Курсоры в MSSQL — перебор выборки в цикле. / MS SQL
Команды манипулирования данными SELECT, UPDATE, DELETE работают сразу с группами строк. Эти группы, вплоть до отдельных строк, можно выбрать с помощью опции WHERE. А если надо перебрать строки некоторой таблицы последовательно, одну за другой? На этот случай в языке SQL существуют курсоры. Курсор (current set of record) – временный набор строк, которые можно перебирать последовательно, с первой до последней.При работе с курсорами используются следующие команды.
Объявление курсора:
DECLARE имя_курсора CURSOR FOR SELECT текст_запроса
Любой курсор создается на основе некоторого оператора SELECT.
Открытие курсора:
OPEN имя_курсора
Для того чтобы с помощью курсора можно было читать строки, его надо обязательно открыть.
Чтение следующей строки из курсора:
FETCH имя_курсора INTO список_переменных
Переменные в списке должны быть в том же количестве и того е типа, что и столбцы курсора.
Закрытие курсора:
CLOSE имя_курсора
Для удаления курсора из памяти используется команда
DEALLOCATE имя_курсора
Для иллюстрации использования курсора создадим процедуру, которая будет выбирать данные из одной таблицы, перебирать их в курсоре анализируя, есть ли такие данные во второй таблице и вставлять в третью таблицу, если данные записи удовлетворяют определённым критериям.
CREATE PROCEDURE [dbo].[MyProcedure] AS
DECLARE @ID INT
DECLARE @QUA INT
DECLARE @VAL VARCHAR (500)
DECLARE @NAM VARCHAR (500)
/*Объявляем курсор*/
DECLARE @CURSOR CURSOR
/*Заполняем курсор*/
SET @CURSOR = CURSOR SCROLL
FOR
SELECT INDEX, QUANTITY, VALUE, NAME
FROM My_First_Table WHERE QUANTITY > 1
/*Открываем курсор*/
OPEN @CURSOR
/*Выбираем первую строку*/
FETCH NEXT FROM @CURSOR INTO @ID, @QUA, @VAL, @NAM
/*Выполняем в цикле перебор строк*/
WHILE @@FETCH_STATUS = 0
BEGIN
IF NOT EXISTS(SELECT VAL FROM My_Second_Table WHERE ID=@ID)
BEGIN
/*Вставляем параметры в третью таблицу если условие соблюдается*/
INSERT INTO My_Third_Table (VALUE, NAME) VALUE(@VAL, @NAM)
END
/*Выбираем следующую строку*/
FETCH NEXT FROM @CURSOR INTO @ID, @QUA, @VAL, @NAM
END
CLOSE @CURSOR
Вот собственно и всё.
kbss.ru
Использование курсоров и циклов в Transact-SQL | Info-Comp.ru
Сегодня будем рассматривать очень много чего интересного, например как запустить уже созданную процедуру, которая принимает параметры, массово, т.е. не только со статическим параметрами, а с параметрами, которые будут меняться, например, на основе какой-нибудь таблицы, как обычная функция, и в этом нам помогут как раз
Как Вы поняли курсоры, и циклы мы будем рассматривать применимо к конкретной задачи. А какой задачи, сейчас расскажу.
Существует процедура, которая выполняет какие-то действия, которые не может выполнить обычная функция SQL например, расчеты и insert на основе этих расчетов. И Вы ее запускаете, например вот так:
exec test_PROCEDURE par1, par2
Другими словами Вы запускаете ее только с теми параметрами, которые были указаны, но если Вам необходимо запустить данную процедуру скажем 100, 200 или еще более раз, то согласитесь это не очень удобно, т.е. долго. Было бы намного проще, если бы мы взяли и запускали процедуру как обычную функцию в запросе select, например:
select my_fun(id) from test_table
Другими словами функция отработает на каждую запись таблицы test_table, но как Вы знаете процедуру так использовать нельзя. Но существует способ, который поможет нам осуществить задуманное, точнее даже два способа первый это с использованием курсора и цикла и второй это просто с использованием цикла, но уже без курсора. Оба варианта подразумевают, что мы будем создавать дополнительную процедуру, которую в дальнейшем мы будем запускать.
