Pascal abc учебник в Беларуси
Регистрация
Вход
Каталог
pascal abc учебник
- Все регионы
- Брест
- Витебск
- Гомель
- Гродно
- Могилев
- Минск
- Все города
Минская область
Березино
Березинский р-н
Борисов
Борисовский р-н
Вилейка
Вилейский р-н
Воложин
Воложинский р-н
Городея
Дзержинск
Дзержинский р-н
Жодино
Заславль
Ивенец
Клецк
Клецкий р-н
Копыль
Копыльский р-н
Красная Слобода
Крупки
Крупский р-н
Логойск
Логойский р-н
Любанский р-н
Любань
Марьина Горка
Минск(2)
Минский р-н
Молодечненский р-н
Молодечно
Мядель
Мядельский р-н
Нарочь
Негорелое
Несвиж
Несвижский р-н
Плещеницы
Пуховичский р-н
Радошковичи
Раков
Руденск
Слуцк
Слуцкий р-н
Смиловичи
Смолевичи
Смолевичский р-н
Солигорск
Солигорский р-н
Старобин
Стародорожский р-н
Старые Дороги
Столбцовский р-н
Столбцы
Узда
Узденский р-н
Уречье
Фаниполь
Холопеничи
Червенский р-н
Червень
Брестская область
Антополь
Барановичи
Барановичский р-н
Белоозерск
Береза
Березовский р-н
Брест
Брестский р-н
Высокое
Ганцевичи
Ганцевичский р-н
Городище
Давид-Городок
Дрогичин
Дрогичинский р-н
Жабинка
Жабинковский р-н
Иваново
Ивановский р-н
Ивацевичи
Ивацевичский р-н
Каменец
Каменецкий р-н
Кобрин
Кобринский р-н
Коссово
Лунинец
Лунинецкий р-н
Ляховичи
Ляховичский р-н
Малорита
Малоритский р-н
Микашевичи
Пинск
Пинский р-н
Пружанский р-н
Пружаны
Ружаны
Столин
Столинский р-н
Телеханы
Витебская область
Барань
Бегомль
Бешенковичи
Бешенковичский р-н
Богушевск
Браслав
Браславский р-н
Верхнедвинск
Верхнедвинский р-н
Витебск
Витебский р-н
Глубокое
Глубокский р-н
Городок
Городокский р-н
Дисна
Докшицкий р-н
Докшицы
Дубровенский р-н
Дубровно
Езерище
Коханово
Лепель
Лепельский р-н
Лиозненский р-н
Лиозно
Миорский р-н
Миоры
Новолукомль
Новополоцк
Оболь
Орша
Оршанский р-н
Освея
Подсвилье
Полоцк
Полоцкий р-н
Поставский р-н
Поставы
Россонский р-н
Россоны
Сенненский р-н
Сенно
Толочин
Толочинский р-н
Ушачи
Ушачский р-н
Чашники
Чашникский р-н
Шарковщина
Шарковщинский р-н
Шумилино
Шумилинский р-н
Гомельская область
Брагин
Брагинский р-н
Буда-Кошелево
Буда-Кошелёвский р-н
Василевичи
Ветка
Ветковский р-н
Гомель
Гомельский р-н
Добруш
Добрушский р-н
Ельск
Ельский р-н
Житковичи
Житковичский р-н
Жлобин
Жлобинский р-н
Калинковичи
Калинковичский р-н
Корма
Кормянский р-н
Лельчицкий р-н
Лельчицы
Лоев
Лоевский р-н
Мозырский р-н
Мозырь
Мозырь-11
Наровля
Наровлянский р-н
