ассемблер — Не работает деление
format pe console
include 'C:\Program Files\FASM\INCLUDE\win32ax.inc'
include 'C:\Program Files\FASM\INCLUDE\api\kernel32.inc'
entry start
.data
Num1 dd 0 ;Первое
Num2 dd 0 ;Второе число
Act db 0 ;Операция
.code
start: cinvoke printf, <'It is console calculator%c+ addition%c- subtraction%c* multiplication%c/ devision%c%c'>, 10, 10, 10, 10, 10, 10
begin:
cinvoke printf, <'First number: '> ;Ввод пользователем чисел и операции
cinvoke scanf, <'%d'>, Num1
cinvoke printf, <'Second number: '>
cinvoke scanf, <'%d'>, Num2
cinvoke printf, <'Operation: '>
cinvoke scanf, <'%s'>, Act
cmp byte [Act], '+' ;Проверка на сложение
jne notAdd ;Если не сложение, то перейти в notAdd
mov eax, dword [Num1] ;Сложение
add eax, dword [Num2]
cinvoke printf, <'Result: %d'>, eax ;Вывод результата
cinvoke getch
cinvoke printf, <'%c%c'>, 10, 10 ;Пропуск 2 строк
jmp begin ;Переход в начало
notAdd: cmp byte [Act], '-' ;Проверка на вычитание
jne notSub ;Если не вычитание, то перейти в notSub
mov eax, dword [Num1] ;Вычитание
sub eax, dword [Num2]
cinvoke printf, <'Result: %d'>, eax ;Вывод результата
cinvoke getch
cinvoke printf, <'%c%c'>, 10, 10 ;Пропуск 2 строк
jmp begin ;Переход в начало
notSub: cmp byte [Act], '*' ;Проверка на умножение
jne notMul ;Если не умножение, то перейти в notMul
mov eax, dword [Num1] ;Умножение
imul dword [Num2]
cinvoke printf, <'Result: %d'>, eax ;Вывод результата
cinvoke getch
cinvoke printf, <'%c%c'>, 10, 10 ;Пропуск 2 строк
jmp begin ;Переход в начало
notMul: cmp byte [Act], '/' ;Проверка на деление
jne notDiv ;Если не деление, то перейти в notDiv
cmp dword [Num2], 0 ;Проверка на деление на ноль
je divisionByZero ;Если деление на ноль, то перейти в divisionByZero
mov eax, dword [Num1] ;Деление
idiv dword [Num2]
cinvoke printf, <'Result: %d'>, eax ;Вывод результата
cinvoke getch
cinvoke printf, <'%c%c'>, 10, 10 ;Пропуск 2 строк
jmp begin ;Переход в начало
notDiv: cinvoke printf, <'Invailid operation'>
cinvoke getch
cinvoke printf, <'%c%c'>, 10, 10 ;Пропуск 2 строк
jmp begin ;Переход в начало
divisionByZero: cinvoke printf, <'Infinity'>
cinvoke getch
cinvoke printf, <'%c%c'>, 10, 10 ;Пропуск 2 строк
jmp begin ;Переход в начало
section '.
idata' import data readable
library kernel32,'kernel32.dll',msvcrt,'msvcrt.dll'
import msvcrt, printf, 'printf', getch, '_getch', scanf, 'scanf'

Я написал калькулатор, где вводятся 2 числа и действие. Сначала проверяется, нужно ли числа сложить. Если действие — не сложение, то проверяется, нужно ли числа вычесть. Потом идёт умножение и деление. Если не деление, то выводится информация о том, что действие неправильное. У меня есть 2 проблемы:
1 Если умножать большие числа, то ответ получается неправильный. Результат разделяется на 2 половины одна записывается в edx, а другая в eax. Я не знаю, как их соединить.
2 Если делить на любое, отличное от 0 число, то приложение вылетает.
