Рекурсия в MS SQL — Fast Reports
Иногда, в хранимой процедуре или функции требуется использовать результаты выборки несколько раз. В таких случаях мы часто используем временные таблицы. Однако, стоит учитывать некоторые преимущества и недостатки временных таблиц. Преимущества:
- Временные таблицы являются полноценными таблицами. Поэтому для них можно создавать индексы и статистику. Это может существенно ускорить работу с ними.
Недостатки:
- Заполнение временной таблицы связано с перемещением данных. Хоть это и простая операция Insert, все же при больших объемах данных есть нагрузка на диски;
- Существует риск увеличения времени выполнения запросов. Временные таблицы создаются в базе tempdb. А нагрузка на эту базу существенная.
Учитывая риски использования временных таблиц, гораздо привлекательнее выглядит применение обобщенного табличного выражения.
Обобщённое табличное выражение
Common Table Expression (CTE) выражение с общей таблицей, которую можно использовать множество раз в запросе. CTE не сохраняет данные, а создает нечто вроде временного представления. Кто-то может сказать, что CTE – это подзапрос, который предшествует основному запросу. Но это не совсем так, ведь подзапрос нельзя использовать несколько раз, а CTE можно.
Когда же стоит использовать обобщенное табличное выражение?
- Для создания рекурсивных запросов, с помощью которых можно получить данные в иерархическом виде;
- При многократных ссылках на набор данных в пределах одного запроса;
- С целью заменить представления, временные таблицы, табличные переменные.
К преимуществам CTE можно отнести: рекурсию, высокую скорость работы запроса, лаконичность запроса.
А к недостаткам отнесем ограниченность использования. CTE может использоваться только для запроса, к которому он принадлежит.
Обобщенные табличные выражения бывают простые и рекурсивные.
Простые не включают ссылки на самого себя, а рекурсивные соответственно включают.
Рекурсивные CTE используются для возвращения иерархических данных
Рассмотрим пример простого CTE предложения:
1 2 3 4 5 6 |
WITH CTEQuery (Field1, Field2) AS ( SELECT (Field1, Field2) FROM TABLE ) SELECT * FROM CTEQuery |
Здесь CTEQuery — имя CTE;
Field1, Field2 – имена полей запроса;
Table – некая таблица, из которой выбираются данные для использования в основном запросе.
В это примере можно и не указывать явно поля выборки, так как мы выбираем все поля из таблицы TestTable:
1 2 3 4 5 6 |
WITH CTEQuery AS ( SELECT * FROM Table ) SELECT * FROM CTEQuery |
С помощью CTE можно оптимизировать основной запрос если вынести часть логики в CTE. Дело в том, что CTE позволяет создавать сразу несколько выражений (запросов). Таким образом вы можете разбить сложный запрос на несколько предварительных «представлений» с помощью CTE, а затем связать их в общем запросе:
Дело в том, что CTE позволяет создавать сразу несколько выражений (запросов). Таким образом вы можете разбить сложный запрос на несколько предварительных «представлений» с помощью CTE, а затем связать их в общем запросе:
1 2 3 4 5 6 7 8 9 10 11 12 |
WITH CTEQuery1 (Field1, Field2) AS ( SELECT Field1 AS ID, Field2 FROM Table1 WHERE Field2 >= 1000 ), CTEQuery2 (Field3, Field4) AS ( SELECT Field3 AS ID, Field4 FROM Table2 WHERE Field4 = 'Москва' ) SELECT * FROM CTEQuery1 INNER JOIN CTEQuery2 ON CTEQuery2.ID = CTEQuery1.ID |
Как было сказано выше, основное назначение CTE – рекурсия. Типовая задача для рекурсии – обход дерева. Так что мы можем строить дерево с помощью with. Структура рекурсивного запроса впервые появилась в SQL Server 2005.
Взгляните на инструкцию WITH:
1 2 3 4 5 6 7 |
WITH RecursiveQuery AS
(
{Anchor}
UNION ALL
{Joined TO RecursiveQuery}
)
SELECT * FROM RecursiveQuery |
{Anchor} – якорь, запрос, который определяет начальный элемент дерева (иерархического списка). Обычно в якоре есть условие WHERE определяющее конкретные строки таблицы.
Обычно в якоре есть условие WHERE определяющее конкретные строки таблицы.
После UNION ALL следует запрос к целевой таблице с JOIN к CTE выражению.
{Joined to RecursiveQuery}- SELECT из целевой таблицы. Обычно это та же таблица, которая используется в якоре. Но в этом запросе она соединяется с CTE выражением, образуя рекурсию. Условие этого соединения определяет отношение родитель – ребенок. От этого зависит переходите ли вы на верхние уровни дерева или на нижние.
Давайте посмотрим на рекурсивный запрос, который возвращает список подразделений организации. Подготовим данные для этого запроса:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
CREATE TABLE Department ( ID INT, ParentID INT, Name VARCHAR(50) ) INSERT INTO Department ( ID, ParentID, Name ) VALUES (1, 0, 'Finance Director') INSERT INTO Department ( ID, ParentID, Name ) VALUES (2, 1, 'Deputy Finance Director') INSERT INTO Department ( ID, ParentID, Name ) VALUES (3, 1, 'Assistance Finance Director') INSERT INTO Department ( ID, ParentID, Name ) VALUES (4, 3, 'Executive Bodget Office') INSERT INTO Department ( ID, ParentID, Name ) VALUES (5, 3, 'Comptroller') INSERT INTO Department ( ID, ParentID, Name ) VALUES (6, 3, 'Purchasing') INSERT INTO Department ( ID, ParentID, Name ) VALUES (7, 3, 'Debt Management') INSERT INTO Department ( ID, ParentID, Name ) VALUES (8, 3, 'Risk Management') INSERT INTO Department ( ID, ParentID, Name ) VALUES (9, 2, 'Public Relations') INSERT INTO Department ( ID, ParentID, Name ) VALUES (10, 2, 'Finance Personnel') INSERT INTO Department ( ID, ParentID, Name ) VALUES (11, 2, 'Finance Accounting') INSERT INTO Department ( ID, ParentID, Name ) VALUES (12, 2, 'Liasion to Boards and Commissions') |
Уже сейчас понятно, что структура подразделений в организации иерархическая. Наша задача получить список подразделений, подчиненных помощнику финансового директора. Если рассуждать в контексте иерархического дерева, то мы должны найти ветвь и ее листья.