Октябрьский
Октябрьский р-н
Петриков
Петриковский р-н
Речица
Речицкий р-н
Рогачев
Рогачевский р-н
Светлогорск
Светлогорский р-н
Туров
Хойники
Хойникский р-н
Чечерск
Чечерский р-н
Гродненская область
Б. Берестовица
Берестовица
Березовка
Берестовицкий р-н
Волковыск
Волковысский р-н
Вороново
Вороновский р-нГродненский р-н
Гродно
Дятлово
Дятловский р-н
Желудок
Зельва
Зельвенский р-н
Ивье
Ивьевский р-н
Козловщина
Кореличи
Кореличский р-н
Красносельский
Лида
Лидский р-н
Мир
Мостовский р-н
Мосты
Новогрудок
Новогрудский р-н
Новоельня
Острино
Островец
Островецкий р-н
Ошмянский р-н
Ошмяны
Радунь
Россь
Свислочский р-н
Свислочь
Скидель
Слоним
Слонимский р-н
Сморгонский р-н
Сморгонь
Сопоцкин
Щучин
Щучинский р-н
Юратишки
Могилевская область
Белыничи
Белыничский р-н
Бобруйск
Бобруйский р-н
Быхов
Быховский р-н
Глуск
Глусский р-н
Горецкий р-н
Горки
Дрибин
Дрибинский р-н
Кировск
Кировский р-н
Климовичи
Климовичский р-н
Кличев
Кличевский р-н
Костюковичский р-н
Краснополье
Краснопольский р-н
Кричев
Кричевский р-н
Круглое
Круглянский р-н
Могилев
Могилевский р-н
Мстиславль
Мстиславский р-н
Осиповичи
Осиповичский р-н
Славгород
Славгородский р-н
Хотимск
Хотимский р-н
Чаусский р-н
Чаусы
Чериков
Чериковский р-н
Шклов
Шкловский р-н
КНИГИ Книжный магазин Филиал ОАО Белкнига
по истории, pascal abc учебник, сказка волшебная.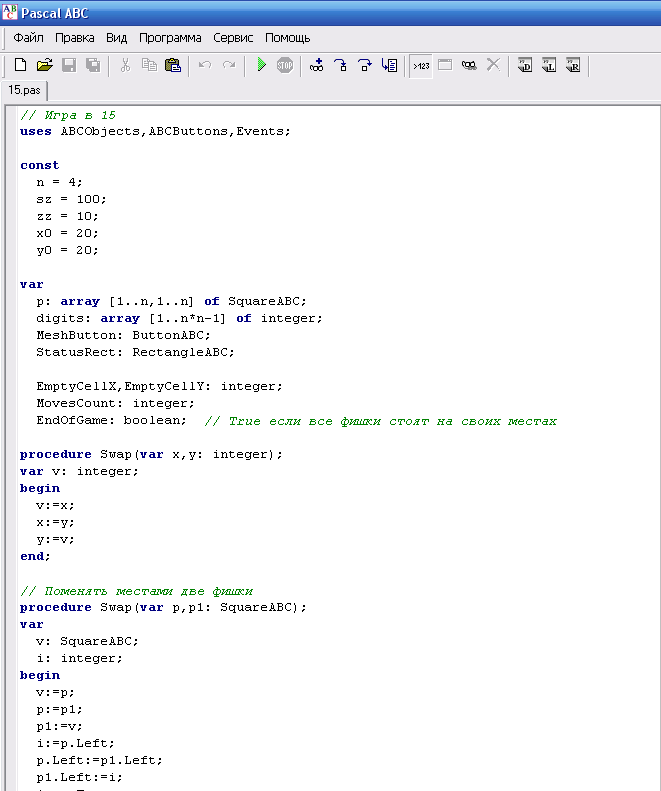 .. истории, pascal abc учебник, сказка волшебная лампа… экономика беларуси учебник,адреса магазинов книг,книжные оптовые базы,поставка…
.. истории, pascal abc учебник, сказка волшебная лампа… экономика беларуси учебник,адреса магазинов книг,книжные оптовые базы,поставка…
Педагогика ОДО
по истории, pascal abc учебник, сказка волшебная… истории, pascal abc учебник, сказка волшебная лампа… pascal abc учебник, сказка волшебная лампа алладина,…
Найдено 2 организаций
Текущие фильтры
Вы искали:pascal abc учебник
Новости компаний
Каталог организаций Беларусинфо – самый полный и подробный справочник организаций в Беларуси. У нас вы найдете описания деятельности, адреса, телефоны, схемы проезда и официальные сайты компаний, которые предлагают услуги и товары в разделе Pascal abc учебник в Беларуси. Сейчас такие услуги и товары предоставляют 2 организаций и список постоянно увеличивается.
Углубленное руководство по Pandas.
