меняем данные в обход триггера / Хабр
KilorВремя на прочтение 3 мин
Количество просмотров 7.8KБлог компании Тензор PostgreSQL *SQL *Администрирование баз данных *
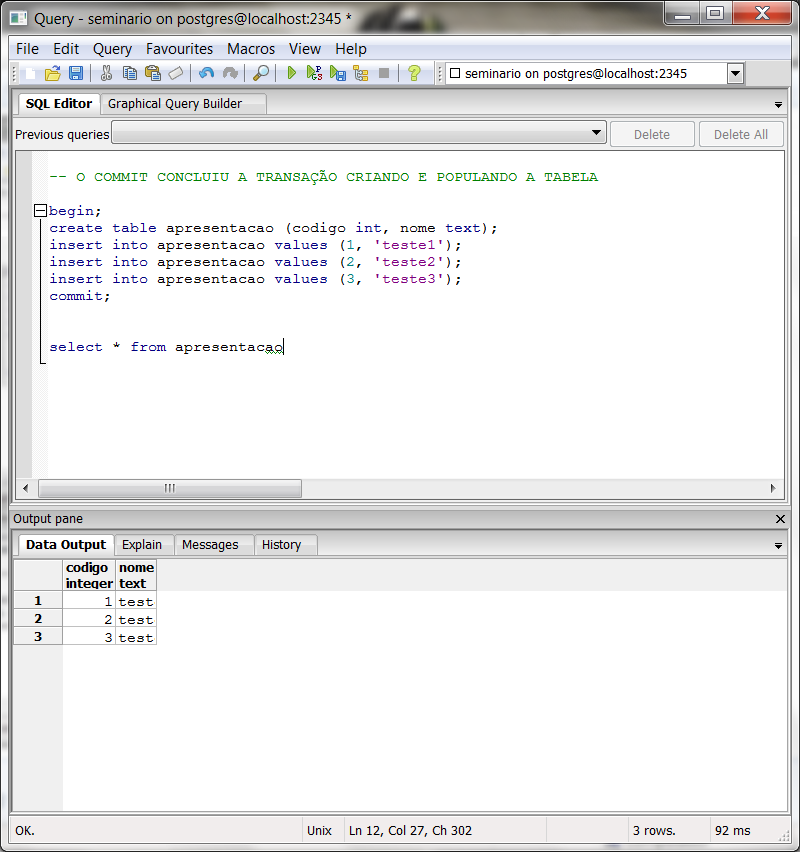
Рано или поздно многие сталкиваются с необходимостью что-то массово исправить в записях таблицы. Я уже рассказывал, как это делать лучше, а как — лучше не делать. Сегодня расскажу о втором аспекте массового обновления — о сработке триггеров.Например, на таблице, в которой вам надо что-то поправить, висит злобный триггер ON UPDATE, переносящий все изменения в какие-нибудь агрегаты. А вам надо все пообновлять (новое поле проинициализировать, например) так аккуратно, чтобы эти агрегаты не затронулись.
Давайте просто отключим триггеры!
BEGIN; ALTER TABLE ... DISABLE TRIGGER ...; UPDATE ...; -- тут долго-долго ALTER TABLE ... ENABLE TRIGGER .Собственно, тут и все —..; COMMIT;
 ..;
COMMIT;
..;
COMMIT;Потому что ALTER TABLE накладывает AccessExclusive-блокировку, под которой никто параллельно выполняющийся, даже простой SELECT, ничего из таблицы прочитать не сможет. То есть пока эта транзакция не закончится, все желающие даже «просто почитать» будут ждать. А мы помним, что UPDATE у нас до-о-олгий…
Давайте тогда быстро отключим, потом быстро включим!
BEGIN; ALTER TABLE ... DISABLE TRIGGER ...; COMMIT; UPDATE ...; BEGIN; ALTER TABLE ... ENABLE TRIGGER ...; COMMIT;Тут ситуация уже лучше, время ожидания существенно меньше. Но всего две проблемы портят всю красоту:
ALTER TABLEсам ждет все другие операции на таблице, включая длинныеSELECT- Пока триггер выключен, «пролетит мимо» любое изменение в таблице, даже не наше. И в агрегаты ну никак не попадет, хотя и должно. Беда!
Управление переменными сессии
Итак, на предыдущем варианте мы наткнулись на принципиальный момент — надо как-то научить триггер отличать «наши» изменения в таблице от «не наших». «Наши» пропускать как есть, а на «не наши» — срабатывать. Для этого можно воспользоваться переменными сессии.
«Наши» пропускать как есть, а на «не наши» — срабатывать. Для этого можно воспользоваться переменными сессии.session_replication_role
Читаем мануал:На механизм срабатывания триггеров также влияет конфигурационная переменная session_replication_role. Включённые без дополнительных указаний (по умолчанию) триггеры будут срабатывать, когда роль репликации — «origin» (по умолчанию) или «local». Триггеры, включённые указаниемОсобо подчеркну, что настройка относится к не ко всем-всем сразу, какENABLE REPLICA, будут срабатывать, только если текущий режим сеанса — «replica», а триггеры, включённые указаниемENABLE ALWAYS, будут срабатывать независимо от текущего режима репликации.
