Запросы WITH (Общие табличные выражения)
WITH предоставляет способ написания вспомогательных операторов для использования в более больших запросах. Эти операторы, которые часто называются как Общие Табличные Выражения или CTE, могут быть задуманы как определяющие временные таблицы, которые существуют только для данного запроса. Каждый вспомогательный оператор в предложении WITH может затем быть подвергнут SELECT, INSERT, UPDATE или DELETE; а само предложение WITH прикрепляется к первичному оператору, которые также может быть одним из SELECT, INSERT, UPDATE или DELETE.
Базовое значение SELECT в WITH должно разбивать сложные запросы на более простые части. Например:
WITH regional_sales AS (
SELECT region, SUM(amount) AS total_sales
FROM orders
GROUP BY region
), top_regions AS (
SELECT region
FROM regional_sales
WHERE total_sales > (SELECT SUM(total_sales)/10 FROM regional_sales)
)
SELECT region,
product,
SUM(quantity) AS product_units,
SUM(amount) AS product_sales
FROM orders
WHERE region IN (SELECT region FROM top_regions)
GROUP BY region, product; запрос показывает общие продажи каждого продукта только в регионах с
высоким объёмом продаж. Преложение WITH определяет два вспомогательных оператора
с именами regional_sales и top_regions,
где вывод regional_sales используется в
top_regions, а вывод top_regions
используется в первичном запросе SELECT.
Этот пример может быть написан без WITH, но тогда
потребуется два уровня вложенных под-SELECT’ов.
Гораздо легче следовать вышеописанному методу.
Преложение WITH определяет два вспомогательных оператора
с именами regional_sales и top_regions,
где вывод regional_sales используется в
top_regions, а вывод top_regions
используется в первичном запросе SELECT.
Этот пример может быть написан без WITH, но тогда
потребуется два уровня вложенных под-SELECT’ов.
Гораздо легче следовать вышеописанному методу.
Необязательный модификатор RECURSIVE изменяет WITH с явного синтаксического комфорта в возможность, выполняющую такие вещи, которые невозможны в стандарте SQL. Используя RECURSIVE, запрос WITH может ссылаться на свой собственный вывод. Простой пример такого запроса состоит в суммировании целых чисел от 1 до 100:
WITH RECURSIVE t(n) AS (
VALUES (1)
UNION ALL
SELECT n+1 FROM t WHERE n < 100
)
SELECT sum(n) FROM t; Общая форма рекурсивного запроса WITH всегда нерекурсивный термин, затем UNION (или
UNION ALL), затем рекурсивный термин,
где только рекурсивный термин может содержать ссылку на свой
собственный вывод запроса. Такой запрос выполняется так:
Рекурсивное выполнение запроса
Выполняется не-рекурсивный термин. Для UNION (но не для UNION ALL), отбрасываются дублирующиеся строки. Включаются все оставшиеся строки из результата рекурсивного запроса и также размещаются во временную рабочую таблицу.
Пока рабочая таблица не окажется пустой, повторяются следующие шаги:
Выполняется рекурсивный термин, подстановка текущего содержимого рабочей таблицы для рекурсивной ссылки на саму себя. Для UNION (но не для UNION ALL), отбрасываются дублирующиеся строки и строки, которые дублируют любые строки в предыдущих результатах. Включаются все оставшиеся строки из результата рекурсивного запроса и также размещаются во временную
Замещается содержимое рабочей таблицы на содержимое промежуточной таблицы, затем промежуточная таблица очищается.
Note: Строго говоря, данный процесс является нерекурсивной итерацией, но RECURSIVE является терминологическим выбором комитета по стандартам SQL.
В данном выше примере, рабочая таблица на каждом шаге содержит только одну строку, в которую на успешных шагах попадают значения от 1 до 100. На 100-м шаге, вывода нет из-за преложения WHERE и таким образом, запрос завершается.
Рекурсивные запросы обычно используются при работе с иерархическими данными или данными, которые имеют древовидную структуру. Полезный пример такого запроса состоит в нахождении всех прямых и непрямых составных частей продукта, представленных как таблица, которая показывает только состав продукта из часте
PostgreSql. Оконные функции.
Оконные функции в PostgreSQL являются очень мощным инструментом, для создания быстрых и лаконичных запросов.