 Лучшая библиотека Python для работы… | Мэнди Гу
Лучшая библиотека Python для работы… | Мэнди ГуУскоренный курс по науке о данных
Полная библиотека Python для работы с реляционными данными
Опубликовано в·
6 мин чтения·
2 мая 202 0 Фото Паскаля Мюллера на UnsplashРанее В этом месяце мы с Эдвардом Цяном начали работу над набором всесторонних уроков для начинающих специалистов по данным, которые можно найти на нашем веб-сайте www.dscrashcourse.com
Я буду публиковать слегка измененные уроки на Medium, чтобы сделать их доступными для более широкой аудитории. Если вы найдете эти статьи полезными, зайдите на сайт, чтобы найти больше уроков и практических задач!
pandas — это библиотека Python, которая упрощает чтение, экспорт и работу с реляционными данными. Этот урок расширит его функциональность и использование. Обычно мы импортируем pandas как pd для ссылки на библиотеку, используя сокращенную форму. Весь приведенный ниже код был написан на Python 3 с
Весь приведенный ниже код был написан на Python 3 с панды==0.24.2 .
Согласно официальной документации, Series — это одномерный массив ndarray с метками осей. ndarray — это специальный тип данных, найденный в библиотеке numpy , который определяет массив элементов фиксированного размера. Проще говоря, ряд — это столбец в таблице или электронной таблице с одним и тем же типом данных. Каждая серия имеет индекс, используемый для обозначения меток осей.
Мы можем создать серию, используя pd.Series(['some', 'array', 'object'])
Серия индексов
Мы можем искать значения серий, используя метки осей или их позиционные метки. Если не указано иное, метки оси рядов (иначе называемые индексом рядов) по умолчанию будут целыми числами. Мы также можем установить индекс для строк.
sample_series = pd.Series(['some', 'array', 'object'], index=list('abc')) # позиционное индексирование: это возвращает первое значение, которое является 'some'
sample_series[ 0]
# индексация метки: это также возвращает первое значение 'some'
sample_series['a']
Так выглядит sample_series .
Мы можем разрезать ряд, чтобы получить диапазон значений. Поведение среза отличается при использовании меток осей — в отличие от обычных срезов Python, включаются как начальная, так и конечная точки!
# позиционный срез: это возвращает первые два значения sample_series[:2] # срез меток: это также возвращает первые два значения
sample_series[:'b']
DataFrames используются для определения двумерных данных. Строки помечаются с помощью индексов, а столбцы помечаются с помощью заголовков столбцов. Каждый столбец можно интерпретировать как серию. Мы можем создать DataFrame, используя pd.DataFrame({'столбец 1': [1, 1], 'столбец 2': [2, 2]}).
В качестве альтернативы мы также можем считывать табличные данные в DataFrames.
# Чтение файла CSV
csv_dataframe = pd.read_csv('my_csv_file.csv')# Чтение файла Excel
xls_dataframe = pd.read_excel('my_xls_file.xls')
Индексирование DataF rames
Мы можем индексировать столбцы DataFrame с помощью квадратных скобок. Давайте используем очень простой DataFrame, который мы создали в качестве примера.
Давайте используем очень простой DataFrame, который мы создали в качестве примера.
sample_dataframe = pd.DataFrame({'столбец 1': [1, 1], 'столбец 2': [2, 2]}) # получить столбец 'column 1'
sample_dataframe['column 1']
Для более сложной индексации мы можем использовать .iloc или .loc.
- loc — это подход к индексации на основе меток, для которого требуются имена строк и столбцов. s)
Поскольку мы не указывали метки осей для строк, они приняли целочисленные значения по умолчанию. Таким образом, позиционные метки и метки осей одинаковы для этого DataFrame.
Мы можем получить первую строку, используя любой из этих способов:
sample_dataframe.iloc[0, :]sample_dataframe.loc[0, :]
Давайте создадим еще один DataFrame, чтобы проиллюстрировать некоторые функции. Можно сделать вид, что эти данные взяты у компании, занимающейся распространением учебных материалов.
данные = pd.DataFrame({'customer_id': [1,2,3,4,5,6,7,8],
'возраст': [29,43,22,82,41,33,63 ,57],
'email_linked': [Правда,Правда,Ложь,Правда,Ложь,Ложь,Правда,Правда],
«профессия»: [«учитель», «учитель средней школы», «студент», «пенсионер»,
«репетитор», «безработный», «предприниматель», «профессор»]})
Для больших фреймов данных мы можем используйте .head(n) для просмотра первых n строк. Чтобы увидеть последние несколько строк, мы можем выполнить аналогичную операцию, используя .tail(n). Ни то, ни другое не требуется для нашего небольшого набора данных, но мы все же можем продемонстрировать, используя data.head(3) .
