java убрать пробелы в строке
На чтение 3 мин. Просмотров 37 Опубликовано
Задача String с пробелами состоит в том, чтобы удалить все пробелы из строки, используя встроенные методы Java.
Рекомендуется: Пожалуйста, сначала попробуйте подход
, прежде чем переходить к решению.Чтобы удалить все пробелы из String, используйте replaceAll() класса String с двумя аргументами, т.е.
48 Aiman Kh [2013-03-26 12:16:00]
У меня есть назначение программирования, и часть его требует от меня сделать код, который читает строку от пользователя и удаляет все пробелы внутри этой строки. строка может состоять из одного или нескольких слов.
То, что я пытаюсь сделать с этой программой, — это проанализировать каждый символ, пока не найдет пробел, а затем сохранит эту подстроку в качестве первого токена. затем повторите цикл, пока не достигнет больше токенов или конца строки.
Я продолжаю получать это, когда пытаюсь его скомпилировать:
Простые способы сделать это оценили, но я все еще хочу, чтобы эта программа работала.
и я не могу использовать часовые входы.
Спасибо всем за помощь,
Я буду использовать более простой метод и прочитаю javadoc.
У меня есть такая строка:
Я хочу удалить пробелы в строке. Я попытался trim() но это удаляет только пробелы до и после всей строки. Я также попробовал replaceAll(«\W», «») но затем = также удаляется.
Как я могу получить строку с:
29 ответов
st.replaceAll(«\s+»,»») удаляет все пробелы и невидимые символы (например, tab,
).
st.replaceAll(«\s+»,»») и st.replaceAll(«\s»,»») дают одинаковый результат.
Второе регулярное выражение на 20% быстрее первого, но по мере увеличения числа последовательных пробелов первое работает лучше, чем второе.
Присвойте значение переменной, если она не используется напрямую:
w = Все, что является символом слова
W = все, что не является символом слова (включая знаки препинания и т. Д.)
Д.)
s = Все, что является пробелом (включая пробел, символы табуляции и т. д.)
S = все, что не является пробелом (включая буквы и цифры, а также знаки препинания и т. Д.)
(Редактировать: как указывалось, вам нужно экранировать обратную косую черту, если вы хотите, чтобы s достиг движка регулярных выражений, что привело к \s .)
Самый правильный ответ на вопрос:
Я просто адаптировал этот код из других ответов. Я публикую его, потому что, помимо того, что он является именно тем, что запрашивался в вопросе, он также демонстрирует, что результат возвращается в виде новой строки, исходная строка не изменяется, как подразумевают некоторые ответы.
(Опытные Java-разработчики могут сказать: «Конечно, вы не можете изменить строку», но целевая аудитория по этому вопросу может и не знать об этом.)
Удаление пробелов в строке XML Ru Python
Как удалить пробелы и разрывы строк в XML-строке в Python 2.6? Я попробовал следующие пакеты:
etree: Этот фрагмент сохраняет исходные пробелы:
Я не могу использовать Python 2. 7, который предоставил бы параметр
7, который предоставил бы параметр method .
Самое легкое решение, вероятно, использует lxml , где вы можете установить параметр парсера, чтобы игнорировать пробел между элементами:
>>> from lxml import etree >>> parser = etree.XMLParser(remove_blank_text=True) >>> xml_str = '''<root> >>> <head></head> >>> <content></content> >>> </root>''' >>> elem = etree.XML(xml_str, parser=parser) >>> print etree.tostring(elem) <root><head/><content/></root> Этого, вероятно, будет достаточно для ваших нужд, но некоторые предупреждения должны быть в безопасности:
Это просто удалит пробельные узлы между элементами и попытается не удалять узлы пробела внутри элементов со смешанным контентом:
>>> elem = etree.XML('<p> spam <a>ham</a> <a>eggs</a></p>', parser=parser) >>> print etree. tostring(elem) <p> spam <a>ham</a> <a>eggs</a></p>
tostring(elem) <p> spam <a>ham</a> <a>eggs</a></p> Ведущие или конечные пробелы из текстовых полей не будут удалены. Однако, тем не менее, в некоторых случаях удалять лишние узлы из смешанного содержимого: если синтаксический анализатор еще не встречал узлы без пробелов на этом уровне.
>>> elem = etree.XML('<p><a> ham</a> <a>eggs</a></p>', parser=parser) >>> print etree.tostring(elem) <p><a> ham</a><a>eggs</a></p>
Если вы этого не хотите, вы можете использовать xml:space="preserve" , который будет соблюдаться. Другим вариантом будет использование etree.XMLParser(load_dtd=True) и использование etree.XMLParser(load_dtd=True) , где синтаксический анализатор будет использовать dtd для определения того, какие узловые узлы значительны или нет.
