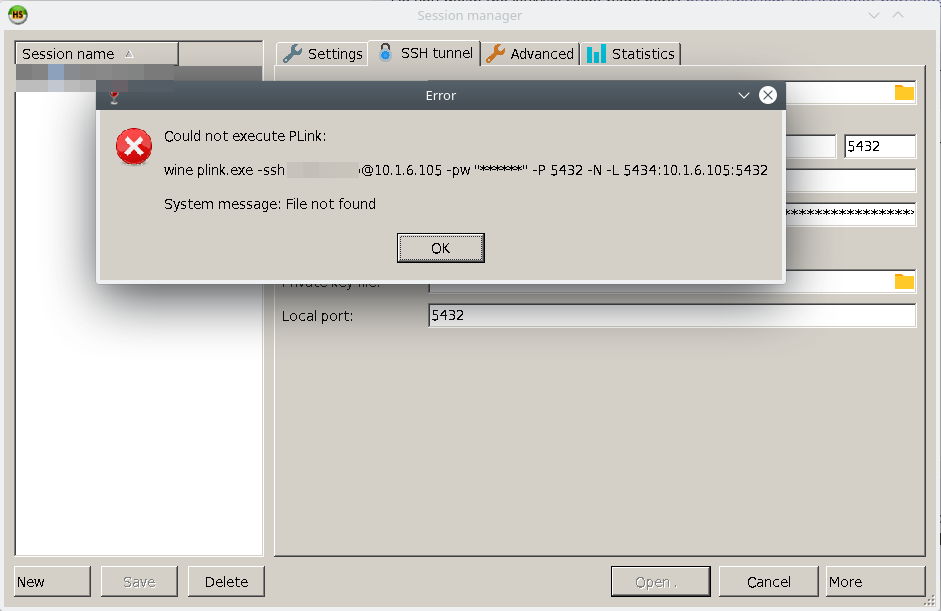
Вред хранимых процедур / Блог компании RUVDS.com / Хабр
В чат подкаста «Цинковый прод» скинули статью о том, как некие ребята перенесли всю бизнес-логику в хранимые процедуры на языке pl/pgsql. И так как у статьи было много плюсов, то значит, есть люди, а может быть, их даже большинство, которые положительно восприняли такой рефакторинг.
Я не буду растекаться мысью по древу, а сразу накидаю кучку минусов использования хранимых процедур.
Минусы хранимых процедур
Версионирование
Если в случае с кодом на php вы можете просто переключиться в git на другую ветку и посмотреть, что получилось, то хранимые процедуры нужно еще засунуть в базу. И традиционные миграции тут плохо помогут: если записывать все изменения хранимок как новый CREATE OR REPLACE PROCEDURE, то на кодревью будет ад: всегда новый файл, который непонятно с чем сравнивать. Поэтому придется искать какие-то дополнительные инструменты или писать свой велосипед.
Сам язык pl/pgsql
Это устаревший процедурный язык из девяностых, который вообще никак не развивается. Никакого ООП или ФП или чего бы то ни было. Синтаксис без малейшего намека на синтаксический сахар.
Сравните две функции, которые делают одно и то же на php и pl/pgsql:
CREATE OR REPLACE FUNCTION sum(x int, y int)
RETURNS int
LANGUAGE plpgsql
AS $$
DECLARE
result int;
BEGIN
result := x + y;
return result;
END;
$$;
function sum(int $x, int $y): int
{
$result = $x + $y;
return $result;
}
Примерно в 2-3 раза больше писанины.
Кроме того, язык интерпретируемый, без JIT и т.д. (поправьте меня, если что-то изменилось в последних версиях). Т.е. все очень медленно и печально. Уж если использовать какие-то хранимки, то на чистом SQL или v8 (т.
Отладка
Поверьте, отлаживать код на php в 100500 раз проще. Ты просто поправил что-то и смотришь результат. Можно обложить echo или смотреть, что там через xdebug прямо в IDE.
Отладка хранимых процедур — это неудобно. Это надо делать в pgadmin (включив специальное расширение). PgAdmin — это далеко не PHPstorm по удобству.
Логирование и обработка ошибок
Забудьте о том, чтобы красивый json c трейсом падал с stdout, а потом в graylog и в sentry. И чтобы все это автоматически происходило, выдавая пользователю ошибку 500, в случае если контроллер не поймал exception.
В хранимках pl/pgsql вы всё будете делать вручную:
GET DIAGNOSTICS stack = PG_CONTEXT;
RAISE NOTICE E'--- Стек вызова ---\n%', stack;
Сбор метрик
Вы не можете, как в golang, просто добавить эндпоинт /metrics, который будет подсасываться Прометеусом, куда вы напихаете бизнесовые и другие метрики для мониторинга. Я просто не знаю, как тут выкрутиться с pl/pgsql.
Масштабирование
Зависимости
В php вы, используя пакетный менеджер composer, одним движением можете подтянуть нужную библиотеку из интернета. Точно так же как в js это будет npm, в Rust это будет cargo и т.д.
В мире pl/pgsql нужно страдать. В этом языке просто нет менеджера зависимостей.
Фреймворки
В современном мире веб-приложение часто не пишут с нуля, а собирают на основе фреймворка, используя его компоненты. К примеру, на Laravel у вас из коробки есть роутинг, валидация запроса, движок шаблонов, аутентификация/авторизация, 100500 хелперов на все случаи жизни и т.д. Писать всё это вручную с нуля, на устаревшем языке — ну нет, спасибо.
Получится много велосипедов, которые потом еще и поддерживать придется.
Юнит-тесты
Сложно даже представить, как удобно организовать unit-тесты в хранимках на pl/pgsql.
 Я ни разу не пробовал. Поделитесь пожалуйста в комментариях.
Я ни разу не пробовал. Поделитесь пожалуйста в комментариях.Рефакторинг
Несмотря на то, что существует IDE для работы с базой данных (Datagrip), для обычных языков средства рефакторинга гораздо богаче. Всевозможные линтеры, подсказки по упрощению кода и т.д.
Маленький пример: в тех кусках кода, которые я привел в начале статьи, PHPStorm дал подсказку, что переменная $result необязательна, и можно просто сделать return $x + $y;
В случае с plpgsql — тишина.
Плюсы хранимых процедур
- Нет оверхеда на перегон промежуточных данных по пути бекенд-БД.
- В хранимых процедурах кешируется план запроса, что может сэкономить пару ms. т.е. как обертка над запросом иногда это имеет смысл делать (в редких случаях и не на pl/pgsql, а на голом sql), если бешеный хайлоад, а сам запрос выполняется быстро.
- Когда пишешь свой extension к посгресу — без хранимок не обойтись.
- Когда хочешь из соображений безопасности спрятать какие-то данные, дав доступ приложению только к одной-двум хранимкам (редкий кейс).
Выводы
На мой взгляд, хранимые процедуры нужны только в очень-очень редких случаях, когда вы уверены, что вы без них вообще не можете обойтись. В остальных кейсах — вы только усложните жизнь разработчикам, причем существенно.
Я бы понял, если в исходной статье часть логики переложили на SQL, это можно понять. Но зачем хранимки — это загадка.
Буду рад, если вы считаете, что я неправ или знаете, какие-то еще ситуации, связанные с хранимыми процедурами (как плюсы, так и минусы), и напишете об этом в коменты.
Создание Хранимых функций и триггеров (важно)
Доброго времени суток.
На днях предстоит экзамен по postgressql, будут два билета про Хранимые процедуры и Триггеры.
Я в общих чертах знаю sql , но ранее с функциями и триггерами не сталкивался…
Почитал про хранимые процедуры
Храни́мая процеду́ра — объект базы данных, представляющий собой набор SQL-инструкций, который компилируется один раз и хранится на сервере.
Хочется понять разницу между обычной процедурой и Хранимой процедурой.
Нашел такую разницу — Вместо хранения часто используемого запроса, клиенты могут ссылаться на соответствующую хранимую процедуру. При вызове хранимой процедуры её содержимое сразу же обрабатывается сервером.
И то что хранимая процедура вызывается с помощью функции CALL и EXECUTE.
Если есть еще какие то различия подскажите пожалуйста…
По поводу Триггеров
Триггеры предназначены для автоматического выполнения отдельных процедур в зависимости от операции, для которой они были назначены. Триггеры могут быть назначены до или после операций INSERT, UPDATE или DELETE как для случаев изменения записи в таблице так и для случая выполнения оператора SQL. Если произошло событие, на которое был назначен триггер, то вызывается закреплённая за этим триггером процедура.
Начиная с 9.0.x есть триггеры на колонки (столбцы) и кроме того, при объявлении триггера можно использовать ключевое слово WHEN, добавляющее дополнительное условие для срабатывания триггера.
Если с теорией еще более менее есть понимание что это такое… То с практикой вообще беда… А билеты по данным вопросам будут именно по части практики, врядли задания сложные будут, но сейчас на данном этапе я даже простые сделать не смогу потому что не представляю как прописывается в postgresql Хранимые процедуры и триггеры на примере какой нибудь самой простой базы данных.
Помогите, покажите простые но рабочие примеры по хранимым процедурам и тригерам на примере простой какой нибудь базе с пару таблиц, чтоб можно было оттолкнутся от этого и чтоб само понимание пришло…
Нашел вот такой пример функции , но так понимаю не хранимой, а простой, но даже это пример не до конца понимаю..
BEGIN
RETURN subtotal * 0.06;
END;
$$ LANGUAGE plpgsql;
В первой строчке понимаю что идет создание функции, название функции sales_tax, тип передаваемого или используемого аргумента типа REAL, А вот эта часть не совсем понятна «RETURNS REAL AS $$ » Ну RETURNS REAL я так понимаю вернуть значение типа Real, AS обычно используется для объявления псевдонима но тут не вижу какого именно псевдонима.
 .. Не понятные два значка $$ что они значат не пойму…
.. Не понятные два значка $$ что они значат не пойму…Потом в теле процедуры снова встречается слово «RETURN» а именно RETURN subtotal * 0.06;
В процедуры нужно дважды указывать слово RETURN? одно в шапке а другое в теле процедуры???
Нашел другой пример той же функции
CREATE FUNCTION sales_tax(REAL) RETURNS REAL AS $$
DECLARE
subtotal ALIAS FOR $1;
BEGIN
END;
$$ LANGUAGE plpgsql;
Только добавилась часть DECLARE в которой обычно описываются переменные и фраза subtotal из шапки перенесена именно в этот раздел…
Помогите все понять это, кто уже этим хорошо владеет а когда то начинал как и я уверен сможет понятно и доходчиво описать все как есть об этих вещах, очень важно для меня, заранее спасибо..
Иллюстрированный самоучитель по PostgreSQL › Нетривиальные возможности › Автоматизация стандартных процедур [страница — 176] | Самоучители по программированию
Автоматизация стандартных процедур
PostgreSQL является объектно-реляционной СУБД, что позволило включить в нее ряд нестандартных расширений SQL. Часть этих расширений связана с автоматизацией часто выполняемых операций с базами данных.
В этом разделе описаны две категории расширений: последовательности и триггеры.
Последовательности
Последовательностью (sequence) в PostgreSQL называется объект базы данных, который фактически представляет собой автоматически увеличивающееся число. В других СУБД последовательности часто называются счетчиками. Последовательности очень часто используются для присваивания уникальных значении идентификаторов в таблицах. Последовательность определяется текущим числовым значением и набором характеристик, определяющих алгоритм автоматического увеличения (или уменьшения) используемых данных.
Наряду с текущим значением в определение последовательности также включается минимальное значение, максимальное значение и приращение. Обычно приращение равно 1, но оно также может быть любым целым числом.
На практике последовательности не рассчитаны на прямой доступ из программы. Работа с ними осуществляется через специальные функции PostgreSQL, предназначенные для увеличения, присваивания или получения текущего значения последовательности.
Создание последовательности
Последовательности создаются командой SQL CREATE SEQUENCE с положительным или отрицательным приращением. Синтаксис команды CREATE SEQUENCE:
CREATE SEQUENCE последовательность [ INCREMENT приращение ] [ MINVALUE минимум ] [ MAXVALUE максимум ] [ START начало ] [ CACHE кэш ] [ CYCLE ]
В этом определении единственный обязательный параметр последовательность определяет имя создаваемой последовательности. Значения последовательности.представляются типом Integer, поэтому максимальное и минимальное значения должны лежать в интервале от 2 147 483 647 до -2 147 483 647.
Ниже описаны необязательные секции команды CREATE SEQUENCE.
- INCREMENT приращение. Числовое изменение текущего значения последовательности. Используется при вызове для последовательности функции nextval(). Отрицательное приращение создает убывающую последовательность. По умолчанию приращение равно 1.
- MINVALUE минимум. Минимальное допустимое значение последовательности. Попытка уменьшить текущее значение ниже заданного минимума приведет к ошибке или циклическому переходу к максимальному значению (если последовательность создавалась с ключевым словом CYCLE). По умолчанию минимальное значение равно 1 для возрастающих последовательностей или -2 147 483 647 для убывающих последовательностей.
- MAXVALUE максимум. Максимальное допустимое значение последовательности. Попытка увеличить текущее значение выше заданного максимума приведет к ошибке или циклическому переходу к минимальному значению. По умолчанию максимальное значение равно 2 147 483 647 для возрастающих последовательностей или -1 для убывающих последовательностей.
- START начало.
 Начальное значение последовательности, которым является любое целое число в интервале между минимальным и максимальным значениями. По умолчанию последовательность начинается с нижнего порога для возрастающих последовательностей или с верхнего порога для убывающих последовательностей.
Начальное значение последовательности, которым является любое целое число в интервале между минимальным и максимальным значениями. По умолчанию последовательность начинается с нижнего порога для возрастающих последовательностей или с верхнего порога для убывающих последовательностей. - CACHE кэш. Возможность предварительного вычисления и хранения значений последовательности в памяти. Кэширование ускоряет доступ к часто используемым последовательностям. Минимальное значение, заданное по умолчанию, равно 1; увеличение объема кэша приводит к увеличению числа кэшируемых значений.
- CYCLE. При достижении нижнего или верхнего порога последовательность продолжает генерировать новые значения. В этом случае она переходит к минимальному значению (для возрастающих последовательностей) или к максимальному значению (для убывающих последовательностей).
В листинге 7.28 создается простая возрастающая последовательность с именем shipments_ship_Td_seq, которая начинается со значения 0 и увеличивается со стандартным приращением 1 до тех пор, пока не достигнет максимального значения по умолчанию 2 147 483 647. Ключевое слово CYCLE не указано, поэтому последовательность заведомо принимает уникальные значения.
