what is it good for)
Алексей Юрченко Работает в области репликации баз данных с 2003 года.Алексей Юрченко: Здравствуйте. Меня зовут Алексей Юрченко. Я представляю компанию «Codership«. Это маленькая финская компания. Мы занимаемся разработкой универсальной репликационной библиотеки для синхронной репликации транзакционных приложений. Она не «завязана» ни на какую базу данных, и вообще ни на какое приложение.
За последние пару лет мы и наши клиенты накопили некий опыт использования синхронной репликации, которым я и собираюсь с вами поделиться в рамках этого доклада. Речь пойдет об использовании синхронной репликации в глобальных сетях, то есть между географически распределенными узлами (грубо говоря, в Интернете).
Традиционно считается, что синхронная репликация слишком медленная. Никто ее не использует. Для целей репликации в глобальных сетях синхронная репликация, как считается, вообще не применима.
Для начала хотел бы поинтересоваться. Кто из вас использует синхронную репликацию? Два человека. Скажите, какой тип синхронной репликации вы применяете?
Реплика из зала: Схема «ведущий-ведущий» (англ. master-master). Если база, то PostgreSQL.
Алексей Юрченко: Итак, этот специалист использует синхронную репликацию в PostgreSQL. А вы?
Реплика из зала: Тоже PostgreSQL, только по схеме «ведущий-ведомый» (англ. master-slave). Ведущий – на записи чтения, и ведомый в других случаях.
Алексей Юрченко: Полусинхронная репликация у вас реализована?
Реплика из зала: Да.
Алексей
Юрченко: В начале стоит рассказать о том, что такое синхронная репликация, как мы ее понимаем.
Мы, конечно, все понимаем, что такое синхронная репликация. Но это понимание зачастую консервативно. Хотелось бы объяснить, откуда берутся представления о синхронной репликации как о медленной и неэффективной. Чтобы потом вам стало понятно, почему это не совсем так.
Мифы о синхронной репликации
Начнем с асинхронной репликации. Зачем нам вообще синхронная репликация, когда у нас есть асинхронная? Она замечательно работает.
Вот примерная схема того, как работает асинхронная репликация в приложении.
От клиента получаем «commit», коммитим транзакцию. Посылаем клиенту «ОК». А потом как-нибудь отсылаем данные на ведомый сервер. В этом месте наши данные могут быть потеряны, если ведущий вдруг «упал». Эти данные могут быть потеряны до восстановления ведущего сервера или навсегда. Если у вас «полетел» блок питания, если у вас не было батарейки в диске или произошла другая подобная вещь, части данных практически всегда приходится говорить «до свиданья».
Для ряда случаев это совершенно не принципиально. Если потеряется какой-нибудь комментарий на бесплатном форуме, то это никого не волнует. А вот в финансовых или телекоммуникационных приложениях потеря данных не должна происходить ни в коем случае. Единственное решение, которое мне известно (может быть, есть и другие) – это синхронная репликация.
Что происходит при синхронной репликации?
Мы получаем «commit» от клиента, отправляем данные транзакции на ведомый сервер. Ждем подтверждение от него. Только после этого «коммитим» и говорим клиенту «ОК». В этом случае, если ведущий сервер «упал», клиент знает, что с ним что-то случилось. Он пойдет на ведомый и проверит, закоммитилась транзакция или нет. Допустим, она закоммитилась, все хорошо.
Здесь у нас возникает некая задержка «общения» с ведомым сервером в момент выполнения операции «commit». Именно эта задержка является причиной представлений о том, что все будет крайне медленно.
Вот что пишут в Интернете по этой теме.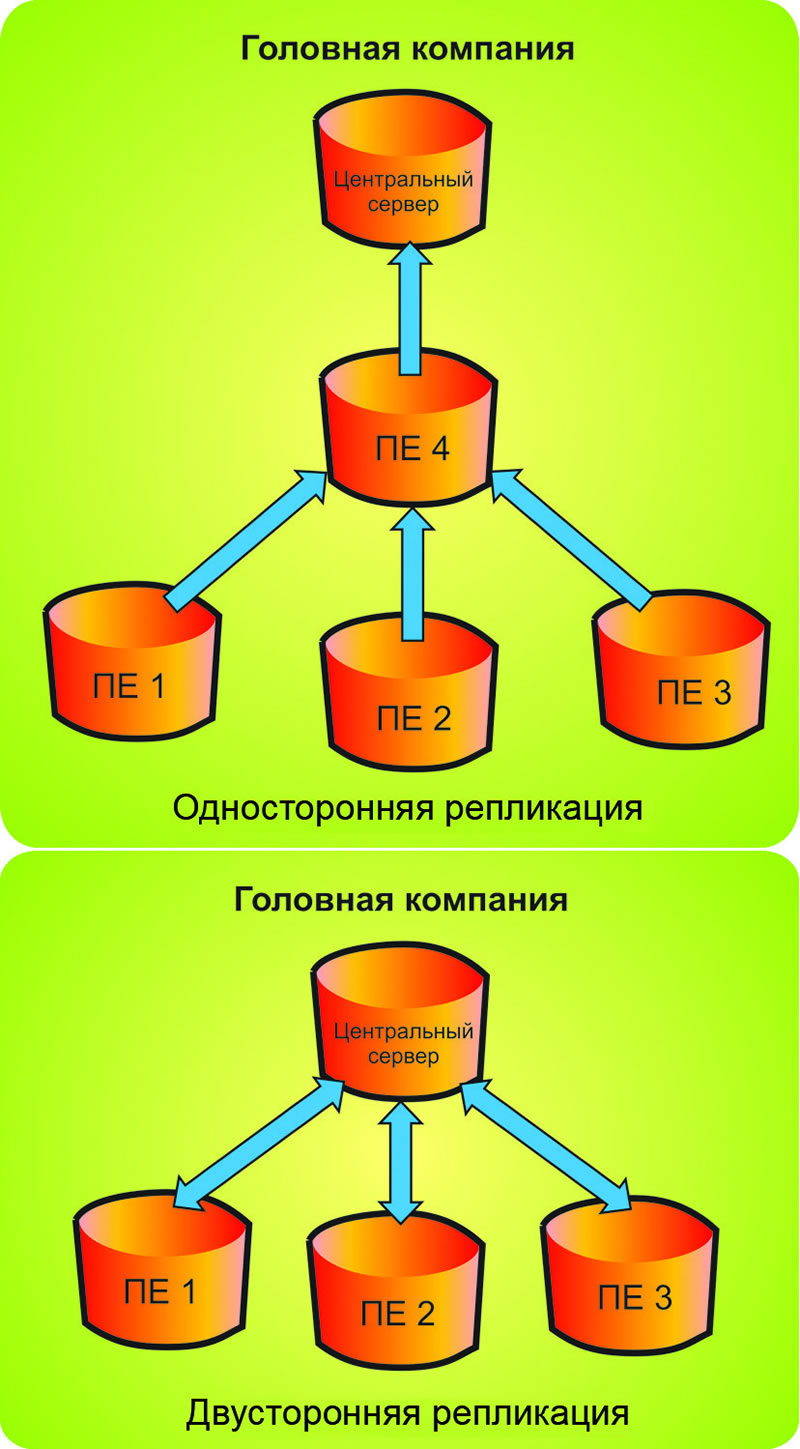
Попробуйте «погуглить» по запросу «synchronous replication»… Я это делал с аккаунта своей жены, потому что «Google» стал слишком умным и выдает мне совсем не то. Если какой-то человек захочет «с нуля» узнать что-то о синхронной репликации, то «Google» в первую очередь выдаст ему эти десять ссылок. Я их пометил особым образом.
«W» – это ссылка на «Википедию». Буквами «P» обозначены ссылки на синхронную репликацию в PostgreSQL. Буквами «M» – на полусинхронную репликацию в MySQL. «G» – это какая-то ссылка на «Google». Красными цифрами пронумерованы четыре ссылки на информационные ресурсы собственно о том, что такое синхронная репликация. По ссылке номер один мы получим следующую информацию: да, синхронная репликация защищает данные, но не применима в глобальных сетях.
Вторая ссылка дает нам точную границу – 300 километров, ни больше, ни меньше.
По ссылке номер четыре мы узнаем, что для использования синхронной репликации требуется очень дорогое высокопроизводительное оборудование, программное обеспечение (а кому не нужно высокопроизводительное программное обеспечение, интересно?) и очень дорогие каналы связи.
Ссылка номер три – это вообще «апофеоз» нападок на синхронную репликацию. Там доктор философии доказывает, что данные, на самом деле, гораздо лучше сохраняются при асинхронной репликации. Он это очень убедительно объясняет, и, собственно, сама статья называется «Правда о синхронной репликации».
Вот что мы получим, если просто «погуглим» на эту тему.
Откуда берутся такие «дикие» представления, мы сейчас посмотрим.
Что значит «синхронная»?
У нас была еще ссылка на «Википедию», помните? В «Википедии» декларируется принципиальное различие между синхронной и полусинхронной репликацией. Синхронная репликация, по мнению «Википедии» – это ситуация, когда мы не просто отправляем какой-то буфер с данными на ведомый сервер, но еще и ждем, пока он его подготовит, применит, запишет на диск, и только после этого пошлет нам «окей». Только после этого мы отвечаем клиенту.
Существует еще и полусинхронная репликация, – например, в MySQL. Когда мы просто копируем буфер на ведомый сервер, он шлет нам «ОК», проверяет контрольную сумму. Все хорошо, мы забываем о ведомом сервере и говорим «окей» клиенту.
Когда мы просто копируем буфер на ведомый сервер, он шлет нам «ОК», проверяет контрольную сумму. Все хорошо, мы забываем о ведомом сервере и говорим «окей» клиенту.
Может показаться, что это принципиальная разница. Мало ли, вдруг ведомый сервер принял наш пакет, а потом на нем что-то случилось – и все, он эту транзакцию не закоммитил. Что делать?
А на самом деле все сводится к тому, останавливаем мы работу ведущего сервера из-за того, что на ведомом произошел сбой, или нет. Работу ведущего сервера мы не останавливаем. Мы завели ведомый сервер не для того, чтобы останавливать ведущий, если на ведомом что-то произошло. Если там что-то произошло, мы «гасим» ведомый сервер, перезапускаем его, ресинхронизуем и так далее. Ведомый сервер предназначен вот для чего: если что-то произойдет с ведущим, то мы пойдем на ведомый и будем использовать его базу.
Поэтому с точки зрения надежности хранения данных на практике нет никакой разницы между синхронной и полусинхронной репликацией. Нас на самом деле не волнует, что происходит с ведомым сервером. Если мы хотим большей надежности, мы устанавливаем больше ведомых серверов.
Нас на самом деле не волнует, что происходит с ведомым сервером. Если мы хотим большей надежности, мы устанавливаем больше ведомых серверов.
Вообще для любой распределенной системы справедливо следующее утверждение: чем больше в ней сущностей, тем выше вероятность того, что на какой-то из этих сущностей произойдет сбой. Как борются против таких вещей? Увеличением числа сущностей. Таким образом, вы живете с кластером. Думаю, что на «Amazon», например, каждую минуту происходят сбои, «вылетают» диски и блоки питания. Они все время это чинят. Мы выживаем просто за счет общего количества машин.
Таким образом, мы делаем вывод о том, что полусинхронная репликация – это то, что нам нужно.
Нам не нужно этих двухфазных коммитов… Классическая академическая теория относительно того, как это должно происходить, в ходу еще с 1960-х годов. Но практика показывает, что она не вполне жизненная. Я дальше покажу, что у нас получится, если мы откажемся от этих академических представлений.
Соответственно, асинхронная репликация у нас сводится к тому же самому, что и синхронная. Мы копируем буфер данных на ведомый сервер и все. В принципе, требования к «железу», программе, каналу точно такие же. Если у вас слишком медленный ведомый сервер, то, независимо от того, синхронная или асинхронная репликация, у вас возникнет недостаток ресурсов ведомого сервера. В конце концов, она станет бессмысленной.
Если у нас слишком узкий канал, мы будем просто не в состоянии послать все данные на ведомый сервер. В данном случае он сам будет «тормозить». Поэтому вся разница, которая у нас есть, состоит в том, что при синхронной репликации существует задержка, которая равна времени отклика другой системы.
Мы сейчас в первом приближении рассмотрели, что такое синхронная репликация, и поняли, что она не так уж страшна и не требует никаких особенных ресурсов по сравнению с асинхронной репликацией.
На этом все и заканчивается (не мой доклад). Что весь смысл введения понятия «синхронная репликация» – это все было придумано для того, чтобы защитить данные от потери.
Мы никогда не задумывались о том, как наша библиотека будет работать в глобальных сетях. Реальность вносит свои коррективы. В данном случае эти коррективы оказались приятной неожиданностью.
Допустим, у нас есть некая база данных. Например, «Ebay». Там товары, пользователи, и так далее. Как мы получаем доступ к «Ebay» в Интернете.
У нас есть глобальные данные. Что мы с ними делаем? Мы их просто «рубим» на региональные. Поэтому немецкие покупатели ходят на немецкий «Ebay», английские – на английский «Ebay». У нас Интернет, но, на самом деле, каждый региональный сегмент живет своей отдельной жизнью. Это, конечно, связано с тем, что доступ к какому-то центральному серверу был бы очень медленным.
Когда у нас получается разделить данные по регионам – это, конечно, очень хорошо. Это самый правильный способ решения таких задач. Скажем, товары и услуги обычно «привязаны» к региону.
Если у нас разделение данных по какой-то причине невозможно или нежелательно, нам приходится где-то иметь центральную базу. В ней, конечно, реализованы резервные копии и так далее, но находится она в конкретном дата-центре. С другого конца планеты придется «лезть» к ней через все эти сети.
В ней, конечно, реализованы резервные копии и так далее, но находится она в конкретном дата-центре. С другого конца планеты придется «лезть» к ней через все эти сети.
Синхронный мультимастер
Вот тут у нас появляется синхронный мультимастер. Чем синхронный мультимастер лучше асинхронного?
То, что в мире MySQL принято понимать под мультимастером (МММ) – это, на самом деле, никакой не мультимастер. Это просто суперпозиция схемы «ведущий-ведомый». Наши данные точно также делятся, и отдельный раздел модифицируется только на одном сервере, который является для него ведущим.
Мы уже выяснили, что мы не хотим разделять данные, – мы хотим иметь их все вместе. Поэтому мы не можем применять асинхронный мультимастер, потому что будем не в состоянии вовремя найти конфликт и исправить его до ответа клиенту.
