btrim(string
bytea, bytes bytea) | bytea | Удалить наиболее длинную строку, содержащую только байты, перечисленные в bytes, от начала и до конца string | btrim(E’\\000trim\\000′::bytea, E’\\000′::bytea) | trim |
decode(string text,
type text) | bytea | Декодировать бианрную строку из string, которая была
ранее закодирована функцией encode. Тип параметра такой же как
и в encode. | decode(E’123\\000456′, ‘escape’) | 123\000456 |
encode(string bytea,
type text) | text | Закодировать бинарную строку в ASCII представление. Поддерживают такие типы кодирования как: base64, hex, escape. | encode(E’123\\000456′::bytea, ‘escape’) | 123\000456 |
get_bit(string, offset) | int | Извлечь бит из строки | get_bit(E’Th\\000omas’::bytea, 45) | 1 |
get_byte(string, offset) | int | Извлечь байт из строки | get_byte(E’Th\\000omas’::bytea, 4) | 109 |
length(string) | int | Длина бинарной строки | length(E’jo\\000se’::bytea) | 5 |
md5(string) | text | Подсчитывает MD5 хэш строки string, возвращая результат в шестнадцетиричном виде | md5(E’Th\\000omas’::bytea) | 8ab2d3c9689aaf18 b4958c334c82d8b1 |
set_bit(string,
offset, newvalue) | bytea | Установить бит в строке | set_bit(E’Th\\000omas’::bytea, 45, 0) | Th\000omAs |
set_byte(string,
offset, newvalue) | bytea | Установить байт в строке | set_byte(E’Th\\000omas’::bytea, 4, 64) | Th\000o@as |
sql — Concat функция в postgresql
У меня есть нижеприведенный оператор выбора в улье. Он выполняется отлично.
Он выполняется отлично.
В улье
select
COALESCE(product_name,CONCAT(CONCAT(CONCAT(TRIM(product_id),' -
'),trim(plan_code)),' - UNKNOWN')) as product_name
from table name;
Я пытаюсь использовать тот же оператор выбора в POSTGRESQL, и он выдает мне сообщение об ошибке «
Ошибка выполнения запроса
Причина:
Ошибка SQL [42883]: ОШИБКА: функция concat (текст, неизвестен) не существует
Подсказка: ни одна функция не соответствует заданному имени и типу аргумента. Возможно, вам придется добавить явное приведение типов.
В postgresql:
select
COALESCE(product_name,CONCAT(CONCAT(CONCAT(TRIM(product_id),' -
'),trim(plan_code)),' - UNKNOWN')) as product_name
from table name;
Может ли кто-нибудь пролить свет на это?
1
user8545255 22 Май 2019 в 21:03
2 ответа
Лучший ответ
Вместо согласования попробуйте ||:
SELECT COALESCE(product_name,
(TRIM(product_id) || ' - ' || TRIM(plan_code) || ' - UNKNOWN')
) AS product_name
FROM tablename;
Или просто один КОНКАТ как:
SELECT COALESCE(product_name,
CONCAT(TRIM(product_id)::text, ' - ', TRIM(plan_code)::text, ' - UNKNOWN')
) AS product_name
FROM tablename;
1
Arulkumar 22 Май 2019 в 19:05
Вы также можете рассмотреть возможность использования функции :
SELECT coalesce(product_name, format('%s - %s - UNKNOWN', trim(product_id), trim(plan_code)))
0
pensnarik 11 Фев 2020 в 10:23
Резюме Администратор баз данных PostgreSQL, Санкт-Петербург, 160 000 руб.
 в месяц
в месяцОсновной круг задач:
Первичная инсталляция баз данных PostgreSQL с 9. х до 11. х.
Настройка баз данных под конкретное железо или виртуальную среду.
Анализ работы базы данных и поиск мест для оптимизации производительности
регулярный мониторинг ключевых показателей метрик базы данных.
Построение систем высокой доступности и отказоустойчивости через репликацию hot standby, Repmgr, Patroni, Londiste, переход virtual IP за мастер нодой, логическая репликация средствами PostgreSQL, ручное и автоматическое переключение серверов мастер нод.
Подключение пуллера коннектов pgbouncer.
Резервное копирование средствами pg_basebackup, Barman, pg_dump. Проверка собранных бэкапов. Непрерывное резервное копирование и сбор WAL логов.
Восстановление БД в рамках экстренных работ. Так же восстановление из резервных копий для создания тестовых стендов. Восстановление на заданную дату Point-in-Time Recovery (PITR).
Построение системы доступа к БД, разграничение прав, группы доступа.
Реализация функционала обращения к удалённым таблицам Foreign Data Wrappers SQL/MED («SQL Management of External Data») и dblink.
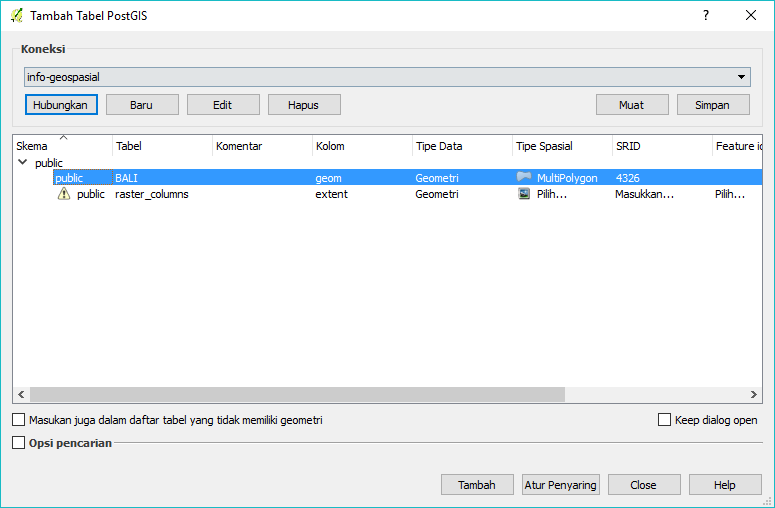 Помогал и консультировал при переносе данных с MySQL (gis система, координатные хранилища), через дампы данных, трансформация скриптами bash, sed.
Помогал и консультировал при переносе данных с MySQL (gis система, координатные хранилища), через дампы данных, трансформация скриптами bash, sed.Как превратить массив JSON в массив Postgres?
Postgres 9.4 или новее
Postgres 9.4, очевидно вдохновленный этим постом , добавил недостающие функции:
спасибо Laurence Rowe за патч и Andrew Dunstan за коммит!
Развернуть массив JSON. Затем используйте array_agg()конструктор ARRAY или для построения массива Postgres из него. Или string_agg()построить text строку .
