Агрегатные функции SQL — SUM, MIN, MAX, AVG, COUNT
Оглавление
- Функция SQL SUM
- Функция SQL MIN
- Функция SQL MAX
- Функция SQL AVG
- Функция SQL COUNT
- Агрегатные функции вместе с SQL GROUP BY (группировкой)
- Разрешены ли агрегатные функции от агрегатных функций?
Связанные темы
- Оператор SELECT
- GROUP BY — группировка в запросах
| Назад | Листать | Вперёд>>> |
Будем учиться подводить итоги. Нет, это ещё не итоги изучения SQL, а итоги значений столбцов таблиц
базы данных. Агрегатные функции SQL действуют в отношении значений столбца с целью получения
единого результирующего значения. Наиболее часто применяются агрегатные функции SQL SUM, MIN, MAX,
AVG и COUNT. Следует различать
два случая применения агрегатных функций. Первый: агрегатные функции используются сами по себе и возвращают
одно результирующее значение. Второй: агрегатные функции используются с оператором SQL GROUP BY, то есть
с группировкой по полям (столбцам) для получения результирующих значений в каждой группе. Рассмотрим сначала случаи использования агрегатных
функций без группировки.
Следует различать
два случая применения агрегатных функций. Первый: агрегатные функции используются сами по себе и возвращают
одно результирующее значение. Второй: агрегатные функции используются с оператором SQL GROUP BY, то есть
с группировкой по полям (столбцам) для получения результирующих значений в каждой группе. Рассмотрим сначала случаи использования агрегатных
функций без группировки.
Функция SQL SUM возвращает сумму значений столбца таблицы базы данных. Она может применяться только к столбцам, значениями которых являются числа. Запросы SQL для получения результирующей суммы начинаются так:
SELECT SUM(ИМЯ_СТОЛБЦА) …
После этого выражения следует FROM (ИМЯ_ТАБЛИЦЫ), а далее с помощью конструкции WHERE может быть
задано условие. Кроме того, перед именем столбца может быть указано DISTINCT, и это означает, что
учитываться будут только уникальные значения. По умолчанию же учитываются все значения (для этого
можно особо указать не DISTINCT, а ALL, но слово ALL не является обязательным).
Если вы хотите выполнить запросы к базе данных из этого урока на MS SQL Server, но эта СУБД не установлена на вашем компьютере, то ее можно установить, пользуясь инструкцией по этой ссылке.
Сначала работать будем с базой данных фирмы — Company1. Скрипт для создания этой базы данных, её таблиц и заполения таблиц данными — в файле по этой ссылке.
Пример 1. Есть база данных фирмы с данными о её подразделениях и сотрудниках. Таблица Staff помимо всего имеет столбец с данными о заработной плате сотрудников. Выборка из таблицы имеет следующий вид (для увеличения картинки щёлкнуть по ней левой кнопкой мыши):
Для получения суммы размеров всех заработных плат используем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT SUM(Salary) FROM Staff
Этот запрос вернёт значение 287664,63.
А теперь упражнение для самостоятельного решения.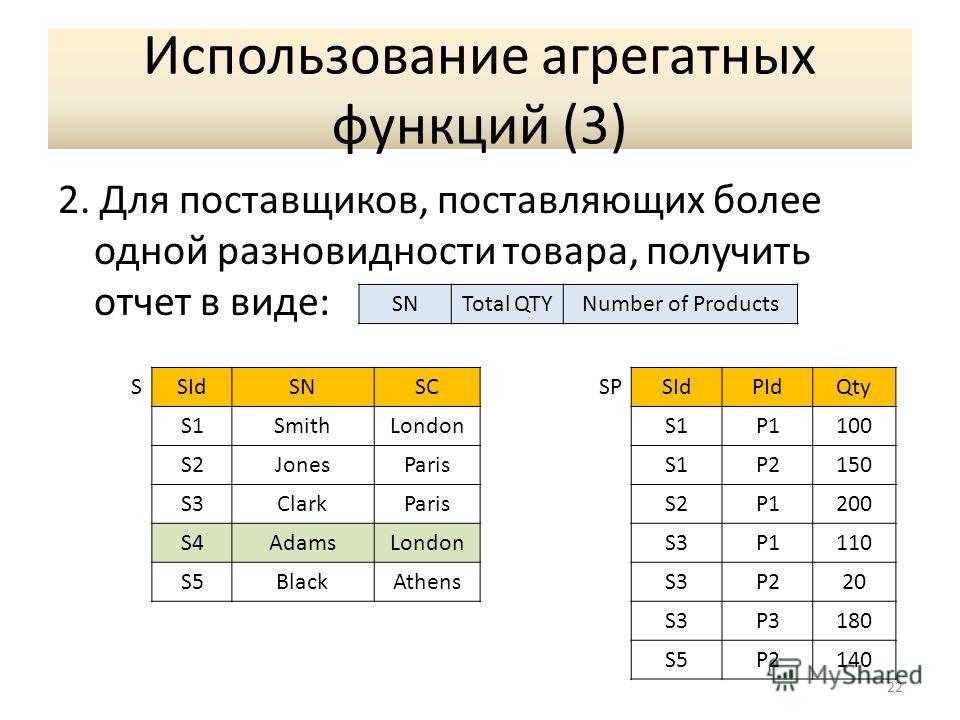 В упражнениях уже начинаем
усложнять задания, приближая их к тем, что встречаются на практике.
В упражнениях уже начинаем
усложнять задания, приближая их к тем, что встречаются на практике.
Пример 2. Вывести сумму комиссионных, получаемых всеми сотрудниками с должностью Clerk.
Правильное решение и ответ.
Функция SQL MIN также действует в отношении столбцов, значениями которых являются числа и возвращает минимальное среди всех значений столбца. Эта функция имеет синтаксис аналогичный синтаксису функции SUM.
Пример 3. База данных и таблица — те же, что и в примере 1.
Требуется узнать минимальную заработную плату сотрудников отдела с номером 42. Для этого пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT MIN(Salary) FROM Staff WHERE Dept=42
Запрос вернёт значение 10505,90.
И вновь упражнение для самостоятельного решения.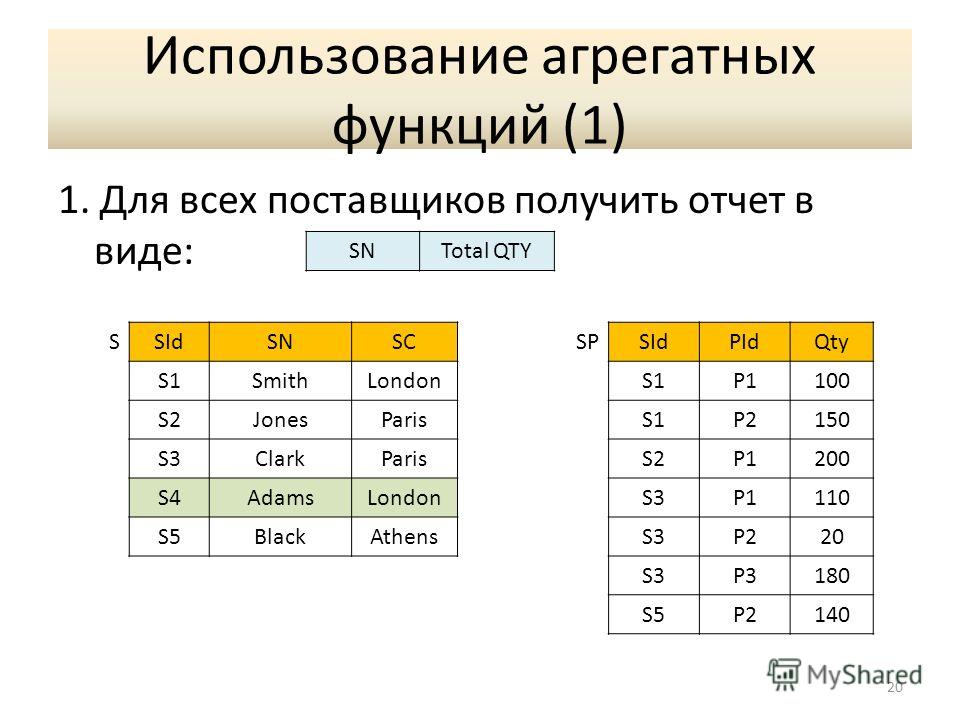 В этом и некоторых
других упражнениях потребуется уже не только таблица Staff, но и таблица Org, содержащая данные о
подразделениях фирмы:
В этом и некоторых
других упражнениях потребуется уже не только таблица Staff, но и таблица Org, содержащая данные о
подразделениях фирмы:
Пример 4. К таблице Staff добавляется таблица Org, содержащая данные о подразделениях фирмы. Вывести минимальное количество лет, проработанных одним сотрудником в отделе, расположенном в Бостоне.
Правильное решение и ответ.
- Страница 2 (Разрешены ли агрегатные функции от агрегатных функций?)
Аналогично работает и имеет аналогичный синтаксис функция SQL MAX, которая применяется, когда требуется определить максимальное значение среди всех значений столбца.
Пример 5. База данных и таблица — те же, что и в предыдущих примерах.
Требуется узнать максимальную заработную плату сотрудников отдела с номером 42. Для этого пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT MAX(Salary) FROM Staff WHERE Dept=42
Запрос вернёт значение 18352,80
Пришло время упражнения для самостоятельного решения.
Пример 6. Вновь работаем с двумя таблицами — Staff и Org. Вывести название отдела и максимальное значение комиссионных, получаемых одним сотрудником в отделе, относящемуся к группе отделов (Division) Eastern. Использовать JOIN (соединение таблиц).
Правильное решение и ответ.
Указанное в отношении синтаксиса для предыдущих описанных функций верно и в отношении функции SQL AVG. Эта функция возвращает среднее значение среди всех значений столбца.
Пример 7. База данных и таблица — те же, что и в предыдущих примерах.
Пусть требуется узнать средний трудовой стаж сотрудников отдела с номером 42. Для этого пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT AVG(Years) FROM Staff WHERE Dept=42
Результатом будет значение 6,33
В следующем упражнении для самостоятельного решения помимо
агрегатной функции требуется использовать также предикат BETWEEN.
Пример 8. Работаем с одной таблицей — Staff. Вывести среднюю зарплату сотрудников со стажем от 4 до 6 лет.
Правильное решение и ответ.
- Страница 2 (Разрешены ли агрегатные функции от агрегатных функций?)
Функция SQL COUNT возвращает количество записей таблицы базы данных. Если в запросе указать SELECT COUNT(ИМЯ_СТОЛБЦА) …, то результатом будет количество записей без учёта тех записей, в которых значением столбца является NULL (неопределённое). Если использовать в качестве аргумента звёздочку и начать запрос SELECT COUNT(*) …, то результатом будет количество всех записей (строк) таблицы.
Пример 9. База данных и таблица — те же, что и в предыдущих примерах.
Требуется узнать число всех сотрудников, которые получают комиссионные. Число сотрудников, у которых значения столбца Comm — не NULL, вернёт следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT COUNT(Comm) FROM Staff
Результатом будет значение 11.
Пример 10. База данных и таблица — те же, что и в предыдущих примерах.
Если требуется узнать общее количество записей в таблице, то применяем запрос со звёздочкой в качестве аргумента функции COUNT (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT COUNT(*) FROM Staff
Результатом будет значение 17.
В следующем упражнении для самостоятельного решения потребуется использовать подзапрос.
Пример 11. Работаем с одной таблицей — Staff. Вывести число сотрудников в отделе планирования (Plains).
Правильное решение и ответ.
- Страница 2 (Разрешены ли агрегатные функции от агрегатных функций?)
Теперь рассмотрим применение агрегатных функций вместе с оператором SQL GROUP BY. Оператор SQL GROUP BY
служит для группировки результирующих значений по столбцам таблицы базы данных. На сайте есть урок,
посвящённый отдельно этому оператору.
На сайте есть урок,
посвящённый отдельно этому оператору.
Работать будем с базой данных «Портал объявлений 1». Скрипт для создания этой базы данных, её таблицы и заполения таблицы данных — в файле по этой ссылке.
Пример 12. Итак, есть база данных портала объявлений. В ней есть таблица Ads, содержащая данные об объявлениях, поданных за неделю. Столбец Category содержит данные о больших категориях объявлений (например, Недвижимость), а столбец Parts — о более мелких частях, входящих в категории (например, части Квартиры и Дачи являются частями категории Недвижимость). Столбец Units содержит данные о количестве поданных объявлений, а столбец Money — о денежных суммах, вырученных за подачу объявлений.
| Category | Part | Units | Money |
| Транспорт | Автомашины | 110 | 17600 |
| Недвижимость | Квартиры | 89 | 18690 |
| Недвижимость | Дачи | 57 | 11970 |
| Транспорт | Мотоциклы | 131 | 20960 |
| Стройматериалы | Доски | 68 | 7140 |
| Электротехника | Телевизоры | 127 | 8255 |
| Электротехника | Холодильники | 137 | 8905 |
| Стройматериалы | Регипс | 112 | 11760 |
| Досуг | Книги | 96 | 6240 |
| Недвижимость | Дома | 47 | 9870 |
| Досуг | Музыка | 117 | 7605 |
| Досуг | Игры | 41 | 2665 |
Используя оператор SQL GROUP BY, найти суммы денег, вырученных за подачу
объявлений в каждой категории. Пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
Пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
SELECT Category, SUM(Money) AS Money FROM ADS GROUP BY Category
Результатом будет следующая таблица:
| Category | Money |
| Досуг | 16510 |
| Недвижимость | 40530 |
| Стройматериалы | 18900 |
| Транспорт | 38560 |
| Электротехника | 17160 |
Пример 13. База данных и таблица — та же, что в предыдущем примере.
