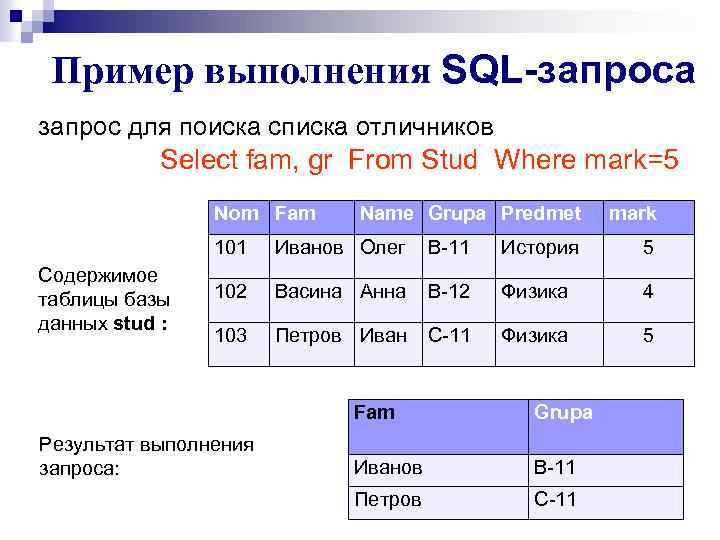
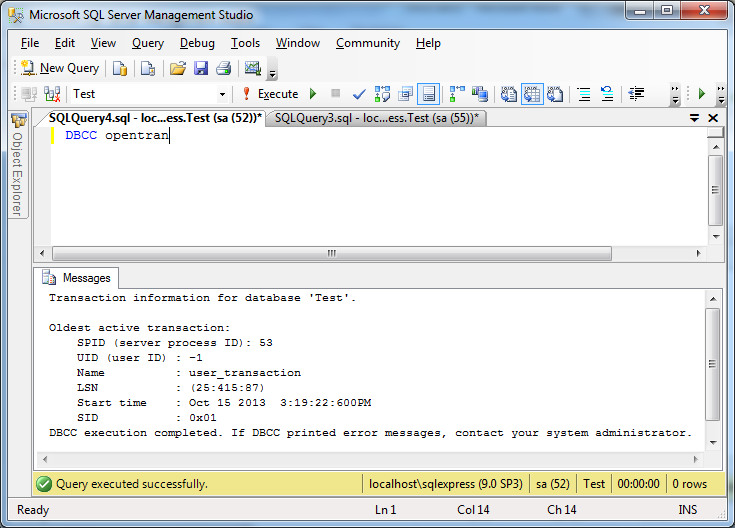
Что такое SQL, как работает язык SQL
Поделиться:
SQL, Structured Query Language — язык структурированных запросов, с помощью которого из базы данных извлекаются, записываются, группируются данные. База данных или БД — это набор файлов, в которых записаны контент, логины, пароли, настройки личных кабинетов, данные о посетителях и клиентах. Другими словами — массивы всевозможных, разнообразных данных.
Кто и для чего использует язык SQL
SQL нужен, чтобы работать с базой данных: записывать в неё новую информацию, менять или удалять старую. Для этого IT-специалисты пишут специальные команды — SQL-запросы.
Среди программистов есть отдельные специалисты, которые знают, как создать базу данных и использовать SQL для работы с ней. К ним относятся:
- Администратор базы данных. С помощью SQL администратор даёт или отнимает у других пользователей доступ к БД. Ещё настраивает резервное копирование базы, чтобы в случае ошибки или бага данные не стерлись.
- Разработчик.
 Создаёт программы, у которых много собственных данных: текста, картинок, анимаций, сведений, паролей, телефонов клиентов. Эти данные разработчик сохраняет в БД через язык SQL.
Создаёт программы, у которых много собственных данных: текста, картинок, анимаций, сведений, паролей, телефонов клиентов. Эти данные разработчик сохраняет в БД через язык SQL. - Тестировщик. Тестировщик проверяет код. А если в коде есть часть, связанная с БД, он использует язык SQL, чтобы проверить, как он работает..
- Бизнес-аналитик. Работает с SQL, чтобы получить из базы данные для изучения, поиска закономерностей и составления отчётов.
 Создаёт программы, у которых много собственных данных: текста, картинок, анимаций, сведений, паролей, телефонов клиентов. Эти данные разработчик сохраняет в БД через язык SQL.
Создаёт программы, у которых много собственных данных: текста, картинок, анимаций, сведений, паролей, телефонов клиентов. Эти данные разработчик сохраняет в БД через язык SQL.Как работает SQL-запрос
SQL-запрос — это команда, через которую айтишники работают с БД: выгружают из них данные, заменяют, сортируют, удаляют. Работает запрос по следующей схеме:
- Программист пишет SQL-запрос — команду, в которой зашифровано, что надо сделать с данными в базе.
- СУБД или система управления базой данных — специальная программа, которая управляет БД — принимает и расшифровывает запрос.
- Если команда написана верно, СУБД выполняет запрос.