Листинг 7.28. Создание последовательности.
booktown-# CREATE SEQUENCE shipments_ship_id_seq booktown-# MINVALUE 0; CREATE
Миграция с SQL Server (MSSQL) на PostgreSQL
Ispirer Systems занимает ведущее положение на рынке услуг по миграции благодаря передовой программе для конвертации Ispirer Migration and Modernization Toolkit (Ispirer MnMTK). Используя нашу программу, Вы сможете легко и быстро осуществить миграцию с MS SQL Server на PostgreSQL. Ispirer MnMTK теперь поддерживает миграцию в самую последнюю версию PostgreSQL 10!
Обзор миграции с SQL Server на PostgreSQL
Ispirer MnMTK конвертирует следующие объекты базы данных:
Кроме SQL-объектов базы данных наш продукт может конвертировать встроенный SQL в коде приложений.
Если Вы хотите увидеть демонстрацию нашего продукта для миграции, наша опытная команда будет рада провести ее в удобное для вас время.
Почему Ispirer MnMTK для миграции с Microsoft SQL Server на PostgreSQL?
Программа для миграции Ispirer MnMTK и наша опытная команда помогут осуществить ваш миграционный проект, сократив ваши усилия и затраты.
Основные преимущества Ispirer:
- Высокая степень автоматизации — Автоматизация до 100%. Сокращение ваших усилий на доводку кода после конвертации до минимума.
- Выполнение миграции по вашим правилам — Автоматическая конвертация с использованием Ispirer MnMTK может быть оперативно приведена в соответствие с вашими требованиями.
- Предпродажное взаимодействие — Демонстрируем результат конвертации Вашего кода, прежде чем Вы примете окончательное решение.
- Сокращение сроков миграции — Ваш миграционный проект будет выполнен в десятки раз быстрее, по сравнению с ручной конвертацией.
- Экономически эффективное решение — Снижение ваших затрат на миграционный проект более чем на 70-90%, по сравнению с ручной конвертацией.
Узнайте больше о Процессе взаимодействия с Ispirer при миграции баз данных.
Наряду с миграцией с Microsoft SQL Server на PostgreSQL, Ispirer может предложить Вам решения для таких направлений миграции, как:
Пожалуйста, свяжитесь с нами для получения более подробной информации.
Оконные функции – то, что должен знать каждый T-SQL программист. Часть 2.
Во второй части статьи мы поговорим о самих функциях, которые применяются для формирования значения. Оконная функция вычисляет значение по набору данных, связанных с текущей строкой, то есть данные из одной группы, если используется Partition by. Обычные агрегатные функции для вычисления по группам требуют группировки строк, при этом теряется нужная уникальная информация из выборки. Поэтому приходится вместо одного запроса использовать 2, чтобы иметь все нужные данные и сумму по группам. Оконные агрегатные функции позволяют в одном запросе добиться того же результата.
Оконная функция вычисляет значение по набору данных, связанных с текущей строкой, то есть данные из одной группы, если используется Partition by. Обычные агрегатные функции для вычисления по группам требуют группировки строк, при этом теряется нужная уникальная информация из выборки. Поэтому приходится вместо одного запроса использовать 2, чтобы иметь все нужные данные и сумму по группам. Оконные агрегатные функции позволяют в одном запросе добиться того же результата.
Напомню, окно – это набор строк, по которым производится вычисление функции. Инструкция OVER разбивает весь набор строк на отдельные группы – окна согласно заданному условию.
Поговорим о типах оконных функций. Выделяют три группы по назначению:
- Агрегатные функции: SUM(), MAX(), MIN(), AVG(). COUNT(). Эти функции возвращают значение, полученное путем арифметических вычислений;
- Функции ранжирования: RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE(). Позволяют получить порядковые номера записей в окне;
- Функции смещения: LAG(), LEAD(), FIRST_VALUE(), LAST_VALUE(). Возвращают значение из другой строки окна.
Для демонстрации работы функций я буду использовать простую таблицу:
1 2 3 4 5 6 7 |
CREATE TABLE ForWindowFunc (ID INT, GroupId INT, Amount INT) GO INSERT INTO ForWindowFunc (ID, GroupId, Amount) VALUES(1, 1, 100), (1, 1, 200), (1, 2, 150), (2, 1, 100), (2, 1, 300), (2, 2, 200), (2, 2, 50), (3, 1, 150), (3, 2, 200), (3, 2, 10); |
Агрегатные функции
SUM()
Функция SUM() работает также как и обычная агрегатная функция – суммирует все значения заданного столбца в наборе данных. Однако, благодаря инструкции OVER() мы разбиваем набор данных на окна. Суммирование производится внутри окон согласно порядку, заданному в предложении ORDER BY. Давайте посмотрим на простой пример — сумма по трем группам.
Давайте посмотрим на простой пример — сумма по трем группам.
1 2 3 |
SELECT ID, Amount, SUM(Amount) OVER (ORDER BY id) AS SUM FROM ForWindowFunc |
|
ID |
Amount |
Sum |
|
1 |
100 |
450 |
|
1 |
200 |
450 |
|
1 |
150 |
450 |
|
2 |
100 |
650 |
|
2 |
300 |
650 |
|
2 |
200 |
650 |
|
2 |
50 |
650 |
|
3 |
150 |
360 |
|
3 |
200 |
360 |
|
3 |
10 |
360 |
Для удобства окна выделены разным цветом. Все значения в окне имеют одинаковую сумму – сумму всех Amount в окне.
Все значения в окне имеют одинаковую сумму – сумму всех Amount в окне.
Давайте добавим еще один столбец в выборку и изменим инструкцию OVER:
1 2 3 4 5 |
SELECT ID, GroupId, Amount, SUM(Amount) OVER (Partition BY id ORDER BY id, GroupId) AS SUM FROM ForWindowFunc |
|
ID |
GroupId |
Amount |
Sum |
|
1 |
1 |
100 |
300 |
|
1 |
1 |
200 |
300 |
|
1 |
2 |
150 |
450 |
|
2 |
1 |
100 |
400 |
|
2 |
1 |
300 |
400 |
|
2 |
2 |
200 |
650 |
|
2 |
2 |
50 |
650 |
|
3 |
1 |
150 |
150 |
|
3 |
2 |
200 |
360 |
|
3 |
2 |
10 |
360 |
Как видите, теперь каждое окно разделено на группы благодаря полю GroupId. Каждая группа теперь имеет свою сумму.
Каждая группа теперь имеет свою сумму.
А теперь, сделаем нарастающий итог внутри каждого окна:
1 2 3 4 5 |
SELECT ID, GroupId, Amount, SUM(Amount) OVER (Partition BY id ORDER BY id, GroupId, Amount) AS SUM FROM ForWindowFunc |
|
ID |
Amount |
Sum |
|
1 |
100 |
100 |
|
1 |
200 |
300 |
|
1 |
150 |
450 |
|
2 |
100 |
100 |
|
2 |
300 |
400 |
|
2 |
50 |
450 |
|
2 |
200 |
650 |
|
3 |
150 |
150 |
|
3 |
10 |
160 |
|
3 |
200 |
360 |
Поле GroupId нам уже не нужно, поэтому мы убрали его из выборки. Теперь для каждой строки в окне рассчитывается свой итог, который представляет собой сумму текущего значения Amount и всех предыдущих.
Теперь для каждой строки в окне рассчитывается свой итог, который представляет собой сумму текущего значения Amount и всех предыдущих.
AVG()
Эта функция рассчитывает среднее значение. Ее можно применять с предложениями Partition by и Order by.
1 2 3 4 |
SELECT ID, Amount, AVG(Amount) OVER (Partition BY id ORDER BY id) AS AVG FROM ForWindowFunc |
|
ID |
Amount |
AVG |
|
1 |
100 |
150 |
|
1 |
200 |
150 |
|
1 |
150 |
150 |
|
2 |
100 |
162 |
|
2 |
300 |
162 |
|
2 |
200 |
162 |
|
2 |
50 |
162 |
|
3 |
150 |
120 |
|
3 |
200 |
120 |
|
3 |
10 |
120 |
Каждая строка в окне имеет среднее значение Amount, которое рассчитывается по формуле: сумма всех Amount / на количество строк.
Поведение этой функции похоже на SUM().
MIN()
Из названия функции понятно, что она возвращает минимальное значение в окне.
1 2 3 4 |
SELECT ID, Amount, MIN(Amount) OVER (Partition BY id ORDER BY id) AS MIN FROM ForWindowFunc |
|
ID |
Amount |
Min |
|
1 |
100 |
100 |
|
1 |
200 |
100 |
|
1 |
150 |
100 |
|
2 |
100 |
50 |
|
2 |
300 |
50 |
|
2 |
200 |
50 |
|
2 |
50 |
50 |
|
3 |
150 |
10 |
|
3 |
200 |
10 |
|
3 |
10 |
10 |
Как вы видите, в столбце Min, выводится минимальное значение Amount в окне.
MAX()
Функция MAX работает аналогично MIN, только выдает максимальное значение поля в окне:
1 2 3 4 |
SELECT ID, Amount, MAX(Amount) OVER (Partition BY id ORDER BY id) AS MAX FROM ForWindowFunc |
|
ID |
Amount |
Max |
|
1 |
100 |
200 |
|
1 |
200 |
200 |
|
1 |
150 |
200 |
|
2 |
100 |
300 |
|
2 |
300 |
300 |
|
2 |
200 |
300 |
|
2 |
50 |
300 |
|
3 |
150 |
200 |
|
3 |
200 |
200 |
|
3 |
10 |
200 |
Все предельно понятно. В первой группе максимальный Amount – 200, во второй 300, а в третьей – 200.
В первой группе максимальный Amount – 200, во второй 300, а в третьей – 200.
COUNT()
Эта функция возвращает количество строк в окне.
1 2 3 |
SELECT ID, Amount, COUNT(Amount) OVER (Partition BY id ORDER BY id) AS COUNT FROM ForWindowFunc |
|
ID |
Amount |
Count |
|
1 |
100 |
3 |
|
1 |
200 |
3 |
|
1 |
150 |
3 |
|
2 |
100 |
4 |
|
2 |
300 |
4 |
|
2 |
200 |
4 |
|
2 |
50 |
4 |
|
3 |
150 |
3 |
|
3 |
200 |
3 |
|
3 |
10 |
3 |
Усложним запрос, добавим поле GroupId.
1 2 3 4 5 |
SELECT ID, GroupId, Amount, COUNT(Amount) OVER (Partition BY id ORDER BY id, GroupId) AS COUNT FROM ForWindowFunc |
|
ID |
GroupId |
Amount |
Count |
|
1 |
1 |
100 |
2 |
|
1 |
1 |
200 |
2 |
|
1 |
2 |
150 |
3 |
|
2 |
1 |
100 |
2 |
|
2 |
1 |
300 |
2 |
|
2 |
2 |
200 |
4 |
|
2 |
2 |
50 |
4 |
|
3 |
1 |
150 |
1 |
|
3 |
2 |
200 |
3 |
|
3 |
2 |
10 |
3 |
В этом случае интереснее. Давайте рассмотрим первое окно. Для первой и второй строки количество записей составило 2. Но для третьей строки значение уже равно 3. У нас получилось накопление количества по группам наподобие накопительной суммы.
Давайте рассмотрим первое окно. Для первой и второй строки количество записей составило 2. Но для третьей строки значение уже равно 3. У нас получилось накопление количества по группам наподобие накопительной суммы.
Если же мы все-таки хотим количество в каждой группе, то GroupId нужно добавить в предложение Partition by.
1 2 3 4 5 |
SELECT ID, GroupId, Amount, COUNT(Amount) OVER (Partition BY id, GroupId) AS COUNT FROM ForWindowFunc |
|
ID |
GroupId |
Amount |
Count |
|
1 |
1 |
100 |
2 |
|
1 |
1 |
200 |
2 |
|
1 |
2 |
150 |
1 |
|
2 |
1 |
100 |
2 |
|
2 |
1 |
300 |
2 |
|
2 |
2 |
200 |
2 |
|
2 |
2 |
50 |
2 |
|
3 |
1 |
150 |
1 |
|
3 |
2 |
200 |
2 |
|
3 |
2 |
10 |
2 |
Функции ранжирования
RANK()/DENSE_RANK()
Функция RANK() возвращает порядковый номер текущей строки в окне. Однако, есть особенность. Если в предложении Order By попадется несколько равнозначных для правила строки, то все они будут считаться текущей строкой. Таким образом функцию RANK() нужно использовать для ранжирования, а не нумерации строк. Хотя, если правильно задать Order by, то можно нумеровать и физические строки. Например:
Однако, есть особенность. Если в предложении Order By попадется несколько равнозначных для правила строки, то все они будут считаться текущей строкой. Таким образом функцию RANK() нужно использовать для ранжирования, а не нумерации строк. Хотя, если правильно задать Order by, то можно нумеровать и физические строки. Например:
1 2 3 4 5 |
SELECT ID, GroupId, Amount, RANK() OVER (Partition BY id ORDER BY id, GroupId, Amount) AS RANK FROM ForWindowFunc |
|
ID |
GroupId |
Amount |
RANK |
|
1 |
1 |
100 |
1 |
|
1 |
1 |
200 |
2 |
|
1 |
2 |
150 |
3 |
|
2 |
1 |
100 |
1 |
|
2 |
1 |
300 |
2 |
|
2 |
2 |
50 |
3 |
|
2 |
2 |
200 |
4 |
|
3 |
1 |
150 |
1 |
|
3 |
2 |
10 |
2 |
|
3 |
2 |
200 |
3 |
А вот случай с одинаковыми строками в контексте Order by:
1 2 3 4 5 |
SELECT ID, GroupId, Amount, RANK() OVER (Partition BY id ORDER BY id, GroupId) AS RANK FROM ForWindowFunc |
|
ID |
GroupId |
Amount |
RANK |
|
1 |
1 |
100 |
1 |
|
1 |
1 |
200 |
1 |
|
1 |
2 |
150 |
3 |
|
2 |
1 |
100 |
1 |
|
2 |
1 |
300 |
1 |
|
2 |
2 |
200 |
3 |
|
2 |
2 |
50 |
3 |
|
3 |
1 |
150 |
1 |
|
3 |
2 |
200 |
2 |
|
3 |
2 |
10 |
2 |
Интересно, что третья строка в первом окне имеет ранг 3, хотя предыдущие две строки отнесены к первому рангу. Не самая понятная логика. В этом случае лучше использовать DENSE_RANK().
Не самая понятная логика. В этом случае лучше использовать DENSE_RANK().
1 2 3 4 5 |
SELECT ID, GroupId, Amount, DENSE_RANK() OVER (Partition BY id ORDER BY id, GroupId) AS DENSE_RANK FROM ForWindowFunc |
|
ID |
GroupId |
Amount |
DENSE_RANK |
|
1 |
1 |
100 |
1 |
|
1 |
1 |
200 |
1 |
|
1 |
2 |
150 |
2 |
|
2 |
1 |
100 |
1 |
|
2 |
1 |
300 |
1 |
|
2 |
2 |
200 |
2 |
|
2 |
2 |
50 |
2 |
|
3 |
1 |
150 |
1 |
|
3 |
2 |
200 |
2 |
|
3 |
2 |
10 |
2 |
Вот теперь все, как и должно быть. DENSE_RANK() не пропускает ранги если предыдущий ранг содержит несколько строк.
