PostgreSQL : Документация: 9.5: 9.7. Поиск по шаблону : Компания Postgres Professional
9.7. Поиск по шаблону
PostgreSQL предлагает три разных способа поиска текста по шаблону: традиционный оператор LIKE языка SQL, более современный SIMILAR TO (добавленный в SQL:1999) и регулярные выражения в стиле POSIX. Помимо простых операторов, отвечающих на вопрос «соответствует ли строка этому шаблону?», в PostgreSQL есть функции для извлечения или замены соответствующих подстрок и для разделения строки по заданному шаблону.
Подсказка
Если этих встроенных возможностей оказывается недостаточно, вы можете написать собственные функции на языке Perl или Tcl.
Внимание
Хотя чаще всего поиск по регулярному выражению бывает очень быстрым, регулярные выражения бывают и настолько сложными, что их обработка может занять приличное время и объём памяти. Поэтому опасайтесь шаблонов регулярных выражений, поступающих из недоверенных источников. Если у вас нет другого выхода, рекомендуется ввести тайм-аут для операторов.
Если у вас нет другого выхода, рекомендуется ввести тайм-аут для операторов.
Поиск с шаблонами SIMILAR TO несёт те же риски безопасности, так как конструкция SIMILAR TO предоставляет во многом те же возможности, что и регулярные выражения в стиле POSIX.
Поиск с LIKE гораздо проще, чем два другие варианта, поэтому его безопаснее использовать с недоверенными источниками шаблонов поиска.
строкаLIKEшаблон[ESCAPEспецсимвол]строкаNOT LIKEшаблон[ESCAPEспецсимвол]
Выражение LIKE возвращает true, если строка соответствует заданному шаблону. (Как можно было ожидать, выражение NOT LIKE возвращает false, когда LIKE возвращает true, и наоборот. Этому выражению равносильно выражение NOT (.строка LIKE шаблон) )
)
Если шаблон не содержит знаков процента и подчёркиваний, тогда шаблон представляет в точности строку и LIKE работает как оператор сравнения. Подчёркивание (_) в шаблоне подменяет (вместо него подходит) любой символ; а знак процента (%) подменяет любую (в том числе и пустую) последовательность символов.
Несколько примеров:
'abc' LIKE 'abc' true 'abc' LIKE 'a%' true 'abc' LIKE '_b_' true 'abc' LIKE 'c' false
При проверке по шаблону LIKE всегда рассматривается вся строка. Поэтому, если нужно найти последовательность символов где-то в середине строки, шаблон должен начинаться и заканчиваться знаками процента.
Чтобы найти в строке буквальное вхождение знака процента или подчёркивания, перед соответствующим символом в шаблоне нужно добавить спецсимвол. По умолчанию в качестве спецсимвола выбрана обратная косая черта, но с помощью предложения ESCAPE можно выбрать и другой. Чтобы включить спецсимвол в шаблон поиска, продублируйте его.
Чтобы включить спецсимвол в шаблон поиска, продублируйте его.
Примечание
Если параметр standard_conforming_strings выключен, каждый символ обратной косой черты, записываемый в текстовой константе, нужно дублировать. Подробнее это описано в Подразделе 4.1.2.1.
Также можно отказаться от спецсимвола, написав ESCAPE ''. При этом механизм спецпоследовательностей фактически отключается и использовать знаки процента и подчёркивания буквально в шаблоне нельзя.
Вместо LIKE можно использовать ключевое слово ILIKE, чтобы поиск был регистр-независимым с учётом текущей языковой среды. Этот оператор не описан в стандарте SQL; это расширение PostgreSQL.
Кроме того, в PostgreSQL есть оператор ~~, равнозначный LIKE, и ~~*, соответствующий ILIKE. Есть также два оператора !~~ и !~~*, представляющие NOT LIKE и NOT ILIKE, соответственно. Все эти операторы относятся к особенностям PostgreSQL. Вы можете увидеть их, например, в выводе команды
Все эти операторы относятся к особенностям PostgreSQL. Вы можете увидеть их, например, в выводе команды EXPLAIN, так как при разборе запроса проверка LIKE и подобные заменяются ими.
Фразы LIKE, ILIKE, NOT LIKE и NOT ILIKE в синтаксисе PostgreSQL обычно обрабатываются как операторы; например, их можно использовать в конструкциях выражение оператор ANY (подвыражение), хотя предложение ESCAPE здесь добавить нельзя. В некоторых особых случаях всё же может потребоваться использовать вместо них нижележащие операторы.
9.7.2. Регулярные выражения SIMILAR TO
строкаSIMILAR TOшаблон[ESCAPEспецсимвол]строкаNOT SIMILAR TOшаблон[ESCAPEспецсимвол]
Оператор SIMILAR TO возвращает true или false в зависимости от того, соответствует ли данная строка шаблону или нет. Он работает подобно оператору
Он работает подобно оператору LIKE, только его шаблоны соответствуют определению регулярных выражений в стандарте SQL. Регулярные выражения SQL представляют собой любопытный гибрид синтаксиса LIKE с синтаксисом обычных регулярных выражений.
Как и LIKE, условие SIMILAR TO истинно, только если шаблон соответствует всей строке; это отличается от условий с регулярными выражениями, в которых шаблон может соответствовать любой части строки. Также подобно LIKE, SIMILAR TO воспринимает символы _ и % как знаки подстановки, подменяющие любой один символ или любую подстроку, соответственно (в регулярных выражениях POSIX им аналогичны символы . и .*).
Помимо средств описания шаблонов, позаимствованных от LIKE, SIMILAR TO поддерживает следующие метасимволы, унаследованные от регулярных выражений POSIX:
|означает выбор (одного из двух вариантов).
*означает повторение предыдущего элемента 0 и более раз.+означает повторение предыдущего элемента 1 и более раз.?означает вхождение предыдущего элемента 0 или 1 раз.{m}означает повторяет предыдущего элемента ровноmраз.{m,}означает повторение предыдущего элементаmили более раз.{m,n}означает повторение предыдущего элемента не менее чемmи не более чемnраз.Скобки
()объединяют несколько элементов в одну логическую группу.Квадратные скобки
[...]обозначают класс символов так же, как и в регулярных выражениях POSIX.
Обратите внимание, точка (.) не является метасимволом для оператора 
SIMILAR TO.
Как и с LIKE, обратная косая черта отменяет специальное значение любого из этих метасимволов, а предложение ESCAPE позволяет выбрать другой спецсимвол.
Несколько примеров:
'abc' SIMILAR TO 'abc' true 'abc' SIMILAR TO 'a' false 'abc' SIMILAR TO '%(b|d)%' true 'abc' SIMILAR TO '(b|c)%' false
Функция substring
substring(строка from шаблон for спецсимвол) извлекает подстроку, соответствующую шаблону регулярного выражения SQL. Как и с SIMILAR TO, указанному шаблону должна соответствовать вся строка; в противном случае функция не найдёт ничего и вернёт NULL. Для обозначения части шаблона, которая должна быть возвращена в случае успеха, шаблон должен содержать два спецсимвола и кавычки (") после каждого. Эта функция возвращает часть шаблона между двумя такими маркерами.
Эта функция возвращает часть шаблона между двумя такими маркерами.Несколько примеров с маркерами #", выделяющими возвращаемую строку:
substring('foobar' from '%#"o_b#"%' for '#') oob
substring('foobar' from '#"o_b#"%' for '#') NULL9.7.3. Регулярные выражения POSIX
В Таблице 9.12 перечислены все существующие операторы для проверки строк регулярными выражениями POSIX.
Таблица 9.12. Операторы регулярных выражений
| Оператор | Описание | Пример |
|---|---|---|
~ | Проверяет соответствие регулярному выражению с учётом регистра | 'thomas' ~ '.*thomas.*' |
~* | Проверяет соответствие регулярному выражению без учёта регистра | 'thomas' ~* '.*Thomas.*' |
!~ | Проверяет несоответствие регулярному выражению с учётом регистра | 'thomas' !~ '. |
!~* | Проверяет несоответствие регулярному выражению без учёта регистра | 'thomas' !~* '.*vadim.*' |
 *Thomas.*'
*Thomas.*'Регулярные выражения POSIX предоставляют более мощные средства поиска по шаблонам, чем операторы LIKE и SIMILAR TO. Во многих командах Unix, таких как egrep, sed и awk используется язык шаблонов, похожий на описанный здесь.
Регулярное выражение — это последовательность символов, представляющая собой краткое определение набора строк (регулярное множество). Строка считается соответствующей регулярному выражению, если она является членом регулярного множества, описываемого регулярным выражением. Как и для LIKE, символы шаблона непосредственно соответствуют символам строки, за исключением специальных символов языка регулярных выражений. При этом спецсимволы регулярных выражений отличается от спецсимволов LIKE. (b|c)’ false
(b|c)’ false
Более подробно язык шаблонов в стиле POSIX описан ниже.
Функция substring с двумя параметрами, substring(, извлекает подстроку, соответствующую шаблону регулярного выражения POSIX.строка from шаблон)
PostgreSQL : Документация: 9.6: 9.7. Поиск по шаблону : Компания Postgres Professional
9.7. Поиск по шаблону
PostgreSQL предлагает три разных способа поиска текста по шаблону: традиционный оператор LIKE языка SQL, более современный SIMILAR TO (добавленный в SQL:1999) и регулярные выражения в стиле POSIX. Помимо простых операторов, отвечающих на вопрос «соответствует ли строка этому шаблону?», в PostgreSQL есть функции для извлечения или замены соответствующих подстрок и для разделения строки по заданному шаблону.
Подсказка
Если этих встроенных возможностей оказывается недостаточно, вы можете написать собственные функции на языке Perl или Tcl.
Внимание
Хотя чаще всего поиск по регулярному выражению бывает очень быстрым, регулярные выражения бывают и настолько сложными, что их обработка может занять приличное время и объём памяти. Поэтому опасайтесь шаблонов регулярных выражений, поступающих из недоверенных источников. Если у вас нет другого выхода, рекомендуется ввести тайм-аут для операторов.
Поиск с шаблонами SIMILAR TO несёт те же риски безопасности, так как конструкция SIMILAR TO предоставляет во многом те же возможности, что и регулярные выражения в стиле POSIX.
Поиск с LIKE гораздо проще, чем два другие варианта, поэтому его безопаснее использовать с недоверенными источниками шаблонов поиска.
строкаLIKEшаблон[ESCAPEспецсимвол]строкаNOT LIKEшаблон[ESCAPEспецсимвол]
Выражение LIKE возвращает true, если строка соответствует заданному шаблону.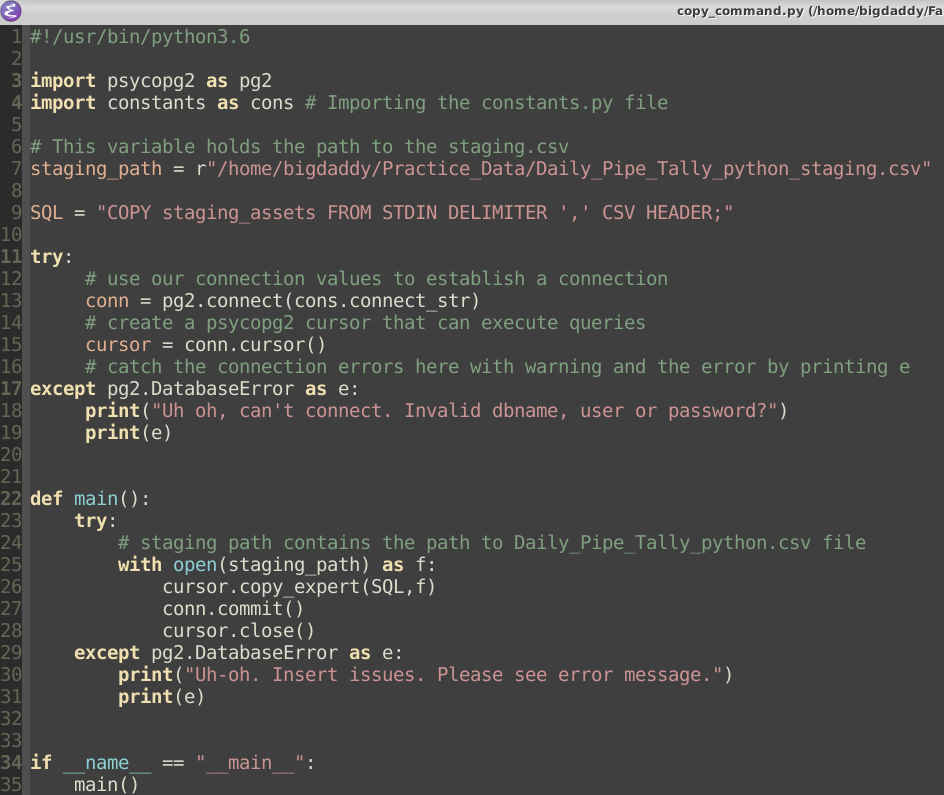
NOT LIKE возвращает false, когда LIKE возвращает true, и наоборот. Этому выражению равносильно выражение NOT (строка LIKE шаблон).)Если шаблон не содержит знаков процента и подчёркиваний, тогда шаблон представляет в точности строку и LIKE работает как оператор сравнения. Подчёркивание (_) в шаблоне подменяет (вместо него подходит) любой символ; а знак процента (%) подменяет любую (в том числе и пустую) последовательность символов.