Читайте также
Как использовать Microsoft SQL для отчётов в Power BI.На примере Mindbox
Операторы в SQL
Оператор SQL — это команда, которая выполняет конкретную операцию в БД. Выглядит оператор как слово, но само по себе не работает. Чтобы работало, его надо вписать в конкретный SQL-запрос.
К примеру, оператор «SELECT» означает, что нужно выбрать из БД данные, которые соответствуют какому-то условию. Если нужно найти в БД информацию о клиенте Семенове Михаиле Александровиче, то SQL-запрос с оператором «SELECT» будет выглядеть так:
SELECT * FROM clients WHERE name = Семенов Михаил Александрович,
Где:
- SELECT — отобрать;
- FROM clients — из таблицы «Клиенты»;
- WHERE name — имя Семенов Михаил Александрович.
Все операторы поделены на группы в зависимости от действий, которые они выполняют.
- Data Definition Language. Или DDL — это операторы для работы с таблицами БД. Они нужны, когда пользователь хочет создать новую, изменить или удалить существующую таблице.
Оператор Действие CREATE Создать таблицу ALTER Изменить таблицу DROP Удалить таблицу - Data Manipulation Language. Или DML — это операторы, которые позволяют редактировать все данные в таблицах или некоторые по определённым условиям. Например, пользователь может изменить название какого-то одного клиента в базе.
Оператор Действие SELECT Отсортировать INSERT Создать запись UPDATE Изменить или обновить значение DELETE Удалить значение - Data Control Language. Или DCL — это операторы, которые выдают или отнимают права у пользователей для работы с БД.
Оператор Действие GRANT Дать пользователю права доступа REVOKE Забрать у пользователя права доступа
- SQL — это язык программирования для работы с базами данных.

- В SQL есть операторы — команды, через которые управляют самой базой и данными внутри её. И запросы: строчки кода, в которых указывают оператора, чтобы он сработал.
- SQL используют администраторы, разработчики, тестировщики и аналитики.
Поделиться:
Что такое база данных и SQL. Как работают с базами и что в них хранят
Если сказать упрощённо, то база данных — это среда, в которой существуют таблицы с данными. Если вы когда-нибудь работали в офисной программе «Excel», в которой можно делать таблицы, то считайте что работали с базой данных.
В базах данных сайтов могут содержаться таблицы, в которых может быть записано всё что угодно:
- данные новостей, которые опубликованы на сайте
- данные пользователей, которые зарегистрированы на сайте
Продемонстрируем типичную таблицу из базы данных. Пускай эта таблица будет называться «Пользователи»:
+--------------------+ | Пользователи | +--------------------+ | Имя | Любимая еда | +------+-------------+ | Мышь | Сыр | +------+-------------+ | Кот | Молоко | +------+-------------+
 Но в таком виде на сайте её увидеть нельзя. Сайт делает запрос к ней с помощью специального языка, который называется SQL (Structured Query Language — «язык структурированных запросов»). Эти запросы возвращают массив строк, которые подходят под параметр запроса. Разберём далее логику запросов.
Но в таком виде на сайте её увидеть нельзя. Сайт делает запрос к ней с помощью специального языка, который называется SQL (Structured Query Language — «язык структурированных запросов»). Эти запросы возвращают массив строк, которые подходят под параметр запроса. Разберём далее логику запросов.
Представьте, что необходимо получить из примера выше все данные таблицы и вывести их на экран. Тогда нужно сделать запрос к базе данных на языке SQL:
SELECT 'Имя пользователя', 'Любимая еда' FROM 'Пользователи';
Как можно догадаться из этой строчки, к базе данных будет сделан запрос на получение данных. Об этом говорит слово SELECT, который переводится как «ВЫБРАТЬ». После слова SELECT стоят названия двух столбцов, значение которых необходимо получить из базы данных. Если название столбца не указать, то его значение не будет получено. Можно написать нужные столбцы через запятую, как это сделано в примере, а если нужно вывести все, то можно просто поставить значок звёздочки *.
Последняя часть запроса содержит слово FROM, которое дословно переводится как «из». После этого слова стоит таблица ИЗ которой надо получить данные. Если не указать из какой таблицы нужны данные, то база данных выдаст ошибку.
Пример SQL запроса, который приведён выше, сильно утрирован для большей наглядности и простоты. Потому что в базах данных крайне нежелательно создавать таблицы с кириллическими названиями таблиц и столбцов. А ещё названия столбцов и самой таблицы нужно заключать не в одинарную кавычку ‘ , а в наколнную `
Перейдём к обработке результатов выполнения запроса. Если утрировать, то после выполнения запроса из примера выше база данных вернёт такой массив:
Array
(
[0] => Array
(
[Имя] => Мышь
[Любимая еда] => Сыр
)
[1] => Array
(
[Имя] => Кот
[Любимая еда] => Молоко
)
)
После получения этого массива необходимо сделать цикл аналогичный foreach( ) по всем элементам полученного массива. Внутри цикла можно обернуть полученные значения в различные HTML теги, чтобы вывод был красивым, чтобы у страницы сайта был дизайн. Так и происходит взаимодействие сайтов с базами данных.
