Сложный расчет итогов с помощью системы компоновки данных (СКД) в «1С»
В чём заключается сложность расчета итогов по ключевым показателям?
В статье мы поговорим о применении СКД для решения очень общей задачи, которую можно описать словами «анализ деятельности предприятия». Более точно ее можно сформулировать так: необходимо разработать инструмент, который позволил бы без дополнительного программирования создавать, настраивать и анализировать произвольное количество числовых показателей деятельности компании с произвольным расчетом итогов.
Определение ключевого показателя (КП)
Из-за общности задачи и возникают сложности. Какие показатели необходимо анализировать? Очень разные, можно даже сказать — разноприродные.
Например:
- Суммовые показатели (прибыль, выручка).
- Количественные (численность персонала, количество обращений клиентов).
- Проценты (процент ФОТ в затратах).
- Любые другие, значения которых можно выразить числом (площадь помещений).

Таким образом, ключевой показатель — это любая сущность, которая может быть выражена числом, подлежащая анализу.
Список КП заранее не известен
Список показателей не определен заранее: деятельность предприятия меняется, потребность в анализе тоже. Состав показателей дополняется, уточняется, расширяется постоянно в течение жизни компании.
Есть показатели общие и общепринятые для всей компании, с общим способом расчета. Например, такие как выручка, прибыль. А есть специфические для какого-то филиала или вида деятельности. Например, молодой филиал с не устоявшимся количеством сотрудников анализирует количество квадратных метров офиса на одного сотрудника.
Производные КП
Часть показателей является производными: их значение бессмысленно хранить, оно напрямую зависит от значений базовых показателей.
Пример:
Удельная прибыль на сотрудника — это общая прибыль, поделенная на количество сотрудников.
Структура отчёта с ключевыми показателями
При большом количестве сотрудников, занимающихся анализом, возникает потребность организовывать эти показатели в уникальные для конкретного менеджера списки и/или структуры.
Если показателей в компании хоть сколько-нибудь значимое количество, то у любого менеджера должна быть возможность быстро сформировать отчет по релевантному именно для него перечню показателей, причем желательно не просто перечню, а особым образом организованному перечню.
Например, структура может быть такой:
Раздел 1: Общая выручка
Выручка от продажи товаров
Выручка от продажи услуг
Раздел 2: Затраты
ФОТ
Командировки
Прочее
Раздел 3: ПрибыльПостановка задачи расчета агрегационных итогов
С требованиями к самим показателям более-менее определились, теперь нужно сформулировать, какие требования возникают непосредственно при анализе данных.
В любой системе хранения данных есть детализированное хранимое значение, то есть такое, набор аналитик которого мы считаем достаточным. Скажем, можно хранить выручку за каждый день и для каждого продавца, а можно — за год и по компании в целом.
Допустим, мы договорились, что детальное значение показателя мы храним или считаем в разрезах Подразделение/Месяц. Задача состоит в корректном расчете итогов для всей компании. Возникают следующие вопросы:
- Как посчитать итог для одного подразделения за год?
- Для всей компании за год?
В самом простом случае ответ — всё сложить. Например, прибыль. Понятно, что прибыль по компании за месяц — это сумма всех прибылей подразделений за этот месяц, а прибыль за год — это сумма всех прибылей за месяц, неважно, для одного подразделения или для всей компании.
Теперь разберем, например, показатель «Численность сотрудников». Что такое численность всей компании за месяц? Это снова сумма численности подразделений (не рассматриваем случаи, когда сотрудник числится сразу в двух подразделениях по полставки). А что такое численность подразделения за год? Сумма численностей за все месяцы? Точно нет.
А что такое численность подразделения за год? Сумма численностей за все месяцы? Точно нет.
На практике оказывается, что решение, как анализировать численность за год, принимает конкретный аналитик. Некоторые считают, что это должен быть максимум от численностей за месяцы, некоторые — что среднее. А что такое численность компании за год? Это, соответственно, максимум (или среднее) от суммы численностей подразделений за каждый месяц.
Отдельный случай — с расчетными показателями. Как посчитать, например, удельную прибыль за год? Можно взять среднюю из рассчитанных удельных прибылей помесячно, а можно рассчитать по своей формуле на уровне года, применив агрегацию к тем показателям, что являются основой для расчета: в таком случае, удельная прибыль за год = сумма прибыли за год / средняя численность за год.
Так, в нашем примере средняя удельная прибыль за год = (214.29 + 133.33 + 177.78) / 3, а удельная прибыль, рассчитанная за год по формуле = 4300 (прибыль за год) / 8. 33 (средняя численность за год).
33 (средняя численность за год).
Система должна предоставить инструмент для того, чтобы реализовать возможность выбора агрегационной функции итога по периоду для каждого показателя, так как этот выбор зависит от нужд конкретного аналитика.
Собрав все возможные требования к расчету итогов, мы пришли к такому перечню агрегаций:
- Сумма.
- Среднее.
- Максимум.
- Количество.
- Количество различных.
- Среднее накопительное.
- Формула (релевантно только для расчетных показателей; имеется в виду расчет по формуле на любом уровне итогов, с применением агрегационных функций базовых показателей).
Архитектура и методика решения для расчета ключевых показателей
Теперь, когда задачи сформулированы, рассмотрим возможные архитектурные подходы для их решения. Начнем с задачи об открытом списке КП, создании новых, модификации имеющихся.
Справочники и регистры
1. Справочник «Ключевые показатели». Справочник открыт для добавления новых элементов ключевых показателей и редактирования существующих. Таким решается задача составления заранее не заданного списка КП.
Справочник «Ключевые показатели». Справочник открыт для добавления новых элементов ключевых показателей и редактирования существующих. Таким решается задача составления заранее не заданного списка КП.
2. В каждом КП возможно задать его собственный способ расчета итога по периоду. Таким образом решается задача произвольного подсчета итогов для каждого отдельно взятого КП. Разумеется, в данном случае это всего лишь декорационная обвязка над сложным математическим аппаратом СКД. Мы рассмотрим ее ниже.
3. Если КП расчетной природы, то можно задать формулу его расчета в терминах языка запроса «1С». Для удобства пользователей коды базовых показателей в пользовательском режиме трансформируются в наименования. Так решается задача произвольного расчета показателя без хранения значений.
4. Для хранения значений всех показателей, кроме формульных, в системе создан регистр сведений «Значения ключевых показателей». Его структура зависит от набора аналитик, определяющих значение ключевого показателя. В нашем примере его структура была бы такова:
Его структура зависит от набора аналитик, определяющих значение ключевого показателя. В нашем примере его структура была бы такова:
- Подразделение,
- Период (месяц),
- Ключевой показатель,
- Значение.
Регистр может заполняться вручную, а может — автоматически, на основании методов расчета, заданных в ключевом показателе.
5. Хотя это не относится к теме статьи, заметим, что один и тот же показатель может рассчитываться по-разному для разных контуров и объектов учета. Например, разными контурами может быть плановая и фактическая деятельность компании, а объектами учета — разные филиалы:
6. Справочник «Виды отчетов» — инструмент для систематизации КП.
Каждый вид отчета представляет собой структуру, которую пользователь наполняет необходимыми для него КП. Также для каждого раздела структуры можно задать способ расчета итога по этому разделу.
Таким образом, решаются следующие задачи:
- составление собственной структуры КП для облегчения анализа;
- хранение в системе произвольного количества таких структур.
Важно понимать, что задача системы — обеспечить максимальную гибкость инструмента; при этом фактическое использование (то есть количество и состав структур и собственно КП) зависит от управленческих задач и решается по‑своему в каждой компании.
Пример структуры КП:
7. Отчет «Сравнительный анализ ключевых показателей».
Наконец мы добрались до главного инструмента анализа — собственно, отчета.
Какие задачи решает отчет:
- Вывод значений хранимых значений показателя / списка показателей.
- Расчет и вывод значений формульных значений показателя / списка показателей.
- Расчет итогов по показателям по периоду.
- Расчет итогов по показателям по произвольному набору группировок.
- Расчет итогов по показателям по разделам структуры.

Концептуальная схема работы отчета
- Запросом собирается предварительная таблица данных.
- Программно модифицируется таблица данных.
- Назначается как набор данных для СКД, которая и занимается окончательной обработкой и выводом отчета.
- Программно формируется схема СКД в части выражения ресурсов и вычисляемых полей.
Сбор данных заключается в формировании массива ключевых показателей и получении для них актуальных значений, хранимых в регистре. Массив формируется следующим образом:
- Отбор показателей по прямому отбору из отчета, будь то по структуре или по ручному отбору, установленному пользователем.
- Раскрутка формул из расчетных показателей, с целью получить список тех показателей, которые являются базой для расчета.
При подготовке исходных данных запрос собирает список показателей, поданных на вход, а также тех показателей, которые являются базовыми для расчетных, и по ним строит плоскую таблицу. Результат выглядит так:
Результат выглядит так:
| Показатель | Рассчитывается | Подразделение | Период | Значение |
|---|---|---|---|---|
| Прибыль (Код = «000000736») | Нет | Отдел внедрений | 01.2020 | 1000 |
| Численность (Код = «000000739») | Нет | Отдел внедрений | 01.2020 | 5 |
| Численность (Код = «000000739») | Нет | Отдел продаж | 01.2020 | 2 |
| Удельная прибыль (Код = «000000740») | Да | Отдел внедрений | 01.2020 | |
| … |
Далее наша работа заключается в том, чтобы модифицировать эту таблицу в тот вид, из которого благодаря вычисляемым полям и ресурсам СКД мы сможем получить все необходимые цифры. Финальная таблица для подачи в СКД выглядит так:
Финальная таблица для подачи в СКД выглядит так:
В ней добавлены колонки с именами, соответствующими кодам ключевых показателей, и в них помещены соответствующие значения. Теперь в каждой строке есть значения каждого КП, и для каждой строки можно вычислить любую формулу (так как в запрос были добавлены все КП, на которые ссылаются формулы в отобранных пользователем показателях).
Расчет итогов и формирование отчета по ключевым показателям
Теперь начинается самое интересное. Перед нами стоит две задачи:
- Вычислить формульные показатели.
- Рассчитать необходимые итоги, используя правильные агрегатные функции для каждого показателя.
Немаловажная подзадача — сделать поле выражения ресурса настолько не громоздким, насколько это возможно. Задача составления выражения сложна. Можно составить настолько сложное выражение, что компиляция текста запроса, которую можно видеть в виде события технологического журнала SDBL, будет занимать большое количество памяти и особенно процессора.
Для приведения значения показателей к одному полю мы используем Вычисляемое поле СКД. Вот как выглядит его выражение для нашего простого демонстрационного примера:
ВЫБОР
КОГДА КлючевойПоказатель.Код = "000000002"
ТОГДА а000000002
КОГДА КлючевойПоказатель.Код = "000000037"
ТОГДА а000000037
ИНАЧЕ 0
КОНЕЦ
Здесь мы превращаем отдельные столбцы с значением конкретных КП обратно в одно значение и подтягиваем сюда все КП, которые не являются формульными. Это нужно для того, чтобы при вычислении ресурса мы могли обращаться к одному полю для всех неформульных показателей и, таким образом, упростить его выражение.
Далее нам нужно рассчитать итоги.
Почти для всех типов итога используется выражение вида:
СРЕДНЕЕ(ВЫЧИСЛИТЬВЫРАЖЕНИЕ
СГРУППИРОВКОЙМАССИВ("СУММА(Значение1)", "Период")),Где:
Среднее — это агрегационная функция, указанная для нашего показателя (см.
Значение1 — это вычисленное поле СКД.
Период — это имя группировки минимального периода, т. е. в нашем случае месяц.
Что делает это выражение:
- Суммирует все значения внутри периода (т. е. в нашем случае значение показателя для всех существующих подразделений).
- Получает массив этих сумм.
- Вычисляет среднее из значений массива.
Как работает это выражение, давайте посмотрим последовательно.
Сначала вычислим выражение без агрегации:
ВЫЧИСЛИТЬВЫРАЖЕНИЕ
СГРУППИРОВКОЙМАССИВ
("СУММА(Значение1)", "Период")Система выдаст массив значений:
Почему важна СУММА(Значение1), почему нельзя взять просто Значение1?
- Потому что нужно посчитать сумму численностей по подразделениям внутри периода, и получить число 7 в январе, 9 в феврале и 9 в марте.

- На уровне же квартала мы видим массив помесячных значений.
Теперь применим агрегацию:
СРЕДНЕЕ(
ВЫЧИСЛИТЬВЫРАЖЕНИЕ
СГРУППИРОВКОЙМАССИВ
("СУММА(Значение1)", "Период")
)И получим то, что нам нужно:
Теперь рассмотрим формульный показатель с двумя способами расчета итога по периоду: по средней и по формуле.
Возьмем показатель Удельная прибыль, которая в минимальном значении будет выражена формулой «Прибыль/Численность».
Формула в терминах кодов показателей и языка запросов выглядит так:
ВЫБОР
КОГДА а000000739 = 0
ТОГДА 0
ИНАЧЕ а000000736 / а000000739
КОНЕЦ
Применим к ней способ расчета по периоду «Среднее»:
СРЕДНЕЕ(ВЫЧИСЛИТЬ
ВЫРАЖЕНИЕСГРУППИРОВКОЙ
МАССИВ("
ВЫБОР
КОГДА СУММА(а000000739) = 0
ТОГДА 0
ИНАЧЕ СУММА(а000000736)/СУММА(а000000739)
КОНЕЦ
", "Период"))
Получим следующий результат
Можно увидеть, что внутри периода (месяца) удельная прибыль рассчитывается по формуле. Так, удельная прибыль в целом не равна сумме удельных прибылей по подразделениям, а рассчитана как общая прибыль за месяц / численность за месяц.
Так, удельная прибыль в целом не равна сумме удельных прибылей по подразделениям, а рассчитана как общая прибыль за месяц / численность за месяц.
В то же время удельная прибыль за квартал рассчитана как средняя из помесячных.
Как задать способ расчета, чтобы на уровне квартала удельная прибыль считалась тоже по формуле, из прибыли за квартал / численность за квартал?
Вот так:
ВЫБОР
КОГДА СРЕДНЕЕ
(ВЫЧИСЛИТЬВЫРАЖЕНИЕ
СГРУППИРОВКОЙМАССИВ
("СУММА(а000000739)", "Период")) = 0
ТОГДА 0
ИНАЧЕ СУММА(а000000736) / СРЕДНЕЕ(ВЫЧИСЛИТЬ
ВЫРАЖЕНИЕСГРУППИРОВКОЙМАССИВ
("СУММА(а000000739)", "Период"))
КОНЕЦ
Что изменилось: мы применили агрегационную функцию вычисления итога не к результату вычисления формулы, а к каждому базовому показателю — свою; и только потом рассчитали формульный показатель.
Результат:
Как мы видим, месячные значения остались теми же самыми, а вот квартальные изменились:
516 = 4300 / 8,333333
Какой способ расчета применять — решает аналитик, в зависимости от решаемых им задач, и настраивает это в справочнике ключевых показателей; важно, что мы можем предоставить любой способ расчета, и отчет будет работать корректно при любом наборе и порядке группировок.
Отдельный случай — средний накопительный итог. Что означает среднее накопительное? Что значение за февраль = (значение за январь + значение за февраль) / 2, значение за март = (значение за январь + значение за февраль + значение за март) / 3, и так далее. Для вычисления такого выражения мы прибегаем к функции ВЫЧИСЛИТЬВЫРАЖЕНИЕ:
ВЫЧИСЛИТЬВЫРАЖЕНИЕ(
"СУММА(Значение1) / КОЛИЧЕСТВО(РАЗЛИЧНЫЕ Период)", "Период",, "Первая", "Текущая"),Где:
Значение1 — это вычисленное поле СКД.
Период — это имя группировки минимального периода, т. е. в нашем случае месяц.
Что делает выражение:
- Суммирует все значения за периоды с первого по текущий в нашей группировке.
- Считает количество этих периодов.
- И делит одно на другое.
Важно! Понятие «первая» и «текущая» группировки существуют только в пределах родительской группировки. Это является на текущий момент ограничением платформенного механизма СКД в «1С». То есть, если у нас есть группировка «Квартал», то «Апрель» для нее станет первым, а не четвертым.
