Непечатаемые символы в Word, читать на computerlikbez.ru
Здравствуйте, Уважаемые Друзья!
Вероятнее всего, вы замечали, когда работали в Word, что при печати документов, принтер «разрывает» ваш документ совсем ненадлежащим образом. Хотя на экране монитора все выглядит аккуратно и правильно.
Кроме того, когда вы сохраняете или конвертируете вордовский документ из формата doc (docx) в формат pdf, то и в этом новом документе можно также наблюдать всевозможные «огрехи» форматирования. Это может быть разорванный текст, неправильные разрывы между словами, предложениями, абзацами и так далее…
Почему так происходит?
Постоянный читатель, в моей закрытой рассылке, получает от меня всевозможные видеокурсы и прочие полезные материалы, и поэтому знает «внутреннее» устройство Word и подобных проблем у него не возникает. Вплоть до таких мелких вопросов как пронумеровать страницы в ворде.
Если вы хотите узнать больше фишек Word, то рекомендую мой самоучитель по этому текстовому редактору.
В этой же статье я решил немного рассказать о непечатаемых символах Word, знакомство с которыми поможет вам лучше «понимать» Word и готовить к печати свои документы правильно и корректно.
Итак, стоит начать с того, что Word – это автоматизированный текстовый редактор. Это значит, что многие процессы в нем не нужно делать вручную, достаточно изначально просто задать определенные параметры редактирования, а дальше Word будет выполнять все в автоматическом режиме.
Это хорошо видно, когда нам часто приходится делать однотипные документы в каком-то определенном стиле. Например, заголовки могут иметь 14 размер шрифта, основной текст 12 шрифт, а в колонтитулах вставлены контакты, даты, нумерация или какие-то фирменные бланки.
Каждый символ набранный в Word имеет свое строгое значение и специальный код, который соответствует каждой клавише клавиатуры, в том числе и «Пробел» и «Enter». Когда мы набираем текст, у нас, разумеется, будут пробелы между словами, какие-то абзацы и всевозможные элементы форматирования.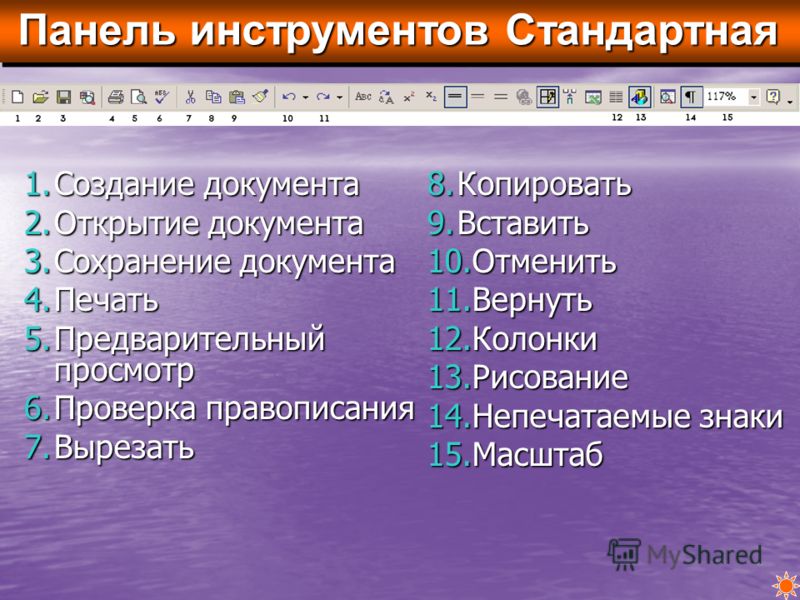
Одним из ключевых моментов здесь будет то, что в любом тексте должен быть только один пробел, а абзацы разделены клавишей «Enter». Однако, большинство пользователей, когда им нужно «подвинуть» или сделать «разрыв» в тексте используют несколько раз пробелы или «энтеры». Это и есть самая главная ошибка. Так делать нельзя!
