Базы данных — SQL Server
- Чтение занимает 2 мин
В этой статье
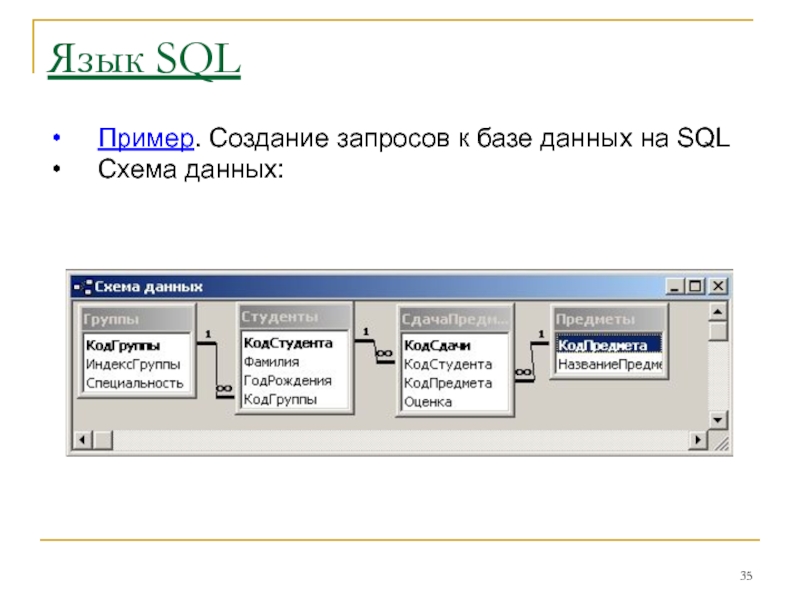
Применимо к:Applies to: SQL ServerSQL Server (все поддерживаемые версии) SQL ServerSQL Server (all supported versions) База данных SQL AzureAzure SQL DatabaseБаза данных SQL AzureAzure SQL DatabaseПрименимо к:Applies to: SQL ServerSQL Server (все поддерживаемые версии) SQL ServerSQL Server (all supported versions) База данных SQL AzureAzure SQL DatabaseБаза данных SQL AzureAzure SQL Database
База данных в SQL ServerSQL Server состоит из коллекции таблиц, в которой хранится особый набор структурированных данных.
Основные сведения о базах данныхBasic Information about Databases
На компьютере можно установить один или несколько экземпляров SQL ServerSQL Server .A computer can have one or more than one instance of SQL ServerSQL Server installed. Каждый экземпляр SQL ServerSQL Server может содержать одну или несколько баз данных.Each instance of SQL ServerSQL Server can contain one or many databases.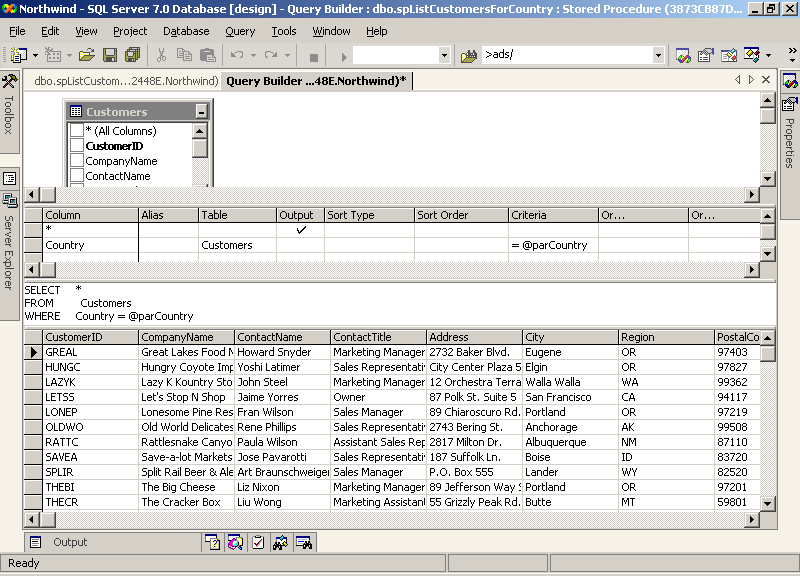
Базы данных SQL ServerSQL Server хранятся в файловой системе в виде файлов.SQL ServerSQL Server databases are stored in the file system in files. Файлы могут быть объединены в группы файлов.Files can be grouped into filegroups. Дополнительные сведения о файлах и файловых группах см.
При получении доступа к экземпляру SQL ServerSQL Server пользователи идентифицируются согласно имени входа.When people gain access to an instance of SQL ServerSQL Server they are identified as a login. При получении доступа к базе данных пользователи идентифицируются как пользователи базы данных.When people gain access to a database they are identified as a database user. Имя пользователя базы данных может быть основано на имени входа.A database user can be based on a login. Если автономные базы данных включены, то пользователь базы данных может быть создан не на основе имени входа.If contained databases are enabled, a database user can be created that is not based on a login. Дополнительные сведения о пользователях см. в статье CREATE USER (Transact-SQL).For more information about users, see CREATE USER (Transact-SQL).
Пользователь, имеющий доступ к базе данных, может получить разрешения на доступ к объектам этой базы данных. A user that has access to a database can be given permission to access the objects in the database. Хотя разрешения и могут быть предоставлены отдельным пользователям, рекомендуется создавать роли базы данных, добавляя при этом пользователей базы данных к соответствующим ролям, а затем предоставлять разрешения ролям.Though permissions can be granted to individual users, we recommend creating database roles, adding the database users to the roles, and then grant access permission to the roles. Предоставление разрешений ролям, а не пользователям позволяет легко и понятно управлять процессом распределения разрешений, несмотря на постоянное изменение и рост числа пользователей.Granting permissions to roles instead of users makes it easier to keep permissions consistent and understandable as the number of users grow and continually change. Дополнительные сведения о ролях и разрешениях см. в разделах CREATE ROLE (Transact-SQL) и Субъекты (ядро СУБД).For more information about roles permissions, see CREATE ROLE (Transact-SQL) and Principals (Database Engine).
A user that has access to a database can be given permission to access the objects in the database. Хотя разрешения и могут быть предоставлены отдельным пользователям, рекомендуется создавать роли базы данных, добавляя при этом пользователей базы данных к соответствующим ролям, а затем предоставлять разрешения ролям.Though permissions can be granted to individual users, we recommend creating database roles, adding the database users to the roles, and then grant access permission to the roles. Предоставление разрешений ролям, а не пользователям позволяет легко и понятно управлять процессом распределения разрешений, несмотря на постоянное изменение и рост числа пользователей.Granting permissions to roles instead of users makes it easier to keep permissions consistent and understandable as the number of users grow and continually change. Дополнительные сведения о ролях и разрешениях см. в разделах CREATE ROLE (Transact-SQL) и Субъекты (ядро СУБД).For more information about roles permissions, see CREATE ROLE (Transact-SQL) and Principals (Database Engine).
Работа с базами данныхWorking with Databases
Большинство пользователей, работающих с базами данных, используют средство SQL Server Management StudioSQL Server Management Studio .Most people who work with databases use the SQL Server Management StudioSQL Server Management Studio tool. Средство Среда Management StudioManagement Studio предоставляет графический пользовательский интерфейс для создания баз данных и их объектов.The Среда Management StudioManagement Studio tool has a graphical user interface for creating databases and the objects in the databases. Среда Management StudioManagement Studio также содержит редактор запросов, позволяющий взаимодействовать с базами данных при написании инструкций Transact-SQLTransact-SQL.also has a query editor for interacting with databases by writing Transact-SQLTransact-SQL statements. Среда Management StudioManagement Studio можно установить с установочного диска SQL ServerSQL Server или загрузить с MSDN.can be installed from the SQL ServerSQL Server installation disk, or downloaded from MSDN.
в этом разделеIn This Section
См. такжеRelated Content
ПредставленияViews
Хранимые процедуры (компонент Database Engine)Stored Procedures (Database Engine)
Функции службы Базы данных SQL Azure — Azure SQL Database
- Чтение занимает 18 мин
В этой статье
ОБЛАСТЬ ПРИМЕНЕНИЯ: База данных SQL Azure
База данных SQL Azure — это полностью управляемое ядро СУБД, предоставляемое по модели «платформа как услуга» (PaaS), которое автоматизирует большинство функций управления базами данных, таких как обновление, исправление, резервное копирование и мониторинг. Azure SQL Database is a fully managed platform as a service (PaaS) database engine that handles most of the database management functions such as upgrading, patching, backups, and monitoring without user involvement. База данных SQL Azure всегда работает на последней стабильной версии ядра СУБД SQL Server и исправленной ОС с 99,99 % доступности.Azure SQL Database is always running on the latest stable version of the SQL Server database engine and patched OS with 99.99% availability. Возможности PaaS, встроенные в Базу данных SQL Azure, позволяют сосредоточиться на важных для бизнеса задачах администрирования и оптимизации баз данных для конкретных областей.PaaS capabilities that are built into Azure SQL Database enable you to focus on the domain-specific database administration and optimization activities that are critical for your business.
Azure SQL Database is a fully managed platform as a service (PaaS) database engine that handles most of the database management functions such as upgrading, patching, backups, and monitoring without user involvement. База данных SQL Azure всегда работает на последней стабильной версии ядра СУБД SQL Server и исправленной ОС с 99,99 % доступности.Azure SQL Database is always running on the latest stable version of the SQL Server database engine and patched OS with 99.99% availability. Возможности PaaS, встроенные в Базу данных SQL Azure, позволяют сосредоточиться на важных для бизнеса задачах администрирования и оптимизации баз данных для конкретных областей.PaaS capabilities that are built into Azure SQL Database enable you to focus on the domain-specific database administration and optimization activities that are critical for your business.
С помощью Базы данных SQL Azure можно создать высокодоступный и высокопроизводительный уровень хранения данных для приложений и решений в Azure.
База данных SQL Azure основана на последней стабильной версии ядра СУБД Microsoft SQL Server.Azure SQL Database is based on the latest stable version of the Microsoft SQL Server database engine. Вы можете использовать расширенные функции обработки запросов, например технологии высокопроизводительных вычислений в памяти и интеллектуальную обработку запросов.You can use advanced query processing features, such as high-performance in-memory technologies and intelligent query processing.
База данных SQL позволяет с легкостью определить и масштабировать производительность в двух разных моделях приобретения: на основе виртуальных ядер и единиц DTU.SQL Database enables you to easily define and scale performance within two different purchasing models: a vCore-based purchasing model and a DTU-based purchasing model. База данных SQL — это полностью управляемая служба со встроенными возможностями высокого уровня доступности, резервного копирования и других общих операций обслуживания.
Если вы не работали с Базой данных Azure SQL, просмотрите это обзорное видео из серии видео, посвященных SQL Azure:If you’re new to Azure SQL Database, check out the Azure SQL Database Overview video from our in-depth Azure SQL video series:
Модели развертыванияDeployment models
База данных SQL Azure предоставляет следующие возможности развертывания для базы данных:Azure SQL Database provides the following deployment options for a database:
Важно!
Чтобы разобраться в различиях между Базой данных SQL и SQL Server, а также различиях между разными вариантами Базы данных SQL Azure, см. описание возможностей Базы данных SQL.To understand the feature differences between SQL Database and SQL Server, as well as the differences among different Azure SQL Database options, see SQL Database features.
описание возможностей Базы данных SQL.To understand the feature differences between SQL Database and SQL Server, as well as the differences among different Azure SQL Database options, see SQL Database features.
База данных SQL обеспечивает прогнозируемую производительность с использованием нескольких типов ресурсов, уровней служб и объемов вычислительных ресурсов.SQL Database delivers predictable performance with multiple resource types, service tiers, and compute sizes. Она предоставляет динамическую масштабируемость без простоя, встроенную интеллектуальную оптимизацию, глобальную масштабируемость и доступность, а также дополнительные параметры безопасности.It provides dynamic scalability with no downtime, built-in intelligent optimization, global scalability and availability, and advanced security options. Эти возможности позволяют вам сосредоточиться не на управлении виртуальными машинами и инфраструктурой, а на быстрой разработке приложений и ускорении их выхода на рынок.These capabilities allow you to focus on rapid app development and accelerating your time-to-market, rather than on managing virtual machines and infrastructure.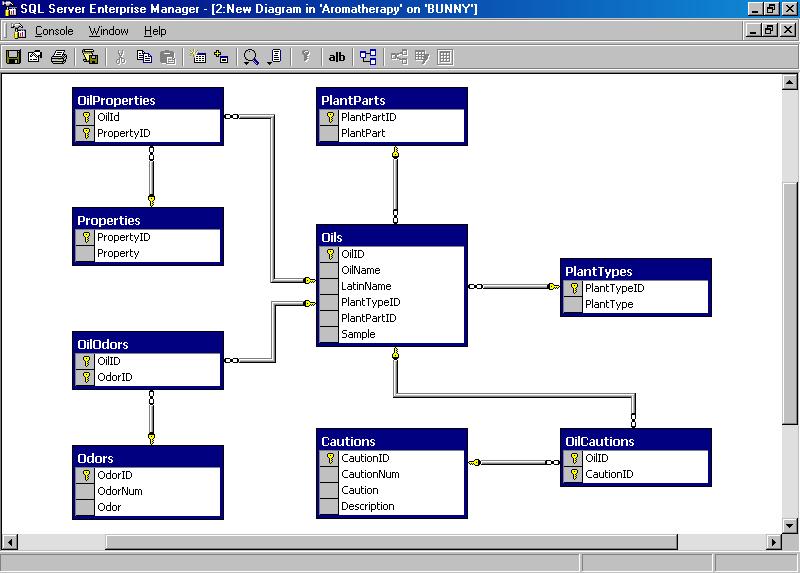 База данных SQL сейчас размещается в 38 центрах обработки данных по всему миру, благодаря чему вы можете выполнять ее в ближайшем к вам центре.SQL Database is currently in 38 datacenters around the world, so you can run your database in a datacenter near you.
База данных SQL сейчас размещается в 38 центрах обработки данных по всему миру, благодаря чему вы можете выполнять ее в ближайшем к вам центре.SQL Database is currently in 38 datacenters around the world, so you can run your database in a datacenter near you.
Масштабируемая производительность и пулыScalable performance and pools
Вы можете самостоятельно определить объем назначаемых ресурсов.You can define the amount of resources assigned.
- При использовании отдельных баз данных каждая из них изолирована от остальных и является переносимой.With single databases, each database is isolated from others and is portable. Каждая из них имеет свой гарантированный объем вычислительных ресурсов, а также ресурсов памяти и хранилища.Each has its own guaranteed amount of compute, memory, and storage resources. Объем ресурсов, назначенных базе данных, выделяется для этой конкретной базы данных и не используется совместно с другими базами данных в Azure.The amount of the resources assigned to the database is dedicated to that database, and isn’t shared with other databases in Azure.
 Количество ресурсов отдельной базы данных можно динамически увеличивать и уменьшать.You can dynamically scale single database resources up and down. Вариант с отдельной базой данных предоставляет различные вычислительные ресурсы, а также ресурсы памяти и хранилища для различных нужд.The single database option provides different compute, memory, and storage resources for different needs. Например, можно получить от 1 до 80 виртуальных ядер или от 32 ГБ до 4 ТБ.For example, you can get 1 to 80 vCores, or 32 GB to 4 TB. Уровень служб «Гипермасштабирование» для отдельной базы данных позволяет увеличить масштаб до 100 ТБ с возможностью быстрого резервирования и восстановления.The hyperscale service tier for single databases enables you to scale to 100 TB, with fast backup and restore capabilities.
Количество ресурсов отдельной базы данных можно динамически увеличивать и уменьшать.You can dynamically scale single database resources up and down. Вариант с отдельной базой данных предоставляет различные вычислительные ресурсы, а также ресурсы памяти и хранилища для различных нужд.The single database option provides different compute, memory, and storage resources for different needs. Например, можно получить от 1 до 80 виртуальных ядер или от 32 ГБ до 4 ТБ.For example, you can get 1 to 80 vCores, or 32 GB to 4 TB. Уровень служб «Гипермасштабирование» для отдельной базы данных позволяет увеличить масштаб до 100 ТБ с возможностью быстрого резервирования и восстановления.The hyperscale service tier for single databases enables you to scale to 100 TB, with fast backup and restore capabilities. - С помощью эластичных пулов можно назначать ресурсы, совместно используемые всеми базами данных в пуле.With elastic pools, you can assign resources that are shared by all databases in the pool.
 Чтобы максимально эффективно использовать ресурсы и сэкономить средства, можно создать новую базу данных в пуле ресурсов или переместить в него имеющиеся отдельные базы данных.You can create a new database, or move the existing single databases into a resource pool to maximize the use of resources and save money. Этот вариант также обеспечивает возможность динамического увеличения и уменьшения количества ресурсов в эластичном пуле.This option also gives you the ability to dynamically scale elastic pool resources up and down.
Чтобы максимально эффективно использовать ресурсы и сэкономить средства, можно создать новую базу данных в пуле ресурсов или переместить в него имеющиеся отдельные базы данных.You can create a new database, or move the existing single databases into a resource pool to maximize the use of resources and save money. Этот вариант также обеспечивает возможность динамического увеличения и уменьшения количества ресурсов в эластичном пуле.This option also gives you the ability to dynamically scale elastic pool resources up and down.
Вы можете создать свое первое приложение в небольшой отдельной базе данных на уровне служб общего назначения с низкой месячной платой.You can build your first app on a small, single database at a low cost per month in the general-purpose service tier. Уровень служб можно в любое время изменить на критически важный для бизнеса в соответствии с потребностями вашего решения. Сделать это можно вручную или программно.You can then change its service tier manually or programmatically at any time to the business-critical service tier, to meet the needs of your solution. Вы можете настроить производительность без простоя для приложения и работы клиентов.You can adjust performance without downtime to your app or to your customers. Благодаря динамической масштабируемости база данных может прозрачно реагировать на быстро меняющиеся требования к ресурсам.Dynamic scalability enables your database to transparently respond to rapidly changing resource requirements. Вы платите только за необходимые ресурсы и только тогда, когда они вам нужны.You pay for only the resources that you need when you need them.
Вы можете настроить производительность без простоя для приложения и работы клиентов.You can adjust performance without downtime to your app or to your customers. Благодаря динамической масштабируемости база данных может прозрачно реагировать на быстро меняющиеся требования к ресурсам.Dynamic scalability enables your database to transparently respond to rapidly changing resource requirements. Вы платите только за необходимые ресурсы и только тогда, когда они вам нужны.You pay for only the resources that you need when you need them.
Динамическое масштабирование отличается от автомасштабирования.Dynamic scalability is different from autoscale. Автомасштабирование — процесс, когда масштабирование службы проходит автоматически (в зависимости от критериев). В то время как динамическая масштабируемость дает возможность для ручного масштабирования без простоев.Autoscale is when a service scales automatically based on criteria, whereas dynamic scalability allows for manual scaling without downtime. В варианте с отдельной базой данных поддерживается только динамическое масштабирование вручную, а автомасштабирование невозможно.The single database option supports manual dynamic scalability, but not autoscale. Чтобы изучить автомасштабирование более детально, необходимо рассмотреть возможность использования эластичных пулов, которые позволяют базам данных обмениваться ресурсами в пуле, исходя из потребностей конкретной базы данных.For a more automatic experience, consider using elastic pools, which allow databases to share resources in a pool based on individual database needs. Другой вариант — использовать скрипты, с помощью которых можно автоматизировать масштабирование отдельной базы данных.Another option is to use scripts that can help automate scalability for a single database. С ними можно ознакомиться в статье Мониторинг и масштабирование отдельной базы данных SQL с помощью PowerShell.For an example, see Use PowerShell to monitor and scale a single database.
