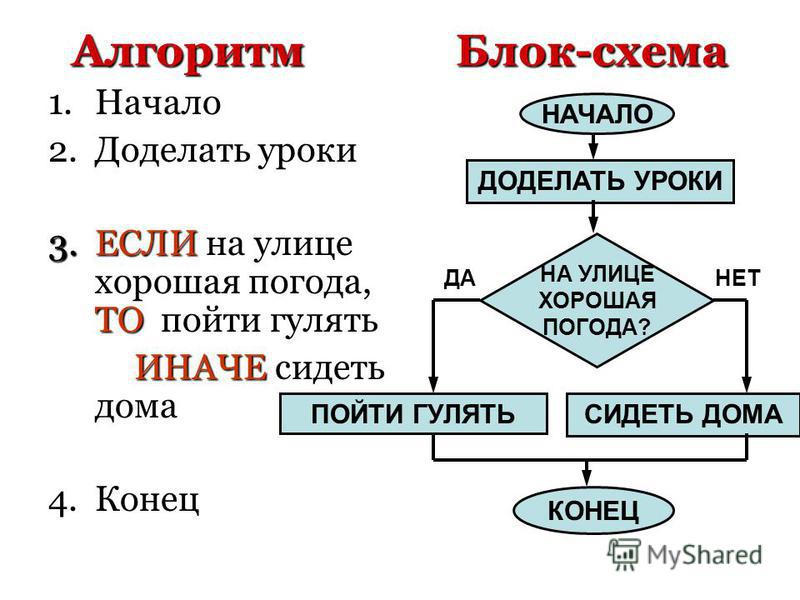
Как создать алгоритм «Ручное соответствие»
- Обновлено 10 Mar 2023
- 2 минуты
-
Темная тема
Светлая тема
-
формат pdf
Можно создать два алгоритма ручного соответствия:
- ручное соответствие категорий
- ручное соответствие категорий к последнему заказу
Оба алгоритма создаются одинаково.
Ручное соответствие категорий
Алгоритм позволяет настроить топ 30 сопутствующих продуктов по соответствию категорий, для отдельного продукта.
Тип алгоритма: рекомендации к продукту
Для клиентов: идентифицированных и анонимных
Способы вызова: API (виджет рекомендаций), email
Частота пересчета: раз в сутки
Автоматически проверяет, что:
- Продукт в наличии в зоне клиента
- Внешние системы продуктов по умолчанию совпадают.
Рекомендуется к использованию:
- в карточке товара на сайте.
Ограничение:
- 5 алгоритмов на проект
Ручное соответствие категорий к последнему заказу
Алгоритм позволяет настроить сопутствующие продукты по соответствию категорий, для каждого товара в последнем заказе клиента, в количестве, пропорциональном его цене. Для дорогих товаров больше рекомендаций, для дешевых меньше. Пересчитывается в реальном времени в зависимости от заказов клиента.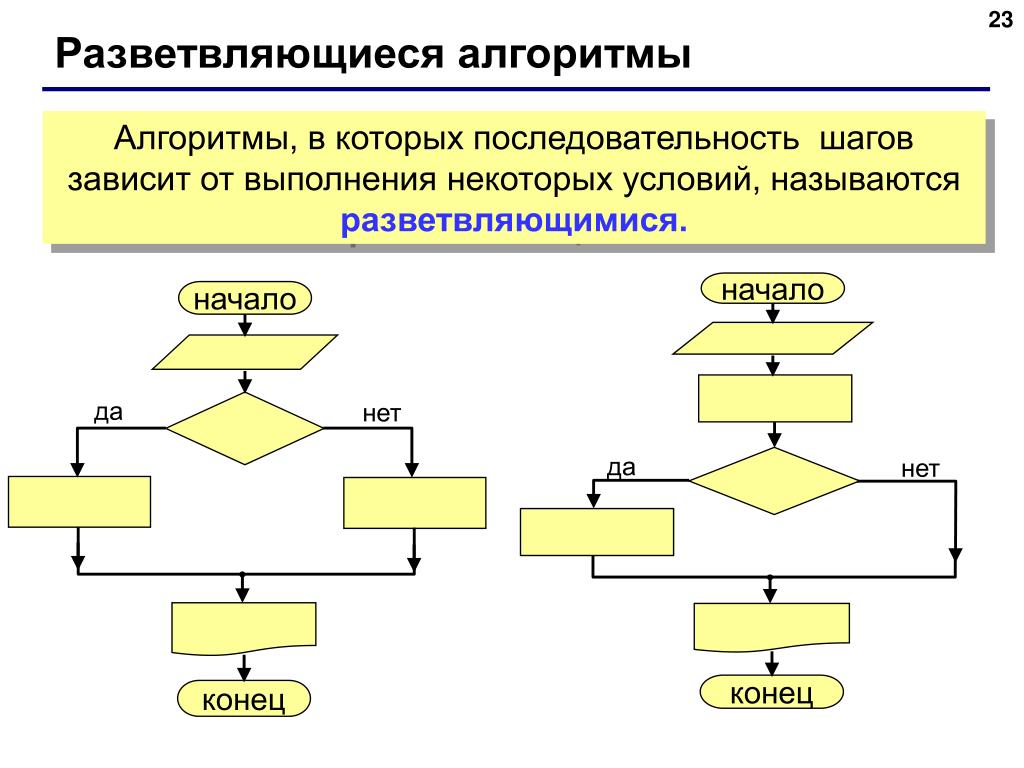
Тип алгоритма: персональные рекомендации
Для клиентов: идентифицированных
Способы вызова: API (виджет рекомендаций), email
Частота пересчета: в реальном времени
Автоматически проверяет, что:
- Продукт в наличии в зоне клиента
- Бренд продукта совпадает с брендом клиента (для многобрендовых проектов)
- Исключает из рекомендаций уже купленные клиентом товары
Рекомендуется к использованию в механиках:
- “Спасибо за заказ”;
- “Предложение к следующей покупке”.