Агрегируйте неопубликованные элементы по строке в ORDER BY, GROUP BYили даже уникальный ключ во внешнем запросе. Видеть:
Замените «json» на «jsonb» jsonbво всем следующем коде SQL.
SELECT t.tbl_id, d.list
FROM tbl t
CROSS JOIN LATERAL (
SELECT string_agg(d.elem::text, ', ') AS list
FROM json_array_elements_text(t.data->'tags') AS d(elem)
) d;Краткий синтаксис:
SELECT t.tbl_id, d.list
FROM tbl t, LATERAL (
SELECT string_agg(value::text, ', ') AS list
FROM json_array_elements_text(t.data->'tags') -- col name default: "value"
) d;Связанный:
Конструктор ARRAY в коррелированном подзапросе:
SELECT tbl_id, ARRAY(SELECT json_array_elements_text(t.data->'tags')) AS txt_arr
FROM tbl t; Связанный:
Тонкое различие : nullэлементы сохраняются в реальных массивах . Это невозможно в вышеупомянутых запросах, создающих textстроку, которая не может содержать nullзначения. Истинное представление является массивом.
Функциональная оболочка
Для повторного использования, чтобы сделать это еще проще, инкапсулируйте логику в функции:
CREATE OR REPLACE FUNCTION json_arr2text_arr(_js json)
RETURNS text[] LANGUAGE sql IMMUTABLE AS
'SELECT ARRAY(SELECT json_array_elements_text(_js))';Сделайте это функцией SQL , чтобы ее можно было вставлять в большие запросы.
Сделайте это IMMUTABLE(потому что это так), чтобы избежать повторной оценки в больших запросах и разрешить это в выражениях индекса.
Вызов:
SELECT tbl_id, json_arr2text_arr(data->'tags')
FROM tbl;дБ <> скрипка здесь
Postgres 9.3 или старше
Используйте функцию json_array_elements(). Но мы получаем строки из двойных кавычек .
Альтернативный запрос с агрегацией во внешнем запросе. CROSS JOINудаляет строки с отсутствующими или пустыми массивами. Может также быть полезным для обработки элементов. Нам нужен уникальный ключ для агрегирования:
SELECT t.tbl_id, string_agg(d.elem::text, ', ') AS list
FROM tbl t
CROSS JOIN LATERAL json_array_elements(t.data->'tags') AS d(elem)
GROUP BY t.tbl_id;Конструктор ARRAY, все еще с кавычками:
SELECT tbl_id, ARRAY(SELECT json_array_elements(t. data->'tags')) AS quoted_txt_arr
FROM tbl t;
data->'tags')) AS quoted_txt_arr
FROM tbl t;Обратите внимание, что nullпреобразуется в текстовое значение «ноль», в отличие от выше. Неправильно, строго говоря, и потенциально неоднозначно.
Бедный мужчина не цитирует trim():
SELECT t.tbl_id, string_agg(trim(d.elem::text, '"'), ', ') AS list
FROM tbl t, json_array_elements(t.data->'tags') d(elem)
GROUP BY 1;Получить одну строку из таблицы:
SELECT string_agg(trim(d.elem::text, '"'), ', ') AS list
FROM tbl t, json_array_elements(t.data->'tags') d(elem)
WHERE t.tbl_id = 1;Строки формируют коррелированный подзапрос:
SELECT tbl_id, (SELECT string_agg(trim(value::text, '"'), ', ')
FROM json_array_elements(t.data->'tags')) AS list
FROM tbl t;ARRAY конструктор:
SELECT tbl_id, ARRAY(SELECT trim(value::text, '"')
FROM json_array_elements(t. data->'tags')) AS txt_arr
FROM tbl t;
data->'tags')) AS txt_arr
FROM tbl t;Оригинальная (устаревшая) SQL Fiddle .
дБ <> скрипка здесь.
Связанный:
Примечания (устарели с 9.4)
Нам понадобится json_array_elements_text(json)двойник json_array_elements(json)для возврата правильных textзначений из массива JSON. Но этого, похоже, не хватает в предоставленном арсенале функций JSON . Или какая-то другая функция для извлечения textзначения из скалярного JSONзначения. Кажется, мне тоже не хватает этого.
Так что я импровизировал trim(), но это не удастся для нетривиальных случаев …
Trim trailing spaces with PostgreSQL
РешениеThere are many different invisible characters. Many of them have the property WSpace=Y («whitespace») in Unicode. But some special characters are not considered «whitespace» and still have no visible representation. The excellent Wikipedia articles about space (punctuation) and whitespace characters should give you an idea.
But some special characters are not considered «whitespace» and still have no visible representation. The excellent Wikipedia articles about space (punctuation) and whitespace characters should give you an idea.
Unicode sucks in this regard: introducing lots of exotic characters that mainly serve to confuse people.
The standard SQL trim() function by default only trims the basic Latin space character (Unicode: U+0020 / ASCII 32). Same with the rtrim() and ltrim() variants. Your call also only targets that particular character.
Use regular expressions with regexp_replace() instead.