Оконные функции необходимы для вычисления строк на основе других строк в выборке. Если запрос содержит какие-либо оконные функции, то эти функции выполняются после выполнения всех предложений группировки, агрегирования и HAVING.
Если запрос содержит какие-либо оконные функции, то эти функции выполняются после выполнения всех предложений группировки, агрегирования и HAVING.
Таким образом, если запрос использует какие-либо агрегаты,
Каждая строчка возвращаемая запросом, ничего не знает про другую. Поэтому разработчики, начинают использовать группировки в подзапросах, чтобы получить уже посчитаннае данные, на основании набора строк. Из-за этого запрос становиться слишком «тяжелым» и сопровождать его, остается очень мало удовольствия.
Все эти проблемы, решаются с помощью оконных функций. Давайте на примере, создадим и наполним данными таблицу «Сотрудники»:
Нам необходимо вытащить из таблицы «Сотрудники», следующие данные:
- Название отдела,
- Номер сотрудника,
- Средняя зарплата по отделу сотрудника,
- Общая сумма зарплат отдела,
- Количество сотрудников, в котором работает сотрудник
Так будет выглядеть запрос, без использования оконных функций:
Время выполнения ~ 4ms.
А так будет выглядеть запрос, с теми же данными, но уже с использованием оконных функций.
Время выполнения ~ 2ms.
Таким образом, на самом простом запросе, выигрыш по времени составил более чем, в 2 раза. Ну и код намного более читабельным стал.
А здесь вы можете узнать, как можно удалить все дублирующие строки в БД, с помощью оконных функций.
Если вам помогла статья, пожалуйста перейдите по одному из рекламных блоков, расположенных на сайте. Таким образом вы поддержите проект. Спасибо
Примеры рекурсивных запросов в PostgreSQL
Вот еще одна задача с PostgreSQL, возникшая по работе. Есть таблица с некими событиями. У событий есть уникальный id. В силу специфики приложения id событий не обязательно идут по порядку. Однако в каждом событии есть id следующего и предыдущего события. Требуется написать функции backward(id, steps), возвращающие id события, произошедшего steps событий вперед или назад относительно заданного. Если такого события нет, требуется вернуть пустой результат.
Если такого события нет, требуется вернуть пустой результат.
Упрощенно таблица событий выглядит так:
CREATE TABLE events(«id» BIGINT PRIMARY KEY,
«prev» BIGINT NOT NULL,
«next» BIGINT NOT NULL,
«descr» TEXT NOT NULL
);
INSERT INTO events
SELECT id*10, (id-1)*10, (id+1)*10, ‘Event ‘ || id*10
FROM generate_series(1,20) AS id;
SELECT * FROM events;
Пример данных:
id | prev | next | descr
——+——+——+————
10 | 0 | 20 | Event 10
20 | 10 | 30 | Event 20
40 | 30 | 50 | Event 40
50 | 40 | 60 | Event 50
60 | 50 | 70 | Event 60
70 | 60 | 80 | Event 70
80 | 70 | 90 | Event 80
90 | 80 | 100 | Event 90
100 | 90 | 110 | Event 100
110 | 100 | 120 | Event 110
120 | 110 | 130 | Event 120
130 | 120 | 140 | Event 130
140 | 130 | 150 | Event 140
150 | 140 | 160 | Event 150
160 | 150 | 170 | Event 160
170 | 160 | 180 | Event 170
180 | 170 | 190 | Event 180
190 | 180 | 200 | Event 190
200 | 190 | 210 | Event 200
(20 rows)
На первый взгляд, можно просто сделать SELECT ., но такое решение неверно. Во-первых, как уже отмечалось, id событий не обязательно идут по порядку. Во-вторых, на самом деле события доезжают в базу с задержкой, и в некоторых случаях в двусвязном списке могут образовываться «дырки». .. ORDER BY id OFFSET ... LIMIT ...
.. ORDER BY id OFFSET ... LIMIT ...
Выгружать событие с заданным id, смотреть на его next или prev, выгружать следующее событие, и так steps раз — более правильное решение. Проблема в том, что нам придется steps раз сходить в СУБД по сети, ей в свою очередь придется пропарсить steps запросов, steps раз взять локи, сходить в кучу, и вот это вот все. В общем, не звучит, как что-то эффективное. Особенно, если учесть, что forward и backward могут вызываться достаточно часто.