Внутри цикла можно обернуть полученные значения в различные HTML теги, чтобы вывод был красивым, чтобы у страницы сайта был дизайн. Так и происходит взаимодействие сайтов с базами данных.
Базы данных — это не лучшее хранилище информации. Конёк баз данных — это быстрый поиск информации и вывод с сортировкой. Поэтому базы данных целесообразно использовать далеко не везде. Если же нужно обрабатывать терабайты статичной информации без необходимости поиска и сортировки, то выгоднее использовать использовать простые файлы для хранения информации.
Базы данных используются для сайтов в основном потому, что с их помощью можно организовать уровни доступа к информации. И базы данных большинства сайтов в интернете очень редко когда превышают 10 Гигабайт (считая размеры всех таблиц в базе).
В следующих статьях мы разберём более сложные примеры обращения с базой данных: научимся создавать и удалять таблицы, объединять результаты выборки из нескольких разных таблиц и обновлять данные в таблицах.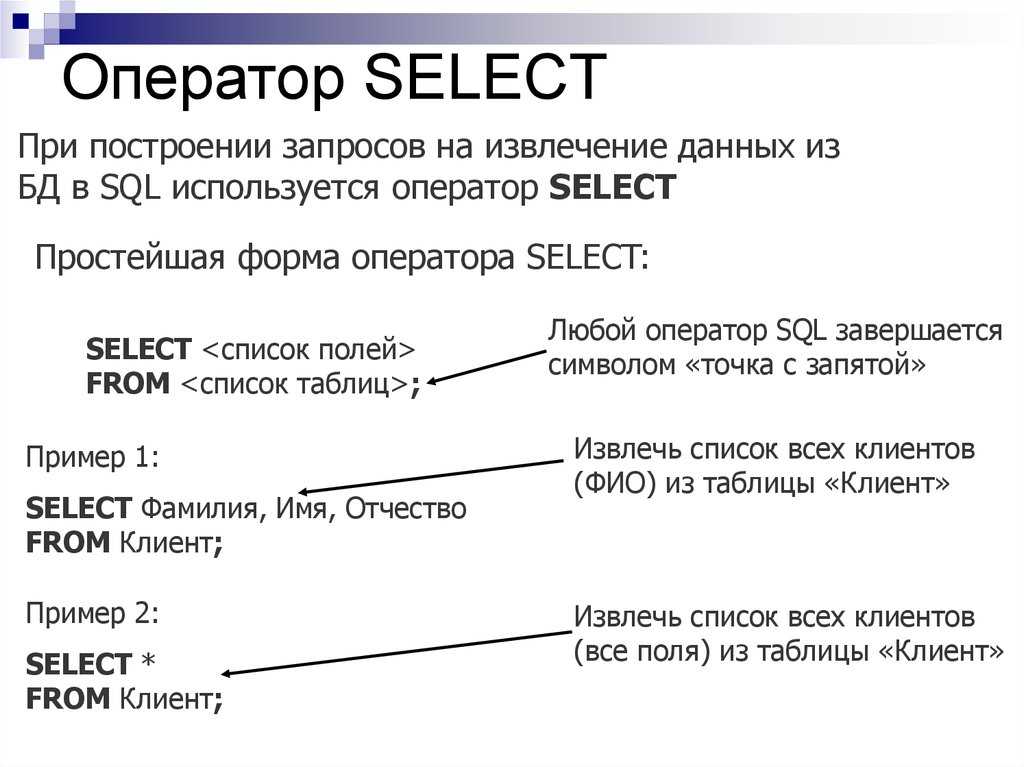 Если вам не терпится приступить к программированию, то рекомендуем ознакомиться со статьёй «Как сделать запрос из PHP к базе данных».
Если вам не терпится приступить к программированию, то рекомендуем ознакомиться со статьёй «Как сделать запрос из PHP к базе данных».
Была ли эта статья полезна? Есть вопрос?
Закажите недорогой хостинг Заказать
всего от 290 руб
SQL-запросы в SQL Server — руководство для начинающих
Введение
Создание SQL-запросов — простой процесс. Эта статья написана на SQL Server, но большую часть содержимого можно применяется к Oracle, PostgreSQL, MySQL, MariaDB и другим базам данных с небольшими изменениями. Запросы SQL позволяют нам отправлять запросы к базе данных. В этой статье у нас будет быстрое практическое руководство по выполнению ваших собственных запросов из царапать.
Что такое запросы SQL?
SQL означает S структурированный Q uery L язык. Это язык, используемый
по базам данных, чтобы получить информацию. Мы научимся делать запросы на языке SQL.
Мы научимся делать запросы на языке SQL.
SQL-запросы в SQL Server
Основой запроса в SQL Server является предложение SELECT, которое позволяет выбрать данные для отображения. Начать при этом мы будем использовать базу данных AdventureWorks, содержащую примеры таблиц и представлений, которые позволят нам иметь одни и те же таблицы и данные. Мы также сможем работать с несколькими уже созданными таблицами.
