Работа со строками в ассемблере — Студопедия
Поделись
Язык программирования ассемблер
Язык программирования ассемблер сейчас редко используется для решения прикладных задач, однако его изучение позволяет лучше понять принципы работы ЭВМ, операционных систем и трансляторов с языков высокого уровня. В разное время в большинстве ПЭВМ использовались и используются процессоры фирмы Intel (8086/8088, 80186, 80286, i386, i486, Celeron, Pentium и т.д., см. с. 23-25). Эти процессоры поддерживают преемственность на уровне машинных команд: программы, написанные для младших моделей процессоров, без всяких изменений могут быть выполнены на более старших моделях. При этом базовой является система команд процессора 8086. Язык ассемблера — это символьная форма записи машинного языка, его использование существенно упрощает написание машинных программ. Приведем перевод английских слов:
assemble:1. собирать, монтировать, 2. компоновать с помощью ассемблера, ассемблировать, транслировать с помощью ассемблера, транслировать программу с помощью ассемблера
assembling:1. сборка, монтаж, 2. компоновка, ассемблирование, трансляция программы с помощью ассемблера
сборка, монтаж, 2. компоновка, ассемблирование, трансляция программы с помощью ассемблера
Для ПЭВМ разработаны разные языки ассемблера. Наиболее распространены язык фирмы Microsoft, названный языком макроассемблера (сокращенно MASM) и язык Turbo Assembler фирмы Borland (сокращенно TASM). Для того, чтобы программы на ассемблере случайно не нанесли вред операционной системе и программному обеспечению, последующие задания рекомендуется выполнять в виртуальной машине.
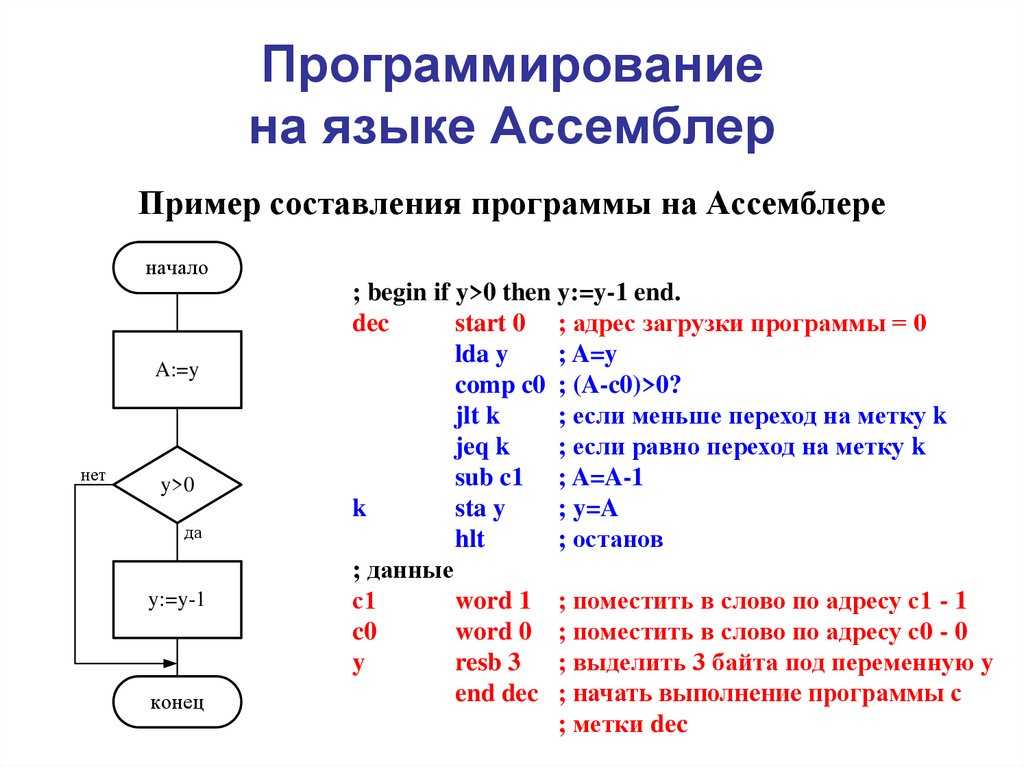
Рассмотрим пример простейшей программы, выводящей на экран надпись Hello world (Здравствуй, мир, англ., greet — приветствие).