Ограничение:
- 1 алгоритм на проект
Создание алгоритма
- Переходим в раздел Кампания -> Продуктовые рекомендации -> нажимаем Добавить механику:
- Выбираем необходимый алгоритм
- Задаем название и нажимаем Продолжить
- Задаем Общие настройки
- Рекомендовать для товаров — к какому пересчитываемому сегменту формируем рекомендации (необязательно)
- Рекомендовать из — из какого пересчитываемого сегмента формируются рекомендации (необязательно)
- Рекомендовать только продукты из той же внешней системы — по умолчанию включено, можно отключить
Также в соответствующем блоке можно настроить Исключение производителей:
- Настраиваем Соответствие категорий
Выбираем категорию для соответствия:
Настраиваем пары для категории , указав количество рекомендуемых товаров:
При указании, что к Категории А нужно рекомендовать товар из Категории Б, к каждому товару из Категории А будет подбираться наиболее часто покупаемый с этим товаром товар из Категории Б.
Указываем настройки соответствия:
Параметры в настройках соответствия определяют сортировку вывода рекомендаций. Если сначала указана «Цена», затем «Производитель», то в первую очередь будут выводиться товары у которых совпадает цена и производитель. Затем, дополнительно сортируются по популярности в заказах и просмотрах.
Нажмите чек-бокс в блоке «Точное соответствие», чтобы определить точное соответствие поля. Например, если выбран чек-бокс у поля «Цвет», то к синим продуктам будут рекомендоваться только синие продукты.
Чем больше выбрано полей, тем меньше товаров будет рекомендовано.
Как выбрать категорию:
Основная категория — это та категория, которая идет ближе к товару
- Запускаем алгоритм:
После запуска в работу на странице будет выведена информация: статус и время обновления:
Была ли эта статья полезной?
Как создать алгоритм «Сопутствующие продукты»
- Обновлено 10 Feb 2023
- 2 минуты
-
Темная тема
Светлая тема
-
формат pdf
Можно создать три алгоритма сопутствующих продуктов:
- сопутствующие продукты
- сопутствующие к списку продуктов
- сопутствующие продукты к последнему заказу
Все три алгоритма создаются одинаково.
Сопутствующие продукты
Сопутствующие продукты рассчитываются на основе частоты, с которой они встречаются вместе в одном чеке. Также, учитываются совместные покупки категорий и признаков товаров. В результате работы ML модели, алгоритм может предсказать рекомендации даже для продуктов без заказов.
Тип алгоритма: рекомендации к продукту
Для клиентов: идентифицированных и анонимных
Способы вызова: API (виджет рекомендаций), email
Частота пересчета: раз в сутки
Автоматически проверяет, что:
- Продукт в наличии в зоне клиента
- Внешние системы продуктов по умолчанию совпадают.
Рекомендуется к использованию:
- в механике “С этим товаром также покупают”
Ограничение:
- 5 алгоритмов на проект
Сопутствующие продукты к списку продуктов
Алгоритм рассчитывает сопутствующие продукты, и формирует рекомендации для каждого продукта в выбранном списке продуктов клиента, в количестве, пропорциональном его цене.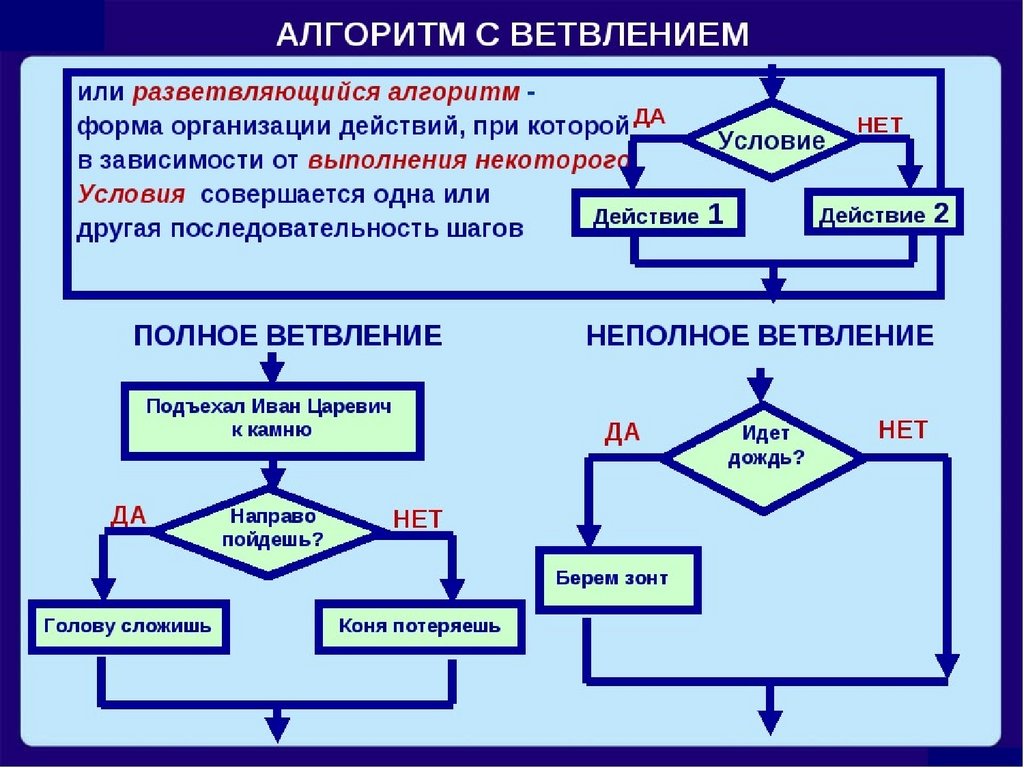
Сопутствующие продукты рассчитываются на основе частоты, с которой они встречаются вместе в одном чеке. Также учитываются совместные покупки категорий и признаков товаров. В результате работы ML модели, алгоритм может предсказать рекомендации даже для продуктов без заказов.
Тип алгоритма: персональные рекомендации
Для клиентов: идентифицированных и анонимных
Способы вызова: *API (виджет рекомендаций), email *
Частота пересчета: в реальном времени
Автоматически проверяет, что:
- Продукт в наличии в зоне клиента
- Бренд продукта совпадает с брендом клиента (для многобрендовых проектов)
- Исключает из рекомендаций уже купленные клиентом товары
Рекомендуется к использованию в механиках:
- “Брошенная корзина”;
- “Рекомендации к избранному”;
- “Корзина на сайте”
Ограничение:
- 3 алгоритмов на проект
Сопутствующие продукты к последнему заказу
Алгоритм рассчитывает сопутствующие продукты, и формирует рекомендации для каждого товара в последнем заказе клиента, в количестве, пропорциональном его цене. Для дорогих продуктов больше рекомендаций, для дешевых меньше. Пересчитывается в реальном времени в зависимости от заказов клиента.