Это является на текущий момент ограничением платформенного механизма СКД в «1С». То есть, если у нас есть группировка «Квартал», то «Апрель» для нее станет первым, а не четвертым.
В нашем примере средненакопительный итог рассчитывается для формульного показателя, поэтому выражение будет сложнее.
Давайте попробуем написать так:
ВЫЧИСЛИТЬВЫРАЖЕНИЕ("СУММА
(
ВЫБОР
КОГДА
а000000739 = 0
ТОГДА 0
ИНАЧЕ а000000736 /а000000739
КОНЕЦ
)", "Период",,"Первая", "Текущая")
/
ВЫЧИСЛИТЬВЫРАЖЕНИЕ
("КОЛИЧЕСТВО(РАЗЛИЧНЫЕ Период)", "Период",, "Первая", "Текущая")
Получим следующий результат:
Результат на уровне отдельных подразделений не может не радовать: он рассчитан верно. Однако если посмотреть на удельную средненакопительную в целом, то мы увидим, что она рассчиталась как сумма удельных средненакопительных по подразделениям, а это совсем не то, что нам было нужно. Нужно посчитать ее по формуле на этом уровне группировки, и потом усреднить.
Нужно посчитать ее по формуле на этом уровне группировки, и потом усреднить.
Финальное выражение выглядит очень громоздко, однако решает поставленную задачу: суммирует базовые показатели только в пределах периода и формула вычисляется корректно на всех уровнях.
ВЫЧИСЛИТЬВЫРАЖЕНИЕ(""
ВЫБОР КОГДА СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 1, 1) ТОГДА а000000739 ИНАЧЕ 0 КОНЕЦ)=0 ТОГДА 0 ИНАЧЕ СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 1, 1) ТОГДА а000000736 ИНАЧЕ 0 КОНЕЦ)/СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 1, 1) ТОГДА а000000739 ИНАЧЕ 0 КОНЕЦ) КОНЕЦ""
,""Период"",, ""Первая"", ""Текущая"")
+
ВЫЧИСЛИТЬВЫРАЖЕНИЕ(""
ВЫБОР КОГДА СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 2, 1) ТОГДА а000000739 ИНАЧЕ 0 КОНЕЦ)=0 ТОГДА 0 ИНАЧЕ СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 2, 1) ТОГДА а000000736 ИНАЧЕ 0 КОНЕЦ)/СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 2, 1) ТОГДА а000000739 ИНАЧЕ 0 КОНЕЦ) КОНЕЦ""
,""Период"",, ""Первая"", ""Текущая"")
+
ВЫЧИСЛИТЬВЫРАЖЕНИЕ(""
ВЫБОР КОГДА СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 3, 1) ТОГДА а000000739 ИНАЧЕ 0 КОНЕЦ)=0 ТОГДА 0 ИНАЧЕ СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 3, 1) ТОГДА а000000736 ИНАЧЕ 0 КОНЕЦ)/СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 3, 1) ТОГДА а000000739 ИНАЧЕ 0 КОНЕЦ) КОНЕЦ""
,""Период"",, ""Первая"", ""Текущая"")
)
/ ВЫЧИСЛИТЬВЫРАЖЕНИЕ(""КОЛИЧЕСТВО(РАЗЛИЧНЫЕ Период)"", ""Период"",, ""Первая"", ""Текущая"")
В каждом складываемом блоке мы принудительно ограничиваем расчет одним (текущим) месяцем, и заставляем СКД просуммировать базовые показатели внутри каждого месяца и рассчитать удельную по формуле внутри этого месяца.
Получаем результат:
Он нас полностью удовлетворяет.
Остался последний шаг: добиться расчета средненакопительного показателя на уровне квартала (или года).
Здесь придется прибегнуть к отдельному ресурсу, который будет рассчитан именно на уровне этих группировок и способ расчета у него для средненакопительного показателя будет совпадать с обычным средним: в самом деле, средненакопительный итог за квартал это ни что иное, как среднее за квартал!
Добавляем в схему компоновки ресурс для группировок «Квартал» и «Год»:
Выражение для нашего средненакопительного показателя в этом ресурсе будет выглядеть следующим образом:
СРЕДНЕЕ(ВЫЧИСЛИТЬ
ВЫРАЖЕНИЕСГРУППИРОВКОЙ
МАССИВ("
ВЫБОР
КОГДА СУММА(а000000739) = 0
ТОГДА 0
ИНАЧЕ СУММА(а000000736)/СУММА(а000000739)
КОНЕЦ
", "Период"))
И мы получим следующий результат:
Каждый показатель разобран нами в примере, у каждого свой способ расчета на разных уровнях. Теперь мы можем посмотреть, как выглядит финальное выражение ресурса в СКД для нашего несложного демонстрационного примера:
Теперь мы можем посмотреть, как выглядит финальное выражение ресурса в СКД для нашего несложного демонстрационного примера:
ВЫБОР
КОГДА Не КлючевойПоказатель.Рассчитываемый
ТОГДА
ВЫБОР
КОГДА КлючевойПоказатель.ИтогПоГоризонтали = Значение(Перечисление.ИтогиГруппировок.Среднее)
ТОГДА
СРЕДНЕЕ(ВЫЧИСЛИТЬВЫРАЖЕНИЕСГРУППИРОВКОЙМАССИВ("СУММА(Значение1)", "Период, КлючевойПоказатель"))
ИНАЧЕ
СУММА(Значение1)
КОНЕЦ
КОГДА КлючевойПоказатель.Код = "000000740"
ТОГДА
ВЫБОР
КОГДА СРЕДНЕЕ(ВЫЧИСЛИТЬВЫРАЖЕНИЕСГРУППИРОВКОЙМАССИВ("СУММА(а000000739)", "Период")) = 0
ТОГДА 0
ИНАЧЕ СУММА(а000000736) / СРЕДНЕЕ(ВЫЧИСЛИТЬВЫРАЖЕНИЕСГРУППИРОВКОЙМАССИВ("СУММА(а000000739)", "Период"))
КОНЕЦ
КОГДА КлючевойПоказатель.Код = "000000741"
ТОГДА
(
ВЫЧИСЛИТЬВЫРАЖЕНИЕ("
ВЫБОР КОГДА СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 1, 1) ТОГДА а000000739 ИНАЧЕ 0 КОНЕЦ)=0 ТОГДА 0 ИНАЧЕ СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 1, 1) ТОГДА а000000736 ИНАЧЕ 0 КОНЕЦ)/СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 1, 1) ТОГДА а000000739 ИНАЧЕ 0 КОНЕЦ) КОНЕЦ"
,"Период",, "Первая", "Текущая")
+
ВЫЧИСЛИТЬВЫРАЖЕНИЕ("
ВЫБОР КОГДА СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 2, 1) ТОГДА а000000739 ИНАЧЕ 0 КОНЕЦ)=0 ТОГДА 0 ИНАЧЕ СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 2, 1) ТОГДА а000000736 ИНАЧЕ 0 КОНЕЦ)/СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 2, 1) ТОГДА а000000739 ИНАЧЕ 0 КОНЕЦ) КОНЕЦ"
,"Период",, "Первая", "Текущая")
+
ВЫЧИСЛИТЬВЫРАЖЕНИЕ("
ВЫБОР КОГДА СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 3, 1) ТОГДА а000000739 ИНАЧЕ 0 КОНЕЦ)=0 ТОГДА 0 ИНАЧЕ СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 3, 1) ТОГДА а000000736 ИНАЧЕ 0 КОНЕЦ)/СУММА(ВЫБОР КОГДА Период = ДАТАВРЕМЯ(2020, 3, 1) ТОГДА а000000739 ИНАЧЕ 0 КОНЕЦ) КОНЕЦ"
,"Период",, "Первая", "Текущая")
) / ВЫЧИСЛИТЬВЫРАЖЕНИЕ("КОЛИЧЕСТВО(РАЗЛИЧНЫЕ Период)", "Период",, "Первая", "Текущая")
ИНАЧЕ
0
КОНЕЦ
Выводы
Какие выводы можно сделать из статьи?
Во-первых, построение отчетов с разноприродными показателями в одной колонке — задача очень сложная. Поскольку требуются различные подходы к подсчету итогов как по горизонтали, так и по вертикали.
Поскольку требуются различные подходы к подсчету итогов как по горизонтали, так и по вертикали.
Во-вторых, для такого подсчета необходим подходящий инструмент. И тут возникает соблазн перейти от декларативного инструмента к алгоритмическому. Но это не позволит добиться необходимой устойчивости расчета итогов при смене группировок. И в большинстве случаев разработчики просто отказываются от вариативности группировок в пользу фиксированного набора и порядка следования.
В-третьих, и это самое главное, СКД является мощнейшим инструментом не только в платформе «1С», но и среди альтернативных систем построения отчетов, например, электронных таблиц.
Вопросы производительности и использования различных инструментов в разработке на 1С:Предприятии мы рассматривали в предыдущих статьях от экспертов «1С‑Рарус»:
Подписывайтесь на наш канал в Telegram и почтовые рассылки, чтобы не пропустить новые статьи.
Авторы статьи
Ротштейн Ольга
Черанев Андрей
Полезные приемы для разработки отчетов на СКД – Проект ‘Курсы 1С’
Ни одно внедрение не обходится без разработки отчетов. Само собой, отчет должен возвращать корректные данные. Но, кроме этого, он должен быть красиво и аккуратно оформлен, в быстрых настройках должны быть доступны поля, по которым чаще всего потребуется установить отбор и т.д. Всё это важно для удобства работы пользователей с отчетом.
Само собой, отчет должен возвращать корректные данные. Но, кроме этого, он должен быть красиво и аккуратно оформлен, в быстрых настройках должны быть доступны поля, по которым чаще всего потребуется установить отбор и т.д. Всё это важно для удобства работы пользователей с отчетом.
Поэтому сегодня мы рассмотрели несколько простых, но в то же время полезных приемов настройки и доработки отчетов на СКД.
Для того, чтобы Вам было проще ориентироваться в материале, мы указали тайминг наиболее важных моментов в каждом видео.
Как вывести заголовок колонки вертикально, а значения в ячейках горизонтально
При помощи условного оформления в отчете можно для ряда полей изменить направление текста с горизонтального на вертикальное.
Также можно ограничить область действия условного оформления, чтобы вертикально выводился только заголовок колонки, при этом сами значения в ячейках значения выводились как обычно – горизонтально.
Тайминг ключевых моментов в видео:
00:39 – Какой параметр в настройках условного оформления необходимо использовать для горизонтального вывода текста.
01:14 – Как сделать, чтобы условное оформление применялось только к заголовкам полей.
01:38 – Как ограничить список полей, к которым применяется условное оформление.
Как сделать, чтобы в итогах кросс-таблицы выводилась только часть ресурсов, при этом в самой таблице отображались все ресурсы
При помощи СКД достаточно просто и без написания программного кода можно создавать кросс-таблицы, где и в строках, и в колонках выводятся данные, а на их пересечении – значения.
Однако, чтобы в таблице вывести все ресурсы из схемы компоновки, а в итогах показать только часть ресурсов (например, в таблице вывести количество и сумму, в итогах – только сумму), нужно знать один простой прием.
Тайминг ключевых моментов в видео:
00:40 – Как настроить структуру отчета для вывода в виде кросс-таблицы.
02:22 – Как отключить вывод общих итогов.
02:55 – Как добавить группировку для вывода итогов по одному ресурсу.
Как в отчете на СКД вывести колонку с расчетом процентов без создания отдельного поля компоновки
Отчеты на СКД часто сравнивают с Excel: «там же просто: добавил колонку, протянул формулу – и всё готово» 🙂
А на СКД может быть даже ещё проще! Например, для расчета процентов по числовым показателям не надо прописывать никаких формул. Это можно сделать при помощи настроек компоновки. В видео покажем, как именно.
Тайминг ключевых моментов в видео:
00:30 – Какие «виртуальные» вложенные поля доступны в настройках компоновки для числовых ресурсов.
02:05 – Чем отличается поле «процент общий» от «процент в группировке».
02:35 – Как в отчете пронумеровать строки и вывести процент проданного количества без создания отдельного поля компоновки.
Как управлять порядком выводимых в отчет ресурсов
Часто встречается следующая ситуация. Разработчик в отчете настроил выбранные поля, указал, в каком порядке поля должны следовать в отчете. Но в отчет они выводятся совсем в другом порядке.
Но в отчет они выводятся совсем в другом порядке.
Причиной может быть всего одна настройка, про которую нужно просто знать. В видео мы покажем такую настройку.
Тайминг ключевых моментов в видео:
00:35 – Какие настройки нужно установить, чтобы вывести в отчете ресурсы после всех полей.
01:10 – Какие настройки нужно установить, чтобы поля выводились в порядке, указанном в списке выбранных полей.
Как в отчете отфильтровать данные при помощи сложного выражения с использованием И, ИЛИ, НЕ
Часто пользователям в отчетах нужно отбирать данные по условиям, намного сложнее, чем просто “Номенклатура = Стол”. Система компоновки позволяет конструировать такие фильтры, используя группы логических условий И, ИЛИ, НЕ. В видео мы покажем, как можно реализовать такие отборы.
Тайминг ключевых моментов в видео:
00:32 – Как в настройках компоновки создать группу отборов (И, ИЛИ, НЕ).
01:52 – Как назначить представление для группы отборов и включить группу отборов в пользовательские настройки.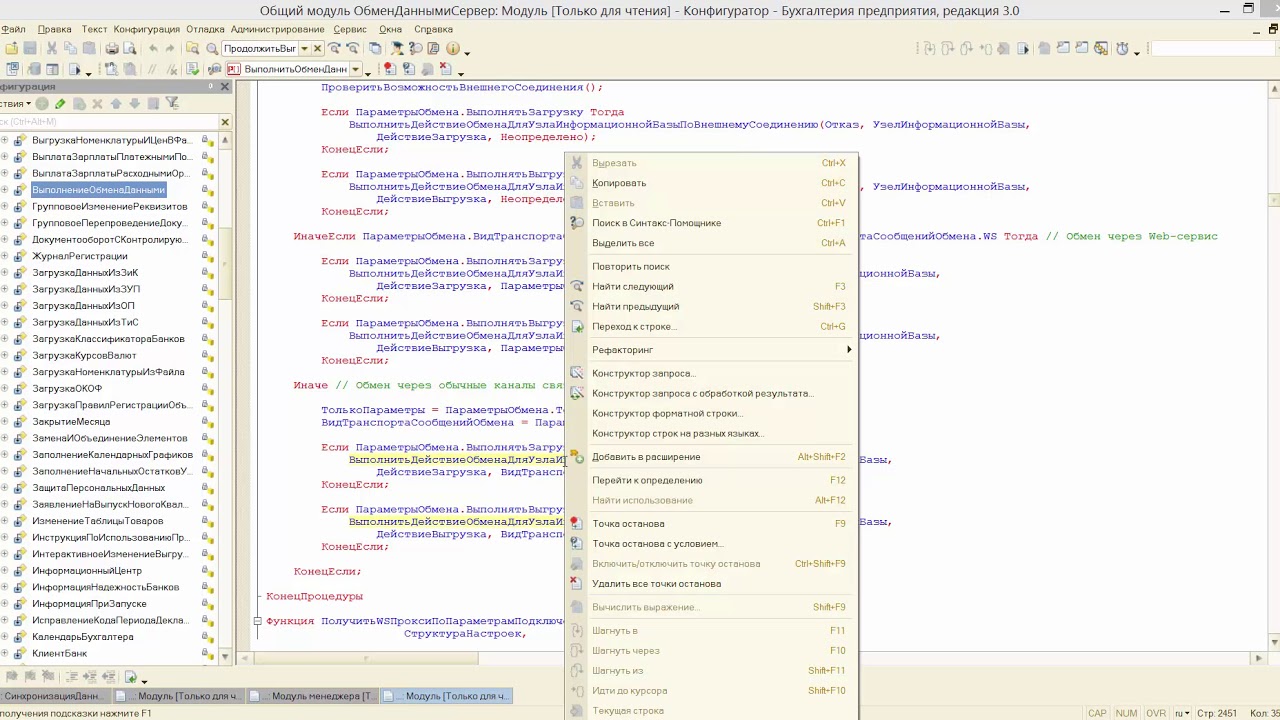
Особенности расчета итогов при использовании нескольких наборов данных
СКД может по-разному рассчитывать итоги в зависимости от того, где используется соединение – в тексте запроса или в схеме компоновки на уровне отдельных наборов данных.