Trailing
Чтобы удалить все конечные пробелы (но не пробелы внутри строки):
SELECT regexp_replace(eventdate, '\s+$', '') FROM eventdates;
В регулярном выражении объясняется: Эффективно принимает первый непробельный символ и все до последнего непробельного символа, если он доступен. Есть еще несколько связанных символов, которые в Unicode не классифицируются как «пробел», поэтому они не содержатся в классе символов Они печатаются как невидимые символы в pgAdmin для меня: «монгольская гласная», «пробел нулевой ширины», «не присоединяющийся к нулевой ширине», «соединитель с нулевой шириной»: Еще два, печать в виде видимых глифов в pgAdmin, но невидимых в моем браузере: «Word Joiner», «Неразрывный пробел нулевой ширины»: В конечном счете, то, будут ли символы отображаться невидимыми или нет, также зависит от шрифта, используемого для отображения. Чтобы удалить все это , замените использовать: или же: Существует также класс символов Posix, который Он работает надежно для символов ASCII в каждой настройке (где он сводится Строго говоря, так обстоит дело с каждой ссылкой на класс символов, но, похоже, больше разногласий с менее часто используемыми, такими как graph . Но вам может понадобиться добавить больше символов в класс символов Руководство: В выражении в скобках имя класса символов, заключенное в него Жирный акцент мой. Также обратите внимание на это ограничение, которое было исправлено в Postgres 10 : Исправлена обработка класса символов в регулярных выражениях для кодов больших символов, особенно символов Юникода выше Ранее такие символы никогда не распознавались как принадлежащие к классам символов, зависящим от локали, таким как Мне нравится Python, а также мне нравится PostgreSQL. И вот я подумал — ей, а почему бы не использовать их вместе? 🙂 Для работы с PostgreSQL в мире Python большой популярностью пользуется пакет psycopg2. Но он, по всей видимости, до сих пор не поддерживает prepared statements. Поэтому для своих задач я пока что остановился на чуть менее популярном пакете py-postgresql. Дополнение: Выяснилось, что py-postgresql не работает с последними версиями PostgreSQL. См заметку Работа с PostgreSQL на Python с помощью psycopg2. Ставится он, как обычно, через pip. Например (но лучше пользоваться virtualenv): sudo pip3 install py-postgresql При изучении новой библиотеки сначала я пытаюсь поделать с ней что-нибудь в REPL. Далее я опускаю приглашение REPL’а, которое Создание новой сессии: import postgresql В реальных скриптах, конечно же, не забываем использовать конструкцию Создание схемы, выполнение простых запросов: db.execute(«CREATE TABLE users (id SERIAL PRIMARY KEY, « Создание prepared statement и выполнение INSERT-запроса: ins(«afiskon», «123») Выполнение SELECT-запроса (делаем trim, так как varchar дополняется пробелами): db. К полям можно обращаться как по номерам, так и по именам: users[0][0] users[0][«id»] users[0][«login»].strip() Выполнение UPDATE- и DELETE-запросов: update(«eax», «789») delete = db.prepare(«DELETE FROM users WHERE id = $1») delete(3) db.query(«DELETE FROM users WHERE id = 3») Пример выполнения транзакции: with db.xact() as xact: Пример выполнения rollback: with db.xact() as xact: Вызов хранимых процедур: ver() Работа с курсорами: c = db.cursor_from_id(«my_cursor») c.read() c.read() c.close() Можно ограничить количество считываемых элементов: Попробуйте заполнить таблицу таким образом и повторить эксперимент: for i in range(1, 1000): И напоследок рассмотрим наброски типа более гибкой альтернативы pgbench: import time testtime = 10 def worker(): for i in range(nthreads): Ссылки по теме: А как вы нынче работаете с базами данных на Python? Дополнение: Пишем REST-сервис на Python с использованием Flask Метки: PostgreSQL, Python, СУБД. [ Внизу страницы доступен редактор для написания и выполнения сценариев. ] Python поставляется с библиотекой стандартных модулей. Некоторые модули встроены в интерпретатор; они обеспечивают доступ к операциям, которые не являются частью ядра языка, но тем не менее встроены, либо для эффективности, либо для обеспечения доступа к примитивам операционной системы, таким как системные вызовы. Следующие упражнения, основанные на важных методах полезных встроенных модулей Python. 1. Напишите программу Python для генерации шестнадцатеричного случайного цвета, случайной алфавитной строки, случайного значения между двумя целыми числами (включительно) и случайным кратным 7 между 0 и 70. Перейдите в редактор 2. 3. Напишите программу Python для генерации случайного алфавитного символа, алфавитной строки и алфавитной строки фиксированной длины. Перейти к редактору 4. Напишите программу Python для создания генератора случайных чисел с начальным числом, а также сгенерируйте число с плавающей запятой между 0 и 1, исключая 1. Перейдите в редактор 5. Напишите программу Python для генерации случайного целого числа от 0 до 6 — исключая 6, случайного целого числа от 5 до 10 — исключая 10, случайного целого числа от 0 до 10, с шагом 3 и случайной датой между двумя даты.Перейдите в редактор 6. Напишите программу Python для перемешивания элементов данного списка. Заходим в редактор 7. Напишите программу Python для генерации числа с плавающей запятой между 0 и 1 включительно и генерации случайного числа с плавающей запятой в пределах определенного диапазона. Перейдите в редактор 8. Напишите программу Python для создания списка случайных целых чисел и случайного выбора нескольких элементов из указанного списка. Перейдите в редактор 9. Напишите программу Python для установки случайного начального числа и получения случайного числа от 0 до 1. Перейдите в редактор Редактор кода Python: Еще больше впереди! Не отправляйте здесь какие-либо решения вышеуказанных упражнений, если вы хотите внести свой вклад, перейдите на соответствующую страницу упражнения. Проверьте свои навыки Python с помощью викторины w3resource [ Внизу страницы доступен редактор для написания и выполнения сценариев. ] Python поставляется с библиотекой стандартных модулей. Некоторые модули встроены в интерпретатор; они обеспечивают доступ к операциям, которые не являются частью ядра языка, но тем не менее встроены, либо для эффективности, либо для обеспечения доступа к примитивам операционной системы, таким как системные вызовы. Следующие упражнения, основанные на важных методах полезных встроенных модулей Python. 1. Напишите программу Python для генерации шестнадцатеричного случайного цвета, случайной алфавитной строки, случайного значения между двумя целыми числами (включительно) и случайным кратным 7 между 0 и 70. Перейдите в редактор 2. Напишите программу Python для выбора случайного элемента из списка, набора, словаря (значения) и файла из каталога. Зайти в редактор 3. Напишите программу Python для генерации случайного алфавитного символа, алфавитной строки и алфавитной строки фиксированной длины. Перейти к редактору 4. Напишите программу Python для создания генератора случайных чисел с начальным числом, а также сгенерируйте число с плавающей запятой между 0 и 1, исключая 1. Перейдите в редактор 5. Напишите программу Python для генерации случайного целого числа от 0 до 6 — исключая 6, случайного целого числа от 5 до 10 — исключая 10, случайного целого числа от 0 до 10, с шагом 3 и случайной датой между двумя даты.