Наша задача получить список подразделений, подчиненных помощнику финансового директора. Если рассуждать в контексте иерархического дерева, то мы должны найти ветвь и ее листья.
Но сначала давайте посмотрим весь список подразделений:
|
ID |
ParentID |
Name |
|
1 |
0 |
Finance Director |
|
2 |
1 |
Deputy Finance Director |
|
3 |
1 |
Assistance Finance Director |
|
4 |
3 |
Executive Bodget Office |
|
5 |
3 |
Comptroller |
|
6 |
3 |
Purchasing |
|
7 |
3 |
Debt Management |
|
8 |
3 |
Risk Management |
|
9 |
2 |
Public Relations |
|
10 |
2 |
Finance Personnel |
|
11 |
2 |
Finance Accounting |
|
12 |
2 |
Liasion to Boards and Commissions |
Во главе стоит финансовый директор, ему подчиняются заместитель и помощник.
Давайте напишем рекурсивный запрос с помощью WITH.
1 2 3 4 5 6 7 8 9 10 11 12 13 |
WITH RecursiveQuery (ID, ParentID, Name) AS ( SELECT ID, ParentID, Name FROM Department dep WHERE dep.ID = 3 UNION ALL SELECT dep.ID, dep.ParentID, dep.Name FROM Department dep JOIN RecursiveQuery rec ON dep.ParentID = rec.ID ) SELECT ID, ParentID, Name FROM RecursiveQuery |
В этом примере явно указаны названия полей, которые нужно выбрать в CTE. Однако, внутренние запросы имеют такие же поля. Так что можно просто убрать это перечисление вместе со скобками.
Внутри CTE мы имеем два похожих запроса. Первый выбирает корневой элемент дерева, которое мы строим. Второй – все последующие подчиненные элементы, благодаря связи с самим CTE. «Рекурсия» в SQL на самом деле не рекурсия, а итерация. Нужно представить запрос с JOIN как цикл, и тогда сразу все станет понятно. В каждой итерации мы знаем значение предыдущей выборки и получаем подчиненные элементы. На следующем шаге мы получим подчиненные элементы для предыдущей выборки. То есть каждая итерация – переход по дереву вниз, или вверх, в зависимости от условия связи.
Первый выбирает корневой элемент дерева, которое мы строим. Второй – все последующие подчиненные элементы, благодаря связи с самим CTE. «Рекурсия» в SQL на самом деле не рекурсия, а итерация. Нужно представить запрос с JOIN как цикл, и тогда сразу все станет понятно. В каждой итерации мы знаем значение предыдущей выборки и получаем подчиненные элементы. На следующем шаге мы получим подчиненные элементы для предыдущей выборки. То есть каждая итерация – переход по дереву вниз, или вверх, в зависимости от условия связи.
Результат выполнения приведенного запроса такой:
|
ID |
ParentID |
Name |
|
3 |
1 |
Assistance Finance Director |
|
4 |
3 |
Executive Bodget Office |
|
5 |
3 |
Comptroller |
|
6 |
3 |
Purchasing |
|
7 |
3 |
Debt Management |
|
8 |
3 |
Risk Management |
А вот как бы выглядел этот запрос без использования CTE:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
DECLARE @Department TABLE (ID INT, ParentID INT, Name VARCHAR(50), Status INT DEFAULT 0) -- Сначала мы выбираем в табличную переменную якорь – начальный элемент от которого строим дерево. |
 INSERT @Department
SELECT ID, ParentID, Name, 0
FROM Department dep
WHERE dep.ID = 3
DECLARE @rowsAdded INT = @@ROWCOUNT
-- Проходим цикл пока новые отделы добавляются в предыдущем шаге
WHILE @rowsAdded > 0
BEGIN
-- Помечаем записи в табличной переменной, как готовые к обработке
UPDATE @Department SET Status = 1 WHERE Status = 0
-- Выбираем дочерние записи для предыдущей записи
INSERT @Department
SELECT dep.ID, dep.ParentID, dep.Name, 0
FROM Department dep
JOIN @Department rec ON dep.ParentID = rec.ID
AND rec. Status = 1
SET @rowsAdded = @@ROWCOUNT
--Помечаем записи, найденные на текущем шаге как обработанные
UPDATE @Department SET Status = 2 WHERE Status = 1
END
SELECT * FROM @Department
INSERT @Department
SELECT ID, ParentID, Name, 0
FROM Department dep
WHERE dep.ID = 3
DECLARE @rowsAdded INT = @@ROWCOUNT
-- Проходим цикл пока новые отделы добавляются в предыдущем шаге
WHILE @rowsAdded > 0
BEGIN
-- Помечаем записи в табличной переменной, как готовые к обработке
UPDATE @Department SET Status = 1 WHERE Status = 0
-- Выбираем дочерние записи для предыдущей записи
INSERT @Department
SELECT dep.ID, dep.ParentID, dep.Name, 0
FROM Department dep
JOIN @Department rec ON dep.ParentID = rec.ID
AND rec. Status = 1
SET @rowsAdded = @@ROWCOUNT
--Помечаем записи, найденные на текущем шаге как обработанные
UPDATE @Department SET Status = 2 WHERE Status = 1
END
SELECT * FROM @Department Такой цикл работает заметно медленнее CTE выражения. Да и к тому же требует создания табличной переменной. И количество кода увеличилось в два раза. Таким образом, CTE выражения являются лучшим решением для организации рекурсивного обхода дерева в MS SQL.