| Программа | Выполняемые действия |
| Data SEGMENT Greet DB ‘Hello world’,13,10, ‘$’ Data ENDS Assume CS: Code, DS:Data Code SEGMENT Start: mov ax, Data mov ds,ax; mov dx, OFFSET Greet mov ah,9 int 21h mov al,0 mov ah, 4ch int 21h Code ENDS Stack1 SEGMENT Stack DB 100h DUP(?) Stack1 ENDS END Start | Начало сегмента данных Конец сегмента данных Объявление, что регистры процессора CS и DS будут содержать номера сегментов с именами Code и Data Начало сегмента команд Метка Поместить в регистр АХ номер сегмента Data Переслать АХ в регистр DS (команды непосредственной загрузки регистра DS нет) В регистр dx помещается смещение надписи относительно DS В регистр ah помещается номер 9 функции DOS “выведи надпись” Прерывание (вывод надписи) Возвращение в систему: в регистр ah помещается номер функции “возврат в систему” Прерывание (окончание выполнения программы) Конец сегмента команд Начало сегмента стека Конец сегмента стека Директива END заканчивает текст программы и предписывает начинать ее с команды, снабженной меткой Start |
Программа на ассемблере – это последовательность предложений, каждое из которых записывается в отдельной строке. Комментарии начинаются с символа “;”. Общий синтаксис предложений-команд:
Комментарии начинаются с символа “;”. Общий синтаксис предложений-команд:
[<метка>:] <мнемокод> [<операнды>] [;<комментарий>]
В квадратных скобках указаны необязательные части команды. Метка нужна для ссылок на команду из других мест программы. Разрешается указывать в строке только одну метку с двоеточием (например, Start: ) и больше ничего, тогда она метит следующую команду программы. Мнемокод (мнемонический код) – это служебное слово, указывающее в символьной форме операцию, которую должна выполнить команда. Примерами операндов являются числа и имена переменных. Если операндов несколько, они отделяются друг от друга запятыми. Операндами могут быть и выражения, составляемые из чисел, имен переменных и операторов. Основные операторы ассемблера приведены в табл. 2.1.
Таблица 2.1
| Категория | Operator | What it is (or does) |
| () [ ] | Подвыражение (Subexpression) Ссылка на ячейку памяти (Memory reference) | |
.
| Селектор структурных элементов (Structure member selector) | |
| Унарные | + - | Унарный плюс (Unary plus) Унарный минус (Unary minus) |
| : | Переопределение сегмента (Segment override) | |
| OFFSET SEG TYPE PTR | Возвращает смещение (Returns offset part) Возвращает сегментную часть Returns segment part Возвращает тип (байтовый размер) Returns type (byte size) Приведение типа (Typecast) | |
| * / MOD SHL SHR | Умножение (Multiplication) Целое деление (Integer division) Integer modulus (remainder) Логический сдвиг влево (Logical shift left) Логический сдвиг вправо (Logical shift right) | |
| Аддитивные | + - | Двоичное сложение (Binary addition) Двоичное вычитание (Binary subtraction) |
| Битовые | NOT AND OR XOR | Битовое НЕ Битовое И Битовое ИЛИ Битовое Исключающее ИЛИ |
В программе на ассемблере для описания переменных и их имен должны присутствовать предложения-директивы с общим синтаксисом:
[<имя>] <название директивы> [<операнды>] [;<комментарий>]
Имя (например, Greet) – это, как правило, имя константы или переменной, описываемой данной директивой. Название директивы – это служебные слова. Директива DB (define byte – определить байт) определяет данные размером в байт. При ее выполнении ассемблер вычисляет операнды и записывает их значения в последовательные байты памяти, начиная с первого незанятого. Первому из байтов дается указанное имя, по которому на этот байт можно ссылаться из других мест программы. Когда ассемблер встретит в программе имя переменной, он заменит его на адрес, который принято называть значением имени. По описанию переменной запоминается также ее размер (тип). Например, директива Greet DB ‘Hello world’,13,10, ‘$’ записывает последовательные байты памяти коды символов, помещенных в кавычки, код 10 (перевод строки), код 13 (возврат каретки) устанавливающий курсор на начало текущей строки, код символа конца строки ‘$’. Директивы определения помещаются в начале программы до команд.
Название директивы – это служебные слова. Директива DB (define byte – определить байт) определяет данные размером в байт. При ее выполнении ассемблер вычисляет операнды и записывает их значения в последовательные байты памяти, начиная с первого незанятого. Первому из байтов дается указанное имя, по которому на этот байт можно ссылаться из других мест программы. Когда ассемблер встретит в программе имя переменной, он заменит его на адрес, который принято называть значением имени. По описанию переменной запоминается также ее размер (тип). Например, директива Greet DB ‘Hello world’,13,10, ‘$’ записывает последовательные байты памяти коды символов, помещенных в кавычки, код 10 (перевод строки), код 13 (возврат каретки) устанавливающий курсор на начало текущей строки, код символа конца строки ‘$’. Директивы определения помещаются в начале программы до команд.
Задания:
1. Найдите в тексте программы директиву определения данных и команды. В командах найдите и выпишите мнемокоды и операции, которые им соответствуют.
2. Выполните в программе-оболочке Far следующие действия (рис. 3.42):
1) Создайте в Far файл Greet.ASM и наберите программу.
