вложенные запросы и временные таблицы
Добро пожаловать в следующую статью из цикла про SQL! В предыдущей статье мы считали Transactions и Gross для приложения на двух платформах и получили отдельный результат для каждого приложения.
Transactions и Gross для приложения «3 in a row». Скриншот из демо devtodevНо что если мы хотим обобщить его и для каждой метрики иметь только одно значение? Для этого мы будем использовать результат, получившийся с помощью операции union, как таблицу в операторе from. И затем в select вычислять сумму по полю transactions и gross из объединенной таблицы (скриншот выше).
Залогиньтесь на сайте, зайдите в демо и найдите SQL отчёт во вкладке Reports.
Результат запроса. Скриншот из демо devtodevselect ‘Metrics for all projects’ as «App»
, sum(transactions) as «Transactions»
, sum(gross) as «Gross»
from (
select count() as transactions
, sum(priceusd) as gross
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date union all
select count() as «Transactions»
, sum(priceusd) as «Gross»
from p104704.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
) as metrics_by_platform
Оператор from теперь содержит целый запрос внутри себя, который обращается сразу к двум таблицам. Тоже самое можно провернуть и с внутренним запросом, добавив в каждый из from еще запрос select, если это необходимо. Важно, чтобы такие запросы были заключены в скобки и им было дано имя – имя результирующей таблицы.
) as metrics_by_platform
Такую конструкцию можно использовать во всех операторах, обращающихся к таблицам. Например, в join
.
Inner join (select … from … where …) as join_table
on join_table.param = t.param
Метрики по отдельным приложениям и суммарно по всем
Давайте в одном запросе посчитаем суммарные метрики по всем приложениям, а также выведем расшифровку (метрики по каждому из приложений) ниже.
Результат запроса. Скриншот из демо devtodevselect ‘Metrics for all projects’ as «App»
, sum(transactions) as «Transactions»
, sum(gross) as «Gross»
from (
select ‘3 in a row. iOS’ as «App»
, count() as transactions
, sum(priceusd) as gross
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_dateunion all
select ‘3 in a row. Android’ as «App»
, count() as transactions
, sum(priceusd) as gross
from p104704.paymentswhere eventtime > current_date — interval ‘7 day’ and eventtime < current_date
) metrics_by_platformunion all
select ‘3 in a row.iOS’ as «App»
, count() as transactions
, sum(priceusd) as gross
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_dateunion
select ‘3 in a row. Android’ as «App»
, count() as «Transactions»
, sum(priceusd) as «Gross»
from p104704.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
order by 3 desc
Получается довольно громоздкий запрос, в котором мы по два раза обращаемся к каждой из таблиц payments, и к тому же мы два раза написали один и тот же код (при изменении запроса нам придётся вносить изменения в двух местах).
Чтобы избежать этого, мы можем создать представление (Common Table Expression – CTE), и затем в ходе запроса обращаться к нему несколько раз. Конструкция может содержать в себе сколь угодно сложные запросы и обращаться к другим представлениям.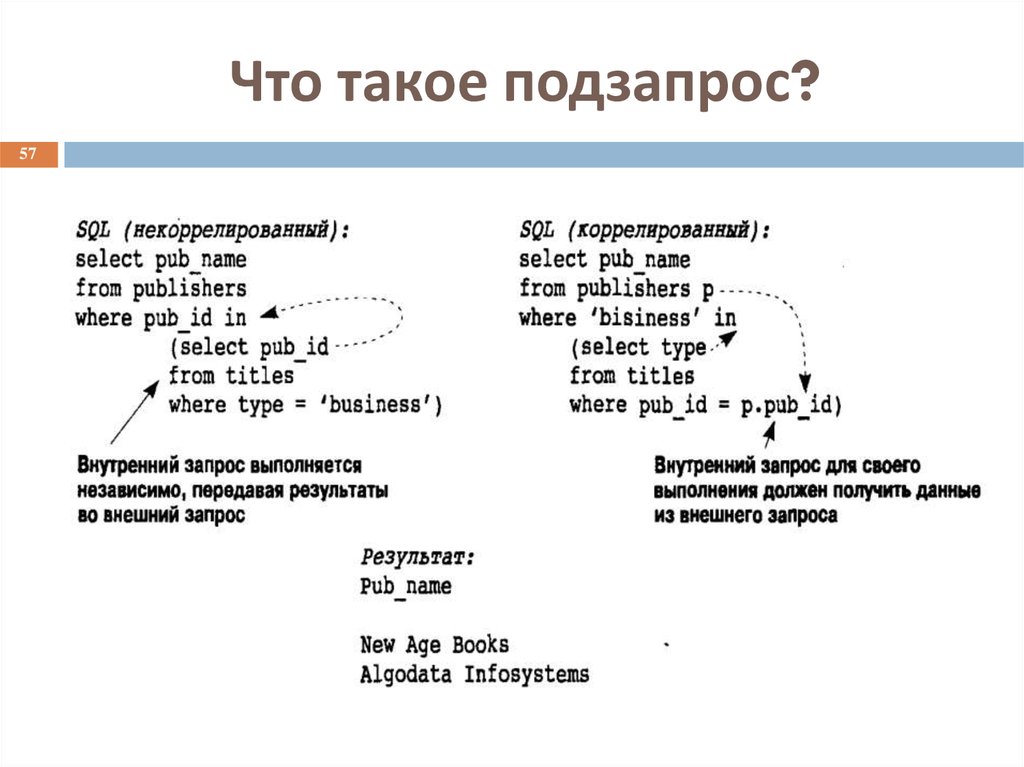 Она выглядит следующим образом:
Она выглядит следующим образом:
with temp_table_name as
(select … from …)
Можно сказать, что мы создаем временную таблицу, которая рассчитывается один раз в ходе выполнения запроса даже если вы обращаетесь к ней из разных мест. Использование представлений CTE также сильно упрощает чтение запроса и его последующее редактирование.
Вот как вышеуказанный запрос будет выглядеть с использованием представлений CTE:
with metrics_by_platform as (
select ‘3 in a row. iOS’ as app
, count() as transactions
, sum(priceusd) as gross
from p102968.payments
where eventtime > current_date — interval ‘9 day’ and eventtime < current_dateunion all
select ‘3 in a row. Android’ as app
, count() as transactions
, sum(priceusd) as gross
from p104704.payments
where eventtime > current_date — interval ‘9 day’ and eventtime < current_date
)
select ‘Metrics for all projects’ as «App»
, sum(transactions) as «Transactions»
, sum(gross) as «Gross»
from metrics_by_platformunion all
select app
, transactions
, gross
from metrics_by_platform
order by 3 desc
Выглядит проще, не правда ли? Если мы добавим новое приложение и захотим анализировать и его метрики, мы просто добавим его в представление metrics_by_platform, а расчет самих метрик и итоговый вывод результатов никак не зависит от количества приложений.
Доля пользователей, совершивших максимальное количество платежей (вложенные запросы)
Рассмотрим более сложный пример. Давайте узнаем, какое максимальное число платежей совершено одним пользователем за 7 дней и сколько таких пользователей.
Сложные запросы всегда лучше писать частями, и начнем мы с максимального количества платежей.
У нас есть таблица со всеми платежами пользователей from p102968.payment. Из нее мы посчитаем количество совершенных платежей для каждого из пользователей, сгруппировав их по devtodevid, а потом найдем максимальное число таких платежей с помощью
Результат запроса.select max(user_payments) as «max_payments»
from (
select devtodevid
, count() user_payments
from p102968.payments
where eventtime > current_date — interval ‘9 day’ and eventtime < current_date
group by devtodevid
) as payments_count
 Скриншот из демо devtodev
Скриншот из демо devtodevОсталось узнать, сколько пользователей совершили 12 платежей за это же время. Для этого только что выполненный запрос мы помещаем в фильтр where user_payments = (запрос), который оставит нам только пользователей с соответствующим максимальному количеством платежей. Сам запрос будет возвращать число таких пользователей select count() as «Users» и максимальное количество платежей max(user_payments) as «Max payments count» из таблицы from (…) as payments_count
.Результат запроса. Скриншот из демо devtodevselect count(devtodevid) as «Users»
, max(user_payments) as «Max payments count»
from (
select devtodevid
, count() user_payments
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
group by devtodevid
) as payments_countwhere user_payments = (select max(user_payments)
from
(select devtodevid
, count() user_payments
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
group by devtodevid) as payments_count
)
При выполнении для каждой строчки из внешнего запроса будет производиться сравнение
with payments_count as (
select devtodevid
, count() user_payments
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
group by devtodevid
)select count() as «Users»
, max(user_payments) as «Payments count»
from payments_count
where user_payments = (select max(user_payments)
from payments_count
А какова доля пользователей с таким количеством платежей среди всех платящих пользователей? Может быть он всего один и платил?
Чтобы узнать это, мы должны добавить вложенный запрос прямо в select, который посчитает всех платящих пользователей.
Результат запроса. Скриншот из демо devtodevwith payments_count as (
select devtodevid
, count() user_payments
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
group by devtodevid
)select count() as «Users with max payments count»
, max(user_payments) as «Payments count»
, round(count()*100::numeric / (select count(distinct devtodevid)
from p102968.payments
where eventtime > current_date — interval ‘7 day’ and eventtime < current_date
, 2) ||’%’ as «% of all payers»
from payments_count
where user_payments = (select max(user_payments)
from payments_count)
 Они часто используются для расчета доли от чего-либо, либо отображения информации из другой таблицы без использования join.
Они часто используются для расчета доли от чего-либо, либо отображения информации из другой таблицы без использования join.P.S.
В этой статье мы рассмотрели несколько примеров использования временных таблиц и вложенных запросов. В следующий раз вы научитесь заполнять пустые даты на графиках и формировать гистограмму распределения.
Вложенные запросы SQL — CodeTown.ru
Здравствуйте, уважаемые читатели! В этой статье мы поговорим о том, что такое вложенные запросы в SQL. Традиционно, рассмотрим несколько примеров с той базой данных, которую создавали в первых статьях.
Введение
Итак, само название говорит о том, что запрос во что-то вложен. Так вот, вложенный запрос в SQL означает, что запрос select выполняется в еще одном запросе select — на самом деле вложенность может быть и многоуровневой, то есть select в select в select и т.д.
Такие запросы обычно используются для получения данных из двух и более таблиц. Они нужны чтобы данные из разных таблиц можно было соотнести и по зависимости осуществить выборку. У вложенных запросов есть и недостаток — зачастую слишком долгое время работы занимает запрос, потому что идет большая нагрузка на сервер. Тем не менее, саму конструкцию необходимо знать и использовать при возможности.
У вложенных запросов есть и недостаток — зачастую слишком долгое время работы занимает запрос, потому что идет большая нагрузка на сервер. Тем не менее, саму конструкцию необходимо знать и использовать при возможности.
Структура ранее созданных таблиц
Прежде чем перейдем к простому примеру, напомним структуру наших таблиц, с которыми будем работать:
- Таблица Salespeople (продавцы):
| snum | sname | city | comm |
|---|---|---|---|
| 1 | Колованов | Москва | 10 |
| 2 | Петров | Тверь | 25 |
| 3 | Плотников | Москва | 22 |
| 4 | Кучеров | Санкт-Петербург | 28 |
| 5 | Малкин | Санкт-Петербург | 18 |
| 6 | Шипачев | Челябинск | 30 |
| 7 | Мозякин | Одинцово | 25 |
| 8 | Проворов | Москва | 25 |
- Таблица Customers (покупатели):
| сnum | сname | city | rating | snum |
|---|---|---|---|---|
| 1 | Деснов | Москва | 90 | 6 |
| 2 | Краснов | Москва | 95 | 7 |
| 3 | Кириллов | Тверь | 96 | 3 |
| 4 | Ермолаев | Обнинск | 98 | 3 |
| 5 | Колесников | Серпухов | 98 | 5 |
| 6 | Пушкин | Челябинск | 90 | 4 |
| 7 | Лермонтов | Одинцово | 85 | 1 |
| 8 | Белый | Москва | 89 | 3 |
| 9 | Чудинов | Москва | 96 | 2 |
| 10 | Лосев | Одинцово | 93 | 8 |
- Таблица Orders (заказы)
| onum | amt | odate | cnum | snum |
|---|---|---|---|---|
| 1001 | 128 | 2016-01-01 | 9 | 4 |
| 1002 | 1800 | 2016-04-10 | 10 | 7 |
| 1003 | 348 | 2017-04-08 | 2 | 1 |
| 1004 | 500 | 2016-06-07 | 3 | 3 |
| 1005 | 499 | 2017-12-04 | 5 | 4 |
| 1006 | 320 | 2016-03-03 | 5 | 4 |
| 1007 | 80 | 2017-09-02 | 7 | 1 |
| 1008 | 780 | 2016-03-07 | 1 | 3 |
| 1009 | 560 | 2017-10-07 | 3 | 7 |
| 1010 | 900 | 2016-01-08 | 6 | 8 |
Основы вложенных запросов в SQL
Вывести сумму заказов и дату, которые проводил продавец с фамилией Колованов.
Начнем с такого примера и для начала вспомним, как бы делали этот запрос ранее: посмотрели бы в таблицу Salespeople, определили бы snum продавца Колыванова — он равен 1. И выполнили бы запрос SQL с помощью условия WHERE. Вот пример такого SQL запроса:
SELECT amt, odate FROM orders WHERE snum = 1
Очевидно, какой будет вывод:
| amt | odate |
|---|---|
| 348 | 2017-04-08 |
| 80 | 2017-09-02 |
Такой запрос, очевидно, не очень универсален, если нам захочется выбрать тоже самое для другого продавца, то всегда придется определять его snum. А теперь посмотрим на вложенный запрос:
SELECT amt, odate
FROM orders
where snum = (SELECT snum
FROM salespeople
WHERE sname = 'Колованов')
В этом примере мы определяем с помощью вложенного запроса идентификатор snum по фамилии из таблицы salespeople, а затем, в таблице orders определяем по этому идентификатору нужные нам значения. Таким образом работают вложенные запросы SQL.
Таким образом работают вложенные запросы SQL.
Рассмотрим еще один пример:
Показать уникальные номера и фамилии продавцов, которые провели сделки в 2016 году.
SELECT snum, sname
FROM salespeople
where snum IN (SELECT snum
FROM orders
WHERE YEAR(odate) = 2016)
Этот SQL запрос отличается тем, что вместо знака = здесь используется оператор IN. Его следует использовать в том случае, если вложенный подзапрос SQL возвращает несколько значений. То есть в запросе происходит проверка, содержится ли идентификатор snum из таблицы salespeople в массиве значений, который вернул вложенный запрос. Если содержится, то SQL выдаст фамилию этого продавца.
Получился такой результат:
| snum | sname |
|---|---|
| 3 | Плотников |
| 4 | Кучеров |
| 7 | Мозякин |
| 8 | Проворов |
Вложенные запросы SQL с несколькими параметрами
Те примеры, которые мы уже рассмотрели, сравнивали в условии WHERE одно поле. Это конечно хорошо, но стоит отметить, что в SQL предусмотрена возможность сравнения сразу нескольких полей, то есть можно использовать вложенный запрос с несколькими параметрами.
Это конечно хорошо, но стоит отметить, что в SQL предусмотрена возможность сравнения сразу нескольких полей, то есть можно использовать вложенный запрос с несколькими параметрами.
Вывести пары покупателей и продавцов, которые осуществили сделку между собой в 2017 году.
Запрос чем то похож на предыдущий, только теперь мы добавляем еще одно поле для сравнения. Итоговый запрос SQL будет выглядеть таким образом:
SELECT cname as 'Покупатель', sname as 'Продавец'
FROM customers cus, salespeople sal
where (cus.cnum, sal.snum) IN (SELECT cnum, snum
FROM orders
WHERE YEAR(odate) = 2017)
Вывод запроса:
| Покупатель | Продавец |
|---|---|
| Краснов | Колованов |
| Колесников | Кучеров |
| Лермонтов | Колованов |
| Кириллов | Мозякин |
В этом примере мы сравниваем сразу два поля одновременно по идентификаторам. То есть из таблицы orders берутся те строки, которые удовлетворяют условию по 2017 году, затем вместо идентификаторов подставляются значение имен покупателей и продавцов.
То есть из таблицы orders берутся те строки, которые удовлетворяют условию по 2017 году, затем вместо идентификаторов подставляются значение имен покупателей и продавцов.
На самом деле, такой запрос SQL используется крайне редко, обычно используют оператор INNER JOIN, о котором будет сказано в следующей статье.
Дополнительно скажем о конструкциях, которые использовались в этом запросе. Оператор as нужен для того, чтобы при выводе SQL показывал не имена полей, а то, что мы зададим. И после оператора FROM за именами таблиц стоят сокращения, которые потом используются — это псевдонимы. Псевдонимы можно называть любыми именами, в этом запросе они используются для явного определения поля, так как мы несколько раз обращаемся к одному и тому же полю, только из разных таблиц.
Примеры на вложенные запросы SQL
1.Напишите запрос, который бы использовал подзапрос для получения всех Заказов для покупателя с фамилией Краснов. Предположим, что вы не знаете номера этого покупателя, указываемого в поле cnum.
