Ограничения — Гипермасштабирование (Citus) — База данных Azure для PostgreSQL
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
ОБЛАСТЬ ПРИМЕНЕНИЯ: База данных Azure для PostgreSQL с Гипермасштабированием (Citus)
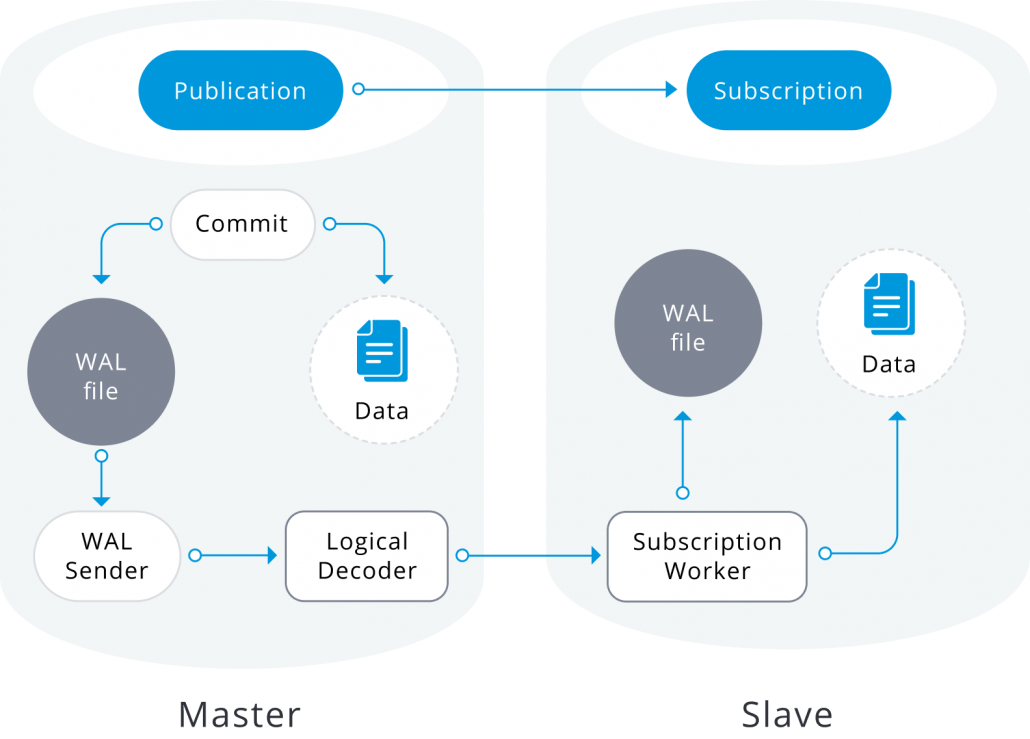
В следующем разделе описываются ограничения производительности и функциональные ограничения в службе гипермасштабирования (Citus).
Именование
Имя серверной группы
Имя группы серверов с Гипермасштабированием (Citus) должно содержать не более 40 символов.
Сеть
Максимальное количество соединений
Каждое соединение PostgreSQL (даже неактивное) использует не менее 10 Мбайт памяти, поэтому важно ограничить одновременные подключения. Ниже приведены ограничения, выбранные для поддержания работоспособности узлов.
- Максимальное число подключений на узел
- 300 для 0-3 виртуальных ядер
- 500 для 4-15 виртуальных ядер
- 1000 для 16+ виртуальных ядер
Указанные выше ограничения подключений предназначены для пользовательских подключений (max_connections минус superuser_reserved_connections). Мы резервируем дополнительные подключения для администрирования и восстановления.
Ограничения применяются как к рабочим узлам, так и к узлам-координаторам. Попытки подключения, превышающие эти ограничения, завершатся ошибкой.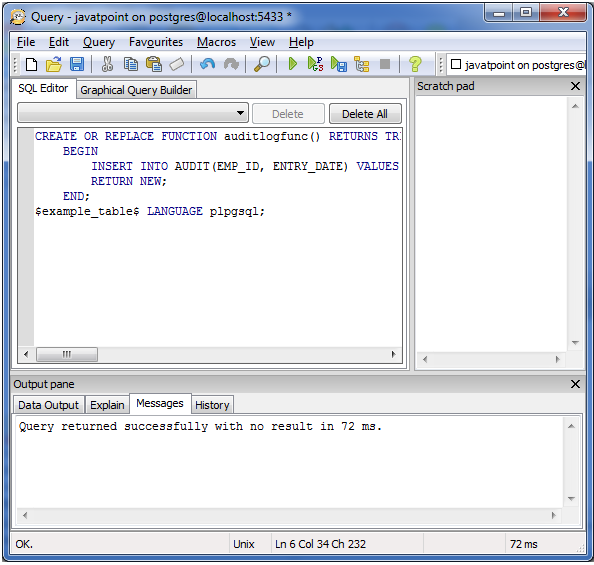
Организация пулов соединений
Вы можете дополнительно масштабировать подключения с помощью пула соединений. Гипермасштабирование (Citus) предлагает управляемый пул подключений pgBouncer, настроенный для поддержки до 2000 одновременных клиентских подключений.
Память
Масштабирование хранилища
Хранилище в узле-координаторе и рабочих узлах можно масштабировать (увеличить), но невозможно уменьшить.
Объем памяти
На узле-координаторе и рабочих узлах поддерживается до 2 ТиБ хранилища. Сведения о доступных параметрах хранилища и расчете операций ввода-вывода для размеров узлов и кластеров приведены выше.
Вычисления
Ограничения Виртуального ядра подписки
Azure применяет квоту на количество виртуальных ядер для одной подписки в каждом регионе. Существуют две независимо изменяемые квоты: виртуальные ядра для узлов-координаторов и виртуальные ядра для рабочих узлов. Квота по умолчанию должна быть больше необходимого размера, чтобы можно было экспериментировать с Гипермасштабированием (Citus). Если вам требуется больше виртуальных ядер для региона в подписке, см. статью о настройке квот вычислений.
Если вам требуется больше виртуальных ядер для региона в подписке, см. статью о настройке квот вычислений.
PostgreSQL
Создание базы данных
Портал Azure предоставляет учетные данные для подключения только к одной базе данных на каждую группу серверов с гипермасштабированием (Citus), к базе данных citus. Создание другой базы данных в настоящее время не разрешено, и команда CREATE DATABASE завершится ошибкой.
Хранение данных по столбцам
Гипермасштабирование (Citus) в настоящее время имеет следующие ограничения для столбчатых таблиц.
- Сжатие выполняется на диске, а не в памяти
- Только добавление (без поддержки обновления и удаления)
- Отсутствие реорганизации пространства (например, для отката транзакций может по-прежнему использоваться место на диске)
- Отсутствие поддержки индексов, сканирования индексов или сканирования индексов растровых изображений
- Отсутствие сканирования ИД транзакций
- Отсутствие сканирования образцов
- Отсутствие поддержки всплывающих уведомлений (поддержка больших значений)
- Отсутствие поддержки операторов ON CONFLICT (кроме действий DO NOTHING без указания цели).
- Отсутствие поддержки блокировок кортежей (SELECT … FOR SHARE, SELECT … FOR UPDATE)
- Отсутствие поддержки упорядочиваемого уровня изоляции
- Поддержка только для серверов PostgreSQL версии 12+
- Отсутствие поддержки внешних ключей, уникальных ограничений или ограничений исключений
- Отсутствие поддержки логического декодирования
- Отсутствие поддержки для параллельного сканирования внутри узла
- Отсутствие поддержки триггеров AFTER … FOR EACH ROW
- Отсутствие столбчатых таблиц UNLOGGED
- Отсутствие столбчатых таблиц TEMPORARY
Следующие шаги
- Сведения о том, как создать группу серверов с гипермасштабированием (Citus) на портале.
- Узнайте, как активировать пул подключений.
Как получить список ограничений одной таблицы? — efim360.ru
У любой базы данных в PostgreSQL есть такая схема данных, которая называется «information_schema«. В тексте мы будем называть её «Информационная схема«.
В тексте мы будем называть её «Информационная схема«.
«Информационная схема» состоит из набора представлений, содержащих информацию об объектах, определённых в текущей базе данных.
«Информационная схема» не относится к каталогам самого PostgreSQL. «Информационная схема» описана в стандарте SQL, который более масштабен и уникален во всём мире. Это значит что «Информационная схема» будет доступна любой базе данных на основе SQL, в том числе и для PostgreSQL.
Как получить все возможные ограничения (CONSTRAINT) одной таблицы в базе данных?
В «Информационной схеме
» существует 64 представления на 2022 год на 14 версию PostgreSQL.Нас интересует представление, которое называется «table_constraints«. Оно показывает все ограничения, принадлежащие таблицам, к которым имеет доступ текущий пользователь (являясь владельцем или имея некоторые права, кроме SELECT).
Если в базе данных много таблиц или много ограничений, то обращение к получению всех ограничений может вызвать перегруз. Записей в итоговой таблице может быть очень много. Но если вы всё равно хотите рискнуть, то команда выглядит так:
SELECT * FROM information_schema.table_constraints;
Но если нас интересует всего одна таблица, то мы можем добавить в запрос оператор WHERE:
SELECT * FROM information_schema.table_constraints WHERE table_name = 't_d_8411';
Скриншот из pgAdmin 4:
Получили список ограничений одной таблицы в PostgreSQLВ нашем случае таблица имеет 6 ограничений:
- 4 CHECK — четыре ограничения на отсутствие пустого значения
- 1 PRIMARY KEY — одно ограничение на первичный ключ
- 1 UNIQUE — одно ограничение на уникальность
Визуально данная таблица выглядит так:
Фрагмент таблицы 8411 в PostgreSQL
Представление «table_constraints» отображает 10 столбцов с полезной информацией:
- constraint_catalog sql_identifier — Имя базы данных, содержащей ограничение (всегда текущая база)
- constraint_schema sql_identifier — Имя схемы, содержащей ограничение
- constraint_name sql_identifier — Имя ограничения
- table_catalog sql_identifier — Имя базы данных, содержащей таблицу (всегда текущая база)
- table_schema sql_identifier — Имя схемы, содержащей таблицу
- table_name sql_identifier — Имя таблицы
- constraint_type character_data — Тип ограничения: CHECK, FOREIGN KEY, PRIMARY KEY или UNIQUE
- is_deferrable yes_or_no — YES, если ограничение откладываемое, или NO в противном случае
- initially_deferred yes_or_no — YES, если ограничение откладываемое и отложенное изначально, или NO в противном случае
- enforced yes_or_no — Относится к функциональности, отсутствующей в PostgreSQL (в настоящее время всегда равно YES)
Как получить список имён ограничений (CONSTRAINT) одной таблицы в PostgreSQL?
SELECT constraint_name FROM information_schema.Получили список имён ограничений одной таблицы в PostgreSQLtable_constraints WHERE table_name = 't_d_8411';

Какую информацию можно получить, зная имя ограничения одной таблицы в PostgreSQL?
Зная имена табличных ограничений можно воспользоваться представлением «check_constraints«, чтобы получить выражение проверки (check_clause) для ограничения типа CHECK. Например:
SELECT * FROM information_schema.check_constraints WHERE constraint_name = '25424_126788_3_not_null'; SELECT check_clause FROM information_schema.check_constraints WHERE constraint_name = '25424_126788_3_not_null';Получили выражение проверки по имени ограничения с типом CHECK в PostgreSQL
Информационные ссылки
Официальный сайт WEB-оболочки pgAdmin — https://www.pgadmin.org
Официальный сайт СУБД PostgreSQL — https://www.postgresql.org
Раздел «Ограничения» — https://postgrespro.
Раздел «Информационная схема» — https://postgrespro.ru/docs/postgresql/14/information-schema
Представление «table_constraints» — https://postgrespro.ru/docs/postgresql/14/infoschema-table-constraints
Ограничения базы данных, специфичные для PostgreSQL | Документация Django 4.0
PostgreSQL поддерживает дополнительные ограничения целостности данных, доступные из модуля django.contrib.postgres.constraints. Они добавляются в опцию модели Meta.constraints.
-
class
ExclusionConstraint(*, name, expressions, index_type=None, condition=None, deferrable=None, include=None, opclasses=())[исходный код] Создает исключающее ограничение в базе данных. Внутри PostgreSQL ограничения исключения реализуются с помощью индексов. Тип индекса по умолчанию GiST.
BtreeGistExtension.Если вы попытаетесь вставить новый ряд, который конфликтует с существующим рядом, будет выдано предупреждение
IntegrityError. Аналогично, если обновление конфликтует с существующим рядом.
name-
ExclusionConstraint.name
Имя ограничения.
expressions-
ExclusionConstraint.expressions
Итерабельность из двух кортежей. Первый элемент — выражение или строка. Второй элемент — оператор SQL, представленный в виде строки. Чтобы избежать опечаток, можно использовать RangeOperators, который сопоставляет операторы со строками. Например:
expressions=[
('timespan', RangeOperators.ADJACENT_TO),
(F('room'), RangeOperators.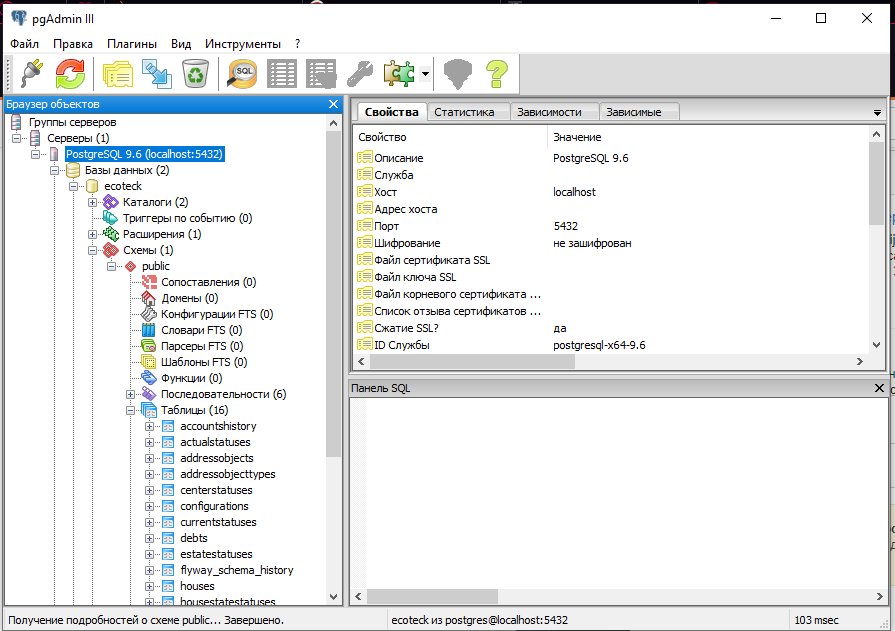 EQUAL),
]
EQUAL),
]
Ограничения для операторов.