Оказывается, что PostgreSQL поддерживает рекурсивные запросы. Такие запросы в состоянии сами сделать обход двухсвязного списка, что позволяет решить задачу в один запрос. Например, простейшая реализация forward(10, 5) может выглядеть так:
WITH RECURSIVE tmp AS (
SELECT «id», «next» FROM events WHERE «id» = 10
UNION ALL
SELECT e. «id», e.»next» FROM tmp t
«id», e.»next» FROM tmp t
) SELECT «id» FROM tmp OFFSET 5 LIMIT 1;
Сперва кажется, что запрос выглядит сложно и непонятно, но на самом деле все очень просто. Сначала выполняется так называемый non-recursive term:
SELECT «id», «next» FROM events WHERE «id» = 10
То, что вернет этот запрос, помещается в результат рекурсивного запроса, а также во временную working table. При этом, если был использован UNION ALL, то все копируется как есть. Если же был использован UNION без ALL, то дубликаты кортежей отбрасываются.
Далее, до тех пор, пока в working table что-то есть, выполняется recursive term:
SELECT e.»id», e.»next» FROM tmp t
INNER JOIN events e ON e.»id» = t.»next»
Здесь tmp как раз ссылается на working table. То есть, делается обычный INNER JOIN двух таблиц. Строки, которые вернет этот запрос, добавляются к результату рекурсивного запроса.
UNION или UNION ALL.Таким образом, WITH RECURSIVE часть запроса выполняет обход двухсвязного списка, возвращая все элементы, начиная с заданного. Нам остается лишь сделать SELECT ... OFFSET ... LIMIT ... по этим элементам, и мы получаем результат.
Вдумчивый читатель мог обратить внимание на одну проблему. Дело в том, что, если читать запрос буквально, то рекурсивная часть сканирует все события до тех пор, пока они не закончатся. Затем из найденных событий мы отбрасываем все, кроме одного, которое нас интересовало. В зависимости от версии PostgreSQL, накопленной статистики, а также положения звезд на небе, планировщик не обязательно окажется достаточно умен для того, чтобы не сканировать все события. Поэтому будет не самой плохой идеей явно ограничить глубину рекурсии.
Сделать это можно так:
примеров кейсов Postgres | ObjectRocket
Введение
Если вы когда-либо писали код, вы знакомы с условными выражениями, такими как IF / ELSE и SWITCH корпуса. Эти выражения используются не только в программировании — мы также можем использовать оператор IF / ELSE в PostgreSQL. PostgreSQL CASE — это еще один тип условных выражений, используемых в PostgreSQL. Это выражение использует структуру WHEN - THEN , которая похожа на классический оператор IF / ELSE .Каждое условие в выражении возвращает логическое значение, равное ИСТИНА или ЛОЖЬ . Как и оператор IF , оператор CASE также может иметь предложение ELSE для обработки ситуаций, когда логическое значение FALSE . В этой статье мы более подробно рассмотрим выражение Postgres CASE — оператор WHEN-THEN .
Предварительные требования
Для того, чтобы следовать примерам, обсуждаемым в этой статье, на вашем компьютере должен быть установлен PostgreSQL.Вам также потребуются некоторые практические знания PostgreSQL, чтобы понять инструкции и примеры.
