Рекурсивные SQL запросы / Хабр
AnthonyВремя на прочтение 2 мин
Количество просмотров137K
Рекурсивны SQL запросы являются одним из способов решения проблемы дерева и других проблем, требующих рекурсивную обработку. Они были добавлены в стандарт SQL 99. До этого они уже существовали в Oracle. Несмотря на то, что стандарт вышел так давно, реализации запоздали. Например, в MS SQL они появились только в 2005-ом сервере.
Рекурсивные запросы используют довольно редко, прежде всего, из-за их сложного и непонятного синтаксиса:
with [recursive] <имя_алиаса_запроса> [ (<список столбцов>) ]
as (<запрос>)
<основной запрос>
В MS SQL нет ключевого слова recursive, а в остальном все тоже самое.
Проще разобрать на примере. Предположим, есть таблица:
create table tree_sample (
id integer not null primary key,
id_parent integer foreign key references tree_sample (id),
nm varchar(31) )
id – идентификатор
id_parent – ссылка на родитель
nm – название.
Для вывода дерева:
with recursive tree (nm, id, level, pathstr)
as (select nm, id, 0, cast(» as text)
from tree_sample
where id_parent is null
union all
select tree_sample.nm, tree_sample.id, t.level + 1, tree.pathstr + tree_sample.nm
from tree_sample
inner join tree on tree.id = tree_sample.id_parent)
select id, space( level ) + nm as nm
from tree
order by pathstr
Этот пример выведет дерево по таблице с отступами. Первый запрос из tree_sample этот запрос выдаст все корни дерева. Второй запрос соединяет между собой таблицу tree_sample и tree, которая определяется этим же запросом. Этот запрос дополняет таблицу узлами дерева.
Первый запрос из tree_sample этот запрос выдаст все корни дерева. Второй запрос соединяет между собой таблицу tree_sample и tree, которая определяется этим же запросом. Этот запрос дополняет таблицу узлами дерева.
Сначала выполняется первый запрос. Потом к его результатам добавляются результаты второго запроса, где данные таблица tree – это результат первого запроса. Затем снова выполняется второй запрос, но данные таблицы tree – это уже результат предыдущего выполнения второго запроса. И так далее. На самом деле база данных работает не совсем так, но результат будет таким же, как результат работы описанного алгоритма.
После этого данные этой таблицы можно использовать в основном запросе как обычно.
Хочу заметить, что я не говорю о применимости конкретно этого примера, а лишь пишу его для демонстрации возможностей рекурсивных запросов. Этот запрос реально будет работать достаточно медленно из-за order by.
Теги:
- SQL
- рекурсия
Хабы:
