Простая программа на ассемблере x86: Решето Эратосфена / Хабр
Вступительное слово
По своей профессии я не сталкиваюсь с низкоуровневым программированием: занимаюсь программированием на скриптовых языках. Но поскольку душа требует разнообразия, расширения горизонтов знаний или просто понимания, как работает машина на низком уровне, я занимаюсь программированием на языках, отличающихся от тех, с помощью которых зарабатываю деньги – такое у меня хобби.
И вот, я хотел бы поделиться опытом создания простой программы на языке ассемблера для процессоров семейства x86, с разбора которой можно начать свой путь в покорение низин уровней абстракции.
До ее написания я сформулировал такие требования к будущей программе:
- Моя программа не должна быть программой под DOS. Слишком много примеров ориентировано на нее в связи с простым API. Моя программа обязательно должна была запускаться на современных ОС.
- Программа должна использовать кучу – получать в свое распоряжение динамически распределяемую память.
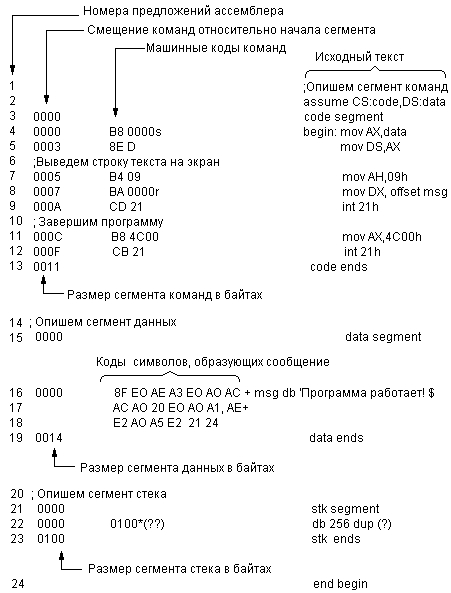
- Чтобы не быть слишком сложной, программа должна работать с целыми беззнаковыми числами без использования переносов.
Задачей для своей программы я выбрал поиск простых чисел с помощью Решета Эратосфена. В качестве ассемблера я выбрал nasm.
Код я писал с упором больше на стиль и понятность, чем на скорость его выполнения. К примеру, обнуление регистра я проводил не с помощью xor eax, eax, а с помощью mov eax, 0 в связи с более подходящей семантикой инструкции. Я решил, что поскольку программа преследует исключительно учебные цели, можно распоясаться и заниматься погоней за стилем кода в ассемблере.
Итак, посмотрим, что получилось.
С чего начать?
Пожалуй, самая сложная вещь, с которой сталкиваешься при переходе от высокоуровневых языков к ассемблеру, это организация памяти. К счастью, на эту тему на Хабре уже была хорошая статья.
Так же встает вопрос, каким образом на таком низком уровне реализуется обмен данными между внутренним миром программы и внешней средой.
SECTION .text
org 0x100
mov ah, 0x9
mov dx, hello
int 0x21
mov ax, 0x4c00
int 0x21
SECTION .data
hello: db "Hello, world!", 0xD, 0xA, '$'
В Windows же для этих целей используется Win32 API, соответственно, программа должна использовать методы соответствующих библиотек:
%include "win32n.inc" extern MessageBoxA import MessageBoxA user32.dll extern ExitProcess import ExitProcess kernel32.dll SECTION code use32 class=code ..start: push UINT MB_OK push LPCTSTR window_title push LPCTSTR banner push HWND NULL call [MessageBoxA] push UINT NULL call [ExitProcess] SECTION data use32 class=data banner: db "Hello, world!", 0xD, 0xA, 0 window_title: db "Hello", 0
Здесь используется файл win32n.inc, где определены макросы, сокращающие код для работы с Win32 API.
Я решил не использовать напрямую API ОС и выбрал путь использования функций из библиотеки Си. Так же это открыло возможность компиляции программы в Linux (и, скорее всего, в других ОС) – не слишком большое и нужное этой программе достижение, но приятное достижение.
Вызов подпрограмм
Потребность вызывать подпрограммы влечет за собой несколько тем для изучения: организация подпрограмм, передача аргументов, создание стекового кадра, работа с локальными переменными.
Подпрограммы представляют собой метку, по которой располагается код. Заканчивается подпрограмма инструкцией ret. К примеру, вот такая подпрограмма в DOS выводит в консоль строку «Hello, world»:
print_hello:
mov ah, 0x9
mov dx, hello
int 0x21
ret
Для ее вызова нужно было бы использовать инструкцию call:
call print_hello
Для себя я решил передавать аргументы подпрограммам через регистры и указывать в комментариях, в каких регистрах какие аргументы должны быть, но в языках высокого уровня аргументы передаются через стек. К примеру, вот так вызывается функция
К примеру, вот так вызывается функция printf из библиотеки Си:
push hello
call _printf
add esp, 4
Аргументы передаются справа налево, обязанность по очистке стека лежит на вызывающей стороне.
При входе в подпрограмму необходимо создать новый стековый кадр. Делается это следующим образом:
print_hello: push ebp ;сохраняем указатель начала стекового кадра на стеке mov ebp, esp ;теперь началом кадра является вершина предыдущего
Соответственно, перед выходом нужно восстановить прежнее состояние стека:
mov esp, ebp
pop ebp
ret
Для локальных переменных так же используется стек, на котором после создания нового кадра выделяется нужное количество байт:
print_hello:
push ebp
mov ebp, esp
sub esp, 8 ;опускаем указатель вершины стека на 8 байт, чтобы выделить память
Так же архитектура x86 предоставляет специальные инструкции, с помощью которых можно более лаконично реализовать эти действия:
print_hello:
enter 8, 0 ;создать новый кадр, выделить 8 байт для локальных переменных
leave ;восстановить стек
ret
Второй параметр инструкции enter – уровень вложенности подпрограммы.
Непосредственно программа
Проект содержит такие файлы:
main.asm– главный файл,functions.asm– подпрограммы,string_constants.asm– определения строковых констант,Makefile– сценарий сборки
Рассмотрим код основного файла:main.asm
%define SUCCESS 0
%define MIN_MAX_NUMBER 3
%define MAX_MAX_NUMBER 4294967294
global _main
extern _printf
extern _scanf
extern _malloc
extern _free
SECTION .text
_main:
enter 0, 0
;ввод максимального числа
call input_max_number
cmp edx, SUCCESS
jne .custom_exit
mov [max_number], eax
;выделяем память для массива флагов
mov eax, [max_number]
call allocate_flags_memory
cmp edx, SUCCESS
jne .custom_exit
mov [primes_pointer], eax
;отсеять составные числа
mov eax, [primes_pointer]
mov ebx, [max_number]
call find_primes_with_eratosthenes_sieve
;вывести числа
mov eax, [primes_pointer]
mov ebx, [max_number]
call print_primes
;освободить память от массива флагов
mov eax, [primes_pointer]
call free_flags_memory
;выход
.
success:
push str_exit_success
call _printf
jmp .return
.custom_exit:
push edx
call _printf
.return:
mov eax, SUCCESS
leave
ret
%include "functions.asm"
SECTION .data
max_number: dd 0
primes_pointer: dd 0
%include "string_constants.asm"
Видно, что программа поделена по смыслу на 5 блоков, оформленных в виде подпрограмм:
input_max_number— с помощью консоли запрашивает у пользователя максимальное число, до которого производится поиск простых; во избежание ошибок значение ограничено константамиMIN_MAX_NUMBERиMAX_MAX_NUMBERallocate_flags_memory— запросить у ОС выделение памяти для массива пометок чисел (простое/составное) в куче; в случае успеха возвращает указатель на выделенную память через регистрeaxfind_primes_with_eratosthenes_sieve— отсеять составные числа с помощью классического решета Эратосфена;print_primes— вывести в консоль список простых чисел;free_flags_memory— освободить память, выделенную для флагов
Для функций было условлено такое правило: значение возвращается через регистр
eax, регистр edx содержит статус. В случае успеха он содержит значение
В случае успеха он содержит значение SUCCESS, то есть, 0, в случае неудачи — адрес строки с сообщением об ошибке, которое будет выведено пользователю.string_constants.asm содержит определение строковых переменных, значения которых, как намекает название файла, менять не предполагается. Только ради этих переменных было сделано исключение к правилу «не использовать глобальные переменные». Я так и не нашел более удобного способа доставлять строковые константы функциям ввода-вывода – подумывал даже записывать на стек непосредственно перед вызовами функций, но решил, что эта идея куда хуже идеи с глобальными переменными.string_constants.asm;подписи ввода-вывода, форматы
str_max_number_label: db "Max number (>=3): ", 0
str_max_number_input_format: db "%u", 0
str_max_number_output_format: db "Using max number %u", 0xD, 0xA, 0
str_print_primes_label: db "Primes:", 0xD, 0xA, 0
str_prime: db "%u", 0x9, 0
str_cr_lf: db 0xD, 0xA, 0
;сообщения выхода
str_exit_success: db "Success!", 0xD, 0xA, 0
str_error_max_num_too_little: db "Max number is too little!", 0xD, 0xA, 0
str_error_max_num_too_big: db "Max number is too big!", 0xD, 0xA, 0
str_error_malloc_failed: db "Can't allocate memory!", 0xD, 0xA, 0
Для сборки применяется такой сценарий:Makefile
ifdef SystemRoot
format = win32
rm = del
ext = . exe
else
format = elf
rm = rm -f
ext =
endif
all: primes.o
gcc primes.o -o primes$(ext)
$(rm) primes.o
primes.o:
nasm -f $(format) main.asm -o primes.o
exe
else
format = elf
rm = rm -f
ext =
endif
all: primes.o
gcc primes.o -o primes$(ext)
$(rm) primes.o
primes.o:
nasm -f $(format) main.asm -o primes.o
Подпрограммы (функции)
input_max_number
Код подпрограммы
; Ввести максимальное число
; Результат: EAX - максимальное число
input_max_number:
;создать стек-фрейм,
;4 байта для локальных переменных
enter 4, 1
;показываем подпись
push str_max_number_label ;см. string_constants.asm
call _printf
add esp, 4
;вызываем scanf
mov eax, ebp
sub eax, 4
push eax
push str_max_number_input_format ;см. string_constants.asm
call _scanf
add esp, 8
mov eax, [ebp-4]
;проверка
cmp eax, MIN_MAX_NUMBER
jb .number_too_little
cmp eax, MAX_MAX_NUMBER
ja .number_too_big
jmp .success
;выход
.number_too_little:
mov edx, str_error_max_num_too_little ;см. string_constants.asm
jmp .return
.number_too_big:
mov edx, str_error_max_num_too_big ;см. string_constants.
asm
jmp .return
.success:
push eax
push str_max_number_output_format ;см. string_constants.asm
call _printf
add esp, 4
pop eax
mov edx, SUCCESS
.return:
leave
ret
Подпрограмма призвана ввести в программу максимальное число, до которого будет производиться поиск простых. Ключевым моментов тут является вызов функции
scanf из библиотеки Си: mov eax, ebp
sub eax, 4
push eax
push str_max_number_input_format ;см. string_constants.asm
call _scanf
add esp, 8
mov eax, [ebp-4]
Таким образом, сначала в
eax записывается адрес памяти на 4 байта ниже указателя базы стека. Это память, выделенная для локальных нужд подпрограммы. Указатель на эту память передается функции scanf как цель для записи данных, введенных с клавиатуры.После вызова функции, в eax из памяти перемещается введенное значение.