Когда у нас применяется синхронный мультимастер, у нас на серверах всегда есть актуальные данные о том, что происходит. Мы всегда можем вовремя обнаружить конфликт и вовремя его разрешить. Таким образом, мы можем модифицировать данные, находящиеся в одной таблице, даже в одной и той же строке на разнесенных серверах.
Таким образом, мы можем модифицировать данные, находящиеся в одной таблице, даже в одной и той же строке на разнесенных серверах.
С помощью такой штуки мы можем попытаться «приблизить» серверы к клиентам. Что это означает? У нас будет глобальный мультимастер и синхронная репликация между этими серверами. Как это повлияет на скорость доступа клиентов к данным?
Специально для этого доклада я протестировал два таких сценария.
Первый сценарий. У нас есть некая база данных в Америке, например. У нас есть клиент в Америке и есть клиент в Европе. Они пытаются получить доступ к этой центральной базе данных. Расстояние между дата-центрами составляет примерно 6 тысяч километров, а время отклика по ping – около 90 миллисекунд. Это многовато, потому что теоретически скорость света ограничивает нас 40 миллисекундами. В принципе, мы можем ожидать, что при реально хорошей ссылке можно уложиться в 60 миллисекунд. Пока у нас 90 миллисекунд.
Вот второй сценарий, когда мы разносим серверы по дата-центрам поближе к клиентам. Соответственно, каждый из клиентов получает доступ к базе данных локально.
Соответственно, каждый из клиентов получает доступ к базе данных локально.
В качестве клиента я использовал «Sysbench». Это пример приложения, которое не поддерживает разделение данных. Там одна таблица, и все пользователи туда обращаются. Она дает хорошую статистику: время средней задержки (среднее время исполнения транзакции), 95 % граница времени исполнения транзакции, общая производительность транзакции в секунду.
То же самое было протестировано в двух режимах. Это умеренная нагрузка 8 клиентов (режим, в котором следует использовать сервер), когда у нас есть некий запас по производительности. Высокая нагрузка – тут я просто взял 64 клиента, чтобы «выжать максимум» из сервера. Естественно, никто в таком режиме не работает. Это было нужно просто для демонстрации общей производительности системы.
Вот что у нас получилось при умеренной нагрузке.
Посмотрим на среднее время исполнения транзакции. Мы видим, что у американского клиента везде все хорошо. Он получает доступ к базе данных локально. У него время исполнения транзакции равно 30 миллисекундам. Зато у европейского клиента время исполнения транзакции – целых 2 секунды. Я подозреваю, что никто даже не будет пытаться глобально работать с базой данных при таких задержках. Я понимаю, что бывают очень тяжелые транзакции, на несколько часов. Но здесь, когда у нас разница почти в два порядка, это практически нерабочий вариант.
Он получает доступ к базе данных локально. У него время исполнения транзакции равно 30 миллисекундам. Зато у европейского клиента время исполнения транзакции – целых 2 секунды. Я подозреваю, что никто даже не будет пытаться глобально работать с базой данных при таких задержках. Я понимаю, что бывают очень тяжелые транзакции, на несколько часов. Но здесь, когда у нас разница почти в два порядка, это практически нерабочий вариант.
Мы используем синхронный мультимастер и таким образом обращаемся на серверы, расположенные поближе к клиентам. Что у нас происходит? Американскому клиенту от этого внезапно стало хуже. У него в четыре раза выросло время исполнения транзакции. Зато у европейского клиента время исполнения транзакции уменьшилось в 16 раз.
Если мы посмотрим на 95 % границу времени исполнения транзакции, то разница между доступом к локальному серверу и доступом к синхронизованному кластеру становится еще меньше. У американского клиента время исполнения транзакции вырастает всего в два с половиной раза, а выгода на европейском клиенте – порядка 12 раз.
Когда мы используем базу в режиме высокой нагрузки (когда задержки становятся значительными по сравнению с задержками репликации), то вообще перестаем замечать существование синхронной репликации между двумя узлами.
Вот тут, например, у нас даже близко нет этих 90 миллисекунд времени отклика, который теоретически должен быть.
Что касается производительности, вот еще один пример. Если у нас есть один центральный сервер, его производительность будет в полтора раза ниже, чем у схемы, где применяется синхронный мультимастер. Это довольно неплохой прирост производительности.
В данном случае мы получили не только более выгодное время исполнения транзакции, но и более высокую производительность. Это довольно искусственный пример. Никто не должен доводить свою базу до такой нагрузки. Вы теряете клиентов, если не можете обрабатывать запросы так быстро, как они к вам приходят. Тем не менее, я продемонстрировал, насколько «страшны» задержки синхронизации на самом деле.
За счет чего это происходит? У нас есть один очень важный и неизбежный источник синхронизации. Это непосредственно общение между клиентом и сервером. Нам от этого никуда не деться.
Клиент-серверный протокол, по определению, синхронный. Он гораздо «тяжелее», чем репликационный протокол. Клиент-серверный протокол включает в себя передачу массы данных туда-сюда. В репликации нам нужно просто отослать изменения, которые мы сделали в базе данных. Результаты селектов и все прочее сюда не попадают. Поэтому и получаем такую выгоду (поскольку у нас репликация гораздо тоньше и менее требовательна к сети, чем клиент-серверный протокол). Имеет смысл «подвинуть» ведущий сервер гораздо ближе к клиенту.
Эти результаты были получены с помощью MySQL и нашей репликационной библиотеки. Эти результаты применимы к любому хранилищу данных просто за счет синхронной репликации, которая теоретически является «тяжелой» и нужна только когда вам нужно защитить ваши данные. Вы можете реально улучшить скорость доступа клиента к данным.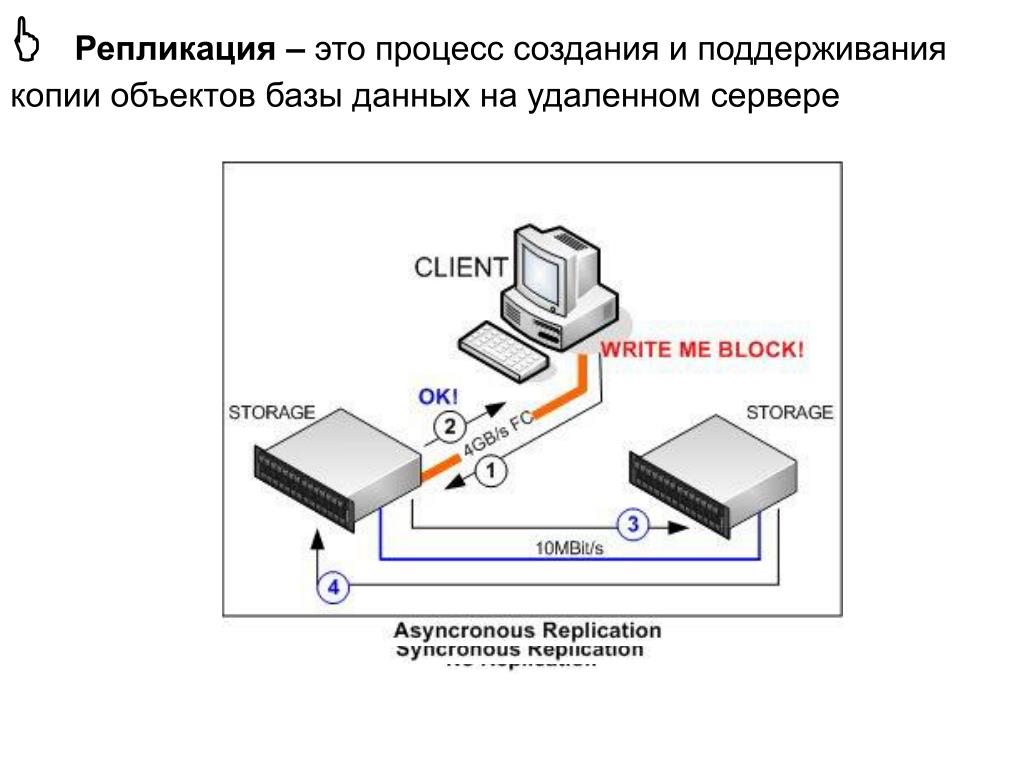
Тем не менее, у нас есть издержки синхронизации. Мы видели, что для локального американского клиента среднее время исполнения транзакции выросло в четыре раза.
Как бороться с задержками?
Что мы можем противопоставить этим задержкам, от которых никуда не деться? То же самое, что мы делаем с задержками, которые происходят где-либо еще. Задержки синхронизации ничуть не отличаются от задержек доступа к диску или памяти.
Что мы делаем, когда нужно записать что-нибудь на диск? Буферизуем эти записи. В данном случае аналогом будет увеличение длины транзакции. Нам всем постоянно советуют делать транзакции покороче. Для локальных сетей это, возможно, правда. А здесь, если мы будем делать транзакции подлиннее, то сможем избежать излишней синхронизации между серверами и делать большую часть работы непосредственно с локальным сервером.
Второй вариант – это то, что случилось уже давно, а частоты процессоров не растут. Любое приложение, так или иначе, должно быть «распараллелено». Это не вопрос. В данном случае, пока у нас идет репликация одной транзакции, мы можем исполнять другую транзакцию. Мы просто повышаем количество одновременных клиентов в базе и таким образом решаем проблему общей производительности. Каждый отдельный клиент будет видеть эту большую задержку исполнения транзакции. Но, в общем и целом, мы будем в состоянии обработать практически такое же количество транзакций, как при доступе к одиночному локальному серверу.
Это не вопрос. В данном случае, пока у нас идет репликация одной транзакции, мы можем исполнять другую транзакцию. Мы просто повышаем количество одновременных клиентов в базе и таким образом решаем проблему общей производительности. Каждый отдельный клиент будет видеть эту большую задержку исполнения транзакции. Но, в общем и целом, мы будем в состоянии обработать практически такое же количество транзакций, как при доступе к одиночному локальному серверу.
Для интересующихся даю ссылку на ресурс, где можно загрузить программное обеспечение, которое использовалось в этом тесте.
Спасибо вам за внимание. Вопросы.
Вопросы и ответы
Реплика из зала: Как потом включить обратно в работу ведущий сервер, если он выйдет из строя? Он может быть включен обратно в работу, у него получится догнать репликацию?
Алексей Юрченко: Простите. Вы не могли бы повторить вопрос еще раз. Я плохо расслышал.
Реплика из зала: Допустим, у нас останавливается ведущий серверв. Ведомый включается в работу и работает какое-то время. Сможем ли мы потом опять включить в работу ведущий сервер, догонит ли он репликацию, или это невозможно?
Алексей Юрченко: Если мы говорим конкретно о наших разработках – да. Но это уже вопрос к тому, как вообще реализована репликация. Мы знаем, что в стандартной репликации MySQL этот процесс довольно сложен из-за отсутствия глобальных идентификаторов транзкций. Но это вопрос того, как вы сделаете ПО. Спасибо!
Масштабирование баз данных — партиционирование, репликация и шардинг
СУБД — это очень часто «узкое место» в производительности веб-приложений, влияющее на быстродействие и устойчивость к высоким нагрузкам. В момент, когда сервер баз данных не может справится с нагрузками, производится масштабирование.
Рассмотрим основные способы увеличения производительности СУБД.
Масштабирование SQL и NoSQL
Описанные ниже схемы масштабирования применимы как для реляционных баз данных, тах и для NoSQL-хранилищ. Разумеется, что у всех баз данных и хранилищ есть своя специфика, поэтому мы рассмотрим только основные направления и в детали реализации вдаваться не будем.
Разумеется, что у всех баз данных и хранилищ есть своя специфика, поэтому мы рассмотрим только основные направления и в детали реализации вдаваться не будем.
Партиционирование (partitioning)
Партиционирование — это разбиение таблиц, содержащих большое количество записей, на логические части по неким выбранным администратором критериям. Партиционирование таблиц делит весь объем операций по обработке данных на несколько независимых и параллельно выполняющихся потоков, что существенно ускоряет работу СУБД. Для правильного конфигурирования параметров партиционирования необходимо, чтобы в каждом потоке было примерно одинаковое количество записей.
Например, на новостных сайтах имеет смысл партиционировать записи по дате публикации, так как свежие новости на несколько порядков более востребованы и чаще требуется работа именно с ними, а не со всех архивом за годы существования новостного ресурса.
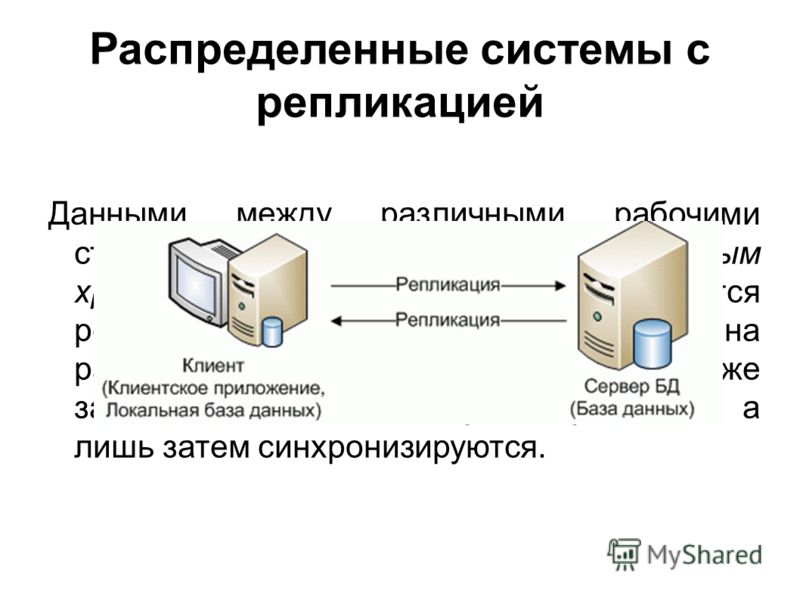
Репликация (replication)
Репликация — это синхронное или асинхронное копирование данных между несколькими серверами. Ведущие сервера называют мастерами (master), а ведомые сервера — слэйвами (slave). Мастера используются для изменения данных, а слэйвы — для считывания. В классической схеме репликации обычно один мастер и несколько слэйвов, так как в большей части веб-проектов операций чтения на несколько порядков больше, чем операций записи. Однако в более сложной схеме репликации может быть и несколько мастеров.
Ведущие сервера называют мастерами (master), а ведомые сервера — слэйвами (slave). Мастера используются для изменения данных, а слэйвы — для считывания. В классической схеме репликации обычно один мастер и несколько слэйвов, так как в большей части веб-проектов операций чтения на несколько порядков больше, чем операций записи. Однако в более сложной схеме репликации может быть и несколько мастеров.
