Кому нужен SQL? Оказывается, всем. А зачем?
Бизнесмены, госкорпорации, государственные органы, все стремятся использовать как можно больше высоких технологий для достижения поставленных целей. Ну буквально всё, что возможно, хочется автоматизировать: бухгалтерский и управленческий учет, финансы и логистику, транспорт и продажи. На высокооплачиваемые должности привлекают специалистов подкованных в современных технологиях.
Предпочтение отдается тем сотрудникам, которые за короткий срок могут обработать большой объем информации. Потому что своевременная и точная информация стоит дорого. Современные технологии убегают от вас далеко вперед? Но на самом деле ещё есть время наверстать упущенное и получить для себя отличные перспективы карьерного роста. Востребованными становятся новые специальности, даже освобождается время на то, о чем раньше вы задумывались только вскользь — переобучение.
Мы уже рассказывали о профессиях, в которых можно успешно развиваться на сегодняшний день.
SQL (ЭсКуЭль) — это и язык для программистов и мощный инструмент для всех специалистов, которым требуется анализировать и обрабатывать информацию из баз данных. Продвинутые аналитики, финансисты, экономисты и даже бухгалтеры или товароведы учат SQL.
SQL — следующая ступень эволюции после общеизвестных программ Excel и Access. Но это не программа, это язык запросов, которые понимают другие приложения и базы данных в целом.
На примере Excel можно объяснить работу SQL запросов
Информация о продажах, закупках, бухгалтерских проводках хранится в связанных между собой таблицах (например, таких как база 1С или база данных вашей товароучетной программы).
Данные имеют свои идентификаторы (id). Благодаря этому вся информация структурирована не в одной громоздкой таблице, а в множестве маленьких и «легких», связанных между собой особенными отношениями таблиц. Таким образом уменьшается объем файла с информацией. Он занимает меньше места на диске, время выполнения запросов сокращается, система работает быстрее.
Таким образом уменьшается объем файла с информацией. Он занимает меньше места на диске, время выполнения запросов сокращается, система работает быстрее.
На языке SQL пишутся специальные запросы (так называемые SQL инструкции) к базе данных с целью получения данных или для манипулирования ими.
Задав правильный запрос к базам, вы можете создавать таблицы, извлекать данные, удалять, фильтровать и т.п.
Плюсы SQL запросов:
- используются на международном уровне;
- инструменты SQL внедрены во все пакетные решения;
- SQL имеет поддержку во всех языках программирования;
- все системы управления базами данных (Oracle Database, Interbase, Firebird, Microsoft SQL Server, PostgreSQL) понимают SQL ;
- запросы открывают доступ к базе данных для разных аналитиков;
- находят ответы на непредсказуемые запросы руководства (это значит, что не нужно будет покупать новое приложение для решения новых и нестандартных задач).
Жизненная необходимость SQL инструментов
SQL активно используется при работе специалистами разных сфер. Например, маркетологами (чтобы реклама била точно в цель) или журналистами, стремящимися подкрепить свои статьи фактами.
Но он также нужен экономисту банка или торговой сети, который хочет стать ведущим аналитиком. Т.е. первая причина для освоения — карьерный рост.
Когда страничек в книге Excel уже не хватает, фильтрация, поиск и обработка занимает все рабочее время аналитиков — значит бизнес достаточно масштабирован и готов общаться на языке программирования. Масштабирование бизнеса — еще одна из причин для привлечения экономистов со знанием SQL.
В растущей компании объем данных увеличивается в геометрической прогрессии, чтобы информацию обработать и не потерять, да еще и проанализировать требуются финансовые аналитики, умеющие говорить на SQL.
В экселе можно долго и упорно настраивать фильтры, сортировать, но на специальном языке запросов компьютер вас поймет быстрее и точнее.
Простые ответы на сложные вопросы с помощью SQL
В огромной сети магазинов, типа Ашан, товаровед решает, сколько товаров нужно заказать у поставщиков для выполнения текущих заказов. Для решения потребуется выполнить множество расчетов: нужно посчитать остатки товара с учетом нормы запаса, посчитать дефицит товара, вывести название продукта и название поставщика. Такую многошаговую задачу решают SQL-запросы.
Для экономиста базы данных выведут список чеков за выбранный день дороже или дешевле нужной суммы и покажут, на каких кассах их пробили.
Финансовый аналитик с помощью SQL получает правильные исходные данные для построения дальнейших гипотез развития бизнеса. Он сможет верно определить причинно-следственных связи в поведении исследуемых реалий.
Можно долго перечислять возможности вашей базы данных после внедрения SQL-запросов, быстрее научиться и решать непосредственно свои задачи.
Как освоить SQL
Приятная новость в том, что в изучении SQL нет ничего сложного, это быстро, а синтаксис запросов прост и понятен.
Исторически SQL создавали, как инструмент для отбора и управления данными, которые закопаны в связанных таблицах. Перед создателями стояла цель — разработать эффективный и простой инструмент. Он должен быть понятен тем, кто не разбирается в языках программирования. Сегодня операторами SQL-запросов могут быть и экономисты, и бухгалтера, и финансисты, даже товароведы и другие специалисты.
Если вы отлично ладите с таблицами Excel, у вас хорошие шансы быстро освоить SQL. Даже если знаний по Excel не хватает, есть специализированные курсы, которые помогут быстро получить нужные навыки.
Чтобы развиваться по специальности экономиста или финансиста, нужны курсы и тренинги по языку SQL. Владение средствами поиска и анализа данных — это то что отличает настоящего аналитика, от обычного экономиста.
Изучив новый язык запросов, вы никогда не останетесь без работы в современном технологичном мире. Наоборот получите шансы подняться вверх по карьерной лестнице или даже выйти на международный уровень.
Истории выпускников Нетологии
Арсений Сова, выпускник курсов по аналитике в Нетологии:
Я работал менеджером проектов долгое время — своя команда, разработка различных программных решений, спектр задач довольно широкий. Потом решил с головой уйти в переквалификацию в менеджера продукта, и посчитал, что скилы аналитика подтянуть нужно. Соответственно оказался в Нетологии и изучал SQL. Для менеджера продукта он нужен как воздух — чем крупнее компания, тем сильнее.
Самое крутое в SQL — это его простота, гибкость, и очень низкий порог входа. Появление clickhouse вдохнуло в sql жизнь, в СНГ особенно. Самое главное — простота получения данных, как для дальнейшего анализа, так и для первичного знакомства с данными.
Например, исследование активности пользователей на проекте; исследования аудитории; получение данных для первичного анализа. Частая история, что менеджер продукта готовит отчетность, и соответственно, данные как-то собирать нужно. Даже проведение А/Б-тестирование — это все начинается с SQL.
Даже проведение А/Б-тестирование — это все начинается с SQL.
Да и вообще, подводя итог, без SQL, на мой взгляд, никуда, уже скоро требование знаний по excel станет для всех — смех-смехом, все чаще вижу, что нужно знание sql, хотя бы на базовом уровне.
Роман Крапивин, руководитель проектов компании ООО «ИНТЭК» и выпускник курсов по аналитике в Нетологии:
Я работаю в строительном секторе руководителем проектов. За последние 3 года мы реализовали три крупных проекта на территории Москвы в сфере гражданского строительства.
И я пошёл на курс SQL по нескольким причинам. Во-первых, данный инструмент является одним из самых важных в арсенале аналитика в современном мире. На мой взгляд, не зная SQL, невозможно в дальнейшем развиваться как аналитик.
Во-вторых, во многих современных компаниях, которые работают с большим объемом информации (большими данными) требуют знания SQL. Так как в дальнейшем я хочу развиваться в финансовой сфере или сфере ритейла, знание данного инструмента просто необходимо для меня.
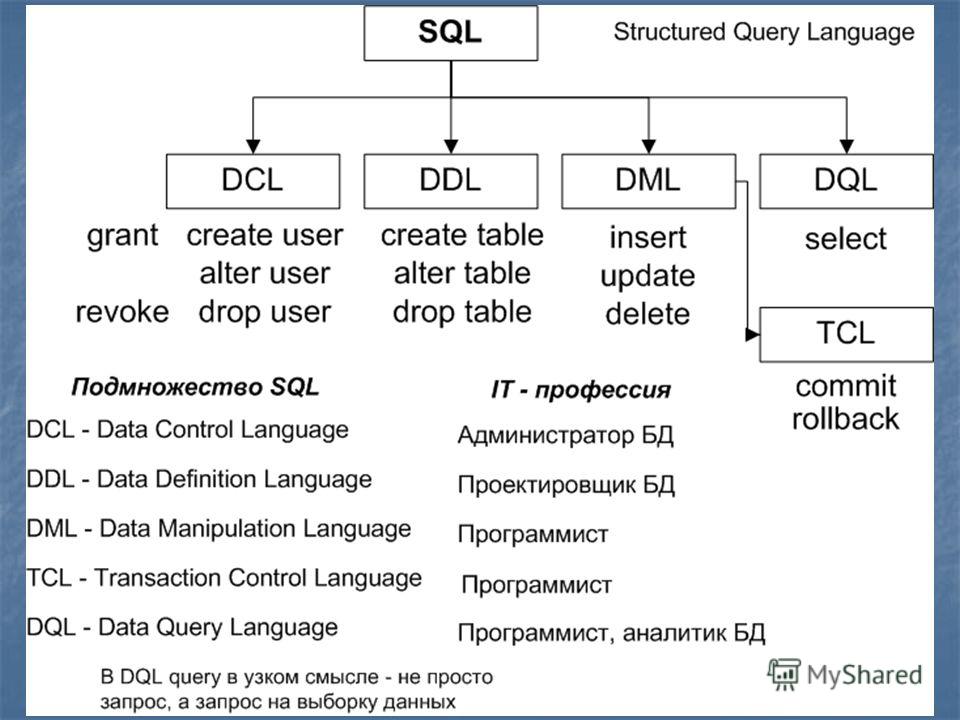
В чем разница между SQL, PL-SQL и T-SQL? – 6 Ответов
SQL
SQL используется для связи с базой данных, это стандартная язык для реляционных систем управления базами данных.
Подробнее Язык структурированных запросов — это специальный язык программирования, предназначенный для управления данными, хранящимися в системе управления реляционными базами данных (RDBMS), или для обработки потока в системе управления реляционными потоками данных (RDSMS).
Первоначально, основываясь на реляционной алгебре и реляционном исчислении кортежей, SQL состоит из языка определения данных и языка обработки данных. Объем SQL включает в себя вставку данных, запрос, обновление и удаление, создание и изменение схемы и контроль доступа к данным. Хотя SQL часто описывается как, и в значительной степени это декларативный язык (4GL), он также включает процедурные элементы.
PL/SQL
PL/SQL представляет собой комбинацию SQL наряду с процедурной характеристикой языков программирования.
Особенности PL/SQL
- полностью портативная высокопроизводительная обработка транзакций язык.
- предоставляет встроенное интерпретируемое и независимое от ОС программирование окружающая среда.
- напрямую вызывается из интерфейса командной строки SQL * Plus.
- Прямой вызов также может быть сделан из внешних вызовов языка программирования к базе данных.
- общий синтаксис основан на программировании ADA и Pascal язык.
- Помимо Oracle, он доступен в базе данных TimesTen in-memory и IBM DB2.
T-SQL
Short для Transaction-SQL, расширенная форма SQL, которая добавляет объявленные переменные, управление транзакциями, обработку ошибок и обработки исключений и обработку строк в SQL
Язык структурированных запросов или SQL — это язык программирования, который фокусируется на управлении реляционными базами данных. У SQL есть свои ограничения, которые подтолкнули гигантский программный гигант Microsoft к построению поверх SQL с их собственными расширениями, чтобы улучшить функциональность SQL.
Microsoft добавила код в SQL и назвала его Transact-SQL или T-SQL. Имейте в виду, что T-SQL является проприетарным и находится под контролем Microsoft, в то время как SQL, хотя и разработанный IBM, уже является открытым форматом.
У SQL есть свои ограничения, которые подтолкнули гигантский программный гигант Microsoft к построению поверх SQL с их собственными расширениями, чтобы улучшить функциональность SQL.
Microsoft добавила код в SQL и назвала его Transact-SQL или T-SQL. Имейте в виду, что T-SQL является проприетарным и находится под контролем Microsoft, в то время как SQL, хотя и разработанный IBM, уже является открытым форматом.
T-SQL добавляет ряд функций, недоступных в SQL.
Это включает в себя процедурные элементы программирования и локальную переменную, чтобы обеспечить более гибкое управление потоком приложения. В T-SQL был добавлен ряд функций, чтобы сделать его более мощным; функции для математических операций, строковых операций, обработки даты и времени и т.п. Эти дополнения делают T-SQL совместимым с тестом на полноту Turing, который определяет универсальность языка вычислений. SQL не является полным Turing и очень ограничен в рамках того, что он может сделать.
