Что такое База Данных (БД) / Хабр
База данных — это место для хранения данных. Используется в том числе в клиент-серверной архитектуре. Это все интернет-магазины, сайты кинотеатров или авиабилетов… Вы делаете заказ, а система сохраняет ваши данные в базе.
В этот статье я на простых примерах расскажу, что такое база данных и как она выглядит. А потом поясню некоторые термины из конкретной (реляционной) базы. Те, с которыми вы почти наверняка столкнетесь на работе.
Статья рассчитана на начинающих тестировщиков или аналитиков, то есть тех, кто будет работать с базой, но не на супер-глубоком уровне. Она для тех, кто только входит в мир ИТ, и многого не знает. Она объясняет, что это за звено в клиент-серверной архитектуре такое, и зачем оно нужно.
Содержание
Что такое база данных
Как она выглядит
Как получить информацию из базы
Как связать данные между собой
Зачем в базе индексы
Что делать, если запрос к БД тормозит
Преимущества базы данных
Что знать для собеседования
Статьи и книги по теме
Резюме
Что такое база данных
База данных — хранилище, куда приложение складывает свои данные. Если приложение небольшое, отдельная база не нужна. Но потом это становится удобнее и выгоднее с точки зрения памяти.
Если приложение небольшое, отдельная база не нужна. Но потом это становится удобнее и выгоднее с точки зрения памяти.
Катя решила открыть свой магазинчик. Она нашла хорошую марку обуви, которую «днем с огнем» не сыскать в ее городе. Заказала оптовую партию и стала потихоньку распродавать через знакомых. Пришлось освободить половину шкафа под коробки, но вроде всё поместилось.
Обувь хорошая, в розницу заказывать в других местах невыгодно — и вот уже у Кати есть постоянные клиенты, которые приводят друзей. Как только какая-то пара заканчивается, Катя делает новый заказ.
Но покупатели хотят новинок, разных размеров. Да и самих покупателей становится все больше и больше. В шкаф коробки уже не влезают!
Теперь, если покупатель просит определенную пару, Катьке сложно её найти. Пока коробок было мало, она помнила наизусть, где что лежит. А теперь уже нет, да и все попытки организовать систему провалились. Места мало, да и детки любят с коробками поиграть.

Тогда Катька решила арендовать складское помещение. И вот теперь красота! Не надо теснить своих домашних, дома чисто и свободно! И на складе место есть, появилась система — тут босоножки, тут сапоги…
Чем больше объемы производства, тем больше нужно места. Если в начале пути склад не нужен, всё поместится дома, то потом это будет оправданно.
То же самое и в приложениях. Если приложение маленькое, то все данные можно хранить в памяти. Но учтите, что это память на вашем компьютере, вашем телефоне. И чем больше данных туда пихать, тем медленнее будет работать программа.
Место в памяти ограничено. Поэтому когда данных много, их нужно куда-то сложить. Можно писать в файлики, а можно сохранять информацию в базу данных (сокращенно БД). Выбор за вами. А точнее, за вашим разработчиком.
Как она выглядит
Да примерно как excel-табличка! Есть колонки с заголовками, и информация внутри:
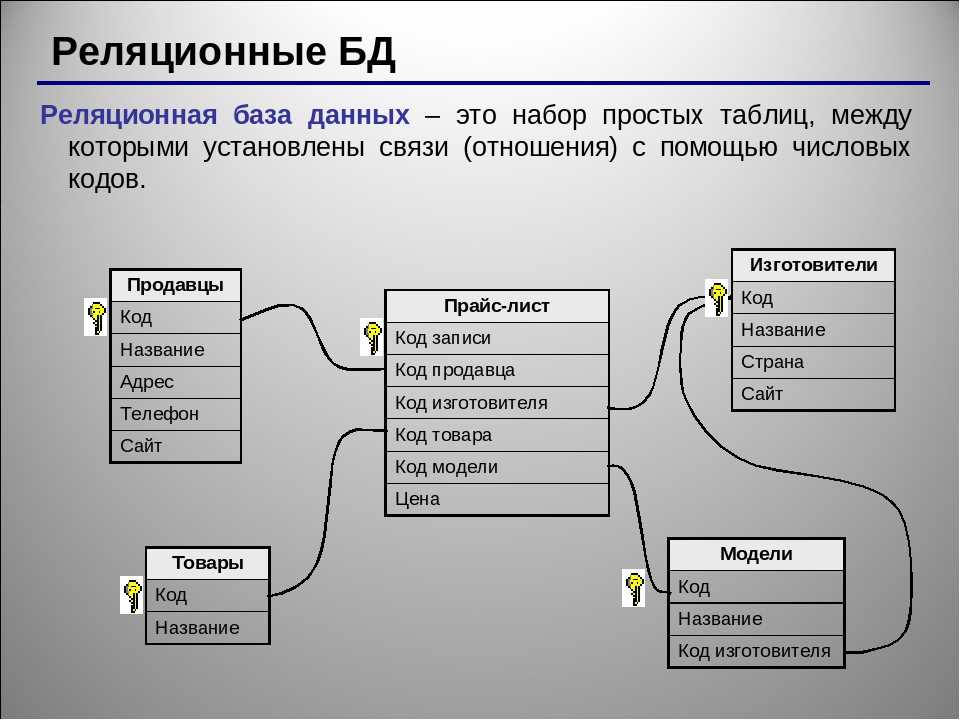
Это называется реляционная база данных — набор таблиц, хранящихся в одном пространстве.
Что за пространство? Ну вот представьте, что вы храните все данные в excel. Можно запихать всю-всю-всю информацию в одну огро-о-о-о-мную таблицу, но это неудобно. Обычно табличек несколько: тут информация по клиентам, там по заказам, а тут по адресам. Эти таблицы удобно хранить в одном месте, поэтому кладем их в отдельную папочку:
Так вот пространство внутри базы данных — это та же самая папочка в винде. Место, куда мы сложили свои таблички, чтобы они все были в одном месте.
Пример базы OracleЦель та же — выделить отдельное место, чтобы у вас не была одна большая свалка:
Хранение данных в виде табличек — это не единственно возможный вариант. Вот вам для примера запись из таблицы в системе Users. Там используется MongoDB база данных, она не реляционная. Поэтому вместо таблички «словно в excel» каждая запись хранится в виде объекта, вот так:
А еще есть файловые базы — когда у вас вся информация хранится в файликах. Да-да, простых текстовых файликах!
Почитать о разных видах баз данных можно в википедии. Я не буду в этой статье углубляться в эту тему, потому что моя задача — объяснить «что это вообще такое» для ребят, которые базу в глаза не видели. А на работе они скорее всего столкнутся именно с реляционной базой данных, поэтому о ней и речь.
Я не буду в этой статье углубляться в эту тему, потому что моя задача — объяснить «что это вообще такое» для ребят, которые базу в глаза не видели. А на работе они скорее всего столкнутся именно с реляционной базой данных, поэтому о ней и речь.
Да, базы бывают разные. Классификацию можно изучить, можно выучить. Но по факту от начинающего тестировщика обычно нужно уметь достать информацию из реляционной БД («обычно» != «всегда», если что).
Как получить информацию из базы
Нужно записать свой запрос в понятном для базы виде — на SQL. SQL (Structured Query Language) — язык общения с базой данных. В нем есть ключевые слова, которые помогут вам сделать выборку:
select — выбери мне такие-то колонки…
from — из такой-то таблицы базы…
where — такую-то информацию…
Например, я хочу получить информацию по клиенту «Назина Ольга». Составляю в уме ТЗ:
Дай мне информацию по клиенту, у которого ФИО = «Назина Ольга»
Переделываю в SQL:
select * from clients where name = 'Назина Ольга';
В дословном переводе:
select -- выбери мне * -- все колонки (можно выбирать конкретные, а можно сразу все) from clients -- из таблицы clients where name = 'Назина Ольга'; -- где поле name имеет значение 'Назина Ольга'
См также:
Комментарии в Oracle/PLSQL — мой перевод остается работающим запросом, потому что я убрала «лишнее» в комментарии
Если бы у меня была не база данных, а простые excel-файлики, то же действие было бы:
Открыть файл с нужными данными (clients)
Поставить фильтр на колонку «ФИО» — «Назина Ольга».

То есть нам в любом случае надо знать название таблицы, где лежат данные, и название колонки, по которой фильтруем. Это не что-то страшное, что есть только в базе данных. То же самое есть в простом экселе.
Бывают запросы и сложнее — когда надо достать данные не из одной таблицы, а из разных. В базе это будет выглядеть даже лучше, чем в эксельке. В экселе вам нужно открыть 1-2-3 таблицы и смотреть в каждую. Неудобно.
А в базе данных вы внутри запроса SQL указываете, какие колонки из каких таблиц вам нужны. И результат запроса их отрисовывает. Скажем, мы хотим увидеть заказ, который сделал клиент, ФИО клиента, и его номер телефона. И всё это в разных таблицах! А мы написали запрос и увидели то, что нам надо:
id_order | order (таблица order) | fio (таблица client) | phone (таблица contacts) |
1 | Пицца «Маргарита» | Иванова Мария | +7 (926) 555-33-44 |
2 | Комбо набор 1 | Петров Павел | +7 (926) 555-22-33 |
И пусть в таблице клиентов у нас будет 30 колонок, а в таблице заказов 50, в результате выборки мы видим ровно 4 запрошенные. Удобно, ничего лишнего!
Удобно, ничего лишнего!
Конечно, написать такой запрос будет немного сложнее обычного селекта. Это уже select join, почитать о нем можно тут. И я рекомендую вам его изучить, потому что он входит в «базовое знание sql», которое требуется на собеседованиях.
Результаты выборки можно группировать, сортировать — это следующий уровень сложности. См раздел «статьи и книги по теме» для получения большей информации.
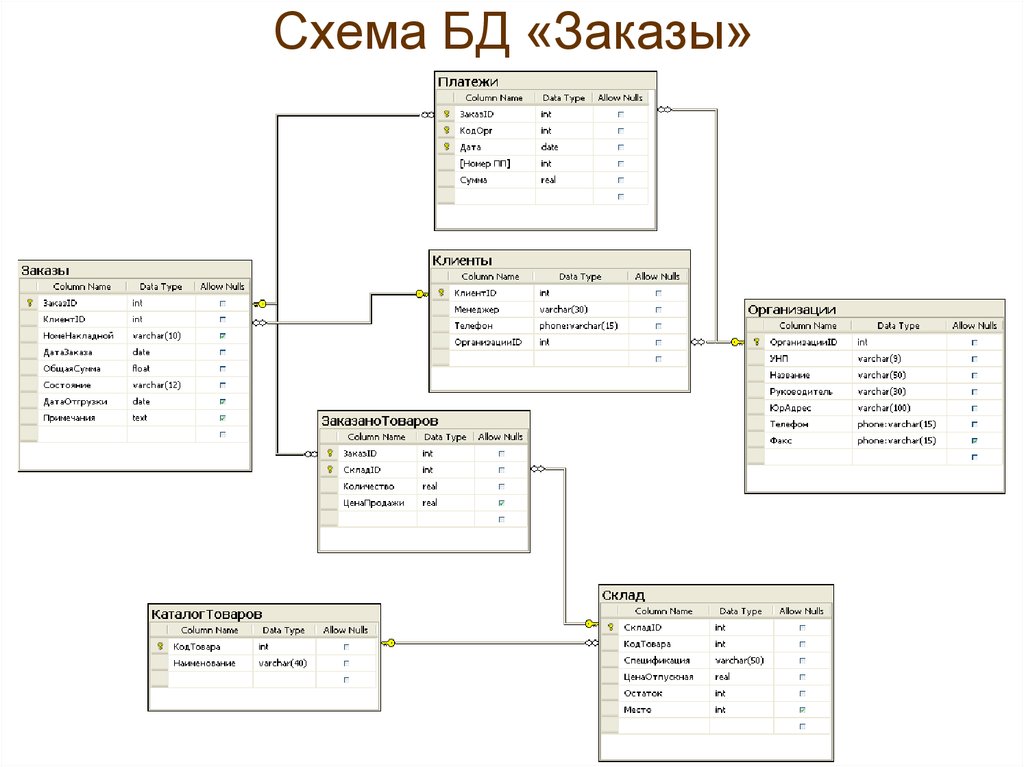
Как связать данные между собой
Вот например, у нас есть интернет-магазин по доставке пиццы. Так выглядит его база данных:
last_name | first_name | birthdate | VIP |
Иванов | Иван | 01.02.1977 | true |
Петрова | Мария | 02.04.1989 | false |
Сидоров | Павел | 03. | false |
Иванов | Вася | 04.04.1987 | false |
Ромашкина | Алина | 16.11.2000 | true |
 02.1991
02.1991В таблице «orders» лежат данные по заказам. Что заказали (пиццу, суши, роллы), когда, насколько довольны доставкой?
order | addr | date | time |
Пицца «Маргарита» | ул Ленина, д5 | 05.05.2020 | 06:00 |
Роллы «Филадельфия» и «Канада» | Студеный пр-д, д 10 | 15.08.2020 | 10:15 |
Пицца 35 см, роллы комбо 1 | Заревый, д10 | 08.09.2020 | 07:13 |
Пицца с сосиками по краям | Турчанинов, 6 | 08. | 08:00 |
Комбо набор 3, обед №4 | Яблочная ул, 20 | 08.09.2020 | 08:30 |
 09.2020
09.2020Но как понять, где чей был заказ? Сколько раз заказывал Вася, а сколько Алина?
Тут есть несколько вариантов:
1. Запихать все данные в одну таблицу: тут и заказы, и информация по клиентам… В целом удобно, открыл табличку и сразу видишь — ага, это Васин заказ, а это Машин.
Но есть минусы:
Таблица все растет и растет, в итоге получается просто огромной! А когда данных много, легкость чтения пропадает, придется листать до нужной колонки.
Поиск будет работать медленнее. Чем меньше информации в таблице, тем быстрее поиск. Когда у нас много строк, количество колонок становится существенным.
Много дублей — один человек может сделать хоть сотню заказов. И вся информация по нему будет продублирована сто раз. Неоптимальненько!
Чтобы избежать дублей, таблицы принято разделять:
Но надо при этом их как-то связать между собой, мы ведь всё еще хотим знать, чей конкретно был заказ. Для связи таблиц используется foreign key, внешний ключ.
Для связи таблиц используется foreign key, внешний ключ.
Нам надо у заказа сделать отметку о клиенте. Значит, таблица «orders» будет ссылаться на таблицу «clients». Ключ можно поставить на любую колонку таблицы (в некоторых базах колонка должна быть уникальной, сначала её нужно такой указать). Какую бы выбрать?
Можно ссылаться на имя. А что, миленько, в таблице заказов будем сразу имя видеть! Но минуточку… А если у нас два клиента Ивана? Или три Маши? Десять Саш… Ну вы поняли =) И как тогда разобраться, где какой клиент? Не подходит!
Можно вешать foreign key на несколько колонок. Например, на фамилию + имя, или фамилию + имя + отчество. Но ведь и ФИО бывают неуникальные! Что тогда? Можно добавить в связку дату рождения. Тогда шанс ошибиться будет минимален, хотя и такие ребята существуют. И чем больше клиентов у вас будет, тем больше шанс встретить дубликат.
А можно не усложнять! Вместо того, чтобы делать внешний ключ на 10 колонок, лучше создать в таблице клиентов primary key, первичный ключ. Первичный ключ отвечает за то, чтобы каждое значение в поле было уникальным, никаких дублей. При попытке добавить в таблицу запись с неуникальным первичным ключом получаешь ошибку:
Первичный ключ отвечает за то, чтобы каждое значение в поле было уникальным, никаких дублей. При попытке добавить в таблицу запись с неуникальным первичным ключом получаешь ошибку:
Вот на него и нужно ссылаться! Обычно таким ключом является ID, идентификатор записи. Его можно сделать автоинкрементальным — это значит, что он генерируется сам по алгоритму «прошлое значение + 1».
Например, у нас гостиница для котиков. Это когда хозяева едут в отпуск, а котика оставить не с кем — оставляем в гостинице!
Есть таблица постояльцев:
ID | name | year |
1 | Барсик | 2 |
2 | Пупсик | 1 |
Тут привозят еще одного Барсика. Добавляем его в таблицу:
— Имя Барсик, 5 лет! (мы не указываем ID)
Система добавляет:
ID | name | year |
1 | Барсик | 2 |
2 | Пупсик | 1 |
3 | Барсик | 5 |
ID сгенерился автоматически.
Последнее значение было 2, значит, новый Барсик получил номер 3. Обратите внимание — Барсиков уже два, но их легко различить, ведь у них разные идентификаторы!
Теперь, если в другой таблице надо будет сослаться на котика, мы будем делать это именно через уникальный идентификатор. Например, у нас есть таблица комнат для постояльцев, куда мы заносим информацию о том, кто там живет:
id_room | square | id_cat (ссылка на id в таблице котиков) |
1 | 5 | 1 |
2 | 10 | 2 |
3 | 10 |
|
Мы видим, что в первой комнате живет котик с id = 1, а во второй — с id = 2. В третьей комнате пока никто не живет. Так, благодаря связке таблиц, мы всегда можем понять, что именно за котофей там проживает.
Итак, теперь мы знаем, что идентификатор лучше делать первичным ключом, дабы обеспечить его уникальность. Можно сделать поле автоинкрементальным, чтобы оно заполнялось само. Так и поступим в таблице клиентов:
Можно сделать поле автоинкрементальным, чтобы оно заполнялось само. Так и поступим в таблице клиентов:
И в таблице заказов! «id_order» пусть генерится сам и всегда будет уникален. А еще в таблицу заказов мы добавим колонку «id_client» и повесим на нее foreign key, ссылку на «id_client» в таблице клиентов.
Ключей может быть несколько. Одна таблица может ссылаться на несколько других. Скажем, в заказе мы ссылаемся на клиента и поставщика.
И наоборот, несколько таблиц могут ссылаться на одну и ту же колонку текущей таблицы. ID клиента мы можем указывать в таблице адресов, телефонов, email адресов, документов, заказов… Ограничений на это нет.
Зачем в базе индексы
Давайте представим, что у нас есть табличка excel. Если она небольшая (пара строк, пара колонок), то найти нужную ячейку не составит труда:
Открыли файлик — открывается моментально (если нет проблем с жестким диском)
Нажали «Ctrl + F», ввели запрос — тут же нашли результат.

Но что, если у нас сотни колонок и миллионы строк в файлике? Тогда начинаются тормоза. Файл открывается долго, в поиск значение ввели и система подвисла, обрабатывая результат…
Всё то же самое и в базе данных. Если табличка маленькая, любой запрос к ней отработает моментально. Если же таблица будет большая и с кучей данных, то результата запроса можно ждать минут по 15. А иногда и пару часов!
Если вы заранее знаете, что данных в базе будет много, нужно продумать основные сценарии поиска. И на колонки, по которым будете искать, нужно повесить индексы.
Индекс — это как алфавитный указатель в библиотеке. Вот представьте, заходите вы в библиотеку и хотите найти «Преступление и наказание» Достоевского. А все книги стоят «от балды», никакого порядка. Чтобы найти нужную, надо обойти все стелажи и просмотреть все полки!
Совсем другое дело, если книги отсортированы по авторам. А внутри автора — по названию. Тогда найти нужную книгу будет легко!
Индекс играет ту же роль для базы данных. Если повесить его на колонку таблицы, поиск по ней пойдет быстрее!
Если повесить его на колонку таблицы, поиск по ней пойдет быстрее!
А можно повесить индекс на несколько нужных колонок (автор + название). Тут главное — не забывать порядок поиска в индексе. Если у нас индекс сначала по автору, а потом по названию, он будет бесполезен для поиска по названию, придется все равно пересматривать все книги. Поэтому, если нам часто нужно искать по названию и почти никогда — только по автору, имеет смысл поменять порядок в индексе — сначала название, потом автор.
Что делать, если запрос к БД тормозит
Если мы говорим о тестировщиках (а статья написана в первую очередь для них), то тут есть 2 варианта:
Вы работаете с базой напрямую, составляете запросы к ней. И эти запросы работают медленно.
Медленно работает система, но уже поняли, что тормозит выборка из БД (например, увидели в логах).
Первый вариант мы разбирать не будем. Потому что это не про базу, а про SQL. И, если вы работаете с базой, то должны уметь писать сложные запросы, применять хинты там, где нужно, и так далее. Это не тема базовой статьи.
Это не тема базовой статьи.
А вот что делать во втором случае? Это не задача тестировщика — разбираться в том, почему запрос работает медленно. Этим занимаются DBA (администраторы баз данных) или разработчики.
Зато задача тестировщика — предоставить разработчику всю нужную информацию. Иногда её можно запросить у заказчика и его админов, а иногда нужно достать самому. Обычно для этого нужно:
Получить план запроса
Пересобрать статистику и проверить, продолжает ли тормозить
План запроса
Смотрите, когда вы выполняете любой запрос, что делает система:
Строит план выполнения запроса (как ей кажется, оптимальный)
Выполняет его
Посмотреть план можно через ключевые слова. В Oracle это EXPLAIN PLAN:
EXPLAIN PLAN FOR -- построй мне план для... SELECT last_name FROM employees; -- вот такого запроса!
А если вы работаете через графический интерфейс, то там обычно можно просто выделить запрос и нажать горячую клавишу.
Сверху на картинке идёт запрос. А снизу — план его выполнения. Нас сейчас не сильно волнует, что значит информация из первых колонок (то, как именно запрос обходит базу, в данном случае фулл-скан по таблице), нас интересует последняя колонка, «COST». Это стоимость запроса — 857 ms.
А теперь изменим запрос, сделав выборку по одному конкретному человеку по колонке с индексом:
Оп, цена запроса уже 5 ms. Это, на минуточку, в 170 раз быстрее!
И это простейший запрос на тестовой базе. В реальной базе данных будет сильно больше, поэтому проход таблицы по индексированной колонке существенно сократит время выполнения запроса.
Вот пример плана чуть более сложного запроса, когда мы делаем выборку из двух таблиц:
Вы не обязаны понимать, «что тут вообще происходит», но вам нужно уметь получать этот план. Пригодится.
Допустим, поступает жалоба от заказчика — клиент открывает карточку в вебе, а она открывается минуту. Что-то где-то тормозит! Но что и где? Начинаем разбираться. Причины бывают разные:
Что-то где-то тормозит! Но что и где? Начинаем разбираться. Причины бывают разные:
Тормозит на уровне БД — тут или сам запрос долго отрабатывает, или статистику давно не пересобирали, или диски подыхают.
Тормозит на уровне приложения — тогда надо копаться внутри кода функции «открыть карточку», что она там делает, получив ответ от Базы (и снова есть вариант «подыхают диски, на которых установлено ПО»).
Тормозит на уровне сети — сервер приложения и сервер БД обычно размещают на разных машинах. Значит, есть общение между ними по интернету. А интернет может тупить.