Несколько примеров:
'abc' LIKE 'abc' true 'abc' LIKE 'a%' true 'abc' LIKE '_b_' true 'abc' LIKE 'c' false
При проверке по шаблону LIKE всегда рассматривается вся строка. Поэтому, если нужно найти последовательность символов где-то в середине строки, шаблон должен начинаться и заканчиваться знаками процента.
Чтобы найти в строке буквальное вхождение знака процента или подчёркивания, перед соответствующим символом в шаблоне нужно добавить спецсимвол. По умолчанию в качестве спецсимвола выбрана обратная косая черта, но с помощью предложения ESCAPE можно выбрать и другой. Чтобы включить спецсимвол в шаблон поиска, продублируйте его.
Примечание
Если параметр standard_conforming_strings выключен, каждый символ обратной косой черты, записываемый в текстовой константе, нужно дублировать. Подробнее это описано в Подразделе 4.1.2.1.
Также можно отказаться от спецсимвола, написав ESCAPE ''. При этом механизм спецпоследовательностей фактически отключается и использовать знаки процента и подчёркивания буквально в шаблоне нельзя.
Вместо LIKE можно использовать ключевое слово ILIKE, чтобы поиск был регистр-независимым с учётом текущей языковой среды. Этот оператор не описан в стандарте SQL; это расширение PostgreSQL.
Кроме того, в PostgreSQL есть оператор ~~, равнозначный LIKE, и ~~*, соответствующий ILIKE. Есть также два оператора !~~ и !~~*, представляющие NOT LIKE и NOT ILIKE, соответственно. Все эти операторы относятся к особенностям PostgreSQL. Вы можете увидеть их, например, в выводе команды EXPLAIN, так как при разборе запроса проверка LIKE и подобные заменяются ими.
Фразы LIKE, ILIKE, NOT LIKE и NOT ILIKE в синтаксисе PostgreSQL обычно обрабатываются как операторы; например, их можно использовать в конструкциях выражение оператор ANY (подвыражение), хотя предложение ESCAPE здесь добавить нельзя. В некоторых особых случаях всё же может потребоваться использовать вместо них нижележащие операторы.
9.7.2. Регулярные выражения SIMILAR TO
строкаSIMILAR TOшаблон[ESCAPEспецсимвол]строкаNOT SIMILAR TOшаблон[ESCAPEспецсимвол]
Оператор SIMILAR TO возвращает true или false в зависимости от того, соответствует ли данная строка шаблону или нет.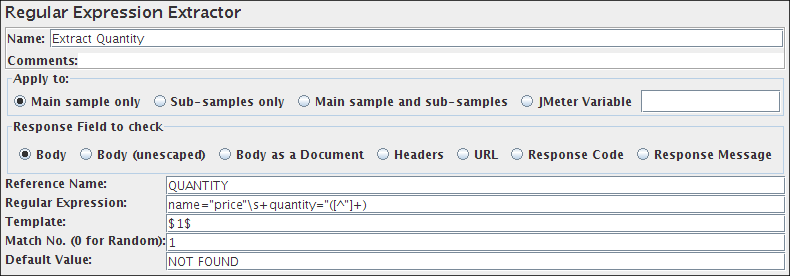
LIKE, только его шаблоны соответствуют определению регулярных выражений в стандарте SQL. Регулярные выражения SQL представляют собой любопытный гибрид синтаксиса LIKE с синтаксисом обычных регулярных выражений.Как и LIKE, условие SIMILAR TO истинно, только если шаблон соответствует всей строке; это отличается от условий с регулярными выражениями, в которых шаблон может соответствовать любой части строки. Также подобно LIKE, SIMILAR TO воспринимает символы _ и % как знаки подстановки, подменяющие любой один символ или любую подстроку, соответственно (в регулярных выражениях POSIX им аналогичны символы . и .*).
Помимо средств описания шаблонов, позаимствованных от LIKE, SIMILAR TO поддерживает следующие метасимволы, унаследованные от регулярных выражений POSIX:
|означает выбор (одного из двух вариантов).
*означает повторение предыдущего элемента 0 и более раз.+означает повторение предыдущего элемента 1 и более раз.?означает вхождение предыдущего элемента 0 или 1 раз.{m}означает повторяет предыдущего элемента ровноmраз.{m,}означает повторение предыдущего элементаmили более раз.{m,n}означает повторение предыдущего элемента не менее чемmи не более чемnраз.Скобки
()объединяют несколько элементов в одну логическую группу.Квадратные скобки
[...]обозначают класс символов так же, как и в регулярных выражениях POSIX.
Обратите внимание, точка (.) не является метасимволом для оператора 
SIMILAR TO.
Как и с LIKE, обратная косая черта отменяет специальное значение любого из этих метасимволов, а предложение ESCAPE позволяет выбрать другой спецсимвол.
Несколько примеров:
'abc' SIMILAR TO 'abc' true 'abc' SIMILAR TO 'a' false 'abc' SIMILAR TO '%(b|d)%' true 'abc' SIMILAR TO '(b|c)%' false
Функция substring с тремя параметрами, substring( извлекает подстроку, соответствующую шаблону регулярного выражения SQL. Как и с строка from шаблон for спецсимвол)SIMILAR TO, указанному шаблону должна соответствовать вся строка; в противном случае функция не найдёт ничего и вернёт NULL. Для обозначения части шаблона, которая должна быть возвращена в случае успеха, шаблон должен содержать два спецсимвола и кавычки (") после каждого. Эта функция возвращает часть шаблона между двумя такими маркерами.
Эта функция возвращает часть шаблона между двумя такими маркерами.
Несколько примеров с маркерами #", выделяющими возвращаемую строку:
substring('foobar' from '%#"o_b#"%' for '#') oob
substring('foobar' from '#"o_b#"%' for '#') NULL9.7.3. Регулярные выражения POSIX
В Таблице 9.14 перечислены все существующие операторы для проверки строк регулярными выражениями POSIX.
Таблица 9.14. Операторы регулярных выражений
REGEXP_REPLACE ФУНКЦИЯ — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
В этом учебном пособии вы узнаете, как использовать функцию REGEXP_REPLACE Oracle/PLSQL с синтаксисом и примерами.
Описание
Функция Oracle/PLSQL REGEXP_REPLACE является расширением функции REPLACE. Эта функция, введенная в Oracle 10g, позволит вам заменить последовательность символов в строке другим набором символов, используя сопоставление шаблонов регулярных выражений. ]
]
replacement_string
Необязательный. Соответствующие шаблоны в строке будут заменены на replace_string. Если параметр replacement_string опущен, то функция просто удаляет все совпадающие шаблоны и возвращает полученную строку.
start_position
Необязательный. Это позиция в строке, откуда начнется поиск. Если этот параметр опущен, по умолчанию он равен 1, который является первой позицией в строке.
nth_appearance
Необязательный. Это n-й вид шаблона в строке. Если этот параметр опущен, по умолчанию он равен 1, который является первым вхождением шаблона в строке. Если вы укажете 0 для этого параметра, все вхождения шаблона в строке будут заменены.
match_parameter
Необязательный. Это позволяет изменять поведение соответствия для условия REGEXP_REPLACE. Это может быть комбинацией следующих значений:
| Значение | Описание | |||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ‘c’ | Выполняет чувствительное к регистру согласование. | |||||||||||||||||||||||||||||||||||||||
| ‘i’ | Выполняет не чувствительное к регистру согласование. | |||||||||||||||||||||||||||||||||||||||
| ‘n’ | Позволяет период символа (.) для соответствия символа новой строки. По умолчанию, период метасимволы. | |||||||||||||||||||||||||||||||||||||||
| ‘m’ | Выражение допускает, что есть несколько строк, где ^ это начало строки, а $ это конец строки, независимо от позиции этих символов в выражении. , а затем найдет первое слово в соответствии с (\S*). Затем функция заменит это первое слово на ‘Google’. , а затем найдет первое слово в соответствии с (\S*). Затем функция заменит это первое слово на ‘Google’.Пример совпадения цифрРассмотрим пример, как мы будем использовать функцию REGEXP_REPLACE для сопоставления шаблону цифровых символов. Например: SELECT REGEXP_REPLACE (‘1, 4, и 10 числа для примера.’, ‘\d’, ‘@’) FROM dual; —Результат: @, @, и @@ числа для примера.
Этот пример заменит все числа в строке, как указано в шаблоне \d, на символ @. Мы могли бы изменить наш шаблон для поиска только двухзначных чисел. Например: SELECT REGEXP_REPLACE (‘1, 4, и 10 числа для примера’, ‘(\d)(\d)’, ‘@’) FROM dual; —Результат: 1, 4, и @ числа для примера
Этот пример заменит число, которое имеет две цифры, как указано в шаблоне (\d)(\d). Теперь рассмотрим, как мы будем использовать функцию REGEXP_REPLACE со столбцом таблицы для замены двухзначных чисел. SELECT REGEXP_REPLACE (address, ‘(\d)(\d)’, ‘Str’) FROM contacts;
В этом примере мы заменим все двузначные значения поля address в таблице contacts на значение ‘Str’. Пример сопоставления нескольких альтернатив.Следующий пример, который мы рассмотрим, включает использование | шаблон. | шаблон используется как «ИЛИ», чтобы указать несколько альтернатив. Например: SELECT REGEXP_REPLACE (‘AeroSmith’, ‘a|e|i|o|u’, ‘R’) FROM dual; —Результат: ARrRSmRth
Этот пример вернет ‘ARrRSmRth’, потому что он ищет первую гласную (a, e, i, o или u) в строке. Мы могли бы изменить наш запрос, чтобы выполнить поиск без учета регистра следующим образом: SELECT REGEXP_REPLACE (‘AeroSmith’, ‘a|e|i|o|u’, ‘R’, 1, 0, ‘i’) FROM dual; —Результат: RRrRSmRth
Теперь, поскольку мы указали match_parameter = ‘i’, запрос заменит ‘A’ в строке. На этот раз ‘A’ в ‘AeroSmith’ сопоставится с шаблоном. Заметим также, что мы указали 5-й параметр как 0, чтобы были заменены все вхождения. Теперь рассмотри, как вы будете использовать эту функцию со столбцом. Итак, допустим, у нас есть таблица contact со следующими данными:
Теперь давайте запустим следующий запрос: SELECT contact_id, last_name, REGEXP_REPLACE (last_name, ‘a|e|i|o|u’, ‘R’, 1, 0, ‘i’) AS «New Name» FROM contacts;
Запрос вернет следующие результаты:
Пример совпадений на основе параметра nth_occurrenceСледующий пример, который мы рассмотрим, включает параметр nth_occurrence. Первое вхождениеРассмотрим, как заменить первое вхождение шаблона в строке. Например: SELECT REGEXP_REPLACE (‘Scorpions’, ‘a|e|i|o|u’, ‘Z’, 1, 1, ‘i’) FROM dual; —Результат: ScZrpions
Этот пример заменит третий символ (‘e’) в ‘Scorpions’, потому что он заменяет первое вхождение гласного (a, e, i, o или u) в строке. Второе вхождениеЗатем мы выберем для второго вхождения шаблона в строку. Например: SELECT REGEXP_REPLACE (‘Scorpions’, ‘a|e|i|o|u’, ‘Z’, 1, 2, ‘i’) FROM dual; —Результат: ScorpZons
Этот пример заменит шестой символ (‘i’) в ‘Scorpions’, потому что он заменяет второе вхождение гласного (a, e, i, o или u) в строке. Третье вхождениеНапример: SELECT REGEXP_REPLACE (‘Scorpions’, ‘a|e|i|o|u’, ‘Z’, 1, 3, ‘i’) FROM dual; —Результат: ScorpiZns
Этот пример заменит седьмой символ (‘o’) в ‘Scorpions’, потому что он заменяет третье вхождение гласного (a, e, i, o или u) в строке. REGEXP_SUBSTR ФУНКЦИЯ — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLiteВ этом учебном пособии вы узнаете, как использовать функцию REGEXP_SUBSTR Oracle/PLSQL с синтаксисом и примерами. ОписаниеФункция Oracle/PLSQL REGEXP_SUBSTR является расширением функции SUBSTR. Эта функция, представленная в Oracle 10g, позволит вам извлечь подстроку из строки, используя сопоставление шаблонов регулярных выражений. СинтаксисСинтаксис функции Oracle/PLSQL REGEXP_SUBSTR : REGEXP_SUBSTR( string, pattern [, start_position [, nth_appearance [, match_parameter [, sub_expression ] ] ] ] ) Параметры или аргументыstring | Используется для указания списка nonmatching, где вы пытаетесь соответствовать любому символу, за исключением тех кто в списке. | ||||||||||||||||||||||||||||||||||||||
| ( ) | Используется для групповых выражений в качестве подвыражений. | |||||||||||||||||||||||||||||||||||||||
| {m} | Соответствует m раз. | |||||||||||||||||||||||||||||||||||||||
| {m,} | Соответствие как минимум m раз. | |||||||||||||||||||||||||||||||||||||||
| {m,n} | Соответствие как минимум m раз, но не более n раз. | |||||||||||||||||||||||||||||||||||||||
| \n | n представляет собой число от 1 до 9. Соответствует n-му подвыражению находящемуся в ( ) перед \n. | |||||||||||||||||||||||||||||||||||||||
| [..] | Соответствует одному сопоставлению элемента, который может быть более одного символа. | |||||||||||||||||||||||||||||||||||||||
| [::] | Соответствует классу символов. | |||||||||||||||||||||||||||||||||||||||
| [==] | Соответствует классу эквивалентности | |||||||||||||||||||||||||||||||||||||||
| \d | Соответствует цифровому символу. | |||||||||||||||||||||||||||||||||||||||
| \D | Соответствует не цифровому символу. | |||||||||||||||||||||||||||||||||||||||
| \w | Соответствует текстовому символу. | |||||||||||||||||||||||||||||||||||||||
| \W | Соответствует не текстовому символу. | |||||||||||||||||||||||||||||||||||||||
| \s | Соответствует символу пробел. | |||||||||||||||||||||||||||||||||||||||
| \S | Соответствует не символу пробел. | |||||||||||||||||||||||||||||||||||||||
| \A | Соответствует началу строки или соответствует концу строки перед символом новой строки. | |||||||||||||||||||||||||||||||||||||||
| \Z | Соответствует концу строки. | |||||||||||||||||||||||||||||||||||||||
| *? | Соответствует предыдущему шаблону ноль или более вхождений. | |||||||||||||||||||||||||||||||||||||||
| +? | Соответствует предыдущему шаблону один или более вхождений. | |||||||||||||||||||||||||||||||||||||||
| ?? | Соответствует предыдущему шаблону ноль или одному вхождению. | |||||||||||||||||||||||||||||||||||||||
| {n}? | Соответствует предыдущему шаблону n раз. | |||||||||||||||||||||||||||||||||||||||
| {n,}? | Соответствует предыдущему шаблону, по меньшей мере n раз. | |||||||||||||||||||||||||||||||||||||||
| {n,m}? | Соответствует предыдущему шаблону, по меньшей мере n раз, но не более m раз. |
 В этом случае он пропустит числовые значения 2 и 5 и заменит 10 символом @.
