PostgreSQL оператор Joins — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
В этом учебном пособии вы узнаете, как использовать PostgreSQL JOINS (внутренний и внешний) с синтаксисом, наглядными иллюстрациями и примерами.
Описание
PostgreSQL JOINS используется для извлечения данных из нескольких таблиц. PostgreSQL JOIN выполняется всякий раз, когда две или более таблицы объединяются в операторе SQL.
Существуют разные типы соединений PostgreSQL:
- PostgreSQL INNER JOIN (или иногда называется простым соединением)
- PostgreSQL LEFT OUTER JOIN (или иногда называется LEFT JOIN
- PostgreSQL RIGHT OUTER JOIN (или иногда называется RIGHT JOIN
- PostgreSQL FULL OUTER JOIN (или иногда называется FULL JOIN
Итак, давайте обсудим синтаксис JOIN в PostgreSQL, посмотрим на визуальные иллюстрации JOIN в PostgreSQL и рассмотрим примеры JOIN.
INNER JOIN (простое соединение)
Скорее всего, вы уже написали запрос, который использует PostgreSQL INNER JOIN. Это самый распространенный тип соединения. INNER JOIN возвращают все строки из нескольких таблиц, где выполняется условие соединения.
Это самый распространенный тип соединения. INNER JOIN возвращают все строки из нескольких таблиц, где выполняется условие соединения.
Синтаксис
Синтаксис для INNER JOIN в PostgreSQL:
SELECT columns FROM table1 INNER JOIN table2 ON table1.column = table2.column;
SELECT columns FROM table1 INNER JOIN table2 ON table1.column = table2.column; |
Визуальная Иллюстрация
На этой визуальной диаграмме PostgreSQL INNER JOIN возвращает затененную область:
PostgreSQL INNER JOIN будет возвращать записи, где пересекаются table1 и table2.
Пример
Вот пример INNER JOIN PostgreSQL:
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers INNER JOIN orders ON suppliers.supplier_id = orders.supplier_id;
SELECT suppliers. FROM suppliers INNER JOIN orders ON suppliers.supplier_id = orders.supplier_id; |
 supplier_id, suppliers.supplier_name, orders.order_date
supplier_id, suppliers.supplier_name, orders.order_dateЭтот пример PostgreSQL INNER JOIN вернет все строки из таблиц suppliers и orders, где в таблицах suppliers и orders есть соответствующее значение supplier_id.
Давайте посмотрим на некоторые данные, чтобы объяснить, как работают внутренние соединения:
У нас есть таблица suppliers с двумя полями (supplier_id и supplier_name). Она содержит следующие данные:
| supplier_id | supplier_name |
|---|---|
| 10000 | IBM |
| 10001 | Hewlett Packard |
| 10002 | Microsoft |
| 10003 | NVIDIA |
У нас есть еще одна таблица под названием orders с тремя полями (order_id, supplier_id и order_date). Она содержит следующие данные:
| order_id | supplier_id | order_date |
|---|---|---|
| 500125 | 10000 | 10. 04.2019 04.2019 |
| 500126 | 10001 | 20.04.2019 |
| 500127 | 10004 | 30.04.2019 |
Если мы запустим оператор PostgreSQL SELECT (который содержит INNER JOIN) ниже:
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers INNER JOIN orders ON suppliers.supplier_id = orders.supplier_id;
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers INNER JOIN orders ON suppliers.supplier_id = orders.supplier_id; |
Наш набор результатов будет выглядеть так:
| supplier_id | name | order_date |
|---|---|---|
| 10000 | IBM | 10.04.2019 |
| 10001 | Hewlett Packard | 20.04.2019 |
Строки для ‘Microsoft’ и ‘NVIDIA’ из таблицы suppliers будут опущены, поскольку 10002 и 10003 supplier_id не существуют в обеих таблицах. Строка для 500127 (order_id) из таблицы orders будет опущена, так как supplier_id 10004 не существует в таблице suppliers.
Строка для 500127 (order_id) из таблицы orders будет опущена, так как supplier_id 10004 не существует в таблице suppliers.
Старый синтаксис
В завершение стоит упомянуть, что приведенный выше пример INGER JOIN PostgreSQL можно переписать с использованием более старого неявного синтаксис следующим образом (но мы все же рекомендуем использовать синтаксис c ключевыми словами INNER JOIN):
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers, orders WHERE suppliers.supplier_id = orders.supplier_id;
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date FROM suppliers, orders WHERE suppliers.supplier_id = orders.supplier_id; |
LEFT OUTER JOIN
Другой тип соединения называется PostgreSQL LEFT OUTER JOIN. Этот тип соединения возвращает все строки из таблиц с левосторонним соединением, указанным в условии ON, и только те строки из другой таблицы, где объединяемые поля равны (выполняется условие соединения).
Синтаксис
Синтаксис для PostgreSQL LEFT OUTER JOIN:
SELECT columns
FROM table1
LEFT OUTER JOIN table2
ON table1.column = table2.column;
Визуальная Иллюстрация
На этой визуальной диаграмме PostgreSQL LEFT OUTER JOIN возвращает затененную область:
PostgreSQL LEFT OUTER JOIN будет возвращать все записи из table1 и только те записи из table2, которые пересекаются с table1.
Пример
Вот пример PostgreSQL LEFT OUTER JOIN:
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date
FROM suppliers
LEFT OUTER JOIN orders
ON suppliers.supplier_id = orders.supplier_id;
В этом примере LEFT OUTER JOIN будут возвращены все строки из таблицы employees и только те строки из таблицы orders, где объединенные поля равны.
Если значение supplier_id в таблице employees не существует в таблице orders, все поля в таблице orders будут отображаться как в результирующем наборе.
Рассмотрим некоторые данные, чтобы объяснить, как работают LEFT OUTER JOINS:
У нас есть таблица suppliers с двумя полями (supplier_id и supplier_name). Она содержит следующие данные:
Она содержит следующие данные:
| supplier_id | supplier_name |
|---|---|
| 10000 | IBM |
| 10001 | Hewlett Packard |
| 10002 | Microsoft |
| 10003 | NVIDIA |
У нас есть вторая таблица с именем orders с тремя полями (order_id, supplier_id и order_date). Она содержит следующие данные:
| order_id | supplier_id | order_date |
|---|---|---|
| 500125 | 10000 | 10.04.2019 |
| 500126 | 10001 | 20.04.2019 |
Если мы запустим оператор SELECT (который содержит LEFT OUTER JOIN) ниже:
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date
FROM suppliers
LEFT OUTER JOIN orders
ON suppliers.supplier_id = orders.supplier_id;
Наш набор результатов будет выглядеть так:
| supplier_id | supplier_name | order_date |
|---|---|---|
| 10000 | IBM | 10. 04.2019 04.2019 |
| 10001 | Hewlett Packard | 20.04.2019 |
| 10002 | Microsoft | |
| 10003 | NVIDIA |
Строки для ‘Microsoft’ и ‘NVIDIA’ будут включены, потому что использовался LEFT OUTER JOIN. Однако вы заметите, что поле order_date для этих записей содержит значение .
RIGHT OUTER JOIN
Другой тип соединения называется PostgreSQL RIGHT OUTER JOIN. Этот тип соединения возвращает все строки из таблицы с правосторонним соединением, указанной в условии ON, и только те строки из другой таблицы, где соединенные поля равны (выполняется условие соединения).