Еще одна существенная разница между T-SQL и SQL — это изменения, сделанные для команд DELETE и UPDATE, которые уже доступны в SQL. С помощью T-SQL команды DELETE и UPDATE позволяют включить предложение FROM, которое позволяет использовать JOIN. Это упрощает фильтрацию записей, чтобы легко выбирать записи, соответствующие определенным критериям, в отличие от SQL, где это может быть немного сложнее.
Выбор между T-SQL и SQL зависит от пользователя. Тем не менее, использование T-SQL по-прежнему лучше, когда вы имеете дело с установками Microsoft SQL Server. Это связано с тем, что T-SQL также принадлежит Microsoft, и использование двух вместе максимизирует совместимость. SQL предпочитают люди, у которых есть несколько бэкэндов.
Ссылки , Википедия , Учебные очки : Www.differencebetween.com
3.3. Хранимые функции Transact-SQL — Transact-SQL В подлиннике : Персональный сайт Михаила Флёнова
С SQL Server вы можете создавать ваши собственные функции, добавляющие и расширяющие функции, предоставляемые системой. Функции могут получать 0 или более параметров и возвращать скалярное значение или таблицу. Входные параметры могут быть любого типа, исключая timestamp, cursor, table.
Функции могут получать 0 или более параметров и возвращать скалярное значение или таблицу. Входные параметры могут быть любого типа, исключая timestamp, cursor, table.
Сервер SQL поддерживает три типа функций определенных пользователем:
- Скалярные функции – похожи на встроенные функции;
- Функция, возвращающая таблицу — возвращает результат единичного оператора SELECT. Он похож на объект просмотра, но имеет большую эластичность благодаря использованию параметров, и расширяет возможности индексированного объекта просмотра;
- Многооператорная функция — возвращает таблицу созданную одним или несколькими операторами Transact-SQL, чем напоминает хранимые процедуры. В отличие от процедур, на такие функции можно ссылаться в WHERE как на объект просмотра.
3.3.1. Создание хранимой функции
Создание функций очень похоже на создание процедур и объектов просмотра. Недаром мы рассматриваем все эти темы в одной главе. Для создания функции используется оператор CREATE FUNCTION. В зависимости от типа, Объявление будет отличаться. Рассмотрим все три типа объявления.
В зависимости от типа, Объявление будет отличаться. Рассмотрим все три типа объявления.
Скалярная функция:
CREATE FUNCTION [ owner_name. ] function_name
( [ { @parameter_name [AS] scalar_parameter_data_type [ = default ] }
[ ,...n ] ] )
RETURNS scalar_return_data_type
[ WITH [ [,] ...n] ]
[ AS ]
BEGIN
function_body
RETURN scalar_expression
END
Функция, возвращающая таблицу:
CREATE FUNCTION [ owner_name. ] function_name
( [ { @parameter_name [AS] scalar_parameter_data_type [ = default ] }
[ ,...n ] ] )
RETURNS TABLE
[ WITH [ [,] ...n ] ]
[ AS ]
RETURN [ ( ] select-stmt [ ) ]
Многооператорные функции:
CREATE FUNCTION [ owner_name. ] function_name
( [ { @parameter_name [AS] scalar_parameter_data_type [ = default ] }
[ ,.. .n ] ] )
RETURNS @return_variable TABLE
[ WITH [ [,] ...n ] ]
[ AS ]
BEGIN
function_body
RETURN
END
::=
{ ENCRYPTION | SCHEMABINDING }
:: =
( { column_definition | table_constraint } [ ,...n ] )
.n ] ] )
RETURNS @return_variable TABLE
[ WITH [ [,] ...n ] ]
[ AS ]
BEGIN
function_body
RETURN
END
::=
{ ENCRYPTION | SCHEMABINDING }
:: =
( { column_definition | table_constraint } [ ,...n ] )
3.3.2. Скалярные функции в Transact-SQL
Давайте для примера создадим функцию, которая будет возвращать скалярное значение. Например, результат перемножение цены на количество указанного товара. Товар будет идентифицироваться по названию и дате, ведь мы договорились, что сочетание этих полей дает уникальность. Но будьте осторожны, при тестировании запроса, если в разделе 3.2.8 вы выполнили запрос на изменение данных и создали дубликаты покупок за 1.1.2005-го года.
Итак, посмотрим сначала на код создание скалярной функции:
CREATE FUNCTION GetSumm
(@name varchar(50), @date datetime)
RETURNS numeric(10,2)
BEGIN
DECLARE @Summ numeric(10,2)
SELECT @Summ = Цена*Количество
FROM Товары
WHERE [Название товара]=@name
AND Дата=@date;
RETURN @Summ
END
После оператора CREATE FUNCTION мы указываем имя функции. Далее, в скобках идут параметры, которые необходимо передать. Да, параметры должны передаваться через запятую в круглых скобках. В этом объявление отличается от процедур и эту разницу необходимо помнить.
Далее, в скобках идут параметры, которые необходимо передать. Да, параметры должны передаваться через запятую в круглых скобках. В этом объявление отличается от процедур и эту разницу необходимо помнить.
Далее указывается ключевое слово RETURNS, за которым идет описание типа возвращаемого значения. Для скалярной функции это могут быть любые типы (строки, числа, даты и т.д.).
Код, который должна выполнять функция пишется между ключевыми словами BEGIN (начало) и END (конец). В коде можно использовать любые операторы Transact-SQL, которые мы изучали ранее. Итак, объявление нашей функции в упрощенном виде можно описать следующим образом:
CREATE FUNCTION GetSumm (@name varchar(50), @date datetime) RETURNS numeric(10,2) BEGIN -- Код функции END
Между ключевыми словами BEGIN и END у нас выполняется следующий код:
-- Объявление переменной DECLARE @Summ numeric(10,2) -- Выполнение запроса на выборку суммы SELECT @Summ = Цена*Количество FROM Товары WHERE [Название товара]=@name AND Дата=@date; -- Возврат результата RETURN @Summ
В первой строке объявляется переменная @Summ. Она нужна для хранения промежуточного результата расчетов. Далее выполняется запрос SELECT, в котором происходит поиск строки по дате и названию товара в таблице товаров. В найденной строке перемножаются поля цены и количества, и результат записывается в переменную @Summ.
Она нужна для хранения промежуточного результата расчетов. Далее выполняется запрос SELECT, в котором происходит поиск строки по дате и названию товара в таблице товаров. В найденной строке перемножаются поля цены и количества, и результат записывается в переменную @Summ.
Обратите внимание, что в конце запроса стоит знак точки с запятой. Каждый запрос должен заканчиваться этим символом, но в большинстве примеров мы этим пренебрегали, но в функции отсутствие символа «;» может привести к ошибке.
В последней строке возвращаем результат. Для этого нужно написать ключевое слово RETURN, после которого пишется возвращаемое значение или переменная. В данном случае, возвращаться будет содержимое переменной @Summ.
Так как функция скалярная, то и возвращаемое значение должно быть скалярным и при этом соответствовать типу, описанному после ключевого слова RETURNS.
3.3.3. Использование функций
Как выполнить такую функцию? Да также, как и многие другие системные функции (например, GETDATE()). Например, следующий пример использует функцию в операторе SELECT:
Например, следующий пример использует функцию в операторе SELECT:
SELECT dbo.GetSumm('Картофель', '03.03.2005')
В этом примере, оператор SELECT возвращает результат выполнения функции GetSumm. Функция принадлежит пользователю dbo, поэтому перед именем я указал владельца. После имени в скобках должны быть перечислены параметры в том же порядке, что и при объявлении функции. В данном примере я запрашиваю затраты на картофель, купленный 3.3.2005.
Выполните следующий запрос и убедитесь, что он вернул тот же результат, что и созданная нами функция:
SELECT Цена*Количество FROM Товары WHERE [Название товара]='Картофель' AND Дата='03.03.2005'
Функции можно использовать не только в операторе SELECT, но и напрямую, присваивая значение переменной. Например:
DECLARE @Summ numeric(10,2)
SET @Summ=dbo.GetSumm('Картофель', '03.03.2005')
PRINT @Summ
В этом примере мы объявили переменную @Summ типа numeric(10,2). Именно такой тип возвращает функция. В следующей строке переменной присваивается результат выполнения Summ, с помощью SET.
Именно такой тип возвращает функция. В следующей строке переменной присваивается результат выполнения Summ, с помощью SET.
Давайте посмотрим, что произойдет, если передать функции такие параметры, при которых запрос функции вернет более одной строки. В нашей таблице товаров сочетание даты и название не дает уникальности, потому что мы ее нарушили. Первичного ключа в таблице также нет, и среди товаров у меня есть четыре строки, которые имеют свои точные копии. Это нарушает правило уникальности строк в реляционных базах, но очень наглядно показывает, что в реальной жизни нарушать его нельзя.
Итак, в моей таблице есть две покупки хлеба 1.1.2005-го числа. Попробую запросить у функцию сумму:
SELECT dbo.GetSumm('Хлеб', '01.01.2005')
Результатом будет только одно число, хотя строки две. А какую строку из двух вернул сервер? Никто точно сказать не может, потому что они обе одинаковые и без единого различия. Поэтому сервер скорей всего вернул первую из строк.
3.3.4. Функция, возвращающая таблицу
В следующем примере мы создаем функцию, которая будет возвращать в качестве результата таблицу. В качестве примера, создадим функцию, которая будет возвращать таблицу товаров, и для каждой строки рассчитаем произведение колонок количества и цены:
CREATE FUNCTION GetPrice()
RETURNS TABLE
AS
RETURN
(
SELECT Дата, [Название товара], Цена,
Количество, Цена*Количество AS Сумма
FROM Товары
)
Начало функции такое же, как у скалярной – указываем оператор CREATE FUNCTION и имя функции. Я специально создал эту функцию без параметров, чтобы вы увидели, как это делается. Не смотря на то, что параметров нет, после имени должны идти круглые скобки, в которых не надо ничего писать. Если не указать скобок, то сервер вернет ошибку и функция не будет создана.
Разница есть и в секции RETURNS, после которой указывается тип TABLE, что говорит о необходимости вернуть таблицу. После этого идет ключевое слово AS и RETURN, после которого должно идти возвращаемое значение. Для функции данного типа в секции RETURN нужно в скобках указать запрос, результат которого и будет возвращаться функцией.
После этого идет ключевое слово AS и RETURN, после которого должно идти возвращаемое значение. Для функции данного типа в секции RETURN нужно в скобках указать запрос, результат которого и будет возвращаться функцией.
Когда пишете запрос, то все его поля должны содержать имена. Если одно из полей не имеет имени, то результатом выполнения оператора CREATE FUNCTION будет ошибка. В нашем примере последнее поле является результатом перемножения полей «Цена» и «Количество», а такие поля не имеют имени, поэтому мы его задаем с помощью ключевого слова AS.
Посмотрим, как можно использовать такую функцию с помощью оператора SELECT:
SELECT * FROM GetPrice()
Так как мы используем простой оператор SELECT, то мы можем и ограничивать вывод определенными строками, с помощью ограничений в секции WHERE. Например, в следующем примере выбираем из результата функции только те строки, в которых поле «Количество» содержит значение 1:
SELECT * FROM GetPrice() WHERE Количество=1
Функция возвращает в качестве результата таблице, которую вы можете использовать как любую другую таблицу базы данных. Давайте создадим пример в котором можно будет увидеть использование функции в связи с таблицами. Для начала создадим функцию, которая будет возвращать идентификатор работников таблицы tbPeoples и объединенные в одно поле ФИО:
Давайте создадим пример в котором можно будет увидеть использование функции в связи с таблицами. Для начала создадим функцию, которая будет возвращать идентификатор работников таблицы tbPeoples и объединенные в одно поле ФИО:
CREATE FUNCTION GetPeoples() RETURNS TABLE AS RETURN ( SELECT idPeoples, vcFamil+' '+vcName+' '+vcSurName AS FIO FROM tbPeoples )
Функция возвращает нам идентификатор строки, с помощью которого мы легко можем связать результат с таблицей телефонов. Попробуем сделать это с помощью простого SQL запроса:
SELECT * FROM GetPeoples() p, tbPhoneNumbers pn WHERE p.idPeoples=pn.idPeoples
Как видите, функции, возвращающие таблицы очень удобны. Они больше, чем процедуры похожи на объекты просмотра, но при этом позволяют принимать параметры. Таким образом, можно сделать так, чтобы сама функция возвращала нам только то, что нужно. Вьюшки такого не могут делать по определению. Чтобы получить нужные данные, вьюшка должна выполнить свой SELECT запрос, а потом уже во внешнем запросе мы пишем еще один оператор SELECT, с помощью которого ограничивается вывод до необходимого. Таким образом, выполняется два запроса SELECT, что для большой таблицы достаточно накладно. Функция же может сразу вернуть только то, что нужно.
Чтобы получить нужные данные, вьюшка должна выполнить свой SELECT запрос, а потом уже во внешнем запросе мы пишем еще один оператор SELECT, с помощью которого ограничивается вывод до необходимого. Таким образом, выполняется два запроса SELECT, что для большой таблицы достаточно накладно. Функция же может сразу вернуть только то, что нужно.