В ограничениях исключения могут использоваться только коммутативные операторы.
index_type-
ExclusionConstraint.index_type
Тип индекса ограничения. Принимаются значения GIST или SPGIST. Соответствие нечувствительно к регистру. Если значение не указано, то по умолчанию используется индексный тип GIST.
condition-
ExclusionConstraint.condition
Объект Q, задающий условие для ограничения подмножества строк. Например, condition=Q(cancelled=False).
Эти условия имеют те же ограничения базы данных, что и
deferrable-
ExclusionConstraint.deferrable
Установите этот параметр для создания откладываемого ограничения исключения. Принимаются значения
Принимаются значения Deferrable.DEFERRED или Deferrable.IMMEDIATE. Например:
from django.contrib.postgres.constraints import ExclusionConstraint
from django.contrib.postgres.fields import RangeOperators
from django.db.models import Deferrable
ExclusionConstraint(
name='exclude_overlapping_deferred',
expressions=[
('timespan', RangeOperators.OVERLAPS),
],
deferrable=Deferrable.DEFERRED,
)
По умолчанию ограничения не откладываются. Отложенное ограничение не будет выполняться до конца транзакции. Немедленное ограничение будет выполняться сразу после каждой команды.
Предупреждение
Отложенные ограничения исключения могут привести к performance penalty.
include-
ExclusionConstraint.include
New in Django 3.2.
Список или кортеж имен полей, которые должны быть включены в охватывающее исключающее ограничение в качестве неключевых столбцов. Это позволяет использовать сканирование только по индексам для запросов, которые выбирают только включенные поля (
Это позволяет использовать сканирование только по индексам для запросов, которые выбирают только включенные поля (include) и фильтруют только по индексированным полям (expressions).
include поддерживается только для индексов GiST на PostgreSQL 12+.
opclasses-
ExclusionConstraint.opclasses
New in Django 3.2.
Имена операторов PostgreSQL operator classes, которые будут использоваться для этого ограничения. Если вам требуется пользовательский класс оператора, вы должны предоставить его для каждого выражения в ограничении.
Например:
ExclusionConstraint(
name='exclude_overlapping_opclasses',
expressions=[('circle', RangeOperators.OVERLAPS)],
opclasses=['circle_ops'],
)
создает ограничение исключения на circle с помощью circle_ops.
Примеры:
Следующий пример ограничивает перекрывающиеся бронирования в одном номере, не принимая во внимание отмененные бронирования:
from django.contrib.postgres.constraints import ExclusionConstraint from django.contrib.postgres.fields import DateTimeRangeField, RangeOperators from django.db import models from django.db.models import Q class Room(models.Model): number = models.IntegerField() class Reservation(models.Model): room = models.ForeignKey('Room', on_delete=models.CASCADE) timespan = DateTimeRangeField() cancelled = models.BooleanField(default=False) class Meta: constraints = [ ExclusionConstraint( name='exclude_overlapping_reservations', expressions=[ ('timespan', RangeOperators.OVERLAPS), ('room', RangeOperators.EQUAL), ], condition=Q(cancelled=False), ), ]
В случае если ваша модель определяет диапазон с использованием двух полей, вместо собственных типов диапазонов PostgreSQL, вы должны написать выражение, которое использует эквивалентную функцию (например, TsTzRange()), и использовать разделители для поля. Чаще всего разделителями являются
Чаще всего разделителями являются '[)', что означает, что нижняя граница является инклюзивной, а верхняя — эксклюзивной. Вы можете использовать RangeBoundary, который обеспечивает отображение выражения для range boundaries. Например:
from django.contrib.postgres.constraints import ExclusionConstraint
from django.contrib.postgres.fields import (
DateTimeRangeField,
RangeBoundary,
RangeOperators,
)
from django.db import models
from django.db.models import Func, Q
class TsTzRange(Func):
function = 'TSTZRANGE'
output_field = DateTimeRangeField()
class Reservation(models.Model):
room = models.ForeignKey('Room', on_delete=models.CASCADE)
start = models.DateTimeField()
end = models.DateTimeField()
cancelled = models.BooleanField(default=False)
class Meta:
constraints = [
ExclusionConstraint(
name='exclude_overlapping_reservations',
expressions=(
(TsTzRange('start', 'end', RangeBoundary()), RangeOperators. OVERLAPS),
('room', RangeOperators.EQUAL),
),
condition=Q(cancelled=False),
),
]
OVERLAPS),
('room', RangeOperators.EQUAL),
),
condition=Q(cancelled=False),
),
]
Функции агрегации, специфичные для PostgreSQL
Выражения запросов, специфичные для PostgreSQL
Вернуться на верх
Ограничения PostgreSql
Существуют следующие ограничения:
Максимальный размер базы неограничен (есть базы на 32 TB)
Максимальный размер таблицы 32 TB
Максимальный размер записи 1.6 TB
Максимальный размер поля 1 GB
Разумеется, понятие «неограниченно» на самом деле ограничивается доступным дисковым пространством и размерами памяти/своппинга. Когда значения перечисленные выше неоправданно большие, может пострадать производительность.
Максимальный размер таблицы в 32 TB не
требует чтобы операционная система
поддерживала файлы больших размеров.
Большие таблицы хранятся как множество
файлов размером в 1 GB, так что ограничения,
которые накладывает файловая система
не важны.
Обзор применения последней версии PostgreSql 8.1.
Версия 8.1 является новым шагом в сторону больших и нагруженных систем, предназначенных для непрерывной работы в режиме 24x7x365. Это подтверждается тем, что большие компании начинают использовать PostgreSQL в реальном бизнесе. Так, Sony Online Entertainment объявила [SOE05] об инвестировании 1.5 млн. USD в Enterprise DB для перехода с Oracle на PostgreSQL 8.1. В России крупнейший оператор сотовой связи компания Вымпелком (Beeline) тестирует ПО работающее с PostgreSQL и находится на стадии заключения контракта на поддержку кластера PostgreSQL. Компания Sun Microsystem объявила [SUN05] об официальной поддержке PostgreSQL (входит в Solaris10), «beta» версия пакетов, оптимизированных для Solaris, уже доступна [SUN06]. Кроме этого, Sun поддерживает PostgreSQL в режиме 24×7.
Традиционно, PostgreSQL широко используется
в научных проектах. Так, был запущен
проект SAI CAS (Catalog Access Service), в рамках
международной программы Virtual Observatory
(Виртуальная Обсерватория), как часть
проекта Астронет (wwww. astronet.ru), ориентированного
на профессиональное астрономическое
сообщество и где в качестве СУБД для
работы с очень большими астрономическими
каталогами (1Tb), используется PostgreSQL 8.1.
Сервер БД HP rx1620 (Itanium2) был предоставлен
HP Russia.
astronet.ru), ориентированного
на профессиональное астрономическое
сообщество и где в качестве СУБД для
работы с очень большими астрономическими
каталогами (1Tb), используется PostgreSQL 8.1.
Сервер БД HP rx1620 (Itanium2) был предоставлен
HP Russia.
PGDG
PostgreSQL развивается силами
международной группы разработчиков
(PGDG), в которую входят как непосредственно
программисты, так и те, кто отвечают за
продвижение PostgreSQL (Public Relation), за поддержание
серверов и сервисов, написание и перевод
документации, всего на 2007 год насчитывается
около 300 человек. Другими словами, PGDG —
это сложившийся коллектив, который
полностью самодостаточен и устойчив.
Проект развивается по общепринятой
среди открытых проектов схеме, когда
приоритеты определяются реальными
нуждами и возможностями. При этом,
практикуется публичное обсуждение всех
вопросов в списке рассылке, что практически
исключает возможность неправильных и
несогласованных решений. Это относится
и к тем предложениям, которые уже имеют
или рассчитывают на финансовую поддержку
коммерческих компаний.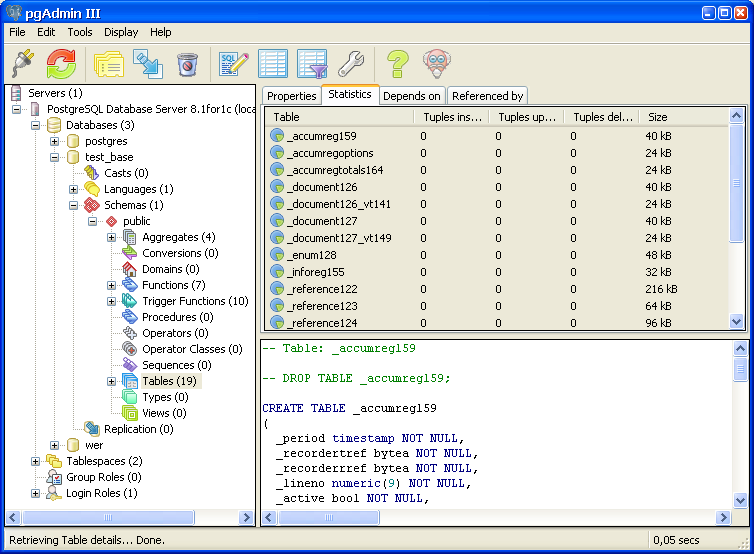
Т.к. при создании интерфейса мне пришлось открывать доступ к своей базе из среды Exlips, то нужно сказать еще и об этом.
Доступ к базам данных из Java-программ
Разумеется, что организовать доступ к
базам данных из современного языка
программирования в наше время не
представляет никакой сложности. Более
того, и сами языки программирования
более всего оцениваются разработчиками
по типу и возможностям заложенных в них
средств доступа к базам данных, удобству
и полноте интерфейсов. В этом смысле
Javaне представляет
исключения. Уже в версииJDK1.1
появился пакет классовjava.sql,
обеспечивающий больщинство функций,
известных к тому времени разработчикамODBC-приложений. В этом
пакете содержится ряд замечательных
классов, например:java.sql.CallableStatement,
который обеспечивает выполнение наJavaхранимых процедур;java.sql.DatabaseMetaData,
который исследует базу данных на предмет
ее реляционной полноты и целостности
с получением самых разнообразных данных
о типах и содержимом таблиц, колонок,
индексов, ключей и т. д.; наконец, -java.sql.ResultSetMetaData,
с помощью которого можно выводить в
удобном виде всю необходимую информацию
из таблиц базы данных или печатать сами
метаданные в виде названий таблиц и
колонок.
д.; наконец, -java.sql.ResultSetMetaData,
с помощью которого можно выводить в
удобном виде всю необходимую информацию
из таблиц базы данных или печатать сами
метаданные в виде названий таблиц и
колонок.
Однако, коренное отличие Javaот других традиционных языков программирования заключается в том, что одни и те же функции доступа к базам данных, с помощью универсальности и кроссплатформенностиJava, можно организовать чрезвычайно гибко, используя все преимущества современных объектно-ориентированных технологий
1. Java-программы и апплеты с интерфейсом JDBC-ODBC
JDBC (Java Database Connectivity) является не протоколом, а интерфейсом и основан на спецификациях SAG CLI (SQL Access Group Call Level Interface — интерфейс уровня вызова группы доступа SQL).
Сам по себе JDBC работать не может и
использует основные абстракции и методы
ODBC. Хотя в стандарте JDBC API и предусмотрена
возможность работы не только через
ODBC, а и через использование прямых линков
к базам данных по двух- или трех-звенной
схеме (см. Рис.1), эту схему используют
гораздо реже, чем повсеместно используемый
JDBC-ODBC-Bridge занимающий центральное место
в общей схеме взаимодействия интерфейсов
(см. Рис. 2)
Рис.1), эту схему используют
гораздо реже, чем повсеместно используемый
JDBC-ODBC-Bridge занимающий центральное место
в общей схеме взаимодействия интерфейсов
(см. Рис. 2)
Рис. 1. Непосредственный доступ к базе данных по 3-х-звенной схеме.
Рис. 2. Схема взаимодействия интерфейсов.
Даже беглого взгляда на Рис. 2 вполне
достаточно, чтобы понять — общая схема
взаимодействия интерфейсов в Java
удивительным образом напоминает столь
всем знакомую схему ODBC с ее гениальным
изобретением драйвер-менеджера к
различным СУБД и единого универсального
пользовательского интерфейса. JDBC Driver
Manager — это основной ствол JDBC-архитектуры.
Его первичные функции очень просты —
соединить Java-программу и соответствующий
JDBC драйвер и затем выйти из игры.
Естественно, что ODBC был взят в качестве
основы JDBC из-за его популярности среди
независимых поставщиков программного
обеспечения и пользователей. Но тогда
возникает законный вопрос — а зачем
вообще нужен JDBC и не легче ли было
организовать интерфейсный доступ к
ODBC-драйверам непосредственно из Java?