Используя оператор SQL GROUP BY, выяснить, в какой части каждой категории было подано наибольшее число объявлений. Пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
SELECT Category, Part, MAX(Units) AS Maximum FROM ADS GROUP BY Category
Результатом будет следующая таблица:
| Category | Part | Maximum |
| Досуг | Музыка | 117 |
| Недвижимость | Квартиры | 89 |
| Стройматериалы | Регипс | 112 |
| Транспорт | Мотоциклы | 131 |
| Электротехника | Холодильники | 137 |
Итоговые и индивидуальные значения в одной таблице можно получить объединением
результатов запросов с помощью оператора UNION.
- Страница 2 (Разрешены ли агрегатные функции от агрегатных функций?)
Поделиться с друзьями
| Назад | Листать | Вперёд>>> |
Агрегатные функции SQL — CodeTown.ru
Здравствуйте! Сегодня мы познакомимся с агрегатными функциями в SQL, подробно разберем их работу с данными из таблиц, которые создавали в прошлых уроках.
Общее понятие
В прошлом уроке по оператору SELECT мы познакомились с тем, как строятся запросы к данным. Агрегатные функции же существуют для того, чтобы была возможность каким либо образом обобщить полученные данные, то есть манипулировать ими так, как нам это захочется.
Эти функции выполняются с помощью ключевых слов, которые включаются в запрос SELECT, и о том, как они прописываются будет рассказано далее. Чтобы было понятно, вот некоторые возможности агрегатных функций в SQL:
- Суммировать выбранные значения
- Находить среднее арифметическое значений
- Находить минимальное и максимальное из значений
Примеры агрегатных функций SQL
Мы разберем самые часто используемые функции и приведем несколько примеров.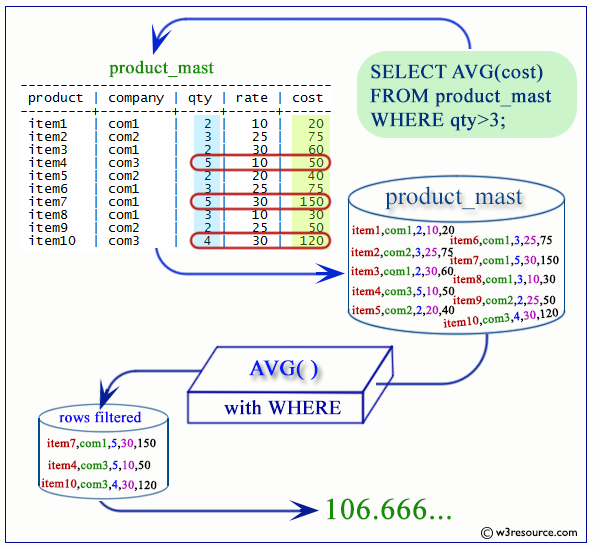
Функция SUM
Эта функция позволяет просуммировать значения какого либо поля при запросе SELECT. Достаточно полезная функция, синтаксис которой довольно прост, как и всех других агрегатных функций в SQL. Для понимания сразу начнем с примера:
Получить сумму всех заказов из таблицы Orders, которые были совершены в 2016 году.
Можно было бы просто вывести сумму заказов, но мне кажется, что это совсем просто. Напомним структуру нашей таблицы:
| onum | amt | odate | cnum | snum |
|---|---|---|---|---|
| 1001 | 128 | 2016-01-01 | 9 | 4 |
| 1002 | 1800 | 2016-04-10 | 10 | 7 |
| 1003 | 348 | 2017-04-08 | 2 | 1 |
| 1004 | 500 | 2016-06-07 | 3 | 3 |
| 1005 | 499 | 2017-12-04 | 5 | 4 |
| 1006 | 320 | 2016-03-03 | 5 | 4 |
| 1007 | 80 | 2017-09-02 | 7 | 1 |
| 1008 | 780 | 2016-03-07 | 1 | 3 |
| 1009 | 560 | 2017-10-07 | 3 | 7 |
| 1010 | 900 | 2016-01-08 | 6 | 8 |
Следующий код осуществит нужную выборку:
SELECT SUM(amt) FROM Orders WHERE odate BETWEEN '2016-01-01' and '2016-12-31';
В результате получим:
| SUM(amt) |
|---|
| 4428 |
В данном запросе мы использовали функцию SUM, после которой в скобках нужно указать поле для суммирования. Затем мы указали условие в WHERE, которое отобрало строчки только с 2016 годом. На самом деле это условие можно записать по другому, но сейчас важнее агрегатная функция суммирования в SQL.
Затем мы указали условие в WHERE, которое отобрало строчки только с 2016 годом. На самом деле это условие можно записать по другому, но сейчас важнее агрегатная функция суммирования в SQL.
Функция AVG
Следующая функция осуществляет подсчет среднего арифметического поля данных, которое мы укажем в качестве параметра. Синтаксис такой функции идентичен функции суммирования. Поэтому сразу перейдем к простейшей задаче:
Вывести среднюю стоимость заказа из таблицы Orders.
И сразу запрос:
SELECT AVG(amt) FROM Orders;
В результате получим:
| AVG(amt) |
|---|
| 591.5 |
В целом, все похоже на предыдущую функцию. И синтаксис достаточно прост. В этом и состоит особенность языка SQL — быть понятным для человека.
Функции MIN и MAX
Еще 2 функции, которые близки по своему действию. Они находят минимальное или максимальное значение соответственно того параметра, который будет передан в скобках. Синтаксис повторяется и поэтому следующий пример:
Синтаксис повторяется и поэтому следующий пример:
Вывести максимальное и минимальное значения цены заказа, для тех заказов в которых цена менее 1000.
Получается такой запрос,
SELECT MAX(amt), MIN(amt) FROM Orders WHERE amt < 1000;
который выведет:
| MAX(amt) | MIN(amt) |
|---|---|
| 900 | 80 |
Также стоит сказать, что в отличие от предыдущих функций, эти 2 могут работать с символьными параметрами, то есть можно написать запрос типа MIN(odate) (в данном случае дата у нас символьная), и тогда нам вернется 2016-01-01.
Дело в том, что в этих функциях есть механизм преобразования символов в ASCII код, который потом они и сравнивают.
Еще одним важным моментом является то, что мы можем производить некоторые простые математические операции в запросе SELECT, например, такой запрос:
SELECT (MAX(amt) - MIN(amt)) AS 'Разница' FROM Orders;
Вернет такой ответ:
| Разница |
|---|
| 1720 |
Функция COUNT
Эта функция необходима для того, чтобы подсчитать количество выбранных значений или строк. Существует два основных варианта ее использования:
Существует два основных варианта ее использования:
Теперь разберем пример использования COUNT в SQL:
Подсчитать количество сделанных заказов и количество продавцов в таблице Orders.
SELECT COUNT(*), COUNT(DISTINCT snum) FROM Orders;
Получаем:
| COUNT(*) | COUNT(snum) |
|---|---|
| 10 | 5 |
Очевидно, что количество заказов — 10, но если вдруг у вас имеется большая таблица, то такая функция будет очень удобной. Что касается уникальных продавцов, то здесь необходимо использовать DISTINCT, потому что один продавец может обслужить несколько заказов.
Оператор GROUP BY
Теперь рассмотрим 2 важных оператора, которые помогают расширить функционал наших запросов в SQL. Первым из них является оператор GROUP BY, который осуществляет группировку по какому либо полю, что иногда является необходимым. И уже для этой группы производит заданное действие. Например:
И уже для этой группы производит заданное действие. Например:
Вывести сумму всех заказов для каждого продавца по отдельности.
То есть теперь нам нужно для каждого продавца в таблице Orders выделить поля с ценой заказа и просуммировать. Все это сделает оператор GROUP BY в SQL достаточно легко:
SELECT snum, SUM(amt) AS 'Сумма всех заказов' FROM Orders GROUP BY snum;
И в итоге получим:
| snum | Сумма всех заказов |
|---|---|
| 1 | 428 |
| 3 | 1280 |
| 4 | 947 |
| 7 | 2360 |
| 8 | 900 |
Как видно, SQL выделил группу для каждого продавца и посчитал сумму всех их заказов.
Оператор HAVING
Этот оператор используется как дополнение к предыдущему. Он необходим для того, чтобы ставить условия для выборки данных при группировке. Если условие выполняется то выделяется группа, если нет — то ничего не произойдет. Рассмотрим следующий код:
Рассмотрим следующий код:
SELECT snum, SUM(amt) AS 'Сумма всех заказов' FROM Orders GROUP BY snum HAVING MAX(amt) > 1000;
Который создаст группу для продавца и посчитает сумму заказов этой группы, только в том случае, если максимальная сумма заказа больше 1000. Очевидно, что такой продавец только один, для него выделится группа и посчитается сумма всех заказов:
| snum | Сумма всех заказов |
|---|---|
| 7 | 2360 |
Казалось бы, почему тут не использовать условие WHERE, но SQL так построен, что в таком случае выдаст ошибку, и именно поэтому в SQL есть оператор HAVING.
Примеры на агрегатные функции в SQL
1. Напишите запрос, который сосчитал бы все суммы заказов, выполненных 1 января 2016 года.
SELECT SUM(amt) FROM Orders WHERE odate = '2016-01-01';
2. Напишите запрос, который сосчитал бы число различных, отличных от NULL значений поля city в таблице заказчиков.
SELECT COUNT(DISTINCT city) FROM customers;
3. Напишите запрос, который выбрал бы наименьшую сумму для каждого заказчика.
SELECT cnum, MIN(amt) FROM orders GROUP BY cnum;
4. Напишите запрос, который бы выбирал заказчиков чьи имена начинаются с буквы Г.
SELECT cname FROM customers WHERE cname LIKE 'Г%' ;
5. Напишите запрос, который выбрал бы высший рейтинг в каждом городе.
SELECT city, MAX(rating) FROM customers GROUP BY city;
Заключение
На этом мы будем заканчивать. В этой статье мы познакомились с агрегатными функциями в SQL. Разобрали основные понятия и базовые примеры, которые могут пригодиться далее.
Если у вас остались вопросы, то задавайте их в комментариях.
17) Агрегатные функции — CoderLessons.com
Агрегатные функции – это все о
- Выполнение расчетов в несколько рядов
- Из одного столбца таблицы
- И возвращая единственное значение.

Стандарт ISO определяет пять (5) агрегатных функций, а именно:
1) COUNT
2) SUM
3) AVG
4) MIN
5) MAX
Зачем использовать агрегатные функции.
С точки зрения бизнеса разные уровни организации предъявляют разные информационные требования. Менеджеры высшего уровня, как правило, заинтересованы в знании целых цифр и не нуждаются в отдельных деталях.
> Агрегатные функции позволяют нам легко получать сводные данные из нашей базы данных.
Например, из нашей базы данных myflix, руководство может потребовать следующих отчетов
- Наименее арендованные фильмы.
- Самые арендованные фильмы.
- Среднее число, которое каждый фильм сдается в месяц.
Мы легко создаем вышеуказанные отчеты, используя агрегатные функции.
Давайте рассмотрим агрегатные функции подробно.
Функция COUNTФункция COUNT возвращает общее количество значений в указанном поле. Он работает как с числовыми, так и с нечисловыми типами данных. Все агрегатные функции по умолчанию исключают нулевые значения перед работой с данными.
Он работает как с числовыми, так и с нечисловыми типами данных. Все агрегатные функции по умолчанию исключают нулевые значения перед работой с данными.
COUNT (*) – это специальная реализация функции COUNT, которая возвращает количество всех строк в указанной таблице. COUNT (*) также считает Null и дубликаты.
В приведенной ниже таблице показаны данные в таблице movierentals
| номер ссылки | Дата сделки | Дата возвращения | членский номер | movie_id | фильм вернулся |
|---|---|---|---|---|---|
| 11 | 20-06-2012 | ЗНАЧЕНИЕ NULL | 1 | 1 | 0 |
| 12 | 22-06-2012 | 25-06-2012 | 1 | 2 | 0 |
| 13 | 22-06-2012 | 25-06-2012 | 3 | 2 | 0 |
| 14 | 21-06-2012 | 24-06-2012 | 2 | 2 | 0 |
| 15 | 23-06-2012 | ЗНАЧЕНИЕ NULL | 3 | 3 | 0 |
Давайте предположим, что мы хотим получить количество раз, когда фильм с идентификатором 2 был сдан в аренду
SELECT COUNT(`movie_id`) FROM `movierentals` WHERE `movie_id` = 2;
Выполнение вышеупомянутого запроса в MySQL Workbench против myflixdb дает нам следующие результаты.
DISTINCT Ключевое слово
COUNT('movie_id') 3
Ключевое слово DISTINCT, которое позволяет нам исключать дубликаты из наших результатов. Это достигается путем группировки похожих значений вместе.