PostgreSQL «КОГДА» case
Ниже приведен простой пример синтаксиса CASE
1 | CASE WHEN условие THEN result_1 |
Ниже показан простой пример синтаксиса CASE , используемого в операторе SELECT :
1 | SELECT |
PostgreSQL, пример «CASE»
Наш следующий пример будет немного более сложным. Мы будем использовать таблицу
Мы будем использовать таблицу Student , показанную ниже, которая содержит идентификатор, имя и оценку учащихся:
1 | id | имя | класс |
PostgreSQL, пример «INSERT INTO»
Если вы хотите создать этот образец таблицы, чтобы использовать его вместе с нашими примерами, вам сначала потребуется база данных PostgreSQL. После создания базы данных с использованием ключевых слов
После создания базы данных с использованием ключевых слов CREATE DATABASE SQL вы можете подключиться к ней с помощью команды \ c . После этого вы можете использовать следующий оператор CREATE TABLE для создания таблицы для данных:
1 | СОЗДАТЬ ТАБЛИЦУ ученик |
Он должен ответить CREATE TABLE , если команда была успешной.Затем вы можете использовать следующий оператор SQL, чтобы вставить некоторые тестовые данные для использования в запросе CASE WHEN :
1 | ВСТАВИТЬ ученика (идентификатор, имя, класс) |
Этот оператор SQL должен вернуть ответ INSERT 0 13 , указывающий, что в таблицу было вставлено 13 записей.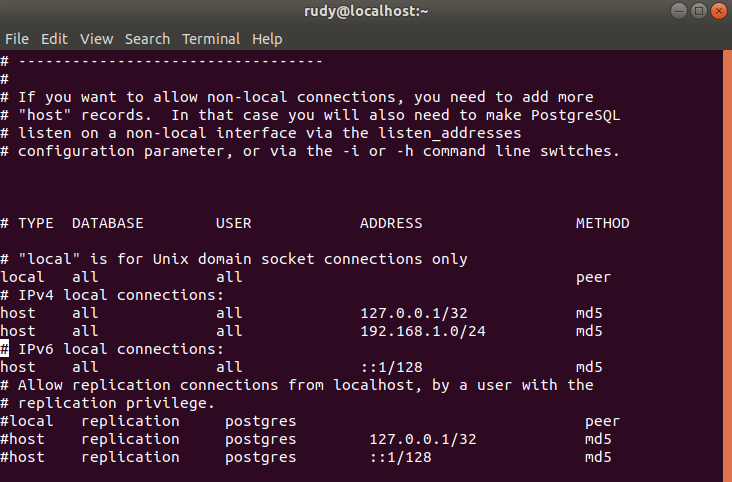
Postgres «CASE WHEN», пример
Давайте представим, что вымышленные ученики в нашей таблице посещают школу, которая предоставляет стипендии ученикам, чей класс 90 и выше. Мы можем использовать CASE WHEN для выбора только записей с оценками больше или равными 90 :
1 | ВЫБРАТЬ имя, оценка, |
Результатом этого запроса будет:
1 | имя | сорт | aspiring_scholar |
Используя оператор CASE , вы также можете получить сумму и легко сравнить данные:
1 | ВЫБРАТЬ |
Результат вышеуказанного запроса будет выглядеть так:
1 | ученых | non_scholars |
Как видите, оператор SQL CASE WHEN очень полезен для запроса данных и организации результатов таким образом, чтобы отражать тонкие различия в значениях записей.
Заключение
Условные выражения являются ключевым компонентом логики программирования, но они также могут играть важную роль в запросах к базе данных. В этой статье мы обсудили оператор Postgres CASE и рассмотрели несколько примеров того, как это условное выражение может использоваться в запросах. С нашими примерами и инструкциями, которые помогут вам, вы сможете включить оператор Postgres CASE в свои собственные запросы к базе данных.
Заявление CASEPostgreSQL | Руководство по PostgreSQL CASE (блок-схема)
Введение в PostgreSQL Заявление CASE
Оператор case PostgreSQL аналогичен оператору if-else, определенному в других языках, таких как C и C ++.PostgreSQL предоставляет две формы или типы оператора case, первый — это оператор case общей формы, а второй — простая форма оператора case. Мы можем использовать оператор case в PostgreSQL, используя ключевое слово when and then, например if и else в других языках программирования. Оператор case очень важен в PostgreSQL для формулирования условного выражения, мы формулируем условное выражение, используя ключевое слово when и then в PostgreSQL.
Оператор case очень важен в PostgreSQL для формулирования условного выражения, мы формулируем условное выражение, используя ключевое слово when и then в PostgreSQL.
Синтаксис
Ниже приведен синтаксис оператора case.
1. Выражение общего случая
Ниже синтаксис показан общий случай выражения.