Примечание! Все примеры будем писать в СУБД MSSql 2008, используя Management Studio. Также все ниже перечисленные действия требуют необходимых знаний в SQL, а точнее в программировании на Transact-SQL. Могу посоветовать для начала ознакомиться со следующим материалом:
И так приступим, и перед тем как писать процедуру, давайте рассмотрим исходные данные нашего примера.
Допустим, есть таблица test_table
CREATE TABLE [dbo].[test_table]( [number] [numeric](18, 0) NULL, [pole1] [varchar](50) NULL, [pole2] [varchar](50) NULL ) ON [PRIMARY] GO
В нее необходимо вставлять данные, на основе каких-то расчетов, которые будет выполнять процедура my_proc_test, в данном случае она просто вставляет данные, но на практике Вы можете использовать свою процедуру, которая может выполнять много расчетов, поэтому в нашем случае именно эта процедура не важна, она всего лишь для примера. Ну, давайте создадим ее:
CREATE PROCEDURE [dbo].[my_proc_test]
(@number numeric, @pole1 varchar(50), @pole2 varchar(50))
AS
BEGIN
INSERT INTO dbo.test_table (number, pole1, pole2) values (@number, @pole1, @pole2)
END
GO
Она просто принимает три параметра и вставляет их в таблицу.
И допустим эту процедуру, нам нужно запустить столько раз, сколько строк в какой-нибудь таблице или представлении (VIEWS) , другими словами запустить ее массово для каждой строки источника.
И для примера создадим такой источник, у нас это будет простая таблица test_table_vrem, а у Вас это может быть, как я уже сказал свой источник, например временная таблица или представление:
CREATE TABLE [dbo].[test_table_vrem]( [number] [numeric](18, 0) NULL, [pole1] [varchar](50) NULL, [pole2] [varchar](50) NULL ) ON [PRIMARY] GO
Заполним ее тестовыми данными:
И теперь нашу процедуру необходимо запустить для каждой строки, т.е. три раза с разными параметрами. Как Вы понимаете значения этих полей и есть наши параметры, другими словами, если бы мы запускали нашу процедуру вручную, это выглядело вот так:
exec my_proc_test 1, ‘pole1_str1’, ‘pole2_str1’
И так еще три раза, с соответствующими параметрами.
Но нам так не охота, поэтому мы напишем еще одну дополнительную процедуру, которая и будет запускать нашу основную процедуру столько раз, сколько нам нужно.
Первый вариант.
Используем курсор и цикл в процедуре
CREATE PROCEDURE [dbo].[my_proc_test_all] AS --объявляем переменные DECLARE @number bigint DECLARE @pole1 varchar(50) DECLARE @pole2 varchar(50) --объявляем курсор DECLARE my_cur CURSOR FOR SELECT number, pole1, pole2 FROM test_table_vrem --открываем курсор OPEN my_cur --считываем данные первой строки в наши переменные FETCH NEXT FROM my_cur INTO @number, @pole1, @pole2 --если данные в курсоре есть, то заходим в цикл --и крутимся там до тех пор, пока не закончатся строки в курсоре WHILE @@FETCH_STATUS = 0 BEGIN --на каждую итерацию цикла запускаем нашу основную процедуру с нужными параметрами exec dbo.my_proc_test @number, @pole1, @pole2 --считываем следующую строку курсора FETCH NEXT FROM my_cur INTO @number, @pole1, @pole2 END --закрываем курсор CLOSE my_cur DEALLOCATE my_cur GO
И теперь осталось нам ее вызвать и проверить результат:
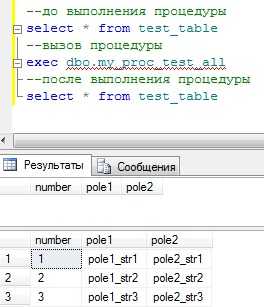
Код:
--до выполнения процедуры select * from test_table --вызов процедуры exec dbo.my_proc_test_all --после выполнения процедуры select * from test_table
Как видите, все у нас отработало как надо, другими словами процедура my_proc_test сработала все три раза, а мы всего лишь один раз запустили дополнительную процедуру.
Второй вариант.
Используем только цикл в процедуре
Сразу скажу, что здесь требуется нумерация строк во временной таблице, т.е. каждая строка должна быть пронумерована, например 1, 2, 3 таким полем у нас во временной таблице служит number.