- Примечание: Дополнительные сведения об установке базы данных AdventureWorks см. в следующей статье — Установка и настройка образца базы данных AdventureWorks2016
Запросы SQL и выбор предложения
Начнем с предложения SELECT, предложение select позволит нам получить данные из таблицы.
Следующий запрос покажет все столбцы из таблицы:
ВЫБЕРИТЕ * ИЗ [Отдел кадров].[Сотрудник] |
Попробуйте использовать оператор SELECT в одной строке и оператор FROM в другой строке.
ВЫБЕРИТЕ [Сотрудник].* ИЗ [Отдел кадров].[Сотрудник]
|
Квадратные скобки необязательны. Они могут помочь, если в именах столбцов есть пробелы (что не рекомендуется). Ты можешь также выберите определенные имена столбцов, например:
ВЫБЕРИТЕ [Идентификатор входа],[Пол] ИЗ [Отдел кадров].[Сотрудник] |
В предыдущем примере показаны столбцы логин и пол. Как видите, данные разделены запятыми. Вы также можете использовать псевдонимы, чтобы иметь более короткое имя, например:
ВЫБЕРИТЕ e.Gender ИЗ [HumanResources].[Employee] e |
В предыдущем примере используется псевдоним e для таблицы Employee.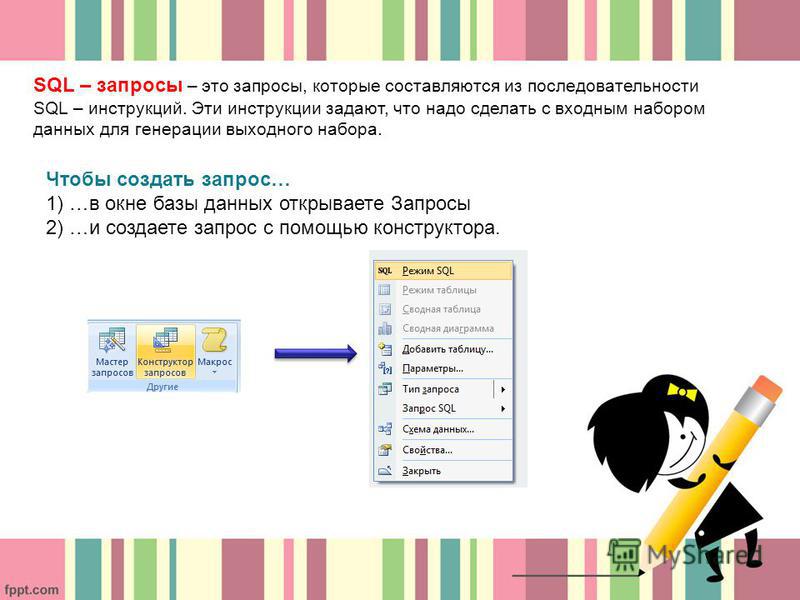 Мы также можем использовать псевдоним для имен столбцов следующим образом:
Мы также можем использовать псевдоним для имен столбцов следующим образом:
ВЫБЕРИТЕ e.Gender g FROM [HumanResources].[Employee] e |
Псевдоним столбца для Пола теперь равен g. В следующем примере будут показаны 2 различных возможных значения в столбце пола (мужской или женский):
ВЫБЕРИТЕ РАЗЛИЧНЫЙ e.Gender g FROM [HumanResources].[Employee] e |
Обратите внимание, что DISTINCT — медленная команда, и если таблица содержит несколько миллионов строк, ее выполнение может занять некоторое время и снизить производительность.
ВЫБЕРИТЕ ПЕРВЫЕ 10 e. FROM [HumanResources].[Employee] e |
 [BusinessEntityID], e.Gender g
[BusinessEntityID], e.Gender gЕсли мы хотим упорядочить данные по столбцу, порядок по будет очень полезен. В следующем примере показано, как показать BusinessEntityID отсортирован в порядке убывания.
ВЫБЕРИТЕ [BusinessEntityID] ИЗ [HumanResources].[Employee] e ЗАКАЗАТЬ ПО [BusinessEntityID] desc |
- Примечание: Дополнительные сведения о запросах на выборку см. по этой ссылке: Изучение SQL: оператор SELECT
SQL-запросы для фильтрации данных с помощью команды WHERE
Команда where является одним из наиболее распространенных предложений, используемых внутри команды SELECT. Этот пункт позволяет фильтровать данные.