Делись, рыбка, быстро и нацело / Хабр
Деление — одна из самых дорогих операций в современных процессорах. За доказательством далеко ходить не нужно: Agner Fog[1] вещает, что на процессорах Intel / AMD мы легко можем получить Latency в 25-119 clock cycles, а reciprocal throughput — 25-120. В переводе на Русский —
В переводе на Русский —
! Тем не менее, возможность избежать инструкции деления в вашем коде — есть. И в этой статье, я расскажу как это работает, в частности в современных компиляторах(они то, умеют так уже лет 20 как), а также, расскажу как полученное знание можно использовать для того чтобы сделать код лучше, быстрее, мощнее.
Собственно, я о чем: если делитель известен на этапе компиляции, есть возможность заменить целочисленное деление умножением и логическим сдвигом вправо (а иногда, можно обойтись и без него вовсе — я конечно про реализацию в Языке Программирования). Звучит весьма обнадеживающе: операция целочисленного умножения и сдвиг вправо на, например, Intel Haswell займут не более 5 clock cycles. Осталось лишь понять, как, например, выполняя целочисленное деление на 10, получить тот же результат целочисленным умножением и логическим сдвигом вправо? Ответ на этот вопрос лежит через понимание… Fixed Point Arithmetic (далее FPA).
При использовании FP, экспоненту (показатель степени 2 => положение точки в двоичном представлении числа) в числе не сохраняют (в отличие от арифметики с плавающей запятой, см. IEE754), а полагают ее некой оговоренной, известной программистам величиной. Сохраняют же, только мантиссу (то, что идёт после запятой). Пример:
0.1 — в двоичной записи имеет ‘бесконечное представление’, что в примере выше отмечено круглыми скобками — именно эта часть будет повторяться от раза к разу, следуя друг за другом в двоичной FP записи числа 0.1.
В примере выше, если мы используем для хранения FP чисел 16-битные регистры, мы не сможем уместить FP представление числа 0.1 в такой регистр не потеряв в точности, а это в свою очередь скажется на результате всех дальнейших вычислений в которых значение этого регистра участвует.
Пусть дано 16-битное целое число A и 16-битная Fraction часть числа B. Произведение A на B результатом дает число с 16 битами в целой части и 16-тью битами в дробной части.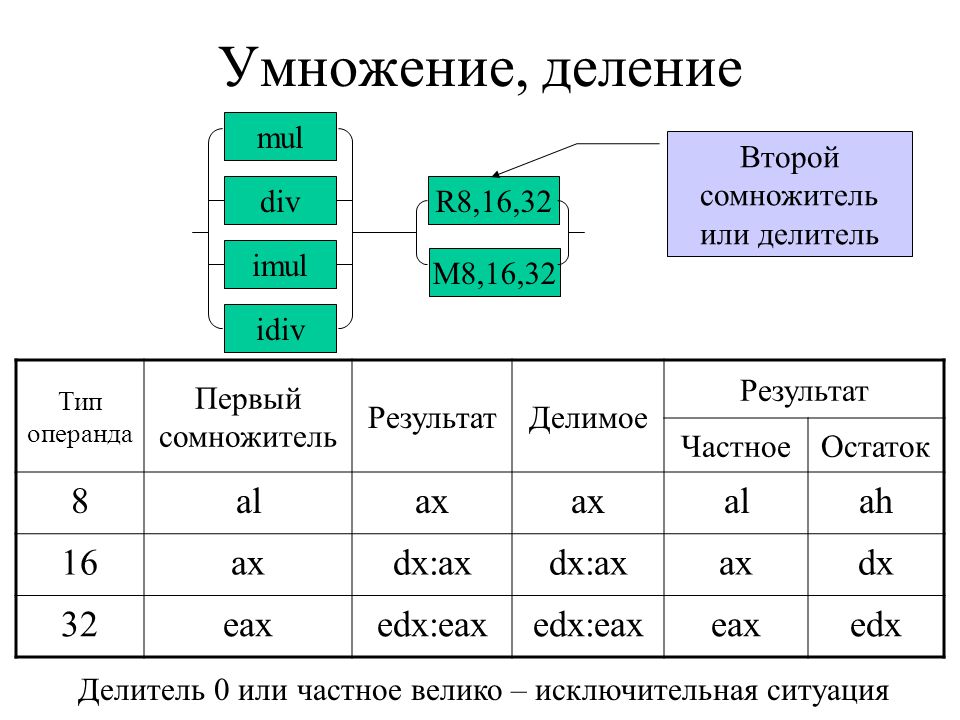 Чтобы получить только целую часть, очевидно, нужно сдвинуть результат на 16 бит вправо.
