2.9. Перекрестные запросы на sql.
Инструкция TRANSFORM позволяет создавать перекрестные запросы, позволяющие осуществлять суммирование некоторого выражения; используя значение заданного столбца или выражения в качестве заголовков столбцов выходных таблиц, а другие столбцы либо выражения используются для задания условия группировки и формирования строк выходной таблицы.
Синтаксис инструкции TRANSFORM:
TRANSFORM выражение_с_итоговой_функцией
<инструкция_SELECT>
PIVOT выражение
где <выражение_с_итоговой_функцией> − выражение, использующее одну из итоговых функций. Оно определяет значения, которые должны появиться в ячейках выходной (перекрестной) таблицы.
Выражение <инструкция_SELECT> должна содержать предложение GROUP BY.
Конструкция <PIVOT
выражение> определяет столбец или
выражение, значения которого используются
в качестве заголовков столбцов
перекрестной таблицы.
При задании условий группировки для строк можно использовать несколько
столбцов или выражений.
Чтобы получить итоговые оценки по предметам, создадим запрос «Сетка успеваемости»:
TRANSFORM MAX(INT((Результаты.Оценка_Т+Результаты.Оценка_П+ Результаты.Оценка_Л)/З))
SELECT Результаты.Номер_С
FROM Результаты
GROUP BY Результаты.Номер_С
PIVOT Предмет;
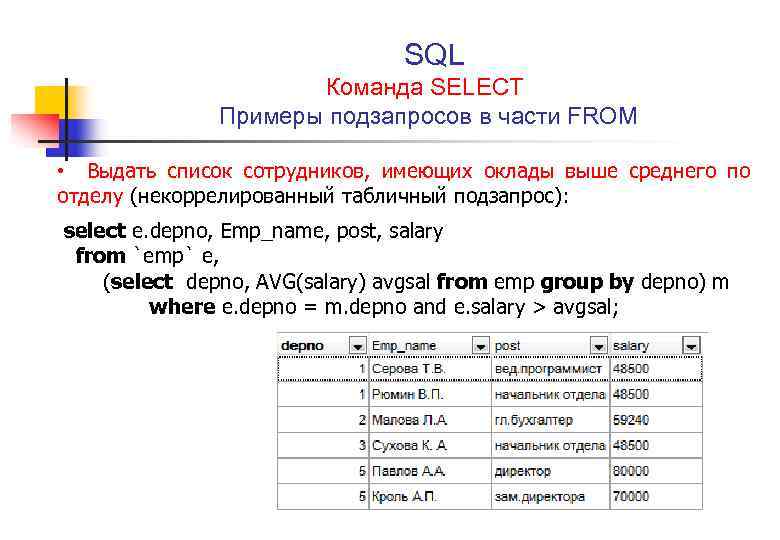
Запросы можно строить не только на основе данных таблиц, но и по данным, которые возвращает запрос. В этом случае имя вызываемого запроса указывается в квадратных скобках. Так, при необходимости сформировать сетку успеваемости за учебный год по прошедшему и текущему семестрах, SQL не дает возможности напрямую произвести объединение таблиц в перекрестном запросе. Приходится создавать запрос на объединение таблиц − «Объединенные результаты», а затем создаваемый перекрестный запрос «Сетка успеваемости за год», который использует результаты уже запроса-объединения:
TRANSFORM
MAX(INT((Результаты. Оценка_Т+Результаты.Оценка_П+
Результаты.Оценка_Л)/))
Оценка_Т+Результаты.Оценка_П+
Результаты.Оценка_Л)/))
SELECT [Объединенные результаты].Номер_С
FROM [Объединенные Результаты]
GROUP BY [Объединенные результаты].Номер_С
PIVOT Предмет;
2.10. Запросы − действия на sql.
SQL содержит инструкции, позволяющие производить различную обработку данных. Существуют команды удаления, вставки, обновления данных и создания новой таблицы из существующих данных.
2.10.1. Запрос на создание таблицы.
Инструкция SELECT…INTO создает новую таблицу, используя значения, выбранные из одной или нескольких таблиц. Обычно этот тип запросов применяется при резервировании данных таблицы, или для вывода отчетов за определенный период.
Синтаксис команды:
SELECT [ALL | DISTINCT | DISTINCTROW | TOP число [PERCENT]] список_выбора
INTO имя_новой_таблицы
FROM {{имя_таблицы [[AS] псевдоним] |
имя_запроса_выборки [[AS] псевдоним]} |
<таблица_объединение> }
[WHERE условие_отбора]
[GROUP BY имя_столбца
,. ..]
..]
[HAVING условие_отбора]
[UNION [ALL] инструкция_выбора]
[ORDER BY { имя_столбца [ ASC | DESC ] },…
IN<«имя_базы_источника_данных»> <[строка_подключения_источника_дан-ных]>
Модификация вставляемых данных возможна только в режиме
SELECT DISTINCTROW.
Данный запрос создает новую таблицу с именем, задаваемым в <имя_новой_таблицы>. Если таблица с таким именем уже существует ACCESS запрашивает, удалять ли старую перед созданием новой.
Создадим запрос «Результат по практике».
SELECT DISTINCTROW Фамилия, Имя, Отчество, Студенты.Номер_С,
Count(Результат.Оценка_П) AS Практика
FROM Студенты
INNER JOIN Результаты
ON Студенты.Номер_С = Результаты.Номер_С
WHERE
((Результаты.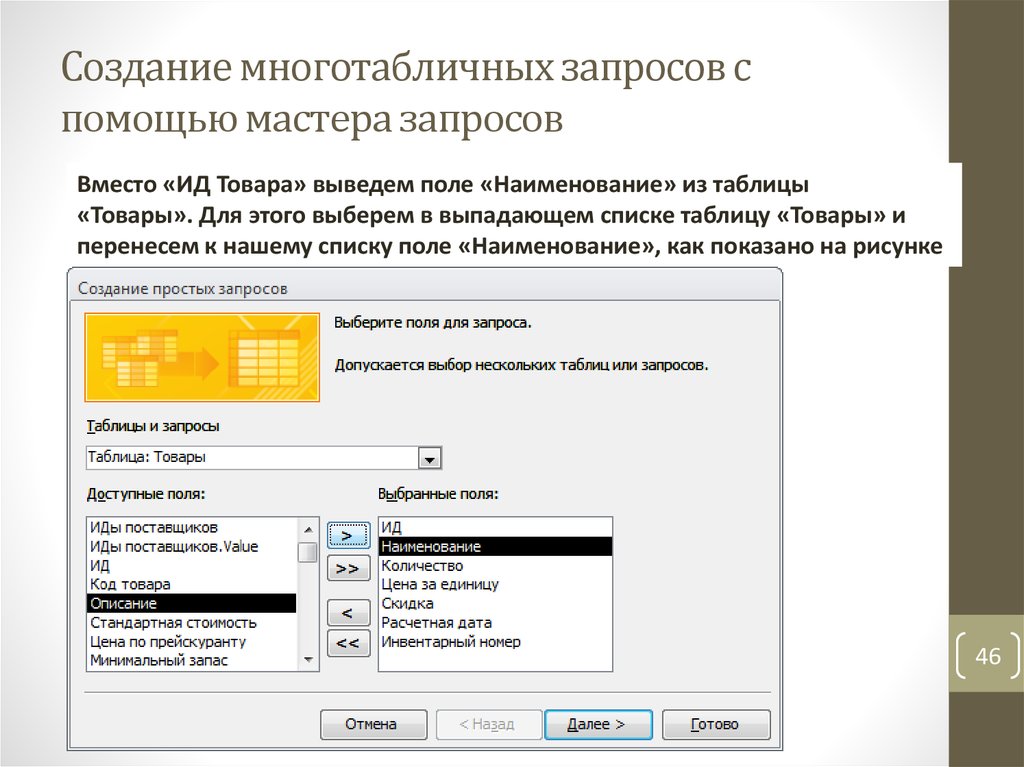 Предмет=[Введите предмет])
Предмет=[Введите предмет])
GROUP BY Фамилия, Имя, Отчество, Студенты.Номер_С;
После этого создадим запрос, который будет по полученной выборке формировать таблицу «Результат»:
SELECT DISTINCTROW [Результат по практике].*
INTO [Результат]
FROM [Результат по практике];
Запустим запрос на выполнение и после введения всех параметров убедимся, что Access создал таблицу «Результат».