Таким образом, CTE выражения являются лучшим решением для организации рекурсивного обхода дерева в MS SQL.
Dmitriy Fedyashov
Технический писатель
Fast Reports Team: Dmitriy Fedyashov — Technical Writer at Fast Reports
SQLДобавить комментарий
Несколько примеров рекурсивных SQL-запросов для системы DIRECTUM | Статья
Чтобы понять рекурсию, нужно сначала понять рекурсию.
Рекурсия — определение, описание, изображение какого-либо объекта или процесса внутри самого этого объекта или процесса, то есть ситуация, когда объект является частью самого себя.
Пожалуй, одним определением и ограничусь, в сети масса информации на эту тему.
В этой небольшой статье хочу привести примеры, которые могут быть полезны разработчику прикладной части DIRECTUM для реализации нескольких вспомогательных задач.
В стандартной поставке системы DIRECTUM есть ряд справочников, которые можно считать рекурсивными. Такие справочники содержат реквизит, сгенерированный по этому же справочнику (Подразделения, Поручения, РКК, Договоры и т.д.).
Косвенно рекурсивным можно считать справочники Работников (через Подразделения: в Работниках есть реквизит Подразделение, в Подразделении указан Руководитель — работник).
Кроме того, рекурсивной можно считать таблицу задач. Косвенно рекурсивной таблицу заданий (через задачи).
Построим несколько запросов на примере справочника Подразделения. Стандартный справочник Подразделения в DIRECTUM можно считать рекурсивным, так как в нем есть реквизит, который ссылается на сам справочник Подразделения: Головное подразделение. Фактически, любой из примеров легко переделать для другого справочника или таблиц ЗЗУ.
Пример 1
В качестве первого примера хочу привести общий запрос, который строит иерархию всех подразделений компании. В качестве подразделения нулевого уровня берется то, у которого не указано головное, далее по уровню подчиненности.
----------------------------------------------------------------- -- Иерархия подразделений ----------------------------------------------------------------- with DipartmentHiererhcy ( ID, HightID, Level) as ( -- Подразделение верхнего уровня (N = 0) select department.Analit, department.Podr, 0 as Level from MBAnalit department where department.Podr is null and department.vid = union ALL -- Подчиненное подразделение (N + 1) select department.Analit, department.Podr, Level + 1 from MBAnalit as department inner join DipartmentHiererhcy as hightdepartment on department.Podr = hightdepartment.ID where department.vid = ) -- Иерархия подразделений select hierarchy.ID as [ИД], department.NameAn as [Подразделение], IsNull(hightdepartment.NameAn, '') as [Ведущее подразделение], Level as [Уровень] from DipartmentHiererhcy hierarchy left join MBAnalit department on department.Analit = hierarchy.ID left join MBAnalit hightdepartment on hightdepartment.Analit = hierarchy.HightID
Результат этого запроса на тестовой базе: список подразделений с указанием ведущего и уровня в иерархии.
Пример 2
Запрос можно модифицировать и под конкретные задачи. Например, при разработке отчетов по определенному подразделению необходимо учитывать не только указанное, но и все подчиненные подразделения. В этом случае можно получить все дерево таким запросом:
----------------------------------------------------------------- -- Иерархия подразделений вниз от указанного ----------------------------------------------------------------- with DipartmentHiererhcy ( ID, HightID, Level) as ( -- Подразделение верхнего уровня (N = 0) select department.Analit, department.Podr, 0 as Level from MBAnalit department where department.Analit = and department.vid = union ALL -- Подчиненное подразделение (N + 1) select department.Analit, department.Podr, Level + 1 from MBAnalit as department inner join DipartmentHiererhcy as hightdepartment on department.Podr = hightdepartment.ID where department.vid = ) -- Иерархия подразделений вниз от указанного select hierarchy.ID as [ИД], department.NameAn as [Подразделение], IsNull(hightdepartment.NameAn, '') as [Ведущее подразделение], Level as [Уровень] from DipartmentHiererhcy hierarchy left join MBAnalit department on department.Analit = hierarchy.ID left join MBAnalit hightdepartment on hightdepartment.Analit = hierarchy.HightID
Пример 3
Также может возникнуть необходимость получить данные по всем подчиненным указанного работника:
----------------------------------------------------------------- -- Список подчиненных указанного работника ----------------------------------------------------------------- with DipartmentHiererhcy ( ID, HightID, Level) as ( -- Подразделение верхнего уровня (N = 0) select department.Analit, department.Podr, 0 as Level from MBAnalit department where department.FIO = and department.vid = union ALL -- Подчиненное подразделение (N + 1) select department.Analit, department.Podr, Level + 1 from MBAnalit as department inner join DipartmentHiererhcy as hightdepartment on department.Podr = hightdepartment.ID where department.vid = ) -- Список подчиненных указанного работника select distinct department.NameAn as [Подразделение], employee.NameAn as [Работник], IsNull(chiefemployee.NameAn, '') as [Руководитель], Level as [Уровень] from DipartmentHiererhcy hierarchy left join MBAnalit department on department.Analit = hierarchy.ID left join MBAnalit hightdepartment on hightdepartment.Analit = hierarchy.HightID left join MBAnalit employee on department.Analit = employee.Podr and employee.Vid = left join MBAnalit chiefemployee on department.FIO = chiefemployee.Analit and chiefemployee.