DENSE_RANK() не пропускает ранги если предыдущий ранг содержит несколько строк.
Функции RANK() и DENSE_RANK() не требуют указания поля в скобках.
ROW_NUMBER()
Функция ROW_NUMBER () отображает номер текущей строки в окне. Как и предыдущие две функции, ROW_NUMBER () не требует указания поля в круглых скобках.
1 2 3 4 5 |
SELECT ID, GroupId, Amount, ROW_NUMBER() OVER (Partition BY id ORDER BY id, GroupId, Amount) AS ROW_NUMBER FROM ForWindowFunc |
|
ID |
GroupId |
Amount |
ROW_NUMBER |
|
1 |
1 |
100 |
1 |
|
1 |
1 |
200 |
2 |
|
1 |
2 |
150 |
3 |
|
2 |
1 |
100 |
1 |
|
2 |
1 |
300 |
2 |
|
2 |
2 |
50 |
3 |
|
2 |
2 |
200 |
4 |
|
3 |
1 |
150 |
1 |
|
3 |
2 |
10 |
2 |
|
3 |
2 |
200 |
3 |
В запросе мы использовали Partition by для разделения набора данных на группы. Здесь все понятно и не должно вызвать вопросов.
Здесь все понятно и не должно вызвать вопросов.
Если вы не используете Partition by, то получите сквозную нумерацию по всему набору данных:
1 2 3 4 5 |
SELECT ID, GroupId, Amount, ROW_NUMBER() OVER (ORDER BY id, GroupId, Amount) AS ROW_NUMBER FROM ForWindowFunc |
|
ID |
GroupId |
Amount |
ROW_NUMBER |
|
1 |
1 |
100 |
1 |
|
1 |
1 |
200 |
2 |
|
1 |
2 |
150 |
3 |
|
2 |
1 |
100 |
4 |
|
2 |
1 |
300 |
5 |
|
2 |
2 |
50 |
6 |
|
2 |
2 |
200 |
7 |
|
3 |
1 |
150 |
8 |
|
3 |
2 |
10 |
9 |
|
3 |
2 |
200 |
10 |
Фактически отсутствие предложения Partition by говорит от том, что весь набор данных является окном.
NTILE()
Функция NTILE() позволяет определить к какой группе относится текущая строка. Количество групп задается в скобках, а предложение ORDER BY определяет, какой столбец используется для определения группы.
К примеруЭто означает, что, если у вас есть 100 строк, и вы хотите создать 4 квартили на основе указанного поля значений, вы можете сделать это легко и посмотреть, сколько строк попадает в каждый квартиль.
Давайте посмотрим пример. В приведенном ниже запросе мы указали, что хотим создать четыре квартили на основе суммы заказа. Затем мы хотим увидеть, сколько заказов попадает в каждый квартиль.
NTILE создает группы на основе следующей формулы:
Количество строк в каждой группе = количество строк в наборе / количество указанных групп
Вот наш пример: в запросе указано всего 10 строк и 4 плитки, поэтому количество строк в каждой плите будет 2,5 (10/4). Поскольку число строк должно быть целым числом, а не десятичным. SQL engine назначит 3 строки для первых двух групп и 2 строки для оставшихся двух групп.
1 2 3 |
SELECT Amount, NTILE(4) OVER(ORDER BY amount) AS Ntile FROM ForWindowFunc |
|
Amount |
Ntile |
|
10 |
1 |
|
50 |
1 |
|
100 |
1 |
|
100 |
2 |
|
150 |
2 |
|
150 |
2 |
|
200 |
3 |
|
200 |
3 |
|
200 |
4 |
|
300 |
4 |
Очень простой пример, но он хорошо демонстрирует работу функции. Все значения Amount отсортированы по возрастанию и разделены на 4 группы.
Все значения Amount отсортированы по возрастанию и разделены на 4 группы.
Функции смещения
LAG() и LEAD()
Эти две функции позволяют получить предыдущее и следующее значение соответственно. Довольно часто бывает нужно сравнивать текущее значение с предыдущим или следующим в вычисляемых колонках.
В качестве параметров вы можете передать в функцию имя поля и количество строк, которое нужно отступить от текущей и взять значение. Как в SUBSTRING() мы указываем позицию с которой брать символы, так и здесь указываем позицию, из которой взять значение. Если не указывать количество значений, то по умолчанию берется одно.
Итак, функция LAG позволяет получать доступ к данным из предыдущей строки в одном окне.
1 2 3 |
SELECT id, Amount, LAG(Amount) OVER(ORDER BY id, amount) AS Lag FROM ForWindowFunc |
|
id |
Amount |
Lag |
|
1 |
100 |
NULL |
|
1 |
150 |
100 |
|
1 |
200 |
150 |
|
2 |
50 |
200 |
|
2 |
100 |
50 |
|
2 |
200 |
100 |
|
2 |
300 |
200 |
|
3 |
10 |
300 |
|
3 |
150 |
10 |
|
3 |
200 |
150 |
В первой строке значение поля Lag навно Null потому, что для этой строки нет предыдущего значения Amount. Для всех последующих строк, берется значение Amount из предыдущей строки.
Для всех последующих строк, берется значение Amount из предыдущей строки.
Функция LEAD работает аналогично, только в другую сторону – берет значение из следующей строки.
1 2 3 |
SELECT id, Amount, LEAD(Amount,2) OVER(ORDER BY id, amount) AS Lag FROM ForWindowFunc |
|
id |
Amount |
Lag |
|
1 |
100 |
200 |
|
1 |
150 |
50 |
|
1 |
200 |
100 |
|
2 |
50 |
200 |
|
2 |
100 |
300 |
|
2 |
200 |
10 |
|
2 |
300 |
150 |
|
3 |
10 |
200 |
|
3 |
150 |
NULL |
|
3 |
200 |
NULL |
Как вы видите, в запросе мы передаем в функцию LEAD параметр 2. Это значит, что мы получаем второе от текущего значение Amount. Для последних двух строк значение Null, т.к. для них нет следующих значений.
Это значит, что мы получаем второе от текущего значение Amount. Для последних двух строк значение Null, т.к. для них нет следующих значений.
FIRST_VALUE() и LAST_VALUE()
С помощью этих функций мы можем получить первое и последнее значение в окне. Если предложение Partition by не задано, то функции будут возвращать первое и последнее значение из всего набора данных.
1 2 3 |
SELECT id, Amount, FIRST_VALUE(Amount) OVER(Partition BY Id ORDER BY Id, amount) AS FIRST FROM ForWindowFunc |
|
id |
Amount |
First |
|
1 |
100 |
100 |
|
1 |
150 |
100 |
|
1 |
200 |
100 |
|
2 |
50 |
50 |
|
2 |
100 |
50 |
|
2 |
200 |
50 |
|
2 |
300 |
50 |
|
3 |
10 |
10 |
|
3 |
150 |
10 |
|
3 |
200 |
10 |
Здесь мы получили первое значение по каждому окну.
А теперь получим первое значение по всему набору данных:
1 2 3 |
SELECT id, Amount, FIRST_VALUE(Amount) OVER(ORDER BY Id, amount) AS FIRST FROM ForWindowFunc |
|
id |
Amount |
First |
|
1 |
100 |
100 |
|
1 |
150 |
100 |
|
1 |
200 |
100 |
|
2 |
50 |
100 |
|
2 |
100 |
100 |
|
2 |
200 |
100 |
|
2 |
300 |
100 |
|
3 |
10 |
100 |
|
3 |
150 |
100 |
|
3 |
200 |
100 |
Мы убрали предложение Partition из запроса, тем самым мы определили весь набор данных окном.
А теперь посмотрим на работу функции LAST_VALUE:
1 2 3 |
SELECT id, Amount, LAST_VALUE(Amount) OVER(ORDER BY id) AS LAST FROM ForWindowFunc |
|
id |
Amount |
Last |
|
1 |
100 |
150 |
|
1 |
200 |
150 |
|
1 |
150 |
150 |
|
2 |
100 |
50 |
|
2 |
300 |
50 |
|
2 |
200 |
50 |
|
2 |
50 |
50 |
|
3 |
150 |
10 |
|
3 |
200 |
10 |
Запрос почти не отличается от предыдущего, но результат совсем другой. Так как у нас нет уникального идентификатора в таблице, мы не можем отсортировать набор данных по нему. Сортировка по полю Id фактически разбила данные на три группы. И функция вернула последнее значение по каждой из них – особенность функции.
Так как у нас нет уникального идентификатора в таблице, мы не можем отсортировать набор данных по нему. Сортировка по полю Id фактически разбила данные на три группы. И функция вернула последнее значение по каждой из них – особенность функции.
На этом завершим рассмотрение оконных функций. Приведенные примеры сильно упрощены специально для лучшего понимания работы функции. Практические задачи зачастую сложнее, поэтому важно хорошо понимать поведение функции в зависимости от предложений в инструкции OVER.
Основы мониторинга PostgreSQL. Алексей Лесовский
Предлагаю ознакомиться с расшифровкой доклада Алексей Лесовский из Data Egret «Основы мониторинга PostgreSQL»
В этом докладе Алексей Лесовский расскажет о ключевых моментах постгресовой статистики, что они означают, и почему они должны присутствовать в мониторинге; о том, какие графики должны быть в мониторинге, как их добавить и как интерпретировать. Доклад будет полезен администраторам баз данных, системным администраторам и разработчикам, которым интересен траблшутинг Postgres’а.
Меня зовут Алексей Лесовский, я представляю компанию Data Egret.
Немного слов о себе. Я начинал когда-то давным-давно системным администратором.
Администрировал всякие разные Linux, занимался разными вещами, связанными с Linux, т. е. виртуализацией, мониторингом, работал с прокси и т. д. Но в какой-то момент я стал заниматься больше базами данных, PostgreSQL. Он мне очень нравился. И в какой-то момент я стал заниматься PostgreSQL основную часть своего рабочего времени. И так постепенно я стал PostgreSQL DBA.
И на протяжении всей своей карьеры мне всегда были интересны темы статистики, мониторинга, снятия телеметрии. И когда я был системным администратором, я занимался очень плотно Zabbix. И написал небольшой набор скриптов как zabbix-extensions. Он был довольно популярным в свое время. И там можно было мониторить очень разные важные штуки, не только Linux, но еще разные компоненты.
И там можно было мониторить очень разные важные штуки, не только Linux, но еще разные компоненты.
Сейчас я занимаюсь уже PostgreSQL. Я пишу уже другую штуку, которая позволяет работать с PostgreSQL-статистикой. Она называется pgCenter (статья на хабре — Постгресовая стата без нервов и напрягов).
Небольшая вводная. Какие бывают ситуации у наших заказчиков, у наших клиентов? Происходит какая-то авария, связанная с базой данной. И когда уже восстановили базу данных, приходит начальник отдела или начальник разработки и говорит: «Друзья, надо бы нам замониторить базу данных, потому что случилось что-то плохое и надо, чтобы в будущем такого не происходило». И здесь начинается интересный процесс выбора системы мониторинга или адаптации существующей системы мониторинга для того, чтобы можно было мониторить свою базу данных – PostgreSQL, MySQL или какие-то другие. И коллеги начинают предлагать: «Я слышал, что есть такая-то база данных. Давайте использовать ее». Коллеги начинают друг с другом спорить. И в итоге получается, что мы выбираем какую-то базу данных, но мониторинг PostgreSQL в ней представлен довольно слабо и всегда приходится что-то допиливать. Брать какие-то репозитории из GitHub, клонировать их, адаптировать скрипты, как-то донастраивать. И в итоге это вываливается в некую ручную работу.
Поэтому в этом докладе я постараюсь дать вам некие знания о том, как выбирать мониторинг не только для PostgreSQL, но и для базы данных. И дать те знания, которые позволят вам допилить ваш мониторинг, чтобы получить от него какую-то пользу, чтобы можно было мониторить свою базу данных с пользой, чтобы вовремя предупреждать какие-то предстоящие аварийные ситуации, которые могут возникнуть.
И те идеи, которые будут в этом докладе, их можно напрямую адаптировать к любой базе данных, будь это СУБД или noSQL. Поэтому тут не только PostgreSQL, но здесь будет много рецептов, как сделать это в PostgreSQL. Будут примеры запросов, примеры сущностей, которые есть в PostgreSQL для мониторинга. И если ваша СУБД имеет такие же вещи, которые позволяют засунуть их в мониторинг, вы тоже можете их адаптировать, добавить и будет хорошо.
И если ваша СУБД имеет такие же вещи, которые позволяют засунуть их в мониторинг, вы тоже можете их адаптировать, добавить и будет хорошо.
рассказывать про то, как доставлять и хранить метрики. Не буду ничего говорить о пост-обработке данных и предоставлению их пользователю. И не буду ничего говорить об алертинге.
Но по ходу повествования я буду показывать разные скриншоты существующих мониторингов, как-то буду их критиковать. Но тем не менее я постараюсь не называть брендов, чтобы не создавать рекламу или антирекламу этим продуктам. Поэтому все совпадения случайны и остаются на вашей фантазии.
Для начала разберемся, что такое мониторинг. Мониторинг – это очень важная штука, которую нужно иметь. Это все понимают. Но в то же самое время мониторинг не относится к бизнес-продукту и на напрямую не влияет на прибыль компании, поэтому на мониторинг всегда уделяют время по остаточному принципу. Если у нас есть время, то мы занимаемся мониторингом, если времени нет, то ОК, поставим в бэклог и когда-нибудь вернемся к этим задачам.
Поэтому из нашей практики, когда мы приходим к клиентам, мониторинг часто недоработан и не имеет каких-то интересных вещей, которые помогали бы нам делать работу лучше с базой данных. И поэтому мониторинг всегда нужно допиливать.
Базы данных – это такие сложные штуки, которые тоже нужно мониторить, потому что базы данных – это хранилище информации. И информация очень важна для компании, ее нельзя никак терять. Но в то же время базы данных – это очень сложные куски программного обеспечения. Они состоят из большого количества компонентов. И многие из этих компонентов нужно мониторить.
Если мы говорим конкретно про PostgreSQL, то его можно представить в виде такой схемы, которая состоит из большого количества компонентов. Эти компоненты взаимодействуют друг с другом. И в то же время в PostgreSQL есть, так называемая, подсистема Stats Collector, которая позволяет собирать статистику о работе этих подсистем и предоставлять некий интерфейс администратору или пользователю, чтобы он мог просматривать эту статистику.
Эта статистика представлена в виде некоторого набора функций и вьюх (view). Их можно еще назвать таблицами. Т. е. с помощью обычного psql клиента вы можете подключиться к базе данных, сделать select к этим функциям и вьюхам, и получить уже какие-то конкретные циферки о работе подсистем PostgreSQL.