В следующих видеоуроках показываются ситуации, когда использование нескольких наборов данных позволяет получить корректный расчет итогов.
Отличия расчета итогов в запросах и СКД
Тайминг ключевых моментов в видео:
02:41 – Почему отличаются итоги при использовании запроса и при использовании соединения наборов данных.
04:05 – Как можно изменить текст запроса набора данных для корректного расчета итогов.
Вывод табличной части документа и корректного итога по сумме документа
Тайминг ключевых моментов в видео:
00:30 – Как решить задачу при помощи одного запроса.
04:14 – Как решить задачу при помощи соединения двух наборов данных.
07:01 – В каких случаях использование запроса приводит к некорректному расчету итогов.
Хотите научиться грамотно создавать отчеты на СКД и дорабатывать отчеты в типовых конфигурациях?
В интернете очень много различных отзывов о системе компоновки данных. Комментаторов даже можно разделить на две большие группы: «да знаю я вашу СКД, ничего там не работает» и «я действительно умею разрабатывать отчеты на СКД» 🙂
Разница между ними просто огромная, в том числе и в заработке.
И если Вы хотите не просто «слышать про СКД», а на самом деле знать возможности и особенности системы компоновки данных и уверенно применять их на практике, рекомендуем пройти курс Профессиональная разработка отчетов в 1С 8.3 на Системе Компоновки Данных (СКД)
&НаКлиенте
Процедура ВыполнитьКод(Команда)
/// Как округлить число в 1с 8.3, 8.2
// https://ru.wikipedia.org/wiki/Округление
// до первого знака после запятой
// случай когда (N + 1) знак < 5
Сообщить(Окр(321. |
 3 = 1000
/// Как вычислить остаток от деления в 1с 8.3, 8.2
Сообщить(5 % 3); // 2
/// Как извлечь квадратный корень из числа в 1с 8.3, 8.2
Сообщить(Sqrt(25)); // 5
/// Как вычислить максимальное из нескольких значений в 1с 8.3, 8.2
Сообщить(Макс(1, 2, 3)); // 3
Сообщить(Макс("aaa", "bbb", "ccc")); // ccc
Сообщить(Макс(ТекущаяДата(), ДобавитьМесяц(ТекущаяДата(), 1)));
Сообщить(Макс(Истина, Ложь)); // Истина
/// Как вычислить минимальное из нескольких значений в 1с 8.3, 8.2
Сообщить(Мин(1, 2, 3)); // 1
Сообщить(Мин("aaa", "bbb", "ccc")); // aaa
Сообщить(Мин(ТекущаяДата(), ДобавитьМесяц(ТекущаяДата(), 1)));
Сообщить(Мин(Истина, Ложь)); // Ложь
/// Как вычислить выражение из строки в 1с 8.3, 8.2
Сообщить(Вычислить("1+2")); // 3
Сообщить(Вычислить("ИСТИНА И ЛОЖЬ")); // Нет
Сообщить(Вычислить("Sin(3.14)")); // ~0
Сообщить(Вычислить("Pow(Sin(3.14), 2) + Pow(Cos(3.14), 2)")); // ~1
/// Тригонометрия в 1с 8.
3 = 1000
/// Как вычислить остаток от деления в 1с 8.3, 8.2
Сообщить(5 % 3); // 2
/// Как извлечь квадратный корень из числа в 1с 8.3, 8.2
Сообщить(Sqrt(25)); // 5
/// Как вычислить максимальное из нескольких значений в 1с 8.3, 8.2
Сообщить(Макс(1, 2, 3)); // 3
Сообщить(Макс("aaa", "bbb", "ccc")); // ccc
Сообщить(Макс(ТекущаяДата(), ДобавитьМесяц(ТекущаяДата(), 1)));
Сообщить(Макс(Истина, Ложь)); // Истина
/// Как вычислить минимальное из нескольких значений в 1с 8.3, 8.2
Сообщить(Мин(1, 2, 3)); // 1
Сообщить(Мин("aaa", "bbb", "ccc")); // aaa
Сообщить(Мин(ТекущаяДата(), ДобавитьМесяц(ТекущаяДата(), 1)));
Сообщить(Мин(Истина, Ложь)); // Ложь
/// Как вычислить выражение из строки в 1с 8.3, 8.2
Сообщить(Вычислить("1+2")); // 3
Сообщить(Вычислить("ИСТИНА И ЛОЖЬ")); // Нет
Сообщить(Вычислить("Sin(3.14)")); // ~0
Сообщить(Вычислить("Pow(Sin(3.14), 2) + Pow(Cos(3.14), 2)")); // ~1
/// Тригонометрия в 1с 8. 3, 8.2
// углы выражаются в радианах
Пи = 3.14;
E = 2.718; // Число Эйлера http://ru.wikipedia.org/wiki/E_(число)
Сообщить(Cos(Пи / 2)); // ~0
Сообщить(ACos(0)); // ~1,57
Сообщить(Sin(Пи / 2)); // ~1
Сообщить(ASin(1)); // ~1,57
Сообщить(Sin(Пи / 2) * Sin(Пи / 2) + Cos(Пи / 2) * Cos(Пи / 2)); // ~1
Сообщить(Sin(Пи / 3) / Cos(Пи / 3)); // 1.73
Сообщить(Tan(Пи / 3)); // 1.73
Сообщить(Tan(ATan(1.73))); // 1.73
// экспонента - возведение числа эйлера в степень X
// http://ru.wikipedia.org/wiki/Экспонента
Сообщить(Pow(E, 2)); // 7,389
Сообщить(Exp(2)); // 7,389
// натуральный логарифм - степень в которую надо
// возвести число эйлера e, чтобы получить X
// http://ru.wikipedia.org/wiki/Натуральный_логарифм
Сообщить(Log(9)); // 2,197
Сообщить(Pow(E, 2.197)); // ~9
// десятичный логарифм - степень в которую надо
// возвести число 10, чтобы получить X
// http://ru.wikipedia.org/wiki/Десятичный_логарифм
Сообщить(Log10(1000)); // 3
Сообщить(Pow(10, 3)); // 1000
/// Как вывести число без пробелов в 1с 8.
3, 8.2
// углы выражаются в радианах
Пи = 3.14;
E = 2.718; // Число Эйлера http://ru.wikipedia.org/wiki/E_(число)
Сообщить(Cos(Пи / 2)); // ~0
Сообщить(ACos(0)); // ~1,57
Сообщить(Sin(Пи / 2)); // ~1
Сообщить(ASin(1)); // ~1,57
Сообщить(Sin(Пи / 2) * Sin(Пи / 2) + Cos(Пи / 2) * Cos(Пи / 2)); // ~1
Сообщить(Sin(Пи / 3) / Cos(Пи / 3)); // 1.73
Сообщить(Tan(Пи / 3)); // 1.73
Сообщить(Tan(ATan(1.73))); // 1.73
// экспонента - возведение числа эйлера в степень X
// http://ru.wikipedia.org/wiki/Экспонента
Сообщить(Pow(E, 2)); // 7,389
Сообщить(Exp(2)); // 7,389
// натуральный логарифм - степень в которую надо
// возвести число эйлера e, чтобы получить X
// http://ru.wikipedia.org/wiki/Натуральный_логарифм
Сообщить(Log(9)); // 2,197
Сообщить(Pow(E, 2.197)); // ~9
// десятичный логарифм - степень в которую надо
// возвести число 10, чтобы получить X
// http://ru.wikipedia.org/wiki/Десятичный_логарифм
Сообщить(Log10(1000)); // 3
Сообщить(Pow(10, 3)); // 1000
/// Как вывести число без пробелов в 1с 8. 3, 8.2
Сообщить(Формат(1000000, "ЧГ=0")); // 1000000
КонецПроцедуры
/// Скачать и выполнить эти примеры на компьютере
3, 8.2
Сообщить(Формат(1000000, "ЧГ=0")); // 1000000
КонецПроцедуры
/// Скачать и выполнить эти примеры на компьютереОбщие сведения о скрипте 1С: Предприятие — Поддержка 1Си
<< Назад Вперед >>
На предыдущем уроке вы написали обработчик события MaterialsQuantityOnChange (листинг 4.1), и мы предоставили краткое описание его работы.
Теперь мы опишем два подхода к пониманию многочисленных незнакомых свойств и методов объекта конфигурации, которые помогут вам изучить фрагменты сценария и создать пользовательские процедуры сценария 1С: Предприятия.
Syntax Assistant — это инструмент разработчика. Он хранит описания всех объектов сценария, доступных на платформе, а также их методы, свойства, события и другую связанную информацию.
Чтобы открыть помощник по синтаксису
Как и любая другая справочная система, Syntax Assistant имеет древовидную структуру с главами, разделами, подразделами и т. Д. Использовать Синтаксический помощник удобнее, чем использовать любую распечатанную документацию по сценариям 1С: Предприятия, поскольку он доступен и поддерживает контекстную справку (Ctrl + F1).
Д. Использовать Синтаксический помощник удобнее, чем использовать любую распечатанную документацию по сценариям 1С: Предприятия, поскольку он доступен и поддерживает контекстную справку (Ctrl + F1).
Кроме того, каждая страница Syntax Assistant имеет внизу гиперссылку «Методическая информация» (см. Рис. 5.20). При нажатии на эту ссылку открывается окно браузера со списком методических материалов по текущей теме. Это могут быть статьи базы знаний 1С: Предприятия, статьи и темы форумов 1С: Сети разработчиков и многое другое. Новые методические материалы добавляются по мере их появления в сети. Это дает разработчикам дополнительные возможности для получения ответов на свои вопросы, не отрываясь от работы.
Помощник по синтаксису удобен, когда вам нужно разобраться в сценарии, написанном другим разработчиком. Мы объясним, как его использовать, на примере обработчика событий MaterialsQuantityOnChange, который вы написали ранее (см. Листинг 4.1).
Метод № 1
Первый метод — это поиск темы в оглавлении, следуя вниз по дереву, раскрывая подразделы, свойства, ссылки и так далее.
Давайте взглянем на первую строку нашего обработчика (листинг 5.19).
Листинг 5.19. MaterialsQuantityOnChange процедура (первая строка)
TabularSectionRow = Items.Materials.CurrentData;
Чтобы понять этот сценарий, вам необходимо знать контекст выполнения. Контекст программы зависит от модуля, в котором находится скрипт. В этом случае процедура-обработчик находится в модуле формы, поэтому мы находимся в контексте модуля формы.
Давайте рассмотрим эту строку сценария слева направо. Что такое TabularSectionRow? Если что-то находится слева от оператора присваивания (=), это либо свойство, которое доступно непосредственно в этом контексте, либо переменная.
В соответствии с алгоритмом, описанным в предыдущем разделе, необходимо выполнить следующие проверки:
- Объявлена ли переменная TabularSectionRow в модуле формы?
Откройте модуль формы (чтобы узнать, как открыть модуль, см. Типы модулей). Строка описания переменной (Variable TabularSectionRow;) отсутствует, поэтому это не переменная модуля формы.

- Есть ли у формы атрибут TabularSectionRow?
Откройте форму документа GoodsReceipt и проверьте панель атрибутов формы, расположенную в правой верхней части редактора формы (рис.5.21).
Рис. 5.21. Список атрибутов формы документа «GoodsReceipt»Вы видите, что эта форма имеет единственный атрибут Object по умолчанию (выделен жирным шрифтом). Это означает, что у формы нет атрибута TabularSectionRow.
- Есть ли у объекта ManagedForm свойство TabularSectionRow?
Давайте посмотрим на список свойств управляемой формы в Syntax Assistant.
Откройте Syntax Assistant и щелкните вкладку Contents .
Управляемая форма — это интерфейсный объект управляемого приложения, поэтому разверните раздел Интерфейс (управляемый) / Управляемая форма , затем разверните объект ManagedForm и его свойства (рис. 5.22).
Рис. 5.22. Список свойств объекта ManagedForm в помощнике по синтаксисуСвойства отсортированы в алфавитном порядке.
 Как видите, среди них нет свойства TabularSectionRow.
Как видите, среди них нет свойства TabularSectionRow. - Есть ли у расширения формы свойство TabularSectionRow?
Вы знаете, что атрибут формы по умолчанию хранит данные DocumentObject.Объект GoodsReceipt (см. Рис. 5.21). Это означает, что свойства и методы объекта сценария 1С: Предприятия Расширение управляемой формы для документов (Синтаксический помощник / Интерфейс (управляемый) / Управляемая форма / Расширение управляемой формы для документов) доступны в модуле формы. Рассмотрим их (рис. 5.23).
Рис. 5.23. Список свойств расширения управляемой формы для документов в Syntax AssistantКак видите, среди них нет свойства TabularSectionRow.
- Существует ли свойство глобального контекста TabularSectionRow?
Откройте свойства глобального контекста в Syntax Assistant (рис. 5.24).
Рис. 5.24. Список свойств глобального контекста в Syntax AssistantКак видите, среди них нет свойства TabularSectionRow.
Выражение TabularSectionRow также не может быть именем неглобального общего модуля, потому что его процедуры должны вызываться с помощью точки (TabularSectionRow.
 ).
).Это выражение также не может быть экспортированной процедурой глобального общего модуля, потому что в этом случае можно было бы вызвать процедуру как TabularSectionRow () вместо того, чтобы присваивать ей что-либо.
- Содержит ли модуль управляемого приложения экспортируемую переменную TabularSectionRow?
Откройте модуль управляемого приложения (чтобы узнать, как открыть модуль, см. Типы модулей). Строка описания переменной (Variable TabularSectionRow Export) отсутствует, поэтому это не переменная модуля управляемого приложения.
Теперь вы видите, что выражение TabularSectionRow является локальной переменной процедуры MaterialsQuantityOnChange. Во время выполнения скрипта переменной присваивается значение.Система скриптовых типов 1С: Предприятия позволяет присвоить значение любого типа. Если переменная является локальной, то есть используется только в контексте этой конкретной процедуры, она не требует явного объявления. Переменная объявляется при первом использовании.
Справа от оператора присваивания вы можете увидеть выражение Items.Materials.CurrentData. Чтобы узнать значение Items, давайте воспользуемся тем же алгоритмом, что и с локальной переменной TabularSectionRow.
- Объявлена ли переменная Items в модуле формы? Нет.
- Есть ли у формы атрибут Items? №
- Есть ли у объекта ManagedForm свойство Items?
Давайте еще раз посмотрим на список свойств объекта ManagedForm. Среди них есть свойство Items, поэтому Items является одним из свойств управляемой формы. Чтобы узнать его значение, дважды щелкните по нему (рис. 5.25).
Рис. 5.25. Описание свойства Items объекта ManagedForm в Syntax AssistantНа нижней панели окна Syntax Assistant отображается описание выбранного свойства.В этом описании указано, что свойство Items содержит объект FormAllItems, в котором хранится коллекция всех элементов управления формы.
Чтобы узнать его значение, щелкните ссылку FormAllItems .
 Откроется описание коллекции FormAllItems (рис. 5.26).
Откроется описание коллекции FormAllItems (рис. 5.26).
Рис. 5.26. Описание коллекции FormAllItems в Syntax Assistant
Примечание. Дерево помощника по синтаксису выше не изменилось. Чтобы найти ветвь дерева, в которой хранится текущая тема, в помощнике по синтаксису нажмите кнопку Найти текущий элемент в дереве над панелью описания объекта.
Эта коллекция содержит элементы управления, доступные в управляемой форме. Вы можете получить доступ к элементу по его имени.
Итак, теперь вы знаете, что означают предметы. Следующее слово отделяется от Items точкой: Items.Materials. Коллекция имеет свойство
Фиг.5.27. Структура элементов управления формой Товарной накладной
Элементы управления формой включают таблицу «Материалы». Если вы откроете палитру свойств этой таблицы, то увидите, что ее заголовок — Свойства: Таблица (рис. 5.28).
Если вы откроете палитру свойств этой таблицы, то увидите, что ее заголовок — Свойства: Таблица (рис. 5.28).
Рис. 5.28. Палитра свойств элемента управления табличной формы
Это означает, что этот элемент управления формой является таблицей, поэтому нам нужен объект коллекции FormTable. Чтобы узнать его значение, щелкните ссылку FormTable (см. Рис. 5.26). Вы увидите список свойств объекта FormTable.Свойства отсортированы в алфавитном порядке (рис. 5.29).
