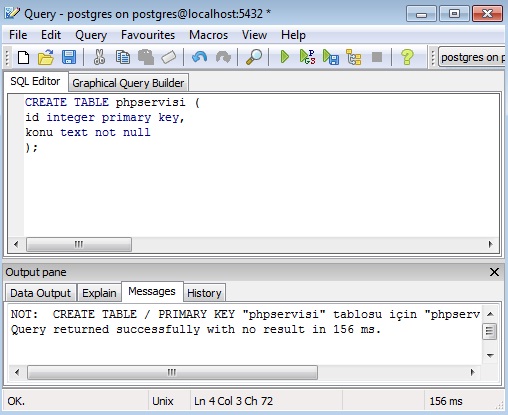
Как очищать данные при помощи SQL / Хабр
За время работы автору довелось использовать многие инструменты анализа, включая Excel, R и Python. Попробовав PostgreSQL и TimescaleDB, автор поняла, насколько простыми могут быть задачи очистки. Делимся подробностями сравнения PostgreSQL и Python из блога TimescaleDB, пока у нас начинается курс по аналитике данных.
Процесс анализа вкратце
Раньше столбцы и значения данных приходилось редактировать вручную. Приходилось извлекать «сырые» данные из CSV-файла или базы данных, а затем изменять их в Python-скрипте.
Приходилось ждать, пока машина настроит и очистит данные. А чтобы поделиться очищенными данными, нужно было запускать скрипт или передавать его другим людям. Но теперь благодаря PostgreSQL я один раз пишу запрос очистки на SQL прямо в базе данных и сохраняю результаты в таблице.
О наборе данных
Бо́льшую часть работы по очистке я проводила после анализа. Но иногда полезно очистить данные, оценить их и снова очистить. Именно с таким случаем мы и будем работать. В одном из наборов данных Kaggle содержатся показания потребления энергии одной из квартир в Сан-Хосе, штат Калифорния. Данные обновляются каждые 15 минут и следуют приблизительно такой схеме:
Именно с таким случаем мы и будем работать. В одном из наборов данных Kaggle содержатся показания потребления энергии одной из квартир в Сан-Хосе, штат Калифорния. Данные обновляются каждые 15 минут и следуют приблизительно такой схеме:
Вот что приходит в голову первым в смысле очистки:
Тариф — текстовый тип, а это вызовет проблемы.
Столбцы времени и даты разделены, что может вызвать проблемы при создании графиков или моделей на основе показателей времени.
Может понадобиться отфильтровать данные по временным параметрам, например по дню недели или конкретным праздникам (оба параметра влияют на потребление энергии).
К процессу очистки в PostgreSQL можно подойти по-разному: можно создать таблицу, а затем изменить её при очистке, создать несколько таблиц при добавлении или изменении данных или работать с представлениями. В зависимости от размера данных эти подходы могут иметь смысл, но вычисления будут выполнятся по-разному.
Учитывая состояние данных в energy_usage_staging, я решила поместить их в промежуточную таблицу, очистить с помощью представлений, а затем вставить в таблицу поудобнее. Всё это можно сделать до оценки данных.
Часто при работе с большим объёмом данных изменение таблицы в PostgreSQL может оказаться дорогим. Я покажу, как с помощью представлений и дополнительных таблиц создать чистые данные.
Проблемы структуры
Разделённые столбцы даты и времени надо преобразовать в метку времени, а столбец тарифов— в тип float4. Подробности ниже.
Гипертаблицы TimescaleDB, и почему важна метка времени
В основе эффективности запроса данных временного ряда и управления этими данными лежат гипертаблицы TimescaleDB. Они разделяются по столбцу времени, который вы укажете при создании таблицы.
Данные разделяются по метке времени на «куски», так что каждая строка таблицы принадлежит какому-то куску исходя из диапазона. Позже эти куски используются в запросах строк, чтобы запросы и манипулирование данными по времени были эффективнее.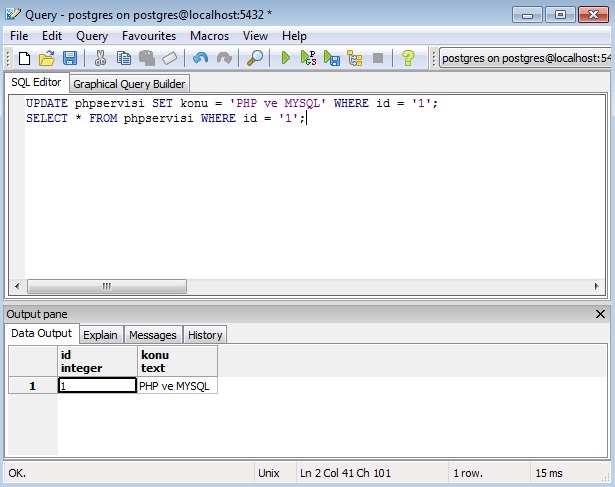 Ниже вы видите разницу между обычной таблицей и гипертаблицей:
Ниже вы видите разницу между обычной таблицей и гипертаблицей:
Изменение структуры даты и времени
Чтобы по максимуму использовать функциональность TimescaleDB, например непрерывное агрегирование и ускоренные временные запросы, надо поменять структуру столбцов даты и времени в таблице energy_usage_staging.
Для разделения гипертаблицы можно использовать столбец даты, но тогда будет ограничен контроль над данными по времени. Один столбец с меткой времени даёт больше гибкости и экономит пространство эффективнее, чем отдельные столбцы с датой и временем.
Структура таблицы должна быть такой, чтобы из столбцов date и start_time можно было получать полезное значение метки времени: end_time не даёт столько информации. Иными словами, надо объединить эти два столбца в один с метками времени.
В PostgreSQL можно создать столбец, не вставляя его в базу данных. Поэтому, чтобы создать из этой промежуточной таблицы новую таблицу, добавлять дополнительные столбцы или таблицы пока не нужно.
time.--добавляем дату в столбец start_time SELECT date, start_time, (date + start_time) AS time FROM energy_usage_staging eus;
Результаты:
В Python с этой же целью проще всего добавить новый столбец во фрейм данных. Нужно конкатенировать два столбца вместе с определённым пространством, а затем преобразовать этот столбец в datetime.
energy_stage_df['time'] = pd.to_datetime(energy_stage_df['date'] + ' ' + energy_stage_df['start_time']) print(energy_stage_df[['date', 'start_time', 'time']])
Изменение типов данных столбцов
Благодаря функции TO_NUMBER() в PostgreSQL это просто.
Формат функции такой: TO_NUMBER('text', 'format'); format — это специальная строка PostgreSQL, которая создаётся в зависимости от типа текста. Мы имеем дело с символом $ и числовым набором 0,00. Строка формата будет такой: ‘
Строка формата будет такой: ‘L99D99‘. L сообщает PostgreSQL, что в начале текста есть символ денег, 9-ки — что есть числовые значения, а D отделяет целую часть от десятичной.
Преобразование ограничим значениями не больше 99,99, поскольку в столбце тарифов нет значений больше 0,65. А что если надо преобразовать столбец с большими числовыми значениями? Тогда добавляем G для запятых.