Для дорогих продуктов больше рекомендаций, для дешевых меньше. Пересчитывается в реальном времени в зависимости от заказов клиента.
Сопутствующие продукты рассчитываются на основе частоты, с которой они встречаются вместе в одном чеке. Также, учитываются совместные покупки категорий и признаков товаров. В результате работы ML модели, алгоритм может предсказать рекомендации даже для товаров без заказов.
Тип алгоритма: персональные рекомендации
Для клиентов: идентифицированных
Способы вызова: API (виджет рекомендаций), email
Частота пересчета: в реальном времени
Автоматически проверяет, что:
- Продукт в наличии в зоне клиента
- Бренд продукта совпадает с брендом клиента (для многобрендовых проектов)
- Исключает из рекомендаций уже купленные клиентом товары
Рекомендуется к использованию в механиках:
- “Спасибо за заказ”;
- “Предложение к следующему заказу”.
Ограничение:
- 1 алгоритм на проект
Создание алгоритма
- Переходим в раздел Кампания -> Продуктовые рекомендации -> нажимаем Добавить механику:
Выбираем необходимый алгоритм
Задаем название и нажимаем Продолжить
Задаем Общие настройки:
- Учитывать действия с товарами за — будет учитываться статистика по заказам за период от 1 до 180
- Рекомендовать для товаров — к какому пересчитываемому сегменту формируем рекомендации (необязательно)
- Рекомендовать из — из какого пересчитываемого сегмента формируются рекомендации (необязательно)
- Рекомендовать только продукты из той же внешней системы — по умолчанию включено, можно отключить
Также в соответствующем блоке можно настроить Исключение производителей:
Для алгоритма «Сопутствующие продукты к списку продуктов» также выбираем список продуктов.
- Запускаем алгоритм:
После запуска в работу на странице рекомендаций будет выведена информация: статус и время обновления:
Пример использования
Например, хотим вывести сопутствующие продукты из сегмента «Шарфы» к сегменту «Пальто» (системное имя Coats).
- Создаём рекомендацию с алгоритмом «Сопутствующие продукты»
- Выбираем в настройках сегменты:
- Запускаем рекомендацию в работу
- Получаем параметр Product.Recommendations.Soputstvuyuschieprodukti:
- Подставляем параметр в письмо
Устанавливаем ограничение на сегмент с помощью функции Take(), чтобы письмо могло сфомироваться даже при большом размере сегмента.
Вёрстка для нашего примера с выводом названия рекомендуемого товара:
@{for prod in Products.GetBySegment("Coats").Take(5)}
@{for item in prod.Product.Recommendations.Soputstvuyuschieprodukti.Take(2)}
...${item. Name}...
@{end for}
@{end for}
Name}...
@{end for}
@{end for}
Готово! Подборка сопутствующих товаров к заказу — как предлагать дополнительные товары к уже купленным.
Была ли эта статья полезной?
Как научиться алгоритмам.
Многие Car Talk Puzzlers являются классическими примерами того, о чем думают компьютерщики, когда учатся строить алгоритмы. Выше, Click and Clack (Рэй и Том Маглиоцци) из Car Talk .Лейн Тернер / Boston Globe через Getty Images
Вы когда-нибудь разбрасывались словом по алгоритму , не зная, что оно означает? Когда люди жалуются на алгоритм Facebook, алгоритм Netflix или алгоритм поиска Google, они не всегда понимают, что это такое, даже если понимают последствия. Но по мере того, как алгоритмы приобретают все большее значение в нашей жизни, крайне важно, чтобы каждый имел базовое представление о том, что они из себя представляют.
По своей сути алгоритмы — это инструкции по решению проблемы. Они аналогичны чертежам здания — программист будет подрядчиком, который фактически его строит. Как вы можете понять и оценить архитектуру без формального обучения, так и с алгоритмами. Если вы хотите развить базовую алгоритмическую грамотность, вы можете сделать это за несколько основных шагов: изучить некоторые общие алгоритмические компоненты, распознать общие алгоритмические проблемы и попробовать создать некоторые алгоритмы самостоятельно.
Основные элементы алгоритмов
Каждый алгоритм имеет входы и выходы. Вывод — это то, что вы обычно видите — это результат работы алгоритма. Это может быть Google Maps, который найдет ваш маршрут домой, TurboTax рассчитает ваш возврат или Netflix порекомендует шоу. Алгоритмы также имеют входные данные. Ввод может быть простым, как число, или может быть намного больше, чем кажется. Например, алгоритм, который находит маршрут из пункта А в пункт Б, использует указанные вами точки в качестве входных данных, но он также использует всю базу данных дорог, маршрутов других водителей и т. д. Когда вы думаете о входных данных, учитывайте все, что может использоваться для решения проблемы.
Вывод — это то, что вы обычно видите — это результат работы алгоритма. Это может быть Google Maps, который найдет ваш маршрут домой, TurboTax рассчитает ваш возврат или Netflix порекомендует шоу. Алгоритмы также имеют входные данные. Ввод может быть простым, как число, или может быть намного больше, чем кажется. Например, алгоритм, который находит маршрут из пункта А в пункт Б, использует указанные вами точки в качестве входных данных, но он также использует всю базу данных дорог, маршрутов других водителей и т. д. Когда вы думаете о входных данных, учитывайте все, что может использоваться для решения проблемы.
После получения входных данных алгоритмы выполняют ряд шагов для создания выходных данных. Большинство алгоритмов строятся на других простых процессах. На самом деле, любая сложная вещь, которую вы делаете на компьютере, может выполняться маленькой машиной, которая считывает единицы и нули с полоски бумаги, ищет что-то в таблице и подстраивает цифру. (Это известно как машина Тьюринга, основа информатики.) Общие процессы включают сортировку списков, поиск элементов в списках и выполнение некоторых математических манипуляций — все они поддерживают множество более крупных алгоритмов.
(Это известно как машина Тьюринга, основа информатики.) Общие процессы включают сортировку списков, поиск элементов в списках и выполнение некоторых математических манипуляций — все они поддерживают множество более крупных алгоритмов.
Общие алгоритмические проблемы
Компьютеры всегда ищут правильное действие и сортируют списки вариантов, чтобы помочь найти его. Поскольку эти процессы настолько распространены, мы хотим иметь возможность выполнять их быстро.