Рис. 5.29. Список свойств объекта FormTable в Syntax Assistant
Итак, теперь вы знаете, что означает Items.Materials. Следующее слово отделяется от Items.Materials точкой: Items.Materials.CurrentData. Прокрутите список свойств таблицы управляемой формы, чтобы найти свойство CurrentData. Это одно из свойств объекта FormTable. Чтобы узнать его значение, дважды щелкните по нему (рис. 5.30).
Фиг.5.30. Описание свойства Current Data объекта FormTable в Syntax Assistant
В нижней панели окна Syntax Assistant отображается описание выбранного свойства. В этом описании указано, что свойство CurrentData содержит объект FormDataStructure, который содержит данные, хранящиеся в текущей строке таблицы.
В этом описании указано, что свойство CurrentData содержит объект FormDataStructure, который содержит данные, хранящиеся в текущей строке таблицы.
Итак, как только первая строка обработчика (TabularSectionRow = Items.Materials.CurrentData;) выполняется, переменная TabularSectionRow содержит объект типа FormDataStructure.
Теперь рассмотрим следующую строку обработчика (листинг 5.20).
Листинг 5.20. MaterialsQuantityOnChange процедура (вторая строка)
TabularSectionRow.Total = TabularSectionRow.Quantity * TabularSectionRow.Price;
Разумно предположить, что Total, Quantity и Price являются свойствами объекта FormDataStructure, который записывается в переменную TabularSectionRow во время выполнения первой строки. Чтобы узнать его значение, щелкните ссылку FormDataStructure (см. Рис.5.30, 5.31).
Рис. 5.31. Описание объекта FormDataStructure в Syntax Assistant
В описании этого объекта указано, что вы можете использовать объект FormDataStructure для доступа к данным определенного столбца табличного раздела, используя имя столбца в качестве свойства объекта. Таким образом, используя выражение TabularSectionRow.Total, вы получаете доступ к данным, хранящимся в столбце Total текущей строки таблицы. И результат данных в столбце «Количество» и данных в столбце «Цена» записывается в столбец «Итоги».
Таким образом, используя выражение TabularSectionRow.Total, вы получаете доступ к данным, хранящимся в столбце Total текущей строки таблицы. И результат данных в столбце «Количество» и данных в столбце «Цена» записывается в столбец «Итоги».
Метод № 2
Второй метод предполагает использование контекстной справки, предоставляемой помощником по синтаксису. Сделать это можно, открыв модуль, наведя курсор на пункт сценария 1С: Предприятия и нажав Ctrl + F1.
- Откройте форму документа «Приемка товаров», щелкните вкладку Module и найдите код процедуры MaterialsQuantityOnChange.
Вы уже знаете, что выражение TabularSectionRow, расположенное слева от оператора присваивания, является локальной переменной.
Справа от оператора присваивания отображается выражение Items.Materials.CurrentData.
- Переместите курсор к слову Items и нажмите Ctrl + F1.
Синтаксический помощник выполняет поиск элементов во всех выражениях скрипта 1С: Предприятия и сортирует результаты в алфавитном порядке (рис.
 5.32).
5.32).
Рис. 5.32. Открытие контекстной справки в Syntax AssistantВы можете видеть, что выражение найдено, потому что отображается новое окно со списком тем, содержащих это выражение.Каждая тема включает в себя полный путь в древовидной структуре Syntax Assistant. Косая черта (/) используется как разделитель между уровнями структуры. Вы можете перемещать указатель по списку тем, чтобы найти нужную.
Но список тем довольно длинный, поэтому поиск в нем вручную может быть затруднен. Найдем свойство Items, которое используется в управляемой форме.
- В списке тем нажмите Ctrl + F, а затем в поле Найти введите ManagedForm .
- Щелкните Найдите .
Выбор перенесен в нужную тему (рис. 5.33).
Рис. 5.33. Поиск по списку тем в контекстной справке - Щелкните Показать .
Выбранная тема открывается в нижней панели Syntax Assistant (рис. 5.34). Обратите внимание, что приведенное выше дерево помощника по синтаксису не изменилось.
 Вы можете найти тему в дереве, нажав кнопку Найти текущий элемент в дереве над панелью, на которой отображается тема.
Вы можете найти тему в дереве, нажав кнопку Найти текущий элемент в дереве над панелью, на которой отображается тема.
Рис. 5.34. Описание свойства Items объекта ManagedFormВкладка Contents помощника по синтаксису отображает положение темы в дереве. Итак, вы можете видеть, что Items — это свойство объекта ManagedForm.
Затем, щелкнув ссылки, как описано в методе № 1, вы узнаете, что присвоено переменной TabularSectionRow и как вы можете получить доступ к данным в ее столбцах.
У синтаксического помощника есть еще одна удобная функция.Вы можете фильтровать набор объектов, включенных в Syntax Assistant. Поскольку вы в данный момент находитесь в клиенте и в форме, разумно просматривать только те объекты скрипта 1С: Предприятия, которые доступны в режимах тонкого клиента и веб-клиента.
- В меню Инструменты щелкните Параметры .
-ИЛИ-
Нажмите кнопку Позволяет изменить настройки. Кнопка над темой объекта в Syntax Assistant.
Кнопка над темой объекта в Syntax Assistant. - На вкладке Help установите или снимите флажки, представляющие доступные режимы (рис.5.35).
Рис. 5.35. Фильтрация объектов, отображаемых в Syntax Assistant
Важно! Если вы хотите использовать Syntax Assistant при написании процедуры, которая будет выполняться, например, на сервере, не забудьте выбрать соответствующий режим выполнения, чтобы в этом режиме были доступны экранные объекты Syntax Assistant.
Инструмент Debugger пригодится при написании собственного скрипта. В то время как помощник по синтаксису требует от вас понимания контекста выполнения, структуры объекта и т. Д., Отладчику ничего из этого не требуется.
Вы можете просто остановиться в любой точке своей программы и просмотреть доступные свойства или объекты скрипта.
Отладчик — инструмент, упрощающий разработку и отладку модулей 1С: Предприятия. Он предоставляет следующие возможности:
- Пошаговое выполнение модуля
- Установка точек останова
- Приостановка и возобновление выполнения модуля
- Одновременная отладка нескольких модулей
- Расчет выражений для анализа состояний переменных
- Просмотр стека вызовов процедур и функций
- Пауза при ошибке
- Редактирование модулей при отладке
Пока мы не будем подробно обсуждать все эти функции, а вместо этого обсудим варианты использования отладчика на примере обработчика событий MaterialsQuantityOnChange (листинг 4. 1).
1).
При редактировании скрипта модуля в Designer доступны команды меню Debug , которые устанавливают и очищают точки останова. Выполнение скрипта приостанавливается на строках с точками останова. Во время паузы вы можете проанализировать текущие значения и типы выражений и переменных модуля и продолжить выполнение до следующей точки останова и так далее.
- Откройте форму документа «Приемка товаров», щелкните вкладку Module и просмотрите процедуру MaterialsQuantityOnChange.
Обратите внимание, что команды для операций с точкой останова теперь доступны в меню Debug и на панели инструментов режима Designer (рис. 5.36).
Рис. 5.36. Панель инструментов точек остановаДля установки точки останова
Очистить точку останова- Дважды щелкните значок точки останова слева от строки сценария.
-ИЛИ-
Переместите курсор на строку сценария с точкой останова и затем в меню Debug щелкните Breakpoint .
-ИЛИ-
Щелкните кнопку Breakpoint на панели инструментов.
- В меню Debug щелкните Clear all breakpoints .
-ИЛИ-
Нажмите кнопку Очистить все точки останова на панели инструментов.
- Дважды щелкните значок точки останова слева от строки сценария.
- Дважды щелкните вертикальную полосу слева от первой строки процедуры MaterialsQuantityOnChange (рис. 5.37).
Рис. 5.37.Установка точки останова в процедуре MaterialsQuantityOnChangeДля отладки алгоритма сценария 1С: Предприятия необходимо запустить приложение, выполняющее этот алгоритм, в режиме отладки.
- В меню Отладка щелкните Начать отладку .
-ИЛИ-
Нажмите кнопку Начать отладку на панели инструментов.Конструктор запускает 1С: Предприятие в режиме отладки. Фактически это именно то, что вы делали раньше, но вы не установили никаких точек останова, и выполнение прикладного решения никогда не приостанавливалось.

- Откройте список документов поступления материала и откройте любой из двух созданных вами документов.
- Измените поле Количество в любой строке документа.
Как только вы это сделаете, выполнение программы будет прервано, и процедура MaterialsQuantityOnChange откроется в Designer в местоположении точки останова. Стрелка над значком точки останова указывает на выполняемую строку модуля (рис. 5.38).
Рис. 5.38. Приостановка программы в точке остановаОбратите внимание, что команды для отладки конфигурации теперь доступны в меню Debug и на панели инструментов режима конструктора (рис.5.39).
Рис. 5.39. Панель инструментов отладки конфигурацииStep Over , Step In и Step Out Кнопки продолжают пошаговое выполнение сценария.
Кнопка «Продолжить отладку» продолжает отладку до следующей точки останова.
Непосредственное окно Кнопки и Evaluate expression предназначены для просмотра значений выражения в текущей точке останова.

Кнопка Call Stack предназначена для отслеживания последовательности вызовов процедур и функций.
Но пока программа уже приостановлена на указанной строке процедуры MaterialsQuantityOnChange. Обратите внимание, что эта строка еще не была выполнена, поэтому значения переменных еще не присвоены. Вы можете использовать кнопку Step Over , чтобы просмотреть их значения после выполнения строки.
Давайте посмотрим на выражение Items.Materials.CurrentData и просмотрим содержимое этого объекта в текущей точке останова.
- Дважды щелкните слово Items , а затем нажмите кнопку Evaluate expression (Shift + F9) на панели инструментов отладки конфигурации.
Значение Items добавляется в поле Expression . Столбцы Value и Type отображают значение и тип этого объекта. Вы можете видеть, что объект Items представляет собой коллекцию значений FormAllItems, в которой хранятся все элементы управления формы.
 Разверните эту ветку объекта (рис. 5.40).
Разверните эту ветку объекта (рис. 5.40).
Рис. 5.40. Объект ItemsНад панелью Result вы можете увидеть кнопку Показать значения в отдельном окне . Если вы нажмете эту кнопку (или нажмете F2), вы сможете просмотреть содержимое коллекции.
Затем давайте проверим выражение Materials .
- Найдите материалов в списке элементов управления формы.
Как видите, это объект FormTable. Разверните этот объект и просмотрите его свойства. Нас интересует свойство CurrentData.
- Найдите ветку CurrentData и разверните ее.
Вы можете просмотреть данные, хранящиеся в текущей строке табличного раздела, со значениями и типами. Обратите внимание, что Quantity имеет значение, которое вы только что установили (рис.5.41).
Рис. 5.41. Items.Materials.CurrentData объект - Закройте окно Expression .
Затем перейдем к процедуре общего модуля DocumentProcessing, где вычисляется значение TabularSectionRow.

- Дважды щелкните Step In на панели инструментов отладки конфигурации. Выполнение этой программы теперь приостанавливается в процедуре CalculateTotal общего модуля DocumentProcessing.
- Дважды щелкните TabularSectionRow , чтобы выбрать его, а затем щелкните Evaluate expression .
- Разверните объект TabularSectionRow (рис. 5.42).
Рис. 5.42. Объект TabularSectionRowВы можете видеть, что переменная TabularSectionRow содержит объект FormDataCollectionItem. Но значения в столбце Итого не пересчитываются, потому что вторая строка еще не была выполнена.
- Закройте окно Expression и нажмите кнопку Step In на панели инструментов отладки конфигурации.
Платформа выполняет процедуру CalculateTotal общего модуля DocumentProcessing и останавливается в конце процедуры.
- Наведите указатель на слово Quantity или Total , чтобы просмотреть всплывающую подсказку с его текущим значением (рис.
 5.43).
5.43).
Рис. 5.43. Объект TabularSectionRowВы можете видеть, что значения в столбце Total пересчитаны, поэтому объект Items.Materials.CurrentData теперь содержит новые значения.
После анализа переменных и выражений можно продолжить отладку.
Продолжить отладку
- Нажмите кнопку Продолжить отладку .
Чтобы остановить отладку
- В меню Отладка щелкните Остановить .
Обратите внимание, что вы можете установить точку останова внутри цикла и посмотреть, как значения меняются во время каждой итерации.
Вы можете редактировать конфигурацию и сохранять изменения во время отладки.
Важно! Хотя вы можете редактировать отлаживаемый модуль, Debugger не компилирует измененный сценарий, и отладка продолжается для сценария конфигурации базы данных (сценарий, который был доступен в момент запуска Debugger или открытия соединения). Чтобы отладить внесенные вами изменения, сначала необходимо обновить конфигурацию базы данных.
Чтобы отладить внесенные вами изменения, сначала необходимо обновить конфигурацию базы данных.
Наконец, давайте обсудим некоторые удобные методы отладки.
Когда вы находитесь в модуле формы и хотите написать обработчик, вы можете использовать свойство ThisObject для просмотра свойств контекста текущей формы вместе с ее доступными расширениями и другими доступными элементами.
Для просмотра свойства ThisObject
- После остановки в точке останова нажмите кнопку Evaluate expression (Shift + F9) на панели инструментов отладки конфигурации.
- В поле Expression введите ThisObject и нажмите Evaluate (рис. 5.44).
Рис. 5.44. Свойство ThisObject управляемой формы
Если развернуть этот элемент, вы увидите тип и свойства объектов скрипта 1С: Предприятия, доступных в текущей точке останова.
И когда вы находитесь в модуле объекта или набора записей, вы можете использовать свойство ThisObject аналогичным образом для просмотра свойств контекста модуля объекта или набора записей.
<< Назад Вперед >>
Срок сдачи: Thu 20 OctВ этом проекте вы расширите язык арифметических выражений с проекта 1b до простого лямбда-исчисления ( вычислительная модель, лежащая в основе языков функционального программирования).Абстрактный синтаксисВ частности, вы определите алгебраический тип данных (тип размеченного объединения), который включает варианты для арифметических выражений вместе со следующими конструкциями функционального языка:
Мы будем беспокоиться о конкретном синтаксисе (строках, которые будут проанализированы в эквивалентное абстрактное синтаксическое дерево) на более поздней стадии этого проекта. СемантикаСемантическая область (значения) — это подобласть абстрактной синтаксической области, состоящая только из
и возвращает значение из семантической области.
Примерыeval (Var «x») [] -> error eval (Var «x») [«x» -> Const 3] -> Const 3 eval (mkFun («x», Plus (Const 7, Var («x»)))) [] -> Fun («x», Plus (7, Var («x»)), []) eval (App (mkFun («x» , Plus (7, Var («x»)))), Const 3) [] -> Const 10 eval (App (Var («x»), Const 3) [] -> error eval (If (Const 7, Const 3, Const 4)) [] -> Const 3 eval (If (Const 0, Const 3, Const 4)) [] -> Const 4 eval (If (Var «y», Const 3, Const 4)) [«y» -> 7] -> Const 3 eval (If (mkFun («x», Var «x»), Const 3, Const 4)) [] -> Const 3 eval (App (Rec (mkFun («f», mkFun («n», If (Var «n», Times (Var «n», App (Var («f»), Minus (Var «n», Const 1))), Const 1)))), 5) [] -> Const 120 где mkFun (x, b) = Fun (x, b, Map. Ссылки |

 Ниже).
Ниже).
 пустой). Кроме того, используемый здесь синтаксис […] карты является псевдокодом; вам нужно будет использовать Map.add x v Map.empty для добавления сопоставлений, а также Map.ofList.