Перекрестные запросы. Макросы — Проектирование баз данных на SQL (Информатика и программирование)
Лекция 18. Перекрестные запросы. Макросы
С помощью перекрестного запроса можно более наглядно представить данные итоговых запросов, предусматривающих группировку по нескольким признакам (по двум, в частности).
В этом случае значение полей по первому признаку группировки могут стать заголовками строк, а по второму — заголовками столбцов.
Для преобразования итогового запроса-выборки необходимо перейти в режим его Конструктора и выполнить команду Запрос/Перекрестный.
После этого в бланке запроса строка «Вывод на экран» будет замещена строкой «Перекрестная таблица». В этой строке нужно задать, как будет использовано данное поле в перекрестной таблице: в виде заголовок строк, полей или значений (рисунок 18.1).
Рисунок 18.1 — Вид окна перекрестного запроса
Существует возможность вывести данные в перекрестной таблице без создания в базе данных отдельного запроса. Для этого следует использовать «Мастер сводных данных». В сводной таблице пользователь имеет возможность изменять заголовки строк или столбцов, что позволяет анализировать данные различными способами.
В перекрестном запросе отображаются результаты статистических расчетов (такие как суммы, количество записей и средние значения), выполненных по данным из одного поля таблицы. Эти результаты группируются по двум наборам данных, один из которых расположен в первом столбце таблицы, а второй — в верхней строке.
Удобно создавать перекрестную таблицу в интерактивном режиме с помощью мастера «Перекрестный запрос». Обращение к Мастеру значительно упрощает процесс создания перекрестной таблицы.
Обращение к Мастеру значительно упрощает процесс создания перекрестной таблицы.
Мастеру необходимо указать исходную таблицу, которая может быть таблицей из базы данных или являться результатом выборки данных из нескольких таблиц. На основе исходной таблицы или запроса Мастер создает итоговую выборку, в которой группирует и сортирует данные по полям, используемым в качестве строки и столбца перекрестной таблицы, а также вычисляет итоговое значение по заданному полю данных.
При создании перекрестной таблицы следует перейти на вкладку «Запросы» и выбрать кнопку «Создать» , а затем в окне диалога выбрать опцию Перекрестный запрос (рисунок 18.1).
Эти действия запустят Мастер создания перекрестной таблицы, который шаг за шагом будет задавать вопросы о параметрах создаваемой таблицы.
На первом шаге Мастер предлагает выбрать исходную таблицу или запрос.
На следующем шаге вам необходимо указать поля, значения которых будут использоваться в качестве заголовков строк. Можно указать от одного до трех полей путем их переноса их переноса из списка Доступные поля в список Выбранные поля. Затем вы переходите в окно диалога определения заголовков столбцов. В качестве заголовка столбцов может использоваться только одно поле.
Можно указать от одного до трех полей путем их переноса их переноса из списка Доступные поля в список Выбранные поля. Затем вы переходите в окно диалога определения заголовков столбцов. В качестве заголовка столбцов может использоваться только одно поле.
На предпоследнем шаге создания перекрестной таблицы нужно задать поле, которое будет использоваться в качестве источника данных для итоговых вычислений, и тип итоговых вычислений для каждой пары строка/столбец (рисунок 18.2).
Рисунок 18.2 — Вид окна для определения типа группировки
В этом же окне диалога можно добавить столбец, который будет содержать итоговое значение по каждой строке результирующей таблицы.
На завершающей стадии создании перекрестной таблицы нужно задать ее имя и выбрать опцию просмотра результатов запроса или изменения структуры запроса в окне конструктора запросов.
Для завершения процесса создания необходимо нажать кнопку «Готово», на экране появится построенная перекрестная таблица.
В перекрестной таблице, созданной с помощью Мастера, присутствует дополнительный столбец Итого, в котором отображаются суммарные итоги данных.
Макросы
Макросом называют набор из одной или более макрокоманд, выполняющих определенные операции, такие как открытие форм или печать отчетов. Макросы могут быть полезны для автоматизации часто выполняемых задач. Например, при нажатии пользователем кнопки можно запустить макрос, который распечатает отчет.
Макрос может быть как собственно макросом, состоящим из последовательности макрокоманд, так и группой макросов, т.е. набором связанных макрокоманд имеющих общее имя. В некоторых случаях для решения, должна ли в запущенном макросе выполняться определенная макрокоманда, может применяться условное выражение.
Запуск окна создания макросов осуществляется кнопкой «Создать», в окне диалога «База данных» при выбранной категории «Макросы» внешний вид окна «Макрос» представлен на рисунке 18.3.
Рисунок 18.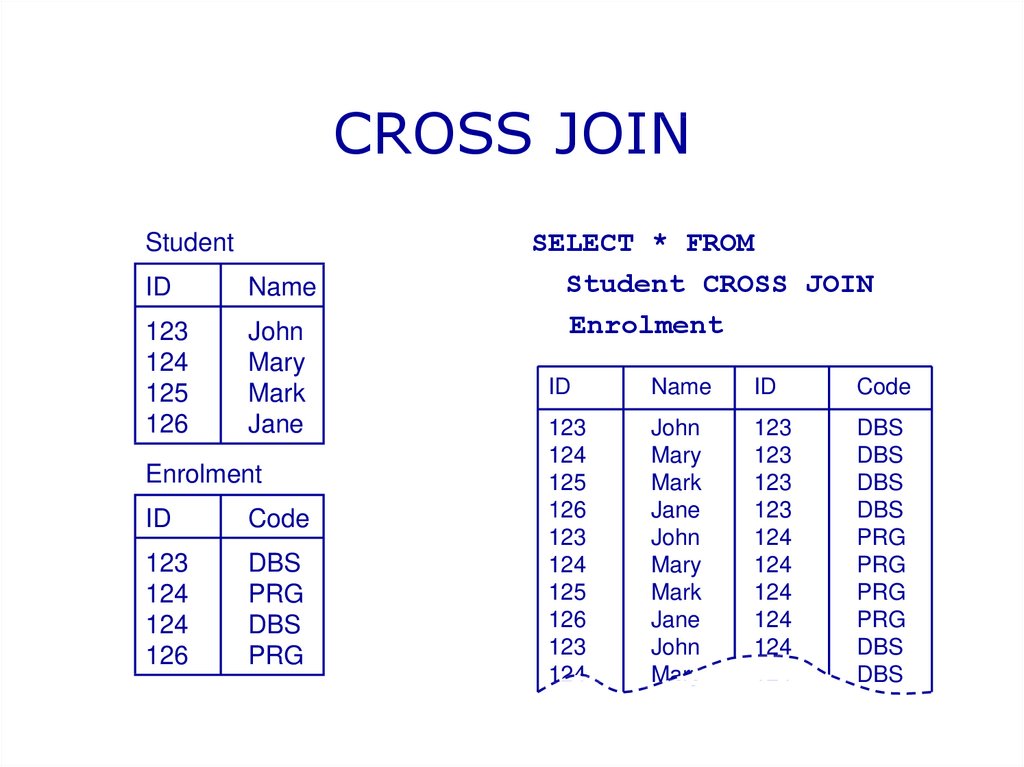 3 — Окно диалога «Макрос»
3 — Окно диалога «Макрос»
В верхней части раскрывшемся окне «Макрос» имеется два столбца: «Макрокоманда» и «Примечание». В столбце «Макрокоманда» осуществляется выбор макроса из раскрывающегося списка, в котором более 50 различных макрокоманд, составляющих базовый набор MS Access. Создаваемый макрос может включать в себя множество макрокоманд, каждая новая команда должна записываться в новой строке.
Заполнение столбца «Примечание» не является обязательным, однако в большинстве случаев его заполнение позволяет быстрее разобраться в действиях макроса, особенно когда в нем множество макрокоманд.
В большинстве случаев макрокоманды имеют аргументы, в этом случае они отображаются в нижней части окна в разделе «Аргументы макрокоманды». В общем случае рекомендуется задавать аргументы макрокоманды в том порядке, в котором они перечислены, поскольку выбор одного аргумента может определять возможные значения следующего аргумента.
В некоторых случаях, при создании сложных макросов может потребоваться ветвление, т. е. использование условий, например, выполнять или не выполнять ту или иную макрокоманду в зависимости от ситуации. В этом случае потребуется добавление нового столбца «Условие» в бланк макрокоманд. Добавить столбец «Условие» можно командой Вид — Условие. Условие можно создать через построитель выражений командой контекстного меню – Построить.