Чтобы оценить концепцию Distinct, давайте выполним простой запрос
SELECT `movie_id` FROM `movierentals`;
movie_id 1 2 2 2 3
Теперь давайте выполним тот же запрос с отдельным ключевым словом –
SELECT DISTINCT `movie_id` FROM `movierentals`;
Как показано ниже, отчет об исключении повторяющихся записей из результатов.
movie_id 1 2 3
Функция MIN
Функция MIN возвращает наименьшее значение в указанном поле таблицы .
В качестве примера, давайте предположим, что мы хотим знать год, в который был выпущен самый старый фильм в нашей библиотеке, мы можем использовать функцию MIN в MySQL, чтобы получить необходимую информацию.
Следующий запрос помогает нам достичь этого
SELECT MIN(`year_released`) FROM `movies`;
Выполнение вышеупомянутого запроса в MySQL Workbench против myflixdb дает нам следующие результаты.
MIN('year_released') 2005
Макс функция
Как следует из названия, функция MAX противоположна функции MIN. Он возвращает наибольшее значение из указанного поля таблицы .
Давайте предположим, что мы хотим получить год, когда был выпущен последний фильм в нашей базе данных. Мы можем легко использовать функцию MAX для достижения этой цели.
В следующем примере возвращается последний год выпуска фильма.
SELECT MAX(`year_released`) FROM `movies`;
Выполнение вышеуказанного запроса в MySQL Workbench с использованием myflixdb дает нам следующие результаты.
MAX('year_released') 2012
СУММА функция
Предположим, мы хотим получить отчет, в котором указана общая сумма выполненных платежей. Мы можем использовать функцию MySQL SUM, которая возвращает сумму всех значений в указанном столбце . SUM работает только с числовыми полями . Нулевые значения исключаются из возвращаемого результата.
В следующей таблице приведены данные в таблице платежей.
| идентификатор платежа | членский номер | дата платежа | описание | выплаченная сумма | external_ reference_number |
|---|---|---|---|---|---|
| 1 | 1 | 23.07.2012 | Оплата проката фильмов | 2500 | 11 |
| 2 | 1 | 25-07-2012 | Оплата проката фильмов | 2000 | 12 |
| 3 | 3 | 30-07-2012 | Оплата проката фильмов | 6000 | ЗНАЧЕНИЕ NULL |
Приведенный ниже запрос возвращает все выполненные платежи и суммирует их, чтобы получить единый результат.
SELECT SUM(`amount_paid`) FROM `payments`;
Выполнение вышеуказанного запроса в MySQL Workbench для myflixdb дает следующие результаты.
Функция AVG
SUM('amount_paid') 10500
Функция MySQL AVG возвращает среднее значение в указанном столбце . Как и функция SUM, она работает только с числовыми типами данных .
Предположим, мы хотим найти среднюю уплаченную сумму. Мы можем использовать следующий запрос –
SELECT AVG(`amount_paid`) FROM `payments`;
Выполнение вышеуказанного запроса в MySQL Workbench дает нам следующие результаты.
AVG('amount_paid') 3500
Резюме
- MySQL поддерживает все пять (5) стандартных агрегатных функций ISO COUNT, SUM, AVG, MIN и MAX.

- Функции SUM и AVG работают только с числовыми данными.
- Если вы хотите исключить повторяющиеся значения из результатов агрегатной функции, используйте ключевое слово DISTINCT. Ключевое слово ALL включает даже дубликаты. Если ничего не указано, по умолчанию принимается ALL.
- Агрегатные функции могут использоваться в сочетании с другими предложениями SQL, такими как GROUP BY
Логические
Вы думаете, что агрегатные функции просты. Попробуй это!
В следующем примере группируются участники по имени, подсчитывается общее количество платежей, средняя сумма платежей и общая сумма сумм платежей.
SELECT m.`full_names`,COUNT(p.`payment_id`) AS `paymentscount`,AVG(p.`amount_paid`) AS `averagepaymentamount`,SUM(p.`amount_paid`) AS `totalpayments` FROM members m, payments p WHERE m.`membership_number` = p.`membership_number` GROUP BY m.`full_names`;
Выполнение приведенного выше примера в MySQL Workbench дает нам следующие результаты.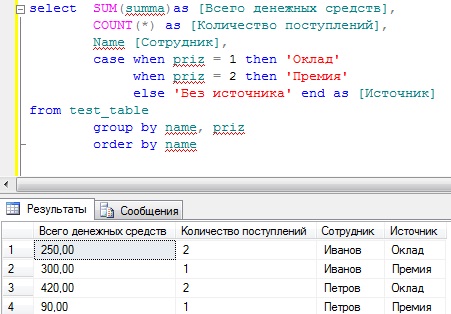
Агрегатные функции в SQL: объяснение на примерах
Перевод статьи «SQL Aggregate Functions – With Example Data Queries for Beginners».
Photo by Ben Harritt on UnsplashЕсли вы когда-либо работали с таблицами Excel или Google Sheets, агрегатные функции SQL покажутся вам знакомыми. Например, вам случалось использовать SUM при работе с таблицами? Функция SUM есть и в SQL. Она как раз относится к агрегатным функциям.
Агрегатные функции выполняют конкретные действия со строками таблиц.
Допустим, вы каждый год запускаете сбор денег на какие-то нужды. У вас есть база жертвователей, где хранятся их имена, адреса электронной почты и перечисленные суммы (по годам).
При помощи функции COUNT вы можете определить, сколько всего пожертвований было сделано. А при помощи SUM можно вычислить общую сумму денег, которую удалось собрать в этом году.
В этой статье мы рассмотрим следующие агрегатные функции: COUNT, SUM, MIN/MAX и AVG. А для иллюстрации будем использовать небольшой набор данных:
А для иллюстрации будем использовать небольшой набор данных:
| NAME | DONATION_2020 | DONATION_2021 | |
|---|---|---|---|
| Andrew Jones | [email protected] | 400 | 500 |
| Maria Rodriguez | [email protected] | 1000 | 350 |
| Gerry Ford | NULL | 25 | 25 |
| Isabella Munn | [email protected] | 250 | NULL |
| Jennifer Ward | [email protected] | 2000 | 2300 |
| Rowan Parker | NULL | 5000 | 4000 |
Функция COUNT
Функция COUNT возвращает количество строк. В самой простой форме
В самой простой форме COUNT подсчитывает общее количество строк в вашей таблице.
Чтобы получить это значение для нашей таблицы с пожертвованиями, нужно запустить запрос SELECT COUNT(*) FROM donors.
Вернется общее число жертвователей, в нашем случае это 6. Мы, конечно, и так видим, что их 6, но представьте, что таблица у нас очень большая.
Возможно, вам нужно сосчитать только какие-то определенные строки. Например, вывести число жертвователей, у которых указан адрес электронной почты.
Запустив запрос SELECT COUNT(email) FROM donors, вы получите 4 — общее число жертвователей с ненулевым значением в столбце email.
Имейте в виду, что если вы не используете псевдонимы, возвращаемый столбец будет обозначен просто как count. Если вам нужно более описательное имя, запустите запрос с созданием псевдонима при помощи AS. Например, SELECT COUNT(email) FROM donors AS email_count.
Функция SUM
SUM — очень полезная агрегатная функция, с помощью которой можно складывать числовые значения в различных строках.
В нашей базе можно использовать SUM, чтобы высчитать сумму денег, полученных в 2021 году. Для этого нужно запустить запрос SELECT SUM(donation_2021) FROM donors. Обратите внимание, что функция SUM игнорирует значения NULL.
Помните, что SUM, как и другие агрегатные функции, работает по строкам, а не по столбцам.
Поэтому в нашем примере при помощи функции SUM можно сложить все донаты всех жертвователей за определенный год, но не суммы, перечисленные каждым отдельным человеком за два года.
Функции MIN и MAX
Как вы наверняка догадываетесь, MIN и MAX используются для поиска минимального и максимального значений в определенном столбце базы данных.
Вернемся к нашему примеру. Допустим, нам нужно найти, каким было самое маленькое и самое большое пожертвование в 2021 году. Для этого мы можем запустить следующий запрос:
SELECT MIN(donation_2021) AS "Minimum donation 2021", MAX(donation_2021) AS "Maximum donation 2021" FROM donors
Обратите внимание, что здесь для возвращаемых столбцов мы добавили псевдонимы, при этом взяли их в кавычки. Если в вашем псевдониме нет пробелов, кавычки не обязательны, но у нас пробелы есть.
Если в вашем псевдониме нет пробелов, кавычки не обязательны, но у нас пробелы есть.
Любопытный факт: функции MIN и MAX можно использовать и для нечисловых значений.
MIN ищет самое маленькое число, букву, которая в алфавите стоит ближе всего к A, или самую раннюю дату. Функция MAX ищет самое большое число, букву, стоящую ближе всего к Z, или самую последнюю дату. Это очень полезная особенность!
Функция AVG
Наконец, функция AVG вычисляет среднее значение в указанном столбце. Как и SUM, эта функция игнорирует NULL.
Чтобы получить средний размер пожертвований в 2020 году, можно запустить следующий запрос:
SELECT AVG(donation_2020) FROM donors
Итоги
Как видите, агрегатные функции — это простые и полезные инструменты для анализа данных в SQL. Умение пользоваться AVG, MIN/MAX, SUM и COUNT — важное дополнение к вашему набору SQL-навыков.
4.4. GROUP BY и агрегатные функции SQL
Ид_Сотр. | Фамилия | Имя | Отчество | Год_рожд. | Пол |
|
|
|
|
|
|
2 | Петров | Иван | Иванович | 1949 | М |
|
|
|
|
|
|
3 | Сидоров | Петр | Петрович | 1947 | М |
|
|
|
|
|
|
4 | Панов | Антон | Михайлович | 1975 | М |
|
|
|
|
|
|
5 | Петухов | Виктор | Борисович | 1940 | М |
|
|
|
|
|
|
7 | Петрова | Нина | Николаевна | 1970 | Ж |
|
|
|
|
|
|
8 | Сидорова | Екатерина | Ивановна | 1970 | Ж |
|
|
|
|
|
|
9 | Никитин | Валентин | Сергеевич | 1952 | М |
|
|
|
|
|
|
11 | Попов | Анатолий | Михайлович | 1947 | М |
|
|
|
|
|
|
| Рис. |
| |||
РЕЗЮМЕ
Теперь Вы можете создавать предикаты в терминах связей специально определенных SQL. Вы можете искать значения в определенном диапазоне (BETWEEN) или в числовом наборе (IN), или Вы можете искать символьные значения, которые соответствуют тексту внутри параметров (LIKE).
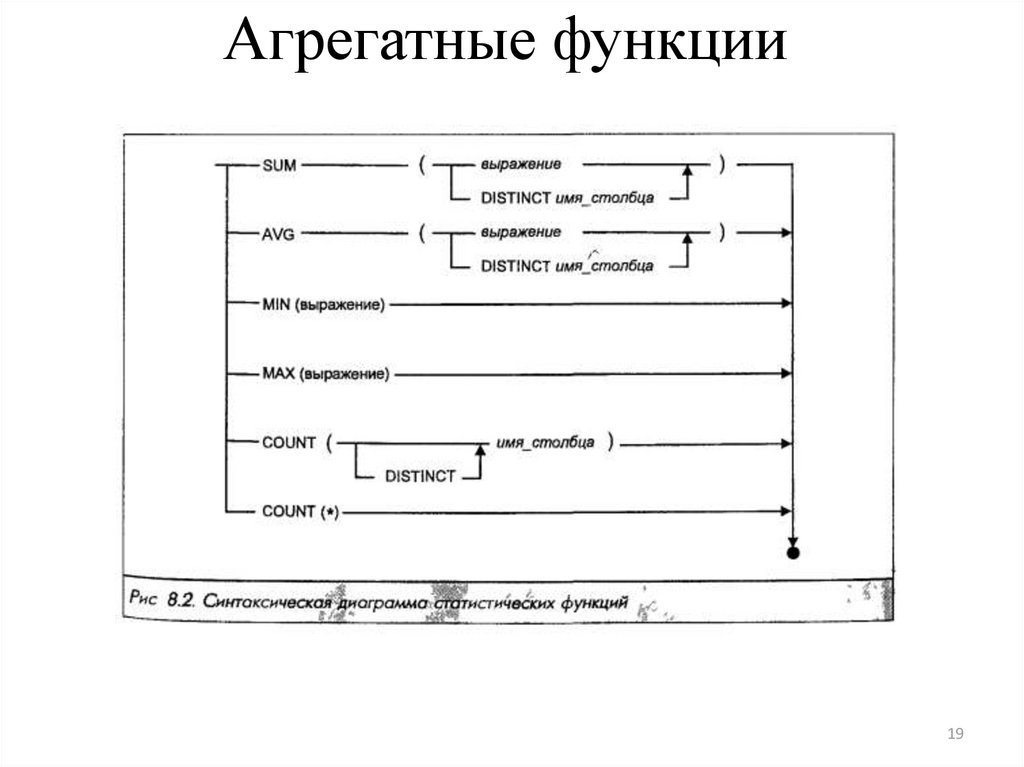
Результатом запроса может быть обобщенное групповое значение полей, точно так же, как и значение одного поля. Это делается с помощью стандартных агрегатных функций SQL, список которых приведен ниже:
COUNT | — число значений в столбце, |
SUM | — арифметическая сумма значений в столбце, |
AVG | — арифметическое среднее значение в столбце, |
MAX | — самое большое значение в столбце, |
MIN | — самое маленькое значение в столбце. |
Кроме специального случая COUNT(*), каждая из этих функций оперирует совокупностью значений столбца некоторой таблицы и выдает только одно значение.