Перейдите в редактор 6. Напишите программу Python для перемешивания элементов данного списка. Заходим в редактор 7. Напишите программу Python для генерации числа с плавающей запятой между 0 и 1 включительно и генерации случайного числа с плавающей запятой в пределах определенного диапазона. Перейдите в редактор 8. Напишите программу Python для создания списка случайных целых чисел и случайного выбора нескольких элементов из указанного списка. Перейдите в редактор 9. Напишите программу Python для установки случайного начального числа и получения случайного числа от 0 до 1. Перейдите в редактор Редактор кода Python: Еще больше впереди! Не отправляйте здесь какие-либо решения вышеуказанных упражнений, если вы хотите внести свой вклад, перейдите на соответствующую страницу упражнения. Проверьте свои навыки Python с помощью викторины w3resource [ Внизу страницы доступен редактор для написания и выполнения сценариев. ] Python поставляется с библиотекой стандартных модулей. Некоторые модули встроены в интерпретатор; они обеспечивают доступ к операциям, которые не являются частью ядра языка, но тем не менее встроены, либо для эффективности, либо для обеспечения доступа к примитивам операционной системы, таким как системные вызовы. Следующие упражнения, основанные на важных методах полезных встроенных модулей Python. 1. Напишите программу Python для генерации шестнадцатеричного случайного цвета, случайной алфавитной строки, случайного значения между двумя целыми числами (включительно) и случайным кратным 7 между 0 и 70. Перейдите в редактор 2. Напишите программу Python для выбора случайного элемента из списка, набора, словаря (значения) и файла из каталога. Зайти в редактор 3. Напишите программу Python для генерации случайного алфавитного символа, алфавитной строки и алфавитной строки фиксированной длины. Перейти к редактору 4. Напишите программу Python для создания генератора случайных чисел с начальным числом, а также сгенерируйте число с плавающей запятой между 0 и 1, исключая 1. Перейдите в редактор 5. Напишите программу Python для генерации случайного целого числа от 0 до 6 — исключая 6, случайного целого числа от 5 до 10 — исключая 10, случайного целого числа от 0 до 10, с шагом 3 и случайной датой между двумя даты.Перейдите в редактор 6. Напишите программу Python для перемешивания элементов данного списка. Заходим в редактор 7. Напишите программу Python для генерации числа с плавающей запятой между 0 и 1 включительно и генерации случайного числа с плавающей запятой в пределах определенного диапазона. Перейдите в редактор 8. Напишите программу Python для создания списка случайных целых чисел и случайного выбора нескольких элементов из указанного списка. Перейдите в редактор 9. Напишите программу Python для установки случайного начального числа и получения случайного числа от 0 до 1. Перейдите в редактор Редактор кода Python: Еще больше впереди! Не отправляйте здесь какие-либо решения вышеуказанных упражнений, если вы хотите внести свой вклад, перейдите на соответствующую страницу упражнения. Проверьте свои навыки Python с помощью викторины w3resource Есть много разных невидимых персонажей. Многие из них имеют свойство Стандартная функция SQL Вместо этого используйте регулярные выражения с Чтобы удалить все завершающие пробелы (но не пробелы внутри строки ): Объяснение регулярного выражения: Демо: Возврат: Да, это одинарная обратная косая черта ( Фактически принимает первый непробельный символ и все, вплоть до последнего непробельного символа, если доступно. Есть еще несколько связанных символов, которые не классифицируются как «пробелы» в Юникоде — поэтому не содержатся в классе символов Для меня они печатаются как невидимые глифы в pgAdmin: «монгольский гласный», «пробел с нулевой шириной», «не соединяемый с нулевой шириной», «соединяющий с нулевой шириной»: Еще два, печатаются как видимых глифов в pgAdmin, но невидимых в моем браузере: «объединитель слов», «неразрывный пробел нулевой ширины»: В конечном счете, будут ли символы отображаться невидимыми или нет, также зависит от шрифта, используемого для отображения. Чтобы удалить все эти , замените использование: или: Существует также класс символов Posix Он надежно работает для символов ASCII в любой настройке (где это сводится к Строго говоря, это относится к на каждую ссылку на класс символов, но, похоже, больше разногласий с менее часто используемыми, такими как graph .Но вам может потребоваться добавить больше символов к классу символов Руководство: В выражении в квадратных скобках — имя класса символов, заключенное в Смелый акцент мой. Также обратите внимание на это ограничение, которое было исправлено в Postgres 10: Исправить обработку класса символов регулярных выражений для больших символов
коды, особенно символы Unicode выше Ранее такие персонажи никогда не признавались принадлежащими
классы символов, зависящие от локали, например После запроса вернет все таблиц и их столбцов , которые могут иметь или не иметь конечных пробелов . ПРИМЕЧАНИЕ : Я предполагаю, что все таблицы имеют префикс , чтобы получить Это вернет строк, например Наконец, Оберните вышеуказанный метод в функцию использование: В этом руководстве мы используем функцию Trim в Postgres SQL для создания различных мини-проектов, связанных с текстом, в том числе: Проще говоря, мы используем функцию PostgreSQL Синтаксис функции TRIM () 1 t_result = TRIM ([LEADING OR TRAILING OR BOTH] [необязательно: t_string_to_remove] ОТ t_string_source); Передаем функции TRIM следующие параметры: Давайте воспользуемся только что изученным синтаксисом и применим функцию TRIM к каждому элементу в массиве. Мы будем использовать WHILE LOOP для выполнения этой задачи. 1 — декларации переменных Анализ Выход 1 Postgres Обратите внимание, как все пробелы, передние и задние, удаляются из каждого из четырех элементов массива? Теперь давайте изучим еще одно возможное использование функции TRIM () в PostgreSQL.Прежде чем мы начнем, давайте сделаем небольшой урок по… Синтаксис 1 t_string_combined = CONCAT (t_string_1, t_string_2, t_string_3); Обратите внимание, что мы передали функции CONCAT три параметра для объединения.
Взяв синтаксис выше и сделав пример немного более реальным: 1 t_name_full = CONCAT (t_name_first, «», t_name_last); Приведенный выше сценарий SQL берет содержимое «t_name_first», добавляет после него пробел, а затем добавляет содержимое «t_name_last» в конец.Итак, если t_name_first содержал «Джим», а t_name_last содержал «Джонсон», тогда s_name_full теперь равно «Джим Джонсон». Но что, если мы не знаем наверняка, существуют ли лишние пробелы в начале или конце «t_name_first» и «t_name_last»? Это хорошая практика — предвидеть и планировать это. Итак, давайте изменим приведенное выше уравнение, чтобы включить функцию TRIM (). 1 t_name_full = CONCAT (TRIM (t_name_first), «», TRIM (t_name_last)); В приведенном выше примере и «t_name_first», и «t_name_last» удаляются от лишних пробелов, прежде чем мы используем функцию CONCAT для их объединения. Примечание: сокращенным методом для CONCAT является использование символа «||» комбинация символов. См .: 1 t_name_full = TRIM (t_name_first) || TRIM (t_name_last); Давайте теперь будем использовать функции Trim () и Concat () в SQL вместе с предложениями SELECT, FROM и WHERE: 1 SELECT В этом учебном пособии мы узнали, как использовать функцию Чтобы удалить начало, конец и все пространство столбца в postgresql, мы используем функцию TRIM, функцию LTRIM, RTRIM и BTRIM.Удаление начального и конечного пробелов в postgresql выполняется с помощью функции TRIM. Давайте посмотрим, как Мы будем использовать состояний таблицу. Чтобы удалить начальное пространство столбца в postgresql, мы используем функцию TRIM или функцию LTRIM В таблице результатов удаляется оставшееся пространство. Чтобы удалить конечный пробел столбца в postgresql, мы используем функцию TRIM или функцию RTRIM В результирующей таблице удаляется правое пространство. Чтобы удалить как начальные, так и конечные пробелы столбца в postgresql, мы используем функцию TRIM или функцию BTRIM В таблице результатов удалено и левое, и правое пространство. Чтобы удалить все пространство столбца, мы будем использовать функцию замены, как показано ниже Таким образом, итоговая таблица будет\s.. сокращение класса регулярного выражения для [[:space:]]
— который представляет собой набор символов пробела — см. \s*(.*\S)’)
substring(eventdate, ‘(\S.*\S)’)
\s*(.*\S)’)
substring(eventdate, ‘(\S.*\S)’) (re).. Захват набор скобокПробелы?