Ответом на этот вопрос может быть только
однозначное нет. Путь через JDBC-ODBC-Bridge,
как ни странно, может оказаться гораздо
короче.
Путь через JDBC-ODBC-Bridge,
как ни странно, может оказаться гораздо
короче.
1. ODBC нельзя использовать непосредственно из Java, поскольку он основан на C-интерфейсе. Вызов из Java C-кода нарушает целостную концепцию Java, пробивает брешь в защите и делает программу трудно-переносимой.
2. Перенос ODBC C-API в Java-API нежелателен. К примеру, Java не имеет указателей, в то время как в ODBC они используются.
3. ODBC слишком сложен для понимания. В нем смешаны простые и сложные вещи, причем сложные опции иногда применяются для самых простых запросов.
4. Java-API необходим, чтобы добиться абсолютно чистых Java решений. Когда ODBC используется, то ODBC-драйвер и ODBC менеджер должны быть инсталлированы на каждой клиентской машине. В то же время, JDBC драйвер написан полностью на Java и может быть легко переносим на любые платформы от сетевых компьютеров до мэйнфреймов.
JDBC API — это естественный Java-интерфейс к
базовым SQL абстракциям и, восприняв дух
и основные абстракции концепции ODBC, он
реализован, все-таки, как настоящий
Java-интерфейс, согласующийся с остальными
частями системы Java.
В отличие от интерфейса ODBC,JDBCорганизован намного проще. Главной его частью является драйвер, поставляемый фирмойJavaSoftдля доступа изJDBCк источникам данных. Этот драйвер является самым верхним в иерархии классовJDBCи называетсяDriverManager. Согласно, установившимся правиламInternet, база данных и средства ее обслуживания идентифируются при помощиURL.
Однако, как уже говорилось выше, чаще
всего, все-таки используется механизм
ODBCблагодаря его
универсальности и доступности. Программа
взаимодействия между драйверомJDBCиODBCразработана фирмойJavaSoftв сотрудничестве сInterSolvи называетсяJDBC-ODBC-Bridge.
Она реализована в видеJdbcOdbc.class(для платформыWindowsJdbcOdbc.dll) и
входит в поставкуJDK1.1.
ПомимоJdbcOdbc-библиотек
должны существовать специальные драйвера
(библиотеки), которые реализуют
непосредственный доступ к базам данных
через стандартный интерфейсODBC.
Как правило эти библиотеки описываются
в файлеODBC.INI.
На внутреннем уровнеJDBC-ODBC-Bridgeотображает медодыJavaв
вызовыODBCи тем самым
позволяет использовать любые существующие
драйверыODBC, которых к
настоящему времени накоплено в изобилии.
SurfCop
SurfCopPostgreSQL
PostgreSQL является свободной альтернативой коммерческим СУБД (таким как Oracle Database, Microsoft SQL Server, IBM DB2, Informix и СУБД производства Sybase) вместе с другими свободными СУБД (такими как MySQL и Firebird).
PostgreSQL базируется на языке SQL и поддерживает многие из возможностей стандарта SQL:2003 (ISO/IEC 9075).
На данный момент (версия 8.4.0), в PostgreSQL имеются следующие ограничения:
| Максимальный размер базы данных | Нет ограничений |
| Максимальный размер таблицы | 32 ТБайт |
| Максимальный размер записи | 1,6 ТБайт |
| Максимальный размер поля | 1 ГБайт |
| Максимум записей в таблице | Нет ограничений |
| Максимум полей в таблице | 250—1600, в зависимости от типов полей |
| Максимум индексов в таблице | Нет ограничений |
Сильными сторонами PostgreSQL считаются:
- поддержка БД практически неограниченного размера;
- мощные и надёжные механизмы транзакций и репликации;
- наследование;
- легкая расширяемость.
Настройка PostgreSQL
Установка PostgreSQL довольно проста — достаточно лишь загрузить дистрибутив с официального сайта: http://www.postgresql.org/download/windows/ и запустить процесс установки. В процессе установки необходимо указать пароль администратора баз данных (пользователя с логином postgres).
В случае если доступ к базе данных будет осуществляться с удалённой машины, то необходимо в настройках СУБД разрешить удалённые подключения.
Ниже представлена пошаговая инструкция:
Необходимо отредактировать файл C:\Program Files\PostgreSQL\8.3\data\postgresql.conf, как показано на Рисунке 1, указав в качестве значения параметра listen_addresses IP адрес, на котором СУБД будет «слушать» и ожидать входящие соединения (По умолчанию там стоит «*», что значит «Все адреса». Можно ничего не менять и оставить это значение).
Рисунок 1.
После редактирования файл postgresql.conf необходимо сохранить
под прежним именем.
Необходимо настроить разрешения доступа с определенных удалённых компьютеров. Для этого необходимо открыть файл C:\Program Files\PostgreSQL\8.3\data\pg_hba.conf любым текстовым редактором и найти в нём следующую строку:
# Ipv4 local connections:
В список расположенный ниже данной строки необходимо добавить запись соответствующую диапазону IP адресов компьютеров, с которых будут инициироваться подключения. Например, вот так:
host all all 192.168.0.7/32 md5
где,
host –означает авторизацию на уровне хоста
all –означает что доступ будет открыть для всех пользователей, ко всем базам данных
192.168.0.7/32 – диапазон IP адресов компьютеров, с которого будет производиться подключение (в формате IP/Mask)
md5 –определяет тип шифрования передаваемой информации
Пример содержимого файла pg_hba.conf показан на Рисунке 2.
Рисунок 2.
После завершения редактирования и сохранения файлов
postgresql. conf и pg_hba.conf необходимо перезапустить сервер базы
данных. Для этого достаточно перезапустить сервис PostgreSQL
Server. Изменения вступят в силу только после перезапуска
PostgreSQL.
conf и pg_hba.conf необходимо перезапустить сервер базы
данных. Для этого достаточно перезапустить сервис PostgreSQL
Server. Изменения вступят в силу только после перезапуска
PostgreSQL.
Следующим шагом является создание базы данных.
Для создания базы данных необходимо запустить консоль PostgreSQL(скрипт C:\Program Files\PostgreSQL\8.3\scripts\runpsql.bat) и выполнить следующую команду:
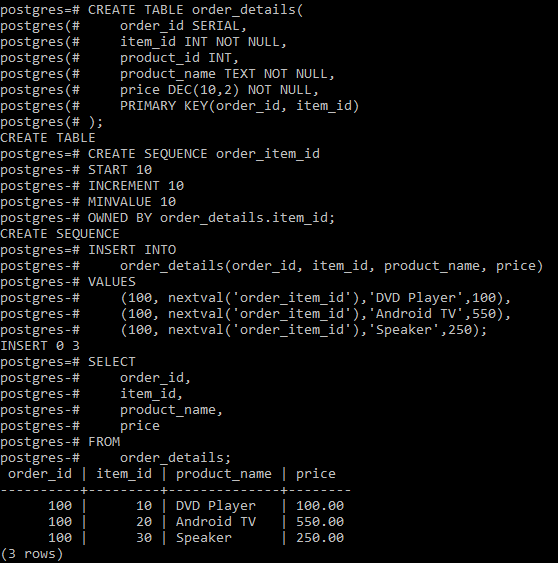
CREATE DATABASE «Activity» WITH OWNER = postgres ENCODING = ‘UTF8’;
где,
Activity — имя создаваемой базы данных
postgres — имя владельца базы данных
utf8 – кодировка, в которой хранятся данные в базе данных.
Результат выполнения команды, изображён на Рисунке 3.
Рисунок 3.
Настройка Дата Центра
После создания новой базы данных следует настроить Дата Центр
для работы с ней. Для этого необходимо запустить консоль управления
программы, перейти на страницу «Конфигурация» изображённую на
Рисунке 4 и выбрать пункт «Настройки хранилища данных».![]()
Рисунок 4.
В открывшемся диалоге необходимо выбрать тип база данных (в нашем случае PostgreSQL).
Рисунок 5.
На второй закладке необходимо ввести параметры подключения как указанно на Рисунке 6,
где,
192.168.0.166 — IP адрес сервера PostgreSQL
5432 — порт, по которому будет производиться подключение (по умолчанию используется 5432)
Логин — имя пользователя, имеющего права на подключение к базе данных (ранее, пользователю postgres были назначены все необходимые права)
Пароль — пароль пользователя postgres, заданный при установке PostgreSQL
Рисунок 6.
Для проверки правильности ввода параметров подключения необходимо нажать кнопку «Проверить подключение».
После нажатия на «Проверить подключение» программа попытается
установить соединение с базой данных и, если настройки подключения
были указаны правильно, то появится сообщение, изображённое на
Рисунке 7.
Рисунок 7.
После того, как тестирование подключения будет завершено, необходимо нажать «ОК».
Появится сообщение уведомляющее о том, что Дата Центр должен быть перезагружен для применения новых параметров (Рисунок 8).
Рисунок 8.
Необходимо нажать «Да», после чего Дата Центр будет автоматически перезагружен. После перезагрузки Дата Центра все изменения вступят в силу и программа начнет использовать для хранения информации новую базу данных.
Состояние базы данных можно просмотреть на закладке «Статистика» диалога управления хранилищем данных (Рисунок 9).
Рисунок 9.
Резюме
PostgreSQL — это свободно распространяемая объектно-реляционная система управления базами данных (ORDBMS), наиболее развитая из открытых СУБД в мире и являющаяся реальной альтернативой коммерческим базам данных.
PostgreSQL считаются лучшей по ряду причин:
- поддержка БД практически неограниченного размера;
- мощные и надёжные механизмы транзакций и репликации;
- наследование;
- легкая расширяемость.
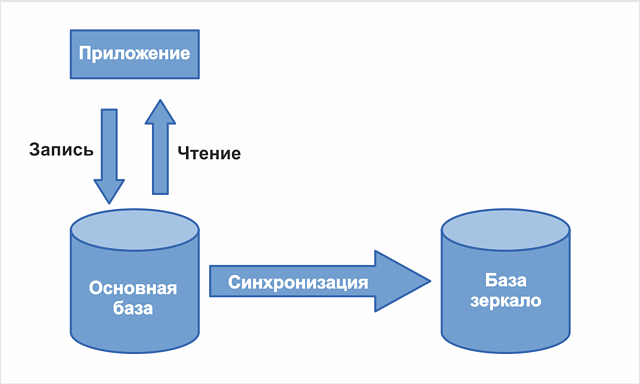
что это за база данных
PostgreSQL — это объектно-реляционная система управления базами данных (ORDBMS), наиболее развитая из открытых СУБД в мире. Имеет открытый исходный код и является альтернативой коммерческим базам данных.
Логотип PostgreSQLРанние версии системы были основаны на старой программе POSTGRES University, созданной университетом Беркли: так появилось название PostgreSQL. И сейчас СУБД иногда называют «Постгрес». Существуют сокращения PSQL и PgSQL — они тоже обозначают PostgreSQL.
СУБД позволяет гибко управлять базами данных (БД). С ее помощью можно создавать, модифицировать или удалять записи, отправлять транзакцию — набор из нескольких последовательных запросов на особом языке запросов SQL.
- Бэкенд-разработчики, которым приходится взаимодействовать с базами данных при работе с «серверной» частью сайта.
- Администраторы и разработчики баз данных — специалисты, основная задача которых заключается в обслуживании и поддержке работоспособности базы.
- DevOps-инженеры, обслуживающие рабочую инфраструктуру проекта.
Курс Уверенный старт в IT Поможем определить подходящую вам IT-профессию и освоить её с нуля. Вы на практике попробуете разные направления: разработку на разных языках, аналитику данных, Data Science, менеджмент в IT. Это самый подходящий курс для построения карьеры в IT в новой реальности. Хочу в IT!
- Гибкий доступ к базам данных, их организация и хранение.
- Управление записями в базах данных: создание, редактирование и удаление, обновление версий и так далее.
- Просмотр нужной информации из базы по запросу, например для ее отправки на сайт или в интерфейс приложения.

- Отправка транзакций, последовательных запросов, собранных в подобие скрипта.
- Настройка и контроль доступа к той или иной информации, группировка пользователей по уровню прав.
- Контроль версий и организация одновременного доступа к базе из разных источников так, чтобы предотвратить сбои.
- Защита информации от возможных утечек и потерь.
- Контроль состояния базы в целом.
Иногда СУБД называют бесплатным аналогом Oracle Database. Обе системы адаптированы под большие проекты и высокую нагрузку. Но есть разница: они по-разному хранят данные, предоставляют разные инструменты и различаются возможностями. Важная особенность PostgreSQL в том, что эта система — feature-rich: так называют проекты с широким функционалом.
Объектно-реляционная модель. Традиционно популярные СУБД — реляционные. Это значит, что данные, которые в них хранятся, представляются в виде записей, связанных друг с другом отношениями, — relations. Получаются связанные списки, которые могут иметь между собой те или иные отношения, — так и образуется таблица.
Это значит, что данные, которые в них хранятся, представляются в виде записей, связанных друг с другом отношениями, — relations. Получаются связанные списки, которые могут иметь между собой те или иные отношения, — так и образуется таблица.
Существует еще одна популярная модель — объектная. Данные представляются в виде объектов, их атрибутов, методов и классов. Объектная модель поддерживает возможности, о которых мы подробно рассказывали в статье про ООП, например наследование.
PostgreSQL — объектно-реляционная СУБД. Это значит, что она поддерживает и объектный, и реляционный подход.
Поддержка множества типов данных. Еще одна особенность PostgreSQL — поддержка большого количества типов записи информации. Это не только стандартные целочисленные значения, числа с плавающей точкой, строки и булевы значения («да/нет»), но и денежный, геометрический, перечисляемый, бинарный и другие типы. PostgreSQL «из коробки» поддерживает битовые строки и сетевые адреса, массивы данных, в том числе многомерные, композитные типы и другие сложные структуры. В ней есть поддержка XML, JSON и NoSQL-баз.