- SQL
Всего голосов 37: ↑35 и ↓2 +33
Комментарии 51
Антон Жердев @Anthony
Пользователь
Комментарии Комментарии 51
PostgreSQL рекурсивный запрос
Рассмотрим создание рекурсивного запроса на Postgresql .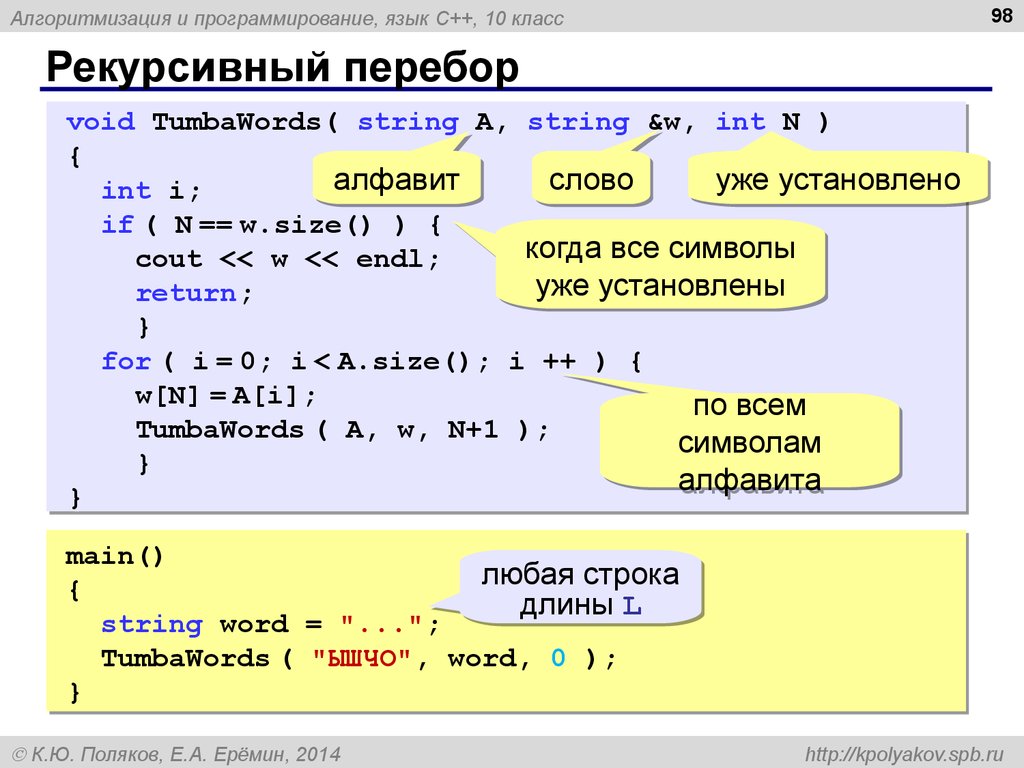
Рекурсивный запрос необходим, для вывода данных на основе предыдущих строк в выборке. Реализуется он с помощью оператора WITH.
Общая схема рекурсивного запроса:
WITH RECURSIVE t AS (
нерекурсивная часть (1)
UNION ALL
рекурсивная часть (2)
)
SELECT * FROM t; (3)
Чтобы не мучать Вас теорией, перейдем сразу к практике. С помощью рекурсивного запроса, можно вывести сумму чисел от 1 до 10.
Также с помощью, рекурсивного запроса можно решать, более сложные математические задачи. Например выведем числа Фибоначчи.
Таким образом, рекурсивный запрос, может помочь в решении, самых разнообразных задач. Осталось только, научиться их писать…
Самое сложное, это выделить нерекурсивную часть. В демо-примерах достаточно просто, начинаются итерации с простых чисел. В коммерческих проектах, все намного сложнее. После того, как выделили нерекурсивную часть, нужно подумать, об алгоритме расчета последующих строк, и когда данный расчет должен закончится.
После того, как выделили нерекурсивную часть, нужно подумать, об алгоритме расчета последующих строк, и когда данный расчет должен закончится.
Приведу пример из моей практики:
Работал я еще тогда мидл-разработчиком, в достаточно известной фирме ООО «Эттон» в городе Казани. Занималась данная компания автоматизацией ЖКХ. Наша команда разрабатывала продукт «Регион», для ведения капитального ремонта. Я в частности отвечал, за модуль «Биллинг».
Модуль «Биллинг» обрабатывал данные по собственникам в БД под управлением PostgreSQL. Обработка данных происходила на стороне сервера, с помощью микросервисов. И чтобы получить данные по входящему и исходящему сальдо, для отчетов. Нам разработчикам, приходилось писать запрос, обрабатывать данные на сервере, и добавлять уже обработанные данные по расчитанной сальдовке.
Все это приводило к тому, что тратили лишнее время на разработку функционала и производительность данных скриптов была крайне низкой.
Чтобы было, более понятно, приведу таблицу, как должен вестись расчет:
| Период | Входящее сальдо | Начислено | Оплачено | Пени | Исходящее сальдо |
| февраль 2017 | 0.00 | 100.00 | 60.00 | 0.00 | 40.00 |
| март 2017 | 40.00 | 100.00 | 0.00 | 0.00 | 140.00 |
| апрель 2017 | 140.00 | 100.00 | 0.00 | 3.00 | 243.00 |
Первым решением, было хранить уже посчитанные данные, в аггрегирующей таблице.