Аргументу всех функций, кроме COUNT(*), может предшествовать ключевое слово DISTINCT (различный), указывающее, что дублирующие значения столбца
должны быть исключены перед тем, как будет применяться функция. Специальная же функция COUNT(*) служит для подсчета всех без исключения строк в таблице (включая дубликаты).
Агрегатные функции используются подобно именам полей в предложении запроса SELECT, но с одним исключением: они берут имена поля как аргументы. Только числовые поля могут использоваться с SUM и AVG.
С COUNT, MAX, и MIN могут использоваться и числовые или символьные поля. Когда они используются с символьными полями, MAX и MIN будут транслировать их в эквивалент ASCII кода, который должен сообщать, что MIN будет означать первое, а MAX — последнее значение в алфавитном порядке.
Чтобы найти SUM всех окладов в таблице ОТДЕЛ_СОТРУДНИК (рис. 2.3) надо ввести следующий запрос:
SELECT SUM ((Оклад)) | AS СУММА |
FROM Отдел_ Сотрудники;
И на экране увидим результат: 46800 (в таблице будет один столбец с именем СУММА).
Подсчет среднего значения по окладам также прост:
SELECT AVG ((Оклад))
FROM Отдел_ Сотрудники;
И на экране увидим результат: | 3342.85 |
Функция COUNT несколько отличается от всех. Она считает число значений в данном столбце или число строк в таблице. Когда она считает значения столбца, она используется с DISTINCT (различных) чтобы производить счет чисел уникальных значений в данном поле.
SELECT COUNT (DISTINCT | ОКЛАД) |
FROM Отдел_ Cотрудники; |
|
Результат: 8. |
|
В таблице восемь строк, в которых находятся различные значения окладов.
Отметим, что в последних трех примерах учитывается информация и об уволенных сотрудниках.
Следующее предложение позволяет определить число подразделений на
предприятии: |
|
SELECT COUNT (DISTINCT | Ид_Отд) |
FROM Отдел_Cотрудники; |
|
Результат: 3. |
|
DISTINCT, сопровождаемый именем поля, с которым он применяется, помещенный в круглые скобки, с COUNT применяется к индивидуальным столбцам.
Чтобы подсчитать общее число строк в таблице, используется COUNT со звездочкой вместо имени поля:
SELECT COUNT (*)
FROM Отдел_ Сотрудники;
Ответ будет: | 11. |
COUNT (*) подсчитывает все без исключения строки таблицы.
DISTINCT не применим c COUNT (*).
Предположим, что таблица ВЕДОМОСТЬ_ОПЛАТЫ (рис. 2.4) имеет еще один столбец, который хранит сумму произведенных вычетов (поле Вычет) для каждой строки ведомости. Тогда если Вас интересует вся сумма, то содержимое столбца Сумма и Вычет надо сложить.
Если же Вас интересует максимальная сумма с учетом вычетов, содержащаяся в ведомости, то это можно сделать с помощью следующего предложения:
SELECT MAX (Сумма + Вычет)
FROM Ведомость_ оплаты;
Для каждой строки таблицы этот запрос будет складывать значение поля Сумма со значением поля Вычет и выбирать самое большое значение, которое он найдет.
ПРЕДЛОЖЕНИЕ GROUP BY (перекомпоновка, порядок)
Предложение GROUP BY позволяет определять подмножество значений в особом поле в терминах другого поля и применять функцию агрегата к подмножеству. Это дает возможность объединять поля и агрегатные функции в едином предложении SELECT.
Например, предположим, что Вы хотите определить, сколько сотрудников находятся в каждом отделе (ответ приведен на рис. 4.21):
SELECT Ид_Отд, COUNT (DISTINCT Ид_Отд) AS Кол-во_сотрудников
FROM | Отдел_ Сотрудники |
| |
WHERE | Дата_ увольнения | NOT NULL | |
GROUP BY |
| Ид_Отд; |
|
|
|
|
|
|
| Ид_Отд | Кол-во_сотрудников |
|
|
|
|
|
| 1 | 5 |
|
|
|
|
|
| 2 | 4 |
|
|
|
|
|
| 3 | 1 |
|
|
|
|
Рис. 4.21. Запрос с группировкой
4.21. Запрос с группировкой
В результате выполнения предложения GROUP BY остаются только уникальные значения столбцов, по умолчанию отсортированные по возрастанию. В этом аспекте предложение GROUP BY отличается от предложения ORDER BY тем, что последнее хотя и сортирует записи по возрастанию, но не удаляет повторяющиеся значения. В приведенном примере запрос группирует строки таблицы по значениям столбца Ид_Отд (по номерам отделов). Строки с одинаковыми номерами отделов сначала объединяются в группы, но при этом для каждой группы отображается только одна строка. Во втором столбце выводится количество строк в каждой группе, т.е. число сотрудников в каждом отделе.
Значение поля, к которому применяется GROUP BY, имеет, по определению, только одно значение на группу вывода так же, как это делает агрегатная функция. Результатом является совместимость, которая позволяет агрегатам и полям объединяться таким образом.
Пусть, например, таблица ВЕДОМОСТЬ_ОПЛАТЫ имеет вид рис. 4. 22 и мы хотим определить максимальную сумму, выплаченную по ведомости каждому сотруднику.
22 и мы хотим определить максимальную сумму, выплаченную по ведомости каждому сотруднику.
Ид_сотр | Ид_Отд | Дата | Сумма | Вид_оплаты |
|
|
|
|
|
1 | 1 | 02.03.03 | 1200 |
|
|
|
|
|
|
2 | 1 | 01.03.03 | 1200 |
|
|
|
|
|
|
3 | 1 | 01.03.03 | 1000 |
|
|
|
|
|
|
1 | 1 | 01. | 1200 |
|
|
|
|
|
|
1 | 1 | 01.03.03 | 800 |
|
|
|
|
|
|
2 | 1 | 02.04.03 | 2000 |
|
|
|
|
|
|
 04.03
04.03
| Рис. 4.22. Состояние таблицы Ведомость1 |
SELECT | ИД_Сотр, MAX (Сумма) AS «Сумма максимальная» |
FROM | Ведомость1 |
GROUP | BY ИД_Сотр; |
В результате получим.
Ид_сотр | Сумма_максимальная |
|
|
3 | 1000 |
|
|
1 | 1200 |
|
|
2 | 2000 |
|
|
Рис. 4.23. Агрегатная функция с AS
4.23. Агрегатная функция с AS
Группировка может быть осуществлена и по нескольким атрибутам: SELECT Ид_сотр, Дата, MAX ((Сумма))
FROM Ведомость1
GROUP BY Ид_сотр, Дата;
Результат:
Ид_сотр | Дата |
|
|
|
|
1 | 01.03.03 | 800 |
|
|
|
1 | 02.03.03 | 1200 |
|
|
|
1 | 01.04.03 | 1200 |
|
|
|
2 | 01.03.03 | 1200 |
|
|
|
2 | 02.04.03 | 2000 |
|
|
|
2 | 01. | 1000 |
|
|
|
 03.03
03.03Рис. 4.24. Группировка по нескольким атрибутам
Если же возникает необходимость ограничить число групп, полученных после GROUP BY, то, используя предложение HAVING, можно это реализовать.
4.5. Использование фразы HAVING
Фраза HAVING играет такую же роль для групп, что и фраза WHERE для строк: она используется для исключения групп, точно так же, как WHERE используется для исключения строк. Эта фраза включается в предложение
лишь при наличии фразы GROUP BY, а выражение в HAVING должно принимать единственное значение для группы.
Например, пусть надо выдать количественный состав всех отделов (рис. 2.3), исключая отдел с номером 3.
SELECT Ид_Отд, COUNT (DISTINCT Ид_Отд) AS Кол-во _сотрудников
FROM | Отдел_ Сотрудники | |||
WHERE | Дата_ увольнения |
| NOT NULL | |
GROUP BY |
| Ид_Отд | HAVING Ид_Отд < > 3; | |
|
|
|
|
|
|
| Ид_Отд |
| Кол_во_сотрудников |
|
|
|
|
|
|
| 1 |
| 5 |
|
|
|
|
|
|
| 2 |
| 4 |
|
|
|
|
|
Рис. 4.25. Запрос с группировкой и ограничением
4.25. Запрос с группировкой и ограничением
Последним элементом при вычислении табличного выражения используется раздел HAVING (если он присутствует). Синтаксис этого раздела следующий:
<having clause> ::=
HAVING <search condition>
Условие поиска этого раздела задает условие на группу строк сгруппированной таблицы. Формально раздел HAVING может присутствовать и в табличном выражении, не содержащем GROUP BY. В этом случае полагается, что результат вычисления предыдущих разделов представляет собой сгруппированную таблицу, состоящую из одной группы без выделенных столбцов группирования.
Условие поиска раздела HAVING строится по тем же синтаксическим правилам, что и условие поиска раздела WHERE, и может включать те же самые предикаты.
Однако имеются специальные синтаксические ограничения по части использования в условии поиска спецификаций столбцов таблиц из раздела FROM данного табличного выражения. Эти ограничения следуют из того, что условие поиска раздела HAVING задает условие на целую группу, а не на индивидуальные строки.
Поэтому в арифметических выражениях предикатов, входящих в условие выборки раздела HAVING, прямо можно использовать только спецификации столбцов, указанных в качестве столбцов группирования в разделе GROUP BY. Остальные столбцы можно специфицировать только внутри спецификаций агрегатных функций COUNT, SUM, AVG, MIN и MAX, вычисляющих в данном случае некоторое агрегатное значение для всей группы строк. Аналогично обстоит дело с подзапросами, входящими в предикаты условия выборки раздела HAVING: если в подзапросе используется характеристика текущей группы, то она может задаваться только путем ссылки на столбцы группирования.
Пусть запрос вида (в качестве базовой таблицы см. рис. 4.22):
SELECT Ид_сотр, Дата, MAX ((Сумма))
FROM Ведомость1
GROUP BY Ид_сотр, Дата;
необходимо уточнить тем, чтобы были показаны только выплаты, превышающие 1000.
Однако по стандарту агрегатную функцию в предложении WHERE использовать запрещено (если вы не используете подзапрос, описанный позже), потому что предикаты оцениваются в терминах одиночной строки, а агрегатные функции оцениваются в терминах группы строк.
Следующее предложение будет неправильным:
SELECT Ид_сотр, Дата, MAX (Сумма)
FROM Ведомость1
WHERE MAX ((Сумма)) > 1000 GROUP BY Ид_сотр, Дата;
Правильным предложением будет:
SELECT Ид_сотр, Дата, MAX ((Сумма))
НОУ ИНТУИТ | Лекция | Группировка и условия раздела HAVING, порождаемые и соединенные таблицы
< Лекция 9 || Лекция 5: 123456789
Аннотация: В этой лекции мы завершаем обсуждение основных (традиционных) конструкций оператора SELECT языка SQL. В разделе «Агрегатные функции, группировка и условия раздела HAVING» обсуждаются разделы GROUP BY и HAVING. Основной акцент делается на способах конструирования условий раздела HAVING. На примерах демонстрируется, что разделы GROUP BY и HAVING действительно полезны, а иногда и необходимы при формулировке запросов с вызовами агрегатных функций. В разделах «Ссылки на порождаемые таблицы в разделе FROM» и «Более сложные конструкции оператора выборки» мы возвращаемся к разновидностям ссылок на таблицу в разделе FROM и последовательно обсуждаем порождаемые таблицы, соединенные таблицы и порождаемые таблицы с горизонтальной связью.