Чтобы получить только целую часть, очевидно, нужно сдвинуть результат на 16 бит вправо.
Поздравляю, вводная часть в FPA окончена.
Формируем следующую гипотезу: для выполнения целочисленного деления на 10, нам нужно выполнить умножение Числа Делимого на FP представление числа 0.1, взять целую часть и дело в шля… минуточку… А будет ли полученный результат точным, точнее его целая часть? — Ведь, как мы помним, в памяти у нас хранится лишь приближенная версия числа 0.1. Ниже я выписал три различных представления числа 0.1: бесконечно точное представление числа 0.1, обрезанное после 16-ого бита без округления представление числа 0.1 и обрезанное после 16 ого бита с округлением вверх представление числа 0.1.
Оценим погрешности truncating представлений числа 0.1:
Чтобы результат умножения целого числа A, на Аппроксимацию числа 0.1 давал точную целую часть, нам нужно чтобы:
, либо
Удобнее использовать первое выражение: при мы всегда получим тождество (но, заметь, не все решения, что в рамках данной задачи — более чем достаточно). Решая, получаем . То есть, умножая любое 14-битное число A на truncating with rounding up представление числа 0.1, мы всегда получим точную целую часть, которую бы получили умножая бесконечно точно 0.1 на A. Но, по условию у нас умножается 16-битные число, а значит, в нашем случае ответ будет неточным и довериться простому умножению на truncating with rounding up 0.1 мы не можем. Вот если бы мы могли сохранить в FP представлении числа 0.1 не 16 бит, а, скажем 19, 20 — то все было бы ОК. И ведь можем же!
Решая, получаем . То есть, умножая любое 14-битное число A на truncating with rounding up представление числа 0.1, мы всегда получим точную целую часть, которую бы получили умножая бесконечно точно 0.1 на A. Но, по условию у нас умножается 16-битные число, а значит, в нашем случае ответ будет неточным и довериться простому умножению на truncating with rounding up 0.1 мы не можем. Вот если бы мы могли сохранить в FP представлении числа 0.1 не 16 бит, а, скажем 19, 20 — то все было бы ОК. И ведь можем же!
Следовательно, мы можем сдвинуть наше число влево на три бита, выполнить округление вверх и, выполнив умножение и логический сдвиг вправо сначала на 16, а затем на 3 (то есть, за один раз на 19 вообще говоря) — получим нужную, точную целую часть. Доказательство корректности такого ’19’ битного умножения аналогично предыдущему, с той лишь разницей, что для 16-битных чисел оно работает правильно.
 Аналогичные рассуждения верны и для чисел большей разрядности, да и не только для деления на 10.
Аналогичные рассуждения верны и для чисел большей разрядности, да и не только для деления на 10.Ранее я писал, что вообще говоря, можно обойтись и без какого-либо сдвига вовсе, ограничившись лишь умножением. Как? Ассемблер x86 / x64 на барабане:
MUL RCX ; умножить RCX на RAX, а результат (128 бит) сохранить в RDX:RAX
В регистре RCX пусть хранится некое целое 62-битное A, а в регистре RAX пускай хранится 64 битное FA представление truncating with rounding up числа 0.1 (заметь, никаких сдвигов влево нету). Выполнив 64-битное умножение получим, что в регистре RDX сохранятся старшие 64 бита результата, или, точнее говоря — целая часть, которая для 62 битных чисел, будет точной.
Возможно, с появлением контрактов (в С++ 20 не ждем) ситуация улучшится, и в каких-то кейсах, мы сможем довериться машине! Хотя, это же С++, тут за все отвечает программист — не иначе.