Добавили триггеры, чтобы пересчитывать данные. Данные пересчитывались, опять же средствами микросервисов.
В качестве эксперимента, попробовал сделать расчет с помощью рекурсивного запроса. Но расчет происходил еще медленнее. Но после того как оптимизировал запрос, добавил ряд индексов и изменил настройки postgresql. Все заработало. Радости не было предела, с помощью данного метода избавились, от множества проблем. Это была любовь по расчету =)
Ниже приведу, с какими проблемами я столкнулся при написании запроса, и как их решил:
Приведу упрощенную схему структуры таблицы «billing_bill_account_operation», где хранятся данные по начислениям собствеников.
Для облегчения понимания, как писать запрос, разделим его на несколько этапов
.Первый этап состоит, из написания нерекурсивной части. Так как, нам необходимо расчитать сальдовку, по всем лицевым счетам по месяцам, напишем запрос который расчитывает начальный период по каждому лицевому счету.
Так как, нам необходимо расчитать сальдовку, по всем лицевым счетам по месяцам, напишем запрос который расчитывает начальный период по каждому лицевому счету.
Получим следующие данные:
| account_id | period | in_saldo | credited | paid | peni | out_saldo |
| 1 | 2017-01-01 | 0 | 300.00 | 150.00 | 0.00 | 450.00 |
| 2 | 2017-01-01 | 0 | 240.00 | 0.00 | 0.00 | 240.00 |
| 3 | 2017-01-01 | 0 | 180.00 | 0.00 | 0.00 | 180.00 |
Вторым этапом, создадим запрос, для рекурсивной части, с одной итерацией.
Данный запрос вернет данные за следующий месяц, то есть за февраль 2017 года.
| account_id | period | credited | paid | peni |
| 1 | 2017-02-01 | 0.00 | 50.00 | 0.00 |
| 2 | 2017-02-01 | 80.00 | 0.00 | 0.00 |
| 3 | 2017-02-01 | 60.00 | 0.00 | 0.00 |
А теперь, третьим этапом, попробуем совершить «магию», соединить нерекурсивную часть, с рекурсивной частью.
Для этого воспользуемся конструкцией WITH RECURSIVE. Итоговый запрос, будет выглядеть следующим образом.
Здесь, самое сложное было, определить, как переходить на следующую запись. Решили данный вопрос переходом на строчку со следующим месяцем. А заканчивается итерация после того, как заканчиваются записи сгрупированные по месяцам. Еще нужно иметь ввиду, если в нерекурсивной части запрос вернул например 3 записи, значит будет 3 отдельных итерации.
Решили данный вопрос переходом на строчку со следующим месяцем. А заканчивается итерация после того, как заканчиваются записи сгрупированные по месяцам. Еще нужно иметь ввиду, если в нерекурсивной части запрос вернул например 3 записи, значит будет 3 отдельных итерации.
В итоге, получим следующие данные:
| account_id | period | in_saldo | paid | peni | out_saldo | |
| 1 | 2017-01-01 | 0 | 300.00 | 150.00 | 0.00 | 450.00 |
| 1 | 2017-02-01 | 450.00 | 0.00 | 50.00 | 0.00 | 500.00 |
| 2 | 2017-01-01 | 0 | 240.00 | 0. 00 00 |
0.00 | 240.00 |
| 2 | 2017-02-01 | 240.00 | 80.00 | 0.00 | 0.00 | 320.00 |
| 2 | 2017-03-01 | 320.00 | 80.00 | 0.00 | 2.00 | 402.00 |
| 3 | 2017-01-01 | 0 | 180.00 | 0.00 | 0.00 | 180.00 |
| 3 | 2017-02-01 | 180.00 | 60.00 | 0.00 | 0.00 | 240.00 |
При написании статьи, были использованы следующие ресурсы:
https://postgrespro.ru/docs/postgrespro/9.6/queries-with
https://habrahabr.ru/company/postgrespro/blog/318398/
Если вам помогла статья, пожалуйста перейдите по одному из рекламных блоков, расположенных на сайте. Таким образом вы поддержите проект. Спасибо
Таким образом вы поддержите проект. Спасибо
Posted on 2018-03-14
Запутались с рекурсивным запросом MySQL? Это для вас
Рекламные объявления
Рекурсивные запросы — один из эффективных способов решения задачи построения иерархии или дерева и обхода по ним. Вот несколько сценариев, в которых это полезно:
- Перечислите сотрудников под руководством отдела или подразделения от самого высокого до самого низкого ранга.