[[:space:]].SELECT E'\u180e', E'\u200B', E'\u200C', E'\u200D';
'' | '' | '' | ''
SELECT E'\u2060', E'\uFEFF';
'' | ''

'\s'на '[\s\u180e\u200B\u200C\u200D\u2060\uFEFF]'или '[\s]'(обратите внимание на невидимые символы!).
Пример вместо:regexp_replace(eventdate, '\s+$', '')
regexp_replace(eventdate, '[\s\u180e\u200B\u200C\u200D\u2060\uFEFF]+$', '')
regexp_replace(eventdate, '[\s]+$', '') -- note invisible characters
Ограничения
[[:graph:]] должен представлять «видимые символы». Пример:substring(eventdate, '([[:graph:]].*[[:graph:]])')
[\x21-\x7E]), но помимо этого вы в настоящее время (включая стр. 10) зависите от информации, предоставленной базовой ОС (для определения ctype), и, возможно, от настроек локали.
[[:space:]](сокращение \s), чтобы перехватить все пробельные символы. Как: \u2007, \u202fи , \u00a0кажется, также не хватает для @XiCoN JFS .[:и :]обозначающее список всех символов, принадлежащих этому классу. Стандартные имена классов символов являются: alnum, alpha, blank, cntrl, digit, graph, lower, print, punct, space, upper, xdigit. Они обозначают классы символов, определенные в ctype. Локаль может предоставить другим.
Локаль может предоставить другим.
Автор: Erwin Brandstetter
Размещён: 27.03.2014 11:17U+7FF(Том Лейн)[[:alpha:]].Простой пример работы с PostgreSQL на Python
 Этот пакет, как я понимаю, поддерживает все, что нужно.
Этот пакет, как я понимаю, поддерживает все, что нужно.>>>.
db = postgresql.open(‘pq://postgres:postgres@localhost:5432/mydb’)with.
«login CHAR(64), password CHAR(64))»)
# (‘INSERT’, 1)
ins(«eax», «456»)
# (‘INSERT’, 1) query(«SELECT id, trim(login), trim(password) FROM users»)
query(«SELECT id, trim(login), trim(password) FROM users»)
# [(1, ‘afiskon’, ‘123’), (2, ‘eax’, ‘456’)]
# 1
# 1
# ‘afiskon’
# (‘UPDATE’, 1)
# (‘DELETE’, 0)
# (‘DELETE’, 0)
db.query(«SELECT id FROM users»)
# [(1,), (2,)]
db.query(«SELECT id FROM users»)
xact.rollback()
# ‘PostgreSQL 9. 5 …’
5 …’
«SELECT id, trim(login) FROM users»)
# [(1, ‘afiskon’), (2, ‘eax’)]
# []
ins(«user» + str(i), «pass» + str(i))
import threading
import postgresql
nthreads = 4
nqueries = 0
with postgresql.open(‘pq://[email protected]/eax’) as db:
query = db.prepare(«SELECT * FROM themes WHERE id = 1»)
starttime = time.time()
while time.time() — starttime < testtime:
query()
nqueries = nqueries + 1
print(«Thread » + str(threading. get_ident()) + » — total » +
get_ident()) + » — total » +
str(nqueries) + » queries executed»)
t = threading.Thread(target = worker)
t.start() модулей Python: упражнения, практика, решение
модулей Python [9 упражнений с решением]
Используйте random.randint ( )
Пример вывода:
Сгенерировать шестнадцатеричный случайный цвет:
#
eb76d4 Создание случайной алфавитному строки:
lGhPpBDqfCgXKzSbGcnmcDWBEZeiqcUqztgvwcXfVyPslOggKdbIxOejJfFMgspqrgskanNYpscJEOVIpYkGGNxQlaqeeubGDbQSBhBedrdOyqOmKPTZvzKmKVoidsuShSCapEXxxNJRCxXOwYUUPBefKmJiidGxHwvOxAEujZGjJjTqjRtuEXgyRsPQpqlqOJJjKHAPHmIJLpMvLTRVqwSeLCIDRdMnYpbg генерировать случайное значение между двумя целыми числами, включительно:
0
4 1
генерировать случайные кратное 7 между 0 и 70:
70
Щелкните здесь, чтобы просмотреть образец решения Напишите программу Python для выбора случайного элемента из списка, набора, словаря (значения) и файла из каталога. Зайти в редактор
Напишите программу Python для выбора случайного элемента из списка, набора, словаря (значения) и файла из каталога. Зайти в редактор
Use random.choice
Пример вывода:
Выберите случайный элемент из списка:
3
4
5
Выберите случайный элемент из набора:
1
3
5
Выберите случайное значение из словаря:
5
4
4
Выберите случайный файл из каталога .:
proc
Щелкните меня, чтобы просмотреть образец решения
Использования random.choice
Примера вывода:
Создание случайного алфавитному символа:
х
Генерация случайной алфавитной строки:
wxEGKdCBCkJZrFscEDXhxAovbTkPzlfCxRQCMbuvquFXyFHivyEeqNGzeWxlKZiFzVIuyKLEtPJHbvqQTpIJoMTPFUbrQjGEfXRTlQNKviduRaNDdtEbExXhdbLKiIprgdYTivZDFjk
Генерировать случайную алфавитную строку фиксированной длиной:
ijdvKiSWwO
Нажмите меня см. образец решения
Используйте random.random ()
Пример вывода:
Создайте генератор случайных чисел с начальным числом:
0,4209937412831368
0,8444218515250481
Сгенерировать число с плавающей запятой между 0 и 1, исключая 1:
0,5000494615698478
Щелкните меня, чтобы увидеть пример решения
Используйте random.randrange ()
Пример вывода:
Сгенерируйте случайное целое число от 0 до 6:
0
Сгенерируйте случайное целое число от 5 до 10, исключая 10:
5
Сгенерируйте случайное целое число от 0 до 10, с шагом 3:
3
Случайная дата между двумя датами:
17.02.2019
Щелкните меня, чтобы увидеть образец решения
Use random.shuffle ()
Пример вывода:
Исходный список:
[1, 2, 3, 4, 5]
Список в случайном порядке:
[4, 2, 1, 5, 3]
Исходный список:
[‘красный’ , «черный», «зеленый», «синий»]
Список в случайном порядке:
[«зеленый», «синий», «черный», «красный»]
Щелкните меня, чтобы просмотреть образец решения
Use random.uniform