Вы можете добавить эти циферки в вашу любимую систему мониторинга, нарисовать графики, добавить функции и получить аналитику в долгосрочной перспективе.
Но в этом докладе я не буду рассматривать поголовно все эти функции, потому что это может занять целый день. Я буду обращаться буквально к двум-трем-четырем штукам и буду рассказывать, как они помогают сделать мониторинг лучше.
И если говорить про мониторинг базы, то что нужно мониторить? В первую очередь нужно мониторить доступность, потому что база – это сервис, который предоставляет доступ к данным клиентам и нам нужно мониторить доступность, а предоставляет также ее некоторые качественные и количественные характеристики.
Также нужно мониторить клиентов, которые подключаются к нашей базе, потому что они могут быть как и нормальными клиентами, так и вредными клиентами, которые могут наносить вред базе данных. Их тоже нужно мониторить и отслеживать их деятельность.
Когда клиенты подключаются к базе данных, то очевидно, что они начинают работать с нашими данными, поэтому нам нужно мониторить и то, как клиенты работают с данными: с какими таблицами, в меньшей степени с какими индексами. Т. е. нам нужно оценить ворклоад (workload), который создается нашими клиентами.
Но и ворклоад состоит, конечно, из запросов. Приложения подключаются к базе, обращаются к данным с помощью запросов, поэтому важно оценивать, какие запросы у нас в базе данных, отслеживать их адекватность, что они не являются криво написанными, что какие-то опции нужно переписать и сделать так, чтобы они работали быстрее и с более лучшей производительностью.
И раз мы говорим про базу данных, то база данных – это всегда фоновые процессы. Фоновые процессы позволяют поддерживать производительность базы данных на хорошем уровне, поэтому для их работы они требуют некое количество ресурсов для себя. И в то же время они могут пересекаться с ресурсами клиентских запросов, поэтому жадная работа фоновых процессов может непосредственно влиять на производительность клиентских запросов. Поэтому их тоже нужно мониторить и отслеживать, что нет никаких перекосов в плане фоновых процессов.
Фоновые процессы позволяют поддерживать производительность базы данных на хорошем уровне, поэтому для их работы они требуют некое количество ресурсов для себя. И в то же время они могут пересекаться с ресурсами клиентских запросов, поэтому жадная работа фоновых процессов может непосредственно влиять на производительность клиентских запросов. Поэтому их тоже нужно мониторить и отслеживать, что нет никаких перекосов в плане фоновых процессов.
И это все в плане мониторинга базы данных остается в системной метрике. Но учитывая, что у нас по большей части вся инфраструктура уезжает в облака, системные метрики отдельного хоста всегда отходят на второй план. Но в базах данных они все еще актуальны и мониторить системные метрики, конечно, тоже нужно.
С системными метриками более-менее все хорошо, все современные системы мониторинга уже поддерживают эти метрики, но в целом каких-то компонентов все-таки недостаточно и нужно некоторые вещи добавлять. Про них я тоже затрону, несколько слайдов будет про них.
Первый пункт плана – это доступность. Что такое доступность? Доступность в моем понимании – это способность базы обслуживать подключения, т. е. база поднята, она, как сервис, принимает подключения от клиентов. И эту доступность можно оценивать некоторыми характеристиками. Эти характеристики очень удобно выносить на дашборды.
Все знают, что такое дашборды. Это когда ты бросил один взгляд на экран, на котором сведена необходимая информация. И вы уже можете сразу определить – есть проблема в базе или нет.
Соответственно доступность базы данных и другие ключевые характеристики всегда необходимо выносить на дашборды, чтобы эта информация была под рукой, была у вас всегда рядом. Какие-то дополнительные детали, которые уже помогают при расследовании инцидентов, при расследовании каких-то аварийных ситуаций, их уже нужно выносить на вторичные дашборды, либо скрывать в drilldown-линках, которые ведут на сторонние системы мониторинга.
Пример одной известной системы мониторинга. Это очень крутая система мониторинга. Она собирает очень много данных, но с моей точки зрения, у нее странное понятие дашбордов. Там есть ссылка «создать дашборд». Но когда вы создаете дашборд, вы создаете некий список, состоящий из двух колонок, некий список графиков. И когда вам нужно что-то посмотреть, вы начинаете мышкой кликать, листать, искать нужный график. И на это уходит время, т. е. дашбордов, как таковых, нет. Есть лишь списки графиков.
Это очень крутая система мониторинга. Она собирает очень много данных, но с моей точки зрения, у нее странное понятие дашбордов. Там есть ссылка «создать дашборд». Но когда вы создаете дашборд, вы создаете некий список, состоящий из двух колонок, некий список графиков. И когда вам нужно что-то посмотреть, вы начинаете мышкой кликать, листать, искать нужный график. И на это уходит время, т. е. дашбордов, как таковых, нет. Есть лишь списки графиков.
Что нужно добавлять на эти дашборды? Можно начать с такой характеристики как время отклика. В PostgreSQL есть вьюха pg_stat_statements. По умолчанию она отключена, но это одна из важных системных вьюх, которую всегда необходимо включать и использовать. Она хранит в себе информацию о всех выполняющихся запросах, которые в базе данных выполнялись.
Соответственно, мы можем оттолкнуться от того, что можно взять суммарное время выполнения всех запросов и поделить на количество запросов с помощью вышеприведенных полей. Но это такая средняя температура по больнице. Мы можем оттолкнуться от других полей – минимальное время выполнения запросов, максимальное и медианное. И даже можем строить перцентили, в PostgreSQL есть соответствующие функции для этого. И мы можем получить какие-то цифры, которые характеризуют время отклика нашей базы по уже выполненным запросам, т. е. мы не выполняем фейковый запрос ‘select 1’ и смотрим время отклика, а мы анализируем время ответов по уже выполненным запросам и рисуем либо отдельной цифрой, либо строим по ней график.
Также важно отслеживать количество ошибок, которые генерируются системой в данный момент. И для этого можно использовать вьюху pg_stat_database. Мы ориентируемся на поле xact_rollback. Это поле показывает не только количество rollback, которые происходят в базе, но еще и учитывает количество ошибок. Условно говоря, мы можем выводить эту цифру в наш дашборд и смотреть сколько у нас ошибок в данный момент. Если ошибок много, то это уже хороший повод заглянуть в логи и посмотреть, что же это за ошибки и почему они происходят, а дальше уже инвестигировать и решать их.
Можно добавить такую штуку, как Тахометр. Это количество транзакций в секунду и количество запросов в секунду. Условно говоря, вы можете использовать эти цифры как текущую производительность вашей базы данных и наблюдать есть ли пики запросов, пики транзакций или, наоборот, база недогружена, потому что какой-то backend отвалился. Эту цифру важно всегда смотреть и помнить, что для нашего проекта вот такая производительность является нормальной, а значения выше и ниже уже какие-то проблемные и непонятные, а значит, нужно смотреть, почему такие цифры.
Для того чтобы оценивать количество транзакций, мы снова можем обратиться к вьюхе pg_stat_database. Мы можем сложить количество commit и количество rollback и получить количество транзакций в секунду.
Все понимают, что в одну транзакцию может уложиться несколько запросов? Поэтому TPS и QPS немного разные.
Количество запросов в секунду можно получить по pg_stat_statements и просто просчитать сумму всех выполненных запросов. Понятно, что мы сравниваем текущее значение с предыдущим, вычитаем, получаем дельту, получаем количество.
Можно добавить дополнительные метрики по желанию, которые также помогают оценивать доступность нашей базы и отслеживать – не было ли каких-то downtime.
Одна из этих метрик – это uptime. Но uptime в PostgreSQL – это немного хитрая штука. Расскажу, почему. Когда PostgreSQL запустился, начинается отчитываться uptime. Но если в какой-то момент, например, ночью выполнялась какая-то задача, пришел OOM-killer и завершил принудительно дочерний процесс PostgreSQL, то в этом случае PostgreSQL завершает соединение всех клиентов, сбрасывает область шардированной памяти и начинает восстановление с последней контрольной точки. И пока длится это восстановление с контрольной точки, база не принимает подключения, т. е. эту ситуацию можно оценивать, как downtime. Но при этом счетчик uptime не сбросится, потому что он учитывает время запуска postmaster с самого первого момента. Поэтому такие ситуации можно пропустить.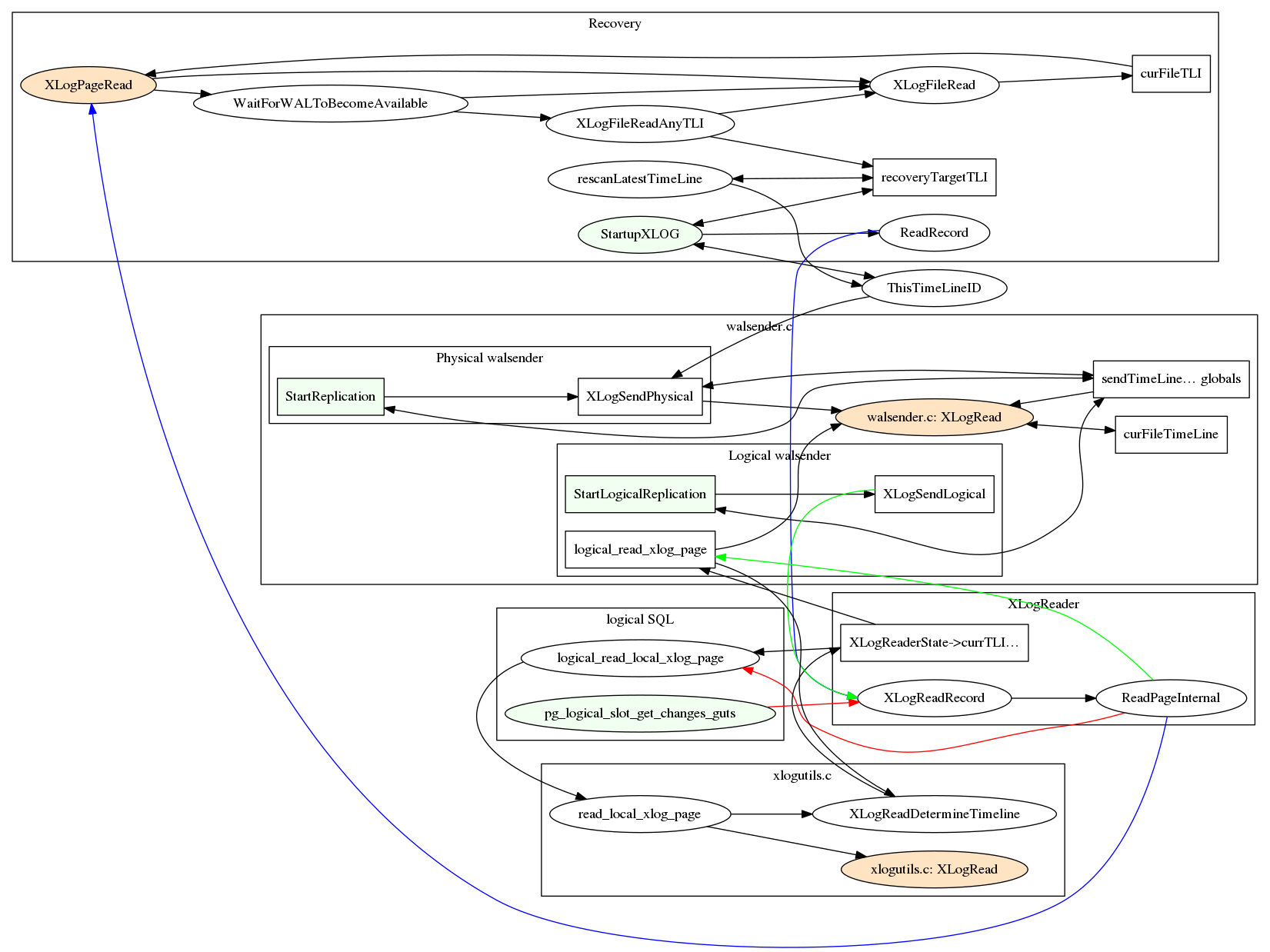
Также следует мониторить количество воркеров вакуума. Все знают, что такое autovacuum в PostgreSQL? Это интересная подсистема в PostgreSQL. Про нее написано много статей, много сделано докладов. Много обсуждений про вакуум, о том, как он должен работать. Многие считают его неизбежным злом. Но так и есть. Это некий аналог сборщика мусора, который чистит устаревшие версии строк, которые не нужны ни одной из транзакции и освобождает место в таблицах, индексах для новых строк.
Почему нужно его мониторить? Потому что вакуум иногда делает очень больно. Он отжирает большое количество ресурсов и клиентские запросы от этого начинают страдать.
И мониторить следует его через вьюху pg_stat_activity, про которую я буду говорить в следующем разделе. Эта вьюха показывает текущую активность в базе данных. И через эту активность мы можем отследить количество вакуумов, которые работают прямо сейчас. Мы можем отслеживать вакуумы и видеть, что если у нас превышен лимит, то это повод заглянуть в настройки PostgreSQL и как-то оптимизировать работу вакуума.
Другой особенностью PostgreSQL является то, что PostgreSQL очень больно от долгих транзакций. Особенно, от транзакций, которые долго висят и ничего не делают. Это, так называемые, stat idle-in-transaction. Такая транзакция удерживает блокировки, она мешает работать вакууму. И как следствие – таблицы пухнут, они увеличиваются в размере. И запросы, которые работают с этими таблицами, они начинают работать медленнее, потому что нужно лопатить все старые версии строк из памяти на диск и обратно. Поэтому время, длительность самых долгих транзакций, самых долгих запросов вакуума тоже нужно мониторить. И если мы видим какие-то процессы, которые работают уже очень долго, уже больше 10-20-30 минут для OLTP-нагрузки, то на них нужно уже обращать внимание и завершать принудительно, либо оптимизировать приложение, чтобы они не вызывались и не висели так долго. Для аналитической нагрузки 10-20-30 минут – это нормально, там бывает еще и более долгие.
Дальше у нас вариант с подключенными клиентами. Когда мы уже сформировали дашборд, вывесили на него ключевые метрики доступности, мы можем также добавить туда и дополнительную информацию о подключенных клиентах.
Информация о подключенных клиентах важна, потому что, с точки зрения PostgreSQL, клиенты бывают разными. Бывают хорошие клиенты, бывают плохие клиенты.
Простой пример. Под клиентом я пониманию приложение. Приложение подключилось к базе данных и начинает сразу слать туда свои запросы, база данных их обрабатывает и выполняет, результаты возвращает клиенту. Это хорошие и правильные клиенты.
Бывают ситуации, что клиент подключился, он удерживает коннект, но при этом ничего не делает. Он находится в состоянии idle.