ALTER TABLE, а только к нашему отдельному спец-коннекту. Итого, чтобы не срабатывали никакие прикладные триггеры:SET session_replication_role = replica; -- выключили триггеры UPDATE ...; SET session_replication_role = DEFAULT; -- вернули в исходное состояние
Условие внутри триггера
Но приведенный выше вариант работает для всех триггеров сразу (или надо «альтерить» заранее триггеры, которые не хочется отключать). А если нам надо «выключить» один конкретный триггер?
А если нам надо «выключить» один конкретный триггер?В этом нам поможет «пользовательская» переменная сессии:
Имена параметров расширений записываются следующим образом: имя расширения, точка и затем собственно имя параметра, подобно полным именам объектов в SQL. Например: plpgsql.variable_conflict.Сначала дорабатываем триггер, примерно так:
Так как внесистемные параметры могут быть установлены в процессах, не загружающих соответствующий модуль расширения, PostgreSQL принимает значения для любых имён с двумя компонентами.
BEGIN
-- процессу конвертации можно делать все
IF current_setting('mycfg.my_table_convert_process') = 'TRUE' THEN
IF TG_OP IN ('INSERT', 'UPDATE') THEN
RETURN NEW;
ELSE
RETURN OLD;
END IF;
END IF;
...
Кстати, это можно сделать «наживую», без блокировок, через CREATE OR REPLACE для триггерной функции. А потом в спец-коннекте взводим «свою» переменную:SET mycfg.Знаете другие способы? Поделитесь в комментариях. Теги:my_table_convert_process = 'TRUE'; UPDATE ...; SET mycfg.my_table_convert_process = ''; -- вернули в исходное состояние
- базы данных
- dba
- sql antipatterns
- sql tips and tricks
- update
- PostgreSQL
- SQL
- Администрирование баз данных
Сравнение MySQL и PostgreSQL – Сравнение систем управления реляционными базами данных (RDBMS) – AWS
В чем разница между MySQL и PostgreSQL?
MySQL – это система управления реляционными базами данных, с помощью которой можно хранить данные в виде таблиц со строками и столбцами. Это популярная система, на которой работают многие веб-приложения, динамические веб-сайты и встроенные системы. PostgreSQL – это система управления объектно-реляционными базами данных, которая предлагает больше возможностей, чем MySQL. Эта система дает вам большую гибкость касательно типов данных, масштабируемости, параллельного доступа и целостности данных.
Подробнее о MySQL »
Подробнее о PostgreSQL »
В чем сходство между PostgreSQL и MySQL?
И PostgreSQL, и MySQL являются системами управления реляционными базами данных. Они хранят данные в таблицах, которые связаны между собой общими значениями столбцов. Вот пример.
- Компания хранит данные клиентов в таблице Клиенты с такими столбцами: customer_id, customer_name и customer_address.
- Она также хранит данные о продуктах в таблице Продукты с такими столбцами: product_id, product_name и product_price.
- Для записи товаров, приобретаемых каждым клиентом, компания имеет таблицу Customer_Orders со столбцами customer_id и product_id.
Ниже приведены другие сходства между PostgreSQL и MySQL.
- Обе системы используют язык SQL в качестве интерфейса для чтения и редактирования данных.

- Обе имеют открытый исходный код и пользуются сильной поддержкой сообщества разработчиков.
- Обе имеют встроенные функции резервного копирования, репликации и контроля доступа.
Подробнее об SQL »
Ключевые различия: PostgreSQL и MySQL
Несмотря на то что PostgreSQL и MySQL являются концептуально похожими, перед их внедрением необходимо учитывать многие их различия.
Соответствие требованиям ACIDАтомарность, согласованность, изолированность и долговечность (Atomicity, Consistency, Isolation and Durability, ACID) – это свойства базы данных, предназначенные для гарантии достоверности ее состояния даже после возникновения непредвиденных ошибок. Например, если вы обновляете большое количество строк и система выходит из строя на полпути, вам не придется вносить изменения ни в одну строку.