SELECT *
FROM orders
where cnum = (SELECT cnum
FROM customers
WHERE cname = 'Краснов')
2. Напишите запрос, который вывел бы имена и рейтинг всех покупателей, которые имеют Заказы, сумма которых выше средней.
SELECT cname, rating
FROM customers
where cnum IN (SELECT cnum
FROM orders
WHERE amt > (SELECT AVG(amt)
from orders))
3. Напишите запрос, который бы выбрал общую сумму всех приобретений в Заказах для каждого продавца, у которого эта общая сумма больше, чем сумма наибольшего Заказа в таблице.
SELECT snum, SUM(AMT)
FROM orders
GROUP BY snum
HAVING SUM(amt) > (SELECT MAX(amt)
FROM orders)
4. Напишите запрос, который бы использовал подзапрос для получения всех Заказов для покупателей проживающих в Москве.
SELECT *
FROM orders
where cnum IN (SELECT cnum
FROM customers
WHERE city = 'Москва')
5. Используя подзапрос определить дату заказа, имеющего максимальное значение суммы приобретений (вывести даты и суммы приобретений).
Используя подзапрос определить дату заказа, имеющего максимальное значение суммы приобретений (вывести даты и суммы приобретений).
SELECT amt, odate
FROM orders
WHERE AMT = (SELECT MAX(AMT)
FROM orders)
6. Определить покупателей, совершивших сделки с максимальной суммой приобретений.
SELECT cname
FROM customers
WHERE cnum IN (SELECT cnum
FROM orders
WHERE amt = (SELECT MAX(amt)
FROM orders))
Заключение
На этом сегодня все, мы познакомились с вложенными запросам в SQL. Очевидно, что это достаточно удобный и понятный способ получения данных из таблиц, но не всегда рационален с точки зрения скорости и нагрузки на сервер. Основные примеры, которые мы разобрали, действительно встречаются на практике языка SQL.
MySQL. Вложеные запросы. JOIN LEFT/RIGHT….
В SQL подзапросы — или внутренние запросы, или вложенные запросы — это запрос внутри другого запроса SQL, который вложен в условие WHERE.
Вложеные запросы
SQL подзапрос — это запрос, вложенный в другой запрос.
Подзапрос используется для возврата данных, которые будут использоваться в основном запросе, в качестве условия для дальнейшей фильтрации данных, подлежащих извлечению.
Существует несколько правил, которые применяются к подзапросам:
- Подзапросы должны быть заключены в круглые скобки.
- Подзапрос может иметь только один столбец в условии SELECT, если только несколько столбцов не указаны в основном запросе для подзапроса для сравнения выбранных столбцов.
- Подзапросы, которые возвращают более одной строки, могут использоваться только с несколькими операторами значений, такими как оператор IN.
- Команда ORDER BY не может использоваться в подзапросе, хотя в основном запросе она использоваться может. В подзапросе может использоваться команда GROUP BY для выполнения той же функции, что и ORDER BY.

- С подзапросом не может использоваться оператор BETWEEN. Однако оператор BETWEEN может использоваться внутри подзапроса.
- Не рекомендуется создавать запросы со степенью вложения больше трех. Это приводит к увеличению времени выполнения и к сложности восприятия кода.
SELECT
Подзапросы чаще всего используются с инструкцией SELECT. При этом используется следующий синтаксис
SELECT имя_столбца FROM имя_таблицы WHERE часть условия IN
(SELECT имя_столбца FROM имя_таблицы WHERE часть условия IN
(SELECT имя_столбца FROM имя_таблицы WHERE условие)
...
)
;
Ниже представлена струтура таблицы для демонстрации примеров
| snum | sname | city | comm |
|---|---|---|---|
| 1 | Колованов | Москва | 10 |
| 2 | Петров | Тверь | 25 |
| 3 | Плотников | Москва | 22 |
| 4 | Кучеров | Санкт-Петербург | 28 |
| 5 | Малкин | Санкт-Петербург | 18 |
| 6 | Шипачев | Челябинск | 30 |
| 7 | Мозякин | Одинцово | 25 |
| 8 | Проворов | Москва | 25 |
| cnum | cname | city | rating | snum |
|---|---|---|---|---|
| 1 | Деснов | Москва | 90 | 6 |
| 2 | Краснов | Москва | 95 | 7 |
| 3 | Кириллов | Тверь | 96 | 3 |
| 4 | Ермолаев | Обнинск | 98 | 3 |
| 5 | Колесников | Серпухов | 98 | 5 |
| 6 | Пушкин | Челябинск | 90 | 4 |
| 7 | Белый | Одинцово | 85 | 1 |
| 8 | Чудинов | Москва | 89 | 3 |
| 9 | Проворов | Москва | 95 | 2 |
| 10 | Лосев | Одинцово | 75 | 8 |
| onum | amt | odate(YEAR) | cnum | snum |
|---|---|---|---|---|
| 1001 | 420 | 2013 | 9 | 4 |
| 1002 | 653 | 2005 | 10 | 7 |
| 1003 | 960 | 2016 | 2 | 1 |
| 1004 | 320 | 2016 | 3 | 3 |
| 1005 | 200 | 2015 | 5 | 4 |
| 1006 | 2560 | 2014 | 5 | 4 |
| 1007 | 1200 | 2013 | 7 | 1 |
| 1008 | 50 | 2017 | 1 | 3 |
| 1009 | 564 | 2012 | 3 | 7 |
| 1010 | 900 | 2018 | 6 | 8 |
Вывести суммы заказов и даты, которые проводил продавец с фамилией «Плотников».
Начнем с такого примера и для начала вспомним, как бы делали этот запрос ранее: посмотрели бы в таблицу SALES(или выполнили отдельный запрос), определили бы snum продавца «Плотников» — он равен 3. И выполнили бы запрос SQL с помощью условия WHERE.
SELECT amt, odate
FROM orders
WHERE snum = 3
| amt | odate |
|---|---|
| 320 | 2016 |
| 50 | 2017 |
Такой запрос, очевидно, не очень универсален, если нам захочется выбрать тоже самое для другого продавца, то всегда придется определять его snum. В SQL предусмотрена возможность объединять такие запросы в один путем превращения одного из них в подзапрос (вложенный запрос).
SELECT amt, odate
FROM orders
WHERE snum = ( SELECT snum
FROM sales
WHERE sname = 'Плотников')
В этом примере мы определяем с помощью вложенного запроса идентификатор snum по фамилии из таблицы SALES, а затем, в таблице ORDERS определяем по этому идентификатору нужные нам значения.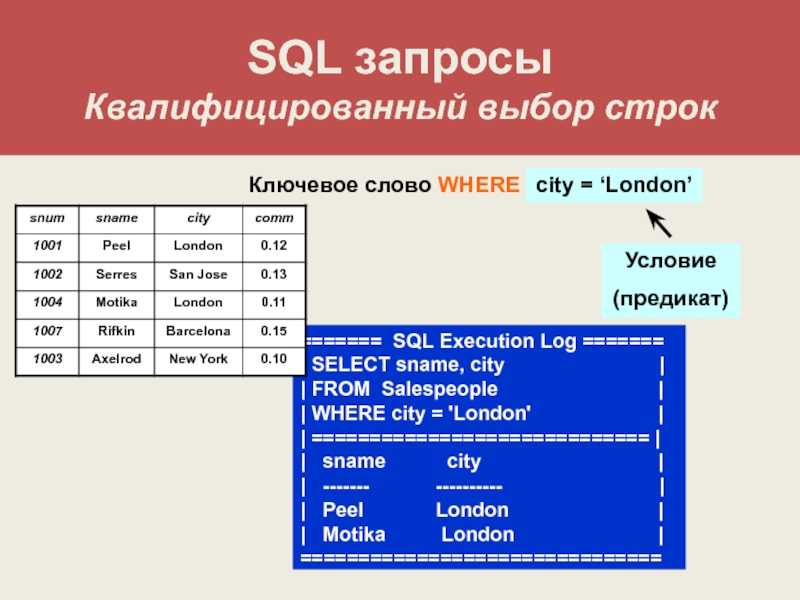
Показать уникальные номера и фамилии продавцов, которые провели сделки в 2016 году.
SELECT snum, sname
FROM sales
WHERE snum IN ( SELECT snum
FROM orders
WHERE odate = 2016)
Этот SQL запрос отличается тем, что вместо знака = здесь используется оператор IN.
Оператор IN следует использовать в том случае, если вложенный подзапрос SQL возвращает несколько значений.
То есть в запросе происходит проверка, содержится ли идентификатор snum из таблицы SALES в массиве значений, который вернул вложенный запрос. Если содержится, то SQL выдаст фамилию этого продавца.
| snum | sname |
|---|---|
| 1 | Колованов |
| 3 | Плотников |
Предыдущие примеры, которые мы уже рассмотрели, сравнивали в условииWHEREодно поле.Это конечно хорошо, но стоит отметить, что в SQL предусмотрена возможность сравнения сразу нескольких полей, то есть можно использовать вложенный запрос с несколькими параметрами.
Вывести пары покупателей и продавцов, которые осуществили сделку между собой, но не позднее 2014 года
Запрос чем то похож на предыдущий, только теперь мы добавляем еще одно поле для сравнения.
SELECT cname as 'Покупатель', sname as 'Продавец'
FROM customers cus, sales sal
WHERE (cus.cnum, sal.snum) IN ( SELECT cnum, snum
FROM orders
WHERE odate < 2014 )
| Покупатель | Продавец |
|---|---|
| Проворов | Кучеров |
| Лосев | Мозякин |
| Белый | Колованов |
| Кириллов | Мозякин |
В этом примере мы сравниваем сразу два поля одновременно по идентификаторам.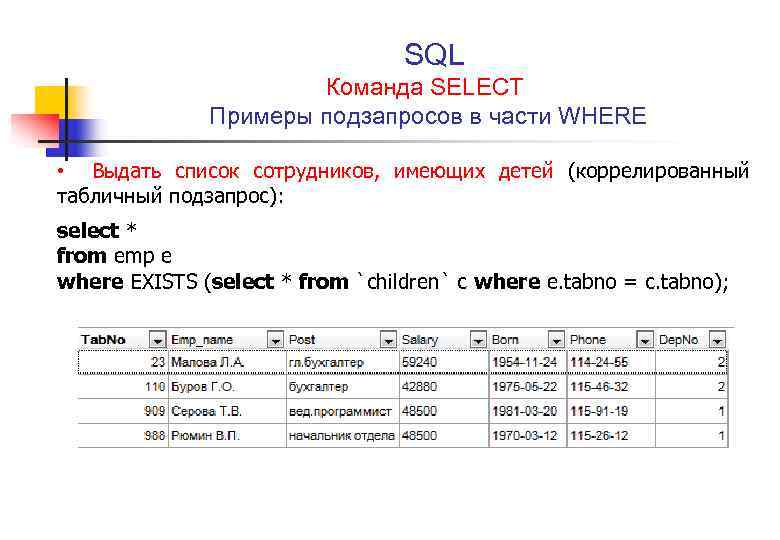 То есть из таблицы
То есть из таблицы ORDERS берутся те строки, которые удовлетворяют условию не позднее 2014 года, затем вместо идентификаторов подставляются значение имен покупателей и продавцов.
На самом деле, такой запрос SQL используется крайне редко, обычно используют оператор INNER JOIN.
Оператор as нужен для того, чтобы при выводе SQL показывал не имена полей, а то, что мы зададим. И после оператора FROM за именами таблиц стоят сокращения, которые потом используются — это псевдонимы. Псевдонимы можно называть любыми именами, в этом запросе они используются для явного определения поля, так как мы несколько раз обращаемся к одному и тому же полю, только из разных таблиц.
Подзапросы могут использоваться с инструкциямиSELECT,INSERT,UPDATEиDELETEвместе с операторами типа=,<,>,>=,<=,IN,BETWEENи т.д.
Далее будут показы примеры использования вложеных запросов с использованием базы данныхworld. БД находится в папке_lec\7\dbвместе с лекцией.
CREATE
Данный пример несовсем относится к теме занятия, но по жизни он очень может пригодиться.
Задача — создать копию существующей таблицы.
Копия существующей таблицы может быть создана с помощью комбинации CREATE TABLE и SELECT.
Новая таблица будет имеет те же определение столбцов, могут быть выбраны все столбцы или отдельные столбцы. При создании новой таблицы с помощью существующей таблицы, новая таблица будет заполняться с использованием существующих значений в старой таблице.
CREATE TABLE NEW_TABLE_NAME AS
SELECT [ column1, column2. ..columnN ]
FROM EXISTING_TABLE_NAME
[ WHERE ]
..columnN ]
FROM EXISTING_TABLE_NAME
[ WHERE ]
Создадим копию таблицы city. Вопрос — почему 1=0?
CREATE TABLE city_bkp AS
SELECT *
FROM city
WHERE 1=0
INSERT
Задача — создать копию существующей таблицы.
Подзапросы также могут использоваться с инструкцией INSERT. Инструкция INSERT использует данные, возвращаемые из подзапроса, для вставки в другую таблицу. Выбранные в подзапросе данные могут быть изменены. Основной синтаксис следующий.
INSERT INTO table_name [ (column1 [, column2 ]) ]
SELECT [ *|column1 [, column2 ]
FROM table1 [, table2 ]
[ WHERE VALUE OPERATOR ]
Копирование всей таблицы полностью
INSERT INTO city_bkp SELECT * FROM city
Копируем города которые находся в стране с численостью не меньше 500тыс. человек, но не больше 1 миллиона.
человек, но не больше 1 миллиона.
INSERT INTO city_bkp
SELECT * FROM city
WHERE CountryCode IN
(SELECT Code FROM country
WHERE Population < 1000000 AND Population > 500000)
UPDATE
Подзапрос может использоваться в сочетании с инструкцией UPDATE. Один или несколько столбцов в таблице могут быть обновлены при использовании подзапроса с помощью инструкции UPDATE. Основной синтаксис следующий.
UPDATE table
SET column_name = new_value
[ WHERE OPERATOR [ VALUE ]
(SELECT COLUMN_NAME
FROM TABLE_NAME)
[ WHERE) ]
Исходя из того, что у нас есть таблица CITY_BKP, которая является резервной копией таблицы CITY, в следующем примере для всех записей, для которых Population больше или равно 100000, применяет коэффициент 0,25.
UPDATE city_bkp SET Population = Population * 0.25
WHERE Population IN (
SELECT Population FROM city
WHERE Population >= 100000 )
DELETE
Подзапрос может использоваться в сочетании с инструкцией DELETE, так же как и со всеми описанными выше инструкциями. Основной синтаксис следующий.
DELETE FROM TABLE_NAME
[ WHERE OPERATOR [ VALUE ]
(SELECT COLUMN_NAME
FROM TABLE_NAME)
[ WHERE) ]
Далее будут показы примеры использования вложеных запросов с использованием базы данныхworld. БД находится в папке_lec\7\dbвместе с лекцией.
Внутреннее объединение
Вывести идентификатор и название города, а так же страну нахождения
Для этого проще всего обратиться к таблице CITY
SELECT ID, Name, CountryCode FROM city
Но, что если нам необходимо, чтобы в ответе на запрос был не код страны, а её название? Вложенные запросы нам не помогут. А нам надо получить данные из двух таблиц и объединить их в одну. Запросы, которые позволяют это сделать, в SQL называются объединениями. Синтаксис самого простого объединения следующий:
А нам надо получить данные из двух таблиц и объединить их в одну. Запросы, которые позволяют это сделать, в SQL называются объединениями. Синтаксис самого простого объединения следующий:
SELECT city.ID, city.Name, country.Name FROM city, country
Получилось не совсем то, что мы ожидали. Такое объединение научно называется декартовым произведением, когда каждой строке первой таблицы ставится в соответствие каждая строка второй таблицы.
Чтобы результирующая таблица выглядела так, как мы хотели, необходимо указать условие объединения. Мы связываем наши таблицы по идентификатору, это и будет нашим условием.
SELECT city.ID, city.Name, country.Name
FROM city, country
WHERE city.CountryCode = country.Code
Т.е. мы в запросе сделали следующее условие: если в обеих таблицах есть одинаковые идентификаторы, то строки с этим идентификатором необходимо объединить в одну результирующую строку.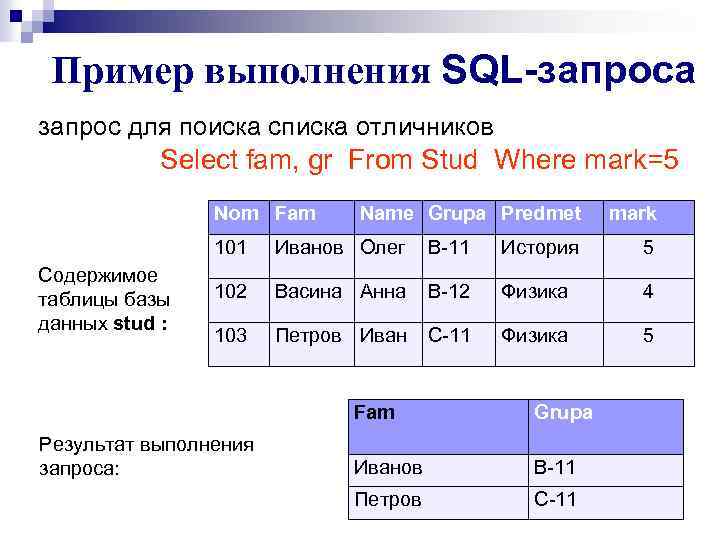
Как вы понимаете, объединения дают возможность выбирать любую информацию из любых таблиц, причем объединяемых таблиц может быть и три, и четыре, да и условие для объединения может быть не одно.