Пишем процедуру my_proc_test_all_v2
CREATE PROCEDURE [dbo].[my_proc_test_all_v2] AS --объявляем переменные DECLARE @number bigint DECLARE @pole1 varchar(50) DECLARE @pole2 varchar(50) DECLARE @cnt int DECLARE @i int --узнаем количество строк во временной таблице select @cnt=count(*) from test_table_vrem --задаем начальное значение идентификатора set @i=1 WHILE @cnt >= @i BEGIN --присваиваем значения нашим параметрам select @number=number, @pole1= pole1, @pole2=pole2 from test_table_vrem where number = @i --на каждую итерацию цикла запускаем нашу основную процедуру с нужными параметрами exec dbo.my_proc_test @number, @pole1, @pole2 --увеличиваем шаг set @i= @i+1 END GO
И проверяем результат, но для начала очистим нашу таблицу, так как мы же ее только что уже заполнили по средствам процедуры my_proc_test_all:

--очистим таблицу delete test_table --до выполнения процедуры select * from test_table --вызов процедуры exec dbo.my_proc_test_all_v2 --после выполнения процедуры select * from test_table
Как и ожидалось результат такой же, но уже без использования курсоров. Какой вариант использовать решать Вам, первый вариант хорош, тем, что в принципе не нужна нумерация, но как Вы знаете, курсоры работают достаточно долго, если строк в курсоре будет много, а второй вариант хорош тем, что отработает, как мне кажется быстрей, опять же таки, если строк будет много, но нужна нумерация, лично мне нравится вариант с курсором, а вообще решать Вам может Вы сами придумаете что-то более удобное, я всего лишь показал основы того, как можно реализовать поставленную задачу. Удачи!
Похожие статьи:
info-comp.ru
Оптимизация SQL Server при работе с курсорами
Здравствуй, человек-читатель блогов на Community.
Хочу рассказать о своем недавнем опыте оптимизации курсора в SQL Server.
Второе, иногда без курсора не обойтись – там где не обойтись без построчного прохода по результату выборки. Вот в таких случаях очень важно правильно создать нужный тип курсора – тот, который соответствует решаемой задаче. Общий синтаксис объявления курсора имеет вид:
DECLARE cursor_name CURSOR
[ LOCAL | GLOBAL ]
[ FORWARD_ONLY | SCROLL ]
[ STATIC | KEYSET | DYNAMIC | FAST_FORWARD ]
[ READ_ONLY | SCROLL_LOCKS | OPTIMISTIC ]
[ TYPE_WARNING ]
FOR select_statement
[ FOR UPDATE [ OF column_name [ ,…n ] ] ] [;]
Остановлюсь на первых трех строчках ключевых параметров.
LOCAL или GLOBAL: если хотим, чтобы курсор был доступен другим процедурам, функциям, пакетам в рамках нашей сессии, то GLOBAL – в этом случае за удалением курсора следим сами (команда DEALLOCATE). Во всех остальных случаях (т.е. в подавляющем своем большинстве) – LOCAL. Внимание, по умолчанию создается именно GLOBAL курсор!
FORWARD_ONLY или SCROLL: если хотим ходить по курсору, как ненормальные, туда-сюда, то SCROLL, иначе – FORWARD_ONLY. Внимание, по умолчанию создается SCROLL курсор!
STATIC или KEYSET, DYNAMIC, FAST_FORWARD: если хотим, чтобы при проходе по курсору отображалась актуальная информация из таблицы (т.е., если после открытия курсора, мы поменяли информацию в одном из полей таблицы и хотим, чтобы при проходе по курсору в нужной строчке курсора была уже обновленная информация), то используем или KEYSET (если КАЖДАЯ таблица, участвующая в выборке, имеет уникальный индекс) или DYNAMIC (самый медленный тип). Если же нам нужен снимок результата выборки после открытия курсора – STATIC (самый быстрый тип – копия результата выборки копируется в базу tempdb и работаем уже с ней). FAST_FORWARD = KEYSET+FORWARD_ONLY+READ_ONLY – пацаны из инета пишут, что STATIC дольше открывается (т.к. создается копия в tempdb), но быстрее работает, а FAST_FORWARD – наоборот. Так что если количество записей велико (насколько большое показывает практика), то применяем STATIC, иначе – FAST_FORWARD. Внимание, по умолчанию создается DYNAMIC курсор.