Помимо этого, вам придется написать свой собственный код, чтобы удалить пробелы, которые вам не нужны (итерация потомков и, при необходимости, задание . и  text
text.tail свойств, которые содержат только пробельные символы в None или пустую строку)
Вот что-то быстрое, что я придумал, потому что я не хотел использовать lxml:
from xml.dom import minidom from xml.dom.minidom import Node def remove_blanks(node): for x in node.childNodes: if x.nodeType == Node.TEXT_NODE: if x.nodeValue: x.nodeValue = x.nodeValue.strip() elif x.nodeType == Node.ELEMENT_NODE: remove_blanks(x) xml = minidom.parse('file.xml') remove_blanks(xml) xml.normalize() with file('file.xml', 'w') as result: result.write(xml.toprettyxml(indent = ' ')) Который мне действительно нужен только для повторного подделки XML-файла с другим сломанным отступом. Он не уважает директиву preserve , но, честно говоря, так поступает так много другого программного обеспечения, связанного с XML, что это довольно забавное требование 🙂 Кроме того, вы сможете легко добавить эту функциональность в код выше ( просто проверьте атрибут space и не возвращайте, если его значение «сохраняется». >\t])(\n[\t]*)(?=<)’) newXmlStr = re.sub(fix, », xmlStr )
>\t])(\n[\t]*)(?=<)’) newXmlStr = re.sub(fix, », xmlStr )
из этого источника
Единственное, что беспокоит меня о toprettyxml () в xml.dom.minidom, состоит в том, что он добавляет пустые строки. Кажется, я не получаю разделенные компоненты, поэтому я просто написал простую функцию для удаления пустых строк:
#!/usr/bin/env python import xml.dom.minidom # toprettyxml() without the blank lines def prettyPrint(x): for line in x.toprettyxml().split('\n'): if not line.strip() == '': print line xml_string = "<monty>\n<example>something</example>\n<python>parrot</python>\n</monty>" # parse XML x = xml.dom.minidom.parseString(xml_string) # clean prettyPrint(x) И это то, что выводит код:
<?xml version="1.0" ?> <monty> <example>something</example> <python>parrot</python> </monty>-<?xml version="1.0" ?> <monty> <example>something</example> <python>parrot</python> </monty>
Если я сам использую toprettyxml (), то есть print (toprettyxml (x)), он добавляет лишние пустые строки:
<?xml version="1.-0" ?> <monty> <example>something</example> <python>parrot</python> </monty>
<?xml version="1.0" ?> <monty> <example>something</example> <python>parrot</python> </monty>
Немного неуклюжее решение без lxml 🙂
data = """<root> <head></head> <content></content> </root>""" data3 = [] data2 = data.split('\n') for x in data2: y = x.strip() if y: data3.append(y) data4 = ''.join(data3) data5 = data4.replace(" ","").replace("> <","><") print data5 Output: <root><head></head><content></content></root>
Если пробелы в «нелистовых» узлах – это то, что мы пытаемся удалить, тогда будет выполняться следующая функция (рекурсивно, если задано):
from xml.dom import Node def stripNode(node, recurse=False): nodesToRemove = [] nodeToBeStripped = False for childNode in node. childNodes: # list empty text nodes (to remove if any should be) if (childNode.nodeType == Node.TEXT_NODE and childNode.nodeValue.strip() == ""): nodesToRemove.append(childNode) # only remove empty text nodes if not a leaf node (ie a child element exists) if childNode.nodeType == Node.ELEMENT_NODE: nodeToBeStripped = True # remove flagged text nodes if nodeToBeStripped: for childNode in nodesToRemove: node.removeChild(childNode) # recurse if specified if recurse: for childNode in node.childNodes: stripNode(childNode, True)
childNodes: # list empty text nodes (to remove if any should be) if (childNode.nodeType == Node.TEXT_NODE and childNode.nodeValue.strip() == ""): nodesToRemove.append(childNode) # only remove empty text nodes if not a leaf node (ie a child element exists) if childNode.nodeType == Node.ELEMENT_NODE: nodeToBeStripped = True # remove flagged text nodes if nodeToBeStripped: for childNode in nodesToRemove: node.removeChild(childNode) # recurse if specified if recurse: for childNode in node.childNodes: stripNode(childNode, True) Однако, Танатос прав. Пробелы могут представлять данные в XML, поэтому используйте их с осторожностью.
xmlStr = ' '.join(xmlStr.split())) Это помещает весь текст в одну строку, заменяя несколько пробелов одним пустым.
xmlStr = ''.join(xmlStr.split())) Это позволит полностью удалить пространство, включая пробелы внутри текста и не может быть использовано.
Первая форма может использоваться с риском (но который вы запрашиваете), для ввода, который вы дали:
xmlStr = '''<root> <head></head> <content></content> </root>''' xmlStr = ' '. join(xmlStr.split()) print xmlStr """ Output: <root> <head></head> <content></content> </root> """
join(xmlStr.split()) print xmlStr """ Output: <root> <head></head> <content></content> </root> """ Это будет действительным xml. Возможно, это должно быть хотя и проверено с помощью какой-либо проверки xml. Вы, кстати, уверены, что хотите XML? Вы читали статью: Python Is Is Java
6.5. Основы Kotlin. Регулярные выражения RegExp — Fandroid.info
Предыдущий раздел
Регулярные выражения (RegExp) — специальный язык для описания множества строк. Они помогают решать задачу поиска какого-либо текста (из описанного множества) в другом тексте, описывают интересующий нас текст и работают достаточно эффективно для быстрого решения задачи поиска.
В некоторых случаях количество вариантов искомого текста настолько велико, что перечислять все варианты становится неудобно. Иногда все эти варианты могут быть представлены одной строкой — регулярным выражением.
Примеры регулярных выражений (см. слайды):
слайды):
KotlinAsFirst[A-Z0-9._%-]@[A-Z0-9.-]+\.[A-Z]{2,}ˆ4[0-9]{12}(?:[0-9]{3})?$[-]?[0-9]*\.?[0-9]<()([ˆ<])(?:>(.)<\/\1>|\s+\/>)
Поиск регулярного выражения осуществляется с помощью автомата с состояниями, или конечного автомата. В данном случае под этим понимается алгоритм, имеющий некоторое количество устойчивых состояний. Для каждого состояния определяются действия, которые алгоритм выполняет в этом состоянии, а также условия, по которым алгоритм переходит в другие состояния.
Возможности языка регулярных выражений
Регулярное выражение в общем случае — это строка, в которой часть символов играет специальную роль. Но большинство символов в регулярном выражении обозначают просто самих себя. Например:
KotlinAsFirstТрансмогрификацияМама мыла раму42
Существует однако ряд специальных символов. обозначает символ-шапку,
обозначает символ-шапку, \$ — символ доллара, \[ — открывающую квадратную скобку,\] — закрывающую квадратную скобку.