Как я говорил выше, Word, практически, полностью автоматизирован и вот такие «пробелы» и «энтеры» «расценивает» как полноценный текст. То есть если у вас стоят три «энтера» подряд, для программы это означает «АБЗАЦЫ», где набран текст. А раз это абзацы, то их можно разорвать на разные листы при печати.
Это, в принципе, вполне логично на программном уровне. Но, как это часто бывает, пользователи буквально набивают «энтерами» свой текст, чтобы оставить место, скажем, для вставки картинки или таблицы…
«Пробелы». Когда вы ставите кучу пробелов между словами, то Word «понимает», что между всеми этими пробелами у вас написаны слова, поэтому при печати, вы можете наблюдать огромные отступы, расстояния между словами и так далее. Word просто «думает», что там есть текст. И это тоже вполне логично.
Word просто «думает», что там есть текст. И это тоже вполне логично.
Как посмотреть все непечатаемые символы в Word? Это очень просто. Достаточно нажать на кнопку непечатаемых символов:
Вот таблица основных непечатаемых символов Word с их значением:
Небольшая рекомендация. Когда вам нужно увеличить расстояние между абзацами, следует пользоваться функцией «Абзац» — «Интервал». Там можно задать абсолютно любые параметры. Когда потребуется поставить большое расстояние между словами, пользуйтесь табуляцией (клавиша Tab на клавиатуре). Расстояние табуляции можно задавать простым перетаскиванием ползунка на горизонтальной линейке Word.
Неразрывные дефисы и пробелы Word
На таблице выше, в числе непечатаемых символов вы можете видеть еще и неразрывные пробелы, и дефисы. Они требуются, когда необходимо жестко зафиксировать слова или предложения в одной строке.
Например, нам нужно написать фамилию и инициалы, причем, чтобы они не разрывались между пробелами, а всегда располагались в одну строку. Здесь и можно применить неразрывный пробел.
Здесь и можно применить неразрывный пробел.
Однако, бывает и такое, что мы копируем какой-то текст из других текстовых редакторов в Word и получаем весь текст с неразрывными символами. Особенно часто это бывает, когда Вы копируете текст со страницы какого-нибудь сайта в Word. Неразрывные пробелы и дефисы обозначаются значком градуса (°) и двойного дефиса (—) соответственно.
Понятное дело, что вы не увидите ничего страшного визуально, однако при попытке распечатать такой текст он будет совсем не тем, каким смотрится на экране монитора.
Поэтому перед печатью нужно включить непечатаемые символы и заменить их обычными пробелами. Если сидеть и вручную заменять каждый пробел в тексте, скажем, на 100 листов, то это займет очень много времени.
Но, повторюсь, Word, практически полностью автоматизирован, поэтому мы можем произвести всю замену автоматически. Делается это очень просто.
В поле «Редактирование» находим кнопку «Заменить». ~, а в поле «Заменить» — обычный дефис.
~, а в поле «Заменить» — обычный дефис.
Кстати, дефисы и тире тоже бывают разные, но об этом я писал в этой статье. Также рекомендую к прочтению, статью про кавычки-елочки, там тоже есть свои нюансы.
Способы выделения текста и непечатаемые символы word
Опубликовано:
Как вы выделяете текст в ворде? Зажимаете левую клавишу мыши и ведете по тексту, до нужного момента. А если текст поместился на 120 листах документа ворд? Многие встречались с подобной проблемой и результат всего этого куча потерянного времени. И вторая ситуация, встречался вам такой текст:
Этот текст является причиной двух действий. Первое действие – не правильное форматирование. Второе действие – несоответствие форматов при конвертировании. Например, вы скопировали текст с интернет страницы.
Первый инструмент который мы изучим это способы выделения текста. Знания по выделению текста будут нам полезны при редактировании плохо отформатированного текста.