Таким образом, для большого кол-ва записей в большинстве случаев мой выбор:
DECLARE cursor_name CURSOR LOCAL FORWARD_ONLY STATIC FOR
select_statement
для небольшого кол-ва записей:
DECLARE cursor_name CURSOR LOCAL FAST_FORWARD FOR
select_statement
Теперь перейдем к практике (что собственно и подтолкнуло меня к писанине сего).
Испокон веков при объявлении курсора я применял конструкцию DECLARE … CURSOR LOCAL FOR…
При разработке интеграции с одной очень нехорошей базой, в которой нет ни одного индекса и не одного ключа, я применил тот же подход при объявлении курсоров, что и всегда. Выборка одного курсора содержала 225 000 записей. В результате процесс импорта данных из такой базы занял 15 часов 14 минут !!! И хотя импорт и был первичный (т.е. одноразовый), но даже для нормального тестирования такого импорта потребовалось бы несколько суток! После замены вышеназванной конструкции при объявлении курсора на DECLARE .. CURSOR LOCAL FORWARD_ONLY STATIC FOR.. весь процесс импорта занял … внимание … 10 минут 5 секунд !!! Так что игра точно стоит свеч.
Хочу повториться, что идеальный вариант — это все же не использовать курсоры вообще — для СУБД MS SQL намного роднее реляционный, а не навигационный подход.
community.terrasoft.ru
НОУ ИНТУИТ | Лекция | Курсоры: принципы работы
Аннотация: Дается определение курсора. Приводится описание его типов и поведения: статические, динамические, последовательные и ключевые курсоры. Описываются принципы управления курсором: создание и открытие курсора, считывание данных, закрытие курсора. Приводятся примеры программирования курсора.
Понятие курсора
Запрос к реляционной базе данных обычно возвращает несколько рядов (записей) данных, но приложение за один раз обрабатывает лишь одну запись. Даже если оно имеет дело одновременно с несколькими рядами (например, выводит данные в форме электронных таблиц), их количество по-прежнему ограничено. Кроме того, при модификации, удалении или добавлении данных рабочей единицей является ряд. В этой ситуации на первый план выступает концепция курсора, и в таком контексте курсор – указатель на ряд.
Курсор в SQL – это область в памяти базы данных, которая предназначена для хранения последнего оператора SQL. Если текущий оператор – запрос к базе данных, в памяти сохраняется и строка данных запроса, называемая текущим значением, или текущей строкой курсора. Указанная область в памяти поименована и доступна для прикладных программ.
Обычно курсоры используются для выбора из базы данных некоторого подмножества хранимой в ней информации. В каждый момент времени прикладной программой может быть проверена одна строка курсора. Курсоры часто применяются в операторах SQL, встроенных в написанные на языках процедурного типа прикладные программы. Некоторые из них неявно создаются сервером базы данных, в то время как другие определяются программистами.
В соответствии со стандартом SQL при работе с курсорами можно выделить следующие основные действия:
- создание или объявление курсора ;
- открытие курсора, т.е. наполнение его данными, которые сохраняются в многоуровневой памяти ;
- выборка из курсора и изменение с его помощью строк данных;
- закрытие курсора, после чего он становится недоступным для пользовательских программ;
- освобождение курсора, т.е. удаление курсора как объекта, поскольку его закрытие необязательно освобождает ассоциированную с ним память.
В разных реализациях определение курсора может иметь некоторые отличия. Так, например, иногда разработчик должен явным образом освободить выделяемую для курсора память. После освобождения курсора ассоциированная с ним память также освобождается. При этом становится возможным повторное использование его имени. В других реализациях при закрытии курсора освобождение памяти происходит неявным образом. Сразу после восстановления она становится доступной для других операций: открытие другого курсора и т.д.
В некоторых случаях применение курсора неизбежно. Однако по возможности этого следует избегать и работать со стандартными командами обработки данных: SELECT, UPDATE, INSERT, DELETE. Помимо того, что курсоры не позволяют проводить операции изменения над всем объемом данных, скорость выполнения операций обработки данных посредством курсора заметно ниже, чем у стандартных средств SQL.
