Копирование и преобразование данных в базе данных Azure для PostgreSQL — Фабрика данных Azure и Azure Synapse
- Статья
- 15 минут на чтение
ПРИМЕНЯЕТСЯ К: Фабрика данных Azure Azure Synapse Analytics
В этой статье рассказывается, как использовать действие копирования в конвейерах Фабрики данных Azure и Synapse Analytics для копирования данных из и в базу данных Azure для PostgreSQL, а также использовать поток данных для преобразования данных в базе данных Azure для PostgreSQL. Чтобы узнать больше, прочтите вводные статьи о Фабрике данных Azure и Synapse Analytics.
Этот соединитель предназначен для службы базы данных Azure для PostgreSQL. Чтобы скопировать данные из универсальной базы данных PostgreSQL, расположенной локально или в облаке, используйте коннектор PostgreSQL.
Поддерживаемые возможности
Этот соединитель базы данных Azure для PostgreSQL поддерживается для следующих возможностей:
| Поддерживаемые возможности | ИК | Управляемая частная конечная точка |
|---|---|---|
| Копирование (источник/приемник) | ① ② | ✓ |
| Отображение потока данных (источник/приемник) | ① | ✓ |
| Поисковая активность | ① ② | ✓ |
① Среда выполнения интеграции Azure ② Локальная среда выполнения интеграции
Три действия работают со всеми вариантами развертывания базы данных Azure для PostgreSQL:
- Отдельный сервер
- Гибкий сервер
- Гипермасштаб (Цитус)
Приступая к работе
Для выполнения операции копирования с конвейером можно использовать один из следующих инструментов или SDK:
- Инструмент копирования данных
- Портал Azure
- Пакет SDK для .
 NET
NET - Пакет SDK для Python
- Azure PowerShell
- REST API
- Шаблон Azure Resource Manager
Создайте связанную службу с базой данных Azure для PostgreSQL с помощью пользовательского интерфейса
Выполните следующие действия, чтобы создать связанную службу с базой данных Azure для PostgreSQL в пользовательском интерфейсе портала Azure.
Перейдите на вкладку «Управление» в фабрике данных Azure или рабочей области Synapse и выберите «Связанные службы», затем нажмите «Создать»:
.- Фабрика данных Azure
- Синапс Azure
Найдите PostgreSQL и выберите базу данных Azure для соединителя PostgreSQL.
Настройте сведения о службе, проверьте соединение и создайте новую связанную службу.
Сведения о конфигурации соединителя
В следующих разделах приведены сведения о свойствах, которые используются для определения сущностей фабрики данных, характерных для соединителя базы данных Azure для PostgreSQL.
Для связанной службы базы данных Azure для PostgreSQL поддерживаются следующие свойства:
| Свойство | Описание | Обязательно |
|---|---|---|
| тип | Для свойства type должно быть установлено значение: Азурепостгрескл . | Да |
| строка соединения | Строка подключения ODBC для подключения к базе данных Azure для PostgreSQL. Вы также можете указать пароль в Azure Key Vault и извлечь конфигурацию пароля из строки подключения. Дополнительные сведения см. в следующих примерах и учетных данных Store в Azure Key Vault. | Да |
| подключение через | Это свойство представляет среду выполнения интеграции, которая будет использоваться для подключения к хранилищу данных. Вы можете использовать среду выполнения интеграции Azure или локальную среду выполнения интеграции (если ваше хранилище данных находится в частной сети). Если он не указан, используется среда выполнения интеграции Azure по умолчанию. Если он не указан, используется среда выполнения интеграции Azure по умолчанию. | № |
Типичная строка подключения: Server= . Вот дополнительные свойства, которые вы можете установить для своего случая:
| Свойство | Описание | Опции | Обязательно |
|---|---|---|---|
| Метод шифрования (EM) | Метод, используемый драйвером для шифрования данных, передаваемых между драйвером и сервером базы данных. Например, | 0 (Без шифрования) (По умолчанию) / 1 (SSL) / 6 (RequestSSL) | № |
| Проверка сертификата сервера (VSC) | Определяет, проверяет ли драйвер сертификат, отправленный сервером базы данных, когда включено шифрование SSL (метод шифрования = 1). Например, Например, ValidateServerCertificate=<0/1>; | 0 (отключено) (по умолчанию) / 1 (включено) | № |
Пример :
{
"name": "AzurePostgreSqlLinkedService",
"характеристики": {
"тип": "AzurePostgreSql",
"типСвойства": {
"connectionString": "Server=.postgres.database.azure.com;Database= ;Port=;UID=;Password="
}
}
}
Пример :
Сохранить пароль в Azure Key Vault
{
"name": "AzurePostgreSqlLinkedService",
"характеристики": {
"тип": "AzurePostgreSql",
"типСвойства": {
"connectionString": "Server=.postgres.database.azure.com;Database=;Port=;UID=;",
"пароль": {
"type": "AzureKeyVaultSecret",
"хранить": {
"referenceName": "<имя связанной службы Azure Key Vault>",
"type": "LinkedServiceReference"
},
"secretName": ""
}
}
}
}
Свойства набора данных
Полный список разделов и свойств, доступных для определения наборов данных, см.