Способы выделения текста word
На мой взгляд, достаточно необходимый инструмент при работе с текстом, особенно при его редактировании.
1 способ: самый простой и все его знают, зажимаем левую клавишу мыши и ведем по нужному нам тексту. Но есть небольшие хитрости, например что бы выделить весь текст на страницы достаточно провести мышью по левому или правому полю страницы с зажатой левой клавишей мыши.
2 способ: необходим для выделения всего что находится в документе, текста, картинок, таблиц. Для этого нам потребуется сочетание клавиш Ctrl+A. Символ-А в английской раскладке, в русской раскладке буква-Ф.
3 способ: необходим для выделения слова или абзаца. Для этого ставим курсор на нужное слово и кликаем два раза левую клавишу мыши. Для выделения абзаца кликаем три раза левой клавишей мыши.
4 способ: выделяем нужный участок в тексте. Ставим курсор в конец нужного участка текста, а указатель мыши в начало текста. Затем нажимаем клавишу Shift на клавиатуре и кликаем правой клавишей мыши.
Затем нажимаем клавишу Shift на клавиатуре и кликаем правой клавишей мыши.
5 способ: выделяем несколько отдельных участков текста. Для этого используем первый способ в сочетании с клавишей Ctrl. Этот способ необходим для редактирования нескольких участков текста не связанных между собой.
6 способ: необходим при отсутствии компьютерной мыши. Данный способ удобен на ноутбуках или при отсутствии или неисправности мыши. Зажимаем на клавиатуре клавишу Shift, перемещаем курсор по тексту с помощью стрелок на клавиатуре.
Необходимо запомнить все способы и при желании отработать несколько раз на практике. Данный способы выделения необходимы в первую очередь для повышения навыков и производительности в работе с текстом.
Непечатаемые символы word
Рассмотрим основные символы которые не отображаются в тексте. Смотрим рисунок:
Данные символы являются скрытой разметкой текста. Это необходимо для того что бы правильно применять редактирование текста.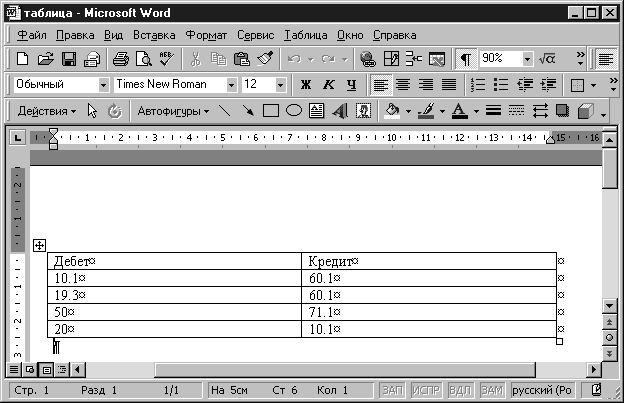 А так же отображения формата текста. Например, необходимо ставить после оглавления два пробела или использовать табуляцию при отступах.
А так же отображения формата текста. Например, необходимо ставить после оглавления два пробела или использовать табуляцию при отступах.
Для того что бы увидеть скрытые символы необходимо, во вкладке «Главная» кликнуть на инструмент «Отобразить все знаки». Так же можно воспользоваться сочетанием клавиш на клавиатуре Ctrl+Shift+8
Смотрим рисунок:
Как мы видим на рисунке, текст содержит большое количество пробелов. Для их удаления необходимо воспользоваться одним из способов выделения и удалить. Знак табуляции удаляется точно так же как и пробел.
Внизу документа мы видим таблицу, но без отображения границ. Что бы изменить ситуацию необходимо сделать границы таблицы видимыми.
Изучение и знание навыков выделения и редактирования является неотъемлемой частью при работе в текстовом редакторе Word. Каждый из навыков важен по своему и не стоит пренебрегать их изучению. Все появившиеся вопросы вы сможете написать в форме комментарии.