е. использование условий, например, выполнять или не выполнять ту или иную макрокоманду в зависимости от ситуации. В этом случае потребуется добавление нового столбца «Условие» в бланк макрокоманд. Добавить столбец «Условие» можно командой Вид — Условие. Условие можно создать через построитель выражений командой контекстного меню – Построить.
Таблица 18.1 – Макрокоманды MS Access
Продолжение таблицы 18.1
Контрольные вопросы
1. В чем заключается назначение перекрестного запроса?
2. Чем связаны перекрестные запросы и итоговые запросы?
3. Что такое макрос?
4. В чем назначение макросов?
5. Какие средства существуют для создания макроса?
6. Какие макросы вы знаете?
7. Как запускается макрос?
Задания для самостоятельной работы
Задание 1. Создайте перекрестный запрос для учета часов учебной работы преподавателя по описанию.
Пусть требуется вести учет часов учебной работы преподавателя для учебной части. Фрагмент бланка учета часов представлен в таблице 18.2. Определим схему БД для одного преподавателя (рисунок 18.4).
Фрагмент бланка учета часов представлен в таблице 18.2. Определим схему БД для одного преподавателя (рисунок 18.4).
Таблица 18.2 – Фрагмент бланка учета часов преподавателя
Рисунок 18.4 – Схема БД «Учет часов учебной работы»
После создания таблиц и установки связей выполним следующие действия:
1. С помощью мастера создадим запрос на выборку, содержащий только те поля, которые должны войти в перекрестный запрос (рисунок 18.5) и присвоим ему имя «Сводный_запрос».
2. Выполним команду Создать – Перекрестный запрос, в результате откроется окно диалога «Создание перекрестных таблиц».
3. На первом этапе выбираем источник данных – «Сводный_запрос» и нажимаем кнопку «Далее».
4. На втором шаге в запрос включаем те поля, которые будут использоваться в качестве заголовков строк, таких полей может быть несколько, например, «Дисциплина», «Группа», «План на год». Поля, которые хотелось бы также разместить в заголовках строк, но мастер этого не позволяет, можно в последствии добавить в конструкторе запросов. Нажимаем кнопку «Далее».
Нажимаем кнопку «Далее».
Рисунок 18.5 – Запрос на выборку «Сводный запрос»
5. На третьем шаге выберем поле, значения которого требуется разместить в качестве заголовков столбцов, в данном примере это поле «Месяц». Нажимаем кнопку «Далее».
6. На четвертом шаге выберем поле, по которому требуется провести вычисления на пересечении строк и столбцов, поле «Отведено». Также требуется определить функцию, по которой будет проводиться вычисление итоговых значений, в данном случае «Сумма». Нажимаем кнопку «Далее».
7. На последнем шаге можно задать имя, например, «Учет часов учебной работы» и способ дальнейшее работы (мы планировали добавить в запрос поля, не «вместившиеся» при использовании мастера). Нажимаем кнопку «Готово».
Обратите внимание на лекцию «Часть 4».
Рисунок 18.6 – Перекрестный запрос «Учет часов учебной работы»
Результат работы запроса после некоторых модификаций представлен на рисунке 18.6. Несложно создать для него соответствующий отчет.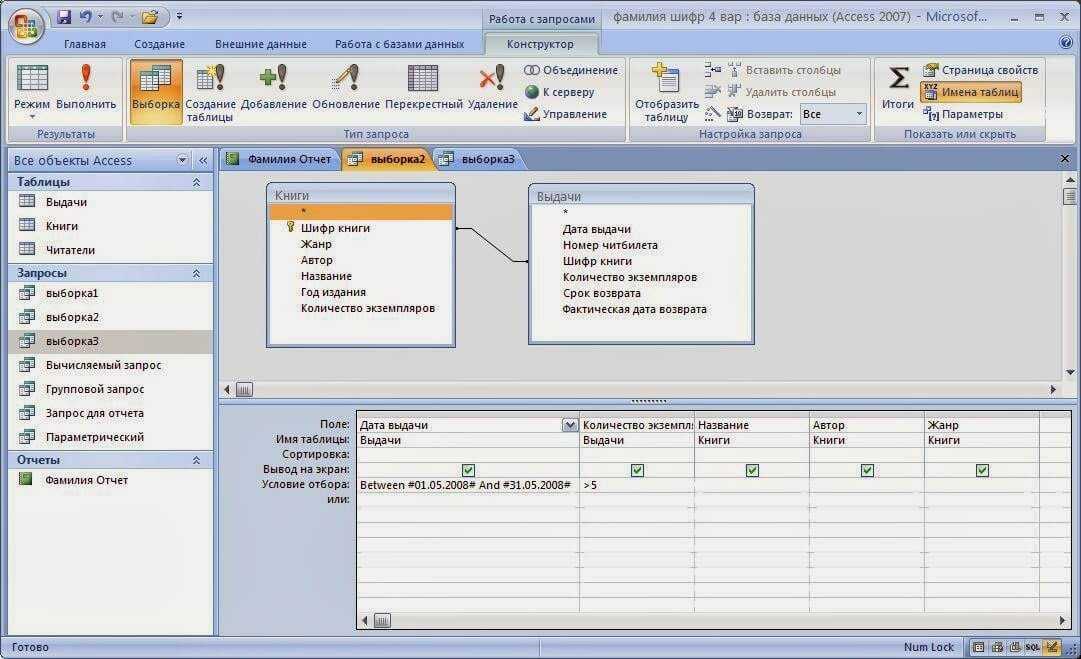
Задание 2. Модифицируйте базу данных «Учтет часов учебной работы так, чтобы можно было учитывать данные многих преподавателей.
Задание 3. Разработайте перекрестный запрос учета успеваемости групп по разным предметам, по итогам выполнения контрольных работ
Создание перекрестных запросов и сводных таблиц в SQL
В тех случаях, когда вам абсолютно необходимо выполнить перекрестный запрос в SQL, хранимая процедура Кейта Флетчера T-SQL позволит вам сделать это «на лету». Вы можете добавить его в свою базу данных и сразу начать кросс-таблицу, без каких-либо дополнительных настроек или изменений в вашем коде SQL. Проверьте это, а затем примите вызов кросс-таблицы. Если вы сможете составить перекрестный отчет, отображающий стоимость заказа по клиентам, по кварталам, используя хранимую процедуру, вы можете выиграть столь желанный приз!
Иногда вам просто необходимо сгенерировать перекрестную таблицу в SQL. Система отчетности не годится для этого, и невозможно встроить эту функциональность в приложение.
- Возможно, вы используете решение для создания отчетов, которое не поддерживает эту функцию.
- Вы используете устаревшее приложение, с которым лучше не возиться.
- Вы хотите экспортировать некоторые данные, уже представленные в требуемом формате, в текстовый файл.
Именно для этих исключительных случаев я решил написать динамическую хранимую процедуру перекрестной таблицы.
Скорее исключение, чем правило
Существует общее правило, согласно которому манипулирование данными такого рода лучше оставить на уровне приложений или отчетов системы, и на то есть веские причины. Основная роль ядра базы данных SQL заключается в хранении и поиске информации, а не в ее сложной обработке. Любой, кто пытался превратить данные в SQL в осмысленный набор информации, используя сложный набор бизнес-правил, вероятно, согласится с тем, что SQL имеет тенденцию отговаривать вас от этого, и чем более причудливым и творческим вы пытаетесь сделать свое решение, тем сильнее становится это уныние.
Говорят, что если вы можете что-то сделать, это не значит, что вы должны это делать. Верно, но я, например, думаю, что применимо и обратное. Если вам кажется, что вы чего-то не можете, это не значит, что вы не должны этого делать. Это уравновешивание, которое требует тщательного рассмотрения. Я нашел несколько приложений, для которых эта хранимая процедура была идеальным решением — я намекнул на них в первом абзаце. Однако есть столько же, если не больше, где его не следует использовать. Хранимая процедура может отрицательно сказаться на производительности, если она используется неправильно или используется в дорогом или большом источнике данных. Я оставляю вас с советом, что описанный здесь скрипт следует использовать осторожно и экономно, а не рассыпать волей-неволей о ваших базах данных.
Требования
Весь мой демонстрационный код будет использовать надежную базу данных Northwind . По умолчанию он поставляется с SQL Server 2000, но если вы избавились от него или используете Server 2005, вы можете загрузить его с веб-сайта Microsoft.
После загрузки и подключения Northwind создайте хранимую процедуру sys_CrossTab в базе данных, и все готово.