В следующем примере показано, как проверить BusinessEntityID сотрудников, занимающих должность инженера-конструктора.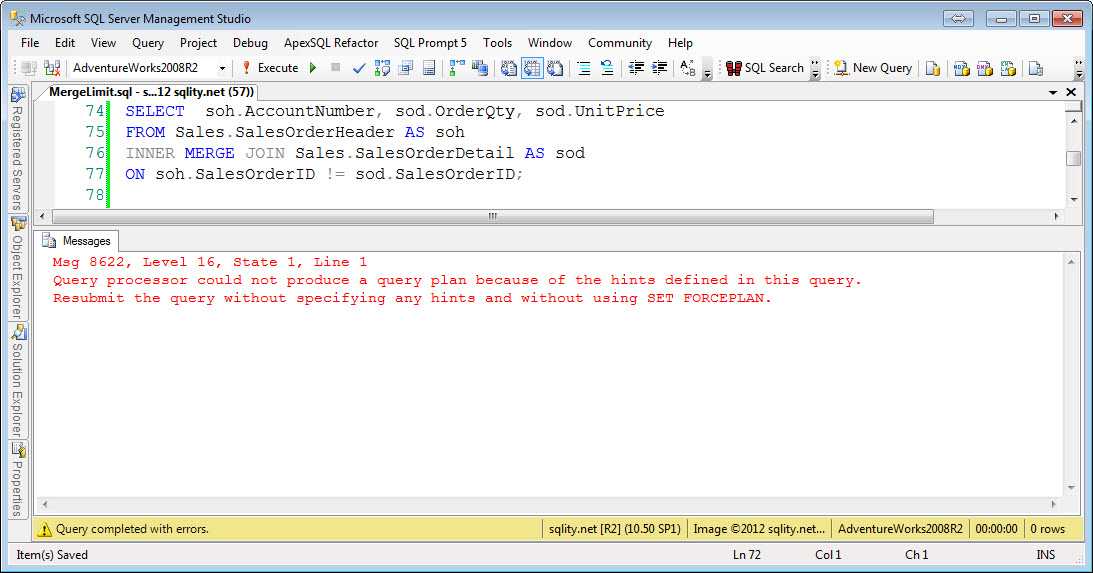
выберите [BusinessEntityID], [JobTitle] из [HumanResources].[Employee] e , где JobTitle=’Инженер-конструктор’ |
- В примере мы использовали оператор равенства. Полный список операторов T-SQL см. по этой ссылке: Логические операторы (Transact-SQL)
Еще одним мощным оператором является LIKE. Мол, может поможет нам в поисках. В следующем примере показаны BusinessEntityID и Должность сотрудников, должности которых начинаются с Design:
ВЫБЕРИТЕ [BusinessEntityID], [JobTitle] FROM [HumanResources].[Employee] e WHERE JobTitle LIKE ‘Design%’ |
- Дополнительные сведения об операторе LIKE см. по этой ссылке: SQL Like: введение и обзор логического оператора
Оператор IN также является очень распространенным оператором, в следующем примере показаны все сотрудники, чей Должность равна Техническому менеджеру или Старшему конструктору инструментов:
ВЫБЕРИТЕ [BusinessEntityID],JobTitle FROM [HumanResources]. WHERE JobTitle в («Инженерный менеджер», «Старший конструктор инструментов») |
 [Employee] e
[Employee] eЗапросы SQL с агрегатными функциями и оператором use или group by
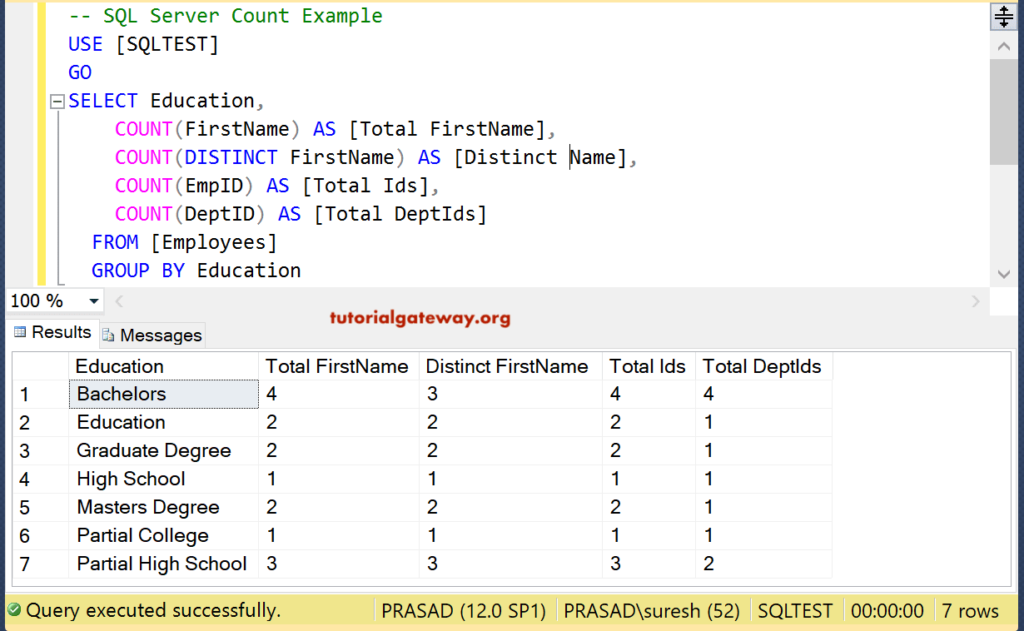
В запросах SQL нам нужна СУММА строк, среднее значение и другие функции агрегирования. Эти функции часто используются с операторами group by и have.
