Сказ о deadlock-ах — Блог 7even
Каждый разработчик, работавший над нагруженным проектом, сталкивался с дедлоками — это ситуация, которая возникает в БД, когда две транзакции блокируют друг друга, и в результате одна из них сбрасывается (во всяком случае такое поведение реализовано в PostgreSQL). Недавно пришло время и мне столкнуться с такой ситуацией.
Бэкграунд
Есть rails-приложение, построенное по принципу RIA, в котором фронт-энд логически разделен с бэк-эндом. Фронт-энду нужно знать, что происходит на серверсайде, и поэтому раз в секунду приходит запрос на некий урл, где определенный экшен определенного контроллера производит какие-то действия и рендерит ответ в формате JSON.
И среди действий этого контроллера есть обновление времени последнего доступа. Реализовано оно одним UPDATE-запросом примерно следующего вида:
1 | UPDATE items SET access_time = NOW() WHERE id IN (34256, 34978, 34147) |
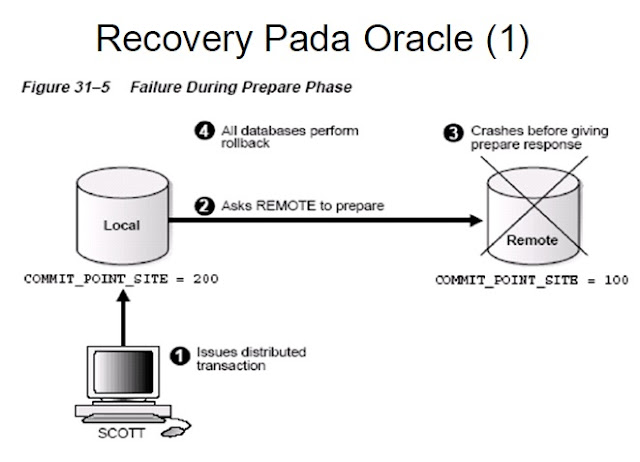
На первый взгляд человека, незнакомого с дедлоками, тут нет ничего потенциально проблематичного. Но, тем не менее, в логе продакшен-сервера время от времени попадаются записи вида:
Но, тем не менее, в логе продакшен-сервера время от времени попадаются записи вида:
1 2 3 4 5 6 7 | postgres[22432]: [30-1] ERROR: deadlock detected postgres[22432]: [30-2] DETAIL: Process 22432 waits for ShareLock on transaction 189302415; blocked by process 22443. postgres[22432]: [30-3] Process 22443 waits for ShareLock on transaction 189302416; blocked by process 22432. postgres[22432]: [30-4] Process 22432: UPDATE "items" SET "access_time" = '2011-07-08 08:49:03.429301' WHERE "items"."id" IN (691, 690, 692, 689, 686, 688, 687) postgres[22432]: [30-5] Process 22443: UPDATE "items" SET "access_time" = '2011-07-08 08:49:03.414084' WHERE "items"."id" IN (686, 687, 688, 689, 691, 690) postgres[22432]: [30-6] HINT: See server log for query details. postgres[22432]: [30-7] STATEMENT: UPDATE "items" SET "access_time" = '2011-07-08 08:49:03.429301' WHERE "items"."id" IN (691, 690, 692, 689, 686, 688, 687) |
Присмотревшись повнимательнее, можно увидеть, что оба запроса меняют записи с одними и теми же id, в одной и той же таблице — но в разном порядке.
Первый запрос меняет записи 691, 690, 692 и 689; второй в то же время обновляет 686, 687 и 688. Далее происходит следующее: первый запрос пытается обновить запись 686, но на нее уже установлен ShareLock вторым запросом; а второй запрос пытается изменить запись 689, запертую первым запросом. Потом оба запроса ожидают определенное время (которое устанавливается в настройках постгреса, и по умолчанию равно 1 секунде), один запрос отваливается (вместе со своим ShareLock), а второй продолжает выполнение до победного конца.