пустой). Кроме того, используемый здесь синтаксис […] карты является псевдокодом; вам нужно будет использовать Map.add x v Map.empty для добавления сопоставлений, а также Map.ofList.Изменения мРНК и уровней экспрессии белка 1c и Kv4.2 (A) …
Контекст 1
… и Вестерн-блот-анализ Уровень мРНК 1С немного увеличился в сердце диабетической крысы. Однако он был снижен примерно на 16% в группах DMC по сравнению с группой DM (p0.05) (рис. 2А). Уровень Kv4.2 снизился в группе DM, но увеличился на 19,2% в группе DMC по сравнению с диабетическими крысами (рис. 2B). Изменения уровня мРНК напрямую не отражают функциональные изменения; поэтому мы оценили экспрессию белков Ca v 1.2 и Kv4.2 с помощью вестерн-блоттинга с образцами мембранных белков, извлеченных из сердец каждой группы. При нормализации к внутреннему контролю с b-актином для ввода образца белка плотность полосы Ca v 1.2 снизилась на 23% у крыс DMC по сравнению с крысами DM, но все же увеличилась на 11% по сравнению с крысами Ctr. Тот же метод был выполнен для оценки экспрессии белка Kv4.2. Плотность полосы Kv4.2 была увеличена на 22% у крыс DMC по сравнению с крысами с диабетом (Рис. …
Тот же метод был выполнен для оценки экспрессии белка Kv4.2. Плотность полосы Kv4.2 была увеличена на 22% у крыс DMC по сравнению с крысами с диабетом (Рис. …
Контекст 2
… и вестерн-блот-анализ. диабетическое сердце крысы. Однако он был уменьшен примерно на 16% в группах DMC по сравнению с группой DM (p0,05) (рис. 2A). Уровень Kv4.2 снизился в группе DM, но увеличился на 19,2%. в группе DMC по сравнению с диабетическими крысами (рис.2Б). Изменения уровня мРНК напрямую не отражают функциональные изменения; поэтому мы оценили экспрессию белков Ca v 1.2 и Kv4.2 с помощью вестерн-блоттинга с образцами мембранных белков, извлеченных из сердец каждой группы. При нормализации к внутреннему контролю с b-актином для ввода образца белка плотность полосы Ca v 1.2 снизилась на 23% у крыс DMC по сравнению с крысами DM, но все же увеличилась на 11% по сравнению с крысами Ctr. Тот же метод был выполнен для оценки экспрессии белка Kv4.2. Плотность полосы Kv4.2 была увеличена на 22% у крыс DMC по сравнению с крысами с диабетом (Рис. …
…
Контекст 3
… и вестерн-блот-анализ Уровень мРНК 1С незначительно увеличился в диабетическом сердце крысы. Однако он был снижен примерно на 16% в группах DMC по сравнению с группой DM (p0,05) (рис. 2A). Уровень Kv4.2 снизился в группе DM, но увеличился на 19,2% в группе DMC по сравнению с диабетическими крысами (рис. 2B) .Изменения уровня мРНК напрямую не отражают функциональные изменения, поэтому мы оценили экспрессию белка Ca v 1.2 и Kv4.2 по данным вестерн-блоттинга с образцами мембранных белков, извлеченных из сердец каждой группы. При нормализации к внутреннему контролю с b-актином для ввода образца белка плотность полосы Ca v 1.2 снизилась на 23% у крыс DMC по сравнению с крысами DM, но все же увеличилась на 11% по сравнению с крысами Ctr. Тот же метод был выполнен для оценки экспрессии белка Kv4.2. Плотность полосы Kv4.2 была увеличена на 22% у крыс DMC по сравнению с крысами с диабетом (Рис. …
Комплексная оценка методов обнаружения модулей для данных экспрессии генов
Регуляторные сети и определения модулей
Для E . coli , мы использовали регуляторную сеть из базы данных RegulonDB версии 8 (Regulondb.ccg.unam.mx, по состоянию на 06.03.2015), базы данных, объединяющей как мелкомасштабные экспериментальные данные, так и данные по всему геному регуляция транскрипции 38 . Мы включили взаимодействия по крайней мере с одним сильным типом доказательств (APPH, BPP, FP, IDA, SM, TA, CHIP-SV, GEA, ROMA и gSELEX). Мы не группировали регуляторные взаимодействия на уровне оперонов, так как обнаружили, что это оказывает лишь минимальное влияние на общий рейтинг различных методов (дополнительный рис.17а). Мы также не включили правила сигма-фактора, так как обнаружили, что это окажет незначительное влияние на производительность (дополнительный рисунок 17b). Для наборов данных о дрожжах мы использовали две нормативные сети. Одна сеть была создана путем интеграции данных иммуноочистки хроматина на чипе и консервативных связывающих мотивов, как описано MacIsaac et al. 39 . Другая регуляторная сеть была создана путем объединения данных о связывании факторов транскрипции в масштабе всего генома, данных о нокаутной экспрессии и консервации последовательности 40 .
coli , мы использовали регуляторную сеть из базы данных RegulonDB версии 8 (Regulondb.ccg.unam.mx, по состоянию на 06.03.2015), базы данных, объединяющей как мелкомасштабные экспериментальные данные, так и данные по всему геному регуляция транскрипции 38 . Мы включили взаимодействия по крайней мере с одним сильным типом доказательств (APPH, BPP, FP, IDA, SM, TA, CHIP-SV, GEA, ROMA и gSELEX). Мы не группировали регуляторные взаимодействия на уровне оперонов, так как обнаружили, что это оказывает лишь минимальное влияние на общий рейтинг различных методов (дополнительный рис.17а). Мы также не включили правила сигма-фактора, так как обнаружили, что это окажет незначительное влияние на производительность (дополнительный рисунок 17b). Для наборов данных о дрожжах мы использовали две нормативные сети. Одна сеть была создана путем интеграции данных иммуноочистки хроматина на чипе и консервативных связывающих мотивов, как описано MacIsaac et al. 39 . Другая регуляторная сеть была создана путем объединения данных о связывании факторов транскрипции в масштабе всего генома, данных о нокаутной экспрессии и консервации последовательности 40 .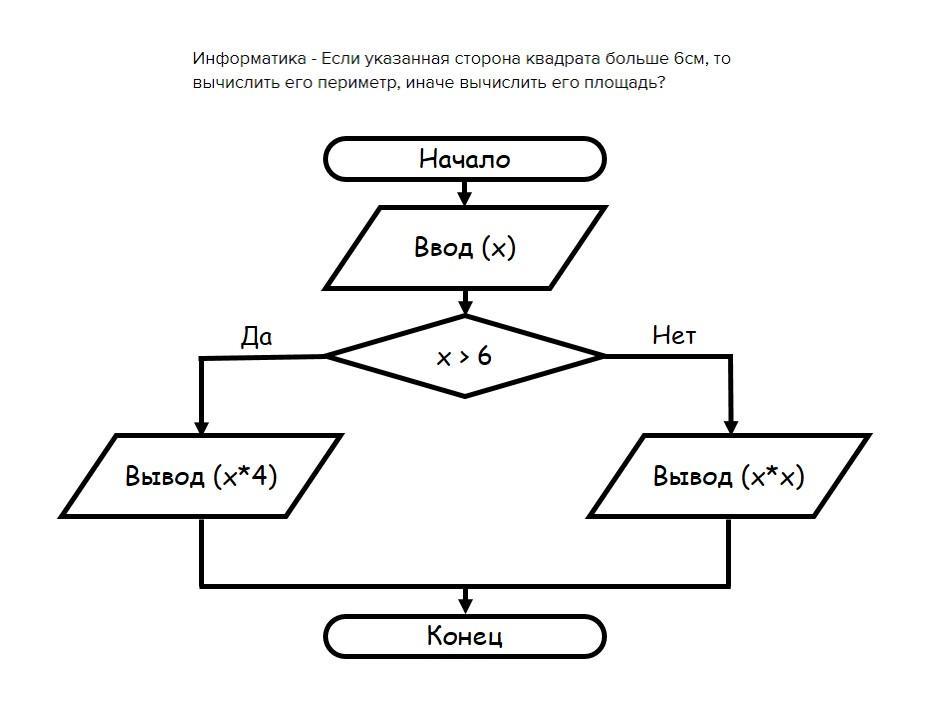 Мы использовали самый строгий набор данных, который требовал эволюционного сохранения как минимум двух видов. Для наборов данных о людях мы использовали «регуляторные схемы», разработанные Marbach et al. 41 , в котором регуляторы были связаны с генами-мишенями через ряд этапов, начиная с мотивов связывания в активных энхансерах с использованием данных проекта FANTOM5.
Мы использовали самый строгий набор данных, который требовал эволюционного сохранения как минимум двух видов. Для наборов данных о людях мы использовали «регуляторные схемы», разработанные Marbach et al. 41 , в котором регуляторы были связаны с генами-мишенями через ряд этапов, начиная с мотивов связывания в активных энхансерах с использованием данных проекта FANTOM5.
Для каждого золотого стандарта мы получили наборы известных модулей на основе трех различных определений модулей. Мы определили минимально совместно регулируемые модули как перекрывающиеся группы генов, которые имеют по крайней мере один общий регулятор.Строго совместно регулируемые модули были определены как группы генов, которые, как известно, регулируются одним и тем же набором регуляторов. С другой стороны, сильно взаимосвязанные известные модули были определены как группы генов, которые сильно взаимосвязаны, и, следовательно, это не обязательно отражает совместную регуляцию. Мы использовали три различных алгоритма кластеризации графов (кластеризация Маркова, кластеризация транзитивности и распространение аффинности) с тремя различными настройками параметров, представляющими разные уровни компактности кластера. Для алгоритма марковской кластеризации 42 мы использовали параметры инфляции 2, 10 и 50. Для кластеризации транзитивности 43 мы использовали два разных параметра отсечения для нечеткой принадлежности 0,1 и 0,9. Эти две настройки параметров позволили модулям перекрываться (дополнительный рис. 18). В третьем параметре кластеризации транзитивности мы назначили каждый ген модулю с наивысшим значением нечеткой принадлежности. Для аффинного размножения 44 мы варьировали значение предпочтения от 0.5, 2 и автоматически оцененное значение (см. Дополнительное примечание 2). Затем все известные модули были отфильтрованы на наличие генов в матрице экспрессии. Наконец, мы отфильтровали сильно перекрывающиеся известные модули, объединив два модуля, если они сильно перекрываются (коэффициент Жаккара> 0,8), и удалили небольшие модули, потребовав не менее пяти генов. Последний предел был определен на основе того, где средняя оптимальная производительность всех методов достигла максимума.
Для алгоритма марковской кластеризации 42 мы использовали параметры инфляции 2, 10 и 50. Для кластеризации транзитивности 43 мы использовали два разных параметра отсечения для нечеткой принадлежности 0,1 и 0,9. Эти две настройки параметров позволили модулям перекрываться (дополнительный рис. 18). В третьем параметре кластеризации транзитивности мы назначили каждый ген модулю с наивысшим значением нечеткой принадлежности. Для аффинного размножения 44 мы варьировали значение предпочтения от 0.5, 2 и автоматически оцененное значение (см. Дополнительное примечание 2). Затем все известные модули были отфильтрованы на наличие генов в матрице экспрессии. Наконец, мы отфильтровали сильно перекрывающиеся известные модули, объединив два модуля, если они сильно перекрываются (коэффициент Жаккара> 0,8), и удалили небольшие модули, потребовав не менее пяти генов. Последний предел был определен на основе того, где средняя оптимальная производительность всех методов достигла максимума.
Для дальнейшей проверки известных модулей мы оценили степень совместного выражения модулей в наших наборах данных выражений.Мы обнаружили, что все три основных определения модулей генерируют модули, которые являются как более глобальными, так и более локальными (в соответствии с определением экстремальной бикластеризации выражений, см. Дополнительное примечание 2) совместно выраженными по сравнению с переставленными модулями (дополнительный рисунок 19). Определенные определения модулей, в частности строгое регулирование, и наборы данных, E . coli , а синтетические данные генерируют модули, которые лучше коэкспрессируются в данных выражений, что может объяснить, почему методы обнаружения модулей в целом также лучше работают с этими наборами данных и определениями модулей (рис.2в, г). Мы также подтвердили биологическую значимость известных модулей, исследуя их функциональное обогащение. Мы обнаружили это на модели E . Наборы данных coli , 50–70% всех функциональных терминов (как для путей генной онтологии (GO) 45 , так и путей Киотской энциклопедии генов и геномов (KEGG) 46 ) были обогащены по крайней мере одним известным модулем, и это 60–80% всех известных модулей были обогащены хотя бы одним функциональным термином (дополнительный рис. 20). Охват всего функционального пространства был намного меньше по дрожжевым данным, с охватом около 5–15% терминов GO и 10–30% путей KEGG (дополнительный рис.20а). С другой стороны, значительное количество всех известных модулей было обогащено по крайней мере одним функциональным термином, в диапазоне от 30% до 60% в терминах GO и от 30% до 50% в путях KEGG (дополнительный рисунок 20b). По сравнению с известными модулями, наблюдаемые модули покрывали функциональное пространство в большинстве случаев немного лучше для лучших методов (дополнительный рис. 21).
20). Охват всего функционального пространства был намного меньше по дрожжевым данным, с охватом около 5–15% терминов GO и 10–30% путей KEGG (дополнительный рис.20а). С другой стороны, значительное количество всех известных модулей было обогащено по крайней мере одним функциональным термином, в диапазоне от 30% до 60% в терминах GO и от 30% до 50% в путях KEGG (дополнительный рисунок 20b). По сравнению с известными модулями, наблюдаемые модули покрывали функциональное пространство в большинстве случаев немного лучше для лучших методов (дополнительный рис. 21).
Данные экспрессии генов
Мы использовали в общей сложности девять наборов данных экспрессии для исследования, два из E . coli , два из Saccharomyces cerevisae , три набора данных для человека и два синтетических набора данных.Наборы данных состояли из сотен образцов в различных геномных и / или изменчивых условиях окружающей среды.
Получили первый E . coli набор данных из базы данных Colombos (версия 2.0, colombos.net) 47 . Этот набор данных является уникальным среди четырех, потому что он не содержит необработанных значений экспрессии из одного образца, а вместо этого содержит логарифмические отношения между тестовыми и эталонными условиями, что позволило авторам интегрировать различные платформы микрочипов и эксперименты по секвенированию РНК.Второй E . Набор данных coli был загружен с веб-сайта DREAM5 network inference challenge 15 (synapse.org/#!Synapse:syn2787209/wiki/70349).
Для S . cerevisiae , мы агрегировали сборник экспрессий путем интеграции данных из 127 экспериментов (отфильтрованных на образцах S . cerevisae ) с использованием платформы GPL2529 от Gene Expression Omnibus (ncbi.nlm.nih.gov/geo). Необработанные данные экспрессии были нормализованы с использованием Robust Multichip Average, реализованного в пакете Affy Bioconductor .Второй набор данных о дрожжах был получен с веб-сайта DREAM5 (synapse.org/#!Synapse:syn2787209/wiki/70349).
Мы получили наборы данных TCGA человека в результате панкологического исследования 12 типов рака (synapse.org/#!Synapse:syn1715755) 48 . Набор данных GTEX человека, который содержит профили экспрессии различных органов от сотен доноров 49 , был загружен с веб-сайта GTEX (gtexportal.org). Набор данных SEEK GPL5175 представляет собой совокупность общедоступных наборов данных с использованием платформы микрочипов GPL5175 и был получен из поиска.princeton.edu.
Мы создали два синтетических набора данных, начиная с E . coli, Regulondb сеть и дрожжевую сеть MacIsaac (обе описаны выше) с использованием GeneNetWeaver. Этот сетевой симулятор моделирует регуляцию генов, используя подробную термодинамическую модель, и моделирует эту модель, используя обыкновенные дифференциальные уравнения 50 . Различные экспериментальные условия были смоделированы с использованием настройки «Multifactorial Perturbations», где скорости транскрипции для подмножества генов изменяются случайным образом.
Для всех наборов данных экспрессии мы отфильтровали наименее вариабельные гены, потребовав минимального стандартного отклонения в экспрессии 0,5 (для дрожжей и E . coli) и 1 (для наборов данных для человека). Тепловые карты для каждого набора данных (дополнительный рис. 21).
У каждого набора данных есть свои преимущества и недостатки. Реальные наборы данных лучше соответствуют реальному варианту использования и, таким образом, являются наиболее биологически значимыми, хотя ограниченная доступность золотого стандарта может затруднить оценку реальных данных.Хотя наши знания о регуляторных сетях модельных микроорганизмов, в первую очередь E . coli , уже значительна, она еще далека от полной 51 . Хотя оценка данных с использованием более сложных регуляторных сетей, таких как люди, безусловно, необходима для обеспечения широкой актуальности оценки, определение золотых стандартов для этих наборов данных может быть еще более проблематичным из-за широкой распространенности ложноположительных и ложноотрицательных результатов. взаимодействия из-за множества причин, таких как клеточный контекст 12 и нефункциональное связывание 52 .Поэтому мы также включили синтетические наборы данных, в которых полностью указана известная регуляторная сеть, что позволяет точно оценить как чувствительность, так и точность метода. Вместе мы считаем, что эти наборы данных дополняют нашу стратегию оценки и обеспечивают ее широкую актуальность.