Чтобы скопировать данные из базы данных Azure для PostgreSQL, задайте для свойства type набора данных значение AzurePostgreSqlTable . Поддерживаются следующие свойства:
| Свойство | Описание | Обязательно |
|---|---|---|
| тип | Для свойства типа набора данных должно быть задано значение AzurePostgreSqlTable | .Да |
| имя_таблицы | Имя таблицы | Нет (если в источнике активности указан запрос) |
Пример :
{
"name": "AzurePostgreSqlDataset",
"характеристики": {
"тип": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<имя связанной службы AzurePostgreSql> ",
"type": "ЛинкедСервисРеференс"
},
"типпропертиес": {}
}
}
Копировать свойства действий
Полный список разделов и свойств, доступных для определения действий, см. в разделе Конвейеры и действия. В этом разделе приведен список свойств, поддерживаемых базой данных Azure для исходного кода PostgreSQL.
в разделе Конвейеры и действия. В этом разделе приведен список свойств, поддерживаемых базой данных Azure для исходного кода PostgreSQL.
База данных Azure для PostgreSql в качестве источника
Чтобы скопировать данные из базы данных Azure для PostgreSQL, установите тип источника в действии копирования на AzurePostgreSqlSource . Следующие свойства поддерживаются в действии копирования источник раздел:
| свойство | Описание | Обязательно |
|---|---|---|
| тип | Для свойства type источника действия копирования должно быть задано значение AzurePostgreSqlSource | .Да |
| запрос | Используйте пользовательский запрос SQL для чтения данных. Например: SELECT * FROM mytable или SELECT * FROM "MyTable" . Обратите внимание, что в PostgreSQL имя сущности обрабатывается без учета регистра, если оно не заключено в кавычки. | Нет (если указано свойство tableName в наборе данных) |
| Параметры раздела | Указывает параметры секционирования данных, используемые для загрузки данных из базы данных SQL Azure. Допустимые значения: Нет (по умолчанию), PhysicalPartitionsOfTable и DynamicRange . Если параметр раздела включен (то есть не Нет ), степень параллелизма для одновременной загрузки данных из базы данных SQL Azure контролируется параметр parallelCopies для действия копирования. | № |
| Настройки раздела | Укажите группу настроек для разделения данных. Применить, если параметр раздела не равен Нет . | № |
Под Настройки раздела : | ||
| имена разделов | Список физических разделов, которые необходимо скопировать. Применить, если параметр раздела равен ФизическиеРазделыТаблицы . Если вы используете запрос для получения исходных данных, перехватите ?AdfTabularPartitionName в предложении WHERE. Пример см. в разделе Параллельная копия из базы данных Azure для PostgreSQL. | № |
| имя_раздела_столбца | Укажите имя исходного столбца в формате integer или date/datetime ( int , smallint , bigint , date , timestamp без часового пояса , метка времени с часовым поясом или время без часового пояса ), которые будут использоваться при разделении диапазона для параллельного копирования. Если не указано, первичный ключ таблицы определяется автоматически и используется в качестве столбца раздела. DynamicRange . Если вы используете запрос для получения исходных данных, перехватите ?AdfRangePartitionColumnName в предложении WHERE. Пример см. в разделе Параллельная копия из базы данных Azure для PostgreSQL. Пример см. в разделе Параллельная копия из базы данных Azure для PostgreSQL. | № |