Ключевые слова: SQL, предикат, условное выражение, разделы, запрос, агрегатная функция, ORDER, соединенная таблица, порождаемая таблица с горизонтальной связью (lateral derived table), ПО, вычисление выражения, таблица, ссылка, SQL/92, логические выражения, декартово произведение, естественное правое внешнее соединение, внешний ключ, естественное соединение, EMP, natural, joining, неопределенное значение, левое внешнее соединение, внешнее соединение, симметричное внешнее соединение, outer, COMP, UNION, кортеж, модель данных, полное внешнее соединение, стандарт языка, прямое соединение (CROSS JOIN), внутреннее соединение по условию (INNER JOIN … ON), внутреннее соединение по совпадению значений указанных одноименных столбцов (INNER JOIN … USING), естественное внутреннее соединение (NATURAL INNER JOIN), левое внешнее соединение по условию (LEFT OUTER JOIN … ON), правое внешнее соединение по условию (RIGHT OUTER JOIN … ON), полное внешнее соединение по условию (FULL OUTER JOIN … ON), левое внешнее соединение по совпадению значений указанных одноименных столбцов (LEFT OUTER JOIN … USING), правое внешнее соединение по совпадению значений указанных одноименных столбцов (RIGHT OUTER JOIN … USING), полное внешнее соединение по совпадению значений указанных одноименных столбцов (FULL OUTER JOIN … USING), естественное левое внешнее соединение (NATURAL LEFT OUTER JOIN), естественное правое внешнее соединение (NATURAL RIGHT OUTER JOIN), естественное полное внешнее соединение (NATURAL FULL OUTER JOIN), соединение объединением (UNION JOIN), систематический, Мультимножество, стандарт SQL:1999, AVG, среднее значение, булевский тип, списки значений, скалярное выражение, тип значения агрегатной функции, тип символьной строки, значение выражения, distinction, логическое выражение раздела HAVING, табличное выражение, подзапрос, предикат like, EXISTS, ссылка на порождаемые таблицы в разделе FROM, MNG, заработная плата, PRO, предикат сравнения, CP/M, cross-section, NATURAL INNER JOIN, соответствующий столбец соединения, список выборки соответствующих столбцов соединения, выражение с переключателем, UNION JOIN, C2, коммутативность, NATURAL LEFT OUTER JOIN, NATURAL FULL OUTER JOIN, мощность, избыточность, программирование, компилятор, план выполнения, базы данных, метаданные, правильный ответ
Введение
 intuit.ru/2010/edi»>В предыдущих двух лекциях мы обсудили допускаемые в стандарте SQL виды ссылок на таблицы в разделе FROM оператора SELECT и подробно, с многочисленными примерами, рассмотрели возможные способы построения условных выражений раздела WHERE. Данную лекцию мы начинаем с анализа возможностей и целесообразности использования в запросах разделов GROUP BY и HAVING. В ней обсуждаются виды предикатов, которые можно использовать в условных выражениях раздела HAVING, и приводятся иллюстрирующие примеры. Но в действительности мы преследуем большую цель: показать, что во многих случаях разделы GROUP BY и HAVING являются избыточными; запрос можно сформулировать более понятным образом без их использования. Применение разделов GROUP BY и HAVING оказывается действительно полезным, а иногда и необходимым, в тех случаях, когда в запросе присутствует несколько вызовов агрегатных функций на группах строк.
intuit.ru/2010/edi»>В предыдущих двух лекциях мы обсудили допускаемые в стандарте SQL виды ссылок на таблицы в разделе FROM оператора SELECT и подробно, с многочисленными примерами, рассмотрели возможные способы построения условных выражений раздела WHERE. Данную лекцию мы начинаем с анализа возможностей и целесообразности использования в запросах разделов GROUP BY и HAVING. В ней обсуждаются виды предикатов, которые можно использовать в условных выражениях раздела HAVING, и приводятся иллюстрирующие примеры. Но в действительности мы преследуем большую цель: показать, что во многих случаях разделы GROUP BY и HAVING являются избыточными; запрос можно сформулировать более понятным образом без их использования. Применение разделов GROUP BY и HAVING оказывается действительно полезным, а иногда и необходимым, в тех случаях, когда в запросе присутствует несколько вызовов агрегатных функций на группах строк.
После обсуждения разделов GROUP BY и HAVING можно будет считать, что мы полностью рассмотрели базовые конструкции оператора выборки (раздел ORDER BY не заслуживает дополнительного обсуждения). Поэтому в разделах «Ссылки на порождаемые таблицы в разделе FROM » и «Более сложные конструкции оператора выборки» мы рассматриваем темы порождаемых таблиц, соединенных таблиц и порождаемых таблиц с горизонтальной связью.
Поэтому в разделах «Ссылки на порождаемые таблицы в разделе FROM » и «Более сложные конструкции оператора выборки» мы рассматриваем темы порождаемых таблиц, соединенных таблиц и порождаемых таблиц с горизонтальной связью.
В обычных порождаемых таблицах SQL нет ничего особенного. По всей видимости, возможность указывать в разделе FROM выражения запросов, а не только ссылки на базовые или представляемые таблицы, была введена в SQL на основе следующих естественных соображений. Результатом вычисления выражения запросов в SQL является таблица. Следовательно, в любой конструкции языка, где может присутствовать ссылка на таблицу SQL, следует допустить присутствие выражения запросов. Одновременное наличие возможностей определения представляемых таблиц, указания именованного выражения запросов в разделе WITH и указания выражения запросов порождаемой таблицы непосредственно в списке раздела FROM, очевидно, является избыточным.
 intuit.ru/2010/edi»>Соединенные таблицы появились еще в стандарте SQL/92, и внедрение в стандарт SQL этой возможности было действительно обоснованным. В соответствии с традиционной общей семантикой оператора SELECT в нем вообще не предусматривались явные средства для выражения потребности в соединении двух или более таблиц. Наличие возможности указывать несколько ссылок на таблицы в разделе FROM и спецификации произвольного логического выражения в разделе WHERE для ограничения расширенного декартова произведения этих таблиц позволяет выражать с помощью традиционных средств SQL соединение общего вида в смысле Кодда, и до поры до времени это считалось достаточным.
intuit.ru/2010/edi»>Соединенные таблицы появились еще в стандарте SQL/92, и внедрение в стандарт SQL этой возможности было действительно обоснованным. В соответствии с традиционной общей семантикой оператора SELECT в нем вообще не предусматривались явные средства для выражения потребности в соединении двух или более таблиц. Наличие возможности указывать несколько ссылок на таблицы в разделе FROM и спецификации произвольного логического выражения в разделе WHERE для ограничения расширенного декартова произведения этих таблиц позволяет выражать с помощью традиционных средств SQL соединение общего вида в смысле Кодда, и до поры до времени это считалось достаточным.
Внешние соединения
Но имеются два важных частных случая соединений, которые выражаются с помощью традиционных средств SQL излишне громоздко,- это естественные и внешние соединения. При наличии возможности определения внешних ключей таблицы кажется достаточно странной потребность всякий раз явно указывать в запросах условие естественного соединения. Например, во многих примерах запросов в лекции 14 присутствует условие соединения EMP.DEPT_NO = DEPT.DEPT_NO в тех случаях, когда в действительности нам требовался результат операции EMP NATURAL JOIN DEPT.
Например, во многих примерах запросов в лекции 14 присутствует условие соединения EMP.DEPT_NO = DEPT.DEPT_NO в тех случаях, когда в действительности нам требовался результат операции EMP NATURAL JOIN DEPT.
Внешние соединения были введены еще Эдгаром Коддом в 1979 г. В целом, основная идея этой разновидности операции соединения состояла в том, что, с одной стороны, результат операции обычного соединения двух отношений повышает информационный уровень данных, поскольку в результате операции мы имеем информационно связанные данные. Но, с другой стороны, в результирующем отношении мы теряем информацию об исходных объектах, которые оказались несвязанными и не вошли в результат соединения. Кодд придумал, как, используя неопределенные значения, определить обобщенную операцию, которая будет обладать достоинствами обычной операции соединения, не приводя к потере исходной информации. Вернее, он предложил три операции: левое внешнее соединение, правое внешнее соединение и полное (симметричное) внешнее соединение. Приведем их определения (в реляционных терминах данного курса).
Приведем их определения (в реляционных терминах данного курса).
Пусть имеются отношения r1 и r2, совместимые относительно операции взятия расширенного декартова произведения. Пусть s является результатом операции r1 LEFT OUTER JOIN r2 WHERE comp (левое внешнее соединение r1 и r2 по условию comp ). Тогда Hs = Hr1 union Hr2. Пусть и . Тогда в том и только в том случае, когда comp (tr1 union tr2) = true. Если имеется кортеж , для которого нет ни одного кортежа , такого, что comp (tr1 union tr2) = true, то , где tr2null — кортеж, соответствующий Hr2, все значения которого являются неопределенными1Здесь мы прибегаем к компромиссу между реляционной терминологией и моделью данных SQL: конечно, в реляционной модели кортеж из неопределенных значений не может соответствовать заголовку отношения, поскольку NULL не является значением ни одного типа данных..
Пусть s является результатом операции r1 RIGHT OUTER JOIN r2 WHERE comp (правое внешнее соединение r1 и r2 по условию comp ). Тогда Hs = Hr1 union Hr2. Пусть и . Тогда в том и только в том случае, когда comp (tr1 union tr2) = true. Если имеется кортеж , для которого нет ни одного такого кортежа , что comp (tr1 union tr2) = true, то , где tr1null — кортеж, соответствующий Hr1, все значения которого являются неопределенными.
Тогда Hs = Hr1 union Hr2. Пусть и . Тогда в том и только в том случае, когда comp (tr1 union tr2) = true. Если имеется кортеж , для которого нет ни одного такого кортежа , что comp (tr1 union tr2) = true, то , где tr1null — кортеж, соответствующий Hr1, все значения которого являются неопределенными.
Наконец, пусть s является результатом операции r1 FULL OUTER JOIN r2 WHERE comp (полное внешнее соединение r1 и r2 по условию comp ). Тогда Hs = Hr1 union Hr2. Пусть и . Тогда в том и только в том случае, когда comp (tr1 union tr2) = true. Если имеется кортеж , для которого нет ни одного кортежа , такого, что comp (tr1 union tr2) = true, то , где tr2null — кортеж, соответствующий Hr2, все значения которого являются неопределенными. Если имеется кортеж , для которого нет ни одного кортежа , такого,
что comp (tr1 union tr2) = true, то , где tr1null — кортеж, соответствующий Hr1, все значения которого являются неопределенными.
Понятно, что традиционными средствами SQL можно выразить все виды внешних соединений (например, с использованием переключателей), но такие запросы будут очень громоздкими. Компании-производители SQL-ориентированных СУБД пытались обеспечивать выразительные средства внешних соединений путем расширения системы обозначений для операций сравнения. Этот подход был не слишком удачным и не обеспечивал общего решения.
В стандарте языка SQL специфицирован отдельный специализированный подъязык для формирования выражений соединения таблиц. Такие выражения называются соединенными таблицами, и их можно использовать в качестве ссылок на таблицы в списке раздела FROM. Разработчики стандарта SQL не любят мельчить — в языке допускается 14 видов соединений:
- прямое соединение ;
- внутреннее соединение по условию ;
 intuit.ru/2010/edi»>
внутреннее соединение по совпадению значений указанных одноименных столбцов ;
intuit.ru/2010/edi»>
внутреннее соединение по совпадению значений указанных одноименных столбцов ;- естественное внутреннее соединение ;
- левое внешнее соединение по условию ;
- правое внешнее соединение по условию ;
- полное внешнее соединение по условию ;
- левое внешнее соединение по совпадению значений указанных одноименных столбцов ;
- правое внешнее соединение по совпадению значений указанных одноименных столбцов ;
- полное внешнее соединение по совпадению значений указанных одноименных столбцов ;
- естественное левое внешнее соединение ;
- естественное правое внешнее соединение ;
 intuit.ru/2010/edi»>
естественное полное внешнее соединение ;
intuit.ru/2010/edi»>
естественное полное внешнее соединение ;- соединение объединением.
Во всех этих операциях нет ничего сложного, но их неформальное описание исключительно громоздко. Поэтому в разделе «Более сложные конструкции оператора выборки» мы определяем операции на формальном уровне, а потом иллюстрируем их на примерах.
Наконец, последняя тема этой лекции относится к еще одному типу ссылок на таблицу, допускаемых в разделе FROM: порождаемым таблицам с горизонтальной связью. Фактически порождаемая таблица с горизонтальной связью представляет собой выражение запросов, в котором может присутствовать корреляция со строками таблиц, специфицированных в списке раздела FROM слева от данной порождаемой таблицы с горизонтальной связью. Наличие порождаемых таблиц с горизонтальной связью требует некоторого уточнения семантики выполнения раздела FROM оператора SELECT. По нашему мнению, это средство является полностью избыточным, хотя и не вредным, поскольку его реализация не должна вызывать затруднений и/или снижать эффективность системы.
По нашему мнению, это средство является полностью избыточным, хотя и не вредным, поскольку его реализация не должна вызывать затруднений и/или снижать эффективность системы.
Дальше >>
< Лекция 9 || Лекция 5: 123456789
AVG (Transact-SQL) — SQL Server
- Статья
- 5 минут на чтение
Применимо к: SQL Server (все поддерживаемые версии) База данных SQL Azure Управляемый экземпляр Azure SQL Аналитика синапсов Azure Система аналитической платформы (PDW)
Эта функция возвращает среднее значение в группе. Он игнорирует нулевые значения.
Соглашения о синтаксисе Transact-SQL
Синтаксис
AVG ([ALL | DISTINCT] выражение) [ ПЕРЕД ( [ раздел_по_пункту ] заказ_по_пункту ) ]
Примечание
Чтобы просмотреть синтаксис Transact-SQL для SQL Server 2014 и более ранних версий, см. документацию по предыдущим версиям.
документацию по предыдущим версиям.
Аргументы
ВСЕ
Применяет агрегатную функцию ко всем значениям. ВСЕ по умолчанию.
DISTINCT
Указывает, что AVG работает только с одним уникальным экземпляром каждого значения, независимо от того, сколько раз встречается это значение.
выражение
Выражение категории точного или приблизительного числового типа данных, за исключением типа данных бит . Агрегатные функции и подзапросы не допускаются.
БОЛЕЕ ( [ раздел_по_пункту ] заказ_по_пункту )
раздел_по_пункту делит набор результатов, созданный предложением FROM, на разделы, к которым применяется функция. Если не указано, функция обрабатывает все строки набора результатов запроса как одну группу. order_by_clause определяет логический порядок, в котором выполняется операция. Требуется order_by_clause . Дополнительные сведения см. в разделе Предложение OVER (Transact-SQL).
в разделе Предложение OVER (Transact-SQL).