Рассмотрим пример, функция GetPeoples у нас возвращает все строки таблицы. Чтобы получить только нужную фамилию, нужно писать запрос типа:
SELECT * FROM GetPeoples() WHERE FIO LIKE 'ПОЧЕЧКИН%'
В этом случае будут выполняться два запроса: этот и еще один внутри функции. Но если передавать фамилию в качестве параметра в функцию и там сделать секцию WHERE, то можно обойтись и одним запросом SELECT:
CREATE FUNCTION GetPeoples1(@Famil varchar(50)) RETURNS TABLE AS RETURN ( SELECT idPeoples, vcFamil+' '+vcName+' '+vcSurName AS FIO FROM tbPeoples WHERE vcFamil=@Famil )
3. 3.5. Много операторная функция возвращающая таблицу
3.5. Много операторная функция возвращающая таблицу
Все функции, созданные в разделе 3.3.5 могут возвращать таблицу, сгенерированную только одним оператором SQL. А как же тогда сделать возможность выполнять несколько операций? Например, вы можете захотеть выполнять дополнительные проверки входных параметров для обеспечения безопасности. Проверки лишними не бывает, особенно входных данных и особенно, если эти входные данные указываются пользователем.
Следующий пример показывает, как создать функцию, которая может вернуть в качестве результата таблицу, и при этом, в теле функции могут выполняться несколько операторов:
CREATE FUNCTION имя (параметры) RETURNS имя_переменной TABLE (описание вида таблицы, в которой будет представлен результат) AS BEGIN Выполнение любого количества операций RETURN END
Это упрощенный вид создания процедуры. Более полный вид мы рассматривали в начале главы, а сейчас я упростил объявление, чтобы проще было его разбирать.
Объявление больше похоже на создание скалярных функций. Первая строка без изменений. В секции RETURNS объявляется переменная, которая имеет тип TABLE. После этого, в скобках нужно описать поля результирующей таблицы. После ключевого слова AS идtт пара операторов BEGIN и END, между которыми может выполняться какое угодно количество операций. Выполнение операций заканчивается ключевым словом RETURN.
Вот тут есть одно отличие от скалярных функций – после RETURN мы указывали имя переменной, значение которой должно стать результатом. В данном случае ничего указывать не надо. Мы уже объявили переменную в секции RETURNS и описали формат этой переменной. В теле функции мы можем и должны наполнить эту переменную значениями и именно это попадет в результат.
Теперь посмотрим на пример создания функции:
CREATE FUNCTION getFIO () RETURNS @ret TABLE (idPeoples int primary key, vcFIO varchar(100)) AS BEGIN INSERT @ret SELECT idPeoples, vcFamil+' '+vcName+' '+vcSurName FROM tbPeoples; RETURN END
В данном примере в качестве результата объявлена переменная @ret, которая является таблицей из двух полей «idPeoples» типа int и «vcFIO» типа varchar длинной в 50 символов. В теле функции в эту таблицу записываются значения из таблицы tbPeoples и выполняется оператор RETURN, завершающий выполнение функции.
В теле функции в эту таблицу записываются значения из таблицы tbPeoples и выполняется оператор RETURN, завершающий выполнение функции.
В использовании, такая функция ничем не отличается от рассмотренных ранее. Например, следующий запрос выбирает все данные, которые возвращает функция:
SELECT * FROM GetFIO()
3.3.6. Опции функций
При создании функций могут использоваться следующие опции SCHEMABINDING (привязать к схеме) и/или ENCRYPTION (шифровать текст функции). Если вторая опция нам уже известна по вьюшкам и процедурам (позволяет шифровать исходный код функции в системных таблицах), то вторая встречается впервые, но при этом предоставляет удобное средство защиты данных.
Если функция создана с опцией SCHEMABINDING, то объекты базы данных, на которые ссылается функция, не могут быть изменены (с использованием оператора ALTER) или удалены (с помощью оператора DROP). Например, следующая функция использует таблицу tbPeoples и при этом используется опция SCHEMABINDING:
CREATE FUNCTION GetPeoples2(@Famil varchar(50)) RETURNS TABLE WITH SCHEMABINDING AS RETURN ( SELECT idPeoples, vcFamil+' '+vcName+' '+vcSurName AS FIO FROM dbo.tbPeoples WHERE vcFamil=@Famil )
Функция может быть связанной со схемой, только если следующие ограничения истины:
- все функции объявленные пользователем и просмотрщики на которые ссылается функция, также связаны со схемой с помощью опции SCHEMABINDING;
- объекты, на которые ссылается функция, должны использовать имя из двух частей именования: owner.objectname. При создании функции GetPeoples2 ссылка на таблицу указана именно в таком формате – dbo.tbPeoples;
- Функция и объекты должны быть расположены в одной базе данных;
- Пользователь, который создает функцию, имеет право доступа ко всем объектам, на которые ссылается функция.
Создайте функцию и попробуйте после этого удалить таблицу tbPeoples.
DROP TABLE tbPeoples
В ответ на это сервер выдаст сообщение с ошибкой о том, что объект не может быть удален, из-за присутствия внешнего ключа. Даже если избавиться от ключа, удаление будет невозможно, потому что на таблицу ссылается функция, привязанная к схеме.
Чтобы увидеть сообщение без удаления ключа, давайте добавим к таблице колонку, а потом попробуем ее удалить:
-- Добавим колонку ALTER TABLE dbo.tbPeoples ADD vcTemp VARCHAR(30) NOT NULL default '' -- Попробуем ее удалить ALTER TABLE dbo.tbPeoples DROP COLUMN vcTemp
Создание пройдет успешно, а вот во время уда
SQL Server 2005. Программирование на T-SQL (Урок 8)
Программирование на T—SQL
Синтаксис и соглашения T-SQL
Правила формирования идентификаторов
Все объекты в SQL Server имеют имена (идентификаторы). Примерами объектов являются таблицы, представления, хранимые процедуры и т.д. Идентификаторы могут включать до 128 символов, в частности, буквы, символы _ @ $ # и цифры.
Первый символ всегда должен быть буквенным. Для переменных и временных таблиц используются специальные схемы именования. Имя объекта не может содержать пробелов и совпадать с зарезервированным ключевым словом SQL Server, независимо от используемого регистра символов. Путем заключения идентификаторов в квадратные скобки, в именах объектов можно использовать запрещенные символы.
Для переменных и временных таблиц используются специальные схемы именования. Имя объекта не может содержать пробелов и совпадать с зарезервированным ключевым словом SQL Server, независимо от используемого регистра символов. Путем заключения идентификаторов в квадратные скобки, в именах объектов можно использовать запрещенные символы.
Завершение инструкции
Стандарт ANSI SQL требует помещения в конце каждой инструкции точки с запятой. В то же время при программировании на языке T-SQL точка с запятой не обязательна.
Комментарии
Язык T-SQL допускает использование комментариев двух стилей: ANCI и языка С. Первый из них начинается с двух дефисов и заканчивается в конце строки:
— Это однострочный комментарий стиля ANSI
Также комментарии стиля ANSI могут вставляться в конце строки инструкции:
SELECT CityName – извлекаемые столбцы
FROM City – исходная таблица
WHERE IdCity = 1; — ограничение на строки
Редактор SQL может применять и удалять комментарии во всех выделенных строках. Для этого нужно выбрать соответствующие команды в меню Правка или на панели инструментов .
Комментарии стиля языка С начинаются с косой черты и звездочки (/*) и заканчиваются теми же символами в обратной последовательности. Этот тип комментариев лучше использовать для комментирования блоков строк, таких как заголовки или большие тестовые запросы.
/*
Пример
многострочного
комментария
*/
Одним из главных достоинств комментариев стиля С является то, что многострочные запросы в них можно выполнять, даже не раскомментируя.
Пакеты T-SQL
Запросом называют одну инструкцию T-SQL, а пакетом — их набор. Вся последовательность инструкций пакета отправляется серверу из клиентских приложений как одна цельная единица.
SQL Server рассматривает весь пакет как рабочую единицу. Наличие ошибки хотя бы в одной инструкции приведет к невозможности выполнения всего пакета. В то же время грамматический разбор не проверяет имена объектов и схем, так как сама схема может измениться в процессе выполнения инструкции.
Файл сценария SQL и окно анализатора запросов (Query Analyzer) может содержать несколько пакетов. В данном случае все пакеты разделяют ключевые слова терминаторов. По умолчанию этим ключевым словом является GO, и оно должно быть единственным в строке. Все другие символы (даже комментарии) нейтрализуют разделитель пакета.
Отладка T-SQL
Когда редактор SQL обнаруживает ошибку, он отображает ее характер и номер строки в пакете. Дважды щелкнув на ошибке, можно сразу же переместиться к соответствующей строке.
В утилиту Management Studio версии SQL Server 2005 не включен отладчик языка T-SQL, — он присутствует в пакете Visual Studio.
SQL Server предлагает несколько команд, облегчающих отладку пакетов. В частности, команда PRINT отправляет сообщение без генерации результирующего набора данных. Команду PRINT можно использовать для отслеживания хода выполнения пакета. Когда анализатор запросов находится в режиме сетки, выполните следующий пакет:
SELECT CityName
FROM City
WHERE IdCity = 1;
PRINT ‘Контрольная точка’;
Результирующий набор данных отобразится в сетке и будет состоять из одной строки. В то же время во вкладке «Сообщения» отобразится следующий результат:
(строк обработано: 1)
Контрольная точка
Переменные
Переменные T-SQL создаются с помощью команды DECLARE, имеющей следующий синтаксис:
DECLARE @Имя_Переменной Тип_Данных [,
@Имя_Переменной Тип_Данных, …]
Все имена локальных переменных должны начинаться символом @. Например, для объявления локальной переменной UStr, которая хранит до 16 символов Unicode, можно использовать следующую инструкцию:
Например, для объявления локальной переменной UStr, которая хранит до 16 символов Unicode, можно использовать следующую инструкцию:
DECLARE @UStr varchar(16)
Используемые для переменных типы данных в точности совпадают с существующими в таблицах. В одной команде DECLARE через запятую может быть перечислено несколько переменных. В частности в следующем примере создаются две целочисленные переменные a и b:
DECLARE
@a int,
@b int
Область определения переменных (т.е. срок их жизни) распространяется только на текущий пакет. По умолчанию только что созданные переменные содержат пустые значения NULL и до включения в выражения должны быть инициализированы.
Задание значений переменных
В настоящее время в языке SQL предусмотрены два способа задания значения переменной — для этой цели можно использовать оператор SELECT или SET.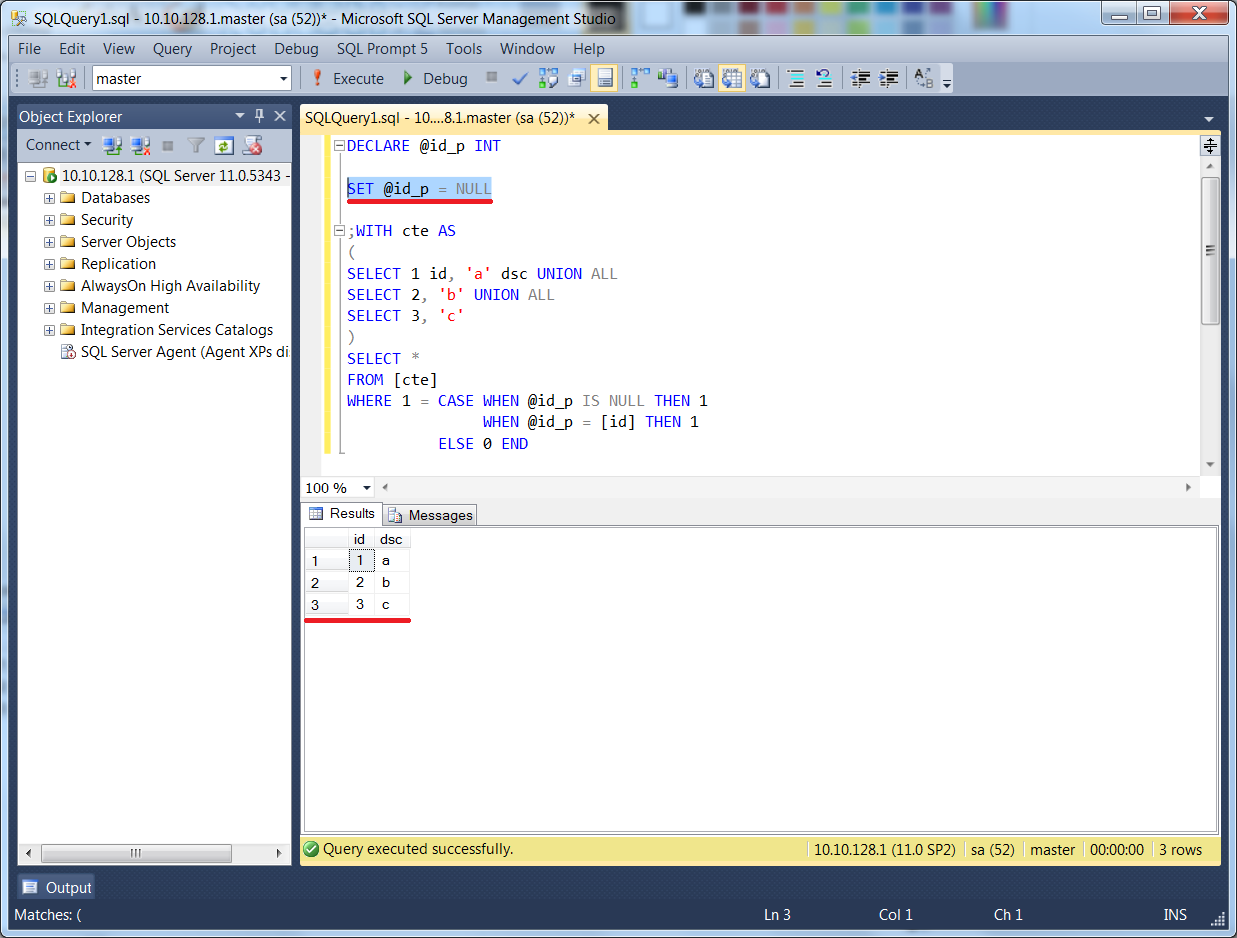 С точки зрения выполняемых функций эти операторы действуют почти одинаково, не считая того, что оператор SELECT позволяет получить исходное присваиваемое значение из таблицы, указанной в операторе SELECT.