| перегородка Апперграунд | Максимальное значение столбца раздела для копирования данных. Применить, если параметр раздела равен DynamicRange . Если вы используете запрос для получения исходных данных, перехватите ?AdfRangePartitionUpbound в предложении WHERE. Пример см. в разделе Параллельная копия из базы данных Azure для PostgreSQL. | № |
| перегородкаЛоуэрграунд | Минимальное значение столбца раздела для копирования данных. Применить, если параметр раздела равен DynamicRange . Если вы используете запрос для получения исходных данных, перехватите ?AdfRangePartitionLowbound в предложении WHERE. Пример см. в разделе Параллельная копия из базы данных Azure для PostgreSQL. | № |
Пример :
"деятельность":[
{
"name": "КопироватьFromAzurePostgreSql",
"тип": "Копировать",
"входы": [
{
"referenceName": "<имя входного набора данных AzurePostgreSql>",
"тип": "Ссылка на набор данных"
}
],
"выход": [
{
"referenceName": "<имя выходного набора данных>",
"тип": "Ссылка на набор данных"
}
],
"типСвойства": {
"источник": {
"тип": "AzurePostgreSqlSource",
"query": "<пользовательский запрос, например, SELECT * FROM mytable>"
},
"раковина": {
"type": "<тип раковины>"
}
}
}
]
База данных Azure для PostgreSQL в качестве приемника
Чтобы скопировать данные в базу данных Azure для PostgreSQL, в разделе действия копирования приемника поддерживаются следующие свойства:
| Свойство | Описание | Обязательно |
|---|---|---|
| тип | Для свойства type приемника действия копирования должно быть задано значение AzurePostgreSQLSink . | Да |
| преКопиСкрипт | Укажите SQL-запрос для действия копирования, которое будет выполняться перед записью данных в базу данных Azure для PostgreSQL при каждом запуске. Это свойство можно использовать для очистки предварительно загруженных данных. | № |
| метод записи | Метод, используемый для записи данных в базу данных Azure для PostgreSQL. Допустимые значения: CopyCommand (по умолчанию, что более эффективно), BulkInsert . | № |
| writeBatchSize | Количество строк, загруженных в базу данных Azure для PostgreSQL за пакет. Допустимое значение — целое число, представляющее количество строк. | Нет (по умолчанию 1 000 000) |
| writeBatchTimeout | Время ожидания завершения операции пакетной вставки до истечения времени ожидания. Допустимые значения — строки временного интервала.  Например, 00:30:00 (30 минут). Например, 00:30:00 (30 минут). | Нет (по умолчанию 00:30:00) |
Пример :
"деятельность":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"тип": "Копировать",
"входы": [
{
"referenceName": "<имя входного набора данных>",
"тип": "Ссылка на набор данных"
}
],
"выход": [
{
"referenceName": "<имя выходного набора данных Azure PostgreSQL>",
"тип": "Ссылка на набор данных"
}
],
"типСвойства": {
"источник": {
"type": "<тип источника>"
},
"раковина": {
"тип": "AzurePostgreSQLSink",
"preCopyScript": "<пользовательский скрипт SQL>",
"writeMethod": "КопироватьКоманду",
"writeBatchSize": 1000000
}
}
}
]
Параллельное копирование из базы данных Azure для PostgreSQL
Соединитель базы данных Azure для PostgreSQL в действии копирования обеспечивает встроенное разделение данных для параллельного копирования данных. Параметры разделения данных можно найти на вкладке Source действия копирования.
Параметры разделения данных можно найти на вкладке Source действия копирования.