Vid = where employee.Analit is not null
Пример 4
Обратный к примеру 3: цепочка руководителей указанного работника по иерархии вверх (например, может понадобиться для построения списка согласующих):
-----------------------------------------------------------------
-- Список руководителей указанного работника
-----------------------------------------------------------------
with DipartmentHiererhcy (
ID,
HightID,
Level)
as
(
-- Подразделение нижнего уровня (N = 0)
select
department.Analit,
department.Podr,
0 as Level
from
MBAnalit department
where
department.Analit =
and department.vid =
union ALL
-- Ведущее подразделение (N + 1)
select
department.Analit,
department.Podr,
Level + 1
from
MBAnalit as department
inner join DipartmentHiererhcy as hightdepartment
on department.Analit = hightdepartment.HightID
where
department.vid =
)
-- Список руководителей указанного работника
select distinct
department. NameAn as [Подразделение],
IsNull(chiefemployee.NameAn, '') as [Руководитель],
Level as [Уровень]
from
DipartmentHiererhcy hierarchy
left join MBAnalit department
on department.Analit = hierarchy.ID
left join MBAnalit chiefemployee
on department.FIO = chiefemployee.Analit and chiefemployee.Vid =
NameAn as [Подразделение],
IsNull(chiefemployee.NameAn, '') as [Руководитель],
Level as [Уровень]
from
DipartmentHiererhcy hierarchy
left join MBAnalit department
on department.Analit = hierarchy.ID
left join MBAnalit chiefemployee
on department.FIO = chiefemployee.Analit and chiefemployee.Vid = В качестве P.S.
Не стоит забывать о возможности существования бесконечной рекурсии. Во избежание используйте:
OPTION (MAXRECURSION )
НОУ ИНТУИТ | Лекция | Средства формулировки аналитических и рекурсивных запросов
< Лекция 5 || Лекция 6: 123456 || Лекция 7 >
Аннотация: В этой лекции мы завершаем обсуждение средств выборки данных языка SQL коротким описанием сравнительно недавно появившихся в языке SQL средств формулировки аналитических и рекурсивных запросов.
Ключевые слова: SQL, стандарт SQL:1999, аналитический запрос к базе данных, рекурсивный запрос, заработная плата, агрегатные функции, СУБД, Внешняя сортировка, агрегирование, динамическая, базы данных, OLTP, оперативная аналитическая обработка баз данных, OLAP, стандарт языка, разделы, раздел GROUP BY ROLLUP, раздел GROUP BY CUBE, агрегатная функция GROUPING, неопределенное значение, операторы SQL, частное решение, логическое программирование, Prolog, реляционная база данных, рекурсивный запрос с разделом WITH, выражение, линейная рекурсия, взаимная рекурсия, рекурсивное определение, расходы, основные средства, таблица, EMP, ORDER, определение столбца, контекст, обход дерева в ширину, обход дерева в глубину, цикл в ориентированном графе, Ориентированный граф, прямая рекурсия, виртуальная таблица, подзапрос, монотонная прогрессия, отрицание, INTERSECT, distinction, начальный источник рекурсии, рекурсивные вычисления, стратификация, семантика фиксированной точки, конструкция SEARCH, cycle, CAR, атомарность, UNION, шасси, частичный результат, потомок, раздел CYRCLE, значение выражения, тип символьной строки, Типы данных столбцов, рекурсивное представление, recursive
Введение
 intuit.ru/2010/edi»>Две темы, которым посвящается эта лекция, касаются сравнительно новых возможностей оператора SELECT языка SQL, впервые появившихся в стандарте SQL:1999 и открывающих возможность использования языка в приложениях, для которых ранее он не был приспособлен. Речь идет о возможностях аналитических и рекурсивных запросов. Эти темы логически не связаны, их объединяет лишь то, что соответствующие средства очень громоздки и не всегда легко понимаются. В данной краткой лекции мы не стремимся привести полное описание возможностей, специфицированных в стандарте SQL. Наша цель состоит лишь в том, чтобы в общих чертах описать подход SQL в указанных направлениях.
intuit.ru/2010/edi»>Две темы, которым посвящается эта лекция, касаются сравнительно новых возможностей оператора SELECT языка SQL, впервые появившихся в стандарте SQL:1999 и открывающих возможность использования языка в приложениях, для которых ранее он не был приспособлен. Речь идет о возможностях аналитических и рекурсивных запросов. Эти темы логически не связаны, их объединяет лишь то, что соответствующие средства очень громоздки и не всегда легко понимаются. В данной краткой лекции мы не стремимся привести полное описание возможностей, специфицированных в стандарте SQL. Наша цель состоит лишь в том, чтобы в общих чертах описать подход SQL в указанных направлениях.
В аналитических приложениях обычно требуются не детальные данные, непосредственно хранящиеся в базе данных, а некоторые их обобщения, агрегаты. Например, аналитика интересует не заработная плата конкретного человека в конкретное время, а изменение заработной платы некоторой категории людей в течение определенного промежутка времени. Если пользоваться терминологией SQL, то типичный запрос к базе данных со стороны аналитического приложения содержит раздел GROUP BY и вызовы агрегатных функций. Хотя в этом курсе мы почти не касаемся вопросов реализации SQL-ориентированных СУБД, из общих соображений должно быть понятно, что запросы с разделом GROUP BY в общем случае являются «трудными» для СУБД, поскольку для группирования таблицы, вообще говоря, требуется внешняя сортировка.