С точки зрения выполняемых функций эти операторы действуют почти одинаково, не считая того, что оператор SELECT позволяет получить исходное присваиваемое значение из таблицы, указанной в операторе SELECT.
Оператор SET обычно используется для задания значений переменных в такой форме, какая более часто встречается в процедурных языках. В качестве типичных примеров применения этого оператора можно указать следующие:
SET @a = 1;
SET @b = @a * 1.5
Обратите внимание на то, что во всех этих операторах непосредственно осуществляются операции присваивания, в которых используются либо явно заданные значения, либо другие переменные. С помощью оператора SET невозможно присвоить переменной значение, полученное с помощью запроса; запрос должен быть выполнен отдельно и только после этого полученный результат может быть присвоен с помощью оператора SET. Например, попытка выполнения такого оператора вызывает ошибку:
DECLARE @c int
SET @c = COUNT(*) FROM City
SELECT @c
а следующий оператор выполняется вполне успешно:
DECLARE @c int
SET @c = (SELECT COUNT(*) FROM City)
SELECT @c
Оператор SELECT обычно используется для присваивания значений переменным, если источником информации, которая должна быть сохранена в переменной, является запрос. Например, действия, осуществляемые в приведенном выше коде, гораздо чаще реализуются с помощью оператора SELECT:
Например, действия, осуществляемые в приведенном выше коде, гораздо чаще реализуются с помощью оператора SELECT:
DECLARE @c int
SELECT @c = COUNT(*) FROM City
SELECT @c
Обратите внимание на то, что данный код немного понятнее (в частности, он более лаконичен, хотя и выполняет те же действия).
Таким образом, можно, сформулировать следующее общепринятое соглашение по использованию того и другого оператора.
Оператор SET используется, если должна быть выполнена простая операция присваивания значения переменной, т.е. если присваиваемое значение уже задано явно в форме определенного значения или в виде какой-то другой переменной.
- Оператор SELECT применяется, если присваивание значения переменной должно быть основано на запросе.
Использование переменных в запросах SQL
Одним из полезных свойств языка T-SQL является то, что переменные могут использоваться в запросах без необходимости создания сложных динамических строк, встраивающих переменные в программный код. Динамический SQL продолжает свое существование, но одиночное значение можно изменить проще — с помощью переменной.
Динамический SQL продолжает свое существование, но одиночное значение можно изменить проще — с помощью переменной.
Везде, где в запросе может использоваться выражение, может использоваться и переменная. В следующем примере продемонстрировано использование переменной в предложении WHERE:
DECLARE @IdProd int;
SET @IdProd = 1;
SELECT [Description]
FROM Product
WHERE IdProd = @IdProd;
Глобальные системные переменные
В SQL Server имеется более тридцати глобальных переменных, не имеющих параметров, которые определяются и поддерживаются системой. Все глобальные переменные имеют префикс в виде двух символов @. Вы можете извлечь значение любой из них с помощью простого запроса SELECT, как в следующем примере:
SELECT @@CONNECTIONS
Здесь используется глобальная переменная @@CONNECTIONS для извлечения количества подключений к SQL Server со времени запуска программы.
Среди наиболее часто применяемых системных переменных можно отметить следующие:
- @@ERROR — Содержит номер ошибки, возникшей при выполнении последнего оператора T-SQL в текущем соединении. Если ошибка не обнаружена, содержит 0. Значение этой системной переменной переустанавливается после выполнения каждого очередного оператора. Если требуется сохранить содержащееся в ней значение, то это значение следует переносить в локальную переменную сразу же после выполнения оператора, для которого должен быть сохранен код ошибки.
- @@IDENTITY — Содержит последнее идентификационное значение, вставленное в базу данных в результате выполнения последнего оператора INSERT. Если в последнем операторе INSERT не произошла выработка идентификационного значения, системная переменная @@IDENTITY содержит NULL. Это утверждение остается справедливым, даже если отсутствие идентификационного значения было вызвано аварийным завершением при выполнении оператора.
 А если с помощью одного оператора осуществляется несколько операций вставки, этой системной переменной присваивается только последнее идентификационное значение.
А если с помощью одного оператора осуществляется несколько операций вставки, этой системной переменной присваивается только последнее идентификационное значение. - @@ROWCOUNT — Одна из наиболее широко используемых системных переменных. Возвращает информацию о количестве строк, затронутых последним оператором. Обычно применяется для контроля ошибок, отличных от тех, которые относятся к категории ошибок этапа прогона программы. Например, если в программе обнаруживается, что после вызова на выполнение оператора DELETE с конструкцией WHERE количество затронутых строк равно нулю, то можно сделать вывод, что произошло нечто непредвиденное. После этого сообщение об ошибке может быть активизировано вручную.
! Следует отметить, что с версии SQL Server 2000 глобальные переменные принято называть функциями. Название глобальные сбивало пользователей с толку, позволяя думать, что область действия таких переменных шире, чем у локальных. Глобальным переменным часто ошибочно приписывалась возможность хранить информацию, независимо от того, включена она в пакет либо нет, что, естественно, не соответствовало действительности.
Глобальным переменным часто ошибочно приписывалась возможность хранить информацию, независимо от того, включена она в пакет либо нет, что, естественно, не соответствовало действительности.
Средства управления потоком команд. Программные конструкции
В языке T-SQL предусмотрена большая часть классических процедурных средств управления ходом выполнения программы, в т.ч. условная конструкция и циклы.
Оператор IF. . . ELSE
Операторы IF. . .ELSE действуют в языке T-SQL в основном так же, как и в любых других языках программирования. Общий синтаксис этого оператора имеет следующий вид:
IF Логическое выражение
SQL инструкция I BEGIN Блок SQL инструкций END
[ELSE
SQL инструкция | BEGIN Блок SQL инструкций END]
В качестве логического выражения может быть задано практически любое выражение, результат вычисления которого приводит к возврату булева значения.
Следует учитывать, что выполняемым по условию считается только тот оператор, который непосредственно следует за оператором IF (ближайшим к нему). Вместо одного оператора можно предусмотреть выполнение по условию нескольких операторов, объединив их в блок кода с помощью конструкции BEGIN…END.
В приведенном ниже примере условие IF не выполняется, что предотвращает выполнение следующего за ним оператора.
IF 1 = 0
PRINT ‘Первая строка’
PRINT ‘Вторая строка’
Необязательная команда ELSE позволяет задать инструкцию, которая будет выполнена в случае, если условие IF не будет выполнено. Подобно IF, оператор ELSE управляет только непосредственно следующей за ним командой или блоком кода заключенным между BEGIN…END.
Несмотря на то, что оператор IF выглядит ограниченным, его предложение условия может включать в себя мощные функции, подобно предложению WHERE. В частности это выражения IF EXISTS().
В частности это выражения IF EXISTS().
Выражение IF EXISTS() использует в качестве условия наличие какой-либо строки, возвращенной инструкцией SELECT. Так как ищутся любые строки, список столбцов в инструкции SELECT можно заменить звездочкой. Этот метод работает быстрее, чем проверка условия @@ROWCOUNT>0, потому что не требуется подсчет общего количества строк. Как только хотя бы одна строка удовлетворяет условию IF EXISTS(), запрос может продолжать выполнение.
В следующем примере выражение IF EXISTS используется для проверки наличия у клиента с кодом 1 каких-либо заказов перед удалением его из базы. Если по данному клиенту есть информация хотя бы по одному заказу, удаление не производится.
IF EXISTS(SELECT * FROM [Order] WHERE IdCust = 1)
PRINT ‘Невозможно удалить клиента поскольку в базе имеются связанные с ним записи’
ELSE
BEGIN
DELETE Customer
WHERE IdCust = 1
PRINT ‘Удаление произведено успешно’
END
Операторы WHILE, BREAK и CONTINUE
Оператор WHILE в языке SQL действует во многом так же, как и в других языках, с которыми обычно приходится работать программисту. По сути, в этом операторе до начала каждого прохода по циклу проверяется некоторое условие. Если перед очередным проходом по циклу проверка условия приводит к получению значения TRUE, осуществляется проход по циклу, в противном случае выполнение оператора завершается.
По сути, в этом операторе до начала каждого прохода по циклу проверяется некоторое условие. Если перед очередным проходом по циклу проверка условия приводит к получению значения TRUE, осуществляется проход по циклу, в противном случае выполнение оператора завершается.
Оператор WHILE имеет следующий синтаксис:
WHILE Логическое выражение
SQL инструкция I
[BEGIN
[BREAK]
Блок SQL инструкций
[CONTINUE]
END]
Безусловно, с помощью оператора WHILE можно обеспечить выполнение в цикле только одного оператора (по аналогии с тем, как обычно используется оператор IF), но на практике конструкции WHILE, за которыми не следует блок BEGIN. . .END, соответствующий полному формату оператора, встречаются редко.
Оператор BREAK позволяет немедленно выйти из цикла, не ожидая того, как будет выполнен проход до конца цикла и произойдет повторная проверка условного выражения.
Оператор CONTINUE позволяет прервать отдельную итерацию цикла. Кратко можно описать действие оператора CONTINUE так, что он обеспечивает переход в начало цикла WHILE. Сразу после обнаружения оператора CONTINUE в цикле, независимо от того, где он находится, происходит переход в начало цикла и повторное вычисление условного выражения (а если значение этого выражения больше не равно TRUE, осуществляется выход из цикла).
Следующий короткий сценарий демонстрирует использование оператора WHILE для создания цикла:
DECLARE @Temp int;
SET @Temp = 0;
WHILE @Temp < 3
BEGIN
PRINT @Temp;
SET @Temp = @Temp + 1;
END
Здесь в цикле целочисленная переменная @Temp увеличивается с 0 до 3 и на каждой итерации ее значение выводится на экран.
Оператор RETURN
Оператор RETURN используется для останова выполнения пакета, а следовательно, хранимой процедуры и триггера (рассматриваются в следующих лабораторных занятиях).
Еще записи по теме
Соединение строк SQL – CODE BLOG
В процессе работы я столкнулся с необходимостью объединения строк в базе данных. Казалось бы, это достаточно тривиальная задача, но не все так просто, как кажется на первый взгляд. Давайте подробнее рассмотрим различные методы конкатенации строк в SQL и те проблемы, с которыми я столкнулся.
Подпишись на группу Вконтакте и Телеграм-канал. Там еще больше полезного контента для программистов.
А на YouTube-канале ты найдешь обучающие видео по программированию. Подписывайся!
Оператор +
Наиболее простым методом объединения строк является использование обычного оператора +. При этом к первому аргументу будет добавлен второй. Например если мы возьмем слово «Чудо» и слово «Женщина» в результате получим строку «ЧудоЖенщина».
При этом к первому аргументу будет добавлен второй. Например если мы возьмем слово «Чудо» и слово «Женщина» в результате получим строку «ЧудоЖенщина».
SELECT 'чудо' + 'женщина' AS Result
Пока все просто, но это не то, что было мне нужно. Потому что, мне было нужно объединять большое количество значений, а делать это через знак + было не удобно. Давайте рассмотрим и другие способы конкатенации.
Функция CONCAT
Данная функция позволяет объединить все параметры, передаваемые в нее в качестве аргументов. Минимальное количество параметров два. Добавлю очень важное замечание, данная функция появилась в SQL Server начиная с 2012 версии. Это, кстати, принципиально. Потому что зачастую используются старые версии сервера, и вы не сможете использовать новые возможности языка. Всегда проверяйте, поддерживает ли ваша версия SQL сервера используемые возможности. Особенно при переносе с одного сервера на другой.