В этом случае он пропустит числовые значения 2 и 5 и заменит 10 символом @. Поскольку мы не указали значение match_parameter, функция REGEXP_REPLACE будет выполнять поиск с учетом регистра, что означает, что ‘A’ в ‘AeroSmith’ не будет сопоставляться.
Поскольку мы не указали значение match_parameter, функция REGEXP_REPLACE будет выполнять поиск с учетом регистра, что означает, что ‘A’ в ‘AeroSmith’ не будет сопоставляться. Параметр nth_occurrence позволяет вам выбрать, какое вхождение шаблона вы хотите заменить в строке.
Параметр nth_occurrence позволяет вам выбрать, какое вхождение шаблона вы хотите заменить в строке.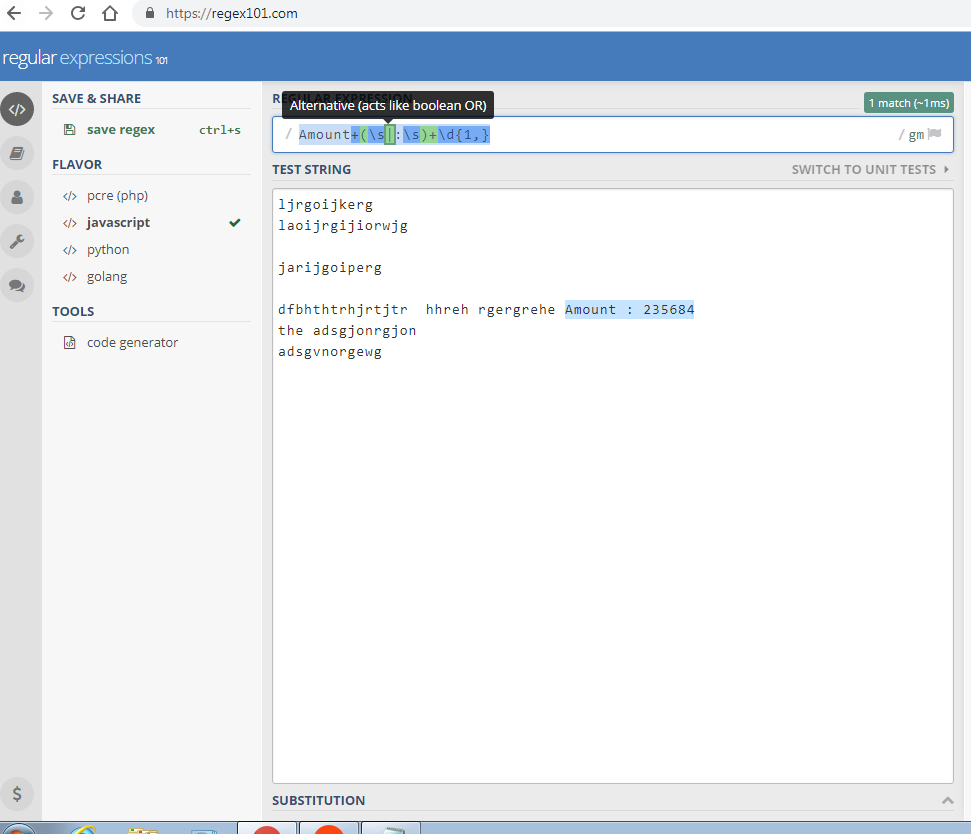
 ]
]start_position
Необязательный. Это позиция в строке, откуда начнется поиск. Если этот параметр опущен, по умолчанию он равен 1, который является первой позицией в строке. это начало строки, а $ это конец строки, независимо от позиции этих символов в выражении. По умолчанию предполагается, что выражение в одной строке.
это начало строки, а $ это конец строки, независимо от позиции этих символов в выражении. По умолчанию предполагается, что выражение в одной строке.
subexpression
Необязательный. Используется, когда шаблон имеет подвыражения, и вы хотите указать, какое подвыражение в шаблоне является целью. Это целочисленное значение от 0 до 9, указывающее, что подвыражение соответствует шаблону.
- Функция REGEXP_SUBSTR возвращает строковое значение.
- Если функция REGEXP_SUBSTR не обнаруживает какого-либо вхождения шаблона, она возвращает NULL.
Примечание
- Если для параметра match_parameter имеются конфликтующие значения, функция REGEXP_SUBSTR будет использовать последнее значение.
- См. Также функцию SUBSTR.
Применение
Функция REGEXP_SUBSTR может использоваться в следующих версиях Oracle / PLSQL:
- Oracle 12c, Oracle 11g, Oracle 10g
Пример совпадения в словах
Начнем с извлечения первого слова из строки.
Например:
SELECT REGEXP_SUBSTR (‘Google is a great search engine.’, ‘(\S*)(\s)’) FROM dual; —Результат: ‘Google ‘
SELECT REGEXP_SUBSTR (‘Google is a great search engine.’, ‘(\S*)(\s)’) FROM dual; —Результат: ‘Google ‘ |
Этот пример вернет ‘Google ‘, потому что он будет извлекать все символы без пробелов, как указано (\S*), а затем первый символ пробела, заданный (\s). Результат будет включать как первое слово, так и пробел после слова.
Если вы не хотите включать пробел в результат, то изменим наш пример следующим образом:
SELECT REGEXP_SUBSTR (‘Google is a great search engine.’, ‘(\S*)’) FROM dual; —Результат: ‘Google’
SELECT REGEXP_SUBSTR (‘Google is a great search engine.’, ‘(\S*)’) FROM dual; —Результат: ‘Google’ |
Этот пример вернет ‘Google’ без пробела в конце.
Если нам необходимо найти второе слово в строке, то изменим нашу функцию следующим образом:
SELECT REGEXP_SUBSTR (‘Google is a great search engine. ‘, ‘(\S*)(\s)’, 1, 2)
FROM dual;
—Результат: ‘is ‘
‘, ‘(\S*)(\s)’, 1, 2)
FROM dual;
—Результат: ‘is ‘
SELECT REGEXP_SUBSTR (‘Google is a great search engine.’, ‘(\S*)(\s)’, 1, 2) FROM dual; —Результат: ‘is ‘ |
Этот пример вернет ‘is ‘ с пробелом в конце строки.
Если нам необходимо найти четвертое слово в строке, мы изменим нашу функцию следующим образом:
SELECT REGEXP_SUBSTR (‘Google is a great search engine.’, ‘(\S*)(\s)’, 1, 4) FROM dual; —Результат: ‘great ‘
SELECT REGEXP_SUBSTR (‘Google is a great search engine.’, ‘(\S*)(\s)’, 1, 4) FROM dual; —Результат: ‘great ‘ |
Этот пример вернет ‘great ‘ с пробелом в конце строки.
Пример совпадения цифр
Рассмотрим, как мы будем использовать функцию REGEXP_SUBSTR для сопоставления шаблону цифровых символов.
Например:
SELECT REGEXP_SUBSTR (‘2, 4, и 10 числа для примера’, ‘\d’) FROM dual; —Результат: ‘2 ‘
SELECT REGEXP_SUBSTR (‘2, 4, и 10 числа для примера’, ‘\d’) FROM dual; —Результат: ‘2 ‘ |
В этом примере будет извлечена первая цифра из строки, как указано в \d.
Мы могли бы изменить наш шаблон для поиска двузначного числа.
Например:
SELECT REGEXP_SUBSTR (‘2, 4, и 10 числа для примера’, ‘(\d)(\d)’) FROM dual; —Результат: ’10’
SELECT REGEXP_SUBSTR (‘2, 4, и 10 числа для примера’, ‘(\d)(\d)’) FROM dual; —Результат: ’10’ |
В этом примере будет выведено число, которое имеет две цифры, как указано в (\d)(\d). В этом случае он пропустит числовые значения 2 и 4 и вернет 10.
Рассмотрим, как мы будем использовать функцию REGEXP_SUBSTR со столбцом таблицы и искать двухзначное число.
Например:
SELECT REGEXP_SUBSTR (address, ‘(\d)(\d)’) FROM contacts;
SELECT REGEXP_SUBSTR (address, ‘(\d)(\d)’) FROM contacts; |
В этом примере мы собираемся извлечь первое двузначное значение из поля address в таблице contacts.
Пример сопоставления несколько альтернатив.
Следующий пример, который мы рассмотрим, включает использование | шаблон. | шаблон используется как «ИЛИ», чтобы указать несколько альтернатив.
Например:
SELECT REGEXP_SUBSTR (‘AeroSmith’, ‘a|e|i|o|u’) FROM dual; —Результат: ‘e’
SELECT REGEXP_SUBSTR (‘AeroSmith’, ‘a|e|i|o|u’) FROM dual; —Результат: ‘e’ |
Этот пример вернет ‘e’, потому что он ищет первую гласную (a, e, i, o или u) в строке. Поскольку мы не указали значение match_parameter, функция REGEXP_SUBSTR выполнит поиск с учетом регистра, что означает, что ‘A’ в ‘AeroSmith’ сопоставляться не будет.
Чтобы выполнить поиск без учета регистра изменим наш запрос следующим образом:
SELECT REGEXP_SUBSTR (‘AeroSmith’, ‘a|e|i|o|u’, 1, 1, ‘i’) FROM dual; —Результат: ‘A’
SELECT REGEXP_SUBSTR (‘AeroSmith’, ‘a|e|i|o|u’, 1, 1, ‘i’) FROM dual;
—Результат: ‘A’ |
Теперь, поскольку мы предоставили match_parameter = ‘i’, запрос в качестве результата вернет ‘A’. На этот раз ‘A’ в ‘AeroSmith’ будет сопоставляться.
На этот раз ‘A’ в ‘AeroSmith’ будет сопоставляться.
Теперь рассмотри, как вы будете использовать эту функцию со столбцом.