Простой перекрестный запрос
В базе данных Northwind есть таблица под названием Categories , которая используется для разделения всего набора продуктов на восемь отдельных групп, а именно: напитки, приправы, кондитерские изделия, молочные продукты, зерновые/хлопья, мясо/птица, продукты и морепродукты. . Если бы торговая компания «Северный ветер» была реальным юридическим лицом, было бы немыслимо, чтобы один из счетчиков бобов запросил отчет с указанием общей стоимости заказов, размещенных по годам и по категориям. Это была бы прекрасная возможность попробовать кросс-таб-запрос. Самый простой способ сделать это — использовать
1 2 3 4 5 6 7 8 10 110003 12 13 14 199991111000114 9000 3 9000 3 9000 3 9000 2 9000 214 9000 3 9000 3 9000 29000 3 9000 3 9000 3 18 19 20 21 22 23 24 25 26 27 28 29 | Выберите Год (Ord. SUM (Case Prod.CategoryId, когда 1 затем Det.Unitprice * Det.quantity else 0 End) Beverages, Sum (Case prod.categoryid, когда 2 затем det.UnitPrice * det.Quantity ELSE 0 END) Приправы, SUM(CASE prod.CategoryID WHEN 3 THEN det.UnitPrice * det.Quantity ELSE 0 END) Кондитерские изделия0003 сумма (case prod.categoryid, когда 4 затем Det.unitprice * det.quantity else 0 End) [Dairy Products], Sum (Case Prod.categoryId, когда 5 затем Det.Unitprice * Det.quantity Else 0 END) [Зерна/злаки], SUM (Case Prod.CategoryId, когда 6 затем Det.Unitprice * Det.quantity else 0 End) [Мясо/Птица], SUM (Case Prod.categoryId, когда 7 затем det.unitprice * det.quantity else 0 end) Производство, Sum (Case prod.categoryid, когда 8 затем Det.unitprice * det.quantity else 0 End) Морепродукты Из Orders Ord INNER JOIN [Сведения о заказе] det ON det.
INNER JOIN Products prod ON prod.ProductID = det.03ProductID 2СГРУППИРОВАТЬ ПО ГОДУ(Order.OrderDate)
ORDER BY YEAR(order.OrderDate) |
 OrderDate) Год,
OrderDate) Год, OrderID = ord.OrderID
OrderID = ord.OrderIDЭто вернет
Итак, вы быстро набираете запрос, показываете бухгалтеру, как импортировать данные в электронную таблицу Excel, и идете за пинтой, чтобы отпраздновать свою изобретательность.
Вскоре после этого парень решает, что отчет с данными недостаточно детализирован, и хотел бы, чтобы аналогичный отчет был разделен по названиям продуктов, а не по категориям. Товаров 77, поэтому в нем задействовано еще несколько CASE операторов. Вы тихо ворчите себе под нос, демонстрируя свое мастерство вырезания и вставки, и создаете новый отчет, показывающий разбивку по продуктам.
Благодаря вашему отчету компания решает, что некоторые линейки продуктов не приносят должного дохода, поэтому они отказываются от этих продуктов и добавляют несколько новых. Бухгалтер встревожен, обнаружив, что отчет, который вы написали для него, по-прежнему показывает старые продукты и не включает в отчет новые продукты. Здесь ваше быстрое решение начинает идти на юг.
Бухгалтер встревожен, обнаружив, что отчет, который вы написали для него, по-прежнему показывает старые продукты и не включает в отчет новые продукты. Здесь ваше быстрое решение начинает идти на юг.Введите динамическую кросс-таблицу
Наступает момент, когда поддержание всех этих «жестко закодированных» кросс-таблиц требует больше усилий, чем тратить некоторое время на разработку более универсального, постоянного решения. Решение, к которому я пришел, все еще по существу использует функцию CASE для перекрестной таблицы данных. Единственное реальное отличие состоит в том, что список операторов CASE создается динамически на основе данных, которые вы хотите использовать для описания столбцов.
Созданная мной хранимая процедура запустилась как простая динамическая Построитель инструкций CASE с использованием sp_executesql . Это сразу же стало полезным, и вскоре люди задавали вопросы: « Как мне заставить его делать …». Постепенно он превратился в монстра, которым он является сегодня.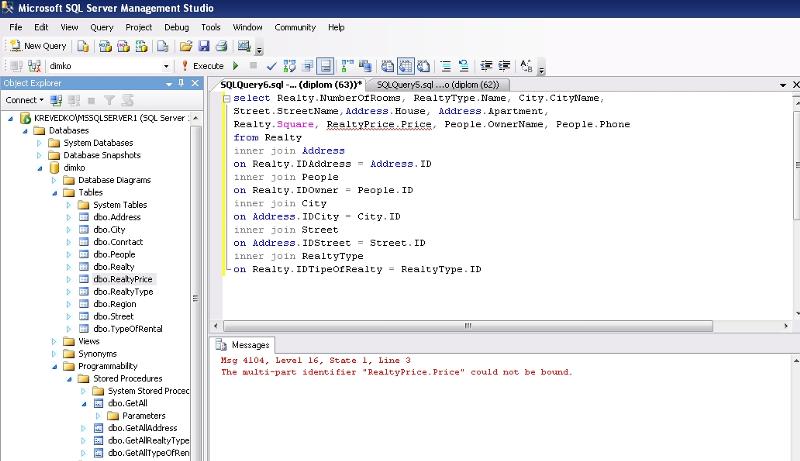 Намерение всегда состояло в том, чтобы иметь процедуру, которая была бы настолько общей и переносимой, чтобы ее можно было добавить в любую базу данных, а кросс-таблицы можно было бы создавать немедленно без какой-либо дополнительной настройки или изменения в коде SQL. Хотя простота использования, возможно, немного пострадала, я чувствую, что основная цель была достигнута.
Намерение всегда состояло в том, чтобы иметь процедуру, которая была бы настолько общей и переносимой, чтобы ее можно было добавить в любую базу данных, а кросс-таблицы можно было бы создавать немедленно без какой-либо дополнительной настройки или изменения в коде SQL. Хотя простота использования, возможно, немного пострадала, я чувствую, что основная цель была достигнута.
Используя хранимую процедуру
Для начала давайте создадим набор результатов кросс-таблицы со списком компаний в первом столбце, именем контакта в компании во втором столбце и списком товаров на складе из третьего столбца. вперед. Внутри сетки мы укажем общую стоимость заказов, размещенных этой компанией для этого продукта. Он должен быть отсортирован по названию компании.
SQL-запрос, возвращающий исходные данные, которые нам нужны:
1 2 4 5 6 7 8 10 110003 12 13 14 199991111000114 9000 3 9000 3 9000 3 9000 2 9000 214 9000 3 9000 3 9000 29000 3 9000 3 9000 3 18 19 20 21 22 23 24 25 26 27 28 29 30 31 3230 31 9000 3 29000 230 32 32 32 30 31000 3 28 30 9000 2 2830 9000 2 289000 2 28 000333 34 | Select Cus. prod.productname, det.unitprice, det.quantity от Orders Ord Внутреннее соединение [Подробная информация о заказа] DET на DET . .OrderID = ord.OrderID
INNER JOIN Products prod ON prod.ProductID = det.ProductID Внутреннее соединение клиентов CUS на cus.customerid = ord.customerid и вот как мы это сделаем: Exec sys_crosstab Orders ord Внутреннее соединение [Подробная информация о заказа] Det на Det.Orders = = Ord.OrderId Inner Join Products Products Prod на prod.productid = det.productid Внутреннее соединение клиентов Cus на cus.customerid = ord.customerid ‘, -@SQLSource ‘prod.productid’,-@colfieldid ‘prod.productname’,-@colfieldname ‘prod.productname’,-@colfieldorder ‘det.unitprice * det.quantity’,- @CalcFieldName ‘cus. NULL, —0003 ‘sum’,-@calcoperation 0,-@debug NULL,-@Sourcefilter 0,-@NumColordering ‘Всего’,-@RowTotals NULL,—- @ColTotals ‘CompanyName’, -@orderby ‘int’ -@calcfieldtype |
 companyname, cus.contactname, prod.productid,
companyname, cus.contactname, prod.productid, CompanyName, cus.ContactName’, — @RowFieldNames
CompanyName, cus.ContactName’, — @RowFieldNamesПервые несколько возвращаемых строк и столбцов будут
Структура хранимой процедуры
Если вы хотите отрегулировать процедуру, сделать ее более эффективной, возможно, адаптировать ее к вашим индивидуальным потребностям и вырезать некоторые функциональность, которую вы никогда не будете использовать, вам может быть интересно, как она была собрана. Если у вас есть идеи, как сделать что-то лучше, пожалуйста, поделитесь ими со всеми нами. Хранимая процедура достаточно хорошо задокументирована, и вы сможете разобраться в коде.