- CASE (начало оператора Case)
- WHEN (Когда ключевое слово используется для формулирования условия) condition_1 THEN (Then ключевое слово, используемое для формулирования условия) result_1 (Результат первого оператора case)
- WHEN (Когда ключевое слово используется для формулирования условия) condition_2 THEN (Then ключевое слово, используемое для формулирования условия) result_2 (Результат второго оператора case)
- [КОГДА…] (Мы можем использовать несколько условий в одном операторе case)
- [ELSE result_n] (Если результат оператора case не работает, выполните этот оператор)
- END (оператор конца регистра)
2. Простое падежное выражение
Простое падежное выражение
Синтаксис ниже показывает простое выражение регистра.
- Выражение CASE
- WHEN (Когда ключевое слово используется для формулировки условия) value_1 THEN (Then ключевое слово используется для формулирования условия)
- result_1 (Результат первого оператора case)
- WHEN (Когда ключевое слово используется для формулирования условия) value_2 THEN (Then ключевое слово используется для формулирования условия)
- результат_2 (результат второго оператора case)
- [КОГДА…] (Мы можем использовать несколько условий в одном операторе case)
- ELSE
- result_n
- КОНЕЦ; (инструкция в конце регистра)
Параметр
Ниже приводится описание параметра синтаксиса выше.
- Case: Мы можем запустить оператор case в PostgreSQL, используя ключевое слово case.
 Тело оператора case начинается с case и заканчивается ключевым словом END.
Тело оператора case начинается с case и заканчивается ключевым словом END. - Когда: Когда ключевое слово используется для формулирования условия оператора case в PostgreSQL.
- Then: Ключевое слово Then используется для формулирования условия оператора case в PostgreSQL.
- Условие 1 и условие 2: Мы можем использовать оператор условия для получения результата данных.Если одно условие не выполняется, триггер переходит на второй, если оно истинно, он отображает результат всех условий.
- Результат 1 к результату N: Это фактический результат оператора case в PostgreSQL.
- Else: Ключевое слово Else используется для определения истинного или ложного условия в операторе case. Если условие оператора case ложно, тогда будет выполняться часть else, в противном случае она не будет выполняться.
- End: Мы можем завершить оператор case в PostgreSQL, используя ключевое слово end.
 Тело оператора case начинается с
Тело оператора case начинается с
Как работать с управляющими структурами в хранимых процедурах PostgreSQL: Использование операторов IF, CASE и LOOP
РЕЗЮМЕ: В этой статье рассматриваются управляющие структуры, которые можно использовать в хранимых процедурах PostgreSQL, с синтаксисом и примерами для каждой из них.
1. Операторы IF
а. Простые операторы IF
г. Операторы IF-THEN-ELSE
2. Операторы CASE
3. Операторы LOOP
Хранимые процедуры в PostgreSQL — это те, которые определяют функцию для создания триггеров или пользовательских функций.В PostgreSQL есть три основных типа управляющих структур для использования с хранимыми процедурами: IF, CASE и LOOP.
Операторы IF
1. Простые операторы ЕСЛИ
Синтаксис
ЕСЛИ условие ТО
заявление;
КОНЕЦ ЕСЛИ; Условие IF выполняется, когда условие оценивается как истинное. Если условие ложно, оно переходит к следующему оператору после END IF.
Пример
DO $$
ЗАЯВИТЬ
целое число x: = 10;
y целое: = 20;
НАЧАТЬ
ЕСЛИ x> y ТО
ПОДНЯТЬ УВЕДОМЛЕНИЕ 'x больше, чем y';
КОНЕЦ ЕСЛИ;
ЕСЛИ x В приведенном выше примере в начале объявляются 2 переменные.X и y были присвоены значения. То есть x = 10 и y = 20.
Далее, есть три условия: когда x больше y, x меньше y, и x равно y. В зависимости от выполнения условия будет выведено уведомление - в этом случае «x меньше y».
2. Операторы IF-THEN-ELSE
Синтаксис
ЕСЛИ условие ТО
заявления;
ELSE
дополнительные заявления;
КОНЕЦ ЕСЛИ; Пример
DO $$
ЗАЯВИТЬ
целое число x: = 10;
y целое: = 20;
НАЧАТЬ
ЕСЛИ x> y ТО
ПОДНЯТЬ УВЕДОМЛЕНИЕ 'x больше, чем y';
ELSE
ПОДНЯТЬ УВЕДОМЛЕНИЕ 'x не больше, чем y';
КОНЕЦ ЕСЛИ;
END $$; Как и в первом примере, здесь в начале объявлены 2 переменные: x = 10 и y = 20.