Реализация курсоров в среде MS SQL Server
SQL Server поддерживает три вида курсоров:
- курсоры SQL применяются в основном внутри триггеров, хранимых процедур и сценариев;
- курсоры сервера действуют на сервере и реализуют программный интерфейс приложений для ODBC, OLE DB, DB_Library;
- курсоры клиента реализуются на самом клиенте. Они выбирают весь результирующий набор строк из сервера и сохраняют его локально, что позволяет ускорить операции обработки данных за счет снижения потерь времени на выполнение сетевых операций.
Различные типы многопользовательских приложений требуют и различных типов организации параллельного доступа к данным. Некоторым приложениям необходим немедленный доступ к информации об изменениях в базе данных. Это характерно для систем резервирования билетов. В других случаях, например, в системах статистической отчетности, важна стабильность данных, ведь если они постоянно модифицируются, программы не смогут эффективно отображать информацию. Различным приложениям нужны разные реализации курсоров.
В среде SQL Server типы курсоров различаются по предоставляемым возможностям. Тип курсора определяется на стадии его создания и не может быть изменен. Некоторые типы курсоров могут обнаруживать изменения, сделанные другими пользователями в строках, включенных в результирующий набор. Однако SQL Server отслеживает изменения таких строк только на стадии обращения к строке и не позволяет отслеживать изменения, когда строка уже считана.
Курсоры делятся на две категории: последовательные и прокручиваемые. Последовательные позволяют выбирать данные только в одном направлении – от начала к концу. Прокручиваемые же курсоры предоставляют большую свободу действий – допускается перемещение в обоих направлениях и переход к произвольной строке результирующего набора курсора.Если программа способна модифицировать данные, на которые указывает курсор, он называется прокручиваемым и модифицируемым. Говоря о курсорах, не следует забывать об изолированности транзакций. Когда один пользователь модифицирует запись, другой читает ее при помощи собственного курсора, более того, он может модифицировать ту же запись, что делает необходимым соблюдение целостности данных.
SQL Server поддерживает курсоры статические, динамические, последовательные и управляемые набором ключей.
В схеме со статическим курсором информация читается из базы данных один раз и хранится в виде моментального снимка (по состоянию на некоторый момент времени), поэтому изменения, внесенные в базу данных другим пользователем, не видны. На время открытия курсора сервер устанавливает блокировку на все строки, включенные в его полный результирующий набор. Статический курсор не изменяется после создания и всегда отображает тот набор данных, который существовал на момент его открытия.
Если другие пользователи изменят в исходной таблице включенные в курсор данные, это никак не повлияет на статический курсор.
В статический курсор внести изменения невозможно, поэтому он всегда открывается в режиме «только для чтения».
Динамический курсор поддерживает данные в «живом» состоянии, но это требует затрат сетевых и программных ресурсов. При использовании динамических курсоров не создается полная копия исходных данных, а выполняется динамическая выборка из исходных таблиц только при обращении пользователя к тем или иным данным. На время выборки сервер блокирует строки, а все изменения, вносимые пользователем в полный результирующий набор курсора, будут видны в курсоре. Однако если другой пользователь внес изменения уже после выборки данных курсором, то они не отразятся в курсоре .
Курсор, управляемый набором ключей, находится посередине между этими крайностями. Записи идентифицируются на момент выборки, и тем самым отслеживаются изменения . Такой тип курсора полезен при реализации прокрутки назад – тогда добавления и удаления рядов не видны, пока информация не обновится, а драйвер выбирает новую версию записи, если в нее были внесены изменения.
Последовательные курсоры не разрешают выполнять выборку данных в обратном направлении. Пользователь может выбирать строки только от начала к концу курсора . Последовательный курсор не хранит набор всех строк. Они считываются из базы данных, как только выбираются в курсоре, что позволяет динамически отражать все изменения, вносимые пользователями в базу данных с помощью команд INSERT, UPDATE, DELETE. В курсоре видно самое последнее состояние данных.
Статические курсоры обеспечивают стабильный взгляд на данные. Они хороши для систем «складирования» информации: приложений для систем отчетности или для статистических и аналитических целей. Кроме того, статический курсор лучше других справляется с выборкой большого количества данных. Напротив, в системах электронных покупок или резервирования билетов необходимо динамическое восприятие обновляемой информации по мере внесения изменений. В таких случаях используется динамический курсор. В этих приложениях объем передаваемых данных, как правило, невелик, а доступ к ним осуществляется на уровне рядов (отдельных записей). Групповой доступ встречается очень редко.
www.intuit.ru
Создание и использование курсоров в СУБД MS SQL Server. — МегаЛекции
Курсор в SQL – это область в памяти базы данных, которая предназначена для хранения последнего оператора SQL. Если текущий оператор – запрос к базе данных, в памяти сохраняется и строка данных запроса, называемая текущим значением, или текущей строкой курсора. Указанная область в памяти поименована и доступна для прикладных программ.