Итак, допустим, у нас есть таблица contact со следующими данными:
| contact_id | last_name |
|---|---|
| 1000 | AeroSmith |
| 2000 | Joy |
| 3000 | Scorpions |
Теперь давайте запустим следующий запрос:
SELECT contact_id, last_name, REGEXP_SUBSTR (last_name, ‘a|e|i|o|u’, 1, 1, ‘i’) AS «First Vowel» FROM contacts;
SELECT contact_id, last_name, REGEXP_SUBSTR (last_name, ‘a|e|i|o|u’, 1, 1, ‘i’) AS «First Vowel» FROM contacts; |
Результаты, которые будут возвращены запросом:
| contact_id | last_name | First Vowel |
|---|---|---|
| 1000 | AeroSmith | A |
| 2000 | Joy | o |
| 3000 | Scorpions | o |
Пример совпадений на основе параметра nth_occurrence
Следующий пример, который мы рассмотрим, включает параметр nth_occurrence. Параметр nth_occurrence позволяет вам выбрать, из какого вхождения шаблона вы хотите извлечь подстроку.
Параметр nth_occurrence позволяет вам выбрать, из какого вхождения шаблона вы хотите извлечь подстроку.
Первое вхождение
Рассмотрим, как извлечь первое вхождение шаблона в строку.
Например:
SELECT REGEXP_SUBSTR (‘AeroSmith’, ‘a|e|i|o|u’, 1, 1, ‘i’) FROM dual; —Результат: ‘A’
SELECT REGEXP_SUBSTR (‘AeroSmith’, ‘a|e|i|o|u’, 1, 1, ‘i’) FROM dual; —Результат: ‘A’ |
Этот пример вернет ‘A’, потому что он извлекает первое вхождение гласного (a, e, i, o или u) в строке.
Второе вхождение
Затем мы выберем для второго вхождения шаблона в строку.
Например:
SELECT REGEXP_SUBSTR (‘AeroSmith’, ‘a|e|i|o|u’, 1, 2, ‘i’) FROM dual; —Результат: ‘e’
SELECT REGEXP_SUBSTR (‘AeroSmith’, ‘a|e|i|o|u’, 1, 2, ‘i’) FROM dual; —Результат: ‘e’ |
Этот пример вернет ‘e’, потому что он извлекает второе вхождение гласного (a, e, i, o или u) в строке.
Третье вхождение
Например:
SELECT REGEXP_SUBSTR (‘AeroSmith’, ‘a|e|i|o|u’, 1, 3, ‘i’) FROM dual; —Результат: ‘o’
SELECT REGEXP_SUBSTR (‘AeroSmith’, ‘a|e|i|o|u’, 1, 3, ‘i’) FROM dual; —Результат: ‘o’ |
Этот пример вернет ‘o’, потому что он извлекает третье вхождение гласного (a, e, i, o или u) в строке.
Сравнение MySQL и PostgreSQL | Losst
Реляционные базы данных использовались на протяжении длительного времени. Они стали популярными благодаря системам управления, которые реализуют реляционную модель настолько хорошо, что она является наилучшим способом работы с данными, особенно для критически важных приложений и служб.
MySQL существует достаточно давно и зарекомендовала себя как отличное решение, Postgresql пришла на рынок приблизительно в то же самое время, но предоставляет достаточно много интересных функций и возможностей, благодаря чему стремительно набирает популярность.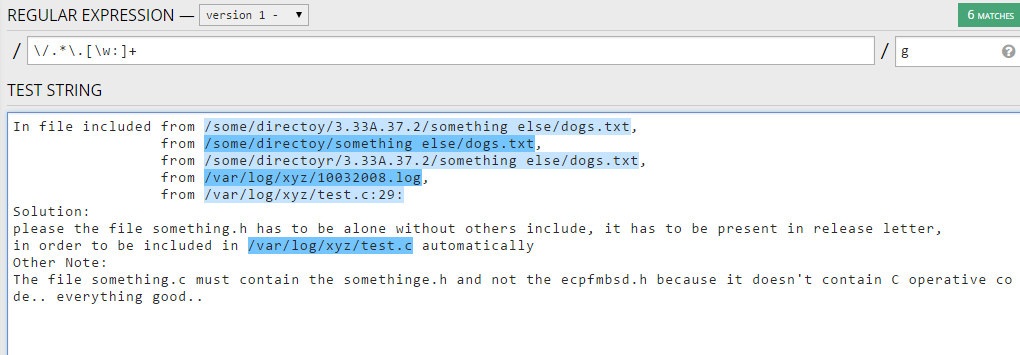 В этой статье мы попытаемся выполнить сравнение MySQL vs Postgresql, сравним основные отличия этих систем, выясним как они работают и попытаемся понять какая система будет лучше для вашего проекта.
В этой статье мы попытаемся выполнить сравнение MySQL vs Postgresql, сравним основные отличия этих систем, выясним как они работают и попытаемся понять какая система будет лучше для вашего проекта.
Содержание статьи:
Системы управления базами данных
Базы данных предназначены для структурированного хранения и быстрого доступа к различным данным. Каждая база данных, кроме самих данных, должна иметь определенную модель работы, по которой будет выполняться обработка данных. Для управления базами данных используются СУБД или системы управления базами данных, именно к таким программам относятся MySQL и Postgresql.
Реляционные системы управления базами данных позволяют размещать данные в таблицах, связывая строки из разных таблиц и, таким образом, связывая разные, объединенные логически данные. Перед тем, как вы сможете сохранять данные, необходимо создать таблицы определенного размера и указать тип данных для каждого столбца. Столбы представляют поля данных, а сами данные размещены в строках. Обе системы управления базами данных, и MySQL vs Postgresql принадлежат к реляционным. Дальше мы рассмотрим подробнее чем отличаются обе программы. А теперь перейдем к более детальному рассмотрению.
Обе системы управления базами данных, и MySQL vs Postgresql принадлежат к реляционным. Дальше мы рассмотрим подробнее чем отличаются обе программы. А теперь перейдем к более детальному рассмотрению.
Краткая история
MySQL
Разработка MySQL началась еще в 90х годах. Первый внутренний выпуск базы данных состоялся в 1995 году. За это время разработкой программы занимались несколько компаний. Разработка была начата шведской компанией MySQL AB, которую приобрела Sun Microsystems, которая, собственно перешла в собственность Oracle. На данный момент, начиная с 2010 года, разработкой занимается Oracle.
Postgresql
Разработка Postrgresql началась в далеком 1986 году в стенах Калифорнийского университета Беркли. Разработка длилась почти восемь лет, затем проект разделился на две части коммерческую базу данных IIlustra и полностью свободный проект Postrgesql, который разрабатывается энтузиастами.
Хранение данных
MySQL
MySQL — это реляционная база данных, для хранения данных в таблицах используются различные движки, но работа с движками спрятана в самой системе. На синтаксис запросов и их выполнение движок не влияет. Поддерживаются такие основные движки MyISAM, InnoDB, MEMORY, Berkeley DB. Они отличаются между собой способом записи данных на диск, а также методами считывания.
На синтаксис запросов и их выполнение движок не влияет. Поддерживаются такие основные движки MyISAM, InnoDB, MEMORY, Berkeley DB. Они отличаются между собой способом записи данных на диск, а также методами считывания.
Postgresql
Postgresql представляет из себя объектно реляционную базу данных, которая работает только на одном движке — storage engine. Все таблицы представлены в виде объектов, они могут наследоваться, а все действия с таблицами выполняются с помощью объективно ориентированных функций. Как и в MySQL все данные хранятся на диске, в специально отсортированных файлах, но структура этих файлов и записей в них очень сильно отличается.
Стандарт SQL
Независимо от используемой системы управления базами данных, SQL — это стандартизированный язык выполнения запросов. И он поддерживается всеми решениями, даже MySQL или Postgresql. Стандарт SQL был разработан в 1986 году и за это время уже вышло нескольких версий.
MySQL
MySQL поддерживает далеко не все новые возможности стандарта SQL. Разработчики выбрали именно этот путь развития, чтобы сохранить MySQL простым для использования. Компания пытается соответствовать стандартам, но не в ущерб простоте. Если какая-то возможность может улучшить удобство, то разработчики могут реализовать ее в виде своего расширения не обращая внимания на стандарт.
Разработчики выбрали именно этот путь развития, чтобы сохранить MySQL простым для использования. Компания пытается соответствовать стандартам, но не в ущерб простоте. Если какая-то возможность может улучшить удобство, то разработчики могут реализовать ее в виде своего расширения не обращая внимания на стандарт.
Postgresql
Postgresql — это проект с открытым исходным кодом, он разрабатывается командой энтузиастов, и разработчики пытаются максимально соответствовать стандарту SQL и реализуют все самые новые стандарты. Но все это приводит к ущербу простоты. Postgresql очень сложный и из-за этого он не настолько популярен как MySQL.
Возможности обработки
Из предыдущего пункта выплывают и другие отличия postgresql от mysql, это возможности обработки данных и ограничения. Естественно, соответствие более новым стандартам дает более новые возможности.
MySQL
При выполнении запроса MySQL загружает весь ответ сервера в память клиента, при больших объемах данных это может быть не совсем удобно. В основном по функциям Postgresql превосходит Mysql, дальше рассмотрим в каких именно.
В основном по функциям Postgresql превосходит Mysql, дальше рассмотрим в каких именно.
Postgresql
Postgresql поддерживает использование курсоров для перемещения по полученным данным. Вы получаете только указатель, весь ответ хранится в памяти сервера баз данных. Этот указатель можно сохранять между сеансами. Здесь поддерживается построение индексов сразу для нескольких столбцов таблицы. Кроме того, индексы могут быть различных типов, кроме hash и b-tree доступны GiST и SP-GiST для работы с городами, GIN для поиска по тексту, BRIN и Bloom.
Postgresql поддерживает регулярные выражения в запросах, рекурсивных запросов и наследования таблиц. Но тут есть несколько ограничений, например, вы можете добавить новое поле только в конец таблицы.
Производительность
Базы данных должны обязательно быть оптимизированы для окружения, в котором вы будете работать. Исторически так сложилось что MySQL ориентировалась на максимальную производительность, а Postgresql разрабатывалась как база данных с большим количеством настроек и максимально соответствующую стандарту. Но со временем Postgresql получил много улучшений и оптимизаций.
Но со временем Postgresql получил много улучшений и оптимизаций.
MySQL
В большинстве случаев для организации работы с базой данных в MySQL используется таблица InnoDB, эта таблица представляет из себя B-дерево с индексами. Индексы позволяют очень быстро получить данные из диска, и для этого будет нужно меньше дисковых операций. Но сканирование дерева требует нахождения двух индексов, а это уже медленно. Все это значит что MySQL будет быстрее Postgresql только при использовании первичного ключа.
Postgresql
Вся заголовочная информация таблиц Postgresql находится в оперативной памяти. Вы не можете создать таблицу, которая будет не в памяти. Записи таблицы сортируются по индексу, а поэтому вы можете их очень быстро извлечь. Для большего удобства вы можете применять несколько индексов к одной таблице.
В целом PostgreSQL работает быстрее, за исключениям использования первичных ключей. Давайте рассмотрим несколько тестов с различными операциями:
Типы данных
Один из основных моментов обоих баз данных это поддерживаемые типы данных, которые вы можете использовать. Поскольку оба решения пытаются соответствовать синтаксису SQL, то они имеют похожие наборы, но все же кое-чем отличаются.
Поскольку оба решения пытаются соответствовать синтаксису SQL, то они имеют похожие наборы, но все же кое-чем отличаются.
MySQL
MySQL поддерживает такие типы данных:
- TINYINT: очень маленькое целое.;
- SMALLINT: маленькое целое;
- MEDIUMINT: целое среднего размера;
- INT: целое нормального размера;
- BIGINT: большое целое;
- FLOAT: знаковое число с плавающей запятой одинарной точности;
- DOUBLE, DOUBLE PRECISION, REAL: знаковое число с плавающей запятой двойной точности
- DECIMAL, NUMERIC: знаковое число с плавающей запятой;
- DATE: дата;
DATETIME: комбинация даты и времени; - TIMESTAMP: отметка времени;
- TIME: время;
YEAR: год в формате YY или YYYY; - CHAR: строка фиксированного размера, дополняемая справа пробелами до максимальной длины;
- VARCHAR: строка переменной длины;
- TINYBLOB, TINYTEXT: двоичные или текстовые данные максимальной длиной 255 символов;
- BLOB, TEXT: двоичные или текстовые данные максимальной длиной 65535 символов;
- MEDIUMBLOB, MEDIUMTEXT: текст или двоичные данные;
- LONGBLOB, LONGTEXT: текст или двоичные максимальной данные длиной 4294967295 символов;
- ENUM: перечисление;
- SET: множества.