JOIN LEFT/RIGHT
JOIN — оператор языка SQL, который является реализацией операции соединения реляционной алгебры. Входит в предложение FROM операторов SELECT, UPDATE и DELETE.
JOIN используется для объединения строк из двух или более таблиц на основе соответствующего столбца между ними.
Операция соединения, как и другие бинарные операции, предназначена для обеспечения выборки данных из двух таблиц и включения этих данных в один результирующий набор.
Особенности операции соединения
- в схему таблицы-результата входят столбцы обеих исходных таблиц
- каждая строка таблицы-результата является «сцеплением» строки из одной таблицы со строкой второй таблицы
Определение того, какие именно исходные строки войдут в результат и в каких сочетаниях, зависит от типа операции соединения и от явно заданного условия соединения. Условие соединения, то есть условие сопоставления строк исходных таблиц друг с другом, представляет собой логическое выражение (предикат).
Условие соединения, то есть условие сопоставления строк исходных таблиц друг с другом, представляет собой логическое выражение (предикат).
Ниже представлена струтура таблицы для демонстрации примеров
| id | name | city_id |
|---|---|---|
| 1 | Колованов | 1 |
| 2 | Петров | 3 |
| 3 | Плотников | 12 |
| 4 | Кучеров | 4 |
| 5 | Малкин | 2 |
| 6 | Иванов | 13 |
Ниже представлена струтура таблицы для демонстрации примеров
| id | name | population |
|---|---|---|
| 1 | Москва | 100 |
| 2 | Нижний Новгород | 25 |
| 3 | Тверь | 22 |
| 4 | Санкт-Петербург | 80 |
| 5 | Выборг | 18 |
| 6 | Челябинск | 30 |
| 7 | Одинцово | 5 |
| 8 | Павлово | 5 |
INNER JOIN
Оператор внутреннего соединения INNER JOIN соединяет две таблицы. Порядок таблиц для оператора неважен, поскольку оператор является симметричным.
Порядок таблиц для оператора неважен, поскольку оператор является симметричным.
Заголовок таблицы-результата является объединением (конкатенацией) заголовков соединяемых таблиц.
SELECT * FROM Person
INNER JOIN
City
ON Person.city_id = City.id
| Person.id | Person.name | Person.city_id | City.id | City.name | City.population |
|---|---|---|---|---|---|
| 1 | Колованов | 1 | 1 | Москва | 100 |
| 2 | Петров | 3 | 3 | Тверь | 22 |
| 4 | Кучеров | 4 | 4 | Санкт-Петербург | 80 |
| 5 | Малкин | 2 | 2 | Нижний Новгород | 25 |
INNER JOINТело результата логически формируется следующим образом. Каждая строка одной таблицы сопоставляется с каждой строкой второй таблицы, после чего для полученной «соединённой» строки проверяется условие соединения (вычисляется предикат соединения). Если условие истинно, в таблицу-результат добавляется соответствующая «соединённая» строка.
Каждая строка одной таблицы сопоставляется с каждой строкой второй таблицы, после чего для полученной «соединённой» строки проверяется условие соединения (вычисляется предикат соединения). Если условие истинно, в таблицу-результат добавляется соответствующая «соединённая» строка.
В SQL существуют разные типы объединений. Мы рассмотрим только некоторые из них.
LEFT JOIN
Возвращает все строки из левой таблицы, даже если в правой таблице нет совпадений.
LEFT JOIN
SELECT * FROM Person
LEFT JOIN
City
ON Person.city_id = City.id
Для записей неудовлетворяющих условия объединения поля правой таблицы заполняются значениями NULL
| Person.id | Person. name name | Person.city_id | City.id | City.name | City.population |
|---|---|---|---|---|---|
| 1 | Колованов | 1 | 1 | Москва | 100 |
| 2 | Петров | 3 | 3 | Тверь | 22 |
| 3 | Плотников | 12 | NULL | NULL | NULL |
| 4 | Кучеров | 4 | 4 | Санкт-Петербург | 80 |
| 5 | Малкин | 2 | 2 | Нижний Новгород | 25 |
| 6 | Иванов | 13 | NULL | NULL | NULL |
RIGHT JOIN
Возвращает все строки из правой таблицы, даже если в левой таблице нет совпадений.
RIGHT JOIN
SELECT * FROM Person
RIGHT JOIN
City
ON Person.city_id = City.id
Для записей неудовлетворяющих условия объединения поля левой таблицы заполняются значениями NULL
Person. id id | Person.name | Person.city_id | City.id | City.name | City.population |
|---|---|---|---|---|---|
| 1 | Колованов | 1 | 1 | Москва | 100 |
| 2 | Петров | 3 | 3 | Тверь | 22 |
| 4 | Кучеров | 4 | 4 | Санкт-Петербург | 80 |
| 5 | Малкин | 2 | 2 | Нижний Новгород | 25 |
| NULL | NULL | NULL | 5 | Выборг | 18 |
| NULL | NULL | NULL | 6 | Челябинск | 30 |
| NULL | NULL | NULL | 7 | Одинцово | 5 |
| NULL | NULL | NULL | 8 | Павлово | 5 |
Python SQLite: вложенные SQL-запросы
Смотреть материал на видео
На этом занятии
поговорим о возможности создавать вложенные запросы к СУБД. Лучше всего это
понять на конкретном примере. Предположим, что у нас имеются две таблицы:
Предположим, что у нас имеются две таблицы:
Первая students содержит информацию о студентах, а вторая marks – их отметки по разным дисциплинам. Каждый из студентов (кроме четвертого) проходил язык Си. От нас требуется выбрать всех студентов, у которых оценка по языку Си выше, чем у Маши (студент с id = 2). По идее нам тут нужно реализовать два запроса: первый получает значение оценки для Маши по языку Си:
SELECT mark FROM marks WHERE id = 2 AND subject LIKE 'Си'
А второй выбирает всех студентов, у которых оценка по этому предмету выше, чем у Маши:
SELECT name, subject, mark FROM marks JOIN students ON students.rowid = marks.id WHERE mark > 3 AND subject LIKE 'Си'
Так вот, в языке SQL эти два запроса можно объединить, используя идею вложенных запросов:
SELECT name, subject, mark FROM marks JOIN students ON students.rowid = marks.id WHERE mark > (SELECT mark FROM marks WHERE id = 2 AND subject LIKE 'Си') AND subject LIKE 'Си'
Мы здесь во второй запрос вложили первый для определения оценки Маши по предмету Си. Причем, этот вложенный запрос следует записывать в круглых скобках, говоря СУБД, что это отдельная конструкция, которую следует выполнить независимо. То, что будет получено на его выходе и будет фигурировать в качестве Машиной оценки.
Но, что если вложенный запрос вернет несколько записей (оценок), например, если записать его вот так:
SELECT name, subject, mark FROM marks JOIN students ON students.rowid = marks.id WHERE mark > (SELECT mark FROM marks WHERE id = 2 ) AND subject LIKE 'Си'
В этом случае будет использован только первый полученный результат, другие попросту проигнорируются и результат будет тем же (так как первое значение – это оценка Маши по предмету Си).
Если же
вложенный SELECT ничего не
находит (возвращает значение NULL), то внешний запрос не будет возвращать
никаких записей.
Также следует обращать внимание, что подзапросы не могут обрабатывать свои результаты, поэтому в них нельзя указывать, например, оператор GROUP BY. Но агрегирующие функции вполне можно использовать, например, так:
SELECT name, subject, mark FROM marks JOIN students ON students.rowid = marks.id WHERE mark > (SELECT avg(mark) FROM marks WHERE id = 2 ) AND subject LIKE 'Си'
Вложения в команде INSERT
Вложенные запросы можно объявлять и в команде INSERT. Предположим, что у нас имеется еще одна таблица female вот с такой структурой:
Она идентична по структуре таблице students со списком студентов. Наша задача добавить в female всех студентов женского пола.
Для начала запишем запрос выбора девушек из таблицы students:
SELECT * FROM students WHERE sex = 2
А, затем, укажем, что их нужно поместить в таблицу female:
INSERT INTO female SELECT * FROM students WHERE sex = 2
После выполнения этого запроса таблица female будет содержать следующие записи:
Но если
выполнить запрос еще раз, то возникнет ошибка, т. к. мы попытаемся добавить
строки с уже существующими id, что запрещено по структуре этого поля
– оно определено как главный ключ и содержит только уникальные значения.
к. мы попытаемся добавить
строки с уже существующими id, что запрещено по структуре этого поля
– оно определено как главный ключ и содержит только уникальные значения.
Чтобы поправить ситуацию, можно вложенный запрос написать так:
INSERT INTO female SELECT NULL, name, sex, old FROM students WHERE sex = 2
Мы здесь в качестве значения первого поля указали NULL и, соответственно, СУБД вместо него сгенерирует уникальный ключ для добавляемых записей. Теперь таблица female выглядит так:
Вложения в команде UPDATE
Похожим образом можно создавать вложенные запросы и для команды UPDATE. Допустим, мы хотим обнулить все оценки в таблице marks, которые меньше или равны минимальной оценки студента с id = 1. Такой запрос можно записать в виде:
UPDATE marks SET mark = 0 WHERE mark <= (SELECT min(mark) FROM marks WHERE id = 1)
И на выходе получим измененную таблицу:
Как видите,
минимальная оценка у первого студента была равна 3 и все тройки обнулились.
Вложения в команде DELETE
Ну, и наконец, аналогичные действия можно выполнять и в команде DELETE. Допустим, требуется удалить из таблицы students всех студентов, возраст которых меньше, чем у Маши (студента с id = 2). Запрос будет выглядеть так:
DELETE FROM students WHERE old < (SELECT old FROM students WHERE id = 2)
В результате, получим таблицу:
Вот так создаются вложенные запросы в языке SQL. Однако, прибегать к ним следует в последнюю очередь, если никакими другими командами не удается решить поставленную задачу. Так как они создают свое отдельное обращение к БД и на это тратятся дополнительные вычислительные ресурсы.
Конечно, на этом
занятии мы лишь рассмотрели примеры, принцип создания вложенных запросов. На
практике они могут разрастаться и становиться довольно объемными, включать в
себя различные дополнительные операции для выполнения нетривиальных действий с таблицами
БД.
На этом мы завершим обзор SQL-языка. Этого материала вам будет вполне достаточно для начальной работы с БД. По мере развития сможете дальше углубляться в эту тему и узнавать множество новых подходов к реализации различных задач с помощью SQL-запросов.
Видео по теме
Python SQLite #1: что такое СУБД и реляционные БД
Python SQLite #2: подключение к БД, создание и удаление таблиц
Python SQLite #3: команды SELECT и INSERT при работе с таблицами БД
Python SQLite #4: команды UPDATE и DELETE при работе с таблицами
Python SQLite #5: агрегирование и группировка GROUP BY
Python SQLite #6: оператор JOIN для формирования сводного отчета
Python SQLite #7: оператор UNION объединения нескольких таблиц
Python SQLite #8: вложенные SQL-запросы
Python SQLite #9: методы execute, executemany, executescript, commit, rollback и свойство lastrowid
Python SQLite #10: методы fetchall, fetchmany, fetchone, Binary, iterdump
Видео курс SQL Essential.
 Вложенные запросы
Вложенные запросы- Главная >
- Каталог >
- SQL Базовый >
- Вложенные запросы
Для прохождения теста нужно авторизироваться
Войти Регистрация
×
Вы открыли доступ к тесту! Пройти тест
Для просмотра полной версии видеокурса, онлайн тестирования и получения доступа к дополнительным учебным материалам купите курс Купить курс
Для просмотра всех видеокурсов ITVDN, представленных в Каталоге, а также для получения доступа к учебным материалам и онлайн тестированию купите подписку Купить подписку
№1
Введение в SQL
0:59:17
Материалы урокаДомашние заданияТестирование
На этом уроке по SQL Вы получите необходимые знания о базах данный – ознакомитесь с терминологией, узнаете принцип функционирования SQL сервера и его архитектуру. На уроке Вы узнаете о программной среде SQL Management Studio, в которой будете работать на протяжении всех последующих уроков. Вы ознакомитесь с правилами построения запросов и изучите типы данных, которые используются в SQL Server. После прохождения этого урока Вы сможете создать базу данных с несколькими таблицами, определить содержимое таблиц, указав типы данных и названия колонок, а также сможете создать простые SQL запросы для того, чтобы получить данные из таблиц.
На уроке Вы узнаете о программной среде SQL Management Studio, в которой будете работать на протяжении всех последующих уроков. Вы ознакомитесь с правилами построения запросов и изучите типы данных, которые используются в SQL Server. После прохождения этого урока Вы сможете создать базу данных с несколькими таблицами, определить содержимое таблиц, указав типы данных и названия колонок, а также сможете создать простые SQL запросы для того, чтобы получить данные из таблиц.
Читать дальше…
Запросы. Манипуляция данными.
0:55:28
Материалы урокаДомашние заданияТестирование
На этом уроке по SQL Вы научитесь манипулировать данными, хранящимися в таблицах базы данных. Вы узнаете, как можно добавить, удалить, изменить или просто прочитать информацию, которая находится в таблице. Вы познакомитесь с командами SQL SELECT, INSERT, UPDATE, DELETE и научитесь правильно их использовать.
Читать дальше…
Основы DDL.
1:27:42
Материалы урокаДомашние заданияТестирование
На этом видео уроке из курса SQL Essential Вы познакомитесь с языком описания структуры хранения данных Data Definition Language. В этом уроке Вы изучите основные команды (CREATE, ALTER, DROP) для создания, редактирования и удаления сущностный в базе данных. Также Вы узнаете, что такое реляционная база данных и как строятся связи между таблицами в базах данных, что такое первичный ключ и внешний ключ, для чего они нужны в базе. В конце урока Вы увидите, как можно создать диаграмму базы данных для того, чтобы графически представить структуру таблиц и связи между ними.
В этом уроке Вы изучите основные команды (CREATE, ALTER, DROP) для создания, редактирования и удаления сущностный в базе данных. Также Вы узнаете, что такое реляционная база данных и как строятся связи между таблицами в базах данных, что такое первичный ключ и внешний ключ, для чего они нужны в базе. В конце урока Вы увидите, как можно создать диаграмму базы данных для того, чтобы графически представить структуру таблиц и связи между ними.
Читать дальше…
Проектирование БД
0:41:32
Материалы урокаДомашние заданияТестирование
Видео урок расскажет о сложностях проектирования базы данных. Чтобы создать правильную структуру базы данных, нужно следовать различным рекомендациям и лучшим практикам. На занятии подробно расматриваетчся набор правил, которые следует помнить и соблюдать при проектировании баз данных. Вы узнаете, что такое нормализация баз данных и какие нормальные формы баз данных существуют. Этот урок даст Вам представление о том, как должна выглядеть правильно спроектированная база данных.
Читать дальше…
Команда JOIN
0:38:29
Материалы урокаДомашние заданияТестирование
Редко вся информация, которая нам необходима, находится в одной таблице. Зачастую в реляционных базах данные находятся в разных таблицах и связанны между собой. В этом видеоуроке по SQL Вы изучите команды JOIN, LEFT JOIN, RIGHT JOIN, CROSS JOIN, которые используются для получения данных из связанных таблиц.
Читать дальше…
Вложенные запросы
0:59:18
Материалы урокаДомашние заданияТестирование
Иногда для того, чтобы получить всю необходимую информацию из базы, простого запроса не достаточно. В данном видео уроке по SQL для начинающих Вы увидите, как можно создавать запросы со вложенными запросами для создания сложных правил выборки данных из базы. Также Вы узнаете, что такое курсор и на примерах увидите в каких ситуациях можно применять курсоры.
Читать дальше…
Индексирование
0:55:11
Материалы урокаДомашние заданияТестирование
На этом видео уроке Вы узнаете, как SQL сервер организовывает хранение данных таблиц на жестком диске.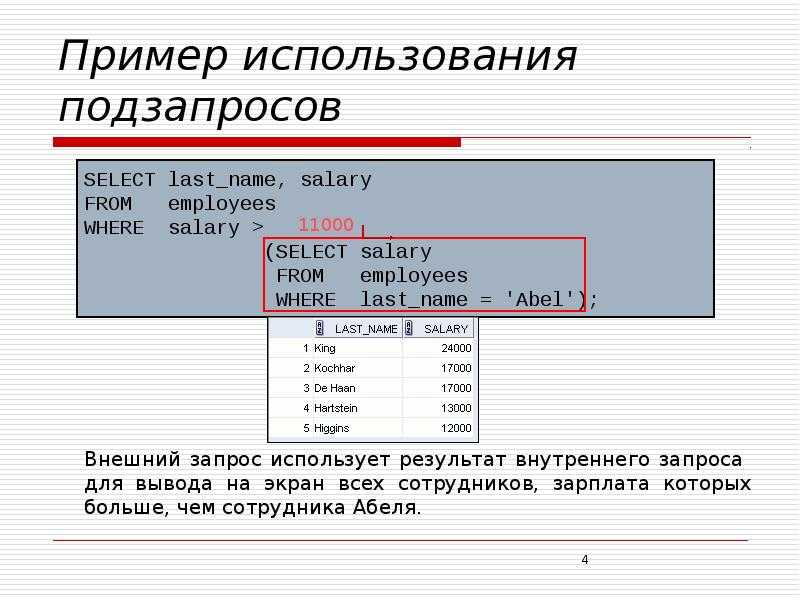 Вы узнаете, что такое B-деревья и индексы, научитесь использовать индексы для более быстрого поиска информации в базе данных.