К примеру, есть столбец тарифов с текстовыми значениями 1,672,278.23. Тогда отформатируем строку так: L9G999G999D99.
--создаём новый столбец cost_new с функцией to_number()
SELECT cost, TO_NUMBER("cost", 'L9G999D99') AS cost_new
FROM energy_usage_staging eus
ORDER BY cost_new DESCРезультаты:
Код на Python:
energy_stage_df['cost_new'] = pd.to_numeric(energy_stage_df.cost.apply(lambda x: x.replace('$','')))
print(energy_stage_df[['cost', 'cost_new']])В случае Python используем лямбда-функцию, которая заменяет все знаки $ пустыми строками. И это снова может быть неэффективно.
И это снова может быть неэффективно.
energy_stage_df['cost_new'] = pd.to_numeric(energy_stage_df.cost.apply(lambda x: x.replace('$','')))
print(energy_stage_df[['cost', 'cost_new']])Представления PostgreSQL
Представление — это объект PostgreSQL, который позволяет определять запрос и вызывать его по имени представления, как если бы это была таблица БД. Сгенерируем данные и создадим представление:
--запрашиваем нужные данные
SELECT type,
(date + start_time) AS time,
"usage",
units,
TO_NUMBER("cost", 'L9G999D99') AS cost,
notes
FROM energy_usage_stagingРезультаты:
Назовём наше представление energy_view, а при последующей очистке просто укажем его имя в операторе FROM.
--из запроса выше создаём представление
CREATE VIEW energy_view AS
SELECT type,
(date + start_time) AS time,
"usage",
units,
TO_NUMBER("cost", 'L9G999D99') AS cost,
notes
FROM energy_usage_stagingКод Python:
energy_df = energy_stage_df[['type','time','usage','units','cost_new','notes']] energy_df.rename(columns={'cost_new':'cost'}, inplace = True) print(energy_df.head(20))
Важно: данные внутри представлений PostgreSQL должны пересчитываться при каждом запросе. Вот почему надо вставлять данные представления в гипертаблицу, как только они подготовлены.
Cоздание или генерирование необходимых данных
Столбец примечаний (notes) в этом наборе пуст. Чтобы проверить это, просто включаем оператор WHERE и указываем, где notes не равны пустой строке.
SELECT * FROM energy_view ew -- когда notes — не пустые строки WHERE notes!='';
И код на Python:
print(energy_df[energy_df['notes'].notnull()])
Столбец примечаний пуст, поэтому заменим его различными наборами дополнительной информации, чтобы использовать эту информацию при моделировании.
Добавим столбец дня недели при помощи EXTRACT() — функции даты/времени PostgreSQL, которая позволяет извлекать из даты и времени различные элементы.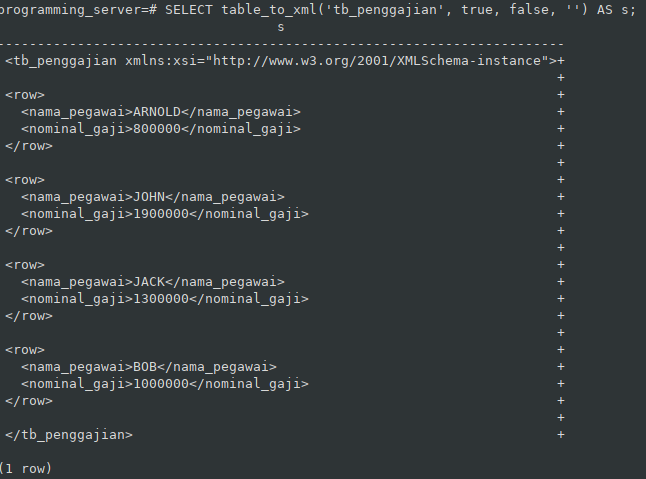 У наших колонок в PostgreSQL есть обозначение дня недели DOW (day-of-week): 0 — это воскресенье, а 6 — суббота.
У наших колонок в PostgreSQL есть обозначение дня недели DOW (day-of-week): 0 — это воскресенье, а 6 — суббота.
-- извлекаем day-of-week from date и приводим вывод к int SELECT *, EXTRACT(DOW FROM time)::int AS day_of_week FROM energy_view
Результаты:
Код Python:
energy_df['day_of_week'] = energy_df['time'].dt.dayofweek
Можно добавить столбец, где указывается, приходится ли день на выходные или будни. Для этого воспользуемся оператором CASE:
SELECT type, time, usage, units, cost, EXTRACT(DOW FROM time)::int AS day_of_week, -- --используйте оператор case, чтобы сделать столбец истинным, если записи выпадают на выходные дни и 6 CASE WHEN (EXTRACT(DOW FROM time)::int) IN (0,6) then true ELSE false END AS is_weekend FROM energy_view ew
Результаты:
Интересный факт: тот же запрос можно выполнить без CASE, но только для столбцов с двоичными данными.
--другой метод создания столбца с двоичными данными SELECT type, time, usage, units, cost, EXTRACT(DOW FROM time)::int AS day_of_week, EXTRACT(DOW FROM time)::int IN (0,6) AS is_weekend FROM energy_view ew
Код Python:
energy_df['is_weekend'] = np.where(energy_df['day_of_week'].isin([5,6]), 1, 0) print(energy_df.head(20))
Обратите внимание: в Python выходные представлены числами 5 и 6, а в PostgreSQL — числами 0 и 6.
А что, если добавить другие параметры? Например, праздники. Люди в праздники чаще всего не работают и проводят время дома, а значит, в эти дни потребление энергии может быть другим. Поэтому включим в анализ определение праздников. Для этого создадим ещё один столбец логических значений, который определяет наступление национального праздника. Для этого используем функцию TimescaleDB time_bucket().
Эта функция нужна, чтобы гарантировать, что учитываются все значения времени за день. Создав таблицу праздников, используем данные из неё в запросе без оператора CASE, но можно написать запрос и с ним.
--создаём таблицу для праздников
CREATE TABLE holidays (
date date)
--вставляем праздники в таблицу
INSERT INTO holidays
VALUES ('2016-11-11'),
('2016-11-24'),
('2016-12-24'),
('2016-12-25'),
('2016-12-26'),
('2017-01-01'),
('2017-01-02'),
('2017-01-16'),
('2017-02-20'),
('2017-05-29'),
('2017-07-04'),
('2017-09-04'),
('2017-10-9'),
('2017-11-10'),
('2017-11-23'),
('2017-11-24'),
('2017-12-24'),
('2017-12-25'),
('2018-01-01'),
('2018-01-15'),
('2018-02-19'),
('2018-05-28'),
('2018-07-4'),
('2018-09-03'),
('2018-10-8')
SELECT type, time, usage, units, cost,
EXTRACT(DOW FROM time)::int AS day_of_week,
EXTRACT(DOW FROM time)::int IN (0,6) AS is_weekend,
-- Затем я могу выбрать данные из таблицы прямо внутри IN
time_bucket('1 day', time) IN (SELECT date FROM holidays) AS is_holiday
FROM energy_view ew Результаты:
Код Python:
holidays = ['2016-11-11', '2016-11-24', '2016-12-24', '2016-12-25', '2016-12-26', '2017-01-01', '2017-01-02', '2017-01-16', '2017-02-20', '2017-05-29', '2017-07-04', '2017-09-04', '2017-10-9', '2017-11-10', '2017-11-23', '2017-11-24', '2017-12-24', '2017-12-25', '2018-01-01', '2018-01-15', '2018-02-19', '2018-05-28', '2018-07-4', '2018-09-03', '2018-10-8'] energy_df['is_holiday'] = np.where(energy_df['day_of_week'].isin(holidays), 1, 0) print(energy_df.head(20))
Пока сохраним эту расширенную таблицу в другом представлении, чтобы воспользоваться представлением позже.