Синтаксис
Синтаксис для PostgreSQL RIGHT OUTER JOIN:
SELECT columns
FROM table1
RIGHT OUTER JOIN table2
ON table1.column = table2.column;
Визуальная Иллюстрация
На этой визуальной диаграмме PostgreSQL RIGHT OUTER JOIN возвращает заштрихованную область:
PostgreSQL RIGHT OUTER JOIN будет возвращать все записи из table2 и только те записи из table1, которые пересекаются с table2.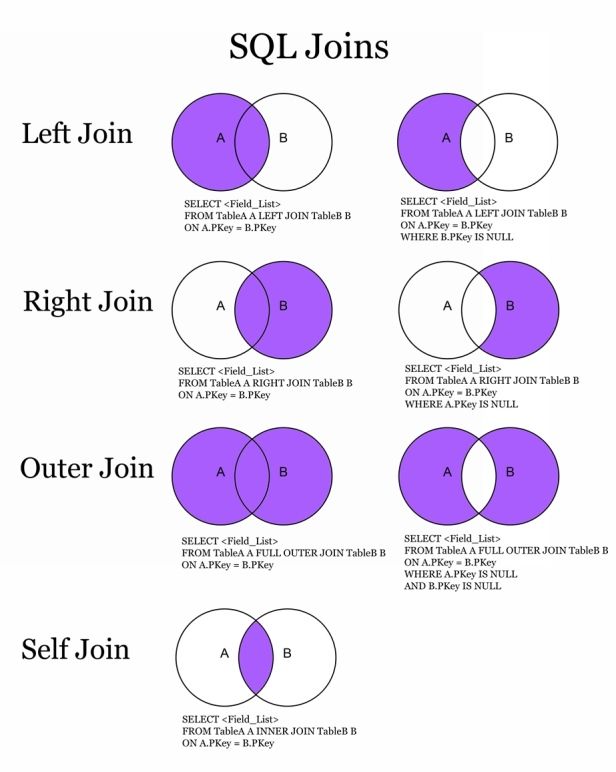
Пример
Вот пример RIGHT OUTER JOIN для PostgreSQL:
SELECT orders.order_id, orders.order_date, suppliers.supplier_name
FROM suppliers
RIGHT OUTER JOIN orders
ON suppliers.supplier_id = orders.supplier_id;
В этом примере RIGHT OUTER JOIN будет возвращать все строки из таблицы orders и только те строки из таблицы suppliers, где соединенные поля равны.
Если значение supplier_id в таблице orders не существует в таблице suppliers, все поля таблицы suppliers будут отображаться как в результирующем наборе.
Давайте посмотрим на некоторые данные, чтобы объяснить, как работают RIGHT OUTER JOINS:
У нас есть таблица suppliers с двумя полями (supplier_id и supplier_name). Она содержит следующие данные:
| supplier_id | supplier_name |
|---|---|
| 10000 | Yandex |
| 10001 |
У нас есть вторая таблица с именем orders с тремя полями (order_id, supplier_id и order_date). Она содержит следующие данные:
Она содержит следующие данные:
| order_id | supplier_id | order_date |
|---|---|---|
| 500125 | 10000 | 10.04.2019 |
| 500126 | 10001 | 20.04.2019 |
| 500127 | 10002 | 30.04.2019 |
Если мы запустим оператор SELECT (который содержит RIGHT OUTER JOIN) ниже:
SELECT orders.order_id, orders.order_date, suppliers.supplier_name
FROM suppliers
RIGHT OUTER JOIN orders
ON suppliers.supplier_id = orders.supplier_id;
Наш набор результатов будет выглядеть так:
| order_id | order_date | supplier_name |
|---|---|---|
| 500125 | 10.04.2019 | Yandex |
| 500126 | 20.04.2019 | |
| 500127 | 30.04.2019 |
Строка для 500127 (order_id) будет включена, поскольку используется RIGHT OUTER JOIN. Однако вы заметите, что поле supplier_name для этой записи содержит значение.
Однако вы заметите, что поле supplier_name для этой записи содержит значение.
FULL OUTER JOIN
Другой тип соединения называется PostgreSQL FULL OUTER JOIN. Этот тип соединения возвращает все строки из левой таблицы и правой таблицы с NULL — значениями в месте, где условие соединения не выполняется.
Синтаксис
Синтаксис для PostgreSQL FULL OUTER JOIN:
SELECT columns
FROM table1
FULL OUTER JOIN table2
ON table1.column = table2.column;
Визуальная Иллюстрация
На этой визуальной диаграмме PostgreSQL FULL OUTER JOIN возвращает затененную область:
PostgreSQL FULL OUTER JOIN будет возвращать все записи из table1 и table2.
Пример
Рассмотрим пример FULL OUTER JOIN в PostgreSQL :
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date
FROM suppliers
FULL OUTER JOIN orders
ON suppliers.supplier_id = orders.supplier_id;
Этот пример FULL OUTER JOIN будет возвращать все строки из таблицы suppliers и все строки из таблицы orders и всякий раз, когда условие соединения не выполняется, то поля в результирующем наборе будут принимать значения .
Если значение supplier_id в таблице suppliers не существует в таблице orders, все поля в таблице orders будут отображаться как в результирующем наборе. Если значение supplier_id в таблице orders не существует в таблице suppliers, все поля в таблице suppliers будут отображаться как в результирующем наборе.
Давайте посмотрим на некоторые данные, чтобы объяснить, как работают FULL OUTER JOINS:
У нас есть таблица suppliers с двумя полями (supplier_id и supplier_name). Она содержит следующие данные:
| supplier_id | supplier_name |
|---|---|
| 10000 | IBM |
| 10001 | Hewlett Packard |
| 10002 | Microsoft |
| 10003 | NVIDIA |
У нас есть вторая таблица с именем orders с тремя полями (order_id, supplier_id и order_date). Она содержит следующие данные:
| order_id | supplier_id | order_date |
|---|---|---|
| 500125 | 10000 | 10.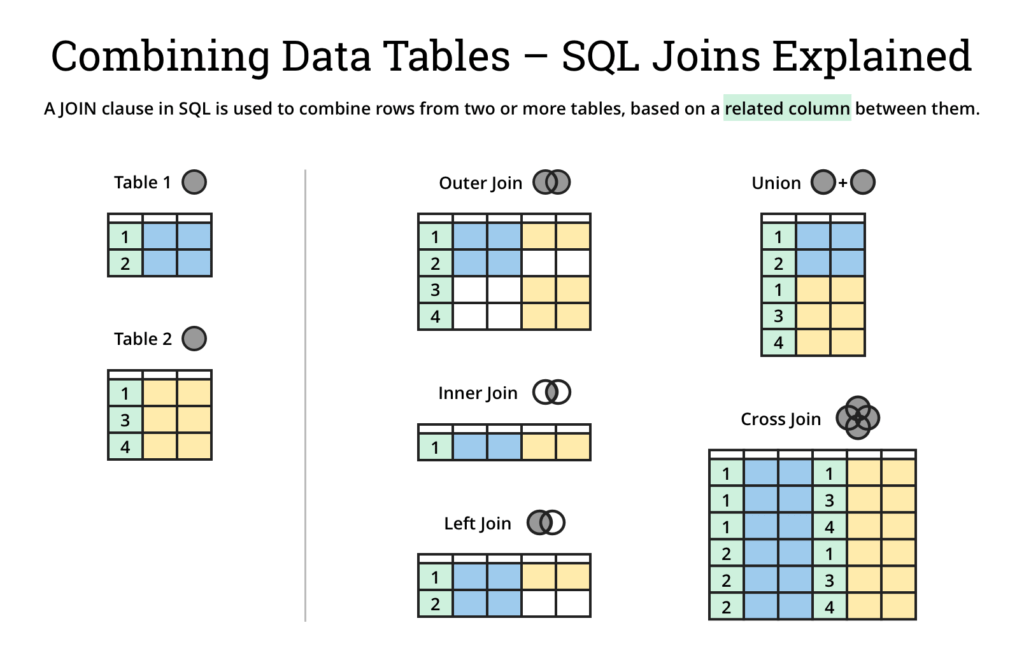 04.2019 04.2019 |
| 500126 | 10001 | 20.04.2019 |
| 500127 | 10004 | 30.04.2019 |
Если мы запустим SQL запрос (который содержит FULL OUTER JOIN) ниже:
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date
FROM suppliers
FULL OUTER JOIN orders
ON suppliers.supplier_id = orders.supplier_id;
Наш набор результатов будет выглядеть так:
| supplier_id | supplier_name | order_date |
|---|---|---|
| 10000 | IBM | 10.04.2019 |
| 10001 | Hewlett Packard | 20.04.2019 |
| 10002 | Microsoft | |
| 10003 | NVIDIA | |
| 30.04.2019 |
Строки для ‘Microsoft’ и ‘NVIDIA’ будут включены, поскольку использовался FULL OUTER JOIN. Однако вы заметите, что поле order_date для этих записей содержит значение.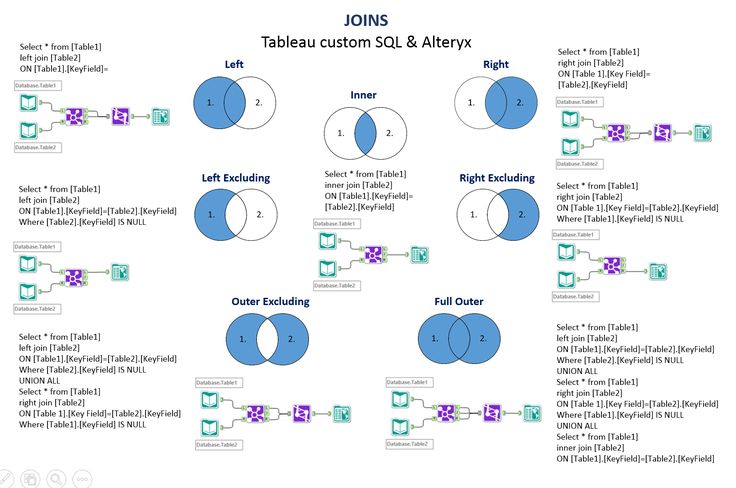
Строка для supplier_id 10004 также будет включена, поскольку используется FULL OUTER JOIN. Тем не менее, вы заметите, что поля supplier_id и supplier_name для этих записей содержат значение.
вредные JOIN и OR / Хабр
Бойтесь операций, buffers приносящих…
На примере небольшого запроса рассмотрим некоторые универсальные подходы к оптимизации запросов на PostgreSQL. Пользоваться ими или нет — выбирать вам, но знать о них стоит.
В каких-то последующих версиях PG ситуация может измениться с «поумнением» планировщика, но для 9.4/9.6 она выглядит примерно одинаково, как примеры тут.
Возьму вполне реальный запрос:
SELECT
TRUE
FROM
"Документ" d
INNER JOIN
"ДокументРасширение" doc_ex
USING("@Документ")
INNER JOIN
"ТипДокумента" t_doc ON
t_doc."@ТипДокумента" = d."ТипДокумента"
WHERE
(d."Лицо3" = 19091 or d."Сотрудник" = 19091) AND
d."$Черновик" IS NULL AND
d."Удален" IS NOT TRUE AND
doc_ex.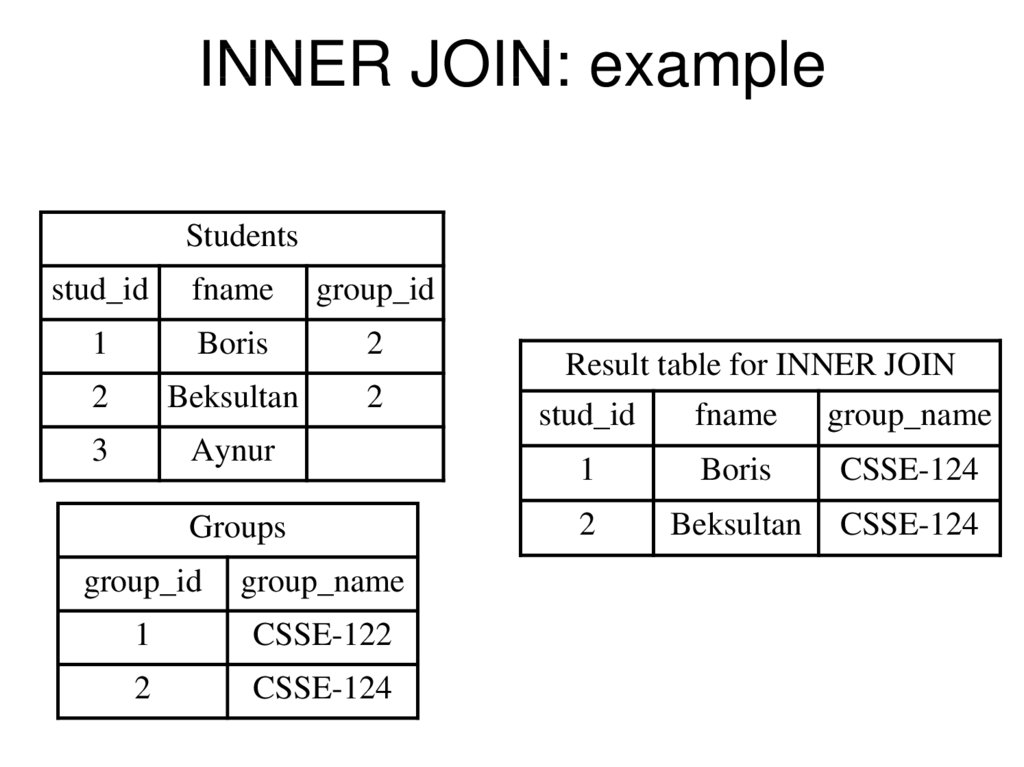 "Состояние"[1] IS TRUE AND
t_doc."ТипДокумента" = 'ПланРабот'
LIMIT 1;
"Состояние"[1] IS TRUE AND
t_doc."ТипДокумента" = 'ПланРабот'
LIMIT 1;про имена таблиц и полей
К «русским» названиям полей и таблиц можно относиться по-разному, но это дело вкуса. Поскольку у нас в «Тензоре» нет разработчиков-иностранцев, а PostgreSQL позволяет нам давать названия хоть иероглифами, если они заключены в кавычки, то мы предпочитаем именовать объекты однозначно-понятно, чтобы не возникало разночтений.
Посмотрим на получившийся план:
[посмотреть на explain.tensor.ru]
144ms и почти 53K buffers — то есть больше 400MB данных! И нам повезет, если все они окажутся в кэше к моменту нашего запроса, иначе он станет в разы дольше при вычитывании с диска.
Алгоритм важнее всего!
Чтобы как-то оптимизировать любой запрос, надо сначала понять, что же он вообще должен делать.
Оставим пока за рамками этой статьи разработку самой структуры БД, и договоримся, что мы можем относительно «дешево» переписать запрос и/или накатить на базу какие-то нужные нам индексы.
Итак, запрос:
— проверяет существование хоть какого-то документа
— в нужном нам состоянии и определенного типа
— где автором или исполнителем является нужный нам сотрудник
JOIN + LIMIT 1
Достаточно часто разработчику проще написать запрос, где сначала делается соединение большого количества таблиц, а потом из всего этого множества остается одна-единственная запись. Но проще для разработчика — не значит эффективнее для БД.