Если статья была для Вас полезной, буду признателен если вы напишите не большой отзыв в комментарии.
Как вам статья?
Неизвестные непечатаемые символы (Microsoft Word)
Филлис часто сталкивалась с двумя непечатаемыми символами, когда копировала что-либо из Интернета в Word. Эти символы представляют собой изогнутую стрелку в конце абзаца (которая, как она понимает, является символом новой строки) и крошечные «пончики» между словами (где она ожидала увидеть только пробел). Филлис задается вопросом, может ли кто-нибудь сказать ей, что это за второй персонаж, а также как/почему/что/когда использовать оба персонажа.
То, что видит Филлис, требует некоторого объяснения. Поскольку она копирует информацию из Интернета, это кажется хорошим местом для начала. Я собрал простой HTML-код для отображения текста. В коде я разместил несколько тегов для начала и конца абзаца, разрывов строк и неразрывных пробелов. HTML-код выглядел так. (См. рис. 1.)
Рис. 1. Некоторый текст, закодированный тегами HTML.
Когда это было отображено в браузере HTML, теги, которые я поместил в текст, не были видны, но браузер сделал разрывы строк так, как я указал с моими тегами. (См. рис. 2.)
Рис. 2. Просмотр HTML-текста в браузере.
Затем я выделил текст в своем браузере, нажал Ctrl+C , чтобы скопировать его в буфер обмена, переключился на документ Word и нажал Ctrl+V , чтобы вставить его туда. Затем я включил отображение непечатаемых символов и увидел то же самое, что и Филлис. (См. рис. 3.)
Рис. 3. Вставка текста браузера в Word.
Обратите внимание на «изогнутые стрелки» в конце строк. Это действительно символы новой строки. Они соответствуют расположению тегов разрыва строки, которые я разместил в исходном HTML-коде. Маленькие «пончики» или «знаки градусов» соответствуют каждому неразрывному пробелу, который я разместил в HTML-коде.
Другими словами, Word вставляет текст — закодированный в HTML текст — максимально близко к тому, каким он был изначально.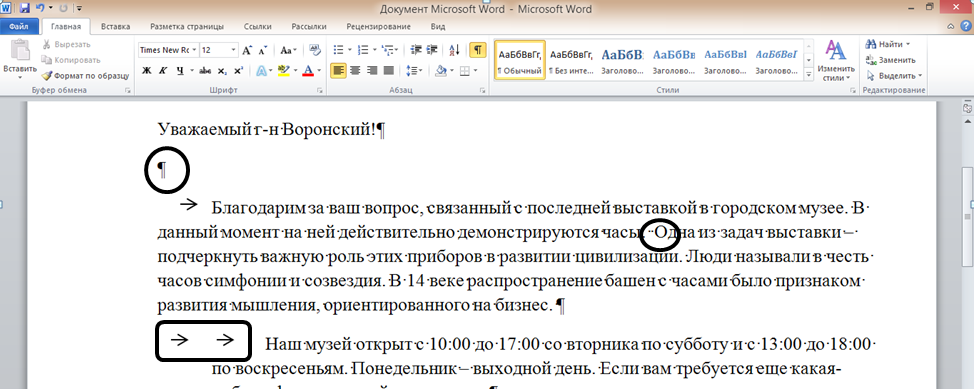
Если вы не хотите, чтобы эти коды были там, у вас есть несколько вариантов. Первый (и, как мне кажется, самый простой) — изменить способ вставки информации в документ, скопированный из Интернета. Вместо нажатия Ctrl+V выберите «Только текст». В итоге вы получите более «чистую» версию нужного вам текста. (См. рис. 4.)
Рис. 4. Вставка текста браузера с помощью функции «Только текст».