Фильтрация и индексация DataFrame
Предположим, мы хотим запустить кампанию по электронной почте. Мы начинаем с извлечения соответствующих столбцов для проведения нашей кампании.
# используйте двойные скобки для индексации нескольких столбцов, одинарные скобки для одного столбца
email_data = data[['customer_id', 'email_linked']]
не.
# условие заключено в квадратные скобки email_data = email_data[email_data['email_linked']]
Применение функции столбца
Давайте напишем очень простую функцию, чтобы определить, является ли клиент преподавателем. Вот как мы определяем воспитателя.
def is_educator(occupation):
вернуть 'учитель' в оккупации.lower() или оккупацию.lower() в ['наставник', 'профессор', 'лектор']
Мы можем применить эту функцию к профессии , чтобы создать новый столбец.
data['is_educator'] = data['occupation'].apply(is_educator)
Мы также можем преобразовать все строки в каждом столбце DataFrame. Это требует, чтобы мы установили ось = 0 (что также является настройкой по умолчанию). Мы можем написать функцию для столбцов, чтобы удалить все столбцы, содержащие пропущенные значения. Это только для демонстрации — есть лучшие способы обработки пропущенных значений (см. официальную документацию Pandas).
def remove_missing_columns(col):
if col.isnull().values.any():
return coldata.apply(remove_missing_columns, axis=0)
Применение построчной функции
Мы также можем применить функцию для преобразования каждого столбца в строке. Это требует, чтобы мы установили ось = 1.
def is_educator_above_50(row):
return row['age'] > 50 and is_educator(row['occupation'])data['is_educator_above_50'] = data.apply(is_educator_above_50, axis=1)
Операция Groupby
Операции Groupby полезны для анализа объектов Pandas и создания новых функций из больших объемов данных. Все групповые операции можно разбить на следующие этапы:
- Разделить объект на группы
- Применить функцию к каждой группе
- Объединить результаты
 Мы можем использовать операцию groupby, чтобы вычислить средний возраст для каждой профессии.
Мы можем использовать операцию groupby, чтобы вычислить средний возраст для каждой профессии.- Разделить DataFrame по занятиям
- Применить функцию среднего к каждому занятию
- Объединить средний возраст в отдельный объект
Код для этой операции очень прост: данные .groupby(by= ['occupation']).mean()['age']
Параметр на указывает, как определяются группы, mean() представляет интересующую статистику, а индексирование по возрасту захватывает групповую статистику для возраст. Выход представляет собой ряд, где занятие — это метки осей.
Мы можем разделить группы, используя несколько параметров, например, комбинацию занятий и того, связана ли их электронная почта: data.groupby(by=['email_linked', 'occupation']).mean()['age ']
В дополнение к mean есть другие встроенные функции, которые мы можем применить к каждой группе: min, max, count, sum и это лишь некоторые из них. Мы также можем использовать
Мы также можем использовать agg() для применения любых пользовательских функций. Метод агрегирования также полезен для возврата нескольких сводных статистических данных.
Например, data.groupby(by=['occupation']).agg(['mean', 'sum'])['age'] вернет средний возраст, а также сумму возрастов для каждая группа.
Атрибуты DataFrame
Эти атрибуты помогают нам исследовать и знакомиться с новыми DataFrames.
-
data.columnsвозвращает список всех столбцов -
data.shapeвозвращает измерения в виде (количество строк, количество столбцов) -
data.dtypesвозвращает типы данных каждого столбца -
data.indexвозвращает диапазон значений индекса
Вот некоторые дополнительные сведения, которые могут быть полезны: использование и другие примеры.
Если вам понравилась эта статья, вы можете ознакомиться с другими моими статьями о науке о данных, математике и программировании. Следите за мной на Medium, чтобы быть в курсе последних обновлений!
Следите за мной на Medium, чтобы быть в курсе последних обновлений!
JAN166.dvi
%PDF-1.5 % 1 0 объект > эндообъект 5 0 объект > эндообъект 2 0 объект > транслировать Acrobat Distiller 10.1.1 (Windows) dvips 5.512 Copyright 1986, 1993 Radical Eye Software