В варианте с отдельной базой данных поддерживается только динамическое масштабирование вручную, а автомасштабирование невозможно.The single database option supports manual dynamic scalability, but not autoscale. Чтобы изучить автомасштабирование более детально, необходимо рассмотреть возможность использования эластичных пулов, которые позволяют базам данных обмениваться ресурсами в пуле, исходя из потребностей конкретной базы данных.For a more automatic experience, consider using elastic pools, which allow databases to share resources in a pool based on individual database needs. Другой вариант — использовать скрипты, с помощью которых можно автоматизировать масштабирование отдельной базы данных.Another option is to use scripts that can help automate scalability for a single database. С ними можно ознакомиться в статье Мониторинг и масштабирование отдельной базы данных SQL с помощью PowerShell.For an example, see Use PowerShell to monitor and scale a single database.
Модели приобретенияPurchasing models
Для Базы данных SQL предлагаются следующие модели приобретения. SQL Database offers the following purchasing models:
SQL Database offers the following purchasing models:
- Модель приобретения на основе виртуальных ядер позволяет выбрать число виртуальных ядер, объем памяти, а также объем и скорость хранилища.The vCore-based purchasing model lets you choose the number of vCores, the amount of memory, and the amount and speed of storage. Модель приобретения на основе виртуальных ядер также позволяет применять Преимущество гибридного использования Azure для SQL Server, чтобы добиться снижения затрат.The vCore-based purchasing model also allows you to use Azure Hybrid Benefit for SQL Server to gain cost savings. Дополнительные сведения о Преимуществе гибридного использования Azure см. в разделе часто задаваемых вопросов далее в этой статье.For more information about the Azure Hybrid Benefit, see the «Frequently asked questions» section later in this article.
- В модели приобретения на основе единиц DTU набор вычислительных операций, памяти и ресурсов ввода-вывода предоставляется на трех уровнях обслуживания (каждый из которых предусматривает поддержку различных рабочих нагрузок баз данных).
 The DTU-based purchasing model offers a blend of compute, memory, and I/O resources in three service tiers, to support light to heavy database workloads. Для каждого объема вычислительных ресурсов на всех уровнях обслуживания предусмотрено отдельное сочетание этих ресурсов, к которым можно добавить ресурсы хранилища.Compute sizes within each tier provide a different mix of these resources, to which you can add additional storage resources.
The DTU-based purchasing model offers a blend of compute, memory, and I/O resources in three service tiers, to support light to heavy database workloads. Для каждого объема вычислительных ресурсов на всех уровнях обслуживания предусмотрено отдельное сочетание этих ресурсов, к которым можно добавить ресурсы хранилища.Compute sizes within each tier provide a different mix of these resources, to which you can add additional storage resources. - В бессерверной модели вычислительные ресурсы автоматически масштабируются в соответствии с потребностями в рабочей нагрузке, а счета выставляются за количество использованных вычислительных ресурсов в секунду.The serverless model automatically scales compute based on workload demand, and bills for the amount of compute used per second. Уровень бессерверных вычислений также автоматически приостанавливает базы данных в периоды отсутствия активности, когда оплачивается только хранилище, и автоматически возобновляет работу баз данных, когда активность восстанавливается.
The serverless compute tier also automatically pauses databases during inactive periods when only storage is billed, and automatically resumes databases when activity returns.
Уровни службыService tiers
Для Базы данных SQL Azure предлагается три уровня служб, предназначенные для различных типов приложений.Azure SQL Database offers three service tiers that are designed for different types of applications:
- Уровень служб «Общего назначения» и «Стандартный», предназначенный для распространенных рабочих нагрузок.General Purpose/Standard service tier designed for common workloads. На нем предлагаются бюджетные сбалансированные варианты вычислительных ресурсов и ресурсов хранилища.It offers budget-oriented balanced compute and storage options.
- Уровень служб «Критически важный для бизнеса» и «Премиум», предназначенный для приложений OLTP с высокой частотой транзакций и минимальными задержками ввода-вывода.Business Critical/Premium service tier designed for OLTP applications with high transaction rate and lowest-latency I/O.
 Обеспечивает самую высокую отказоустойчивость благодаря использованию нескольких изолированных реплик.It offers the highest resilience to failures by using several isolated replicas.
Обеспечивает самую высокую отказоустойчивость благодаря использованию нескольких изолированных реплик.It offers the highest resilience to failures by using several isolated replicas. - Уровень служб Гипермасштабирование, предназначенный для очень большой базы данных OLTP и обеспечивающий возможность плавного автомасштабирования хранилища и масштабирования вычислительных ресурсов.Hyperscale service tier designed for very large OLTP database and the ability to autoscale storage and scale compute fluidly.
Эластичные пулы для максимального использования ресурсовElastic pools to maximize resource utilization
Для многих организаций и приложений достаточно иметь возможность создавать отдельные базы данных и уменьшать или увеличивать их производительность по запросу, особенно если закономерности использования базы данных предсказуемы.For many businesses and applications, being able to create single databases and dial performance up or down on demand is enough, especially if usage patterns are relatively predictable.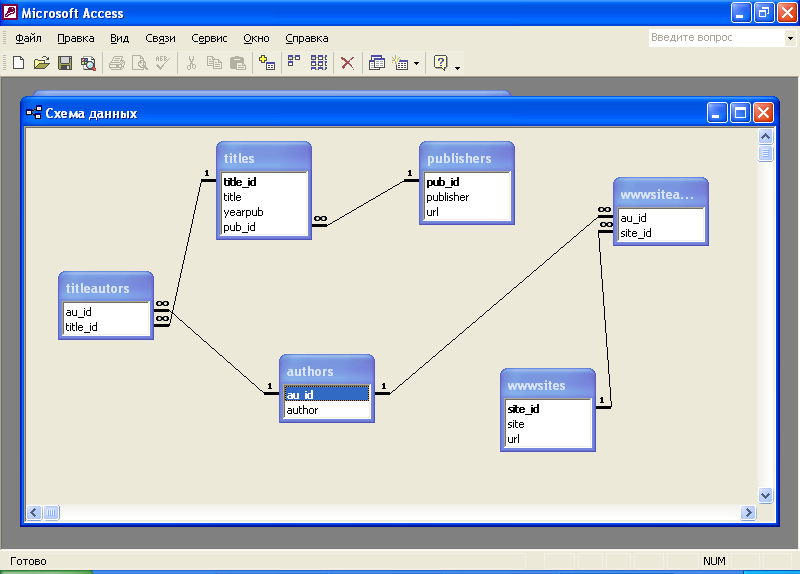 Непредсказуемые изменения в закономерностях использования могут усложнить управление расходами и бизнес-моделью.Unpredictable usage patterns can make it hard to manage costs and your business model. Эластичные пулы предназначены для решения этой проблемы.Elastic pools are designed to solve this problem. Предназначенные для обеспечения производительности ресурсы выделяются не отдельной базе данных, а пулу.You allocate performance resources to a pool rather than an individual database. Вы платите за общую производительность пула, а не производительность отдельной базы данных.You pay for the collective performance resources of the pool rather than for single database performance.
Непредсказуемые изменения в закономерностях использования могут усложнить управление расходами и бизнес-моделью.Unpredictable usage patterns can make it hard to manage costs and your business model. Эластичные пулы предназначены для решения этой проблемы.Elastic pools are designed to solve this problem. Предназначенные для обеспечения производительности ресурсы выделяются не отдельной базе данных, а пулу.You allocate performance resources to a pool rather than an individual database. Вы платите за общую производительность пула, а не производительность отдельной базы данных.You pay for the collective performance resources of the pool rather than for single database performance.
Благодаря использованию эластичных пулов нет необходимости тщательно отслеживать колебания потребностей в ресурсах для повышения или понижения производительности базы данных.With elastic pools, you don’t need to focus on dialing database performance up and down as demand for resources fluctuates. Базы данных в пуле потребляют ресурсы производительности пула эластичных баз данных по мере необходимости. The pooled databases consume the performance resources of the elastic pool as needed. Базы данных в пуле используют его ресурсы, но не превышают ограничений пула, поэтому ваши расходы остаются прогнозируемыми, даже если производительность отдельной базы данных прогнозировать сложно.Pooled databases consume but don’t exceed the limits of the pool, so your cost remains predictable even if individual database usage doesn’t.
The pooled databases consume the performance resources of the elastic pool as needed. Базы данных в пуле используют его ресурсы, но не превышают ограничений пула, поэтому ваши расходы остаются прогнозируемыми, даже если производительность отдельной базы данных прогнозировать сложно.Pooled databases consume but don’t exceed the limits of the pool, so your cost remains predictable even if individual database usage doesn’t.
При этом вы можете добавлять базы данных в пул и удалять их из него, масштабируя приложение так, чтобы количество используемых баз данных составляло от нескольких экземпляров до многих тысяч, не выходя за рамки бюджета.You can add and remove databases to the pool, scaling your app from a handful of databases to thousands, all within a budget that you control. Вы также можете управлять минимальным и максимальным объемом ресурсов, доступных для баз данных в пуле. Таким образом ни одна база данных в пуле не будет потреблять все ресурсы пула и в каждой из этих баз данных будет гарантированный минимальный объем ресурсов. You can also control the minimum and maximum resources available to databases in the pool, to ensure that no database in the pool uses all the pool resources, and that every pooled database has a guaranteed minimum amount of resources. Дополнительные сведения о конструктивных шаблонах для предоставляемых в виде услуги приложений SaaS, использующих эластичные пулы, см. в статье Конструктивные шаблоны для приложений SaaS на нескольких клиентах с Базой данных SQL Azure.To learn more about design patterns for software as a service (SaaS) applications that use elastic pools, see Design patterns for multi-tenant SaaS applications with SQL Database.
You can also control the minimum and maximum resources available to databases in the pool, to ensure that no database in the pool uses all the pool resources, and that every pooled database has a guaranteed minimum amount of resources. Дополнительные сведения о конструктивных шаблонах для предоставляемых в виде услуги приложений SaaS, использующих эластичные пулы, см. в статье Конструктивные шаблоны для приложений SaaS на нескольких клиентах с Базой данных SQL Azure.To learn more about design patterns for software as a service (SaaS) applications that use elastic pools, see Design patterns for multi-tenant SaaS applications with SQL Database.
Сценарии могут быть полезны для использования в мониторинге и масштабировании эластичных пулов.Scripts can help with monitoring and scaling elastic pools. Примеры приведены в статье Отслеживание и масштабирование эластичного пула в Базе данных SQL Azure с помощью PowerShell.For an example, see Use PowerShell to monitor and scale an elastic pool in Azure SQL Database.
Совмещение отдельных баз данных и баз данных в пулеBlend single databases with pooled databases
Вы можете смешивать отдельные базы данных с эластичными пулами и изменять уровни служб отдельных баз данных и эластичных пулов, что позволяет адаптировать их под конкретные задачи.You can blend single databases with elastic pools, and change the service tiers of single databases and elastic pools to adapt to your situation. Вы сможете сочетать службы Azure с Базой данных SQL, чтобы восполнить уникальные потребности архитектуры приложений, повысить эффективность использования ресурсов и снизить расходы, а также узнать о новых возможностях для развития бизнеса.You can also mix and match other Azure services with SQL Database to meet your unique app design needs, drive cost and resource efficiencies, and unlock new business opportunities.
Возможности комплексного мониторинга и оповещенияExtensive monitoring and alerting capabilities
База данных SQL Azure предоставляет расширенные возможности мониторинга и устранения неполадок, которые позволяют получить более подробные сведения о характеристиках рабочей нагрузки. Azure SQL Database provides advanced monitoring and troubleshooting features that help you get deeper insights into workload characteristics. К числу этих возможностей и средств относятся следующие.These features and tools include:
Azure SQL Database provides advanced monitoring and troubleshooting features that help you get deeper insights into workload characteristics. К числу этих возможностей и средств относятся следующие.These features and tools include:
- Встроенные возможности мониторинга, предоставляемые последней версией ядра СУБД SQL Server.The built-in monitoring capabilities provided by the latest version of the SQL Server database engine. Они позволяют получать полезные сведения о производительности в режиме реального времени.They enable you to find real-time performance insights.
- Предоставляемые Azure возможности мониторинга PaaS, которые позволяют следить за большим количеством экземпляров базы данных и устранять в них неполадки.PaaS monitoring capabilities provided by Azure that enable you to monitor and troubleshoot a large number of database instances.
Хранилище запросов — это встроенная функция мониторинга SQL Server, которая записывает производительность при обработке запросов в режиме реального времени и позволяет выявить потенциальные проблемы с производительностью и основные потребители ресурсов. Query Store, a built-in SQL Server monitoring feature, records the performance of your queries in real time, and enables you to identify the potential performance issues and the top resource consumers. Автоматическая настройка и рекомендации предоставляют полезные сведения о запросах с пониженной производительностью, а также об отсутствующих или повторяющихся индексах.Automatic tuning and recommendations provide advice regarding the queries with the regressed performance and missing or duplicated indexes. Автоматическая настройка в Базе данных SQL позволяет либо применить скрипты для устранения проблем вручную, либо воспользоваться автоматическим исправлением.Automatic tuning in SQL Database enables you to either manually apply the scripts that can fix the issues, or let SQL Database apply the fix. База данных SQL может также протестировать исправление и убедиться в его результативности, а также сохранить или отменить изменения в зависимости от результата.SQL Database can also test and verify that the fix provides some benefit, and retain or revert the change depending on the outcome.
Query Store, a built-in SQL Server monitoring feature, records the performance of your queries in real time, and enables you to identify the potential performance issues and the top resource consumers. Автоматическая настройка и рекомендации предоставляют полезные сведения о запросах с пониженной производительностью, а также об отсутствующих или повторяющихся индексах.Automatic tuning and recommendations provide advice regarding the queries with the regressed performance and missing or duplicated indexes. Автоматическая настройка в Базе данных SQL позволяет либо применить скрипты для устранения проблем вручную, либо воспользоваться автоматическим исправлением.Automatic tuning in SQL Database enables you to either manually apply the scripts that can fix the issues, or let SQL Database apply the fix. База данных SQL может также протестировать исправление и убедиться в его результативности, а также сохранить или отменить изменения в зависимости от результата.SQL Database can also test and verify that the fix provides some benefit, and retain or revert the change depending on the outcome. Помимо возможностей хранилища запросов и автоматической настройки, для мониторинга производительности рабочей нагрузки можно использовать стандартные динамические административные представления и XEvent.In addition to Query Store and automatic tuning capabilities, you can use standard DMVs and XEvent to monitor the workload performance.
Помимо возможностей хранилища запросов и автоматической настройки, для мониторинга производительности рабочей нагрузки можно использовать стандартные динамические административные представления и XEvent.In addition to Query Store and automatic tuning capabilities, you can use standard DMVs and XEvent to monitor the workload performance.
Azure предоставляет встроенные средства мониторинга производительности и оповещения в сочетании с рейтингами производительности, которые позволяют отслеживать состояние тысяч баз данных.Azure provides built-in performance monitoring and alerting tools, combined with performance ratings, that enable you to monitor the status of thousands of databases. Используя эти средства, вы сможете быстро оценить эффект от увеличения и уменьшения масштаба, исходя из текущей или планируемой загрузки.Using these tools, you can quickly assess the impact of scaling up or down, based on your current or projected performance needs. Кроме того, База данных SQL может выдавать значения метрик и журналы ресурсов для упрощения мониторинга. Additionally, SQL Database can emit metrics and resource logs for easier monitoring. Вы можете настроить Базу данных SQL для хранения сведений об использовании ресурсов, о рабочих ролях и сеансах, а также настроить подключение к одному из этих ресурсов Azure:You can configure SQL Database to store resource usage, workers and sessions, and connectivity into one of these Azure resources:
Additionally, SQL Database can emit metrics and resource logs for easier monitoring. Вы можете настроить Базу данных SQL для хранения сведений об использовании ресурсов, о рабочих ролях и сеансах, а также настроить подключение к одному из этих ресурсов Azure:You can configure SQL Database to store resource usage, workers and sessions, and connectivity into one of these Azure resources:
- Служба хранилища Azure: для архивации больших объемов телеметрии по оптимальной стоимости.Azure Storage: For archiving vast amounts of telemetry for a small price.
- Центры событий Azure. Для интеграции телеметрии Базы данных SQL с настраиваемым решением для мониторинга или горячими конвейерами.Azure Event Hubs: For integrating SQL Database telemetry with your custom monitoring solution or hot pipelines.
- Журналы Azure Monitor. Для встроенного решения для мониторинга с возможностями предоставления отчетов, предупреждений и выполнения исправлений.
 Azure Monitor logs: For a built-in monitoring solution with reporting, alerting, and mitigating capabilities.
Azure Monitor logs: For a built-in monitoring solution with reporting, alerting, and mitigating capabilities.
Возможности доступностиAvailability capabilities
База данных SQL Azure позволяет продолжать выполнение бизнес-операций во время прерываний в работе.Azure SQL Database enables your business to continue operating during disruptions. В традиционной среде SQL Server обычно настроены по крайней мере два локальных компьютера.In a traditional SQL Server environment, you generally have at least two machines locally set up. На этих компьютерах хранятся точные синхронно обслуживаемые копии данных для защиты от сбоя одного компьютера или компонента.These machines have exact, synchronously maintained, copies of the data to protect against a failure of a single machine or component. Эта среда обеспечивает высокий уровень доступности, но не защищает ваш центр обработки данных от уничтожения вследствие стихийного бедствия.This environment provides high availability, but it doesn’t protect against a natural disaster destroying your datacenter.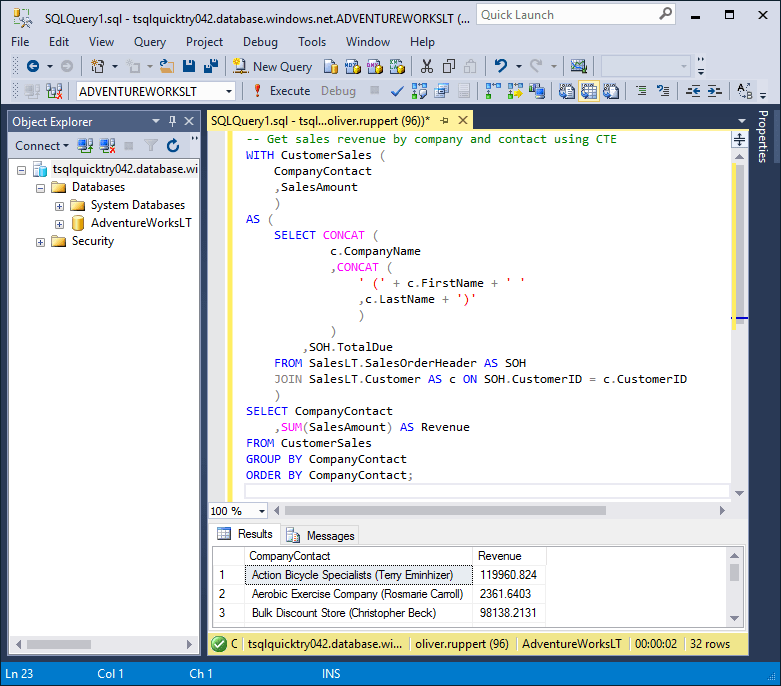
Аварийное восстановление предполагает, что катастрофическое событие локализовано в определенной географической зоне, поэтому другой компьютер или набор компьютеров с копией данных располагаются на достаточном удалении.Disaster recovery assumes that a catastrophic event is geographically localized enough to have another machine or set of machines with a copy of your data far away. Чтобы получить эту возможность в SQL Server, можно воспользоваться группами доступности Always On, работающими в асинхронном режиме.In SQL Server, you can use Always On Availability Groups running in async mode to get this capability. Пользователи часто не хотят дожидаться окончания репликации в удаленное расположение перед фиксацией транзакции, поэтому при внеплановой отработке отказа возможна потеря данных.People often don’t want to wait for replication to happen that far away before committing a transaction, so there’s potential for data loss when you do unplanned failovers.