Далее, есть одно условие: когда x больше y, возникает заметка, что «x больше y». Когда это условие не выполняется, возникает предупреждение: «x не больше y». В этом случае условие не выполняется, поэтому выполняется предложение ELSE и печатается вывод для части ELSE.
Операторы CASE
Оператор CASE использует логику IF-THEN-ELSE в одном операторе. Он упрощает выполнение условных запросов, выполняя работу оператора IF-THEN-ELSE и применяя его ко многим возможным условиям.
Синтаксис
CASE условие
WHEN значение условия THEN выражение
ELSE дополнительное заявление; Пример
Мы можем использовать CASE для оценки нескольких условий для одной переменной job_id. Если «job_id» - «ACCOUNT», увеличение заработной платы составляет 10%; если job_id равен IT_PROG, зарплата увеличивается на 15%; если «job_id» - «ПРОДАЖИ», зарплата увеличивается на 20%. Для всех остальных должностей повышение зарплаты не производится.
ВЫБЕРИТЕ last_name, job_id, salary,
CASE job_id
КОГДА "АККАУНТ" ТО 1.10 * зарплата
КОГДА 'IT_PROG' ТО 1.15 * зарплата
КОГДА "ПРОДАЖА" ТОГДА 1,20 * зарплата
ELSE зарплата END "REVISED_SALARY" ОТ сотрудников; Операторы LOOP
Синтаксис
ПЕТЛЯ
<запуск блока выполнения>
<Условие выхода на основе требования>
КОНЕЦ ПЕТЛИ; Ключевое слово LOOP объявляет начало цикла, а END LOOP объявляет конец цикла. Блок выполнения содержит весь код, который необходимо выполнить, включая условие EXIT.
Пример
DO $$
ЗАЯВИТЬ
НОМЕР: = 1;
НАЧАТЬ
ПОДНИМАТЬ УВЕДОМЛЕНИЕ «Цикл запущен.»;
ПЕТЛЯ
ПОДНЯТЬ УВЕДОМЛЕНИЕ 'a';
а: = а + 1;
ВЫЙТИ, ЕСЛИ a> 5;
КОНЕЦ ПЕТЛИ;
ПОДНИМАТЬ УВЕДОМЛЕНИЕ «Цикл завершен»;
КОНЕЦ;
END $$; CASE с набором функций возврата в PostgreSQL 10
Одно из изменений, которые появятся в PostgreSQL 10, - это возможность CASE . . WHEN
оператор для возврата нескольких строк, если выражение содержит функцию возврата набора.Чтобы продемонстрировать эту функцию,
мы будем использовать классическую функцию generate_series:
. WHEN
оператор для возврата нескольких строк, если выражение содержит функцию возврата набора.Чтобы продемонстрировать эту функцию,
мы будем использовать классическую функцию generate_series:
generate_series с CASE WHEN
SELECT CASE generate_series (1,10) WHEN 1 THEN 'Первый' ELSE 'Не первый' END; В PostgreSQL 10 это возвращает:
чехол ----------- Первый Не первый Не первый Не первый Не первый Не первый Не первый Не первый Не первый Не первый (10 рядов)
В PostgreSQL 9.6 и ниже вы получите сообщение об ошибке:
ОШИБКА: функция с множеством значений, вызванная в контексте, который не может принять набор
Интересно, а чем это полезно? Зачем мне делать это вместо чего-то вроде этого, которое будет работать во всех версиях?
ВЫБРАТЬ СЛУЧАЙ i КОГДА 1 ТОГДА «Первый» Иначе «Не первый» КОНЕЦ
FROM generate_series (1,10) AS i; Ответ, кажется, читается из примечаний к фиксации,
что это побочный эффект других оптимизаций и введения нового узла исполнителя ProjectSet.
В качестве побочного эффекта ранее запрещенный случай возврата нескольких наборов аргументы функции, теперь разрешено. Не потому, что это особенно желательно, но потому что он работает и, кажется, нет аргументов для добавления кода, запрещающего это.