В соответствии со стандартом SQL при работе с курсорами можно выделить следующие основные действия:
- создание или объявление курсора ;
- открытие курсора, т.е. наполнение его данными, которые сохраняются в многоуровневой памяти ;
- выборка из курсора и изменение с его помощью строк данных;
- закрытие курсора, после чего он становится недоступным для пользовательских программ;
- освобождение курсора, т.е. удаление курсора как объекта, поскольку его закрытие необязательно освобождает ассоциированную с ним память.
SQL Server поддерживает три вида курсоров:
- курсоры SQL применяются в основном внутри триггеров, хранимых процедур и сценариев;
- курсоры сервера действуют на сервере и реализуют программный интерфейс приложений для ODBC, OLE DB, DB_Library;
- курсоры клиента реализуются на самом клиенте. Они выбирают весь результирующий набор строк из сервера и сохраняют его локально, что позволяет ускорить операции обработки данных за счет снижения потерь времени на выполнение сетевых операций.
Управление курсором в среде MS SQL Server
Управление курсором реализуется путем выполнения следующих команд:
- DECLARE – создание или объявление курсора ;
- OPEN – открытие курсора, т.е. наполнение его данными;
- FETCH – выборка из курсора и изменение строк данных с помощью курсора;
- CLOSE – закрытие курсора ;
- DEALLOCATE – освобождение курсора, т.е. удаление курсора как объекта.
Объявление курсора
В стандарте SQL для создания курсора предусмотрена следующая команда:
::= DECLARE имя_курсора [INSENSITIVE][SCROLL] CURSOR FOR SELECT_оператор [FOR { READ_ONLY | UPDATE [OF имя_столбца[,…n]]}]При использовании ключевого слова INSENSITIVE будет создан статический курсор. Изменения данных не разрешаются, кроме того, не отображаютсяизменения, сделанные другими пользователями. Если ключевое слово INSENSITIVE отсутствует, создается динамический курсор.
При указании ключевого слова SCROLL созданный курсор можно прокручивать в любом направлении, что позволяет применять любые команды выборки. Если этот аргумент опускается, то курсор окажется последовательным, т.е. его просмотр будет возможен только в одном направлении – от начала к концу.
SELECT-оператор задает тело запроса SELECT, с помощью которого определяется результирующий набор строк курсора.
При указании аргумента FOR READ_ONLY создается курсор «только для чтения», и никакие модификации данных не разрешаются. Он отличается отстатического, хотя последний также не позволяет менять данные. В качестве курсора «только для чтения» может быть объявлен динамический курсор, что позволит отображать изменения, сделанные другим пользователем.
Создание курсора с аргументом FOR UPDATE позволяет выполнять в курсоре изменение данных либо в указанных столбцах, либо, при отсутствии аргумента OF имя_столбца, во всех столбцах.
В среде MS SQL Server принят следующий синтаксис команды создания курсора:
::= DECLARE имя_курсора CURSOR [LOCAL | GLOBAL] [FORWARD_ONLY | SCROLL] [STATIC | KEYSET | DYNAMIC | FAST_FORWARD] [READ_ONLY | SCROLL_LOCKS | OPTIMISTIC] [TYPE_WARNING] FOR SELECT_оператор [FOR UPDATE [OF имя_столбца[,…n]]]При использовании ключевого слова LOCAL будет создан локальный курсор, который виден только в пределах создавшего его пакета, триггера, хранимой процедуры или пользовательской функции. По завершении работы пакета, триггера, процедуры или функции курсор неявно уничтожается. Чтобы передать содержимое курсора за пределы создавшей его конструкции, необходимо присвоить его параметру аргумент OUTPUT.
Если указано ключевое слово GLOBAL, создается глобальный курсор ; он существует до закрытия текущего соединения.
При указании FORWARD_ONLY создается последовательный курсор ; выборку данных можно осуществлять только в направлении от первой строки к последней.