Вариант решения
Так как проблема проявлялась на продакшен-сервере, и была довольно критичной, нужно было найти решение в максимально сжатые сроки.
В итоге некоторого обсуждения было решено просто отсортировать id обновляемых записей в обоих запросах. Таким образом, если два запроса одновременно будут обновлять записи, даже если список id будет совпадать, один запрос начнет выполнение раньше другого, и не будет заблокирован; а второй запрос выполнится после снятия ShareLock после завершения первого запроса.
Таким образом, изменения в коде минимальны:
1 2 3 4 | # было Item.where(id: item_ids).update_all(access_time: Time.now) unless item_ids.empty? # стало Item.where(id: item_ids.sort).update_all(access_time: Time.now) unless item_ids.empty? |
З.Ы. на прошлых выходных установка/настройка нового сервера не позволила мне продолжить серию статей “Краткое введение в Ruby” — она обязательно будет продолжена.
postgresql — Является ли «обнаружение тупика» действительно ошибкой? Должен ли я подавлять их после обработки?
спросил
Изменено 1 год, 8 месяцев назад
Просмотрено 4к раз
Некоторое время назад я провел кошмарное количество недель, пытаясь выяснить, как с этим справиться. В конце концов я обработал его таким образом, что мой код может определить, когда это происходит, а затем бесконечно повторять один и тот же запрос с 50000 микросекундами между каждой повторной попыткой, пока он не сработает.
В конце концов я обработал его таким образом, что мой код может определить, когда это происходит, а затем бесконечно повторять один и тот же запрос с 50000 микросекундами между каждой повторной попыткой, пока он не сработает.
Возможно, это плохая практика, но до сих пор (месяцы) это не вызывало никаких проблем, кроме регистрации так называемых «ошибок» «обнаружена взаимоблокировка».
Могу ли я теперь подавлять ошибки «обнаружена взаимоблокировка», помечая их как «неважные» и, таким образом, не отображая их для меня, даже если они все еще зарегистрированы в моей таблице журнала ошибок?
Пожалуйста, не говорите мне «вообще избегать их». Это просто невозможно. Они
Очевидно, поскольку я спрашиваю об этом вместо того, чтобы просто добавить правило игнорирования и покончить с этим, меня волнуют ответы/ответы. Тем не менее, я не думаю, что на данный момент меня можно убедить, что их можно полностью избежать. Я не говорю, что я получаю тысячи таких запросов каждый час или что-то в этом роде, но несколько каждый день, по-видимому, всегда в начале, когда у меня есть много параллельных процессов, работающих над одной и той же таблицей/запросом.
Тем не менее, я не думаю, что на данный момент меня можно убедить, что их можно полностью избежать. Я не говорю, что я получаю тысячи таких запросов каждый час или что-то в этом роде, но несколько каждый день, по-видимому, всегда в начале, когда у меня есть много параллельных процессов, работающих над одной и той же таблицей/запросом.
- postgresql
- тупик
- обработка ошибок
- журнал ошибок
7
Взаимная блокировка — это своего рода ошибка сериализации : вы не делали ничего запрещенного, просто так получилось, что произошло взаимодействие с другими активными транзакциями, которое помешало завершить вашу транзакцию. Ваша реакция правильная: повторите транзакцию. Нет абсолютно никакой необходимости ждать перед повторной попыткой.
Я согласен с тем, что при достаточно сложной рабочей нагрузке крупных транзакций почти невозможно полностью исключить взаимоблокировки. Пока они случаются редко, они не представляют реальной проблемы, если правильно с ними обращаться.
Пока они случаются редко, они не представляют реальной проблемы, если правильно с ними обращаться.
Взаимоблокировки становятся проблемой, если они случаются слишком часто: это означает, что вам приходится переделывать много работы, что плохо сказывается на производительности и создает дополнительную нагрузку на вашу базу данных. Кроме того, ожидание в одну секунду до разрешения взаимоблокировки означает, что блокировки удерживаются в течение длительного времени (секунда — это долго), что не очень хорошо для параллелизма.