Например, создание нескольких дополнительных slave-серверов позволяет снять с основного сервера нагрузку и повысить общую производительность системы, а также можно организовать слэйвы под конкретные ресурсоёмкие задачи и таким образом, например, упростить составление серьёзных аналитических отчётов — используемый для этих целей slave может быть нагружен на 100%, но на работу других пользователей приложения это не повлияет.
Шардинг (sharding)
Шардинг — это прием, который позволяет распределять данные между разными физическими серверами. Процесс шардинга предполагает разнесения данных между отдельными шардами на основе некого ключа шардинга. Связанные одинаковым значением ключа шардинга сущности группируются в набор данных по заданному ключу, а этот набор хранится в пределах одного физического шарда. Это существенно облегчает обработку данных.
Связанные одинаковым значением ключа шардинга сущности группируются в набор данных по заданному ключу, а этот набор хранится в пределах одного физического шарда. Это существенно облегчает обработку данных.
Например, в системах типа социальных сетей ключом для шардинга может быть ID пользователя, таким образом все данные пользователя будут храниться и обрабатываться на одном сервере, а не собираться по частям с нескольких.
Модель репликации AD
Сунулся почитать на технете про репликацию, и не обнаружил статей на русском. Вот и решил восполнить этот пробел и позаниматься переводом. В этот раз немного про модель репликации AD.
Репликация AD
Active Directory — это распределённая служба каталогов. Объекты в каталоге распределены посредством контроллеров домена по всему лесу, и контроллеры домена в домене обновляются непосредственно. Репликация – это процесс, посредством которого изменения, сделанные на одном контроллере домена синхронизируются с другими контроллерами домена, в домене или в лесе, которые хранят копию той же самой информации. Целостность данных поддерживается отслеживанием изменений на каждом контроллере домена и систематическим обновлением других контроллеров домена. Репликация AD использует топологию соединений, создаваемую автоматически, которая оптимально использует преимущества сетевого соединения и освобождает администратора от принятия таких решений.
Целостность данных поддерживается отслеживанием изменений на каждом контроллере домена и систематическим обновлением других контроллеров домена. Репликация AD использует топологию соединений, создаваемую автоматически, которая оптимально использует преимущества сетевого соединения и освобождает администратора от принятия таких решений.
Модель репликации AD
В AD дерево каталогов представляет все объекты в лесу, и это дерево каталогов разделено таким образом, который позволяет его распределить на контроллеры домена в других доменах в лесу. Модель репликации AD охватывает способы, которыми изменения производятся и отслеживаются среду контроллеров домена. Каждый контроллер домена в лесу хранит копию определенной части каталога. Каждый определённый сегмент каталога называется «разделом каталога». Копия содержимого одного раздела каталога на определенном контроллере домена называется «реплика». Обновления реплики синхронизируются среди контроллеров домена, которые хранят такую же копию разделов каталога, в процессе репликации.
Репликация PULL
AD использует репликацию «pull». В репликации «pull» реплика назначения запрашивает информацию из исходной реплики. Запрос определяет информацию, нужную реплике назначения, основываясь на собственном знании об уже полученных изменениях от источника и от других контроллерах домена в домене. Когда реплика назначения получает информацию от источника, она применяет эту информацию, делая себя более свежей. Следующий запрос реплики назначения исключает информацию, которая уже была получена и применена.
Альтернативой является репликация «push». В репликации «push» реплика источник посылает незапрашиваемую информацию реплике назначению в попытке сделать реплику назначения более свежей. Репликация «push» более проблемная, так как реплике источнику сложно знать об информации требуемой для реплики назначения. Возможно реплика назначения получит ту же самую информацию из другого источника. Если реплика источник посылает информацию реплике назначения, то нет гарантии, что реплика назначения применит эту информацию, если реплика источник решит иначе, то это приведет к ненадежности системы.
Компоненты модели репликации
Следующие механизмы способствуют всей системе репликации:
- Мультимастер теряет последовательность с конвергенцией, которые поддерживают целостность данных. — Мультимастер означает, что раздел каталога может иметь множество реплик, или копий, доступных для записи, которые должны хранить последовательность между контроллерами домена в том же лесу. Система репликации распространяет изменения, сделанные на определенном контроллере домена, на другие контроллеры домена в лесу, которые хранят раздел каталога, в котором произошли изменения.
- Потеря последовательности означает, что не гарантируется достоверность реплики с другими репликами в любой определенный момент времени, так как изменения могут применяться к любой полной реплике в любое время.
- Конвергенция (сходимость) означает, что при разрешении достижения системой стабильного состояния, при котором не происходят новые обновления и все предыдущие обновления были успешно отреплицированы, гарантируется, что все реплики сходятся на том же наборе значений.

- Репликация с промежуточной буферизацией означает, что изменения не посылаются прямо от одного контроллера домена к другим контроллерам домена. Вместо этого изменение посылается прямо на некоторый набор контроллеров домена. Этот набор контроллеров домена становится ответственным за отсылку изменения на другие контроллеры домена и так далее, пока изменение не достигнет каждого контроллера домена.
- Репликация «pull» означает, что контроллер домена запрашивает (тянет) обновления от партнеров по репликации. Контроллер домена, на котором происходят изменения не проталкивает незапрашиваемые изменения на другие контроллеры домена.
- Репликация «state-based» означает, что вместо хранения полного журнала изменений, каждый раздел каталога хранит только данные об объекте и атрибуте для поддержки репликации.
Мультимастерная репликация
AD использует мультимастерную репликацию для выполнения синхронизации информации каталога. Истинная мультимастерная репликация может контрастировать с другими службами каталога, которые используют подход ведущий-ведомый для обновления, где все обновления должны быть сделаны на основной копии каталога и затем отреплицированы на подчиненные копии. Эта система подходит для каталога, в котором малое количество копий и для окружения, где все изменения применяются центрально. Но этот подход не масштабируется за пределы для малых организаций, и не учитывает потребности децентрализованных организаций. С AD ни один контроллер домена не является главным. Вместо этого все контроллеры домена в домене равноправны. Изменения могут производиться на любом контроллере домена, в отличие от системы с одним ведущим, где все изменения должны проводиться на одном сервере. В системе с одним ведущим, основной сервер реплицирует обновленную информацию на все серверы каталога в домене.
Эта система подходит для каталога, в котором малое количество копий и для окружения, где все изменения применяются центрально. Но этот подход не масштабируется за пределы для малых организаций, и не учитывает потребности децентрализованных организаций. С AD ни один контроллер домена не является главным. Вместо этого все контроллеры домена в домене равноправны. Изменения могут производиться на любом контроллере домена, в отличие от системы с одним ведущим, где все изменения должны проводиться на одном сервере. В системе с одним ведущим, основной сервер реплицирует обновленную информацию на все серверы каталога в домене.
С мультимастерной репликацией не важно, чтобы каждый контроллер домена реплицировался каждым контроллером домена. Вместо этого система реализует широкий набор соединений, которые определяют, какие контроллеры домена реплицируются с другими контроллерам домена, чтобы быть уверенным, что сети не перегружены трафиком репликации и что задержка не такая большая, чтобы создавать неудобства для пользователей.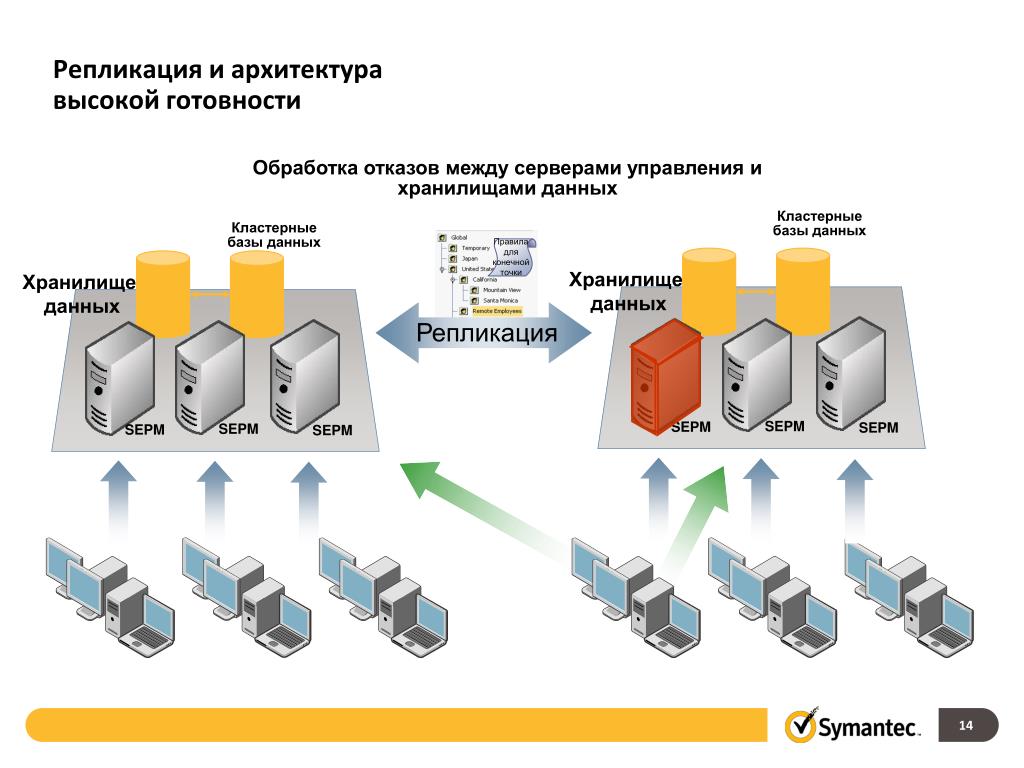 Набор соединений, через которые изменения реплицируются на контроллеры домена на предприятии называется «топология репликации».
Набор соединений, через которые изменения реплицируются на контроллеры домена на предприятии называется «топология репликации».
Мультимастерная возможность обновления предоставляет высокую доступность доступа записи к объектам каталога, так как несколько серверов могут содержать копии объекта, доступных для записи. Каждый контроллер домена в домене может получить обновления независимо, без связи с другими контроллерами домена. Система разрешает любые конфликты в обновлениях для определенного объекта каталога. Если обновление прекращается и репликация продолжается, все копии объектов в конечном счете достигают таких же значений.
Способ, которым служба каталогов хранит информацию, непосредственно определяет производительность и масштабируемость службы каталогов. Служба каталогов должна обрабатывать большее количество запросов, по сравнению с количеством обновлений, которые она должна обработать. Обычно отношение запросов и обновлений 99 к 1. Созданием нескольких копий каталога и сохраняя целостность этих копий, служба каталогов может обрабатывать больше запросов в секунду.
Мультимастерная репликация предоставляет следующие преимущества перед репликацией с одним ведущим:
- Если один контроллер домена станет недоступен, то другие контроллеры домена продолжают обновлять каталог. При репликации с одним ведущим, при недоступности основного контроллера домена, обновления каталога не могут производиться. Например, если отказавший сервер хранил пароль, и пароль истек, то нет возможности сбросить пароль, вследствие чего невозможно войти в домен.
- Серверы, способные к производству изменений в каталоге, контроллеры домена, могут быть распространены по сети и могут находиться в различных физических сайтах.
Репликация «state-based»
AD использует подход репликации, основанный на состоянии. В репликации, основанной на состоянии, каждый ведущий в мультимастерной системе применяет обновления к своей реплике по их приходу, без обслуживания журнала изменений. База данных, используемая AD, использует транзакционный журнал, но этот журнал часть системы базы данных, не системы репликации.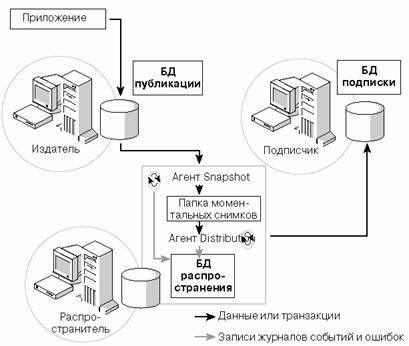 В обычной системе репликации, основанной на журналах, каждый ведущий хранит журнал изменений, которые на нем происходят. В системе репликации, основанной на журналах, целью каждого ведущего является связь собственного журнала с каждой другой репликой. После того, как журнал попадет в реплику, реплика применяет журнал, делая свое состояние более свежим.
В обычной системе репликации, основанной на журналах, каждый ведущий хранит журнал изменений, которые на нем происходят. В системе репликации, основанной на журналах, целью каждого ведущего является связь собственного журнала с каждой другой репликой. После того, как журнал попадет в реплику, реплика применяет журнал, делая свое состояние более свежим.
Репликация AD запускается не журналами, хранимых с исходной репликой, а текущим «состоянием» (текущим значением объектов) исходной реплики. Это состояние включает информацию, которая используется для разрешения конфликтов и избегания посылания полной реплики каждым циклом репликации. Каждой производимой операции записи назначается порядковый номер на исходном контроллере домена. Все реплики поддерживают информацию о том, насколько они обновлены по отношению к другим репликам, и значения в каталоге помечаются порядковыми номерами их обновления, происходившим при записи. Используя эту информацию источник репликации может фильтровать изменения состояния, которые он реплицирует.
Подход, основанный на состоянии, использует единый механизм для инкрементной и полной синхронизации, и совершает меньше обновлений базы данных, так как повторяющиеся или конфликтные обновления атрибута сжимаются в единственное состояние.
В общем говоря, реплика раздела AD обслуживает все свои записи в списке, отсортированном по времени изменения. Это своего рода отсортированный список, но по своим размерам является крошечной частью размера самой точной копии. Обычный запрос репликации может быть удовлетворен проверкой только нескольких последних изменений в своем списке, так как сервер реплики назначения знает о том, сколько списков репликации источника уже были обработаны.
Поведение репликации
Поведение репликации последовательно и предсказуемо, данный набор изменений определенной реплики может предсказывать, какие изменения собираются распространяться на все остальные реплики.
Следующие ключевые моменты имеют решающее значение для понимания поведения репликации:
- Объект доступен для репликации как только он был изменен.
 Записи в один объект атомарны, и запись разделов объектов невозможна.
Записи в один объект атомарны, и запись разделов объектов невозможна. - Объектам нет необходимости реплицироваться в том порядке, в котором было произведено обновление.
- После инициации цикла обновления определенный цикл репликации посылает все доступные изменения от реплики источника к реплике назначению, включая изменения, которые происходят в процессе цикла репликации.
- Репликация с промежуточной буферизацией колеблется между набором подсоединенных реплик.
- Мультимастерное гарантированное разрешение конфликтов надежно даже если часы не синхронизированы или идут назад.