Postgresql
Поддерживаемые типы полей в Postgresql достаточно сильно отличаются, но позволяют записывать точно те же данные:
- bigint: знаковое 8-байтовое целое;
- bigserial: автоматически увеличиваемое 8-байтовое целое;
- bit: двоичная строка фиксированной длины;
- bit varying: двоичная строка переменной длины;
- boolean: флаг;
- box: прямоугольник на плоскости;
- byte: бинарные данные;
- character varying: строка символов фиксированной длины;
- character: строка символов переменной длины;
- cidr: сетевой адрес IPv4 или IPv6;
- circle: круг на плоскости;
- date: дата в календаре;
- double precision: число с плавающей запятой двойной точности;
- inet: адрес интернет IPv4 или IPv6;
- integer: знаковое 4-байтное целое число;
- interval: временной промежуток;
- line: бесконечная прямая на плоскости;
- lseg: отрезок на плоскости;
- macaddr: MAC-адрес;
- money: денежная величина;
- path: геометрический путь на плоскости;
- point: геометрическая точка на плоскости;
- polygon: многоугольник на плоскости;
- real: число с плавающей точкой одинарной точности;
- smallint: двухбайтовое целое число;
- serial: автоматически увеличиваемое четырехбитное целое число;
- text: строка символов переменной длины;
- time: время суток;
- timestamp: дата и время;
- tsquery: запрос текстового поиска;
- tsvector: документ текстового поиска;
- uuid: уникальный идентификатор;
- xml: XML-данные.
Как видите, типов данных в Postgresql больше и они более разнообразны, есть свои типы полей для определенных видов данных, которых нет MySQL. Отличие MySQL от Postgresql очевидно.
Разработка
Оба проекта имеют открытый исходный код, но развиваются по-разному. Развитие MySQL нравится далеко не всем. И в этом сравнение mysql и postgresql дает много отличий.
MySQL
База данных MySQL разрабатывается компанией Oracle и ходят слухи, что компания намерено тормозит развитие движка. Было создано очень много форков проекта, в том числе форк MariaDB от разработчика оригинальной MySQL. Но все же развитие остается медленным.
Postgresql
Как было сказано в начале статьи разработка началась в университете Беркли. Затем перешла в коммерческую компанию. Сейчас программа разрабатывается независимой группой программистов и советом нескольких компаний. Новые версии выпускаются достаточно активно и получают все новые и новые функции.
Выводы
В этой статье мы выполнили сравнение mysql и postgresql, рассмотрели основные отличия обоих систем управления базами данных и попытались понять что лучше postgresql или mysql. В общем результате лучшим по возможностях получается Postgresql, но он сложен и не везде его можно применять. MySQL проще, но не поддерживает некоторых интересных функций. А какую базу данных вы выберите для своего проекта? Почему именно ее? Напишите в комментариях!
В общем результате лучшим по возможностях получается Postgresql, но он сложен и не везде его можно применять. MySQL проще, но не поддерживает некоторых интересных функций. А какую базу данных вы выберите для своего проекта? Почему именно ее? Напишите в комментариях!
На завершение видео с описанием возможностей и перспектив Postgresql:
Модуль Python Re на примерах + задания и шаблоны ~ PythonRu
Регулярные выражения, также называемые regex, синтаксис или, скорее, язык для поиска, извлечения и работы с определенными текстовыми шаблонами большего текста. Он широко используется в проектах, которые включают проверку текста, NLP (Обработка естественного языка) и интеллектуальную обработку текста.
Введение в регулярные выражения
Регулярные выражения, также называемые regex, используются практически во всех языках программирования. В python они реализованы в стандартном модуле
В python они реализованы в стандартном модуле re.
Он широко используется в естественной обработке языка, веб-приложениях, требующих проверки ввода текста (например, адреса электронной почты) и почти во всех проектах в области анализа данных, которые включают в себя интеллектуальную обработку текста.
Эта статья разделена на 2 части.
Прежде чем перейти к синтаксису регулярных выражений, для начала вам лучше понять, как работает модуль re.
Итак, сначала вы познакомитесь с 5 основными функциями модуля re, а затем посмотрите, как создавать регулярные выражения в python.
Узнаете, как построить практически любой текстовый шаблон, который вам, скорее всего, понадобится при работе над проектами, связанными с поиском текста.
Что такое шаблон регулярного выражения и как его скомпилировать?
Шаблон регулярного выражения представляет собой специальный язык, используемый для представления общего текста, цифр или символов, извлечения текстов, соответствующих этому шаблону.
Основным примером является \s+.
Здесь \ s соответствует любому символу пробела. Добавив в конце оператор +, шаблон будет иметь не менее 1 или более пробелов. Этот шаблон будет соответствовать даже символам tab \t.
В конце этой статьи вы найдете больший список шаблонов регулярных выражений. Но прежде чем дойти до этого, давайте посмотрим, как компилировать и работать с регулярными выражениями.
>>> import re
>>> regex = re.compile('\s+')
Вышеупомянутый код импортирует модуль re и компилирует шаблон регулярного выражения, который соответствует хотя бы одному или нескольким символам пробела.
Как разбить строку, разделенную регулярным выражением?
Рассмотрим следующий фрагмент текста.
>>> text = """100 ИНФ Информатика
213 МАТ Математика
156 АНГ Английский"""
У меня есть три курса в формате “[Номер курса] [Код курса] [Название курса]”. Интервал между словами разный.
Интервал между словами разный.
Передо мной стоит задача разбить эти три предмета курса на отдельные единицы чисел и слов. Как это сделать?
Их можно разбить двумя способами:
- Используя метод
re.split. - Вызвав метод
splitдля объектаregex.
>>> re.split('\s+', text)
>>> regex.split(text)
['100', 'ИНФ', 'Информатика', '213', 'МАТ', 'Математика', '156', 'АНГ', 'Английский']
Оба эти метода работают. Но какой же следует использовать на практике?
Если вы намерены использовать определенный шаблон несколько раз, вам лучше скомпилировать регулярное выражение, а не использовать re.split множество раз.
Поиск совпадений с использованием findall, search и match
Предположим, вы хотите извлечь все номера курсов, то есть 100, 213 и 156 из приведенного выше текста. Как это сделать?
Что делает re.findall()?
>>> print(text)
100 ИНФ Информатика
213 МАТ Математика
156 АНГ Английский
>>> regex_num = re. compile('\d+')
>>> regex_num.findall(text)
['100', '213', '156']
compile('\d+')
>>> regex_num.findall(text)
['100', '213', '156']
В приведенном выше коде специальный символ \ d является регулярным выражением, которое соответствует любой цифре. В этой статье вы узнаете больше о таких шаблонах.
Добавление к нему символа + означает наличие по крайней мере 1 числа.
Подобно +, есть символ *, для которого требуется 0 или более чисел. Это делает наличие цифры не обязательным, чтобы получилось совпадение. Подробнее об этом позже.
В итоге, метод findall извлекает все вхождения 1 или более номеров из текста и возвращает их в список.
re.search() против re.match()
Как понятно из названия, regex.search() ищет шаблоны в заданном тексте.
Но, в отличие от findall, который возвращает согласованные части текста в виде списка, regex.search() возвращает конкретный объект соответствия. Он содержит первый и последний индекс первого соответствия шаблону.
Аналогично, regex.match() также возвращает объект соответствия. Но разница в том, что он требует, чтобы шаблон находился в начале самого текста.
>>>
>>> text2 = """ИНФ Информатика
213 МАТ Математика 156"""
>>>
>>> regex_num = re.compile('\d+')
>>> s = regex_num.search(text2)
>>> print('Первый индекс: ', s.start())
>>> print('Последний индекс: ', s.end())
>>> print(text2[s.start():s.end()])
Первый индекс: 17
Последний индекс: 20
213
В качестве альтернативы вы можете получить тот же результат, используя метод group() для объекта соответствия.
>>> print(s.group())
205
>>> m = regex_num.match(text2)
>>> print(m)
None
Как заменить один текст на другой, используя регулярные выражения?
Для изменения текста, используйте regex.. sub()
sub()
Рассмотрим следующую измененную версию текста курсов. Здесь добавлена табуляция после каждого кода курса.
>>> text = """100 ИНФ \t Информатика
213 МАТ \t Математика
156 АНГ \t Английский"""
>>> print(text)
100 ИНФ Информатика
213 МАТ Математика
156 АНГ Английский
Из вышеприведенного текста я хочу удалить все лишние пробелы и записать все слова в одну строку.
Для этого нужно просто использовать regex.sub для замены шаблона \s+ на один пробел .
>>> regex = re.compile('\s+')
>>> print(regex.sub(' ', text))
или
>>> print(re.sub('\s+', ' ', text))
101 COM Computers 205 MAT Mathematics 189 ENG English
Предположим, вы хотите избавиться от лишних пробелов и выводить записи курса с новой строки. Чтобы это сделать, используйте регулярное выражение, которое пропускает символ новой строки, но учитывает все другие пробелы.
Это можно сделать, используя отрицательное соответствие (?!\n). Шаблон проверяет наличие символа новой строки, в python это \n, и пропускает его.
>>> regex = re.compile('((?!\n)\s+)')
>>> print(regex.sub(' ', text))
100 ИНФ Информатика
213 МАТ Математика
156 АНГ Английский
Группы регулярных выражений
Группы регулярных выражений — функция, позволяющая извлекать нужные объекты соответствия как отдельные элементы.
Предположим, что я хочу извлечь номер курса, код и имя как отдельные элементы. Не имея групп мне придется написать что-то вроде этого.
>>> text = """100 ИНФ Информатика
213 МАТ Математика
156 АНГ Английский"""
>>> re.findall('[0-9]+', text)
>>> re.findall('[А-ЯЁ]{3}', text)
>>> re.findall('[а-яА-ЯёЁ]{4,}', text)
['100', '213', '156']
['ИНФ', 'МАТ', 'АНГ']
['Информатика', 'Математика', 'Английский']
Давайте посмотрим, что получилось.
Я скомпилировал 3 отдельных регулярных выражения по одному для соответствия номерам курса, коду и названию.
Для номера курса, шаблон [0-9]+ указывает на соответствие всем числам от 0 до 9. Добавление символа + в конце заставляет найти по крайней мере 1 соответствие цифрам 0-9. Если вы уверены, что номер курса, будет иметь ровно 3 цифры, шаблон мог бы быть [0-9] {3}.
Для кода курса, как вы могли догадаться, [А-ЯЁ]{3} будет совпадать с 3 большими буквами алфавита А-Я подряд (буква “ё” не включена в общий диапазон букв).
Для названий курса, [а-яА-ЯёЁ]{4,} будем искать а-я верхнего и нижнего регистра, предполагая, что имена всех курсов будут иметь как минимум 4 символа.
Можете ли вы догадаться, каков будет шаблон, если максимальный предел символов в названии курса, скажем, 20?
Теперь мне нужно написать 3 отдельные строки, чтобы разделить предметы. Но есть лучший способ. Группы регулярных выражений.
Поскольку все записи имеют один и тот же шаблон, вы можете создать единый шаблон для всех записей курса и внести данные, которые хотите извлечь из пары скобок ().
>>> course_pattern = '([0-9]+)\s*([А-ЯЁ]{3})\s*([а-яА-ЯёЁ]{4,})'
>>> re.findall(course_pattern, text)
[('100', 'ИНФ', 'Информатика'), ('213', 'МАТ', 'Математика'), ('156', 'АНГ', 'Английский')]
Обратите внимание на шаблон номера курса: [0-9]+, код: [А-ЯЁ]{3} и название: [а-яА-ЯёЁ]{4,} они все помещены в круглую скобку (), для формирования группы.
Что такое “жадное” соответствие в регулярных выражениях?
По умолчанию, регулярные выражения должны быть жадными. Это означает, что они пытаются извлечь как можно больше, пока соответствуют шаблону, даже если требуется меньше.
Давайте рассмотрим пример фрагмента HTML, где нам необходимо получить тэг HTML.
>>> text = "<body>Пример жадного соответствия регулярных выражений</body>"
>>> re. findall('<.*>', text)
['<body>Пример жадного соответствия регулярных выражений</body>']
findall('<.*>', text)
['<body>Пример жадного соответствия регулярных выражений</body>']
Вместо совпадения до первого появления ‘>’, которое, должно было произойти в конце первого тэга тела, он извлек всю строку. Это по умолчанию “жадное” соответствие, присущее регулярным выражениям.
С другой стороны, ленивое соответствие “берет как можно меньше”. Это можно задать добавлением ? в конец шаблона.
>>> re.findall('<.*?>', text)
['<body>', '</body>']
Если вы хотите получить только первое совпадение, используйте вместо этого метод поиска search.
re.search('<.*?>', text).group()
'<body>'
Наиболее распространенный синтаксис и шаблоны регулярных выражений
Теперь, когда вы знаете как пользоваться модулем re, давайте рассмотрим некоторые обычно используемые шаблоны подстановок.