PostgreSQL «из коробки» поддерживает битовые строки и сетевые адреса, массивы данных, в том числе многомерные, композитные типы и другие сложные структуры. В ней есть поддержка XML, JSON и NoSQL-баз.
При необходимости к СУБД можно подключить поддержку типов данных, которые нужны в конкретном проекте. В PostgreSQL есть несколько внутренних форматов, которые используются только в ней.
Работа с большими объемами. В большинстве СУБД, рассчитанных на средние и небольшие проекты, есть ограничения по объему базы и количеству записей в ней. В PostgreSQL ограничений нет.
Ограничения касаются только конкретных записей. Одна таблица может занимать не больше 32 Тб, а одна запись — 1,6 Тб. В одном поле записи может быть не больше 1 Гб данных, а максимальное количество полей зависит от типа и составляет от 250 до 1600 штук. Максимальных значений хватает, чтобы хранить в БД любые данные.
Поддержка сложных запросов. PostgreSQL работает со сложными, составными запросами. Система справляется с задачами разбора и выполнения трудоемких операций, которые подразумевают и чтение, и запись, и валидацию одновременно. Она медленнее аналогов, если речь заходит только о чтении, но в других аспектах превосходит конкурентов.
PostgreSQL работает со сложными, составными запросами. Система справляется с задачами разбора и выполнения трудоемких операций, которые подразумевают и чтение, и запись, и валидацию одновременно. Она медленнее аналогов, если речь заходит только о чтении, но в других аспектах превосходит конкурентов.
Написание функций на нескольких языках. В PostgreSQL можно писать собственные функции — пользовательские блоки кода, которые выполняют те или иные действия. Эта возможность есть практически в любых СУБД, но PostgreSQL поддерживает больше языков, чем аналоги. Кроме стандартного SQL, в PostgreSQL можно писать на C и C++, Java, Python, PHP, Lua и Ruby. Он поддерживает V8 — один из движков JavaScript, поэтому JS тоже можно использовать совместно с PgSQL. Реализована поддержка Delphi, Lisp и прочих редких языков. При необходимости можно расширить систему под другие ЯП.
Модификация SQL, которая используется в PostgreSQL, называется PL/pgSQL. Это процедурное расширение, которое поддерживает сложные вычисления и дополняет «классический» SQL новыми возможностями.
Это процедурное расширение, которое поддерживает сложные вычисления и дополняет «классический» SQL новыми возможностями.
Читайте также: SQL, R или Python: какой язык учить аналитику данных?
Одновременная модификация базы. Важная особенность PostgreSQL — возможность одновременного доступа к базе с нескольких устройств. В СУБД реализована клиент-серверная архитектура, когда база данных хранится на сервере, а доступ к ней осуществляется с клиентских компьютеров. Так, например, реализуются разнообразные сайты. Одна из возможных сложностей — ситуация, когда несколько человек одновременно модифицируют базу и нужно избежать конфликтов.
В PostgreSQL для этого используется технология MVCC — Multiversion Concurrency Control, многоверсионное управление параллельным доступом. Каждый пользователь получает снапшот — «снимок» базы, в который вносятся изменения. Только после фиксации транзакции они поступают в исходную базу данных. Пока человек вносит изменения, они не видны другим пользователям. Конфликтов не возникает, как и необходимости блокировать чтение или запись.
Пока человек вносит изменения, они не видны другим пользователям. Конфликтов не возникает, как и необходимости блокировать чтение или запись.
Соответствие ACID. ACID — это набор принципов для обеспечения целостности данных. Аббревиатура расшифровывается как Atomicity, Consistency, Isolation, Durability — атомарность, согласованность, изолированность, прочность. Если база данных соответствует этим принципам, она ведет себя максимально предсказуемо и надежно. В ней низок риск конфликта или непредвиденного поведения системы.
PostgreSQL соблюдает требования ACID благодаря технологии MVCC. Это делает систему надежной и безопасной в использовании, а данные — защищенными от возможных сбоев, ошибок и потерь.
Возможность расширения. Разработчик может написать для СУБД собственные типы и их преобразования, операции и функции, ограничения и индексы, собственный процедурный язык для запросов. PostgreSQL можно модифицировать практически под любую нестандартную задачу.
PostgreSQL можно модифицировать практически под любую нестандартную задачу.
Высокая мощность и широкая функциональность. PostgreSQL — возможно, единственная бесплатная СУБД с открытым исходным кодом, которая рассчитана на работу с объемными и сложными проектами. Она мощная, производительная, способна эффективно работать с большими массивами данных. Есть примеры реального использования СУБД для баз данных в несколько петабайт с сотнями тысяч запросов в секунду. На главной странице официального сайта PostgreSQL называют «самой продвинутой бесплатной СУБД». Система действительно имеет высокую функциональность и не уступает платным продуктам.
Открытость. PostgreSQL — ПО с открытым исходным кодом, которое распространяется по свободной лицензии. Это означает, что любой разработчик может посмотреть, как написана система, или предложить для нее свои правки. СУБД разрабатывается сообществом энтузиастов и в определенной степени никому не принадлежит, а значит, ее можно свободно и без ограничений использовать в своих проектах.
На базе PostgreSQL существуют коммерческие продукты с платным доступом — ими обычно пользуются крупные компании, которым нужна дополнительная функциональность. Это, например, связь с Oracle Database или продвинутый веб-интерфейс для администрирования БД.
Минимальное количество багов. PostgreSQL — проект, который известен высоким качеством отладки. Каждая версия системы появляется в доступе только после полной проверки, поэтому СУБД очень стабильна. Частая проблема бесплатных проектов — новые версии с большим количеством багов, но в случае с PostgreSQL такой проблемы нет.
Согласно независимым автоматизированным исследованиям, в исходном коде СУБД есть одна ошибка на 39 000 строк кода. Это в пять раз меньше, чем в MySQL, и в пятьдесят раз меньше, чем в ядре операционной системы Linux.
Кроссплатформенность.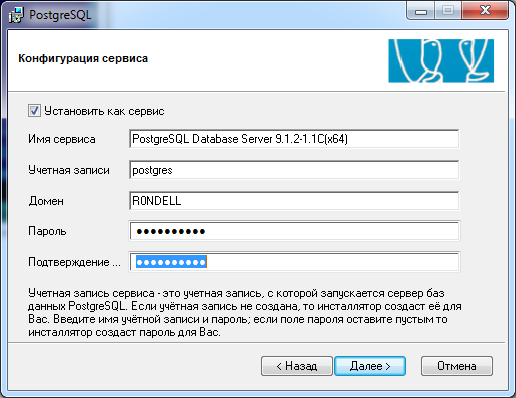 Чаще всего PostgreSQL используют на серверах с операционными системами семейства Linux, но СУБД поддерживает и другие ОС. Ее можно установить в системы на базе Windows, BSD, macOS и Solaris. Кроме того, у PostgreSQL есть автономный веб-сервер PostgREST, с которым можно работать с помощью REST API. СУБД можно развернуть и в облаке.
Чаще всего PostgreSQL используют на серверах с операционными системами семейства Linux, но СУБД поддерживает и другие ОС. Ее можно установить в системы на базе Windows, BSD, macOS и Solaris. Кроме того, у PostgreSQL есть автономный веб-сервер PostgREST, с которым можно работать с помощью REST API. СУБД можно развернуть и в облаке.
PostgreSQL не имеет однозначных недостатков. Она подходит для проектов, где нужна мощная база данных с высокой функциональностью. Но для большинства приложений и сайтов требуется менее мощная и более быстрая, легковесная, простая в освоении СУБД. Обычно в таких случаях используется MySQL.
Скачать программное обеспечение можно с официального сайта: на странице загрузки представлены готовые к установке пакеты для разных операционных систем. Там же есть ссылка на репозиторий, где в том числе можно посмотреть, как менялись версии проекта, и ознакомиться с новыми правками.
После скачивания потребуется место для размещения серверной части СУБД. Обычно для этого арендуются мощности веб-серверов хостингов.
Обычно для этого арендуются мощности веб-серверов хостингов.
Более сложный процесс — настройка и развертывание базы данных, управление ей. Для этого потребуются знания бэкенд-разработчика или администратора БД. В случае с PostgreSQL нужно заранее ознакомиться с документацией или мануалами. Также получить все перечисленные знания можно на курсах SkillFactory.
Профессия Fullstack-разработчик на Python Получите навыки программирования, освойте backend на Python и frontend на JavaScript, чтобы стать востребованным специалистом в IT. Посмотреть программу
Максимальное количество баз данных для одного экземпляра PostgreSQL 9
При разработке многопользовательского приложения мы планируем использовать разные базы данных для каждого клиента. Но это может быть и более 1000 клиентов (заявок).
Справится ли PostgreSQL без проблем?
Кто-нибудь пробовал что-то подобное?
Примечание: 35 таблиц для каждой, в среднем до 3000 записей для каждой базы данных.
- postgresql
- postgresql-9.1
Я сам не пробовал, но есть люди, которые пробовали. Здесь вы можете видеть, что даже 10 000 баз данных работают без проблем на одном экземпляре. Вы даже можете найти некоторые практические аспекты на ServerFault.
Поскольку ваши базы данных довольно малы, вы не столкнетесь с каким-либо ограничением количества файлов в операционной системе хоста. Единственная проблема, о которой я могу думать, заключается в том, что при одновременном доступе ко всем этим базам данных обработка всех этих соединений будет сложной.
И последнее замечание: добро пожаловать на этот сайт. Мы надеемся, что вы останетесь с нами надолго.
1
Звучит грязно с точки зрения руководства. Как вы планируете создавать резервные копии такого количества баз данных? со сценарием, который зацикливается на каждом?
Если у вас нет действительно веской причины, почему бы просто не иметь одну базу данных, структура которой разработана таким образом, чтобы все данные были связаны с идентификатором клиента. Добавьте индексы/внешний ключ/первичные ключи на основе этого поля, что обеспечит целостность данных.
Добавьте индексы/внешний ключ/первичные ключи на основе этого поля, что обеспечит целостность данных.
Тогда вам просто нужно иметь предложение where во всех ваших запросах, чтобы получить доступ только к одному идентификатору клиента. Это будет намного проще поддерживать и так же легко разрабатывать (потому что в любом случае вам нужно разрешить идентификацию клиента)
4
Есть люди, которые делают это, особенно для хостинга общих серверов.
Раздумывая над вопросами здесь бесплатного обеда не бывает. Вероятно, вы могли бы сделать это со схемами прозрачным для приложения способом. Однако тогда вы получите тысячи схем и десятки тысяч таблиц, что создаст дополнительные проблемы.
Я думаю, что в целом подход с несколькими базами данных является наиболее разумным, учитывая ваши комментарии.
Управление (вроде резервных копий) станет интереснее. Также я думаю, что в какой-то момент подключения к БД начнут занимать больше времени.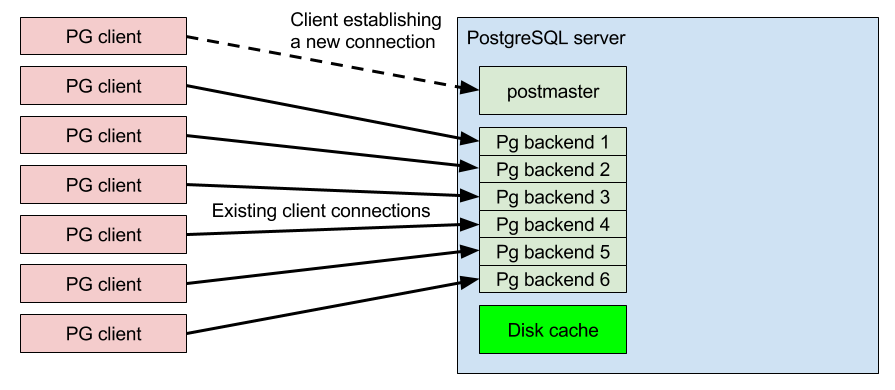 Если вы используете pg_hba.conf для ограничения доступа (что вы и должны делать), это тоже станет головной болью, и вы, вероятно, захотите создать решение для создания этого файла для вас…..
Если вы используете pg_hba.conf для ограничения доступа (что вы и должны делать), это тоже станет головной болью, и вы, вероятно, захотите создать решение для создания этого файла для вас…..
2
Я надеюсь, что эту ссылку лучше читать: 10 000 баз данных в кластере PostgreSQL, Джон Дженсен, 2008 г.
Одна выписка:
Краткий ответ: Postgres 8.1 прекрасно справляется с 10 000 баз данных.
\лв psql генерирует длинный список баз данных, конечно, но возвращает достаточно быстро. Специальное параллельное тестирование было в порядке. Запуск запросов, вставки и т. д. в отобранной группе различных игровых баз данных работал нормально, в том числе и при создании новых баз данных.[…]
Фактический предел для этой [ Linux ext3 ] платформы, вероятно, составляет 31995 баз данных, потому что каждая база данных занимает подкаталог в data/base/ и ext3 файловая система имеет ограничение в 31998 подкаталогов на один каталог, из-за его ограничения в 32000 ссылок на инод.

1
TLDR; Без ограничений, если ваша база данных находится в Linux с использованием ext4, 31995, если она использует ext3. Для окна в NFTS: 4 294 967 295. Пользователи Mac: 2,1 миллиарда
Расширение ответа:
Каждая база данных Postgres использует подкаталог на диске, отсюда и ограничение. Вы, вероятно, исчерпаете количество операций ввода-вывода в секунду, прежде чем столкнетесь с узким местом в количестве баз данных. Если вы не используете ext3, который ограничен 32k подкаталогами, ext4 позволяет вам иметь неограниченное количество подкаталогов.