При указании SCROLL создается прокручиваемый курсор ; обращаться к данным можно в любом порядке и в любом направлении.
При указании STATIC создается статический курсор.
При указании KEYSET создается ключевой курсор.
При указании DYNAMIC создается динамический курсор.
Если для курсора READ_ONLY указать аргумент FAST_FORWARD, то созданный курсор будет оптимизирован для быстрого доступа к данным. Этот аргумент не может быть использован совместно с аргументами FORWARD_ONLY и OPTIMISTIC.
В курсоре, созданном с указанием аргумента OPTIMISTIC, запрещается изменение и удаление строк, которые были изменены после открытия курсора.
При указании аргумента TYPE_WARNING сервер будет информировать пользователя о неявном изменении типа курсора, если он несовместим с запросомSELECT.
Открытие курсора
Для открытия курсора и наполнения его данными из указанного при создании курсора запроса SELECT используется следующая команда:
OPEN {{[GLOBAL]имя_курсора } |@имя_переменной_курсора}После открытия курсора происходит выполнение связанного с ним оператора SELECT, выходные данные которого сохраняются в многоуровневой памяти.
Выборка данных из курсора
Сразу после открытия курсора можно выбрать его содержимое (результат выполнения соответствующего запроса) посредством следующей команды:
FETCH [[NEXT | PRIOR | FIRST | LAST | ABSOLUTE {номер_строки | @переменная_номера_строки} | RELATIVE {номер_строки | @переменная_номера_строки}] FROM ]{{[GLOBAL ]имя_курсора }| @имя_переменной_курсора } [INTO @имя_переменной [,…n]]При указании FIRST будет возвращена самая первая строка полного результирующего набора курсора, которая становится текущей строкой.
При указании LAST возвращается самая последняя строка курсора. Она же становится текущей строкой.
При указании NEXT возвращается строка, находящаяся в полном результирующем наборе сразу же после текущей. Теперь она становится текущей. По умолчанию команда FETCH использует именно этот способ выборки строк.
Ключевое слово PRIOR возвращает строку, находящуюся перед текущей. Она и становится текущей.
Аргумент ABSOLUTE {номер_строки | @переменная_номера_строки} возвращает строку по ее абсолютному порядковому номеру в полном результирующем наборе курсора. Номер строки можно задать с помощью константы или как имя переменной, в которой хранится номер строки. Переменная должна иметь целочисленный тип данных. Указываются как положительные, так и отрицательные значения. При указании положительного значения строка отсчитывается от начала набора, отрицательного – от конца. Выбранная строка становится текущей. Если указано нулевое значение, строка не возвращается.
Аргумент RELATIVE {кол_строки | @переменная_кол_строки} возвращает строку, находящуюся через указанное количество строк после текущей. Если указать отрицательное значение числа строк, то будет возвращена строка, находящаяся за указанное количество строк перед текущей. При указании нулевого значения возвратится текущая строка. Возвращенная строка становится текущей.
Чтобы открыть глобальный курсор, перед его именем требуется указать ключевое слово GLOBAL. Имя курсора также может быть указано с помощью переменной.
В конструкции INTO @имя_переменной [,…n] задается список переменных, в которых будут сохранены соответствующие значения столбцов возвращаемой строки. Порядок указания переменных должен соответствовать порядку столбцов в курсоре, а тип данных переменной – типу данных в столбце курсора. Если конструкция INTO не указана, то поведение команды FETCH будет напоминать поведение команды SELECT – данные выводятся на экран.
Рекомендуемые страницы:
Воспользуйтесь поиском по сайту:
megalektsii.ru
sql-server — Курсор SQL медленный
Я начинаю с первого использования курсора в хранимой процедуре в sql server 2008. Я сделал предварительное чтение, и я понимаю, что они имеют значительные ограничения производительности. В моем текущем случае я думаю, что они необходимы (я хочу запустить несколько хранимых процедур для каждого символа запаса в таблице символов.