Особые символы ищут символы по специальным правилам:
…..\t— табуляция,\n— новая строка,\r— возврат каретки (два последних символа унаследованы компьютерами от эпохи пишущих машинок, когда для начала печати с новой строки необходимо было выполнить два действия — возврат каретки в начало строки и перевод каретки на новую строку)\s— произвольный вид пробела (пробел, табуляция, новая строка, возврат каретки)\d— произвольная цифра, аналог[0-9]\w— произвольная «символ в слове», обычно аналог[a-zA-z0-9], то есть, латинская буква или цифра\S— НЕ пробел,\D— НЕ цифра,\W— НЕ «символ в слове»
Шаблон выбора | ищет одну строку из нескольких, например:
Марат|Михаил— Марат или Михаил^\[|\]$— открывающая квадратная скобка в начале строки или закрывающая в концеfor.— цикл (val|var).
(val|var).forс последующимvalилиvar
Шаблоны количества ищут определённое число совпадений:
.*— любое количество (в том числе ноль) любых символов(Марат)+— строка Марат один или более раз (но не ноль)(Михаил)?— строка Михаил ноль или один раз([0-9]{4})— последовательность из ровно четырёх любых цифр\w{8,16}— последовательность из 8-16 «символов в слове»
Круглые скобки () задают так называемые группы поиска, объединяя несколько символов вместе.
(Kotlin)+AsFirst— KotlinAsFirst, KotlinKotlinAsFirst, KotlinKotlinKotlinAsFirst, …(?:\$\$)+—,,(\w+)\s\1— слово, за которым следует пробел и то же самое слово.fun\s+(/w+)\s*\{.— \1.\}
\1.\}funс последующими пробелами, произвольным словом в круглых скобках, пробелами и тем же словом в фигурных скобках
Здесь \1 (\2, \3, …) ищет уже описанную группу поиска по её номеру внутри регулярного выражения (в данном случае — первую группу). Комбинация (?:…) задаёт группу поиска без номера. В целом, (?…) задаёт группы особого поиска:
Марат(?=\sАхин)— Марат, за которым следует пробел и Ахин(?⇐Михаил\s)Глухих— Глухих, перед которым стоит Михаил с пробелом\d+(?![$\d])— число, после которого НЕ стоит знак доллара(?<!root\s)beer— beer, перед которым НЕ стоит root с пробелом
Зачистка текста
Зачастую текст, который достается нам для работы в ячейках листа Microsoft Excel далек от совершенства. Если он был введен другими пользователями (или выгружен из какой-нибудь корпоративной БД или ERP-системы) не совсем корректно, то он легко может содержать:
Если он был введен другими пользователями (или выгружен из какой-нибудь корпоративной БД или ERP-системы) не совсем корректно, то он легко может содержать:
- лишние пробелы перед, после или между словами (для красоты!)
- ненужные символы («г.» перед названием города)
- невидимые непечатаемые символы (неразрывный пробел, оставшийся после копирования из Word или «кривой» выгрузки из 1С, переносы строк, табуляция)
- апострофы (текстовый префикс – спецсимвол, задающий текстовый формат у ячейки)
Давайте рассмотрим способы избавления от такого «мусора».
Замена
«Старый, но не устаревший» трюк. Выделяем зачищаемый диапазон ячеек и используем инструмент Заменить с вкладки Главная – Найти и выделить (Home – Find & Select – Replace) или жмем сочетание клавиш Ctrl+H.
Изначально это окно было задумано для оптовой замены одного текста на другой по принципу «найди Маша – замени на Петя», но мы его, в данном случае, можем использовать его и для удаления лишнего текста. Например, в первую строку вводим «г.» (без кавычек!), а во вторую не вводим ничего и жмем кнопку Заменить все (Replace All). Excel удалит все символы «г.» перед названиями городов:
Например, в первую строку вводим «г.» (без кавычек!), а во вторую не вводим ничего и жмем кнопку Заменить все (Replace All). Excel удалит все символы «г.» перед названиями городов:
Только не забудьте предварительно выделить нужный диапазон ячеек, иначе замена произойдет на всем листе!
Удаление пробелов
Если из текста нужно удалить вообще все пробелы (например они стоят как тысячные разделители внутри больших чисел), то можно использовать ту же замену: нажать Ctrl+H, в первую строку ввести пробел, во вторую ничего не вводить и нажать кнопку Заменить все (Replace All).
Однако, часто возникает ситуация, когда удалить надо не все подряд пробелы, а только лишние – иначе все слова слипнутся друг с другом. В арсенале Excel есть специальная функция для этого – СЖПРОБЕЛЫ (TRIM) из категории Текстовые. Она удаляет из текста все пробелы, кроме одиночных пробелов между словами, т. е. мы получим на выходе как раз то, что нужно:
Удаление непечатаемых символов
В некоторых случаях, однако, функция СЖПРОБЕЛЫ (TRIM) может не помочь. Иногда то, что выглядит как пробел – на самом деле пробелом не является, а представляет собой невидимый спецсимвол (неразрывный пробел, перенос строки, табуляцию и т.д.). У таких символов внутренний символьный код отличается от кода пробела (32), поэтому функция СЖПРОБЕЛЫ не может их «зачистить».
Вариантов решения два:
- Аккуратно выделить мышью эти спецсимволы в тексте, скопировать их (Ctrl+C) и вставить (Ctrl+V) в первую строку в окне замены (Ctrl+H). Затем нажать кнопку Заменить все (Replace All) для удаления.
- Использовать функцию ПЕЧСИМВ (CLEAN). Эта функция работает аналогично функции СЖПРОБЕЛЫ, но удаляет из текста не пробелы, а непечатаемые знаки. К сожалению, она тоже способна справится не со всеми спецсимволами, но большинство из них с ее помощью можно убрать.