В базах данных на уровнях служб «Премиум» и «Критически важный для бизнеса» уже реализован механизм, сходный с синхронизацией группы доступности.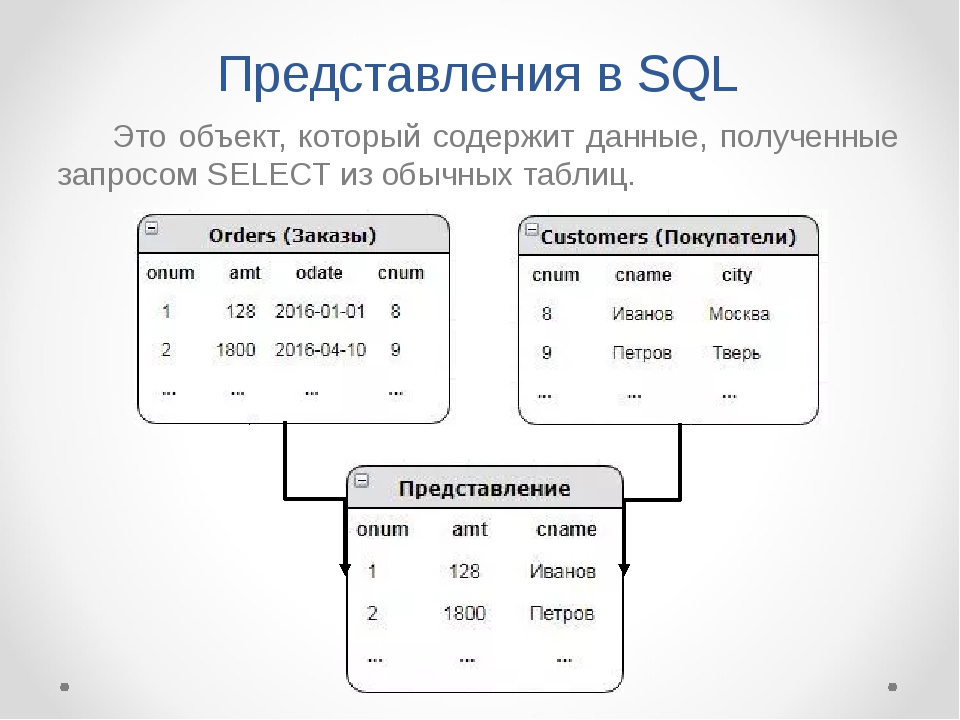 Databases in the Premium and Business Critical service tiers already do something similar to the synchronization of an availability group. Базы данных на более низких уровнях служб обеспечивают избыточность через хранилище, используя несколько иной, но по сути эквивалентный механизм.Databases in lower service tiers provide redundancy through storage by using a different but equivalent mechanism. Защититься от сбоев одного компьютера помогает встроенная логика.Built-in logic helps protect against a single machine failure. Функция активной георепликации дает возможность защититься от аварии, при которой уничтожается весь регион.The active geo-replication feature gives you the ability to protect against disaster where a whole region is destroyed.
Databases in the Premium and Business Critical service tiers already do something similar to the synchronization of an availability group. Базы данных на более низких уровнях служб обеспечивают избыточность через хранилище, используя несколько иной, но по сути эквивалентный механизм.Databases in lower service tiers provide redundancy through storage by using a different but equivalent mechanism. Защититься от сбоев одного компьютера помогает встроенная логика.Built-in logic helps protect against a single machine failure. Функция активной георепликации дает возможность защититься от аварии, при которой уничтожается весь регион.The active geo-replication feature gives you the ability to protect against disaster where a whole region is destroyed.
Зоны доступности Azure используются для защиты от сбоя одного здания центра обработки данных в одном регионе.Azure Availability Zones tries to protect against the outage of a single datacenter building within a single region. Эта возможность помогает защититься от потери питания или сбоя сети в здании. It helps you protect against the loss of power or network to a building. В Базе данных SQL разные реплики помещаются в разные зоны доступности (по сути в разные здания).In SQL Database, you place the different replicas in different availability zones (different buildings, effectively).
It helps you protect against the loss of power or network to a building. В Базе данных SQL разные реплики помещаются в разные зоны доступности (по сути в разные здания).In SQL Database, you place the different replicas in different availability zones (different buildings, effectively).
Фактически Соглашение об уровне обслуживания (SLA) в Azure предусматривает использование глобальной сети центров обработки данных под управлением корпорации Майкрософт для обеспечения непрерывной работы приложения — 24 часа в сутки и 7 дней в неделю.In fact, the service level agreement (SLA) of Azure, powered by a global network of Microsoft-managed datacenters, helps keep your app running 24/7. Платформа Azure полностью управляет каждой базой данных и гарантирует высокий процент доступности данных без их потери.The Azure platform fully manages every database, and it guarantees no data loss and a high percentage of data availability. Azure автоматически обрабатывает исправления, резервное копирование, репликацию, выявление сбоев, потенциальные сбои основного оборудования, программного обеспечения или сети, исправления ошибок при развертывании, отработку отказа, обновления баз данных и другие задачи обслуживания. Azure automatically handles patching, backups, replication, failure detection, underlying potential hardware, software or network failures, deploying bug fixes, failovers, database upgrades, and other maintenance tasks. На уровне «Стандартный» доступность достигается за счет разделения уровня вычислений и уровня хранения.Standard availability is achieved by a separation of compute and storage layers. На уровне «Премиум» доступность достигается за счет интеграции вычислительных систем и хранилища на одном узле для повышения производительности, а также за счет реализации технологии, схожей с группами доступности Always On.Premium availability is achieved by integrating compute and storage on a single node for performance, and then implementing technology similar to Always On Availability Groups. Полное описание возможностей для обеспечения высокого уровня доступности, предоставляемых в Базе данных SQL Azure, см. в статье Высокая доступность и база данных SQL Azure.For a full discussion of the high availability capabilities of Azure SQL Database, see SQL Database availability.
Azure automatically handles patching, backups, replication, failure detection, underlying potential hardware, software or network failures, deploying bug fixes, failovers, database upgrades, and other maintenance tasks. На уровне «Стандартный» доступность достигается за счет разделения уровня вычислений и уровня хранения.Standard availability is achieved by a separation of compute and storage layers. На уровне «Премиум» доступность достигается за счет интеграции вычислительных систем и хранилища на одном узле для повышения производительности, а также за счет реализации технологии, схожей с группами доступности Always On.Premium availability is achieved by integrating compute and storage on a single node for performance, and then implementing technology similar to Always On Availability Groups. Полное описание возможностей для обеспечения высокого уровня доступности, предоставляемых в Базе данных SQL Azure, см. в статье Высокая доступность и база данных SQL Azure.For a full discussion of the high availability capabilities of Azure SQL Database, see SQL Database availability.
Кроме того, База данных SQL обеспечивает встроенные функции непрерывности бизнес-процессов и глобальной масштабируемости.In addition, SQL Database provides built-in business continuity and global scalability features. К ним относятся следующие объекты.These include:
Автоматическое резервное копированиеAutomatic backups:
База данных SQL автоматически создает полные, разностные резервные копии и резервные копии журналов транзакций баз данных, обеспечивая восстановление до любой точки во времени.SQL Database automatically performs full, differential, and transaction log backups of databases to enable you to restore to any point in time. Для отдельных баз данных и баз данных в пуле можно настроить Базу данных SQL для сохранения полных резервных копий в службе хранилища Azure для долгосрочного хранения резервной копии.For single databases and pooled databases, you can configure SQL Database to store full database backups to Azure Storage for long-term backup retention.
 Для управляемых экземпляров также можно создать резервную копию только для копирования для долгосрочного хранения.For managed instances, you can also perform copy-only backups for long-term backup retention.
Для управляемых экземпляров также можно создать резервную копию только для копирования для долгосрочного хранения.For managed instances, you can also perform copy-only backups for long-term backup retention.Восстановление на определенный момент времениPoint-in-time restores:
Все варианты развертывания Базы данных SQL поддерживают восстановление до любой точки во времени в пределах автоматического периода хранения резервной копии для любой базы данных.All SQL Database deployment options support recovery to any point in time within the automatic backup retention period for any database.
Активная георепликация.Active geo-replication:
Варианты с отдельной базой данных и базой данных в пуле позволяют настроить до четырех доступных для чтения баз данных-получателей в одном центре обработки данных или в глобально распределенных центрах обработки данных Azure.The single database and pooled databases options allow you to configure up to four readable secondary databases in either the same or globally distributed Azure datacenters.
 Например, при наличии приложения SaaS с базой данных каталога, содержащей большой объем параллельных транзакций, доступных только для чтения, необходимо использовать активную георепликацию, чтобы включить глобальное масштабирование для чтения.For example, if you have a SaaS application with a catalog database that has a high volume of concurrent read-only transactions, use active geo-replication to enable global read scale. Это устраняет узкие места в основной системе, вызванные рабочими нагрузками чтения.This removes bottlenecks on the primary that are due to read workloads. Используйте группы автоматической отработки отказа для управляемых экземпляров.For managed instances, use auto-failover groups.
Например, при наличии приложения SaaS с базой данных каталога, содержащей большой объем параллельных транзакций, доступных только для чтения, необходимо использовать активную георепликацию, чтобы включить глобальное масштабирование для чтения.For example, if you have a SaaS application with a catalog database that has a high volume of concurrent read-only transactions, use active geo-replication to enable global read scale. Это устраняет узкие места в основной системе, вызванные рабочими нагрузками чтения.This removes bottlenecks on the primary that are due to read workloads. Используйте группы автоматической отработки отказа для управляемых экземпляров.For managed instances, use auto-failover groups.Группы автоматической отработки отказа.Auto-failover groups:
Все варианты развертывания Базы данных SQL позволяют использовать группы отработки отказа для обеспечения высокого уровня доступности и балансировки нагрузки в глобальном масштабе.All SQL Database deployment options allow you to use failover groups to enable high availability and load balancing at global scale.
 В частности, они обеспечивают прозрачную георепликацию и отработку отказа больших наборов баз данных, эластичные пулы и управляемые экземпляры.This includes transparent geo-replication and failover of large sets of databases, elastic pools, and managed instances. Группы отработки отказа позволяют создавать глобально распределенные приложения SaaS с минимальными затратами на администрирование.Failover groups enable the creation of globally distributed SaaS applications, with minimal administration overhead. При этом все сложные процессы оркестрации мониторинга, маршрутизации и отработки отказа выполняются в Базе данных SQL.This leaves all the complex monitoring, routing, and failover orchestration to SQL Database.
В частности, они обеспечивают прозрачную георепликацию и отработку отказа больших наборов баз данных, эластичные пулы и управляемые экземпляры.This includes transparent geo-replication and failover of large sets of databases, elastic pools, and managed instances. Группы отработки отказа позволяют создавать глобально распределенные приложения SaaS с минимальными затратами на администрирование.Failover groups enable the creation of globally distributed SaaS applications, with minimal administration overhead. При этом все сложные процессы оркестрации мониторинга, маршрутизации и отработки отказа выполняются в Базе данных SQL.This leaves all the complex monitoring, routing, and failover orchestration to SQL Database.Избыточные между зонами базы данныхZone-redundant databases:
База данных SQL позволяет подготовить базы данных и эластичные пулы уровня «Премиум» или «Критически важный для бизнеса» в нескольких зонах доступности.SQL Database allows you to provision Premium or Business Critical databases or elastic pools across multiple availability zones.
 Так как эти базы данных или эластичные пулы имеют несколько избыточных реплик для обеспечения высокого уровня доступности, размещение этих реплик в нескольких зонах доступности гарантирует более высокую устойчивость.Because these databases and elastic pools have multiple redundant replicas for high availability, placing these replicas into multiple availability zones provides higher resilience. Это, в частности, обеспечивает возможность автоматического восстановления без потери данных после масштабных сбоев центра обработки данных.This includes the ability to recover automatically from the datacenter scale failures, without data loss.
Так как эти базы данных или эластичные пулы имеют несколько избыточных реплик для обеспечения высокого уровня доступности, размещение этих реплик в нескольких зонах доступности гарантирует более высокую устойчивость.Because these databases and elastic pools have multiple redundant replicas for high availability, placing these replicas into multiple availability zones provides higher resilience. Это, в частности, обеспечивает возможность автоматического восстановления без потери данных после масштабных сбоев центра обработки данных.This includes the ability to recover automatically from the datacenter scale failures, without data loss.
Встроенная система аналитикиBuilt-in intelligence
С Базой данных SQL вы получаете встроенную систему аналитики, которая позволяет значительно сократить расходы на выполнение и обслуживание баз данных, а также повышает производительность и безопасность приложения.With SQL Database, you get built-in intelligence that helps you dramatically reduce the costs of running and managing databases, and that maximizes both performance and security of your application. Круглосуточно выполняя миллионы пользовательских рабочих нагрузок, База данных SQL собирает и обрабатывает большие объемы данных телеметрии при обеспечении полной конфиденциальности пользователей.Running millions of customer workloads around the clock, SQL Database collects and processes a massive amount of telemetry data, while also fully respecting customer privacy. Различные алгоритмы постоянно оценивают данные телеметрии, чтобы служба могла согласовать работу с приложением.Various algorithms continuously evaluate the telemetry data so that the service can learn and adapt with your application.
Круглосуточно выполняя миллионы пользовательских рабочих нагрузок, База данных SQL собирает и обрабатывает большие объемы данных телеметрии при обеспечении полной конфиденциальности пользователей.Running millions of customer workloads around the clock, SQL Database collects and processes a massive amount of telemetry data, while also fully respecting customer privacy. Различные алгоритмы постоянно оценивают данные телеметрии, чтобы служба могла согласовать работу с приложением.Various algorithms continuously evaluate the telemetry data so that the service can learn and adapt with your application.
Автоматический мониторинг и настройка производительностиAutomatic performance monitoring and tuning
База данных SQL обеспечивает точное представление о запросах, которые необходимо отслеживать.SQL Database provides detailed insight into the queries that you need to monitor. База данных SQL дает возможность адаптировать схемы базы данных к рабочей нагрузке на основе шаблонов базы данных.SQL Database learns about your database patterns, and enables you to adapt your database schema to your workload. База данных SQL предоставляет рекомендации по настройке производительности. Вы можете просмотреть действия по настройке и применить их.SQL Database provides performance tuning recommendations, where you can review tuning actions and apply them.
При этом постоянный мониторинг базы данных — это сложная и трудоемкая задача, особенно при работе с несколькими базами данных.However, constantly monitoring a database is a hard and tedious task, especially when you’re dealing with many databases. Средство Intelligent Insights делает это автоматически, отслеживая производительность Базы данных SQL в нужном масштабе.Intelligent Insights does this job for you by automatically monitoring SQL Database performance at scale. Оно информирует вас об ухудшении производительности, определяет причину каждой проблемы и по возможности предоставляет рекомендации по повышению производительности.It informs you of performance degradation issues, it identifies the root cause of each issue, and it provides performance improvement recommendations when possible.
Эффективное управление огромным числом баз данных невозможно даже с учетом всех доступных средств и отчетов, предоставленных Базой данных SQL и Azure.Managing a huge number of databases might be impossible to do efficiently even with all available tools and reports that SQL Database and Azure provide. Вместо того чтобы вручную выполнять мониторинг и настройку базы данных, мы рекомендуем делегировать некоторые действия по настройке и мониторингу Базе данных SQL с помощью автоматической настройки.Instead of monitoring and tuning your database manually, you might consider delegating some of the monitoring and tuning actions to SQL Database by using automatic tuning. База данных SQL автоматически применяет рекомендации, тестирует и проверяет все действия по настройке, чтобы гарантировать оптимальную производительность.SQL Database automatically applies recommendations, tests, and verifies each of its tuning actions to ensure the performance keeps improving. В этом случае База данных SQL автоматически безопасно адаптируется к рабочей нагрузке.This way, SQL Database automatically adapts to your workload in a controlled and safe way. Автоматическая настройка означает, что производительность базы данных тщательно отслеживается и сравнивается перед выполнением действия настройки и после него.Automatic tuning means that the performance of your database is carefully monitored and compared before and after every tuning action. Если производительность не улучшается, действие настройки отменяется.If the performance doesn’t improve, the tuning action is reverted.
Многие наши партнеры, выполняющие приложения SaaS на нескольких клиентах на основе Базы данных SQL, используют автоматическую настройку производительности для обеспечения стабильности и предсказуемой производительности приложений.Many of our partners that run SaaS multi-tenant apps on top of SQL Database are relying on automatic performance tuning to make sure their applications always have stable and predictable performance. Они уверены, что эта функция значительно уменьшает риск снижения производительности ночью.For them, this feature tremendously reduces the risk of having a performance incident in the middle of the night. Кроме того, так как часть клиентской базы также использует SQL Server, они применяют те же рекомендации по индексации, предоставленные Базой данных SQL, для поддержки клиентов SQL Server.In addition, because part of their customer base also uses SQL Server, they’re using the same indexing recommendations provided by SQL Database to help their SQL Server customers.
В Базе данных SQL есть две функции автоматической настройки.Two automatic tuning aspects are available in SQL Database:
- Автоматическое управление индексами: определяет индексы, которые необходимо добавить в базу данных или удалить.Automatic index management: Identifies indexes that should be added in your database, and indexes that should be removed.
- Автоматическое изменение плана. Определяет проблемные планы и исправляет проблемы с производительностью плана SQL.Automatic plan correction: Identifies problematic plans and fixes SQL plan performance problems.
Адаптивная обработка запросовAdaptive query processing
Вы можете использовать адаптивную обработку запросов, включая чередующееся выполнение для функций с табличными значениями и несколькими инструкциями, обратную связь с выделением памяти в пакетном режиме и адаптивные соединения в пакетном режиме.You can use adaptive query processing, including interleaved execution for multi-statement table-valued functions, batch mode memory grant feedback, and batch mode adaptive joins. Каждая из этих функций адаптивной обработки запросов применяет сходные методы «обучения и адаптации», чтобы устранить в дальнейшем проблемы производительности, связанные с традиционно трудноразрешимыми проблемами оптимизации запросов.Each of these adaptive query processing features applies similar «learn and adapt» techniques, helping further address performance issues related to historically intractable query optimization problems.
Расширенный уровень безопасности и соответствие требованиямAdvanced security and compliance
База данных SQL обеспечивает ряд встроенных функций безопасности и соответствия, чтобы выполнить различные требования по защите вашего приложения.SQL Database provides a range of built-in security and compliance features to help your application meet various security and compliance requirements.
Важно!
Корпорация Майкрософт сертифицировала Базу данных SQL Azure (все варианты развертывания) по ряду стандартов соответствия.Microsoft has certified Azure SQL Database (all deployment options) against a number of compliance standards. Дополнительные сведения см. в центре управления безопасностью Microsoft Azure, где представлен актуальный список сертификатов соответствия Базы данных SQL.For more information, see the Microsoft Azure Trust Center, where you can find the most current list of SQL Database compliance certifications.
Расширенная защита от угрозAdvance threat protection
Azure Defender для SQL — это унифицированный пакет расширенных функций защиты SQL,Azure Defender for SQL is a unified package for advanced SQL security capabilities. включая управление уязвимостями базы данных и выявление аномальных действий, которые могут указывать на угрозу для базы данных.It includes functionality for managing your database vulnerabilities, and detecting anomalous activities that might indicate a threat to your database. Эта служба предоставляет единый центр для включения этих возможностей и управления ими.It provides a single location for enabling and managing these capabilities.
Оценка уязвимости.Vulnerability assessment:
Эта служба может обнаруживать, отслеживать потенциальные уязвимости базы данных и помогает устранять их.This service can discover, track, and help you remediate potential database vulnerabilities. Эта служба обеспечивает представление о состоянии безопасности и предлагает практические действия для устранения проблем безопасности и усиления защиты базы данных.It provides visibility into your security state, and includes actionable steps to resolve security issues, and enhance your database fortifications.