Система MySQL обеспечивает соответствие требованиям ACID только при использовании ее с механизмами хранения InnoDB и NDB Cluster или программными модулями.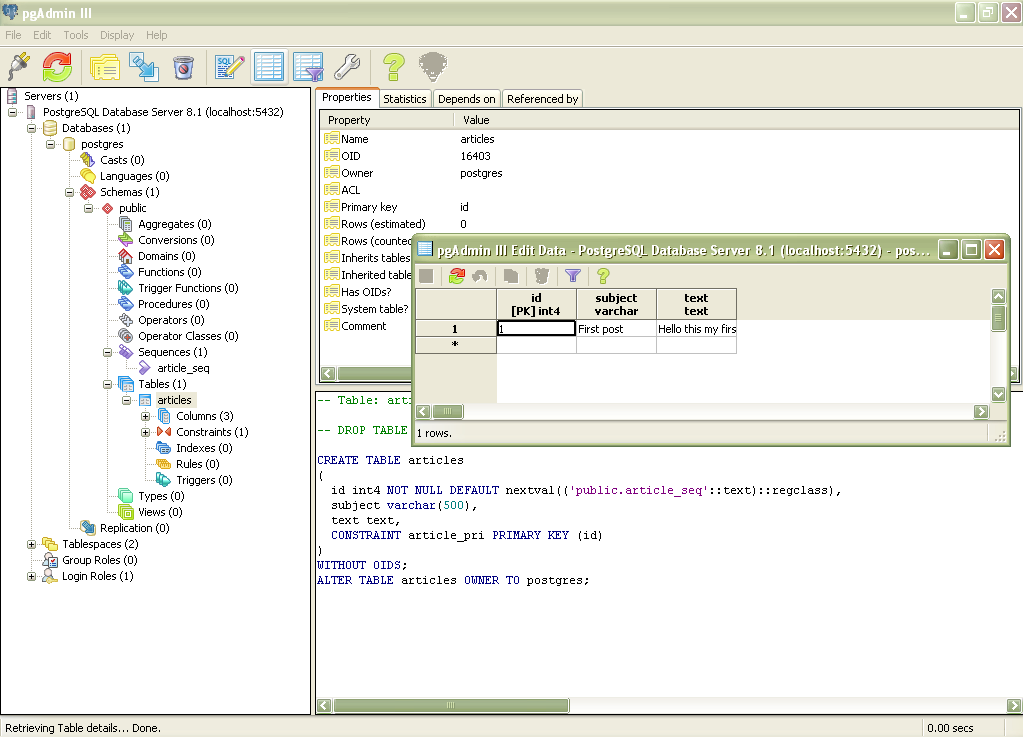 PostgreSQL полностью соответствует требованиям ACID во всех конфигурациях.
PostgreSQL полностью соответствует требованиям ACID во всех конфигурациях.
Управление параллельным доступом с помощью многоверсионности (Multiversion concurrency control, MVCC) – это усовершенствованная функция базы данных, которая создает дубликаты записей для безопасного одновременного чтения и обновления одних и тех же данных. Таким образом несколько пользователей могут одновременно читать и изменять одни и те же данные без ущерба для их целостности.
В отличие от PostgreSQL, базы данных MySQL не поддерживают MVCC.
ИндексыБазы данных используют индексы для более быстрого извлечения данных. Вы можете индексировать часто используемые данные, настроив систему управления базами данных таким образом, чтобы она сортировала и сохраняла их другим способом, отличным от остальных данных.
MySQL поддерживает индексацию B- и R-дерева, которая сохраняет данные, индексированные в иерархическом порядке. Типы индексов PostgreSQL включают деревья, индексы выражений, частичные индексы и хэш-индексы. Существуют и другие способы удовлетворения требований к производительности баз данных по мере масштабирования.
Типы индексов PostgreSQL включают деревья, индексы выражений, частичные индексы и хэш-индексы. Существуют и другие способы удовлетворения требований к производительности баз данных по мере масштабирования.
MySQL – реляционная база данных, а PostgreSQL – объектно-реляционная. Это означает, что в PostgreSQL можно хранить данные в качестве объектов со свойствами. Объекты являются распространенным типом данных во многих языках программирования, таких как Java и .NET. Объекты поддерживают такие парадигмы, как взаимосвязи типа «предок‑потомок» и наследование.
Системы PostgreSQL являются более интуитивно понятными для разработчиков баз данных. PostgreSQL также поддерживает такие типы данных, как массивы и XML.
ПредставленияПредставление – это подмножество данных, которое создает система баз данных путем извлечения из нескольких таблиц необходимых данных.
В то время как MySQL поддерживает представления, PostgreSQL предлагает для них расширенные возможности. К примеру, вы можете заранее вычислить некоторые значения (например, общую стоимость всех заказов за определенный период) для создания материализованных представлений. Материализованные представления повышают производительность баз данных при выполнении сложных запросов.
К примеру, вы можете заранее вычислить некоторые значения (например, общую стоимость всех заказов за определенный период) для создания материализованных представлений. Материализованные представления повышают производительность баз данных при выполнении сложных запросов.
Хранимые процедуры – это операторы кода или запросы на языке структурированных запросов (SQL), которые можно писать и сохранять заблаговременно. Один и тот же код можно использовать несколько раз, что позволяет повысить эффективность задач по управлению базами данных.
Несмотря на то что и MySQL, и PostgreSQL поддерживают хранимые процедуры, PostgreSQL позволяет вызывать хранимые процедуры, написанные на языках, отличных от SQL.
ТриггерыТриггер – это хранимая процедура, которая запускается автоматически при возникновении соответствующего события в системе управления базами данных.
В базах данных MySQL можно использовать только триггеры AFTER и BEFORE для таких операторов SQL, как INSERT, UPDATE и DELETE. Это означает, что процедура будет выполняться автоматически до или после изменения данных пользователем. Напротив, PostgreSQL поддерживает триггер INSTEAD OF, благодаря чему можно выполнять сложные операторы SQL с использованием функций.
Это означает, что процедура будет выполняться автоматически до или после изменения данных пользователем. Напротив, PostgreSQL поддерживает триггер INSTEAD OF, благодаря чему можно выполнять сложные операторы SQL с использованием функций.
Как выбрать между PostgreSQL и MySQL
Обе реляционные базы данных подходят для большинства примеров использования. Однако перед принятием окончательного решения вы можете рассмотреть нижеприведенные факторы.