allocate_flags_memory и free_flags_memory
Код подпрограмм
; Выделить память для массива флагов
; Аргумент: EAX - максимальное число
; Результат: EAX - указатель на память
allocate_flags_memory:
enter 8, 1
;выделить EAX+1 байт
inc eax
mov [ebp-4], eax
push eax
call _malloc
add esp, 4
;проверка
cmp eax, 0
je . fail
mov [ebp-8], eax
;инициализация
mov byte [eax], 0
cld
mov edi, eax
inc edi
mov edx, [ebp-4]
add edx, eax
mov al, 1
.write_true:
stosb
cmp edi, edx
jb .write_true
;выход
mov eax, [ebp-8]
jmp .success
.fail:
mov edx, str_error_malloc_failed ;см. string_constants.asm
jmp .return
.success:
mov edx, SUCCESS
.return:
leave
ret
; Освободить память от массива флагов
; Аргумент: EAX - указатель на память
free_flags_memory:
enter 0, 1
push eax
call _free
add esp, 4
leave
ret
fail
mov [ebp-8], eax
;инициализация
mov byte [eax], 0
cld
mov edi, eax
inc edi
mov edx, [ebp-4]
add edx, eax
mov al, 1
.write_true:
stosb
cmp edi, edx
jb .write_true
;выход
mov eax, [ebp-8]
jmp .success
.fail:
mov edx, str_error_malloc_failed ;см. string_constants.asm
jmp .return
.success:
mov edx, SUCCESS
.return:
leave
ret
; Освободить память от массива флагов
; Аргумент: EAX - указатель на память
free_flags_memory:
enter 0, 1
push eax
call _free
add esp, 4
leave
ret
Ключевыми местами этих подпрограмм являются вызовы функций
malloc и free из библиотеки Си.malloc в случае удачи возвращает через регистр eax адрес выделенной памяти, в случае неудачи этот регистр содержит 0. Это самое узкое место программы касательно максимального числа. 32 бит вполне достаточно для поиска простых чисел до 4 294 967 295, но выделить разом столько памяти не получится.
find_primes_with_eratosthenes_sieve
Код подпрограммы
;Найти простые числа с помощью решета Эратосфена
;Аргументы: EAX - указатель на массив флагов, EBX - максимальное число
find_primes_with_eratosthenes_sieve:
enter 8, 1
mov [ebp-4], eax
add eax, ebx
inc eax
mov [ebp-8], eax
;вычеркиваем составные числа
cld
mov edx, 2 ;p = 2
mov ecx, 2 ;множитель с = 2
.strike_out_cycle:
;x = c*p
mov eax, edx
push edx
mul ecx
pop edx
cmp eax, ebx
jbe .strike_out_number
jmp .increase_p
.strike_out_number:
mov edi, [ebp-4]
add edi, eax
mov byte [edi], 0
inc ecx ;c = c + 1
jmp .strike_out_cycle
.increase_p:
mov esi, [ebp-4]
add esi, edx
inc esi
mov ecx, edx
inc ecx
.check_current_number:
mov eax, ecx
mul eax
cmp eax, ebx
ja .return
lodsb
inc ecx
cmp al, 0
jne .new_p_found
jmp .check_current_number
.new_p_found:
mov edx, ecx
dec edx
mov ecx, 2
jmp . strike_out_cycle
.return:
leave
ret
strike_out_cycle
.return:
leave
ret
Подпрограмма реализует классический алгоритм для вычеркивания составных чисел, решето Эратосфена, на языке ассемблера x86. Приятна тем, что не использует вызовы внешних функций и не требует обработки ошибок 🙂
print_primes
Код подпрограммы
; Вывести простые числа
; Параметры: EAX - указатель на массив флагов, EBX - максимальное число
print_primes:
enter 12, 1
mov [ebp-4], eax
mov [ebp-8], ebx
push str_print_primes_label
call _printf
add esp, 4
cld
mov esi, [ebp-4]
mov edx, esi
add edx, [ebp-8]
inc edx
mov [ebp-12], edx
mov ecx, 0
.print_cycle:
lodsb
cmp al, 0
jne .print
jmp .check_finish
.print:
push esi
push ecx
push str_prime ;см. string_constants.asm
call _printf
add esp, 4
pop ecx
pop esi
mov edx, [ebp-12]
.check_finish:
inc ecx
cmp esi, edx
jb .print_cycle
push str_cr_lf
call _printf
add esp, 4
leave
ret
Подпрограмма выводит в консоль простые числа.
 Ключевым моментом тут является вызов функции
Ключевым моментом тут является вызов функции printf из библиотеки Си.Заключение
Что ж, программа отвечает всем сформулированным требованиям и, кажется, проста для понимания. Хочется надеяться, кому-нибудь ее разбор поможет вникнуть в программирование на низком уровне и он получит от него такое же удовольствие, какое получил я.
Так же привожу полные исходники программы.
Могу так же привести интересный факт. Поскольку с детства нас учили, что программы на языке ассемблера выполняются быстрее, я решил сравнить скорость выполнения этой программы со скоростью программы на C++, которую я писал когда-то и которая искала простые числа с помощью Решета Аткина. Программа на С++, скомпилированная в Visual Studio с /O2 выполняла поиск до числа 230 примерно за 25 секунд на моей машине. Программа же на ассемблере показала 15 секунд с Решетом Эратосфена.
Это, конечно, скорее байка, чем научный факт, поскольку не было серьезного тестирования не было выяснения причин, но как интересный факт для завершения статьи подойдет, как мне кажется.
Полезные ссылки
- Список ресурсов для изучения ассемблера
- Организация памяти
- Решето Эратосфена
- Решето Аткина
- Стек
- Стековый кадр
Готовые программы Assembler. Примеры, задачи.
Готовые программы Assembler. Примеры, задачи.- Главная
- Готовые программы Assembler
- Замена одного символа на два
- ASM + C++ Как вывести в консоль ?
- Как прописывается 16-байтная переменная на masm32
- NASM Крис касперски
- Вычислить значение выражения: ((2*c)-(d/3)) / (b-(a/4))
- Как на фасме объявить прототип пользовательской функции
- [МС68HC11] Заполнить ячейки. Индексная адресация
- MASM, cannot use 16-bit register with a 32-bit address
- Вывести на экран символы, которые содержатся в обеих строках
- Адресация информации
- Перенести из массива в стек
- Вычисление выражения по формуле
- Что в данном фрагменте кода не соответствует соглашению stdcall?
- Определить значения полей структуры по содержимому файла
- Ошибка в программе по замене символов
- Поменять числа местами
- Реализация функции возведения в степень
- Сортировка массива целых чисел по возрастанию
- Записать алфавит в файл
- Проверка байт статуса
- Числа Фибоначчи
- Ввести два 16-битовых целых числа А и В.
 Вычислить результат логического побитового исключающего ИЛИ чисел 10*
Вычислить результат логического побитового исключающего ИЛИ чисел 10* - Сколько элементов строки превышают код введенного символа
- Сложение нескольких десятичных чисел
- Умножение/деление (сдвиг)
- Первые n строк треугольника Паскаля (TASM)
- Создания образа размещения программы в памяти
- Обработка двумерного массива (матрицы): поиск минимума из положительных значений, новая матрица по условию
- Обработка массива: поиск минимума, сортировка
- Дизассемблирование команд с помощью W32Dasm
- Найти максимальный элемент матрицы
- _RUNDUDE.ASM
- Матрица a не работает в другой прог
- Инкремент, не работает флаг переполнения
- Вычислить значение выражения
- Зеркально отобразить байты из al в ah
- Напечатать «да», если введенное число делится на 3 и на 2 одновременно…
- Как вывести остаток от деления
- Вычисление по формуле
- Вычислить значение выражения
- Организация программы
- Ввести число в 16-ричном виде, вывести соответствующий ASCII символ
- Программа вычисления выражения
- Перепечатать заданный текст, удалив из него символы «b», непосредственно перед которыми следует цифра
- [TASM] Магический квадрат (3х3)
- Вывод элементов, находящихся после максимального элемента в массиве
- Настройка DosBox
- В цикле найти сумму целочисленного ряда
- Циклы: определить сумму первых n чисел, кратных двум
- Заполнение блока памяти из N слов рядом натуральных чисел
Решение: Примеры кода с пояснениями
format PE GUI 4.0 entry MyEntry include 'C:\INCLUDE\Win32ax.inc' section '.data' data readable writeable ;;## В секции данных представлены 2 строки и 2 класса нужных для создания окна. ;;## szClsName обязательная строка - это имя класса окна, который мы зарегиструем. ;;## поиск среди классов окон ведется именно по этому ключевому параметру. szClsName db "TestWndClass",0 szWindowName db "Tutorial #1",0 ;;## WNDCLASS это структура класса окна, в ней содержится самая разная информация. ;;## от иконки и курсора, до адреса процедуры обработки сообщений. wCls WNDCLASS ;;## Структура MSG это структура которая принимает сообщения и из нее же ;;## берут нужные данные пре-обработчики этих сообщений. wMsg MSG section '.code' code readable executable MyEntry: ;;## Заполняем структуру WNDCLASS нужными данными. ;;## CS_VREDRAW и CS_HREDRAW это стили которые отвечают за ;;## перерисовку окна при измении высоты и ширины сответственно. mov [wCls.style],CS_VREDRAW+CS_HREDRAW ;;## Указываем процедуру обработки окна.
В данном случае в поле lpfnWndProc ;;## помещается адрес нашей процедуры обработки сообщений - WndProc. mov [wCls.lpfnWndProc],WndProc ;;## Помещаем в структуру адрес на строку с именем нашего класса mov [wCls.lpszClassName],szClsName ;;## Указываем цвет фона окна. В данном случае это белый. mov [wCls.hbrBackground],COLOR_WINDOW+1 ;;## После занесения всех нужных данных можно регистрировать класс. invoke RegisterClass,wCls ;;## Создаем само окно. Второй параметр это как раз адрес на строку ;;## именем класса нашего окна. По этому параметру будет найден наш класс. ;;## invoke CreateWindowEx,0,szClsName,szWindowName,\ ;;## WS_VISIBLE стиль - указывает на то что окно будет сразу видно. ;;## Если его не указать, окно можно будет показать функцией ShowWindow ;;## вызвав ее единожды. Скрыть окно тоже можно - той же функцией но с другим ;;## параметров - SW_HIDE а не SW_SHOW. ;;## WS_SYSMENU указывает на то что бы к окну были добавлены кнопки, свернуть ;;## максимизировать и закрыть.
WS_VISIBLE or WS_SYSMENU,\ ;;## Кордината Х кордината Y ;;## длина и ширина. А так же некоторые другие пока не нужные нам параметры. ;;## о которых будет рассказано в следующем примере. 200,200,200,200,0,0,0,0
Погружение в ассемблер. Зачем учить ассемблер в 2020 году — «Хакер»
Ты решил освоить ассемблер, но перед этим хочешь понять, что тебе это даст как программисту? Стоит ли входить в мир программирования через ассемблер, или лучше начать с какого‑нибудь языка высокого уровня? И вообще, нужно ли знать ассемблер, чтобы стать полноценным программистом? Давай разберемся во всем этом по порядку.
Погружение в ассемблер
Это вводная статья цикла «Погружение в ассемблер», которую мы публикуем в честь его завершения. Ее полный текст доступен без подписки. Прочитав ее, ты можешь переходить к другим статьям этого курса:
Ради чего стоит изучать ассемблер?
Стоит освоить ассемблер, если ты хочешь:
- разобраться, как работают компьютерные программы.
 Разобраться в деталях, на всех уровнях, вплоть до машинного кода;
Разобраться в деталях, на всех уровнях, вплоть до машинного кода; - разрабатывать программы для микроскопических встраиваемых систем. Например, для 4-битных микроконтроллеров;
- понять, что находится под капотом у языков высокого уровня;
- создать свой собственный компилятор, оптимизатор, среду исполнения JIT, виртуальную машину или что‑то в этом роде;
- ломать, отлаживать или защищать компьютерные системы на самом низком уровне. Многие изъяны безопасности проявляются только на уровне машинного кода и могут быть устранены только с этого уровня.
Не стоит осваивать ассемблер, если ты хочешь ускорить другие свои программы. Современные оптимизирующие компиляторы справляются с этой задачей очень хорошо. Ты вряд ли сможешь обогнать их.
Кто выдаст лучший ассемблерный код?
Почему обогнать компилятор практически невозможно? Смотри, для тебя же очевидно, что компьютер в шахматы не обыграть, даже если ты играешь лучше, чем создатель шахматной программы? С оптимизирующими компиляторами та же история. Только оптимизирующий компилятор играет не шахматными фигурами, а контекстными обстоятельствами.
Только оптимизирующий компилятор играет не шахматными фигурами, а контекстными обстоятельствами.
В современных процессорах практически ничто из того, что влияет на производительность, нельзя обсуждать в отрыве от контекста. Одна и та же комбинация из десятка ассемблерных инструкций выполняется с резкими отличиями по скорости (в тысячи или даже миллионы раз), в зависимости от целой кучи самых разнообразных обстоятельств.
- Те данные, к которым ты сейчас обращаешься, загружены в кеш или нет? А сама комбинация ассемблерных инструкций?
- Если ни данные, ни код не размещены в кеше, то не перетаскивает ли их процессор туда втихомолку, предполагая, что к ним будут обращаться в ближайшее время?