Но бывают плохие клиенты. Например, тот же клиент подключился, открыл транзакцию, что-то поделал в базе и потом ушел в код, допустим, чтобы обратиться ко внешнему источнику или для того, чтобы сделать там обработку, полученных данных. Но при этом он не закрыл транзакцию. И транзакция висит в базе и удерживает в блокировку на строке. Это плохое состояние. И если вдруг приложение где-то внутри у себя упадет по эксепшену (Exception), то транзакция может остаться открытой на очень долгое время. И это влияет напрямую на производительность PostgreSQL. PostgreSQL будет работать медленнее. Поэтому таких клиентов важно вовремя отслеживать и завершать их работу принудительно. И нужно оптимизировать свое приложение, чтобы не было таких ситуаций.
Другими плохими клиентами являются ожидающие клиенты. Но они становятся плохими из-за обстоятельств. Например, простая простаивающая транзакция: может открыть транзакцию, взять блокировки на какие-то строки, потом где-то в коде она упадет, останется висящая транзакция. Придет другой клиент, запросит те же самые данные, но он столкнется с блокировкой, потому что та висящая транзакция уже удерживает блокировки на какие-то нужные строки. И вторая транзакция будет висеть в ожидании, когда первая транзакция завершится или ее администратор принудительно закроет. Таким образом, ждущие транзакции могут накапливаться и переполнять лимит подключений к базе данных. И когда лимит переполнен, то приложение уже не может работать с базой. Это уже аварийная ситуация для проекта. Поэтому плохих клиентов нужно отслеживать и своевременно на них реагировать.
Таким образом, ждущие транзакции могут накапливаться и переполнять лимит подключений к базе данных. И когда лимит переполнен, то приложение уже не может работать с базой. Это уже аварийная ситуация для проекта. Поэтому плохих клиентов нужно отслеживать и своевременно на них реагировать.
Другой пример мониторинга. И здесь уже приличный дашборд. Есть информация по коннектам сверху. DB connection – 8 штук. И это все. У нас нет информации о том, какие клиенты активные, какие клиенты просто idle, ничего не делают. Нет информации о висящих транзакциях и об ожидающих коннектах, т. е. это такая цифра, которая показывает количество коннектов и все. А дальше гадайте сами.
Соответственно, чтобы добавить эту информацию в мониторинг, нужно обратиться к системной вьюхе pg_stat_activity. Если вы много времени проводите в PostgreSQL, то это очень хорошая вьюха, которая должна стать вашим другом, потому что она показывает текущую активность в PostgreSQL, т. е. что происходит в нем. На каждый процесс есть отдельная строчка, которая показывает информацию по этому процессу: с какого хоста выполнено подключение, под каким пользователем, под каким именем, когда запущена транзакция, какой сейчас выполняется запрос, какой запрос выполнялся последним. И, соответственно, состояние клиента мы можем оценивать по полю stat. Условно говоря, мы можем сделать группировку по этому полю и получить те stats-ы, которые есть сейчас в базе данных и количество коннектов, которые с этим stat-ом в базе данных. И уже полученные цифры мы можем отправлять в наш мониторинг и рисовать по ним графики.
Также важно оценивать длительность транзакции. Я уже говорил, что важно оценивать длительность вакуумов, но и транзакции оцениваются точно так же. Есть поля xact_start и query_start. Они, условно говоря, показывают время старта транзакции и время старта запроса. Мы берем функцию now(), которая показывает текущую отметку времени и вычитаем timestamp транзакции и запроса. И получаем длительность транзакции, длительность запроса.

Если мы видим длинные транзакции, мы должны их уже завершать. Для OLTP-нагрузки длинные транзакции – это уже больше 1-2-3 минут. Для OLAP-нагрузки длинные транзакции являются нормальными, но если они выполняются больше двух часов, то это тоже признак того, что где-то у нас есть перекос.
Когда клиенты подключились к базе данных, они начинают работать с нашими данными. Они обращаются к таблицам, они обращаются к индексам, чтобы получить данные из таблицы. И важно оценивать то, как клиенты работают с этими данными.
Это нужно для того, чтобы оценивать наш ворклоад и примерно понимать, какие таблицы у нас самые «горячие». Например, это нужно в ситуациях, когда мы хотим «горячие» таблицы поместить на какое-то быстрое SSD хранилище. Например, какие-то архивные таблицы, которые мы уже давно не используем можно вынести на какой-то «холодный» архив, на SATA диски и пусть они там живут, к ним обращение будет идти по необходимости.
Также это полезно для обнаружения аномалий после всяких релизов и деплоев. Допустим, проект выкатил какую-то новую фичу. Например, добавили новую функциональность для работы с базой. И если мы построим графики использования таблиц, мы на этих графиках сможем легко обнаружить эти аномалии. Например, всплески update или всплески delete. Это очень хорошо будет видно.
Также можно обнаружить аномалии «поплывшей» статистики. Что это значит? В PostgreSQL очень сильный и очень хороший планировщик запросов. И разработчики много времени уделяют его развитию. Как он работает? Для того чтобы строить хорошие планы, PostgreSQL с некоторым интервалом времени, с некоторой периодичностью собирает статистику о распределении данных в таблицах. Это самые частые значения: количество уникальных значений, информация о NULL в таблице, очень много информации.
На основе этой статистики планировщик строит несколько запросов, выбирает наиболее оптимальный и использует этот план запроса для выполнения самого запроса и возвращения данных.
И бывает, что статистика «плывет». Данные качества, количества поменялись как-то в таблице, но статистика при этом не собралась. И сформированные планы могут оказаться не оптимальными. И если у нас планы окажутся неоптимальными по собираемому мониторингу, по таблицам, мы сможем увидеть эти аномалии. Например, где-то качественно изменились данные и вместе индекса стал использоваться последовательный проход по таблице, т.е. если запросу нужно вернуть всего лишь 100 строк (стоит ограничение limit 100), то для этого запроса будет выполнен полный перебор. И это всегда очень плохо сказывается на производительности.
И мы сможем увидеть это в мониторинге. И уже посмотреть на этот запрос, выполнить для него explain, собрать статистику, построить новый дополнительный индекс. И уже отреагировать на эту проблему. Поэтому это важно.
Другой пример мониторинга. Я думаю, многие его узнали, потому что он очень популярный. Кто использует у себя в проектах Prometheus? А кто использует этот продукт совместно с Prometheus? Дело в том, что в стандартном репозитории этого мониторинга есть дашборд для работы с PostgreSQL – postgres_exporter Prometheus. Но тут есть одна плохая деталь.
Есть несколько графиков. И в качестве unity указаны байты, т. е. там 5 графиков. Это Insert data, Update data, Delete data, Fetch data и Return data. В качестве unit измерения указаны байты. Но дело в том, что статистика в PostgreSQL возвращает данные в tuple (строках). И, соответственно, эти графики – это очень хороший способ занизить ваш ворклоад в несколько раз, в десятки раз, потому что tuple – это не байт, tuple – это строка, это много байтов и она всегда переменной длины. Т. е. вычислить ворклоад в байтах с помощью tuples – это нереальная задача или очень сложная. Поэтому, когда вы используете дашборд или встроенный мониторинг, всегда важно понимать, что он работает правильно и возвращает вам корректно оцененные данные.
Как получать статистику по этим таблицам? Для этого в PostgreSQL есть некоторое семейство вьюх. И основная вьюха – это pg_stat_user_tables. User_tables – это означает, что таблицы, созданные от лица пользователя. В противовес есть системные вьюхи, которые используются самим PostgreSQL. И есть сводная таблица Alltables, которая включает и системные, и пользовательские. Вы можете отталкиваться от любой из них, которая вам больше всего нравится.
И основная вьюха – это pg_stat_user_tables. User_tables – это означает, что таблицы, созданные от лица пользователя. В противовес есть системные вьюхи, которые используются самим PostgreSQL. И есть сводная таблица Alltables, которая включает и системные, и пользовательские. Вы можете отталкиваться от любой из них, которая вам больше всего нравится.
По вышеуказанным полям можно оценивать количество insert, update и delete. Тот пример дашборда, который я использовал, как раз использует эти поля для оценки характеристик ворклоада. Поэтому мы также можем отталкиваться от них. Но стоит помнить, что это tuples, а не байты, поэтому мы не можем взять и сделать это байтами.
На основе этих данных мы можем строить, так называемые, TopN-таблицы. Например, Top-5, Top-10. И можно отслеживать те горячие таблицы, которые утилизируются больше остальных. Например, 5 «горячих» таблиц по вставке. И по этим TopN-таблицам мы оцениваем наш ворклоад и можем оценивать всплески ворклоада после всяких релизов и апдейтов, и деплоев.
Также важно оценивать размеры таблицы, потому что иногда разработчики выкатывают новую фичу, и у нас таблицы начинают пухнуть в своих больших размерах, потому что решили дописать дополнительный объем данных, но при этом не спрогнозировали, как это скажется на размере базы данных. Такие случае тоже бывают для нас сюрпризами.
И сейчас небольшой вопрос для вас. Какой возникает вопрос, когда вы замечаете нагрузку на сервере с базой данных? Какой следующий вопрос у вас возникает?
Но на самом деле вопрос возникает следующий. Какие запросы вызывает нагрузка? Т. е. не интересно смотреть процессы, какие вызывает нагрузка. Понятно, что если host с базой данных, то там запущена база данных и понятно, что только базы данных там и будет утилизировать. Если мы откроем Top, то увидим там список процессов в PostgreSQL, которые что-то делают. Из Top будет не понятно, что они делают.
Соответственно, нужно обнаружить те запросы, которые вызывают наибольшую загрузку, потому что тюнинг запросов, как правило, дает больше профит, чем тюнинг конфигурации PostgreSQL или операционной системы, или даже тюнинг железа. По моей оценке – это примерно 80-85-90 %. И это делается гораздо быстрее. Быстрее поправить запрос, чем поправить конфигурацию, запланировать рестарт, особенно, если базу рестартовать нельзя, либо добавлять железо. Проще где-то переписать запрос или добавить индекс, чтобы получить уже более лучший результат от этого запроса.
По моей оценке – это примерно 80-85-90 %. И это делается гораздо быстрее. Быстрее поправить запрос, чем поправить конфигурацию, запланировать рестарт, особенно, если базу рестартовать нельзя, либо добавлять железо. Проще где-то переписать запрос или добавить индекс, чтобы получить уже более лучший результат от этого запроса.
Соответственно, нужно мониторить запросы и их адекватность. Возьмем другой пример мониторинга. И тут тоже вроде прекрасный мониторинг. Есть информация по репликации, есть информация по пропускной способности, блокировкам, утилизации ресурсов. Все прекрасно, но нет информации по запросам. Не понятно, какие запросы выполняются в нашей базе данных, как долго они выполняются, сколько этих запросов. Нам нужно в мониторинге всегда иметь эту информацию.
И для получения этой информации мы можем использовать модуль pg_stat_statements. На его основе можно строить самые разные графики. Например, можно получать информацию по самым частым запросам, т. е. по тем запросам, которые выполняются чаще всех. Да, после деплоев тоже очень полезно посмотреть на него и понимать, нет ли какого-то всплеска запросов.
Можно мониторить самые долгие запросы, т. е. те запросы, которые выполняются дольше всех. Они работают на процессоре, они потребляют ввод-вывод. Мы это тоже можем оценивать по полям total_time, mean_time, blk_write_time и blk_read_time.
Мы можем оценивать и мониторить самые тяжелые запросы в плане использования ресурсов, те, которые читают с диска, которые работают с памятью или, наоборот, создают какую-то пишущую нагрузку.
Можем оценивать самые щедрые запросы. Это те запросы, которые возвращают большое количество строк. Например, это может быть какой-то запрос, где забыли поставить лимит. И он просто возвращает все содержимое таблицы или запроса по запрошенным таблицам.
И можно также мониторить запросы, которые используют временные файлы или временные таблицы.
И у нас остались фоновые процессы. Фоновые процессы – это в первую очередь чекпоинты или их еще называют контрольными точками, это autovacuum и репликация.

Другой пример мониторинга. Есть слева вкладка Maintenance, переходим на нее и надеемся увидеть, что-то полезное. Но здесь только время работы вакуума и сбора статистики, больше ничего. Это очень бедная информация, поэтому всегда нужно иметь информацию о том, как работают фоновые процессы у нас в базе данных и нет ли проблем от их работы.
Когда мы рассматриваем контрольные точки, то следует помнить, что контрольные точки у нас сбрасывают «грязные» страницы из области шардированной памяти на диск, затем создают контрольную точку. И эта контрольная точка уже дальше может использоваться как некое место при восстановлении, если вдруг PostgreSQL был завершен в аварийном порядке.
Соответственно, чтобы сбросить все «грязные» страницы на диск, нужно проделать некий объем записи. И, как правило, на системах с большим объемом памяти – это очень много. И если у нас чекпоинты делаются очень часто в какой-то короткий интервал, то дисковая производительность будет очень сильно проседать. И клиентские запросы будут страдать от нехватки ресурсов. Они будут бороться за ресурсы и им будет не хватать производительности.
Соответственно, через pg_stat_bgwriter по указанным полям мы можем мониторить количество случающихся чекпоинтов. И если у нас за какой-то промежуток времени (за 10-15-20 минут, за полчаса) очень много чекпоинтов, например, 3-4-5, то это уже может быть проблемой. И уже нужно посмотреть в базе данных, посмотреть в конфигурации, что вызывает такое обилие чекпоинтов. Может быть, какая-то большая запись идет. По ворклоаду можем уже оценить, потому что у нас графики ворклоада уже добавлены. Мы можем уже подтюнить параметры контрольных точек и сделать так, чтобы они не сильно влияли на производительность запросов.
Я снова возвращаюсь к autovacuum, потому что это такая штука, как я уже говорил, которая запросто может сложить производительность как дисков, так и запросов, поэтому всегда важно оценивать количество autovacuum.
Количество воркеров autovacuum в базе данных ограничено. По умолчанию их три, поэтому если у нас все время три воркера работают в базе, то это значит, что у нас autovacuum недонастроен, нужно поднимать лимиты, пересматривать настройки autovacuum и уже лезть в конфигурацию.
По умолчанию их три, поэтому если у нас все время три воркера работают в базе, то это значит, что у нас autovacuum недонастроен, нужно поднимать лимиты, пересматривать настройки autovacuum и уже лезть в конфигурацию.
Важно оценивать какие у нас работают воркера вакуума. Либо это запущенный от пользователя, DBA пришел и руками запустил какой-то вакуум, и это создало нагрузку. У нас появилась какая-то проблема. Либо это количество вакуумов, которые откручивают счетчик транзакций. Для некоторых версий PostgreSQL – это очень тяжелые вакуумы. И они могут запросто сложить производительность, потому что они вычитывают всю таблицу целиком, сканируют все блоки в этой таблице.