Типы возвращаемых значений
Результат вычисления выражения определяет тип возвращаемого значения.
| Результат выражения | Тип возврата |
|---|---|
| крошечный | Интервал |
| малое целое | Интервал |
| внутр. | Интервал |
| большое число | большое число |
| десятичный разряд (р, с) | десятичный(38, макс(с,6)) |
| деньги и мелкие деньги категория | деньги |
| плавающая и реальная категория | поплавок |
Если тип данных выражения является типом данных псевдонима, возвращаемый тип также относится к типу данных псевдонима. Однако, если базовый тип данных псевдонима повышается, например, с tinyint до int , возвращаемое значение будет принимать продвинутый тип данных, а не псевдоним.
Однако, если базовый тип данных псевдонима повышается, например, с tinyint до int , возвращаемое значение будет принимать продвинутый тип данных, а не псевдоним.
AVG () вычисляет среднее значение набора значений путем деления суммы этих значений на количество ненулевых значений. Если сумма превышает максимальное значение для типа данных возвращаемого значения, AVG() вернет ошибку.
AVG является детерминированной функцией при использовании без предложений OVER и ORDER BY. Он недетерминирован, если указан с предложениями OVER и ORDER BY. Дополнительные сведения см. в разделе Детерминированные и недетерминированные функции.
Примеры
A. Использование функций SUM и AVG для расчетов
В этом примере вычисляется среднее количество часов отпуска и сумма отпусков по болезни, которые использовали вице-президенты Adventure Works Cycles. Каждая из этих агрегатных функций создает одно итоговое значение для всех извлеченных строк.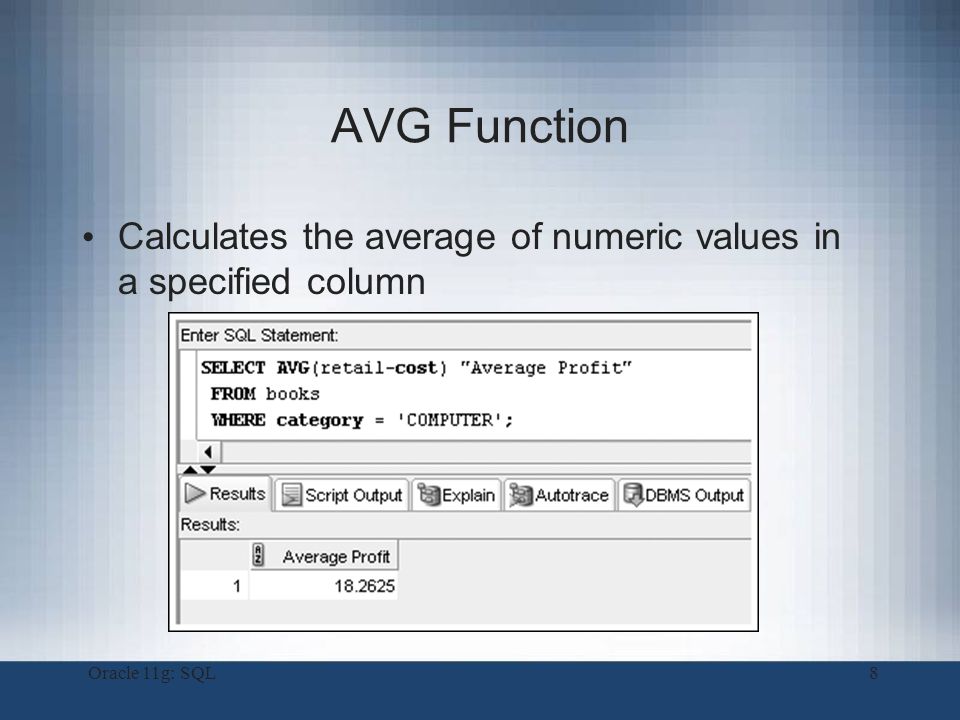 В примере используется база данных AdventureWorks2019.
В примере используется база данных AdventureWorks2019.
ВЫБРАТЬ AVG(VacationHours)AS 'Среднее количество часов отпуска',
SUM(SickLeaveHours) AS 'Общее количество часов отпуска по болезни'
ОТ HumanResources.Employee
ГДЕ JobTitle НРАВИТСЯ «Вице-президент%»;
Вот набор результатов.
Среднее количество часов отпуска Всего часов отпуска по болезни ---------------------- ---------------------- 25 97 (затронуты 1 ряд)
B. Использование функций SUM и AVG с предложением GROUP BY
При использовании с предложением GROUP BY каждая агрегатная функция выдает одно значение, охватывающее каждую группу, вместо одного значения, охватывающего всю таблицу. В следующем примере создаются сводные значения для каждой территории продаж в AdventureWorks2019.база данных. В сводке перечислены средние бонусы, полученные продавцами в каждой территории, и сумма продаж с начала года для каждой территории.
SELECT TerritoryID, AVG(Bonus) как «Средний бонус», SUM(SalesYTD) как «Продажи с начала года» ОТ Sales.
Вот набор результатов.
TerritoryID Средний бонус продаж с начала года ------------------------- ------------------------------------ ------------------ --- НУЛЕВОЕ 0,00 1252127,9471 1 4133.3333 4502152.2674 2 4100.00 3763178.1787 3 2500,00 3189418,3662 4 2775.00 6709904.1666 5 6700.00 2315185.611 6 2750.00 4058260.1825 7 985.00 3121616.3202 8 75.00 1827066.7118 9 5650.00 1421810.9242 10 5150.00 4116871.2277 (затронуты 11 рядов)
C. Использование AVG с DISTINCT
Этот оператор возвращает среднюю прейскурантную цену продуктов в AdventureWorks2019.база данных. Благодаря использованию DISTINCT при расчете учитываются только уникальные значения.
ВЫБЕРИТЕ СРЕДНЕЕ (DISTINCT ListPrice) ОТ Производство.Продукт;
Вот набор результатов.
--------------------------------------------- 437.4042 (затронуты 1 ряд)
D. Использование AVG без DISTINCT
Без DISTINCT функция AVG находит среднюю прейскурантную цену всех продуктов в таблице Product в базе данных AdventureWorks2019, включая все повторяющиеся значения.
ВЫБЕРИТЕ СРЕДНЮЮ (СписочнаяЦена) ОТ Производство.Продукт;
Вот набор результатов.
--------------------------------------------- 438,6662 (затронуты 1 ряд)
E. Использование предложения OVER
В следующем примере используется функция AVG с предложением OVER для получения скользящего среднего годового объема продаж для каждой территории в таблице Sales.SalesPerson в базе данных AdventureWorks2019. Данные разделены по TerritoryID и логически упорядочены по Продажи с начала года . Это означает, что функция AVG вычисляется для каждой территории на основе года продаж. Обратите внимание, что для TerritoryID 1 есть две строки для 2005 года продаж, которые представляют двух продавцов с продажами в этом году. Рассчитывается средний объем продаж для этих двух строк, а затем в расчет включается третья строка, представляющая продажи за 2006 год.
ВЫБЕРИТЕ BusinessEntityID, TerritoryID
,DATEPART(yy,ModifiedDate) AS SalesYear
,Преобразовать(VARCHAR(20),ПродажиYTD,1) КАК ПродажиYTD
,CONVERT(VARCHAR(20),AVG(SalesYTD) OVER (PARTITION BY TerritoryID
ORDER BY DATEPART(yy,ModifiedDate)
),1) AS MovingAvg
,CONVERT(VARCHAR(20),SUM(SalesYTD) OVER (PARTITION BY TerritoryID
ORDER BY DATEPART(yy,ModifiedDate)
),1) AS CumulativeTotal
ОТ Sales. SalesPerson
ГДЕ TerritoryID равен NULL ИЛИ TerritoryID < 5
ЗАКАЗАТЬ ПО TerritoryID,SalesYear;
Вот набор результатов.
BusinessEntityID TerritoryID SalesYear SalesYTD MovingAvg CumulativeTotal ---------------- ----------- ----------- ------------ -------- -------------------- -------------------- 274 НЕТ 2005 559 697,56 559 697,56 559 697,56 287 НЕТ 2006 519 905,93 539 801,75 1 079 603,50 285 НЕТ 2007 172 524,45 417 375,98 1 252 127,95 283 1 2005 1 573 012,94 1 462 795,04 2 925 590,07 280 1 2005 1 352 577,13 1 462 795,04 2 925 590,07 284 1 2006 1 576 562,20 1 500 717,42 4 502 152,27 275 2 2005 3 763 178,18 3 763 178,18 3 763 178,18 277 3 2005 3 189 418,37 3 189 418,37 3 189,418,37 276 4 2005 4 251 368,55 3 354 952,08 6 709 904,17 281 4 2005 2 458 535,62 3 354 952,08 6 709 904,17 (затронуты 10 строк)
В этом примере предложение OVER не включает PARTITION BY. Это означает, что функция будет применяться ко всем строкам, возвращаемым запросом. Предложение ORDER BY, указанное в предложении OVER, определяет логический порядок, к которому применяется функция AVG. Запрос возвращает скользящее среднее продаж по годам для всех территорий продаж, указанных в предложении WHERE. Предложение ORDER BY, указанное в инструкции SELECT, определяет порядок, в котором инструкция SELECT отображает строки запроса.
ВЫБЕРИТЕ BusinessEntityID, TerritoryID
,DATEPART(yy,ModifiedDate) AS SalesYear
,Преобразовать(VARCHAR(20),ПродажиYTD,1) КАК ПродажиYTD
,CONVERT(VARCHAR(20),AVG(SalesYTD) OVER (ORDER BY DATEPART(yy,ModifiedDate)
),1) AS MovingAvg
,CONVERT(VARCHAR(20),SUM(SalesYTD) OVER (ORDER BY DATEPART(yy,ModifiedDate)
),1) AS CumulativeTotal
ОТ Sales.SalesPerson
ГДЕ TerritoryID равен NULL ИЛИ TerritoryID < 5
ЗАКАЗАТЬ ПО Году продаж;
Вот набор результатов.
BusinessEntityID TerritoryID SalesYear SalesYTD MovingAvg CumulativeTotal ---------------- ----------- ----------- ------------ -------- -------------------- -------------------- 274 НЕТ 2005 559 697,56 2 449 684,05 17 147 788,35 275 2 2005 3 763 178,18 2 449 684,05 17 147 788,35 276 4 2005 4 251 368,55 2 449684,05 17 147 788,35 277 3 2005 3 189 418,37 2 449 684,05 17 147 788,35 280 1 2005 1 352 577,13 2 449 684,05 17 147 788,35 281 4 2005 2 458 535,62 2 449 684,05 17 147 788,35 283 1 2005 1 573 012,94 2 449 684,05 17 147 788,35 284 1 2006 1 576 562,20 2 138 250,72 19244 256,47 287 НЕТ 2006 519 905,93 2 138 250,72 19 244 256,47 285 НЕТ 2007 172 524,45 1 941 678,09 19 416 780,93 (затронуты 10 строк)
См.
также Агрегированные функции (Transact-SQL)
Предложение OVER (Transact-SQL)
MAX (Transact-SQL) — SQL Server
Редактировать
Твиттер LinkedIn Фейсбук Эл. адрес
- Статья
- 2 минуты на чтение
Применимо к: SQL Server (все поддерживаемые версии) База данных SQL Azure Управляемый экземпляр Azure SQL Аналитика синапсов Azure Analytics Platform System (PDW)
Возвращает максимальное значение в выражении.
Соглашения о синтаксисе Transact-SQL
Синтаксис
-- Синтаксис функции агрегирования MAX([ALL | DISTINCT] выражение) -- Синтаксис аналитической функции MAX ([ALL] выражение) OVER ([ ])
Примечание
Чтобы просмотреть синтаксис Transact-SQL для SQL Server 2014 и более ранних версий, см. документацию по предыдущим версиям.
Аргументы
ВСЕ
Применяет агрегатную функцию ко всем значениям. ВСЕ по умолчанию.
DISTINCT
Указывает, что учитывается каждое уникальное значение. DISTINCT не имеет смысла в MAX и доступен только для совместимости с ISO.
выражение
Является константой, именем столбца или функцией и любой комбинацией арифметических, побитовых и строковых операторов. MAX можно использовать с числовыми , символьными , uniqueidentifier и datetime столбцами, но не с битными столбцами. Агрегатные функции и подзапросы не допускаются.
Дополнительные сведения см. в разделе Выражения (Transact-SQL).
OVER ( partition_by_clause [ order_by_clause ] )
partition_by_clause делит набор результатов, созданный предложением FROM, на разделы, к которым применяется функция. Если не указано, функция обрабатывает все строки набора результатов запроса как одну группу. order_by_clause определяет логический порядок выполнения операции. partition_by_clause требуется. Дополнительные сведения см. в разделе Предложение OVER (Transact-SQL).
Типы возвращаемых значений
Возвращает значение, аналогичное выражению .
MAX игнорирует любые нулевые значения.
MAX возвращает NULL, когда нет строки для выбора.
Для символьных столбцов функция MAX находит наибольшее значение в последовательности сопоставления.
MAX является детерминированной функцией при использовании без предложений OVER и ORDER BY. Он недетерминирован, если указан с предложениями OVER и ORDER BY. Дополнительные сведения см. в разделе Детерминированные и недетерминированные функции.
Примеры
A. Простой пример
В следующем примере возвращается самая высокая (максимальная) налоговая ставка в базе данных AdventureWorks2019.
ВЫБЕРИТЕ МАКС(Ставка налога) FROM Sales.SalesTaxRate; ИДТИ
Вот набор результатов.