Если пользоваться терминологией SQL, то типичный запрос к базе данных со стороны аналитического приложения содержит раздел GROUP BY и вызовы агрегатных функций. Хотя в этом курсе мы почти не касаемся вопросов реализации SQL-ориентированных СУБД, из общих соображений должно быть понятно, что запросы с разделом GROUP BY в общем случае являются «трудными» для СУБД, поскольку для группирования таблицы, вообще говоря, требуется внешняя сортировка.
В системах баз данных, специально спроектированных в расчете на аналитические приложения, проблему обычно решают за счет явного избыточного хранения агрегированных данных (т.е. результатов вызовов агрегатных функций). Конечно, для этого требуется динамическая корректировка хранимых агрегатных значений при изменении детальных данных, но для таких специализированных баз данных это не слишком обременительно, поскольку аналитические базы данных обновляются сравнительно редко.
 intuit.ru/2010/edi»>Однако далеко не каждое предприятие может позволить себе одновременно поддерживать оперативную базу данных для работы обычных приложений оперативной обработки транзакций (OLTP), таких, как бухгалтерские, кадровые и другие приложения, и аналитическую базу данных для приложений оперативной аналитической обработки ( OLAP ). Приходится выполнять аналитические приложения над детальными оперативными базами данных, и эти приложения обращаются к СУБД с многочисленными трудоемкими запросами с разделами GROUP BY и вызовами агрегатных функций.
intuit.ru/2010/edi»>Однако далеко не каждое предприятие может позволить себе одновременно поддерживать оперативную базу данных для работы обычных приложений оперативной обработки транзакций (OLTP), таких, как бухгалтерские, кадровые и другие приложения, и аналитическую базу данных для приложений оперативной аналитической обработки ( OLAP ). Приходится выполнять аналитические приложения над детальными оперативными базами данных, и эти приложения обращаются к СУБД с многочисленными трудоемкими запросами с разделами GROUP BY и вызовами агрегатных функций.
Разработчики стандарта языка SQL старались одновременно решить две задачи: сократить число запросов, требуемых в аналитических приложениях, и добиться снижения стоимости запросов с разделом GROUP BY, обеспечивающих требуемые суммарные данные. В этой лекции мы обсудим наиболее важные, с нашей точки зрения, конструкции языка SQL, облегчающие формулировку, выполнение и использование результатов аналитических запросов: разделы GROUP BY ROLLUP и GROUP BY CUBE и новую агрегатную функцию GROUPING , позволяющую правильно трактовать результаты аналитических запросов при наличии неопределенных значений.
Традиционно язык SQL никогда не обладал возможностью формулировки рекурсивных запросов, где под рекурсивным запросом (упрощенно говоря) мы понимаем запрос к таблице, которая сама каким-либо образом изменяется при выполнении этого запроса. Напомню, что это заложено в базовую семантику оператора SQL: до выполнения раздела WHERE результат раздела FROM должен быть полностью вычислен.
Однако разработчикам приложений часто приходится решать задачи, для которых недостаточно традиционных средств формулировки запросов языка SQL: например, нахождение маршрута движения между двумя заданными географическими точками, определения общего набора комплектующих для сбора некоторого агрегата и т.д. Компании-производители SQL-ориентированных СУБД пытались удовлетворять такие потребности за счет частных решений, обладающих ограниченными рекурсивными свойствами, но до появления стандарта SQL:1999 общие стандартизованные средства отсутствовали.
Следует отметить и некоторое давление на SQL-сообщество со стороны сообщества логических систем баз данных. На основе языка логического программирования Prolog был разработан язык реляционных баз данных Datalog, обеспечивающий все необходимые средства для обычной работы с базами данных наряду с развитыми возможностями рекурсивных запросов. Требовался адекватный ответ со стороны разработчиков стандарта SQL.
Компромиссное (не слишком красивое) решение для введения рекурсии в SQL было найдено на основе введения раздела WITH в выражение запроса. Только в этом разделе допускается как линейная, так и взаимная рекурсия между вводимыми порождаемыми таблицами. При этом только для линейной рекурсии обеспечиваются дополнительные возможности управления порядком вычисления рекурсивно определенной порождаемой таблицы и контроля отсутствия циклов. Следует заметить, что при чтении стандарта временами возникает впечатление, что его авторы сами не до конца еще осознали всех возможных последствий, к которым может привести использование введенных конструкций.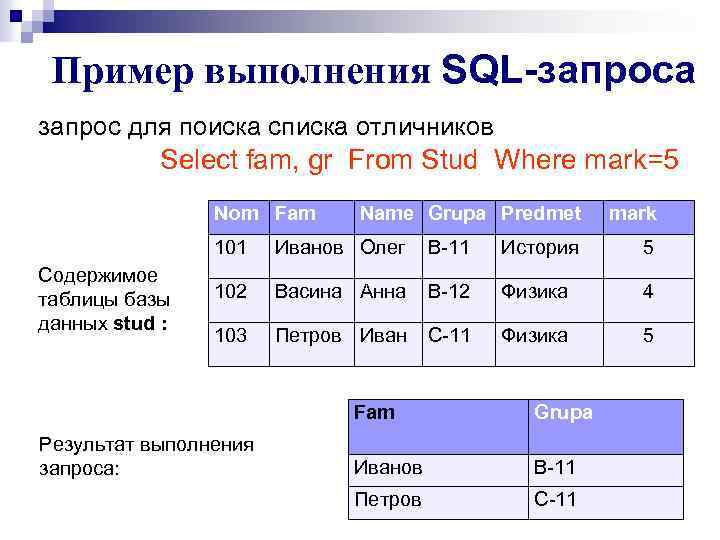 Я думаю, что в следующих версиях стандарта следует ожидать уточнений и/или ограничений использования названных конструкций. В связи с этим в данной лекции мы ограничиваемся общими определениями рекурсивных конструкций языка SQL и обсуждением простого случая рекурсивного запроса.