Если есть подозрение, что тормозит сам select, разработчик попросит прислать план его выполнения на реальной базе. Конечно, если «с той стороны» грамотные админы, они это сделают сами. Но иногда это нужно уметь вам. Например, если вас отправили в банк разбираться на месте, что пошло не так. Вы проверяете разные гипотезы и собираете информацию для разработчика.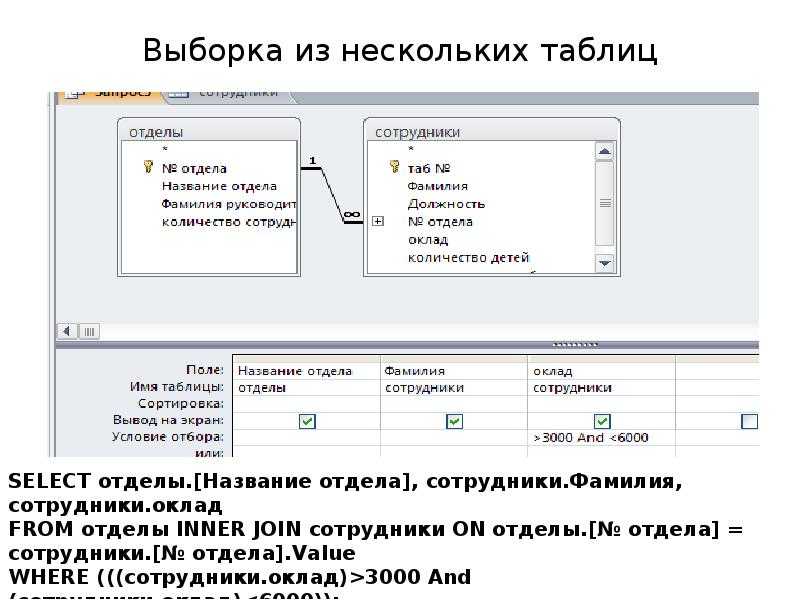
Собираете план, сохраняете в файлик и прикладываете в задачу в джире. Или отправляете по почте.
У меня бывало, что именно так находился баг — на тестовой базе запрос идет по правильному пути, а на боевой — нет. И на боевой идет не по индексам, что сильно его тормозит. Тут уже дальше разработчик думает, почему так получилось и как именно это исправить.
Статистика в БД
Именно статистика позволяет базе данных выбрать оптимальный план выполнения запроса. Почему вообще возникают проблемы вида «на тестовой базе один план, на боевой другой»?
Да потому, что один и тот же запрос можно выполнить несколькими способами. Например, у нас есть таблица клиентов и таблица телефонов, и мы пишем такой запрос:
Найди мне всех клиентов, созданных в этом году,
У которых оператор связи в телефоне — Мегафон
Как можно выполнить запрос? Можно сначала обойти таблицу клиентов и поискать тех, кто создан в этом году. А потом уже для них проверять телефоны. Можно наоборот, проверить все телефоны на оператора и потом уже для связанных клиентов проверять дату создания.
А потом уже для них проверять телефоны. Можно наоборот, проверить все телефоны на оператора и потом уже для связанных клиентов проверять дату создания.
Какой вариант будет лучше? Никто не скажет без данных по таблицам. Может, у нас мало клиентов, но кучи телефонов (база перекупщиков), тогда быстрее будет начать с клиентов. А может, у нас миллионы клиентов, но всего пара сотен телефонов, тогда мы начнем с них.
Так вот, в статистике по БД хранится в том числе информация о распределении данных и характеристики хранения таблиц и индексов. И когда вы запускаете запрос, база (а точнее, оптимизатор внутри нее) строит возможные планы выполнения. Для каждого плана рассчитывает примерное время выполнения, а потом выбирает лучшее.
Время же он рассчитывает, ориентируясь на статистику:
Именно поэтому просто пересбор статистики иногда убирает проблему «у нас тут тормозит». Прилетело в таблицу много данных, а статистика об этом не знает, и чешет по таблице через фуллскан, считая, что информации там мало.
См также:
Ручной и автоматический сбор статистики оптимизатора в базе данных Oracle
Практические методы оптимизации запросов в Apache Spark — подробнее об оптимизации запросов, в том числе и про индексы
Преимущества реляционных баз данных
Почему используют реляционную базу данных:
Она поддерживают требования ACID (по крайней мере транзакционная БД)
Это единый синтаксис SQL, который используется повсеместно
Требования ACID
ACID — это аббревиатура из требований, которые обеспечивают сохранность ваших данных:
Atomicity — Атомарность
Consistency — Согласованность
Isolation — Изолированность
Durability — Надёжность
Если база данных не поддерживает их, то могут быть печальные последствия из серии «Деньги с одного счета ушли, на другой не пришли? Ну сорян, бывает».
См также:
Требования ACID на простом языке — подробнее об этих требованиях
Единый синтаксис SQL
Я спросила знакомого разработчика:
— Ну и что, что единый синтаксис? В чем его плюшка то?
Ответ прекрасен, так что делюсь с вами:
— Почему в школе все преподают на русском? Почему не каждый свой язык? Одна школа — один, другая — другой. А ещё лучше не школа, а для каждого человека. Почему вавилонскую башню недостроили?
Как разработчик пишет код? Написал, проверил на коленке. Если не работает — думает, почему. Если непонятно, идет гуглить похожие ошибки. А что проще нагуглить? Ошибку распространенной БД, или сделанный на коленке костыль для работы с файлами? Вот то-то и оно…
Что знать для собеседования
Для начала я хочу уточнить, что я сама тестировщик. И мои статьи в первую очередь для тестировщиков ))
Зато тестировщика спрашивают про SQL. Вот вам обсуждение из чатика выпускников, пригодится для повторения материала:
— В вакансии написано: уметь составлять простые SQL запросы. А простые это какие в народном понимании?
А простые это какие в народном понимании?
— (inner, outer) join, select, insert, update, create, последнее время популярны индексы, group by, having, distinct.
SQL выходит за рамки данной статьи, здесь я лишь пояснила, что это вообще такое. А дальше читайте статьи / книги из следующего раздела, или гуглите каждое слово из цитаты выше.
Статьи и книги по теме
База данных
Википедия
Какие бывают базы данных
Базы данных. Виды и типы баз данных. Структура реляционных баз данных. Проектирование баз данных. Сетевые и иерархические базы данных.
SQL
Книги:
Изучаем SQL. Линн Бейли — Обожаю эту линейку книг, серию Head First O`Reilly. И всем рекомендую)) Просто и доступно даже о сложном пишут.
Статьи:
Как изучить основы SQL за 2 дня
Полезные запросы
Тренажеры:
http://www.sql-ex.ru/ — Бесплатный тренажер для практики
Ресурсы и инструменты для практики с базами данных | SQL
Задачка по SQL.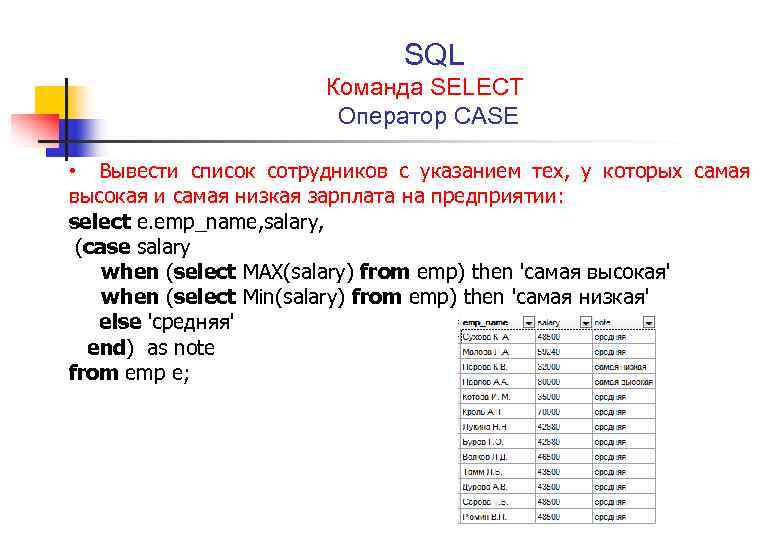 Найти объединенные данные
Найти объединенные данные
Резюме
База данных — это место для хранения данных. Они бывают самых разных видов, даже файловые! Но самые распространенные — реляционные базы данных, где данные хранятся в виде таблиц.
Если посмотреть на информацию о таблице в БД, мы можем увидеть ее ключи и индексы. Что это такое:
1. PK — primary key, первичный ключ. Гарантирует уникальность данных, часто используется для колонки с ID. Если ключ наложен на одну колонку — каждое значение в ячейках этой колонки уникальное. Если на несколько — комбинации строк по колонкам уникальны.
2. FK — foreign key, внешний ключ. Нужен для связки двух таблиц в разных соотношениях (1:1, 1:N, N:N). Этот ключ указываем в «дочерней» таблице, то есть в той, которая ссылается на родительскую (в таблице с данными по лицевому счету отсылка на client_id из таблицы клиентов).
3. Индекс. Нужен для ускорения выборки из таблицы.
Транзакционные базы данных выполняют требования ACID:
Atomicity — Атомарность
Consistency — Согласованность
Isolation — Изолированность
Durability — Надежность
См также:
Что такое транзакция
И за это их выбирают разработчики. Мы получаем не просто хранилище данных. Наши данные защищены от неприятностей типа отключения электричества на середине бизнес-операции (с одного счета деньги списать, на другой записать). А еще по ним можно быстро искать, ведь разработчики баз данных оптимизируют свои приложения для этого.
Поэтому логика приложения — отдельно, база — отдельно. Так и получается клиент-серверная архитектура =)
См также:
Клиент-серверная архитектура в картинках
Чтобы достать данные из базы, надо написать запрос к ней на языке SQL (Structured Query Language). Разработчики пишут SQL-запросы внутри кода приложения. А тестировщики используют SQL для:
Разработчики пишут SQL-запросы внутри кода приложения. А тестировщики используют SQL для:
Поиска по базе — правильно ли данные сохранились? В нужные таблицы легли? Это select-запросы.
Подготовки тестовых данных — а что, если это значение будет пустое? А что, если у меня будет 2 лицевых счета на одной карточке? Можно готовить данные через графический интерфейс, но намного быстрее отправить несколько запросов в базу. Когда есть к ней доступ и вы знаете SQL =)
План-минимум для изучения: select, join, insert, update, create, delete, group by, having, distinct.
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
Так вот, тестировщика на собеседовании не будут спрашивать про базы данных. Разработчика ещё могут спросить, а вас то зачем? Вполне достаточно понимания, что это вообще такое. И про ключи могут спросить — что такое primary или foreign key, зачем они вообще нужны.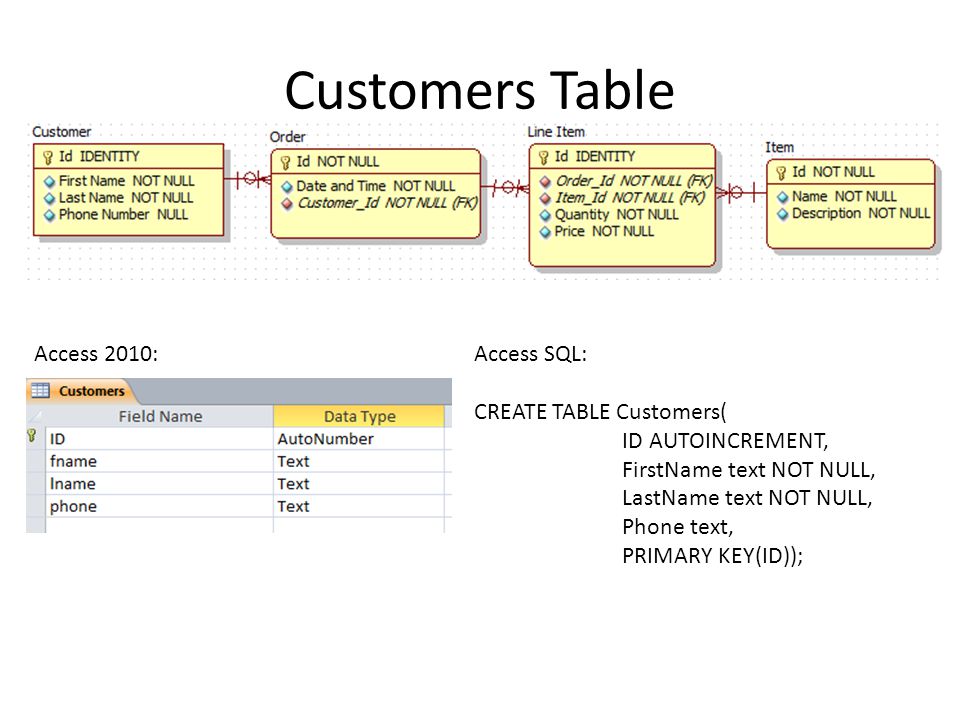
7 типов современных баз данных: предназначение, достоинства и недостатки
Артём Гогин
руководитель направления в хранилище данных в Сбербанке
Существуют сотни баз данных SQL и NoSQL. Одни популярны, другие игнорируются. Некоторые просты и хорошо документированы, а некоторые сложны в использовании. Одни имеют открытый код, а другие проприетарные. Что, возможно, наиболее важно, некоторые масштабируемы, оптимизированы, высокодоступны, а некоторые сложно масштабировать или поддерживать.
Возникает естественный вопрос: какую базу данных выбрать? Чтобы ответить на него, мы должны решить, чего мы хотим достичь с помощью базы данных. Чтобы составить представление, необходимо ответить на следующие вопросы:
- Нужен ли нам аналитический доступ к базе данных?
- Нужно ли нам писать или читать в реальном времени?
- Сколько таблиц / записей мы хотим сохранить?
- Какая доступность нам нужна?
- Нужны ли нам столбцы?
- Сможем ли мы получить доступ к таблицам, отфильтрованным по столбцам или по строкам?
Принимая решение, нужно помнить, что может предложить та или иная база данных. Специфика каждой БД может отличаться, но в целом существует только несколько типов, в рамках которых мы можем достичь в основном одинаковых целей. Рассмотрим их подробнее.
Специфика каждой БД может отличаться, но в целом существует только несколько типов, в рамках которых мы можем достичь в основном одинаковых целей. Рассмотрим их подробнее.
Реляционные базы данных SQL
Если вы когда-либо работали с базами данных, скорее всего, вы начали с этого типа, потому что он самый популярный и распространенный. Такие БД позволяют хранить данные в реляционных таблицах с определенными столбцами определенного типа. Реляционные таблицы хороши для нормализации и объединения.
Достоинства:
- Поддержка SQL
- ACID-транзакции (атомарность, согласованность, изоляция и долговечность)
- Поддержка индексации и разделения
Недостатки:
- Плохая поддержка неструктурированных данных / сложных типов
- Плохая оптимизация обработки событий
- Сложное / дорогое масштабирование
Примеры: Oracle DB, MySQL, PostgreSQL.
Документно-ориентированные базы данных
Если мы не хотим объединять несколько таблиц для получения нужных данных, мы можем взглянуть на документно-ориентированные базы данных. Они позволяют хранить записи в формате JSON. В этом формате мы можем создать сложное значение для любого ключа и сразу включить всю структуру данных в одну запись.
Они позволяют хранить записи в формате JSON. В этом формате мы можем создать сложное значение для любого ключа и сразу включить всю структуру данных в одну запись.
Достоинства:
- Нет привязки к схеме
- Нет необходимости всегда писать все поля в каждой записи
- Хорошая поддержка сложных типов
- Подходит для OLTP
Недостатки:
- Плохая поддержка транзакций
- Слабая аналитическая поддержка
- Сложное / дорогое масштабирование
Примеры: MongoDB.
Базы данных в оперативной памяти
Базы данных этого типа могут предоставлять в реальном времени ответ для выбора и вставки определенных записей. Большинство из них в основном хранят данные в ОЗУ, но в некоторых случаях они также предлагают постоянное хранилище на жестких дисках или твердотельных накопителях. Большинство этих баз данных работают с записями «ключ-значение», поэтому значения можно запоминать в формате, ориентированном на документы. Но некоторые базы данных также работают со столбцами и позволяют вторичное индексирование той же таблицы. Использование ОЗУ позволяет обрабатывать данные быстро, но делает их более нестабильными и дорогостоящими.
Но некоторые базы данных также работают со столбцами и позволяют вторичное индексирование той же таблицы. Использование ОЗУ позволяет обрабатывать данные быстро, но делает их более нестабильными и дорогостоящими.
Достоинства:
- Быстрое написание
- Быстрое чтение
Недостатки:
- Труднодостижимая надёжность
- Дорогое масштабирование
Примеры: Redis, Tarantool, Apache Ignite.
Базы данных с широкими столбцами
Эти базы данных хранят данные в виде записей ключ / значение на жестком диске или твердотельном накопителе. Эти решения предназначены для достаточно хорошего масштабирования, чтобы управлять петабайтами данных на тысячах общих серверов в распределенной системе. Они представляют архитектуру SSTable. Эта архитектура была разработана для двух случаев использования: быстрый доступ к ключу и быстрая запись с высокой доступностью.
Достоинства:
- Быстрая запись построчно
- Быстрое чтение по ключу
- Хорошая масштабируемость
- Высокая доступность
Недостатки:
- Формат «ключ-значение»
- Нет поддержки аналитики
Примеры: Cassandra, HBase.
Столбчатые базы данных
Иногда нам нужно быстро получить доступ к данным не с помощью определенных ключей, а с помощью определенных столбцов. В этом случае лучше отказаться от построчной вставки и перейти к пакетной записи. Пакетная вставка позволяет столбчатым базам данных готовить данные для быстрого чтения по столбцам.
Достоинства:
- Быстрое чтение столбец за столбцом
- Хорошая аналитическая поддержка
- Хорошая масштабируемость
Недостатки:
- Подходит только для пакетных вставок
Примеры: Vertica, Clickhouse.
Поисковая система
Если мы хотим получить доступ к данным с помощью фильтра по любому значению и даже по любому слову в столбце, мы должны вспомнить про поисковые системы. Эти базы данных выполняют индексацию каждого слова в столбцах и позволяют выполнять полнотекстовый поиск. Они идеально подходят для хранения и анализа журналов или больших текстовых значений.
Достоинства:
- Быстрый доступ по любому слову
- Хорошая масштабируемость
Недостатки:
- Подходит только для пакетных вставок
- Плохая аналитическая поддержка
Примеры: Elastic.
Графовые базы данных
Для некоторых случаев подходят графовые структуры данных. Если ваши задачи требуют работы с графами, существуют специальные базы данных, которые удовлетворят ваши потребности.
Достоинства:
- Структура данных графа
- Управляемые отношения между сущностями
- Гибкие конструкции
Недостатки:
- Специальный язык запросов
- Трудно масштабировать
Примеры: Neo4j.
Выводы
Практически любую задачу можно выполнить практически с любым типом базы данных. Вопрос в том, насколько это будет дорого и оптимизировано. Выбор инструмента, к которому вы привыкли, может сократить ваше время вывода на рынок. Но он также может стоить вам огромных денег на обслуживание и расширение вашего оборудования, которое может быть использовано неэффективно. Всегда старайтесь использовать базу данных так, как она задумана. Возможно, решение, соответствующее вашим потребностям, уже существует.
Но он также может стоить вам огромных денег на обслуживание и расширение вашего оборудования, которое может быть использовано неэффективно. Всегда старайтесь использовать базу данных так, как она задумана. Возможно, решение, соответствующее вашим потребностям, уже существует.
Если вы готовитесь к собеседованию, посмотрите также статью, в которой собраны 27 распространённых вопросов по SQL и ответы на них.
Реклама на Tproger: найдем для вас разработчиков нужного стека и уровня.
Подробнее
Реклама на tproger.ru
Загрузка
Задачка и теория по SQL (изучаем базы данных) · GitHub
Этот урок переехал по адресу https://github.com/codedokode/pasta/blob/master/db/databases.md . Копия ниже устарела и не будет больше обновляться.
База данных — это хранилище, в которое можно сохранять данные, а позже делать по ним поиск и загружать их. Ну например, на форуме в базе данных может храниться информация о пользователях сайта и написанных ими сообщениях. При просмотре страницы скрипт на сервере ищет в БД сообщения на определенную тему и выводит их на странице. Почти любой интерактивный сайт использует БД.
При просмотре страницы скрипт на сервере ищет в БД сообщения на определенную тему и выводит их на странице. Почти любой интерактивный сайт использует БД.
Конечно, можно попробовать сделать свое хранилище (к примеру, на файлах), но вряд ли оно будет работать так же быстро и надежно, как профессиональная база данных. Хорошая база данных гарантирует отсутствие потерь сохраненных данных, даже если неожиданно отключится питание, отсутствие проблем при одновременной работе нескольких пользователей, позволяет искать информацию по произвольным критериям.
Есть разные виды баз данных, но этот урок посвящен базам данных, поддерживающим язык SQL. В них любые операции над данными — добавление, удаление, поиск — делаются с помощью отправки SQL-запросов. Сам язык достаточно простой и запросы на нем напоминают обычные предложения на английском языке. Ну к примеру, запрос на удаление из БД пользователя с email [email protected] выглядит так: DELETE FROM users WHERE email = 'ivan@exaple.. Если знать английский («удалить из пользователей где email равен ‘[email protected]'»), то смысл запроса легко понять, даже не зная SQL. Запросы может отправлять как сам разработчик вручную, так и написанная им программа. com'
com'
SQL это что-то вроде стандарта в мире баз данных. Зная этот язык, можно работать с разными БД от разных производителей.
Есть разные программы, которые позволяют создавать и управлять базой данных. Они называются СУБД (системы управления БД). Из бесплатных самые известные — это MySQL и PostgreSQL. MySQL (в 2016 году) более распространена, а в PostgreSQL больше интересных нестандартных возможностей (а также, считается что она более полно поддерживает стандарт).
Есть и коммерческие СУБД — например, MSSQL, Oracle DB.
Наконец, есть еще встраиваемые СУБД, которые используются не отдельно, а встраиваются в другую программу и используются только ей. Ну например, (в 2016 году) встроенную бесплатную СУБД SQLite использовали браузер Chrome, который хранил с ее помощью историю и закладки, Skype для хранения сообщений и множество мобильных приложений под Android и iOS.
Со всеми этими БД можно работать, зная язык SQL.