Обнаружение угроз.Threat detection:
Эта функция обнаружения угроз выявляет аномальные операции, указывающие на нестандартные и потенциально вредоносные попытки получить доступ к базам данных или воспользоваться ими.This feature detects anomalous activities that indicate unusual and potentially harmful attempts to access or exploit your database. Она непрерывно отслеживает базу данных для выявления подозрительных действий и немедленно выдает оповещения системы безопасности о потенциальных уязвимостях, атаках путем внедрения кода SQL и аномальных шаблонах доступа к базам данных.It continuously monitors your database for suspicious activities, and provides immediate security alerts on potential vulnerabilities, SQL injection attacks, and anomalous database access patterns. Оповещения защиты от угроз содержат сведения о подозрительных операциях и рекомендации для исследования причины угрозы и ее устранения.Threat detection alerts provide details of the suspicious activity, and recommend action on how to investigate and mitigate the threat.
Аудит для обеспечения безопасности и соответствияAuditing for compliance and security
Аудит позволяет отслеживать события базы данных и записывать их в журнал аудита в учетной записи хранения Azure.Auditing tracks database events and writes them to an audit log in your Azure storage account. Аудит может помочь вам соблюсти стандарты, проанализировать работу с базой данных и получить аналитические сведения о расхождениях и аномалиях, которые могут указывать на бизнес-проблемы или предполагаемые нарушения безопасности.Auditing can help you maintain regulatory compliance, understand database activity, and gain insight into discrepancies and anomalies that might indicate business concerns or suspected security violations.
Шифрование данныхData encryption
База данных SQL помогает защитить ваши данные с помощью шифрования.SQL Database helps secure your data by providing encryption. Для передаваемых данных в ней используется протокол TLS,For data in motion, it uses transport layer security. для неактивных данных — прозрачное шифрование данных,For data at rest, it uses transparent data encryption. а для используемых данных — шифрование Always Encrypted.For data in use, it uses Always Encrypted.
Обнаружение и классификация данныхData discovery and classification
Функции обнаружения и классификации данных в Базе данных SQL Azure предоставляют встроенные возможности для обнаружения, классификации, маркировки и защиты конфиденциальных данных в базах данных.Data discovery and classification provides capabilities built into Azure SQL Database for discovering, classifying, labeling, and protecting the sensitive data in your databases. Она обеспечивает возможность просмотра состояния классификации базы данных, а также отслеживания доступа к конфиденциальным данным в базе данных и за ее пределами.It provides visibility into your database classification state, and tracks the access to sensitive data within the database and beyond its borders.
Интеграция Azure Active Directory и Многофакторная идентификацияAzure Active Directory integration and multi-factor authentication
База данных SQL позволяет централизованно управлять удостоверениями пользователя базы данных и другими службами Майкрософт с помощью интеграции Azure Active Directory.SQL Database enables you to centrally manage identities of database user and other Microsoft services with Azure Active Directory integration. Эта возможность упрощает управление разрешениями и повышает уровень безопасности.This capability simplifies permission management and enhances security. Azure Active Directory поддерживает многофакторную проверку подлинности для повышения безопасности данных и приложений, поддерживая процесс единого входа.Azure Active Directory supports multi-factor authentication to increase data and application security, while supporting a single sign-in process.
База данных SQL делает создание и обслуживание приложений более удобным и эффективным.SQL Database makes building and maintaining applications easier and more productive. Она позволяет сконцентрироваться на том, что у вас получается лучше всего, — на создании отличных приложений.SQL Database allows you to focus on what you do best: building great apps. В Базе данных SQL вы можете разрабатывать и обслуживать базы данных, используя имеющиеся средства и навыки.You can manage and develop in SQL Database by using tools and skills you already have.
| СредствоTool | ОписаниеDescription |
|---|---|
| Портал AzureThe Azure portal | Веб-приложение для управления всеми службами Azure.A web-based application for managing all Azure services. |
| Azure Data StudioAzure Data Studio | Кросс-платформенное средство для работы с базами данных для Windows, macOS и Linux.A cross-platform database tool that runs on Windows, macOS, and Linux. |
| Среда SQL Server Management StudioSQL Server Management Studio | Бесплатное, доступное для скачивания клиентское приложение для управления любой инфраструктурой SQL, от SQL Server до Базы данных SQL.A free, downloadable client application for managing any SQL infrastructure, from SQL Server to SQL Database. |
| SQL Server Data Tools в Visual StudioSQL Server Data Tools in Visual Studio | Бесплатное и доступное для скачивания клиентское приложение для разработки реляционных баз данных SQL Server, баз данных в Базе данных SQL Azure, пакетов Integration Services, моделей данных Analysis Services и отчетов Reporting Services.A free, downloadable client application for developing SQL Server relational databases, databases in Azure SQL Database, Integration Services packages, Analysis Services data models, and Reporting Services reports. |
| Visual Studio CodeVisual Studio Code | Бесплатный скачиваемый редактор кода с открытым кодом для Windows, macOS и Linux.A free, downloadable, open-source code editor for Windows, macOS, and Linux. Он поддерживает расширения, включая расширение mssql, для выполнения запросов к Microsoft SQL Server, Базе данных SQL Azure и Azure Synapse Analytics.It supports extensions, including the mssql extension for querying Microsoft SQL Server, Azure SQL Database, and Azure Azure Synapse Analytics. |
База данных SQL поддерживает создание приложений на языках Python, Java, Node.js, PHP, Ruby и .NET для операционных систем macOS, Windows и Linux.SQL Database supports building applications with Python, Java, Node.js, PHP, Ruby, and .NET on macOS, Linux, and Windows. База данных SQL поддерживает те же библиотеки подключений, что и SQL Server.SQL Database supports the same connection libraries as SQL Server.
Создание ресурсов SQL Azure и управление ими с помощью портала AzureCreate and manage Azure SQL resources with the Azure portal
Портал Azure предоставляет отдельную страницу, на которой вы можете управлять всеми ресурсами SQL Azure, а также виртуальными машинами SQL.The Azure portal provides a single page where you can manage all of your Azure SQL resources including your SQL virtual machines.
Чтобы получить доступ к странице SQL Azure в меню на портале Azure, выберите SQL Azure или найдите и выберите SQL Azure на любой странице.To access the Azure SQL page, from the Azure portal menu, select Azure SQL or search for and select Azure SQL in any page.
Примечание
Azure SQL — это быстрый и простой способ получения доступа ко всем ресурсам SQL на портале Azure, включая отдельную базу данных и базу данных в пуле в Базе данных SQL Azure, а также логические экземпляры SQL Server, на которых размещены эти ресурсы, Управляемые экземпляры SQL и виртуальные машины SQL.Azure SQL provides a quick and easy way to access all of your SQL resources in the Azure portal, including single and pooled database in Azure SQL Database as well as the logical SQL server hosting them, SQL Managed Instances, and SQL virtual machines. SQL Azure — это не служба или ресурс, а семейство служб, связанных с SQL.Azure SQL is not a service or resource, but rather a family of SQL-related services.
Чтобы управлять существующими ресурсами, выберите нужный элемент в списке.To manage existing resources, select the desired item in the list. Чтобы создать ресурсы SQL Azure, выберите + Добавить.To create new Azure SQL resources, select + Add.
После выбора параметра + Добавить, просмотрите дополнительные сведения о различных параметрах, щелкнув Показать сведения для любой плитки.After selecting + Add, view additional information about the different options by selecting Show details on any tile.
Подробная информация доступна в следующих статьях:For details, see:
База данных SQLSQL Database frequently asked questions
Могу ли я контролировать простой в связи с установкой исправлений?Can I control when patching downtime occurs?
Нет.No. Влияние исправления в основном незаметно, если в вашем приложении применяется логика повторных попыток.The impact of patching is generally not noticeable if you employ retry logic in your app. Дополнительные сведения см. в статье Планирование событий обслуживания Azure в Базе данных SQL Azure.For more information, see Planning for Azure maintenance events in Azure SQL Database.
Связаться с командой разработчиков SQL ServerEngage with the SQL Server engineering team
Дальнейшие действияNext steps
Сравнение цен и калькуляторы для отдельных баз данных и эластичных пулов см. на странице расценок.See the pricing page for cost comparisons and calculators regarding single databases and elastic pools.
См. эти краткие руководства по быстрому запуску:See these quickstarts to get started:
Примеры использования Azure CLI и PowerShell:For a set of Azure CLI and PowerShell samples, see:
Дополнительные сведения о новых возможностях см. в стратегии развития Azure для Базы данных SQL.For information about new capabilities as they’re announced, see Azure Roadmap for SQL Database.
Читайте блог о Базе данных SQL Azure, в котором участники команды по разработке продукта SQL Server публикуют новые сведения о возможностях и новостях, касающихся Базы данных SQL.See the Azure SQL Database blog, where SQL Server product team members blog about SQL Database news and features.
Пример базы данных SQL Server для обучения SQL
1- Введение
LearningSQL это маленькая база данных, использующаяся для примера в инструкциях по изучению SQL имеющиеся на вебсайте o7planning, существует 3 версии на Database:
- Oracle
- MySQL
- SQLServer.
В данной статье я покажу вам как создать данную базу данных на SQLServer.
Эта база данных предоставлена как модельная база данных для изучения SQL Server по ссылке:
- Руководство SQL для начинающих с SQL Server
2- Download Script
Скачать script по ссылке:
| Direct | Mediafire |
| Download | Download |
С SQLServer вам нужно обратить внимание только на файл:
- LearningSQL-SQLServer-Script.sql
3- Запуск Script
3.1- Создать LearningSQL SCHEMA на SQLServer Management Studio
Создайть новый Database
- Database Name: learingsql
Скопировать содержание файла LearningSQL-SQLServer-Script.sql в окоSQL и выполнить
4- Обзор LearningSQL
LearningSQL это маленькая база данных симулирующая данные банка:
| НАЗВАНИЕ ТАБЛИЦЫ | ЗНАЧЕНИЕ |
| ACCOUNT | Таблица хранящая банковский счет. Каждый клиет может зарегистрировать несколько счетов, каждый счет соответствует услуге предоставленной банком. (Смотрите так же PRODUCT) |
| ACC_TRANSACTION | Таблица хранящая информацию транзакции с банком определенного счета. |
| BRANCH | Филиал банка |
| BUSSINESS | |
| CUSTOMER | Таблица клиентов |
| DEPARTMENT | Таблица департаментов банка. |
| EMPLOYEE | Таблица работников банка. |
| OFFICER | |
| PRODUCT | Продукты услуг банка, например:
|
| PRODUCT_TYPE | Продукты услуг банка, например:
|
5- Структура таблиц
5.1- ACCOUNT
5.2- ACC_TRANSACTION
5.3- BRANCH
5.4- BUSINESS
5.5- CUSTOMER
5.6- DEPARTMENT
5.7- EMPLOYEE
5.8- INDIVIDUAL
5.9- OFFICER
5.10- PRODUCT
5.11- PRODUCT_TYPE
Что такое база данных и SQL. Как работают с базами и что в них хранят
Если сказать упрощённо, то база данных — это среда, в которой существуют таблицы с данными. Если вы когда-нибудь работали в офисной программе «Excel», в которой можно делать таблицы, то считайте что работали с базой данных.В базах данных сайтов могут содержаться таблицы, в которых может быть записано всё что угодно:
- данные новостей, которые опубликованы на сайте
- данные пользователей, которые зарегистрированы на сайте
+--------------------+ | Пользователи | +--------------------+ | Имя | Любимая еда | +------+-------------+ | Мышь | Сыр | +------+-------------+ | Кот | Молоко | +------+-------------+Как можно заметить, это обычная таблица. Но в таком виде на сайте её увидеть нельзя. Сайт делает запрос к ней с помощью специального языка, который называется SQL (Structured Query Language — «язык структурированных запросов»). Эти запросы возвращают массив строк, которые подходят под параметр запроса. Разберём далее логику запросов.
Представьте, что необходимо получить из примера выше все данные таблицы и вывести их на экран. Тогда нужно сделать запрос к базе данных на языке SQL:
SELECT 'Имя пользователя', 'Любимая еда' FROM 'Пользователи';Последняя часть запроса содержит слово FROM, которое дословно переводится как «из». После этого слова стоит таблица ИЗ которой надо получить данные. Если не указать из какой таблицы нужны данные, то база данных выдаст ошибку.
Пример SQL запроса, который приведён выше, сильно утрирован для большей наглядности и простоты. Потому что в базах данных крайне нежелательно создавать таблицы с кириллическими названиями таблиц и столбцов. А ещё названия столбцов и самой таблицы нужно заключать не в одинарную кавычку ‘ , а в наколнную `
Перейдём к обработке результатов выполнения запроса. Если утрировать, то после выполнения запроса из примера выше база данных вернёт такой массив:Array
(
[0] => Array
(
[Имя] => Мышь
[Любимая еда] => Сыр
)
[1] => Array
(
[Имя] => Кот
[Любимая еда] => Молоко
)
)После получения этого массива необходимо сделать цикл аналогичный foreach( ) по всем элементам полученного массива. Внутри цикла можно обернуть полученные значения в различные HTML теги, чтобы вывод был красивым, чтобы у страницы сайта был дизайн. Так и происходит взаимодействие сайтов с базами данных. Базы данных — это не лучшее хранилище информации. Конёк баз данных — это быстрый поиск информации и вывод с сортировкой. Поэтому базы данных целесообразно использовать далеко не везде. Если же нужно обрабатывать терабайты статичной информации без необходимости поиска и сортировки, то выгоднее использовать использовать простые файлы для хранения информации.Базы данных используются для сайтов в основном потому, что с их помощью можно организовать уровни доступа к информации. И базы данных большинства сайтов в интернете очень редко когда превышают 10 Гигабайт (считая размеры всех таблиц в базе).
В следующих статьях мы разберём более сложные примеры обращения с базой данных: научимся создавать и удалять таблицы, объединять результаты выборки из нескольких разных таблиц и обновлять данные в таблицах. Если вам не терпится приступить к программированию, то рекомендуем ознакомиться со статьёй «Как сделать запрос из PHP к базе данных».Когда переводить базу данных 1С на SQL? Предпосылки для перехода на SQL
Как известно программа 1С имеет две основных архитектурных реализации касательно хранения данных: файловая версия и версия на СУБД. Все знают, что файловая база подходит для работы нескольких пользователей малого предприятия, при условии что сама база также не большая, а для средних и крупных предприятий без СУБД не обойтись. Также очень типичны случаи, когда ведение учета начинается в небольшой файловой базе, а далее она начинает стремительно расти – увеличивается количество бизнес-процессов, которые автоматизируют данной программой, в следствии чего увеличивается количество пользователей, которые в ней работает, а также сама база. Со временем база начинает притормаживать и наступаем момент когда необходимо переходить на СУБД. Как же определить тот момент, когда стоит задуматься о переходе на SQL? Ведь сам переход и подготовка для него инфраструктуры требует немало времени, а также денежных затрат.
Предпосылки, которые заставляют задуматься о переходе на СУБД следующие:
-
Блокировки. Основной и самой важной предпосылкой перевода 1С на
СУБД есть возникновение ошибок блокировки данных. Дело в том, что при
работе с файловой базой таблицы с данными хранятся в файлах, и нет
возможности параллельного доступа к ним нескольких пользователей в один
момент времени.
Если несколько пользователей обратились к данным, хранящимся в одной таблице — то данные будут доступны только первому пользователю, а всем следующим будет выдано сообщение «Ошибка блокировки данных».
Если в базе работает от 1 до 5 пользователей, то данная проблема практически не заметна, так как вероятность того, что в один момент времени к одной и той же таблице обратятся несколько пользователей невелика, но с каждым дополнительным пользователем эта вероятность возрастет.
- Замедление работы. А именно, медленное проведения документов, формирование отчетов, снижение скорости загрузки самой программы. Подробнее о методах ускорения 1С можно почитать здесь.
- Загруженность диска. Во время работы с файловой версией базы происходит активное чтение/запись данных с дисков, на которых размещена база, в следствии чего их производительности может быть недостаточно.
Это что касается симптомов, которые могут указать на необходимость перехода.
Теоретически момент перехода возможно просчитать заранее. Производительность 1С зависит от 3 ключевых факторов:
- количества пользователей;
- типа конфигурации;
- объема базы.
Основным показателем, который влияет на производительность базы 1С является количество пользователей работающих с базой. Файловая база при количестве пользователей от 1 до 5 работает значительно быстрее чем СУБД и в таком случаи перевод на SQL повлечет не только дополнительные затраты, но и ухудшение работы системы.
При количестве пользователей порядка 5-10 работа файловой базы отличается от работы СУБД не значительно, после 10-15 пользователей производительность файловой базы очень сильно падает и если количество пользователей довести до 20-25 с базой практически не возможно будет работать по причине блокировок и очень сильному замедлению работы. Ниже приведены графики зависимости производительности 1С от количества пользователей для разных конфигураций.
Рисунок 1 — Схема работы с зашифрованной базой данных
Также весомой характеристикой базы есть ее размер, в случае, если файловая база занимает более 1 Гб данных, ее целесообразно перевести на СУБД.
Рассмотрим и другие преимущества использования СУДБ SQL вместо файловой базы
- Масштабируемость. Использование СУБД MSSQL даст возможность расширять количество пользователей, создавать большое количество баз и, при выделении дополнительного количества аппаратных ресурсов, это не приведет к торможению базы и блокировкам данных.
- Отказоустойчивость. Реализация базы на СУБД дает возможность использовать технологии кластеризации, что обеспечит горячее резервирование работы с 1С.
- Обслуживание. В СУБД MS SQL есть возможность настроить автоматические регламентные операции, которые будут периодически оптимизировать работу с базой.
- Резервирование. Благодаря использованию СУБД, возможно реализовать более надежную систему резервного копирования средствами самого SQL, также резервное копирование лога СУБД дает возможность восстановить данные с точностью до транзакции.
- Мониторинг. MS SQL имеет ряд датчиков, отслеживая которые заранее возможно увидеть проблемы с производительностью, безопасностью, а также, отслеживать успешное выполнение операций оптимизации и резервного копирования.
- Использование для других приложений. MS SQL является одной из самых популярных СУБД, большинство приложений использующих СУБД работают c MS SQL. Таким образом внедрение MS SQL для 1С может служить подготовкой почвы для внедрения или оптимизации других приложений.
Концептуальное описание подготовки к процессу перехода на СУБД:
1
Закупить ПО. Для перехода на СУБД вам понадобятся следующие лицензии:- лицензия для Сервера 1С предприятие;
- лицензия на сервер MS SQL;
- лицензии для клиентского подключения к MS SQL.
2
Настроить СУБД. Для того, чтобы MS SQL правильно функционировал, его нужно предварительно настроить и под работу с 1С, а также настроить планы оптимизации и резервного копирования.
3
Настроить сервер приложений 1С.
Выше приведена информация, которая поможет понять, когда же нужно переводить 1С на СУБД, а также зачем и что для этого нужно. Но перед тем как тратить деньги на закупку оборудования и ПО настоятельно рекомендуется протестировать работу базы в режиме СУБД в тестовом режиме. Если не хватает для это своих ресурсов, не достаточно специалистов или просто не хочется тратить время на настройку тестового стенда – всегда возможно арендовать облачный сервер 1С (услуга включает бесплатный перевод базы на SQL). Далее проверить все на арендованном оборудовании и по результату принять решения переходить ли на SQL или работать далее с файловой базой.
Техническая документация — Техническая документация — Помощь
Наши пользователи могут использовать базы данных Microsoft SQL Server 2012 на своих виртуальных площадках в рамках, предусмотренных соответствующими тарифами.
В стоимость тарифных планов виртуального хостинга, где поддерживаются услуги Microsoft SQL Server, входит определенное число баз данных Microsoft SQL Server и один пользователь Microsoft SQL Server. Сверх этого базы создаются за дополнительную плату по действующему прейскуранту.
Параметры и способы соединения с Microsoft SQL Server
- Имя хоста (сервера), на котором размещена база данных Microsoft SQL Server: uXXXXX.mssql.masterhost.ru;
- Порт: 1433;
- Логин: соответствует названию виртуальной площадки — uXXXXX;
- Пароль: указан в письме, которое пользователь получает при регистрации;
- Имя базы данных: соответствует названию виртуальной площадки — uXXXXX;
- Подключение нужно осуществлять по протоколу TCP/IP.