Другие ответы беспокоят ад управления, потому что сам вопрос старый, а мир сильно изменился.
Резервные копии
- Если вы используете облачное решение, это решено. Большинство облачных провайдеров выполняют резервное копирование на уровне дисков, поэтому объем баз данных не имеет значения.
- Если вы используете локальное решение, вам нужно будет просмотреть каждую базу данных, создав резервную копию всего.
 Да, ничего страшного.
Да, ничего страшного.
Многопользовательская безопасность
- Наличие у каждого клиента отдельной базы данных:
плюсы:
- каждый клиент может быть на разной версии ПО
- каждый клиент может иметь пользовательские таблицы
- клиентский доступ перемещается из вашего программного обеспечения в Postgres
- клиенты могут быть легко перемещены с серверов баз данных
минусы:
- сценарии мониторинга должны циклически проходить через каждую базу данных
- миграция базы данных, индексы, обслуживание должны выполняться для каждой базы данных
нейтральный:
- меньше кода в sass, больше кода в ваших операциях
Твой ответ
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания, политикой конфиденциальности и политикой использования файлов cookie
.
Квоты и лимиты | Облачный SQL для PostgreSQL
MySQL | PostgreSQL | SQL Server
На этой странице представлена информация о квотах и ограничениях Cloud SQL. Квоты применяются для каждого проекта; ограничения применяются к экземпляру или к проекта, в зависимости от лимита.
Примечание. Создание или увеличение емкости хранилища до 64 ТБ может увеличить задержка общих операций, таких как резервное копирование, зависит от вашей рабочей нагрузки.Проверьте свои квоты
Чтобы проверить текущие квоты для ресурсов в вашем проекте, перейдите на страницу Квоты в Консоль Google Cloud и фильтр для API администратора Cloud SQL . Эти квоты распространяются только на вызовы API; они не включают запросы к базе данных.
Увеличьте свои квоты
По мере расширения использования Google Cloud ваши квоты могут увеличиваться
соответственно.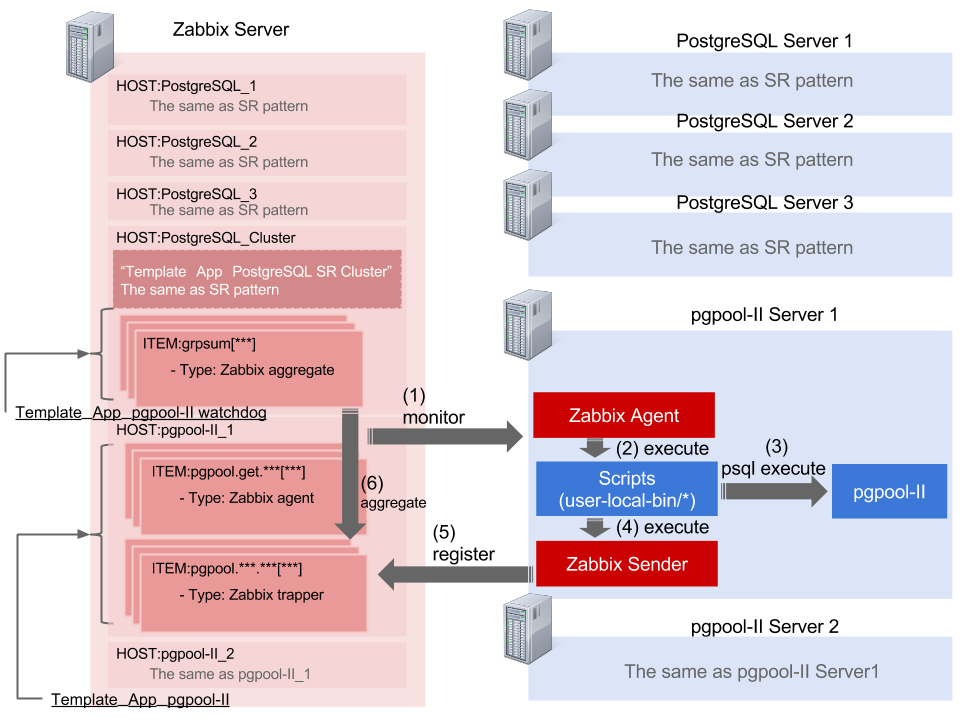 Если вы ожидаете заметного роста использования,
сделайте запрос за несколько дней, чтобы убедиться, что ваши квоты адекватны
размера.
Если вы ожидаете заметного роста использования,
сделайте запрос за несколько дней, чтобы убедиться, что ваши квоты адекватны
размера.
serviceusage.quotas.update разрешение. Это разрешение включено по умолчанию
для следующих предопределенных ролей: Владелец,
Редактор и администратор квот.На странице «Квоты» выберите Cloud SQL Admin API из раскрывающегося списка Services .
Если вы не видите Cloud SQL Admin API , Cloud SQL Admin API не был включен.
Выберите квоты, которые вы хотите изменить.
Нажмите Изменить квоты .
Введите свое имя, адрес электронной почты и номер телефона и нажмите Далее .
Заполните запрос на квоты и нажмите Отправить запрос .
Вы получите ответ от группы Cloud SQL для PostgreSQL в течение 48 часов вашего запроса.
Как пополняются квоты ресурсов
Ежедневные квоты пополняются ежедневно в полночь по тихоокеанскому времени.
Квоты и доступность ресурсов
Квоты ресурсов — это максимальное количество ресурсов, которое вы можете создать для этого тип ресурса, если эти ресурсы доступны. Квоты не гарантируют, что ресурсы будут доступны в любое время. Если ресурс физически не доступных для вашего региона, вы не сможете создавать новые ресурсы этого type, даже если у вас все еще есть оставшаяся квота в вашем проекте.
Ограничения
Существуют ограничения на некоторые ресурсы Cloud SQL, которые не периодически пополняется и не отображается на странице квот в консоли Google Cloud. Одни лимиты можно увеличить, а другие нет.
Настраиваемые ограничения
Экземпляров на проект
По умолчанию в каждом проекте может быть до 100 экземпляров. Если вам нужно больше,
обратиться в службу поддержки
запросить прибавку. Реплики чтения считаются экземплярами.
Если вам нужно больше,
обратиться в службу поддержки
запросить прибавку. Реплики чтения считаются экземплярами.
Мы рекомендуем распределить количество экземпляров между несколькими проекты по уменьшению зависимости от запросов на увеличение квот. Это поможет вы избегаете любых потенциальных блокировок.
Максимальное количество одновременных подключений
Вы можете использовать max_connections флаг для настройки лимитов соединений. Когда
вы создаете экземпляр Cloud SQL для PostgreSQL, настройки конфигурации типа машины автоматически регулируют диапазон памяти
доступные размеры в зависимости от количества выбранных вами ядер. Это также определяет
начальные ограничения на подключение по умолчанию, установленные для экземпляра.
Вы можете узнать лимиты подключений для вашего экземпляра, подключившись к
базу данных и запустив эту команду: SELECT * FROM pg_settings WHERE name = 'max_connections';
Примечание: Чтобы определить максимальное значение, которое вы можете
установленный для этого флага, необходимо сначала вычислить число
внутренних подключений, которые уже используются. Этот расчет представляет собой сумму
значения для max_connections (максимальное количество
клиентских подключений), autovacuum_max_workers (максимум
количество процессов автоочистки) и
макс_рабочие_процессы.
Сумма не может превышать
Этот расчет представляет собой сумму
значения для max_connections (максимальное количество
клиентских подключений), autovacuum_max_workers (максимум
количество процессов автоочистки) и
макс_рабочие_процессы.
Сумма не может превышать 262142 .
Значение на репликах должно быть больше или равно значению на начальный. Изменения на первичном сервере распространяются на реплики, имеющие значение, ниже, чем новое значение на первичном, или которые не были изменены с значение по умолчанию.
Предостережения
Использование квоты прокси-сервера аутентификации Cloud SQL
Прокси-сервер аутентификации Cloud SQL использует квоту Cloud SQL Admin API. Использование квоты для прокси-сервера аутентификации Cloud SQL рассчитывается следующим образом:
Используемая квота = Экземпляры прокси * Экземпляры Cloud SQL * 2 на попытку обновления
Попытка обновления обычно происходит каждый час, но может происходить и раз в 30 секунд, если что-то пойдет не так.
Максимальное использование API происходит при запуске прокси-сервера Cloud SQL Auth; это особенно верно, если вы используете автоматическое обнаружение экземпляров или -параметр проектов . Во время работы прокси-сервера Cloud SQL Auth он выполняет 2 вызова API в час для каждого подключенного экземпляра.
Если вы новый клиент, то обратите внимание на приведенную выше формулу и обратите внимание на:
Как быстро вы масштабируете новые клиенты БД
Насколько быстро вы добавляете экземпляры
Использование разных учетных записей служб для каждого приложения
Проверка подлинности базы данных Cloud SQL IAM
Для каждого экземпляра существует поминутная квота на вход, которая включает как
успешные и неуспешные входы в систему. При превышении квоты логины
временно недоступен. Мы рекомендуем вам избегать частых входов в систему и
ограничить вход в систему с использованием авторизованных сетей. Квота на авторизацию логинов составляет 3000 в минуту на экземпляр.
Квота на авторизацию логинов составляет 3000 в минуту на экземпляр.
Квота правила переадресации
Каждый экземпляр Cloud SQL состоит из правила переадресации и балансировщика нагрузки. Для правила переадресации существует ограничение квоты, основанное на типе балансировщика нагрузки, на который оно указывает. Существует несколько квот для каждого типа правил переадресации, для каждого проекта, для каждой сети и для каждой группы пиринга. Существует также правило переопределения квоты на сеть и квоты на группу пиринга для Cloud SQL. Это означает, что когда мы увеличиваем квоту на сеть для сетей производителей, квота на группу пиринга также увеличивается до того же значения.
VPC поставщика Cloud SQL связан с VPC клиента, поэтому мы часто используем сетевую квоту для сети производителя Cloud SQL и квоту группы пиринга для VPC клиента.
Когда мы достигнем квоты, некоторые операции могут завершиться неудачно, в том числе:
Создать операцию: нам нужны новые правила пересылки при создании новых экземпляров.

Операция обновления: мы разрешаем клиентам переключать сеть экземпляров, поэтому нам потребуются новые правила переадресации в новой сети.
Операция технического обслуживания: пересоздаются правила переадресации.
Если у вас возникнут такие проблемы, отправьте запрос в службу поддержки, и мы увеличим для вас соответствующие квоты.
Фиксированные ограничения
IOPS
IOPS — количество операций ввода/вывода (или чтения/записи) операций, которые ваш диск может обработать в секунду.
Cloud SQL использует виртуальные машины (ВМ) Compute Engine с постоянным хранилищем диски. Дополнительные сведения о конкретных характеристиках производительности ВМ см. максимальный устойчивый IOPS таблица на страница производительности постоянного диска.
Ограничение операций
Типы компьютеров микро- и малого уровня ограничивают количество одновременных операций. Превышение этих ограничений приводит к ошибке
Превышение этих ограничений приводит к ошибке Слишком много операций .
Ограничение типа машины db-custom-1-3840 (один ЦП) составляет 50 одновременных операций.
Ограничение типа машины f1-micro (процессор с общим ядром) составляет 20 одновременных операций.
Лимит сбора метрик
Метрики PostgreSQL собираются для 500 баз данных.
Ограничения хранилища Cloud SQL
Варианты хранения Cloud SQL
Чтобы настроить хранилище для максимальной производительности, важно понимать вашу рабочую нагрузку. и выберите соответствующий тип и размер диска. За дополнительную информацию о доступных вариантах для Cloud SQL см. настройки экземпляра.
Ограничения App Engine
Каждый экземпляр App Engine, работающий в стандартной среде
не может быть больше 100 одновременных подключений к экземпляру. За
Приложения PHP 5.5, ограничение составляет 60 одновременных подключений .
За
Приложения PHP 5.5, ограничение составляет 60 одновременных подключений .
Для приложений App Engine действуют ограничения по времени запроса в зависимости от использования и Окружающая среда. Дополнительные сведения см. в статье об управлении экземплярами в стандартной среде App Engine. стандартный и гибкий среды.
Приложения App Engine также подлежат дополнительным проверкам App Engine. квоты и лимиты, как обсуждалось на Страница квот App Engine.
Ограничения Cloud Run
Службы Cloud Run ограничены 100 подключениями к Облачная база данных SQL. Это ограничение применяется к экземпляру службы. Этот означает, что каждый экземпляр службы Cloud Run может иметь 100 подключений к базе данных, и по мере масштабирования общее количество соединений на развертывание может расти.
Ограничения облачных функций
Облачные функции (1-го поколения) ограничивают одновременные выполнения одним экземпляром. Ты
никогда не было ситуации, когда один экземпляр функции 1-го поколения обрабатывает два
запросы одновременно. В большинстве случаев только одна база данных
подключение необходимо.
Ты
никогда не было ситуации, когда один экземпляр функции 1-го поколения обрабатывает два
запросы одновременно. В большинстве случаев только одна база данных
подключение необходимо.
Облачные функции (2-го поколения) основаны на Cloud Run и имеют ограничение в 100 подключений к базе данных на экземпляр.
Ограничения— База данных Azure для PostgreSQL — Один сервер
Обратная связь Редактировать
Твиттер LinkedIn Фейсбук Эл. адрес
- Статья
- 3 минуты на чтение
ПРИМЕНЯЕТСЯ К: База данных Azure для PostgreSQL — отдельный сервер
В следующих разделах описываются ограничения емкости и функциональных возможностей службы базы данных. Если вы хотите узнать об уровнях ресурсов (вычислений, памяти, хранилища), см. статью об уровнях ценообразования.
Если вы хотите узнать об уровнях ресурсов (вычислений, памяти, хранилища), см. статью об уровнях ценообразования.