Рассуждения описанные выше — применимы к любым делителям константам, ну а ниже список полезных ссылок:
[1] https://www.agner.org/optimize/instruction_tables.pdf
[2] Круче чем Агнер Фог
[3] Телеграмм канал, с полезной информацией о оптимизациях под Intel / AMD / ARM
[4] Про деление нацело, но по Английски
Получить частное и остаток и отобразить их вместе на ассемблере
0.00/5 (Нет голосов)
Узнать больше:
АСМ
Привет всем, не могли бы вы помочь мне получить остаток и частное и отобразить их вместе? Я действительно не знаю, как кодировать это на языке ассемблера, так как я новичок.
В приведенном ниже коде я создал программу, которая складывает два числа и отображает их сумму в десятичной форме. Сумма будет разделена на 7, так как нам нужно отобразить сумму в форме Base 7. Так например, я добавил 7 и 6, сумма должна быть 16 вместо 13.
Чтобы получить 16, сумму 13 (основание 10/десятичная) нужно разделить на 7 (основание) 13/7=1 остаток 6.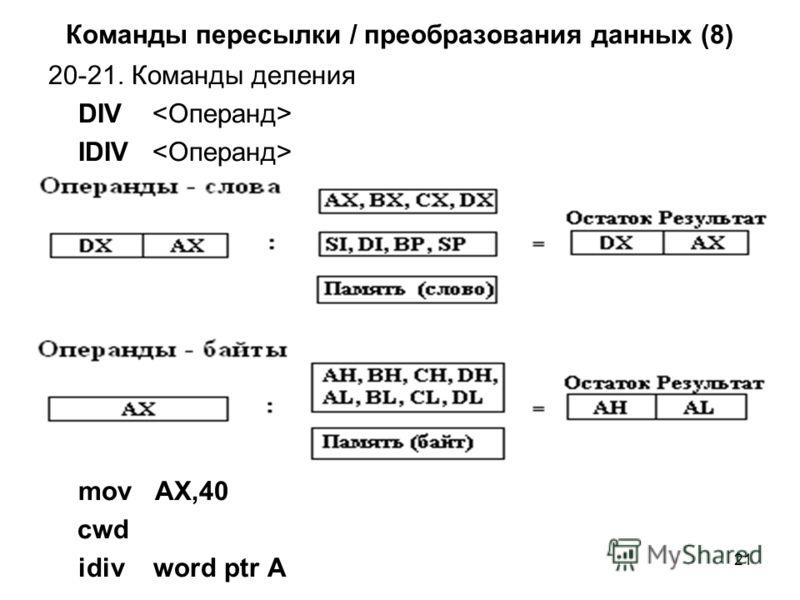 1 и 6 должны отображаться вместе (16).
1 и 6 должны отображаться вместе (16).
Надеюсь, кто-нибудь поможет мне понять, как кодировать это.
Что я пробовал:
.МОДЕЛЬ МАЛЕНЬКАЯ
.СТЕК 1000ч
.ДАННЫЕ
abase7 db 0dh,0ah,'Добавление базы 07$'
ad db 0dh,0ah, 'Добавить (00-99): $'
au db 0dh,0ah, 'Агент(00-99): $'
sum db 0dh,0ah,'Сумма: $'
сев дб 7
.КОД
начинать:
мов топор,@данные
мов дс, топор
mov dx, смещение abase7
мов ах, 09через 21 час
мин:
mov dx, офсетная реклама
мов ах, 09
через 21 час
мов ах, 01
через 21 час
мов кл, ал
саб кл, 30ч
mov dx, смещение au
мов ах, 09
через 21 час
мов ах, 01
через 21 час
саб аль, 30ч
хор ах, ах
добавить al,cl
ааа
мов сх, топор
добавить cx, 3030h
mov dx, сумма смещения
мов ах, 09через 21 час
мов ах, 2
мов дл,ч
через 21 час
мов дл,кл
через 21 час
мов ах, 4ch
через 21 час
конец начало Добавить решение
2 раствора
- Самые популярные
- Самые последние
Раствор 1
Цитата:
... можете ли вы помочь мне получить остаток и частное и отобразить их вместе? Я действительно не знаю, как кодировать это на языке ассемблера, так как я новичок.