Давайте рассмотрим пару алгоритмов поиска. Скажем, я даю вам колоду карт. Сначала он сортируется по достоинству карты (двойки, затем тройки, затем четверки и т. д.) и по масти. Итак, у нас будет двойка треф, двойка червей, двойка бубен, двойка пик, тройка треф, тройка червей и т. д.
Сначала он сортируется по достоинству карты (двойки, затем тройки, затем четверки и т. д.) и по масти. Итак, у нас будет двойка треф, двойка червей, двойка бубен, двойка пик, тройка треф, тройка червей и т. д.
Нам нужен алгоритм для поиска определенной карты в этой колоде. Какой процесс вы бы использовали? Алгоритмы должны быть очень явными, поэтому вы не можете просто сказать: «Пролистай колоду, пока не увидишь ее».
Один алгоритм может начать сначала и проверить каждую карту, чтобы убедиться, что это наша карта. Если это так, мы закончили! Если нет, то переходим к следующей карте. В худшем случае, если я попрошу туз пик, вам придется просмотреть все 52 карты, чтобы найти его. В лучшем случае я говорю двойка треф, и вы сразу ее найдете. Если вы усредните это для всех возможных карт, которые я прошу, в среднем вам придется пройти около половины колоды или 26 карт, прежде чем найти ее.
Если вы усредните это для всех возможных карт, которые я прошу, в среднем вам придется пройти около половины колоды или 26 карт, прежде чем найти ее.
Лучший алгоритм называется двоичным поиском. Поскольку наша колода отсортирована, давайте начнем с того, что разделим ее пополам и посмотрим на центральную карту (это 26 -я -я карта). Проверьте, не та ли это карта, которую мы ищем. Если это так, отлично! Если нет, мы определяем, будет ли нужная нам карта раньше или позже в колоде. Скажем, раньше. Потом выбрасываем всю половину колоды, которая позже. Берем переднюю половину колоды, делим ее пополам (до 13 й карты) и смотрим, наша ли это карта. Повторяйте этот процесс, пока не найдем нужную карту. Каждый раз мы делим колоду пополам. Это означает, что нам понадобится не более шести сравнений, чтобы найти нашу карту — намного быстрее, чем наш первый метод.
Подобные простые алгоритмы поиска и сортировки являются базовыми строительными блоками, которые вместе используются для решения сложных задач. Например, один из способов поиска в Интернете (при условии, что у вас есть доступ ко всем веб-страницам) — это выполнить поиск для каждой страницы, на которой есть ваш термин. Затем проведите небольшую математику, чтобы подсчитать, насколько хорошо они соответствуют поисковому запросу. Затем отсортировать этих страниц по количеству баллов и вернуть их в порядке от лучшего к худшему.
Признание этих основных строительных блоков и того, как они сочетаются друг с другом, является отличным началом алгоритмической грамотности. Но есть также некоторые действительно сложные проблемы, о которых вы должны знать, потому что они появляются повсюду.
Но есть также некоторые действительно сложные проблемы, о которых вы должны знать, потому что они появляются повсюду.
Такие задачи называются NP-полными. Мы пропустим здесь формальное определение, но в основном это задачи, в которых вам нужно проверить множество комбинаций, чтобы найти лучший ответ. Например, есть одна NP-полная задача, которая называется «задача о рюкзаке». Я даю вам рюкзак, который может выдержать заданный вес (скажем, 20 фунтов). Затем я даю вам кучу объектов. У каждого есть вес и ценность. Вы хотите поместить в свой рюкзак самую ценную комбинацию предметов, но не можете превысить ее предельный вес. Какую коллекцию предметов вы выбираете?
Еще одна NP-полная задача — задача коммивояжера. В этом у вас есть список городов, список рейсов между городами и стоимость каждого рейса. Коммивояжер хочет посетить каждый город по самому дешевому маршруту, и он не будет проходить ни один город более одного раза.
В этом у вас есть список городов, список рейсов между городами и стоимость каждого рейса. Коммивояжер хочет посетить каждый город по самому дешевому маршруту, и он не будет проходить ни один город более одного раза.
NP-полные задачи сложны (мы думаем). Как сложно? Если бы я дал вам 100 городов в задаче о коммивояжере, на ее решение ушло бы больше времени, чем известный возраст Вселенной. Быстрый алгоритм мог бы существовать, но мы, компьютерщики, думаем, что его, вероятно, нет (подробнее об этом см. в статье о проблеме P vs. NP). Более интересно то, что если бы у нас был быстрый алгоритм для любой из этих задач, этот алгоритм решил бы все из них. Если вы придумаете быстрый способ решения задачи о рюкзаке, вы сможете напрямую применить этот алгоритм к задаче о коммивояжере и наоборот. (Хотите доказательства? Посмотрите эти слайды). Распознавание чего-то похожего на NP-полную задачу — важный шаг на вашем пути к алгоритмической грамотности.
Распознавание чего-то похожего на NP-полную задачу — важный шаг на вашем пути к алгоритмической грамотности.
Как только вы узнаете об этих алгоритмических основах, вы сможете искать их в своей повседневной жизни. В качестве примера подумайте о музыкальном сайте, рекомендующем песни. Какие входы? Сайт знает, какие песни я слушал один раз или неоднократно, и какие мне нравились (или не нравились) в прошлом. Они знают жанр, исполнителя и другую информацию об этих песнях. Они могли искать в своем списке песен похожие, подсчитывать оценку схожести для каждой песни, сортировать список и показывать мне лучшие из них.
Они также знают, какие песни слушали и что им нравилось. Если это часть входных данных, алгоритм может найти самые популярные песни среди людей со вкусами, похожими на мои. Это включает в себя поиск во всех его записях, чтобы найти информацию о том, кто что слушал, оценку моего сходства с этими людьми, затем оценку песен и сортировку списка песен по количеству баллов. Алгоритм может даже объединить информацию о предпочтениях других людей с информацией об исполнителе и жанре, чтобы получить оценку. Эти входные данные влияют на выходные данные алгоритма. Иногда люди говорят об алгоритмической предвзятости — это то, что может начаться с предвзятости входных данных. В этом случае это могут быть плохие жанровые ярлыки или группа пользователей с необычными привычками прослушивания.