Обратите внимание, что разрывы строк заменены жесткими возвратами, а неразрывные пробелы заменены обычными пробелами. 9s
Я также должен отметить, что маленькие «пончики» или «знаки градусов», которые видит Филлис, на самом деле не являются неразрывными пробелами. В тесте, о котором я рассказал выше, это были именно те символы, но если исходный HTML-код включает пробелы en или em, они также отображаются в Word после вставки в виде «пончиков» или «знаков градусов». Если это относится к тому, что вы вставляете, вам нужно изменить то, что вы ищете в «Найти и заменить», чтобы точно отразить эти символы.
Теперь Филлис также спросила о том, «как/почему/что/когда» использовать такие символы. Когда дело доходит до копирования информации из Интернета, я думаю, что на все они были даны ответы. Однако, если вы просто печатаете и редактируете свой документ Word, это еще не все.
Если вы хотите использовать эти символы в своих собственных документах, «как» легко — используйте сочетание клавиш Ctrl+Shift+Пробел , чтобы добавить неразрывный пробел, и Shift+Enter , чтобы добавить новый- линейный характер. «Почему» столь же просто — неразрывные пробелы используются, когда вы хотите, чтобы текст по обе стороны от неразрывного пробела находился на одной строке. Символы новой строки используются, когда вы хотите перевести текст на следующую строку, но при этом хотите, чтобы этот текст находился в том же абзаце, что и текущий текст.
«Почему» столь же просто — неразрывные пробелы используются, когда вы хотите, чтобы текст по обе стороны от неразрывного пробела находился на одной строке. Символы новой строки используются, когда вы хотите перевести текст на следующую строку, но при этом хотите, чтобы этот текст находился в том же абзаце, что и текущий текст.
WordTips — ваш источник недорогого обучения работе с Microsoft Word. (Microsoft Word — самая популярная в мире программа для обработки текстов.) Этот совет (13627) относится к Microsoft Word 2007, 2010, 2013, 2016, 2019 и Word в Microsoft 365. его кредит, Аллен Вятт является всемирно признанным автором. Он является президентом Sharon Parq Associates, компании, предоставляющей компьютерные и издательские услуги. Узнать больше об Аллене…
Учебное пособие по регулярным выражениям. Непечатаемые символы
Вы можете использовать специальные последовательности символов, чтобы вставить в регулярное выражение непечатаемые символы. Используйте \t для соответствия символу табуляции (ASCII 0x09), \r для возврата каретки (0x0D) и \n для перевода строки (0x0A). Более экзотическими непечатаемыми являются \a (звонок, 0x07), \e (escape, 0x1B) и \f (перевод страницы, 0x0C). Помните, что текстовые файлы Windows используют \r\n для завершения строк, а текстовые файлы UNIX используют \n.
Более экзотическими непечатаемыми являются \a (звонок, 0x07), \e (escape, 0x1B) и \f (перевод страницы, 0x0C). Помните, что текстовые файлы Windows используют \r\n для завершения строк, а текстовые файлы UNIX используют \n.
В некоторых разновидностях \v соответствует вертикальной вкладке (ASCII 0x0B). В других разновидностях \v — это сокращение, которое соответствует любому вертикальному пробельному символу. Это включает в себя вертикальную вкладку, перевод страницы и все символы разрыва строки. Perl 5.10, PCRE 7.2, PHP 5.2.4, R, Delphi XE и более поздние версии рассматривают его как сокращение. Более ранние версии обрабатывали его как литерал v с ненужным экранированием. Вариант JGsoft изначально соответствовал только вертикальной вкладке с \v. JGsoft V2 сопоставляет любой вертикальный пробел с \v.
Многие разновидности регулярных выражений также поддерживают токены от \cA до \cZ для вставки управляющих символов ASCII. Буква после обратной косой черты всегда строчная c. Вторая буква — это заглавная буква от A до Z, обозначающая от Control+A до Control+Z. Они эквивалентны от \x01 до \x1A (26 десятичных знаков). Например. \cM соответствует возврату каретки, точно так же, как \r, \x0D и \u000D. В большинстве вариантов вторая буква может быть строчной без разницы в значении. Только Java требует, чтобы буквы от A до Z были в верхнем регистре.