Вы узнаете, что такое B-деревья и индексы, научитесь использовать индексы для более быстрого поиска информации в базе данных.
Читать дальше…
Хранимые процедуры. Пользовательские функции
1:24:53
Материалы урокаДомашние заданияТестирование
Для того, чтобы оптимизировать работу базы и не отправлять на сервер большие объемы SQL запросов, можно создать хранимую процедуру, которая будет представлять блок кода, хранящийся на сервере для неоднократного запуска со стороны клиента. В этом видео уроке по SQL Вы изучите тонкости написания хранимых процедур, а также научитесь создавать функции, которые также помогут оптимизировать и упростить работу с данными.
Читать дальше…
Транзакции. Триггеры
0:49:13
Материалы урокаДомашние заданияТестирование
Для того, чтобы гарантировать целостность информации в базе данных после применения ряда запросов, в SQL сервере используются транзакции. В этом видео уроке Вы узнаете, как выполнять запросы в контексте транзакции. На уроке будут рассмотрены триггеры, порядок их создания, задачи, которые принято решать с помощью триггеров.
В этом видео уроке Вы узнаете, как выполнять запросы в контексте транзакции. На уроке будут рассмотрены триггеры, порядок их создания, задачи, которые принято решать с помощью триггеров.
Читать дальше…
Следующий курс:
Entity Framework 6
ПОКАЗАТЬ ВСЕ
основные темы, рассматриваемые на уроке
0:00:00
Рассмотрение понятия «Подзапрос»
0:05:45
Связанные запросы
0:09:18
Пример создания вложенных запросов
0:15:43
Пример создания вложенного запроса совместно с JOIN
0:19:16
Пример создания связанного вложенного запроса
0:26:22
Связанный вложенный запрос — EXISTS
0:43:28
Временные таблицы
0:46:13
Связанные вложенные запросы — WITH … AS
0:49:23
Пример создания и использования «Курсора»
ПОКАЗАТЬ ВСЕ
Рекомендуемая литература
Ицик Бен-Ган- Microsoft SQL Server 2008. Основы T-SQL В книге изложены теоретические основы формирования запросов и программирования на языке T-SQL: однотабличные запросы, соединения, подзапросы, табличные выражения, операции над множествами, реорганизация данных и наборы группирования. Описываются различные аспекты извлечения и модификации данных, обсуждаются параллелизм и транзакции, приводится обзор программируемых объектов. Для дополнения теории практическими навыками в книгу включены упражнения, в том числе и повышенной сложности.
Описываются различные аспекты извлечения и модификации данных, обсуждаются параллелизм и транзакции, приводится обзор программируемых объектов. Для дополнения теории практическими навыками в книгу включены упражнения, в том числе и повышенной сложности.
Крис Дейт- Введение в системы баз данных. 8-е издание Новое издание фундаментального труда Криса Дейта представляет собой исчерпывающее введение в очень обширную в настоящее время теорию систем баз данных. С помощью этой книги читатель сможет приобрести фундаментальные знания в области технологии баз данных, а также ознакомиться с направлениями, по которым рассматриваемая сфера деятельности, вероятно, будет развиваться в будущем. Книга предназначена для использования в основном в качестве учебника, а не справочника, поэтому, несомненно, вызовет интерес у программистов-профессионалов, научных работников и студентов, изучающих соответствующие курсы в высших учебных заведениях. В ней сделан акцент на усвоении сути и глубоком понимании излагаемого материала, а не просто на его формальном изложении. Книга, безусловно, будет полезна всем, кому приходится работать с базами данных или просто пользоваться ими.
Книга, безусловно, будет полезна всем, кому приходится работать с базами данных или просто пользоваться ими.
Титры видеоурока
Титров к данному уроку не предусмотрено
ПОДРОБНЕЕ
ПОДРОБНЕЕ
ПОДРОБНЕЕ
ПОДРОБНЕЕ
Многотабличные и вложенные запросы — Проектирование баз данных на SQL (Информатика и программирование)
Лекция 22. Многотабличные и вложенные запросы
Как правило, запросы выполняют обработку данных, расположенных во множестве таблиц. Попытка соединить таблицы по «умолчанию » , приведет к декартовому произведению двух таблиц и вернет бессмысленный результат, например, если построить запрос по таблицам 7.3 и 7.4, следующим образом:
SELECT *
FROM А, В
Из раздела реляционной алгебры известно, что под соединением двух таблиц (будем рассматривать экви-соединение) понимается последовательность выполнения операции декартового произведения и выборки, т. е.:
е.:
SELECT *
FROM А, В
WHERE А.Код_товара = В.Код_тов
Использование подобного метода возвратит верный результат, приведенный в таблице 7.6. Описанный способ соединения, был единственным в первом стандарте языка SQL.
Стандарт SQL2 расширил возможности соединения до так называемого внешнего соединения (внутренним принято считать соединение с использованием предложения WHERE).
В общем случае синтаксис внешнего соединения выглядит следующим образом:
FROM <Таблица1> <вид соединения> JOIN <Таблица2> ON <Условие соединения>
Вид соединения определяет главную (ведущую) таблицу в соединении и может определяться следующими служебными словами:
§ LEFT – левое внешнее соединение, когда ведущей является таблица слева от вида соединения;
§ RIGHT – правое внешнее соединение, когда ведущей является таблица справа от вида соединения;
§ FULL — полное внешнее соединение, когда обе таблица равны в соединении;
§ INNER – вариант внутреннего соединения.
По правилу внешних соединений, ведущая таблица должна войти в результат запроса всеми своими записями, независимо от наличия соответствующих записей в присоединяемой таблице.
Приведем пример реализации внутреннего соединения для стандарта SQL2:
SELECT *
FROM А INNER JOIN В ON А.Код_товара = В.Код_тов
Вариант внешнего соединения, когда левая таблица является главной (ведущей):
SELECT *
FROM А LEFT JOIN В ON А.Код_товара = В.Код_тов
Продемонстрируем соединение нескольких таблиц на основе проекта «Библиотека » . Пусть требуется получить информацию о принадлежности книг к тем или иным предметным областям. Известно, что каталог областей знаний и таблица «Книга » соединяются через промежуточную таблицу «Связь » , в этом случае запрос может выглядеть следующим образом:
SELECT Каталог.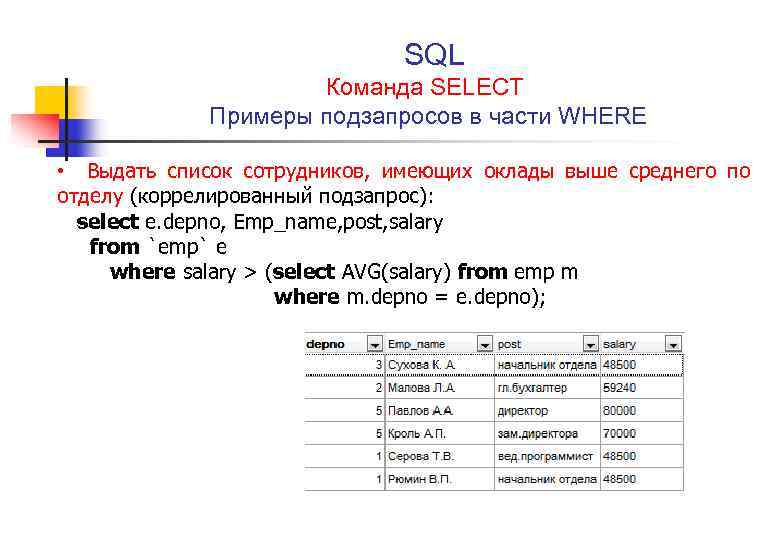 Наименование as Область_знаний, Книги.ISBN, Книги.Название as Книга
Наименование as Область_знаний, Книги.ISBN, Книги.Название as Книга
FROM Книги INNER JOIN (Каталог INNER JOIN Связь ON Каталог.Код_ОЗ = Связь.Код_ОЗ) ON Книги.ISBN = Связь.ISBN;
Группировка по соединяемым таблицам не отличается от группировки по данным одной таблицы. Пусть требуется отобразить перечень читателей библиотеки с указанием количества книг, находящихся у них на руках, тогда запрос может выглядеть следующим образом:
SELECT DISTINCT Читатели.ФИО, Count(*) AS (Количество_книг)
FROM Читатели INNER JOIN Экземпляры ON Читатели.Номер_ЧБ = Экземпляры.Номер_ЧБ
GROUP BY Читатели.ФИО, Читатели.Номер_ЧБ, Экземпляры.Наличие
HAVING Экземпляры.Наличие = No;
Следующий запрос возвращает информацию о должниках и книгах, которые они должны были сдать в библиотеку с сортировкой по дате возврата:
SELECT Книги. Название, Книги.Автор, Экземпляры.Инв_номер, Экземпляры.Дата_возврата, Читатели.Номер_ЧБ, Читатели.ФИО, Читатели.Тел_дом, Читатели.Тел_раб
Название, Книги.Автор, Экземпляры.Инв_номер, Экземпляры.Дата_возврата, Читатели.Номер_ЧБ, Читатели.ФИО, Читатели.Тел_дом, Читатели.Тел_раб
FROM Книги INNER JOIN (Читатели INNER JOIN Экземпляры ON Читатели.Номер_ЧБ = Экземпляры.Номер_ЧБ) ON Книги.ISBN = Экземпляры.ISBN
WHERE Экземпляры.Дата_возврата < Now() AND Экземпляры.Наличие=No
ORDER BY Экземпляры.Дата_возврата;
Вложенные запросы
Язык SQL позволяет вкладывать запросы друга в друга, это относится к оператору SELECT. Оператор SELECT, вложенный в другой оператор SELECT, INSERT, UPDATE или DELETE., называется вложенным запросом.
Вложенный оператор SELECT может употребляться в разделах WHERE или HAVING основного запроса и возвращать наборы данных, которые будут использоваться для формирования условий выборки требуемых значений основным запросом.
Средства языка SQL для создания и использования вложенных запросов можно считать избыточными, т.е. вложенность может быть реализована разными способами.
Если вложенный запрос возвращает одно значение (например, агрегат), то оно может использоваться в любом месте, где применяется подобное значение соответствующего типа. Если вложенный запрос возвращает один столбец, то его можно использовать только в директиве WHERE. Во многих случаях вместо вложенного запроса используется оператор объединения, однако некоторые задачи выполняются только с помощью вложенных запросов.
Вложенный запрос всегда заключается в скобки и, если только это не связанный вложенный запрос, завершает выполнение раньше, чем внешний запрос. Вложенный запрос может содержать другой вложенный запрос, который, в свою очередь, тоже может содержать вложенный запрос, и так далее. Глубина вложенности ограничивается только ресурсами системы. Синтаксис вложенного оператора SELECT более короткий и имеет следующий вид:
(SELECT [ALL | DISTINCT] слисок_ столбцов _вложенного_запроса
[FROM список_ таблиц]
[WHERE директива]
[GROUP BY директива]
[HAVING директива])
Приведем пример сложного вложенного запроса. Пусть необходимо получить список читателей имеющих максимальное число книг на руках, при условии, что максимальное количество книг у читателя не ограничено:
Пусть необходимо получить список читателей имеющих максимальное число книг на руках, при условии, что максимальное количество книг у читателя не ограничено:
SELECT Читатели.Номер_ЧБ, Читатели.ФИО, COUNT(*) AS Количество
FROM Читатели INNER JOIN Экземпляры ON Читатели.Номер_ЧБ = Экземпляры.Номер_ЧБ
GROUP BY Читатели.Номер_ЧБ, Читатели.ФИО, Экземпляры.Наличие
HAVING Экземпляры.Наличие = No AND COUNT(*) =
(SELECT MAX(Количество)
FROM
(SELECT COUNT(*) AS Количество
FROM Экземпляры
GROUP BY Экземпляры.Номер_ЧБ, Экземпляры. Наличие
Наличие
HAVING Экземпляры.Наличие = No))
Как и положено вложенным запросом первым выполняется самый «глубокий » по уровню вложенности подзапрос, который определяет количество книг на руках у каждого читателя:
SELECT COUNT(*) AS Количество
FROM Экземпляры
GROUP BY Экземпляры.Номер_ЧБ, Экземпляры.Наличие
HAVING Экземпляры.Наличие = No
Результат работы этого подзапроса список – количество книг по каждому номеру читательского билета. Особенным является то, что результат этого запроса используется в качестве источника строк для запроса более высокого уровня, который находит максимальное значение в этом списке, соответствующее максимальному количеству книг на руках у одного из читателей:
(SELECT MAX(Количество) FROM (SELECT …))
И, наконец, внешний запрос, выполняется в последнюю очередь, подсчитывает количество книг на руках у конкретного читателя и сравнивает его с максимальным количеством книг, полученным в результате работы вложенного запроса. Таким образом, может оказаться несколько читателей имеющих на руках максимальное количество книг.
Таким образом, может оказаться несколько читателей имеющих на руках максимальное количество книг.
В данном примере вложенный запрос возвращает агрегированное значение, полученное в результате итоговой функции MAX, поэтому условное выражение COUNT(*) = (SELECT MAX(Количество)…) имеет смысл. Если вложенный подзапрос может вернуть множество значений, то простое сравнение не подходит, необходимо использование служебных слов ANY или предиката IN, множество значений которого будет формировать вложенный подзапрос. Служебное слово ANY указывает на необходимость использования условного выражения для каждого значения, полученного во вложенном запросе.
Контрольные вопросы
1. Как можно получить декартово произведение двух таблиц?
2. Чем отличается соединение от объединения?
3. Какие виды соединений предусмотрены первым стандартом SQL?
4. Какой синтаксис имеют соединения?
5. Какие виды соединений вы знаете?
6. Для чего необходимы вложенные запросы?
Для чего необходимы вложенные запросы?
7. Какие ограничения налагаются на вложенные запросы?
8. Как можно использовать предикат IN или служебное слово ANY?
Задания для самостоятельной работы
Рекомендуем посмотреть лекцию «3.4. Примеры по прогнозированию инженерной обстановки».
Задание 1. Запишите запрос для определения:
1. к каким предметным областям относится какая-либо книга;
2. какие книги относятся к определенной предметной области.
Задание 2. Дана таблица «Книг_у_читателей » , содержащая поля «ФИО_читателя » и «Книг_на_руках » . Запишите текст запроса для определения:
1. читателей держащих больше всего книг на руках;
2. читателей держащих меньше всего книг на руках.
Написание подзапросов в SQL | Расширенный SQL
Начиная здесь? Этот урок является частью полного учебника по использованию SQL для анализа данных. Проверьте начало.
В этом уроке мы рассмотрим:
- Основы подзапросов
- Использование подзапросов для агрегирования в несколько этапов
- Подзапросы в условной логике
- Объединение подзапросов
- Подзапросы и UNION
На этом уроке вы продолжите работать с теми же данными о преступности в Сан-Франциско, что и на предыдущем уроке.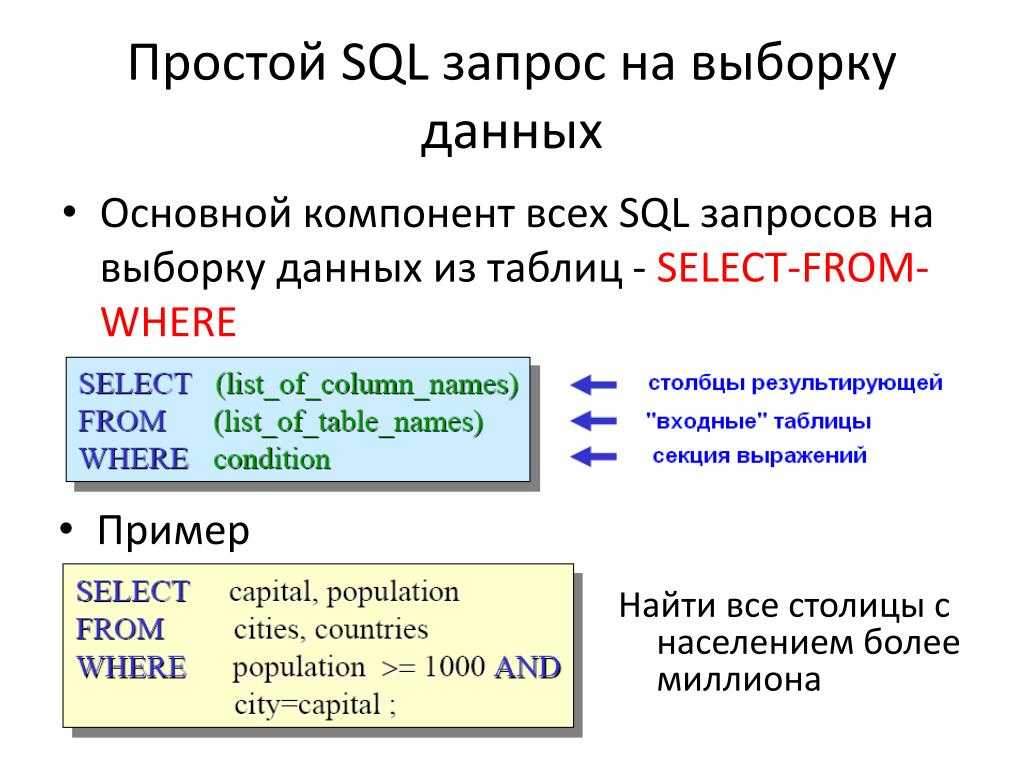
Основы подзапросов
Подзапросы (также известные как внутренние запросы или вложенные запросы) — это инструмент для выполнения операций в несколько шагов. Например, если вы хотите взять суммы нескольких столбцов, а затем усреднить все эти значения, вам нужно будет выполнить каждую агрегацию на отдельном шаге.