Вы заметите, что сразу несколько varchar(8000) объявлений переменных. В самом начале проекта я обнаружил, что varchar(8000) недостаточно для чего-либо, кроме самого тривиального запроса. Единственным способом обойти эту проблему хранения было создать диапазон этих переменных, и по мере заполнения первого я начинал добавлять информацию в следующий. Для каждой части окончательного запроса, который мы строим, был объявлен ряд переменных, а именно CASE операторов, список полей выбора, итоги и так далее.
В самом начале проекта я обнаружил, что varchar(8000) недостаточно для чего-либо, кроме самого тривиального запроса. Единственным способом обойти эту проблему хранения было создать диапазон этих переменных, и по мере заполнения первого я начинал добавлять информацию в следующий. Для каждой части окончательного запроса, который мы строим, был объявлен ряд переменных, а именно CASE операторов, список полей выбора, итоги и так далее.
Первым делом необходимо определить имена столбцов кросс-таблицы. Это будет первый из двух запросов к вашим исходным данным. Мы вставляем все отдельные имена столбцов в таблицу памяти (#Columns ) в том порядке, в котором они должны появляться в кросс-таблице. Если вы выбрали отображение итогов по столбцам, они будут рассчитаны и сохранены на этом этапе.
Затем удаляются все префиксы из полей строки. Это важно, так как мы будем группировать по этим полям, а псевдонимы или ссылки на таблицы могут усложнить сгенерированный запрос.
Затем я определяю курсор, который перемещается по элементам, которые были вставлены в таблицу памяти #Columns . При этом создаются операторы CASE , которые используются для выполнения агрегатных функций над исходными данными. Некоторая работа также выполняется над созданием частей оператора SQL для сумм строк и столбцов, а также оператора вставки в целевую временную таблицу, если эти параметры были выбраны.
После того, как мы собрали части и кусочки, мы связываем их вместе и запускаем запрос. Если вы посмотрите на код хранимой процедуры, то увидите, что я определил восемь различных сценариев в зависимости от того, решили ли мы сохранять данные во временную таблицу или использовать итоговые данные по строкам и столбцам. Определяется применимый сценарий, после чего окончательный оператор SQL соответствующим образом объединяется вместе с отладочной версией, если отладка была включена. Это будет второй запрос к вашему источнику данных.
Было бы трудно описать хранимую процедуру более подробно, если не вдаваться в подробности. Тем не менее, я чувствую, что код адекватно прокомментирован, и у вас не должно возникнуть особых проблем с внесением изменений, если вы решите это сделать. Лучший совет, который я могу дать, — использовать средства отладки, так как вы сразу же увидите эффект ваших изменений на сгенерированном коде SQL.
Тем не менее, я чувствую, что код адекватно прокомментирован, и у вас не должно возникнуть особых проблем с внесением изменений, если вы решите это сделать. Лучший совет, который я могу дать, — использовать средства отладки, так как вы сразу же увидите эффект ваших изменений на сгенерированном коде SQL.
Параметры хранимой процедуры, объяснение
Прототип хранимой процедуры выглядит следующим образом:
1 2 3 4 5 6 7 8 10 110003 12 13 14 1993 16000313 14 9000.9000 313 14 9000 3 | CREATE PROC [dbo].[sys_CrossTab] @SQLSource varchar(8000), @ColFieldID varchar(8000), @colfieldname varchar (8000), @colfieldorder varchar (8000), @calcfieldname varchar (8000), @rowfieldnames varchar (8000), @temptablename (200) = Null, @TempleAbleName (200) = Null, @TempleAbleNam Calcoperation varchar (50) = ‘sum’, @debug bit = 0, @sourcefilter varchar (8000) = null, @numcolordering bit = 0, @rowtotals varchar (100) = nul0003 @ColTotals varchar(100) = null, @OrderBy varchar(8000) = null, @CalcFieldType varchar(100) = ‘int’ 333 |
Моему исходному приложению не нужны были nvarchar s, а мне действительно нужно было дополнительное место для хранения, поэтому я решил использовать тип данных varchar .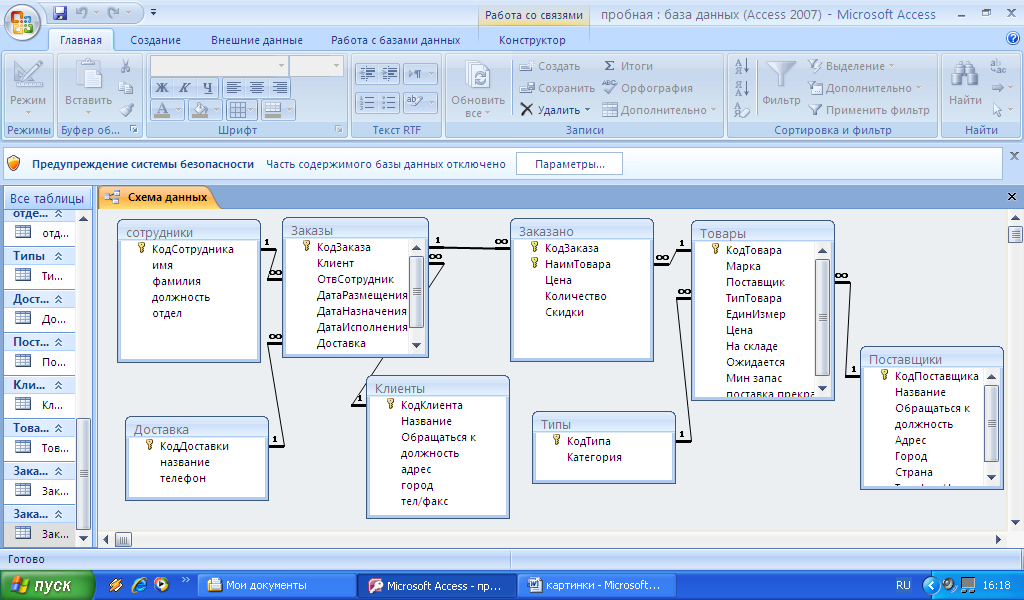 Я бы порекомендовал вам изменить их на nvarchar s, если вы хотите, чтобы код был культурно-безопасным.
Я бы порекомендовал вам изменить их на nvarchar s, если вы хотите, чтобы код был культурно-безопасным.
Приведены некоторые подробности назначения и использования каждого параметра. Если мое описание кажется вам слишком расплывчатым, взгляните на приведенный выше пример скрипта и результат, который он сгенерировал, или, что еще лучше, запустите скрипт сами и поэкспериментируйте с ним.
@SQLSource
Первый параметр, @SQLSource , именно таков; источник данных, из которого вы хотите создать кросс-таблицу. Это может быть имя таблицы, имя представления, имя функции или даже предложение FROM оператора SELECT , как мы использовали в примере. Еще раз взгляните на представленную мной инструкцию SQL и сравните ее с текстом, используемым для параметра @SQLSource . По сути, это часть оператора SQL после Ключевое слово FROM , вплоть до предложения WHERE , если оно существует, но не включая его. Если вы хотите использовать таблицу, представление или функцию, используйте только имя и, возможно, псевдоним — не используйте ключевое слово SELECT .
@ColFieldID
Нам нужно решить для каждой строки исходных данных, какому столбцу присвоить значения. Параметр @ColFieldID используется для выбора столбца, который будет использоваться для этой функции. В нашем примере используется поле ProductID . Количество различных значений, которые этот столбец имеет в исходных данных, скажет вам, сколько столбцов будет использоваться в кросс-таблице. Это важное соображение, особенно если вы хотите использовать результаты перекрестной таблицы в электронной таблице Excel, так как Excel накладывает верхний предел на количество столбцов, которые он может обрабатывать.
@ColFieldName
Используйте @ColFieldName, чтобы указать имя поля, которое будет содержать заголовки для каждого столбца кросс-таблицы. Это может быть то же поле, которое используется для @ColFieldID .