Работает данная функция аналогично оператору +. Например:
SELECT CONCAT('чудо','женщина') AS ResultНо этот вариант меня тоже не устраивал, потому что мне нужно было объединить результаты через запятую.
Функция CONCAT_WS
Данная функция позволяет конкатенировать строки через разделитель. Но ее основной проблемой, как и многих других, которые мы рассмотрим в дальнейшем, что она была добавлена только в версии SQL Server 2017, который пока практически нигде не используется. Первым параметром указывается разделитель, затем перечисляются параметры.
SELECT CONCAT_WS(' ', 'чудо','женщина') AS ResultТак как у меня используется SQL куда более старой версии, то воспользоваться я ей благополучно не смог… Поэтому пришлось начать куда более не стандартные функции для конкатенации.
Функция STAFF
Переходим к более сложным примерам, и для начала рассмотрим предметную область. У нас есть три таблицы, это Человек, Проект и Назначение. Все достаточно просто, обычная реализация связи многие к многим человека и проекта.
Если очень упростить, то задача состояла в том, чтобы вывести через запятую все проекты назначенные на человека. Сначала я попытался воспользоваться функцией STAFF. Рассмотрим элементарный, но бесполезный пример
Рассмотрим элементарный, но бесполезный пример
SELECT
STUFF(
(SELECT ';' + proj.Name
FROM Project AS proj
FOR XML PATH (''))
, 1, 1, '') AS Projects
FROM Assignment AS assignЗдесь, в подзапросе мы получаем все элементы таблицы Project, и соединяем их через точку с запятой, начиная именно с точки запятой, а затем просто удаляем первый символ (как раз не нужную точку с запятой). И выводим для каждого назначения.
Но когда я захотел сгруппировать результаты по идентификатору пользователя с помощью GROUP BY я узнал, что сделать этого не смогу, так как STAFF не является агрегирующей функцией. Поэтому пошел дальше изучать просторы интернета.
Функция STRING_AGG
Отличная функция которая полностью решила все мои проблемы. За исключением одного, она появилась в SQL Server 2017, поэтому оказалась хоть и очень хорошей, но бесполезной
SELECT assign.PersonId,
STRING_AGG (proj.Name, ',') AS Projects
FROM Assignment AS assign
LEFT JOIN Project AS proj ON assign. ProjectId = proj.Id
GROUP BY assign.PersonId
ProjectId = proj.Id
GROUP BY assign.PersonIdФункция GROUP_CONCAT
Ну и наконец самое сладкое. Не найдя ни одной подходящей конкатенирующей агрегирующей функции, я нашел возможность с помощью кастомной агрерирующей функции. Есть проект на github orlando-colamatteo/ms-sql-server-group-concat-sqlclr, который предоставляет готовый скрипт, который добавляет новую конкатенирующую функцию GROUP_CONCAT. Посмотрим пример.
SELECT assign.PersonId,
dbo.GROUP_CONCAT(proj.Name) AS Projects
FROM Assignment AS assign
LEFT JOIN Project AS proj ON assign.ProjectId = proj.Id
GROUP BY assign.PersonIdИменно благодаря этой функции я решил все свои проблемы и выполнил поставленную задачу. Моя огромная благодарность ее создателю. Ну а теперь давайте рассмотрим процесс установки и что это вообще такое.
Установка GROUP_CONCAT в MS SQL Server
Для начала заходим на github и скачиваем проект. Распаковываем его в любую директорию. Заходим в папку D:\ms-sql-server-group-concat-sqlclr-master\GroupConcat\Installation Scripts и открываем файл GroupConcatInstallation. sql. Он уже практически готов к использованию. Единственно что нужно сделать, это изменить имя базы данных на используемое у вас.
sql. Он уже практически готов к использованию. Единственно что нужно сделать, это изменить имя базы данных на используемое у вас.
-- !! MODIFY TO SUIT YOUR TEST ENVIRONMENT !! USE GroupConcatTest /*МЕНЯТЬ ЗДЕСЬ!*/
Обратите внимание, что для выполнения вам потребуются права администратора на SQL Server. После этого вы сможете использовать данную агрегатную функцию в пределах базы данных. MS SQL Management Studio может подчеркивать функцию как ошибку, но не пугайтесь, он будет успешно работать.
Что такое SQL CLR?
SQL CLR это технология компании Microsoft, которая позволяет добавлять новый функционал в MS SQL Server 2005 и более поздних версий при помощи внедрения сборок написанных с помощью языков входящих в .NET, такие как VB.NET или C#.
С ее помощью предоставляется возможность создания пользовательских функций, типов данных, аргегатных функций, триггеров, хранимых процедур, написанных на высокопроизводительных языках. Благодаря этому можно значительно увеличить производительность, а также расширять функционал стандартного SQL. Пример можно изучить в статье на Habr.
Пример можно изучить в статье на Habr.
Соединение строк sql — Заключение
На этом у меня все. Надеюсь данный материал будет полезен. Но больше всего меня поражает то, что компания Microsoft ввела агрегирующую функцию конкатенации строк только в 2017 году…
Кроме того, рекомендую прочитать статью Работа с XML на языке C#. А также подписывайтесь на группу ВКонтакте, Telegram и YouTube-канал. Там еще больше полезного и интересного для программистов.
Похожее
Топ-10 лучших онлайн-редакторов SQL в 2020 году
Самые популярные онлайн-редакторы SQL в 2020 году:
Когда вы подписывались на любой веб-сайт или заполняли любую форму подписки, задумывались ли вы, где хранятся все эти данные?
или Вы когда-нибудь задумывались, как управлять этими веб-сайтами или данными в Интернете?
или Каков внутренний процесс для хранения, доступа, обработки и обновления данных в Интернете?
Что ж, я надеюсь, что если вы из области информатики, значит, вы знаете об этом лучше.
Что такое редактор SQL?
РедакторSQL позволяет администратору данных и веб-разработчику выполнять и выполнять запросы SQL. Эти редакторы помогают установить соединение с базой данных, где вы можете получать доступ, управлять и контролировать данные в базе данных.
РедакторSQL предоставляет вам самый простой и быстрый способ выполнить запрос, сохранить данные и проанализировать данные в базе данных. Если вы используете какой-либо редактор SQL, вы должны заранее знать, что такое SQL.Не зная, что такое SQL и почему он используется, вы не можете работать с ним.
Кроме того, при использовании любого редактора SQL имейте в виду, что данные, которые вы храните, доступ к базе данных чувствительны к регистру, но сам SQL не чувствителен к регистру.
Редактор SQL выполняет следующие функции:
- Вырезать, копировать, вставить, отменить, повторить и найти данные в базе данных.
- Создание объектов базы данных.

- Определение схемы и экземпляра базы данных.
- Отладка
- Проверка данных
- Выделение ключевых слов и мониторинг эффективности.
- Выход данного запроса или оператора.
- Анализ и управление пользователями.
Онлайн-редактор SQL
Онлайн-редакторы SQL изменили способ администрирования и управления данными в базе данных. Эти редакторы упростили работу веб-разработчиков по управлению и доступу к данным в любом месте и в любое время по мере необходимости.
Онлайн-редакторы легко доступны из любого браузера, подключенного к Интернету.Вам не нужно устанавливать какое-либо программное обеспечение или инструмент на локальный рабочий стол для создания или управления базой данных.
Можно сразу приступить к работе над онлайн-редактором SQL , достаточно:
- Откройте любой браузер на вашем компьютере.
- Найдите «Онлайн-редактор SQL» в поисковой системе.

- Откройте инструмент или редактор, над которым вы хотите поработать.
Но всегда помните, что использование онлайн-редакторов SQL может варьироваться в зависимости от их функциональности.Дело не в том, что все онлайн-редакторы работают одинаково. Некоторые из них могут иметь дополнительные функции и возможности, чем другие, в то время как некоторые редакторы могут иметь ограниченные функции.
Но все же возникает вопрос, зачем понадобился онлайн-редактор SQL?
Ну, есть много причин для перехода на онлайн-редактор SQL, и некоторые из них следующие:
- Вам не нужно загружать и устанавливать программное обеспечение на локальный компьютер. Вы можете легко получить доступ к этим редакторам и запустить их в браузере.Вам нужно только подключение к Интернету.
- Эти редакторы можно использовать или получить к ним доступ в любом месте в любое время из любого места. Так что просто не наткнитесь на программное обеспечение, установленное на вашем компьютере.
 Сделайте шаг и двигайтесь вперед в цифровом мире.
Сделайте шаг и двигайтесь вперед в цифровом мире. - Они легко интегрируются с базой данных за меньшее время.
- Многие онлайн-редакторы SQL предоставляют интерактивный интерфейс, такой как DRAG-DROP, для интуитивного использования.
- Он обеспечивает всестороннюю поддержку пользователей, поскольку они поддерживают все распространенные типы реляционных баз данных.
- Кроме того, он предоставляет своим пользователям информационные панели в реальном времени для мгновенного получения информации, отчетов и анализа.
- Отчеты, созданные с их помощью, можно легко отправить кому угодно через электронную почту, One Drive или Dropbox.
- Они не только экономят время, силы и деньги, но также помогают диверсифицировать ваш бизнес и достигать конкретных целей.
Функции онлайн-редактора SQL
# 1) Не ограничивается одной машиной
Если вы используете автономный редактор SQL и работаете над SQL, то, во-первых, вам необходимо установить программное обеспечение на свой компьютер. Теперь, если предположим, что вы хотите работать с другой машины, вам снова нужно установить то же программное обеспечение на этой машине.
Теперь, если предположим, что вы хотите работать с другой машины, вам снова нужно установить то же программное обеспечение на этой машине.
Но онлайн-редактор SQL позволяет легко и безопасно получать доступ к базе данных и управлять ею из любого веб-браузера.
# 2) Интерактивный пользовательский интерфейс
В отличие от других редакторов SQL, онлайн-редакторы более всеобъемлющие и интерактивные с прекрасным пользовательским интерфейсом. PhpMyAdmin — один из лучших подходящих примеров, так как у него отличный пользовательский интерфейс, вы можете делать все в одном месте.Вы можете создавать трехмерные диаграммы, создавать специальные отчеты SQL и планировать задания.
# 3) Поддержка различных платформ
Старый или мы можем сказать, что традиционные редакторы SQL были ограничены только платформой Windows. Новые онлайн-редакторы SQL поддерживают другие платформы, такие как Mac, Linux, Unix и т. Д. Таким образом, он просто работает и прогрессирует, без оправданий.
# 4) Безопасность и аутентификация
Хороший онлайн-редактор поддерживает высокий уровень безопасности и двухфакторную аутентификацию, так что пароли базы данных и имя пользователя или любые другие данные не будут доступны неавторизованному пользователю.
# 5) Универсальность
В автономном редакторе SQL необходимо также установить другие инструменты и функции для дополнительной функциональности и целостности. Но в онлайн-редакторе вам просто нужен браузер. Эти редакторы уже включают эти функции, и вам просто нужно получить к ним доступ с помощью любого браузера.
Самые популярные онлайн-редакторы SQL
Несмотря на то, что на рынке доступны различные типы инструментов SQL, вам необходимо оценить и выяснить, какой из них лучше всего подходит для каких обстоятельств.Некоторые инструменты предлагают высокую производительность с отличным интерфейсом и множеством функций, а некоторые в какой-то мере ограничены.
Давайте рассмотрим некоторые лучшие и лучшие редакторы SQL, доступные на рынке.
# 1) Редактор SQL Datapine
Datapine возник с целью дать менеджерам и лицам, принимающим решения, возможность эффективно генерировать аналитические данные и отчеты для управления своим бизнесом. Помимо этого, отчеты о KPI в datapine включают инструмент визуализации данных, который позволяет создавать представление данных таким образом, чтобы каждый пользователь мог их понять.
Кроме того, эти аналитические данные и отчеты могут быть легко опубликованы с помощью автоматизации в отчетах.
Характеристики
- Datapine — это инструмент SaaS BI, что означает, что к нему можно получить доступ в любое время из любого места.
- Помогает в создании содержательных трехмерных диаграмм, отчетов и аналитических данных в режиме реального времени.
- Легко настроить всего за 10 минут, и вы готовы к использованию.
- Автоматическая генерация кода и расширенное окно запроса SQL.
- Также доступна опция хранения данных.
Стоимость
Datapine предлагает четыре различных типа тарифных планов, как показано ниже:
Официальный сайт: Datapine
# 2) SQL Fiddle
SQL Fiddle — еще один популярный инструмент. Если вы посмотрите на этот сайт, вы увидите, что это редактор SQL с открытым исходным кодом, который поддерживает множество различных типов баз данных. Основная цель этого инструмента заключалась в том, чтобы провести простое онлайн-тестирование и поделиться проблемами и соответствующими решениями базы данных.