--создаём другое представление с данными из первой очистки
CREATE VIEW energy_view_exp AS
SELECT type, time, usage, units, cost,
EXTRACT(DOW FROM time)::int AS day_of_week,
EXTRACT(DOW FROM time)::int IN (0,6) AS is_weekend,
time_bucket('1 day', time) IN (select date from holidays) AS is_holiday
FROM energy_view ewВы спросите: «Зачем создавать столбцы логических значений?». Для фильтрации. В PostgreSQL благодаря логическим столбцам очень легко фильтровать данные. Например, если нужно показать данные только за выходные и праздничные дни, добавим WHERE
--если используете столбцы с двоичными данными, то фильтровать их можно простым WHERE SELECT * FROM energy_view_exp WHERE is_weekend AND is_holiday
Результаты:
Код Python:
print(energy_df[(energy_df['is_weekend']==1) & (energy_df['is_holiday']==1)].head(10))
Добавление данных в гипертаблицу
Подготовив новые столбцы и организовав таблицу, создадим новую гипертаблицу и вставим очищенные данные.
CREATE TABLE energy_usage (
type text,
time timestamptz,
usage float4,
units text,
cost float4,
day_of_week int,
is_weekend bool,
is_holiday bool,
)
--команда создания гипертаблицы
SELECT create_hypertable('energy_usage', 'time')
INSERT INTO energy_usage
SELECT *
FROM energy_view_expВ случае работы с постоянно поступающими данными можно создать скрипт, который при импорте данных автоматически вносит эти изменения.
Переименование значений
Ещё один ценный метод очистки данных — переименование элементов или повторное отображение категориальных значений.
Его важность подчёркивается популярностью вопроса об анализе данных Python на StackOverflow: «Как во фрейме Pandas поменять одно значение индекса». PostgreSQL и TimescaleDB используют структуры реляционных таблиц, поэтому переименовывать уникальные значения просто.
Определённые значения индекса в таблице переименовываются «на лету» через CASE внутри SELECT. Например, поменяем 0 воскресенья в столбце day_of_week на 7 :
SELECT type, time, usage, cost, is_weekend, -- чтобы переписать значения, можно воспользоваться CASE CASE WHEN day_of_week = 0 THEN 7 ELSE day_of_week END FROM energy_usage
Внимание: код ниже сделает понедельник равным 7, потому что в функции DOW (day-of-week) Python значение понедельника 0, а воскресенья — 6. Но так и обновляется одно значение в столбце. При этом обновлять значения, скорее всего, не придётся, а эквивалент на Python показан просто для справки.
energy_df.day_of_week[energy_df['day_of_week']==0] = 7 print(energy_df.head(250))
А если вместо числовых значений использовать названия дней недели? Убираем CASE и создаём таблицу сопоставления. При изменении различных значений будет эффективнее создать её, а затем объединиться с ней командой JOIN.
--создаём таблицу CREATE TABLE day_of_week_mapping ( day_of_week_int int, day_of_week_name text ) --затем добавляем в неё данные INSERT INTO day_of_week_mapping VALUES (0, 'Sunday'), (1, 'Monday'), (2, 'Tuesday'), (3, 'Wednesday'), (4, 'Thursday'), (5, 'Friday'), (6, 'Saturday') --объединяем её с таблицей очистки для повторного отображения дней недели SElECT type, time, usage, units, cost, dowm.day_of_week_name, is_weekend FROM energy_usage eu LEFT JOIN day_of_week_mapping dowm ON dowm.day_of_week_int = eu.day_of_week
Результаты:
Аналогичные функции отображения есть в Python.
energy_df['day_of_week_name'] = energy_df['day_of_week'].map({0 : 'Sunday', 1 : 'Monday', 2: 'Tuesday', 3: 'Wednesday', 4: 'Thursday', 5: 'Friday', 6: 'Saturday'})
print(energy_df.head(20))Кроме того, помните: поменять название столбца в таблице можно при помощи оператора SELECT.
SELECT type AS usage_type, time as time_stamp, usage, units, cost AS dollar_amount FROM energy_view_exp LIMIT 20;
Результаты:
SQL здесь быстрее и элегантнее. На Python переименование столбцов может стать большой проблемой.
На Python переименование столбцов может стать большой проблемой.
energy_df.rename(columns={'type':'usage_type', 'time':'time_stamp', 'cost':'dollar_amount'}, inplace=True)
print(energy_df[['usage_type','time_stamp','usage','units','dollar_amount']].head(20))Заполнение недостающих данных
Другая проблема в процессе очистки данных — это их отсутствие. В нашем наборе нет явно отсутствующих точек данных, но наверняка найдутся недостающие данные по часам, возникающие из-за отключения электроэнергии или других обстоятельств. Здесь и пригодятся функции заполнения TimescaleDB.
Недостающие данные часто оказывают большое и негативное влияние на точность или надёжность модели. Иногда проблема решается заполнением недостающих данных данными, которые получены обоснованными оценками. Чтобы получить такие данные, TimescaleDB предоставляет встроенные функции.
Например, при моделировании потребления энергии в отдельные дни недели по некоторым дням из-за отключения электроснабжения или проблем с датчиком данных нет. Данные можно удалить или заполнить недостающие значения обоснованными оценками.
Данные можно удалить или заполнить недостающие значения обоснованными оценками.
Для примера я создала данные и назвала таблицу energy_data. В ней нет показаний времени и энергии между 7:45 и 11:30 утра.
Чтобы добавить эти недостающие значения, используем гиперфункции TimescaleDB; interpolate() — ещё одна гиперфункция TimescaleDB. Она создаёт точки данных, которые следуют линейной аппроксимации с учётом точек данных до и после отсутствующего диапазона.
Есть альтернативная гиперфункция locf(), которая переносит последнее записанное значение вперёд, чтобы заполнить пробел (locf так и расшифровывается: last-one-carried-forward, т. е. «последнее переносимое вперёд»). Обе гиперфункции должны использоваться вместе с time_bucket_gapfill().