@ColFieldOrder
Если вам требуется сортировка столбцов, вы можете указать поле, по которому должно происходить упорядочение. Параметр @ColFieldOrder должен содержать имя этого поля заказа. Это тоже может быть то же поле, что и @ColFieldID 9.0026 . Вы также можете установить параметр @NumColOrdering , если порядок важен. По умолчанию столбцы будут отсортированы в алфавитно-цифровом порядке. Если вам требуется численная сортировка, установите для @NumColOrdering значение 1. Описание этого параметра даст немного больше деталей.
Параметр @ColFieldOrder должен содержать имя этого поля заказа. Это тоже может быть то же поле, что и @ColFieldID 9.0026 . Вы также можете установить параметр @NumColOrdering , если порядок важен. По умолчанию столбцы будут отсортированы в алфавитно-цифровом порядке. Если вам требуется численная сортировка, установите для @NumColOrdering значение 1. Описание этого параметра даст немного больше деталей.
@CalcFieldName
@CalcFieldName должно содержать имя поля, которое будет использоваться для создания данных в сетке кросс-таблицы. Это будут базовые данные подсчета, суммы, среднего значения или любой другой агрегатной функции, которую вы выберете. Естественно, вы должны убедиться, что тип данных этого поля соответствует операции, которую вы хотите выполнить. Вы не можете выполнить SUM операция в поле varchar , хотя операция COUNT вполне приемлема.
@RowFieldNames
Здесь вы предоставите разделенный запятыми список, состоящий из одного или нескольких имен полей, которые будут использоваться в качестве первых нескольких столбцов сетки. Агрегатная функция, которую вы намереваетесь выполнить, будет выполняться как функция группировки полей, которые вы укажете здесь, поэтому выбирайте их с умом.
Агрегатная функция, которую вы намереваетесь выполнить, будет выполняться как функция группировки полей, которые вы укажете здесь, поэтому выбирайте их с умом.
@TempTableName
Иногда перекрестная таблица является не окончательным результатом, а средством достижения цели. Возможно, вы захотите выполнить дополнительные запросы к сгенерированным данным перекрестной таблицы или соединить их с другими таблицами. По этой причине был добавлен параметр @TempTableName . Он позволяет вставлять данные перекрестной таблицы во временную таблицу, которую затем можно использовать для дальнейшей обработки.
Здесь есть ряд предостережений. Во-первых, вам необходимо создать временную таблицу, прежде чем вызывать хранимую процедуру перекрестной таблицы (из-за правил области видимости SQL). Однако при создании таблицы вам необходимо указать хотя бы один столбец. Проще всего сделать что-то вроде
CREATE TABLE #CrossTab (фиктивный TINYINT NULL) |
Затем вы передадите имя временной таблицы (в данном случае #CrossTab ) хранимой процедуре. После завершения создания кросс-таблицы ваша временная таблица будет содержать информацию кросс-таблицы в дополнение к вашему фиктивному полю. Если, как и я, вы считаете, что фиктивное поле «тратится впустую», вы можете объявить его как поле идентификации, тем самым добавив порядковый номер в свою таблицу.
После завершения создания кросс-таблицы ваша временная таблица будет содержать информацию кросс-таблицы в дополнение к вашему фиктивному полю. Если, как и я, вы считаете, что фиктивное поле «тратится впустую», вы можете объявить его как поле идентификации, тем самым добавив порядковый номер в свою таблицу.
CREATE TABLE #CrossTab (последовательность INT IDENTITY(1,1)) |
Пользователей вашего запроса гораздо меньше беспокоит порядковый номер, чем пустой, бесполезный столбец в начале набора результатов.
@CalcOperation
Здесь мы сообщаем хранимой процедуре, что делать с исходными данными, которые мы предоставляем. Приемлемыми значениями этого параметра являются любые агрегатные функции SQL, а именно AVG , SUM , COUNT , MIN , MAX и им подобные. Убедитесь, что вы сопоставляете операцию с типом данных, то есть не SUM ming данных varchar.
@Debug
Параметр @Debug , отключенный по умолчанию, может оказаться очень удобным. Когда включено (установлено на 1), он распечатает код SQL, используемый для создания кросс-таблицы. Если вы не ожидаете, что столбцы вашей кросс-таблицы изменятся, вы можете запустить SQL, распечатанный кодом отладки, вместо использования хранимой процедуры, что будет значительно эффективнее. Таким образом, вы можете использовать хранимую процедуру в качестве инструмента генерации SQL.
Когда включено (установлено на 1), он распечатает код SQL, используемый для создания кросс-таблицы. Если вы не ожидаете, что столбцы вашей кросс-таблицы изменятся, вы можете запустить SQL, распечатанный кодом отладки, вместо использования хранимой процедуры, что будет значительно эффективнее. Таким образом, вы можете использовать хранимую процедуру в качестве инструмента генерации SQL.
Обратите внимание, что итоги строк не будут вычисляться отладочным SQL. Хранимая процедура «жестко закодирует» итоги, рассчитанные во время ее запуска.
@SourceFilter
@SourceFilter позволяет ввести некоторый код SQL для фильтрации исходных данных до того, как они будут объединены в перекрестные таблицы. Это будет код предложения WHERE , соответствующий коду предложения SELECT , указанному в параметре @SQLSource . Нет причин, по которым вы не можете включить 9Предложение 0025 WHERE как часть данных, передаваемых @SQLSource , хотя мне проще и удобнее указывать его отдельно.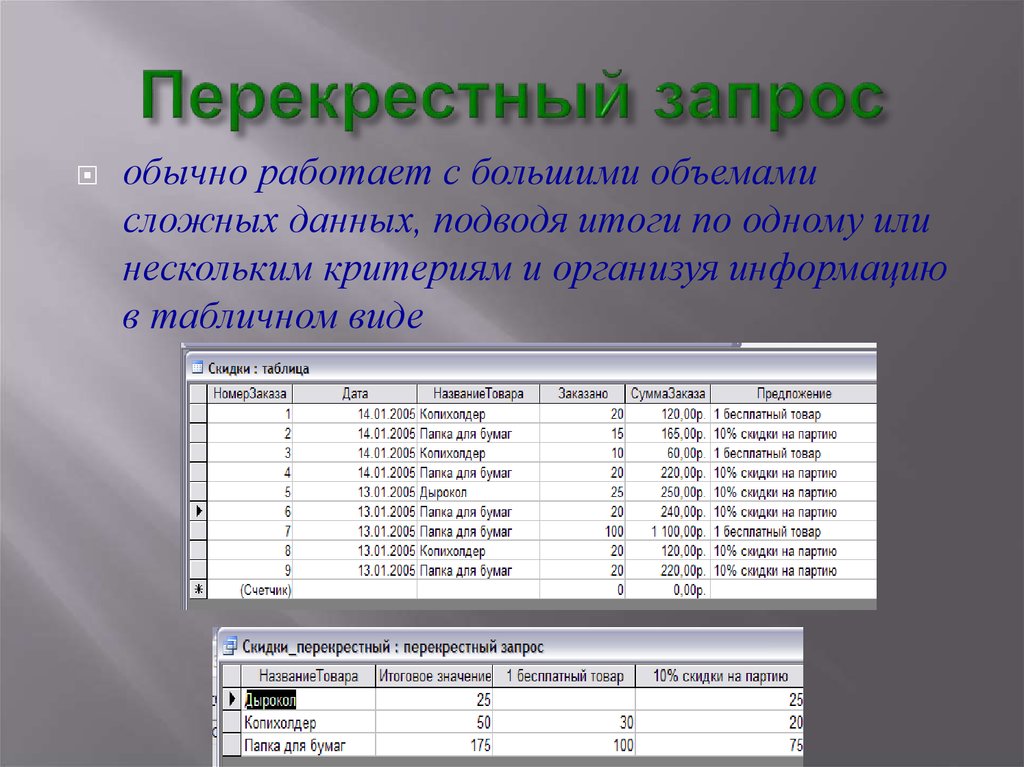
@NumColOrdering
Если вы хотите, чтобы ваши столбцы были расположены в определенном порядке, вы укажете имя поля, чтобы упорядочить их по параметру @ColFieldOrder , и вы будете использовать поле @NumColOrdering чтобы указать, как будет происходить заказ. При значении 0 (по умолчанию) данные будут отсортированы в алфавитно-цифровом порядке, а при значении 1 — в числовом.