Даже если вы не можете полностью избавиться от взаимоблокировок, вы можете принять меры для их уменьшения:
И то, и другое уменьшит вероятность возникновения взаимоблокировок.
Безопасно игнорировать ошибки взаимоблокировки в вашем файле журнала, но тогда вы должны отслеживать pg_stat_database.deadlocks и принимать меры, если количество взаимоблокировок в час превышает допустимое число.
Видно, вы возражаете против того, чтобы называть тупик ошибкой. По определению, ошибка — это условие, прерывающее выполнение оператора SQL. Таким образом, взаимоблокировка — это явно ошибка.
По определению, ошибка — это условие, прерывающее выполнение оператора SQL. Таким образом, взаимоблокировка — это явно ошибка.
1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания, политикой конфиденциальности и политикой использования файлов cookie
взаимоблокировок postgresql: SELECT заблокирован и блокирует запрос
спросил
Изменено 3 месяца назад
Просмотрено 1к раз
На основе второго ответа на https://stackoverflow.com/questions/22775150/how-to-simulate-deadlock-in-postgresql я выполнил следующий фрагмент:
Транзакция 1 Транзакция 2
НАЧИНАТЬ;
НАЧИНАТЬ;
ВЫБЕРИТЕ зарплату1
ОТ дедлок_демонстрация
ГДЕ worker_id = 1
ДЛЯ ОБНОВЛЕНИЯ;
ВЫБЕРИТЕ зарплату1
ОТ дедлок_демонстрация
ГДЕ worker_id = 2
ДЛЯ ОБНОВЛЕНИЯ;
ОБНОВЛЕНИЕ
УСТАНОВИТЬ оклад1 = 100
ГДЕ worker_id = 2;
ОБНОВЛЕНИЕ
УСТАНОВИТЬ оклад1 = 100
ГДЕ worker_id = 1;
--> . .. 💣 тупик!
.. 💣 тупик!
Теперь, следуя рекомендациям на https://wiki.postgresql.org/wiki/Lock_Monitoring, я выполнил
select block_locks.pid AS block_pid, заблокированное_деятельность.имя_пользователя КАК заблокированный_пользователь, blocking_locks.pid КАК blocking_pid, blocking_activity.usename КАК blocking_user, блокированный_активность.запрос КАК блокируемый_оператор, blocking_activity.query AS current_statement_in_blocking_process, заблокированное_активность.имя_приложения КАК заблокированное_приложение, blocking_activity.application_name КАК blocking_application ИЗ pg_catalog.pg_locks заблокированные_блокировки внутреннее СОЕДИНЕНИЕ pg_catalog.pg_stat_activity Blocked_Activity on Blocked_Activity.pid = Blocked_Locks.pid внутреннее СОЕДИНЕНИЕ pg_catalog.pg_locks И blocking_locks.DATABASE НЕ ОТЛИЧАЕТСЯ ОТ Blocking_locks.DATABASE И blocking_locks.relation НЕ ОТЛИЧАЕТСЯ ОТ Blocked_locks.relation И blocking_locks.page НЕ ОТЛИЧАЕТСЯ ОТ Blocked_locks.page И blocking_locks.tuple НЕ ОТЛИЧАЕТСЯ ОТ Blocked_locks.tuple И blocking_locks.virtualxid НЕ ОТЛИЧАЕТСЯ ОТ Blocked_locks.virtualxid И blocking_locks.transactionid НЕ ОТЛИЧАЕТСЯ ОТ block_locks.transactionid И blocking_locks.classid НЕ ОТЛИЧАЕТСЯ ОТ block_locks.classid И blocking_locks.objid НЕ ОТЛИЧАЕТСЯ ОТ Blocked_locks.objid И blocking_locks.objsubid НЕ ОТЛИЧАЕТСЯ ОТ Blocked_locks.objsubid И blocking_locks.