- Получение списка товаров по категории и подкатегориям.
- Из генеалогического древа перечислите предков кого-либо.
В математике вы, вероятно, слышали о таких:
- Последовательность Фибоначчи
- Факториалы
- Наборы
И да, вы можете делать такие рекурсии в SQL.
Основы рекурсии
Проще говоря, вы выполняете рекурсию, если создаете процедуру или функцию. И один из шагов в этой процедуре или функции многократно вызывает сам себя.
Для этого он должен удовлетворять двум требованиям:
- Базовый вариант (или варианты) в качестве отправной точки. Иногда это называется якорным элементом.
- И рекурсивный шаг. Здесь происходит обход иерархии или последовательности вычислений. Иногда это называется рекурсивным членом.
Чтобы понять это, давайте воспользуемся примером генеалогического древа. Давайте сделаем это, пройдя вперед по вашему генеалогическому древу.
- Базовый вариант: вам . Это означает, что вы и ваш партнер по браку находитесь в верхней части списка.
- И рекурсивный шаг перечисляет ваших детей и их детей. Дальше идут ваши правнуки и так далее.
А вот как это происходит, если вы перемещаетесь назад:
- Базовый случай снова: вы .
- И рекурсивный шаг — список ваших родителей. А потом ваши бабушки и дедушки и так далее.
Выглядит просто, правда? Но как это происходит в SQL?
Иерархические и рекурсивные запросы в SQL
Запросы в SQL являются рекурсивными, если вы получаете иерархическую информацию из одного и того же источника. Источником является таблица или связанные таблицы, из которых вы получаете дерево или иерархию.
Источником является таблица или связанные таблицы, из которых вы получаете дерево или иерархию.
Например, потомки в генеалогическом древе происходят из того же источника, из которого произошел родитель. Уровни вложенности каждого потомка также увеличиваются по мере многократных запросов к источнику. Так происходит до тех пор, пока не будет достигнут последний уровень. Или, по крайней мере, до тех пор, пока он не достигнет установленного вами предела.
Вы можете отобразить список иерархий с помощью рекурсивного запроса с помощью следующих средств:
- с помощью сценария или хранимой процедуры, где определена логика рекурсии,
- рекурсивное общее табличное выражение или рекурсивное CTE,
- и повторяющиеся самосоединения
Давайте рассмотрим каждый.
- Первый вариант не самый простой. Это может быть сложно в зависимости от структуры вашей таблицы. Кроме того, SQL – это декларативный язык, основанный на наборах. Описание логики с потоками управления в SQL — не лучшее применение.
 Но если используемый вами продукт SQL не поддерживает второй вариант ниже, вы можете использовать его.
Но если используемый вами продукт SQL не поддерживает второй вариант ниже, вы можете использовать его. - Второй вариант доступен в основных продуктах баз данных SQL, таких как MySQL. Рекурсивный CTE также проще и гибче.
- Наконец, третий вариант хорош только тогда, когда у вас фиксированная и не очень глубокая иерархия. Повторяющиеся самосоединения также просты, но не так гибки, как рекурсивный CTE.
Как создать рекурсивный запрос MySQL
Перед выполнением шагов, вот версия MySQL, которую я использую: 8.0.31-0ubuntu0.22.04.1. Приведенный ниже код не будет работать в версиях ниже MySQL 8. И я использую dbForge Studio для MySQL версии 9.1.21 в качестве инструмента с графическим интерфейсом. Чтобы получить свою версию MySQL, запустите в редакторе кода MySQL следующее:
Рекурсивный запрос MySQL проще объяснить на примере. Итак, давайте начнем с очень простого примера с использованием рекурсивного CTE:
В приведенном выше запросе есть две вещи, необходимые для рекурсивного запроса:
- SELECT ‘2022-11-22’ — базовый вариант .