- Граф соединений репликации не всегда связанное дерево (чье определение не содержит избыточных связей) — граф может, и в общем случае, содержит циклы. Избыточные соединения уменьшают задержку репликации, главным образом в случае сбоя. Механизм гашения распространения устраняет избыточные репликации.
- Репликация между сайтами обычно происходит в запланированные интервалы (уведомления об изменения между сайтами опциональны).
- Система устойчива в условиях пиков нагрузки и временных сбоях.
- Система репликации разработана чтобы быть стабильной. Каждый раз, когда репликация назначения получается информацию от источника репликации, репликация назначения становится более свежей. Восстановление после сбоев включает в себя минимум дополнительной работы.
- Репликация с промежуточной буферизацией эффективно использует WAN каналы – каждое обновление пересекает дорогой канал только один раз и в сжатом виде.
- Топология репликации управляется автоматически и оптимизирует существующие соединения.
Реплики разделов каталога
Реплика разделов каталога может быть полной (ведущая) или частичная реплика. Полная реплика содержит все атрибуты всех объектов разделов каталога для чтения и для записи. Каждый контроллер домена хранит, по крайней мере, три полных, доступных для записи разделов каталога:
- Раздел схемы, который содержит все классы и атрибуты, определенные для леса.
 Есть только один раздел схемы для каждого леса.
Есть только один раздел схемы для каждого леса. - Раздел конфигурации, который содержит информацию о конфигурации репликации (и другую информацию) для всего леса. Есть только один раздел конфигурации для каждого леса.
- Раздел домена, которые содержит все объекты, которые хранятся одним доменом. Есть только один раздел домена для каждого домена в лесу.
Полная реплика доменного раздела хранится на всех контроллерах домена этого домена (и нигде более), полная реплика разделов схемы и конфигурации леса хранятся на контроллерах домена этого леса (и нигде более).
Частичная реплика содержит набор атрибутов всех объектов разделов каталога и она только для чтения. Частичная реплика хранится только на серверах Глобального Каталога. Атрибут содержится в частичной реплике если и только если у атрибута объекта attributeSchema есть *isMemberOfPartialAttributeSet *равное Истина.
Поэтому, на определённом контроллере домена, единичная база данных хранит копии этих объектов, подходящих только этому домену, в дополнении к копиям объектов конфигурации и схемы, которые применяются ко всем доменам в лесу. На контроллерах домена, являющихся Глобальным каталогом, база данных также хранит частичные реплики объектов разделов каталога из других доменов. Частичные реплики хранятся на серверах Глобального каталога, и поиск по всему каталогу может выполняться без необходимости рефералов с одного контроллера домена к другому.
На контроллерах домена, являющихся Глобальным каталогом, база данных также хранит частичные реплики объектов разделов каталога из других доменов. Частичные реплики хранятся на серверах Глобального каталога, и поиск по всему каталогу может выполняться без необходимости рефералов с одного контроллера домена к другому.
Следует отметить различия между деревом каталога и физической базой данных на определенном контроллере домена в этом лесу. Каталог включает все объекты в лесу. База данных каталога на определенном контроллере домена в лесу включает реплики объектов домена только для этого домена, в дополнение к репликам разделов конфигурации и схемы для всего леса.
Репликация с промежуточной буферизацией
Репликация с промежуточной буферизацией разработана для уменьшения передачи через медленным WAN каналам. Обновление реплицируется первым на ближайшие реплики и оттуда на реплики, которые находятся дальше.
Репликация с промежуточной буферизацией устраняет необходимость посылать каждое изменение непосредственно от сервера, получающего изменения ко всем серверам, держащим реплику с затрагиваемым разделом каталога. Сервер, получающий изменения, может посылать изменения на ближайшие серверы. Один из этих серверов может послать изменение на удаленный сервер, который, в свою очередь направляет изменения на близлежащие серверы. Репликация с промежуточной буферизацией значительно уменьшает WAN трафик, который производится репликацией.
Сервер, получающий изменения, может посылать изменения на ближайшие серверы. Один из этих серверов может послать изменение на удаленный сервер, который, в свою очередь направляет изменения на близлежащие серверы. Репликация с промежуточной буферизацией значительно уменьшает WAN трафик, который производится репликацией.
Для устранения административных сложностей управления связями между всеми контроллерами домена система может создавать топологию автоматически. Вы управляете репликацией косвенно, путем определения упрощенной сетевой моделью в каталоге. Эта модель основан на концепции сайтов, сайтлинков, и мостов сайтлинков. Основанная на этой модели, AD создает соединения репликации, которые позволяют AD выполнить репликацию. При возникновении сбоя AD модифицирует соединения репликации для сохранения процесса репликации. Также есть возможность вручную создавать соединения репликации для проявления лучшего контроля. Соединения, созданные вручную, сосуществуют с автоматически созданными соединениями, итак при необходимости тонкой настройки одного соединения совсем не обязательно жертвовать преимуществами автоматического управления для других соединений.
Знакомимся с репликацией транзакций | Windows IT Pro/RE
Репликация SQL Server включает набор возможностей, которые полностью пока еще не заменены другими функциями, реализованными в SQL Server. Некоторые из распространенных примеров использования предусматривают возможность распределения данных между различными экземплярами SQL Server и базами данных для формирования отчетов и разгрузки основной производственной базы данных. Репликация может приблизить данные к пользователям в распределенных средах и масштабировать производительность путем многоадресной пересылки данных. Кроме того, некоторые находят место для репликации даже в задачах восстановления после аварий и обеспечения высокой доступности (более подробно об этом рассказано в статье Пола Рэндала In defense of transactional replication as an HA technology по адресу http://www. sqlskills.com/blogs/paul/in-defense-of-transactional-replication-as-an-ha-technology).
sqlskills.com/blogs/paul/in-defense-of-transactional-replication-as-an-ha-technology).
Хотя процесс изучения репликации может казаться сложным, для успешного использования репликации достаточно разобраться в составляющих ее компонентах. А это позволяет сделать практическое развертывание базовых конфигураций и последующее изучение сопутствующих модификаций пользовательской схемы, объектов метаданных, заданий агента SQL Server Agent и связанных с этим настроек агента. Чтобы вам помочь, вначале я кратко пройдусь по терминологии репликации и покажу, как работают различные компоненты. Затем мы выполним типовое развертывание репликации транзакций, одного из самых распространенных типов репликации.
Базовые понятия репликации
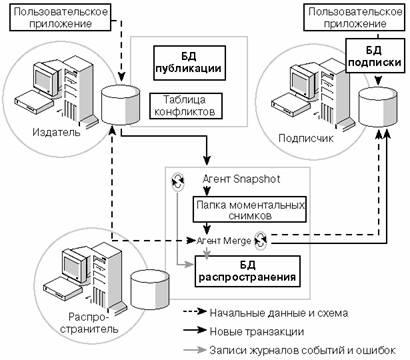
Существуют различные типы репликации, поэтому я начну описание набора возможностей с самого верхнего уровня. Репликация — это набор технологий, позволяющий копировать, распространять и синхронизировать определенные типы объектов базы данных и связанных с ними данных и зависимостей между ними из одной базы данных в одну или несколько других баз данных в одном и том же экземпляре или в разных экземплярах SQL Server. Экземпляр SQL Server, содержащий базу данных, из которой распространяются данные, называется издателем (Publisher). В одной базе данных можно определить одну или более публикаций (Publication), которые логически объединяются в одну или более статей (Article). Статья представляет собой особый объект в базе данных публикации, который требуется переслать в другую базу данных. Допустимые типы объектов в статьях включают в себя определяемые пользователем таблицы, хранимые процедуры и представления.
Для репликации необходима отдельная база данных для хранения метаданных и пересылаемых данных. Такая база данных называется базой данных распространителя (Distribution Database), а экземпляр SQL Server, на котором она хранится, — распространителем (Distributor). Распространитель может быть тем же экземпляром SQL Server, что и издатель, отдельными экземпляром или экземпляром, на который пересылаются данные. Решение о размещении базы данных распространителя обычно базируется на рассмотрении таких моментов как загруженность или доступность (например, если репликация транзакций сочетается с зеркалированием баз данных).
Сервер, получающий данные от издателя, называется подписчиком (Subscriber). Подписчиком может быть тот же экземпляр SQL Server, что и издатель, экземпляр, являющийся распространителем, или отдельный экземпляр SQL Server. Подписчик определяется с помощью добавления подписки на определенную публикацию. База данных подписчика может содержать как реплицированные, так и нереплицированные объекты, и хранить более одной подписки от разных публикаций.
Подписка может быть определена как принудительная (push), при этом данные принудительно пересылаются от распространителя в базу данных подписчика, или как подписка по запросу (pull), когда данные запрашиваются подписчиком. Принудительные подписки более распространены при развертывании репликации моментальных снимков (snapshot replication) и репликации транзакций (transactional replication). Подписки по запросу обычно используются при репликации слиянием (merge replication), так как подписчик может чаще отключаться от коммуникаций и требовать проверки данных, обновляемых по запросу. Решение о выборе вида подписки также может базироваться на емкости и объеме избыточной нагрузки серверов, участвующих в топологии репликации.
Внешние исполняемые модули, называемые агентами репликации, передают данные от издателя к распространителю и затем к подписчику. Тип агента репликации зависит от используемого типа репликации.
Выбор типа репликации
Существует три основных типа репликации: репликация моментального снимка, репликация транзакций и репликация слиянием. Встречаются и базирующиеся на этих типах различные вариации, например одноранговая репликация (peer-to-peer replication), но мы не будем в этой статье их обсуждать.
Репликация моментального снимка позволяет распространять данные на определенный момент времени. Снимок пересылается и более не обновляется процессом репликации, пока не будет сделан новый снимок, который будет отправлен подписчику. Репликация моментального снимка обычно используется для формирования схемы статей и связанных с ней данных у подписчика для репликации транзакций и репликации слиянием.
Репликация слиянием позволяет подписчику напрямую модифицировать данные подписки (статьи) и затем синхронизировать модифицированные строки с издателем. Как указывалось ранее, подписчики могут быть некоторое время отключены от коммуникаций, периодически подключаться и синхронизировать данные по запросу. В этот момент их изменения синхронизируются с издателем и наоборот. Это может привести к конфликту данных, когда издатель и один или более подписчиков пытаются модифицировать одни и те же данные.
Последний тип репликации — тот, который мы рассмотрим, — репликация транзакций. При правильном проектировании репликация транзакций может обеспечивать потоковое изменение данных с низким уровнем задержек, выполняемое издателем для одного или более подписчиков. Реплицируемые данные, как правило, обрабатываются подписчиком в режиме «только чтение». Модификация данных у подписчика может привести к нарушению синхронизации всего набора данных с данными издателя. Репликация транзакций предоставляет не рекомендуемую сейчас функцию обновляемых подписок (updatable subscriptions), которая позволяет подписчику реплицировать данные в обратном направлении, к издателю. Одноранговая репликация (возможность SQL Server редакции Enterprise) также позволяет выполнять двунаправленную репликацию изменений в данных, используемых в базах данных с репликацией транзакций.
Развертывание репликации транзакций
Поскольку данная статья представляет собой введение в репликацию транзакций, я продемонстрирую использование различных мастеров консоли SQL Server Management Studio (SSMS) для реализации соответствующих функций. Кроме того, вы можете использовать сценарии. Более подробно об этом рассказано во врезке «Мастера или сценарии?». Чтобы воспроизвести описанные в статье действия, необходимо иметь аналог среды со следующими характеристиками.
- В демонстрациях используются два экземпляра SQL Server 2008 R2 SP1 на двух разных серверах в одном домене. Заметим, что редакция Enterprise не является обязательным требованием. Подойдут и виртуальные серверы, при условии корректных сетевых настроек. Некоторые экраны содержат информацию о моих тестовых серверах, названных SQLSKILLS-NODE1 (издатель и распространитель) и SQLSKILLS-NODE2 (подписчик).
- Оба экземпляра SQL Server требуют наличия установленных компонентов репликации. Если вы выбрали вариант SQL Server Replication при установке SQL Server, то компоненты репликации будут загружены. Если вы этого не сделали во время установки, компоненты репликации можно установить отдельно.
- Служба Agent должна быть запущена на экземпляре издателя.
- Тестовый домен в идеале должен иметь отдельные учетные записи для процессов Snapshot Agent, Log Reader Agent и Distribution Agent. Например, я создал три учетные записи: SQLskills\SQLskillsSnapshotAGT, SQLskills\SQLskillsLogReaderAGT, и SQLskills\SQLskillsDistAGT.
- Подписка будет создана для базы данных с именем AWReporting.
В качестве базы данных публикации используется демонстрационная база данных AdventureWorks версии SQL Server 2008 R2 (http://msftdbprodsamples.codeplex.com/). Мы будем реплицировать описания таблиц и соответствующие данные для следующих таблиц базы данных AdventureWorks:
[Person].[Address]
[Person].[Contact]
[Person].[CountryRegion]
[Person].[StateProvince]
[HumanResources].[Employee]
[HumanResources].[EmployeeAddress]
Кроме того, будет реплицироваться описание представления [HumanResources].[vEmployee]. И хотя представление не содержит данных, можно реплицировать описание этого объекта, при условии, что все зависимые объекты включены в публикацию.
Настройка экземпляра SQL Server для публикации
Далее описаны шаги по настройке экземпляра SQL Server в качестве издателя.
- В левой панели окна консоли SSMS Object Explorer щелкните раскрывающийся список Connect и выберите экземпляр SQL Server, который будет настраиваться в качестве издателя или распространителя.
- В окне Object Explorer раскройте узел нужного экземпляра SQL Server. Щелкните правой кнопкой мыши на папке Replication и выберите пункт Configure Distribution.
- На экране мастера Configure Distribution нажмите кнопку Next. Этот экран больше не будет появляться, если вы отключите его, поставив галочку у поля Do not show this starting page again.
- На экране Distributor, как показано на экране 1, вы указываете, будет ли данный SQL Server функционировать в качестве распространителя или распространителем для данного издателя будет другой сервер. Для нашего примера назначьте издателя собственным распространителем и нажмите Next.
- Экран SQL Server Agent Start позволяет настроить автоматический запуск службы SQL Server Agent. Выберите автоматический запуск Yes, configure the SQL Server Agent service to start automatically и нажмите Next.
- Экран Snapshot Folder задает размещение хранилища моментальных снимков. Мы в данном примере используем настройки по умолчанию. Выбор локального хранилища приводит к появлению предупреждения о том, что такая папка не поддерживает репликацию по запросу (для данного варианта необходим общий сетевой ресурс). Запишите путь к выбранной папке, так как он потребуется в дальнейшем. Нажмите Next.