В первом примере будет показана сумма и среднее значение промежуточного итога таблиц SalesOrderHeader:
ВЫБРАТЬ СУММУ([Промежуточный итог]) КАК ПРОМЕЖУТОЧНЫЙ ИТОГ,СРЕДНИЙ([Промежуточный итог]) КАК СРЕДНИЙПромежуточный итог ИЗ [Продажи].[ЗаголовокЗаказаПродаж] |
В следующем примере показано, как получить сумму столбца orderQty и salesorderid из таблицы salesorderdetail. Мы группируем информацию по salesorderid и упорядочиваем сумму в порядке убывания:
SELECT SUM([OrderQty]) AS Qty, [SalesOrderID] FROM [Sales]. ГРУППИРОВАТЬ ПО [SalesOrderID] ORDER BY SUM([OrderQty]) DESC |
 [SalesOrderDetail]
[SalesOrderDetail]- Список агрегатных функций см. по этой ссылке: Агрегатные функции (Transact-SQL)
Запросы SQL для получения данных из нескольких таблиц
Одной из наиболее важных особенностей таблиц является то, что вы можете запрашивать несколько таблиц в одном запросе. Для этого мы используем СОЕДИНЕНИЯ. Существует несколько типов СОЕДИНЕНИЙ. ВНУТРЕННЕЕ СОЕДИНЕНИЕ, ВНЕШНЕЕ СОЕДИНЕНИЕ, ЛЕВОЕ СОЕДИНЕНИЕ, ПРАВОЕ СОЕДИНЕНИЕ. Различные типы объединений позволяют соединять таблицы другим способом.
- Для этих типов соединений мы создали специальную статью. Дополнительные сведения см. по следующей ссылке: Несколько объединений SQL для начинающих с примерами
Заключение
В этой статье мы изучили SQL-запросы, используемые в SQL Server для получения данных. Мы только что рассмотрели основы, но T-SQL — сложная работа, требующая больших знаний для обеспечения хорошей производительности. Тем не менее, мы изучили самые основные и полезные запросы.
Тем не менее, мы изучили самые основные и полезные запросы.
- Автор
- Последние сообщения
Даниэль Кальбимонте
Дэниел Кальбимонте — Microsoft Most Valuable Professional, Microsoft Certified Trainer и Microsoft Certified IT Professional for SQL Server. Он опытный автор SSIS, преподаватель ИТ-академий и имеет более чем 13-летний опыт работы с различными базами данных.
Он работал на правительство, нефтяные компании, веб-сайты, журналы и университеты по всему миру. Дэниел также регулярно выступает на конференциях и в блогах, посвященных SQL Server. Он пишет учебные материалы по SQL Server для сертификационных экзаменов.
Он также помогает с переводом статей SQLShack на испанский язык
Просмотреть все сообщения Даниэля Кальбимонте
Последние сообщения Даниэля Кальбимонте (посмотреть все)
Устранение неполадок запросов, которые, кажется, никогда не выполняются в SQL Server — SQL Server
Редактировать
Твиттер LinkedIn Фейсбук Электронная почта
- Статья
- 12 минут на чтение
В этой статье описываются действия по устранению неполадок, связанных с тем, что у вас есть запрос, который, кажется, никогда не завершается или его выполнение может занять много часов или дней.
Что такое бесконечный запрос?
В этом документе основное внимание уделяется запросам, которые продолжают выполняться или компилироваться, то есть их ЦП продолжает увеличиваться. Это не относится к запросам, которые заблокированы или ожидают на каком-либо ресурсе, который никогда не освобождается (ЦП остается постоянным или меняется очень мало).
Важная информация
Если запрос не завершен, он в конце концов завершится. Это может занять всего несколько секунд, а может занять несколько дней.
Термин «бесконечный» используется для описания восприятия незавершенного запроса, хотя на самом деле запрос в конечном итоге будет завершен.
Идентификация бесконечного запроса
Чтобы определить, выполняется ли запрос непрерывно или застрял на узком месте, выполните следующие действия:
Запустите следующий запрос:
DECLARE @cntr int = 0 ПОКА (@cntr < 3) НАЧИНАТЬ ВЫБЕРИТЕ ТОП 10 s. session_id,
р.статус,
r.wait_time,
r.wait_type,
r.wait_resource,
r.cpu_time,
r.logical_reads,
р.читает,
р.пишет,
r.total_elapsed_time / (1000 * 60) «Прошло M»,
ПОДСТРОКА (st.TEXT, (r.statement_start_offset / 2) + 1,
((СЛУЧАЙ r.statement_end_offset
КОГДА -1 ТОГДА ДЛИНА ДАННЫХ (СТ.ТЕКСТ)
ИНАЧЕ r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ Н'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
р.команда,
s.логин_имя,
s.имя_хоста,
s.имя_программы,
s.