 Ожидайте, что это будет первая строка в наборе результатов.
Ожидайте, что это будет первая строка в наборе результатов. - SELECT DATE_ADD(d, INTERVAL 1 DAY) FROM cte_date_sample — это рекурсивный шаг . Он вызывает себя внутри того же CTE. Это создаст последующие строки. Каждая строка добавляет 1 день, начиная с «2022-11-22» до «2022-12-31».
См. результат ниже.
Итак, вы можете создать рекурсивный запрос MySQL, используя рекурсивное CTE, выполнив следующие шаги:
- Определите CTE с помощью WITH RECURSIVE, за которым следует имя CTE.
- Добавьте базовый вариант или запрос элемента привязки.
- Затем добавьте UNION ALL или UNION DISTINCT, чтобы соединить якорный элемент с рекурсивным элементом.
- Добавьте запрос для рекурсивного шага. Он должен запросить себя с именем, которое вы определили в # 1.
- Добавьте запрос SELECT под CTE (или INSERT, если вы хотите вставить результат рекурсивного CTE в таблицу).
Вот тот же запрос с частями, упомянутыми выше:
Теперь мы закончили с легкой частью. Перейдем к лучшим примерам.
Перейдем к лучшим примерам.
Примеры иерархических рекурсивных запросов MySQL
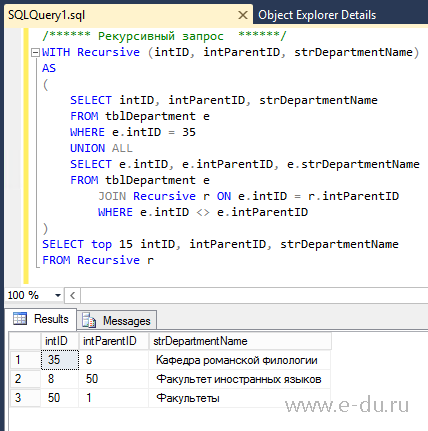
Пример иерархии сотрудников
Типичным примером является список сотрудников, показывающий, кто кому подчиняется. Сначала определим структуру таблицы.
Далее давайте вставим несколько записей.
Из этих 10 рядов мы можем увидеть, кто главный, кто под ним и так далее. Теперь это так просто. Мы также можем сделать простой запрос, и вы получите иерархию как есть. Но простота этого поможет нам понять, как работает рекурсивный запрос.
Вот рекурсивный запрос:
Анализ
Первая строка определяет идентификатор сотрудника, с которого начинается обход. Мы сохраняем его в локальной переменной MySQL. ( УСТАНОВИТЬ @employee_id = 1; )
Затем мы определяем рекурсивный CTE и называем его employee_ranks . ( С РЕКУРСИВНЫМИ employee_ranks AS … ). Обратите внимание на это имя, потому что оно используется внутри рекурсивного члена.
Затем первый запрос SELECT является элементом привязки или базовым вариантом. ( SELECT id, report_to, 1 AS employee_level FROM Employee WHERE id = @employee_id ). Это просто запросит вершину иерархии. Ожидайте, что это будет первая строка в наборе результатов. Мы также добавляем уровень сотрудника, и он начинается с уровня 1.
Затем предложение UNION ALL соединит элемент привязки с рекурсивным элементом. Затем продолжайте запрашивать следующие уровни.
Затем второй запрос SELECT является рекурсивным элементом. Это будет запрашиваться неоднократно, пока не будут перечислены все сотрудники более низкого ранга. Обратите внимание, что рекурсивный элемент вызывает тот же CTE ( employee_ranks ) во ВНУТРЕННЕМ СОЕДИНЕНИИ. При первом проходе он отобразит сотрудников 2-го уровня под руководством Сэма Беккета. Следующие 2 прохода отобразят сотрудников 3-го уровня. И тогда он остановится, потому что больше не существует рядов и уровней. Обратите внимание, что мы добавили 1 для каждого найденного нового уровня сотрудника ( уровень_сотрудника + 1 КАК уровень_сотрудника ).