Максимальное количество подключений
Ниже показано максимальное количество подключений для каждой ценовой категории и виртуальных ядер. Системе Azure требуется пять подключений для мониторинга базы данных Azure для сервера PostgreSQL.
| Ценовая категория | Виртуальные ядра | Максимальное количество соединений | Максимальное число подключений пользователей |
|---|---|---|---|
| Базовый | 1 | 55 | 50 |
| Базовый | 2 | 105 | 100 |
| Общего назначения | 2 | 150 | 145 |
| Общего назначения | 4 | 250 | 245 |
| Общего назначения | 8 | 480 | 475 |
| Общего назначения | 16 | 950 | 945 |
| Общего назначения | 32 | 1500 | 1495 |
| Общего назначения | 64 | 1900 | 1895 |
| Оптимизация памяти | 2 | 300 | 295 |
| Оптимизация памяти | 4 | 500 | 495 |
| Оптимизация памяти | 8 | 960 | 955 |
| Оптимизация памяти | 16 | 1900 | 1895 |
| Оптимизация памяти | 32 | 1987 | 1982 |
Когда количество подключений превышает лимит, вы можете получить следующую ошибку:
FATAL: извините, уже слишком много клиентов
Important
Для оптимальной работы мы рекомендуем использовать пул соединений, такой как pgBouncer, для эффективного управления соединениями.
Соединение с PostgreSQL, даже бездействующее, может занимать до 2 МБ памяти. Кроме того, создание новых связей требует времени. Большинство приложений запрашивают множество кратковременных соединений, что усугубляет эту ситуацию. В результате для вашей фактической рабочей нагрузки доступно меньше ресурсов, что приводит к снижению производительности. Избежать этого поможет пул соединений, который уменьшает количество неиспользуемых соединений и повторно использует существующие соединения. Чтобы узнать больше, посетите наш блог.
Функциональные ограничения
Операции масштабирования
- Динамическое масштабирование до базовых ценовых категорий и обратно в настоящее время не поддерживается.
- Уменьшение размера хранилища сервера в настоящее время не поддерживается.
Обновление версии сервера
- Автоматическая миграция между основными версиями ядра базы данных в настоящее время не поддерживается. Если вы хотите перейти на следующую основную версию, сделайте дамп и восстановите его на сервере, который был создан с новой версией движка.

Обратите внимание, что до PostgreSQL версии 10 политика управления версиями PostgreSQL рассматривала обновление основной версии до версии как увеличение первого числа или второго числа (например, с 9,5 до 9,6 считалось обновлением основной версии до версии ). Начиная с версии 10, только изменение первого числа считается обновлением основной версии (например, с 10.0 на 10.1 — это обновление младшей версии до версии , а с 10 на 11 — это обновление основной версии до версии ).
Конечные точки службы виртуальной сети
- Поддержка конечных точек службы виртуальной сети доступна только для серверов общего назначения и серверов с оптимизацией памяти.
Восстановление сервера
- При использовании функции PITR новый сервер создается с теми же конфигурациями ценовой категории, что и сервер, на котором он основан.
- Новый сервер, созданный во время восстановления, не имеет правил брандмауэра, существовавших на исходном сервере.
 Правила брандмауэра необходимо настроить отдельно для этого нового сервера.
Правила брандмауэра необходимо настроить отдельно для этого нового сервера. - Восстановление удаленного сервера не поддерживается.
Символы UTF-8 в Windows
- В некоторых сценариях символы UTF-8 не полностью поддерживаются в PostgreSQL с открытым исходным кодом в Windows, что влияет на базу данных Azure для PostgreSQL. Для получения дополнительной информации см. ветку об ошибке № 15476 в архиве postgresql.
Ошибка GSS
Если вы видите ошибку, связанную с GSS , вы, вероятно, используете более новую версию клиента/драйвера, которая еще не полностью поддерживается единым сервером Azure Postgres. Известно, что эта ошибка затрагивает версии драйвера JDBC 42.2.15 и 42.2.16.
- Мы планируем завершить обновление к концу ноября. Тем временем рассмотрите возможность использования рабочей версии драйвера.
- Или рассмотрите возможность отключения запроса GSS. Используйте параметр подключения, например
gssEncMode=disable.
Уменьшение размера хранилища
Размер хранилища нельзя уменьшить. Вам необходимо создать новый сервер с желаемым размером хранилища, выполнить дамп вручную, восстановить и перенести базы данных на новый сервер.
Следующие шаги
- Узнайте, что доступно в каждой ценовой категории
- Узнайте о поддерживаемых версиях базы данных PostgreSQL
- Узнайте, как выполнить резервное копирование и восстановление сервера в базе данных Azure для PostgreSQL с помощью портала Azure
Обратная связь
Отправить и просмотреть отзыв для
Этот продукт Эта страница
Просмотреть все отзывы о странице
Ограничения— база данных Azure для PostgreSQL — гибкий сервер
Обратная связь Редактировать
Твиттер LinkedIn Фейсбук Эл. адрес
адрес
- Статья
- 4 минуты на чтение
ПРИМЕНЯЕТСЯ К: База данных Azure для PostgreSQL — гибкий сервер
В следующих разделах описаны емкость и функциональные ограничения в службе базы данных. Если вы хотите узнать об уровнях ресурсов (вычислений, памяти, хранилища), см. статью о вычислениях и хранилище.
Максимальное количество подключений
Ниже показано максимальное количество подключений для каждой ценовой категории и виртуальных ядер. Системе Azure требуется три подключения для мониторинга базы данных Azure для PostgreSQL — гибкий сервер.
| Артикул | виртуальных ядер | Объем памяти | Максимальное количество соединений | Максимальное число подключений пользователей |
|---|---|---|---|---|
| Разрывной | ||||
| B1ms | 1 | 2 ГиБ | 50 | 47 |
| Б2с | 2 | 4 ГиБ | 100 | 97 |
| Общего назначения | ||||
| D2s_v3 / D2ds_v4 | 2 | 8 ГиБ | 859 | 856 |
| D4s_v3 / D4ds_v4 | 4 | 16 ГиБ | 1719 | 1716 |
| D8s_v3 / D8ds_V4 | 8 | 32 ГиБ | 3438 | 3435 |
| Д16с_в3 / Д16дс_в4 | 16 | 64 ГиБ | 5000 | 4997 |
| D32s_v3 / D32ds_v4 | 32 | 128 ГиБ | 5000 | 4997 |
| Д48с_в3 / Д48дс_в4 | 48 | 192 ГиБ | 5000 | 4997 |
| D64s_v3 / D64ds_v4 | 64 | 256 ГиБ | 5000 | 4997 |
| Оптимизация памяти | ||||
| E2s_v3 / E2ds_v4 | 2 | 16 ГиБ | 1719 | 1716 |
| E4s_v3 / E4ds_v4 | 4 | 32 ГиБ | 3438 | 3433 |
| E8s_v3 / E8ds_v4 | 8 | 64 ГиБ | 5000 | 4997 |
| E16s_v3 / E16ds_v4 | 16 | 128 ГиБ | 5000 | 4997 |
| E20ds_v4 | 20 | 160 ГиБ | 5000 | 4997 |
| E32s_v3 / E32ds_v4 | 32 | 256 ГиБ | 5000 | 4997 |
| E48s_v3 / E48ds_v4 | 48 | 384 ГиБ | 5000 | 4997 |
| E64s_v3 / E64ds_v4 | 64 | 432 ГиБ | 5000 | 4997 |
Когда количество подключений превышает лимит, вы можете получить следующую ошибку:
FATAL: извините, уже слишком много клиентов.

Important
Для оптимальной работы рекомендуется использовать диспетчер пула соединений, например PgBouncer, для эффективного управления соединениями. База данных Azure для PostgreSQL — гибкий сервер предлагает pgBouncer в качестве встроенного решения для управления пулом подключений.
Соединение с PostgreSQL, даже бездействующее, может занимать около 10 МБ памяти. Кроме того, создание новых связей требует времени. Большинство приложений запрашивают множество кратковременных соединений, что усугубляет эту ситуацию. В результате для вашей фактической рабочей нагрузки доступно меньше ресурсов, что приводит к снижению производительности. Пул подключений можно использовать для уменьшения количества неиспользуемых подключений и повторного использования существующих подключений. Чтобы узнать больше, посетите наш блог.
Функциональные ограничения
Операции с весами
- Масштабирование хранилища сервера требует перезагрузки сервера.
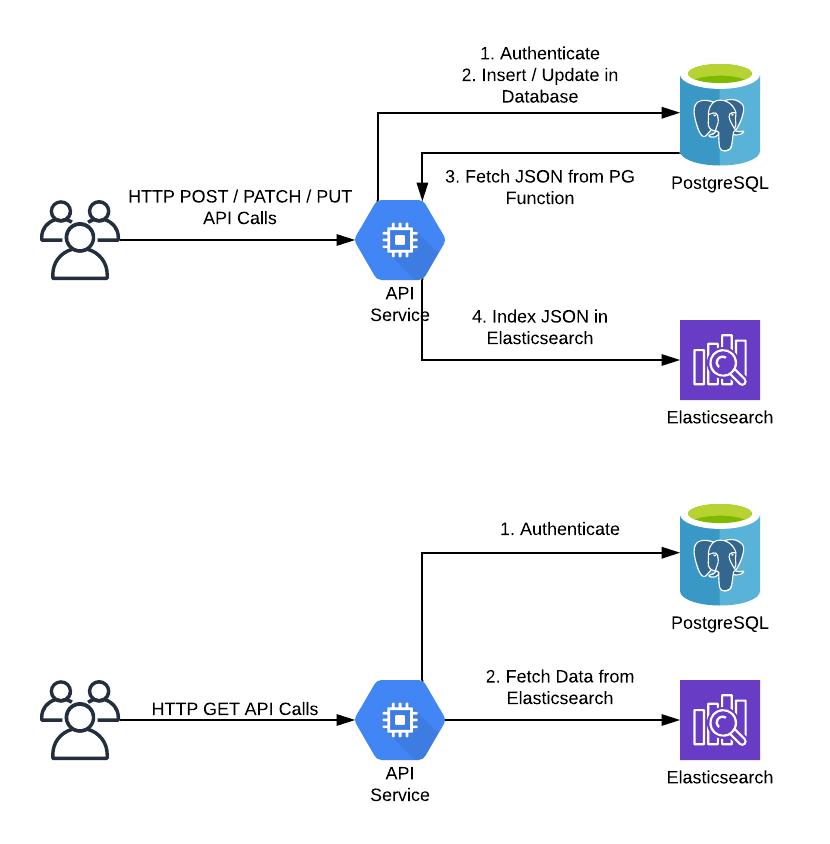
- Хранилище сервера можно масштабировать только с шагом 2x. Дополнительные сведения см. в разделе Вычисления и хранилище.
- Уменьшение размера хранилища сервера в настоящее время не поддерживается.
Обновление версии сервера
- Автоматическая миграция между основными версиями ядра базы данных в настоящее время не поддерживается. Если вы хотите перейти на следующую основную версию, сделайте дамп и восстановите его на сервере, который был создан с новой версией движка.
Хранилище
- После настройки размер хранилища нельзя уменьшить. Вам необходимо создать новый сервер с желаемым размером хранилища, выполнить дамп вручную, восстановить и перенести базы данных на новый сервер.
- В настоящее время функция автоматического увеличения хранилища недоступна. Вы можете отслеживать использование и увеличивать объем хранилища.
- Когда использование хранилища достигает 95% или доступная емкость меньше 5 ГиБ, сервер автоматически переключается на режим только для чтения , чтобы избежать ошибок, связанных с переполнением диска.
- Мы рекомендуем установить правила оповещения для хранилища
, используемогоилипроцента хранилища, когда они превышают определенные пороговые значения, чтобы вы могли заранее принять меры, например увеличить размер хранилища. Например, вы можете установить оповещение, если процент использования хранилища превышает 80%.
Сеть
- В настоящее время вход и выход из виртуальной сети не поддерживается.
- Объединение общего доступа с развертыванием в виртуальной сети в настоящее время не поддерживается.
- Правила брандмауэра не поддерживаются в виртуальной сети, вместо них можно использовать группы безопасности сети.
- Серверы баз данных общего доступа могут подключаться к общедоступному Интернету, например, через
postgres_fdw, и этот доступ не может быть ограничен. Серверы на основе виртуальной сети могут иметь ограниченный исходящий доступ с помощью групп безопасности сети.
Высокая доступность (HA)
- См.
 документацию по ограничениям высокой готовности.
документацию по ограничениям высокой готовности.
Зоны доступности
- Перемещение серверов вручную в другую зону доступности в настоящее время не поддерживается.
Механизм Postgres, расширения и PgBouncer
- Postgres 10 и более ранние версии не поддерживаются. Мы рекомендуем использовать вариант с одним сервером, если вам требуются более старые версии Postgres. Поддержка расширений
- в настоящее время ограничена расширениями Postgres
contrib. - Встроенный пул соединений PgBouncer в настоящее время недоступен для серверов Burstable. Аутентификация
- SCRAM не поддерживается при подключении с использованием встроенного PgBouncer.
Останов/запуск операции
- Сервер не может быть остановлен более чем на семь дней.
Плановое техническое обслуживание
- Изменение периода обслуживания менее чем за пять дней до уже запланированного обновления не повлияет на это обновление.
 Изменения вступят в силу только после следующего планового технического обслуживания.
Изменения вступят в силу только после следующего планового технического обслуживания.
Резервное копирование сервера
- Резервные копии управляются системой, в настоящее время нет возможности запустить эти резервные копии вручную. Мы рекомендуем использовать
вместо pg_dump. - Резервные копии всегда представляют собой полные резервные копии на основе моментальных снимков (а не дифференциальные резервные копии), что может привести к увеличению использования хранилища резервных копий. Журналы транзакций (журналы упреждающей записи — WAL) отделены от полных/дифференциальных резервных копий и постоянно архивируются.