------------------- 19.60 Предупреждение, нулевое значение удалено из агрегата. (затронуты 1 ряд)
B. Использование предложения OVER
В следующем примере используются функции MIN, MAX, AVG и COUNT с предложением OVER для предоставления агрегированных значений для каждого отдела в 9Таблица 0181 HumanResources.Department в базе данных AdventureWorks2019.
ВЫБЕРИТЕ ОТЛИЧНОЕ Имя
, МИН(Ставка) БОЛЕЕ (РАЗДЕЛ ПО edh.DepartmentID) AS MinSalary
, MAX(Rate) OVER (PARTITION BY edh.DepartmentID) AS MaxSalary
, AVG(Rate) OVER (PARTITION BY edh.DepartmentID) AS AvgSalary
,COUNT(edh.BusinessEntityID) OVER (PARTITION BY edh.DepartmentID) AS EmployeesPerDept
ОТ HumanResources.EmployeePayHistory AS eph
ПРИСОЕДИНЯЙТЕСЬ к HumanResources.EmployeeDepartmentHistory AS edh
ON eph.BusinessEntityID = edh.BusinessEntityID
ПРИСОЕДИНЯЙТЕСЬ к HumanResources. Department AS d
ON d.DepartmentID = edh.DepartmentID
ГДЕ edh.EndDate IS NULL
ЗАКАЗАТЬ ПО имени;
Вот набор результатов.
Имя MinSalary MaxSalary AvgSalary EmployeesPerDept ----------------------------- --------------------- --------------------- -------------------- -------- -------- Документооборот 10,25 17,7885 14,3884 5 Машиностроение 32,6923 63,4615 40,1442 6 Представительский 39.06 125,50 68,3034 4 Помещения и техническое обслуживание 9,25 24,0385 13,0316 7 Финансы 13,4615 43,2692 23,935 10 Человеческие ресурсы 13,9423 27,1394 18,0248 6 Информационные услуги 27.4038 50.4808 34.1586 10 Маркетинг 13,4615 37,50 18,4318 11 Производство 6,50 84,1346 13,5537 195 Производственный контроль 8,62 24,5192 16,7746 8 Закупки 9,86 30,00 18,0202 14 Обеспечение качества 10,5769 28,8462 15,4647 6 Исследования и разработки 40,8654 50,4808 43,6731 4 Продажи 23.0769 72.1154 29.9719 18 Доставка и получение 9.00 19.2308 10.8718 6 Конструкция инструмента 8,62 29,8462 23,5054 6 (затронуты 16 рядов)
C.
Использование MAX с символьными данными В следующем примере возвращается имя базы данных, которое сортируется как фамилия в алфавитном порядке. В примере используется WHERE database_id < 5 для рассмотрения только системных баз данных.
SELECT MAX(name) FROM sys.databases WHERE database_id < 5;
Последняя системная база данных: tempdb .
См. также
Агрегированные функции (Transact-SQL)
Предложение OVER (Transact-SQL)
Агрегированные функции SQL Server
Резюме : в этом руководстве вы узнаете об агрегатных функциях SQL Server и о том, как их использовать для вычисления агрегатов.
Агрегатная функция выполняет вычисление одного или нескольких значений и возвращает одно значение. Агрегатная функция часто используется с Предложение GROUP BY и Предложение HAVING оператора SELECT .
В следующей таблице показаны функции агрегирования SQL Server:
| Функция агрегата | Описание |
|---|---|
| AVG | FUNDAI установлен. |
| CHECKSUM_AGG | Функция CHECKSUM_AGG() вычисляет значение контрольной суммы на основе группы строк. |
| COUNT | Агрегатная функция COUNT() возвращает количество строк в группе, включая строки со значениями NULL. |
| COUNT_BIG | Агрегатная функция COUNT_BIG() возвращает количество строк (с типом данных BIGINT) в группе, включая строки со значениями NULL. |
| MAX | Агрегатная функция MAX() возвращает наибольшее значение (максимум) в наборе значений, отличных от NULL. |
| MIN | Агрегатная функция MIN() возвращает наименьшее значение (минимум) в наборе значений, отличных от NULL. |
| СТАНДОТКЛОН | Функция СТАНДОТКЛОН() возвращает статистическое стандартное отклонение всех значений, представленных в выражении , на основе выборки совокупности данных. |
| СТАНДОТКЛОН | Функция СТАНДОТКЛОН() также возвращает стандартное отклонение для всех значений в предоставленном , но делает это на основе всей совокупности данных. |
| СУММ | Агрегатная функция СУММ() возвращает сумму всех ненулевых значений набора. |
| VAR | Функция VAR() возвращает статистическую дисперсию значений в выражении на основе выборки указанной совокупности. |
| VARP | Функция VARP() возвращает статистическую дисперсию значений в выражении, но не , поэтому на основе всей совокупности данных. |
Синтаксис агрегатной функции SQL Server
Ниже показан синтаксис агрегатной функции:
Язык кода: SQL (язык структурированных запросов) (sql)
агрегатное_имя_функции(DISTINCT | ALL expression)
В этом синтаксисе;
- Сначала укажите имя агрегатной функции, которую вы хотите использовать, например
AVG,SUMиМАКС. - Во-вторых, используйте
DISTINCT, если вы хотите, чтобы при расчете учитывались только отдельные значения, илиALL, если при расчете учитывались все значения. По умолчанию используетсяВСЕ, если вы не укажете какой-либо модификатор. - В-третьих, выражение
Примеры агрегатных функций SQL Server
Для демонстрации мы будем использовать таблицу products из примера базы данных.
Пример AVG
В следующем операторе используется функция AVG() для возврата средней прейскурантной цены всех продуктов в таблице продуктов:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT AVG(списочная_цена) avg_product_price ИЗ производство.
Ниже показаны выходные данные:
Поскольку прейскурантная цена указана в долларах США, она должна содержать не более двух знаков после запятой. Поэтому нужно округлить результат до числа с двумя знаками после запятой. Для этого используйте функции ROUND и CAST , как показано в следующем запросе:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT CAST(ROUND(AVG(list_price),2) AS DEC(10,2)) средняя_цена_продукта ИЗ производство.продукции;
Первый, Функция ROUND возвращает округленную среднюю прейскурантную цену. А затем функция CAST преобразует результат в десятичное число с двумя знаками после запятой.
COUNT пример
Следующий оператор использует функцию COUNT() для возврата количества товаров, цена которых превышает 500:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT COUNT(*) число_продуктов ИЗ производство.продукция КУДА цена_списка > 500;
Ниже показаны выходные данные:
В этом примере:
- Во-первых, предложение
WHEREполучает товары, прейскурантная цена которых превышает 500. - Во-вторых, функция
COUNTвозвращает количество товаров с прейскурантные цены выше 500.
Пример MAX
В следующем операторе используется функция MAX() для возврата максимальной прейскурантной цены всех продуктов:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT MAX(цена_списка) max_price_list ИЗ производство.
На следующем рисунке показан результат: продукты:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ MIN(списочная_цена) min_списочная_цена ИЗ производство.продукции;
Вывод:
СУММА пример
Для демонстрации функции SUM() мы будем использовать таблицу stocks из примера базы данных.
Следующий оператор использует функцию СУММ() для расчета общего запаса по идентификатору продукта на всех складах:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT Код товара, СУММ(количество) ИЗ производство.
Вот результат:
Вот как работает оператор:
- Во-первых, предложение
GROUP BYсуммирует строки по идентификатору продукта в группы. - Во-вторых, функция
SUM()вычислила сумму количества для каждой группы.
Пример STDEV
В следующем операторе используется функция STDEV() для расчета статистического стандартного отклонения всех прейскурантных цен:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT CAST(ROUND(STDEV(list_price),2) as DEC(10,2)) stdev_list_price ИЗ производство.продукции;
В этом руководстве вы узнали об агрегатных функциях SQL Server и о том, как их использовать для вычисления агрегатов.
Агрегированные функции SQL
Резюме : в этом руководстве вы узнаете об агрегатных функциях SQL, включая AVG() , COUNT() , MIN() , MAX() , 8 и 8 СУММ() .
Агрегатная функция SQL вычисляет набор значений и возвращает одно значение. Например, функция среднего ( AVG ) принимает список значений и возвращает среднее значение.
Поскольку агрегатная функция работает с набором значений, она часто используется с предложением GROUP BY инструкции SELECT . Предложение GROUP BY делит набор результатов на группы значений, и агрегатная функция возвращает одно значение для каждой группы.
Ниже показано, как агрегатная функция используется с предложением GROUP BY :
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ c1, агрегатная_функция (c2) ИЗ таблицы СГРУППИРОВАТЬ ПО c1;
Ниже приведены часто используемые агрегатные функции SQL:
-
AVG()— возвращает среднее значение набора. -
COUNT()– возвращает количество элементов в наборе. -
MAX()– возвращает максимальное значение в наборе. -
MIN()– возвращает минимальное значение в наборе -
SUM()– возвращает сумму всех или отдельных значений в наборе
За исключением функции COUNT() , агрегатные функции SQL игнорируют null.
Вы можете использовать агрегатные функции в качестве выражений только в следующих случаях:
- Список выбора оператора
SELECT, либо подзапрос, либо внешний запрос. - A
HAVINGпункт
AVG Функция AVG() возвращает средние значения в наборе. Ниже показан синтаксис AVG() функция:
Язык кода: SQL (язык структурированных запросов) (sql)
AVG( ALL | DISTINCT)
среднее значение всех значений, в то время как ключевое слово DISTINCT заставляет функцию работать только с различными значениями. По умолчанию используется опция ВСЕ .
В следующем примере показано, как использовать функцию AVG() для расчета средней заработной платы каждого отдела:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ имя_отдела, ОКРУГЛ(СРЕДНЯЯ(зарплата), 0) средняя_зарплата ИЗ сотрудники ВНУТРЕННЕЕ СОЕДИНЕНИЕ отделы USING (department_id) СГРУППИРОВАТЬ ПО имя_отдела ЗАКАЗАТЬ ПО имя_отдела;
MIN Функция MIN() возвращает минимальное значение набора. Ниже показан синтаксис функции MIN() :
Язык кода: SQL (язык структурированных запросов) (sql)
MIN(столбец | выражение)
Например, следующий оператор возвращает минимальную заработную плату сотрудников в каждом отделе:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT имя_отдела, MIN(зарплата) min_salary ИЗ сотрудники ВНУТРЕННЕЕ СОЕДИНЕНИЕ отделы USING (department_id) СГРУППИРОВАТЬ ПО имя_отдела ЗАКАЗАТЬ ПО имя_отдела;
MAX Функция MAX() возвращает максимальное значение набора. Функция MAX() имеет следующий синтаксис:
Язык кода: SQL (язык структурированных запросов) (sql)
MAX(столбец | выражение)
Например, следующий оператор возвращает самую высокую зарплату сотрудников в каждом отделе:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ имя_отдела, МАКС(зарплата) самая высокая_зарплата ИЗ сотрудники ВНУТРЕННЕЕ СОЕДИНЕНИЕ отделы USING (department_id) СГРУППИРОВАТЬ ПО имя_отдела ЗАКАЗАТЬ ПО имя_отдела;
COUNT Функция COUNT() возвращает количество элементов в наборе. Ниже показан синтаксис функции COUNT() . Например, в следующем примере функция COUNT(*) используется для возврата численности персонала каждого отдела:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ имя_отдела, COUNT(*) численность персонала ИЗ сотрудники ВНУТРЕННЕЕ СОЕДИНЕНИЕ отделы USING (department_id) СГРУППИРОВАТЬ ПО имя_отдела ЗАКАЗАТЬ ПО имя_отдела;
SUM Функция SUM() возвращает сумму всех значений. Ниже показан синтаксис функции СУММ() :
Язык кода: SQL (язык структурированных запросов) (sql)
СУММ(ВСЕ | РАЗЛИЧНЫЕ столбцы)
Например, следующая инструкция возвращает общую зарплату всех сотрудников в каждом отделе:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT id_отдела, СУММА(зарплата) ИЗ сотрудники СГРУППИРОВАТЬ ПО ИД_отдела;
В этом руководстве вы изучили наиболее часто используемые агрегатные функции SQL, включая AVG() , COUNT() , MIN() , MAX() и SUM() функции.
Изучение SQL: агрегатные функции
SQL имеет много интересных функций, и агрегатные функции определенно являются одной из этих функций, фактически функциями. Хотя они не являются специфическими для SQL, они часто используются. Они являются частью оператора SELECT , и это позволяет нам иметь все преимущества SELECT (объединение таблиц, фильтрация только нужных нам строк и столбцов), в сочетании с мощностью этих функций.
Модель
Прежде чем мы начнем говорить об агрегатных функциях, мы коротко прокомментируем модель данных, которую будем использовать.
Это та же самая модель, которую мы использовали в нескольких прошлых статьях. Не буду вдаваться в подробности, а отмечу, что все
6 таблиц в модели содержат данные. На некоторые записи в таблицах есть ссылки в других, а на некоторые нет. Например.
у нас есть страны без родственного города, и у нас есть города без родственных клиентов. Мы прокомментируем это в статье, где это будет важно.