И, наконец, третий запрос SELECT отобразит все результаты уровней с 1 по 3.
См. результаты ниже:
В следующем примере будет показан рекурсивный запрос с более чем одним элементом привязки и рекурсивным элементом.
Пример Семейного древа
Если вы вернетесь к рассмотренным выше основам рекурсии, вы увидите, что можно определить более одного базового варианта. Вы также можете сделать это в MySQL. В рекурсивном запросе MySQL вы также можете определить более одного рекурсивного члена.
С этой идеей давайте воспользуемся примером генеалогического древа. И мы будем использовать известную семью — британскую королевскую семью. Вот структура данных и способы заполнения данных:
Мы начали с королевы Елизаветы II и принца Филиппа, герцога Эдинбургского. И дерево включает в себя детей и внуков вплоть до самого младшего на сегодняшний день.
Итак, что мы будем делать дальше? Давайте создадим запрос, проходящий вверх по генеалогическому древу, начиная с кого-то. И давайте выберем принца Джорджа, сына принца Уильяма.
И давайте выберем принца Джорджа, сына принца Уильяма.
Вот код:
Это довольно долго. Он имеет 3 базовых случая или якорных элемента: идентификатор члена семьи и его 2 родителей. Затем у него есть 2 рекурсивных шага, чтобы поднять бабушку и дедушку на вершину генеалогического древа. Мы указываем «Н/Д», если предок отсутствует в таблице, используя COALESCE. Обратите также внимание, что мы сделали INNER JOIN с самим собой ( Ancestor ) в двух рекурсивных элементах.
Вот набор результатов:
Кроме того, вы можете получить аналогичные результаты с другим представлением, используя повторяющиеся самосоединения:
Приведенный выше код ограничен фиксированным уровнем. И предки матери, при наличии, тоже никогда не появятся. Таким образом, в этом случае рекурсивный CTE намного превосходит запросы к иерархическим данным.
Вот результат приведенного выше кода:
Вот как мы запрашиваем иерархические данные, используя рекурсивный запрос MySQL.
Но есть еще кое-что, что вам нужно знать о рекурсивном CTE MySQL. И это как-то ограничительно.
Ограничения рекурсивных членов в MySQL
Уловка с рекурсивными шагами или рекурсивными элементами в MySQL CTE заключается в том, что вы можете попасть в бесконечный цикл. Чтобы решить эту проблему, MySQL по умолчанию имеет ограничение в 1000 рекурсий. Это определено в @@cte_max_recursion_depth .
В dbForge Studio для MySQL вы можете просмотреть переменные сервера в верхнем меню, нажав База данных -> Переменные сервера .
Выше выделен предел @@cte_max_recursion_depth , равный 1000. Вы можете использовать оператор SET, чтобы увеличить или уменьшить его значение.
Приведенный выше оператор SET уменьшает ограничение до 10. Теперь попробуйте выполнить этот запрос еще раз.
Вы получите ошибку времени выполнения, подобную этой:
Рекурсивный запрос прерван после 11 итераций. Попробуйте увеличить @@cte_max_recursion_depth до большего значения.
Попробуйте увеличить @@cte_max_recursion_depth до большего значения.
Итак, что мы можем сделать отсюда?
Как разрешить ограничения рекурсивных запросов MySQL с помощью dbForge Studio для MySQL
Вы можете либо следовать приведенным выше рекомендациям, чтобы увеличить ограничение. Затем повторно запустите запрос. Или у вас есть еще 2 варианта:
- Измените предложение WHERE с условием, которое гарантирует, что предел не будет достигнут.
- Добавьте предложение LIMIT.
Первый подход очень прост. Просто увеличьте лимит. Сделайте это в редакторе SQL dbForge Studio для MySQL.
После этого вы не столкнетесь с ошибкой.
Но если это другой запрос, вы можете увеличить лимит всякий раз, когда возникает ошибка.