SELECT
--новые данные должны появляться каждые 15 минут
time_bucket_gapfill('15 min', time) AS timestamp,
interpolate(avg(energy)),
locf(avg(energy))
FROM energy_data
--чтобы использовать gapfill, придётся удалять любые данные времени, связанные со значениями null. Сделать это можно с помощью оператора IS NOT NULL
WHERE energy IS NOT NULL AND time > '2021-01-01 07:00:00.000' AND time < '2021-01-01 13:00:00.000'
GROUP BY timestamp
ORDER BY timestamp;
Сделать это можно с помощью оператора IS NOT NULL
WHERE energy IS NOT NULL AND time > '2021-01-01 07:00:00.000' AND time < '2021-01-01 13:00:00.000'
GROUP BY timestamp
ORDER BY timestamp;Результаты:
Код Python:
energy_test_df['time'] = pd.to_datetime(energy_test_df['time'])
energy_test_df_locf = energy_test_df.set_index('time').resample('15 min').fillna(method='ffill').reset_index()
energy_test_df = energy_test_df.set_index('time').resample('15 min').interpolate().reset_index()
energy_test_df['locf'] = energy_test_df_locf['energy']
print(energy_test_df)Следующий вопрос: как игнорировать отсутствующие данные. Я покажу, как легко исключить данные с NULL.
SELECT * FROM energy_data WHERE energy IS NOT NULL
Можно также использовать оператор WHERE, чтобы указать игнорируемое время.
SELECT * FROM energy_data WHERE time <= '2021-01-01 07:45:00.000' OR time >= '2021-01-01 11:30:00.000'
Продолжить изучение SQL и Python вы сможете на наших курсах:
Профессия Data Scientist (24 месяца)
Профессия Data Analyst (10 месяцев)
Узнайте подробности здесь.
Data Science и Machine Learning
Профессия Data Scientist
Профессия Data Analyst
Курс «Математика для Data Science»
Курс «Математика и Machine Learning для Data Science»
Курс по Data Engineering
Курс «Machine Learning и Deep Learning»
Курс по Machine Learning
Python, веб-разработка
Профессия Fullstack-разработчик на Python
Курс «Python для веб-разработки»
Профессия Frontend-разработчик
Профессия Веб-разработчик
Мобильная разработка
Профессия iOS-разработчик
Профессия Android-разработчик
Java и C#
Профессия Java-разработчик
Профессия QA-инженер на JAVA
Профессия C#-разработчик
Профессия Разработчик игр на Unity
От основ — в глубину
Курс «Алгоритмы и структуры данных»
Профессия C++ разработчик
Профессия Этичный хакер
А также
Курс по DevOps
Все курсы
Процедура очистки VACUUM в PostgreSQL
Познакомимся поближе с процессом VACUUM и теми задачами, которые он решает в PostgreSQL.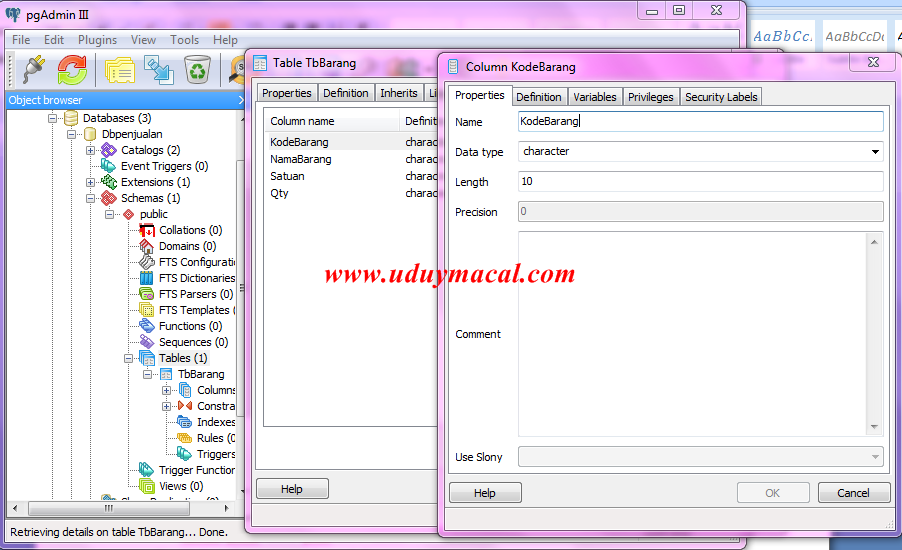 Этот процесс чистит таблицы, обновляет статистику и обновляет карты видимости и свободного пространства. А также борется с переполнением счетчика транзакций.
Этот процесс чистит таблицы, обновляет статистику и обновляет карты видимости и свободного пространства. А также борется с переполнением счетчика транзакций.
Варианты запуска очистки
Обновление статистики
Обновление карт видимости и свободного пространства
Переполнение счётчика транзакций и заморозка
Варианты запуска очистки
Очищать таблицы или базы данных от ненужных версий строк можно с помощью следующих команд:
VACUUM таблица;– очищает таблицу;VACUUM;– базу данных;$ vacuumdb– обёртка для использования в ОС.
Процедура VACUUM выполняется параллельно с другими транзакциями. При этом частый запуск нагружает систему, редкий запуск приводит к росту размера файлов. Подробнее почитать про очистку PostgreSQL можно тут. Мы уже встречались с понятием VACUUM в статье “Изоляция и многоверсионность в Postgresql“.
Подробнее почитать про очистку PostgreSQL можно тут. Мы уже встречались с понятием VACUUM в статье “Изоляция и многоверсионность в Postgresql“.
Дополнительно к этому существует процесс автоматической очистки AUTOVACUUM:
- autovacuum launcher – следит за таблицами и в случае необходимости запускает autovacuum worker;
- autovacuum worker – занимается очисткой таблиц.
Частота работы autovacuum worker зависит от частоты изменений таблицы. Чем активнее ведётся работа с таблицей, тем чаще туда приходит autovacuum. Autovacuum настраивается конфигурационными параметрами.
Как уже рассматривалось VACUUM и AUTOVACUUM не сжимает файл, а только очищает его образовывая в нем пустые пространства. Для полного перестроения файла, другими словами чтобы файл уменьшился, нужно использовать VACUUM FULL:
VACUUM FULL таблица;– очистка таблицы;VACUUM FULL;– очистка базы;$ vacuumdb --full– обёртка для использования в ОС.
VACUUM FULL очищает таблицу и перезаписывает её в новый файл, при этом файл уменьшается в размере. Для этого на таблицу навешивают блокировку, поэтому на некоторое время таблица становится недоступной. Похожим образом работает TRUNCATE.
Команда TRUNCATE блокирует таблицу и очищает её, при этом старые версии строк не сохраняются и файл уменьшается физически. Другой способ очистить таблицу это выполнить DELETE всех строк в ней, а затем запустить по этой таблице VACUUM FULL для очистки. TRUNCATE это транзакционная команда, поэтому её можно отменить (ROLLBACK).
Обновление статистики
Фоновый процесс autovacuum обновляет статистику. А статистика необходима планировщику, чтобы строить план запроса.
В ручную сбор статистику можно запустить с помощью следующих команд:
ANALYZE [таблица];– обновить статистику по таблице;ANALYZE;– обновить статистику по базе данных;$ vacuumdb --analyze-only– обёртка для использования в ОС;VACUUM ANALYZE;– выполнить очистку, а затем сбор статистики.