- Какие инструкции были выполнены непосредственно перед нашим десятком? Они сейчас все еще на конвейере?
- Мы случаем не достигли конца текущей страницы виртуальной памяти? А то, не дай бог, добрая половина нашего десятка попадет на новую страницу, которая к тому же сейчас, по закону подлости, вытеснена на диск.
 Но если нам повезло и новая страница таки в физической памяти, можем ли мы добраться до нее через TLB-буфер? Или нам придется продираться к ней через полный адрес, используя таблицы страниц? И все ли нужные нам таблицы страниц загружены в физическую память? Или какие‑то из них вытеснены на диск?
Но если нам повезло и новая страница таки в физической памяти, можем ли мы добраться до нее через TLB-буфер? Или нам придется продираться к ней через полный адрес, используя таблицы страниц? И все ли нужные нам таблицы страниц загружены в физическую память? Или какие‑то из них вытеснены на диск? - Какой именно процессор выполняет код? Дешевенький i3 или мощный i7? Бывает, что у дешевых процессоров тот же набор инструкций, что и у мощных, но продвинутые инструкции выполняются в несколько шагов, а не за один.
И все это только верхушка айсберга, малая часть того, что тебе придется учитывать и анализировать, когда будешь стараться переиграть компилятор.
Есть такой миф, что программы, написанные на ассемблере, работают в десять раз быстрее. Этот миф уходит корнями в семидесятые годы. Компиляторы в те далекие времена генерировали код настолько бездарно, что у каждого уважающего себя программиста был черный список запрещенных языковых конструкций.
Когда наши коллеги из прошлого писали программы, они либо держали в уме этот черный список и не давали своим пальцам набивать проблемные конструкции, либо настраивали специальный препроцессор, который конвертировал исходник в более низкоуровневое беспроблемное представление на том же языке. С тех пор минуло 50 лет. Компиляторы возмужали, но миф остался.
Конечно, даже сегодня можно изредка встретить уникума, который пишет более быстрый код, чем компилятор. Вот только времени у него на это уходит так много, что ни в какие ворота не лезет. Плюс для оптимизации от тебя требуется, чтобы ты назубок знал весь набор инструкций процессора.
Вдобавок, поскольку ты шлифуешь свой код вручную, никакой компилятор не подстрахует тебя, не поможет отловить баги, которые ты неизбежно плодишь, когда пишешь программу.
Кроме того, твой ассемблерный код будет непереносимым. То есть, если ты захочешь, чтобы твоя программа запускалась на другом типе процессора, тебе придется полностью переписать ее, чтобы создать модификацию, заточенную под набор инструкций этого другого процессора. Само собой, тебе эти инструкции тоже надо знать назубок.
Само собой, тебе эти инструкции тоже надо знать назубок.
В итоге ты потратишь в десятки и сотни раз больше времени, чем если бы доверился оптимизирующему компилятору, — но результат, скорее всего, окажется медленнее, а не быстрее.
При этом иногда оптимизирующий компилятор выплевывает ассемблерный код, логика которого ну совсем непонятна. Однако не спеши обвинять компилятор в глупости. Давай разберем пример.
Когда ты пишешь на С что‑то вроде x , то естественным образом ожидаешь увидеть в ассемблере инструкцию, которая умножает переменную a на двойку. Но компилятор знает, что сложение дешевле умножения. Поэтому он не умножает a на двойку, а складывает ее с самой собой.
Больше того, глядя на b, компилятор может счесть, что b предпочтительнее, чем b*3. Иногда тройное сложение быстрее умножения, иногда нет. А иногда компилятор приходит к выводу, что вместо исходного выражения быстрее будет вычислить
Иногда тройное сложение быстрее умножения, иногда нет. А иногда компилятор приходит к выводу, что вместо исходного выражения быстрее будет вычислить (. Или даже ((.
А если x используется лишь однократно — причем в связке с парой строк последующего кода, — компилятор может вообще не вычислять x, а просто вставить a*2 вместо икса. Но даже если x используется и компилятор видит что‑то вроде y , он может исправить эти расчеты на y , удивляясь твоей расточительности. Расточительности в плане вычислительной сложности.
Размышления подобного рода неизбежно заводят тебя в запутанный лабиринт альтернативных вариантов. Все их нужно просчитать, чтобы выбрать лучший. Но даже когда ты сделаешь это, вариант ассемблерного кода, сгенерированный компилятором, скорее всего, будет работать быстрее, чем твой.
Но даже когда ты сделаешь это, вариант ассемблерного кода, сгенерированный компилятором, скорее всего, будет работать быстрее, чем твой.
Кстати, если используешь GCC или Clang, активируй опции оптимизации для SSE, AVX и всего остального, чем богат твой процессор. Затем откинься на спинку кресла и удивись, когда компилятор векторизует твой сишный код. Причем сделает это так, как тебе и не снилось.
Какие программы нельзя написать на ассемблере?
Нет таких. Все, что можно сделать на компьютере, можно сделать в том числе и на ассемблере. Ассемблер — это текстовое представление сырого машинного кода, в который переводятся все программы, запущенные на компьютере.
Ты при желании можешь написать на ассемблере даже веб‑сайт. В девяностые С был вполне разумным выбором для этой цели. Используя такую вещь, как CGI BIN, веб‑сервер мог вызывать программу, написанную на С. Через stdin сайт получал запрос, а через stdout отправлял результат в браузер. Ты можешь легко реализовать тот же принцип на ассемблере.
Ты можешь легко реализовать тот же принцип на ассемблере.
Но зачем? Ты должен быть мазохистом, чтобы проделывать такое. Потому что когда ты пишешь на ассемблере, то сталкиваешься вот с такими проблемами.
- У тебя более низкая продуктивность, чем если бы ты работал на языке высокого уровня.
- У твоего кода нет никакой структуры, поэтому другим разработчикам будет трудно читать его.
- Тебе придется писать много букв. А там, где больше букв, больше потенциальных багов.
- С Secure Coding здесь все очень печально. На ассемблере писать так, чтобы код был безопасным, сложнее всего. На С в этом плане ты чувствуешь себя куда более комфортно.
Да, все можно написать на ассемблере. Но сегодня это нецелесообразно. Лучше пиши на С. Скорее всего, будет безопаснее, быстрее и более лаконично.
От редакции
Автор статьи — большой поклонник С и настоятельно рекомендует этот язык. Мы не будем лишать его такой возможности. С — отличная штука и помогает как освоить основные концепции программирования, так и прочувствовать принципы работы компьютера. Однако при выборе языка для изучения ты можешь руководствоваться самыми разными соображениями. Например:
Мы не будем лишать его такой возможности. С — отличная штука и помогает как освоить основные концепции программирования, так и прочувствовать принципы работы компьютера. Однако при выборе языка для изучения ты можешь руководствоваться самыми разными соображениями. Например:
- Надо учить Python или Lua, чтобы моментально получать результаты. Это мотивирует!
- Надо учить Scheme или Haskell из тех же соображений, что в школе учат алгебру, а не, к примеру, автомеханику.
- Надо учить Go для того же, для чего C, но в 2020 году.
- Надо учить JavaScript и React.js, чтобы как можно быстрее найти работу.
- Надо учить Java, чтобы максимизировать заработок.
- Надо учить Swift, потому что почему нет?
- Надо учить HolyC, чтобы славить Господа.
- Надо учить Perl во имя Сатаны.
И так далее. Ответ на вопрос о том, с какого языка начать, зависит от многих факторов, и выбор — дело индивидуальное.
Конечно, когда ты знаешь ассемблер, у тебя будут значительные преимущества перед теми программистами, которые его не знают. Но прежде чем ознакомиться с этими преимуществами, запомни одну простую вещь: хорошие программисты знают ассемблер, но почти никогда не пишут на нем.
Какие преимущества ассемблер дает программисту?
Чтобы писать эффективные программы (в плане быстродействия и экономии ресурсов), тебе обязательно надо знать ассемблер того железа, для которого ты пишешь. Когда ты знаешь ассемблер, ты не обманываешься внешней простотой и краткостью высокоуровневых функций, а понимаешь, во что в итоге превращается каждая из них: в пару‑тройку ассемблерных инструкций или в длиннющую их последовательность, переплетенную циклами.
Если работаешь с языками высокого уровня, такими как С, научись хотя бы читать и понимать ассемблерный код. Даже если ты в обозримом будущем не видишь себя пишущим на ассемблере (на самом деле мало кто себя так видит), знание ассемблера тебе пригодится.
Если будешь с ассемблером на ты, он сослужит тебе хорошую службу в отладке. Освоив ассемблер, ты будешь понимать, что происходит под капотом языков высокого уровня, как компьютер делает то, что он делает, и почему высокоуровневый компилятор иногда работает не так, как ты ждешь от него. Ты сможешь видеть причину этого и понимать, как ее устранить.
Плюс иногда ты ну никак не можешь понять, что у тебя за баг, пока не пройдешься в отладчике в пошаговом режиме по ассемблерному коду.
И вот еще тонкий намек: некоторые работодатели хотели бы видеть в твоем резюме слово «ассемблер». Это говорит им, что ты не просто по верхам нахватался, а действительно интересуешься программированием, копаешь вглубь.
Стоит ли начинать изучать программирование с ассемблера?
Когда ты осваиваешь программирование, начиная с самых низов, в этом есть свои плюсы. Но ассемблер — это не самый низ. Если хочешь начать снизу, начни с логических вентилей и цифровой электроники. Затем поковыряйся с машинным кодом. И только потом приступай к ассемблеру.
Затем поковыряйся с машинным кодом. И только потом приступай к ассемблеру.
Время от времени тебя будут посещать мысли, что ты занимаешься какой‑то ерундой. Но ты узнаешь много полезного для своей будущей работы, даже если она будет связана только с языками высокого уровня. Ты узнаешь, как именно компьютер делает те вещи, которые он делает.
Однако я бы не советовал начинать с ассемблера и более низких слоев. Во всем том, что перечислено в двух предыдущих абзацах, легче разобраться, когда ты начинаешь с какого‑нибудь языка высокого уровня. Так ты достигнешь желаемого результата быстрее, чем оно тебе наскучит.
Но в какой‑то момент тебе и правда обязательно надо познакомиться с ассемблером, особенно если программируешь на С. Я сомневаюсь, что ты сможешь стать полноценным программистом на С, не зная ассемблера. Но начинать с ассемблера не стоит.
Насколько легче учить другие языки, когда уже знаешь ассемблер?
Ассемблер совершенно не похож на языки высокого уровня. Поэтому народная мудрость «Тот опыт, который ты получил на одном языке, может быть легко сконвертирован на другой язык» с ассемблером не работает.
Поэтому народная мудрость «Тот опыт, который ты получил на одном языке, может быть легко сконвертирован на другой язык» с ассемблером не работает.
Если ты начнешь с ассемблера, то после того, как выучишь его и решишь освоить новый язык, тебе придется начинать как с чистого листа. Помню, мой однокашник еще в школе выучил ассемблер, написал на нем игрушку, с которой победил на конференции. Но при этом так и не смог хорошо освоиться в С, когда мы учились в универе.
Чем же ассемблер отличается от языков высокого уровня? Переменные в нем — это просто области памяти. Здесь нет ни int, ни char. Здесь нет массивов!
Есть только память. Причем ты работаешь с ней не так, как на языке высокого уровня. Ты можешь забыть, что в какую‑то область памяти поместил строку, и обратиться к ней как к числу. Программа все равно скомпилируется. Но только обрушится в рантайме. Причем обрушится жестко, без вежливого сообщения об ошибке.
В ассемблере нет do.., нет for.., нет if... Вместо них там есть только операции сравнения и условного перехода. Строго говоря, там даже функций нет.
Но! Изучив ассемблер, ты будешь понимать, как реализуются и функции, и циклы, и все остальное. А разница между передачей параметра «по значению» и «по ссылке» станет для тебя самоочевидной. Плюс если ты пишешь на С, но не можешь до конца разобраться, как работают указатели, то, когда ты узнаешь, что такое регистры и относительная адресация, увидишь, что понять указатели совсем нетрудно.
Лучше начинай с С. На нем удобно осваивать основы: переменные, условия, циклы, логические построения и остальное. Опыт, который ты получишь при изучении С, легко сконвертировать на любой другой язык высокого уровня, будь то Java, Python или какой‑то еще. Да и с ассемблером легче разобраться, когда ты уже освоил С.