При включении секционированного копирования действие копирования выполняет параллельные запросы к базе данных Azure для источника PostgreSQL для загрузки данных по секциям. Степень параллельности контролируется параметр parallelCopies для действия копирования. Например, если вы установите для parallelCopies значение четыре, служба одновременно создаст и выполнит четыре запроса на основе указанного параметра и параметров раздела, и каждый запрос извлечет часть данных из вашей базы данных Azure для PostgreSQL.
Рекомендуется включить параллельное копирование с разделением данных, особенно при загрузке большого объема данных из базы данных Azure для PostgreSQL. Ниже приведены рекомендуемые конфигурации для различных сценариев. При копировании данных в файловое хранилище данных рекомендуется записывать в папку как несколько файлов (указывать только имя папки), в этом случае производительность выше, чем при записи в один файл.
| Сценарий | Предлагаемые настройки |
|---|---|
| Полная загрузка из большой таблицы с физическими разделами. | Параметр раздела : Физические разделы таблицы. Во время выполнения служба автоматически определяет физические разделы и копирует данные по разделам. |
| Полная загрузка из большой таблицы, без физических разделов, но с целочисленным столбцом для разделения данных. | Параметры раздела : Раздел динамического диапазона. Столбец раздела : укажите столбец, используемый для разделения данных. Если не указано, используется столбец первичного ключа. |
| Загрузка большого объема данных с помощью пользовательского запроса с физическими разделами. | Параметр раздела : Физические разделы таблицы. Запрос : SELECT * FROM ?AdfTabularPartitionName WHERE . Имя раздела : Укажите имена разделов, из которых следует копировать данные. Если не указано иное, служба автоматически обнаружит физические разделы в таблице, которую вы указали в наборе данных PostgreSQL. Во время выполнения служба заменяет |
| Загрузка большого объема данных с помощью пользовательского запроса без физических разделов, но с целочисленным столбцом для разделения данных. | Параметры раздела : Раздел динамического диапазона. Запрос : SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND . Столбец раздела : укажите столбец, используемый для разделения данных. Вы можете разделить столбец с целочисленным типом данных или датой/датой и временем.  Верхняя граница раздела и нижняя граница раздела : Укажите, хотите ли вы фильтровать по столбцу раздела, чтобы получать данные только между нижним и верхним диапазоном. Во время выполнения служба заменяет |
Рекомендации по загрузке данных с опцией разделения:
- Выберите особый столбец в качестве столбца раздела (например, первичный ключ или уникальный ключ), чтобы избежать перекоса данных.
- Если таблица имеет встроенный раздел, используйте параметр раздела «Физические разделы таблицы» для повышения производительности.
- Если вы используете Azure Integration Runtime для копирования данных, вы можете установить более крупные «Единицы интеграции данных (DIU)» (> 4), чтобы использовать больше вычислительных ресурсов. Проверьте применимые сценарии там.
- «Степень параллелизма копирования» управляет номерами разделов, слишком большое значение этого числа иногда снижает производительность, рекомендуется установить это число как (DIU или количество собственных IR-узлов) * (от 2 до 4).
Пример: полная загрузка из большой таблицы с физическими разделами
"источник": {
"тип": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Пример: запрос с разделом динамического диапазона
"источник": {
"тип": "AzurePostgreSqlSource",
"query":"SELECT * FROM WHERE ?AdfDynamicRangePartitionCondition AND ",
"partitionOption": "Динамический диапазон",
"Настройки раздела": {
"partitionColumnName": "",
"partitionUpperBound": "",
"partitionLowerBound": ""
}
}
Свойства потока данных сопоставления
При преобразовании данных в потоке сопоставления данных вы можете читать и записывать в таблицы из базы данных Azure для PostgreSQL. Дополнительные сведения см. в разделе преобразование источника и преобразование приемника в сопоставлении потоков данных. Вы можете использовать базу данных Azure для набора данных PostgreSQL или встроенный набор данных в качестве типа источника и приемника.
Дополнительные сведения см. в разделе преобразование источника и преобразование приемника в сопоставлении потоков данных. Вы можете использовать базу данных Azure для набора данных PostgreSQL или встроенный набор данных в качестве типа источника и приемника.