Пример вывода:
Сгенерируйте число с плавающей запятой между 0 и 1 включительно:
0.9332552133311842
Сгенерировать случайное число с плавающей запятой в диапазоне:
1,3166101982165992
Щелкните меня, чтобы просмотреть образец решения
Use random.sample
Пример вывода:
Создайте список случайных целых чисел:
[46, 4, 45, 50, 43, 85, 74, 42, 99, 7]
Выберите случайным образом 4 кратных элементов из указанного списка:
[99, 45, 85, 50]
Произвольно выберите 8 элементов из указанного списка:
[46, 43, 74, 4, 45, 85, 99, 50]
Щелкните меня, чтобы увидеть образец раствора
Пример вывода:
Задайте случайное начальное число и получите случайное число от 0 до 1:
0,8444218515250481
0,13436424411240122
0,9560342718892494
Щелкните меня, чтобы просмотреть образец решения модулей Python: упражнения, практика, решение
модулей Python [9 упражнений с решением]
Используйте random.randint ( )
Пример вывода:
Сгенерировать шестнадцатеричный случайный цвет:
#
eb76d4 Создание случайной алфавитному строки:
lGhPpBDqfCgXKzSbGcnmcDWBEZeiqcUqztgvwcXfVyPslOggKdbIxOejJfFMgspqrgskanNYpscJEOVIpYkGGNxQlaqeeubGDbQSBhBedrdOyqOmKPTZvzKmKVoidsuShSCapEXxxNJRCxXOwYUUPBefKmJiidGxHwvOxAEujZGjJjTqjRtuEXgyRsPQpqlqOJJjKHAPHmIJLpMvLTRVqwSeLCIDRdMnYpbg генерировать случайное значение между двумя целыми числами, включительно:
0
4 1
генерировать случайные кратное 7 между 0 и 70:
70
Щелкните здесь, чтобы просмотреть образец решения
Use random.choice
Пример вывода:
Выберите случайный элемент из списка:
3
4
5
Выберите случайный элемент из набора:
1
3
5
Выберите случайное значение из словаря:
5
4
4
Выберите случайный файл из каталога .:
proc
Щелкните меня, чтобы просмотреть образец решения
Использования random.choice
Примера вывода:
Создание случайного алфавитному символа:
х
Генерация случайной алфавитной строки:
wxEGKdCBCkJZrFscEDXhxAovbTkPzlfCxRQCMbuvquFXyFHivyEeqNGzeWxlKZiFzVIuyKLEtPJHbvqQTpIJoMTPFUbrQjGEfXRTlQNKviduRaNDdtEbExXhdbLKiIprgdYTivZDFjk
Генерировать случайную алфавитную строку фиксированной длиной:
ijdvKiSWwO
Нажмите меня см. образец решения
Используйте random.random ()
Пример вывода:
Создайте генератор случайных чисел с начальным числом:
0,4209937412831368
0,8444218515250481
Сгенерировать число с плавающей запятой между 0 и 1, исключая 1:
0,5000494615698478
Щелкните меня, чтобы увидеть пример решения
Используйте random.randrange ()
Пример вывода:
Сгенерируйте случайное целое число от 0 до 6:
0
Сгенерируйте случайное целое число от 5 до 10, исключая 10:
5
Сгенерируйте случайное целое число от 0 до 10, с шагом 3:
3
Случайная дата между двумя датами:
17.02.2019
Щелкните меня, чтобы увидеть образец решения
Use random.shuffle ()
Пример вывода:
Исходный список:
[1, 2, 3, 4, 5]
Список в случайном порядке:
[4, 2, 1, 5, 3]
Исходный список:
[‘красный’ , «черный», «зеленый», «синий»]
Список в случайном порядке:
[«зеленый», «синий», «черный», «красный»]
Щелкните меня, чтобы просмотреть образец решения
Use random.uniform
Пример вывода:
Сгенерируйте число с плавающей запятой между 0 и 1 включительно:
0.9332552133311842
Сгенерировать случайное число с плавающей запятой в диапазоне:
1,3166101982165992
Щелкните меня, чтобы просмотреть образец решения
Use random.sample
Пример вывода:
Создайте список случайных целых чисел:
[46, 4, 45, 50, 43, 85, 74, 42, 99, 7]
Выберите случайным образом 4 кратных элементов из указанного списка:
[99, 45, 85, 50]
Произвольно выберите 8 элементов из указанного списка:
[46, 43, 74, 4, 45, 85, 99, 50]
Щелкните меня, чтобы увидеть образец раствора
Пример вывода:
Задайте случайное начальное число и получите случайное число от 0 до 1:
0,8444218515250481
0,13436424411240122
0,9560342718892494
Щелкните меня, чтобы просмотреть образец решения модулей Python: упражнения, практика, решение
модулей Python [9 упражнений с решением]
Используйте random.randint ( )
Пример вывода:
Сгенерировать шестнадцатеричный случайный цвет:
#
eb76d4 Создание случайной алфавитному строки:
lGhPpBDqfCgXKzSbGcnmcDWBEZeiqcUqztgvwcXfVyPslOggKdbIxOejJfFMgspqrgskanNYpscJEOVIpYkGGNxQlaqeeubGDbQSBhBedrdOyqOmKPTZvzKmKVoidsuShSCapEXxxNJRCxXOwYUUPBefKmJiidGxHwvOxAEujZGjJjTqjRtuEXgyRsPQpqlqOJJjKHAPHmIJLpMvLTRVqwSeLCIDRdMnYpbg генерировать случайное значение между двумя целыми числами, включительно:
0
4 1
генерировать случайные кратное 7 между 0 и 70:
70
Щелкните здесь, чтобы просмотреть образец решения
Use random.choice
Пример вывода:
Выберите случайный элемент из списка:
3
4
5
Выберите случайный элемент из набора:
1
3
5
Выберите случайное значение из словаря:
5
4
4
Выберите случайный файл из каталога .:
proc
Щелкните меня, чтобы просмотреть образец решения
Использования random.choice
Примера вывода:
Создание случайного алфавитному символа:
х
Генерация случайной алфавитной строки:
wxEGKdCBCkJZrFscEDXhxAovbTkPzlfCxRQCMbuvquFXyFHivyEeqNGzeWxlKZiFzVIuyKLEtPJHbvqQTpIJoMTPFUbrQjGEfXRTlQNKviduRaNDdtEbExXhdbLKiIprgdYTivZDFjk
Генерировать случайную алфавитную строку фиксированной длиной:
ijdvKiSWwO