Насколько доходно уметь программировать на ассемблере?
Если заглянешь на HH.ru, то, скорее всего, не найдешь ни одной вакансии, у которой в заголовке написано слово «ассемблер». Но время от времени какая‑нибудь контора лихорадочно ищет мага‑волшебника, который знает нутро компьютера настолько глубоко, что может полностью подчинить операционную систему своей воле. Мага‑волшебника, который умеет (1) латать систему, не имея на руках исходного кода, (2) перехватывать потоки данных на лету и вмешиваться в них.
Некоторая часть этой глубокой магии — а сейчас потребность в такой магии становится все более редкой — может быть воплощена только на языке очень низкого уровня.
Я слышал о конторе, которая ищет человека на разработку новой платформы для высокочастотного трейдинга. Там идея в том, что если ты получаешь информацию о котировках быстрее своих конкурентов и принимаешь решение быстрее их, то будешь грести баснословные суммы.
«Когда ты получаешь котировки, проходя через весь стек TCP/IP, это слишком медленно», — говорят парни из этой фирмы. Поэтому у них есть примочка, которая перехватывает трафик на уровне Ethernet, прямо внутри сетевой карты, куда залита кастомизированная прошивка.
Но эти ребята пошли еще дальше. Они собираются разработать девайс для фильтрации трафика Ethernet — на ПЛИС. Зачем? Чтобы ловить котировки на аппаратном уровне и тем самым экономить драгоценные микросекунды трейдингового времени и в итоге получать небольшое, очень небольшое преимущество перед конкурентами. Язык С им не подошел. Им даже ассемблер не подошел. Так что эти парни выцарапывают программу прямо на кремнии!
Первая программа на ассемблере — Hellow World в стиле TASM.
Наша первая программа на ассемблере.
Наша первая программа на ассемблере будет в формате *.COM — как мы уже знаем, исполняемые файлы указанного формата очень крохотные (tiny) по размеру и состоят из одного сегмента, в котором размещаются код, данные и стек.
Ещё мы знаем, что в указанном формате пишутся резидентные программы, драйверы и вирусы.
Резидентная (TSR-программа, от англ. Terminate and Stay Resident) — это программа, которая после запуска передает управление операционной системе, но сама не завершается, а остаётся в оперативной памяти, реагируя на определённые действия пользователя. Например, при нажатии сочетания горячих клавиш делает снимок экрана.
Код в статьях отображается в удобочитаемой форме: каждая строка имеет свой номер, строки и код подсвечиваются. Чтобы скопировать «чистый исходник», наведите курсор мыши на текст, дождитесь всплывающего меню и нажмите в меню кнопочку «копировать» (изображение двух листочков бумаги с текстом). Чистый код не содержит нумерации строк!
Наша первая программа выведет на экран монитора (консоль) надпись «Hello, World!». Итак, как говорил Юрий Алексеевич, поехали!
Создаём исполняемый файл PRG.COM.
Для достижения нашей цели делаем следующее.
- Скачиваем с нашего сайта архив (DOS-1.rar) с предустановленными DOSBox и программами. Запускаем DOSBox. Стартует эмулятор MS-DOS и Norton Commander пятой версии.
- В папке D:\TASM.2_0\TASM\ находим текстовый файл PRG.ASM. Это обычный текстовый файл, который можно создать
с помощью любого текстового редактора, с расширением ASM вместо TXT. - В файл вносим код:
;Строка, после точки с запятой является комментарием ;и не обрабатывается ассемблером ; prg.asm — название файла. .model tiny ; создаём программу типа СОМ .code ; начало сегмента кода org 100h ; начальное значение смещения программы в памяти — 100h start: mov ah,9 ; номер функции DOS — в АН mov dx,offset message ; адрес строки — в DX int 21h ; вызов т.н. «прерывания» — системной функции DOS ret ; завершение СОМ-программы message db «Hello, World!»,0Dh,0Ah,’$’ ; строка для вывода end start ; конец программы.
;Строка, после точки с запятой является комментарием ;и не обрабатывается ассемблером ; prg. .model tiny ; создаём программу типа СОМ .code ; начало сегмента кода org 100h ; начальное значение смещения программы в памяти — 100h start: mov ah,9 ; номер функции DOS — в АН mov dx,offset message ; адрес строки — в DX int 21h ; вызов т.н. «прерывания» — системной функции DOS ret ; завершение СОМ-программы message db «Hello, World!»,0Dh,0Ah,’$’ ; строка для вывода end start ; конец программы. |
 asm — название файла.
asm — название файла.- В папке D:\TASM.2_0\TASM\ находим «батник» ASM-COM.BAT со следующим текстом:
tasm.exe prg.asm tlink.exe /t /x prg.obj
tasm.exe prg.asm tlink.exe /t /x prg.obj |
Первая строка — запуск транслятора с названием нашего файла с кодом, расположенного в одной директории с транслятором.
Вторая строка — запуск компилятора с параметрами /t /x и название объектного файла — prg. obj, получившегося в результате выполнения первой команды.
obj, получившегося в результате выполнения первой команды.
Чтобы посмотреть список всех возможных параметров с пояснениями для файлов tasm.exe и tlink.exe необходимо запустить эти программы без параметров. Если вы сделаете это, не выходя из оболочки NC, то, чтобы просмотреть чистое окно DOS нажмите Ctrl+O, чтобы вернуться в NC, нажмите сочетание клавиш повторно.
- После запуска ASM-COM.BAT в этой же директории появится файл prg.com. Запустив его мы увидим сообщение «Hello World!» в окне MS-DOS (при необходимости просмотра, снова применяем Ctrl+O).
Батник ASM-EXE.BAT предназначен для создания исполняемого файла формате *.EXE (предусматривает раздельную сегментацию для кода, данных и стека — наиболее распространённый формат исполняемых файлов DOS).
Батник COMPLEX.BAT предназначен для создания исполняемых файлов из двух файлов кода (названия обязательно должны быть prg.asm, prg1.asm).
Наша первая программа на ассемблере прекрасно работает!
TASMED (Tasm Editor) — среда разработки приложений DOS на ассемблере.
Выше мы рассмотрели стандартный подход к программированию на TASM в системе MS-DOS. Указанным алгоритмом создания программ можно пользоваться и далее.
Для более удобной работы с кодом целесообразно применять какую-либо среду разработки. Среда разработки — это громко сказано для времён MS-DOS, правильнее сказать — специфический редактор.
Можете попробывать TASMED в папке D:\UTILS\TASMED\. Программа уж
Ассемблер с нуля — просто о сложном языке программирования.
Просто о сложном.
Для начала уясним цели и задачи, которые будут рассматриваться в цикле статей в рамках рубрики «Ассемблер с нуля», определим потенциальную аудиторию.
«Ассемблер с нуля» заинтересует тех, кто желает научиться программировать на языке ассемблер, не будучи профессиональным математиком.
Информация излагается понятной для любого начинающего, не обладающего никакими (совершенно никакими) дополнительными знаниями выше уровня школьника седьмого — восьмого класса среднеобразовательной школы.
Дополнительная, но не менее важная цель — наработать общий подход к изучению любого языка программирования. Показать, насколько просто научиться программировать самостоятельно при наличии времени и желания.
Статьи заинтересуют преподавателей программирования с практической направленностью изложения материала.
Несомненную пользу в излагаемом материале найдут студенты, изучающие ассемблер — лишними знания не бывают, к тому же форма изложения материала проста и общедоступна.
Опытных гуру программирования может возмутить наш подход к форме подачи материала. Ох как любят программисты считать себя избранными, обладающими недоступными для других способностями. Ох как любят усложнять простые вещи, чтобы пустить пыль в глаза и набить себе цену! Призываю всех не становиться на тёмную сторону силы — знаниями нужно делиться, рассказывая просто о сложном и избегая усложнения простых вещей!
Ассемблер с нуля — практический подход.
Чтобы не показаться полными теоретиками, оторванными от практического применения знаний и умений, мы постараемся не отходить от конкретики, создавать и изучать конкретный код. Будут приводиться ссылки на литературу, позволяющую более глубоко проникнуть в конкретные языки, на примере которых мы стараемся изложить наш подход к программированию. При этом основы современного программирования будут играть роль своеобразного скелета, на который будут накладываться отдельные строки программного кода.
Будут приводиться ссылки на литературу, позволяющую более глубоко проникнуть в конкретные языки, на примере которых мы стараемся изложить наш подход к программированию. При этом основы современного программирования будут играть роль своеобразного скелета, на который будут накладываться отдельные строки программного кода.
В качестве примеров будет рассмотрено написание конкретных простейших программ «хакерской» направленности, а также изучены основы крекинга (взлома программных защит), использования дизассемблированного кода в сторонних программах.
Заранее оговоримся, что информация будет излагаться в ознакомительных целях. Чтобы обеспечивать компьютерную безопасность, защищать свой код, предотвращать возможные риски утраты интеллектуальной собственности, необходимо знать потенциальные угрозы, а также способы их реализации.
Наш план действий.
Изучать ассемблер мы будем по следующему плану :
1. Суть программирования.
2. Понятие кода и данных на примере разработки простейших MS-DOS программы на Ассемблере с учётом возможностей простой, с точки зрения современности, операционной системы.
3. Программирование Windows приложений на ассемблере и Си.
4. Основы вирусологии — просто о сложном. Создание простейшего вируса и антивируса для Windows.
5. Основы крэкинга. Исследование программ.
6. Дизассемблирование — ассемблирование. Сложно ли «украсть» чужой код.
7. Применение ассемблера и Си для создания современных Windows приложений.
8. Итоги, выводы, применение полученных знаний и умений на практике.
Как вы видите, мы уделим внимание не только ассемблеру, но и языкам программирования Си и С++, как наиболее близким по сути и форме. Вы помните, одна из целей цикла статей — дать заинтересованному читателю основы современного программирования, которые позволят изучить любой язык с нуля за достаточно сжатые сроки.
40 Базовые практики программирования на языке ассемблера
Содержание
Введение
Ассемблер — это язык программирования низкого уровня для нишевых платформ, таких как Интернет вещей, драйверы устройств и встроенные системы. Обычно это тот язык, который студенты-информатики должны использовать в своей курсовой работе и редко используют в своей будущей работе. Согласно индексу сообщества программистов TIOBE, в последнее время в рейтингах самых популярных языков программирования язык ассемблера постоянно растет.
Обычно это тот язык, который студенты-информатики должны использовать в своей курсовой работе и редко используют в своей будущей работе. Согласно индексу сообщества программистов TIOBE, в последнее время в рейтингах самых популярных языков программирования язык ассемблера постоянно растет.
В первые дни, когда приложение было написано на языке ассемблера, оно должно было умещаться в небольшом объеме памяти и работать с максимальной эффективностью на медленных процессорах. Когда памяти становится много, а скорость процессора резко возрастает, мы в основном полагаемся на языки высокого уровня с готовыми структурами и библиотеками в разработке. При необходимости можно использовать язык ассемблера для оптимизации критических секций по скорости или для прямого доступа к непереносимому оборудованию. Сегодня ассемблер по-прежнему играет важную роль в проектировании встроенных систем, где эффективность производительности по-прежнему считается важным требованием.
В этой статье мы поговорим о некоторых основных критериях и навыках работы с кодом, характерных для программирования на ассемблере. Кроме того, следует обратить внимание на скорость выполнения и потребление памяти. Я проанализирую несколько примеров, связанных с концепциями регистра, памяти и стека, операторами и константами, циклами и процедурами, системными вызовами и т. Д. Для простоты все образцы представлены в 32-битном формате, но большинство идей будет легко применяется к 64-битной.
Кроме того, следует обратить внимание на скорость выполнения и потребление памяти. Я проанализирую несколько примеров, связанных с концепциями регистра, памяти и стека, операторами и константами, циклами и процедурами, системными вызовами и т. Д. Для простоты все образцы представлены в 32-битном формате, но большинство идей будет легко применяется к 64-битной.
Все представленные здесь материалы взяты из моего обучения [1] в течение многих лет.Таким образом, для чтения этой статьи необходимо общее понимание ассемблера Intel x86-64 и предполагается, что вы знакомы с Visual Studio 2010 или более поздней версии. Желательно, прочитав учебник Кипа Ирвина [2] и Руководство программиста MASM [3]. Если вы посещаете курс программирования на языке ассемблера, это может быть дополнительным чтением для учебы.