В нашем случае таблиц было всего 3 — а какой эффект…
Давайте для начала избавимся от соединения с таблицей «ТипДокумента», а заодно подскажем базе, что у запись типа у нас уникальна (мы-то это знаем, а вот планировщик пока не догадывается):
WITH T AS (
SELECT
"@ТипДокумента"
FROM
"ТипДокумента"
WHERE
"ТипДокумента" = 'ПланРабот'
LIMIT 1
)
...
WHERE
d."ТипДокумента" = (TABLE T)
...Да, если таблица/CTE состоит из единственного поля единственной же записи, то в PG можно писать даже так, вместо
d."ТипДокумента" = (SELECT "@ТипДокумента" FROM T LIMIT 1)
«Ленивые» вычисления в запросах PostgreSQL
BitmapOr vs UNION
В некоторых случаях Bitmap Heap Scan будет стоить нам очень дорого — например, в нашей ситуации, когда достаточно много записей подпадает под требуемое условие. Получили мы его из-за OR-условия, превратившегося в BitmapOr-операцию в плане.
Вернемся к исходной задаче — надо найти запись, соответствующую
из условий — то есть незачем искать все 59K записей по обоим условиям. Есть способ отработать одно условие, а
ко второму перейти только когда по первому ничего не нашлось. Нам поможет такая конструкция:
(
SELECT
...
LIMIT 1
)
UNION ALL
(
SELECT
...
LIMIT 1
)
LIMIT 1
«Внешний» LIMIT 1 гарантирует, что поиск завершится при нахождении первой же записи.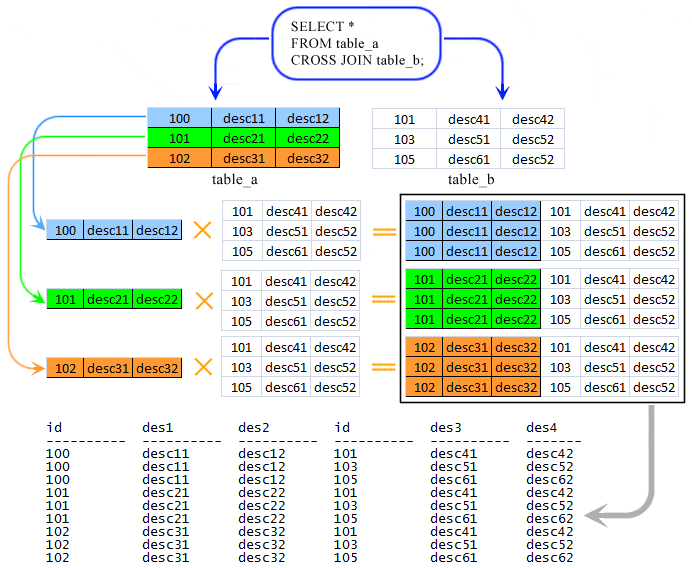 И если она найдется уже в первом блоке, выполнение второго осуществляться не будет (never executed в плане).
И если она найдется уже в первом блоке, выполнение второго осуществляться не будет (never executed в плане).
«Прячем под CASE» сложные условия
В исходном запросе есть крайне неудобный момент — проверка состояния по связанной таблице «ДокументРасширение». Независимо от истинности остальных условий в выражении (например, d.«Удален» IS NOT TRUE), это соединение выполняется всегда и «стоит ресурсов». Больше или меньше их будет потрачено — зависит от объема этой таблицы.
Но можно модифицировать запрос так, чтобы поиск связанной записи происходил бы только когда это действительно необходимо:
SELECT
...
FROM
"Документ" d
WHERE
... /*index cond*/ AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
ENDРаз из связываемой таблицы нам
не нужно для результата ни одно из полей, то мы имеем возможность превратить JOIN в условие по подзапросу.
Оставим индексируемые поля «за скобками» CASE, простые условия от записи вносим в WHEN-блок — и теперь «тяжелый» запрос выполняется только при переходе в THEN.
Моя фамилия «Итого»
Собираем результирующий запрос со всеми описанными выше механиками:
WITH T AS (
SELECT
"@ТипДокумента"
FROM
"ТипДокумента"
WHERE
"ТипДокумента" = 'ПланРабот'
)
(
SELECT
TRUE
FROM
"Документ" d
WHERE
("Лицо3", "ТипДокумента") = (19091, (TABLE T)) AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
END
LIMIT 1
)
UNION ALL
(
SELECT
TRUE
FROM
"Документ" d
WHERE
("ТипДокумента", "Сотрудник") = ((TABLE T), 19091) AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d. "@Документ"
)
END
LIMIT 1
)
LIMIT 1;
"@Документ"
)
END
LIMIT 1
)
LIMIT 1;Подгоняем [под] индексы
Наметанный глаз заметил, что индексируемые условия в подблоках UNION чуть разнятся — это потому, что у нас уже есть подходящие индексы на таблице. А если бы их не было — то стоило бы создать: Документ(Лицо3, ТипДокумента) и Документ(ТипДокумента, Сотрудник).
о порядке полей в ROW-условиях
С точки зрения планировщика, конечно, можно написать и (A, B) = (constA, constB), и (B, A) = (constB, constA). Но при записи в порядке следования полей в индексе, такой запрос просто удобнее потом отлаживать.
Что в плане?
[посмотреть на explain.tensor.ru]
К сожалению, нам не повезло, и в первом UNION-блоке ничего не нашлось, поэтому второй все-таки пошел на выполнение. Но даже при этом — всего 0.037ms и 11 buffers!
Мы ускорили запрос и сократили «прокачку» данных в памяти в несколько тысяч раз, воспользовавшись достаточно простыми методиками — неплохой результат при небольшой копипасте.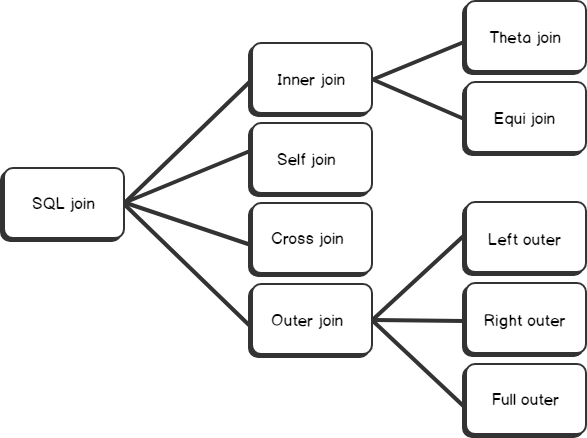 🙂
🙂
PostgreSQL: Документация: 15: 2.6. Соединения между таблицами
До сих пор наши запросы обращались только к одной таблице за раз. Запросы могут обращаться к нескольким таблицам одновременно или обращаться к одной и той же таблице таким образом, что несколько строк таблицы обрабатываются одновременно. Запросы, которые одновременно обращаются к нескольким таблицам (или к нескольким экземплярам одной и той же таблицы), называются запросами join . Они объединяют строки из одной таблицы со строками из второй таблицы с выражением, указывающим, какие строки должны быть объединены в пары. Например, чтобы вернуть все записи о погоде вместе с местоположением соответствующего города, база данных должна сравнить город столбец каждой строки таблицы погода со столбцом имя всех строк в таблице городов и выберите пары строк, в которых эти значения совпадают. [4] Это можно сделать с помощью следующего запроса:
ВЫБЕРИТЕ * ИЗ ПОГОДЫ ПРИСОЕДИНЯЙТЕСЬ к городам ON city = name;
город | temp_lo | temp_hi | пркп | дата | имя | расположение
---------------+---------+----------+------+------- -----+---------------+-----------
Сан-Франциско | 46 | 50 | 0,25 | 1994-11-27 | Сан-Франциско | (-194,53)
Сан-Франциско | 43 | 57 | 0 | 1994-11-29 | Сан-Франциско | (-194,53)
(2 ряда)
Обратите внимание на две особенности результирующего набора:
Нет строки результатов для города Хейворд.