- На экране Distribution Database предлагаются варианты настройки имени базы данных распространителя (Distribution Database) и размещения файлов базы данных. В производственной базе данных файлы базы данных распространителя нужно размещать так, чтобы обеспечить максимальную пропускную способность и минимальные задержки, необходимые для вашей топологии репликации. Для тестового сценария выбираем настройки по умолчанию и нажимаем кнопку Next.
- На экране Publishers определяем серверы, которые будут использовать данного распространителя для своих публикаций. В нашем примере необходимый SQL Server уже выбран. Нажатие кнопки со значком многоточия (…) справа от столбца Distribution Database отобразит дополнительные настройки, такие как режим подключения агента (Agent Connection Mode), задающий способ подключения к издателю, и папку по умолчанию для хранения моментальных снимков (Default Snapshot Folder). Нажимаем Next.
- На экране Wizard Actions вы либо даете мастеру команду для автоматической настройки распространения, либо генерируете сценарий, с помощью которого можно настроить распространение, либо делаете и то и другое. В нашем примере оставляем все по умолчанию и нажимаем Next.
- На завершающем экране Complete the Wizard нажимаем кнопку Finish. Далее вы будете наблюдать статус всех выполняемых шагов. Когда мастер успешно завершит свою работу, нажмите кнопку Close.
| Экран 1. Назначение экземпляра SQL Server в качестве собственного распространителя |
Разрешение публикации базы данных
Ниже описаны шаги для разрешения публикации базы данных.
- В окне Object Explorer раскройте тот узел SQL Server, который только что сделали издателем. Щелкните правой кнопкой мыши на папке Replication и выберите пункт Publisher Properties (свойства издателя).
- Заметим, что в левой части окна свойств издателя в панели Select a page имеются два параметра, требующие настройки. На странице General показаны настройки распространителя для выбранных издателей. В нашем демо-примере для указания издателя необходимо выбрать вариант This server acts as its own Distributor (данный сервер является собственным распространителем).
- Выберите в панели Select a page пункт Select Publication Databases («Выбор баз данных для публикации»). Вам будет представлен список баз данных для включения репликации. Поставьте флажок на пересечении строки AdventureWorks и столбца Transactional, как показано на экране 2. Нажмите OK.
| Экран 2. Выбор базы данных для ?репликации |
Настройка параметров безопасности для агентов
Далее приведены шаги для подготовки минимальных требуемых разрешений для трех учетных записей службы агентов репликации, используемых в данной демонстрационной топологии.
- На сервере-издателе в окне выполнения запросов выполните код, приведенный в листинге 1. Данный код создаст в базах данных публикации и распространения имя регистрации (login) для агента моментальных снимков (Snapshot Agent), сгенерирует учетную запись пользователя и добавит ей роль db_owner.
- Выполните код из листинга 2. Данный код создаст в базах данных публикации и распространения имя входа для агента чтения журнала (Log Reader Agent), создаст учетную запись пользователя и добавит ей роль db_owner.
- Выполните код из листинга 3. Данный код создаст в базе данных распространения имя регистрации для агента распространителя (Distribution Agent), создаст учетную запись пользователя и добавит ей роль db_owner. Заметим, что в электронной документации SQL Server Books Online (BOL) утверждается, что для агента распространителя требуется членство в списке доступа к публикации Publication Access List (PAL). PAL обеспечивает защиту доступа к публикациям и предотвращает создание неавторизованных подписок. Однако в функционировании PAL в некоторых сценариях имеются определенные недочеты, более подробно с этой информацией можно ознакомиться в моем блоге When is the Publication Access List required? (http://www.sqlskills.com/blogs/joe/when-is-the-publication-access-list-required/).
- Подключитесь к серверу-подписчику и выполните код из листинга 4. Данный код создаст в базе данных подписки имя регистрации для агента распространителя, создаст учетную запись пользователя и добавит ей разрешения db_owner.
- Назначьте учетной записи агента моментальных снимков разрешения на запись для папки снимков.
- Назначьте учетной записи агента распространителя разрешения на чтение для папки моментальных снимков.
Хотя вы в нескольких местах назначили разрешения db_owner, это официально объявлено минимально необходимыми разрешениями. По сравнению с разрешениями sysadmin вы создали более защищенную конфигурацию.
Создание публикации
Для создания новой публикации выполните следующие действия.
- В окне Object Explorer раскройте объект SQL Server для сервера-издателя и откройте папку Replication. Щелкните правой кнопкой мыши на папке Local Publications и выберите в меню пункт New Publication («Новая публикация»).
- На экране мастера новой публикации выберите Next (при условии, что вы ранее не отключили данный экран).
- На экране Publication Database выберите базы данных AdventureWorks. Имейте в виду, что вы не можете выбрать несколько баз данных одновременно, так как отдельная публикация всегда привязана к отдельной базы данных. Нажмите Next.
- На экране Publication Type выберите тип Transactional publication и нажмите Next.
- На экране Articles, как показано на экране 3, раскройте список таблиц Tables и выберите таблицы, перечисленные ранее в разделе «Развертывание репликации транзакций». Затем прокрутите экран вниз, откройте список представлений Views и выберите представление vEmployee (HumanResources).
- В списке публикуемых объектов Objects to publish щелкните мышью на самом верхнем узле списка Tables, нажмите кнопку Article Properties и выберите Set Properties of All Table Articles. Просмотрите различные параметры статьи в диалоговой панели Properties for All Table Articles, как показано на экране 4. Нажмите OK.
- На экране Articles выберите Next.
- Экран Article Issues содержит предупреждение о том, что, поскольку мы включили в статью представление, нам необходимо обеспечить, чтобы все используемые в представлении объекты были доступны для подписчика. Нажмите Next.
- На экране Filter Table Rows можно задать предикаты для фильтрации строк таблицы, которые необходимо реплицировать. Помните, что фильтры могут вызвать дополнительные задержки при создании топологии с высокой пропускной способностью. Мы здесь не вносим никаких изменений и нажимаем Next.
- Экран Snapshot Agent задает время запуска агента моментальных снимков и создания нового снимка. Выберите вариант Create a snapshot immediately and keep the snapshot available to initialize subscriptions («Создать снимок и сохранять его доступным для инициализации подписок»). При выборе этого варианта вы устанавливаете значение параметра immediate_sync равным True, что приводит к сохранению данных в базе данных распространения. Необходимо учитывать эффект, который может иметь этот параметр, в топологии с высокой пропускной способностью. Нажмите Next.
- Экран Agent Security задает учетные данные агента моментальных снимков и агента чтения журнала. Снимите галочку у параметра Use the security setting from the Snapshot Agent («И
Репликация Active Directory. Часть 2
Продолжение разговора об репликации Active Directory. Первая часть доступна по ссылке.
Репликация Active Directory: Разговор на «Ты» (Продолжение)
Продолжаем разговор о репликации, начатый ссылке. Усложним задачу и внесем территориальное разделение сегментов вашей сети.
Межсайтовая репликация
И вот ваша фирма обзавелась несколькими филиалами, каждый из которых имеет свое территориальное местоположение. Естественно эти офисы выделены в отдельные подсети, которые соединены WAN каналами и произведена настройка маршрутизации. Как быть в такой ситуации? Можно оставить все контроллеры в одном офисе и тогда клиентам не останется ничего кроме общения с контроллерами доменов по WAN-каналам. Конечно, данный трафик можно шифровать, используя IPsec, но как быть в случае падения WAN канала. Ведь при недоступности контроллера домена клиенты не смогут войти в сеть и начать работу в домене.
Примечание: Надо заметить, что трафик Kerberos шифровать не обязательно, т.к. он уже имеет защиту от man-in-the-middle, что касается RPC то он более уязвим, но только в ситуации «по умолчанию», когда разрешено незащищенное RPC взаимодействие. Однако можно включить жесткое требование в групповой политике домена для шифрования и подписывания RPC и SMB.
Вывод напрашивается сам собой – установить в каждом филиале по контроллеру домена.
Просто раскидав по офисам контроллеры домена проблемы не решить. Необходимо обеспечить выполнения двух задач:
1. Каждый клиент при аутентификации должен обращаться к ближайшему контроллеру домена для получения билетов Kerberos. При этом и групповые политики также должны применяться с ближайшего контроллера (эти взаимодействия называются трафиком регистрации компьютеров и пользователей).
2. Репликация изменений внутри сайта (например одного офиса) осуществляется согласно схеме уведомлений с расписанием, описанной в первой части статьи. Репликация же между контроллерами, находящимися в разных сайтах (например в разных филиалах) происходит только по расписанию. Хотя при желании систему уведомлений для межсайтовой репликации можно включить, воспользовавшись repadmin-ом.
Чтобы эти задачи выполнялись эффективно необходимо сконфигурировать сайты, которые по сути являются логической группировкой клиентов и контроллеров, связанных скоростными соединениями.
Создание сайта производится через оснастку «Active Direcory Сайты и службы». Если до этого сайты не конфигурировались, то все контроллеры домена будут принадлежать к сайту с именем «Default-First-Site-Namе».
При создании нового сайта, вы обязаны указать какой «SiteLink» будет использоваться для соединения. SiteLink или Связь сайтов это логическая цепочка связывающая два и более сайтов , если будет проще для восприятия можно ассоциировать ее с физическим каналом, соединяющим сайты. Для чего же нужна эта цепочка – ее задача управлять межсайтовой репликацией. Одна Связь сайтов уже создана по-умолчанию, в ней задано использование IP протокола для репликации с запуском ее раз в 180 минут.
Как только сайтов становится больше двух может возникнуть потребность в создании новых SiteLink-ов. Рассмотри жизненную ситуацию. Ваша фирма имеет два офиса, главный находится в Москве, он соединен каналом с Ростовским офисом. Открывается еще один филиалл в г. Сальск и этот филиал имеет медленный, загруженный и нестабильный канал с Ростовским участком. Перед вами стоит задача, обеспечить выполнение двух вышеназванных пунктов и вдобавок гибко настроить репликацию между сайтами. Вы решили, что новые данные из москвы в Ростов-на-Дону должны реплицироваться ежечасно, а вот из Ростова в Сальск репликация должна проходить только в ночное время, дабы не нагружать и без того проблемный канал.
Рис. 13 Схема сайтов и их связей.
Действия администратора в такой ситуации довольно просты, первым делом он создает сами сайты, эта процедура предельно проста и требует ввода только имени сайта и используемой связи. Настоятельно рекомендуется при этом сразу назначить на вновь созданные сайты соответствующие им IP-подсети. Первоначально для связи сайтов можно использовать созданную автоматически при инсталляции службы каталогов связь «DEFAULTIPSITELINK».
После этого администратор создает две «Связи сайтов», одну для стыковки сайтов Москва и Ростов, вторую для Ростов-Сальск. После создания необходимо сконфигурировать расписание открытия окна репликации, доступ к настройкам которого легко получить в свойствах нужной связи.
Получив нужную структуру сайтов, следует задать какие контроллеры в каком сайте должны обсуживать клиентов, сделать это можно обычным перетаскиванием объектов контроллеров домена между папками «Servers» в разных сайтах. Однако более правильным и рекомендуемым компанией Microsoft способом распределения между сайтами считается инсталляция контроллера домена с таким IP-адресом, который попадает в заданную вами подсеть, принадлежащую нужному вам сайту. Внимательные администраторы заметили, что при создании Связей кроме расписания задается их стоимость. Это неспроста, возможны ситуации когда сайты связанны сразу с несколькими другими и возникает ситуация когда у репликационного трафика есть несколько возможных путей. Именно тогда и начинают учитываться стоимости, чем меньше стоимость связи, тем приоритетней путь для репликации.
Правил несколько:
1. Межсайтовая репликация идет по самому «дешевому» маршруту.
2. Если между двумя сайтами есть несколько маршрутов и они одинаковы по стоимости, то будет выбран тот маршрут, который использует меньше «прыжков» или «SiteLink-ов»
3. Если и стоимость, и количество прыжков одинаково, будут учитываться названия сайтов, где приоритет получат пути через сайты, имена которых начинаются с первых букв алфавита.
Рис. 14 Схема сайтов и их связей со стоимостью.
Зная это можно точно сказать, что при репликации с контроллеров домена Москвы в Сальск информация будет реплицирована используя Связь 3, так как при одинаковой цене (100=50+50) этот вариант предполагает единственный прыжок.
Пока мы не ответили на один очень важный вопрос, как клиент Москвы поймет, что ему нужно обращаться в первую очередь к контроллерам B1, B2 или B3. И только если они недоступны, пытаться аутентифицироваться на каком-либо другом контроллере. В той же оснастке в папке «Subnets» администратором создаются объекты подсеть, которые в последствии закрепляются за нужным сайтом . Т.е если вы создали сайт “Ростов-на-Дону” и закрепили за ним подсеть “192.168.5.0/24”, все клиенты имеющие IP-адрес в данной подсети будут считать себя членами данного сайта. За одним сайтом может быть закреплено сразу несколько подсетей. Более того, если получиться так, что у сайта «А» подсеть будет скажем 192.168.0.0/16, а у сайта «Б» подсеть будет 192.168.1.0/24, то для рабочей станции или сервера скажем с IP адресом 192.168.1.15 будет выбран сайт «Б». Отсюда вывод, что выбор сайта при совпадении назначенных подсетей с разными масками производиться в пользу сайта с наиболее «узкой маской» подсети. То есть с маской с большим числом единиц в двоичной нотации.
Чтобы убедиться в том, что клиенты начали обращаться к «правильному» контроллеру домена, можно использовать команду set logonserver, которая вернет вам, имя контроллера, аутентифицировавшего клиента: LOGONSERVER=\B1, однако в Windows 2000 и XP эта переменная далеко не всегда оперативно обновляется. Поэтому можно воспользоваться еще одной командой:
nltest /DSGETDC:<имя домена> /KDC /GC.
В случае если контроллер, который был выбран рабочей станцией в качестве Logon Server-а окажется недоступен, примерно через 15 минут это будет обнаружено и будет выбран другой доступный контроллер домена. Этот процесс называется DC Locator и имеет первостепенное значение в части отказоустойчивости работы AD. Так же этот процесс можно запустить принудительно командой nltest /DSGETDC:<имя домена> /force.
В межсайтовой репликации есть одна особенность, связанная с наличием Сервера Платцдарма (Bridgehead Server) в задачу которого входит обеспечение межсайтовой репликации, т.е. если контроллер домена B3 создаст новый обьект в базе то он должен его реплицировать на сервер плацдарм сайта Москва, а тот в свою очередь реплицирует на плацдарм Ростовского сайта, где последующее распространение будет идти по стандартной внутрисайтовой схеме.