Область примененияPostgreSQL лучше подходит для корпоративных приложений с частыми операциями записи и сложными запросами.
Однако вы можете начать проект MySQL, если хотите создать прототип, внутренние приложения с меньшим количеством пользователей или механизм хранения информации с большим количеством операций чтения и редким обновлением данных.
Опыт разработки баз данныхСистемы MySQL больше подходят для начинающих разработчиков, которым будет проще их освоить. Создание в них нового проекта базы данных с нуля занимает меньше времени. MySQL легко настроить как отдельный продукт или объединить его с другими технологиями веб-разработки, такими как стек LAMP.
Создание в них нового проекта базы данных с нуля занимает меньше времени. MySQL легко настроить как отдельный продукт или объединить его с другими технологиями веб-разработки, такими как стек LAMP.
С другой стороны, PostgreSQL может быть намного сложнее для новичков. Для работы с этими системами обычно требуется сложная настройка инфраструктуры и опыт устранения неполадок.
Подробнее о стеках LAMP »
Требования к производительностиPostgreSQL является лучшим вариантом, если ваше приложение требует частого обновления данных. Однако если вам требуется частое чтение данных, лучше отдать предпочтение MySQL.
Производительность операций записиСистемы MySQL используют блокировки операций записи для достижения реального параллельного доступа. Например, если один пользователь редактирует таблицу, другому пользователю, возможно, придется дождаться завершения этой операции, прежде чем вносить в нее изменения.
С другой стороны, PostgreSQL имеет встроенную поддержку MVCC без блокировок операций чтения и записи. Таким образом базы данных PostgreSQL лучше работают при выполнении частых и параллельных операций записи.
Производительность операций чтенияPostgreSQL создает новый системный процесс, выделяя для каждого пользователя, подключенного к базе данных, значительный объем памяти (около 10 МБ). Масштабирование для нескольких пользователей требует интенсивных ресурсов памяти.
С другой стороны, в системах MySQL используется один процесс для нескольких пользователей. В результате базы данных MySQL превосходят базы PostgreSQL для приложений, которые в основном считывают данные и отображают их пользователям.
Краткое описание различий: PostgreSQL и MySQL
Категория | MySQL | PostgreSQL |
Технология баз данных | MySQL – это система управления реляционными базами данных, | а PostgreSQL – объектно-реляционными. |
Возможности | MySQL имеет ограниченную поддержку функций баз данных, таких как представления, триггеры и процедуры. | PostgreSQL поддерживает самые передовые функции баз данных, в частности материализованные представления, триггеры INSTEAD OF и хранимые процедуры на нескольких языках. |
Типы данных | MySQL поддерживает такие типы данных: числовые, символьные, пространственные, даты и времени и JSON. | PostgreSQL поддерживает все типы данных MySQL, включая геометрические, перечисляемые и композитные, а также сетевые адреса, массивы, диапазоны, XML и hstore. |
Соответствие требованиям ACID | MySQL совместим с ACID только при использовании механизмов хранения InnoDB и NDB Cluster. | PostgreSQL всегда совместим с ACID. |
Индексы | MySQL поддерживает индексы B- и R-дерева. | PostgreSQL поддерживает несколько типов индексов, например индексы выражений, частичные индексы и хэш-индексы, а также деревья. |
Производительность | В MySQL улучшена производительность высокочастотных операций чтения, | а в PostgreSQL – операций записи. |
Поддержка начинающих | С системами MySQL легче начать работу. Они имеют более широкий набор инструментов для неопытных пользователей. | Начать работу с системами PostgreSQL сложнее, поскольку они предлагают ограниченный набор инструментов для неопытных пользователей. |

Как AWS может удовлетворить ваши требования к PostgreSQL и MySQL?
Amazon Web Services (AWS) предлагает несколько сервисов для удовлетворения ваших требований к PostgreSQL и MySQL.
Служба реляционных баз данных Amazon (Amazon RDS) – это набор управляемых сервисов, который упрощает настройку, использование и масштабирование реляционных баз данных в облаке. С помощью Службы реляционных баз данных Amazon (Amazon RDS) для MySQL можно всего за несколько минут выполнить экономичное развертывание масштабируемых серверов MySQL с возможностью настройки объема аппаратных ресурсов.
Аналогичным образом Служба реляционных баз данных Amazon (Amazon RDS) для PostgreSQL позволяет с легкостью настраивать, использовать и масштабировать развертывания PostgreSQL в облаке. Она также берет на себя сложные и трудоемкие задачи по администрированию, такие как обновление ПО PostgreSQL, управление хранилищем и резервное копирование для аварийного восстановления.
Ниже перечислены другие преимущества использования Amazon RDS.
- Масштабируемое и недорогое развертывание MySQL и PostgreSQL с возможностью настройки объема аппаратных ресурсов за считанные минуты.

- Повторное использование кода, приложений и инструментов, связанных с существующими базами данных.
- Просмотр важнейших операционных показателей, в частности об использовании вычислительных ресурсов, памяти и емкости хранилища.
Amazon Aurora – это система управления реляционными базами данных (СУРБД), разработанная для облака и совместимая с MySQL и PostgreSQL. Aurora совмещает в себе скорость и доступность высокопроизводительных коммерческих баз данных с простотой и экономичностью баз данных с открытым исходным кодом.