Подключение к SQL-серверу через «Microsoft SQL Server Management Studio Express»
Чтобы получить доступ к базе данных Microsoft SQL Server, возможно использовать Microsoft SQL Server Management Studio Express.
В свойствах подключения («Options», закладка «Connection Properties») выберите в качестве сетевого протокола («Network Protocol») TCP/IP.
Создание новой базы данных
Новую базу данных вы можете создать через раздел Древо услуг, в Личном кабинете. Выберите нужную «виртуальную площадку», затем в строке «MS SQL — База данных» нажмите кнопку «Добавить».
Использовать Microsoft SQL Server Management Studio для создания новых баз данных нельзя.
Создание нового логина
Создать новый логин для базы данных Microsoft SQL вы можете через раздел Древо услуг, в Личном кабинете. Выберите нужную «виртуальную площадку», затем в строке «MS SQL — Пользователь» нажмите кнопку «Добавить».
Использовать Microsoft SQL Server Management Studio для создания новых логинов нельзя. Также ознакомьтесь с вопросом: «Можно ли на разные базы данных давать разные пароли доступа?».
Увеличение размера базы данных
Увеличить размер базы данных можно самостоятельно, через раздел Древо услуг, в Личном кабинете.
Выберите нужную «виртуальную площадку», затем напротив интересующей базы данных, для услуги «MS SQL — База данных» нажмите кнопку «Изменить» и в выпадающем списке выберите необходимый вам объем базы данных.
Предварительно рекомендуется произвести операцию сжатия базы данных согласно инструкции.
Уменьшение физического размера файлов баз данных и лога транзакций MS SQL Server.
Из графического интерфейса Microsoft SQL Server Management Studio:
- В обозревателе объектов подключитесь к экземпляру SQL Server 2012 Database Engine и разверните его.
- Разверните узел «Базы данных», затем правой кнопкой мыши щелкните базу данных, которую нужно сжать.
В меню «Задачи» выберите «Сжать» и щелкните «База данных». Или установите флажок «Реорганизовать файлы перед освобождением неиспользуемого места».
Если он установлен, необходимо указать значение параметра «Максимально доступное свободное место в файлах после сжатия».
Стандартным t-sql запросом вида:
где uXXXXX — имя вашей базы данных.DBCC SHRINKFILE (N'uXXXXXX.Log' , 0, TRUNCATEONLY) DBCC SHRINKDATABASE (N'uXXXXXX')
Изменение кодировки сравнения (collation)
По умолчанию кодировка collation выставлена как Cyrillic_General_CI_AS, изменить кодировку для сравнений можно следующим SQL-запросом:
ALTER DATABASE [uXXXXX] COLLATE SQL_Latin1_General_CP1251_CS_AS
GOгде uXXXXX — имя БД, где требуется данная операция.
Список доступных кодировок можно узнать так:
SELECT * FROM ::fn_helpcollations()Можно ли использовать MSSQL Server Enterprise Manager для работы со своей базой данных Microsoft SQL Server 2012?
Microsoft SQL Server Enterprise Manager не предназначен для работы с базами данных Microsoft SQL Server 2012. Для управления своей БД можно использовать SQL Server Management Studio, или её бесплатный вариант — Microsoft SQL Server 2012 Management Studio Express.
Как дать права на доступ к базе определенному логину
Для SQL — дополнительный SQL логин, но настраивать права нужно самому: Заводим ещё один SQL логин — uXXX_Ann
Для начала используем нашу базу:
USE [uXXXX]
GOСоздаём пользователя для определённого «логина»:
CREATE USER [InetUser] FOR LOGIN [uXXX_Ann]
GOНаделяем его правами (например только чтение таблиц):
EXEC sp_addrolemember N'db_datareader', N'InetUser'
GOИли можем дать пользователю только конкретные права, на конкретные таблицы. Например, давайте дадим пользователю InetUser права на SELECT, INSERT, UPDATE для таблицы test, следующим SQL-запросом:
USE [uXXXXXX]
GO
GRANT SELECT ON [dbo].[test] TO [InetUser]
GO
GRANT INSERT ON [dbo].[test] TO [InetUser]
GO
GRANT UPDATE ON [dbo].[test] TO [InetUser]
GOПри всем при этом, при осуществлении доступа через SQL Management Studio, под дополнительным логином не являющимся владельцем базы, не будет видно базу данных в списке доступных баз, но будет возможность выполнять разрешенные SQL-запросы.
Как получить раскладку по размеру таблиц в базе
Это можно сделать следующим SQL-запросом:
SET NOCOUNT ON
DBCC UPDATEUSAGE(0)
-- DB size.
EXEC sp_spaceused
-- Table row counts and sizes.
CREATE TABLE #t
(
[name] NVARCHAR(128),
[rows] CHAR(11),
reserved VARCHAR(18),
data VARCHAR(18),
index_size VARCHAR(18),
unused VARCHAR(18)
)
INSERT #t EXEC sp_msForEachTable 'EXEC sp_spaceused ''?'''
SELECT *
FROM #t
-- # of rows.
SELECT SUM(CAST([rows] AS int)) AS [rows]
FROM #t
DROP TABLE #t
Полезные ссылки, которые могут облегчить вам работу с базами данных, размещенными на нашем хостинге
Обслуживание базы данных Microsoft SQL Server
Если вы работаете в компании, которая использует продукты Ivanti в полнофункциональной среде SQL Server, и у вас есть администратор базы данных, который использует политики обслуживания и резервного копирования SQL Server, уже работающие с нашими базами данных, это прекрасно! Если вы используете SQL Server Express или полную версию SQL Server, но у вас нет плана обслуживания и резервного копирования, продолжайте читать эту статью.
Нестабильность работы и повреждение базы данных — это единственная основная причина появления проблем обновления и основная причина многих проблем производительности графического интерфейса, которые зачастую можно устранить посредством профилактического обслуживания базы данных. Далее представлены наши рекомендации по регулярному обслуживанию вашей базы данных для ее поддержки в рабочем состоянии с хорошей производительностью и минимумом проблем.
Запомните эту начальную точку. Если вы используете нормативные требования в отношении наличия доступности данных в рабочем порядке, вы должны выполнить конфигурацию для обеспечения такой доступности. В этом случае вы можете проанализировать, как часто выполняется сканирование. 1000 агентов, выполняющих сканирование восемь раз в день, расширят вашу базу данных гораздо быстрее, чем сканирование только один раз в день или в неделю. В большинстве случаев вам будут не нужны все эти данные.
Далее приведены наши рекомендации по регулярному обслуживанию базы данных.
Хранение данных
Определите объем данных, которые необходимо хранить для рабочих задач. Обычно 60 — 90 достаточно для производственных целей. Используйте средство обслуживания баз данных Ivanti Security Controls для очистки данных, которые старше указанного числа дней, и планирования задач выполнения этого она регулярной основе.
Отчеты
Определите, какие данные отчетов необходимы для аудита\нормативных требований. Запускайте ежемесячные отчеты для удовлетворения этих потребностей и храните отчеты в файлах столько, сколько этого требует ваша политика. Обычно 13 месяцев — это достаточное количество времени для хранения данных отчетов.
Резервные копии базы данных
Ivanti рекомендует запускать еженедельные инкрементные и ежемесячные полные резервные копирования. Резервное копирование должно быть выполнено непосредственно перед запланированной очисткой. Сохраняйте резервные копии достаточно долго в качестве данных отчетности.
Расписание обслуживания базы данных
•Резервные копии: Полные ежемесячно, сразу после обслуживания исправлений в этом месяце. Еженедельное приращение в конце каждой недели (желательно после установки исправлений в выходной).
•Дата очистки: После выполнения полного ежемесячного резервного копирования
•Реиндексация: После очистки данных
•Целостность: После реиндексации
Средство обслуживания базы данных
Пользователи SQL Server Express, которые не имеют доступа к Мастеру планов обслуживания SQL Server, могут использовать средство Ivanti Security Controls для обслуживания баз данных. Средство обслуживания базы данных позволяет:
•Удалять старые результаты выполнения
•Перестраивать индексы на сервере SQL Server
•Создавать резервные копии вашей базы данных и журнала транзакций
Это выполняется посредством выбора Управление > Обслуживание базы данных и указания, когда требуется выполнять задачи обслуживания базы данных. Для получения информации см. тему справки Управление базами данных.
Мастер планов обслуживания SQL Server
Если вы используете полную версию SQL Server, вам необходимо запустить Мастер планов обслуживания SQL Server для настройки планов обслуживания, поскольку это приложение более надежно и имеет дополнительные функции. Вы можете использовать средство обслуживания баз данных Ivanti Security Controls, но Мастер планов обслуживания SQL Server является более надежным и имеет дополнительные функции.
Родственные темы
•Рекомендации для программных и аппаратных средств консоли
•Требования к конфигурации портов и брандмауэра
•Управление распределенными средами
•Конфигурация безагентного управления исправлениями
•Лучшие методы установки исправлений в среде без агентов
•Автоматизация управления исправлениями в среде без агентов
•Управление исправлениями на основе агентов
•Параметры развертывания агентов
•Установка и поддержка агентов на подключенных к Интернету компьютерах
•Уровень продукта на основе агента и процесс развертывания исправлений
•Руководство по установке исправлений
•Выполнение исправления в автономном среде
SQL Basics — практическое руководство по SQL для начинающих Анализируя совместное использование велосипедов
В этом руководстве мы будем работать с набором данных из службы проката велосипедов Hubway, который включает данные о более чем 1,5 миллионах поездок, совершенных с помощью этой службы.
Мы начнем с небольшого изучения баз данных, того, что они такое и почему мы их используем, прежде чем приступить к написанию некоторых собственных запросов на SQL.
Если вы хотите продолжить, вы можете загрузить файл hubway.db здесь (130 МБ).
Основы SQL: реляционные базы данных
Реляционная база данных — это база данных, которая хранит связанную информацию в нескольких таблицах и позволяет запрашивать информацию в нескольких таблицах одновременно.
Проще понять, как это работает, на примере. Представьте, что вы работаете в бизнесе и хотите отслеживать информацию о продажах. Вы можете настроить электронную таблицу в Excel со всей информацией, которую вы хотите отслеживать, в виде отдельных столбцов: номер заказа, дата, сумма к оплате, номер для отслеживания отгрузки, имя клиента, адрес клиента и номер телефона клиента.
Эта установка отлично подойдет для отслеживания информации, которая вам нужна для начала, но когда вы начнете получать повторные заказы от одного и того же клиента, вы обнаружите, что их имя, адрес и номер телефона хранятся в нескольких строках вашей электронной таблицы.
По мере роста вашего бизнеса и увеличения количества отслеживаемых заказов эти избыточные данные будут занимать ненужное место и в целом снизят эффективность вашей системы отслеживания продаж. Вы также можете столкнуться с проблемами с целостностью данных.Например, нет гарантии, что каждое поле будет заполнено правильным типом данных или что имя и адрес будут вводиться каждый раз точно так же.
С реляционной базой данных, подобной той, что показана на диаграмме выше, вы избегаете всех этих проблем. Вы можете настроить две таблицы, одну для заказов и одну для клиентов. Таблица «клиенты» будет включать уникальный идентификационный номер для каждого клиента, а также имя, адрес и номер телефона, которые мы уже отслеживаем.Таблица «заказы» будет включать номер вашего заказа, дату, сумму к оплате, номер отслеживания и вместо отдельного поля для каждого элемента данных о клиенте будет иметь столбец для идентификатора клиента.
Это позволяет нам получить всю информацию о клиенте для любого конкретного заказа, но нам нужно сохранить ее в нашей базе данных только один раз, а не выводить ее повторно для каждого отдельного заказа.
Наш набор данных
Начнем с рассмотрения нашей базы данных. В базе есть две таблицы, поездок и станций .Для начала просто посмотрим на таблицу поездок и . Он содержит следующие столбцы:
-
id— Уникальное целое число, которое служит ссылкой для каждой поездки -
duration— Продолжительность поездки, измеряется в секундах -
start_date— Дата и время начала поездки -
start_station— Целое число, которое соответствует столбцуidв таблицестанцийдля станции, с которой началось путешествие с . -
end_date— Дата и время окончания поездки -
end_station— ‘id’ станции, на которой завершилась поездка -
bike_number— Уникальный идентификатор Hubway для велосипеда, использованного в поездке -
sub_type— Тип подписки пользователя.«Зарегистрированный»для пользователей с членством,«Обычный»для пользователей без членства -
zip_code— Почтовый индекс пользователя (доступен только для зарегистрированных пользователей) -
Birth_date— Год рождения пользователя (доступно только для зарегистрированных участников) -
пол— Пол пользователя (доступно только для зарегистрированных пользователей)
Наш анализ
С этой информацией и командами SQL, которые мы вскоре узнаем, вот несколько вопросов, на которые мы попытаемся ответить в ходе этого поста:
- Какова была самая длинная поездка?
- Сколько поездок совершили «зарегистрированные» пользователи?
- Какая была средняя продолжительность поездки?
- Бывают ли более длительные поездки зарегистрированные или случайные пользователи?
- Какой велосипед использовался для большинства поездок?
- Какова средняя продолжительность поездок пользователей старше 30 лет?
Для ответа на эти вопросы мы будем использовать команды SQL:
-
ВЫБРАТЬ -
ГДЕ -
ПРЕДЕЛ -
ЗАКАЗАТЬ В -
ГРУППА ПО -
И -
ИЛИ -
МИН -
МАКС -
СРЕДНЕЕ -
СУМ -
СЧЕТ
Установка и настройка
Для целей этого руководства мы будем использовать систему баз данных под названием SQLite3.SQLite входит в состав Python начиная с версии 2.5, поэтому, если у вас установлен Python, у вас почти наверняка будет SQLite. Python и библиотеку SQLite3 можно легко установить и настроить с помощью Anaconda, если у вас их еще нет.
Использование Python для запуска нашего кода SQL позволяет нам импортировать результаты в фреймворк Pandas, чтобы упростить отображение наших результатов в удобном для чтения формате. Это также означает, что мы можем выполнять дальнейший анализ и визуализацию данных, которые мы извлекаем из базы данных, хотя это выходит за рамки данного руководства.
В качестве альтернативы, если мы не хотим использовать или устанавливать Python, мы можем запустить SQLite3 из командной строки. Просто загрузите «предварительно скомпилированные двоичные файлы» с веб-страницы SQLite3 и используйте следующий код для открытия базы данных:
~ $ sqlite hubway.db Версия SQLite 3.14.0 2016-07-26 15: 17: 14 Введите ".help" для использования hints.sqlite> Отсюда мы можем просто ввести запрос, который хотим запустить, и мы увидим данные, возвращенные в окне нашего терминала.
Альтернативой использованию терминала является подключение к базе данных SQLite через Python.Это позволит нам использовать записную книжку Jupyter, чтобы мы могли видеть результаты наших запросов в аккуратно отформатированной таблице.
Для этого мы определим функцию, которая принимает наш запрос (сохраненный в виде строки) в качестве входных данных и отображает результат в виде отформатированного фрейма данных:
импорт sqlite3
импортировать панд как pd
db = sqlite3.connect ('hubway.db')
def run_query (запрос):
вернуть pd.read_sql_query (запрос, БД) Конечно, нам не обязательно использовать Python с SQL. Если вы уже являетесь программистом R, наш курс «Основы SQL для пользователей R» станет отличным местом для начала.ВЫБРАТЬ
Первая команда, с которой мы будем работать, — это SELECT . SELECT будет основой почти каждого написанного нами запроса — он сообщает базе данных, какие столбцы мы хотим видеть. Мы можем указать столбцы по имени (через запятую) или использовать подстановочный знак * для возврата каждого столбца в таблице.
Помимо столбцов, которые мы хотим получить, мы также должны указать базе данных, из какой таблицы их получить. Для этого мы используем ключевое слово FROM , за которым следует имя таблицы.Например, если бы мы хотели видеть start_date и bike_number для каждой поездки в таблице trips , мы могли бы использовать следующий запрос:
ВЫБРАТЬ start_date, bike_number ИЗ поездок; В этом примере мы начали с команды SELECT , чтобы база данных знала, что мы хотим, чтобы она нашла нам некоторые данные. Затем мы сообщили базе данных, что нас интересуют столбцы start_date и bike_number .Наконец, мы использовали FROM , чтобы сообщить базе данных, что столбцы, которые мы хотим видеть, являются частью таблицы trips .
Одна важная вещь, о которой следует помнить при написании SQL-запросов, заключается в том, что мы хотим заканчивать каждый запрос точкой с запятой (; ). Не каждая база данных SQL на самом деле требует этого, но некоторые требуют, поэтому лучше сформировать эту привычку.
ПРЕДЕЛ
Следующая команда, которую нам нужно знать, прежде чем мы начнем выполнять запросы в нашей базе данных Hubway, — это LIMIT . LIMIT просто сообщает базе данных, сколько строк вы хотите вернуть.
Запрос SELECT , который мы рассмотрели в предыдущем разделе, вернет запрошенную информацию для каждой строки в таблице поездок , но иногда это может означать большой объем данных. Мы можем не захотеть всего этого. Если бы вместо этого мы хотели видеть start_date и bike_number для первых пяти поездок в базе данных, мы могли бы добавить LIMIT к нашему запросу следующим образом:
ВЫБРАТЬ start_date, bike_number ИЗ поездок LIMIT 5; Мы просто добавили команду LIMIT , а затем число, представляющее количество строк, которые мы хотим вернуть.В этом случае мы использовали 5, но вы можете заменить его любым числом, чтобы получить соответствующий объем данных для проекта, над которым вы работаете.
Мы будем часто использовать LIMIT в наших запросах к базе данных Hubway в этом руководстве — таблица поездок содержит более 1,5 миллиона строк данных, и нам, конечно, не нужно отображать их все!
Давайте запустим наш первый запрос к базе данных Hubway. Сначала мы сохраним наш запрос в виде строки, а затем воспользуемся функцией, которую мы определили ранее, чтобы запустить его в базе данных.Взгляните на следующий пример:
query = 'ВЫБРАТЬ * ИЗ ОТКЛЮЧЕНИЯ ОГРАНИЧЕНИЯ 5;'
run_query (запрос) | id | продолжительность | start_date | start_station | end_date | конечная станция | номер велосипеда | подтип | почтовый индекс | дата рождения | пол | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 9 | 28.07.2011 10:12:00 | 23 | 28.07.2011 10:12:00 | 23 | B00468 | Зарегистрировано | ‘97217 | 1976.0 | Мужской |
| 1 | 2 | 220 | 28.07.2011 10:21:00 | 23 | 28.07.2011 10:25:00 | 23 | B00554 | Зарегистрировано | ‘02215 | 1966,0 | Мужской |
| 2 | 3 | 56 | 28.07.2011 10:33:00 | 23 | 28.07.2011 10:34:00 | 23 | B00456 | Зарегистрировано | ‘02108 | 1943 г.0 | Мужской |
| 3 | 4 | 64 | 28.07.2011 10:35:00 | 23 | 28.07.2011 10:36:00 | 23 | B00554 | Зарегистрировано | ‘02116 | 1981,0 | Женский |
| 4 | 5 | 12 | 28.07.2011 10:37:00 | 23 | 28.07.2011 10:37:00 | 23 | B00554 | Зарегистрировано | ‘97214 | 1983.0 | Женский |
В этом запросе в качестве подстановочного знака используется * вместо указания возвращаемых столбцов. Это означает, что команда SELECT дала нам каждый столбец в таблице поездок . Мы также использовали функцию LIMIT , чтобы ограничить вывод первыми пятью строками таблицы.
Вы часто будете видеть, что люди используют ключевые слова команды в своих запросах (соглашение, которому мы будем следовать в этом руководстве), но это в основном вопрос предпочтений.Использование заглавных букв упрощает чтение кода, но на самом деле никоим образом не влияет на работу кода. Если вы предпочитаете писать запросы с помощью команд в нижнем регистре, запросы по-прежнему будут выполняться правильно.