Подзапросы могут использоваться в нескольких местах внутри запроса, но проще всего начать с оператора FROM . Вот пример простого подзапроса:
SELECT sub.*
ИЗ (
ВЫБРАТЬ *
ИЗ tutorial.sf_crime_incidents_2014_01
ГДЕ day_of_week = 'Пятница'
) суб
ГДЕ подразрешение = 'НЕТ'
Давайте разберем, что происходит, когда вы выполняете приведенный выше запрос:
Сначала база данных выполняет «внутренний запрос» — часть в круглых скобках:
SELECT * ИЗ tutorial.sf_crime_incidents_2014_01 ГДЕ day_of_week = 'Пятница'
Если бы вы запустили этот запрос самостоятельно, он выдал бы набор результатов, как и любой другой запрос.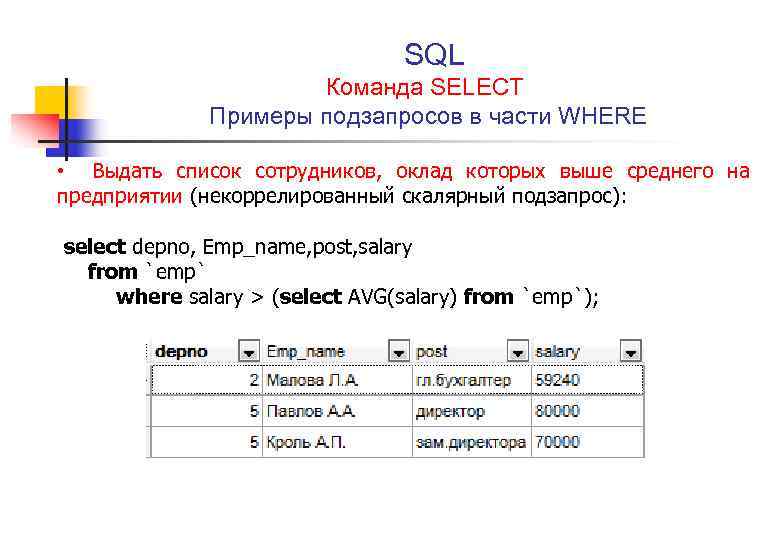 Это может показаться пустяком, но это важно: ваш внутренний запрос должен фактически выполняться сам по себе, так как база данных будет рассматривать его как независимый запрос. После запуска внутреннего запроса внешний запрос будет запущен с использованием результатов внутреннего запроса в качестве базовой таблицы :
Это может показаться пустяком, но это важно: ваш внутренний запрос должен фактически выполняться сам по себе, так как база данных будет рассматривать его как независимый запрос. После запуска внутреннего запроса внешний запрос будет запущен с использованием результатов внутреннего запроса в качестве базовой таблицы :
SELECT sub.*
ИЗ (
<<результаты внутреннего запроса идут сюда>>
) суб
ГДЕ подразрешение = 'НЕТ'
Подзапросы должны иметь имена, которые добавляются после круглых скобок так же, как вы добавляете псевдоним к обычной таблице. В данном случае мы использовали имя «sub».
Небольшое замечание по форматированию. Важно помнить, что при использовании подзапросов необходимо предоставить читателю возможность легко определить, какие части запроса будут выполняться вместе. Большинство людей делают это, тем или иным образом делая отступ в подзапросе. Примеры в этом руководстве имеют довольно большой отступ — вплоть до круглых скобок. Это нецелесообразно, если вы вкладываете много подзапросов, поэтому довольно часто отступ делается только на два пробела или около того.
Это нецелесообразно, если вы вкладываете много подзапросов, поэтому довольно часто отступ делается только на два пробела или около того.
Практическая задача
Напишите запрос, который выбирает все ордера на арест из набора данных tutorial.sf_crime_incidents_2014_01 , а затем оберните его во внешний запрос, который отображает только неразрешенные инциденты.
Попробуйте См. ответ
Вышеприведенные примеры, как и практическая задача, на самом деле не требуют подзапросов — они решают проблемы, которые также можно решить, добавив несколько условий в предложение WHERE . В следующих разделах приводятся примеры, для которых подзапросы являются лучшим или единственным способом решения соответствующих проблем.
Использование подзапросов для агрегирования в несколько этапов
Что делать, если вы хотите выяснить, сколько инцидентов сообщается в каждый день недели? А что, если вы хотите узнать, сколько инцидентов происходит в среднем в пятницу декабря? В январе? Этот процесс состоит из двух шагов: подсчет количества инцидентов каждый день (внутренний запрос), затем определение среднемесячного значения (внешний запрос):
суб. день_недели,
AVG(sub.incidents) КАК среднее_происшествие
ИЗ (
ВЫБЕРИТЕ день_недели,
свидание,
COUNT(incidnt_num) инцидентов AS
ИЗ tutorial.sf_crime_incidents_2014_01
СГРУППИРОВАТЬ НА 1,2
) суб
СГРУППИРОВАТЬ НА 1,2
ЗАКАЗАТЬ ПО 1,2
день_недели,
AVG(sub.incidents) КАК среднее_происшествие
ИЗ (
ВЫБЕРИТЕ день_недели,
свидание,
COUNT(incidnt_num) инцидентов AS
ИЗ tutorial.sf_crime_incidents_2014_01
СГРУППИРОВАТЬ НА 1,2
) суб
СГРУППИРОВАТЬ НА 1,2
ЗАКАЗАТЬ ПО 1,2
Если вы не можете понять, что происходит, попробуйте запустить внутренний запрос отдельно, чтобы понять, как выглядят его результаты. В общем, проще всего сначала написать внутренние запросы и пересматривать их до тех пор, пока результаты не станут для вас понятными, а затем перейти к внешнему запросу.
Практическая задача
Напишите запрос, отображающий среднее количество инцидентов в месяц для каждой категории. Подсказка: используйте tutorial.sf_crime_incidents_cleandate , чтобы немного облегчить себе жизнь.
Попробуйте См. ответ
Подзапросы в условной логике
Вы можете использовать подзапросы в условной логике (в сочетании с WHERE , JOIN / ON или CASE ). Следующий запрос возвращает все записи с самой ранней даты в наборе данных (теоретически — плохое форматирование столбца даты на самом деле заставляет возвращать значение, отсортированное первым в алфавитном порядке):
Следующий запрос возвращает все записи с самой ранней даты в наборе данных (теоретически — плохое форматирование столбца даты на самом деле заставляет возвращать значение, отсортированное первым в алфавитном порядке):
SELECT *
ИЗ tutorial.sf_crime_incidents_2014_01
ГДЕ Дата = (ВЫБЕРИТЕ МИН (дата)
ИЗ tutorial.sf_crime_incidents_2014_01
)
Приведенный выше запрос работает, поскольку результатом подзапроса является только одна ячейка. Большая часть условной логики будет работать с подзапросами, содержащими результаты с одной ячейкой. Однако IN — это единственный тип условной логики, который будет работать, когда внутренний запрос содержит несколько результатов:
SELECT *
ИЗ tutorial.sf_crime_incidents_2014_01
ГДЕ Дата В (ВЫБЕРИТЕ дату
ИЗ tutorial.sf_crime_incidents_2014_01
ЗАКАЗАТЬ ПО дате
ПРЕДЕЛ 5
)
Обратите внимание, что вы не должны включать псевдоним при написании подзапроса в условном выражении. Это связано с тем, что подзапрос обрабатывается как отдельное значение (или набор значений в случае IN ), а не как таблица.
Объединение подзапросов
Возможно, вы помните, что вы можете фильтровать запросы в соединениях. Довольно часто присоединяется к подзапросу, который обращается к той же таблице, что и внешний запрос, а не фильтруется в предложении WHERE . Следующий запрос дает те же результаты, что и в предыдущем примере:
ВЫБОР *
ИЗ tutorial.sf_crime_incidents_2014_01 происшествий
ПРИСОЕДИНЯЙТЕСЬ ( ВЫБЕРИТЕ дату
ИЗ tutorial.sf_crime_incidents_2014_01
ЗАКАЗАТЬ ПО дате
ПРЕДЕЛ 5
) суб
ON инциденты.дата = суб.дата
Это может быть особенно полезно в сочетании с агрегатами. При присоединении требования к выходным данным вашего подзапроса не такие строгие, как при использовании предложения WHERE . Например, ваш внутренний запрос может выводить несколько результатов. Следующий запрос ранжирует все результаты в зависимости от того, сколько инцидентов было зарегистрировано в данный день. Он делает это путем агрегирования общего количества инцидентов каждый день во внутреннем запросе, а затем использует эти значения для сортировки внешнего запроса:
ВЫБЕРИТЕ инциденты.*,
sub.incidents AS инциденты_этот_день
ИЗ tutorial.sf_crime_incidents_2014_01 происшествий
ПРИСОЕДИНЯЙТЕСЬ ( ВЫБЕРИТЕ дату,
COUNT(incidnt_num) инцидентов AS
ИЗ tutorial.sf_crime_incidents_2014_01
СГРУППИРОВАТЬ ПО 1
) суб
ON инциденты.дата = суб.дата
ORDER BY sub.incidents DESC, время
Практическая задача
Напишите запрос, который отображает все строки из трех категорий с наименьшим количеством зарегистрированных инцидентов.
ПопробуйтеСмотреть ответ
Подзапросы могут быть очень полезны для повышения производительности ваших запросов. Давайте кратко вернемся к данным Crunchbase. Представьте, что вы хотите собрать все компании, получающие инвестиции, и компании, приобретаемые каждый месяц. Вы можете сделать это без подзапросов, если хотите, но на самом деле не запускайте это, так как для возврата :
SELECT COALESCE(acquisitions.acquired_month, Investments.funded_month) AS month,
COUNT(DISTINCT Acquirements.company_permalink) КАК компании_приобретены,
COUNT(DISTINCT Investments.company_permalink) КАК инвестиции
ИЗ приобретения tutorial.crunchbase_acquisitions
FULL JOIN tutorial.crunchbase_investments инвестиции
ON приобретения.acquired_month = инвестиции.funded_month
СГРУППИРОВАТЬ ПО 1
Обратите внимание, что для того, чтобы сделать это правильно, вы должны соединить поля даты, что вызывает массовый «взрыв данных». По сути, происходит то, что вы соединяете каждую строку в данном месяце из одной таблицы с каждым месяцем в данной строке в другой таблице, поэтому количество возвращаемых строк невероятно велико. Из-за этого мультипликативного эффекта вы должны использовать COUNT(DISTINCT) вместо COUNT , чтобы получить точные подсчеты. Вы можете увидеть это ниже:
Следующий запрос показывает 7414 строк:
ВЫБРАТЬ СЧЕТЧИК(*) ИЗ tutorial.crunchbase_acquisitions
Следующий запрос показывает 83 893 строки:
SELECT COUNT(*) FROM tutorial.crunchbase_investments
Следующий запрос показывает 6 237 396 строк:
SELECT COUNT(*)
ИЗ приобретения tutorial.crunchbase_acquisitions
FULL JOIN tutorial.crunchbase_investments инвестиции
ON приобретения.acquired_month = инвестиции.funded_month
Если вы хотите понять это немного лучше, вы можете провести дополнительное исследование декартовых произведений. Также стоит отметить, что FULL JOIN и COUNT , приведенные выше, на самом деле работают довольно быстро — это COUNT(DISTINCT) , который занимает вечность. Подробнее об этом в уроке по оптимизации запросов.
Конечно, вы могли бы решить эту проблему намного эффективнее, объединив две таблицы по отдельности, а затем соединив их вместе, чтобы подсчеты выполнялись для гораздо меньших наборов данных: приобретения.companies_acquired, Investments.companies_rec_investment ИЗ ( ВЫБЕРИТЕ приобретаете_месяц КАК месяц, COUNT(DISTINCT company_permalink) AS company_acquired ИЗ tutorial.crunchbase_acquisitions СГРУППИРОВАТЬ ПО 1 ) приобретения ПОЛНОЕ СОЕДИНЕНИЕ ( ВЫБЕРИТЕ funded_month AS месяц, COUNT(DISTINCT company_permalink) КАК company_rec_investment ИЗ tutorial.crunchbase_investments СГРУППИРОВАТЬ ПО 1 )инвестиции ON приобретения.месяц = инвестиции.месяц ЗАКАЗАТЬ ПО 1 ДЕСК
Примечание. Мы использовали FULL JOIN выше на тот случай, если в одной таблице были наблюдения за месяц, которых не было в другой таблице. Мы также использовали COALESCE для отображения месяцев, когда в подзапросе поступлений не было записей о месяцах (предположительно, в эти месяцы не было поступлений). Мы настоятельно рекомендуем вам повторно выполнить запрос без некоторых из этих элементов, чтобы лучше понять, как они работают. Вы также можете запускать каждый из подзапросов независимо, чтобы лучше понять их.
Практическая задача
Напишите запрос, который подсчитывает количество основанных и приобретенных компаний по кварталам, начиная с первого квартала 2012 года. Создайте агрегации в двух отдельных запросах, а затем соедините их.
Попробуйте См. ответ
Подзапросы и ОБЪЕДИНЕНИЯ
В следующем разделе мы возьмем урок, посвященный ОБЪЕДИНЕНИЯМ, снова используя данные Crunchbase:
SELECT * ИЗ tutorial.crunchbase_investments_part1 СОЮЗ ВСЕХ ВЫБРАТЬ * ИЗ tutorial.crunchbase_investments_part2
Набор данных нередко бывает разделен на несколько частей, особенно если данные проходят через Excel в какой-либо момент (Excel может обрабатывать только около 1 млн строк на электронную таблицу). Две использованные выше таблицы можно рассматривать как разные части одного и того же набора данных — почти наверняка вы захотите выполнять операции со всем объединенным набором данных, а не с отдельными его частями. Вы можете сделать это с помощью подзапроса:
SELECT COUNT(*) AS total_rows
ИЗ (
ВЫБРАТЬ *
ИЗ tutorial.crunchbase_investments_part1
СОЮЗ ВСЕХ
ВЫБРАТЬ *
ИЗ tutorial.crunchbase_investments_part2
) суб
Это довольно просто. Попробуйте сами:
Практическая задача
Напишите запрос, который ранжирует инвесторов из приведенного выше комбинированного набора данных по общему количеству сделанных ими инвестиций.
ПопробуйтеСмотреть ответ
Практическая задача
Напишите запрос, который делает то же самое, что и в предыдущей задаче, но только для компаний, которые все еще работают. Подсказка: рабочий статус указан в tutorial. crunchbase_companies 9.0030 .
ПопробуйтеСмотреть ответ
Пример вложенного подзапроса SQL Вопрос для интервью
Обзор вложенных запросов запрос. Это эффективный способ получить желаемый результат, который может потребовать нескольких шагов запроса или для обработки взаимозависимых запросов.
Когда использовать вложенные подзапросы
Вы можете использовать вложенные подзапросы несколькими способами:
- Вы можете запрашивать подзапросы (например, выбирать из подзапроса)
- Вы можете заменить одномерные массивы (например, типичный список элементов) и соединения отдельных полей одним подзапросом в предложении WHERE или HAVING
Чтобы использовать подзапрос, необходимо соблюдать несколько синтаксических правил:
- Подзапрос должен быть заключен в круглые скобки
- В зависимости от используемого механизма SQL вам может потребоваться псевдоним для данного подзапроса
- При использовании в предложении WHERE или HAVING оператор SELECT подзапроса может возвращать только одно оцениваемое поле
Пример вопроса SQL для собеседования с использованием вложенного подзапроса
Предположим, вам дана следующая таблица, показывающая продажи компании:
01.2020Рассчитать совокупный процент от общего объема продаж в данный день. Вывод таблицы должен выглядеть примерно так, как показано ниже.
| дата | pct_total_sales |
|---|---|
| 05.01.2020 | Х% |
| 07.01.2020 | Д% |
Вы можете работать с этим примером, используя интерактивную скрипку SQL здесь.