В настоящее время поведение COALESCE и CASE, содержащих SRF, изменилось. возвращает несколько строк из выражения, даже если SRF, содержащий «рука» выражения не оценивается.Это потому, что SRF оценивается в отдельном узле ProjectSet. Поскольку это довольно сбивает с толку, мы скорее всего, вместо этого запретит SRF в этих местах. Но это все еще обсуждалось, и код будет находиться в местах, не затронутых здесь, так что задача на потом.
Тем не менее, следует отметить, что новый подход, если вы хотите сделать что-то вроде безумного, действительно кажется быстрее, чем стандартный подход.
Вот небольшой тест, который я сделал, чтобы сравнить результаты и время:
Новая функция:
ВЫБРАТЬ количество (*)
FROM (SELECT CASE generate_series (1,10000000) WHEN 1 THEN 'First' ELSE 'Not First' END) AS f; Использует эту новую вещь, называемую исполнителем ProjectSet, и занимает ~ 1 секунду
Совокупный (стоимость = 32.52..32,53 ряда = 1 ширина = 8) (фактическое время = 1036,048..1036,048 рядов = 1 петля = 1) Вывод: количество (*) -> Результат (стоимость = 0,00..20,02 рядов = 1000 ширина = 32) (фактическое время = 0,004..722,375 рядов = 10000000 петель = 1) Вывод: CASE (generate_series (1, 10000000)) WHEN 1 THEN 'First' :: text ELSE 'Not First' :: text END -> ProjectSet (стоимость = 0,00..5,02 строк = 1000 ширина = 4) (фактическое время = 0,002..329,822 строк = 10000000 петель = 1) Вывод: generate_series (1, 10000000) -> Результат (стоимость = 0.00..0.01 рядов = 1 ширина = 0) (фактическое время = 0.000..0.001 рядов = 1 петля = 1) Время планирования: 0,034 мс Время выполнения: 1036.082 мс
Старый добрый способ обратной совместимости:
ВЫБРАТЬ количество (*)
ОТ (ВЫБЕРИТЕ СЛУЧАЙ i КОГДА 1 ЗАТЕМ «Первый» ИЛИ «Не первый» КОНЕЦ
FROM generate_series (1,10000000) AS i) AS f; Агрегат (стоимость = 12,50..12,51 строки = 1 ширина = 8) (фактическое время = 1800,258..1800,259 рядов = 1 петля = 1) Вывод: количество (*) -> Сканирование функций в pg_catalog.generate_series i (стоимость = 0,00..10,00 строк = 1000 ширина = 0) (фактическое время = 863,841..1469,087 рядов = 10000000 петель = 1) Выход: i.i Вызов функции: generate_series (1, 10000000) Время планирования: 0,032 мс Время выполнения: 1818,415 мс
Вау, это намного медленнее.
Что мне нравится в PostgreSQL, чего вам не хватает в проектах с закрытым исходным кодом и даже в других проектах с открытым исходным кодом, так это то, что когда вам интересно узнать о новой функции или почему это там, есть много диалогов в списке хакеров и журналы фиксации, чтобы вас развлечь.
PostgreSQL КЕЙС: programming-lang.com
КОРПУС
SQL, , PostgreSQL CASE, SQL SQL CASE, КОГДА, ЗАТЕМ КОНЕЦ .
CASE SELECT.
CASE случай,
,. ВЫБОР ДЕЛА:
ВЫБОР ДЕЛА:
ДЕЛО КОГДА! ТОГДА ! КОГДА 2 ТО 2
[...]
[ELSE __ END [AS]
CASE-WHEN-THEN-ELSE f-then-else (4.50). КОГДА .
КОГДА, ТОГДА . , Иначе. Иначе, NULL.
4,50. ДЕЛО
booktown = # SELECT isbn,
booktown- # CASE WHEN cost> 20 THEN 'более 20 долларов США'
booktown- # WHEN cost = 20 THEN '$ 20.00 cost1
книжный городок - № ELSE «до 20 долларов США»
booktown- # END AS диапазон_ затрат
booktown- # со склада
booktown- # LIMIT 8;
Исбн | диапазон_ затрат
0385121679 | более 20 долларов.00 стоимость
039480001X | более $ 20.00 стоимость
044100590X | свыше $ 20,00 стоимость
0451198492 | более $ 20.00 стоимость
03944 | свыше $ 20,00 стоимость
0441172717 | до $ 20. 00 стоимость
00 стоимость
0451160916 | свыше $ 20,00 стоимость
0679803335 | 20 долларов США стоимость
(8 рядов)
PostgreSQL CASE (. «»).4.51, .