Это включает в себя поиск во всех его записях, чтобы найти информацию о том, кто что слушал, оценку моего сходства с этими людьми, затем оценку песен и сортировку списка песен по количеству баллов. Алгоритм может даже объединить информацию о предпочтениях других людей с информацией об исполнителе и жанре, чтобы получить оценку. Эти входные данные влияют на выходные данные алгоритма. Иногда люди говорят об алгоритмической предвзятости — это то, что может начаться с предвзятости входных данных. В этом случае это могут быть плохие жанровые ярлыки или группа пользователей с необычными привычками прослушивания.
Ключ здесь не в том, чтобы точно понять, как работает алгоритм, а в том, чтобы понять, что он может использовать в качестве входных данных, какие операции он может выполнять с этими входными данными и как он может генерировать выходные данные.
Создание собственного алгоритма
Наконец, попробуйте создать собственный алгоритм. Это хороший способ развить грамотность, так же как чтение — хороший способ стать лучшим писателем.
Разработчики алгоритмов обычно следят за процессом рассмотрения большой проблемы и разбивают ее на более мелкие шаги. Затем мы разбиваем эти более мелкие шаги дальше, пока не начнем видеть шаблоны или основные шаги, которые нам необходимо выполнить. По сути, решение головоломок.
Если вы послушаете Car Talk Puzzler, многие из них являются классическими примерами, о которых думают компьютерщики, когда учатся строить алгоритмы.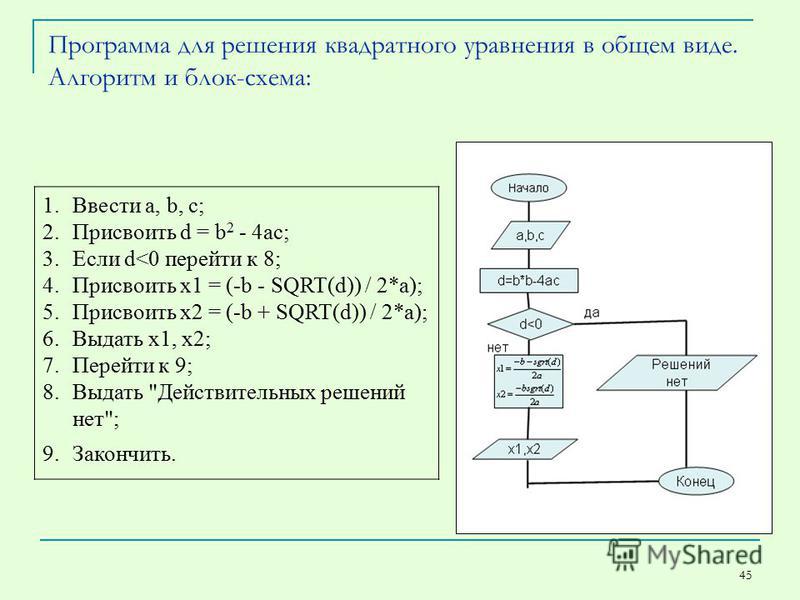 Давайте рассмотрим одну из таких головоломок:
Давайте рассмотрим одну из таких головоломок:
Мы собираемся сыграть в небольшую карточную игру. Я собираюсь разложить 21 карту из обычной колоды карт в стопку перед нами. Будем поочередно брать карты из стопки.
Вот правила:
Когда наступает ваш ход, вы можете взять до трех карт, но обязательно хотя бы одну. Таким образом, вы можете взять одну, две или три карты из стопки. Победителем игры становится тот, кто берет последнюю карту или карты со стола.
Например, если осталось шесть карт и я возьму три, вы возьмете последние три, потому что мы чередуем ходы, и вы выиграете. Итак, ясно, что если бы осталось шесть карт, я бы не взял три.
Вопрос в том, можете ли вы использовать стратегию, которая гарантировала бы вам победу?
Эта головоломка просит вас построить алгоритм для игры.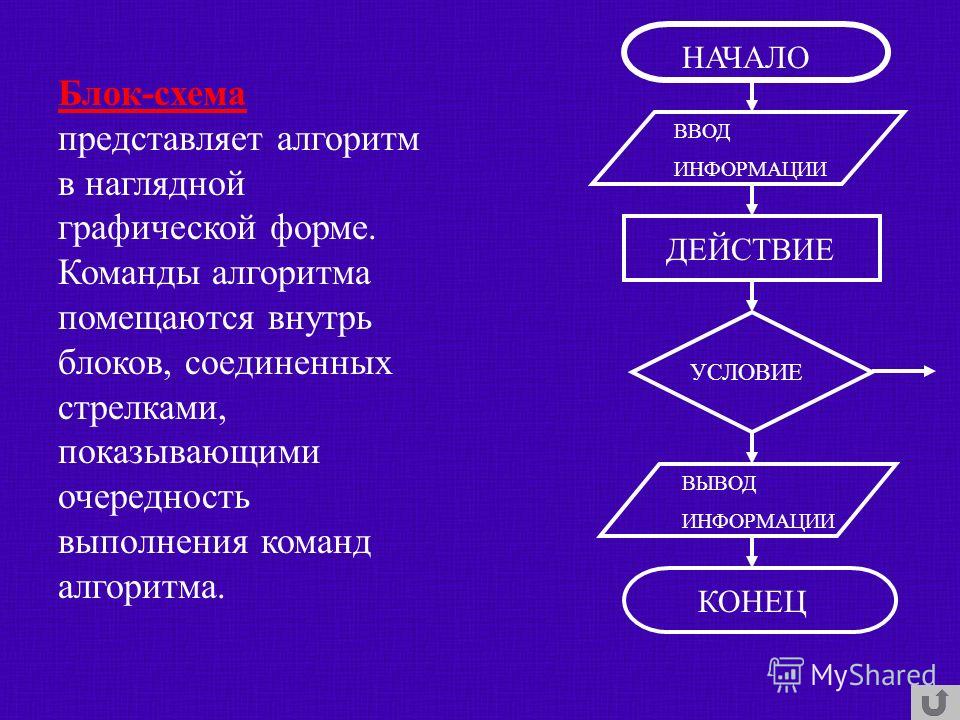 Начните с рассмотрения основных случаев, а затем ищите закономерности. Здесь мы знаем, что я выиграю, если на столе будет одна, две или три карты, так как я могу взять их все. Я проиграю, если на столе четыре карты, потому что, что бы я ни делал, мой противник сможет взять все, что осталось.
Начните с рассмотрения основных случаев, а затем ищите закономерности. Здесь мы знаем, что я выиграю, если на столе будет одна, две или три карты, так как я могу взять их все. Я проиграю, если на столе четыре карты, потому что, что бы я ни делал, мой противник сможет взять все, что осталось.