Вторая буква — это заглавная буква от A до Z, обозначающая от Control+A до Control+Z. Они эквивалентны от \x01 до \x1A (26 десятичных знаков). Например. \cM соответствует возврату каретки, точно так же, как \r, \x0D и \u000D. В большинстве вариантов вторая буква может быть строчной без разницы в значении. Только Java требует, чтобы буквы от A до Z были в верхнем регистре.
Использование символов, отличных от букв, после \c не рекомендуется, так как поведение разных приложений несовместимо. Некоторые разрешают любой символ после \c, в то время как другие разрешают символы ASCII. Приложение может использовать последние 5 бит индекса этого символа в кодовой странице или его кодовую точку Unicode для формирования управляющего символа ASCII. Или приложение может просто перевернуть бит 0x40. В любом случае от \c@ до \c_ будут соответствовать управляющие символы от 0x00 до 0x1F. Но \c* может соответствовать переводу строки или букве j. Звездочка — это символ 0x2A в таблице ASCII, поэтому младшие 5 бит равны 0x0A, а перевернутый бит 0x40 дает 0x6A. Метасимволы действительно теряют свое значение сразу после \c в приложениях, поддерживающих от \cA до \cZ для сопоставления управляющих символов. Оригинальный вариант JGsoft, .NET и XRegExp более разумны. Они рассматривают все, кроме буквы после \c, как ошибку.
Метасимволы действительно теряют свое значение сразу после \c в приложениях, поддерживающих от \cA до \cZ для сопоставления управляющих символов. Оригинальный вариант JGsoft, .NET и XRegExp более разумны. Они рассматривают все, кроме буквы после \c, как ошибку.
В регулярных выражениях схемы XML и XPath \c — это сокращенный класс символов, который соответствует любому символу, разрешенному в имени XML.
Версия JGsoft изначально рассматривала символы от \cA до \cZ как управляющие символы. Но JGsoft V2 рассматривает \c как сокращение XML.
Если ваш механизм регулярных выражений поддерживает Unicode, вы можете использовать \uFFFF или \x{FFFF} для вставки символа Unicode. Знак валюты евро занимает кодовую точку Юникода U+20AC. Если вы не можете ввести его на клавиатуре, вы можете вставить его в регулярное выражение с помощью \u20AC или \x{20AC}. Дополнительные сведения о сопоставлении кодовых точек Unicode см. в разделе руководства по Unicode.
Если ваш движок регулярных выражений работает с 8-битными кодовыми страницами вместо Unicode, вы можете включать в регулярное выражение любой символ, если знаете его положение в наборе символов, с которым работаете. В наборе символов Latin-1 символом авторского права является символ 0xA9. Таким образом, для поиска символа авторского права вы можете использовать \xA9. Другой способ поиска вкладки — использовать \x09. Обратите внимание, что начальный нуль обязателен. В Tcl 8.5 и более ранних версиях вы должны быть осторожны с этим синтаксисом, потому что Tcl поглощал все шестнадцатеричные символы после \x и рассматривал последние 4 как кодовую точку Unicode. Итак, \xA9ABC20AC будет соответствовать символу евро. Tcl 8.6 принимает только первые две шестнадцатеричные цифры как часть \x, как и все другие разновидности регулярных выражений, поэтому \xA9ABC20AC соответствует ©ABC20AC.
В наборе символов Latin-1 символом авторского права является символ 0xA9. Таким образом, для поиска символа авторского права вы можете использовать \xA9. Другой способ поиска вкладки — использовать \x09. Обратите внимание, что начальный нуль обязателен. В Tcl 8.5 и более ранних версиях вы должны быть осторожны с этим синтаксисом, потому что Tcl поглощал все шестнадцатеричные символы после \x и рассматривал последние 4 как кодовую точку Unicode. Итак, \xA9ABC20AC будет соответствовать символу евро. Tcl 8.6 принимает только первые две шестнадцатеричные цифры как часть \x, как и все другие разновидности регулярных выражений, поэтому \xA9ABC20AC соответствует ©ABC20AC.