Характеристики
- Поддерживает несколько баз данных, таких как Oracle, SQLite, MS SQL, MySQL и т. Д.
- Экспорт операторов SQL разрешен в различные форматы, такие как таблица, иерархия, текстовый формат и т. Д.
- SQL Fiddle предлагает очень удобные тарифные планы для пользователей.
Стоимость
Как вы можете видеть на картинке выше, проекты ZZZ просят вас внести свой вклад в их проект. Проекты ZZZ владеют SQL Fiddle, и, поскольку они предоставляют вам бесплатный редактор исходного кода, они просят (не обязательно) внести вклад в свой веб-сайт для поддержки и покрытия его регулярных расходов.
Официальный веб-сайт: SQL Fiddle
# 3) DBHawk
Характеристики
- SQL Intellisense и автозаполнение помогут вам повысить производительность.
- Экономьте время, выполняя запросы SQL в фоновом режиме.
- Знайте, что такое командное сотрудничество и совместное использование SQL с DBHawk.
- Работайте с несколькими запросами и выполняйте их одновременно с помощью редактора SQL.
- Выполняйте свою работу, внедряя или выполняя планы SQL.
- Создавайте трехмерные диаграммы, рисунки и интерактивные рисунки для экспорта в онлайн.
Стоимость
DBHawk предлагает два тарифных плана:
- DBHawk Cloud: свяжитесь с ними, чтобы узнать цену
- DBHawk Enterprise: 30 долларов в месяц
Официальный сайт: DBHawk
# 4) SQuirreL SQL
SQuirreL SQL — еще один инструмент с открытым исходным кодом для клиентов.Он использует драйвер JDBC для взаимодействия с базами данных. Этот редактор SQL был полностью разработан на языке JAVA и должен работать на каждой платформе, поддерживающей JVM.
Характеристики
- Это бесплатное программное обеспечение с открытым исходным кодом, работающее на JVM.
- Он предоставляет графики и диаграммы для установления взаимосвязи между таблицами.
- SQuirreL SQL обеспечивает сравнение и совместное использование данных, поскольку поддерживает несколько сеансов.
- Также доступны функции создания закладок и создания пользовательского кода.
Стоимость
SQuirreL SQL не определяет тарифных планов, поскольку это бесплатный встроенный редактор с открытым исходным кодом.
Веб-сайт: SQuirreL SQL
# 5) Jdoodle Online SQL Editor
Jdoodle — это онлайн-инструмент для простого и безопасного выполнения строк шорткода. Его цель — предоставить платформу для создания новых проектов коротких кодов и легкого их выполнения. Он поддерживает такие языки, как PHP, Ruby, Python, HTML и т. Д.Он поддерживает базы данных MongoDB и MySQL.
Характеристики
- Он имеет ярлык, например ctrl + space / alt + space для автозаполнения.
- Включает в себя функцию простого сохранения файла и быстрого и безопасного обмена им с другими.
- Вставьте код на свой веб-сайт и выполните выполнение оттуда.
- Имеется дополнительный интерактивный онлайн-калькулятор.
Цена: Свяжитесь с ними напрямую для получения информации о ценах.
Официальный веб-сайт: Jdoodle
# 6) Блок сравнения БД
DB Comparer — это инструмент для профессионалов, которым необходимо сравнивать базы данных, таблицы, графики, диаграммы и т. Д. Он имеет простой и понятный пользовательский интерфейс, который отображает четкое сравнение баз данных. Для администратора базы данных его можно рассматривать как идеальный инструмент для сравнения и получения точных результатов.
Характеристики
- Сравнивайте базы данных с легкостью автоматизации.
- Сравните и увидите различия в базе данных с большим количеством вариантов.
- Расширенный пользовательский интерфейс для получения точных результатов и четкого визуального представления различий.
- Сравните вашу базу данных с выбранными или всеми доступными вариантами.
Цена: DB Comparer — бесплатный инструмент для сравнения баз данных.
Веб-сайт: DB Comparer
# 7) Oracle Live SQL
Oracle Live SQL больше ориентирован на тестирование и совместное использование данных.Его недостатком является то, что другие базы данных не поддерживаются, пока вы не используете стандартный SQL. Инструмент предоставляет вам руководство и полную документацию. Было бы хорошо использовать инструмент Oracle, поскольку он также предоставляет примеры данных для PHP и Java.
Характеристики
- Предоставляет такие функции, как расширенная безопасность, аналитика и сжатие.
- Он поддерживает Active Data Guards и Database Vault.
- Кроме того, он также обеспечивает тестирование баз данных в реальном времени.
- Дает аналитические данные и создает отчеты с помощью пространственных данных и графиков.
- Label security и Online Analytical Processing также поддерживаются.
Цена: Почти все продукты Oracle можно загрузить и использовать бесплатно.
Официальный веб-сайт: Oracle Live SQL
# 8) DBeaver
DBeaver — это сообщество, в котором несколько разработчиков, программистов SQL, аналитиков данных и администраторов данных работают как единое сообщество.Он также предоставляет пользователям бесплатный многоплатформенный инструмент базы данных.
DBeaver поддерживает все распространенные типы баз данных, такие как MySQL, Oracle, DB2, SQLite, Sybase, Derby и многие другие.
Лучшая часть DBeaver заключается в том, что он поддерживает диаграммы ER для определения отношений и сравнения структур баз данных. В дополнение к этому вы также можете использовать поиск данных и метаданных.
Характеристики
- Он поддерживает базы данных NoSQL и Big-Data.
- Выберите драйвер базы данных, который вам нужен, из множества вариантов.
- Создайте свои собственные драйверы базы данных в соответствии с вашими потребностями.
- Поддерживает несколько представлений данных и расширенную систему безопасности.
- Advanced mock data и Visual Query Builder.
Стоимость
DBeaver в основном предлагает три типа тарифных планов в зависимости от продолжительности, например, месяц / год. План точно такой же, но разница в сроке погашения плана.
Официальный сайт: DBeaver
# 9) Microsoft SQL Server Management Studio Express
Этот инструмент поставляется с Management Studio Express, которая является бесплатной версией Microsoft.SSMSE (SQL Server Management Studio Express) впервые был запущен с SQL 2005 с целью предоставления таких услуг, как администрирование данных, управление и настройка данных.
Также обратите внимание, что этот инструмент не поддерживает такие службы, как службы Integration Services, Reporting Services, Analysis Services, уведомления и т. Д.
Характеристики
- Самое приятное то, что он бесплатный и действительно очень простой в использовании.
- Он предоставляет графический инструмент управления и редакторы скриптов.
- Вы также можете очень легко экспортировать и импортировать SQL server studio.
- Этот инструмент автоматически сохраняет файлы XML, созданные сервером.
Цена: Цена для этого инструмента совершенно бесплатна.
Официальный веб-сайт: Microsoft SQL Server Management Studio Express
# 10) Визуальный эксперт
Характеристики
- Вы можете проверить и просмотреть грубые операции для вашего кода SQL.
- Это помогает вам организовать и документировать код вашего SQL-сервера.
- Сравнение кода может быть выполнено для выявления последствий изменения.
- Простое для понимания сложное кодирование.
- Также доступна панель расширенного поиска.
Цена: Чтобы получить расценки от Visual Expert, нужно заполнить форму.
Официальный веб-сайт: Visual Expert
# 11) dbForge Studio для SQL Server
Редактор SQL для dbForge Studio для SQL Server был создан для взаимодействия с базами данных MS SQL Server путем написания, редактирования и выполнения SQL-запросов, операторов, хранимых процедур и скриптов.
РедакторSQL поможет во взаимодействии с базой данных, обеспечивая подсветку синтаксиса, надежную функциональность завершения кода, возможность получать информацию о параметрах функции и другие функции, которые делают ваш опыт кодирования более эффективным.
РедакторSQL для dbForge Studio для SQL Server был разработан с учетом всего этого, чтобы удовлетворить как профессиональных разработчиков, так и новичков. Это позволит оптимизировать и упростить вашу работу с документами SQL и, что самое главное, сэкономит ваше время.
Характеристики:
- Раскрашенные заявления
- Завершение кода с учетом контекста.
- Сворачивание / расширение кода с поддержкой определяемых пользователем областей форматирования SQL с широкими возможностями. Библиотека
- фрагментов кода SQL с окном браузера и редактором.
- Окно структуры документа для быстрой навигации по большим скриптам.
- Одношаговый доступ к редактору объекта схемы из кода (перейти к определению).
- Информация о параметрах для хранимых процедур и функций.
- Краткая информация об объектах схемы.
- Выполненное окно истории SQL для документа.
Официальный веб-сайт: dbForge Studio для SQL Server
Что такое базы данных?
База данных называется системой, которая представляет собой набор данных или информации , которая находится на сервере. Его также можно рассматривать как систематическую организацию данных, в которой поддерживаются манипулирование, вставка и удаление данных.
(Данные могут быть определены как необработанные факты и цифры, которые в совокупности известны как информация. Эта информация используется для целей анализа, анализа и создания отчетов.)
Только представьте, как Instagram должен хранить свои данные для каждого участника.
Очевидно, Instagram следил бы за любой СУБД (системой управления базами данных) для хранения данных своих участников. Кроме того, участники могут получать доступ, управлять и удалять свои собственные данные с помощью СУБД.
СУБД (Система управления базами данных)
Обычно СУБД — это систематическая организация и сбор данных в последовательном, иерархическом или случайном порядке. Он позволяет пользователю получать доступ, манипулировать, вставлять и удалять данные из базы данных. Кроме того, доступ к базе данных контролируется с помощью СУБД.
Рекомендуемое чтение => Наиболее часто задаваемые вопросы на собеседовании по СУБД
С течением времени и необходимостью изменения функциональности существуют различные типы СУБД i.е. Реляционные СУБД, СУБД SQL, Иерархические СУБД и т. Д.
Теперь вопрос: , что такое SQL ? Для хранения, доступа и управления данными в базе данных нам нужен язык или, скажем, платформа, которая позволяет пользователю работать с базой данных.
Например:
Давайте рассмотрим, как Instagram хранит свои данные в базе данных, но как эти данные могут быть сохранены или как можно установить соединение для доступа к базе данных. Именно здесь мы почувствовали потребность в технологии или языке (например, SQL), которые помогли бы пользователю хранить и извлекать данные из базы данных.
SQL (язык структурированных запросов)
SQL (иногда произносится как «See-quel») — это язык, который используется в программировании и работе с реляционными базами данных. Другими словами, SQL — это язык, который используется для обработки данных в базе данных.
Изначально SQL появился в 1970 году как стандартизованный язык программирования, а затем был принят ANSI (Американский национальный институт стандартов) и ISO (Международная организация по стандартизации) в 1986 и 1987 годах соответственно.
ЯзыкSQL включает следующие операции для обработки данных в базе данных, такие как ввод, удаление, сортировка, поиск и обновление.
Тем не менее, SQL не может делать что-то по ту сторону, если правду сказать, тогда он также сделает массу вещей. Было бы неверно определять SQL как язык баз данных только потому, что он имеет несколько реализаций. Язык SQL используется многими реляционными базами данных, такими как Oracle, MySQL и т. Д.
В этих базах данных можно использовать синтаксис языка SQL, поскольку они в чем-то похожи, но единственное отличие состоит в объявлении синтаксиса.
Типы операторов SQL
Операторы SQL делятся на пять различных типов:
- DDL (язык определения данных)
- DML (язык обработки данных)
- DCL (язык управления данными)
- SCS (операторы управления сеансом) и
- TCS (операторы управления транзакциями)
# 1) Язык определения данных используется для разработки схемы или экземпляра базы данных.Или это также можно назвать определением структуры базы данных.
# 2) Язык манипуляции данными используется для изменения / модификации данных в базе данных. Это помогает в хранении и извлечении данных из базы данных.
# 3) Язык управления данными обеспечивает контроль доступа к данным, хранящимся в базе данных (также известный как авторизация).
# 4) Операторы управления сеансом используются для управления периодом сеанса конкретного пользователя. В конечном итоге сеанс пользователя управляется с помощью операторов SCS. Пример: ALTER SESSION и SET ROLE.
# 5) Операторы управления транзакциями постоянно сохраняют внесенные изменения в базу данных. Пример: COMMIT AND ROLLBACK.
Пример SQL:
ВЫБРАТЬ * ИЗ сотрудников ГДЕ Возраст> 45
Приведенный выше запрос помогает получить данные о сотрудниках, возраст которых превышает 45 лет, из таблицы «сотрудников».
Заключение
SQL — один из наиболее часто используемых языков для администрирования, управления и контроля данных в базе данных.Нужно понять, что такое SQL, только тогда человек сможет понять его дальнейшее функционирование.
Кроме того, если вы разработчик или программист на языке SQL, вы должны четко представлять себе количество инструментов, доступных на рынке. Следовательно, выбрать или выбрать какой-либо конкретный инструмент из лучших доступных вариантов — сложная задача.