Таким образом, это говорит нам о том, что это выигрышное предложение, когда на столе одна, две или три карты, и проигрышное, если их четыре. Мы можем использовать это для построения шаблона. Если я могу поставить своего противника в проигрышную позицию (например, заставить его увидеть четыре карты), то я знаю, что выиграю. Я могу сделать это, если есть пять карт (взяв одну), шесть карт (взяв две) или семь карт (взяв три). Если есть восемь карт, я ничего не могу сделать, чтобы мой противник увидел четыре карты, поэтому я проиграю (если только мой противник не совершит ошибку).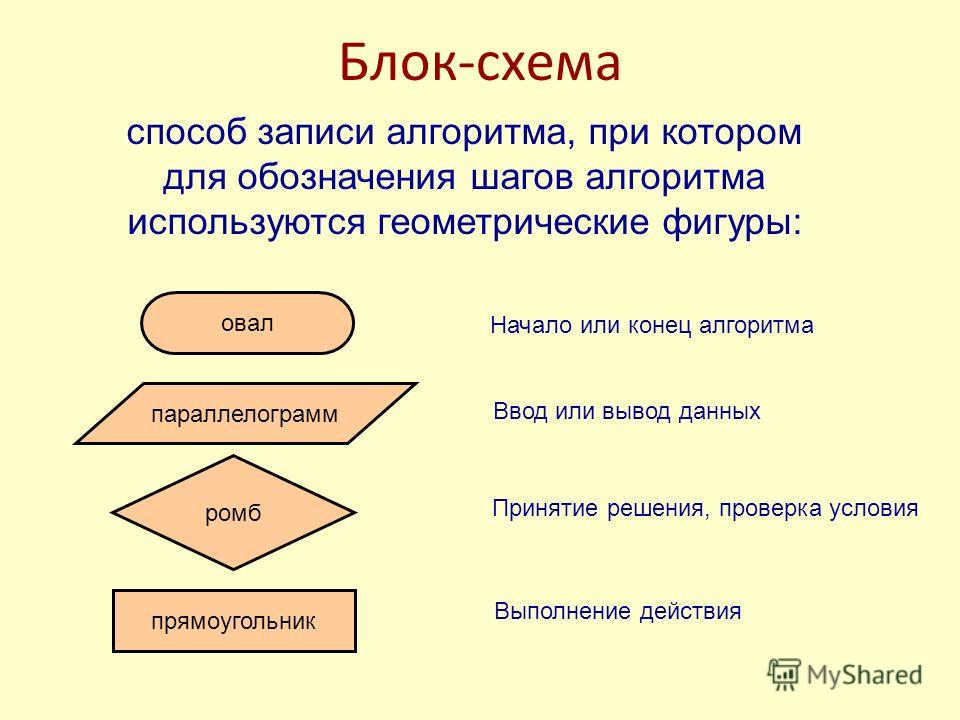
Теперь мы видим закономерность. Раз, два, три выигрышные сетапы. Четыре — неудачник. Пять, шесть, семь — победители. Восьмерка — проигрыш. Если вы последуете этому, то увидите, что любые комбинации, кратные четырем, будут проигрышными, поскольку все, что вы делаете, ставит вашего оппонента в выигрышную конфигурацию. Все, что не кратно четырем, является выигрышным, потому что вы можете сделать ход, чтобы вывести противника в проигрышную позицию.
Здесь указывается количество карт на столе. Ваш алгоритм подсчитает, сколько карт нужно взять, чтобы получить общую сумму, кратную четырем, а затем сделает этот ход. Противник уходит, а затем ваш алгоритм повторяет процесс.
 com/_components/slate-paragraph/instances/cq-article-9124682cf6e8ba06bbbfb789b2854e89-component-33@published»> Эта головоломка на самом деле является версией обычной игры под названием Ним, которую часто изучают студенты, изучающие информатику. В ним вы можете изменить правила, касающиеся того, что вы можете брать за каждый ход (например, сказать, что вы можете брать только два или семь предметов за каждый ход) и количества стопок. Паттерны меняются, но всегда есть алгоритм выигрышной стратегии.
com/_components/slate-paragraph/instances/cq-article-9124682cf6e8ba06bbbfb789b2854e89-component-33@published»> Эта головоломка на самом деле является версией обычной игры под названием Ним, которую часто изучают студенты, изучающие информатику. В ним вы можете изменить правила, касающиеся того, что вы можете брать за каждый ход (например, сказать, что вы можете брать только два или семь предметов за каждый ход) и количества стопок. Паттерны меняются, но всегда есть алгоритм выигрышной стратегии.
Большинство алгоритмов, с которыми вы сталкиваетесь в повседневной жизни, чрезвычайно сложны, но это не значит, что вы не можете развить базовую грамотность, чтобы понять их. Проанализируйте входные данные и попытайтесь понять все данные, с которыми может работать алгоритм. Изучите строительные блоки алгоритмов, таких как поиск и сортировка, которые в сочетании с некоторой математикой составляют множество алгоритмов, которые вы видите.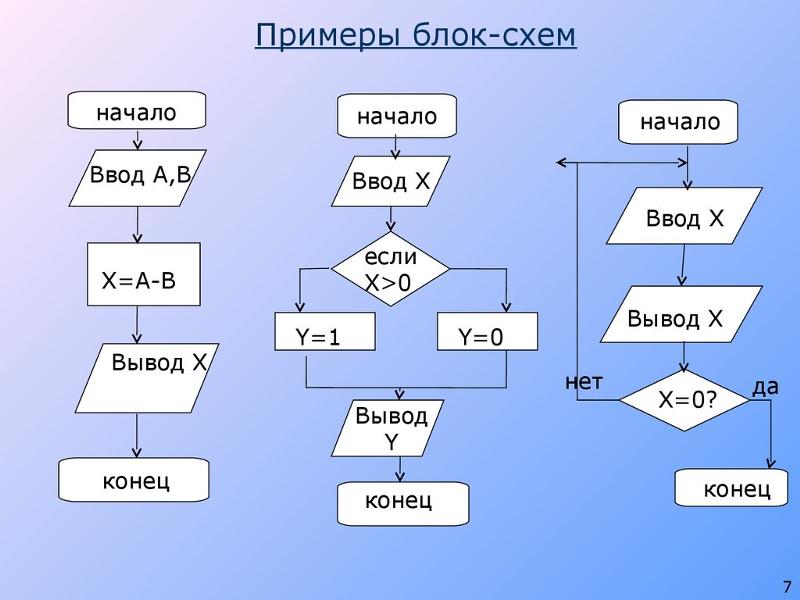 Распознавайте распространенные алгоритмические проблемы, которые постоянно возникают вокруг вас. И, наконец, потренируйтесь в изготовлении. Хотя вы не станете профессионалом, вы научитесь ценить и критиковать эти процессы, которые так сильно влияют на нашу повседневную жизнь.