2) Cкомпилируйте с помощью команды tasm greet.
3) Скомпонуйте с помощью команды tlink greet.
Получив исполняемый файл Greet.EXE выполните программу, например, введя имя Greet в командную строку.
Рис. 2.12. Команды и результаты компиляции и компоновки программы
3. Выполните то же самое задание с помощью интегрированной среды TASM. Скопируйте папку ТА из папки Student_MUPK_NW:\COMMON\LANGV в папку C:\Student, запустите файл ta.exe. Нажмите клавишу F10 для перехода в главное меню, выполните команду File-Load (Файл-Загрузить), нажмите Enter, выберите из списка нужный файл. Выполните настройку — отключите опцию создания com-файла (рис. 2.13) и сохраните ее командой Options-Save options.
Рис. 2.13. Изменение опций компоновщика с отключением опции создания
com-файла
Затем выполните команды Compile to OBJ (компиляция), Make EXE file(компоновка) (рис. 2.14). В случае успеха выполните команду Run-Run program, затем Run-User screen.
2.14). В случае успеха выполните команду Run-Run program, затем Run-User screen.
Рис. 2.14. Создание exe-файла
В рассмотренных здесь и ниже примерах использованы вывод и ввод символов, реализуемых при выполнении одной из группы команд прерывания с шестнадцатиричным номером 21h дисковой операционной системы MS DOS. Перед выполнением команды прерывания INT в регистр AH записывают номер нужной функции. Функции с номерами 4Сh, 2 и 9 выполняют возврат управления операционной системе для продолжения выполнения программы, вывод одного символа на экран и вывод строки. Символ с кодами 10 (перевод строки) перемещает курсор в следующую строку экрана, оставляя его в той же колонке. Символ 13 (возврат каретки) устанавливает курсор на начало текущей строки. Функция 0Ch прерывания 21h вводит с клавиатуры символы (с эхо-печатью их на экране) до тех пор, пока не будет нажата клавиша Enter, и записывает их в буфер размером 15 позиций. Пока не нажата клавиша Enter, набираемый текст можно редактировать клавишами Backspace (отмена последнего символа) и Esc (отмена всего набранного текста).
Изучение работы микропроцессора с помощью Турбо Отладчика (Borland Turbo Debugger)
Турбо Отладчик (входящий в состав среды Borland C++) позволяет прослеживать выполнение инструкций ассемблера, содержимое ячеек оперативной памяти и регистров процессора и математического сопроцессора [58]. Он также позволяет отлаживать программы на языках Си и Паскаль. Общий вид команды запуска отладчика
TD opt name args
где opt – опции, name – имя запускаемой программы, args – ее аргументы.
assembler работа со строками : Низкоуровневое программирование
Сообщения без ответов | Активные темы | Избранное
| BAHOO |
| ||
26/11/11 |
| ||
| |||
 05.2014, 18:26
05.2014, 18:26 | venco |
| |||
04/05/09 |
| |||
| ||||
 05.2014, 19:00
05.2014, 19:00  При этом аргументы movs используются только для определения типа данных, пересылка же по прежнему будет из [ds:si] в [es:di].
При этом аргументы movs используются только для определения типа данных, пересылка же по прежнему будет из [ds:si] в [es:di].| BAHOO |
| ||
26/11/11 |
| ||
| |||
 И не надо оборачивать команды долларами, это ведь не формулы, а код. Имеет смысл использовать тэг [
И не надо оборачивать команды долларами, это ведь не формулы, а код. Имеет смысл использовать тэг [| Показать сообщения за: Все сообщения1 день7 дней2 недели1 месяц3 месяца6 месяцев1 год Поле сортировки АвторВремя размещенияЗаголовокпо возрастаниюпо убыванию |
| Страница 1 из 1 | [ Сообщений: 3 ] |
Модераторы: Karan, Toucan, PAV, maxal, Супермодераторы
Кто сейчас на конференции |
Сейчас этот форум просматривают: нет зарегистрированных пользователей |
| Вы не можете начинать темы Вы не можете отвечать на сообщения Вы не можете редактировать свои сообщения Вы не можете удалять свои сообщения Вы не можете добавлять вложения |
| Найти: |
Хранение и работа со строками на языке ассемблера x86
Задай вопрос
спросил
Изменено 6 лет, 6 месяцев назад
Просмотрено 9к раз
Я только что начал изучать программирование на ассемблере.
Q: Преобразование строки символов, представляющей любое целое число со знаком, в его значение в дополнении до 2, с сохранением результата в последовательных ячейках памяти в порядке с прямым порядком байтов.