В нашем предыдущем примере возвращались все столбцы в таблице поездок . Если бы нас интересовали только столбцы duration и start_date , мы могли бы заменить подстановочный знак именами столбцов следующим образом:
query = 'ВЫБЕРИТЕ продолжительность, начальная_дата ИЗ ПРЕДЕЛ 5 отключений'
run_query (запрос) | продолжительность | start_date | |
|---|---|---|
| 0 | 9 | 28.07.2011 10:12:00 |
| 1 | 220 | 28.07.2011 10:21:00 |
| 2 | 56 | 28.07.2011 10:33:00 |
| 3 | 64 | 28.07.2011 10:35:00 |
| 4 | 12 | 28.07.2011 10:37:00 |
ЗАКАЗАТЬ ПО
Последняя команда, которую нам нужно знать, прежде чем мы сможем ответить на первый из наших вопросов, — это ORDER BY .Эта команда позволяет нам отсортировать базу данных по заданному столбцу.
Чтобы использовать его, мы просто указываем имя столбца, по которому хотим выполнить сортировку. По умолчанию ORDER BY сортируется по возрастанию. Если мы хотим указать, в каком порядке база данных должна быть отсортирована, мы можем добавить ключевое слово ASC для возрастания или DESC для убывания.
Например, если мы хотим отсортировать таблицу поездок от самой короткой продолжительности до самой длинной, мы могли бы добавить следующую строку в наш запрос:
ЗАКАЗАТЬ ПО продолжительности ASC С помощью команд SELECT , LIMIT и ORDER BY в нашем репертуаре мы можем теперь попытаться ответить на наш первый вопрос: Какова была продолжительность самой продолжительной поездки?
Чтобы ответить на этот вопрос, полезно разбить его на разделы и определить, какие команды нам понадобятся для решения каждой части.
Сначала нам нужно извлечь информацию из столбца длительности таблицы поездок . Затем, чтобы определить, какая поездка самая длинная, мы можем отсортировать столбец длительностью в порядке убывания. Вот как мы можем проработать это, чтобы придумать запрос, который получит информацию, которую мы ищем:
- Используйте
SELECTдля получения продолжительностиИЗотключенийтаблица - Используйте
ORDER BYдля сортировки столбца длительностии используйте ключевое словоDESC, чтобы указать, что вы хотите отсортировать в порядке убывания - Используйте
LIMIT, чтобы ограничить вывод одной строкой
Использование этих команд таким образом вернет единственную строку с самой длинной продолжительностью, которая даст нам ответ на наш вопрос.
Еще одно замечание - по мере того, как ваши запросы добавляют больше команд и усложняются, вам может быть легче читать, если вы разделите их на несколько строк. Это, как и использование заглавных букв, зависит от личных предпочтений. Это не влияет на выполнение кода (система просто считывает код с самого начала до точки с запятой), но может сделать ваши запросы более понятными и понятными. В Python мы можем разделить строку на несколько строк, используя тройные кавычки.
Давайте продолжим и запустим этот запрос и выясним, как долго длилась самая длинная поездка.
запрос = '' '
ВЫБРАТЬ ДЛИТЕЛЬНОСТЬ ИЗ поездок
ЗАКАЗАТЬ ПО длительности DESC
LIMIT 1;
'' '
run_query (запрос) Теперь мы знаем, что самая длинная поездка длилась 9999 секунд, или чуть более 166 минут. Однако при максимальном значении 9999 мы не знаем, действительно ли это длина самой длинной поездки или база данных была настроена только для четырехзначного числа.
Если правда, что база данных сокращает особенно длинные поездки, то мы можем ожидать увидеть много поездок на 9999 секундах, где они достигают предела.Давайте попробуем выполнить тот же запрос, что и раньше, но скорректируем LIMIT , чтобы вернуть 10 самых высоких значений длительности, чтобы проверить, так ли это:
запрос = '' '
ВЫБРАТЬ ДЛИТЕЛЬНОСТЬ ОТ поездок
ЗАКАЗАТЬ ПО длительности DESC
ПРЕДЕЛ 10
'' '
run_query (запрос) | продолжительность | |
|---|---|
| 0 | 9999 |
| 1 | 9998 |
| 2 | 9998 |
| 3 | 9997 |
| 4 | 9996 |
| 5 | 9996 |
| 6 | 9995 |
| 7 | 9995 |
| 8 | 9994 |
| 9 | 9994 |
Что мы видим здесь, так это то, что на 9999 не так много поездок, поэтому не похоже, что мы сокращаем верхний предел нашей продолжительности, но все же трудно сказать, является ли это реальная длина поездка или просто максимально допустимое значение.
Hubway взимает дополнительную плату за поездки продолжительностью более 30 минут (кто-то, кто держит велосипед в течение 9999 секунд, должен будет заплатить дополнительные 25 долларов США), поэтому вполне вероятно, что они решили, что 4 цифры будет достаточно для отслеживания большинства поездок.
ГДЕ
Предыдущие команды отлично подходят для извлечения отсортированной информации для определенных столбцов, но что, если есть определенное подмножество данных, которые мы хотим просмотреть? Вот где появляется WHERE . Команда WHERE позволяет нам использовать логический оператор, чтобы указать, какие строки должны быть возвращены.Например, вы можете использовать следующую команду, чтобы возвращать информацию о каждой поездке на велосипеде B00400 :
ГДЕ bike_number = "B00400" Вы также заметите, что в этом запросе используются кавычки. Это потому, что bike_number хранится в виде строки. Если столбец содержит числовые типы данных, в кавычках нет необходимости.
Давайте напишем запрос, который использует WHERE для возврата каждого столбца в таблице поездок для каждой строки с длительностью дольше 9990 секунд:
запрос = '' '
ВЫБРАТЬ * ИЗ поездок
ГДЕ длительность> 9990;
'' '
run_query (запрос) | id | продолжительность | start_date | start_station | end_date | конечная станция | номер велосипеда | подтип | почтовый индекс | дата рождения | пол | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4768 | 9994 | 2011-08-03 17:16:00 | 22 | 2011-08-03 20:03:00 | 24 | B00002 | Повседневный | |||
| 1 | 8448 | 9991 | 2011-08-06 13:02:00 | 52 | 2011-08-06 15:48:00 | 24 | B00174 | Повседневный | |||
| 2 | 11341 | 9998 | 2011-08-09 10:42:00 | 40 | 2011-08-09 13:29:00 | 42 | B00513 | Повседневный | |||
| 3 | 24455 | 9995 | 2011-08-20 12:20:00 | 52 | 2011-08-20 15:07:00 | 17 | B00552 | Повседневный | |||
| 4 | 55771 | 9994 | 14.09.2011 15:44:00 | 40 | 14.09.2011 18:30:00 | 40 | B00139 | Повседневный | |||
| 5 | 81191 | 9993 | 2011-10-03 11:30:00 | 22 | 2011-10-03 14:16:00 | 36 | B00474 | Повседневный | |||
| 6 | 89335 | 9997 | 2011-10-09 02:30:00 | 60 | 2011-10-09 05:17:00 | 45 | B00047 | Повседневный | |||
| 7 | 124500 | 9992 | 2011-11-09 09:08:00 | 22 | 2011-11-09 11:55:00 | 40 | B00387 | Повседневный | |||
| 8 | 133967 | 9996 | 2011-11-19 13:48:00 | 4 | 2011-11-19 16:35:00 | 58 | B00238 | Повседневный | |||
| 9 | 147451 | 9996 | 23.03.2012 14:48:00 | 35 | 23.03.2012 17:35:00 | 33 | B00550 | Повседневный | |||
| 10 | 315737 | 9995 | 2012-07-03 18:28:00 | 12 | 2012-07-03 21:15:00 | 12 | B00250 | Зарегистрировано | '02120 | 1964 | Мужской |
| 11 | 319597 | 9994 | 05.07.2012 11:49:00 | 52 | 05.07.2012 14:35:00 | 55 | B00237 | Повседневный | |||
| 12 | 416523 | 9998 | 2012-08-15 12:11:00 | 54 | 15.08.2012 14:58:00 | 80 | B00188 | Повседневный | |||
| 13 | 541247 | 9999 | 26.09.2012 18:34:00 | 54 | 26.09.2012 21:21:00 | 54 | T01078 | Повседневный |
Как мы видим, этот запрос вернул 14 различных поездок, каждая длительностью 9990 секунд или более.В этом запросе выделяется то, что все результаты, кроме одного, имеют sub_type из «Случайный» . Возможно, это показатель того, что «зарегистрированных» пользователей более осведомлены о дополнительных сборах за дальние поездки. Возможно, Hubway сможет лучше донести свою структуру ценообразования до обычных пользователей, чтобы помочь им избежать дополнительных расходов.
Мы уже видим, как команда SQL даже для начинающих может помочь нам ответить на бизнес-вопросы и найти понимание в наших данных.
Возвращаясь к WHERE , мы также можем объединить несколько логических тестов в нашем предложении WHERE , используя AND или OR . Если, например, в нашем предыдущем запросе мы хотели вернуть только поездки с длительностью за 9990 секунд, которые также имели подтип Зарегистрированный, мы могли бы использовать И , чтобы указать оба условия.
Вот еще одна личная рекомендация: используйте круглые скобки для разделения каждого логического теста, как показано в блоке кода ниже.Это не является строго обязательным для работы кода, но круглые скобки упрощают понимание ваших запросов по мере увеличения сложности.
Теперь давайте запустим этот запрос. Мы уже знаем, что он должен возвращать только один результат, поэтому будет легко убедиться, что мы все правильно поняли:
запрос = '' '
ВЫБРАТЬ * ИЗ поездок
ГДЕ (продолжительность> = 9990) И (sub_type = "Зарегистрировано")
ЗАКАЗАТЬ ПО длительности DESC;
'' '
run_query (запрос) | id | продолжительность | start_date | start_station | end_date | конечная станция | номер велосипеда | подтип | почтовый индекс | дата рождения | пол | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 315737 | 9995 | 2012-07-03 18:28:00 | 12 | 2012-07-03 21:15:00 | 12 | B00250 | Зарегистрировано | '02120 | 1964 г.0 | Мужской |
Следующий вопрос, который мы задали в начале поста, - «Сколько поездок совершили« зарегистрированные »пользователи?» Чтобы ответить на него, мы могли бы выполнить тот же запрос, что и выше, и изменить выражение WHERE , чтобы вернуть все строки, где sub_type равен 'Registered' , а затем подсчитать их.
Однако на самом деле в SQL есть встроенная команда для этого подсчета: COUNT .
COUNT позволяет перенести вычисления в базу данных и избавить нас от необходимости писать дополнительные скрипты для подсчета результатов. Чтобы использовать его, мы просто включаем COUNT (column_name) вместо (или в дополнение к) столбцов, которые вы хотите SELECT , например:
ВЫБРАТЬ СЧЕТЧИК (id)
ИЗ поездок В этом случае не имеет значения, какой столбец мы выбираем для подсчета, потому что каждый столбец должен содержать данные для каждой строки в нашем запросе.Но иногда в запросе могут отсутствовать (или быть "нулевые") значения для некоторых строк. Если мы не уверены, содержит ли столбец нулевые значения, мы можем запустить наш COUNT для столбца id - столбец id никогда не будет нулевым, поэтому мы можем быть уверены, что наш счетчик ничего не пропустил.
Мы также можем использовать COUNT (1) или COUNT (*) для подсчета каждой строки в нашем запросе. Стоит отметить, что иногда нам может потребоваться запустить COUNT для столбца с нулевыми значениями.Например, нам может потребоваться узнать, сколько строк в нашей базе данных имеют отсутствующие значения для столбца.
Давайте взглянем на запрос, чтобы ответить на наш вопрос. Мы можем использовать SELECT COUNT (*) для подсчета общего количества возвращенных строк и WHERE sub_type = "Registered" , чтобы убедиться, что мы подсчитываем только поездки, совершенные зарегистрированными пользователями.
запрос = '' '
ВЫБРАТЬ КОЛИЧЕСТВО (*) ИЗ поездок
ГДЕ sub_type = "Зарегистрировано";
'' '
run_query (запрос) Этот запрос сработал и вернул ответ на наш вопрос.Но заголовок столбца не особо описательный. Если бы кто-то еще взглянул на эту таблицу, он не смог бы понять, что это значит. Если мы хотим сделать наши результаты более удобочитаемыми, мы можем использовать AS , чтобы дать нашему выводу псевдоним (или псевдоним). Давайте повторно запустим предыдущий запрос, но дадим заголовку нашего столбца псевдоним Всего поездок по зарегистрированным пользователям :
запрос = '' '
ВЫБЕРИТЕ СЧЕТЧИК (*) КАК «Общее количество поездок зарегистрированных пользователей»
ИЗ поездок
ГДЕ sub_type = "Зарегистрировано";
'' '
run_query (запрос) | Всего поездок по зарегистрированным пользователям | |
|---|---|
| 0 | 1105192 |
Агрегатные функции
COUNT - не единственный математический трюк, который SQL использует в своих рукавах.Мы также можем использовать SUM , AVG , MIN и MAX для возврата суммы, среднего, минимального и максимального значения столбца соответственно. Они, наряду с COUNT , известны как агрегатные функции.
Итак, чтобы ответить на наш третий вопрос, «Какова была средняя продолжительность поездки?» , мы можем использовать функцию AVG в столбце duration (и, опять же, использовать AS , чтобы дать нашему выходному столбцу более информативное имя):
запрос = '' '
ВЫБЕРИТЕ СРЕДНЮЮ (продолжительность) КАК "Средняя продолжительность"
ОТ поездок;
'' '
run_query (запрос) | Средняя продолжительность | |
|---|---|
| 0 | 912.409682 |
Получается, что средняя продолжительность поездки составляет 912 секунд, то есть примерно 15 минут. В этом есть смысл, поскольку мы знаем, что Hubway взимает дополнительную плату за поездки продолжительностью более 30 минут. Услуга предназначена для пассажиров, совершающих короткие поездки в одну сторону.
Что насчет нашего следующего вопроса, , совершают ли более длительные поездки зарегистрированные или случайные пользователи? Мы уже знаем один способ ответить на этот вопрос - мы могли бы запустить два запроса SELECT AVG (duration) FROM trips с предложениями WHERE , которые ограничивают один до «зарегистрированных» и один до «случайных» пользователей.
Но давайте сделаем по-другому. SQL также включает способ ответить на этот вопрос в одном запросе с помощью команды GROUP BY .
ГРУППА ПО
GROUP BY разделяет строки на группы в зависимости от содержимого определенного столбца и позволяет нам выполнять агрегированные функции для каждой группы.
Чтобы лучше понять, как это работает, давайте взглянем на столбец пол . Каждая строка может иметь одно из трех возможных значений в столбце пол , «Мужской» , «Женский» или Нулевой (отсутствует; у нас нет данных пол для случайных пользователей).
Когда мы используем GROUP BY , база данных разделяет каждую из строк в другую группу на основе значения в столбце пол , почти так же, как мы могли бы разделить колоду карт на разные масти. . Мы можем представить себе две стопки, одну из самцов, одну из самок.
Когда у нас есть две отдельные стопки, база данных будет выполнять любые агрегатные функции в нашем запросе для каждой из них по очереди. Если бы мы использовали, например, COUNT , запрос подсчитал бы количество строк в каждой стопке и вернул бы значение для каждой отдельно.
Давайте подробно рассмотрим, как написать запрос, чтобы ответить на наш вопрос о том, совершают ли более длительные поездки зарегистрированные или случайные пользователи.
- Как и в случае с каждым из наших запросов, мы начнем с
SELECT, чтобы сообщить базе данных, какую информацию мы хотим видеть. В этом случае нам понадобитсяsub_typeиAVG (продолжительность). - Мы также включим
GROUP BY sub_type, чтобы разделить наши данные по типу подписки и отдельно вычислить средние значения зарегистрированных и случайных пользователей.
Вот как выглядит код, если собрать все вместе:
запрос = '' '
ВЫБЕРИТЕ sub_type, AVG (продолжительность) AS "Средняя продолжительность"
ИЗ поездок
GROUP BY sub_type;
'' '
run_query (запрос) | подтип | Средняя продолжительность | |
|---|---|---|
| 0 | Повседневный | 1519.643897 |
| 1 | Зарегистрировано | 657.026067 |
Вот это большая разница! В среднем зарегистрированные пользователи совершают поездки продолжительностью около 11 минут, тогда как обычные пользователи тратят почти 25 минут на поездку.Зарегистрированные пользователи, вероятно, будут совершать более короткие и частые поездки, возможно, по дороге на работу. С другой стороны, обычные пользователи тратят примерно вдвое больше времени на поездку.
Возможно, что случайные пользователи, как правило, происходят из демографических групп (например, туристов), которые более склонны совершать длительные поездки, убедитесь, что они передвигаются и видят все достопримечательности. Как только мы обнаружим эту разницу в данных, компания сможет исследовать ее разными способами, чтобы лучше понять, что ее вызывает.
Однако для целей этого урока давайте продолжим. Наш следующий вопрос: , какой велосипед использовался для большинства поездок? . Мы можем ответить на этот вопрос, используя очень похожий запрос. Взгляните на следующий пример и посмотрите, сможете ли вы выяснить, что делает каждая строка - позже мы рассмотрим это шаг за шагом, чтобы вы могли убедиться, что все правильно:
запрос = '' '
ВЫБЕРИТЕ bike_number как "Номер велосипеда", COUNT (*) как "Количество поездок"
ИЗ поездок
ГРУППА ПО номеру велосипеда
ЗАКАЗАТЬ ПО КОЛИЧЕСТВУ (*) УДАЛ.
LIMIT 1;
'' '
run_query (запрос) | Номер велосипеда | Количество поездок | |
|---|---|---|
| 0 | B00490 | 2120 |
Как видно из выходных данных, наибольшее количество поездок ездил на велосипеде B00490 .Давайте разберемся, как мы туда попали:
- Первая строка - это предложение
SELECT, чтобы сообщить базе данных, что мы хотим видеть столбецbike_numberи количество каждой строки. Он также используетAS, чтобы указать базе данных отображать каждый столбец с более удобным именем. - Во второй строке используется
ИЗ, чтобы указать, что данные, которые мы ищем, находятся в таблицепоездок. - В третьей строке начинаются сложности.Мы используем
GROUP BY, чтобы указать функцииCOUNTв строке 1 для отдельного подсчета каждого значения дляbike_number. - В четвертой строке у нас есть предложение
ORDER BY, чтобы отсортировать таблицу в порядке убывания и убедиться, что наш наиболее часто используемый велосипед находится наверху. - Наконец, мы используем
LIMIT, чтобы ограничить вывод первой строкой, которая, как мы знаем, будет велосипедом, который использовался в наибольшем количестве поездок, из-за того, как мы отсортировали данные в четвертой строке.
Арифметические операторы
Наш последний вопрос немного сложнее остальных. Нам нужна средняя продолжительность поездок зарегистрированных пользователей старше 30 лет .
Мы могли бы просто вычислить год, в котором 30-летние родились в нашей голове, а затем подключить его, но более элегантное решение - использовать арифметические операции непосредственно в нашем запросе. SQL позволяет нам использовать + , - , * и / для выполнения арифметической операции сразу над всем столбцом.
запрос = '' '
ВЫБРАТЬ СРЕДНЕЕ (длительность) ИЗ поездок
ГДЕ (2017 - дата рождения)> 30;
'' '
run_query (запрос) | AVG (продолжительность) | |
|---|---|
| 0 | 923.014685 |
ПРИСОЕДИНЯЙТЕСЬ
До сих пор мы рассматривали запросы, которые извлекают данные только из таблицы trips . Однако одна из причин, по которой SQL является настолько мощным, заключается в том, что он позволяет нам извлекать данные из нескольких таблиц в одном запросе.
Наша база данных по прокату велосипедов содержит вторую таблицу, станций . Таблица станций содержит информацию о каждой станции в сети Hubway и включает столбец id , на который ссылается таблица поездок .