Об инструкции
Первые два правила являются общими. Если вы можете использовать меньше, не используйте больше.
1.Использование меньше инструкций
Предположим, что у нас есть 32-битная DWORD переменная:
. Данные
var1 DWORD 123
Данные
var1 DWORD 123 Пример: добавляем var1 к EAX . Это верно с MOV и ADD :
mov ebx, var1
добавить eax, ebx Но поскольку ADD может принимать один операнд памяти, вы можете только
добавить eax, var1 2. Использование инструкции с меньшим количеством байтов
Предположим, что у нас есть массив:
.данные
массив DWORD 1,2,3 Если вы хотите изменить порядок значений на 3,1,2, вы можете
mov eax, массив
xchg eax, [массив + 4]
xchg eax, [массив + 8]
Массив xchg, eax Но обратите внимание, что последняя инструкция должна быть MOV вместо XCHG . Хотя оба могут назначить 3 в EAX первому элементу массива, наоборот, вместо XCHG в этом нет необходимости.
Помните о размере кода, MOV принимает 5-байтовый машинный код, но XCHG принимает 6, что является еще одной причиной для выбора MOV здесь:
00000011 87 05 00000000 R массив xchg, eax
00000017 A3 00000000 R mov массив, eax Чтобы проверить машинный код, вы можете создать файл списка при сборке или открыть окно «Разборка» во время выполнения в Visual Studio. Кроме того, вы можете найти в руководстве по эксплуатации Intel.
О регистре и памяти
В этом разделе мы будем использовать популярный пример, n-е число Фибоначчи, чтобы проиллюстрировать несколько решений на языке ассемблера.Функция C будет иметь вид:
целое число без знака Фибоначчи (целое число без знака n)
{
беззнаковое int предыдущее = 1, текущее = 1, следующее = 0;
for (unsigned int i = 3; i <= n; ++ i)
{
следующий = текущий + предыдущий;
предыдущий = текущий;
текущий = следующий;
}
вернуться дальше;
} 3. Реализация с переменными памяти
Реализация с переменными памяти
Сначала давайте скопируем ту же идею сверху с двумя переменными: предыдущий и текущий , созданные здесь
.данные
предыдущий DWORD?
текущий DWORD? Мы можем использовать EAX , чтобы сохранить результат без переменной next . Поскольку MOV не может перемещаться из памяти в память, регистр, такой как EDX , должен быть задействован для присвоения предыдущий = текущий . Ниже приводится процедура FibonacciByMemory . Он получает n от ECX и возвращает EAX как n-е вычисленное число Фибоначчи:
FibonacciByMemory PROC
mov eax, 1
mov предыдущий, 0
mov текущий, 0
L1:
добавить eax, предыдущий
mov edx, текущий
mov предыдущая, edx
mov current, eax
петля L1
Ret
FibonacciByMemory ENDP 4. Если вы можете использовать регистры, не используйте память
Если вы можете использовать регистры, не используйте память
Основное правило программирования на ассемблере заключается в том, что если вы можете использовать регистр, не используйте переменную. Операция с регистром намного быстрее, чем с памятью. В 32-битном формате доступны регистры общего назначения: EAX , EBX , ECX , EDX , ESI и EDI . Не прикасайтесь к ESP и EBP , которые используются в системе.
Теперь позвольте EBX заменить предыдущую переменную , а EDX заменить текущую .Следующее - FibonacciByRegMOV , просто с тремя инструкциями, необходимыми в цикле:
ПРОЦЕСС ФибоначчиByRegMOV
mov eax, 1
xor ebx, ebx
xor edx, edx
L1:
добавить eax, ebx
mov ebx, edx
mov edx, eax
петля L1
Ret
ФибоначчиByRegMOV ENDP Еще одна упрощенная версия заключается в использовании XCHG , который увеличивает последовательность без необходимости EDX . Ниже показан машинный код
Ниже показан машинный код FibonacciByRegXCHG в его Листинге, где только две инструкции из трех байтов машинного кода в теле цикла:
000000DF FibonacciByRegXCHG PROC
000000DF 33 C0 xor eax, eax
000000E1 BB 00000001 mov ebx, 1
000000E6 L1:
000000E6 93 xchg eax, ebx
000000E7 03 C3 добавить eax, ebx
000000E9 E2 Петля FB L1
000000EB C3 ret
000000EC FibonacciByRegXCHG ENDP
В параллельном программировании
Набор инструкций x86-64 предоставляет множество атомарных инструкций с возможностью временного запрета прерываний, гарантируя, что текущий выполняющийся процесс не может переключаться по контексту, и достаточен для однопроцессорного процессора.В некотором роде это также позволило бы избежать состояния гонки при многозадачности. Эти инструкции могут напрямую использоваться разработчиками компилятора и операционной системы.
5. Использование атомарных инструкций
Как видно выше, используемый XCHG , так называемый атомарный своп, является более мощным, чем какой-либо язык высокого уровня с одним оператором:
xchg eax, var1
Классический способ поменять местами регистр с памятью var1 мог быть
mov ebx, eax
mov eax, var1
mov var1, ebx
Более того, если вы используете набор инструкций Intel486 с расширением. 486 или выше, простое использование атомарного
486 или выше, простое использование атомарного XADD более лаконично в процедуре Фибоначчи. XADD обменивает первый операнд (назначение) со вторым операндом (источником), затем загружает сумму двух значений в операнд-адресат. Таким образом, мы имеем
000000EC FibonacciByRegXADD PROC
000000EC 33 C0 xor eax, eax
000000EE BB 00000001 mov ebx, 1
000000F3 L1:
000000F3 0F C1 D8 xadd eax, ebx
000000F6 E2 Петля FB L1
000000F8 C3 ret
000000F9 FibonacciByRegXADD ENDP
Два расширения атомарного перемещения: MOVZX и MOVSX .Также стоит упомянуть инструкции битового тестирования: BT , BTC , BTR и BTS . Для следующего примера
. Данные
Семафор WORD 10001000b
.код
btc Семафор, 6 Представьте себе набор инструкций без BTC , одна неатомарная реализация той же логики будет
mov ax, семафор
топор, 7
xor Семафор, 01000000b
Младший порядок байтов
Процессор x86 хранит и извлекает данные из памяти в порядке от младшего к старшему. Младший байт хранится по первому адресу памяти, выделенному для данных. Остальные байты сохраняются в следующих последовательных позициях памяти.
Младший байт хранится по первому адресу памяти, выделенному для данных. Остальные байты сохраняются в следующих последовательных позициях памяти.
6. Представления памяти
Рассмотрим следующие определения данных:
. Данные
dw1 DWORD 12345678h
dw2 DWORD 'AB', '123', 123h
на 3 байта 'ABCDE', 0FFh, 'A', 0Dh, 0Ah, 0
w1 СЛОВО 123h, 'AB', 'A' Для простоты в качестве инициализатора используются шестнадцатеричные константы. Представление памяти следующее:
Что касается многобайтовых дат DWORD и WORD , то они представлены в порядке от младшего к старшему.Исходя из этого, второй DWORD , инициализированный с помощью 'AB' , должен быть 00004142h , а следующий '123' - это 00313233h в исходном порядке. Вы не можете инициализировать dw3 как 'ABCDE' , который содержит пять байтов 4142434445h , в то время как вы действительно можете инициализировать на 3 в байтовой памяти, поскольку для байтовых данных нет прямого порядка байтов. Точно так же см.
Точно так же см. w1 для памяти WORD .
7.Ошибка кода, скрытая little-endian
Из последнего раздела использования XADD мы пытаемся заполнить байтовый массив первыми 7 числами Фибоначчи, как 01 , 01 , 02 , 03 , 05 , 08 , 0D . Ниже приводится такая простая реализация, но с ошибкой. Ошибка не обнаруживается сразу, потому что она была скрыта с прямым порядком байтов.
FibCount = 7
.данные
FibArray BYTE FibCount DUP (0ffh)
БАЙТ 'ABCDEF'
.код
mov edi, СМЕЩЕНИЕ FibArray
mov eax, 1
xor ebx, ebx
mov ecx, FibCount
L1:
mov [edi], eax
xadd eax, ebx
inc edi
петля L1 Для отладки я намеренно сделал память 'ABCDEF' в конце массива байтов FibArray с семью инициализированными 0ffh . Начальная память выглядит так:
Установим точку останова в цикле. Когда первое число
Когда первое число 01 заполнено, за ним следуют три нуля, например:
Но хорошо, второе число 01 приходит, чтобы заполнить второй байт, чтобы перезаписать три нуля, оставленные первым. И так далее, до седьмого 0D , здесь просто помещается последний байт:
Все в порядке с ожидаемым результатом в FibArray из-за прямого порядка байтов. Только когда вы определяете некоторую память сразу после этого FibArray , ваши первые три байта будут перезаписаны нулями, так как здесь 'ABCDEF' становится 'DEF' .Как сделать простое исправление?
О стеке времени выполнения
Стек выполнения - это массив памяти, которым напрямую управляет ЦП, причем регистр указателя стека ESP содержит 32-битное смещение в стеке. ESP модифицируется инструкциями CALL , RET , PUSH , POP и т. Д. При использовании
Д. При использовании PUSH и POP или аналогичных вы явно изменяете содержимое стека. Вы должны быть очень осторожны, не затрагивая другое неявное использование, например CALL и RET , потому что вы, программист, и система используют один и тот же стек времени выполнения.
8. Назначение с помощью PUSH и POP неэффективно
В ассемблерном коде вы определенно можете использовать стек для присвоения предыдущий = текущий , как в FibonacciByMemory . Следующее - это FibonacciByStack , где единственная разница заключается в использовании PUSH и POP вместо двух инструкций MOV с EDX .
FibonacciByStack
mov eax, 1
mov предыдущий, 0
mov текущий, 0
L1:
добавить eax, предыдущий
нажмите ток
поп предыдущий
mov current, eax
петля L1
Ret
ФибоначчиByStack ENDP Как вы понимаете, стек времени выполнения, построенный на памяти, намного медленнее, чем регистры. Если вы создадите тестовый эталон для сравнения вышеуказанных процедур в длинном цикле, вы обнаружите, что
Если вы создадите тестовый эталон для сравнения вышеуказанных процедур в длинном цикле, вы обнаружите, что FibonacciByStack является наиболее неэффективным. Я предлагаю, если вы можете использовать регистр или память, не используйте PUSH и POP .
9. Использование INC для предотвращения PUSHFD и POPFD
Когда вы используете инструкцию ADC или SBB для добавления или вычитания целого числа с предыдущим переносом, вы разумно хотите зарезервировать предыдущий флаг переноса ( CF ) с PUSHFD и POPFD , поскольку адрес обновление с ADD перезапишет CF .Следующий пример Extended_Add , заимствованный из учебника [2], предназначен для вычисления суммы двух расширенных длинных целых чисел BYTE на BYTE :
Extended_Add PROC
clc
L1:
mov al, [esi]
adc al, [edi]
pushfd
mov [ebx], al
добавить esi, 1
добавить edi, 1
добавить ebx, 1
popfd
петля L1
mov dword ptr [ebx], 0
adc dword ptr [ebx], 0
Ret
Extended_Add ENDP Как мы знаем, инструкция INC выполняет приращение на 1, не затрагивая CF . Очевидно, мы можем заменить выше
Очевидно, мы можем заменить выше ADD на INC , чтобы избежать PUSHFD и POPFD . Таким образом, цикл упрощается так:
L1:
mov al, [esi]
adc al, [edi]
mov [ebx], al
inc esi
inc edi
inc ebx
петля L1
Теперь вы можете спросить, что делать, если вычислить сумму двух длинных целых чисел DWORD на DWORD , где каждая итерация должна обновлять адреса на 4 байта, как TYPE DWORD .Мы все еще можем использовать INC для такой реализации:
clc
xor ebx, ebx
L1:
mov eax, [esi + ebx * ТИП DWORD]
adc eax, [edi + ebx * ТИП DWORD]
mov [edx + ebx * ТИП DWORD], eax
inc ebx
петля L1
Применение коэффициента масштабирования здесь было бы более общим и предпочтительным. Точно так же, когда необходимо, вы также можете использовать команду DEC , которая выполняет уменьшение на 1, не затрагивая флаг переноса.
10. Еще одна веская причина избегать PUSH и POP
Поскольку вы и система используете один и тот же стек, вы должны быть очень осторожны, чтобы не мешать использованию системы.Если вы забудете сделать PUSH и POP в паре, может произойти ошибка, особенно при условном переходе, когда процедура возвращается.