Bridgehead сервера для каждого сайта выбираются автоматически с помощью службы KCC, но при желании администратор может самостоятельно задать один или более Bridgehead-ов для сайта. Данная манипуляция производится в свойствах нужного сервера оснастки «Active Direcory Сайты и службы» где указывается для каких протоколов данный сервер будет плацдармом. Поскольку в большинстве ситуаций это протокол IP, то его и нужно добавить на выбранном сервере.
Рис. 15 Ручное указание Bridgehead сервера.
При ручном назначении Серверов Плацдармов следует учитывать, что в случае недоступности выбранных серверов межсайтовая репликация работать перестанет, плюсом же выбора через KCC является автоматическое переназначение данной задачи другому контроллеру в случае недоступности ранее выбранного Bridgehead-сервера .
Посмотреть, кто является текущим сервером плацдармом можно через: repadmin /bridgeheads
Важно отметить, что при ручном указании сервера Bridgehead для сайта он будет один выполнять эту функцию. Если же сервер Bridgehead не задан и выбор делает KCC автоматически то для Windows Server 2003 KCC осуществляет балансировку количества линков репликации между несколькими контроллерами в сайте. Кроме того, такую балансировку можно выполнить и в ручном режиме утилитой adlb.exe.
Поговорим о межсайтовых мостах.
Посмотрим на рисунок 16. На нем изображена схема сети, состоящей из 3-х сайтов, каждый из которых находится в своей подсети и своем городе. Связи сайтов настроены так, что Белград имеет SiteLink соединяющий его с Москвой и SiteLink, соединяющий его с Токио. Москва и Токио между собой напрямую не связаны.
Рис. 16. Идеология Site Link Bridge
А теперь давайте попробуем ответить на вопрос: Каким путем будут реплицироваться изменения с контроллера домена А1 на контроллер домена С1, Те, кто внимательно читали статью скажут, что контроллер домена А1 передаст изменения серверу плацдарму в своем сайте. Тот в свою очередь согласно расписанию «Связи» передаст их на сервер плацдарм сайта Белград. И только потом плацдарм Белграда опять же по расписанию передаст их на Токийский плацдарм. И уже с него они будут реплицированы на контроллер С1. Те, кто так скажут, будут правы.
Что же произойдет, если Белградские контроллеры станут недоступны или просто этот сегмент сети окажется отключен? Остановится ли репликация между сайтами Москва и Токио?
По умолчанию Active Directory пытается решить данную проблему. Она (AD DS) видит, что Москва связана с Белградом, Белград с Токио, а сайт Белграда пропал с радаров и репликация остановилась. Видит и допускает, что мы имеем полностью маршрутизируемую сеть. А если сеть полностью маршрутизируемая, то почему не передать напрямую? (с контроллера А1 на С1 сразу)
Такая транзитивность называется «Site Link Bridging». Служба KCC начинает создавать репликационные связи между контроллерами из несвязанных SiteLink-ми сайтов и реплицировать данные напрямую. Естественно, если вы не имеете полностью маршрутизируемой сети, то такая дефолтная логика вас не устроит. Поэтому вам может потребоваться отключить автоматический «Site Link Bridging». Делается это довольно просто и уже после отключения логика репликации будет идти по классической схеме. А при падении канала с центральным сайтом, в моем случае Белград, репликация между сайтами попросту остановится.
Рис. 17 Включение и отключение функции автоматического “Site Link Bridging” (опция Установить мост для всех связей сайтов )
Важно отметить и то, что с появление связи с центральным Белградским сайтом служба KCC заново пересчитает топологию репликации, и все лишние репликационные связи между контроллерами будут удалены.
В сети, где сеть не полностью маршрутизируемая автоматическое создание мостов (Site Link Bridging) следует отключать. Но как быть, если сеть довольно крупная и в ней присутствуют как группы сегментов с полной маршрутизацией, так и с частичной. Отключение Site Link Bridging лишит нас резервного механизма репликации для всех сегментов сети.
Специально для таких целей существует функции создания мостов межу конкретными сайтами, осуществляется она также через оснастку «Active Directory Сайты и Службы»
Рис. 18 Создание моста между сайтами.
Создавай мост, вы можете быть уверены, что контроллеры в сайтах сайт-линки которых соединены мостом в штатном режиме будет реплицировать изменения согласно топологии межсайтовой репликации (используя контроллеры доменов в других сайтах как посредников). И только если передать данные по этой логике не получится (обратите внимание, что для передачи данных через мост необходимо несколько сбойных попыток репликации) будут созданы прямые репликационные связи и начнут передаваться данные.
Системный администратор ответственный за работу двух и более сайтов Active Directory непременно столкнется с проблемой настройки Файрволов , ограничивающих трафик, передаваемый между сегментами его сети (или между сайтами). И здесь присутствуют определенные трудности.
По-умолчанию при репликации контроллеры домена устанавливают соденение по 135/tcp, 135/udp портам (так называемый RPC endpoint mapper), после чего согласовывают порты, которые будут использоваться при репликации данных. Тут то и появляется проблема, диапазон портов, которые могут быть задействованы очень велик 1024-65535/tcp. Открытие этих портов полностью нивелирует файрвол, превращая его в головку швейцарского сыра.
Поэтому перед администратором может встать задача четкой фиксации портов, используемых при репликации, а делается это через правку реестра на контроллерах домена.
Для жесткой привязки порта репликации Active Directory используется ключ:
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesNTDSParameters
Registry value: TCP/IP Port
Value type: REG_DWORD
Еще один очень полезный ключ для фиксации RPC-трафика регистрации пользователей и компьютеров в процессе NetLogon-а и DC Locator-а: (трафика от клиентов к контроллерам домена при установлении SChannel и при поиске «родных» сайтов)
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesNetlogonParameters
Registry value: DCTcpipPort
Value type: REG_DWORD
Вот здесь не стоит забывать, что групповая политика важная часть доменной структуры Active Directory, а каждый контроллер домена хранит свою копию политик. Групповая политика состоит из двух частей связывающего объекта GPO (в нем название политики, ее идентификатор («GUID»), дата создания, дата изменения, версия) который хранится в Active Directory и реплицируется ее средствами и собственно настроек политики, а так же ее шаблонов (параметры политики, передаваемые клиентам как двоичные файлы и файлы adm, admx, adml) находящегося в папке SYSVOL.
Папка SYSVOL не реплицируется средствами AD, ее синхронизация обеспечивается технологией NtFRS или DFS-R.
Расписание межсайтововй репликации SYSVOL соответствует расписанию AD, но не допускает межсайтовой нотификации. Внутрисайтовая репликация тоже осуществляется по расписанию NTFRS/DFS-R задаваемые в реестре. Репликация является мульти-мастерной, т.е источником изменений может быть любой контроллер. Если изменения произошли на нескольких контроллерах, приоритет будет иметь изменение сделанное последним. Более подробно мы не будем рассматривать репликацию NTFRS или DFS-R в этой статье, т.к. это совершенно другая тема.
Когда вы добавляете в ваш домен Active Directory, построенный на базе Windows Server 2003 новый контроллер Windows Server 2008, он по прежнему использует для репликации групповой политики «File Replication service» (NtFRS).
Для фиксации порта NtFRS используется ключ:
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesNtFrsParameters
Registry Value: RPC TCP/IP Port Assignment
Value type: REG_DWORD
При создании нового домена Active Directory на базе Windows Server 2008 (режим работы домена Windows Server 2008 и новее), для репликации « групповой политики» используется «Distributed File System («DFS») Replication». Если вы обновили ваш домен с Windows Server 2003 до уровня 2008, то «DFS Replication» этот функционал нужно активировать дополнительно утилитой DFSRMIG.exe.
Distributed File System (DFS) Replication это сервис, реплицирующий папку SYSVOL на всех контроллерах домена, работающего в функциональном режиме Windows Server 2008. Впервые DFS Replication появилась в Windows Server 2003 R2, но для репликации SYSVOL ее можно использовать только в Windows Server 2008.
Какие преимущества имеет «DFS Replication»?
• В Windows Server 2003 при изменении файла в SYSVOL служба «FRS» реплицировала весь файл целиком. При использовании «DFS Replication» измененный файл больше 64 KB реплицируется частично, т.е только блоки размером 64KB с изменениями.
При передачи данных DFS-R эффективно сжимает их алгоритмом схожим с ZIP.
• Масштабируемое решение. Размер папки SYSVOL может достигать нескольких терабайт.
• Новая графическая оснастка «Управление DFS» для более удобного администрирования.
• Улучшенная поддержка Read Only Domain Controllers.
• Наличие встроенных средств мониторинга и утилиты для развертывания.
• Технология, требующая минимального контроля и администрирования со стороны системного администратора.
Тем, кого заинтересовал процесс перехода, необходимо познакомиться с утилитой dfsrmig, которая позволяет произвести процесс миграции с FRS на DFS. Основными ключами для работы будут /GetMigrationState и /SetGlobalState. Подробней о процессе миграции можно прочитать в статье ссылке .
Если вы идете в ногу с прогресом и ваша папка SYSVOL реплицируется средствами DFS-R, вам так же ничто не мешает статически закрепить порты, которые будут использоваться при DFS-репликации.
Делается это следующим образом:
1. Вводим команду «dfsrdiag dumpmachinecfg». Если команда возвращает 0, значит у вас используется динамическое назначение портов для DFS-репликации.
2. Указываем статический порт «dfsrdiag StaticRPC /port:nnnnn /Member:dc.itband.ru».
Информация о порте репликации будет храниться в XML-файле по следующему пути %SYSTEMDRIVE%System Volume InformationDFSRConfigDfsrMachineConfig.XML.
Вдобавок к теме используемых портов, остается добавить ссылку на статью базы знаний Microsoft “Службы и сетевые порты в серверных системах Microsoft Windows” (http://support.microsoft.com/kb/832017). В ней приведен список портов, которые могу понадобиться для работы различных сервисов Microsoft Windows и в частности Active Directory.
Утилита repadmin
Для управления репликацией существует две утилиты repadmin (консольная) и replmon (графическая). С выходом Windows Server 2008 продолжение развития получила только утилита repadmin, ее функционала вполне достаточно, чтобы дополнить оснастку «Active Directory – сайты и службы» и дать администраторам возможность гибко управлять репликацией.
Рассмотрим несколько примеров ее использования:
repadmin /syncall DC1 dc=itband,dc=ru
repadmin /syncall DC1 cn=configuration,dc=itband,dc=ru
repadmin /syncall DC1 cn=schema,cn=configuration,dc=itband,dc=ru
Три приведенных варианта repadmin запускают репликацию различных разделов каталога контроллера DC1 с его репликационными партнерами в сайте Active Directory.
repadmin /replsummary
Ключ replsummary возвращает состояние репликации на всех контроллерах домена, по данной информации легко найти не реплицирующиеся контроллеры, а также те сервера, которые по каким-то причинам часто завершают репликацию ошибкой.
Следующий ключ (showchanges) дает возможность посмотреть какие изменения не были прореплицированы между двумя контроллерами.
repadmin /showchanges dc1 7b2b9e16-895f-414d-a7b0-5e48f502935c dc=lab,dc=itband,dc=ru
В данном примере указан контроллер с которым нужно произвести сравнение (DC1) и invocationID (уникальный идентификатор экземпляра базы Active Directory ) контроллера с которого производится запуск. InvocationID в свою очередь можно узнать командой:
repadmin /showsig dc2
Набор ключей, которые имеет repadmin несколько шире, чем представлено в стандартной справке и часть их спрятана. Получить доступ к полной версии можно через repadmin /? /experthelp.
Рис. 16. Не реплицированное изменение.
Несмотря на предупреждение о том, что данные команды должны использоваться только под присмотром premier support microsoft некоторые из них стоит взять на вооружение.
repadmin /options DC1 +DISABLE_OUTBOUND_REPL +DISABLE_INBOUND_REPL
Эта команда отключает входящую и исходящую репликацию на контроллере DC1, очень удобное средство, в случае если необходимо срочно остановить распространение изменений. Обратно включение производится аналогично только перед параметром необходимо установить минус. (-DISABLE_INBOUND_REPL)
Заключение
Информация полученная после вдумчивого прочтения двух частей данной статьи должна сформировать понимание у специалиста идеологии репликации и построения многосайтовых систем. Но все же очень много осталось за кадром. А именно: задачи и сценарии SMTP-репликации, объемы трафика репликации для разных типов объектов, влияние на репликацию таких вещей как захоронение и восстановление объектов, ну и конечно USN rollback. И пусть не в каждой организации вам понадобится знание вышеперечисленного, но для реализации крупных решений эти нюансы в голове должны быть проработаны.
Илья Рудь
Константин Леонтьев
Оринигал статьи взят с ресурса itband.ru
Репликация базы данных — Configuration Manager
- Читать 12 минут
В этой статье
Применимо к: Configuration Manager (текущая ветвь)
Репликация базы данных Configuration Manager использует SQL Server для передачи данных. Он использует этот метод для объединения изменений в базе данных своего сайта с информацией из базы данных на других сайтах в иерархии.
Обратите внимание на следующие моменты репликации базы данных:
Все сайты имеют одинаковую информацию.
Когда вы устанавливаете сайт в иерархии, Configuration Manager автоматически устанавливает репликацию базы данных между новым сайтом и его родительским сайтом.
По завершении установки сайта автоматически запускается репликация базы данных.
Когда вы добавляете новый сайт в иерархию, Configuration Manager создает общую базу данных на новом сайте.Родительский сайт создает моментальный снимок соответствующих данных в своей базе данных. Затем он передает снимок на новый сайт, используя репликацию на основе файлов. Затем новый сайт использует программу массового копирования SQL Server (BCP) для загрузки информации в свою локальную копию базы данных Configuration Manager. После загрузки моментального снимка каждый сайт выполняет репликацию базы данных с другим сайтом.
Для репликации данных между сайтами Configuration Manager использует собственную службу репликации базы данных. Служба репликации базы данных использует отслеживание изменений SQL Server для отслеживания изменений в локальной базе данных сайта.Затем он реплицирует изменения на другие сайты с помощью SQL Server Service Broker (SSB). По умолчанию этот процесс использует TCP-порт 4022.
Группы репликации
Configuration Manager группирует данные, которые реплицируются путем репликации базы данных, в разные группы репликации. Каждая группа репликации имеет отдельное фиксированное расписание репликации. Сайт использует это расписание, чтобы определить, как часто он реплицирует изменения на другие сайты.