Второй вариант дает вам больше контроля, изменяя предложение WHERE. Если вам действительно нужно ограничение в 10 глубин, вот исправление в предложении WHERE:
Почему интервал 9 дней, если у нас @@cte_max_recursion_depth = 10?
Поскольку первая из 10 записей является базовым вариантом («2022-11-22»). Еще девять дней и у нас 10 рядов. Попробуйте изменить интервал на 10. И вы снова увидите ошибку времени выполнения.
Еще девять дней и у нас 10 рядов. Попробуйте изменить интервал на 10. И вы снова увидите ошибку времени выполнения.
Вот результат успешного запуска с ИНТЕРВАЛОМ 9 ДНЕЙ:
В качестве альтернативы третий вариант использует LIMIT. Вот код, который даст тот же результат.
Предложение LIMIT гарантирует, что ошибки не произойдет. И вы все равно увидите тот же результат, установленный ранее. Хотя предложение WHERE странно, потому что оно никогда не достигнет значения «2022-12-31». Но вы поняли.
Заключение
Возможно, вы имеете в виду другие иерархии, кроме тех, которые мы здесь имеем. И рекурсивный CTE MySQL может помочь вам в этом. У вас также был другой пример, но не такой гибкий, с использованием повторяющихся самосоединений.
Вы также можете загрузить инструмент с графическим интерфейсом, такой как dbForge Studio для MySQL. Многочисленные функции, предоставляемые этим инструментом, такие как предложения кода, автозаполнение, рефакторинг, профилировщик запросов и т. д., помогают повысить производительность.
д., помогают повысить производительность.
Продолжить чтение:
Лучшие языки программирования для изучения
Слепая инъекция SQL — предотвращение и последствия node Вы можете запустить следующее (весь приведенный ниже код доступен на скрипке здесь): Результат: Эти запросы хитрые и может потребоваться некоторое время (ну, во всяком случае, мне) чтобы разобраться в них, так что я пройдусь по ним строчка за строчкой — как для меня, так и для вас! 🙂 (или любой другой, кто борется с этими деликатными и (потенциально очень ) сложными зверями!). Итак, первая строка Ключевое слово Затем: Наш «начальный» или «якорный» запрос — первые значения в нашем За обязательным Итак, начиная с WITH RECURSIVE cte (id_, next_id_) AS
(
ВЫБЕРИТЕ id, next_id ИЗ теста, ГДЕ id = (ВЫБЕРИТЕ MIN (id) ИЗ теста)
СОЮЗ ВСЕХ
ВЫБИРАТЬ
c.next_id_, t.next_id
ОТ
ктэ с
ПРИСОЕДИНЯЙТЕСЬ к тесту
ON c.next_id_ = t.id
)
ВЫБЕРИТЕ * ОТ CTE;
р-н id_ next_id_
1 1 3
2 3 6
3 6 8
4 8 9
WITH RECURSIVE cte (id_, next_id_) AS
RECURSIVE является обязательным для MySQL, MariaDB и PostgreSQL и вызывает ошибку для SQL Server, SQLite и Oracle. Вам могут потребоваться или не потребоваться определения полей в скобках — проверьте это сами — большинство, кажется, принимает это, и это помогает, когда вы фактически формулируете свой запрос!
Вам могут потребоваться или не потребоваться определения полей в скобках — проверьте это сами — большинство, кажется, принимает это, и это помогает, когда вы фактически формулируете свой запрос! ВЫБЕРИТЕ id, next_id ИЗ теста, ГДЕ id = (ВЫБЕРИТЕ MIN (id) ИЗ теста)
RECURSIVE CTE — в данном случае это кортеж (1, 3) . UNION ALL следует ядро рекурсивной части запроса: SELECT
c.next_id_, t.next_id
ОТ
ктэ с
ПРИСОЕДИНЯЙТЕСЬ к тесту
ON c.next_id_ = t.id
(1,3) , мы SELECT 3 ( c.next_id ) из RCTE и значение из test by JOIN т.id — это тест PK и, следовательно, UNIQUE , поэтому мы получаем кортеж (3, 6) .
В следующей итерации у нас есть 6 как наш cte.