Восстановление сервера
- При использовании функции восстановления на момент времени новый сервер создается с теми же конфигурациями вычислительных ресурсов и хранилища, что и сервер, на котором он основан.
- Серверы баз данных на основе виртуальной сети восстанавливаются в ту же виртуальную сеть при восстановлении из резервной копии.
- Новый сервер, созданный во время восстановления, не имеет правил брандмауэра, существовавших на исходном сервере. Правила брандмауэра необходимо создавать отдельно для нового сервера.
- Восстановление удаленного сервера не поддерживается.
- Восстановление между регионами не поддерживается.
Другие функции
- Проверка подлинности Azure AD еще не поддерживается. Мы рекомендуем использовать вариант с одним сервером, если вам требуется проверка подлинности Azure AD.
- Реплики чтения пока не поддерживаются. Мы рекомендуем использовать вариант с одним сервером, если вам требуются реплики чтения.
- Перемещение ресурсов в другую подписку не поддерживается.
Дальнейшие действия
- Понимание доступных вариантов вычислений и хранения
- Узнайте о поддерживаемых версиях базы данных PostgreSQL
- Узнайте, как выполнить резервное копирование и восстановление сервера в базе данных Azure для PostgreSQL с помощью портала Azure
Обратная связь
Отправить и просмотреть отзыв для
Этот продукт Эта страница
Просмотреть все отзывы о странице
Выбор правильного плана Heroku Postgres
Последнее обновление: 29 августа 2022 г.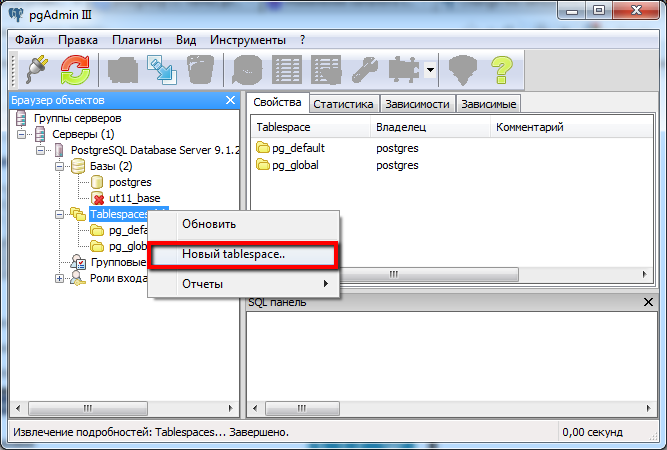
Содержание
- Уровни плана
- Уровень Hobby
- Уровень Standard
- Уровень Premium
- Уровни Private и Shield
- Размер кэша
С 28 ноября 2022 г. бесплатные планы Heroku Dynos, Heroku Postgres и Heroku Data for Redis® больше не будут доступны. Если у вас есть приложения, использующие какой-либо из этих ресурсов, вы должны перейти на платные планы к этой дате, чтобы ваши приложения продолжали работать и сохраняли ваши данные. Для студентов мы объявим новую программу к концу сентября. Смотрите наш блог и часто задаваемые вопросы для получения дополнительной информации.
Heroku Postgres предлагает широкий спектр планов для обслуживания вариантов использования, размер которых варьируется от личных блогов до
приложения с большим набором данных и большим количеством транзакций. Правильный выбор
план зависит от конкретных характеристик использования вашего приложения, включая требования к доступности и времени безотказной работы.
Уровни плана
Множество планов Heroku Postgres разделены на пять высокоуровневых уровней . Основное различие между каждым уровнем заключается в допустимом ежемесячном простое баз данных на уровне. Пять уровней:
- Hobby Tier — для приложений, которые могут работать до 4 часов простоя в месяц
- Стандартный уровень — для приложений, которые могут допускать простои до 1 часа в месяц
- Премиум-уровень — для приложений, которые могут допускать простои до 15 минут в месяц
- Частный уровень — для клиентов Heroku Enterprise
- Shield Tier — для клиентов Heroku Enterprise, которым нужны базы данных, отвечающие требованиям
Вот разбивка различий между уровнями:
| Уровень Heroku Postgres | Допустимое время простоя | Вилка | Подписаться | Откат | ГА | Шифрование диска |
|---|---|---|---|---|---|---|
| Хобби | < 4 часа простоя в месяц. | Нет | Нет | Нет | Нет | Нет |
| Стандартный | < 1 часа простоя в месяц. | Да | Да | 4 дня | Нет | Да |
| Премиум | < 15 минут простоя в месяц. | Да | Да | 1 неделя | Да | Да |
| Частный | < 15 минут простоя в месяц. | Да | Да | 1 неделя | Да | Да |
| Экран | < 15 минут простоя в месяц. | Да | Да | 1 неделя | Да | Да |
Допустимое время простоя основано на 30-дневном месяце.
Общие функции
Все уровни плана Heroku Postgres имеют следующие функции:
- Полностью управляемая служба базы данных с автоматическими проверками работоспособности
- Журнал упреждающей записи (WAL) за пределами предприятия каждые 60 секунд, что обеспечивает минимальная потеря данных в случае катастрофического сбоя
- Ежедневное резервное копирование логических баз данных с помощью PG Backups (необязательно, но бесплатно)
- Датаклипы для простого и безопасного обмена данными и запросами
- Доступ к psql/libpq с защитой SSL
- Запуск немодифицированного PostgreSQL 10 (устарело), 11, 12, 13, 14
- Расширения Postgres
- Полнофункциональный веб-интерфейс
Подборки данных и ежедневные логические резервные копии недоступны для планов баз данных уровня Shield.
Уровень хобби
Уровень хобби, который включает в себя хобби-дев и хобби-базовый планы, имеет следующие
ограничения:
- Принудительное ограничение количества строк в 10 000 строк для
хобби-разработчики 10 000 000 дляхобби-базовыйпланов - Максимальный объем хранилища: 1 ГБ для хобби-разработчика и 10 ГБ для хобби-базового плана
- Максимум 20 соединений
- Нет кеша в памяти: отсутствие кеша в памяти ограничивает производительность, потому что данные не могут быть доступны на хранилище с низкой задержкой.
- Нет поддержки вилки/следа: вилка и следовать, используется для создания баз данных реплик и лидера-последователя установки, не поддерживаются.
- Нет поддержки дорогостоящих запросов.
- Ожидаемое время безотказной работы 99,5 % каждый месяц.
- Внезапное техническое обслуживание и обновление базы данных.
- Нет журналов Postgres.

- Нет дополнительных учетных данных.
Контроль ограничения плана
При превышении ограничений на количество строк или размеров хобби-уровня и попытке вставки появляется сообщение об ошибке Postgres:
.разрешение отклонено для отношения <имя таблицы>
Ограничения строк в планах базы данных хобби-уровня применяются с помощью следующего механизма:
- Когда база данных
хобби-разработчикдостигает 7000 строк или база данныххобби-базовыйдостигает 7 миллионов строк, владелец получает электронное письмо с предупреждением о том, что он приближаются к их пределам строк. - Когда база данных превышает емкость строк, владелец получает дополнительное уведомление. В этот момент база данных получает 7-дневный льготный период, чтобы либо уменьшить количество записей, либо перейти на другой план.
- Если количество строк по-прежнему превышает плановую емкость после 7
дней,
INSERTправа доступа к базе данных отозваны. Данные могут
могут быть прочитаны, обновлены или удалены из базы данных. Это гарантирует, что
пользователи могут привести свою базу данных в соответствие
и сохранить доступ к своим данным.
Данные могут
могут быть прочитаны, обновлены или удалены из базы данных. Это гарантирует, что
пользователи могут привести свою базу данных в соответствие
и сохранить доступ к своим данным. - Когда количество строк снова соответствует лимиту плана,
INSERTПривилегии автоматически восстанавливаются в базе данных. Примечание что размеры базы данных проверяются асинхронно, поэтому может потребоваться несколько минут для восстановления привилегий.
Стандартный уровень
Уровень «Стандартный» предназначен для производственных приложений, которые могут допускать простои до 1 часа в любой заданный месяц. Все базы данных стандартного уровня включают:
- Нет ограничений по ряду
- Увеличение объема кэш-памяти
- Разветвите и следуйте опоре
- Откат до 4 дней
- Показатели базы данных опубликованы в потоке журнала приложения для дальнейшего анализа
- Приоритетное восстановление обслуживания при сбоях
- Автоматическое шифрование в состоянии покоя всех данных, записанных на диск
- Управление учетными данными
В рамках уровня Standard планы имеют разные ограничения по объему памяти, подключению и хранилищу. Планы стандартного уровня:
Планы стандартного уровня:
| Название плана | Имя инициализации | Объем ОЗУ | Ограничение хранения | Ограничение соединения |
|---|---|---|---|---|
| Стандарт-0 | героку-postgresql: стандарт-0 | 4 ГБ | 64 ГБ | 120 |
| Стандарт-2 | героку-postgresql: стандарт-2 | 8 ГБ | 256 ГБ | 400 |
| Стандарт-3 | героку-postgresql: стандарт-3 | 15 ГБ | 512 ГБ | 500 |
| Стандарт-4 | героку-postgresql: стандарт-4 | 30 ГБ | 768 ГБ | 500 |
| Стандарт-5 | героку-postgresql: стандарт-5 | 61 ГБ | 1 ТБ | 500 |
| Стандарт-6 | героку-postgresql: стандарт-6 | 122 ГБ | 1,5 ТБ | 500 |
| Стандарт-7 | героку-postgresql: стандарт-7 | 244 ГБ | 2 ТБ | 500 |
| Стандарт-8 | героку-postgresql: стандарт-8 | 488 ГБ | 3 ТБ | 500 |
| Стандарт-9 | героку-postgresql: стандарт-9 | 768 ГБ | 4 ТБ | 500 |
Премиум-уровень
Уровень Premium предназначен для производственных приложений, которые могут допускать простои до 15 минут в любой месяц. Все базы данных премиум-уровня включают:
Все базы данных премиум-уровня включают:
- Нет ограничений по ряду
- Увеличение объема кэш-памяти
- Разветвите и следуйте опоре
- Откат до 7 дней
- Показатели базы данных опубликованы в потоке журнала приложения для дальнейшего анализа
- Приоритетное восстановление обслуживания при сбоях
- Автоматическое шифрование в состоянии покоя всех данных, записываемых на диск.
- Управление учетными данными
В рамках уровня Premium планы имеют разные ограничения на объем памяти, количество подключений и объем хранилища. Планы для премиального уровня:
| Название плана | Имя инициализации | Объем ОЗУ | Ограничение хранения | Лимит соединений |
|---|---|---|---|---|
| Премиум-0 | героку-postgresql: премиум-0 | 4 ГБ | 64 ГБ | 120 |
| Премиум-2 | героку-postgresql: премиум-2 | 8 ГБ | 256 ГБ | 400 |
| Премиум-3 | героку-postgresql: премиум-3 | 15 ГБ | 512 ГБ | 500 |
| Премиум-4 | героку-postgresql: премиум-4 | 30 ГБ | 768 ГБ | 500 |
| Премиум-5 | героку-postgresql: премиум-5 | 61 ГБ | 1 ТБ | 500 |
| Премиум-6 | героку-postgresql: премиум-6 | 122 ГБ | 1,5 ТБ | 500 |
| Премиум-7 | героку-postgresql: премиум-7 | 244 ГБ | 2 ТБ | 500 |
| Премиум-8 | героку-postgresql: премиум-8 | 488 ГБ | 3 ТБ | 500 |
| Премиум-9 | героку-postgresql: премиум-9 | 768 ГБ | 4 ТБ | 500 |
Частные и защищенные уровни
Heroku предлагает Heroku Postgres в частных пространствах для клиентов Heroku Enterprise. Кроме того, планы защиты Postgres доступны для клиентов, которым нужны базы данных, отвечающие требованиям. Подробную информацию о наших частных и щитовых планах см. в статье Heroku Postgres and Private Spaces.
Кроме того, планы защиты Postgres доступны для клиентов, которым нужны базы данных, отвечающие требованиям. Подробную информацию о наших частных и щитовых планах см. в статье Heroku Postgres and Private Spaces.
Размер кэша
Каждый план производственного уровня Размер оперативной памяти указывает общий объем системной памяти на аппаратное обеспечение базового экземпляра, большая часть которого отдана Postgres и используется для кэширования. Несмотря на небольшой объем оперативной памяти используемый для управления подключениями и другими задачами, Postgres берет Преимущество почти всей этой оперативной памяти для его кеша. Учить больше о том, как это работает в этой статье.
Postgres постоянно управляет кешем ваших данных: строки, которые вы
написанные, созданные вами индексы и метаданные, которые Postgres хранит. Когда
данные, необходимые для запроса, полностью содержатся в кеше, производительность очень высока. Запросы, сделанные из кэшированных данных, часто в 100–1000 раз быстрее, чем запросы, сделанные из полного набора данных.
99 % или более запросов обслуживаются хорошо спроектированными и высокопроизводительными веб-приложения обслуживаются из кэша.
И наоборот, необходимость возврата к диску составляет не менее порядка величина медленнее. Кроме того, столбцы с большими типами данных (например, большие текстовые столбцы) хранятся вне очереди через ТОСТ, и доступ к большим объемам данных TOAST может быть медленным.
Общие указания
Шаблоны доступа сильно различаются от приложения к приложению. Много приложения получают доступ только к небольшой, недавно измененной части своих общих данных. Postgres всегда может хранить эту часть в своем кеше как время. продолжается, и, следовательно, эти приложения могут хорошо работать на меньшие планы.