Основной синтаксис
. ab-d] ab-d] | Любой символ, кроме: a, b, c, d |
| () | Извлечение элементов в скобках |
| (a(bc)) | Извлечение элементов в скобках второго уровня |
Повторы
| [ab]{2} | 2 непрерывных появления a или b |
| [ab]{2,5} | от 2 до 5 непрерывных появления a или b |
| [ab]{2,} | 2 и больше непрерывных появления a или b |
| + | одно или больше |
| * | 0 или больше |
| ? | 0 или 1 |
Примеры регулярных выражений
Любой символ кроме новой строки
>>> text = 'python.org'
>>> print(re.findall('.', text))
['p', 'y', 't', 'h', 'o', 'n', '.', 'o', 'r', 'g']
>>> print(re.findall('...', text))
['pyt', 'hon', '.or']
Точки в строке
>>>text = 'python.\.]', text))
['p', 'y', 't', 'h', 'o', 'n', 'o', 'r', 'g']
Любая цифра
>>> text = '01, Янв 2018'
>>> print(re.findall('\d+', text))
['01', '2018']
Все, кроме цифры
>>> text = '01, Янв 2018'
>>> print(re.findall('\D+', text))
[', Янв ']
Любая буква или цифра
>>> text = '01, Янв 2018'
>>> print(re.findall('\w+', text))
['01', 'Янв', '2018']
Все, кроме букв и цифр
>>> text = '01, Янв 2018'
>>> print(re.findall('\W+', text))
[', ', ' ']
Только буквы
>>> text = '01, Янв 2018'
>>> print(re.findall('[а-яА-ЯёЁ]+', text))
['Янв']
Соответствие заданное количество раз
>>> text = '01, Янв 2018'
>>> print(re.findall('\d{4}', text))
['2018']
>>> print(re.findall('\d{2,4}', text))
['01', '2018']
1 и более вхождений
>>> print(re.findall(r'Co+l', 'So Cooool'))
['Cooool']
Любое количество вхождений (0 или более раз)
>>> print(re.findall(r'Pi*lani', 'Pilani'))
['Pilani']
0 или 1 вхождение
>>> print(re.findall(r'colou?r', 'color'))
['color']
Граница слова
Границы слов \b обычно используются для обнаружения и сопоставления началу или концу слова. То есть, одна сторона является символом слова, а другая сторона является пробелом и наоборот.
Например, регулярное выражение \btoy совпадает с ‘toy’ в ‘toy cat’, но не в ‘tolstoy’. Для того, чтобы ‘toy’ соответствовало ‘tolstoy’, используйте toy\b.
Можете ли вы придумать регулярное выражение, которое будет соответствовать только первой ‘toy’в ‘play toy broke toys’? (подсказка: \ b с обеих сторон)
Аналогично, \ B будет соответствовать любому non-boundary( без границ).
Например, \ Btoy \ B будет соответствовать ‘toy’, окруженной словами с обеих сторон, как в ‘antoynet’.
>>> re.findall(r'\btoy\b', 'play toy broke toys')
['toy']
Практические упражнения
Давайте немного попрактикуемся. Пришло время открыть вашу консоль. (Варианты ответов здесь)
1. Извлеките никнейм пользователя, имя домена и суффикс из данных email адресов.
emails = """[email protected]
[email protected]
[email protected]"""
[('zuck26', 'facebook', 'com'), ('page33', 'google', 'com'), ('jeff42', 'amazon', 'com')]
2. Извлеките все слова, начинающиеся с ‘b’ или ‘B’ из данного текста.
text = """Betty bought a bit of butter, But the butter was so bitter, So she bought some better butter, To make the bitter butter better."""
['Betty', 'bought', 'bit', 'butter', 'But', 'butter', 'bitter', 'bought', 'better', 'butter', 'bitter', 'butter', 'better']
3. Уберите все символы пунктуации из предложения
sentence = """A, very very; irregular_sentence"""
A very very irregular sentence
4. Очистите следующий твит, чтобы он содержал только одно сообщение пользователя. То есть, удалите все URL, хэштеги, упоминания, пунктуацию, RT и CC.
tweet = '''Good advice! RT @TheNextWeb: What I would do differently if I was learning to code today https://t.co/lbwej0pxOd cc: @garybernhardt #rstats'''
'Good advice What I would do differently if I was learning to code today'
- Извлеките все текстовые фрагменты между тегами с HTML страницы: https://raw.githubusercontent.com/selva86/datasets/master/sample.html
Код для извлечения HTML страницы:
import requests
r = requests.get("https://raw.githubusercontent.com/selva86/datasets/master/sample.html")
r.text
['Your Title Here', 'Link Name', 'This is a Header', 'This is a Medium Header', 'This is a new paragraph! ', 'This is a another paragraph!', 'This is a new sentence without a paragraph break, in bold italics.']
Ответы
>>> pattern = r'(\w+)@([A-Z0-9]+)\.([A-Z]{2,4})'
>>> re.findall(pattern, emails, flags=re.IGNORECASE)
[('zuck26', 'facebook', 'com'), ('page33', 'google', 'com'), ('jeff42', 'amazon', 'com')]
Есть больше шаблонов для извлечения домена и суфикса. Это лишь один из них.
>>> import re
>>> re.findall(r'\bB\w+', text, flags=re.IGNORECASE)
['Betty', 'bought', 'bit', 'butter', 'But', 'butter', 'bitter', 'boughtрегулярных выражений в PostgreSQL — Postgres OnLine Journal
Каждый программист должен понимать и использовать регулярные выражения (ВКЛЮЧАЯ программистов баз данных). Есть много мест, где можно использовать регулярные выражения для сокращения 20-строчного фрагмента кода в 1 вкладыш. Зачем писать 20 строк кода, если можно написать 1.
Регулярные выражения — это предметный язык, как и SQL. Как и SQL, они встроены во многие места. Они есть у вас в редакторе программ.Вы видите это в sed, grep, perl, PHP, Python, VB.NET, C #, в валидаторах ASP.NET и javascript для проверки правильности ввода. Они есть и в PostgreSQL, где вы можете использовать их в операторах SQL, определениях доменов и проверять ограничения. Вы можете смешать регулярные выражения с SQL. Когда вы смешиваете два предметных языка, вы можете творить очаровательные вещи одним движением запястья, которое поразит ваших менее информированных друзей. Воспользуйтесь мощью языков предметной области и смешайте их.PostgreSQL делает это намного проще, чем любая другая СУБД, о которой мы можем думать.
Для получения дополнительных сведений об использовании регулярных выражений в PostgreSQL ознакомьтесь со страницами справочника Сопоставление шаблонов в PostgreSQL.
Проблема с регулярными выражениями в том, что они немного отличаются в зависимости от языковой среды, в которой вы находитесь. запускать их. Достаточно разные, чтобы расстраивать. Мы просто сосредоточимся на их использовании в PostgreSQL, хотя эти уроки применимы к другим средам.
Обычное использование
Мы собираемся вернуться немного назад. Мы начнем с демонстрации операторов SQL PostgreSQL, которые находят и заменить вещи и перечислить вещи с помощью регулярных выражений. Для этих упражнений мы будем использовать надуманную таблицу под названием заметки, которую вы можете создать с помощью следующего кода.
CREATE TABLE notes (серийный первичный ключ note_id, текст описания); ВСТАВИТЬ примечания (описание) ЗНАЧЕНИЯ (адрес электронной почты Джона - johnny @ johnnydoessql.com. Присцилла управляет сайтом http://www.johnnydoessql.com. Она также управляет сайтом http://jilldoessql.com, с ним можно связаться по телефону 345.678.9999. С ней можно связаться по телефону (123) 456-7890, а ее адрес электронной почты - [email protected] или [email protected]. '); ВСТАВИТЬ примечания (описание) ЦЕННОСТИ ('Мне нравится `# знаки и другие вещи, которые раздражают [email protected]. Воинствующий, если у вас есть проблемы, позвоните кому-нибудь, кому наплевать, по телефону (999) 666-6666.');
Регулярные выражения в PostgreSQL
PostgreSQL имеет богатый набор функций и операторов для работы с регулярными выражениями. Обычно мы используем ~ , regexp_replace и regexp_matches .
Мы чаще всего используем флаг PostgreSQL g . Флаг g — это жадный флаг, который возвращает, заменяет все вхождения шаблона. Если вы оставите флаг, только первый вхождение заменяется или возвращается в конструкциях regexp_replace, regexp_matches.Оператор ~ похож на оператор LIKE, но для регулярных выражений.
Уничтожение информации
Сила баз данных не только в том, что они позволяют быстро сохранять / извлекать информацию, но и в том, что они позволяют так же быстро уничтожать информацию. Каждый программист баз данных должен разбираться в искусстве уничтожения информации.
Примечания к ОБНОВЛЕНИЮ SET description = regexp_replace (description,
E '[A-Za-z0-9 ._% -] + @ [A-Za-z0-9 .-] + [.] [A-Za-z] {2,4}',
'---', 'г')
ГДЕ описание
~ E '[A-Za-z0-9._% -] + @ [A-Za-z0-9 .-] + [.] [A-Za-z] {2,4} ';
Примечания к ОБНОВЛЕНИЮ SET description = regexp_replace (description,
E'http: // [[[: alnum:]] +.] * [[: Alnum:]] + [.] [[: Alnum:]] + ',
E '-', 'g')
ГДЕ описание
~ E'http: // [[[: alnum:]] +.] * [[: Alnum:]] + [.] [[: Alnum:]] + ';
Примечания к ОБНОВЛЕНИЮ SET description = regexp_replace (description,
E '[\ (] {0,1} [0-9] {3} [\) .-] {0,1} [[: space:]] * [0-9] {3} [.-] {0,1} [0-9] {4} ',
'---', 'г')
ГДЕ описание
~ E '[\ (] {0,1} [0-9] {3} [\).\ x01- \ x7E] ';
Получение списка совпадений
Эти примеры используют аналогично нашему уничтожению, но показывают нам в таблице список подходящих материалов. Здесь мы используем нашу любимую функцию regexp_matches PostgreSQL .
ВЫБЕРИТЕ note_id, (regexp_matches (описание, E '[A-Za-z0-9 ._% -] + @ [A-Za-z0-9 .-] + [.] [A-Za-z] +')) [1] По электронной почте ИЗ заметок ГДЕ описание ~ E '[A-Za-z0-9 ._% -] + @ [A-Za-z0-9 .-] + [.] [A-Za-z] +' ЗАКАЗАТЬ По note_id, email; note_id | Эл. адрес --------- + ------------------------------- 1 | Джонни @ johnnydoessql.com 2 | [email protected]ВЫБЕРИТЕ note_id, разложить ( regexp_matches (описание, E '[A-Za-z0-9 ._% -] + @ [A-Za-z0-9 .-] + [.] [A-Za-z] +', 'g') ) По электронной почте ИЗ заметок ГДЕ описание ~ E '[A-Za-z0-9 ._% -] + @ [A-Za-z0-9 .-] + [.] [A-Za-z] +' ЗАКАЗАТЬ По note_id, email; note_id | Эл. адрес --------- + ------------------------------- 1 | [email protected] 1 | prissy @ jilldoessql.com 1 | [email protected] 2 | [email protected]
Части регулярного выражения
Здесь мы просто рассмотрим то, что мы считаем теми частями, которые вам необходимо знать, если у вас нет терпение или память, чтобы помнить больше. Регулярные выражения намного богаче, чем наш упрощенный взгляд на вещи. Есть отличная функция обратной ссылки, в которую мы не войдем. позволяет ссылаться на выражение и использовать его как часть выражения замены.
| Часть | Пример |
|---|---|
| Классы [] | Классы регулярных выражений — это набор символов, которые можно рассматривать как взаимозаменяемые. Они образуются заключением символов в скобки. У них также могут быть вложенные классы. Например, [A-Za-z] будет соответствовать любой букве от A-Z до a-z. [A-Za-z [: space:]] будет соответствовать этим плюсам пробелы в PostgreSQL. Если вам нужно сопоставить символ регулярного выражения, например (, вы экранируете его с помощью \.поэтому [A-Za-z \ (\)] будет соответствовать A через Z, через z и (). Классы могут содержать в качестве членов другие классы и выражения. |
| . | Знаменитый. соответствует любому символу. Итак, печально известный. * Означает одно или несколько из чего угодно. |
| Количество {} + * | Вы обозначаете количества с помощью {}, +, * + означает 1 или более. * означает 0 или более, а {} обозначает допустимые диапазоны количества. [A-Za-z] {1,5} означает, что у вас может быть от 1 до 5 буквенных символов и выражение, которое будет совпадением.A-Za-z] будет соответствовать любому символу, отсутствующему в алфавите. |
| Специальные классы | [[: alnum:]] любой буквенно-цифровой, [[: space:]] любой символ пробела. Есть и другие, но они используются чаще всего. |
PostgreSQL SUBSTRING () с примером
- Домашняя страница
Тестирование
- Назад
- Гибкое тестирование
- BugZilla
- Cucumber
- JB Тестирование базы данных
- Назад
- JUnit
- LoadRunner
- Ручное тестирование
- Мобильное тестирование
- Mantis
- Почтальон
- QTP
- Назад
- Центр качества
- Центр качества SAP SoapUI
- Управление тестированием
- TestLink
SAP
- Назад 9 0103 ABAP
- APO
- Начинающий
- Basis
- BODS
- BI
- BPC
- CO
- Назад
- CRM 9010 HRO10 HRO10 HRO103 Crystal Reports
- Расчет заработной платы
- Назад
- PI / PO
- PP
- SD
- SAPUI5
- Безопасность
- Менеджер решений
- Successfactors
- SAP Tutorials
- Назад
- Java
- JSP
- Kotlin
- Linux
- Linux
- Kotlin
- MySQL Linux. js
- Perl
- Назад
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala
- SQL Server
- SQL SQL Server Back
- SQL
- UML
- VB.Net
- VBScript
- Веб-службы
- WPF
Обязательно учите!