Следующий Search3DAry выполняет поиск в двумерном массиве значения, переданного в EAX . Если он найден, просто перейдите к метке FOUND , вернув единицу в EAX как истину, иначе установите EAX в ноль как ложь.
Search3DAry PROC
mov ecx, NUM_ROW
СТРОКА:
нажать ecx
mov ecx, NUM_COL
COL:
cmp al, [esi + ecx-1]
je НАЙДЕНА
петля COL
добавить esi, NUM_COL
поп ecx
петля ROW
mov eax, 0
jmp ВЫЙТИ
НАЙДЕННЫЙ:
mov eax, 1
УВОЛИТЬСЯ:
Ret
Search3DAry ENDP Давайте вызовем его в main , подготовив аргумент ESI , указывающий на адрес массива и значение поиска EAX как 31h или 30h соответственно для не найденного или найденного тестового примера:
. данные
ary2D BYTE 10 ч, 20 ч, 30 ч , 40 ч, 50 ч
БАЙТ 60h, 70h, 80h, 90h, 0A0h
NUM_COL = 5
NUM_ROW = 2
.код
главный ПРОЦ
mov esi, OFFSET ary2D
mov eax, 31ч
позвонить в Search3DAry
Выход
основной ENDP
данные
ary2D BYTE 10 ч, 20 ч, 30 ч , 40 ч, 50 ч
БАЙТ 60h, 70h, 80h, 90h, 0A0h
NUM_COL = 5
NUM_ROW = 2
.код
главный ПРОЦ
mov esi, OFFSET ary2D
mov eax, 31ч
позвонить в Search3DAry
Выход
основной ENDP К сожалению, работает только в not-found для 31h . При успешном поиске типа 30h происходит сбой из-за остатка стека после нажатия счетчика внешнего цикла. К сожалению, то, что осталось от RET , становится обратным адресом для вызывающего.
Следовательно, здесь лучше использовать регистр или переменную для сохранения счетчика внешнего цикла. Хотя логическая ошибка сохраняется, сбой не произойдет без вмешательства в систему. В качестве хорошего упражнения можно попробовать исправить.
Время сборки и время работы
Я хотел бы подробнее поговорить об этой особенности языка ассемблера. Желательно, если вы можете что-то делать во время сборки, не делайте этого во время выполнения. Логика организации при сборке указывает на выполнение работы в статическое время (компиляция), а не на время выполнения.В отличие от языков высокого уровня, все операторы на языке ассемблера обрабатываются при сборке, например + , - , * и /, в то время как во время выполнения работают только инструкции, такие как ADD , SUB , MUL и DIV .
11. Выполнение с плюсом (+) вместо ADD
Давайте повторим вычисление Фибоначчи для реализации eax = ebx + edx при ассемблировании с оператором «плюс» с помощью инструкции LEA .Следующее - FibonacciByRegLEA с изменением только одной линии с FibonacciByRegMOV .
ФибоначчиByRegLEA
xor eax, eax
xor ebx, ebx
mov edx, 1
L1:
lea eax, DWORD PTR [ebx + edx]
mov edx, ebx
mov ebx, eax
петля L1
Ret
ФибоначчиByRegLEA ENDP Этот оператор закодирован в виде трех байтов, реализованных в машинном коде без операции сложения явно во время выполнения:
000000CE 8D 04 1A lea eax, DWORD PTR [ebx + edx] Этот пример не слишком сильно влияет на производительность по сравнению с FibonacciByRegMOV .Но этого достаточно в качестве демонстрации реализации.
12. Если вы умеете пользоваться оператором, не используйте инструкцию
Для массива, определенного как:
. Данные
Ary1 DWORD 20 DUP (?) Если вы хотите пройти его от второго элемента к среднему, вы можете думать об этом, как на другом языке:
mov esi, OFFSET Ary1
добавить esi, ТИП DWORD
mov ecx LENGTHOF Ary1
sub ecx, 1
div ecx, 2
L1:
Петля L1 Помните, что ADD , SUB и DIV - это динамическое поведение во время выполнения.Если вы знаете значения заранее, их не нужно вычислять во время выполнения, вместо этого примените операторы при сборке:
mov esi, OFFSET Ary1 + TYPE DWORD
mov ecx (LENGTHOF Ary1 -1) / 2
L1:
Петля L1 Это сохраняет три инструкции в сегменте кода во время выполнения. Затем давайте сэкономим память в сегменте данных.
13. Если вы можете использовать символическую константу, не используйте переменную
. Как и операторы, все директивы обрабатываются во время сборки.Переменная потребляет память и должна быть доступна во время выполнения. Что касается последнего Ary1 , вы можете запомнить его размер в байтах и количество таких элементов:
. Данные
Ary1 DWORD 20 DUP (?)
arySizeInByte DWORD ($ - Ary1)
aryLength DWORD LENGTHOF Ary1 Это правильно, но не рекомендуется из-за использования двух переменных. Почему бы просто не сделать их символическими константами, чтобы сохранить память двух DWORD ?
. Данные
Ary1 DWORD 20 DUP (?)
arySizeInByte = ($ - Ary1)
aryLength EQU LENGTHOF Ary1 Допускается использование знака равенства или директивы EQU.Константа - это просто замена во время предварительной обработки кода.
14. Генерация блока памяти в макросе
Для количества данных для инициализации, если вы уже знаете логику создания, вы можете использовать макрос для создания блоков памяти при сборке, а не во время выполнения. Следующий макрос создает все 47 чисел Фибоначчи в массиве DWORD с именем FibArray :
. Данные
val1 = 1
val2 = 1
значение3 = значение1 + значение2
FibArray LABEL DWORD
DWORD val1
DWORD val2
WHILE val3 LT 0FFFFFFFFh
DWORD val3
val1 = val2
val2 = val3
значение3 = значение1 + значение2
ENDM Поскольку макрос передается ассемблеру для статической обработки, это значительно экономит инициализацию во время выполнения, в отличие от FibonacciByXXX , упомянутого ранее.
Подробнее о макросах в MASM см. В моей статье «Что-то, чего вы можете не знать о макросах в MASM» [4]. Я также сделал обратный инжиниринг для оператора switch в реализации компилятора VC ++. Интересно, что при определенных условиях оператор switch выбирает двоичный поиск, но не раскрывает предварительное условие реализации сортировки во время выполнения. Разумно подумать о препроцессоре, который выполняет сортировку со всеми известными значениями case при компиляции.Поведение статической сортировки (в отличие от динамического поведения во время выполнения) может быть реализовано с помощью макрос-процедуры, директив и операторов. Дополнительные сведения см. В разделе «Что-то, чего вы могли не знать об операторе Switch в C / C ++ [5]».
О конструкции контура
Почти каждый язык обеспечивает безусловный переход, как GOTO , но большинство из нас редко используют его на основе принципов разработки программного обеспечения. Вместо этого мы используем другие, такие как break и continue .В ассемблере мы больше полагаемся на условные или безусловные переходы, чтобы сделать рабочий процесс управления более свободным. В следующих разделах я перечисляю некоторые плохо закодированные шаблоны.
15. Инкапсуляция всей логики цикла в теле цикла
Чтобы построить цикл, попробуйте поместить все содержимое цикла в тело цикла. Не прыгайте, чтобы что-то сделать, а затем снова прыгайте в петлю. Пример здесь - прохождение одномерного целочисленного массива. Если найдете нечетное число, увеличьте его, иначе ничего не делать.
Два неясных решения с правильным результатом, возможно, будут примерно такими:
mov ecx, массив LENGTHOF
xor esi, esi
L1:
тестовый массив [esi], 1
jnz ODD
ПРОХОДИТЬ:
добавить esi, ТИП DWORD
петля L1
jmp СДЕЛАНО
СТРАННЫЙ:
inc array [esi]
jmp PASS
СДЕЛАНО: | mov ecx, массив LENGTHOF
xor esi, esi
jmp L1
СТРАННЫЙ:
inc array [esi]
jmp PASS
L1:
тестовый массив [esi], 1
JNZ ODD
ПРОХОДИТЬ:
добавить esi, ТИП DWORD
петля L1 |
Однако они оба выполняют приращение снаружи, а затем возвращаются назад.Они производят проверку в цикле, но левый делает приращение после цикла, а правый - до цикла. По простой логике, вы можете так не думать; в то время как для сложной задачи язык ассемблера может сбить с толку, создав такой шаблон спагетти. Следующее - хорошее, которое инкапсулирует всю логику в теле цикла, краткое, читаемое, обслуживаемое и эффективное.
mov ecx, массив LENGTHOF
xor esi, esi
L1:
тестовый массив [esi], 1
jz PASS
inc array [esi]
ПРОХОДИТЬ:
добавить esi, ТИП DWORD
петля L1 16.Петля вход и выход
Обычно предпочтительна петля с одним входом и одним выходом. Но при необходимости можно использовать два или более условных выхода, как показано в Search3DAry с найденными и ненайденными результатами.
Ниже приведен плохой шаблон с двумя входами, когда один попадает в START через инициализацию, а другой напрямую идет в MIDDLE . Такой код довольно сложно понять. Требуется реорганизация или рефакторинг логики цикла.
je MIDDLE
НАЧАЛО:
СРЕДНИЙ:
петля СТАРТ Ниже приведен плохой образец двухпетлевых концов, когда некоторая логика выходит из первого конца цикла, а другая выходит из второго.Такой код довольно запутанный. Попробуйте пересмотреть с меткой jum
Знать язык программирования 8086
Программирование на уровне сборки очень важно для низкоуровневого проектирования встроенных систем, которое используется для доступа к инструкциям процессора для управления оборудованием. Это наиболее примитивный язык машинного уровня, используемый для создания эффективного кода, который потребляет меньшее количество тактовых циклов и занимает меньше памяти по сравнению с языком программирования высокого уровня. Это полный аппаратно-ориентированный язык программирования для написания программы, которую программист должен знать о встроенном оборудовании.Здесь мы предоставляем основы программирования на уровне ассемблера 8086.
Программирование на уровне ассемблера 8086Программирование на уровне ассемблера 8086
Язык программирования ассемблера - это язык низкого уровня, который разработан с использованием мнемоники. Микроконтроллер или микропроцессор может понимать только двоичный язык, такой как 0 или 1, поэтому ассемблер преобразует язык ассемблера в двоичный язык и сохраняет его в памяти для выполнения задач. Перед написанием программы разработчики встраиваемых систем должны иметь достаточные знания о конкретном аппаратном обеспечении контроллера или процессора, поэтому сначала нам нужно было знать аппаратное обеспечение процессора 8086.
Аппаратное обеспечение процессора
Архитектура процессора 8086
8086 - это процессор, который представлен для всех периферийных устройств, таких как последовательная шина, а также ОЗУ и ПЗУ, устройства ввода-вывода и т. Д., Которые все внешне подключены к ЦП с помощью системная шина. Микропроцессор 8086 имеет архитектуру на основе CISC и имеет периферийные устройства, такие как 32 ввода-вывода, последовательную связь, память и счетчики / таймеры. Микропроцессору требуется программа для выполнения операций, требующих памяти для чтения и сохранения функций.
Архитектура процессора 8086Программирование 8086 на уровне сборки основано на регистрах памяти. Регистр - это основная часть микропроцессоров и контроллеров, расположенных в памяти, что обеспечивает более быстрый способ сбора и хранения данных. Если мы хотим управлять данными в процессоре или контроллере, выполняя умножение, сложение и т. Д., Мы не можем делать это непосредственно в памяти, где нужны регистры для обработки и хранения данных. Микропроцессор 8086 содержит различные типы регистров, которые можно классифицировать в соответствии с их инструкциями, например:
Регистры общего назначения: ЦП 8086 состоит из 8 регистров общего назначения, и каждый регистр имеет собственное имя, как показано на рисунке, например, AX, BX, CX, DX, SI, DI, BP, SP.Все это 16-битные регистры, в которых четыре регистра разделены на две части, такие как AX, BX, CX и DX, которые в основном используются для хранения чисел.
Регистры специального назначения: ЦП 8086 состоит из 2 регистров специальных функций, таких как регистры IP и регистры флагов. Регистр IP указывает на текущую выполняющуюся инструкцию и всегда работает для сбора с регистром сегмента CS. Основная функция регистров флагов заключается в изменении операций ЦП после завершения механических функций, и мы не можем получить прямой доступ к регистрам сегментов
: ЦП 8086 состоит из 4-сегментных регистров, таких как CS, DS, ES, SS, которые в основном используются для возможных для хранения любых данных в сегментных регистрах, и мы можем получить доступ к блоку памяти, используя сегментные регистры.