Разрывы строк
\R — это специальный экран, который соответствует любому разрыву строки, включая разрывы строк Unicode. Что делает его особенным, так это то, что он рассматривает пары CRLF как неделимые. Если попытка сопоставления \R начинается до пары CRLF в строке, то одиночный \R соответствует всей паре CRLF. \R не будет возвращаться, чтобы соответствовать только CR в паре CRLF. Таким образом, в то время как \R может соответствовать одиночному CR или одинокому LF, \R{2} или \R\R не могут соответствовать одной паре CRLF. Первый \R соответствует всей паре CRLF, не оставляя ничего для второго.
\R не будет возвращаться, чтобы соответствовать только CR в паре CRLF. Таким образом, в то время как \R может соответствовать одиночному CR или одинокому LF, \R{2} или \R\R не могут соответствовать одной паре CRLF. Первый \R соответствует всей паре CRLF, не оставляя ничего для второго.
По крайней мере, так должна работать \R. Точно так же это работает в JGsoft V2, Ruby 2.0 и более поздних версиях, Java 8 и PCRE 8.13 и более поздних версиях. В Java 9 появилась ошибка, которая позволяет \R\R соответствовать одной паре CRLF. В версиях PCRE 7.0–8.12 была ошибка, из-за которой \R{2} соответствовал одной паре CRLF. В Perl есть другая ошибка с тем же результатом.
Обратите внимание, что \R ожидает совпадения только с парами CRLF. Регулярное выражение \r\R может соответствовать одной паре CRLF. После того, как \r израсходовал CR, оставшийся одинокий LF является допустимым разрывом строки для соответствия \R. Такое поведение одинаково для всех вкусов.
Восьмеричные escape-последовательности
Многие приложения также поддерживают восьмеричные escape-последовательности в виде \0377 или \377, где 377 — это восьмеричное представление позиции символа в наборе символов (в данном случае 255 десятичное число).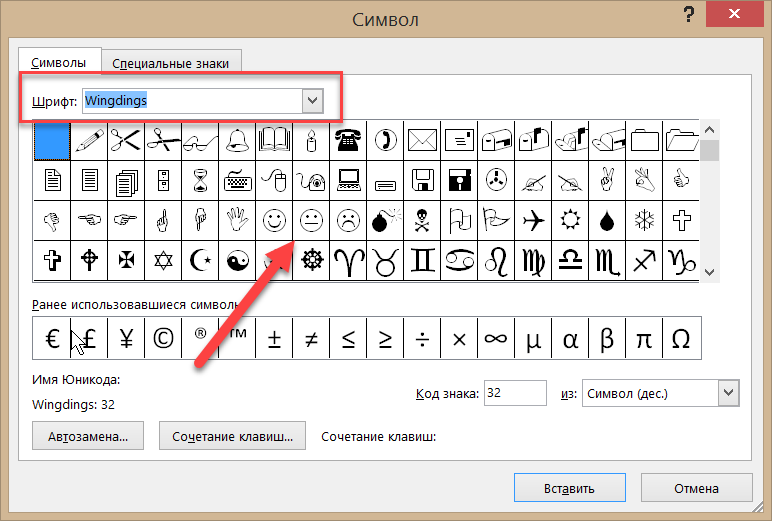 Существует много различий между разновидностями регулярных выражений в отношении количества восьмеричных цифр, разрешенных или требуемых после обратной косой черты, требуется ли начальный ноль или нет, и соответствует ли \0 без дополнительных цифр байту NULL. В некоторых разновидностях это вызывает сложности, поскольку от \1 до \77 могут быть восьмеричные escape-последовательности от 1 до 63 (десятичные) или обратные ссылки от 1 до 77 (десятичные), в зависимости от того, сколько групп захвата есть в регулярном выражении. Поэтому использование этих восьмеричных экранов в регулярных выражениях настоятельно не рекомендуется. Вместо этого используйте шестнадцатеричные escape-последовательности.