Например, изменение конфигурации администрирования на основе ролей быстро реплицируется на другие сайты.Такое поведение гарантирует, что другой сайт сможет быстро применить эти изменения. Изменение конфигурации с более низким приоритетом, например запрос на установку нового вторичного сайта, реплицируется с меньшей срочностью. Передача запроса нового сайта на целевой первичный сайт может занять несколько минут.
Настройки
Вы можете изменить следующие параметры репликации базы данных:
Ссылки репликации базы данных : контроль прохождения определенного трафика по сети.
Распределенные представления : когда сайт центра администрирования (CAS) запрашивает данные выбранного сайта, он может получить доступ к данным непосредственно из базы данных на дочернем первичном сайте.
Расписания : укажите, когда используется ссылка репликации и когда реплицируются разные типы данных сайта.
Суммирование : изменение параметров суммирования данных о сетевом трафике, проходящем по ссылкам репликации.По умолчанию суммирование происходит каждые 15 минут. Используется в отчетах для репликации базы данных.
Пороги репликации базы данных : Определите, когда сайт сообщает о ссылках как об ухудшенных или неисправных. Вы также можете настроить, когда Configuration Manager будет выдавать предупреждения о ссылках репликации, которые имеют ухудшенный или неисправный статус.
Типы данных
Configuration Manager в первую очередь классифицирует данные, которые он реплицирует, как глобальные данные или данные сайта .Когда происходит репликация базы данных, сайт передает изменения в глобальные данные и данные сайта по ссылке репликации базы данных. Глобальные данные реплицируются на родительский или дочерний сайт. Данные сайта реплицируются только на родительский сайт. Третий тип данных, локальных данных , не реплицируется на другие сайты. Локальные данные — это информация, которая не требуется другим сайтам.
Глобальные данные
Глобальные данные — это созданные администратором объекты, которые реплицируются на все сайты в иерархии. Вторичные сайты получают только часть глобальных данных в качестве данных глобального прокси.Вы создаете глобальные данные на CAS и первичных сайтах. К этому типу относятся следующие данные:
- Развертывание программного обеспечения
- Обновления программного обеспечения
- Определения коллекций
- Области безопасности администрирования на основе ролей
Данные объекта
Данные сайта — это рабочая информация, созданная первичными сайтами Configuration Manager и назначенными им клиентами. Данные сайта реплицируются на CAS, но не на другие первичные сайты. Данные сайта доступны для просмотра только в CAS и на первичном сайте, откуда они исходят.Вы можете изменять данные сайта только на первичном сайте, на котором вы их создали. К этому типу относятся следующие данные:
- Инвентаризация оборудования
- Сообщения о состоянии
- Предупреждения
- Результаты коллекций на основе запросов
Все данные сайта реплицируются в CAS. CAS выполняет администрирование и отчетность для всей иерархии сайта.
Ссылки репликации базы данных
При установке нового сайта в иерархии Configuration Manager автоматически создает связь репликации базы данных между родительским сайтом и новым сайтом.Он создает единую ссылку для соединения двух сайтов.
Чтобы управлять передачей данных по ссылке репликации, измените настройки для каждой ссылки. Каждая ссылка репликации поддерживает отдельные конфигурации. Каждая ссылка репликации базы данных включает следующие элементы управления:
Остановить репликацию данных выбранного сайта с первичного сайта на CAS. Это действие заставляет CAS обращаться к этим данным непосредственно из базы данных первичного сайта.
Запланировать передачу данных выбранного сайта с дочернего первичного сайта на CAS.
Определите параметры, которые определяют, когда ссылка репликации базы данных находится в ухудшенном состоянии или в состоянии сбоя.
Укажите, когда следует создавать предупреждения для сбойного канала репликации.
Укажите, как часто Configuration Manager обобщает данные о трафике репликации, который использует канал репликации. Он использует эти данные в отчетах.
Чтобы настроить ссылку репликации базы данных, в консоли Configuration Manager перейдите в рабочее пространство Monitoring .Выберите узел Database Replication и отредактируйте свойства ссылки. Этот узел также находится в рабочем пространстве Администрирование , в узле Конфигурация иерархии . Измените ссылку репликации либо с родительского, либо с дочернего сайта ссылки репликации.
Подсказка
Вы можете редактировать ссылки репликации базы данных из узла Репликация базы данных в любой рабочей области. Однако при использовании узла Репликация базы данных в рабочем пространстве Мониторинг можно также просматривать состояние репликации базы данных.Он также обеспечивает доступ к инструменту Replication Link Analyzer. Используйте этот инструмент, чтобы помочь исследовать проблемы с репликацией базы данных.
Дополнительные сведения о настройке ссылок репликации см. В разделе Элементы управления репликацией базы данных сайта. Дополнительные сведения о том, как отслеживать репликацию, см. В разделе Мониторинг репликации базы данных.
Распределенные просмотры
Через распределенные представления, когда вы делаете запрос в CAS для данных выбранного сайта, он напрямую обращается к базе данных на дочернем первичном сайте.Такой прямой доступ устраняет необходимость реплицировать данные сайта с первичного сайта в CAS. Поскольку каждая ссылка репликации независима от других ссылок репликации, вы можете использовать распределенные представления для выбранных вами ссылок репликации. Вы не можете использовать распределенные представления между первичным и вторичным сайтами.
Распределенные представления обеспечивают следующие преимущества:
Уменьшите нагрузку на ЦП для обработки изменений базы данных на CAS и первичных сайтах
Уменьшите объем данных, передаваемых по сети в CAS
Повышение производительности SQL Server, на котором размещена база данных CAS
Уменьшить дисковое пространство, используемое базой данных CAS
Рассмотрите возможность использования распределенных представлений, когда первичный сайт находится близко к CAS в сети, два сайта всегда включены и всегда подключены.Распределенные представления заменяют репликацию выбранных данных между сайтами прямыми соединениями между серверами базы данных сайта на каждом сайте. CAS устанавливает прямое соединение каждый раз, когда вы запрашиваете эти данные.
Сайт запрашивает данные распределенного представления в следующих примерах сценариев:
- При запуске отчетов или запросов
- При просмотре информации в обозревателе ресурсов
- Оценка коллекций для коллекций, которые включают правила на основе данных сайта
По умолчанию распределенные представления отключены для каждой ссылки репликации.Когда вы включаете распределенные представления, вы выбираете данные сайта, которые не будут реплицироваться в CAS по этой ссылке. CAS получает доступ к этим данным непосредственно из базы данных дочернего первичного сайта, который использует ссылку. Вы можете настроить следующие типы данных сайта для распределенных представлений:
- Инвентаризация оборудования данные от клиентов
- Инвентаризация программного обеспечения и учет программного обеспечения данные от клиентов
- Сообщения о состоянии от клиентов, первичного сайта и всех вторичных сайтов
Когда вы просматриваете данные в консоли Configuration Manager или в отчетах, распределенные представления для вас в рабочем состоянии невидимы.Когда вы запрашиваете данные, которые включены для распределенных представлений, сервер базы данных сайта CAS напрямую обращается к базе данных дочернего первичного сайта для получения информации.
Например, вы используете консоль Configuration Manager, подключенную к CAS. Вы запрашиваете информацию об инвентаризации оборудования с двух основных сайтов: ABC и XYZ. Вы включили инвентаризацию оборудования только для распределенных представлений на сайте ABC. CAS извлекает инвентарную информацию для клиентов XYZ из своей собственной базы данных. CAS получает инвентарную информацию для клиентов ABC непосредственно из базы данных на сайте ABC.Эта информация отображается в консоли Configuration Manager или в отчете без указания источника.
Если в ссылке репликации включен тип данных для распределенных представлений, дочерний первичный сайт не реплицирует эти данные в CAS. Когда вы выключаете распределенные представления для определенного типа данных, дочерний первичный сайт возобновляет нормальную репликацию данных в CAS. Прежде чем эти данные будут доступны на CAS, группы репликации для этих данных должны повторно инициализироваться между первичным сайтом и CAS.После удаления первичного сайта, на котором включены распределенные представления, CAS должен завершить повторную инициализацию своих данных, прежде чем вы сможете получить доступ к данным, которые вы включили для распределенных представлений на CAS.
Важно
При использовании распределенных представлений для любой ссылки репликации в иерархии сайта перед удалением любого первичного сайта отключите распределенные представления для всех ссылок репликации. Дополнительные сведения см. В разделе Удаление основного сайта, использующего распределенные представления.
Предварительные требования и ограничения для распределенных представлений
Используйте только распределенные представления для каналов репликации между CAS и первичным сайтом.
CAS должен использовать выпуск SQL Server Enterprise. На первичном сайте это требование отсутствует.
CAS может иметь только один экземпляр поставщика SMS. Установите этот единственный экземпляр на сервер базы данных сайта. Эта конфигурация поддерживает проверку подлинности Kerberos. SQL Server в CAS требует Kerberos для доступа к SQL Server на дочернем первичном сайте. Для поставщика SMS на дочернем первичном сайте ограничений нет.
В CAS можно установить только одну точку служб отчетов.Установите службы отчетов SQL Server на сервер базы данных сайта. Эта конфигурация поддерживает проверку подлинности Kerberos. SQL Server в CAS требует Kerberos для доступа к SQL Server на дочернем первичном сайте.
Невозможно разместить базу данных сайта в экземпляре отказоустойчивого кластера SQL Server AlwaysOn.
Для учетной записи компьютера сервера базы данных CAS требуется Разрешение на чтение в базе данных первичного сайта.
Важно
Распределенные представления и расписания, когда данные могут реплицироваться, являются взаимоисключающими параметрами для ссылки репликации базы данных.
График передачи данных сайта
Чтобы помочь вам контролировать полосу пропускания сети, которая используется для репликации данных сайта с дочернего первичного сайта на CAS, запланируйте, когда будет использоваться ссылка репликации. Затем укажите, когда реплицируются разные типы данных сайта. Вы можете контролировать, когда первичный сайт реплицирует сообщения о состоянии, данные инвентаризации и измерения. Ссылки репликации базы данных со вторичных сайтов не поддерживают расписания для данных сайта. Вы не можете запланировать передачу глобальных данных.
При настройке расписания связи репликации базы данных можно ограничить передачу данных выбранного сайта с первичного сайта на CAS. Вы также можете настроить разное время для репликации разных типов данных сайта.
Важно
Распределенные представления и расписания, когда данные могут реплицироваться, являются взаимоисключающими конфигурациями для ссылки репликации базы данных.
Обобщение трафика
Каждый сайт периодически обобщает данные о сетевом трафике, который проходит по ссылкам репликации базы данных для сайта.Сайт использует сводные данные в отчетах для репликации базы данных. Оба сайта в канале репликации суммируют сетевой трафик, который проходит через ссылку репликации. Сервер базы данных сайта суммирует данные. После обобщения данных информация реплицируется на другие сайты в виде глобальных данных.
По умолчанию суммирование происходит каждые 15 минут. Чтобы изменить частоту суммирования для сетевого трафика, в свойствах ссылки репликации базы данных отредактируйте Интервал суммирования .Частота суммирования влияет на информацию, которую вы просматриваете в отчетах о репликации базы данных. Вы можете выбрать интервал от 5 до 60 минут. Когда вы увеличиваете частоту суммирования, вы увеличиваете нагрузку обработки на SQL Server на каждом сайте в ссылке репликации.
Пороги репликации базы данных
Пороговые значения репликации базы данных определяют, когда Configuration Manager сообщает о состоянии ссылки репликации базы данных как об ухудшенной или отказавшей.По умолчанию он устанавливает ссылку как degraded , когда любая из групп репликации не может завершить репликацию в течение 12 последовательных попыток. Он устанавливает связь как сбой , когда любая группа репликации не может реплицироваться в 24 последовательных попытках.
Вы можете указать пользовательские значения для состояния пониженной производительности или неисправности. Если вы настроите эти значения, вы сможете более точно отслеживать состояние репликации базы данных по ссылкам.
Одна или несколько групп репликации могут не реплицироваться, в то время как другие группы репликации продолжают успешно реплицироваться.Запланируйте проверку статуса репликации ссылки, когда она впервые сообщает о снижении производительности.
Рассмотрите возможность изменения значений повторных попыток для ухудшенного состояния или состояния отказа канала в следующих ситуациях:
Существуют повторяющиеся задержки для определенных групп репликации, и их задержка не является проблемой
Сетевая ссылка между сайтами имеет низкую доступную пропускную способность
Когда вы увеличиваете количество повторных попыток до того, как сайт установит ссылку на ухудшенную или неудачную, вы можете исключить ложные предупреждения об известных проблемах.Это действие позволяет более точно отслеживать статус ссылки.
Чтобы понять, как часто происходит репликация этой группы, рассмотрите интервал синхронизации репликации для каждой группы репликации. Чтобы просмотреть Synchronization Interval для групп репликации, перейдите в рабочее пространство Monitoring в консоли Configuration Manager. В узле репликации базы данных выберите вкладку Replication Detail ссылки репликации.
Дополнительные сведения о том, как отслеживать репликацию базы данных, в том числе о том, как просматривать состояние репликации, см. В разделе Мониторинг репликации базы данных.
Элементы управления репликацией базы данных сайта
Чтобы помочь вам контролировать полосу пропускания сети, используемую для репликации базы данных, измените настройки для каждой базы данных сайта. Параметры применяются только к базе данных сайта, в которой вы настраиваете параметры. Параметры всегда используются, когда сайт реплицирует любые данные путем репликации базы данных на любой другой сайт.
Вы можете изменить следующие элементы управления репликацией для каждой базы данных сайта:
SSB порт
Период времени, в течение которого сбои репликации заставят сайт повторно инициализировать свою копию базы данных сайта
Сжимайте данные, реплицируемые сайтом.Он сжимает данные только для передачи между сайтами, но не для хранения в базе данных сайта на любом сайте.
Чтобы изменить настройки элементов управления репликацией для базы данных сайта, в консоли Configuration Manager на узле Database Replication измените свойства базы данных сайта. Этот узел появляется под узлом Hierarchy Configuration в рабочем пространстве Administration , а также появляется в рабочем пространстве Monitoring .Чтобы изменить свойства базы данных сайта, выберите ссылку репликации между сайтами, а затем откройте Свойства родительской базы данных или Свойства дочерней базы данных .
Подсказка
Вы можете настроить элементы управления репликацией базы данных из узла Репликация базы данных в любом рабочем пространстве. Однако при использовании узла Database Replication в рабочем пространстве Monitoring вы также можете просмотреть состояние репликации базы данных для связи репликации и получить доступ к инструменту Replication Link Analyzer, чтобы помочь вам исследовать проблемы с репликацией.