Функция ПОДСТАВИТЬ
Замену одних символов на другие можно реализовать и с помощью формул. Для этого в категории Текстовые в Excel есть функция ПОДСТАВИТЬ (SUBSTITUTE). У нее три обязательных аргумента:
- Текст в котором производим замену
- Старый текст – тот, который заменяем
- Новый текст – тот, на который заменяем
С ее помощью можно легко избавиться от ошибок (замена «а» на «о»), лишних пробелов (замена их на пустую строку «»), убрать из чисел лишние разделители (не забудьте умножить потом результат на 1, чтобы текст стал числом):
Удаление апострофов в начале ячеек
Апостроф (‘) в начале ячейки на листе Microsoft Excel – это специальный символ, официально называемый текстовым префиксом. Он нужен для того, чтобы дать понять Excel, что все последующее содержимое ячейки нужно воспринимать как текст, а не как число. По сути, он служит удобной альтернативой предварительной установке текстового формата для ячейки (Главная – Число – Текстовый) и для ввода длинных последовательностей цифр (номеров банковских счетов, кредитных карт, инвентарных номеров и т. д.) он просто незаменим. Но иногда он оказывается в ячейках против нашей воли (после выгрузок из корпоративных баз данных, например) и начинает мешать расчетам. Чтобы его удалить, придется использовать небольшой макрос. Откройте редактор Visual Basic сочетанием клавиш Alt+F11, вставьте новый модуль (меню Insert — Module) и введите туда его текст:
д.) он просто незаменим. Но иногда он оказывается в ячейках против нашей воли (после выгрузок из корпоративных баз данных, например) и начинает мешать расчетам. Чтобы его удалить, придется использовать небольшой макрос. Откройте редактор Visual Basic сочетанием клавиш Alt+F11, вставьте новый модуль (меню Insert — Module) и введите туда его текст:
Sub Apostrophe_Remove()
For Each cell In Selection
If Not cell.HasFormula Then
v = cell.Value
cell.Clear
cell.Formula = v
End If
Next
End Sub
Теперь, если выделить на листе диапазон и запустить наш макрос (Alt+F8 или вкладка Разработчик – кнопка Макросы), то апострофы перед содержимым выделенных ячеек исчезнут.
Английские буквы вместо русских
Это уже, как правило, чисто человеческий фактор. При вводе текстовых данных в ячейку вместо русских букв случайно вводятся похожие английские («це» вместо русской «эс», «игрек» вместо русской «у» и т. д.) Причем снаружи все прилично, ибо начертание у этих символов иногда абсолютно одинаковое, но Excel воспринимает их, конечно же, как разные значения и выдает ошибки в формулах, дубликаты в фильтрах и т.д.
д.) Причем снаружи все прилично, ибо начертание у этих символов иногда абсолютно одинаковое, но Excel воспринимает их, конечно же, как разные значения и выдает ошибки в формулах, дубликаты в фильтрах и т.д.
Можно, конечно, вручную заменять символы латинцы на соответствующую им кириллицу, но гораздо быстрее будет сделать это с помощью макроса. Откройте редактор Visual Basic сочетанием клавиш Alt+F11, вставьте новый модуль (меню Insert — Module) и введите туда его текст:
Sub Replace_Latin_to_Russian()
Rus = "асекорхуАСЕНКМОРТХ"
Eng = "acekopxyACEHKMOPTX"
For Each cell In Selection
For i = 1 To Len(cell)
c1 = Mid(cell, i, 1)
If c1 Like "[" & Eng & "]" Then
c2 = Mid(Rus, InStr(1, Eng, c1), 1)
cell.Value = Replace(cell, c1, c2)
End If
Next i
Next cell
End Sub
Теперь, если выделить на листе диапазон и запустить наш макрос (Alt+F8 или вкладка Разработчик – кнопка Макросы), то все английские буквы, найденные в выделенных ячейках, будут заменены на равноценные им русские. Только будьте осторожны, чтобы не заменить случайно нужную вам латиницу 🙂
Только будьте осторожны, чтобы не заменить случайно нужную вам латиницу 🙂
Ссылки по теме
Как удалить Java с компьютера Windows полностью?
Одной из причин неправильного функционирования операционной системы может быть Java. Чтобы наладить работу, проблемную версию виртуальной машины следует удалить. Из этой статьи вы узнаете, как правильно и полностью удалить Java с компьютера различными способами.
Зачем удалять Java?
Как и любое программное обеспечение, Джава – такой же софт, который может работать не так, как положено.
Причины:
- вирусное заражение;
- старая (неактуальная) версия;
- несовместимость с разрядностью браузера.
При появлении подобных неполадок удаление Java — первостепенная задача. После деинсталляции, чтобы сайты, игры и программы корректно работали, скачайте новую версию Java 32 bit или 64 bit.
Если пробовать обновить Джаву без полной деинсталляции старой, велика вероятность, что проблемы никуда не денутся.![]()
Как удалить Java с компьютера вручную
Для ПК под управлением операционной системой Windows 10, 8 или 7 способы, как удалить Java, практически не отличаются.
Следуйте пошаговой инструкции:
- Откройте «Панель управления» – нажмите комбинацию клавиш Win+R. В открывшемся окне встроенной утилиты «Выполнить» напишите команду control.
- Переключите режим просмотра на «Категория».
- Откройте раздел «Удаление программы».
- Подождите, пока закончится построение списка, выделите кликом мыши Java.
- Нажмите над списком кнопку «Удалить».
- Подтвердите деинсталляцию.
Для Windows XP:
- В меню «Пуск» щелкните по настройкам, откройте «Панель управления».
- Выберите раздел «Установка и удаление программ».
- Удалите программу стандартным способом.
Повторите это действие для каждой версии, если у вас их больше одной.
Для полного удаления Java с компьютера с ОС Windows 7 следующий этап — очистка от папок, созданных в процессе установки:
- Откройте проводник.

- Выберите в левой колонке «Этот компьютер», дальше – «Локальный диск C:» (он может называться иначе: E:, F:, M:).
