.
У этого есть приятный побочный эффект, заключающийся в том, что многие компьютерные числа представляют собой круглые числа в
шестнадцатеричные, даже если они не десятичные. Например, в ассемблерном коде
чуть выше я использовал число 20200000 16 . Если бы я решил написать это
в десятичном виде это было бы 538968064 10 , что гораздо менее запоминающееся.
Чтобы преобразовать числа из десятичных в шестнадцатеричные, я считаю, что проще всего использовать следующий метод:
- Начните с десятичного числа, скажем, 567.
- Разделите на 16 и вычислите остаток. Например 567 ÷ 16 = остаток 35 7.
- Остаток — это последняя цифра ответа в шестнадцатеричном формате, в примере это 7.
- Повторите шаги 2 и 3 еще раз с результатом последнего деления, пока не будет получен результат
равно 0.
 Например, 35 ÷ 16 = 2, остаток 3, поэтому 3 — это следующая цифра
отвечать. 2 ÷ 16 = 0, остаток 2, поэтому 2 — следующая цифра ответа.
Например, 35 ÷ 16 = 2, остаток 3, поэтому 3 — это следующая цифра
отвечать. 2 ÷ 16 = 0, остаток 2, поэтому 2 — следующая цифра ответа. - Как только результат деления равен 0, вы можете остановиться. Ответ только остатки в порядке, обратном тому, в котором вы их получили, поэтому 567 10 = 237 16 .
Чтобы преобразовать шестнадцатеричные числа обратно в десятичные, проще всего расширить число, поэтому 237 16 = 2×16 2 + 3×16 1 +7 ×16 0 = 2×256 + 3×16 + 7×1 = 512 + 48 + 7 = 567.
Итак, наша первая команда — поместить число 20200000 16 в r0. Это не
звучит так, как будто это было бы очень полезно, но это так. В компьютерах ужасно много
блоков памяти и устройств. Чтобы получить к ним доступ, мы даем каждому
адрес. Подобно почтовому адресу или веб-адресу, это всего лишь средство идентификации.
расположение устройства или блоков памяти, которые мы хотим. Адреса в компьютерах
просто цифры, и так число 20200000 16 оказался адресом
контроллера GPIO. Это просто дизайнерское решение, принятое производителями,
они могли использовать любой другой адрес (при условии, что он ни с чем не конфликтует
еще). Я знаю этот адрес только потому, что я посмотрел его в руководстве [3] , там нет конкретного
системы по адресам (кроме того, что все они представляют собой большие круглые числа в шестнадцатеричном формате).
Это просто дизайнерское решение, принятое производителями,
они могли использовать любой другой адрес (при условии, что он ни с чем не конфликтует
еще). Я знаю этот адрес только потому, что я посмотрел его в руководстве [3] , там нет конкретного
системы по адресам (кроме того, что все они представляют собой большие круглые числа в шестнадцатеричном формате).
4 Включение выхода
Прочитав руководство, я знаю, что нам нужно будет отправить два сообщения на GPIO. контроллер. Нам нужно говорить на его языке, но если мы это сделаем, он услужливо сделает то, что мы хотим и включаем светодиод ОК. К счастью, это такой простой чип, что только нужно несколько цифр, чтобы понять, что делать.
мов р1,#1
лсл р1,#18
ул r1,[r0,#4]
mov reg,#val ставит номер val в регистр с именем reg.
lsl reg,#val сдвигает двоичное представление из числа в reg по val мест слева.
str reg,[dest,#val] сохраняет число в reg по адресу, заданному
наст + вал.
Эти команды включают вывод на 16-й контакт GPIO. Сначала получаем необходимое значение в r1, затем отправьте его на контроллер GPIO. Поскольку первые две инструкции просто пытаясь получить значение в r1, мы могли бы использовать другой ldr, как и раньше, но позже она нам пригодится, чтобы иметь возможность установить любой данный вывод GPIO, поэтому лучше вывести значение из формулы, чем запишите это прямо. Светодиод OK подключен к 16-му контакту GPIO, поэтому нам нужно отправить команду на включение 16-го контакта.
Значение в r1 необходимо для включения вывода светодиода. В первой строке ставится число
1 10 в р1. Команда mov быстрее
чем команда ldr, потому что она не требует
взаимодействие с памятью, тогда как ldr загружает значение
мы хотим поместить в реестр из памяти. Тем не менее, мов
может использоваться только для загрузки определенных значений [4] . В ассемблере ARM почти каждая инструкция
начинается с трехбуквенного кода. Это называется мнемоникой и должно
подскажите, что делает операция. мов короткий
для перемещения, а ldr — это сокращение от регистра загрузки.
mov перемещает второй аргумент
#1 в первый ряд r1. В общем,
# должен использоваться для обозначения чисел, но у нас есть
уже видел контрпример к этому.