Если вы не уверены в разнице между ними, рассмотрите следующий список: 2, 1, 10, 11, 20, 100. При численной сортировке это будет 1, 2, 10, 11, 20. , 100. Однако сортировка по алфавиту приведет к 1, 10, 100, 11, 2, 20. Естественно, сортировка по буквам и цифрам также будет обрабатывать A, B и C, тогда как сортировка по числам вызовет ошибку несоответствия типов.
@RowTotals
Если для этого параметра задано значение, отличное от NULL, в качестве последнего столбца результирующего набора будет добавлен дополнительный столбец (имя столбца является приведенным здесь значением) и будет содержать сумму перекрестных значений.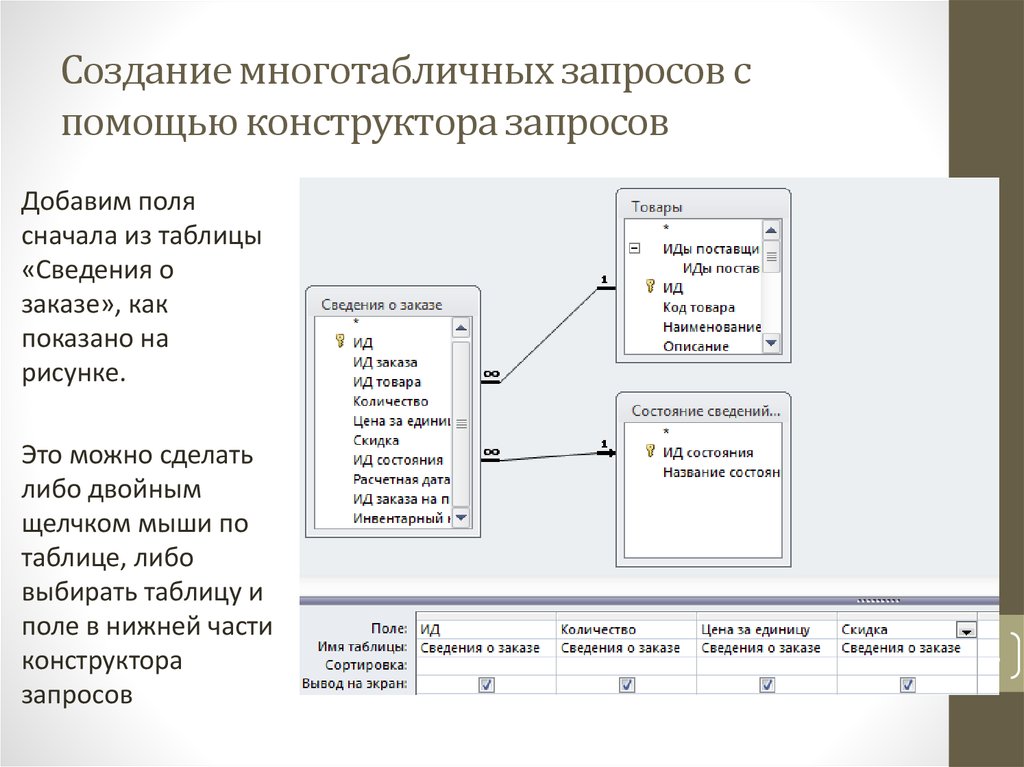 значения табуляции для каждой строки.
значения табуляции для каждой строки.
@ColTotals
Если установлено значение, отличное от NULL, в качестве последней строки результирующего набора будет добавлена дополнительная строка, которая будет содержать сумму значений перекрестной таблицы для каждого столбца. Однако есть ряд вещей, на которые следует обратить внимание. Во-первых, вам нужно будет передать имена полей, уже заключенные в кавычки, в параметр. Например, если вы хотите, чтобы строка была помечена как Total, вам нужно установить @ColTotals на «Total». Во-вторых, вам нужно будет указать столько значений, сколько полей, которые вы указали в Параметр @RowFieldNames . В нашем примере мы использовали два поля, поэтому нам нужно указать два значения для @ColTotals . Наконец, эта общая строка может не обязательно отображаться в нижней части набора результатов, в зависимости от того, указали ли вы значение параметра @OrderBy . Итоги добавляются 90 193 до 90 194 к сортируемой кросс-таблице.
Если вы включили опцию отладочной печати, предоставленный вам код SQL также не будет динамически вычислять итоги по столбцам. Итоги будут определены во время первоначального выполнения хранимой процедуры, а затем эти фиксированные значения присоединятся к остальной части результирующего набора.
@OrderBy
Параметр @OrderBy позволяет указать условие ORDER BY . Если используется, это должно быть одно или несколько полей, используемых в параметре @RowFieldnames . Если вы используете @ColTotals , имейте в виду, что строка итогов столбца будет считаться частью данных кросс-таблицы и будет упорядочена вместе с другими строками.
@CalcFieldType
Тип данных вычисляемых полей в сетке кросс-таблицы можно указать с помощью Параметр @CalcFieldType . По умолчанию это будет типов INT . Установите тип, соответствующий типу выполняемой операции и типу данных, которые вы ожидаете увидеть в кросс-таблице.
Вызов!
Если вы собираетесь опробовать хранимую процедуру, вы также можете получить кое-что за свои усилия. Редактор Simple-Talk Тони Дэвис любезно предложил спонсировать приз за первые три правильных ответа на вызов. Он также основан на базе данных Northwind, и вам нужно будет сделать следующее:
Скомпилируйте отчет в виде кросс-таблицы, отображающий стоимость заказа по клиентам за квартал. Вы также должны сгруппировать клиентов по стране, в которой они находятся. Отсортируйте список по стране, а затем по названию компании. Отображать итоги как по строке, так и по столбцу, чтобы они отображались справа и внизу отчета соответственно. Я включил снимок экрана, чтобы вы могли видеть, как должен выглядеть отчет.
Опубликуйте исходный код своего решения в комментариях к этой статье (или отправьте его Тони по адресу [email protected]).
В заключение
Вы обнаружите, что как только вы сделали одну кросс-таблицу, вы почти сделали их все.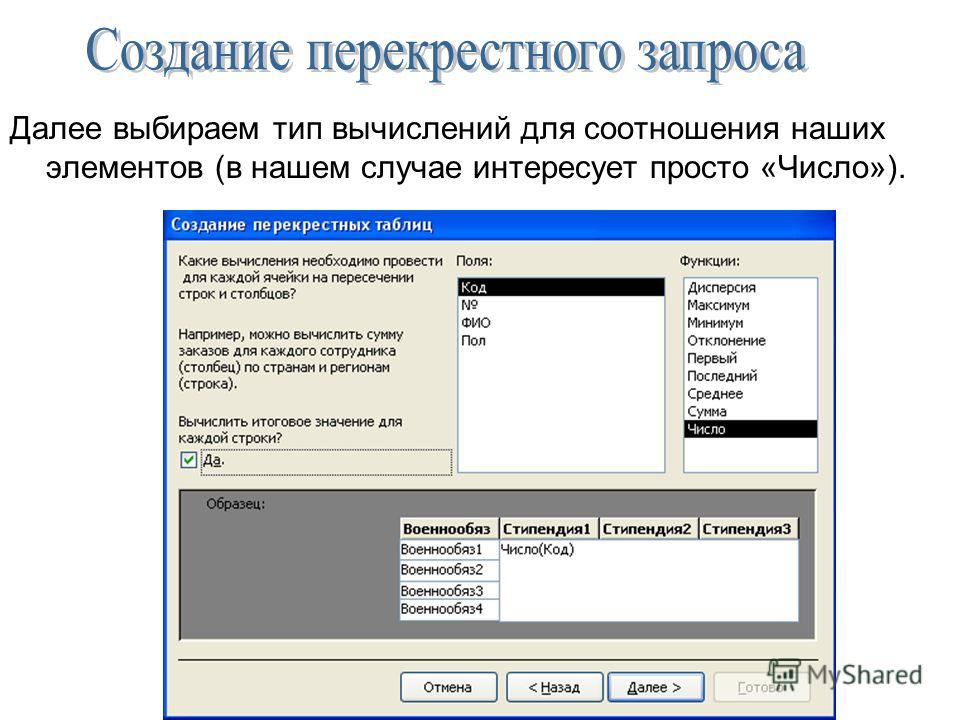 Наибольшая трудность заключается в том, чтобы действительно решить, что вы хотите отобразить, а затем собрать исходные данные для хранимой процедуры. Фактическое создание кросс-таблицы — это просто вопрос сопоставления имен полей с входными параметрами.