Простейшая агрегатная функция
Мы, конечно же, начнем с простейшей агрегатной функции. Но, прежде чем мы это сделаем, давайте проверим содержимое двух таблиц, которые мы будем использовать в этой статье. Есть таблицы страна и город . Мы будем использовать следующие утверждения:
ВЫБЕРИТЕ * ИЗ страны;
ВЫБЕРИТЕ * ИЗ город; |
Результат вы можете увидеть на картинке ниже:
В этом нет ничего нового и неожиданного. Мы только что перечислили все, что есть в наших таблицах («*» в запросе будет привести к возврату всех столбцов/атрибутов, в то время как отсутствие какого-либо условия/ ГДЕ часть запроса приведет к возврату всех строк).
Единственное, что я хотел бы отметить, это то, что страна таблица имеет 7 строк и что
Таблица city имеет 6 строк. Теперь давайте рассмотрим следующие запросы и их результат:
Мы можем заметить, что для каждого запроса мы получили в результате одну строку, а возвращаемое число представляет собой количество строк в каждой из этих двух таблиц. Вот что делает агрегатная функция COUNT . Он берет то, что вернул бы запрос без COUNT , а затем возвращает количество строк в этом результате. Еще одна важная вещь, о которой вы должны знать, это то, что только COUNT может использоваться с «*». Все другие функции требуют атрибута (или формулы) в скобках. Мы увидим это позже.
Агрегированные функции и соединения
Теперь давайте попробуем еще две вещи. Во-первых, мы проверим, как работает COUNT при объединении таблиц. Сделать что мы будем использовать следующие запросы:
1 2 3 4 5 6 7 | ВЫБЕРИТЕ * ИЗ страны ВНУТРЕННЕЕ СОЕДИНЕНИЕ city ON city.
SELECT COUNT(*) AS number_of_rows ИЗ страны ВНУТРЕННЕЕ СОЕДИНЕНИЕ city ON city.country_id = country.id; |
Хотя первый запрос не нужен, я использовал его, чтобы показать, что он вернет. Я сделал это, потому что именно это учитывается во втором запросе. Когда две таблицы соединяются, вы можете думать об этом результате как о некоторой промежуточной таблице, которую можно использовать как любые другие таблицы (например, для вычислений с использованием агрегатных функций в подзапросах).
- Совет: Всякий раз, когда вы пишете сложный запрос, вы можете проверить, что будут возвращать части и таким образом вы будете уверены, что ваш запрос работает и будет работать, как и ожидалось.
Также, мы должны заметить, еще один момент. Мы использовали INNER JOIN при объединении таблиц. страна и город . Это исключит из результатов страны без городов.
(вы можете проверить, почему здесь). Теперь мы будем работать 3
больше запросов, в которых таблицы соединяются с помощью ЛЕВОЕ СОЕДИНЕНИЕ :
1 2 3 4 5 6 7 8 9 10 11 | ВЫБЕРИТЕ * ИЗ страны LEFT JOIN city ON city.country_id = country.id;
SELECT COUNT(*) AS number_of_rows ИЗ страны LEFT JOIN city ON city.country_id = country.id;
ВЫБРАТЬ COUNT(country.country_name) КАК страны, COUNT(city.city_name) КАК города ИЗ страны LEFT JOIN city ON city.country_id = country.id; |
Мы можем заметить несколько вещей:
- 1 st запрос вернул 8 строк. Это те же 6 строк, что и в запросе с использованием INNER JOIN . и еще 2 строки для стран, у которых нет родственных городов (Россия и Испания)
- 2 nd запрос подсчитывает количество строк 1 st возвращает запрос, так что это число равно 8
- 3 rd Запрос содержит два важных замечания. Во-первых, мы использовали агрегатную функцию
( COUNT ), дважды в части SELECT запроса. Обычно это так, потому что вас интересуют более подробные сведения о группе, которую вы хотите проанализировать (количество записей, средние значения и т. д.). Вторая важная вещь заключается в том, что эти 2 счетчика использовали имена столбцов вместо «*» и возвращали разные значения. Это происходит потому, что COUNT был создан таким образом. Если вы поместите имена столбцов в квадратные скобки , COUNT подсчитает, сколько значений есть (не включая значения NULL).
Все наши записи имели значение для country_name, поэтому 1 st COUNT вернуло 8. С другой стороны, city_name
не был определен 2 раза (=NULL), поэтому 2 nd COUNT вернул 6 (8-2=6)
- Примечание: Это означает и другие агрегатные функции. Если они сталкиваются со значениями NULL, они просто проигнорируют их и посчитают, что их не существует.
Агрегированные функции SQL
Теперь пришло время упомянуть все агрегатные функции T-SQL. Наиболее часто используются:
- COUNT – подсчитывает количество элементов в определенной группе
- SUM – вычисляет сумму данного атрибута/выражения в определенной группе
- AVG — вычисляет среднее значение данного атрибута/выражения в определенной группе
- MIN – находит минимум в заданной группе
- MAX – находит максимум в заданной группе
Эти 5 наиболее часто используются и стандартизированы, поэтому они понадобятся вам не только в SQL Server, но и в других СУБД. Остальные агрегатные функции:
- APPROX_COUNT_DISTINCT
- КОНТРОЛЬНАЯ СУММА_AGG
- COUNT_BIG
- ГРУППА
- GROUPING_ID
- СТАНДОТКЛОН
- СТДЕВП
- STRING_AGG
- ВАР
- ВАРПБ
Хотя все агрегатные функции можно было бы использовать без GROUP BY , весь смысл в том, чтобы использовать пункт GROUP BY . Это предложение служит местом, где вы определите условие того, как создать группу. Когда группа будет создана, вы рассчитаете агрегированные значения.
- Пример: Представьте, что у вас есть список профессиональных спортсменов и вы знаете, какой вид спорта
каждый из них играет. Вы можете задать себе что-то вроде: «Верните из моего списка минимальное, максимальное и
средний рост игроков, сгруппированных по видам спорта, которыми они занимаются. Результатом, конечно же, будут MIN, MAX и AVG.
высота для групп – «футболисты», «баскетболисты» и т. д.
Агрегированные функции – примеры
Теперь давайте посмотрим, как эти функции работают на одной таблице. Они редко используются таким образом, но это хорошо чтобы увидеть это, по крайней мере, в образовательных целях:
Запрос возвратил агрегированное значение для всех городов. Хотя эти значения не имеют практического применения, они демонстрируют мощь агрегатных функций.
Сейчас мы сделаем что-нибудь поумнее. Мы будем использовать эти функции намного ближе, чем вы могли бы ожидать в жизненные ситуации:
Это гораздо более «умный» запрос, чем предыдущий. Он вернул список всех стран с количеством городов в них, а также SUM, AVG, MIN и MAX их значений lat .
Обратите внимание, что мы использовали предложение GROUP BY . Разместив country.id и страна. country_name , мы определили группу. Все города, принадлежащие одной стране, будут в та же группа. После создания группы вычисляются агрегированные значения.
- Примечание: Предложение GROUP BY должно содержать все атрибуты, которые не являются агрегатными функциями (в нашем случае это была страна.название_страны). Вы также можете включить другие атрибуты. Мы включили country.id, потому что уверены, что он однозначно определяет каждую страну.
Заключение
Агрегатные функции — очень мощный инструмент в базах данных. Они служат той же цели, что и их эквиваленты в MS.
Excel, но магия в том, что вы можете запрашивать данные и применять функции в одном операторе. Сегодня мы рассмотрели основные примеры. Позже в этой серии мы будем использовать их для решения более сложных задач (с более сложными запросами). так что следите за обновлениями.
Содержание
| Изучение SQL: операции CREATE DATABASE & CREATE TABLE | |
| Выучить SQL: ВСТАВИТЬ В ТАБЛИЦУ | |
| Изучение SQL: первичный ключ | |
| Изучение SQL: внешний ключ | |
| Изучение SQL: инструкция SELECT | |
| Изучение SQL: ВНУТРЕННЕЕ СОЕДИНЕНИЕ и ЛЕВОЕ СОЕДИНЕНИЕ | |
| Изучение SQL: сценарии SQL | |
| Изучение SQL: типы отношений | |
| Изучение SQL: объединение нескольких таблиц | |
| Изучение SQL: агрегатные функции | |
| Изучение SQL: как написать сложный запрос SELECT | |
| Изучение SQL: база данных INFORMATION_SCHEMA | |
| Изучение SQL: типы данных SQL | |
| Изучение SQL: теория множеств | |
| Изучение SQL: пользовательские функции | |
| Изучение SQL: определяемые пользователем хранимые процедуры | |
| Изучение SQL: представления SQL | |
| Изучение SQL: триггеры SQL | |
| Изучение SQL: Практика запросов SQL | |
| Изучение SQL: примеры запросов SQL | |
| Изучение SQL: создание отчета вручную с помощью SQL-запросов | |
| Изучение SQL: функции даты и времени SQL Server | |
| Изучение SQL: создание отчетов SQL Server с использованием функций даты и времени | |
| Изучение SQL: сводные таблицы SQL Server | |
| Изучение SQL: экспорт SQL Server в Excel | |
| Изучение SQL: введение в циклы SQL Server | |
| Изучение SQL: Курсоры SQL Server | |
| Изучение SQL: передовые методы SQL для удаления и обновления данных | |
| Изучение SQL: соглашения об именах | |
| Изучение SQL: задания, связанные с SQL | |
| Изучение SQL: неэквивалентные соединения в SQL Server | |
| Изучение SQL: SQL-инъекция | |
| Изучение SQL: динамический SQL | |
| Изучение SQL: как предотвратить атаки SQL Injection |
- Автор
- Последние сообщения
Эмиль Дркусич
Эмиль — специалист по базам данных с более чем 10-летним опытом работы во всем, что связано с базами данных. В разные годы он работал в сфере информационных технологий и финансов, а сейчас работает фрилансером.
Его прошлые и настоящие занятия варьируются от проектирования баз данных и кодирования до обучения, консультирования и написания статей о базах данных. Также не забывайте, BI, создание алгоритмов, шахматы, филателия, 2 собаки, 2 кошки, 1 жена, 1 ребенок...
Вы можете найти его на LinkedIn
Посмотреть все сообщения Эмиля Дркусича
Последние сообщения Эмиля Drkusic (посмотреть все)
Learn SQL: Памятка по агрегатным функциям
Ссылки на столбцы
The GROUP BY 9Предложения 0182 и ORDER BY могут ссылаться на выбранные столбцы по номеру, в котором они появляются в операторе SELECT . Пример запроса будет подсчитывать количество фильмов на рейтинг и будет:
-
GROUP BYстолбец2(рейтинг) -
ORDER BYстолбец1(total_movies)
ВЫБРАТЬ СЧЕТЧИК(*) КАК 'total_movies',
рейтинг
ИЗ фильмов
СГРУППИРОВАТЬ ПО 2
ПОРЯДОК ПО 1;
SUM() Агрегирующая функция Агрегатная функция SUM() принимает имя столбца в качестве аргумента и возвращает сумму всех значений в этом столбце.
ВЫБЕРИТЕ СУММУ(зарплата)
ИЗ зарплата_расход;
MAX() Агрегирующая функция Агрегатная функция MAX() принимает имя столбца в качестве аргумента и возвращает наибольшее значение в столбце. Данный запрос вернет наибольшее значение из сумма столбец.
SELECT MAX(сумма)
ИЗ транзакций;
COUNT() Агрегирующая функция Агрегатная функция COUNT() возвращает общее количество строк, соответствующих указанным критериям. Например, чтобы найти общее количество сотрудников со стажем менее 5 лет, можно использовать данный запрос.
Примечание: Имя столбца таблицы также можно использовать вместо * . В отличие от COUNT(*) , этот вариант COUNT(столбец) не будет подсчитывать NULL значений в этом столбце.
SELECT COUNT(*)
ОТ сотрудников
ГДЕ опыт < 5;
GROUP BY Предложение Предложение GROUP BY группирует записи в результирующем наборе по идентичным значениям в одном или нескольких столбцах. Он часто используется в сочетании с агрегатными функциями для запроса информации о похожих записях. 9Предложение 0181 GROUP BY может стоять после FROM или WHERE , но должно стоять перед любым предложением ORDER BY или LIMIT .
Данный запрос подсчитает количество фильмов на рейтинг.
ВЫБЕРИТЕ рейтинг,
СЧЕТ(*)
ИЗ фильмов
СГРУППИРОВАТЬ ПО рейтингу;
МИН() Агрегированная функция Агрегированная функция МИН() возвращает наименьшее значение в столбце. Например, чтобы найти наименьшее значение сумма из таблицы с именем транзакции можно использовать данный запрос.
ВЫБРАТЬ МИН(сумма)
ИЗ транзакций;
AVG() Агрегированная функция Агрегированная функция AVG() возвращает среднее значение в столбце. Например, чтобы найти среднюю заработную плату для сотрудников со стажем менее 5 лет, можно использовать данный запрос.
ВЫБЕРИТЕ СРЕДНЕЕ (зарплата)
ОТ сотрудников
ГДЕ стаж < 5;
Предложение HAVING Предложение HAVING используется для дополнительной фильтрации групп наборов результатов, предоставляемых предложением GROUP BY . HAVING часто используется с агрегатными функциями для фильтрации групп наборов результатов на основе агрегатного свойства. Данный запрос выберет только те записи (строки) только за те годы, когда в год выпускалось более 5 фильмов.
Предложение HAVING всегда должно стоять после предложения GROUP BY , но должно предшествовать любому предложению ORDER BY или LIMIT .