- Удалите папки под названием Java в разделах Program Files и Program Files x86.
- Откройте папку приложений пользователя — для этого запустите классическое приложение «Выполнить», введите команду appdata.
- Откройте раздел LocalLow и удалите папки Oracle и Sun.
- В разделе Roaming удалите папки с такими же названиями.
Осталось убрать все остаточные элементы записей в реестре:
- Запустите классическое приложение «Выполнить».
- Напишите команду regedit и нажмите OK.
- Раскройте дерево реестра HKEY_CURRENT_USER.
- Откройте ветку в разделе Software, удалите из неё папку JavaSoft.
- Раскройте ветку реестра HKEY_LOCAL_MACHINE\SOFTWARE и также удалите папку JavaSoft (если она там имеется).
Деинсталляция с помощью Java UninstallTool
Удаление всех папок и записей в реестре для неопытного пользователя может быть сложной задачей.
Для этих целей разработчики Oracle создали инструмент Java Uninstall.
Чтобы полностью удалить Java с компьютера, запустите Java UninstallTool. Выполните действия:
- В окне удаления нажмите «Я согласен» (Agree).
- Подтвердите действие.
- Выберите версию и нажмите «Продолжить» (Next).
- Нажмите «Да» (Yes).
Чтобы восстановить (загрузить и установить) новую версию Java на ПК, нажмите Get Java или выберите Close.
Удаление программы с помощью Revo Uninstaller
Вышеописанные способы – не единственные для удаления программ. Утилита Revo Uninstaller также предоставляет возможность убрать старую Джаву с Виндовс.
Инструкция:
- Запустите Revo Uninstaller, дважды кликнув по ярлыку на рабочем столе.
- В разделе «Деинсталлятор» найдите Джаву.
- Выделите ее и удалите, кликнув по соответствующей кнопке в верхней панели.
- Выберите режим деинсталляции.
 Рекомендуем «Продвинутый» – он медленнее, но удалит хвосты и остаточные компоненты, которые другие режимы могут пропустить.
Рекомендуем «Продвинутый» – он медленнее, но удалит хвосты и остаточные компоненты, которые другие режимы могут пропустить. - После завершения нажмите «Далее» для поиска и очистки оставшейся информации.
- Перезагрузите компьютер.
Видео: Как удалить Java с компьютера с ОС Windows 10.
При полном удалении Java и других программ, как правило, неполадки с софтом не возникают. Приложения работают исправно, и нет проблем с обновлением.
Загрузка…
Что такое Java и как её отключить
Современные браузеры — не просто окна для просмотра веб страниц. Они содержат в себе дополнительные инструменты, которые выполняют ряд задач, связанных с отображением страниц, работой сетевого кода, передачей данных, просмотром медиафайлов и прочими функциями, которые используются в работе браузера. Сами по себе эти функции полезны, поэтому они часто включены в браузере изначально, чтобы избавить пользователей от утомительной настройки браузера после его установки.
Сами по себе эти функции полезны, поэтому они часто включены в браузере изначально, чтобы избавить пользователей от утомительной настройки браузера после его установки.
И Java — пример такой технологии. Сама по себе, Java — платформа и язык программирования, который используется разработчиками для создания приложений, скриптов, а также элементов Web странице. Java также используется при работе большого количества программ и приложений, с которыми вы работаете. Браузеры также используются технологию Java для корректного отображения содержимого страниц, а также для работы встроенных элементов. Несмотря на всю пользу, которую приносит эта технология, в ней присутствует критичные недостатки, которые просто недопустим для некоторых пользователей. Дело в том, что в Java присутствуют уязвимости, которые приводят к утечке сведений о вашем устройстве, IP адреса, и прочей информации.
Также, Java замедляет работу браузеров и приводит к активации вредоносных элементов, которые размещаются на вредоносных сайтах, что приводит к заражению устройства. Поэтому рекомендуется отключать Java в браузерах и даже в вашей ОС, чтобы избежать серьёзных проблем с безопасностью.
Поэтому рекомендуется отключать Java в браузерах и даже в вашей ОС, чтобы избежать серьёзных проблем с безопасностью.
Теперь разберёмся, как отключить Java в Windows. Это также отключит Java во всех браузерах сразу. Прежде чем сделать это, закройте все программы, которые используют Java. После этого, выполните следующие шаги:
- Нажимаем «Пуск», после чего переходим в «Панель управления».
- В строке поиска вписываем «Java», после чего нажимаем на иконку, которая появится на панели.
- После того, как мы перешли в меню управления Java, открываем вкладку «Security».
- Находим пункт «Enable Java content for browser and Web Start applications и снимаем галочку напротив него.
- Нажимаем на кнопку «Apply», после чего жмём «ОК».
Отключение Java в MacOS
Теперь рассмотрим отключение Java на Mac OS. Принцип схож с Windows. Для отключения вам потребуется:
- Закрыть все приложения, которые используют Java.

- Нажать на значок «Яблока в левом верхнем углу экрана».
- Выбрать вкладку «System Preference».
- У вас откроется панель управления. В ней нужно найти рездел «Others», после чего кликнуть на значок «Java».
- В открывшемся меню выбираем вкладку «Security», в ней находим пункт «Enable Java content in browsers» и снимаем галочку напротив.
- Нажимаем кнопку «Apply», а после «ОК».
Отключение Java в браузерах
Если вариант в отключением в ОС вам не подходит, то можно отключить Java в браузере. Таким образом, компонент отключится только в выбранном браузере, а не во всех сразу. Теперь разберёмся, как отключить Java в популярных браузерах.