Исходное преобразование
В таблице ниже перечислены свойства, поддерживаемые базой данных Azure для источника PostgreSQL. Вы можете редактировать эти свойства в Параметры источника вкладка.
| Имя | Описание | Обязательно | Допустимые значения | Свойство сценария потока данных |
|---|---|---|---|---|
| Стол | Если в качестве входных данных выбрать Таблица, поток данных извлечет все данные из таблицы, указанной в наборе данных. | № | — | (только для встроенного набора данных) tableName |
| Запрос | Если вы выберете Запрос в качестве входных данных, укажите SQL-запрос для извлечения данных из источника, который переопределяет любую таблицу, указанную вами в наборе данных. Использование запросов — отличный способ уменьшить количество строк для тестирования или поиска. Использование запросов — отличный способ уменьшить количество строк для тестирования или поиска. Предложение Order By не поддерживается, но вы можете установить полный оператор SELECT FROM. Вы также можете использовать пользовательские табличные функции. select * from udfGetData() — это пользовательская функция в SQL, которая возвращает таблицу, которую можно использовать в потоке данных. | № | Строка | запрос |
| Имя схемы | Если вы выберете Хранимая процедура в качестве входных данных, укажите имя схемы хранимой процедуры или выберите Обновить, чтобы попросить службу обнаружить имена схем. | № | Строка | имя_схемы |
| Хранимая процедура | Если вы выберете Хранимая процедура в качестве входных данных, укажите имя хранимой процедуры для чтения данных из исходной таблицы или выберите Обновить, чтобы попросить службу обнаружить имена процедур. | Да (если в качестве входных данных выбрана хранимая процедура) | Строка | имя_процедуры |
| Параметры процедуры | Если вы выбрали Хранимая процедура в качестве входных данных, укажите любые входные параметры для хранимой процедуры в порядке, установленном в процедуре, или выберите Импорт, чтобы импортировать все параметры процедуры, используя форму @paraName . | № | Массив | входов |
| Размер партии | Укажите размер пакета для разделения больших данных на пакеты. | № | Целое число | размер партии |
| Уровень изоляции | Выберите один из следующих уровней изоляции: — Чтение подтверждено — Чтение не зафиксировано (по умолчанию) — Повторяемое чтение — Сериализуемый — Нет (игнорировать уровень изоляции) | № | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE НЕТ | уровень изоляции |
Пример исходного сценария базы данных Azure для PostgreSQL
При использовании базы данных Azure для PostgreSQL в качестве типа источника связанный сценарий потока данных:
источник (allowSchemaDrift: true,
валидатесхема: ложь,
уровень изоляции: «READ_UNCOMMITTED»,
запрос: 'выбрать * из mytable',
формат: 'запрос') ~> AzurePostgreSQLSource
Преобразование приемника
В таблице ниже перечислены свойства, поддерживаемые базой данных Azure для приемника PostgreSQL. Вы можете редактировать эти свойства на вкладке Опции приемника .
Вы можете редактировать эти свойства на вкладке Опции приемника .