Ядро Aurora полностью совместимо с MySQL и PostgreSQL, поэтому для работы с существующими приложениями и инструментами не потребуется вносить изменения. Благодаря переходу на Amazon Aurora вы сможете повысить пропускную способность в три раза по сравнению со своей текущей настройкой.
Amazon EC2Эластичное вычислительное облако Amazon (Amazon EC2) предлагает самую масштабную и разноплановую вычислительную платформу.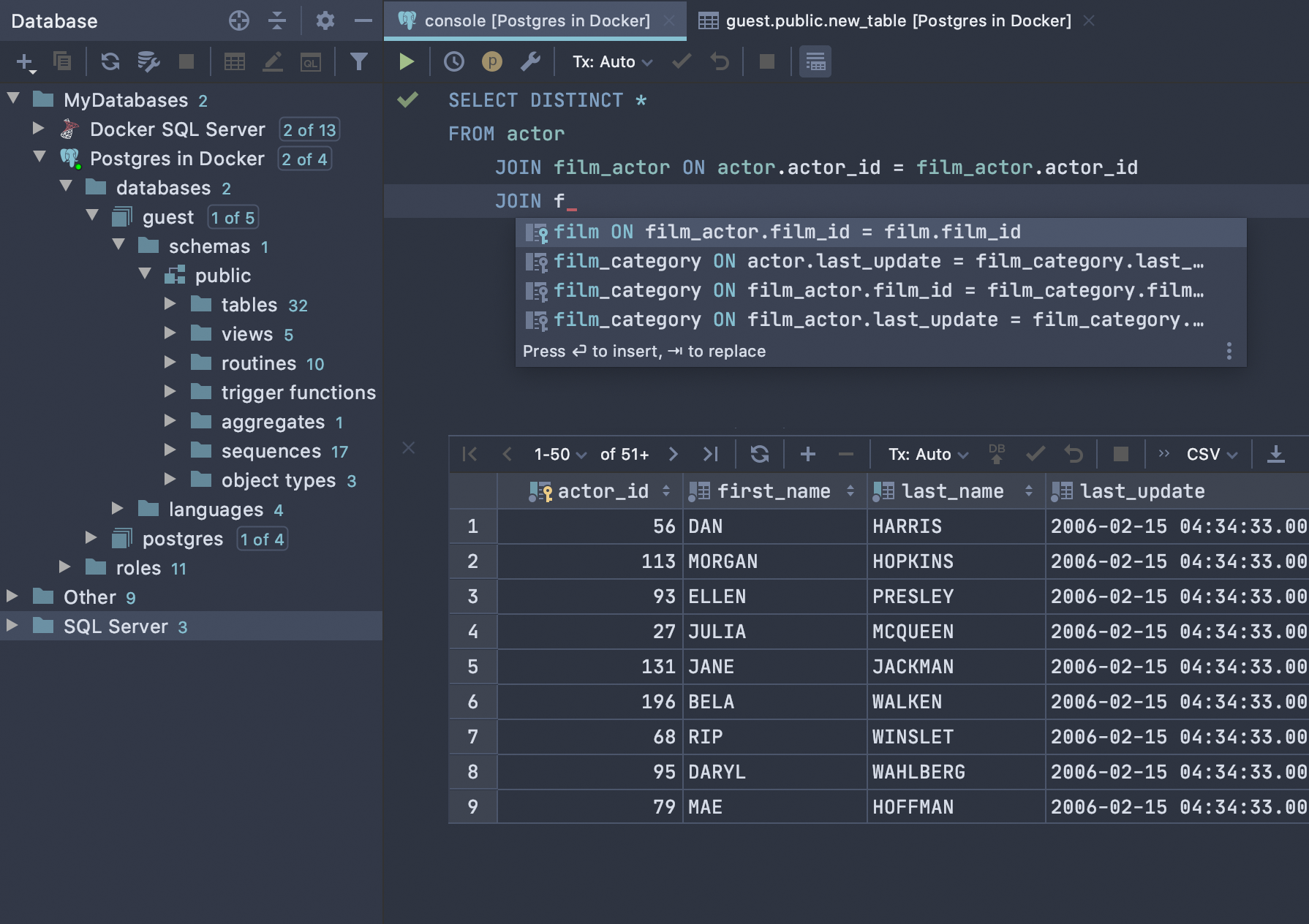 Оно насчитывает более 500 инстансов и позволяет выбрать новейший процессор, систему хранения данных, сетевую систему, операционную систему и модель покупки, которые помогут вам наилучшим образом удовлетворить потребности вашей рабочей нагрузки.
Оно насчитывает более 500 инстансов и позволяет выбрать новейший процессор, систему хранения данных, сетевую систему, операционную систему и модель покупки, которые помогут вам наилучшим образом удовлетворить потребности вашей рабочей нагрузки.
Amazon EC2 можно использовать для запуска в облаке баз данных MySQL и PostgreSQL. При таком подходе необходимо выполнять такие задачи по управлению базами данных, как выделение инфраструктуры и настройка, исправление, резервное копирование и масштабирование баз данных.
Начните работу с PostgreSQL и MySQL в AWS, создав бесплатный аккаунт уже сегодня.