База данных хранит данные в таблицах. Таблицы создает разработчик, и обычно каждая из них предназначается для своей сущности — например, таблица со списком пользователей, таблица тем на форуме, таблица сообщений на форуме. Таблица состоит из колонок, каждая из которых имеет определенных тип (число, строка). Ну к примеру, таблица для хранения информации о пользователях форума может выглядеть так:
| id | name | password_hash | salt | registered | |
|---|---|---|---|---|---|
| 1 | Администратор | [email protected] | abbs09s7s6s6 | gt9xbxvx4x30 | 2014-08-02 |
| 2 | Иван | [email protected] | hd6bc00c8c7c665ce | gs65s4s4sb0x | 2015-01-01 |
При регистрации скрипт добавляет в нее информацию о новом пользователе, а при логине — проверяет введенные email и пароль. Мы, конечно, в целях безопасности не храним в базе сами пароли в открытом виде, а получаем из них хеш с солью и сохраняем их в колонках
Мы, конечно, в целях безопасности не храним в базе сами пароли в открытом виде, а получаем из них хеш с солью и сохраняем их в колонках password_hash и salt (по которым можно проверить правильность введенного при логине пароля, но нельзя восстановить его). Также, мы присваиваем каждому пользователю уникальный числовой идентификатор (id), который еще называют первичный ключ — это позволяет потом в других таблицах ссылаться на него (например, в таблице сообщений мы можем хранить id автора сообщения, по которому можно достать информацию о нем).
А вот, как может выглядеть таблица сообщений, которые оставили пользователи на форуме. Для простоты представим, что у нас нет отдельных тем, а есть один большой общий поток сообщений:
| id | author_id | posted | text |
|---|---|---|---|
| 1 | 1 | 2014-08-03 | Добро пожаловать на наш форум! Жду ваших сообщений. |
| 2 | 1 | 2014-08-04 | Что-то никого нету… |
| 3 | 1 | 2014-08-05 | Ни души… |
| 4 | 2 | 2015-01-01 | Всем привет. Я новый тут. |
Здесь колонка id хранит идентификатор сообщения, author_id — идентификатор автора сообщения (по которому можно найти его имя, email в первой таблице), posted — дату отправки и text — тело сообщения. Первые 3 сообщения оставил Администратор, а четвертое — Иван.
Все операции с таблицами, включая их создание и заполнение делаются с помощью запросов на языке SQL. Подробнее о том, как это делать, написано ниже по ссылкам.
Как правило сам сервер базы данных (программа, которая обеспечивает ее работу) не имеет своего интерфейса и каких-то окошек, кнопочек, чтобы с ним взаимодействовать. Управление базой данных делается с помощью запуска программы-клиента, который подсоединяется к серверу, пересылает ему SQL запросы и выводит полученные ответы. Одновременно к БД может подсоединиться несколько клиентов.
Одновременно к БД может подсоединиться несколько клиентов.
Как правило, у каждой базы данных есть клиент для командной строки. Это программа с минималистичным интерфейсом, в которой можно писать SQL запросы и видеть полученные ответы. Это то, что стоит использовать начинающему.
Те, кто освоил основы, могут использовать и более сложные программы-клиенты с графическим интерфейсом. Они могут отображать информацию из базы данных в виде таблиц, перемещаться по ним, менять значения в них. При этом можно запускать и вручную написанные SQL запросы. Я не буду тут писать названия конкретных программ, но их легко найти по словам вроде «mysql gui», «mysql admin», «postgresql gui» и так далее. Я бы советовал сначала научиться работать исключительно в клиенте командной строки, а только потом переходить к этим программам.
Наконец, подсоединяться и отправлять запросы к БД можно из программы. Например, скрипт на языке PHP может таким образом выбирать данные из базы и отображать на веб-странице. Для этого нужна библиотека или расширение-клиент для базы данных. В PHP есть даже 2 расширения для этого (PDO и MySQLi), я рекомендую использовать расширение PDO, так как оно поддерживает исключения, за счет чего при какой-то ошибке проще получить информацию о ней.
Для этого нужна библиотека или расширение-клиент для базы данных. В PHP есть даже 2 расширения для этого (PDO и MySQLi), я рекомендую использовать расширение PDO, так как оно поддерживает исключения, за счет чего при какой-то ошибке проще получить информацию о ней.
Теория и туториалы для начинающих:
- основы и туториал по MySQL (немного старый, но еще актуальный): http://phpclub.ru/mysql/doc/tutorial.html
- руководство на русском по PostgreSQL: https://postgrespro.ru/docs/postgresql
- большой учебник по SQL: http://www.pyramidin.narod.ru/rusql/index.htm
Если ты хранишь данные в нескольких таблицах, то необходимо уметь создавать связи между ними. Вот уроки по этой теме:
- отношения между таблицами в БД: http://jtest.ru/bazyi-dannyix/sql-dlya-nachinayushhix-chast-3.html
- внешние ключи: http://denis.in.ua/foreign-keys-in-mysql.htm
После этого надо научиться правильно проектировать таблицы и связи между ними. Для этого надо изучить нормализацию БД. По этой теме есть разные статьи — некоторые написаны простым языком, а некоторые нет. Это важная тема, если не соблюдать принципы нормализации, то потом с такой базой будет неудобно работать.
Для этого надо изучить нормализацию БД. По этой теме есть разные статьи — некоторые написаны простым языком, а некоторые нет. Это важная тема, если не соблюдать принципы нормализации, то потом с такой базой будет неудобно работать.
Приведу пример. Теория требует избегать дублирования данных. Допустим, разработчик не изучал нормализацию и сделал так, что в форуме в таблице сообщений у каждого сообщения хранится имя написавшего его пользователя. Таким образом, если пользователь оставил много сообщений, то его имя будет сохранено много раз. Если теперь пользователь захочет поменять имя, то нам придется поменять его в таблице пользователей, а также найти все его сообщения и поменять имя там. В лучшем случае это потребует дополнительного труда (найти все таблицы, где это имя упоминается), в худшем случае мы можем сделать ошибку, и поменяв имя в одном месте, забыть поменять его в другом. На базе из нескольких таблиц это маловероятно, но в больших системах таблиц могут быть детсяки и даже сотни.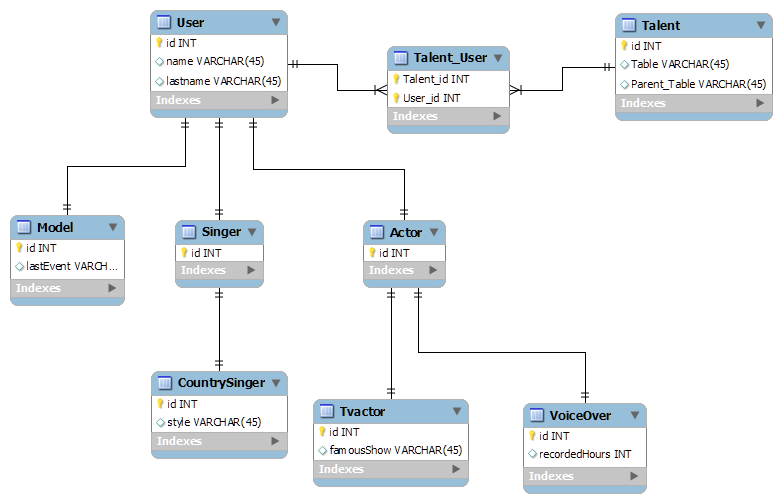 Получается, что несоблюдение принципов проектирования базы данных приводит к тому, что на написание кода будет уходить больше времени разработчиков.
Получается, что несоблюдение принципов проектирования базы данных приводит к тому, что на написание кода будет уходить больше времени разработчиков.
- https://habrahabr.ru/post/129195/
- https://habrahabr.ru/post/254773/
- http://club.shelek.ru/viewart.php?id=177
- http://alexvolkov.ru/database-normalizatio.html
Поскольку нормализация — это очень важная тема, я наверно напишу еще ниже про нее своими словами, на случай, если кто-то не прочел статьи, но не все понял.
А пока еще несколько полезных ссылок:
- сборник запросов на все случаи жизни (англ): http://www.artfulsoftware.com/infotree/queries.php
- таблицы отличий в диалектах SQL в разных СУБД (англ): http://en.wikibooks.org/wiki/SQL_dialects_reference
- манга-учебник про SQL в картинках: http://www.nostarch.com/mg_databases.htm
Под Windows в командной строке не работают русские буквы
Надо выполнить команду SET NAMES cp866; после соединения: http://gahcep. github.io/blog/2013/01/05/mysql-utf8/
github.io/blog/2013/01/05/mysql-utf8/
Еще ссылки на тему кодировок при соединении с mysql из php:
- http://fstrange.ru/coder/mysql/kodirovka-krakozyably.html
- http://phpfaq.ru/charset
На что стоит обратить внимание?
Вот список понятий, которые стоит знать если ты хочешь очень хорошо разбираться в MySQL:
- управление базами данных: CREATE DATABASE, DROP DATABASE, SHOW DATABASES
- управление таблицами: CREATE TABLE, ALTER TABLE, DROP TABLE, SHOW TABLES, SHOW CREATE TABLE, DESC table, TRUNCATE table
- управление правами доступа: GRANT, SHOW GRANTS
- типы колонок: ENUM, SET, CHAR, VARCHAR, TEXT, DATE, TIME, DATETIME, TIMESTAMP, INT, FLOAT, TINYINT, DECIMAL, MEDIUMTEXT, LONGTEXT. В чем разница между TIMESTAMP и DATETIME? Между FLOAT и DECIMAL? CHAR и VARCHAR?
- DECIMAL — тип с фиксированной точностью. В отличие от FLOAT/DOUBLE, которые приближенные и могут терять знаки после запятой, DECIMAL хранит заданное число знаков.
 Используется например, для хранения суммы денег.
Используется например, для хранения суммы денег. - NULL и троичная логика (в БД NULL значит «неизвестно». Например, возраст пользователя неизвестен. Соответственно, все операции с NULL это учитывают: NULL + 5 тоже дает в итоге NULL (5 + неизвестное число дает неизвестное число), сравнение (NULL = NULL) возвращает ложь, чтобы проверить равно ли поле NULL надо использовать IS NULL/IS NOT NULL. http://ru.wikipedia.org/wiki/NULL_(SQL))
- можно ли искать пустые поля условием WHERE x = NULL?
- при создании таблицы можно сделать поля обязательными для заполнения, указав NOT NULL
- SELECT/INSERT/DELETE/UPDATE
- порядок выполнения запроса выборки: FROM+JOIN, WHERE, GROUP, HAVING, ORDER, LIMIT, SELECT (его надо знать наизусть)
- REPLACE, INSERT IGNORE, INSERT .. ON DUPLICATE KEY UPDATE
- выборка данных: DISTINCT, JOIN, ORDER BY, GROUP BY, HAVING, LIMIT
- группировка и аггрегатные функции: GROUP BY, COUNT, MAX, MIN, AVG, SUM
- транзакции: BEGIN, ROLLBACK, COMMIT
- внешние ключи: FOREIGN KEY.
 Внешний ключ — это поле, которое хранит id записи в другой таблице
Внешний ключ — это поле, которое хранит id записи в другой таблице - первичный ключ: естественный и искуственный
- обычные и уникальные индексы (ключи)
- оптимизация запросов, команда EXPLAIN
- отличие InnoDB от MyISAM
Теория по проектированию БД
Чтобы уметь проектировать базы данных и новые таблицы, нужно знать следующее:
- виды отношений между таблицами: один-к-одному, один-ко-многим, многие-ко-многим
- принципы нормализации БД. В интернете можно найти статьи где «нормальные формы» объясняют простыми словами, например http://club.shelek.ru/viewart.php?id=311 или https://habrahabr.ru/post/193756/
- способы хранения древовидных (иерархических) данных в БД. Ну например, это нужно для реализации дерева комментариев к статье или дерева категорий товаров в интернет-магазине. Есть такие паттерны: Adjacency List, Closure Path, Nested Sets, Materialized Path. Вот мой урок про них: https://github.
 com/codedokode/pasta/blob/master/db/trees.md
com/codedokode/pasta/blob/master/db/trees.md - способы реализации наследования таблиц (когда есть похожие, но не одинаковые сущности с общим набором свойств: например Пользователи и Администраторы, или несколько видов приложений к сообщению: Видеозапись, Аудиозапись, Файл, Ссылка на сайт). Для таких случаев есть паттерны Single Table Inheritance, Concrete table Inheritance, Class Table Inheritance
- паттерн EAV (Entity-Attribute-Value), описание на англ., на русском. Этот паттерн можно исплоьзовать в тех случаях, когда есть сущности с разным набором свойств, и свойства могут добавляться (например объявление: объявления о сдаче квартиры и продаже машины имеют разный набор свойств). Также, в интернете можно найти много обсуждений по поводу того, зло это или нет. Есть также альтернативные подходы, например в PostgreSQL можно использовать индексируемые hstore (англ.) или json (англ.) колонки
Вот цикл статей на Хабре, который подойдет в качестве вступления: 1-3, 4-6, 7-9, 10-13, 14-15, бонус
Чем отличаются движки для таблиц MyISAM и InnoDB?
- http://rtfm.
 co.ua/mysql-otlichiya-mezhdu-myisam-i-innodb/
co.ua/mysql-otlichiya-mezhdu-myisam-i-innodb/ - http://itif.ru/otlichiya-myisam-innodb/
Если кратко: MyISAM более простой и не поддеживает внешние ключи и транзакции. А они нужны почти всегда. Потому в 99% случаев тебе нужен InnoDB.
Индексы
Индексы позволяют ускорить поиск по условиям вроде x = ?, x < ?, x BETWEEN ? AND ?, x LIKE 'xxx%', x IN (?, ?, ?), а также сортировку (поля по которым идет сортировка должны идти в конце индекса). Разница на большой таблице может быть огромная — порядка 1 тысячной секунды против нескольких секунд. Ну например, если у нас есть таблица размером в миллион записей и мы делаем запрос
SELECT a, b FROM table ORDER BY y LIMIT 10
то без индекса MySQL вынуждена будет прочитать с диска в память миллион значений, отсортировать их только ради того, чтобы взять первые 10. Если же есть индекс по полю y (который хранит отсортированные по возрастанию значения этого поля) то MySQL просто возьмет из него первые 10 записей.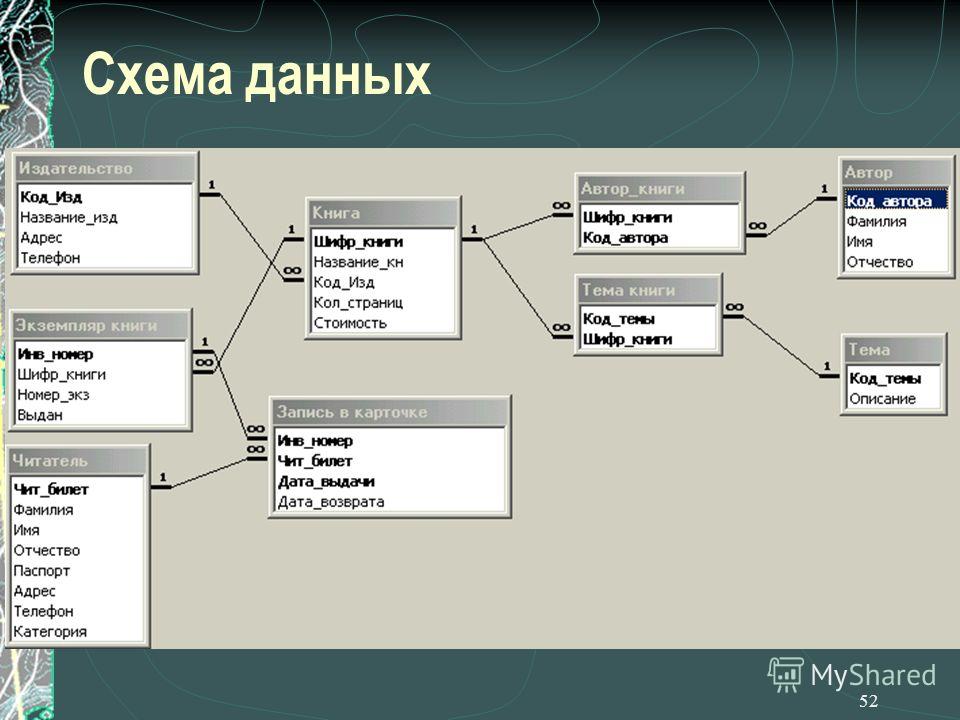 Разница в скорости работы будет огромная.
Разница в скорости работы будет огромная.
Вот статьи для начинающих про индексы:
- http://ruhighload.com/post/%D0%A0%D0%B0%D0%B1%D0%BE%D1%82%D0%B0+%D1%81+%D0%B8%D0%BD%D0%B4%D0%B5%D0%BA%D1%81%D0%B0%D0%BC%D0%B8+%D0%B2+MySQL
- http://www.mysql.ru/docs/man/MySQL_indexes.html
- http://habrahabr.ru/post/211022/
Если ты все прочел внимательно, ответь на вопрос, может ли индекс (если да, то какой) ускорить такие запросы:
SELECT * FROM table WHERE x <> 1SELECT * FROM table WHERE x + y < 100SELECT MAX(a) FROM table WHERE b = 2SELECT * FROM table WHERE name LIKE '%Иван%'SELECT * FROM table WHERE b = 1 AND a < 10
Задачка про лайки
С полученными знаниями ты легко сможешь решить эту задачу: есть пользователи (id, имя) и они могут ставить друг другу лайки.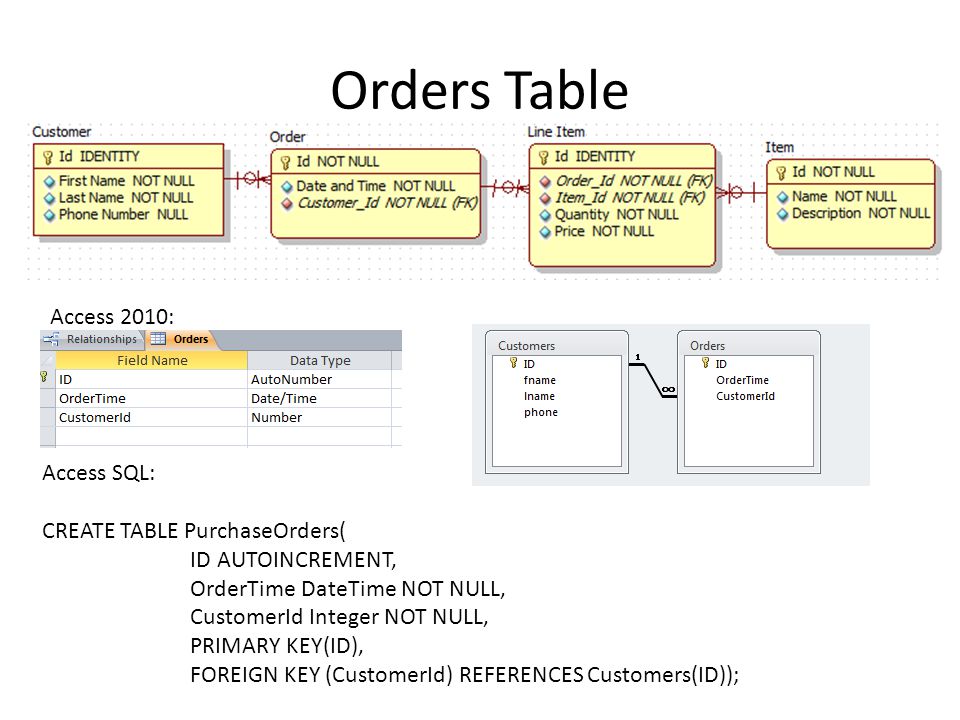 Сделай таблицы для хранения всей этой информации и напиши запрос, который выведет такую таблицу:
Сделай таблицы для хранения всей этой информации и напиши запрос, который выведет такую таблицу:
- ид пользователя
- имя
- лайков получено
- лайков поставлено
- взаимных лайков
Далее, выведи список всех пользователей, которые лайкнули пользователей A и B, но при этом не лайкнули пользователя C. Тут есть несколько вариантов решения.
Сложно? Ну ок, давай начнем с более простой задачи: просто выведи 5 самых популярных пользователей.
- Если ты используешь несколько связанных друг с другом таблиц, связи необходимо пометить с помощью внешних ключей
- Желательно на уровне БД запретить возможность ставить пользователю лайк другому пользователю дважды
- Подсказка: эта задача решается без подзапросов
- Подсказка: достаточно использовать всего 2 джойна и группировку
Усложненная (но более жизненная) задача про лайки
В воображаемой социальной сети есть Пользователи (id, имя), Фото (id, название, автор) и Комментарии К Фото (id, текст, автор, к какому Фото относится).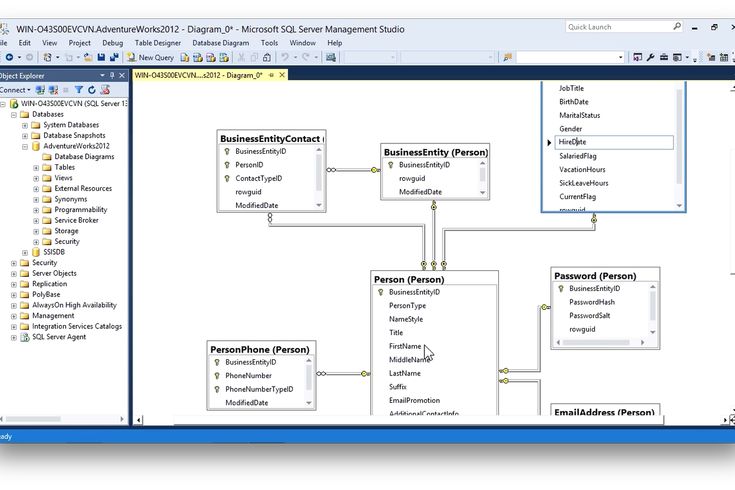 Необходимо добавить возможность для Пользователей ставить лайки другим Пользователям, Фото или Комментариям К Фото. Нужно реализовать такие возможности:
Необходимо добавить возможность для Пользователей ставить лайки другим Пользователям, Фото или Комментариям К Фото. Нужно реализовать такие возможности:
- пользователь не может поставить 2 лайка одной и той же сущности (например одному и тому же Фото)
- пользователь может отозвать лайк
- необходимо иметь возможность посчитать число полученных сущностью лайков и вывести список Пользователей, поставивших лайки
- в будущем могут появиться новые виды сущностей которые можно лайкать
Для начала, нужно решить задачу без оглядки на производительность. Очень желательно следовать принципам нормализации и помечать связи внешними ключами (а также на уровне Бд предотвратить возможность повторной отправки лайка). Далее, можно дополнить решение комментариями по поводу оптимизаций производительности.
Тут есть несколько вариантов решения.
Задачка про кинотеатр
Вот дополнительная, более сложная задачка. Есть кинотеатр, в нем идут фильмы. У фильма есть название, длительность (пусть для простоты будет 60, 90 или 120 минут), цена билета (в разное время и дни может быть разная), время начала сеанса (один фильм может быть показан несколько раз в разное время за разную цену). Также, есть информация о купленных билетах (номер билета, на какой сеанс).