Прежде чем мы начнем работать с некоторыми реальными примерами из этой базы данных, давайте вернемся к гипотетической базе данных отслеживания заказов из ранее. В этой базе данных у нас было две таблицы, заказов и клиентов , и они были связаны столбцом customer_id .
Допустим, мы хотели написать запрос, который возвращал бы номер заказа и имя для каждого заказа в базе данных. Если бы они оба хранились в одной таблице, мы могли бы использовать следующий запрос:
ВЫБРАТЬ номер_заказа, имя
ОТ заказов; К сожалению, столбец order_number и столбец name хранятся в двух разных таблицах, поэтому нам нужно добавить несколько дополнительных шагов. Давайте поразмышляем над дополнительными вещами, которые необходимо знать базе данных, прежде чем она сможет вернуть нужную нам информацию:
- В какой таблице находится столбец
order_number? - В какой таблице находится столбец
name? - Как информация в таблице
ordersсвязана с информацией в таблицеcustomers?
Чтобы ответить на первые два из этих вопросов, мы можем включить имена таблиц для каждого столбца в нашу команду SELECT .Мы делаем это просто путем записи имени таблицы и имени столбца, разделенных . . Например, вместо SELECT order_number, name мы должны написать SELECT orders.order_number, customers.name . Добавление сюда имен таблиц помогает базе данных находить нужные столбцы, сообщая ей, в какой таблице искать каждый.
Чтобы сообщить базе данных, как связаны таблицы orders и customers , мы используем JOIN и ON . JOIN указывает, какие таблицы должны быть связаны, а ON указывает, какие столбцы в каждой таблице связаны.
Мы собираемся использовать внутреннее соединение, что означает, что строки будут возвращаться только тогда, когда есть совпадения в столбцах, указанных в ON . В этом примере мы захотим использовать JOIN для той таблицы, которую мы не включили в команду FROM . Таким образом, мы можем использовать FROM заказов INNER JOIN клиентов или FROM клиентов INNER JOIN orders .
Как мы обсуждали ранее, эти таблицы связаны по столбцу customer_id в каждой таблице. Следовательно, мы захотим использовать ON , чтобы сообщить базе данных, что эти два столбца относятся к одному и тому же, например:
ON orders.customer_ID = customers.customer_id Мы снова используем . , чтобы убедиться, что база данных знает, в какой таблице находится каждый из этих столбцов. Итак, когда мы сложим все это вместе, мы получим запрос, который выглядит следующим образом:
ВЫБРАТЬ заказы.order_number, customers.name
ИЗ заказов
INNER JOIN клиенты
ON orders.customer_id = customers.customer_id Этот запрос вернет порядковый номер каждого заказа в базе данных вместе с именем клиента, который связан с каждым заказом.
Возвращаясь к нашей базе данных Hubway, теперь мы можем написать несколько запросов, чтобы увидеть JOIN в действии.
Прежде чем мы начнем, мы должны взглянуть на остальные столбцы в таблице станций . Вот запрос, показывающий нам первые 5 строк, чтобы мы могли увидеть, как выглядит таблица станций :
запрос = '' '
ВЫБРАТЬ * ИЗ станций
LIMIT 5;
'' '
run_query (запрос) | id | станция | муниципалитет | шир. | lng | |
|---|---|---|---|---|---|
| 0 | 3 | Колледжи Фенуэя | Бостон | 42.340021 | -71.100812 |
| 1 | 4 | Тремонт-стрит, Беркли-стрит, | Бостон | 42.345392 | -71.069616 |
| 2 | 5 | Северо-Восточный U / Северная парковка | Бостон | 42,341814 | -71.0 |
| 3 | 6 | Кембридж-стрит, Джой-стрит, | Бостон | 42,361284999999995 | -71.06514 |
| 4 | 7 | Пирс вентилятора | Бостон | 42,35 3412 | -71.044624 |
-
id- уникальный идентификатор для каждой станции (соответствует столбцамstart_stationиend_stationв таблицеtrips) -
станция- Название станции -
муниципалитет- муниципалитет, в котором находится станция (Бостон, Бруклин, Кембридж или Сомервилль) -
lat- Широта станции -
lng- Долгота станции - Какие станции чаще всего используются для поездок туда и обратно?
- Сколько поездок начинается и заканчивается в разных муниципалитетах?
Как и раньше, мы попытаемся ответить на некоторые вопросы в данных, начиная с , какая станция является наиболее частой отправной точкой? Давайте поработаем пошагово:
- Сначала мы хотим использовать
SELECT, чтобы вернуть столбецstationиз таблицыstationиCOUNTколичества строк. - Затем мы указываем таблицы, которые хотим
JOIN, и говорим базе данных подключить ихON, столбецstart_stationв таблицеtripsи столбецidв таблицеstation. - Затем мы переходим к сути нашего запроса - мы
GROUP BYстолбецstationв таблицеstation, чтобы нашCOUNTподсчитывал количество поездок для каждой станции отдельно - Наконец, мы можем
ORDER BYнашиCOUNTиLIMITвыводить на управляемое количество результатов
запрос = '' '
ВЫБЕРИТЕ станции.станция AS "Станция", COUNT (*) AS "Count"
ИЗ поездок INNER JOIN станции
ВКЛ. Trips.start_station = station.idGROUP BY station.station ORDER BY COUNT (*) DESC
LIMIT 5;
'' '
run_query (запрос) | Станция | Счетчик | |
|---|---|---|
| 0 | Южный вокзал - 700 Атлантик авеню, | 56123 |
| 1 | Публичная библиотека Бостона - 700 Boylston St. | 41994 |
| 2 | Charles Circle - Charles St.на Кембридж-стрит | 35984 |
| 3 | Beacon St / Mass Ave | 35275 |
| 4 | MIT на Mass Ave / Amherst St | 33644 |
Если вы знакомы с Бостоном, вы поймете, почему это самые популярные станции. Южный вокзал - одна из главных станций пригородной железной дороги в городе, Чарльз-стрит проходит вдоль реки рядом с красивыми живописными маршрутами, а улицы Бойлстон и Бикон находятся в самом центре города, рядом с несколькими офисными зданиями.
Следующий вопрос, который мы рассмотрим, - это , какие станции наиболее часто используются для поездок туда и обратно? Мы можем использовать почти тот же запрос, что и раньше. Мы будем SELECT для тех же выходных столбцов и JOIN для таблиц таким же образом, но на этот раз мы добавим предложение WHERE , чтобы ограничить наш COUNT поездками, где start_station совпадает с конечная станция .
query = '' 'ВЫБРАТЬ станции. Станция КАК "Станция", СЧЁТ (*) КАК "Счетчик"
ИЗ поездок INNER JOIN станции
ПО поездкам.start_station = station.id
ГДЕ trips.start_station = trips.end_station
ГРУППА ПО станциям. Станции
ЗАКАЗАТЬ ПО КОЛИЧЕСТВУ (*) УДАЛ.
LIMIT 5;
'' '
run_query (запрос) | Станция | Счетчик | |
|---|---|---|
| 0 | Эспланада - Бикон-стрит на Арлингтон-стрит | 3064 |
| 1 | Чарльз Серкл - Чарльз-стрит, Кембридж-стрит, | 2739 |
| 2 | Публичная библиотека Бостона - 700 Boylston St. | 2548 |
| 3 | Бойлстон-стрит на Арлингтон-стрит | 2163 |
| 4 | Beacon St / Mass Ave | 2144 |
Как мы видим, количество этих станций такое же, как и в предыдущем вопросе, но их количество намного меньше. Самые загруженные станции по-прежнему остаются самыми загруженными, но в целом более низкие цифры говорят о том, что люди обычно используют велосипеды Hubway, чтобы добраться из точки A в точку B, а не какое-то время кататься на велосипеде, прежде чем вернуться туда, откуда они начали.
Здесь есть одно существенное отличие - Esplande, которая не была одной из самых загруженных станций из нашего первого запроса, кажется, самая загруженная для поездок туда и обратно. Почему? Что ж, картинка стоит тысячи слов. Это определенно выглядит как хорошее место для велосипедной прогулки:
Переходим к следующему вопросу: сколько поездок начинается и заканчивается в разных муниципалитетах? Этот вопрос продвигает дальше. Мы хотим знать, сколько поездок начинается и заканчивается в другом районе .Для этого нам нужно JOIN , чтобы дважды подключала таблицу к таблице станций . После ON столбец start_station , а затем ON столбец end_station .
Для этого мы должны создать псевдоним для таблицы station , чтобы мы могли различать данные, относящиеся к start_station , и данные, относящиеся к end_station . Мы можем сделать это точно так же, как мы создавали псевдонимы для отдельных столбцов, чтобы они отображались с более интуитивно понятным именем, используя AS .
Например, мы можем использовать следующий код для ПРИСОЕДИНЯЙТЕСЬ к таблице станций к таблице поездок , используя псевдоним «start». Затем мы можем объединить «начало» с именами столбцов, используя . для ссылки на данные, которые поступают из этого конкретного JOIN (вместо второго JOIN мы будем делать ON в столбце end_station ):
INNER JOIN станции AS start ON trips.start_station = start.id Вот как будет выглядеть окончательный запрос, когда мы его запустим. Обратите внимание, что мы использовали <> для обозначения «не равно», но ! = также будет работать.
запрос =
'' '
ВЫБЕРИТЕ СЧЕТЧИК (trips.id) КАК "Счетчик"
ИЗ поездок ВНУТРЕННИЕ СОЕДИНЯЙТЕ станции КАК старт
ВКЛ. Trips.start_station = start.id
INNER JOIN станции как конец
ВКЛ. Trips.end_station = end.id
ГДЕ start.municipality <> end.municipality;
'' '
run_query (запрос) Это показывает, что около 300000 из 1.5 миллионов поездок (или 20%) закончились в другом муниципалитете, чем начали, - еще одно свидетельство того, что люди в основном используют велосипеды Hubway для относительно коротких поездок, а не для длительных поездок между городами.
Если вы зашли так далеко, поздравляем! Вы начали осваивать основы SQL. Мы рассмотрели ряд важных команд, SELECT , LIMIT , WHERE , ORDER BY , GROUP BY и JOIN , а также агрегатные и арифметические функции.Это даст вам прочную основу для дальнейшего развития SQL.
Вы освоили основы SQL. Что теперь?
После завершения этого учебника по SQL для начинающих вы сможете выбрать базу данных, которая вам интересна, и написать запросы для получения информации. Хорошим первым шагом может быть продолжение работы с базой данных Hubway, чтобы посмотреть, что еще вы можете узнать. Вот еще несколько вопросов, на которые вы, возможно, захотите ответить:
- За сколько поездок взимается дополнительная плата (продолжительностью более 30 минут)?
- Какой велосипед использовался дольше всего?
- Были ли у зарегистрированных или случайных пользователей больше поездок туда и обратно?
- У какого муниципалитета была самая длинная средняя продолжительность?
Если вы хотите сделать еще один шаг вперед, ознакомьтесь с нашими интерактивными курсами по SQL, которые охватывают все, что вам нужно знать, от начального уровня до SQL продвинутого уровня для работы аналитиком и специалистом по данным.
Вы также можете прочитать нашу публикацию об экспорте данных из ваших SQL-запросов в Pandas или ознакомьтесь с нашей шпаргалкой по SQL и нашей статьей о сертификации SQL.
SQL: что это такое?
Язык структурированных запросов, широко известный как SQL, является стандартным языком программирования для реляционных баз данных. Несмотря на то, что он старше многих других типов кода, это наиболее широко используемый язык баз данных.
Поскольку SQL настолько распространен, знание его важно для всех, кто занимается компьютерным программированием или использует базы данных для сбора и организации информации.Узнайте больше о том, что такое SQL, и о возможностях карьерного роста в этой области.
Что такое SQL?
SQL можно использовать для совместного использования и управления данными, особенно данными, которые находятся в системах управления реляционными базами данных, которые включают данные, организованные в таблицы. Несколько файлов, каждый из которых содержит таблицы данных, также могут быть связаны общим полем. Используя SQL, вы можете запрашивать, обновлять и реорганизовывать данные, а также создавать и изменять схему (структуру) системы баз данных и контролировать доступ к ее данным.
В электронную таблицу, такую как Microsoft Excel, можно скомпилировать много информации, но SQL предназначен для компиляции и управления данными в гораздо больших объемах. В то время как электронные таблицы могут стать громоздкими из-за слишком большого количества информации, базы данных SQL могут обрабатывать миллионы или даже миллиарды ячеек данных.
Используя SQL, вы можете хранить данные обо всех клиентах, с которыми когда-либо работал ваш бизнес, от основных контактов до сведений о продажах. Так, например, если вы хотите найти каждого клиента, который потратил не менее 5000 долларов на ваш бизнес за последнее десятилетие, база данных SQL могла бы получить эту информацию для вас мгновенно.
Как работает изучение SQL
Язык структурированных запросов более простой, чем другие более сложные языки программирования. Как правило, новичкам легче изучить SQL, чем им освоить такие языки, как Java, C ++, PHP или C #.
Некоторые онлайн-ресурсы, включая бесплатные учебные пособия и платные курсы дистанционного обучения, доступны для тех, у кого мало опыта программирования, но которые хотят изучить SQL. Официальные курсы университета или колледжа также обеспечат более глубокое понимание языка.
История SQL
История SQL насчитывает более полувека. В 1969 году исследователь IBM Эдгар Ф. Кодд определил модель реляционной базы данных, которая стала основой для разработки языка SQL. Эта модель построена на общих порциях информации (или «ключах»), связанных с различными данными. Например, имя пользователя может быть связано с фактическим именем и номером телефона.
Несколько лет спустя IBM начала работу над новым языком для систем управления реляционными базами данных, основанным на выводах Кодда.Первоначально этот язык назывался SEQUEL, или язык структурированных английских запросов. Названный System R, проект претерпел несколько реализаций и изменений, и название языка менялось несколько раз, прежде чем окончательно перейти на SQL.
После начала тестирования в 1978 году IBM приступила к разработке коммерческих продуктов, включая SQL / DS (1981) и DB2 (1983). Другие производители последовали их примеру, объявив о своих собственных коммерческих предложениях на основе SQL. К ним относятся Oracle, выпустившая свой первый продукт в 1979 году, а также Sybase и Ingres.Взаимодействие с другими людьми
SQL в действии: MySQL
Обычное программное обеспечение, используемое для серверов SQL, включает MySQL Oracle, возможно, самую популярную программу для управления базами данных SQL. MySQL - это программное обеспечение с открытым исходным кодом, что означает, что его можно использовать бесплатно и важно для веб-разработчиков, потому что большая часть Интернета и очень много приложений построены на базах данных.
Рассмотрим музыкальную программу, такую как iTunes, которая хранит музыку по исполнителям, песням, альбомам, спискам воспроизведения и т. Д. Как пользователь, вы можете искать музыку по любому из этих и других параметров, чтобы найти то, что ищете.Чтобы создать подобное приложение, вам понадобится программное обеспечение для управления вашей базой данных SQL, и это то, что делает MySQL.
Требуемые навыки SQL
Большинству организаций нужен кто-то со знанием SQL. Заработная плата на должностях, основанных на SQL, варьируется в зависимости от типа работы и опыта, но обычно выше среднего.
Некоторые должности, требующие навыков SQL, включают:
- Администратор базы данных (DBA ): это тот, кто специализируется на обеспечении правильного и эффективного хранения и управления данными.Базы данных наиболее ценны, когда они позволяют пользователям быстро и легко извлекать желаемые комбинации данных.
- Инженер по миграции баз данных : Этот человек специализируется на перемещении данных из различных баз данных на сервер SQL.
- Специалист по анализу данных : Эта должность очень похожа на должность аналитика данных, но перед специалистами по обработке данных обычно стоит задача обрабатывать данные в гораздо больших объемах и накапливать их с гораздо большей скоростью.
- Архитектор больших данных : Кто-то в этой роли создает продукты для обработки больших объемов данных.
Ключевые выводы
- Язык структурированных запросов (SQL) - стандартный и наиболее широко используемый язык программирования для реляционных баз данных.
- Он используется для управления и организации данных во всех видах систем, в которых существуют различные отношения данных.
- SQL - ценный язык программирования с хорошими карьерными перспективами.
баз данных - SQL Server | Документы Microsoft
- 2 минуты на чтение
В этой статье
Применимо к: SQL Server (все поддерживаемые версии) База данных SQL Azure
База данных в SQL Server состоит из набора таблиц, в которых хранится определенный набор структурированных данных.Таблица содержит набор строк, также называемых записями или кортежами, и столбцов, также называемых атрибутами. Каждый столбец в таблице предназначен для хранения информации определенного типа, например дат, имен, сумм в долларах и чисел.
Основная информация о базах данных
На компьютере может быть установлен один или несколько экземпляров SQL Server. Каждый экземпляр SQL Server может содержать одну или несколько баз данных. В базе данных существует одна или несколько групп владения объектами, называемых схемами.В каждой схеме есть объекты базы данных, такие как таблицы, представления и хранимые процедуры. Некоторые объекты, такие как сертификаты и асимметричные ключи, содержатся в базе данных, но не содержатся в схеме. Для получения дополнительной информации о создании таблиц см. Таблицы.
Базы данных SQL Server хранятся в файловой системе в файлах. Файлы можно сгруппировать в файловые группы. Дополнительные сведения о файлах и файловых группах см. В разделе Файлы базы данных и файловые группы.
Когда люди получают доступ к экземпляру SQL Server, они идентифицируются как логин.Когда люди получают доступ к базе данных, они идентифицируются как пользователь базы данных. Пользователь базы данных может быть основан на логине. Если включены автономные базы данных, можно создать пользователя базы данных, не основанного на имени входа. Дополнительные сведения о пользователях см. В разделе CREATE USER (Transact-SQL).
Пользователь, имеющий доступ к базе данных, может получить разрешение на доступ к объектам в базе данных. Хотя разрешения могут быть предоставлены отдельным пользователям, мы рекомендуем создавать роли базы данных, добавлять пользователей базы данных к ролям, а затем предоставлять разрешения на доступ к ролям.Предоставление разрешений ролям вместо пользователей упрощает сохранение согласованности и понятности разрешений по мере того, как количество пользователей растет и постоянно меняется. Дополнительные сведения о разрешениях ролей см. В разделах CREATE ROLE (Transact-SQL) и Principals (Database Engine).
Работа с базами данных
Большинство людей, работающих с базами данных, используют инструмент SQL Server Management Studio. Инструмент Management Studio имеет графический пользовательский интерфейс для создания баз данных и объектов в базах данных.В Management Studio также есть редактор запросов для взаимодействия с базами данных путем написания операторов Transact-SQL. Management Studio можно установить с установочного диска SQL Server или загрузить с MSDN. Дополнительные сведения об инструменте SQL Server Management Studio см. В разделе SQL Server Management Studio (SSMS).
В этом разделе
Связанное содержимое
Индексы
Просмотры
Хранимые процедуры (ядро СУБД)
Что такое SQL Engine? Определение и ответы на часто задаваемые вопросы
Определение ядра SQL
Механизм SQL определяется как программное обеспечение, которое распознает и интерпретирует команды SQL для доступа к реляционной базе данных и опроса данных.Механизм SQL также обычно называют механизмом базы данных SQL или механизмом запросов SQL.
Часто задаваемые вопросы
Что такое SQL Engine?
Типичная конфигурация ядра базы данных SQL-сервера включает в себя механизм хранения и обработчик запросов. Различные типы механизмов SQL поддерживают разные архитектуры ядра СУБД SQL-сервера, но в целом механизм SQL - это компонент системы, который используется для создания, чтения, обновления и удаления данных (CRUD) из базы данных. Предприятия используют механизмы баз данных SQL-серверов для создания реляционных баз данных для оперативной обработки транзакций (OLTP) и оперативной аналитической обработки (OLAP).