| Имя | Описание | Обязательно | Допустимые значения | Свойство сценария потока данных |
|---|---|---|---|---|
| Метод обновления | Укажите, какие операции разрешены для вашей базы данных. По умолчанию разрешены только вставки. Чтобы обновить, добавить или удалить строки, требуется преобразование строки "Изменить", чтобы пометить строки для этих действий. | Да | верно или неверно | удаляемый вставляемый обновляемый вставляемый |
| Ключевые столбцы | Для обновлений, вставок и удалений ключевые столбцы должны быть установлены, чтобы определить, какую строку следует изменить. Имя столбца, выбранное вами в качестве ключа, будет использоваться как часть последующего обновления, добавления и удаления.  Следовательно, вы должны выбрать столбец, существующий в отображении приемника. Следовательно, вы должны выбрать столбец, существующий в отображении приемника. | № | Массив | ключи |
| Пропустить запись ключевых столбцов | Если вы не хотите записывать значение в ключевой столбец, выберите «Пропустить запись ключевых столбцов». | № | верно или неверно | скипКейВрайтс |
| Действие стола | Определяет, следует ли воссоздавать или удалять все строки из целевой таблицы перед записью. - Нет : С таблицей не будет выполнено никаких действий. - Воссоздать : Таблица будет удалена и создана заново. Требуется при динамическом создании новой таблицы. - Truncate : все строки из целевой таблицы будут удалены. | № | верно или неверно | воссоздать урезать |
| Размер партии | Укажите, сколько строк записывается в каждом пакете.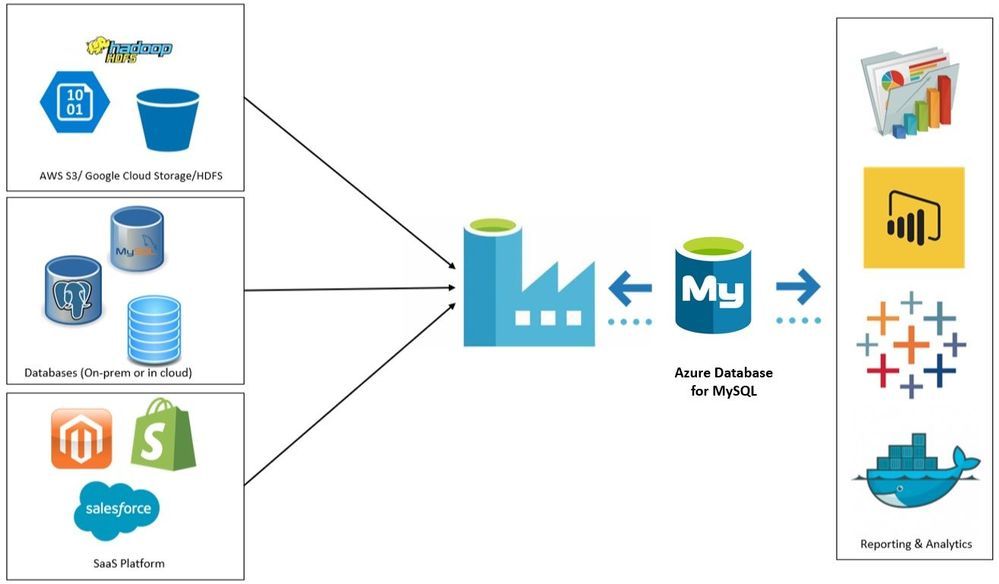 Пакеты большего размера улучшают сжатие и оптимизацию памяти, но при кэшировании данных возникает риск нехватки памяти. Пакеты большего размера улучшают сжатие и оптимизацию памяти, но при кэшировании данных возникает риск нехватки памяти. | № | Целое число | размер партии |
| Выберите пользовательскую схему БД | По умолчанию временная таблица будет создана в схеме приемника как промежуточная. В качестве альтернативы можно снять флажок Использовать схему приемника и вместо этого указать имя схемы, под которым Фабрика данных создаст промежуточную таблицу для загрузки восходящих данных и их автоматической очистки после завершения. Убедитесь, что у вас есть разрешение на создание таблицы в базе данных и разрешение на изменение схемы. | № | Строка | stagingSchemaName |
| Скрипты до и после SQL | Укажите многострочные сценарии SQL, которые будут выполняться до (предварительная обработка) и после (постобработка) данных, записанных в базу данных Sink. | № | Строка | preSQL postSQL |
Совет
- Рекомендуется разбивать одиночные пакетные сценарии с несколькими командами на несколько пакетов.
- Только операторы языка определения данных (DDL) и языка манипулирования данными (DML), которые возвращают простой счетчик обновлений, могут выполняться как часть пакета. Дополнительные сведения см. в разделе Выполнение пакетных операций .
Включить добавочное извлечение. Используйте этот параметр, чтобы указать ADF обрабатывать только те строки, которые изменились с момента последнего выполнения конвейера.
Добавочный столбец: при использовании функции добавочного извлечения вы должны выбрать дату/время или числовой столбец, который вы хотите использовать в качестве водяного знака в исходной таблице.
Начать чтение с начала: установка этого параметра с добавочным извлечением заставит ADF читать все строки при первом выполнении конвейера с включенным добавочным извлечением.