Существует много параметров конфигурации, которые управляют процессом autovacuum:
postgres@s-pg13:~$ grep autovacuum $PGDATA/postgresql.conf #autovacuum_work_mem = -1 # min 1MB, or -1 to use maintenance_work_mem #autovacuum = on # Enable autovacuum subprocess? 'on' #log_autovacuum_min_duration = -1 # -1 disables, 0 logs all actions and #autovacuum_max_workers = 3 # max number of autovacuum subprocesses #autovacuum_naptime = 1min # time between autovacuum runs #autovacuum_vacuum_threshold = 50 # min number of row updates before #autovacuum_vacuum_insert_threshold = 1000 # min number of row inserts #autovacuum_analyze_threshold = 50 # min number of row updates before #autovacuum_vacuum_scale_factor = 0.2 # fraction of table size before vacuum #autovacuum_vacuum_insert_scale_factor = 0.2 # fraction of inserts over table #autovacuum_analyze_scale_factor = 0.1 # fraction of table size before analyze #autovacuum_freeze_max_age = 200000000 # maximum XID age before forced vacuum #autovacuum_multixact_freeze_max_age = 400000000 # maximum multixact age #autovacuum_vacuum_cost_delay = 2ms # default vacuum cost delay for # autovacuum, in milliseconds; #autovacuum_vacuum_cost_limit = -1 # default vacuum cost limit for # autovacuum, -1 means use
Обновление карт видимости и свободного пространства
Карта видимости – помечает те страницы, где есть только актуальные версии строк, значит очищать такие страницы не нужно.
Карта свободного пространства – нужна чтобы быстро вставлять новые версии строк.
Эти карты обновляет autovacuum:
- после очистки, если на странице не осталось старых версий строк, autovacuum ставит галочку в карте видимости.
 Любой процесс, который запишет в эту страницу, эту галочку снимает.
Любой процесс, который запишет в эту страницу, эту галочку снимает. - когда autovacuum почистит страницу, в ней образуются дыры, и он обновляет карту свободного пространства.
Переполнение счётчика транзакций и заморозка
Счетчик транзакций 32-битный – это примерно 4 миллиарда значений. И он постоянно растёт! Если счетчик транзакций переполнится и начтет считать с нуля, то это приведет к большим проблемам на сервере. Для борьбы с этой проблемой существует процесс “Заморозка“.
При заморозке берутся версии строчек, в которых номер транзакции достаточно старый. То есть эта транзакция должна быть видна во всех новых снимках. Этот номер транзакции меняется на “минус бесконечность“. Система понимает, что эта строчка была создана когда-то давно и номер транзакции создавший её уже не имеет значения. Значит этот номер транзакции можно использовать повторно. Замороженные номера транзакций можно повторно использовать.
Почему не сделать счетчик 64 битным? В каждой версии строчки есть заголовок. Если счетчик будет 64 битным, то будет слишком много служебной информации на каждую версию строки.
Заморозкой тоже занимается VACUUM.
Сводка
By adminPostgreSQLLeave a Comment on Процедура очистки VACUUM в PostgreSQL
PHP: PostgreSQL — Manual
- Введение
- Установка и настройка
- Требования
- Установка
- Настройка во время выполнения
- Типы ресурсов
- Предопределённые константы
- Примеры
- Базовое использование
- Базовое использование
- Функции PostgreSQL
- pg_affected_rows — Возвращает количество затронутых запросом записей (кортежей)
- pg_cancel_query — Остановка асинхронного запроса.
- pg_client_encoding — Получение кодировки клиента.
- pg_close — Закрывает соединение с базой данных PostgreSQL
- pg_connect_poll — Опросить статус попытки асинхронного соединения PostgreSQL.
- pg_connect — Открывает соединение с базой данных PostgreSQL
- pg_connection_busy — Проверяет, занято ли соединение в данный момент.
- pg_connection_reset — Сброс подключения (переподключение)
- pg_connection_status — Определяет состояние подключения
- pg_consume_input — Читает вводные данные на соединении
- pg_convert — Преобразует значения ассоциативного массива в приемлемые для использования в SQL-запросах
- pg_copy_from — Вставляет записи из массива в таблицу
- pg_copy_to — Копирует данные из таблицы в массив
- pg_dbname — Определяет имя базы данных
- pg_delete — Удаляет записи
- pg_end_copy — Синхронизирует с бэкендом PostgreSQL
- pg_escape_bytea — Экранирует спецсимволы в строке для вставки в поле типа bytea
- pg_escape_identifier — Экранирует идентификатор для вставки в текстовое поле
- pg_escape_literal — Экранировать литерал при вставке в текстовое поле
- pg_escape_string — Экранирование спецсимволов в строке запроса
- pg_execute — Запускает выполнение ранее подготовленного параметризованного запроса и ждёт результат
- pg_fetch_all_columns — Выбирает все записи из одной колонки результата запроса и помещает их в массив
- pg_fetch_all — Выбирает все данные из результата запроса и помещает их в массив
- pg_fetch_array — Возвращает строку результата в виде массива
- pg_fetch_assoc — Выбирает строку результата запроса и помещает данные в ассоциативный массив
- pg_fetch_object — Выбирает строку результата запроса и возвращает данные в виде объекта
- pg_fetch_result — Возвращает запись из результата запроса
- pg_fetch_row — Выбирает строку результата запроса и помещает данные в массив
- pg_field_is_null — Проверка поля на значение SQL NULL
- pg_field_name — Возвращает наименование поля
- pg_field_num — Возвращает порядковый номер именованного поля
- pg_field_prtlen — Возвращает количество печатаемых символов
- pg_field_size — Возвращает размер поля
- pg_field_table — Возвращает наименование или идентификатор таблицы, содержащей заданное поле
- pg_field_type_oid — Возвращает идентификатор типа заданного поля
- pg_field_type — Возвращает имя типа заданного поля
- pg_flush — Сбросить данные исходящего запроса на соединении
- pg_free_result — Очистка результата запроса и освобождение памяти
- pg_get_notify — Получение SQL NOTIFY сообщения
- pg_get_pid — Получает ID процесса сервера БД
- pg_get_result — Получение результата асинхронного запроса
- pg_host — Возвращает имя хоста, соответствующего подключению
- pg_insert — Заносит данные из массива в таблицу базы данных
- pg_last_error — Получает сообщение о последней произошедшей ошибке на соединении с базой данных
- pg_last_notice — Возвращает последнее уведомление от сервера PostgreSQL
- pg_last_oid — Возвращает OID последней добавленной в базу строки
- pg_lo_close — Закрывает большой объект
- pg_lo_create — Создаёт большой объект
- pg_lo_export — Вывод большого объекта в файл
- pg_lo_import — Импорт большого объекта из файла
- pg_lo_open — Открывает большой объект базы данных
- pg_lo_read_all — Читает содержимое большого объекта и посылает напрямую в браузер
- pg_lo_read — Читает данные большого объекта
- pg_lo_seek — Перемещает внутренний указатель большого объекта