См. Также
Монитор репликации
Устранение неполадок репликации SQL Server
Репликация данных в СУБД — GeeksforGeeks
Репликация данных в СУБД
Репликация данных — это процесс хранения данных более чем на одном сайте или узле. Это полезно в для улучшения доступности данных . Это просто копирование данных из базы данных с одного сервера на другой, чтобы все пользователи могли использовать одни и те же данные без какой-либо несогласованности.Результатом является распределенная база данных , в которой пользователи могут получать доступ к данным, относящимся к их задачам, не мешая работе других.
Репликация данных включает в себя дублирование транзакций на постоянной основе, так что реплика находится в постоянно обновляемом состоянии и синхронизируется с источником. Однако при репликации данных данные доступны в разных местах, но конкретное отношение должно находиться только в одно место.
Может быть полная репликация, при которой вся база данных хранится на каждом сайте.Также может быть частичная репликация, при которой одни часто используемые фрагменты базы данных реплицируются, а другие не реплицируются.
Типы репликации данных —
- Репликация транзакций — В режиме репликации транзакций пользователи получают полные начальные копии базы данных, а затем получают обновления по мере изменения данных. Данные копируются в реальном времени от издателя к принимающей базе данных (подписчику) в том же порядке, в каком они происходят с издателем, поэтому в этом типе репликации гарантируется транзакционная согласованность . Репликация транзакций обычно используется в межсерверных средах. Он не просто копирует изменения данных, а последовательно и точно воспроизводит каждое изменение.
- Репликация моментальных снимков — Репликация моментальных снимков распределяет данные точно так, как они появляются в определенный момент времени, не отслеживая обновления данных. Полный снимок создается и отправляется пользователям. Репликация моментальных снимков обычно используется, когда данные меняются нечасто .Это немного медленнее, чем транзакционный, потому что при каждой попытке он перемещает несколько записей с одного конца на другой. Репликация моментальных снимков — хороший способ выполнить начальную синхронизацию между издателем и подписчиком.
- Репликация слиянием — Данные из двух или более баз данных объединяются в единую базу данных. Репликация слиянием — это наиболее сложный тип репликации, поскольку он позволяет издателю и подписчику независимо вносить изменения в базу данных. Репликация слиянием обычно используется в средах от сервера к клиенту.Это позволяет отправлять изменения от одного издателя нескольким подписчикам.
Схемы репликации —
1. Полная репликация — Самым крайним случаем является репликация всей базы данных на каждом сайте в распределенной системе. Это улучшит доступность системы, поскольку система может продолжать работать, пока работает хотя бы один сайт.
Преимущества полной репликации —
- Высокая доступность данных.
- Повышает производительность при получении глобальных запросов, так как результат может быть получен локально с любого локального сайта.
- Более быстрое выполнение запросов.
Недостатки полной репликации —
- При полной репликации сложно добиться параллелизма.
- Медленный процесс обновления, так как одно обновление должно выполняться в разных базах данных, чтобы копии были согласованы.
- Данные можно легко восстановить.
- Параллелизм достигается без репликации.
- Поскольку несколько пользователей обращаются к одному серверу, это может замедлить выполнение запросов.
- Данные недоступны из-за отсутствия репликации.
- Количество копий фрагмента зависит от важности данных.
- Для обеспечения согласованной копии данных на всех узлах базы данных.
- Для увеличения доступности данных.
- Надежность данных повышается за счет репликации данных.
- Data Replication поддерживает нескольких пользователей и обеспечивает высокую производительность.
- Чтобы удалить любую избыточность данных, базы данных объединяются, а подчиненные базы данных обновляются устаревшими или неполными данными.
- Поскольку создаются реплики, есть вероятность, что данные будут обнаружены там, где выполняется транзакция, что снижает перемещение данных.
- Для более быстрого выполнения запросов.
- Требуется больше места для хранения, так как хранение реплик одних и тех же данных на разных сайтах требует больше места.
- Data Replication становится дорогостоящим, когда необходимо обновить реплики на всех разных сайтах.
- Поддержание согласованности данных на всех сайтах требует комплексных мер.
2. Без репликации — Другой случай репликации включает отсутствие репликации, то есть каждый фрагмент хранится только на одном сайте.
Преимущества отсутствия репликации —
Недостатки отсутствия репликации —
3. Частичная репликация — В этом типе репликации некоторые фрагменты базы данных могут быть реплицированы, а другие — нет.Количество копий фрагмента может составлять от одной до общего количества сайтов в распределенной системе. Описание репликации фрагментов иногда называют схемой репликации.
Преимущества частичной репликации —
ПРЕИМУЩЕСТВА РЕПЛИКАЦИИ ДАННЫХ — Репликация данных обычно выполняется на:
НЕДОСТАТКИ РЕПЛИКАЦИИ ДАННЫХ —
Вниманию читателя! Не переставай учиться сейчас.Ознакомьтесь со всеми важными концепциями теории CS для собеседований SDE с помощью курса CS Theory Course по доступной для студентов цене и подготовьтесь к работе в отрасли.
Репликация базы данных — методы и методы
Итак, у вас есть хранилище данных (новая поговорка), и вы хотите лучше понять, как оно работает, особенно как ваши данные попадают в хранилище — или как процесс репликации данных.
Что такое репликация базы данных?
Проще говоря, репликация данных берет данные из ваших исходных баз данных — Oracle, MySQL, Microsoft SQL Server, PostgreSQL, MongoDB и т. Д.- и копирует в ваше облачное хранилище данных. Это может быть разовая операция или постоянный процесс по мере обновления ваших данных. Поскольку ваше хранилище данных является важным механизмом, с помощью которого вы можете получить доступ к своим данным и проанализировать их, необходима надлежащая репликация данных, чтобы избежать потери, дублирования или иного искажения ценной информации.
Например, если вы сделаете это неправильно, вы можете импортировать старые данные или одни и те же данные снова и снова, или вы можете пропустить обновления данных, которые включают изменения или удаления.Более того, ваш провайдер хранилища данных, скорее всего, будет нести расходы за каждый из этих циклов репликации независимо от результатов. Выполнение анализа устаревших или неверных данных по существу сводит на нет цель хранилища данных и может оказаться пустой тратой времени и денег.
К счастью, существуют методы репликации данных, предназначенные для интеграции с сегодняшними облачными хранилищами данных и подходящие для различных сценариев использования. Давайте обсудим каждый из трех распространенных методов репликации данных и выделим вариант, который может быть лучше всего для вас.
Понимание трех методов репликации
Если вас интересует простота, скорость, тщательность или все вышеперечисленное, выбор правильного метода репликации данных во многом зависит от вашей конкретной исходной базы данных и того, как вы храните и собираете данные.
Полный дамп и загрузка: Начав с самого простого метода, полный дамп и репликация нагрузки начинается с определения интервала репликации (может быть два, четыре, шесть часов — в зависимости от ваших потребностей).Затем в каждом интервале выполняются запросы к таблицам, которые вы реплицируете, и создается моментальный снимок. Новый снимок (дамп) заменяет (загружает) предыдущий снимок в вашем хранилище данных. Этот метод лучше всего подходит для небольших таблиц (обычно менее 100 миллионов строк), статических данных или одноразового импорта. Поскольку для выполнения дампа требуется время, это, как правило, более медленный метод, чем другие.
Incremental: При инкрементном методе вы определяете индикатор обновления для каждой из ваших таблиц — обычно столбец, который отслеживает время последнего обновления (обычно что-то вроде «updated_at»).Каждый раз, когда строка в вашей базе данных вставляется или обновляется, индикатор обновления обновляется. Ваши таблицы данных регулярно запрашиваются, чтобы фиксировать, что изменилось. Изменения копируются в ваше хранилище данных и объединяются. Несмотря на некоторую предварительную работу по настройке столбца индикатора, этот метод обеспечивает меньшую задержку и меньшую нагрузку на вашу базу данных. Инкрементный метод хорошо работает для баз данных, в которые добавляется новая информация или обновляются существующие данные.
Репликация журналов или сбор данных об изменениях (CDC): Самый быстрый метод — более или менее золотой стандарт репликации данных — это репликация журналов, или CDC.Он включает в себя опрос внутреннего журнала изменений вашей базы данных каждые несколько секунд, копирование изменений в хранилище данных и частое их включение. Все изменения в указанных таблицах и объектах загружаются по умолчанию, включая удаления, поэтому ничего не пропадает. CDC — это не только более быстрый и надежный метод, он также гораздо меньше влияет на производительность базы данных во время запросов и помогает избежать загрузки повторяющихся событий. Однако для этого требуется больше работы по первоначальной настройке и, возможно, несколько циклов от администратора базы данных.CDC — лучший метод для постоянно обновляемых баз данных, полностью поддерживающих удаление.
Определим, что подходит вам
Если у вас небольшие таблицы и ограниченный доступ к циклам администрирования базы данных, дамп / загрузка, вероятно, будет хорошим выбором. Однако, если у вас есть больший доступ к администрированию базы данных и если у вас есть огромные объемы данных или если они часто обновляются, вы захотите использовать инкрементную репликацию или репликацию журнала.
Каждый из этих методов имеет свои преимущества, и знание того, какой из них использовать, является ключевым.Имейте в виду, что простейший метод репликации не обязательно может быть лучшим вариантом для вас, особенно если у вас большие, сложные или постоянно меняющиеся базы данных.
Alooma, платформа корпоративных данных, созданная для облака, поддерживает все три метода репликации данных, подходящие для различных уровней административных возможностей и опыта, а также конфигурации и сложности базы данных. Хотя метод репликации CDC / журнала является предпочтительным — с большей гибкостью, адаптируемостью, мощностью и рентабельностью, чем другие методы, ваша ситуация может диктовать другой подход.Если дамп / загрузка или инкрементный режим подходят для вашей среды, Alooma поможет вам.
Свяжитесь с Alooma сегодня, чтобы узнать больше о нашем решении для репликации баз данных.
Репликация базы данных— документация кластера Galera
Репликация базы данных — это частое копирование данных с одного узла — базы данных на сервере — на другой. Думайте о системе репликации базы данных как о распределенной базе данных, где все узлы совместно используют один и тот же уровень информации. Эта система также известна как кластер базы данных .
Клиенты базы данных, такие как веб-браузеры или компьютерные приложения, не видят систему репликации базы данных, но они выигрывают от поведения, близкого к собственному DBMS .
Мастера и рабы
Многие системы управления базами данных реплицируют базу данных.
Наиболее распространенная настройка репликации использует отношения главный / подчиненный между исходным набором данных и копиями.
Репликация ведущий / ведомый
В этой системе главный сервер базы данных регистрирует обновления данных и распространяет эти журналы по сети на подчиненные устройства.Подчиненные серверы баз данных получают поток обновлений от главного и применяют эти изменения.
Другая распространенная установка репликации использует репликацию с несколькими главными узлами, при которой все узлы работают как мастера.
Репликация с несколькими мастерами
В системе репликации с несколькими мастерами вы можете отправлять обновления на любой узел базы данных. Затем эти обновления распространяются по сети на другие узлы базы данных. Все узлы базы данных работают как мастера. Нет доступных журналов, и система не отправляет индикаторы, чтобы сообщить вам, были ли обновления успешными.
Асинхронная и синхронная репликация
В дополнение к настройке того, как разные узлы связаны друг с другом, существует также протокол, по которому они распространяют транзакции базы данных через кластер.
- Синхронная репликация Использует подход активной репликации. Узлы поддерживают синхронизацию всех реплик, обновляя все реплики за одну транзакцию. Другими словами, когда транзакция фиксируется, все узлы имеют одинаковое значение.
- Асинхронная репликация Использует подход ленивой репликации.База данных master асинхронно распространяет обновления реплик на другие узлы. После того, как главный узел распространяет реплику, транзакция фиксируется. Другими словами, когда транзакция фиксируется, по крайней мере, на короткое время, некоторые узлы сохраняют разные значения.
Преимущества синхронной репликации
Теоретически синхронная репликация имеет несколько преимуществ перед асинхронной. Например:
- Высокая доступность Синхронная репликация обеспечивает высокодоступные кластеры и гарантирует круглосуточную доступность услуг, при условии, что:
- Отсутствие потери данных при сбое узлов.
- Реплики данных остаются согласованными.
- Отсутствие сложных, требующих много времени отработки отказов.
- Повышенная производительность Синхронная репликация позволяет выполнять транзакции на всех узлах кластера параллельно друг другу, повышая производительность.
- Причинно-следственная связь в кластере Синхронная репликация гарантирует причинность во всем кластере. Например, запрос
SELECT, выпущенный после транзакции, всегда видит результаты транзакции, даже если она была выполнена на другом узле.
Недостатки синхронной репликации
Традиционно протоколы активной репликации координируют узлы по одной операции за раз. Они используют двухфазную фиксацию или распределенную блокировку. Система с \ (n \) количеством узлов из-за операций процесса \ (o \) с пропускной способностью \ (t \) транзакций в секунду дает вам \ (m \) сообщений в секунду с:
\ [т = п \ раз о \ раз т \]
Что это означает, что любое увеличение количества узлов приводит к экспоненциальному росту времени отклика транзакции, а также вероятности конфликтов и показателей взаимоблокировок.
По этой причине асинхронная репликация остается доминирующим протоколом репликации для производительности, масштабируемости и доступности базы данных. Широко распространенные базы данных с открытым исходным кодом, такие как MySQL и PostgreSQL, предоставляют только решения для асинхронной репликации.
Решение проблем при синхронной репликации
Есть несколько проблем с традиционным подходом к синхронным системам репликации. За последние несколько лет исследователи со всего мира начали предлагать альтернативные подходы к синхронной репликации баз данных.
Помимо теории, многообещающие реализации показали несколько прототипов. Вот некоторые из наиболее важных улучшений, к которым привели эти исследования:
- Групповая связь Это абстракция высокого уровня, которая определяет шаблоны для взаимодействия узлов базы данных. Реализация гарантирует согласованность данных репликации.
- Наборы записей Объединяет записи в базу данных в одно сообщение набора записей.Реализация позволяет избежать координации узлов по одной операции за раз.
- Конечный автомат базы данных Обрабатывает транзакции только для чтения локально на сайте базы данных. Транзакции обновлений реализации сначала выполняются локально на сайте базы данных, на мелких копиях, а затем транслируются как набор для чтения на другие сайты баз данных для сертификации и, возможно, фиксации.
- Переупорядочивание транзакций Переупорядочивает транзакции до того, как сайт базы данных фиксирует и передает их другим сайтам базы данных.Внедрение увеличивает количество транзакций, успешно прошедших сертификационный тест.