Пример сценария приемника базы данных Azure для PostgreSQL
При использовании базы данных Azure для PostgreSQL в качестве типа приемника связанный сценарий потока данных:
Приемник IncomingStream (allowSchemaDrift: true,
валидатесхема: ложь,
удаляемый: ложь,
вставляемый: правда,
обновляемый: правда,
upsertable: правда,
ключи: ['keyColumn'],
формат: 'таблица',
skipDuplicateMapInputs: правда,
skipDuplicateMapOutputs: true) ~> AzurePostgreSQLSink
Свойства действия поиска
Дополнительные сведения о свойствах см. в разделе Действие поиска.
в разделе Действие поиска.
Следующие шаги
Список хранилищ данных, поддерживаемых действием копирования в качестве источников и приемников, см. в разделе Поддерживаемые хранилища данных.
Использование COPY TO и COPY FROM
Переключить боковую панель оглавления
Psycopg позволяет работать с протоколом COPY PostgreSQL. КОПИЯ есть
один из наиболее эффективных способов загрузки данных в базу данных (и изменения
это, с некоторой изобретательностью SQL).
Копирование поддерживается с помощью метода Cursor.copy() , передавая ему запрос
форму COPY... FROM STDIN или COPY... TO STDOUT и управлять
результирующий Скопируйте объект в с блоком :
с cursor.copy("COPY table_name (col1, col2) FROM STDIN") в качестве копии:
# передать данные объекту 'copy' с помощью write()/write_row()
Вы можете составить оператор COPY динамически, используя объекты из psycopg. sql 9Модуль 0164:
sql 9Модуль 0164:
с курсором.copy(
sql.SQL("КОПИРОВАТЬ {} В STDOUT").format(sql.Identifier("table_name"))
) как копия:
# прочитать данные из объекта 'copy', используя read()/read_row()
Изменено в версии 3.1: Вы также можете передавать параметры в copy() , как в execute() :
с помощью cur.copy("COPY (SELECT * FROM table_name LIMIT %s) TO STDOUT", (3 ,)) как копия:
# ожидать не более трех записей
Соединение подчиняется обычному поведению транзакций, поэтому, если соединение находится в состоянии автоматической фиксации, в конце операции COPY вы все равно будете должны зафиксировать ожидающие изменения, и вы все равно можете их откатить. Видеть Управление транзакциями для деталей.
Запись данных построчно
Используя операцию копирования, вы можете загрузить данные в базу данных из любого Python
iterable (список кортежей или любая итерируемая последовательность): значения Python
адаптированы так, как они были бы в обычном запросе. Для выполнения такой операции используйте
a
Для выполнения такой операции используйте
a COPY... FROM STDIN с Cursor.copy() и использовать write_row() на полученный объект в блоке с . При выходе из блока
операция будет завершена:
записей = [(10, 20, "привет"), (40, нет, "мир")]
с помощью cursor.copy("COPY sample (col1, col2, col3) FROM STDIN") в качестве копии:
для записи в протоколы:
copy.write_row(запись)
Если внутри блока возникает исключение, операция прерывается и вставленные до сих пор записи отбрасываются.
Для чтения или записи из Копировать построчно можно не указывать КОПИРОВАТЬ параметры, такие как ФОРМАТ CSV , DELIMITER , НУЛЕВОЕ :
пожалуйста, оставьте эти данные в покое, спасибо 🙂
Чтение данных построчно
Вы также можете сделать обратное, читая строки из COPY ... TO STDOUT операция, повторяя rows() . Однако это не то, что вы
может захотеть сделать как обычно: обычно обычный процесс запроса будет проще
использовать.
Однако это не то, что вы
может захотеть сделать как обычно: обычно обычный процесс запроса будет проще
использовать.
В настоящее время PostgreSQL не предоставляет полную информацию о типе COPY.
TO , поэтому возвращаемые строки будут содержать не проанализированные данные в виде строк или байтов,
согласно формату.
с cur.copy("COPY (VALUES (10::int, current_date)) TO STDOUT") как копия:
для строки в copy.rows():
print(row) # вернуть непроанализированные данные: ('10', '2046-12-24')
Вы можете улучшить результаты, используя set_types() перед чтением, но
вы должны указать их самостоятельно.