Большинство механизмов SQL поддерживают стандартный SQL, и многие системы управления базами данных (СУБД) также предлагают интерфейсы прикладного программирования (API) для доступа к инструментам базы данных, помимо фактического пользовательского интерфейса базы данных. Например, OmniSci поддерживает API визуализации под названием OpenGL как часть платформы OmniSci Immerse для обработки визуальной аналитики на основе больших данных.
Механизмы SQL часто представляют собой проприетарные архитектуры, предлагающие уникальные возможности для хранения и запроса данных в системе реляционной базы данных.Каждый экземпляр базы данных поддерживает различные API, языки программирования, методы разделения, возможности и многое другое.
Как работают механизмы базы данных SQL
Чтобы пользователи могли взаимодействовать с реляционной СУБД, их запрос на допустимом языке запроса / базы данных должен быть преобразован в запрос SQL, прежде чем механизм SQL сможет его обработать. Механизм хранения SQL записывает и извлекает данные с сервера хранилища данных, что часто выполняется путем преобразования данных в совместимый формат, такой как файл JSON.
Для извлечения данных обработчик запросов принимает, анализирует и выполняет команды SQL для хранилища данных для пересылки на сервер приложений. Сервер приложений обрабатывает запрос SQL и отправляет его на веб-сервер, где клиент может получить доступ к информации через таблицы данных SQL.
Механизм SQL обрабатывает данные поэтапно. Этапы обработки различаются в зависимости от клиента, но в целом первый этап обработки SQL начинается с того, что СУБД анализирует инструкцию SQL с помощью вызова синтаксического анализа, чтобы подготовиться к выполнению.Оператор разделяется на структуру данных, которую могут обрабатывать другие подпрограммы, после чего выполняется три проверки - проверка синтаксиса, семантическая проверка и проверка общего пула.
Второй шаг - оптимизация запроса. РСУБД оптимизирует запрос и выбирает лучшие алгоритмы для поиска и просеивания данных. Наконец, СУБД выполняет инструкцию SQL, выполняя план запроса.
Что такое механизм хранения SQL Server?
Механизм хранения SQL-сервера - это программное обеспечение, используемое для создания, чтения и обновления данных между диском и памятью.Сервер SQL сопоставляет базу данных с файлами, в которых хранятся объекты базы данных, таблицы и индексы. Затем эти файлы можно сохранить в файловой системе FAT или NTFS. Существует три основных типа файлов базы данных SQL-сервера: первичный файл данных, вторичный файл данных и файл журнала транзакций.
Что такое механизм распределенных запросов SQL?
Механизм распределенных запросов SQL - это программный инструмент с архитектурой, использующей кластерные вычисления (MPP), позволяющий пользователям запрашивать различные источники данных или данные из нескольких источников данных в рамках одного запроса.Распределенные SQL-запросы важны, потому что они могут более эффективно справляться со сложностью различных платформ и технологий. Это позволяет аналитикам данных объединять данные, хранящиеся на нескольких независимых механизмах, для выполнения сложных аналитических запросов.
Предлагает ли OmniSci решение для ядра SQL?
OmniSciDB изначально поддерживает стандартные запросы SQL, а также предлагает API визуализации, который отображает примитивы OpenGL на наборы результатов SQL. OmniSciDB использует возможности ускоренной аналитики, чтобы возвращать результаты запросов в сотни раз быстрее, чем традиционные платформы аналитических баз данных.
OmniSciDB использует платформу JIT (Just-In-Time) компиляции, основанную на LLVM (низкоуровневую виртуальную машину), чтобы избежать многих недостатков пропускной способности памяти и кэш-пространства, характерных для традиционных подходов к виртуальной машине или транспилятору, что делает его одним из самые быстрые механизмы баз данных SQL. Время компиляции намного меньше с LLVM - обычно менее 30 миллисекунд для новых SQL-запросов, что позволяет пользователям использовать OmniSci Immerse для перекрестной фильтрации миллиардов строк по нескольким коррелированным визуализациям.
См. «Полное введение в науку о данных» OmniSci, чтобы узнать больше о том, как предприятия обрабатывают большие данные для выявления закономерностей и получения важной информации.
Что такое SQL: определение и ключевая информация | База данных SQL
SQL - это предметно-ориентированный язык (DSL), используемый в программировании. SQL предназначен для управления данными в системах управления реляционными базами данных (СУБД) или, в системах управления реляционными потоками данных (RDSMS), для потоковой обработки.
SQL создал возможность доступа к нескольким записям базы данных с помощью одной команды и без указания индекса.Это чрезвычайно полезно для обработки структурированных данных (моделей данных).
Что мне нужно знать о SQL?
SQL был разработан на основе работ по реляционной алгебре, впервые предпринятых Эдгаром Ф. Коддом из IBM. Эта основа в теоретической математике и информатике привела к созданию реляционной модели, основы реляционной базы данных.
SQL строит ряд неформальных подъязыков для управления этими реляционными функциями: языки запросов данных (DQL), язык определения данных (DDL), язык управления данными (DCL) и язык обработки данных (DML).Эти четыре подъязыка управляют ключевыми функциями SQL: запросом данных, манипулированием, определением и контролем доступа.
Что такое SQL и как им управляет Atmosera?
База данных SQL от Microsoft Azure предлагает самую широкую на рынке совместимость с ядром SQL Server, что позволяет легко переносить существующие базы данных SQL. Это означает, что нельзя менять приложения. Продолжайте использовать инструменты, связанные с SQL, которые вы знаете и любите, ускоряя циклы разработки и обслуживания с помощью защищенной базы данных с революционной производительностью.
Встроенный интеллект Microsoft SQL Server вместе с вашим приложением учится управлять надежностью, скоростью и безопасностью.
Если вы все еще задаетесь вопросом: «Что такое SQL?» наша команда с радостью ответит на любые ваши вопросы и объяснит вам наши управляемые услуги. Профессионалы Atmosera готовы вместе с вами воспользоваться нашими услугами, чтобы вы могли принять обоснованное решение о наилучшем варианте для вас и вашего бизнеса с помощью облачных сервисов. Мы доступны 24x7x365, чтобы предоставить вам любую необходимую помощь.
Самые популярные базы данных в 2020 году
Какое решение для баз данных в настоящее время наиболее популярно? Какой диалект SQL вам следует изучить? В этой статье я поделюсь результатами своего исследования и своим личным опытом. Вот базы данных, которые стоит изучить с помощью SQL.
Во-первых, давайте ответим на несколько простых вопросов: полезен ли SQL по-прежнему? Стоит ли учиться? Если вы пройдете онлайн-курс SQL, упростит ли это вашу работу? Ответ ДА!
Почему? Взгляните на результаты опроса разработчиков StackOverflow 2020.StackOverflow - гигантский веб-сайт с более чем 50 миллионами пользователей. В обзоре обобщены последние тенденции в сфере ИТ. StackOverflow задавал программистам вопросы о том, как они учатся, какие инструменты используют и как они хотят развиваться дальше. Участвовали 65 000 разработчиков.
Один вопрос опроса касался самых популярных технологий. Что ответили профессиональные разработчики?
Неудивительно, что первые два места в рейтинге заняли JavaScript и HTML, популярные языки веб-разработки.SQL занял третье место в списке, набрав 54,7% голосов для всех пользователей и 57% для профессионалов. Это не совпадение. Использование и обработка данных были важной задачей ИТ в течение многих лет. Ежедневно генерируются тысячи терабайт данных. Вопрос не в том, почему вы должны изучать SQL, а в том, почему вы его не изучаете?
Самые популярные базы данных в 2020 году
А теперь конкретика. Какие решения для баз данных в настоящее время наиболее популярны? Какие набирают пользователей?
Как и в прошлом году, подиум принадлежит большой тройке: MySQL, PostgreSQL и MS SQL Server.Нет никаких признаков того, что в ближайшее время для этих троих что-то изменится. MySQL и PostgreSQL бесплатны и работают под лицензиями с открытым исходным кодом. Кроме того, у них есть огромные сообщества пользователей, которые продолжают их развивать и добавлять новые плагины и улучшения.
Давайте кратко рассмотрим пятерку лучших баз данных в этом рейтинге:
1. MySQL
MySQL находится на вершине рейтинга популярности в течение нескольких лет. Почему? Он бесплатный, работает с большинством приложений и работает на большинстве популярных платформ, включая Linux, Windows и macOS.
Недавно мы отметили 25-летие MySQL; он был запущен в 1994 году шведскими программистами Дэвидом Аксмарком и Майклом Видениусом. В 2008 году MySQL была приобретена ИТ-гигантом Sun Microsystems; в 2010 году Sun (и, следовательно, MySQL) была приобретена Oracle. Здесь некоторые пользователи замечают противоречие: хотя представители Oracle поклялись, что одна версия MySQL останется с открытым исходным кодом, многие люди опасаются, что она перейдет на проприетарную (лицензионную) версию. (Примечание: доступны как версии с открытым исходным кодом, так и проприетарные версии.Поэтому они отдают предпочтение решениям, не относящимся к ИТ-лидерам - например, следующему в рейтинге PostgreSQL.
2. PostgreSQL
PostgreSQL является бесплатным, с открытым исходным кодом и будет работать во всех возможных ситуациях и на всех платформах. У него очень динамичное сообщество пользователей, которые помогают развивать проект и писать свои собственные плагины и расширения.
PostgreSQL (сокращенно Postgres) - мой личный фаворит. Я недавно писал об этом в книге «Какие крупные компании используют PostgreSQL?» Для чего они его используют ?.Это система баз данных, используемая Instagram, Twitch и Skype. Этого должно быть достаточно. К тому же исследования StackOverflow подтверждают это: PostgreSQL с каждым годом набирает пользователей.
Вы еще не знаете Postgres? Начни изучать это сегодня; это действительно хороший ход для карьерного роста. Я рекомендую отслеживать SQL от А до Я в PostgreSQL. Вы найдете все необходимое, чтобы стать профессиональным пользователем Postgres. Не бойтесь, если у вас нет опыта работы с ИТ или базами данных - наши курсы SQL разработаны таким образом, чтобы вы постепенно накапливали знания и осваивали новые навыки с практикой.
3. Microsoft SQL Server
Это продукт Microsoft, созданный в 1989 году и с тех пор постоянно развивающийся.
Это продукт Microsoft, созданный в 1989 году и с тех пор постоянно развивающийся.
Многие компании доверяют Microsoft, используют другие решения этой компании и не хотят включать что-либо еще в свою ИТ-экосистему. Таким образом, вы найдете MS Server во многих компаниях, особенно в крупных корпорациях.
Несмотря на доминирование на рынке решений с открытым исходным кодом, MS Server преуспевает.Не бойтесь, что однажды выучив его, вы никогда не воспользуетесь им. Каждый доллар, потраченный на изучение MS SQL Server, окупится.
Также полезно знать, что, хотя обычно используется платная коммерческая версия, есть и бесплатные версии. У них очень ограниченные возможности и возможности. Например, в экспресс-версии можно использовать только один процессор, 1 ГБ памяти и файлы базы данных 10 ГБ. Эта версия идеально подходит для изучения SQL, если не для использования в бизнесе.
Помимо SQL Server, Microsoft также предлагает отличную облачную платформу Azure.Это означает, что вы можете не устанавливать MS Server на физический компьютер, а вместо этого размещать его в облаке. Это облегчает работу с базой данных для нескольких пользователей, а также обеспечивает большую безопасность по сравнению с одной установкой на месте.
SQL Azure, как и MS SQL Server, использует язык реляционных запросов T-SQL. Вы хотите этому научиться? LearnSQL.com предлагает несколько отличных курсов. Если вы начинаете свое приключение с SQL, я рекомендую курс «Основы SQL в MS SQL Server». Если вы уже являетесь пользователем SQL, попробуйте курс «Рекурсивные запросы в MS SQL Server».Это улучшит ваши навыки работы с SQL.
Если вы хотите узнать больше о MS SQL Server, мой коллега Роман очень хорошо описал его в своей статье Microsoft SQL Server: плюсы и минусы. Проверить это.
4. SQLite
Это отличное решение набирает популярность. Его можно использовать бесплатно и по лицензии с открытым исходным кодом. Даже исходный код SQLite находится в открытом доступе.
SQLite чаще всего выбирают разработчики мобильных приложений. Содержимое базы данных хранится в одном файле (до 140 ТБ).Библиотека реализует механизм SQL, что позволяет использовать базу данных без запуска отдельного процесса СУБД. Для приложений это часто бывает очень практично.
SQLite основан на стандарте SQL-92. Это означает, что вы сможете работать с ним после того, как закончите наш SQL от А до Я.
Проект SQLite находится в разработке с 2000 года и получает постоянную поддержку. В 2018 году только 19,7% профессиональных разработчиков указали, что использовали эту базу данных; в этом году - более 30 процентов.И это не случайно. Это отличное решение для конкретных приложений.
5. MongoDB
MongoDB - единственное решение в пятерке лидеров, не основанное на реляционной базе данных. В этом предложении с открытым исходным кодом данные хранятся в файлах JSON или BSON (двоичный JSON).
Если вы работали с классическими реляционными базами данных, MongoDB может показаться немного странным. Но он может легко справиться с конкретными приложениями, например в качестве хранилища данных веб-сайта или агрегатора журналов. В традиционной базе данных обработка файлов такого типа может быть обременительной.
Признаюсь, я не фанат движения NoSQL. Я считаю, что SQL настолько совершенен, что вам больше ничего не нужно в базах данных. Ясно, что не все согласны с этим мнением: 26% опрошенных StackOverflow указали, что предпочитают MongoDB. И технологические гиганты, такие как eBay, Adobe и Google, используют его.
Хотя рыночные тенденции показывают, что, хотя NoSQL используется, SQL и его диалекты еще долгое время будут оставаться отраслевым стандартом.
А теперь перейдем к другому вопросу: нужно ли вам формальное образование в области информатики, чтобы стать программистом?
Насколько важно формальное образование для программистов?
Не волнуйтесь, вам не нужна степень, чтобы стать программистом и писать код.Большинство опрошенных профессиональных программистов считают, что формальное образование важно, но не обязательно. Так что работать в этом бизнесе не обязательно. Более того, 15% считают, что формальное образование вообще не важно.
Что делать, если вы хотите заниматься программированием без ученой степени? Лучше всего сосредоточиться на конкретных навыках и получить знания с помощью профессиональных онлайн-курсов, например, предлагаемых на LearnSQL.com. Вы найдете что-то для полных новичков (курс «Основы SQL») и пользователей среднего / продвинутого уровня (оконные функции или анализ тенденций доходов в SQL).Все курсы интерактивны и требуют только подключения к Интернету, браузера и немного мотивации.
Дайте себе шанс стать профессиональным разработчиком SQL, аналитиком SQL или инженером по данным. Узнайте, какие варианты доступны в статье Типы заданий для баз данных: выберите одно из них и начните быть крутым.
Пример операторов SQL для извлечения данных из таблицы
Обзор
Structured Query Language (SQL) - это специализированный язык для обновления, удаления и запроса информации из базы данных.SQL - это стандарт ANSI и ISO, а также фактический стандартный язык запросов к базам данных. Многие известные продукты для баз данных поддерживают SQL, включая продукты Oracle и Microsoft SQL Server. Он широко используется как в промышленности, так и в академических кругах, часто для огромных сложных баз данных.
В системе распределенных баз данных программа, которую часто называют «серверной частью» базы данных, постоянно выполняется на сервере, интерпретируя файлы данных на сервере как стандартную реляционную базу данных. Программы на клиентских компьютерах позволяют пользователям манипулировать этими данными, используя таблицы, столбцы, строки и поля.Для этого клиентские программы отправляют на сервер операторы SQL. Затем сервер обрабатывает эти операторы и возвращает наборы результатов клиентской программе.
Операторы SELECT
Оператор SQL SELECT извлекает записи из таблицы базы данных в соответствии с предложениями (например, FROM и ГДЕ ), которые определяют критерии. Синтаксис:
ВЫБРАТЬ столбец1, столбец2 ИЗ таблицы1, таблицы2 ГДЕ столбец2 = 'значение';
В приведенном выше операторе SQL:
- Предложение
SELECTопределяет один или несколько столбцов для извлечения; чтобы указать несколько столбцов, используйте запятую и пробел между именами столбцов.Чтобы получить все столбцы, используйте подстановочный знак*(звездочка). - Предложение
FROMопределяет одну или несколько таблиц для запроса. При указании нескольких таблиц используйте запятую и пробел между именами таблиц. - Предложение
WHEREвыбирает только те строки, в которых указанный столбец содержит указанное значение. Значение заключено в одинарные кавычки (например,WHERE last_name = 'Vader'). - Точка с запятой (
;) - это признак конца оператора.Технически, если вы отправляете в серверную часть только один оператор, терминатор оператора вам не нужен; если вы отправляете более одного, вам это нужно. Лучше всего включить его.
Примечание:
SQL не чувствителен к регистру (например, SELECT совпадает с select ). Для лучшей читаемости некоторые программисты используют прописные буквы для команд и предложений и строчные для всего остального.
Примеры
Ниже приведены примеры операторов SQL SELECT :
- Чтобы выбрать все столбцы из таблицы (
клиентов) для строк, в которых столбецLast_Nameимеет значениеSmith, вы должны отправить этот операторSELECTна серверную часть:ВЫБРАТЬ * ОТ клиентов ГДЕ Фамилия = 'Смит';
Серверная часть ответит с набором результатов, подобным этому:
+ --------- + ----------- + ------------ + | Cust_No | Фамилия | Имя | + --------- + ----------- + ------------ + | 1001 | Смит | Джон | | 2039 | Смит | Дэвид | | 2098 | Смит | Мэтью | + --------- + ----------- + ------------ + 3 ряда в наборе (0.05 сек)
- Для возврата только
Cust_NoиFirst_Nameстолбцов, основанных на тех же критериях, что и выше, используйте этот оператор:ВЫБЕРИТЕ Cust_No, First_Name FROM Customers WHERE Last_Name = 'Smith';
Последующий набор результатов может выглядеть так:
+ --------- + ------------ + | Cust_No | Имя | + --------- + ------------ + | 1001 | Джон | | 2039 | Дэвид | | 2098 | Мэтью | + --------- + ------------ + 3 ряда в наборе (0.05 сек)
Чтобы предложение WHERE находило неточные совпадения, добавьте оператор сопоставления с образцом LIKE . Оператор LIKE использует подстановочный знак % (символ процента) для сопоставления нуля или более символов, а символ подчеркивания ( _ ) подстановочный знак, соответствующий ровно одному символу. Например:
- Чтобы выбрать столбцы
First_NameиNicknameиз таблицыFriendsдля строк, в которыхПсевдонимстолбец содержит строку «мозг», используйте эту инструкцию:ВЫБЕРИТЕ Имя, Псевдоним ОТ друзей, ГДЕ Псевдоним LIKE '% brain%';
Последующий набор результатов может выглядеть так:
+ ------------ + ------------ + | Имя | Ник | + ------------ + ------------ + | Бен | Brainiac | | Глен | Peabrain | | Стивен | Nobrainer | + ------------ + ------------ + 3 ряда в наборе (0.03 сек)
- Чтобы запросить ту же таблицу и получить все столбцы для строк, в которых значение столбца
First_Nameначинается с любой буквы и заканчивается на «en», используйте этот оператор:SELECT * FROM Friends WHERE First_Name LIKE '_en';
Результат может выглядеть так:
+ ------------ + ------------ + ----------- + | Имя | Фамилия | Ник | + ------------ + ------------ + ----------- + | Бен | Смит | Brainiac | | Джен | Питерс | Горошек | + ------------ + ------------ + ----------- + 2 ряда в наборе (0.03 сек)
- Если вместо этого вы использовали подстановочный знак
%(например,'% en') в приведенном выше примере набор результатов может выглядеть так:+ ------------ + ------------ + ----------- + | Имя | Фамилия | Ник | + ------------ + ------------ + ----------- + | Бен | Смит | Brainiac | | Глен | Джонс | Peabrain | | Джен | Питерс | Горошек | | Стивен | Гриффин | Nobrainer | + ------------ + ------------ + ----------- + 4 ряда в наборе (0.