- pg_lo_tell — Возвращает текущее положение внутреннего указателя большого объекта
- pg_lo_truncate — Обрезает большой объект
- pg_lo_unlink — Удаление большого объекта
- pg_lo_write — Записывает данные в большой объект
- pg_meta_data — Получение метаданных таблицы
- pg_num_fields — Возвращает количество полей в выборке
- pg_num_rows — Возвращает количество строк в выборке
- pg_options — Получение параметров соединения с сервером баз данных
- pg_parameter_status — Просмотр текущих значений параметров сервера
- pg_pconnect — Открывает постоянное соединение с сервером PostgreSQL
- pg_ping — Проверка соединения с базой данных
- pg_port — Возвращает номер порта, соответствующий заданному соединению
- pg_prepare — Посылает запрос на создание параметризованного SQL выражения и ждёт его завершения
- pg_put_line — Передаёт на PostgreSQL сервер строку с завершающим нулём
- pg_query_params — Посылает параметризованный запрос на сервер, параметры передаются отдельно от текста SQL запроса
- pg_query — Выполняет запрос
- pg_result_error_field — Возвращает конкретное поле из отчёта об ошибках
- pg_result_error — Возвращает сообщение об ошибке, связанное с запросом результата
- pg_result_seek — Смещает указатель на строку выборки в экземпляре результата запроса
- pg_result_status — Возвращает состояние результата запроса
- pg_select — Выбирает записи из базы данных
- pg_send_execute — Запускает предварительно подготовленный SQL-запрос и передаёт ему параметры; не ожидает возвращаемого результата
- pg_send_prepare — Посылает запрос на создание параметризованного SQL-выражения, не дожидаясь его завершения
- pg_send_query_params — Посылает параметризованный запрос на сервер, не ожидает возвращаемого результата
- pg_send_query — Отправляет асинхронный запрос
- pg_set_client_encoding — Устанавливает клиентскую кодировку
- pg_set_error_verbosity — Определяет объем текста сообщений, возвращаемых функциями pg_last_error и pg_result_error
- pg_socket — Получить дескриптор только для чтения на сокет, лежащего в основе соединения PostgreSQL
- pg_trace — Включает трассировку подключения PostgreSQL
- pg_transaction_status — Возвращает текущее состояние транзакции на сервере
- pg_tty — Возвращает имя терминала TTY, связанное с соединением
- pg_unescape_bytea — Убирает экранирование двоичных данных типа bytea
- pg_untrace — Отключает трассировку соединения с PostgreSQL
- pg_update — Обновление данных в таблице
- pg_version — Возвращает массив, содержащий версии клиента, протокола клиент-серверного взаимодействия и сервера (если доступно)
- PgSql\Connection — Класс PgSql\Connection
- PgSql\Result — Класс PgSql\Result
- PgSql\Lob — Класс PgSql\Lob
+add a note
User Contributed Notes
There are no user contributed notes for this page.
PostgreSQL TRUNCATE TABLE с практическими примерами
Резюме : в этом руководстве вы узнаете, как использовать инструкцию PostgreSQL TRUNCATE TABLE для быстрого удаления всех данных из больших таблиц.
Введение в оператор PostgreSQL TRUNCATE TABLE
Чтобы удалить все данные из таблицы, используйте оператор DELETE . Однако когда вы используете оператор DELETE для удаления всех данных из таблицы с большим количеством данных, это неэффективно. В этом случае вам нужно использовать TRUNCATE TABLE оператор:
Язык кода: SQL (язык структурированных запросов) (sql)
TRUNCATE TABLE имя_таблицы;
Оператор TRUNCATE TABLE удаляет все данные из таблицы без ее сканирования. По этой причине он быстрее, чем оператор
По этой причине он быстрее, чем оператор DELETE .
Кроме того, оператор TRUNCATE TABLE высвобождает хранилище сразу, поэтому вам не нужно выполнять последующие 9 операций.0005 VACUMM операция, полезная в случае больших таблиц.
Удалить все данные из одной таблицы
Простейшая форма оператора TRUNCATE TABLE выглядит следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
TRUNCATE TABLE имя_таблицы;
В следующем примере используется оператор TRUNCATE TABLE для удаления всех данных из таблицы инвойсов :
Язык кода: SQL (язык структурированных запросов) (sql)
TRUNCATE TABLE счета-фактуры;
Помимо удаления данных, вы можете сбросить значения в столбце идентификаторов с помощью параметра RESTART IDENTITY , например:
Язык кода: SQL (язык структурированных запросов) (sql)
TRUNCATE TABLE имя_таблицы ПЕРЕЗАПУСТИТЬ ИДЕНТИФИКАЦИЮ;
Например, следующая инструкция удаляет все строки из invoices table и сбрасывает последовательность, связанную со столбцом invoice_no :
Язык кода: SQL (язык структурированных запросов) (sql)
TRUNCATE TABLE инвойсы ПЕРЕЗАПУСТИТЬ ИДЕНТИФИКАЦИЮ;
По умолчанию оператор TRUNCATE TABLE использует параметр CONTINUE IDENTITY . Этот параметр в основном не перезапускает значение в последовательности, связанной со столбцом в таблице.
Этот параметр в основном не перезапускает значение в последовательности, связанной со столбцом в таблице.
Удалить все данные из нескольких таблиц
Чтобы удалить все данные сразу из нескольких таблиц, разделите каждую таблицу запятой (,) следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
TRUNCATE TABLE имя_таблицы1, имя_таблицы2, ...;
Например, следующая инструкция удаляет все данные из счетов-фактур и клиентов таблиц:
Язык кода: SQL (язык структурированных запросов) (sql)
TRUNCATE TABLE накладные, клиенты;
Удалить все данные из таблицы со ссылками на внешние ключи
На практике таблица, которую вы хотите усечь, часто содержит ссылки на внешние ключи из других таблиц, которые не указаны в операторе TRUNCATE TABLE .
По умолчанию оператор TRUNCATE TABLE не удаляет данные из таблицы, имеющей ссылки на внешний ключ.
Чтобы удалить данные из таблицы и других таблиц, в которых внешний ключ ссылается на таблицу, используйте Опция CASCADE в операторе TRUNCATE TABLE следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
TRUNCATE TABLE имя_таблицы КАСКАД;
В следующем примере удаляются данные из таблицы invoices и других таблиц, которые ссылаются на таблицу invoices через ограничения внешнего ключа:
Язык кода: SQL (язык структурированных запросов) (sql)
TRUNCATE TABLE накладные КАСКАД;
Вариант CASCADE следует использовать с дальнейшим рассмотрением, иначе вы можете удалить данные из таблиц, которые вам не нужны.
По умолчанию оператор TRUNCATE TABLE использует параметр RESTRICT , который предотвращает усечение таблицы, содержащей ссылки на ограничение внешнего ключа.
PostgreSQL TRUNCATE TABLE и триггер ON DELETE
Несмотря на то, что оператор TRUNCATE TABLE удаляет все данные из таблицы, он не запускает никаких ON DELETE триггеров, связанных с таблицей.
Чтобы активировать триггер при применении к таблице команды TRUNCATE TABLE , необходимо определить триггеры BEFORE TRUNCATE и/или AFTER TRUNCATE для этой таблицы.