Это называется мнемоникой и должно
подскажите, что делает операция. мов короткий
для перемещения, а ldr — это сокращение от регистра загрузки.
mov перемещает второй аргумент
#1 в первый ряд r1. В общем,
# должен использоваться для обозначения чисел, но у нас есть
уже видел контрпример к этому.
Вторая инструкция — это lsl или логический сдвиг оставил. Это означает сдвиг двоичного представления для первого аргумента влево на второй аргумент. В этом случае это сдвинет двоичное представление 1 10 . (то есть 1 2 ) осталось на 18 позиций (что составляет 10000000000000000000 2 = 262144 10 ).
Если вы не знакомы с двоичным кодом, раскройте поле ниже:
Так же, как шестнадцатеричный двоичный код — это еще один способ записи чисел. В двоичном формате мы только
иметь 2 цифры, 0 и 1. Это полезно для компьютеров, потому что мы можем реализовать это
в цепи, говоря, что электричество, протекающее по цепи, означает 1, и
не означает 0. Так на самом деле работают и выполняют вычисления компьютеры. Несмотря на наличие только
2-значный двоичный код все еще можно использовать для представления каждого числа, просто это занимает много времени.
дольше.
Так на самом деле работают и выполняют вычисления компьютеры. Несмотря на наличие только
2-значный двоичный код все еще можно использовать для представления каждого числа, просто это занимает много времени.
дольше.
На изображении показано двоичное представление числа 567 10 , которое 1000110111 2 . Мы используем 2 для обозначения чисел, записанных в двоичном формате.
Одной из особенностей двоичного кода, которую мы активно используем в ассемблере, является простота. на которые числа можно умножать или делить на степени 2 (например, 1,2,4,8,16). Обычно умножение и деление — сложные операции, однако эти специальные случаи очень просты, и поэтому очень важны.
Сдвиг двоичного числа влево на n разрядов аналогичен умножению
номер по 2 n . Итак, если мы хотим умножить на 4, мы
просто сдвиньте число влево на 2 места. Если мы хотим умножить на 256, мы можем сдвинуть
он ушел на 8 мест. Если бы мы хотели умножить на число вроде 12, мы могли бы вместо этого
умножьте его на 8, затем отдельно на 4 и сложите результаты (N × 12 = N ×
(8 + 4) = N × 8 + N × 4).
Если бы мы хотели умножить на число вроде 12, мы могли бы вместо этого
умножьте его на 8, затем отдельно на 4 и сложите результаты (N × 12 = N ×
(8 + 4) = N × 8 + N × 4).
Сдвиг двоичного числа вправо на n разрядов аналогичен делению номер по 2 n . Оставшаяся часть деления – это биты, которые были потеряны при сдвиге вправо. К сожалению, деление на двоичное число это не точная степень числа 2, очень сложно и будет рассмотрено в Урок 9: Экран04.
На этой диаграмме показана общая терминология, используемая с двоичными файлами. Бит — это один двоичный файл
цифра. Полубайт — это 4 двоичных бита. Байт — это 2 полубайта или 8 бит. Половина есть половина
размер слова, в данном случае 2 байта. Слово относится к размеру регистров
на процессоре и так далее на Raspberry Pi это 4 байта. Конвенция заключается в
нумеровать старший значащий бит слова 31, а младший значащий бит — 0.
Верхние или старшие биты относятся к старшим битам, а младшие или нижние
биты относятся к наименее значимым. Килобайт (КБ) — это 1000 байт, мегабайт — это
1000 КБ. Существует некоторая путаница относительно того, должно ли это быть 1000 или 1024 (раунд
число в двоичном формате). Таким образом, новый международный стандарт заключается в том, что КБ составляет 1000
байт, а Кибибайт (КиБ) составляет 1024 байта. Kb — это 1000 бит, а Kib — 1024 бита.
биты.
Килобайт (КБ) — это 1000 байт, мегабайт — это
1000 КБ. Существует некоторая путаница относительно того, должно ли это быть 1000 или 1024 (раунд
число в двоичном формате). Таким образом, новый международный стандарт заключается в том, что КБ составляет 1000
байт, а Кибибайт (КиБ) составляет 1024 байта. Kb — это 1000 бит, а Kib — 1024 бита.
биты.
Raspberry Pi по умолчанию использует обратный порядок байтов, что означает, что загрузка байта из адрес, на который вы только что написали слово, загрузит младший байт слова.
Еще раз повторюсь, что это значение нам нужно только из прочтения руководства [3]. В руководстве говорится
что в контроллере GPIO есть набор из 24 байт, которые определяют настройки
контакта GPIO. Первые 4 относятся к первым 10 контактам GPIO, вторые 4 относятся к
к следующим 10 и так далее. Есть 54 контакта GPIO, поэтому нам нужно 6 наборов по 4 байта,
всего 24 байта. В каждой 4-байтовой секции каждые 3 бита относятся к
конкретный вывод GPIO. Поскольку нам нужен 16-й контакт GPIO, нам нужен второй набор
4 байта, потому что мы имеем дело с контактами 10-19., и нам нужен 6-й набор из 3 бит,
отсюда и число 18 (6×3) в приведенном выше коде.