Я думаю, что в следующих версиях стандарта следует ожидать уточнений и/или ограничений использования названных конструкций. В связи с этим в данной лекции мы ограничиваемся общими определениями рекурсивных конструкций языка SQL и обсуждением простого случая рекурсивного запроса.
Дальше >>
< Лекция 5 || Лекция 6: 123456 || Лекция 7 >
Визуальное объяснение рекурсии в SQL | Денис Лукичев | Рекурсия Startup
в SQL? Но почему? О, этому есть много применений. В SQL принято хранить иерархические данные, а рекурсивные запросы — удобный способ извлечения информации из таких графов. Организационная структура, структура меню приложения, набор задач с подзадачами в проекте, ссылки между веб-страницами, разбивка модуля оборудования на части и подчасти являются примерами иерархических данных. В посте не будут подробно описаны эти многочисленные варианты использования, а рассмотрим два игрушечных примера, чтобы понять концепцию — простейший возможный случай рекурсии чисел и запроса данных из генеалогического дерева.
Давайте рассмотрим запросы как функцию. В том смысле, что функция принимает входные данные и производит выходные данные. Запросы оперируют отношениями или, можно сказать, таблицами. Мы будем обозначать их как Rn. Вот картинка запроса. Он принимает три отношения R1, R2, R3 и дает выход R. Достаточно просто.
Заголовок: Изображение того, как работает запрос. Пример SQL: SELECT
Запрос может взять что-то и ничего не выдать:
Визуальное представление запроса, принимающего что-то и ничего не производящего. Пример SQL: SELECT
Ничего не брать и что-то производить:
Визуальное представление запроса, который ничего не берет и что-то производит. Пример SQL: SELECT 1
Или ничего не брать и ничего не производить
Визуальное представление запроса, ничего не принимающего и ничего не производящего. ВЫБЕРИТЕ 1, ГДЕ 1 = 2
Рекурсия достигается оператором WITH , который на жаргоне SQL называется Common Table Expression (CTE). Это позволяет назвать результат и ссылаться на него в других запросах через некоторое время.
Это позволяет назвать результат и ссылаться на него в других запросах через некоторое время.
Вот образец.
С R AS (ВЫБРАТЬ 1 КАК n)
ВЫБРАТЬ n + 1 ИЗ R
Запрос (ВЫБРАТЬ 1 КАК n) теперь есть имя — R . Мы ссылаемся на это имя в SELECT n + 1 FROM R . Здесь р — это таблица с одной строкой и одним столбцом, содержащая число 1. Результатом всего выражения является число 2.
Рекурсивная версия инструкции WITH ссылается на себя при вычислении выходных данных.
Чтобы рекурсия работала, нам нужно с чего-то начать и решить, когда рекурсия должна остановиться. Для этого обычно рекурсивный оператор с оператором имеет следующую форму.
Важно отметить, что базовый запрос не использует R, но рекурсивный запрос ссылается на R. На первый взгляд кажется, что это бесконечный цикл, для вычисления R нам нужно вычислить R. Но здесь есть загвоздка. R на самом деле не ссылается на себя, он просто ссылается на предыдущий результат, и когда предыдущий результат является пустой таблицей, рекурсия останавливается. На самом деле было бы полезно думать об этом как об итерации, а не о рекурсии!
На первый взгляд кажется, что это бесконечный цикл, для вычисления R нам нужно вычислить R. Но здесь есть загвоздка. R на самом деле не ссылается на себя, он просто ссылается на предыдущий результат, и когда предыдущий результат является пустой таблицей, рекурсия останавливается. На самом деле было бы полезно думать об этом как об итерации, а не о рекурсии!
Вот что происходит: базовый запрос выполняется первым, беря все необходимое для вычисления результата R0. Второй рекурсивный запрос выполняется с R0 в качестве входных данных, то есть R ссылается на R0 в рекурсивном запросе при первом выполнении. Рекурсивный запрос дает результат R1, и это то, на что R будет ссылаться при следующем вызове. И так до тех пор, пока рекурсивный запрос не вернет пустой результат. В этот момент все промежуточные результаты объединяются.
Блок-схема алгоритма выполнения рекурсивного запросаПоследовательность выполнения рекурсивного запроса Довольно абстрактно. Возьмем конкретный пример, посчитаем до 3.
Базовый запрос возвращает число 1 , рекурсивный запрос берет его под именем countUp и выдает число 2 , которое является входом для следующего рекурсивного вызова. Когда рекурсивный запрос возвращает пустую таблицу ( n >= 3 ), результаты вызовов складываются вместе.
Осторожно, на таком счете далеко не уедешь. Есть предел рекурсии. По умолчанию он равен 100, но его можно расширить с помощью параметра MAXRECURSION (зависит от MS SQL Server). Практически, было бы плохой идеей увеличить лимит рекурсии. Графики могут иметь циклы, а ограниченная глубина рекурсии может быть хорошим защитным механизмом, позволяющим предотвратить плохое поведение запроса.
ОПЦИЯ (MAXRECURSION 200)
Вот еще один пример, поиск предков человека:
Использование рекурсии для поиска предков человека. Оператор кода для использования рекурсии для поиска предков человека.