И, конечно, длительность вакуумов. Если у нас долгие вакуумы, которые работают очень долгое время, то это значит, что нам снова стоит обратить внимание на конфигурацию вакуума и, возможно, пересмотреть его настройки. Потому что может появиться ситуация, когда вакуум работает над таблицей долгое время (3-4 часа), но за время работы вакуума в таблице успели накопиться снова большой объем мертвых строк. И как только вакуум завершится, ему снова нужно вакуумить эту таблицу. И мы приходим к ситуации – бесконечного вакуума. И в таком случае вакуум не справляется со своей работы, и таблицы начинают постепенно пухнуть в размерах, хотя объем полезных данных в ней остается прежним. Поэтому при долгих вакуумах мы всегда смотрим на конфигурацию и пытаемся оптимизировать ее, но при этом, чтобы не страдали производительность клиентских запросов.
Сейчас практически нет инсталляции PostgreSQL, где не было потоковой репликации. Репликация – это процесс переноса данных с мастера на реплику.
Репликация в PostgreSQL устроена через журнал транзакций. Мастер генерирует журнал транзакций. Журнал транзакции по сетевому соединению едет на реплику, дальше на реплике он воспроизводится. Все просто.
Соответственно, для мониторинга лага репликации используется вьюха pg_stat_replication. Но с ней не все просто. В версии 10 вьюха претерпела несколько изменений. Во-первых, часть полей была переименована. И часть полей была добавлена. В 10-ой версии появились поля, которые позволяют оценивать лаг репликации в секундах. Это очень удобно. До версии 10 была возможность оценивать лаг репликации в байтах. Такая возможность осталась и в 10-ой версии, т. е. вы можете выбирать, что вам удобнее – оценивать лаг в байтах или оценивать лаг в секундах. Многие делают и то и другое.
В версии 10 вьюха претерпела несколько изменений. Во-первых, часть полей была переименована. И часть полей была добавлена. В 10-ой версии появились поля, которые позволяют оценивать лаг репликации в секундах. Это очень удобно. До версии 10 была возможность оценивать лаг репликации в байтах. Такая возможность осталась и в 10-ой версии, т. е. вы можете выбирать, что вам удобнее – оценивать лаг в байтах или оценивать лаг в секундах. Многие делают и то и другое.
Но тем не менее, чтобы оценивать лаг репликации, нужно знать позицию журнала в транзакции. И эти позиции журнала транзакции как раз есть во вьюхе pg_stat_replication. Условно говоря, мы с помощью функции pg_xlog_location_diff() можем взять две точки в журнале транзакции. Посчитать между ними дельту и получить лаг репликации в байтах. Это очень удобно и просто.
В 10-ой версии эта функция была переименована в pg_wal_lsn_diff(). Вообще, во всех функциях, вьюхах, утилитах, где встречалось слово «xlog», оно было заменено на значение «wal». Это и во вьюхах, и в функциях. Это вот такое нововведение.
Плюс в 10-ой версии добавились строчки, которые конкретно показывают лаг. Это write lag, flush lag, replay lag. Т. е. эти штуки важно мониторить. Если мы видим, что у нас лаг репликации, то нужно исследовать, почему он появился, откуда взялся и устранять проблему.
С системными метриками практически все в порядке. Когда зарождается любой мониторинг, он начинает с системных метрик. Это утилизация процессоров, памяти, swap, сети и диска. Но тем не менее многих параметров там по умолчанию нет.
Если с утилизацией процесса все в порядке, то с утилизацией диска есть проблемы. Как правило, разработчики мониторингов добавляют информацию о пропускной способности. Она может быть в iops или байтах. Но они забывают про latency и утилизацию дисковых устройств. Это более важные параметры, которые позволяют оценивать, насколько у нас загружены диски и насколько они тормозят. Если у нас высокий latency, то это значит, что есть какие-то проблемы с дисками. Если у нас высокая утилизация, то это значит, что диски не справляются. Это более качественные характеристики, чем пропускная способность.
Если у нас высокая утилизация, то это значит, что диски не справляются. Это более качественные характеристики, чем пропускная способность.
При том, что эту статистику можно также получить из файловой системы /proc, как это делается для утилизации процессоров. Почему эту информацию не добавляют в мониторинги, я не знаю. Но тем не менее важно иметь это в своем мониторинге.
Тоже самое относительно сетевых интерфейсов. Есть информация о пропускной способности сети в пакетах, в байтах, но тем не менее нет информации о latency и нет информации об утилизации, хотя это тоже полезная информация.
Любые мониторинги имеют недостатки. И какой мониторинг вы бы не взяли, он всегда будет не соответствовать каким-то критериям. Но тем не менее они развиваются, добавляются новые фичи, новые вещи, поэтому выбирайте что-то и допиливайте.
И для того чтобы допиливать, нужно всегда иметь представление, что означает отдаваемая статистика и как с помощью ее можно решать проблемы.
И несколько ключевых моментов:
- Всегда нужно мониторить доступность, иметь дашборды, чтобы вы могли быстро оценить, что с базой все в порядке.
- Всегда нужно иметь представление о том, какие клиенты работают с вашей базой данной, чтобы отсеивать плохих клиентов и отстреливать их.
- Важно оценивать то, как эти клиенты работают с данными. Нужно иметь представление о вашем ворклоаде.
- Важно оценивать, как формируется этот ворклоад, с помощью каких запросов. Вы можете оценивать запросы, вы можете их оптимизировать, рефакторить, строить для них индексы. Это очень важно.
- Фоновые процессы могут негативно влиять на клиентские запросы, поэтому важно отслеживать, чтобы они не используют слишком много ресурсов.
- Системные метрики позволяют вам делать планы на масштабирование, на увеличение емкости ваших серверов, поэтому важно тоже их отслеживать и оценивать.
Если вас заинтересовала эта тема, то вы можете пройтись по этим ссылкам.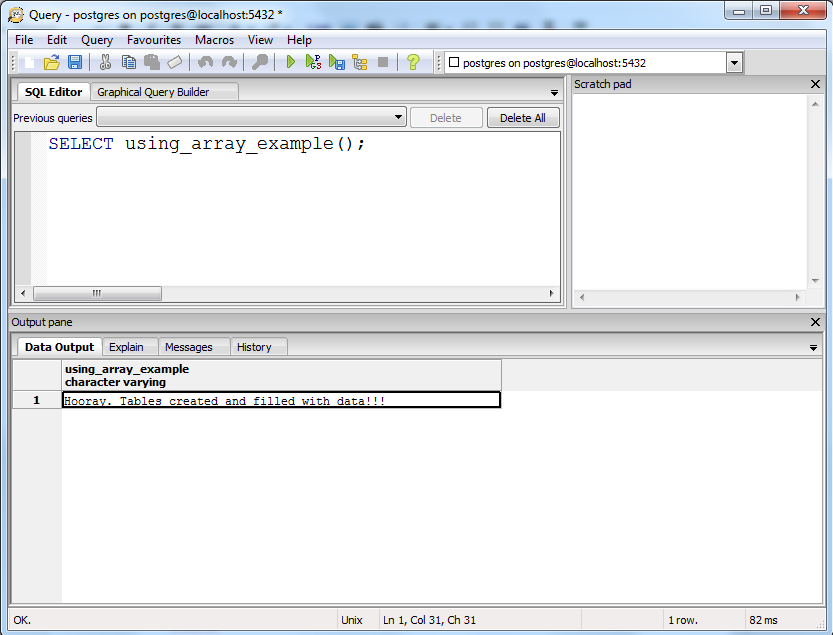
http://bit.do/stats_collector — это официальная документация с коллектора статистики. Там есть описание всех статистических вьюх и описание всех полей. Вы можете их прочитать, понять и проанализировать. И уже на основе них строить свои графики, добавлять в свои мониторинги.
Примеры запросов:
http://bit.do/dataegret_sql
http://bit.do/lesovsky_sql
Это корпоративный наш репозиторий и мой собственный. В них есть примеры запросов. Там нет запросов из серии select* from что-то там. Там уже готовые запросы с джойнами, с применением интересных функций, которые позволяют из сырых цифр сделать читаемые, удобные значения, т. е. это байты, время. Вы можете их ковырять, смотреть, анализировать, добавлять в свои мониторинги, строить на их основе свои мониторинги.
Вопросы
Вопрос: Вы сказали, что не будете рекламировать бренды, но мне все-таки интересно – в своих проектах вы какие дашборды используете?
Ответ: По-разному. Бывает, что мы приходим к заказчику и у него уже есть свой мониторинг. И мы консультируем заказчика о том, что нужно добавить в его мониторинг. Хуже всего обстоят дела с Zabbiх. Потому что у него нет возможности строить TopN-графики. Сами мы используем Okmeter, потому что мы консультировали этих парней по мониторингу. Они делали мониторинг PostgreSQL на основе нашего ТЗ. Я пишу свой pet-project, который данные собирает через Prometheus и отрисовывает их в Grafana. У меня задача сделать в Prometheus свой экспортер и дальше уже отрисовывать все в Grafana.
Вопрос: Есть ли какие-то аналоги AWR-отчетов или … агрегации? Известно вам о чем-то таком?
Ответ: Да, я знаю, что такое AWR, это крутая штука. На данный момент есть самые разные велосипеды, которые реализуют примерно следующую модель. С некоторым интервалом времени пишутся некоторые baselines в тот же самый PostgreSQL или в отдельное хранилище. Их можно погуглить в интернете, они есть. Один из разработчиков такой штуки сидит на форуме sql.ru в ветке PostgreSQL. Его можно там поймать. Да, такие штуки есть, их можно использовать. Плюс в своем pgCenter я тоже пишу штуку, которая позволяет делать то же самое.
Да, такие штуки есть, их можно использовать. Плюс в своем pgCenter я тоже пишу штуку, которая позволяет делать то же самое.
P.S.1 Если вы иcпользуете postgres_exporter, то какой дашборд вы используете? Их там несколько. Они уже устаревшие. Может сообщество создатm обновленный шаблон?
P.S.2 Убрал pganalyze, так как is a proprietary SaaS offering which focuses on performance monitoring and automated tuning suggestions.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Какой self-hosted мониторинг postgresql (с дашбордом) вы считаете самым лучшим?
30,0%Zabbix + дополнения от Алексея Лесовского или zabbix 4.4 или libzbxpgsql + zabbix libzbxpgsql + zabbix3
0,0%https://github.com/lesovsky/pgcenter0
0,0%https://github.com/pg-monz/pg_monz0
20,0%https://github.com/cybertec-postgresql/pgwatch32
20,0%https://github.com/postgrespro/mamonsu2
0,0%https://www.percona.com/doc/percona-monitoring-and-management/conf-postgres.html0
10,0%pganalyze is a proprietary SaaS — удалить не могу1
10,0%https://github.com/powa-team/powa1
0,0%https://github.com/darold/pgbadger0
0,0%https://github.com/darold/pgcluu0
0,0%https://github.com/zalando/PGObserver0
10,0%https://github.com/spotify/postgresql-metrics1
Проголосовали 10 пользователей. Воздержались 26 пользователей.
Источник: habr.com
postgresql — Когда использовать хранимую процедуру / пользовательскую функцию?
Обновление
Postgres 11 , наконец, представляет процедур SQL («хранимые процедуры»), которые также могут запускать и завершать транзакции:
Однако команды, которые не разрешены в блоке транзакции, (пока) не могут быть включены. Важные примеры
Важные примеры CREATE DATABASE или CREATE INDEX CONCURRENTLY или VACUUM .
И процедуры могут возвращать только одну строку результата, но при создании с параметрами INOUT .
Настоящие хранимые процедуры не налагают этих ограничений. Дальнейшие улучшения могут появиться в более поздних выпусках.
Оригинальный ответ
До Postgres 11, строго говоря, не было «хранимых процедур». Всего функционирует, делает почти то же самое, но не совсем то же самое. Что наиболее важно, функции всегда выполняются внутри транзакции, что имеет значение для управления блокировками, ошибок перехвата или команд, которые не могут быть запущены в контексте транзакции (см. Выше). Связанный:
Обработка данных в SQL может иметь серьезные преимущества перед извлечением всех необработанных данных в ваше приложение и выполнением там вычислений:
Тот же принцип может применяться к более крупным операциям, которые не могут быть выполнены в одном операторе, даже при использовании «связанных» команд в (модифицирующем данные) CTE:
В зависимости от варианта использования функция может быть лучше по производительности и часто более удобна, особенно когда несколько приложений обращаются к одной и той же базе данных.Вы должны выбрать серверный язык, чаще всего SQL или PL / pgSQL:
При наличии конкурирующих одновременных транзакций (многопользовательские среды) Короче . Вкладывайте в одну и ту же функцию столько, сколько должно быть атомарным. По возможности избегайте длительных транзакций с множеством блокировок. Блокировки снимаются только в конце транзакции. Длинные транзакции могут остановить одновременный доступ, даже привести к тупикам (которые обнаруживаются и разрешаются Postgres автоматически, вызывая ошибку для одной или нескольких конкурирующих транзакций, которые затем откатываются)…
Если вы избегаете этих анти-шаблонов, серверные функции могут стать отличным инструментом. Для некоторых целей нужно, чтобы все равно использовал функции, например функции триггеров.
Для некоторых целей нужно, чтобы все равно использовал функции, например функции триггеров.
Внутреннее устройство PL / pgSQL ⋆ Bitnine Global Inc.
Цель этой публикации — кратко понять внутреннюю реализацию PL / pgSQL. Сегодня мы сначала покажем значение PL и представим исходные коды PL / pgSQL.
Почему мы используем PL?Каждый оператор SQL должен выполняться отдельно сервером базы данных.Таким образом, клиентское приложение должно отправлять каждый запрос на сервер базы данных, ждать его обработки, получать и обрабатывать результаты и выполнять некоторые вычисления, а затем отправлять дальнейшие запросы на сервер. Все это приводит к межпроцессному взаимодействию, а также к накладным расходам сети, если клиент находится на другом компьютере, чем сервер базы данных.
С помощью PL вы можете сгруппировать блок вычислений и серию запросов внутри сервера базы данных, таким образом обладая мощью процедурного языка и простотой использования SQL, но со значительной экономией накладных расходов на связь клиент / сервер.
PL в PostgreSQLPL в PostgreSQL поддерживаются как расширения. Это означает, что если вы хотите удалить процедурный язык из производственной базы данных из-за некоторых проблем с безопасностью, вы можете просто удалить его как суперпользователь.
Исходные кодыИсходные коды PL / pgSQL находятся в `src / pl / plpgsql / src /`. Краткие описания некоторых известных файлов перечислены ниже.
| Файл | Описание |
| пл_комп.c | Компилирует блок кода PL / pgSQL в исполняемую функцию |
| pl_exec.c | Выполняет скомпилированный блок кода |
| pl_funcs.c | Разное для пространства имен, памяти и дампа |
| пл_грамм | Парсер PL / pgSQL (вызывается компилятором) |
pl_handler. c c | Точки входа для выполнения процедур PL / pgSQL |
| pl_scanner.c | Сканер для PL / pgSQL (использует сканер ядра PostgreSQL) |
Мы собираемся связать файлы с этапами выполнения процедуры по порядку.