Подобно предыдущему исследованию оценки методов бикластеризации 53 , наши наборы данных могут содержать как большие различия между выборками, так и небольшие различия, на что указывает распределение всех логарифмических изменений между выборками (дополнительный рис.22).
Методы обнаружения модулей
Мы выбрали в общей сложности 42 метода обнаружения модулей на основе (i) свободно доступной реализации, (ii) производительности в рамках предыдущих оценочных исследований 17,19,20,21 и (iii) новизны алгоритм. См. Дополнительное примечание 2 для краткого обзора каждого метода и дополнительную таблицу 1 для обзора реализаций, используемых в этом исследовании, и альтернативных реализаций. Мы классифицировали все методы обнаружения модулей по пяти основным категориям.Однако мы признаем, что границы между различными категориями не всегда ясны, поскольку некоторые методы кластеризации и бикластеризации, например, также используют этап разложения матрицы в своем алгоритме. Общая тема методов кластеризации состоит в том, что они группируют гены в соответствии с глобальным сходством в экспрессии генов. Даже если методы кластеризации могут обнаруживать (после некоторой постобработки) перекрывающиеся кластеры, это перекрытие обнаруживается только потому, что определенный ген все еще глобально подобен обоим двум кластерам, и не обязательно из-за локальной совместной экспрессии.Методы разложения пытаются аппроксимировать матрицу выражения, используя произведение матриц меньшего размера. Две из этих матриц содержат индивидуальные вклады соответственно генов и образцов в конкретный модуль. Поскольку семплам разрешено вносить вклад в конкретный модуль только в определенной степени, методы декомпозиции могут обнаруживать локальное совместное выражение. С этими методами связаны методы бикластеризации, которые обнаруживают группы генов, и образцы, которые показывают некоторую локальную коэкспрессию только внутри бикластера.При бикластеризации образцы либо вносят свой вклад в конкретный модуль, либо нет, в отличие от методов разложения, где все образцы вносят свой вклад в определенной степени. Модули, обнаруженные методами бикластеризации, поэтому легче интерпретировать по сравнению с модулями методов декомпозиции, поскольку точное происхождение локального ко-выражения лучше определено. В некоторых случаях метод бикластеризации является просто расширением существующего метода декомпозиции, но с дополнительным требованием, чтобы вклад гена и образца в модуль был разреженным (т.е., содержит много нулей). Прямые методы NI пытаются создать простую модель регуляции генов, в большинстве случаев с помощью матрицы экспрессии для присвоения баллов каждой паре регулятор-ген 15 . Хотя их основное применение заключается в прогнозировании новых регуляторных отношений между генами, в некоторых исследованиях также использовалась полученная взвешенная регуляторная сеть для обнаружения генных модулей 54,55 . Список регуляторов был сформирован для E . coli путем поиска генов, аннотированных ГО с помощью «транскрипции, ДНК-темплейта» или «связывания ДНК», а для дрожжей и человека с «последовательностью-специфической активностью фактора транскрипции ДНК-связывающей РНК-полимеразы II».Тот же список также использовался для итеративных методов NI, которые начинаются с начальной кластеризации и итеративно уточняют эту кластеризацию и предполагаемую регулирующую сеть.
Далее мы классифицировали методы кластеризации в соответствии с их «принципом индукции», классификация, которая не использует способ представления кластеров в алгоритме (модели), а скорее рассматривает проблему оптимизации, лежащую в основе алгоритма кластеризации 56 . Алгоритмы кластеризации на основе графов используют графоподобные структуры, такие как графы K-ближайших соседей и графы сродства, и группируют гены, если они прочно связаны в рамках этой графоподобной структуры.Методы, основанные на представлении, итеративно уточняют назначение кластера и репрезентативность (например, центроид) кластера. Методы иерархической кластеризации создают иерархию всех генов в матрице экспрессии. Наконец, основанные на плотности методы обнаруживают модули, глядя на смежные области с высокой плотностью. Также следует отметить, что некоторые методы кластеризации используют элементы из нескольких категорий. FLAME (метод кластеризации A), например, использует элементы из кластеризации на основе графа, на основе репрезентативности и на основе плотности, тогда как распространение сродства содержит оба элемента из методов на основе графа и на основе репрезентативности.В подобных случаях мы в конечном итоге классифицируем алгоритм на основе того, какой аспект алгоритма, по нашему мнению, имеет наибольшее влияние на окончательный результат кластеризации. Методы бикластеризации были дополнительно классифицированы в соответствии с типом обнаруживаемых ими бикластеров. Экспрессия в постоянных бикластерах остается относительно стабильной, тогда как гены в экстремальных бикластерах имеют относительно высокую экспрессию в подмножестве условий по сравнению с другими генами. Выражение в бикластерах на основе паттернов следует более сложным моделям, таким как аддитивные модели 57 , мультипликативные модели 53 и когерентная эволюция 58 .
Для некоторых методов требовались шаги постобработки, чтобы получить результаты в правильном формате для сравнения с известными модулями. Все параметры для этих шагов постобработки были оптимизированы в рамках подхода поиска по сетке (как описано в дополнительном примечании 2 для каждого метода). Для методов нечеткой кластеризации мы получили четкие, но потенциально перекрывающиеся модули, ограничив значения членства. Для прямых методов NI мы сначала использовали отсечку, чтобы преобразовать взвешенную сеть в невзвешенную, а затем обнаружили модули, используя те же определения модулей, что и ранее.Для методов декомпозиции мы исследовали несколько шагов постобработки в литературе (см. Дополнительное примечание 2).
Поскольку сети регуляции генов, даже в этих модельных организмах, все еще очень неполны 51 , небольшое большинство генов не было включено ни в один из известных модулей (дополнительный рис. 23). Хотя мы сохранили эти гены в матрице экспрессии перед обнаружением модуля, мы удалили эти гены в наблюдаемых модулях перед подсчетом баллов. Это было сделано для того, чтобы избежать сильной переоценки количества ложноположительных результатов в наблюдаемых модулях, поскольку большинство этих генов, вероятно, принадлежат одному или нескольким совместно регулируемым модулям, о которых мы еще не знаем.Наконец, подобно известным модулям, мы отфильтровали наблюдаемые модули так, чтобы каждый модуль содержал не менее пяти генов.
Подобно нашему анализу с известными модулями, мы оценили степень, в которой гены, обнаруженные каждым из методов, коэкспрессируются в наборах данных на основе трех показателей коэкспрессии, основанных на трех типах показателей бикластеризации (дополнительный рис. 24). (1) общая метрика коэкспрессии с использованием средней корреляции, (2) метрика экстремальной экспрессии с учетом верхних 5% средних баллов z для каждого гена в модуле, и (3) среднеквадратическое значение корня. отклонение в пределах значений выражений каждого модуля.Для каждой метрики мы сравнили распределение реальных модулей с переставленными модулями, вычислив медианную разность с помощью функции wilcox.test в R. Мы обнаружили, что каждый метод обнаружения модулей находил модули, которые были более выражены вместе, чем переставленные модули. По сравнению с коэкспрессией известных модулей, методы обнаружения модулей также давали модули, которые более сильно коэкспрессируются. Специально для методов бикластеризации мы также исследовали коэкспрессию только в тех выборках в пределах каждого бикластера.Здесь мы обнаружили, что, за исключением некоторых методов бикластеризации на основе шаблонов, большинство методов бикластеризации обнаруживают типы модулей, для обнаружения которых они предназначены (дополнительный рис. 24).
Настройка параметров
Настройка параметров — необходимая, но часто упускаемая из виду проблема с методами обнаружения модулей. Слишком часто в оценочных исследованиях используются параметры по умолчанию, которые были оптимизированы авторами для некоторых конкретных тестовых случаев. Это не очень хорошо согласуется с истинной биологической установкой, когда некоторая оптимизация параметров почти всегда необходима для понимания данных.Следовательно, чтобы оценка была максимально объективной, всегда требуется оптимизация некоторых параметров. Тем не менее, следует быть осторожным с переобучением параметров по конкретным характеристикам одного набора данных, поскольку такие параметры приведут к неоптимальным результатам при обобщении настроек параметров для других наборов данных. Это может снова внести систематическую ошибку в анализ, когда методы с большим количеством параметров лучше адаптируются к конкретным наборам данных, но не будут хорошо обобщаться на других наборах данных.В этом исследовании мы попытались решить обе проблемы следующим образом. Сначала мы использовали поиск по сетке, чтобы исследовать пространство параметров каждого метода и определить их наиболее оптимальные параметры с учетом определенного набора данных и определения модуля, что привело к оценке обучения. Затем, в процессе, похожем на перекрестную проверку, мы использовали оптимальные параметры одного набора обучающих данных из другого организма, чтобы оценить производительность другого набора тестовых данных, в результате чего были получены оценки для каждого набора обучающих данных. Поскольку мы видели, что оптимальные параметры в большинстве случаев сильно различаются между синтетическими и реальными наборами данных, мы использовали только реальные наборы данных для обучения параметров для других реальных наборов данных и синтетических наборов данных для других синтетических наборов данных.Мы обращаемся к дополнительному примечанию 2 для обзора того, какие параметры менялись для каждого метода.
Оценочные показатели
Мы использовали четыре разных балла для сравнения набора известных модулей с набором наблюдаемых модулей и после нормализации объединили их в одну общую оценку. Обратите внимание, что классические оценки, сравнивающие кластеризацию, такие как индекс Рэнда, F1 или нормализованная взаимная информация, не могут использоваться, поскольку эти оценки не могут обрабатывать перекрытие и / или перекрытие 59 (дополнительное примечание 1).Воспоминание и специфичность в рамках недавно предложенной системы оценки CICE-BCubed измеряют, сопоставимо ли количество модулей, содержащих определенную пару генов, между известными и наблюдаемыми модулями 60 . Он основан на Extended BCubed 59 , но набирает 1 балл только тогда, когда как известные, так и наблюдаемые перекрывающиеся кластеры равны. Если G представляет все гены, M набор известных модулей, M ‘набор наблюдаемых модулей, M ( g ) модули, содержащие g и E ( g , M ) набор генов, которые вместе с g по крайней мере в одном модуле M (включая сам g ), точность определяется как:
$$ {\ mathrm {Precision} } = \ frac {1} {{\ left | G \ right |}} \ mathop {\ sum} \ limits_ {g \ in G} {\ frac {1} {{\ left | {E \ left ({g, M \ prime} \ right)} \ right |}}} \ hskip10pc \\ \ mathop {\ sum} \ limits_ {g {\ prime} \ in E \ left ({g, M {\ prime}} \ right)} {\ frac {{\ mathrm {min} \ left ({\ left | {M \ prime (g) \ cap M \ prime (g \ prime) \ left |, \ right | M (g) \ cap M (g \ prime)} \ right |} \ right) \ cdot {\ mathrm {\ Phi (}} g, g \ prime {\ mathrm {)}}}} {{\ left | {M \ prime (g) \ cap M \ prime (g \ prime)} \ right |}}} $$
, где
$$ {\ mathrm {\ Phi}} \ left ({g, g \ prime } \ right) = \ frac {1} {{\ left | {M \ prime \ left ({g, g \ prime} \ right)} \ right |}} \ mathop {\ sum} \ limits_ {m \ prime \ in M \ prime \ left ({g, g \ prime} \ right)} {\ mathop {{{\ it {\ mathrm {max}}}}} \ limits_ {m \ in M \ left ({g, g \ prime} \ right)} \, {\ mathrm {Жаккар }} \ left ({m \ prime, m} \ right)} $$
Отзыв рассчитывается таким же образом, но с переключением M ‘и M .Баллы восстановления и релевантности, которые ранее использовались в оценочных исследованиях методов бикластеризации, позволяют оценить, можно ли сопоставить каждый наблюдаемый модуль с известным модулем и наоборот 17,19 . Релевантность определяется как
$$ {\ mathrm {Relevance}} = \ frac {1} {{\ left | {M \ prime} \ right |}} \ mathop {\ sum} \ limits_ {m \ prime \ in M \ prime} {\ mathop {{\ mathrm {max}}} \ limits_ {m \ in M} \, {\ mathrm {Jaccard}} \ left ({m \ prime, m} \ right)} $$
Восстановление рассчитывается таким же образом, но с переключением M ‘и M .
Перед объединением оценок по разным наборам данных и определениям модулей мы сначала нормализовали каждую оценку, разделив ее на среднюю оценку 500 переставленных версий известных модулей (дополнительный рисунок 25). Целью этого шага было предотвратить непропорциональное влияние более простых структур модулей (небольшие модули, небольшое количество модулей и отсутствие перекрытия) определенных определений модулей и наборов данных на итоговую оценку. Перестановочные модули были сгенерированы путем случайного сопоставления генов набора данных со случайной перестановкой генов и замены каждого вхождения гена в известном модуле его сопоставленной версией.На основе этой случайной модели структура модуля (размер, количество и перекрытие) осталась прежней, а изменилось только назначение. Мы также протестировали две альтернативные случайные модели. Случайная модель STICKY была ранее описана 61 . Мы адаптировали эту модель для направленных сетей, рассчитав индекс липкости отдельно для входящих и исходящих ребер. Для безмасштабируемой сети 62 мы использовали пакет Python networkx с параметрами по умолчанию.
Наконец, мы вычислили гармоническое среднее между нормализованными версиями всех четырех оценок, чтобы получить окончательную оценку, представляющую производительность конкретного метода для данного набора данных и определения модуля.
Для человеческих данных мы использовали альтернативную оценку, которая оценивает степень, в которой цели каждого регулирующего органа обогащены по крайней мере одним модулем набора данных. Как описано ранее, мы использовали кластерную версию набора данных по регуляторным цепям 41 , который содержит веса для каждого регулятора и комбинации целевого гена в 32 контекстах тканей и типов клеток. Для каждой комбинации генов-мишеней и наблюдаемого модуля мы рассчитали значение обогащения p с использованием точного критерия Фишера с правым хвостом (с поправкой на множественное тестирование с использованием процедуры Холма-Шидака 63 ) и силу этого обогащения с использованием отношение шансов.Хотя мы рассчитали эти значения для каждого типа клеток и тканевого контекста отдельно, мы сохранили для каждого регулятора его минимальное значение p и соответствующее отношение шансов в разных контекстах, поскольку мы не знаем точного типа клеток и тканевого контекста в гены наблюдаемых модулей коэкспрессируются. Затем мы извлекли для каждого регулятора его максимальное отношение шансов по наблюдаемым модулям, в которых цели регуляторов были обогащены (исправлено p -value <0.1). Затем рассчитывалась оценка aucodds путем измерения площади под кривой, образованной процентом регуляторов с отношением шансов, равным или превышающим конкретное пороговое значение, и логарифмическими отношениями шансов 10 в пределах интервала 1 и 1000-кратного обогащения. Чтобы работать независимо от ограничений по весу, мы усредняли оценки aucodds по диапазону ограничений по весу. Производительность в целом снижалась при более строгих порогах отсечки (дополнительный рис. 26a, b), хотя некоторые методы бикластеризации и прямые методы NI оставались более стабильными в широком диапазоне значений отсечки (дополнительный рис.26в, г). Эта оценка была нормализована таким же образом, как описано ранее, где начальные известные модули были определены с использованием определения минимального модуля совместной регуляции и впоследствии случайным образом переставлены путем сопоставления генов внутри модулей со случайной перестановкой.