Наибольшая трудность заключается в том, чтобы действительно решить, что вы хотите отобразить, а затем собрать исходные данные для хранимой процедуры. Фактическое создание кросс-таблицы — это просто вопрос сопоставления имен полей с входными параметрами.
Я надеюсь, что вы найдете эту хранимую процедуру столь же полезной, как и я — это один из самых ценных предметов в моем наборе инструментов. Если вы обнаружите для него какое-то новое применение или новую идею о том, как его немного улучшить, поделитесь им с нами. Мне, например, было бы интересно услышать об этом.
Ключевое слово MySQL CROSS JOIN
❮ Предыдущий Далее ❯
Ключевое слово SQL CROSS JOIN
Ключевое слово CROSS JOIN возвращает все записи
из обеих таблиц (таблица1 и таблица2).
Синтаксис CROSS JOIN
SELECT имя_столбца
FROM table1
CROSS JOIN table2 ;
Примечание: CROSS JOIN потенциально может возвращать очень большие
наборы результатов!
Демонстрационная база данных
В этом руководстве мы будем использовать известную учебную базу данных Northwind.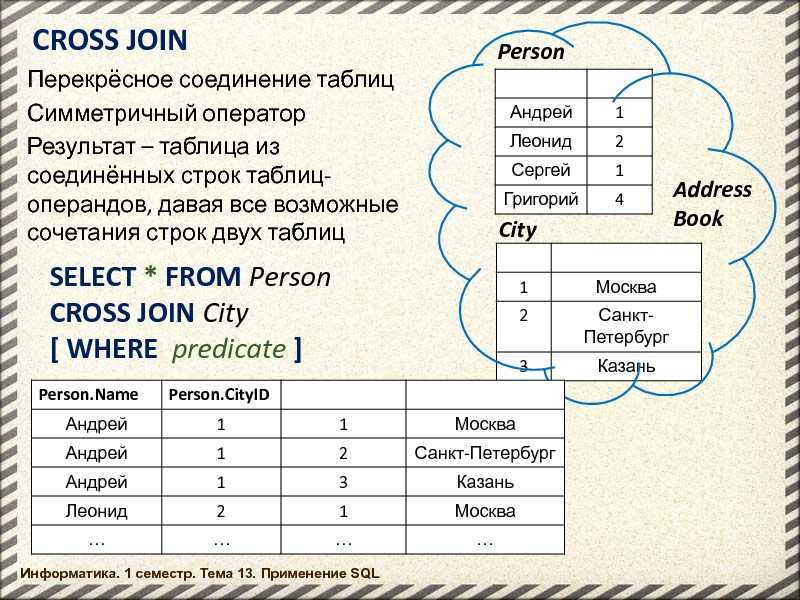
Ниже представлена выборка из таблицы «Клиенты»:
| CustomerID | ИмяКлиента | Имя контакта | Адрес | Город | Почтовый индекс | Страна |
|---|---|---|---|---|---|---|
| 1 | Альфред Футтеркисте | Мария Андерс | ул. Обере 57 | Берлин | 12209 | Германия |
| 2 | Ана Трухильо Emparedados y helados | Ана Трухильо | Авда. Конститусьон 2222 | Мексика Д.Ф. | 05021 | Мексика |
| 3 | Антонио Морено Такерия | Антонио Морено | Матадерос 2312 | Мексика Д.Ф. | 05023 | Мексика |
И выбор из таблицы «Заказы»:
| OrderID | идентификатор клиента | ID сотрудника | Дата заказа | Код отправителя |
|---|---|---|---|---|
| 10308 | 2 | 7 | 1996-09-18 | 3 |
| 10309 | 37 | 3 | 1996-09-19 | 1 |
| 10310 | 77 | 8 | 1996-09-20 | 2 |
MySQL CROSS JOIN Пример
Следующая инструкция SQL выбирает всех клиентов и все заказы:
Пример
SELECT Customers.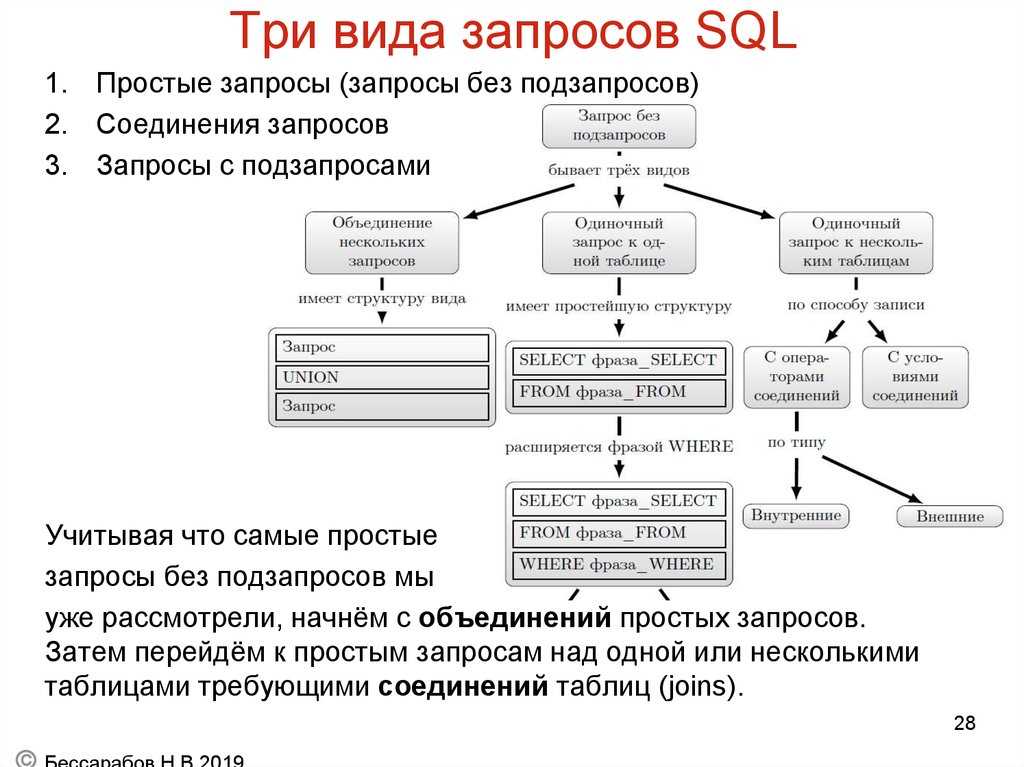 CustomerName, Orders.OrderID
CustomerName, Orders.OrderID
FROM CROSS JOIN Заказы
;
Попробуйте сами »
Примечание: Ключевое слово CROSS JOIN возвращает все совпадения
записи из обеих таблиц независимо от того, совпадает ли другая таблица или нет. Так что если
есть строки в «Клиентах», которым нет совпадений в «Заказах», или если есть
являются строками в «Заказах», которые не имеют совпадений в «Клиентах», эти строки будут
также перечислено.
Если добавить предложение WHERE (если таблица1 и
table2 имеет отношение), CROSS JOIN будет
дает тот же результат, что и предложение INNER JOIN :
Пример
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
CROSS JOIN Orders
WHERE Customers.CustomerID=Orders.CustomerID;
Попробуйте сами »
❮ Предыдущая Следующий ❯
ВЫБОР ЦВЕТА
Лучшие учебники
Учебник HTMLУчебник CSS
Учебник JavaScript
How To Tutorial
Учебник SQL
Учебник Python
Учебник W3.
 CSS
CSS Учебник Bootstrap
Учебник PHP
Учебник Java
Учебник C++
Учебник jQuery
9008 Справочник
9008
Справочник по HTML
Справочник по CSS
Справочник по JavaScript
Справочник по SQL
Справочник по Python
Справочник по W3.CSS
Справочник по Bootstrap
Справочник по PHP
Цвета HTML
Справочник по Java
Справочник по Angular
Справочник по jQuery
Основные примеры
Примеры HTMLПримеры CSS
Примеры JavaScript
Примеры инструкций
Примеры SQL
Примеры Python
Примеры W3.CSS
Примеры Bootstrap
Примеры PHP
Примеры Java
Примеры XML
Примеры jQuery
- FORUM |
О
W3Schools оптимизирован для обучения и обучения. Примеры могут быть упрощены для улучшения чтения и обучения.
Учебники, ссылки и примеры постоянно пересматриваются, чтобы избежать ошибок, но мы не можем гарантировать полную правильность всего содержания.