Прежде чем мы начнем писать SQL, мы разобьем вопрос на шаги:
- Подсчитаем общий объем продаж за день
- Рассчитать кумулятивную сумму общего объема продаж за день и общего объема продаж за все дни
- Разделить общий объем продаж за день на общую сумму
1. Подсчитайте сумму продаж за день
Сначала мы напишем базовый запрос, который на следующем шаге станет подзапросом. Приведенный ниже запрос вычисляет общий объем продаж за день, и вы можете взаимодействовать с запросом с помощью этой скрипки SQL.
ВЫБОР #нам нужно просуммировать sale_usd по дате свидание, сумма (sale_usd) как total_usd ОТ sales_info #поскольку мы агрегируем sale_usd по дате, нам нужно #нужно группировать по дате СГРУППИРОВАТЬ ПО дате
2. Вычислите совокупную сумму общего объема продаж за день и общего объема продаж за все дни
Приведенный ниже запрос вычисляет совокупную сумму общего объема продаж за день и общего объема продаж за все дни. Вы можете взаимодействовать с приведенным ниже запросом с помощью этой скрипты SQL.
На этом шаге вы заметите, что мы строим запрос вокруг предыдущего запроса из предыдущего шага. Чтобы успешно построить подзапрос, нам нужно было заключить подзапрос в круглые скобки и убедиться, что мы используем псевдоним для таблицы (поскольку мы используем MySQL, обратите внимание, что это не является требованием для некоторых вариантов SQL). Нам также необходимо убедиться, что мы включили все поля, необходимые для внешнего запроса (например, дату и общий объем продаж).
ВЫБОР
#в этом запросе мы не группируем по, так как используем оконную функцию
свидание,
СУММА(total_usd) ПРЕВЫШЕ (
ORDER BY даты ASC строки
МЕЖДУ неограниченной предыдущей и текущей строкой)
as cum_total, # это оконная функция для
# вычисляем общую сумму
SUM(total_usd) OVER () как итог # это оконная функция для
# подсчитать итог
ИЗ(
ВЫБРАТЬ
#нам нужно просуммировать sale_usd по дате
свидание,
сумма (sale_usd) как total_usd
ОТ sales_info
#поскольку мы агрегируем sale_usd по дате, нам нужно
#нужно группировать по дате
СГРУППИРОВАТЬ ПО дате
) as q1 #создаем псевдоним для этой таблицы, как того требует MySQL 3. Разделите совокупный общий объем продаж на совокупную сумму
Последний шаг — разделить cum_total на общую сумму. Мы можем сделать это на том же шаге, что и выше (просто разделив две оконные функции), или мы можем построить подзапрос поверх предыдущего шага. В приведенном ниже запросе используется другой подзапрос, в результате чего конечный запрос имеет 2 вложенных подзапроса. Вы можете взаимодействовать с приведенным ниже запросом с помощью этой скрипты SQL.
ВЫБОР
свидание,
100 * cum_total / всего как
ИЗ(
#в этом запросе мы не группируем по
#поскольку мы используем оконную функцию
ВЫБРАТЬ
свидание,
СУММ(total_usd) ПРЕВЫШЕНО (ПО ДАТЕ ASC
строки МЕЖДУ неограниченной предыдущей и текущей строкой)
as cum_total, # это оконная функция для
# вычисляем общую сумму
SUM(total_usd) OVER () как итог # это оконная функция
# для расчета суммы
ИЗ(
ВЫБРАТЬ
#нам нужно просуммировать sale_usd по дате
свидание,
сумма (sale_usd) как total_usd
ОТ sales_info
#поскольку мы агрегируем sale_usd по дате, нам нужно
#нужно группировать по дате
СГРУППИРОВАТЬ ПО дате
) as q1 #мы создаем псевдоним для этой таблицы, как того требует MySQL
) как q2 Вложенные запросы — данные отчета
[00:00]
В этом уроке я покажу вам, как настроить в отчете вложенный запрос, чтобы использовать результаты одного запроса для управления другим. Давайте сначала взглянем на два примера таблиц, которые есть в моей базе данных. Сначала у меня есть таблица с записями оборудования. Он имеет столбцы имени идентификатора и описания. Кроме того, есть таблица, содержащая информацию о событиях простоя. В нем есть столбец с идентификатором события простоя, столбец с идентификатором оборудования, которое вышло из строя, а затем столбцы с указанием причины простоя и минут, в течение которых оно было недоступно. Я хочу включить данные из обеих этих таблиц в свой отчет. Мы можем видеть, что они связаны между собой через столбец ID в таблице Equipment_table и ID оборудования в таблице downtime_table. Что я хотел бы сделать, так это запустить запрос, который возвращает данные о каждой единице оборудования, а затем я могу использовать его, чтобы сообщить мне о любом времени простоя для каждой единицы оборудования. К счастью, вложенный запрос поможет мне сделать это. Я начну с создания источника данных SQL-запроса и изменю имя ключа данных на «оборудование». У меня уже есть скопированный запрос, который я вставлю сюда, и мы можем быстро перейти к нему.
[01:07]
По сути, этот запрос возвращает каждый из столбцов из таблицы Equipment_table и назначает им псевдонимы. Идентификатор становится идентификационным номером оборудования, имя становится именем оборудования, а описание становится описанием оборудования. Это будет мой родительский запрос. Чтобы добавить дочерний запрос. Я перейду к разделу вложенных запросов и щелкну значок плюса. Мне нужен только один ребенок для этого примера. Но если вам нужно больше в вашей вложенной системе запросов, вы можете продолжать щелкать значок плюса, чтобы добавить дочерние элементы к своему дочернему, или вы также можете добавить одноранговые узлы. Я изменю ключ данных своего дочернего запроса, чтобы оборудовать время простоя, и возьму другой запрос. Этот запрос возвращает столбцы причины и минут простоя из таблицы времени простоя и назначает им псевдонимы. Он также использует предложение «где» для фильтрации результатов в столбце Equipment_ID. Я хочу отфильтровать результаты этого запроса на основе результатов родительского запроса, чтобы сделать это. Мне понадобится параметр, использующий синтаксис фигурных скобок. И тогда моим именем параметра будет имя столбца из первой таблицы, которая относится к этой таблице. Если вы помните, этот столбец называется «id», но я указал его в псевдониме «идентификационный номер оборудования» в своем запросе.
[02:17]
Таким образом, я могу использовать идентификационный номер оборудования в качестве своего параметра, если бы я не использовал псевдоним, я бы просто использовал здесь идентификатор. Это хорошая идея использовать здесь псевдонимы, потому что если бы я этого не сделал и у меня была бы опечатка в поле параметра, дочерний элемент будет искать совпадение в каждом столбце каждого родительского запроса, а если он не нашел бы его там, он бы искал в параметры для матча, а также. Если в конечном итоге он найдет что-то с похожим названием, вы можете оказаться в ситуации, когда вы просматриваете неправильные данные, и может быть трудно определить, почему. Так что псевдонимы могут быть здесь полезны. Итак, у меня настроен вложенный запрос, и я хочу проверить это. Я перейду на вкладку предварительного просмотра, и мы сможем посмотреть на результаты. Я не буду рассказывать, как я устанавливал этот стол. При желании вы можете сослаться на страницу групп таблиц в руководстве пользователя. Все, что вам нужно знать, это то, что результаты родительского запроса отображаются серым цветом, а результаты дочернего запроса — красным.
[03:04]
Это работает так, что родительские запросы, выполняемые в, возвращают определенное количество строк. Затем дочерние запросы выполняются для каждой строки, возвращаемой родителем. Важно отметить, что для каждой строки, возвращаемой родительским запросом, запускается новый запрос. Если у вас есть дополнительные вложенные дочерние запросы, которые выполняются для каждой строки, возвращаемой первым набором дочерних элементов. Количество запросов может увеличиваться в геометрической прогрессии. Важно знать о последствиях во время выполнения. Производительность системы может снизиться из-за достаточно сложной системы запросов, и вам, возможно, придется некоторое время ждать результатов. Теперь вы можете подумать, что этот пример также можно реализовать с помощью соединения SQL, и вы будете правы. Однако вложенные запросы выгодны, поскольку их гораздо проще писать и поддерживать по сравнению со сложными операторами соединения, и они обеспечивают больший контроль. Самым большим преимуществом также является то, что вложенные запросы имеют гораздо меньше ограничений, чем соединение SQL, если бы вложенные запросы можно было настроить для связывания данных между базами данных различных схем и даже другими источниками данных, такими как архиватор тегов, что делает их чрезвычайно мощным инструментом.
В этом уроке я покажу вам, как настроить в отчете вложенный запрос, чтобы использовать результаты одного запроса для управления другим. Давайте сначала взглянем на два примера таблиц, которые есть в моей базе данных. Сначала у меня есть таблица с записями оборудования. Он имеет столбцы имени идентификатора и описания. Кроме того, есть таблица, содержащая информацию о событиях простоя. В нем есть столбец с идентификатором события простоя, столбец с идентификатором оборудования, которое вышло из строя, а затем столбцы с указанием причины простоя и минут, в течение которых оно было недоступно. Я хочу включить данные из обеих этих таблиц в свой отчет. Мы можем видеть, что они связаны между собой через столбец ID в таблице Equipment_table и ID оборудования в таблице downtime_table. Что я хотел бы сделать, так это запустить запрос, который возвращает данные о каждой единице оборудования, а затем я могу использовать его, чтобы сообщить мне о любом времени простоя для каждой единицы оборудования. К счастью, вложенный запрос поможет мне сделать это. Я начну с создания источника данных SQL-запроса и изменю имя ключа данных на «оборудование». У меня уже есть скопированный запрос, который я вставлю сюда, и мы можем быстро перейти к нему.
[01:07] По сути, этот запрос возвращает каждый из столбцов из таблицы Equipment_table и назначает им псевдонимы. Идентификатор становится идентификационным номером оборудования, имя становится именем оборудования, а описание становится описанием оборудования. Это будет мой родительский запрос. Чтобы добавить дочерний запрос. Я перейду к разделу вложенных запросов и щелкну значок плюса. Мне нужен только один ребенок для этого примера. Но если вам нужно больше в вашей вложенной системе запросов, вы можете продолжать щелкать значок плюса, чтобы добавить дочерние элементы к своему дочернему, или вы также можете добавить одноранговые узлы. Я изменю ключ данных своего дочернего запроса, чтобы оборудовать время простоя, и возьму другой запрос. Этот запрос возвращает столбцы причины и минут простоя из таблицы времени простоя и назначает им псевдонимы. Он также использует предложение «где» для фильтрации результатов в столбце Equipment_ID. Я хочу отфильтровать результаты этого запроса на основе результатов родительского запроса, чтобы сделать это. Мне понадобится параметр, использующий синтаксис фигурных скобок. И тогда моим именем параметра будет имя столбца из первой таблицы, которая относится к этой таблице. Если вы помните, этот столбец называется «id», но я указал его в псевдониме «идентификационный номер оборудования» в своем запросе.
[02:17] Таким образом, я могу использовать идентификационный номер оборудования в качестве своего параметра, если бы я не использовал псевдоним, я бы просто использовал идентификатор здесь. Это хорошая идея использовать здесь псевдонимы, потому что если бы я этого не сделал и у меня была бы опечатка в поле параметра, дочерний элемент будет искать совпадение в каждом столбце каждого родительского запроса, а если он не нашел бы его там, он бы искал в параметры для матча, а также. Если в конечном итоге он найдет что-то с похожим названием, вы можете оказаться в ситуации, когда вы просматриваете неправильные данные, и может быть трудно определить, почему. Так что псевдонимы могут быть здесь полезны. Итак, у меня настроен вложенный запрос, и я хочу проверить это. Я перейду на вкладку предварительного просмотра, и мы сможем посмотреть на результаты. Я не буду рассказывать, как я устанавливал этот стол. При желании вы можете сослаться на страницу групп таблиц в руководстве пользователя. Все, что вам нужно знать, это то, что результаты родительского запроса отображаются серым цветом, а результаты дочернего запроса — красным.
[03:04] Это работает так, что родительские запросы, выполняемые в, возвращают определенное количество строк. Затем дочерние запросы выполняются для каждой строки, возвращаемой родителем. Важно отметить, что для каждой строки, возвращаемой родительским запросом, запускается новый запрос. Если у вас есть дополнительные вложенные дочерние запросы, которые выполняются для каждой строки, возвращаемой первым набором дочерних элементов. Количество запросов может увеличиваться в геометрической прогрессии. Важно знать о последствиях во время выполнения. Производительность системы может снизиться из-за достаточно сложной системы запросов, и вам, возможно, придется некоторое время ждать результатов. Теперь вы можете подумать, что этот пример также можно реализовать с помощью соединения SQL, и вы будете правы. Однако вложенные запросы выгодны, поскольку их гораздо проще писать и поддерживать по сравнению со сложными операторами соединения, и они обеспечивают больший контроль. Самым большим преимуществом также является то, что вложенные запросы имеют гораздо меньше ограничений, чем соединение SQL, если бы вложенные запросы можно было настроить для связывания данных между базами данных различных схем и даже другими источниками данных, такими как архиватор тегов, что делает их чрезвычайно мощным инструментом.
подзапросов в инструкциях SELECT
подзапросов в инструкциях SELECT
|
Следующие ситуации определяют типы подзапросов, которые поддерживает сервер баз данных:
- Оператор SELECT , вложенный в список SELECT других ВЫБЕРИТЕ оператор
- оператор SELECT , вложенный в предложение WHERE другого оператора SELECT (или в оператор INSERT , DELETE или UPDATE )
Каждый подзапрос должен содержать предложение SELECT и предложение FROM . Подзапросы могут быть коррелированными или некоррелированными . Подзапрос (или внутренний SELECT оператор) коррелируется, когда получаемое им значение зависит от значения, производимого SELECT .0041 внешний SELECT оператор, который его содержит. Любой другой вид подзапроса считается некоррелированным.
Важной особенностью коррелированного подзапроса является то, что, поскольку он зависит от значения из внешнего SELECT , он должен выполняться многократно, по одному разу для каждого значения, которое производит внешний SELECT . Некоррелированный подзапрос выполняется только один раз.
Вы можете создать оператор SELECT с подзапросом для замены двух отдельных SELECT операторов.
Подзапросы в операторах SELECT позволяют выполнять следующие действия:
- Сравните выражение с результатом другого оператора SELECT
- Определите, включают ли результаты другого оператора SELECT выражение
- Определить, выбирает ли другая инструкция SELECT какие-либо строки
Необязательное предложение WHERE в подзапросе часто используется для сужения условия поиска.
Подзапрос выбирает и возвращает значения для первого или внешнего оператора SELECT . Подзапрос может не возвращать значения, одно значение или набор значений, как показано ниже:
- Если подзапрос возвращает без значения , запрос не возвращает никаких строк. Такой подзапрос эквивалентен нулевому значению.
- Если подзапрос возвращает одно значение , это значение имеет форму либо одного агрегатного выражения, либо ровно одной строки и одного столбца. Такой подзапрос эквивалентен одному числу или символьному значению.
- Если подзапрос возвращает список или набор значений, значения представляют либо одну строку, либо один столбец.
Подзапросы в списке выбора
Подзапрос может появиться в списке выбора другого оператора SELECT . Запрос 5-20 показывает, как вы можете использовать подзапрос в списке выбора, чтобы получить общую стоимость доставки (из таблицы заказов ) для каждого клиента в таблице клиентов . Вы также можете написать этот запрос как соединение между двумя таблицами.
Запрос 5-20
- ВЫБЕРИТЕ customer.customer_num,
- (ВЫБЕРИТЕ СУММУ(ship_charge)
- ОТ заказов
- ГДЕ customer.customer_num = orders.customer_num)
- КАК total_ship_chg
- ОТ заказчика
Результат запроса 5-20 |
Подзапросы в разделах WHERE
В этом разделе описываются подзапросы, которые встречаются в виде оператора SELECT , вложенного в предложение WHERE другого оператора SELECT .
Следующие ключевые слова вводят подзапрос в предложение WHERE оператора SELECT :
- ВСЕ
- ЛЮБОЙ
- В
- СУЩЕСТВУЕТ
Вы можете использовать любой оператор отношения с ALL и ANY для сравнения чего-либо с каждым из ( ALL ) или с любым из ( ANY ) значений, выдаваемых подзапросом. Вы можете использовать ключевое слово SOME вместо ANY . Оператор IN эквивалентен = ANY . Чтобы создать противоположное условие поиска, используйте ключевое слово NOT или другой оператор отношения.
Оператор EXISTS проверяет подзапрос на наличие каких-либо значений; то есть он спрашивает, не является ли результат подзапроса нулевым. Вы не можете использовать EXISTS ключевое слово в подзапросе, который содержит столбец с типом данных TEXT или BYTE .
Синтаксис, который вы используете для создания условия с подзапросом, см. в Informix Guide to SQL : Syntax .
Использование ВСЕХ
Используйте ключевое слово ALL перед подзапросом, чтобы определить, верно ли сравнение для каждого возвращаемого значения. Если подзапрос не возвращает значений, условие поиска равно true . (Если он не возвращает никаких значений, условие истинно для всех нулевых значений. )
Запрос 5-21 перечисляет следующую информацию для всех заказов, содержащих товар, общая цена которого меньше общей цены на каждые товара в заказе с номером 1023.