PostgreSQL TRUNCATE TABLE и транзакция
TRUNCATE TABLE безопасна для транзакций. Это означает, что если вы поместите его в транзакцию, вы можете безопасно откатить его.
Сводка
- Используйте оператор
TRUNCATE TABLE, чтобы удалить все данные из большой таблицы. - Используйте параметр
CASCADEдля усечения таблицы и других таблиц, которые ссылаются на таблицу через ограничение внешнего ключа.
- Триггер
TRUNCATE TABLEне запускает триггерON DELETE. Вместо этого он запускает триггерыBEFORE TRUNCATEиAFTER TRUNCATE. - Оператор
TRUNCATE TABLEбезопасен для транзакций.
Было ли это руководство полезным?
PostgreSQL TRUNCATE VS DROP VS DELETE
Каждый разработчик, пользователь базы данных и т. д. сталкивается с ситуацией, когда он не понимает, «в чем разница между командами DROP, TRUNCATE и DELETE ». Если вы испытываете те же проблемы? Тогда не о чем беспокоиться. Этот пост разрешит все ваши неясности с помощью практических примеров.
В этой статье будет представлен сравнительный анализ команд Postgres TRUNCATE, DROP и DELETE с практическими примерами. Итак, начнем.
Как использовать команду TRUNCATE в Postgres?
Команда TRUNCATE TABLE представляет собой операцию DDL (акроним языка определения данных), которая удаляет все данные/записи из целевой таблицы. Команда TRUNCATE TABLE только удаляет данные таблицы и сохраняет структуру таблицы.
Команда TRUNCATE TABLE только удаляет данные таблицы и сохраняет структуру таблицы.
Таблица со ссылкой на внешний ключ не может быть усечена командой TRUNCATE TABLE в Postgres. Для достижения этой цели необходимо использовать пункт/опцию CASCADE с параметром 9.0225 Команда TRUNCATE TABLE .
Синтаксис
В приведенном ниже фрагменте показано, как обрезать конкретную таблицу в Postgres:
TRUNCATE TABLE tab_name;
Здесь tab_name — это таблица, которую нужно усечь.
Пример №1: Как обрезать таблицу в Postgres?
Предположим, нам нужно обрезать таблицу с именем «emp_data», содержимое которой показано на приведенном ниже снимке экрана:
SELECT * FROM emp_data;
emp_data содержит шесть записей. Давайте воспользуемся командой TRUNCATE table, чтобы обрезать целевую таблицу, т. е. emp_data: 9.0007
Давайте воспользуемся командой TRUNCATE table, чтобы обрезать целевую таблицу, т. е. emp_data: 9.0007
TRUNCATE TABLE emp_data;
Таблица emp_data успешно усечена. Воспользуемся командой SELECT для проверки усечения таблицы:
SELECT * FROM emp_data;
Из вывода видно, что команда TRUNCATE TABLE усекла данные таблицы и сохранила ее структуру. Для получения дополнительной информации о TRUNCATE TABLE нажмите здесь.
Как использовать команду DELETE в Postgres?
Команда DELETE представляет собой команду DML (акроним языка обработки данных), которая удаляет одну или несколько существующих записей из целевой таблицы. Постгрес Предложение WHERE можно использовать с командой DELETE для указания условия, и на основе этого условия записи таблицы будут удалены. Пропуск предложения WHERE в команде DELETE приведет к удалению всех записей из определенной таблицы.
Синтаксис
В приведенном ниже фрагменте показано, как использовать команду DELETE в Postgres:
DELETE FROM tab_name [WHERE condition/criteria];
Tab_name представляет имя таблицы, которую нужно удалить. ГДЕ является необязательным условием, которое определяет, будет ли удалена вся таблица или будут удалены некоторые определенные записи таблицы?
Пример: как использовать инструкцию DELETE в Postgres?
Предположим, мы хотим удалить таблицу с именем «staff_details», содержащую следующие записи:
SELECT * FROM staff_details;
Давайте воспользуемся командой DELETE , чтобы удалить выделенную таблицу, т. е. таблицу staff_details:
DELETE FROM staff_details ГДЕ staff_id = 4;
Вывод показывает, что целевая запись была удалена из таблицы «staff_details». Чтобы проверить удаление записи, вы можете использовать следующую команду:
Чтобы проверить удаление записи, вы можете использовать следующую команду:
SELECT * FROM staff_details;
Указанная запись, т. е. «staff_id=4», была удалена из таблицы staff_details. Вы можете узнать больше о команде DELETE из этой статьи.
Как удалить таблицу в Postgres?
Команда DROP — это команда DDL (акроним языка определения данных), которая безвозвратно удаляет/удаляет существующие объекты базы данных. Использование 9Команда 0225 DROP позволяет удалить базу данных, таблицу, триггер и т. д. Если говорить о команде DROP TABLE , она удаляет существующую таблицу из базы данных. Он не только удаляет таблицу, но и навсегда удаляет структуру таблицы.
Синтаксис
Следующий фрагмент демонстрирует использование команды DROP TABLE в Postgres:
DROP TABLE tab_name;
Имя_вкладки представляет таблицу, которая будет удалена.
Пример. Как работает команда DROP TABLE в Postgres?
Допустим, нам нужно удалить таблицу языков программирования, состоящую из следующих записей:
SELECT * FROM языки программирования;
Чтобы удалить таблицуprogram_languages, мы выполним следующую команду:
DROP TABLEprogramming_languages;
В приведенном выше фрагменте указано, что таблицаprogramming_languages была удалена из соответствующей базы данных. Проверим удаление таблицы с помощью команды SELECT:
ВЫБРАТЬ * ИЗ языков программирования;
Выходные данные подтвердили, что команда DROP TABLE успешно удалила структуру и данные таблицыprogramming_languages.
Это была вся необходимая информация об операторах TRUNCATE, DROP и DELETE.
Заключение
В Postgres команда TRUNCATE TABLE только удаляет данные таблицы и сохраняет структуру таблицы. Команда DELETE удаляет одну, несколько или все существующие записи из целевой таблицы. В то время как DROP TABLE Команда не только удаляет данные таблицы, но и безвозвратно удаляет структуру таблицы. На соответствующих примерах в этом посте объясняется разница между командами TRUNCATE, DROP и DELETE.
Команда DELETE удаляет одну, несколько или все существующие записи из целевой таблицы. В то время как DROP TABLE Команда не только удаляет данные таблицы, но и безвозвратно удаляет структуру таблицы. На соответствующих примерах в этом посте объясняется разница между командами TRUNCATE, DROP и DELETE.
Когда очистка PostgreSQL не удалит мертвые строки из таблицы?
Что такое VACUUM в PostgreSQL?