 Это связано с тем, что в таблице
Это связано с тем, что в таблице городовдля Хейворда нет соответствующей записи, поэтому объединение игнорирует несопоставленные строки в таблицеWeather. Вскоре мы увидим, как это можно исправить.Есть две колонки, содержащие название города. Это правильно, потому что списки столбцов из таблиц
.Weatherиcityобъединены. Однако на практике это нежелательно, поэтому вы, вероятно, захотите указать выходные столбцы явно, а не использовать*:ВЫБЕРИТЕ город, temp_lo, temp_hi, prcp, дату, местоположение ОТ ПОГОДЫ ПРИСОЕДИНЯЙТЕСЬ к городам ПО city = name;
Поскольку все столбцы имели разные имена, синтаксический анализатор автоматически нашел, к какой таблице они принадлежат. Если бы в двух таблицах были повторяющиеся имена столбцов, вам нужно было бы уточните имена столбцов, чтобы показать, какой из них вы имели в виду, например:
ВЫБЕРИТЕ погода.город, погода.temp_lo, погода.temp_hi, погода.prcp, погода.дата, города.местоположение ИЗ ПОГОДЫ ПРИСОЕДИНЯЙТЕСЬ к городам ПО Weather.city = city.name;
Считается хорошим стилем уточнять все имена столбцов в запросе на соединение, чтобы запрос не завершился ошибкой, если позже в одну из таблиц будет добавлено повторяющееся имя столбца.
Запросы соединения того типа, которые мы видели до сих пор, также могут быть записаны в такой форме:
ВЫБРАТЬ *
ОТ погоды, города
ГДЕ город = имя;
Этот синтаксис предшествует синтаксису JOIN / ON , который был введен в SQL-92. Таблицы просто перечислены в предложении FROM , а выражение сравнения добавлено в предложение WHERE . Результаты этого старого неявного синтаксиса и более нового явного синтаксиса JOIN / ON идентичны. Но для читателя запроса явный синтаксис облегчает понимание его смысла: условие соединения вводится своим собственным ключевым словом, тогда как ранее условие было смешано с 9Пункт 0005 WHERE вместе с другими условиями.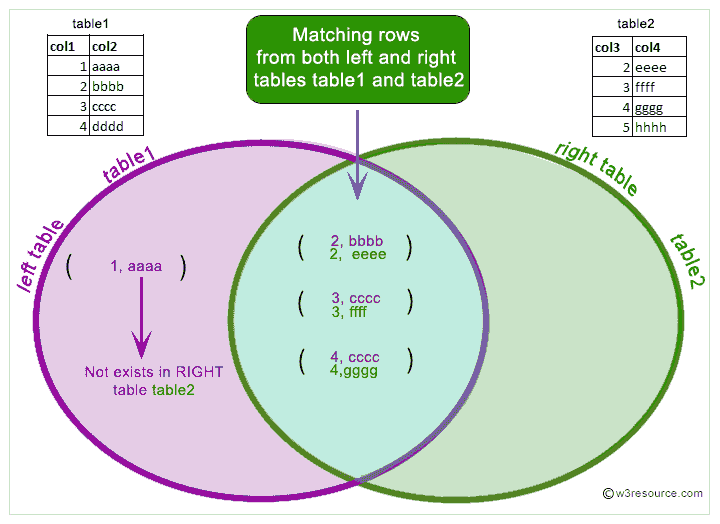
Теперь мы выясним, как вернуть записи Хейворда. Мы хотим, чтобы запрос сканировал таблицу Weather и для каждой строки находил соответствующие городов строк. Если подходящая строка не найдена, мы хотим, чтобы некоторые «пустые значения» были заменены на столбцы таблицы городов . Такой запрос называется внешним соединением . (Соединения, которые мы видели до сих пор, это внутренних соединения .) Команда выглядит так:
ВЫБРАТЬ *
ОТ погоды ЛЕВЫЙ ВНЕШНИЙ СОЕДИНЯЙТЕ города НА Weather.city = city.name;
город | temp_lo | temp_hi | пркп | дата | имя | расположение
---------------+---------+----------+------+------- -----+---------------+-----------
Хейворд | 37 | 54 | | 1994-11-29 | |
Сан-Франциско | 46 | 50 | 0,25 | 1994-11-27 | Сан-Франциско | (-194,53)
Сан-Франциско | 43 | 57 | 0 | 1994-11-29 | Сан-Франциско | (-194,53)
(3 ряда)
Этот запрос называется левым внешним соединением , потому что таблица, указанная слева от оператора соединения, будет иметь каждую из своих строк в выходных данных по крайней мере один раз, тогда как таблица справа будет иметь только те строки, которые соответствуют некоторую строку левой таблицы. При выводе строки левой таблицы, для которой нет совпадения с правой таблицей, столбцы правой таблицы заменяются пустыми (нулевыми) значениями.
При выводе строки левой таблицы, для которой нет совпадения с правой таблицей, столбцы правой таблицы заменяются пустыми (нулевыми) значениями.
Упражнение: Существуют также правые внешние соединения и полные внешние соединения. Попробуйте узнать, что они делают.
Мы также можем объединить таблицу против себя. Это называется самосоединением . В качестве примера предположим, что мы хотим найти все записи о погоде, которые находятся в температурном диапазоне других записей о погоде. Поэтому нам нужно сравнить столбцы temp_lo и temp_hi каждой строки Weather со столбцами temp_lo и temp_hi всех остальных 9.0005 погода строк. Мы можем сделать это с помощью следующего запроса:
ВЫБЕРИТЕ w1.city, w1.temp_lo как низкий, w1.temp_hi как высокий,
w2.city, w2.temp_lo низкий уровень AS, w2.temp_hi высокий уровень AS
ОТ погоды w1 ПРИСОЕДИНЯЙТЕСЬ к погоде w2
ON w1. temp_lo < w2.temp_lo И w1.temp_hi > w2.temp_hi;
temp_lo < w2.temp_lo И w1.temp_hi > w2.temp_hi;
город | низкий | высокий | город | низкий | высокая
---------------+-----+------+---------------+----- +------
Сан-Франциско | 43 | 57 | Сан-Франциско | 46 | 50
Хейворд | 37 | 54 | Сан-Франциско | 46 | 50
(2 ряда)
Здесь мы переименовали таблицу погоды как w1 и w2 , чтобы можно было различать левую и правую стороны соединения. Вы также можете использовать эти виды псевдонимов в других запросах, чтобы сэкономить время на вводе, например:
.
ВЫБРАТЬ *
ОТ погоды w ПРИСОЕДИНЯЙТЕ города c ПО w.city = c.name;
Вы будете часто сталкиваться с этим стилем сокращения.
[4] Это только концептуальная модель. Соединение обычно выполняется более эффективно, чем реальное сравнение каждой возможной пары строк, но это незаметно для пользователя.
PostgreSQL: соединения
В этом руководстве по PostgreSQL объясняется, как использовать PostgreSQL JOINS (внутреннее и внешнее) с синтаксисом, наглядными иллюстрациями и примерами.