Нажмите меня см. образец решения
Используйте random.random ()
Пример вывода:
Создайте генератор случайных чисел с начальным числом:
0,4209937412831368
0,8444218515250481
Сгенерировать число с плавающей запятой между 0 и 1, исключая 1:
0,5000494615698478
Щелкните меня, чтобы увидеть пример решения
Используйте random.randrange ()
Пример вывода:
Сгенерируйте случайное целое число от 0 до 6:
0
Сгенерируйте случайное целое число от 5 до 10, исключая 10:
5
Сгенерируйте случайное целое число от 0 до 10, с шагом 3:
3
Случайная дата между двумя датами:
17.02.2019
Щелкните меня, чтобы увидеть образец решения
Use random.shuffle ()
Пример вывода:
Исходный список:
[1, 2, 3, 4, 5]
Список в случайном порядке:
[4, 2, 1, 5, 3]
Исходный список:
[‘красный’ , «черный», «зеленый», «синий»]
Список в случайном порядке:
[«зеленый», «синий», «черный», «красный»]
Щелкните меня, чтобы просмотреть образец решения
Use random.uniform
Пример вывода:
Сгенерируйте число с плавающей запятой между 0 и 1 включительно:
0.9332552133311842
Сгенерировать случайное число с плавающей запятой в диапазоне:
1,3166101982165992
Щелкните меня, чтобы просмотреть образец решения
Use random.sample
Пример вывода:
Создайте список случайных целых чисел:
[46, 4, 45, 50, 43, 85, 74, 42, 99, 7]
Выберите случайным образом 4 кратных элементов из указанного списка:
[99, 45, 85, 50]
Произвольно выберите 8 элементов из указанного списка:
[46, 43, 74, 4, 45, 85, 99, 50]
Щелкните меня, чтобы увидеть образец раствора
Пример вывода:
Задайте случайное начальное число и получите случайное число от 0 до 1:
0,8444218515250481
0,13436424411240122
0,9560342718892494
Щелкните меня, чтобы просмотреть образец решения sql — обрезать конечные пробелы с помощью PostgreSQL
WSpace = Y («пробел») в Юникоде. Но некоторые специальные символы не считаются «пробелами» и по-прежнему не имеют видимого представления. Прекрасные статьи в Википедии о пробелах (пунктуации) и пробельных символах должны дать вам представление. trim () по умолчанию обрезает только основной латинский символ пробела (Unicode: U + 0020 / ASCII 32). То же самое с вариантами rtrim () и ltrim () . Ваш призыв также нацелен только на этого конкретного персонажа. regexp_replace () . Висячий
ВЫБРАТЬ regexp_replace (eventdate, '\ s + $', '') FROM eventdates;
\ s … Сокращение класса регулярного выражения для [[: space:]]
— который представляет собой набор символов пробела — см. ограничения ниже
+ … 1 или несколько последовательных совпадений
$ . .. конец строки
ВЫБРАТЬ regexp_replace ('внутренний белый', '\ s + $', '') || '|'
внутренний белый |
\ ).\SS)’)
подстрока (дата события, ‘(\ S. * \ S)’) ( re ) … Набор скобок Пробел?
[[: space:]] .
ВЫБЕРИТЕ E '\ u180e', E '\ u200B', E '\ u200C', E '\ u200D';
'' | '' | '' | ''
ВЫБРАТЬ E '\ u2060', E '\ uFEFF';
'' | ''
'\ s' на '[\ s \ u180e \ u200C \ u200C \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 / u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u2060 \ u20510 / ] ' (обратите внимание на невидимые символы в конце!).
Пример вместо:
regexp_replace (дата события, '\ s + $', '')
regexp_replace (eventdate, '[\ s \ u180e \ u200C \ u2060 \ u2060 \ u2060 \ uFEFF] + $', '')
regexp_replace (eventdate, '[\ s ] + $', '') - обратите внимание на невидимые символы
Ограничения
[[: graph:]] , который должен представлять «видимые символы».Пример:
подстрока (eventdate, '([[: graph:]]. * [[: Graph:]])')
[\ x21- \ x7E] ), но помимо этого вы в настоящее время (включая стр. 10) зависите от информации, предоставляемой базовой ОС (для определения ctype ) и, возможно, настройки локали. [[: space:]] (сокращение \ s ), чтобы перехватить все символы пробела. Например: \ u2007 , \ u202f и \ u00a0 , похоже, также отсутствуют для @XiCoN JFS. [: и :] обозначает список всех символов, принадлежащих этому
класс. Стандартные имена классов символов: alnum , alpha , blank , cntrl , цифра , диаграмма , нижняя , печать , пунктир , пробел , верхний , xdigit .Они обозначают классы символов , определенные в ctype.
Локаль может предоставить другие. U + 7FF (Tom Lane) [[: alpha:]] . sql — как обрезать конечные пробелы из каждого столбца во всех таблицах в базе данных PostgreSQL
tbl_ .
выбрать
table_name, COLUMN_NAME
из
INFORMATION_SCHEMA.COLUMNS
где
table_name LIKE 'tbl_%' and (data_type = 'text' или data_type = 'character change')
ОБНОВЛЕНИЕ запрос для всех таблиц используйте следующий выберите
выбрать
'ОБНОВЛЕНИЕ' || quote_ident (ок.имя_таблицы) || ' SET '|| c.COLUMN_NAME ||' = TRIM ('|| quote_ident (c.COLUMN_NAME) ||')
ГДЕ '|| quote_ident (c.COLUMN_NAME) ||' ILIKE ''% '' 'как скрипт
из (
Выбрать
table_name, COLUMN_NAME
из
INFORMATION_SCHEMA.COLUMNS
где
table_name LIKE 'tbl_%' and (data_type = 'text' или data_type = 'character change')
) c
update tbl_sale set product = trim (product), где product LIKE '%' обновит все столбцов во всех таблицах .
Используйте этот метод для обновления всех столбцов в базе данных , имеющей конечное пространство .