Триггер PostgreSQL — javatpoint
следующий → ← предыдущая В этом разделе мы собираемся понять работу триггеров PostgreSQL, почему нам нужно использовать триггеры и когда их использовать, а также рассмотрим достоинства и недостатки из триггеров PostgreSQL, особенности триггеров PostgreSQL и различные команды, которые выполняются в разделе PostgreSQL Trigger. Что такое триггеры PostgreSQL?Триггер — это специальная определяемая пользователем функция, связанная с таблицей. если мы хотим сгенерировать новый триггер:
Примечание. Основное различие между триггером и определяемой пользователем функцией заключается в том, что при возникновении любого триггерного события триггер срабатывает автоматически.Триггер PostgreSQL — это функция, которая автоматически включается всякий раз, когда событие связано с таблицей. Событие может быть описано как любое из следующих INSERT, UPDATE, DELETE или TRUNCATE. Тип триггеровВ PostgreSQL триггер можно разделить на две части, а именно:
Например, если мы вводим команду UPDATE , которая влияет на 10 строк, триггер уровня строки будет вызываться 10 раз , с другой стороны, будет вызываться триггер уровня оператора 1 1 время . Как можно использовать триггер в PostgreSQL?
Использование триггеровТриггеры можно использовать в следующих аспектах:
Различные команды, используемые в триггерах PostgreSQLВ триггере PostgreSQL мы можем выполнить следующие команды:
Разберем их по порядку:
Особенности триггеров PostgreSQLВот некоторые важные функции триггеров PostgreSQL:
Преимущество использования PostgreSQL TriggerУ нас есть следующие преимущества использования триггера PostgreSQL:
Недостаток использования триггера PostgreSQLОсновной недостаток использования триггера PostgreSQL заключается в том, что мы должны знать, что триггер срабатывает, и понимать его логику и последствия изменения данных. ОбзорВ разделе триггеров PostgreSQL мы изучили следующие темы:
Next TopicPostgreSQL Create Trigger ← предыдущая следующий → |

 Нам нужно сохранить кросс-функциональность в базе данных, которая выполняется многократно всякий раз, когда данные таблицы изменяются.
Нам нужно сохранить кросс-функциональность в базе данных, которая выполняется многократно всякий раз, когда данные таблицы изменяются.
3 способа вывести список всех триггеров для данной таблицы в PostgreSQL
Вот три варианта вывода списка триггеров для данной таблицы в PostgreSQL.
Это представление содержит все функции и процедуры в текущей базе данных, которые принадлежат текущему пользователю или имеют какие-либо привилегии, кроме ВЫБЕРИТЕ вкл.
Одним из столбцов в этом представлении является event_object_table , который содержит имя таблицы, для которой определен триггер.
Таким образом, мы можем использовать это представление для получения триггеров для конкретной таблицы, например:
SELECT
триггер_схема,
имя_триггера,
event_manipulation,
action_statement
ИЗ information_schema.triggers
ГДЕ event_object_table = 'фильм'; Пример результата:
+-----------------+---------+- ------------------+--------------------------------------------- -------------------------------------------------- --------------------+
| схема_триггера | имя_триггера | event_manipulation | action_statement |
+--+----------+-------- ---------------------------+------------------------------------- -------------------------------------------------- -------------+
| общественный | фильм_полный текст_триггер | ВСТАВИТЬ | ВЫПОЛНИТЬ ФУНКЦИЮ tsvector_update_trigger('полный текст', 'pg_catalog. english', 'название', 'описание') |
| общественный | фильм_полный текст_триггер | ОБНОВЛЕНИЕ | ВЫПОЛНИТЬ ФУНКЦИЮ tsvector_update_trigger('полный текст', 'pg_catalog.english', 'название', 'описание') |
| общественный | последнее_обновлено | ОБНОВЛЕНИЕ | ВЫПОЛНИТЬ ФУНКЦИЮ last_updated() |
+--+----------+-------- ---------------------------+------------------------------------- -------------------------------------------------- -------------+
english', 'название', 'описание') |
| общественный | фильм_полный текст_триггер | ОБНОВЛЕНИЕ | ВЫПОЛНИТЬ ФУНКЦИЮ tsvector_update_trigger('полный текст', 'pg_catalog.english', 'название', 'описание') |
| общественный | последнее_обновлено | ОБНОВЛЕНИЕ | ВЫПОЛНИТЬ ФУНКЦИЮ last_updated() |
+--+----------+-------- ---------------------------+------------------------------------- -------------------------------------------------- -------------+ Поскольку представление возвращает только те триггеры, которыми владеет текущий пользователь или которые имеют какие-либо привилегии, отличные от SELECT , полученный список может представлять только подмножество фактических триггеров, определенных в таблице.