Описание
СОЕДИНЕНИЯ PostgreSQL используются для извлечения данных из нескольких таблиц. PostgreSQL JOIN выполняется всякий раз, когда две или более таблиц объединяются в операторе SQL.
Существуют различные типы соединений PostgreSQL:
- ВНУТРЕННЕЕ СОЕДИНЕНИЕ PostgreSQL (иногда называемое простым соединением)
- PostgreSQL LEFT OUTER JOIN (или иногда называется LEFT JOIN)
- PostgreSQL ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ (или иногда называемое ПРАВЫМ СОЕДИНЕНИЕМ)
- PostgreSQL ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ (или иногда называемое ПОЛНОЕ СОЕДИНЕНИЕ)
Итак, давайте обсудим синтаксис JOIN в PostgreSQL, посмотрим на визуальные иллюстрации JOIN в PostgreSQL и рассмотрим примеры JOIN.
INNER JOIN (простое соединение)
Скорее всего, вы уже написали оператор, использующий INNER JOIN в PostgreSQL. Это наиболее распространенный тип соединения. ВНУТРЕННИЕ СОЕДИНЕНИЯ PostgreSQL возвращают все строки из нескольких таблиц, в которых выполняется условие соединения.
Синтаксис
Синтаксис INNER JOIN в PostgreSQL:
SELECT столбцы ИЗ таблицы1 ВНУТРЕННЕЕ СОЕДИНЕНИЕ таблица2 ON таблица1.столбец = таблица2.столбец;
Визуальная иллюстрация
На этой визуальной диаграмме ВНУТРЕННЕЕ СОЕДИНЕНИЕ PostgreSQL возвращает заштрихованную область:
ВНУТРЕННЕЕ СОЕДИНЕНИЕ PostgreSQL возвращает записи, где table1 и table2 пересекаются.
Пример
Вот пример ВНУТРЕННЕГО СОЕДИНЕНИЯ PostgreSQL:
ВЫБЕРИТЕ Suppliers.supplier_id, Suppliers.supplier_name, orders.order_date ОТ поставщиков ВНУТРЕННЕЕ СОЕДИНЕНИЕ заказы ПО Suppliers.supplier_id = orders.supplier_id;
В этом примере PostgreSQL INNER JOIN будут возвращены все строки из таблиц поставщиков и заказов, для которых в обеих таблицах поставщиков и заказов есть совпадающее значение supplier_id.
Давайте посмотрим на некоторые данные, чтобы объяснить, как работают ВНУТРЕННИЕ СОЕДИНЕНИЯ:
У нас есть таблица с именем поставщиков с двумя полями (supplier_id и supplier_name).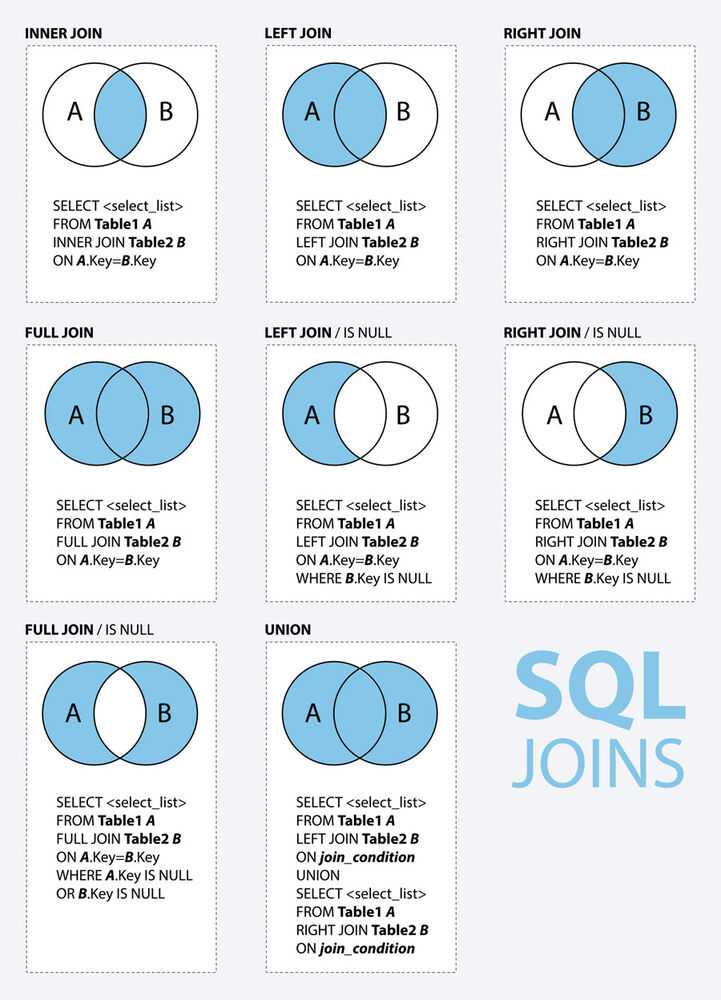 Он содержит следующие данные:
Он содержит следующие данные:
| идентификатор_поставщика | имя_поставщика |
|---|---|
| 10000 | ИБМ |
| 10001 | Хьюлетт Паккард |
| 10002 | Майкрософт |
| 10003 | NVIDIA |
У нас есть другая таблица с именем заказы с тремя полями (order_id, supplier_id и order_date). Он содержит следующие данные:
| идентификатор_заказа | идентификатор_поставщика | дата_заказа |
|---|---|---|
| 500125 | 10000 | 12.05.2013 |
| 500126 | 10001 | 13.05.2013 |
| 500127 | 10004 | 14.05.2013 |
Если мы запустим инструкцию PostgreSQL SELECT (содержащую INNER JOIN) ниже:
ВЫБЕРИТЕ Suppliers.supplier_id, Suppliers.supplier_name, orders.order_date ОТ поставщиков ВНУТРЕННЕЕ СОЕДИНЕНИЕ заказы ПО Suppliers.supplier_id = orders.supplier_id;
Наш результирующий набор будет выглядеть следующим образом:
| supplier_id | имя | дата_заказа |
|---|---|---|
| 10000 | ИБМ | 12.05.2013 |
| 10001 | Хьюлетт Паккард | 13.05.2013 |
Строки для Microsoft и NVIDIA из таблицы поставщиков будут опущены, поскольку идентификаторы Supplier_id 10002 и 10003 не существуют в обеих таблицах. Строка для 500127 (order_id) из таблицы заказов будет опущена, так как supplier_id 10004 не существует в таблице поставщиков.
Старый синтаксис
В заключение стоит упомянуть, что приведенный выше пример PostgreSQL INNER JOIN можно переписать с использованием старого неявного синтаксиса следующим образом (но мы по-прежнему рекомендуем использовать синтаксис ключевого слова INNER JOIN):
ВЫБЕРИТЕ Suppliers.supplier_id, Suppliers.supplier_name, orders.order_date ОТ поставщиков, заказы ГДЕ Suppliers.supplier_id = orders.supplier_id;
ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
Другой тип соединения называется ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ PostgreSQL. Этот тип соединения возвращает все строки из ЛЕВОЙ таблицы, указанной в условии ON, и только те строки из другой таблицы, в которых соединяемые поля равны (соблюдено условие соединения).
Синтаксис
Синтаксис LEFT OUTER JOIN в PostgreSQL:
ВЫБЕРИТЕ столбцы ИЗ таблицы1 ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ table2 ON таблица1.столбец = таблица2.столбец;
Визуальная иллюстрация
На этой визуальной диаграмме LEFT OUTER JOIN в PostgreSQL возвращает заштрихованную область:
PostgreSQL LEFT OUTER JOIN возвращает все записи из таблицы table1 и только те записи из таблицы table2 , которые пересекаются с таблица1 .