Есть кинотеатр, в нем идут фильмы. У фильма есть название, длительность (пусть для простоты будет 60, 90 или 120 минут), цена билета (в разное время и дни может быть разная), время начала сеанса (один фильм может быть показан несколько раз в разное время за разную цену). Также, есть информация о купленных билетах (номер билета, на какой сеанс).
Задания:
- составь грамотную нормализованную схему хранения этих данных в БД. Внеси в нее 4-5 фильмов, расписание на один день и несколько проданных билетов.
Сделай запросы, считающие и выводящие в понятном виде:
- ошибки в расписании (фильмы накладываются друг на друга), отсортированные по возрастанию времени. Выводить надо колонки «фильм 1», «время начала», «длительность», «фильм 2», «время начала», «длительность».
- перерывы больше или равные 30 минут между фильмами, выводятся по уменьшению длительности перерыва. Выводить надо колонки «фильм 1», «время начала», «длительность», «время начала второго фильма», «длительность перерыва».

- список фильмов, для каждого указано общее число посетителей за все время, среднее число зрителей за сеанс и общая сумма сбора по каждому, отсортированные по убыванию прибыли. Внизу таблицы должна быть строчка «итого», содержащая данные по всем фильмам сразу.
- число посетителей и кассовые сборы, сгруппированные по времени начала фильма: с 9 до 15, с 15 до 18, с 18 до 21, с 21 до 00:00. (то есть сколько посетителей пришло с 9 до 15 часов, сколько с 15 до 18 и т.д.).
Сложная задача про календарь
Решил предыдущие задачи и они слишком простые? Ок, давай возьмемся за действительно сложную задачу. Напиши SQL-код, выводящий календарь на текущий месяц в виде:
| Пн | Вт | Ср | Чт | Пт | Сб | Вс |
|---|
| | | | | 1 | 2
3 | 4 | 5 | 6 | 7 | 8 | 9 10 | 11 | 12 | 13 | 14 | 15 | 16 17 | 18 | 19 | 20 | 21 | 22 | 23 24 | 25 | 26 | 27 | 28 | 29 | 30
- Подсказка: ты можешь делать запросы без таблиц, например
SELECT 2 + 3, 'Hello' - Подсказка: здесь не надо использовать циклы или процедуры
- Подсказка: функции работы с датой и временем ты можешь найти тут http://dev.
 mysql.com/doc/refman/5.0/en/date-and-time-functions.html (англ.)
mysql.com/doc/refman/5.0/en/date-and-time-functions.html (англ.) - Подсказка: для сокращения объема кода ты можешь использовать переменные (создаются командой
SET)
Иллюстрированный самоучитель по SQL для начинающих › Основы реляционных баз данных [страница — 6] | Самоучители по программированию
Тематика: Самоучители по программированию
Основы реляционных баз данных
Модели баз данных
Независимо от размеров баз данных все они относятся к одной из трех нижеприведенных моделей.
- Реляционная. Если сейчас где-нибудь развертывают новую систему, предназначенную для управления базами данных, то почти всегда такая система является реляционной. Конечно, в организациях, где уже вложено много ресурсов в иерархическую и сетевую технологии, могут наращивать и имеющуюся модель. Однако в группах, где нет необходимости поддерживать совместимость с унаследованными от прошлого системами, для своих баз данных почти всегда выбирают реляционную модель.
- Иерархическая. Иерархические базы данных получили такое название потому, что имеют простую иерархическую структуру, позволяющую иметь быстрый доступ к данным. Их недостатками являются избыточность данных, т.е. их дублирование, и негибкость структуры, что усложняет модификацию таких баз данных.
- Сетевая. В сетевых базах данных дублирование минимально, но за это приходится платить сложностью структуры.
Первыми базами данных, получившими широкое распространение, были большие базы данных организаций, созданные в соответствии с иерархической или сетевой моделью. Через несколько лет появились системы, созданные в соответствии с реляционной моделью. Язык SQL является по-настоящему современным; он применяется только к реляционной модели и ее производной – объектно-реляционной модели. Так что в этом месте книги остается сказать иерархической и сетевой моделям: «Приятно было познакомиться, а теперь – до свидания».
Новые системы управления базами данных, которые не являются реляционными, соответствуют, скорее всего, более новой, чем реляционная, объектной модели или гибридной объектно-реляционной модели.
Реляционная модель
Впервые реляционную модель баз данных сформулировал в 1970 году работавший в компании IBM доктор И.Ф. Кодд (E. F. Codd), а примерно десятилетие спустя эта модель начала появляться в готовых продуктах. По иронии судьбы первую реляционную СУБД разработала не IBM. Такая честь выпала на долю маленькой компании-новичка, назвавшей свой продукт Oracle.
Базы данных, созданные на основе предыдущих моделей, были заменены реляционными, потому что не имели тex ценных свойств, которые и отличают реляционные базы от баз других типов. Вероятно, самым важным из этих свойств является то, что в реляционной базе данных можно менять структуру, не внося изменений в приложения. Такого не скажешь о приложениях, созданных на основе старых структур. Предположим, например, что в таблицу базы данных вы добавили один или несколько новых столбцов. В этом случае нет необходимости менять никакое из уже написанных приложений, которые будут продолжать обрабатывать эту таблицу, – только если вы не изменили столбцы, с которыми работают эти приложения.
Внимание:
Конечно, если вы удалили столбец, к которому обращается имеющееся приложение, то какая бы модель базы данных ни применялась, вы столкнетесь с трудностями. Один из лучших способов устроить аварийное завершение работы приложения базы данных – запросить у него такую информацию, которой нет в вашей базе данных.
Почему реляционная модель лучше
В приложениях, работающих с СУБД, которые следуют иерархической или сетевой модели, структура базы данных «зашита» в само приложение. Это означает, что приложение зависит от определенной физической реализации базы данных. При добавлении в базу данных нового атрибута вам, чтобы привести свое приложение в соответствие с изменением базы, придется это приложение изменить, причем неважно, будет ли оно использовать новый атрибут.
У реляционных баз данных более гибкая структура. Приложения для таких баз поддерживать легче, чем те, что написаны для иерархических или сетевых баз данных. Эта гибкость структуры дает возможность получать такие комбинации данных, которые, возможно, еще не были нужны при проектировании базы данных.
Компоненты реляционной базы данных
Гибкость реляционных баз данных объясняется тем, что их данные находятся в таблицах, которые в значительной степени независимы друг от друга. В таблицу данные можно добавлять, удалять их из нее, вносить в них изменения и при этом не затрагивать данные из других таблиц – если только таблица не является родительской по отношению к этим другим таблицам. (Об отношениях родительских и дочерних таблиц рассказывается в главе 5, но там речь пойдет не о конфликте поколений.) В этом разделе будет показано из чего состоят таблицы и как они связаны с другими частями реляционной базы данных.
- « первая
- ‹ предыдущая
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- …
- следующая ›
- последняя »
Если Вы заметили ошибку, выделите, пожалуйста, необходимый текст и нажмите CTRL + Enter, чтобы сообщить об этом редактору.
Что такое база данных | Oracle СНГ
База данных — определение
База данных — это упорядоченный набор структурированной информации или данных, которые обычно хранятся в электронном виде в компьютерной системе. База данных обычно управляется системой управления базами данных (СУБД). Данные вместе с СУБД, а также приложения, которые с ними связаны, называются системой баз данных, или, для краткости, просто базой данных.
Данные в наиболее распространенных типах современных баз данных обычно хранятся в виде строк и столбцов формирующих таблицу. Этими данными можно легко управлять, изменять, обновлять, контролировать и упорядочивать. В большинстве баз данных для записи и запросов данных используется язык структурированных запросов (SQL).
Подробнее о СУБД Oracle Database
Что такое язык структурированных запросов (SQL)?
SQL — это язык программирования, используемый в большинстве реляционных баз данных для запросов, обработки и определения данных, а также контроля доступа. SQL был разработан в IBM в 1970-х годах. Со временем у стандарта SQL ANSI появились многочисленные расширения разработанные такими компаниями как IBM, Oracle и Microsoft. Хотя в настоящее время SQL все еще широко используется, начали появляться новые языки программирования запросов.
SQL был разработан в IBM в 1970-х годах. Со временем у стандарта SQL ANSI появились многочисленные расширения разработанные такими компаниями как IBM, Oracle и Microsoft. Хотя в настоящее время SQL все еще широко используется, начали появляться новые языки программирования запросов.
Эволюция базы данных
Базы данных значительно изменились с момента их появления в начале 1960-х годов. Исходными системами, которые использовались для хранения и обработки данных, были навигационные базы данных – например, иерархические базы данных (которые опирались на древовидную модель и допускали только отношение «один-ко-многим») и базы данных с сетевой структурой (более гибкая модель, допускающая множественные отношения). Несмотря на простоту, эти ранние системы были негибкими. В 1980-х годах стали популярными реляционные базы данных, в 1990-х годах за ними последовали объектно-ориентированные базы данных. Совсем недавно вследствие роста Интернета и возникновения необходимости анализа неструктурированных данных появились базы данных NoSQL. В настоящее время облачные базы данных и автономные базы данных открывают новые возможности в отношении способов сбора, хранения, использования данных и управления ими.
В настоящее время облачные базы данных и автономные базы данных открывают новые возможности в отношении способов сбора, хранения, использования данных и управления ими.
В чем заключается различие между базой данных и электронной таблицей?
Базы данных и электронные таблицы (в частности, Microsoft Excel) предоставляют удобные способы хранения информации. Основные различия между ними заключаются в следующем.
- Способ хранения и обработки данных
- Полномочия доступа к данным
- Объем хранения данных
Электронные таблицы изначально разрабатывались для одного пользователя, и их свойства отражают это. Они отлично подходят для одного пользователя или небольшого числа пользователей, которым не нужно производить сложные операции с данными. С другой стороны, базы данных предназначены для хранения гораздо больших наборов упорядоченной информации иногда огромных объемов. Базы данных дают возможность множеству пользователей в одно и то же время быстро и безопасно получать доступ к данным и запрашивать их, используя развитую логику и язык запросов.
Типы баз данных
Существует множество различных типов баз данных. Выбор наилучшей базы данных для конкретной компании зависит от того, как она намеревается использовать данные.
- Реляционные базы данных стали преобладать в 1980-х годах. Данные в реляционной базе организованы в виде таблиц, состоящих из столбцов и строк. Реляционная СУБД обеспечивает быстрый и эффективный доступ к структурированной информации.
- Информация в объектно-ориентированной базе данных представлена в форме объекта, как в объектно-ориентированном программировании.
- Распределенная база данных состоит из двух или более частей, расположенных на разных серверах. Такая база данных может храниться на нескольких компьютерах.
- Будучи централизованным репозиторием для данных, хранилище данных представляет собой тип базы данных, специально предназначенной для быстрого выполнения запросов и анализа.

- База данных NoSQL, или нереляционная база данных, дает возможность хранить и обрабатывать неструктурированные или слабоструктурированные данные (в отличие от реляционной базы данных, задающей структуру содержащихся в ней данных). Популярность баз данных NoSQL растет по мере распространения и усложнения веб-приложений.
- Графовая база данных хранит данные в контексте сущностей и связей между сущностями.
- Базы данных OLTP. База данных OLTP — это база данных предназначенная для выполнения бизнес-транзакций, выполняемых множеством пользователей.
Реляционные базы данных
Объектно-ориентированные базы данных
Распределенные базы данных
Хранилища данных
Oracle NoSQL Database
Графовые базы данных
Это лишь некоторые из десятков типов баз данных, используемых в настоящее время. Другие, менее распространенные базы данных, предназначены для очень специфических научных, финансовых и иных задач. Помимо появления новых типов, базы данных развиваются в абсолютно новых направлениях — изменяются подходы к разработке технологий, происходят значительные сдвиги, такие как внедрение облачных технологий и автоматизации. В частности, в последнее время появились следующие базы данных.
В частности, в последнее время появились следующие базы данных.
- Такие базы данных имеют открытый исходный код и могут управляться средствами как SQL, так и NoSQL.
- Облачная база данных представляет собой набор структурированных или неструктурированных данных, размещенный на частной, публичной или гибридной платформе облачных вычислений. Существует два типа моделей облачных баз данных: традиционная база данных и база данных как услуга (DBaaS). В модели DBaaS административные задачи и обслуживание выполняются поставщиком облачных услуг.
- Многомодельная база данных объединяет разные типы моделей баз данных в единую интегрированную серверную СУБД. Это означает, что она может содержать различные типы данных.
- Базы данных документов предназначены для хранения, извлечения и обработки документоориентированной информации и предоставляют современный способ хранения данных в формате JSON, а не в виде строк и столбцов.

- Самоуправляемые базы данных (также называемые автономными) — это новейшие и самые революционные облачные базы данных, которые используют машинное обучение для автоматизации настройки, защиты, резервного копирования, обновления и других стандартных задач обслуживания, обычно выполняемых администраторами баз данных.
Базы данных с открытым исходным кодом
Облачные базы данных
Многомодельные базы данных
Документные базы данных/JSON
Автономные базы данных
Подробнее об автономных базах данных
Что такое программное обеспечение базы данных?
Программное обеспечение базы данных используется для создания, редактирования и обслуживания файлов и записей базы данных, что упрощает создание файлов и записей, ввод данных, редактирование, обновление и отчетность. Программное обеспечение также помогает хранить данных, осуществлять резервное копирование и формировать отчетность, предоставлять управление множественным доступом и поддерживать безопасность. Сегодня надежная безопасность базы данных особенно важна, поскольку случаи кражи данных значительно участились. Программное обеспечение для баз данных иногда называют системой управления базами данных (СУБД).
Программное обеспечение баз данных упрощает управление данными, помогая пользователям хранить данные в структурированной форме, а затем получать к ним доступ. Обычно программа имеет графический интерфейс, помогающий создавать данные и управлять ими, и в некоторых случаях пользователи могут создавать собственные базы данных с помощью такого ПО.
Что такое система управления базами данных (DBMS)?
Для базы данных обычно требуется комплексное программное обеспечение, которое называется системой управления базами данных (СУБД). СУБД служит интерфейсом между базой данных и пользователями или программами, предоставляя пользователям возможность получать и обновлять информацию, а также управлять ее упорядочением и оптимизацией. СУБД обеспечивает контроль и управление данными, позволяя выполнять различные административные операции, такие как мониторинг производительности, настройка, а также резервное копирование и восстановление.
В качестве примеров популярного программного обеспечения для управления базами данных, или СУБД, можно назвать MySQL, Microsoft Access, Microsoft SQL Server, FileMaker Pro, СУБД Oracle Database и dBASE.
Что такое база данных MySQL?
MySQL — это реляционная система управления базами данных с открытым исходным кодом на основе языка SQL. Она была разработана и оптимизирована для веб-приложений и может работать на многих платформах. Она обладает всеми возможностями которые требуются веб-разработчикам. База данных MySQL предназначена для обработки миллионов запросов и тысяч транзакций, поэтому ее часто выбирают компании электронной коммерции, которым требуется управлять большим количеством денежных переводов. Гибкость по мере необходимости — основная характеристика MySQL.
Многие ведущие веб-сайты и веб-приложения используют СУБД MySQL, в том числе Airbnb, Uber, LinkedIn, Facebook, Twitter и YouTube.
Подробнее о MySQL
Использование баз данных для повышения производительности бизнеса и улучшения процесса принятия решений
Обширный сбор данных из Интернета вещей меняет действительность и производственный сектор по всему миру: современные компании имеют доступ к большему количеству данных, чем когда-либо прежде.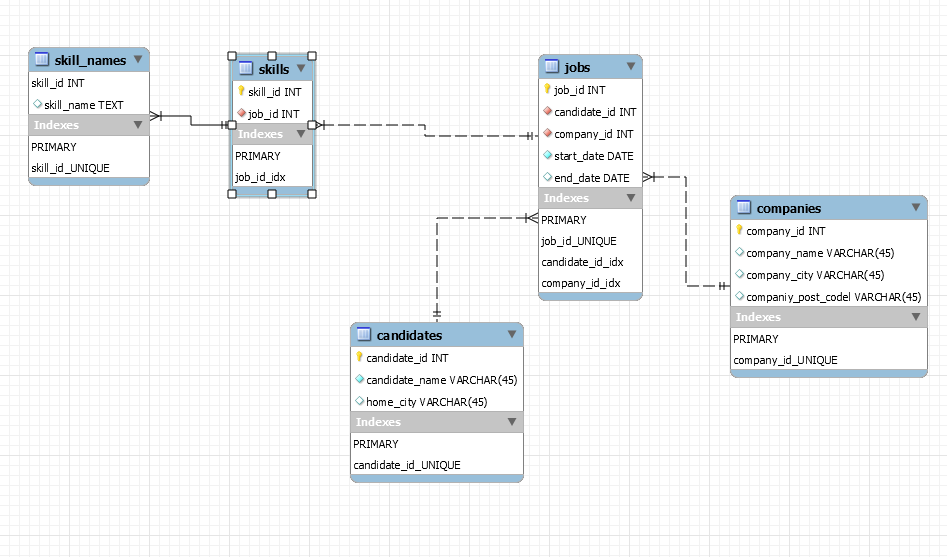 Прогрессивные компании теперь могут использовать базы данных, чтобы от обычного хранения данных и базовых транзакций перейти к анализу огромных объемов данных из множества систем. Благодаря базам данных и другим средствам вычислений и бизнес-аналитики современные компании могут использовать собираемые ими данные для более эффективной работы, эффективного принятия решений, гибкости и масштабируемости. Сегодня важнейшим для коммерческих компаний является оптимизация доступа и пропускной способности для данных, что связано с постоянным ростом объема данных. Очень важно иметь платформу, способную обеспечить производительность, масштаб и гибкость, необходимые компаниям по мере их роста.
Прогрессивные компании теперь могут использовать базы данных, чтобы от обычного хранения данных и базовых транзакций перейти к анализу огромных объемов данных из множества систем. Благодаря базам данных и другим средствам вычислений и бизнес-аналитики современные компании могут использовать собираемые ими данные для более эффективной работы, эффективного принятия решений, гибкости и масштабируемости. Сегодня важнейшим для коммерческих компаний является оптимизация доступа и пропускной способности для данных, что связано с постоянным ростом объема данных. Очень важно иметь платформу, способную обеспечить производительность, масштаб и гибкость, необходимые компаниям по мере их роста.
Автономная база данных способна значительно расширить эти возможности. Автономные базы данных автоматизируют дорогостоящие и длительные ручные процедуры, благодаря чему бизнес-пользователи могут сосредоточиться на работе со своими данными. За счет возможностей создания и использования баз данных пользователи приобретают контроль и автономию, поддерживая при этом важные стандарты безопасности.
Задачи для баз данных
Современные крупные корпоративные базы данных нередко поддерживают очень сложные запросы, и предполагается, что они должны предоставлять почти мгновенные ответы на них. В результате администраторы баз данных вынуждены применять самые разные методы для повышения производительности. Вот некоторые из наиболее распространенных вызовов, с которыми они сталкиваются.
- Значительно возросшие объемы данных. Стремительный рост данных от датчиков, подключенных приборов и десятков других источников заставляет администраторов искать способы эффективного управления и упорядочивания данных своих компаний.
- Обеспечение безопасности данных. В наши дни регулярно случаются утечки данных и хакеры становятся все более изобретательными. Сейчас как никогда важно обеспечить защиту данных, но в то же время их легкую доступность для пользователей.
- Удовлетворение растущих потребностей. В современной, динамичной бизнес-среде компаниям необходим доступ к данным в режиме реального времени – для своевременного принятия решений и использования новых возможностей.

- Управление и обслуживание базы данных и инфраструктуры. Администраторы базы данных должны осуществлять постоянный мониторинг базы данных на наличие проблем, выполнять профилактическое обслуживание, а также устанавливать обновления и исправления программного обеспечения. Но базы данных становятся все более сложными, объемы данных растут, и компании сталкиваются с необходимостью привлечения дополнительных специалистов для мониторинга и настройки баз данных.
- Устранение границ масштабируемости. Если бизнес хочет выжить, он должен развиваться, и возможности управления данными должны расти вместе с ним. Но администраторам баз данных очень сложно предугадать, какие мощности потребуются компании, особенно при использовании локальных баз данных.
- Соблюдение требований к размещению данных, суверенитету данных и времени ожидания. Для одних компаний предпочтительнее, чтобы базы данных работали в локальной среде. В таких случаях идеальным вариантом являются готовые системы, настроенные и оптимизированные для размещения баз данных.
 При использовании Oracle Exadata заказчики достигают высокой доступности, повышают производительность и снижают затраты до 40 %.
При использовании Oracle Exadata заказчики достигают высокой доступности, повышают производительность и снижают затраты до 40 %.
Решение всех этих задач может занимать много времени и отвлекать администраторов баз данных от решения стратегических задач.
Как автономные технологии улучшают управление базами данных
Автономные базы данных — это модель будущего, представляющая исключительный интерес для компаний, которые хотят использовать лучшую из имеющихся технологий баз данных, при этом не сталкиваясь с проблемами при запуске и эксплуатации этой технологии.
Автономные базы данных используют облачные технологии и машинное обучение для автоматизации множества стандартных задач управления базами данных, таких как настройка, защита, резервное копирование, обновление и другие повседневные задачи администрирования. Благодаря автоматизации этой рутины администраторы баз данных могут сосредоточиться на более стратегической работе. Возможности самоуправления, самозащиты и самовосстановления автономных баз данных могут радикально изменить способы управления и защиты данных, улучшая эффективность, снижая затраты и повышая безопасность.
Будущее баз данных и автономных баз данных
О выходе первой автономной базы данных было объявлено в конце 2017 года, и многие независимые отраслевые аналитики быстро оценили возможности этой технологии и ее потенциальное воздействие на обработку данных.