Распознавайте распространенные алгоритмические проблемы, которые постоянно возникают вокруг вас. И, наконец, потренируйтесь в изготовлении. Хотя вы не станете профессионалом, вы научитесь ценить и критиковать эти процессы, которые так сильно влияют на нашу повседневную жизнь.
Эта статья является частью статьи об алгоритмах Futurography, серии, в которой Future Tense знакомит читателей с технологиями, которые определят будущее . Каждый месяц с января по июнь 2016 года мы будем выбирать новую технологию и анализировать ее. Подробнее об алгоритмах читайте в Futurography:
- «Что делать с алгоритмами?»
- «Шпаргалка по вашим алгоритмам»
- «Ученый по этическим данным»
- «Как привлечь правительства к ответственности за используемые ими алгоритмы»
- «Как алгоритмы меняют наши аргументы»
- «Какой правительственный алгоритм борьбы с мошенничеством работает лучше всего — нацеленный на бедных или богатых?»
- «Алгоритмы могут стать хорошими коллегами»
- «Алгоритмы не как у Спока — они как у капитана Кирка»
- «Что мы , а не хотим, чтобы алгоритмы сделали для нас?»
 com/_components/slate-paragraph/instances/cq-article-9124682cf6e8ba06bbbfb789b2854e89-component-37@published»> Будущее время является результатом сотрудничества между Университет штата Аризона , Новая Америка и Шифер . Чтобы получать последние новости от Futurography по электронной почте, подпишитесь на еженедельную рассылку Future Tense.
com/_components/slate-paragraph/instances/cq-article-9124682cf6e8ba06bbbfb789b2854e89-component-37@published»> Будущее время является результатом сотрудничества между Университет штата Аризона , Новая Америка и Шифер . Чтобы получать последние новости от Futurography по электронной почте, подпишитесь на еженедельную рассылку Future Tense.
- Алгоритмы
- Футурография
Искусственный интеллект: как алгоритмы делают системы умными
Пропустить заголовок статьи. Перейти к: Начало статьи.
Слово «алгоритм» можно услышать гораздо чаще, чем раньше. Одна из причин заключается в том, что ученые узнали, что компьютеры могут учиться самостоятельно, если дать им несколько простых инструкций. Вот собственно и все, что алгоритмы — это математические инструкции. Википедия утверждает, что алгоритм «представляет собой пошаговую процедуру вычислений.
Википедия утверждает, что алгоритм «представляет собой пошаговую процедуру вычислений.
используются для вычислений, обработки данных и автоматизированных рассуждений». Осознаете вы это или нет, но алгоритмы становятся повсеместной частью нашей жизни. Некоторые эксперты видят в этой тенденции опасность. Например, Лео Хикман (@LeoHickman) пишет: «Откровения АНБ подчеркивают роль сложных алгоритмов в просеивании массивов данных. Но еще более удивительным является их широкое использование в нашей повседневной жизни. Так должны ли мы быть более осторожными с их силой?» [«Как алгоритмы правят миром», The Guardian , 1 июля 2013 г.] Было бы несколько преувеличением заявить, что алгоритмы правят миром; но я согласен, что их использование становится все более распространенным. Это связано с тем, что компьютеры играют все более важную роль во многих аспектах нашей жизни. Мне нравится объяснение HowStuffWorks :
«Чтобы заставить компьютер что-то делать, нужно написать компьютерную программу.
Чтобы написать компьютерную программу, вы должны шаг за шагом сказать компьютеру, что именно вы хотите, чтобы он сделал. Затем компьютер «выполняет» программу, механически выполняя каждый шаг, чтобы достичь конечной цели. Когда вы говорите компьютеру, что делать, вы также можете выбрать, как он будет это делать. Вот где на помощь приходят компьютерные алгоритмы. Алгоритм — это основная техника, используемая для выполнения работы».
Единственный момент, в котором объяснение неверно, заключается в том, что вы должны шаг за шагом говорить компьютеру, «что именно вы хотите, чтобы он делал». Вместо того, чтобы следовать только явно запрограммированным инструкциям, некоторые компьютерные алгоритмы предназначены для того, чтобы позволить компьютерам учиться самостоятельно (т. Е. Упрощать машинное обучение). Использование машинного обучения включает интеллектуальный анализ данных и распознавание образов. Клинт Финли сообщает: «Сегодня в Интернете правят алгоритмы. Эти математические вычисления определяют, что вы видите в своей ленте на Facebook, какие фильмы рекомендует вам Netflix и какую рекламу вы видите в своем Gmail». [«Хотите создать свой собственный Google? Посетите App Store, чтобы найти алгоритмы», Wired , 11 августа 2014 г.].
[«Хотите создать свой собственный Google? Посетите App Store, чтобы найти алгоритмы», Wired , 11 августа 2014 г.].
Как математические уравнения, алгоритмы не являются ни хорошими, ни плохими. Однако ясно, что алгоритмами пользовались люди как с хорошими, так и с плохими намерениями. Доктор Панос Парпас, преподаватель кафедры вычислительной техники в Имперском колледже Лондона, сказал Хикману: «[Алгоритмы] теперь интегрированы в нашу жизнь. С одной стороны, они хороши тем, что освобождают наше время и выполняют рутинные процессы за нас. Вопросы, которые поднимаются об алгоритмах в настоящее время, касаются не алгоритмов как таковых, а того, как общество структурировано в отношении использования данных и конфиденциальности данных. Это также о том, как модели используются для предсказания будущего. В настоящее время существует неловкое сочетание данных и алгоритмов. По мере развития технологий будут возникать ошибки, но важно помнить, что это всего лишь инструмент. Мы не должны винить наши инструменты».