- Назад
- Бухгалтерский учет
- Алгоритмы
- Android
- Блокчейн
- Business Analyst
- Создание веб-сайта
- Облачные вычисления
- COBOL
- Встроенный компилятор
Python RegEx (с примерами)
A Re gular Ex нажатие (RegEx) — это последовательность символов, определяющая шаблон поиска. a…s $ ‘ test_string = ‘бездна’ результат = re.match (шаблон, тестовая_строка) если результат: print («Успешный поиск.») еще: print («Неудачный поиск.»)
Здесь мы использовали функцию re.match () для поиска шаблона в строке test_string . Метод возвращает объект соответствия, если поиск успешен. Если нет, возвращается Нет .
Есть несколько других функций, определенных в модуле re для работы с RegEx. $ * + ? {} () \ |
[] — Квадратные скобки
Квадратные скобки обозначают набор символов, которые вы хотите сопоставить.
| Выражение | Строка | Совпадает? |
|---|---|---|
[abc] | a | 1 матч |
ac | 2 совпадения | |
Привет, Джуд | Нет совпадений | |
abc de ca | 5 совпадений |
Здесь [abc] будет соответствовать, если строка, которую вы пытаетесь сопоставить, содержит любое из a , b или c . используется для проверки, начинается ли строка с определенного символа.ab
abc акб a , но не сопровождается b ) $ — Доллар
Символ доллара $ используется для проверки, заканчивается ли строка на определенного символа.
| Выражение | Строка | Совпадает? |
|---|---|---|
a $ | a | 1 матч |
формула | 1 матч | |
кабина | Нет совпадений |
* — Звезда
Звездочка * соответствует нулю или более вхождений оставшегося образца.
| Выражение | Строка | Совпадает? |
|---|---|---|
ма * н | мин | 1 матч |
человек | 1 матч | |
maaan | 1 матч | |
основной | Нет совпадений (за a не следует n ) | |
женщина | 1 матч |
+ — Plus
Знак плюс + соответствует одному или нескольким вхождениям шаблона, оставленному ему.
| Выражение | Строка | Совпадает? |
|---|---|---|
ма + н | мин | Нет совпадений (нет a символа) |
человек | 1 матч | |
maaan | 1 матч | |
основной | Нет совпадений (за a не следует n) | |
женщина | 1 матч |
? — Вопросительный знак
Знак вопроса ? соответствует нулю или одному вхождению оставшегося образца.
| Выражение | Строка | Совпадает? |
|---|---|---|
ма? Н | мин | 1 матч |
человек | 1 матч | |
maaan | Нет совпадений (более одного символа a ) | |
основной | Нет совпадений (за a не следует n) | |
женщина | 1 матч |
{} — Раскосы
Рассмотрим этот код: {n, m} .Это означает, что ему осталось не менее n и не более m повторений шаблона.
| Выражение | Строка | Совпадает? |
|---|---|---|
a {2,3} | abc dat | Нет совпадений |
abc daat | 1 матч (на d aa t ) | |
aabc daaat | 2 совпадения (на aa bc и d aaa t ) | |
aabc daaaat | 2 совпадения (на aa bc и d aaa на ) |
Попробуем еще один пример.Этот RegEx [0-9] {2, 4} соответствует не менее 2 цифрам, но не более 4 цифрам
| Выражение | Строка | Совпадает? |
|---|---|---|
[0-9] {2,4} | ab123csde | 1 совпадение (совпадение в ab 123 csde ) |
12 и 345673 | 3 совпадения ( 12 , 3456 , 73 ) | |
1 и 2 | Нет совпадений |
| — Чередование
Вертикальная полоса | используется для чередования (оператор или ).
| Выражение | Строка | Совпадает? |
|---|---|---|
a | b | код | Нет совпадений |
аде | 1 совпадение (совпадение в a de ) | |
acdbea | 3 совпадения (на a cd b e a ) |
Здесь a | b соответствует любой строке, содержащей либо a , либо b
() — Группа
Круглые скобки () используются для группировки подшаблонов.Например, (a | b | c) xz соответствует любой строке, которая соответствует a или b или c , за которым следует xz
| Выражение | Строка | Совпадает? |
|---|---|---|
(a | b | c) xz | ab xz | Нет совпадений |
abxz | 1 совпадение (совпадение в a bxz ) | |
axz cabxz | 2 совпадения (на axz bc ca bxz ) |
\ — Обратная косая черта
Люфт \ используется для экранирования различных символов, включая все метасимволы.Например,
\ $ соответствует , если строка содержит $ , за которым следует . Здесь $ не интерпретируются механизмом RegEx особым образом.
Если вы не уверены, имеет ли символ особое значение, вы можете поставить перед ним \ . Это гарантирует, что с персонажем не будут обращаться особым образом.
Особые последовательности
Специальные последовательности упрощают написание часто используемых шаблонов.Вот список специальных последовательностей:
\ A — Соответствует, если указанные символы находятся в начале строки.
| Выражение | Строка | Совпадает? |
|---|---|---|
\ Athe | солнце | Матч |
На солнце | Нет совпадений |
\ b — соответствует, если указанные символы находятся в начале или в конце слова.
| Выражение | Строка | Совпадает? |
|---|---|---|
\ bfoo | футбол | Матч |
футбольный мяч | Матч | |
футбольный мяч | Нет совпадений | |
foo \ b | Foo | Матч |
тест afoo | Матч | |
самый быстрый | Нет совпадений |
\ B — Напротив \ b .Соответствует указанным символам , а не в начале или конце слова.
| Выражение | Строка | Совпадает? |
|---|---|---|
\ Bfoo | футбол | Нет совпадений |
футбольный мяч | Нет совпадений | |
футбольный мяч | Матч | |
foo \ B | Foo | Нет совпадений |
тест afoo | Нет совпадений | |
самый быстрый | Матч |
\ d — соответствует любой десятичной цифре. 0-9]
| Выражение | Строка | Совпадает? |
|---|---|---|
\ D | 1ab34 "50 | 3 совпадения (в 1 ab 34 " 50 ) |
1345 | Нет совпадений |
\ s — соответствует, где строка содержит любой символ пробела.Эквивалент [\ t \ n \ r \ f \ v] .
| Выражение | Строка | Совпадает? |
|---|---|---|
\ с | Python RegEx | 1 матч |
PythonRegEx | Нет совпадений |
\ S — соответствует, где строка содержит любой непробельный символ. \ t \ n \ r \ f \ v] .
| Выражение | Строка | Совпадает? |
|---|---|---|
\ S | а б | 2 совпадения (в a b ) |
| Нет совпадений |
\ w — соответствует любому буквенно-цифровому символу (цифрам и алфавитам). Эквивалент [a-zA-Z0-9_] .Кстати, подчеркивание _ также считается буквенно-цифровым символом.
| Выражение | Строка | Совпадает? |
|---|---|---|
\ w | 12 & ":; c | 3 совпадения (в 12 & ":; c ) |
% ">! | Нет совпадений |
\ W — соответствует любому небуквенно-цифровому символу.a-zA-Z0-9_]
| Выражение | Строка | Совпадает? |
|---|---|---|
\ W | 1a2% c | 1 совпадение (в 1 a 2 % c ) |
Python | Нет совпадений |
\ Z — соответствует, если указанные символы находятся в конце строки.
| Выражение | Строка | Совпадает? |
|---|---|---|
Python \ Z | Мне нравится Python | 1 матч |
Мне нравится программирование на Python | Нет совпадений | |
Python - это весело. | Нет совпадений |
Совет: Для создания и тестирования регулярных выражений вы можете использовать инструменты тестера RegEx, такие как regex101. Этот инструмент не только помогает вам создавать регулярные выражения, но и помогает вам их изучить.
Теперь вы понимаете основы RegEx, давайте обсудим, как использовать RegEx в вашем коде Python.
Python RegEx
Python имеет модуль re для работы с регулярными выражениями.Чтобы использовать его, нам нужно импортировать модуль.
импорт повторно Модуль определяет несколько функций и констант для работы с RegEx.
re.findall ()
Метод re.findall () возвращает список строк, содержащих все совпадения.
Пример 1: re.findall ()
# Программа для извлечения чисел из строки
импорт ре
строка = 'привет 12 привет 89. Привет 34'
шаблон = '\ d +'
результат = re.findall (шаблон, строка)
печать (результат)
# Вывод: ['12', '89', '34']
Если шаблон не найден, re.findall () возвращает пустой список.
re.split ()
Метод re.split разбивает строку, в которой есть совпадение, и возвращает список строк, в которых произошло разбиение.
Пример 2: re.split ()
импорт ре
string = 'Двенадцать: 12 Восемьдесят девять: 89.'
шаблон = '\ d +'
результат = re.split (шаблон, строка)
печать (результат)
# Вывод: ['Двенадцать:', 'Восемьдесят девять:', '.']
Если шаблон не найден, re.split () возвращает список, содержащий исходную строку.
Вы можете передать аргумент maxsplit методу re.split () . Это максимальное количество разбиений, которое произойдет.
импорт ре
string = 'Двенадцать: 12 Восемьдесят девять: 89 Девять: 9.'
шаблон = '\ d +'
# maxsplit = 1
# разделить только при первом вхождении
результат = re.split (шаблон, строка, 1)
печать (результат)
# Вывод: ['Двенадцать:', 'Восемьдесят девять: 89 Девять: 9.']
Кстати, по умолчанию значение maxsplit равно 0; имея в виду все возможные расколы.
re.sub ()
Синтаксис re.sub () :
re.sub (шаблон, заменить, строка) Метод возвращает строку, в которой совпавшие вхождения заменяются содержимым переменной replace .
Пример 3: re.sub ()
# Программа для удаления всех пробелов
импорт ре
# многострочная строка
строка = 'abc 12 \
de 23 \ n f45 6 '
# соответствует всем пробельным символам
шаблон = '\ s +'
# пустой строкой
заменить = ''
new_string = re.sub (шаблон, замена, строка)
печать (новая_строка)
# Вывод: abc12de23f456
Если шаблон не найден, re.sub () возвращает исходную строку.
Вы можете передать count в качестве четвертого параметра методу re.sub () . Если опущено, результат будет 0. Это заменит все вхождения.
импорт ре
# многострочная строка
строка = 'abc 12 \
de 23 \ n f45 6 '
# соответствует всем пробельным символам
шаблон = '\ s +'
заменить = ''
new_string = re.sub (r '\ s +', заменить, строка, 1)
печать (новая_строка)
# Вывод:
# abc12de 23
# f45 6
re.subn ()
re.subn () похож на re.sub () , за исключением того, что он возвращает кортеж из 2 элементов, содержащий новую строку и количество сделанных замен.
Пример 4: re.subn ()
# Программа для удаления всех пробелов
импорт ре
# многострочная строка
строка = 'abc 12 \
de 23 \ n f45 6 '
# соответствует всем пробельным символам
шаблон = '\ s +'
# пустой строкой
заменить = ''
new_string = re.subn (шаблон, заменить, строка)
печать (новая_строка)
# Вывод: ('abc12de23f456', 4)
re.search ()
Метод re.search () принимает два аргумента: шаблон и строку. Метод ищет первое место, в котором шаблон RegEx дает совпадение со строкой.
Если поиск успешен, re.search () возвращает объект соответствия; в противном случае возвращается Нет .
match = re.search (шаблон, str) Пример 5: re.поиск ()
импорт ре
string = "Python - это весело"
# проверяем, стоит ли Python в начале
match = re.search ('\ APython', строка)
если совпадение:
print ("шаблон найден внутри строки")
еще:
print («шаблон не найден»)
# Вывод: шаблон найден внутри строки
Здесь совпадение содержит объект совпадения.
Сопоставить объект
Вы можете получить методы и атрибуты объекта соответствия с помощью функции dir ().
Некоторые из наиболее часто используемых методов и атрибутов объектов сопоставления:
совпадение.группа ()
Метод group () возвращает часть строки, в которой есть совпадение.
Пример 6: сопоставить объект
импорт ре
строка = '39801 356, 2102 1111'
# Трехзначное число, за которым следует пробел, за которым следует двузначное число
шаблон = '(\ d {3}) (\ d {2})'
# Переменная соответствия содержит объект Match.
match = re.search (шаблон, строка)
если совпадение:
печать (match.group ())
еще:
print («шаблон не найден»)
# Вывод: 801 35
Здесь match переменная содержит объект соответствия.