Приложения, которые часто обращаются ко всем своим данным, не
иметь эту роскошь. Эти приложения могут наблюдать резкое увеличение производительности за счет
гарантируя, что весь их набор данных помещается в памяти.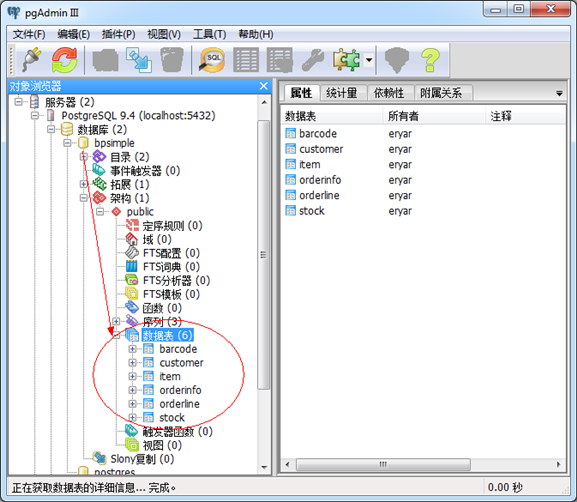 Чтобы определить
общий размер вашего набора данных, используйте
Чтобы определить
общий размер вашего набора данных, используйте heroku pg:info команда и смотри
для строки размера данных :
$ геройку пг:информация === HEROKU_POSTGRESQL_CHARCOAL_URL (DATABASE_URL) План: кран Статус: доступен Размер данных: 9,4 МБ ...
Хотя грубая мера, выбор плана, который имеет по крайней мере столько же кеш в памяти, доступный в размере вашего общего набора данных обеспечивает высокие коэффициенты кэширования. Тем не менее, вы в конечном итоге достигнете точки где у вас больше данных, чем самый большой план, и вам придется осколок. Планируйте шардинг заранее: выполнение стратегия шардинга.
Определение необходимого размера кэша
Ничто не заменит наблюдения за требованиями базы данных вашего
приложение с живым трафиком для определения подходящего
размер кэша. В идеале коэффициент попаданий в кеш должен быть в диапазоне 99%+. Необычные запросы должны требовать менее 100 мс, а обычные — менее 10 мс.
Этот пост в блоге включает более глубокое обсуждение проблем производительности Postgres и методов.
Чтобы измерить коэффициент попаданий в кэш для таблиц:
ВЫБЕРИТЕ
'коэффициент попаданий в кэш' имя AS,
сумма (heap_blks_hit) / (сумма (heap_blks_hit) + сумма (heap_blks_read)) соотношение AS
ИЗ pg_statio_user_tables;
или коэффициент попаданий в кэш для индексов:
ВЫБЕРИТЕ
'индекс совпадений' название AS,
(сумма (idx_blks_hit)) / сумма (idx_blks_hit + idx_blks_read) соотношение AS
ИЗ pg_statio_user_indexes
Вы можете установить плагин pg extras а затем просто запустите heroku pg:cache_hit.
Оба запроса должны указывать соотношение около 0,99 :
чтение_кучи | куча_хит | соотношение
-----------+-----------+----------
171 | 503551 | 0,99966041175571094090
Когда коэффициент попаданий в кэш начинает уменьшаться, обновление базы данных обычно возвращает этот показатель до 99%.
Изменение планов Postgres
Можно изменить план базы данных после ее создания. Вы можете найти подробную информацию о вариантах изменения планов здесь.
Продолжайте читать
- Основы Postgres
Отзыв
Войдите, чтобы отправить отзыв.
Обновление Heroku
Начиная с 28 ноября 2022 года бесплатные Heroku Dynos, бесплатные Heroku Postgres и бесплатные данные Heroku для Redis® больше не будут доступны.
Если у вас есть приложения, использующие какой-либо из этих ресурсов, вы должны перейти на платные планы к этой дате, чтобы ваши приложения продолжали работать и сохраняли ваши данные. Для студентов мы объявим новую программу к концу сентября.
Узнать больше
PostgreSQL — Возможности и ограничения
Последнее обновление 13 июля 2022 г.
Цель
На этой странице представлены технические возможности и ограничения предложения общедоступных облачных баз данных для PostgreSQL.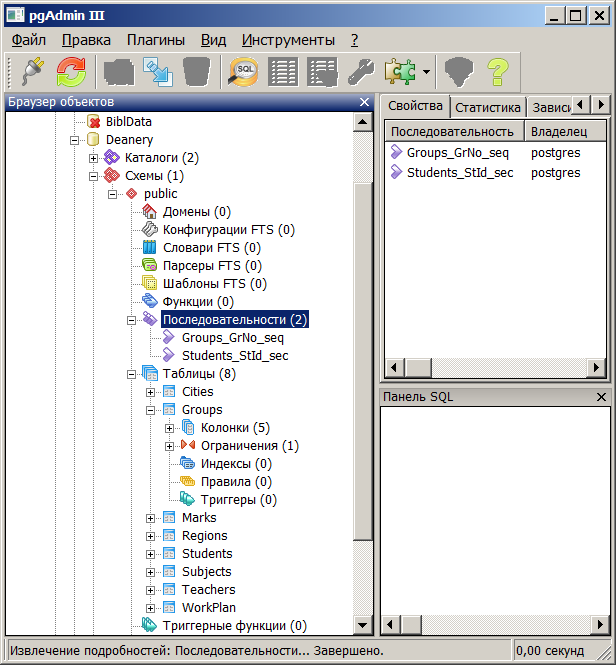
Мы постоянно совершенствуем наши предложения. Вы можете подписаться и отправить идеи для добавления в нашу дорожную карту по адресу https://github.com/ovh/public-cloud-roadmap/projects/2.
Возможности и ограничения
Поддерживаемые регионы и мультизоны доступности
Предложение общедоступных облачных баз данных доступно в следующих регионах:
-
BHS(Бохарнуа, Канада) -
DE(Франкфурт, Германия) -
GRA(Гравлин, Франция) -
SBG(Страсбург, Франция) -
Великобритания(Лондон, Великобритания) -
WAW(Варшава, Польша)
Узлы базы данных должны находиться в одном регионе. Несколько зон доступности в настоящее время не поддерживаются.
Версии PostgreSQL
Предложение общедоступных облачных баз данных поддерживает следующие версии PostgreSQL:
- PostgreSQL 10
- PostgreSQL 11
- PostgreSQL 12
- PostgreSQL 13
- PostgreSQL 14
Вы можете следить за жизненным циклом EOL для версии PostgreSQL на их официальной странице: https://www. postgresql.org/support/versioning/
postgresql.org/support/versioning/
Коннекторы PostgreSQL
пример.
Планы
Доступны три плана:
- Essential
- Бизнес
- Предприятие
Вот обзор возможностей различных планов:
| План | Количество узлов по умолчанию | Чтение реплик | Сеть |
|---|---|---|---|
| Основной | 1 | Нет | Публичный только |
| Бизнес | 2 | Запланировано | Общедоступная и частная vRack |
| Предприятие | 3 | Запланировано | Общедоступная и частная vRack |
Ваш выбор плана влияет на количество узлов, которые может запустить ваш кластер, соглашение об уровне обслуживания и некоторые другие функции, такие как частная сеть, реплики чтения и хранение резервных копий.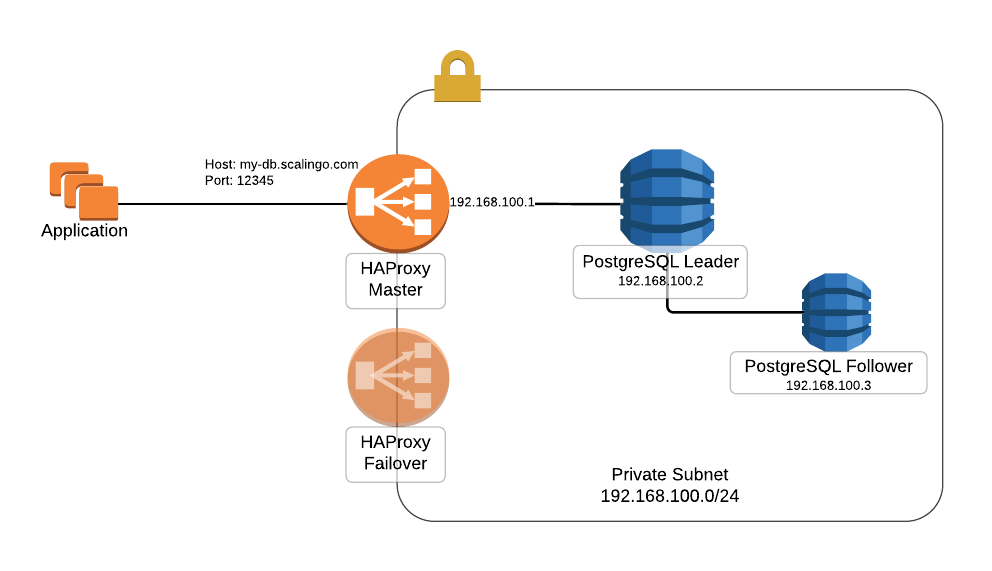
Узлы и реплики
- Essential : кластер может поддерживать не более одного узла.
- Business : по умолчанию кластер поставляется с 2 узлами. Планируется добавление реплик чтения.
- Enterprise : Кластер поставляется с 3 узлами по умолчанию. Планируется добавление реплик чтения.
Тип лицензии
Программное обеспечение PostgreSQL находится под лицензией PostgreSQL, либеральной лицензией с открытым исходным кодом, аналогичной лицензиям BSD или MIT. Больше информации на https://www.postgresql.org/about/licence/.
Аппаратные ресурсы
Вот типы узлов, которые вы можете выбрать:
| Имя | Диск (ГБ) | ядер | Память (ГБ) |
|---|---|---|---|
| дб1-7 | 160 | 2 | 7 |
| дб1-15 | 320 | 4 | 15 |
| дб1-30 | 640 | 8 | 30 |
| дб1-60 | 1280 | 16 | 60 |
| дб1-120 | 2560 | 32 | 120 |
Прямо сейчас все узлы данного кластера должны быть одного типа и распределены в одном регионе.
Эффективное хранилище
Размер диска, указанный выше, представляет собой общий размер диска базовой машины. Однако небольшая часть уходит на установку ОС.
Мы прилагаем все усилия, чтобы избежать ситуаций «переполнения диска», которые могут нанести вред здоровью кластера. Следовательно:
- При достижении емкости 97 % экземпляр базы данных клиента будет перемещен в состояние «DISK_FULL» и режим «только для чтения», что означает, что дальнейшая запись невозможна.
- Затем у вас есть возможность перейти на более высокий тарифный план с большим объемом памяти.
Функции
Сеть
Кластеры PostgreSQL доступны через стандартный порт 5432.
Общедоступная сеть может использоваться для всех предложений.
Частная сеть (vRack) доступна для Бизнес и Предприятие .
При использовании частной сети некоторые сетевые порты создаются в выбранной вами частной сети. Таким образом, дальнейшие операции в этой сети могут иметь некоторые ограничения, например.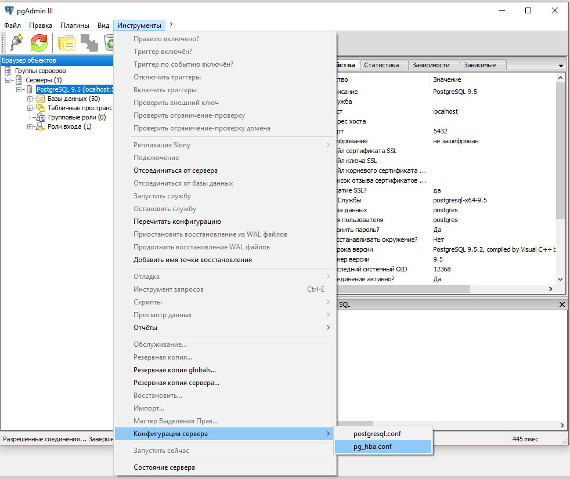 вы не сможете удалить сеть, если сначала не остановите службы общедоступных облачных баз данных.
вы не сможете удалить сеть, если сначала не остановите службы общедоступных облачных баз данных.
Входящий и исходящий трафик включен в тарифные планы и не измеряется.
Максимальное количество одновременных подключений
Количество одновременных подключений в общедоступных облачных базах данных для PostgreSQL зависит от доступной общей памяти на узле. Мы разрешаем примерно 100 подключений на 4 ГБ оперативной памяти, но не более 1000 активных подключений.
Так, например, на сервере с 7 ГБ памяти вы получите примерно 200 подключений, а с 15 ГБ памяти вы получите 400 подключений.
Дополнительные параметры
В настоящее время мы не поддерживаем дополнительные параметры PostgreSQL.
Резервное копирование
Кластеры плана Essential автоматически резервируются ежедневно в течение окна обслуживания. Хранение резервной копии — 2 дня.
Кластеры плана Business автоматически резервируются ежедневно во время периода обслуживания. Хранение резервной копии составляет 14 дней.
Хранение резервной копии составляет 14 дней.
Кластеры плана Enterprise автоматически резервируются ежедневно во время периода обслуживания. Хранение резервной копии составляет 30 дней.
Журналы и метрики
Журналы и метрики доступны через панель управления OVHcloud Public Cloud. На сегодняшний день вы не можете экспортировать журналы и метрики или подключать их к удаленному инструменту.
- Хранение журналов : 1000 строк журналов
- Сохранение показателей : 1 календарный месяц
Обратите внимание, что при удалении экземпляра базы данных журналы и метрики также автоматически удаляются.
Пользователи и роли
Создание пользователей разрешено через панель управления и API с ролями и привилегиями администратора по умолчанию. Вы не можете выбрать определенные привилегии.
Нам нужны ваши отзывы!
Мы будем рады помочь ответить на вопросы и будем признательны за любой ваш отзыв.