с cur.copy("COPY (VALUES (10::int, current_date)) TO STDOUT") как копия:
copy.set_types(["int4", "дата"])
для строки в copy.rows():
print(row) # (10, datetime.date(2046, 12, 24))
Поблочное копирование
Если данные уже отформатированы таким образом, чтобы их можно было копировать (например, потому что
он исходит из файла, полученного в результате предыдущей операции COPY TO ), он может
быть загружены в базу данных с помощью Copy. вместо этого. write()
write()
с открытым ("данные", "r") как f:
с cursor.copy("COPY data FROM STDIN") в качестве копии:
в то время как данные: = f.read (BLOCK_SIZE):
копировать.записать(данные)
В этом случае вы можете использовать любые КОПИРОВАТЬ вариант и формат, если
входные данные совместимы с тем, что ожидает операция в copy() . Данные
можно передать как str , если копия имеет формат FORMAT TEXT , или как байт ,
который работает как с FORMAT TEXT , так и с FORMAT BINARY .
Для создания данных в формате COPY вы можете использовать команду COPY ... TO
Оператор STDOUT и повторите полученный объект Copy , который будет
создать поток байта объекта:
с open("data.out", "wb") как f:
с помощью cursor.copy("COPY table_name TO STDOUT") в качестве копии:
для данных в копии:
f. запись (данные)
запись (данные)
Двоичная копия
Двоичная копия поддерживается указанием FORMAT BINARY в поле COPY .
утверждение. Чтобы импортировать двоичные данные с помощью write_row() , все
типы, передаваемые в базу данных, должны иметь зарегистрированный бинарный дампер; это не
необходимо, если данные копируются поблочно с использованием запись() .
Предупреждение
PostgreSQL особенно привередлив при загрузке данных в двоичном режиме и
будет применяться без правил приведения . Это означает, например, что прохождение
значение 100 в целое число столбец не , потому что Psycopg пройдет
это значение smallint , и сервер отклонит его, потому что его размер
не соответствует ожидаемому.
Вы можете обойти проблему, используя метод set_types() Скопируйте объект, тщательно указав типы для загрузки.
См. также
также
Дополнительные сведения о двоичных запросах см. в разделе Двоичные параметры и результаты.
Поддержка асинхронного копирования
Асинхронные операции поддерживаются с использованием тех же шаблонов, что и выше, с использованием
объекты, полученные AsyncConnection . Например, если f является
объект, поддерживающий асинхронный метод read() , возвращающий данные COPY ,
полностью асинхронная операция копирования может быть:
async с cursor.copy("COPY data FROM STDIN") в качестве копии:
в то время как данные := ждут f.read():
ожидание копирования.запись (данные)
Документация по объекту AsyncCopy описывает подпись
асинхронные методы и отличия от его аналога sync Copy .
См. также
Дополнительные сведения об использовании асинхронных объектов см. в разделе Асинхронные операции.
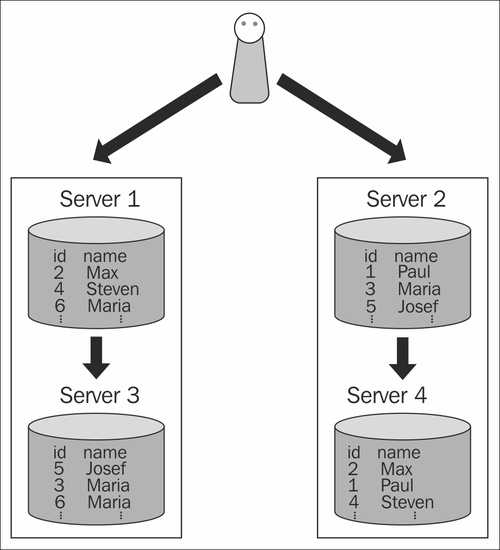
Пример: копирование таблицы между серверами
Чтобы скопировать таблицу или часть таблицы между серверами, вы можете использовать
две операции COPY на двух разных соединениях, чтение с первого и
пишу второму.