В PostgreSQL всякий раз, когда строки в таблице удаляются, существующая строка или кортеж помечаются как мертвые (физически не удаляются), и во время обновления соответствующий существующий кортеж помечается как мертвый и вставляется новый кортеж, поэтому в операциях PostgreSQL UPDATE = УДАЛИТЬ + ВСТАВИТЬ. Эти мертвые кортежи потребляют ненужное хранилище, и в конечном итоге вы получаете раздутую базу данных PostgreSQL. Это серьезная проблема, которую необходимо решить администратору базы данных PostgreSQL. VACUUM восстанавливает хранилище, занятое мертвыми кортежами. Обратите внимание, что освобожденное пространство хранения никогда не возвращается резидентной операционной системе, а просто дефрагментируется на той же странице базы данных и, таким образом, хранилище для повторного использования для будущих вставок данных в ту же таблицу. . Здесь прекращается боль? Нет, это не так. Раздувание серьезно влияет на производительность запросов PostgreSQL. В PostgreSQL таблицы и индексы хранятся в виде массива страниц фиксированного размера (обычно размером 8 КБ). Всякий раз, когда запрос запрашивает строки, экземпляр PostgreSQL загружает эти страницы в память, а мертвые строки приводят к дорогостоящему дисковому вводу-выводу во время загрузки данных.
Обратите внимание, что освобожденное пространство хранения никогда не возвращается резидентной операционной системе, а просто дефрагментируется на той же странице базы данных и, таким образом, хранилище для повторного использования для будущих вставок данных в ту же таблицу. . Здесь прекращается боль? Нет, это не так. Раздувание серьезно влияет на производительность запросов PostgreSQL. В PostgreSQL таблицы и индексы хранятся в виде массива страниц фиксированного размера (обычно размером 8 КБ). Всякий раз, когда запрос запрашивает строки, экземпляр PostgreSQL загружает эти страницы в память, а мертвые строки приводят к дорогостоящему дисковому вводу-выводу во время загрузки данных.
Как следить за тем, чтобы автоочистка обработала раздутые таблицы?
Если вы подозреваете, что в вашей инфраструктуре PostgreSQL есть раздутые таблицы, первое, что нужно проверить, это то, что вакуум обработал эти раздутые таблицы. Мы используем следующий скрипт для сбора данных о последней обработанной очистке:
SELECT schemaname, relname, n_live_tup, n_dead_tup, last_autovacuum
ИЗ pg_stat_all_tables
ЗАКАЗАТЬ n_dead_tup
/ (n_live_tup
* current_setting('autovacuum_vacuum_scale_factor')::float8
+ current_setting('autovacuum_vacuum_threshold')::float8)
DESC
ПРЕДЕЛ 10;
Но иногда вы можете видеть, что очистка была запущена недавно и все еще не освободила мертвые кортежи:
schemaname | имя | n_live_tup | n_dead_tup | last_autovacuum -----------+--------------+------------+---------- ---------- ad_ops_dB | рекламные_клики | 96100 | 96100 | 2020-04-18 16:33:47 pg_каталог | pg_атрибут | 11 | 259 | pg_каталог | pg_amp | 193 | 81 | pg_каталог | pg_класс | 61 | 29| pg_каталог | pg_type | 39 | 14 | pg_каталог | pg_index | 8 | 21 | pg_каталог | pg_зависимость | 7349 | 962 | pg_каталог | pg_trigger | 6 | 37 | pg_каталог | pg_proc | 469 | 87 | pg_каталог | pg_shзависимость | 18 | 11 | (10 строк)
Итак, теперь очевидно, что иногда очистка PostgreSQL не удаляет мертвые строки.
Когда PostgreSQL Vacuum не удалит мертвые строки?
Транзакции в PostgreSQL идентифицируются с помощью xid (идентификатор транзакции или «xact»), PostgreSQL назначит xid транзакции только в том случае, если начнет изменять данные, потому что это только с той точки, где другой процесс должен начать отслеживать его изменения. Это не применимо для транзакций только для чтения.
Мы скопировали ниже структуру данных PostgreSQL (из proc.c), которая обрабатывает транзакции:
typedef struct PGXACT
{
идентификатор транзакции xid; /* идентификатор текущей транзакции верхнего уровня
* выполняется этим процессом, если запущен и XID
* присваивается; иначе InvalidTransactionId */
идентификатор транзакции xmin; /* минимальный рабочий XID, как это было, когда мы
* начиная наш xact, исключая LAZY VACUUM:
* вакуум не должен удалять кортежи, удаленные
* xid >= xmin ! */
. ..
} PGXACT;
..
} PGXACT; PostgreSQL Vacuum удаляет только мертвые строки, которые больше не используются. Кортеж считается ненужным, если идентификатор удаляемой транзакции старше, чем самая старая транзакция, которая все еще активна в базе данных PostgreSQL. Очистные процессы вычисляют минимальную границу данных, которые им необходимо сохранить, отслеживая минимум xmins всех активных транзакций.
Ниже приведены три ситуации, которые сдерживают горизонт xmin в инфраструктуре PostgreSQL:
1. Длинные транзакции
Подробную информацию о длительных запросах и их соответствующие значения xmin можно найти в запросе, скопированном ниже:
SELECT pid, datname, username, state, backend_xmin ОТ pg_stat_activity ГДЕ backend_xmin НЕ NULL ORDER BY age(backend_xmin) DESC;
П.С. Если вы считаете, что эти транзакции больше не нужны, используйте pg_terminate_backend() , чтобы завершить сеансы PostgreSQL, блокирующие процессы Vacuum
9.0377 2. Заброшенные слоты репликации В PostgreSQL слот репликации — это структура данных, позволяющая PostgreSQL удалять данные, которые все еще требуются резервному серверу, чтобы догнать первичный экземпляр базы данных. Если когда-либо репликация на резервный сервер/подчиненное устройство задерживается или подчиненный экземпляр PostgreSQL выходит из строя на более длительный срок, слот репликации не позволит вакууму удалить старые записи/строки. Чтобы контролировать слоты репликации и их относительное значение xmin, используйте запрос ниже
Если когда-либо репликация на резервный сервер/подчиненное устройство задерживается или подчиненный экземпляр PostgreSQL выходит из строя на более длительный срок, слот репликации не позволит вакууму удалить старые записи/строки. Чтобы контролировать слоты репликации и их относительное значение xmin, используйте запрос ниже
ВЫБРАТЬ имя_слота, тип_слота, база данных, xmin ОТ pg_replication_slots ORDER BY age(xmin) DESC;
П.С. – Чтобы удалить слоты репликации, которые больше не нужны, используйте функцию pg_drop_replication_slot()
3. Потерянные подготовленные транзакции
Оператор COMMIT PREPARED. Чтобы отслеживать все подготовленные транзакции и их соответствующее значение xmin, выполните следующий запрос:
SELECT gid, подготовленный, владелец, база данных, транзакция КАК xmin ИЗ pg_prepared_xacts ORDER BY age(transaction) DESC;
П.С. – Мы рекомендуем оператор ROLLBACK PREPARED SQL для удаления подготовленных транзакций
Заключение
PostgreSQL Autovacuum эффективно устраняет раздувание таблиц, но бывают ситуации, когда очистка не работает должным образом, поэтому мы настоятельно рекомендуем регулярно проверять, как очистка обрабатывает раздутые таблицы
Справочные ссылки
- https://www.