Пример
Вот пример ЛЕВОГО ВНЕШНЕГО СОЕДИНЕНИЯ PostgreSQL:
ВЫБЕРИТЕ Suppliers.supplier_id, Suppliers.supplier_name, orders.order_date ОТ поставщиков LEFT OUTER JOIN заказы ПО Suppliers.supplier_id = orders.supplier_id;
Этот пример LEFT OUTER JOIN вернет все строки из таблицы поставщиков и только те строки из таблицы заказов, в которых объединенные поля равны.
Если значение supplier_id в таблице поставщиков не существует в таблице заказов, все поля в таблице заказов будут отображаться как
Давайте посмотрим на некоторые данные, чтобы объяснить, как работают ЛЕВЫЕ ВНЕШНИЕ СОЕДИНЕНИЯ:
У нас есть таблица с именем поставщиков с двумя полями (supplier_id и supplier_name). Он содержит следующие данные:
| supplier_id | имя_поставщика |
|---|---|
| 10000 | ИБМ |
| 10001 | Хьюлетт Паккард |
| 10002 | Майкрософт |
| 10003 | NVIDIA |
У нас есть вторая таблица с именем orders с тремя полями (order_id, supplier_id и order_date).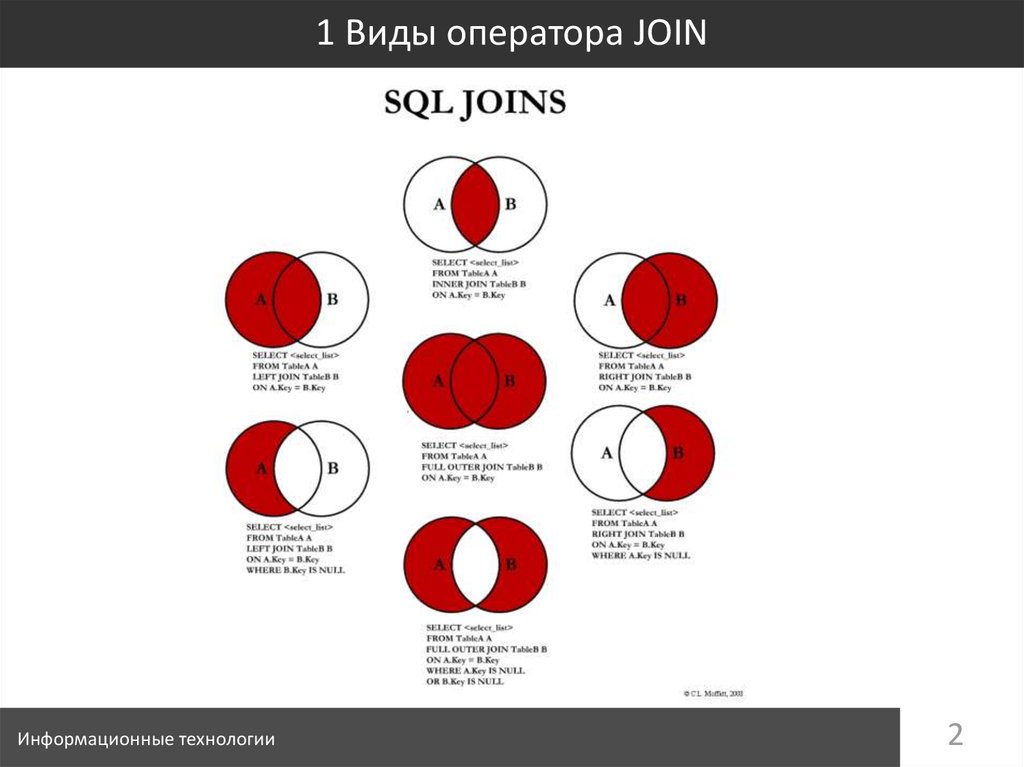 Он содержит следующие данные:
Он содержит следующие данные:
| order_id | идентификатор_поставщика | дата_заказа |
|---|---|---|
| 500125 | 10000 | 12.05.2013 |
| 500126 | 10001 | 13.05.2013 |
Если мы запустим оператор SELECT (который содержит LEFT OUTER JOIN) ниже:
SELECT Suppliers.supplier_id, Suppliers.supplier_name, orders.order_date ОТ поставщиков LEFT OUTER JOIN заказы ПО Suppliers.supplier_id = orders.supplier_id;
Наш результирующий набор будет выглядеть следующим образом:
| supplier_id | имя_поставщика | дата_заказа |
|---|---|---|
| 10000 | ИБМ | 12.05.2013 |
| 10001 | Хьюлетт Паккард | 13.05.2013 |
| 10002 | Майкрософт | <ноль> |
| 10003 | NVIDIA | <ноль> |
Строки для Microsoft и NVIDIA будет включено, потому что использовалось ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ.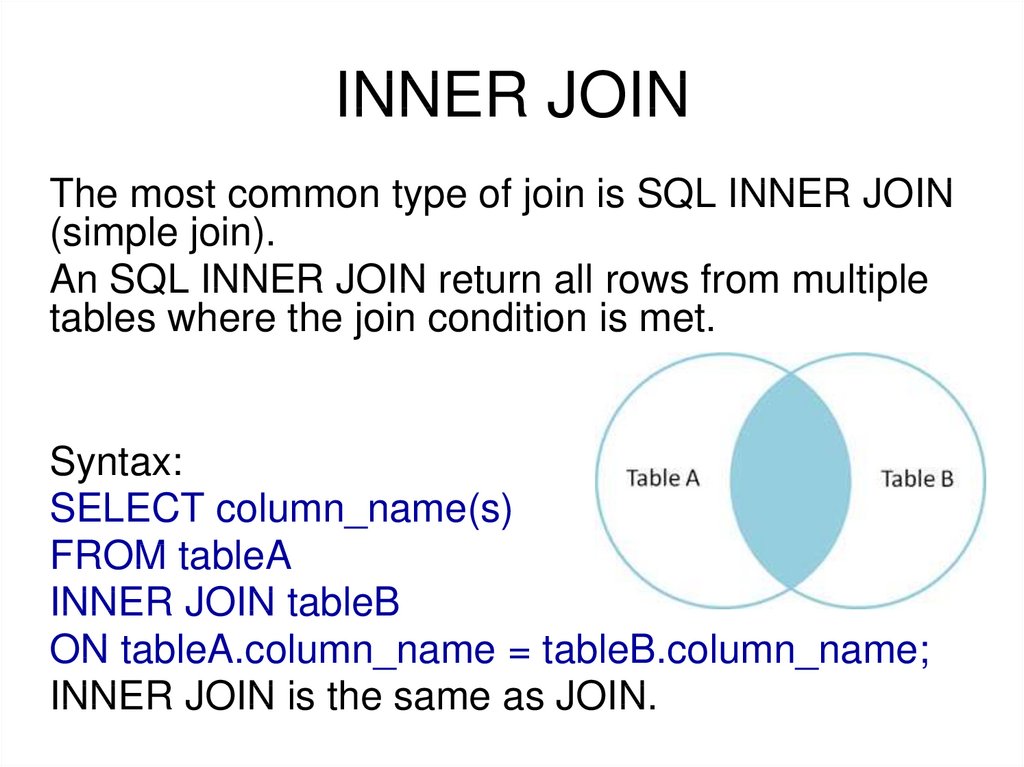 Однако вы заметите, что поле order_date для этих записей содержит значение
Однако вы заметите, что поле order_date для этих записей содержит значение
RIGHT OUTER JOIN
Другой тип соединения называется PostgreSQL RIGHT OUTER JOIN. Этот тип соединения возвращает все строки из ПРАВОЙ таблицы, указанной в условии ON, и только те строки из другой таблицы, где соединяемые поля равны (соблюдено условие соединения).