4.51. ДЕЛО
booktown = # SELECT isbn,
booktown- # CASE WHEN cost> 20 THEN 'N / A - (Вне цены диапазон) '
booktown- # ELSE (ВЫБЕРИТЕ название ИЗ книг b ПРИСОЕДИНЯЙТЕСЬ к выпускам e
книжный городок (# ON (b.id = e.book_id)
книжный город (# WHERE e.isbn = stock.isbn)
booktown- # END AS диапазон_ затрат
booktown- # со склада
книжный городок- № ЗАКАЗАТЬ по диапазону_оценки ASC
booktown- # LIMIT 8;
исбн | диапазон_ затрат
0451457994 | 2001: Космическая одиссея
0394800753 | Варфоломей и Облек
0441172717 | Дюна
0760720002 | Маленькие женщины
0385121679 | N / A - (Вне ценового диапазона)
039480001X | N / A - (Вне ценового диапазона)
044100590X | N / A - (Вне ценового диапазона)
0451198492 | N / A - (Вне ценового диапазона)
(8 рядов)
, 20, г. (книги) ISBN (
акции).
О чувствительности к регистру в PostgreSQL - Блог Xojo
Я и раньше сталкивался с чувствительностью к регистру PostgreSQL, и я видел, как это поднималось на форумах, поэтому я подумал, что, возможно, стоит упомянуть здесь.
Иногда можно услышать, что PostgreSQL нечувствителен к регистру, но на самом деле это не так. На самом деле он по умолчанию преобразует ваш SQL в нижний регистр. Так что взгляните на этот SQL:
ВЫБРАТЬ ФИО ОТ ЛИЦА
Преобразуется в:
ВЫБЕРИТЕ полное имя ОТ человека
Это хорошо, если вам нравится писать запросы в смешанном регистре.
Но вы столкнетесь с проблемой, если действительно создали таблицу с именами с учетом регистра, что происходит, когда вы используете кавычки вокруг имен. Например, рассмотрим эти операторы SQL CREATE:
CREATE TABLE person (полное имя VARCHAR (100), адрес VARCHAR (100))
CREATE TABLE Person (FullName VARCHAR (100), Address VARCHAR (100))
СОЗДАТЬ ТАБЛИЦУ «Человек» («Полное имя» VARCHAR (100), «Адрес» VARCHAR (100))
В первых двух примерах вы получаете таблицу под названием «человек» с двумя столбцами, называемыми «полное имя» и «адрес». Это может быть неочевидно во втором примере, поскольку имена не строчные, но помните, что PostgreSQL преобразует ваш SQL в нижний регистр за вас.
Это может быть неочевидно во втором примере, поскольку имена не строчные, но помните, что PostgreSQL преобразует ваш SQL в нижний регистр за вас.
В последнем примере имена заключены в кавычки, поэтому их регистр сохраняется. Это означает, что вы получите таблицу под названием «Человек» с двумя столбцами: «Полное имя» и «Адрес». Что произойдет, если вы попытаетесь выполнить запрос с таблицей под названием «Человек»? Ну, используя SQL вот так:
ВЫБРАТЬ ФИО ОТ ЛИЦА
, вы получите синтаксическую ошибку:
ОШИБКА: связь «человек» не существует
СТРОКА 1: ВЫБРАТЬ FullName FROM Person
Это связано с тем, что PostgreSQL преобразует «Person» в «person», но таблицы с именем «person» нет.На самом деле он называется «Человек».
Чтобы избежать этой ошибки, вместо этого вам нужно написать SQL в кавычках, например:
ВЫБЕРИТЕ «FullName» из «Person»
Очевидно, это может стать немного неудобно, поэтому мораль этой истории - не использовать кавычки при создании таблиц или написании SQL-запросов, чтобы все было создано в нижнем регистре, и все будет работать так, как вы, вероятно, ожидаете.