И в этом суть: вы учитесь, как это делать, применяя то, чему вас учили до сих пор.
Мы более чем готовы помочь тем, кто застрял: но это не значит, что мы здесь, чтобы сделать все это за вас! Мы не можем делать всю работу, вам либо платят за это, либо это часть ваших оценок, и было бы совершенно несправедливо, если бы мы делали все это за вас.
Итак, нам нужно, чтобы вы выполнили работу, и мы поможем вам, когда вы застрянете. Это не означает, что мы дадим вам пошаговое решение, которое вы можете предоставить!
Начните с объяснения того, где вы находитесь в данный момент, и каков следующий шаг в этом процессе. Затем расскажите нам, что вы пытались сделать, чтобы следующий шаг заработал, и что получилось, когда вы это сделали.
Просто сбрасывание на нас ненужного кода и надежда, что мы «заполним пробелы», не поможет вам в долгосрочной перспективе, даже если мы дадим вам решение. ..
..
Добавить решение
Этот контент вместе со всем связанным исходным кодом и файлами находится под лицензией The Code Project Open License (CPOL)
DIV — Unsigned Divide
DIV — Беззнаковое деление| Код операции | Инструкция | Оп/Ан | 64-битный режим | Режим совместимости/этапа | Описание |
|---|---|---|---|---|---|
| F6/6 | РАЗДЕЛ об/м8 | М | Действительно | Действительный | Беззнаковое деление AX на об/м8 , результат сохраняется в AL := Частное, AH := Остаток. |
| REX + F6/6 | ДЕЛ об/м8 * | М | Действительный | Н.В. | Беззнаковое деление AX на об/м8 , результат сохраняется в AL := Частное, AH := Остаток. |
| Ф7/6 | РАЗДЕЛ об/м16 | М | Действительный | Действительно | Беззнаковое деление DX:AX на об/м16 , результат сохраняется в AX := Частное, DX := Остаток. |
| Ф7/6 | РАЗДЕЛ об/м32 | М | Действительный | Действительный | Беззнаковое деление EDX:EAX на об/м32 , результат сохраняется в EAX := Частное, EDX := Остаток. |
| REX.W + F7/6 | РАЗДЕЛ об/м64 | М | Действительный | Н.В. | Беззнаковое деление RDX:RAX на об/м64 , результат сохраняется в RAX := Частное, RDX := Остаток. |
* В 64-битном режиме r/m8 не может быть закодирован для доступа к следующим байтовым регистрам, если используется префикс REX: AH, BH, CH, DH.
Кодирование операнда инструкции ¶
| Оп/Р | Операнд 1 | Операнд 2 | Операнд 3 | Операнд 4 |
| М | ModRM:r/m (ж) | нет данных | нет данных | Нет данных |
Описание ¶
Делит беззнаковое значение в регистрах AX, DX:AX, EDX:EAX или RDX:RAX (делимое) на исходный операнд (делитель) и сохраняет результат в регистрах AX (AH:AL), DX:AX, EDX :EAX или RDX:RAX. Исходным операндом может быть регистр общего назначения или ячейка памяти. Действие этой инструкции зависит от размера операнда (делимое/делитель). Деление с использованием 64-битного операнда доступно только в 64-битном режиме.
Исходным операндом может быть регистр общего назначения или ячейка памяти. Действие этой инструкции зависит от размера операнда (делимое/делитель). Деление с использованием 64-битного операнда доступно только в 64-битном режиме.
Нецелочисленные результаты усекаются (отрезаются) в сторону 0. Остаток всегда меньше делителя по величине. Переполнение обозначается исключением #DE (ошибка деления), а не флагом CF.
В 64-битном режиме размер операции инструкции по умолчанию составляет 32 бита. Использование префикса REX.R разрешает доступ к дополнительным регистрам (R8-R15). Использование префикса REX.W способствует работе до 64 бит. В 64-битном режиме, когда применяется REX.W, инструкция делит значение без знака в RDX:RAX на исходный операнд и сохраняет частное в RAX, а остаток в RDX.