В алгоритмах нет ничего нового. Как отмечалось выше, это просто математические инструкции. Их использование в компьютерах восходит к одному из гигантов вычислительной теории Алану Тьюрингу. Еще в 1952 году Тьюринг «опубликовал набор уравнений, которые пытались объяснить узоры, которые мы наблюдаем в природе, от пятнистых полосок, украшающих спину зебры, до мутовчатых листьев на стебле растения или даже сложного скручивания и складывания, которое превращает клубок клеток в организм». [«Мощные уравнения, объясняющие закономерности, которые мы наблюдаем в природе», Кэт Арни (@harpistkat), Gizmodo , 13 августа 2014] Тьюринг прославился во время Второй мировой войны, потому что помог взломать код Enigma. К сожалению, Тьюринг покончил с собой через два года после публикации своей книги. К счастью, влияние Тьюринга на мир не закончилось его самоубийством. Арни сообщает, что ученые до сих пор используют его алгоритмы для обнаружения закономерностей в природе. Арни заключает:
«В последние годы жизни Алана Тьюринга он видел, как его математическая мечта — программируемый электронный компьютер — воплотилась в жизнь из темпераментного набора проводов и трубок.
Тогда он был способен обрабатывать несколько чисел со скоростью улитки. Сегодня смартфон в вашем кармане напичкан вычислительными технологиями, которые поразили бы его воображение. Потребовалась почти целая жизнь, чтобы воплотить его биологическое видение в научную реальность, но оказалось, что это больше, чем аккуратное объяснение и несколько причудливых уравнений».
Хотя алгоритмы Тьюринга оказались полезными для определения того, как закономерности возникают в природе, другие корреляции, генерируемые алгоритмами, вызывают больше подозрений. Дебора Гейдж (@deborahgage) напоминает нам: «Корреляция… отличается от причинно-следственной связи». [«Большие данные раскрывают некоторые странные корреляции», The Wall Street Journal , 23 марта 2014 г.] Она добавляет: «Благодаря потоку данных, которые теперь доступны, поиск удивительных корреляций никогда не был таким простым». Гейдж сообщает, что одна «компания обнаружила, что сделки, заключенные в новолуние, в среднем на 43% больше, чем в полнолуние». Были обнаружены и другие странные корреляции: «Люди чаще отвечают на звонки, когда идет снег, холодно или очень влажно; когда солнечно или менее влажно, они больше отвечают на электронную почту. Предварительный анализ показывает, что они также покупают больше, когда солнечно, хотя некоторые люди покупают больше, когда пасмурно. …Онлайн-кредитор ZestFinance Inc. обнаружил, что люди, которые заполняют свои заявки на кредит, используя все заглавные буквы, чаще не выполняют свои обязательства, чем люди, которые используют все строчные буквы, и еще чаще, чем люди, которые правильно используют прописные и строчные буквы». Гейдж продолжает:
Были обнаружены и другие странные корреляции: «Люди чаще отвечают на звонки, когда идет снег, холодно или очень влажно; когда солнечно или менее влажно, они больше отвечают на электронную почту. Предварительный анализ показывает, что они также покупают больше, когда солнечно, хотя некоторые люди покупают больше, когда пасмурно. …Онлайн-кредитор ZestFinance Inc. обнаружил, что люди, которые заполняют свои заявки на кредит, используя все заглавные буквы, чаще не выполняют свои обязательства, чем люди, которые используют все строчные буквы, и еще чаще, чем люди, которые правильно используют прописные и строчные буквы». Гейдж продолжает:
«Влияют ли на сделки купли-продажи циклы луны? Можно ли определить кредитный риск по тому, как человек печатает? Быстрое новое программное обеспечение для обработки данных в сочетании с потоком общедоступных и частных данных позволяет компаниям проверять эти и другие, казалось бы, надуманные теории, задавая вопросы, которые раньше мало кто додумался задать.
Объединяя человеческий и искусственный интеллект, они стремятся раскрыть умные идеи и сделать прогнозы, которые могут дать компаниям преимущество на все более конкурентном рынке».
Главный исполнительный директор ZestFinance Дуглас Меррилл сказал Гейджу: «Ученым, работающим с данными, необходимо проверить, имеют ли смысл их выводы. Машинное обучение не заменит людей». Часть проблемы заключается в том, что большинство систем машинного обучения не сочетают рассуждения с вычислениями. Они просто выплевывают корреляции независимо от того, имеют они смысл или нет. Гейдж сообщает: «ZestFinance отвергла еще один вывод своего программного обеспечения о том, что более высокие люди лучше выплачивают кредиты, — гипотезу, которую г-н Меррилл называет глупой». Добавляя рассуждения в системы машинного обучения, корреляции и идеи становятся гораздо более полезными. «Часть проблемы, — пишет Кэтрин Хаваси (@havasi), генеральный директор и соучредитель Luminoso, — заключается в том, что, когда мы, люди, общаемся, мы полагаемся на обширный фон невысказанных предположений. … Мы предполагаем, что все, кого мы встречаем, разделяют это знание. Он формирует основу нашего взаимодействия и позволяет нам общаться быстро, эффективно и с глубоким смыслом». [«Кто рассуждает на основе здравого смысла и почему это важно», стр. 9.0002 TechCrunch , 9 августа 2014 г.] Она добавляет: «Сколько бы технологии ни были развиты сегодня, их главный недостаток, поскольку они становятся значительной частью повседневной жизни общества, заключается в том, что они не разделяют эти предположения».
… Мы предполагаем, что все, кого мы встречаем, разделяют это знание. Он формирует основу нашего взаимодействия и позволяет нам общаться быстро, эффективно и с глубоким смыслом». [«Кто рассуждает на основе здравого смысла и почему это важно», стр. 9.0002 TechCrunch , 9 августа 2014 г.] Она добавляет: «Сколько бы технологии ни были развиты сегодня, их главный недостаток, поскольку они становятся значительной частью повседневной жизни общества, заключается в том, что они не разделяют эти предположения».
Хаваси продолжает:
«Рассуждения на основе здравого смысла — это область искусственного интеллекта, цель которой — помочь компьютерам более естественно понимать людей и взаимодействовать с ними, находя способы собирать эти предположения и обучать им компьютеры. Рассуждение на основе здравого смысла было наиболее успешным в области обработки естественного языка (НЛП), хотя заметная работа была проделана и в других областях. Эта область машинного обучения со своим странным названием начинает потихоньку проникать в различные приложения, начиная от понимания текста и заканчивая обработкой и пониманием того, что изображено на фотографии.