Оператор кода для использования рекурсии для поиска предков человека. Базовый запрос находит родителя Фрэнка — Мэри, рекурсивный запрос берет этот результат под именем Ancestor и находит родителей Мэри, которыми являются Дэйв и Ева, и это продолжается до тех пор, пока мы больше не сможем найти родителей.
Теперь этот запрос обхода дерева может быть основой для дополнения запроса некоторой другой интересующей информацией. Например, имея в таблице год рождения, мы можем вычислить, сколько лет было родителю, когда родился ребенок. Следующий запрос делает именно это вместе с отображением родословных. Для этого он обходит дерево сверху вниз. parentAge равно нулю в первой строке, потому что мы не знаем, когда родилась Алиса, по имеющимся у нас данным.
 Таблица, представляющая результаты рекурсии для нахождения года рождения и предков человека.
Таблица, представляющая результаты рекурсии для нахождения года рождения и предков человека.Забрать — рекурсивный запрос ссылается на результат базового запроса или предыдущего вызова рекурсивного запроса. Цепочка останавливается, когда рекурсивный запрос возвращает пустую таблицу.
В следующем посте мы рассмотрим рекурсию SQL с алгебраической точки зрения и рассмотрим рекурсивные хранимые процедуры.
[ОБНОВЛЕНИЕ] Сообщение дополнено комментариями пользователей Reddit kagato87 и GuybrushFourpwood.
[ПРИМЕЧАНИЕ] Примеры кода предназначены для MS-SQL. Другие СУБД могут иметь немного другой синтаксис.
Понимание рекурсивного CTE SQL Server на практических примерах
Резюме : в этом руководстве вы узнаете, как использовать рекурсивное CTE SQL Server для запроса иерархических данных.
Введение в рекурсивное CTE SQL Server
Рекурсивное общее табличное выражение (CTE) — это CTE, которое ссылается на себя. Таким образом, CTE многократно выполняется, возвращает подмножества данных, пока не вернет полный набор результатов.
Рекурсивный CTE полезен при запросе иерархических данных, таких как организационные диаграммы, в которых один сотрудник отчитывается перед менеджером, или многоуровневая спецификация материалов, когда продукт состоит из многих компонентов, и каждый компонент сам по себе также состоит из многих других компонентов.
Ниже показан синтаксис рекурсивного CTE:
Язык кода: SQL (язык структурированных запросов) (sql)
WITH имя_выражения (список_столбцов) В КАЧЕСТВЕ ( -- Якорный член начальный_запрос СОЮЗ ВСЕХ -- Рекурсивный элемент, который ссылается на имя_выражения. рекурсивный_запрос ) -- ссылается на имя выражения ВЫБРАТЬ * ОТ имя_выражения
В общем, рекурсивный CTE состоит из трех частей:
- Исходный запрос, возвращающий базовый набор результатов CTE.
 Первоначальный запрос называется элементом привязки.
Первоначальный запрос называется элементом привязки. - Рекурсивный запрос, ссылающийся на общее табличное выражение, поэтому он называется рекурсивным членом. Рекурсивный элемент объединяется с элементом привязки с помощью оператора
UNION ALL. - Условие завершения, указанное в рекурсивном члене, которое завершает выполнение рекурсивного члена.
Порядок выполнения рекурсивного CTE следующий:
- Сначала выполните элемент привязки для формирования базового набора результатов (R0), используйте этот результат для следующей итерации.
- Во-вторых, выполнить рекурсивный элемент с входным набором результатов из предыдущей итерации (Ri-1) и вернуть набор подрезультатов (Ri), пока не будет выполнено условие завершения.
- В-третьих, объедините все наборы результатов R0, R1, … Rn, используя оператор
UNION ALL, чтобы получить окончательный набор результатов.
Следующая блок-схема иллюстрирует выполнение рекурсивного CTE:
Примеры рекурсивного CTE для SQL Server
Рассмотрим несколько примеров использования рекурсивных CTE
A) Пример простого рекурсивного CTE для SQL Server
возвращает дни недели с Понедельник по Суббота :
Язык кода: SQL (язык структурированных запросов) (sql)
С cte_numbers(n, день недели) В КАЧЕСТВЕ ( ВЫБРАТЬ 0, ДАТАИМЯ(DW, 0) СОЮЗ ВСЕХ ВЫБРАТЬ п + 1, ДАТАИМЯ(DW, n + 1) ИЗ cte_numbers ГДЕ n < 6 ) ВЫБРАТЬ будний день ИЗ cte_numbers;
Вот набор результатов:
В этом примере:
Функция DATENAME() возвращает название дня недели на основе номера дня недели .
Элемент привязки возвращает Понедельник
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT 0, ДАТАИМЯ(DW, 0)
Рекурсивный элемент возвращается на следующий день, начиная с вторник до воскресенье .
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ п + 1, ДАТАИМЯ(DW, n + 1) ИЗ cte_numbers ГДЕ n < 6
Условие в предложении WHERE является условием завершения, которое останавливает выполнение рекурсивного члена, когда n равно 6
Язык кода: SQL (язык структурированных запросов) (sql)
n < 6
B) Использование рекурсивного CTE SQL Server для запроса иерархических данных
См. следующую таблицу
следующую таблицу sales.staffs из примера базы данных:
В этой таблице персонал подчиняется нулю или одному менеджеру. У менеджера может быть ноль или более сотрудников. У топ-менеджера нет менеджера. Связь указана в значениях столбца manager_id . Если персонал не подчиняется никакому персоналу (в случае топ-менеджера), значение в manager_id равно NULL.