См. сводную таблицу в начале этого раздела для кодирования данных и ограничений. См. Таблицу 3-15.
| Размер операнда | Дивиденд | Делитель | Частное | Остаток | Максимальное частное |
|---|---|---|---|---|---|
| Слово/байт | ТОПОР | об/м8 | АЛ | АХ | 255 |
| Двойное слово/слово | DX:AX | об/м16 | ТОПОР | ДС | 65 535 |
| Четырехслово/двойное слово | EDX:EAX | об/м32 | ЭАКС | ЭДС | 2 32 − 1 |
| Двойное четверное слово/четверное слово | гексоген: РАКС | об/м64 | РАКС | гексоген | 2 64 − 1 |
 DIV Действие
DIV ДействиеОперация ¶
ИФСРЦ = 0
ТОГДА #DE; ФИ; (* Ошибка деления *)
IF OperandSize = 8 (* Операция Word/Byte *)
ЗАТЕМ
темп := AX/SRC;
ЕСЛИ температура > FFH
ТОГДА #DE; (*Ошибка деления*)
ЕЩЕ
АЛ := темп;
АХ := AX MOD SRC;
ФИ;
ELSE IF OperandSize = 16 (* операция двойное слово/слово *)
ЗАТЕМ
темп:= DX:AX/SRC;
ЕСЛИ температура > FFFFH
ТОГДА #DE; (*Ошибка деления*)
ЕЩЕ
AX := темп;
DX := DX:AX MOD SRC;
ФИ;
ФИ;
ELSE IF Размер операнда = 32 (* Операция с квадрословом/двойным словом *)
ЗАТЕМ
темп:= EDX:EAX/SRC;
ЕСЛИ температура > FFFFFFFFH
ТОГДА #DE; (*Ошибка деления*)
ЕЩЕ
EAX := темп;
EDX := EDX:EAX MOD SRC;
ФИ;
ФИ;
ИНАЧЕ, ЕСЛИ 64-битный режим и размер операнда = 64 (* операция двойного четверного слова/четверенного слова *)
ЗАТЕМ
темп:= RDX:RAX/SRC;
ЕСЛИ температура > FFFFFFFFFFFFFFFFH
ТОГДА #DE; (*Ошибка деления*)
ЕЩЕ
РАКС := темп;
RDX := RDX:RAX MOD SRC;
ФИ;
ФИ;
ФИ;
Затронутые флаги ¶
Флаги CF, OF, SF, ZF, AF и PF не определены.
Исключения защищенного режима ¶
| #DE | Если исходный операнд (делитель) равен 0 |
| Если частное слишком велико для указанного регистра. | |
| #GP(0) | Если эффективный адрес операнда памяти выходит за пределы сегмента CS, DS, ES, FS или GS. |
| Если регистр DS, ES, FS или GS содержит селектор сегмента NULL. | |
| #СС(0) | Если эффективный адрес операнда памяти выходит за пределы сегмента SS. |
| #PF(код неисправности) | Если происходит ошибка страницы. |
| #AC(0) | Если включена проверка выравнивания и делается невыровненная ссылка на память при текущем уровне привилегий 3. |
| #UD | Если используется префикс LOCK. |
Исключения режима реального адреса ¶
| #DE | Если исходный операнд (делитель) равен 0. |
| Если частное слишком велико для указанного регистра. | |
| #GP | Если эффективный адрес операнда памяти выходит за пределы сегмента CS, DS, ES, FS или GS. |
| Если регистр DS, ES, FS или GS содержит селектор сегмента NULL. | |
| #СС(0) | Если эффективный адрес операнда памяти выходит за пределы сегмента SS. |
| #УД | Если используется префикс LOCK. |
Исключения режима Virtual-8086 ¶
| #DE | Если исходный операнд (делитель) равен 0. |
| Если частное слишком велико для указанного регистра. | |
| #GP(0) | Если эффективный адрес операнда памяти выходит за пределы сегмента CS, DS, ES, FS или GS. |
| #SS | Если эффективный адрес операнда памяти выходит за пределы сегмента SS. |
| #PF(код неисправности) | Если происходит ошибка страницы. |