Существует много различий между разновидностями регулярных выражений в отношении количества восьмеричных цифр, разрешенных или требуемых после обратной косой черты, требуется ли начальный ноль или нет, и соответствует ли \0 без дополнительных цифр байту NULL. В некоторых разновидностях это вызывает сложности, поскольку от \1 до \77 могут быть восьмеричные escape-последовательности от 1 до 63 (десятичные) или обратные ссылки от 1 до 77 (десятичные), в зависимости от того, сколько групп захвата есть в регулярном выражении. Поэтому использование этих восьмеричных экранов в регулярных выражениях настоятельно не рекомендуется. Вместо этого используйте шестнадцатеричные escape-последовательности.
Perl 5.14, PCRE 8.34, PHP 5.5.10 и R 3.0.3 поддерживают новый синтаксис \o{377} для восьмеричных экранов. Вы можете иметь любое количество восьмеричных цифр между фигурными скобками, с начальным нулем или без него. Нет никакой путаницы с обратными ссылками, и буквенные цифры, которые следуют, четко разделены закрывающей фигурной скобкой.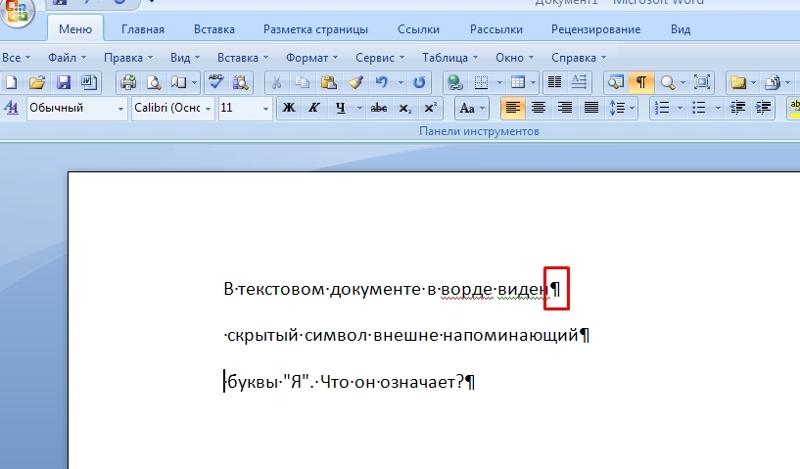 Будьте осторожны, помещайте только восьмеричные цифры между фигурными скобками. В Perl \o{что угодно} не является ошибкой, а соответствует байту NULL.
Будьте осторожны, помещайте только восьмеричные цифры между фигурными скобками. В Perl \o{что угодно} не является ошибкой, а соответствует байту NULL.
Версия JGsoft изначально поддерживала восьмеричные escape-последовательности в форме \0377. JGsoft V2 поддерживает \o{377} и интерпретирует \0377 как ошибку.
Сравнение синтаксиса регулярных выражений и синтаксиса строк
Многие языки программирования поддерживают аналогичные escape-последовательности для непечатаемых символов в их синтаксисе для литеральных строк в исходном коде. Затем такие escape-последовательности транслируются компилятором в их фактические символы, прежде чем строка будет передана механизму регулярных выражений. Если обработчик регулярных выражений не поддерживает одинаковые escape-последовательности, это может привести к очевидной разнице в поведении, когда регулярное выражение указывается в виде буквальной строки в исходном коде по сравнению с регулярным выражением, считываемым из файла или полученным от пользователя.
Аналогичная проблема существует в Python 3.2 и более ранних версиях с escape-последовательностью Unicode \uFFFF. Python поддерживает этот синтаксис как часть строковых литералов (Unicode) с тех пор, как в Python была добавлена поддержка Unicode.