GoogleChrome
Отключить Java в Google Chrome возможно только в старых версиях. Для этого в адресной строке впишите команду chrome://plugins. Это откроет окно дополнительных компонентов, в которым нужно найти «Java» и нажать на синюю надпись «Disable». На этом всё, Java в браузере отключена. В новых версиях такой способ не сработает, поэтому придётся выключать Java в ОС. Также рекомендуется отключить JavaScript, для этого зайдите в меню настроек, нажмите дополнительно, после чего зайдите в раздел «Настройки контента». В нём найдите пункт «JavaScript» и сдвиньте ползунок в сторону отключения.
Также рекомендуется отключить JavaScript, для этого зайдите в меню настроек, нажмите дополнительно, после чего зайдите в раздел «Настройки контента». В нём найдите пункт «JavaScript» и сдвиньте ползунок в сторону отключения.
Mozilla Firefox
Теперь разберёмся, как отключить Java в Firefox. Как и в других современных браузеров, поддержка Java в новых версиях браузера отключена. Если вы пользуетесь старой версией, то вам потребуется выполнить следующие шаги:
- Открыть меню браузера, найти вкладку «Дополнения» и кликнуть на неё.
- В открывшемся окне, находим «Java», после чего, в ползунке рядом выбираем вариант «Никогда не включать». Если у вас новая Mozilla, то отключите Java в ОС.
Internet Explorer
Для отключения Java в Internet Explorer, воспользуйтесь способом для Windows. Это единственный способ, поскольку IE — компонент Windows.
Safari
Чтобы отключить Java в Safari, откройте браузер, перейдите в меню браузера, после чего выберите вкладку «Настройки». В открывшемся окне выберите вкладку «Security, расположенную вверху посередине. После этого, уберите галчоку с пункта «Enable JavaScript» и «Enable Java». Закройте окно настроек, после чего компонент будет отключен.
В открывшемся окне выберите вкладку «Security, расположенную вверху посередине. После этого, уберите галчоку с пункта «Enable JavaScript» и «Enable Java». Закройте окно настроек, после чего компонент будет отключен.
Yandex Browser
Как и в случае с Google Chrome, отключить Java в Yandex Browser напрямую не получится. Для этого воспользуйтесь отключением Java в на ОС. Но в браузере можно отключить JavaScript. Для этого перейдите в настройки браузера, пролистайте окно вниз, после чего, нажмите на кнопку «Показать дополнительные настройки». Далее, найдите раздел «Личные данные» и нажмите на кнопку «Настройки содержимого». В открывшемся меню снимите галочку в окне «Разрешить Javascript на всех сайтах» и нажмите на кнопку «Готово».
Java и прокси
Таким образом, отключение Java положительно влияет на вашу безопасность в интернете. Это снизит количество утечек IP адреса, поможет избежать активации нежелательного кода на некоторых страницах, а также избавит от уязвимостей в самой платформе. Поэтому большинство опытных пользователей отключает Java в ОС и браузерах. Особенно при действиях, которые требуют высокого уровня анонимности. Недостатком является некорректное отображение элементов Web страниц, а также невозможность работать с программами и приложениями, использующими Java. Несмотря на это, изменения легко обратить назад, поэтому при необходимости, можно включить Java в любой момент.
Поэтому большинство опытных пользователей отключает Java в ОС и браузерах. Особенно при действиях, которые требуют высокого уровня анонимности. Недостатком является некорректное отображение элементов Web страниц, а также невозможность работать с программами и приложениями, использующими Java. Несмотря на это, изменения легко обратить назад, поэтому при необходимости, можно включить Java в любой момент.
Но помните, что отключение Java — дополнительная мера, которая поможет слегка поднять уровень анонимности и не допустить утечек IP адреса. Для обеспечение полной анонимности, рекомендуется использовать более проверенные методы. Например, прокси сервер, который пропустит ваше сетевое соединение через себя, подменяя IP адрес, местоположение и прочие сетевые данные. Купить Российские прокси вы можете у нас на сайте.
Удаление начальных и конечных пробелов из строки в примере Java
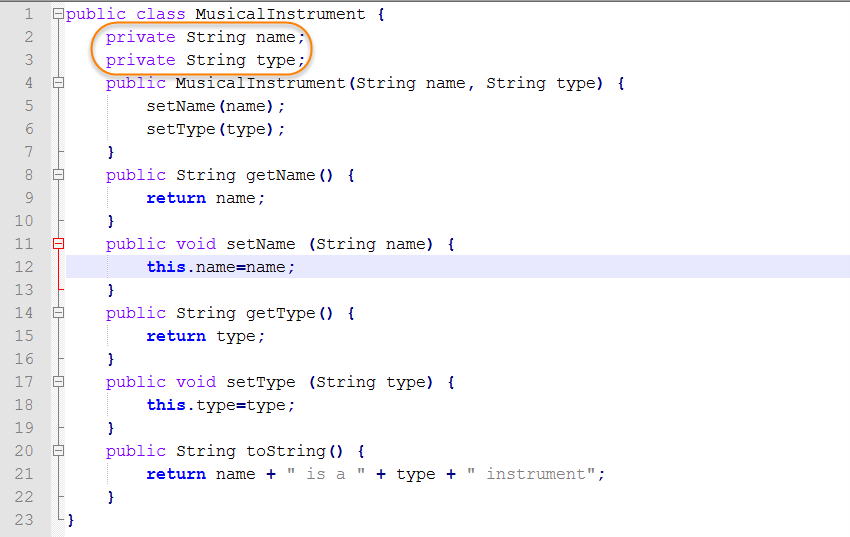
Удаление начальных и конечных пробелов из строки в примере Java показывает, как удалить пробелы в начале и конце строки или обрезать строку с использованием различных подходов.
Как удалить начальные и конечные пробелы из строки в Java?
Рассмотрим нижеприведенный строковый объект, который содержит несколько пробелов в начале и в конце строки.
Строка str = «строка с пробелами»; |
Используйте метод trim класса String, чтобы удалить эти пробелы из строки.