Дополнительные продукты
- Oracle Autonomous Database
- СУБД Oracle Database
- Oracle Exadata
- Oracle Autonomous Data Warehouse
Что такое NoSQL? | Нереляционные базы данных, модели данных с гибкой схемой | AWS
Высокопроизводительные нереляционные базы данных с гибкими моделями данных
Базы данных NoSQL специально созданы для определенных моделей данных и обладают гибкими схемами, что позволяет разрабатывать современные приложения. Базы данных NoSQL получили широкое распространение в связи с простотой разработки, функциональностью и производительностью при любых масштабах. Ресурсы, представленные на этой странице, помогут разобраться с базами данных NoSQL и начать работу с ними.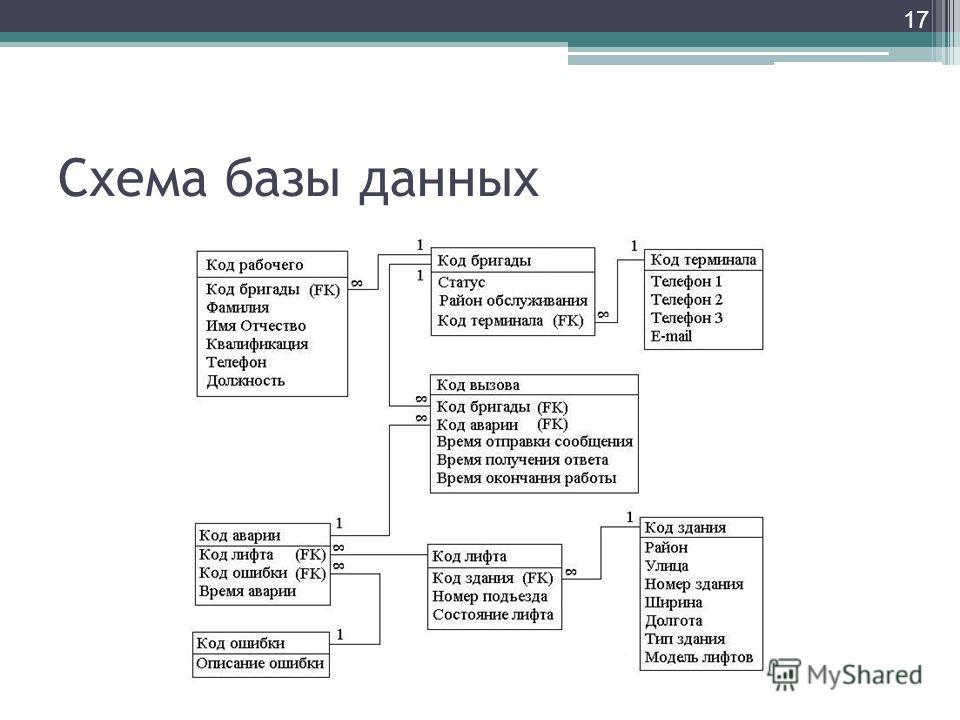
Базы данных в AWS: подходящий инструмент для подходящей работы
Базы данных NoSQL используют разнообразные модели данных для доступа к данным и управления ими. Базы данных таких типов оптимизированы для приложений, которые работают с большим объемом данных, нуждаются в низкой задержке и гибких моделях данных. Все это достигается путем смягчения жестких требований к непротиворечивости данных, характерных для других типов БД.
Рассмотрим пример моделирования схемы для простой базы данных книг.
- В реляционной базе данных запись о книге часто разделяется на несколько частей (или «нормализуется») и хранится в отдельных таблицах, отношения между которыми определяются ограничениями первичных и внешних ключей. В этом примере в таблице «Книги» имеются столбцы «ISBN», «Название книги» и «Номер издания», в таблице «Авторы» – столбцы «ИД автора» и «Имя автора», а в таблице «Автор–ISBN» – столбцы «Автор» и «ISBN».
 Реляционная модель создана таким образом, чтобы обеспечить целостность ссылочных данных между таблицами в базе данных. Данные нормализованы для снижения избыточности и в целом оптимизированы для хранения.
Реляционная модель создана таким образом, чтобы обеспечить целостность ссылочных данных между таблицами в базе данных. Данные нормализованы для снижения избыточности и в целом оптимизированы для хранения.
- В базе данных NoSQL запись о книге обычно хранится как документ JSON. Для каждой книги, или элемента, значения «ISBN», «Название книги», «Номер издания», «Имя автора и «ИД автора» хранятся в качестве атрибутов в едином документе. В такой модели данные оптимизированы для интуитивно понятной разработки и горизонтальной масштабируемости.
Базы данных NoSQL хорошо подходят для многих современных приложений, например мобильных, игровых, интернет‑приложений, когда требуются гибкие масштабируемые базы данных с высокой производительностью и широкими функциональными возможностями, способные обеспечивать максимальное удобство использования.
- Гибкость. Как правило, базы данных NoSQL предлагают гибкие схемы, что позволяет осуществлять разработку быстрее и обеспечивает возможность поэтапной реализации.
 Благодаря использованию гибких моделей данных БД NoSQL хорошо подходят для частично структурированных и неструктурированных данных.
Благодаря использованию гибких моделей данных БД NoSQL хорошо подходят для частично структурированных и неструктурированных данных. - Масштабируемость. Базы данных NoSQL рассчитаны на масштабирование с использованием распределенных кластеров аппаратного обеспечения, а не путем добавления дорогих надежных серверов. Некоторые поставщики облачных услуг проводят эти операции в фоновом режиме, обеспечивая полностью управляемый сервис.
- Высокая производительность. Базы данных NoSQL оптимизированы для конкретных моделей данных и шаблонов доступа, что позволяет достичь более высокой производительности по сравнению с реляционными базами данных.
- Широкие функциональные возможности. Базы данных NoSQL предоставляют API и типы данных с широкой функциональностью, которые специально разработаны для соответствующих моделей данных.
БД на основе пар «ключ‑значение». Базы данных с использованием пар «ключ‑значение» поддерживают высокую разделяемость и обеспечивают беспрецедентное горизонтальное масштабирование, недостижимое при использовании других типов БД. Хорошими примерами использования для баз данных типа «ключ‑значение» являются игровые, рекламные приложения и приложения IoT. Amazon DynamoDB обеспечивает стабильную работу БД с задержкой не более нескольких миллисекунд при любом масштабе. Такая устойчивая производительность послужила основной причиной переноса Snapchat Stories в сервис DynamoDB, поскольку эта возможность Snapchat связана с самой большой нагрузкой на запись в хранилище.
Хорошими примерами использования для баз данных типа «ключ‑значение» являются игровые, рекламные приложения и приложения IoT. Amazon DynamoDB обеспечивает стабильную работу БД с задержкой не более нескольких миллисекунд при любом масштабе. Такая устойчивая производительность послужила основной причиной переноса Snapchat Stories в сервис DynamoDB, поскольку эта возможность Snapchat связана с самой большой нагрузкой на запись в хранилище.
Документ В коде приложения данные часто представлены как объект или документ в формате, подобном JSON, поскольку для разработчиков это эффективная и интуитивная модель данных. Документные базы данных позволяют разработчикам хранить и запрашивать данные в БД с помощью той же документной модели, которую они используют в коде приложения. Гибкий, полуструктурированный, иерархический характер документов и документных баз данных позволяет им развиваться в соответствии с потребностями приложений. Документная модель хорошо работает в каталогах, пользовательских профилях и системах управления контентом, где каждый документ уникален и изменяется со временем. Amazon DocumentDB (совместимая с MongoDB) и MongoDB — распространенные документные базы данных, которые предоставляют функциональные и интуитивно понятные API для гибкой разработки.
Amazon DocumentDB (совместимая с MongoDB) и MongoDB — распространенные документные базы данных, которые предоставляют функциональные и интуитивно понятные API для гибкой разработки.
Графовые БД. Графовые базы данных упрощают разработку и запуск приложений, работающих с наборами сложносвязанных данных. Типичные примеры использования графовых баз данных – социальные сети, сервисы рекомендаций, системы выявления мошенничества и графы знаний. Amazon Neptune – это полностью управляемый сервис графовых баз данных. Neptune поддерживает модель Property Graph и Resource Description Framework (RDF), предоставляя на выбор два графовых API: TinkerPop и RDF / SPARQL. К числу распространенных графовых БД относятся Neo4j и Giraph.
БД в памяти. Часто в игровых и рекламных приложениях используются таблицы лидеров, хранение сессий и аналитика в реальном времени. Такие возможности требуют отклика в пределах нескольких микросекунд, при этом резкое возрастание трафика возможно в любой момент. Amazon MemoryDB для Redis – это совместимый с Redis надежный сервис базы данных в памяти, который уменьшает задержку чтения до миллисекунд и обеспечивает надежность в нескольких зонах доступности. MemoryDB специально создана для обеспечения сверхвысокой производительности и надежности, поэтому ее можно использовать как основную базу данных для современных приложений на базе микросервисов. Amazon ElastiCache – это полностью управляемый сервис кэширования в памяти, совместимый с Redis и Memcached для обслуживания рабочих нагрузок с низкой задержкой и высокой пропускной способностью. Такие клиенты, как Tinder, которым требуется, чтобы их приложения давали отклик в режиме реального времени, пользуются системами хранения данных в памяти, а не на диске. Еще одним примером специально разработанного хранилища данных является Amazon DynamoDB Accelerator (DAX). DAX позволяет DynamoDB считывать данные в несколько раз быстрее.
Amazon MemoryDB для Redis – это совместимый с Redis надежный сервис базы данных в памяти, который уменьшает задержку чтения до миллисекунд и обеспечивает надежность в нескольких зонах доступности. MemoryDB специально создана для обеспечения сверхвысокой производительности и надежности, поэтому ее можно использовать как основную базу данных для современных приложений на базе микросервисов. Amazon ElastiCache – это полностью управляемый сервис кэширования в памяти, совместимый с Redis и Memcached для обслуживания рабочих нагрузок с низкой задержкой и высокой пропускной способностью. Такие клиенты, как Tinder, которым требуется, чтобы их приложения давали отклик в режиме реального времени, пользуются системами хранения данных в памяти, а не на диске. Еще одним примером специально разработанного хранилища данных является Amazon DynamoDB Accelerator (DAX). DAX позволяет DynamoDB считывать данные в несколько раз быстрее.
Поисковые БД. Многие приложения формируют журналы, чтобы разработчикам было проще выявлять и устранять неполадки. Сервис Amazon OpenSearch – специально разработанный сервис для визуализации и аналитики автоматически генерируемых потоков данных в режиме, близком к реальному времени, путем индексирования, агрегации частично структурированных журналов и метрик и поиска по ним. Кроме того, сервис Amazon OpenSearch – это мощный, высокопроизводительный сервис для полнотекстового поиска. Компания Expedia задействует более 150 доменов сервиса Amazon OpenSearch, 30 ТБ данных и 30 миллиардов документов для разнообразных особо важных примеров использования – от операционного мониторинга и устранения неисправностей до отслеживания стека распределенных приложений и оптимизации затрат.
Сервис Amazon OpenSearch – специально разработанный сервис для визуализации и аналитики автоматически генерируемых потоков данных в режиме, близком к реальному времени, путем индексирования, агрегации частично структурированных журналов и метрик и поиска по ним. Кроме того, сервис Amazon OpenSearch – это мощный, высокопроизводительный сервис для полнотекстового поиска. Компания Expedia задействует более 150 доменов сервиса Amazon OpenSearch, 30 ТБ данных и 30 миллиардов документов для разнообразных особо важных примеров использования – от операционного мониторинга и устранения неисправностей до отслеживания стека распределенных приложений и оптимизации затрат.
В течение десятилетий центральное место в разработке приложений занимала реляционная модель данных, которая использовалась в реляционных базах данных, таких как Oracle, DB2, SQL Server, MySQL и PostgreSQL. Но в середине – конце 2000‑х годов заметное распространение стали получать и другие модели данных. Для обозначения появившихся классов БД и моделей данных был введен термин «NoSQL». Часто «NoSQL» используется в качестве синонима к термину «нереляционный».
Часто «NoSQL» используется в качестве синонима к термину «нереляционный».
Существует множество типов БД NoSQL с различными особенностями, но в таблице ниже приведены основные отличия баз данных NoSQL от SQL.
Начало работы с NoSQL
В следующей таблице приведено сравнение терминологии некоторых баз данных NoSQL с терминологией баз данных SQL.
| SQL | MongoDB | DynamoDB | Cassandra | Couchbase |
|---|---|---|---|---|
| Таблица | Коллекция | Таблица | Таблица | Корзина данных |
| Ряд | Документ | Элемент | Ряд | Документ |
| Столбец | Поле | Атрибут | Столбец | Поле |
| Первичный ключ | ObjectId | Первичный ключ | Первичный ключ | ИД документа |
| Индекс | Индекс | Вторичный индекс | Индекс | Индекс |
| Представление | Представление | Глобальный вторичный индекс | Материализованное представление | Представление |
| Вложенная таблица или объект | Встроенный документ | Карта | Карта | Карта |
| Массив | Массив | Список | Список | Список |
| Список |
| Список |
| Первичный ключ |
Начать работу с DynamoDB очень просто.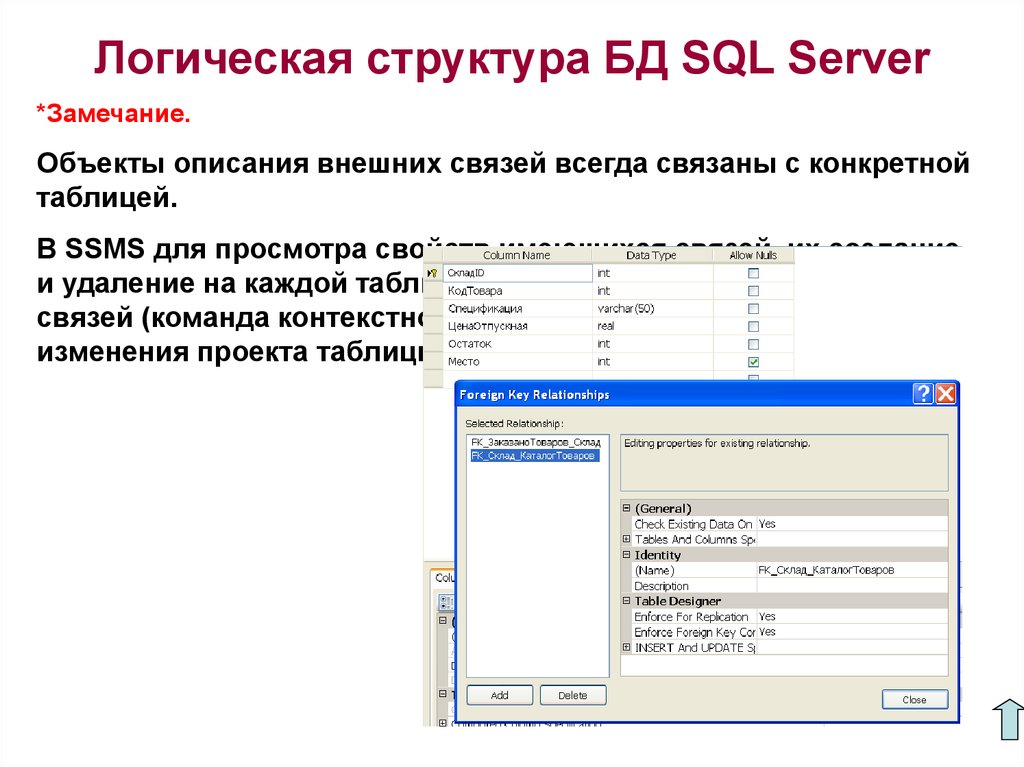 Страница по началу работы с DynamoDB поможет создать первую таблицу за несколько щелчков мышью. Можно загрузить техническое описание AWS, чтобы изучить рекомендации по миграции рабочих нагрузок из реляционной системы управления базой данных (РСУБД) в DynamoDB.
Страница по началу работы с DynamoDB поможет создать первую таблицу за несколько щелчков мышью. Можно загрузить техническое описание AWS, чтобы изучить рекомендации по миграции рабочих нагрузок из реляционной системы управления базой данных (РСУБД) в DynamoDB.
Начать работу с Amazon DynamoDB
What is Amazon DynamoDB?
Вход в Консоль
Подробнее об AWS
- Что такое AWS?
- Что такое облачные вычисления?
- Инклюзивность, многообразие и равенство AWS
- Что такое DevOps?
- Что такое контейнер?
- Что такое озеро данных?
- Безопасность облака AWS
- Новые возможности
- Блоги
- Пресс‑релизы
Ресурсы для работы с AWS
- Начало работы
- Обучение и сертификация
- Портфолио решений AWS
- Центр архитектурных решений
- Вопросы и ответы по продуктам и техническим темам
- Отчеты аналитиков
- Партнерская сеть AWS
Разработчики на AWS
- Центр разработчика
- Пакеты SDK и инструментарий
- .
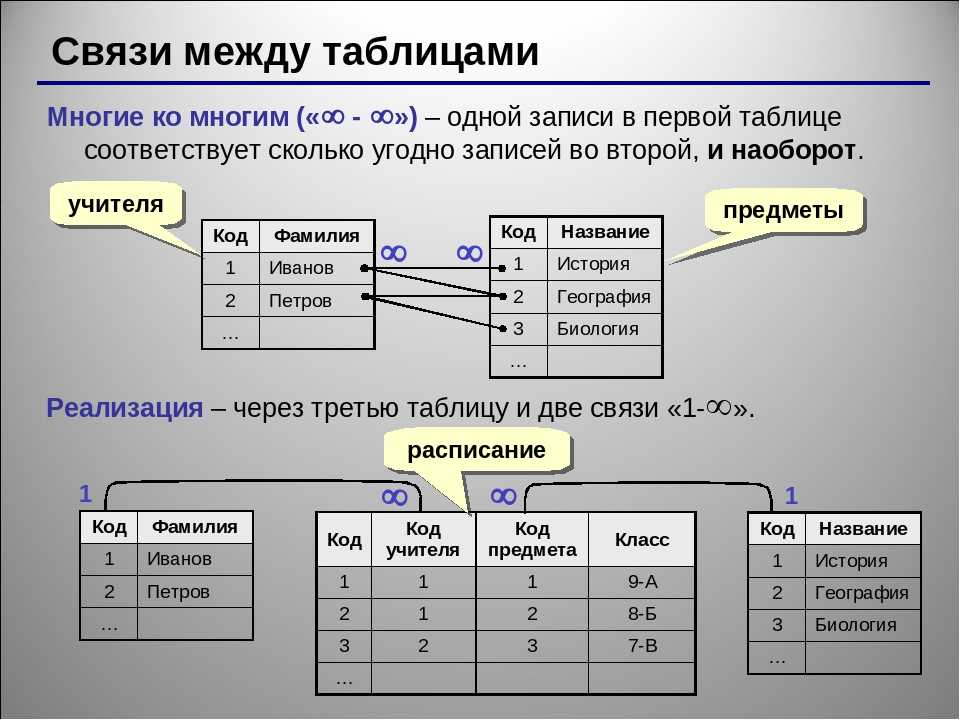 NET на AWS
NET на AWS - Python на AWS
- Java на AWS
- PHP на AWS
- JavaScript на AWS
Поддержка
- Связаться с нами
- Работа в AWS
- Обратиться в службу поддержки
- Центр знаний
- AWS re:Post
- Обзор AWS Support
- Юридическая информация
Amazon.com – работодатель равных возможностей. Мы предоставляем равные права представителям меньшинств, женщинам, лицам с ограниченными возможностями, ветеранам боевых действий и представителям любых гендерных групп любой сексуальной ориентации независимо от их возраста.
Поддержка AWS для Internet Explorer заканчивается 07/31/2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari. Подробнее »
SQL для чат-шпаргалки Dummies
BY: Allen G. Taylor и
Обновлен: 01-27-2022
Из книги: SQL для Dummies
SQL для Dummies
16. Amazon
Amazon
Критерии SQL для нормальных форм
Чтобы убедиться, что таблицы базы данных спроектированы таким образом, чтобы они надежно хранили ваши данные, вы должны быть уверены, что они не подвержены аномалиям модификации. Нормализация ваших баз данных даст вам эту уверенность. Сравните критерии SQL в следующем списке с таблицами в вашей базе данных. Это предупредит вас о возможности аномалий, когда вы обнаружите, что ваша база данных недостаточно нормализована.
Первая нормальная форма (1NF):
Таблица должна быть двухмерной, со строками и столбцами.
Каждая строка содержит данные, относящиеся к одному предмету или части предмета.

Каждый столбец содержит данные для одного признака описываемой вещи.
Каждая ячейка (пересечение строки и столбца) таблицы должна быть однозначной.
Все записи в столбце должны быть одного типа.
Каждый столбец должен иметь уникальное имя.
Не может быть двух одинаковых строк.
Порядок столбцов и строк не имеет значения.
Вторая нормальная форма (2NF):
Третья нормальная форма (3NF):
Нормальная форма ключа домена (DK/NF):
Типы данных SQL
Вот список всех формальных типов данных, которые распознает стандартный SQL ISO/IEC. В дополнение к ним вы можете определить дополнительные типы данных, производные от них.
Точные цифры:
ЦЕЛОЕ ЧИСЛО
МАЛЕНЬКИЙ
БОЛЬШОЙ
ЦИФРОВОЙ
ДЕСЯТИЧНОЕ
Приблизительные цифры:
НАСТОЯЩИЙ
ДВОЙНАЯ ТОЧНОСТЬ
ПЛАВАЮЩАЯ
- СБРОС
Двоичные строки:
ДВОИЧНЫЙ
ДВОИЧНЫЕ ВАРИАНТЫ
ДВОЙНОЙ БОЛЬШОЙ ОБЪЕКТ
Булево значение:
логическое значение
Строки символов:
СИМВОЛ
ИЗМЕНЕНИЕ СИМВОЛА (VARCHAR)
ПЕРСОНАЖ БОЛЬШОЙ ОБЪЕКТ
НАЦИОНАЛЬНЫЙ ХАРАКТЕР
НАЦИОНАЛЬНЫЙ ХАРАКТЕР РАЗЛИЧАЕТСЯ
НАЦИОНАЛЬНЫЙ ХАРАКТЕР БОЛЬШОЙ ОБЪЕКТ
Дата и время:
ДАТА
ВРЕМЯ БЕЗ ЧАСОВОГО ПОЯСА
ВРЕМЕННАЯ МЕТКА БЕЗ ЧАСОВОГО ПОЯСА
ВРЕМЯ С ЧАСОВЫМ ПОЯСОМ
ВРЕМЕННАЯ МЕТКА С ЧАСОВЫМ ПОЯСОМ
Интервалы:
ИНТЕРВАЛ ДЕНЬ
ИНТЕРВАЛ ГОД
Типы коллекций:
МАССИВ
МУЛЬТИКОМПЛЕКТ
Другие типы:
РЯД
XML
Функции значений SQL
Эти функции значений SQL выполняют операции над данными. Существуют всевозможные операции, которые можно было бы выполнять над элементами данных, но именно эти операции необходимы чаще всего.