session_id,
р.статус,
r.wait_time,
r.wait_type,
r.wait_resource,
r.cpu_time,
r.logical_reads,
р.читает,
р.пишет,
r.total_elapsed_time / (1000 * 60) «Прошло M»,
ПОДСТРОКА (st.TEXT, (r.statement_start_offset / 2) + 1,
((СЛУЧАЙ r.statement_end_offset
КОГДА -1 ТОГДА ДЛИНА ДАННЫХ (СТ.ТЕКСТ)
ИНАЧЕ r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ Н'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
р.команда,
s.логин_имя,
s.имя_хоста,
s.имя_программы,
s. last_request_end_time,
с.время_входа,
r.open_transaction_count,
atrn.name как имя_транзакции,
atrn.transaction_id,
atrn.transaction_state
ОТ sys.dm_exec_sessions КАК s
ПРИСОЕДИНЯЙТЕСЬ к sys.dm_exec_requests AS r ON r.session_id = s.session_id
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ sys.Dm_exec_sql_text(r.sql_handle) КАК st
LEFT JOIN sys.dm_tran_session_transactions stran ON stran.session_id =s.session_id
ПРИСОЕДИНЯЙТЕСЬ к sys.dm_tran_active_transactions КАК atrn ON stran.transaction_id = atrn.transaction_id
ГДЕ r.session_id != @@SPID
ЗАКАЗАТЬ ПО r.cpu_time DESC
НАБОР @управление = @управление + 1
ОЖИДАНИЕ ЗАДЕРЖКИ '00:00:05'
КОНЕЦ
last_request_end_time,
с.время_входа,
r.open_transaction_count,
atrn.name как имя_транзакции,
atrn.transaction_id,
atrn.transaction_state
ОТ sys.dm_exec_sessions КАК s
ПРИСОЕДИНЯЙТЕСЬ к sys.dm_exec_requests AS r ON r.session_id = s.session_id
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ sys.Dm_exec_sql_text(r.sql_handle) КАК st
LEFT JOIN sys.dm_tran_session_transactions stran ON stran.session_id =s.session_id
ПРИСОЕДИНЯЙТЕСЬ к sys.dm_tran_active_transactions КАК atrn ON stran.transaction_id = atrn.transaction_id
ГДЕ r.session_id != @@SPID
ЗАКАЗАТЬ ПО r.cpu_time DESC
НАБОР @управление = @управление + 1
ОЖИДАНИЕ ЗАДЕРЖКИ '00:00:05'
КОНЕЦ
Проверьте образец вывода.
Если вы наблюдаете вывод, аналогичный приведенному ниже, когда загрузка ЦП увеличивается пропорционально прошедшему времени и нет ожиданий, применяются шаги по устранению неполадок, описанные в этой статье.
идентификатор сеанса статус процессор_время логические_чтения время ожидания тип_ожидания 56 работает 7038 101000 0 НУЛЕВОЙ 56 работающий 12040 301000 0 НУЛЕВОЙ 56 работает 17020 523000 0 НУЛЕВОЙ Если вы наблюдаете сценарий ожидания, подобный следующему, когда ЦП не изменяется или изменяется очень незначительно, а сеанс ожидает ресурса, эта статья неприменима.
идентификатор сеанса статус процессор_время логические_чтения время ожидания тип_ожидания 56 подвесной 0 3 8312 LCK_M_U 56 подвесной 0 3 13318 LCK_M_U 56 подвесной 0 5 18331 LCK_M_U
Дополнительные сведения см.
 в разделе Диагностика ожиданий или узких мест.
в разделе Диагностика ожиданий или узких мест.
Длительное время компиляции
В редких случаях можно заметить, что загрузка ЦП постоянно увеличивается с течением времени. Это использование ЦП может быть вызвано чрезмерно длительной компиляцией (анализом и компиляцией запроса). В этих случаях проверьте выходной столбец transaction_name и найдите значение 9.0487 sqlsource_transform . Это имя транзакции указывает на компиляцию.
Сбор диагностических данных
- SQL Server 2008 — SQL Server 2014 (до SP2)
- SQL Server 2014 (после пакета обновления 2) и SQL Server 2016 (до пакета обновления 1)
- SQL Server 2016 (после SP1) и SQL Server 2017
- SQL Server 2019 и более поздние версии
Чтобы собрать диагностические данные с помощью SQL Server Management Studio (SSMS), выполните следующие действия:
Захватите предполагаемый план выполнения запроса в формате XML.

Просмотрите план запроса, чтобы увидеть, есть ли какие-либо явные признаки того, откуда может исходить медлительность. Типичные примеры включают:
- Сканирование таблиц/индексов (просмотр оценочных строк)
- Вложенные циклы, управляемые огромным набором данных внешней таблицы
- Вложенные циклы с большим ответвлением на внутренней стороне цикла
- Настольные катушки
- Функции в списке SELECT, которым требуется много времени для обработки каждой строки
Если запрос выполняется быстро в любое время, вы можете зафиксировать «быстрые» выполнения Actual XML Execution Plan для сравнения.
Метод просмотра собранных планов
В этом разделе показано, как просматривать собранные данные. Он будет использовать несколько планов запросов XML (с расширением * .sqlplan ), собранных в SQL Server 2016 SP1 и более поздних сборках и версиях.