Например, — 1 = 0xFFFFFFFFFFFFFFFFFE, предполагая, что коды дополнения 2 являются 64-битными. Я сделал число -149 в своем коде, что должно привести к 0xffff ffff ffff ff6b
.данные
S: .строка "-149"
Результат: .quad
.текст
.globl основной
главный:
мов S,%rax
cmp%rax,0
jl положительный
суб% rax,% rax
не С
добавить S,%rax
до $30,% rax
не %rax
добавить $1, %rax
mov %rax,Результат
положительный:
до $30,% rax
не %rax
добавить $1,%rax
mov %rax,Результат
В GDB значение для сохраненного целочисленного значения строки таково.
(gdb) x/24xb &S 0x601038: 0x2d 0x31 0x34 0x39 0x00 0x00 0x00 0x00 0x601040: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x601048: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
, если бы я хотел выполнить какие-либо вычисления до -149, мне нужно было бы каким-то образом получить доступ к этим местам в памяти — как мне это сделать?
Если я знаю, что 4 находится на месте 10, я могу умножить его на 10, чтобы получить 40, а затем добавить 9и аналогичный 1×100, чтобы получить 100 и добавить это.
Как мне получить к ним доступ для выполнения вычислений?
- струна
- сборка
- x86
2
Как получить к ним доступ для выполнения вычислений?
Строка хранится в памяти как последовательные символы. Если это ASCII (не UTF-8), каждый символ представляет собой один байт.
Таким образом, вы можете получить к ним доступ по одному с загрузкой/сохранением байтов, например movzbl 2(%rsi), %eax для получения третьего символа, если rsi указывает на начало строки.
Или, если %rdi указывает на последний символ (единицы в десятичном числе), то imul $10, -1(%rdi), %ecx установит %cl на предпоследний символ плюс его позиционное значение. (И верхние байты %ecx в мусор; вероятно, лучше сначала выполнить загрузку movzx , а затем умножить. Однако это работает, чтобы получить правильные младшие 8 бит).
Однако это работает, чтобы получить правильные младшие 8 бит).
На другом конце спектра сложности взгляните на этот преобразователь четырехточечной строки SSE4.1 IPv4 в 32-битное целое число. В частности, десятичная разрядная часть после перетасовки с использованием pmaddubsw ( _mm_maddubs_epi16 ) с вектором [ ..., 100, 10, 1 ] для применения разрядного значения и одного шага горизонтального сложения , затем phaddw , чтобы добавить по горизонтали до трех цифр из каждого четырехугольника с точками.
Также Как реализовать atoi с помощью SIMD?
См. также вики тегов x86 для множества других ссылок.
2
Ну, я ожидаю, что это даже не скомпилируется (например, cmp %rax,0 недопустимая комбинация в синтаксисе AT&T, похоже, вам нужен синтаксис Intel).
И есть некоторые вещи, которые не имеют никакого смысла, например, , а не S . .. как вы думаете, что бы это сделало? Если бы вы аннотировали его как byte ptr, он инвертировал бы символ «<» (на самом деле, почему у вас есть «<» и «>» в строке S, меня тоже смущает).
.. как вы думаете, что бы это сделало? Если бы вы аннотировали его как byte ptr, он инвертировал бы символ «<» (на самом деле, почему у вас есть «<» и «>» в строке S, меня тоже смущает).
и т. д. и т. д.
Итак, сначала попробуйте скомпилировать его, затем откройте его в отладчике, пошагово выполняйте инструкцию за инструкцией и продолжайте просматривать регистры ЦП, память и справочное руководство по инструкциям … до тех пор, пока это не станет понятным. … может занять некоторое время, но на самом деле не так уж и долго, может быть, несколько дней, и вы освоитесь.
2
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Как работать со строками на ассемблере x86?
спросил
Изменено 12 лет, 3 месяца назад
Просмотрено 14 тысяч раз
Я пишу программу на ассемблере, которая принимает на вход две строки и объединяет их. Вот что у меня есть: (с использованием синтаксиса NASM)
Вот что у меня есть: (с использованием синтаксиса NASM)
РАЗДЕЛ .data
привет: дб "Привет", 0
мир: дб "мир!",0
РАЗДЕЛ .text
; сделать конкатенацию
Поскольку я никогда раньше не работал со строками в ассемблере x86, мне нужно знать, как работает хранение строк и управление ими.
Я предполагаю, что, как только длина каждой строки станет известна, это объединение будет просто включать перемещение фрагментов памяти. Эту часть можно упростить, используя libc 9.0048 . (Я могу использовать strlen() и strcat() .)
Моя настоящая проблема в том, что я не знаком с тем, как строки хранятся в ассемблере x86. Они просто добавляются в стек...? Они куда-то кучкой идут? Должен ли я использовать malloc() (как-то)?
- строка
- сборка
- x86
- конкатенация
Строки в вашем примере хранятся так же, как глобальный массив символов хранится в программе C. Это просто последовательность байтов в разделе данных вашего исполняемого файла.