Существуют всевозможные операции, которые можно было бы выполнять над элементами данных, но именно эти операции необходимы чаще всего.
| Функция | Эффект |
|---|---|
| ПОДСТРОКА | Извлекает подстроку из исходной строки |
| ПОДСТРОКА ПОХОЖАЯ | Извлекает подстроку из исходной строки, используя регулярные выражения на основе POSIX |
| SUBSTRING_REGEX | Извлекает из строки первое вхождение шаблона регулярного выражения XQuery и возвращает одно вхождение соответствующей подстроки |
| TRANSLATE_REGEX | Извлекает из строки первое или каждое вхождение числа 9.0246 Шаблон регулярного выражения XQuery и заменяет его или их строкой замены XQuery |
| ВЕРХНИЙ | Преобразует строку символов в верхний регистр |
| НИЖНИЙ | Преобразует строку символов во все строчные буквы |
| НАКЛАДКА | Обрезка передних и задних заготовок |
| ПЕРЕВОД | Преобразует исходную строку из одного набора символов в другой |
| ПРЕОБРАЗОВАТЬ | Преобразует исходную строку из одного набора символов в другой |
| Функция | Эффект |
|---|---|
| ПОЛОЖЕНИЕ | Возвращает начальную позицию целевой строки в исходной строке |
| CHARACTER_LENGTH | Возвращает количество символов в строке |
| ОКТЕТ_ДЛИНА | Возвращает количество октетов (байтов) в строке символов |
| ЭКСТРАКТ | Извлекает одно поле из даты и времени или интервала |
| Функция | Эффект |
|---|---|
| ТЕКУЩАЯ_ДАТА | Возвращает текущую дату |
| ТЕКУЩЕЕ_ВРЕМЯ(п) | Возвращает текущее время; (p) — точность секунд |
| CURRENT_TIMESTAMP(p) | Возвращает текущую дату и текущее время; (p) — точность секунд |
Функции набора SQL
Функции набора SQL дают вам быстрый ответ на вопросы, которые могут у вас возникнуть о характеристиках ваших данных в целом. Сколько строк в таблице? Какое самое высокое значение в таблице? Что самое низкое? Это вопросы, на которые могут ответить функции набора SQL.
Сколько строк в таблице? Какое самое высокое значение в таблице? Что самое низкое? Это вопросы, на которые могут ответить функции набора SQL.
| Функция | Эффект |
СЧЕТ | Возвращает количество строк в указанной таблице |
МАКС | Возвращает максимальное значение, которое встречается в указанной способности |
МИН | Возвращает минимальное значение, встречающееся в указанной таблице |
СУММА | Суммирует значения в указанном столбце |
АВГ | Возвращает среднее значение всех значений в указанном столбце |
СПИСОК | Преобразует значения из группы строк в строку с разделителями |
Тригонометрические и логарифмические функции
sin , cos , tan , asin , acos , atan , sinh , cosh , tanh , log(<база>, <значение>) , log10(<значение>) .
лн(<значение>)
Функции конструктора JSON
JSON_OBJECT
JSON_ARRAY
JSON_OBJECTAGG
JSON_ARRAYAGG
Функции запросов JSON
JSON_EXISTS
JSON_VALUE
JSON_QUERY
JSON_TABLE
Знание формата предложения MySQL WHERE
Предложение WHERE используется для изменения запроса DELETE, SELECT или UPDATE SQL. В этом списке показан формат, который вы можете использовать при написании предложения WHERE:
.ГДЕ exp И|ИЛИ exp И|ИЛИ exp …
, где exp может быть одним из следующих:
столбец = значение столбец > значение столбец >= значение столбец < значение столбец <= значение столбец МЕЖДУ значением 1 И значением 2 столбец IN ( значение1 , значение2 ,…) столбец НЕ ВХОДИТ ( значение1 , значение2 ,…) столбец НРАВИТСЯ значение столбец НЕ КАК значение
Об этой статье
Эта статья из книги:
- SQL для чайников ,
Об авторе книги:
Аллен Г. Тейлор — ветеран компьютерной индустрии с 30-летним стажем и автор более 40 книг, в том числе SQL для чайников и Crystal Отчеты для чайников. Он читает лекции по базам данных, инновациям и предпринимательству. Он также преподает разработку баз данных на международном уровне через ведущего поставщика онлайн-образования.
Тейлор — ветеран компьютерной индустрии с 30-летним стажем и автор более 40 книг, в том числе SQL для чайников и Crystal Отчеты для чайников. Он читает лекции по базам данных, инновациям и предпринимательству. Он также преподает разработку баз данных на международном уровне через ведущего поставщика онлайн-образования.
Этот артикул находится в категории:
- SQL ,
Как выучить SQL быстро, бесплатно, за 30 дней или меньше
SQL — это аббревиатура языка структурированных запросов, который является важным навыком для любого аналитика.
В этом посте я познакомлю вас с ключевыми понятиями SQL и помогу вам в изучении этого мощного языка.
Я самостоятельно изучил SQL из бесплатных онлайн-ресурсов и сегодня использую его, чтобы приносить пользу своим клиентам и помогать развивать свой бизнес. Я изучил основы SQL за несколько часов обучения, и вы тоже сможете.
Что такое SQL и почему он важен для аналитиков?
SQL — это язык, используемый для общения с базами данных. Если вам нужно извлечь, изменить или удалить данные из базы данных, вам нужно будет написать команды на SQL. Мы называем эти команды запросами. Аналитик может написать тысячи запросов за свою карьеру.
Аналитики работают с данными и поэтому должны знать, как обращаться к базам данных. SQL — один из самых важных навыков для аналитиков, но, к счастью, изучение SQL довольно просто.
SQL — наиболее распространенный язык запросов, но не единственный язык, используемый для взаимодействия с данными. SQL обычно используется для запросов к реляционным базам данных, таким как MySQL, Postgres и BigQuery. Примером нереляционной базы данных является MongoDB.
Основы SQL
Представьте, что вам нужно извлечь определенный набор данных из базы данных вашей компании. Предположим, вам нужен список пользователей с указанием их возраста и пола, и вы хотите упорядочить этих пользователей по соответствующим организациям.
В вашей базе данных может быть следующее:
Таблица №1 — Пользователи
Первая таблица содержит пользователей продукта компании. Как и следовало ожидать, у нас есть строка для каждого пользователя с «id» в качестве первичного ключа. Затем у нас есть несколько столбцов, которые рассказывают нам о пользователях. Обратите внимание на последний столбец, Organization_id. Это внешний ключ, который позволяет нам присоединять пользователей к их соответствующим организациям. Этот столбец можно использовать для присоединения таблицы пользователей к таблице организаций.
Таблица №2 — Организации
Вторая таблица содержит организационную информацию наших пользователей.
Итак, теперь, когда мы определили, где находятся нужные нам данные, мы можем структурировать SQL-запрос для получения соответствующих данных.
Структура SQL-запроса
Ниже приведен пример SQL-запроса среднего уровня сложности. Этот запрос поможет нам получить список пользователей из примера базы данных, рассмотренного ранее. Не волнуйтесь, я проведу вас шаг за шагом.
Не волнуйтесь, я проведу вас шаг за шагом.
ВЫБЕРИТЕ
users.id как user_id,
users.gender как user_gender,
users.age как user_age,
Organizations.id как Organization_id,
organizations.name как Organization_name
ИЗ
пользователей
ПРИСОЕДИНЯЙТЕСЬ users.id
WHERE
users.is_deleted = 0
Первая часть запроса используется, чтобы сообщить базе данных, что мы извлекаем, обновляем или удаляем данные. Я выделил эту часть запроса фиолетовым цветом. В нашем примере у нас есть «ВЫБРАТЬ».
Наиболее частым запросом, который вы будете писать, будет запрос «SELECT». Эти запросы используются для получения данных из базы данных.
Следующая часть запроса содержит список столбцов, которые мы запрашиваем из базы данных. Помните, мы говорим о стандартных реляционных базах данных, таблицы которых состоят из столбцов и строк. Чтобы указать базе данных, что нам показывать, нам нужно указать, какие столбцы нам нужны.
В примере список столбцов окрашен оранжевым цветом. Мы видим 5 столбцов: идентификатор, пол и возраст, принадлежащие таблице пользователей, и идентификатор и имя, принадлежащие таблице организаций. Операторы as, которые следуют за каждым столбцом, называются псевдонимами. Мы можем переименовать столбцы, которые мы возвращаем, во что угодно. Псевдонимы — это хорошая привычка, поскольку вам часто нужно стандартизировать соглашения об именах столбцов.
Мы видим 5 столбцов: идентификатор, пол и возраст, принадлежащие таблице пользователей, и идентификатор и имя, принадлежащие таблице организаций. Операторы as, которые следуют за каждым столбцом, называются псевдонимами. Мы можем переименовать столбцы, которые мы возвращаем, во что угодно. Псевдонимы — это хорошая привычка, поскольку вам часто нужно стандартизировать соглашения об именах столбцов.
Третья часть запроса сообщает базе данных, из какой таблицы извлекать данные. В нашем примере это таблица пользователей. Но подождите, мы также запросили столбцы из таблицыorganizations, так как же это работает?
Причина, по которой мы смогли вывести столбцы из двух таблиц, заключалась в том, что мы выполнили соединение. Обратите внимание на секцию черного цвета. Эта часть запроса указывает базе данных соединить два столбца, чтобы можно было включить данные из второй таблицы.
Объединение таблиц очень распространено и является одним из наиболее сложных аспектов SQL.
Последняя часть запроса — это предложение «ГДЕ». Предложение WHERE используется для фильтрации данных, которые нам не нужны. В нашем примере мы указываем базе данных возвращать пользователей, которые не были удалены (is_deleted = 0).
Предложение WHERE используется для фильтрации данных, которые нам не нужны. В нашем примере мы указываем базе данных возвращать пользователей, которые не были удалены (is_deleted = 0).
Обратите внимание, как я написал пример запроса. Вы видите, как я написал основные команды с заглавной буквы и упорядоченно распределил запросы? Как аналитик, вы должны начать писать SQL четко и организованно с первого дня. Это поможет вам привыкнуть. Попробуйте проверить 40-строчный запрос, который написан неорганизованно, и вы поймете, почему я сделал это предложение.
Как получить все данные из таблицы в SQL?
Чтобы получить все данные из таблицы в SQL, вам просто нужно использовать оператор звездочки (*). Пример такого запроса можно увидеть ниже.
ВЫБЕРИТЕ
*
ИЗ
пользователей
Что еще можно сделать с помощью SQL-запроса?
SQL — мощный, популярный язык с большим количеством дополнительных функций. Приведенный выше пример просто извлекает данные как есть из двух таблиц, но SQL можно использовать для управления вашими данными до того, как будут возвращены выходные данные.
Допустим, вместо того, чтобы возвращать список пользователей, я хотел подсчитать количество пользователей, принадлежащих каждой организации? В этом случае я бы добавил в свой запрос функции группировки и подсчета.
Below is a list of the most frequently used SQL functions:
- Distinct
- Count
- Sum
- Order BY
- Group By
- Min
- Max
- Avg
- Case
- Limit
- Union
Где я могу изучать SQL онлайн?
Существует несколько способов изучения SQL в Интернете. Ниже приведен список моих любимых ресурсов.
- W3schools [бесплатно]
- Онлайн-курс — полный курс SQL Bootcamp [платно]
- онлайн-курс — Master SQL для науки о данных [платно]
- онлайн-курс — SQL для науки о данных [платно]
- онлайн-курс — обучение SQL от Codecademy [бесплатно]
- Онлайн-курс — Введение в SQL: запросы и управление данными от Khan Academy [бесплатно]
- Памятка по SQL [бесплатно]
Ресурсы YouTube по SQL
Ниже приведены некоторые из лучших ресурсов YouTube, которые я нашел по SQL.
- SQL — Полный курс для начинающих
- Изучите базовый SQL за 10 минут
- Изучите SQL за 1 час — Основы SQL для начинающих
Спасибо за внимание.
SQL для чайников, 9-е издание
Выбранный тип: Мягкая обложка
Количество:
$34,99
Аллен Г. Тейлор
ISBN: 978-1-119-52707-7 декабрь 2018 г. 512 страниц
Электронная книга
От 21 долл.
 США
СШАПечать
От 34,99 долл. США
Электронная книга  </li><li>E-books are non-returnable and non-refundable.</li><li>To learn more about our e-books, please refer to our <a href="https://www.wiley.com/wiley-ebooks" target="_blank">FAQ</a>.</li></ul>» data-original-title=»» title=»»/>
</li><li>E-books are non-returnable and non-refundable.</li><li>To learn more about our e-books, please refer to our <a href="https://www.wiley.com/wiley-ebooks" target="_blank">FAQ</a>.</li></ul>» data-original-title=»» title=»»/>
21,00 $
Мягкая обложка
34,99 $
Загрузить рекламный проспект
Загрузить рекламный проспект
Загрузить флаер продукта для загрузки PDF в новой вкладке. Это фиктивное описание.
Загрузить флаер продукта — загрузить PDF в новой вкладке. Это фиктивное описание.
Загрузить флаер продукта — загрузить PDF в новой вкладке.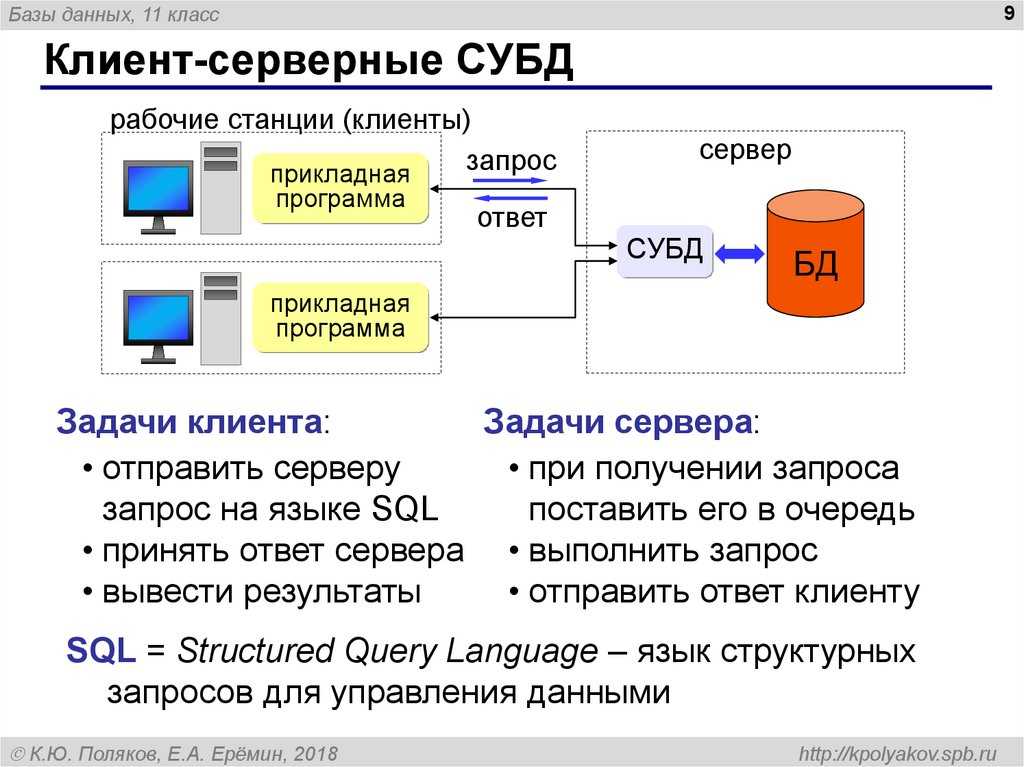 Это фиктивное описание.
Загрузить флаер продукта — загрузить PDF в новой вкладке. Это фиктивное описание.
Это фиктивное описание.
Загрузить флаер продукта — загрузить PDF в новой вкладке. Это фиктивное описание.
Описание
Будьте готовы сделать SQL проще!
Обновленное для последней версии SQL, новое издание этого многолетнего бестселлера показывает программистам и веб-разработчикам, как использовать SQL для создания реляционных баз данных и получения из них ценной информации. Охватывая все, что вам нужно знать, чтобы сделать работу с SQL проще, чем когда-либо, темы включают, как использовать SQL для структурирования СУБД и реализации проекта базы данных; защитить базу данных; и получить информацию из базы данных; и многое другое.
SQL — это международный стандартный язык баз данных, используемый для создания, доступа, управления, обслуживания и хранения информации в системах управления реляционными базами данных (СУБД), таких как Access, Oracle, SQL Server и MySQL. SQL добавляет к обычным языкам мощные возможности обработки и извлечения данных, и эта книга покажет вам, как с легкостью использовать основной элемент реляционных баз данных.
- Серверная платформа, позволяющая выбирать языки разработки, типы данных, локальные или облачные, а также операционные системы
- Найдите отличные примеры использования темпоральных данных
- Сразу приступайте к работе — без предварительных знаний в области программирования баз данных или SQL
По мере роста популярности и сложности веб-сайтов, управляемых базами данных, SQL для чайников — это просто -чтобы понять, перейти к ресурсу, который вам нужен, чтобы использовать его беспрепятственно.
Об авторе
Аллен Г. Тейлор — ветеран компьютерной индустрии с 30-летним стажем и автор более 40 книг, в том числе SQL для чайников и Crystal Reports для чайников. Он читает лекции по базам данных, инновациям и предпринимательству. Он также преподает разработку баз данных на международном уровне через ведущего поставщика онлайн-образования.
Разрешения
Запросить разрешение на повторное использование контента с этого сайта
Содержание
Введение 1
Об этой книге 1
Глупые предположения 2
ИКОНЫ, Используемые в этой книге 2
За пределами книги 3
, куда идти отсюда 3
Часть 1: Начало с SQL 5
. Глава 1: Основы реляционных баз данных 7
Отслеживание событий 8
Что такое база данных? 9
Размер и сложность базы данных 10
Что такое система управления базами данных? 10
плоские файлы 12
Модели баз данных 13
Соображения дизайна баз данных 20
Глава 2: Основы SQL 23
Что такое SQL, а не 23
A Операторы 26
Зарезервированные слова 28
Типы данных 28
Нулевые значения 49
Ограничения 50
Использование SQL в системе клиент/сервер 50
Использование SQL в Интернете или интранете 52
Глава 3: Компоненты SQL 55
Язык определения данных 56
Язык манипуляции с данными 68
Язы : Построение и поддержка структуры простой базы данных 85
Использование инструмента RAD для построения простой базы данных 86
Повышение мощности с помощью SQL DDL 98
Вопросы переносимости 107
ГЛАВА 5: Построение многотоковой реляционной базы данных 109
Проектирование базы данных 110
Работа с индексами 119
. Данные 141
Данные 141
Глава 6. Управление данными базы данных 143
Извлечение данных 144
Создание представлений 145
Обновление представлений 149
Добавление новых данных 150
ГЛАВА 7: Обработка временных данных 163
Понимание Время и периоды 164
Работа с таблицами периода применения 165
Работа с системой. Данные времени с битовыми таблицами 175
Форматирование и анализ даты и времени 176
0005
Выражения значений 186
Функции 189
Глава 9: Использование расширенных выражений значения SQL 209
СОВЕТЫ СОПУСМОСТИ СОВЕТА Обнуление нужных данных 223
Модификация предложений 224
Предложения FROM 225
Предложения WHERE 226
Логические связки 243
GROUP BY Clauses 245
HAVING Clauses 247
ORDER BY Clauses 248
Limited FETCH 250
Peering through a Window to Create a Result Set 251
Chapter 11: Using Relational Operators 259
UNION 259
INTERSECT 262
ЗА ИСКЛЮЧЕНИЕМ 264
Операторы соединения 265
ON и WHERE 282
0571
Что делают подзапросы 285
Глава 13. Рекурсивные запросы 303
Рекурсивные запросы 303
Что такое рекурсия? 303
Что такое рекурсивный запрос? 306
Где можно использовать рекурсивный запрос? 306
Где еще можно использовать рекурсивный запрос? 311
Часть 4. Управление операциями 313
Глава 14. Обеспечение безопасности базы данных 315
Язык управления данными SQL 316
Уровни доступа к пользователям 316
Привилегии предоставления пользователям 318
Привилегии по предоставлению уровней 325
Предоставление полномочий для предоставления привилегий 327
Убрать привилегии 328
Использование гранта и отмены, чтобы сэкономить время и усилия 329
. Глава 15: Защита данных 331
Угрозы целостности данных 332
Снижение уязвимости к повреждению данных 336
Ограничения в транзакциях 345
Избегание атак в инъекциях SQL 350
Глава 16: Использование SQL в рамках приложений 351
SQL в применении 352
Clocking SQL.
Глава 17. Доступ к данным с помощью ODBC и JDBC 367
ODBC 368
ODBC в среде клиент/сервер 370
ODBC и Интернет 370
ODBC и интранет 373
JDBC 373
Глава 18: Работа на данных XML с SQL 377
Как XML обращается с SQL 377
. в SQL 380
Функции SQL, работающие с данными XML 385
Предикаты 390
Преобразование данных XML в таблицы SQL 392
Отображение непредопределенных типов данных в XML 393
Брак SQL и XML 398
Chapter 19: SQL and JSON 399
Using JSON with SQL 400
The SQL/JSON Data Model 401
SQL/JSON Functions 403
SQL/JSON Path Language 411
There’s More 412
ЧАСТЬ 6: Усовершенствованные темы 413
Глава 20: Занять набор данных с курсорами 415
Объявление Cursor 416
Открытие A -cursor 421
letshor 416
. 0005
0005
Закрытие курсора 425
ГЛАВА 21: Добавление процедурных возможностей с постоянными хранимыми модулями 427
СОЕДИНЕНИЯ 428
Поток контрольных операторов 435
STRED.
Сохраненные модули 443
Глава 22. Обработка ошибок 445
SQLSTATE 445
WHENEVER Пункт 447
Диагностические области 448
Исключения обработки 455
Глава 23: Триггеры 457
Осмотр некоторых применений триггеров 457
Создание триггера 458
. 461
Запуск нескольких триггеров на одном столе 462
Часть 7. Доли десятков 463
Глава 24. Десять распространенных ошибок 465
Предполагая, что ваши клиенты знают, что им нужно 465
Игнорирование применения проекта 466
Учитывая только технические факторы 466
Не спрашивая клиентскую отзыв 466
Всегда использование вашей любимой развития 467
. Исключительно архитектура 467
Исключительно архитектура 467
Проектирование таблиц базы данных в изоляции 467
Пренебрежение проверками проекта 468
Пропуск бета-тестирования 468
Не документирование вашего процесса 468
Глава 25: Десять советов по поиску 469
Проверьте структуру базы данных 470
Попробуйте запросы на тестовую базу базы 470
. Запросы с подзапросами 470
Суммирование данных с помощью GROUP BY 471
Просмотр ограничений предложения GROUP BY 471
Использование скобок с И, ИЛИ и НЕ 471
Управление правами извлечения 472
Регулярно создавайте резервные копии баз данных 472
Изящно обрабатывайте условия ошибок 472
Приложение: ISO/IEC SQL: 2016 Зарезервированные слова 473
Указатель 479
Как писать простые запросы
Как делать запросы к базе данных SQL:
- Убедитесь, что у вас есть приложение для управления базой данных (например, MySQL Workbench, Sequel Pro).

- Если нет, загрузите приложение для управления базой данных и обратитесь в свою компанию, чтобы подключить базу данных.
- Поймите свою базу данных и ее иерархию.
- Узнайте, какие поля есть в ваших таблицах.
- Начните писать запрос SQL, чтобы получить нужные данные.