Запрос 5-21
- ВЫБЕРИТЕ order_num, stock_num, manu_code, total_price
ИЗ товаров
WHERE total_price < ALL
(ВЫБЕРИТЕ total_price ИЗ товаров
WHERE order_num = 1023)
Результат запроса 5-21 |
Использование ЛЮБОГО
Используйте ключевое слово ANY (или его синоним SOME ) перед подзапросом, чтобы определить, верно ли сравнение хотя бы для одного из возвращаемых значений. Если подзапрос не возвращает значений, условием поиска является false . (Поскольку значений не существует, условие не может быть истинным ни для одного из них. )
Запрос 5-22 находит номер заказа для всех заказов, содержащих товар, общая цена которого больше, чем общая цена любой один из позиций в заказе № 1005.
Запрос 5-22
- ВЫБРАТЬ ОТЛИЧНЫЙ номер_заказа
ИЗ товаров
ГДЕ total_price > ЛЮБОЙ
(ВЫБРАТЬ total_price
ИЗ товаров
ГДЕ номер_заказа = 1005)
Результат запроса 5-22 |
Однозначные подзапросы
Вам не нужно включать ключевое слово ВСЕ или ЛЮБОЙ , если вы знаете, что подзапрос может вернуть ровно одно значение в запрос внешнего уровня. Подзапрос, возвращающий ровно одно значение, можно рассматривать как функцию. Этот вид подзапроса часто использует агрегатную функцию, поскольку агрегатные функции всегда возвращают одиночные значения.
Запрос 5-23 использует агрегатную функцию MAX в подзапросе, чтобы найти order_num для заказов, включающих максимальное количество волейбольных сеток.
Запрос 5-23
- ВЫБЕРИТЕ order_num ИЗ товаров
ГДЕ stock_num = 9
И количество =
(ВЫБЕРИТЕ MAX (количество)
ИЗ товаров
ГДЕ stock_num = 9)
Результат запроса 5-23 |
Запрос 5-24 использует агрегатную функцию MIN в подзапросе для выбора товаров, общая цена которых превышает минимальную цену более чем в 10 раз.
Запрос 5-24
- ВЫБЕРИТЕ order_num, stock_num, manu_code, total_price
FROM items x
WHERE total_price >
(SELECT 10 * MIN (total_price)
FROM items
WHERE order_num = x.order_num)
Результат запроса 5-24 |
Коррелированные подзапросы
Запрос 5-25 — это пример коррелированного подзапроса, который возвращает список из 10 последних дат доставки в заказов табл. Он включает предложение ORDER BY после подзапроса для упорядочения результатов, поскольку вы не можете включить ORDER BY в подзапрос.
Запрос 5-25
- ВЫБЕРИТЕ po_num, ship_date ИЗ основных заказов
ГДЕ 10 >
(ВЫБЕРИТЕ СЧЕТЧИК (DISTINCT ship_date)
ИЗ заказов sub
ГДЕ sub.ship_date < main.ship_date)
AND ship_date НЕ НУЛЕВОЕ
ORDER BY ship_date, po_num
Подзапрос коррелирован, потому что число, которое он выдает, зависит от main.ship_date , значения, которое выдает внешний SELECT . Таким образом, подзапрос должен выполняться повторно для каждой строки, которую рассматривает внешний запрос.
Запрос 5-25 использует функцию COUNT для возврата значения в основной запрос. Затем предложение ORDER BY упорядочивает данные. Запрос находит и возвращает 16 строк с 10 последними датами доставки, как показано в результате запроса 5-25.
Результат запроса 5-25 |
Если вы используете коррелированный подзапрос, такой как запрос 5-25, в большой таблице, вы должны проиндексировать столбец ship_date для повышения производительности. В противном случае этот оператор SELECT неэффективен, поскольку он выполняет подзапрос один раз для каждой строки таблицы. Сведения об индексации и проблемах с производительностью см. в Руководстве администратора и в вашем Руководство по производительности .
Использование EXISTS
Ключевое слово EXISTS известно как квалификатор существования , потому что подзапрос истинен только в том случае, если внешний SELECT , как показывает запрос 5-26а, находит хотя бы одну строку.
Запрос 5-26a
- ВЫБЕРИТЕ УНИКАЛЬНОЕ имя_производителя, время выполнения
ОТ производителя
ГДЕ СУЩЕСТВУЕТ
(ВЫБЕРИТЕ * ИЗ ЗАПАСА
ГДЕ описание СОВПАДАЕТ '*shoe*'
AND manufact.
manu_code = stock.manu_code) Часто можно создать запрос с EXISTS , который эквивалентен запросу, использующему IN . В запросе 5-26b используется предикат IN для создания запроса, возвращающего тот же результат, что и в запросе 5-26a.
Запрос 5-26b
- ВЫБЕРИТЕ УНИКАЛЬНОЕ manu_name, lead_time
FROM stock, manufact
WHERE manufact.manu_code IN
(SELECT manu_code FROM stock
WHERE description MATCHES '*shoe*')
AND stock.manu_code = manufact.manu_code
Запрос 5-26a и запрос 5-26b возвращают строки для производителей, которые производят определенную обувь, а также время выполнения заказа на продукт. Результат запроса 5-26 показывает возвращаемые значения.
Результат запроса 5-26 |
Добавьте ключевое слово NOT к IN или к EXISTS , чтобы создать условие поиска, противоположное условию в предыдущих запросах. Вы также можете заменить != ВСЕ для НЕ В .
Запрос 5-27 показывает два способа сделать одно и то же. Один способ может позволить серверу базы данных выполнять меньше работы, чем другой, в зависимости от структуры базы данных и размера таблиц. Чтобы выяснить, какой запрос может быть лучше, используйте команду SET EXPLAIN , чтобы получить список плана запроса. SET EXPLAIN обсуждается в Руководстве по производительности и Informix Guide to SQL : Syntax .
Запрос 5-27
- ВЫБЕРИТЕ номер_клиента, компанию ОТ клиента
ГДЕ номер_клиента НЕ В
(ВЫБЕРИТЕ номер_клиента ИЗ заказов
ГДЕ номер_клиента = номер_заказа)
ВЫБЕРИТЕ номер_клиента, компанию ИЗ клиента
ГДЕ НЕ СУЩЕСТВУЕТ
(ВЫБЕРИТЕ * ИЗ заказов
ГДЕ клиент. номер_клиента = заказы.номер_клиента)
Каждый оператор в запросе 5-27 возвращает строки, показанные в результате запроса 5-27, которые идентифицируют клиентов, которые не размещали заказы.
Результат запроса 5-27 |
Ключевые слова EXISTS и IN используются для операции множества, известной как пересечение , а ключевые слова NOT EXISTS и NOT IN используются для операции множества, известной как разность . Эти концепции обсуждаются в разделе Операции над множествами.
Запрос 5-28 выполняет подзапрос к таблице элементов , чтобы идентифицировать все элементы в сток стол, которые еще не заказывали.
Запрос 5-28
- ВЫБЕРИТЕ * ИЗ запаса
ГДЕ НЕ СУЩЕСТВУЕТ
(ВЫБЕРИТЕ * ИЗ товаров
ГДЕ stock.stock_num = items.stock_num
AND stock.manu_code = items.manu_code)
Запрос 5-28 возвращает строки, показанные в Результате Запроса 5-28.
Результат запроса 5-28 |
Не существует логического ограничения на количество подзапросов a Оператор SELECT может иметь, но размер любого оператора физически ограничен, когда он рассматривается как строка символов. Однако этот предел, вероятно, больше, чем любое практическое утверждение, которое вы, вероятно, сочините.
Возможно, вы хотите проверить, правильно ли введена информация в базу данных. Один из способов найти ошибки в базе данных — написать запрос, возвращающий выходные данные только при наличии ошибок. Подзапрос этого типа служит своего рода контрольным запросом 9.0042 , как показывает запрос 5-29.
Запрос 5-29
- ВЫБЕРИТЕ * ИЗ товаров
ГДЕ общая_цена != количество *
(ВЫБЕРИТЕ цену за единицу ИЗ запаса
ГДЕ запас.номер_запаса = номер_запаса
И код_запаса = код_к_запаса)
Запрос 5-29 возвращает только те строки, для которых общая цена товара в заказе не равна цене единицы запаса, умноженной на количество заказа. Если скидка не применялась, вероятно, такие строки были неправильно введены в базу данных. Запрос возвращает строки только при возникновении ошибок. Если информация правильно вставлена в базу данных, строки не возвращаются.
Результат запроса 5-29 |
Informix Guide to SQL: Tutorial , Version 9.2
Copyright 1999, Informix Software, Inc. Все права защищены
соединений и подзапросов в SQL
Оператор SQL Join используется для объединения данных или строк из двух или более таблиц на основе общего поля между ними. Подзапрос — это запрос, вложенный в инструкцию SELECT, INSERT, UPDATE или DELETE или в другой подзапрос.
Узнайте все, что вам нужно знать о соединениях и подзапросах SQL, и многое другое!
Продолжайте читать...
Оператор SQL Join используется для объединения данных или строк из двух или более таблиц на основе общего поля между ними.
Подзапрос — это запрос, вложенный в инструкцию SELECT , INSERT , UPDATE или DELETE или внутри другого подзапроса.
Соединения и подзапросы используются для объединения данных из разных таблиц в один результат.
Первичный ключ – это столбец в таблице, который используется для уникальной идентификации строки в этой таблице.
Внешний ключ используется для формирования связи между двумя таблицами. Например, предположим, что у вас есть отношение «один ко многим» между клиентами в таблице CUSTOMER и заказами в таблице ORDER. Чтобы связать две таблицы, вы должны определить столбец ORDER_ID в таблице CUSTOMER, который соответствует столбцу ORDER_ID в таблице ORDER.
Примечание. Имя столбца внешнего ключа не обязательно должно совпадать с именем столбца первичного ключа.
Значения, определенные в столбце внешнего ключа, ДОЛЖНЫ соответствовать значениям, определенным в столбце первичного ключа. Это называется ссылочной целостностью и обеспечивается реляционной СУБД. Если первичный ключ для таблицы является составным ключом, внешний ключ также должен быть составным ключом.
1.2
Внутренний СоединенияВнутренние соединения используются для объединения связанной информации из нескольких таблиц. Внутреннее соединение извлекает совпадающие строки между двумя таблицами. Совпадения обычно выполняются на основе существующих отношений между первичным и внешним ключами. Если есть совпадение, строка включается в результаты. В противном случае это не так.
Синтаксис:
Выбрать <столбцы>
Из
соединение
на
Технически внешний ключ не должен существовать в связанной таблице для выполнения внутреннего соединения. Однако, чтобы гарантировать ссылочную целостность и производительность, рекомендуется иметь его.
Если первичный ключ и внешний ключ являются составными ключами, то при указании соединения вы должны объединить И вместе с любыми дополнительными столбцами.
Например, если у вас есть составной ключ из двух столбцов, синтаксис будет следующим:
SELECT
FROM
JOIN
ON
AND
Схема базы данных представляет организацию и структуру базы данных. Он содержит таблицы и другие объекты базы данных (например, представления, индексы, хранимые процедуры). База данных может иметь более одной схемы, как в данном случае. База данных AdventureWorks на самом деле имеет 6 схем (dbo, HumanResources, Person, Production, Purchases и Sales). В SQL Server dbo является схемой по умолчанию. С другой стороны, Northwind имеет только схему dbo.
В приведенном выше примере идентификатор HumanResources.Employee означает, что HumanResources — это имя схемы, а Employee — имя таблицы. Персона. Идентификатор человека означает, что Person — это имя схемы, а Person — имя таблицы.
1.
3 Внутреннее соединение Примеры Объединение 2 таблиц:
SELECT Персона.Имя, Персона.Фамилия, Сотрудник.ДатаРождения, Сотрудник.НаемДата ОТ HumanResources.Employee ПРИСОЕДИНЯЙТЕСЬ к Person.Person ON Сотрудник.BusinessEntityID = Person.BusinessEntityID
Объединение N таблиц:
SELECT Person.FirstName, Person.LastName, Employee.BirthDate, Employee.HireDate, EmailAddress.EmailAddress ОТ HumanResources.Employee ПРИСОЕДИНЯЙТЕСЬ к Человеку.Человеку ON Сотрудник.BusinessEntityID = Person.BusinessEntityID ПРИСОЕДИНЯЙТЕСЬ к Person.EmailAddress ON Person.BusinessEntityID = EmailAddress.BusinessEntityID
Эта статья была адаптирована из нашего курса Введение в обучение SQL .
Узнайте все о соединениях и подзапросах в SQL и многое другое!
Свяжитесь с нами, чтобы получить код скидки
50%
на этот курс.
1.4
Префикс столбцов с именами таблицОбычно рекомендуется ставить имена столбцов с именами таблиц, чтобы было ясно, из какой таблицы взяты столбцы. Однако, если нет двусмысленности, т. е. в обеих таблицах нет одних и тех же столбцов, их можно опустить.
Пример:
ВЫБОР Имя Фамилия, Дата Рождения, Дата Найма ОТ HumanResources.Employee ПРИСОЕДИНЯЙСЯ ON Employee.BusinessEntityID = Person.BusinessEntityIDЗапрос транзакционных и аналитических баз данных с использованием SQL , MDX и DAX
Посмотрите наше видео на YouTube прямо сейчас!
Транзакционные базы данных (также известные как OLTP) оптимизированы для большого объема транзакций, таких как вставка, обновление и удаление.
В основном они используются приложениями для ввода данных.
Аналитические базы данных (также известные как OLAP) оптимизированы для больших объемов данных, которые часто запрашиваются для принятия бизнес-решений/отчетности. Вам нужно использовать различные языки запросов для запросов к этим разным типам баз данных.
Присоединяйтесь к нам в этом часовом видеоролике, в котором будут изучены такие языки запросов, как SQL , MDX и DAX .
1.5 Использование псевдонимов таблиц
Чтобы сделать имена столбцов короче и удобнее для чтения при объединении двух таблиц, мы можем использовать псевдонимы таблиц. Псевдонимы таблиц аналогичны псевдонимам столбцов. Вместо сокращения имени столбца мы сокращаем имя таблицы. Часто псевдонимы таблиц имеют длину в один или два символа. Псевдонимы таблиц можно использовать, даже если вы не объединяете таблицы.
Синтаксис:
SELECT
FROM
<Таблица 2>
соединение
на
ВЫБОР р. Имя, р. Фамилия, эл. Дата Рождения, г. н.э. HireDate ОТ HumanResources.Employee e СОЕДИНИТЬ Person.Person p НА э. BusinessEntityID = р. BusinessEntityID
Наши следующие предстоящие
бесплатные веб -бинарПолучите много действенных знаний за короткое время
1,7 arderate
Inner innec join, который использует предложение WHERE для указания критериев соединения. Вы можете увидеть, что этот стиль соединения используется в устаревшем коде SQL.Синтаксис:
ВЫБЕРИТЕ
ИЗ ,
ГДЕ . знак равно
Пример:
ВЫБОР Персона.Имя, Персона.Фамилия, Сотрудник.ДатаРождения, Сотрудник.НаемДата ИЗ HumanResources.Сотрудник, Человек.Человек WHERE Employee.BusinessEntityID = Person.BusinessEntityID
Чтобы указать внешние соединения, необходимо использовать синтаксис, зависящий от поставщика. Например, в Oracle вам нужно использовать оператор (+), а в SQL Server вам нужно использовать операторы *= и =*.
Эта статья была адаптирована из нашего курса
Введение в SQL .
Узнайте здесь все и НАМНОГО больше!
Способность писать на языке SQL — краеугольном камне всех операций с реляционными базами данных — необходима для всех, кто разрабатывает приложения для баз данных.
Научитесь использовать все возможности языка SQL.
Просмотр сведений о курсе
1.8
Внешний СоединенияЧто произойдет, если вы выполняете внутреннее соединение и одной из записей в таблице не соответствует запись в другой таблице?
Тогда в результирующем наборе не появится ни одной строки. Однако вы можете по-прежнему захотеть увидеть эту строку в своем отчете.
Например, у вас может быть клиент, но он еще не размещал заказы. Вы все еще хотите перечислить клиента.
Вот где внешний присоединяется к и приходит на помощь. Есть несколько типов внешних объединений , которые мы обсудим далее.
Свяжитесь с Web Age Solutions, чтобы получить
СКИДКА 50%Скидка на курс «Введение в SQL» операции с базами данных —
необходим для всех, кто разрабатывает приложения для баз данных.Научитесь использовать все возможности языка SQL.
В этом учебном курсе «Введение в SQL» вы узнаете, как оптимизировать доступность и обслуживание данных с помощью языка программирования SQL, а также получите прочную основу для построения баз данных, выполнения запросов и управления ими.
Узнайте, как быстро и эффективно извлекать большие объемы данных.
Начните работу с Web Age Введение в SQL Обучение сегодня!
Просмотр сведений о курсе
1.
9 Слева Внешние соединенияA левое внешнее соединение возвращает все записи из таблицы слева и соответствующие записи из таблицы справа.
Если соответствующей записи нет, то для любых столбцов, выбранных из таблицы справа, возвращается NULL.
Это эквивалент внутреннего соединения плюс несопоставленные строки из таблицы слева.