Изменить: Скроки, которые я буду называть каждым символом, в большинстве случаев будут выполнять операции вставки для вычисления значений, зависящих от символа, таких как 5-дневная скользящая средняя, средний дневной объем, ATR (средний истинный диапазон). Большинство из этих значений будут вычисляться по данным ежедневной таблицы цен и томов… Я хотел бы упорядочить поиск значений данных, которые будут извлекаться избыточно в противном случае… например, я хотел бы получить для каждого символ ежедневных данных о ценах и объемах в переменную таблицы… эта временная таблица будет передана в хранимую процедуру, которая вызывает каждую из агрегированных функций, о которых я только что упомянул. Надеюсь, что это имеет смысл…
Итак, моя начальная хранимая процедура на основе курсора «внешний цикл» находится ниже.. он истекает через несколько минут, не возвращая ничего в окно вывода.
ALTER PROCEDURE dbo.sprocSymbolDependentAggsDriver2
AS
DECLARE @symbol nchar(10)
DECLARE symbolCursor CURSOR
STATIC FOR
SELECT Symbol FROM tblSymbolsMain ORDER BY Symbol
OPEN symbolCursor
FETCH NEXT FROM symbolCursor INTO @symbol
WHILE @@FETCH_STATUS = 0
SET @symbol = @symbol + ': Test.'
FETCH NEXT FROM symbolCursor INTO @symbol
CLOSE symbolCursor
DEALLOCATE symbolCursor
Когда я запускаю его без локальной переменной @symbol и исключаю его назначение в цикле while, он, кажется, работает нормально. Существует ли явное нарушение лучших практик в рамках этого задания? Спасибо..
задан StatsViaCsh 15 февр. ’12 в 19:462012-02-15 19:46 источник поделитьсяqaru.site
sql — SQL Server: распечатать значения курсора
Хотя я не уверен, что это самый эффективный способ сделать это (лучше было бы SQL Server подавать данные на что-то, предназначенное для создания отображаемых данных, SSRS или даже Excel), вот что я буду делать как Начало:
--Create somewhere to put the proc data and fill it. This will give us something tangible to query against.
CREATE TABLE #NotPaid
(
bookingID INT ,
totalCost DECIMAL(7, 2) ,
bookingDate DATE ,
paymentConfirmation VARCHAR(50) ,
customersID INT ,
firstname VARCHAR(50) ,
surname VARCHAR(50) ,
contactNum VARCHAR(50)
)
CREATE TABLE #HasPaid
(
bookingID INT ,
totalCost DECIMAL(7, 2) ,
bookingDate DATE ,
paymentConfirmation VARCHAR(50) ,
customersID INT ,
firstname VARCHAR(50) ,
surname VARCHAR(50) ,
contactNum VARCHAR(50)
)
INSERT #NotPaid
EXEC AdminReport1
INSERT #HasPaid
EXEC AdminReport2
--Variables for use in our cursor. I'm only loading one table up as a demonstration.
DECLARE @bookingID INT ,
@totalCost DECIMAL(7, 2) ,
@bookingDate DATE ,
@paymentConfirmation VARCHAR(50) ,
@customersID INT ,
@firstname VARCHAR(50) ,
@surname VARCHAR(50) ,
@contactNum VARCHAR(50)
DECLARE @Library CURSOR
SET
@Library = CURSOR FOR
SELECT bookingID ,
totalCost ,
bookingDate ,
paymentConfirmation ,
customersID ,
firstname,
surname ,
contactNum FROM #HasPaid
--Run the cursor and print out the variables as we loop again. Any formatting will need to be done in here. Again, I'm not sure this is the best way to achieve what you are trying to achieve.
OPEN @Library
FETCH NEXT FROM @getProductID INTO @bookingID, @totalCost, @bookingDate,
@paymentConfirmation, @customersID, @firstname, @surname, @contactNum
PRINT 'I''m a header line'
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT @firstname + ' Hasnt paid! His booking date is ' + STR(@bookingDate)
+ '. This is the middle part'
FETCH NEXT FROM @Library INTO @bookingID, @totalCost, @bookingDate,
@paymentConfirmation, @customersID, @firstname, @surname, @contactNum
END
PRINT 'I''m at the bottom'
CLOSE @Library
DEALLOCATE @Library
GO
Это должно дать вам неплохое стартовое место.
Что касается общей эффективности, было бы лучше иметь только один прок, и вы передаете информацию, которую хотите, поэтому передайте тот факт, что вы просто хотите Paids или просто хотите NotPaids или всех. И чтобы быть скучным, SQL на самом деле не место для такого типа форматирования. Для этого есть намного лучшие инструменты!
qaru.site