до $$
объявлять
запись selectrow;
начинать
для выбора
Выбрать
'ОБНОВЛЕНИЕ' || quote_ident (c.table_name) || ' SET '|| c.COLUMN_NAME ||' = TRIM ('|| c.COLUMN_NAME ||') WHERE '|| quote_ident (c.COLUMN_NAME) ||' ILIKE ''% '' 'как скрипт
из (
Выбрать
table_name, COLUMN_NAME
из
ИНФОРМАЦИЯ_СХЕМА.КОЛОННЫ
где
table_name LIKE 'tbl_%' and (data_type = 'text' или data_type = 'character change')
) c
петля
выполнить selectrow.script;
конец петли;
конец;
$$;
, чтобы было удобнее использовать будущее
create function rm_trail_spaces () возвращает void как
$$
объявлять
запись selectrow;
начинать
для выбора
Выбрать
'ОБНОВЛЕНИЕ' || quote_ident (c.table_name) || ' SET '|| quote_ident (ок.COLUMN_NAME) || '= TRIM (' || quote_ident (c.COLUMN_NAME) || ') WHERE' || quote_ident (c.COLUMN_NAME) || ' ILIKE ''% '' 'как скрипт
из (
Выбрать
table_name, COLUMN_NAME
из
INFORMATION_SCHEMA.COLUMNS
где
table_name LIKE 'tbl_%' and (data_type = 'text' или data_type = 'character change')
) c
петля
выполнить selectrow.script;
конец петли;
конец;
$$
язык plpgsql
SELECT rm_trail_spaces () в Postgres SQL
Введение
TRIM и что она делает? Как мы используем функцию Trim () в наших командах запросов PostgreSQL? Какие параметры он использует? SELECT, , FROM и WHERE .Мы немного поработаем с типом переменной ARRAY, , функцией ARRAY_LENGTH , циклом WHILE, , RAISE NOTICE и тем, как CAST целое число как текст. Предварительные требования
SELECT, , FROM и WHERE . REPEAT , ddd и ddd . Что делает функция TRIM в Postgres SQL и каков ее синтаксис?
TRIM для удаления пробелов.Используется без параметров, ВЕДУЩИЙ : Необязательно. Сообщает Postgres начать с начала t_string_source и двигаться дальше. TRAILING : Необязательно.Сообщает Postgres начать с конца t_string_source и двигаться назад. ОБА : Необязательно. Сообщает Postgres удалить символ t_string_to_remove как из начала, так и из конца t_string_source. t_string_to_remove : Необязательно. Предоставляет TRIM () необязательную строку для поиска. Если не указан, предполагается пробел (chr (32)). t_string_source : Обязательный параметр. Строка, которую мы передаем функции. Это единственный обязательный параметр. Примеры с параметрами
trim (ВЕДУЩИЙ ОТ «Какая ваша любимая база данных?») возвращает «Какая ваша любимая база данных? « trim (ОТСЛЕЖИВАНИЕ ОТ «Какая ваша любимая база данных?») возвращает «Какая ваша любимая база данных?» trim (ОБА ИЗ «Какая ваша любимая база данных?») возвращает «Какая ваша любимая база данных?» trim («Какая ваша любимая база данных?») возвращает «Какая ваша любимая база данных?» Да, так же, как при использовании «ОБА ОТ». Как использовать функцию обрезки с массивом
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
DECLARE
a_t_technologies TEXT [4];
a_t_technologies: = {«Python», «Postgres», «MS SQL», «Javascript»};
t_string_to_remove ТЕКСТ: = «»;
i_current_array_spot INTEGER: = 0;
i_size_of_array INTEGER: = ARRAY_LENGTH (a_t_technologies, 1); — это 4
BEGIN
— пропустите наши четыре фразы
WHILE i_current_array_spot
i_current_array_spot: = i_current_array_spot + 1;
t_string_source: = a_t_technologies [i_current_array_spot]
t_result: = TRIM (ОБА t_string_to_remove ИЗ t_string_source);
УВЕДОМЛЕНИЕ О ПОВЫШЕНИИ t_result;
КОНЕЧНАЯ ПЕТЛЯ;
КОНЕЦ ЗАЯВИТЬ : В этой области мы (а) Инициализируем и заполняем массив «a_t_technologies» четырьмя элементами.(b) Для «t_string_to_remove» мы выбрали пробел. (c) Мы устанавливаем «i_current_array_spot» как целое число, равное нулю, чтобы запустить наш цикл. Это будет использоваться для подсчета WHILE LOOP, выбора слова в нашем массиве, над которым мы сейчас работаем, а затем END LOOP. (d) Мы используем «i_size_of_array» в нашем цикле ниже, чтобы сообщить Postgres, когда следует выйти из цикла. WHILE : Здесь мы настраиваем цикл для цикла от 0 до 3. Ниже мы добавляем 1 к значению непосредственно перед доступом к тому слову в массиве, в которое мы хотим внести изменения. LOOP : Здесь мы увеличиваем «i_current_array_spot» на 1 каждый раз, поэтому фактический извлекаемый элемент массива на единицу больше 0 до 3; которые становятся от 1 до 4. УВЕДОМЛЕНИЕ О ПОВЫШЕНИИ : Верните «t_result», чтобы увидеть следующий результат.
2
3
4
MS SQL
Javascript
Python Функция СЦЕПИТЬ
2
3
4
5
6
CONCAT (TRIM (t_name_first), «», TRIM (t_name_last))
FROM
tbl_data
_ WHERE_data
TRUEERE
= TRUEERE Заключение
TRIM () в нашем Postgres SQL, включая работу с некоторыми подробными примерами из реальной жизни.Мы также исследовали использование функции CONCAT () и различных операторов запросов PostgreSQL, включая SELECT , FROM и WHERE . Кроме того, мы поиграли с типом ARRAY , функцией ARRAY_LENGTH , конструкцией цикла WHILE и оператором RAISE NOTICE . Удалить начало, конец и все пространство столбца в postgresql
SELECT *, TRIM (ВЕДУЩИЙ ОТ имени_состоянии) как имя_состояния_L из состояний
SELECT *, LTRIM (colname) как state_name_L из состояний
Удалить TRAILING пространство столбца в postgresql:
SELECT *, TRIM (TRAILING FROM state_name) как state_name_R из состояний
SELECT *, RTRIM (state_name) как state_name_R из состояний
Удалите пространство LEADING и TRAILING столбца в postgresql:
ВЫБЕРИТЕ *, ОБРЕЗАТЬ (ОБА ИЗ имени_состоянии) как имя_стояния_B из состояний
SELECT *, BTRIM (state_name) как state_name_B из состояний
Убрать все пробелы столбца в postgresql
SELECT *, REPLACE (state_name, '', '') как state_name_B из состояний