Синтаксис
Синтаксис для PostgreSQL RIGHT OUTER JOIN:
ВЫБЕРИТЕ столбцы ИЗ таблицы1 ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ table2 ON таблица1.столбец = таблица2.столбец;
Визуальная иллюстрация
На этой визуальной диаграмме ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ PostgreSQL возвращает заштрихованную область:
ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ PostgreSQL возвращает все записи из table2 и только те записи из table1 , которые пересекаются с таблица2 .
Пример
Вот пример ПРАВОГО ВНЕШНЕГО СОЕДИНЕНИЯ PostgreSQL:
ВЫБЕРИТЕ orders.order_id, orders.order_date, Suppliers.supplier_name ОТ поставщиков Заказы RIGHT OUTER JOIN ПО Suppliers.supplier_id = orders.supplier_id;
Этот пример RIGHT OUTER JOIN вернет все строки из таблицы заказов и только те строки из таблицы поставщиков, в которых объединенные поля равны.
Если значение supplier_id в таблице заказов не существует в таблице поставщиков, все поля в таблице поставщиков будут отображаться как
Давайте посмотрим на некоторые данные, чтобы объяснить, как работают RIGHT OUTER JOINS:
У нас есть таблица с именем Suppliers с двумя полями (supplier_id и supplier_name). Он содержит следующие данные:
| supplier_id | имя_поставщика |
|---|---|
| 10000 | Яблоко |
| 10001 | Гугл |
У нас есть вторая таблица с именем заказа с тремя полями (order_id, supplier_id и order_date). Он содержит следующие данные:
Он содержит следующие данные:
| order_id | идентификатор_поставщика | дата_заказа |
|---|---|---|
| 500125 | 10000 | 12.08.2013 |
| 500126 | 10001 | 13.08.2013 |
| 500127 | 10002 | 14.08.2013 |
Если мы запустим оператор SELECT (который содержит ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ) ниже:
SELECT orders.order_id, orders.order_date, Suppliers.supplier_name ОТ поставщиков Заказы RIGHT OUTER JOIN ПО Suppliers.supplier_id = orders.supplier_id;
Наш результирующий набор будет выглядеть так:
| order_id | дата_заказа | имя_поставщика |
|---|---|---|
| 500125 | 12.08.2013 | Яблоко |
| 500126 | 13. 08.2013 08.2013 | Гугл |
| 500127 | 14.08.2013 | <ноль> |
Строка для 500127 (order_id) будет включена, поскольку использовалось ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ. Однако вы заметите, что поле supplier_name для этой записи содержит значение
FULL OUTER JOIN
Другой тип соединения называется FULL OUTER JOIN в PostgreSQL. Этот тип соединения возвращает все строки из таблицы LEFT-hand и RIGHT-hand таблицы с нулевыми значениями в местах, где условие соединения не выполняется.
Синтаксис
Синтаксис FULL OUTER JOIN в PostgreSQL:
SELECT columns ИЗ таблицы1 ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ table2 ON таблица1.столбец = таблица2.столбец;
Визуальная иллюстрация
На этой визуальной диаграмме FULL OUTER JOIN PostgreSQL возвращает заштрихованную область:
ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ PostgreSQL вернет все записи из таблиц table1 и table2 .
Пример
Вот пример ПОЛНОГО ВНЕШНЕГО СОЕДИНЕНИЯ PostgreSQL:
ВЫБОР ОТ поставщиков ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ ПО Suppliers.supplier_id = orders.supplier_id;
В этом примере FULL OUTER JOIN будут возвращены все строки из таблицы поставщиков и все строки из таблицы заказов, и всякий раз, когда условие соединения не выполняется,
Если значение supplier_id в таблице поставщиков не существует в таблице заказов, все поля в таблице заказов будут отображаться как
Давайте посмотрим на некоторые данные, чтобы объяснить, как работают ПОЛНЫЕ ВНЕШНИЕ СОЕДИНЕНИЯ:
У нас есть таблица с именем поставщиков с двумя полями (supplier_id и supplier_name). Он содержит следующие данные:
| идентификатор_поставщика | имя_поставщика |
|---|---|
| 10000 | ИБМ |
| 10001 | Хьюлетт Паккард |
| 10002 | Майкрософт |
| 10003 | NVIDIA |
У нас есть вторая таблица с именем orders с тремя полями (order_id, supplier_id и order_date). Он содержит следующие данные:
Он содержит следующие данные:
| идентификатор_заказа | идентификатор_поставщика | дата_заказа |
|---|---|---|
| 500125 | 10000 | 12.08.2013 |
| 500126 | 10001 | 13.08.2013 |
| 500127 | 10004 | 14.08.2013 |
Если мы запустим оператор SQL (который содержит ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ) ниже:
ВЫБЕРИТЕ Suppliers.supplier_id, Suppliers.supplier_name, orders.order_date ОТ поставщиков ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ ПО Suppliers.supplier_id = orders.supplier_id;
Наш результирующий набор будет выглядеть следующим образом:
| supplier_id | имя_поставщика | дата_заказа |
|---|---|---|
| 10000 | ИБМ | 12.08.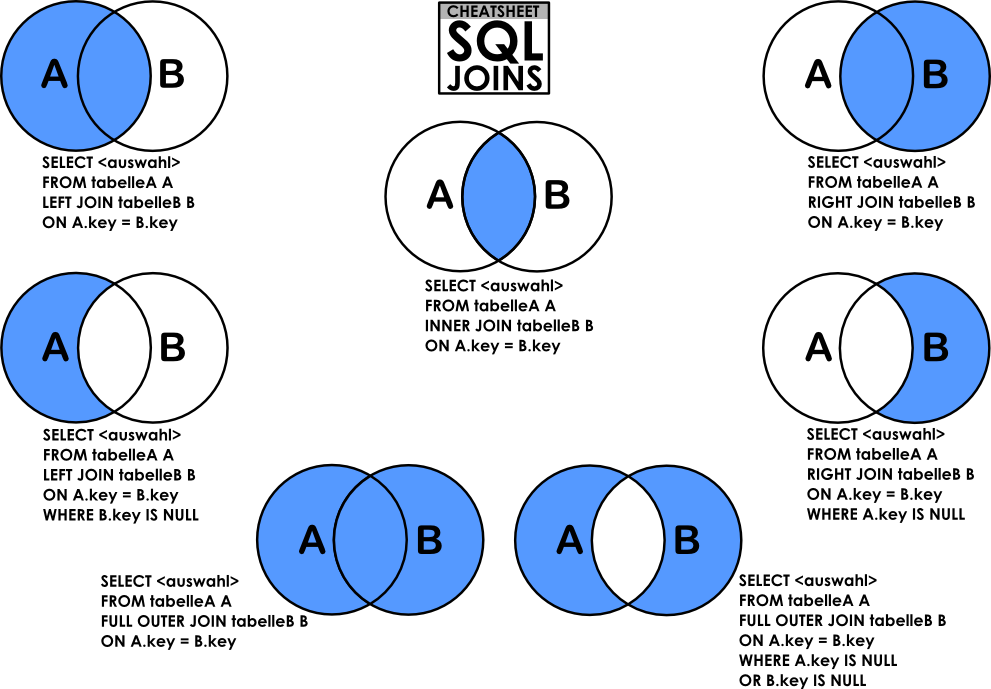 |