Каталог
pg_trigger Каталог pg_catalog.pg_trigger хранит триггеры для таблиц и представлений, и он не ограничивается только теми триггерами, которыми владеет текущий пользователь или имеет какие-либо привилегии, отличные от ВЫБЕРИТЕ на:
ВЫБЕРИТЕ
tgname AS имя_триггера
ОТ
pg_trigger
ГДЕ
tgrelid = 'public. film'::regclass
СОРТИРОВАТЬ ПО
имя_триггера;
film'::regclass
СОРТИРОВАТЬ ПО
имя_триггера; Пример результата:
+------------------------------+ | имя_триггера | +-------------------------------+ | RI_ConstraintTrigger_a_24890 | | RI_ConstraintTrigger_a_24891 | | RI_ConstraintTrigger_a_24900 | | RI_ConstraintTrigger_a_24901 | | RI_ConstraintTrigger_a_24915 | | RI_ConstraintTrigger_a_24916 | | RI_ConstraintTrigger_c_24907 | | RI_ConstraintTrigger_c_24908 | | RI_ConstraintTrigger_c_24912 | | RI_ConstraintTrigger_c_24913 | | фильм_полный текст_триггер | | последнее_обновлено | +--------------------------------------------+
Чтобы получить исходный код, мы можем включить представление pg_proc в наш запрос :
ВЫБЕРИТЕ
t.tgname,
p.prosrc
ОТ
pg_trigger t JOIN pg_proc p ON p.oid = t.tgfoid
ГДЕ
t.tgrelid = 'public.film'::regclass
СОРТИРОВАТЬ ПО
t.tgname; Пример результата:
+------------------------------------------------------------+---------------- --------------------------+ | тег | prosrc | +-------------------------------+------------------ ------------------------+ | RI_ConstraintTrigger_a_24890 | RI_FKey_restrict_del | | RI_ConstraintTrigger_a_24891 | RI_FKey_cascade_upd | | RI_ConstraintTrigger_a_24900 | RI_FKey_restrict_del | | RI_ConstraintTrigger_a_24901 | RI_FKey_cascade_upd | | RI_ConstraintTrigger_a_24915 | RI_FKey_restrict_del | | RI_ConstraintTrigger_a_24916 | RI_FKey_cascade_upd | | RI_ConstraintTrigger_c_24907 | RI_FKey_check_ins | | RI_ConstraintTrigger_c_24908 | RI_FKey_check_upd | | RI_ConstraintTrigger_c_24912 | RI_FKey_check_ins | | RI_ConstraintTrigger_c_24913 | RI_FKey_check_upd | | фильм_полный текст_триггер | tsvector_update_trigger_byid | | последнее_обновлено | +| | | НАЧАТЬ +| | | NEW.last_update = CURRENT_TIMESTAMP;+| | | ВОЗВРАТ НОВОГО; +| | | КОНЕЦ | +-------------------------------+------------------ ------------------------+
Имейте в виду, что содержимое столбца pg_proc.prosrc зависит от языка реализации/соглашения о вызовах. Он может содержать фактический исходный код функции для интерпретируемых языков, символ ссылки, имя файла или что-то еще.
Команда
\dS При использовании psql команда \dS — это быстрый способ получить информацию о таблицах, представлениях и т. д., включая любые триггеры, определенные для них.
Мы можем добавить имя таблицы к этой команде, чтобы вернуть информацию только об этой таблице:
\dS film
Пример результата:
+--------------------------------- ----+---------------+------------+--- -------+--------------------------+
| Колонка | Тип | сортировка | Обнуляемый | По умолчанию |
+-------------------------------------+------------- ---+------------+------------+----------------------- --+
| ид_фильма | целое число | | не нуль | nextval('film_film_id_seq'::regclass) |
| название | переменный характер(255) | | не нуль | |
| описание | текст | | | |
| выпуск_год | год | | | |
| идентификатор_языка | малыйинт | | не нуль | |
| оригинальный_язык_идентификатор | малыйинт | | | |