Мы повторно взвесили баллы между наборами данных и определениями модулей, используя взвешенное среднее, чтобы определения модулей (минимальная совместная регуляция, строгая совместная регуляция и взаимосвязанные подграфы) и каждый организм ( E .\ ast} {\ frac {1} {{\ left | {E \ left ({g, M \ prime} \ right)} \ right |}}} \ hskip9pc \\ \ mathop {\ sum} \ limits_ {g \ prime \ in E \ left ({g, M \ prime } \ right)} {\ frac {{\ mathrm {min} \ left ({\ left | {M \ prime \ left (g \ right) \ cap M \ prime \ left ({g \ prime} \ right) \ left |, \ right | M \ left (g \ right) \ cap M \ left ({g {\ prime}} \ right)} \ right |} \ right) \ cdot {\ mathrm {\ Phi}} \ left ({g, g \ prime} \ right)}} {{\ left | {M \ prime \ left (g \ right) \ cap M \ prime \ left ({g \ prime} \ right)} \ right |}}} $$
Оценка отзыва * рассчитывалась аналогично, но с M ‘и M переключены.Окончательная оценка для конкретного набора генов была получена путем взятия гармонического среднего между нормализованными версиями Recall * и Precision *.
Автоматическая оценка параметров
Все четыре кластерных индекса достоверности, оцененные в этом исследовании, хорошо проявили себя в недавнем оценочном исследовании и определены там 28 . Большинство индексов пытаются оптимизировать баланс между плотностью (изменчивость выражений в модуле) и разделением (различиями выражений между модулями).Для показателей, требующих матрицы расстояний, мы вычитали абсолютную корреляцию Пирсона из единицы.
Мы также исследовали два показателя для оценки функциональной согласованности модулей в соответствии с базой данных GO 45 и базой данных путей KEGG 46 . Мы отфильтровали избыточные наборы генов, начиная с самого большого набора генов, удалив наборы генов, если они слишком сильно перекрываются с более крупными неотделенными наборами генов (индекс Жаккара> 0,7). Индекс биологической однородности измеряет долю пар генов в модуле, которые также соответствуют функциональному классу 22 .Для оценки F-aucodds мы вычислили оценку aucodds, как описано ранее, как для измерения наборов генов (обозначающего, насколько хорошо все функциональные наборы охватываются наблюдаемыми модулями), так и для измерения наблюдаемых модулей (обозначающих, насколько хорошо модули обогащен по крайней мере одним набором функциональных генов) и объединил обе оценки, вычислив их гармоническое среднее.
Поскольку автоматическая оценка параметров выполнялась очень плохо для неполных методов обнаружения модулей (которые включают некоторые методы кластеризации, см. Дополнительное примечание 2), мы назначили каждый неназначенный ген модулю, с которым средняя корреляция была наивысшей до расчета кластера. показатели достоверности.
Меры сходства
Для методов кластеризации, требующих в качестве входных данных матрицы сходства, мы использовали корреляцию Пирсона в нашей первоначальной оценке. Для методов, требующих матрицы несходства, мы вычитали значения корреляции Пирсона из двух. Для сравнения различных показателей сходства мы выбрали четыре основных метода кластеризации, для которых в качестве входных данных требуется показатель сходства. Мы сравнили в общей сложности 10 альтернативных мер, которые кратко описаны в дополнительном примечании 3 вместе с указаниями по внедрению.Мы не оценивали корреляцию расстояния, корреляцию процентного изгиба, D Хёффдинга и максимальный информационный коэффициент 64 , потому что они требовали чрезмерного количества вычислительного времени и / или памяти, что было бы непрактично для обнаружения модулей в общих случаях использования. Чтобы преобразовать матрицу сходства в матрицу несходства или наоборот, мы вычли значения из максимального значения между всеми парами генов в данном наборе данных. Чтобы определить влияние альтернативной меры сходства на производительность методов кластеризации, мы повторно выполнили все шаги оптимизации параметров для каждой альтернативной меры и снова рассчитали результаты тестов, как описано ранее.
Доступность кода
Код для оценки методов обнаружения модулей и дальнейшего расширения оценки доступен как Jupyter Notebooks 65,66 (jupyter.org) на www.github.com/saeyslab/moduledetection-evaluation.
Доступность данных
Данные доступны в репозитории Zenodo 67 (doi: 10.5281 / zenodo.1157938).
Неочищенные экстракты Lycium barbarum подавляют экспрессию SREBP-1c и предотвращают ожирение печени, вызванное диетой, за счет активации AMPK
Полисахарид Lycium barbarum (LBP) хорошо известен в традиционной китайской фитотерапии и обладает благотворным действием.Предыдущее исследование показало, что LBP снижает уровень глюкозы в крови и липидов сыворотки. Однако лежащие в основе механизмы регуляции LBP остаются в значительной степени неизвестными. Основная цель этого исследования состояла в том, чтобы выяснить, предотвращает ли LBP ожирение печени за счет активации аденозинмонофосфат-активируемой протеинкиназы (AMPK) и подавления белка-1c, связывающего регуляторный элемент стерола (SREBP-1c). Самцы мышей C57BL / 6J получали диету с низким содержанием жиров, диету с высоким содержанием жиров или диету, содержащую 100 мг / кг LBP, в течение 24 недель. Клетки HepG2 обрабатывали LBP в присутствии пальмитиновой кислоты.В нашем исследовании LBP может улучшить состав тела и профили липидного обмена у мышей, получавших диету с высоким содержанием жиров. Окрашивание Oil Red O in vivo и in vitro показало, что LBP значительно снижает накопление внутриклеточного триацилглицерина в печени. Окрашивание H&E также показало, что LBP может ослаблять стеатоз печени. Профили экспрессии генов печени продемонстрировали, что LBP может активировать фосфорилирование AMPK, подавлять ядерную экспрессию SREBP-1c и снижать экспрессию белков и мРНК липогенных генов in vivo или in vitro .Более того, LBP значительно повышал экспрессию несвязывающего белка-1 (UCP1) и рецептора-коактиватора-1, активируемого пролифератором пероксисом (PGC-1), в коричневой жировой ткани. Таким образом, LBP является потенциально новым средством предотвращения ожирения печени, вызванного диетой.
1. Введение
Дисбаланс между потреблением и расходом энергии может вызвать чрезмерное накопление триацилглицерина в тканях эукариотических организмов [1, 2]. Накопление триацилглицерина в жировой ткани может привести к ожирению и к ожирению в тканях, не содержащих жировой ткани, особенно в ткани печени, что связано с диабетом 2 типа и неалкогольной жировой болезнью печени (НАЖБП) [3, 4].Жирная печень, вызванная диетой с высоким содержанием жиров, характеризуется чрезмерным накоплением триацилглицерина в печени, также нарушает окисление жирных кислот и увеличивает липогенез в печени [4–6]. Кроме того, длительное нарушение регуляции метаболизма липидов в печени, вызванное диетой с высоким содержанием жиров, увеличивает липолиз, вызывая повышение уровня свободных жирных кислот [7]. Эти метаболические изменения вызывают ожирение печени и приводят к системному усугублению дисфункции липидного обмена [8].
Стерол-регуляторный элемент-связывающий белок-1c (SREBP-1c) является ключевым регулятором липидного обмена, влияющего на статус питания.Активация SREBP-1c увеличивает липогенез печени при высоких диетических условиях и приводит к ожирению печени [9]. Напротив, было показано, что активация аденозинмонофосфат-активируемой протеинкиназы (AMPK) снижает липогенез в печени путем ингибирования экспрессии SREBP-1c и дополнительно предотвращает развитие ожирения печени [10]. Таким образом, некоторые фармакологические агенты, которые ингибируют экспрессию SREBP-1c посредством стимуляции активности AMPK в гепатоцитах, могут предоставить более эффективные варианты лечения жировой болезни печени.
Предыдущие исследования показали, что LBP способен улучшать профили липидного метаболизма на животных и людях. Например, LBP явно снижает общий холестерин (TC), триацилглицерин (TG) и липопротеины высокой плотности (HDL) в сыворотке у животных с гиперлипидемией [11]. Клиническое исследование предоставило доказательства того, что LBP может играть важную роль в лечении пациентов с гиперлипидемией [12]. Однако основные механизмы гепатопротекторного действия LBP остаются в значительной степени неизвестными. Наша цель этого исследования — определить, оказывает ли LBP защитный эффект против ожирения печени, вызванного диетой.Для дальнейшего изучения и оценки антилипидных эффектов LBP на экспрессию SREBP-1c-опосредованных липогенных генов, участвующих в синтезе триацилглицерина посредством AMPK-зависимого пути, были исследованы на модели индуцированной диетой жировой ткани печени in vivo и in vitro .
2. Материал и методы
2.1. Получение
Lycium barbarum Полисахарид (LBP)LBP экстрагировали из L. barbarum , как описано ранее [13].Вкратце, сушеные плоды L. barbarum помещали в кипящую деионизированную воду. Водный экстракт фильтровали через фильтровальную бумагу для удаления примесей. Неочищенный экстракт концентрировали до объема в вакууме при 40 ° C и разбавляли деионизированной водой. Затем экстракт осаждали 95% этанолом с последующим центрифугированием для удаления супернатанта. Затем осадок собирали и измельчали в порошок. Порошок LBP растворяли в физиологическом растворе для эксперимента на мышах, фильтровали через фильтр 0.22 мкм мкм и хранят при -20 ° C.
2.2. Животные и диета
Самцов мышей C57BL / 6J от Beijing Vital River Biological Co., Ltd. содержали в стандартных клеточных условиях (температура: 22 ± 1 ° C; относительная влажность: 56 ± 5 ° C) при 12/12 освещении. / темный цикл. Все мыши имели свободный доступ к диете и воде в течение 2 недель. Мышей разделили на три группы (на группу): диета с низким содержанием жиров (LFD) (D12450B, США), диета с высоким содержанием жиров (HFD) (D12492, США) и HFD плюс LBP (100 мг / кг). Низкожировая диета содержит 10% ккал в виде жира с энергетической плотностью 3.85 Ккал на грамм, в то время как диета с высоким содержанием жиров содержит 60% Ккал в виде жира с плотностью энергии 5,24 Ккал на грамм. Мы наблюдали массу тела, потребление пищи, потребление воды и уровень глюкозы в крови каждую неделю. Мы рассчитали потребление пищи по следующей формуле: потребление пищи (г / день мыши) = общее потребление пищи (г / в неделю) / [7 (d) × 5 (мыши / клетка)]. Мы рассчитали потребление энергии в соответствии со следующей формулой, представленной в исследовательских диетах: потребление энергии (ккал / сутки мыши) = 3,85 или 5,24 (ккал / г) × потребление пищи (г / сутки мыши).Всех мышей лишали диеты и не кормили в течение ночи на 24 неделе. Образцы крови собирали из глазных яблок мышей и помещали на 10 мин при комнатной температуре. Сыворотку получали центрифугированием при 3000 об / мин в течение 15 мин при 4 ° C и хранили при -80 ° C. Выделяли печень и коричневую жировую ткань, замораживали в жидком азоте и хранили при -80 ° C. Эксперименты на животных были одобрены Комитетом по исследованиям на животных Медицинского университета Нинся, Китай.
2.3. Культура клеток и обработка
Клетки HepG2 (Пекинский университет, Китай) культивировали в среде Игла, модифицированной Дульбекко (DMEM), содержащей 30 мМ глюкозы, 10% фетальной бычьей сыворотки (Gibco, США) и 1% пенициллина и стрептомицина (Invitrogen, CA , США) в 5% CO 2 при 37 ° C.Клетки предварительно обрабатывали 250 мкг M пальмитата (Sigma) в течение 12 часов, а затем обрабатывали 30-600 мкг / мл LBP в течение 12 часов.
2.4. Биохимический анализ
Биохимические профили сыворотки, включая TG, TC, AST, ALT, HDL и LDL, определяли с использованием Biochem-Immunoautoanalyser (Brea, CA, USA). Уровни глюкозы определяли с помощью глюкометра (Accu-Chek; Roche Diagnostics). Уровни NEFA и DAG в сыворотке и ткани печени измеряли с помощью набора ELISA для мышей (CUSABIO) в соответствии с инструкциями производителя.Триацилглицерин ткани печени измеряли с помощью набора для анализа триацилглицеридов (Applygen Technologies Inc., Китай).
2,5. Гистологический анализ
Ткань печени фиксировали в 4% параформальдегидном буфере, заливали парафином и разрезали на 5 срезов размером мкм. Срезы печени окрашивали гематоксилином и эозином (H&E). Оценка гистологии печени была описана ранее [14]. Для дальнейшего подтверждения накопления липидных капель засеянные клетки и замороженные срезы печени окрашивали Oil Red O.
2.6. Иммуногистохимия
Срезы готовили, как описано для окрашивания H&E. Иммуногистохимический анализ проводили с использованием следующих первичных антител: антитела против кроличьего SREBP-1c и -FAS, а затем окрашивали козьим антителом против кроличьего IgG-HRP в качестве вторичного антитела. Реактивность антител определяли с использованием набора для окрашивания пероксидазой хрена DAB. Срезы контрастировали гематоксилином и наблюдали под микроскопом (Olympus IX71).
2.7. Выделение РНК, полуколичественная и количественная ОТ-ПЦР
Полную РНК экстрагировали из ткани печени с использованием реагента TRIzol (Invitrogen). Концентрации РНК определяли с помощью SmartSpec Plus (BIO-RAD, США). 1 мкМ г общей РНК транскрибировали в кДНК с использованием набора для синтеза первой цепи с надстрочным индексом (Thermo), следуя инструкциям. Экспрессию UCP1 и PGC-1 α анализировали с помощью полуколичественной ОТ-ПЦР. КДНК служила шаблоном в реакционной смеси 50 мкл л и обрабатывалась с использованием начальной стадии при 94 ° C в течение 5 минут с последующими 32 циклами амплификации (94 ° C в течение 30 секунд, 55 ° C в течение 30 секунд. , 72 ° C в течение 35 с) и 72 ° C в течение 5 мин.Праймеры были следующими: UCP1 (прямой, 5′-GGTTTTGCACCACACTCCTG-3 ‘; обратный, 5′-ACATGGACATCGCACAGCTT-3’), PGC-1 α (прямой, 5′-TAAATCTGCGGGATGATGGA’-3 ‘; обратный, 5’- GTTTCGTTCGACCTGCGTAA-3 ‘) и GAPDH (прямой, 5′-AGAACATCATCCCTGCATCC-3′; обратный, 5’-TCCACCACCCTGTTGCTGTA-3 ‘). Количественный анализ ОТ-ПЦР выполняли с помощью прибора LightCycler (Roche Applied Science) и детекции амплифицированных продуктов SYBR green. Праймеры для SREBP-1c, ACC, FAS, CPT-1 , α и CD36 были описаны ранее [15].Реакции ПЦР были выполнены в трех экземплярах и нормализованы по циклофилину с использованием этого метода.
2,8. Вестерн-блот
Целые и ядерные белки экстрагировали из клеток печени и HepG2, как описано ранее [10]. Концентрацию белка определяли количественно методом BCA в соответствии с инструкциями поставщика (Sigma). 50 мкМ г белка добавляли к 8% SDS-PAGE и наносили электроблоттинг на мембраны PVDF (Pall Corporation, Pensacola). Мембраны блокировали и инкубировали со специфическими антителами против AMPK, AMPK (pThr 172 ), FAS, ACC (pSer 79 ) и ACC (технология передачи сигналов клеток) и SREBP-1c, β -актин и ламин. A / C (Санта-Крус Биотехнология).Следовательно, мембраны инкубировали с соответствующими козьими пероксидазами хрена против кроличьих IgG-HRP или против мышиных IgG-HRP в качестве вторичных антител (Santa Cruz Biotechnology). Иммунореактивные белки детектировали с помощью усиленной хемилюминесценции (Pierce Biotechnology, США). Интенсивность полос сканировали (Epson Perfection V33) и количественно оценивали с помощью программного обеспечения Image J.
2.9. Статистический анализ
Все результаты были выражены как средние значения ± стандартная ошибка среднего. Данные анализировали с помощью теста множественного сравнения ANOVA (SPSS 13.0). считался статистически значимым.