Вы когда-нибудь слышали о SQL? Возможно, вы слышали об этом в контексте анализа данных, но никогда не думали, что это применимо к вам как к маркетологу. Или, возможно, вы подумали: «Это для продвинутых пользователей данных. Я бы никогда не смог этого сделать».
Что ж, ошибаться нельзя! Самые успешные маркетологи управляются данными, и одна из самых важных частей управления данными — быстрый сбор данных из баз данных. SQL — самый популярный инструмент для этого.
Если ваша компания уже хранит данные в базе данных, вам может потребоваться изучить SQL для доступа к данным. Но не беспокойтесь — вы находитесь в правильном месте, чтобы начать. Давайте сразу приступим.
Зачем использовать SQL?
SQL (часто произносится как «sequel») означает «язык структурированных запросов» и используется, когда компании имеют массу данных, которыми они хотят манипулировать. Прелесть SQL в том, что его может использовать любой, кто работает в компании, которая хранит данные в реляционной базе данных. (И, скорее всего, у вас так и есть.)
Например, если вы работаете в компании-разработчике программного обеспечения и хотите получить данные об использовании ваших клиентов, вы можете сделать это с помощью SQL. Если вы помогаете разрабатывать веб-сайт для компании электронной коммерции, у которой есть данные о покупках клиентов, вы можете использовать SQL, чтобы узнать, какие клиенты покупают какие продукты. Конечно, это лишь некоторые из многих возможных применений.
Подумайте об этом так: вы когда-нибудь открывали очень большой набор данных в Excel только для того, чтобы ваш компьютер завис или даже выключился? SQL позволяет вам получить доступ только к определенным частям ваших данных за раз, поэтому вам не нужно загружать все данные в CSV, манипулировать ими и, возможно, перегружать Excel. Другими словами, SQL позаботится об анализе данных, который вы, возможно, привыкли делать в Excel.
Другими словами, SQL позаботится об анализе данных, который вы, возможно, привыкли делать в Excel.
Как писать простые SQL-запросы
Прежде чем мы начнем, убедитесь, что у вас есть приложение для управления базой данных, которое позволит вам извлекать данные из базы данных. Некоторые варианты включают MySQL или Sequel Pro.
Начните с загрузки одного из этих вариантов, а затем поговорите с ИТ-отделом вашей компании о том, как подключиться к вашей базе данных. Выбранный вами вариант будет зависеть от серверной части вашего продукта, поэтому проконсультируйтесь с командой по продукту, чтобы убедиться, что вы выбрали правильный вариант.
Понимание иерархии вашей базы данных
Далее важно привыкнуть к вашей базе данных и ее иерархии. Если у вас есть несколько баз данных данных, вам нужно уточнить расположение данных, с которыми вы хотите работать.
Например, давайте представим, что мы работаем с несколькими базами данных о людях в Соединенных Штатах. Введите запрос «ПОКАЗАТЬ БАЗЫ ДАННЫХ;». Результаты могут показать, что у вас есть несколько баз данных для разных местоположений, в том числе одна для Новой Англии.
Введите запрос «ПОКАЗАТЬ БАЗЫ ДАННЫХ;». Результаты могут показать, что у вас есть несколько баз данных для разных местоположений, в том числе одна для Новой Англии.
В вашей базе данных у вас будут разные таблицы, содержащие данные, с которыми вы хотите работать. Используя тот же пример выше, предположим, что мы хотим узнать, какая информация содержится в одной из баз данных. Если мы воспользуемся запросом «ПОКАЗАТЬ ТАБЛИЦЫ в Новой Англии;», мы обнаружим, что у нас есть таблицы для каждого штата Новой Англии: people_connecticut, people_maine, people_massachusetts, people_newhampshire, people_rhodeisland и people_vermont.
Наконец, вам нужно узнать, какие поля есть в таблицах. Поля — это определенные фрагменты данных, которые вы можете извлечь из своей базы данных. Например, если вы хотите получить чей-то адрес, имя поля может быть не просто «адрес» — оно может быть разделено на адрес_город, адрес_штат, адрес_zip. Чтобы это выяснить, воспользуйтесь запросом «Describe people_massachusetts;». Это предоставляет список всех данных, которые вы можете получить с помощью SQL.
Это предоставляет список всех данных, которые вы можете получить с помощью SQL.
Давайте кратко рассмотрим иерархию на примере Новой Англии:
- Наша база данных: NewEngland.
- Наши таблицы в этой базе данных:
- Наши поля в таблице people_massachusetts включают: address_city, address_state, address_zip, hair_color, age, first_name и last_name.
Теперь давайте напишем несколько простых SQL-запросов для извлечения данных из нашей базы данных NewEngland.
Базовые SQL-запросы
Чтобы научиться писать SQL-запросы, давайте воспользуемся следующим примером:
Кто эти рыжеволосые жители Массачусетса, родившиеся в 2003 году, расположенные в алфавитном порядке?
SELECT
SELECT выбирает поля, которые вы хотите отобразить на диаграмме. Это конкретная часть информации, которую вы хотите извлечь из своей базы данных. В приведенном выше примере мы хотим найти человека из , которые соответствуют остальным критериям.
Вот наш SQL-запрос:
SELECT
first_name,
last_name
4 ;FROM
FROM определяет таблицу, из которой вы хотите извлечь данные. В предыдущем разделе мы узнали, что для каждого из шести штатов Новой Англии существует шесть таблиц: people_connecticut, people_maine, people_massachusetts, people_newhampshire, people_rhodeisland и people_vermont. Поскольку мы ищем людей именно в Массачусетсе, мы будем извлекать данные из этой конкретной таблицы.
Here is our SQL query:
SELECT
first_name,
last_name
FROM
people_massachusetts
;
WHERE
WHERE позволяет отфильтровать запрос, чтобы сделать его более конкретным. В нашем примере мы хотим отфильтровать наш запрос, чтобы включить только людей с рыжими волосами, которые родились в 2003 году. Начнем с фильтра рыжих волос.
Начнем с фильтра рыжих волос.
Here is our SQL query:
SELECT
first_name,
last_name
FROM
people_massachusetts
WHERE
hair_color = ‘red’
;
hair_color мог бы быть частью вашего первоначального оператора SELECT, если бы вы хотели просмотреть всех людей в Массачусетсе вместе с их цветом волос. Но если вы хотите отфильтровать, чтобы увидеть только человека с рыжими волосами, вы можете сделать это с помощью оператора WHERE.
BETWEEN
Помимо равенства (=), BETWEEN — это еще один оператор, который можно использовать для условных запросов. Оператор BETWEEN верен для значений, которые находятся между указанными минимальным и максимальным значениями.
В нашем случае мы можем использовать BETWEEN для извлечения записей за определенный год, например 2003. Вот запрос:
Вот запрос:
SELECT
first_name,
906 04 _ 9 0004
Из
People_massachusetts
, где
Birth_date между ‘2003-01-01’ и ‘2003-12-31’
9000 ;AND
AND позволяет вам добавлять дополнительные критерии в оператор WHERE. Помните, мы хотим отфильтровать людей с рыжими волосами в дополнение к людям, которые родились в 2003 году. Поскольку наше утверждение WHERE используется по критериям рыжих волос, как мы можем фильтровать также и по определенному году рождения?
Здесь на помощь приходит оператор AND. В данном случае оператор AND является свойством даты, но это не обязательно. (Примечание. Уточните формат дат у специалистов по продукту, чтобы убедиться, что они в правильном формате.)
Вот наш SQL-запрос:
SELECT
first_name,
90 0 604 _ lastname ОТ
people_massachusetts
, где
Hair_color = ‘Red’
и
Birth_date между ‘2003-01-01’ и ‘2003-12-31’
;
ИЛИ
ИЛИ также можно использовать с оператором WHERE. При использовании AND оба условия должны быть истинными, чтобы они отображались в результатах (например, цвет волос должен быть рыжим, а дата рождения — 2003 г.). При использовании ИЛИ любое условие должно быть истинным, чтобы оно отображалось в результатах (например, цвет волос должен быть красным или 9).1334 должен родиться в 2003 году).
При использовании AND оба условия должны быть истинными, чтобы они отображались в результатах (например, цвет волос должен быть рыжим, а дата рождения — 2003 г.). При использовании ИЛИ любое условие должно быть истинным, чтобы оно отображалось в результатах (например, цвет волос должен быть красным или 9).1334 должен родиться в 2003 году).
Here’s what an OR statement looks like in action:
SELECT
first_name,
last_name
FROM
people_massachusetts
WHERE
hair_color = ‘red ‘
ИЛИ
дата_рождения МЕЖДУ «01.01.2003» И «31.12.2003»
;
NOT
NOT используется в операторе WHERE для отображения значений, в которых указанное условие не выполняется. Если мы хотели бы поднять все жители Массачусетса без Ред -волосы, мы можем использовать следующий запрос:
SELECT
First_Name,
The Last_name
9000.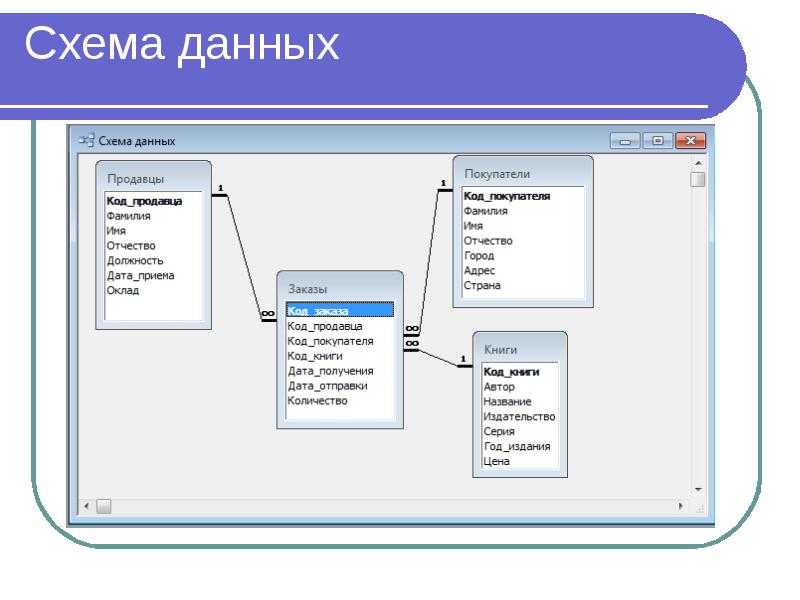 9000.9000STIS 9000STIS 9000STIS 9000STIS 9000STIS 9000STRACHS 9000STIS 9000STRACHISTIS 9000STRACHISTIS 9000STRACHISTIS 9000STIRS 9000STRACHISMACH. ГДЕ НЕТ
9000.9000STIS 9000STIS 9000STIS 9000STIS 9000STIS 9000STRACHS 9000STIS 9000STRACHISTIS 9000STRACHISTIS 9000STRACHISTIS 9000STIRS 9000STRACHISMACH. ГДЕ НЕТ
hair_color = ‘рыжий’
;
ORDER BY
Расчеты и организация также могут быть выполнены в рамках запроса. Вот тут-то и появляются функции ORDER BY и GROUP BY. Сначала мы рассмотрим наши SQL-запросы с функциями ORDER BY, а затем GROUP BY. Затем мы кратко рассмотрим разницу между ними.
Предложение ORDER BY позволяет выполнять сортировку по любому из полей, указанных в операторе SELECT. В этом случае давайте сортировать по фамилии.
Here is our SQL query:
SELECT
first_name,
last_name
FROM
people_massachusetts
WHERE
hair_color = ‘red’
И
дата рождения МЕЖДУ «01. 01.2003» И «31.12.2003»0004
01.2003» И «31.12.2003»0004
;
GROUP BY
GROUP BY похож на ORDER BY, но объединяет сходные данные. Например, если в ваших данных есть дубликаты, вы можете использовать GROUP BY для подсчета количества дубликатов в ваших полях.
Вот ваш запрос SQL:
SELECT
First_Name,
LAST_NAME
Из
PEOROD_MASSACHUSETETTS
PEORO0004
WHERE
hair_color = ‘red’
AND
birth_date BETWEEN ‘2003-01-01’ AND ‘2003-12-31’
GROUP BY
фамилия
;
ЗАКАЗ ПО VS. GROUP BY
Чтобы показать разницу между оператором ORDER BY и оператором GROUP BY, давайте ненадолго отвлечемся от нашего примера из Массачусетса и рассмотрим очень простой набор данных. Ниже приведен список идентификационных номеров и имен четырех сотрудников.
Ниже приведен список идентификационных номеров и имен четырех сотрудников.
Если бы мы использовали оператор ORDER BY в этом списке, имена сотрудников были бы отсортированы в алфавитном порядке. Результат будет выглядеть следующим образом:
Если бы вместо этого мы использовали оператор GROUP BY, сотрудники подсчитывались бы на основе того, сколько раз они появлялись в исходной таблице. Обратите внимание, что в исходной таблице Петр появился дважды, поэтому результат будет выглядеть так:
Пока со мной? Хорошо, давайте вернемся к созданному нами SQL-запросу о рыжеволосых людях из Массачусетса, родившихся в 2003 году.0005
LIMIT
В зависимости от объема данных в базе данных выполнение запросов может занять много времени. Это может быть неприятно, особенно если вы допустили ошибку в своем запросе и теперь вам нужно подождать, прежде чем продолжить. Если вы хотите протестировать запрос, функция LIMIT позволяет ограничить количество получаемых результатов.
Например, если мы подозреваем, что в Массачусетсе проживают тысячи людей с рыжими волосами, мы можем захотеть протестировать наш запрос с помощью LIMIT, прежде чем запускать его полностью, чтобы убедиться, что мы получаем нужную информацию. Скажем, например, мы хотим видеть только первые 100 человек в нашем результате.
Here is our SQL query:
SELECT
first_name,
last_name
FROM
people_massachusetts
WHERE
hair_color = ‘red’
И
дата рождения МЕЖДУ «01.01.2003» И «31.12.2003»0004
ПРЕДЕЛ
100
;
ВСТАВИТЬ В
Помимо извлечения информации из реляционной базы данных, SQL также можно использовать для изменения содержимого базы данных. Конечно, вам потребуются разрешения для внесения изменений в данные вашей компании. Но на случай, если вы когда-либо будете отвечать за управление содержимым базы данных, мы поделимся некоторыми вопросами, которые вам следует знать.
Конечно, вам потребуются разрешения для внесения изменений в данные вашей компании. Но на случай, если вы когда-либо будете отвечать за управление содержимым базы данных, мы поделимся некоторыми вопросами, которые вам следует знать.
Во-первых, это оператор INSERT INTO, который предназначен для помещения новых значений в вашу базу данных. Если мы хотим добавить нового человека в таблицу Massachusetts, мы можем сделать это, сначала указав имя таблицы, которую мы хотим изменить, и поля в таблице, в которую мы хотим добавить. Затем мы пишем VALUE для каждого соответствующего значения, которое хотим добавить.
Here’s what that query could look like:
INSERT INTO
people_massachusetts (address_city, address_state, address_zip, hair_color, age, first_name, last_name)
VALUES
(Cambridge, Massachusetts, 02139 , блондинка, 32 года, Джейн, Доу)
;
В качестве альтернативы, если вы добавляете значение к каждому полю в таблице, вам не нужно указывать поля. Значения будут добавлены в столбцы в том порядке, в котором они перечислены в запросе.
Значения будут добавлены в столбцы в том порядке, в котором они перечислены в запросе.
Вставка в
People_massachusetts
Значения
(Cambridge, Massachusetts, 02139, Blonde, 32, Jane, Doe)
0404040404040404040404040404040404040404040404040404049.
Если вы хотите добавить значения только в определенные поля, вы должны указать эти поля. Скажем, мы хотим вставить только запись с именем, фамилией и состоянием адреса — мы можем использовать следующий запрос:
INSERT INTO
people_massachusetts (имя, фамилия, адрес_штат)
ЗНАЧЕНИЯ
(Джейн, Доу, Массачусетс)
;
ОБНОВЛЕНИЕ
Если вы хотите заменить существующие значения в вашей базе данных другими значениями, вы можете использовать ОБНОВЛЕНИЕ. Что, если, например, кто-то зарегистрирован в базе данных как рыжеволосый, хотя на самом деле у него каштановые волосы? Мы можем обновить эту запись с помощью операторов UPDATE и WHERE:
UPDATE
people_massachusetts
SET
hair_color = ‘brown’
WHERE
first_name = ‘Jane’
AND
last_name = ‘Doe’
;
Или, скажем, в вашей таблице возникла проблема, из-за которой некоторые значения для «address_state» отображаются как «Массачусетс», а другие — как «MA». Чтобы изменить все экземпляры «MA» на «Массачусетс», мы можем использовать простой запрос и обновить сразу несколько записей:
Чтобы изменить все экземпляры «MA» на «Массачусетс», мы можем использовать простой запрос и обновить сразу несколько записей:
Обновление
People_massachusetts
SET
ADDREST_STATE = ‘Massachusetts’
, где
9000 1045044044044044044044044044044044044045045045045045045045.04904440440440440440404. 04904 40002
.
Будьте осторожны при использовании UPDATE. Если вы не укажете, какие записи следует изменить с помощью оператора WHERE, вы измените все значения в таблице.
DELETE
DELETE удаляет записи из вашей таблицы. Как и в случае с UPDATE, не забудьте включить оператор WHERE, чтобы случайно не удалить всю таблицу.
Или, если нам случится найти несколько записей в нашей таблице people_massachusetts, которые действительно жили в штате Мэн, мы можем быстро удалить эти записи, указав поле address_state, например:
УДАЛИТЬ ИЗ
ГДЕ
address_state = 'мэн'
;
Бонус: расширенные советы по SQL
Теперь, когда вы узнали, как создать простой SQL-запрос, давайте обсудим некоторые другие приемы, которые вы можете использовать для повышения уровня запросов, начиная со звездочки.
* (звездочка)
Когда вы добавляете в запрос SQL символ звездочки, он сообщает запросу, что вы хотите включить в результаты все столбцы данных.
В примере с Массачусетсом, который мы использовали, у нас было только два имени столбца: first_name и last_name. Но предположим, что у нас есть 15 столбцов данных, которые мы хотим видеть в наших результатах — было бы сложно ввести имена всех 15 столбцов в операторе SELECT. Вместо этого, если вы замените имена этих столбцов звездочкой, запрос будет знать, что все столбцы должны быть включены в результаты.
Here's what the SQL query would look like:
SELECT
*
FROM
people_massachusetts
WHERE
hair_color = 'red'
AND
Birth_date между '2003-01-01' и '2003-12-31'
Заказ на
The Last_name
0004
100
;
% (символ процента)
Символ процента является подстановочным знаком, означающим, что он может представлять один или несколько символов в значении базы данных. Подстановочные знаки полезны для поиска записей с общими символами. Обычно они используются с оператором LIKE для поиска шаблона в данных.
Подстановочные знаки полезны для поиска записей с общими символами. Обычно они используются с оператором LIKE для поиска шаблона в данных.
Например, если мы хотим получить имена всех людей в нашей таблице, чей почтовый индекс начинается с «02», мы можем написать такой запрос:
SELECT
First_Name,
THAN_NAME
, где
ADDRED_ZIP, как '02%'
;
Здесь «%» обозначает любую группу цифр, следующую за «02», поэтому этот запрос выдает любую запись со значением для address_zip, начинающимся с «02».
ПОСЛЕДНИЕ 30 ДНЕЙ
После того, как я начал регулярно использовать SQL, я обнаружил, что один из моих основных запросов связан с попыткой выяснить, какие люди предприняли действия или выполнили определенный набор критериев в течение последних 30 дней.
Предположим, что сегодня 1 декабря 2021 года. Вы могли бы создать эти параметры, задав диапазон рождения_даты между 1 ноября 2021 года и 30 ноября 2021 года. Этот SQL-запрос будет выглядеть следующим образом:
Этот SQL-запрос будет выглядеть следующим образом:
SELECT
First_Name,
The Last_name
из
People_massachusetts
, где
HAR0005 и
Birth_date между '2021-11-01' и '2021-11-30'
Порядок. ;
Но для этого нужно подумать о том, какие даты охватывают последние 30 дней, и вам придется постоянно обновлять этот запрос.
Вместо этого, чтобы даты автоматически охватывали последние 30 дней, независимо от того, какой сегодня день, вы можете ввести это в AND:birth_date >= (DATE_SUB(CURDATE(),INTERVAL 30))
(Примечание. Вы должны перепроверить этот синтаксис с вашей командой разработчиков, поскольку он может отличаться в зависимости от программного обеспечения, которое вы используете для получения запросов SQL.)
Таким образом, ваш полный запрос SQL будет выглядеть следующим образом:
Выбрать
First_Name,
The Last_name
Из
People_massachusetts
, где
, где
. 0004
0004
и
Birth_date> = (date_sub (curdate (), интервал 30))
Порядок.
COUNT
В некоторых случаях может потребоваться подсчитать, сколько раз появляется критерий поля. Например, допустим, вы хотите подсчитать, сколько раз разные цвета волос появляются у людей, которых вы подсчитываете, из Массачусетса. В этом случае COUNT пригодится, так что вам не придется вручную складывать количество людей с разными цветами волос или экспортировать эту информацию в Excel.
Here's what that SQL query would look like:
SELECT
hair_color,
COUNT(hair_color)
FROM
people_massachusetts
AND
birth_date BETWEEN '2003-01-01' И '2003-12-31'
GROUP BY
hair_color
;
СРЕДНИЙ
AVG вычисляет среднее значение атрибута в результатах вашего запроса, исключая значения NULL (пустые). В нашем примере мы могли бы использовать AVG для расчета среднего возраста жителей Массачусетса в нашем запросе.
В нашем примере мы могли бы использовать AVG для расчета среднего возраста жителей Массачусетса в нашем запросе.
Вот как может выглядеть наш SQL -запрос:
SELECT
AVG (Возраст
Из
PEHES_MASSACHUSETTS
;
СУММ
СУММ — еще одно простое вычисление, которое можно выполнить в SQL. Он вычисляет общее значение всех атрибутов из вашего запроса. Итак, если мы хотим сложить все возрасты жителей Массачусетса, мы можем использовать этот запрос:
ВЫБЕРИТЕ
СУММА(возраст)
ИЗ
люди_массачусетс
2; MIN и MAX
MIN и MAX — это две функции SQL, которые дают вам наименьшее и наибольшее значения заданного поля. Мы можем использовать его для определения самых старых и самых молодых членов нашей таблицы Massachusetts:
Этот запрос даст нам запись самого старого:
SELECT
МИН(возраст)
ОТ
people_massachusetts
;
, и этот запрос дает нам самый старый:
SELECT
MAX (возраст)
Из
PEHAS_MASSACHUSETTS
;
JOIN
Может быть время, когда вам нужно получить доступ к информации из двух разных таблиц в одном запросе SQL. В SQL для этого можно использовать предложение JOIN.
В SQL для этого можно использовать предложение JOIN.