В этом примере используется рекурсивный CTE для получения всех подчиненных топ-менеджера, у которого нет руководителя (или значение в столбце manager_id равно NULL):
Язык кода: SQL (язык структурированных запросов) (sql)
WITH cte_org AS ( ВЫБРАТЬ staff_id, Имя, manager_id ИЗ отдел продаж ГДЕ manager_id имеет значение NULL СОЮЗ ВСЕХ ВЫБРАТЬ e.staff_id, e.first_name, e.manager_id ИЗ отдел продаж ВНУТРЕННЕЕ СОЕДИНЕНИЕ cte_org o ON o.staff_id = e.manager_id ) ВЫБЕРИТЕ * ИЗ cte_org;
Вот результат:
топ-менеджер и так далее.
Из этого руководства вы узнали, как использовать рекурсивное CTE SQL Server для запроса иерархических данных.
Введение в рекурсивный SQL
Крейг С. Маллинз
Если вы программист SQL, изучение методов рекурсивного SQL может повысить вашу производительность. Рекурсивный запрос — это запрос, который ссылается сам на себя. Я думаю, что лучший способ быстро понять концепцию рекурсии — это подумать о зеркале, которое отражается в другом зеркале, и когда вы смотрите в него, вы видите бесконечные отражения себя. Это рекурсия в действии.
Я думаю, что лучший способ быстро понять концепцию рекурсии — это подумать о зеркале, которое отражается в другом зеркале, и когда вы смотрите в него, вы видите бесконечные отражения себя. Это рекурсия в действии.
Различные продукты СУБД реализуют рекурсивный SQL по-разному. Рекурсия реализована в стандарте SQL-99 с использованием общих табличных выражений (CTE). DB2, Microsoft SQL Server, Oracle и PostgreSQL поддерживают рекурсивные запросы с использованием CTE. Обратите внимание, что Oracle также предлагает альтернативный синтаксис с использованием конструкции CONNECT BY, который мы здесь обсуждать не будем.
CTE можно рассматривать как именованную временную таблицу в операторе SQL, которая сохраняется на время выполнения этого оператора. В одном операторе SQL может быть много CTE, но каждое из них должно иметь уникальное имя. CTE определяется в начале запроса с использованием предложения WITH.
Теперь, прежде чем мы углубимся в рекурсию, давайте сначала рассмотрим некоторые данные, которые выиграют от рекурсивного чтения. На рис. 1 показана иерархическая организационная схема.
На рис. 1 показана иерархическая организационная схема.
Рис. 1. Пример иерархии .
Таблица, содержащая эти данные, можно настроить следующим образом:
Создание таблицы org_chart
(MGR_ID Smallint,
EMP_ID Smallint,
EMP_NAME char (20))
;
Конечно, это простая реализация, и для производственной иерархии, вероятно, потребуется гораздо больше столбцов. Но простота этой таблицы подойдет для наших целей изучения рекурсии. Чтобы сделать данные в этой таблице, соответствуют нашей диаграмме, мы загрузили таблицу следующим образом:
MGR_ID EMP_ID EMP_NAME
-1 1 Big Boss
1 2 Lackey
1 3 Lil Boss
1 4 Bootlicker
2 5 Grunt
3 6 Lead Lead
6 7 Low Man
6 8 Scrub
MGR_ID для наиболее максимальной row, в данном случае используется –1. Теперь, когда мы загрузили данные, мы можем написать запрос для обхода иерархии с использованием рекурсивного SQL. Предположим, нам нужно отчитаться по всей организационной структуре под LIL BOSS. Следующий рекурсивный SQL с использованием CTE сделает свое дело:
Предположим, нам нужно отчитаться по всей организационной структуре под LIL BOSS. Следующий рекурсивный SQL с использованием CTE сделает свое дело:
с expl (mgr_id, emp_id, emp_name) как
(
Select root.mgr_id, root.emp_id, root.emp_name
из org_chart root
, где root.mgr_id = 3
All
2
2
2
2
Выберите child.mgr_id, child.emp_id, child.emp_name
от expl parent, org_chart Child
, где parent.emp_id = child.mgr_id
)
SELECT DISTINCT MGR_ID, EMP_ID, EMP_NAME
FROM EXPL
ORDER BY MGR_ID, EMP_ID;
Результаты выполнения этого запроса будут:
MGR_ID EMP_ID EMP_NAME
1 3 LIL BOSS
3 6 Ведущие команды
6 7 Low Man
9 8 Scrub Давайте разбили этот комплекс вниз в его составные части, помогающие понять, что происходит. Во-первых, рекурсивный запрос реализуется с использованием предложения WITH (с использованием CTE). CTE называется EXPL. Первый SELECT запускает насос для инициализации «корня» поиска. В нашем случае начать с EMP_ID 3, то есть LIL BOSS.
CTE называется EXPL. Первый SELECT запускает насос для инициализации «корня» поиска. В нашем случае начать с EMP_ID 3, то есть LIL BOSS.
Следующий SELECT представляет собой внутреннее соединение, объединяющее CTE с таблицей, на которой основано CTE. Вот где в дело вступает рекурсия. Часть определения CTE ссылается сама на себя. Наконец, мы ВЫБИРАЕМ из CTE. Подобные запросы могут быть написаны, чтобы полностью разрушить иерархию, чтобы получить всех потомков любого заданного узла.
Рекурсивный SQL может быть очень элегантным и эффективным. Однако из-за сложности понимания рекурсии разработчиками ее иногда считают «слишком неэффективной для частого использования». Но если у вас есть деловая потребность в обходе или взрыве иерархий в вашей базе данных, рекурсивный SQL, вероятно, будет вашим наиболее эффективным вариантом. Что еще ты собираешься делать? Вы можете создавать предварительно разнесенные таблицы, но это требует денормализации и большой предварительной обработки, которая не будет эффективной.