3. Результаты
3.1. Анализ состава тела
В ходе всего исследования контролировали массу тела, потребление воды и потребление пищи, которые играют центральную роль у мышей, питающихся HFD, во время эксперимента. LBP значительно снизил массу тела по сравнению с мышами, получавшими HFD (рисунки 1 (а) и 1 (b) и таблица 1,). Не было значимости для потребления пищи, потребления энергии и воды между их группами (Рисунки 1 (c) и 1 (d) и Таблица 1).Окружность живота и ИМТ у мышей, получавших LBP, были значительно уменьшены, как показано в Таблице 1 (). Вес печени и общий вес белого жира у мышей, получавших HFD, были выше, чем вес мышей, получавших LFD, и уменьшались, когда мышей лечили LBP (Рисунок 2 (a) и Таблица 1, и). Более того, LBP увеличивал запасы бурого жира у мышей, получавших HFD (Таблица 1,). Как показано на фиг. 2 (b) и 2 (c), гистологический анализ срезов печени показал, что LBP явно снижает индекс стеатоза печени по сравнению с группой, получавшей HFD ().
| Данные выражены как средние значения ± SEM (на группу) и по сравнению с группой HFD.LFD: диета с низким содержанием жиров; HFD: диета с высоким содержанием жиров; 100 LBP + HFD: 100 мг / кг LBP плюс диета с высоким содержанием жиров; ИМТ: индекс массы тела. | ||||||||||||||||||||||||||||||||||||
3.2. Биохимический анализ сыворотки
Для дальнейшей оценки эффекта мышей, обработанных LBP, мы измерили сывороточные TG, TC, HDL, LDL, AST, ALT и NEFA. Как показано в таблице 2, все сывороточные концентрации TC и LDL были значительно ниже у мышей, получавших LBP, чем у мышей, получавших HFD, в то время как уровень HDL был обратным у мышей, получавших LBP (). В группе, получавшей LBP, уровни NEFA были значительно ниже, чем в группе, получавшей HFD ().АЛТ и АСТ также были ниже в группе, получавшей LBP, чем в группе, получавшей HFD (). LBP также снижает уровень глюкозы в крови всего тела мышей, получавших HFD (). Как показано в таблице 3, мы обнаружили, что уровни TG и DAG в сыворотке и печени были значительно снижены в группе, получавшей LBP, по сравнению с таковой в группе, получавшей HFD (). Как и ожидалось, эти данные показали, что лечение LBP было ценным для улучшения состава всего тела и липидных профилей сыворотки у мышей, питающихся HFD.
| ||||||||||||||||||||||||||||||||||||
| Данные выражены как средние значения ± стандартная ошибка среднего (на группу),, и, по сравнению с группой HFD.ЛПВП: липопротеины высокой плотности; ЛПНП: липопротеины низкой плотности; AST: аспартатаминотрансфераза; АЛТ: аланинаминотрансфераза; NEFA: неэтерифицированные жирные кислоты. | ||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||
| Данные выражены как среднее ± SEM (на группу) по сравнению с группой HFD.DAG: диацилглицерин; ТГ: триацилглицерин. | ||||||||||||||||||||||||||||||||||||||||
3.3. LBP активировал фосфорилирование AMPK и подавлял ядерный SREBP-1c
In vivo и In VitroМы оценили уровни фосфо-AMPK, ядерного SREBP-1c, фосфо-АСС и FAS in vivo 905 в печени. vitro экспериментов. У мышей, получавших HFD, были значительно повышены уровни в печени ядерных SREBP-1c и FAS и снизились уровни фосфорилирования в печени AMPK и ACC.Напротив, LBP значительно реверсировал вызванные HFD изменения уровней этих белков в печени (Фигуры 3 (а) и 5 (а) и). Окрашивание SREBP-1c и FAS показало уровни цитоплазматической экспрессии в печени, соответственно (рис. 3 (c)).
3.4. LBP предотвращает ожирение печени посредством пути AMPK / SREBP-1c
Мы проанализировали уровни мРНК генов, участвующих в липогенезе и жирных кислотах β -окисление . Наши результаты показали, что уровни мРНК SREBP-1c, ACC и FAS были увеличены в группе HFD по сравнению с группой LFD.Напротив, LBP значительно снижает экспрессию мРНК этих генов (рис. 4 (а) и). Интересно, что по сравнению с мышами, получавшими HFD, LBP значительно повышал уровень СРТ-1 α и подавлял уровень CD36 (Фиг.4 (b) и). Окрашивание Oil Red O in vivo и in vitro показало ту же тенденцию, при которой LBP значительно снижал накопление внутриклеточного ТГ в печени (Фигуры 2 (d) и 5 (b)). Взятые вместе, LBP подавлял липогенез и стимулировал окисление жирных кислот β через путь AMPK / SREBP-1c, снижал накопление ТГ в печени и предотвращал ожирение печени.
(а) Липогенез
(б) β-Окисление
(а) Липогенез
(б) β-Окисление
3.5. LBP увеличил экспрессию UCP1 и PGC-1
α коричневой жировой тканиМы оценили экспрессию генов UCP1 и PGC-1 α . Как показано на рисунке 3 (а), уровни мРНК UCP1 и PGC-1 α показали большие различия между тремя группами. Экспрессия UCP1 и PGC-1 α у мышей, получавших HFD, была выше, чем у мышей, получавших ND.LBP значительно усиливал экспрессию этих генов в коричневой жировой ткани у мышей, получавших HFD ().
4. Обсуждение
Мышиная модель ожирения печени, вызванного диетой с высоким содержанием жиров, считалась хорошей моделью для изучения метаболического синдрома [16, 17]. В нашем исследовании у мышей, получавших HFD, явно была увеличена масса тела и печени, сывороточные концентрации TG, DAG, TC, LDL, NEFA, AST и ALT, а также концентрации TG и DAG в печени. Напротив, LBP значительно снизил вес тела и печени, а также концентрацию липидов в сыворотке и печени.LBP также ослаблял развитие HFD-индуцированного ожирения печени, как было определено с помощью гистохимического анализа. Эти данные продемонстрировали, что LBP обладает биологической активностью для регуляции липидного обмена и развития жировой дистрофии печени.
Хотя молекулярный механизм, вызывающий развитие жировой дистрофии печени в патогенезе неалкогольной жировой болезни печени (НАЖБП), сложен, модели на животных показали, что модуляция важных ферментов, таких как АЦЦ и ФАС, в синтезе жирных кислот в печени может быть затруднена. ключ к лечению НАЖБП [18–20].Недавние исследования на людях и грызунах показали, что увеличение липогенеза в печени de novo играет ключевую роль в индуцированном HFD избыточном накоплении жира в печени [21, 22]. Эксперименты in vivo, и in vitro, показали, что избыточная экспрессия HFD-индуцированных ACC и FAS существенно подавлялась LBP. Печеночная экспрессия SREBP-1c, который играет главную роль в ожирении печени, отвечает за эти гены в печени [20, 23-25] и влияет на накопление липидов, вызванное диетой с высоким содержанием жиров [26, 27].Наше исследование показало, что мыши, получавшие HFD или предварительно получавшие пальмитат, стимулировали печеночную экспрессию SREBP-1c на уровнях белка и мРНК in vivo и in vitro . Однако SREBP-1c регулируется множеством факторов, включая инсулин [28], AMPK [10, 28, 29] и Х-рецепторы печени (LXR) [20, 29]. Было показано, что активаторы AMPK, включая альфа-липоевую кислоту [30] и метформин [31], подавляют экспрессию SREBP-1c и предотвращают развитие жировой дистрофии печени. Наши результаты подтверждают такой механизм, показывая, что подавление экспрессии SREBP-1c с помощью LBP опосредуется стимуляцией активности AMPK.Взятые вместе, LBP регулирует печеночные гены, ответственные за синтез de novo жирных кислот посредством модуляции пути AMPK / SREBP-1c и уменьшая HFD-индуцированное ожирение печени.
CPT-1 α является основным ферментом, который катализирует -окисление жирных кислот β [32], тогда как CD36 способствует сочетанию накопления липидов и липогенеза [23, 33]. HFD-индуцированная жировая дистрофия печени еще больше усугубила систему окисления жирных кислот β и нарушила баланс липидного обмена [34].Наше исследование показало, что печеночное окисление β действительно снижалось в группе HFD. Напротив, лечение LBP увеличивало уровень мРНК СРТ-1 α и уменьшало уровень мРНК CD36. Эти результаты предполагают, что положительные эффекты LBP при лечении ожирения печени могут быть частично обусловлены улучшенным окислением жирных кислот β в печени.
Белая жировая ткань (WAT) увеличивает производство и высвобождение жирных кислот и, в свою очередь, приводит к ожирению печени [35].В отличие от WAT, коричневая жировая ткань (BAT), являющаяся важным компонентом расхода энергии, расходует энергию за счет производства тепла за счет разобщения белка-1 (UCP-1) и рецептора, активируемого пролифератором пероксисом, γ , коактиватора-1 α (PGC -1 α ) в его митохондриях [36]. Это изменение индуцированного HFD подавления UCP-1 и PGC-1 α в коричневых адипоцитах вызывает морфологическое и метаболическое превращение в белые адипоциты [35, 37, 38]. Как и ожидалось, LBP значительно изменил индуцированное HFD подавление UCP-1 и PGC-1 α коричневой жировой ткани.Следовательно, возможно, что LBP, активирующий или повышающий экспрессию UCP-1 и PGC-1 α , будет иметь решающее влияние на увеличение расхода энергии, чтобы в конечном итоге предотвратить ожирение печени, что, в свою очередь, защищает функцию печени.
5. Заключение
В заключение, наши настоящие результаты впервые демонстрируют, что LBP улучшает индуцированную HFD жировую болезнь печени in vivo и in vitro , в которых модуляция пути AMPK / SREBP-1c играет ключевую роль.Наше открытие может обеспечить лучшее понимание LBP и связанных с ним химических веществ и трав при лечении заболеваний печени, особенно неалкогольной жировой болезни печени.
Сокращения
| ACC: | Ацетил-КоА карбоксилаза | |
| CD36: | Кластер дифференцировки 36 | |
| CPT-1 α 62 | ||
| CPT-1 α 62 Карбоксилаза | 1 α 6251 DAG:Диацилглицерин | |
| FAS: | Синтетаза жирных кислот | |
| HFD: | Диета с высоким содержанием жиров | |
| LBP: | ||
| LBP: | ciumбаракум Лайполид жировая болезнь печени | |
| LFD: | Низкожировая диета | |
| NEFA: | Нестерифицированная жирная кислота | |
| PGC-1 α : | Со-активатор γ592 пероксизомера-рецептора | Пероксизомер-рецептор-592 1 α |
| SREBP-1c: | Связывание с регуляторным элементом стерола Protein-1c | |
| UCP1: | Разобщающий белок-1. |
Конфликт интересов
Авторы заявляют об отсутствии конфликта интересов.
Благодарности
Это исследование было поддержано Национальным фондом естественных наук Китая (81160103) и Проектом научных исследований и международного сотрудничества автономного района Нинся-Хуэй (NXIC2011010).
Программа на языке C: построение средства оценки выражений
/ * Эта программа на языке C вычисляет самые простые арифметические выражения. Программа преобразует инфиксное выражение в постфиксное выражение, а затем вычисляет постфиксное выражение.* / #includechar expr [20]; // массив для хранения введенного выражения char stack [20]; // сохраняем постфиксное выражение приоритет int (char a, char b) {// возвращает истину, если приоритет оператора a больше или равен приоритету b если (((a == '+') || (a == '-')) && ((b == '*') || (b == '/'))) возврат 0; еще возврат 1; } int i; int ctr; int top = -1; // вершина стека постфиксов int topOper = -1; // вершина стека операторов int работают (int a, int b, char oper) { int res = 0; переключатель (опер) { case '+': res = a + b; перерыв; case '-': res = a-b; перерыв; case '*': res = a * b; break; // вернуть результат оценки case '/': res = a / b; перерыв; } return res; } недействительный postfixConvert () { символ topsymb, operatorStack [20]; ctr = 0; в то время как (выражение [ctr]! = '\ 0') {// читать до конца ввода если (выражение [ctr]> = '0' && expr [ctr] <= '9') stack [++ top] = expr [ctr]; // сразу складываем числа еще { while (topOper> = 0 && приоритет (operatorStack [topOper], expr [ctr])) {// проверяем наличие операторов с более высоким приоритетом, а затем добавляем их в стек topsymb = operatorStack [topOper--]; стек [++ вверху] = topsymb; } operatorStack [++ topOper] = выражение [ctr]; } ctr ++; } while (topOper> = 0) // добавляем оставшиеся операторы в стек стек [++ top] = operatorStack [topOper--]; printf ("Результирующее выражение Postfix для данного инфиксного выражения \ n% s \ n", стек); } int main () { printf ("\ t \ tExpression Evaluator \ n"); printf ("Эта программа вычисляет базовые выражения (без скобок) с помощью арифметических операций (+, -, *, /) над однозначным операндом длиной менее 20 \ n"); printf ("Введите выражение \ n"); scanf ("% s", выражение); postfixConvert (); // функция для преобразования в постфиксную форму char oper; int операнд1, операнд2; ctr = 0; int result [2]; // стек для хранения результатов int rTop = -1; // вершина стека результатов в то время как (стек [ctr]! = '\ 0') { опер = стек [ctr]; если (опер> = '0' && опер <= '9') result [++ rTop] = (int) (oper-'0 '); // складываем числа еще {// если оператор встречается, то выскакивает дважды и помещает результат операции в стек operand1 = результат [rTop--]; операнд2 = результат [rTop--]; результат [++ rTop] = операция (операнд2, операнд1, операция); } ctr ++; } printf ("Результат выражения \ n% d \ n", результат [0]); getch (); } / * Пример запуска программы работает как: - Оценщик выражений Эта программа вычисляет базовые выражения (без скобок) с помощью арифметических операций (+, -, *, /) над однозначным операндом длиной менее 20 Введите выражение 2 + 3 * 6-5 + 7 + 8/4 Результирующее выражение Postfix для данного инфиксного выражения 236 * + 5-7 + 84 / + Результат выражения: 24 * /
Нокдаун SREBP-1c повторно индуцирует передачу сигналов Wnt в скелетных мышцах крысы
Нокдаун SREBP-1c повторно индуцирует передачу сигналов Wnt в скелетных мышцах крыс Адипобласты и миобласты, происходящие от адипобластов и миобластов, происходят из мезенхимов.Факторы Wnt - это секретируемые белки, которые контролируют судьбу мезенхимальных клеток: они активируют миогенез, тогда как они подавляют адипогенез. Нарушение передачи сигналов Wnt вызывает трансдифференцировку миобластов в адипоциты. Напротив, белок-1c, связывающий регулирующий элемент стерола (SREBP-1c), представляет собой фактор транскрипции, специфичный для дифференцированных адипоцитов, который активирует несколько важных генов, участвующих в липогенезе. Недавно мы сообщили, что липогенез de novo происходит в мышечных трубках крыс посредством зависимого от SREBP-1c пути.[br] Чтобы оценить корреляцию между передачей сигналов Wnt и экспрессией SREBP-1c в скелетных мышцах крыс, мы измерили уровень белков Wnt-10b и SREBP-1c во время онтогенеза и регенерации скелетных мышц. Wnt-10b увеличился в 10 раз от рождения до отъема; после этого он уменьшился и стал необнаруживаемым на взрослой стадии. Напротив, SREBP-1c был обнаружен на очень низком уровне до отъема и увеличивался в 10 раз до взрослой стадии. Точно так же уровень белка Wnt-10b резко повысился через два дня после механического повреждения в Extensor Digitorum Longus (EDL) и оставался повышенным в течение 30 дней (т.е.е. до завершения регенерации), тогда как белок SREBP-1c подавлялся после раздавливания мышц и оставался не обнаруживаемым в течение периода регенерации. Наконец, мы подавили SREBP-1c в культивируемых мышечных трубках крыс с помощью миРНК, направленной против мРНК SREBP-1. Белок Wnt-10b больше не обнаруживался в этих клетках до трансфекции siRNA, но через 48 часов после нокдауна SREBP-1c мы наблюдали повторную экспрессию белка Wnt-10b, стабилизацию цитозольного бета-катенина за счет дефосфорилирования, предполагая роль SREBP-1c в подавлении экспрессии и передачи сигналов Wnt.[br] Может ли повышенный липогенез, наблюдаемый в мышцах при старении, ожирении и диабете 2 типа, приводящий к адипогенному фенотипу, быть следствием измененной миогенной программы, еще предстоит определить. ИЗАБЕЛЬ ГИЙЛЕ-ДЕНИО, АНН-ЛИЗ ПИЧАР, АМИНАТА КОНЕ, ЖАН ЖИРАР 412-П Париж, Франция Комплексная физиология - биология адипоцитов
Категория:
Комплексная физиология - биология адипоцитов
.