(Для тех, кто знаком с формулами Excel, это похоже на использование формулы ВПР, когда вам нужно объединить информацию из двух разных листов в Excel.)
Допустим, у нас есть одна таблица, в которой есть данные всех идентификаторов пользователей жителей Массачусетса. и даты их рождения. Кроме того, у нас есть совершенно отдельная таблица, содержащая все идентификаторы пользователей жителей Массачусетса и цвет их волос.
Если мы хотим определить цвет волос жителей Массачусетса, родившихся в 2003 году, нам потребуется получить доступ к информации из обеих таблиц и объединить их. Это работает, потому что обе таблицы имеют одинаковый столбец: идентификаторы пользователей.
Поскольку мы вызываем поля из двух разных таблиц, наш оператор SELECT также немного изменится. Вместо того, чтобы просто перечислять поля, которые мы хотим включить в наши результаты, нам нужно указать, из какой таблицы они берутся. (Примечание: здесь может пригодиться функция звездочки, чтобы ваш запрос включал обе таблицы в ваши результаты. )
)
Чтобы указать поле из определенной таблицы, все, что нам нужно сделать, это объединить имя таблицы с именем поле. Например, в нашем операторе SELECT будет указано «table.field» — с точкой, разделяющей имя таблицы и имя поля.
В этом случае мы также предполагаем несколько вещей:
- Таблица дат рождения в штате Массачусетс включает следующие поля: first_name, last_name, user_id, дата рождения
- Таблица цвета волос штата Массачусетс включает следующие поля: user_id, hair_color
Таким образом, ваш SQL-запрос будет выглядеть так:
SELECT
birthdate_massachusetts.first_name,
birthdate_massachusetts9.last_name0004
Из
Birthdate_massachusetts присоединяется 31-12-2003'
ЗАКАЗАТЬ
фамилия
;
Этот запрос соединит две таблицы, используя поле «user_id», которое появляется как в таблице Birthday_massachusetts, так и в таблице haircolor_massachusetts. Затем вы сможете увидеть таблицу людей, родившихся в 2003 году, с рыжими волосами.
Затем вы сможете увидеть таблицу людей, родившихся в 2003 году, с рыжими волосами.
CASE
Используйте оператор CASE, если вы хотите, чтобы ваш запрос возвращал разные результаты в зависимости от того, какое условие выполнено. Условия оцениваются по порядку. Как только условие выполнено, возвращается соответствующий результат, а все последующие условия пропускаются.
В конце можно включить условие ELSE, если никакие условия не выполняются. Без ELSE запрос вернет NULL, если никакие условия не выполняются.
Вот пример использования CASE для возврата строки на основе запроса:
SELECT
First_Name,
The Last_name
от
PEHES_MASSACHUSETTS
9000. 'HARESTRIOR 04.
WHEN hair_color = 'blonde' THEN 'У этого человека светлые волосы.'
WHEN hair_color = 'red' THEN 'У этого человека рыжие волосы.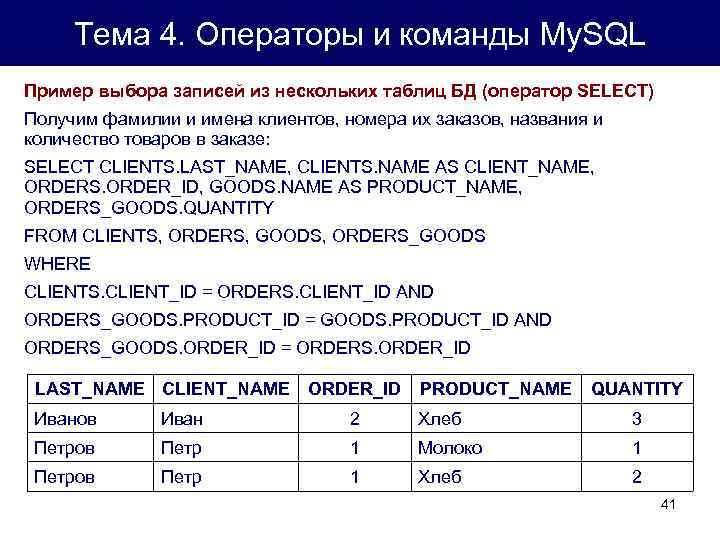 '
'
ELSE ‘Цвет волос неизвестен’
КОНЕЦ
;
Основные запросы SQL, которые должны знать маркетологи
Поздравляем. вы готовы выполнять свои собственные SQL-запросы! Хотя с помощью SQL можно сделать гораздо больше, я надеюсь, что этот обзор основ был вам полезен, и вы могли запачкать руки. Имея прочную основу основ, вы сможете лучше ориентироваться в SQL и работать над некоторыми более сложными примерами.
Примечание редактора: этот пост был первоначально опубликован в марте 2015 года и обновлен для полноты информации.
Первоначально опубликовано 21 марта 2022 г., 7:00:00, обновлено 21 марта 2022 г.
Изучите SQL за 7 дней
Ричард Петерсон
часовОбновлено
Резюме учебника по SQL
Базы данных можно найти практически во всех программных приложениях. SQL — это стандартный язык для запросов к базе данных. Этот учебник по SQL для начинающих научит вас проектировать базы данных. Кроме того, он учит вас базовому и продвинутому SQL.
Что я должен знать?
Курс предназначен для начинающих пользователей SQL. Опыт работы с БД не требуется.
Программа SQL
Основы баз данных
| 👉 Урок 1 | Что такое база данных? — определение, значение, типы, пример |
| 👉 Урок 2 | Что такое SQL? — Изучите основы SQL, полную форму SQL и как использовать |
| 👉 Урок 3 | Учебное пособие по MySQL Workbench для начинающих — Как установить и использовать MySQL Workbench |
Проектирование баз данных
| 👉 Урок 1 | Учебное пособие по проектированию баз данных — Изучите моделирование данных |
| 👉 Урок 2 | Что такое нормализация? — Пример базы данных 1NF, 2NF, 3NF, BCNF |
| 👉 Урок 3 | Что такое ER-моделирование? — Учитесь на примере |
Основы SQL
| 👉 Урок 1 | MySQL Create Table — Как создать базу данных в MySQL |
| 👉 Урок 2 | Инструкция MySQL SELECT — изучите пример |
| 👉 Урок 3 | MySQL WHERE Пункт — AND, OR, IN, NOT IN Пример запроса |
| 👉 Урок 4 | MySQL INSERT INTO Query — Как добавить строку в таблицу (пример) |
| 👉 Урок 5 | MySQL DELETE Query — Как удалить строку из таблицы |
| 👉 Урок 6 | MySQL UPDATE Query — Изучите пример |
Сортировка данных
| 👉 Урок 1 | ORDER BY в MySQL — Запрос DESC и ASC с ПРИМЕРОМ |
| 👉 Урок 2 | SQL GROUP BY и HAVING Пункт — изучите пример |
| 👉 Урок 3 | Учебное пособие по подстановочным знакам MySQL — Нравится, НЕ нравится, Escape, (%), (_) |
| 👉 Урок 4 | Регулярные выражения MYSQL (REGEXP) — Что такое, синтаксис и примеры |
Функции
| 👉 Урок 1 | Функции MySQL — строковые, числовые, пользовательские, сохраненные |
| 👉 Урок 2 | Учебное пособие по агрегатным функциям MySQL, часть — СУММА, СРЕДНЯЯ, МАКСИМАЛЬНАЯ, МИНИМАЛЬНАЯ, СЧЕТЧИК, РАЗЛИЧНЫЕ |
Что нужно знать!
| 👉 Урок 1 | MySQL IS NULL & IS NOT NULL Tutorial — Изучите пример |
| 👉 Урок 2 | MySQL AUTO_INCREMENT — Изучите пример |
| 👉 Урок 3 | MYSQL — ALTER, DROP, RENAME, MODIFY — что такое, синтаксис с примерами |
| 👉 Урок 4 | MySQL LIMIT & OFFSET — Изучите пример |
Самые страшные темы!
| 👉 Урок 1 | Учебное пособие по подзапросам MySQL — обучение на примере |
| 👉 Урок 2 | MySQL JOINS Tutorial — ВНУТРЕННЯЯ, ВНЕШНЯЯ, ЛЕВАЯ, ПРАВАЯ, ПЕРЕКРЕСТНАЯ |
| 👉 Урок 3 | MySQL UNION — Полное руководство |
| 👉 Урок 4 | Представления MySQL — Как создать представление из таблиц с примерами |
| 👉 Урок 5 | Учебное пособие по индексу MySQL — Создание, добавление и удаление |
Что дальше!
| 👉 Урок 1 | Ваше первое приложение с использованием MySQL и PHP — Приступаем к работе! |
| 👉 Урок 2 | Сертификация Oracle MySQL 5. 6 — Учебное пособие по Oracle MySQL 5.6 6 — Учебное пособие по Oracle MySQL 5.6 |
| 👉 Урок 3 | SQL против MySQL — в чем разница между SQL и MySQL? |
| 👉 Урок 4 | Лучшие инструменты SQL — 25 лучших инструментов SQL, ПО для баз данных и IDE |
| 👉 Урок 5 | Построители и редакторы SQL-запросов — 10 лучших конструкторов и редакторов SQL-запросов |
| 👉 Урок 6 | Онлайн-компилятор и редакторы SQL — 10 ЛУЧШИХ онлайн-компиляторов и редакторов SQL |
| 👉 Урок 7 | Бесплатные курсы SQL — 11 лучших бесплатных курсов SQL и сертификация |
| 👉 Урок 8 | Книги по SQL — 14 лучших книг по SQL для начинающих и экспертов |
| 👉 Урок 9 | Памятка по SQL — Памятка по командам SQL |
| 👉 Урок 10 | Вопросы для собеседования по SQL — Топ 50 вопросов и ответов для собеседования по SQL |
| 👉 Урок 11 | Учебное пособие по SQL в формате PDF — Загрузить учебное пособие по SQL в формате PDF для начинающих |
MariaDB
| 👉 Урок 1 | Учебное пособие по MariaDB — Изучение синтаксиса, команды с примерами |
| 👉 Урок 2 | MariaDB против MySQL — в чем разница между MariaDB и MySQL |
Что такое СУБД?
Система управления базами данных (СУБД) — это программное обеспечение, используемое для хранения и управления данными. Это гарантирует качество, долговечность и конфиденциальность информации. Наиболее популярным типом СУБД являются системы управления реляционными базами данных или РСУБД. Здесь база данных состоит из структурированного набора таблиц, и каждая строка таблицы является записью.
Это гарантирует качество, долговечность и конфиденциальность информации. Наиболее популярным типом СУБД являются системы управления реляционными базами данных или РСУБД. Здесь база данных состоит из структурированного набора таблиц, и каждая строка таблицы является записью.
Что такое SQL?
Язык структурированных запросов (SQL) — это стандартный язык для обработки данных в СУБД. Проще говоря, он используется для общения с данными в СУБД. Ниже приведены типы операторов SQL
- Язык определения данных (DDL) позволяет создавать такие объекты, как схемы, таблицы в базе данных
- Язык управления данными (DCL) позволяет управлять правами доступа к объектам базы данных Язык манипулирования данными
- (DML) используется для поиска, вставки, обновления и удаления данных, которые будут частично рассмотрены в этом руководстве по SQL.
Что такое запрос?
Запрос — это набор инструкций, отдаваемых системе управления базой данных. Он сообщает любой базе данных, какую информацию вы хотели бы получить из базы данных. Например, чтобы получить имя студента из таблицы базы данных STUDENT, вы можете написать SQL-запрос следующим образом:
Он сообщает любой базе данных, какую информацию вы хотели бы получить из базы данных. Например, чтобы получить имя студента из таблицы базы данных STUDENT, вы можете написать SQL-запрос следующим образом:
SELECT Student_name from STUDENT;
Процесс SQL
Если вы хотите выполнить команду SQL для какой-либо системы СУБД, вам нужно найти наилучший метод для выполнения вашего запроса, а механизм SQL определяет, как интерпретировать эту конкретную задачу.
Важные компоненты, включенные в этот процесс SQL:
- SQL Query Engine
- Механизмы оптимизации
- Диспетчер запросов
- Классический механизм запросов
Классический механизм запросов позволяет управлять всеми запросами, отличными от SQL.
Процесс SQL
Оптимизация SQL
Знать, как делать запросы, не так уж сложно, но вам нужно действительно изучить и понять, как работает хранилище данных и как читаются запросы, чтобы оптимизировать производительность SQL. Оптимизация основана на двух ключевых факторах:
Оптимизация основана на двух ключевых факторах:
- Правильный выбор при определении структуры базы данных
- Применение наиболее подходящих методов для чтения данных.
Чему вы научитесь на этом курсе SQL?
Этот учебник по основам SQL предназначен для всех, кто планирует работать с базами данных, особенно в роли системных администраторов и разработчиков приложений. Учебники помогают новичкам изучить основные команды SQL, включая SELECT, INSERT INTO, UPDATE, DELETE FROM и другие. Каждая команда SQL поставляется с четкими и краткими примерами.
В дополнение к списку команд SQL в учебнике представлены карточки с функциями SQL, такими как AVG(), COUNT() и MAX(). Наряду с этим тесты помогают проверить ваши базовые знания языка.
Этот курс SQL поможет вам разобраться с различными аспектами языка программирования SQL.
Зачем вам изучать SQL?
SQL — это простой в освоении язык, специально разработанный для работы с базами данных. Растет спрос на специалистов, умеющих работать с базами данных. Почти каждая крупная компания использует SQL. Он широко используется в различных секторах, таких как бронирование билетов, банковское дело, платформы социальных сетей, обмен данными, электронная коммерция и т. д., поэтому для разработчика SQL доступны огромные возможности.
Растет спрос на специалистов, умеющих работать с базами данных. Почти каждая крупная компания использует SQL. Он широко используется в различных секторах, таких как бронирование билетов, банковское дело, платформы социальных сетей, обмен данными, электронная коммерция и т. д., поэтому для разработчика SQL доступны огромные возможности.
Учебное пособие по SQL — основы SQL для начинающих
Это учебное пособие по SQL поможет вам быстро и эффективно начать работу с SQL с помощью множества практических примеров.
Если вы разработчик программного обеспечения, администратор базы данных, аналитик данных или специалист по данным, который хочет использовать SQL для анализа данных, это руководство является хорошим началом.
Каждая тема освещена четко и лаконично с множеством практических примеров, которые помогут вам по-настоящему понять концепцию и применить ее для более эффективного решения проблем с данными.
SQL означает S структурированный Q uery L язык, предназначенный для управления данными в системах управления реляционными базами данных (RDBMS).
Сегодня SQL является одним из наиболее распространенных языков программирования для взаимодействия с данными.
Раздел 1: Введение в SQL
- Что такое SQL — краткий обзор языка SQL и его популярных диалектов.
- Синтаксис SQL — предоставляет вам синтаксис языка SQL.
- Образец базы данных SQL — познакомьте вас с образцом базы данных HR.
Раздел 2. Запрос данных
- Оператор SELECT — показывает, как запрашивать данные из одной таблицы, используя простейшую форму оператора SELECT.
Раздел 3. Сортировка данных
- Пункт ORDER BY — сортировка данных по одному или нескольким столбцам в порядке возрастания и/или убывания.
Раздел 4. Фильтрация данных
- DISTINCT – покажет вам, как удалить дубликаты из набора результатов.
- LIMIT — ограничение количества строк, возвращаемых запросом, с помощью предложения LIMIT и OFFSET.
- FETCH — узнайте, как пропустить N строк в результирующем наборе, прежде чем начать возвращать какие-либо строки.

- Пункт WHERE — фильтрация данных на основе заданных условий.
- Операторы сравнения — узнайте, как использовать операторы сравнения, включая больше, больше или равно, меньше, меньше или равно, равно и не равно, чтобы сформировать условие в предложении WHERE.
- Логические операторы. Расскажите о логических операторах и о том, как их использовать для проверки истинности условия.
- Оператор И — объединение нескольких логических выражений с помощью логического оператора И.
- Оператор ИЛИ — показывает, как использовать другой логический оператор ИЛИ для объединения нескольких логических выражений.
- Оператор BETWEEN — поможет вам использовать оператор BETWEEN для выбора данных в диапазоне значений.
- Оператор IN – показывает, как использовать оператор IN для проверки наличия значения в списке значений.
- Оператор LIKE — запрос данных на основе заданного шаблона.
- Оператор IS NULL – знакомит с концепциями NULL и показывает, как проверить, является ли выражение NULL или нет.
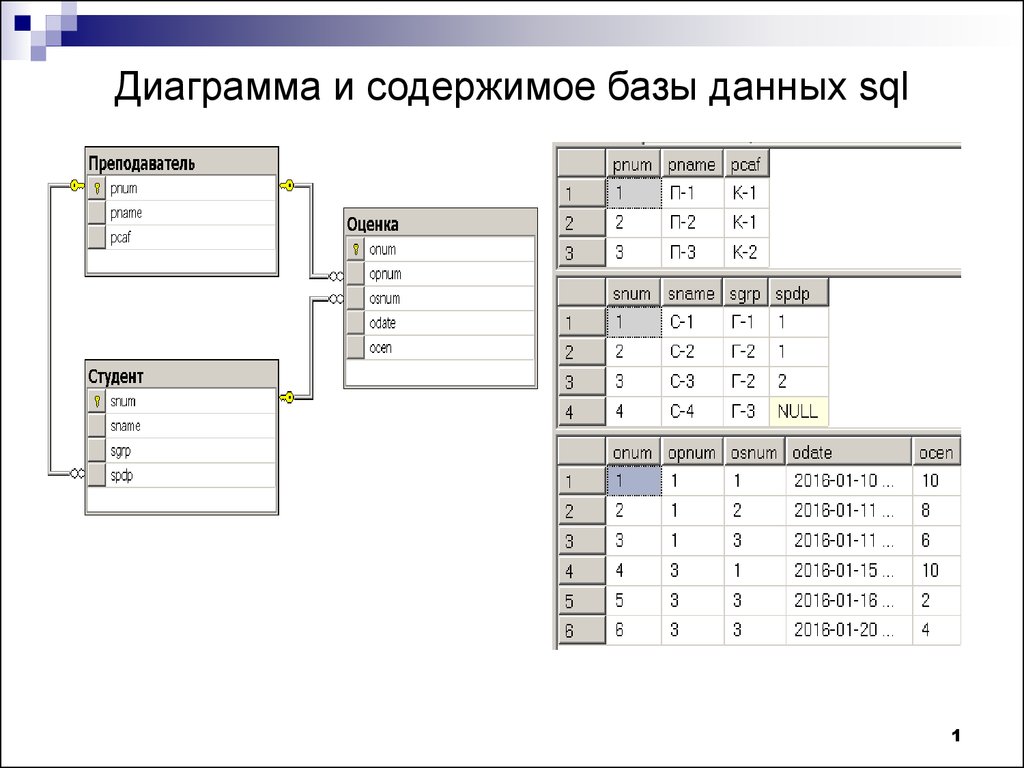
- Оператор НЕ – показывает, как инвертировать логическое выражение с помощью оператора НЕ.
Раздел 5. Условные выражения
- Выражение CASE – добавьте логику if-then-else к операторам SQL.
Раздел 6. Объединение нескольких таблиц
- Псевдонимы SQL — сделайте запрос короче и понятнее.
- INNER JOIN — познакомит вас с концепцией соединения и покажет, как использовать предложение INNER JOIN для объединения данных из нескольких таблиц.
- LEFT OUTER JOIN – предоставляет вам другой тип соединений, позволяющий объединять данные из нескольких таблиц.
- ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ — объединение нескольких таблиц путем включения строк из обеих таблиц независимо от того, имеют ли эти строки совпадающие строки из другой таблицы.
- ПЕРЕКРЕСТНОЕ СОЕДИНЕНИЕ – произвести декартово произведение строк соединяемых таблиц с помощью операции перекрестного соединения.
- SELF JOIN – присоединение таблицы к самой себе с помощью предложения внутреннего соединения или левого соединения.
Раздел 7. Агрегированные функции
- Агрегированные функции — знакомство с наиболее часто используемыми агрегатными функциями в SQL, включая AVG, COUNT, SUM, MAX и MIN.
- AVG — вычислить среднюю стоимость набора.
- COUNT — возвращает количество элементов в наборе.
- SUM – возвращает сумму всех или отдельных элементов набора.
- MAX – найти максимальное значение в наборе.
- MIN – найти минимальное значение в наборе.
Раздел 8: Группировка данных
- СГРУППИРОВАТЬ ПО – объединить строки в группы и применить агрегатную функцию к каждой группе.
- HAVING – укажите условие для фильтрации групп, объединенных предложением GROUP BY.
- НАБОРЫ ГРУППИРОВКИ – создание нескольких наборов группировок.
- ROLLUP — создание нескольких наборов группировок с учетом иерархии входных столбцов.
- CUBE – создание нескольких наборов группировок для всех возможных комбинаций входных столбцов.

Раздел 9. Операторы SET
- UNION и UNION ALL — объединение наборов результатов двух или более запросов в один набор результатов с помощью операторов UNION и UNION ALL.
- INTERSECT — возвращает пересечение двух или более запросов с помощью оператора INTERSECT.
- МИНУС – вычесть набор результатов из другого набора результатов с помощью оператора МИНУС.
Раздел 10. Подзапрос
- Подзапрос — показано, как вложить запрос в другой запрос, чтобы сформировать более гибкий запрос для запроса данных.
- Коррелированный подзапрос — познакомит вас с коррелированным подзапросом, который использует значения из внешнего запроса.
- EXISTS — показать вам, как проверить существование строки, возвращенной из подзапроса.
- ALL — проиллюстрируйте, как запрашивать данные, сравнивая значения в столбце таблицы с набором столбцов.
- ANY – запрашивать данные, если значение в столбце таблицы совпадает с одним из значений в наборе.

Раздел 11: Изменение данных
- INSERT — вставка одной или нескольких строк в таблицу.
- ОБНОВЛЕНИЕ – обновить существующие данные в таблице.
- УДАЛИТЬ — удалить данные из таблицы навсегда.
Раздел 12. Работа со структурами таблиц
- CREATE TABLE — создание новой таблицы в базе данных.
- ALTER TABLE — изменить структуру существующей таблицы.
- УДАЛИТЬ СТОЛ — навсегда удалить столы.
- TRUNCATE TABLE — быстрое и эффективное удаление всех данных в большой таблице.
Раздел 13. Ограничения
- PRIMARY KEY – покажет вам, как определить первичный ключ для таблицы.
- FOREIGN KEY – пошаговые инструкции по обеспечению связи между данными в двух таблицах с использованием ограничения внешнего ключа.
- UNIQUE — обеспечивают уникальность значений в столбце или наборе столбцов.
- NOT NULL — убедитесь, что значения, вставленные в столбец или обновленные для него, не равны NULL.