Наш шаблон (\ d {3}) (\ d {2}) имеет две подгруппы: (\ d {3}) и (\ d {2}) . Вы можете получить часть строки этих подгрупп в скобках. Вот как:
>>> match.group (1)
'801'
>>> match.group (2)
'35'
>>> match.group (1, 2)
('801', '35')
>>> match.groups ()
('801', '35')
match.start (), match.end () и match.span ()
Функция start () возвращает индекс начала сопоставленной подстроки.Точно так же end () возвращает конечный индекс соответствующей подстроки.
>>> match.start ()
2
>>> match.end ()
8 Функция span () возвращает кортеж, содержащий начальный и конечный индексы совпадающей части.
>>> match.span ()
(2, 8) match.re и match.string
Атрибут re сопоставленного объекта возвращает объект регулярного выражения. Аналогично, атрибут string возвращает переданную строку.
>>> match.re
re.compile ('(\\ d {3}) (\\ d {2})')
>>> match.string
'39801 356, 2102 1111'
Мы рассмотрели все часто используемые методы, определенные в модуле re . Если вы хотите узнать больше, посетите модуль Python 3 re.
Использование префикса r перед RegEx
Если перед регулярным выражением используется префикс r или R , это означает необработанную строку. Например, '\ n' — это новая строка, тогда как r '\ n' означает два символа: обратная косая черта \ , за которой следует n .
Люфт \ используется для экранирования различных символов, включая все метасимволы. Однако использование префикса r делает \ нормальным символом.
Пример 7: Необработанная строка с префиксом r
импорт ре
string = '\ n и \ r - escape-последовательности.'
result = re.findall (r '[\ n \ r]', строка)
печать (результат)
# Вывод: ['\ n', '\ r']
T-SQL RegEx команд в SQL Server
В этой статье исследуются команды T-SQL RegEx в SQL Server для выполнения поиска данных с использованием различных условий.
Введение
Мы храним данные в нескольких форматах или типах данных в таблицах SQL Server. Предположим, у вас есть столбец данных, содержащий строковые данные в буквенно-цифровом формате. Мы используем логический оператор LIKE для поиска определенного символа в строке и получения результата. Например, в таблице Employee мы хотим отфильтровать результаты и получить единственного сотрудника, имя которого начинается с символа A.
Мы используем регулярные выражения для определения определенных шаблонов в T-SQL в операторе LIKE и фильтрации результатов на основе определенных условий.Мы также называем эти регулярные выражения функциями T-SQL RegEx. В этой статье мы будем использовать термин T-SQL RegEx functions для регулярных выражений.
У нас может быть несколько типов регулярных выражений:
- Алфавитный RegEx
- Числовое регулярное выражение
- Чувствительность к регистру RegEx
- Специальные символы RegEx
- RegEx для исключения символов
Обязательное
В этой статье мы будем использовать образец базы данных AdventureWorks .Выполните следующий запрос, и мы получим все описания товаров:
ВЫБРАТЬ [Описание] ИЗ [AdventureWorks]. [Производство]. [Описание продукта]; |
Давайте рассмотрим T-SQL RegEx на следующих примерах.
Пример 1: Фильтрация результатов для описания, начинающегося с символа A или L
Предположим, мы хотим получить описание продукта, начинающееся с символа A или L.Мы можем использовать формат [XY]% в функции Like.
Выполните следующий запрос и убедитесь, что на выходе есть строки с первым символом A или L:
SELECT [Описание] FROM [AdventureWorks]. [Производство]. [ProductDescription] где [Описание] как «[AL]%» |
Пример 2: Фильтрация результатов для описания с первым символом A и вторым символом L
В предыдущем примере мы отфильтровали результаты для начального символа A или L.Предположим, нам нужны начальные символы описания AL. Мы можем использовать T-SQL RegEx [X] [Y]% в операторе Like.
ВЫБРАТЬ [Описание] ИЗ [AdventureWorks]. [Производство]. [Описание продукта] , где [Описание] как «[A] [L]%» |
На выходе мы можем получить только записи с первым символом A и вторым символом L.
Мы также можем указать несколько символов для фильтрации записей.Следующий запрос дает результаты для начальных символов [Все] вместе:
ВЫБРАТЬ [Описание] ИЗ [AdventureWorks]. [Производство]. [Описание продукта] где [Описание] как «[A] [L] [L]%» |
Пример 3: Фильтрация результатов по описанию и начальному символу между A и D
В предыдущем примере мы указали конкретный начальный символ для фильтрации результатов.Мы можем указать диапазон символов, используя функции [X-Z]%.
Следующий запрос дает результаты для описания, начиная с символа A и D:
ВЫБРАТЬ [Описание] ИЗ [AdventureWorks]. [Производство]. [Описание продукта] , где [Описание] как «[A-D]%» |
Точно так же мы можем указать несколько условий для каждого символа.Например, приведенный ниже запрос выполняет следующие поиски:
- Первый символ должен быть из алфавитов A и D.
- Второй символ должен быть из алфавита F и L.
SELECT [Описание] FROM [AdventureWorks]. [Производство]. [ProductDescription] где [Описание] как «[A-D] [F-I]%» |
На выходе вы можете видеть, что оба набора результатов удовлетворяют обоим условиям.
Пример 4: Фильтрация результатов по описанию и конечному символу между A и D
В предыдущих примерах мы отфильтровали данные для начальных символов. Мы могли бы также захотеть отфильтровать символ конечной позиции.
В предыдущих примерах обратите внимание на положение оператора процента (%). Мы указали процентный символ в конце символов поиска.
ВЫБРАТЬ [Описание] ИЗ [AdventureWorks].[Производство]. [Описание продукта] , где [Описание] как «[A-D] [F-I]%» |
В следующем запросе мы изменили положение символа процента в начале символа поиска. Ищет персонажей со следующим условием:
- Конечный символ должен быть от G и S
ВЫБРАТЬ [Описание] ИЗ [AdventureWorks].[Производство]. [ProductDescription] , где [Description] как «% [G-S]» |
На выходе мы получаем символ, удовлетворяющий нашему условию поиска.
Пример 5: Фильтрация результатов для начальных букв описания AF и конечных символов между S
Давайте сделаем это немного сложнее. Мы хотим искать, используя следующие условия:
- Начальный символ должен быть A (первый) и F (второй).
- Конечный символ должен быть S
Выполните следующий запрос, и на выходе мы увидим, что он удовлетворяет нашим требованиям:
ВЫБРАТЬ [Описание] ИЗ [AdventureWorks].A-T]% ‘ |
На выходе у нас нет первых символов от A до T.
Пример 7: Фильтрация результатов для описания с определенным шаблоном
В приведенном ниже примере мы хотим отфильтровать записи, используя следующие условия:
- Первый символ должен быть от символа R и S — [R-S]
- У нас может быть любая комбинация после первого символа -%
- Нам нужен символ P — [P]
- За ним следует ставить [P] или [I] — [PI]
- После предыдущего условия может иметь любой другой символ -%
ВЫБРАТЬ [Описание] ИЗ [AdventureWorks].[Производство]. [Описание продукта] , где [Описание] как «[R-S]% [P] [I]%» |
Пример 8: Поиск с учетом регистра с использованием функций T-SQL RegEx
По умолчанию мы не получаем результатов с учетом регистра. Например, следующие запросы возвращают тот же набор результатов:
ВЫБРАТЬ [Описание] ИЗ [AdventureWorks].[Производство]. [ProductDescription] , где [Description] как ‘[rs]% [P] [i]%’ SELECT [Description] FROM [AdventureWorks]. [Production]. [ProductDescription] , где [Описание] как «[RS]% [P] [I]%» |
Мы можем выполнить поиск с учетом регистра двумя способами:
Параметр сортировки базы данных: каждая база данных в SQL Server имеет параметры сортировки.Щелкните правой кнопкой мыши базу данных и на странице свойств вы увидите сопоставление
У нас SQL_Latin1_General_CP1_CI_AS выполняет нечувствительность к регистру для базы данных. Мы можем изменить это сопоставление на сопоставление с учетом регистра. Это не простое решение. Это может создать проблемы для ваших запросов. Это не рекомендуемый способ, если вам явно не требуется сортировка с учетом регистра.
Мы можем использовать Column Collation с функциями T-SQL RegEx для выполнения поиска с учетом регистра.
Создать таблицу Символы
(Символ алфавита (1)
)
Go
Вставить в значения символов (‘A’)
Вставить в значения символов (‘a’)
Go
В таблице у нас есть буква А в верхнем и нижнем регистре. Если мы запустим следующий оператор выбора, он вернет и верхний, и нижний регистр:
SELECT * из символов
, где алфавит, например, «[A]%»
Предположим, мы хотим отфильтровать заглавные буквы в результате.Мы можем использовать сортировку столбцов согласно следующему запросу:
выберите * из символов
, где алфавит COLLATE Latin1_General_BIN как «[A]%»
На выходе он возвращает заглавную букву A.
Точно так же следующий запрос возвращает строчные буквы в выводе:
выберите * из символов
, где алфавит COLLATE Latin1_General_BIN как ‘[a]%’
Мы можем использовать функцию T-SQL RegEx, чтобы найти в выводе символы как верхнего, так и нижнего регистра.
Нам нужен следующий результат:
- Первый символ должен быть заглавной буквой C
- Второй символ должен быть символом нижнего регистра h
- Остальные символы могут быть в любом регистре.
ВЫБРАТЬ [Описание]
ИЗ [AdventureWorks].[Производство]. [ProductDescription]
где [Описание] COLLATE Latin1_General_BIN, например, «[C] [h]%»
Пример 9: Использование T-SQL Regex для поиска текстовых строк, содержащих число
Мы можем найти строку, которая также содержит номер в тексте. Например, мы хотим отфильтровать результаты со строками, которые содержат числа от 0 до 9 в начале.
ВЫБРАТЬ [Описание] ИЗ [AdventureWorks].[Производство]. [ProductDescription] где [Описание] как ‘[0-9]%’ Подобно символам, мы также можем указать числа для разных позиций. В следующем примере нам нужна первая цифра от 1 до 5.Вторая цифра должна находиться в диапазоне от 0 до 9.
ВЫБРАТЬ [Описание] |

Пример 10. Использование T-SQL Regex для поиска действительного идентификатора электронной почты
Давайте рассмотрим практический сценарий функции RegEX. У нас есть таблица клиентов, в которой хранится адрес электронной почты клиента.Мы хотим идентифицировать действующий адрес электронной почты из пользовательских данных. Иногда пользователи делают опечатку и вводят @@ вместо символа @.
Сначала создайте образец таблицы и вставьте в нее адрес электронной почты в разных форматах.
СОЗДАТЬ ТАБЛИЦУ TSQLREGEX ( Электронная почта VARCHAR (1000) ) Вставить в значения TSQLREGEX ('raj @ gmail.com ') Вставить в значения TSQLREGEX ('[email protected]') Вставить в значения TSQLREGEX ('[email protected] ') Вставить в значения TSQLREGEX (' ABC @@ gmail.com ' ) Вставить в значения TSQLREGEX ('ABC.DFG.LKF#@gmail.com ') |
Выполните следующий оператор выбора с функцией T-SQL RegEx, и он удалит недопустимые адреса электронной почты.
Выберите * из TSQLREGEX, где адрес электронной почты LIKE '% [A-Z0-9] [@] [A-Z0-9]% [.] [A-Z0-9]% ' |
В списке нет следующего недействительного адреса электронной почты.
- ABC @@ gmail.com
- ABC.DFG.LKF#@gmail.com
Заключение
В этой статье мы изучили функции T-SQL RegEx для выполнения поиска с использованием различных условий. Вы должны знать об этом, чтобы искать в соответствии с конкретными требованиями.
Будучи сертифицированным MCSA и сертифицированным инструктором Microsoft в Гургаоне, Индия, с 13-летним опытом работы, Раджендра работает в различных крупных компаниях, специализируясь на оптимизации производительности, мониторинге, высокой доступности и стратегиях и внедрении аварийного восстановления. Он является автором сотен авторитетных статей о SQL Server, Azure, MySQL, Linux, Power BI, настройке производительности, AWS / Amazon RDS, Git и связанных технологиях, которые на сегодняшний день просмотрели более 10 миллионов читателей.Он является создателем одного из крупнейших бесплатных онлайн-сборников статей по одной теме с его серией из 50 статей о группах доступности SQL Server Always On. За свой вклад в сообщество SQL Server он был отмечен различными наградами, включая престижную награду «Лучший автор года» в 2020 и 2021 годах на SQLShack.
Радж всегда заинтересован в новых задачах, поэтому, если вам понадобится помощь консультанта по любому вопросу, затронутому в его трудах, с ним можно связаться в Раджендре.