Обработчик ( pl_handler.c )У каждого расширения есть функция, которая сама себя инициализирует. Имя функции — _PG_init (). Он вызывается PostgreSQL, когда расширение динамически загружается. Этот файл имеет функцию расширения PL / pgSQL. А также в этом файле есть точки входа для выполнения процедур PL / pgSQL. Эти точки входа вызываются при вызове процедур PL / pgSQL в SQL. Поскольку PL / pgSQL является встроенным расширением, оно автоматически устанавливается в базу данных `template1`, когда` initdb` использует `postgres.bki`, созданный `genbki.pl`. См. Также BKI и `pg_pltemplate` для получения дополнительной информации.
Компилятор ( pl_comp.c )
Хранимая процедура, написанная на PL / pgSQL, должна быть скомпилирована при первом вызове. Процесс компиляции здесь несколько прост. Он анализирует тело функции (блок кода PL / pgSQL) с помощью парсера PL / pgSQL (pl_gram.y). Парсер строит дерево синтаксического анализа, которое также является исполняемым. Дерево синтаксического анализа состоит из структур PLpgSQL_stmt_xxx.Скомпилированные процедуры кэшируются в «кэше функций PLpgSQL» для каждого процесса.
Исполнитель ( pl_exec.c ) Исполнитель выполняет скомпилированные процедуры PL / pgSQL. Он использует SPI (интерфейс программирования сервера) для оценки выражений и выполнения SQL-запросов. Точнее, выражения оцениваются с помощью запросов SELECT (например, SELECT 1 + 1). Эти запросы кэшируются в текущем процессе как подготовленные операторы. А оператор RETURN NEXT сохраняет результаты во временном хранилище кортежей, которое хранит данные в памяти. Любые данные, превышающие этот объем памяти, выгружаются на диск. Для получения дополнительной информации см. `Tuplestore_begin_heap ()`. Также он поддерживает переменное количество аргументов и полиморфные типы.
Любые данные, превышающие этот объем памяти, выгружаются на диск. Для получения дополнительной информации см. `Tuplestore_begin_heap ()`. Также он поддерживает переменное количество аргументов и полиморфные типы.
В этой публикации мы кратко рассказали, что такое PL / pgSQL и файлы, связанные с реализацией PL / pgSQL. В следующий раз мы продолжим более подробно с Handler, в котором рассказывается, как вызываются процедуры PL / pgSQL, и многое другое.
BITNINE GLOBAL INC., КОМПАНИЯ, СПЕЦИАЛИЗИРУЮЩАЯСЯ НА БАЗЕ ГРАФИЧЕСКИХ ДАННЫХ
비트 나인, 그래프 데이터베이스 전문 기업
СвязанныеНаписание пользовательских функций в PostgreSQL — онлайн-курс SQL
Зачем писать свои собственные функции? В PostgreSQL функции позволяют выполнять операции, которые обычно требуют нескольких запросов и обходов. Проще говоря, это означает, что вы получите результаты намного быстрее. Пользовательские функции расширяют функциональные возможности PostgreSQL и добавляют удобства, улучшают логику запросов и позволяют другим приложениям повторно использовать вашу базу данных.
В этом курсе вы узнаете о PL / pgSQL , наиболее часто используемом процедурном языке в PostgreSQL. Вы познакомитесь с синтаксисом PL / pgSQL, различными типами параметров , которые работают в поддержке PostgreSQL (параметры IN, OUT, INOUT), и как использовать сложные операторы в теле функции. Более того, вы научитесь писать функции с помощью практических примеров, основанных на реальных сценариях использования. В заключительной части курса вы напишете функции, реализующие простой процесс ETL ( Extract-Transform-Load ) в хранилище данных (DWH).
Написание пользовательских функций — это то, что должны знать все продвинутые пользователи баз данных. Этот курс идеально подходит для начинающих программистов баз данных и будущих администраторов баз данных (DBA) .
Этот курс идеально подходит для начинающих программистов баз данных и будущих администраторов баз данных (DBA) .
Примечание: До PostgreSQL 11 пользовательские функции в PostgreSQL иногда также вызывались (и использовались как) хранимых процедур . Не удивляйтесь, если вы увидите, что термин «хранимая процедура» относится к пользовательской функции в Postgres.Этот курс охватывает только создание пользовательских функций в PostgreSQL.
Что это для меня?
- 94 интерактивных упражнения. Учитесь в удобном для вас темпе, в любом месте и в любое время. Взаимодействуйте с практическими упражнениями для улучшения удержания.
- Пожизненный доступ к курсу. Приобретая курс, вы получаете мгновенный персональный доступ ко всему его содержанию.
- Свидетельство об окончании. После успешного завершения всех упражнений вы получите загружаемый сертификат в формате PDF, чтобы продемонстрировать свои достижения.
- 30-дневная гарантия возврата денег. Если вы не удовлетворены качеством курса, вы можете получить возмещение в течение 30 дней с момента покупки.
- Подсказки к упражнениям. Вы можете задавать вопросы и делиться своими идеями с другими членами нашего сообщества на вкладке «Обсудить». Вы также можете написать нам прямо по адресу [email protected], и мы будем более чем рады ответить! 😉
Что нужно для прохождения этого курса?
- Веб-браузер и подключение к Интернету.
- Базовые знания SQL.
- Базовые знания программирования.
Этот курс научит вас:
- Что такое пользовательская функция и когда ее следует использовать.
- Как создать пользовательскую функцию в PostgreSQL.
- Синтаксис PL / pgSQL, наиболее часто используемого процедурного языка PostgreSQL.

- Различные типы параметров в функциях PostgreSQL (IN, OUT и INOUT).
- Как можно использовать результаты SQL-запроса внутри функции.
- Как можно вкладывать вызовы функций.
- Как вернуть таблицу из функции.
Кому следует пройти этот курс?
- Студенты, изучающие реляционные базы данных.
- разработчиков PostgreSQL.
- Начинающие администраторы баз данных (DBA).
- Люди, интересующиеся программированием реляционных баз данных, особенно PostgreSQL.
Выполнить процедуру SQL Server внутри функции
В этой статье мы убедимся, что выполнение процедуры SQL Server внутри функции возможно.Разработчики базы данных обычно понимают, что процедура не может использоваться или выполняться внутри пользовательской функции, поскольку пользовательская функция не позволяет выполнять операцию DML с таблицей. Процедуре разрешено играть с базой данных и ее свойством, независимо от того, не является ли это пользовательской функцией. Это должно быть основной причиной разрешения выполнения процедуры SQL Server внутри функции.
Давайте поговорим о различных типах функций в SQL Server.Два основных типа функций SQL Server — это определяемая пользователем функция и определяемая системой функция. Пользовательские функции могут быть определены двумя типами; скалярная функция и функция табличных значений. В идеале табличная функция и процедура аналогичны только с точки зрения набора результатов выборки данных. И процедура, и функция могут быть определены с параметрами и возвращать набор результатов с помощью манипулирования данными с несколькими таблицами по мере необходимости. Но ограничение функции состоит в том, что функция не может выполнять какие-либо операции ALTER, INSERT, UPDATE или DELETE для таблицы, кроме таблиц временных и переменных.Следующее структурное различие между процедурой и табличной функцией состоит в том, что функция должна указывать RETURNS с типом вывода и завершаться ключевым словом RETURN, которое не требуется для процедуры SQL Server.
Основная цель табличной функции — это альтернатива представления, но в качестве надстройки с функцией пользователь может записать логику в функцию с помощью временной таблицы и табличной переменной для дополнительной обработки данных там, где представление не т.Функции и представления полезны с точки зрения вариантов использования для бизнес-логики и требований, а также с точки зрения производительности.
Согласно стандарту Microsoft, хранимые процедуры не могут выполняться внутри функции, но технически это возможно с некоторыми настройками. Как пользователю требуется использовать процедуру в функции? Это происходит, когда функция вызывается базой данных, и пользователь хочет выполнить операцию INSERT, UPDATE или DELETE в рамках этой функциональной задачи.Прежде чем приступить к этому подходу, пользователь должен четко понимать цель процедуры и функции, а также их различия и ограничения.
Процедура
Хранимая процедура — это программа базы данных, которую можно использовать для выполнения задач CRUD с таблицей. Это требует, чтобы SQL Server составил бизнес-обоснование с различными таблицами с манипуляциями с информацией. Основные стандартные соглашения о сравнении процедуры с функциями перечислены ниже:
- SQL Server Database Engine создаст план выполнения с первым выполнением процедуры.
- Процедура — это предварительно скомпилированный код, который будет запускаться в плане выполнения с разными параметрами.
- Поддержка нескольких наборов результатов при выполнении одной процедуры
- Процедура может возвращать параметр out
- Процедура может вызывать функцию внутри тела программы.
Функция
Табличная функция SQL Server — это программа, которую можно использовать для возврата данных путем объединения нескольких таблиц.Основные стандартные соглашения о сравнении функции с процедурой перечислены ниже;
- Функция используется для подсчета данных из одной или нескольких таблиц и должна возвращать набор результатов.

- Функция — это программа компиляции в реальном времени.
- Функция не позволяет выполнять какие-либо операции ALTER, CREATE, INSERT, UPDATE или DELETE с пользовательской таблицей, кроме временной таблицы и таблицы переменных.
- Функция генерирует план выполнения во время выполнения
- Функция не поддерживает параметр OUTPUT
- Функция не может вызвать процедуру внутри тела программы
Процедура может быть выполнена внутри функции с помощью OPENROWSET () , используя соединение с поставщиком OLE DB MSDASQL .Пользователи могут определить соединение OPENROWSET () с необходимыми деталями экземпляра SQL Server с объявленным связанным сервером и учетными данными, имеющими доступ к базе данных. Здесь у нас будет обработка ошибок и другой сценарий с операциями INSERT и SELECTS в процедуре и вызовом ее функцией SQL Server. Начнем с вызова процедуры с оператором OPENROWSET T-SQL.
Выполнение процедуры SQL Server внутри функции
Соединение MSDASQL устанавливается с локальным экземпляром SQL Server в операторе OPENROWSET.Сервер настроен на localhost, а затем у нас есть Trusted_Connection = yes для создания доверенного соединения, которое не требует учетных данных для подключения к вашей базе данных для соединения MSDASQL:
SELECT * FROM OPENROWSET (‘MSDASQL’, ‘DRIVER = {SQL Server}; SERVER = localhost; Trusted_Connection = yes’, ‘EXEC AdventureWorks .. [usp_get]’); |
Процедура usp_get используется в приведенном выше примере кода, который существует в базе данных AdventureWorks .Если вы не укажете базу данных в операторе соединения и запроса, запрос вернет ошибку, как показано ниже:
Поставщик OLE DB «MSDASQL» для связанного сервера «(null)» вернул сообщение «[Microsoft] [Драйвер ODBC SQL Server] [SQL Server] Не удалось найти хранимую процедуру« usp_get ». ».
».
Msg 7350, уровень 16, состояние 2, строка 11
Невозможно получить информацию о столбце от поставщика OLE DB «MSDASQL» для связанного сервера «(null)».
Операция выборки и вставки с выполнением процедуры SQL Server внутри функции
Процедура usp_get возвращает данные из пользовательской таблицы и вызывает их внутри функции с OPENROWSET ().
Процедура:
СОЗДАТЬ ПРОЦЕДУРУ [usp_get] КАК НАЧАЛО УСТАНОВИТЬ NOCOUNT ON УСТАНОВИТЬ УРОВЕНЬ ИЗОЛЯЦИИ ПЕРЕДАЧИ ЧТЕНИЕ НЕОБХОДИМО ВЫБРАТЬ * FROM counter_ 74 |
Функция:
СОЗДАТЬ ФУНКЦИЮ [fn_getusp] () ТАБЛИЦА ВОЗВРАТА AS ВОЗВРАТ ВЫБРАТЬ * ОТ OPENROWSET (‘MSDASQL’, ‘DRIVER’, ‘DRIVER’ = {SQL Server}; да СЕРВЕР = {local_host}; СЕРВЕР = {local_host}; EXEC AdventureWorks.. [usp_get] ‘) В качестве; |
Исполнение:
ВЫБРАТЬ * ОТ [fn_getusp] () |
Здесь набор результатов процедуры возвращается функцией. Пользователи могут вставлять эти строки во временную таблицу или табличную переменную для дальнейшей обработки. Теперь давайте рассмотрим тот же сценарий с вставкой данных в пользовательскую таблицу в процедуре и их вызовом в функции.
Процедура:
СОЗДАТЬ ПРОЦЕДУРУ [usp_insert] AS НАЧАЛО УСТАНОВИТЬ НЕТ СЧЕТЧИК ВКЛ УСТАНОВИТЬ УРОВЕНЬ ИЗОЛЯЦИИ ТРАНЗАКЦИИ ЧТЕНИЕ НЕОБХОДИМО INSERT INTO counter_ (id) КОНЕЦ |
Функция:
СОЗДАТЬ ФУНКЦИЮ [fn_InsertUsp] () ТАБЛИЦА ВОЗВРАТОВ AS ВОЗВРАТ ВЫБРАТЬ * ОТ OPENROWSET (‘MSDASQL’, ‘DRIVER = {SQL Server}; EXEC AdventureWorks. |
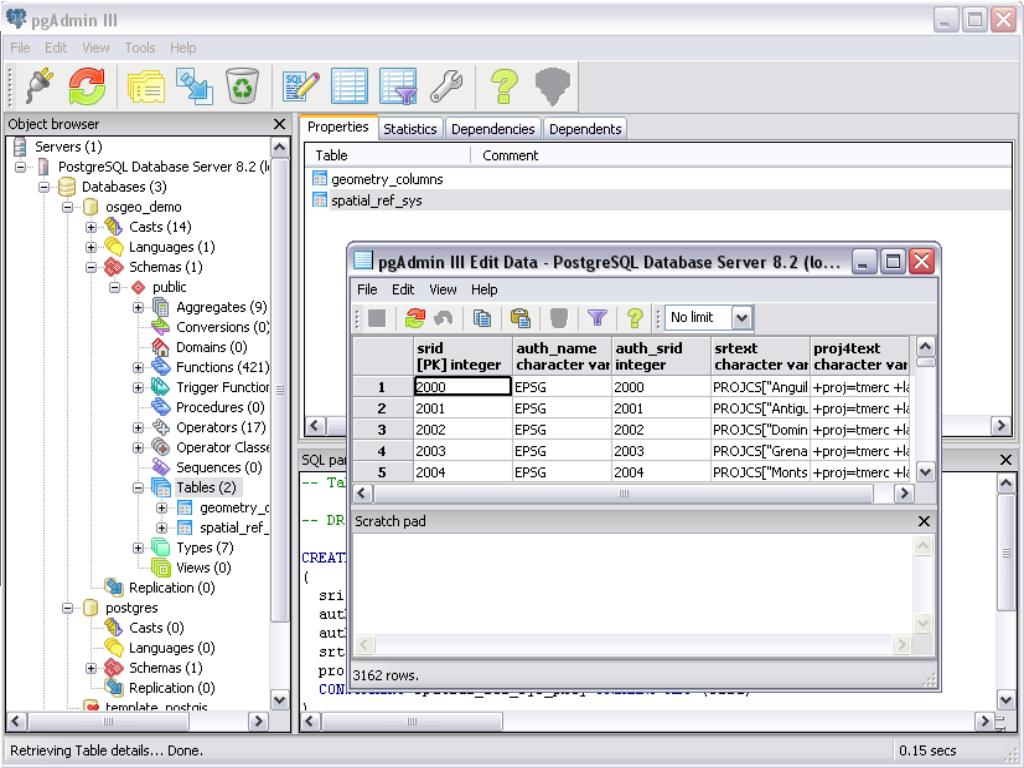 . [usp_insert] ‘) КАК a;
. [usp_insert] ‘) КАК a;Исполнение:
ВЫБРАТЬ * ИЗ fn_InsertUsp () |
Здесь процедура [usp_insert] вставляет строки в определяемую пользователем таблицу и возвращает набор результатов в качестве вывода. Поскольку выполнение процедуры в запросе OPENROWSET должно требовать вывода, операция INSERT, UPDATE, DELETE или SELECT выполняется внутри кода процедуры.Если вы не вернете результат процедуры, запрос OPENROWSET () вернет ошибку, как показано ниже:
Msg 7357, уровень 16, состояние 1, строка 11
Невозможно обработать объект «EXEC Adventureworks .. [usp_insert]». Поставщик OLE DB «MSDASQL» для связанного сервера «(null)» указывает, что либо у объекта нет столбцов, либо у текущего пользователя нет разрешений на этот объект.