Простые программы на языке ассемблера 8086
Программирование на языке ассемблера 8086 имеет некоторые правила, такие как
- Код 8086 программирования на уровне ассемблера должен быть написан заглавными буквами
- За метками должно стоять двоеточие, например: label:
- Все метки и символы должны начинаться с буквы
- Все комментарии набираются в нижнем регистре
- Последняя строка программы должна заканчиваться директивой END
Процессоры 8086 имеют две другие инструкции для доступа к данным , например, WORD PTR - для слова (два байта), BYTE PTR - для байта.
Операционный код и операндОперационный код: Отдельная инструкция вызывается как операционный код, который может быть выполнен ЦП. Здесь инструкция «MOV» называется операционным кодом.
Операнды: Отдельные данные называются операндами, которыми можно управлять с помощью кода операции. Например, операция вычитания выполняется для операндов, которые вычитаются операндом.
Синтаксис: SUB b, c
8086 программы на языке ассемблера микропроцессора
Написать программу для чтения символа с клавиатуры
MOV ah, 1h // подпрограмма ввода с клавиатуры
INT 21h // ввод символов
// символ хранится в al
MOV c, al // копировать символ из alto c
Написать программу для чтения и отображения символа
MOV ah, 1h // подпрограмма ввода с клавиатуры
INT 21h // прочитать символ в al
MOV dl , al // копировать символ в dl
MOV ah, 2h // подпрограмма вывода символов
INT 21h // отображать символ в dl
Написать программу с использованием регистров общего назначения
ORG 100h
MOV AL, VAR1 // проверить значение VAR1, переместив его в AL.
LEA BX, VAR1 // получить адрес VAR1 в BX.
MOV BYTE PTR [BX], 44h // модифицируем содержимое VAR1.
MOV AL, VAR1 // проверяем значение VAR1, перемещая его в AL.
RET
VAR1 DB 22h
END
Напишите программу для отображения строки с использованием библиотечных функций
include emu8086.inc // Объявление макроса
ORG 100h
PRINT 'Hello World!'
GOTOXY 10, 5
PUTC 65 // 65 - это код ASCII для 'A'
PUTC 'B'
RET // возврат в операционную систему.
END // директива для остановки компилятора.
Арифметические и логические команды
Процессы арифметического и логического устройства 8086 разделены на три группы, такие как операции сложения, деления и увеличения. Большинство арифметических и логических инструкций влияют на регистр состояния процессора.
Мнемоника 8086 программирования на ассемблере имеет форму операционного кода, такого как MOV, MUL, JMP и т. Д., Которые используются для выполнения операций. Программирование на языке ассемблера Примеры 8086
Добавление
ORG0000h
MOV DX, # 07H // переместить значение 7 в регистр AX //
MOV AX, # 09H // переместить значение 9 в аккумулятор AX //
Добавить AX , 00H // добавляем значение CX со значением R0 и сохраняем результат в AX //
END
Умножение
ORG0000h
MOV DX, # 04H // перемещаем значение 4 в регистр DX //
MOV AX, # 08H // перемещаем значение 8 в аккумулятор AX //
MUL AX, 06H // Результат умножения сохраняется в аккумуляторе AX //
END
Вычитание
ORG 0000h
MOV DX, # 02H // перемещаем значение 2 в регистр DX //
MOV AX, # 08H // переместить значение 8 в аккумулятор AX //
SUBB AX, 09H // Значение результата сохраняется в аккумуляторе AX //
END
Division
ORG 0000h
MOV DX , # 08H // перемещаем значение 3 в регистр DX //
MOV AX, # 19H // перемещаем значение 5 в накопительное ator AX //
DIV AX, 08H // конечное значение сохраняется в Accumulator AX //
END
Таким образом, это все, что касается программирования на уровне сборки 8086, архитектуры процессора 8086, простых примеров программ для процессоров 8086, арифметических и логических инструкций .Кроме того, с любыми вопросами относительно этой статьи или проектов электроники вы можете связаться с нами, оставив комментарий в разделе комментариев ниже.
Подробное объяснение 8051 Программирование на языке ассемблера
Ассемблер - это язык программирования низкого уровня, используемый для написания программного кода в терминах мнемоники. Несмотря на то, что в настоящее время существует множество востребованных языков высокого уровня, язык программирования ассемблер широко используется во многих приложениях. Его можно использовать для прямых манипуляций с оборудованием.Он также используется для эффективной записи программного кода 8051 с меньшим количеством тактовых циклов за счет использования меньшего объема памяти по сравнению с другими языками высокого уровня.
8051 Программирование8051 Программирование на языке ассемблера
Ассемблер - это язык программирования, полностью связанный с оборудованием. Разработчики встроенных систем должны иметь достаточные знания об аппаратном обеспечении конкретного процессора или контроллеров перед написанием программы. Ассемблер разработан с помощью мнемоники; поэтому пользователи не могут легко понять изменение программы.
8051 Программирование на языке ассемблера
Язык программирования ассемблера разработан различными компиляторами, и «keiluvison» лучше всего подходит для разработки программирования микроконтроллеров. Микроконтроллеры или процессоры могут понимать только двоичный язык в виде «нулей» или «единиц»; Ассемблер преобразует язык ассемблера в двоичный язык, а затем сохраняет его в памяти микроконтроллера для выполнения конкретной задачи.
8051 Архитектура микроконтроллера
Микроконтроллер 8051 представляет собой гарвардскую архитектуру на основе CISC и имеет периферийные устройства, такие как 32 ввода-вывода, таймеры / счетчики, последовательную связь и память.Микроконтроллеру требуется программа для выполнения операций, требующих памяти для сохранения и чтения функций. Микроконтроллер 8051 состоит из памяти RAM и ROM для хранения инструкций.
8051 Архитектура микроконтроллераРегистр - это основная часть процессоров и микроконтроллеров, которая содержится в памяти, что обеспечивает более быстрый способ сбора и хранения данных. Программирование на языке ассемблера 8051 основано на регистрах памяти. Если мы хотим передать данные процессору или контроллеру путем вычитания, сложения и т. Д., мы не можем сделать это непосредственно в памяти, но для обработки и хранения данных нужны регистры. Микроконтроллеры содержат несколько типов регистров, которые можно классифицировать в соответствии с их инструкциями или содержимым, которое в них работает.
8051 Программы для микроконтроллеров на языке ассемблера
Язык ассемблера состоит из элементов, которые все используются для последовательного написания программы. Следуйте данным правилам, чтобы писать программы на ассемблере.
Правила языка ассемблера
- Код сборки должен быть написан заглавными буквами
- За метками должен стоять двоеточие (метка 🙂
- Все символы и метки должны начинаться с буквы
- Все комментарии набирается в нижнем регистре
- Последняя строка программы должна быть директивой END
Мнемоника языка ассемблера имеет форму операционного кода, такого как MOV, ADD, JMP и т. д., которые используются для выполнения операции.
Операционный код: Операционный код - это отдельная инструкция, которая может быть выполнена ЦП. Здесь код операции - это инструкция MOV.
Операнды: Операнды - это отдельные данные, которыми можно управлять с помощью кода операции. Например, операция умножения выполняется операндами, которые умножаются на операнд.
Синтаксис: MUL a, b;
Элементы программирования на языке ассемблера:
- Директивы ассемблера
- Набор команд
- Режимы адресации
Директивы ассемблера:
Директивы ассемблера дают указания ЦП.Микроконтроллер 8051 состоит из различных директив сборки, которые задают направление блоку управления. Наиболее полезными директивами являются 8051 программирование, например:
ORG (origin): Эта директива указывает на начало программы. Это используется для установки адреса регистра во время сборки. Например; ORG 0000h сообщает компилятору весь последующий код, начиная с адреса 0000h.
Синтаксис: ORG 0000h
DB (байт определения): Байт определения используется для разрешения строки байтов.Например, напечатайте «EDGEFX», в котором каждый символ берется по адресу, и, наконец, напечатайте «строку» из БД напрямую с двойными кавычками.
Синтаксис:
ORG 0000h
MOV a, # 00h
————-
————-
DB ”EDGEFX”
EQU (эквивалент): Эквивалентная директива используется для приравнивания адрес переменной.
Синтаксис:
reg equ, 09h
—————–
—————–
MOV reg, # 2h
END: Директива END используется для обозначения конца программы .
Синтаксис:
reg equ, 09h
—————–
—————–
MOV reg, # 2h
END
Режимы адресации:
Способ доступа к данным называется адресацией Режим. ЦП может получать доступ к данным разными способами, используя режимы адресации. Микроконтроллер 8051 имеет пять режимов адресации, таких как:
- Режим немедленной адресации
- Режим адресации регистров
- Режим прямой адресации
- Режим косвенной адресации
- Режим базовой индексной адресации
Режим немедленной адресации: 99 9 В этом режиме адресации источником должно быть значение, за которым может следовать '#', а местом назначения должны быть регистры SFR, регистры общего назначения и адрес.Он используется для немедленного сохранения значения в регистрах памяти. Синтаксис: MOV A, # 20h // A - регистр накопителя, 20 хранится в A // Пример: MOV R0, # 1 Режим адресации регистров: В этом режиме адресации источником и получателем должны быть регистры, но не регистры общего назначения.Таким образом, данные не перемещаются в регистры банка общего назначения. Синтаксис: MOV A, B; // A - регистр SFR, B - регистр общего назначения // EX: MOV R0, # 02h Режим прямой адресации В этом режиме адресации источник или адресат (или оба источника и destination) должен быть адресом, но не значением. Синтаксис: MOV A, 20h // 20h - адрес; A - регистр // Пример: MOV 07h, # 01h Режим косвенной адресации: В этом режиме адресации источник или пункт назначения (или пункт назначения, или источник) должны быть косвенным адресом, но не значением.Этот режим адресации поддерживает концепцию указателя. Указатель - это переменная, которая используется для хранения адреса другой переменной. Эта концепция указателя используется только для регистров R0 и R1. Синтаксис: MOVR0, # 01h // 01 значение хранится в регистре R0, адрес R0 - 08h // Режим адресации базового индекса: Этот режим адресации используется для чтения данных с внешнего память или ПЗУ.Все режимы адресации не могут считывать данные из памяти кода. Код должен считываться через регистр DPTR. DPTR используется для указания данных в коде или внешней памяти. Синтаксис: MOVC A, @ A + DPTR // C указывает кодовую память // Набор команд - это структура контроллера или процессора, который выдает команды контроллеру, чтобы направлять контроллер для обработки данных.Набор команд состоит из инструкций, собственных типов данных, режимов адресации, регистров прерываний, исключительной обработки и архитектуры памяти. Микроконтроллер 8051 может следовать инструкциям CISC с архитектурой Гарварда. В случае программирования 8051 различные типы инструкций CISC включают в себя: Арифметические инструкции выполняют такие основные операции, как:
MOV R0, # 15 // R0 - регистр общего назначения; 15 хранится в регистре R0 //
MOV P0, # 07h // P0 - регистр SFR; 07 хранится в P0 //
MOV 20h, # 05h // 20h - адрес регистра; 05 сохраняется в 20h //
MOV R0, # 20 // R0 <—R0 [15] +20, окончательное значение сохраняется в R0 //
MOV R0, R1 // Неверная инструкция, GPR в GPR невозможен //
MOV A, # 30h
ADD R0, A // R0 <—R0 + A, окончательное значение сохраняется в регистре R0 //
MOV 00h, 07h // оба адресуются в регистрах GPS //
MOV A, # 08h
ADD A, 07h // A < —A + 07h окончательное значение сохраняется в A //
MOV R1, # 08h // R1 - переменная-указатель, в которой хранится адрес (08h) R0 //
MOV 20h, @ R1 // Значение 01 сохраняется в адресе 20h регистра GP //
MOCX A, @ A + DPTR // X указывает внешнюю память //
EX: MOV A, # 00H // 00H хранится в регистре A //
MOV DPTR, # 0500H // DPTR указывает адрес 0500h в памяти //
MOVC A, @ A + DPTR // отправляет значение в регистр A //
MOV P0, A / / дата отправки A регистратору заказа на поставку // Набор команд:
Набор арифметических инструкций:
ORG 0000h
MOV R0, # 03H // перемещаем значение 3 в регистр R0 //
MOV A, # 05H // перемещаем значение 5 в аккумулятор A //
Add A, 00H // addA value with R0 value и сохраняет результат в A //
END
Умножение: 900 07
ORG 0000h
MOV R0, # 03H // переместить значение 3 в регистр R0 //
MOV A, # 05H // переместить значение 5 в аккумулятор A //
MUL A, 03H // сохранен результат умножения в аккумуляторе A //
END
Вычитание:
ORG 0000h
MOV R0, # 03H // перемещаем значение 3 в регистр R0 //
MOV A, # 05H // перемещаем значение 5 в аккумулятор A //
SUBB A, 03H // Значение результата сохраняется в аккумуляторе A //
END
Division:
ORG 0000h
MOV R0, # 03H // перемещаем значение 3 в регистр R0 //
MOV A, # 15H // перемещаем значение 5 в аккумулятор A //
DIV A, 03H // окончательное значение сохраняется в аккумуляторе A //
END
Условные инструкции
ЦП выполняет инструкции на основе условия проверка статуса одного бита или статуса байта.Микроконтроллер 8051 состоит из различных условных инструкций, таких как:
- JB -> Перейти ниже
- JNB -> Перейти, если не ниже
- JC -> Перейти, если нести
- JNC -> Перейти, если не переносить
- JZ -> Перейти, если ноль
- JNZ -> Перейти, если не ноль
1. Синтаксис:
JB P1.0, метка
- - - - - - - -
- - - - - - - -
Этикетка: - - - - - - - -
- - - - - - - -
END
2.Синтаксис:
JNB P1.0, метка
- - - - - - - -
- - - - - - - -
Метка: - - - - - - - -
- - - - - - - -
END
3. Синтаксис:
JC, метка
- - - - - - - -
- - - - - - - -
Этикетка: - - - - - - - -
- - - - - - - -
END
4. Синтаксис:
JNC, метка
- - - - - - - -
- - - - - - - -
Метка: - - - - - - - -
- - - - - - - -
КОНЕЦ
5.Синтаксис:
JZ, метка
- - - - - - -
- - - - - - - -
Метка: - - - - - - - -
- - - - - - - -
END
6. Синтаксис:
JNZ, метка
- - - - - - - -
- - - - - - - -
Метка: - - - - - - - -
- - - - - - - -
END
Инструкции вызова и перехода:
Команды вызова и перехода используются для предотвращения дублирования кода программы. Когда какой-то конкретный код используется более одного раза в разных местах программы, если мы укажем конкретное имя для кода, тогда мы сможем использовать это имя в любом месте программы, не вводя код каждый раз.Это снижает сложность программы. Программирование 8051 состоит из инструкций вызова и перехода, таких как LCALL, SJMP.