| продолжительность_проката | малыйинт | | не нуль | 3 |
| арендная_ставка | числовой (4,2) | | не нуль | 4.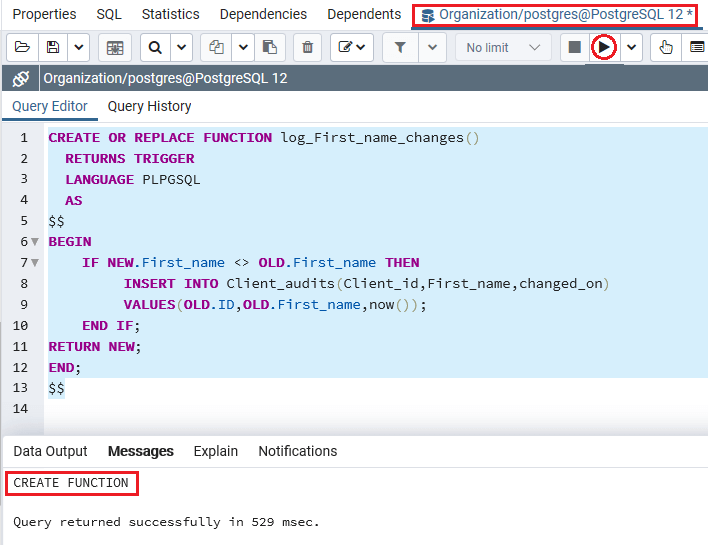 99 |
| длина | малыйинт | | | |
| замена_стоимость | числовой (5,2) | | не нуль | 19,99 |
| рейтинг | mpaa_rating | | | 'G'::mpaa_rating |
| последнее_обновление | отметка времени без часового пояса | | не нуль | сейчас () |
| специальные_функции | текст [] | | | |
| полный текст | вектор | | не нуль | |
+-------------------------------------+------------- ---+------------+------------+----------------------- --+
Индексы:
"film_pkey" ПЕРВИЧНЫЙ КЛЮЧ, btree (film_id)
Суть "film_fulltext_idx" (полный текст)
"idx_fk_language_id" btree (language_id)
"idx_fk_original_language_id" btree (original_language_id)
"idx_title" btree (название)
Ограничения внешнего ключа:
"film_language_id_fkey" ИНОСТРАННЫЙ КЛЮЧ (language_id) ССЫЛКИ language(language_id) НА ОБНОВЛЕНИЕ КАСКАД НА УДАЛЕНИЕ ОГРАНИЧЕНИЯ
"film_original_language_id_fkey" ИНОСТРАННЫЙ КЛЮЧ (original_language_id) ССЫЛКИ язык(language_id) НА КАСКАД ОБНОВЛЕНИЯ НА УДАЛЕНИЕ ОГРАНИЧЕНИЯ
Ссылка на:
ТАБЛИЦА "film_actor" ОГРАНИЧЕНИЕ "film_actor_film_id_fkey" ВНЕШНИЙ КЛЮЧ (film_id) ССЫЛКИ film(film_id) НА ОБНОВЛЕНИЕ КАСКАД НА УДАЛЕНИЕ ОГРАНИЧЕНИЯ
ТАБЛИЦА "film_category" ОГРАНИЧЕНИЕ "film_category_film_id_fkey" ВНЕШНИЙ КЛЮЧ (film_id) ССЫЛКИ film(film_id) НА ОБНОВЛЕНИЕ КАСКАД НА УДАЛЕНИЕ ОГРАНИЧЕНИЯ
ТАБЛИЦА "inventory" ОГРАНИЧЕНИЕ "inventory_film_id_fkey" ВНЕШНИЙ КЛЮЧ (film_id) ССЫЛКИ film(film_id) НА ОБНОВЛЕНИЕ КАСКАД НА УДАЛЕНИЕ ОГРАНИЧЕНИЯ
Триггеры:
film_fulltext_trigger ПЕРЕД ВСТАВКОЙ ИЛИ ОБНОВЛЕНИЕМ В ФИЛЬМЕ ДЛЯ КАЖДОЙ СТРОКИ ВЫПОЛНИТЕ ФУНКЦИЮ tsvector_update_trigger('fulltext', 'pg_catalog.
99 |
| длина | малыйинт | | | |
| замена_стоимость | числовой (5,2) | | не нуль | 19,99 |
| рейтинг | mpaa_rating | | | 'G'::mpaa_rating |
| последнее_обновление | отметка времени без часового пояса | | не нуль | сейчас () |
| специальные_функции | текст [] | | | |
| полный текст | вектор | | не нуль | |
+-------------------------------------+------------- ---+------------+------------+----------------------- --+
Индексы:
"film_pkey" ПЕРВИЧНЫЙ КЛЮЧ, btree (film_id)
Суть "film_fulltext_idx" (полный текст)
"idx_fk_language_id" btree (language_id)
"idx_fk_original_language_id" btree (original_language_id)
"idx_title" btree (название)
Ограничения внешнего ключа:
"film_language_id_fkey" ИНОСТРАННЫЙ КЛЮЧ (language_id) ССЫЛКИ language(language_id) НА ОБНОВЛЕНИЕ КАСКАД НА УДАЛЕНИЕ ОГРАНИЧЕНИЯ
"film_original_language_id_fkey" ИНОСТРАННЫЙ КЛЮЧ (original_language_id) ССЫЛКИ язык(language_id) НА КАСКАД ОБНОВЛЕНИЯ НА УДАЛЕНИЕ ОГРАНИЧЕНИЯ
Ссылка на:
ТАБЛИЦА "film_actor" ОГРАНИЧЕНИЕ "film_actor_film_id_fkey" ВНЕШНИЙ КЛЮЧ (film_id) ССЫЛКИ film(film_id) НА ОБНОВЛЕНИЕ КАСКАД НА УДАЛЕНИЕ ОГРАНИЧЕНИЯ
ТАБЛИЦА "film_category" ОГРАНИЧЕНИЕ "film_category_film_id_fkey" ВНЕШНИЙ КЛЮЧ (film_id) ССЫЛКИ film(film_id) НА ОБНОВЛЕНИЕ КАСКАД НА УДАЛЕНИЕ ОГРАНИЧЕНИЯ
ТАБЛИЦА "inventory" ОГРАНИЧЕНИЕ "inventory_film_id_fkey" ВНЕШНИЙ КЛЮЧ (film_id) ССЫЛКИ film(film_id) НА ОБНОВЛЕНИЕ КАСКАД НА УДАЛЕНИЕ ОГРАНИЧЕНИЯ
Триггеры:
film_fulltext_trigger ПЕРЕД ВСТАВКОЙ ИЛИ ОБНОВЛЕНИЕМ В ФИЛЬМЕ ДЛЯ КАЖДОЙ СТРОКИ ВЫПОЛНИТЕ ФУНКЦИЮ tsvector_update_trigger('fulltext', 'pg_catalog.