Синтаксис:
SELECT
FROM
LEFT JOIN <таблица2>
ON <таблица1>.<столбецA> = <таблица2>.<столбецB>
1.10 Левое внешнее соединение
Примеры совпадающие идентификаторы заказов на покупку.ВЫБОР e.BusinessEntityID, p.PurchaseOrderID ОТ HumanResources.Employee e LEFT JOIN Purchasing.PurchaseOrderHeader p ON e.BusinessEntityID = p.EmployeeID
Получить обратно все идентификаторы сотрудников (т. е. идентификаторы бизнес-объектов) и любые соответствующие идентификаторы кандидатов на работу и резюме
SELECT e.BusinessEntityID, j.JobCandidateID, j.Resume ОТ HumanResources.Employee e LEFT JOIN HumanResources.JobCandidate j ON e.BusinessEntityID = j.BusinessEntityID ЗАКАЗАТЬ ПО j.JobCandidateID DESC
1.11
Правое Внешнее соединениеA Правое внешнее соединение является противоположностью левому внешнему соединению.
Правое внешнее соединение возвращает все записи из таблицы справа и соответствующие записи из таблицы слева. Если соответствующей записи нет, то для любых столбцов, выбранных из таблицы слева, возвращается NULL.
Эквивалент внутреннего соединения плюс несовпадающие строки из таблицы справа .
Синтаксис:
SELECT
FROM
RIGHT JOIN
ON
Пример:
5 резюме и любые соответствующие идентификаторы сотрудников (например, идентификаторы бизнес-объектов)
SELECT e.BusinessEntityID, j.JobCandidateID, j.Resume ОТ HumanResources.Employee e ПРАВОЕ ПРИСОЕДИНЕНИЕ HumanResources.JobCandidate j ON e.BusinessEntityID = j.BusinessEntityID ЗАКАЗАТЬ ПО e.BusinessEntityID DESC
Хотите попрактиковаться в работе с соединениями и подзапросами SQL
?
Загрузите нашу БЕСПЛАТНУЮ практическую лабораторию
Соединения SQL — внутренние и внешние соединения
Бесплатно для вас!
1.12
Полное Внешнее соединение Полное внешнее соединение возвращает все совпадающие записи между таблицами слева и справа, а также все несовпадающие записи с обеих сторон. Это эквивалент внутреннего соединения плюс несовпадающие строки из таблицы слева и несовпадающие строки из таблицы справа.
Синтаксис:
Выбрать <столбцы>
из
Полное соединение
на <Таблица1>. Пример: Получить обратно все идентификаторы сотрудников (т. е. идентификаторы бизнес-объектов), а также идентификаторы и резюме всех кандидатов на работу. Сопоставьте вместе любые записи. Самостоятельное соединение — это соединение, при котором таблица объединяется сама с собой. Синтаксис: SELECT FROM JOIN ON Пример: Чтобы сопоставить адреса из одного и того же города, используйте следующий запрос: Подзапрос — это вложенный запрос (внутренний запрос), который используется для фильтрации результатов внешнего запроса. Синтаксис: SELECT FROM WHERE (SELECT FROM ) Подзапросы всегда должны заключаться в круглые скобки. Оператору может соответствовать одно из следующих значений: IN, =, <>, <, >, >=, <= Если подзапрос возвращает более одного результата, то можно использовать только оператор IN Таблица, указанная в подзапросе, обычно отличается от таблицы во внешнем запросе, но может совпадать. Учебные курсы по SQL Обновите свои навыки работы с ведущими на рынке системами баз данных от Microsoft. Web Age Solutions предлагает обучение для администраторов баз данных, разработчиков, разработчиков бизнес-аналитики и других специалистов по базам данных. Обучение SQL Веб-семинары Web Age предоставляет бесплатные ежемесячные веб-семинары по многим актуальным и своевременным темам. Будьте готовы смеяться и учиться с нашими экспертами. Бесплатные веб-семинары Блоги Ознакомьтесь с последними размышлениями, идеями и анализом непосредственно от наших талантливых экспертов. Блоги Тип подзапроса, который мы изучали до сих пор, который мы будем называть обычный 70378 0 3, является независимым от внешнего подзапроса 3 запрос и выполняется один раз. С другой стороны, коррелированный подзапрос зависит от внешнего запроса и выполняется один раз для каждой строки, возвращаемой внешним запросом. Его также называют повторяющимся подзапросом . Поскольку коррелированные подзапросы выполняются несколько раз, они могут выполняться медленно. Пример: Чтобы получить продавцов, процент комиссионных которых составляет 1%, мы можем использовать следующий коррелированный подзапрос. Внешний запрос извлекает каждого сотрудника. Внутренний запрос оценивает каждую строку, чтобы увидеть, составляет ли их процент комиссии 1%. Получите много практических знаний за короткий промежуток времени В этом руководстве мы рассмотрели, как: Способность писать на языке SQL — краеугольном камне всех операций с реляционными базами данных — необходима для всех, кто разрабатывает приложения для баз данных. Начните сегодня и используйте все возможности языка SQL. Свяжитесь с нами, чтобы узнать больше о захватывающих возможностях, открывающихся перед вами благодаря обучению SQL. Свяжитесь с нами Подзапросы — это запрос в запросе. Подзапросы позволяют вам возвращать записи из другой таблицы или базы данных и использовать набор данных подзапроса для последующего управления записями в других частях вашей базы данных. Подзапросы — это операторы SELECT, вложенные в другие ваши операторы SQL, которые возвращают подмножество данных, которые обычно находятся во внешнем источнике, который вы не можете использовать в стандартных предложениях WHERE или IN. Пересмотр оператора SELECT Прежде чем мы перейдем к подзапросам, давайте вернемся к концепции операторов SELECT. Оператор SELECT возвращает список значений столбца. В наших примерах мы будем использовать следующие таблицы Customer и Order. Клиент идентификатор клиента Имя Фамилия Город Состояние 321 Фрэнк Лоэ Даллас ТХ 455 Эд Томпсон Атланта Г. 456 Эд Томпсон Атланта Г.А. 457 Джо Смит Майами FL 458 Фрэнк Доу Даллас ТХ Заказ идентификатор заказа идентификатор клиента Всего Дата заказа 1 321 10 02.01.2014 2 455 40 02.03.2014 3 456 20 10. Следующий код SQL представляет собой стандартную инструкцию SQL, которая получает имя и фамилию клиента. " Техас." Переходим к подзапросу Подзапрос — это, по сути, запрос SELECT. Отличие подзапроса в том, что вы должны быть осторожны с количеством возвращаемых столбцов. Например, следующий оператор SQL содержит подзапрос, который вернет ошибку. SELECT * FROM Customer WHERE State IN (SELECT * FROM Order) Ошибка в предложении WHERE. Условие IN запрашивает значение состояния. Подзапрос возвращает все строки из таблицы Order, поэтому внешнее предложение IN не может определить, к какому столбцу он должен обращаться. Подзапрос должен вернуть один запрос для сравнения. Например, предположим, что вы хотите вернуть список клиентов, которые также были в таблице Order. Вы можете видеть, что CustomerId также находится в таблице Order, поэтому вы можете использовать подзапрос для возврата списка записей идентификаторов клиентов, а затем использовать набор данных для фильтрации записей Customer. Следующий оператор SQL дает вам пример. SELECT * FROM Customer WHERE CustomerId IN (SELECT CustomerId FROM Order) Обратите внимание, что внутренний подзапрос возвращает только один столбец — столбец CustomerId. Этот столбец затем используется для фильтрации записей в основном внешнем запросе в таблице Customer. В результате получается следующий набор данных. идентификатор клиента Имя Фамилия Город Состояние 321 Фрэнк Лоэ Даллас ТХ 455 Эд Томпсон Атланта Г. А. 456 Эд Томпсон Атланта Г. Возвращенный набор данных соответствует записям клиентов в таблице заказов. Поскольку подзапрос аналогичен обычному оператору SELECT, вы также можете добавить все условия и предложения, которые мы уже изучили. Во-первых, вы можете добавить предложение WHERE в инструкцию SELECT. Предположим, вам нужен список клиентов, разместивших заказы в марте. Дата заказа находится в таблице заказов, но у вас есть только идентификатор клиента в вашей таблице заказов. Вам нужна таблица Customer в качестве внешнего запроса и подзапрос к таблице Order в качестве внутреннего запроса. Следующий код выполняет запрос. SELECT * FROM Customer WHERE CustomerId IN (SELECT CustomerId FROM Order WHERE OrderDate МЕЖДУ '3/1/2014' И '31/31/2014') При выполнении приведенного выше оператора механизм SQL сначала запускает подзапрос ВЫБЕРИТЕ заявление. Этот подзапрос возвращает набор записей, содержащий только список идентификаторов клиентов, соответствующих отфильтрованному предложению WHERE. Далее выполняется внешний запрос SELECT. Звездочка используется для возврата всех столбцов для этого запроса, который допустим во внешнем SELECT. Механизм SQL сопоставляет записи идентификаторов клиентов, возвращаемые подзапросом, и возвращает отфильтрованные результаты. Результатом является следующий набор данных. идентификатор клиента Имя Фамилия Город Состояние 455 Эд Томпсон Атланта Г. А. 456 Эд Томпсон Атланта Г. Несмотря на то, что информация о клиенте одинакова, идентификаторы клиентов различаются. Результатом является набор данных, содержащий две записи 455 и 456. Запросы к внешним базам данных Операторы подзапросов часто используются для запросов к внешним базам данных. Ваши базы данных — это организационные структуры, содержащие таблицы. Эти таблицы содержат ваши данные. Например, у вас есть магазин электронной торговли в одной базе данных и база данных контента для отделения данных электронной торговли от данных контента. Предположим, имя базы данных электронной торговли — «электронная торговля», а имя базы данных контента — «контент». Давайте настроим среду данных для базы данных контента. У вас есть таблица для комментариев к вашим статьям или продуктам. Эта таблица называется «Комментарий» в базе данных контента и содержит идентификатор клиента для комментария. Вот пример таблицы комментариев. идентификатор клиента Идентификатор статьи Комментарий 457 4 Тестовый комментарий. 458 5 Этот товар не для меня. Вам поручено получить список клиентов, оставивших комментарии к вашим продуктам. У вас есть таблица в базе данных Content, которая содержит комментарии, поэтому вы можете использовать подзапрос, чтобы получить эти записи и использовать их для фильтрации по вашей основной таблице Customer. Следующий оператор SQL выполняет ваш запрос. SELECT * FROM Ecommerce.Customer WHERE Ecommerce.Customer.CustomerId IN (SELECT Content.Comment.CustomerId FROM Content.Comment) В приведенном выше выражении используются некоторые идентификаторы. Следующим идентификатором является имя таблицы. «Ecommerce.Customer» означает «использовать таблицу Customer в базе данных электронной торговли». Во внутреннем запросе идентифицируются база данных Content.Comment и имя таблицы. Идентификатор CustomerId — это имя столбца, возвращенное из внутреннего запроса. Поскольку у вас есть два комментария в таблице Comment, оператор SQL возвращает две записи. Возвращается следующий набор записей. идентификатор клиента Имя Фамилия Город Состояние 457 Джо Смит Майами ФЗ 458 Фрэнк Доу Даллас ТХ Когда оператор SQL возвращает записи, он возвращает столбцы и данные, указанные во внешнем операторе SQL, поэтому вы видите данные из таблицы «Клиент», а не из таблицы «Комментарии», хотя SQL действительно возвращает идентификатор клиента из таблицы «Комментарии». Подзапросы также полезны, когда вы хотите ВСТАВИТЬ или ОБНОВИТЬ столбцы. Вы видели, как использовать подзапрос для ВСТАВКИ данных из одной таблицы в другую. Тот же самый тип подзапроса также используется для ОБНОВЛЕНИЯ данных. Предположим, вы добавили столбец даты с именем «OrderDate» в свою таблицу Customer. Теперь ваша таблица Customer выглядит следующим образом. идентификатор клиента Имя Фамилия Город Состояние Дата заказа 321 Фрэнк Лоэ Даллас ТХ 455 Эд Томпсон Атланта Г. А. 456 Эд Томпсон Атланта Г. 457 Джо Смит Майами FL 458 Фрэнк Доу Даллас ТХ Вам нужно добавить OrderDate для каждого клиента, но вы хотите использовать дату, указанную в таблице Order. Посмотрите на следующую инструкцию SQL. UPDATE Customer SET OrderDate = (SELECT TOP 1 OrderDate FROM Order WHERE Order.CustomerId=Customer.CustomerId) Вышеприведенный оператор UPDATE не содержит условия WHERE, поэтому все записи обновляются с датой. Пункт «ТОП 1» является здесь новым. Фраза TOP 1 получает только одну запись из таблицы Order. Если вы не использовали фразу TOP 1 и имели более одной записи для конкретного клиента, SQL возвращает ошибку, поскольку в вашем подзапросе возвращается более одной записи. Подзапрос сопоставляет значение идентификатора клиента в таблице "Клиент" с идентификатором клиента в таблице "Заказ". Этот результат гарантирует, что вы получите дату, соответствующую правильному идентификатору клиента. Затем подзапрос используется для изменения значения в столбце Customer OrderDate. Подзапрос получает только одну запись, поэтому при наличии нескольких записей нет гарантии, что правильная дата будет обновлена в таблице Customer. Вы можете добавить предложение WHERE во внутренний подзапрос, чтобы получить первую или последнюю дату из таблицы Order. Вы также можете использовать предложение ORDER BY для своего внутреннего запроса. Помните, что внутренний запрос — это стандартный оператор SELECT, который может иметь любое предложение WHERE, чтобы гарантировать, что вы возвращаете правильные данные. Следующий набор данных показывает вашу новую таблицу Customer. идентификатор клиента Имя Фамилия Город Состояние Дата заказа 321 Фрэнк Лоэ Даллас ТХ 02. 455 Эд Томпсон Атланта Г. А. 02.03.2014 456 Эд Томпсон Атланта Г. А. 10.03.2014 457 Джо Смит Майами FL НУЛЕВОЙ 458 Фрэнк Доу Даллас ТХ НУЛЕВОЙ Обратите внимание, что последние две записи имеют NULL для значений даты. Посмотрите на свой стол заказов. Заказа для клиентов 457 и 458 нет. Результат внутреннего подзапроса равен NULL, поэтому NULL обновляется в вашей таблице. ВЫБЕРИТЕ e.BusinessEntityID, j.JobCandidateID, j.Resume
ОТ HumanResources.Employee e
ПОЛНОЕ СОЕДИНЕНИЕ HumanResources.JobCandidate j
ON e.BusinessEntityID = j.BusinessEntityID
ORDER BY e.BusinessEntityID DESC
1.13
Strong Соединения Обычно он используется, когда между сущностями существует иерархическая связь (например, сотрудник-менеджер), или вы хотите сравнить строки в одной таблице. Он использует синтаксис либо внутреннего соединения, либо левого внешнего соединения. Псевдонимы таблиц используются для присвоения разных имен одной и той же таблице в запросе. AS
AS
SELECT a1.AddressID, a2.AddressID, a1.City
ОТ Лицо.Адрес a1
ПРИСОЕДИНЯЙТЕСЬ к лицу.Адрес a2
ON a1.AddressID > a2.AddressID
ГДЕ a1.City = a2.City
1.14 Что такое подзапрос
? Подзапросы могут использоваться как альтернатива соединениям. Подзапрос обычно вложен в предложение WHERE. 1.15 Подзапрос
Примеры SELECT Name, ProductNumber
ОТ Производство.Продукт
ГДЕ ProductID В
(ВЫБЕРИТЕ ProductID
ОТ Purchasing.PurchaseOrderDetail
ГДЕ OrderQty > 5)
ВЫБЕРИТЕ Имя, Фамилия
ОТ Лицо.Лицо р
ГДЕ BusinessEntityID =
(ВЫБЕРИТЕ BusinessEntityID
ОТ HumanResources.
Employee
ГДЕ NationalIDNumber = 295847284) У нас много ресурсов
SQL . 1.16
Обычный Подзапрос против Коррелированный Подзапрос Его результаты используются внешним запросом. 1.17 Коррелированный подзапрос
Пример ВЫБЕРИТЕ e.BusinessEntityID, p.FirstName, p.LastName
ОТ Лицо.Лицо р
ПРИСОЕДИНЯЙТЕСЬ к HumanResources.Employee
ON e.BusinessEntityID = p.BusinessEntityID
ГДЕ 0,01 В
(ВЫБРАТЬ s.CommissionPct
ОТ Sales. SalesPerson s
ГДЕ e.BusinessEntityID = s.BusinessEntityID) Наш следующий предстоящий
БЕСПЛАТНЫЙ веб-семинар 1.18
Резюме Как использовать подзапросы в SQL
А. 03.2014 А. В этом примере результатами являются любые заказы, созданные в марте. Внутренний подзапрос возвращает две записи за март или две записи ID клиента. А. Вместо предположения, что запрос выполняется для таблиц в текущей базе данных, оператор SQL указывает имя базы данных, имя таблицы и имя столбца. Первый идентификатор — это имя базы данных. Внешний запрос использует базу данных электронной торговли, а внутренний запрос использует базу данных контента. . А. 01.2014