пакет com.javacodeexamples.stringexamples; открытый класс StringTrimExample { public static void main (String [] args) { String str = «строка с пробелами»; str = str.trim (); System.out.println (str); } } |
Вывод
Примечание :
Метод trim удаляет «\ u0020», который является пробелом.Однако метод trim не удаляет пробел Unicode «\ u00A0». Этот символ обычно встречается в HTML в виде & nbsp; (неразрывный пробел Unicode). Если вы хотите удалить это, вы можете использовать метод
Если вы хотите удалить это, вы можете использовать метод replaceAll класса String, как показано ниже.
Строка str = str.replaceAll («\\ u00A0», «»); |
Как удалить только ведущие пробелы?
Если вы хотите удалить только пробелы в начале строки, метод trim не работает, так как он удалит пробелы с обеих сторон.\\ s + «,» «);
System.out.println (» \ «» + str + «\» «);
Вывод
» строка с пробелами » |
Как удалить только конечные пробелы?
Используйте шаблон «\\ s + $» для удаления только конечных пробелов из строки, где
\\ s — соответствует пробелу + — один или больше $ — конец строки |
String str = «строка с пробелами»; str = str. System.out.println («\» «+ str +» \ «»); |
 replaceAll («\\ s + $», «»);
replaceAll («\\ s + $», «»);Вывод
«строка с пробелами» |
Наконец, если вы используете библиотеку Apache Commons, вы можете использовать метод strip класса StringUtils для удаления пробелов с обоих концов струны, как показано ниже.
Строка str = «строка с пробелами»; str = StringUtils.полоса (ул.); System.out.println («\» «+ str +» \ «»); |
Вывод
«строка с пробелами» |
Этот пример является частью учебника String в Java.
Пожалуйста, дайте мне знать ваше мнение в разделе комментариев ниже.
Программа на Java для удаления всех пробелов из строки
Программа на Java для удаления всех пробелов из строки:
В этом руководстве мы узнаем, как удалить все пустые символы (например, пробелы, табуляции, новую строку и т.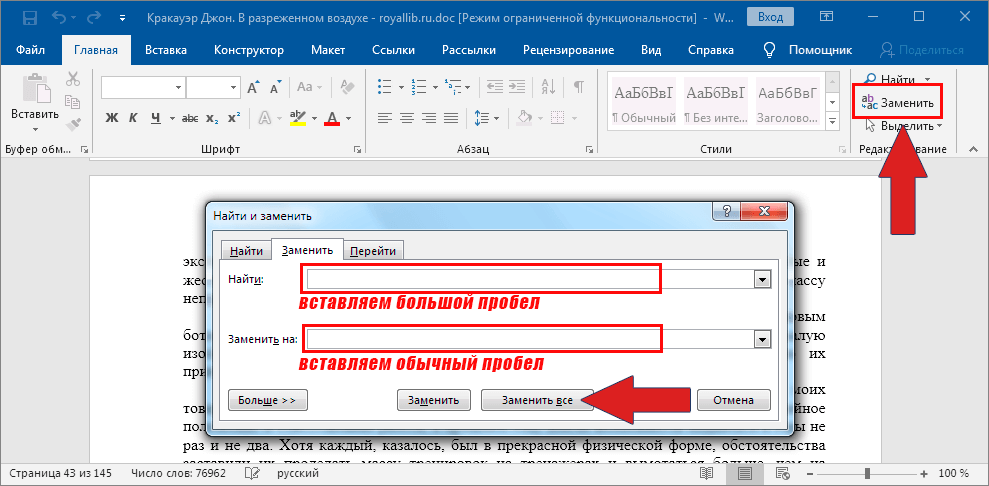 Д.) из строки.Мы изучим два разных метода для достижения этой цели.
Д.) из строки.Мы изучим два разных метода для достижения этой цели.
Давайте посмотрим:
Использование метода replaceAll:
Метод replaceAll определяется как:
общедоступная строка replaceAll (регулярное выражение строки, замена строки) Он сопоставляет всю подстроку строки вызывающего абонента с входным регулярным выражением и заменяет его строкой замены . Вместо регулярного выражения мы передадим \ s , а вместо замены мы передадим пустую строку «» . \ s соответствует всем пробельным символам . Вы можете проверить это на любом сайте, например regex101.
Таким образом, все пустые символы будут заменены пустой строкой после завершения выполнения программы.
Давайте посмотрим на пример программы:
Программа Java с использованием replaceAll:
public class Main {
private static final String INPUT_STRING = "Это строка с вкладкой \ t и \ n новой строкой";
public static void main (String [] args) выбрасывает java. lang.Exception {
Строка finalString = INPUT_STRING.replaceAll ("\\ s", "");
System.out.println ("Исходная строка:" + INPUT_STRING);
System.out.println ("Последняя строка:" + finalString);
}
}
lang.Exception {
Строка finalString = INPUT_STRING.replaceAll ("\\ s", "");
System.out.println ("Исходная строка:" + INPUT_STRING);
System.out.println ("Последняя строка:" + finalString);
}
} Выход:
Исходная строка Это строка с табуляцией и
новая линия
Последняя строка: Thisisastringwithtabandnewline Использование петли:
Мы также можем удалить все пробелы с помощью петли . Давайте сначала взглянем на программу:
Пример программы на Java:
public class Main {
private static final String INPUT_STRING = "Это строка с вкладкой \ t и \ n новой строкой";
public static void main (String [] args) выбрасывает java.lang.Exception {
StringBuilder strBuilder = новый StringBuilder ();
для (int i = 0; i  append (INPUT_STRING.charAt (i));
}
}
Строка finalString = strBuilder.toString ();
System.out.println ("Исходная строка:" + INPUT_STRING);
Система.out.println ("Последняя строка:" + finalString);
}
}
append (INPUT_STRING.charAt (i));
}
}
Строка finalString = strBuilder.toString ();
System.out.println ("Исходная строка:" + INPUT_STRING);
Система.out.println ("Последняя строка:" + finalString);
}
} Выход:
Исходная строка: это строка с табуляцией и
новая линия
Последняя строка: Thisisastringwithtabandnewline Пояснение:
Закомментированные числа в приведенной выше программе обозначают номер шага ниже:
- Создайте один объект StringBuilder для хранения строки окончательного результата.