Например, мы можем воспроизвести эту ошибку с помощью оператора OPENROWSET и вне функции:
Процедура:
ИЗМЕНЕНИЕ ПРОЦЕДУРЫ [usp_insert] AS BEGIN SET NOCOUNT ON SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED INSERT INTO counter_ (id) 79 |
Исполнение:
SELECT * FROM OPENROWSET (‘MSDASQL’, ‘DRIVER = {SQL Server}; SERVER = localhost; Trusted_Connection = yes’, ‘EXEC AdventureWorks.. [usp_insert] ‘) КАК a; |
Сообщение об ошибке:
Msg 7357, уровень 16, состояние 2, строка 1
Невозможно обработать объект «EXEC AdventureWorks .. [usp_insert]». Поставщик OLE DB «MSDASQL» для связанного сервера «(null)» указывает
что либо у объекта нет столбцов, либо у текущего пользователя нет разрешений на этот объект.
Приведенные выше примеры включают ряд сценариев интеграции процедуры с функцией, включая обработку ошибок.Теперь оказывается проще для пользователей, которые хотят включить эту методологию в существующую структуру базы данных. Во всех приведенных выше примерах кода имя экземпляра SQL Server используется в качестве локального хоста, поскольку он выполняет каждую задачу на локальном компьютере. Однако это должно быть имя экземпляра SQL Server. Если пользователи хотят выполнить процедуру на удаленном сервере, тогда имя удаленного SQL Server может использоваться вместо localhost, и это имя удаленного экземпляра SQL Server должно существовать в вашем списке связанных серверов.
Использование процедур внутри функции может потребоваться, когда пользователи интегрируют стороннее приложение в базу данных. Вот один вариант использования: пользователь хочет включить какую-либо операцию INSERT, UPDATE или DELETE; однако пользователь хочет внести любые изменения в код серверного приложения, и наиболее заметными ужасными обстоятельствами могут быть внутренние приложения, вызывающие функцию. При выполнении функции пользователь хочет добавить любую операцию INSERT, UPDATE или DELETE на локальном или удаленном экземпляре SQL Server.Это требование не может быть выполнено непосредственно функцией, и прямое использование процедуры SQL Server внутри функции не является стандартным решением для той же самой. В этом случае пользователь может применить эту стратегию для достижения цели.
Если вы вносите какие-либо улучшения в серверное приложение стороннего приложения, пользователь должен зависеть от этой версии приложения, а также вызывает большую зависимость пользователя. Если мы пойдем с изменениями базы данных, администратор базы данных должен просто изменить функцию только с интеграцией процедур.Однако это похоже на зависимость от администраторов базы данных, потому что каждый должен также сравнивать эту функцию базы данных и соответствующую схему таблицы.
Заключение
Вызов процедуры SQL Server внутри функции рекомендуется, если у вас нет альтернативной альтернативы для выполнения операции INSERT, UPDATE или DELETE без процедуры. Вы не можете использовать этот подход в общих случаях, потому что он вызывает множество проблем с устранением неполадок, и Microsoft также не рекомендует этот метод.
Джигнеш имеет хороший опыт в области решений и архитектуры баз данных, работая с несколькими заказчиками по вопросам проектирования и архитектуры баз данных, разработки SQL, администрирования, оптимизации запросов, настройки производительности, высокой доступности и аварийного восстановления.Посмотреть все сообщения от Jignesh Raiyani
Последние сообщения от Jignesh Raiyani (посмотреть все) Диалог процедур— документация pgAdmin 4 5.1
Используйте диалоговое окно Процедура для создания процедуры; процедуры поддерживаются PostgreSQL v11 + и EDB Postgres Advanced Server.Диалог Процедура позволяет Вам необходимо реализовать параметры команды CREATE PROCEDURE.
Диалог Процедура организует разработку процедуры через следующие вкладки диалогов: Общие , Определение , Параметры , Аргументы , Параметры и Безопасность . На вкладке SQL отображается код SQL, сгенерированный выбор диалогового окна.
Используйте поля на вкладке Общие для определения процедуры:
Используйте поле Name , чтобы добавить описательное имя для процедуры.Название будет отображаться в древовидном элементе управления pgAdmin .
Используйте раскрывающийся список рядом с Владелец , чтобы выбрать роль.
Выберите имя схемы, в которой будет находиться процедура, из раскрывающийся список в поле Схема .
Сохранение примечаний к процедуре в поле Комментарий .

Щелкните вкладку «Определение » , чтобы продолжить.
Используйте поля на вкладке Определение для определения процедуры:
Используйте раскрывающийся список рядом с Язык , чтобы выбрать язык. По умолчанию это edbspl .
Используйте поля в разделе Аргументы , чтобы определить аргумент. Нажмите Добавить , чтобы установить параметры и значения для аргумента:
Используйте раскрывающийся список рядом с Тип данных , чтобы выбрать тип данных.
Используйте раскрывающийся список рядом с Mode , чтобы выбрать режим. Выберите IN для входной параметр; выберите OUT в качестве выходного параметра; выберите INOUT для обоих входной и выходной параметр; или выберите VARIADIC , чтобы указать VARIADIC параметр.
Введите имя аргумента в поле Имя аргумента .
Укажите значение по умолчанию для аргумента в поле Значение по умолчанию .
Щелкните Добавить , чтобы определить другой аргумент; чтобы отменить аргумент, щелкните корзину слева от строки и подтвердите удаление во всплывающем окне Удалить строку .
Щелкните вкладку Code , чтобы продолжить.
Щелкните вкладку Options , чтобы продолжить.
Используйте поля на вкладке Options , чтобы описать или изменить поведение процедура:
Используйте раскрывающийся список под Volatility , чтобы выбрать один из следующих вариантов. VOLATILE — значение по умолчанию.
VOLATILE указывает, что значение может изменяться даже в пределах одной таблицы сканировать, поэтому оптимизация невозможна.
STABLE указывает, что процедура не может изменить базу данных, и что при сканировании одной таблицы он будет постоянно возвращать один и тот же результат для те же значения аргументов, но его результат может измениться в зависимости от SQL заявления.

IMMUTABLE указывает, что процедура не может изменить базу данных и всегда возвращает один и тот же результат при одинаковых значениях аргументов.
Переместить строго? переключатель, чтобы указать, всегда ли процедура возвращает NULL всякий раз, когда любой из его аргументов равен NULL. Если Да , процедура не выполняется. выполняется, когда есть NULL аргументы; вместо этого предполагается NULL результат автоматически. По умолчанию — № .
Переместить Безопасность определителя? переключатель, чтобы указать, что процедура должна быть выполняется с привилегиями пользователя, который его создал.По умолчанию — № .
Используйте поле Ориентировочная стоимость , чтобы указать положительное число, представляющее ориентировочная стоимость выполнения процедуры в единицах cpu_operator_cost. Если процедура возвращает набор, это стоимость возвращаемой строки.
Переместите Герметичность? переключатель, чтобы указать, есть ли у процедуры сторона эффекты — он не раскрывает никакой информации о своих аргументах, кроме возвращаемое значение. По умолчанию — № .
Щелкните вкладку Parameters , чтобы продолжить.
Используйте поля на вкладке Parameters , чтобы указать настройки, которые будут применяться при вызове процедуры:
Используйте раскрывающийся список рядом с именем параметра на панели параметров для выбора параметра.
Нажмите кнопку Добавить , чтобы добавить переменную в поле Имя в таблице.
Используйте поле Value , чтобы указать значение, которое будет связано с выбранная переменная.Это поле зависит от контекста.
Щелкните вкладку Security , чтобы продолжить.
Используйте вкладку Security для назначения привилегий и определения меток безопасности.
Используйте панель Privileges , чтобы назначить права на выполнение процедуры для роль:
Выберите имя роли из раскрывающегося списка в поле Получатель гранта .
Щелкните внутри поля Privileges .Установите флажки слева от одного или дополнительные привилегии для предоставления выбранной привилегии указанному пользователю.
Текущий пользователь, который является лицом, предоставляющим право по умолчанию для предоставления привилегии, отображается в поле Grantor .
Щелкните Добавить , чтобы назначить дополнительные привилегии; чтобы отменить привилегию, щелкните значок значок корзины слева от строки и подтвердите удаление в Удалить строку выскакивать.
Используйте панель Security Labels для определения защитных меток, применяемых к процедура.Нажмите Добавить , чтобы добавить каждую выбранную защитную метку:
Укажите поставщика метки защиты в поле Provider . Именованный провайдер должен быть загружен и должен давать согласие на предложенную операцию маркировки.
Укажите защитную метку в поле Security Label . Значение данная этикетка остается на усмотрение поставщика этикеток. PostgreSQL помещает нет ограничения на то, должен ли поставщик этикеток интерпретировать безопасность этикетки; он просто предоставляет механизм для их хранения.
Щелкните Добавить , чтобы назначить дополнительные метки защиты; отказаться от защитной наклейки, щелкните значок корзины слева от строки и подтвердите удаление в Удалить Всплывающее окно строки .
Щелкните вкладку SQL , чтобы продолжить.
Ваши записи в диалоговом окне Процедура генерируют команду SQL (см. Пример
ниже). Используйте вкладку SQL для обзора; повторно посещайте или переключайте вкладки, чтобы внести какие-либо изменения
к команде SQL.
Пример
Ниже приведен пример команды sql, сгенерированной выбором, сделанным в диалог Процедура :
Пример демонстрирует создание процедуры, которая возвращает список сотрудников. из таблицы с именем emp .Процедура является ОПРЕДЕЛЕНИЕМ БЕЗОПАСНОСТИ и будет выполнять с привилегиями роли, которая определила процедуру.
Нажмите кнопку Информация (i), чтобы получить доступ к интерактивной справке.
Нажмите кнопку Сохранить , чтобы сохранить работу.
Нажмите кнопку Отмена , чтобы выйти без сохранения работы.
Нажмите кнопку Сброс , чтобы восстановить параметры конфигурации.
Написание функций PostgreSQL с помощью Java с использованием PL / Java
Написание функций PostgreSQL с помощью Java с использованием PL / Java | rieckpil Закрыть диалоговое окноСрок действия сеанса истек
Пожалуйста, войдите снова.Страница входа откроется в новой вкладке. После авторизации вы можете закрыть его и вернуться на эту страницу.
Мы используем файлы cookie на нашем веб-сайте. Некоторые из них очень важны, а другие помогают нам улучшить этот веб-сайт и улучшить ваш опыт.
Принять все
Сохранить
Индивидуальные настройки конфиденциальности
Сведения о файлах cookie Политика конфиденциальности Отпечаток
Предпочтение конфиденциальности Здесь вы найдете обзор всех используемых файлов cookie. Вы можете дать свое согласие на использование целых категорий или отобразить дополнительную информацию и выбрать определенные файлы cookie.
Вы можете дать свое согласие на использование целых категорий или отобразить дополнительную информацию и выбрать определенные файлы cookie.
| Имя | Borlabs Cookie |
|---|---|
| Провайдер | Владелец этого сайта |
| Назначение | Сохраняет предпочтения посетителей, выбранные в поле Cookie Borlabs Cookie. |
| Имя файла cookie | borlabs-cookie |
| Срок действия cookie | 1 год |
| Принять | |
|---|---|
| Имя | Пиксель Facebook |
| Провайдер | Facebook Ireland Limited |
| Назначение | Cookie от Facebook, используемый для аналитики веб-сайтов, таргетинга и измерения рекламы. |
| Политика конфиденциальности | https://www.facebook.com/policies/cookies |
| Имя файла cookie | _fbp, act, c_user, datr, fr, m_pixel_ration, pl, присутствие, sb, spin, wd, xs |
| Срок действия cookie | сессия / 1 год |
404 | Микро Фокус
Сформируйте свою стратегию и преобразуйте гибридную ИТ-среду.
Помогите вам внедрить безопасность в цепочку создания стоимости ИТ и наладить сотрудничество между ИТ-подразделениями, приложениями и службами безопасности.
Помогите вам быстрее реагировать и получить конкурентное преимущество благодаря гибкости предприятия.
Ускорьте получение результатов гибридного облака с помощью услуг по консультированию, трансформации и внедрению.
Службы управления приложениями, которые позволяют поручить управление решениями экспертам, разбирающимся в вашей среде.
Услуги стратегического консалтинга для разработки вашей программы цифровой трансформации.
Полнофункциональное моделирование сценариев использования с предустановленной интеграцией всего портфеля программного обеспечения Micro Focus, демонстрирующее реальные сценарии использования
Услуги экспертной аналитики безопасности, которые помогут вам быстро спроектировать, развернуть и проверить реализацию технологии безопасности Micro Focus.
Служба интеграции и управления услугами, которая оптимизирует доставку, гарантии и управление в условиях нескольких поставщиков.
Анализируйте большие данные с помощью аналитики в реальном времени и ищите неструктурированные данные.
Анализируйте большие данные с помощью аналитики в реальном времени и ищите неструктурированные данные.
Анализируйте большие данные с помощью аналитики в реальном времени и ищите неструктурированные данные.
Мобильные услуги, которые обеспечивают производительность и ускоряют вывод продукта на рынок без ущерба для качества.