1. Синтаксис:
ORG 0000h
- - - - - - - -
- - - - - - - -
ACALL, метка
- - - - - - - -
- - - - - - - -
SJMP STOP
Ярлык: - - - - - - - -
- - - - - - -
- - - - - - -
ret
STOP: NOP
2. Синтаксис:
ORG 0000h
- - - - - - - -
- - - - - - - -
LCALL, этикетка
- - - - - - - -
- - - - - - - -
SJMP STOP
Этикетка: - - - - - - - -
- - - - - - - -
- - - - - - - -
ret
STOP: NOP
Команды цикла:
Инструкции цикла используются для повторения блока каждый раз при выполнении операций увеличения и уменьшения.Микроконтроллер 8051 состоит из двух типов инструкций цикла:
- CJNE -> сравнить и перейти, если не равно
- DJNZ -> уменьшить и перейти, если не ноль
1. Синтаксис:
из CJNE
MOV A, # 00H
MOV B, # 10H
Метка: INC A
- - - - - -
- - - - - -
CJNE A, метка
2. Синтаксис:
из DJNE
MOV R0 , # 10H
Этикетка: - - - - - -
- - - - - -
DJNE R0, этикетка
- - - - - -
- - - - - -
END
Набор логических команд:
Набор инструкций микроконтроллера 8051 предоставляет инструкции AND, OR, XOR, TEST, NOT и логической логики для установки и сброса битов в зависимости от потребности в программе.
Набор логических команд1. Синтаксис:
MOV A, # 20H / 00100000/
MOV R0, # 03H / 00000101/
ORL A, R0 // 00100000/00000101 = 00000000 //
2. Синтаксис :
MOV A, # 20H / 00100000/
MOV R0, # 03H / 00000101/
ANL A, R0
3. Синтаксис:
MOV A, # 20H / 00100000/
MOV R0, # 03H / 00000101/
XRL A, R0
Операторы смены
Операторы смены используются для эффективной отправки и получения данных.Микроконтроллер 8051 состоит из четырех операторов сдвига:
- RR -> Повернуть вправо
- RRC -> Повернуть вправо через перенос
- RL -> Повернуть влево
- RLC -> Повернуть влево через перенос
Повернуть вправо (RR) :
В этой операции сдвига старший бит становится младшим битом, и все биты последовательно сдвигаются в правую сторону.
Синтаксис:
MOV A, # 25h
RR A
Повернуть влево (RL):
В этой операции сдвига старший бит становится младшим битом, и все биты смещаются влево побитно, серийно.
Синтаксис:
MOV A, # 25h
RL A
RRC Повернуть вправо через перенос:
В этой операции сдвига младший бит перемещается в перенос, и перенос становится старшим, и все биты сдвигаются ближе к правой стороне по битам.
Синтаксис:
MOV A, # 27h
RRC A
RLC Повернуть влево через перенос:
В этой операции сдвига MSB перемещается в перенос, перенос становится LSB, и все биты сдвигаются влево сторону в побитовой позиции.
Синтаксис:
MOV A, # 27h
RLC A
Базовые встроенные программы C:
Программирование микроконтроллера отличается для каждого типа операционной системы. Есть много операционных систем, таких как Linux, Windows, RTOS и так далее. Однако RTOS имеет несколько преимуществ для разработки встроенных систем. Ниже приведены некоторые примеры программирования на уровне сборки.
Светодиод мигает при использовании микроконтроллера 8051:
- Отображение числа на 7-сегментном дисплее при помощи микроконтроллера 8051
- Расчеты таймера / счетчика и программирование с использованием микроконтроллера 8051
- Расчеты и программирование последовательной связи с использованием микроконтроллера 8051
Светодиодные программы с 8051 Микроконтроллер
1.WAP для переключения светодиодов PORT1
ORG 0000H
TOGLE: MOV P1, # 01 // переместить 00000001 в регистр p1 //
CALL DELAY // выполнить задержку //
MOV A, P1 // переместить p1 значение в аккумулятор //
CPL A // дополняем значение A //
MOV P1, A // перемещаем 11111110 в регистр port1 //
CALL DELAY // выполняем задержку //
SJMP TOGLE
DELAY: MOV R5, # 10H // загружаем регистр R5 с 10 //
TWO: MOV R6, # 200 // загружаем регистр R6 с 200 //
ONE: MOV R7, # 200 // загружаем регистр R7 с 200 //
DJNZ R7, $ // уменьшить R7 до нуля //
DJNZ R6, ONE // уменьшить R7 до нуля //
DJNZ R5, TWO // уменьшить R7 до нуля //
RET // вернуться к основной программе //
END
Вычисления таймера / счетчика и программа с использованием микроконтроллера 8051:
Задержка является одним из важных факторов при разработке прикладного программного обеспечения.Таймеры и счетчики - это аппаратные компоненты микроконтроллера, которые используются во многих приложениях для обеспечения точной временной задержки с счетными импульсами. Обе задачи реализованы программно.
1. WAP для расчета временной задержки 500 мкс.
MOV TMOD, # 10H // выбор режима таймера по регистрам //
MOV Th2, # 0FEH // сохранение времени задержки в старшем бите //
MOV TL1, # 32H // сохранение времени задержки в низком bit //
JNB TF1, $ // уменьшает значение таймера до нуля //
CLR TF1 // очищает бит флага таймера //
CLR TR1 // ВЫКЛ таймер //
2.WAP для переключения светодиодов с задержкой по времени 5 секунд
ORG 0000H
RETURN: MOV PO, # 00H
ACALL DELAY
MOV P0, # 0FFH
ACALL DELAY
SJUMP RETURN
DELAY: MOV R5, # 50H // загрузить регистр R5 с 50 //
DELAY1: MOV R6, # 200 // загружаем регистр R6 200 //
DELAY2: MOV R7, # 229 // загружаем регистр R7 200 //
DJNZ R7, $ // уменьшаем R7 до него равно нулю //
DJNZ R6, DELAY2 // уменьшить R6 до нуля //
DJNZ R5, DELAY1 // уменьшить R5 до нуля //
RET // вернуться к основной программе //
END
3.WAP для подсчета 250 импульсов с использованием mode0 count0
Синтаксис:
ORG 0000H
MOV TMOD, # 50H // выбор счетчика //
MOV TH0, # 15 // перемещение счетчика импульсов на более высокий бит //
MOV Th2, # 9FH // перемещаем счетные импульсы, младший бит //
SET TR0 // ON таймер //
JNB $ // уменьшаем значение счетчика до нуля //
CLR TF0 // очищаем счетчик, бит флага //
CLR TR0 // остановка таймера //
END
Программирование последовательной связи с использованием микроконтроллера 8051:
Последовательная связь обычно используется для передачи и приема данных.Микроконтроллер 8051 состоит из последовательной связи UART / USART, а сигналы передаются и принимаются выводами Tx и Rx. Связь UART последовательно передает данные побитно. UART - это полудуплексный протокол, который передает и принимает данные, но не одновременно.
1. WAP для передачи символов в Hyper Terminal
MOV SCON, # 50H // установка последовательной связи //
MOV TMOD, # 20H // выбор режима таймера //
MOV Th2, # - 3 // установить скорость передачи //
SET TR1 // ВКЛ таймер //
MOV SBUF, # 'S' // передать S в последовательное окно //
JNB TI, $ // уменьшить значение таймера до он равен нулю //
CLR RI // очистить прерывание приема //
CLR TR1 // очистить таймер //
2.WAP для передачи символа приема с помощью Hyper Terminal
MOV SCON, # 50H // установить последовательную связь //
MOV TMOD, # 20H // выбрать режим таймера //
MOV Th2, # -6 // установить скорость передачи //
SET TR1 // на таймере //
MOV SBUF, # 'S' // передать S в последовательное окно //
JNB RI, $ // уменьшить значение таймера до нуля / /
CLR RI // очистить прерывание приема //
MOV P0, SBUF // отправить значение регистра SBUF в порт 0 //
CLR TR1 // очистить таймер //
Это все о программировании 8051 на языке ассемблера в краткое описание программ на основе примеров.Мы надеемся, что эта адекватная информация о языке ассемблера будет, безусловно, полезна для читателей, и с нетерпением ждем их ценных комментариев в разделе комментариев ниже.
Mips Учебники по программированию на языке ассемблера
Учебники по MIPS ПОЛНОЕ СОДЕРЖАНИЕ
# | ТЕМА | Введение |
|---|---|---|
1 | MIPS Instruction Set | Набор инструкций MIPS, используемый в разделе сборки. |
2 | Синтаксис MIPS | Изучите основной синтаксис программы MIPS. Как структурировать программу MIPS. |
3 | Какие комментарии используются в MIPS и почему они используются, также узнают об их преимуществах. | |
4 | Типы данных MIPS | Полный список типов данных, используемых в сборке MIPS, также узнайте об их использовании в различных ситуациях. |
5 | Регистры MIPS | В MIPS ISA используется множество регистров. Каждый из них имеет собственное применение. Различайте типы регистров. |
6 | Форматы наборов инструкций MIPS | MIPS использует разные форматы инструкций для отдельных типов инструкций. В основном их три на широком уровне. |
7 | Системные вызовы MIPS | Изучите использование инструкции SYSCALL в программе.Это очень простая инструкция, используемая для служб, необходимых для ОС. |
8 | Печать и чтение целого числа | Узнайте, как читать и печатать целое число в MIPS на базовом уровне с подробными примерами. |
9 | MIPS Добавление | Очень простая арифметическая операция в программировании. Узнайте, как складывать числа в MIPS. |
10 | MIPS Вычитание | Аналогично сложению изучите использование кода операции SUB. |
11 | Умножение MIPS | Узнайте, как умножать числа в MIPS с подробными пояснениями. |