- Запустите один для цикла , который будет работать так же, как длина строки .
- Сканировать каждый символов . Сначала мы берем символ для этой позиции с помощью метода charAt . Затем мы проверяем, является ли это пустым символом, используя метод isWhiteSpace .
- Если символ , а не пустой символ, добавляет его к объекту StringBuilder .
- Наконец, преобразуйте объект StringBuilder в строку, используя метод toString .
- Распечатайте обе строки.
Подобные уроки:
Как быстро можно удалить пробелы из строки? — Блог Даниэля Лемира
Иногда программисты хотят вырезать символы из строки символов. Например, вы хотите удалить все символы конца строки из фрагмента текста.
Позвольте мне рассмотреть проблему, в которой я хочу удалить все пробелы (‘‘) и символы перевода строки (‘\ n’ и ‘\ r’).
Как бы вы сделали это эффективно?
size_t despace (char * bytes, size_t howmany) {
size_t pos = 0;
for (size_t i = 0; i Этот код будет работать со всеми строками в кодировке UTF-8… а это основная часть строк, которые можно найти в Интернете, если учесть, что UTF-8 является надмножеством ASCII.
Это просто и должно быть быстро… Я получил удовольствие, глядя, как различные компиляторы обрабатывают этот код. В итоге получается несколько инструкций на обработанный байт.
Но мы обрабатываем байты один за другим, а наши процессоры имеют 64-битную архитектуру. Можем ли мы обрабатывать данные по 64-битным словам?
Существует несколько загадочное выражение с изменяющимся битом, которое возвращает истину всякий раз, когда ваше слово содержит нулевой байт:
(((v) -UINT64_C (0x0101010101010101)) & ~ (v) & UINT64_C (0x8080808080808080))
Все, что нам нужно знать, это то, что это работает.mask3; if (haszero (xor1) || haszero (xor2) || haszero (xor3)) {
// проверяем вручную каждый из восьми байтов?
} еще {
memmove (байты + позиция, байты + я, размер (слово));
поз + = 8;
}
}
Это будет быстрее, если большинство блоков из восьми символов не содержат пробелов. Когда это происходит, мы в основном копируем 64-битные слова одно за другим вместе с умеренно дорогой проверкой, которую наши суперскалярные процессоры могут сделать быстро.
Как оказалось, мы можем лучше без использования 64-битных слов.
// таблица с нулями в индексах, соответствующих пробелам
int jump_table [256] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 1, 1, 0, 1, ...};
size_t fast_despace (char * bytes, size_t howmany) {
size_t i = 0, pos = 0;
в то время как (я <сколько)
{
байты [позиция] = байты [я ++];
pos + = jump_table [(символ без знака) байты [pos]];
}
return pos;
}
Этот подход, предложенный Робином Леффманном, очень умен и быстр, поскольку позволяет избежать штрафов из-за неверно предсказанных ветвей.
Можем ли мы сделать еще лучше? Конечно! Начиная с Pentium 4 (в 2001 году) у нас были 128-битные (SIMD) инструкции.
Давайте решим ту же проблему с помощью этих изящных 128-битных инструкций SSE, используя (уродливые?) Встроенные функции Intel…
__m128i пробелы = _mm_set1_epi8 ('');
__m128i новая строка = _mm_set1_epi8 ('\ n');
__m128i каретка = _mm_set1_epi8 ('\ r');
size_t i = 0;
for (; i + 15 Код довольно прост. , если вы знакомы с инструкциями SIMD для процессоров Intel.Я не предпринял никаких усилий, чтобы оптимизировать его ... так что возможно, даже вероятно, что мы могли бы заставить его работать быстрее. У моего исходного кода SIMD была ветка, но Натан Курц понял, что лучше всего упростить код и удалить его.
, если вы знакомы с инструкциями SIMD для процессоров Intel.Я не предпринял никаких усилий, чтобы оптимизировать его ... так что возможно, даже вероятно, что мы могли бы заставить его работать быстрее. У моего исходного кода SIMD была ветка, но Натан Курц понял, что лучше всего упростить код и удалить его.
Посмотрим, как быстро он работает!
Я разработал тест с использованием новейшего процессора Intel (Skylake) для текстовых записей, где только несколько символов являются пробелами.
обычный код 5,5 цикла / байт с использованием 64-битных слов 2.56 циклов / байт с переходным столом 1,7 цикла / байт SIMD (128 бит) код 0,39 цикла / байт memcpy 0,08 цикла / байт
Таким образом, векторизованный код почти в 14 раз быстрее обычного. Это очень хорошо.
Тем не менее, удаление нескольких пробелов в 5 раз медленнее, чем копирование данных с помощью memcpy. Так что, возможно, мы сможем пойти еще быстрее. Как быстро мы могли бы быть?
Так что, возможно, мы сможем пойти еще быстрее. Как быстро мы могли бы быть?
Один совет: наши процессоры Intel могут обрабатывать 256-битные регистры (с инструкциями AVX / AVX2), так что, возможно, мы могли бы работать вдвое быстрее.К сожалению, 256-битные инструкции SIMD на процессорах x64 работают на двух 128-битных независимых дорожках, что затрудняет алгоритмическое проектирование.
Подход Leffmann не так быстр, как инструкции SIMD, но он более общий и переносимый ... и все же в три раза быстрее, чем обычный код!
Доступен мой код C.
Дополнительная литература : Быстрая обрезка элементов в векторах SIMD с использованием библиотеки simdprune
Примечание : На практике мы могли бы удалить все символы с кодовыми значениями, меньшими или равными 32.
.