Поскольку нам нужен 16-й контакт GPIO, нам нужен второй набор
4 байта, потому что мы имеем дело с контактами 10-19., и нам нужен 6-й набор из 3 бит,
отсюда и число 18 (6×3) в приведенном выше коде.
Наконец, команда str ‘store register’ сохраняет значение в первом аргументе, r1 в адрес, вычисленный из выражения впоследствии. Выражение может быть регистром, в данном случае r0, который, как мы знаем, является GPIO адрес контроллера и другое значение, которое нужно добавить к нему, в данном случае № 4. Это означает, что мы добавляем 4 к адресу контроллера GPIO и пишем значение в r1 в это место. Это происходит с быть расположением второго набора из 4 байтов, о котором я упоминал ранее, и поэтому мы отправляем наше первое сообщение контроллеру GPIO, сообщая ему о готовности 16-го GPIO пин для вывода.
Теперь, когда светодиод готов к включению, нам нужно его включить. Это означает
отправка сообщения контроллеру GPIO для отключения контакта 16. Да, выключи . Производители чипов решили, что [5] имеет больше смысла включать светодиод, когда
контакт GPIO выключен. Разработчики аппаратного обеспечения часто принимают такие решения,
казалось бы, просто чтобы держать разработчиков ОС в напряжении. Считай себя предупрежденным.
Производители чипов решили, что [5] имеет больше смысла включать светодиод, когда
контакт GPIO выключен. Разработчики аппаратного обеспечения часто принимают такие решения,
казалось бы, просто чтобы держать разработчиков ОС в напряжении. Считай себя предупрежденным.
мов р1,#1
лсл р1,#16
ул r1,[r0,#40]
Надеюсь, вы должны распознать все вышеперечисленные команды, если не их значения. сначала помещает 1 в r1, как и раньше. Второй сдвигает двоичное представление этого 1 влево на 16 позиций. Поскольку мы хотим превратить вывод 16 отключен, нам нужно иметь 1 в 16-м бите этого следующего сообщения (другие значения будет работать для других контактов). Наконец, мы записываем его по адресу, который равен 40 9.0381 10 добавлен к адресу контроллера GPIO, который является адресом для записи выключите булавку (28 включит булавку).
6. Долго и счастливо
Может быть заманчиво закончить сейчас, но, к сожалению, процессор не знает
были сделаны. На самом деле процессор никогда не остановится. Пока у него есть сила,
он продолжает работать. Таким образом, мы должны дать ему задание делать вечно больше, или
Raspberry Pi выйдет из строя (в данном примере это не проблема, свет уже горит).
на).
На самом деле процессор никогда не остановится. Пока у него есть сила,
он продолжает работать. Таким образом, мы должны дать ему задание делать вечно больше, или
Raspberry Pi выйдет из строя (в данном примере это не проблема, свет уже горит).
на).
петля$:
б петля$
имя: помечает следующую строку имя.
метка b вызывает выполнение следующей строки до быть ярлыком.
Первая строка здесь не команда, а метка. Он называет следующую строку
петля$. Это означает, что теперь мы можем обращаться к строке по имени. Это называется
этикетка. Метки отбрасываются, когда код преобразуется в двоичный, но они полезны
в нашу пользу для обращения к строкам по имени, а не по номеру (адресу). Условно
мы используем $ для меток, которые важны только
к коду в этом блоке кода, чтобы другие знали, что они не важны для
общая программа. Команда b (ветка) вызывает
следующей выполняемой строкой должна быть строка с указанной меткой, а не
один после него. Следовательно, следующей строкой, которая будет выполнена, будет эта
b, что приведет к его повторному выполнению и так далее до бесконечности.![]() Таким образом
процессор застревает в приятном бесконечном цикле, пока он не будет безопасно выключен.
Таким образом
процессор застревает в приятном бесконечном цикле, пока он не будет безопасно выключен.
Новая строка в конце блока является преднамеренной. Инструментальная цепочка GNU ожидает, что все файлы с ассемблерным кодом должны заканчиваться пустой строкой, чтобы быть уверенным, что вы действительно завершено, и файл не был обрезан. Если вы не поставите его, вы получите раздражающее предупреждение при запуске ассемблера.
7 Пи Время
Итак, мы написали код, теперь нужно перенести его на пи. Откройте терминал на своем компьютере
и измените текущий рабочий каталог на родительский каталог исходного каталога.
Введите make и нажмите Enter. Если какие-либо ошибки
возникают, обратитесь к разделу устранения неполадок. Если нет, вы сгенерируете
три файла. kernel.img — это скомпилированный образ вашей операционной системы. ядро.list
представляет собой листинг ассемблерного кода, который вы написали, в том виде, в каком он был фактически сгенерирован. Этот
полезно проверить, что вещи были сгенерированы правильно в будущем.