Чтобы сравнить планы выполнения, выполните следующие действия:
Открытие ранее сохраненного файла плана выполнения запроса ( .
 sqlplan ).
sqlplan ).Щелкните правой кнопкой мыши пустую область плана выполнения и выберите Сравнить Showplan .
Выберите второй файл плана запроса, который вы хотите сравнить.
Ищите толстые стрелки, указывающие на большое количество строк, передаваемых между операторами. Затем выберите оператор до или после стрелки и сравните число фактическое строк в двух планах.
Сравните второй и третий планы, чтобы увидеть, происходит ли самый большой поток строк в одних и тех же операторах.
Вот пример:
Разрешение
Убедитесь, что статистика обновлена для таблиц, используемых в запросе.
Найдите отсутствующую рекомендацию по индексу в плане запроса и примените любую.
Перепишите запрос с целью его упрощения:
- Используйте более избирательные предикаты
WHERE, чтобы уменьшить количество обрабатываемых данных.
- Разбейте его на части.
- Выберите некоторые части во временные таблицы и соедините их позже.
- Удалить
TOP,EXISTSиFAST(T-SQL) в запросах, которые выполняются в течение очень долгого времени из-за цели строки оптимизатора. Для получения дополнительной информации см. раздел Цели строки стали мошенническими. - Избегайте использования общих табличных выражений (CTE) в таких случаях, поскольку они объединяют операторы в один большой запрос.
- Используйте более избирательные предикаты
Попробуйте использовать подсказки для составления лучшего плана:
- Подсказка HASH JOIN или MERGE JOIN
- ПОДСКАЗКА ПРИНУДИТЕЛЬНОГО ЗАКАЗА
- Подсказка FORCESEEK
- ПЕРЕСОБРАТЬ
- ИСПОЛЬЗУЙТЕ
PLAN N', если у вас есть план быстрого запроса, который вы можете форсировать'
Используйте хранилище запросов (QDS) для принудительного применения хорошо известного плана, если такой план существует и если ваша версия SQL Server поддерживает хранилище запросов.
Диагностика ожиданий или узких мест
Этот раздел включен сюда в качестве справки на тот случай, если ваша проблема не связана с длительным запросом, нагружающим ЦП. Вы можете использовать его для устранения неполадок в запросах, длительных из-за ожидания.
Чтобы оптимизировать запрос, ожидающий узких мест, определите, как долго длится ожидание и где находится узкое место (тип ожидания). После подтверждения типа ожидания уменьшите время ожидания или полностью отмените ожидание.
Чтобы рассчитать приблизительное время ожидания, вычтите время процессора (рабочее время) из времени, прошедшего с момента запроса. Как правило, процессорное время — это фактическое время выполнения, а оставшаяся часть времени жизни запроса приходится на ожидание.
Примеры расчета приблизительной продолжительности ожидания:
| Прошедшее время (мс) | Время процессора (мс) | Время ожидания (мс) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
Определите узкое место или подождите
Чтобы определить исторические запросы с длительным ожиданием (например, >20% общего затраченного времени приходится на время ожидания), выполните следующий запрос.
 Этот запрос использует статистику производительности для кэшированных планов запросов с момента запуска SQL Server.
Этот запрос использует статистику производительности для кэшированных планов запросов с момента запуска SQL Server.ВЫБЕРИТЕ т.текст, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count КАК avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count КАК среднее_время_ожидания, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time ИЗ sys.dm_exec_query_stats qs CROSS применить sys.Dm_exec_sql_text (sql_handle) t ГДЕ (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0,2 ЗАКАЗАТЬ ПО qs.total_elapsed_time / qs.execution_count DESCЧтобы определить выполняющиеся в данный момент запросы с ожиданием более 500 мс, выполните следующий запрос:
ВЫБРАТЬ r.
 session_id, r.wait_type, r.wait_time AS wait_time_ms
ИЗ sys.dm_exec_requests r
ПРИСОЕДИНЯЙТЕСЬ к sys.dm_exec_sessions s ON r.session_id = s.session_id
ГДЕ время_ожидания> 500
И is_user_process = 1
session_id, r.wait_type, r.wait_time AS wait_time_ms
ИЗ sys.dm_exec_requests r
ПРИСОЕДИНЯЙТЕСЬ к sys.dm_exec_sessions s ON r.session_id = s.session_id
ГДЕ время_ожидания> 500
И is_user_process = 1
Если вы можете собрать план запроса, проверьте WaitStats в свойствах плана выполнения в SSMS:
- Выполнить запрос с Включить фактическое выполнение Планировать дальше.
- Щелкните правой кнопкой мыши самого левого оператора на вкладке План выполнения
- Выберите Свойства , а затем свойство WaitStats .
- Проверьте WaitTimeMs и WaitType .
Если вы знакомы со сценариями PSSDiag/SQLdiag или SQL LogScout LightPerf/GeneralPerf, рассмотрите возможность использования любого из них для сбора статистики производительности и выявления ожидающих запросов в вашем экземпляре SQL Server.