В конечном итоге вам нужно найти идеальный инструмент, который лучше всего подходит для вашей работы и потребностей. Таким образом, просто не забывайте оценивать и учитывать факторы каждого инструмента.Все это определенно гарантирует, что разработчики не будут терять время зря и продолжат работу с инструментом вовремя.
Надеюсь, это руководство идеально поможет вам в выборе правильного онлайн-редактора SQL !!
SQL Sorguları ve SQL Sorgu Örnekleri (100+ Adet) — Web Tasarım & Programlama
SQL Sorgu Örnekleri. SQL SELECT, SQL WHERE, SQL DISTINCT, SQL AND OR, SQL ORDER BY, SQL INSERT INTO, SQL UPDATE, SQL DELETE, SQL INJECTION, SQL SELECT TOP, SQL LIKE, SQL WILDCARDS SQL IN, SQL BETWEEN, SQL ALIAS, SQL JOINS , SQL INNER JOIN, SQL SELECT INTO, SQL CREATE, SQL AVG, SQL COUNT, SQL MAX, SQL MIN, SQL LEN, SQL ROUND объединены в любой другой SQL-запрос.
Sql Komutları açıklamaları ve SQL Örnekleri ile bu sorgular kullanılarak hazırlanmış örnek çalışma soruları ve cevapları.
İlginizi çekebilir: SQL Çalışma Sorguları
| musterino | н.э. | сояд | дтарих | sehir | cinsiyet | пуан |
| 1 | Ахмет | Кансевер | 1956-02-19 00:00:00.000 | Стамбул | E | 64 |
| 2 | Мехмет | Айдын | 1976-02-19 00: 00: 00.000 | Самсун | E | 55 |
| 3 | Алие | Семь | 1966-06-10 00: 00: 00.000 | Конья | К | 45 |
| 4 | Бурак | Сайын | 1996-02-19 00: 00: 00.000 | Стамбул | E | 23 |
| 5 | Бейза | Кылыч | 1955-12-30 00:00:00.000 | Маниса | К | 85 |
ВЫБОР SQL
musteri tablosunda bulunan ad, soyad sütunlarını listelemek için;
Выбрать объявление, soyad FROM musteri
Выбрать объявление, soyad FROM musteri |
Musteri tablosunda bulunan tüm kayıtları listelemek için;
SQL ВЫБРАТЬ ОТЛИЧИТЕЛЬНО
Bir tabloda bir sütun yinelenen değerleri içerebilir.Отличный ile farklı değerleri listeleyebiliriz.
ВЫБРАТЬ ОТЛИЧИТЕЛЬНЫЙ sehir ИЗ musteri;
ВЫБЕРИТЕ ОТЛИЧИТЕЛЬНЫЙ sehir ИЗ musteri; |
SQL ГДЕ
Где anahtar sözcüğü ile sadece belirlenen kurala uygun olan kayıtların listelenmesini sağlayabiliriz.
Örne musin musteri tablosunda sehir sütunu İstanbul olan kayıtları listelemek için;
ВЫБРАТЬ * ИЗ musteri WHERE sehir = ‘istanbul’
ВЫБРАТЬ * ИЗ musteri ГДЕ sehir = ‘istanbul’ |
яда чинсиет «К» олан кайытлары листелемек ичин;
ВЫБРАТЬ * FROM musteri WHERE cinsiyet = ‘K’
ВЫБРАТЬ * FROM musteri WHERE cinsiyet = ‘K’ |
Где ile kullanabileceğimiz operatörler;
| Оператор | Açıklama |
|---|---|
| = | Eşit |
| <> | EşitDeğil. Примечание: Bazı versiyonlarda «! =» Kullanılabilir. |
| > | Büyüktür |
| < | Küçüktür. |
| > = | Бююк Эшит |
| <= | Кючюк Эшит |
| МЕЖДУ | arasında |
| КАК | Örüntü arama |
| IN | Bir sütun için birden çok olası değerleri belirtmek için |
SQL AND — OR Kullanımı
AND Operatörü 1.Koşul ve 2. Koşulun doğru olması durumunda çalışır.
Örnein musteri tablosunda Cinsiyeti «E» ve ehri «İstanbul» olanları listelemek için;
ВЫБРАТЬ * ИЗ musteri ГДЕ sehir = ‘Стамбул’ И cinsiyet = ‘E’
ВЫБРАТЬ * ИЗ musteri ГДЕ sehir = ‘İstanbul’ И cinsiyet = ‘E’ |
OR operatörü 1.Koşul yada 2. Koşulun doğru olması durumunda çalışır.
Örnein musteri tablosunda şehri İstanbul yada Samsun olanları listelemek için;
ВЫБРАТЬ * ИЗ musteri ГДЕ sehir = ‘Стамбул’ ИЛИ sehir = ‘Самсун’
ВЫБРАТЬ * ИЗ musteri ГДЕ sehir = ‘İstanbul’ OR sehir = ‘Samsun’ |
И ве ИЛИ operatörü birliktede kullanılabilir.
Örnek olarak musteri tablosunda cinsiyeti ‘K’ olan ve ehri «Konya» yada «Manisa» olanları listelemek için.
ВЫБРАТЬ * ИЗ musteri ГДЕ cinsiyet = ‘K’ И (Город = «Конья» ИЛИ Город = «Маниса»)
ВЫБРАТЬ * ИЗ musteri ГДЕ cinsiyet = ‘K’ И (Город = ‘Конья’ ИЛИ Город = ‘Маниса’) |
ЗАКАЗ SQL ПО Kullanımı
ЗАКАЗАТЬ, varsayılan olarak artan düzende kayıtları sıralar.Azalan kayıtları sıralamak için DESC anahtar sözcüğünü kullanabilirsiniz.
Örnek olarak musteri tablosundaki kayıtları ad sütünuna göre artan ve azan olarak sıralayalım.
ВЫБРАТЬ * ИЗ musteri ЗАКАЗАТЬ ПО объявлению
ВЫБРАТЬ * ИЗ musteri ЗАКАЗАТЬ ПО объявлению |
Азалан сыралама ёрнечи;
ВЫБРАТЬ * ИЗ musteri ЗАКАЗАТЬ ПО ОБЪЯВЛЕНИЮ
ВЫБРАТЬ * ИЗ musteri ЗАКАЗАТЬ ПО объявлению DESC |
ВСТАВИТЬ В Kullanımı
Kayıt eklemek için kullanılır.
örnek olarak musteri tablosuna bir kayıt ekleyelim.
ВСТАВИТЬ В musteri (ad, soyad, dtarih, sehir, cinsiyet, puan) ЦЕННОСТИ (‘Али’, ‘Шахин’, ‘2000-10-12’, ‘Бурдур’, ‘Э’, 68)
ВСТАВИТЬ В musteri (ad, soyad, dtarih, sehir, cinsiyet, puan) ЗНАЧЕНИЯ (‘Ali’, ‘ahin’, ‘2000-10-12’, ‘Burdur’, ‘E’, 68) |
SQL UPDATE kullanımı
Kayıtlar üzerinde değişiklik güncelleme yapmak için kullanılır.
Örnek olarak musterino su 3 olan kaydın puanını 90 olarak değiştirelim.
ОБНОВЛЕНИЕ сборщика УСТАНОВИТЬ puan = 90 ГДЕ musterino = 3
UPDATE musteriler SET puan = 90 WHERE musterino = 3 |
SQL DELETE Kullanımı
Tablodan kayıt silmek için kullanılır.
Örnek olarak musterino su 4 olan kaydı silmek için
УДАЛИТЬ ИЗ сборщика ГДЕ musterino = 4
УДАЛИТЬ ИЗ сборщика ГДЕ musterino = 4 |
сборщик таблосундаки tüm kayıtları silmek için
УДАЛИТЬ * ИЗ сборщика
УДАЛИТЬ * ИЗ сборщика |
SQL SELECT TOP Kullanımı
Belirtilen sayıda kaydı görüntülemek için kullanılır.
örnek olarak musteriler tablosundaki ilk 5 kaydı listeleylim.
ВЫБЕРИТЕ ТОП 5 * ИЗ сборщика
SELECT TOP 5 * ИЗ сборщика |
SQL КАК Kullanımı
Belirtilen bir değeri aramak için kullanılır.
Örnek olarak musteriler tablosunda şehri S ile başlayan kayıtları listeleyelim.
ВЫБРАТЬ * ИЗ сборщика ГДЕ sehir LIKE ‘s%’
ВЫБРАТЬ * ИЗ сборщика ГДЕ sehir LIKE ‘s%’ |
Ehri sile biten kayıtları listelemek için;
ВЫБРАТЬ * ИЗ сборщика ГДЕ sehir LIKE ‘% s’
ВЫБРАТЬ * FROM musteriler WHERE sehir LIKE ‘% s’ |
Ehrin içerisinde «тан» булунан kayıtları listelemek için;
ВЫБРАТЬ * ИЗ сборщика ГДЕ sehir КАК ‘% tan%’
ВЫБРАТЬ * FROM musteriler WHERE sehir LIKE ‘% tan%’ |
SQL YER TUTUCU KARAKTERLER
сборщик таблосунда ады «ал» иле башлаян кайытлары листелемек ичин;
ВЫБРАТЬ * ИЗ сборщика ГДЕ ОБЪЯВЛЕНИЕ КАК ‘al%’
ВЫБРАТЬ * ИЗ сборщика ГДЕ AD КАК ‘al%’ |
сборщик таблосунда ады «ал» иле битен кайытлары листелемек ичин;
ВЫБРАТЬ * ИЗ сборщика ГДЕ ОБЪЯВЛЕНИЕ КАК «% al»
ВЫБРАТЬ * FROM musteriler ГДЕ AD КАК ‘% al’ |
сборщик таблосунда исми A ile başlayıp ondan sonraki 2 karakteri herhangi бир harf olan ve e ile devam eden ve ondan sonraki harfi belli olmayan kayıtları listeleyelim.(Adı Ahmet olanları listeleyeceğiz. :))
ВЫБРАТЬ * ИЗ сборщика ГДЕ объявление КАК ‘A _ _ e _’
ВЫБРАТЬ * ИЗ сборщика ГДЕ ad LIKE ‘A _ _ e _’ |
Adı a ile b ile yada s ile başlayan kayıtları listeleyelim.
ВЫБРАТЬ * ИЗ сборщика ГДЕ adLIKE ‘[абс]%’
ВЫБРАТЬ * ИЗ сборщика ГДЕ adLIKE ‘[абс]%’ |
şimdide tam tersi a ile b ile yada s ile başlamayan kayıtları listeleyelim.
ВЫБРАТЬ * ИЗ сборщика ГДЕ adLIKE ‘[! Abs]%’
ВЫБРАТЬ * ИЗ сборщика ГДЕ adLIKE ‘[! Abs]%’ |
SQL IN Kullanımı
IN operatörü, WHERE yan tümcesinde birden fazla değer belirlemenizi sağlar.
Örnek olarak şehri İstanbul ve Konya olan kayıtları listeleyelim.
ВЫБРАТЬ * ИЗ сборщика ГДЕ sehir IN (‘Стамбул’, ‘Конья’)
ВЫБРАТЬ * ИЗ сборщика ГДЕ sehir IN («Стамбул», «Конья») |
SQL МЕЖДУ КУЛЛАНИМИ
Между operatörü belirli kriterler arasındaki kayıtları listelemek için kullanılır.Сайы метин йада тарих аралиы верилебилир.
Örnek olarak musteriler tablosunda puanı 70 ile 90 arasında olan kayıtları listeleyelim.
ВЫБРАТЬ * ИЗ сборщика ГДЕ puan НЕ МЕЖДУ 70 И 90
ВЫБРАТЬ * ОТ MUSTERILER ГДЕ puan НЕ МЕЖДУ 70 И 90 |
Doum tarihi 01.01.1996 ile 01.01.2006 arasındaki kişileri listelemek için;
Индексыв SQL Server
Индексы SQL используются в реляционных базах данных для быстрого извлечения данных.Они похожи на указатели в конце книг, цель которых — быстро найти тему. SQL предоставляет команды «Создать индекс», «Изменить индекс» и «Удалить индекс», которые используются для создания нового индекса, обновления существующего индекса и удаления индекса в SQL Server.
- Данные хранятся внутри базы данных SQL Server в виде «страниц», где размер каждой страницы составляет 8 КБ.
- Непрерывные 8 страниц называются «Экстент».
- Когда мы создаем таблицу, тогда один экстент будет выделен для двух таблиц, и когда этот экстент будет вычислен, он будет заполнен данными, тогда будет выделен другой экстент, и этот экстент может быть или не быть непрерывным для первого экстента.
Сканирование стола
В SQL Server есть системная таблица с именем sysindexes, в которой информация об индексах доступна для таблиц в базе данных. У таблицы даже нет индекса, в таблице sysindexes будет одна строка, связанная с этой таблицей, указывающая, что в таблице нет индекса. Когда вы пишете оператор выбора с условием where, первый SQL Server будет ссылаться на «indid» (идентификатор индекса).
Столбцы таблицы «Sysindex» определяют, есть ли индекс у столбца, в котором вы пишете условия.Когда это indid столбцы, чтобы получить адрес первого экстента таблицы, а затем выполнить поиск в каждой строке таблицы для данного значения. Этот процесс проверяет данное условие с каждой строкой таблицы, что называется сканированием таблицы. Недостатком tablescan является то, что если количество строк в таблице не увеличивается, время, необходимое для извлечения данных, увеличивается, что влияет на производительность.
Тип индексов
SQL Server поддерживает два типа индексов:
- Кластерный индекс
- Некластеризованный индекс.
1. Кластерный индекс
Кластерный индекс B-Tree (вычисляемый) — это индекс, который физически упорядочивает строки в памяти в отсортированном порядке.
Преимущество кластерного индекса в том, что поиск диапазона значений будет быстрым. Кластеризованный индекс поддерживается внутри с использованием конечного узла структуры данных B-Tree из b-дерева кластерного индекса, который будет содержать данные таблицы; вы можете создать только один кластерный индекс для таблицы.
Получение данных с кластеризованным индексом
Когда вы пишете оператор select с условием в предложении where, тогда первый SQL-сервер будет ссылаться на столбцы «indid» таблицы «Sysindexes», и когда этот столбец содержит значение «1».
Затем он индексирует таблицу с помощью кластеризованного индекса, и в этом случае он ссылается на столбцы. «Корневой» узел B-дерева кластеризованного индекса и ищет в B-дереве конечный узел, содержащий row, которая удовлетворяет заданным условиям и извлекает все строки, удовлетворяющие заданному условию, которые будут находиться в последовательности.
Вставка и обновление с кластеризованным индексом
- Поскольку кластеризованный индекс упорядочивает строки физически в памяти в отсортированном порядке, вставка и обновление будут медленными, потому что строки должны быть вставлены или обновлены в отсортированном порядке.
- Наконец, страница, на которую должна быть вставлена или обновлена строка, и если на странице нет свободного места, создается свободное пространство, а затем выполняется вставка, обновление и удаление.
- Чтобы решить эту проблему при создании индекса кластеризации, укажите коэффициент заполнения, и когда вы укажете коэффициент заполнения как 70, тогда на каждой странице этой таблицы 70% заполнят ее данными, а оставшиеся 30% останутся свободными.
- Поскольку на каждой странице доступно свободное место, вставка и обновление будут быстрыми.
2. Некластеризованный индекс
- Некластеризованный индекс — это индекс, который физически не упорядочивает строки в памяти в отсортированном порядке.
- Преимущество некластеризованного индекса в том, что поиск значений в диапазоне будет быстрым.
- В таблице можно создать не более 999 некластеризованных индексов, что составляет 254 до SQL Server 2005.
- Некластеризованный индекс также поддерживается в структуре данных B-Tree, но конечные узлы B- Дерево некластеризованного индекса содержит указатели на страницы, содержащие данные таблицы, а не непосредственно данные таблицы.
Получение данных с некластеризованным индексом
- Когда вы пишете оператор select с условием в предложении where, тогда SQL Server будет ссылаться на «indid» столбцы таблицы sysindexes, и когда этот столбец содержит значение в диапазон от 2 до 1000, то это означает, что таблица имеет некластеризованный индекс, и в этом случае он будет обращаться к корню столбцов таблицы sysindexes для получения двух адресов.
Из корневого узла B-дерева некластеризованного индекса, а затем выполните поиск в B-дереве, чтобы найти конечный узел, который содержит указатели на строки, которые содержат значение, которое вы ищете, и извлеките эти строки .
Вставка и обновление с некластеризованным индексом
- Не будет эффекта от вставки и обновления с некластеризованным индексом, потому что он не будет размещать строку в памяти физически в отсортированном порядке.
- При некластеризованном индексе строки вставляются и обновляются в конце таблицы.
| Кластерный индекс | Некластеризованный индекс |
| Это упорядочит строки в памяти физически в отсортированном порядке. | Это не приведет к физическому расположению строк в памяти в отсортированном порядке. |
| Это ускорит поиск диапазона значений. | Это ускорит поиск значений, выходящих за пределы диапазона. |
| Указатель для таблицы. | Для таблицы можно создать не более 999 некластеризованных индексов. |
| Конечный узел 3-го уровня кластеризованного индекса содержит, содержит данные таблицы. | Конечные узлы b-дерева некластеризованного индекса содержат указатели для получения, а также указатели для получения, которые содержат данные двух таблиц, а не данные таблицы напрямую. |
Создание индексов в SQL Server
Для создания индекса используйте команду create index со следующей системой.
создать [уникальный] [кластерный / некластеризованный] индекс:
-
на <имя объекта> (<список столбцов>) - [include (
)] - [with fillfactor =
]
По умолчанию индекс не кластеризован.
Например, следующие примеры создают некластеризованный индекс для Department_no таблиц emp.
- создать индекс DNoINdex в Emp (DeptNo)
Простые и составные индексы
- В зависимости от количества столбцов, на которых создается индекс, индексы подразделяются на простые и составные.
- Когда индексы создаются для отдельных столбцов, он называется простым индексом, а когда индекс создается в сочетании с несколькими столбцами, он называется составным индексом.
Например, в следующем примере создается некластеризованный индекс в сочетании с номерами отдела и столбцами заданий в таблице emp.
- create index dnotedxi on emp (deptno asc, job desc)
Уникальный индекс
- Когда индекс создается с использованием ключевого слова unique, он называется уникальным индексом, для которого вы создаете уникальный индекс. столбцы, тогда вместе с ограничением уникальности индекса будет создано для столбцов.
- Если столбцы, для которых вы создаете уникальный индекс, содержат повторяющиеся значения, уникальный индекс не будет создан, и вы получите сообщение об ошибке.
Изменение индекса
Для изменения индекса используйте команду alter index, имеющую следующий синтаксис:
- Изменить индекс
на <имя объекта> - перестроить / распознать / отключить.
Параметр «Перестроить» воссоздает индекс компьютера, параметр распознавания реорганизует листовые узлы b-дерева для индексации, а параметр отключения отключает индекс, когда индекс соответствует требованиям, а затем включает его.измените индекс, используя опцию перестроения.
Например, в следующем примере изменяется индекс «dnoidx», доступный для количества столбцов отдела в таблице emp.
- изменить индекс DNOiDX при восстановлении EMp
Получение списка индексов
Эта хранимая процедура используется для вычисления списка индексов, доступных для таблицы.
sp_helpindex ‘Stud’
Удаление индексов
Используйте команду drop index со следующим синтаксисом:
- drop index
на
Например, в следующем примере удаляется индекс dnoidex, доступный в столбцах номеров отделов таблицы emp.
- drop index doindex для студента
MS SQL Series — DatabaseJournal.com
Индекс Database Journal Series — это список статей, которые содержат более трех частей. Он классифицируется по базе данных, имени автора, заголовку серии и заголовку статьи.
Майкл Обер
Изучите администрирование SQL Server 2000 за 15 минут в неделю Серия
Александр Чигрик
Поиск и устранение неисправностей
Сравнения
Советы по оптимизации
Пошаговые инструкции
Сумит Дхингра
SQL «Как сделать»
Ограбить Гаррисон
SqlCredit — Разработка полного проекта базы данных OLTP для SQL Server
Грегори А.Ларсен
Лучшие практики T-SQL
Программирование T-SQL
Работа с переменными даты и времени SQL Server
MAK
Аудит в SQL Server 2008
Работа с файлами .MDF и .LDF в SQL Server 2008
Зеркальное отображение базы данных в SQL Server 2008
Microsoft Windows PowerShell и SQL Server 2008 AMO
Проверьте свой SQL Server с помощью Windows PowerShell
Microsoft SQL Server 2008 — система отслеживания измененных данных
Шифрование данных в SQL Server 2005
Microsoft Windows PowerShell и SQL Server 2005 SMO
Функции регистра в SQL Server
Инструмент командной строки SQL Server 2005 «SQLCMD»
Разделение данных в SQL Server 2005
SQL Server 2005 — автоматическая установка
Александр Непомнящий
SQL Server 7.0
OLAP и хранилища данных
Ян Пань
Настройка кластера SQL Server 2008 с двумя узлами из командной строки
Уильям Э. Пирсон
Введение в MSSQL Server Analysis Services Series
Введение в безопасность в службах Analysis ServicesХранилище кубов: планирование разделов из перспективы SQL Server Management Studio
Хранилище кубов: планирование разделов (перспектива Business Intelligence Development Studio)
Хранилище кубов: введение в разделы
Введение в хранилище кубов
Дискретизация атрибутов: настройка группирования Имена
Дискретизация атрибутов: использование метода «кластеров»
Дискретизация атрибутов: использование метода «равных площадей»
Дискретизация атрибутов: использование автоматического метода
Введение в дискретизацию атрибутов
Более подробное знакомство с настройками и свойствами в отношениях атрибутов служб Analysis Services
Взаимосвязи атрибутов : Параметры и свойства
Введение в отношения атрибутов в службах MSSQL Server Analysis Services
Значения элементов атрибутов в службах Analysis Services
Службы анализа MSSQL — Имена элементов атрибутов
Ключи элементов атрибутов — Часть II: Составные ключи
Attribute Me mber Keys — Pt 1: Introduction and Simple Keys
Dimension Attributes: Introduction and Overview, Part V
Dimension Attributes: Introduction and Overview, Part IV
Dimension Attributes: Introduction and Overview, Part III
Dimension Attributes: Introduction and Overview, Part II
Атрибуты измерения: введение и обзор, часть I
Компоненты размерной модели: измерения, часть II
Компоненты размерной модели: измерения, часть I
Управление неизвестными элементами в службах Analysis Services 2005, часть II
Управление неизвестными элементами в службах Analysis Services 2005, часть I
в качестве альтернативы Сортировка элементов атрибутов в службах Analysis Services 2005
Введение в связанные объекты в службах Analysis Services 2005
Счетчики различий в службах Analysis Services 2005
Постановка аналитики: условное форматирование на уровне служб Analysis Services
Администрирование и оптимизация: профилировщик SQL Server для запросов служб Analysis Services
Mastering Enterprise BI: Time Intelligence ence Pt.II
Освоение корпоративной бизнес-аналитики: Time Intelligence Pt. I
Дизайн и документация: Введение в сводную диаграмму Visio 2007
Действия в службах Analysis Services 2005: Действие URL-адреса
Действия в службах Analysis Services 2005: Действие детализации
Освоение корпоративной бизнес-аналитики: введение в действия в службах Analysis Services 2005
Освоение корпоративной бизнес-аналитики: Введение в переводы
Освоение корпоративной бизнес-аналитики: введение в перспективы
Введение в журнал запросов служб Analysis Services 2005
Освоение корпоративной бизнес-аналитики: работа с группами мер
Освоение корпоративной бизнес-аналитики: введение в ключевые показатели эффективности
Освоение корпоративной бизнес-аналитики: расширение источника данных с помощью именованных вычислений, Pt .II
Освоение корпоративной бизнес-аналитики: расширение источника данных с помощью именованных вычислений, Pt. I
Process Analysis Services Objects with Integration Services
Usage-Based Optimization in Analysis Services 2005
Introduction to MSSQL Server Analysis Services: Named Sets Revisited
Introduction to MSSQL Server Analysis Services: Migrating an Analysis Services 2000 Database to Analysis Services 2005
Introduction to Службы MSSQL Server Analysis Services: введение в представления источников данных
Введение в службы MSSQL Server Analysis Services: параметры отчетов для кубов служб Analysis Services: MS Excel 2003 и другие…
Введение в MSSQL Server Analysis Services: Освоение корпоративной бизнес-аналитики: создание устаревших «сегментов» в кубе
Введение в MSSQL Server Analysis Services: освоение корпоративной бизнес-аналитики: относительные периоды времени в кубе служб Analysis Services, часть II
Введение в MSSQL Server Службы Analysis Services: освоение корпоративной бизнес-аналитики: относительные периоды времени в кубе служб Analysis Services
Знакомство с сервером MSSQL Службы анализа: обработка кубов служб анализа с помощью DTS
Введение в MSSQL Server Службы аналитики: нюансы представления: представление CrossTab — то же измерение
Введение в сервер MSSQL Службы Analysis Services: упрощение схемы куба «наведи и щелкни»
Знакомство с MSSQL Server 2000 Службы Analysis Services: управление числом отдельных объектов с помощью виртуального куба
Введение в службы аналитики MSSQL Server 2000: Основы подсчета отдельных объектов: две точки зрения
Введение в службы анализа MSSQL Server 2000 : Полуаддитивные меры и периодические остатки
Intr Введение в MSSQL Server 2000 Analysis Services: выполнение инкрементных обновлений куба — введение
Введение в MSSQL Server 2000 Analysis Services: секционирование куба в службах Analysis Services — введение
Введение в MSSQL Server 2000 Analysis Services: базовая конструкция хранилища
Введение в MSSQL Server 2000 Анализ.